├── Article
├── art1.md
├── art2.md
└── img
│ ├── art2_1.png
│ └── art2_2.png
├── Hadoop
├── Hadoop.md
├── Hbase.md
├── Hive.md
├── conf
│ ├── core-site.xml
│ ├── hadoop-env.sh
│ ├── hbase-env.sh
│ ├── hbase-site.xml
│ ├── hdfs-site.xml
│ ├── hive-site.xml
│ ├── mapred-site.xml
│ ├── slaves
│ └── yarn-site.xml
└── img
│ ├── hadoop.gif
│ ├── hbase.gif
│ ├── hive.gif
│ └── hive2.gif
├── Persistence
├── Ignite.md
├── Ignite2.md
├── Mongodb.md
├── Redis.md
├── conf
│ ├── ignite-backup1.xml
│ ├── ignite-backup2.xml
│ └── ignite-persist.xml
└── img
│ ├── ignite-backup.gif
│ ├── ignite-backup2.gif
│ ├── ignite-backup3.gif
│ ├── ignite-cache.jpg
│ ├── ignite-join.gif
│ ├── ignite-persist.gif
│ ├── ignite-tables.jpg
│ ├── ignite-web1.jpg
│ ├── ignite-web2.jpg
│ ├── ignite-web3.jpg
│ ├── ignite1.gif
│ ├── ignite2.gif
│ └── ignite3.gif
├── PostgreSQL
├── GPDB.md
├── img
│ ├── GPDB.gif
│ ├── GPDB1.png
│ ├── pipelinedb1.gif
│ └── pipelinedb2.gif
└── pipelinedb.md
├── README.md
├── Search
└── Elasticsearch.md
├── Spark
├── SparkDataset.md
├── SparkIO.md
├── SparkRDD.md
├── SparkSQL.md
├── SparkStream.md
├── conf
│ ├── slaves
│ └── spark-env.sh
└── img
│ ├── spark.gif
│ ├── spark1.png
│ ├── spark2.gif
│ ├── spark3.gif
│ ├── spark4.gif
│ ├── spark5.gif
│ ├── spark6.gif
│ ├── spark7.gif
│ ├── spark8.gif
│ ├── sparksql1.gif
│ ├── sparksql2.gif
│ ├── sparkstream.gif
│ ├── sparkstream.png
│ └── sparkstream1.png
└── _config.yml
/Article/art1.md:
--------------------------------------------------------------------------------
1 | # 大数据分析的两大核心:存储构架和计算构架
2 | 在大数据领域的技术无非是在两个领域进行着探索和改进,一个是存储构架,另一个是计算构架。
3 | ## 存储
4 | 随着互联网的发展,数据量越来越大从GB到TB再到PB,对于数据的存储就出现了问题。**单机存储**的情况下,如果机器损坏则数据全部丢失,再者TB级别的数据单机磁盘容量吃紧。**主从式的分布式存储**在一定程度上解决了机器损坏导致数据丢失的问题,但是主从一致性非常麻烦,从节点全都copy主节点磁盘性能没有利用起来。`HDFS`是一种**分布式文件系统**,通过将文件变成块状均匀的分布到每台分布式节点上的方式充分利用了每台机器的磁盘,并且设置了备份策略对每一个文件块都备份3份(默认设置)。这样即使一台机器损坏,上面的所有文件块都丢失了,也能保证在其他两台机子上总能找到每个文件块的备份。`HDFS`是谷歌分布式文件系统的开源实现,具有非常好的特性,直到现在仍然是最受欢迎的开源分布式文件系统,在各大计算框架中都有对`HDFS`的支持。`HDFS`尤其适合存储TB甚至PB级别的数据量,集群规模可以成千上万。而且对于存储的机器没有要求,甚至是性能落后的机子也可以参与到存储中来,贡献自己的一份力量,`HDFS`会根据每台机子的状态进行存储和读取。在数据存储部分。
5 |
6 | 本系列除了介绍了`HDFS`后续还会介绍一些sql和nosql的框架,一般的场景是小型数据量例如GB级别的数据存储可以直接放到`Postgresql` `Mysql`这样的关系型数据库中,而TB级别数据则可以放到`GreenPlum` `Mongodb`这样的分布式数据库,如果是PB级别的数据就可以放到`HDFS`(当然TB GB也可以应对)。
7 |
8 | 这是因为如果数据量较少的时候传统关系型数据库提供了强大的查询功能,存储和查询响应都很快,如果在较小的数据量情况下用`HDFS`反而因为网络IO的开销太大读写速度远低于前者。而TB级别的数据如果也想支持关系型数据库的操作则可以放到`GreenPlum`(简称GPDB)上面,对于该数据库的操作就和操作postgresql一样,后续会介绍,他是MPP的一种实现,支持分布式事务。而对于TB级别的数据,`GreenPlum`则会有些吃力,因为事务过程中开销可能过大,所以一般这个级别都会转向`HDFS`。当然`HDFS`只是一个文件系统,本身和前面的数据库是有不同的,他可以存储任何格式的文件,这就导致查询数据的时候非常麻烦。给出的解决方案有很多,比如在文件存储的时候按照一定的结构进行存储(如逗号隔开每列),然后用`Hive`对文件进行"表化",用sql查询文件内容。再比如`HBase`基于键值对的存储数据在`HDFS`上,不过最终都没有实现关系型数据库的全部功能。
9 | ## 计算
10 | 大数据分析除了能把文件完好的存下来,还要提供分析的功能,这就是计算框架要实现的。在传统关系型数据sql查询本身就是一种计算框架(**查询本质就是计算**),比如选出最大的10个这种查询。我们也看到`Hive`在`HDFS`文件上实现了sql的部分常用功能,这对于只会sql的数据分析师来说更容易操作了。不可否认的是,sql是最好的数据统计查询工具了,所以有一种说法是`SQL on EveryThing`。到后面我们发现直接将关系型数据库性能加强,支持分布式也是一种大数据分析的解决方案,`Pipelinedb`和`GPDB`就是这样的产物。不过大数据分析除了分析这种结构化的数据还应该能够挖掘更灵活的数据类型,比如WordCount程序(数一篇文章的每个单词出现次数)就是一种灵活的数据类型(纯文本)上进行的灵活查询。这是sql不能实现的,这时候就需要写程序来实现,这里的程序就是要借助计算框架。
11 | Hadoop提供的计算框架叫`MapReduce`,我在前面都没有仔细讲这个计算框架,是因为大多数情况下MR的表现没有`Spark`好,所以直接就用更好的了。至于为啥有这种性能差异,会在下一篇浅谈中仔细讲述。Spark本身其实就是计算框架,有说法说Spark完全可以取代Hadoop,这是不准确的,因为HDFS也是Hadoop的重要组成,而Spark的大数据分析也可能是基于HDFS上的数据进行的分析。
12 | ## 小结
13 | 对于存储框架除了`HDFS`后面还会介绍基于`Postgresql`改进的数据库存储方式,以及`NoSQL`的存储方式,还有强大的分布式内存存储方式。而计算框架则会介绍数据库的sql方言,Spark以及一些快速查询框架、全文查询框架。
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/Article/art2.md:
--------------------------------------------------------------------------------
1 | # Spark计算为什么比Hadoop快
2 | 大家都说Spark要快,可是究竟怎么个快法。他们的计算模型具体是什么样子的呢?你可能从网上搜到了较为笼统的答案,Hadoop是基于磁盘的,Spark是基于内存的。所以后者要快,但是究竟是什么地方放到了内存里呢?是整个操作的数据吗?显然不太可能。让我们从`WordCount`的例子看下,Hadoop的MR计算模型和Spark的DAG计算模型。
3 | 我们设定这样一个场景,有一个文件被分成三份存到三台机器上了,刚好这个文件有30行每一行都是"A B"这个字符串,三台机子干好是平均分得十行字符串。都来运行WC程序,我们知道最后的结果肯定是A-30 B-30。来看下Hadoop和Spark执行过程吧。
4 | # WordCount in MapReduce
5 | 从[网上](http://blog.csdn.net/a60782885/article/details/71308256)拷贝了一份代码
6 | ```java
7 | public static class WordCountMap extends
8 | Mapper {
9 | private final IntWritable one = new IntWritable(1);
10 | private Text word = new Text();
11 |
12 | public void map(LongWritable key, Text value, Context context)
13 | throws IOException, InterruptedException {
14 | String line = value.toString();
15 | StringTokenizer token = new StringTokenizer(line);
16 | while (token.hasMoreTokens()) {
17 | word.set(token.nextToken());
18 | context.write(word, one);
19 | }
20 | }
21 | }
22 | ```
23 | ```java
24 | public static class WordCountReduce extends
25 | Reducer {
26 | public void reduce(Text key, Iterable values,
27 | Context context) throws IOException, InterruptedException {
28 | int sum = 0;
29 | for (IntWritable val : values) {
30 | sum += val.get();
31 | }
32 | context.write(key, new IntWritable(sum));
33 | }
34 | }
35 | ```
36 | 上面是map和reduce部分,我们来分析下具体的执行过程,Map过程是三台机器同时执行的每台机器最后得到A-1 B-1 A-1 B-1...(一共十个)这样的结果,因为大家统计并行计算,所以这里提高了速度,而这个中间结果在MR中是存储到磁盘上的。之后在Reduce中收集这些中间结果则需要将这些磁盘文件读出来进行网络传输,传到Reduce的机器上(下图2这一步),reduce的机器可能是任意一台PC也可指定,例如就是PC1,然后在PC1上将收集到的三份子结果进行reduce操作获得最后的结果。
37 | 
38 | 注意这里有两个重点,第一**中间结果是存到硬盘**的,这样在存储和后面读取的时候速度较慢;第二Reduce操作必须等三台机器的Map操作全部执行完成才能开始,如果PC3性能极差则要一直等他Map完,才能开始后续操作。
39 |
40 | 这个WC方法其实还可以稍作改进在Map后添加一个combiner过程每台机子先统计下自己的WC。即每台机器获得A-1 B-1 ...这个中间结果后,再对其处理获得A-10 B-10这个结果,这样又将部分计算压力分散到了Mapper,最后交给reduce计算的压力就少一些。这里就又多了一组中间结果,同样也是存到硬盘文件。
41 | # WordCount in Spark
42 | Spark采用的算法叫做`DAGScheduler`,有向无环图的操作流程。这里要注意MapReduce其实广义上是指,将任务分给Mapper执行,最后交给少数Reducer汇总的思想,Hadoop的MapReduce是一种实现方法。Spark的DAG其实也是一种MapReduce,只不过Hadoop比较不要脸的直接把自己的计算方法起名MapReduce了,后面都不好起名字了。其实所有的计算框架都是在实践广义的MR,只不过细节上出现了分歧。
43 | ```java
44 | sc.textFile("hdfs://192.168.4.106:9000/README.md")
45 |
46 | //一行一个元素--->一个单词一个元素
47 | .flatMap(new FlatMapFunction() {
48 | @Override
49 | public Iterator call(String o) throws Exception {
50 | return Arrays.asList(o.split(" ")).iterator();
51 | }
52 | })
53 |
54 | //一个单词一个元素--->[单词,1]为元素
55 | .mapToPair(new PairFunction() {
56 | @Override
57 | public Tuple2 call(String s) throwsException {
58 | return new Tuple2<>(new Text(s),new IntWritable(1));
59 | }
60 | })
61 |
62 | //对相同的单词 的个数进行聚合(相加)
63 | .reduceByKey(new Function2() {
64 | @Override
65 | public IntWritable call(IntWritable i, IntWritable i2)throws Exception {
66 | return new IntWritable(i.get()+i2.get());
67 | }
68 | })
69 |
70 | //结果保存到HDFS另一个文件下,以便日后使用
71 | .saveAsHadoopFile("hdfs://192.168.4.106:9000/res2",Text.class,
72 | IntWritable.class,SequenceFileOutputFormat.class);
73 | ```
74 | 上述程序其实是画了一个流程图(有向无环图)就是对数据集进行第一步flatmap操作,然后mapToPair操作,最后是reduceByKey操作就可以获得W-C了。而这个程序的作用是启动SparkContext然后向Master节点提交这个流程图。
75 | Master节点拿到流程图之后向Worker节点下发这个流程图,意思就是这个是家庭作业大家都按照这个作业要求在自己的家里去做吧。
76 | Worker节点收到流程图后开始做作业,如果是yarn模式,对在自己能访问到的文件块进行着相关操作,如果不是yarn则需要master分配每个Work应该统计的文件块,然后再开始执行流程图。
77 | 每个节点按照流程图执行完毕,如果有行动操作例如count函数,则需要每个节点都进行数个数最后加一个总和交给驱动程序。
78 | 这是从[网上](https://www.cnblogs.com/tgzhu/p/5818374.html)盗的一张图
79 | 
80 | 这里我们可以看出虽然也是每个节点并行执行一些操作最后做汇总的思路,但是细节上和Hadoop有很大的不同,每个节点都拿到了整个程序的流程图。都按照流程图去执行,在理解和编程模型上要比MR简单很多。而且重点是RDD的连续操作的中间结果是存到内存里的,例如上面的flatMap操作之后得到的结果是[A,B,A,B...],每个Worker有10个AB,这个中间结果就是存到每台机器的内存中的,在下一步mapToPair的时候就是直接操作这个内存变量。而且这种计算模型另一个优点是每台机器是独立展开的,例如worker1完成了flatMap操作直接就进行mapToPair操作,不需要等待其他worker,不过在混洗数据(shuffle)的时候还是要等待上一个阶段(stage)。所以spark最大的改进在于中间结果放到了内存。
81 | # 小结
82 | Hadoop的MR其实并非完败于Spark,比如在机器性能较差内存较低的情况或者中间结果占用内存不能承受的情况,将中间结果存放到硬盘中是不得已的选择,这时候Hadoop是适用的,不过Spark也可以选择将中间结果固化到硬盘[囧]。
83 | 从这里简单的执行过程介绍,我们大体上了解了两者的执行流程,也明白了Spark在内存中计算的说法来源。
84 |
--------------------------------------------------------------------------------
/Article/img/art2_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Article/img/art2_1.png
--------------------------------------------------------------------------------
/Article/img/art2_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Article/img/art2_2.png
--------------------------------------------------------------------------------
/Hadoop/Hadoop.md:
--------------------------------------------------------------------------------
1 | # Hadoop
2 | # 1.介绍
