 14 |
14 |
13 |
14 |
16 | Figure 1: Urban Layout 17 |
18 | 19 | ## Dataset 20 | - CARLA Simulator contains different urban layouts and can also generate objects. 21 | - Urban layout **Town05** is used as experimental site 22 | - Objects (**Vehicle**, **Bike**, **Motobike**, **Traffic light**, **Traffic sign**) can be recognized in different urban layouts 23 | - Download [Carla-Object-Detection-Dataset](https://github.com/DanielHfnr/Carla-Object-Detection-Dataset) 24 | - Put `.png` and `.xml` to the `VOCdevkit/VOC2007/JPEGImages` and `VOCdevkit/VOC2007/Annotations`, respectively 25 | - Obtain label format: (2007_train.txt) 26 | ``` 27 | python voc_annotation.py 28 | ``` 29 | 30 | ## Result 31 | ``` 32 | python predict.py 33 | ``` 34 |
35 |  36 |
36 |  37 |
37 |  38 |
38 |  39 |
39 |
41 | Figure 2: Image Detection 42 |
43 | 44 | ``` 45 | python video.py 46 | ``` 47 |
48 |
49 |  50 |
51 |
50 |
51 |
53 | Figure 3: Video Detection 54 |
55 | 56 | ``` 57 | python ADS_object_detection.py 58 | ``` 59 |
60 |
61 |  62 |
63 |
62 |
63 |
65 | Figure 4: Object Detection for CARLA Driving Simulator by using YOLOv4 66 |
67 | 68 |
69 |
70 | 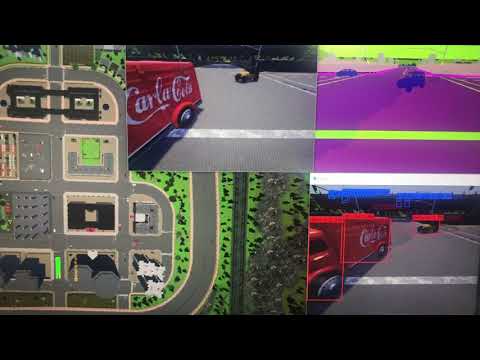 71 |
72 |
71 |
72 |
74 | Figure 5: Object Detection for CARLA Driving Simulator by using YOLOv4 (path trajectory) 75 |
76 | 77 | ## Reference 78 | https://github.com/AlexeyAB/darknet 79 | https://github.com/bubbliiiing/yolov4-pytorch 80 | [Introduction-Self-driving cars with Carla and Python](https://pythonprogramming.net/introduction-self-driving-autonomous-cars-carla-python/) 81 | https://github.com/DanielHfnr/Carla-Object-Detection-Dataset -------------------------------------------------------------------------------- /README/ADS.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/ADS.jpg -------------------------------------------------------------------------------- /README/ADS2.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/ADS2.jpg -------------------------------------------------------------------------------- /README/Town03_013260_predict.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/Town03_013260_predict.png -------------------------------------------------------------------------------- /README/Town03_015500_predict.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/Town03_015500_predict.png -------------------------------------------------------------------------------- /README/Town04_002280_predict.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/Town04_002280_predict.png -------------------------------------------------------------------------------- /README/Town05_017100_predict.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/Town05_017100_predict.png -------------------------------------------------------------------------------- /README/carla.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/carla.jpg -------------------------------------------------------------------------------- /README/data00.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data00.jpg -------------------------------------------------------------------------------- /README/data01.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data01.jpg -------------------------------------------------------------------------------- /README/data02.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data02.jpg -------------------------------------------------------------------------------- /README/data03.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data03.jpg -------------------------------------------------------------------------------- /README/data10.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data10.jpg -------------------------------------------------------------------------------- /README/data11.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data11.jpg -------------------------------------------------------------------------------- /README/data12.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data12.jpg -------------------------------------------------------------------------------- /README/data13.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/data13.jpg -------------------------------------------------------------------------------- /README/video.gif: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/README/video.gif -------------------------------------------------------------------------------- /__pycache__/yolo.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/__pycache__/yolo.cpython-37.pyc -------------------------------------------------------------------------------- /img/Town03_013260.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/img/Town03_013260.png -------------------------------------------------------------------------------- /img/Town03_015500.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/img/Town03_015500.png -------------------------------------------------------------------------------- /img/Town04_002280.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/img/Town04_002280.png -------------------------------------------------------------------------------- /img/Town05_017100.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/img/Town05_017100.png -------------------------------------------------------------------------------- /model_data/simhei.ttf: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/model_data/simhei.ttf -------------------------------------------------------------------------------- /model_data/voc_classes.txt: -------------------------------------------------------------------------------- 1 | vehicle 2 | bike 3 | motobike 4 | traffic_light 5 | traffic_sign 6 | -------------------------------------------------------------------------------- /model_data/yolo_anchors.txt: -------------------------------------------------------------------------------- 1 | 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401 -------------------------------------------------------------------------------- /nets/CSPdarknet.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn.functional as F 3 | import torch.nn as nn 4 | import math 5 | from collections import OrderedDict 6 | 7 | class Mish(nn.Module): 8 | def __init__(self): 9 | super(Mish, self).__init__() 10 | 11 | def forward(self, x): 12 | return x * torch.tanh(F.softplus(x)) 13 | 14 | class BasicConv(nn.Module): 15 | def __init__(self, in_channels, out_channels, kernel_size, stride=1): 16 | super(BasicConv, self).__init__() 17 | '''CONV + BATCHNORM + MISH''' 18 | self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False) 19 | self.bn = nn.BatchNorm2d(out_channels) 20 | self.activation = Mish() 21 | 22 | def forward(self, x): 23 | x = self.conv(x) 24 | x = self.bn(x) 25 | x = self.activation(x) 26 | return x 27 | 28 | class Resblock(nn.Module): 29 | def __init__(self, channels, hidden_channels=None, residual_activation=nn.Identity()): 30 | super(Resblock, self).__init__() 31 | 32 | if hidden_channels is None: 33 | hidden_channels = channels 34 | 35 | self.block = nn.Sequential( 36 | BasicConv(channels, hidden_channels, 1), 37 | BasicConv(hidden_channels, channels, 3) 38 | ) 39 | 40 | def forward(self, x): 41 | return x + self.block(x) 42 | 43 | class Resblock_body(nn.Module): 44 | def __init__(self, in_channels, out_channels, num_blocks, first): 45 | super(Resblock_body, self).__init__() 46 | 47 | self.downsample_conv = BasicConv(in_channels, out_channels, 3, stride=2) 48 | 49 | if first: 50 | self.split_conv0 = BasicConv(out_channels, out_channels, 1) 51 | self.split_conv1 = BasicConv(out_channels, out_channels, 1) 52 | self.blocks_conv = nn.Sequential( 53 | Resblock(channels=out_channels, hidden_channels=out_channels//2), 54 | BasicConv(out_channels, out_channels, 1) 55 | ) 56 | self.concat_conv = BasicConv(out_channels*2, out_channels, 1) 57 | else: 58 | self.split_conv0 = BasicConv(out_channels, out_channels//2, 1) 59 | self.split_conv1 = BasicConv(out_channels, out_channels//2, 1) 60 | 61 | self.blocks_conv = nn.Sequential( 62 | *[Resblock(out_channels//2) for _ in range(num_blocks)], 63 | BasicConv(out_channels//2, out_channels//2, 1) 64 | ) 65 | self.concat_conv = BasicConv(out_channels, out_channels, 1) 66 | 67 | def forward(self, x): 68 | x = self.downsample_conv(x) 69 | 70 | x0 = self.split_conv0(x) 71 | 72 | x1 = self.split_conv1(x) 73 | x1 = self.blocks_conv(x1) 74 | 75 | x = torch.cat([x1, x0], dim=1) 76 | x = self.concat_conv(x) 77 | 78 | return x 79 | 80 | class CSPDarkNet(nn.Module): 81 | def __init__(self, layers): 82 | super(CSPDarkNet, self).