![]()
 "
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": 2,
58 | "metadata": {},
59 | "outputs": [
60 | {
61 | "name": "stdout",
62 | "output_type": "stream",
63 | "text": [
64 | "字符串的第一个词为: 原\n",
65 | "字符串的最后一个词为: 。\n",
66 | "字符串的第六到第九个字为: 每一个字\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "print(f\"字符串的第一个词为: {str_text[0]}\") #序列的第一位索引从0开始\n",
72 | "print(f\"字符串的最后一个词为: {str_text[-1]}\") #标点符号算一个字符\n",
73 | "print(f\"字符串的第六到第九个字为: {str_text[5:9]}\") "
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "**注:最后一种为字符串的分片(切片)操作,为左闭右开区间,例如:**\n",
81 | " \n",
82 | "
"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": 2,
58 | "metadata": {},
59 | "outputs": [
60 | {
61 | "name": "stdout",
62 | "output_type": "stream",
63 | "text": [
64 | "字符串的第一个词为: 原\n",
65 | "字符串的最后一个词为: 。\n",
66 | "字符串的第六到第九个字为: 每一个字\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "print(f\"字符串的第一个词为: {str_text[0]}\") #序列的第一位索引从0开始\n",
72 | "print(f\"字符串的最后一个词为: {str_text[-1]}\") #标点符号算一个字符\n",
73 | "print(f\"字符串的第六到第九个字为: {str_text[5:9]}\") "
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "**注:最后一种为字符串的分片(切片)操作,为左闭右开区间,例如:**\n",
81 | " \n",
82 | " "
83 | ]
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "**在分片时,除了可以指定左边界和右边界的索引外,还可以增加第三个值,即步长:**"
90 | ]
91 | },
92 | {
93 | "cell_type": "code",
94 | "execution_count": 3,
95 | "metadata": {},
96 | "outputs": [
97 | {
98 | "name": "stdout",
99 | "output_type": "stream",
100 | "text": [
101 | "abc\n"
102 | ]
103 | }
104 | ],
105 | "source": [
106 | "# [开始:结束:步长]\n",
107 | "print(\"aaabbbccc\"[0:9:3]) "
108 | ]
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "metadata": {},
113 | "source": [
114 | "**字符串为可迭代变量:**"
115 | ]
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": 4,
120 | "metadata": {},
121 | "outputs": [
122 | {
123 | "name": "stdout",
124 | "output_type": "stream",
125 | "text": [
126 | "原!始!文!本!的!每!一!个!字!符!为!一!个!汉!字!。!\n"
127 | ]
128 | }
129 | ],
130 | "source": [
131 | "str_text2 =\"\"\n",
132 | "for i in str_text:\n",
133 | " str_text2 += i+\"!\"\n",
134 | "print(str_text2)"
135 | ]
136 | },
137 | {
138 | "cell_type": "markdown",
139 | "metadata": {},
140 | "source": [
141 | "**字符串基本操作符:**"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 5,
147 | "metadata": {},
148 | "outputs": [
149 | {
150 | "name": "stdout",
151 | "output_type": "stream",
152 | "text": [
153 | "16\n",
154 | "True\n",
155 | "False\n",
156 | "原始文本的每一个字符为一个汉字。原始文本的每一个字符为一个汉字。\n",
157 | "原始文本的每一个字符为一个汉字。!!!!!!\n",
158 | "2\n",
159 | "2\n"
160 | ]
161 | }
162 | ],
163 | "source": [
164 | "# str_text = \"原始文本的每一个字符为一个汉字。\"\n",
165 | "print(len(str_text)) #字符串长度\n",
166 | "print('原始文本' in str_text) #判断\n",
167 | "print('汉字' not in str_text)\n",
168 | "print(str_text*2) #复制\n",
169 | "print(str_text+\"!!!!!!\") #连接\n",
170 | "print(str_text.count(\"一个\")) #计数\n",
171 | "print(str_text.find(\"文本\")) #返回查找内容开头的索引"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "## 2.文本清洗与正则表达式\n",
179 | "\n",
180 | "**现实中的文本数据中不仅包括了中文字符、数字、英文字符等字符,还存在一些网页乱码不需要的内容,需要进行处理:**"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 6,
186 | "metadata": {},
187 | "outputs": [],
188 | "source": [
189 | "with open('金融新闻_example.txt', 'r',encoding='utf-8') as text_file: # 读取中文文本时要注意encoding\n",
190 | " example = text_file.read()"
191 | ]
192 | },
193 | {
194 | "cell_type": "code",
195 | "execution_count": 7,
196 | "metadata": {},
197 | "outputs": [
198 | {
199 | "data": {
200 | "text/plain": [
201 | "'
"
83 | ]
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "**在分片时,除了可以指定左边界和右边界的索引外,还可以增加第三个值,即步长:**"
90 | ]
91 | },
92 | {
93 | "cell_type": "code",
94 | "execution_count": 3,
95 | "metadata": {},
96 | "outputs": [
97 | {
98 | "name": "stdout",
99 | "output_type": "stream",
100 | "text": [
101 | "abc\n"
102 | ]
103 | }
104 | ],
105 | "source": [
106 | "# [开始:结束:步长]\n",
107 | "print(\"aaabbbccc\"[0:9:3]) "
108 | ]
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "metadata": {},
113 | "source": [
114 | "**字符串为可迭代变量:**"
115 | ]
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": 4,
120 | "metadata": {},
121 | "outputs": [
122 | {
123 | "name": "stdout",
124 | "output_type": "stream",
125 | "text": [
126 | "原!始!文!本!的!每!一!个!字!符!为!一!个!汉!字!。!\n"
127 | ]
128 | }
129 | ],
130 | "source": [
131 | "str_text2 =\"\"\n",
132 | "for i in str_text:\n",
133 | " str_text2 += i+\"!\"\n",
134 | "print(str_text2)"
135 | ]
136 | },
137 | {
138 | "cell_type": "markdown",
139 | "metadata": {},
140 | "source": [
141 | "**字符串基本操作符:**"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 5,
147 | "metadata": {},
148 | "outputs": [
149 | {
150 | "name": "stdout",
151 | "output_type": "stream",
152 | "text": [
153 | "16\n",
154 | "True\n",
155 | "False\n",
156 | "原始文本的每一个字符为一个汉字。原始文本的每一个字符为一个汉字。\n",
157 | "原始文本的每一个字符为一个汉字。!!!!!!\n",
158 | "2\n",
159 | "2\n"
160 | ]
161 | }
162 | ],
163 | "source": [
164 | "# str_text = \"原始文本的每一个字符为一个汉字。\"\n",
165 | "print(len(str_text)) #字符串长度\n",
166 | "print('原始文本' in str_text) #判断\n",
167 | "print('汉字' not in str_text)\n",
168 | "print(str_text*2) #复制\n",
169 | "print(str_text+\"!!!!!!\") #连接\n",
170 | "print(str_text.count(\"一个\")) #计数\n",
171 | "print(str_text.find(\"文本\")) #返回查找内容开头的索引"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "## 2.文本清洗与正则表达式\n",
179 | "\n",
180 | "**现实中的文本数据中不仅包括了中文字符、数字、英文字符等字符,还存在一些网页乱码不需要的内容,需要进行处理:**"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 6,
186 | "metadata": {},
187 | "outputs": [],
188 | "source": [
189 | "with open('金融新闻_example.txt', 'r',encoding='utf-8') as text_file: # 读取中文文本时要注意encoding\n",
190 | " example = text_file.read()"
191 | ]
192 | },
193 | {
194 | "cell_type": "code",
195 | "execution_count": 7,
196 | "metadata": {},
197 | "outputs": [
198 | {
199 | "data": {
200 | "text/plain": [
201 | "'通讯社3月6日讯,在周三的投资者开放日活动中,聚飞光电(300303.SZ)董秘殷敬煌介绍,公司的传统优势业务是面向智能手机为主的智能终端产品的小尺寸背光LED;\\\\u3000\\\\u3000\\\\u3000而在小尺寸背光 LED 的基础上,公司向中大尺寸背光 LED 市场展开了扩张,同时积极布局潜力无限的照明LED市场。\\\\n\\\\n\\\\n\\\\n凭借着产品的高性价比、产业链精益化管理效率以及客户积累上的优势,2013年实现超过9亿元的发货额,净利润首次突破亿元。
'" 202 | ] 203 | }, 204 | "execution_count": 7, 205 | "metadata": {}, 206 | "output_type": "execute_result" 207 | } 208 | ], 209 | "source": [ 210 | "example" 211 | ] 212 | }, 213 | { 214 | "cell_type": "code", 215 | "execution_count": 8, 216 | "metadata": {}, 217 | "outputs": [ 218 | { 219 | "data": { 220 | "text/plain": [ 221 | "'通讯社3月6日讯,在周三的投资者开放日活动中,聚飞光电(300303.SZ)董秘殷敬煌介绍,公司的传统优势业务是面向智能手机为主的智能终端产品的小尺寸背光LED;\\\\u3000\\\\u3000\\\\u3000而在小尺寸背光 LED 的基础上,公司向中大尺寸背光 LED 市场展开了扩张,同时积极布局潜力无限的照明LED市场。\\\\n\\\\n\\\\n\\\\n凭借着产品的高性价比、产业链精益化管理效率以及客户积累上的优势,2013年实现超过9亿元的发货额,净利润首次突破亿元。
'" 222 | ] 223 | }, 224 | "execution_count": 8, 225 | "metadata": {}, 226 | "output_type": "execute_result" 227 | } 228 | ], 229 | "source": [ 230 | "example.replace('
', '') # 将html标记
替换为空\n", 231 | "#
,
难道不可以一起删除吗?"
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {},
237 | "source": [
238 | "**简单的文本清洗可以用``replace``方法处理,但对于复杂结构的文本可以使用``正则表达式``来匹配对应的乱码并进行处理:**"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 9,
244 | "metadata": {},
245 | "outputs": [
246 | {
247 | "name": "stdout",
248 | "output_type": "stream",
249 | "text": [
250 | "通讯社3月6日讯,在周三的投资者开放日活动中,聚飞光电(300303.SZ)董秘殷敬煌介绍,公司的传统优势业务是面向智能手机为主的智能终端产品的小尺寸背光LED;\\u3000\\u3000\\u3000而在小尺寸背光 LED 的基础上,公司向中大尺寸背光 LED 市场展开了扩张,同时积极布局潜力无限的照明LED市场。\\n\\n\\n\\n凭借着产品的高性价比、产业链精益化管理效率以及客户积累上的优势,2013年实现超过9亿元的发货额,净利润首次突破亿元。\n"
251 | ]
252 | }
253 | ],
254 | "source": [
255 | "import re\n",
256 | "print(re.sub(r'(<.*?>)','',example)) #re.sub(r 查找的内容,替换的内容,传入文本)\n",
257 | "# <.*?>代表将左边界为<和右边界为>的文本内容进行匹配"
258 | ]
259 | },
260 | {
261 | "cell_type": "code",
262 | "execution_count": 10,
263 | "metadata": {},
264 | "outputs": [
265 | {
266 | "name": "stdout",
267 | "output_type": "stream",
268 | "text": [
269 | "通讯社3月6日讯,在周三的投资者开放日活动中,聚飞光电(300303.SZ)董秘殷敬煌介绍,公司的传统优势业务是面向智能手机为主的智能终端产品的小尺寸背光LED;而在小尺寸背光 LED 的基础上,公司向中大尺寸背光 LED 市场展开了扩张,同时积极布局潜力无限的照明LED市场。凭借着产品的高性价比、产业链精益化管理效率以及客户积累上的优势,2013年实现超过9亿元的发货额,净利润首次突破亿元。\n"
270 | ]
271 | }
272 | ],
273 | "source": [
274 | "print(re.sub(r'(<.*?>)|(\\\\n)|\\\\u3000', '', example))\n",
275 | "# 可以利用()和|同时替换多个内容"
276 | ]
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "metadata": {},
281 | "source": [
282 | "**常见正则表达式符号:**\n",
283 | "* ?匹配零次或一次前面的分组。\n",
284 | "* *匹配零次或多次前面的分组。\n",
285 | "* +匹配一次或多次前面的分组。\n",
286 | "* {n}匹配n 次前面的分组。\n",
287 | "* {n,}匹配n 次或更多前面的分组。\n",
288 | "* {,m}匹配零次到m 次前面的分组。\n",
289 | "* {n,m}匹配至少n 次、至多m 次前面的分组。\n",
290 | "* {n,m}?或*?或+?对前面的分组进行非贪心匹配。\n",
291 | "* ^hello 意味着字符串必须以hello开始。\n",
292 | "* hello$意味着字符串必须以hello结束。\n",
293 | "* .匹配所有字符,换行符除外。\n",
294 | "* \\d、\\w 和\\s 分别匹配数字、单词和空格。\n",
295 | "* \\D、\\W 和\\S 分别匹配除数字、单词和空格外的所有字符。\n",
296 | "* [abc]匹配方括号内的任意字符(诸如a、b 或c)。\n",
297 | "* [^abc]匹配不在方括号内的任意字符。\n",
298 | "\n",
299 | "**文本正则表达的匹配十分灵活多变,不用刻意去记忆,可以根据今后的具体问题再去查找对应的匹配方法**"
300 | ]
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {},
305 | "source": [
306 | "## 3.中文切词分词方法\n",
307 | "\n",
308 | "**将一个连续文本分解为词的过程称为分词,先考虑一个英文的情况:**"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 11,
314 | "metadata": {},
315 | "outputs": [
316 | {
317 | "name": "stdout",
318 | "output_type": "stream",
319 | "text": [
320 | "['i', 'love', 'natural', 'language', 'processing', '.']\n"
321 | ]
322 | }
323 | ],
324 | "source": [
325 | "eng_text = 'I love natural language processing.'\n",
326 | "eng_text = eng_text.lower() #所有字母转化为小写\n",
327 | "eng_text = eng_text.replace('.',' .') #在句号前插入空格\n",
328 | "words = eng_text.split(' ') #split方法将字符串按照引号内的内容(此例子中为空格)进行切分并传入一个list\n",
329 | "print(words)\n",
330 | "# 可以用正则表达式re.split('(\\w+)?',eng_text)直接实现,不必在句号前先插入空格"
331 | ]
332 | },
333 | {
334 | "cell_type": "markdown",
335 | "metadata": {},
336 | "source": [
337 | "**中文不像英文一样词和词之间是靠空格隔开的,单个的字并不能形成语义,将词确定下来是中文自然语言理解的第一步**:"
338 | ]
339 | },
340 | {
341 | "cell_type": "code",
342 | "execution_count": 12,
343 | "metadata": {},
344 | "outputs": [
345 | {
346 | "name": "stdout",
347 | "output_type": "stream",
348 | "text": [
349 | "['中', '文', '以', '字', '为', '单', '位', ',', '单', '个', '的', '字', '连', '成', '词', '才', '能', '表', '达', '语', '义', '。']\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "words = []\n",
355 | "cn_text = '中文以字为单位,单个的字连成词才能表达语义。'\n",
356 | "for i in cn_text:\n",
357 | " words.append(i)\n",
358 | "print(words)"
359 | ]
360 | },
361 | {
362 | "cell_type": "markdown",
363 | "metadata": {},
364 | "source": [
365 | "**调用``jieba``来进行中文分词:**"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 13,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "name": "stderr",
375 | "output_type": "stream",
376 | "text": [
377 | "Building prefix dict from the default dictionary ...\n",
378 | "Loading model from cache C:\\Users\\PC\\AppData\\Local\\Temp\\jieba.cache\n",
379 | "Loading model cost 0.643 seconds.\n",
380 | "Prefix dict has been built successfully.\n"
381 | ]
382 | },
383 | {
384 | "name": "stdout",
385 | "output_type": "stream",
386 | "text": [
387 | "['中文', '以字', '为', '单位', ',', '单个', '的', '字', '连成', '词', '才能', '表达', '语义', '。']\n"
388 | ]
389 | }
390 | ],
391 | "source": [
392 | "import jieba # 若还未安装jieba,可以使用pip install jieba或conda install jieba(基于Anaconda)进行安装\n",
393 | "words = jieba.lcut(cn_text) #默认为精确模式\n",
394 | "print(words)"
395 | ]
396 | },
397 | {
398 | "cell_type": "code",
399 | "execution_count": 14,
400 | "metadata": {},
401 | "outputs": [
402 | {
403 | "name": "stdout",
404 | "output_type": "stream",
405 | "text": [
406 | "['我', '今天', '学习', '了', '可', '接纳', '资产', '净值', '和', '累积', '优先股', '股息', '两个', '概念']\n"
407 | ]
408 | }
409 | ],
410 | "source": [
411 | "words = jieba.lcut('我今天学习了可接纳资产净值和累积优先股股息两个概念') \n",
412 | "print(words)"
413 | ]
414 | },
415 | {
416 | "cell_type": "markdown",
417 | "metadata": {},
418 | "source": [
419 | "**在实际情况中,可能会出现一些复杂专有词汇不想被切分开,可以调用`add_word`方法添加专有名词:**"
420 | ]
421 | },
422 | {
423 | "cell_type": "code",
424 | "execution_count": 15,
425 | "metadata": {},
426 | "outputs": [
427 | {
428 | "name": "stdout",
429 | "output_type": "stream",
430 | "text": [
431 | "['我', '今天', '学习', '了', '可接纳资产净值', '和', '累积', '优先股', '股息', '两个', '概念']\n"
432 | ]
433 | }
434 | ],
435 | "source": [
436 | "jieba.add_word('可接纳资产净值') \n",
437 | "words = jieba.lcut('我今天学习了可接纳资产净值和累积优先股股息两个概念') \n",
438 | "print(words)"
439 | ]
440 | },
441 | {
442 | "cell_type": "markdown",
443 | "metadata": {},
444 | "source": [
445 | "**也可以使用`load_userdict`方法,批量添加用户自定义词典(UTF-8编码):**\n",
446 | " 近年来,自然语言处理处于快速发展阶段。各种词表、语义语法词典、语料库等数据资源的日益丰富,词语切分、词性标注、句法分析等技术的快速进步,各种新理论、新方法、新模型的出现推动了自然语言处理研究的繁荣。互联网与移动互联网和世界经济社会一体化的潮流对自然语言处理技术的迫切需求,为自然语言处理研究发展提供了强大的市场动力。我国直到上世纪80年代中期才开始较大规模和较系统的自然语言处理研究,尽管较国际水平尚有较大差距,但已经有了比较稳定的研究内容,包括语料库、知识库等数据资源建设,词语切分、句法分析等基础技术,以及信息检索、机器翻译等应用技术。当前国内外出现了一批基于自然语言处理技术的应用系统。自然语言处理的对象有词、句子、篇章和段落、文本等,但是大多归根到底在句子的处理上,自然语言处理中的自然语言句子级分析技术,可以大致分为词法分析、句法分析、语义分析三个层面。\n"
497 | ]
498 | }
499 | ],
500 | "source": [
501 | "with open('词频统计example.txt', 'r',encoding='utf-8') as text_file: # 读取txt文件\n",
502 | " example = text_file.read()\n",
503 | "print(example)"
504 | ]
505 | },
506 | {
507 | "cell_type": "code",
508 | "execution_count": 18,
509 | "metadata": {},
510 | "outputs": [
511 | {
512 | "name": "stdout",
513 | "output_type": "stream",
514 | "text": [
515 | "自然语言理解和自然语言生成是自然语言处理的两大内核,机器翻译是自然语言理解方面最早的研究工作。自然语言处理的主要任务是:研究表示语言能力和语言应用的模型,建立和实现计算框架并提出相应的方法不断地完善模型,根据这样的语言模型设计有效地实现自然语言通信的计算机系统,并研讨关于系统的评测技术,最终实现用自然语言与计算机进行通信。目前,具有一定自然语言处理能力的典型应用包括计算机信息检索系统、多语种翻译系统等。语言是逻辑思维和交流的工具,宇宙万物中,只有人类才具有这种高级功能。要实现人与计算机间采用自然语言通信,必须使计算机同时具备自然语言理解和自然语言生成两大功能。因此,自然语言处理作为人工智能的一个子领域,其主要目的就包括两个方面:自然语言理解,让计算机理解自然语言文本的意义;自然语言生成,让计算机能以自然语言文本来表达给定的意图、思想等。自然语言是人类智慧的结晶,自然语言处理是人工智能中最为困难的问题之一,而对自然语言处理的研究也是充满魅力和挑战的。近年来,自然语言处理处于快速发展阶段。各种词表、语义语法词典、语料库等数据资源的日益丰富,词语切分、词性标注、句法分析等技术的快速进步,各种新理论、新方法、新模型的出现推动了自然语言处理研究的繁荣。互联网与移动互联网和世界经济社会一体化的潮流对自然语言处理技术的迫切需求,为自然语言处理研究发展提供了强大的市场动力。我国直到上世纪80年代中期才开始较大规模和较系统的自然语言处理研究,尽管较国际水平尚有较大差距,但已经有了比较稳定的研究内容,包括语料库、知识库等数据资源建设,词语切分、句法分析等基础技术,以及信息检索、机器翻译等应用技术。当前国内外出现了一批基于自然语言处理技术的应用系统。自然语言处理的对象有词、句子、篇章和段落、文本等,但是大多归根到底在句子的处理上,自然语言处理中的自然语言句子级分析技术,可以大致分为词法分析、句法分析、语义分析三个层面。\n"
516 | ]
517 | }
518 | ],
519 | "source": [
520 | "example = re.sub(r'(<.*?>)','',example) #正则表达式清洗<>内容\n",
521 | "print(example)"
522 | ]
523 | },
524 | {
525 | "cell_type": "code",
526 | "execution_count": 19,
527 | "metadata": {},
528 | "outputs": [
529 | {
530 | "name": "stdout",
531 | "output_type": "stream",
532 | "text": [
533 | "['自然语言', '理解', '和', '自然语言', '生成', '是', '自然语言处理', '的', '两大', '内核', ',', '机器翻译', '是', '自然语言', '理解', '方面', '最早', '的', '研究', '工作', '。', '自然语言处理', '的', '主要', '任务', '是', ':', '研究', '表示', '语言', '能力', '和', '语言', '应用', '的', '模型', ',', '建立', '和', '实现', '计算', '框架', '并', '提出', '相应', '的', '方法', '不断', '地', '完善']\n"
534 | ]
535 | }
536 | ],
537 | "source": [
538 | "jieba.add_word('自然语言处理') \n",
539 | "words = jieba.lcut(example) #jieba分词\n",
540 | "print(words[:50])"
541 | ]
542 | },
543 | {
544 | "cell_type": "markdown",
545 | "metadata": {},
546 | "source": [
547 | "**在进行词频分析时,一般我们会希望去除“的”、“是”以及标点符号等不重要的词汇,可以创建一个停用词典来删除对于研究并无实际贡献的词汇:**\n",
548 | " 近年来,自然语言处理处于快速发展阶段。各种词表、语义语法词典、语料库等数据资源的日益丰富,词语切分、词性标注、句法分析等技术的快速进步,各种新理论、新方法、新模型的出现推动了自然语言处理研究的繁荣。互联网与移动互联网和世界经济社会一体化的潮流对自然语言处理技术的迫切需求,为自然语言处理研究发展提供了强大的市场动力。我国直到上世纪80年代中期才开始较大规模和较系统的自然语言处理研究,尽管较国际水平尚有较大差距,但已经有了比较稳定的研究内容,包括语料库、知识库等数据资源建设,词语切分、句法分析等基础技术,以及信息检索、机器翻译等应用技术。当前国内外出现了一批基于自然语言处理技术的应用系统。自然语言处理的对象有词、句子、篇章和段落、文本等,但是大多归根到底在句子的处理上,自然语言处理中的自然语言句子级分析技术,可以大致分为词法分析、句法分析、语义分析三个层面。
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/金融新闻_example.txt:
--------------------------------------------------------------------------------
1 | 通讯社3月6日讯,在周三的投资者开放日活动中,聚飞光电(300303.SZ)董秘殷敬煌介绍,公司的传统优势业务是面向智能手机为主的智能终端产品的小尺寸背光LED;\u3000\u3000\u3000而在小尺寸背光 LED 的基础上,公司向中大尺寸背光 LED 市场展开了扩张,同时积极布局潜力无限的照明LED市场。\n\n\n\n凭借着产品的高性价比、产业链精益化管理效率以及客户积累上的优势,2013年实现超过9亿元的发货额,净利润首次突破亿元。
--------------------------------------------------------------------------------
/Chapter 3 经典文本向量化方法/Chapter 3 经典文本向量化方法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | " \n",
174 | "(2)计算逆文档频率IDF = log(D/d),D表示语料中所有的文档总数,d表示语料中出现某个词的文档数量。 \n",
175 | "(2)最终值为两者的乘积:TF*IDF"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "**调用sklearn库进行TFIDF计算**"
183 | ]
184 | },
185 | {
186 | "cell_type": "code",
187 | "execution_count": 50,
188 | "metadata": {},
189 | "outputs": [
190 | {
191 | "data": {
192 | "text/plain": [
193 | " "
447 | ]
448 | },
449 | {
450 | "cell_type": "code",
451 | "execution_count": 16,
452 | "metadata": {},
453 | "outputs": [
454 | {
455 | "name": "stdout",
456 | "output_type": "stream",
457 | "text": [
458 | "['我', '今天', '学习', '了', '可接纳资产净值', '和', '累积优先股股息', '两个', '概念']\n"
459 | ]
460 | }
461 | ],
462 | "source": [
463 | "jieba.load_userdict('jieba自定义词典_example.txt')\n",
464 | "words = jieba.lcut('我今天学习了可接纳资产净值和累积优先股股息两个概念') \n",
465 | "print(words)"
466 | ]
467 | },
468 | {
469 | "cell_type": "markdown",
470 | "metadata": {},
471 | "source": [
472 | "**更多关于jieba库的使用可以参考https://github.com/fxsjy/jieba ,其他的中文分词工具有:**\n",
473 | "* `THULAC`: https://github.com/thunlp/THULAC\n",
474 | "* `pkuseg`: https://github.com/lancopku/pkuseg-python\n",
475 | " "
476 | ]
477 | },
478 | {
479 | "cell_type": "markdown",
480 | "metadata": {},
481 | "source": [
482 | "## 4.词频统计\n",
483 | "\n",
484 | "**词频统计任务会结合上述学习到的文本读取,清洗,分词等内容,接下来以一个例子进行回顾并进一步学习:**"
485 | ]
486 | },
487 | {
488 | "cell_type": "code",
489 | "execution_count": 17,
490 | "metadata": {},
491 | "outputs": [
492 | {
493 | "name": "stdout",
494 | "output_type": "stream",
495 | "text": [
496 | "自然语言理解和自然语言生成是自然语言处理的两大内核,机器翻译是自然语言理解方面最早的研究工作。
"
447 | ]
448 | },
449 | {
450 | "cell_type": "code",
451 | "execution_count": 16,
452 | "metadata": {},
453 | "outputs": [
454 | {
455 | "name": "stdout",
456 | "output_type": "stream",
457 | "text": [
458 | "['我', '今天', '学习', '了', '可接纳资产净值', '和', '累积优先股股息', '两个', '概念']\n"
459 | ]
460 | }
461 | ],
462 | "source": [
463 | "jieba.load_userdict('jieba自定义词典_example.txt')\n",
464 | "words = jieba.lcut('我今天学习了可接纳资产净值和累积优先股股息两个概念') \n",
465 | "print(words)"
466 | ]
467 | },
468 | {
469 | "cell_type": "markdown",
470 | "metadata": {},
471 | "source": [
472 | "**更多关于jieba库的使用可以参考https://github.com/fxsjy/jieba ,其他的中文分词工具有:**\n",
473 | "* `THULAC`: https://github.com/thunlp/THULAC\n",
474 | "* `pkuseg`: https://github.com/lancopku/pkuseg-python\n",
475 | " "
476 | ]
477 | },
478 | {
479 | "cell_type": "markdown",
480 | "metadata": {},
481 | "source": [
482 | "## 4.词频统计\n",
483 | "\n",
484 | "**词频统计任务会结合上述学习到的文本读取,清洗,分词等内容,接下来以一个例子进行回顾并进一步学习:**"
485 | ]
486 | },
487 | {
488 | "cell_type": "code",
489 | "execution_count": 17,
490 | "metadata": {},
491 | "outputs": [
492 | {
493 | "name": "stdout",
494 | "output_type": "stream",
495 | "text": [
496 | "自然语言理解和自然语言生成是自然语言处理的两大内核,机器翻译是自然语言理解方面最早的研究工作。 "
549 | ]
550 | },
551 | {
552 | "cell_type": "code",
553 | "execution_count": 20,
554 | "metadata": {},
555 | "outputs": [
556 | {
557 | "name": "stdout",
558 | "output_type": "stream",
559 | "text": [
560 | "['自然语言', '理解', '自然语言', '生成', '自然语言处理', '两大', '内核', '机器翻译', '自然语言', '理解', '方面', '最早', '研究', '工作', '自然语言处理', '主要', '任务', '研究', '表示', '语言', '能力', '语言', '应用', '模型', '建立', '实现', '计算', '框架', '提出', '相应', '方法', '不断', '完善', '模型', '根据', '这样', '语言', '模型', '设计', '有效', '实现', '自然语言', '通信', '计算机系统', '研讨', '关于', '系统', '评测', '技术', '最终']\n"
561 | ]
562 | }
563 | ],
564 | "source": [
565 | "with open('停用词典.txt', 'r',encoding='utf-8') as f: # 停用词典\n",
566 | " stopwords = [s.rstrip() for s in f.readlines()] #.readlines()\n",
567 | "new_words = []\n",
568 | "for w in words:\n",
569 | " if w not in stopwords:\n",
570 | " new_words.append(w)\n",
571 | "print(new_words[:50])"
572 | ]
573 | },
574 | {
575 | "cell_type": "markdown",
576 | "metadata": {},
577 | "source": [
578 | "**词频统计:**"
579 | ]
580 | },
581 | {
582 | "cell_type": "code",
583 | "execution_count": 21,
584 | "metadata": {},
585 | "outputs": [
586 | {
587 | "name": "stdout",
588 | "output_type": "stream",
589 | "text": [
590 | "总词数: 283\n",
591 | "不重复的词数: 183\n"
592 | ]
593 | }
594 | ],
595 | "source": [
596 | "print(f\"总词数: {len(new_words)}\") \n",
597 | "print(f\"不重复的词数: {len(set(new_words))}\") "
598 | ]
599 | },
600 | {
601 | "cell_type": "code",
602 | "execution_count": 22,
603 | "metadata": {},
604 | "outputs": [
605 | {
606 | "name": "stdout",
607 | "output_type": "stream",
608 | "text": [
609 | "自然语言 14\n",
610 | "自然语言处理 14\n",
611 | "研究 7\n",
612 | "技术 7\n",
613 | "理解 5\n"
614 | ]
615 | }
616 | ],
617 | "source": [
618 | "counts = {} #使用字典得到每个词出现的次数\n",
619 | "for word in new_words:\n",
620 | " counts[word] = counts.get(word,0)+1\n",
621 | "\n",
622 | "# 也可以直接调用函数Counter得到counts:\n",
623 | "# from collections import Counter\n",
624 | "# counts = Counter(new_words)\n",
625 | "\n",
626 | "counts = list(counts.items()) #转化为列表格式\n",
627 | "counts.sort(key = lambda x:x[1],reverse=True) #对词频进行排序\n",
628 | "for i in range(5): #展示出现次数最多的5个词\n",
629 | " print(counts[i][0],counts[i][1])"
630 | ]
631 | },
632 | {
633 | "cell_type": "markdown",
634 | "metadata": {},
635 | "source": [
636 | "## 5.绘制词云图"
637 | ]
638 | },
639 | {
640 | "cell_type": "code",
641 | "execution_count": 23,
642 | "metadata": {},
643 | "outputs": [],
644 | "source": [
645 | "from wordcloud import WordCloud #若未安装,可以使用pip install wordcloud安装\n",
646 | "import imageio"
647 | ]
648 | },
649 | {
650 | "cell_type": "code",
651 | "execution_count": 24,
652 | "metadata": {},
653 | "outputs": [
654 | {
655 | "name": "stdout",
656 | "output_type": "stream",
657 | "text": [
658 | "自然语言 理解 自然语言 生成 自然语言处理 两大 内核 机器翻译 自然语言 理解 方面 最早 研究 工作 自然语言处理 主要 任务 研究 表示 语言 能力 语言 应用 模型 建立 实现 计算 框架 提出 相应 方法 不断 完善 模型 根据 这样 语言 模型 设计 有效 实现 自然语言 通信 计算机系统 研讨 关于 系统 评测 技术 最终 实现 用 自然语言 计算机 进行 通信 一定 自然语言处理 能力 典型 应用 包括 计算机信息 检索系统 多语种 翻译 系统 语言 逻辑思维 交流 工具 宇宙 万物 只有 人类 才 这种 高级 功能 要 实现 人 计算机 间 采用 自然语言 通信 必须 计算机 同时 具备 自然语言 理解 自然语言 生成 两大 功能 因此 自然语言处理 作为 人工智能 一个 子 领域 主要 目的 就 包括 两个 方面 自然语言 理解 让 计算机 理解 自然语言 文本 意义 ; 自然语言 生成 让 计算机 能以 自然语言 文 本来 表达 给定 意图 思想 自然语言 人类 智慧 结晶 自然语言处理 人工智能 最为 困难 问题 之一 而 对 自然语言处理 研究 也 充满 魅力 挑战 近年来 自然语言处理 处于 快速 发展 阶段 各种 词表 语义 语法 词典 语料库 数据 资源 日益 丰富 词语切分 词性 标注 句法分析 技术 快速 进步 各种 新 理论 新 方法 新 模型 出现 推动 自然语言处理 研究 繁荣 互联网 移动 互联网 世界 经济社会 一体化 潮流 对 自然语言处理 技术 迫切 需求 为 自然语言处理 研究 发展 提供 强大 市场 动力 我国 直到 世纪 80 年代 中期 才 开始 较 大规模 较 系统 自然语言处理 研究 尽管 较 国际 水平 尚有 较大 差距 已经 有 比较稳定 研究 内容 包括 语料库 知识库 数据 资源 建设 词语切分 句法分析 基础 技术 以及 信息检索 机器翻译 应用 技术 当前 国内外 出现 一批 基于 自然语言处理 技术 应用 系统 自然语言处理 对象 有词 句子 篇章 段落 文本 但是 大多 归根到底 在 句子 处理 自然语言处理 自然语言 句子 级 分析 技术 可以 大致 分为 词法 分析 句法分析 语义 分析 三个 层面\n"
659 | ]
660 | }
661 | ],
662 | "source": [
663 | "cloud_words =' '.join(new_words) #词频统计里面的分词\n",
664 | "print(cloud_words)"
665 | ]
666 | },
667 | {
668 | "cell_type": "code",
669 | "execution_count": 25,
670 | "metadata": {},
671 | "outputs": [
672 | {
673 | "data": {
674 | "text/plain": [
675 | "
"
549 | ]
550 | },
551 | {
552 | "cell_type": "code",
553 | "execution_count": 20,
554 | "metadata": {},
555 | "outputs": [
556 | {
557 | "name": "stdout",
558 | "output_type": "stream",
559 | "text": [
560 | "['自然语言', '理解', '自然语言', '生成', '自然语言处理', '两大', '内核', '机器翻译', '自然语言', '理解', '方面', '最早', '研究', '工作', '自然语言处理', '主要', '任务', '研究', '表示', '语言', '能力', '语言', '应用', '模型', '建立', '实现', '计算', '框架', '提出', '相应', '方法', '不断', '完善', '模型', '根据', '这样', '语言', '模型', '设计', '有效', '实现', '自然语言', '通信', '计算机系统', '研讨', '关于', '系统', '评测', '技术', '最终']\n"
561 | ]
562 | }
563 | ],
564 | "source": [
565 | "with open('停用词典.txt', 'r',encoding='utf-8') as f: # 停用词典\n",
566 | " stopwords = [s.rstrip() for s in f.readlines()] #.readlines()\n",
567 | "new_words = []\n",
568 | "for w in words:\n",
569 | " if w not in stopwords:\n",
570 | " new_words.append(w)\n",
571 | "print(new_words[:50])"
572 | ]
573 | },
574 | {
575 | "cell_type": "markdown",
576 | "metadata": {},
577 | "source": [
578 | "**词频统计:**"
579 | ]
580 | },
581 | {
582 | "cell_type": "code",
583 | "execution_count": 21,
584 | "metadata": {},
585 | "outputs": [
586 | {
587 | "name": "stdout",
588 | "output_type": "stream",
589 | "text": [
590 | "总词数: 283\n",
591 | "不重复的词数: 183\n"
592 | ]
593 | }
594 | ],
595 | "source": [
596 | "print(f\"总词数: {len(new_words)}\") \n",
597 | "print(f\"不重复的词数: {len(set(new_words))}\") "
598 | ]
599 | },
600 | {
601 | "cell_type": "code",
602 | "execution_count": 22,
603 | "metadata": {},
604 | "outputs": [
605 | {
606 | "name": "stdout",
607 | "output_type": "stream",
608 | "text": [
609 | "自然语言 14\n",
610 | "自然语言处理 14\n",
611 | "研究 7\n",
612 | "技术 7\n",
613 | "理解 5\n"
614 | ]
615 | }
616 | ],
617 | "source": [
618 | "counts = {} #使用字典得到每个词出现的次数\n",
619 | "for word in new_words:\n",
620 | " counts[word] = counts.get(word,0)+1\n",
621 | "\n",
622 | "# 也可以直接调用函数Counter得到counts:\n",
623 | "# from collections import Counter\n",
624 | "# counts = Counter(new_words)\n",
625 | "\n",
626 | "counts = list(counts.items()) #转化为列表格式\n",
627 | "counts.sort(key = lambda x:x[1],reverse=True) #对词频进行排序\n",
628 | "for i in range(5): #展示出现次数最多的5个词\n",
629 | " print(counts[i][0],counts[i][1])"
630 | ]
631 | },
632 | {
633 | "cell_type": "markdown",
634 | "metadata": {},
635 | "source": [
636 | "## 5.绘制词云图"
637 | ]
638 | },
639 | {
640 | "cell_type": "code",
641 | "execution_count": 23,
642 | "metadata": {},
643 | "outputs": [],
644 | "source": [
645 | "from wordcloud import WordCloud #若未安装,可以使用pip install wordcloud安装\n",
646 | "import imageio"
647 | ]
648 | },
649 | {
650 | "cell_type": "code",
651 | "execution_count": 24,
652 | "metadata": {},
653 | "outputs": [
654 | {
655 | "name": "stdout",
656 | "output_type": "stream",
657 | "text": [
658 | "自然语言 理解 自然语言 生成 自然语言处理 两大 内核 机器翻译 自然语言 理解 方面 最早 研究 工作 自然语言处理 主要 任务 研究 表示 语言 能力 语言 应用 模型 建立 实现 计算 框架 提出 相应 方法 不断 完善 模型 根据 这样 语言 模型 设计 有效 实现 自然语言 通信 计算机系统 研讨 关于 系统 评测 技术 最终 实现 用 自然语言 计算机 进行 通信 一定 自然语言处理 能力 典型 应用 包括 计算机信息 检索系统 多语种 翻译 系统 语言 逻辑思维 交流 工具 宇宙 万物 只有 人类 才 这种 高级 功能 要 实现 人 计算机 间 采用 自然语言 通信 必须 计算机 同时 具备 自然语言 理解 自然语言 生成 两大 功能 因此 自然语言处理 作为 人工智能 一个 子 领域 主要 目的 就 包括 两个 方面 自然语言 理解 让 计算机 理解 自然语言 文本 意义 ; 自然语言 生成 让 计算机 能以 自然语言 文 本来 表达 给定 意图 思想 自然语言 人类 智慧 结晶 自然语言处理 人工智能 最为 困难 问题 之一 而 对 自然语言处理 研究 也 充满 魅力 挑战 近年来 自然语言处理 处于 快速 发展 阶段 各种 词表 语义 语法 词典 语料库 数据 资源 日益 丰富 词语切分 词性 标注 句法分析 技术 快速 进步 各种 新 理论 新 方法 新 模型 出现 推动 自然语言处理 研究 繁荣 互联网 移动 互联网 世界 经济社会 一体化 潮流 对 自然语言处理 技术 迫切 需求 为 自然语言处理 研究 发展 提供 强大 市场 动力 我国 直到 世纪 80 年代 中期 才 开始 较 大规模 较 系统 自然语言处理 研究 尽管 较 国际 水平 尚有 较大 差距 已经 有 比较稳定 研究 内容 包括 语料库 知识库 数据 资源 建设 词语切分 句法分析 基础 技术 以及 信息检索 机器翻译 应用 技术 当前 国内外 出现 一批 基于 自然语言处理 技术 应用 系统 自然语言处理 对象 有词 句子 篇章 段落 文本 但是 大多 归根到底 在 句子 处理 自然语言处理 自然语言 句子 级 分析 技术 可以 大致 分为 词法 分析 句法分析 语义 分析 三个 层面\n"
659 | ]
660 | }
661 | ],
662 | "source": [
663 | "cloud_words =' '.join(new_words) #词频统计里面的分词\n",
664 | "print(cloud_words)"
665 | ]
666 | },
667 | {
668 | "cell_type": "code",
669 | "execution_count": 25,
670 | "metadata": {},
671 | "outputs": [
672 | {
673 | "data": {
674 | "text/plain": [
675 | " "
702 | ]
703 | },
704 | {
705 | "cell_type": "code",
706 | "execution_count": null,
707 | "metadata": {},
708 | "outputs": [],
709 | "source": []
710 | }
711 | ],
712 | "metadata": {
713 | "kernelspec": {
714 | "display_name": "Python 3",
715 | "language": "python",
716 | "name": "python3"
717 | },
718 | "language_info": {
719 | "codemirror_mode": {
720 | "name": "ipython",
721 | "version": 3
722 | },
723 | "file_extension": ".py",
724 | "mimetype": "text/x-python",
725 | "name": "python",
726 | "nbconvert_exporter": "python",
727 | "pygments_lexer": "ipython3",
728 | "version": "3.8.8"
729 | }
730 | },
731 | "nbformat": 4,
732 | "nbformat_minor": 4
733 | }
734 |
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/jieba自定义词典_example.txt:
--------------------------------------------------------------------------------
1 | 可接纳资产净值
2 | 累积优先股股息
3 |
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/jieba词典.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/jieba词典.jpg
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/panda.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/panda.png
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/wc.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/wc.jpg
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/停用词典.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/停用词典.jpg
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/停用词典.txt:
--------------------------------------------------------------------------------
1 | 是
2 | 的
3 | 和
4 | 地
5 | 并
6 | 目前
7 | 具有
8 | 等
9 | 中
10 | 与
11 | 使
12 | 其
13 | 但
14 | 了
15 | 上
16 | 、
