├── README.md
├── assets
├── js_1.webp
├── js_2.webp
├── html_1.webp
├── html_2.webp
├── js7.1.webp
├── js7.2.webp
├── js7.3.webp
├── js7.4.webp
├── js7.5.webp
├── js7.6.webp
├── js7.7.webp
├── js8-1.webp
├── vue
│ ├── 1.webp
│ ├── 2.webp
│ ├── 3.webp
│ ├── 4.webp
│ ├── 5.webp
│ ├── 6.webp
│ ├── 7.webp
│ ├── 2_1.webp
│ ├── 2_10.webp
│ ├── 2_11.webp
│ ├── 2_12.webp
│ ├── 2_13.webp
│ ├── 2_14.webp
│ ├── 2_15.webp
│ ├── 2_16.webp
│ ├── 2_17.webp
│ ├── 2_18.webp
│ ├── 2_19.webp
│ ├── 2_2.webp
│ ├── 2_3.webp
│ ├── 2_4.webp
│ ├── 2_5.webp
│ ├── 2_6.webp
│ ├── 2_7.webp
│ ├── 2_8.webp
│ ├── 2_9.webp
│ ├── 3_1.webp
│ ├── 3_2.webp
│ ├── 3_3.webp
│ ├── 3_4.webp
│ ├── 3_5.webp
│ ├── 3_6.webp
│ ├── 3_7.webp
│ ├── 3_8.webp
│ ├── 5_1.webp
│ ├── 5_2.webp
│ ├── 5_3.webp
│ ├── 5_4.webp
│ ├── 5_5.webp
│ ├── 6_1.webp
│ ├── 6_2.webp
│ ├── 6_3.webp
│ ├── 6_4.webp
│ ├── 6_5.webp
│ └── 6_6.webp
├── browser
│ ├── 1.webp
│ ├── 2.webp
│ ├── 3.webp
│ ├── 4.webp
│ └── 5.webp
└── writeCode
│ ├── writeCode4_1.webp
│ └── writeCode4_2.webp
├── .idea
├── .gitignore
├── vcs.xml
├── modules.xml
├── marks.iml
└── git_toolbox_prj.xml
├── js面试题八(JS基础).md
├── V8引擎.md
├── nodejsEventLoop.md
├── 论前端工程师核心竞争力.md
├── ES6-->class继承.md
├── js面试题三(JS基础).md
├── eventLoop.md
├── 前端手撕代码面试题(二).md
├── promise2.md
├── js面试题二(JS基础).md
├── 前端手撕代码面试题(三).md
├── 前端手撕代码面试题(四).md
├── 原型.md
├── browser_two.md
├── this指向.md
├── 前端手撕代码面试题(一).md
├── vue面试题四.md
├── vue面试题六.md
├── vue面试题二.md
├── vue面试题三.md
├── vue面试题五.md
├── vue面试题一.md
├── 迭代器:可迭代对象:生成器.md
├── browser_three.md
├── js面试题四(JS基础).md
└── js面试题七(JS基础).md
/README.md:
--------------------------------------------------------------------------------
1 | # marks
2 | 日常笔记分享
3 |
--------------------------------------------------------------------------------
/assets/js_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js_1.webp
--------------------------------------------------------------------------------
/assets/js_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js_2.webp
--------------------------------------------------------------------------------
/assets/html_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/html_1.webp
--------------------------------------------------------------------------------
/assets/html_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/html_2.webp
--------------------------------------------------------------------------------
/assets/js7.1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.1.webp
--------------------------------------------------------------------------------
/assets/js7.2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.2.webp
--------------------------------------------------------------------------------
/assets/js7.3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.3.webp
--------------------------------------------------------------------------------
/assets/js7.4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.4.webp
--------------------------------------------------------------------------------
/assets/js7.5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.5.webp
--------------------------------------------------------------------------------
/assets/js7.6.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.6.webp
--------------------------------------------------------------------------------
/assets/js7.7.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js7.7.webp
--------------------------------------------------------------------------------
/assets/js8-1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/js8-1.webp
--------------------------------------------------------------------------------
/assets/vue/1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/1.webp
--------------------------------------------------------------------------------
/assets/vue/2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2.webp
--------------------------------------------------------------------------------
/assets/vue/3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3.webp
--------------------------------------------------------------------------------
/assets/vue/4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/4.webp
--------------------------------------------------------------------------------
/assets/vue/5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/5.webp
--------------------------------------------------------------------------------
/assets/vue/6.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6.webp
--------------------------------------------------------------------------------
/assets/vue/7.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/7.webp
--------------------------------------------------------------------------------
/assets/browser/1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/browser/1.webp
--------------------------------------------------------------------------------
/assets/browser/2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/browser/2.webp
--------------------------------------------------------------------------------
/assets/browser/3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/browser/3.webp
--------------------------------------------------------------------------------
/assets/browser/4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/browser/4.webp
--------------------------------------------------------------------------------
/assets/browser/5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/browser/5.webp
--------------------------------------------------------------------------------
/assets/vue/2_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_1.webp
--------------------------------------------------------------------------------
/assets/vue/2_10.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_10.webp
--------------------------------------------------------------------------------
/assets/vue/2_11.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_11.webp
--------------------------------------------------------------------------------
/assets/vue/2_12.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_12.webp
--------------------------------------------------------------------------------
/assets/vue/2_13.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_13.webp
--------------------------------------------------------------------------------
/assets/vue/2_14.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_14.webp
--------------------------------------------------------------------------------
/assets/vue/2_15.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_15.webp
--------------------------------------------------------------------------------
/assets/vue/2_16.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_16.webp
--------------------------------------------------------------------------------
/assets/vue/2_17.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_17.webp
--------------------------------------------------------------------------------
/assets/vue/2_18.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_18.webp
--------------------------------------------------------------------------------
/assets/vue/2_19.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_19.webp
--------------------------------------------------------------------------------
/assets/vue/2_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_2.webp
--------------------------------------------------------------------------------
/assets/vue/2_3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_3.webp
--------------------------------------------------------------------------------
/assets/vue/2_4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_4.webp
--------------------------------------------------------------------------------
/assets/vue/2_5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_5.webp
--------------------------------------------------------------------------------
/assets/vue/2_6.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_6.webp
--------------------------------------------------------------------------------
/assets/vue/2_7.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_7.webp
--------------------------------------------------------------------------------
/assets/vue/2_8.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_8.webp
--------------------------------------------------------------------------------
/assets/vue/2_9.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/2_9.webp
--------------------------------------------------------------------------------
/assets/vue/3_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_1.webp
--------------------------------------------------------------------------------
/assets/vue/3_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_2.webp
--------------------------------------------------------------------------------
/assets/vue/3_3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_3.webp
--------------------------------------------------------------------------------
/assets/vue/3_4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_4.webp
--------------------------------------------------------------------------------
/assets/vue/3_5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_5.webp
--------------------------------------------------------------------------------
/assets/vue/3_6.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_6.webp
--------------------------------------------------------------------------------
/assets/vue/3_7.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_7.webp
--------------------------------------------------------------------------------
/assets/vue/3_8.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/3_8.webp
--------------------------------------------------------------------------------
/assets/vue/5_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/5_1.webp
--------------------------------------------------------------------------------
/assets/vue/5_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/5_2.webp
--------------------------------------------------------------------------------
/assets/vue/5_3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/5_3.webp
--------------------------------------------------------------------------------
/assets/vue/5_4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/5_4.webp
--------------------------------------------------------------------------------
/assets/vue/5_5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/5_5.webp
--------------------------------------------------------------------------------
/assets/vue/6_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6_1.webp
--------------------------------------------------------------------------------
/assets/vue/6_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6_2.webp
--------------------------------------------------------------------------------
/assets/vue/6_3.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6_3.webp
--------------------------------------------------------------------------------
/assets/vue/6_4.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6_4.webp
--------------------------------------------------------------------------------
/assets/vue/6_5.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6_5.webp
--------------------------------------------------------------------------------
/assets/vue/6_6.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/vue/6_6.webp
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # 默认忽略的文件
2 | /shelf/
3 | /workspace.xml
4 | # 基于编辑器的 HTTP 客户端请求
5 | /httpRequests/
6 |
--------------------------------------------------------------------------------
/assets/writeCode/writeCode4_1.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/writeCode/writeCode4_1.webp
--------------------------------------------------------------------------------
/assets/writeCode/writeCode4_2.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/summmer-is-hot/marks/HEAD/assets/writeCode/writeCode4_2.webp
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/marks.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/.idea/git_toolbox_prj.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
9 |
14 |
15 |
--------------------------------------------------------------------------------
/js面试题八(JS基础).md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(JS篇)八
2 |
3 | ## 八、其他类型问题补充
4 |
5 | ## 8.1 简单说说你对观察者模式的理解
6 |
7 | 观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新
8 |
9 | 观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式就是观察者和被观察者之间的通讯
10 |
11 | 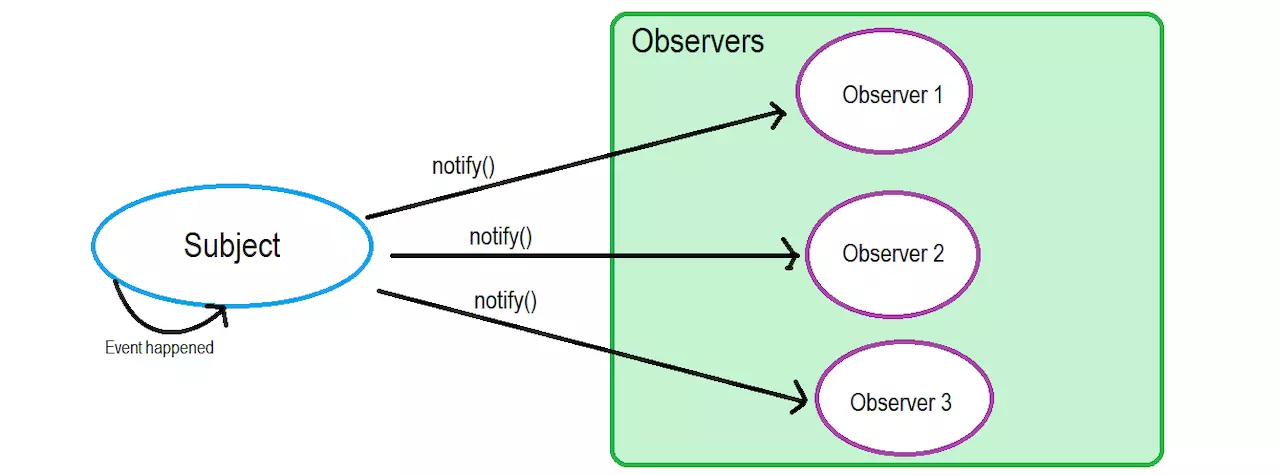
12 |
13 | 例如生活中,我们可以用报纸期刊的订阅来形象的说明,当你订阅了一份报纸,每天都会有一份最新的报纸送到你手上,有多少人订阅报纸,报社就会发多少份报纸
14 |
15 | 报社和订报纸的客户就形成了一对多的依赖关系
16 |
17 | ## 8.2 简单说说你对发布订阅模式的理解
18 |
19 | 发布-订阅是一种消息范式,消息的发送者(称为发布者)不会将消息直接发送给特定的接收者(称为订阅者)。而是将发布的消息分为不同的类别,无需了解哪些订阅者(如果有的话)可能存在
20 |
21 | 同样的,订阅者可以表达对一个或多个类别的兴趣,只接收感兴趣的消息,无需了解哪些发布者存在
22 |
23 | ## 8.3 观察者模式与发布订阅的区别
24 |
25 | - 在观察者模式中,观察者是知道Subject的,Subject一直保持对观察者进行记录。然而,在发布订阅模式中,发布者和订阅者不知道对方的存在。它们只有通过消息代理进行通信。
26 | - 在发布订阅模式中,组件是松散耦合的,正好和观察者模式相反。
27 | - 观察者模式大多数时候是同步的,比如当事件触发,Subject就会去调用观察者的方法。而发布-订阅模式大多数时候是异步的(使用消息队列)
28 |
29 | ## 8.4 说说你对正则表达式的理解
30 |
31 | 正则表达式是一种用来匹配字符串的强有力的武器
32 |
33 | 它的设计思想是用一种描述性的语言定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的
34 |
35 | 在 `JavaScript`中,正则表达式也是对象,构建正则表达式有两种方式:
36 |
37 | 1. 字面量创建,其由包含在斜杠之间的模式组成
38 |
39 | ```js
40 | const re = /\d+/g;
41 | ```
42 |
43 | 1. 调用`RegExp`对象的构造函数
44 |
45 | ```js
46 | const re = new RegExp("\d+","g");
47 |
48 | const rul = "\d+"
49 | const re1 = new RegExp(rul,"g");
50 | ```
51 |
52 | 使用构建函数创建,第一个参数可以是一个变量,遇到特殊字符``需要使用`\`进行转义
53 |
54 | ## 8.5 如何判断当前的Js代码是否在浏览器环境中运行
55 |
56 | 如果Javascript在浏览器环境中运行,则会有一个全局对象:`window`。因此,可以通过以下方式判断环境:
57 |
58 | ```javascript
59 | typeof window.self !== "undefined";
60 | // 在web worker或者sevice worker下是无法获取到windows全局变量, 所以需要通过self变量判断
61 | ```
62 |
63 | ## 结语
64 |
65 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
66 |
67 | ## 作者
68 |
69 | | Coder | 小红书ID | 创建时间 |
70 | | :---------- | :-------- | :--------- |
71 | | 落寞的前端👣 | 121450513 | 2022.10.18 |
72 |
--------------------------------------------------------------------------------
/V8引擎.md:
--------------------------------------------------------------------------------
1 | ## 大多数前端工程师不了解V8引擎
2 |
3 | ## 一.浏览器的工作原理
4 |
5 | 1. 首先,我们的静态资源是存放在服务器上,当我们在浏览器输入地址时(域名或者ip地址),当我们输入域名时,会通过DNS解析域名到所在的IP地址上。
6 | 2. 开始先解析到Index.html文件,当遇到Link标签开始下载Css文件
7 | 3. 遇到Script标签开始下载JavaScript文件
8 |
9 | ## 二.认识浏览器的内核
10 |
11 | 不同的浏览器有不同的内核组成
12 |
13 | 1. Gecko:早期被Netscape和Mozilla Firefox浏览器浏览器使用;
14 | 2. Trident:微软开发,被IE4~IE11浏览器使用,但是Edge浏览器已经转向Blink;
15 | 3. Webkit:苹果基于KHTML开发、开源的,用于Safari,Google Chrome之前也在使用;
16 | 4. Blink:是Webkit的一个分支,Google开发,目前应用于Google Chrome、Edge、Opera
17 |
18 | ## 三.浏览器渲染过程
19 |
20 | 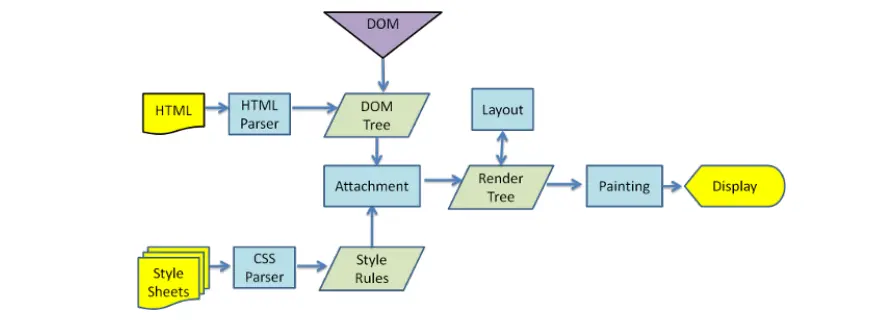
21 | HTML解析的时候遇到了JavaScript标签,应该怎么办呢?
22 | 会停止解析HTML,而去加载和执行JavaScript代码;
23 | Js代码由js引擎来执行
24 |
25 | ## 四.认识JavaScript引擎
26 |
27 | 为什么要使用js引擎?
28 | 高级的编程语言都是需要转成最终的机器指令来执行的,事实上我们编写的JavaScript无论你交给浏览器或者Node执行,最后都是需要被CPU执行的,但是CPU只认识自己的指令集,实际上是机器语言,才能被CPU所执行,所以我们需要js引擎来帮我们解析成CPU认识的指令集,才能被cpu执行,**
29 | 所以js引擎帮助我们把代码翻译成CPU所认识的指令,最后交给CPU来执行。**
30 |
31 | ## 五.浏览器内核和JS引擎的关系
32 |
33 | 我们拿主流的WebKit内核为例,事实上他们由两部分组合
34 | **WebCore**:负责HTML解析、布局、渲染等等相关的工作;
35 | **JavaScriptCore**:解析、执行JavaScript代码;
36 |
37 | ## 六.V8引擎的原理
38 |
39 | V8是用C ++编写的Google开源高性能JavaScript和WebAssembly引擎,它用于Chrome和Node.js等。 V8可以独立运行,也可以嵌入到任何C ++应用程序中。
40 | V8引擎本身的源码非常复杂,大概有超过100w行C++代码,通过了解它的架构,我们可以知道它是如何对JavaScript执行的。
41 | Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码; 如果函数没有被调用,那么是不会被转换成AST的;
42 | Parse的V8官方文档:[v8.dev/blog/scanner](https://v8.dev/blog/scanner)
43 | Ignition是一个解释器,会将AST转换成ByteCode(字节码) 同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
44 | 如果函数只调用一次,Ignition会执行解释执行ByteCode;
45 | Ignition的V8官方文档:[https://v8.dev/blog/ignition-interpreter](https://v8.dev/blog/ignition-interpreter)
46 | TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;
47 | 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;
48 | 但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
49 |
50 | ## 七.V8引擎的解析图
51 |
52 | 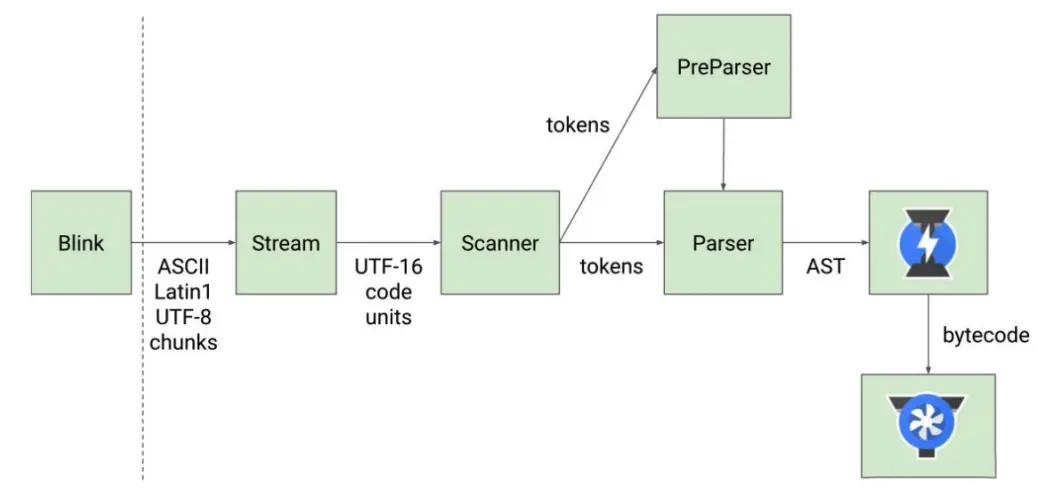
53 |
54 | ## 八.V8执行的细节
55 |
56 | **Blink将源码交给V8引擎,Stream获取到源码并且进行编码转换;**
57 | Scanner会进行词法分析(lexical analysis), 词法分析会将代码转换成tokens;
58 | 接下来tokens会被转换成AST树,经过Parser和PreParser;
59 | Parser就是直接将tokens转成AST树架构;
60 | PreParser称之为预解析,为什么需要预解析呢?
61 | 这是因为并不是所有的JavaScript代码,在一开始时就会被执行。那么对所有的JavaScript代码进行解析,必然会影响网页的运行效率;
62 | 所以V8引擎就实现了Lazy Parsing(延迟解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析时需要的内容,而对函数的全量解析是在函数被调用时才会进行;
63 | 比如我们在一个函数outer内部定义了另外一个函数inner,那么inner函数就会进行预解析; 生成AST树后,会被Ignition转成字节码(bytecode),之后的过程就是代码的执行过程。
64 |
65 | ## 作者
66 |
67 | | Coder | 小红书ID | 创建时间 |
68 | | :---------- | :-------- | :--------- |
69 | | 落寞的前端👣 | 121450513 | 2022.10.04 |
70 |
--------------------------------------------------------------------------------
/nodejsEventLoop.md:
--------------------------------------------------------------------------------
1 | # 彻底搞懂Node中的事件循环
2 |
3 | ## 前文再续,接上一回
4 |
5 | > 昨天给大家介绍了,[什么是浏览器的事件循环](https://github.com/summmer-is-hot/marks/blob/main/eventLoop.md, 这回给大家介绍浏览器中的事件循环以及常见的面试题。
6 |
7 | ## 1.Node的事件循环
8 |
9 | 浏览器中的EventLoop是根据HTML5定义的规范来实现的,不同的浏览器可能会有不同的实现,而Node中是由libuv实现的。 下面我们来查看Node的架构图:
10 |
11 | - 我们会发现libuv中主要维护了一个EventLoop和workerthreads
12 | - EventLoop主要是调用一些文件IO、Network等
13 | - libuv是一个多平台的专注于异步IO的库,它最初是为Node开发的,但是现在也被使用到Luvit、Julia、pyuv等其他地方
14 |
15 | 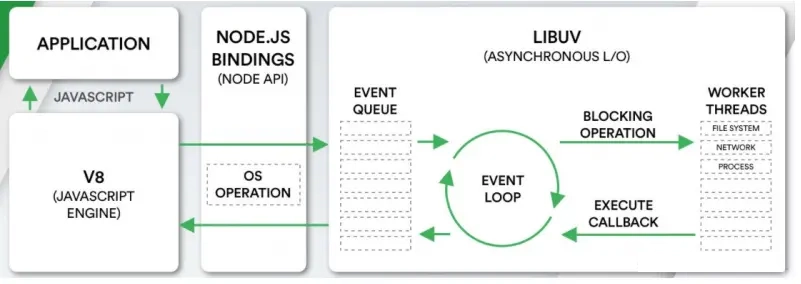
16 |
17 | ## 2.Node事件循环的阶段
18 |
19 | `事件循环就像是一个桥梁,连接着应用程序的JavaScript和系统调用之间的通道`
20 |
21 | - 无论是我们对文件的IO操作、数据库操作,都会有对应的结果和回调函数放到事件循环队列中
22 | - 事件循环会不断从任务队列中取出对应的回调函数然后进行执行。 一次完整的事件循环可以称之为一次Tick(时钟的滴答类似) 分为多个阶段:
23 |
24 | 1. 定时器(Timers):本阶段执行已经被 setTimeout() 和 setInterval() 的调度回调函数。
25 | 2. 待定回调(pading callback):对某些操作系统(如Tcp)的执行回调
26 | 3. idle,perpase:仅系统内部使用
27 | 4. 轮询(Poll):探索检测新的IO事件、执行IO相关的回调
28 | 5. setImmediate()回调函数在这里执行
29 | 6. 关闭的回调函数:一些关闭的回调函数,如:socket.on('close', ...)。
30 |
31 | ## 3.Node事件循环的阶段图解
32 |
33 | 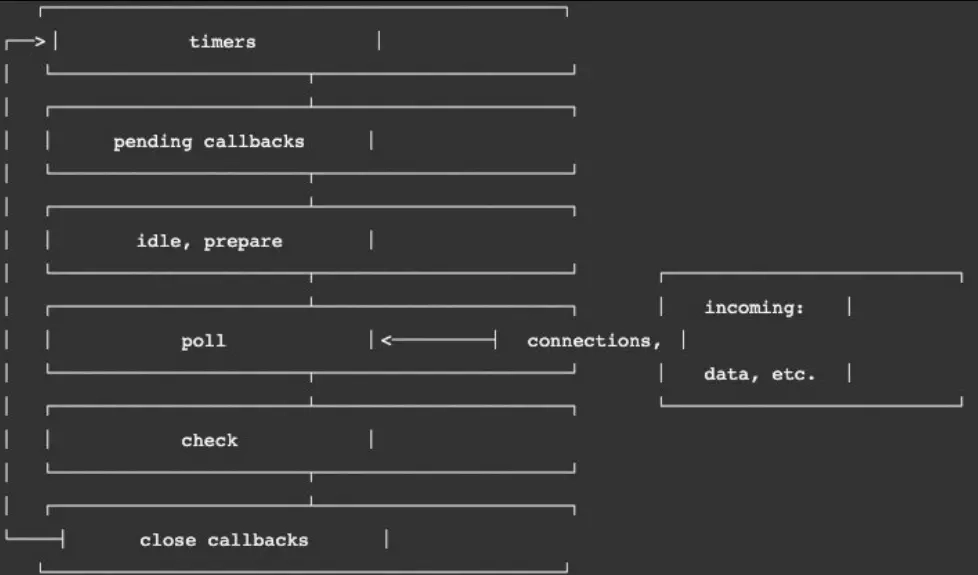
34 |
35 | ## 4.Node的宏任务和微任务
36 |
37 | - 我们会发现从一次事件循环的Tick来说,Node的事件循环更复杂,它也分为微任务和宏任务:
38 | - 宏任务(macrotask):setTimeout、setInterval、IO事件、setImmediate、close事件;
39 | - 微任务(microtask):Promise的then回调、process.nextTick、queueMicrotask; 但是,Node中的事件循环不只是 微任务队列和 宏任务队列:
40 | - 微任务队列:
41 |
42 | 1. `next tick queue:process.nextTick;`
43 | 2. `other queue:Promise的then回调、queueMicrotask;`
44 |
45 | - 宏任务队列:
46 |
47 | 1. `timer queue:setTimeout、setInterval`
48 | 2. ` poll queue:IO事件;`
49 | 3. `check queue:setImmediate;`
50 | 4. `close queue:close事件;`
51 |
52 | ## 5. Node事件循环的顺序
53 |
54 | 所以,在每一次事件循环的tick中,会按照如下顺序来执行代码:
55 |
56 | next tick microtask queue other microtask queue timer queue poll queue check queue close queue
57 |
58 | ## 6. 面试题
59 |
60 | ```js
61 | async function async1() {
62 | console.log("async1 start");
63 | await async2();
64 | console.log("async1 end");
65 | }
66 |
67 | async function async2() {
68 | console.log("async2");
69 | }
70 |
71 | console.log("script start");
72 |
73 | setTimeout(function () {
74 | console.log("setTimeout0");
75 | }, 0);
76 |
77 | setTimeout(function () {
78 | console.log("setTimeout2");
79 | }, 300);
80 |
81 | setImmediate(() => console.log("setImmediate"));
82 |
83 | process.nextTick(() => console.log("nextTick1"));
84 |
85 | async1();
86 |
87 | process.nextTick(() => console.log("nextTick2"));
88 |
89 | new Promise(function (resolve) {
90 | console.log("promise1");
91 | resolve();
92 | console.log("promise2");
93 | }).then(function () {
94 | console.log("promise3");
95 | });
96 |
97 | console.log("script end");
98 |
99 | //script start
100 | //async1 start
101 | // async2 promise1 promise2 scriptend nextTick1 nextTick2
102 | // async1 end promise3 settimeout0 setImmediate settimeout2
103 |
104 | ```
105 |
106 | ## 结语
107 |
108 | 最后浏览器与Node中的事件循环就介绍到这里了,期待我们的下次见面~
109 |
110 | ## 作者
111 |
112 | | Coder | 小红书ID | 创建时间 |
113 | | :---------- | :-------- | :--------- |
114 | | 落寞的前端👣 | 121450513 | 2022.10.06 |
115 |
116 |
--------------------------------------------------------------------------------
/论前端工程师核心竞争力.md:
--------------------------------------------------------------------------------
1 | # 论前端工程师核心竞争力
2 |
3 | ## 若你已做多年前端(5年+),你觉得你目前的核心竞争力在哪?
4 |
5 | ### 前言
6 |
7 | ```
8 | 前端是个入门门槛很低,深度挖掘又非常复杂的一门职业;现在涌现出很多前端的培训机构,和很多学生时代就完全入门前端的应届生,
9 | 还有工作一年以后能力不错的全栈,他们的产出和能力都不赖;那么,当你做了很多年前端后,开发、测试、部署;
10 | 从前端到后端,从桌面到移动,从嵌入式到物联网,你觉得有什么优势或者竞争力呢?
11 | * 喜欢写代码,知道自己的瓶颈,并接受它
12 | * 做越来越多的事就是挑战自己原来的想法,作总结和交流
13 | * 能写出比较复杂的代码
14 | * 业务理的顺,有一些产品思维
15 | * 还不错的审美
16 | * 沟通和协调的能力,可以组织很多人一起写一些比较复杂的代码
17 | * ppt excel用的比一般程序员要好一些,也挺会写邮件的
18 | * 对新知识有热情,学东西较快,是一个擅长解决问题的人
19 | ```
20 |
21 | ---
22 |
23 | ### 挑战
24 |
25 | ```
26 | * 每天工作会积累很多经验,久而久之,你会很熟悉你的工作内容,熟悉配合的人,越来越像机械一样在工作。那么,你会从这份工作中已经慢慢地失去成长的动力。可能你需要有一些转变,不论是工作内容或是岗位。
27 | * 与不同岗位人的沟通,你会得到他们的问题与角度。接触不熟悉的技术,你会遇到它们的问题与角度。
28 | 这些都是让自己走出舒服区,让自己从无限的重复中获得新的成长。
29 | ```
30 |
31 | ---
32 |
33 | ### 总结
34 |
35 | ```
36 | * 我们日复一日在做coding,隔三岔五在修复bug,解决各种技术难题是家常便饭。这些问题日复一日,我们是否有过思考,他们的本质是什么,他们有没有共性。
37 | * 从总结中思考,从解决问题到定义问题。定义问题就是从点到面,让自己有布局解决一类问题的能力。这是我们职业生涯中一直需要锻炼的。
38 | ```
39 |
40 | ### 交流
41 |
42 | ```
43 | * 我们写文章并不是为了写而写,而是把自己的成果,自己的想法写下来,可以说写文章也是为了交流。
44 | * 交流,就是去碰撞,碰撞你那些不坚定的想法,说服别人,或被说服,过程中帮助你进步,帮助你理解其它人的经验,完善你自己的经验世界。
45 | * 对我来说最大的竞争力除了还可以写点复杂的代码,更多的是这些软性的东西。
46 | * 我会运维,新项目给个服务器权限就够了,Docker 快速部署
47 | * 我会写 Java,NodeJS,
48 | * 我会撸各种后台框架,Spring,Express,Koa,egg之类的
49 | * 我会撸各种前端框架,新框架看看 API 就搞定了,觉得不爽就自己改源码,造新轮子。
50 | * 我能解决各种问题,不用等着别人教
51 | * 我知道产品要的是啥,虽然他们说出来的不知道是个什么鬼,
52 | * 我知道怎么跟测试说我的需求
53 | * 我也知道怎么背锅
54 | * 我还知道怎么带人
55 | * 我知道各种行业架构,运行流程,好像产品经理的活干着也挺顺的。
56 | * 不断学习,不断否定之前的自己,重新认识自己,有自知之明
57 | * 接触了很多前端周边的技术,如果说前端是自己的一套房产,那么我的这套房产的周边配套相对来讲还算比较齐全,所以虽然房子烂点,但不太影响价值
58 | * 前后端(vue,react,java,shell,mysql)都能搞起来,可以自己完成一个项目,就算没工作了也不会太担心
59 | * 自信很重要,永保自信
60 | * 基础扎实,js的一些基本原理、浏览器机制,vue react 的封装思路不求很透彻,起码得了解,知道个大概其。http机制,接口的实现思路,sql怎么写,数据库表结构 这些可以不会,但是得了解。最后就是前端工程化,脚手架那么多,不需要你手撸脚手架,但是得会用,会修改
61 | * 亮点:比如 webgl、大屏可视化、移动端app、跨平台的小程序、C端sass系统,这里面总得有一两个自己很熟的吧,经常做、有经验,而且积累了一些东西,设计思路、复杂情况的解决方案,通用代码等等,都可以。
62 | ```
63 |
64 | ### 核心竞争力
65 |
66 | ```
67 | * 做服务端的能力——我掌握了Java,node.js,还学了一点Go(没有用于生产),虽然在分工中不一定需要我做大量的服务端开发,但一方面我可以不求人的完成很多小项目,一方面我可以更好的换位思考我的合作伙伴们。
68 | * 查文档或文献的能力——不仅是文档,还要有文献,虽然做业务开发很少会需要看论文,不过当我需要做一些新奇的玩意,
69 | 比如以前心血来潮的一些计算几何和多边形算法相关的文献,最近倒腾的MIDI和SoundFont2的技术白皮书,这还帮我保证了一定的英语阅读能力。
70 | *【Make Boss Happy的能力】——这不是贬义的,不仅是理解KPI,更重要的是平衡个人技术追求和团队需求。
71 | * 一些算法基础——知道或验证过大多数技术的性能瓶颈和优劣,对网站不同阶段遇到的问题都有处理经验。
72 | * 做过抽丝剥茧的重构,也做过推到重建的大项目,对于可能出问题的地方有着准确的直觉。
73 | * 能快速识别人,快速上手新技术,有自己在这些事情的一套工作方法。
74 | * 带过各种各样的团队,管理过的各式各样的人,知道各种道道但同样能守住本心。
75 | * 5年以后更多的是软实力,对行业的了解,对上下游的协调,沟通,对组织玩法的了解,对项目的管理能力,对人的管理能力等等
76 | * 做管理的没有我懂技术,能做技术的没我懂管理,差异化才是核心竞争力,复合型人才
77 | *** (最重要)快速学习新知识,信息检索,解决开放问题,工程直觉这是 10 年开发经验带给我最大的收获看起来很虚,但确实存在,并且极为重要编程语言是相通的
78 | * 技术选型:根据业务的规模、复杂程度、团队的配置和现状合理的选型。不盲目在项目中尝试新的技术,但是要跟进对新技术的了解,了解其利弊和使用场景,作为选型时的依据。可以在非核心项目或者小模块里尝试。
79 | * 沟通交流:了解对接职位(通常就是后端、交互、产品)的一些基础知识和职能,方便在需求沟通时期就把潜在的问题暴露出来,PK掉不合理的需求,把复杂的问题简单处理。尤其是在项目的初期,很多需求和方案都是拍脑袋决定的,把这些需求用最简单粗暴的方式处理,不要让他们成为前期快速迭代的绊脚石。从项目的角度考虑合理性问题,不要一下扎进坑里,在不必要非核心的功能上浪费太多时间。
80 | * 价值和定位(可能和现在前端的主流价值观有很大出入):前端作为从web开发者中分离出来的职位,其使命和其他客户端程序员一样,除了实现基础的业务功能,最重要的是提升用户的体验。极端的说,即使没有前端工程师,后端一样可以实现现在的业务,只不过是体验不好,性能不佳。所以我认为,用户体验是前端最核心的价值。然而,在我看来社区里越来越多的前端致力于流程化和工程化的研究和优化,提升了开发者体验(但对于新手而言,可能提升了学习成本),而对于用户而言却没有带来太多实质的价值(个人体验来看,新框架初期匹配的组件体验往往不如同类型的 jquery 插件 -- 主要原因可能是年代够久远,体验优化的够好)。结和技术选型,在一些不是特别需要用户体验 且 业务逻辑复杂 且 项目周期短 且 团队技术基础好 的项目中,是非常合适的。然而这么苛刻的条件决定了他们不适合绝大部分业务。
81 | * 工程化实践经验,多端开发经验,多语言跨平台
82 | ```
83 |
84 | ---
85 |
86 | #### 作者
87 |
88 | | Coder | 小红书ID | 创建时间 |
89 | | :--- | :---| :--- |
90 | | 落寞的前端👣 | 121450513 |2022.09.29 |
91 |
92 |
--------------------------------------------------------------------------------
/ES6-->class继承.md:
--------------------------------------------------------------------------------
1 | ## 大多数前端工程师不了解的ES6 Class继承
2 |
3 | ## 前文再续,接上一回 ES5 继承
4 |
5 | ## 6. 面向对象ES6 -> 继承
6 |
7 | - 我们前面介绍了,通过构造函数的形式来模仿“类”,在ES6的新标准中,使用`class`关键字来定义类
8 | - 其class的本质就是前面构造函数、原型链的那一套东西,就是几个API调用而已
9 |
10 | ### 6.1 定义类
11 |
12 | ```arduino
13 | //1. 类申明
14 | class Person1 {}
15 |
16 | //2. 类表达式
17 | const Person2 = class {}
18 | ```
19 |
20 | ### 6.2 类与构造函数
21 |
22 | - 其本质是跟构造函数一样
23 |
24 | ```javascript
25 | class Person {}
26 |
27 | const p1 = new Person()
28 |
29 | console.log(Person.prototype)
30 | console.log(Person.prototype.constructor)
31 | console.log(p1.__proto__ === Person.prototype)
32 |
33 | //{}
34 | //[class Person]
35 | //true
36 | ```
37 |
38 | ### 6.3 类的构造函数
39 |
40 | - 如果我们希望在创建对象的时候给类传递一些参数,这个时候应该如何做呢?
41 | - 每个类都可以有一个自己的构造函数(方法),这个方法的名称是固定的constructor;
42 | - 当我们通过new操作符,操作一个类的时候会调用这个类的构造函数constructor;
43 | - 每个类只能有一个构造函数,如果包含多个构造函数,那么会抛出异常;
44 |
45 | ```javascript
46 | class Person {
47 | constructor(name, age, money) {
48 | this.name = name
49 | this.age = age
50 | this.money = money
51 | }
52 |
53 | running() {
54 | console.log(`${this.name} running!!!`)
55 | }
56 | eating() {
57 | console.log(`${this.name} eating!!!`)
58 | }
59 | }
60 |
61 | const p1 = new Person('ice', 22, 100)
62 | console.log(p1)
63 | p1.running()
64 | p1.eating()
65 |
66 | // Person { name: 'ice', age: 22, money: 100 }
67 | // ice running!!!
68 | // ice eating!!!
69 | ```
70 |
71 | ### 6.4 类的实例方法
72 |
73 | ```javascript
74 | class Person {
75 | running() {
76 | console.log('running!!!')
77 | }
78 | eating() {
79 | console.log('eating!!!')
80 | }
81 | }
82 |
83 | const p1 = new Person()
84 |
85 | p1.running()
86 | p1.eating()
87 |
88 | console.log(p1.running === Person.prototype.running)
89 | console.log(p1.eating === Person.prototype.eating)
90 |
91 | // running!!!
92 | // eating!!!
93 | // true
94 | // true
95 | ```
96 |
97 | - 从打印结果我们可以看出,通过类关键字定义的方法,是存放在Person的原型对象上的,这样的话可以给多个实例进行共享
98 |
99 | ### 6.5 类的静态方法(类方法)
100 |
101 | - 静态方法通常用于定义直接使用类来执行的方法,不需要有类的实例,使用static关键字来定义:
102 |
103 | ```javascript
104 | Function.prototype.money = 100
105 | class Person {
106 | static getMoney() {
107 | console.log(this.money)
108 | }
109 | }
110 |
111 | Person.getMoney() //100
112 | ```
113 |
114 | - 这里给大家留两个问题
115 | - 第一:静态方法中的this指向谁?(this指向这个类本身,即Class Person{})
116 | - 第二: Person作为对象身份,它的隐式原型是谁? (指向`Function`的`prototype`)
117 |
118 | ### 6.6 类实现继承
119 |
120 | ```scala
121 | class Person {}
122 |
123 | class Student extends Person {}
124 | ```
125 |
126 | - 对你没有看错,两行代码就实现了以前ES5以前的一系列繁琐的操作,很容易实现了继承。
127 | - 在ES6中新增了使用extends关键字,可以方便的帮助我们实现继承
128 | - 即 `Sub extend Super`
129 |
130 | ### 6.7 类继承初体验
131 |
132 | ```javascript
133 | class Person {
134 | constructor(name, age) {
135 | this.name = name
136 | this.age = age
137 | }
138 |
139 | running() {
140 | console.log('running!!!')
141 | }
142 | }
143 |
144 | class Student extends Person {
145 | constructor(name, age, sno) {
146 | super(name, age)
147 | this.sno = sno
148 | }
149 |
150 | studying() {
151 | console.log('studying!!!')
152 | }
153 | }
154 |
155 | const s1 = new Student('ice', 22, 200010)
156 |
157 | console.log(s1)
158 | s1.running()
159 | s1.studying()
160 |
161 | // Student { name: 'ice', age: 22, sno: 200010 }
162 | // running!!!
163 | // studying!!!
164 | ```
165 |
166 | - 我们会发现在上面的代码中我使用了一个super关键字,这个super关键字有不同的使用方式:
167 | - 注意:在子(派生)类的构造函数中使用this或者返回默认对象之前,必须先通过super调用父类的构造函数!
168 | - super的使用位置有三个:子类的构造函数、实例方法、静态方法
169 |
170 | ```js
171 | class Person {
172 | constructor(name, age) {
173 | this.name = name
174 | this.age = age
175 | }
176 |
177 | running() {
178 | console.log('person running!!!')
179 | }
180 | }
181 |
182 |
183 | class Student extends Person {
184 | stuRunning() {
185 | //调用父类的方法
186 | super.running()
187 | }
188 | }
189 |
190 | const s1 = new Student()
191 | s1.stuRunning()
192 |
193 | //person running!!!
194 | ```
195 |
196 | - 静态方法调用就不演示了,想演练的可以自己尝试一下,都比较简单就是API调用而已。
197 |
198 | ### 6.8 继承内置类
199 |
200 | ```js
201 | class ICEArray extends Array {
202 | lastItem() {
203 | return this[this.length - 1]
204 | }
205 | }
206 |
207 | const arr = new ICEArray(1, 2, 3)
208 | console.log(arr.lastItem()) //3
209 | ```
210 |
211 | - 继承字内置Array类,调用`lastItem`,每次获取最后一个元素。
212 |
213 | ## 结语
214 | > 今天ES6 Class继承的分享就到这边了,原型、继承系列就分享完啦。期待我们的下次见面~
215 |
216 | ## 作者
217 |
218 | | Coder | 小红书ID | 创建时间 |
219 | | :---------- | :-------- | :--------- |
220 | | 落寞的前端👣 | 121450513 | 2022.10.09 |
221 |
--------------------------------------------------------------------------------
/js面试题三(JS基础).md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(JS篇)三
2 |
3 | ## 三、 函数与函数式编程
4 |
5 | ### 3.1 什么是函数式编程
6 |
7 | 函数式编程是一种"编程范式"(programming paradigm),一种编写程序的方法论
8 |
9 | 主要的编程范式有三种:命令式编程,声明式编程和函数式编程
10 |
11 | 相比命令式编程,函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而非设计一个复杂的执行过程
12 |
13 | ### 3.2 函数式编程的优缺点
14 |
15 | **优点**
16 |
17 | - 更好的管理状态:因为它的宗旨是无状态,或者说更少的状态,能最大化的减少这些未知、优化代码、减少出错情况
18 | - 更简单的复用:固定输入->固定输出,没有其他外部变量影响,并且无副作用。这样代码复用时,完全不需要考虑它的内部实现和外部影响
19 | - 更优雅的组合:往大的说,网页是由各个组件组成的。往小的说,一个函数也可能是由多个小函数组成的。更强的复用性,带来更强大的组合性
20 | - 隐性好处。减少代码量,提高维护性
21 |
22 | **缺点**
23 |
24 | - 性能:函数式编程相对于指令式编程,性能绝对是一个短板,因为它往往会对一个方法进行过度包装,从而产生上下文切换的性能开销
25 | - 资源占用:在 JS 中为了实现对象状态的不可变,往往会创建新的对象,因此,它对垃圾回收所产生的压力远远超过其他编程方式
26 | - 递归陷阱:在函数式编程中,为了实现迭代,通常会采用递归操作
27 |
28 | ### 3.3 什么是纯函数,它有什么优点
29 |
30 | 纯函数是对给定的输入返还相同输出的函数,并且要求你所有的数据都是不可变的,即纯函数=无状态+数据不可变
31 |
32 | 特性:
33 |
34 | - 函数内部传入指定的值,就会返回确定唯一的值
35 | - 不会造成超出作用域的变化,例如修改全局变量或引用传递的参数
36 |
37 | 优势:
38 |
39 | - 使用纯函数,我们可以产生可测试的代码
40 | - 不依赖外部环境计算,不会产生副作用,提高函数的复用性
41 | - 可读性更强 ,函数不管是否是纯函数 都会有一个语义化的名称,更便于阅读
42 | - 可以组装成复杂任务的可能性。符合模块化概念及单一职责原则
43 |
44 | ### 3.4 什么是组合函数 (compose)
45 |
46 | 在函数式编程中,有一个很重要的概念就是函数组合,实际上就是把处理的函数数据像管道一样连接起来,然后让数据穿过管道连接起来,得到最终的结果。
47 |
48 | 组合函数,其实大致思想就是将 多个函数组合成一个函数,c(b(a(a(1)))) 这种写法简写为 compose(c, b, a, a)(x)
49 | 。但是注意这里如果一个函数都没有传入,那就是传入的是什么就返回什么,并且函数的执行顺序是和传入的顺序相反的。
50 |
51 | ```js
52 | var compose = (...funcs) => {
53 | // funcs(数组):记录的是所有的函数
54 | // 这里其实也是利用了柯里化的思想,函数执行,生成一个闭包,预先把一些信息存储,供下级上下文使用
55 | return (x) => {
56 | var len = funcs.length;
57 | // 如果没有函数执行,直接返回结果
58 | if (len === 0) return x;
59 | if (len === 1) funcs[0](x);
60 | return funcs.reduceRight((res, func) => {
61 | return func(res);
62 | }, x);
63 | };
64 | };
65 | var resFn = compose(c, b, a, a);
66 | resFn(1);
67 | ```
68 |
69 | 组合函数的思想,在很多框架中也被使用,例如:redux,实现效果来说是其实和上面的代码等价。
70 |
71 | ### 3.5 什么是惰性函数
72 |
73 | 惰性载入表示函数执行的分支只会在函数第一次掉用的时候执行,在第一次调用过程中,该函数会被覆盖为另一个按照合适方式执行的函数,这样任何对原函数的调用就不用再经过执行的分支了
74 |
75 | **惰性函数相当于有记忆的功能一样,当它已经判断了一遍的话,第二遍就不会再判断了。**
76 |
77 | 比如现在要求写一个test函数,这个函数返回首次调用时的new Date().getTime(),注意是首次,而且不允许有全局变量的污染
78 |
79 | ```javascript
80 | //一般会这样实现
81 | var test = (function () {
82 | var t = null;
83 | return function () {
84 | if (t) {
85 | return t;
86 | }
87 | t = new Date().getTime();
88 | return t;
89 | }
90 | })();
91 | // 用惰性函数实现
92 | var test = function () {
93 | var t = new Date().getTime();
94 | test = function () {
95 | return t;
96 | }
97 | return test();
98 | }
99 | console.log(test());
100 | console.log(test());
101 | console.log(test());
102 | ```
103 |
104 | ### 3.6 什么是高阶函数
105 |
106 | 高阶函数是指使用其他函数作为参数、或者返回一个函数作为结果的函数。
107 |
108 | ### 3.7 说说你对函数柯里化的理解
109 |
110 | 柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。
111 |
112 | 函数柯里化的好处:
113 |
114 | (1)参数复用:需要输入多个参数,最终只需输入一个,其余通过 arguments 来获取
115 |
116 | (2)提前确认:避免重复去判断某一条件是否符合,不符合则 return 不再继续执行下面的操作
117 |
118 | (3)延迟运行:避免重复的去执行程序,等真正需要结果的时候再执行
119 |
120 | ### 3.8 什么是箭头函数,有什么特征
121 |
122 | 使用 "箭头" ( => ) 来定义函数. 箭头函数相当于匿名函数, 并且简化了函数定义
123 |
124 | **箭头函数的特征:**
125 |
126 | - 箭头函数没有this, this指向定义箭头函数所处的外部环境
127 | - 箭头函数的this永远不会变,call、apply、bind也无法改变
128 | - 箭头函数只能声明成**匿名函数**,但可以通过表达式的方式让箭头函数具名
129 | - 箭头函数没有原型prototype
130 | - 箭头函数不能当做一个构造函数 因为 this 的指向问题
131 | - 箭头函数没有 arguments 在箭头函数内部访问这个变量访问的是外部环境的arguments, 可以使用 ...代替
132 |
133 | ### 3.9 说说你对递归函数的理解
134 |
135 | 如果一个函数在内部调用自身本身,这个函数就是递归函数
136 |
137 | 其核心思想是把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解
138 |
139 | 一般来说,递归需要有边界条件、递归前进阶段和递归返回阶段。当边界条件不满足时,递归前进;当边界条件满足时,递归返回
140 |
141 | **优点**:结构清晰、可读性强
142 |
143 | **缺点**:效率低、调用栈可能会溢出,其实每一次函数调用会在内存栈中分配空间,而每个进程的栈的容量是有限的,当调用的层次太多时,就会超出栈的容量,从而导致栈溢出。
144 |
145 | ### 3.10 什么是尾递归
146 |
147 | 尾递归,即在函数尾位置调用自身(或是一个尾调用本身的其他函数等等)。
148 |
149 | 在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储,递归次数过多容易造成栈溢出
150 |
151 | 这时候,我们就可以使用尾递归,即一个函数中所有递归形式的调用都出现在函数的末尾,对于尾递归来说,由于只存在一个调用记录,所以永远不会发生"栈溢出"错误
152 |
153 | ### 3.11 函数传参,传递复杂数据类型和简单数据类型有什么区别
154 |
155 | 传递复杂数据类型传递的是引用的地址,修改会改变
156 |
157 | 简单数据类型传递的是具体的值,不会相互影响
158 |
159 | ```js
160 | let a = 8
161 |
162 | function fn(a) {
163 | a = 9
164 | }
165 |
166 | fn(a)
167 | console.log(a) // 8 */
168 |
169 | let a = {age: 8}
170 |
171 | function fn(a) {
172 | a.age = 9
173 | }
174 |
175 | fn(a)
176 | console.log(a.age) // 9
177 | ```
178 |
179 | ### 3.12 函数声明与函数表达式的区别
180 |
181 | **函数声明:** function开头,有函数提升
182 |
183 | **函数表达式**: 不是function开头,没有函数提升
184 |
185 | ### 3.13 什么是函数缓存,如何实现?