__init__() 83 | self.inplanes = 32 84 | self.conv1 = BasicConv(3, self.inplanes, kernel_size=3, stride=1) 85 | self.feature_channels = [64, 128, 256, 512, 1024] 86 | 87 | self.stages = nn.ModuleList([ 88 | Resblock_body(self.inplanes, self.feature_channels[0], layers[0], first=True), 89 | Resblock_body(self.feature_channels[0], self.feature_channels[1], layers[1], first=False), 90 | Resblock_body(self.feature_channels[1], self.feature_channels[2], layers[2], first=False), 91 | Resblock_body(self.feature_channels[2], self.feature_channels[3], layers[3], first=False), 92 | Resblock_body(self.feature_channels[3], self.feature_channels[4], layers[4], first=False) 93 | ]) 94 | 95 | self.num_features = 1 96 | 97 | # weight init. 98 | for m in self.modules(): 99 | if isinstance(m, nn.Conv2d): 100 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels 101 | m.weight.data.normal_(0, math.sqrt(2. / n)) 102 | elif isinstance(m, nn.BatchNorm2d): 103 | m.weight.data.fill_(1) 104 | m.bias.data.zero_() 105 | 106 | def forward(self, x): 107 | x = self.conv1(x) 108 | 109 | x = self.stages[0](x) 110 | x = self.stages[1](x) 111 | out3 = self.stages[2](x) 112 | out4 = self.stages[3](out3) 113 | out5 = self.stages[4](out4) 114 | 115 | return out3, out4, out5 116 | 117 | def darknet53(pretrained, **kwargs): 118 | model = CSPDarkNet([1, 2, 8, 8, 4]) 119 | if pretrained: 120 | if isinstance(pretrained, str): 121 | model.load_state_dict(torch.load(pretrained)) 122 | else: 123 | raise Exception("darknet request a pretrained path. got [{}]".format(pretrained)) 124 | return model 125 | -------------------------------------------------------------------------------- /nets/__pycache__/CSPdarknet.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/nets/__pycache__/CSPdarknet.cpython-37.pyc -------------------------------------------------------------------------------- /nets/__pycache__/yolo4.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/nets/__pycache__/yolo4.cpython-37.pyc -------------------------------------------------------------------------------- /nets/__pycache__/yolo_training.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/nets/__pycache__/yolo_training.cpython-37.pyc -------------------------------------------------------------------------------- /nets/yolo4.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn as nn 3 | from collections import OrderedDict 4 | from nets.CSPdarknet import darknet53 5 | 6 | def conv2d(filter_in, filter_out, kernel_size, stride=1): 7 | pad = (kernel_size - 1) // 2 if kernel_size else 0 8 | return nn.Sequential(OrderedDict([ 9 | ("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=stride, padding=pad, bias=False)), 10 | ("bn", nn.BatchNorm2d(filter_out)), 11 | ("relu", nn.LeakyReLU(0.1)), 12 | ])) 13 | 14 | class SpatialPyramidPooling(nn.Module): 15 | def __init__(self, pool_sizes=[5, 9, 13]): 16 | super(SpatialPyramidPooling, self).__init__() 17 | 18 | self.maxpools = nn.ModuleList([nn.MaxPool2d(pool_size, 1, pool_size//2) for pool_size in pool_sizes]) 19 | 20 | def forward(self, x): 21 | features = [maxpool(x) for maxpool in self.maxpools[::-1]] 22 | features = torch.cat(features + [x], dim=1) 23 | 24 | return features 25 | 26 | class Upsample(nn.Module): 27 | def __init__(self, in_channels, out_channels): 28 | super(Upsample, self).__init__() 29 | 30 | self.upsample = nn.Sequential( 31 | conv2d(in_channels, out_channels, 1), 32 | nn.Upsample(scale_factor=2, mode='nearest') 33 | ) 34 | 35 | def forward(self, x,): 36 | x = self.upsample(x) 37 | return x 38 | 39 | def make_three_conv(filters_list, in_filters): 40 | m = nn.Sequential( 41 | conv2d(in_filters, filters_list[0], 1), 42 | conv2d(filters_list[0], filters_list[1], 3), 43 | conv2d(filters_list[1], filters_list[0], 1), 44 | ) 45 | return m 46 | 47 | def make_five_conv(filters_list, in_filters): 48 | m = nn.Sequential( 49 | conv2d(in_filters, filters_list[0], 1), 50 | conv2d(filters_list[0], filters_list[1], 3), 51 | conv2d(filters_list[1], filters_list[0], 1), 52 | conv2d(filters_list[0], filters_list[1], 3), 53 | conv2d(filters_list[1], filters_list[0], 1), 54 | ) 55 | return m 56 | 57 | def yolo_head(filters_list, in_filters): 58 | m = nn.Sequential( 59 | conv2d(in_filters, filters_list[0], 3), 60 | nn.Conv2d(filters_list[0], filters_list[1], 1), 61 | ) 62 | return m 63 | 64 | class YoloBody(nn.Module): 65 | def __init__(self, num_anchors, num_classes): 66 | super(YoloBody, self).__init__() 67 | # backbone 68 | self.backbone = darknet53(None) 69 | 70 | self.conv1 = make_three_conv([512,1024],1024) 71 | self.SPP = SpatialPyramidPooling() 72 | self.conv2 = make_three_conv([512,1024],2048) 73 | 74 | self.upsample1 = Upsample(512,256) 75 | self.conv_for_P4 = conv2d(512,256,1) 76 | self.make_five_conv1 = make_five_conv([256, 512],512) 77 | 78 | self.upsample2 = Upsample(256,128) 79 | self.conv_for_P3 = conv2d(256,128,1) 80 | self.make_five_conv2 = make_five_conv([128, 256],256) 81 | # 3*(5+num_classes) 82 | final_out_filter2 = num_anchors * (5 + num_classes) 83 | self.yolo_head3 = yolo_head([256, final_out_filter2],128) 84 | 85 | self.down_sample1 = conv2d(128,256,3,stride=2) 86 | self.make_five_conv3 = make_five_conv([256, 512],512) 87 | # 3*(5+num_classes) 88 | final_out_filter1 = num_anchors * (5 + num_classes) 89 | self.yolo_head2 = yolo_head([512, final_out_filter1],256) 90 | 91 | self.down_sample2 = conv2d(256,512,3,stride=2) 92 | self.make_five_conv4 = make_five_conv([512, 1024],1024) 93 | # 3*(5+num_classes) 94 | final_out_filter0 = num_anchors * (5 + num_classes) 95 | self.yolo_head1 = yolo_head([1024, final_out_filter0],512) 96 | 97 | def forward(self, x): 98 | # backbone 99 | x2, x1, x0 = self.backbone(x) 100 | 101 | P5 = self.conv1(x0) 102 | P5 = self.SPP(P5) 103 | P5 = self.conv2(P5) 104 | 105 | P5_upsample = self.upsample1(P5) 106 | P4 = self.conv_for_P4(x1) 107 | P4 = torch.cat([P4,P5_upsample],axis=1) 108 | P4 = self.make_five_conv1(P4) 109 | 110 | P4_upsample = self.upsample2(P4) 111 | P3 = self.conv_for_P3(x2) 112 | P3 = torch.cat([P3,P4_upsample],axis=1) 113 | P3 = self.make_five_conv2(P3) 114 | 115 | P3_downsample = self.down_sample1(P3) 116 | P4 = torch.cat([P3_downsample,P4],axis=1) 117 | P4 = self.make_five_conv3(P4) 118 | 119 | P4_downsample = self.down_sample2(P4) 120 | P5 = torch.cat([P4_downsample,P5],axis=1) 121 | P5 = self.make_five_conv4(P5) 122 | 123 | out2 = self.yolo_head3(P3) 124 | out1 = self.yolo_head2(P4) 125 | out0 = self.yolo_head1(P5) 126 | 127 | return out0, out1, out2 128 | 129 | -------------------------------------------------------------------------------- /nets/yolo_training.py: -------------------------------------------------------------------------------- 1 | from random import shuffle 2 | import numpy as np 3 | import torch 4 | import torch.nn as nn 5 | import math 6 | import torch.nn.functional as F 7 | from matplotlib.colors import rgb_to_hsv, hsv_to_rgb 8 | from PIL import Image 9 | from utils.utils import bbox_iou, merge_bboxes 10 | 11 | def jaccard(_box_a, _box_b): # box, box (ground truth) 12 | 13 | # box (xy - wh_half, xy + wh_half) 14 | b1_x1, b1_x2 = _box_a[:, 0] - _box_a[:, 2] / 2, _box_a[:, 0] + _box_a[:, 2] / 2 15 | b1_y1, b1_y2 = _box_a[:, 1] - _box_a[:, 3] / 2, _box_a[:, 1] + _box_a[:, 3] / 2 16 | b2_x1, b2_x2 = _box_b[:, 0] - _box_b[:, 2] / 2, _box_b[:, 0] + _box_b[:, 2] / 2 17 | b2_y1, b2_y2 = _box_b[:, 1] - _box_b[:, 3] / 2, _box_b[:, 1] + _box_b[:, 3] / 2 18 | box_a = torch.zeros_like(_box_a) 19 | box_b = torch.zeros_like(_box_b) 20 | 21 | box_a[:, 0], box_a[:, 1], box_a[:, 2], box_a[:, 3] = b1_x1, b1_y1, b1_x2, b1_y2 22 | box_b[:, 0], box_b[:, 1], box_b[:, 2], box_b[:, 3] = b2_x1, b2_y1, b2_x2, b2_y2 23 | A = box_a.size(0) 24 | B = box_b.size(0) 25 | 26 | # intersect 27 | min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2), 28 | box_b[:, :2].unsqueeze(0).expand(A, B, 2)) 29 | max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2), 30 | box_b[:, 2:].unsqueeze(0).expand(A, B, 2)) 31 | 32 | inter = torch.clamp((max_xy - min_xy), min=0) 33 | inter = inter[:, :, 0] * inter[:, :, 1] 34 | 35 | # union 36 | area_a = ((box_a[:, 2]-box_a[:, 0]) * 37 | (box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B] 38 | area_b = ((box_b[:, 2]-box_b[:, 0]) * 39 | (box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B] 40 | 41 | union = area_a + area_b - inter 42 | 43 | # iou 44 | return inter / union # [A,B] 45 | 46 | def smooth_labels(y_true, label_smoothing, num_classes): 47 | return y_true * (1.0 - label_smoothing) + label_smoothing / num_classes 48 | 49 | def box_ciou(b1, b2): 50 | 51 | # box 52 | b1_xy = b1[..., :2] 53 | b1_wh = b1[..., 2:4] 54 | b1_wh_half = b1_wh/2. 55 | b1_mins = b1_xy - b1_wh_half 56 | b1_maxes = b1_xy + b1_wh_half 57 | 58 | # box (ground truth) 59 | b2_xy = b2[..., :2] 60 | b2_wh = b2[..., 2:4] 61 | b2_wh_half = b2_wh/2. 62 | b2_mins = b2_xy - b2_wh_half 63 | b2_maxes = b2_xy + b2_wh_half 64 | 65 | # both box iou 66 | intersect_mins = torch.max(b1_mins, b2_mins) 67 | intersect_maxes = torch.min(b1_maxes, b2_maxes) 68 | intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes)) 69 | intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1] 70 | b1_area = b1_wh[..., 0] * b1_wh[..., 1] 71 | b2_area = b2_wh[..., 0] * b2_wh[..., 1] 72 | union_area = b1_area + b2_area - intersect_area 73 | iou = intersect_area / torch.clamp(union_area, min = 1e-6) 74 | 75 | # both box center distance (d*d) 76 | center_distance = torch.sum(torch.pow((b1_xy - b2_xy), 2), axis=-1) 77 | 78 | # enclosing box 79 | enclose_mins = torch.min(b1_mins, b2_mins) 80 | enclose_maxes = torch.max(b1_maxes, b2_maxes) 81 | enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes)) 82 | 83 | # enclose diagonal distance (c*c) 84 | enclose_diagonal = torch.sum(torch.pow(enclose_wh,2), axis=-1) 85 | ciou = iou - 1.0 * (center_distance) / torch.clamp(enclose_diagonal, min = 1e-6) 86 | 87 | v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(b1_wh[..., 0]/torch.clamp(b1_wh[..., 1], min = 1e-6)) - torch.atan(b2_wh[..., 0]/torch.clamp(b2_wh[..., 1], min = 1e-6))), 2) 88 | alpha = v / torch.clamp((1.0 - iou + v), min=1e-6) 89 | ciou = ciou - alpha * v 90 | return ciou 91 | 92 | def clip_by_tensor(t, t_min, t_max): 93 | t=t.float() 94 | result = (t >= t_min).float() * t + (t < t_min).float() * t_min 95 | result = (result <= t_max).float() * result + (result > t_max).float() * t_max 96 | return result 97 | 98 | def MSELoss(pred, target): 99 | return (pred-target)**2 100 | 101 | def BCELoss(pred, target): 102 | epsilon = 1e-7 103 | pred = clip_by_tensor(pred, epsilon, 1.0 - epsilon) 104 | output = -target * torch.log(pred) - (1.0 - target) * torch.log(1.0 - pred) 105 | return output 106 | 107 | class YOLOLoss(nn.Module): 108 | def __init__(self, anchors, num_classes, img_size, label_smooth=0, cuda=True): 109 | super(YOLOLoss, self).