17 | ,
18 | 。
19 | :
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/切片操作.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/切片操作.png
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/序列.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/序列.png
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/词频统计example.txt:
--------------------------------------------------------------------------------
1 | 自然语言理解和自然语言生成是自然语言处理的两大内核,机器翻译是自然语言理解方面最早的研究工作。
"
702 | ]
703 | },
704 | {
705 | "cell_type": "code",
706 | "execution_count": null,
707 | "metadata": {},
708 | "outputs": [],
709 | "source": []
710 | }
711 | ],
712 | "metadata": {
713 | "kernelspec": {
714 | "display_name": "Python 3",
715 | "language": "python",
716 | "name": "python3"
717 | },
718 | "language_info": {
719 | "codemirror_mode": {
720 | "name": "ipython",
721 | "version": 3
722 | },
723 | "file_extension": ".py",
724 | "mimetype": "text/x-python",
725 | "name": "python",
726 | "nbconvert_exporter": "python",
727 | "pygments_lexer": "ipython3",
728 | "version": "3.8.8"
729 | }
730 | },
731 | "nbformat": 4,
732 | "nbformat_minor": 4
733 | }
734 |
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/jieba自定义词典_example.txt:
--------------------------------------------------------------------------------
1 | 可接纳资产净值
2 | 累积优先股股息
3 |
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/jieba词典.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/jieba词典.jpg
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/panda.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/panda.png
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/wc.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/wc.jpg
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/停用词典.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/停用词典.jpg
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/停用词典.txt:
--------------------------------------------------------------------------------
1 | 是
2 | 的
3 | 和
4 | 地
5 | 并
6 | 目前
7 | 具有
8 | 等
9 | 中
10 | 与
11 | 使
12 | 其
13 | 但
14 | 了
15 | 上
16 | 、
17 | ,
18 | 。
19 | :
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/切片操作.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/切片操作.png
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/序列.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 2 文本的基本处理/序列.png
--------------------------------------------------------------------------------
/Chapter 2 文本的基本处理/词频统计example.txt:
--------------------------------------------------------------------------------
1 | 自然语言理解和自然语言生成是自然语言处理的两大内核,机器翻译是自然语言理解方面最早的研究工作。![]() "
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "#
"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "#  "
123 | ]
124 | },
125 | "metadata": {},
126 | "output_type": "display_data"
127 | }
128 | ],
129 | "source": [
130 | "from sklearn.feature_extraction.text import CountVectorizer\n",
131 | "import seaborn as sns \n",
132 | "sns.set(font=\"simhei\") #设置中文字体,不然作图出现乱码\n",
133 | "\n",
134 | "corpus = ['利用代码实现这个方法','怎么去实现呢','我不知道'] #给定三个句子作为语料库\n",
135 | "for index,text in enumerate(corpus): # enumerate方法:同时返回索引和值\n",
136 | " corpus[index] = jieba.lcut(text) # 将语料库中句子进行分词\n",
137 | " corpus[index] = ' '.join(corpus[index]) # 将分词之间用空格连接起来\n",
138 | "\n",
139 | "print(corpus)\n",
140 | " \n",
141 | "one_hot_encoder = CountVectorizer(binary = True,token_pattern='[\\u4e00-\\u9fa5_a-zA-Z0-9]{1,}') \n",
142 | "#调用sklearn的CountVectorizer(),用正则设置token_pattern,避免无法识别中文单字 \n",
143 | "one_hot = one_hot_encoder.fit_transform(corpus).toarray() # one_hot向量\n",
144 | "label_name = one_hot_encoder.get_feature_names() # one_hot值对应的label(单词)\n",
145 | "sns.heatmap(one_hot,annot = True,cbar = False,xticklabels=label_name,yticklabels=['句子一','句子二','句子三'],cmap=\"YlGnBu\")"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "**也可使用kreas库的`keras.preprocessing.text`进行文本onehot处理**"
153 | ]
154 | },
155 | {
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "## 2.TF-IDF"
160 | ]
161 | },
162 | {
163 | "cell_type": "markdown",
164 | "metadata": {},
165 | "source": [
166 | "**TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量;用以衡量一个关键词w对于查询(Query,可看作文档)所能提供的信息**"
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "(1)计算词频TF = n/N,n表示某个词在文档中出现的次数,N表示文档中所有词出现的次数总和。 "
205 | ]
206 | },
207 | "metadata": {},
208 | "output_type": "display_data"
209 | }
210 | ],
211 | "source": [
212 | "from sklearn.feature_extraction.text import TfidfVectorizer\n",
213 | "\n",
214 | "corpus = ['利用代码实现这个方法','怎么去实现呢','我不知道'] #语料库\n",
215 | "\n",
216 | "for index,text in enumerate(corpus):\n",
217 | " corpus[index] = jieba.lcut(text)\n",
218 | " corpus[index] = ' '.join(corpus[index])\n",
219 | " \n",
220 | "Tfidf_encoder = TfidfVectorizer(token_pattern='[\\u4e00-\\u9fa5_a-zA-Z0-9]{1,}') #调用sklearn的TfidfVectorizer() \n",
221 | "Tfidf = Tfidf_encoder.fit_transform(corpus).toarray() #得到tfidf值\n",
222 | "label_name = Tfidf_encoder.get_feature_names() #值对应的label(单词)\n",
223 | "sns.heatmap(Tfidf,annot = True,cbar = False,xticklabels=label_name,yticklabels=['句子一','句子二','句子三'],cmap=\"YlGnBu\")"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "metadata": {},
229 | "source": [
230 | "**调用jieba库,根据TFIDF抽取文档关键词**"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": 79,
236 | "metadata": {},
237 | "outputs": [
238 | {
239 | "name": "stdout",
240 | "output_type": "stream",
241 | "text": [
242 | "上月,欧洲央行完成了近11年来的首次加息,并超预期加息50个基点,抑制通胀同时追赶美联储加息脚步。相较于美联储,欧洲央行的加息周期显然开始较晚,但该行的谨慎并非无的放矢,债务风险是欧洲央行加息路上的一大障碍。当前,欧元区政府债务和财政赤字压力并不弱于2010年欧债危机爆发前夕。疫情下为配合财政刺激,欧盟阶段性摆脱了财政束缚,使得成员国政府债务率和财政赤字率显著上升,继而中期债务风险上升,其中希腊、意大利等债务压力相对更大。而欧洲央行的货币紧缩可能使成员国政府债务风险进一步扩大。在低通胀、低利率时期,欧洲央行可以通过大量增持“高债国”债券兜底。但眼下,“类滞胀”格局迫使欧洲央行进入紧缩周期,目前该行已宣布停止资产购买计划、结束扩表。在此背景下,欧债危机会重现吗?考虑到这一问题,欧洲央行颁布了新的应对措施:一方面,将灵活运用大流行紧急购买计划(PEPP)中的再投资额度;另一方面,推出传导保护工具(TPI),目的是“保障其货币政策立场在整个欧元区的顺利传输”。欧洲央行行长拉加德表示,TPI将允许央行在二级市场上购买国债,购买规模取决于传导风险,重点购买1至10年期的公共部门证券,也会考虑购买私营部门债券。不过,平安证券首席经济学家钟正生认为,欧洲央行新工具的实际运作和效果仍待观察。首先,由于受制于控通胀目标,欧洲央行很难大规模购买资产、大幅扩表。虽然欧洲央行没有给出TPI的规模上限,但预计实际操作规模有限。其次,如何判定干预市场的时机和程度,料将会有争议。过早干预市场或受德国方面的阻力,而过晚干预市场或难起到预期效果。此外,还需要防止成员国对欧洲央行救助措施的过度依赖,这或也意味着欧洲央行行动的果断性将受到制约。最后,若欧元区经济受到更大冲击,成员国财政可持续性受到挑战,新工具的判定或有争议,“预期引导”仍有失效的可能。\n"
243 | ]
244 | }
245 | ],
246 | "source": [
247 | "with open('Tfidf_example.txt', 'r',encoding='utf-8') as text_file: # 读取txt文件\n",
248 | " example = text_file.read()\n",
249 | "print(example)"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 80,
255 | "metadata": {},
256 | "outputs": [
257 | {
258 | "name": "stdout",
259 | "output_type": "stream",
260 | "text": [
261 | "[('欧洲央行', 0.4188328159991984), ('购买', 0.15350847079816793), ('债务', 0.1468613104703817), ('TPI', 0.13688665079656487), ('加息', 0.11997822456431298)]\n"
262 | ]
263 | }
264 | ],
265 | "source": [
266 | "import jieba.analyse\n",
267 | "print(jieba.analyse.extract_tags(example, topK=5, withWeight=True))\n",
268 | "# topK 为返回几个 TF/IDF 权重最大的关键词,withWeight 为是否一并返回关键词权重值"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "* 当一个词在文档频率越高并且新鲜度高(即普遍度低),其TF-IDF值越高。\n",
276 | "* TF-IDF兼顾词频与新鲜度,过滤一些常见词(例如“的,得,了”),保留能提供更多信息的关键词。"
277 | ]
278 | },
279 | {
280 | "cell_type": "markdown",
281 | "metadata": {},
282 | "source": [
283 | "## 3.基于语料库的词典方法"
284 | ]
285 | },
286 | {
287 | "cell_type": "markdown",
288 | "metadata": {},
289 | "source": [
290 | "**基于语料库将文本编码成一个个数字id,使计算机可以进行处理,这样就得到了一个 词(字)与数字 一一对应的计算机“词典”**"
291 | ]
292 | },
293 | {
294 | "cell_type": "code",
295 | "execution_count": 1,
296 | "metadata": {},
297 | "outputs": [],
298 | "source": [
299 | "#在one-hot方法第二步我们已经生成了输入文本的词典,将其打包成一个函数如下:\n",
300 | "def preprocess(text):\n",
301 | " words = jieba.lcut(text) #分词\n",
302 | " \n",
303 | " word_to_id = {}\n",
304 | " for index,word in enumerate(words):\n",
305 | " word_to_id[word] = index #词到id的字典\n",
306 | " \n",
307 | " id_to_word = {index: word for index,word in enumerate(words)} #id到词的字典,此代码为上面词到id的字典的简写形式\n",
308 | " \n",
309 | " text_id = np.array([word_to_id[word] for word in words])\n",
310 | " return word_to_id,id_to_word,text_id"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 86,
316 | "metadata": {
317 | "scrolled": true
318 | },
319 | "outputs": [
320 | {
321 | "name": "stdout",
322 | "output_type": "stream",
323 | "text": [
324 | "词到id的字典: {'首先': 0, ',': 7, '由于': 2, '受制于': 3, '控': 4, '通胀': 5, '目标': 6, '欧洲央行': 8, '很难': 9, '大规模': 10, '购买': 11, '资产': 12, '、': 13, '大幅': 14, '扩表': 15}\n",
325 | "\n",
326 | "d到词的字典: {0: '首先', 1: ',', 2: '由于', 3: '受制于', 4: '控', 5: '通胀', 6: '目标', 7: ',', 8: '欧洲央行', 9: '很难', 10: '大规模', 11: '购买', 12: '资产', 13: '、', 14: '大幅', 15: '扩表'}\n",
327 | "\n",
328 | "将输入文本转化为id形式: [ 0 7 2 3 4 5 6 7 8 9 10 11 12 13 14 15]\n"
329 | ]
330 | }
331 | ],
332 | "source": [
333 | "text = \"首先,由于受制于控通胀目标,欧洲央行很难大规模购买资产、大幅扩表\"\n",
334 | "word_to_id,id_to_word,text_id = preprocess(text)\n",
335 | "print(f\"词到id的字典: {word_to_id}\",end='\\n\\n')\n",
336 | "print(f\"id到词的字典: {id_to_word}\",end='\\n\\n')\n",
337 | "print(f\"将输入文本转化为id形式: {text_id}\")"
338 | ]
339 | }
340 | ],
341 | "metadata": {
342 | "kernelspec": {
343 | "display_name": "Python 3",
344 | "language": "python",
345 | "name": "python3"
346 | },
347 | "language_info": {
348 | "codemirror_mode": {
349 | "name": "ipython",
350 | "version": 3
351 | },
352 | "file_extension": ".py",
353 | "mimetype": "text/x-python",
354 | "name": "python",
355 | "nbconvert_exporter": "python",
356 | "pygments_lexer": "ipython3",
357 | "version": "3.8.8"
358 | }
359 | },
360 | "nbformat": 4,
361 | "nbformat_minor": 4
362 | }
363 |
--------------------------------------------------------------------------------
/Chapter 3 经典文本向量化方法/Tfidf_example.txt:
--------------------------------------------------------------------------------
1 | 上月,欧洲央行完成了近11年来的首次加息,并超预期加息50个基点,抑制通胀同时追赶美联储加息脚步。相较于美联储,欧洲央行的加息周期显然开始较晚,但该行的谨慎并非无的放矢,债务风险是欧洲央行加息路上的一大障碍。当前,欧元区政府债务和财政赤字压力并不弱于2010年欧债危机爆发前夕。疫情下为配合财政刺激,欧盟阶段性摆脱了财政束缚,使得成员国政府债务率和财政赤字率显著上升,继而中期债务风险上升,其中希腊、意大利等债务压力相对更大。而欧洲央行的货币紧缩可能使成员国政府债务风险进一步扩大。在低通胀、低利率时期,欧洲央行可以通过大量增持“高债国”债券兜底。但眼下,“类滞胀”格局迫使欧洲央行进入紧缩周期,目前该行已宣布停止资产购买计划、结束扩表。在此背景下,欧债危机会重现吗?考虑到这一问题,欧洲央行颁布了新的应对措施:一方面,将灵活运用大流行紧急购买计划(PEPP)中的再投资额度;另一方面,推出传导保护工具(TPI),目的是“保障其货币政策立场在整个欧元区的顺利传输”。欧洲央行行长拉加德表示,TPI将允许央行在二级市场上购买国债,购买规模取决于传导风险,重点购买1至10年期的公共部门证券,也会考虑购买私营部门债券。不过,平安证券首席经济学家钟正生认为,欧洲央行新工具的实际运作和效果仍待观察。首先,由于受制于控通胀目标,欧洲央行很难大规模购买资产、大幅扩表。虽然欧洲央行没有给出TPI的规模上限,但预计实际操作规模有限。其次,如何判定干预市场的时机和程度,料将会有争议。过早干预市场或受德国方面的阻力,而过晚干预市场或难起到预期效果。此外,还需要防止成员国对欧洲央行救助措施的过度依赖,这或也意味着欧洲央行行动的果断性将受到制约。最后,若欧元区经济受到更大冲击,成员国财政可持续性受到挑战,新工具的判定或有争议,“预期引导”仍有失效的可能。
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/EE.txt:
--------------------------------------------------------------------------------
1 | 高频监控敢死队涨停股 免费下载 证券时报网03月03日讯 全国政协会议今日正式开幕,细读政协工作报告,其中透露出的八个经济方面的亮点值得投资者注意。 一、“一带一路”建设。“一带一路”战略作为连接中国与世界的新的桥梁,不仅将为中国发展开拓更大的空间,也让中国红利更好地造福世界。这是国际舆论不断形成的一项重要共识。 媒体近日透露,“一带一路”规划已经获批并在小范围内下发,即将正式出台,这意味着以“一带一路”为统领,以京津冀一体化和长江经济带等为着力点的区域协同发展已是箭在弦上。有分析预测,“一带一路”、京津冀协同发展、长江经济带等顶层方案有望在两会后陆续亮相。 A股市场上,“一带一路”概念已提前预热。2月27日 ,“一带一路”概念股无疑是当日市场最大的热点。中国电建 、中铁二局 、中国交建等近10股当日集体上演涨停秀。龙头股中铁二局接连拉出多个涨停板,股价创出历史新高。 二、推进非公有制企业走出去。近年来,中国“走出去”的资本已经超越所吸引的资本。随着中国开放政策的深入和企业在全球的扩张,资本“走出去”的速度会呈现增长的趋势。资本的“走出去”是中国外部崛起的经济基础。 在“走出去”战略中,目前高铁、核电等高端制造业领域有相对的优势。数据显示,2014年中国整个装备制造业出口2.1万亿元,占国家整个出口收入的17%,其中包括电力、通讯、石化、矿业、航空等行业,大型的成套设备出口快速增长。中国60万千瓦的燃煤发电机组已经成为出口的主力机型,华为公司68%的销售收入来自于海外市场,另外工程机械、汽车等领域在境外的投资也取得了积极的进展。 三、知识产权保护。今年1月初,国务院办公厅转发知识产权局等二十八个部委局的《深入实施国家知识产权战略行动计划》,要求各部门认真贯彻执行。该行动计划首次明确提出了“努力建设知识产权强国”的新目标,强调要“认真谋划我国知识产权强国的发展路径,努力建设知识产权强国。” 分析人士指出,在中国经济面临产业结构调整和转型升级的关键时期,该行动计划的实施对促进我国知识产权保护、推动知识产权的持续增长产生深远的影响,在此过程中,一批拥有自主知识产权和创新能力的成长型公司,必然会在这一轮产业升级的浪潮中脱颖而出,考虑到行动计划的具体内容,建议投资者从推进软件正版化工作、服务现代农业发展二条主线寻找投资机会,建议重点关注用友软件、中国软件、久其软件等优质个股。 四、医药卫生体制改革。医疗保健行业在2015年的关键词是消费升级和医疗改革。中金公司分析师邹朋认为 ,2015年卫生工作的第一项任务就是全面推进深化医药卫生体制改革向纵深发展,包括全力推进公立医院改革、健全完善全民医保体系以及大力推进分级诊疗工作等。政策转向使得行业进入新增长区间,因此,看好医疗服务、社会办医以及流通领域改革三方面。 对于今年医药行业的投资机会,西南证券指出,新技术催化的投资机会贯穿2015年,主要体现在,生物药新技术如干细胞治疗将受到追捧。而安信证券认为,在政策的大力推动下,智慧医疗正在超级大风口上。例如万达信息,作为医疗O2O闭环模式的标杆,其在医改的各项创举有望在全国推广。建议关注东华软件、卫宁软件、宜华地产、朗玛信息、荣科科技、海虹控股等。 从消费升级方面看,基础医疗保健生产商仍旧具有较好的投资价值。兴业证券梅郜越建议配置恒瑞医药、华东医药、云南白药、天士力等,同时关注上海医药、东阿阿胶、复星医药等低估值蓝筹的估值修复机会。安信基金研究部总经理姜诚还认为,民营医院服务相关股票也值得在关注,例如国际医学。 五、加快体育产业发展。在羊年的首次中央全面深化改革领导小组会议上,《中国足球改革总体方案》获审议通过,发展振兴足球成为建设体育强国的“头羊”。通过此轮改革探索的新体制,无疑将为足球产业乃至整个体育产业的快速发展奠定基础。 分析认为,自从体育产业被明确为国家支柱产业以来,相关的扶持政策也在紧锣密鼓的制定当中,而市场对于体育概念股的关注度也明显提升。随着政策扶持力度的加大,体育产业的发展将迎来高速发展的阶段。篮球和足球作为其中市场化程度较高的产业,未来有望获得更多的政策支持,而从事相关产业的企业有也望分享政策带来的红利。国际重大赛事的申办不仅可以提升我国的体育品牌价值,同时也有望进一步激发人们参与体育运劢的热情,推劢体育产业的快速发展。 相关个股:探路者、中体产业、江苏舜天、亚泰集团、双象股份、中信国安、信隆实业等。 六、转基因农产品。转基因农产品一直是网民热议的话题。中央日前发布的“一号文件”明确提出,加强农业转基因生物技术研究、安全管理、科学普及。其中加强转基因科学普及首次写入。 俞正声在部署2015年工作时指出,要加快体育产业发展、转基因农产品的机遇与风险、加强京津冀协同发展中的大气污染防治、推进长江经济带发展中的湿地保护、加强黑土地保护、资源枯竭城市转型等重要课题开展调研议政。 七、大气污染防治。面对日益严重的环境污染问题,以及严峻的节能减排压力,国家不断加大对大气污染防治工作的监察力度。对高污染、高耗能产业的环保标准也不断提高,随着环保新标准的推行,势必引发传统行业加快对落后产能的淘汰进程,并推劢企业加大对生产线和生产设备的环保技术改造,这为从事相关环保业务的企业开启了巨大的市场空间。而《防治法》的制定更是为我国的大气污染防治工作提供可靠的法律依据,推劢污染防治工作的顺利进行。在政策不断加码的推劢下,脱硫脱销、尾气治理、环保锅炉和大气污染监测等行业有望持续景气,相关概念股值得关注。 相关个股:科林环保、先河环保、聚光科技、天瑞仪器、雪迪龙,国电清新、九龙电力、燃控科技、龙源技术、银轮股份、海越股份、威孚高科等。 八、湿地保护。长江中游地区是我国湿地资源集中分布区之一。几个世纪以来,受长江冲淤变化导致河势自然改变的自然裁弯,以及人为改造河道实施的人工裁弯的综合影响,长江中游下荆江河道周边最终形成了长江故道群湿地。故道群湿地类型独特、物种丰富、生态地位突出、生态功能显著,对于维持长江中游及江汉平原地区的水安全、生态安全及粮食安全意义重大。 湿地概念股:大湖股份、华侨城A、中青旅等。 新浪声明:此消息系转载自新浪合作媒体,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。 进入【新浪财经股吧】讨论
2 | 高频监控敢死队涨停股 免费下载 高超 国务院总理李克强5日的政府工作报告亮点频出,对宏观经济、资本市场做出了高屋建瓴的部署。此外,对A股市场而言,环保、养老、普惠金融、O2O、PPP等领域的最新工作安排,也蕴含着巨大的投资机会。 稳健的货币政策要松紧适度积极的财政政策要加力增效 对于2015年的经济发展,报告指出,要着眼于保持中高速增长和迈向中高端水平“双目标”,坚持稳政策稳预期和促改革调结构“双结合”,打造大众创业、万众创新和增加公共产品、公共服务“双引擎”。 具体经济指标方面,国内生产总值增长7%左右,居民消费价格涨幅3%左右。城镇新增就业1000万人以上,城镇登记失业率4.5%以内。进出口增长6%左右。能耗强度下降3.1%以上。积极的财政政策要加力增效。今年拟安排财政赤字1.62万亿元,比去年增加2700亿元,赤字率从去年的2.1%提高到2.3%。 稳健的货币政策要松紧适度。广义货币M2预期增长12%左右,在实际执行中,根据经济发展需要也可以略高些。 分析人士认为,3%左右的消费价格涨幅目标,意味着未来货币政策仍有较大的腾挪空间,2015年的A股市场面对的宏观政策基调仍相对宽松。 开展个人投资者境外投资试点适时启动“深港通”试点 对于2015年的金融改革,报告指出要加强多层次资本市场体系建设,实施股票发行注册制改革,推进信贷资产证券化,扩大企业债券发行规模,发展金融衍生品市场。 大力发展普惠金融,围绕服务实体经济推进金融改革。推动具备条件的民间资本依法发起设立中小型银行等金融机构,成熟一家,批准一家,不设限额。 推出存款保险制度。推进利率市场化改革,健全中央银行利率调控框架。保持人民币汇率处于合理均衡水平,增强人民币汇率双向浮动弹性。 稳步实现人民币资本项目可兑换,扩大人民币国际使用,加快建设人民币跨境支付系统,完善人民币全球清算服务体系,开展个人投资者境外投资试点,适时启动“深港通”试点。 分析人士认为,普惠金融的大力发展,将加速诸如阿里、腾讯等新型互联网企业主导的民营金融机构发展壮大。其中腾讯控股在香港上市,是沪港通标的。而公开信息显示,阿里系的蚂蚁金融,正在筹划A股IPO。 环保、医疗、养老领域投资机会大 政府工作报告指出,今年二氧化碳排放强度要降低3.1%以上,化学需氧量、氨氮排放都要减少2%左右,二氧化硫、氮氧化物排放要分别减少3%左右和5%左右。促进重点区域煤炭消费零增长。在重点区域内重点城市全面供应国五标准车用汽柴油。2005年底前注册营运的黄标车要全部淘汰。推进京津冀协同发展,在交通一体化、生态环保、产业升级转移等方面率先取得实质性突破。 实施水污染防治行动计划,加强江河湖海水污染、水污染源和农业面源污染治理,实行从水源地到水龙头全过程监管。以垃圾、污水为重点加强环境治理,建设美丽宜居乡村。推行环境污染第三方治理。分析人士认为,2015年的环保治理力度将超出预期,大气治理、水处理、垃圾处理领域最值得关注。 报告提到,要促进养老家政健康消费,壮大信息消费,提升旅游休闲消费,推动绿色消费,稳定住房消费,扩大教育文化体育消费。鼓励社会力量兴办养老设施,发展社区和居家养老。 要把以互联网为载体、线上线下互动的新兴消费搞得红红火火。制定“互联网+”行动计划,推动移动互联网、云计算、大数据、物联网等与现代制造业结合,促进电子商务、工业互联网和互联网金融健康发展,引导互联网企业拓展国际市场。分析认为,上述表述明显有利于O20题材向纵深发展。 除此以外,要把“一带一路”建设与区域开发开放结合起来,加强新亚欧大陆桥、陆海口岸支点建设。组织好西藏自治区成立50周年和新疆维吾尔自治区成立60周年庆祝活动。做好2022年冬奥会申办工作;办好纪念世界反法西斯战争和中国人民抗日战争胜利70周年相关活动。实施“中国制造2025”,坚持创新驱动、智能转型、强化基础、绿色发展,加快从制造大国转向制造强国。全面加强现代后勤建设,加大国防科研和高新技术武器装备建设力度,发展国防科技工业。 在基础设施、公用事业等领域,积极推广政府和社会资本合作模式。铁路投资要保持在8000亿元以上,新投产里程8000公里以上,在全国基本实现高速公路电子不停车收费联网,使交通真正成为发展的先行官。在建重大水利工程投资规模超过8000亿元。 《投资快报》记者注意到,A股市场上这样的模式被定义为PPP模式,该领域已经诞生过诸如华夏幸福、碧水源这样的大牛股。展望未来,PPP模式可能进一步通过定向增发等多种融资模式,向环保、基建领域的上市公司全面扩散。 新浪声明:此消息系转载自新浪合作媒体,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。 进入【新浪财经股吧】讨论
3 | 消息股汇总:6月12日盘前提示十只股整体涨幅达4.93% 新浪财经讯 6月12日晚间,沪深两市多家上市公司发布了公告。以下是公告利好消息一览: 国投电力和川投能源获批建设雅砻江水电站 国投电力和川投能源6月12日晚间公告,6月10日,四川省发改委对建设雅砻江杨房沟水电站进行了核准批复,由二者负责建设和管理,其中,国投电力投资占比52%,川投能源投资占比48%。 杨房沟水电站位于四川省凉山州木里县境内,为雅砻江中游水电站。电站总装机容量150万千瓦,单独运行时年均发电量59.623亿千瓦时,与上游两河口水库电站联合运行时年均发电量68.557 亿千瓦时。工程建设总工期95个月。 按2014年四季度价格水平测算,工程静态投资148.94亿元,动态总投资200.02亿元。项目资本金40亿元,占动态总投资的20%。 三维工程5000万设子公司 布局石油及制品销售 三维工程6月12日晚间公告,公司拟在大连市设立中油三维能源有限公司,注册资本5000万元,公司拟以自有资金出资,出资比例占注册资本的100%。新公司将主营石油及制品销售和贸易经纪等。 通过设立中油三维,三维工程进一步将产业链延伸至石油及制品销售和贸易经纪等领域,一方面有利于进一步扩大公司业务范围,完善公司产业链;另一方面有利于进一步促进公司与参股公司上海志商电子商务有限公司的协同发展,助力其打造全国性化工、石化原材料B2B电子商务平台。 三维工程同时公告,近日控股子公司青岛联信催化材料有限公司与神华宁夏煤业集团有限责任公司在银川市签订的《神华宁煤集团400万吨/年煤炭间接液化项目一氧化碳耐硫变换装置耐硫变换催化剂订货合同》,合同总价为7724.4万元,占三维工程最近一个会计年度经审计营业收入的10.03%。 华丽家族收购标的子公司中标工信部石墨烯相关项目 华丽家族6月12日晚间公告,公司关联企业重庆墨掀技有限公司近日收到工信部2015年工业转型升级强基工程国家级公开招标项目的中标通知书,中标内容为第二代单层石墨烯薄膜实施方案,中标金额1000万元。 据悉,华丽家族正筹划2015年度非公开发行股票,部分募集资金拟用于收购北京墨烯控股集团股份有限公司100%股份并对其增资,重庆墨希为墨烯控股下属控股公司,为公司关联企业。 华丽家族表示,该项中标内容为工信部对强基工程关键基础材料的专项补助,与重庆墨希是否实现批量化销售并无必然联系。 和邦股份与青羊区政府合作农业电商项目 继与平安银行成都分行以及农业银行四川省分行展开农业电商项目合作以后,和邦股份牵手成都市青羊区政府。公司6月12日晚间发布公告,公司今日与成都市青羊区政府签署了《互联网+现代农业电子商务投资合作协议》,双方将在农业电商项目方面展开合作。 此外,青羊区政府还将协助和邦股份在青羊区于2015年6月17日前,设立和邦电子商务有限公司,注册资本2亿元。 会稽山募资逾18亿 收购两家酒企做强黄酒行业 会稽山6月12日晚间发布非公开发行股票预案,公司控股股东精功集团、第一期员工持股计划及多家机构参与认购。公司股票6月15日起复牌。 根据预案,会稽山拟以13.86元/股,非公开发行1.3亿股,募资不超过18.02亿元,扣除发行费用后将用于年产10万千升黄酒后熟包装物流自动化技术改造项目、收购乌毡帽酒业有限公司100%股权项目、收购绍兴县唐宋酒业有限公司100%股权项目,以及补充流动资金及偿还银行贷款。 会稽山此次非公开发行股票对象包括公司控股股东静功集团、会稽山第一期员工持股计划、上海大丰、上海达顺、宁波信达风盛、北京世欣钲兴、北京合聚天建、中汇同创、钜洲资产管理及金鹰基金共计10名投资者。其中,静功集团拟认购3200万股,认购金额为4.44亿元,员工持股计划将认购300万股,认购金额为4158万元。 该员工持股计划的资金总额为4158万元,全部用于认购会稽山此次非公开发行的相应股份。参加该员工持股计划的总人数为145人,其中董事、监事、高级管理人员合计7人,合计出资1510.74万元,占员工持股计划总规模的36.33%;其他员工出资2647.26万元,占员工持股计划总规模的 63.67%。 Wind数据显示,2006年至2014年,我国的黄酒行业销售收入由55.18亿元增长至158.56 亿元,累计增长约187.35%,年均复合增长率约为14.1%。会稽山表示,未来黄酒行业集中度提高将成为行业发展的主要趋势之一。通过行业整合,龙头企业有可能实现跨越式发展,并带动黄酒行业实现做大做强。 会稽山此次拟募投的黄酒项目包括建设机械黄酒车间、传统手工黄酒车间、半成品车间、制曲车间等,对黄酒的后熟、储存、灌装和物流等设施进行投资建设,以完全释放10万千升优质绍兴黄酒的产能。 此外,会稽山拟收购两家酒企拓展销售渠道,增加原酒储量。收购完成后,公司黄酒产能和销量将继续提升,在江浙沪及全国其他省市的销售渠道得到进一步拓展,从而实现公司主营业务在短期内做大做强。 天地科技拟收购控股股东部分资产 15日复牌 6月12日,停牌一周的天地科技公告,公司已与控股股东中国煤炭科工集团初步达成收购意向,拟以现金方式收购中国煤炭科工集团全资子公司煤炭科学技术研究院有限公司以及全资子公司中煤科工集团上海有限公司的股权。公司股票6月15日复牌。 具体将收购控股股东旗下2家全资子公司的股权。其中,拟收购的煤炭科学技术研究院有限公司成立于2013年3月,注册资本5000万元。主要从事煤炭转化与清洁利用、矿山安全环保与节能工程、矿用产品检测检验、煤矿自动化与信息化等技术研发和推广应用。 拟收购的中煤科工集团上海有限公司成立于2008年5月,注册资本2亿元。主要从事胶带输送机、煤矿电液控制、矿用产品检验检测、大型游乐设备以及大型市政挖掘装备等研制及相关服务。 资料显示,天地科技2014年已换股收购了控股股东中国煤炭科工集团所持重庆研究院、西安研究院以及北京华宇的全部股权,公司业务增加了煤矿安全技术与装备板块,增加了设计与工程总包板块以及节能环保和新能源板块。 银河证券研报称,天地科技将成为南北车外又一央企改革典范,优质资产注入的过程中,后续资本运作将进一步提升其业绩和估值。 神州高铁拟收购两公司 发力轨道交通业务 神州高铁6月12日晚间公告,公司拟以现金13.7亿元,购买嘉兴九鼎持有的交大微联90%股权;拟16.73元/股向王纯政等27名交易对方发行2962万股,并支付现金3.4亿元,收购其持有的武汉利德100%股权,作价8.35亿元。同时,公司拟不低于19.35元/股,非公开发行不超过1.1亿股,募集配套资金不超过22亿元,其中,17亿元用于支付此次交易的现金对价,5亿元用于支付此次交易相关的中介费用和补充上市公司流动资金。公司股票将继续停牌。 据介绍,交大微联作为轨道交通信号系统的重要供应商,一直专注于该领域产品的研发、生产和销售,拥有较强的自主研发能力和独立自主的知识产权,其主要产品计算机联锁系统、列控中心系统、分散自律调度集中系统、信号集中监测系统,广泛应用于轨道交通信号系统领域。交易对方承诺交大微联2015年度至2017年度净利润分别为1.2亿元、1.5亿元、1.8亿元。 武汉利德是国内轨道线路装备及维护的重要供应商,以铁路线路测控系统、高铁钢轨加工成套装备、铁路养护智能装备的研制、销售与服务为主营业务。主要产品包括铁路安全检测监控设备、钢轨焊接加工及铁路养护装备、物流装备定位及信息管理系统、轨道交通装备工业化连锁服务等。交易对方承诺武汉利德2015年度至2017年度净利润分别为6500万元、8450万元、10985万元。 神州高铁表示,此次交易完成后,武汉利德成为公司全资子公司,交大微联成为公司控股子公司,公司的营业收入和盈利能力将得到较大幅度的提升;交大微联、武汉利德与上市公司现有轨道交通业务将相互补充和协调,形成跨平台协同的核心竞争能力;配套资金的到位将改善公司的资本结构、提高公司的流动性和抗风险能力,助于增强上市公司的盈利能力。 隆平高科合资设立耕地修复公司 隆平高科12日晚间公告,公司与控股股东湖南新大新股份有限公司)、中国科学院亚热带农业生态研究所及自然人杜志艳,共同出资设立湖南隆平高科耕地修复技术有限公司。 其中,隆平高科将以货币形式出资1298万元,股权比例达64.9%;控股股东新大新股份将出资200万元,股权比例达10%。由于出资方中国科学院亚热带农业生态研究所参股的无形资产,该耕地修复公司成立后,在重金属污染土壤治理领域优先享有前者科研技术和专利成果的受让权。 隆平高科称,根据公司农业服务发展战略,农田重金属污染治理将成为公司农业服务体系的重要一环。 联建光电联合两大股东分别发起投资基金 联建光电6月12日晚间公告,为更好地实施公司成为“数字户外传媒集团”的发展战略,公司拟与控股股东刘虎军和重要股东何吉伦分别发起设立投资基金,作为公司产业布局的平台。 其中,公司与控股股东刘虎军拟设立的基金的总规模不超过5亿元。其中联建光电作为有限合伙人投资持有20%的基金份额,刘虎军或刘虎军指定的其他方作为有限合伙人认购77%的基金份额,普通合伙人认购3%的基金份额。 公司与主要股东何吉伦拟设立基金的总规模不超过5亿元。其中联建光电作为有限合伙人投资持有20%的基金份额,何吉伦或何吉伦指定的其他方作为有限合伙人认购77%的基金份额,普通合伙人认购3%的基金份额。 何吉伦未在公司任职,截至公告日,何吉伦直接持有公司15.23%股份,为公司主要股东之一。 大东方定增募资11亿 押注汽车和食品电子商务 大东方6月12日晚间发布非公开发行股票预案,公司拟以13.48 元/股,向不超过10名特定对象,发行不超过8162.09万股,募资总额不超过11亿元,扣除发行费用后将用于汽车后市场综合服务O2O平台建设项目、三凤桥食品O2O综合服务平台建设项目及补充流动资金项目。公司股票6月15日复牌。 具体来说,在线下建设方面,大东方将建设社区快修快保店、综合维修服务中心以及零配件仓储物流中心,增强公司后市场服务及市场覆盖能力;线上建设方面,通过购置相关软硬件,引进开发及运营人员,建立线上系统平台,通过与线下相结合,抢占汽车后市场,扩大汽车领域业务范围。公司力图打造互联网成为公司未来发展的驱动器。 此外,为了将“三凤桥”品牌及产品由本地品牌升级至以长三角及珠三角地区为主要市场的全国品牌,大东方拟新建生产车间、购置生产设备,提升产品品质和供应能力,增加产品种类,同时加大渠道建设,在无锡地区新建食品专营店和物流配送中心。大东方还将建立线上系统平台,实现线上线下渠道融合,促进线下销售增长。 大东方表示,公司子公司东方汽车近年来营业收入的增长和业务规模的扩大,带来了巨大的流动资金需求。2012年末、2013年末、2014年末和2015年3月末,东方汽车的流动比率分别为0.58、0.56、0.69和0.67,速动比率分别为 0.35、0.31、0.34和0.36,资产负债率分别为87.21%、87.09%、77.3%和75.65%,偿债能力较弱。 大东方已于去年通过增资方式向东方汽车提供资金支持,但公司表示,未来随着汽车后市场综合服务O2O平台的建设,汽车维修服务、零部件销售、汽车保险和金融等其他服务的业务规模将进一步扩大,进而产生更大的流动资金需求,因而公司急需补充流动资金。 网宿科技定增36亿扩展主业 引入员工持股计划 网宿科技6月12日晚间发布定增预案,公司拟以43.95元/股,非公开发行不超过8191.13万股,募资总额不超过36亿元,全部用于投资社区云项目、海外CDN项目和云安全项目。公司股票将6月15日复牌。 公司此次非公开发行对象为五名,分别为兴证资管、九泰基金、博时基金、平安资管、泰康资管,认购金额分别为5亿元、 8亿元、13亿元、5亿元 、5亿元。 其中,兴证资管拟设立的兴证资管鑫众-网宿科技1号定向资产管理计划委托人为公司第1期员工持股计划。该员工持股计划参与人数共计245人,包括公司控股股东、董事长、总裁刘成彦、其他董事、监事、高级管理人员以及其他员工。九泰基金拟设立的九泰基金-泰增战略6号资产管理计划的委托人为公司控股股东、实际控制人陈宝珍。发行完成后,刘成彦及陈宝珍将共同直接和间接持有公司33.35%的股份,仍为公司控股股东、实际控制人。 募投项目中,社区云项目总投资22.07亿元,拟投入募资22亿元。项目主要由内容及应用运营平台、社区云节点、智慧家庭终端以及配套的业务运营支撑平台组成。项目建设期3年,建设完成后年新增营业收入为27.64亿元,年新增利润总额41968万元。 海外CDN项目总投资10.68亿元,拟投入募资10.5亿元。项目计划完成海内外CDN节点及全球CDN管控平台的建设,设立本地化营销团队和营销子公司,并通过成立海外研发中心进一步增强公司CDN业务实力。项目建设期3年,建设完成后年新增营业收入为12.28亿元,年新增利润总额28995万元。 另外,云安全项目拟投入募集资金3.5亿元,拟建设并运营基于网宿科技成熟网络安全防护技术的云安全平台,建设期为3年,建设完成后年新增营业收入为3亿元,年新增利润总额11221万元。 网宿科技表示,此次非公开发行募集资金投资项目建成后,可有效提高公司主营业务能力及海外市场占有率,进一步提升公司的核心竞争力,并将为公司“社区云”、“国际化”和“云技术产品化”三大战略的实施和快速推进提供有力保障,实现公司的持续健康发展。 金鹰股份募资16亿 转型新能源汽车行业 自今年1月中旬便停牌的金鹰股份12日晚间发布非公开发行股票预案,公司控股股东和员工持股计划将倾情认购。公司股票6月15复牌。 根据预案,公司拟向控股股东浙江金鹰集团有限公司、深圳市橡树林资本管理有限公司、喀什得心股权投资有限公司,金鹰股份第1期员工持股计划共计4名特定对象,以6.33元/股,非公开发行股票约2.53亿股,募集资金约16亿元。扣除发行费用后将用于新能源汽车动力电池项目、新能源汽车动力总成项目以及补充流动资金。 其中,控股股东金鹰集团将认购逾1.08亿股,认购金额6.85亿元;金鹰股份第1期员工持股计划认购2370万股,认购金额1.5亿元。 公司员工持股计划设立时计划份额合计不超过1.5亿份,资金总额不超过1.5亿元,全部用于认购公司此次非公开发行股票的相应份额。 参与公司员工持股计划的为公司董事、监事和高级管理人员合计不超过16人,包括公司董事长、董事会秘书、财务总监等,总计认购不超过2500万元;其他部分员工不超过1500名,认购不超过1.25亿元。 金鹰股份目前主要从事麻、绢、丝、毛成套纺机装备和塑料、食品机械装备研发、制造以及亚麻、绢丝纺织、染整、服装生产、销售,自2011年以来,纺机、塑机、纺织行业增速放缓,公司面临结构调整的局面。金鹰股份此次力图通过非公开发行募集资金进入新能源汽车产业领域,实现公司产业的战略调整。 金鹰股份此次拟投建的新能源汽车动力电池项目建设规模为年产3亿安时锂电池、2万套电池系统,全部用于满足金鹰新能源汽车动力总成生产的需要。该项目的实施主体为金鹰新能源汽车动力电池有限公司,将由公司与日本技术合作方通过出资的方式设立。 公司已于5月26日与日本株式会社共创、日本小沢能量研究所、日本小沢英耐时会社三家企业签订了合作框架协议。据悉,三家企业长期致力于电池技术、产品的研究、开发,拥有电动汽车动力电池的核心技术,其实际控制人是小沢和典博士,是日本ENAX公司的创始人,也是世界上第一款商用锂离子电池的发明人。 另一募投项目——新能源汽车动力总成项目目建成后将实现年产2万套电动汽车动力总成的能力,由阿尔特汽车技术股份有限公司提供动力总成产品工艺、技术等方面的服务,公司已于年5月26日与其签订了合作框架协议。 东方金钰拟募资逾80亿 延伸珠宝金融产业链 东方金钰6月12日晚间发布非公开发行股票预案,公司拟以25.86 元/股,向不超过10名特定投资者,非公开发行股票不超过3.1亿股,募资总额不超过80.08亿元。公司股票将于6月15日复牌。 东方金珏实际控制人为赵兴龙家族,其分别通过兴龙实业和瑞丽金泽间接持有公司32.99%和 21.72%的股份,合计持有公司54.71%股份。此次非公开发行完成后,赵兴龙家族的持股比例将降至32.4%。不过,仍为公司实际控制人。 公司拟将募投资金投向“互联网+”珠宝产业综合服务平台项目、设立深圳市东方金钰小额贷款有限公司、对深圳市鼎泰典当行有限公司增资、设立云南东方金钰资本管理有限公司以及偿还金融机构贷款。 东方金珏表示,公司在黄金珠宝行业已经取得了领先优势,现有业务经营稳定,在互联网的新常态下,公司希望延伸业务板块、转型升级。同时,珠宝企业已从单一珠宝产品贸易到珠宝金融合作,进而形成以珠宝金融为基石的珠宝生态圈模式。 公司表示,将依托原有珠宝行业采购、加工、销售的专业和能力,利用自身鉴定、估值和处置等优势,向产业金融服务领域延伸,以资金流服务于实体经济,构建珠宝行业的交易和融资平台,并推动行业整合与发展。 募投项目实施后,东方金珏将在既有传统珠宝业务基础上,向珠宝行业金融服务领域延伸,打造面向中小珠宝商户及珠宝消费者、投资者的珠宝金融平台,提供鉴定、评估、典当、小额贷款、P2P 网贷等配套金融服务。 中能电气设两子公司 投资新能源项目 中能电气6月12日晚间公告,公司拟设立境外全资子公司和上海全资子公司,加码新能源项目投资。公司股票6月15日上午开市起复牌。 据公告,中能电气将在开曼投资设立全资子公司,投资总额约5000万美元,拟开展境外电网能源工程、太阳能新能源电站建设及运营等电力能源投资项目,寻求新的利润增长点。同时,开曼子公司为公司海外投资的总平台,公司将通过开曼子公司在境外各地进行项目投资。 同时,为提升公司新能源产业的核心竞争力,公司拟投资设立全资子公司“上海中能新能源有限责任公司”,注册资本8000万元,并拟以该全资子公司为主体投资建设光伏并网发电项目,项目三年计划总投资28亿元。 宝鼎重工3.6亿并购上海复榆 布局新材料 宝鼎重工6月12日晚间公告,拟以现金方式收购上海复榆新材料科技有限公司100%股权,交易总金额约3.6亿元。 上海复榆成立于2011年,致力于新型材料的研发以及新材料在新能源、环保技术和化工领域内的应用开发、技术服务以及产品生产及销售。目前已经拥有全系列亚微米单晶型ZSM-5分子筛,疏水硅沸石吸附剂等产品的创新工艺与技术,且在行业内具有独创性。 从财务数据看,上海复榆2014年实现营业收入1667.02万元,实现净利润60.82万元。交易对方承诺,公司2015年净利润不低于2000万元,2016年不低于3000万元,2017年不低于4500万元。 宝鼎重工表示,上海复榆主要从事新型材料的研发与应用,公司围绕“稳定发展传统业务、积极拓展新兴产业”的战略规划,通过收购上海复榆,进一步拓展新材料、新能源、化工及环保技术领域的研发、生产与销售,提升盈利空间,加快公司在新材料研究及应用领域的布局速度。 信威集团与海南省政府合作 建设海南信息产业 信威集团6月12日晚间公告,为加快发展海南信息产业,优化海南经济结构,公司今日与海南省政府签订了战略合作协议,双方将在在信息产业和信息化建设等领域开展紧密合作。 协议内容包括,在海南省按照国际一流科技园区标准规划建设信威产业基地,规划建设信威全球移动互联网应用软件研发中心、信威全国智慧城市运营及研发中心、信威海南省4G无线通信网络平台运营中心等。产业基地将以公司自身产业为主,同时带动公司上下游企业入驻,打造完整的信息化产业链,全面支撑产业基地发展以及海南省信息化建设。此外,公司规划未来三年内,在海南全省范围投资建设基于信威4G宽带无线多媒体集群系统的基础信息化设施。 海南省政府还将信威集团建设项目列为省重点项目,依法解决项目建设用地指标,并支持信威产业基地或所在园区申请成为国家级产业基地。 信威集团表示,与海南省政府的合作有利于推进公司在海南省的政企行业共网建设,相关项目建设需要公司进行相应资金投入,建成后带来的投资收益或利润,对公司业绩产生积极影响。 中航重机与贵州省国资委合作 推进钛产业重组 6月12日,中航重机与贵州省国资委签订了战略合作框架协议,双方将共同培育和壮大钛产业集群。贵州省国资委表示,支持中航重机对该所属独资企业在条件允许情况下进行战略重组。 根据协议,贵州省国资委将全力配合贵州省政府支持中航重机在黔企业的发展与改革,建立信息沟通机构;贵州省国资委提供监管企业改革改制信息,优先考虑与中航重机合作。 贵州省国资委持最大的开放态度,创造条件先行对贵州省国资委所属的钛行业龙头企业的债务进行重组,剥离其社会化职能,然后贵州省国资委支持中航重机对该所属独资企业在条件允许情况下进行战略重组,实现其技术改造及产业的转型升级,形成贵州钛产业集群。 双方一致同意双方建立工作沟通机制,加强沟通协调,制定相应工作计划,全力协调推进贵州省钛产业战略重组及战略合作。 中航重机在8日刚刚发布定增预案,出手37亿元加码主业锻铸产业。其在2014年年报中表示,国内锻铸行业集中度较低,专业化程度不高,行业竞争激烈,锻造企业之间兼并重组将是大趋势。 鱼跃医疗7亿并购上械集团 布局医用耗材 鱼跃医疗6月12日晚间公告,为了加快公司医用耗材领域的推进和布局,公司拟以自有资金7亿元,收购控股股东鱼跃科技持有的上械集团100%股权。交易完成后,鱼跃科技不再持有上械集团股权。 上械集团成立于1991年,经营范围包括各类医疗器械经营,从事货物及技术进出口业务,在医疗器械领域内的技术服务。该公司2014年和2015年第一季度分别实现营业收入6.37亿元和1.45亿元,实现净利润-3470.25万元和606.87万元。 上械集团核心产品主要有手术器械、卫生材料及敷料、药用膏贴等,产品品类众多,核心产品均具有较高的行业地位和市场占有率,尤其是手术器械,为国内行业龙头企业,而医用卫生材料、辅料和膏贴等产品与本公司在渠道上有较大的协同性。 鱼跃医疗表示,上械集团注入完全符合公司“家用医疗器械和医用高值耗材”的战略发展方向,有利于促进公司在医用高值耗材领域的迅速扩张。 兴森科技2300万美元收购半导体测试板资产 兴森科技6月12日晚间公告,公司全资子公司兴森快捷香港有限公司与美国纳斯达克上市公司Xcerra Corporation达成意向协议,协议的主要内容是收购Xcerra集团的半导体测试板相关资产及业务,交易价格不超过2300万美元。公司股票将于15日复牌。 兴森香港此次收购的业务主要包括在硅晶圆测试及芯片封装测试中使用的测试板的方案设计、生产、贴装、销售及服务。 资料显示,Xcerra集团业务在半导体和电子制造测试领域为客户提供创新且具有最佳成本效益的测试分类、测试接口及各类测试机的半导体测试全方位解决方案。Xcerra集团的半导体测试板及其相关业务2014年底资产总额约1445万美元,2014年实现销售收入3922万美元。 兴森科技表示,此次收购的标的在全球半导体测试板整体解决方案领域具有优势地位,其主要客户均为一流半导体公司。收购完成后将使得公司拥有该细分行业全球领先的方案设计、生产、贴装、服务一站式能力;同时这也是公司在半导体材料、半导体测试行业进一步的布局。随着国内半导体行业的蓬勃发展,预计该项业务在国内的市场空间将迅速扩大。 万向德农1.92亿增资控股子公司 加码种业 万向德农6月12日晚间公告,公司拟对控股子公司北京德农种业有限公司增资1.92亿元,其中以所持万向财务有限公司6.5%的股权的评估价1.52亿元增资,以现金增资3929.29万元。 增资完成后,北京德农的注册资本增至1.86亿元,万向德农的持股比例由92.78%上升至96.12%。万向德农表示,此次增资系为了支持北京德农的发展,做大、做强种业,北京德农是公司的重要利润来源,增资后,有利于北京德农种业提高信用度,增加流动资金,有利于企业长远发展。 截至2014年12月31日,北京德农实现营业收入4.35亿元,净利润-1144.49万元。2015年第一季度,北京德农实现营业收入1.09亿元,净利润734.58万元。 徐工机械转让巴西投资90%股权 10亿加码资本运作 徐工机械6月12日晚间公告,公司全资子公司徐工香港贸易,将以37967.11万元作为对价,向公司实际控制人徐工集团的全资子公司徐工香港发展,转让徐工集团巴西投资有限公司90%股权。 徐工巴西投资系由徐工香港贸易、徐工香港发展出资组建的有限责任公司,于2011年9月注册成立。目前,徐工香港贸易持有其95%的股权;徐工香港发展持股5%。截至2015年5月31日,徐工巴西投资资产总计105720.08万元,负债总计73921.37万元,净资产31798.7万元。2015年1-5月,实现营业收入426.05万元,净利润亏损1464.17万元。 近几年,巴西国内的政治、经济形势发生了很大变化,货币贬值、通过膨胀和高失业率影响了巴西各项经济政策的调整和落实。徐工机械主营业务的市场规模也与原投资预测时有一定的差距。 因此,此次交易是为了优化公司资产结构,提高资产使用效率。同时,此次交易也有利于公司更好的聚焦产品在巴西及南美市场的开拓。 徐工机械同时公告,公司全资子公司徐工投资,拟以现金方式向重庆昊融睿工投资中心追加出资10亿元。昊融睿工另一有限合伙人中融信托同时追加出资10亿元。追加出资完成后,昊融睿工全体合伙人出资额将由15亿元增至35亿元。此举意在实施公司“产业+资本”双轮驱动战略,夯实资本运作平台建设,进一步提升公司盈利能力。 另外,徐工机械拟向徐工投资增资3亿元,占注册资本增加额的100%。 长青集团ppp项目再下一城 成雄县热电项目投资人 长青集团本月连续拿下河北省的两个热电联产项目的投资资格。6月12日晚间,长青集团公告,公司被选为河北省保定市雄县经济开发区热电联产项目的投资人;就在本月9日,该公司刚刚拿下了河北省保定市雄县经济开发区热电联产项目投资资格。两个项目的投资额度分别为4到10亿元、5到10亿元。 长青集团2014年年报显示,公司主营业务为制造燃气具产品及环保产业,在2014年其主营业务收入为137461.55万元,同比增长23.88%。其中,环保业务营业收入同比增长42.87%,高于制造业营业收入17.35%的增长。 据悉,河北省的两个热电联产项目都采取BOO模式。在广义的PPP模式中,BOO模式即社会资本承担融资、建立、拥有并永久的经营基础设施部件,与常见的BOT模式不同的是,前者项目的所有权不再交还给政府。 长青集团表示,两个项目将加大公司在环保产业方面的比重,如果项目顺利进行,将对公司未来经营业绩产生积极影响。资料显示,除了前述两个项目,今年2月份至今,长青集团还先后签订了4个集中供热项目,投资总额达253,000万元。 安洁科技1100万收购广得利电子 安洁科技6月12日晚间公告,公司以自有资金向全资子公司重庆安洁电子有限公司增资1500万元,增资后,重庆安洁的注册资本将由5500万元增至7000万元。同时,重庆安洁拟使用自有资金1100万元收购重庆广得利电子科技有限公司100%的股权。 广得利电子营业范围包括电子科技技术开发,生产销售电子产品、塑胶制品、金属制品等。公司2014年和2015年前4个月分别实现营业收入3488.42万元和1075.46万元,实现净利润214.2万元和41万元。 安洁科技表示,广得利电子一直致力于自主创新和技术研发,长年累积绝缘类制品、胶粘类制品、金属制品等相关部件的模切生产技术及经验。重庆安洁为了顺应模切行业的发展,需要在既有的技术基础下,持续投资以扩大技术团队和业务团队、巩固核心技术,并藉此扩展市场。 横店东磁推员工持股计划 15日复牌 横店东磁6月12日晚间披露员工持股计划,参加员工持股计划的员工总人数共计49人,包含公司部分董事、高级管理人员及核心骨干。该计划涉及的标的股票数量不超过2300万股,占公司现有股本总额的5.6%。该计划设立时以“份”作为认购单位,每份份额的对价为22.46元。公司股票将于15日复牌。 该员工持股计划将在股东大会审议通过后6个月内实施,由博驰投资以协议方式受让控股股东横店控股持有的不超过2300万股横店东磁股票。博驰投资协议受让标的股票之价格为转让协议签订日前一天公司股票二级市场交易均价的50%,即22.46元/股。 据悉,博驰投资是为横店东磁员工持股计划设立的一家有限合伙企业,是此次员工持股计划的运作平台,内部管理权力机构为持有人会议,横店控股为执行事务合伙人且代为持有本次员工持股计划预留股份所对应的权益份额。 普洛药业1.7亿增资子公司安徽康裕 6月12日,普洛药业6月12日晚间公告,公司全资子公司浙江普洛康裕制药有限公司拟现金出资1.7亿元,对其全资子公司安徽普洛康裕制药有限公司进行增资。增资完成后,安徽康裕的注册资本将由1亿元增至2.7亿元。 截至2014年12月31日,安徽康裕资产总额为42552.77万元,负债总额为34551.46万元,净资产8002.31万元,净利润为-1387.48万元。此次增资主要用于补充安徽康裕的资本金,满足企业自身发展的需求,降低资产负债率。 上海莱士1.98亿二级市场购买富春环保股份 上海莱士6月12日晚间公告,公司6月11日,使用自有资金1.98亿元,通过深交所大宗交易系统,购入富春环保1000万股,均价19.8元/股,所耗资金占公司2014年经审计的总资产的2.11%。公司与富春环保无关联关系。 上海莱士表示,目前我国环保行业总体规模逐步扩大,产业领域不断拓展,已经逐步成为我国国民经济不可或缺的新兴产业,未来节能环保领域的市场潜力巨大,看好富春环保围绕固废产业,打造以污泥处理为住的核心业务,认为其商业模式具备巨大优势。 今年早些时候,上海莱士董事会和股东大会审议通过了《公司关于进行风险投资事项的议案》,使用自有资金不超过10亿元进行风险投资。截至目前,公司累计参与的风险投资金额为约6.94亿元。 春兴精工拟7.65亿控股安投融 布局互联网金融 春兴精工6月12日晚间公告,公司与安投融金融信息服务有限公司的股东赵春霞、王博、谷云及刘博签署了《股权收购框架协议》,约定公司拟收购取得安投融51%的股权。标的股权对应初步估值为7.65亿元。 安投融成立于2014年,经营范围包括金融信息服务;经济贸易咨询;投资管理;资产管理等。安投融的“爱投资”网站是国内首创P2C互联网金融交易模式的平台,致力于提供链金融服务,为自然人和中小企业之间搭建投融资的桥梁,解决个人投资收益低和中小企业融资难的问题。 安投融2014年和2015年第一季度分别实现营业收入7508.46万元和1498.22万元,实现净利润1026.85万元和-901.16万元。交易对方承诺,目标公司2015年至2017年三年的交易额持续增长,分别不低于60亿、150亿、300亿元;收入持续增长,分别不低于1.5亿、3亿、6亿元。 春兴精工表示,公司出于战略规划及长远利益实施了此次收购。收购后,有利于快速实现公司在供应链金融和互联网金融领域的战略布局,也有利于公司将传统业务与互联网业务相结合。 科士达与华住酒店合作共建充电桩网络 科士达6月12日晚间公告,公司与华住酒店管理有限公司签署《战略合作协议》,双方将共同构建智能化充电桩网络。 华住酒店集团是国内第一家多品牌的连锁酒店管理集团,全球酒店20强。在中国超过200个城市里已经拥有2100多家酒店和3万多名员工。2010年3月26日,“华住酒店集团”的前身“汉庭酒店集团”在纳斯达克成功上市。 双方约定,华住酒店将提供集团旗下各品牌酒店的停车场或停车位,由科士达负责设计电动汽车整体解决方案;华住酒店提供的集团旗下各品牌酒店的停车场或停车位将帮助科士达在构建全国性充电桩网络的战略上提供落脚点,加快布局新能源汽车充电桩网络业务。 天宸股份子公司清仓盛运环保 获利2300万 天宸股份6月12日晚间公告,公司下属子公司上海宸乾投资有限公司6月10日至6月12日期间,通过上交所股票交易系统出售盛运环保股票逾205.49万股。减持后,宸乾公司不再持有盛运环保股票。 经初步测算,此次宸乾公司出售盛运环保股票获得投资收益约2300万元,约占2014年度经审计的上市公司净利润的29%。该笔投资收益将计入公司2015年半年度收益。 进入【新浪财经股吧】讨论