3 | Hadoop家族的族长,最初的1.x版本的Hadoop由两大部分组成:`HDFS`和`MapReduce`。
4 | ## 1.1 HDFS
5 | Hadoop分布式文件系统,就是将文件存储到多台计算机上面,例如一个1PB大的文件,一台机子存不过来,可以将其存到多台机子(如100台)上面。HDFS帮我们做的就是实际存储到了多台机子上,但是对外提供访问的时候是一个文件例如`hdfs://myserver:9000/myfile`。这得益于文件的分块功能,默认将每个文件按照128M分成一个文件块,例如1PB就有1024x1024x8个文件块,文件块均匀放到100台机子上面进行存储。
6 |
7 | 除了可以存储海量数据,HDFS还提供了备份策略,上述场景下如果存储文件的机器有一台坏掉了,则无法复原整个文件,所以备份策略是为了更高的可靠性,默认会将每个文件块在3台机器上进行存储。即上述的文件块中每一块都必须在三台机子上面进行分别存储。这样虽然占用了三倍的存储空间,但是换来了可靠性。
8 |
9 | 名词解释
10 | **NameNode**:hdfs访问的入口,从这里访问集群中的文件,也肩负着管理和调度文件块的作用,是hdfs系统的"管理员"。
11 | **SecondNameNode**:管理员万一遇到不幸,需要有个能接替者,相当于NameNode的冷备份。
12 | **DataNode**:存储数据的机子,管理员的下属,文件最终存储在这些节点上面。
13 | 三者可以分开,也可以是同一台机子兼职多个角色。一般学习过程中由于机器缺乏,往往将三者全都放到一台机子上面。
14 | ## 1.2 MapReduce
15 | 一种计算思想:一个人的力量再强也比不过一个军队。举个简单的例子数红楼梦中<林黛玉>三个字出现的次数,给一个来数,可能需要数很久,但是如果把这本书平均分给一个班的所有同学,第一个人数1-100页,第二个人101-200页,第三个人.......这样分配下去,很快每个人都数出了自己负责的部分的林黛玉数,汇报到一起运行一步加法运算,就完成了任务。
16 |
17 | 上面例子中每个人相当于进行Map运算,这个运算是并行的,而最后汇报到一起的加法相当于Reduce运算。不过值得一提的是Hadoop的MapReduce运算是基于文件系统的,即需要磁盘读取来进行操作。因而速度并不快,所以Hadoop的MapReduce用的越来越少了,一些基于内存操作的执行器如Spark,体现出了更高的性能。
18 | ## 1.3 Yarn
19 | 一个平台,为了海乃百川。正如上面所说Spark等更高性能的执行器逐渐取代着MapReduce部分,但是HDFS却没有过时,其他分析和执行的框架想要建立在HDFS这样的分布式文件系统上面。于是有了Yarn,Yarn是一个平台,他允许其他框架如Spark、Storm等在Yarn调度下运行在HDFS上面。
20 | 名词解释
21 | **ResourceManager**:Yarn调度中的管理员
22 | **NodeManager**:Yarn中的节点,管理员下属
23 | # 2.搭建[2.8.0]
24 | ## 2.1 配置SSH密钥
25 | 在集群中需要能互相免密钥访问,因而需要配置SSH密钥。就算是伪集群也最好配置下,总之是有益无害的配置。
26 | ```
27 | ssh-keygen -trsa -P ''
28 | ```
29 | 生成的密钥在用户目录的`.ssh`文件夹下,`id_rsa.pub`文件中的内容就是公钥,需要追加到同级目录下的`authorized_keys`文件中,如果是多台机子集群则需要将每台机子产生的pub文件写到一个`authorized_keys`中,然后将这个文件复制到每台机子上面。集群模式最好每台机子都有个域名,放到hosts文件中,方便后续配置。
30 |
31 | 验证免密钥配置成功,直接ssh server1,如果不用输账密直接连上这说明配置成功。
32 |
33 |
34 | ## 2.2 搭建HDFS
35 | HDFS和Yarn是分开的,他们可以独立运行,没有互相依赖。例如如果不常使用Yarn,则可以只搭建HDFS。
36 |
37 | 1 到官网下载Hadoop安装包,并解压
38 | 2 修改配置文件在安装包下的`etc/hadoop`目录下,主要修改四个配置文件:
39 | [hadoop-env.sh](conf/hadoop-env.sh)
40 | [core-site.xml](conf/core-site.xml)
41 | [hdfs-site.xml](conf/hdfs-site.xml)
42 | [slaves](conf/slaves)指定哪些节点作为DataNode
43 | 3 初始化NameNode
44 | ```
45 | hadoop namenode -format
46 | ```
47 | 4 开启HDFS
48 | ```
49 | sbin/start-dfs.sh
50 | ```
51 | 5 验证是否启动
52 | 通过JPS查看是否有NameNode DataNode和SecondNameNode。
53 | ## 2.3 搭建Yarn
54 | 如果你不确定需要Yarn,就先不用搭建Yarn等用到的时候再来搭建也不迟。
55 | 1.修改配置文件同样在`etc/hadoop`路径下,主要修改俩文件:
56 | [mapred-site.xml](conf/mapred-site.xml)只有ResourceManager节点才能有这个文件
57 | [yarn-site.xml](conf/yarn-site.xml)
58 | 2.启动yarn
59 | ```
60 | sbin/start-yarn.sh
61 | ```
62 | 3.验证启动
63 | jps中有ResourceManager和NodeManager
64 | # 3 操作HDFS
65 | 既然是文件系统,那一定可以像文件一样的操作,HDFS和windows下的NTFS都是文件系统,我们的磁盘中文件可以读写,同样HDFS也应该能进行读写操作。hadoop提供了操作文件的shell和Java API,我们这里只介绍前者。我们先将Hadoop目录的bin和sbin目录加到环境变量PATH中。
66 |
67 | 列出hdfs根目录下的文件:
68 | ```
69 | hadoop fs -ls /
70 | ```
71 | 创建目录和复制本地文件到hdfs
72 | ```
73 | hadoop fs -mkdir /test
74 | hadoop fs -put /root/1.txt /test
75 | ```
76 | 读取hdfs中的文件内容
77 | ```
78 | hadoop fs -cat /test/1.txt
79 | ```
80 | 
81 | # 4 小结
82 | Hadoop的HDFS是非常重要的分布式文件系统,在大数据分析领域很多实现都是基于HDFS的,所以是必须掌握和会使用的内容。MapReduce的思想也必须要理解,在后续可能使用的较少。Yarn则是在HadoopMapReduce程序的时候或者用到其他框架的时候需要使用的平台。本文中没有用MapReduce进行编程,主要是考虑到MapReduce程序较为难懂,且效率不高,在后来的工具和框架中完全可以替代。
83 | 文章篇幅有限,希望能帮助理解,想要更深入的理解HDFS的工作原理和MapReduce的原理还需要查询其他资料。
84 |
--------------------------------------------------------------------------------
/Hadoop/Hbase.md:
--------------------------------------------------------------------------------
1 | # Hbase
2 | # 1 简介
3 | Hadoop DataBase的简称,不是有了Hive了吗,为什么又有Hbase呢?两者都是基于HadoopHDFS存储的能进行查询的数据仓库。
4 | 不过Hive针对的是结构化的已经存在的文件导入表中,对这个文件进行查询。其数据本身还是文件本身,而查询语句则是按照表结构封装成MapReduce程序去执行,响应没有那么即时。
5 | Hbase则是一种非关系型数据库,不能将现成的文件转化,而是必须通过自己的API插入数据。数据格式是键值对的方式,不支持复杂条件查询如where语句(和`Redis`很像),设置过滤器可进行有限的条件查询。可以认为是海量键值对数据的存储,键值对的查找速度会很快(通过键找值),因而支持即时响应的查询。
6 | ##1.1 存储特点
7 | 传统数据库一个表有很多行,也有很多列。而Hbase则将多个列的基础上加了一个列族(cf)并对每一行自动添加行键(row-key)和时间戳。参考[这里](https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-bigdata-hbase/index.html)。
8 |
9 |
10 | # 2 搭建[1.2.6]
11 | Hbase依赖于HDFS,请先完成[HDFS搭建](Hadoop.md#2.2 搭建HDFS)
12 | 这里我们搭建`单机运行`的Hbase,注意Hbase存储虽然在hdfs但是Hbase的服务器是和HDFS独立的,我们接入Hbase服务器可以查询其存在HDFS上的数据,这里并不矛盾,也就是说Hbase是单机的,HDFS是集群的这样的情况也是可以的。
13 | 1 官网下载安装包,解压配置环境变量
14 | 2 修改配置文件
15 | [hbase-env.sh](conf/hbase-env.sh)
16 | [hbase-site.xml](conf/hbase-site.xml)
17 | 3 启动hbase
18 | ```
19 | start-hbase.sh
20 | ```
21 | 4 客户端连接
22 | ```
23 | hbase shell
24 | ```
25 |
26 | 注:单机版的ZooKeeper是内置的,不用自己安装ZooKeeper。
27 | # 3 使用Hbase
28 | 和前面一样Hbase提供了shell客户端和JavaAPI这里我们只讲前者。
29 | 常用的指令如创建表和增删改查:
30 | ```
31 | //test是表名 info和pwd都是列族
32 | //创建
33 | create 'test','info','pwd'
34 | //test是表 1是行键 pwd是列族 p是列族中一列 123是值 相当于1|pwd|p三个部分组成的键指向一个值
35 | //增(已存在就是改)
36 | put 'test','1','pwd:p','123'
37 | //删
38 | delete 'test','1','pwd:p'
39 | //查 可以查整个表 也可以查表中一行 也可以是一列族 或一列下面4个参数可以有1-4个
40 | get 'test'[,'1','pwd:p']
41 | ```
42 | FILTER过滤器的使用
43 | 参考[这里](http://blog.csdn.net/qq_27078095/article/details/56482010),如下是一个Row-Key过滤器过滤含有1的行数据。过滤器有行过滤、值过滤、列族过滤,这也就要求我们在命名的时候有一定的讲究才方便以后查询。
44 |
45 | ```
46 | scan 'test', FILTER=>"RowFilter(=,'substring:1')"
47 | ```
48 | 
49 | # 4 小结
50 | Hbase是非关系型数据库,用于存储海量数据,因为键值对策略能达到即时查询的效果。
51 |
52 |
--------------------------------------------------------------------------------
/Hadoop/Hive.md:
--------------------------------------------------------------------------------
1 | # Hive
2 | # 1 简介
3 | Hive是Hadoop家族的一员,它能在HDFS存储的结构化或者半结构化的文件上运行类似sql的查询。通俗讲就是能将普通文件抽象成表,例如有个1.txt文件内容如下。三列分别是id name和age。
4 | ```
5 | 1 张三 22
6 | 2 李四 33
7 | 3 王五 12
8 | ```
9 | 通过Hive就可以将这个文件看成一张表,只要设置列之间是'\t'隔开。就可以运行sql查询,如
10 | ```
11 | select count(*) from tablename where age>20;
12 | ```
13 | 反过来想,我们将这些数据直接存到`MySQL`不是更好吗,为什么要存到Hadoop然后用Hive查询呢?
14 | 原因主要有:
15 | - 1 海量数据MySQL无法应对,而HDFS可以
16 | - 2 MySQL只能存储结构化数据,Hive可以将半结构化的文件约束成表
17 | - 3 MySQL在大量数据的查询的时候是一台机子孤军奋战,Hive是将sql转化为MapReduce程序运行
18 | 当然Hive也有很多缺点:
19 | - 1 将sql转化为MapReduce程序,MapReduce前面提到过逐渐被Spark等代替,以任务的形式提交程序不是实时返回结果的查询。
20 | - 2 写的sql其实是Hivesql,只能实现一部分sql,很多功能不支持,例如表关联,事务等等
21 | - 3 完全的关系型、结构化存储有更好的方案`GreenPlum`(后续文章会介绍)
22 | # 2 搭建[2.3.0]
23 | Hive依赖于HDFS,请先完成[HDFS搭建](Hadoop.md)
24 | 1 下载安装包并解压,配置环境变量`HIVE_HOME`为解压后的目录,并添加bin目录到PATH中
25 | 2 安装mysql用于存储hive的元数据,同时需要将mysql的jdbc的jar放入hive的lib目录下。
26 | 3 修改$HIVE_HOME/conf/[hive-site.xml](conf/hive-site.xml)
27 | 在$HIVE_HOME/conf/hive-env.sh中也添加一行
28 | ```
29 | export HADOOP_HOME=xxxxxxxxx
30 | ```
31 | 4 初始化元数据
32 | ```shell
33 | nohup hive --service metastore &
34 |
35 | schematool -dbType mysql -initSchema
36 | ```
37 | 5 启动hiveserver2
38 | ```shell
39 | nohup hive --service hiveserver2 &
40 | ```
41 | 6 客户端查询工具
42 | ```
43 | beeline
44 | ```
45 | 1.x版本的hive指令在2.x中也进行了保留,但已经不推荐使用:
46 | ```
47 | hive
48 | ```
49 | # 3 使用hive查询
50 | 查询方式同样有自己提供的CLI和JavaAPI的方式,这里我们同样只讲前者。
51 | 使用create table指令可以创建表row format可以界定列之间的隔开。
52 | ```
53 | CREATE TABLE test(id int,name string,age int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
54 | ```
55 | 利用load指令可以将本地或者hdfs中的文件转化成hive中的表。
56 | ```
57 | load data local inpath '/root/2.txt' into table test;
58 | ```
59 | 不加local参数则是hdfs文件导入表中,如果文件中某一行和表格不一致,则尽量匹配,实在匹配不到的字段就是NULL
60 | 
61 |
62 | Hive运行order by或group by的时候会转化成MapReduce程序去执行,这里会有警告Hive-On-MR将会被弃用,请选择Spark等执行器。
63 | 
64 |
--------------------------------------------------------------------------------
/Hadoop/conf/core-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 | fs.defaultFS
8 | hdfs://wy:9000
9 |
10 |
11 | hadoop.tmp.dir
12 | /opt/hadoop
13 |
14 |
15 |
16 |
17 | hadoop.proxyuser.root.hosts
18 | *
19 |
20 |
21 | hadoop.proxyuser.root.groups
22 | *
23 |
24 |
25 |
--------------------------------------------------------------------------------
/Hadoop/conf/hadoop-env.sh:
--------------------------------------------------------------------------------
1 | # 需要修改的只有下面这一行
2 | export JAVA_HOME=/usr/java/default
3 |
4 |
5 | # 后面的全都不需要改动
6 | export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
7 | # The jsvc implementation to use. Jsvc is required to run secure datanodes
8 | # that bind to privileged ports to provide authentication of data transfer
9 | # protocol. Jsvc is not required if SASL is configured for authentication of
10 | # data transfer protocol using non-privileged ports.