186 |
187 | **概念**
188 |
189 | 函数缓存,就是将函数运算过的结果进行缓存
190 |
191 | 本质上就是用空间(缓存存储)换时间(计算过程)
192 |
193 | 常用于缓存数据计算结果和缓存对象
194 |
195 | **如何实现**
196 |
197 | 实现函数缓存主要依靠闭包、柯里化、高阶函数
198 |
199 | **应用场景**
200 |
201 | - 对于昂贵的函数调用,执行复杂计算的函数
202 | - 对于具有有限且高度重复输入范围的函数
203 | - 对于具有重复输入值的递归函数
204 | - 对于纯函数,即每次使用特定输入调用时返回相同输出的函数
205 |
206 | ### 3.14 call、apply、bind三者的异同
207 |
208 | **共同点** :
209 |
210 | - 都可以改变this指向;
211 | - 三者第一个参数都是`this`要指向的对象,如果如果没有这个参数或参数为`undefined`或`null`,则默认指向全局`window`
212 |
213 | **不同点**:
214 |
215 | - call 和 apply 会调用函数, 并且改变函数内部this指向.
216 | - call 和 apply传递的参数不一样,call传递参数使用逗号隔开,apply使用数组传递,且`apply`和`call`是一次性传入参数,而`bind`可以分为多次传入
217 | - `bind`是返回绑定this之后的函数
218 |
219 | **应用场景**
220 |
221 | 1. call 经常做继承.
222 | 2. apply经常跟数组有关系. 比如借助于数学对象实现数组最大值最小值
223 | 3. bind 不调用函数,但是还想改变this指向. 比如改变定时器内部的this指向
224 |
225 | ## 结语
226 |
227 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
228 |
229 | ## 作者
230 |
231 | | Coder | 小红书ID | 创建时间 |
232 | | :---------- | :-------- | :--------- |
233 | | 落寞的前端👣 | 121450513 | 2022.10.13 |
234 |
--------------------------------------------------------------------------------
/eventLoop.md:
--------------------------------------------------------------------------------
1 | ## 彻底搞懂浏览器 Event Loop 事件循环
2 |
3 | ## 前言
4 |
5 | > 浏览器的事件循环和Node的事件循环是每个前端工程师必须掌握的知识点,我们平常最多的就是跟浏览器打交道。本文先介绍浏览器的事件循环,笔者从以下几个角度去分析问题从而引出到底什么是事件循环?
6 |
7 | 1. 你们了解操作系统中 什么是进程? 什么是线程?
8 | 2. JS是单线程还是多线程的?
9 | 3. 浏览器是多进程还是单进程? 为什么?
10 | 4. 如果JS是单线程的,它是如何实现异步处理的?
11 | 5. 引出事件循环
12 |
13 | ## 1.什么是进程? 什么是线程?
14 |
15 | 首先给大家推荐一本《现代操作系统》这本书,真正的理解了操作系统的本质,许多开发问题都会豁然开朗。`在操作系统中无论是运行系统中的什么应用,最终都是会编译成二进制交CPU给执行。`
16 | 我们在日常使用电脑中,我们可能会一边听歌、一边写代码、一边写博客。这些应用中都会在操作系统中开启一个进程或多个进程,不同的应用开启的进程是不一样的。为了大家好理解就比喻某个应用中只会开启一个进程,而一个进程当中会开启多个线程。如果只有一个线程的话,我们称之为主线程。`结论:一个进程当中包含多个线程或只有一个主线程。`
17 | **画了一幅图让大家更加直观的了解进程和线程的关系**
18 |
19 | 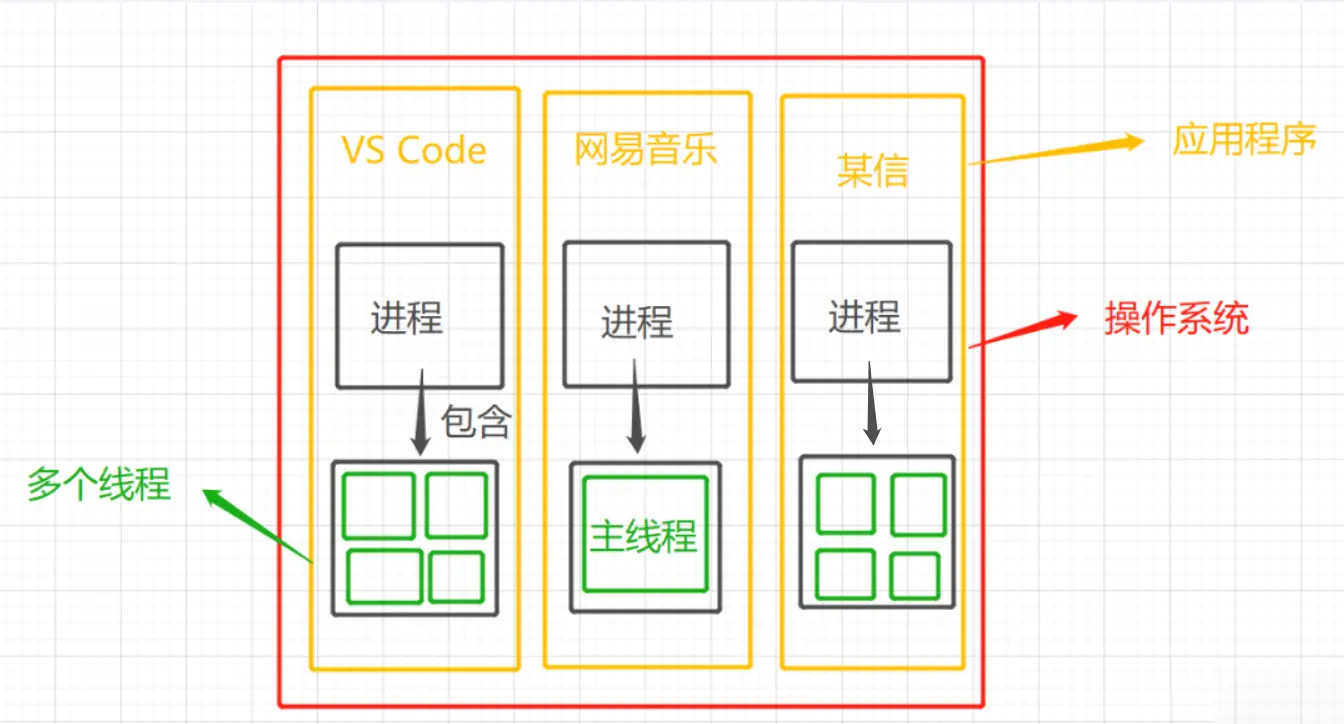
20 | 在这副图中,最外层的就相当于操作系统,我们在会在操作系统下载很多应用,当我们运行VsCode、网易云音乐、某信等...
21 | 他们都会开启一个进程或多个进程(这个跟应用程序本身有关),一个进程里面又包含了多个线程,如果只有一个线程称之为主线程。
22 | 如果当您看到了这里,还是对进程跟线程不是特别了解,请允许我用一个通俗易懂的例子来描述他们之间的关系。
23 | `操作系统就跟工厂一样,一个工厂会包含多个车间,其中多个车间就好比是我们的应用程序有多个进程,车间里面有工人在工作,就相当于是线程的概念。`
24 |
25 | ## 2.JS是单线程还是多线程的?
26 |
27 | `答案:JS是单线程。`如果您深究为什么是单线程的呢?
28 | 其实这是与它的用途有关,因为JS是一门浏览器脚本语言,主要用途是进行用户操作和操作DOM,所以它只能是单线程的,否则会带来很多复杂的同步问题。
29 |
30 | ## 3.浏览器是多进程还是单进程
31 |
32 | `答案:浏览器是多进程的。`为什么说是多进程的? 你说是就是吗? 凭什么呢?
33 | 当我们浏览网页的时候,有的时候是不是会遇到浏览器卡死的情况。如果我们开了多个会话,就假如我们一边刷力扣,一边开发程序,写循环的时候,写了一个死循环,导致了我们开发的这个会话的崩溃,如果浏览器是单进程的情况下,力扣这个时候也会崩溃。
34 | 当然浏览器肯定不会允许这样的事情发生,它就是多进程的,多个会话互相不影响,你要崩溃你崩溃去,跟我可没关系~~~。
35 |
36 | ## 4.JS实现异步处理
37 |
38 | 首先当您看到了这里,其实你们离成功只有一步之遥了,跟着我继续探讨下去,把Event Loop一点一点捣碎了,喂进你们的嘴里。
39 |
40 | `我们先来看一段同步的JS代码`
41 |
42 | ```js
43 | const foo = 'foo'
44 |
45 | function bar() {
46 | console.log('bar')
47 | }
48 |
49 | console.log(foo) //foo
50 | bar() //bar
51 |
52 | ```
53 |
54 | JS的代码执行顺序是`从上至下`进行的,所以答案如注释所示,我们是毫无疑问的
55 |
56 | 现在玩点花样,来一点同步和异步代码给大家看看
57 |
58 | ```js
59 | const foo = 'foo'
60 |
61 | function bar() {
62 | console.log('bar')
63 | }
64 |
65 | queueMicrotask(() => {
66 | console.log('microtask')
67 | })
68 |
69 | console.log(foo)
70 |
71 | setTimeout(() => {
72 | console.log('setTimeout')
73 | },1000)
74 |
75 | bar()
76 |
77 | //主线程: foo bar
78 | //微任务队列:microtask
79 | //宏任务队列:setTimeout
80 | //执行顺序: foo bar microtask setTimeout(1s过后)
81 |
82 | ```
83 |
84 | 现在穿插了异步的代码,如果把上面从上至下运行代码的结论用到异步,肯定是错误的! 正确的执行顺序的答案,大家可以先看一下,可能对异步不太了解的人会产生疑惑,不要慌,我们一点一点来看,引出下面的事件循环。
85 |
86 | ## 5.事件循环
87 |
88 | 首先我们又回到 JS 代码是`单线程`开始讲起,当我们编写的`同步`的代码的时候,代码的执行顺序是从上至下的,但是当有`异步`操作或者一些耗时操作的时候,如果还是按照之前的结论从上至下的话,那么一定会堵塞我们主线程的代码 也就是 main script中的代码,这样在js当中肯定是不被允许的。假如我有耗时操作(setTimeout)或者网络请求(ajax),延迟了5s才执行,那我后面的代码都`堵塞`了。
89 | 用文字的形式,还是有点抽象,我们直接上图,到底是一个怎么样的机制,完美解决这一问题。
90 |
91 | 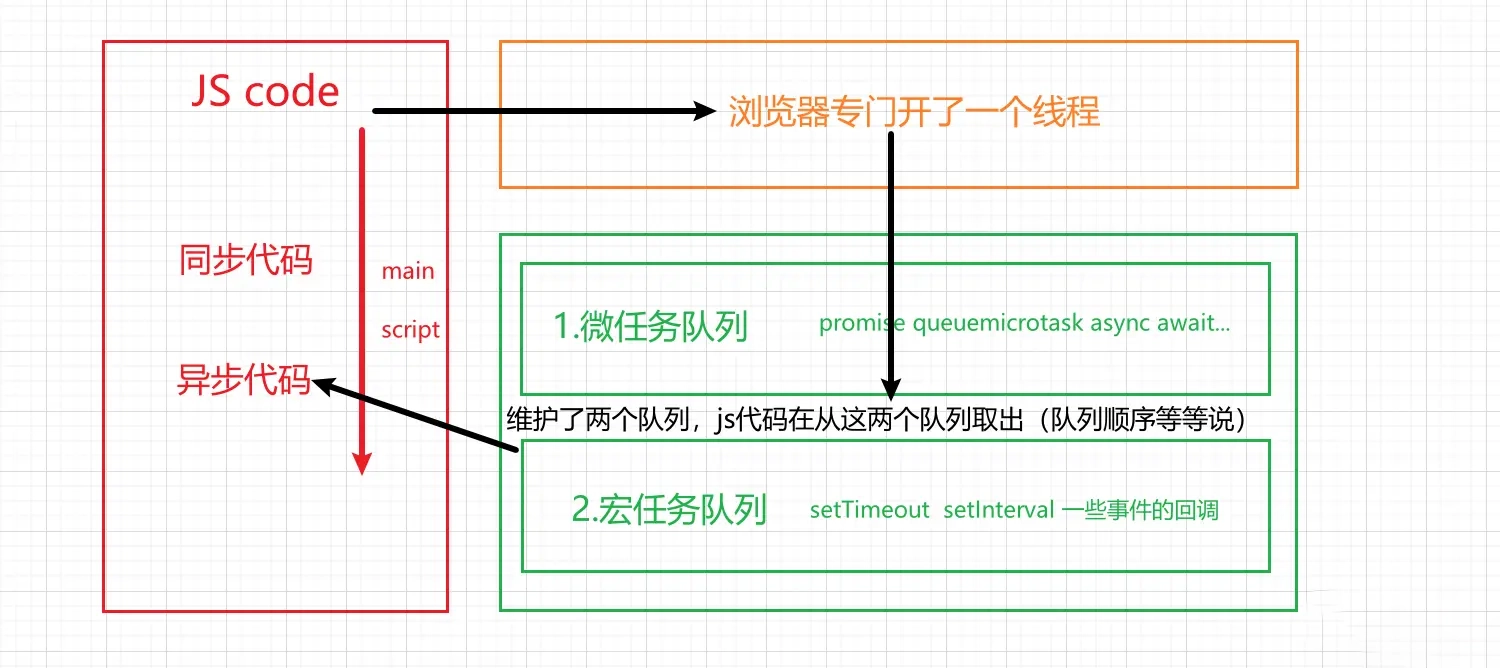
92 | 简单描述一下这幅图:首先js代码先执行主线程的代码,也就是同步的代码,从上至下,遇到异步代码交给浏览器,浏览器专门开了一个线程,其中浏览器线程中维护这两个队列,`一个微任务队列,一个宏任务队列`。
93 |
94 | `宏任务队列 Macrotask Queue: ajax、setTimeout、setInterval、Dom监听等 ` ;
95 |
96 | `微任务队列 Microtask Queue: Promise的then回调、 Mutation Observer API、queueMicrotask `;
97 |
98 | `注意:每一次执行宏任务之前,都是要确保我微任务的队列是空的,也就是说从代码执行的顺序来说微任务优先于宏任务。`
99 |
100 | 但是存在插队的情况,也就是说当我微任务执行完了,要开始执行宏任务了(有多个宏任务),宏任务队列当队列中的代码执行了,宏任务队列里面又有微任务代码,又把微任务放入到微任务队列当中。
101 |
102 | 此时特别注意!!!从严格的意义来说,紧接着是先进行编译的宏任务,但是此时微任务里面有任务才去执行的微任务队列,而不是直接去执行的。这些异步的代码交给js执行,`这样三者形成了一个闭环,我们称之为事件循环`。
103 |
104 | ## 6.常见面试题
105 |
106 | ### 1.面试题一
107 |
108 | 看到下面的代码,直接copy到编辑器当中,跟我来分析一波。学会了什么是事件循环?
109 |
110 | ```js
111 | setTimeout(function () {
112 | console.log("setTimeout1");
113 | new Promise(function (resolve) {
114 | resolve();
115 | }).then(function () {
116 | new Promise(function (resolve) {
117 | resolve();
118 | }).then(function () {
119 | console.log("then4");
120 | });
121 | console.log("then2");
122 | });
123 | });
124 |
125 | new Promise(function (resolve) {
126 | console.log("promise1");
127 | resolve();
128 | }).then(function () {
129 | console.log("then1");
130 | });
131 |
132 | setTimeout(function () {
133 | console.log("setTimeout2");
134 | });
135 |
136 | console.log(2);
137 |
138 | queueMicrotask(() => {
139 | console.log("queueMicrotask1");
140 | });
141 |
142 | new Promise(function (resolve) {
143 | resolve();
144 | }).then(function () {
145 | console.log("then3");
146 | });
147 |
148 | //promise1 2 then1 queueMicrotask1 then3 setTimeout1 then2 then4 setTimeout2
149 | ```
150 |
151 | 请耐心观看 下面执行顺序图(你想要的都在图里):
152 |
153 | 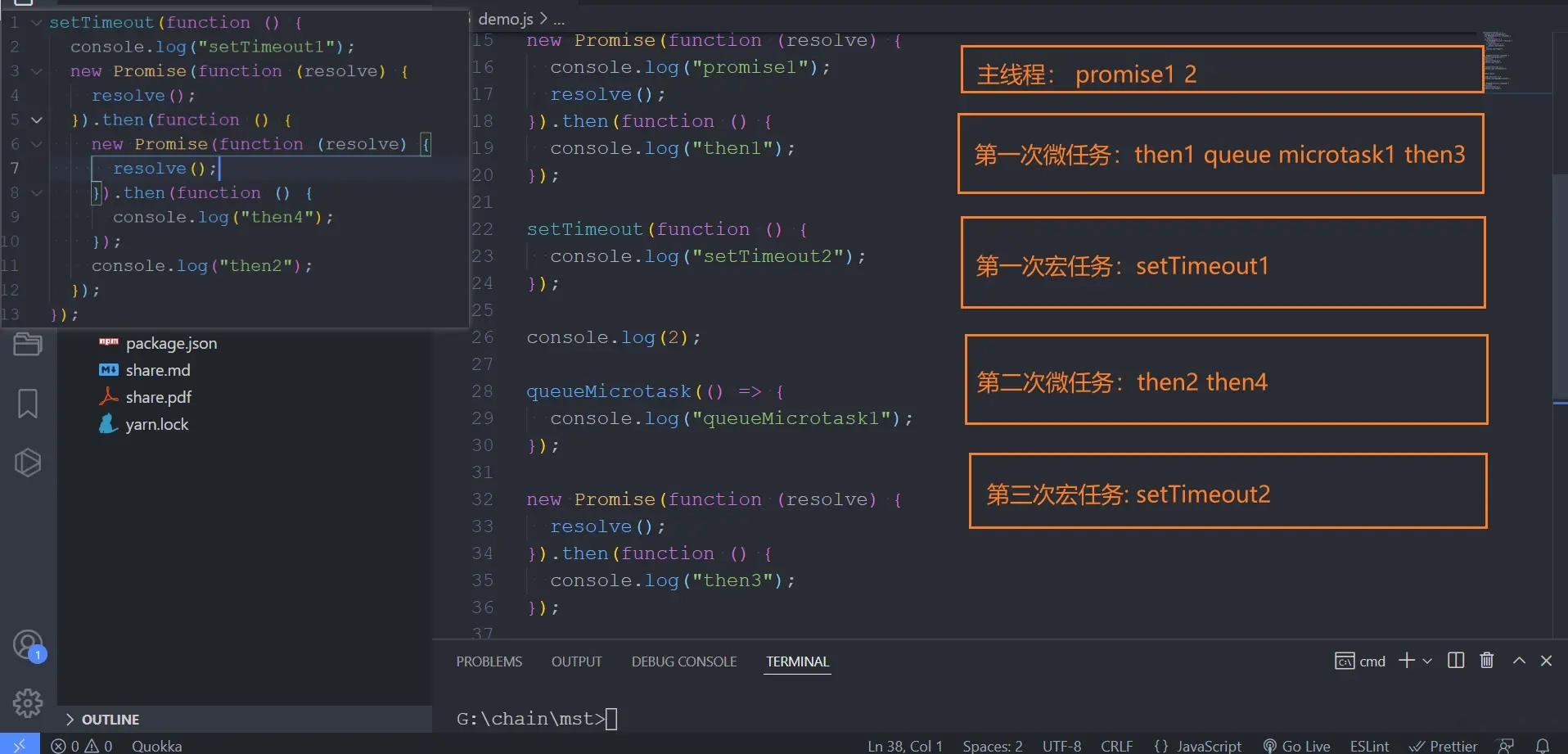
154 |
155 | ### 2.面试题二
156 |
157 | 我们穿插一道简单的吧,首先您要对async await 有一定的了解,如果您不太了解,下方评论,我会尽快更新的,直接告诉您`结论:async函数当中,await后面的代码相当于promise.then的代码,是一个微任务,但是await所在的函数可是会直接执行的,不能混淆了。` 话不多说,我们直接上代码。
158 |
159 | ```js
160 | async function bar() {
161 | console.log("222222");
162 | return new Promise((resolve, reject) => {
163 | reject();
164 | });
165 | }
166 |
167 | async function foo() {
168 | console.log("111111");
169 | await bar().catch((err) => {});
170 | console.log("333333");
171 | }
172 | foo();
173 | console.log("444444");
174 |
175 | //111111 222222 444444 333333
176 |
177 | ```
178 |
179 | 执行顺序分析图:
180 |
181 | 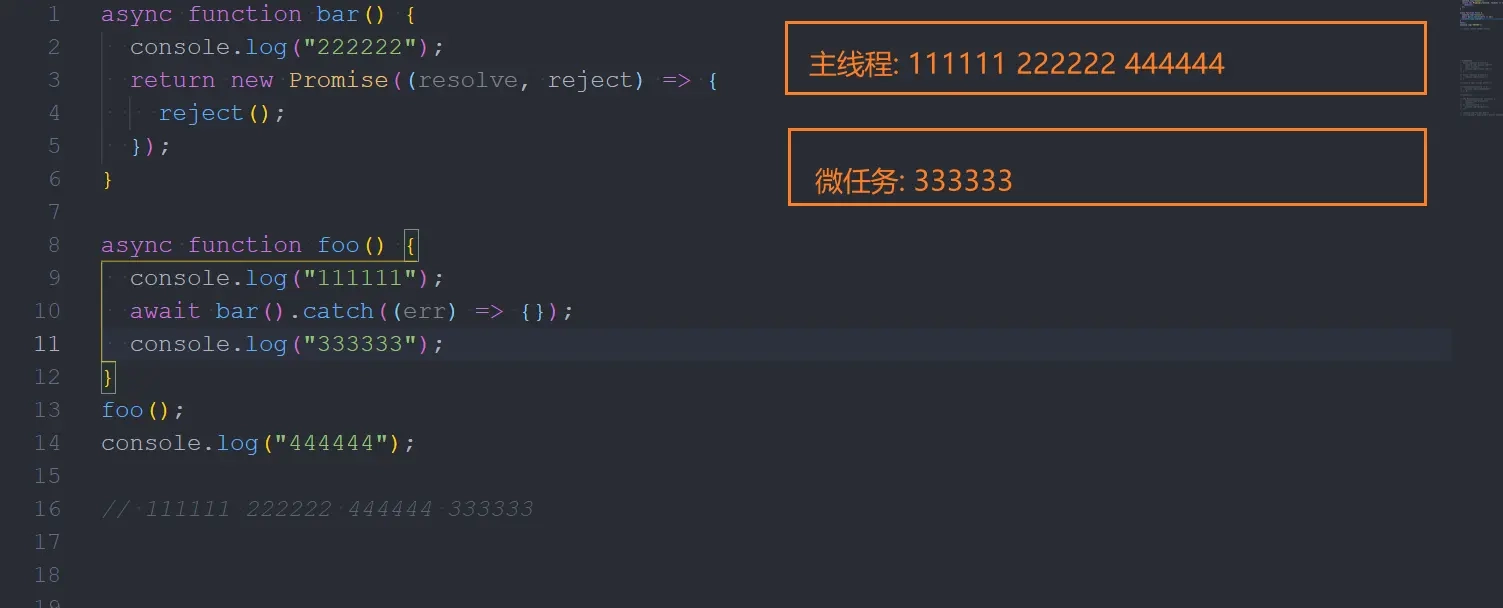
182 |
183 | ### 3.面试题三
184 |
185 | `这是一道字节的面试题,让我们来给它撕烂吧`,废话少说直接上代码
186 |
187 | ```js
188 | //字节面试题
189 | async function async1() {
190 | console.log("async1 start");
191 | await async2();
192 | console.log("async1 end");
193 | }
194 |
195 | async function async2() {
196 | console.log("async2");
197 | }
198 |
199 | console.log("script start");
200 |
201 | setTimeout(function () {
202 | console.log("setTimeout");
203 | }, 0);
204 |
205 | async1();
206 |
207 | new Promise(function (resolve) {
208 | console.log("promise1");
209 | resolve();
210 | }).then(function () {
211 | console.log("promise2");
212 | });
213 |
214 | console.log("script end");
215 |
216 | /*
217 | script start
218 | async1 start
219 | async2
220 | promise1
221 | script end
222 | async1 end
223 | promise2
224 | setTimeout
225 | */
226 |
227 | ```
228 |
229 | 请仔细查看分析图:
230 |
231 | 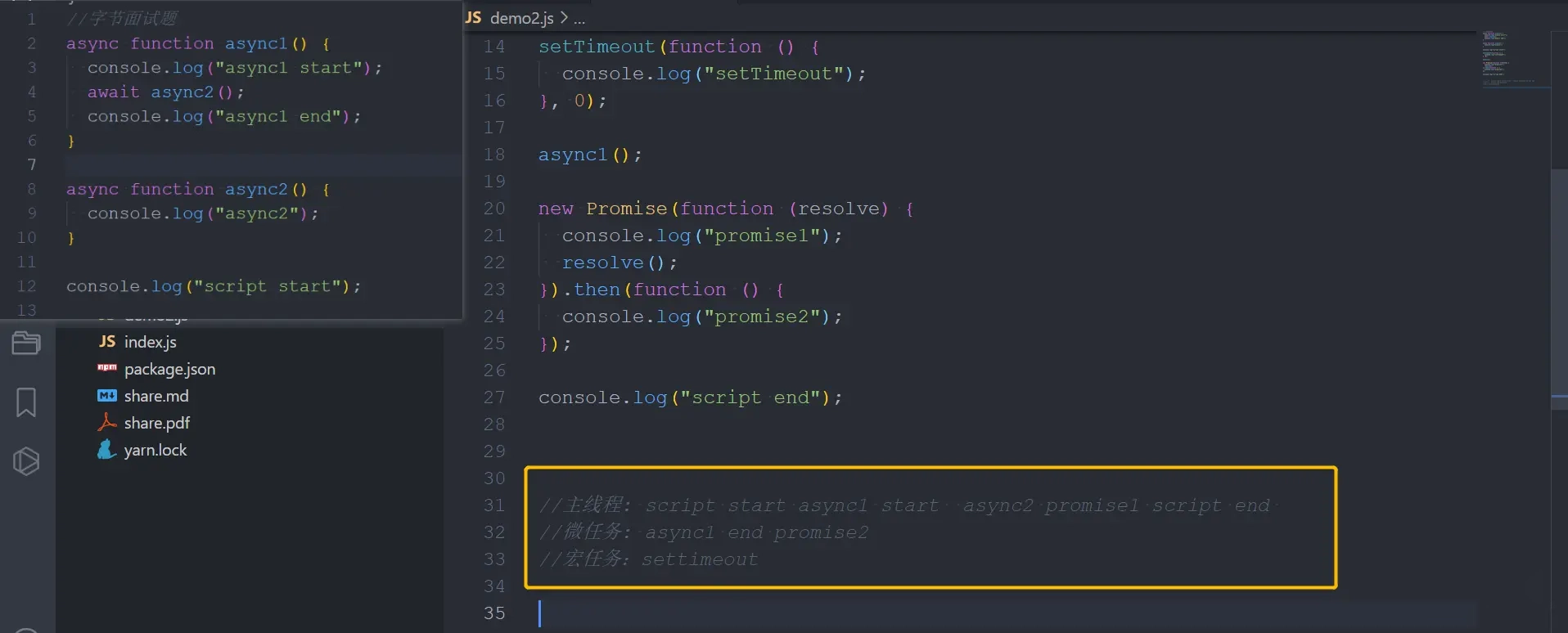
232 |
233 | ## 结语
234 |
235 | 看完本期分享,浏览器的事件循环告一段落了,基本可以手撕90%以上的面试题~
236 |
237 | ## 作者
238 |
239 | | Coder | 小红书ID | 创建时间 |
240 | | :---------- | :-------- | :--------- |
241 | | 落寞的前端👣 | 121450513 | 2022.10.05 |
242 |
--------------------------------------------------------------------------------
/前端手撕代码面试题(二).md:
--------------------------------------------------------------------------------
1 | ## 前端手写代码题(二)
2 |
3 | ## 11. 使用Promise封装AJAX请求
4 |
5 | ```javascript
6 | // promise 封装实现:
7 | function getJSON(url) {
8 | // 创建一个 promise 对象
9 | let promise = new Promise(function (resolve, reject) {
10 | let xhr = new XMLHttpRequest();
11 | // 新建一个 http 请求
12 | xhr.open("GET", url, true);
13 | // 设置状态的监听函数
14 | xhr.onreadystatechange = function () {
15 | if (this.readyState !== 4) return;
16 | // 当请求成功或失败时,改变 promise 的状态
17 | if (this.status === 200) {
18 | resolve(this.response);
19 | } else {
20 | reject(new Error(this.statusText));
21 | }
22 | };
23 | // 设置错误监听函数
24 | xhr.onerror = function () {
25 | reject(new Error(this.statusText));
26 | };
27 | // 设置响应的数据类型
28 | xhr.responseType = "json";
29 | // 设置请求头信息
30 | xhr.setRequestHeader("Accept", "application/json");
31 | // 发送 http 请求
32 | xhr.send(null);
33 | });
34 | return promise;
35 | }
36 |
37 | ```
38 |
39 | ## 12. 手写深拷贝
40 |
41 | ```javascript
42 | function fn(obj) {
43 | // 判断数据是否是复杂类型
44 | if (obj instanceof Object) {
45 | //判断数据是否是数组
46 | if (Array.isArray(obj)) {
47 | //声明一个空数组来接收拷贝后的数据
48 | let result = []
49 | obj.forEach(item => {
50 | // 需要递归深层遍历,否则复制的是地址
51 | result.push(fn(item))
52 | })
53 | // 返回输出这个数组,数组拷贝完成
54 | return result
55 | } else {
56 | //如果是对象,就声明一个空对象来接收拷贝后的数据
57 | let result = {}
58 | for (let k in obj) {
59 | // 使用递归深层遍历
60 | result[k] = fn(obj[k])
61 | }
62 | // 返回输出这个对象,对象拷贝完成
63 | return result
64 | }
65 | }
66 | // 简单数据类型则直接返回输出
67 | return obj
68 | }
69 |
70 | ```
71 |
72 | ## 13. 手写打乱数组顺序的方法
73 |
74 | 主要的实现思路就是:
75 |
76 | - 取出数组的第一个元素,随机产生一个索引值,将该第一个元素和这个索引对应的元素进行交换。
77 | - 第二次取出数据数组第二个元素,随机产生一个除了索引为1的之外的索引值,并将第二个元素与该索引值对应的元素进行交换
78 | - 按照上面的规律执行,直到遍历完成
79 |
80 | ```js
81 | let arr = [1,2,3,4,5,6,7,8,9,10];
82 | for (let i = 0; i < arr.length; i++) {
83 | const randomIndex = Math.round(Math.random() * (arr.length - 1 - i)) + i;
84 | [arr[i], arr[randomIndex]] = [arr[randomIndex], arr[i]];
85 | }
86 | console.log(arr)
87 |
88 | ```
89 |
90 | ## 14. 实现数组扁平化
91 |
92 | 通过循环递归的方式,一项一项地去遍历,如果每一项还是一个数组,那么就继续往下遍历,利用递归程序的方法,来实现数组的每一项的连接:
93 |
94 | ```js
95 | let arr = [1, [2, [3, 4, 5]]];
96 | function flatten(arr) {
97 | let result = [];
98 |
99 | for(let i = 0; i < arr.length; i++) {
100 | if(Array.isArray(arr[i])) {
101 | result = result.concat(flatten(arr[i]));
102 | } else {
103 | result.push(arr[i]);
104 | }
105 | }
106 | return result;
107 | }
108 | flatten(arr); // [1, 2, 3, 4,5]
109 | ```
110 |
111 | ## 15. 实现数组的flat方法
112 |
113 | ```javascript
114 | function _flat(arr, depth) {
115 | if (!Array.isArray(arr) || depth <= 0) {
116 | return arr;
117 | }
118 | return arr.reduce((prev, cur) => {
119 | if (Array.isArray(cur)) {
120 | return prev.concat(_flat(cur, depth - 1))
121 | } else {
122 | return prev.concat(cur);
123 | }
124 | }, []);
125 | }
126 |
127 | ```
128 |
129 | ## 16. 实现数组的push方法
130 |
131 | ```js
132 | let arr = [];
133 | Array.prototype.push = function() {
134 | for( let i = 0 ; i < arguments.length ; i++){
135 | this[this.length] = arguments[i] ;
136 | }
137 | return this.length;
138 | }
139 |
140 | ```
141 |
142 | ## 17. 实现数组的filter方法
143 |
144 | ```javascript
145 | Array.prototype._filter = function (fn) {
146 | if (typeof fn !== "function") {
147 | throw Error('参数必须是一个函数');
148 | }
149 | const res = [];
150 | for (let i = 0, len = this.length; i < len; i++) {
151 | fn(this[i]) && res.push(this[i]);
152 | }
153 | return res;
154 | }
155 | ```
156 |
157 | ## 18. 实现数组的map方法
158 |
159 | ```javascript
160 | Array.prototype._map = function (fn) {
161 | if (typeof fn !== "function") {
162 | throw Error('参数必须是一个函数');
163 | }
164 | const res = [];
165 | for (let i = 0, len = this.length; i < len; i++) {
166 | res.push(fn(this[i]));
167 | }
168 | return res;
169 | }
170 | ```
171 |
172 | ## 19. 实现 add(1)(2)(3)(4)
173 |
174 | 可以实现任意数量数字相加,但是需要用+号隐式转换
175 |
176 | ```javascript
177 | function fn() {
178 | let result = [];
179 |
180 | function add(...args) {
181 | // ...args剩余参数,可以获取到传进来的参数
182 | result = [...result, ...args]
183 | return add;
184 | }
185 | ;
186 | // 创建一个取代 valueOf 方法的函数,覆盖自定义对象的 valueOf 方法
187 | add.toString = () => result.reduce((sum, k) => sum + k, 0);
188 | return add;
189 | };
190 | let add = fn()
191 | console.log(+add(1)(2)(3)(4)) // --->10
192 | // let add2 = fn();
193 | console.log(+add2(1, 2, 3)(4)) // --->10
194 | ```
195 |
196 | 参数固定的情况下,不需要用+号,可以根据参数长度来判断返回值
197 |
198 | ```js
199 | function currying(fn, length) {
200 | length = length || fn.length; // 第一次调用,给length赋值fn的长度,后面每次重复调用,length的长度都会减去参数的长度
201 | return function (...args) {
202 | return args.length >= length // 当前传递进来的参数的长度与length长度进行比较
203 | ? fn.apply(this, args) // 把最后一组实参传给为赋值的形参,此时所有形参都已赋值,并调用fn函数
204 | : currying(fn.bind(this, ...args), length - args.length)
205 | // 每一次调用fn.bind,都会把当前的args里的实参依次传给fn的形参,length的长度减去参数的长度
206 | // 相当于fn.bind(this, 1).bind(this, 2, 3),bind的连续调用,来填充fn的参数
207 | // 直到某一次调用,fn的形参即将全部都被赋值时,条件成立,会执行fn.apply,把最后的参数传递过去,并且调用fn
208 | }
209 | }
210 |
211 | function fn(a, b, c, d) {
212 | return a + b + c + d
213 | }
214 |
215 | const add = currying(fn)
216 | add(4)(3)(1)(2) //10
217 | add(1, 3)(4)(2) //10
218 | add(1)(3, 4, 2) //10
219 | ```
220 |
221 | ## 20. 用Promise实现图片的异步加载
222 |
223 | ```javascript
224 | let imageAsync = (url) => {
225 | return new Promise((resolve, reject) => {
226 | let img = new Image();
227 | img.src = url;
228 | img.οnlοad = () => {
229 | console.log(`图片请求成功,此处进行通用操作`);
230 | resolve(image);
231 | }
232 | img.οnerrοr = (err) => {
233 | console.log(`失败,此处进行失败的通用操作`);
234 | reject(err);
235 | }
236 | })
237 | }
238 |
239 | imageAsync("url").then(() => {
240 | console.log("加载成功");
241 | }).catch((error) => {
242 | console.log("加载失败");
243 | })
244 | ```
245 | ## 结语
246 |
247 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
248 |
249 | ## 作者
250 |
251 | | Coder | 小红书ID | 创建时间 |
252 | | :---------- | :-------- | :--------- |
253 | | 落寞的前端👣 | 121450513 | 2022.10.28 |
254 |
--------------------------------------------------------------------------------
/promise2.md:
--------------------------------------------------------------------------------
1 | ## 大多数前端工程师不了解的promise/async await《二》
2 |
3 | ## 3. Promise的回调地狱 (进阶)
4 |
5 | - 我还是以一个需求作为切入点,把知识点嚼碎了,一点一点喂进你们嘴里。
6 | - 当我发送网络请求的时候,需要拿到这次网络请求的数据,再发送网络请求,就这样重复三次,才能拿到我最终的结果。
7 |
8 | ### 3.1 卧龙解法
9 |
10 | ```javascript
11 | function requestData(url) {
12 | return new Promise((resolve, reject) => {
13 | setTimeout(() => {
14 | if (url.includes('iceweb')) {
15 | resolve(url)
16 | } else {
17 | reject('请求错误')
18 | }
19 | }, 1000);
20 | })
21 | }
22 |
23 |
24 | requestData('iceweb.io').then(res => {
25 | requestData(`iceweb.org ${res}`).then(res => {
26 | requestData(`iceweb.com ${res}`).then(res => {
27 | console.log(res)
28 | })
29 | })
30 | })
31 | //iceweb.com iceweb.org iceweb.io
32 | ```
33 |
34 | - 虽然能够实现,但是多层代码的嵌套,可读性非常差,我们把这种多层次代码嵌套称之为回调地狱
35 |
36 | ### 3.2 凤雏解法
37 |
38 | ```javascript
39 | function requestData(url) {
40 | return new Promise((resolve, reject) => {
41 | setTimeout(() => {
42 | if (url.includes('iceweb')) {
43 | resolve(url)
44 | } else {
45 | reject('请求错误')
46 | }
47 | }, 1000);
48 | })
49 | }
50 |
51 | requestData('iceweb.io').then(res => {
52 | return requestData(`iceweb.org ${res}`)
53 | }).then(res => {
54 | return requestData(`iceweb.com ${res}`)
55 | }).then(res => {
56 | console.log(res)
57 | })
58 | //iceweb.com iceweb.org iceweb.io
59 | ```
60 |
61 | - 利用了then链式调用这一特性,返回了一个新的promise,但是不够优雅,思考一下能不能写成同步的方式呢?
62 |
63 | ### 3.3 生成器+Promise解法
64 |
65 | ```javascript
66 | function requestData(url) {
67 | return new Promise((resolve, reject) => {
68 | setTimeout(() => {
69 | if (url.includes('iceweb')) {
70 | resolve(url)
71 | } else {
72 | reject('请求错误')
73 | }
74 | }, 1000);
75 | })
76 | }
77 |
78 | function* getData(url) {
79 | const res1 = yield requestData(url)
80 | const res2 = yield requestData(res1)
81 | const res3 = yield requestData(res2)
82 |
83 | console.log(res3)
84 | }
85 |
86 | const generator = getData('iceweb.io')
87 |
88 | generator.next().value.then(res1 => {
89 | generator.next(`iceweb.org ${res1}`).value.then(res2 => {
90 | generator.next(`iceweb.com ${res2}`).value.then(res3 => {
91 | generator.next(res3)
92 | })
93 | })
94 | })
95 |
96 | //iceweb.com iceweb.org iceweb.io
97 | ```
98 |
99 | - 大家可以发现我们的`getData`已经变为同步的形式,可以拿到我最终的结果了。那么很多同学会问,generator一直调用`.next`不是也产生了回调地狱吗?
100 | - 其实不用关心这个,我们可以发现它这个是有规律的,我们可以封装成一个自动化执行的函数,我们就不用关心内部是如何调用的了。
101 |
102 | ### 3.4 自动化执行函数封装
103 |
104 | ```javascript
105 | function requestData(url) {
106 | return new Promise((resolve, reject) => {
107 | setTimeout(() => {
108 | if (url.includes('iceweb')) {
109 | resolve(url)
110 | } else {
111 | reject('请求错误')
112 | }
113 | }, 1000);
114 | })
115 | }
116 |
117 | function* getData() {
118 | const res1 = yield requestData('iceweb.io')
119 | const res2 = yield requestData(`iceweb.org ${res1}`)
120 | const res3 = yield requestData(`iceweb.com ${res2}`)
121 |
122 | console.log(res3)
123 | }
124 |
125 | //自动化执行 async await相当于自动帮我们执行.next
126 | function asyncAutomation(genFn) {
127 | const generator = genFn()
128 |
129 | const _automation = (result) => {
130 | let nextData = generator.next(result)
131 | if(nextData.done) return
132 |
133 | nextData.value.then(res => {
134 | _automation(res)
135 | })
136 | }
137 |
138 | _automation()
139 | }
140 |
141 | asyncAutomation(getData)
142 |
143 | //iceweb.com iceweb.org iceweb.io
144 | ```
145 |
146 | - 利用promise+生成器的方式变相实现解决回调地狱问题,其实就是`async await`的一个变种而已
147 | - 最早为**TJ**实现,**前端大神人物**
148 | - async await核心代码就类似这些,内部主动帮我们调用`.next`方法
149 |
150 | ### 3.5 最终解决回调地狱的办法
151 |
152 | ```javascript
153 | function requestData(url) {
154 | return new Promise((resolve, reject) => {
155 | setTimeout(() => {
156 | if (url.includes('iceweb')) {
157 | resolve(url)
158 | } else {
159 | reject('请求错误')
160 | }
161 | }, 1000);
162 | })
163 | }
164 |
165 | async function getData() {
166 | const res1 = await requestData('iceweb.io')
167 | const res2 = await requestData(`iceweb.org ${res1}`)
168 | const res3 = await requestData(`iceweb.com ${res2}`)
169 |
170 | console.log(res3)
171 | }
172 |
173 | getData()
174 |
175 | //iceweb.com iceweb.org iceweb.io
176 | ```
177 |
178 | - 你会惊奇的发现,只要把`getData`生成器函数函数,改为`async`函数,`yeild`的关键字替换为`await`就可以实现异步代码同步写法了。
179 |
180 | ## 4. async/await 剖析
181 |
182 | - async(异步的)
183 | - async 用于申明一个异步函数
184 |
185 | ### 4.1 async内部代码同步执行
186 |
187 | - 异步函数的内部代码执行过程和普通的函数是一致的,默认情况下也是会被同步执行
188 |
189 | ```javascript
190 | async function sayHi() {
191 | console.log('hi ice')
192 | }
193 |
194 | sayHi()
195 |
196 | //hi ice
197 | ```
198 |
199 | ### 4.2 异步函数的返回值
200 |
201 | - 异步函数的返回值和普通返回值有所区别
202 | - 普通函数主动返回什么就返回什么,不返回为`undefined`
203 | - 异步函数的返回值特点
204 | - 明确有返回一个普通值,相当于`Promise.resolve`(返回值)
205 | - 返回一个thenble对象则由,then方法中的`resolve`,或者`reject`有关
206 | - 明确返回一个promise,则由这个promise决定
207 | - 异步函数中可以使用`await`关键字,现在在全局也可以进行`await`,但是不推荐。会阻塞主进程的代码执行
208 |
209 | ### 4.3 异步函数的异常处理
210 |
211 | - 如果函数内部中途发生错误,可以通过try catch的方式捕获异常
212 | - 如果函数内部中途发生错误,也可以通过函数的返回值.catch进行捕获
213 |
214 | ```js
215 | async function sayHi() {
216 | console.log(res)
217 | }
218 | sayHi().catch(e => console.log(e))
219 |
220 | //或者
221 |
222 | async function sayHi() {
223 | try {
224 | console.log(res)
225 | }catch(e) {
226 | console.log(e)
227 | }
228 | }
229 |
230 | sayHi()
231 |
232 | //ReferenceError: res is not defined
233 | ```
234 |
235 | ### 4.4 await 关键字
236 |
237 | - 异步函数中可以使用`await`关键字,普通函数不行
238 | - await特点
239 | - 通常await关键字后面都是跟一个Promise
240 | - 可以是普通值
241 | - 可以是thenble
242 | - 可以是Promise主动调用`resolve或者reject`
243 | - 这个promise状态变为fulfilled才会执行`await`后续的代码,所以`await`后面的代码,相当于包括在`.then`方法的回调中,如果状态变为rejected,你则需要在函数内部`try catch`,或者进行链式调用进行`.catch`操作
244 |
245 | ```javascript
246 | function requestData(url) {
247 | return new Promise((resolve, reject) => {
248 | setTimeout(() => {
249 | if (url.includes('iceweb')) {
250 | resolve(url)
251 | } else {
252 | reject('请求错误')
253 | }
254 | }, 1000);
255 | })
256 | }
257 |
258 | async function getData() {
259 | const res = await requestData('iceweb.io')
260 | console.log(res)
261 | }
262 |
263 | getData()
264 | // iceweb.io
265 | ```
266 |
267 | ## 5. 结语
268 |
269 | - 在如今互联网寒冬下,如果现在真的看不到未来是怎样,你就不如一直往前走,不知道什么时候天亮,去奔跑就好,跑着跑着天就亮了。
270 |
271 | # 作者
272 |
273 | | Coder | 小红书ID | 创建时间 |
274 | | :---------- | :-------- | :--------- |
275 | | 落寞的前端👣 | 121450513 | 2022.10.01 |
276 |
277 |
--------------------------------------------------------------------------------
/js面试题二(JS基础).md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(JS篇)二
2 |
3 | ## 二、闭包与作用域
4 |
5 | ### 2.1 什么是闭包?