4 | 5月12日,第22场银行业新闻例行发布会在北京举行。平安银行副行长赵继臣以“商业银行供给侧改革”为主题,介绍了该行供给侧改革思路、取得的成果以及该行围绕国家“去产能、去库存、去杠杆、降成本、补短板”五大重点任务,支持国家供给侧改革的具体举措。平安银行医疗健康文化旅游金融事业部总裁成建新、风险管理部副总经理石明华等出席发布会。 在国家推动以结构调整为核心的供给侧改革的大背景下,商业银行过往基于需求侧的粗放经营方式已难以为继,以绿色经济、循环经济、共享经济为代表的新兴经济业态对金融业提出了更高的要求。在平安银行看来,作为国家经济的重要组成部分,银行要支持经济结构调整,就必须充分发挥金融资源投向的引导作用,银行业的供给侧改革势在必行,它既是银行业对当前国家政策的呼应,也是实现银行变革转型的客观需求。 近年来,平安银行坚持以客户为中心的智慧经营模式,以“跳出银行办银行”等带有鲜明供给侧改革特征的经营理念,业绩取得了快速增长。以2015年为例,平安银行是唯一实现行净利润双位数增长的全国性上市银行,其贷款增速、存款增速均居同业前列。另一方面,平安银行收入结构持续改善,中收占比提升至2016年一季度的33.18%。同时,银行成本收入比持续下降,资产负债结构大幅改善,净利差、净息差持续逆市提升,银行经营日趋健康。 加快自身产能出清 银行有所为、有所不为 为支持国家调控过剩产能,优化信贷资源配置,平安银行一直大力压缩“两高一剩”过剩产能授信,严控重点过剩产能行业,截至2016年一季度末,平安银行“两高一剩”贷款压缩至137.76亿,较2013年年初下降58%;重点过剩产能行业贷款占全行贷款比例压缩至8.56%。 在严控两高(高污染、高耗能)及产能过剩行业的信贷投放的同时,平安银行腾挪出大量的信贷资源投向国家政策支持的重点行业、新兴产业,甄选了节能环保制造业、服务业、清洁能源行业、新能源汽车行业、绿色建筑行业等作为重点支持对象,并逐步建立绿色审批通道专项支持。截至2016年一季度末,该行支持绿色信贷额度550.38亿元,低碳金融授信余额达3006.61亿元。 此外,为顺应国家“互联网+”战略的要求,平安银行致力于推动“互联网金融生态圈+产业金融生态圈”的同步发展,以“互联网”+“物联网”支持小微企业、个人用户和产业链客户,以“橙E网”、“贷贷平安” 、“新一贷” 三大重点平台为互联网、产业链、实体商圈等多类双创和小微企业提供金融服务支持。 创新产业基金模式 支持重大项目和国企混改 据了解,从2014年开始,平安银行全面开展产业基金战略布局,短短两年时间里,平安银行产业基金累计签约项目逾700个,签约规模超过2万亿元,落地出账规模8208亿元,70%以上投向民生基建、国企改制和产业升级。 仅在2015年平安银行就实现产业基金投放规模超过5000亿元,其中大量投向政府国企金融、公用事业建设、棚户区改造、三旧改造、产业园区建设等方面,并落地了昆明交通产业基金、沈阳中德汽车产业园基金、重庆国资负债管理基金、郑州航空港产业基金等一系列典范案例项目,在支持实体经济发展、支持基础设施建设及支持产业升级等方面,发挥了积极作用,形成了良好的社会效应。 2016年以来,平安银行在过往经验的基础上,设计整合了“供给侧改革类产业基金”系列产品,将更大力度地加强对国家供给侧改革的响应与支持。 支持地产去库存、调整 供给结构 对于国家重点关注的房地产去库存,平安银行提前布局,通过“专业化、集约化”管理,在支持国家化解房地产库存,促进房地产业务持续发展的同时,实现了自身业绩的迅速提升。 2013年,平安银行地产金融事业部正式成立,作为该行“事业部改革”后成立的首批行业事业部,该事业部深入研究行业发展特点,通过“专业化、集约化”的服务,促进房地产业务健康发展。事业部注重区域性、结构性的供给,聚焦一二线城市投资,释放有效供给;压缩库存大、去化慢城市的地产投资,通过差异化的信贷策略,促进房地产业务的调整与良性发展。截至2016年一季度,平安银行地产金融事业部管理资产规模2162亿,成立分部24家。在业务类型上,以改善型和刚需住宅项目为主,积极参与城中村改造和保障房建设,助力新型城镇化进程。 在零售住房业务领域,平安银行积极优化按揭业务的流程,提高按揭业务的审批效率。2016年,平安银行在“易贷e通平台”实现了房贷业务的线上化,客户只需登录APP即可线上申请贷款,无需手工填写和提供资料复印件,以拍照上传取代了原件审核、复印件扫描流程,提升了申请的便捷性,实现了随时随地申请、现场审批、当天放款的目标。 深化事业部改革 满足客户全方位金融需求 在支持民生和消费升级方面,平安银行通过行业事业部和产品事业部,以专业金融服务“医、食、住、行、玩”等与百姓民生息息相关的产业,不断推进资源跨界整合,积极助力实体经济转型发展。 通过事业部改革,平安银行大大提升了对于重点行业、主流客户的研究了解深度,得以根据行业属性、客户特点,针对细分行业的客户需求,设计包括咨询、融资、平台搭建、技术支持、资源整合、交易撮合等方式在内的综合金融解决方案,大大提升了金融供给的有效性,为“商业银行供给侧改革”提供了强大的行业金融专业支持。截至2015年末,平安银行行业事业部和产品事业部管理资产规模超过15000亿元。 以该行医健文旅事业部的“平安文旅荟”模式为例,2015年,平安银行与华谊兄弟、大连海昌、砂之船艺术、奥特莱斯、艺术北京、碧桂园共同发起了“平安文旅荟”,针对各类主力消费人群,通过整合“大消费、大休闲”产业细分市场的龙头企业,集聚国内高端旅游、休闲、消费产业资源,搭建起业态互补、客流共享、风险共担的区域文化旅游商业生态。 据平安银行介绍,“平安文旅荟”的创新之处,对消费者来说,是解决了平常下班以及周末无处可去的问题,在城市中心以及城市新区都有了可以“旅游、休闲、体验、消费”的目的地。对企业来说,在平安文旅荟的平台上,可与合作伙伴优势互补,共享客户,加速商业生态培育。同时,大家一起拓展有很好的协同效应,既受欢迎,也有更强的议价能力。对地方政府来说,通过引入平安文旅荟,一下子就能引入多个行业顶级企业,“人流、物流、消费流、信息流”会迅速活跃起来。对银行来说,它突破了传统银行服务客户的限制,变革“银政企”合作模式,主动创造细分市场并锁定融资份额,发挥事业部“专业化、集约化、跨区域”优势,打造了该行营销行业龙头企业的差异化竞争优势。 平安银行表示,推动商业银行的供给侧改革,是在当前中国经济发展阶段和金融形势下,银行经营者所作出的全新探索和尝试。未来,平安银行将全面考量该行的资源禀赋和内外环境,制定符合自身需求的改革策略,在实施中科学决策、系统引导、把握节奏,既要从上到下实现思想和观念的根本性转变,也要激发市场端的供给活力和服务水平,更要通过中后台的管理变革和机制优化,形成集成化、系统化的整体作业模式,为银行供给侧改革的真正落地铺平道路。(CIS) 进入【新浪财经股吧】讨论
5 | 国家能源局:推动我国能源转型向纵深发展 □本报记者 刘杨 在8月19日举行的2017年能源大转型高层论坛上,国家能源局局长努尔·白克力指出,在经济发展进入“新常态”背景下,推动我国能源革命向纵深发展,要做好包括节能优先、绿色低碳、科技创新、深化改革和开放的合作在内的“五个坚持”。 同时,本次论坛上发布了由国家能源局石油天然气司、国务院发展研究中心资源与环境政策研究所以及国土资源部油气资源战略研究中心共同编制的《中国天然气发展报告2017》(简称《报告》)。多位与会者指出,加快推动天然气发展,是我国能源结构优化调整的战略举措和现实选择。 非化石能源消费比重再度提升 努尔·白克力指出,能源革命领域“五个坚持”,是在我国经济进入“新常态”背景下,深入贯彻落实习近平总书记“四个革命,一个合作”能源革命战略思想的重要实践。 国务院发展研究中心主任李伟表示,经济发展逐渐稳定的形势下,我国能源转型进展明显。2016年,全国能源消费总量43.6亿吨标准煤,同比仅增长1.4%,以较低的能源消费增速保障了国民经济发展的需要;能源消费结构进一步优化,非化石能源的消费比重达到13.3%,同比提高1.3个百分点;超过两亿千瓦煤电机组实现节能改造,超过一亿千瓦机组实现超低排放改造;非化石能源发电装机比重达36.4%。“但我国的能源转型是一个长期的过程,一定要从我国的国情、资源禀赋和发展阶段出发,来审视和推动我们国家的能源转型。” 新奥集团创始人、董事局主席王玉锁认为,只有从理念、结构、模式上进行系统的创新,创建现代能源体系,才能引领世界能源变革。首先,技术和政策的创新为创建现代能源体系奠定了基础;其次,标准体系重构为构建现代能源体系提供了牵引;再者,泛能网实践为创建现代能源体系提供支撑。此外,我国现代能源体系的建立还需树立以创新实现弯道超车的意识,加大新技术,新模式的推广和支持力度;同时,进一步深化电力体制改革,营造公平高效的市场环境,加大新型标准体系建设支持力度。 三分之二天然气市场有待开拓 根据《报告》,2016年中国天然气表观消费量为2058亿立方米,同比增长幅度达6.6%,增速超过2015年,天然气的一次能源消费占比增至6.4%。其中,受气价走低、清洁取暖和新型城镇化等利好推动,城镇燃气和天然气发电消费增长明显。数据显示,2016年城镇燃气和天然气发电的天然气消费量分别由2015年的628亿立方米、284亿立方米增至2016年的729亿立方米和366亿立方米,在天然气消费总量的占比分别由32.5%、14.7%升至35.4%、17.8%;工业燃料消费量712亿立方米,在天然气消费中占比达34.6%;化工用气略有下降,为251亿立方米,占比从14.6%降为12.2%。 对此,努尔·白克力指出,天然气是我国推进能源生产和消费革命,实现主体能源绿色低碳更替的重要基础。2020年要实现天然气一次能源占比10%的目标依然任重道远。“我国13.7亿人口,按去年约2100亿立方米的天然气消费总量测算,现在涵盖的人口是4亿多,即当前天然气供应只能满足全国1/3人口的需求,还有2/3的市场需要开拓。” 他强调,为兑现我国天然气市场的巨大潜力,要实施城镇燃气工程、天然气发电工程及工业燃料升级工程;同时,还要加大常规天然气、页岩气勘探开发和利用,增强国内供给;要加快天然气管网等基础设施建设,加强基础设施的互联互通;要加大储气调峰建设,大幅度提高储气调峰能力。 进入【新浪财经股吧】讨论
6 | 本报记者 苏锶 上海报道在中国企业走出去、“一带一路”和双创背景结合之下,产业地产全球孵化创新已势不可挡。其中,尤以万科布局产业地产起点较高,公司最近两次重大签约均与海外资源对接合作有关。12月11日,上海万科产业服务品牌星商汇和以色列国际孵化器相关公司股票走势华夏幸福万科A张江高科、美国创新技术投资、意大利米兰时尚科技创新及保加利亚对外投资合作等展开了战略签约及挂牌合作。两天之后,万科、华大基因、招商新能源这三家深圳本土代表性企业又与“太阳城”阿布扎比马斯达尔城项目、马斯达尔理工学院签订合作备忘录,就未来科技、清洁能源和生物基因等科技领域开展交流合作。一名产业园区业内人士向记者分析指出,产业地产的转型具有不确定性,对于企业而言是一个内部权衡的隐性问题。与此同时,不少业内人士对于赢利周期较长的产业地产在短期内也不甚看好,如今这块也正处于“萌芽期”,绿地、万科、招商等大型房企也在该领域进行探索。万科发力国际孵化器不难看出,万科牵头在海外建立研发基地,目的就是整合全球科技资源,服务万科国内国际的业务,这本是万科国际化战略的重要一环。根据12月11日的协议,万科星商汇将通过与以色列孵化器、美国创投机构等海外资源的对接合作,搭建跨国际创新合作平台,为双边孵化、项目合作、技术转移、人才交流等方面提供支撑,以促进万科国际孵化器的建立。而马斯达尔城项目则是万科要在海外复制其产业园区试水之作前海企业公馆的成功经验。位于阿布扎比的马斯达尔城项目2008年正式启动,该项目由阿布扎比政府所有的未来能源公司投资建设,规划投资总额187亿-198亿美元,目标是建成全球首座零碳城市和清洁技术世界级研发基地。万科方面透露,将把马斯达尔城项目建成深圳在海外的首个集群式旗舰研发中心,并通过与东西交通枢纽、信息和展示中心的迪拜城,成为深圳的创新技术进入中东、欧洲、印度、北非市场的桥头堡和跳板。在此之前,以华夏幸福(600340.SH)为代表的很多产业地产商已纷纷走向海外。上述业内人士认为,这类整合全球资源进行无国界孵化的做法也是很多产业地产商都在不约而同摸索的,其中包括张江高科、天安数码城、宏泰发展、亿达中国和启迪控股等,它们也都在和美国、以色列、德国、日本的潜在合作方进行着频繁的互动探索。而在去年9月,万科总裁郁亮就明确透露了万科白银时代的新三大业务包括“住宅地产、消费体验地产和产业地产”。再创“万达模式”?2014年华夏幸福就在美国硅谷率先设立了孵化器公司,现已完成了52个产业园的谋划和布局,并计划到2016年完成200个产业园的规划。对比之下,万科做国际孵化器的模式则更多是试图通过孵化投资老手的经验与资源来实现撬动效果。在克而瑞2015年上半年销售金额前十名中,华夏幸福是唯一一家依靠产业地产实现高增长的“黑马”,公司的运营逻辑更像是“产业地产版”的万达。“万达模式”即在新区进行商住综合体的开发――完善的商业配套吸引购房者从而带动住宅销售;住宅销售带来的现金流补贴商业运营,并支持企业进一步扩张,总体可概括为“以售养租”。目前华夏幸福的收入大部分仍然来自于产业园区配套的住宅销售,不过华夏幸福的营收结构早已区别于一般房企。该公司产业运营类收入占营业收入总额的29%,其中,产业发展服务单项几乎包揽全部份额,占比27%;从利润方面来看,产业发展服务毛利高达96%;主要包含产业定位、产业规划、城市规划、招商引资、投资服务等。据了解,华夏幸福目前在美国硅谷有建设产业孵化器,国内已有的成果案例是固安肽谷生物医药孵化港。此外,公司还携手专注孵化器运营管理和科技创业企业培育的专业机构――太库,双方合作打造创新孵化体系,年内委托给太库的经营孵化项目共计10个,具体产业落地数目在未来三年内应分别不低于3个、6个、10个。根据2015年中报显示,华夏幸福在全国范围内委托开发园区面积为2433平方公里,其中京津冀区域合计1982平方公里,占比82%,长三角区域合计298.6平方公里,以沈阳、湖北为主的其他区域合计152.6平方公里。不过,上述业内人士指出,华夏幸福定位是产城运营商,起家还是靠“造城”,在“产”的运营与服务上,华夏幸福也仅是刚入门。除招商引资带来的产业发展服务收益外,综合服务、参投分红等,都还是在孕育的盈利 “种子”。作者:苏锶media_span_url('http://epaper.21jingji.com/html/2015-12/16/content_27794.htm')
7 | 中国人民银行23日消息,为贯彻落实《生态文明体制改革总体方案》和十八届五中全会精神,日前,中国人民银行发布2015年39号公告,在银行间债券市场推出绿色金融债券。据介绍,绿色金融债券是金融机构法人依法在银行间债券市场发行的、募集资金用于支持绿色产业项目相关公司股票走势万科A并按约定还本付息的有价证券。绿色金融债券的推出,为金融机构通过债券市场筹集资金支持环保、节能、清洁能源、清洁交通等绿色产业项目创新了筹资渠道,有利于增加绿色信贷特别是中长期绿色信贷的有效供给,是建设绿色金融体系的一项重要举措。人民银行有关负责人在回答记者提问时表示,绿色金融债券市场的培育和发展,需要坚持绿色发展理念,创新和完善制度安排,形成既有政策引导和激励、又有社会声誉和市场约束的绿色金融发展机制。一方面,要引导金融机构把发行绿色金融债券作为践行绿色发展社会责任的重要体现。另一方面,又要通过制度安排和政策倾斜,充分调动市场主体参与绿色金融债券市场的积极性和主动性。与此同时,也欢迎其他政府部门和地方政府出台税收、贴息、增信等配套优惠政策,欢迎社会保障基金、企业年金、社会公益基金等在内的各类投资者投资绿色金融债券,以共同推动绿色金融债券市场发展,促进各类资金参与支持绿色产业。(刘国锋)media_span_url('http://epaper.cs.com.cn/html/2015-12/24/nw.D110000zgzqb_20151224_9-A02.htm?div=-1')
8 | 序号受理编号交办问题基本情况行政区域污染类型核查核实情况是否属实处理和整改情况问责情况1D340000201810310027亳州市谯城区古井镇附近105路段河水污染严重,古井产业园区北侧路面损害导致扬尘严重。亳州市水,大气1.经查,谯城区古井镇105国道东侧河为亳宋河,该河道上游在河南省商丘市睢阳区宋集镇,自北向南流经古井镇柳行行政村、后老家行政村、张集行政村、吕楼新村、古井产业园区东侧,至下游谯城区华佗镇周溜闸。因目前为枯水期,该段河流上游至柳行行政村刘楼自然村处、吕楼行政村北侧桥下为断流状态。经对该段河道13个断面取样监测,后老家行政村、张集行政村等9个断面水质化学需氧量(COD)、氨氮、总磷等指标均达到地表水Ⅴ类标准;柳行行政村、吕楼新村、古井产业园区东侧、周溜闸等4个断面COD超地表水Ⅴ类标准0.55―0.125倍,氨氮、总磷等指标均达到地表水Ⅴ类标准。经走访调查分析,造成水质差的原因一是因下游周溜闸长期闭闸,吕楼行政村北侧桥下至周溜闸段水体不流动,造成水质变差;二是受2018年8月温比亚台风强降雨影响,上游污水下泄并有部分滞留在亳宋河古井镇段;三是柳行行政村尚未建设生活污水集中处理设施,村内污水随雨水进入河道;四是吕楼新村东西沟支流水质较差(COD55mg/L),与亳宋河交汇后影响主河道水质。2.古井产业园区北侧路面损坏导致扬尘严重问题属实。属实1.已责成谯城区制定亳宋河水质改善方案,一是加强涵闸调度,促进水体流动,增强水体自净能力;二是加强与上游地市、县、镇沟通协作和联防联控,避免污水集中下泄;三是加快柳行行政村等村庄生活污水集中收集处理设施建设进度,污水处理后达标排放;四是加强张集行政村、吕楼新村等生活污水处理设施的运营管理,促进亳宋河水质不断好转。2.该路段已纳入古井镇小康路修建方案,目前正在施工,因投诉反映的破损路面位于小康路末端,预计2019年3月动工建设,2019年12月底全线贯通。对扬尘污染问题,谯城区古井镇党委、政府已安排专人高密度洒水保洁,最大限度地降低扬尘污染。无2D340000201811010098合肥市庐阳区阜阳北路经济开发区的伟宏钢构经常在夜间喷漆作业,废气影响居民生活;融乔悦城小区东面空地有大型设备破碎石料作业,扬尘较大,噪音扰民。合肥市大气,噪音10月31日凌晨,庐阳区环保局对该公司突击检查,发现该公司二分厂、三分厂生产中的产生的焊接烟气未经过处理直接排放。经核查,投诉人反映情况属实。11月1日,庐阳区环保局依法对其生产设备供电设施进行查封合庐环查(扣)字〔2018〕34号。1.2018年8月28日庐阳区环保局执法人员对伟宏钢构现场检查时发现该公司二分厂在无任何污染防治设施下进行喷漆作业,依法对其立案查处,罚款20万元,并责令企业进行整改。该公司于2018年9月新增3台移动式喷漆房。2018年10月下旬,庐阳区环保局多次接到群众举报反映伟宏钢件夜间喷漆扰民,均组织执法人员夜间检查,未发现该公司进行喷漆作业。2.融侨小区东面空地,原为京福铁路桥梁场。京福铁路施工结束后,因对该处地面恢复硬化的需要而临时设立的破碎厂。属实1.11月3日,该企业邀请相关专家对其整改方案进行论证,目前处于停产状态,下一步按照专家意见进行整改。2.11月3日,已对该碎石场机械进行拆除,目前正在搬离现场,预计11月7日晚全部搬完,剩余碎石已全部覆盖并逐步清运。无3D340000201810310011六安市裕安区分路口镇裕龙新城小区47号楼顶楼安装有信号接收器,辐射影响居民健康,要求拆除。2017年中央环保督察时曾投诉小区旁边铁塔,该铁塔拆除后直接安装在47号楼小区顶楼。投诉人质疑环评手续的合法性。六安市辐射经调查核实,裕安区分路口镇邮电局旁边移动发射塔已在2016年10月7日由中国铁塔股份有限公司六安市分公司进行拆除完毕。分路口裕龙星城小区46、47号楼楼顶的2套信号接收器均于2018年10月19日履行环评登记备案手续(备案号201834150300000356、201834150300000354),2018年10月21日开始安装,2018年10月23日安装完毕,截止目前基站尚未开通。2套信号接收器现在属于中国联合网络通信有限公司六安市分公司建设及运营。另外,在裕龙星城小区47号楼还布设了350兆警用数字集群通信系统基站,基站于2018年3月开始建设,2018年4月建成,现已开通运行,通过该系统的技术参数证明材料,证实350兆警用数字集群通信系统的等效辐射功率为12.5W,符合国家《电磁环境控制限值》(GB8702-2014)中豁免管理的条件。属实现场由六安市环境监测中心站人员对350兆警用数字集群通信系统产生的辐射进行监测,现场监测结果范围为:0.16-0.86V/m,满足《电磁环境控制限值》(GB8702-2014)及安徽省环境保护厅《关于安徽省无线通信基站单址多套环境影响评价暂行标准的函》(环辐射函〔2009〕474号)确定的多套系统基站公众总的受照射电场强度8.5V/m限值要求,监测结果均不超标。下一步,在基站开通后,督促企业履行无线基站电磁辐射污染防治和辐射安全主体责任,采取有效辐射安全与防护措施,积极开展监测工作,公布监测结果。无4D340000201811010041安庆市太湖县新仓镇花园老乡边上的黑河水体污染严重。安庆市水举报人所反映的“黑河”是潜山和太湖两县为解决防洪排涝问题修建的人工河道。黑河太湖段水域流经晋熙镇、新仓镇、小池镇,与长河交汇,注入皖河。黑河太湖段河水源自上游的汪洋水库、罗河、观音河。由于今年降雨量偏少,上游主要来水的汪洋水库正在进行除险加固,基本无水外放。现场调查时,黑河太湖段河水水体流量较小,水体感官偏黑,其上游观音河道河段存在污水管道堵塞情形,有少量生活污水排入河道。沿黑河太湖新仓段有部分居民生活污水排入河道。导致黑河水体污染,有异味。属实根据现场调查情况,太湖县政府正在制定整改方案,整改分两个阶段实施。第一阶段,在黑河太湖段上游观音河的经一路与纬一路交口处设置临时拦水坝一道,将排入河内的生活污水截流接入城东污水泵站内,计划2018年底前完成。第二阶段,从三个方面实施,一是在黑河太湖段上游观音河道自文博园至城东污水泵站段,设置一道D800排污管道,收集排入观音河内的生活污水。总投资约260万计划2019年8月31日前完成。二是对黑河太湖段进行堤坝护彻、清淤治理。目前,黑河加固整治项目正在进行项目规划设计,计划于2019年启动实施,2019年12月前完工。整改时限:预计2019年12月底。三是面源污染治理,新仓镇人民政府将结合美丽乡村建设、改水改厕等工作,优先安排黑河沿线新仓段境内的居民改水改厕工作,减少居民生活污水直接排入黑河,封堵向黑河直排的污水管口,计划2019年6月底前完成。无5D340000201811010057马鞍山市和县石杨镇如山湖城碧桂园小区居民饮用水受到污染,经常停水,不能满足居民日常使用。该小区建设时未建设生活污水处理设施。马鞍山市水经核实,反映问题与2017年中央环保督察受理编号88号信访件为重复点位,举报情况部分属实。马鞍山市和县石杨镇如山湖城碧桂园小区居民饮用水受到污染。该问题不属实,2018年10月30日和县卫计委对碧桂园水务有限公司出厂水和末梢水进行了现场快速检测,所检指标均符合国家水质卫生标准,同时对水厂的生产状况进行检查,未发现居民饮用水受到污染。经常停水,不能满足居民日常使用。该问题属实,经和县石杨镇、水务局核实,碧桂园小区自来水源水为滁河水(接石杨镇自来水厂管道),目前其从石杨自来水厂接入水约为3000t/日,碧桂园自来水厂除日常居民供水外,还存在部分绿化用水,造成无法满足全日居民用水。该小区建设时未建设生活污水处理设施。该问题不属实,和县规划局核实石杨镇如山湖城碧桂园小区污水处理设施建设于2008年,与如山湖小区同步建设。2018年5月28日,和县环保局对发现的小区污水处理厂存在的不正常运行治污设施进行了立案查处并罚款40万元(已缴纳),责令企业对存在的问题进行整改并委托第三方有资质单位运维。后该污水处理厂进行了整改并由第三方(安徽蓝清源环保科技有限公司)有资质公司运维。环保部门持续加大对该问题的监管,2018年10月12日,针对第三方运营公司运维时存在环境违法行为进行了立案查处(目前案件正在办理),目前该污水处理厂运行正常。针对污水处理厂进水量及进水浓度不足,经住建部门排查为小区内部污水管网未完善,导致小区生活污水不能做到应收尽收所致。属实1.和县水务局要求碧桂园水务有限公司暂停绿化供水(已暂停),保障居民生活用水。碧桂园水务有限公司已与石杨镇水厂方面商议加大了每日供水量。2.碧桂园水务有限公司已委托专业的第三方机构(江苏新元盛投资有限公司)对水厂进行托管,负责水质控制和日常管理。3.和县卫计委要求碧桂园水务有限公司加强水质净化工作,更换过滤池石英砂和沉淀池斜板,水净化处理设备、设施必须满足净水工艺要求,必须有消毒设施,并保证正常运转,目前此项工作已完成。4.安徽和县碧桂园房地产开发有限公司对碧桂园如山湖城污水管网实施改造,目前大部分主管网已建成,支管网于2019年4月15日前完成建设。针对2017年中央环保督察组交办情况,和县已实施问责7人;2018年无问责情形。6D340000201811010048安徽省芜湖市繁昌县荻港镇庆大村工业循环园的博圆环保材料有限公司生产性污水简单处理后直接排入大西河,污染周边环境;庆大村扬尘污染严重。芜湖市水,大气经繁昌县荻港镇政府会同循环园综合办、县环保局等部门工作人员现场核查,投诉情况部分属实。具体情况如下:被投诉企业为芜湖博元材料科技有限公司,位于芜湖市繁昌县荻港镇庆大村,厂区距大西河约400―500米。该企业前期已履行项目环评审批手续,环评文件及批复中均明确要求企业生产废水必须做到全部循环使用、不外排。现场检查时,企业正常生产,厂区内雨、污水管道均未发现有废水排放迹象,未发现私设暗管行为,厂区围墙区域附近也未发现有废水排放痕迹。此外,经现场核查,庆大村内没有产生粉尘污染的企业,但村内部分道路因货物运输量大,存在道路扬尘情况。属实针对污水排放问题,循环园综合办和县环保局等部门将加大环境监管力度,并不定期开展巡查,督促企业切实履行环保主体责任,一旦发现环境违法行为,将依法予以惩处。针对道路扬尘问题,荻港镇政府和县交通运输等部门将加大道路运输污染整治力度,对货源单位实施严格监管,加强路面稽查,增加道路洒水降尘频次,进一步改善环境质量。无7D340000201811010104合肥高新区明珠和石楠路交会口的会通新材料有限公司附近有强烈刺鼻性气味,影响居民身体健康;燕美新材料有限公司和力世通材料有限公司夜间偷排废气;肥西县明皓机械有限公司夜间焚烧工业垃圾。合肥市大气高新区:群众反映会通新材料股份有限公司产生气味属实,反映合肥力世通塑料制品有限公司和合肥市燕美粉末涂料有限公司夜间偷排废气不属实。1.会通新材料股份有限公司位于高新区柏堰科技园芦花路2号,主要从事改性塑料的生产,其建设项目已履行环评审批及验收手续。主要生产废气为熔融和挤出工序产生的有机废气,经集气罩收集,通过废气治理设施处理后,经排气筒高空排放。企业于2017年4月对原有机废气治理设施进行提标改造(改为蓄热式焚烧炉处理工艺),并于2017年9月通过专家技术验收。2018年10月30日中央生态环境保护督察组对企业进行了督察,发现存在有机废气收集措施不完善,污染治理设施运转不正常。2018年10月31日,高新区环保分局对该企业现场检查时企业停产,由专业公司对污染治理设施进行全面检修停产至11月2日白天,11月2日晚少量生产线恢复生产,11月3日现场检查时,企业污染防治设施正常运转。2.合肥市燕美粉末涂料有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事环保型热固性粉末涂料生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为配料预混投料产生的粉尘,经除尘设备处理后排放。在达标排放的基础上,为进一步降低污染物排放,企业于2018年7月完成混料段粉尘密闭收集改造并投入使用。高新区环保分局于11月2日对该企业开展现场监察和监督性监测,检查时企业处于生产状态,污染防治设施正常运行,监督性监测结果第三方检测机构尚未提供。3.合肥力世通塑料制品有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事注塑件的生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为注塑过程产生的有机废气。企业在达标排放的基础上,为进一步降低污染物排放,于2018年8月完成注塑车间有机废气治理项目(采用分子击断处理工艺)建设,目前已投入使用。高新区环保分局于11月2日、11月3日、11月4日对该企业现场检查时,企业处于生产状态,污染防治设施均正常运行。监督性监测结果显示企业大气污染物达标排放。肥西县:肥西县环保局会同桃花镇于2018年11月2日赴合肥明昊机械制造有限公司现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况一致。被投诉企业名称为合肥明昊机械制造有限公司,项目建设过程中已执行环评审批手续,该公司自身未办实体生产加工,厂房主要租赁给小微企业从事机械、服装加工等。2018年10月27日夜间,肥西县环保12369投诉热线接到群众投诉,反映肥西县明皓机械有限公司夜间焚烧垃圾问题。经查,群众反映的焚烧垃圾行为是因企业管理不善,厂区内工作人员夜间点燃垃圾造成的。主要焚烧的是食品包装盒、服装废料和生活垃圾,违反大气污染防治法相关法律规定。属实高新区:1.针对会通新材料股份有限公司异味影响问题,高新区管委会成立工委、管委会主要领导为组长,工委领导班子其他成员为副组长,相关责任部门主要负责人为成员的会通新材料股份有限公司中央生态环境保护督察转办信访件整改工作领导小组,全面领导和协调整改工作,主要领导亲自抓、分管领导具体抓、责任部门分工协作。日常具体工作分别由环境监管执法组、群众信访协调组、转型升级(搬迁)协调组承担。当前采取以下整改措施:一是驻点执法监察,实时响应监控。高新区环境执法人员在会通公司整改期间24小时实施驻场监察,重点监管企业污染防治设施运行情况及限产落实情况;二是加大监测频次,及时掌握企业排污状况。高新区环境执法人员带领监测机构每日对污染物排放因子进行监测,一个月完成大气污染物在线监测设备安装并投入运行;三是禁止生产产生高异味产品,企业目前已主动转移产能,将产生高异味产品全部转移,高新区管委会将持续跟踪督办。减量生产其他产品,对企业限产措施进行监督,确保企业生产情况满足其承诺限产的内容(落实线体开机率不超过70%;重污染天气条件下按照合肥市应急措施统一部署,线体开机率不超过60%),并建立限产台账。四是督促企业加大投入。督促企业全面排查异味源,废气治理专业厂家驻厂调试培训,建立专业规范维保机制。同时持续开展提标改造,保持污染防治设施高效运行,加强环境管理,减少对周边环境影响。五是合理产业布局,指导企业启动搬迁。加快推进企业转型升级和产业布局调整,指导企业启动搬迁,立即启动新厂选址论证工作,列入高新区重大项目定期调度。六是强化居民沟通和环境信息公开,增强群众满意率。群众信访协调组建立主动与群众见面沟通机制,同时督促企业主动听取居民意见,及时将整改工作和日常环境管理情况向居民告知。2.高新区环保分局会同柏堰科技园管委会继续依法加强对合肥市燕美粉末涂料有限公司和合肥力世通塑料制品有限公司的环境监管,督促企业切实履行主体责任,加强厂区日常环境管理,对污染防治设施建立专业规范维保机制,确保污染防治设施正常运转,污染物达标排放。肥西县:桃花镇当日夜间值班人员现场已立即予以制止,并要求企业及时对垃圾进行清理并对垃圾进行规范处理。县环保局已依法向其下达了肥西县环保局责令改正通知书(0012731)及肥西县环境保护局行政处罚事先(听证)告知书(肥环罚告字201849号),要求其停止环境违法行为并依法行政处罚。无8D340000201811010058合肥市包河区巢湖南路东二环向南,现有十余家搅拌站,过往运输车辆存在抛洒滴漏现象,造成路面扬尘污染严重,影响周边居民正常出行。合肥市大气经包河区淝河镇工作人员会同经开区住建局、城管委执法人员于11月2日赴巢湖南路现场核查,现场核查情况如下:巢湖南路扬尘污染较大,核查投诉的情况与投诉人反映的情况一致。包河区淝河片区东临南淝河、西至十五里河中段高铁南站片区、北接老城区、南抵包河经开区,总占地面积32600亩。2016年8月,经摸底调查,反映的区域居住群众12260户,多为“城中村”,环境脏乱差。巢湖南路大型车辆出入频繁,导致路况变差、道路基础设施破损严重,致使路基垫层外渗,道路清扫保洁难度大;并且巢湖南路周边存在南淝河路(东二环―长春街)、郎溪路二、三标等施工工地,途经上述工地的南淝河路及郎溪路尚未完全开通,工地渣土运输主要经过巢湖南路,加剧路面循环污染。虽然已采取了加大清扫保洁频次和洒水降尘力度等措施,但无法根治该区域严重的扬尘污染问题。位于巢湖南路、南淝河路沿线集聚混凝土搅拌站共19家。其生产、运输过程带来的扬尘、噪音及水污染问题严重,居民苦不堪言。近几年,有关淝河镇混凝土搅拌站污染的热线投诉、网友留言居高不下。针对淝河片区脏乱差的状况,包河区委、区政府高度重视,深入研判,自2016年初,即开始全面谋划论证淝河片区整体改造工作。其中,针对片区范围内的19家混凝土企业,由于不符合片区土地利用总体规划及未来改造发展业态布局,包河区将其全部纳入搬迁改造范围,并迅速启动相关工作。1、加快签订搬迁协议。对19家混凝土搅拌站下达搬迁改造通知,并陆续启动丈量、评估、签订协议及补偿相关工作。针对企业主反映的补偿问题,包河区本着“尊重历史、面对现实”的原则,耐心开展政策解释和上门沟通工作,尽量取得企业的理解和支持。截至目前,已与16家搅拌站签订了搬迁协议。下剩3家企业由于对搬迁补偿存有一定异议,目前正在积极洽谈推进中。2、积极对接复建事宜。考虑到混凝土企业搬迁可能带来的订单协议违约、员工就业及往来债务等问题,包河区积极协调对接,全力支持搬迁企业开展复建工作。3、加强日常巡查监管。针对混凝土搅拌站搬迁复建前的生产运营,包河区持续加强监督管理,加大扬尘等环境污染防治工作。一是加大宣传教育。中央环保督察期间,针对淝河片区混凝土企业的信访投诉量大的情况,辖区淝河镇、村居对混凝土企业加强宣传教育,要求其文明生产,并落实相关降尘抑尘等环保措施。二是强化监控巡查。区住建局通过行业视频系统,常态化监控搅拌站内洒水降尘、物料覆盖及生产运营环节的扬尘防治;区环保局、辖区淝河镇等加大日常巡查频次,督促企业将各项环保措施落到实处。三是依法行政处罚。对于环保不达标、未通过项目竣工环保验收、违反《建设项目环境保护管理条例》等相关规定的混凝土企业经营行为,区环保等相关部门依法对其进行行政处罚,并责令其落实整改措施。属实1、包河区淝河镇将加大对周边工地巡查力度,严格落实扬尘污染防治要求,确保物料堆放覆盖、出入车辆清洗、渣土车辆密闭运输等措施落实到位。同时,对巢湖南路等重点路段进行严格巡查,对过往抛洒滴漏车辆进行依法查处。2、2018年至今,包河区住建局对淝河镇巢湖南路周边混凝土企业共巡查54次,下达监督意见书39份,对巡查发现的问题均敦促企业落实专人限期整改到位。3、针对巢湖南路路面扬尘的路况实际,为做好大气污染控制,包河区环卫服务中心不断增加了作业车辆,加大洒水降尘频次,实行循环作业。在夜间完成全区主次干道统一的冲洗保洁作业,在白天做好路面保湿抑尘工作,并在晚间薄弱时段增派车辆加强路面降尘保湿。具体措施:(1)洒水车依次循环路面洒水作业,保持路面湿润,抑制扬尘;(2)洗扫车湿扫路牙灰砂,将路牙边的灰砂洗扫干净;(3)小货车清运石子、灰砂;(4)道路养护车配合人工对人行道进行冲洗作业。无9D340000201811010044宣城市经开区管委会旁的乐方瓜子,晚上排的气体有刺激性,方圆几公里的居民都能闻到,严重影响居民休息;经开区的鸿越大道与景德路交叉口,有人在晚上焚烧垃圾,气味难闻。宣城市大气(一)信访人反映的宣城市经开区管委会旁的乐方瓜子应为安徽乐方食品有限公司,位于宣城经济技术开发区(以下简称“市经开区”)柏枧山路。11月1日晚上,现场核查时该公司多味瓜子生产线和焦糖味瓜子生产线在生产,废气处理设施正在运行,废气经喷淋设施处理后排放,车间内有较重香味,车间外厂区内有较浓香味。信访人反映的乐方瓜子气味系瓜子生产过程中使用食用香精挥发出的香精味,信访人反映情况属实。(二)11月1日晚上,对举报地点鸿越大道与景德路交叉口进行核查时,未发现焚烧垃圾现象。11月2日上午,再次对该区域巡查时,发现鸿越大道与景德路交叉口西南角栅栏内荒地有焚烧痕迹。上述地点存在周边某些居民擅自焚烧生活垃圾,产生难闻气味的现象。信访人反映情况属实。属实(一)针对安徽乐方食品有限公司:要求该公司增强生产厂房的密封性,杜绝跑冒滴漏,改善废气收集效果;进一步减少食用香精使用量,调整产品结构和规模,将食用香精使用量再下降10%(较去年下降70%);调整生产时间,将使用食用香精的产品生产调整到白天,晚间和夜间不生产含有香精的产品;在原有已安装废气收集治理设施基础上(4套)再增加一套收集处理设施;香精味瓜子生产线于2019年年底前完成搬迁。截至11月6日,该公司已对蒸煮车间主要通道口加装软帘,对车间所有窗户进行密封。已减少食用香精使用量,减少核桃味等香味瓜子的生产量。香味瓜子生产时间已由夜间调整为白天,减轻对周边居民的影响。已新购置一套废气收集治理设施,近期将安装到位。(二)针对焚烧垃圾问题:一是由属地办事处社区加强宣传,通过在鸿越大道与景德路交叉口及其他闲置土地周边醒目位置设置“禁止焚烧垃圾”警示牌或条幅等方式做好辖区居民宣传告知工作。二是进一步加大薄弱时段巡查管控力度,安排人员巡查值守,对发现的焚烧垃圾行为第一时间制止,并第一时间扑灭火点。三是城管部门加大处罚力度,对焚烧垃圾的行为人,一经查实,一律依法予以从重处罚。四是开展隐患排查工作,举一反三,对辖区内可能存在焚烧垃圾的地点开展逐一排查,尽可能减少或避免发生焚烧垃圾现象。五是建立长效机制,充分利用网格化管理、路段长责任制、门前三包巡查、联点共建等切实有效的工作机制,扎实做好垃圾、秸秆禁烧工作。截至11月6日,已完成鸿越大道与景德路交叉口等其他焚烧易发点位警示牌或条幅的设置,共悬挂条幅27条、设置警示牌10块;对鸿越大道与景德路交叉口周边的鑫鸿交通等企业上门进行了宣传。已制定人员排班表,将每天晚间的巡查值守作为一项常态化工作开展。无10D340000201810310032安庆市望江县鸦滩镇麦元行政村畈上组北侧,去年建了一个200平方左右的垃圾场,目前垃圾只进不出,味道很臭,蝇虫很多,造成道路堵塞,使村民无法在地里干活。安庆市其他污染,大气经查,投诉人反映的望江县鸦滩镇麦元村畈上组垃圾场是一座由麦元村建设的垃圾暂放点,建筑面积约120平米,主要用于该村垃圾收集后临时堆放待镇转运。近年来,鸦滩镇环卫工作始终按照“户入桶、组保洁、村收集、镇运转、县处理”的机制运行,各类生活垃圾经集中收集后,再转运至望江县环卫基地处理。麦元村位处集镇,垃圾收集量大,因县环卫基地接收处理能力有限,而鸦滩镇没有垃圾处理设备,也不具备无害焚烧和其他规范处理条件,导致该村生活垃圾无法及时清运处理,且不断积存。目前,鸦滩镇麦元村积存生活垃圾近300吨,一定程度上影响周边群众生活。属实望江县部分生活垃圾主要依托安庆皖能中科公司处理,因该公司10月底停产重建,目前望江县部分生活垃圾不能及时处置,临时进行暂存,望江县已采取如下整改措施:一是立行立改,迅速安排环卫人员对垃圾存放点周边零散垃圾进行清理;对存放点垃圾采取遮盖措施;并安排环卫工人在存放点垃圾喷洒灭虫药水和消毒液;二是进行转运规范处置,正在积极联系规范化处置公司,尽快安排对存放点积存垃圾进行转运处置,计划年内清理完成。无11D340000201811010060合肥市肥东县新城开发区肥东烟草局对面的真心食品利用风扇排放食品加工过程中产生的异味,特别是夜间20点左右,对周边环境造成严重影响。合肥市大气经肥东县环保局执法监察人员会同经开区环保办人员于11月1日赴现场核查,现场核实情况如下:核查投诉的情况与投诉人反映的情况不一致。安徽真心食品有限公司位于肥东经开区长江东路北侧21号,从事休闲食品加工,项目于2009年12月履行环评审批手续(东建审字2009220号),并通过环保三同时验收手续(东环验字201010号)。经现场查看,该公司食品加工项目已于2017年12月停产至今。厂区内共有3幢厂房,东侧2幢车间为原料仓库。厂区西侧1幢厂房为原瓜子加工车间,车间内存放有生产产品、大量纸箱及原辅材料,车间西侧墙上安装有4个排风扇长期未使用,部分生产设备已拆除,生产线已不具备生产能力。现场未闻到明显气味,在原瓜子加工车间北侧有一密闭的小仓库存有部分食品调味品(八角、桂皮等),调味品原料有香味逸散,目前该公司已将调味品原料搬离北侧仓库。不属实无无12D340000201810310006马鞍山市雨山区佳山乡超山村红桥村民组的马钢南山和尚桥铁矿,开采铁矿时炮震噪音震动,导致居民房屋开裂,污染和尚桥下河流,该铁矿抽取地下水导致土地下陷,出行路面破损严重,扬尘污染严重,严重影响居民身体健康。马鞍山市生态经调查,举报扬尘和和尚桥下河流污染情况部分属实。1.近年来,在当地政府支持下,和尚桥铁矿投资近2000余万元对和尚桥周边区域的双松路、银向路等社会化道路实施了升级硬化改造,总长近3km。由于路线较长,存在清扫保洁和路面洒水不及时的问题,车辆通行时会产生一定扬尘。2.和尚桥铁矿矿坑涌水和地表汇水主要通过多级沉淀后,用于喷淋、洒水及回用生产系统,不外排。但是矿区生活污水处理设施不完善,处理后的生活污水,不能做到达标排放。3.和尚桥铁矿爆破作业采用国内先进的逐孔微差爆破控制技术。和尚桥铁矿于2018年4月,10月两次委托中钢集团马鞍山矿山设计研究院对采场200m-600m范围进行了爆破震动检测,检测结果均小于《爆破安全规程》规定的主震频率和安全允许质点振动速度。2017年5月11日,马鞍山市安监局也曾组织专家对爆破振动检测结果进行专题论证,认为开采爆破时会产生一定的震动和噪音,但不会对200米范围外的正常民房造成破坏。4.和尚桥铁矿投产至今未抽取地下水。和尚桥铁矿环评报告对区域地下水分析的结论为:和尚桥铁矿开发不会对采石河、周边农田水系及地下水造成影响。2018年11月2日,南山矿业公司委托马鞍山测绘技术院对和尚桥采场东南部超山村红桥村民组所在区域地质变化情况开展了现场勘查及测量工作,检测结论为和尚桥铁矿的开采未造成周边地面下沉和路面破损。属实已经进一步完善道路洒水保洁制度,增加清扫保洁频次,加大执行考核力度。同时,增设车辆行驶限速标牌,提醒社会车辆减速行驶。立即着手矿区生活污水处理设施建设,确保11月30日前建成投运。无问责情形13D340000201811010102合肥市经开区大学城附近的居民区,由于临近肥西县桃花镇工业园,大气环境污染情况较为严重,周边佳通轮胎,会通材料,燕美材料,力士通材料等几家企业排放的工业废气污染周边环境。合肥市大气肥西县:经肥西县环保局会同桃花镇、肥西经开区于11月1日至3日,对辖区内重点废气排放企业进行认真排查并先后开展3次夜查,现场核查情况如下:核查投诉的情况与投诉人反映的情况不一致。肥西经开区范围内重点排查15家涉气排放重点单位,桃花镇范围内重点排查10家涉气排放重点单位。现场核查,相关企业均执行环评、“三同时”制度,按要求落实污染防治措施,废气达标排放,未发现存在违法及废气污染严重现象。通过测量,以上重点企业距离大学城最近距离达5公里以上。经开区:经合肥经开区环保分局执法人员于11月1日赴安徽佳通轮胎有限公司现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。安徽佳通轮胎有限公司位于经开始信路8号,法人代表陈应毅,主要从事轮胎生产,建设项目已履行环境影响评价和环保工程竣工验收手续,已办理工商营业执照。企业主要生产工艺:密炼-预备-成型-硫化。企业生产中产生的异味主要来自密炼、硫化工序产生的工艺废气(主要污染物为恶臭气体和非甲烷总烃)及污水站运行产生的恶臭气体。2017年以来,佳通公司累计投入2500万元,推进密炼、硫化车间和污水站的废气收集与治理。将密炼车间13台母炼机的投料、卸料和挤出共39个排口废气引入锅炉燃烧;对剩余6台母炼及32#母炼机挤出另1个排口、10台终炼机挤出排口及所有母炼终炼的胶冷共59个废气排口均已安装废气异味治理设施,其中35个排口采用碳纤维过滤+光催化氧化+生物膜片处理工艺,23个胶冷和1台30#打胶机共24个排口采用过滤+低温等离子处理工艺;完成硫化车间已18条围闭罩收集系统和36套过滤+碳纤维吸附+光催化氧化+生物膜片处理工艺的废气异味治理设施建设;对污水站进行封闭并安装1套喷淋+低温等离子+催化吸附废气治理设施。为减少废气的无组织排放,提升治理效果,对密炼车间和硫化车间门窗实施封闭;对密炼车间17台母炼机下辅机到胶料引出爬坡段进行了封闭;对密炼废气光催化治理设施加装了434只紫外灯管,并完成对密炼车间10台终炼机下辅机到胶料引出爬坡段进行了封闭。另外,为确保企业废气排放达标,自2018年6月起,经开区环保分局对佳通轮胎实施限产措施,全钢胎、半钢胎限产比例分别为40%、20%。11月1日夜间,合肥市环保局经开区分局对佳通轮胎进行了现场检查,企业正在生产,其中半钢胎生产负荷约67.2%,全钢胎生产负荷约59.7%,硫化、密炼车间门窗封闭,废气治理设施运行正常,对废气排放开展监督性监测。11月3日,对企业再次开展突击检查,未发现废气治理设施异常运行,硫化、密炼车间门窗封闭。监督性监测数据达标。高新区:群众反映会通新材料股份有限公司产生气味属实,反映合肥力世通塑料制品有限公司和合肥市燕美粉末涂料有限公司夜间偷排废气不属1.会通新材料股份有限公司位于高新区柏堰科技园芦花路2号,主要从事改性塑料的生产,其建设项目已履行环评审批及验收手续。主要生产废气为熔融和挤出工序产生的有机废气,经集气罩收集,通过废气治理设施处理后,经排气筒高空排放。企业于2017年4月对原有机废气治理设施进行提标改造(改为蓄热式焚烧炉处理工艺),并于2017年9月通过专家技术验收。2018年10月30日中央生态环境保护督察组对企业进行了督察,发现存在有机废气收集措施不完善,污染治理设施运转不正常。2018年10月31日,高新区环保分局对该企业现场检查时企业停产,由专业公司对污染治理设施进行全面检修停产至11月2日白天,11月2日晚少量生产线恢复生产,11月3日现场检查时,企业污染防治设施正常运转。2.合肥市燕美粉末涂料有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事环保型热固性粉末涂料生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为配料预混投料产生的粉尘,经除尘设备处理后排放。在达标排放的基础上,为进一步降低污染物排放,企业于2018年7月完成混料段粉尘密闭收集改造并投入使用。高新区环保分局于11月2日对该企业开展现场监察和监督性监测,检查时企业处于生产状态,污染防治设施正常运行,监督性监测结果第三方检测机构尚未提供。3.合肥力世通塑料制品有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事注塑件的生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为注塑过程产生的有机废气。注塑机自带密封设施,企业在达标排放的基础上,为进一步降低污染物排放,于2018年8月完成注塑车间有机废气治理项目(采用分子击断处理工艺,国内同行业率先使用)建设,并进行调试运行。高新区环保分局于11月2日对该企业开展现场检查和监督性监测,检查时企业处于生产状态,污染防治设施正常运行,监督性监测结果第三方检测机构尚未提供。属实肥西县:肥西经开区、桃花镇将进一步按照网格化管理要求,全面开展辖区内企业排查整治,对发现的环境问题及时督促企业限期整改;肥西县环保局加强该区域重点废气排放企业环境监管,联合肥西经开区、桃花镇开展对辖区内重点废气排放企业专项检查及夜间巡查,一经发现违法排污行为将依法立案查处。经开区:一是督促企业按照限产整治方案继续实施限产整治,并落实重污染天气生产应急管控措施;二是继续加强日常监管,督促企业加强废气治理设施运行管理,发现违法行为将严肃予以查处;三是加快实施搬迁工作,目前,企业已初步确定在肥西县中派范围内选址2500亩,用于佳通公司搬迁用地,现已报规划部门论证审查。新项目建设将采用先进的轮胎生产制造技术及污染治理设备,真正实现生产车间全封闭,彻底消除无组织废气排放,实现企业的绿色发展。高新区:1.针对会通新材料股份有限公司异味影响问题,高新区管委会成立工委、管委会主要领导为组长,工委领导班子其他成员为副组长,相关责任部门主要负责人为成员的会通新材料股份有限公司中央生态环境保护督察转办信访件整改工作领导小组,全面领导和协调整改工作,主要领导亲自抓、分管领导具体抓、责任部门分工协作。日常具体工作分别由环境监管执法组、群众信访协调组、转型升级(搬迁)协调组承担。当前采取以下整改措施:一是驻点执法监察,实时响应监控。高新区环境执法人员在会通公司整改期间24小时实施驻场监察,重点监管企业污染防治设施运行情况及限产落实情况;二是加大监测频次,及时掌握企业排污状况。高新区环境执法人员带领监测机构每日对污染物排放因子进行监测,一个月完成大气污染物在线监测设备安装并投入运行;三是禁止生产产生高异味产品,企业目前已主动转移产能,将产生高异味产品全部转移,高新区管委会将持续跟踪督办。减量生产其他产品,对企业限产措施进行监督,确保企业生产情况满足其承诺限产的内容(落实线体开机率不超过70%;重污染天气条件下按照合肥市应急措施统一部署,线体开机率不超过60%),并建立限产台账。四是督促企业加大投入。督促企业全面排查异味源,废气治理专业厂家驻厂调试培训,建立专业规范维保机制。同时持续开展提标改造,保持污染防治设施高效运行,加强环境管理,减少对周边环境影响。五是合理产业布局,指导企业启动搬迁。加快推进企业转型升级和产业布局调整,指导企业启动搬迁,立即启动新厂选址论证工作,列入高新区重大项目定期调度。六是强化居民沟通和环境信息公开,增强群众满意率。群众信访协调组建立主动与群众见面沟通机制,同时督促企业主动听取居民意见,及时将整改工作和日常环境管理情况向居民告知。2.高新区环保分局会同柏堰科技园管委会继续依法加强对合肥市燕美粉末涂料有限公司和合肥力世通塑料制品有限公司的环境监管,督促企业切实履行主体责任,加强厂区日常环境管理,对污染防治设施建立专业规范维保机制,确保污染防治设施正常运转,污染物达标排放。无14D340000201811010103合肥市经开区的佳通轮胎,每天放排塑料味很重的气体,周边居民不能开窗,严重影响居民生活。合肥市大气经合肥经开区环保分局执法人员于11月1日赴安徽佳通轮胎有限公司现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。安徽佳通轮胎有限公司位于经开始信路8号,法人代表陈应毅,主要从事轮胎生产,建设项目已履行环境影响评价和环保工程竣工验收手续,已办理工商营业执照。企业主要生产工艺:密炼-预备-成型-硫化。企业生产中产生的异味主要来自密炼、硫化工序产生的工艺废气(主要污染物为恶臭气体和非甲烷总烃)及污水站运行产生的恶臭气体。2017年以来,佳通公司累计投入2500万元,推进密炼、硫化车间和污水站的废气收集与治理。将密炼车间13台母炼机的投料、卸料和挤出共39个排口废气引入锅炉燃烧;对剩余6台母炼及32#母炼机挤出另1个排口、10台终炼机挤出排口及所有母炼终炼的胶冷共59个废气排口均已安装废气异味治理设施,其中35个排口采用碳纤维过滤+光催化氧化+生物膜片处理工艺,23个胶冷和1台30#打胶机共24个排口采用过滤+低温等离子处理工艺;完成硫化车间已18条围闭罩收集系统和36套过滤+碳纤维吸附+光催化氧化+生物膜片处理工艺的废气异味治理设施建设;对污水站进行封闭并安装1套喷淋+低温等离子+催化吸附废气治理设施。为减少废气的无组织排放,提升治理效果,对密炼车间和硫化车间门窗实施封闭;对密炼车间17台母炼机下辅机到胶料引出爬坡段进行了封闭;对密炼废气光催化治理设施加装了434只紫外灯管,并完成对密炼车间10台终炼机下辅机到胶料引出爬坡段进行了封闭。另外,为确保企业废气排放达标,自2018年6月起,经开区环保分局对佳通轮胎实施限产措施,全钢胎、半钢胎限产比例分别为40%、20%。11月1日夜间,合肥市环保局经开区分局对佳通轮胎进行了现场检查,企业正在生产,其中半钢胎生产负荷约67.2%,全钢胎生产负荷约59.7%,硫化、密炼车间门窗封闭,废气治理设施运行正常,对废气排放开展监督性监测。11月3日,对企业再次开展突击检查,未发现废气治理设施异常运行,硫化、密炼车间门窗封闭。监督性监测数据达标。属实一是督促企业按照限产整治方案继续实施限产整治,并落实重污染天气生产应急管控措施;二是继续加强日常监管,督促企业加强废气治理设施运行管理,发现违法行为将严肃予以查处;三是加快实施搬迁工作,目前,企业已初步确定在肥西县中派范围内选址2500亩,用于佳通公司搬迁用地,现已报规划部门论证审查。新项目建设将采用先进的轮胎生产制造技术及污染治理设备,真正实现生产车间全封闭,彻底消除无组织废气排放,实现企业的绿色发展。无15D340000201810310021滁州市琅�e区西涧街道雷桥村,有垃圾污水倾倒至西涧街道垃圾场,污水污染特别严重。滁州市水,土壤琅琊区高度重视,立即组织辖区街道、区城管执法局、市环保局琅琊分局主要负责人赶赴扬子街道雷桥村垃圾填埋场(交办反映的倾倒至西涧街道垃圾场,经现场查看实际为扬子街道雷桥村垃圾填埋场)核查,同时联系皖能垃圾焚烧厂负责人,经过对垃圾填埋场、生活垃圾渗滤液及周边区域认真排查,未发现有垃圾污水倾倒至扬子街道雷桥村垃圾填埋场现象,信访投诉问题不属实。不属实无无16D340000201810310007淮北市濉溪县濉溪镇五里郢排灌站有一臭水沟(此臭水沟通向濉溪县城),附近一公园旁臭气熏天,严重影响周围居民生活及锻炼的群众。淮北市水、大气经现场调查:此沟为濉溪镇城西沟下游西分支(汴河路至新濉河),全长约350米,已作为黑臭水体逐级上报,同时该城西沟亦为濉溪县行洪排涝沟使用。附近居民房紧邻渠道建设,施工场地受限,上游段部分民房建在大沟上,临沟居民生活污水直排入沟,影响大沟整治和大沟两侧截污工程。属实治理方案分两步进行:第一步:濉溪县近期将在此段黑臭水体前段设置拦截坝,用污水处理设备对污水进行处理,处理后的中水就近浇灌河堤两岸花草树木,既能够节约水资源,也有助于提升附近群众的生活环境质量。第二步:濉溪县将加快对周边地块实施雨污分流,雨水排入大沟作为补水水源,污水接入市政污水管进入污水处理厂处理达标后排放。在推进雨污分流工作的同时,为满足日渐增加的污水处理量,濉溪县将加快实施濉溪县污水处理厂二期工程,届时城西沟将仅保留防洪排涝功能。原濉溪县建委主任:王震原濉溪县建委副主任:朱利茂濉溪县建委主任:陈安厚濉溪县建委副主任:赵夫鸣濉溪镇副镇长:桂沛春已被问责17D340000201811010105合肥市高新区长宁大道与磨子潭路交叉口航空新城附近经常有刺激性味道,疑似橡胶与塑料气味,怀疑是大陆马轮胎厂和禾盛新型材料有限公司排放的刺激性气味。合肥市大气经高新区环保分局执法人员会同南岗科技园管委会环保办于2018年11月2日赴合肥禾盛新型材料有限公司和大陆马牌轮胎(中国)有限公司现场核查,现场核查情况如下:1.合肥禾盛新型材料有限公司位于高新区大别山路0818号,主要从事彩色复合钢板生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为辊涂等工序产生的有机废气。企业在达标排放的基础上,为进一步降低污染物排放,于2017年9月完成原有废气处理设施提标改造工作(由催化燃烧工艺改为蓄热式热力焚化炉处理工艺)。检查时企业生产工况正常,配套污染防治设施运行正常,厂区内均未见明显异味,监督性监测结果显示,企业大气污染物达标排放。2.大陆马牌轮胎(中国)有限公司位于高新区南岗科技园大别山路1588号,主要从事乘用车子午胎、两轮车轮胎的生产,其建设项目已履行环评审批手续,其中一期、二期及两轮车轮胎项目已履行验收手续,三期项目正在安装调试。企业主要生产废气为密炼、硫化等工序产生的有机废气,分别通过干式过滤器、低温等离子和蓄热式焚烧炉废气治理设施处理后,通过排气筒高空排放。检查时企业生产工况正常,配套污染防治设施运行正常,厂区内均未见明显异味,监督性监测结果显示,企业大气污染物达标排放。属实高新区环保分局会同南岗科技园管委会继续依法加强对企业的环境监管,督促企业切实履行主体责任,加强厂区日常环境管理,对污染防治设施建立专业规范维保机制,确保污染防治设施正常运转,污染物达标排放。无18D340000201811010049蚌埠市淮上区沫河口镇五埠路工业园工业污水一部分排入三铺灌溉站河内,另一部分怀疑排入地下,污染周边环境。蚌埠市水三铺灌溉站位于三铺大沟北端尽头,该灌溉站距离沫河口园区建成区北边界约4公里,灌溉站内泵房从三铺大沟取水用于周边农田灌溉。接交办单后,沫河口园区管委会于11月2日组织人员对园区范围内三铺大沟段进行现场排查,未发现偷排暗管。沫河口工业园区内重点涉水企业共有14家,淮上区自筹资金对园区化工基地污水管网采取架空主管网设计,其中9家企业污水一企一管通过架空管网排入园区污水处理厂,5家企业污水单管单送接入园区污水处理厂。14家企业全部加装水污染在线监控设施,4家联入市级监控平台,其余连入区级监控平台,环保部门实时监控企业污水排放。2016年开始淮上区环保局组织对辖区企业进行排查,未发现沫河口园区企业污水有偷排或排入地下现象。2017年开始,淮上区对园区地下污水管网进行全面排查,利用CCTV影像技术、井下机器人对园区23公里管网进行排查修复。园区现有20000t/d污水处理设施,能够满足现有企业污水处理需要,出水稳定达到一级A标准。污水处理厂出水口加装在线监控设施,连入国发软件平台。2017年9月开始,每季度由第三方检测公司对园区周边地下水取样检测。检测报告结果符合地下水环境质量标准,无企业污水排入地下迹象。检测结果公示在沫河口园区和沫河口镇公示栏公示。不属实下一步,淮上区一是继续做好园区内涉水企业的日常监管,同时加强对园区内地下污水管的日常监管和维护;二是继续加大对企业检查力度,严厉查处违法企业;三是定期检测园区及周边地下水水质。无19D340000201810310022马鞍山市花山区清河湾小区的168饭店,鼓风机噪音扰民,油烟通过私自接通的道管排放,严重影响小区居民正常生活,对该饭店多次投诉至今没有解决。马鞍山市大气,噪音经调查,举报情况属实。该饭店营业时安装在平台上的鼓风机声音较大,油烟未经处理通过管道直接排放,未安装油烟净化设施,对周边居民生活产生不良影响。属实责令该饭店立即停业整改,拆除原有油烟排放管道和鼓风机,将鼓风机安装在操作间内,安装油烟净化设施。目前,油烟排放管道和鼓风机已全部拆除,鼓风机已安装在操作间内,油烟净化设施已安装到位。无问责情形20D340000201810310013举报人在芜湖市鸠江区白茆镇省级农业示范园内承包了193亩地用于水产养殖,乡镇政府安排环卫工人直接向莲花河喷洒草甘膦农药和百草枯除草剂用于除草,导致承包塘里的螃蟹河虾大面积死亡,造成经济损失达到百万以上。芜湖市水经核查,2016年6月,芜湖市鸠江区白茆都市农业示范区通过招标方式确定将清除杂草和打捞沟渠漂浮物等事项交由紫香劳务公司处理。2018年7月底至8月初,该劳务公司两名工作人员在举报人(承包户)承包的池塘西部渠道内不当使用农药草甘膦除草剂清除渠道内杂草时,被人发现后及时制止,用量不超过4瓶(1千克装,41%草甘膦水剂),喷洒长约500米,造成部分水体受到污染。白茆都市农业示范区从事河蟹养殖共2户,生产用水均取自该渠道。9月29日,举报人(养殖户)到鸠江区白茆镇农服中心反映,因在紫香劳务公司工作人员喷洒过除草剂的渠道取水导致承包的约100亩池塘河蟹死亡。镇农服中心工作人员于9月29日、10月2日,两次到现场核实情况,该养殖户承包的池塘内仍可见河蟹零星死亡。另一养殖户也在同一渠道内取水,池塘内河蟹生长正常。10月30日,该养殖户到区信访局反映情况,11月1日又到市信访局反映。市信访局会同市环保部门工作人员现场核查后初步研判,认为属于草甘膦除草剂使用不当。建议举报人通过司法程序或商请水产专家对损失进行评估、协商解决。11月2日,区政法委负责人在区信访局接待了举报人,处理意见如下:1、通过司法程序依法处理。2、由区农林局请省水产专家到现场研判,对损失评估。11月4日,省水产专家和省司法鉴定中心、市、区水产专家到现场进行察看,建议举报人会同政府相关部门及第三方检测机构多处取水样检测,对损失进行评估。属实1、芜湖市鸠江区白茆都市农业示范区管委会已要求紫香劳务公司在辖区内使用除草剂时,需提前告知种(养)殖户,并采取相应措施。该劳务公司今后不得在沟渠内水体使用除草剂。2、建议举报人(养殖户)按照法律途径依法依规解决河蟹死亡受损事宜。3.鸠江区政府及相关部门将按照各自职责做好相关工作。无21D340000201811010033亳州市谯城区双沟镇孟大行政村前李村南侧空地上,一家腌制泡椒的作坊,离居民区很近,气味浓影响居民正常生活,去年的腌制水排到灌溉井里影响居民灌溉。亳州市大气,水经查,该作坊为土法腌制泡椒,主要生产设施为在田地里挖掘的12个地窖(长10米、宽2.5米、深1.5米),每个地窖下用3层、上用2层防水塑料布用于防渗;生产工艺为将辣椒和盐、醋混合后,用土封存约1个月后,将泡椒连同腌制水出售给其他加工厂家进行深加工。现场检查未发现泡椒腌制水外排和和排入灌溉井现象。属实对该作坊擅自进行土法泡椒生产行为,已责令其待本批次泡椒出产后,停止土法加工,若继续生产经营的,必须完善经营证照和用地、环评等手续,优化生产工艺。无22D340000201810310008安庆市岳西县温泉镇桃林村寨岩组105国道旁,2017年建有一所临时沥青搅拌站,生产时产生刺鼻沥青气味,运输车产生大量扬尘,污染周边环境;建搅拌站修路时将约1万立方渣土倾倒至周围山上,部分渣土落入河流被河水冲走。多次投诉没有解决。安庆市大气,土壤2018年11月4日岳西县住建局会同县城市管理局、环保局、温泉镇党委、人民政府到温泉镇桃岭村沥青搅拌站现场进行核实,该搅拌站为安徽中升新型建筑材料有限公司。目前该处沥青混凝土搅拌站已停产多时,检查时未发现扬尘等问题,场地、道路已进行硬化,砂石材料已进行覆盖,现场设有固定和移动雾炮、现场无污染周边环境的状况,建设搅拌站修路的土方倾倒到周边的矿山上,目前该处山场植被已恢复,据搅拌站负责人口述建搅拌站修路为原矿场道路扩建,渣土方量较少,现场河道旁未发现渣土。但石料堆场未完全密闭,危废仓库内将新旧活性炭混放,未建立危废管理台账,部分喷淋设施不能正常使用,未设置进出车辆冲洗设施,淋溶水收集设施不完善。属实岳西县于2018年11月5日向该当事人下达了《关于对安徽中升新型建筑材料有限公司的环境监察意见》岳环监察〔2018〕94号,并告知应严格按照文件要求进行整改,要求该单位于2019年1月30日前完成整改并报送整改销号材料。整改措施:1、对沥青搅拌站石料堆场进行密闭,搅拌站石料堆场未完全密闭的地方,增加三方围挡,完全密闭,2018年11月6日开始实施围挡,在2018年11月15日前完成。混放在危废仓库中的新旧活性炭分开堆放,建立危废管理台帐;2、检查维修喷淋设施,2018年11月6日开始对喷淋设施进行维修,15日前完成修复工作,以后定期检修,保持喷淋设施正常使用。3、设置进出车辆冲洗设施,完善淋溶水收集设施。由于该公司产品对温度有要求,禁止喷淋,现在搅拌站进出处口设立雨水槽清洗车辆,在沉淀池旁边增设雨水收集槽,最终注入沉淀,经沉淀过滤变成清水后循环使用。无23D340000201811010052滁州市天长市铜城镇精细化工集中区内修一制药、开林化工等几家企业排放工业废气严重影响周边居民正常生活,生产废水直接排入铜龙河,造成河水严重污染。滁州市大气,水,其他污染天长市组织天长市环保局、水利局、铜城镇等对该信访件开展调查处理。经查:1.信访件涉及的安徽修一制药有限公司。主要从事医药中间体的生产,由于该公司调试期间群众投诉不断,目前已停止生产。其“年产198吨普仑司特无水物等十二种医药中间体项目”环境影响报告书,于2016年11月2日经滁州市环境保护局审批(滁环〔2016〕500号);2018年4月16日,该公司完成二号精制车间、二号合成车间、仓储、办公场所及环评及批复要求的各类防治污染设施建设,进入调试状态。该公司建成设计能力500吨/天污水处理站一座,采用混凝预处理-铁碳微电解-芬顿-厌氧-水解酸化-一级接触氧化-二级接触氧化-臭氧杀菌工艺,对工艺废水、冲洗水、生活废水进行预处理符合接管标准后通过高架明管汇入铜城镇污水处理厂经深度处理后外排,不直接向环境排放。该公司合成车间、精细车间针对不同的废气各安装了3套废气处理设施,分别为碱淋洗+活性炭吸附装置,主要用于吸收盐酸等酸性挥发性溶剂;布袋除尘+活性炭吸附装置,主要用于车间粉尘的处理;UV光解+活性炭吸附装置,UV光解主要使有机或无机高分子恶臭化合物分子链,在高能紫外线光束照射下,降解转变成低分子化合物从而有助于活性炭的吸附,3套废气处理装置分区处理提高废气处理效果;同时,采取了封闭收集+碱液淋洗的工艺对污水处理站废气进行收集处置。针对群众多次投诉该公司气味影响,天长市环境保护局责令该公司委托具备相应资质的第三方检测机构对无组织废气进行监测,2018年6月下旬“合肥海正环境监测有限责任公司”对该公司无组织废气进行了监测,2018年6月30日出具的编号为:HZ18F1401Z的《检测报告》,结果显示无组织甲醇、甲苯、氨、硫化氢、臭气浓度五项指标均符合国家规定标准。