11 | #export JSVC_HOME=${JSVC_HOME}
12 |
13 | export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
14 |
15 | # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
16 | for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
17 | if [ "$HADOOP_CLASSPATH" ]; then
18 | export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
19 | else
20 | export HADOOP_CLASSPATH=$f
21 | fi
22 | done
23 |
24 | # The maximum amount of heap to use, in MB. Default is 1000.
25 | #export HADOOP_HEAPSIZE=
26 | #export HADOOP_NAMENODE_INIT_HEAPSIZE=""
27 |
28 | # Enable extra debugging of Hadoop's JAAS binding, used to set up
29 | # Kerberos security.
30 | # export HADOOP_JAAS_DEBUG=true
31 |
32 | # Extra Java runtime options. Empty by default.
33 | # For Kerberos debugging, an extended option set logs more invormation
34 | # export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true -Dsun.security.krb5.debug=true -Dsun.security.spnego.debug"
35 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
36 |
37 | # Command specific options appended to HADOOP_OPTS when specified
38 | export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
39 | export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
40 |
41 | export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
42 |
43 | export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
44 | export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
45 |
46 | # The following applies to multiple commands (fs, dfs, fsck, distcp etc)
47 | export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS"
48 | # set heap args when HADOOP_HEAPSIZE is empty
49 | if [ "$HADOOP_HEAPSIZE" = "" ]; then
50 | export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
51 | fi
52 | #HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
53 |
54 | # On secure datanodes, user to run the datanode as after dropping privileges.
55 | # This **MUST** be uncommented to enable secure HDFS if using privileged ports
56 | # to provide authentication of data transfer protocol. This **MUST NOT** be
57 | # defined if SASL is configured for authentication of data transfer protocol
58 | # using non-privileged ports.
59 | export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
60 |
61 | # Where log files are stored. $HADOOP_HOME/logs by default.
62 | #export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
63 |
64 | # Where log files are stored in the secure data environment.
65 | #export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
66 |
67 | ###
68 | # HDFS Mover specific parameters
69 | ###
70 | # Specify the JVM options to be used when starting the HDFS Mover.
71 | # These options will be appended to the options specified as HADOOP_OPTS
72 | # and therefore may override any similar flags set in HADOOP_OPTS
73 | #
74 | # export HADOOP_MOVER_OPTS=""
75 |
76 | ###
77 | # Advanced Users Only!
78 | ###
79 |
80 | # The directory where pid files are stored. /tmp by default.
81 | # NOTE: this should be set to a directory that can only be written to by
82 | # the user that will run the hadoop daemons. Otherwise there is the
83 | # potential for a symlink attack.
84 | export HADOOP_PID_DIR=${HADOOP_PID_DIR}
85 | export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
86 |
87 | # A string representing this instance of hadoop. $USER by default.
88 | export HADOOP_IDENT_STRING=$USER
89 |
--------------------------------------------------------------------------------
/Hadoop/conf/hbase-env.sh:
--------------------------------------------------------------------------------
1 | export JAVA_HOME=/opt/ins/jdk1.8.0_131
2 |
3 | export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
4 |
5 | export HBASE_MANAGES_ZK=true
6 |
7 |
--------------------------------------------------------------------------------
/Hadoop/conf/hbase-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | hbase.cluster.distributed
7 | true
8 |
9 |
10 | hbase.rootdir
11 | hdfs://wy:9000/hbase
12 |
13 |
14 | hbase.zookeeper.property.clientPort
15 | 2181
16 |
17 |
18 | hbase.zookeeper.property.dataDir
19 | /home/frank/zookeeper
20 |
21 |
22 |
--------------------------------------------------------------------------------
/Hadoop/conf/hdfs-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 | dfs.namenode.secondary.http-address
8 | wy:50090
9 |
10 |
11 |
--------------------------------------------------------------------------------
/Hadoop/conf/mapred-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | mapreduce.framework.name
7 | yarn
8 |
9 |
10 |
--------------------------------------------------------------------------------
/Hadoop/conf/slaves:
--------------------------------------------------------------------------------
1 | wy
2 |
3 |
--------------------------------------------------------------------------------
/Hadoop/conf/yarn-site.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | yarn.nodemanager.aux-services
7 | mapreduce_shuffle
8 |
9 |
10 | yarn.resourcemanager.address
11 | wy:8032
12 |
13 |
14 | yarn.resourcemanager.scheduler.address
15 | wy:8030
16 |
17 |
18 | yarn.resourcemanager.resource-tracker.address
19 | wy:8031
20 |
21 |
22 |
--------------------------------------------------------------------------------
/Hadoop/img/hadoop.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Hadoop/img/hadoop.gif
--------------------------------------------------------------------------------
/Hadoop/img/hbase.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Hadoop/img/hbase.gif
--------------------------------------------------------------------------------
/Hadoop/img/hive.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Hadoop/img/hive.gif
--------------------------------------------------------------------------------
/Hadoop/img/hive2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Hadoop/img/hive2.gif
--------------------------------------------------------------------------------
/Persistence/Ignite.md:
--------------------------------------------------------------------------------
1 | # Ignite
2 | # 一、介绍
3 | `Apache Ignite`是一种存储构架,他实现了非常多的功能。比如他有这样几个标签:内存数据库、键值对数据库、分布式数据库、完整的SQL支持等。可以说Ignite关注了关系型数据库和非关系型数据库数据库的优缺点,将其进行了融合。功能虽然很多,但是在使用的过程中,我们只需要关注怎么使用能满足我们的需求就可以了。Ignite的文档内容非常丰富,而且有[中文版](https://www.zybuluo.com/liyuj/note/230739),如果想要深入研究Ignite的话,官方文档是最好的途径了。下面的内容我将官方文档内容和例子进行简化,可以带你粗略了解Ignite,我使用的是java版本。
4 | # 二、启动
5 | 这里没有安装,下载压缩包后,只要有jdk就能就地启动,甚至不用改配置文件,可以说是零部署。如果想要本地启动集群则多次启动即可,这里启动的默认配置文件在`config/default-config.xml`里,就是一个Bean然后没有配置参数(即默认参数)。
6 | 
7 | 因为默认参数就在本机找集群的其他节点,所以直接多次启动就能启动集群,实际情况下可能是多台机器、多个ip的集群,此时需要修改配置文件,在Bean中添加如下属性
8 | ```xml
9 |
10 |
11 |
12 |
13 |
18 |
19 |
20 |
21 |
22 |
23 |
24 | 127.0.0.1:47500..47509
25 | 192.168.1.4:47500..47509
26 |
27 |
28 |
29 |
30 |
31 |
32 | ```
33 | 上面的方式是最常用的基于组播的集群,会向固定的一组ip进行组播。组播的方式具有传染性,即A机器中写了向B组播,B写了向C组播,则三者全都加入集群。另一种常用的集群组织方式是ZooKeeper
34 | ```xml
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 | ```
45 | 不管用什么方式我们可以快速的启动ignite服务并能构建集群。
46 | # 三、SQL
47 | 因为Ignite功能太多,我们从基本的功能挨个来看。首先Ignite支持完整的sql,也就是说他有MySQL的几乎全部功能。
48 | ## 通过`sqlline`连接
49 | 在刚才的bin目录下有个sqlline.bat/sqlline.sh可以直接连接Ignite数据库服务
50 | ```
51 | ./sqlline.bat
52 | > !connect jdbc:ignite:thin://localhost
53 | > !tables
54 | > create table user(id int,name varchar(50),PRIMARY KEY (id));
55 | > insert into user(id,name) values (1,"liming");
56 | > select * from user;
57 | > update user set name='lili' where id=1;
58 | ```
59 | 
60 | 注意ignite支持几乎全部的sql语法,但不支持自增设置。可以[参考支持的sql文档](https://www.zybuluo.com/liyuj/note/990557)。
61 | ## 通过`JDBC`连接
62 | 客户端程序,需要引入`ignite-core-{version}.jar`或者maven方式,version当前最新的是2.3.0
63 | ```xml
64 |
65 | org.apache.ignite
66 | ignite-core
67 | ${ignite.version}
68 |
69 | ```
70 | 基本的的用法如下
71 | ```java
72 | public class IgniteSQL {
73 | public static void main(String[] args) throws Exception {
74 | // Register JDBC driver.
75 | Class.forName("org.apache.ignite.IgniteJdbcThinDriver");
76 | // Open JDBC connection.
77 | Connection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");
78 | // Create database tables.
79 | try (Statement stmt = conn.createStatement()) {
80 | // Create table based on REPLICATED template.
81 | stmt.executeUpdate("CREATE TABLE City (id int PRIMARY KEY, name VARCHAR)");
82 |
83 | // Create an index on the City table.
84 | stmt.executeUpdate("CREATE INDEX idx_city_name ON City (name)");
85 | }
86 | // Insert
87 | try (PreparedStatement stmt =
88 | conn.prepareStatement("INSERT INTO City (id, name) VALUES (?, ?)")) {
89 | stmt.setLong(1, 1L);
90 | stmt.setString(2, "Beijing");
91 | stmt.executeUpdate();
92 | }
93 | // Select
94 | try (Statement stmt = conn.createStatement()) {
95 | try (ResultSet rs =
96 | stmt.executeQuery("SELECT * FROM City ")) {
97 | while (rs.next())
98 | System.out.println(rs.getString(1) + ", " + rs.getString(2));
99 | }
100 | }
101 | }
102 | }
103 | ```
104 | ignite使用了H2数据库作为存储结构,在集群中查询的时候有着类似GreenPlum的查询原理
105 | # 四、分布式和内存化
106 | 我们在上面部分创建了表,插入了数据。可是数据是存到哪里了呢?Ignite默认会将数据存到内存中,即默认就是一个分布式纯内存数据库。如果节点宕机后,存在上面的数据全部丢失,重新启动,数据还是全部丢失(因为只存到了内存)。这是默认的策略我们后面介绍怎么修改这些策略。
107 | ## 修改缓存模式
108 | Ignite提供[三种缓存模式](https://www.zybuluo.com/liyuj/note/964191#33%E7%BC%93%E5%AD%98%E6%A8%A1%E5%BC%8F)分区、复制和本地(PARTITIONED,REPLICATED,LOCAL)。分区策略是默认策略。
109 | 分区就是每个节点存部分数据,并且保证每个数据块有另一个热备份节点也存储了(类似HDFS)
110 | 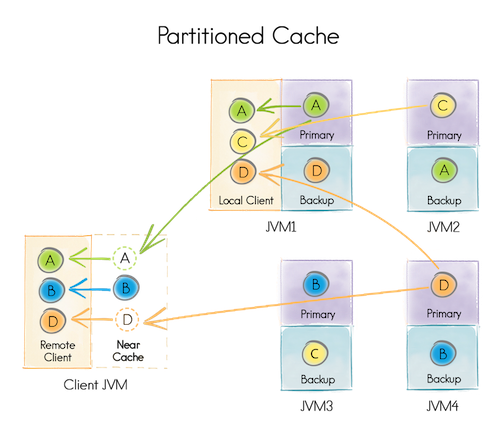
111 | 复制就是每个节点都存储所有数据
112 | 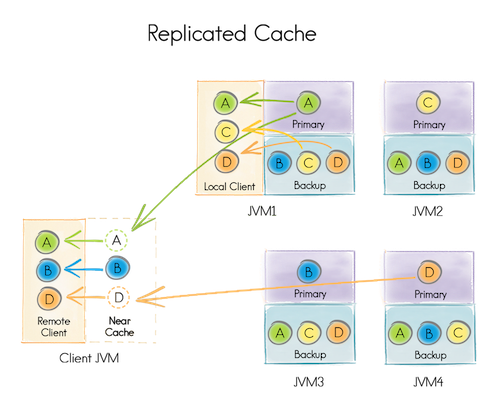
113 | 本地模式就是只在当前节点存储数据的方式(官网没给图,这里就不贴了)。
114 | 在创建表的时候可以单独制定分布式模式和备份数目:
115 | ```sql
116 | create table zz(id int,n varchar, primary key(id)) with "TEMPLATE=PARTITIONED,BACKUPS=1,CACHE_NAME=zzCache";
117 | ```
118 | 除了这几个参数还可以定义同步/异步备份策略,key和value的类名等,可以参考[ignite sql文档](https://apacheignite-sql.readme.io/docs/create-table)。
119 |
120 | 我们发现在创建表的时候还可以指定键值的类型,这其实是因为Ignite的sql存储和键值对存储其实是一个东西,到后面我们就会发现sql存储只不过是可以通过sqlline命令行或者jdbc的方式可以操作这个`存储结构`。而键值对存储则是这种存储结构本质上其实是键-值的方式,键是主键,值是整个数据条目,ps:创建没有主键的表会失败也是这个原因了。
121 |
122 | 除了创建表的时候直接指定也可以通过修改配置文件中bean的属性修改模式,但是这种配置文件的方式实际上是这个cacheName没有的话会创建的。
123 | ```xml
124 |
125 | ...