__init__() 110 | 111 | self.anchors = anchors 112 | ''' 113 | [[142. 110.] 114 | [192. 243.] 115 | [459. 401.] 116 | [ 36. 75.] 117 | [ 76. 55.] 118 | [ 72. 146.] 119 | [ 12. 16.] 120 | [ 19. 36.] 121 | [ 40. 28.]] 122 | ''' 123 | self.num_anchors = len(anchors) # 9 124 | self.num_classes = num_classes # 5 125 | self.bbox_attrs = 5 + num_classes # 10 -> (x,y,w,h,conf) + num_classes 126 | self.img_size = img_size # (608, 608) 127 | self.feature_length = [img_size[0]//32, img_size[0]//16, img_size[0]//8] # [19, 38, 76] 128 | self.label_smooth = label_smooth # 0 129 | 130 | self.ignore_threshold = 0.5 131 | self.lambda_conf = 1.0 132 | self.lambda_cls = 1.0 133 | self.lambda_loc = 1.0 134 | self.cuda = cuda 135 | 136 | def forward(self, input, targets=None): 137 | 138 | # input -> torch.Size([bs, 3*(5+num_classes), feature_length[i], feature_length[i]]) 139 | bs = input.size(0) 140 | in_h = input.size(2) 141 | in_w = input.size(3) 142 | 143 | stride_h = self.img_size[1] / in_h # feature_length[i] 144 | stride_w = self.img_size[0] / in_w # feature_length[i] 145 | 146 | # anchors size (original) -> anchors size (feature_length[i]) 147 | scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors] 148 | 149 | # input, torch.Size([bs, 3*(5+num_classes), feature_length[i], feature_length[i]]) 150 | # -> prediction, torch.Size([bs, 3 , feature_length[i], feature_length[i], (5+num_classes)]) 151 | prediction = input.view(bs, int(self.num_anchors/3), 152 | self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4, 2).contiguous() 153 | 154 | conf = torch.sigmoid(prediction[..., 4]) # Conf 155 | pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred. 156 | 157 | # detect object 158 | mask, noobj_mask, t_box, tconf, tcls, box_loss_scale_x, box_loss_scale_y = self.get_target(targets, scaled_anchors, in_w, in_h, self.ignore_threshold) 159 | 160 | noobj_mask, pred_boxes_for_ciou = self.get_ignore(prediction, targets, scaled_anchors, in_w, in_h, noobj_mask) 161 | 162 | if self.cuda: 163 | mask, noobj_mask = mask.cuda(), noobj_mask.cuda() 164 | box_loss_scale_x, box_loss_scale_y= box_loss_scale_x.cuda(), box_loss_scale_y.cuda() 165 | tconf, tcls = tconf.cuda(), tcls.cuda() 166 | pred_boxes_for_ciou = pred_boxes_for_ciou.cuda() 167 | t_box = t_box.cuda() 168 | 169 | box_loss_scale = 2 - box_loss_scale_x * box_loss_scale_y 170 | # losses. 171 | ciou = (1 - box_ciou( pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()])) * box_loss_scale[mask.bool()] 172 | 173 | loss_loc = torch.sum(ciou / bs) 174 | loss_conf = torch.sum(BCELoss(conf, mask) * mask / bs) + \ 175 | torch.sum(BCELoss(conf, mask) * noobj_mask / bs) 176 | 177 | # print(smooth_labels(tcls[mask == 1],self.label_smooth,self.num_classes)) 178 | loss_cls = torch.sum(BCELoss(pred_cls[mask == 1], smooth_labels(tcls[mask == 1], self.label_smooth, self.num_classes)) / bs) 179 | # print(loss_loc,loss_conf,loss_cls) 180 | loss = loss_conf * self.lambda_conf + loss_cls * self.lambda_cls + loss_loc * self.lambda_loc 181 | return loss, loss_conf.item(), loss_cls.item(), loss_loc.item() 182 | 183 | def get_target(self, target, anchors, in_w, in_h, ignore_threshold): 184 | 185 | bs = len(target) 186 | 187 | anchor_index = [[0,1,2],[3,4,5],[6,7,8]][self.feature_length.index(in_w)] 188 | subtract_index = [0,3,6][self.feature_length.index(in_w)] 189 | 190 | mask = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 191 | noobj_mask = torch.ones(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 192 | 193 | tx = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 194 | ty = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 195 | tw = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 196 | th = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 197 | t_box = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, 4, requires_grad=False) # tx,ty,tw,th 198 | 199 | tconf = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 200 | tcls = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, self.num_classes, requires_grad=False) 201 | 202 | box_loss_scale_x = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 203 | box_loss_scale_y = torch.zeros(bs, int(self.num_anchors/3), in_h, in_w, requires_grad=False) 204 | 205 | for b in range(bs): # image number 206 | for t in range(target[b].shape[0]): # object number 207 | 208 | # x,y,w,h (grid) 209 | gx = target[b][t, 0] * in_w 210 | gy = target[b][t, 1] * in_h 211 | gw = target[b][t, 2] * in_w 212 | gh = target[b][t, 3] * in_h 213 | 214 | # grid location 215 | gi = int(gx) 216 | gj = int(gy) 217 | 218 | # anchor ground truth (w, h) 219 | gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0) 220 | 221 | # anchor feature_length[i] (w, h) 222 | anchor_shapes = torch.FloatTensor(np.concatenate((np.zeros((self.num_anchors, 2)), 223 | np.array(anchors)), 1)) 224 | # anchor iou (w, h) 225 | anch_ious = bbox_iou(gt_box, anchor_shapes) 226 | 227 | # Find the best matching anchor box 228 | best_n = np.argmax(anch_ious) 229 | if best_n not in anchor_index: 230 | continue 231 | # Masks 232 | if (gj < in_h) and (gi < in_w): 233 | best_n = best_n - subtract_index 234 | 235 | # contain object 236 | mask[b, best_n, gj, gi] = 1 237 | noobj_mask[b, best_n, gj, gi] = 0 238 | 239 | tx[b, best_n, gj, gi] = gx 240 | ty[b, best_n, gj, gi] = gy 241 | tw[b, best_n, gj, gi] = gw 242 | th[b, best_n, gj, gi] = gh 243 | 244 | tconf[b, best_n, gj, gi] = 1 # conf 245 | tcls[b, best_n, gj, gi, int(target[b][t, 4])] = 1 # class 246 | 247 | box_loss_scale_x[b, best_n, gj, gi] = target[b][t, 2] # w 248 | box_loss_scale_y[b, best_n, gj, gi] = target[b][t, 3] # h 249 | 250 | else: 251 | print('Step {0} out of bound'.format(b)) 252 | print('gj: {0}, height: {1} | gi: {2}, width: {3}'.format(gj, in_h, gi, in_w)) 253 | continue 254 | t_box[...,0] = tx 255 | t_box[...,1] = ty 256 | t_box[...,2] = tw 257 | t_box[...,3] = th 258 | return mask, noobj_mask, t_box, tconf, tcls, box_loss_scale_x, box_loss_scale_y 259 | 260 | def get_ignore(self, prediction, target, scaled_anchors, in_w, in_h, noobj_mask): 261 | 262 | bs = len(target) 263 | 264 | anchor_index = [[0,1,2],[3,4,5],[6,7,8]][self.feature_length.index(in_w)] 265 | scaled_anchors = np.array(scaled_anchors)[anchor_index] 266 | 267 | x = torch.sigmoid(prediction[..., 0]) 268 | y = torch.sigmoid(prediction[..., 1]) 269 | w = prediction[..., 2] # Width 270 | h = prediction[..., 3] # Height 271 | 272 | FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor 273 | LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor 274 | 275 | # draw grids and its x,y number 276 | grid_x = torch.linspace(0, in_w - 1, in_w).repeat(in_w, 1).repeat( 277 | int(bs*self.num_anchors/3), 1, 1).view(x.shape).type(FloatTensor) 278 | grid_y = torch.linspace(0, in_h - 1, in_h).repeat(in_h, 1).t().repeat( 279 | int(bs*self.num_anchors/3), 1, 1).view(y.shape).type(FloatTensor) 280 | 281 | # generate anchor (w, h) 282 | anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0])) 283 | anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1])) 284 | 285 | # torch.Size([bs, 3, feature_length[i], feature_length[i]]) 286 | anchor_w = anchor_w.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(w.shape) 287 | anchor_h = anchor_h.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(h.shape) 288 | 289 | # calculate box (xy and wh) 290 | pred_boxes = FloatTensor(prediction[..., :4].shape) 291 | pred_boxes[..., 0] = x + grid_x 292 | pred_boxes[..., 1] = y + grid_y 293 | pred_boxes[..., 2] = torch.exp(w) * anchor_w 294 | pred_boxes[..., 3] = torch.exp(h) * anchor_h 295 | 296 | for i in range(bs): 297 | pred_boxes_for_ignore = pred_boxes[i] # torch.Size([3, feature_length[i], feature_length[i], 4]) 298 | pred_boxes_for_ignore = pred_boxes_for_ignore.view(-1, 4) 299 | if len(target[i]) > 0: 300 | gx = target[i][:, 0:1] * in_w 301 | gy = target[i][:, 1:2] * in_h 302 | gw = target[i][:, 2:3] * in_w 303 | gh = target[i][:, 3:4] * in_h 304 | gt_box = torch.FloatTensor(np.concatenate([gx, gy, gw, gh],-1)).type(FloatTensor) 305 | 306 | anch_ious = jaccard(gt_box, pred_boxes_for_ignore) 307 | for t in range(target[i].shape[0]): 308 | anch_iou = anch_ious[t].view(pred_boxes[i].size()[:3]) 309 | noobj_mask[i][anch_iou>self.ignore_threshold] = 0 310 | return noobj_mask, pred_boxes 311 | 312 | def rand(a=0, b=1): 313 | return np.random.rand() * (b - a) + a 314 | 315 | class Generator(object): 316 | def __init__(self,batch_size, 317 | train_lines, image_size): 318 | 319 | self.batch_size = batch_size 320 | self.train_lines = train_lines 321 | self.train_batches = len(train_lines) 322 | self.image_size = image_size 323 | 324 | def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5): 325 | '''random preprocessing for real-time data augmentation''' 326 | line = annotation_line.split() 327 | image = Image.open(line[0]) 328 | iw, ih = image.size 329 | h, w = input_shape 330 | box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]]) 331 | 332 | # resize image 333 | new_ar = w / h * rand(1 - jitter, 1 + jitter) / rand(1 - jitter , 1 + jitter) 334 | scale = rand(.25, 2) 335 | if new_ar < 1: 336 | nh = int(scale * h) 337 | nw = int(nh * new_ar) 338 | else: 339 | nw = int(scale * w) 340 | nh = int(nw / new_ar) 341 | image = image.resize((nw, nh), Image.BICUBIC) 342 | 343 | # place image with gray area 344 | dx = int(rand(0, w - nw)) 345 | dy = int(rand(0, h - nh)) 346 | new_image = Image.new('RGB', (w, h), (128,128,128)) 347 | new_image.paste(image, (dx, dy)) 348 | image = new_image 349 | 350 | # flip image or not 351 | flip = rand() < .5 352 | if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT) 353 | 354 | # distort image 355 | hue = rand(-hue, hue) 356 | sat = rand(1, sat) if rand() < .5 else 1 / rand(1, sat) 357 | val = rand(1, val) if rand() < .5 else 1 / rand(1, val) 358 | x = rgb_to_hsv(np.array(image) / 255.) 