6 |
7 | - ✅ 官方说法:闭包就是指有权访问另一个函数作用域中的变量的函数。
8 | - ✅ MDN说法:闭包是一种特殊的对象。它由两部分构成:函数,以及创建该函数的环境。环境由闭包创建时在作用域中的任何局部变量组成。
9 |
10 | **深度回答**
11 |
12 | 浏览器在加载页面会把代码放在栈内存( ECStack )中执行,函数进栈执行会产生一个私有上下文( EC ),此上下文能保护里面的使用变量( AO
13 | )不受外界干扰,并且如果当前执行上下文中的某些内容,被上下文以外的内容占用,当前上下文不会出栈释放,这样可以保存里面的变量和变量值,所以我认为闭包是一种保存和保护内部私有变量的机制。
14 |
15 | ### 2.2 闭包的作用
16 |
17 | 闭包有两个常用的用途;
18 |
19 | - 闭包的第一个用途是使我们在函数外部能够访问到函数内部的变量。通过使用闭包,可以通过在外部调用闭包函数,从而在外部访问到函数内部的变量,可以使用这种方法来**创建私有变量**。
20 | - 闭包的另一个用途是使已经运行结束的函数上下文中的**变量对象继续留在内存中**,因为闭包函数保留了这个变量对象的引用,所以这个变量对象不会被回收。
21 |
22 | ### 2.3 闭包在项目中的引用场景,以及带来的问题
23 |
24 | 在实际的项目中,会基于闭包把自己编写的模块内容包裹起来,这样编写就可以保护自己的代码是私有的,防止和全局变量或者是其他的代码冲突,这一点是利用保护机制。
25 |
26 | 但是不建议过多的使用闭包,因为使用不被释放的上下文,是占用栈内存空间的,过多的使用会导致导致内存泄漏。
27 |
28 | 解决闭包带来的内存泄漏问题的方法是:使用完闭包函数后手动释放。
29 |
30 | ### 2.4 闭包的使用场景
31 |
32 | 1. `return` 回一个函数
33 | 2. 函数作为参数
34 | 3. IIFE(自执行函数)
35 | 4. 循环赋值
36 | 5. 使用回调函数就是在使用闭包
37 | 6. 节流防抖
38 | 7. 函数柯里化
39 |
40 | ### 2.5 闭包的执行过程
41 |
42 | 1. 形成私有上下文
43 |
44 | 2. 进栈执行
45 |
46 | 3. 一系列操作
47 |
48 | (1). 初始化作用域链(两头<当前作用域,上级作用域>)
49 |
50 | (2). 初始化this
51 |
52 | (3). 初始化arguments
53 |
54 | (4). 赋值形参
55 |
56 | (5). 变量提升
57 |
58 | (6). 代码执行
59 |
60 | - 遇到变量就先看是否是自己私有的,不是自己私有的按照作用域链上查找,如果不是上级的就继续线上查找,,直到 EC(G),变量的查找其实就是一个作用域链的拼接过程,拼接查询的链式就是作用域链。
61 |
62 | 4. 正常情况下,代码执行完成之后,私有上下文出栈被回收。但是遇到特殊情况,如果当前私有上下文执行完成之后中的某个东西被执行上下文以外的东西占用,则当前私有上下文就不会出栈释放,也就是形成了不被销毁的上下文,闭包。
63 |
64 | ### 2.6 执行上下文的类型
65 |
66 | **(1)全局执行上下文**
67 |
68 | 任何不在函数内部的都是全局执行上下文,它首先会创建一个全局的window对象,并且设置this的值等于这个全局对象,一个程序中只有一个全局执行上下文。
69 |
70 | **(2)函数执行上下文**
71 |
72 | 当一个函数被调用时,就会为该函数创建一个新的执行上下文,函数的上下文可以有任意多个。
73 |
74 | **(3)** `eval`**函数执行上下文**
75 |
76 | 执行在eval函数中的代码会有属于他自己的执行上下文,不过eval函数不常使用,不做介绍。
77 |
78 | ### 2.7 执行上下文栈是什么
79 |
80 | - JavaScript引擎使用执行上下文栈来管理执行上下文
81 | - 当JavaScript执行代码时,首先遇到全局代码,会创建一个全局执行上下文并且压入执行栈中,每当遇到一个函数调用,就会为该函数创建一个新的执行上下文并压入栈顶,引擎会执行位于执行上下文栈顶的函数,当函数执行完成之后,执行上下文从栈中弹出,继续执行下一个上下文。当所有的代码都执行完毕之后,从栈中弹出全局执行上下文。
82 |
83 | ### 2.8 执行上下文的三个阶段
84 |
85 | **创建阶段 → 执行阶段 → 回收阶段**
86 |
87 | ------
88 |
89 | **创建阶段**
90 |
91 | (1)this绑定
92 |
93 | - 在全局执行上下文中,this指向全局对象(window对象)
94 | - 在函数执行上下文中,this指向取决于函数如何调用。如果它被一个引用对象调用,那么 this 会被设置成那个对象,否则 this 的值被设置为全局对象或者 undefined
95 |
96 | (2)创建词法环境组件
97 |
98 | - 词法环境是一种有**标识符——变量映射**的数据结构,标识符是指变量/函数名,变量是对实际对象或原始数据的引用。
99 | - 词法环境的内部有两个组件:**加粗样式**:环境记录器:用来储存变量个函数声明的实际位置**外部环境的引用**:可以访问父级作用域
100 |
101 | (3)创建变量环境组件
102 |
103 | - 变量环境也是一个词法环境,其环境记录器持有变量声明语句在执行上下文中创建的绑定关系。
104 |
105 | **执行阶段**
106 |
107 | 在这阶段,执行变量赋值、代码执行
108 |
109 | 如果 `Javascript` 引擎在源代码中声明的实际位置找不到变量的值,那么将为其分配 `undefined` 值
110 |
111 | **回收阶段**
112 |
113 | 执行上下文出栈等待虚拟机回收执行上下文
114 |
115 | ### 2.9 谈谈你对作用域的理解
116 |
117 | - 作用域可以视为一套规则,这套规则用来管理引擎如何在当前作用域以及嵌套的子作用域根据标识符名称进行变量查找。
118 | - 简单来说作用域就是变量的有效范围。在一定的空间里可以对变量数据进行读写操作,这个空间就是变量的作用域。
119 |
120 | #### (1)全局作用域
121 |
122 | - 直接写在script标签的JS代码,都在全局作用域。在全局作用域下声明的变量叫做全局变量(在块级外部定义的变量)。
123 |
124 | - 全局变量在全局的任何位置下都可以使用;全局作用域中无法访问到局部作用域的中的变量。
125 |
126 | - 全局作用域在页面打开的时候创建,在页面关闭时销毁。
127 |
128 | - **所有 window 对象的属性拥有全局作用域**
129 |
130 | *var和function命令声明的全局变量和函数是window对象的属性和方法*
131 |
132 | let命令、const命令、class命令声明的全局变量,不属于window对象的属性
133 |
134 | #### (2)函数作用域(局部作用域)
135 |
136 | - 调用函数时会创建函数作用域,函数执行完毕以后,作用域销毁。每调用一次函数就会创建一个新的函数作用域,他们之间是相互独立的。
137 | - 在函数作用域中可以访问全局变量,在函数的外面无法访问函数内的变量。
138 | - 当在函数作用域操作一个变量时,它会先在自身作用域中寻找,如果有就直接使用,如果没有就向上一作用域中寻找,直到找到全局作用域,如果全局作用域中仍然没有找到,则会报错。
139 |
140 | #### (3)块级作用域
141 |
142 | - ES6之前JavaScript采用的是函数作用域+词法作用域,ES6引入了块级作用域。
143 | - 任何一对花括号{}中的语句集都属于一个块,**在块中使用let和const声明的变量**,外部是访问不到的,这种作用域的规则就叫块级作用域。
144 | - 通过var声明的变量或者非严格模式下创建的函数声明没有块级作用域。
145 |
146 | #### (4)词法作用域
147 |
148 | - 词法作用域是静态的作用域,无论函数在哪里被调用,也无论它如何被调用,它的词法作用域都只由**函数被声明时所处的位置**决定。
149 | - 编译的词法分析阶段基本能够知道全部标识符在哪里以及是如何声明的,从而能够预测在执行过中如何对它们进行查找。
150 | - 换句话说,词法作用域就是你在写代码的时候就已经决定了变量的作用域。
151 |
152 | ### 2.10 什么是作用域链
153 |
154 | 当在`js`中使用一个变量的时候,首先`js`引擎会尝试在当前作用域下去寻找该变量,如果没找到,再到它的上层作用域寻找,以此类推直到找到该变量或是已经到了全局作用域,这样的变量作用域访问的链式结构, 被称之为作用域链
155 |
156 | **深度回答**
157 |
158 | 作用域链的本质上是一个指向变量对象的指针列表。变量对象是一个包含了执行环境中所有变量和函数的对象。作用域链的前端始终都是当前执行上下文的变量对象。全局执行上下文的变量对象(也就是全局对象)始终是作用域链的最后一个对象。
159 |
160 | ### 2.11 作用域链的作用
161 |
162 | 作用域链的作用是**保证对执行环境有权访问的所有变量和函数的有序访问,通过作用域链,可以访问到外层环境的变量和函数。**
163 |
164 | ### 2.12 作用域的常见应用场景
165 |
166 | 作用域的一个常见运用场景之一,就是 **模块化**。
167 |
168 | 由于 javascript 并未原生支持模块化导致了很多令人口吐芬芳的问题,比如全局作用域污染和变量名冲突,代码结构臃肿且复用性不高。在正式的模块化方案出台之前,开发者为了解决这类问题,想到了使用函数作用域来创建模块的方案。
169 |
170 | ### 2.13 说说Js中的预解析?
171 |
172 | JS 引擎在运行一份代码的时候,会按照下面的步骤进行工作:
173 |
174 | 1.把变量的声明提升到当前作用域的最前面,只会提升声明,不会提升赋值
175 |
176 | 2.把函数的声明提升到当前作用域的最前面,只会提升声明,不会提升调用
177 |
178 | 3.先提升 function,在提升 var
179 |
180 | ### 2.14 变量提升与函数提升的区别?
181 |
182 | **变量提升**
183 |
184 | 简单说就是在 JavaScript 代码执行前引擎会先进行预编译,预编译期间会将`变量声明与函数声明`提升至其`对应作用域的最顶端`,`函数内声明的变量`只会提升至`该函数作用域最顶层`,`当函数内部定义的一个变量与外部相同时`
185 | ,那么`函数体内的这个变量就会被上升到最顶端`。
186 |
187 | **函数提升**
188 |
189 | 函数提升只会提升函数声明式写法,函数表达式的写法不存在函数提升
190 |
191 | 函数提升的优先级大于变量提升的优先级,即函数提升在变量提升之上
192 |
193 | ### 2.15 如何延长作用域链?
194 |
195 | 作用域链是可以延长的。
196 |
197 | 延长作用域链: 执行环境的类型只有两种,全局和局部(函数)。但是有些语句可以在作用域链的前端临时增加一个变量对象,该变量对象会在代码执行后被移除。
198 |
199 | 具体来说就是执行这两个语句时,作用域链都会得到加强
200 |
201 | 1. try - catch 语句的 catch 块:会创建一个新的变量对象,包含的是被抛出的错误对 象的声明。
202 | 2. with 语句:with 语句会将指定的对象添加到作用域链中。
203 |
204 | ### 2.16 浏览器的垃圾回收机制
205 |
206 | #### (1)内存的生命周期
207 |
208 | JS 环境中分配的内存, 一般有如下生命周期:
209 |
210 | 1. 内存分配:当我们声明变量、函数、对象的时候,系统会自动为他们分配内存
211 |
212 | 2. 内存使用:即读写内存,也就是使用变量、函数等
213 |
214 | 3. 内存回收:使用完毕,由垃圾回收自动回收不再使用的内存
215 |
216 | 全局变量一般不会回收, 一般局部变量的的值, 不用了, 会被自动回收掉
217 |
218 | #### (2)垃圾回收的概念
219 |
220 | **垃圾回收**:JavaScript代码运行时,需要分配内存空间来储存变量和值。当变量不在参与运行时,就需要系统收回被占用的内存空间,这就是垃圾回收。
221 |
222 | **回收机制**:
223 |
224 | - Javascript 具有自动垃圾回收机制,会定期对那些不再使用的变量、对象所占用的内存进行释放,原理就是找到不再使用的变量,然后释放掉其占用的内存。
225 | - JavaScript中存在两种变量:局部变量和全局变量。全局变量的生命周期会持续要页面卸载;而局部变量声明在函数中,它的生命周期从函数执行开始,直到函数执行结束,在这个过程中,局部变量会在堆或栈中存储它们的值,当函数执行结束后,这些局部变量不再被使用,它们所占有的空间就会被释放。
226 |
227 | - 不过,当局部变量被外部函数使用时,其中一种情况就是闭包,在函数执行结束后,函数外部的变量依然指向函数内部的局部变量,此时局部变量依然在被使用,所以不会回收。
228 |
229 | #### (3)垃圾回收的方式
230 |
231 | **1.引用计数法**
232 |
233 | - 这个用的相对较少,IE采用的引用计数算法。引用计数就是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型赋值给该变量时,则这个值的引用次数就是1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数就减1。当这个引用次数变为0时,说明这个变量已经没有价值,因此,在在机回收期下次再运行时,这个变量所占有的内存空间就会被释放出来。
234 |
235 | - 这种方法会引起**循环引用**的问题:例如:`obj1`和`obj2`通过属性进行相互引用,两个对象的引用次数都是2。当使用循环计数时,由于函数执行完后,两个对象都离开作用域,函数执行结束,`obj1`和`obj2`
236 | 还将会继续存在,因此它们的引用次数永远不会是0,就会引起循环引用。
237 |
238 | **2.标记清除法**
239 |
240 | 现代的浏览器已经不再使用引用计数算法了。
241 |
242 | 现代浏览器通用的大多是基于标记清除算法的某些改进算法,总体思想都是一致的。
243 |
244 | - 标记清除是浏览器常见的垃圾回收方式,当变量进入执行环境时,就标记这个变量“进入环境”,被标记为“进入环境”的变量是不能被回收的,因为他们正在被使用。当变量离开环境时,就会被标记为“离开环境”,被标记为“离开环境”的变量会被内存释放。
245 |
246 | - 垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记。然后,它会去掉环境中的变量以及被环境中的变量引用的标记。而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后。垃圾收集器完成内存清除工作,销毁那些带标记的值,并回收他们所占用的内存空间。
247 |
248 | #### (4)如何减少垃圾回收
249 |
250 | 虽然浏览器可以进行垃圾自动回收,但是当代码比较复杂时,垃圾回收所带来的代价比较大,所以应该尽量减少垃圾回收。
251 |
252 | - **对数组进行优化:** 在清空一个数组时,最简单的方法就是给其赋值为[ ],但是与此同时会创建一个新的空对象,可以将数组的长度设置为0,以此来达到清空数组的目的。
253 | - **对**`object`**进行优化:** 对象尽量复用,对于不再使用的对象,就将其设置为null,尽快被回收。
254 | - **对函数进行优化:** 在循环中的函数表达式,如果可以复用,尽量放在函数的外面。
255 |
256 | #### (5)内存泄漏是什么
257 |
258 | 是指由于疏忽或错误造成程序未能释放已经不再使用的内存
259 |
260 | #### (6)哪些情况会导致内存泄漏
261 |
262 | 以下四种情况会造成内存的泄漏:
263 |
264 | - **意外的全局变量:** 由于使用未声明的变量,而意外的创建了一个全局变量,而使这个变量一直留在内存中无法被回收。
265 | - **被遗忘的计时器或回调函数:** 设置了 setInterval 定时器,而忘记取消它,如果循环函数有对外部变量的引用的话,那么这个变量会被一直留在内存中,而无法被回收。
266 | - **脱离 DOM 的引用:** 获取一个 DOM 元素的引用,而后面这个元素被删除,由于一直保留了对这个元素的引用,所以它也无法被回收。
267 | - **闭包:** 不合理的使用闭包,从而导致某些变量一直被留在内存当中。
268 |
269 | ## 结语
270 |
271 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
272 |
273 | ## 作者
274 |
275 | | Coder | 小红书ID | 创建时间 |
276 | | :---------- | :-------- | :--------- |
277 | | 落寞的前端👣 | 121450513 | 2022.10.12 |
278 |
--------------------------------------------------------------------------------
/前端手撕代码面试题(三).md:
--------------------------------------------------------------------------------
1 | ## 前端手写代码题(三)
2 |
3 | ## 21. 手写发布-订阅模式
4 |
5 | ```typescript
6 | class EventCenter {
7 | // 1. 定义事件容器,用来装事件数组
8 | let
9 | handlers = {}
10 |
11 | // 2. 添加事件方法,参数:事件名 事件方法
12 | addEventListener(type, handler) {
13 | // 创建新数组容器
14 | if (!this.handlers[type]) {
15 | this.handlers[type] = []
16 | }
17 | // 存入事件
18 | this.handlers[type].push(handler)
19 | }
20 |
21 | // 3. 触发事件,参数:事件名 事件参数
22 | dispatchEvent(type, params) {
23 | // 若没有注册该事件则抛出错误
24 | if (!this.handlers[type]) {
25 | return new Error('该事件未注册')
26 | }
27 | // 触发事件
28 | this.handlers[type].forEach(handler => {
29 | handler(...params)
30 | })
31 | }
32 |
33 | // 4. 事件移除,参数:事件名 要删除事件,若无第二个参数则删除该事件的订阅和发布
34 | removeEventListener(type, handler) {
35 | if (!this.handlers[type]) {
36 | return new Error('事件无效')
37 | }
38 | if (!handler) {
39 | // 移除事件
40 | delete this.handlers[type]
41 | } else {
42 | const index = this.handlers[type].findIndex(el => el === handler)
43 | if (index === -1) {
44 | return new Error('无该绑定事件')
45 | }
46 | // 移除事件
47 | this.handlers[type].splice(index, 1)
48 | if (this.handlers[type].length === 0) {
49 | delete this.handlers[type]
50 | }
51 | }
52 | }
53 | }
54 |
55 | ```
56 |
57 | ## 22. Object.defineProperty(简易版)
58 |
59 | ```javascript
60 | // Vue2的响应式原理,结合了Object.defineProperty的数据劫持,以及发布订阅者模式
61 | // Vue2的数据劫持,就是通过递归遍历data里的数据,用Object.defineProperty给每一个属性添加getter和setter,
62 | // 并且把data里的属性挂载到vue实例中,修改vue实例上的属性时,就会触发对应的setter函数,向Dep订阅器发布更新消息,
63 | // 对应的Watcher订阅者会收到通知,调用自身的回调函数,让编译器去更新视图。
64 | const obj = {
65 | name: '刘逍',
66 | age: 20
67 | }
68 | const p = {}
69 | for (let key in obj) {
70 | Object.defineProperty(p, key, {
71 | get() {
72 | console.log(`有人读取p里的${key}属性`);
73 | return obj[key]
74 | },
75 | set(val) {
76 | console.log(`有人修改了p里的${key}属性,值为${val},需要去更新视图`);
77 | obj[key] = val
78 | }
79 | })
80 | }
81 | ```
82 |
83 | ## 23. Proxy数据劫持(简易版)
84 |
85 | ```javascript
86 | // Vue3的数据劫持通过Proxy函数对代理对象的属性进行劫持,通过Reflect对象里的方法对代理对象的属性进行修改,
87 | // Proxy代理对象不需要遍历,配置项里的回调函数可以通过参数拿到修改属性的键和值
88 | // 这里用到了Reflect对象里的三个方法,get,set和deleteProperty,方法需要的参数与配置项中回调函数的参数相同。
89 | // Reflect里的方法与Proxy里的方法是一一对应的,只要是Proxy对象的方法,就能在Reflect对象上找到对应的方法。
90 | const obj = {
91 | name: '刘逍',
92 | age: 20
93 | }
94 | const p = new Proxy(obj, {
95 | // 读取属性的时候会调用getter
96 | get(target, propName) { //第一个参数为代理的源对象,等同于上面的Obj参数。第二个参数为读取的那个属性值
97 | console.log(`有人读取p对象里的${propName}属性`);
98 | return Reflect.get(target, propName)
99 | },
100 | // 添加和修改属性的时候会调用setter
101 | set(target, propName, value) { //参数等同于get,第三个参数为修改后的属性值
102 | console.log(`有人修改了p对象里的${propName}属性,值为${value},需要去修改视图`);
103 | Reflect.set(target, propName, value)
104 | },
105 | // 删除属性时,调用deleteProperty
106 | deleteProperty(target, propName) { // 参数等同于get
107 | console.log(`有人删除了p对象里的${propName}属性,需要去修改视图`);
108 | return Reflect.deleteProperty(target, propName)
109 | }
110 | })
111 | ```
112 |
113 | ## 24. 实现路由(简易版)
114 |
115 | ```js
116 | // hash路由
117 | class Route {
118 | constructor() {
119 | // 路由存储对象
120 | this.routes = {}
121 | // 当前hash
122 | this.currentHash = ''
123 | // 绑定this,避免监听时this指向改变
124 | this.freshRoute = this.freshRoute.bind(this)
125 | // 监听
126 | window.addEventListener('load', this.freshRoute, false)
127 | window.addEventListener('hashchange', this.freshRoute, false)
128 | }
129 |
130 | // 存储
131 | storeRoute(path, cb) {
132 | this.routes[path] = cb || function () {
133 | }
134 | }
135 |
136 | // 更新
137 | freshRoute() {
138 | this.currentHash = location.hash.slice(1) || '/'
139 | this.routes[this.currentHash]()
140 | }
141 | }
142 | ```
143 |
144 | ## 25. 使用 setTimeout 实现 setInterval
145 |
146 | 实现思路是使用递归函数,不断地去执行 setTimeout 从而达到 setInterval 的效果
147 |
148 | ```js
149 | function mySetInterval(fn, timeout) {
150 | // 控制器,控制定时器是否继续执行
151 | var timer = {flag: true};
152 |
153 | // 设置递归函数,模拟定时器执行。
154 | function interval() {
155 | if (timer.flag) {
156 | fn();
157 | setTimeout(interval, timeout);
158 | }
159 | }
160 |
161 | // 启动定时器
162 | setTimeout(interval, timeout);// 返回控制器
163 | return timer;
164 | }
165 | ```
166 |
167 | ## 26. 使用setInterval实现setTimeout
168 |
169 | ```js
170 | function mySetInterval(fn, t) {
171 | const timer = setInterval(() => {
172 | clearInterval(timer)
173 | fn()
174 | }, t)
175 | }
176 |
177 | mySetInterval(() => {
178 | console.log('hoho');
179 | }, 1000)
180 | ```
181 |
182 | ## 27. 实现 jsonp
183 |
184 | ```js
185 | // 动态的加载js文件
186 | function addScript(src) {
187 | const script = document.createElement('script');
188 | script.src = src;
189 | script.type = "text/javascript";
190 | document.body.appendChild(script);
191 | }
192 |
193 | addScript("http://xxx.xxx.com/xxx.js?callback=handleRes");
194 |
195 | // 设置一个全局的callback函数来接收回调结果
196 | function handleRes(res) {
197 | console.log(res);
198 | }
199 |
200 | // 接口返回的数据格式
201 | handleRes({a: 1, b: 2});
202 |
203 | ```
204 |
205 | ## 28. 提取出url 里的参数并转成对象
206 |
207 | ```javascript
208 | function getUrlParams(url) {
209 | let reg = /([^?&=]+)=([^?&=]+)/g
210 | let obj = {}
211 | url.replace(reg, function () {
212 | obj[arguments[1]] = arguments[2]
213 | })
214 | // 或者
215 | const search = window.location.search
216 | search.replace(/([^&=?]+)=([^&]+)/g, (m, $1, $2) => {
217 | obj[$1] = decodeURIComponent($2)
218 | })
219 |
220 | return obj
221 | }
222 |
223 | let url = 'https://www.junjin.cn?a=1&b=2'
224 | console.log(getUrlParams(url)) // { a: 1, b: 2 }
225 | ```
226 |
227 | ## 29. 请写至少三种数组去重的方法?(原生js)
228 |
229 | ```javascript
230 | //利用filter
231 | function unique(arr) {
232 | return arr.filter(function (item, index, arr) {
233 | //当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素
234 | return arr.indexOf(item, 0) === index;
235 | });
236 | }
237 |
238 | var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}];
239 | console.log(unique(arr))
240 |
241 | //利用ES6 Set去重(ES6中最常用)
242 | function unique(arr) {
243 | return Array.from(new Set(arr))
244 | }
245 |
246 | var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}];
247 | console.log(unique(arr))
248 | //[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {}, {}]
249 |
250 | //利用for嵌套for,然后splice去重(ES5中最常用)
251 | function unique(arr) {
252 | for (var i = 0; i < arr.length; i++) {
253 | for (var j = i + 1; j < arr.length; j++) {
254 | if (arr[i] == arr[j]) { //第一个等同于第二个,splice方法删除第二个
255 | arr.splice(j, 1);
256 | j--;
257 | }
258 | }
259 | }
260 | return arr;
261 | }
262 |
263 | var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}];
264 | console.log(unique(arr))
265 | //[1, "true", 15, false, undefined, NaN, NaN, "NaN", "a", {…}, {…}]
266 | //NaN和{}没有去重,两个null直接消失了
267 | ```
268 |
269 | ## 结语
270 |
271 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
272 |
273 | ## 作者
274 |
275 | | Coder | 小红书ID | 创建时间 |
276 | | :---------- | :-------- | :--------- |
277 | | 落寞的前端👣 | 121450513 | 2022.10.29 |
278 |
279 |
--------------------------------------------------------------------------------
/前端手撕代码面试题(四).md:
--------------------------------------------------------------------------------
1 | ## 前端手写代码题(四)
2 |
3 | ## 算法基础
4 |
5 | ## 1. 时间&空间复杂度
6 |
7 | - 复杂度是数量级(方便记忆、推广),不是具体数字。
8 | - 常见复杂度大小比较:O(n^2) > O(nlogn) > O(n) > O(logn) > O(1)
9 |
10 | ### 1.1 时间复杂度
11 |
12 | 常见时间复杂度对应关系:
13 |
14 | - O(n^2):2层循环(嵌套循环)
15 | - O(nlogn):快速排序(循环 + 二分)
16 | - O(n):1层循环
17 | - O(logn):二分
18 |
19 | ### 1.2 空间复杂度
20 |
21 | 常见空间复杂度对应关系:
22 |
23 | - O(n):传入一个数组,处理过程生成一个新的数组大小与传入数组一致
24 |
25 | ## 2. 八大数据结构
26 |
27 | ### 1. 栈
28 |
29 | `栈`是一个`后进先出`的数据结构。`JavaScript`中没有`栈`,但是可以用`Array`实现`栈`的所有功能。
30 |
31 | ```js
32 | // 数组实现栈数据结构
33 | const stack = []
34 |
35 | // 入栈
36 | stack.push(0)
37 | stack.push(1)
38 | stack.push(2)
39 |
40 | // 出栈
41 | const popVal = stack.pop() // popVal 为 2
42 | ```
43 |
44 | **使用场景**
45 |
46 | - 场景一:十进制转二进制
47 | - 场景二:有效括号
48 | - 场景三:函数调用堆栈
49 |
50 | ### 2. 队列
51 |
52 | `队列`是一个`先进先出`的数据结构。`JavaScript`中没有`队列`,但是可以用`Array`实现`队列`的所有功能。
53 |
54 | ```js
55 | // 数组实现队列数据结构
56 | const queue = []
57 |
58 | // 入队
59 | stack.push(0)
60 | stack.push(1)
61 | stack.push(2)
62 |
63 | // 出队
64 | const shiftVal = stack.shift() // shiftVal 为 0
65 |
66 | ```
67 |
68 | **使用场景**
69 |
70 | - 场景一:日常测核酸排队
71 | - 场景二:JS异步中的任务队列
72 | - 场景三:计算最近请求次数
73 |
74 | ### 3. 链表
75 |
76 | `链表`是多个元素组成的列表,元素存储不连续,用`next`指针连在一起。`JavaScript`中没有`链表`,但是可以用`Object`模拟`链表`。
77 |
78 | **使用场景**
79 |
80 | - 场景一:JS中的原型链
81 | - 场景二:使用链表指针获取 JSON 的节点值
82 |
83 | ### 4. 集合
84 |
85 | `集合`是一个`无序且唯一`的数据结构。`ES6`中有集合:`Set`,集合常用操作:去重、判断某元素是否在集合中、求交集。
86 |
87 | ```js
88 | // 去重
89 | const arr = [1, 1, 2, 2]
90 | const arr2 = [...new Set(arr)]
91 |
92 | // 判断元素是否在集合中
93 | const set = new Set(arr)
94 | const has = set.has(3) // false
95 |
96 | // 求交集
97 | const set2 = new Set([2, 3])
98 | const set3 = new Set([...set].filter(item => set2.has(item)))
99 | ```
100 |
101 | **使用场景**
102 |
103 | - 场景一:求交集、差集
104 |
105 | ### 5. 字典(哈希)
106 |
107 | `字典`也是一种存储`唯一值`的数据结构,但它以`键值对`的形式存储。`ES6`中的字典名为`Map`,
108 |
109 | ```js
110 | // 字典
111 | const map = new Map()
112 |
113 | // 增
114 | map.set('key1', 'value1')
115 | map.set('key2', 'value2')
116 | map.set('key3', 'value3')
117 |
118 | // 删
119 | map.delete('key3')
120 | // map.clear()
121 |
122 | // 改
123 | map.set('key2', 'value222')
124 |
125 | // 查
126 | map.get('key2')
127 |
128 | ```
129 |
130 | **使用场景**
131 |
132 | - 场景:leetcode刷题
133 |
134 | ### 6. 树
135 |
136 | `树`是一种`分层`的数据模型。前端常见的树包括:DOM、树、级联选择、树形控件……。`JavaScript`中没有`树`,但是可以通过`Object`和`Array`构建`树`。树的常用操作:深度/广度优先遍历、先中后序遍历。
137 |
138 | **使用场景**
139 |
140 | - 场景一:DOM树
141 | - 场景二:级联选择器
142 |
143 | ### 7. 图
144 |
145 | `图`是网络结构的抽象模型,是一组由边连接的节点。图可以表示任何二元关系,比如道路、航班。JS中没有图,但是可以用`Object`和`Array`构建`图`。图的表示法:邻接矩阵、邻接表、关联矩阵。
146 |
147 | **使用场景**
148 |
149 | - 场景一:道路
150 | - 场景二:航班
151 |
152 | ### 8. 堆
153 |
154 | `堆`是一种特殊的完全二叉树。所有的节点都大于等于(最大堆)或小于等于(最小堆)它的子节点。由于`堆`的特殊结构,我们可以用`数组`表示`堆`。
155 |
156 | **使用场景**
157 |
158 | - 场景:leetcode刷题
159 |
160 | ## 3. 排序方法
161 |
162 | ### 3.1 冒泡排序
163 |
164 | 比较两个记录键值的大小,如果这两个记录键值的大小出现逆序,则交换这两个记录
165 |
166 | **每遍历一个元素,都会把之前的所有相邻的元素都两两比较一遍,即便是已经排序好的元素**
167 |
168 | ```js
169 | //[1,3,4,2]->[1,3,2,4]->[1,2,3,4]->[1,2,3,4]
170 |
171 | let n = 0
172 | function bubbleSort(arr){
173 | for(let i = 1;i < arr.length;i++){
174 | for(let j = i;j > 0;j--){
175 | n++ // 1+2+3+...+arr.length-1
176 | if(arr[j] < arr[j-1]){
177 | [arr[j],arr[j-1]] = [arr[j-1],arr[j]];
178 | }
179 | }
180 | }
181 | return arr;
182 | }
183 |
184 | ```
185 |
186 | ### 3.2 插入排序
187 |
188 | 第i(i大于等于1)个记录进行插入操作时,R1、 R2,...,是排好序的有序数列,取出第i个元素,在序列中找到一个合适的位置并将她插入到该位置上即可。
189 |
190 | **相当于把当前遍历的元素取出,在序列中找到一个合适的位置将它插入。它的第二层循环不必遍历当前元素之前的所有元素,因为当前元素之前的序列是排序好的,碰到第一个小于当前元素的值,就可以停止继续向前查找了,然后把当前元素插入当前位置即可**
191 |
192 | ```js
193 | function insertSort(arr){
194 | for(let i = 1;i < arr.length;i++){
195 | let j = i-1;
196 | if(arr[i]= 0 && temp < arr[j]){
199 | arr[j+1] = arr[j];
200 | j--;
201 | }
202 | arr[j+1] = temp;
203 | }
204 | }
205 | return arr;
206 | }
207 |
208 | //[1,3,4,2] ->[1,3,4,4]->[1,3,3,4]->[1,2,3,4]
209 | //i=3 temp=2 j=2 arr[j]=4 arr[3]=4 [1,3,4,4]; j=1 arr[2]=3 [1,3,3,4]; j=0 [1,2,3,4]
210 | ```
211 |
212 | ### 3.3 希尔排序
213 |
214 | 算法先将要排序的一组数按某个增量d(n/2,n为要排序数的个数)分成若干组,每组中记录的下标相差d.对每组中全部元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,在每组中再进行直接插入排序。当增量减到1时,进行直接插入排序后,排序完成。
215 |
216 | ```js
217 | function hillSort(arr){
218 | let len = arr.length;
219 | for(let gap = parseInt(len / 2);gap >= 1;gap = parseInt(gap / 2)){
220 | for(let i = gap;i < len;i++){
221 | if(arr[i] < arr[i-gap]){
222 | let temp = arr[i];
223 | let j = i - gap;
224 | while(j >= 0 && arr[j] > temp){
225 | arr[j+gap] = arr[j];
226 | j -= gap;
227 | }
228 | arr[j+gap] = temp;
229 | }
230 | }
231 | }
232 | return arr;
233 | }
234 |
235 | ```
236 |
237 | 
238 |
239 | ### 3.4 选择排序
240 |
241 | 在第i次选择操作中,通过n-i次键值间比较,从n-i+1个记录中选出键值最小的记录,并和第i(1小于等于1小于等于n-1)个记录交换
242 |
243 | **每一次遍历,都把当前元素与剩下元素里的最小值交换位置**
244 |
245 | ```js
246 | //[4,1,3,2]->[1,4,3,2]->[1,2,4,3]->[1,2,3,4]
247 |
248 | function selectSort(arr){
249 | for(let i = 0;i < arr.length;i++){
250 | let min = Math.min(...arr.slice(i));
251 | let index
252 | for (let j = i; j < arr.length; j++) {
253 | if (arr[j] === min) {
254 | index = j
255 | break
256 | }
257 | }
258 | [arr[i],arr[index]] = [arr[index],arr[i]];
259 | }
260 | return arr;
261 | }
262 |
263 | ```
264 |
265 | ### 3.5 快排
266 |
267 | 在n个记录中取某一个记录的键值为标准,通常取第一个记录键值为基准,通过一趟排序将待排的记录分为小于或等于这个键值的两个独立的部分,这是一部分的记录键值均比另一部分记录的键值小,然后,对这两部分记录继续分别进行快速排序,以达到整个序列有序
268 |
269 | **取当前排序数组的第一个值作为基准值keys,通过一次遍历把数组分为right大于基准值和left小于等于基准值的两部分,然后对两个部分重复以上步骤排序,最后return的时候按照[left,keys,right]的顺序返回**
270 |
271 | ```js
272 | function quickSort(arr) {
273 | if (arr.length <= 1) return arr;
274 | let right = [], left = [], keys = arr.shift();
275 | for (let value of arr) {
276 | if (value > keys) {
277 | right.push(value)
278 | } else {
279 | left.push(value);
280 | }
281 | }
282 | return quickSort(left).concat(keys, quickSort(right));
283 | }
284 |
285 | //[4,1,3,2]-->quickSort([1,3,2]).concat(4,quickSort([]))
286 | // -->quickSort([]).concant(1,quickSort([3,2])).concat(4,quickSort([]))
287 | // -->quickSort([]).concant(1,quickSort([2]).concant(3)).concat(4,quickSort([]))
288 | // -->[1,2,3,4]
289 | //keys=4 R[] L[1,3,2]
290 | //-------quickSort(left)
291 | //keys=1 R[3,2] L[]
292 | //keys=3 R[] L[2]
293 | //quickSort(left)=[1,2,3]
294 |
295 | ```
296 |
297 | ### **3.6各排序算法的稳定性,时间复杂度,空间复杂度**
298 |
299 | 
300 |
301 | 每个语言的排序内部实现都是不同的。
302 |
303 | 对于 JS 来说,数组长度大于 10 会采用快排,否则使用插入排序。选择插入排序是因为虽然时间复杂度很差,但是在数据 量很小的情况下和 O(N * logN) 相差无几,然而插入排序需要的常数时间很小,所以相对别的排序来说更快。
304 |
305 | ## 4. JS尾递归优化斐波拉契数列
306 |
307 | 正常的斐波拉契数列js实现方式
308 |
309 | ```js
310 | const Fibonacci = (n) => {
311 | if (n <= 1) return 1;
312 | return Fibonacci(n - 1) + Fibonacci(n - 2);
313 | }
314 | Fibonacci(10) // 89
315 | Fibonacci(40) // 165580141 计算缓慢有延迟了
316 | Fibonacci(100) // 栈溢出,无法得到结果
317 | ```
318 |
319 | 使用尾递归优化该方法
320 |
321 | ```js
322 | const Fibonacci = (n, sum1 = 1, sum2 = 1) => {
323 | if (n <= 1) return sum2;
324 | return Fibonacci(n - 1, sum2, sum1 + sum2)
325 | }
326 | Fibonacci(10) // 89
327 | Fibonacci(100) // 573147844013817200000 速度依旧很快
328 | Fibonacci(1000) // 7.0330367711422765e+208 还是没有压力
329 | ```
330 |
331 | 尾递归优化可以在数量较大的计算中,可以起到很好的作用
332 |
333 | ## 结语
334 |
335 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
336 |
337 | ## 作者
338 |
339 | | Coder | 小红书ID | 创建时间 |
340 | | :---------- | :-------- | :--------- |
341 | | 落寞的前端👣 | 121450513 | 2022.10.30 |
342 |
343 |
--------------------------------------------------------------------------------
/原型.md:
--------------------------------------------------------------------------------
1 | ## 大多数前端工程师不了解的原型prototype
2 |
3 | ## 前言
4 |
5 | > JS中的原型/继承,我个人觉得是JS中最难的一个知识点。从对象的`[[prototype]]`(即隐式原型),再到函数`prototype`(显示原型),再到原型链、再到继承的多种方式原型链继承、借用构造函数继承、组合借用继承、寄生组合式继承,最终再到`ES6`的`class`关键字实现继承。
6 | > 无论再多的术语,其实都离不开生活,技术也是如此,技术源于生活,却不会高于生活,大部分都是现实的一种抽象。
7 | > 今天给大家先分享一下原型。
8 |
9 | ## 1. 对象的原型(隐式原型)
10 |
11 | 在JS当中,每个对象中都有一个特殊的内置属性(`[[prototype]]`)/隐式原型,其实就是对于其他对象的引用而已,换句话说就是:这个特殊的内置属性指向着另外一个对象,它也称之为对象的隐式原型。
12 |
13 | ### 1.1 查看隐式原型
14 |
15 | - `obj.__proto__`,早期由浏览器实现,兼容性较差
16 | - `Object.getPrototypeOf`方法也能获取到
17 |
18 | ```javascript
19 | const info = {
20 | name: 'ice',
21 | age: 22
22 | }
23 |
24 | console.log(info.__proto__)
25 | console.log(Object.getPrototypeOf(info))
26 |
27 | console.log(info.__proto__ === Object.getPrototypeOf(info)) // true
28 |
29 | ```
30 |
31 | - 打印结果如下:
32 | - 我们从打印结果可以看出,通过`__proto__`和`Object.getPrototypeOf`方法,获取的对象应用是同一个 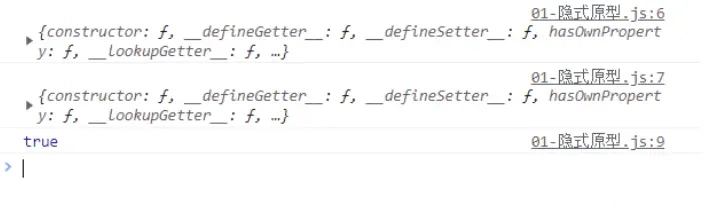
33 | - `constructor`这个特殊的属性,我们在后面再来剖析,它默认会指向当前的函数对象
34 |
35 | ### 1.2 隐式原型有什么用?
36 |
37 | 1. 当你访问该对象的属性时会触发`[[GET]]`操作(对象的存取描述符)
38 | 2. 当我访问`info.name`的时候,首先会查找该`info`对象中,是否有这个属性,有就使用它
39 |
40 | ```js
41 | const info = {
42 | name: 'ice',
43 | age: 22
44 | }
45 |
46 | console.log(info.name)
47 | ```
48 |
49 | 1. 如果无法在该`info`对象中找到,就会沿着该对象的隐式原型`[[prototype]]`(沿着原型链),有就使用它。直到查询到“尽头”后,还未找到该属性的值,返回`undefined`
50 |
51 | ```javascript
52 | //1. 未找到
53 | const info1 = {
54 | name: 'ice',
55 | age: 22
56 | }
57 |
58 | console.log(info1.money) //undefined
59 |
60 | //2. 隐式原型中找到
61 | const info2 = {
62 | name: 'ice',
63 | age: 22
64 | }
65 |
66 | ///后续会讲到是什么
67 | Object.prototype.money = 100
68 |
69 | console.log(info2.money) //100
70 | ```
71 |
72 | ## 2. 函数的显示原型
73 |
74 | 多年以来,js中有一种奇怪的行为,一直被“无耻”的滥用,那就是模仿类(早期是面向对象编程的天下)。这种奇怪的“类似类”的行为,就是利用函数的特殊属性,因为所有函数都会有一个显示原型(`prototype`)属性,它会指向另外一个对象,可以通过这一特性变相实现继承。
75 |
76 | ### 2.1 查看函数的原型
77 |
78 | - 所有的函数都一个`prototype`属性(**箭头函数除外**),注意:**不是对象的__proto__**
79 |
80 | ```javascript
81 | function bar() {}
82 |
83 | //所有的函数都有prototype属性
84 | console.log(bar.prototype)
85 |
86 | const info = {}
87 | //对象没有prototype属性
88 | console.log(info.prototype)
89 | ```
90 |
91 | ### 2.2 显示原型有什么用呢?