2018年11月2日上午,天长市环境保护局会同铜城镇党委、政府及该公司负责人在铜城镇召开“安徽修一制药有限公司环保问题专家咨询会”,邀请南京工业大学、安徽省化工研究院专家踏勘该公司现场并审阅环评文件。专家一致认为:该公司已按环评要求建设了各项污染防治设施;同时,对在达标排放的基础上进一步优化技术措施,最大程度的降低排放浓度给出了指导性意见。前期根据群众举报线索,对安徽修一制药有限公司厂区内进行开挖,发现私自开凿的水井一口,水样经天长市环境监测站监测PH值7.63、COD10Lmg/L(低于检出限)、氨氮0.127mg/L,指标未见异常,排除利用水井排污的可能。2.信访涉及的安徽开林新材料股份有限公司。主要从事水性涂料、防腐涂料生产,目前处于正常生产状态。其“年产1万吨水性涂料及1万吨新型环保防腐涂料技术改造项目”环境影响报告书于2014年1月9日,经滁州市环境保护局审批(滁环〔2014〕25号);企业在完成水、气自主验收的同时于2018年5月25日完成固废、噪声竣工验收(滁环评函〔2018〕33号)。该公司工艺废水、生活废水、地面设备清洗水及初期雨水经自建污水处理站预处理符合接管标准后,通过高架明管汇入铜城镇污水处理厂经深度处理后外排,不直接向环境排放;该公司工艺废气按环评要求配套建设了布袋除尘器、活性炭吸附装置;危险废物交由安徽超越环保科技有限公司集中处置。该公司已通过环保竣工验收,验收监测数据、委托监测数据显示:该公司各类污染物排放均符合国家规定标准。3.铜龙河水质。2018年11月2日天长市环境保护局采集了铜龙河水样进行监测,同时梳理了2018年5月2日至10月9日的五次监督性监测数据,汇总六次监督性监测数据显示:铜龙河水样所监测指标符合《地表水环境质量标准》(GB3838-2002)表1中IV类标准限值;主要指标接近或符合III类标准。铜龙河水质状况优良。属实对安徽修一制药有限公司在厂区内私自开凿水井的违法行为,天长市水利局已依法下达《水行政处罚决定书》(天水罚字〔2018〕第01号),当事人已履行处罚决定,将非法开凿的水井封填完毕并将罚没款5万元缴纳到位。无24D340000201811010034马鞍山市花山区红旗桥铁道口沿铁道西侧800米处,一家非法钢渣加工点扬尘污染严重,设备生产时噪声严重扰民,属于散乱污企业。马鞍山市大气,噪音经调查,举报情况属实。在红旗桥铁道口沿铁道西侧800米处,发现一座无名废旧仓库,现场无序堆放少量钢渣及筛选设备,现场无加工生产活动。投诉人反映的钢渣加工点为赵承锁钢渣加工厂,无任何手续,属于散乱污企业,该钢渣加工点前期有生产加工行为,存在扬尘污染和噪声扰民问题。属实对赵承锁钢渣加工厂负责人进行了约谈,责令立即清除仓库钢渣及筛选设备。目前,露天堆放的钢渣及筛选设备已全部清运。无问责情形25D340000201811010056淮南市凤台县尚塘镇黄圩村大李庄西侧、凤利路南侧的砂石料经营点粉尘污染严重。淮南市大气信访件反映地点位于淮南市凤台县尚塘镇黄圩村大李庄西侧、凤利路南侧“尚塘乡液化气充装站”项目闲置场地内。尚塘镇进行农村道路提升工程建设,施工方在此处临时堆放道路施工用料,并非砂石料经营点。属实接转办信访件后,凤台县委、县政府立即组织环保、公安、市场监管等部门赶到现场进行核查督办,要求尚塘镇对该临时堆放点的砂石立即清除。截止11月4日,该处临时堆放点砂石等杂物已全部清除,地磅已拆除,地面实施了覆土。无26D340000201811010100合肥市滨湖新区巴黎都市小区一期东广场,夜间广场噪音扰民。合肥市噪音经包河区方兴社区工作人员会同公安包河分局执法人员于11月2日赴巴黎都市小区一期东广场现场核查,现场核查情况如下:该广场夜间有居民跳广场舞,噪声较大,核查投诉的情况与投诉人反映的情况一致。巴黎都市小区一期东广场位于合肥市滨湖新区湖北路与长沙路交口西南角,噪音污染来源于该小区十五名居民跳广场舞播放音乐,每晚19点30分左右开始至20点30分左右结束。属实包河区方兴社区已与广场舞组织者沟通协商,组织者已同意在广场舞活动中将降低音乐音量,减少对附近居民的影响。下一步,包河方兴社区将加大此地巡查力度,并联合公安包河分局与佳源物业和广场舞组织者对接,共同将广场舞噪音的影响降到最低。无27D340000201810310017合肥市经开区翡翠湖今年以来水质恶化,怀疑有养鱼、捕鱼,周边有生活污水排放入翡翠湖。合肥市水经合肥经开区建设发展局工作人员会同翡翠湖管养单位公用事业发展公司现场于11月2日赴翡翠湖现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。因翡翠湖上游汇水区域部分小区等单位管网存在损坏或错接,导致有少量生活污水入湖,同时因翡翠湖自2006年改造蓄水后水位较高,死水湾水体得不到交换,加上建成区城市径流初期雨水携带一定的污染物对湖区水质产生一定影响。湖内投放了一定数量的鱼苗,主要是为改善翡翠湖水质,净化水体,没有投放饵料等饲养行为。属实一是对投放的鱼苗种类和数量严格控制,禁止投放饵料;二是在2018年11月4日前完成入湖生活污水截流应急整改;三是加大管养力度,由合肥经开区公用公司及时打捞水面垃圾、杂物,收割处理水生植物,减轻对水体水质影响;同时为进一步改善水质,邀请专业水治理单位在水质较差的死水湾区域做改善水质实验,成功后立即推广应用,并持续推进上游雨污管网错接混接排查整治,督促存在错接混接单位制定整改方案及时完成整改。无28D340000201811010055合肥市包河区巢湖南路路面积尘严重,影响出行。合肥市大气经包河区淝河镇工作人员会同区城管委执法人员于11月2日赴巢湖南路现场核查,现场核查情况如下:巢湖南路扬尘污染较大,核查投诉的情况与投诉人反映的情况一致。包河区淝河片区东临南淝河、西至十五里河中段高铁南站片区、北接老城区、南抵包河经开区,总占地面积32600亩。2016年8月,经摸底调查,该区域居住群众12260户,多为“城中村”,环境脏乱差。巢湖南路大型车辆出入频繁,导致路况变差、道路基础设施破损严重,致使路基垫层外渗,道路清扫保洁难度大;并且巢湖南路周边存在南淝河路、郎溪路二、三标等施工工地,途经上述工地的南淝河路及郎溪路尚未完全开通,工地渣土运输主要经过巢湖南路,加剧路面循环污染。虽然已采取了加大清扫保洁频次和洒水降尘力度等措施,但无法根治该区域严重的扬尘污染问题。位于巢湖南路、南淝河路沿线集聚混凝土搅拌站共19家。其生产、运输过程带来的扬尘、噪音及水污染问题严重,居民苦不堪言。近几年,有关淝河镇混凝土搅拌站污染的热线投诉、网友留言居高不下。针对淝河片区脏乱差的状况,包河区委、区政府高度重视,深入研判,自2016年初,即开始全面谋划论证淝河片区整体改造工作。其中,针对片区范围内的19家混凝土企业,由于不符合片区土地利用总体规划及未来改造发展业态布局,包河区将其全部纳入搬迁改造范围,并迅速启动相关工作。1、加快签订搬迁协议。对19家混凝土搅拌站下达搬迁改造通知,并陆续启动丈量、评估、签订协议及补偿相关工作。针对企业主反映的补偿问题,包河区本着“尊重历史、面对现实”的原则,耐心开展政策解释和上门沟通工作,尽量取得企业的理解和支持。截至目前,已与16家搅拌站签订了搬迁协议。下剩3家企业由于对搬迁补偿存有一定异议,目前正在积极洽谈推进中。2、积极对接复建事宜。考虑到混凝土企业搬迁可能带来的订单协议违约、员工就业及往来债务等问题,包河区积极协调对接,全力支持搬迁企业开展复建工作。3、加强日常巡查监管。针对混凝土搅拌站搬迁复建前的生产运营,包河区持续加强监督管理,加大扬尘等环境污染防治工作。一是加大宣传教育。中央环保督察期间,针对淝河片区混凝土企业的信访投诉量大的情况,辖区淝河镇、村居对混凝土企业加强宣传教育,要求其文明生产,并落实相关降尘抑尘等环保措施。二是强化监控巡查。区住建局通过行业视频系统,常态化监控搅拌站内洒水降尘、物料覆盖及生产运营环节的扬尘防治;区环保局、辖区淝河镇等加大日常巡查频次,督促企业将各项环保措施落到实处。三是依法行政处罚。对于环保不达标、未通过项目竣工环保验收、违反《建设项目环境保护管理条例》等相关规定的混凝土企业经营行为,区环保等相关部门依法对其进行行政处罚,并责令其落实整改措施。属实1、包河区淝河镇加大对周边工地巡查力度,严格落实扬尘污染防治要求,确保物料堆放覆盖、出入车辆清洗、渣土车辆密闭运输等措施落实到位。同时,对巢湖南路等重点路段进行严格巡查,对过往抛洒滴漏车辆进行依法查处。2、2018年至今,包河区住建局对淝河镇巢湖南路周边混凝土企业共巡查54次,下达监督意见书39份,对巡查发现的问题均敦促企业落实专人限期整改到位。3、针对巢湖南路路面扬尘的路况实际,为做好大气污染控制,包河区环卫服务中心不断增加了作业车辆,加大洒水降尘频次,实行循环作业。在夜间完成全区主次干道统一的冲洗保洁作业,在白天做好路面保湿抑尘工作,并在晚间薄弱时段增派车辆加强路面降尘保湿。具体措施:(1)洒水车依次循环路面洒水作业,保持路面湿润,抑制扬尘;(2)洗扫车湿扫路牙灰砂,将路牙边的灰砂洗扫干净;(3)小货车清运石子、灰砂;(4)道路养护车配合人工对人行道进行冲洗作业。无29D340000201811010037合肥市包河区巢湖南路绿色港湾小区东北边的小河,污水管网修之前河水很清,修后今年夏天河水很臭,目前不臭,怀疑是污水管道接错了或者小区污水倒灌;小区西侧的小河常年发臭。合肥市水经包河区淝河镇工作人员会同住建局、农林水务局工作人员于11月2日赴绿色港湾小区现场核查,现场核查情况如下:东北侧小河水质较清,西侧小河河水发臭,核查投诉的情况与投诉人反映的情况一致。绿色港湾小区东北边的小河为徐涵中心沟,目前水质较好无异味,前期包河区淝河镇、住建局已对大蒋站排涝沟进行检测,共排查8处排水口,其中3处已废弃,另有4处排水口位于拆迁区域内民房生活用水排放和农田灌溉沟渠排口,属于雨污混排口,后期将结合淝河片区改造,对其进行整改修复。检测过程中未发现该沟渠污水管道混接或者小区污水倒灌现象,新修的巢湖南路雨污水管网均未接入该沟渠。2018年6月包河区住建局已安排检测单位对小区西侧小河污水来源进行检测,检测结果为兰渡路雨污合流管线及两侧明渠、暗渠和污染源导致该沟渠水质较差。属实根据《包河区分流制排水系统雨污混接调查和整治工作方案》,包河区淝河镇联合区住建局、农林水务局将对小区西侧小河进行后续溯源、整治工作。淝河镇牵头组织溯源排查后制定截污方案,实施截污工程。区农林水务局负责明渠、暗渠调查和整治工作,包河区市政处调查和整治兰渡路合流管道,沿线城中村污染源由包河区淝河镇调查和整治。目前,包河区淝河镇已定期对徐涵中心沟进行河面浮萍打捞清理,保持河面整洁。无30D340000201810310030合肥市庐江县白湖镇泉水村李庄村民组西边的永祥塑料厂夜间生产排放难闻废气,废渣偷偷在厂内挖深沟填埋,。合肥市大气,土壤反映的永祥塑料厂全称为庐江县永祥废旧再生塑料厂,位于庐江县白湖镇泉水村境内,主要从事废旧塑料加工,法人代表王永祥。该厂年产600吨再生塑料颗粒项目环境影响报告表于2008年4月份经庐江县环保局审批(庐环[2008]68号)。2010年12月份,该项目通过了庐江县环保局组织的竣工环境保护验收(庐环验[2010]30号)。2009年4月份办理了工商营业执照。11月1日夜间,庐江县环保局会同白湖镇政府工作人员到该厂核查,现场该厂未生产,也未发现有生产痕迹。之前该厂存在环境违法行为,庐江县环保局于2018年8月9日向该公司下达了责令改正违法行为决定书(庐环2018124号)责令其停产整改,该厂将整改期间废渣存放在防渗池内。现场厂区未发现深沟填埋废渣痕迹。不属实庐江县环保局和白湖镇政府将加大对庐江县永祥废旧再生塑料厂监管力度,监督其未经批准不得擅自恢复生产,一旦发现有环境违法行为从严查处。无31D340000201811010036合肥市蜀山区肥西路与煤场路交口西南角(休宁路与合作化路交口东北角)的合肥热电集团有限公司粉尘、噪声污染扰民;合肥市地方铁路投资建设有限公司每周至少两次卸煤粉尘、噪声污染扰民。合肥市大气,噪音经蜀山区环保局执法人员会同经促局、发改局、稻香村街道于2018年11月2日赴企业现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。1.该企业目前处于正常生产状态,现有5台锅炉(其中1台正常使用,4台停用进行升级改造),锅炉升级改造过程存在施工噪声污染。该公司煤堆场处于露天状态,未落实防尘措施。2.合肥市地方铁路投资建设有限公司南七货场作业场所(卸煤区)为露天作业场所,未建大棚覆盖。现场约10名工作人员正在清扫卸煤区地面,地面干燥,粉尘大,清扫过程无降尘措施。通过前期检查和翻阅台账发现装卸物料未采取密闭或者喷淋等方式控制扬尘,据了解,该货场于2018年10月投入使用雾炮车,2018年11月2日现场监察时雾炮车洒水台账已记录到2018年11月5日。属实1.蜀山区环保局对企业下达《责令改正违法行为决定书》(蜀环决〔20181103号),并约谈该公司负责人,要求其立即整改,同时对该公司环境违法行为进行立案查处。该公司整改如下:由该企业集团公司统一调度,将该公司1/4的热负荷分配至皖能合肥电厂及天源分公司,以降低该公司火车来煤量,减少对周边环境的影响;减少卸煤噪音,在卸煤过程中,车门轻关轻开,禁止鸣笛;该企业原有移动式喷雾机一台,计划在2018年12月底前再购买一台车载式移动雾炮设备,用于抑制火车卸煤及运转过程中产生的扬尘;该企业在原有水管及喷头的基础上增加固定水管40米,洒水喷头5个,用于煤场东部洒水抑尘;购买防风抑尘网或者人工草皮对煤场进行全覆盖;加装视频监控设备,对煤场实现无死角监控;加强对生产现场的管理,设置煤场专职管理班组,在火车卸煤后进行喷水降尘,并对燃煤进行覆盖,燃煤转运过程中进行洒水、清扫等,严控噪音及扬尘的产生;根据“621”发展战略计划2年内由皖能合肥发电厂及金源热电机组改扩建,取代该企业供热负荷2.蜀山区环保局对合肥市地方铁路投资建设有限公司南七货运站的环境违法行为进行立案查处。该单位整改如下:自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货运站Ⅰ道(北侧铁路线)无限期停止接卸煤炭运输列车;自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货场Ⅱ道(南侧铁路线)在地铁公司和该企业共同达成关于铁路货场环保整体改造方案并获得环保部门核准同意前,暂停止接卸煤炭运输列车。此项措施书面通知企业。2018年11月2日函告中国铁路总公司上海局集团有限公司合肥货运中心,即日起合肥市地方铁路投资建设有限公司南七货运站Ⅰ道停止接卸、Ⅱ道暂停接卸煤炭。自2018年11月3日起30天内,责成南七货运站内各经营户将现有存煤全部清运出南七货运站,在此期间除煤炭外运车辆外,禁止一切车辆进入货运站;煤炭外运车辆严格按照环保部门要求,落实限高、苫盖、车身、车胎清扫冲洗等措施。自2018年11月3日起,合肥市地方铁路投资建设有限公司南七货场Ⅰ道(北侧铁路线)仅留5米宽路面作为雾炮洒水车作业通道,路面每日清扫;货场内其余地面,用绿色苫布进行苫盖,并组织人力不定期对苫盖地面进行清扫,清扫后恢复苫盖,场地清扫与洒水跟班作业。自2018年11月4日起,对站内各煤炭经营户现存煤炭外运车辆,严格按照地铁公司2018年第4号专题会议纪要规定,进行装车作业。合肥市地方铁路投资建设有限公司针对无法禁止的国铁货运列车在南七货运站调车及存车作业,与国铁相关部门积极协调,最大程度减少鸣笛。公司相关业务部门相互协作,要明确任务,强化责任,严格检查,严肃纪律,对违反公司相关规定的行为,一律从重处罚。无32D340000201810310015合肥市蜀山区康馨民家小区附近煤场和众城热电厂,无防尘措施,噪音污染严重,多次投诉整改不到位,要求企业搬迁。合肥市大气,噪音经蜀山区环保局执法人员会同经促局、发改局、稻香村街道于2018年11月2日赴企业场现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。1.该企业目前处于正常生产状态,现有5台锅炉(其中1台正常使用,4台停用进行升级改造),锅炉升级改造过程存在施工噪声污染。该公司煤堆场处于露天状态,未落实防尘措施。2.合肥市地方铁路投资建设有限公司南七货场作业场所(卸煤区)为露天作业场所,未建大棚覆盖。现场约10名工作人员正在清扫卸煤区地面,地面干燥,粉尘大,清扫过程无降尘措施。通过前期检查和翻阅台账发现装卸物料未采取密闭或者喷淋等方式控制扬尘,据了解,该货场于2018年10月投入使用雾炮车,2018年11月2日现场监察时雾炮车洒水台账已记录到2018年11月5日。属实1.蜀山区环保局对企业下达《责令改正违法行为决定书》(蜀环决〔20181103号),并约谈该公司负责人,要求其立即整改,同时对该公司环境违法行为进行立案查处。该公司整改如下:由该企业集团公司统一调度,将该公司1/4的热负荷分配至皖能合肥电厂及天源分公司,以降低该公司火车来煤量,减少对周边环境的影响;减少卸煤噪音,在卸煤过程中,车门轻关轻开,禁止鸣笛;该企业原有移动式喷雾机一台,计划在2018年12月底前再购买一台车载式移动雾炮设备,用于抑制火车卸煤及运转过程中产生的扬尘;该企业在原有水管及喷头的基础上增加固定水管40米,洒水喷头5个,用于煤场东部洒水抑尘;购买防风抑尘网或者人工草皮对煤场进行全覆盖;加装视频监控设备,对煤场实现无死角监控;加强对生产现场的管理,设置煤场专职管理班组,在火车卸煤后进行喷水降尘,并对燃煤进行覆盖,燃煤转运过程中进行洒水、清扫等,严控噪音及扬尘的产生;根据“621”发展战略计划2年内由皖能合肥发电厂及金源热电机组改扩建,取代该企业供热负荷。2.蜀山区环保局对合肥市地方铁路投资建设有限公司南七货运站的环境违法行为进行立案查处。该单位整改如下:自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货运站Ⅰ道(北侧铁路线)无限期停止接卸煤炭运输列车;自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货场Ⅱ道(南侧铁路线)在地铁公司和该公司共同达成关于铁路货场环保整体改造方案并获得环保部门核准同意前,暂停止接卸煤炭运输列车。此项措施书面通知企业。2018年11月2日函告中国铁路总公司上海局集团有限公司合肥货运中心,即日起合肥市地方铁路投资建设有限公司南七货运站Ⅰ道停止接卸、Ⅱ道暂停接卸煤炭。自2018年11月3日起30天内,责成南七货运站内各经营户将现有存煤全部清运出南七货运站,在此期间除煤炭外运车辆外,禁止一切车辆进入货运站;煤炭外运车辆严格按照环保部门要求,落实限高、苫盖、车身、车胎清扫冲洗等措施。自2018年11月3日起,合肥市地方铁路投资建设有限公司南七货场Ⅰ道(北侧铁路线)仅留5米宽路面作为雾炮洒水车作业通道,路面每日清扫;货场内其余地面,用绿色苫布进行苫盖,并组织人力不定期对苫盖地面进行清扫,清扫后恢复苫盖,场地清扫与洒水跟班作业。自2018年11月4日起,对站内各煤炭经营户现存煤炭外运车辆,严格按照地铁公司2018年第4号专题会议纪要规定,进行装车作业。合肥市地方铁路投资建设有限公司针对无法禁止的国铁货运列车在南七货运站调车及存车作业,与国铁相关部门积极协调,最大程度减少鸣笛。公司相关业务部门相互协作,要明确任务,强化责任,严格检查,严肃纪律,对违反公司相关规定的行为,一律从重处罚。无33D340000201810310003合肥市新站区梅冲湖路与九顶山路向南150米,原爱瑞德企业院内有二家木材厂,隔壁有一家木材厂,共3家木材厂进行木材破碎,粉尘、噪音污染严重,多次投诉没有得到解决。合肥市大气,噪音新站区环保局会同三十头社区管委会工作人员于11月2日赴投诉企业现场核查,情况如下:投诉反映的爱瑞德企业实际为原安徽国仓管桩集团有限公司,该公司院内有两处露天木材破碎加工点(无营业执照,实际经营者为同一人:王闫)、该公司南侧围墙外有一家木材破碎加工点(营业执照注册名:合肥肥东环能生物质能源有限公司),三处木材加工点现场灰尘较大。属实转办投诉前,我区已在调查处理,11月1日现场约谈了两处木材加工厂负责人,要求立即停止生产,清理现场。11月2日区环保分局针对合肥肥东环能生物质能源有限公司、王闫分别下达行政处罚事先(听证)告知书:合环(新)罚告字〔2018〕183号、〔2018〕190号,分别罚款2万元,共计4万元。目前,投诉的3处木材加工点均已停产,现场生产设备已拆除。无34D340000201810310009合肥市包河区巢湖南路有十余家混凝土搅拌站,进出搅拌车辆扬尘污染严重,搅拌车辆闯红灯有安全隐患,多次投诉问题没有得到解决。合肥市大气经包河区淝河镇工作人员会同区住建局、交警包河大队执法人员于11月2日赴巢湖南路现场核查,现场核查情况如下:巢湖南路扬尘污染较大,确实存在大型车辆闯红灯现象,核查投诉的情况与投诉人反映的情况一致。包河区淝河片区东临南淝河、西至十五里河中段高铁南站片区、北接老城区、南抵包河经开区,总占地面积32600亩。2016年8月,经摸底调查,该区域居住群众12260户,多为“城中村”,环境脏乱差。巢湖南路大型车辆出入频繁,导致路况变差、道路基础设施破损严重,致使路基垫层外渗,道路清扫保洁难度大;并且巢湖南路周边存在南淝河路(东二环―长春街)、郎溪路二、三标等施工工地,途经上述工地的南淝河路及郎溪路尚未完全开通,工地渣土运输主要经过巢湖南路,加剧路面循环污染。虽然已采取了加大清扫保洁频次和洒水降尘力度等措施,但无法根治该区域严重的扬尘污染问题。位于巢湖南路、南淝河路沿线集聚混凝土搅拌站共19家。其生产、运输过程带来的扬尘、噪音及水污染问题严重,居民苦不堪言。近几年,有关淝河镇混凝土搅拌站污染的热线投诉、网友留言居高不下。针对淝河片区脏乱差的状况,包河区委、区政府高度重视,深入研判,自2016年初,即开始全面谋划论证淝河片区整体改造工作。其中,针对片区范围内的19家混凝土企业,由于不符合片区土地利用总体规划及未来改造发展业态布局,包河区将其全部纳入搬迁改造范围,并迅速启动相关工作。1、加快签订搬迁协议。对19家混凝土搅拌站下达搬迁改造通知,并陆续启动丈量、评估、签订协议及补偿相关工作。针对企业主反映的补偿问题,包河区本着“尊重历史、面对现实”的原则,耐心开展政策解释和上门沟通工作,尽量取得企业的理解和支持。截至目前,已与16家搅拌站签订了搬迁协议。下剩3家企业由于对搬迁补偿存有一定异议,目前正在积极洽谈推进中。2、积极对接复建事宜。考虑到混凝土企业搬迁可能带来的订单协议违约、员工就业及往来债务等问题,包河区积极协调对接,全力支持搬迁企业开展复建工作。3、加强日常巡查监管。针对混凝土搅拌站搬迁复建前的生产运营,包河区持续加强监督管理,加大扬尘等环境污染防治工作。一是加大宣传教育。中央环保督察期间,针对淝河片区混凝土企业的信访投诉量大的情况,辖区淝河镇、村居对混凝土企业加强宣传教育,要求其文明生产,并落实相关降尘抑尘等环保措施。二是强化监控巡查。区住建局通过行业视频系统,常态化监控搅拌站内洒水降尘、物料覆盖及生产运营环节的扬尘防治;区环保局、辖区淝河镇等加大日常巡查频次,督促企业将各项环保措施落到实处。三是依法行政处罚。对于环保不达标、未通过项目竣工环保验收、违反《建设项目环境保护管理条例》等相关规定的混凝土企业经营行为,区环保等相关部门依法对其进行行政处罚,并责令其落实整改措施。属实1、包河区淝河镇加大对周边工地巡查力度,严格落实扬尘污染防治要求,确保物料堆放覆盖、出入车辆清洗、渣土车辆密闭运输等措施落实到位。同时,对巢湖南路等重点路段进行严格巡查,对过往抛洒滴漏车辆进行依法查处。2、2018年至今,包河区住建局对淝河镇巢湖南路周边混凝土企业共巡查54次,下达监督意见书39份,对巡查发现的问题均敦促企业落实专人限期整改到位。3、针对巢湖南路路面扬尘的路况实际,为做好大气污染控制,包河区环卫服务中心不断增加了作业车辆,加大洒水降尘频次,实行循环作业。在夜间完成全区主次干道统一的冲洗保洁作业,在白天做好路面保湿抑尘工作,并在晚间薄弱时段增派车辆加强路面降尘保湿。具体措施:(1)洒水车依次循环路面洒水作业,保持路面湿润,抑制扬尘;(2)洗扫车湿扫路牙灰砂,将路牙边的灰砂洗扫干净;(3)小货车清运石子、灰砂;(4)道路养护车配合人工对人行道进行冲洗作业。4、加强交通管理。交警包河大队在二环路和巢湖南路设置了固定岗,对该片区的大型车辆进行严格管理,特别是针对闯红灯重点违法行为,一律予以200元记6分的处罚,同时加大对辖区货运企业开展交通安全宣传,倡导文明行车,目前该区域交通环境良好。无35D340000201810310001合肥市庐阳区南国花园小区9号楼南侧5米左右,变压器产生低频噪音,影响居民正常生活。合肥市噪音11月2日上午,亳州路街道、庐阳区环保局工作人员联合供电部门对南国花园9号楼南侧5米变压器进行现场查看,并委托有资质的第三方检测机构对噪声进行检测。经检测噪声超标,投诉人反映情况属实。属实亳州路街道于11月5日向供电部门去函要求落实整改。目前供电部门正联系对该处变压器安装隔音罩,预计11月8日前制作完成,亳州路街道督促其尽快落实整改。无36D340000201810310010合肥政务区附近的发能太阳海岸、恒大华府小区、融科城小区附近每隔两三天夜间就能闻到刺鼻性气味。合肥市大气经开区:经合肥经开区环保分局执法人员会同环保第三方巡查人员于11月1日开始连续3天昼间、夜间赴融科城小区周边现场核查,情况如下:核查投诉的情况与投诉人反映的情况部分一致。经排查,融科城小区附近合肥经开区辖区范围均为商住小区,排查未发现该小区周边合肥经开范围有反映类似气味企业。蜀山区:经蜀山区环保局执法人员会同笔架山街道于2018年11月2日赴政务区发能太阳海岸、恒大华府2个小区现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。(但未在我辖区发现气味源)。经查,2个小区周边为居民楼及匡河景观带,环境质量较好,未发现刺鼻性气味,且笔架山街道辖区范围内无工业企业。通过进一步走访群众,发现刺鼻性气味是间歇性的,且在高层闻到的概率较大。属实经开区:安排环保第三方巡查人员每天昼间、夜间对融科城周边区域进行巡查,发现问题及时处理。蜀山区:2018年11月3日,笔架山街道牵头召开发能太阳海岸、恒大华府2个小区居民“关于晚间刺鼻性气味问题基本调查摸底情况通报会”,参加会议人员有小区业委会、业主、党员、物业公司等代表。会议通报了该信访件调查情况。无打印关闭(责任编辑: HN666)
9 |
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/词嵌入图1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 4 词嵌入与word2vec/词嵌入图1.jpg
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/词嵌入图2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 4 词嵌入与word2vec/词嵌入图2.jpg
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/词嵌入图片2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 4 词嵌入与word2vec/词嵌入图片2.png
--------------------------------------------------------------------------------
/Chapter 5 文本数据增强/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 5 文本数据增强/logo.png
--------------------------------------------------------------------------------
/Chapter 5 文本数据增强/停用词.txt:
--------------------------------------------------------------------------------
1 | !
2 | "
3 | #
4 | $
5 | %
6 | &
7 | '
8 | (
9 | )
10 | *
11 | +
12 | ,
13 | -
14 | --
15 | .
16 | ..
17 | ...
18 | ......
19 | ...................
20 | ./
21 | .一
22 | .数
23 | .日
24 | /
25 | //
26 | 0
27 | 1
28 | 2
29 | 3
30 | 4
31 | 5
32 | 6
33 | 7
34 | 8
35 | 9
36 | :
37 | ://
38 | ::
39 | ;
40 | <
41 | =
42 | >
43 | >>
44 | ?
45 | @
46 | A
47 | Lex
48 | [
49 | \
50 | ]
51 | ^
52 | _
53 | `
54 | exp
55 | sub
56 | sup
57 | |
58 | }
59 | ~
60 | ~~~~
61 | ·
62 | ×
63 | ×××
64 | Δ
65 | Ψ
66 | γ
67 | μ
68 | φ
69 | φ.
70 | В
71 | —
72 | ——
73 | ———
74 | ‘
75 | ’
76 | ’‘
77 | “
78 | ”
79 | ”,
80 | …
81 | ……
82 | …………………………………………………③
83 | ′∈
84 | ′|
85 | ℃
86 | Ⅲ
87 | ↑
88 | →
89 | ∈[
90 | ∪φ∈
91 | ≈
92 | ①
93 | ②
94 | ②c
95 | ③
96 | ③]
97 | ④
98 | ⑤
99 | ⑥
100 | ⑦
101 | ⑧
102 | ⑨
103 | ⑩
104 | ──
105 | ■
106 | ▲
107 |
108 | 、
109 | 。
110 | 〈
111 | 〉
112 | 《
113 | 》
114 | 》),
115 | 」
116 | 『
117 | 』
118 | 【
119 | 】
120 | 〔
121 | 〕
122 | 〕〔
123 | ㈧
124 | 一
125 | 一.
126 | 一一
127 | 一下
128 | 一个
129 | 一些
130 | 一何
131 | 一切
132 | 一则
133 | 一则通过
134 | 一天
135 | 一定
136 | 一方面
137 | 一旦
138 | 一时
139 | 一来
140 | 一样
141 | 一次
142 | 一片
143 | 一番
144 | 一直
145 | 一致
146 | 一般
147 | 一起
148 | 一转眼
149 | 一边
150 | 一面
151 | 七
152 | 万一
153 | 三
154 | 三天两头
155 | 三番两次
156 | 三番五次
157 | 上
158 | 上下
159 | 上升
160 | 上去
161 | 上来
162 | 上述
163 | 上面
164 | 下
165 | 下列
166 | 下去
167 | 下来
168 | 下面
169 | 不
170 | 不一
171 | 不下
172 | 不久
173 | 不了
174 | 不亦乐乎
175 | 不仅
176 | 不仅...而且
177 | 不仅仅
178 | 不仅仅是
179 | 不会
180 | 不但
181 | 不但...而且
182 | 不光
183 | 不免
184 | 不再
185 | 不力
186 | 不单
187 | 不变
188 | 不只
189 | 不可
190 | 不可开交
191 | 不可抗拒
192 | 不同
193 | 不外
194 | 不外乎
195 | 不够
196 | 不大
197 | 不如
198 | 不妨
199 | 不定
200 | 不对
201 | 不少
202 | 不尽
203 | 不尽然
204 | 不巧
205 | 不已
206 | 不常
207 | 不得
208 | 不得不
209 | 不得了
210 | 不得已
211 | 不必
212 | 不怎么
213 | 不怕
214 | 不惟
215 | 不成
216 | 不拘
217 | 不择手段
218 | 不敢
219 | 不料
220 | 不断
221 | 不日
222 | 不时
223 | 不是
224 | 不曾
225 | 不止
226 | 不止一次
227 | 不比
228 | 不消
229 | 不满
230 | 不然
231 | 不然的话
232 | 不特
233 | 不独
234 | 不由得
235 | 不知不觉
236 | 不管
237 | 不管怎样
238 | 不经意
239 | 不胜
240 | 不能
241 | 不能不
242 | 不至于
243 | 不若
244 | 不要
245 | 不论
246 | 不起
247 | 不足
248 | 不过
249 | 不迭
250 | 不问
251 | 不限
252 | 与
253 | 与其
254 | 与其说
255 | 与否
256 | 与此同时
257 | 专门
258 | 且
259 | 且不说
260 | 且说
261 | 两者
262 | 严格
263 | 严重
264 | 个
265 | 个人
266 | 个别
267 | 中小
268 | 中间
269 | 丰富
270 | 串行
271 | 临
272 | 临到
273 | 为
274 | 为主
275 | 为了
276 | 为什么
277 | 为什麽
278 | 为何
279 | 为止
280 | 为此
281 | 为着
282 | 主张
283 | 主要
284 | 举凡
285 | 举行
286 | 乃
287 | 乃至
288 | 乃至于
289 | 么
290 | 之
291 | 之一
292 | 之前
293 | 之后
294 | 之後
295 | 之所以
296 | 之类
297 | 乌乎
298 | 乎
299 | 乒
300 | 乘
301 | 乘势
302 | 乘机
303 | 乘胜
304 | 乘虚
305 | 乘隙
306 | 九
307 | 也
308 | 也好
309 | 也就是说
310 | 也是
311 | 也罢
312 | 了
313 | 了解
314 | 争取
315 | 二
316 | 二来
317 | 二话不说
318 | 二话没说
319 | 于
320 | 于是
321 | 于是乎
322 | 云云
323 | 云尔
324 | 互
325 | 互相
326 | 五
327 | 些
328 | 交口
329 | 亦
330 | 产生
331 | 亲口
332 | 亲手
333 | 亲眼
334 | 亲自
335 | 亲身
336 | 人
337 | 人人
338 | 人们
339 | 人家
340 | 人民
341 | 什么
342 | 什么样
343 | 什麽
344 | 仅
345 | 仅仅
346 | 今
347 | 今后
348 | 今天
349 | 今年
350 | 今後
351 | 介于
352 | 仍
353 | 仍旧
354 | 仍然
355 | 从
356 | 从不
357 | 从严
358 | 从中
359 | 从事
360 | 从今以后
361 | 从优
362 | 从古到今
363 | 从古至今
364 | 从头
365 | 从宽
366 | 从小
367 | 从新
368 | 从无到有
369 | 从早到晚
370 | 从未
371 | 从来
372 | 从此
373 | 从此以后
374 | 从而
375 | 从轻
376 | 从速
377 | 从重
378 | 他
379 | 他人
380 | 他们
381 | 他是
382 | 他的
383 | 代替
384 | 以
385 | 以上
386 | 以下
387 | 以为
388 | 以便
389 | 以免
390 | 以前
391 | 以及
392 | 以后
393 | 以外
394 | 以後
395 | 以故
396 | 以期
397 | 以来
398 | 以至
399 | 以至于
400 | 以致
401 | 们
402 | 任
403 | 任何
404 | 任凭
405 | 任务
406 | 企图
407 | 伙同
408 | 会
409 | 伟大
410 | 传
411 | 传说
412 | 传闻
413 | 似乎
414 | 似的
415 | 但
416 | 但凡
417 | 但愿
418 | 但是
419 | 何
420 | 何乐而不为
421 | 何以
422 | 何况
423 | 何处
424 | 何妨
425 | 何尝
426 | 何必
427 | 何时
428 | 何止
429 | 何苦
430 | 何须
431 | 余外
432 | 作为
433 | 你
434 | 你们
435 | 你是
436 | 你的
437 | 使
438 | 使得
439 | 使用
440 | 例如
441 | 依
442 | 依据
443 | 依照
444 | 依靠
445 | 便
446 | 便于
447 | 促进
448 | 保持
449 | 保管
450 | 保险
451 | 俺
452 | 俺们
453 | 倍加
454 | 倍感
455 | 倒不如
456 | 倒不如说
457 | 倒是
458 | 倘
459 | 倘使
460 | 倘或
461 | 倘然
462 | 倘若
463 | 借
464 | 借以
465 | 借此
466 | 假使
467 | 假如
468 | 假若
469 | 偏偏
470 | 做到
471 | 偶尔
472 | 偶而
473 | 傥然
474 | 像
475 | 儿
476 | 允许
477 | 元/吨
478 | 充其极
479 | 充其量
480 | 充分
481 | 先不先
482 | 先后
483 | 先後
484 | 先生
485 | 光
486 | 光是
487 | 全体
488 | 全力
489 | 全年
490 | 全然
491 | 全身心
492 | 全部
493 | 全都
494 | 全面
495 | 八
496 | 八成
497 | 公然
498 | 六
499 | 兮
500 | 共
501 | 共同
502 | 共总
503 | 关于
504 | 其
505 | 其一
506 | 其中
507 | 其二
508 | 其他
509 | 其余
510 | 其后
511 | 其它
512 | 其实
513 | 其次
514 | 具体
515 | 具体地说
516 | 具体来说
517 | 具体说来
518 | 具有
519 | 兼之
520 | 内
521 | 再
522 | 再其次
523 | 再则
524 | 再有
525 | 再次
526 | 再者
527 | 再者说
528 | 再说
529 | 冒
530 | 冲
531 | 决不
532 | 决定
533 | 决非
534 | 况且
535 | 准备
536 | 凑巧
537 | 凝神
538 | 几
539 | 几乎
540 | 几度
541 | 几时
542 | 几番
543 | 几经
544 | 凡
545 | 凡是
546 | 凭
547 | 凭借
548 | 出
549 | 出于
550 | 出去
551 | 出来
552 | 出现
553 | 分别
554 | 分头
555 | 分期
556 | 分期分批
557 | 切
558 | 切不可
559 | 切切
560 | 切勿
561 | 切莫
562 | 则
563 | 则甚
564 | 刚
565 | 刚好
566 | 刚巧
567 | 刚才
568 | 初
569 | 别
570 | 别人
571 | 别处
572 | 别是
573 | 别的
574 | 别管
575 | 别说
576 | 到
577 | 到了儿
578 | 到处
579 | 到头
580 | 到头来
581 | 到底
582 | 到目前为止
583 | 前后
584 | 前此
585 | 前者
586 | 前进
587 | 前面
588 | 加上
589 | 加之
590 | 加以
591 | 加入
592 | 加强
593 | 动不动
594 | 动辄
595 | 勃然
596 | 匆匆
597 | 十分
598 | 千
599 | 千万
600 | 千万千万
601 | 半
602 | 单
603 | 单单
604 | 单纯
605 | 即
606 | 即令
607 | 即使
608 | 即便
609 | 即刻
610 | 即如
611 | 即将
612 | 即或
613 | 即是说
614 | 即若
615 | 却
616 | 却不
617 | 历
618 | 原来
619 | 去
620 | 又
621 | 又及
622 | 及
623 | 及其
624 | 及时
625 | 及至
626 | 双方
627 | 反之
628 | 反之亦然
629 | 反之则
630 | 反倒
631 | 反倒是
632 | 反应
633 | 反手
634 | 反映
635 | 反而
636 | 反过来
637 | 反过来说
638 | 取得
639 | 取道
640 | 受到
641 | 变成
642 | 古来
643 | 另
644 | 另一个
645 | 另一方面
646 | 另外
647 | 另悉
648 | 另方面
649 | 另行
650 | 只
651 | 只当
652 | 只怕
653 | 只是
654 | 只有
655 | 只消
656 | 只要
657 | 只限
658 | 叫
659 | 叫做
660 | 召开
661 | 叮咚
662 | 叮当
663 | 可
664 | 可以
665 | 可好
666 | 可是
667 | 可能
668 | 可见
669 | 各
670 | 各个
671 | 各人
672 | 各位
673 | 各地
674 | 各式
675 | 各种
676 | 各级
677 | 各自
678 | 合理
679 | 同
680 | 同一
681 | 同时
682 | 同样
683 | 后
684 | 后来
685 | 后者
686 | 后面
687 | 向
688 | 向使
689 | 向着
690 | 吓
691 | 吗
692 | 否则
693 | 吧
694 | 吧哒
695 | 吱
696 | 呀
697 | 呃
698 | 呆呆地
699 | 呐
700 | 呕
701 | 呗
702 | 呜
703 | 呜呼
704 | 呢
705 | 周围
706 | 呵
707 | 呵呵
708 | 呸
709 | 呼哧
710 | 呼啦
711 | 咋
712 | 和
713 | 咚
714 | 咦
715 | 咧
716 | 咱
717 | 咱们
718 | 咳
719 | 哇
720 | 哈
721 | 哈哈
722 | 哉
723 | 哎
724 | 哎呀
725 | 哎哟
726 | 哗
727 | 哗啦
728 | 哟
729 | 哦
730 | 哩
731 | 哪
732 | 哪个
733 | 哪些
734 | 哪儿
735 | 哪天
736 | 哪年
737 | 哪怕
738 | 哪样
739 | 哪边
740 | 哪里
741 | 哼
742 | 哼唷
743 | 唉
744 | 唯有
745 | 啊
746 | 啊呀
747 | 啊哈
748 | 啊哟
749 | 啐
750 | 啥
751 | 啦
752 | 啪达
753 | 啷当
754 | 喀
755 | 喂
756 | 喏
757 | 喔唷
758 | 喽
759 | 嗡
760 | 嗡嗡
761 | 嗬
762 | 嗯
763 | 嗳
764 | 嘎
765 | 嘎嘎
766 | 嘎登
767 | 嘘
768 | 嘛
769 | 嘻
770 | 嘿
771 | 嘿嘿
772 | 四
773 | 因
774 | 因为
775 | 因了
776 | 因此
777 | 因着
778 | 因而
779 | 固
780 | 固然
781 | 在
782 | 在下
783 | 在于
784 | 地
785 | 均
786 | 坚决
787 | 坚持
788 | 基于
789 | 基本
790 | 基本上
791 | 处在
792 | 处处
793 | 处理
794 | 复杂
795 | 多
796 | 多么
797 | 多亏
798 | 多多
799 | 多多少少
800 | 多多益善
801 | 多少
802 | 多年前
803 | 多年来
804 | 多数
805 | 多次
806 | 够瞧的
807 | 大
808 | 大不了
809 | 大举
810 | 大事
811 | 大体
812 | 大体上
813 | 大凡
814 | 大力
815 | 大多
816 | 大多数
817 | 大大
818 | 大家
819 | 大张旗鼓
820 | 大批
821 | 大抵
822 | 大概
823 | 大略
824 | 大约
825 | 大致
826 | 大都
827 | 大量
828 | 大面儿上
829 | 失去
830 | 奇
831 | 奈
832 | 奋勇
833 | 她
834 | 她们
835 | 她是
836 | 她的
837 | 好
838 | 好在
839 | 好的
840 | 好象
841 | 如
842 | 如上
843 | 如上所述
844 | 如下
845 | 如今
846 | 如何
847 | 如其
848 | 如前所述
849 | 如同
850 | 如常
851 | 如是
852 | 如期
853 | 如果
854 | 如次
855 | 如此
856 | 如此等等
857 | 如若
858 | 始而
859 | 姑且
860 | 存在
861 | 存心
862 | 孰料
863 | 孰知
864 | 宁
865 | 宁可
866 | 宁愿
867 | 宁肯
868 | 它
869 | 它们
870 | 它们的
871 | 它是
872 | 它的
873 | 安全
874 | 完全
875 | 完成
876 | 定
877 | 实现
878 | 实际
879 | 宣布
880 | 容易
881 | 密切
882 | 对
883 | 对于
884 | 对应
885 | 对待
886 | 对方
887 | 对比
888 | 将
889 | 将才
890 | 将要
891 | 将近
892 | 小
893 | 少数
894 | 尔
895 | 尔后
896 | 尔尔
897 | 尔等
898 | 尚且
899 | 尤其
900 | 就
901 | 就地
902 | 就是
903 | 就是了
904 | 就是说
905 | 就此
906 | 就算
907 | 就要
908 | 尽
909 | 尽可能
910 | 尽如人意
911 | 尽心尽力
912 | 尽心竭力
913 | 尽快
914 | 尽早
915 | 尽然
916 | 尽管
917 | 尽管如此
918 | 尽量
919 | 局外
920 | 居然
921 | 届时
922 | 属于
923 | 屡
924 | 屡屡
925 | 屡次
926 | 屡次三番
927 | 岂
928 | 岂但
929 | 岂止
930 | 岂非
931 | 川流不息
932 | 左右
933 | 巨大
934 | 巩固
935 | 差一点
936 | 差不多
937 | 己
938 | 已
939 | 已矣
940 | 已经
941 | 巴
942 | 巴巴
943 | 带
944 | 帮助
945 | 常
946 | 常常
947 | 常言说
948 | 常言说得好
949 | 常言道
950 | 平素
951 | 年复一年
952 | 并
953 | 并不
954 | 并不是
955 | 并且
956 | 并排
957 | 并无
958 | 并没
959 | 并没有
960 | 并肩
961 | 并非
962 | 广大
963 | 广泛
964 | 应当
965 | 应用
966 | 应该
967 | 庶乎
968 | 庶几
969 | 开外
970 | 开始
971 | 开展
972 | 引起
973 | 弗
974 | 弹指之间
975 | 强烈
976 | 强调
977 | 归
978 | 归根到底
979 | 归根结底
980 | 归齐
981 | 当
982 | 当下
983 | 当中
984 | 当儿
985 | 当前
986 | 当即
987 | 当口儿
988 | 当地
989 | 当场
990 | 当头
991 | 当庭
992 | 当时
993 | 当然
994 | 当真
995 | 当着
996 | 形成
997 | 彻夜
998 | 彻底
999 | 彼
1000 | 彼时
1001 | 彼此
1002 | 往
1003 | 往往
1004 | 待
1005 | 待到
1006 | 很
1007 | 很多
1008 | 很少
1009 | 後来
1010 | 後面
1011 | 得
1012 | 得了
1013 | 得出
1014 | 得到
1015 | 得天独厚
1016 | 得起
1017 | 心里
1018 | 必
1019 | 必定
1020 | 必将
1021 | 必然
1022 | 必要
1023 | 必须
1024 | 快
1025 | 快要
1026 | 忽地
1027 | 忽然
1028 | 怎
1029 | 怎么
1030 | 怎么办
1031 | 怎么样
1032 | 怎奈
1033 | 怎样
1034 | 怎麽
1035 | 怕
1036 | 急匆匆
1037 | 怪
1038 | 怪不得
1039 | 总之
1040 | 总是
1041 | 总的来看
1042 | 总的来说
1043 | 总的说来
1044 | 总结
1045 | 总而言之
1046 | 恍然
1047 | 恐怕
1048 | 恰似
1049 | 恰好
1050 | 恰如
1051 | 恰巧
1052 | 恰恰
1053 | 恰恰相反
1054 | 恰逢
1055 | 您
1056 | 您们
1057 | 您是
1058 | 惟其
1059 | 惯常
1060 | 意思
1061 | 愤然
1062 | 愿意
1063 | 慢说
1064 | 成为
1065 | 成年
1066 | 成年累月
1067 | 成心
1068 | 我
1069 | 我们
1070 | 我是
1071 | 我的
1072 | 或
1073 | 或则
1074 | 或多或少
1075 | 或是
1076 | 或曰
1077 | 或者
1078 | 或许
1079 | 战斗
1080 | 截然
1081 | 截至
1082 | 所
1083 | 所以
1084 | 所在
1085 | 所幸
1086 | 所有
1087 | 所谓
1088 | 才
1089 | 才能
1090 | 扑通
1091 | 打
1092 | 打从
1093 | 打开天窗说亮话
1094 | 扩大
1095 | 把
1096 | 抑或
1097 | 抽冷子
1098 | 拦腰
1099 | 拿
1100 | 按
1101 | 按时
1102 | 按期
1103 | 按照
1104 | 按理
1105 | 按说
1106 | 挨个
1107 | 挨家挨户
1108 | 挨次
1109 | 挨着
1110 | 挨门挨户
1111 | 挨门逐户
1112 | 换句话说
1113 | 换言之
1114 | 据
1115 | 据实
1116 | 据悉
1117 | 据我所知
1118 | 据此
1119 | 据称
1120 | 据说
1121 | 掌握
1122 | 接下来
1123 | 接着
1124 | 接著
1125 | 接连不断
1126 | 放量
1127 | 故
1128 | 故意
1129 | 故此
1130 | 故而
1131 | 敞开儿
1132 | 敢
1133 | 敢于
1134 | 敢情
1135 | 数/
1136 | 整个
1137 | 断然
1138 | 方
1139 | 方便
1140 | 方才
1141 | 方能
1142 | 方面
1143 | 旁人
1144 | 无
1145 | 无宁
1146 | 无法
1147 | 无论
1148 | 既
1149 | 既...又
1150 | 既往
1151 | 既是
1152 | 既然
1153 | 日复一日
1154 | 日渐
1155 | 日益
1156 | 日臻
1157 | 日见
1158 | 时候
1159 | 昂然
1160 | 明显
1161 | 明确
1162 | 是
1163 | 是不是
1164 | 是以
1165 | 是否
1166 | 是的
1167 | 显然
1168 | 显著
1169 | 普通
1170 | 普遍
1171 | 暗中
1172 | 暗地里
1173 | 暗自
1174 | 更
1175 | 更为
1176 | 更加
1177 | 更进一步
1178 | 曾
1179 | 曾经
1180 | 替
1181 | 替代
1182 | 最
1183 | 最后
1184 | 最大
1185 | 最好
1186 | 最後
1187 | 最近
1188 | 最高
1189 | 有
1190 | 有些
1191 | 有关
1192 | 有利
1193 | 有力
1194 | 有及
1195 | 有所
1196 | 有效
1197 | 有时
1198 | 有点
1199 | 有的
1200 | 有的是
1201 | 有着
1202 | 有著
1203 | 望
1204 | 朝
1205 | 朝着
1206 | 末##末
1207 | 本
1208 | 本人
1209 | 本地
1210 | 本着
1211 | 本身
1212 | 权时
1213 | 来
1214 | 来不及
1215 | 来得及
1216 | 来看
1217 | 来着
1218 | 来自
1219 | 来讲
1220 | 来说
1221 | 极
1222 | 极为
1223 | 极了
1224 | 极其
1225 | 极力
1226 | 极大
1227 | 极度
1228 | 极端
1229 | 构成
1230 | 果然
1231 | 果真
1232 | 某
1233 | 某个
1234 | 某些
1235 | 某某
1236 | 根据
1237 | 根本
1238 | 格外
1239 | 梆
1240 | 概
1241 | 次第
1242 | 欢迎
1243 | 欤
1244 | 正值
1245 | 正在
1246 | 正如
1247 | 正巧
1248 | 正常
1249 | 正是
1250 | 此
1251 | 此中
1252 | 此后
1253 | 此地
1254 | 此处
1255 | 此外
1256 | 此时
1257 | 此次
1258 | 此间
1259 | 殆
1260 | 毋宁
1261 | 每
1262 | 每个
1263 | 每天
1264 | 每年
1265 | 每当
1266 | 每时每刻
1267 | 每每
1268 | 每逢
1269 | 比
1270 | 比及
1271 | 比如
1272 | 比如说
1273 | 比方
1274 | 比照
1275 | 比起
1276 | 比较
1277 | 毕竟
1278 | 毫不
1279 | 毫无
1280 | 毫无例外
1281 | 毫无保留地
1282 | 汝
1283 | 沙沙
1284 | 没
1285 | 没奈何
1286 | 没有
1287 | 沿
1288 | 沿着
1289 | 注意
1290 | 活
1291 | 深入
1292 | 清楚
1293 | 满
1294 | 满足
1295 | 漫说
1296 | 焉
1297 | 然
1298 | 然则
1299 | 然后
1300 | 然後
1301 | 然而
1302 | 照
1303 | 照着
1304 | 牢牢
1305 | 特别是
1306 | 特殊
1307 | 特点
1308 | 犹且
1309 | 犹自
1310 | 独
1311 | 独自
1312 | 猛然
1313 | 猛然间
1314 | 率尔
1315 | 率然
1316 | 现代
1317 | 现在
1318 | 理应
1319 | 理当
1320 | 理该
1321 | 瑟瑟
1322 | 甚且
1323 | 甚么
1324 | 甚或
1325 | 甚而
1326 | 甚至
1327 | 甚至于
1328 | 用
1329 | 用来
1330 | 甫
1331 | 甭
1332 | 由
1333 | 由于
1334 | 由是
1335 | 由此
1336 | 由此可见
1337 | 略
1338 | 略为
1339 | 略加
1340 | 略微
1341 | 白
1342 | 白白
1343 | 的
1344 | 的确
1345 | 的话
1346 | 皆可
1347 | 目前
1348 | 直到
1349 | 直接
1350 | 相似
1351 | 相信
1352 | 相反
1353 | 相同
1354 | 相对
1355 | 相对而言
1356 | 相应
1357 | 相当
1358 | 相等
1359 | 省得
1360 | 看
1361 | 看上去
1362 | 看出
1363 | 看到
1364 | 看来
1365 | 看样子
1366 | 看看
1367 | 看见
1368 | 看起来
1369 | 真是
1370 | 真正
1371 | 眨眼
1372 | 着
1373 | 着呢
1374 | 矣
1375 | 矣乎
1376 | 矣哉
1377 | 知道
1378 | 砰
1379 | 确定
1380 | 碰巧
1381 | 社会主义
1382 | 离
1383 | 种
1384 | 积极
1385 | 移动
1386 | 究竟
1387 | 穷年累月
1388 | 突出
1389 | 突然
1390 | 窃
1391 | 立
1392 | 立刻
1393 | 立即
1394 | 立地
1395 | 立时
1396 | 立马
1397 | 竟
1398 | 竟然
1399 | 竟而
1400 | 第
1401 | 第二
1402 | 等
1403 | 等到
1404 | 等等
1405 | 策略地
1406 | 简直
1407 | 简而言之
1408 | 简言之
1409 | 管
1410 | 类如
1411 | 粗
1412 | 精光
1413 | 紧接着
1414 | 累年
1415 | 累次
1416 | 纯
1417 | 纯粹
1418 | 纵
1419 | 纵令
1420 | 纵使
1421 | 纵然
1422 | 练习
1423 | 组成
1424 | 经
1425 | 经常
1426 | 经过
1427 | 结合
1428 | 结果
1429 | 给
1430 | 绝
1431 | 绝不
1432 | 绝对
1433 | 绝非
1434 | 绝顶
1435 | 继之
1436 | 继后
1437 | 继续
1438 | 继而
1439 | 维持
1440 | 综上所述
1441 | 缕缕
1442 | 罢了
1443 | 老
1444 | 老大
1445 | 老是
1446 | 老老实实
1447 | 考虑
1448 | 者
1449 | 而
1450 | 而且
1451 | 而况
1452 | 而又
1453 | 而后
1454 | 而外
1455 | 而已
1456 | 而是
1457 | 而言
1458 | 而论
1459 | 联系
1460 | 联袂
1461 | 背地里
1462 | 背靠背
1463 | 能
1464 | 能否
1465 | 能够
1466 | 腾
1467 | 自
1468 | 自个儿
1469 | 自从
1470 | 自各儿
1471 | 自后
1472 | 自家
1473 | 自己
1474 | 自打
1475 | 自身
1476 | 臭
1477 | 至
1478 | 至于
1479 | 至今
1480 | 至若
1481 | 致
1482 | 般的
1483 | 良好
1484 | 若
1485 | 若夫
1486 | 若是
1487 | 若果
1488 | 若非
1489 | 范围
1490 | 莫
1491 | 莫不
1492 | 莫不然
1493 | 莫如
1494 | 莫若
1495 | 莫非
1496 | 获得
1497 | 藉以
1498 | 虽
1499 | 虽则
1500 | 虽然
1501 | 虽说
1502 | 蛮
1503 | 行为
1504 | 行动
1505 | 表明
1506 | 表示
1507 | 被
1508 | 要
1509 | 要不
1510 | 要不是
1511 | 要不然
1512 | 要么
1513 | 要是
1514 | 要求
1515 | 见
1516 | 规定
1517 | 觉得
1518 | 譬喻
1519 | 譬如
1520 | 认为
1521 | 认真
1522 | 认识
1523 | 让
1524 | 许多
1525 | 论
1526 | 论说
1527 | 设使
1528 | 设或
1529 | 设若
1530 | 诚如
1531 | 诚然
1532 | 话说
1533 | 该
1534 | 该当
1535 | 说明
1536 | 说来
1537 | 说说
1538 | 请勿
1539 | 诸
1540 | 诸位
1541 | 诸如
1542 | 谁
1543 | 谁人
1544 | 谁料
1545 | 谁知
1546 | 谨
1547 | 豁然
1548 | 贼死
1549 | 赖以
1550 | 赶
1551 | 赶快
1552 | 赶早不赶晚
1553 | 起
1554 | 起先
1555 | 起初
1556 | 起头
1557 | 起来
1558 | 起见
1559 | 起首
1560 | 趁
1561 | 趁便
1562 | 趁势
1563 | 趁早
1564 | 趁机
1565 | 趁热
1566 | 趁着
1567 | 越是
1568 | 距
1569 | 跟
1570 | 路经
1571 | 转动
1572 | 转变
1573 | 转贴
1574 | 轰然
1575 | 较
1576 | 较为
1577 | 较之
1578 | 较比
1579 | 边
1580 | 达到
1581 | 达旦
1582 | 迄
1583 | 迅速
1584 | 过
1585 | 过于
1586 | 过去
1587 | 过来
1588 | 运用
1589 | 近
1590 | 近几年来
1591 | 近年来
1592 | 近来
1593 | 还
1594 | 还是
1595 | 还有
1596 | 还要
1597 | 这
1598 | 这一来
1599 | 这个
1600 | 这么
1601 | 这么些
1602 | 这么样
1603 | 这么点儿
1604 | 这些
1605 | 这会儿
1606 | 这儿
1607 | 这就是说
1608 | 这时
1609 | 这样
1610 | 这次
1611 | 这点
1612 | 这种
1613 | 这般
1614 | 这边
1615 | 这里
1616 | 这麽
1617 | 进入
1618 | 进去
1619 | 进来
1620 | 进步
1621 | 进而
1622 | 进行
1623 | 连
1624 | 连同
1625 | 连声
1626 | 连日
1627 | 连日来
1628 | 连袂
1629 | 连连
1630 | 迟早
1631 | 迫于
1632 | 适应
1633 | 适当
1634 | 适用
1635 | 逐步
1636 | 逐渐
1637 | 通常
1638 | 通过
1639 | 造成
1640 | 逢
1641 | 遇到
1642 | 遭到
1643 | 遵循
1644 | 遵照
1645 | 避免
1646 | 那
1647 | 那个
1648 | 那么
1649 | 那么些
1650 | 那么样
1651 | 那些
1652 | 那会儿
1653 | 那儿
1654 | 那时
1655 | 那末
1656 | 那样
1657 | 那般
1658 | 那边
1659 | 那里
1660 | 那麽
1661 | 部分
1662 | 都
1663 | 鄙人
1664 | 采取
1665 | 里面
1666 | 重大
1667 | 重新
1668 | 重要
1669 | 鉴于
1670 | 针对
1671 | 长期以来
1672 | 长此下去
1673 | 长线
1674 | 长话短说
1675 | 问题
1676 | 间或
1677 | 防止
1678 | 阿
1679 | 附近
1680 | 陈年
1681 | 限制
1682 | 陡然
1683 | 除
1684 | 除了
1685 | 除却
1686 | 除去
1687 | 除外
1688 | 除开
1689 | 除此
1690 | 除此之外
1691 | 除此以外
1692 | 除此而外
1693 | 除非
1694 | 随
1695 | 随后
1696 | 随时
1697 | 随着
1698 | 随著
1699 | 隔夜
1700 | 隔日
1701 | 难得
1702 | 难怪
1703 | 难说
1704 | 难道
1705 | 难道说
1706 | 集中
1707 | 零
1708 | 需要
1709 | 非但
1710 | 非常
1711 | 非徒
1712 | 非得
1713 | 非特
1714 | 非独
1715 | 靠
1716 | 顶多
1717 | 顷
1718 | 顷刻
1719 | 顷刻之间
1720 | 顷刻间
1721 | 顺
1722 | 顺着
1723 | 顿时
1724 | 颇
1725 | 风雨无阻
1726 | 饱
1727 | 首先
1728 | 马上
1729 | 高低
1730 | 高兴
1731 | 默然
1732 | 默默地
1733 | 齐
1734 | ︿
1735 | !