359 | x[..., 0] += hue 360 | x[..., 0][x[..., 0] > 1] -= 1 361 | x[..., 0][x[..., 0] < 0] += 1 362 | x[..., 1] *= sat 363 | x[..., 2] *= val 364 | x[x > 1] = 1 365 | x[x < 0] = 0 366 | image_data = hsv_to_rgb(x) * 255 # numpy array, 0 to 1 367 | 368 | # correct boxes 369 | box_data = np.zeros((len(box), 5)) 370 | if len(box) > 0: 371 | np.random.shuffle(box) 372 | box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx 373 | box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy 374 | if flip: box[:, [0, 2]] = w - box[:, [2, 0]] 375 | box[:, 0:2][box[:, 0:2] < 0] = 0 376 | box[:, 2][box[:, 2] > w] = w 377 | box[:, 3][box[:, 3] > h] = h 378 | box_w = box[:, 2] - box[:, 0] 379 | box_h = box[:, 3] - box[:, 1] 380 | box = box[np.logical_and(box_w > 1, box_h > 1)] # discard invalid box 381 | box_data = np.zeros((len(box), 5)) 382 | box_data[:len(box)] = box 383 | if len(box) == 0: 384 | return image_data, [] 385 | 386 | if (box_data[:, :4] > 0).any(): 387 | return image_data, box_data 388 | else: 389 | return image_data, [] 390 | 391 | def get_random_data_with_Mosaic(self, annotation_line, input_shape, hue=.1, sat=1.5, val=1.5): 392 | '''random preprocessing for real-time data augmentation''' 393 | h, w = input_shape 394 | # final ratio of each picture (four pictures) 395 | min_offset_x = 0.4 396 | min_offset_y = 0.4 397 | scale_low = 1 - min(min_offset_x, min_offset_y) 398 | scale_high = scale_low + 0.2 399 | 400 | image_datas = [] 401 | box_datas = [] 402 | index = 0 403 | 404 | place_x = [0, 0, int(w * min_offset_x),int(w * min_offset_x)] 405 | place_y = [0, int(h * min_offset_y),int(w * min_offset_y), 0] 406 | for line in annotation_line: 407 | line_content = line.split() 408 | image = Image.open(line_content[0]) 409 | image = image.convert("RGB") 410 | iw, ih = image.size 411 | # x_min, y_min, x_max, y_max, class 412 | box = np.array([np.array(list(map(int, box.split(',')))) for box in line_content[1:]]) 413 | 414 | # flip image or not 415 | flip = rand() < .5 416 | if flip and len(box) > 0: 417 | image = image.transpose(Image.FLIP_LEFT_RIGHT) 418 | box[:, [0, 2]] = iw - box[:, [2, 0]] 419 | 420 | # resize image 421 | new_ar = w / h 422 | scale = rand(scale_low, scale_high) 423 | if new_ar < 1: 424 | nh = int(scale * h) 425 | nw = int(nh * new_ar) 426 | else: 427 | nw = int(scale * w) 428 | nh = int(nw / new_ar) 429 | image = image.resize((nw, nh), Image.BICUBIC) 430 | 431 | # distort image 432 | hue = rand(-hue, hue) 433 | sat = rand(1, sat) if rand() < .5 else 1 / rand(1, sat) 434 | val = rand(1, val) if rand() < .5 else 1 / rand(1, val) 435 | x = rgb_to_hsv(np.array(image)/255.) 436 | x[..., 0] += hue 437 | x[..., 0][x[..., 0] > 1] -= 1 438 | x[..., 0][x[..., 0] < 0] += 1 439 | x[..., 1] *= sat 440 | x[..., 2] *= val 441 | x[x>1] = 1 442 | x[x<0] = 0 443 | image = hsv_to_rgb(x) 444 | 445 | image = Image.fromarray((image*255).astype(np.uint8)) 446 | # place images to correspond to the positions (four pictures) with gray area 447 | dx = place_x[index] 448 | dy = place_y[index] 449 | new_image = Image.new('RGB', (w,h), (128,128,128)) 450 | new_image.paste(image, (dx, dy)) 451 | image_data = np.array(new_image) 452 | 453 | index = index + 1 454 | box_data = [] 455 | # correct boxes 456 | if len(box)>0: 457 | np.random.shuffle(box) 458 | box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx 459 | box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy 460 | box[:, 0:2][box[:, 0:2] < 0] = 0 461 | box[:, 2][box[:, 2] > w] = w 462 | box[:, 3][box[:, 3] > h] = h 463 | box_w = box[:, 2] - box[:, 0] 464 | box_h = box[:, 3] - box[:, 1] 465 | box = box[np.logical_and(box_w > 1, box_h > 1)] 466 | box_data = np.zeros((len(box), 5)) 467 | box_data[:len(box)] = box 468 | 469 | image_datas.append(image_data) 470 | box_datas.append(box_data) 471 | 472 | # split the image and merge it by x, y axis (cutx, cuty) 473 | cutx = np.random.randint(int(w * min_offset_x), int(w * (1 - min_offset_x))) 474 | cuty = np.random.randint(int(h * min_offset_y), int(h * (1 - min_offset_y))) 475 | 476 | new_image = np.zeros([h,w,3]) 477 | new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :] 478 | new_image[cuty:, :cutx, :] = image_datas[1][cuty:, :cutx, :] 479 | new_image[cuty:, cutx:, :] = image_datas[2][cuty:, cutx:, :] 480 | new_image[:cuty, cutx:, :] = image_datas[3][:cuty, cutx:, :] 481 | 482 | # merge_bboxes 483 | new_boxes = np.array(merge_bboxes(box_datas, cutx, cuty)) 484 | 485 | if len(new_boxes) == 0: 486 | return new_image, [] 487 | if (new_boxes[:,:4]>0).any(): 488 | return new_image, new_boxes 489 | else: 490 | return new_image, [] 491 | 492 | def generate(self, train = True, mosaic = True): 493 | while True: 494 | shuffle(self.train_lines) 495 | lines = self.train_lines 496 | inputs = [] 497 | targets = [] 498 | flag = True 499 | n = len(lines) 500 | for i in range(len(lines)): 501 | if mosaic == True: 502 | if flag and (i+4) < n: 503 | img,y = self.get_random_data_with_Mosaic(lines[i:i+4], self.image_size[0:2]) 504 | i = (i+4) % n 505 | else: 506 | img,y = self.get_random_data(lines[i], self.image_size[0:2]) 507 | i = (i+1) % n 508 | flag = bool(1-flag) 509 | else: 510 | img,y = self.get_random_data(lines[i], self.image_size[0:2]) 511 | i = (i+1) % n 512 | if len(y)!=0: 513 | boxes = np.array(y[:,:4],dtype=np.float32) 514 | boxes[:,0] = boxes[:,0]/self.image_size[1] 515 | boxes[:,1] = boxes[:,1]/self.image_size[0] 516 | boxes[:,2] = boxes[:,2]/self.image_size[1] 517 | boxes[:,3] = boxes[:,3]/self.image_size[0] 518 | 519 | boxes = np.maximum(np.minimum(boxes,1),0) 520 | boxes[:,2] = boxes[:,2] - boxes[:,0] 521 | boxes[:,3] = boxes[:,3] - boxes[:,1] 522 | 523 | boxes[:,0] = boxes[:,0] + boxes[:,2]/2 524 | boxes[:,1] = boxes[:,1] + boxes[:,3]/2 525 | y = np.concatenate([boxes,y[:,-1:]],axis=-1) 526 | 527 | img = np.array(img,dtype = np.float32) 528 | 529 | inputs.append(np.transpose(img/255.0,(2,0,1))) 530 | targets.append(np.array(y,dtype = np.float32)) 531 | if len(targets) == self.batch_size: 532 | tmp_inp = np.array(inputs) 533 | tmp_targets = np.array(targets) 534 | inputs = [] 535 | targets = [] 536 | yield tmp_inp, tmp_targets 537 | -------------------------------------------------------------------------------- /predict.py: -------------------------------------------------------------------------------- 1 | from yolo import YOLO 2 | from PIL import Image 3 | 4 | yolo = YOLO() 5 | 6 | # predict image 7 | while True: 8 | 9 | img = input('Input image filename:') 10 | try: 11 | image = Image.open(img) 12 | except: 13 | print('Open Error! Try again!') 14 | continue 15 | else: 16 | r_image = yolo.detect_image(image) 17 | 18 | # save predict image as predict_img.png 19 | r_image.save("predict_img.png","png") 20 | r_image.show() -------------------------------------------------------------------------------- /test.py: -------------------------------------------------------------------------------- 1 | from torchsummary import summary 2 | from nets.CSPdarknet import darknet53 3 | from nets.yolo4 import YoloBody 4 | 5 | if __name__ == "__main__": 6 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') 7 | model = YoloBody(3,5).to(device) 8 | summary(model, input_size=(3, 608, 608)) -------------------------------------------------------------------------------- /train.py: -------------------------------------------------------------------------------- 1 | import os 2 | import numpy as np 3 | import time 4 | import torch 5 | from torch.autograd import Variable 6 | import torch.nn as nn 7 | import torch.optim as optim 8 | import torch.nn.functional as F 9 | import torch.backends.cudnn as cudnn 10 | from torch.utils.data import DataLoader 11 | from utils.dataloader import yolo_dataset_collate, YoloDataset 12 | from nets.yolo_training import YOLOLoss, Generator 13 | from nets.yolo4 import YoloBody 14 | 15 | def get_classes(classes_path): 16 | '''loads the classes''' 17 | with open(classes_path) as f: 18 | class_names = f.readlines() 19 | class_names = [c.strip() for c in class_names] 20 | return class_names 21 | 22 | def get_anchors(anchors_path): 23 | '''loads the anchors from a file''' 24 | with open(anchors_path) as f: 25 | anchors = f.readline() 26 | anchors = [float(x) for x in anchors.split(',')] 27 | return