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 | ```
138 | 上面配置为使用分区策略,并配置了有一个节点作为备份,这样的策略可以使得任意节点挂掉后数据不丢失。展示部分在下一届键值对存储中一并介绍。
139 | 下面这个例子可以看出,默认设置情况下,两个服务端存储数据。
140 |
141 | 当一个服务器关闭后,会损失部分数据,这代表数据默认是分布式(分区)存储的,每台机器存储部分数据。
142 |
143 | 当运行联合查询的时候,发现结果出现了错误丢失了一些数据,这说明Ignite的查询方式是每台服务器并行运行同一句sql,最后将结果汇总,而分区模式下,联合查询必然会出现错误,这警告我们有join查询的时候,至少将其中一组设为复制模式。
144 | 
145 | 一个有意思的现象是,如果有两个节点,配置了backup=1,直接进行联合查询,结果是有遗失的,而宕机一个节点后,结果反而正确。即数据块只能从主数据节点获取,主数据节点挂掉后,备用节点变成主数据节点。
146 |
147 | ## 修改磁盘持久化
148 | 发现全部节点停掉后,因为存到内存的缘故,导致数据全部丢失,
149 | >Ignite的原生持久化会在磁盘上存储一个数据的超集,以及根据容量在内存中存储一个子集。比如,如果有100个条目,然后内存只能存储20条,那么磁盘上会存储所有的100条,然后为了提高性能在内存中缓存20条。 另外值得一提的是,和纯内存的使用场景一样,当打开持久化时,每个独立的节点只会持久化数据的一个子集,不管是主还是备节点,都是只包括节点所属的分区的数据,总的来说,整个集群包括了完整的数据集。
150 |
151 | 要开启Ignite的原生持久化,需要给集群的配置传递一个PersistentStoreConfiguration的实例:
152 | ```xml
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 | ```
167 | 注意在集群开启了持久化之后,默认不能进行增删改查操作了。需要手动激活,有多种方式可以激活,比如直接在客户端中激活,用web页面激活,用指令激活等这里我们用指令激活。还是bin目录下
168 | ```
169 | ./control.bat --activate
170 | ```
171 | 开启磁盘持久化之后会在work目录下产生数据的文件化存储。
172 | 持久化可以防止数据的丢失,例如两个server的集群在表中插入5个数据,关闭一个server后,数据会减少,然后再次开启,数据从磁盘中restore恢复到内存重新变成5条。如下图,该场景下[配置文件](conf/ignite-persist.xml)
173 | 
174 | # 5 小结
175 | 到这里,我们已经了解了ignite的部分功能。
176 | - 1 Ignite是个sql数据库,支持大部分的sql语法,但是要记得在分区模式的时候小心使用join等连接查询。
177 |
178 | - 2 Ignite是个内存数据库,在分区模式下我们看到停掉部分机器后数据丢失,且开启后不能回复。
179 |
180 | - 3 硬盘存储的设置,通过配置文件可以设置硬盘存储数据,这样在机器重启后就能回复全部的数据。
181 |
182 | - 4 分区模式下backup节点的设置,通过配置文件可以设置每个数据块有备份节点,类似HDFS,但是我们发现PUBLIC的schem下失败了,但后面会介绍在键值对存储下才能正常工作。
183 |
184 | [让我们在下一篇继续](Ignite2.md)
185 | --
186 |
187 |
188 |
--------------------------------------------------------------------------------
/Persistence/Ignite2.md:
--------------------------------------------------------------------------------
1 | # 6 键值对存储
2 | Ignite实现了Jcache标准,可以对序列化的对象进行存储。通俗讲就是可以直接存储对象了,比如我们在java中有个user集合,就可以将他存到Ignite中。你只需要引入依赖,然后就可以写程序了。
3 | ```xml
4 |
5 | org.apache.ignite
6 | ignite-core
7 | ${ignite.version}
8 |
9 |
10 | org.apache.ignite
11 | ignite-spring
12 | ${ignite.version}
13 |
14 |
15 | org.apache.ignite
16 | ignite-indexing
17 | ${ignite.version}
18 |
19 | ```
20 | ```java
21 | Ignite ignite= Ignition.start("config/default-config.xml");
22 | Ignition.setClientMode(true);
23 |
24 | CacheConfiguration cfg1 = new CacheConfiguration();
25 | cfg1.setName("personCache");
26 | //cfg1.setBackups(1);
27 |
28 | //这里约定是IndexedType接成对的参数,每对参数为K.class,V.class
29 | cfg1.setIndexedTypes(Integer.class, Person.class);
30 |
31 | IgniteCache cache1 = ignite.getOrCreateCache(cfg1);
32 |
33 | cache1.put(1,new Person(1,"lili",20,202));
34 | cache1.put(2,new Person(2,"liwei",30,101));
35 | cache1.put(3,new Person(3,"likui",40,303));
36 | cache1.put(4,new Person(4,"zs",50,202));
37 | cache1.put(5,new Person(5,"yii",60,404));
38 | cache1.put(6,new Person(6,"awang",70,202));
39 |
40 | //简单查询
41 | String sql = "select p.id,p.name,p.age from \"personCache\".Person as p where p.age > ?";
42 | QueryCursor cursor = cache1.query(new SqlFieldsQuery(sql).setArgs(12));
43 | System.out.println(cursor.getAll());
44 | ```
45 | ```java
46 | public class Person implements Serializable {
47 | @QuerySqlField(index = true)
48 | Integer id;
49 | @QuerySqlField(index = true)
50 | String name;
51 | @QuerySqlField
52 | Integer age;
53 | @QuerySqlField(index=true)
54 | Integer schoolId;
55 | }
56 | ```
57 | 从这个例子中我们发现了可以将java的类进行cache存储,通过简单的put get就可以存和查,我们发现这和HashMap的用法类似,只是需要对类实现序列化接口,并对字段添加查询的注解,不同于HashMap这些数据是存到Ignite中了。
58 | 
59 | ## backup
60 | 我们可以在java代码中设置(提倡这种方式,比较灵活,可以无侵入接入已有集群)
61 | ```java
62 | cfg1.setBackups(1);
63 | ```
64 | 或者修改配置文件(注意修改cacheName,配置文件启动后如果没有这个cacheName则会创建,有的话则会修改属性)
65 | ```xml
66 |
67 | ...
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 | ```
80 | 
81 | 设置backup=1,也就意味着,任意一个节点宕机后,一定有个备份节点可以顶替上来。于是我们看到上图中宕机一个节点后,再次查询仍然能够查到数据。(注意:这次查询的时候出现了几秒钟的阻塞)
82 | # 7 WebConsole
83 | [web监视器教程](https://youtu.be/V-o3IFVnk5k),有了他你可以监控集群各个节点的健康状态,查看各个cache的配置信息,查看cache中数据分别在哪些机子上存储了,强制GC,还可以在web界面下进行sql查询。
84 | 你要做的只是登录[https://console.gridgain.com](https://console.gridgain.com)页面,然后按照提示下载web-agent。
85 |
86 | 然后到集群中找任意一个节点将`libs\optional\ignite-rest-http`文件夹放到`libs`即向上移动了一层,然后重启这一个节点。
87 |
88 | 最后启动下载的agent下的{sh/bat}文件就可以。
89 |
90 | 下面是一些界面功能的展示:
91 | 
92 | 
93 | 
94 | 该网页的工作原理是和本地的rest服务做实时交互并图形化显示,本地rest服务则是在上述文件拷贝重启后就在8080端口启动了,ignite有着丰富的rest接口,可以参考这个[文档](https://www.zybuluo.com/liyuj/note/977079#122rest-api)
95 | # 8 小结
96 | 我们看到了Ignite的sql存储本质是一种键值对的存储,并且我们知道了最原始的键值对操作的方法,他遵循Jcache规范,我们可以用java进行一些列的查询。甚至我们了解到有些方便的监控状态的rest接口和图形化界面。
97 |
98 | Ignite给我们带来了很多惊喜,但是他却不止这些功能。他还可以作为分布式内存文件系统IGFS来加速HDFS,共享内存加速Spark;他还提供了分布式数据结构Queue和Set可以存到集群的内存中;他还有将web session放到集群共享的功能;他甚至不只是个存储构架,还有计算构架和机器学习功能。这里我们不再分别介绍,感兴趣可以自己去了解。
99 |
--------------------------------------------------------------------------------
/Persistence/Mongodb.md:
--------------------------------------------------------------------------------
1 | # Mongodb
2 | # 简介
3 | mongo是非关系型数据库,使用上非常简单。可以直接将其理解为是一个用来存json格式数据的数据库。
4 |
5 | MongoDB是一个NoSQL数据库。
6 |
7 | # 安装与配置
8 | 其安装过程非常简单,只需要到官网下载相应的操作系统版本就行,然后将bin目录添加到环境变量即可。
9 | # 运行与连接
10 | 运行指令`mongod --dbpath=指定路径`。这里不加--dbpath参数默认会在`/data/db`目录存储,但需要先创建这个目录。
11 |
12 | 连接指令`mongo`可以直接连接本机27017端口。如果是其他server则可以通过`mongo ip:port`连接。
13 | # 概念
14 | ## database
15 | 数据库,可以通过`show dbs`指令查看当前所有数据库,`use dbname`则进入某个数据库,这里和mysql的概念一致。默认MongoDB中有admin和local这两个数据库,一般我们不在这里直接存数据,而是自己创建创建不需要特殊的指令,直接use如果dbname不存在则会先创建。
16 | ## collection
17 | 集合,可以通过`show collections`指令查看所有集合,集合的概念类似于sql中的表概念,`db.createCollection('c1')`在当前db下创建c1集合。
18 | ## document
19 | 文档,文档的概念类似于sql中表的一行。不太一样的是sql中的行都需要有一样的字段结构,但是MongoDB是NoSQL所以字段是没有约束的。查看一个collection中的所有document的指令是`db.collectionname.find()`。find函数也可以传递多个参数,在后面详细介绍。
20 | # 基本操作
21 | 先进入一个collection:`use test`>>`db.createCollection('c1')`,可选参数我用/**/中显示
22 | ## 增
23 | ```javascript
24 | db.c1.insert({name:'xiaoming',age:29})
25 | ```
26 | 如果没有c1集合,这句话会先创建c1集合。
27 | ## 删
28 | ```javascript
29 | db.c1.remove({age:29}./*false*/)//默认删除多行
30 | ```
31 | 删除age字段是29的,可选参数为justOne只删除一条,默认是删除所有符合条件的
32 | ## 改
33 |
34 | ```javascript
35 | db.c1.update({'name':'xiaoming'},{$set:{'age':30}},/*false,false*/)//默认修改一行
36 | ```
37 | 更改名字为xiaomning的年龄改为30。注意可以传递2-4个参数,后两个参数默认值是false,分别代表如果当前没有符合条件的是否插入新的,以及是否应用于多行。
38 | ```javascript
39 | db.c1.save({"_id" : ObjectId("56064f89ade2f21f36b03136"),"title" : "MongoDB"})
40 | ```
41 | 直接save一个document,需要有_id字段,这样会直接替换原来的该id的document。
42 |
43 | ## 查
44 | ```javascript
45 | db.c1.find(/*query, fields, limit, skip, batchSize, options*/)
46 | ```
47 | 查,无参则是全部查询。条件json格式,查询列json格式(可以随便定一个值,不影响查询结果),最多几条,跳过几条。分页参数也可以在find之后链式编程写,形如
48 | ```javascript
49 | db.c1.find().skip(1).limit(2)
50 | ```
51 | 如果条件是true或Field是所有列,则写{}
52 | # 条件的写法
53 | 在update delete和find中都有条件参数,这个条件上面的例子中都是`等于`而实际上会有大于小于等情况,而且上面的列子中多列关系是and关系实际上会有or,以及and or混合的情况。
54 | ## or条件
55 | ```javascript
56 | {$or:[{"age":33},{"name": "xiaobai"}]}//$or:数组 数据间为或条件
57 | ```
58 | ```javascript
59 | {$or:[{"age":33},{"name": "xiaobai"}],"father":"李刚"}//and or混合
60 | ```
61 | ## 大小比较条件
62 | ```javascript
63 | {age:{$gt:5}}//$gt大于 年龄大于5
64 | ```
65 | (>) 大于 `$gt`
66 | (<) 小于 `$lt`
67 | (>=) 大于等于 `$gte`
68 | (<= ) 小于等于 `$lte`
69 | num在[1,2,3]中`{num:{$in:[1,2,3]}}`
70 | # 追加函数
71 | `limit skip`已经介绍,`count`是求个数的,`sort(field:1)`按照列升序排列-1则是降序。
72 | # 其他
73 | mongo还支持很多聚合函数,这里就不再介绍,在用到的时候可以去搜。
--------------------------------------------------------------------------------
/Persistence/Redis.md:
--------------------------------------------------------------------------------
1 | # Redis
2 | # 简介
3 | `redis`是内存存储的键值对数据库,可以认为是将编程语言中的一些数据存储类型做成了数据库。`redis`支持`String`、`Hash`、`List`、`Set`、`ZSet`这几种数据类型的存储。他将数据存到内存,支持一定策略的磁盘持久化,所以也不用太担心数据丢失的问题。
4 | # String
5 | String类型就是一个键对应一个字符串值,这个值是按照String存储的。读写命令为
6 | ```
7 | get key
8 | set key value
9 | mset k1 v1 k2 v2
10 | mget k1 k2
11 | ```
12 | # Hash
13 | Hash类型就是一个键对应一个HashMap,例如`key:{name:'xx',age:'xx'}`。常用读写命令为
14 | ```
15 | hget k field
16 | hset k field value
17 | hmget k f1 f2 ...