1736 | #
1737 | $
1738 | %
1739 | &
1740 | '
1741 | (
1742 | )
1743 | )÷(1-
1744 | )、
1745 | *
1746 | +
1747 | +ξ
1748 | ++
1749 | ,
1750 | ,也
1751 | -
1752 | -β
1753 | --
1754 | -[*]-
1755 | .
1756 | /
1757 | 0
1758 | 0:2
1759 | 1
1760 | 1.
1761 | 12%
1762 | 2
1763 | 2.3%
1764 | 3
1765 | 4
1766 | 5
1767 | 5:0
1768 | 6
1769 | 7
1770 | 8
1771 | 9
1772 | :
1773 | ;
1774 | <
1775 | <±
1776 | <Δ
1777 | <λ
1778 | <φ
1779 | <<
1780 | =
1781 | =″
1782 | =☆
1783 | =(
1784 | =-
1785 | =[
1786 | ={
1787 | >
1788 | >λ
1789 | ?
1790 | @
1791 | A
1792 | LI
1793 | R.L.
1794 | ZXFITL
1795 | [
1796 | [①①]
1797 | [①②]
1798 | [①③]
1799 | [①④]
1800 | [①⑤]
1801 | [①⑥]
1802 | [①⑦]
1803 | [①⑧]
1804 | [①⑨]
1805 | [①A]
1806 | [①B]
1807 | [①C]
1808 | [①D]
1809 | [①E]
1810 | [①]
1811 | [①a]
1812 | [①c]
1813 | [①d]
1814 | [①e]
1815 | [①f]
1816 | [①g]
1817 | [①h]
1818 | [①i]
1819 | [①o]
1820 | [②
1821 | [②①]
1822 | [②②]
1823 | [②③]
1824 | [②④
1825 | [②⑤]
1826 | [②⑥]
1827 | [②⑦]
1828 | [②⑧]
1829 | [②⑩]
1830 | [②B]
1831 | [②G]
1832 | [②]
1833 | [②a]
1834 | [②b]
1835 | [②c]
1836 | [②d]
1837 | [②e]
1838 | [②f]
1839 | [②g]
1840 | [②h]
1841 | [②i]
1842 | [②j]
1843 | [③①]
1844 | [③⑩]
1845 | [③F]
1846 | [③]
1847 | [③a]
1848 | [③b]
1849 | [③c]
1850 | [③d]
1851 | [③e]
1852 | [③g]
1853 | [③h]
1854 | [④]
1855 | [④a]
1856 | [④b]
1857 | [④c]
1858 | [④d]
1859 | [④e]
1860 | [⑤]
1861 | [⑤]]
1862 | [⑤a]
1863 | [⑤b]
1864 | [⑤d]
1865 | [⑤e]
1866 | [⑤f]
1867 | [⑥]
1868 | [⑦]
1869 | [⑧]
1870 | [⑨]
1871 | [⑩]
1872 | [*]
1873 | [-
1874 | []
1875 | ]
1876 | ]∧′=[
1877 | ][
1878 | _
1879 | a]
1880 | b]
1881 | c]
1882 | e]
1883 | f]
1884 | ng昉
1885 | {
1886 | {-
1887 | |
1888 | }
1889 | }>
1890 | ~
1891 | ~±
1892 | ~+
1893 | ¥
1894 |
--------------------------------------------------------------------------------
/Chapter 5 文本数据增强/文本截断.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 5 文本数据增强/文本截断.jpg
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/LSTM公式.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/LSTM公式.jpeg
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/RNN.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/RNN.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/RNN公式.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/RNN公式.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula_1.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/TextRNN.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/TextRNN.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/apple_onehot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/apple_onehot.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/中文停用词表.txt:
--------------------------------------------------------------------------------
1 | !
2 | "
3 | #
4 | $
5 | %
6 | &
7 | '
8 | (
9 | )
10 | *
11 | +
12 | ,
13 | -
14 | --
15 | .
16 | ..
17 | ...
18 | ......
19 | ...................
20 | ./
21 | .一
22 | .数
23 | .日
24 | /
25 | //
26 | 0
27 | 1
28 | 2
29 | 3
30 | 4
31 | 5
32 | 6
33 | 7
34 | 8
35 | 9
36 | :
37 | ://
38 | ::
39 | ;
40 | <
41 | =
42 | >
43 | >>
44 | ?
45 | @
46 | A
47 | Lex
48 | [
49 | \
50 | ]
51 | ^
52 | _
53 | `
54 | exp
55 | sub
56 | sup
57 | |
58 | }
59 | ~
60 | ~~~~
61 | ·
62 | ×
63 | ×××
64 | Δ
65 | Ψ
66 | γ
67 | μ
68 | φ
69 | φ.
70 | В
71 | —
72 | ——
73 | ———
74 | ‘
75 | ’
76 | ’‘
77 | “
78 | ”
79 | ”,
80 | …
81 | ……
82 | …………………………………………………③
83 | ′∈
84 | ′|
85 | ℃
86 | Ⅲ
87 | ↑
88 | →
89 | ∈[
90 | ∪φ∈
91 | ≈
92 | ①
93 | ②
94 | ②c
95 | ③
96 | ③]
97 | ④
98 | ⑤
99 | ⑥
100 | ⑦
101 | ⑧
102 | ⑨
103 | ⑩
104 | ──
105 | ■
106 | ▲
107 |
108 | 、
109 | 。
110 | 〈
111 | 〉
112 | 《
113 | 》
114 | 》),
115 | 」
116 | 『
117 | 』
118 | 【
119 | 】
120 | 〔
121 | 〕
122 | 〕〔
123 | ㈧
124 | 一
125 | 一.
126 | 一一
127 | 一下
128 | 一个
129 | 一些
130 | 一何
131 | 一切
132 | 一则
133 | 一则通过
134 | 一天
135 | 一定
136 | 一方面
137 | 一旦
138 | 一时
139 | 一来
140 | 一样
141 | 一次
142 | 一片
143 | 一番
144 | 一直
145 | 一致
146 | 一般
147 | 一起
148 | 一转眼
149 | 一边
150 | 一面
151 | 七
152 | 万一
153 | 三
154 | 三天两头
155 | 三番两次
156 | 三番五次
157 | 上
158 | 上下
159 | 上升
160 | 上去
161 | 上来
162 | 上述
163 | 上面
164 | 下
165 | 下列
166 | 下去
167 | 下来
168 | 下面
169 | 不
170 | 不一
171 | 不下
172 | 不久
173 | 不了
174 | 不亦乐乎
175 | 不仅
176 | 不仅...而且
177 | 不仅仅
178 | 不仅仅是
179 | 不会
180 | 不但
181 | 不但...而且
182 | 不光
183 | 不免
184 | 不再
185 | 不力
186 | 不单
187 | 不变
188 | 不只
189 | 不可
190 | 不可开交
191 | 不可抗拒
192 | 不同
193 | 不外
194 | 不外乎
195 | 不够
196 | 不大
197 | 不如
198 | 不妨
199 | 不定
200 | 不对
201 | 不少
202 | 不尽
203 | 不尽然
204 | 不巧
205 | 不已
206 | 不常
207 | 不得
208 | 不得不
209 | 不得了
210 | 不得已
211 | 不必
212 | 不怎么
213 | 不怕
214 | 不惟
215 | 不成
216 | 不拘
217 | 不择手段
218 | 不敢
219 | 不料
220 | 不断
221 | 不日
222 | 不时
223 | 不是
224 | 不曾
225 | 不止
226 | 不止一次
227 | 不比
228 | 不消
229 | 不满
230 | 不然
231 | 不然的话
232 | 不特
233 | 不独
234 | 不由得
235 | 不知不觉
236 | 不管
237 | 不管怎样
238 | 不经意
239 | 不胜
240 | 不能
241 | 不能不
242 | 不至于
243 | 不若
244 | 不要
245 | 不论
246 | 不起
247 | 不足
248 | 不过
249 | 不迭
250 | 不问
251 | 不限
252 | 与
253 | 与其
254 | 与其说
255 | 与否
256 | 与此同时
257 | 专门
258 | 且
259 | 且不说
260 | 且说
261 | 两者
262 | 严格
263 | 严重
264 | 个
265 | 个人
266 | 个别
267 | 中小
268 | 中间
269 | 丰富
270 | 串行
271 | 临
272 | 临到
273 | 为
274 | 为主
275 | 为了
276 | 为什么
277 | 为什麽
278 | 为何
279 | 为止
280 | 为此
281 | 为着
282 | 主张
283 | 主要
284 | 举凡
285 | 举行
286 | 乃
287 | 乃至
288 | 乃至于
289 | 么
290 | 之
291 | 之一
292 | 之前
293 | 之后
294 | 之後
295 | 之所以
296 | 之类
297 | 乌乎
298 | 乎
299 | 乒
300 | 乘
301 | 乘势
302 | 乘机
303 | 乘胜
304 | 乘虚
305 | 乘隙
306 | 九
307 | 也
308 | 也好
309 | 也就是说
310 | 也是
311 | 也罢
312 | 了
313 | 了解
314 | 争取
315 | 二
316 | 二来
317 | 二话不说
318 | 二话没说
319 | 于
320 | 于是
321 | 于是乎
322 | 云云
323 | 云尔
324 | 互
325 | 互相
326 | 五
327 | 些
328 | 交口
329 | 亦
330 | 产生
331 | 亲口
332 | 亲手
333 | 亲眼
334 | 亲自
335 | 亲身
336 | 人
337 | 人人
338 | 人们
339 | 人家
340 | 人民
341 | 什么
342 | 什么样
343 | 什麽
344 | 仅
345 | 仅仅
346 | 今
347 | 今后
348 | 今天
349 | 今年
350 | 今後
351 | 介于
352 | 仍
353 | 仍旧
354 | 仍然
355 | 从
356 | 从不
357 | 从严
358 | 从中
359 | 从事
360 | 从今以后
361 | 从优
362 | 从古到今
363 | 从古至今
364 | 从头
365 | 从宽
366 | 从小
367 | 从新
368 | 从无到有
369 | 从早到晚
370 | 从未
371 | 从来
372 | 从此
373 | 从此以后
374 | 从而
375 | 从轻
376 | 从速
377 | 从重
378 | 他
379 | 他人
380 | 他们
381 | 他是
382 | 他的
383 | 代替
384 | 以
385 | 以上
386 | 以下
387 | 以为
388 | 以便
389 | 以免
390 | 以前
391 | 以及
392 | 以后
393 | 以外
394 | 以後
395 | 以故
396 | 以期
397 | 以来
398 | 以至
399 | 以至于
400 | 以致
401 | 们
402 | 任
403 | 任何
404 | 任凭
405 | 任务
406 | 企图
407 | 伙同
408 | 会
409 | 伟大
410 | 传
411 | 传说
412 | 传闻
413 | 似乎
414 | 似的
415 | 但
416 | 但凡
417 | 但愿
418 | 但是
419 | 何
420 | 何乐而不为
421 | 何以
422 | 何况
423 | 何处
424 | 何妨
425 | 何尝
426 | 何必
427 | 何时
428 | 何止
429 | 何苦
430 | 何须
431 | 余外
432 | 作为
433 | 你
434 | 你们
435 | 你是
436 | 你的
437 | 使
438 | 使得
439 | 使用
440 | 例如
441 | 依
442 | 依据
443 | 依照
444 | 依靠
445 | 便
446 | 便于
447 | 促进
448 | 保持
449 | 保管
450 | 保险
451 | 俺
452 | 俺们
453 | 倍加
454 | 倍感
455 | 倒不如
456 | 倒不如说
457 | 倒是
458 | 倘
459 | 倘使
460 | 倘或
461 | 倘然
462 | 倘若
463 | 借
464 | 借以
465 | 借此
466 | 假使
467 | 假如
468 | 假若
469 | 偏偏
470 | 做到
471 | 偶尔
472 | 偶而
473 | 傥然
474 | 像
475 | 儿
476 | 允许
477 | 元/吨
478 | 充其极
479 | 充其量
480 | 充分
481 | 先不先
482 | 先后
483 | 先後
484 | 先生
485 | 光
486 | 光是
487 | 全体
488 | 全力
489 | 全年
490 | 全然
491 | 全身心
492 | 全部
493 | 全都
494 | 全面
495 | 八
496 | 八成
497 | 公然
498 | 六
499 | 兮
500 | 共
501 | 共同
502 | 共总
503 | 关于
504 | 其
505 | 其一
506 | 其中
507 | 其二
508 | 其他
509 | 其余
510 | 其后
511 | 其它
512 | 其实
513 | 其次
514 | 具体
515 | 具体地说
516 | 具体来说
517 | 具体说来
518 | 具有
519 | 兼之
520 | 内
521 | 再
522 | 再其次
523 | 再则
524 | 再有
525 | 再次
526 | 再者
527 | 再者说
528 | 再说
529 | 冒
530 | 冲
531 | 决不
532 | 决定
533 | 决非
534 | 况且
535 | 准备
536 | 凑巧
537 | 凝神
538 | 几
539 | 几乎
540 | 几度
541 | 几时
542 | 几番
543 | 几经
544 | 凡
545 | 凡是
546 | 凭
547 | 凭借
548 | 出
549 | 出于
550 | 出去
551 | 出来
552 | 出现
553 | 分别
554 | 分头
555 | 分期
556 | 分期分批
557 | 切
558 | 切不可
559 | 切切
560 | 切勿
561 | 切莫
562 | 则
563 | 则甚
564 | 刚
565 | 刚好
566 | 刚巧
567 | 刚才
568 | 初
569 | 别
570 | 别人
571 | 别处
572 | 别是
573 | 别的
574 | 别管
575 | 别说
576 | 到
577 | 到了儿
578 | 到处
579 | 到头
580 | 到头来
581 | 到底
582 | 到目前为止
583 | 前后
584 | 前此
585 | 前者
586 | 前进
587 | 前面
588 | 加上
589 | 加之
590 | 加以
591 | 加入
592 | 加强
593 | 动不动
594 | 动辄
595 | 勃然
596 | 匆匆
597 | 十分
598 | 千
599 | 千万
600 | 千万千万
601 | 半
602 | 单
603 | 单单
604 | 单纯
605 | 即
606 | 即令
607 | 即使
608 | 即便
609 | 即刻
610 | 即如
611 | 即将
612 | 即或
613 | 即是说
614 | 即若
615 | 却
616 | 却不
617 | 历
618 | 原来
619 | 去
620 | 又
621 | 又及
622 | 及
623 | 及其
624 | 及时
625 | 及至
626 | 双方
627 | 反之
628 | 反之亦然
629 | 反之则
630 | 反倒
631 | 反倒是
632 | 反应
633 | 反手
634 | 反映
635 | 反而
636 | 反过来
637 | 反过来说
638 | 取得
639 | 取道
640 | 受到
641 | 变成
642 | 古来
643 | 另
644 | 另一个
645 | 另一方面
646 | 另外
647 | 另悉
648 | 另方面
649 | 另行
650 | 只
651 | 只当
652 | 只怕
653 | 只是
654 | 只有
655 | 只消
656 | 只要
657 | 只限
658 | 叫
659 | 叫做
660 | 召开
661 | 叮咚
662 | 叮当
663 | 可
664 | 可以
665 | 可好
666 | 可是
667 | 可能
668 | 可见
669 | 各
670 | 各个
671 | 各人
672 | 各位
673 | 各地
674 | 各式
675 | 各种
676 | 各级
677 | 各自
678 | 合理
679 | 同
680 | 同一
681 | 同时
682 | 同样
683 | 后
684 | 后来
685 | 后者
686 | 后面
687 | 向
688 | 向使
689 | 向着
690 | 吓
691 | 吗
692 | 否则
693 | 吧
694 | 吧哒
695 | 吱
696 | 呀
697 | 呃
698 | 呆呆地
699 | 呐
700 | 呕
701 | 呗
702 | 呜
703 | 呜呼
704 | 呢
705 | 周围
706 | 呵
707 | 呵呵
708 | 呸
709 | 呼哧
710 | 呼啦
711 | 咋
712 | 和
713 | 咚
714 | 咦
715 | 咧
716 | 咱
717 | 咱们
718 | 咳
719 | 哇
720 | 哈
721 | 哈哈
722 | 哉
723 | 哎
724 | 哎呀
725 | 哎哟
726 | 哗
727 | 哗啦
728 | 哟
729 | 哦
730 | 哩
731 | 哪
732 | 哪个
733 | 哪些
734 | 哪儿
735 | 哪天
736 | 哪年
737 | 哪怕
738 | 哪样
739 | 哪边
740 | 哪里
741 | 哼
742 | 哼唷
743 | 唉
744 | 唯有
745 | 啊
746 | 啊呀
747 | 啊哈
748 | 啊哟
749 | 啐
750 | 啥
751 | 啦
752 | 啪达
753 | 啷当
754 | 喀
755 | 喂
756 | 喏
757 | 喔唷
758 | 喽
759 | 嗡
760 | 嗡嗡
761 | 嗬
762 | 嗯
763 | 嗳
764 | 嘎
765 | 嘎嘎
766 | 嘎登
767 | 嘘
768 | 嘛
769 | 嘻
770 | 嘿
771 | 嘿嘿
772 | 四
773 | 因
774 | 因为
775 | 因了
776 | 因此
777 | 因着
778 | 因而
779 | 固
780 | 固然
781 | 在
782 | 在下
783 | 在于
784 | 地
785 | 均
786 | 坚决
787 | 坚持
788 | 基于
789 | 基本
790 | 基本上
791 | 处在
792 | 处处
793 | 处理
794 | 复杂
795 | 多
796 | 多么
797 | 多亏
798 | 多多
799 | 多多少少
800 | 多多益善
801 | 多少
802 | 多年前
803 | 多年来
804 | 多数
805 | 多次
806 | 够瞧的
807 | 大
808 | 大不了
809 | 大举
810 | 大事
811 | 大体
812 | 大体上
813 | 大凡
814 | 大力
815 | 大多
816 | 大多数
817 | 大大
818 | 大家
819 | 大张旗鼓
820 | 大批
821 | 大抵
822 | 大概
823 | 大略
824 | 大约
825 | 大致
826 | 大都
827 | 大量
828 | 大面儿上
829 | 失去
830 | 奇
831 | 奈
832 | 奋勇
833 | 她
834 | 她们
835 | 她是
836 | 她的
837 | 好
838 | 好在
839 | 好的
840 | 好象
841 | 如
842 | 如上
843 | 如上所述
844 | 如下
845 | 如今
846 | 如何
847 | 如其
848 | 如前所述
849 | 如同
850 | 如常
851 | 如是
852 | 如期
853 | 如果
854 | 如次
855 | 如此
856 | 如此等等
857 | 如若
858 | 始而
859 | 姑且
860 | 存在
861 | 存心
862 | 孰料
863 | 孰知
864 | 宁
865 | 宁可
866 | 宁愿
867 | 宁肯
868 | 它
869 | 它们
870 | 它们的
871 | 它是
872 | 它的
873 | 安全
874 | 完全
875 | 完成
876 | 定
877 | 实现
878 | 实际
879 | 宣布
880 | 容易
881 | 密切
882 | 对
883 | 对于
884 | 对应
885 | 对待
886 | 对方
887 | 对比
888 | 将
889 | 将才
890 | 将要
891 | 将近
892 | 小
893 | 少数
894 | 尔
895 | 尔后
896 | 尔尔
897 | 尔等
898 | 尚且
899 | 尤其
900 | 就
901 | 就地
902 | 就是
903 | 就是了
904 | 就是说
905 | 就此
906 | 就算
907 | 就要
908 | 尽
909 | 尽可能
910 | 尽如人意
911 | 尽心尽力
912 | 尽心竭力
913 | 尽快
914 | 尽早
915 | 尽然
916 | 尽管
917 | 尽管如此
918 | 尽量
919 | 局外
920 | 居然
921 | 届时
922 | 属于
923 | 屡
924 | 屡屡
925 | 屡次
926 | 屡次三番
927 | 岂
928 | 岂但
929 | 岂止
930 | 岂非
931 | 川流不息
932 | 左右
933 | 巨大
934 | 巩固
935 | 差一点
936 | 差不多
937 | 己
938 | 已
939 | 已矣
940 | 已经
941 | 巴
942 | 巴巴
943 | 带
944 | 帮助
945 | 常
946 | 常常
947 | 常言说
948 | 常言说得好
949 | 常言道
950 | 平素
951 | 年复一年
952 | 并
953 | 并不
954 | 并不是
955 | 并且
956 | 并排
957 | 并无
958 | 并没
959 | 并没有
960 | 并肩
961 | 并非
962 | 广大
963 | 广泛
964 | 应当
965 | 应用
966 | 应该
967 | 庶乎
968 | 庶几
969 | 开外
970 | 开始
971 | 开展
972 | 引起
973 | 弗
974 | 弹指之间
975 | 强烈
976 | 强调
977 | 归
978 | 归根到底
979 | 归根结底
980 | 归齐
981 | 当
982 | 当下
983 | 当中
984 | 当儿
985 | 当前
986 | 当即
987 | 当口儿
988 | 当地
989 | 当场
990 | 当头
991 | 当庭
992 | 当时
993 | 当然
994 | 当真
995 | 当着
996 | 形成
997 | 彻夜
998 | 彻底
999 | 彼
1000 | 彼时
1001 | 彼此
1002 | 往
1003 | 往往
1004 | 待
1005 | 待到
1006 | 很
1007 | 很多
1008 | 很少
1009 | 後来
1010 | 後面
1011 | 得
1012 | 得了
1013 | 得出
1014 | 得到
1015 | 得天独厚
1016 | 得起
1017 | 心里
1018 | 必
1019 | 必定
1020 | 必将
1021 | 必然
1022 | 必要
1023 | 必须
1024 | 快
1025 | 快要
1026 | 忽地
1027 | 忽然
1028 | 怎
1029 | 怎么
1030 | 怎么办
1031 | 怎么样
1032 | 怎奈
1033 | 怎样
1034 | 怎麽
1035 | 怕
1036 | 急匆匆
1037 | 怪
1038 | 怪不得
1039 | 总之
1040 | 总是
1041 | 总的来看
1042 | 总的来说
1043 | 总的说来
1044 | 总结
1045 | 总而言之
1046 | 恍然
1047 | 恐怕
1048 | 恰似
1049 | 恰好
1050 | 恰如
1051 | 恰巧
1052 | 恰恰
1053 | 恰恰相反
1054 | 恰逢
1055 | 您
1056 | 您们
1057 | 您是
1058 | 惟其
1059 | 惯常
1060 | 意思
1061 | 愤然
1062 | 愿意
1063 | 慢说
1064 | 成为
1065 | 成年
1066 | 成年累月
1067 | 成心
1068 | 我
1069 | 我们
1070 | 我是
1071 | 我的
1072 | 或
1073 | 或则
1074 | 或多或少
1075 | 或是
1076 | 或曰
1077 | 或者
1078 | 或许
1079 | 战斗
1080 | 截然
1081 | 截至
1082 | 所
1083 | 所以
1084 | 所在
1085 | 所幸
1086 | 所有
1087 | 所谓
1088 | 才
1089 | 才能
1090 | 扑通
1091 | 打
1092 | 打从
1093 | 打开天窗说亮话
1094 | 扩大
1095 | 把
1096 | 抑或
1097 | 抽冷子
1098 | 拦腰
1099 | 拿
1100 | 按
1101 | 按时
1102 | 按期
1103 | 按照
1104 | 按理
1105 | 按说
1106 | 挨个
1107 | 挨家挨户
1108 | 挨次
1109 | 挨着
1110 | 挨门挨户
1111 | 挨门逐户
1112 | 换句话说
1113 | 换言之
1114 | 据
1115 | 据实
1116 | 据悉
1117 | 据我所知
1118 | 据此
1119 | 据称
1120 | 据说
1121 | 掌握
1122 | 接下来
1123 | 接着
1124 | 接著
1125 | 接连不断
1126 | 放量
1127 | 故
1128 | 故意
1129 | 故此
1130 | 故而
1131 | 敞开儿
1132 | 敢
1133 | 敢于
1134 | 敢情
1135 | 数/
1136 | 整个
1137 | 断然
1138 | 方
1139 | 方便
1140 | 方才
1141 | 方能
1142 | 方面
1143 | 旁人
1144 | 无
1145 | 无宁
1146 | 无法
1147 | 无论
1148 | 既
1149 | 既...又
1150 | 既往
1151 | 既是
1152 | 既然
1153 | 日复一日
1154 | 日渐
1155 | 日益
1156 | 日臻
1157 | 日见
1158 | 时候
1159 | 昂然
1160 | 明显
1161 | 明确
1162 | 是
1163 | 是不是
1164 | 是以
1165 | 是否
1166 | 是的
1167 | 显然
1168 | 显著
1169 | 普通
1170 | 普遍
1171 | 暗中
1172 | 暗地里
1173 | 暗自
1174 | 更
1175 | 更为
1176 | 更加
1177 | 更进一步
1178 | 曾
1179 | 曾经
1180 | 替
1181 | 替代
1182 | 最
1183 | 最后
1184 | 最大
1185 | 最好
1186 | 最後
1187 | 最近
1188 | 最高
1189 | 有
1190 | 有些
1191 | 有关
1192 | 有利
1193 | 有力
1194 | 有及
1195 | 有所
1196 | 有效
1197 | 有时
1198 | 有点
1199 | 有的
1200 | 有的是
1201 | 有着
1202 | 有著
1203 | 望
1204 | 朝
1205 | 朝着
1206 | 末##末
1207 | 本
1208 | 本人
1209 | 本地
1210 | 本着
1211 | 本身
1212 | 权时
1213 | 来
1214 | 来不及
1215 | 来得及
1216 | 来看
1217 | 来着
1218 | 来自
1219 | 来讲
1220 | 来说
1221 | 极
1222 | 极为
1223 | 极了
1224 | 极其
1225 | 极力
1226 | 极大
1227 | 极度
1228 | 极端
1229 | 构成
1230 | 果然
1231 | 果真
1232 | 某
1233 | 某个
1234 | 某些
1235 | 某某
1236 | 根据
1237 | 根本
1238 | 格外
1239 | 梆
1240 | 概
1241 | 次第
1242 | 欢迎
1243 | 欤
1244 | 正值
1245 | 正在
1246 | 正如
1247 | 正巧
1248 | 正常
1249 | 正是
1250 | 此
1251 | 此中
1252 | 此后
1253 | 此地
1254 | 此处
1255 | 此外
1256 | 此时
1257 | 此次
1258 | 此间
1259 | 殆
1260 | 毋宁
1261 | 每
1262 | 每个
1263 | 每天
1264 | 每年
1265 | 每当
1266 | 每时每刻
1267 | 每每
1268 | 每逢
1269 | 比
1270 | 比及
1271 | 比如
1272 | 比如说
1273 | 比方
1274 | 比照
1275 | 比起
1276 | 比较
1277 | 毕竟
1278 | 毫不
1279 | 毫无
1280 | 毫无例外
1281 | 毫无保留地
1282 | 汝
1283 | 沙沙
1284 | 没
1285 | 没奈何
1286 | 没有
1287 | 沿
1288 | 沿着
1289 | 注意
1290 | 活
1291 | 深入
1292 | 清楚
1293 | 满
1294 | 满足
1295 | 漫说
1296 | 焉
1297 | 然
1298 | 然则
1299 | 然后
1300 | 然後
1301 | 然而
1302 | 照
1303 | 照着
1304 | 牢牢
1305 | 特别是
1306 | 特殊
1307 | 特点
1308 | 犹且
1309 | 犹自
1310 | 独
1311 | 独自
1312 | 猛然
1313 | 猛然间
1314 | 率尔
1315 | 率然
1316 | 现代
1317 | 现在
1318 | 理应
1319 | 理当
1320 | 理该
1321 | 瑟瑟
1322 | 甚且
1323 | 甚么
1324 | 甚或
1325 | 甚而
1326 | 甚至
1327 | 甚至于
1328 | 用
1329 | 用来
1330 | 甫
1331 | 甭
1332 | 由
1333 | 由于
1334 | 由是
1335 | 由此
1336 | 由此可见
1337 | 略
1338 | 略为
1339 | 略加
1340 | 略微
1341 | 白
1342 | 白白
1343 | 的
1344 | 的确
1345 | 的话
1346 | 皆可
1347 | 目前
1348 | 直到
1349 | 直接
1350 | 相似
1351 | 相信
1352 | 相反
1353 | 相同
1354 | 相对
1355 | 相对而言
1356 | 相应
1357 | 相当
1358 | 相等
1359 | 省得
1360 | 看
1361 | 看上去
1362 | 看出
1363 | 看到
1364 | 看来
1365 | 看样子
1366 | 看看
1367 | 看见
1368 | 看起来
1369 | 真是
1370 | 真正
1371 | 眨眼
1372 | 着
1373 | 着呢
1374 | 矣
1375 | 矣乎
1376 | 矣哉
1377 | 知道
1378 | 砰
1379 | 确定
1380 | 碰巧
1381 | 社会主义
1382 | 离
1383 | 种
1384 | 积极
1385 | 移动
1386 | 究竟
1387 | 穷年累月
1388 | 突出
1389 | 突然
1390 | 窃
1391 | 立
1392 | 立刻
1393 | 立即
1394 | 立地
1395 | 立时
1396 | 立马
1397 | 竟
1398 | 竟然
1399 | 竟而
1400 | 第
1401 | 第二
1402 | 等
1403 | 等到
1404 | 等等
1405 | 策略地
1406 | 简直
1407 | 简而言之
1408 | 简言之
1409 | 管
1410 | 类如
1411 | 粗
1412 | 精光
1413 | 紧接着
1414 | 累年
1415 | 累次
1416 | 纯
1417 | 纯粹
1418 | 纵
1419 | 纵令
1420 | 纵使
1421 | 纵然
1422 | 练习
1423 | 组成
1424 | 经
1425 | 经常
1426 | 经过
1427 | 结合
1428 | 结果
1429 | 给
1430 | 绝
1431 | 绝不
1432 | 绝对
1433 | 绝非
1434 | 绝顶
1435 | 继之
1436 | 继后
1437 | 继续
1438 | 继而
1439 | 维持
1440 | 综上所述
1441 | 缕缕
1442 | 罢了
1443 | 老
1444 | 老大
1445 | 老是
1446 | 老老实实
1447 | 考虑
1448 | 者
1449 | 而
1450 | 而且
1451 | 而况
1452 | 而又
1453 | 而后
1454 | 而外
1455 | 而已
1456 | 而是
1457 | 而言
1458 | 而论
1459 | 联系
1460 | 联袂
1461 | 背地里
1462 | 背靠背
1463 | 能
1464 | 能否
1465 | 能够
1466 | 腾
1467 | 自
1468 | 自个儿
1469 | 自从
1470 | 自各儿
1471 | 自后
1472 | 自家
1473 | 自己
1474 | 自打
1475 | 自身
1476 | 臭
1477 | 至
1478 | 至于
1479 | 至今
1480 | 至若
1481 | 致
1482 | 般的
1483 | 良好
1484 | 若
1485 | 若夫
1486 | 若是
1487 | 若果
1488 | 若非
1489 | 范围
1490 | 莫
1491 | 莫不
1492 | 莫不然
1493 | 莫如
1494 | 莫若
1495 | 莫非
1496 | 获得
1497 | 藉以
1498 | 虽
1499 | 虽则
1500 | 虽然
1501 | 虽说
1502 | 蛮
1503 | 行为
1504 | 行动
1505 | 表明
1506 | 表示
1507 | 被
1508 | 要
1509 | 要不
1510 | 要不是
1511 | 要不然
1512 | 要么
1513 | 要是
1514 | 要求
1515 | 见
1516 | 规定
1517 | 觉得
1518 | 譬喻
1519 | 譬如
1520 | 认为
1521 | 认真
1522 | 认识
1523 | 让
1524 | 许多
1525 | 论
1526 | 论说
1527 | 设使
1528 | 设或
1529 | 设若
1530 | 诚如
1531 | 诚然
1532 | 话说
1533 | 该
1534 | 该当
1535 | 说明
1536 | 说来
1537 | 说说
1538 | 请勿
1539 | 诸
1540 | 诸位
1541 | 诸如
1542 | 谁
1543 | 谁人
1544 | 谁料
1545 | 谁知
1546 | 谨
1547 | 豁然
1548 | 贼死
1549 | 赖以
1550 | 赶
1551 | 赶快
1552 | 赶早不赶晚
1553 | 起
1554 | 起先
1555 | 起初
1556 | 起头
1557 | 起来
1558 | 起见
1559 | 起首
1560 | 趁
1561 | 趁便
1562 | 趁势
1563 | 趁早
1564 | 趁机
1565 | 趁热
1566 | 趁着
1567 | 越是
1568 | 距
1569 | 跟
1570 | 路经
1571 | 转动
1572 | 转变
1573 | 转贴
1574 | 轰然
1575 | 较
1576 | 较为
1577 | 较之
1578 | 较比
1579 | 边
1580 | 达到
1581 | 达旦
1582 | 迄
1583 | 迅速
1584 | 过
1585 | 过于
1586 | 过去
1587 | 过来
1588 | 运用
1589 | 近
1590 | 近几年来
1591 | 近年来
1592 | 近来
1593 | 还
1594 | 还是
1595 | 还有
1596 | 还要
1597 | 这
1598 | 这一来
1599 | 这个
1600 | 这么
1601 | 这么些
1602 | 这么样
1603 | 这么点儿
1604 | 这些
1605 | 这会儿
1606 | 这儿
1607 | 这就是说
1608 | 这时
1609 | 这样
1610 | 这次
1611 | 这点
1612 | 这种
1613 | 这般
1614 | 这边
1615 | 这里
1616 | 这麽
1617 | 进入
1618 | 进去
1619 | 进来
1620 | 进步
1621 | 进而
1622 | 进行
1623 | 连
1624 | 连同
1625 | 连声
1626 | 连日
1627 | 连日来
1628 | 连袂
1629 | 连连
1630 | 迟早
1631 | 迫于
1632 | 适应
1633 | 适当
1634 | 适用
1635 | 逐步
1636 | 逐渐
1637 | 通常
1638 | 通过
1639 | 造成
1640 | 逢
1641 | 遇到
1642 | 遭到
1643 | 遵循
1644 | 遵照
1645 | 避免
1646 | 那
1647 | 那个
1648 | 那么
1649 | 那么些
1650 | 那么样
1651 | 那些
1652 | 那会儿
1653 | 那儿
1654 | 那时
1655 | 那末
1656 | 那样
1657 | 那般
1658 | 那边
1659 | 那里
1660 | 那麽
1661 | 部分
1662 | 都
1663 | 鄙人
1664 | 采取
1665 | 里面
1666 | 重大
1667 | 重新
1668 | 重要
1669 | 鉴于
1670 | 针对
1671 | 长期以来
1672 | 长此下去
1673 | 长线
1674 | 长话短说
1675 | 问题
1676 | 间或
1677 | 防止
1678 | 阿
1679 | 附近
1680 | 陈年
1681 | 限制
1682 | 陡然
1683 | 除
1684 | 除了
1685 | 除却
1686 | 除去
1687 | 除外
1688 | 除开
1689 | 除此
1690 | 除此之外
1691 | 除此以外
1692 | 除此而外
1693 | 除非
1694 | 随
1695 | 随后
1696 | 随时
1697 | 随着
1698 | 随著
1699 | 隔夜
1700 | 隔日
1701 | 难得
1702 | 难怪
1703 | 难说
1704 | 难道
1705 | 难道说
1706 | 集中
1707 | 零
1708 | 需要
1709 | 非但
1710 | 非常
1711 | 非徒
1712 | 非得
1713 | 非特
1714 | 非独
1715 | 靠
1716 | 顶多
1717 | 顷
1718 | 顷刻
1719 | 顷刻之间
1720 | 顷刻间
1721 | 顺
1722 | 顺着
1723 | 顿时
1724 | 颇
1725 | 风雨无阻
1726 | 饱
1727 | 首先
1728 | 马上
1729 | 高低
1730 | 高兴
1731 | 默然
1732 | 默默地
1733 | 齐
1734 | ︿
1735 | !
1736 | #
1737 | $
1738 | %
1739 | &
1740 | '
1741 | (
1742 | )
1743 | )÷(1-
1744 | )、
1745 | *
1746 | +
1747 | +ξ
1748 | ++
1749 | ,
1750 | ,也
1751 | -
1752 | -β
1753 | --
1754 | -[*]-
1755 | .
1756 | /
1757 | 0
1758 | 0:2
1759 | 1
1760 | 1.
1761 | 12%
1762 | 2
1763 | 2.3%
1764 | 3
1765 | 4
1766 | 5
1767 | 5:0
1768 | 6
1769 | 7
1770 | 8
1771 | 9
1772 | :
1773 | ;
1774 | <
1775 | <±
1776 | <Δ
1777 | <λ
1778 | <φ
1779 | <<
1780 | =
1781 | =″
1782 | =☆
1783 | =(
1784 | =-
1785 | =[
1786 | ={
1787 | >
1788 | >λ
1789 | ?
1790 | @
1791 | A
1792 | LI
1793 | R.L.