np.array(anchors).reshape([-1,3,2])[::-1,:,:] 28 | 29 | def fit_ont_epoch(net, yolo_losses, epoch, epoch_size, epoch_size_val, gen, genval, Epoch, cuda): 30 | 31 | total_loss = 0 32 | val_loss = 0 33 | start_time = time.time() 34 | for iteration, batch in enumerate(gen): 35 | 36 | if iteration >= epoch_size: 37 | break 38 | # input, numpy.ndarray(bs, 3, input_shape[0], input_shape[1]) 39 | # targets, numpy.ndarray(bs) 40 | images, targets = batch[0], batch[1] 41 | 42 | with torch.no_grad(): 43 | if cuda: 44 | images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda() 45 | targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets] 46 | else: 47 | images = Variable(torch.from_numpy(images).type(torch.FloatTensor)) 48 | targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets] 49 | optimizer.zero_grad() 50 | outputs = net(images) # head1, head2, head3 51 | 52 | losses = [] 53 | for i in range(3): # feature_length[i] 54 | # outputs[i] -> torch.Size([bs, 3*(5+num_classes), feature_length[i], feature_length[i]]) 55 | loss_item = yolo_losses[i](outputs[i], targets) 56 | losses.append(loss_item[0]) 57 | loss = sum(losses) 58 | loss.backward() 59 | optimizer.step() 60 | 61 | total_loss += loss 62 | waste_time = time.time() - start_time 63 | print('\nEpoch:'+ str(epoch+1) + '/' + str(Epoch)) 64 | print('iter:' + str(iteration) + '/' + str(epoch_size) + ' || Total Loss: %.4f || %.4fs/step' % (total_loss/(iteration+1),waste_time)) 65 | start_time = time.time() 66 | 67 | print('Start Validation') 68 | for iteration, batch in enumerate(genval): 69 | if iteration >= epoch_size_val: 70 | break 71 | images_val, targets_val = batch[0], batch[1] 72 | 73 | with torch.no_grad(): 74 | if cuda: 75 | images_val = Variable(torch.from_numpy(images_val).type(torch.FloatTensor)).cuda() 76 | targets_val = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets_val] 77 | else: 78 | images_val = Variable(torch.from_numpy(images_val).type(torch.FloatTensor)) 79 | targets_val = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets_val] 80 | optimizer.zero_grad() 81 | outputs = net(images_val) 82 | losses = [] 83 | for i in range(3): 84 | loss_item = yolo_losses[i](outputs[i], targets_val) 85 | losses.append(loss_item[0]) 86 | loss = sum(losses) 87 | val_loss += loss 88 | print('Finish Validation') 89 | print('\nEpoch:'+ str(epoch+1) + '/' + str(Epoch)) 90 | print('Total Loss: %.4f || Val Loss: %.4f ' % (total_loss/(epoch_size+1),val_loss/(epoch_size_val+1))) 91 | 92 | print('Saving state, iter:', str(epoch+1)) 93 | torch.save(model.state_dict(), 'logs/Epoch%d-Total_Loss%.4f-Val_Loss%.4f.pth'%((epoch+1),total_loss/(epoch_size+1),val_loss/(epoch_size_val+1))) 94 | 95 | 96 | if __name__ == "__main__": 97 | 98 | input_shape = (608,608) 99 | 100 | Cosine_lr = False 101 | mosaic = True 102 | smoooth_label = 0 103 | 104 | Cuda = False 105 | Use_Data_Loader = True 106 | 107 | annotation_path = '2007_train.txt' # your dataset [change content] 108 | 109 | anchors_path = 'model_data/yolo_anchors.txt' 110 | classes_path = 'model_data/voc_classes.txt' # your clesses [change content] 111 | class_names = get_classes(classes_path) 112 | anchors = get_anchors(anchors_path) 113 | num_classes = len(class_names) 114 | 115 | model = YoloBody(len(anchors[0]), num_classes) 116 | 117 | model_path = "model_data/yolo4_voc_weights.pth" # pre-traing model 118 | 119 | print('Loading weights into state dict...') 120 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') 121 | model_dict = model.state_dict() 122 | pretrained_dict = torch.load(model_path, map_location=device) 123 | pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)} 124 | model_dict.update(pretrained_dict) 125 | model.load_state_dict(model_dict) 126 | print('Finished!') 127 | 128 | net = model.train() 129 | 130 | if Cuda: 131 | net = torch.nn.DataParallel(model) 132 | cudnn.benchmark = True 133 | net = net.cuda() 134 | 135 | # bulid loss function 136 | yolo_losses = [] 137 | for i in range(3): # feature_length[i] 138 | yolo_losses.append(YOLOLoss(np.reshape(anchors,[-1,2]), num_classes, \ 139 | (input_shape[1], input_shape[0]), smoooth_label, Cuda)) 140 | 141 | # dataset setting -> 10% validation, 90% training 142 | val_split = 0.1 143 | with open(annotation_path) as f: 144 | lines = f.readlines() 145 | np.random.seed(10101) 146 | np.random.shuffle(lines) 147 | np.random.seed(None) 148 | num_val = int(len(lines)*val_split) 149 | num_train = len(lines) - num_val 150 | 151 | Batch_size = 4 152 | Freeze_lr = 1e-3 153 | Unfreeze_lr = 1e-4 154 | Init_Epoch = 0 155 | Freeze_Epoch = 25 156 | Unfreeze_Epoch = 50 157 | 158 | if Use_Data_Loader: 159 | train_dataset = YoloDataset(lines[:num_train], (input_shape[0], input_shape[1]), mosaic=mosaic) 160 | val_dataset = YoloDataset(lines[num_train:], (input_shape[0], input_shape[1]), mosaic=False) 161 | gen = DataLoader(train_dataset, batch_size=Batch_size, num_workers=8, pin_memory=True, 162 | drop_last=True, collate_fn=yolo_dataset_collate) 163 | gen_val = DataLoader(val_dataset, batch_size=Batch_size, num_workers=8,pin_memory=True, 164 | drop_last=True, collate_fn=yolo_dataset_collate) 165 | else: 166 | gen = Generator(Batch_size, lines[:num_train], 167 | (input_shape[0], input_shape[1])).generate(mosaic = mosaic) 168 | gen_val = Generator(Batch_size, lines[num_train:], 169 | (input_shape[0], input_shape[1])).generate(mosaic = False) 170 | 171 | epoch_size = max(1, num_train//Batch_size) 172 | epoch_size_val = num_val//Batch_size 173 | 174 | '''Freeze backbone for training''' 175 | lr = Freeze_lr 176 | optimizer = optim.Adam(net.parameters(),lr,weight_decay=5e-4) 177 | if Cosine_lr: 178 | lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-5) 179 | else: 180 | lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.9) 181 | 182 | for param in model.backbone.parameters(): 183 | param.requires_grad = False 184 | 185 | for epoch in range(Init_Epoch,Freeze_Epoch): 186 | fit_ont_epoch(net,yolo_losses,epoch,epoch_size,epoch_size_val,gen,gen_val,Freeze_Epoch,Cuda) 187 | lr_scheduler.step() 188 | 189 | '''Unfreeze whole network for training''' 190 | lr = Unfreeze_lr 191 | optimizer = optim.Adam(net.parameters(),lr,weight_decay=5e-4) 192 | if Cosine_lr: 193 | lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-5) 194 | else: 195 | lr_scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=1,gamma=0.9) 196 | 197 | for param in model.backbone.parameters(): 198 | param.requires_grad = True 199 | 200 | for epoch in range(Freeze_Epoch,Unfreeze_Epoch): 201 | fit_ont_epoch(net,yolo_losses,epoch,epoch_size,epoch_size_val,gen,gen_val,Unfreeze_Epoch,Cuda) 202 | lr_scheduler.step() 203 | -------------------------------------------------------------------------------- /utils/__pycache__/dataloader.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/utils/__pycache__/dataloader.cpython-37.pyc -------------------------------------------------------------------------------- /utils/__pycache__/utils.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/stemsgrpy/Object-Detection-for-CARLA-Driving-Simulator-by-using-YOLOv4/7227a2c8eb7dd26515950b1a48d8698fbaf8b8d9/utils/__pycache__/utils.cpython-37.pyc -------------------------------------------------------------------------------- /utils/dataloader.py: -------------------------------------------------------------------------------- 1 | from random import shuffle 2 | import numpy as np 3 | import torch 4 | import torch.nn as nn 5 | import math 6 | import torch.nn.functional as F 7 | from PIL import Image 8 | from torch.autograd import Variable 9 | from torch.utils.data import DataLoader 10 | from torch.utils.data.dataset import Dataset 11 | from utils.utils import bbox_iou, merge_bboxes 12 | from matplotlib.colors import rgb_to_hsv, hsv_to_rgb 13 | from nets.yolo_training import Generator 14 | 15 | class YoloDataset(Dataset): 16 | def __init__(self, train_lines, image_size, mosaic=True): 17 | super(YoloDataset, self).__init__() 18 | 19 | self.train_lines = train_lines 20 | self.train_batches = len(train_lines) 21 | self.image_size = image_size 22 | self.mosaic = mosaic 23 | self.flag = True 24 | 25 | def __len__(self): 26 | return self.train_batches 27 | 28 | def rand(self, a=0, b=1): 29 | return np.random.rand() * (b - a) + a 30 | 31 | def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5): 32 | '''random preprocessing for real-time data augmentation''' 33 | line = annotation_line.split() 34 | image = Image.open(line[0]) 35 | iw, ih = image.size 36 | h, w = input_shape 37 | box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]]) 38 | 39 | # resize image 40 | new_ar = w / h * self.rand(1 - jitter, 1 + jitter) / self.rand(1 - jitter, 1 + jitter) 41 | scale = self.rand(.25, 2) 42 | if new_ar < 1: 43 | nh = int(scale * h) 44 | nw = int(nh * new_ar) 45 | else: 46 | nw = int(scale * w) 47 | nh = int(nw / new_ar) 48 | image = image.resize((nw, nh), Image.BICUBIC) 49 | 50 | # # place image with random clolor area 51 | dx = int(self.rand(0, w - nw)) 52 | dy = int(self.rand(0, h - nh)) 53 | new_image = Image.new('RGB', (w, h), 54 | (np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255))) 55 | new_image.paste(image, (dx, dy)) 56 | image = new_image 57 | 58 | # flip image or not 59 | flip = self.rand() < .5 60 | if flip: 61 | image = image.transpose(Image.FLIP_LEFT_RIGHT) 62 | 63 | # distort image 64 | hue = self.rand(-hue, hue) 65 | sat = self.rand(1, sat) if self.rand() < .5 else 1 / self.rand(1, sat) 66 | val = self.rand(1, val) if self.rand() < .5 else 1 / self.rand(1, val) 67 | x = rgb_to_hsv(np.array(image) / 255.) 