18 | hmset k f1 v1 f2 v2 ...
19 | hgetall k
20 | ```
21 | # List
22 | List类型就是一个键对应一个双向链表,可以类似的看成是java中的`LinkedList`,当做双向链表来用。常用的压入和弹出指令为:
23 | ```
24 | lpush k v1 v2 ...
25 | rpush k v1 v2 ...
26 | lpop k
27 | rpop k
28 | ```
29 | # Set
30 | Set类型就是一个键对应一个String集合,集合插入已有的值不会有任何反应,常用的集合操作增删有:
31 | ```
32 | sadd k v
33 | srem k v
34 | ```
35 | # ZSet
36 | ZSet是有序集合,在存储数据的时候,需要为元素指定`Order`序号,在某些特定场景下有用。
37 | # 小结
38 | 从上面来看Redis的使用是非常简单的,他就像操作编程语言中的数据结构一样。当然上面的描述是非常简单的,除了数据读写redis还可以配置分布式主从模式,简单的事务以及持久化配置,当然还提供了一个简单的订阅发布服务器。更多地用法和操作可以参照官网或者参考这个[使用手册](http://microfrank.top/redis/)
39 |
--------------------------------------------------------------------------------
/Persistence/conf/ignite-backup1.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 | 127.0.0.1:47500..47509
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
--------------------------------------------------------------------------------
/Persistence/conf/ignite-backup2.xml:
--------------------------------------------------------------------------------
1 |
2 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
25 |
26 |
27 |
28 |
29 |
30 |
31 | 127.0.0.1:47500..47509
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
--------------------------------------------------------------------------------
/Persistence/conf/ignite-persist.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 | 127.0.0.1:47500..47509
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/Persistence/img/ignite-backup.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-backup.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite-backup2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-backup2.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite-backup3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-backup3.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite-cache.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-cache.jpg
--------------------------------------------------------------------------------
/Persistence/img/ignite-join.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-join.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite-persist.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-persist.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite-tables.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-tables.jpg
--------------------------------------------------------------------------------
/Persistence/img/ignite-web1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-web1.jpg
--------------------------------------------------------------------------------
/Persistence/img/ignite-web2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-web2.jpg
--------------------------------------------------------------------------------
/Persistence/img/ignite-web3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite-web3.jpg
--------------------------------------------------------------------------------
/Persistence/img/ignite1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite1.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite2.gif
--------------------------------------------------------------------------------
/Persistence/img/ignite3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Persistence/img/ignite3.gif
--------------------------------------------------------------------------------
/PostgreSQL/GPDB.md:
--------------------------------------------------------------------------------
1 | # GreenPlum(GPDB)
2 | # 简介
3 | `GPDB`是一种分布式的关系型数据库,它基于`PostgreSQL`改装而成,可以形象的将其理解为分布式的PostgreSQL。和传统分布的数据库不一样,GPDB采用了ShareNothing的模式,在存储数据(Insert)的时候是按照一定规则存到不同的Segement节点上面的。例如第一条insert可能存到了PC1上,第二条可能就是PC2,按照一定的规则使数据可以均匀的分布到各个节点上面。
4 | 
5 | 图片来自互联网。
6 | 在而在查询数据的时候例如`SELECT * FROM tbname WHERE age = 20`则是master节点将sql语句下发到每个数据节点,分别运行该查询,最后将结果汇总返回给用户。SQL本身就是查询是一种计算,这样将计算分到了每个节点上,本质上也是一种MapReduce的思想。
7 | GPDB用法非常简单,他和pipelinedb一样是基于postgresql的数据库,所以只需要通过sql就可以操作。
8 | # 搭建
9 | 搭建过程可以参考[网上的教程](https://www.cnblogs.com/liuyungao/p/5689588.html),这里因为设备问题我就没有搭建集群的GPDB。而是用docker的形式启动了一个单机版的GPDB
10 | ```
11 | docker run -i -p 5432:5432 -t kevinmtrowbridge/greenplumdb_singlenode
12 | ```
13 | # 读写
14 | GPDB在进行写操作的时候,对用户是透明的,都是通过一条Insert语句即可完成写入,其实底层是在多台机器上存储的。这取决于在创建数据库的时候使用的分布策略。例如
15 | ```
16 | create table mytb(id int,name varchar(100)) distributed by (id);
17 | ```
18 | 就是按照id的hash值进行分布式存储的,即将id做hash运算后获得一个整数除以总的集群机器的余数就是他要存到的机器的编号。常用的分布策略还有随机分布`distributed randomly;`更多的分布策略可以看这篇[博客](http://blog.chinaunix.net/uid-23284114-id-5601403.html)。
19 | 对于读操作则是将sql语句下发到每台机器上面单独去执行。这也是很好理解的。我们像平时操作Postgresql一样的操作GPDB
20 | ```sql
21 | create table mygroup(gid int,gname varchar(100)) distributed by (gid);
22 |
23 | create table myuser(uid int,gid int,uname varchar(100)) distributed randomly;
24 |
25 |
26 | INSERT into mygroup (gid,gname) VALUES (1,'g1'),(2,'g2'),(3,'g3');
27 | INSERT into myuser (uid,gid,uname) VALUES (1,1,'u1'),(2,1,'u2'),(3,3,'u3'),(4,2,'u4');
28 |
29 | SELECT * FROM myuser JOIN mygroup on myuser.gid=mygroup.gid;
30 |
31 | SELECT gid,count(*) from myuser GROUP BY gid;
32 | ```
33 | 
34 | # 备份
35 | 前面的讲述中,我们会发现没有备份的策略,如果有一台存储的机器坏掉了,则会造成这些数据的永久丢失。还好有mirror设置,对于每个存储数据的segment,都可以设置mirror,当segment宕机后mirror就可以顶替上来。
--------------------------------------------------------------------------------
/PostgreSQL/img/GPDB.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/PostgreSQL/img/GPDB.gif
--------------------------------------------------------------------------------
/PostgreSQL/img/GPDB1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/PostgreSQL/img/GPDB1.png
--------------------------------------------------------------------------------
/PostgreSQL/img/pipelinedb1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/PostgreSQL/img/pipelinedb1.gif
--------------------------------------------------------------------------------
/PostgreSQL/img/pipelinedb2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/PostgreSQL/img/pipelinedb2.gif
--------------------------------------------------------------------------------
/PostgreSQL/pipelinedb.md:
--------------------------------------------------------------------------------
1 | # pipelinedb
2 | # 1 简介
3 | 现在的数据分析除了之前讲的`spark` `hadoop`等框架,也出现了另一个分支:数据库直接用sql分析数据。这样的好处是不需要使用者会编程语言,只需要会sql查询即可完成数据分析。`pipelinedb`就是这样的数据库,它基于`postgresql`进行扩展,如果不想用流式数据分析的部分,也可以当做一个普通的`postgresql`来使用。
4 | pipelinedb有以下特点:可以控制数据的存活周期,可以进行滑动窗口化分析,可以判断数据触发事件,提供了常用的数学分析函数。
5 | [官方文档](http://docs.pipelinedb.com/)写的也非常翔实,建议阅读。
6 | # 2 安装与配置
7 | # Docker
8 | Docker方式是最快的安装方式,不过缺点是本机没有连接postgresql的客户端会比较难直接测试
9 | ```
10 | docker run -d -p5432:5432 --name pipelinedb pipelinedb/pipelinedb
11 | ```
12 | ## 2.1 下载安装
13 | 下载页面:[https://www.pipelinedb.com/download](https://www.pipelinedb.com/download)
14 | ubuntu下安装
15 | ```shell
16 | dpkg -i pipelinedb-0.9.8u2-ubuntu16-x86_64.deb
17 | ```
18 | ## 2.2 配置启动
19 | 创建一个非root用户
20 | ```shell
21 | useradd -g root frank
22 | ```
23 | 切换到用户:
24 | ```shell
25 | su frank
26 | ```
27 | 初始化数据目录:
28 | ```shell
29 | pipeline-init -D
30 | ```
31 | 修改配置:进入刚才指定的目录下修改`pipelinedb.conf`
32 | ```
33 | listen_address="*"
34 | log_timezone = 'PRC'
35 | timezone = 'PRC'
36 | shared_preload_libraries = plsh
37 | ```
38 | `pg_hba.conf`配置所有ip都是白名单(方便测试)
39 | ```
40 | host all all 0.0.0.0/0 trust
41 | ```
42 | 安装plsh扩展:
43 | ```shell
44 | git clone https://github.com/petere/plsh.git
45 | make
46 | make install
47 | ```
48 | 后台启动:
49 | ```shell
50 | pipeline-ctl -D /home/frank/pipedb/ -l p.log start
51 | ```
52 | ## 2.3 连接测试
53 | 连接:
54 | ```
55 | pipeline pipeline (如果是root下进入则要加-u frank)
56 | ```
57 | enable plsh扩展:
58 | ```
59 | CREATE EXTENSION plsh;
60 | ```
61 | 这里指令`pipeline pipeline`是指进入默认数据库`pipeline`,如果你创建了其他库
62 | ```
63 | CREATE DATABASE dbname;
64 | ```
65 | 则可以通过`pipeline dbname`进入,数据库远程连接用户名是新创建的用户,这里为`frank`,密码默认是`pipeline`
66 | ```
67 | pipeline dbname;
68 | ```
69 | # 3 核心概念
70 | ## 3.1 stream
71 | stream在pipelinedb中代表一个数据流,他的地位和表/视图是同级的,可以通过create进行创建流,drop删除流,insert将数据插入流:
72 | ```
73 | --创建 stream
74 | pipeline=# CREATE STREAM mystream (x integer, y integer);
75 |
76 | --插入 stream
77 | pipeline=# INSERT INTO mystream (x, y) VALUES (1, 2);
78 | pipeline=# INSERT INTO mystream (x, y) VALUES (1, 2),(2,2),(3,1);
79 |
80 | --删除 stream
81 | pipeline=# DROP STREAM mystream;
82 | ```
83 | 注意这里并没有查询的select命令,这和stream的特性有关,stream代表的是一个流的入口,数据可以从这个入口进入(insert),但是stream并不保存任何数据,因而不能在stream上运行任何查询,要想将stream的数据"兜"住,则需要一个持续视图。
84 | ## 3.2 continuous view
85 | 我们知道视图view是一个抽象的表,即有x,y,z三列的表tb1上可以选出x,y两列组成一个视图,其实就是一张表,只不过区别于table,view并没有单独创建。
86 | 上面是sql中view的简述,那么continuous view又是指什么呢?pipelinedb中将数据流进行圈定的方式就是持续视图,对照关系如下
87 | ```
88 | table--->stream
89 | view--->continuous view
90 | ```
91 | 区别在于流不能直接用select进行查询,持续视图比起视图有着随着流数据进入会持续更新的效果。概念表述上可能略微复杂,让我们看个例子:
92 | ```sql
93 | pipeline=# CREATE STREAM mystream (x integer, y integer);
94 |
95 | --myview1保存流中的每一条数据
96 | pipeline=# CREATE CONTINUOUS VIEW myview1 AS SELECT x, y FROM mystream;
97 |
98 | --myview2只保存最大的一条x和y的总和
99 | pipeline=# CREATE CONTINUOUS VIEW myview2 AS SELECT max(x), sum(y) FROM mystream;
100 |
101 | --插入 stream
102 | pipeline=# INSERT INTO mystream (x, y) VALUES (1, 2),(2,1),(3,3);
103 |
104 | --查看 view中数据
105 | pipeline=# SELECT * FROM myview1;