1794 | ZXFITL
1795 | [
1796 | [①①]
1797 | [①②]
1798 | [①③]
1799 | [①④]
1800 | [①⑤]
1801 | [①⑥]
1802 | [①⑦]
1803 | [①⑧]
1804 | [①⑨]
1805 | [①A]
1806 | [①B]
1807 | [①C]
1808 | [①D]
1809 | [①E]
1810 | [①]
1811 | [①a]
1812 | [①c]
1813 | [①d]
1814 | [①e]
1815 | [①f]
1816 | [①g]
1817 | [①h]
1818 | [①i]
1819 | [①o]
1820 | [②
1821 | [②①]
1822 | [②②]
1823 | [②③]
1824 | [②④
1825 | [②⑤]
1826 | [②⑥]
1827 | [②⑦]
1828 | [②⑧]
1829 | [②⑩]
1830 | [②B]
1831 | [②G]
1832 | [②]
1833 | [②a]
1834 | [②b]
1835 | [②c]
1836 | [②d]
1837 | [②e]
1838 | [②f]
1839 | [②g]
1840 | [②h]
1841 | [②i]
1842 | [②j]
1843 | [③①]
1844 | [③⑩]
1845 | [③F]
1846 | [③]
1847 | [③a]
1848 | [③b]
1849 | [③c]
1850 | [③d]
1851 | [③e]
1852 | [③g]
1853 | [③h]
1854 | [④]
1855 | [④a]
1856 | [④b]
1857 | [④c]
1858 | [④d]
1859 | [④e]
1860 | [⑤]
1861 | [⑤]]
1862 | [⑤a]
1863 | [⑤b]
1864 | [⑤d]
1865 | [⑤e]
1866 | [⑤f]
1867 | [⑥]
1868 | [⑦]
1869 | [⑧]
1870 | [⑨]
1871 | [⑩]
1872 | [*]
1873 | [-
1874 | []
1875 | ]
1876 | ]∧′=[
1877 | ][
1878 | _
1879 | a]
1880 | b]
1881 | c]
1882 | e]
1883 | f]
1884 | ng昉
1885 | {
1886 | {-
1887 | |
1888 | }
1889 | }>
1890 | ~
1891 | ~±
1892 | ~+
1893 | ¥
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/循环神经网络(RNN LSTM).ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "
"
123 | ]
124 | },
125 | "metadata": {},
126 | "output_type": "display_data"
127 | }
128 | ],
129 | "source": [
130 | "from sklearn.feature_extraction.text import CountVectorizer\n",
131 | "import seaborn as sns \n",
132 | "sns.set(font=\"simhei\") #设置中文字体,不然作图出现乱码\n",
133 | "\n",
134 | "corpus = ['利用代码实现这个方法','怎么去实现呢','我不知道'] #给定三个句子作为语料库\n",
135 | "for index,text in enumerate(corpus): # enumerate方法:同时返回索引和值\n",
136 | " corpus[index] = jieba.lcut(text) # 将语料库中句子进行分词\n",
137 | " corpus[index] = ' '.join(corpus[index]) # 将分词之间用空格连接起来\n",
138 | "\n",
139 | "print(corpus)\n",
140 | " \n",
141 | "one_hot_encoder = CountVectorizer(binary = True,token_pattern='[\\u4e00-\\u9fa5_a-zA-Z0-9]{1,}') \n",
142 | "#调用sklearn的CountVectorizer(),用正则设置token_pattern,避免无法识别中文单字 \n",
143 | "one_hot = one_hot_encoder.fit_transform(corpus).toarray() # one_hot向量\n",
144 | "label_name = one_hot_encoder.get_feature_names() # one_hot值对应的label(单词)\n",
145 | "sns.heatmap(one_hot,annot = True,cbar = False,xticklabels=label_name,yticklabels=['句子一','句子二','句子三'],cmap=\"YlGnBu\")"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "**也可使用kreas库的`keras.preprocessing.text`进行文本onehot处理**"
153 | ]
154 | },
155 | {
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "## 2.TF-IDF"
160 | ]
161 | },
162 | {
163 | "cell_type": "markdown",
164 | "metadata": {},
165 | "source": [
166 | "**TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量;用以衡量一个关键词w对于查询(Query,可看作文档)所能提供的信息**"
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "(1)计算词频TF = n/N,n表示某个词在文档中出现的次数,N表示文档中所有词出现的次数总和。 "
205 | ]
206 | },
207 | "metadata": {},
208 | "output_type": "display_data"
209 | }
210 | ],
211 | "source": [
212 | "from sklearn.feature_extraction.text import TfidfVectorizer\n",
213 | "\n",
214 | "corpus = ['利用代码实现这个方法','怎么去实现呢','我不知道'] #语料库\n",
215 | "\n",
216 | "for index,text in enumerate(corpus):\n",
217 | " corpus[index] = jieba.lcut(text)\n",
218 | " corpus[index] = ' '.join(corpus[index])\n",
219 | " \n",
220 | "Tfidf_encoder = TfidfVectorizer(token_pattern='[\\u4e00-\\u9fa5_a-zA-Z0-9]{1,}') #调用sklearn的TfidfVectorizer() \n",
221 | "Tfidf = Tfidf_encoder.fit_transform(corpus).toarray() #得到tfidf值\n",
222 | "label_name = Tfidf_encoder.get_feature_names() #值对应的label(单词)\n",
223 | "sns.heatmap(Tfidf,annot = True,cbar = False,xticklabels=label_name,yticklabels=['句子一','句子二','句子三'],cmap=\"YlGnBu\")"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "metadata": {},
229 | "source": [
230 | "**调用jieba库,根据TFIDF抽取文档关键词**"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": 79,
236 | "metadata": {},
237 | "outputs": [
238 | {
239 | "name": "stdout",
240 | "output_type": "stream",
241 | "text": [
242 | "上月,欧洲央行完成了近11年来的首次加息,并超预期加息50个基点,抑制通胀同时追赶美联储加息脚步。相较于美联储,欧洲央行的加息周期显然开始较晚,但该行的谨慎并非无的放矢,债务风险是欧洲央行加息路上的一大障碍。当前,欧元区政府债务和财政赤字压力并不弱于2010年欧债危机爆发前夕。疫情下为配合财政刺激,欧盟阶段性摆脱了财政束缚,使得成员国政府债务率和财政赤字率显著上升,继而中期债务风险上升,其中希腊、意大利等债务压力相对更大。而欧洲央行的货币紧缩可能使成员国政府债务风险进一步扩大。在低通胀、低利率时期,欧洲央行可以通过大量增持“高债国”债券兜底。但眼下,“类滞胀”格局迫使欧洲央行进入紧缩周期,目前该行已宣布停止资产购买计划、结束扩表。在此背景下,欧债危机会重现吗?考虑到这一问题,欧洲央行颁布了新的应对措施:一方面,将灵活运用大流行紧急购买计划(PEPP)中的再投资额度;另一方面,推出传导保护工具(TPI),目的是“保障其货币政策立场在整个欧元区的顺利传输”。欧洲央行行长拉加德表示,TPI将允许央行在二级市场上购买国债,购买规模取决于传导风险,重点购买1至10年期的公共部门证券,也会考虑购买私营部门债券。不过,平安证券首席经济学家钟正生认为,欧洲央行新工具的实际运作和效果仍待观察。首先,由于受制于控通胀目标,欧洲央行很难大规模购买资产、大幅扩表。虽然欧洲央行没有给出TPI的规模上限,但预计实际操作规模有限。其次,如何判定干预市场的时机和程度,料将会有争议。过早干预市场或受德国方面的阻力,而过晚干预市场或难起到预期效果。此外,还需要防止成员国对欧洲央行救助措施的过度依赖,这或也意味着欧洲央行行动的果断性将受到制约。最后,若欧元区经济受到更大冲击,成员国财政可持续性受到挑战,新工具的判定或有争议,“预期引导”仍有失效的可能。\n"
243 | ]
244 | }
245 | ],
246 | "source": [
247 | "with open('Tfidf_example.txt', 'r',encoding='utf-8') as text_file: # 读取txt文件\n",
248 | " example = text_file.read()\n",
249 | "print(example)"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 80,
255 | "metadata": {},
256 | "outputs": [
257 | {
258 | "name": "stdout",
259 | "output_type": "stream",
260 | "text": [
261 | "[('欧洲央行', 0.4188328159991984), ('购买', 0.15350847079816793), ('债务', 0.1468613104703817), ('TPI', 0.13688665079656487), ('加息', 0.11997822456431298)]\n"
262 | ]
263 | }
264 | ],
265 | "source": [
266 | "import jieba.analyse\n",
267 | "print(jieba.analyse.extract_tags(example, topK=5, withWeight=True))\n",
268 | "# topK 为返回几个 TF/IDF 权重最大的关键词,withWeight 为是否一并返回关键词权重值"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "* 当一个词在文档频率越高并且新鲜度高(即普遍度低),其TF-IDF值越高。\n",
276 | "* TF-IDF兼顾词频与新鲜度,过滤一些常见词(例如“的,得,了”),保留能提供更多信息的关键词。"
277 | ]
278 | },
279 | {
280 | "cell_type": "markdown",
281 | "metadata": {},
282 | "source": [
283 | "## 3.基于语料库的词典方法"
284 | ]
285 | },
286 | {
287 | "cell_type": "markdown",
288 | "metadata": {},
289 | "source": [
290 | "**基于语料库将文本编码成一个个数字id,使计算机可以进行处理,这样就得到了一个 词(字)与数字 一一对应的计算机“词典”**"
291 | ]
292 | },
293 | {
294 | "cell_type": "code",
295 | "execution_count": 1,
296 | "metadata": {},
297 | "outputs": [],
298 | "source": [
299 | "#在one-hot方法第二步我们已经生成了输入文本的词典,将其打包成一个函数如下:\n",
300 | "def preprocess(text):\n",
301 | " words = jieba.lcut(text) #分词\n",
302 | " \n",
303 | " word_to_id = {}\n",
304 | " for index,word in enumerate(words):\n",
305 | " word_to_id[word] = index #词到id的字典\n",
306 | " \n",
307 | " id_to_word = {index: word for index,word in enumerate(words)} #id到词的字典,此代码为上面词到id的字典的简写形式\n",
308 | " \n",
309 | " text_id = np.array([word_to_id[word] for word in words])\n",
310 | " return word_to_id,id_to_word,text_id"
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": 86,
316 | "metadata": {
317 | "scrolled": true
318 | },
319 | "outputs": [
320 | {
321 | "name": "stdout",
322 | "output_type": "stream",
323 | "text": [
324 | "词到id的字典: {'首先': 0, ',': 7, '由于': 2, '受制于': 3, '控': 4, '通胀': 5, '目标': 6, '欧洲央行': 8, '很难': 9, '大规模': 10, '购买': 11, '资产': 12, '、': 13, '大幅': 14, '扩表': 15}\n",
325 | "\n",
326 | "d到词的字典: {0: '首先', 1: ',', 2: '由于', 3: '受制于', 4: '控', 5: '通胀', 6: '目标', 7: ',', 8: '欧洲央行', 9: '很难', 10: '大规模', 11: '购买', 12: '资产', 13: '、', 14: '大幅', 15: '扩表'}\n",
327 | "\n",
328 | "将输入文本转化为id形式: [ 0 7 2 3 4 5 6 7 8 9 10 11 12 13 14 15]\n"
329 | ]
330 | }
331 | ],
332 | "source": [
333 | "text = \"首先,由于受制于控通胀目标,欧洲央行很难大规模购买资产、大幅扩表\"\n",
334 | "word_to_id,id_to_word,text_id = preprocess(text)\n",
335 | "print(f\"词到id的字典: {word_to_id}\",end='\\n\\n')\n",
336 | "print(f\"id到词的字典: {id_to_word}\",end='\\n\\n')\n",
337 | "print(f\"将输入文本转化为id形式: {text_id}\")"
338 | ]
339 | }
340 | ],
341 | "metadata": {
342 | "kernelspec": {
343 | "display_name": "Python 3",
344 | "language": "python",
345 | "name": "python3"
346 | },
347 | "language_info": {
348 | "codemirror_mode": {
349 | "name": "ipython",
350 | "version": 3
351 | },
352 | "file_extension": ".py",
353 | "mimetype": "text/x-python",
354 | "name": "python",
355 | "nbconvert_exporter": "python",
356 | "pygments_lexer": "ipython3",
357 | "version": "3.8.8"
358 | }
359 | },
360 | "nbformat": 4,
361 | "nbformat_minor": 4
362 | }
363 |
--------------------------------------------------------------------------------
/Chapter 3 经典文本向量化方法/Tfidf_example.txt:
--------------------------------------------------------------------------------
1 | 上月,欧洲央行完成了近11年来的首次加息,并超预期加息50个基点,抑制通胀同时追赶美联储加息脚步。相较于美联储,欧洲央行的加息周期显然开始较晚,但该行的谨慎并非无的放矢,债务风险是欧洲央行加息路上的一大障碍。当前,欧元区政府债务和财政赤字压力并不弱于2010年欧债危机爆发前夕。疫情下为配合财政刺激,欧盟阶段性摆脱了财政束缚,使得成员国政府债务率和财政赤字率显著上升,继而中期债务风险上升,其中希腊、意大利等债务压力相对更大。而欧洲央行的货币紧缩可能使成员国政府债务风险进一步扩大。在低通胀、低利率时期,欧洲央行可以通过大量增持“高债国”债券兜底。但眼下,“类滞胀”格局迫使欧洲央行进入紧缩周期,目前该行已宣布停止资产购买计划、结束扩表。在此背景下,欧债危机会重现吗?考虑到这一问题,欧洲央行颁布了新的应对措施:一方面,将灵活运用大流行紧急购买计划(PEPP)中的再投资额度;另一方面,推出传导保护工具(TPI),目的是“保障其货币政策立场在整个欧元区的顺利传输”。欧洲央行行长拉加德表示,TPI将允许央行在二级市场上购买国债,购买规模取决于传导风险,重点购买1至10年期的公共部门证券,也会考虑购买私营部门债券。不过,平安证券首席经济学家钟正生认为,欧洲央行新工具的实际运作和效果仍待观察。首先,由于受制于控通胀目标,欧洲央行很难大规模购买资产、大幅扩表。虽然欧洲央行没有给出TPI的规模上限,但预计实际操作规模有限。其次,如何判定干预市场的时机和程度,料将会有争议。过早干预市场或受德国方面的阻力,而过晚干预市场或难起到预期效果。此外,还需要防止成员国对欧洲央行救助措施的过度依赖,这或也意味着欧洲央行行动的果断性将受到制约。最后,若欧元区经济受到更大冲击,成员国财政可持续性受到挑战,新工具的判定或有争议,“预期引导”仍有失效的可能。
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/EE.txt:
--------------------------------------------------------------------------------
1 | 高频监控敢死队涨停股 免费下载 证券时报网03月03日讯 全国政协会议今日正式开幕,细读政协工作报告,其中透露出的八个经济方面的亮点值得投资者注意。 一、“一带一路”建设。“一带一路”战略作为连接中国与世界的新的桥梁,不仅将为中国发展开拓更大的空间,也让中国红利更好地造福世界。这是国际舆论不断形成的一项重要共识。 媒体近日透露,“一带一路”规划已经获批并在小范围内下发,即将正式出台,这意味着以“一带一路”为统领,以京津冀一体化和长江经济带等为着力点的区域协同发展已是箭在弦上。有分析预测,“一带一路”、京津冀协同发展、长江经济带等顶层方案有望在两会后陆续亮相。 A股市场上,“一带一路”概念已提前预热。2月27日 ,“一带一路”概念股无疑是当日市场最大的热点。中国电建 、中铁二局 、中国交建等近10股当日集体上演涨停秀。龙头股中铁二局接连拉出多个涨停板,股价创出历史新高。 二、推进非公有制企业走出去。近年来,中国“走出去”的资本已经超越所吸引的资本。随着中国开放政策的深入和企业在全球的扩张,资本“走出去”的速度会呈现增长的趋势。资本的“走出去”是中国外部崛起的经济基础。 在“走出去”战略中,目前高铁、核电等高端制造业领域有相对的优势。数据显示,2014年中国整个装备制造业出口2.1万亿元,占国家整个出口收入的17%,其中包括电力、通讯、石化、矿业、航空等行业,大型的成套设备出口快速增长。中国60万千瓦的燃煤发电机组已经成为出口的主力机型,华为公司68%的销售收入来自于海外市场,另外工程机械、汽车等领域在境外的投资也取得了积极的进展。 三、知识产权保护。今年1月初,国务院办公厅转发知识产权局等二十八个部委局的《深入实施国家知识产权战略行动计划》,要求各部门认真贯彻执行。该行动计划首次明确提出了“努力建设知识产权强国”的新目标,强调要“认真谋划我国知识产权强国的发展路径,努力建设知识产权强国。” 分析人士指出,在中国经济面临产业结构调整和转型升级的关键时期,该行动计划的实施对促进我国知识产权保护、推动知识产权的持续增长产生深远的影响,在此过程中,一批拥有自主知识产权和创新能力的成长型公司,必然会在这一轮产业升级的浪潮中脱颖而出,考虑到行动计划的具体内容,建议投资者从推进软件正版化工作、服务现代农业发展二条主线寻找投资机会,建议重点关注用友软件、中国软件、久其软件等优质个股。 四、医药卫生体制改革。医疗保健行业在2015年的关键词是消费升级和医疗改革。中金公司分析师邹朋认为 ,2015年卫生工作的第一项任务就是全面推进深化医药卫生体制改革向纵深发展,包括全力推进公立医院改革、健全完善全民医保体系以及大力推进分级诊疗工作等。政策转向使得行业进入新增长区间,因此,看好医疗服务、社会办医以及流通领域改革三方面。 对于今年医药行业的投资机会,西南证券指出,新技术催化的投资机会贯穿2015年,主要体现在,生物药新技术如干细胞治疗将受到追捧。而安信证券认为,在政策的大力推动下,智慧医疗正在超级大风口上。例如万达信息,作为医疗O2O闭环模式的标杆,其在医改的各项创举有望在全国推广。建议关注东华软件、卫宁软件、宜华地产、朗玛信息、荣科科技、海虹控股等。 从消费升级方面看,基础医疗保健生产商仍旧具有较好的投资价值。兴业证券梅郜越建议配置恒瑞医药、华东医药、云南白药、天士力等,同时关注上海医药、东阿阿胶、复星医药等低估值蓝筹的估值修复机会。安信基金研究部总经理姜诚还认为,民营医院服务相关股票也值得在关注,例如国际医学。 五、加快体育产业发展。在羊年的首次中央全面深化改革领导小组会议上,《中国足球改革总体方案》获审议通过,发展振兴足球成为建设体育强国的“头羊”。通过此轮改革探索的新体制,无疑将为足球产业乃至整个体育产业的快速发展奠定基础。 分析认为,自从体育产业被明确为国家支柱产业以来,相关的扶持政策也在紧锣密鼓的制定当中,而市场对于体育概念股的关注度也明显提升。随着政策扶持力度的加大,体育产业的发展将迎来高速发展的阶段。篮球和足球作为其中市场化程度较高的产业,未来有望获得更多的政策支持,而从事相关产业的企业有也望分享政策带来的红利。国际重大赛事的申办不仅可以提升我国的体育品牌价值,同时也有望进一步激发人们参与体育运劢的热情,推劢体育产业的快速发展。 相关个股:探路者、中体产业、江苏舜天、亚泰集团、双象股份、中信国安、信隆实业等。 六、转基因农产品。转基因农产品一直是网民热议的话题。中央日前发布的“一号文件”明确提出,加强农业转基因生物技术研究、安全管理、科学普及。其中加强转基因科学普及首次写入。 俞正声在部署2015年工作时指出,要加快体育产业发展、转基因农产品的机遇与风险、加强京津冀协同发展中的大气污染防治、推进长江经济带发展中的湿地保护、加强黑土地保护、资源枯竭城市转型等重要课题开展调研议政。 七、大气污染防治。面对日益严重的环境污染问题,以及严峻的节能减排压力,国家不断加大对大气污染防治工作的监察力度。对高污染、高耗能产业的环保标准也不断提高,随着环保新标准的推行,势必引发传统行业加快对落后产能的淘汰进程,并推劢企业加大对生产线和生产设备的环保技术改造,这为从事相关环保业务的企业开启了巨大的市场空间。而《防治法》的制定更是为我国的大气污染防治工作提供可靠的法律依据,推劢污染防治工作的顺利进行。在政策不断加码的推劢下,脱硫脱销、尾气治理、环保锅炉和大气污染监测等行业有望持续景气,相关概念股值得关注。 相关个股:科林环保、先河环保、聚光科技、天瑞仪器、雪迪龙,国电清新、九龙电力、燃控科技、龙源技术、银轮股份、海越股份、威孚高科等。 八、湿地保护。长江中游地区是我国湿地资源集中分布区之一。几个世纪以来,受长江冲淤变化导致河势自然改变的自然裁弯,以及人为改造河道实施的人工裁弯的综合影响,长江中游下荆江河道周边最终形成了长江故道群湿地。故道群湿地类型独特、物种丰富、生态地位突出、生态功能显著,对于维持长江中游及江汉平原地区的水安全、生态安全及粮食安全意义重大。 湿地概念股:大湖股份、华侨城A、中青旅等。 新浪声明:此消息系转载自新浪合作媒体,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。 进入【新浪财经股吧】讨论
2 | 高频监控敢死队涨停股 免费下载 高超 国务院总理李克强5日的政府工作报告亮点频出,对宏观经济、资本市场做出了高屋建瓴的部署。此外,对A股市场而言,环保、养老、普惠金融、O2O、PPP等领域的最新工作安排,也蕴含着巨大的投资机会。 稳健的货币政策要松紧适度积极的财政政策要加力增效 对于2015年的经济发展,报告指出,要着眼于保持中高速增长和迈向中高端水平“双目标”,坚持稳政策稳预期和促改革调结构“双结合”,打造大众创业、万众创新和增加公共产品、公共服务“双引擎”。 具体经济指标方面,国内生产总值增长7%左右,居民消费价格涨幅3%左右。城镇新增就业1000万人以上,城镇登记失业率4.5%以内。进出口增长6%左右。能耗强度下降3.1%以上。积极的财政政策要加力增效。今年拟安排财政赤字1.62万亿元,比去年增加2700亿元,赤字率从去年的2.1%提高到2.3%。 稳健的货币政策要松紧适度。广义货币M2预期增长12%左右,在实际执行中,根据经济发展需要也可以略高些。 分析人士认为,3%左右的消费价格涨幅目标,意味着未来货币政策仍有较大的腾挪空间,2015年的A股市场面对的宏观政策基调仍相对宽松。 开展个人投资者境外投资试点适时启动“深港通”试点 对于2015年的金融改革,报告指出要加强多层次资本市场体系建设,实施股票发行注册制改革,推进信贷资产证券化,扩大企业债券发行规模,发展金融衍生品市场。 大力发展普惠金融,围绕服务实体经济推进金融改革。推动具备条件的民间资本依法发起设立中小型银行等金融机构,成熟一家,批准一家,不设限额。 推出存款保险制度。推进利率市场化改革,健全中央银行利率调控框架。保持人民币汇率处于合理均衡水平,增强人民币汇率双向浮动弹性。 稳步实现人民币资本项目可兑换,扩大人民币国际使用,加快建设人民币跨境支付系统,完善人民币全球清算服务体系,开展个人投资者境外投资试点,适时启动“深港通”试点。 分析人士认为,普惠金融的大力发展,将加速诸如阿里、腾讯等新型互联网企业主导的民营金融机构发展壮大。其中腾讯控股在香港上市,是沪港通标的。而公开信息显示,阿里系的蚂蚁金融,正在筹划A股IPO。 环保、医疗、养老领域投资机会大 政府工作报告指出,今年二氧化碳排放强度要降低3.1%以上,化学需氧量、氨氮排放都要减少2%左右,二氧化硫、氮氧化物排放要分别减少3%左右和5%左右。促进重点区域煤炭消费零增长。在重点区域内重点城市全面供应国五标准车用汽柴油。2005年底前注册营运的黄标车要全部淘汰。推进京津冀协同发展,在交通一体化、生态环保、产业升级转移等方面率先取得实质性突破。 实施水污染防治行动计划,加强江河湖海水污染、水污染源和农业面源污染治理,实行从水源地到水龙头全过程监管。以垃圾、污水为重点加强环境治理,建设美丽宜居乡村。推行环境污染第三方治理。分析人士认为,2015年的环保治理力度将超出预期,大气治理、水处理、垃圾处理领域最值得关注。 报告提到,要促进养老家政健康消费,壮大信息消费,提升旅游休闲消费,推动绿色消费,稳定住房消费,扩大教育文化体育消费。鼓励社会力量兴办养老设施,发展社区和居家养老。 要把以互联网为载体、线上线下互动的新兴消费搞得红红火火。制定“互联网+”行动计划,推动移动互联网、云计算、大数据、物联网等与现代制造业结合,促进电子商务、工业互联网和互联网金融健康发展,引导互联网企业拓展国际市场。分析认为,上述表述明显有利于O20题材向纵深发展。 除此以外,要把“一带一路”建设与区域开发开放结合起来,加强新亚欧大陆桥、陆海口岸支点建设。组织好西藏自治区成立50周年和新疆维吾尔自治区成立60周年庆祝活动。做好2022年冬奥会申办工作;办好纪念世界反法西斯战争和中国人民抗日战争胜利70周年相关活动。实施“中国制造2025”,坚持创新驱动、智能转型、强化基础、绿色发展,加快从制造大国转向制造强国。全面加强现代后勤建设,加大国防科研和高新技术武器装备建设力度,发展国防科技工业。 在基础设施、公用事业等领域,积极推广政府和社会资本合作模式。铁路投资要保持在8000亿元以上,新投产里程8000公里以上,在全国基本实现高速公路电子不停车收费联网,使交通真正成为发展的先行官。在建重大水利工程投资规模超过8000亿元。 《投资快报》记者注意到,A股市场上这样的模式被定义为PPP模式,该领域已经诞生过诸如华夏幸福、碧水源这样的大牛股。展望未来,PPP模式可能进一步通过定向增发等多种融资模式,向环保、基建领域的上市公司全面扩散。 新浪声明:此消息系转载自新浪合作媒体,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。 进入【新浪财经股吧】讨论
3 | 消息股汇总:6月12日盘前提示十只股整体涨幅达4.93% 新浪财经讯 6月12日晚间,沪深两市多家上市公司发布了公告。以下是公告利好消息一览: 国投电力和川投能源获批建设雅砻江水电站 国投电力和川投能源6月12日晚间公告,6月10日,四川省发改委对建设雅砻江杨房沟水电站进行了核准批复,由二者负责建设和管理,其中,国投电力投资占比52%,川投能源投资占比48%。 杨房沟水电站位于四川省凉山州木里县境内,为雅砻江中游水电站。电站总装机容量150万千瓦,单独运行时年均发电量59.623亿千瓦时,与上游两河口水库电站联合运行时年均发电量68.557 亿千瓦时。工程建设总工期95个月。 按2014年四季度价格水平测算,工程静态投资148.94亿元,动态总投资200.02亿元。项目资本金40亿元,占动态总投资的20%。 三维工程5000万设子公司 布局石油及制品销售 三维工程6月12日晚间公告,公司拟在大连市设立中油三维能源有限公司,注册资本5000万元,公司拟以自有资金出资,出资比例占注册资本的100%。新公司将主营石油及制品销售和贸易经纪等。 通过设立中油三维,三维工程进一步将产业链延伸至石油及制品销售和贸易经纪等领域,一方面有利于进一步扩大公司业务范围,完善公司产业链;另一方面有利于进一步促进公司与参股公司上海志商电子商务有限公司的协同发展,助力其打造全国性化工、石化原材料B2B电子商务平台。 三维工程同时公告,近日控股子公司青岛联信催化材料有限公司与神华宁夏煤业集团有限责任公司在银川市签订的《神华宁煤集团400万吨/年煤炭间接液化项目一氧化碳耐硫变换装置耐硫变换催化剂订货合同》,合同总价为7724.4万元,占三维工程最近一个会计年度经审计营业收入的10.03%。 华丽家族收购标的子公司中标工信部石墨烯相关项目 华丽家族6月12日晚间公告,公司关联企业重庆墨掀技有限公司近日收到工信部2015年工业转型升级强基工程国家级公开招标项目的中标通知书,中标内容为第二代单层石墨烯薄膜实施方案,中标金额1000万元。 据悉,华丽家族正筹划2015年度非公开发行股票,部分募集资金拟用于收购北京墨烯控股集团股份有限公司100%股份并对其增资,重庆墨希为墨烯控股下属控股公司,为公司关联企业。 华丽家族表示,该项中标内容为工信部对强基工程关键基础材料的专项补助,与重庆墨希是否实现批量化销售并无必然联系。 和邦股份与青羊区政府合作农业电商项目 继与平安银行成都分行以及农业银行四川省分行展开农业电商项目合作以后,和邦股份牵手成都市青羊区政府。公司6月12日晚间发布公告,公司今日与成都市青羊区政府签署了《互联网+现代农业电子商务投资合作协议》,双方将在农业电商项目方面展开合作。 此外,青羊区政府还将协助和邦股份在青羊区于2015年6月17日前,设立和邦电子商务有限公司,注册资本2亿元。 会稽山募资逾18亿 收购两家酒企做强黄酒行业 会稽山6月12日晚间发布非公开发行股票预案,公司控股股东精功集团、第一期员工持股计划及多家机构参与认购。公司股票6月15日起复牌。 根据预案,会稽山拟以13.86元/股,非公开发行1.3亿股,募资不超过18.02亿元,扣除发行费用后将用于年产10万千升黄酒后熟包装物流自动化技术改造项目、收购乌毡帽酒业有限公司100%股权项目、收购绍兴县唐宋酒业有限公司100%股权项目,以及补充流动资金及偿还银行贷款。 会稽山此次非公开发行股票对象包括公司控股股东静功集团、会稽山第一期员工持股计划、上海大丰、上海达顺、宁波信达风盛、北京世欣钲兴、北京合聚天建、中汇同创、钜洲资产管理及金鹰基金共计10名投资者。其中,静功集团拟认购3200万股,认购金额为4.44亿元,员工持股计划将认购300万股,认购金额为4158万元。 该员工持股计划的资金总额为4158万元,全部用于认购会稽山此次非公开发行的相应股份。参加该员工持股计划的总人数为145人,其中董事、监事、高级管理人员合计7人,合计出资1510.74万元,占员工持股计划总规模的36.33%;其他员工出资2647.26万元,占员工持股计划总规模的 63.67%。 Wind数据显示,2006年至2014年,我国的黄酒行业销售收入由55.18亿元增长至158.56 亿元,累计增长约187.35%,年均复合增长率约为14.1%。会稽山表示,未来黄酒行业集中度提高将成为行业发展的主要趋势之一。通过行业整合,龙头企业有可能实现跨越式发展,并带动黄酒行业实现做大做强。 会稽山此次拟募投的黄酒项目包括建设机械黄酒车间、传统手工黄酒车间、半成品车间、制曲车间等,对黄酒的后熟、储存、灌装和物流等设施进行投资建设,以完全释放10万千升优质绍兴黄酒的产能。 此外,会稽山拟收购两家酒企拓展销售渠道,增加原酒储量。收购完成后,公司黄酒产能和销量将继续提升,在江浙沪及全国其他省市的销售渠道得到进一步拓展,从而实现公司主营业务在短期内做大做强。 天地科技拟收购控股股东部分资产 15日复牌 6月12日,停牌一周的天地科技公告,公司已与控股股东中国煤炭科工集团初步达成收购意向,拟以现金方式收购中国煤炭科工集团全资子公司煤炭科学技术研究院有限公司以及全资子公司中煤科工集团上海有限公司的股权。公司股票6月15日复牌。 具体将收购控股股东旗下2家全资子公司的股权。其中,拟收购的煤炭科学技术研究院有限公司成立于2013年3月,注册资本5000万元。主要从事煤炭转化与清洁利用、矿山安全环保与节能工程、矿用产品检测检验、煤矿自动化与信息化等技术研发和推广应用。 拟收购的中煤科工集团上海有限公司成立于2008年5月,注册资本2亿元。主要从事胶带输送机、煤矿电液控制、矿用产品检验检测、大型游乐设备以及大型市政挖掘装备等研制及相关服务。 资料显示,天地科技2014年已换股收购了控股股东中国煤炭科工集团所持重庆研究院、西安研究院以及北京华宇的全部股权,公司业务增加了煤矿安全技术与装备板块,增加了设计与工程总包板块以及节能环保和新能源板块。 银河证券研报称,天地科技将成为南北车外又一央企改革典范,优质资产注入的过程中,后续资本运作将进一步提升其业绩和估值。 神州高铁拟收购两公司 发力轨道交通业务 神州高铁6月12日晚间公告,公司拟以现金13.7亿元,购买嘉兴九鼎持有的交大微联90%股权;拟16.73元/股向王纯政等27名交易对方发行2962万股,并支付现金3.4亿元,收购其持有的武汉利德100%股权,作价8.35亿元。同时,公司拟不低于19.35元/股,非公开发行不超过1.1亿股,募集配套资金不超过22亿元,其中,17亿元用于支付此次交易的现金对价,5亿元用于支付此次交易相关的中介费用和补充上市公司流动资金。公司股票将继续停牌。 据介绍,交大微联作为轨道交通信号系统的重要供应商,一直专注于该领域产品的研发、生产和销售,拥有较强的自主研发能力和独立自主的知识产权,其主要产品计算机联锁系统、列控中心系统、分散自律调度集中系统、信号集中监测系统,广泛应用于轨道交通信号系统领域。交易对方承诺交大微联2015年度至2017年度净利润分别为1.2亿元、1.5亿元、1.8亿元。 武汉利德是国内轨道线路装备及维护的重要供应商,以铁路线路测控系统、高铁钢轨加工成套装备、铁路养护智能装备的研制、销售与服务为主营业务。主要产品包括铁路安全检测监控设备、钢轨焊接加工及铁路养护装备、物流装备定位及信息管理系统、轨道交通装备工业化连锁服务等。交易对方承诺武汉利德2015年度至2017年度净利润分别为6500万元、8450万元、10985万元。 神州高铁表示,此次交易完成后,武汉利德成为公司全资子公司,交大微联成为公司控股子公司,公司的营业收入和盈利能力将得到较大幅度的提升;交大微联、武汉利德与上市公司现有轨道交通业务将相互补充和协调,形成跨平台协同的核心竞争能力;配套资金的到位将改善公司的资本结构、提高公司的流动性和抗风险能力,助于增强上市公司的盈利能力。 隆平高科合资设立耕地修复公司 隆平高科12日晚间公告,公司与控股股东湖南新大新股份有限公司)、中国科学院亚热带农业生态研究所及自然人杜志艳,共同出资设立湖南隆平高科耕地修复技术有限公司。 其中,隆平高科将以货币形式出资1298万元,股权比例达64.9%;控股股东新大新股份将出资200万元,股权比例达10%。由于出资方中国科学院亚热带农业生态研究所参股的无形资产,该耕地修复公司成立后,在重金属污染土壤治理领域优先享有前者科研技术和专利成果的受让权。 隆平高科称,根据公司农业服务发展战略,农田重金属污染治理将成为公司农业服务体系的重要一环。 联建光电联合两大股东分别发起投资基金 联建光电6月12日晚间公告,为更好地实施公司成为“数字户外传媒集团”的发展战略,公司拟与控股股东刘虎军和重要股东何吉伦分别发起设立投资基金,作为公司产业布局的平台。 其中,公司与控股股东刘虎军拟设立的基金的总规模不超过5亿元。其中联建光电作为有限合伙人投资持有20%的基金份额,刘虎军或刘虎军指定的其他方作为有限合伙人认购77%的基金份额,普通合伙人认购3%的基金份额。 公司与主要股东何吉伦拟设立基金的总规模不超过5亿元。其中联建光电作为有限合伙人投资持有20%的基金份额,何吉伦或何吉伦指定的其他方作为有限合伙人认购77%的基金份额,普通合伙人认购3%的基金份额。 何吉伦未在公司任职,截至公告日,何吉伦直接持有公司15.23%股份,为公司主要股东之一。 大东方定增募资11亿 押注汽车和食品电子商务 大东方6月12日晚间发布非公开发行股票预案,公司拟以13.48 元/股,向不超过10名特定对象,发行不超过8162.09万股,募资总额不超过11亿元,扣除发行费用后将用于汽车后市场综合服务O2O平台建设项目、三凤桥食品O2O综合服务平台建设项目及补充流动资金项目。公司股票6月15日复牌。 具体来说,在线下建设方面,大东方将建设社区快修快保店、综合维修服务中心以及零配件仓储物流中心,增强公司后市场服务及市场覆盖能力;线上建设方面,通过购置相关软硬件,引进开发及运营人员,建立线上系统平台,通过与线下相结合,抢占汽车后市场,扩大汽车领域业务范围。公司力图打造互联网成为公司未来发展的驱动器。 此外,为了将“三凤桥”品牌及产品由本地品牌升级至以长三角及珠三角地区为主要市场的全国品牌,大东方拟新建生产车间、购置生产设备,提升产品品质和供应能力,增加产品种类,同时加大渠道建设,在无锡地区新建食品专营店和物流配送中心。大东方还将建立线上系统平台,实现线上线下渠道融合,促进线下销售增长。 大东方表示,公司子公司东方汽车近年来营业收入的增长和业务规模的扩大,带来了巨大的流动资金需求。2012年末、2013年末、2014年末和2015年3月末,东方汽车的流动比率分别为0.58、0.56、0.69和0.67,速动比率分别为 0.35、0.31、0.34和0.36,资产负债率分别为87.21%、87.09%、77.3%和75.65%,偿债能力较弱。 大东方已于去年通过增资方式向东方汽车提供资金支持,但公司表示,未来随着汽车后市场综合服务O2O平台的建设,汽车维修服务、零部件销售、汽车保险和金融等其他服务的业务规模将进一步扩大,进而产生更大的流动资金需求,因而公司急需补充流动资金。 网宿科技定增36亿扩展主业 引入员工持股计划 网宿科技6月12日晚间发布定增预案,公司拟以43.95元/股,非公开发行不超过8191.13万股,募资总额不超过36亿元,全部用于投资社区云项目、海外CDN项目和云安全项目。公司股票将6月15日复牌。 公司此次非公开发行对象为五名,分别为兴证资管、九泰基金、博时基金、平安资管、泰康资管,认购金额分别为5亿元、 8亿元、13亿元、5亿元 、5亿元。 其中,兴证资管拟设立的兴证资管鑫众-网宿科技1号定向资产管理计划委托人为公司第1期员工持股计划。该员工持股计划参与人数共计245人,包括公司控股股东、董事长、总裁刘成彦、其他董事、监事、高级管理人员以及其他员工。九泰基金拟设立的九泰基金-泰增战略6号资产管理计划的委托人为公司控股股东、实际控制人陈宝珍。发行完成后,刘成彦及陈宝珍将共同直接和间接持有公司33.35%的股份,仍为公司控股股东、实际控制人。 募投项目中,社区云项目总投资22.07亿元,拟投入募资22亿元。项目主要由内容及应用运营平台、社区云节点、智慧家庭终端以及配套的业务运营支撑平台组成。项目建设期3年,建设完成后年新增营业收入为27.64亿元,年新增利润总额41968万元。 海外CDN项目总投资10.68亿元,拟投入募资10.5亿元。项目计划完成海内外CDN节点及全球CDN管控平台的建设,设立本地化营销团队和营销子公司,并通过成立海外研发中心进一步增强公司CDN业务实力。项目建设期3年,建设完成后年新增营业收入为12.28亿元,年新增利润总额28995万元。 另外,云安全项目拟投入募集资金3.5亿元,拟建设并运营基于网宿科技成熟网络安全防护技术的云安全平台,建设期为3年,建设完成后年新增营业收入为3亿元,年新增利润总额11221万元。 网宿科技表示,此次非公开发行募集资金投资项目建成后,可有效提高公司主营业务能力及海外市场占有率,进一步提升公司的核心竞争力,并将为公司“社区云”、“国际化”和“云技术产品化”三大战略的实施和快速推进提供有力保障,实现公司的持续健康发展。 金鹰股份募资16亿 转型新能源汽车行业 自今年1月中旬便停牌的金鹰股份12日晚间发布非公开发行股票预案,公司控股股东和员工持股计划将倾情认购。公司股票6月15复牌。 根据预案,公司拟向控股股东浙江金鹰集团有限公司、深圳市橡树林资本管理有限公司、喀什得心股权投资有限公司,金鹰股份第1期员工持股计划共计4名特定对象,以6.33元/股,非公开发行股票约2.53亿股,募集资金约16亿元。扣除发行费用后将用于新能源汽车动力电池项目、新能源汽车动力总成项目以及补充流动资金。 其中,控股股东金鹰集团将认购逾1.08亿股,认购金额6.85亿元;金鹰股份第1期员工持股计划认购2370万股,认购金额1.5亿元。 公司员工持股计划设立时计划份额合计不超过1.5亿份,资金总额不超过1.5亿元,全部用于认购公司此次非公开发行股票的相应份额。 参与公司员工持股计划的为公司董事、监事和高级管理人员合计不超过16人,包括公司董事长、董事会秘书、财务总监等,总计认购不超过2500万元;其他部分员工不超过1500名,认购不超过1.25亿元。 金鹰股份目前主要从事麻、绢、丝、毛成套纺机装备和塑料、食品机械装备研发、制造以及亚麻、绢丝纺织、染整、服装生产、销售,自2011年以来,纺机、塑机、纺织行业增速放缓,公司面临结构调整的局面。金鹰股份此次力图通过非公开发行募集资金进入新能源汽车产业领域,实现公司产业的战略调整。 金鹰股份此次拟投建的新能源汽车动力电池项目建设规模为年产3亿安时锂电池、2万套电池系统,全部用于满足金鹰新能源汽车动力总成生产的需要。该项目的实施主体为金鹰新能源汽车动力电池有限公司,将由公司与日本技术合作方通过出资的方式设立。 公司已于5月26日与日本株式会社共创、日本小沢能量研究所、日本小沢英耐时会社三家企业签订了合作框架协议。据悉,三家企业长期致力于电池技术、产品的研究、开发,拥有电动汽车动力电池的核心技术,其实际控制人是小沢和典博士,是日本ENAX公司的创始人,也是世界上第一款商用锂离子电池的发明人。 另一募投项目——新能源汽车动力总成项目目建成后将实现年产2万套电动汽车动力总成的能力,由阿尔特汽车技术股份有限公司提供动力总成产品工艺、技术等方面的服务,公司已于年5月26日与其签订了合作框架协议。 东方金钰拟募资逾80亿 延伸珠宝金融产业链 东方金钰6月12日晚间发布非公开发行股票预案,公司拟以25.86 元/股,向不超过10名特定投资者,非公开发行股票不超过3.1亿股,募资总额不超过80.08亿元。公司股票将于6月15日复牌。 东方金珏实际控制人为赵兴龙家族,其分别通过兴龙实业和瑞丽金泽间接持有公司32.99%和 21.72%的股份,合计持有公司54.71%股份。此次非公开发行完成后,赵兴龙家族的持股比例将降至32.4%。不过,仍为公司实际控制人。 公司拟将募投资金投向“互联网+”珠宝产业综合服务平台项目、设立深圳市东方金钰小额贷款有限公司、对深圳市鼎泰典当行有限公司增资、设立云南东方金钰资本管理有限公司以及偿还金融机构贷款。 东方金珏表示,公司在黄金珠宝行业已经取得了领先优势,现有业务经营稳定,在互联网的新常态下,公司希望延伸业务板块、转型升级。同时,珠宝企业已从单一珠宝产品贸易到珠宝金融合作,进而形成以珠宝金融为基石的珠宝生态圈模式。 公司表示,将依托原有珠宝行业采购、加工、销售的专业和能力,利用自身鉴定、估值和处置等优势,向产业金融服务领域延伸,以资金流服务于实体经济,构建珠宝行业的交易和融资平台,并推动行业整合与发展。 募投项目实施后,东方金珏将在既有传统珠宝业务基础上,向珠宝行业金融服务领域延伸,打造面向中小珠宝商户及珠宝消费者、投资者的珠宝金融平台,提供鉴定、评估、典当、小额贷款、P2P 网贷等配套金融服务。 中能电气设两子公司 投资新能源项目 中能电气6月12日晚间公告,公司拟设立境外全资子公司和上海全资子公司,加码新能源项目投资。公司股票6月15日上午开市起复牌。 据公告,中能电气将在开曼投资设立全资子公司,投资总额约5000万美元,拟开展境外电网能源工程、太阳能新能源电站建设及运营等电力能源投资项目,寻求新的利润增长点。同时,开曼子公司为公司海外投资的总平台,公司将通过开曼子公司在境外各地进行项目投资。 同时,为提升公司新能源产业的核心竞争力,公司拟投资设立全资子公司“上海中能新能源有限责任公司”,注册资本8000万元,并拟以该全资子公司为主体投资建设光伏并网发电项目,项目三年计划总投资28亿元。 宝鼎重工3.6亿并购上海复榆 布局新材料 宝鼎重工6月12日晚间公告,拟以现金方式收购上海复榆新材料科技有限公司100%股权,交易总金额约3.6亿元。 上海复榆成立于2011年,致力于新型材料的研发以及新材料在新能源、环保技术和化工领域内的应用开发、技术服务以及产品生产及销售。目前已经拥有全系列亚微米单晶型ZSM-5分子筛,疏水硅沸石吸附剂等产品的创新工艺与技术,且在行业内具有独创性。 从财务数据看,上海复榆2014年实现营业收入1667.02万元,实现净利润60.82万元。交易对方承诺,公司2015年净利润不低于2000万元,2016年不低于3000万元,2017年不低于4500万元。 宝鼎重工表示,上海复榆主要从事新型材料的研发与应用,公司围绕“稳定发展传统业务、积极拓展新兴产业”的战略规划,通过收购上海复榆,进一步拓展新材料、新能源、化工及环保技术领域的研发、生产与销售,提升盈利空间,加快公司在新材料研究及应用领域的布局速度。 信威集团与海南省政府合作 建设海南信息产业 信威集团6月12日晚间公告,为加快发展海南信息产业,优化海南经济结构,公司今日与海南省政府签订了战略合作协议,双方将在在信息产业和信息化建设等领域开展紧密合作。 协议内容包括,在海南省按照国际一流科技园区标准规划建设信威产业基地,规划建设信威全球移动互联网应用软件研发中心、信威全国智慧城市运营及研发中心、信威海南省4G无线通信网络平台运营中心等。产业基地将以公司自身产业为主,同时带动公司上下游企业入驻,打造完整的信息化产业链,全面支撑产业基地发展以及海南省信息化建设。此外,公司规划未来三年内,在海南全省范围投资建设基于信威4G宽带无线多媒体集群系统的基础信息化设施。 海南省政府还将信威集团建设项目列为省重点项目,依法解决项目建设用地指标,并支持信威产业基地或所在园区申请成为国家级产业基地。 信威集团表示,与海南省政府的合作有利于推进公司在海南省的政企行业共网建设,相关项目建设需要公司进行相应资金投入,建成后带来的投资收益或利润,对公司业绩产生积极影响。 中航重机与贵州省国资委合作 推进钛产业重组 6月12日,中航重机与贵州省国资委签订了战略合作框架协议,双方将共同培育和壮大钛产业集群。贵州省国资委表示,支持中航重机对该所属独资企业在条件允许情况下进行战略重组。 根据协议,贵州省国资委将全力配合贵州省政府支持中航重机在黔企业的发展与改革,建立信息沟通机构;贵州省国资委提供监管企业改革改制信息,优先考虑与中航重机合作。 贵州省国资委持最大的开放态度,创造条件先行对贵州省国资委所属的钛行业龙头企业的债务进行重组,剥离其社会化职能,然后贵州省国资委支持中航重机对该所属独资企业在条件允许情况下进行战略重组,实现其技术改造及产业的转型升级,形成贵州钛产业集群。 双方一致同意双方建立工作沟通机制,加强沟通协调,制定相应工作计划,全力协调推进贵州省钛产业战略重组及战略合作。 中航重机在8日刚刚发布定增预案,出手37亿元加码主业锻铸产业。其在2014年年报中表示,国内锻铸行业集中度较低,专业化程度不高,行业竞争激烈,锻造企业之间兼并重组将是大趋势。 鱼跃医疗7亿并购上械集团 布局医用耗材 鱼跃医疗6月12日晚间公告,为了加快公司医用耗材领域的推进和布局,公司拟以自有资金7亿元,收购控股股东鱼跃科技持有的上械集团100%股权。交易完成后,鱼跃科技不再持有上械集团股权。 上械集团成立于1991年,经营范围包括各类医疗器械经营,从事货物及技术进出口业务,在医疗器械领域内的技术服务。该公司2014年和2015年第一季度分别实现营业收入6.37亿元和1.45亿元,实现净利润-3470.25万元和606.87万元。 上械集团核心产品主要有手术器械、卫生材料及敷料、药用膏贴等,产品品类众多,核心产品均具有较高的行业地位和市场占有率,尤其是手术器械,为国内行业龙头企业,而医用卫生材料、辅料和膏贴等产品与本公司在渠道上有较大的协同性。 鱼跃医疗表示,上械集团注入完全符合公司“家用医疗器械和医用高值耗材”的战略发展方向,有利于促进公司在医用高值耗材领域的迅速扩张。 兴森科技2300万美元收购半导体测试板资产 兴森科技6月12日晚间公告,公司全资子公司兴森快捷香港有限公司与美国纳斯达克上市公司Xcerra Corporation达成意向协议,协议的主要内容是收购Xcerra集团的半导体测试板相关资产及业务,交易价格不超过2300万美元。公司股票将于15日复牌。 兴森香港此次收购的业务主要包括在硅晶圆测试及芯片封装测试中使用的测试板的方案设计、生产、贴装、销售及服务。 资料显示,Xcerra集团业务在半导体和电子制造测试领域为客户提供创新且具有最佳成本效益的测试分类、测试接口及各类测试机的半导体测试全方位解决方案。Xcerra集团的半导体测试板及其相关业务2014年底资产总额约1445万美元,2014年实现销售收入3922万美元。 兴森科技表示,此次收购的标的在全球半导体测试板整体解决方案领域具有优势地位,其主要客户均为一流半导体公司。收购完成后将使得公司拥有该细分行业全球领先的方案设计、生产、贴装、服务一站式能力;同时这也是公司在半导体材料、半导体测试行业进一步的布局。随着国内半导体行业的蓬勃发展,预计该项业务在国内的市场空间将迅速扩大。 万向德农1.92亿增资控股子公司 加码种业 万向德农6月12日晚间公告,公司拟对控股子公司北京德农种业有限公司增资1.92亿元,其中以所持万向财务有限公司6.5%的股权的评估价1.52亿元增资,以现金增资3929.29万元。 增资完成后,北京德农的注册资本增至1.86亿元,万向德农的持股比例由92.78%上升至96.12%。万向德农表示,此次增资系为了支持北京德农的发展,做大、做强种业,北京德农是公司的重要利润来源,增资后,有利于北京德农种业提高信用度,增加流动资金,有利于企业长远发展。 截至2014年12月31日,北京德农实现营业收入4.35亿元,净利润-1144.49万元。2015年第一季度,北京德农实现营业收入1.09亿元,净利润734.58万元。 徐工机械转让巴西投资90%股权 10亿加码资本运作 徐工机械6月12日晚间公告,公司全资子公司徐工香港贸易,将以37967.11万元作为对价,向公司实际控制人徐工集团的全资子公司徐工香港发展,转让徐工集团巴西投资有限公司90%股权。 徐工巴西投资系由徐工香港贸易、徐工香港发展出资组建的有限责任公司,于2011年9月注册成立。目前,徐工香港贸易持有其95%的股权;徐工香港发展持股5%。截至2015年5月31日,徐工巴西投资资产总计105720.08万元,负债总计73921.37万元,净资产31798.7万元。2015年1-5月,实现营业收入426.05万元,净利润亏损1464.17万元。 近几年,巴西国内的政治、经济形势发生了很大变化,货币贬值、通过膨胀和高失业率影响了巴西各项经济政策的调整和落实。徐工机械主营业务的市场规模也与原投资预测时有一定的差距。 因此,此次交易是为了优化公司资产结构,提高资产使用效率。同时,此次交易也有利于公司更好的聚焦产品在巴西及南美市场的开拓。 徐工机械同时公告,公司全资子公司徐工投资,拟以现金方式向重庆昊融睿工投资中心追加出资10亿元。昊融睿工另一有限合伙人中融信托同时追加出资10亿元。追加出资完成后,昊融睿工全体合伙人出资额将由15亿元增至35亿元。此举意在实施公司“产业+资本”双轮驱动战略,夯实资本运作平台建设,进一步提升公司盈利能力。 另外,徐工机械拟向徐工投资增资3亿元,占注册资本增加额的100%。 长青集团ppp项目再下一城 成雄县热电项目投资人 长青集团本月连续拿下河北省的两个热电联产项目的投资资格。6月12日晚间,长青集团公告,公司被选为河北省保定市雄县经济开发区热电联产项目的投资人;就在本月9日,该公司刚刚拿下了河北省保定市雄县经济开发区热电联产项目投资资格。两个项目的投资额度分别为4到10亿元、5到10亿元。 长青集团2014年年报显示,公司主营业务为制造燃气具产品及环保产业,在2014年其主营业务收入为137461.55万元,同比增长23.88%。其中,环保业务营业收入同比增长42.87%,高于制造业营业收入17.35%的增长。 据悉,河北省的两个热电联产项目都采取BOO模式。在广义的PPP模式中,BOO模式即社会资本承担融资、建立、拥有并永久的经营基础设施部件,与常见的BOT模式不同的是,前者项目的所有权不再交还给政府。 长青集团表示,两个项目将加大公司在环保产业方面的比重,如果项目顺利进行,将对公司未来经营业绩产生积极影响。资料显示,除了前述两个项目,今年2月份至今,长青集团还先后签订了4个集中供热项目,投资总额达253,000万元。 安洁科技1100万收购广得利电子 安洁科技6月12日晚间公告,公司以自有资金向全资子公司重庆安洁电子有限公司增资1500万元,增资后,重庆安洁的注册资本将由5500万元增至7000万元。同时,重庆安洁拟使用自有资金1100万元收购重庆广得利电子科技有限公司100%的股权。 广得利电子营业范围包括电子科技技术开发,生产销售电子产品、塑胶制品、金属制品等。公司2014年和2015年前4个月分别实现营业收入3488.42万元和1075.46万元,实现净利润214.2万元和41万元。 安洁科技表示,广得利电子一直致力于自主创新和技术研发,长年累积绝缘类制品、胶粘类制品、金属制品等相关部件的模切生产技术及经验。重庆安洁为了顺应模切行业的发展,需要在既有的技术基础下,持续投资以扩大技术团队和业务团队、巩固核心技术,并藉此扩展市场。 横店东磁推员工持股计划 15日复牌 横店东磁6月12日晚间披露员工持股计划,参加员工持股计划的员工总人数共计49人,包含公司部分董事、高级管理人员及核心骨干。该计划涉及的标的股票数量不超过2300万股,占公司现有股本总额的5.6%。该计划设立时以“份”作为认购单位,每份份额的对价为22.46元。公司股票将于15日复牌。 该员工持股计划将在股东大会审议通过后6个月内实施,由博驰投资以协议方式受让控股股东横店控股持有的不超过2300万股横店东磁股票。博驰投资协议受让标的股票之价格为转让协议签订日前一天公司股票二级市场交易均价的50%,即22.46元/股。 据悉,博驰投资是为横店东磁员工持股计划设立的一家有限合伙企业,是此次员工持股计划的运作平台,内部管理权力机构为持有人会议,横店控股为执行事务合伙人且代为持有本次员工持股计划预留股份所对应的权益份额。 普洛药业1.7亿增资子公司安徽康裕 6月12日,普洛药业6月12日晚间公告,公司全资子公司浙江普洛康裕制药有限公司拟现金出资1.7亿元,对其全资子公司安徽普洛康裕制药有限公司进行增资。增资完成后,安徽康裕的注册资本将由1亿元增至2.7亿元。 截至2014年12月31日,安徽康裕资产总额为42552.77万元,负债总额为34551.46万元,净资产8002.31万元,净利润为-1387.48万元。此次增资主要用于补充安徽康裕的资本金,满足企业自身发展的需求,降低资产负债率。 上海莱士1.98亿二级市场购买富春环保股份 上海莱士6月12日晚间公告,公司6月11日,使用自有资金1.98亿元,通过深交所大宗交易系统,购入富春环保1000万股,均价19.8元/股,所耗资金占公司2014年经审计的总资产的2.11%。公司与富春环保无关联关系。 上海莱士表示,目前我国环保行业总体规模逐步扩大,产业领域不断拓展,已经逐步成为我国国民经济不可或缺的新兴产业,未来节能环保领域的市场潜力巨大,看好富春环保围绕固废产业,打造以污泥处理为住的核心业务,认为其商业模式具备巨大优势。 今年早些时候,上海莱士董事会和股东大会审议通过了《公司关于进行风险投资事项的议案》,使用自有资金不超过10亿元进行风险投资。截至目前,公司累计参与的风险投资金额为约6.94亿元。 春兴精工拟7.65亿控股安投融 布局互联网金融 春兴精工6月12日晚间公告,公司与安投融金融信息服务有限公司的股东赵春霞、王博、谷云及刘博签署了《股权收购框架协议》,约定公司拟收购取得安投融51%的股权。标的股权对应初步估值为7.65亿元。 安投融成立于2014年,经营范围包括金融信息服务;经济贸易咨询;投资管理;资产管理等。安投融的“爱投资”网站是国内首创P2C互联网金融交易模式的平台,致力于提供链金融服务,为自然人和中小企业之间搭建投融资的桥梁,解决个人投资收益低和中小企业融资难的问题。 安投融2014年和2015年第一季度分别实现营业收入7508.46万元和1498.22万元,实现净利润1026.85万元和-901.16万元。交易对方承诺,目标公司2015年至2017年三年的交易额持续增长,分别不低于60亿、150亿、300亿元;收入持续增长,分别不低于1.5亿、3亿、6亿元。 春兴精工表示,公司出于战略规划及长远利益实施了此次收购。收购后,有利于快速实现公司在供应链金融和互联网金融领域的战略布局,也有利于公司将传统业务与互联网业务相结合。 科士达与华住酒店合作共建充电桩网络 科士达6月12日晚间公告,公司与华住酒店管理有限公司签署《战略合作协议》,双方将共同构建智能化充电桩网络。 华住酒店集团是国内第一家多品牌的连锁酒店管理集团,全球酒店20强。在中国超过200个城市里已经拥有2100多家酒店和3万多名员工。2010年3月26日,“华住酒店集团”的前身“汉庭酒店集团”在纳斯达克成功上市。 双方约定,华住酒店将提供集团旗下各品牌酒店的停车场或停车位,由科士达负责设计电动汽车整体解决方案;华住酒店提供的集团旗下各品牌酒店的停车场或停车位将帮助科士达在构建全国性充电桩网络的战略上提供落脚点,加快布局新能源汽车充电桩网络业务。 天宸股份子公司清仓盛运环保 获利2300万 天宸股份6月12日晚间公告,公司下属子公司上海宸乾投资有限公司6月10日至6月12日期间,通过上交所股票交易系统出售盛运环保股票逾205.49万股。减持后,宸乾公司不再持有盛运环保股票。 经初步测算,此次宸乾公司出售盛运环保股票获得投资收益约2300万元,约占2014年度经审计的上市公司净利润的29%。该笔投资收益将计入公司2015年半年度收益。 进入【新浪财经股吧】讨论