92 |
93 | - 最直接的解释,通过`new`关键字调用的函数(`new Foo()`),创建的对象,最终这个对象的`[[prototype]]` (`__proto__`/隐式原型),会指向`Foo.prototype`(**函数的显示原型**)这个对象。
94 |
95 | ```javascript
96 | function Person() {}
97 |
98 | const p1 = new Person()
99 | const p2 = new Person()
100 |
101 | console.log(p1.__proto__ === Person.prototype) //true
102 | console.log(p1.__proto__ === p2.__proto__) //true
103 | ```
104 |
105 | **内存表现**
106 |
107 | 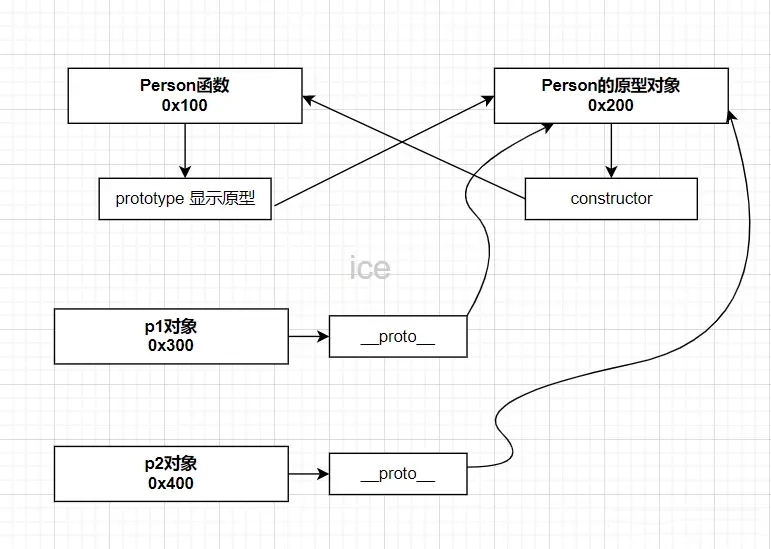
108 |
109 | ### 2.3 构造函数(类)
110 |
111 | 当首字母大写的函数,我们称之为构造函数(社区约定规范),早期ES5模仿类,在JS中也可以把`new Fn()`这种行为称之为`类`
112 |
113 | #### 2.3.1 `new Fn()` 发生了什么
114 |
115 | 1. 创建一个空对象
116 | 2. `this`指向创建出来的对象
117 | 3. 这个对象的隐式原型指向了函数的显示原型,(即`p1.__proto__ === Person.prototype`)
118 | 4. 运行函数体代码
119 | 5. 如果没有明确返回一个非空对象,那么返回的就是创建出来的对象
120 |
121 | ```js
122 | function Person(name, age) {
123 | this.name = name
124 | this.age = age
125 | }
126 |
127 | const p1 = new Person('ice', 22)
128 |
129 | console.log(p1) //{ name: 'ice', age: 22 }
130 | console.log(p1.__proto__ === Person.prototype) //true
131 | ```
132 |
133 | **内存表现**
134 |
135 | 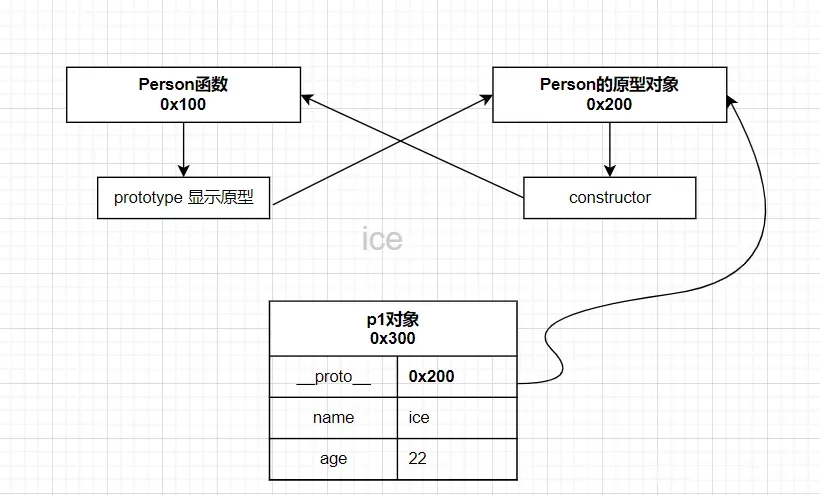
136 |
137 | #### 2.3.2 显示原型上添加属性/方法
138 |
139 | 函数的显示原型,是一个对象,我们当然可以在对象上面添加我们自定义属性,思考以下代码
140 |
141 | ```javascript
142 | function Person() {}
143 |
144 | Person.prototype.money = 100
145 | Person.prototype.getDoubleMoney = function() {
146 | return this.money * 2
147 | }
148 |
149 | const p1 = new Person()
150 |
151 | console.log(p1.money) //100
152 | console.log(p1.getDoubleMoney()) //200
153 | ```
154 |
155 | - 我们在构造函数的显示原型上,添加了`money`属性和`getDoubleMoney`方法,方法中设计到了`this`的概念,不懂的小伙伴可以翻一下,之前写的[有关this的文章](https://github.com/summmer-is-hot/marks/blob/main/this%E6%8C%87%E5%90%91.md)
156 | - 当我们对象自身上没有该`money`属性和`getDoubleMoney`方法,就会沿着对象的原型链一直查找,直至找到“尽头”,还未找到则为`undefined`,其实很明显这些属性/方法,存放在`Person`函数的原型上
157 | - `p1`对象为`Person`的实例(instance),即 `p1.__proto__ === Person.prototype`
158 |
159 | **内存表现**
160 |
161 | 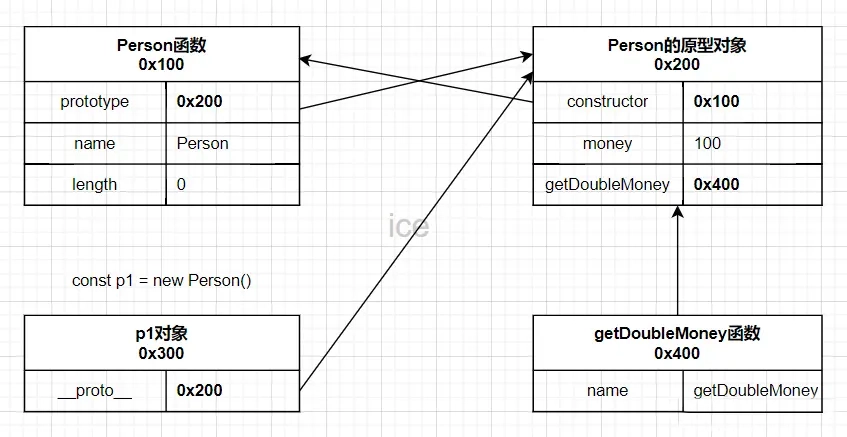
162 |
163 | - 每个函数都会有`name`和`length`属性,`name`为函数的名称,`length`为函数的形参个数
164 |
165 | **为什么添加到原型上?**
166 |
167 | - 为什么我要添加到原型上? 我为啥不能把属性/方法写在函数内部呢?
168 | - 思考以下代码
169 |
170 | ```javascript
171 | function Person(name, age, money) {
172 | this.name = name
173 | this.age = age
174 | this.money = money
175 |
176 | this.getDoubleMoney = function() {
177 | return this.money * 2
178 | }
179 | }
180 |
181 | const p1 = new Person('ice', 22, 100)
182 | const p2 = new Person('panda', 22, 200)
183 |
184 | console.log(p1.name, p1.money) //ice 100
185 | console.log(p1.name, p1.getDoubleMoney()) //ice 200
186 |
187 | console.log(p2.name, p2.money) //panda 200
188 | console.log(p2.name, p2.getDoubleMoney()) //panda 400
189 | ```
190 |
191 | - 我这里直接说结论:
192 | - 属性应该写在函数内部,而不是写在原型对象上,因为对于构造函数来说,每个实例对象应该有属于自己的属性,而不是同一个。
193 | - **公共方法**应该放在构造函数的原型上,因为**可以复用**。当我创建一个实例都会运行构造函数,我创建多个实例,那么就要调用多次。如果方法在函数体中,调用多次构造函数,方法就会被定义多次,这样其实是没有必要的。(多次调用、多次定义、浪费性能)
194 |
195 | ### 2.4 constructor属性
196 |
197 | 我们无论是前面打印原型对象,还是查看内存表现图,多次提到了`constructor`,那`constructor`到底是什么呢?
198 |
199 | - 每个原型对象上都有一个`constructor`,它默认指向了当前的函数,形成循环引用,V8引擎GC采用标记清除算法,不会存在内存泄漏问题
200 | - `Person.prototype.constructor === Person`
201 |
202 | ```javascript
203 | function Person() {}
204 |
205 | const p1 = new Person()
206 |
207 | console.log(Person.prototype.constructor.name) //person
208 | console.log(Person.prototype.constructor === Person) //true
209 | console.log(p1.__proto__.constructor === Person.prototype.constructor) //true
210 | ```
211 |
212 | ### 2.5 重写函数的显示原型
213 |
214 | ```javascript
215 | function Person(name, age, money) {
216 | this.name = name
217 | this.age = age
218 | this.money = money
219 | }
220 |
221 | //重写了显示原型,是一个全新的对象
222 | Person.prototype = {
223 | getDoubleMoney () {
224 | return this.money * 2
225 | }
226 | }
227 |
228 | const p1 = new Person('ice', 22, 100)
229 |
230 | console.log(p1.getDoubleMoney()) //200
231 | ```
232 |
233 | - 我们之前采用赋值的方式,是添加属性的方式添加方法,即`Person.prototype.getDoubleMoney = function() {} `,这是相当于在原对象上添加
234 | - 这个案例是,是直接赋值了一个新对象,在内存中的表现为,指向了另外一个对象,而不是默认的显示原型了。
235 |
236 | **探究constructor**
237 | 上面的案例中我们把函数的原型进行了**重写**的操作,你们有思考过`constructor`属性吗,原来的原型已经被我重写,赋值为一个全新的对象了,那这个全新的对象`constructor`又指向谁了呢?
238 | 绕来绕去都快被绕晕了,什么乱七八糟的!接下来跟我一起探究
239 |
240 | ```javascript
241 | function Person(name, age, money) {
242 | this.name = name
243 | this.age = age
244 | this.money = money
245 | }
246 |
247 | Person.prototype = {
248 | getDoubleMoney () {
249 | return this.money * 2
250 | }
251 | }
252 |
253 | console.log(Person.prototype.constructor === Object) // true
254 | ```
255 |
256 | - 你会惊讶的发现,woc,这是什么意思? 为什么指向的却是Object呢?难道是bug吗?其实并不是,原型/原型链/继承都是环环相扣,一环扣着一环,一个点没吃透,剩下的就很难明白。
257 |
258 | **继续推断探究**
259 |
260 | - 探索`Person.prototype.constructor === Object`
261 |
262 | ```js
263 | /*解: Person.prototype.constructor === Object
264 | 1. 首先我们对原对象进行了重写
265 | 2. 每个原型对象上都有constructor属性,我们赋值的那个对象身上肯定也有原型对象啊!
266 | Person.prototype = { getDoubleMoney () { return this.money * 2 } }
267 | 3. 此时的Person.prototype = {},等于了一个全新的对象,并不用关心里面的方法getDoubleMoney
268 | 4. 伪代码: const obj = {}(字面量写法) 等同于 const obj = new Object(),所以obj对象的隐式原型即(obj.__proto__ === Object.prototype),obj为Object的实例对象。
269 | 5. 我们赋值的新对象的隐式原型指向了Object.prototype,所以Person.prototype.constructor去查找constructor的时候,自己没有constructor,找到的其实Object.prototype.constructor,所以它的值等于Object
270 | 6. js中的一句话:万物皆对象(虽然不严谨),因为Object.prototype是"尽头",在查找就等于null了
271 | */
272 | ```
273 |
274 | **自定义constructor**
275 |
276 | ```javascript
277 | function Person(name, age, money) {
278 | this.name = name
279 | this.age = age
280 | this.money = money
281 | }
282 |
283 | Person.prototype = {
284 | getDoubleMoney () {
285 | return this.money * 2
286 | }
287 | }
288 |
289 | Object.defineProperty(Person.prototype, "constructor", {
290 | value: Person,
291 | writable:true,
292 | configurable: false,
293 | enumerable: false
294 | })
295 |
296 | console.log(Person.prototype.constructor === Person) // true
297 | ```
298 |
299 | - 这样才是正确重写函数显示原型的正确方法,跟默认提供的显示原型一致
300 |
301 | ## 3. 函数的隐式原型
302 |
303 | - 函数是一个函数,(写累了就开始水文章,说废话了是吧?),但它也是一个特殊的对象。函数就像我们人类一样,在生活中,扮演着许多角色(身份)。
304 | - 函数,既有函数身份,也有对象身份,既然是对象那肯定有隐式原型,我们又绕回来了哈哈哈哈哈哈。
305 |
306 | ```javascript
307 | function Person() {}
308 |
309 | Person.fullName = 'ice'
310 |
311 | console.log(Person.fullName) //ice
312 | console.log(Person.__proto__ === Function.prototype) //true
313 | ```
314 |
315 | - 为什么
316 |
317 | ```
318 | Person.__proto__ === Function.prototype
319 | ```
320 |
321 | 相等,在介绍constructor,我们已经详细的分析过类似的了,其实本质都一样
322 |
323 | - `Person`作为对象的身份有`__proto__`,`Person`则是 `new Function()`的实例对象,所以`Person.__proto__ === Function.prototype`
324 |
325 | - 这里涉及到了原型的继承关系,我们不在这里继续深挖下去,不然不好理解。
326 |
327 | ## 结语
328 | > 今天原型的分享就到这边啦,明天分享继承相关内容~
329 |
330 | ## 作者
331 |
332 | | Coder | 小红书ID | 创建时间 |
333 | | :---------- | :-------- | :--------- |
334 | | 落寞的前端👣 | 121450513 | 2022.10.07 |
335 |
--------------------------------------------------------------------------------
/browser_two.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(浏览器篇)二
2 |
3 | ## 11. **什么是队头堵塞**
4 |
5 | 队头阻塞是由 HTTP 基本的“请求 - 应答”模型所导致的。HTTP
6 | 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求是没有优先级的,只有入队的先后顺序,排在最前面的请求会被最优先处理。如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本,造成了队头堵塞的现象。
7 |
8 | ### 11.2 **队头阻塞的解决方案:**
9 |
10 | (1)并发连接:对于一个域名允许分配多个长连接,那么相当于增加了任务队列,不至于一个队伍的任务阻塞其它所有任务。 (2)域名分片:将域名分出很多二级域名,它们都指向同样的一台服务器,能够并发的长连接数变多,解决了队头阻塞的问题。
11 |
12 | ## 12. HTTP和HTTPS协议的区别
13 |
14 | HTTP和HTTPS协议的主要区别如下:
15 |
16 | - HTTPS协议需要CA证书,费用较高;而HTTP协议不需要;
17 | - HTTP协议是超文本传输协议,信息是明文传输的,HTTPS则是具有安全性的SSL加密传输协议;
18 | - 使用不同的连接方式,端口也不同,HTTP协议端口是80,HTTPS协议端口是443;
19 | - HTTP协议连接很简单,是无状态的;HTTPS协议是有SSL和HTTP协议构建的可进行加密传输、身份认证的网络协议,比HTTP更加安全。
20 |
21 | ## 13. GET方法URL长度限制的原因
22 |
23 | 实际上HTTP协议规范并没有对get方法请求的url长度进行限制,这个限制是特定的**浏览器**及**服务器**对它的限制。 IE对URL长度的限制是**2083**字节(2K+35)。由于IE浏览器对URL长度的允许值是**最小的**
24 | ,所以开发过程中,只要URL不超过2083字节,那么在所有浏览器中工作都不会有问题。
25 |
26 | ```markdown
27 | GET的长度值 = URL(2083)- (你的Domain+Path)-2(2是get请求中?=两个字符的长度)
28 | ```
29 |
30 | 下面看一下主流浏览器对get方法中url的长度限制范围:
31 |
32 | - Microsoft Internet Explorer (Browser):IE浏览器对URL的最大限制为**2083**个字符,如果超过这个数字,提交按钮没有任何反应。
33 | - Firefox (Browser):对于Firefox浏览器URL的长度限制为 **65,536** 个字符。
34 | - Safari (Browser):URL最大长度限制为 **80,000** 个字符。
35 | - Opera (Browser):URL最大长度限制为 **190,000** 个字符。
36 | - Google (chrome):URL最大长度限制为 **8182** 个字符。
37 |
38 | 主流的服务器对get方法中url的长度限制范围:
39 |
40 | - Apache (Server):能接受最大url长度为**8192**个字符。
41 | - Microsoft Internet Information Server(IIS):能接受最大url的长度为**16384**个字符。
42 |
43 | 根据上面的数据,可以知道,get方法中的URL长度最长不超过2083个字符,这样所有的浏览器和服务器都可能正常工作。
44 |
45 | ## 14.一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
46 |
47 | (1)**解析URL:** **首先会对 URL 进行解析,分析所需要使用的传输协议和请求的资源的路径**。如果输入的 URL 中的协议或者主机名不合法,将会把地址栏中输入的内容传递给搜索引擎。如果没有问题,浏览器会检查 URL
48 | 中是否出现了非法字符,如果存在非法字符,则对非法字符进行转义后再进行下一过程。
49 |
50 | (2)**缓存判断:** **浏览器会判断所请求的资源是否在缓存里**,如果请求的资源在缓存里并且没有失效,那么就直接使用,否则向服务器发起新的请求。
51 |
52 | (3)**DNS解析:** 下一步首先需要获取的是输入的 URL 中的域名的 IP 地址,首先会**判断本地是否有该域名的 IP 地址的缓存**,如果有则使用,**如果没有则向本地 DNS 服务器发起请求**。**本地 DNS
53 | 服务器也会先检查是否存在缓存**,如果**没有就会先向根域名服务器发起请求**,获得负责的顶级域名服务器的地址后,**再向顶级域名服务器请求**,然后获得负责的权威域名服务器的地址后,**再向权威域名服务器发起请求**,**最终获得域名的
54 | IP 地址后,本地 DNS 服务器再将这个 IP 地址返回给请求的用户**。用户向本地 DNS 服务器发起请求属于递归请求,本地 DNS 服务器向各级域名服务器发起请求属于迭代请求。
55 |
56 | (4)**获取MAC地址(选说)** 当浏览器得到 IP 地址后,**数据传输还需要知道目的主机 MAC 地址**,因为应用层下发数据给传输层,TCP 协议会指定源端口号和目的端口号,然后下发给网络层。网络层会将本机地址作为源地址,获取的
57 | IP 地址作为目的地址。然后将下发给数据链路层,数据链路层的发送需要加入通信双方的 MAC 地址,本机的 MAC 地址作为源 MAC 地址,目的 MAC 地址需要分情况处理。通过将 IP
58 | 地址与本机的子网掩码相与,可以判断是否与请求主机在同一个子网里,如果在同一个子网里,可以使用 APR 协议获取到目的主机的 MAC 地址,如果不在一个子网里,那么请求应该转发给网关,由它代为转发,此时同样可以通过 ARP 协议来获取网关的
59 | MAC 地址,此时目的主机的 MAC 地址应该为网关的地址。
60 |
61 | (5)**TCP三次握手:** ,**确认客户端与服务器的接收与发送能力**,下面是 TCP 建立连接的三次握手的过程,首先客户端向服务器发送一个 SYN 连接请求报文段和一个随机序号,服务端接收到请求后向服务器端发送一个 SYN
62 | ACK报文段,确认连接请求,并且也向客户端发送一个随机序号。客户端接收服务器的确认应答后,进入连接建立的状态,同时向服务器也发送一个ACK 确认报文段,服务器端接收到确认后,也进入连接建立状态,此时双方的连接就建立起来了。
63 |
64 | (6)**HTTPS握手(选说):** **如果使用的是 HTTPS 协议,在通信前还存在 TLS 的一个四次握手的过程**
65 | 。首先由客户端向服务器端发送使用的协议的版本号、一个随机数和可以使用的加密方法。服务器端收到后,确认加密的方法,也向客户端发送一个随机数和自己的数字证书。客户端收到后,首先检查数字证书是否有效,如果有效,则再生成一个随机数,并使用证书中的公钥对随机数加密,然后发送给服务器端,并且还会提供一个前面所有内容的
66 | hash 值供服务器端检验。服务器端接收后,使用自己的私钥对数据解密,同时向客户端发送一个前面所有内容的 hash
67 | 值供客户端检验。这个时候双方都有了三个随机数,按照之前所约定的加密方法,使用这三个随机数生成一把秘钥,以后双方通信前,就使用这个秘钥对数据进行加密后再传输。
68 |
69 | (7)**发送HTTP请求**
70 |
71 | **服务器处理请求,返回HTTP报文**(响应)(文件)
72 |
73 | (8)**页面渲染:** 浏览器首先会根据 html 文件(响应) **建 DOM 树**,根据解析到的 css 文件构**建 CSSOM 树**,如果遇到 script 标签,则判端是否含有 defer 或者 async 属性,要不然
74 | script 的加载和执行会造成页面的渲染的阻塞。**当 DOM 树和 CSSOM 树建立好后,根据它们来构建渲染树**。渲染树构建好后,会根据渲染树来进行布局。布局完成后,最后使用浏览器的 UI
75 | 接口对页面进行绘制。这个时候整个页面就显示出来了。
76 |
77 | (9)**TCP四次挥手:** **最后一步是 TCP 断开连接的四次挥手过程**。若客户端认为数据发送完成,则它需要向服务端发送连接释放请求。服务端收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入
78 | CLOSE_WAIT 状态,此时表明客户端到服务端的连接已经释放,不再接收客户端发的数据了。但是因为 TCP
79 | 连接是双向的,所以服务端仍旧可以发送数据给客户端。服务端如果此时还有没发完的数据会继续发送,完毕后会向客户端发送连接释放请求,然后服务端便进入 LAST-ACK 状态。客户端收到释放请求后,向服务端发送确认应答,此时客户端进入
80 | TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有服务端的重发请求的话,就进入 CLOSED 状态。当服务端收到确认应答后,也便进入 CLOSED 状态。
81 |
82 | ## 15.页面有多张图片,HTTP是怎样的加载表现?
83 |
84 | 在`HTTP 1`下,浏览器对一个域名下最大TCP连接数为6,所以会请求多次。可以用**多域名部署**解决。这样可以提高同时请求的数目,加快页面图片的获取速度。
85 |
86 | 在`HTTP 2`下,可以一瞬间加载出来很多资源,因为,HTTP2支持多路复用,可以在一个TCP连接中发送多个HTTP请求。
87 |
88 | ## 16. HTTP2的头部压缩算法是怎样的?
89 |
90 | HTTP2的头部压缩是HPACK算法。在客户端和服务器两端建立“字典”,用索引号表示重复的字符串,采用哈夫曼编码来压缩整数和字符串,可以达到50%~90%的高压缩率。
91 |
92 | 具体来说:
93 |
94 | - 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键值对,对于相同的数据,不再通过每次请求和响应发送;
95 | - 首部表在HTTP/2的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
96 | - 每个新的首部键值对要么被追加到当前表的末尾,要么替换表中之前的值。
97 |
98 | ## 17. HTTP请求报文的是什么样的?
99 |
100 | 请求报⽂有4部分组成:
101 |
102 | - 请求⾏
103 | - 请求头部
104 | - 空⾏
105 | - 请求体
106 |
107 | **其中:**
108 |
109 | (1)请求⾏包括:请求⽅法字段、URL字段、HTTP协议版本字段。它们⽤空格分隔。例如,GET /index.html HTTP/1.1。
110 |
111 | (2)请求头部:请求头部由关键字/值对组成,每⾏⼀对,关键字和值⽤英⽂冒号“:”分隔
112 |
113 | - User-Agent:产⽣请求的浏览器类型。
114 | - Accept:客户端可识别的内容类型列表。
115 | - Host:请求的主机名,允许多个域名同处⼀个IP地址,即虚拟主机。
116 |
117 | (3)请求体: post put等请求携带的数据
118 |
119 | ## 18. HTTP响应报文的是什么样的?
120 |
121 | 请求报⽂有4部分组成:
122 |
123 | - 响应⾏:由网络协议版本,状态码和状态码的原因短语组成,例如 HTTP/1.1 200 OK
124 | - 响应头:响应部⾸组成
125 | - 空⾏
126 | - 响应体:服务器响应的数据
127 |
128 | ## 19. HTTP协议的优点和缺点
129 |
130 | HTTP 是超文本传输协议,它定义了客户端和服务器之间交换报文的格式和方式,默认使用 80 端口。它使用 TCP 作为传输层协议,保证了数据传输的可靠性。
131 |
132 | HTTP协议具有以下**优点**:
133 |
134 | - 支持客户端/服务器模式
135 | - **简单快速**:客户向服务器请求服务时,只需传送请求方法和路径。由于 HTTP 协议简单,使得 HTTP 服务器的程序规模小,因而通信速度很快。
136 | - **无连接**:无连接就是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接,采用这种方式可以节省传输时间。
137 | - **无状态**:HTTP 协议是无状态协议,这里的状态是指通信过程的上下文信息。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能会导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就比较快。
138 | - **灵活**:HTTP 允许传输任意类型的数据对象。正在传输的类型由 Content-Type 加以标记。
139 |
140 | HTTP协议具有以下**缺点**:
141 |
142 | - **无状态:** HTTP 是一个无状态的协议,HTTP 服务器不会保存关于客户的任何信息。
143 | - **明文传输:** 协议中的报文使用的是文本形式,这就直接暴露给外界,不安全。
144 | - **不安全**
145 |
146 | (1)通信使用明文(不加密),内容可能会被窃听; (2)不验证通信方的身份,因此有可能遭遇伪装; (3)无法证明报文的完整性,所以有可能已遭篡改;
147 |
148 | ## 20. 说一下HTTP 3.0
149 |
150 | HTTP3.0,也称作HTTP over QUIC。HTTP3.0的核心是QUIC(读音quick)协议,由Google在 2015年提出的SPDY
151 | v3演化而来的新协议,传统的HTTP协议是基于传输层TCP的协议,而QUIC是基于传输层UDP上的协议,可以定义成:HTTP3.0基于UDP的安全可靠的HTTP2.0协议。
152 |
153 | ## 21. HTTP的两种连接模式
154 |
155 | HTTP 协议是基于 TCP/IP,并且使用了**请求-应答**的通信模式。
156 |
157 | **HTTP协议有两种连接模式,一种是持续连接,一种非持续连接**。 (1)非持续连接指的是服务器必须为每一个请求的对象建立和维护一个全新的连接。 (2)持续连接下,TCP
158 | 连接默认不关闭,可以被多个请求复用。采用持续连接的好处是可以避免每次建立 TCP 连接三次握手时所花费的时间。
159 |
160 | ## 22. URL有哪些组成部分
161 |
162 | 以下面的URL为例www.aspxfans.com:8080/news/index?ID=246188#name
163 |
164 | 从上面的URL可以看出,一个完整的URL包括以下几部分:
165 |
166 | - **协议部分**:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符;
167 | - **域名部分**:该URL的域名部分为www.aspxfans.com。一个URL中,也可以使用IP地址作为域名使用
168 | - **端口部分**:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口(HTTP协议默认端口是80,HTTPS协议默认端口是443);
169 | - **虚拟目录部分**:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”;
170 | - **文件名部分**
171 | :从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名;
172 | - **锚部分**:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分;
173 | - **参数部分**:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
174 |
175 | ## 23.与缓存相关的HTTP请求头有哪些
176 |
177 | 强缓存:
178 |
179 | - Expires
180 | - Cache-Control
181 |
182 | 协商缓存:
183 |
184 | - Etag、If-None-Match
185 | - Last-Modified、If-Modified-Since
186 |
187 | ## 24. 强缓存和协商缓存
188 |
189 | **1.强缓存:** 不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的Network选项中可以看到该请求返回200的状态码,并且size显示from disk cache或from memory
190 | cache两种(灰色表示缓存)。
191 |
192 | **2.协商缓存:** 向服务器发送请求,服务器会根据这个请求的request header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的response header通知浏览器从缓存中读取资源;
193 |
194 | > 共同点:都是从客户端缓存中读取资源; 区别是强缓存不会发请求,协商缓存会发请求。
195 |
196 | ## 25. HTTP的keep-alive有什么作用?
197 |
198 | **http1.0默认关闭,需要手动开启。http1.1后默认开启**
199 |
200 | **作用:** 使客户端到服务器端的链接持续有效(**长连接**),当出现对服务器的后续请求时,keep-Alive功能避免了建立或者重新建立链接。
201 |
202 | **使用方法:** 在请求头中加上Connection:keep-alive。
203 |
204 | **优点:**
205 |
206 | - 较少的CPU和内存的占用(因为要打开的连接数变少了,复用了连接)
207 | - 减少了后续请求的延迟(无需再进行握手)
208 |
209 | **缺点:** 本来可以释放的资源仍旧被占用。有的请求已经结束了,但是还一直连接着。
210 |
211 | **解决方法:** 服务器设置过期时间和请求次数,超过这个时间或者次数就断掉连接。
212 |
213 | ## 26. OSI的七层模型是什么?
214 |
215 | ISO于1978年开发的一套标准架构ISO模型,被引用来说明数据通信协议的结构和功能。
216 |
217 | OSI在功能上可以划分为两组:
218 |
219 | 网络群组:物理层、数据链路层、网络层
220 |
221 | 使用者群组:传输层、会话层、表示层、应用层
222 |
223 | | `OSI`七层网络模型 | `TCP/IP`四层概念模型 | 对应网络协议 |
224 | | ----------------- | -------------------- | ------------------------------------------------------------ |
225 | | 7:应用层 | 应用层 | `HTTP`、`RTSP` `TFTP(简单文本传输协议)、`FTP`、` NFS`(数域筛法,数据加密)、`WAIS`(广域信息查询系统) |
226 | | 6:表示层 | 应用层 | `Telnet`(internet远程登陆服务的标准协议)、`Rlogin`、`SNMP`(网络管理协议)、Gopher |
227 | | 5:会话层 | 应用层 | `SMTP`(简单邮件传输协议)、`DNS`(域名系统) |
228 | | 4:传输层 | 传输层 | `TCP`(传输控制协议)、`UDP`(用户数据报协议)) |
229 | | 3:网络层 | 网际层 | `ARP`(地域解析协议)、`RARP`、`AKP`、`UUCP`(Unix to Unix copy) |
230 | | 2:数据链路层 | 数据链路层 | `FDDI`(光纤分布式数据接口)、`Ethernet、Arpanet、PDN`(公用数据网)、`SLIP`(串行线路网际协议)`PPP`(点对点协议,通过拨号或专线方建立点对点连接发送数据) |
231 | | 1:物理层 | 物理层 | `SMTP`(简单邮件传输协议)、`DNS`(域名系统) |
232 |
233 | 其中高层(7、6、5、4层)定义了应用程序的功能,下面三层(3、2、1层)主要面向通过网络的端到端的数据流
234 |
235 | ## 结语
236 |
237 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
238 |
239 | ## 作者
240 |
241 | | Coder | 小红书ID | 创建时间 |
242 | | :---------- | :-------- | :--------- |
243 | | 落寞的前端👣 | 121450513 | 2022.11.03 |
244 | | | | |
245 |
--------------------------------------------------------------------------------
/this指向.md:
--------------------------------------------------------------------------------
1 | # 大多数前端工程师不了解的this指向问题
2 |
3 | ## 前言
4 |
5 | > 今天应某小薯提的问题,给大家分享大多数前端工程师不了解的`this`指向问题。
6 |
7 | ## 1. 调用位置
8 |
9 | - 作用域跟在哪里定义有关,与在哪里执行无关
10 | - `this`指向跟在哪里定义无关,跟如何调用,通过什么样的形式调用有关
11 | - `this`(这个) 这个函数如何被调用(方便记忆)
12 | - 为了方便理解,默认情况下不开启严格模式
13 |
14 | ## 2. 绑定规则
15 |
16 | 上面我们介绍了,`this`的指向主要跟通过什么样的形式调用有关。接下来我就给大家介绍一下调用规则,没有规矩不成方圆,大家把这几种调用规则牢记于心就行了,没有什么难的地方。
17 |
18 | - 你必须找到调用位置,然后判断是下面四种的哪一种绑定规则
19 | - 其次你要也要晓得,这四种绑定规则的优先顺序
20 | - 这两点你都知道了,知道this的指向对于你来说就是易如反掌
21 |
22 | ### 2.1 默认绑定
23 |
24 | 函数最常用的调用方式,调用函数的类型:独立函数调用
25 |
26 | ```js
27 | function bar() {
28 | console.log(this) // window
29 | }
30 | ```
31 |
32 | - bar是不带任何修饰符的直接调用 所以为默认绑定 为`window`
33 | - 在严格模式下 这里的`this`为`undefined`
34 |
35 | ### 2.2 隐式绑定
36 |
37 | 用最通俗的话表示就是:对象拥有某个方法,通过这个对象访问方法且直接调用(注:箭头函数特殊,下面会讲解)
38 |
39 | ```js
40 | const info = {
41 | fullName: 'ice',
42 | getName: function() {
43 | console.log(this.fullName)
44 | }
45 | }
46 |
47 | info.getName() // 'ice'
48 | ```
49 |
50 | - 这个函数被`info`发起调用,进行了隐式绑定,所以当前的`this`为`info`,通过`this.fullName`毫无疑问的就访问值为`ice`
51 |
52 | **2.2.1 隐式丢失 普通**
53 |
54 | 有些情况下会进行隐式丢失,被隐式绑定的函数会丢失绑定对象,也就是说它为变为默认绑定,默认绑定的`this`值,为`window`还是`undefined`取决于您当前所处的环境,是否为严格模式。
55 |
56 | ```js
57 | const info = {
58 | fullName: 'ice',
59 | getName: function() {
60 | console.log(this.fullName)
61 | }
62 | }
63 |
64 | const fn = info.getName
65 |
66 | fn() //undefined
67 | ```
68 |
69 | 这种情况下就进行了隐式丢失,丢失了绑定的对象,为什么会产生这样的问题呢?如果熟悉内存的小伙伴,就会很容易理解。
70 |
71 | - 这里并没有直接调用,而是通过`info`找到了对应`getName`的内存地址,赋值给变量`fn`
72 | - 然后通过`fn` 直接进行了调用
73 | - 其实这里的本质 就是独立函数调用 也就是为`window`,从`window`中取出`fullName`属性,必定为`undefined`
74 |
75 | **2.2.2 隐式丢失 进阶**
76 | 这里大家首先要理解什么是回调函数。其实可以这样理解,就是我现在不调用它,把他通过参数的形式传入到其他地方,在别的地方调用它。
77 |
78 | ```javascript
79 |
80 | //申明变量关键字必须为var
81 | var fullName = 'panpan'
82 |
83 | const info = {
84 | fullName: 'ice',
85 | getName: function() {
86 | console.log(this.fullName)
87 | }
88 | }
89 |
90 | function bar(fn) {
91 | //fn = info.getName
92 | fn() // panpan
93 | }
94 |
95 | bar(info.getName)
96 | ```
97 |
98 | - 首先`bar`中的`fn`为一个回调函数
99 |
100 | - `fn = info.getName` 参数传递就是一种隐式赋值,其实跟上面的隐式丢失是一个意思,他们都是指向的`fn = info.getName`引用,也就是它们的内存地址
101 |
102 | - 因为他们的`this`丢失,也就是函数独立调用,默认绑定规则,`this`为全局的`window`对象
103 |
104 | - 注意: 为什么申明必须为`var`呢?
105 |
106 | - 因为只有`var`申明的变量才会加入到全局`window`对象上
107 | - 如果采用`let\const` 则不是,具体的后续介绍一下这两个申明变量的关键字
108 |
109 | - 但是有些场景,我不想让隐式丢失怎么办,下面就来给大家介绍一下显示绑定,也就是固定调用。
110 |
111 | ### 2.3 显示绑定
112 |
113 | 但是在某些场景下,`this`的改变都是意想不到的,实际上我们无法控制回调函数的执行方式,因此没有办法控制调用位置已得到期望的绑定即this指向。
114 |
115 | 接下来的显示绑定就可以用来解决这一隐式丢失问题。
116 |
117 | #### 2.3.1 call/apply/bind
118 |
119 | js中的 ”所有“函数都有一些有用的特性,这个跟它的原型链有关系,后续我会在原型介绍,通过原型链js中变相实现继承的方法,其中`call/apply/bind`这三个方法就是函数原型链上的方法,可以在函数中调用它们。
120 |
121 | #### 2.3.2 call
122 |
123 | - `call()` 方法使用一个指定的`this` 值和单独给出的一个或多个参数来调用一个函数。
124 | - 第一个参数为固定绑定的`this`对象
125 | - 第二个参数以及二以后的参数,都是作为参数进行传递给所调用的函数
126 |
127 | - 备注
128 |
129 | - 该方法的语法和作用与`apply()` 方法类似,只有一个区别,就是 `call()` 方法接受的是**一个参数列表**,而 `apply()` 方法接受的是**一个包含多个参数的数组**。
130 |
131 | ```js
132 | var fullName = 'panpan'
133 |
134 | const info = {
135 | fullName: 'ice',
136 | getName: function(age, height) {
137 | console.log(this.fullName, age, height)
138 | }
139 | }
140 |
141 | function bar(fn) {
142 | fn.call(info, 20, 1.88) //ice 20 1.88
143 | }
144 |
145 | bar(info.getName)
146 | ```
147 |
148 | #### 2.3.3 apply
149 |
150 | - 与`call`的方法类似,只是参数列表有所不同
151 |
152 | - 参数
153 | - `call` 参数为单个传递
154 | - `apply` 参数为数组传递
155 |
156 | ```js
157 | var fullName = 'panpan'
158 |
159 | const info = {
160 | fullName: 'ice',
161 | getName: function(age, height) {
162 | console.log(this.fullName, age, height)
163 | }
164 | }
165 |
166 | function bar(fn) {
167 | fn.apply(info, [20, 1.88]) //ice 20 1.88
168 | }
169 |
170 | bar(info.getName)
171 | ```
172 |
173 | #### 2.3.4 bind
174 |
175 | - `bind`与`apply/call`之间有所不同,`bind`传入`this`,则是返回一个`this`绑定后的函数,调用返回后的函数,就可以拿到期望的this。
176 | - 参数传递则是
177 | - 调用`bind`时,可以传入参数
178 | - 调用`bind`返回的参数也可以进行传参
179 |
180 | ```javascript
181 | var fullName = 'panpan'
182 |
183 | const info = {
184 | fullName: 'ice',
185 | getName: function(age, height) {
186 | console.log(this.fullName, age, height) //ice 20 1.88
187 | }
188 | }
189 |
190 | function bar(fn) {
191 | let newFn = fn.bind(info, 20)
192 | newFn(1.88)
193 | }
194 |
195 | bar(info.getName)
196 | ```
197 |
198 | ### 2.4 new绑定
199 |
200 | 谈到`new`关键字,就不得不谈构造函数,也就是JS中的 "类",后续原型篇章在跟大家继续探讨这个new关键字,首先要明白以下几点,`new Fn()`的时候发生了什么,有利于我们理解`this`的指向。
201 |
202 | 1. 创建了一个空对象
203 | 2. 将this指向所创建出来的对象
204 | 3. 把这个对象的`[[prototype]]` 指向了构造函数的prototype属性
205 | 4. 执行代码块代码
206 | 5. 如果没有明确返回一个非空对象,那么返回的对象就是这个创建出来的对象
207 |
208 | ```js
209 | function Person(name, age) {
210 | this.name = name
211 | this.age = age
212 |
213 | }
214 |
215 | const p1 = new Person('ice', 20)
216 |
217 | console.log(p1) // {name:'ice', age:20}
218 |
219 | ```
220 |
221 | - 当我调用`new Person()`的时候,那个this所指向的其实就是`p1`对象
222 |
223 | ## 3. 绑定优先级
224 |
225 | ### 3.1 隐式绑定 > 默认绑定
226 |
227 | ```js
228 | function bar() {
229 | console.log(this) //info
230 | }
231 |
232 | const info = {
233 | bar: bar
234 | }
235 | info.bar()
236 | ```
237 |
238 | - 虽然这边比较有些勉强,有些开发者会认为这是默认绑定的规则不能直接的显示谁的优先级高
239 | - 但是从另外一个角度来看,隐式绑定,的this丢失以后this才会指向`widonw或者undefined`,变相的可以认为隐式绑定 > 默认绑定
240 |
241 | ### 3.2 显示绑定 > 隐式绑定
242 |
243 | ```js
244 | var fullName = 'global ice'
245 | const info = {
246 | fullName: 'ice',
247 | getName: function() {
248 | console.log(this.fullName)
249 | }
250 | }
251 |
252 | info.getName.call(this) //global ice
253 | info.getName.apply(this) //global ice
254 | info.getName.bind(this)() //global ice
255 | ```
256 |
257 | - 通过隐式绑定和显示绑定的一起使用很明显 显示绑定 > 隐式绑定
258 |
259 | ### 3.3 bind(硬绑定) > apply/call
260 |
261 | ```js
262 | function bar() {
263 | console.log(this) //123
264 | }
265 |
266 | const newFn = bar.bind(123)
267 | newFn.call(456)
268 | ```
269 |
270 | ### 3.4 new绑定 > bind绑定
271 |
272 | 首先我们来说一下,为什么是和`bind`比较,而不能对`call`和`apply`比较,思考下面代码
273 |
274 | ```js
275 | const info = {
276 | height: 1.88
277 | }
278 |
279 | function Person(name, age) {
280 | this.name = name
281 | this.age = age
282 | }
283 |
284 | const p1 = new Person.call('ice', 20)
285 | //报错: Uncaught TypeError: Person.call is not a constructor
286 | ```
287 |
288 | **new绑定和bind绑定比较**
289 |
290 | ```js
291 | const info = {
292 | height: 1.88
293 | }
294 |
295 | function Person(name, age) {
296 | this.name = name
297 | this.age = age
298 | }
299 |
300 | const hasBindPerson = Person.bind(info)
301 |
302 | const p1 = new hasBindPerson('ice', 20)
303 |
304 | console.log(info) //{height: 1.88}
305 | ```
306 |
307 | - 我们通过`bind`对`Person`进行了一次劫持,硬绑定了this为`info`对象
308 | - `new` 返回的固定this的函数
309 | - 但是我们发现 并不能干预this的指向
310 |
311 | ### 3.5 总结
312 |
313 | `new关键字` > `bind` > `apply/call` > `隐式绑定` > `默认绑定`
314 |
315 | ## 4. 箭头函数 (arrow function)
316 |
317 | 首先箭头函数是`ES6`新增的语法
318 |
319 | ```JS
320 | const foo = () => {}
321 | ```
322 |
323 | ### 4.1 箭头函数this
324 |
325 | ```js
326 | var fullName = 'global ice'
327 |
328 | const info = {
329 | fullName: 'ice',
330 | getName: () => {
331 | console.log(this.fullName)
332 | }
333 | }
334 |
335 | info.getName() //global ice
336 | ```
337 |
338 | - 你会神奇的发现? 为什么不是默认绑定,打印结果为`ice`
339 | - 其实这是`ES6`的新特性,箭头函数不绑定`this`,它的`this`是上一层作用域,上一层作用域为`window`
340 | - 所以打印的结果是 `global ice`
341 |
342 | ### 4.2 箭头函数的应用场景 进阶
343 |
344 | - 需求: 在`getObjName`通过`this`拿到`info`中的`fullName` (值为`ice`的`fullName`)
345 |
346 | ```js
347 | const info = {
348 | fullName: 'ice',
349 | getName: function() {
350 | let _this = this
351 | return {
352 | fullName: 'panpan',
353 | getObjName: function() {
354 | console.log(this) // obj
355 | console.log(_this.fullName)
356 | }
357 | }
358 | }
359 | }
360 |
361 | const obj = info.getName()
362 | obj.getObjName()
363 | ```
364 |
365 | 1. 当我调用 `info.getName()` 返回了一个新对象
366 | 2. 当我调用返回对象的`getObjName`方法时,我想拿到最外层的`fullName`,我通过,`getObjName`的this访问,拿到的this却是`obj`,不是我想要的结果
367 | 3. 我需要在调用`info.getName()` 把this保存下来,`info.getName()` 是通过隐式调用,所以它内部的this就是info对象
368 | 4. `getObjName`是obj对象,因为也是隐式绑定,this必定是obj对象,绕了一大圈我只是想拿到上层作用域的this而已,恰好箭头函数解决了这一问题
369 |
370 | ```js
371 | const info = {
372 | fullName: 'ice',
373 | getName: function() {
374 | return {
375 | fullName: 'panpan',
376 | getObjName: () => {
377 | console.log(this.fullName)
378 | }
379 | }
380 | }
381 | }
382 |
383 | const obj = info.getName()
384 | obj.getObjName()
385 | ```
386 |
387 | ## 5. 总结
388 |
389 | ### 5.1 this的四种绑定规则
390 |
391 | 1. 默认绑定
392 | 2. 隐式绑定
393 | 3. 显示绑定 apply/call/bind(也称硬绑定)
394 | 4. new绑定
395 |
396 | ### 5.2 this的优先级 从高到低
397 |
398 | 1. new绑定
399 | 2. bind
400 | 3. call/apply
401 | 4. 隐式绑定
402 | 5. 默认绑定
403 |
404 | # 作者
405 |
406 | | Coder | 小红书ID | 创建时间 |
407 | | :---------- | :-------- | :--------- |
408 | | 落寞的前端👣 | 121450513 | 2022.10.02 |
409 |
--------------------------------------------------------------------------------
/前端手撕代码面试题(一).md:
--------------------------------------------------------------------------------
1 | ## 前端手写代码题(一)
2 |
3 | ## 1. 手写Object.create
4 |
5 | 思路:将传入的对象作为原型
6 |
7 | ```javascript
8 | function create(obj) {
9 | function F() {
10 | }
11 |
12 | F.prototype = obj
13 | return new F()
14 | }
15 | ```
16 |
17 | ## 2. 手写instanceof
18 |
19 | instanceof 运算符用于判断构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
20 |
21 | 实现步骤:
22 |
23 | 1. 首先获取类型的原型
24 | 2. 然后获得对象的原型
25 | 3. 然后一直循环判断对象的原型是否等于类型的原型,直到对象原型为 `null`,因为原型链最终为 `null`
26 |
27 | ```javascript
28 | function myInstanceof(left, right) {
29 | let proto = Object.getPrototypeOf(left), // 获取对象的原型
30 | prototype = right.prototype; // 获取构造函数的 prototype 对象
31 |
32 | // 判断构造函数的 prototype 对象是否在对象的原型链上
33 | while (true) {
34 | if (!proto) return false;
35 | if (proto === prototype) return true;
36 |
37 | proto = Object.getPrototypeOf(proto);
38 | }
39 | }
40 |
41 | ```
42 |
43 | ## 3. 手写 new
44 |
45 | (1)首先创建了一个新的空对象
46 |
47 | (2)设置原型,将对象的原型设置为函数的 prototype 对象。
48 |
49 | (3)让函数的 this 指向这个对象,执行构造函数的代码(为这个新对象添加属性)
50 |
51 | (4)判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个引用类型的对象。
52 |
53 | ```javascript
54 | function myNew(fn, ...args) {
55 | // 判断参数是否是一个函数
56 | if (typeof fn !== "function") {
57 | return console.error("type error");
58 | }
59 | // 创建一个对象,并将对象的原型绑定到构造函数的原型上
60 | const obj = Object.create(fn.prototype);
61 | const value = fn.apply(obj, args); // 调用构造函数,并且this绑定到obj上
62 | // 如果构造函数有返回值,并且返回的是对象,就返回value ;否则返回obj
63 | return value instanceof Object ? value : obj;
64 | }
65 |
66 | ```
67 |
68 | ## 4. 手写promise(简易版)
69 |
70 | ```javascript
71 | class MyPromise {
72 | constructor(fn) {
73 | // 存储 reslove 回调函数列表
74 | this.callbacks = []
75 | const resolve = (value) => {
76 | this.data = value // 返回值给后面的 .then
77 | while (this.callbacks.length) {
78 | let cb = this.callbacks.shift()
79 | cb(value)
80 | }
81 | }
82 | fn(resolve)
83 | }
84 |
85 | then(onResolvedCallback) {
86 | return new MyPromise((resolve) => {
87 | this.callbacks.push(() => {
88 | const res = onResolvedCallback(this.data)
89 | if (res instanceof MyPromise) {
90 | res.then(resolve)
91 | } else {
92 | resolve(res)
93 | }
94 | })
95 | })
96 | }
97 | }
98 |
99 | // 这是测试案例
100 | new MyPromise((resolve) => {
101 | setTimeout(() => {
102 | resolve(1)
103 | }, 1000)
104 | }).then((res) => {
105 | console.log(res)
106 | return new MyPromise((resolve) => {
107 | setTimeout(() => {
108 | resolve(2)
109 | }, 1000)
110 | })
111 | }).then(res => {
112 | console.log(res)
113 | })
114 |
115 | ```
116 |
117 | ### 4.2 Promise.all()
118 |
119 | ```javascript
120 | MyPromise.all = function (promisesList) {
121 | return new MyPromise((resolve, reject) => {
122 | if (!Array.isArray(promiselList)) return reject(new Error('必须是数组'))
123 | if (!promisesList.length) return resolve([])
124 | let arr = [], count = 0
125 | // 直接循环同时执行传进来的promise
126 | for (let i = 0, len = promisesList.length; i < len; i++) {
127 | // 因为有可能是 promise 有可能不是,所以用resolve()不管是不是都会自动转成promise
128 | Promise.resolve(promise).then(result => {
129 | // 由到promise在初始化的时候就执行了,.then只是拿结果而已,所以执行完成的顺序有可能和传进来的数组不一样
130 | // 也就是说直接push到arr的话,顺序有可能会出错
131 | count++
132 | arr[i] = result
133 | // 不能用arr.length===len,是因为数组的特性
134 | // arr=[]; arr[3]='xx'; console.log(arr.length) 这打印出来会是4 而不是1
135 | if (count === len) resolve(arr)
136 | }).catch(err => reject(err))
137 | }
138 | })
139 | }
140 | ```
141 |
142 | ### 4.3 Promise.race()
143 |
144 | 传参和上面的 all 一模一样,传入一个 Promise 实例集合的数组,然后全部同时执行,谁先快先执行完就返回谁,只返回一个结果
145 |
146 | ```javascript
147 | MyPromise.race = function (promisesList) {
148 | return new MyPromise((resolve, reject) => {
149 | // 直接循环同时执行传进来的promise
150 | for (const promise of promisesList) {
151 | // 直接返回出去了,所以只有一个,就看哪个快
152 | promise.then(resolve, reject)
153 | }
154 | })
155 | }
156 | ```
157 |
158 | ## 5. 防抖和节流
159 |
160 | 函数防抖是指在事件被触发 n 秒后再执行回调,如果在这 n 秒内事件又被触发,则重新计时。这可以使用在一些点击请求的事件上,避免因为用户的多次点击向后端发送多次请求。
161 |
162 | 函数节流是指规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。节流可以使用在 scroll 函数的事件监听上,通过事件节流来降低事件调用的频率。
163 |
164 | ```javascript
165 | // //防抖
166 | function debounce(fn, date) {
167 | let timer //声明接收定时器的变量
168 | return function (...arg) { // 获取参数
169 | timer && clearTimeout(timer) // 清空定时器
170 | timer = setTimeout(() => { // 生成新的定时器
171 | //因为箭头函数里的this指向上层作用域的this,所以这里可以直接用this,不需要声明其他的变量来接收
172 | fn.apply(this, arg) // fn()
173 | }, date)
174 | }
175 | }
176 |
177 | //--------------------------------
178 | // 节流
179 | function debounce(fn, data) {
180 | let timer = +new Date() // 声明初始时间
181 | return function (...arg) { // 获取参数
182 | let newTimer = +new Date() // 获取触发事件的时间
183 | if (newTimer - timer >= data) { // 时间判断,是否满足条件
184 | fn.apply(this, arg) // 调用需要执行的函数,修改this值,并且传入参数
185 | timer = +new Date() // 重置初始时间
186 | }
187 | }
188 | }
189 |
190 | ```
191 |
192 | ## 6. 手写 call 函数
193 |
194 | **call 函数的实现步骤:**
195 |
196 | 1. 判断调用对象是否为函数,即使我们是定义在函数的原型上的,但是可能出现使用 call 等方式调用的情况。
197 | 2. 判断传入上下文对象是否存在,如果不存在,则设置为 window 。
198 | 3. 处理传入的参数,截取第一个参数后的所有参数。
199 | 4. 将函数作为上下文对象的一个属性。
200 | 5. 使用上下文对象来调用这个方法,并保存返回结果。
201 | 6. 删除刚才新增的属性。
202 | 7. 返回结果。
203 |
204 | ```javascript
205 | // call函数实现
206 | Function.prototype.myCall = function (context) {
207 | // 判断调用对象
208 | if (typeof this !== "function") {
209 | console.error("type error");
210 | }
211 | // 获取参数
212 | let args = [...arguments].slice(1),
213 | result = null;
214 | // 判断 context 是否传入,如果未传入则设置为 window
215 | context = context || window;
216 | // 将调用函数设为对象的方法
217 | context.fn = this;
218 | // 调用函数
219 | result = context.fn(...args);
220 | // 将属性删除
221 | delete context.fn;
222 | return result;
223 | };
224 | ```
225 |
226 | ## 7. 手写 apply 函数
227 |
228 | **apply 函数的实现步骤:**
229 |
230 | 1. 判断调用对象是否为函数,即使我们是定义在函数的原型上的,但是可能出现使用 call 等方式调用的情况。
231 | 2. 判断传入上下文对象是否存在,如果不存在,则设置为 window 。
232 | 3. 将函数作为上下文对象的一个属性。
233 | 4. 判断参数值是否传入
234 | 5. 使用上下文对象来调用这个方法,并保存返回结果。
235 | 6. 删除刚才新增的属性
236 | 7. 返回结果
237 |
238 | ```javascript
239 | // apply 函数实现
240 | Function.prototype.myApply = function (context) {
241 | // 判断调用对象是否为函数
242 | if (typeof this !== "function") {
243 | throw new TypeError("Error");
244 | }
245 | let result = null;
246 | // 判断 context 是否存在,如果未传入则为 window
247 | context = context || window;
248 | // 将函数设为对象的方法
249 | context.fn = this;
250 | // 调用方法
251 | if (arguments[1]) {
252 | result = context.fn(...arguments[1]);
253 | } else {
254 | result = context.fn();
255 | }
256 | // 将属性删除
257 | delete context.fn;
258 | return result;
259 | };
260 | ```
261 |
262 | ## 8. 手写 bind 函数
263 |
264 | **bind 函数的实现步骤:**
265 |
266 | 1. 判断调用对象是否为函数,即使我们是定义在函数的原型上的,但是可能出现使用 call 等方式调用的情况。
267 | 2. 保存当前函数的引用,获取其余传入参数值。
268 | 3. 创建一个函数返回
269 | 4. 函数内部使用 apply 来绑定函数调用,需要判断函数作为构造函数的情况,这个时候需要传入当前函数的 this 给 apply 调用,其余情况都传入指定的上下文对象。
270 |
271 | ```javascript
272 | // bind 函数实现
273 | Function.prototype.myBind = function (context) {
274 | // 判断调用对象是否为函数
275 | if (typeof this !== "function") {
276 | throw new TypeError("Error");
277 | }
278 | // 获取参数
279 | var args = [...arguments].slice(1),
280 | fn = this;
281 | return function Fn() {
282 | // 根据调用方式,传入不同绑定值
283 | return fn.apply(
284 | this instanceof Fn ? this : context,
285 | args.concat(...arguments)
286 | );
287 | };
288 | };
289 | ```
290 |
291 | ## 9. 函数柯里化的实现
292 |
293 | 函数柯里化指的是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。
294 |
295 | ```js
296 | function curry(fn, ...args) {
297 | return fn.length <= args.length ? fn(...args) : curry.bind(null, fn, ...args);
298 | }
299 | ```
300 |
301 | ## 10. 手写AJAX请求
302 |
303 | **创建AJAX请求的步骤:**
304 |
305 | - 创建一个 XMLHttpRequest 对象。
306 | - 在这个对象上**使用 open 方法创建一个 HTTP 请求**,open 方法所需要的参数是请求的方法、请求的地址、是否异步和用户的认证信息。
307 | - 在发起请求前,可以为这个对象**添加一些信息和监听函数**。比如说可以通过 setRequestHeader 方法来为请求添加头信息。还可以为这个对象添加一个状态监听函数。一个 XMLHttpRequest 对象一共有 5
308 | 个状态,当它的状态变化时会触发onreadystatechange 事件,可以通过设置监听函数,来处理请求成功后的结果。当对象的 readyState 变为 4
309 | 的时候,代表服务器返回的数据接收完成,这个时候可以通过判断请求的状态,如果状态是 2xx 或者 304 的话则代表返回正常。这个时候就可以通过 response 中的数据来对页面进行更新了。
310 | - 当对象的属性和监听函数设置完成后,最后调**用 sent 方法来向服务器发起请求**,可以传入参数作为发送的数据体。
311 |
312 | ```javascript
313 | const SERVER_URL = "/server";
314 | let xhr = new XMLHttpRequest();
315 | // 创建 Http 请求
316 | xhr.open("GET", SERVER_URL, true);
317 | // 设置状态监听函数
318 | xhr.onreadystatechange = function () {
319 | if (this.readyState !== 4) return;
320 | // 当请求成功时
321 | if (this.status === 200) {
322 | handle(this.response);
323 | } else {
324 | console.error(this.statusText);
325 | }
326 | };
327 | // 设置请求失败时的监听函数
328 | xhr.onerror = function () {
329 | console.error(this.statusText);
330 | };
331 | // 设置请求头信息
332 | xhr.responseType = "json";
333 | xhr.setRequestHeader("Accept", "application/json");
334 | // 发送 Http 请求
335 | xhr.send(null);
336 | ```
337 | ## 结语
338 |
339 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
340 |
341 | ## 作者
342 |
343 | | Coder | 小红书ID | 创建时间 |
344 | | :---------- | :-------- | :--------- |
345 | | 落寞的前端👣 | 121450513 | 2022.10.27 |
346 |
--------------------------------------------------------------------------------
/vue面试题四.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(Vue篇)(四)
2 |
3 | ## 27. 简述 mixin、extends 的覆盖逻辑
4 |
5 | **(1)mixin 和 extends** mixin 和 extends均是用于合并、拓展组件的,两者均通过 mergeOptions 方法实现合并。
6 |
7 | - mixins 接收一个混入对象的数组,其中混入对象可以像正常的实例对象一样包含实例选项,这些选项会被合并到最终的选项中。Mixin 钩子按照传入顺序依次调用,并在调用组件自身的钩子之前被调用。
8 | - extends 主要是为了便于扩展单文件组件,接收一个对象或构造函数。
9 |
10 | 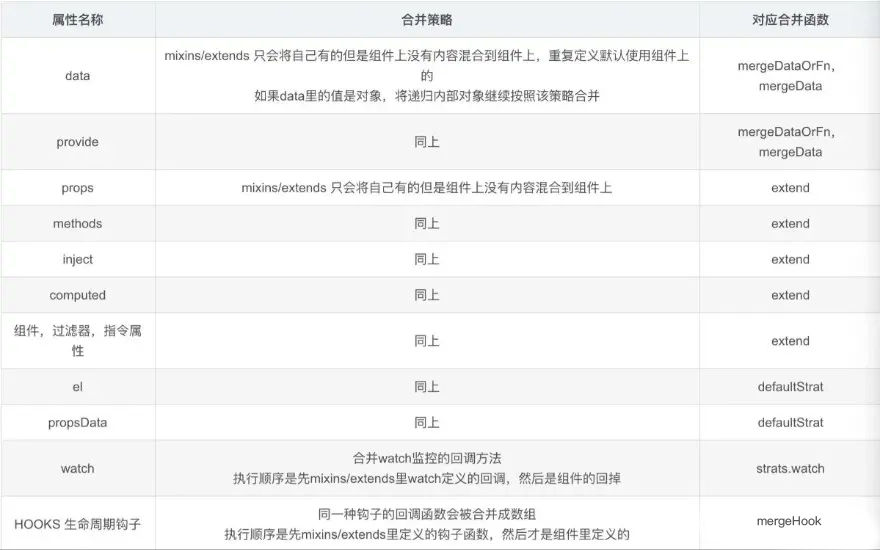
11 |
12 | **(2)mergeOptions 的执行过程**
13 |
14 | - 规范化选项(normalizeProps、normalizeInject、normalizeDirectives)
15 | - 对未合并的选项,进行判断
16 |
17 | 
18 |
19 | - 合并处理。根据一个通用 Vue 实例所包含的选项进行分类逐一判断合并,如 props、data、 methods、watch、computed、生命周期等,将合并结果存储在新定义的 options 对象里。
20 | - 返回合并结果 options。
21 |
22 | ### extend 有什么作用
23 |
24 | 这个 API 很少用到,作用是扩展组件生成一个构造器,通常会与 `$mount` 一起使用。
25 |
26 | ### 什么是 mixin ?