106 | pipeline=# SELECT * FROM myview2;
107 | ```
108 | 
109 | 从这个例子中不难看出持续视图可以始终记录数据流中最大的x值 以及 y值的和,所以流式数据分析可以通过创建视图的形式就是在实时分析了,要想获得分析的结果只需要通过一个数据库Select语句即可,而又因为pipelinedb本身基于postgresql,所以任何能连接后者的驱动如jdbc/odbc都可以连接改数据库。
110 | ## 3.3 sliding windows
111 | 上例中我们可能不是想一直存储历史以来的max(x)和sum(y),而是想存储1小时以内的max(x)和sum(y),这就需要一个滑动窗口,约束分析的时间范围。
112 | ```sql
113 | --对10s内的数据分析
114 | pipeline=# CREATE CONTINUOUS VIEW myview3 WITH (sw = '10 seconds') AS SELECT x,y FROM mystream;
115 | pipeline=# CREATE CONTINUOUS VIEW myview4 WITH (sw = '10 seconds') AS SELECT max(x),sum(y) FROM mystream;
116 | ```
117 | 
118 | ## 3.4 continuous transforms
119 | 如果想要在数据出现异常值的时候能够触发事件执行`shell`脚本该怎么做呢?pipelinedb提供了持续转换,持续转换和持续视图很像不过他并不存储任何数据,只是提供判断如果数据满足条件则触发事件执行自定义的函数。
120 | 例如x的值超过100,则执行一段shell指令(可能是curl调用rest接口去发送邮件,操作空间很大)
121 | ### 3.4.1 创建函数
122 | 这里用到了我们之前安装的`plsh`扩展
123 | ```sql
124 | CREATE or REPLACE FUNCTION myfunc() RETURNS trigger AS
125 | $$
126 | #!/bin/bash
127 | #curl -x http://localhost/sendemail
128 | echo "hi">/home/frank/1.txt
129 | $$
130 | LANGUAGE plsh;
131 | ```
132 | ### 3.4.2 创建transform:
133 | 当x的值大于100的时候触发我们自定义的函数
134 | ```sql
135 | CREATE CONTINUOUS TRANSFORM myct AS
136 | SELECT x FROM mystream WHERE x > 100
137 | THEN EXECUTE PROCEDURE myfunc();
138 | ```
139 | # 4 小结
140 | pipelinedb的性能是非常强的,具体有多强可以自行百度,而且使用方法非常简单。提供的聚合函数很多,不只是sql中就有的sum max等,可以[查看这里](http://docs.pipelinedb.com/aggregates.html)。缺点当然也很明显,首先必须是结构化的数据才能存储,其次sql语言不是万能的,不能进行灵活的分析。
141 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 小白学习大数据
2 | ## 关于这个系列的文章
3 | 我本人算是大数据的初学者,在学习大数据的过程中,经常遇到为什么用这个东西,为什么他能提高效率,为什么这个技术能更好的提高性能,这段代码会在哪些机子上执行这些问题。而搭建过程中也会遇到一些明明按照教程来的为什么就失败了。
4 |
5 | 我在学习过程中记录下这些细节,为了理清思路,让新手更容易学习和理解大数据,写了这个系列的文章。
6 |
7 | ## Hadoop家族
8 | - [1.Hadoop](Hadoop/Hadoop.md)
9 | - [2.Hive](Hadoop/Hive.md)
10 | - [3.Hbase](Hadoop/Hbase.md)
11 |
12 | [浅谈-----大数据分析的两大核心:存储构架和计算构架](Article/art1.md)
13 |
14 | ## Spark家族
15 | - [1.SparkRDD](Spark/SparkRDD.md)
16 | - [2.SparkIO](Spark/SparkIO.md)
17 | - [3.SparkSQL](Spark/SparkSQL.md)
18 | - [4.SparkDataset](Spark/SparkDataset.md)
19 | - [5.SparkStream](Spark/SparkStream.md)
20 |
21 | [浅谈-----Spark计算为什么比Hadoop快](Article/art2.md)
22 |
23 | ## Postgresql家族
24 | - 1.流式数据库[pipelinedb](PostgreSQL/pipelinedb.md)
25 | - 2.分布式关系型数据库[GreenPlum](PostgreSQL/GPDB.md)
26 |
27 | [扩展阅读-----MPP和Hadoop的定位以及分别适合的场景](http://www.jianshu.com/p/5191daa1a454)
28 |
29 | ## 其他存储系统
30 | - [1.Ignite](Persistence/Ignite.md)
31 | - 2 Ignite与Hadoop/Spark(还没写)
32 | - [3.Redis](Persistence/Redis.md)
33 | - [4.Mongodb](Persistence/Mongodb.md)
34 | - [5.Cassandra]()
35 |
36 | ## 快速查询
37 | - [1.Elasticsearch](Search/Elasticsearch.md)
38 | - [2.Presto](Search/Presto.md)
39 |
--------------------------------------------------------------------------------
/Search/Elasticsearch.md:
--------------------------------------------------------------------------------
1 | # ElasticSearch
2 | # 简介
3 | ElasticSearch后面简称es,从名字中可以看出是一个搜索引擎。其本身也是一个数据(仓)库。有以下几个特点
4 | - 1 存储json格式的数据,可以是非结构化,和mongo很像
5 | - 2 支持Rest方式查询数据,在搜索上性能突出
6 | - 3 支持集群化
7 |
8 | 其中第二个特点是最突出的。
9 | # 安装
10 | Es的安装非常简单,只需要官方下载,然后直接shell/cmd运行即可。我们这里同时下载es公司另一款产品Kibana,用于后续的图形化操作。同样是下载后直接shell/cmd运行。
11 |
12 | 或者docker compose的方式
13 | ```yaml
14 | version: '3.1'
15 |
16 | services:
17 | kibana:
18 | image: kibana
19 | ports:
20 | - 5601:5601
21 |
22 | elasticsearch:
23 | image: elasticsearch
24 | ```
25 | # 概念
26 | `index`索引,索引和mysql数据库中索引可不是一个东西,可以认为这是一个mysql中的库database。
27 | `type`类型,对应mysql中的table。最新版的es中一个index中只允许有一个type了。
28 | `document`文档,相当于mysql中一条数据。
29 |
30 | # 增删改查操作
31 | Rest方式则是直接通过http访问9200(默认)端口:
32 | ## 1 添加/修改一条数据
33 | ```
34 | PUT /alibaba/employee/1
35 | {
36 | "name":"wuyao",
37 | "age":25,
38 | "interests":["music","sport"]
39 | }
40 | ```
41 | PUT方法后面要有id,如果没有则插入一条,如果有了则修改这条数据内容。同样没有index和type叫这个名字,也会创建。返回create字段是true则是创建,false则是修改。
42 | ## 2 添加一条随机id数据
43 | ```
44 | POST /alibaba/employee
45 | {
46 | "name":"wuyao"
47 | }
48 | ```
49 | POST添加数据,不需要最后跟id,会自动生成_id字段。
50 | ## 3 查询数据
51 | ```
52 | GET /alibaba/employee/1
53 | ```
54 | 根据id查询这条数据,没有id返回404
55 |
56 | ```
57 | GET /alibaba/employee/_search
58 | ```
59 | 查询所有数据,GET也可以改为POST和PUT也能查询。
60 | ```
61 | GET /alibaba/employee/_search?q=age:25
62 | ```
63 | 条件查询age为25的数据
64 | ## 4 删除一条数据
65 | ```
66 | DELETE /alibaba/employee/1
67 | ```
68 | 删除成功200,没有该id返回404
69 |
70 |
--------------------------------------------------------------------------------
/Spark/SparkDataset.md:
--------------------------------------------------------------------------------
1 | # Dataset
2 | # 1 概述
3 | 一开始我们介绍了`RDD`的使用,后来在`SparkSQL`中我们又介绍了`Dataset`。并且我们知道`Dataset`比`Dataframe`有更好的性质,所以已经替代掉了后者。这一节我们来对比下RDD和DS,看看两者的不同和使用环境。
4 |
5 | 首先你可以读一下[这篇文章](http://blog.csdn.net/wo334499/article/details/51689549)、和[这篇文章](http://www.jianshu.com/p/c0181667daa0)。
6 | # 2 对比
7 | # 2.1 创建
8 | JavaRDD的创建入口是`JavaSparkContext`
9 | RDD的创建入口是`SparkContext`
10 | 如果用Java写则最好用JavaRDD会方便些
11 | ```java
12 | SparkConf conf = new SparkConf().setAppName("app").setMaster("local");
13 | JavaSparkContext sparkContext = new JavaSparkContext(conf);
14 |
15 | //List变量转化为JavaRDD
16 | List list= Arrays.asList("r","vd","azhao","hia zo");
17 | JavaRDD rdd = sc.parallelize(list);
18 |
19 | //从文件中读取为JavaRDD
20 | JavaRDD textRdd = sc.textFile("text");
21 | JavaRDD textRdd2 = rdd.objectFile("object");
22 |
23 | //从DS(DF)转化为JavaRDD
24 | ds.javaRdd();
25 | df.javaRdd();
26 | ```
27 |
28 |
DS的创建入口是`SparkSession`(ss)
29 | ```java
30 | SparkSession sparkSession = SparkSession.builder().appName("app").master("local").getOrCreate();
31 |
32 | //从List变量转化为DS 注意后面Encoder必须写这个否则报错
33 | //目前提供了基本类型的Encoder
34 | sparkSession.createDataset(Arrays.asList(1,2,3),Encoders.INT());
35 |
36 | //从文件中读取为DS(DF) DS以前叫DF
37 | Dataset df = spark.read().textFile("text");//纯文本Row一列字符串
38 | Dataset df2 = spark.read().json("1.json");//json格式Row分多列
39 | Dataset df3 = spark.read().load("parquet");//Row也是分多列的
40 |
41 | //从JavaRDD转化为DS
42 | Dataset ds1= sparkSession.createDataset(javardd.rdd(),Encoders.STRING());
43 | Dataset ds2= sparkSession.createDataset(javardd.rdd(),Encoders.javaSerialization(Person.class));
44 | //注意Person需要实现Serializable接口
45 | ```
46 | 上面的Person类
47 | ```java
48 | //必须有getter setter否则转为df是空
49 | //必须实现Serializable否则无法转ds
50 | class Person implements Serializable{
51 | long group;
52 | long age;
53 | String name;
54 | public long getAge() {
55 | return age;
56 | }
57 |
58 | public void setAge(long age) {
59 | this.age = age;
60 | }
61 |
62 | public long getGroup() {
63 | return group;
64 | }
65 |
66 | public void setGroup(long group) {
67 | this.group = group;
68 | }
69 |
70 | public String getName() {
71 | return name;
72 | }
73 | public void setName(String name) {
74 | this.name = name;
75 | }
76 |
77 | public Person(long age, long group, String name){
78 | this.group=group;this.name=name;this.age=age;
79 | }
80 | }
81 | ```
82 | # 2.2 API
83 | RDD的API在之前已经介绍了,更多的方法可以参考[RddDemo](https://github.com/sunwu51/SparkDemo/blob/master/src/main/java/RddDemo.java)。
84 | DS的部分功能我们在SQL中也有所介绍,最大的特点就是DS封装了sql查询的相关方法,可以组合出任意sql(hql)语句。尤其是在查询方面,sql语句比rdd中调用filter来实现易读性要好很多。
85 | 例如选出22-36岁名字中含有John的行,分别用DS和RDD实现
86 | DS:
87 | ```java
88 | //ds类型是Dataset
89 | Dataset sqlDF = ds.where(col("age").between("22","36"))
90 | .where(col("name").like("%John%")).select(col("*"));
91 | ```
92 | RDD:
93 | ```java
94 | //rdd类型是JavaRDD
95 | JavaRDD newRdd = rdd.filter(new Function() {
96 | @Override
97 | public Boolean call(Person person) throws Exception {
98 | return person.getAge()>22 && person.getAge()<36 &&person.getName().contains("John");
99 | }
100 | });
101 | ```
102 | DS的where可以用RDD的filter实现,DS的group等某些聚合类型的函数则需要RDD进行PairRDD变换后才能实现,所以在一些情况下简化了代码开发。使对SparkRDD API并不那么熟悉的只懂sql的程序员,也能写出高效的代码。而且DS通过显示的Encoder的声明方式,在序列化上取得了性能优势(相比RDD),而且因为ds操作过程中较少的中间项创建(相比RDD)GC压力稍小些。
103 | 注:DS也有`map`和`flatMap`方法可以进行泛型类型转化。
104 | # 4 小结
105 | rdd的优点是高度的灵活性,高度的可自定义编程。缺点是网络IO中序列化反序列化消耗高,GC高。
106 | ds的优点是sql的易读易上手,显式Encoder序列化反序列化消耗稍小,GC稍小。
107 | 在一般的应用中我们建议使用ds进行操作,实在没法实现的则转换成rdd操作。
108 |
--------------------------------------------------------------------------------
/Spark/SparkIO.md:
--------------------------------------------------------------------------------
1 | # SparkIO
2 | # 1 简介
3 | 在上一节RDD中,我们有两点是走了捷径:
4 | -- 1 没有搭建Spark服务直接通过maven依赖就可以对RDD进行编程了。
5 | -- 2 操作的数据是java变量或者本地文件读入的数据。
6 | 而实际场景下,我们往往会操作HDFS上的文件,而且会以集群的方式运行程序。这一节我们就来看看怎么做到这两点。
7 | # 2 File
8 | 最常见的例如`sc.textFile(path)`可以读取文件内容,与之对应的`rdd.saveAsTextFile(path)`则可以将RDD存储到文件(路径已存在则报错)。但是在存储的时候只能存成块状文件,在文件块中可以拼出文件完成信息。
9 | 
10 | 而读取的时候则既可以读取单个文件也可以读取块状文件。
11 | 
12 |
13 | ## 2.1 TextFile
14 | 纯文本文件的读写。`JavaRDD`是读取的返回值,每一行作为一个元素。
15 | ```
16 | rdd.textFile(path)//读取文件
17 |
18 | sc.saveAsTextFile(path)//写入文件
19 | ```
20 | 注意`path`参数不加协议前缀则是本地文件,如果要读写hadoop文件只需要将path改为`hdfs://server:port/path`
21 | 
22 | ## 2.2 ObjectFile
23 | 对象文件的读写,如果遇到不是字符串的数据存储,例如`JavaRDD`类型,如果按照`saveAsTextFile`写入文件,则是将每个元素运行`toString()`后写入每一行,此时文件还是只能通过如果`textFile`读取,返回值只能是`JavaRDD`而非`JavaRDD`。
24 | 
25 | 希望从文件中读取出来还是`JavaRDD`类型则要用ObjectFile进行存储。
26 | ```
27 | rdd.objectFile(path)//读取文件
28 |
29 | sc.saveAsObjectFile(path)//写入文件
30 | ```
31 | 
32 | ## 2.3 SequenceFile
33 | 序列化文件的读写,前面两种文件我们可以轻松应对RDD的存储了,尤其是ObjectFile可以自动转换,提供了很大的灵活性。可以对于PairRDD的存储该怎么办呢?