68 | x[..., 0] += hue 69 | x[..., 0][x[..., 0] > 1] -= 1 70 | x[..., 0][x[..., 0] < 0] += 1 71 | x[..., 1] *= sat 72 | x[..., 2] *= val 73 | x[x > 1] = 1 74 | x[x < 0] = 0 75 | image_data = hsv_to_rgb(x) * 255 # numpy array, 0 to 1 76 | 77 | # correct boxes 78 | box_data = np.zeros((len(box), 5)) 79 | if len(box) > 0: 80 | np.random.shuffle(box) 81 | box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx 82 | box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy 83 | if flip: 84 | box[:, [0, 2]] = w - box[:, [2, 0]] 85 | box[:, 0:2][box[:, 0:2] < 0] = 0 86 | box[:, 2][box[:, 2] > w] = w 87 | box[:, 3][box[:, 3] > h] = h 88 | box_w = box[:, 2] - box[:, 0] 89 | box_h = box[:, 3] - box[:, 1] 90 | box = box[np.logical_and(box_w > 1, box_h > 1)] # discard invalid box 91 | box_data = np.zeros((len(box), 5)) 92 | box_data[:len(box)] = box 93 | if len(box) == 0: 94 | return image_data, [] 95 | 96 | if (box_data[:, :4] > 0).any(): 97 | return image_data, box_data 98 | else: 99 | return image_data, [] 100 | 101 | def get_random_data_with_Mosaic(self, annotation_line, input_shape, hue=.1, sat=1.5, val=1.5): 102 | '''random preprocessing for real-time data augmentation''' 103 | h, w = input_shape 104 | # final ratio of each picture (four pictures) 105 | min_offset_x = 0.3 106 | min_offset_y = 0.3 107 | scale_low = 1 - min(min_offset_x, min_offset_y) 108 | scale_high = scale_low + 0.2 109 | 110 | image_datas = [] 111 | box_datas = [] 112 | index = 0 113 | 114 | place_x = [0, 0, int(w * min_offset_x), int(w * min_offset_x)] 115 | place_y = [0, int(h * min_offset_y), int(w * min_offset_y), 0] 116 | for line in annotation_line: 117 | line_content = line.split() 118 | image = Image.open(line_content[0]) 119 | image = image.convert("RGB") 120 | iw, ih = image.size 121 | # x_min, y_min, x_max, y_max, class 122 | box = np.array([np.array(list(map(int, box.split(',')))) for box in line_content[1:]]) 123 | 124 | # flip image or not 125 | flip = self.rand() < .5 126 | if flip and len(box) > 0: 127 | image = image.transpose(Image.FLIP_LEFT_RIGHT) 128 | box[:, [0, 2]] = iw - box[:, [2, 0]] 129 | 130 | # resize image 131 | new_ar = w / h 132 | scale = self.rand(scale_low, scale_high) 133 | if new_ar < 1: 134 | nh = int(scale * h) 135 | nw = int(nh * new_ar) 136 | else: 137 | nw = int(scale * w) 138 | nh = int(nw / new_ar) 139 | image = image.resize((nw, nh), Image.BICUBIC) 140 | 141 | # distort image 142 | hue = self.rand(-hue, hue) 143 | sat = self.rand(1, sat) if self.rand() < .5 else 1 / self.rand(1, sat) 144 | val = self.rand(1, val) if self.rand() < .5 else 1 / self.rand(1, val) 145 | x = rgb_to_hsv(np.array(image) / 255.) 146 | x[..., 0] += hue 147 | x[..., 0][x[..., 0] > 1] -= 1 148 | x[..., 0][x[..., 0] < 0] += 1 149 | x[..., 1] *= sat 150 | x[..., 2] *= val 151 | x[x > 1] = 1 152 | x[x < 0] = 0 153 | image = hsv_to_rgb(x) 154 | 155 | image = Image.fromarray((image * 255).astype(np.uint8)) 156 | # place images to correspond to the positions (four pictures) with random clolor area 157 | dx = place_x[index] 158 | dy = place_y[index] 159 | new_image = Image.new('RGB', (w, h), 160 | (np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255))) 161 | new_image.paste(image, (dx, dy)) 162 | image_data = np.array(new_image) 163 | 164 | index = index + 1 165 | box_data = [] 166 | # correct boxes 167 | if len(box) > 0: 168 | np.random.shuffle(box) 169 | box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx 170 | box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy 171 | box[:, 0:2][box[:, 0:2] < 0] = 0 172 | box[:, 2][box[:, 2] > w] = w 173 | box[:, 3][box[:, 3] > h] = h 174 | box_w = box[:, 2] - box[:, 0] 175 | box_h = box[:, 3] - box[:, 1] 176 | box = box[np.logical_and(box_w > 1, box_h > 1)] 177 | box_data = np.zeros((len(box), 5)) 178 | box_data[:len(box)] = box 179 | 180 | image_datas.append(image_data) 181 | box_datas.append(box_data) 182 | 183 | # split the image and merge it by x, y axis (cutx, cuty) 184 | cutx = np.random.randint(int(w * min_offset_x), int(w * (1 - min_offset_x))) 185 | cuty = np.random.randint(int(h * min_offset_y), int(h * (1 - min_offset_y))) 186 | 187 | new_image = np.zeros([h, w, 3]) 188 | new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :] 189 | new_image[cuty:, :cutx, :] = image_datas[1][cuty:, :cutx, :] 190 | new_image[cuty:, cutx:, :] = image_datas[2][cuty:, cutx:, :] 191 | new_image[:cuty, cutx:, :] = image_datas[3][:cuty, cutx:, :] 192 | 193 | # merge_bboxes 194 | new_boxes = np.array(merge_bboxes(box_datas, cutx, cuty)) 195 | 196 | if len(new_boxes) == 0: 197 | return new_image, [] 198 | if (new_boxes[:, :4] > 0).any(): 199 | return new_image, new_boxes 200 | else: 201 | return new_image, [] 202 | 203 | def __getitem__(self, index): 204 | if index == 0: 205 | shuffle(self.train_lines) 206 | lines = self.train_lines 207 | n = self.train_batches 208 | index = index % n 209 | if self.mosaic: 210 | if self.flag and (index + 4) < n: 211 | img, y = self.get_random_data_with_Mosaic(lines[index:index + 4], self.image_size[0:2]) 212 | else: 213 | img, y = self.get_random_data(lines[index], self.image_size[0:2]) 214 | self.flag = bool(1-self.flag) 215 | else: 216 | img, y = self.get_random_data(lines[index], self.image_size[0:2]) 217 | 218 | if len(y) != 0: 219 | # convert from coordinates to percentage (0~1) 220 | boxes = np.array(y[:, :4], dtype=np.float32) 221 | boxes[:, 0] = boxes[:, 0] / self.image_size[1] 222 | boxes[:, 1] = boxes[:, 1] / self.image_size[0] 223 | boxes[:, 2] = boxes[:, 2] / self.image_size[1] 224 | boxes[:, 3] = boxes[:, 3] / self.image_size[0] 225 | 226 | boxes = np.maximum(np.minimum(boxes, 1), 0) 227 | boxes[:, 2] = boxes[:, 2] - boxes[:, 0] 228 | boxes[:, 3] = boxes[:, 3] - boxes[:, 1] 229 | 230 | boxes[:, 0] = boxes[:, 0] + boxes[:, 2] / 2 231 | boxes[:, 1] = boxes[:, 1] + boxes[:, 3] / 2 232 | y = np.concatenate([boxes, y[:, -1:]], axis=-1) 233 | 234 | img = np.array(img, dtype=np.float32) 235 | 236 | tmp_inp = np.transpose(img / 255.0, (2, 0, 1)) 237 | tmp_targets = np.array(y, dtype=np.float32) 238 | return tmp_inp, tmp_targets 239 | 240 | 241 | # DataLoader (collate_fn) 242 | def yolo_dataset_collate(batch): 243 | images = [] 244 | bboxes = [] 245 | for img, box in batch: 246 | images.append(img) 247 | bboxes.append(box) 248 | images = np.array(images) 249 | bboxes = np.array(bboxes) 250 | return images, bboxes 251 | 252 | -------------------------------------------------------------------------------- /utils/utils.py: -------------------------------------------------------------------------------- 1 | from __future__ import division 2 | import os 3 | import math 4 | import time 5 | import torch 6 | import torch.nn as nn 7 | import torch.nn.functional as F 8 | from torch.autograd import Variable 9 | import numpy as np 10 | from PIL import Image, ImageDraw, ImageFont 11 | import matplotlib.pyplot as plt 12 | 13 | class DecodeBox(nn.Module): 14 | def __init__(self, anchors, num_classes, img_size): 15 | super(DecodeBox, self).__init__() 16 | self.anchors = anchors 17 | self.num_anchors = len(anchors) 18 | self.num_classes = num_classes 19 | self.bbox_attrs = 5 + num_classes 20 | self.img_size = img_size 21 | 22 | def forward(self, input): 23 | 24 | # input -> torch.Size([bs, 3*(5+num_classes), feature_length[i], feature_length[i]]) 25 | batch_size = input.size(0) 26 | input_height = input.size(2) 27 | input_width = input.size(3) 28 | 29 | stride_h = self.img_size[1] / input_height # feature_length[i] 30 | stride_w = self.img_size[0] / input_width # feature_length[i] 31 | 32 | # anchors size (original) -> anchors size (feature_length[i]) 33 | scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in self.anchors] 34 | 35 | # input, torch.Size([bs, 3*(5+num_classes), feature_length[i], feature_length[i]]) 36 | # -> prediction, torch.Size([bs, 3 , feature_length[i], feature_length[i], (5+num_classes)]) 37 | prediction = input.view(batch_size, self.num_anchors, 38 | self.bbox_attrs, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous() 39 | 40 | x = torch.sigmoid(prediction[..., 0]) 41 | y = torch.sigmoid(prediction[..., 1]) 42 | w = prediction[..., 2] # Width 43 | h = prediction[..., 3] # Height 44 | 45 | conf = torch.sigmoid(prediction[..., 4]) # Conf 46 | pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred. 47 | 48 | FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor 49 | LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor 50 | 51 | # draw grids and its x,y number 52 | grid_x = torch.linspace(0, input_width - 1, input_width).repeat(input_width, 1).repeat( 53 | batch_size * self.num_anchors, 1, 1).view(x.shape).type(FloatTensor) 54 | grid_y = torch.linspace(0, input_height - 1, input_height).repeat(input_height, 1).t().repeat( 55 | batch_size * self.num_anchors, 1, 1).view(y.shape).type(FloatTensor) 56 | 57 | # generate anchor (w, h) 58 | anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0])) 59 | anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1])) 60 | 61 | # torch.Size([bs, 3, feature_length[i], feature_length[i]]) 62 | anchor_w = anchor_w.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(w.shape) 63 | anchor_h = anchor_h.