4 | 5月12日,第22场银行业新闻例行发布会在北京举行。平安银行副行长赵继臣以“商业银行供给侧改革”为主题,介绍了该行供给侧改革思路、取得的成果以及该行围绕国家“去产能、去库存、去杠杆、降成本、补短板”五大重点任务,支持国家供给侧改革的具体举措。平安银行医疗健康文化旅游金融事业部总裁成建新、风险管理部副总经理石明华等出席发布会。 在国家推动以结构调整为核心的供给侧改革的大背景下,商业银行过往基于需求侧的粗放经营方式已难以为继,以绿色经济、循环经济、共享经济为代表的新兴经济业态对金融业提出了更高的要求。在平安银行看来,作为国家经济的重要组成部分,银行要支持经济结构调整,就必须充分发挥金融资源投向的引导作用,银行业的供给侧改革势在必行,它既是银行业对当前国家政策的呼应,也是实现银行变革转型的客观需求。 近年来,平安银行坚持以客户为中心的智慧经营模式,以“跳出银行办银行”等带有鲜明供给侧改革特征的经营理念,业绩取得了快速增长。以2015年为例,平安银行是唯一实现行净利润双位数增长的全国性上市银行,其贷款增速、存款增速均居同业前列。另一方面,平安银行收入结构持续改善,中收占比提升至2016年一季度的33.18%。同时,银行成本收入比持续下降,资产负债结构大幅改善,净利差、净息差持续逆市提升,银行经营日趋健康。 加快自身产能出清 银行有所为、有所不为 为支持国家调控过剩产能,优化信贷资源配置,平安银行一直大力压缩“两高一剩”过剩产能授信,严控重点过剩产能行业,截至2016年一季度末,平安银行“两高一剩”贷款压缩至137.76亿,较2013年年初下降58%;重点过剩产能行业贷款占全行贷款比例压缩至8.56%。 在严控两高(高污染、高耗能)及产能过剩行业的信贷投放的同时,平安银行腾挪出大量的信贷资源投向国家政策支持的重点行业、新兴产业,甄选了节能环保制造业、服务业、清洁能源行业、新能源汽车行业、绿色建筑行业等作为重点支持对象,并逐步建立绿色审批通道专项支持。截至2016年一季度末,该行支持绿色信贷额度550.38亿元,低碳金融授信余额达3006.61亿元。 此外,为顺应国家“互联网+”战略的要求,平安银行致力于推动“互联网金融生态圈+产业金融生态圈”的同步发展,以“互联网”+“物联网”支持小微企业、个人用户和产业链客户,以“橙E网”、“贷贷平安” 、“新一贷” 三大重点平台为互联网、产业链、实体商圈等多类双创和小微企业提供金融服务支持。 创新产业基金模式 支持重大项目和国企混改 据了解,从2014年开始,平安银行全面开展产业基金战略布局,短短两年时间里,平安银行产业基金累计签约项目逾700个,签约规模超过2万亿元,落地出账规模8208亿元,70%以上投向民生基建、国企改制和产业升级。 仅在2015年平安银行就实现产业基金投放规模超过5000亿元,其中大量投向政府国企金融、公用事业建设、棚户区改造、三旧改造、产业园区建设等方面,并落地了昆明交通产业基金、沈阳中德汽车产业园基金、重庆国资负债管理基金、郑州航空港产业基金等一系列典范案例项目,在支持实体经济发展、支持基础设施建设及支持产业升级等方面,发挥了积极作用,形成了良好的社会效应。 2016年以来,平安银行在过往经验的基础上,设计整合了“供给侧改革类产业基金”系列产品,将更大力度地加强对国家供给侧改革的响应与支持。 支持地产去库存、调整 供给结构 对于国家重点关注的房地产去库存,平安银行提前布局,通过“专业化、集约化”管理,在支持国家化解房地产库存,促进房地产业务持续发展的同时,实现了自身业绩的迅速提升。 2013年,平安银行地产金融事业部正式成立,作为该行“事业部改革”后成立的首批行业事业部,该事业部深入研究行业发展特点,通过“专业化、集约化”的服务,促进房地产业务健康发展。事业部注重区域性、结构性的供给,聚焦一二线城市投资,释放有效供给;压缩库存大、去化慢城市的地产投资,通过差异化的信贷策略,促进房地产业务的调整与良性发展。截至2016年一季度,平安银行地产金融事业部管理资产规模2162亿,成立分部24家。在业务类型上,以改善型和刚需住宅项目为主,积极参与城中村改造和保障房建设,助力新型城镇化进程。 在零售住房业务领域,平安银行积极优化按揭业务的流程,提高按揭业务的审批效率。2016年,平安银行在“易贷e通平台”实现了房贷业务的线上化,客户只需登录APP即可线上申请贷款,无需手工填写和提供资料复印件,以拍照上传取代了原件审核、复印件扫描流程,提升了申请的便捷性,实现了随时随地申请、现场审批、当天放款的目标。 深化事业部改革 满足客户全方位金融需求 在支持民生和消费升级方面,平安银行通过行业事业部和产品事业部,以专业金融服务“医、食、住、行、玩”等与百姓民生息息相关的产业,不断推进资源跨界整合,积极助力实体经济转型发展。 通过事业部改革,平安银行大大提升了对于重点行业、主流客户的研究了解深度,得以根据行业属性、客户特点,针对细分行业的客户需求,设计包括咨询、融资、平台搭建、技术支持、资源整合、交易撮合等方式在内的综合金融解决方案,大大提升了金融供给的有效性,为“商业银行供给侧改革”提供了强大的行业金融专业支持。截至2015年末,平安银行行业事业部和产品事业部管理资产规模超过15000亿元。 以该行医健文旅事业部的“平安文旅荟”模式为例,2015年,平安银行与华谊兄弟、大连海昌、砂之船艺术、奥特莱斯、艺术北京、碧桂园共同发起了“平安文旅荟”,针对各类主力消费人群,通过整合“大消费、大休闲”产业细分市场的龙头企业,集聚国内高端旅游、休闲、消费产业资源,搭建起业态互补、客流共享、风险共担的区域文化旅游商业生态。 据平安银行介绍,“平安文旅荟”的创新之处,对消费者来说,是解决了平常下班以及周末无处可去的问题,在城市中心以及城市新区都有了可以“旅游、休闲、体验、消费”的目的地。对企业来说,在平安文旅荟的平台上,可与合作伙伴优势互补,共享客户,加速商业生态培育。同时,大家一起拓展有很好的协同效应,既受欢迎,也有更强的议价能力。对地方政府来说,通过引入平安文旅荟,一下子就能引入多个行业顶级企业,“人流、物流、消费流、信息流”会迅速活跃起来。对银行来说,它突破了传统银行服务客户的限制,变革“银政企”合作模式,主动创造细分市场并锁定融资份额,发挥事业部“专业化、集约化、跨区域”优势,打造了该行营销行业龙头企业的差异化竞争优势。 平安银行表示,推动商业银行的供给侧改革,是在当前中国经济发展阶段和金融形势下,银行经营者所作出的全新探索和尝试。未来,平安银行将全面考量该行的资源禀赋和内外环境,制定符合自身需求的改革策略,在实施中科学决策、系统引导、把握节奏,既要从上到下实现思想和观念的根本性转变,也要激发市场端的供给活力和服务水平,更要通过中后台的管理变革和机制优化,形成集成化、系统化的整体作业模式,为银行供给侧改革的真正落地铺平道路。(CIS) 进入【新浪财经股吧】讨论
5 | 国家能源局:推动我国能源转型向纵深发展 □本报记者 刘杨 在8月19日举行的2017年能源大转型高层论坛上,国家能源局局长努尔·白克力指出,在经济发展进入“新常态”背景下,推动我国能源革命向纵深发展,要做好包括节能优先、绿色低碳、科技创新、深化改革和开放的合作在内的“五个坚持”。 同时,本次论坛上发布了由国家能源局石油天然气司、国务院发展研究中心资源与环境政策研究所以及国土资源部油气资源战略研究中心共同编制的《中国天然气发展报告2017》(简称《报告》)。多位与会者指出,加快推动天然气发展,是我国能源结构优化调整的战略举措和现实选择。 非化石能源消费比重再度提升 努尔·白克力指出,能源革命领域“五个坚持”,是在我国经济进入“新常态”背景下,深入贯彻落实习近平总书记“四个革命,一个合作”能源革命战略思想的重要实践。 国务院发展研究中心主任李伟表示,经济发展逐渐稳定的形势下,我国能源转型进展明显。2016年,全国能源消费总量43.6亿吨标准煤,同比仅增长1.4%,以较低的能源消费增速保障了国民经济发展的需要;能源消费结构进一步优化,非化石能源的消费比重达到13.3%,同比提高1.3个百分点;超过两亿千瓦煤电机组实现节能改造,超过一亿千瓦机组实现超低排放改造;非化石能源发电装机比重达36.4%。“但我国的能源转型是一个长期的过程,一定要从我国的国情、资源禀赋和发展阶段出发,来审视和推动我们国家的能源转型。” 新奥集团创始人、董事局主席王玉锁认为,只有从理念、结构、模式上进行系统的创新,创建现代能源体系,才能引领世界能源变革。首先,技术和政策的创新为创建现代能源体系奠定了基础;其次,标准体系重构为构建现代能源体系提供了牵引;再者,泛能网实践为创建现代能源体系提供支撑。此外,我国现代能源体系的建立还需树立以创新实现弯道超车的意识,加大新技术,新模式的推广和支持力度;同时,进一步深化电力体制改革,营造公平高效的市场环境,加大新型标准体系建设支持力度。 三分之二天然气市场有待开拓 根据《报告》,2016年中国天然气表观消费量为2058亿立方米,同比增长幅度达6.6%,增速超过2015年,天然气的一次能源消费占比增至6.4%。其中,受气价走低、清洁取暖和新型城镇化等利好推动,城镇燃气和天然气发电消费增长明显。数据显示,2016年城镇燃气和天然气发电的天然气消费量分别由2015年的628亿立方米、284亿立方米增至2016年的729亿立方米和366亿立方米,在天然气消费总量的占比分别由32.5%、14.7%升至35.4%、17.8%;工业燃料消费量712亿立方米,在天然气消费中占比达34.6%;化工用气略有下降,为251亿立方米,占比从14.6%降为12.2%。 对此,努尔·白克力指出,天然气是我国推进能源生产和消费革命,实现主体能源绿色低碳更替的重要基础。2020年要实现天然气一次能源占比10%的目标依然任重道远。“我国13.7亿人口,按去年约2100亿立方米的天然气消费总量测算,现在涵盖的人口是4亿多,即当前天然气供应只能满足全国1/3人口的需求,还有2/3的市场需要开拓。” 他强调,为兑现我国天然气市场的巨大潜力,要实施城镇燃气工程、天然气发电工程及工业燃料升级工程;同时,还要加大常规天然气、页岩气勘探开发和利用,增强国内供给;要加快天然气管网等基础设施建设,加强基础设施的互联互通;要加大储气调峰建设,大幅度提高储气调峰能力。 进入【新浪财经股吧】讨论
6 | 本报记者 苏锶 上海报道在中国企业走出去、“一带一路”和双创背景结合之下,产业地产全球孵化创新已势不可挡。其中,尤以万科布局产业地产起点较高,公司最近两次重大签约均与海外资源对接合作有关。12月11日,上海万科产业服务品牌星商汇和以色列国际孵化器相关公司股票走势华夏幸福万科A张江高科、美国创新技术投资、意大利米兰时尚科技创新及保加利亚对外投资合作等展开了战略签约及挂牌合作。两天之后,万科、华大基因、招商新能源这三家深圳本土代表性企业又与“太阳城”阿布扎比马斯达尔城项目、马斯达尔理工学院签订合作备忘录,就未来科技、清洁能源和生物基因等科技领域开展交流合作。一名产业园区业内人士向记者分析指出,产业地产的转型具有不确定性,对于企业而言是一个内部权衡的隐性问题。与此同时,不少业内人士对于赢利周期较长的产业地产在短期内也不甚看好,如今这块也正处于“萌芽期”,绿地、万科、招商等大型房企也在该领域进行探索。万科发力国际孵化器不难看出,万科牵头在海外建立研发基地,目的就是整合全球科技资源,服务万科国内国际的业务,这本是万科国际化战略的重要一环。根据12月11日的协议,万科星商汇将通过与以色列孵化器、美国创投机构等海外资源的对接合作,搭建跨国际创新合作平台,为双边孵化、项目合作、技术转移、人才交流等方面提供支撑,以促进万科国际孵化器的建立。而马斯达尔城项目则是万科要在海外复制其产业园区试水之作前海企业公馆的成功经验。位于阿布扎比的马斯达尔城项目2008年正式启动,该项目由阿布扎比政府所有的未来能源公司投资建设,规划投资总额187亿-198亿美元,目标是建成全球首座零碳城市和清洁技术世界级研发基地。万科方面透露,将把马斯达尔城项目建成深圳在海外的首个集群式旗舰研发中心,并通过与东西交通枢纽、信息和展示中心的迪拜城,成为深圳的创新技术进入中东、欧洲、印度、北非市场的桥头堡和跳板。在此之前,以华夏幸福(600340.SH)为代表的很多产业地产商已纷纷走向海外。上述业内人士认为,这类整合全球资源进行无国界孵化的做法也是很多产业地产商都在不约而同摸索的,其中包括张江高科、天安数码城、宏泰发展、亿达中国和启迪控股等,它们也都在和美国、以色列、德国、日本的潜在合作方进行着频繁的互动探索。而在去年9月,万科总裁郁亮就明确透露了万科白银时代的新三大业务包括“住宅地产、消费体验地产和产业地产”。再创“万达模式”?2014年华夏幸福就在美国硅谷率先设立了孵化器公司,现已完成了52个产业园的谋划和布局,并计划到2016年完成200个产业园的规划。对比之下,万科做国际孵化器的模式则更多是试图通过孵化投资老手的经验与资源来实现撬动效果。在克而瑞2015年上半年销售金额前十名中,华夏幸福是唯一一家依靠产业地产实现高增长的“黑马”,公司的运营逻辑更像是“产业地产版”的万达。“万达模式”即在新区进行商住综合体的开发――完善的商业配套吸引购房者从而带动住宅销售;住宅销售带来的现金流补贴商业运营,并支持企业进一步扩张,总体可概括为“以售养租”。目前华夏幸福的收入大部分仍然来自于产业园区配套的住宅销售,不过华夏幸福的营收结构早已区别于一般房企。该公司产业运营类收入占营业收入总额的29%,其中,产业发展服务单项几乎包揽全部份额,占比27%;从利润方面来看,产业发展服务毛利高达96%;主要包含产业定位、产业规划、城市规划、招商引资、投资服务等。据了解,华夏幸福目前在美国硅谷有建设产业孵化器,国内已有的成果案例是固安肽谷生物医药孵化港。此外,公司还携手专注孵化器运营管理和科技创业企业培育的专业机构――太库,双方合作打造创新孵化体系,年内委托给太库的经营孵化项目共计10个,具体产业落地数目在未来三年内应分别不低于3个、6个、10个。根据2015年中报显示,华夏幸福在全国范围内委托开发园区面积为2433平方公里,其中京津冀区域合计1982平方公里,占比82%,长三角区域合计298.6平方公里,以沈阳、湖北为主的其他区域合计152.6平方公里。不过,上述业内人士指出,华夏幸福定位是产城运营商,起家还是靠“造城”,在“产”的运营与服务上,华夏幸福也仅是刚入门。除招商引资带来的产业发展服务收益外,综合服务、参投分红等,都还是在孕育的盈利 “种子”。作者:苏锶media_span_url('http://epaper.21jingji.com/html/2015-12/16/content_27794.htm')
7 | 中国人民银行23日消息,为贯彻落实《生态文明体制改革总体方案》和十八届五中全会精神,日前,中国人民银行发布2015年39号公告,在银行间债券市场推出绿色金融债券。据介绍,绿色金融债券是金融机构法人依法在银行间债券市场发行的、募集资金用于支持绿色产业项目相关公司股票走势万科A并按约定还本付息的有价证券。绿色金融债券的推出,为金融机构通过债券市场筹集资金支持环保、节能、清洁能源、清洁交通等绿色产业项目创新了筹资渠道,有利于增加绿色信贷特别是中长期绿色信贷的有效供给,是建设绿色金融体系的一项重要举措。人民银行有关负责人在回答记者提问时表示,绿色金融债券市场的培育和发展,需要坚持绿色发展理念,创新和完善制度安排,形成既有政策引导和激励、又有社会声誉和市场约束的绿色金融发展机制。一方面,要引导金融机构把发行绿色金融债券作为践行绿色发展社会责任的重要体现。另一方面,又要通过制度安排和政策倾斜,充分调动市场主体参与绿色金融债券市场的积极性和主动性。与此同时,也欢迎其他政府部门和地方政府出台税收、贴息、增信等配套优惠政策,欢迎社会保障基金、企业年金、社会公益基金等在内的各类投资者投资绿色金融债券,以共同推动绿色金融债券市场发展,促进各类资金参与支持绿色产业。(刘国锋)media_span_url('http://epaper.cs.com.cn/html/2015-12/24/nw.D110000zgzqb_20151224_9-A02.htm?div=-1')
8 | 序号受理编号交办问题基本情况行政区域污染类型核查核实情况是否属实处理和整改情况问责情况1D340000201810310027亳州市谯城区古井镇附近105路段河水污染严重,古井产业园区北侧路面损害导致扬尘严重。亳州市水,大气1.经查,谯城区古井镇105国道东侧河为亳宋河,该河道上游在河南省商丘市睢阳区宋集镇,自北向南流经古井镇柳行行政村、后老家行政村、张集行政村、吕楼新村、古井产业园区东侧,至下游谯城区华佗镇周溜闸。因目前为枯水期,该段河流上游至柳行行政村刘楼自然村处、吕楼行政村北侧桥下为断流状态。经对该段河道13个断面取样监测,后老家行政村、张集行政村等9个断面水质化学需氧量(COD)、氨氮、总磷等指标均达到地表水Ⅴ类标准;柳行行政村、吕楼新村、古井产业园区东侧、周溜闸等4个断面COD超地表水Ⅴ类标准0.55―0.125倍,氨氮、总磷等指标均达到地表水Ⅴ类标准。经走访调查分析,造成水质差的原因一是因下游周溜闸长期闭闸,吕楼行政村北侧桥下至周溜闸段水体不流动,造成水质变差;二是受2018年8月温比亚台风强降雨影响,上游污水下泄并有部分滞留在亳宋河古井镇段;三是柳行行政村尚未建设生活污水集中处理设施,村内污水随雨水进入河道;四是吕楼新村东西沟支流水质较差(COD55mg/L),与亳宋河交汇后影响主河道水质。2.古井产业园区北侧路面损坏导致扬尘严重问题属实。属实1.已责成谯城区制定亳宋河水质改善方案,一是加强涵闸调度,促进水体流动,增强水体自净能力;二是加强与上游地市、县、镇沟通协作和联防联控,避免污水集中下泄;三是加快柳行行政村等村庄生活污水集中收集处理设施建设进度,污水处理后达标排放;四是加强张集行政村、吕楼新村等生活污水处理设施的运营管理,促进亳宋河水质不断好转。2.该路段已纳入古井镇小康路修建方案,目前正在施工,因投诉反映的破损路面位于小康路末端,预计2019年3月动工建设,2019年12月底全线贯通。对扬尘污染问题,谯城区古井镇党委、政府已安排专人高密度洒水保洁,最大限度地降低扬尘污染。无2D340000201811010098合肥市庐阳区阜阳北路经济开发区的伟宏钢构经常在夜间喷漆作业,废气影响居民生活;融乔悦城小区东面空地有大型设备破碎石料作业,扬尘较大,噪音扰民。合肥市大气,噪音10月31日凌晨,庐阳区环保局对该公司突击检查,发现该公司二分厂、三分厂生产中的产生的焊接烟气未经过处理直接排放。经核查,投诉人反映情况属实。11月1日,庐阳区环保局依法对其生产设备供电设施进行查封合庐环查(扣)字〔2018〕34号。1.2018年8月28日庐阳区环保局执法人员对伟宏钢构现场检查时发现该公司二分厂在无任何污染防治设施下进行喷漆作业,依法对其立案查处,罚款20万元,并责令企业进行整改。该公司于2018年9月新增3台移动式喷漆房。2018年10月下旬,庐阳区环保局多次接到群众举报反映伟宏钢件夜间喷漆扰民,均组织执法人员夜间检查,未发现该公司进行喷漆作业。2.融侨小区东面空地,原为京福铁路桥梁场。京福铁路施工结束后,因对该处地面恢复硬化的需要而临时设立的破碎厂。属实1.11月3日,该企业邀请相关专家对其整改方案进行论证,目前处于停产状态,下一步按照专家意见进行整改。2.11月3日,已对该碎石场机械进行拆除,目前正在搬离现场,预计11月7日晚全部搬完,剩余碎石已全部覆盖并逐步清运。无3D340000201810310011六安市裕安区分路口镇裕龙新城小区47号楼顶楼安装有信号接收器,辐射影响居民健康,要求拆除。2017年中央环保督察时曾投诉小区旁边铁塔,该铁塔拆除后直接安装在47号楼小区顶楼。投诉人质疑环评手续的合法性。六安市辐射经调查核实,裕安区分路口镇邮电局旁边移动发射塔已在2016年10月7日由中国铁塔股份有限公司六安市分公司进行拆除完毕。分路口裕龙星城小区46、47号楼楼顶的2套信号接收器均于2018年10月19日履行环评登记备案手续(备案号201834150300000356、201834150300000354),2018年10月21日开始安装,2018年10月23日安装完毕,截止目前基站尚未开通。2套信号接收器现在属于中国联合网络通信有限公司六安市分公司建设及运营。另外,在裕龙星城小区47号楼还布设了350兆警用数字集群通信系统基站,基站于2018年3月开始建设,2018年4月建成,现已开通运行,通过该系统的技术参数证明材料,证实350兆警用数字集群通信系统的等效辐射功率为12.5W,符合国家《电磁环境控制限值》(GB8702-2014)中豁免管理的条件。属实现场由六安市环境监测中心站人员对350兆警用数字集群通信系统产生的辐射进行监测,现场监测结果范围为:0.16-0.86V/m,满足《电磁环境控制限值》(GB8702-2014)及安徽省环境保护厅《关于安徽省无线通信基站单址多套环境影响评价暂行标准的函》(环辐射函〔2009〕474号)确定的多套系统基站公众总的受照射电场强度8.5V/m限值要求,监测结果均不超标。下一步,在基站开通后,督促企业履行无线基站电磁辐射污染防治和辐射安全主体责任,采取有效辐射安全与防护措施,积极开展监测工作,公布监测结果。无4D340000201811010041安庆市太湖县新仓镇花园老乡边上的黑河水体污染严重。安庆市水举报人所反映的“黑河”是潜山和太湖两县为解决防洪排涝问题修建的人工河道。黑河太湖段水域流经晋熙镇、新仓镇、小池镇,与长河交汇,注入皖河。黑河太湖段河水源自上游的汪洋水库、罗河、观音河。由于今年降雨量偏少,上游主要来水的汪洋水库正在进行除险加固,基本无水外放。现场调查时,黑河太湖段河水水体流量较小,水体感官偏黑,其上游观音河道河段存在污水管道堵塞情形,有少量生活污水排入河道。沿黑河太湖新仓段有部分居民生活污水排入河道。导致黑河水体污染,有异味。属实根据现场调查情况,太湖县政府正在制定整改方案,整改分两个阶段实施。第一阶段,在黑河太湖段上游观音河的经一路与纬一路交口处设置临时拦水坝一道,将排入河内的生活污水截流接入城东污水泵站内,计划2018年底前完成。第二阶段,从三个方面实施,一是在黑河太湖段上游观音河道自文博园至城东污水泵站段,设置一道D800排污管道,收集排入观音河内的生活污水。总投资约260万计划2019年8月31日前完成。二是对黑河太湖段进行堤坝护彻、清淤治理。目前,黑河加固整治项目正在进行项目规划设计,计划于2019年启动实施,2019年12月前完工。整改时限:预计2019年12月底。三是面源污染治理,新仓镇人民政府将结合美丽乡村建设、改水改厕等工作,优先安排黑河沿线新仓段境内的居民改水改厕工作,减少居民生活污水直接排入黑河,封堵向黑河直排的污水管口,计划2019年6月底前完成。无5D340000201811010057马鞍山市和县石杨镇如山湖城碧桂园小区居民饮用水受到污染,经常停水,不能满足居民日常使用。该小区建设时未建设生活污水处理设施。马鞍山市水经核实,反映问题与2017年中央环保督察受理编号88号信访件为重复点位,举报情况部分属实。马鞍山市和县石杨镇如山湖城碧桂园小区居民饮用水受到污染。该问题不属实,2018年10月30日和县卫计委对碧桂园水务有限公司出厂水和末梢水进行了现场快速检测,所检指标均符合国家水质卫生标准,同时对水厂的生产状况进行检查,未发现居民饮用水受到污染。经常停水,不能满足居民日常使用。该问题属实,经和县石杨镇、水务局核实,碧桂园小区自来水源水为滁河水(接石杨镇自来水厂管道),目前其从石杨自来水厂接入水约为3000t/日,碧桂园自来水厂除日常居民供水外,还存在部分绿化用水,造成无法满足全日居民用水。该小区建设时未建设生活污水处理设施。该问题不属实,和县规划局核实石杨镇如山湖城碧桂园小区污水处理设施建设于2008年,与如山湖小区同步建设。2018年5月28日,和县环保局对发现的小区污水处理厂存在的不正常运行治污设施进行了立案查处并罚款40万元(已缴纳),责令企业对存在的问题进行整改并委托第三方有资质单位运维。后该污水处理厂进行了整改并由第三方(安徽蓝清源环保科技有限公司)有资质公司运维。环保部门持续加大对该问题的监管,2018年10月12日,针对第三方运营公司运维时存在环境违法行为进行了立案查处(目前案件正在办理),目前该污水处理厂运行正常。针对污水处理厂进水量及进水浓度不足,经住建部门排查为小区内部污水管网未完善,导致小区生活污水不能做到应收尽收所致。属实1.和县水务局要求碧桂园水务有限公司暂停绿化供水(已暂停),保障居民生活用水。碧桂园水务有限公司已与石杨镇水厂方面商议加大了每日供水量。2.碧桂园水务有限公司已委托专业的第三方机构(江苏新元盛投资有限公司)对水厂进行托管,负责水质控制和日常管理。3.和县卫计委要求碧桂园水务有限公司加强水质净化工作,更换过滤池石英砂和沉淀池斜板,水净化处理设备、设施必须满足净水工艺要求,必须有消毒设施,并保证正常运转,目前此项工作已完成。4.安徽和县碧桂园房地产开发有限公司对碧桂园如山湖城污水管网实施改造,目前大部分主管网已建成,支管网于2019年4月15日前完成建设。针对2017年中央环保督察组交办情况,和县已实施问责7人;2018年无问责情形。6D340000201811010048安徽省芜湖市繁昌县荻港镇庆大村工业循环园的博圆环保材料有限公司生产性污水简单处理后直接排入大西河,污染周边环境;庆大村扬尘污染严重。芜湖市水,大气经繁昌县荻港镇政府会同循环园综合办、县环保局等部门工作人员现场核查,投诉情况部分属实。具体情况如下:被投诉企业为芜湖博元材料科技有限公司,位于芜湖市繁昌县荻港镇庆大村,厂区距大西河约400―500米。该企业前期已履行项目环评审批手续,环评文件及批复中均明确要求企业生产废水必须做到全部循环使用、不外排。现场检查时,企业正常生产,厂区内雨、污水管道均未发现有废水排放迹象,未发现私设暗管行为,厂区围墙区域附近也未发现有废水排放痕迹。此外,经现场核查,庆大村内没有产生粉尘污染的企业,但村内部分道路因货物运输量大,存在道路扬尘情况。属实针对污水排放问题,循环园综合办和县环保局等部门将加大环境监管力度,并不定期开展巡查,督促企业切实履行环保主体责任,一旦发现环境违法行为,将依法予以惩处。针对道路扬尘问题,荻港镇政府和县交通运输等部门将加大道路运输污染整治力度,对货源单位实施严格监管,加强路面稽查,增加道路洒水降尘频次,进一步改善环境质量。无7D340000201811010104合肥高新区明珠和石楠路交会口的会通新材料有限公司附近有强烈刺鼻性气味,影响居民身体健康;燕美新材料有限公司和力世通材料有限公司夜间偷排废气;肥西县明皓机械有限公司夜间焚烧工业垃圾。合肥市大气高新区:群众反映会通新材料股份有限公司产生气味属实,反映合肥力世通塑料制品有限公司和合肥市燕美粉末涂料有限公司夜间偷排废气不属实。1.会通新材料股份有限公司位于高新区柏堰科技园芦花路2号,主要从事改性塑料的生产,其建设项目已履行环评审批及验收手续。主要生产废气为熔融和挤出工序产生的有机废气,经集气罩收集,通过废气治理设施处理后,经排气筒高空排放。企业于2017年4月对原有机废气治理设施进行提标改造(改为蓄热式焚烧炉处理工艺),并于2017年9月通过专家技术验收。2018年10月30日中央生态环境保护督察组对企业进行了督察,发现存在有机废气收集措施不完善,污染治理设施运转不正常。2018年10月31日,高新区环保分局对该企业现场检查时企业停产,由专业公司对污染治理设施进行全面检修停产至11月2日白天,11月2日晚少量生产线恢复生产,11月3日现场检查时,企业污染防治设施正常运转。2.合肥市燕美粉末涂料有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事环保型热固性粉末涂料生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为配料预混投料产生的粉尘,经除尘设备处理后排放。在达标排放的基础上,为进一步降低污染物排放,企业于2018年7月完成混料段粉尘密闭收集改造并投入使用。高新区环保分局于11月2日对该企业开展现场监察和监督性监测,检查时企业处于生产状态,污染防治设施正常运行,监督性监测结果第三方检测机构尚未提供。3.合肥力世通塑料制品有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事注塑件的生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为注塑过程产生的有机废气。企业在达标排放的基础上,为进一步降低污染物排放,于2018年8月完成注塑车间有机废气治理项目(采用分子击断处理工艺)建设,目前已投入使用。高新区环保分局于11月2日、11月3日、11月4日对该企业现场检查时,企业处于生产状态,污染防治设施均正常运行。监督性监测结果显示企业大气污染物达标排放。肥西县:肥西县环保局会同桃花镇于2018年11月2日赴合肥明昊机械制造有限公司现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况一致。被投诉企业名称为合肥明昊机械制造有限公司,项目建设过程中已执行环评审批手续,该公司自身未办实体生产加工,厂房主要租赁给小微企业从事机械、服装加工等。2018年10月27日夜间,肥西县环保12369投诉热线接到群众投诉,反映肥西县明皓机械有限公司夜间焚烧垃圾问题。经查,群众反映的焚烧垃圾行为是因企业管理不善,厂区内工作人员夜间点燃垃圾造成的。主要焚烧的是食品包装盒、服装废料和生活垃圾,违反大气污染防治法相关法律规定。属实高新区:1.针对会通新材料股份有限公司异味影响问题,高新区管委会成立工委、管委会主要领导为组长,工委领导班子其他成员为副组长,相关责任部门主要负责人为成员的会通新材料股份有限公司中央生态环境保护督察转办信访件整改工作领导小组,全面领导和协调整改工作,主要领导亲自抓、分管领导具体抓、责任部门分工协作。日常具体工作分别由环境监管执法组、群众信访协调组、转型升级(搬迁)协调组承担。当前采取以下整改措施:一是驻点执法监察,实时响应监控。高新区环境执法人员在会通公司整改期间24小时实施驻场监察,重点监管企业污染防治设施运行情况及限产落实情况;二是加大监测频次,及时掌握企业排污状况。高新区环境执法人员带领监测机构每日对污染物排放因子进行监测,一个月完成大气污染物在线监测设备安装并投入运行;三是禁止生产产生高异味产品,企业目前已主动转移产能,将产生高异味产品全部转移,高新区管委会将持续跟踪督办。减量生产其他产品,对企业限产措施进行监督,确保企业生产情况满足其承诺限产的内容(落实线体开机率不超过70%;重污染天气条件下按照合肥市应急措施统一部署,线体开机率不超过60%),并建立限产台账。四是督促企业加大投入。督促企业全面排查异味源,废气治理专业厂家驻厂调试培训,建立专业规范维保机制。同时持续开展提标改造,保持污染防治设施高效运行,加强环境管理,减少对周边环境影响。五是合理产业布局,指导企业启动搬迁。加快推进企业转型升级和产业布局调整,指导企业启动搬迁,立即启动新厂选址论证工作,列入高新区重大项目定期调度。六是强化居民沟通和环境信息公开,增强群众满意率。群众信访协调组建立主动与群众见面沟通机制,同时督促企业主动听取居民意见,及时将整改工作和日常环境管理情况向居民告知。2.高新区环保分局会同柏堰科技园管委会继续依法加强对合肥市燕美粉末涂料有限公司和合肥力世通塑料制品有限公司的环境监管,督促企业切实履行主体责任,加强厂区日常环境管理,对污染防治设施建立专业规范维保机制,确保污染防治设施正常运转,污染物达标排放。肥西县:桃花镇当日夜间值班人员现场已立即予以制止,并要求企业及时对垃圾进行清理并对垃圾进行规范处理。县环保局已依法向其下达了肥西县环保局责令改正通知书(0012731)及肥西县环境保护局行政处罚事先(听证)告知书(肥环罚告字201849号),要求其停止环境违法行为并依法行政处罚。无8D340000201811010058合肥市包河区巢湖南路东二环向南,现有十余家搅拌站,过往运输车辆存在抛洒滴漏现象,造成路面扬尘污染严重,影响周边居民正常出行。合肥市大气经包河区淝河镇工作人员会同经开区住建局、城管委执法人员于11月2日赴巢湖南路现场核查,现场核查情况如下:巢湖南路扬尘污染较大,核查投诉的情况与投诉人反映的情况一致。包河区淝河片区东临南淝河、西至十五里河中段高铁南站片区、北接老城区、南抵包河经开区,总占地面积32600亩。2016年8月,经摸底调查,反映的区域居住群众12260户,多为“城中村”,环境脏乱差。巢湖南路大型车辆出入频繁,导致路况变差、道路基础设施破损严重,致使路基垫层外渗,道路清扫保洁难度大;并且巢湖南路周边存在南淝河路(东二环―长春街)、郎溪路二、三标等施工工地,途经上述工地的南淝河路及郎溪路尚未完全开通,工地渣土运输主要经过巢湖南路,加剧路面循环污染。虽然已采取了加大清扫保洁频次和洒水降尘力度等措施,但无法根治该区域严重的扬尘污染问题。位于巢湖南路、南淝河路沿线集聚混凝土搅拌站共19家。其生产、运输过程带来的扬尘、噪音及水污染问题严重,居民苦不堪言。近几年,有关淝河镇混凝土搅拌站污染的热线投诉、网友留言居高不下。针对淝河片区脏乱差的状况,包河区委、区政府高度重视,深入研判,自2016年初,即开始全面谋划论证淝河片区整体改造工作。其中,针对片区范围内的19家混凝土企业,由于不符合片区土地利用总体规划及未来改造发展业态布局,包河区将其全部纳入搬迁改造范围,并迅速启动相关工作。1、加快签订搬迁协议。对19家混凝土搅拌站下达搬迁改造通知,并陆续启动丈量、评估、签订协议及补偿相关工作。针对企业主反映的补偿问题,包河区本着“尊重历史、面对现实”的原则,耐心开展政策解释和上门沟通工作,尽量取得企业的理解和支持。截至目前,已与16家搅拌站签订了搬迁协议。下剩3家企业由于对搬迁补偿存有一定异议,目前正在积极洽谈推进中。2、积极对接复建事宜。考虑到混凝土企业搬迁可能带来的订单协议违约、员工就业及往来债务等问题,包河区积极协调对接,全力支持搬迁企业开展复建工作。3、加强日常巡查监管。针对混凝土搅拌站搬迁复建前的生产运营,包河区持续加强监督管理,加大扬尘等环境污染防治工作。一是加大宣传教育。中央环保督察期间,针对淝河片区混凝土企业的信访投诉量大的情况,辖区淝河镇、村居对混凝土企业加强宣传教育,要求其文明生产,并落实相关降尘抑尘等环保措施。二是强化监控巡查。区住建局通过行业视频系统,常态化监控搅拌站内洒水降尘、物料覆盖及生产运营环节的扬尘防治;区环保局、辖区淝河镇等加大日常巡查频次,督促企业将各项环保措施落到实处。三是依法行政处罚。对于环保不达标、未通过项目竣工环保验收、违反《建设项目环境保护管理条例》等相关规定的混凝土企业经营行为,区环保等相关部门依法对其进行行政处罚,并责令其落实整改措施。属实1、包河区淝河镇将加大对周边工地巡查力度,严格落实扬尘污染防治要求,确保物料堆放覆盖、出入车辆清洗、渣土车辆密闭运输等措施落实到位。同时,对巢湖南路等重点路段进行严格巡查,对过往抛洒滴漏车辆进行依法查处。2、2018年至今,包河区住建局对淝河镇巢湖南路周边混凝土企业共巡查54次,下达监督意见书39份,对巡查发现的问题均敦促企业落实专人限期整改到位。3、针对巢湖南路路面扬尘的路况实际,为做好大气污染控制,包河区环卫服务中心不断增加了作业车辆,加大洒水降尘频次,实行循环作业。在夜间完成全区主次干道统一的冲洗保洁作业,在白天做好路面保湿抑尘工作,并在晚间薄弱时段增派车辆加强路面降尘保湿。具体措施:(1)洒水车依次循环路面洒水作业,保持路面湿润,抑制扬尘;(2)洗扫车湿扫路牙灰砂,将路牙边的灰砂洗扫干净;(3)小货车清运石子、灰砂;(4)道路养护车配合人工对人行道进行冲洗作业。无9D340000201811010044宣城市经开区管委会旁的乐方瓜子,晚上排的气体有刺激性,方圆几公里的居民都能闻到,严重影响居民休息;经开区的鸿越大道与景德路交叉口,有人在晚上焚烧垃圾,气味难闻。宣城市大气(一)信访人反映的宣城市经开区管委会旁的乐方瓜子应为安徽乐方食品有限公司,位于宣城经济技术开发区(以下简称“市经开区”)柏枧山路。11月1日晚上,现场核查时该公司多味瓜子生产线和焦糖味瓜子生产线在生产,废气处理设施正在运行,废气经喷淋设施处理后排放,车间内有较重香味,车间外厂区内有较浓香味。信访人反映的乐方瓜子气味系瓜子生产过程中使用食用香精挥发出的香精味,信访人反映情况属实。(二)11月1日晚上,对举报地点鸿越大道与景德路交叉口进行核查时,未发现焚烧垃圾现象。11月2日上午,再次对该区域巡查时,发现鸿越大道与景德路交叉口西南角栅栏内荒地有焚烧痕迹。上述地点存在周边某些居民擅自焚烧生活垃圾,产生难闻气味的现象。信访人反映情况属实。属实(一)针对安徽乐方食品有限公司:要求该公司增强生产厂房的密封性,杜绝跑冒滴漏,改善废气收集效果;进一步减少食用香精使用量,调整产品结构和规模,将食用香精使用量再下降10%(较去年下降70%);调整生产时间,将使用食用香精的产品生产调整到白天,晚间和夜间不生产含有香精的产品;在原有已安装废气收集治理设施基础上(4套)再增加一套收集处理设施;香精味瓜子生产线于2019年年底前完成搬迁。截至11月6日,该公司已对蒸煮车间主要通道口加装软帘,对车间所有窗户进行密封。已减少食用香精使用量,减少核桃味等香味瓜子的生产量。香味瓜子生产时间已由夜间调整为白天,减轻对周边居民的影响。已新购置一套废气收集治理设施,近期将安装到位。(二)针对焚烧垃圾问题:一是由属地办事处社区加强宣传,通过在鸿越大道与景德路交叉口及其他闲置土地周边醒目位置设置“禁止焚烧垃圾”警示牌或条幅等方式做好辖区居民宣传告知工作。二是进一步加大薄弱时段巡查管控力度,安排人员巡查值守,对发现的焚烧垃圾行为第一时间制止,并第一时间扑灭火点。三是城管部门加大处罚力度,对焚烧垃圾的行为人,一经查实,一律依法予以从重处罚。四是开展隐患排查工作,举一反三,对辖区内可能存在焚烧垃圾的地点开展逐一排查,尽可能减少或避免发生焚烧垃圾现象。五是建立长效机制,充分利用网格化管理、路段长责任制、门前三包巡查、联点共建等切实有效的工作机制,扎实做好垃圾、秸秆禁烧工作。截至11月6日,已完成鸿越大道与景德路交叉口等其他焚烧易发点位警示牌或条幅的设置,共悬挂条幅27条、设置警示牌10块;对鸿越大道与景德路交叉口周边的鑫鸿交通等企业上门进行了宣传。已制定人员排班表,将每天晚间的巡查值守作为一项常态化工作开展。无10D340000201810310032安庆市望江县鸦滩镇麦元行政村畈上组北侧,去年建了一个200平方左右的垃圾场,目前垃圾只进不出,味道很臭,蝇虫很多,造成道路堵塞,使村民无法在地里干活。安庆市其他污染,大气经查,投诉人反映的望江县鸦滩镇麦元村畈上组垃圾场是一座由麦元村建设的垃圾暂放点,建筑面积约120平米,主要用于该村垃圾收集后临时堆放待镇转运。近年来,鸦滩镇环卫工作始终按照“户入桶、组保洁、村收集、镇运转、县处理”的机制运行,各类生活垃圾经集中收集后,再转运至望江县环卫基地处理。麦元村位处集镇,垃圾收集量大,因县环卫基地接收处理能力有限,而鸦滩镇没有垃圾处理设备,也不具备无害焚烧和其他规范处理条件,导致该村生活垃圾无法及时清运处理,且不断积存。目前,鸦滩镇麦元村积存生活垃圾近300吨,一定程度上影响周边群众生活。属实望江县部分生活垃圾主要依托安庆皖能中科公司处理,因该公司10月底停产重建,目前望江县部分生活垃圾不能及时处置,临时进行暂存,望江县已采取如下整改措施:一是立行立改,迅速安排环卫人员对垃圾存放点周边零散垃圾进行清理;对存放点垃圾采取遮盖措施;并安排环卫工人在存放点垃圾喷洒灭虫药水和消毒液;二是进行转运规范处置,正在积极联系规范化处置公司,尽快安排对存放点积存垃圾进行转运处置,计划年内清理完成。无11D340000201811010060合肥市肥东县新城开发区肥东烟草局对面的真心食品利用风扇排放食品加工过程中产生的异味,特别是夜间20点左右,对周边环境造成严重影响。合肥市大气经肥东县环保局执法监察人员会同经开区环保办人员于11月1日赴现场核查,现场核实情况如下:核查投诉的情况与投诉人反映的情况不一致。安徽真心食品有限公司位于肥东经开区长江东路北侧21号,从事休闲食品加工,项目于2009年12月履行环评审批手续(东建审字2009220号),并通过环保三同时验收手续(东环验字201010号)。经现场查看,该公司食品加工项目已于2017年12月停产至今。厂区内共有3幢厂房,东侧2幢车间为原料仓库。厂区西侧1幢厂房为原瓜子加工车间,车间内存放有生产产品、大量纸箱及原辅材料,车间西侧墙上安装有4个排风扇长期未使用,部分生产设备已拆除,生产线已不具备生产能力。现场未闻到明显气味,在原瓜子加工车间北侧有一密闭的小仓库存有部分食品调味品(八角、桂皮等),调味品原料有香味逸散,目前该公司已将调味品原料搬离北侧仓库。不属实无无12D340000201810310006马鞍山市雨山区佳山乡超山村红桥村民组的马钢南山和尚桥铁矿,开采铁矿时炮震噪音震动,导致居民房屋开裂,污染和尚桥下河流,该铁矿抽取地下水导致土地下陷,出行路面破损严重,扬尘污染严重,严重影响居民身体健康。马鞍山市生态经调查,举报扬尘和和尚桥下河流污染情况部分属实。1.近年来,在当地政府支持下,和尚桥铁矿投资近2000余万元对和尚桥周边区域的双松路、银向路等社会化道路实施了升级硬化改造,总长近3km。由于路线较长,存在清扫保洁和路面洒水不及时的问题,车辆通行时会产生一定扬尘。2.和尚桥铁矿矿坑涌水和地表汇水主要通过多级沉淀后,用于喷淋、洒水及回用生产系统,不外排。但是矿区生活污水处理设施不完善,处理后的生活污水,不能做到达标排放。3.和尚桥铁矿爆破作业采用国内先进的逐孔微差爆破控制技术。和尚桥铁矿于2018年4月,10月两次委托中钢集团马鞍山矿山设计研究院对采场200m-600m范围进行了爆破震动检测,检测结果均小于《爆破安全规程》规定的主震频率和安全允许质点振动速度。2017年5月11日,马鞍山市安监局也曾组织专家对爆破振动检测结果进行专题论证,认为开采爆破时会产生一定的震动和噪音,但不会对200米范围外的正常民房造成破坏。4.和尚桥铁矿投产至今未抽取地下水。和尚桥铁矿环评报告对区域地下水分析的结论为:和尚桥铁矿开发不会对采石河、周边农田水系及地下水造成影响。2018年11月2日,南山矿业公司委托马鞍山测绘技术院对和尚桥采场东南部超山村红桥村民组所在区域地质变化情况开展了现场勘查及测量工作,检测结论为和尚桥铁矿的开采未造成周边地面下沉和路面破损。属实已经进一步完善道路洒水保洁制度,增加清扫保洁频次,加大执行考核力度。同时,增设车辆行驶限速标牌,提醒社会车辆减速行驶。立即着手矿区生活污水处理设施建设,确保11月30日前建成投运。无问责情形13D340000201811010102合肥市经开区大学城附近的居民区,由于临近肥西县桃花镇工业园,大气环境污染情况较为严重,周边佳通轮胎,会通材料,燕美材料,力士通材料等几家企业排放的工业废气污染周边环境。合肥市大气肥西县:经肥西县环保局会同桃花镇、肥西经开区于11月1日至3日,对辖区内重点废气排放企业进行认真排查并先后开展3次夜查,现场核查情况如下:核查投诉的情况与投诉人反映的情况不一致。肥西经开区范围内重点排查15家涉气排放重点单位,桃花镇范围内重点排查10家涉气排放重点单位。现场核查,相关企业均执行环评、“三同时”制度,按要求落实污染防治措施,废气达标排放,未发现存在违法及废气污染严重现象。通过测量,以上重点企业距离大学城最近距离达5公里以上。经开区:经合肥经开区环保分局执法人员于11月1日赴安徽佳通轮胎有限公司现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。安徽佳通轮胎有限公司位于经开始信路8号,法人代表陈应毅,主要从事轮胎生产,建设项目已履行环境影响评价和环保工程竣工验收手续,已办理工商营业执照。企业主要生产工艺:密炼-预备-成型-硫化。企业生产中产生的异味主要来自密炼、硫化工序产生的工艺废气(主要污染物为恶臭气体和非甲烷总烃)及污水站运行产生的恶臭气体。2017年以来,佳通公司累计投入2500万元,推进密炼、硫化车间和污水站的废气收集与治理。将密炼车间13台母炼机的投料、卸料和挤出共39个排口废气引入锅炉燃烧;对剩余6台母炼及32#母炼机挤出另1个排口、10台终炼机挤出排口及所有母炼终炼的胶冷共59个废气排口均已安装废气异味治理设施,其中35个排口采用碳纤维过滤+光催化氧化+生物膜片处理工艺,23个胶冷和1台30#打胶机共24个排口采用过滤+低温等离子处理工艺;完成硫化车间已18条围闭罩收集系统和36套过滤+碳纤维吸附+光催化氧化+生物膜片处理工艺的废气异味治理设施建设;对污水站进行封闭并安装1套喷淋+低温等离子+催化吸附废气治理设施。为减少废气的无组织排放,提升治理效果,对密炼车间和硫化车间门窗实施封闭;对密炼车间17台母炼机下辅机到胶料引出爬坡段进行了封闭;对密炼废气光催化治理设施加装了434只紫外灯管,并完成对密炼车间10台终炼机下辅机到胶料引出爬坡段进行了封闭。另外,为确保企业废气排放达标,自2018年6月起,经开区环保分局对佳通轮胎实施限产措施,全钢胎、半钢胎限产比例分别为40%、20%。11月1日夜间,合肥市环保局经开区分局对佳通轮胎进行了现场检查,企业正在生产,其中半钢胎生产负荷约67.2%,全钢胎生产负荷约59.7%,硫化、密炼车间门窗封闭,废气治理设施运行正常,对废气排放开展监督性监测。11月3日,对企业再次开展突击检查,未发现废气治理设施异常运行,硫化、密炼车间门窗封闭。监督性监测数据达标。高新区:群众反映会通新材料股份有限公司产生气味属实,反映合肥力世通塑料制品有限公司和合肥市燕美粉末涂料有限公司夜间偷排废气不属1.会通新材料股份有限公司位于高新区柏堰科技园芦花路2号,主要从事改性塑料的生产,其建设项目已履行环评审批及验收手续。主要生产废气为熔融和挤出工序产生的有机废气,经集气罩收集,通过废气治理设施处理后,经排气筒高空排放。企业于2017年4月对原有机废气治理设施进行提标改造(改为蓄热式焚烧炉处理工艺),并于2017年9月通过专家技术验收。2018年10月30日中央生态环境保护督察组对企业进行了督察,发现存在有机废气收集措施不完善,污染治理设施运转不正常。2018年10月31日,高新区环保分局对该企业现场检查时企业停产,由专业公司对污染治理设施进行全面检修停产至11月2日白天,11月2日晚少量生产线恢复生产,11月3日现场检查时,企业污染防治设施正常运转。2.合肥市燕美粉末涂料有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事环保型热固性粉末涂料生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为配料预混投料产生的粉尘,经除尘设备处理后排放。在达标排放的基础上,为进一步降低污染物排放,企业于2018年7月完成混料段粉尘密闭收集改造并投入使用。高新区环保分局于11月2日对该企业开展现场监察和监督性监测,检查时企业处于生产状态,污染防治设施正常运行,监督性监测结果第三方检测机构尚未提供。3.合肥力世通塑料制品有限公司位于高新区柏堰科技园石楠路与明珠大道交口,主要从事注塑件的生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为注塑过程产生的有机废气。注塑机自带密封设施,企业在达标排放的基础上,为进一步降低污染物排放,于2018年8月完成注塑车间有机废气治理项目(采用分子击断处理工艺,国内同行业率先使用)建设,并进行调试运行。高新区环保分局于11月2日对该企业开展现场检查和监督性监测,检查时企业处于生产状态,污染防治设施正常运行,监督性监测结果第三方检测机构尚未提供。属实肥西县:肥西经开区、桃花镇将进一步按照网格化管理要求,全面开展辖区内企业排查整治,对发现的环境问题及时督促企业限期整改;肥西县环保局加强该区域重点废气排放企业环境监管,联合肥西经开区、桃花镇开展对辖区内重点废气排放企业专项检查及夜间巡查,一经发现违法排污行为将依法立案查处。经开区:一是督促企业按照限产整治方案继续实施限产整治,并落实重污染天气生产应急管控措施;二是继续加强日常监管,督促企业加强废气治理设施运行管理,发现违法行为将严肃予以查处;三是加快实施搬迁工作,目前,企业已初步确定在肥西县中派范围内选址2500亩,用于佳通公司搬迁用地,现已报规划部门论证审查。新项目建设将采用先进的轮胎生产制造技术及污染治理设备,真正实现生产车间全封闭,彻底消除无组织废气排放,实现企业的绿色发展。高新区:1.针对会通新材料股份有限公司异味影响问题,高新区管委会成立工委、管委会主要领导为组长,工委领导班子其他成员为副组长,相关责任部门主要负责人为成员的会通新材料股份有限公司中央生态环境保护督察转办信访件整改工作领导小组,全面领导和协调整改工作,主要领导亲自抓、分管领导具体抓、责任部门分工协作。日常具体工作分别由环境监管执法组、群众信访协调组、转型升级(搬迁)协调组承担。当前采取以下整改措施:一是驻点执法监察,实时响应监控。高新区环境执法人员在会通公司整改期间24小时实施驻场监察,重点监管企业污染防治设施运行情况及限产落实情况;二是加大监测频次,及时掌握企业排污状况。高新区环境执法人员带领监测机构每日对污染物排放因子进行监测,一个月完成大气污染物在线监测设备安装并投入运行;三是禁止生产产生高异味产品,企业目前已主动转移产能,将产生高异味产品全部转移,高新区管委会将持续跟踪督办。减量生产其他产品,对企业限产措施进行监督,确保企业生产情况满足其承诺限产的内容(落实线体开机率不超过70%;重污染天气条件下按照合肥市应急措施统一部署,线体开机率不超过60%),并建立限产台账。四是督促企业加大投入。督促企业全面排查异味源,废气治理专业厂家驻厂调试培训,建立专业规范维保机制。同时持续开展提标改造,保持污染防治设施高效运行,加强环境管理,减少对周边环境影响。五是合理产业布局,指导企业启动搬迁。加快推进企业转型升级和产业布局调整,指导企业启动搬迁,立即启动新厂选址论证工作,列入高新区重大项目定期调度。六是强化居民沟通和环境信息公开,增强群众满意率。群众信访协调组建立主动与群众见面沟通机制,同时督促企业主动听取居民意见,及时将整改工作和日常环境管理情况向居民告知。2.高新区环保分局会同柏堰科技园管委会继续依法加强对合肥市燕美粉末涂料有限公司和合肥力世通塑料制品有限公司的环境监管,督促企业切实履行主体责任,加强厂区日常环境管理,对污染防治设施建立专业规范维保机制,确保污染防治设施正常运转,污染物达标排放。无14D340000201811010103合肥市经开区的佳通轮胎,每天放排塑料味很重的气体,周边居民不能开窗,严重影响居民生活。合肥市大气经合肥经开区环保分局执法人员于11月1日赴安徽佳通轮胎有限公司现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。安徽佳通轮胎有限公司位于经开始信路8号,法人代表陈应毅,主要从事轮胎生产,建设项目已履行环境影响评价和环保工程竣工验收手续,已办理工商营业执照。企业主要生产工艺:密炼-预备-成型-硫化。企业生产中产生的异味主要来自密炼、硫化工序产生的工艺废气(主要污染物为恶臭气体和非甲烷总烃)及污水站运行产生的恶臭气体。2017年以来,佳通公司累计投入2500万元,推进密炼、硫化车间和污水站的废气收集与治理。将密炼车间13台母炼机的投料、卸料和挤出共39个排口废气引入锅炉燃烧;对剩余6台母炼及32#母炼机挤出另1个排口、10台终炼机挤出排口及所有母炼终炼的胶冷共59个废气排口均已安装废气异味治理设施,其中35个排口采用碳纤维过滤+光催化氧化+生物膜片处理工艺,23个胶冷和1台30#打胶机共24个排口采用过滤+低温等离子处理工艺;完成硫化车间已18条围闭罩收集系统和36套过滤+碳纤维吸附+光催化氧化+生物膜片处理工艺的废气异味治理设施建设;对污水站进行封闭并安装1套喷淋+低温等离子+催化吸附废气治理设施。为减少废气的无组织排放,提升治理效果,对密炼车间和硫化车间门窗实施封闭;对密炼车间17台母炼机下辅机到胶料引出爬坡段进行了封闭;对密炼废气光催化治理设施加装了434只紫外灯管,并完成对密炼车间10台终炼机下辅机到胶料引出爬坡段进行了封闭。另外,为确保企业废气排放达标,自2018年6月起,经开区环保分局对佳通轮胎实施限产措施,全钢胎、半钢胎限产比例分别为40%、20%。11月1日夜间,合肥市环保局经开区分局对佳通轮胎进行了现场检查,企业正在生产,其中半钢胎生产负荷约67.2%,全钢胎生产负荷约59.7%,硫化、密炼车间门窗封闭,废气治理设施运行正常,对废气排放开展监督性监测。11月3日,对企业再次开展突击检查,未发现废气治理设施异常运行,硫化、密炼车间门窗封闭。监督性监测数据达标。属实一是督促企业按照限产整治方案继续实施限产整治,并落实重污染天气生产应急管控措施;二是继续加强日常监管,督促企业加强废气治理设施运行管理,发现违法行为将严肃予以查处;三是加快实施搬迁工作,目前,企业已初步确定在肥西县中派范围内选址2500亩,用于佳通公司搬迁用地,现已报规划部门论证审查。新项目建设将采用先进的轮胎生产制造技术及污染治理设备,真正实现生产车间全封闭,彻底消除无组织废气排放,实现企业的绿色发展。无15D340000201810310021滁州市琅�e区西涧街道雷桥村,有垃圾污水倾倒至西涧街道垃圾场,污水污染特别严重。滁州市水,土壤琅琊区高度重视,立即组织辖区街道、区城管执法局、市环保局琅琊分局主要负责人赶赴扬子街道雷桥村垃圾填埋场(交办反映的倾倒至西涧街道垃圾场,经现场查看实际为扬子街道雷桥村垃圾填埋场)核查,同时联系皖能垃圾焚烧厂负责人,经过对垃圾填埋场、生活垃圾渗滤液及周边区域认真排查,未发现有垃圾污水倾倒至扬子街道雷桥村垃圾填埋场现象,信访投诉问题不属实。不属实无无16D340000201810310007淮北市濉溪县濉溪镇五里郢排灌站有一臭水沟(此臭水沟通向濉溪县城),附近一公园旁臭气熏天,严重影响周围居民生活及锻炼的群众。淮北市水、大气经现场调查:此沟为濉溪镇城西沟下游西分支(汴河路至新濉河),全长约350米,已作为黑臭水体逐级上报,同时该城西沟亦为濉溪县行洪排涝沟使用。附近居民房紧邻渠道建设,施工场地受限,上游段部分民房建在大沟上,临沟居民生活污水直排入沟,影响大沟整治和大沟两侧截污工程。属实治理方案分两步进行:第一步:濉溪县近期将在此段黑臭水体前段设置拦截坝,用污水处理设备对污水进行处理,处理后的中水就近浇灌河堤两岸花草树木,既能够节约水资源,也有助于提升附近群众的生活环境质量。第二步:濉溪县将加快对周边地块实施雨污分流,雨水排入大沟作为补水水源,污水接入市政污水管进入污水处理厂处理达标后排放。在推进雨污分流工作的同时,为满足日渐增加的污水处理量,濉溪县将加快实施濉溪县污水处理厂二期工程,届时城西沟将仅保留防洪排涝功能。原濉溪县建委主任:王震原濉溪县建委副主任:朱利茂濉溪县建委主任:陈安厚濉溪县建委副主任:赵夫鸣濉溪镇副镇长:桂沛春已被问责17D340000201811010105合肥市高新区长宁大道与磨子潭路交叉口航空新城附近经常有刺激性味道,疑似橡胶与塑料气味,怀疑是大陆马轮胎厂和禾盛新型材料有限公司排放的刺激性气味。合肥市大气经高新区环保分局执法人员会同南岗科技园管委会环保办于2018年11月2日赴合肥禾盛新型材料有限公司和大陆马牌轮胎(中国)有限公司现场核查,现场核查情况如下:1.合肥禾盛新型材料有限公司位于高新区大别山路0818号,主要从事彩色复合钢板生产,其建设项目已履行环评审批及验收手续。企业主要生产废气为辊涂等工序产生的有机废气。企业在达标排放的基础上,为进一步降低污染物排放,于2017年9月完成原有废气处理设施提标改造工作(由催化燃烧工艺改为蓄热式热力焚化炉处理工艺)。检查时企业生产工况正常,配套污染防治设施运行正常,厂区内均未见明显异味,监督性监测结果显示,企业大气污染物达标排放。2.大陆马牌轮胎(中国)有限公司位于高新区南岗科技园大别山路1588号,主要从事乘用车子午胎、两轮车轮胎的生产,其建设项目已履行环评审批手续,其中一期、二期及两轮车轮胎项目已履行验收手续,三期项目正在安装调试。企业主要生产废气为密炼、硫化等工序产生的有机废气,分别通过干式过滤器、低温等离子和蓄热式焚烧炉废气治理设施处理后,通过排气筒高空排放。检查时企业生产工况正常,配套污染防治设施运行正常,厂区内均未见明显异味,监督性监测结果显示,企业大气污染物达标排放。属实高新区环保分局会同南岗科技园管委会继续依法加强对企业的环境监管,督促企业切实履行主体责任,加强厂区日常环境管理,对污染防治设施建立专业规范维保机制,确保污染防治设施正常运转,污染物达标排放。无18D340000201811010049蚌埠市淮上区沫河口镇五埠路工业园工业污水一部分排入三铺灌溉站河内,另一部分怀疑排入地下,污染周边环境。蚌埠市水三铺灌溉站位于三铺大沟北端尽头,该灌溉站距离沫河口园区建成区北边界约4公里,灌溉站内泵房从三铺大沟取水用于周边农田灌溉。接交办单后,沫河口园区管委会于11月2日组织人员对园区范围内三铺大沟段进行现场排查,未发现偷排暗管。沫河口工业园区内重点涉水企业共有14家,淮上区自筹资金对园区化工基地污水管网采取架空主管网设计,其中9家企业污水一企一管通过架空管网排入园区污水处理厂,5家企业污水单管单送接入园区污水处理厂。14家企业全部加装水污染在线监控设施,4家联入市级监控平台,其余连入区级监控平台,环保部门实时监控企业污水排放。2016年开始淮上区环保局组织对辖区企业进行排查,未发现沫河口园区企业污水有偷排或排入地下现象。2017年开始,淮上区对园区地下污水管网进行全面排查,利用CCTV影像技术、井下机器人对园区23公里管网进行排查修复。园区现有20000t/d污水处理设施,能够满足现有企业污水处理需要,出水稳定达到一级A标准。污水处理厂出水口加装在线监控设施,连入国发软件平台。2017年9月开始,每季度由第三方检测公司对园区周边地下水取样检测。检测报告结果符合地下水环境质量标准,无企业污水排入地下迹象。检测结果公示在沫河口园区和沫河口镇公示栏公示。不属实下一步,淮上区一是继续做好园区内涉水企业的日常监管,同时加强对园区内地下污水管的日常监管和维护;二是继续加大对企业检查力度,严厉查处违法企业;三是定期检测园区及周边地下水水质。无19D340000201810310022马鞍山市花山区清河湾小区的168饭店,鼓风机噪音扰民,油烟通过私自接通的道管排放,严重影响小区居民正常生活,对该饭店多次投诉至今没有解决。马鞍山市大气,噪音经调查,举报情况属实。该饭店营业时安装在平台上的鼓风机声音较大,油烟未经处理通过管道直接排放,未安装油烟净化设施,对周边居民生活产生不良影响。属实责令该饭店立即停业整改,拆除原有油烟排放管道和鼓风机,将鼓风机安装在操作间内,安装油烟净化设施。目前,油烟排放管道和鼓风机已全部拆除,鼓风机已安装在操作间内,油烟净化设施已安装到位。无问责情形20D340000201810310013举报人在芜湖市鸠江区白茆镇省级农业示范园内承包了193亩地用于水产养殖,乡镇政府安排环卫工人直接向莲花河喷洒草甘膦农药和百草枯除草剂用于除草,导致承包塘里的螃蟹河虾大面积死亡,造成经济损失达到百万以上。芜湖市水经核查,2016年6月,芜湖市鸠江区白茆都市农业示范区通过招标方式确定将清除杂草和打捞沟渠漂浮物等事项交由紫香劳务公司处理。2018年7月底至8月初,该劳务公司两名工作人员在举报人(承包户)承包的池塘西部渠道内不当使用农药草甘膦除草剂清除渠道内杂草时,被人发现后及时制止,用量不超过4瓶(1千克装,41%草甘膦水剂),喷洒长约500米,造成部分水体受到污染。白茆都市农业示范区从事河蟹养殖共2户,生产用水均取自该渠道。9月29日,举报人(养殖户)到鸠江区白茆镇农服中心反映,因在紫香劳务公司工作人员喷洒过除草剂的渠道取水导致承包的约100亩池塘河蟹死亡。镇农服中心工作人员于9月29日、10月2日,两次到现场核实情况,该养殖户承包的池塘内仍可见河蟹零星死亡。另一养殖户也在同一渠道内取水,池塘内河蟹生长正常。10月30日,该养殖户到区信访局反映情况,11月1日又到市信访局反映。市信访局会同市环保部门工作人员现场核查后初步研判,认为属于草甘膦除草剂使用不当。建议举报人通过司法程序或商请水产专家对损失进行评估、协商解决。11月2日,区政法委负责人在区信访局接待了举报人,处理意见如下:1、通过司法程序依法处理。2、由区农林局请省水产专家到现场研判,对损失评估。11月4日,省水产专家和省司法鉴定中心、市、区水产专家到现场进行察看,建议举报人会同政府相关部门及第三方检测机构多处取水样检测,对损失进行评估。属实1、芜湖市鸠江区白茆都市农业示范区管委会已要求紫香劳务公司在辖区内使用除草剂时,需提前告知种(养)殖户,并采取相应措施。该劳务公司今后不得在沟渠内水体使用除草剂。2、建议举报人(养殖户)按照法律途径依法依规解决河蟹死亡受损事宜。3.鸠江区政府及相关部门将按照各自职责做好相关工作。无21D340000201811010033亳州市谯城区双沟镇孟大行政村前李村南侧空地上,一家腌制泡椒的作坊,离居民区很近,气味浓影响居民正常生活,去年的腌制水排到灌溉井里影响居民灌溉。亳州市大气,水经查,该作坊为土法腌制泡椒,主要生产设施为在田地里挖掘的12个地窖(长10米、宽2.5米、深1.5米),每个地窖下用3层、上用2层防水塑料布用于防渗;生产工艺为将辣椒和盐、醋混合后,用土封存约1个月后,将泡椒连同腌制水出售给其他加工厂家进行深加工。现场检查未发现泡椒腌制水外排和和排入灌溉井现象。属实对该作坊擅自进行土法泡椒生产行为,已责令其待本批次泡椒出产后,停止土法加工,若继续生产经营的,必须完善经营证照和用地、环评等手续,优化生产工艺。无22D340000201810310008安庆市岳西县温泉镇桃林村寨岩组105国道旁,2017年建有一所临时沥青搅拌站,生产时产生刺鼻沥青气味,运输车产生大量扬尘,污染周边环境;建搅拌站修路时将约1万立方渣土倾倒至周围山上,部分渣土落入河流被河水冲走。