34 |
35 | 通过SequenceFile来存储:
36 | ```
37 | //写入文件,参数依次为path keytype valuetype outputformattype
38 | pairRDD.saveAsHadoopFile("seqfile",IntWritable.class,NullWritable.class,SequenceFileOutputFormat.class);
39 |
40 | JavaPairRDD pairRDD2= sc.sequenceFile("seqfile",IntWritable.class,NullWritable.class);
41 | ```
42 | 注意这里的类型都是Hadoop的可序列化到文件里的类型不能直接用Integer String这种。
43 | # 3 搭建[2.1.0]
44 | 经过前面的学习,对于Spark已经有了初步的了解,Spark本身有着独立集群,提供scala以及python的交互式客户端。在用Java写的时候,可以看出经常需要写接口类例如Function,代码非常冗长,Scala和Python中则精简了很多。使用交互式客户端可以完成上一节我们的所有例子。
45 | 1 官网下载安装包,配置环境变量
46 | 2 将之前的Hive的tmp存储目录设为777,我之前是/tmp/hive
47 | ```
48 | chmod -R 777 /tmp/hive
49 | ```
50 | 3 启动`pyspark`
51 | 
52 | ## 3.1 Spark独立集群
53 | 独立集群有两种角色Master和Worker,即班长和普通员工。我们在一台机子上运行的话,只能将这俩角色强加在一个人身上了。配置以下两个文件:
54 | 1 [slaves](conf/slaves)
55 | 2 [spark-env.sh](conf/spark-env.sh)
56 | 注意默认web端口是8080,我将其改为了[18080](conf/spark-env.sh)
57 |
58 | 修改后即可启动:
59 | ```
60 | ./sbin/start-all.sh
61 | ```
62 | 最好是到该目录下运行这个脚本,因为前面Hadoop中也有个start-all.sh。环境变量写的先后影响指向。
63 |
64 | 检查是否启动成功:jps指令看到Master和Worker即成功
65 | ## 3.2 提交到独立集群运行
66 | 1 在windows下编程,修改`setMaster`,可以直接删掉`Sparkconf`中的setMaster部分,通过运行的脚本中指定`--master`参数
67 | ```
68 | SparkConf conf = new SparkConf().setAppName("app");
69 | ```
70 | 2 打jar包
71 | ```
72 | mvn package
73 | ```
74 | 3 到服务器运行spark-submit
75 | ```
76 | ./bin/spark-submit \
77 | --class \
78 | --master \
79 | --deploy-mode \
80 | --conf = \
81 | ... # other options
82 | \
83 | [application-arguments]
84 | ```
85 | 例如:
86 | ```
87 | ./bin/spark-submit --class IODemo --master spark://192.168.4.106:7077 --deploy-mode cluster sparkdemo-1.0-SNAPSHOT.jar
88 | ```
89 | 
90 |
91 | ## 3.3 提交到Yarn集群运行
92 | 独立集群对于HDFS的读取没有更大的收益,独立集群在读取文件和写入文件的时候都是通过HDFS的NameNode进行操作,有大量的网络IO产生,所以效率较低。
93 | Hadoop为了让其他计算框架能更好的运行在HDFS上,提供了yarn平台,对于HDFS有着更好的访问速度。
94 | 1 先确保搭建了yarn平台
95 | 2 提交jar包
96 | ```
97 | ./bin/spark-submit --class IODemo --master yarn --deploy-mode cluster sparkdemo-1.0-SNAPSHOT.jar
98 | ```
99 | 3 检查运行状态和文件内容
100 | 
101 |
102 |
103 |
104 |
105 |
--------------------------------------------------------------------------------
/Spark/SparkRDD.md:
--------------------------------------------------------------------------------
1 | # Spark
2 | # 1 简介
3 | `Spark`的出生就是为了针对`Hadoop`的`MapReduce`计算思想,我们现在仍然能从Spark的官网首页看到一个`Spark vs Hadoop(MapRed)`的速度比较。
4 | 
5 | Spark除了速度上体现出巨大的优势,在使用上也比MapReduce更加容易,对所有的数据流程抽象除了RDD的概念。学习者只要掌握RDD的通用API就可以轻松编程。
6 | Spark还封装了`SparkSQL`来顶替Hive中的MapReduce运算,`SparkStream`来进行流式计算,还有针对机器学习的`SparkMLib`。
7 |
8 | 正因为使用简单、性能强大、涉足领域广这些特点,Spark已经是大数据分析最受欢迎的框架之一了。
9 | 不过我们始终要明白一点,Hadoop没有被代替,尤其是HDFS。即使Spark有这么多优点,他也只是个计算框架,而非存储框架。仍要依赖于HDFS的分布式存储或其他存储。
10 | 之前的HDFS是部署为主,学会操作文件就够了。而Spark则需要学习使用语言进行编程。可选的语言有`Scala`,`Java`,`Python`。我以Java为主进行讲述
11 | # 2 RDD
12 | RDD(Resilient Distributed Datasets)翻译过来是弹性分布式数据集,一听这个名字似乎是非常复杂的概念。单纯去理解这个概念是很难的,我们可以直接看RDD的使用,能更好的理解这个东西。
13 | ## 2.1 JavaRDD
14 | **知识点1**:RDD作为一种数据集他可以来自一个java的集合变量,也可以来自一个文本文件,可以把它看做一个List。
15 | ```java
16 | //List可以转RDD
17 | List list= Arrays.asList("a","b","c","d");
18 | JavaRDD rdd = sc.parallelize(list);
19 | //文件也可以转RDD(文本每行是一个元素)
20 | JavaRDD rdd2=sc.textFile("/root/1.txt");
21 | ```
22 | **知识点2**:RDD是抽象的过程,即上述例子中RDD声明后,实际并不存储数据,而是代表一个过程,更像是有向无环图,封装了各种操作流程,但是实际上并没有执行操作,所以虽然在编程中可以先按照list理解但是实际上却是一片虚无,更准确的讲应该是产生我们想象的List的蓝图。
23 | 下图展示RDD的惰性:
24 | 
25 | **知识点3**:我们发现了,只要返回值还是RDD的操作(转化操作),其实都没有实际执行操作,只有返回值为实际类型的时候(行动操作)才会触发这个结果所需要的所有操作。这一点一定要理解。
26 | ```java
27 | List list= new ArrayList(Arrays.asList(0,1,2,3));
28 |
29 | JavaRDD rdd = sc.parallelize(list).filter(new Function(){
30 | @Override
31 | public Boolean call(Integer integer) throws Exception {
32 | return integer<3;
33 | }
34 | });
35 |
36 | list.remove(1);
37 |
38 | System.out.println(rdd.collect());//打印[0,2]而非[0,1,2]
39 | ```
40 | **知识点4**:JavaRDD都有哪些可选操作?
41 | **常见RDD->RDD转化操作:**
42 |
43 | | 函数名 | 效果 |
44 | | -------- | ---- |
45 | | filter | 去掉不想要的 |
46 | | map | 对每个元素执行指定转化 |
47 | | flatmap | 每个元素可以转化为多个 |
48 |
49 | **常见[RDD1+RDD2]->RDD转化操作:**
50 |
51 | | 函数名 | 效果 |
52 | | -------- | ---- |
53 | | union | 操作俩RDD返回并集(不去重)|
54 | | intersection| 操作俩RDD返回交集|
55 |
56 | **常见行动操作**
57 |
58 | | 函数名 | 返回类型 |
59 | | -------- | ---- |
60 | | collect | List|
61 | | top | List|
62 | | take | List|
63 | | count | Long |
64 | | countByValue | Map |
65 | | reduce | 元素类型 |
66 | | aggregate| 任意类型 |
67 |
68 | 我们可以看出RDD有着很多集合的操作,在大数据处理中过滤操作,映射操作以及聚合操作都是经常用到的。例如统计一篇英文文章中每个单词出现的次数,并且不要统计全是大写的单次。就可以用:
69 | ```
70 | rdd.filter(new Function{
71 | public Boolean call(String s) throws Exception {
72 | return !s.matches("^[A-Z]*$");
73 | }
74 | })
75 | .countByValue()
76 | ;
77 | ```
78 |
79 | ## 2.2 JavaPairRDD
80 | **知识点1**:如果说JavaRDD是List抽象,那么JavaPairRDD就是Map抽象。
81 | **知识点2**:JavaPairRDD是一种特殊的JavaRDD,所以JavaRDD的函数他都有,即将每个`Tuple<_1,_2>`看做一个元素。
82 | **知识点3**:JavaPairRDD特有的操作(其实可以通过基本的操作实现)简单列举。
83 |
84 | | 函数名 | 效果 |
85 | | -------- | ---- |
86 | | keys| key组成的RDD|
87 | | values| value组成的RDD|
88 | | groupByKey| key分组|
89 | | reduceByKey| 在分组基础上对每组value进行聚合|
90 | | combineByKey| 也是聚合但是更复杂|
91 | | mapValues| 只对value进行map运算key保持返回等大的pairRdd |
92 | | flatMapValues| 只对value进行的flatmap运算返回扩大版pairRdd |
93 | | lookUp| 取出某一个特定key的value集返回一个list|
94 | ## 3 实战
95 | 环境要求:java+maven
96 | 学习Spark并不需要下载Spark,只有需要Spark任务运行在独立集群或者Yarn上的时候才需要搭建Spark服务。
97 | maven依赖
98 | ```
99 |
100 | org.apache.spark
101 | spark-core_2.10
102 | 2.2.0
103 |
104 | ```
105 | 在开始之前,需要自己练习上述函数的使用,了解他们的效果,这里提供了[Demo项目](https://github.com/sunwu51/SparkDemo)可以参考里面[RDD](https://github.com/sunwu51/SparkDemo/blob/master/src/main/java/RddDemo.java)和[PairRDD](https://github.com/sunwu51/SparkDemo/blob/master/src/main/java/PairRddDemo.java)的示例代码。
106 | ### 3.1 从均值的例子切入
107 | 给定一个含有好多整数的rdd,求这些数的均值?
108 | **错误思路1**
109 | ```java
110 | Integer sum = rdd.reduce(new Function2() {
111 | public Integer call(Integer o, Integer o2) throws Exception {
112 | return o+o2;
113 | }
114 | });
115 |
116 | Integer count = rdd.count();
117 |
118 | Double avg = (sum*1.0)/count;
119 | ```
120 | 最简单的思路,求和再求个数,最后除下就是均值。结果是没有问题,但是这个思路确实有问题,问题就在于用了两个行动操作,分别求了sum和count,遍历了两遍集合,不可取。
121 | 从这个思路中,我们得到的启发是可以在一次循环的过程中同时完成求和和计数的运算是最好的方案。
122 |
123 | **错误思路2**
124 | ```java
125 | final int[] sum = {0};
126 | rdd.foreach(new VoidFunction() {
127 | public void call(Integer i) throws Exception {
128 | sum[0]+=i;
129 | }
130 | });
131 |
132 | Integer count = rdd.count();
133 |
134 | Double avg = (sum[0]*1.0)/count;
135 | ```
136 | 这种思路和思路1 是一样的,不过不同的是这种方法是错误的,最后结果是0。原因在于`foreach`函数对每个元素执行操作是在这个元素所在的节点上面执行的。而sum数组是一个全局数据,驱动程序将全局数组和RDD操作下发给每个节点,每个节点都拿到一个sum数组的初值即{0},节点间的变量不能共享,操作结束后也不能将变量回传,所以sum在驱动程序中的值始终为{0}。
137 | 从这个思路中,我们得到的启发是变量在节点间是不能共享的,RDD的函数看似是一个整体,但是RDD集合是零散的分布在多台机子上面的数据,每台机子操作自己含有的部分元素。如果是行为操作例如count函数则会每台机子对自己上面的元素求个数,最后汇总给驱动程序,驱动程序将这些值加起来作为返回值。
138 | 【名词解释:驱动程序,就是我们的java代码。驱动程序将序列化的RDD有向无环执行图提交给master。master从中创建任务,并将其提交给worker执行。master协调不同的工作阶段。】
139 |
140 | **正确思路**
141 | ```java
142 | JavaPairRDD pairRDD = rdd2.mapToPair(
143 | new PairFunction() {
144 | @Override
145 | public Tuple2 call(Integer i) throws Exception {
146 | return new Tuple2(i,1);
147 | }
148 | }
149 | );
150 |
151 | Tuple2 tuple2 = pairRDD.reduce(
152 | new Function2,
153 | Tuple2, Tuple2>() {
154 | @Override
155 | public Tuple2 call(Tuple2 t1, Tuple2 t2) throws Exception {
156 | return new Tuple2(t1._1()+t2._1(),t1._2()+t2._2());
157 | }
158 | );
159 |
160 | Double avg =(tuple2._1()*1.0)/tuple2._2();
161 | ```
162 | 将整数RDD转化为【整数,1】的PairRDD,然后对PairRDD运行一次聚合,分别对两个元素求和,前者得到的就是整数和,后者就是个数。最后一除。搞定,一次行动操作完成了求均值。
163 | 从这种思想中我们发现,对于RDD的一些扩展操作我们就可以将其扩展为PariRDD,因为转化操作在真正执行的时候是每个节点并行转化存在自己那里的元素的,所以效率很高。
164 | 也不应该拘泥于上述实现方式,只要是通过一次执行操作能获得正确的结果的都是好的。比如不用PairRDD而是借助Spark提供的累加器和RDD的foreach方法也可以实现这个一次循环求出均值的效果。读者可以自己探索下,这里不再赘述。
165 |
166 | ### 3.2 WordCount的例子
167 | 数每个单词出现的个数,是大数据分析的Hello World。通过前面的方法介绍,我们明显可以看出最简单的数单词就是直接调用`countByValue`方法。但是我们需要注意的是该方法是个行动操作,会将最后的结果直接返回给驱动程序,有时候我们想要的可能是将结果存储到HDFS中。
168 | 下面给出能实现WordCount的程序(函数式)
169 | ```java
170 | //!!!!!!一定注意在聚合操作之前要将聚合的KV类型提前注册如下
171 | static SparkConf conf = new SparkConf().setAppName("app")
172 | .registerKryoClasses(new Class[]{
173 | org.apache.hadoop.io.IntWritable.class,
174 | org.apache.hadoop.io.Text.class
175 | });
176 | static JavaSparkContext sc = new JavaSparkContext(conf);
177 |
178 | public static void main(String[] a){
179 |
180 | sc.textFile("hdfs://192.168.4.106:9000/README.md")
181 |
182 | //一行一个元素--->一个单词一个元素
183 | .flatMap(new FlatMapFunction() {
184 | @Override
185 | public Iterator call(String o) throws Exception {
186 | return Arrays.asList(o.split(" ")).iterator();
187 | }
188 | })
189 |
190 | //一个单词一个元素--->[单词,1]为元素
191 | .mapToPair(new PairFunction() {
192 | @Override
193 | public Tuple2 call(String s) throws Exception {
194 | return new Tuple2<>(new Text(s),new IntWritable(1));
195 | }
196 | })
197 |
198 | //对相同的单词 的个数进行聚合(相加)
199 | .reduceByKey(new Function2() {
200 | @Override
201 | public IntWritable call(IntWritable i, IntWritable i2) throws Exception {
202 | return new IntWritable(i.get()+i2.get());
203 | }
204 | })
205 |
206 | //结果保存到HDFS另一个文件下,以便日后使用
207 | .saveAsHadoopFile("hdfs://192.168.4.106:9000/res2",Text.class,
208 | IntWritable.class,SequenceFileOutputFormat.class);
209 | }
210 | ```
211 | # 4 小结
212 | 最初版本就有的`RDD`是经常使用的编程模型封装了很多基本的操作,在后面会提到另外两个模型`DataFrames`和`DataSet`,也有着相似的API。
213 |
214 |
215 |
--------------------------------------------------------------------------------
/Spark/SparkSQL.md:
--------------------------------------------------------------------------------
1 | # SparkSQL
2 | # 1 简介
3 | SparkSQL的功能和Hive很像,可以对结构或半结构化的文件,以表的形式进行查询。SparkSQL效率要更高一些,在Hive那一节中我们也可以看到在执行MR操作的时候,提示`Hive-On-MR`已经不被赞成使用了。
4 |
5 | SparkSQL用法上也更为简单:
6 | 可以选择直接执行sql语句,也可以通过封装好的方法来执行操作。