27 |
28 | Mixin 使我们能够为 Vue 组件编写可插拔和可重用的功能。
29 |
30 | 如果希望在多个组件之间重用一组组件选项,例如生命周期 hook、 方法等,则可以将其编写为 mixin,并在组件中简单的引用它。
31 |
32 | 然后将 mixin 的内容合并到组件中。如果你要在 mixin 中定义生命周期 hook,那么它在执行时将优化于组件自已的 hook。
33 |
34 | ### mixin 和 mixins 区别
35 |
36 | `mixin` 用于全局混入,会影响到每个组件实例,通常插件都是这样做初始化的。
37 |
38 | 虽然文档不建议在应用中直接使用 `mixin`,但是如果不滥用的话也是很有帮助的,比如可以全局混入封装好的 `ajax` 或者一些工具函数等等。
39 |
40 | `mixins` 应该是最常使用的扩展组件的方式了。如果多个组件中有相同的业务逻辑,就可以将这些逻辑剥离出来,通过 `mixins` 混入代码,比如上拉下拉加载数据这种逻辑等等。 另外需要注意的是 `mixins` 混入的钩子函数会先于组件内的钩子函数执行,并且在遇到同名选项的时候也会有选择性的进行合并。
41 |
42 | ## 28. data为什么是一个函数而不是对象
43 |
44 | 对象为引用类型,当复用组件时,由于数据对象都指向同一个data对象,当在一个组件中修改data时,其他重用的组件中的data会同时被修改;而使用返回对象的函数,由于每次返回的都是一个新对象(Object的实例),引用地址不同,则不会出现这个问题。
45 |
46 | ## 29. 动态给vue的data添加一个新的属性时会发生什么?怎样解决?
47 |
48 | **问题:** 数据虽然更新了, 但是页面没有更新
49 |
50 | **原因:**
51 |
52 | 1. `vue2`是用过`Object.defineProperty`实现数据响应式
53 | 2. 当我们访问定义的属性或者修改属性值的时候都能够触发`setter`与`getter`
54 | 3. 但是我们为`obj`添加新属性的时候,却无法触发事件属性的拦截
55 | 4. 原因是一开始`obj`的要定义的属性被设成了响应式数据,而`新增的属性`并没有通过`Object.defineProperty`设置成响应式数据
56 |
57 | **解决方案:**
58 |
59 | 1. Vue.set()
60 | - 通过`Vue.set`向响应式对象中添加一个`property`,并确保这个新 `property`同样是响应式的,且触发视图更新
61 | 2. Object.assign()
62 | - 直接使用`Object.assign()`添加到对象的新属性不会触发更新
63 | - 应创建一个新的对象,合并原对象和混入对象的属性
64 | 3. $forceUpdate
65 | - 如果你发现你自己需要在 `Vue`中做一次强制更新,99.9% 的情况,是你在某个地方做错了事
66 | - `$forceUpdate`迫使`Vue` 实例重新渲染
67 | - PS:仅仅影响实例本身和插入插槽内容的子组件,而不是所有子组件。
68 |
69 | 总结
70 |
71 | - 如果为对象添加**少量**的新属性,可以直接采用`Vue.set()`
72 | - 如果需要为新对象添加**大量**的新属性,则通过`Object.assign()`创建新对象
73 | - 如果你实在不知道怎么操作时,可采取`$forceUpdate()`进行强制刷新 (不建议)
74 |
75 | PS:`vue3`是用过`proxy`实现数据响应式的,直接动态添加新属性仍可以实现数据响应式
76 |
77 | ## 30. Vue data 中某一个属性的值发生改变后,视图会立即同步执行重新渲染吗
78 |
79 | **不会立即同步执行重新渲染**。Vue 实现响应式并不是数据发生变化之后 DOM 立即变化,而是按一定的策略进行 DOM 的更新。Vue 在更新 DOM 时是`异步`执行的。只要侦听到数据变化, Vue 将开启一个队列,并缓冲在同一事件循环中发生的所有数据变更。
80 |
81 | 如果同一个watcher被多次触发,只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环tick中,Vue 刷新队列并执行实际(已去重的)工作。
82 |
83 | ## 31. vue如何监听(检测)对象或者数组某个属性的变化
84 |
85 | 当在项目中直接设置数组的某一项的值,或者直接设置对象的某个属性值,这个时候,你会发现页面并没有更新。这是因为Object.defineProperty()限制,监听不到变化。
86 |
87 | 解决方式:
88 |
89 | - this.$set(你要改变的数组/对象,你要改变的位置/key,你要改成什么value)
90 |
91 | ```js
92 | this.$set(this.arr, 0, "OBKoro1"); // 改变数组
93 | this.$set(this.obj, "c", "OBKoro1"); // 改变对象
94 | ```
95 |
96 | - 调用以下几个数组的方法
97 |
98 | ```markdown
99 | splice()、push()、pop()、shift()、unshift()、sort()、reverse()
100 | ```
101 |
102 | vue源码里缓存了array的原型链,然后重写了这几个方法,触发这几个方法的时候会observer数据,意思是使用这些方法不用我们再进行额外的操作,视图自动进行更新。 推荐使用splice方法会比较好自定义,因为splice可以在数组的任何位置进行删除/添加操作
103 |
104 | **vm.`$set` 的实现原理是:**
105 |
106 | - 如果目标是数组,直接使用数组的 splice 方法触发相应式;
107 | - 如果目标是对象,会先判读属性是否存在、对象是否是响应式,最终如果要对属性进行响应式处理,则是通过调用 defineReactive 方法进行响应式处理( defineReactive 方法就是 Vue 在初始化对象时,给对象属性采用 Object.defineProperty 动态添加 getter 和 setter 的功能所调用的方法)
108 |
109 | ## **32. assets和static的区别**
110 |
111 | - **相同点:** `assets` 和 `static` 两个都是存放静态资源文件。项目中所需要的资源文件图片,字体图标,样式文件等都可以放在这两个文件下,这是相同点
112 | - **不相同点:** `assets` 中存放的静态资源文件在项目打包时,也就是运行 `npm run build` 时会将 `assets` 中放置的静态资源文件进行打包上传,所谓打包简单点可以理解为压缩体积,代码格式化。而压缩后的静态资源文件最终也都会放置在 `static` 文件中跟着 `index.html` 一同上传至服务器。`static` 中放置的静态资源文件就不会要走打包压缩格式化等流程,而是直接进入打包好的目录,直接上传至服务器。因为避免了压缩直接进行上传,在打包时会提高一定的效率,但是 `static` 中的资源文件由于没有进行压缩等操作,所以文件的体积也就相对于 `assets` 中打包后的文件提交较大点。在服务器中就会占据更大的空间。
113 | - **建议:** 将项目中 `template`需要的样式文件js文件等都可以放置在 `assets` 中,走打包这一流程。减少体积。而项目中引入的第三方的资源文件如`iconfoont.css` 等文件可以放置在 `static` 中,因为这些引入的第三方文件已经经过处理,不再需要处理,直接上传。
114 |
115 | ## 33. Vue的性能优化(项目优化)有哪些
116 |
117 | ### **(1)编码阶段**
118 |
119 | - 尽量减少data中的数据,data中的数据都会增加getter和setter,会收集对应的watcher
120 | - v-if和v-for不能连用
121 | - 如果需要使用v-for给每项元素绑定事件时使用事件代理
122 | - SPA 页面采用keep-alive缓存组件
123 | - 在更多的情况下,使用v-if替代v-show
124 | - key保证唯一
125 | - 使用路由懒加载、异步组件
126 | - 防抖、节流
127 | - 第三方模块按需导入
128 | - 长列表滚动到可视区域动态加载
129 | - 图片懒加载
130 |
131 | ### **(2)SEO优化**
132 |
133 | - 预渲染
134 | - 服务端渲染SSR
135 |
136 | ### **(3)打包优化**
137 |
138 | - 压缩代码
139 | - Tree Shaking/Scope Hoisting
140 | - 使用cdn加载第三方模块
141 | - 多线程打包happypack
142 | - splitChunks抽离公共文件
143 | - sourceMap优化
144 |
145 | ### **(4)用户体验**
146 |
147 | - 骨架屏
148 | - PWA
149 | - 还可以使用缓存(客户端缓存、服务端缓存)优化、服务端开启gzip压缩等。
150 |
151 | ## 34. Vue的template模版编译原理
152 |
153 | vue中的模板template无法被浏览器解析并渲染,因为这不属于浏览器的标准,不是正确的HTML语法,所有需要将template转化成一个JavaScript函数,这样浏览器就可以执行这一个函数并渲染出对应的HTML元素,就可以让视图跑起来了,这一个转化的过程,就成为模板编译。模板编译又分三个阶段,解析parse,优化optimize,生成generate,最终生成可执行函数render。
154 |
155 | - **解析阶段**:使用大量的正则表达式对template字符串进行解析,将标签、指令、属性等转化为抽象语法树AST。
156 | - **优化阶段**:遍历AST,找到其中的一些静态节点并进行标记,方便在页面重渲染的时候进行diff比较时,直接跳过这一些静态节点,优化runtime的性能。
157 | - **生成阶段**:将最终的AST转化为render函数字符串。
158 |
159 | ## 35. template和jsx的有什么分别?
160 |
161 | 对于 runtime 来说,只需要保证组件存在 render 函数即可,而有了预编译之后,只需要保证构建过程中生成 render 函数就可以。在 webpack 中,使用`vue-loader`编译.vue文件,内部依赖的`vue-template-compiler`模块,在 webpack 构建过程中,将template预编译成 render 函数。与 react 类似,在添加了jsx的语法糖解析器`babel-plugin-transform-vue-jsx`之后,就可以直接手写render函数。
162 |
163 | 所以,**template和jsx的都是render的一种表现形式**,不同的是:JSX相对于template而言,具有更高的灵活性,在复杂的组件中,更具有优势,而 template 虽然显得有些呆滞。但是 template 在代码结构上更符合视图与逻辑分离的习惯,更简单、更直观、更好维护。
164 |
165 | ## 35.2 讲讲什么是 JSX ?
166 |
167 | jsx是JavaScript的一种语法扩展,它跟模板语言很接近,但是它充分具备JavaScript的能力 当 Facebook 第一次发布 React 时,他们还引入了一种新的 JS 方言 JSX,将原始 HTML 模板嵌入到 JS 代码中。JSX 代码本身不能被浏览器读取,必须使用Babel和webpack等工具将其转换为传统的JS。 JSX中的标签可以是单标签,也可以是双标签,但必须保证标签是闭合的。
168 |
169 | ## 36. 对SSR的理解
170 |
171 | SSR也就是服务端渲染,也就是将Vue在客户端把标签渲染成HTML的工作放在服务端完成,然后再把html直接返回给客户端
172 |
173 | **SSR的优势**:
174 |
175 | - 更好的SEO
176 | - 首屏加载速度更快
177 |
178 | **SSR的缺点**:
179 |
180 | - 开发条件会受到限制,服务器端渲染只支持beforeCreate和created两个钩子;
181 | - 当需要一些外部扩展库时需要特殊处理,服务端渲染应用程序也需要处于Node.js的运行环境;
182 | - 更多的服务端负载。
183 |
184 | ## 37. vue初始化页面闪动问题
185 |
186 | 使用vue开发时,在vue初始化之前,由于div是不归vue管的,所以我们写的代码在还没有解析的情况下会容易出现花屏现象,看到类似于{{message}}的字样,虽然一般情况下这个时间很短暂,但是还是有必要让解决这个问题的。
187 |
188 | 首先:在css里加上以下代码:
189 |
190 | 
191 |
192 | 如果没有彻底解决问题,则在根元素加上`style="display: none;" :style="{display: 'block'}"`
193 |
194 | ## 38. 虚拟DOM
195 |
196 | ### (1). 什么是虚拟DOM
197 |
198 | 虚拟(Virtual) DOM 其实就是一棵以 JavaScript 对象(VNode 节点)作为基础的树,用对象属性来描述节点,**相当于在js和真实dom中间加来一个缓存**,利用dom **diff算法避免没有必要的dom操作**,从而提高性能。当然算法有时并不是最优解,因为它需要兼容很多实际中可能发生的情况,比如后续会讲到两个节点的dom树移动。
199 |
200 | 在vue中一般都是通过修改元素的state,订阅者根据state的变化进行编译渲染,底层的实现可以简单理解为三个步骤:
201 |
202 | - 1、用JavaScript对象结构表述dom树的结构,然后用这个树构建一个真正的dom树,插到浏览器的页面中。
203 | - 2、当状态改变了,也就是我们的state做出修改,vue便会重新构造一棵树的对象树,然后用这个新构建出来的树和旧树进行对比(只进行同层对比),记录两棵树之间的差异。
204 | - 3、把记录的差异再重新应用到所构建的真正的dom树,视图就更新了。
205 |
206 | 它的表达方式就是把每一个标签都转为一个对象,这个对象可以有三个属性:`tag`、`props`、`children`
207 |
208 | - **tag**:必选。就是标签。也可以是组件,或者函数
209 | - **props**:非必选。就是这个标签上的属性和方法
210 | - **children**:非必选。就是这个标签的内容或者子节点,如果是文本节点就是字符串,如果有子节点就是数组。换句话说 如果判断 children 是字符串的话,就表示一定是文本节点,这个节点肯定没有子元素
211 |
212 | ### (2). 虚拟DOM的解析过程
213 |
214 | 虚拟DOM的解析过程:
215 |
216 | - 首先对将要插入到文档中的 DOM 树结构进行分析,使用 js 对象将其表示出来,比如一个元素对象,包含 TagName、props 和 Children 这些属性。然后将这个 js 对象树给保存下来,最后再将 DOM 片段插入到文档中。
217 | - 当页面的状态发生改变,需要对页面的 DOM 的结构进行调整的时候,首先根据变更的状态,重新构建起一棵对象树,然后将这棵新的对象树和旧的对象树进行比较,记录下两棵树的的差异。
218 | - 最后将记录的有差异的地方应用到真正的 DOM 树中去,这样视图就更新了。
219 |
220 | ### (3). 为什么要用虚拟DOM
221 |
222 | **① 保证性能下限,在不进行手动优化的情况下,提供过得去的性能** 看一下页面渲染的流程:**解析HTML -> 生成DOM -> 生成 CSSOM -> Layout -> Paint -> Compiler** 下面对比一下修改DOM时真实DOM操作和Virtual DOM的过程,来看一下它们重排重绘的性能消耗∶
223 |
224 | - 真实DOM∶ 生成HTML字符串+重建所有的DOM元素
225 | - 虚拟DOM∶ 生成vNode+ DOMDiff+必要的dom更新
226 |
227 | Virtual DOM的更新DOM的准备工作耗费更多的时间,也就是JS层面,相比于更多的DOM操作它的消费是极其便宜的。尤雨溪在社区论坛中说道∶ 框架给你的保证是,你不需要手动优化的情况下,依然可以给你提供过得去的性能。
228 |
229 | **② 跨平台** Virtual DOM本质上是JavaScript的对象,它可以很方便的跨平台操作,比如服务端渲染、uniApp等。
230 |
231 | ### (4). 虚拟DOM真的比真实DOM性能好吗
232 |
233 | - 首次渲染大量DOM时,由于多了一层虚拟DOM的计算,会比innerHTML插入慢。
234 | - 正如它能保证性能下限,在真实DOM操作的时候进行针对性的优化时,还是更快的。
235 |
236 | ## 39. Diff算法
237 |
238 | 在新老虚拟DOM对比时:
239 |
240 | - 首先,对比节点本身,**判断是否为同一节点**,如果不为相同节点,则删除该节点重新创建节点进行替换
241 | - 如果为相同节点,进行**patchVNode**,判断如何对该节点的子节点进行处理,先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
242 | - 比较如果都有子节点,则进行**updateChildren**,判断如何对这些新老节点的子节点进行操作(diff核心)。
243 | - 匹配时,找到相同的子节点,递归比较子节点
244 |
245 | 在diff中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从O(n3)降低值O(n),也就是说,只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
246 |
247 | ## 40. SPA单页面应用
248 |
249 | **概念:**
250 |
251 | - SPA单页面应用(SinglePage Web Application),指只有一个主页面的应用,一开始只需要加载一次js、css等相关资源。所有内容都包含在主页面,对每一个功能模块组件化。单页应用跳转,就是切换相关组件,仅仅刷新局部资源。
252 | - MPA多页面应用 (MultiPage Application),指有多个独立页面的应用,每个页面必须重复加载js、css等相关资源。多页应用跳转,需要整页资源刷新。
253 |
254 | **单页应用优缺点**
255 |
256 | 1. 优点:
257 | - 具有桌面应用的即时性、网站的可移植性和可访问性
258 | - 用户体验好、快,内容的改变不需要重新加载整个页面
259 | 2. 缺点:
260 | - 首次渲染速度相对较慢
261 | - 不利于搜索引擎的抓取
262 |
263 | **解决首次加载慢的问题**
264 |
265 | ```markdown
266 | 1. 减少入口文件体积
267 | 2. 静态资源本地缓存
268 | 3. UI框架按需加载
269 | 4. 路由懒加载
270 | ```
271 |
272 | ## 41. 使用异步组件有什么好处?
273 |
274 | 1. 节省打包出的结果,异步组件分开打包,采用jsonp的方式进行加载,有效解决文件过大的问题。
275 | 2. 核心就是包组件定义变成一个函数,依赖`import()` 语法,可以实现文件的分割加载。
276 |
277 | ## 结语
278 |
279 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
280 |
281 | ## 作者
282 |
283 | | Coder | 小红书ID | 创建时间 |
284 | | :---------- | :-------- | :--------- |
285 | | 落寞的前端👣 | 121450513 | 2022.10.22 |
286 |
--------------------------------------------------------------------------------
/vue面试题六.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(Vue篇)(六)
2 |
3 | ## Vuex
4 |
5 | ## 1. 什么Vuex ,谈谈你对它的理解?
6 |
7 | 1. 首先vuex的出现是为了解决web组件化开发的过程中,各组件之间传值的复杂和混乱的问题
8 | 2. 将我们在多个组件中需要共享的数据放到state中,
9 | 3. 要获取或格式化数据需要使用getters,
10 | 4. 改变state中的数据,可以使用mutation,但是只能包含同步的操作,在具体组件里面调用的方式`this.$store.commit('xxxx')`
11 | 5. Action也是改变state中的数据,不过是提交的mutation,并且可以包含异步操作,在组件中的调用方式`this.$store.dispatch('xxx')`; 在actions里面使用的commit('调用mutation')
12 |
13 | **Vuex** 是一个专为 Vue.js应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。Vuex 也集成到 Vue 的官方调试工具 devtools extension,提供了诸如零配置的 time-travel 调试、状态快照导入导出等高级调试功能。
14 |
15 | ## 2. Vuex**各模块在核心流程中的主要功能:**
16 |
17 | `Vue Components`∶ Vue组件。HTML页面上,负责接收用户操作等交互行为,执行dispatch方法触发对应action进行回应。
18 |
19 | `dispatch`∶操作行为触发方法,是唯一能执行action的方法。
20 |
21 | `actions`∶ 操作行为处理模块。负责处理Vue Components接收到的所有交互行为。包含同步/异步操作,支持多个同名方法,按照注册的顺序依次触发。向后台API请求的操作就在这个模块中进行,包括触发其他action以及提交mutation的操作。该模块提供了Promise的封装,以支持action的链式触发。
22 |
23 | `commit`∶状态改变提交操作方法。对mutation进行提交,是唯一能执行mutation的方法。
24 |
25 | `mutations`∶状态改变操作方法。是Vuex修改state的唯一推荐方法,其他修改方式在严格模式下将会报错。该方法只能进行同步操作,且方法名只能全局唯一。操作之中会有一些hook暴露出来,以进行state的监控等。
26 |
27 | `state`∶ 页面状态管理容器对象。集中存储VueComponents中data对象的零散数据,全局唯一,以进行统一的状态管理。页面显示所需的数据从该对象中进行读取,利用Vue的细粒度数据响应机制来进行高效的状态更新。
28 |
29 | `getters`∶ state对象读取方法。图中没有单独列出该模块,应该被包含在了render中,Vue Components通过该方法读取全局state对象。
30 |
31 | ## 2.1 简述Vuex的数据传输流程
32 |
33 | 当组件进行数据修改的时候我们需要调**用dispatch来触发actions里面的方法**。actions里面的每个方法中都会有一个commit方法,当方法执行的时候会通过**commit来触发mutations里面的方法进行数据的修改**。mutations里面的每个函数都会有一个state参数,这样就可以在**mutations里面进行state的数据修改**,当数据修改完毕后,会传导给页面。页面的数据也会发生改变
34 |
35 | ## 3. vuex中有几个核心属性,分别是什么?
36 |
37 | 一共有5个核心属性,分别是:
38 |
39 | - `state`唯一数据源,Vue 实例中的 data 遵循相同的规则
40 | - `mutation`更改 Vuex 的 store 中的状态的唯一方法是提交 mutation,非常类似于事件,通过store.commit 方法触发
41 | - `action`action 类似于 mutation,不同在于action 提交的是 mutation,而不是直接变更状态,action 可以包含任意异步操作
42 | - `module` 由于使用单一状态树,应用的所有状态会集中到一个比较大的对象。当应用变得非常复杂时,store 对象就有可能变得相当臃肿。为了解决以上问题,Vuex 允许我们将 store 分割成模块(module)。
43 |
44 | ```js
45 | const moduleA = {
46 | state: () => ({ ... }),
47 | mutations: { ... },
48 | actions: { ... },
49 | getters: { ... }
50 | }
51 |
52 | const moduleB = {
53 | state: () => ({ ... }),
54 | mutations: { ... },
55 | actions: { ... }
56 | }
57 |
58 | const store = new Vuex.Store({
59 | modules: {
60 | a: moduleA,
61 | b: moduleB
62 | }
63 | })
64 |
65 | store.state.a // -> moduleA 的状态
66 | store.state.b // -> moduleB 的状态
67 | ```
68 |
69 | - `getters` 可以认为是 store 的计算属性,就像计算属性一样,getter 的返回值会根据它的依赖被缓存起来,且只有当它的依赖值发生了改变才会被重新计算。Getter 会暴露为 store.getters 对象,你可以以属性的形式访问这些值.
70 |
71 | ```js
72 | const store = new Vuex.Store({
73 | state: {
74 | todos: [
75 | { id: 1, text: '...', done: true },
76 | { id: 2, text: '...', done: false }
77 | ]
78 | },
79 | getters: {
80 | doneTodos: state => {
81 | return state.todos.filter(todo => todo.done)
82 | }
83 | }
84 | })
85 |
86 | store.getters.doneTodos // -> [{ id: 1, text: '...', done: true }]
87 | ```
88 |
89 | ## 4. Vuex中action和mutation的区别
90 |
91 | `mutation`中的操作是一系列的同步函数,用于修改state中的变量的的状态。当使用vuex时需要通过commit来提交需要操作的内容。mutation 非常类似于事件:每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。这个回调函数就是实际进行状态更改的地方,并且它会接受 state 作为第一个参数:
92 |
93 | 
94 |
95 | 当触发一个类型为 increment 的 mutation 时,需要调用此函数:
96 |
97 | 
98 |
99 | 而`action`类似于mutation,不同点在于:
100 |
101 | - action 可以包含任意异步操作。
102 | - action 提交的是 mutation,而不是直接变更状态。
103 |
104 | 
105 |
106 | `action`函数接受一个与 store 实例具有相同方法和属性的 context 对象,因此你可以调用 context.commit 提交一个 mutation,或者通过 context.state 和 context.getters 来获取 state 和 getters。 所以,两者的不同点如下:
107 |
108 | - mutation专注于修改State,理论上是修改State的唯一途径;action 用来处理业务代码、异步请求。
109 | - mutation:必须同步执行;action :可以异步,但不能直接操作State。
110 | - 在视图更新时,先触发actions,actions再触发mutation
111 | - mutation的参数是state,它包含store中的数据;store的参数是context,它是 state 的父级,包含 state、getters
112 |
113 | ## 5. vuex的getter的作用
114 |
115 | `getter`有点类似 Vue.js 的**计算属性**,当我们需要从 store 的 state 中派生出一些状态,那么我们就需要使用 getter,getter 会接收 state 作为第 一个参数,而且 getter 的返回值会根据它的依赖被缓存起来,只有 getter 中的依赖值(state 中的某个需要派生状态的值)发生改变的时候才会被重新计算。
116 |
117 | ## 6. Vuex 和 localStorage 的区别
118 |
119 | **(1)** **最重要的区别**
120 |
121 | - vuex存储在**内存**中
122 | - localstorage 则以**文件**的方式存储在**本地**,只能存储字符串类型的数据,存储对象需要 JSON的stringify和parse方法进行处理。 读取内存比读取硬盘速度要快
123 |
124 | **(2)应用场景**
125 |
126 | - Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。vuex用于组件之间的传值。
127 | - localstorage是本地存储,是将数据存储到浏览器的方法,一般是在跨页面传递数据时使用 。
128 | - Vuex能做到数据的响应式,localstorage不能
129 |
130 | **(3)永久性**
131 |
132 | **刷新页面时vuex存储的值会丢失,localstorage不会。**
133 |
134 | **注意:** 对于不变的数据确实可以用localstorage可以代替vuex,但是当两个组件共用一个数据源(对象或数组)时,如果其中一个组件改变了该数据源,希望另一个组件响应该变化时,localstorage无法做到,原因就是上面的最重要的区别。
135 |
136 | ## 7. Vuex页面刷新时丢失怎么处理
137 |
138 | 用sessionStorage 或者 localstorage 存储数据
139 |
140 | 存储: sessionStorage.setItem( '名', JSON.stringify(值) ) 使用: sessionStorage.getItem('名') ---得到的值为字符串类型,用JSON.parse()去引号;
141 |
142 | ## 8. Vuex和单纯的全局对象有什么区别?
143 |
144 | - Vuex 的状态存储是**响应式**的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
145 | - 不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样可以方便地跟踪每一个状态的变化,从而能够实现一些工具帮助更好地了解我们的应用。
146 |
147 | ## 9. Redux(react的) 和 Vuex 有什么区别,它们的共同思想
148 |
149 | **(1)Redux 和 Vuex区别**
150 |
151 | - Vuex改进了Redux中的Action和Reducer函数,以mutations变化函数取代Reducer,无需switch,只需在对应的mutation函数里改变state值即可
152 | - Vuex由于Vue自动重新渲染的特性,无需订阅重新渲染函数,只要生成新的State即可
153 | - Vuex数据流的顺序是∶View调用store.commit提交对应的请求到Store中对应的mutation函数->store改变(vue检测到数据变化自动渲染)
154 |
155 | 通俗点理解就是,vuex 弱化 dispatch,通过commit进行 store状态的一次更变;取消了action概念,不必传入特定的 action形式进行指定变更;弱化reducer,基于commit参数直接对数据进行转变,使得框架更加简易;
156 |
157 | **(2)共同思想**
158 |
159 | - 单—的数据源
160 | - 变化可以预测
161 |
162 | 本质上:redux与vuex都是对mvvm思想的服务,将数据从视图中抽离的一种方案; 形式上:vuex借鉴了redux,将store作为全局的数据中心,进行mode管理;
163 |
164 | ## 10. 为什么要用 Vuex 或者 Redux
165 |
166 | 由于传参的方法对于多层嵌套的组件将会非常繁琐,并且对于兄弟组件间的状态传递无能为力。我们经常会采用父子组件直接引用或者通过事件来变更和同步状态的多份拷贝。以上的这些模式非常脆弱,通常会导致代码无法维护。
167 |
168 | 所以需要把组件的**共享**状态抽取出来,以一个全局单例模式管理。在这种模式下,组件树构成了一个巨大的"视图",不管在树的哪个位置,任何组件都能获取状态或者触发行为。
169 |
170 | 另外,通过定义和隔离状态管理中的各种概念并强制遵守一定的规则,代码将会变得更结构化且易维护。
171 |
172 | ## 11. 为什么 Vuex 的 mutation 中不能做异步操作?
173 |
174 | - Vuex中所有的状态更新的唯一途径都是mutation,异步操作通过 Action 来提交 mutation实现,这样可以方便地跟踪每一个状态的变化,从而能够实现一些工具帮助更好地了解我们的应用。
175 | - 每个mutation执行完成后都会对应到一个新的状态变更,这样devtools就可以打个快照存下来,然后就可以实现 time-travel 了。如果mutation支持异步操作,就没有办法知道状态是何时更新的,无法很好的进行状态的追踪,给调试带来困难。
176 |
177 | ## 12. Vuex的严格模式是什么,有什么作用,如何开启?
178 |
179 | 在严格模式下,无论何时发生了状态变更且不是由mutation函数引起的,将会抛出错误。这能保证所有的状态变更都能被调试工具跟踪到。
180 |
181 | 在Vuex.Store 构造器选项中开启,如下
182 |
183 | 
184 |
185 | ## 13. 如何在组件中批量使用Vuex的getter属性
186 |
187 | 使用`mapGetters`辅助函数, 利用对象展开运算符将getter混入computed 对象中
188 |
189 | 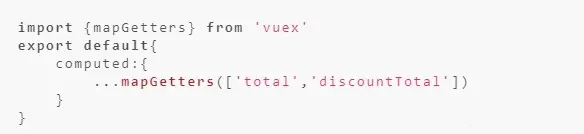
190 |
191 | ## 14. 如何在组件中重复使用Vuex的mutation
192 |
193 | 使用`mapMutations`辅助函数,在组件中这么使用
194 |
195 | 
196 |
197 | 然后调用`this.setNumber(10)`相当调用`this.$store.commit('SET_NUMBER',10)`
198 |
199 | ## 15. Vuex的辅助函数怎么用
200 |
201 | 比如当一个组件需要获取多个状态时候,将这些状态都声明为计算属性会有些重复和冗余。为了解决这个问题,我们可以使用 `mapState`辅助函数帮助我们生成计算属性,让你少按几次键。
202 |
203 | ### mapState
204 |
205 | ```javascript
206 | import { mapState } from 'vuex'
207 |
208 | export default {
209 | // ...
210 | computed:{
211 | ...mapState({
212 | // 箭头函数可使代码更简练
213 | count: state => state.count,
214 | // 传字符串参数 'count' 等同于 `state => state.count`
215 | countAlias: 'count',
216 |
217 | // 为了能够使用 `this` 获取局部状态,必须使用常规函数
218 | countPlusLocalState (state) {
219 | return state.count + this.localCount
220 | }
221 | })
222 | }
223 | }
224 | ```
225 |
226 | 定义的属性名与state中的名称相同时,可以传入一个数组
227 |
228 | ```vue
229 | //定义state
230 | const state={
231 | count:1,
232 | }
233 |
234 | //在组件中使用辅助函数
235 | computed:{
236 | ...mapState(['count'])
237 | }
238 | ```
239 |
240 | ### mapGetters
241 |
242 | ```vue
243 | computed:{
244 | ...mapGetters({
245 | // 把 `this.doneCount` 映射为 `this.$store.getters.doneTodosCount`
246 | doneCount: 'doneTodosCount'
247 | })
248 | }
249 | ```
250 |
251 | 当属性名与getters中定义的相同时,可以传入一个数组
252 |
253 | 总结:
254 |
255 | - mapState与mapGetters都用computed来进行映射
256 | - 在组件中映射完成后,通过this.映射属性名进行使用
257 |
258 | ### mapMutations
259 |
260 | ```vue
261 | methods:{
262 | ...mapMutations({
263 | add: 'increment' // 将 `this.add()` 映射为 `this.$store.commit('increment')`
264 | })
265 | }
266 | ```
267 |
268 | 当属性名与mapMutations中定义的相同时,可以传入一个数组
269 |
270 | ```vue
271 | methods:{
272 | ...mapMutations([
273 | 'increment', // 将 `this.increment()` 映射为 `this.$store.commit('increment')`
274 |
275 | // `mapMutations` 也支持载荷:
276 | 'incrementBy' // 将 `this.incrementBy(amount)` 映射为 `this.$store.commit('incrementBy', amount)`
277 | ]),
278 | }
279 | ```
280 |
281 | ### mapActions
282 |
283 | ```vue
284 | methods:{
285 | ...mapActions({
286 | add: 'increment' // 将 `this.add()` 映射为 `this.$store.dispatch('increment')`
287 | })
288 | }
289 | ```
290 |
291 | 当属性名与mapActions中定义的相同时,可以传入一个数组
292 |
293 | ```vue
294 | methods:{
295 | ...mapActions([
296 | 'increment', // 将 `this.increment()` 映射为 `this.$store.dispatch('increment')`
297 | // `mapActions` 也支持载荷:
298 | 'incrementBy' // 将 `this.incrementBy(amount)` 映射为 `this.$store.dispatch('incrementBy', amount)`
299 | ]),
300 | }
301 | ```
302 |
303 | 总结
304 |
305 | - mapMutations与mapActions都在methods中进行映射
306 | - 映射之后变成一个方法
307 |
308 | ## 结语
309 |
310 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
311 |
312 | ## 作者
313 |
314 | | Coder | 小红书ID | 创建时间 |
315 | | :---------- | :-------- | :--------- |
316 | | 落寞的前端👣 | 121450513 | 2022.10.24 |
317 |
--------------------------------------------------------------------------------
/vue面试题二.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(Vue篇)(二)
2 |
3 | ## 13. v-model 可以被用在自定义组件上吗?如果可以,如何使用?
4 |
5 | **可以**。v-model 实际上是一个语法糖,用在自定义组件上也是同理:
6 |
7 | 
8 |
9 | 相当于
10 |
11 | 
12 |
13 | 显然,custom-input 与父组件的交互如下:
14 |
15 | 1. 父组件将`searchText`变量传入custom-input 组件,使用的 prop 名为`value`;
16 | 2. custom-input 组件向父组件传出名为`input`的事件,父组件将接收到的值赋值给`searchText`;
17 |
18 | 所以,custom-input 组件的实现应该类似于这样:
19 |
20 | 
21 |
22 | ## 14. v-model和.sync的对比
23 |
24 | v-model与.sync的共同点:都是`语法糖`,都可以实现父子组件中的数据的双向通信。
25 |
26 | v-model与.sync的不共同点:
27 |
28 | **v-model:**
29 |
30 | 1.父组件 v-model="" 子组件 @(input,value)
31 |
32 | 2.一个组件只能绑定`一个`v-model
33 |
34 | 3.v-model针对更多的是最终操作结果,是`双向绑定的结果`,是`value`,是一种`change操作`。
35 |
36 | **.sync:**
37 |
38 | 1.父组件 :my-prop-name.sync 子组件@update:my-prop-name 的模式来替代事件触发,实现父子组件间的双向绑定。
39 |
40 | 2.一个组件可以`多个`属性用.sync修饰符,可以同时"双向绑定多个“prop”
41 |
42 | 3..sync针对更多的是各种各样的状态,是`状态的互相传递`,是`status`,是一种`update操作`。
43 |
44 | ## 15. 计算属性computed 和watch 的区别是什么?