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(h.shape) 64 | 65 | # calculate box (xy and wh) 66 | pred_boxes = FloatTensor(prediction[..., :4].shape) 67 | pred_boxes[..., 0] = x.data + grid_x 68 | pred_boxes[..., 1] = y.data + grid_y 69 | pred_boxes[..., 2] = torch.exp(w.data) * anchor_w 70 | pred_boxes[..., 3] = torch.exp(h.data) * anchor_h 71 | 72 | # fig = plt.figure() 73 | # ax = fig.add_subplot(121) 74 | # if input_height==13: 75 | # plt.ylim(0,13) 76 | # plt.xlim(0,13) 77 | # elif input_height==26: 78 | # plt.ylim(0,26) 79 | # plt.xlim(0,26) 80 | # elif input_height==52: 81 | # plt.ylim(0,52) 82 | # plt.xlim(0,52) 83 | # plt.scatter(grid_x.cpu(),grid_y.cpu()) 84 | 85 | # anchor_left = grid_x - anchor_w/2 86 | # anchor_top = grid_y - anchor_h/2 87 | 88 | # rect1 = plt.Rectangle([anchor_left[0,0,5,5],anchor_top[0,0,5,5]],anchor_w[0,0,5,5],anchor_h[0,0,5,5],color="r",fill=False) 89 | # rect2 = plt.Rectangle([anchor_left[0,1,5,5],anchor_top[0,1,5,5]],anchor_w[0,1,5,5],anchor_h[0,1,5,5],color="r",fill=False) 90 | # rect3 = plt.Rectangle([anchor_left[0,2,5,5],anchor_top[0,2,5,5]],anchor_w[0,2,5,5],anchor_h[0,2,5,5],color="r",fill=False) 91 | 92 | # ax.add_patch(rect1) 93 | # ax.add_patch(rect2) 94 | # ax.add_patch(rect3) 95 | 96 | # ax = fig.add_subplot(122) 97 | # if input_height==13: 98 | # plt.ylim(0,13) 99 | # plt.xlim(0,13) 100 | # elif input_height==26: 101 | # plt.ylim(0,26) 102 | # plt.xlim(0,26) 103 | # elif input_height==52: 104 | # plt.ylim(0,52) 105 | # plt.xlim(0,52) 106 | # plt.scatter(grid_x.cpu(),grid_y.cpu()) 107 | # plt.scatter(pred_boxes[0,:,5,5,0].cpu(),pred_boxes[0,:,5,5,1].cpu(),c='r') 108 | 109 | # pre_left = pred_boxes[...,0] - pred_boxes[...,2]/2 110 | # pre_top = pred_boxes[...,1] - pred_boxes[...,3]/2 111 | 112 | # rect1 = plt.Rectangle([pre_left[0,0,5,5],pre_top[0,0,5,5]],pred_boxes[0,0,5,5,2],pred_boxes[0,0,5,5,3],color="r",fill=False) 113 | # rect2 = plt.Rectangle([pre_left[0,1,5,5],pre_top[0,1,5,5]],pred_boxes[0,1,5,5,2],pred_boxes[0,1,5,5,3],color="r",fill=False) 114 | # rect3 = plt.Rectangle([pre_left[0,2,5,5],pre_top[0,2,5,5]],pred_boxes[0,2,5,5,2],pred_boxes[0,2,5,5,3],color="r",fill=False) 115 | 116 | # ax.add_patch(rect1) 117 | # ax.add_patch(rect2) 118 | # ax.add_patch(rect3) 119 | 120 | # plt.show() 121 | 122 | # map output to input_shape (608x608) 123 | _scale = torch.Tensor([stride_w, stride_h] * 2).type(FloatTensor) 124 | output = torch.cat((pred_boxes.view(batch_size, -1, 4) * _scale, 125 | conf.view(batch_size, -1, 1), pred_cls.view(batch_size, -1, self.num_classes)), -1) 126 | return output.data 127 | 128 | def letterbox_image(image, size): 129 | iw, ih = image.size 130 | w, h = size 131 | scale = min(w / iw, h / ih) 132 | nw = int(iw * scale) 133 | nh = int(ih * scale) 134 | 135 | image = image.resize((nw, nh), Image.BICUBIC) 136 | new_image = Image.new('RGB', size, (128,128,128)) 137 | new_image.paste(image, ((w - nw)//2, (h - nh)//2)) 138 | return new_image 139 | 140 | def yolo_correct_boxes(top, left, bottom, right, input_shape, image_shape): 141 | new_shape = image_shape * np.min(input_shape / image_shape) 142 | 143 | offset = (input_shape - new_shape) / 2. / input_shape 144 | scale = input_shape / new_shape 145 | 146 | box_yx = np.concatenate(((top+bottom)/2, (left+right)/2), axis=-1) / input_shape 147 | box_hw = np.concatenate((bottom-top, right-left), axis=-1) / input_shape 148 | 149 | box_yx = (box_yx - offset) * scale 150 | box_hw *= scale 151 | 152 | box_mins = box_yx - (box_hw / 2.) 153 | box_maxes = box_yx + (box_hw / 2.) 154 | boxes = np.concatenate([ 155 | box_mins[:, 0:1], 156 | box_mins[:, 1:2], 157 | box_maxes[:, 0:1], 158 | box_maxes[:, 1:2] 159 | ],axis=-1) 160 | print(np.shape(boxes)) 161 | boxes *= np.concatenate([image_shape, image_shape], axis=-1) 162 | return boxes 163 | 164 | def bbox_iou(box1, box2, x1y1x2y2=True): 165 | 166 | # iou = Area of Overlap / Area of Union 167 | if not x1y1x2y2: 168 | b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2 169 | b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2 170 | b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2 171 | b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2 172 | else: 173 | b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3] 174 | b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3] 175 | 176 | inter_rect_x1 = torch.max(b1_x1, b2_x1) 177 | inter_rect_y1 = torch.max(b1_y1, b2_y1) 178 | inter_rect_x2 = torch.min(b1_x2, b2_x2) 179 | inter_rect_y2 = torch.min(b1_y2, b2_y2) 180 | 181 | inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0) * \ 182 | torch.clamp(inter_rect_y2 - inter_rect_y1 + 1, min=0) 183 | 184 | b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1) 185 | b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1) 186 | 187 | iou = inter_area / (b1_area + b2_area - inter_area + 1e-16) 188 | 189 | return iou 190 | 191 | def non_max_suppression(prediction, num_classes, conf_thres=0.5, nms_thres=0.4): 192 | 193 | # box (xy - wh_half, xy + wh_half) 194 | box_corner = prediction.new(prediction.shape) 195 | box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2 196 | box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2 197 | box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2 198 | box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2 199 | prediction[:, :, :4] = box_corner[:, :, :4] 200 | 201 | output = [None for _ in range(len(prediction))] 202 | 203 | for image_i, image_pred in enumerate(prediction): # 204 | 205 | # foreground phase1_1 (confidence threshold) 206 | conf_mask = (image_pred[:, 4] >= conf_thres).squeeze() 207 | image_pred = image_pred[conf_mask] 208 | 209 | if not image_pred.size(0): 210 | continue 211 | 212 | # foreground phase1_2 (class & class confidence) 213 | class_conf, class_pred = torch.max(image_pred[:, 5:5 + num_classes], 1, keepdim=True) 214 | 215 | # detections -> (x1, y1, x2, y2, obj_conf, class_conf, class_pred) 216 | detections = torch.cat((image_pred[:, :5], class_conf.float(), class_pred.float()), 1) 217 | 218 | # require classes 219 | unique_labels = detections[:, -1].cpu().unique() 220 | 221 | if prediction.is_cuda: 222 | unique_labels = unique_labels.cuda() 223 | 224 | for c in unique_labels: 225 | # foreground phase2_1 (obtain speific class (c)) 226 | detections_class = detections[detections[:, -1] == c] 227 | # foreground phase2_2 (sort speific class base on thier confidence) 228 | _, conf_sort_index = torch.sort(detections_class[:, 4], descending=True) 229 | detections_class = detections_class[conf_sort_index] 230 | 231 | # nms 232 | max_detections = [] 233 | while detections_class.size(0): # object contain not empty 234 | # foreground phase2_3 (start nms by max confidence of speific class) 235 | max_detections.append(detections_class[0].unsqueeze(0)) 236 | if len(detections_class) == 1: 237 | break 238 | # foreground phase2_4 (ious between max and others) 239 | ious = bbox_iou(max_detections[-1], detections_class[1:]) 240 | # foreground phase2_5 (delete silmar box base on nms threshold) 241 | detections_class = detections_class[1:][ious < nms_thres] 242 | 243 | # stack speific class 244 | max_detections = torch.cat(max_detections).data 245 | # Add max detections to outputs 246 | output[image_i] = max_detections if output[image_i] is None else torch.cat( 247 | (output[image_i], max_detections)) 248 | 249 | return output 250 | 251 | def merge_bboxes(bboxes, cutx, cuty): 252 | merge_bbox = [] 253 | for i in range(len(bboxes)): 254 | for box in bboxes[i]: 255 | tmp_box = [] 256 | x1,y1,x2,y2 = box[0], box[1], box[2], box[3] 257 | 258 | if i == 0: 259 | if y1 > cuty or x1 > cutx: 260 | continue 261 | if y2 >= cuty and y1 <= cuty: 262 | y2 = cuty 263 | if y2-y1 < 5: 264 | continue 265 | if x2 >= cutx and x1 <= cutx: 266 | x2 = cutx 267 | if x2-x1 < 5: 268 | continue 269 | 270 | if i == 1: 271 | if y2 < cuty or x1 > cutx: 272 | continue 273 | 274 | if y2 >= cuty and y1 <= cuty: 275 | y1 = cuty 276 | if y2-y1 < 5: 277 | continue 278 | 279 | if x2 >= cutx and x1 <= cutx: 280 | x2 = cutx 281 | if x2-x1 < 5: 282 | continue 283 | 284 | if i == 2: 285 | if y2 < cuty or x2 < cutx: 286 | continue 287 | 288 | if y2 >= cuty and y1 <= cuty: 289 | y1 = cuty 290 | if y2-y1 < 5: 291 | continue 292 | 293 | if x2 >= cutx and x1 <= cutx: 294 | x1 = cutx 295 | if x2-x1 < 5: 296 | continue 297 | 298 | if i == 3: 299 | if y1 > cuty or x2 < cutx: 300 | continue 301 | 302 | if y2 >= cuty and y1 <= cuty: 303 | y2 = cuty 304 | if y2-y1 < 5: 305 | continue 306 | 307 | if x2 >= cutx and x1 <= cutx: 308 | x1 = cutx 309 | if x2-x1 < 5: 310 | continue 311 | 312 | tmp_box.append(x1) 313 | tmp_box.append(y1) 314 | tmp_box.append(x2) 315 | tmp_box.append(y2) 316 | tmp_box.append(box[-1]) 317 | merge_bbox.append(tmp_box) 318 | return merge_bbox -------------------------------------------------------------------------------- /video.py: -------------------------------------------------------------------------------- 1 | from yolo import YOLO 2 | from PIL import Image 3 | import numpy as np 4 | import cv2 5 | import time 6 | 7 | yolo = YOLO() 8 | 9 | # capture camera 10 | # capture=cv2.VideoCapture(0) 11 | capture=cv2.VideoCapture("img/test.mp4") 12 | 13 | fps = 0.0 14 | while(True): 15 | t1 = time.time() 16 | 17 | # read frame 18 | ref, source = capture.read() 19 | 20 | # transform Image 21 | frame = cv2.cvtColor(source, cv2.COLOR_BGR2RGB) 22 | frame = Image.fromarray(np.uint8(frame)) 23 | 24 | frame = np.array(yolo.detect_image(frame)) 25 | frame = cv2.cvtColor(frame,cv2.COLOR_RGB2BGR) 26 | 27 | fps = ( fps + (1./(time.time()-t1)) ) / 2 28 | print("fps= %.2f"%(fps)) 29 | frame = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) 30 | 31 | both = np.hstack((source, frame)) 32 | cv2.imshow("(source, frame)", both) 33 | 34 | c= cv2.waitKey(30) & 0xff 35 | if c==27: 36 | capture.release() 37 | break 38 | -------------------------------------------------------------------------------- /voc2yolo4.py: -------------------------------------------------------------------------------- 1 | import os 2 | import random 3 | 4 | xmlfilepath=r'./VOCdevkit/VOC2007/Annotations' 5 | saveBasePath=r"./VOCdevkit/VOC2007/ImageSets/Main/" 6 | 7 | trainval_percent=1 8 | train_percent=1 9 | 10 | temp_xml = os.listdir(xmlfilepath) 11 | total_xml = [] 12 | for xml in temp_xml: 13 | if xml.endswith(".xml"): 14 | total_xml.append(xml) 15 | 16 | num=len(total_xml) 17 | list=range(num) 18 | tv=int(num*trainval_percent) 19 | tr=int(tv*train_percent) 20 | trainval= random.sample(list,tv) 21 | train=random.sample(trainval,tr) 22 | 23 | print("train and val size",tv) 24 | print("traub suze",tr) 25 | ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w') 26 | ftest = open(os.path.join(saveBasePath,'test.txt'), 'w') 27 | ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w') 28 | fval = open(os.path.join(saveBasePath,'val.txt'), 'w') 29 | 30 | for i in list: 31 | name=total_xml[i][:-4]+'\n' 32 | if i in trainval: 33 | ftrainval.write(name) 34 | if i in train: 35 | ftrain.write(name) 36 | else: 37 | fval.write(name) 38 | else: 39 | ftest.write(name) 40 | 41 | ftrainval.close() 42 | ftrain.close() 43 | fval.close() 44 | ftest .close() 45 | -------------------------------------------------------------------------------- /voc_annotation.py: -------------------------------------------------------------------------------- 1 | import xml.etree.ElementTree as ET 2 | from os import getcwd 3 | 4 | sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] 5 | 6 | wd = getcwd() 7 | classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] 8 | 9 | def convert_annotation(year, image_id, list_file): 10 | in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) 11 | tree=ET.parse(in_file) 12 | root = tree.getroot() 13 | list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id)) 14 | for obj in root.iter('object'): 15 | difficult = obj.find('difficult').text 16 | cls = obj.find('name').text 17 | if cls not in classes or int(difficult)==1: 18 | continue 19 | cls_id = classes.index(cls) 20 | xmlbox = obj.find('bndbox') 21 | b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text)) 22 | list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id)) 23 | 24 | list_file.write('\n') 25 | 26 | for year, image_set in sets: 27 | image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() 28 | list_file = open('%s_%s.txt'%(year, image_set), 'w') 29 | for image_id in image_ids: 30 | convert_annotation(year, image_id, list_file) 31 | list_file.close() 32 | -------------------------------------------------------------------------------- /yolo.py: -------------------------------------------------------------------------------- 1 | import cv2 2 | import numpy as np 3 | import colorsys 4 | import os 5 | import torch 6 | import torch.nn as nn 7 | from nets.yolo4 import YoloBody 8 | import torch.backends.cudnn as cudnn 9 | from PIL import Image, ImageFont, ImageDraw 10 | from torch.autograd import Variable 11 | from utils.utils import non_max_suppression, bbox_iou, DecodeBox, letterbox_image, yolo_correct_boxes 12 | 13 | 14 | class YOLO(object): 15 | _defaults = { 16 | "model_path": 'model_data/test1.pth', # your model [change content] 17 | "anchors_path": 'model_data/yolo_anchors.txt', 18 | "classes_path": 'model_data/voc_classes.txt', # your clesses [change content] 19 | "model_image_size" : (608,608,3), 20 | "confidence": 0.5, 21 | "cuda": True 22 | } 23 | 24 | @classmethod 25 | def get_defaults(cls, n): 26 | if n in cls._defaults: 27 | return cls._defaults[n] 28 | else: 29 | return "Unrecognized attribute name '" + n + "'" 30 | 31 | def __init__(self, **kwargs): 32 | self.__dict__.update(self._defaults) 33 | self.class_names = self._get_class() 34 | self.anchors = self._get_anchors() 35 | self.generate() 36 | 37 | def _get_class(self): 38 | '''loads the classes''' 39 | classes_path = os.path.expanduser(self.classes_path) 40 | with open(classes_path) as f: 41 | class_names = f.readlines() 42 | class_names = [c.strip() for c in class_names] 43 | return class_names 44 | 45 | def _get_anchors(self): 46 | '''loads the anchors from a file''' 47 | anchors_path = os.path.expanduser(self.anchors_path) 48 | with open(anchors_path) as f: 49 | anchors = f.readline() 50 | anchors = [float(x) for x in anchors.split(',')] 51 | return np.array(anchors).reshape([-1, 3, 2])[::-1,:,:] 52 | 53 | def generate(self): 54 | 55 | self.net = YoloBody(len(self.anchors[0]), len(self.class_names)).eval() 56 | 57 | print('Loading weights into state dict...') 58 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') 59 | state_dict = torch.load(self.model_path, map_location=device) 60 | self.net.load_state_dict(state_dict) 61 | 62 | if self.cuda: 63 | os.environ["CUDA_VISIBLE_DEVICES"] = '0' 64 | self.net = nn.DataParallel(self.net) 65 | self.net = self.net.cuda() 66 | 67 | print('Finished!') 68 | 69 | self.yolo_decodes = [] 70 | for i in range(3): # feature_length[i] 71 | self.yolo_decodes.append(DecodeBox(self.anchors[i], len(self.class_names), (self.model_image_size[1], self.model_image_size[0]))) 72 | 73 | print('{} model, anchors, and classes loaded.'.format(self.model_path)) 74 | 75 | # setting color 76 | hsv_tuples = [(x / len(self.class_names), 1., 1.) 77 | for x in range(len(self.class_names))] 78 | self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples)) 79 | self.colors = list( 80 | map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), 81 | self.colors)) 82 | 83 | def detect_image(self, image): 84 | image_shape = np.array(np.shape(image)[0:2]) # source image size 85 | 86 | crop_img = np.array(letterbox_image(image, (self.model_image_size[0], self.model_image_size[1]))) 87 | photo = np.array(crop_img,dtype = np.float32) 88 | photo /= 255.0 89 | photo = np.transpose(photo, (2, 0, 1)) 90 | photo = photo.astype(np.float32) 91 | images = [] 92 | images.append(photo) 93 | images = np.asarray(images) 94 | 95 | with torch.no_grad(): 96 | images = torch.from_numpy(images) 97 | if self.cuda: 98 | images = images.cuda() 99 | outputs = self.net(images) 100 | 101 | output_list = [] 102 | for i in range(3): 103 | output_list.append(self.yolo_decodes[i](outputs[i])) 104 | output = torch.cat(output_list, 1) 105 | batch_detections = non_max_suppression(output, len(self.class_names), 106 | conf_thres=self.confidence, 107 | nms_thres=0.3) 108 | try: 109 | batch_detections = batch_detections[0].cpu().numpy() 110 | except: 111 | return image 112 | 113 | top_index = batch_detections[:,4]*batch_detections[:,5] > self.confidence 114 | top_conf = batch_detections[top_index,4]*batch_detections[top_index,5] 115 | top_label = np.array(batch_detections[top_index,-1],np.int32) 116 | top_bboxes = np.array(batch_detections[top_index,:4]) 117 | top_xmin, top_ymin, top_xmax, top_ymax = np.expand_dims(top_bboxes[:,0],-1),np.expand_dims(top_bboxes[:,1],-1),np.expand_dims(top_bboxes[:,2],-1),np.expand_dims(top_bboxes[:,3],-1) 118 | 119 | # get rid of gray area 120 | boxes = yolo_correct_boxes(top_ymin,top_xmin,top_ymax,top_xmax,np.array([self.model_image_size[0],self.model_image_size[1]]),image_shape) 121 | 122 | font = ImageFont.truetype(font='model_data/simhei.ttf',size=np.floor(3e-2 * np.shape(image)[1] + 0.5).astype('int32')) 123 | 124 | thickness = (np.shape(image)[0] + np.shape(image)[1]) // self.model_image_size[0] 125 | 126 | for i, c in enumerate(top_label): 127 | predicted_class = self.class_names[c] 128 | score = top_conf[i] 129 | 130 | top, left, bottom, right = boxes[i] 131 | top = top - 5 132 | left = left - 5 133 | bottom = bottom + 5 134 | right = right + 5 135 | 136 | top = max(0, np.floor(top + 0.5).astype('int32')) 137 | left = max(0, np.floor(left + 0.5).astype('int32')) 138 | bottom = min(np.shape(image)[0], np.floor(bottom + 0.5).astype('int32')) 139 | right = min(np.shape(image)[1], np.floor(right + 0.5).astype('int32')) 140 | 141 | # draw box 142 | label = '{} {:.2f}'.format(predicted_class, score) 143 | draw = ImageDraw.Draw(image) 144 | label_size = draw.textsize(label, font) 145 | label = label.encode('utf-8') 146 | print(label) 147 | 148 | if top - label_size[1] >= 0: 149 | text_origin = np.array([left, top - label_size[1]]) 150 | else: 151 | text_origin = np.array([left, top + 1]) 152 | 153 | for i in range(thickness): 154 | draw.rectangle( 155 | [left + i, top + i, right - i, bottom - i], 156 | outline=self.colors[self.class_names.index(predicted_class)]) 157 | draw.rectangle( 158 | [tuple(text_origin), tuple(text_origin + label_size)], 159 | fill=self.colors[self.class_names.index(predicted_class)]) 160 | draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font) 161 | del draw 162 | return image 163 | 164 | --------------------------------------------------------------------------------