7 | 可以在本机查询本地的文件,也可以放到集群上查询。
8 | 可以借助Hive,也可以独立运行。
9 |
10 | 灵活性太大,有时候使得学习起来变得复杂。本节我们先以本地模式运行`SparkSQL`,且不借助`Hive`,来快速了解基本的操作方法,之后再结合Hive和集群介绍生产环境下的使用方式。
11 |
12 | # 2 快速开始
13 | 其实Spark的[官方文档](http://spark.apache.org/docs/latest/sql-programming-guide.html)写的非常详细,建议去读一下。
14 | 加入依赖
15 | ```
16 |
17 | org.apache.spark
18 | spark-core_2.10
19 | 2.2.0
20 |
21 |
22 | org.apache.spark
23 | spark-hive_2.10
24 | 2.2.0
25 |
26 | ```
27 | 切入点是`SparkSession`而不是之前的`SparkContext`
28 | ```
29 | SparkSession spark = SparkSession
30 | .builder()
31 | .appName("Spark SQL")
32 | .master("local")
33 | .getOrCreate();
34 | ```
35 | 这部分的示例代码可以参考[SparkDemo仓库](https://github.com/sunwu51/SparkDemo)的[SqlDemo.java](https://github.com/sunwu51/SparkDemo/blob/master/src/main/java/SqlDemo.java)
36 | ## 2.1 查询JSON文件
37 | 注意在大数据里,JSON文件一般是一行是一个JSON对象的文件。
38 | 读取并展示JSON内容:
39 | ```java
40 | Dataset df = spark.read().json("1.json");
41 | df.show();
42 | //+---+-----+-------+
43 | //|age|group| name|
44 | //+---+-----+-------+
45 | //| 23| 1| Frank|
46 | //| 32| 2| David|
47 | //| 34| 1| Lily|
48 | //| 27| 1|Johnson|
49 | //+---+-----+-------+
50 | ```
51 | df写入json文件:
52 | (明明是DataSet为什么叫df呢?因为早期版本read返回的是DataFrame,2.0后具有更好特性的DataSet替换掉了DataFrame)
53 | ```
54 | df.write().json("2.json")
55 | ```
56 | 运行复杂的SQL查询语句:
57 | ```java
58 | Dataset df = spark.read().json("1.json");
59 |
60 | //建立视图--相当于起个表名方便之后sql查询
61 | df.createOrReplaceTempView("people");
62 |
63 | //并没有告诉age字段是整形,即使json中是字符串"23"也能自动转整数
64 | Dataset sqlDF = spark.sql("select name,age from people where age>14 and name like '%Frank%'");
65 |
66 | sqlDF.show();
67 | //+--------+---+
68 | //| name|age|
69 | //+--------+---+
70 | //| Frank| 23|
71 | //|Franklin| 42|
72 | //+--------+---+
73 | ```
74 | 使用函数封装运行查询(等价于SQL查询):
75 | ```java
76 | Dataset df = spark.read().json("1.json");
77 |
78 | Dataset sqlDF = df.where(col("age").between("22","36")).where(col("name").like("%John%")).select(col("*"));
79 |
80 | sqlDF.show();
81 | //+---+-----+-------+
82 | //|age|group| name|
83 | //+---+-----+-------+
84 | //| 27| 1|Johnson|
85 | //+---+-----+-------+
86 |
87 | sqlDF = df.groupBy("group").agg(col("group"), max("age"),sum("age"));
88 |
89 | sqlDF.show();
90 | //+-----+-----+--------+--------+
91 | //|group|group|max(age)|sum(age)|
92 | //+-----+-----+--------+--------+
93 | //| 1| 1| 34| 84.0|
94 | //| 3| 3| 42| 42.0|
95 | //| 2| 2| 32| 53.0|
96 | //+-----+-----+--------+--------+
97 | ```
98 | 不想存json,Spark默认支持6种文件格式的读写`'sequencefile', 'rcfile', 'orc', 'parquet', 'textfile' and 'avro'.`。默认的save和load方法是`parquet`格式。
99 | ```
100 | df.write().save("file");
101 | Dataset newdf = spark.read().load("file");
102 | ```
103 | ## 2.2 spark on hive
104 | 需要将hadoop的配置文件`hdfs-site.xml` `core-site.xml`以及`hive的hive-site.xml`放到`$SPARK_HOME/conf`里
105 | ```java
106 | //创建自己的仓库存储目录(hive的在/user/hive/warehouse如果想使用hive已有的表则配置这个路径)
107 | String warehouseLocation = new File("/spark-hive-warehouse").getAbsolutePath();
108 | SparkSession spark = SparkSession
109 | .builder()
110 | .appName("Spark Hive")
111 | .config("spark.sql.warehouse.dir", warehouseLocation)
112 | .enableHiveSupport()
113 | .getOrCreate();
114 |
115 | //enableHiveSupport
116 | //可以直接运行hql
117 | spark.sql("CREATE TABLE test(id int,name string,age int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'");
118 |
119 | spark.sql("load data local inpath '/root/2.txt' into table test");
120 | spark.sql("select * from test").show();
121 | ```
122 | 
123 | # 3 小结
124 | SparkSQL可以对结构化/半结构化文件,如json进行快速查询。通过`SparkOnHive`我们可以像使用hive客户端工具一样的使用SparkSQL,有着比Hive更高的效率,Spark将细节屏蔽,因而用起来非常方便。
125 | 对于sql不能应付的灵活数据分析处理,Spark允许我们将`DataSet`转化为`JavaRDD`类型,使用RDD的API进行分析和操作。【这里还有个DataFrames的概念因为新的API中都开始用DataSet所以就不讲了】
126 | 需要注意如果运行SparkOnHive的程序,必须先安装Hive并且将配置文件hive-site.xml拷贝到spark的conf目录。Spark只是将底层计算框架进行了替换,而上层的查询语句(HiveSql)以及表的结构化方式仍然需要Hive。
127 | 另外提一句,DF也是惰性的,在调用行动方法之前,他也是只代表我们产生想要结果需要对数据执行的步骤,而通常我们都理解成了这些步骤的结果。
128 | *Datasets are "lazy", i.e. computations are only triggered when an action is invoked. Internally, a Dataset represents a logical plan that describes the computation required to produce the data.*
129 |
130 |
131 |
132 |
--------------------------------------------------------------------------------
/Spark/SparkStream.md:
--------------------------------------------------------------------------------
1 | # SparkStream
2 | # 1 简介
3 | 之前讲的数据分析方式都是对离线文件的数据进行分析,对于大型的文件库,我们可以通过HDFS进行分布式文件存储,而对于半结构化或者结构化的数据,如Json文件,我们可以运行SparkSQL或者Hive直接用Sql语句进行查询。当然也可以选择在存储的时候使用Hbase这种非关系型数据库,牺牲条件查询的灵活性以求更快的查询速度。对于没有明显结构性或者需要更灵活的分析的情况,我们则需要用Spark编程分析。
4 | SparkStream可以进行实时的流式数据分析,为什么需要流式数据分析呢?有些时候我们必须及时作出响应,如果等到数据传完或者一段时间之后再去分析数据就已经来不及了。SparkStream就是这样的可以实时分析数据的框架,另一个也很有名的框架叫Storm,这里没有专门写文章介绍。两者区别是Spark更擅长滑动时间窗口下的数据集分析,例如十分钟内的数据分析。而Storm则注重高并发情况下的实时性,立即响应,例如淘宝双十一成交订单数。
5 | SparkStream在执行的时候需要明白集群过程的分布方式,接收数据的点一般设置为一个来收数据,接收之后的数据集处理分到多个worker上面去执行。
6 | 
7 |
8 | # 2 WordCount
9 | ```java
10 | //这里启动的是SparkStreamContext
11 | //至少设置两个节点,否则因为数据至少在俩节点备份
12 | SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
13 | JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
14 |
15 |
16 | //直接连接本地9999端口TCP套接字服务,来接收数据[lines是回车隔开的行元素集合]
17 | JavaReceiverInputDStream lines = jssc.socketTextStream("localhost",9999);
18 |
19 | //DStream的操作和RDD的类似,我们照抄之前的WordCount步骤
20 | JavaPairDStream wc = lines.flatMap(
21 | new FlatMapFunction() {
22 | public Iterator call(String s) throws Exception {
23 | return Arrays.asList(s.split(" ")).iterator();
24 | }
25 | })
26 | .mapToPair(new PairFunction() {
27 | public Tuple2 call(String s) throws Exception {
28 | return new Tuple2(s,1);
29 | }
30 | })
31 | .reduceByKey(new Function2() {
32 | public Integer call(Integer integer, Integer integer2) throws Exception {
33 | return integer+integer2;
34 | }
35 | })
36 |
37 | //到这里已经得到结果,但是流式分析中需要应用到窗口中,因为上述统计的W-C是一簇一簇的数据流中的W-C
38 | //需要按照一定的时间窗口将簇聚合,如下为每10s钟聚合一次(滑动时间),聚合的是30s内的数据(窗口时间)
39 | .reduceByKeyAndWindow(
40 | new Function2() {
41 | @Override
42 | public Integer call(Integer integer, Integer integer2) throws Exception {
43 | return integer+integer2;
44 | }
45 | },
46 | Durations.seconds(30),
47 | Durations.seconds(10)
48 | );
49 |
50 |
51 | wc.print();
52 | jssc.start();
53 | jssc.awaitTermination();
54 | ```
55 | 如果将master设为3个有可能有两个负责接收,一个负责处理
56 | 
57 | # 3 小结
58 | 流式数据分析的API,DStream的操作和之前的RDD操作是一样的,我们只需要将其理解为一小簇的RDD,在进行一样的操作,相当于是RDD的微分的操作,要看到实际数据还需要框定积分的上下限进行聚合,即滑动窗口。
59 | 在大数据分析中,一般不太会用上面例子中的TCP服务器进行数据采集,往往常用的是接入Kafka作为消费者获取数据,可以参考[例子](https://github.com/sunwu51/SparkDemo/blob/master/src/main/java/KafkaDemo.java)的写法。
--------------------------------------------------------------------------------
/Spark/conf/slaves:
--------------------------------------------------------------------------------
1 | wy
2 |
--------------------------------------------------------------------------------
/Spark/conf/spark-env.sh:
--------------------------------------------------------------------------------
1 | export JAVA_HOME=/opt/ins/jdk
2 | export SPARK_MASTER_WEBUI_PORT=18080
3 | export HADOOP_CONF_DIR=/opt/ins/hadoop/etc/hadoop
4 | export MASTER=spark://192.168.4.106:7077
5 | export SPARK_WORKER_CORES=1
6 |
7 |
--------------------------------------------------------------------------------
/Spark/img/spark.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark.gif
--------------------------------------------------------------------------------
/Spark/img/spark1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark1.png
--------------------------------------------------------------------------------
/Spark/img/spark2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark2.gif
--------------------------------------------------------------------------------
/Spark/img/spark3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark3.gif
--------------------------------------------------------------------------------
/Spark/img/spark4.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark4.gif
--------------------------------------------------------------------------------
/Spark/img/spark5.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark5.gif
--------------------------------------------------------------------------------
/Spark/img/spark6.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark6.gif
--------------------------------------------------------------------------------
/Spark/img/spark7.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark7.gif
--------------------------------------------------------------------------------
/Spark/img/spark8.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/spark8.gif
--------------------------------------------------------------------------------
/Spark/img/sparksql1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/sparksql1.gif
--------------------------------------------------------------------------------
/Spark/img/sparksql2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/sparksql2.gif
--------------------------------------------------------------------------------
/Spark/img/sparkstream.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/sparkstream.gif
--------------------------------------------------------------------------------
/Spark/img/sparkstream.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/sparkstream.png
--------------------------------------------------------------------------------
/Spark/img/sparkstream1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sunwu51/bigdatatutorial/5a02c4998991b55593331ad88b73ccfc769a1d23/Spark/img/sparkstream1.png
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-cayman
--------------------------------------------------------------------------------