45 |
46 | #### **`Computed`:**
47 |
48 | - 它**支持缓存**,只有依赖的数据发生了变化,才会重新计算
49 | - **不支持异步**,当Computed中有异步操作时,无法监听数据的变化
50 | - computed的值会**默认走缓存**,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data声明过,或者父组件传递过来的props中的数据进行计算的。
51 | - **如果一个属性是由其他属性计算而来的,这个属性依赖其他的属性,一般会使用computed**
52 | - 如果computed属性的属性值是函数,那么**默认使用get方法**,函数的返回值就是属性的属性值;在computed中,属性有一个get方法和一个set方法,当数据发生变化时,会调用set方法。
53 |
54 | #### **`Watch`:**
55 |
56 | - 它**不支持缓存**,数据变化时,它就会触发相应的操作
57 | - **支持异步**监听
58 | - 监听的函数接收**两个参数**,第一个参数是最新的值,第二个是变化之前的值
59 | - 当一个属性发生变化时,就需要执行相应的操作
60 | - 监听数据必须是data中声明的或者父组件传递过来的props中的数据,当发生变化时,会触发其他操作,函数有两个的参数:
61 | - **immediate**:组件加载立即触发回调函数
62 | - **deep**:深度监听,发现数据内部的变化,在复杂数据类型中使用,例如数组中的对象发生变化。需要注意的是,deep无法监听到数组和对象内部的变化。
63 |
64 | 当想要执行异步或者昂贵的操作以响应不断的变化时,就需要使用watch。
65 |
66 | **总结:**
67 |
68 | - `computed` 计算属性 : 依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值。
69 | - `watch` 侦听器 : 更多的是**观察**的作用,**无缓存性**,类似于某些数据的监听回调,每当监听的数据变化时都会执行回调进行后续操作。
70 |
71 | **运用场景:**
72 |
73 | - 当需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时都要重新计算。
74 | - 当需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许执行异步操作 ( 访问一个 API ),限制执行该操作的频率,并在得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
75 |
76 | ## 16. Computed 和 Methods 的区别
77 |
78 | 可以将同一函数定义为一个 method 或者一个计算属性。对于最终的结果,两种方式是相同的
79 |
80 | **不同点:**
81 |
82 | - `computed`: 计算属性是基于它们的依赖进行缓存的,只有在它的相关依赖发生改变时才会重新求值;
83 | - `method` 调用总会执行该函数。
84 |
85 | ## 17. 什么是组件
86 |
87 | **组件就是把图形、非图形的各种逻辑均抽象为一个`统一的概念`(组件)来实现开发的模式,在`Vue`中每一个`.vue`文件都可以视为一个组件**
88 |
89 | #### **组件的优势**
90 |
91 | 1. 降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快速完成需求
92 | 2. 调试方便,由于整个系统是通过组件组合起来的,在出现问题的时候,可以用排除法直接移除组件,或者根据报错的组件快速定位问题,之所以能够快速定位,是因为每个组件之间低耦合,职责单一,所以逻辑会比分析整个系统要简单
93 | 3. 提高可维护性,由于每个组件的职责单一,并且组件在系统中是被复用的,所以对代码进行优化可获得系统的整体升级
94 |
95 | ## 18. 什么是插件
96 |
97 | **插件通常用来为 `Vue` 添加全局功能**。插件的功能范围没有严格的限制——一般有下面几种:
98 |
99 | - 添加全局方法或者属性。如: `vue-custom-element`
100 | - 添加全局资源:指令/过滤器/过渡等。如 `vue-touch`
101 | - 添加全局公共组件 Vue.component()
102 | - 添加全局公共指令 Vue.directive()
103 | - 通过全局混入来添加一些组件选项。如`vue-router`
104 | - 添加 `Vue` 实例方法,通过把它们添加到 `Vue.prototype` 上实现。
105 | - 一个库,提供自己的 `API`,同时提供上面提到的一个或多个功能。如`vue-router`
106 |
107 | ### 18.2 Vue2和Vue3怎么注册全局组件
108 |
109 | Vue2使用
110 | ```js
111 | //main.js
112 | import Vue from 'vue'
113 | import header from "@/components/header.vue"
114 | Vue.component("header", header)
115 | ```
116 |
117 | Vue3使用
118 | ```js
119 | //main.js
120 | import { createApp } from 'vue'
121 | import App from './App.vue'
122 | import header from "@/components/header.vue"
123 |
124 | const app = createApp(App)
125 | app.component('header', header )
126 |
127 | ```
128 |
129 | ```js
130 | const app = createApp(App)
131 | app.component('组件名','组件对象')
132 | ```
133 |
134 | ### 18.3 Vue2、Vue3怎么封装自定义插件并使用/ Vue.use() (install)
135 |
136 | **Vue2**
137 |
138 | 在components.index.js里,定义一个函数或对象,在里面可以使用Vue.component全局注册组件,并暴露出去
139 |
140 | 在main.js里使用Vue.use( ),参数类型必须是 object 或 Function
141 |
142 | **Vue3**
143 |
144 | 在components.index.ts里,定义一个函数或对象,在里面可以使用app.component全局注册组件,并暴露出去
145 |
146 | 在main.ts里使用app.use( ),参数类型必须是 object 或 Function
147 |
148 | ------
149 |
150 | 如果是 Function 那么这个函数就被当做 install 方法
151 |
152 | 如果是 object 则需要定义一个 install 方法
153 |
154 | ## 19. 组件通信/ 组件传值的方法
155 |
156 | **什么是组件通信**
157 |
158 | 组件(`.vue`)通过某种方式来传递信息以达到某个目的
159 |
160 | **组件通信解决了什么问题**
161 |
162 | 每个组件之间的都有独自的作用域,组件间的数据是无法共享的但实际开发工作中我们常常需要让组件之间共享数据,这也是组件通信的目的要让它们互相之间能进行通讯,这样才能构成完整系统
163 |
164 | ### **(1)props / $emit (父子)**
165 |
166 | 父组件通过`props`向子组件传递数据,子组件通过`$emit`和父组件通信
167 |
168 | **1. 父组件向子组件传值**
169 |
170 | `props`只能是父组件向子组件进行传值,`props`使得父子组件之间形成了一个单向下行绑定。子组件的数据会随着父组件不断更新。
171 |
172 | `props` 可以显示定义一个或一个以上的数据,对于接收的数据,可以是各种数据类型,同样也可以传递一个函数。
173 |
174 | `props`属性名规则:若在`props`中使用驼峰形式,模板中需要使用短横线的形式
175 |
176 | 
177 |
178 | 
179 |
180 | **2. 子组件向父组件传值**
181 |
182 | - `$emit`绑定一个自定义事件,当这个事件被执行的时就会将参数传递给父组件,而父组件通过`v-on`监听并接收参数。
183 |
184 | ### (2)依赖注入 provide / inject(父子、祖孙)
185 |
186 | 这种方式就是Vue中的**依赖注入**,该方法用于**父子组件之间的通信**。当然这里所说的父子不一定是真正的父子,也可以是祖孙组件,在层数很深的情况下,可以使用这种方法来进行传值。就不用一层一层的传递了。
187 |
188 | `provide / inject`是Vue提供的两个钩子,和`data`、`methods`是同级的。并且`provide`的书写形式和`data`一样。
189 |
190 | - `provide` 钩子用来发送数据或方法
191 | - `inject`钩子用来接收数据或方法
192 |
193 | 在父组件中:
194 |
195 | 
196 |
197 | 在子组件中:
198 |
199 | 
200 |
201 | 还可以这样写,这样写就可以访问父组件中的所有属性:
202 |
203 | 
204 |
205 | **注意:** 依赖注入所提供的属性是**非响应式**的。
206 |
207 | ### (3)ref / $refs (父子,兄弟)
208 |
209 | `ref`: 这个属性用在子组件上,它的引用就指向了子组件的实例。可以通过实例来访问组件的数据和方法。
210 |
211 | 这种方式也是实现**兄弟组件**之间的通信。子组件1通过**this.`$emit`\**通知父组件调用函数,父组件的函数里用\**this.$refs**拿到子组件2的方法,这样就实现兄弟组件之间的通信。
212 |
213 | 在子组件中:
214 |
215 | 
216 |
217 | 在父组件中:
218 |
219 | 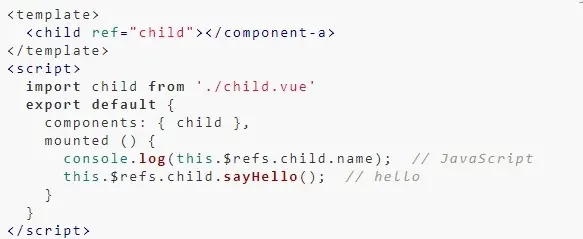
220 |
221 | ### (4)`$parent` / `$children` (父子)
222 |
223 | - 使用`$parent`可以让组件访问父组件的实例(访问的是上一级父组件的属性和方法)
224 | - 使用`$children`可以让组件访问子组件的实例,但是,`$children`并不能保证顺序,并且访问的数据也不是响应式的。
225 |
226 | 在子组件中:
227 |
228 | 
229 |
230 | 在父组件中:
231 |
232 | 
233 |
234 | 在上面的代码中,子组件获取到了父组件的`parentVal`值,父组件改变了子组件中`message`的值。 **需要注意:**
235 |
236 | - 通过`$parent`访问到的是上一级父组件的实例,可以使用`$root`来访问根组件的实例
237 | - 在组件中使用`$children`拿到的是所有的子组件的实例,它是一个数组,并且是无序的
238 | - 在根组件`#app`上拿`$parent`得到的是`new Vue()`的实例,在这实例上再拿`$parent`得到的是`undefined`,而在最底层的子组件拿`$children`是个空数组
239 | - `$children` 的值是**数组**,而`$parent`是个**对象**
240 |
241 | ### (5)`$attrs` / `$listeners` (祖孙)
242 |
243 | 考虑一种场景,如果A是B组件的父组件,B是C组件的父组件。如果想要组件A给组件C传递数据,这种隔代的数据,该使用哪种方式呢?
244 |
245 | 如果是用`props/$emit`来一级一级的传递,确实可以完成,但是比较复杂;如果使用事件总线,在多人开发或者项目较大的时候,维护起来很麻烦;如果使用Vuex,的确也可以,但是如果仅仅是传递数据,那可能就有点浪费了。
246 |
247 | 针对上述情况,Vue引入了`$attrs / $listeners`,实现组件之间的跨代通信。
248 |
249 | 先来看一下`inheritAttrs`,它的默认值true,继承所有的父组件属性除`props`之外的所有属性;`inheritAttrs:false` 只继承class属性 。
250 |
251 | - `$attrs`:继承所有的父组件属性(除了prop传递的属性、class 和 style ),一般用在子组件的子元素上
252 | - `$listeners`:该属性是一个对象,里面包含了作用在这个组件上的所有监听器,可以配合 `v-on="$listeners"` 将所有的事件监听器指向这个组件的某个特定的子元素。(相当于子组件继承父组件的事件)
253 |
254 | A组件(`APP.vue`):
255 |
256 | 
257 |
258 | B组件(`Child1.vue`):
259 |
260 | 
261 |
262 | C 组件 (`Child2.vue`):
263 |
264 | 
265 |
266 | 在上述代码中:
267 |
268 | - C组件中能直接触发test的原因在于 B组件调用C组件时 使用 v-on 绑定了`$listeners` 属性
269 | - 在B组件中通过v-bind 绑定`$attrs`属性,C组件可以直接获取到A组件中传递下来的props(除了B组件中props声明的)
270 |
271 | ### (6)eventBus事件总线(`$emit / $on`)(任意组件通信)
272 |
273 | `eventBus`事件总线适用于**父子组件**、**非父子组件**等之间的通信,使用步骤如下:
274 |
275 | **(1)创建事件中心管理组件之间的通信**
276 |
277 | 
278 |
279 | **(2)发送事件** 假设有两个兄弟组件`firstCom`和`secondCom`:
280 |
281 | 
282 |
283 | 在`firstCom`组件中发送事件:
284 |
285 | 
286 |
287 | **(3)接收事件** 在`secondCom`组件中接收事件:
288 |
289 | 
290 |
291 | 在上述代码中,这就相当于将`num`值存贮在了事件总线中,在其他组件中可以直接访问。事件总线就相当于一个桥梁,不用组件通过它来通信。
292 |
293 | 虽然看起来比较简单,但是这种方法也有不变之处,如果项目过大,使用这种方式进行通信,后期维护起来会很困难。
294 |
295 | ### (7)总结
296 |
297 | **(1)父子组件间通信**
298 |
299 | - 子组件通过 props 属性来接受父组件的数据,然后父组件在子组件上注册监听事件,子组件通过 emit 触发事件来向父组件发送数据。
300 | - 通过 ref 属性给子组件设置一个名字。父组件通过 `$refs` 组件名来获得子组件,子组件通过 `$parent` 获得父组件,这样也可以实现通信。
301 | - 使用 provide/inject,在父组件中通过 provide提供变量,在子组件中通过 inject 来将变量注入到组件中。不论子组件有多深,只要调用了 inject 那么就可以注入 provide中的数据。
302 |
303 | **(2)兄弟组件间通信**
304 |
305 | - 使用 eventBus 的方法,它的本质是通过创建一个空的 Vue 实例来作为消息传递的对象,通信的组件引入这个实例,通信的组件通过在这个实例上监听和触发事件,来实现消息的传递。
306 | - 通过 `$parent/$refs` 来获取到兄弟组件,也可以进行通信。
307 |
308 | **(3)任意组件之间**
309 |
310 | - 使用 eventBus ,其实就是创建一个事件中心,相当于中转站,可以用它来传递事件和接收事件。
311 |
312 | 如果业务逻辑复杂,很多组件之间需要同时处理一些公共的数据,这个时候采用上面这一些方法可能不利于项目的维护。这个时候可以使用 vuex ,vuex 的思想就是将这一些公共的数据抽离出来,将它作为一个全局的变量来管理,然后其他组件就可以对这个公共数据进行读写操作,这样达到了解耦的目的。
313 |
314 |
315 | ## 结语
316 |
317 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
318 |
319 | ## 作者
320 |
321 | | Coder | 小红书ID | 创建时间 |
322 | | :---------- | :-------- | :--------- |
323 | | 落寞的前端👣 | 121450513 | 2022.10.20 |
324 |
--------------------------------------------------------------------------------
/vue面试题三.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(Vue篇)(三)
2 |
3 | ## 20. 子组件可以直接改变父组件的数据吗?
4 |
5 | 子组件不可以直接改变父组件的数据。这样做主要是为了维护父子组件的单向数据流。每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值。如果这样做了,Vue 会在浏览器的控制台中发出警告。
6 |
7 | Vue提倡单向数据流,即父级 props 的更新会流向子组件,但是反过来则不行。这是为了防止意外的改变父组件状态,使得应用的数据流变得难以理解,导致数据流混乱。如果破坏了单向数据流,当应用复杂时,debug 的成本会非常高。
8 |
9 | **只能通过 `$emit` 派发一个自定义事件,父组件接收到后,由父组件修改。**
10 |
11 | ## 21. 生命周期
12 |
13 | ### (1). 说一下Vue的生命周期
14 |
15 | vue 实例从创建到销毁的过程就是生命周期。
16 |
17 | 也就是从开始创建、初始化数据、编译模板、挂在 dom -> 渲染、更新 -> 渲染、准备销毁、销毁在等一系列过程
18 |
19 | vue的声明周期常见的主要分为4大阶段8大钩子函数
20 |
21 | **第一阶段:创建前 / 后**
22 |
23 | **beforeCreate(创建前)** :数据观测和初始化事件还未开始,此时 data 的响应式追踪、event/watcher 都还没有被设置,也就是说不能访问到data、computed、watch、methods上的方法和数据。
24 |
25 | **created(创建后)** :实例创建完成,实例上配置的 options 包括 data、computed、watch、methods 等都配置完成,但是此时渲染得节点还未挂载到 DOM,所以不能访问到 `$el` 属性。
26 |
27 | **第二阶段: 渲染前 / 后**
28 |
29 | **beforeMount(挂载前)** :在挂载开始之前被调用,相关的render函数首次被调用。实例已完成以下的配置:编译模板,把data里面的数据和模板生成html。此时还没有挂载html到页面上。
30 |
31 | **mounted(挂载后)** :在el被新创建的 vm.$el 替换,并挂载到实例上去之后调用。实例已完成以下的配置:用上面编译好的html内容替换el属性指向的DOM对象。完成模板中的html渲染到html 页面中。此过程中进行ajax交互。
32 |
33 | **第三阶段: 更新前 / 后**
34 |
35 | **beforeUpdate(更新前)** :响应式数据更新时调用,此时虽然响应式数据更新了,但是对应的真实 DOM 还没有被渲染。
36 |
37 | **updated(更新后)** :在由于数据更改导致的虚拟DOM重新渲染和打补丁之后调用。此时 DOM 已经根据响应式数据的变化更新了。调用时,组件 DOM已经更新,所以可以执行依赖于DOM的操作。然而在大多数情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不被调用。
38 |
39 | **第四阶段: 销毁前 / 后**
40 |
41 | **beforeDestroy(销毁前)** :实例销毁之前调用。这一步,实例仍然完全可用,`this` 仍能获取到实例。
42 |
43 | **destroyed(销毁后)** :实例销毁后调用,调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。该钩子在服务端渲染期间不被调用。
44 |
45 | **另外三个生命周期函数不常用**
46 |
47 | 另外还有 `keep-alive` 独有的生命周期,分别为 `activated` 和 `deactivated` 。用 `keep-alive` 包裹的组件在切换时不会进行销毁,而是缓存到内存中并执行 `deactivated` 钩子函数,命中缓存渲染后会执行 `activated` 钩子函数。
48 |
49 | `errorCapured`钩子,当捕获一个来自子孙组件的错误时被调用。此钩子会收到三个参数:错误对象、发生错误的组件实例以及一个包含错误来源信息的字符串。此钩子可以返回 `false` 以阻止该错误继续向上传播。
50 |
51 | 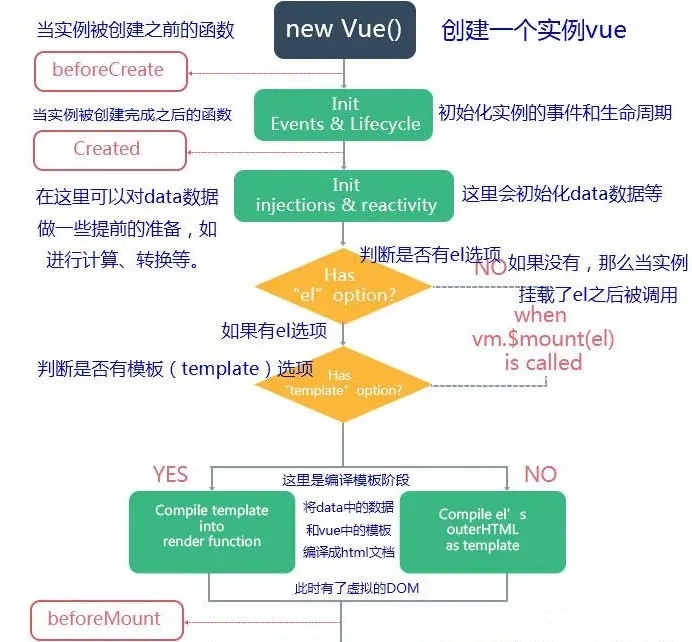
52 |
53 | 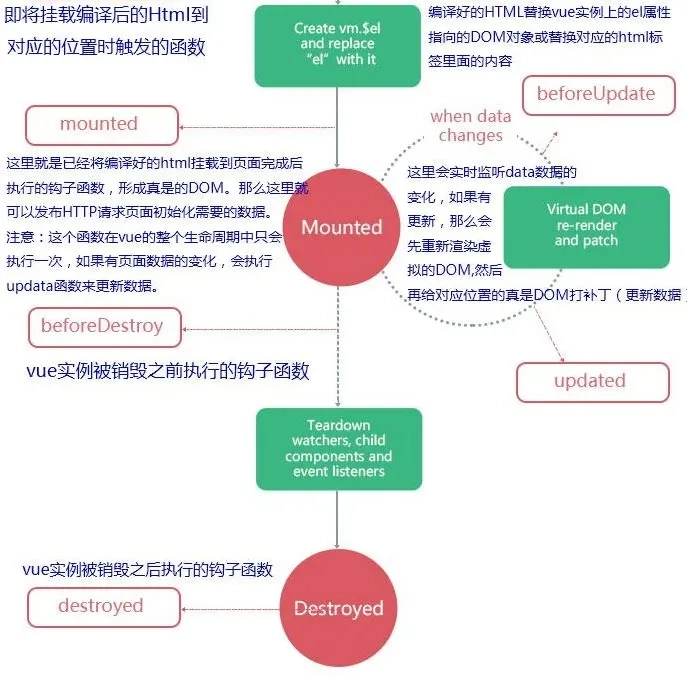
54 |
55 | ### (2). Vue 子组件和父组件执行顺序
56 |
57 | **加载渲染过程:**
58 |
59 | 1. 父组件 beforeCreate
60 | 2. 父组件 created
61 | 3. 父组件 beforeMount
62 | 4. 子组件 beforeCreate
63 | 5. 子组件 created
64 | 6. 子组件 beforeMount
65 | 7. 子组件 mounted
66 | 8. 父组件 mounted
67 |
68 | **更新过程:**
69 |
70 | 1. 父组件 beforeUpdate
71 | 2. 子组件 beforeUpdate
72 | 3. 子组件 updated
73 | 4. 父组件 updated
74 |
75 | **销毁过程:**
76 |
77 | 1. 父组件 beforeDestroy
78 | 2. 子组件 beforeDestroy
79 | 3. 子组件 destroyed
80 | 4. 父组件 destroyed
81 |
82 | ### (3). created和mounted的区别
83 |
84 | - `created`:在模板渲染成html前调用,即通常初始化某些属性值,然后再渲染成视图。
85 | - `mounted`:在模板渲染成html后调用,通常是初始化页面完成后,再对html的dom节点进行一些需要的操作。
86 |
87 | ### (4). 一般在哪个生命周期请求异步数据
88 |
89 | 我们可以在钩子函数`created`、`beforeMount`、`mounted` 中进行调用,因为在这三个钩子函数中,data 已经创建,可以将服务端端返回的数据进行赋值。
90 |
91 | 推荐在 created 钩子函数中调用异步请求,因为在 created 钩子函数中调用异步请求有以下优点:
92 |
93 | - 能更快获取到服务端数据,减少页面加载时间,用户体验更好;
94 | - SSR不支持 beforeMount 、mounted 钩子函数,放在 created 中有助于一致性。
95 |
96 | ## 22. 组件缓存 keep-alive
97 |
98 | **组件缓存**
99 |
100 | 组件的缓存可以在进行动态组件切换的时候对组件内部数据进行缓存,而不是走销毁流程
101 |
102 | 使用场景: 多表单切换,对表单内数据进行保存
103 |
104 | **keep-alive**
105 |
106 | 包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们。
107 |
108 | 是一个抽象组件:它自身不会渲染一个 DOM 元素,也不会出现在父组件链中。 当组件在``内被切换,它的`activated`和 `deactivated`这两个生命周期钩子函数将会被对应执行 。
109 |
110 | ### keep-alive的参数(include,exclude)
111 |
112 | - include(包含): 名称匹配的组件会被缓存-->include的值为组件的name。
113 | - exclude(排除): 任何名称匹配的组件都不会被缓存。
114 | - max - 数量 决定最多可以缓存多少组件。
115 |
116 | ### **keep-alive的使用**
117 |
118 | 1. 搭配``使用
119 | 2. 搭配路由使用 ( 需配置路由meta信息的`keepAlive`属性 )
120 | 3. 清除缓存组件
121 | - 在组件跳转之前使用后置路由守卫判断组件是否缓存
122 | - ( beforeRouteLeave( to, from, next ){ from.meta.keepAlive = false }
123 |
124 | ### **keep-alive的两个钩子函数**
125 |
126 | | activated | deactivated |
127 | | ------------------------------------ | -------------------------------- |
128 | | 在 `keep-alive` 组件激活时调用 | 在`keep-alive` 组件停用时调用 |
129 | | 该钩子函数在服务器端渲染期间不被调用 | 该钩子在服务器端渲染期间不被调用 |
130 |
131 | 使用`keep-alive`会将数据保留在内存中,如果要在每次进入页面的时候获取最新的数据,需要在 `activated`阶段获取数据,承担原来`created`钩子函数中获取数据的任务。
132 |
133 | **注意:** 只有组件被`keep-alive`包裹时,这两个生命周期函数才会被调用,如果作为正常组件使用,是不会被调用的
134 |
135 | 使用 exclude 排除之后,就算被包裹在 keep-alive 中,这两个钩子函数依然不会被调用!在服务端渲染时,此钩子函数也不会被调用。
136 |
137 | 设置了缓存的组件钩子调用情况:
138 |
139 | 第一次进入:beforeRouterEnter ->created->…->activated->…->deactivated> beforeRouteLeave
140 |
141 | 后续进入时:beforeRouterEnter ->activated->deactivated> beforeRouteLeave
142 |
143 | ### **keep-alive主要流程**
144 |
145 | 1. 判断组件 name ,不在 include 或者在 exclude 中,直接返回 VNode,说明该组件不被缓存。
146 | 2. 获取组件实例 key ,如果有获取实例的 key,否则重新生成。
147 | 3. key生成规则,cid +"∶∶"+ tag ,仅靠cid是不够的,因为相同的构造函数可以注册为不同的本地组件。
148 | 4. 如果缓存对象内存在,则直接从缓存对象中获取组件实例给 VNode ,不存在则添加到缓存对象中。 5.最大缓存数量,当缓存组件数量超过 max 值时,清除 keys 数组内第一个组件。
149 |
150 | ### **keep-alive 的实现**
151 |
152 | 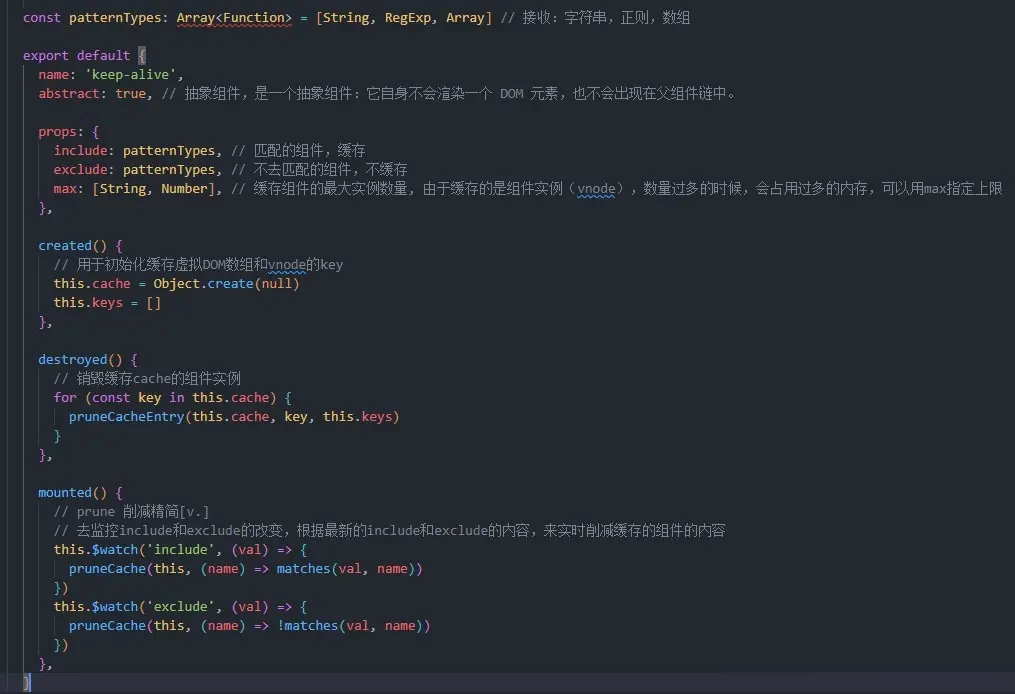
153 |
154 | ## 23. 过滤器的作用,如何实现一个过滤器
155 |
156 | 根据过滤器的名称,过滤器是用来过滤数据的,在Vue中使用`filters`来过滤数据,`filters`不会修改数据,而是过滤数据,改变用户看到的输出(计算属性 `computed` ,方法 `methods` 都是通过修改数据来处理数据格式的输出显示)。
157 |
158 | **使用场景:**
159 |
160 | - 需要格式化数据的情况,比如需要处理时间、价格等数据格式的输出 / 显示。
161 | - 比如后端返回一个 **年月日的日期字符串**,前端需要展示为 **多少天前** 的数据格式,此时就可以用`fliters`过滤器来处理数据。
162 |
163 | 过滤器是一个函数,它会把表达式中的值始终当作函数的第一个参数。过滤器用在**插值表达式 {{ }} 和 v-bind 表达式** 中,然后放在操作符“ `|` ”后面进行指示。
164 |
165 | 例如,在显示金额,给商品价格添加单位:
166 |
167 | 
168 |
169 | ## 24. 说说你对slot插槽的理解?slot使用场景有哪些?
170 |
171 | ### **slot是什么**
172 |
173 | `slot`又名插槽,**是Vue的内容分发机制**,组件内部的模板引擎使用slot元素作为承载分发内容的出口。插槽slot是子组件的一个模板标签元素,而这一个标签元素是否显示,以及怎么显示是由父组件决定的。
174 |
175 | 通过插槽可以让用户可以拓展组件,去更好地复用组件和对其做定制化处理
176 |
177 | 通过`slot`插槽向组件内部指定位置传递内容,完成这个复用组件在不同场景的应用
178 |
179 | 比如布局组件、表格列、下拉选、弹框显示内容等
180 |
181 | **分类**
182 |
183 | ### **默认插槽**
184 |
185 | 子组件用``标签来确定渲染的位置,标签里面可以放`DOM`结构,当父组件使用的时候没有往插槽传入内容,标签内`DOM`结构就会显示在页面
186 |
187 | 父组件在使用的时候,直接在子组件的标签内写入内容即可
188 |
189 | ### **具名插槽**
190 |
191 | 子组件用`name`属性来表示插槽的名字,不传为默认插槽
192 |
193 | 父组件中在使用时在默认插槽的基础上加上`slot`属性,值为子组件插槽`name`属性值
194 |
195 | ### **作用域插槽**
196 |
197 | 子组件在作用域上绑定属性来将子组件的信息传给父组件使用,这些属性会被挂在父组件`v-slot`接受的对象上
198 |
199 | 父组件中在使用时通过`v-slot:`(简写:#)获取子组件的信息,在内容中使用
200 |
201 | ### **小结**
202 |
203 | - `v-slot`属性只能在``上使用,但在只有默认插槽时可以在组件标签上使用
204 | - 默认插槽名为`default`,可以省略default直接写`v-slot`
205 | - 缩写为`#`时不能不写参数,写成`#default`
206 | - 可以通过解构获取`v-slot={user}`,还可以重命名`v-slot="{user: newName}"`和定义默认值`v-slot="{user = '默认值'}"`
207 |
208 | ## 25. Vue为什么采用异步渲染呢?
209 |
210 | `Vue` 是组件级更新,如果不采用异步更新,那么每次更新数据都会对当前组件进行重新渲染,所以为了性能,`Vue` 会在本轮数据更新后,在异步更新视图。核心思想`nextTick` 。
211 |
212 | `dep.notify()` 通知 watcher进行更新,`subs[i].update` 依次调用 watcher 的`update` ,`queueWatcher` 将watcher 去重放入队列, nextTick(`flushSchedulerQueue` )在下一tick中刷新watcher队列(异步)。
213 |
214 | ## 25.2 $nextTick 原理及作用
215 |
216 | 其实一句话就可以把`$nextTick`这个东西讲明白:就是你放在`$nextTick`当中的操作不会立即执行,而是等数据更新、DOM更新完成之后再执行,这样我们拿到的肯定就是最新的了。
217 |
218 | Vue的响应式并不是只数据发生变化之后,DOM就立刻发生变化,而是按照一定的策略进行DOM的更新。
219 |
220 | DOM更新有两种选择,一个是在本次事件循环的最后进行一次DOM更新,另一种是把DOM更新放在下一轮的事件循环当中。Vue优先选择第一种,只有当环境不支持的时候才触发第二种机制。
221 |
222 | 虽然性能上提高了很多,但这个时候问题就出现了。我已经把数据改掉了,但是它的更新异步的,而我在获取的时候,它还没有来得及改,这个时候就需要用到nextTick
223 |
224 | **原理:**
225 |
226 | **Vue 的 nextTick 其本质是对 JavaScript 执行原理 `EventLoop` 的一种应用。**
227 |
228 | - Vue2刚开始的时候, $nextTick是宏任务(setTimeout),但是宏任务的性能太差。
229 | - 后来改成了微任务Mutation Observer,但是还是有一些问题:
230 | - 速度太快了,在一些特殊场景下,DOM还没更新就去获取了
231 | - 兼容性不好,很多浏览器不支持
232 | - 后来又更新成了微宏并行阶段:先判断是否支持Mutation Observer,如果支持就使用,否则使用宏任务
233 | - Vue2.5版本之后,修复了微任务的那些问题,目前最新的$nextTick采用的是纯微任务。
234 |
235 | 由于Vue的DOM操作是异步的,所以,在上面的情况中,就要将DOM2获取数据的操作写在`$nextTick`中。
236 |
237 | 
238 |
239 | 所以,在以下情况下,会用到nextTick:
240 |
241 | - **在数据变化后执行的某个操作,而这个操作需要使用随数据变化而变化的DOM结构的时候,这个操作就需要方法在`nextTick()`的回调函数中。**
242 | - **在vue生命周期中,如果在created()钩子进行DOM操作,也一定要放在`nextTick()`的回调函数中。**
243 |
244 | 因为在created()钩子函数中,页面的DOM还未渲染,这时候也没办法操作DOM,所以,此时如果想要操作DOM,必须将操作的代码放在`nextTick()`的回调函数中。
245 |
246 | ## 26. 描述下Vue2的自定义指令
247 |
248 | 在 Vue2.0 中,代码复用和抽象的主要形式是组件。然而,有的情况下,你仍然需要对普通 DOM 元素进行底层操作,这时候就会用到自定义指令。 一般需要对DOM元素进行底层操作时使用,尽量只用来操作 DOM展示,不修改内部的值。当使用自定义指令直接修改 value 值时绑定v-model的值也不会同步更新;如必须修改可以在自定义指令中使用keydown事件,在vue组件中使用 change事件,回调中修改vue数据;
249 |
250 | **(1)自定义指令基本内容**
251 |
252 | - 全局定义:`Vue.directive("focus",{})`
253 |
254 | - 局部定义:`directives:{focus:{}}`
255 |
256 | - 钩子函数:指令定义对象提供钩子函数
257 |
258 | 1. ```markdown
259 | bind:只调用一次,指令第一次绑定到元素时调用。在这里可以进行一次性的初始化设置。
260 | ```
261 |
262 | 2. ```markdown
263 | inserted:被绑定元素插入父节点时调用(仅保证父节点存在,但不一定已被插入文档中)。
264 | ```
265 |
266 | 3. ```markdown
267 | update:所在组件的VNode更新时调用,但是可能发生在其子VNode更新之前调用。指令的值可能发生了改变,
268 | 也可能没有。但是可以通过比较更新前后的值来忽略不必要的模板更新。
269 | ```
270 |
271 | 4. ```markdown
272 | ComponentUpdate:指令所在组件的 VNode及其子VNode全部更新后调用。
273 | ```
274 |
275 | 5. ```markdown
276 | unbind:只调用一次,指令与元素解绑时调用。
277 | ```
278 |
279 | - 钩子函数的参数 :
280 |
281 | 1. el:指令所绑定的元素,可以用来直接操作 DOM
282 | 2. bing: 一个对象,包含以下属性:
283 | - name: 指令名,不包括 v- 前缀。
284 | - value: 指令的绑定值, 例如: v-my-directive="1 + 1", value 的值是2。
285 | - oldValue: 指令绑定的前一个值,仅在 update 和 componentUpdated钩子中可用。无论值是否改变都可用。
286 | - expression: 绑定值的表达式或变量名。 例如 v-my-directive="1 + 1", expression 的值是 "1 + 1"。
287 | - arg: 传给指令的参数。例如 v-my-directive:foo, arg 的值是 "foo"。
288 | - modifiers: 一个包含修饰符的对象。 例如: v-my-directive.foo.bar, 修饰符对象 modifiers 的值是 { foo: true, bar: true }。
289 | 3. VNode: 编译生成的虚拟节点
290 | 4. oldVNode:上一个虚拟节点(更新钩子函数中才有用)
291 |
292 | **(2)使用场景**
293 |
294 | - 普通DOM元素进行底层操作的时候,可以使用自定义指令
295 | - 自定义指令是用来操作DOM的。尽管Vue推崇数据驱动视图的理念,但并非所有情况都适合数据驱动。自定义指令就是一种有效的补充和扩展,不仅可用于定义任何的DOM操作,并且是可复用的。
296 |
297 | **(3)使用案例**
298 |
299 | 初级应用:
300 |
301 | - 鼠标聚焦
302 | - 下拉菜单
303 | - 相对时间转换
304 | - 滚动动画
305 |
306 | 高级应用:
307 |
308 | - 自定义指令实现图片懒加载
309 | - 自定义指令集成第三方插件
310 |
311 | ## 结语
312 |
313 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
314 |
315 | ## 作者
316 |
317 | | Coder | 小红书ID | 创建时间 |
318 | | :---------- | :-------- | :--------- |
319 | | 落寞的前端👣 | 121450513 | 2022.10.21 |
320 |
--------------------------------------------------------------------------------
/vue面试题五.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(Vue篇)(五)
2 |
3 | ## Vue-Router 路由
4 |
5 | ## 1. 对前端路由的理解
6 |
7 | 在前端技术早期,一个 url 对应一个页面,如果要从 A 页面切换到 B 页面,那么必然伴随着页面的刷新。这个体验并不好,不过在最初也是无奈之举——用户只有在刷新页面的情况下,才可以重新去请求数据。
8 |
9 | 后来,改变发生了——Ajax 出现了,它允许人们在不刷新页面的情况下发起请求;与之共生的,还有“不刷新页面即可更新页面内容”这种需求。在这样的背景下,出现了 **SPA(单页面应用**)。
10 |
11 | SPA极大地提升了用户体验,它允许页面在不刷新的情况下更新页面内容,使内容的切换更加流畅。但是在 SPA 诞生之初,人们并没有考虑到“定位”这个问题——在内容切换前后,页面的 URL 都是一样的,这就带来了两个问题:
12 |
13 | - SPA 其实并不知道当前的页面“进展到了哪一步”。可能在一个站点下经过了反复的“前进”才终于唤出了某一块内容,但是此时只要刷新一下页面,一切就会被清零,必须重复之前的操作、才可以重新对内容进行定位——SPA 并不会“记住”你的操作。
14 | - 由于有且仅有一个 URL 给页面做映射,这对 SEO 也不够友好,搜索引擎无法收集全面的信息
15 |
16 | **为了解决这个问题,前端路由出现了**。
17 |
18 | 前端路由可以帮助我们在仅有一个页面的情况下,“记住”用户当前走到了哪一步——为 SPA 中的各个视图匹配一个唯一标识。这意味着用户前进、后退触发的新内容,都会映射到不同的 URL 上去。此时即便他刷新页面,因为当前的 URL 可以标识出他所处的位置,因此内容也不会丢失。
19 |
20 | 那么如何实现这个目的呢?首先要解决两个问题:
21 |
22 | - 当用户刷新页面时,浏览器会默认根据当前 URL 对资源进行重新定位(发送请求)。这个动作对 SPA 是不必要的,因为我们的 SPA 作为单页面,无论如何也只会有一个资源与之对应。此时若走正常的请求-刷新流程,反而会使用户的前进后退操作无法被记录。
23 | - 单页面应用对服务端来说,就是一个URL、一套资源,那么如何做到用“不同的URL”来映射不同的视图内容呢?
24 |
25 | 从这两个问题来看,服务端已经完全救不了这个场景了。所以要靠咱们前端自力更生,不然怎么叫“前端路由”呢?作为前端,可以提供这样的解决思路:
26 |
27 | - 拦截用户的刷新操作,避免服务端盲目响应、返回不符合预期的资源内容。把刷新这个动作完全放到前端逻辑里消化掉。
28 | - 感知 URL 的变化。这里不是说要改造 URL、凭空制造出 N 个 URL 来。而是说 URL 还是那个 URL,只不过我们可以给它做一些微小的处理——这些处理并不会影响 URL 本身的性质,不会影响服务器对它的识别,只有我们前端感知的到。一旦我们感知到了,我们就根据这些变化、用 JS 去给它生成不同的内容。
29 |
30 | ## 2. VueRouter是什么, 有那些组件
31 |
32 | - Vue Router 是官方的路由管理器。它和 Vue.js 的核心深度集成,路径和组件的映射关系, 让构建单页面应用变得易如反掌。
33 | - router-link 实质上最终会渲染成a链接
34 | - router-view 子级路由显示
35 | - keep-alive 包裹组件缓存
36 |
37 | ## 3. route和route 和route和router 的区别
38 |
39 | - $route 是“路由信息对象”,包括 path,params,hash,query,fullPath,matched,name 等路由信息参数
40 | - $router 是“路由实例”对象包括了路由的跳转方法,钩子函数等。
41 |
42 | ## 4. 路由开发的优缺点
43 |
44 | 优点:
45 |
46 | - 整体不刷新页面,用户体验更好
47 | - 数据传递容易, 开发效率高
48 |
49 | 缺点:
50 |
51 | - 开发成本高(需要学习专门知识)
52 | - 首次加载会比较慢一点。不利于seo
53 |
54 | ## 5. VueRouter的使用方式
55 |
56 | 1. 使用Vue.use( )将VueRouter插入
57 | 2. 创建路由规则
58 | 3. 创建路由对象
59 | 4. 将路由对象挂到 Vue 实例上
60 | 5. 设置路由挂载点
61 |
62 | ## 6. vue-router 路由模式有几种?
63 |
64 | **hash模式、history模式、Abstract模式**
65 |
66 | ### 前端路由原理
67 |
68 | 前端路由的核心,就在于改变视图的同时不会向后端发出请求;而是加载路由对应的组件
69 |
70 | vue-router就是将组件映射到路由, 然后渲染出来的。并实现了三种模式
71 |
72 | Hash模式、History模式以及Abstract模式。默认Hash模式
73 |
74 | **hash模式**
75 |
76 | 是指 url 尾巴后的 # 号以及后面的字符。hash 虽然出现在url中,但不会被包括在http请求中,对后端完全没有影响,因此改变hash不会被重新加载页面。
77 |
78 | **history 模式**
79 |
80 | URL 就像正常的 url, 不过这种模式要玩好,还需要后台配置支持。因为我们的应用是个单页客户端应用,如果后台没有正确的配置,当用户在浏览器直接访问 `http://oursite.com/user/id` 就会返回 404,这就不好看了
81 |
82 | **Abstract模式**
83 |
84 | 支持所有javascript运行模式。vue-router 自身会对环境做校验,如果发现没有浏览器的 API,路由会自动强制进入 abstract 模式。在移动端原生环境中也是使用 abstract 模式。
85 |
86 | **修改路由模式:** 在实例化路由对象时, 传入mode选项和值修改
87 |
88 | ### Hash模式
89 |
90 | **原理** **基于浏览器的hashchange事件**,地址变化时,通过window.location.hash 获取地址上的hash值;并通过构造Router类,配置routes对象设置hash值与对应的组件内容。
91 |
92 | **优点**
93 |
94 | 1. **hash值会出现在URL中, 但是不会被包含在Http请求中, 因此hash值改变不会重新加载页面**
95 | 2. **hash改变会触发hashchange事件, 能控制浏览器的前进后退**
96 | 3. **兼容性好**
97 |
98 | **缺点**
99 |
100 | 1. 地址栏中携带#,不美观
101 | 2. 只可修改 # 后面的部分,因此只能设置与当前 URL 同文档的 URL
102 | 3. hash有体积限制,故只可添加短字符串
103 | 4. **设置的新值必须与原来不一样才会触发hashchange事件**,并将记录添加到栈中
104 | 5. **每次URL的改变不属于一次http请求,所以不利于SEO优化**
105 |
106 | ### History模式
107 |
108 | **原理**
109 |
110 | **基于HTML5新增的pushState()和replaceState()两个api,以及浏览器的popstate事件**,地址变化时,通过window.location.pathname找到对应的组件。并通过构造Router类,配置routes对象设置pathname值与对应的组件内容。
111 |
112 | **优点**
113 |
114 | 1. 没有#,更加美观
115 | 2. pushState() 设置的新 URL 可以是与当前 URL 同源的任意 URL
116 | 3. pushState() 设置的新 URL 可以与当前 URL 一模一样,这样也会把记录添加到栈中
117 | 4. pushState() 通过 stateObject 参数可以添加任意类型的数据到记录中
118 | 5. pushState() 可额外设置 title 属性供后续使用
119 | 6. 浏览器的进后退能触发浏览器的popstate事件,获取window.location.pathname来控制页面的变化
120 |
121 | **缺点**
122 |
123 | 1. URL的改变属于http请求,借助history.pushState实现页面的无刷新跳转,因此会重新请求服务器。所以**前端的 URL 必须和实际向后端发起请求的 URL 一致**。如果用户输入的URL回车或者浏览器刷新或者分享出去某个页面路径,用户点击后,URL与后端配置的页面请求URL不一致,则匹配不到任何静态资源,就会返回404页面。所以需要后台配置支持,覆盖所有情况的候选资源,如果 URL 匹配不到任何静态资源,则应该返回app 依赖的页面或者应用首页。
124 | 2. **兼容性差**,特定浏览器支持
125 |
126 | ### 为什么history模式下路由跳转会报404
127 |
128 | 1. URL的改变属于http请求,借助history.pushState实现页面的无刷新跳转,因此会重新请求服务器
129 | 2. 所以前端的 URL 必须和实际向后端发起请求的 URL 一致
130 |
131 | ## 7. 路由跳转有那些方式
132 |
133 | 1、this.$router.push()跳转到指定的url,并在history中添加记录,点击回退返回到上一个页面
134 |
135 | 2、this.$router.replace()跳转到指定的url,但是history中不会添加记录,点击回退到上上个页面
136 |
137 | 3、this.$router.go(n)向前或者后跳转n个页面,n可以是正数也可以是负数
138 |
139 | ### 编程式导航使用的方法以及常用的方法
140 |
141 | - 路由跳转 : this.$router.push()
142 | - 路由替换 : this.$router.replace()
143 | - 后退: this.$router.back()
144 | - 前进 :this.$router.forward()
145 |
146 | ## 8. Vue-router跳转和location.href有什么区别
147 |
148 | - 使用 `location.href= /url`来跳转,简单方便,但是刷新了页面;
149 | - 使用 `history.pushState( /url )` ,无刷新页面,静态跳转;
150 | - 引进 router ,然后使用 `router.push( /url )` 来跳转,使用了 `diff` 算法,实现了按需加载,减少了 dom 的消耗。其实使用 router 跳转和使用 `history.pushState()` 没什么差别的,因为vue-router就是用了 `history.pushState()` ,尤其是在history模式下。
151 |
152 | ## 9. 如何获取页面的hash变化
153 |
154 | **(1)监听$route的变化**
155 |
156 | 
157 |
158 | **(2)window.location.hash读取#值**
159 |
160 | window.location.hash 的值可读可写,读取来判断状态是否改变,写入时可以在不重载网页的前提下,添加一条历史访问记录。
161 |
162 | ## 10. 路由的传参方式
163 |
164 | ### 声明式导航传参
165 |
166 | 在 router-link 上的 to 属性传值,
167 |
168 | 1. /path?参数名=值
169 | - 接收传递过来的值: $route.query.参数名
170 | 2. /path/值/值 –> 需要路由对象提前配置 path: “/path/参数名”
171 | - 接收传递过来的值: $route.params.参数名
172 |
173 | ### 编程式导航传参
174 |
175 | this.$router.push( ) 可以不参数,根据传的值自动匹配是path还是name
176 |
177 | 因为使用path会自动忽略params ,所以会出现两种组合
178 |
179 | **(1) name+params 方式传参**
180 |
181 | A页面传参
182 |
183 | ```vue
184 | this.$router.push({
185 | name: 'xxx', // 跳转的路由
186 | params: {
187 | id: id // 发送的参数
188 | }
189 | })
190 | ```
191 |
192 | B页面接收传参:
193 |
194 | this.$route.params.id
195 |
196 | **(2) path+query 方式传参**
197 |
198 | A页面传参
199 |
200 | ```vue
201 | this.$router.push({
202 | path: '/xxx', // 跳转的路由
203 | query: {
204 | id: id // 发送的参数
205 | }
206 | })
207 | ```
208 |
209 | B页面接参:
210 |
211 | this.$route.query.id
212 |
213 | **params 和query 方式传参的区别**
214 |
215 | 1. 写法上不同
216 | 2. 地址栏不同
217 | 3. 刷新方式不同
218 |
219 | ## 11. params和query的区别
220 |
221 | **用法**:query要用path来引入,params要用name来引入,接收参数都是类似的,分别是 `this.$route.query.name` 和 `this.$route.params.name` 。
222 |
223 | **url地址显示**:query更加类似于ajax中get传参,params则类似于post,说的再简单一点,前者在浏览器地址栏中显示参数,后者则不显示
224 |
225 | **注意**:query刷新不会丢失query里面的数据 params刷新会丢失 params里面的数据。
226 |
227 | ## 12. 路由配置项常用的属性及作用
228 |
229 | 路由配置参数:
230 |
231 | path : 跳转路径 component : 路径相对于的组件 name:命名路由 children:子路由的配置参数(路由嵌套) props:路由解耦 redirect : 重定向路由
232 |
233 | ## 13. 路由重定向和404
234 |
235 | **路由重定向**
236 |
237 | 1. 匹配path后, 强制切换到另一个目标path上
238 | 2. redirect 是设置要重定向到哪个路由路径
239 | 3. 网页默认打开, 匹配路由"/", 强制切换到"/find"上
240 | 4. redirect配置项, 值为要强制切换的路由路径
241 | 5. 强制重定向后, 还会重新来数组里匹配一次规则
242 |
243 | **404页面**
244 |
245 | 1. 如果路由hash值, 没有和数组里规则匹配
246 | 2. path: ' * ' (任意路径)
247 | 3. 默认给一个404页面
248 | 4. 如果路由未命中任何规则, 给出一个兜底的404页面
249 |
250 | ## 14. Vue-router 导航守卫有哪些
251 |
252 | - 全局守卫:**beforeEach**、beforeResolve、**afterEach**
253 | - 路由独享的守卫:beforeEnter
254 | - 组件内的守卫:beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave
255 |
256 | ## 15. Vue-router 路由钩子在生命周期的体现
257 |
258 | - ### Vue-Router导航守卫
259 |
260 | 有的时候,需要通过路由来进行一些操作,比如最常见的登录权限验证,当用户满足条件时,才让其进入导航,否则就取消跳转,并跳到登录页面让其登录。 为此有很多种方法可以植入路由的导航过程:全局的,单个路由独享的,或者组件级的
261 |
262 | **1. 全局路由钩子**
263 |
264 | vue-router全局有三个路由钩子;
265 |
266 | - router.beforeEach 全局前置守卫 进入路由之前
267 | - router.beforeResolve 全局解析守卫(2.5.0+)在 beforeRouteEnter 调用之后调用
268 | - router.afterEach 全局后置钩子 进入路由之后
269 |
270 | 具体使用∶
271 |
272 | - beforeEach(判断是否登录了,没登录就跳转到登录页)
273 |
274 | 
275 |
276 | - afterEach (跳转之后滚动条回到顶部)
277 |
278 | 
279 |
280 | **2. 单个路由独享钩子**
281 |
282 | **beforeEnter** 如果不想全局配置守卫的话,可以为某些路由单独配置守卫,有三个参数∶ to、from、next
283 |
284 | 
285 |
286 | **3. 组件内钩子**
287 |
288 | beforeRouteUpdate、beforeRouteEnter、beforeRouteLeave
289 |
290 | 这三个钩子都有三个参数∶to、from、next
291 |
292 | - beforeRouteEnter∶ 进入组件前触发
293 | - beforeRouteUpdate∶ 当前地址改变并且改组件被复用时触发,举例来说,带有动态参数的路径foo/∶id,在 /foo/1 和 /foo/2 之间跳转的时候,由于会渲染同样的foa组件,这个钩子在这种情况下就会被调用
294 | - beforeRouteLeave∶ 离开组件被调用
295 |
296 | 注意点,beforeRouteEnter组件内还访问不到this,因为该守卫执行前组件实例还没有被创建,需要传一个回调给 next来访问,例如:
297 |
298 | 
299 |
300 | - ### Vue路由钩子在生命周期函数的体现
301 |
302 | **1. 完整的路由导航解析流程(不包括其他生命周期)**
303 |
304 | - 触发进入其他路由。
305 | - 调用要离开路由的组件守卫beforeRouteLeave
306 | - 调用局前置守卫∶ beforeEach
307 | - 在重用的组件里调用 beforeRouteUpdate
308 | - 调用路由独享守卫 beforeEnter。
309 | - 解析异步路由组件。
310 | - 在将要进入的路由组件中调用 beforeRouteEnter
311 | - 调用全局解析守卫 beforeResolve
312 | - 导航被确认。
313 | - 调用全局后置钩子的 afterEach 钩子。
314 | - 触发DOM更新(mounted)。
315 | - 执行beforeRouteEnter 守卫中传给 next 的回调函数
316 |
317 | **2. 触发钩子的完整顺序**
318 |
319 | 路由导航、keep-alive、和组件生命周期钩子结合起来的,触发顺序,假设是从a组件离开,第一次进入b组件∶
320 |
321 | - beforeRouteLeave:路由组件的组件离开路由前钩子,可取消路由离开。
322 | - beforeEach:路由全局前置守卫,可用于登录验证、全局路由loading等。
323 | - beforeEnter:路由独享守卫
324 | - beforeRouteEnter:路由组件的组件进入路由前钩子。
325 | - beforeResolve:路由全局解析守卫
326 | - afterEach:路由全局后置钩子
327 | - beforeCreate:组件生命周期,不能访问tAis。
328 | - created;组件生命周期,可以访问tAis,不能访问dom。
329 | - beforeMount:组件生命周期
330 | - deactivated:离开缓存组件a,或者触发a的beforeDestroy和destroyed组件销毁钩子。
331 | - mounted:访问/操作dom。
332 | - activated:进入缓存组件,进入a的嵌套子组件(如果有的话)。
333 | - 执行beforeRouteEnter回调函数next。
334 |
335 | **3. 导航行为被触发到导航完成的整个过程**
336 |
337 | - 导航行为被触发,此时导航未被确认。
338 | - 在失活的组件里调用离开守卫 beforeRouteLeave。
339 | - 调用全局的 beforeEach守卫。
340 | - 在重用的组件里调用 beforeRouteUpdate 守卫(2.2+)。
341 | - 在路由配置里调用 beforeEnter。
342 | - 解析异步路由组件(如果有)。
343 | - 在被激活的组件里调用 beforeRouteEnter。
344 | - 调用全局的 beforeResolve 守卫(2.5+),标示解析阶段完成。
345 | - 导航被确认。
346 | - 调用全局的 afterEach 钩子。
347 | - 非重用组件,开始组件实例的生命周期:beforeCreate&created、beforeMount&mounted
348 | - 触发 DOM 更新。
349 | - 用创建好的实例调用 beforeRouteEnter守卫中传给 next 的回调函数。
350 | - 导航完成
351 |
352 | ## 结语
353 |
354 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
355 |
356 | ## 作者
357 |
358 | | Coder | 小红书ID | 创建时间 |
359 | | :---------- | :-------- | :--------- |
360 | | 落寞的前端👣 | 121450513 | 2022.10.23 |
361 |
--------------------------------------------------------------------------------
/vue面试题一.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(Vue篇)(一)
2 |
3 | ## 1. Vue的基本原理
4 |
5 | 当一个Vue实例创建时,Vue会遍历data中的属性,用 **Object.defineProperty**(vue3.0使用proxy )将它们转为 getter/setter,并且在内部追踪相关依赖,在属性被访问和修改时通知变化。 每个组件实例都有相应的 **watcher 程序实例**,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的setter被调用时,会通知watcher重新计算,从而致使它关联的组件得以更新。
6 |
7 | 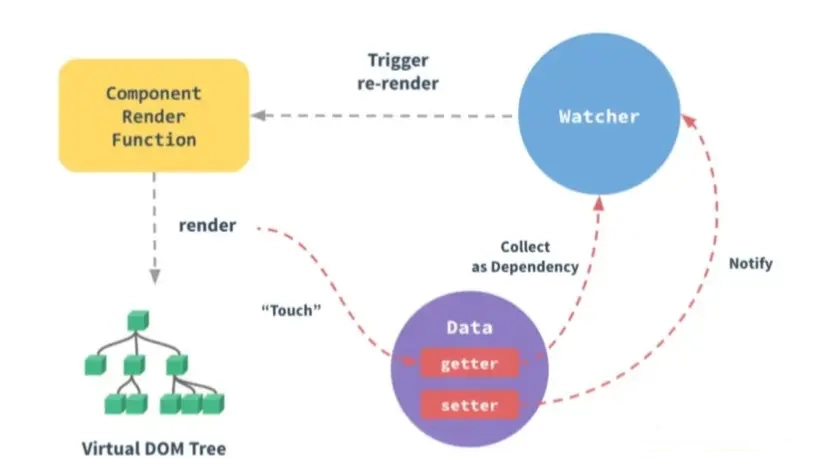
8 |
9 | ### 1.2 Vue的优点
10 |
11 | - 轻量级框架:只关注视图层,是一个构建数据的视图集合,大小只有几十 `kb` ;
12 | - 简单易学:国人开发,中文文档,不存在语言障碍 ,易于理解和学习;
13 | - 双向数据绑定:保留了 `angular` 的特点,在数据操作方面更为简单;
14 | - 组件化:保留了 `react` 的优点,实现了 `html` 的封装和重用,在构建单页面应用方面有着独特的优势;
15 | - 视图,数据,结构分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作;
16 | - 虚拟DOM:`dom` 操作是非常耗费性能的,不再使用原生的 `dom` 操作节点,极大解放 `dom` 操作,但具体操作的还是 `dom` 不过是换了另一种方式;
17 | - 运行速度更快:相比较于 `react` 而言,同样是操作虚拟 `dom`,就性能而言, `vue` 存在很大的优势。
18 |
19 | ## 2. Vue响应式的原理
20 |
21 | ### **2.1 什么是数据劫持**
22 |
23 | 数据劫持比较好理解,通常我们利用`Object.defineProperty`劫持对象的访问器,在属性值发生变化时我们可以获取变化,从而进行进一步操作。
24 |
25 | ### **2.2 发布者模式 / 订阅者模式**
26 |
27 | 在软件架构中,**发布订阅**是一种消息范式,消息的发送者(称为发布者)不会将消息直接发送给特定的接收者(称为订阅者)。而是将发布的消息分为不同的类别,无需了解哪些订阅者(如果有的话)可能存在。同样的,订阅者可以表达对一个或多个类别的兴趣,只接收感兴趣的消息,无需了解哪些发布者(如果有的话)存在。
28 |
29 | 这里很明显了,区别就在于,不同于观察者和被观察者,**发布者和订阅者是互相不知道对方的存在的,发布者只需要把消息发送到订阅器里面,订阅者只管接受自己需要订阅的内容**
30 |
31 | ### **2.3 响应式原理**
32 |
33 | Vue响应式的原理就是采用**数据劫持**结合**发布者-订阅者模式**的方式,通过**Object.defineProperty()** 来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。主要分为以下几个步骤:
34 |
35 | **Observe**(被劫持的数据对象) **Compile**(vue的编译器) **Watcher**(订阅者) **Dep**(用于收集Watcher订阅者们)
36 |
37 | 1.需要给**Observe**的数据对象进行递归遍历,包括子属性对象的属性,都加上**setter**和**getter**这样的属性,给这个对象的某个值赋值,就会触发**setter**,那么就能监听到了数据变化。
38 |
39 | 2.**Compile**解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
40 |
41 | 3.**Watcher**订阅者是**Observer**和**Compile**之间通信的桥梁,主要做的事情是: ①在自身实例化时往属性订阅器(**Dep**)里面添加自己 ②自身必须有一个**update**()方法 ③待属性变动**dep.notice()** 通知时,能调用自身的**update()** 方法,并触发**Compile**中绑定的回调,则功成身退。
42 |
43 | 4.MVVM作为数据绑定的入口,整合**Observer**、**Compile**和**Watcher**三者,通过**Observer**来监听自己的**model**数据变化,通过**Compile**来解析编译模板指令,最终利用**Watcher**搭起**Observer**和**Compile**之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
44 |
45 | 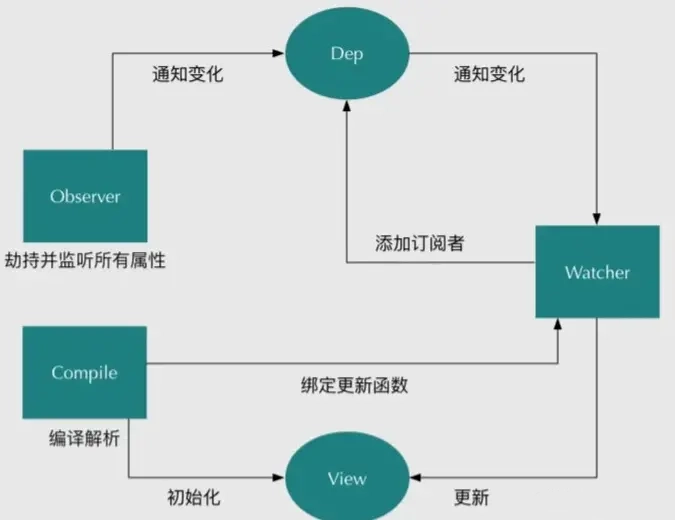
46 |
47 | ## 3. Object.defineProperty的使用方式,有什么缺点
48 |
49 | **使用方法**
50 |
51 | **Object.defineProperty( obj, prop, descriptor )**
52 |
53 | 三个参数:
54 |
55 | **obj** 要定义的对象
56 |
57 | **prop** 要定义或修改的属性名称或 Symbol
58 |
59 | **descriptor** 要定义或修改的属性描述符(配置对象)
60 |
61 | 属性描述符(配置对象)
62 |
63 | **get** 属性的 getter 函数,如果没有 getter,则为 `undefined`。当访问该属性时,会调用此函数。执行时不传入任何参数,但是会传入 `this` 对象(由于继承关系,这里的`this`并不一定是定义该属性的对象)。该函数的返回值会被用作属性的值。 **默认为 [`undefined`]** **set** 属性的 setter 函数,如果没有 setter,则为 `undefined`。当属性值被修改时,会调用此函数。该方法接受一个参数(也就是被赋予的新值),会传入赋值时的 `this` 对象。 **默认为 [`undefined`]**
64 |
65 | **缺点:**
66 |
67 | 在对一些属性进行操作时,使用这种方法无法拦截,比如**通过下标方式修改数组**数据或者**给对象新增属性**,这都不能触发组件的重新渲染,因为 Object.defineProperty 不能拦截到这些操作。更精确的来说,对于数组而言,大部分操作都是拦截不到的,只是 Vue 内部通过重写函数的方式解决了这个问题。
68 |
69 | 在 Vue3.0 中已经不使用这种方式了,而是通过使用 Proxy 对对象进行代理,从而实现数据劫持。使用Proxy 的好处是它可以完美的监听到任何方式的数据改变,唯一的缺点是兼容性的问题,因为 Proxy 是 ES6 的语法。
70 |
71 | ### 3.2 Object.defineProperty(target, key, options),options可传什么参数?
72 |
73 | - value:给target[key]设置初始值
74 | - get:调用target[key]时触发
75 | - set:设置target[key]时触发
76 | - writable:规定target[key]是否可被重写,默认false
77 | - enumerable:规定了key是否会出现在target的枚举属性中,默认为false
78 | - configurable:规定了能否改变options,以及删除key属性,默认false,具体详细请看
79 |
80 | ## 4. MVVM、MVC、MVP的区别
81 |
82 | ### **(1)MVC**
83 |
84 | **M: model数据模型, V:view视图模型, C: controller控制器**
85 |
86 | MVC 通过分离 Model、View 和 Controller 的方式来组织代码结构。其中 View 负责页面的显示逻辑,Model 负责存储页面的业务数据,以及对相应数据的操作。并且 View 和 Model 应用了**观察者模式**,当 Model 层发生改变的时候它会**通知**有关 View 层更新页面。Controller 层是 View 层和 Model 层的**纽带**,它主要负责用户与应用的响应操作,当用户与页面产生交互的时候,Controller 中的事件触发器就开始工作了,通过调用 Model 层,来完成对 Model 的修改,然后 Model 层再去通知View视图更新。
87 |
88 | 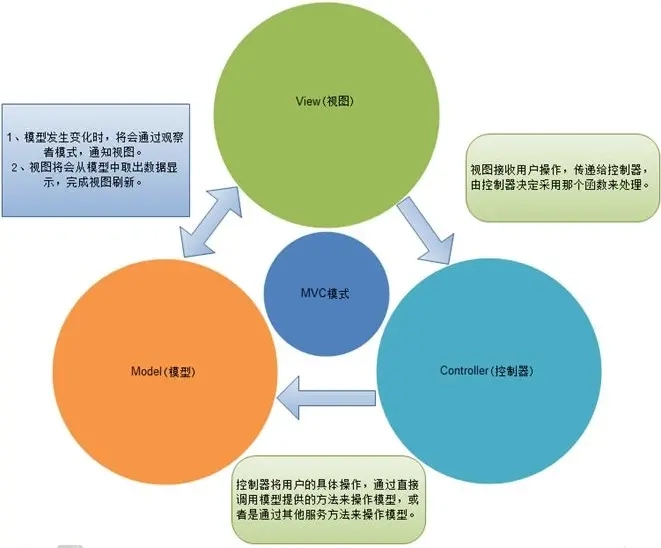
89 |
90 | ### **(2)MVP**
91 |
92 | **M: model数据模型, V:view视图模型, P: Presenter 控制器**
93 |
94 | MVP 模式与 MVC 唯一不同的在于 Presenter 和 Controller。在 MVC 模式中使用观察者模式,来实现当 Model 层数据发生变化的时候,通知 View 层的更新。这样 View 层和 Model 层耦合在一起,当项目逻辑变得复杂的时候,可能会造成代码的混乱,并且可能会对代码的复用性造成一些问题。
95 |
96 | MVP 的模式通过使用 Presenter 来实现对 View 层和 Model 层的**解耦**。MVC 中的Controller 只知道 Model 的接口,因此它没有办法控制 View 层的更新,MVP 模式中,View 层的接口暴露给了 Presenter 因此可以在 Presenter 中将 Model 的变化和 View 的变化**绑定**在一起,以此来实现 View 和 Model 的**同步更新**。这样就实现了对 View 和 Model 的解耦,Presenter 还包含了其他的响应逻辑。
97 |
98 | ### **(3)MVVM**
99 |
100 | MVVM 分为 Model、View、ViewModel:
101 |
102 | - **Model代表数据模型,数据和业务逻辑都在Model层中定义;**
103 | - **View代表UI视图,负责数据的展示;**
104 | - **ViewModel负责监听Model中数据的改变并且控制视图的更新,处理用户交互操作;**
105 |
106 | Model和View并无直接关联,而是通过ViewModel来进行联系的,Model和ViewModel之间有着**双向数据绑定**的联系。因此当Model中的数据改变时会触发View层的刷新,View中由于用户交互操作而改变的数据也会在Model中同步。
107 |
108 | 这种模式实现了 Model和View的**数据自动同步**,因此开发者只需要专注于数据的维护操作即可,而不需要自己操作DOM。
109 |
110 | 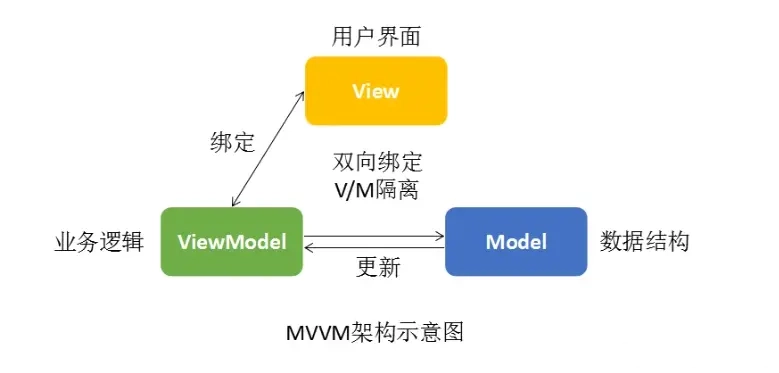
111 |
112 | ### 4.2 **MVVM**的优缺点?
113 |
114 | 优点:
115 |
116 | - 分离视图(View)和模型(Model),降低代码耦合,提⾼视图或者逻辑的重⽤性: ⽐如视图(View)可以独⽴于Model变化和修改,⼀个ViewModel可以绑定不同的"View"上,当View变化的时候Model不可以不变,当Model变化的时候View也可以不变。你可以把⼀些视图逻辑放在⼀个ViewModel⾥⾯,让很多view重⽤这段视图逻辑
117 | - 提⾼可测试性: ViewModel的存在可以帮助开发者更好地编写测试代码
118 | - ⾃动更新dom: 利⽤双向绑定,数据更新后视图⾃动更新,让开发者从繁琐的⼿动dom中解放
119 |
120 | 缺点:
121 |
122 | - Bug很难被调试: 因为使⽤双向绑定的模式,当你看到界⾯异常了,有可能是你View的代码有Bug,也可能是Model的代码有问题。数据绑定使得⼀个位置的Bug被快速传递到别的位置,要定位原始出问题的地⽅就变得不那么容易了。另外,数据绑定的声明是指令式地写在View的模版当中的,这些内容是没办法去打断点debug的
123 | - ⼀个⼤的模块中model也会很⼤,虽然使⽤⽅便了也很容易保证了数据的⼀致性,当时⻓期持有,不释放内存就造成了花费更多的内存
124 | - 对于⼤型的图形应⽤程序,视图状态较多,ViewModel的构建和维护的成本都会⽐较⾼
125 |
126 | ## 5. Vue的常用指令及作用
127 |
128 | - v-on 给标签绑定函数,可以缩写为@,例如绑定一个点击函数 函数必须写在methods里面
129 | - v-bind 动态绑定 作用: 及时对页面的数据进行更改, 可以简写成:冒号
130 | - v-slot: 缩写为#, 组件插槽
131 | - v-for 根据数组的个数, 循环数组元素的同时还生成所在的标签
132 | - v-show 显示内容
133 | - v-if 显示与隐藏
134 | - v-else 必须和v-if连用 不能单独使用 否则报错
135 | - v-text 解析文本
136 | - v-html 解析html标签
137 |
138 | ### 5.2 Vue怎么动态绑定Class 与 Style
139 |
140 | ```markdown
141 | v-bind:class="{{ '类名': bool, '类名': bool ......}}"
142 | v-bind:class="{ '类名': bool, '类名': bool ......}"
143 | 如果值为true 该类样式就会被应用在元素身上, false则不会
144 | 注意点:如果类名有 - ,则需要使用引号包起来
145 | ```
146 |
147 | `v-bind:style` 的对象语法十分直观——看着非常像 CSS,但其实是一个 JavaScript 对象。CSS property 名可以用驼峰式 (camelCase) 或短横线分隔 (kebab-case,记得用引号括起来) 来命名
148 |
149 | 直接绑定到一个样式对象通常更好,这会让模板更清晰:
150 |
151 | ```vue
152 |
153 |
154 | data: {
155 | styleObject: {
156 | color: 'red',
157 | fontSize: '13px'
158 | }
159 | }
160 | ```
161 |
162 | ## 6. vue常用的修饰符
163 |
164 | **v-on**
165 |
166 | - `.stop` - 调用 `event.stopPropagation()`。 阻止默认事件
167 | - `.prevent` - 调用 `event.preventDefault()`。阻止默认行为
168 | - `.native` - 监听组件根元素的原生事件。
169 |
170 | **v-bind**
171 |
172 | - `.prop` - 作为一个 DOM property 绑定而不是作为 attribute 绑定。
173 | - `.camel` - (2.1.0+) 将 kebab-case attribute 名转换为 camelCase。(从 2.1.0 开始支持)
174 | - `.sync` (2.3.0+) 语法糖,会扩展成一个更新父组件绑定值的 `v-on` 侦听器。
175 |
176 | **v-model**
177 |
178 | - [`.lazy`]- 取代 `input` 监听 `change` 事件
179 | - [`.number`] - 输入字符串转为有效的数字
180 | - [`.trim`] - 输入首尾空格过滤
181 |
182 | ## 7. Vue的内置组件
183 |
184 | ### **component**
185 |
186 | 渲染一个“元组件”为动态组件。依 is 的值,来决定哪个组件被渲染
187 |
188 | 在一个多标签的界面中使用 is attribute 来切换不同的组件:tap栏切换
189 |
190 | ### **transition**
191 |
192 | 用于在 Vue 插入、更新或者移除 DOM 时, 提供多种不同方式的应用过渡、动画效果。
193 |
194 | ### **transition-group**
195 |
196 | `` 用于给列表统一设置过渡动画。
197 |
198 | ### **keep-alive**
199 |
200 | - 主要用于保留组件状态或避免组件重新渲染。
201 | - **include** 属性用于指定哪些组件会被缓存,具有多种设置方式。
202 | - **exclude** 属性用于指定哪些组件不会被缓存。
203 | - **max** 属性用于设置最大缓存个数。
204 |
205 | ### **slot**
206 |
207 | - **name** - string,用于命名插槽。
208 | - < slot> 元素作为组件模板之中的内容分发插槽。< slot> 元素自身将被替换。
209 |
210 | ## 8. v-if、v-show、v-html 的原理
211 |
212 | `v-if`会调用addIfCondition方法,VNode,render的时候就不会渲染;
213 |
214 | `v-show`会生成VNode,render的时候也会渲染成真实节点,只是在render过程中会在节点的属性中修改show属性值,也就是常说的display;
215 |
216 | `v-html`会先移除节点下的所有节点,调用html方法,通过addProp添加innerHTML属性,归根结底还是设置innerHTML为v-html的值。
217 |
218 | ## 9. v-show和v-if的区别
219 |
220 | - v-show和v-if的区别? 分别说明其使用场景?
221 | - 相同点: v-show 和v-if都是true的时候显示,false的时候隐藏
222 | - 不同点1:原理不同
223 | - `v-show`:一定会渲染,只是修改display属性
224 | - `v-if`:根据条件渲染
225 | - 不同点2:应用场景不同
226 | - 频繁切换用v-show,不频繁切换用v-if
227 |
228 | `v-if` 是“真正”的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建,操作的实际上是dom元素的创建或销毁。
229 |
230 | `v-show` 就简单得多——不管初始条件是什么,元素总是会被渲染,并且只是简单地基于 CSS 进行切换 它操作的是display:none/block属性。
231 |
232 | 一般来说,`v-if` 有更高的切换开销,而 `v-show` 有更高的初始渲染开销。因此,如果需要非常频繁地切换,则使用 `v-show` 较好;如果在运行时条件很少改变,则使用 `v-if` 较好。
233 |
234 | ## 10. 为什么避免v-for和v-if在一起使用?
235 |
236 | Vue 处理指令时,v-for 比 v-if 具有更高的`优先级`, 虽然用起来也没报错好使, 但是性能不高, 如果你有5个元素被v-for循环, v-if也会分别执行5次.
237 |
238 | ## 11. v-for 循环为什么一定要绑定key ?
239 |
240 | > 提升vue渲染性能
241 |
242 | - 1.vue在渲染的时候,会 先把 新DOM 与 旧DOM 进行对比, 如果dom结构一致,则vue会复用旧的dom。 (此时可能造成数据渲染异常)
243 | - 2.使用key可以给dom添加一个标识符,让vue强制更新dom
244 |
245 | 比如有一个列表 li1 到 li4,我们需要在中间插入一个li3,`li1` 和 `li2` 不会重新渲染,而 `li3、li4、li5` 都会重新渲染
246 |
247 | 因为在不使用 `key` 或者列表的 `index` 作为 `key` 的时候,每个元素对应的位置关系都是 index,直接导致我们插入的元素到后面的全部元素,对应的位置关系都发生了变更,所以全部都会执行更新操作, 这是不可取的
248 |
249 | 而在使用唯一 `key` 的情况下,每个元素对应的位置关系就是 `key`,来看一下使用唯一 `key` 值的情况下
250 |
251 | 这样如图中的 `li3` 和 `li4` 就不会重新渲染,因为元素内容没发生改变,对应的位置关系也没有发生改变。
252 |
253 | 这也是为什么 v-for 必须要写 key,而且不建议开发中使用数组的 index 作为 key 的原因
254 |
255 | 总结一下:
256 |
257 | - key 的作用主要是为了更高效的更新虚拟 DOM,因为它可以非常精确的找到相同节点,因此 patch 过程会非常高效
258 | - Vue 在 patch 过程中会判断两个节点是不是相同节点时,key 是一个必要条件。比如渲染列表时,如果不写 key,Vue 在比较的时候,就可能会导致频繁更新元素,使整个 patch 过程比较低效,影响性能
259 | - 应该避免使用数组下标作为 key,因为 key 值不是唯一的话可能会导致上面图中表示的 bug,使 Vue 无法区分它他,还有比如在使用相同标签元素过渡切换的时候,就会导致只替换其内部属性而不会触发过渡效果
260 | - 从源码里可以知道,Vue 判断两个节点是否相同时主要判断两者的元素类型和 key 等,如果不设置 key,就可能永远认为这两个是相同节点,只能去做更新操作,就造成大量不必要的 DOM 更新操作,明显是不可取的
261 |
262 | ### 11.2 为什么不建议用index索引作为key?
263 |
264 | 使用index 作为 key和没写基本上没区别,因为不管数组的顺序怎么颠倒,index 都是 0, 1, 2...这样排列,导致 Vue 会复用错误的旧子节点,做很多额外的工作。
265 |
266 | ## 12. v-model 是如何实现的,语法糖实际是什么?
267 |
268 | **(1)作用在表单元素上** 动态绑定了 input 的 value 指向了 message 变量,并且在触发 input 事件的时候去动态把 message设置为目标值:
269 |
270 | 
271 |
272 | **(2)作用在组件上** 在自定义组件中,v-model 默认会利用名为 value 的 prop和名为 input 的事件
273 |
274 | **本质是一个父子组件通信的语法糖,通过prop和$.emit实现。** 因此父组件 v-model 语法糖本质上可以修改为:
275 |
276 | 
277 |
278 | 在组件的实现中,可以通过 v-model属性来配置子组件接收的prop名称,以及派发的事件名称。 例子:
279 |
280 | 
281 |
282 | 默认情况下,一个组件上的v-model 会把 value 用作 `prop`且把 input 用作 `event`。但是一些输入类型比如单选框和复选框按钮可能想使用 value prop 来达到不同的目的。使用 model 选项可以回避这些情况产生的冲突。js 监听input 输入框输入数据改变,用oninput,数据改变以后就会立刻出发这个事件。通过input事件把数据`$emit` 出去,在父组件接受。父组件设置v-model的值为input `$emit`过来的值。
283 |
284 | ## 结语
285 |
286 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
287 |
288 | ## 作者
289 |
290 | | Coder | 小红书ID | 创建时间 |
291 | | :---------- | :-------- | :--------- |
292 | | 落寞的前端👣 | 121450513 | 2022.10.19 |
293 |
--------------------------------------------------------------------------------
/迭代器:可迭代对象:生成器.md:
--------------------------------------------------------------------------------
1 | ## 大多数前端工程师不了解的迭代器/可迭代对象/生成器
2 |
3 | ## 1. 什么是迭代器?
4 |
5 | 概念(维基百科): **迭代器**(iterator),是确使用户可在容器对象(container,例如链表或数组)上遍访的对象`[1][2][3]`,设计人员使用此接口无需关心容器对象的内存分配的实现细节。
6 | **JS中的迭代器**
7 |
8 | - 其本质就是一个对象,符合迭代器协议(iterator protocol)
9 | - 迭代器协议
10 | 1. 其对象返回一个next函数
11 | 2. 调用next函数返回一个对象,其对象中包含两个属性
12 | - `done`(完成),它的值为布尔类型,也就是`true/false`。
13 | - 如果这个迭代器没有迭代完成即返回`{done:false}`
14 | - 当这个迭代器完成了即返回`{done:true}`
15 | - `value`(值),它可以返回js中的任何值,TS中表示可为:`value:any`类型
16 |
17 | ### 1.1 迭代器的基本实现
18 |
19 | 思考以下代码:
20 |
21 | ```js
22 | let index = 0
23 | const bears = ['ice', 'panda', 'grizzly']
24 |
25 | let iterator = {
26 | next() {
27 | if (index < bears.length) {
28 | return { done: false, value: bears[index++] }
29 | }
30 |
31 | return { done: true, value: undefined }
32 | }
33 | }
34 |
35 | console.log(iterator.next()) //{ done: false, value: 'ice' }
36 | console.log(iterator.next()) //{ done: false, value: 'panda' }
37 | console.log(iterator.next()) //{ done: false, value: 'grizzly' }
38 | console.log(iterator.next()) //{ done: true, value: undefined }
39 |
40 | ```
41 |
42 | 1. 是一个对象,实现了`next`方法,`next`方法返回了一个对象,有`done`属性和`value`属性,且`key`的值类型也为`boolean`或`any`,符合迭代器协议,是一个妥妥的迭代器没跑了。
43 | 2. 弊端
44 | - 违背了高内聚思想,明明`index`和`iterator`对象是属于一个整体,我却使用了全局变量,从V8引擎的GC,可达性(也就是标记清除)来看,如果`bears = null` ,不手动设置为null很有可能会造成内存泄漏,并且内聚性低。
45 | - 假如我要创建一百个迭代器对象呢? 那我就自己定义一百遍吗?肯定错误的,我们要把它封装起来,这样内聚性又高,又能进行复用,一举两得,一石二鸟,真的是`very beautiful`,`very 优雅。`
46 |
47 | ### 1.2 迭代器的封装实现
48 |
49 | 思考一下代码:
50 |
51 | ```javascript
52 | const bears = ['ice', 'panda', 'grizzly']
53 |
54 | function createArrIterator(arr) {
55 | let index = 0
56 |
57 | let _iterator = {
58 | next() {
59 | if (index < arr.length) {
60 | return { done: false, value: arr[index++] }
61 | }
62 |
63 | return { done: true, value: undefined }
64 | }
65 | }
66 |
67 | return _iterator
68 | }
69 |
70 | let iter = createArrIterator(bears)
71 |
72 | console.log(iter.next())
73 | console.log(iter.next())
74 | console.log(iter.next())
75 | console.log(iter.next())
76 | ```
77 |
78 | - 内聚性非常高,尽最大可能进行了复用,减少冗余代码
79 |
80 | ## 2. 什么是可迭代对象
81 |
82 | 迭代器对象和可迭代对象是一个不同的东西,虽然它们存在关联,而且面试的时候经常面这些概念,废话不多说,我们直接进入主题。
83 |
84 | - 首先就是一个对象,且符合可迭代对象协议(iterable protocol)
85 | - 可迭代对象协议
86 | 1. 实现了[Symbol.iterator]为key的方法,且这个方法返回了一个迭代器对象
87 | - 绕了一大圈终于把概念搞明白了,那可迭代对象有什么好处呢? 有什么应用场景呢?
88 | 1. for of 的时候,其本质就是调用的这个函数,也就是[Symbol.iterator]为key的方法
89 |
90 | ### 2.1 原生可迭代对象(JS内置)
91 |
92 | 1. String
93 | 2. Array
94 | 3. Set
95 | 4. NodeList 类数组对象
96 | 5. Arguments 类数组对象
97 | 6. Map
98 |
99 | #### 2.1.1 部分for of 演示
100 |
101 | ```js
102 | let str = 'The Three Bears'
103 |
104 | const bears = ['ice', 'panda', 'grizzly']
105 |
106 | for( let text of str) {
107 | console.log(text) //字符串每个遍历打印
108 | }
109 |
110 | for( let bear of bears) {
111 | console.log(bear)
112 | }
113 |
114 | //ice panda grizzly
115 |
116 | ```
117 |
118 | #### 2.1.2 查看内置的[Symbol.iterator]方法
119 |
120 | - 上面给大家举例了很多可迭代对象,那它们必定是符合可迭代对象协议的,思考以下代码
121 |
122 | ```js
123 | const bears = ['ice', 'panda', 'grizzly']
124 | //数组的Symbol.iterator方法
125 | const iter = bears[Symbol.iterator]()
126 |
127 | console.log(iter.next())
128 | console.log(iter.next())
129 | console.log(iter.next())
130 | console.log(iter.next())
131 |
132 |
133 | const nickName = 'ice'
134 | //字符串的Symbol.iterator方法
135 | const strIter = nickName[Symbol.iterator]()
136 |
137 | console.log(strIter.next())
138 | console.log(strIter.next())
139 | console.log(strIter.next())
140 | console.log(strIter.next())
141 |
142 | ```
143 |
144 | ### 2.2 可迭代对象的实现
145 |
146 | ```js
147 | let info = {
148 | bears: ['ice', 'panda', 'grizzly'],
149 | [Symbol.iterator]: function() {
150 | let index = 0
151 | let _iterator = {
152 | //这里一定要箭头函数,或者手动保存上层作用域的this
153 | next: () => {
154 | if (index < this.bears.length) {
155 | return { done: false, value: this.bears[index++] }
156 | }
157 |
158 | return { done: true, value: undefined }
159 | }
160 | }
161 |
162 | return _iterator
163 | }
164 | }
165 |
166 | let iter = info[Symbol.iterator]()
167 | console.log(iter.next())
168 | console.log(iter.next())
169 | console.log(iter.next())
170 | console.log(iter.next())
171 |
172 | //符合可迭代对象协议 就可以利用 for of 遍历
173 | for (let bear of info) {
174 | console.log(bear)
175 | }
176 | //ice panda grizzly
177 |
178 | ```
179 |
180 | - 符合可迭代对象协议,是一个对象,有`[Symbol.iterator]`方法,并且这个方法返回了一个迭代器对象。
181 | - 当我利用for of 遍历,就会自动的调用这个方法。
182 |
183 | ### 2.3 可迭代对象的应用
184 |
185 | - for of
186 | - 展开语法
187 | - 解构语法
188 | - promise.all(iterable)
189 | - promise.race(iterable)
190 | - Array.from(iterable)
191 | - ...
192 |
193 | ### 2.4 自定义类迭代实现
194 |
195 | ```javascript
196 | class myInfo {
197 | constructor(name, age, friends) {
198 | this.name = name
199 | this.age = age
200 | this.friends = friends
201 | }
202 |
203 | [Symbol.iterator]() {
204 | let index = 0
205 |
206 | let _iterator = {
207 | next: () => {
208 | const friends = this.friends
209 | if (index < friends.length) {
210 | return {done: false, value: friends[index++]}
211 | }
212 |
213 | return {done: true, value: undefined}
214 | }
215 | }
216 |
217 | return _iterator
218 | }
219 | }
220 |
221 | const info = new myInfo('ice', 22, ['panda','grizzly'])
222 |
223 | for (let bear of info) {
224 | console.log(bear)
225 | }
226 |
227 | //panda
228 | //grizzly
229 |
230 | ```
231 |
232 | - 此案例只是简单的对`friends`进行了迭代,你也可以迭代你想要的一切东西...
233 | - 记住此案例,后续我们会对这个案例进行重构,优雅的会让你不能用言语来形容。
234 |
235 | ## 3. 生成器函数
236 |
237 | 生成器是ES6新增的一种可以对函数控制的方案,能灵活的控制函数的暂停执行,继续执行等。
238 |
239 | **生成器函数和普通函数的不同**
240 |
241 | - 定义: 普通函数`function`定义,生成器函数`function*`,要在后面加`*`
242 | - 生成器函数可以通过 `yield` 来控制函数的执行
243 | - 生成器函数返回一个生成器(generator),**生成器是一个特殊的迭代器**
244 |
245 | ### 3.1 生成器函数基本实现
246 |
247 | ```javascript
248 | function* bar() {
249 | console.log('fn run')
250 | }
251 |
252 | bar()
253 | ```
254 |
255 | - 我们会发现,这个函数竟然没有执行。我们前面说过,它是一个生成器函数,它的返回值是一个生成器,**同时也是一个特殊的迭代器**,所以跟普通函数相比,好像暂停了,那如何让他执行呢?接下来我们进一步探讨。
256 |
257 | ### 3.2 生成器函数单次执行
258 |
259 | ```javascript
260 | function* bar() {
261 | console.log('fn run')
262 | }
263 |
264 | const generator = bar()
265 |
266 | console.log(generator.next())
267 | //fn run
268 | //{ value: undefined, done: true }
269 | ```
270 |
271 | - 返回了一个生成器,我们调用next方法就可以让函数执行,并且next方法是有返回值的,我们上面讲迭代器的时候有探讨过,而value没有返回值那就是undefined。那上面说的yield关键字在哪,到底是如何控制函数的呢?是如何用的呢?
272 |
273 | ### 3.3 生成器函数多次执行
274 |
275 | ```javascript
276 | function* bar() {
277 | console.log('fn run start')
278 | yield 100
279 | console.log('fn run...')
280 | yield 200
281 | console.log('fn run end')
282 | return 300
283 | }
284 |
285 | const generator = bar()
286 |
287 | //1. 执行到第一个yield,暂停之后,并且把yield的返回值 传入到value中
288 | console.log(generator.next())
289 | //2. 执行到第一个yield,暂停之后,并且把yield的返回值 传入到value中
290 | console.log(generator.next())
291 | //3. 执行剩余代码
292 | console.log(generator.next())
293 |
294 | //打印结果:
295 | //fn run start
296 | //{done:false, value: 100}
297 | //fn run...
298 | //{done:false, value: 200}
299 | //fn run end
300 | //{done:true, value: 300}
301 | ```
302 |
303 | - 现在我们恍然大悟,每当调用next方法的时候,代码就会开始执行,执行到`yield x`,后就会暂停,等待下一次调用next继续往下执行,周而复始,没有了`yield`关键字,进行最后一次next调用返回`done:true`。
304 |
305 | ### 3.4 生成器函数的分段传参
306 |
307 | 我有一个需求,既然生成器能控制函数分段执行,我要你实现一个分段传参。
308 | 思考以下代码:
309 |
310 | ```js
311 | function* bar(nickName) {
312 | const str1 = yield nickName
313 | const str2 = yield str1 + nickName
314 |
315 | return str2 + str1 + nickName
316 | }
317 |
318 | const generator = bar('ice')
319 |
320 | console.log(generator.next())
321 | console.log(generator.next('panda '))
322 | console.log(generator.next('grizzly '))
323 | console.log(generator.next())
324 |
325 | // { value: 'ice', done: false }
326 | // { value: 'panda ice', done: false }
327 | // { value: 'grizzly panda ice', done: true }
328 | // { value: undefined, done: true }
329 |
330 | ```
331 |
332 | - 如果没有接触过这样的代码会比较奇怪
333 | - 当我调用next函数的时候,yield的左侧是可以接受参数的,也并不是所有的next方法的实参都能传递到生成器函数内部
334 | - yield左侧接收的,是第二次调用next传入的实参,那第一次传入的就没有yield关键字接收,所有只有当我调用bar函数的时候传入。
335 | - 最后一次next调用,传入的参数我也调用不了,因为没有yield关键字可以接收了。
336 | - 很多开发者会疑惑,这样写有什么用呢? 可读性还差,但是在处理异步数据的时候就非常有用了,后续会在promise中文章中介绍。
337 |
338 | ### 3.5 生成器代替迭代器
339 |
340 | 前面我们讲到,**生成器是一个特殊的迭代器**,那生成器必定是可以代替迭代器对象的,思考以下代码。
341 |
342 | ```js
343 | let bears = ['ice','panda','grizzly']
344 |
345 | function* createArrIterator(bears) {
346 | for (let bear of bears) {
347 | yield bear
348 | }
349 | }
350 |
351 | const generator = createArrIterator(bears)
352 |
353 | console.log(generator.next())
354 | console.log(generator.next())
355 | console.log(generator.next())
356 | console.log(generator.next())
357 |
358 | ```
359 |
360 | 其实这里还有一种**语法糖**的写法**yield***
361 |
362 | - yield* 依次迭代这个可迭代对象,相当于遍历拿出每一项 yield item(伪代码)
363 |
364 | 思考以下代码:
365 |
366 | ```lua
367 | let bears = ['ice','panda','grizzly']
368 |
369 | function* createArrIterator(bears) {
370 | yield* bears
371 | }
372 |
373 | const generator = createArrIterator(bears)
374 |
375 | console.log(generator.next())
376 | console.log(generator.next())
377 | console.log(generator.next())
378 | console.log(generator.next())
379 |
380 | ```
381 |
382 | - 依次迭代这个可迭代对象,返回每个item值
383 |
384 | ## 4. 可迭代对象的终极封装
385 |
386 | ```javascript
387 | class myInfo {
388 | constructor(name, age, friends) {
389 | this.name = name
390 | this.age = age
391 | this.friends = friends
392 | }
393 |
394 | *[Symbol.iterator]() {
395 | yield* this.friends
396 | }
397 | }
398 |
399 | const info = new myInfo('ice', 22, ['panda','grizzly'])
400 |
401 | for (let bear of info) {
402 | console.log(bear)
403 | }
404 |
405 | //panda
406 | //grizzly
407 |
408 | ```
409 |
410 | - 回顾以下可迭代对象协议
411 | - 是一个对象并且有[Symbol.iterator]方法
412 | - 这个方法返回一个迭代器对象 生成器函数返回一个生成器,是一个特殊的**迭代器**
413 |
414 | ## 5. 总结
415 |
416 | ### 5.1 迭代器对象
417 |
418 | 1. 本质就是一个对象,要符合迭代器协议
419 | 2. 有自己对应的next方法,next方法则返回一组数据`{done:boolean, value:any}`
420 |
421 | ### 5.2 可迭代对象
422 |
423 | 1. 本质就是对象,要符合可迭代对象协议
424 | 2. 有`[Symbol.iterator]`方法,并且调用这个方法返回一个迭代器
425 |
426 | ### 5.3 生成器函数
427 |
428 | 1. 可以控制函数的暂停执行和继续执行
429 | 2. 通过`function* bar() {}` 这种形式定义
430 | 3. 不会立马执行,而是返回一个生成器,**生成器是一个特殊的迭代器对象**
431 | 4. `yield` 关键字可以控制函数分段执行
432 | 5. 调用返回生成器的next方法进行执行
433 |
434 |
435 |
436 | ## 6. 作者
437 |
438 | | Coder | 小红书ID | 创建时间 |
439 | | :---------- | :-------- | :--------- |
440 | | 落寞的前端👣 | 121450513 | 2022.10.03 |
441 |
442 |
--------------------------------------------------------------------------------
/browser_three.md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(浏览器篇)三
2 |
3 | ## 二、HTTPS
4 |
5 | ## 1. 什么是HTTPS协议?
6 |
7 | `超文本传输安全协议`(Hypertext Transfer Protocol Secure,简称:HTTPS)是一种通过计算机网络进行安全通信的传输协议。**HTTPS经由HTTP进行通信,利用SSL/TLS来加密数据包。**
8 | HTTPS的主要目的是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。 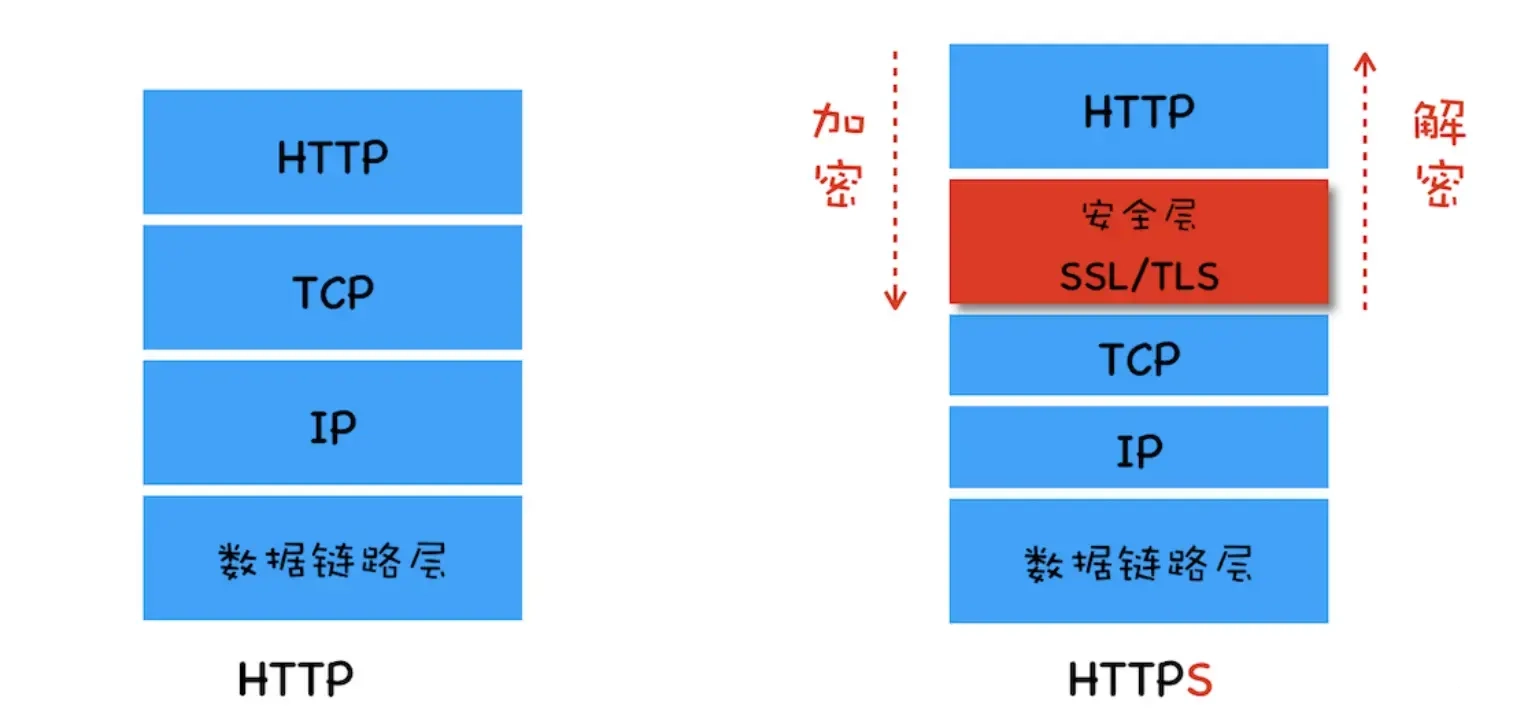
9 | HTTP协议采用**明文传输**信息,存在**信息窃听**、**信息篡改**和**信息劫持**的风险,而协议TLS/SSL具有**身份验证**、**信息加密**和**完整性校验**的功能,可以避免此类问题发生。
10 |
11 | 安全层的主要职责就是**对发起的HTTP请求的数据进行加密操作** 和 **对接收到的HTTP的内容进行解密操作**。
12 |
13 | ## 2. TLS/SSL的工作原理
14 |
15 | **TLS**全称**安全传输层协议**(Transport Layer Security)及其前身**安全套接层**(Secure Sockets Layer,缩写作**SSL**)
16 | 是介于TCP和HTTP之间的一层安全协议,不影响原有的TCP协议和HTTP协议,所以使用HTTPS基本上不需要对HTTP页面进行太多的改造。
17 |
18 | TLS/SSL的功能实现主要依赖三类基本算法:**散列函数hash**、**对称加密**、**非对称加密**。这三类算法的作用如下:
19 |
20 | - 散列算法用来验证信息的完整性
21 | - 对称加密算法采用协商的秘钥对数据加密
22 | - 非对称加密实现身份认证和秘钥协商
23 |
24 | 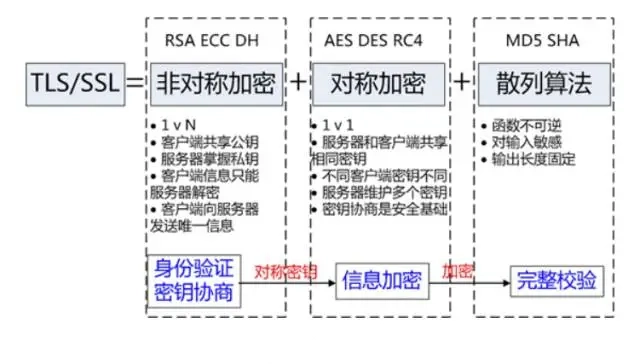
25 |
26 | ## 3. 对称加密、非对称加密是什么,有什么区别?
27 |
28 | **对称加密和非对称加密是安全传输层里的加密算法**
29 |
30 | **对称加密**
31 |
32 | - 对称加密的特点是文件加密和解密使用相同的密钥,即加密密钥也可以用作解密密钥,
33 |
34 | 这种方法在密码学中叫做对称加密算法,对称加密算法使用起来简单快捷,密钥较短,且破译困难
35 |
36 | **通信的双⽅都使⽤同⼀个秘钥进⾏加密, 解密。** ⽐如,两个人事先约定的暗号,就属于对称加密。
37 |
38 | 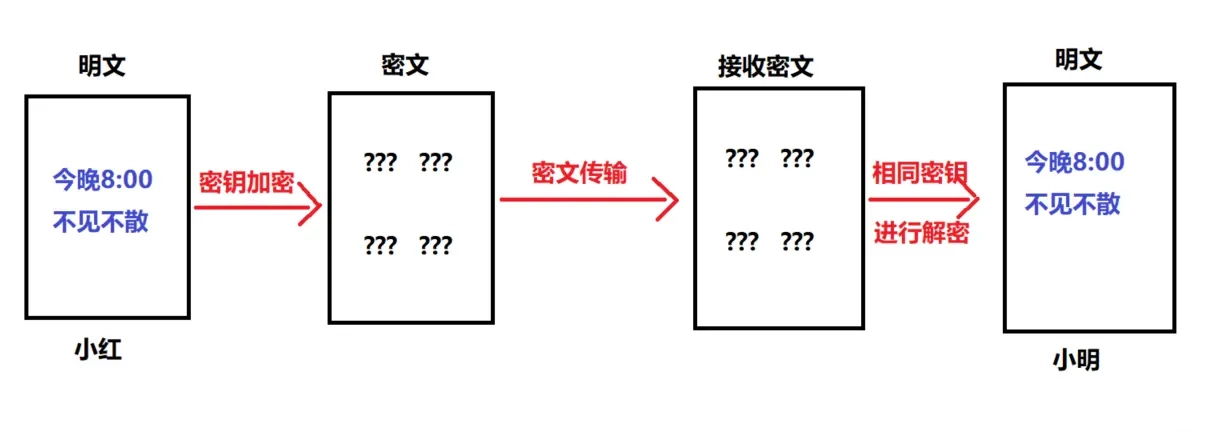
39 |
40 | **优点:**
41 |
42 | 计算量小、加密速度快、加密效率高。
43 |
44 | **缺点:**
45 |
46 | **在数据传送前,发送方和接收方必须商定好秘钥,然后双方保存好秘钥。**
47 |
48 | **如果一方的秘钥被泄露,那么加密信息也就不安全了**
49 |
50 | 最不安全的地方, 就在于第一开始, 互相约定密钥的时候!!! 传递密钥!
51 |
52 | 使用场景:本地数据加密、https 通信、网络传输等
53 |
54 | **非对称加密**
55 |
56 | 通信的双方使用不同的秘钥进行加密解密,即秘钥对(私钥 + 公钥)。
57 |
58 | 特征: 私钥可以解密公钥加密的内容, 公钥可以解密私钥加密的内容
59 |
60 | 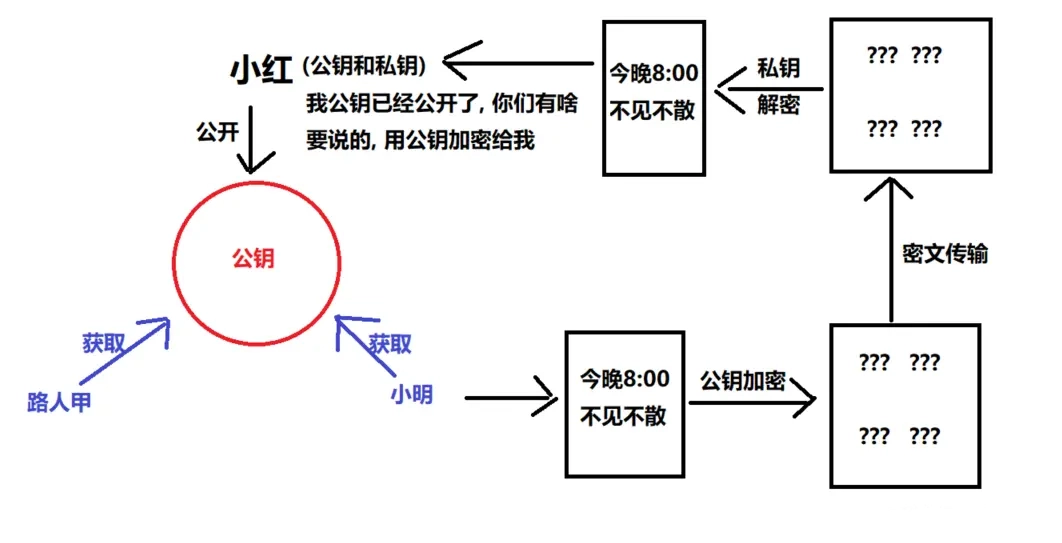
61 |
62 | 非对称加密的特点是:
63 |
64 | - 优点:非对称加密与对称加密相比其安全性更好
65 | - **缺点:加密和解密花费时间长、速度慢,只适合对少量数据进行加密。**
66 |
67 | 使用场景:https 会话前期、CA 数字证书、信息加密、登录认证等
68 |
69 | ## 4. 数字证书是什么?
70 |
71 | 使用一种 Hash 算法来对公钥和其他信息进行加密,生成一个信息摘要,然后让有公信力的认证中心(简称 CA )用它的私钥对消息摘要加密,形成签名。最后将原始的信息和签名合在一起,称为**数字证书**
72 | 。当接收方收到数字证书的时候,先根据原始信息使用同样的 Hash 算法生成一个摘要,然后使用公证处的公钥来对数字证书中的摘要进行解密,最后将解密的摘要和生成的摘要进行对比,就能发现得到的信息是否被更改了。
73 |
74 | ### 4.2 数字证书的作用
75 |
76 | 现在的方法也不一定是安全的,因为没有办法确定得到的公钥就一定是安全的公钥。可能存在一个中间人,截取了对方发给我们的公钥,然后将他自己的公钥发送给我们,当我们使用他的公钥加密后发送的信息,就可以被他用自己的私钥解密。然后他伪装成我们以同样的方法向对方发送信息,这样我们的信息就被窃取了,然而自己还不知道。为了解决这样的问题,可以使用**
77 | 数字证书**。
78 |
79 | ### 4.3 数字签名是什么?
80 |
81 | 数字签名就是先用CA自带的Hash算法来计算出证书内容的一个摘要,然后使用CA私钥进行加密,组成数字签名。
82 |
83 | 当别人把他的数字证书发过来时,接收方用同样的算法再次生成摘要,用CA公钥解密后得到CA生成的摘要,两者进行对比后,就能确定中间是否被人篡改。这样就能最大程度的保证通信的安全了。
84 |
85 | ## 5. HTTPS通信(握手)过程
86 |
87 | HTTPS的通信过程如下:
88 |
89 | 1. 客户端向服务器发起请求,请求中包含使用的协议版本号、生成的一个随机数、以及客户端支持的加密方法。
90 | 2. 服务器端接收到请求后,确认双方使用的加密方法、并给出服务器的证书、以及一个服务器生成的随机数。
91 | 3. 客户端确认服务器证书有效后,生成一个新的随机数,并使用数字证书中的公钥,加密这个随机数,然后发给服 务器。并且还会提供一个前面所有内容的 hash 的值,用来供服务器检验。
92 | 4. 服务器使用自己的私钥,来解密客户端发送过来的随机数。并提供前面所有内容的 hash 值来供客户端检验。
93 | 5. 客户端和服务器端根据约定的加密方法使用前面的三个随机数,生成对话秘钥,以后的对话过程都使用这个秘钥来加密信息。
94 |
95 | ## 6. HTTPS的优缺点
96 |
97 | HTTPS的**优点**如下:
98 |
99 | - 使用HTTPS协议可以认证用户和服务器,确保数据发送到正确的客户端和服务器;
100 | - 使用HTTPS协议可以进行加密传输、身份认证,通信更加安全,防止数据在传输过程中被窃取、修改,确保数据安全性;
101 | - HTTPS是现行架构下最安全的解决方案,虽然不是绝对的安全,但是大幅增加了中间人攻击的成本;
102 |
103 | HTTPS的**缺点**如下:
104 |
105 | - HTTPS需要做服务器和客户端双方的加密个解密处理,耗费更多服务器资源,过程复杂;
106 | - HTTPS协议握手阶段比较费时,增加页面的加载时间;
107 | - SSL证书是收费的,功能越强大的证书费用越高;
108 | - HTTPS连接服务器端资源占用高很多,支持访客稍多的网站需要投入更大的成本;
109 | - SSL证书需要绑定IP,不能再同一个IP上绑定多个域名。
110 |
111 | ## 7. **HTTPS**是如何保证安全的?
112 |
113 | 结合**对称加密**和**非对称加密**两种加密⽅式,将对称加密的密钥使⽤⾮对称加密的公钥进⾏加密,然后发送出去,接收⽅使⽤私钥进⾏解密得到对称加密的密钥,然后双⽅可以使⽤对称加密来进⾏沟通。
114 |
115 | 这个时候还需要⼀个安全的**第三⽅颁发证书**(CA),证明身份的身份,防⽌被中间⼈攻击。
116 |
117 | 为了防止中间人篡改证书,需要用到**数字签名**这个技术
118 |
119 | *
120 |
121 | 数字签名就是⽤CA⾃带的HASH算法对证书的内容进⾏HASH得到⼀个摘要,再⽤CA的私钥加密,最终组成数字签名。当别⼈把他的证书发过来的时候,我再⽤同样的Hash算法,再次⽣成消息摘要,然后⽤CA的公钥对数字签名解密,得到CA创建的消息摘要,两者⼀⽐,就知道中间有没有被⼈篡改了。这个时候就能最⼤程度保证通信的安全了。*
122 |
123 | ## 8.HTTP状态码分别代表什么意思?
124 |
125 | | **类别** | **原因** | **描述** |
126 | | -------- | ------------------------------- | -------------------------- |
127 | | 1xx | Informational(信息性状态码) | 接受的请求正在处理 |
128 | | 2xx | Success(成功状态码) | 请求正常处理完毕 |
129 | | 3xx | Redirection(重定向状态码) | 需要进行附加操作一完成请求 |
130 | | 4xx | Client Error (客户端错误状态码) | 服务器无法处理请求 |
131 | | 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 |
132 |
133 | **(1)2XX 成功**
134 |
135 | - 200 OK,表示从客户端发来的请求在服务器端被正确处理
136 | - 201 Created 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立。通常是在POST请求,或者是某些PUT请求之后创建了内容,进行的返回的响应。
137 | - 202 Accepted 请求服务器已接受,但是尚未处理,不保证完成请求。适合异步任务或者说需要处理时间比较长的请求,避免HTTP链接一直占用。
138 | - 204 No content,表示请求成功,但响应报文不含实体的主体部分
139 | - 205 Reset Content,表示请求成功,但响应报文不含实体的主体部分,但是与 204 响应不同在于要求请求方重置内容
140 | - 206 Partial Content,进行的是范围请求,表示服务器已经成功处理了部分GET请求,响应头中会包含获取的内容范围(常用于分段下载)
141 |
142 | **(2)3XX 重定向**
143 |
144 | - 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
145 | - 302 found,临时性重定向,表示资源临时被分配了新的 URL,支持搜索引擎优化
146 | - 303 see other,表示资源存在着另一个 URL,应使用 GET 方法获取资源
147 | - 304 not modified,自从上次请求后,请求的网页内容未修改过。服务器返回此响应时,不会返回网页内容。(**协商缓存**)
148 | - 307 temporary redirect,临时重定向,和302含义类似,但是期望客户端保持请求方法不变向新的地址发出请求
149 |
150 | **(3)4XX 客户端错误**
151 |
152 | - 400 bad request,请求报文存在语法错误(传参格式不正确)
153 | - 401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息(没有权限)
154 | - 403 forbidden,表示对请求资源的访问被服务器拒绝
155 | - 404 not found,表示在服务器上没有找到请求的资源
156 | - 408 Request Timeout 客户端请求超时
157 | - 409 Conflict 请求的资源可能引起冲突
158 |
159 | **(4)5XX 服务器错误**
160 |
161 | - 500 internal sever error,表示服务器端在执行请求时发生了错误
162 | - 501 Not Implemented,表示服务器不支持当前请求所需要的某个功能
163 | - 503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求
164 |
165 | ## 9. 同样是重定向,**307**,**303**,**302**的区别?
166 |
167 | **302**是http1.0的协议状态码,在http1.1版本的时候为了细化302状态码⼜出来了两个303和307。
168 |
169 | **303**明确表示客户端应当采⽤get⽅法获取资源,他会把POST请求变为GET请求进⾏重定向。
170 |
171 | **307**会遵照浏览器标准,不会从post变为get。
172 |
173 | ## 10. DNS 协议是什么
174 |
175 | **概念**: DNS 是**域名系统** (Domain Name System) 的缩写,提供的是一种主机名到 IP 地址的转换服务,就是我们常说的域名系统。它是一个由分层的 DNS
176 | 服务器组成的分布式数据库,是定义了主机如何查询这个分布式数据库的方式的应用层协议。能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。
177 |
178 | **作用**: 将域名解析为IP地址,客户端向DNS服务器(DNS服务器有自己的IP地址)发送域名查询请求,DNS服务器告知客户机Web服务器的 IP 地址。
179 |
180 | ## 11. DNS完整的查询过程
181 |
182 | DNS服务器解析域名的过程:
183 |
184 | - 首先会在**浏览器的缓存**中查找对应的IP地址,如果查找到直接返回,若找不到继续下一步
185 | - 将请求发送给**本地DNS服务器**,在本地域名服务器缓存中查询,如果查找到,就直接将查找结果返回,若找不到继续下一步
186 | - 本地DNS服务器向**根域名服务器**发送请求,根域名服务器会返回一个所查询域的顶级域名服务器地址
187 | - 本地DNS服务器向**顶级域名服务器**发送请求,接受请求的服务器查询自己的缓存,如果有记录,就返回查询结果,如果没有就返回相关的下一级的权威域名服务器的地址
188 | - 本地DNS服务器向**权威域名服务器**发送请求,域名服务器返回对应的结果
189 | - 本地DNS服务器将返回结果保存在缓存中,便于下次使用
190 | - 本地DNS服务器将返回结果返回给浏览器
191 |
192 | ## 12. 简述一下TCP的三次握手
193 |
194 | **第一次握手:** 客户端向服务端发送连接请求报文段。该报文段中包含自身的数据通讯初始序号。请求发送后,客户端便进入 SYN-SENT 状态。
195 |
196 | **第二次握手:** 服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED 状态。
197 |
198 | **第三次握手:** 当客户端收到连接同意的应答后,还要向服务端发送一个确认报文。客户端发完这个报文段后便进入 ESTABLISHED 状态,服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
199 |
200 | ## 13. **TCP什么要三次握手呢?两次不行吗?**
201 |
202 | - 为了确认双方的接收能力和发送能力都正常
203 | - 如果是用两次握手,则会出现下面这种情况:
204 |
205 | 如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时客户端忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源。
206 |
207 | ## 14. 简述一下TCP的四次挥手
208 |
209 | **第一次挥手:** 若客户端认为数据发送完成,则它需要向服务端发送连接释放请求。
210 |
211 | **第二次挥手**:服务端收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明客户端到服务端的连接已经释放,不再接收客户端发的数据了。但是因为 TCP
212 | 连接是双向的,所以服务端仍旧可以发送数据给客户端。
213 |
214 | **第三次挥手**:服务端如果此时还有没发完的数据会继续发送,完毕后会向客户端发送连接释放请求,然后服务端便进入 LAST-ACK 状态。
215 |
216 | **第四次挥手:** 客户端收到释放请求后,向服务端发送确认应答,此时客户端进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有服务端的重发请求的话,就进入
217 | CLOSED 状态。当服务端收到确认应答后,也便进入 CLOSED 状态。
218 |
219 | ## 15. TCP**为什么需要四次挥手呢?**
220 |
221 | 因为当服务端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当服务端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉客户端,“你发的FIN报文我收到了”。只有等到我服务端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送,故需要四次挥手。
222 |
223 | ## 16. TCP粘包是怎么回事,如何处理?
224 |
225 | 默认情况下, TCP 连接会启⽤**延迟传送算法** (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到⼀起作⼀次发送 (缓冲⼤⼩⻅ socket.bufferSize ), 这样可以减少 IO
226 | 消耗提⾼性能.
227 |
228 | 如果是传输⽂件的话, 那么根本不⽤处理粘包的问题, 来⼀个包拼⼀个包就好了。但是如果是多条消息, 或者是别的⽤途的数据那么就需要处理粘包.
229 |
230 | ⽽对于处理粘包的问题, 常⻅的解决⽅案有:
231 |
232 | **多次发送之前间隔⼀个等待时间**:只需要等上⼀段时间再进⾏下⼀次 send 就好, 适⽤于交互频率特别低的场景. 缺点也很明显, 对于⽐较频繁的场景⽽⾔传输效率实在太低,不过⼏乎不⽤做什么处理.
233 |
234 | **关闭 Nagle 算法**:关闭 Nagle 算法, 在 Node.js 中你可以通过 socket.setNoDelay() ⽅法来关闭 Nagle 算法, 让每⼀次 send
235 | 都不缓冲直接发送。该⽅法⽐较适⽤于每次发送的数据都⽐较⼤ (但不是⽂件那么⼤), 并且频率不是特别⾼的场景。如果是每次发送的数据量⽐较⼩, 并且频率特别⾼的, 关闭 Nagle 纯属⾃废武功。另外, 该⽅法不适⽤于⽹络较差的情况, 因为
236 | Nagle 算法是在服务端进⾏的包合并情况, 但是如果短时间内客户端的⽹络情况不好, 或者应⽤层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从⽽粘包的情况。 (如果是在稳定的机房内部通信那么这个概率是⽐较⼩可以选择忽略的)
237 |
238 | **进⾏封包/拆包:** 封包/拆包是⽬前业内常⻅的解决⽅案了。即给每个数据包在发送之前, 于其前/后放⼀些有特征的数据, 然后收到数据的时 候根据特征数据分割出来各个数据包。
239 |
240 | ## 17. token是什么?
241 |
242 | 1. token也可以称做**令牌**,一般由 `uid+time+sign(签名)+[固定参数]` 组成
243 |
244 | ```markdown
245 | uid: 用户唯一身份标识
246 | time: 当前时间的时间戳
247 | sign: 签名, 使用 hash/encrypt 压缩成定长的十六进制字符串,以防止第三方恶意拼接
248 | 固定参数(可选): 将一些常用的固定参数加入到 token 中是为了避免重复查库
249 | ```
250 |
251 | 2. token在客户端一般存放于localStorage,cookie,或sessionStorage中。在服务器一般存于数据库中
252 |
253 | 3. token 的认证流程
254 |
255 | ```markdown
256 | 用户登录,成功后服务器返回Token给客户端。
257 | 客户端收到数据后保存在客户端
258 | 客户端再次访问服务器,将token放入headers中 或者每次的请求 参数中
259 | 服务器端采用filter过滤器校验。校验成功则返回请求数据,校验失败则返回错误码
260 | ```
261 |
262 | 4. token可以抵抗csrf,cookie+session不行
263 |
264 | 5. session时有状态的,一般存于服务器内存或硬盘中,当服务器采用分布式或集群时,session就会面对负载均衡问题。负载均衡多服务器的情况,不好确认当前用户是否登录,因为多服务器不共享session
265 |
266 | 6.
267 |
268 | 客户端登陆传递信息给服务端,服务端收到后把用户信息加密(token)传给客户端,客户端将token存放于localStorage等容器中。客户端每次访问都传递token,服务端解密token,就知道这个用户是谁了。通过cpu加解密,服务端就不需要存储session占用存储空间,就很好的解决负载均衡多服务器的问题了。这个方法叫做JWT(
269 | Json Web Token)
270 |
271 | ## 18. token是怎么加密的
272 |
273 | 1. 需要一个secret(随机数)
274 | 2. 后端利用secret和加密算法(如:HMAC-SHA256)对payload(如账号密码)生成一个字符串(token),返回前端
275 | 3. 前端每次request在header中带上token
276 | 4. 后端用同样的算法解密
277 |
278 | ## 19. cookie和token都放在header中,为什么会劫持cookie,不会劫持token
279 |
280 | - **cookie**: 登陆后后端生成一个sessionId放在cookie中返回给客户端, 并且服务端一直记录着这个 sessionId, 客户端以后每次请求都会带上这个sessionId,
281 | 服务端通过这个sessionId来验证身份之类的操作。所以别人拿到了cookie就相当于拿到了sessionId ,就可以完全替代你。同时浏览器会自动携带cookie
282 | - token: 同样是登录后服务端返回一个token,客户端保存起来,在以后http请求里手动的加入到请求头里,服务端根据token 进行身份的校验。浏览器不会自动携带token,所以不会劫持 token。
283 |
284 | ## 20. token过期后,页面如何实现无感刷新?
285 |
286 | **什么是无感刷新**
287 |
288 | 后台返回的token是有时效性的,时间到了,你在交互后台的时候,后台会判断你的token是否过期(安全需要),如果过期了就会逼迫你重新登陆!
289 |
290 | **token无感刷新其本质是为了优化用户体验,当token过期时不需要用户跳回登录页重新登录,而是当token失效时,进行拦截,发送刷新token的ajax,获取最新的token进行覆盖,让用户感受不到token已经过期**
291 |
292 | **实现无感刷新**
293 |
294 | 1、后端返回过期时间,前端判断token过期时间,去调用刷新token接口。
295 |
296 | 缺点:需要后端额外提供一个Token过期时间的字段;使用了本地时间判断,若本地时间篡改,特别是本地时间比服务器时间慢时,拦截会失败。
297 |
298 | 2、写个定时器,定时刷新Token接口。缺点:浪费资源,消耗性能,不建议采用。
299 |
300 | 3、在响应拦截器中拦截,判断Token 返回过期后,调用刷新token接口。
301 |
302 | ## 21. 介绍下304过程
303 |
304 | - a. 浏览器请求资源时首先命中资源的Expires 和 Cache-Control,Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效,可以通过Cache-control:
305 | max-age指定最大生命周期,状态仍然返回200,但不会请求数据,在浏览器中能明显看到from cache字样。
306 | - b. 强缓存失效,进入协商缓存阶段,首先验证ETagETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据客户端上送的If-None-Match值来判断是否命中缓存。
307 | - c.
308 | 协商缓存Last-Modify/If-Modify-Since阶段,客户端第一次请求资源时,服务服返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间。再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存
309 |
310 | ## 结语
311 |
312 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
313 |
314 | ## 作者
315 |
316 | | Coder | 小红书ID | 创建时间 |
317 | | :---------- | :-------- | :--------- |
318 | | 落寞的前端👣 | 121450513 | 2022.11.04 |
319 |
--------------------------------------------------------------------------------
/js面试题四(JS基础).md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(JS篇)四
2 |
3 | ## 四、原型与继承
4 |
5 | ## 4.1说说面向对象的特性与特点
6 |
7 | - 封装性
8 | - 继承性
9 | - 多态性
10 |
11 | 面向对象编程具有灵活、代码可复用、容易维护和开发的有点、更适合多人合作的大型软件项目
12 |
13 | ## 4.2 说说你对工厂模式的理解
14 |
15 | 工厂模式是用来创建对象的一种最常用的设计模式,不暴露创建对象的具体逻辑,而是将将逻辑封装在一个函数中,那么这个函数就可以被视为一个工厂
16 |
17 | 其就像工厂一样重复的产生类似的产品,工厂模式只需要我们传入正确的参数,就能生产类似的产品
18 |
19 | ## 4.3 创建对象有哪几种方式?
20 |
21 | 1. 字面量的形式直接创建对象
22 | 2. 函数方法
23 | 1. **工厂模式**,工厂模式的主要工作原理是用函数来封装创建对象的细节,从而通过调用函数来达到复用的目的。
24 | 2. **构造函数模式**
25 | 3. **原型模式**
26 | 4. **构造函数模式+原型模式**,这是创建自定义类型的最常见方式。
27 | 5. **动态原型模式**
28 | 6. **寄生构造函数模式**
29 | 3. class创建
30 |
31 | ## 4.4 JS宿主对象和原生对象的区别
32 |
33 | ```
34 | 原生对象
35 | ```
36 |
37 | “`独立于宿主环境的 ECMAScript 实现提供的对象`”
38 |
39 | 包含:Object、Function、Array、String、Boolean、Number、Date、RegExp、Error、EvalError、RangeError、ReferenceError、SyntaxError、TypeError、URIError
40 |
41 | ```
42 | 内置对象
43 | ```
44 |
45 | 开发者不必明确实例化内置对象,它已被内部实例化了
46 |
47 | 同样是“独立于宿主环境”。而 ECMA-262 只定义了两个内置对象,即 Global 和 Math
48 |
49 | ```
50 | 宿主对象
51 | ```
52 |
53 | BOM 和 DOM 都是宿主对象。因为其对于不同的“宿主”环境所展示的内容不同。其实说白了就是,ECMAScript 官方未定义的对象都属于宿主对象,因为其未定义的对象大多数是自己通过 ECMAScript 程序创建的对象
54 |
55 | ## 4.5 JavaScript 内置的常用对象有哪些?并列举该对象常用的方法?
56 |
57 | **Number 数值对象,数值常用方法**
58 |
59 | - Number.toFixed( ) 采用定点计数法格式化数字
60 | - Number.toString( ) 将—个数字转换成字符串
61 | - Number.valueOf( ) 返回原始数值
62 |
63 | **String 字符串对象,字符串常用方法**
64 |
65 | - Length 获取字符串的长度
66 | - split()将一个字符串切割数组
67 | - concat() 连接字符串
68 | - indexOf()返回一个子字符串在原始字符串中的索引值。如果没有找到,则返回固定值 -1
69 | - lastIndexOf() 从后向前检索一个字符串
70 | - slice() 抽取一个子串
71 |
72 | **Boolean 布尔对象,布尔常用方法**
73 |
74 | - Boolean.toString() 将布尔值转换成字符串
75 | - Boolean.valueOf() Boolean 对象的原始值的布尔值
76 |
77 | **Array 数组对象,数组常用方法**
78 |
79 | - join() 将一个数组转成字符串。返回一个字符串
80 | - reverse() 将数组中各元素颠倒顺序
81 | - delete 运算符只能删除数组元素的值,而所占空间还在,总长度没变(arr.length)
82 | - shift()删除数组中第一个元素,返回删除的那个值,并将长度减 1
83 | - pop()删除数组中最后一个元素,返回删除的那个值,并将长度减 1
84 | - unshift() 往数组前面添加一个或多个数组元素,长度会改变
85 | - push() 往数组结尾添加一个或多个数组元素,长度会改变
86 | - () 连接数组
87 | - slice() 切割数组,返回数组的一部分
88 | - splice()插入、删除或替换数组的元素
89 | - toLocaleString() 把数组转换成局部字符串
90 | - toString()将数组转换成一个字符串
91 | - forEach()遍历所有元素
92 | - every()判断所有元素是否都符合条件
93 | - sort()对数组元素进行排序
94 | - map()对元素重新组装,生成新数组
95 | - filter()过滤符合条件的元素
96 | - find() 查找 返回满足提供的测试函数的第一个元素的值。否则返回 undefined。
97 | - some() 判断是否有一个满足条件 ,返回布尔值
98 | - fill() 填充数组
99 | - flat() 数组扁平化
100 |
101 | **Function 函数对象,函数常用方法**
102 |
103 | - Function.arguments 传递给函数的参数
104 | - Function.apply() 将函数作为一个对象的方法调用
105 | - Function.call() 将函数作为对象的方法调用
106 | - Function.caller 调用当前函数的函数
107 | - Function.length 已声明的参数的个数
108 | - Function.prototype 对象类的原型
109 | - Function.toString() 把函数转换成字符串
110 |
111 | **Object 基础对象,对象常用方法**
112 |
113 | - Object 含有所有 JavaScript 对象的特性的超类
114 | - Object.constructor 对象的构造函数
115 | - Object.hasOwnProperty( ) 检查属性是否被继承
116 | - Object.isPrototypeOf( ) 一个对象是否是另一个对象的原型
117 | - Object.propertyIsEnumerable( ) 是否可以通过 for/in 循环看到属性
118 | - Object.toLocaleString( ) 返回对象的本地字符串表示
119 | - Object.toString( ) 定义一个对象的字符串表示
120 | - Object.valueOf( ) 指定对象的原始值
121 |
122 | **Date 日期时间对象,日期常用方法**
123 |
124 | - Date.getFullYear() 返回 Date 对象的年份字段
125 | - Date.getMonth() 返回 Date 对象的月份字段
126 | - Date.getDate() 返回一个月中的某一天
127 | - Date.getDay() 返回一周中的某一天
128 | - Date.getHours() 返回 Date 对象的小时字段
129 | - Date.getMinutes() 返回 Date 对象的分钟字段
130 | - Date.getSeconds() 返回 Date 对象的秒字段
131 | - Date.getMilliseconds() 返回 Date 对象的毫秒字段
132 | - Date.getTime() 返回 Date 对象的毫秒表示
133 |
134 | **Math 数学对象,数学常用方法**
135 |
136 | - Math 对象是一个`静态对象`
137 | - Math.PI 圆周率
138 | - Math.abs() 绝对值
139 | - Math.ceil() 向上取整(整数加 1,小数去掉)
140 | - Math.floor() 向下取整(直接去掉小数)
141 | - Math.round() 四舍五入
142 | - Math.pow(x,y) 求 x 的 y 次方
143 | - Math.sqrt() 求平方根
144 |
145 | **RegExp 正则表达式对象,正则常用方法**
146 |
147 | - RegExp.exec() 检索字符串中指定的值。返回找到的值,并确定其位置。
148 | - RegExp.test( ) 检索字符串中指定的值。返回 true 或 false。
149 | - RegExp.toString( ) 把正则表达式转换成字符串
150 | - RegExp.global 判断是否设置了 "g" 修饰符
151 | - RegExp.ignoreCase 判断是否设置了 "i" 修饰符
152 | - RegExp.lastIndex 用于规定下次匹配的起始位置
153 | - RegExp.source 返回正则表达式的匹配模式
154 |
155 | **Error 异常对象**
156 |
157 | - Error.message 设置或返回一个错误信息(字符串)
158 | - Error.name 设置或返回一个错误名
159 | - Error.toString( ) 把 Error 对象转换成字符串
160 |
161 | ## 4.6 说一下hasOwnProperty、instanceof方法
162 |
163 | **hasOwnProperty()** 方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。
164 |
165 | **instanceof** **运算符**用于检测构造函数的 `prototype` 属性是否出现在某个实例对象的原型链上。
166 |
167 | ## 4.7 什么是原型对象,说说对它的理解
168 |
169 | **构造函数的内部的 prototype 属性指向的对象,就是构造函数的原型对象。**
170 |
171 | 原型对象包含了可以由该构造函数的所有实例共享的属性和方法。当使用构造函数新建一个实例对象后,在这个对象的内部将包含一个指针(***\*proto\****),这个指针指向构造函数的 原型对象,在 ES5 中这个指针被称为对象的原型。
172 |
173 | ## 4.8 什么是原型链
174 |
175 | **原型链是一种查找规则**
176 |
177 | 当访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,这种链式查找过程称之为原型链
178 |
179 | ## 4.9 原型链的终点是什么?
180 |
181 | 原型链的尽头是null。也就是`Object.prototype.__proto__`
182 |
183 | ## 4.10 Js实现继承的方法
184 |
185 | ### 1.原型链继承
186 |
187 | **关键:子类构造函数的原型为父类构造函数的实例对象**
188 |
189 | **缺点**:1、子类构造函数无法向父类构造函数传参。
190 |
191 | 2、所有的子类实例共享着一个原型对象,一旦原型对象的属性发生改变,所有子类的实例对象都会收影响
192 |
193 | 3、如果要给子类的原型上添加方法,必须放在Son.prototype = new Father()语句后面
194 |
195 | ```javascript
196 | function Father(name) {
197 | this.name = name
198 | }
199 | Father.prototype.showName = function () {
200 | console.log(this.name);
201 | }
202 | function Son(age) {
203 | this.age = 20
204 | }
205 | // 原型链继承,将子函数的原型绑定到父函数的实例上,子函数可以通过原型链查找到复函数的原型,实现继承
206 | Son.prototype = new Father()
207 | // 将Son原型的构造函数指回Son, 否则Son实例的constructor会指向Father
208 | Son.prototype.constructor = Son
209 | Son.prototype.showAge = function () {
210 | console.log(this.age);
211 | }
212 | let son = new Son(20, '刘逍') // 无法向父构造函数里传参
213 | // 子类构造函数的实例继承了父类构造函数原型的属性,所以可以访问到父类构造函数原型里的showName方法
214 | // 子类构造函数的实例继承了父类构造函数的属性,但是无法传参赋值,所以是this.name是undefined
215 | son.showName() // undefined
216 | son.showAge() // 20
217 | ```
218 |
219 | ### 2.借用构造函数继承
220 |
221 | **关键:用 .call() 和 .apply()方法,在子类构造函数中,调用父类构造函数**
222 |
223 | **缺点**:1、只继承了父类构造函数的属性,没有继承父类原型的属性。
224 |
225 | 2、无法实现函数复用,如果父类构造函数里面有一个方法,会导致每一个子类实例上面都有相同的方法。
226 |
227 | ```javascript
228 | function Father(name) {
229 | this.name = name
230 | }
231 | Father.prototype.showName = function () {
232 | console.log(this.name);
233 | }
234 | function Son(name, age) {
235 | Father.call(this, name) // 在Son中借用了Father函数,只继承了父类构造函数的属性,没有继承父类原型的属性。
236 | // 相当于 this.name = name
237 | this.age = age
238 | }
239 | let s = new Son('刘逍', 20) // 可以给父构造函数传参
240 | console.log(s.name); // '刘逍'
241 | console.log(s.showName); // undefined
242 | ```
243 |
244 | ### 3.组合继承
245 |
246 | **关键:原型链继承+借用构造函数继承**
247 |
248 | **缺点**:1、使用组合继承时,父类构造函数会被调用两次,子类实例对象与子类的原型上会有相同的方法与属性,浪费内存。
249 |
250 | ```javascript
251 | function Father(name) {
252 | this.name = name
253 | this.say = function () {
254 | console.log('hello,world');
255 | }
256 | }
257 | Father.prototype.showName = function () {
258 | console.log(this.name);
259 | }
260 | function Son(name, age) {
261 | Father.call(this, name) //借用构造函数继承
262 | this.age = age
263 | }
264 | // 原型链继承
265 | Son.prototype = new Father() // Son实例的原型上,会有同样的属性,父类构造函数相当于调用了两次
266 | // 将Son原型的构造函数指回Son, 否则Son实例的constructor会指向Father
267 | Son.prototype.constructor = Son
268 | Son.prototype.showAge = function () {
269 | console.log(this.age);
270 | }
271 | let p = new Son('刘逍', 20) // 可以向父构造函数里传参
272 | // 也继承了父函数原型上的方法
273 | console.log(p);
274 | p.showName() // '刘逍'
275 | p.showAge() // 20
276 | ```
277 |
278 | ### 4.原型式继承
279 |
280 | **关键:创建一个函数,将要继承的对象通过参数传递给这个函数,最终返回一个对象,它的隐式原型指向传入的对象。** (***Object.create()方法的底层就是原型式继承***)
281 |
282 | **缺点**:只能继承父类函数原型对象上的属性和方法,无法给父类构造函数传参
283 |
284 | ```javascript
285 | function createObj(obj) {
286 | function F() { } // 声明一个构造函数
287 | F.prototype = obj //将这个构造函数的原型指向传入的对象
288 | F.prototype.construct = F // construct属性指回子类构造函数
289 | return new F // 返回子类构造函数的实例
290 | }
291 | function Father() {
292 | this.name = '刘逍'
293 | }
294 | Father.prototype.showName = function () {
295 | console.log(this.name);
296 | }
297 | const son = createObj(Father.prototype)
298 | son.showName() // undefined 继承了原型上的方法,但是没有继承构造函数里的name属性
299 | ```
300 |
301 | ### 5.寄生式继承
302 |
303 | **关键:在原型式继承的函数里,给继承的对象上添加属性和方法,增强这个对象**
304 |
305 | **缺点**:只能继承父类函数原型对象上的属性和方法,无法给父类构造函数传参
306 |
307 | ```javascript
308 | function createObj(obj) {
309 | function F() { }
310 | F.prototype = obj
311 | F.prototype.construct = F
312 | F.prototype.age = 20 // 给F函数的原型添加属性和方法,增强对象
313 | F.prototype.showAge = function () {
314 | console.log(this.age);
315 | }
316 | return new F
317 | }
318 | function Father() {
319 | this.name = '刘逍'
320 | }
321 | Father.prototype.showName = function () {
322 | console.log(this.name);
323 | }
324 | const son = createObj(Father.prototype)
325 | son.showName() // undefined
326 | son.showAge() // 20
327 | ```
328 |
329 | ### 6.寄生组合继承
330 |
331 | **关键:原型式继承 + 构造函数继承**
332 |
333 | **Js最佳的继承方式,只调用了一次父类构造函数**
334 |
335 | ```javascript
336 | function Father(name) {
337 | this.name = name
338 | this.say = function () {
339 | console.log('hello,world');
340 | }
341 | }
342 | Father.prototype.showName = function () {
343 | console.log(this.name);
344 | }
345 | function Son(name, age) {
346 | Father.call(this, name)
347 | this.age = age
348 | }
349 | Son.prototype = Object.create(Father.prototype) // Object.create方法返回一个对象,它的隐式原型指向传入的对象。
350 | Son.prototype.constructor = Son
351 | const son = new Son('刘逍', 20)
352 | console.log(son.prototype.name); // 原型上已经没有name属性了,所以这里会报错
353 | ```
354 |
355 | ### 7.混入继承
356 |
357 | **关键:利用Object.assign的方法多个父类函数的原型拷贝给子类原型**
358 |
359 | ```javascript
360 | function Father(name) {
361 | this.name = name
362 | }
363 | Father.prototype.showName = function () {
364 | console.log(this.name);
365 | }
366 |
367 | function Mather(color) {
368 | this.color = color
369 | }
370 | Mather.prototype.showColor = function () {
371 | console.log(this.color);
372 | }
373 |
374 | function Son(name, color, age) {
375 | // 调用两个父类函数
376 | Father.call(this, name)
377 | Mather.call(this, color)
378 | this.age = age
379 | }
380 | Son.prototype = Object.create(Father.prototype)
381 | Object.assign(Son.prototype, Mather.prototype) // 将Mather父类函数的原型拷贝给子类函数
382 | const son = new Son('刘逍', 'red', 20)
383 | son.showColor() // red
384 | ```
385 |
386 | ### 8. class继承
387 |
388 | **关键:class里的extends和super关键字,继承效果与寄生组合继承一样**
389 |
390 | ```javascript
391 | class Father {
392 | constructor(name) {
393 | this.name = name
394 | }
395 | showName() {
396 | console.log(this.name);
397 | }
398 | }
399 | class Son extends Father { // 子类通过extends继承父类
400 | constructor(name, age) {
401 | super(name) // 调用父类里的constructor函数,等同于Father.call(this,name)
402 | this.age = age
403 | }
404 | showAge() {
405 | console.log(this.age);
406 | }
407 | }
408 | const son = new Son('刘逍', 20)
409 | son.showName() // '刘逍'
410 | son.showAge() // 20
411 | ```
412 | ## 结语
413 |
414 | > 今天的面试题的分享就到这边啦,明天继续给大家分享~
415 |
416 | ## 作者
417 |
418 | | Coder | 小红书ID | 创建时间 |
419 | | :---------- | :-------- | :--------- |
420 | | 落寞的前端👣 | 121450513 | 2022.10.14 |
421 |
--------------------------------------------------------------------------------
/js面试题七(JS基础).md:
--------------------------------------------------------------------------------
1 | ## 前端常见面试题(JS篇)七
2 |
3 | ## 七、 DOM
4 |
5 | ## 7.1说一下 DOM 事件流
6 |
7 | ⼜称为事件传播,是⻚⾯中接收事件的顺序。DOM2级事件规定的事件流包括了3个阶段:
8 |
9 | - 事件捕获阶段(capture phase)
10 | - 处于⽬标阶段(target phase)
11 | - 事件冒泡阶段(bubbling phase)
12 |
13 | 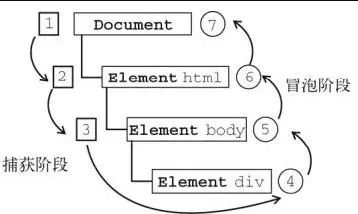
14 |
15 | 如上图所示,事件流的触发顺序是:
16 |
17 | 1. 事件捕获阶段,为截获事件提供了机会
18 | 2. 实际的⽬标元素接收到事件
19 | 3. 事件冒泡阶段,可在这个阶段对事件做出响应
20 |
21 | ## 7.2 什么是事件冒泡(Event Bubbling)
22 |
23 | 事件开始由最具体的元素(⽂档中嵌套层次最深的那个节点)接收到后,开始逐级向上传播到较为不具体的节点。
24 |
25 | ```xml
26 |
27 |
28 |
29 |
30 | Document
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 | ```
39 |
40 | 如果点击了上面页面代码中的 `