多次投诉没有解决。安庆市大气,土壤2018年11月4日岳西县住建局会同县城市管理局、环保局、温泉镇党委、人民政府到温泉镇桃岭村沥青搅拌站现场进行核实,该搅拌站为安徽中升新型建筑材料有限公司。目前该处沥青混凝土搅拌站已停产多时,检查时未发现扬尘等问题,场地、道路已进行硬化,砂石材料已进行覆盖,现场设有固定和移动雾炮、现场无污染周边环境的状况,建设搅拌站修路的土方倾倒到周边的矿山上,目前该处山场植被已恢复,据搅拌站负责人口述建搅拌站修路为原矿场道路扩建,渣土方量较少,现场河道旁未发现渣土。但石料堆场未完全密闭,危废仓库内将新旧活性炭混放,未建立危废管理台账,部分喷淋设施不能正常使用,未设置进出车辆冲洗设施,淋溶水收集设施不完善。属实岳西县于2018年11月5日向该当事人下达了《关于对安徽中升新型建筑材料有限公司的环境监察意见》岳环监察〔2018〕94号,并告知应严格按照文件要求进行整改,要求该单位于2019年1月30日前完成整改并报送整改销号材料。整改措施:1、对沥青搅拌站石料堆场进行密闭,搅拌站石料堆场未完全密闭的地方,增加三方围挡,完全密闭,2018年11月6日开始实施围挡,在2018年11月15日前完成。混放在危废仓库中的新旧活性炭分开堆放,建立危废管理台帐;2、检查维修喷淋设施,2018年11月6日开始对喷淋设施进行维修,15日前完成修复工作,以后定期检修,保持喷淋设施正常使用。3、设置进出车辆冲洗设施,完善淋溶水收集设施。由于该公司产品对温度有要求,禁止喷淋,现在搅拌站进出处口设立雨水槽清洗车辆,在沉淀池旁边增设雨水收集槽,最终注入沉淀,经沉淀过滤变成清水后循环使用。无23D340000201811010052滁州市天长市铜城镇精细化工集中区内修一制药、开林化工等几家企业排放工业废气严重影响周边居民正常生活,生产废水直接排入铜龙河,造成河水严重污染。滁州市大气,水,其他污染天长市组织天长市环保局、水利局、铜城镇等对该信访件开展调查处理。经查:1.信访件涉及的安徽修一制药有限公司。主要从事医药中间体的生产,由于该公司调试期间群众投诉不断,目前已停止生产。其“年产198吨普仑司特无水物等十二种医药中间体项目”环境影响报告书,于2016年11月2日经滁州市环境保护局审批(滁环〔2016〕500号);2018年4月16日,该公司完成二号精制车间、二号合成车间、仓储、办公场所及环评及批复要求的各类防治污染设施建设,进入调试状态。该公司建成设计能力500吨/天污水处理站一座,采用混凝预处理-铁碳微电解-芬顿-厌氧-水解酸化-一级接触氧化-二级接触氧化-臭氧杀菌工艺,对工艺废水、冲洗水、生活废水进行预处理符合接管标准后通过高架明管汇入铜城镇污水处理厂经深度处理后外排,不直接向环境排放。该公司合成车间、精细车间针对不同的废气各安装了3套废气处理设施,分别为碱淋洗+活性炭吸附装置,主要用于吸收盐酸等酸性挥发性溶剂;布袋除尘+活性炭吸附装置,主要用于车间粉尘的处理;UV光解+活性炭吸附装置,UV光解主要使有机或无机高分子恶臭化合物分子链,在高能紫外线光束照射下,降解转变成低分子化合物从而有助于活性炭的吸附,3套废气处理装置分区处理提高废气处理效果;同时,采取了封闭收集+碱液淋洗的工艺对污水处理站废气进行收集处置。针对群众多次投诉该公司气味影响,天长市环境保护局责令该公司委托具备相应资质的第三方检测机构对无组织废气进行监测,2018年6月下旬“合肥海正环境监测有限责任公司”对该公司无组织废气进行了监测,2018年6月30日出具的编号为:HZ18F1401Z的《检测报告》,结果显示无组织甲醇、甲苯、氨、硫化氢、臭气浓度五项指标均符合国家规定标准。2018年11月2日上午,天长市环境保护局会同铜城镇党委、政府及该公司负责人在铜城镇召开“安徽修一制药有限公司环保问题专家咨询会”,邀请南京工业大学、安徽省化工研究院专家踏勘该公司现场并审阅环评文件。专家一致认为:该公司已按环评要求建设了各项污染防治设施;同时,对在达标排放的基础上进一步优化技术措施,最大程度的降低排放浓度给出了指导性意见。前期根据群众举报线索,对安徽修一制药有限公司厂区内进行开挖,发现私自开凿的水井一口,水样经天长市环境监测站监测PH值7.63、COD10Lmg/L(低于检出限)、氨氮0.127mg/L,指标未见异常,排除利用水井排污的可能。2.信访涉及的安徽开林新材料股份有限公司。主要从事水性涂料、防腐涂料生产,目前处于正常生产状态。其“年产1万吨水性涂料及1万吨新型环保防腐涂料技术改造项目”环境影响报告书于2014年1月9日,经滁州市环境保护局审批(滁环〔2014〕25号);企业在完成水、气自主验收的同时于2018年5月25日完成固废、噪声竣工验收(滁环评函〔2018〕33号)。该公司工艺废水、生活废水、地面设备清洗水及初期雨水经自建污水处理站预处理符合接管标准后,通过高架明管汇入铜城镇污水处理厂经深度处理后外排,不直接向环境排放;该公司工艺废气按环评要求配套建设了布袋除尘器、活性炭吸附装置;危险废物交由安徽超越环保科技有限公司集中处置。该公司已通过环保竣工验收,验收监测数据、委托监测数据显示:该公司各类污染物排放均符合国家规定标准。3.铜龙河水质。2018年11月2日天长市环境保护局采集了铜龙河水样进行监测,同时梳理了2018年5月2日至10月9日的五次监督性监测数据,汇总六次监督性监测数据显示:铜龙河水样所监测指标符合《地表水环境质量标准》(GB3838-2002)表1中IV类标准限值;主要指标接近或符合III类标准。铜龙河水质状况优良。属实对安徽修一制药有限公司在厂区内私自开凿水井的违法行为,天长市水利局已依法下达《水行政处罚决定书》(天水罚字〔2018〕第01号),当事人已履行处罚决定,将非法开凿的水井封填完毕并将罚没款5万元缴纳到位。无24D340000201811010034马鞍山市花山区红旗桥铁道口沿铁道西侧800米处,一家非法钢渣加工点扬尘污染严重,设备生产时噪声严重扰民,属于散乱污企业。马鞍山市大气,噪音经调查,举报情况属实。在红旗桥铁道口沿铁道西侧800米处,发现一座无名废旧仓库,现场无序堆放少量钢渣及筛选设备,现场无加工生产活动。投诉人反映的钢渣加工点为赵承锁钢渣加工厂,无任何手续,属于散乱污企业,该钢渣加工点前期有生产加工行为,存在扬尘污染和噪声扰民问题。属实对赵承锁钢渣加工厂负责人进行了约谈,责令立即清除仓库钢渣及筛选设备。目前,露天堆放的钢渣及筛选设备已全部清运。无问责情形25D340000201811010056淮南市凤台县尚塘镇黄圩村大李庄西侧、凤利路南侧的砂石料经营点粉尘污染严重。淮南市大气信访件反映地点位于淮南市凤台县尚塘镇黄圩村大李庄西侧、凤利路南侧“尚塘乡液化气充装站”项目闲置场地内。尚塘镇进行农村道路提升工程建设,施工方在此处临时堆放道路施工用料,并非砂石料经营点。属实接转办信访件后,凤台县委、县政府立即组织环保、公安、市场监管等部门赶到现场进行核查督办,要求尚塘镇对该临时堆放点的砂石立即清除。截止11月4日,该处临时堆放点砂石等杂物已全部清除,地磅已拆除,地面实施了覆土。无26D340000201811010100合肥市滨湖新区巴黎都市小区一期东广场,夜间广场噪音扰民。合肥市噪音经包河区方兴社区工作人员会同公安包河分局执法人员于11月2日赴巴黎都市小区一期东广场现场核查,现场核查情况如下:该广场夜间有居民跳广场舞,噪声较大,核查投诉的情况与投诉人反映的情况一致。巴黎都市小区一期东广场位于合肥市滨湖新区湖北路与长沙路交口西南角,噪音污染来源于该小区十五名居民跳广场舞播放音乐,每晚19点30分左右开始至20点30分左右结束。属实包河区方兴社区已与广场舞组织者沟通协商,组织者已同意在广场舞活动中将降低音乐音量,减少对附近居民的影响。下一步,包河方兴社区将加大此地巡查力度,并联合公安包河分局与佳源物业和广场舞组织者对接,共同将广场舞噪音的影响降到最低。无27D340000201810310017合肥市经开区翡翠湖今年以来水质恶化,怀疑有养鱼、捕鱼,周边有生活污水排放入翡翠湖。合肥市水经合肥经开区建设发展局工作人员会同翡翠湖管养单位公用事业发展公司现场于11月2日赴翡翠湖现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。因翡翠湖上游汇水区域部分小区等单位管网存在损坏或错接,导致有少量生活污水入湖,同时因翡翠湖自2006年改造蓄水后水位较高,死水湾水体得不到交换,加上建成区城市径流初期雨水携带一定的污染物对湖区水质产生一定影响。湖内投放了一定数量的鱼苗,主要是为改善翡翠湖水质,净化水体,没有投放饵料等饲养行为。属实一是对投放的鱼苗种类和数量严格控制,禁止投放饵料;二是在2018年11月4日前完成入湖生活污水截流应急整改;三是加大管养力度,由合肥经开区公用公司及时打捞水面垃圾、杂物,收割处理水生植物,减轻对水体水质影响;同时为进一步改善水质,邀请专业水治理单位在水质较差的死水湾区域做改善水质实验,成功后立即推广应用,并持续推进上游雨污管网错接混接排查整治,督促存在错接混接单位制定整改方案及时完成整改。无28D340000201811010055合肥市包河区巢湖南路路面积尘严重,影响出行。合肥市大气经包河区淝河镇工作人员会同区城管委执法人员于11月2日赴巢湖南路现场核查,现场核查情况如下:巢湖南路扬尘污染较大,核查投诉的情况与投诉人反映的情况一致。包河区淝河片区东临南淝河、西至十五里河中段高铁南站片区、北接老城区、南抵包河经开区,总占地面积32600亩。2016年8月,经摸底调查,该区域居住群众12260户,多为“城中村”,环境脏乱差。巢湖南路大型车辆出入频繁,导致路况变差、道路基础设施破损严重,致使路基垫层外渗,道路清扫保洁难度大;并且巢湖南路周边存在南淝河路、郎溪路二、三标等施工工地,途经上述工地的南淝河路及郎溪路尚未完全开通,工地渣土运输主要经过巢湖南路,加剧路面循环污染。虽然已采取了加大清扫保洁频次和洒水降尘力度等措施,但无法根治该区域严重的扬尘污染问题。位于巢湖南路、南淝河路沿线集聚混凝土搅拌站共19家。其生产、运输过程带来的扬尘、噪音及水污染问题严重,居民苦不堪言。近几年,有关淝河镇混凝土搅拌站污染的热线投诉、网友留言居高不下。针对淝河片区脏乱差的状况,包河区委、区政府高度重视,深入研判,自2016年初,即开始全面谋划论证淝河片区整体改造工作。其中,针对片区范围内的19家混凝土企业,由于不符合片区土地利用总体规划及未来改造发展业态布局,包河区将其全部纳入搬迁改造范围,并迅速启动相关工作。1、加快签订搬迁协议。对19家混凝土搅拌站下达搬迁改造通知,并陆续启动丈量、评估、签订协议及补偿相关工作。针对企业主反映的补偿问题,包河区本着“尊重历史、面对现实”的原则,耐心开展政策解释和上门沟通工作,尽量取得企业的理解和支持。截至目前,已与16家搅拌站签订了搬迁协议。下剩3家企业由于对搬迁补偿存有一定异议,目前正在积极洽谈推进中。2、积极对接复建事宜。考虑到混凝土企业搬迁可能带来的订单协议违约、员工就业及往来债务等问题,包河区积极协调对接,全力支持搬迁企业开展复建工作。3、加强日常巡查监管。针对混凝土搅拌站搬迁复建前的生产运营,包河区持续加强监督管理,加大扬尘等环境污染防治工作。一是加大宣传教育。中央环保督察期间,针对淝河片区混凝土企业的信访投诉量大的情况,辖区淝河镇、村居对混凝土企业加强宣传教育,要求其文明生产,并落实相关降尘抑尘等环保措施。二是强化监控巡查。区住建局通过行业视频系统,常态化监控搅拌站内洒水降尘、物料覆盖及生产运营环节的扬尘防治;区环保局、辖区淝河镇等加大日常巡查频次,督促企业将各项环保措施落到实处。三是依法行政处罚。对于环保不达标、未通过项目竣工环保验收、违反《建设项目环境保护管理条例》等相关规定的混凝土企业经营行为,区环保等相关部门依法对其进行行政处罚,并责令其落实整改措施。属实1、包河区淝河镇加大对周边工地巡查力度,严格落实扬尘污染防治要求,确保物料堆放覆盖、出入车辆清洗、渣土车辆密闭运输等措施落实到位。同时,对巢湖南路等重点路段进行严格巡查,对过往抛洒滴漏车辆进行依法查处。2、2018年至今,包河区住建局对淝河镇巢湖南路周边混凝土企业共巡查54次,下达监督意见书39份,对巡查发现的问题均敦促企业落实专人限期整改到位。3、针对巢湖南路路面扬尘的路况实际,为做好大气污染控制,包河区环卫服务中心不断增加了作业车辆,加大洒水降尘频次,实行循环作业。在夜间完成全区主次干道统一的冲洗保洁作业,在白天做好路面保湿抑尘工作,并在晚间薄弱时段增派车辆加强路面降尘保湿。具体措施:(1)洒水车依次循环路面洒水作业,保持路面湿润,抑制扬尘;(2)洗扫车湿扫路牙灰砂,将路牙边的灰砂洗扫干净;(3)小货车清运石子、灰砂;(4)道路养护车配合人工对人行道进行冲洗作业。无29D340000201811010037合肥市包河区巢湖南路绿色港湾小区东北边的小河,污水管网修之前河水很清,修后今年夏天河水很臭,目前不臭,怀疑是污水管道接错了或者小区污水倒灌;小区西侧的小河常年发臭。合肥市水经包河区淝河镇工作人员会同住建局、农林水务局工作人员于11月2日赴绿色港湾小区现场核查,现场核查情况如下:东北侧小河水质较清,西侧小河河水发臭,核查投诉的情况与投诉人反映的情况一致。绿色港湾小区东北边的小河为徐涵中心沟,目前水质较好无异味,前期包河区淝河镇、住建局已对大蒋站排涝沟进行检测,共排查8处排水口,其中3处已废弃,另有4处排水口位于拆迁区域内民房生活用水排放和农田灌溉沟渠排口,属于雨污混排口,后期将结合淝河片区改造,对其进行整改修复。检测过程中未发现该沟渠污水管道混接或者小区污水倒灌现象,新修的巢湖南路雨污水管网均未接入该沟渠。2018年6月包河区住建局已安排检测单位对小区西侧小河污水来源进行检测,检测结果为兰渡路雨污合流管线及两侧明渠、暗渠和污染源导致该沟渠水质较差。属实根据《包河区分流制排水系统雨污混接调查和整治工作方案》,包河区淝河镇联合区住建局、农林水务局将对小区西侧小河进行后续溯源、整治工作。淝河镇牵头组织溯源排查后制定截污方案,实施截污工程。区农林水务局负责明渠、暗渠调查和整治工作,包河区市政处调查和整治兰渡路合流管道,沿线城中村污染源由包河区淝河镇调查和整治。目前,包河区淝河镇已定期对徐涵中心沟进行河面浮萍打捞清理,保持河面整洁。无30D340000201810310030合肥市庐江县白湖镇泉水村李庄村民组西边的永祥塑料厂夜间生产排放难闻废气,废渣偷偷在厂内挖深沟填埋,。合肥市大气,土壤反映的永祥塑料厂全称为庐江县永祥废旧再生塑料厂,位于庐江县白湖镇泉水村境内,主要从事废旧塑料加工,法人代表王永祥。该厂年产600吨再生塑料颗粒项目环境影响报告表于2008年4月份经庐江县环保局审批(庐环[2008]68号)。2010年12月份,该项目通过了庐江县环保局组织的竣工环境保护验收(庐环验[2010]30号)。2009年4月份办理了工商营业执照。11月1日夜间,庐江县环保局会同白湖镇政府工作人员到该厂核查,现场该厂未生产,也未发现有生产痕迹。之前该厂存在环境违法行为,庐江县环保局于2018年8月9日向该公司下达了责令改正违法行为决定书(庐环2018124号)责令其停产整改,该厂将整改期间废渣存放在防渗池内。现场厂区未发现深沟填埋废渣痕迹。不属实庐江县环保局和白湖镇政府将加大对庐江县永祥废旧再生塑料厂监管力度,监督其未经批准不得擅自恢复生产,一旦发现有环境违法行为从严查处。无31D340000201811010036合肥市蜀山区肥西路与煤场路交口西南角(休宁路与合作化路交口东北角)的合肥热电集团有限公司粉尘、噪声污染扰民;合肥市地方铁路投资建设有限公司每周至少两次卸煤粉尘、噪声污染扰民。合肥市大气,噪音经蜀山区环保局执法人员会同经促局、发改局、稻香村街道于2018年11月2日赴企业现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。1.该企业目前处于正常生产状态,现有5台锅炉(其中1台正常使用,4台停用进行升级改造),锅炉升级改造过程存在施工噪声污染。该公司煤堆场处于露天状态,未落实防尘措施。2.合肥市地方铁路投资建设有限公司南七货场作业场所(卸煤区)为露天作业场所,未建大棚覆盖。现场约10名工作人员正在清扫卸煤区地面,地面干燥,粉尘大,清扫过程无降尘措施。通过前期检查和翻阅台账发现装卸物料未采取密闭或者喷淋等方式控制扬尘,据了解,该货场于2018年10月投入使用雾炮车,2018年11月2日现场监察时雾炮车洒水台账已记录到2018年11月5日。属实1.蜀山区环保局对企业下达《责令改正违法行为决定书》(蜀环决〔20181103号),并约谈该公司负责人,要求其立即整改,同时对该公司环境违法行为进行立案查处。该公司整改如下:由该企业集团公司统一调度,将该公司1/4的热负荷分配至皖能合肥电厂及天源分公司,以降低该公司火车来煤量,减少对周边环境的影响;减少卸煤噪音,在卸煤过程中,车门轻关轻开,禁止鸣笛;该企业原有移动式喷雾机一台,计划在2018年12月底前再购买一台车载式移动雾炮设备,用于抑制火车卸煤及运转过程中产生的扬尘;该企业在原有水管及喷头的基础上增加固定水管40米,洒水喷头5个,用于煤场东部洒水抑尘;购买防风抑尘网或者人工草皮对煤场进行全覆盖;加装视频监控设备,对煤场实现无死角监控;加强对生产现场的管理,设置煤场专职管理班组,在火车卸煤后进行喷水降尘,并对燃煤进行覆盖,燃煤转运过程中进行洒水、清扫等,严控噪音及扬尘的产生;根据“621”发展战略计划2年内由皖能合肥发电厂及金源热电机组改扩建,取代该企业供热负荷2.蜀山区环保局对合肥市地方铁路投资建设有限公司南七货运站的环境违法行为进行立案查处。该单位整改如下:自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货运站Ⅰ道(北侧铁路线)无限期停止接卸煤炭运输列车;自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货场Ⅱ道(南侧铁路线)在地铁公司和该企业共同达成关于铁路货场环保整体改造方案并获得环保部门核准同意前,暂停止接卸煤炭运输列车。此项措施书面通知企业。2018年11月2日函告中国铁路总公司上海局集团有限公司合肥货运中心,即日起合肥市地方铁路投资建设有限公司南七货运站Ⅰ道停止接卸、Ⅱ道暂停接卸煤炭。自2018年11月3日起30天内,责成南七货运站内各经营户将现有存煤全部清运出南七货运站,在此期间除煤炭外运车辆外,禁止一切车辆进入货运站;煤炭外运车辆严格按照环保部门要求,落实限高、苫盖、车身、车胎清扫冲洗等措施。自2018年11月3日起,合肥市地方铁路投资建设有限公司南七货场Ⅰ道(北侧铁路线)仅留5米宽路面作为雾炮洒水车作业通道,路面每日清扫;货场内其余地面,用绿色苫布进行苫盖,并组织人力不定期对苫盖地面进行清扫,清扫后恢复苫盖,场地清扫与洒水跟班作业。自2018年11月4日起,对站内各煤炭经营户现存煤炭外运车辆,严格按照地铁公司2018年第4号专题会议纪要规定,进行装车作业。合肥市地方铁路投资建设有限公司针对无法禁止的国铁货运列车在南七货运站调车及存车作业,与国铁相关部门积极协调,最大程度减少鸣笛。公司相关业务部门相互协作,要明确任务,强化责任,严格检查,严肃纪律,对违反公司相关规定的行为,一律从重处罚。无32D340000201810310015合肥市蜀山区康馨民家小区附近煤场和众城热电厂,无防尘措施,噪音污染严重,多次投诉整改不到位,要求企业搬迁。合肥市大气,噪音经蜀山区环保局执法人员会同经促局、发改局、稻香村街道于2018年11月2日赴企业场现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。1.该企业目前处于正常生产状态,现有5台锅炉(其中1台正常使用,4台停用进行升级改造),锅炉升级改造过程存在施工噪声污染。该公司煤堆场处于露天状态,未落实防尘措施。2.合肥市地方铁路投资建设有限公司南七货场作业场所(卸煤区)为露天作业场所,未建大棚覆盖。现场约10名工作人员正在清扫卸煤区地面,地面干燥,粉尘大,清扫过程无降尘措施。通过前期检查和翻阅台账发现装卸物料未采取密闭或者喷淋等方式控制扬尘,据了解,该货场于2018年10月投入使用雾炮车,2018年11月2日现场监察时雾炮车洒水台账已记录到2018年11月5日。属实1.蜀山区环保局对企业下达《责令改正违法行为决定书》(蜀环决〔20181103号),并约谈该公司负责人,要求其立即整改,同时对该公司环境违法行为进行立案查处。该公司整改如下:由该企业集团公司统一调度,将该公司1/4的热负荷分配至皖能合肥电厂及天源分公司,以降低该公司火车来煤量,减少对周边环境的影响;减少卸煤噪音,在卸煤过程中,车门轻关轻开,禁止鸣笛;该企业原有移动式喷雾机一台,计划在2018年12月底前再购买一台车载式移动雾炮设备,用于抑制火车卸煤及运转过程中产生的扬尘;该企业在原有水管及喷头的基础上增加固定水管40米,洒水喷头5个,用于煤场东部洒水抑尘;购买防风抑尘网或者人工草皮对煤场进行全覆盖;加装视频监控设备,对煤场实现无死角监控;加强对生产现场的管理,设置煤场专职管理班组,在火车卸煤后进行喷水降尘,并对燃煤进行覆盖,燃煤转运过程中进行洒水、清扫等,严控噪音及扬尘的产生;根据“621”发展战略计划2年内由皖能合肥发电厂及金源热电机组改扩建,取代该企业供热负荷。2.蜀山区环保局对合肥市地方铁路投资建设有限公司南七货运站的环境违法行为进行立案查处。该单位整改如下:自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货运站Ⅰ道(北侧铁路线)无限期停止接卸煤炭运输列车;自2018年11月2日24时起,合肥市地方铁路投资建设有限公司南七货场Ⅱ道(南侧铁路线)在地铁公司和该公司共同达成关于铁路货场环保整体改造方案并获得环保部门核准同意前,暂停止接卸煤炭运输列车。此项措施书面通知企业。2018年11月2日函告中国铁路总公司上海局集团有限公司合肥货运中心,即日起合肥市地方铁路投资建设有限公司南七货运站Ⅰ道停止接卸、Ⅱ道暂停接卸煤炭。自2018年11月3日起30天内,责成南七货运站内各经营户将现有存煤全部清运出南七货运站,在此期间除煤炭外运车辆外,禁止一切车辆进入货运站;煤炭外运车辆严格按照环保部门要求,落实限高、苫盖、车身、车胎清扫冲洗等措施。自2018年11月3日起,合肥市地方铁路投资建设有限公司南七货场Ⅰ道(北侧铁路线)仅留5米宽路面作为雾炮洒水车作业通道,路面每日清扫;货场内其余地面,用绿色苫布进行苫盖,并组织人力不定期对苫盖地面进行清扫,清扫后恢复苫盖,场地清扫与洒水跟班作业。自2018年11月4日起,对站内各煤炭经营户现存煤炭外运车辆,严格按照地铁公司2018年第4号专题会议纪要规定,进行装车作业。合肥市地方铁路投资建设有限公司针对无法禁止的国铁货运列车在南七货运站调车及存车作业,与国铁相关部门积极协调,最大程度减少鸣笛。公司相关业务部门相互协作,要明确任务,强化责任,严格检查,严肃纪律,对违反公司相关规定的行为,一律从重处罚。无33D340000201810310003合肥市新站区梅冲湖路与九顶山路向南150米,原爱瑞德企业院内有二家木材厂,隔壁有一家木材厂,共3家木材厂进行木材破碎,粉尘、噪音污染严重,多次投诉没有得到解决。合肥市大气,噪音新站区环保局会同三十头社区管委会工作人员于11月2日赴投诉企业现场核查,情况如下:投诉反映的爱瑞德企业实际为原安徽国仓管桩集团有限公司,该公司院内有两处露天木材破碎加工点(无营业执照,实际经营者为同一人:王闫)、该公司南侧围墙外有一家木材破碎加工点(营业执照注册名:合肥肥东环能生物质能源有限公司),三处木材加工点现场灰尘较大。属实转办投诉前,我区已在调查处理,11月1日现场约谈了两处木材加工厂负责人,要求立即停止生产,清理现场。11月2日区环保分局针对合肥肥东环能生物质能源有限公司、王闫分别下达行政处罚事先(听证)告知书:合环(新)罚告字〔2018〕183号、〔2018〕190号,分别罚款2万元,共计4万元。目前,投诉的3处木材加工点均已停产,现场生产设备已拆除。无34D340000201810310009合肥市包河区巢湖南路有十余家混凝土搅拌站,进出搅拌车辆扬尘污染严重,搅拌车辆闯红灯有安全隐患,多次投诉问题没有得到解决。合肥市大气经包河区淝河镇工作人员会同区住建局、交警包河大队执法人员于11月2日赴巢湖南路现场核查,现场核查情况如下:巢湖南路扬尘污染较大,确实存在大型车辆闯红灯现象,核查投诉的情况与投诉人反映的情况一致。包河区淝河片区东临南淝河、西至十五里河中段高铁南站片区、北接老城区、南抵包河经开区,总占地面积32600亩。2016年8月,经摸底调查,该区域居住群众12260户,多为“城中村”,环境脏乱差。巢湖南路大型车辆出入频繁,导致路况变差、道路基础设施破损严重,致使路基垫层外渗,道路清扫保洁难度大;并且巢湖南路周边存在南淝河路(东二环―长春街)、郎溪路二、三标等施工工地,途经上述工地的南淝河路及郎溪路尚未完全开通,工地渣土运输主要经过巢湖南路,加剧路面循环污染。虽然已采取了加大清扫保洁频次和洒水降尘力度等措施,但无法根治该区域严重的扬尘污染问题。位于巢湖南路、南淝河路沿线集聚混凝土搅拌站共19家。其生产、运输过程带来的扬尘、噪音及水污染问题严重,居民苦不堪言。近几年,有关淝河镇混凝土搅拌站污染的热线投诉、网友留言居高不下。针对淝河片区脏乱差的状况,包河区委、区政府高度重视,深入研判,自2016年初,即开始全面谋划论证淝河片区整体改造工作。其中,针对片区范围内的19家混凝土企业,由于不符合片区土地利用总体规划及未来改造发展业态布局,包河区将其全部纳入搬迁改造范围,并迅速启动相关工作。1、加快签订搬迁协议。对19家混凝土搅拌站下达搬迁改造通知,并陆续启动丈量、评估、签订协议及补偿相关工作。针对企业主反映的补偿问题,包河区本着“尊重历史、面对现实”的原则,耐心开展政策解释和上门沟通工作,尽量取得企业的理解和支持。截至目前,已与16家搅拌站签订了搬迁协议。下剩3家企业由于对搬迁补偿存有一定异议,目前正在积极洽谈推进中。2、积极对接复建事宜。考虑到混凝土企业搬迁可能带来的订单协议违约、员工就业及往来债务等问题,包河区积极协调对接,全力支持搬迁企业开展复建工作。3、加强日常巡查监管。针对混凝土搅拌站搬迁复建前的生产运营,包河区持续加强监督管理,加大扬尘等环境污染防治工作。一是加大宣传教育。中央环保督察期间,针对淝河片区混凝土企业的信访投诉量大的情况,辖区淝河镇、村居对混凝土企业加强宣传教育,要求其文明生产,并落实相关降尘抑尘等环保措施。二是强化监控巡查。区住建局通过行业视频系统,常态化监控搅拌站内洒水降尘、物料覆盖及生产运营环节的扬尘防治;区环保局、辖区淝河镇等加大日常巡查频次,督促企业将各项环保措施落到实处。三是依法行政处罚。对于环保不达标、未通过项目竣工环保验收、违反《建设项目环境保护管理条例》等相关规定的混凝土企业经营行为,区环保等相关部门依法对其进行行政处罚,并责令其落实整改措施。属实1、包河区淝河镇加大对周边工地巡查力度,严格落实扬尘污染防治要求,确保物料堆放覆盖、出入车辆清洗、渣土车辆密闭运输等措施落实到位。同时,对巢湖南路等重点路段进行严格巡查,对过往抛洒滴漏车辆进行依法查处。2、2018年至今,包河区住建局对淝河镇巢湖南路周边混凝土企业共巡查54次,下达监督意见书39份,对巡查发现的问题均敦促企业落实专人限期整改到位。3、针对巢湖南路路面扬尘的路况实际,为做好大气污染控制,包河区环卫服务中心不断增加了作业车辆,加大洒水降尘频次,实行循环作业。在夜间完成全区主次干道统一的冲洗保洁作业,在白天做好路面保湿抑尘工作,并在晚间薄弱时段增派车辆加强路面降尘保湿。具体措施:(1)洒水车依次循环路面洒水作业,保持路面湿润,抑制扬尘;(2)洗扫车湿扫路牙灰砂,将路牙边的灰砂洗扫干净;(3)小货车清运石子、灰砂;(4)道路养护车配合人工对人行道进行冲洗作业。4、加强交通管理。交警包河大队在二环路和巢湖南路设置了固定岗,对该片区的大型车辆进行严格管理,特别是针对闯红灯重点违法行为,一律予以200元记6分的处罚,同时加大对辖区货运企业开展交通安全宣传,倡导文明行车,目前该区域交通环境良好。无35D340000201810310001合肥市庐阳区南国花园小区9号楼南侧5米左右,变压器产生低频噪音,影响居民正常生活。合肥市噪音11月2日上午,亳州路街道、庐阳区环保局工作人员联合供电部门对南国花园9号楼南侧5米变压器进行现场查看,并委托有资质的第三方检测机构对噪声进行检测。经检测噪声超标,投诉人反映情况属实。属实亳州路街道于11月5日向供电部门去函要求落实整改。目前供电部门正联系对该处变压器安装隔音罩,预计11月8日前制作完成,亳州路街道督促其尽快落实整改。无36D340000201810310010合肥政务区附近的发能太阳海岸、恒大华府小区、融科城小区附近每隔两三天夜间就能闻到刺鼻性气味。合肥市大气经开区:经合肥经开区环保分局执法人员会同环保第三方巡查人员于11月1日开始连续3天昼间、夜间赴融科城小区周边现场核查,情况如下:核查投诉的情况与投诉人反映的情况部分一致。经排查,融科城小区附近合肥经开区辖区范围均为商住小区,排查未发现该小区周边合肥经开范围有反映类似气味企业。蜀山区:经蜀山区环保局执法人员会同笔架山街道于2018年11月2日赴政务区发能太阳海岸、恒大华府2个小区现场核查,现场核查情况如下:核查投诉的情况与投诉人反映的情况基本一致。(但未在我辖区发现气味源)。经查,2个小区周边为居民楼及匡河景观带,环境质量较好,未发现刺鼻性气味,且笔架山街道辖区范围内无工业企业。通过进一步走访群众,发现刺鼻性气味是间歇性的,且在高层闻到的概率较大。属实经开区:安排环保第三方巡查人员每天昼间、夜间对融科城周边区域进行巡查,发现问题及时处理。蜀山区:2018年11月3日,笔架山街道牵头召开发能太阳海岸、恒大华府2个小区居民“关于晚间刺鼻性气味问题基本调查摸底情况通报会”,参加会议人员有小区业委会、业主、党员、物业公司等代表。会议通报了该信访件调查情况。无打印关闭(责任编辑: HN666)
9 |
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/词嵌入图1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 4 词嵌入与word2vec/词嵌入图1.jpg
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/词嵌入图2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 4 词嵌入与word2vec/词嵌入图2.jpg
--------------------------------------------------------------------------------
/Chapter 4 词嵌入与word2vec/词嵌入图片2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 4 词嵌入与word2vec/词嵌入图片2.png
--------------------------------------------------------------------------------
/Chapter 5 文本数据增强/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 5 文本数据增强/logo.png
--------------------------------------------------------------------------------
/Chapter 5 文本数据增强/停用词.txt:
--------------------------------------------------------------------------------
1 | !
2 | "
3 | #
4 | $
5 | %
6 | &
7 | '
8 | (
9 | )
10 | *
11 | +
12 | ,
13 | -
14 | --
15 | .
16 | ..
17 | ...
18 | ......
19 | ...................
20 | ./
21 | .一
22 | .数
23 | .日
24 | /
25 | //
26 | 0
27 | 1
28 | 2
29 | 3
30 | 4
31 | 5
32 | 6
33 | 7
34 | 8
35 | 9
36 | :
37 | ://
38 | ::
39 | ;
40 | <
41 | =
42 | >
43 | >>
44 | ?
45 | @
46 | A
47 | Lex
48 | [
49 | \
50 | ]
51 | ^
52 | _
53 | `
54 | exp
55 | sub
56 | sup
57 | |
58 | }
59 | ~
60 | ~~~~
61 | ·
62 | ×
63 | ×××
64 | Δ
65 | Ψ
66 | γ
67 | μ
68 | φ
69 | φ.
70 | В
71 | —
72 | ——
73 | ———
74 | ‘
75 | ’
76 | ’‘
77 | “
78 | ”
79 | ”,
80 | …
81 | ……
82 | …………………………………………………③
83 | ′∈
84 | ′|
85 | ℃
86 | Ⅲ
87 | ↑
88 | →
89 | ∈[
90 | ∪φ∈
91 | ≈
92 | ①
93 | ②
94 | ②c
95 | ③
96 | ③]
97 | ④
98 | ⑤
99 | ⑥
100 | ⑦
101 | ⑧
102 | ⑨
103 | ⑩
104 | ──
105 | ■
106 | ▲
107 |
108 | 、
109 | 。
110 | 〈
111 | 〉
112 | 《
113 | 》
114 | 》),
115 | 」
116 | 『
117 | 』
118 | 【
119 | 】
120 | 〔
121 | 〕
122 | 〕〔
123 | ㈧
124 | 一
125 | 一.
126 | 一一
127 | 一下
128 | 一个
129 | 一些
130 | 一何
131 | 一切
132 | 一则
133 | 一则通过
134 | 一天
135 | 一定
136 | 一方面
137 | 一旦
138 | 一时
139 | 一来
140 | 一样
141 | 一次
142 | 一片
143 | 一番
144 | 一直
145 | 一致
146 | 一般
147 | 一起
148 | 一转眼
149 | 一边
150 | 一面
151 | 七
152 | 万一
153 | 三
154 | 三天两头
155 | 三番两次
156 | 三番五次
157 | 上
158 | 上下
159 | 上升
160 | 上去
161 | 上来
162 | 上述
163 | 上面
164 | 下
165 | 下列
166 | 下去
167 | 下来
168 | 下面
169 | 不
170 | 不一
171 | 不下
172 | 不久
173 | 不了
174 | 不亦乐乎
175 | 不仅
176 | 不仅...而且
177 | 不仅仅
178 | 不仅仅是
179 | 不会
180 | 不但
181 | 不但...而且
182 | 不光
183 | 不免
184 | 不再
185 | 不力
186 | 不单
187 | 不变
188 | 不只
189 | 不可
190 | 不可开交
191 | 不可抗拒
192 | 不同
193 | 不外
194 | 不外乎
195 | 不够
196 | 不大
197 | 不如
198 | 不妨
199 | 不定
200 | 不对
201 | 不少
202 | 不尽
203 | 不尽然
204 | 不巧
205 | 不已
206 | 不常
207 | 不得
208 | 不得不
209 | 不得了
210 | 不得已
211 | 不必
212 | 不怎么
213 | 不怕
214 | 不惟
215 | 不成
216 | 不拘
217 | 不择手段
218 | 不敢
219 | 不料
220 | 不断
221 | 不日
222 | 不时
223 | 不是
224 | 不曾
225 | 不止
226 | 不止一次
227 | 不比
228 | 不消
229 | 不满
230 | 不然
231 | 不然的话
232 | 不特
233 | 不独
234 | 不由得
235 | 不知不觉
236 | 不管
237 | 不管怎样
238 | 不经意
239 | 不胜
240 | 不能
241 | 不能不
242 | 不至于
243 | 不若
244 | 不要
245 | 不论
246 | 不起
247 | 不足
248 | 不过
249 | 不迭
250 | 不问
251 | 不限
252 | 与
253 | 与其
254 | 与其说
255 | 与否
256 | 与此同时
257 | 专门
258 | 且
259 | 且不说
260 | 且说
261 | 两者
262 | 严格
263 | 严重
264 | 个
265 | 个人
266 | 个别
267 | 中小
268 | 中间
269 | 丰富
270 | 串行
271 | 临
272 | 临到
273 | 为
274 | 为主
275 | 为了
276 | 为什么
277 | 为什麽
278 | 为何
279 | 为止
280 | 为此
281 | 为着
282 | 主张
283 | 主要
284 | 举凡
285 | 举行
286 | 乃
287 | 乃至
288 | 乃至于
289 | 么
290 | 之
291 | 之一
292 | 之前
293 | 之后
294 | 之後
295 | 之所以
296 | 之类
297 | 乌乎
298 | 乎
299 | 乒
300 | 乘
301 | 乘势
302 | 乘机
303 | 乘胜
304 | 乘虚
305 | 乘隙
306 | 九
307 | 也
308 | 也好
309 | 也就是说
310 | 也是
311 | 也罢
312 | 了
313 | 了解
314 | 争取
315 | 二
316 | 二来
317 | 二话不说
318 | 二话没说
319 | 于
320 | 于是
321 | 于是乎
322 | 云云
323 | 云尔
324 | 互
325 | 互相
326 | 五
327 | 些
328 | 交口
329 | 亦
330 | 产生
331 | 亲口
332 | 亲手
333 | 亲眼
334 | 亲自
335 | 亲身
336 | 人
337 | 人人
338 | 人们
339 | 人家
340 | 人民
341 | 什么
342 | 什么样
343 | 什麽
344 | 仅
345 | 仅仅
346 | 今
347 | 今后
348 | 今天
349 | 今年
350 | 今後
351 | 介于
352 | 仍
353 | 仍旧
354 | 仍然
355 | 从
356 | 从不
357 | 从严
358 | 从中
359 | 从事
360 | 从今以后
361 | 从优
362 | 从古到今
363 | 从古至今
364 | 从头
365 | 从宽
366 | 从小
367 | 从新
368 | 从无到有
369 | 从早到晚
370 | 从未
371 | 从来
372 | 从此
373 | 从此以后
374 | 从而
375 | 从轻
376 | 从速
377 | 从重
378 | 他
379 | 他人
380 | 他们
381 | 他是
382 | 他的
383 | 代替
384 | 以
385 | 以上
386 | 以下
387 | 以为
388 | 以便
389 | 以免
390 | 以前
391 | 以及
392 | 以后
393 | 以外
394 | 以後
395 | 以故
396 | 以期
397 | 以来
398 | 以至
399 | 以至于
400 | 以致
401 | 们
402 | 任
403 | 任何
404 | 任凭
405 | 任务
406 | 企图
407 | 伙同
408 | 会
409 | 伟大
410 | 传
411 | 传说
412 | 传闻
413 | 似乎
414 | 似的
415 | 但
416 | 但凡
417 | 但愿
418 | 但是
419 | 何
420 | 何乐而不为
421 | 何以
422 | 何况
423 | 何处
424 | 何妨
425 | 何尝
426 | 何必
427 | 何时
428 | 何止
429 | 何苦
430 | 何须
431 | 余外
432 | 作为
433 | 你
434 | 你们
435 | 你是
436 | 你的
437 | 使
438 | 使得
439 | 使用
440 | 例如
441 | 依
442 | 依据
443 | 依照
444 | 依靠
445 | 便
446 | 便于
447 | 促进
448 | 保持
449 | 保管
450 | 保险
451 | 俺
452 | 俺们
453 | 倍加
454 | 倍感
455 | 倒不如
456 | 倒不如说
457 | 倒是
458 | 倘
459 | 倘使
460 | 倘或
461 | 倘然
462 | 倘若
463 | 借
464 | 借以
465 | 借此
466 | 假使
467 | 假如
468 | 假若
469 | 偏偏
470 | 做到
471 | 偶尔
472 | 偶而
473 | 傥然
474 | 像
475 | 儿
476 | 允许
477 | 元/吨
478 | 充其极
479 | 充其量
480 | 充分
481 | 先不先
482 | 先后
483 | 先後
484 | 先生
485 | 光
486 | 光是
487 | 全体
488 | 全力
489 | 全年
490 | 全然
491 | 全身心
492 | 全部
493 | 全都
494 | 全面
495 | 八
496 | 八成
497 | 公然
498 | 六
499 | 兮
500 | 共
501 | 共同
502 | 共总
503 | 关于
504 | 其
505 | 其一
506 | 其中
507 | 其二
508 | 其他
509 | 其余
510 | 其后
511 | 其它
512 | 其实
513 | 其次
514 | 具体
515 | 具体地说
516 | 具体来说
517 | 具体说来
518 | 具有
519 | 兼之
520 | 内
521 | 再
522 | 再其次
523 | 再则
524 | 再有
525 | 再次
526 | 再者
527 | 再者说
528 | 再说
529 | 冒
530 | 冲
531 | 决不
532 | 决定
533 | 决非
534 | 况且
535 | 准备
536 | 凑巧
537 | 凝神
538 | 几
539 | 几乎
540 | 几度
541 | 几时
542 | 几番
543 | 几经
544 | 凡
545 | 凡是
546 | 凭
547 | 凭借
548 | 出
549 | 出于
550 | 出去
551 | 出来
552 | 出现
553 | 分别
554 | 分头
555 | 分期
556 | 分期分批
557 | 切
558 | 切不可
559 | 切切
560 | 切勿
561 | 切莫
562 | 则
563 | 则甚
564 | 刚
565 | 刚好
566 | 刚巧
567 | 刚才
568 | 初
569 | 别
570 | 别人
571 | 别处
572 | 别是
573 | 别的
574 | 别管
575 | 别说
576 | 到
577 | 到了儿
578 | 到处
579 | 到头
580 | 到头来
581 | 到底
582 | 到目前为止
583 | 前后
584 | 前此
585 | 前者
586 | 前进
587 | 前面
588 | 加上
589 | 加之
590 | 加以
591 | 加入
592 | 加强
593 | 动不动
594 | 动辄
595 | 勃然
596 | 匆匆
597 | 十分
598 | 千
599 | 千万
600 | 千万千万
601 | 半
602 | 单
603 | 单单
604 | 单纯
605 | 即
606 | 即令
607 | 即使
608 | 即便
609 | 即刻
610 | 即如
611 | 即将
612 | 即或
613 | 即是说
614 | 即若
615 | 却
616 | 却不
617 | 历
618 | 原来
619 | 去
620 | 又
621 | 又及
622 | 及
623 | 及其
624 | 及时
625 | 及至
626 | 双方
627 | 反之
628 | 反之亦然
629 | 反之则
630 | 反倒
631 | 反倒是
632 | 反应
633 | 反手
634 | 反映
635 | 反而
636 | 反过来
637 | 反过来说
638 | 取得
639 | 取道
640 | 受到
641 | 变成
642 | 古来
643 | 另
644 | 另一个
645 | 另一方面
646 | 另外
647 | 另悉
648 | 另方面
649 | 另行
650 | 只
651 | 只当
652 | 只怕
653 | 只是
654 | 只有
655 | 只消
656 | 只要
657 | 只限
658 | 叫
659 | 叫做
660 | 召开
661 | 叮咚
662 | 叮当
663 | 可
664 | 可以
665 | 可好
666 | 可是
667 | 可能
668 | 可见
669 | 各
670 | 各个
671 | 各人
672 | 各位
673 | 各地
674 | 各式
675 | 各种
676 | 各级
677 | 各自
678 | 合理
679 | 同
680 | 同一
681 | 同时
682 | 同样
683 | 后
684 | 后来
685 | 后者
686 | 后面
687 | 向
688 | 向使
689 | 向着
690 | 吓
691 | 吗
692 | 否则
693 | 吧
694 | 吧哒
695 | 吱
696 | 呀
697 | 呃
698 | 呆呆地
699 | 呐
700 | 呕
701 | 呗
702 | 呜
703 | 呜呼
704 | 呢
705 | 周围
706 | 呵
707 | 呵呵
708 | 呸
709 | 呼哧
710 | 呼啦
711 | 咋
712 | 和
713 | 咚
714 | 咦
715 | 咧
716 | 咱
717 | 咱们
718 | 咳
719 | 哇
720 | 哈
721 | 哈哈
722 | 哉
723 | 哎
724 | 哎呀
725 | 哎哟
726 | 哗
727 | 哗啦
728 | 哟
729 | 哦
730 | 哩
731 | 哪
732 | 哪个
733 | 哪些
734 | 哪儿
735 | 哪天
736 | 哪年
737 | 哪怕
738 | 哪样
739 | 哪边
740 | 哪里
741 | 哼
742 | 哼唷
743 | 唉
744 | 唯有
745 | 啊
746 | 啊呀
747 | 啊哈
748 | 啊哟
749 | 啐
750 | 啥
751 | 啦
752 | 啪达
753 | 啷当
754 | 喀
755 | 喂
756 | 喏
757 | 喔唷
758 | 喽
759 | 嗡
760 | 嗡嗡
761 | 嗬
762 | 嗯
763 | 嗳
764 | 嘎
765 | 嘎嘎
766 | 嘎登
767 | 嘘
768 | 嘛
769 | 嘻
770 | 嘿
771 | 嘿嘿
772 | 四
773 | 因
774 | 因为
775 | 因了
776 | 因此
777 | 因着
778 | 因而
779 | 固
780 | 固然
781 | 在
782 | 在下
783 | 在于
784 | 地
785 | 均
786 | 坚决
787 | 坚持
788 | 基于
789 | 基本
790 | 基本上
791 | 处在
792 | 处处
793 | 处理
794 | 复杂
795 | 多
796 | 多么
797 | 多亏
798 | 多多
799 | 多多少少
800 | 多多益善
801 | 多少
802 | 多年前
803 | 多年来
804 | 多数
805 | 多次
806 | 够瞧的
807 | 大
808 | 大不了
809 | 大举
810 | 大事
811 | 大体
812 | 大体上
813 | 大凡
814 | 大力
815 | 大多
816 | 大多数
817 | 大大
818 | 大家
819 | 大张旗鼓
820 | 大批
821 | 大抵
822 | 大概
823 | 大略
824 | 大约
825 | 大致
826 | 大都
827 | 大量
828 | 大面儿上
829 | 失去
830 | 奇
831 | 奈
832 | 奋勇
833 | 她
834 | 她们
835 | 她是
836 | 她的
837 | 好
838 | 好在
839 | 好的
840 | 好象
841 | 如
842 | 如上
843 | 如上所述
844 | 如下
845 | 如今
846 | 如何
847 | 如其
848 | 如前所述
849 | 如同
850 | 如常
851 | 如是
852 | 如期
853 | 如果
854 | 如次
855 | 如此
856 | 如此等等
857 | 如若
858 | 始而
859 | 姑且
860 | 存在
861 | 存心
862 | 孰料
863 | 孰知
864 | 宁
865 | 宁可
866 | 宁愿
867 | 宁肯
868 | 它
869 | 它们
870 | 它们的
871 | 它是
872 | 它的
873 | 安全
874 | 完全
875 | 完成
876 | 定
877 | 实现
878 | 实际
879 | 宣布
880 | 容易
881 | 密切
882 | 对
883 | 对于
884 | 对应
885 | 对待
886 | 对方
887 | 对比
888 | 将
889 | 将才
890 | 将要
891 | 将近
892 | 小
893 | 少数
894 | 尔
895 | 尔后
896 | 尔尔
897 | 尔等
898 | 尚且
899 | 尤其
900 | 就
901 | 就地
902 | 就是
903 | 就是了
904 | 就是说
905 | 就此
906 | 就算
907 | 就要
908 | 尽
909 | 尽可能
910 | 尽如人意
911 | 尽心尽力
912 | 尽心竭力
913 | 尽快
914 | 尽早
915 | 尽然
916 | 尽管
917 | 尽管如此
918 | 尽量
919 | 局外
920 | 居然
921 | 届时
922 | 属于
923 | 屡
924 | 屡屡
925 | 屡次
926 | 屡次三番
927 | 岂
928 | 岂但
929 | 岂止
930 | 岂非
931 | 川流不息
932 | 左右
933 | 巨大
934 | 巩固
935 | 差一点
936 | 差不多
937 | 己
938 | 已
939 | 已矣
940 | 已经
941 | 巴
942 | 巴巴
943 | 带
944 | 帮助
945 | 常
946 | 常常
947 | 常言说
948 | 常言说得好
949 | 常言道
950 | 平素
951 | 年复一年
952 | 并
953 | 并不
954 | 并不是
955 | 并且
956 | 并排
957 | 并无
958 | 并没
959 | 并没有
960 | 并肩
961 | 并非
962 | 广大
963 | 广泛
964 | 应当
965 | 应用
966 | 应该
967 | 庶乎
968 | 庶几
969 | 开外
970 | 开始
971 | 开展
972 | 引起
973 | 弗
974 | 弹指之间
975 | 强烈
976 | 强调
977 | 归
978 | 归根到底
979 | 归根结底
980 | 归齐
981 | 当
982 | 当下
983 | 当中
984 | 当儿
985 | 当前
986 | 当即
987 | 当口儿
988 | 当地
989 | 当场
990 | 当头
991 | 当庭
992 | 当时
993 | 当然
994 | 当真
995 | 当着
996 | 形成
997 | 彻夜
998 | 彻底
999 | 彼
1000 | 彼时
1001 | 彼此
1002 | 往
1003 | 往往
1004 | 待
1005 | 待到
1006 | 很
1007 | 很多
1008 | 很少
1009 | 後来
1010 | 後面
1011 | 得
1012 | 得了
1013 | 得出
1014 | 得到
1015 | 得天独厚
1016 | 得起
1017 | 心里
1018 | 必
1019 | 必定
1020 | 必将
1021 | 必然
1022 | 必要
1023 | 必须
1024 | 快
1025 | 快要
1026 | 忽地
1027 | 忽然
1028 | 怎
1029 | 怎么
1030 | 怎么办
1031 | 怎么样
1032 | 怎奈
1033 | 怎样
1034 | 怎麽
1035 | 怕
1036 | 急匆匆
1037 | 怪
1038 | 怪不得
1039 | 总之
1040 | 总是
1041 | 总的来看
1042 | 总的来说
1043 | 总的说来
1044 | 总结
1045 | 总而言之
1046 | 恍然
1047 | 恐怕
1048 | 恰似
1049 | 恰好
1050 | 恰如
1051 | 恰巧
1052 | 恰恰
1053 | 恰恰相反
1054 | 恰逢
1055 | 您
1056 | 您们
1057 | 您是
1058 | 惟其
1059 | 惯常
1060 | 意思
1061 | 愤然
1062 | 愿意
1063 | 慢说
1064 | 成为
1065 | 成年
1066 | 成年累月
1067 | 成心
1068 | 我
1069 | 我们
1070 | 我是
1071 | 我的
1072 | 或
1073 | 或则
1074 | 或多或少
1075 | 或是
1076 | 或曰
1077 | 或者
1078 | 或许
1079 | 战斗
1080 | 截然
1081 | 截至
1082 | 所
1083 | 所以
1084 | 所在
1085 | 所幸
1086 | 所有
1087 | 所谓
1088 | 才
1089 | 才能
1090 | 扑通
1091 | 打
1092 | 打从
1093 | 打开天窗说亮话
1094 | 扩大
1095 | 把
1096 | 抑或
1097 | 抽冷子
1098 | 拦腰
1099 | 拿
1100 | 按
1101 | 按时
1102 | 按期
1103 | 按照
1104 | 按理
1105 | 按说
1106 | 挨个
1107 | 挨家挨户
1108 | 挨次
1109 | 挨着
1110 | 挨门挨户
1111 | 挨门逐户
1112 | 换句话说
1113 | 换言之
1114 | 据
1115 | 据实
1116 | 据悉
1117 | 据我所知
1118 | 据此
1119 | 据称
1120 | 据说
1121 | 掌握
1122 | 接下来
1123 | 接着
1124 | 接著
1125 | 接连不断
1126 | 放量
1127 | 故
1128 | 故意
1129 | 故此
1130 | 故而
1131 | 敞开儿
1132 | 敢
1133 | 敢于
1134 | 敢情
1135 | 数/
1136 | 整个
1137 | 断然
1138 | 方
1139 | 方便
1140 | 方才
1141 | 方能
1142 | 方面
1143 | 旁人
1144 | 无
1145 | 无宁
1146 | 无法
1147 | 无论
1148 | 既
1149 | 既...又
1150 | 既往
1151 | 既是
1152 | 既然
1153 | 日复一日
1154 | 日渐
1155 | 日益
1156 | 日臻
1157 | 日见
1158 | 时候
1159 | 昂然
1160 | 明显
1161 | 明确
1162 | 是
1163 | 是不是
1164 | 是以
1165 | 是否
1166 | 是的
1167 | 显然
1168 | 显著
1169 | 普通
1170 | 普遍
1171 | 暗中
1172 | 暗地里
1173 | 暗自
1174 | 更
1175 | 更为
1176 | 更加
1177 | 更进一步
1178 | 曾
1179 | 曾经
1180 | 替
1181 | 替代
1182 | 最
1183 | 最后
1184 | 最大
1185 | 最好
1186 | 最後
1187 | 最近
1188 | 最高
1189 | 有
1190 | 有些
1191 | 有关
1192 | 有利
1193 | 有力
1194 | 有及
1195 | 有所
1196 | 有效
1197 | 有时
1198 | 有点
1199 | 有的
1200 | 有的是
1201 | 有着
1202 | 有著
1203 | 望
1204 | 朝
1205 | 朝着
1206 | 末##末
1207 | 本
1208 | 本人
1209 | 本地
1210 | 本着
1211 | 本身
1212 | 权时
1213 | 来
1214 | 来不及
1215 | 来得及
1216 | 来看
1217 | 来着
1218 | 来自
1219 | 来讲
1220 | 来说
1221 | 极
1222 | 极为
1223 | 极了
1224 | 极其
1225 | 极力
1226 | 极大
1227 | 极度
1228 | 极端
1229 | 构成
1230 | 果然
1231 | 果真
1232 | 某
1233 | 某个
1234 | 某些
1235 | 某某
1236 | 根据
1237 | 根本
1238 | 格外
1239 | 梆
1240 | 概
1241 | 次第
1242 | 欢迎
1243 | 欤
1244 | 正值
1245 | 正在
1246 | 正如
1247 | 正巧
1248 | 正常
1249 | 正是
1250 | 此
1251 | 此中
1252 | 此后
1253 | 此地
1254 | 此处
1255 | 此外
1256 | 此时
1257 | 此次
1258 | 此间
1259 | 殆
1260 | 毋宁
1261 | 每
1262 | 每个
1263 | 每天
1264 | 每年
1265 | 每当
1266 | 每时每刻
1267 | 每每
1268 | 每逢
1269 | 比
1270 | 比及
1271 | 比如
1272 | 比如说
1273 | 比方
1274 | 比照
1275 | 比起
1276 | 比较
1277 | 毕竟
1278 | 毫不
1279 | 毫无
1280 | 毫无例外
1281 | 毫无保留地
1282 | 汝
1283 | 沙沙
1284 | 没
1285 | 没奈何
1286 | 没有
1287 | 沿
1288 | 沿着
1289 | 注意
1290 | 活
1291 | 深入
1292 | 清楚
1293 | 满
1294 | 满足
1295 | 漫说
1296 | 焉
1297 | 然
1298 | 然则
1299 | 然后
1300 | 然後
1301 | 然而
1302 | 照
1303 | 照着
1304 | 牢牢
1305 | 特别是
1306 | 特殊
1307 | 特点
1308 | 犹且
1309 | 犹自
1310 | 独
1311 | 独自
1312 | 猛然
1313 | 猛然间
1314 | 率尔
1315 | 率然
1316 | 现代
1317 | 现在
1318 | 理应
1319 | 理当
1320 | 理该
1321 | 瑟瑟
1322 | 甚且
1323 | 甚么
1324 | 甚或
1325 | 甚而
1326 | 甚至
1327 | 甚至于
1328 | 用
1329 | 用来
1330 | 甫
1331 | 甭
1332 | 由
1333 | 由于
1334 | 由是
1335 | 由此
1336 | 由此可见
1337 | 略
1338 | 略为
1339 | 略加
1340 | 略微
1341 | 白
1342 | 白白
1343 | 的
1344 | 的确
1345 | 的话
1346 | 皆可
1347 | 目前
1348 | 直到
1349 | 直接
1350 | 相似
1351 | 相信
1352 | 相反
1353 | 相同
1354 | 相对
1355 | 相对而言
1356 | 相应
1357 | 相当
1358 | 相等
1359 | 省得
1360 | 看
1361 | 看上去
1362 | 看出
1363 | 看到
1364 | 看来
1365 | 看样子
1366 | 看看
1367 | 看见
1368 | 看起来
1369 | 真是
1370 | 真正
1371 | 眨眼
1372 | 着
1373 | 着呢
1374 | 矣
1375 | 矣乎
1376 | 矣哉
1377 | 知道
1378 | 砰
1379 | 确定
1380 | 碰巧
1381 | 社会主义
1382 | 离
1383 | 种
1384 | 积极
1385 | 移动
1386 | 究竟
1387 | 穷年累月
1388 | 突出
1389 | 突然
1390 | 窃
1391 | 立
1392 | 立刻
1393 | 立即
1394 | 立地
1395 | 立时
1396 | 立马
1397 | 竟
1398 | 竟然
1399 | 竟而
1400 | 第
1401 | 第二
1402 | 等
1403 | 等到
1404 | 等等
1405 | 策略地
1406 | 简直
1407 | 简而言之
1408 | 简言之
1409 | 管
1410 | 类如
1411 | 粗
1412 | 精光
1413 | 紧接着
1414 | 累年
1415 | 累次
1416 | 纯
1417 | 纯粹
1418 | 纵
1419 | 纵令
1420 | 纵使
1421 | 纵然
1422 | 练习
1423 | 组成
1424 | 经
1425 | 经常
1426 | 经过
1427 | 结合
1428 | 结果
1429 | 给
1430 | 绝
1431 | 绝不
1432 | 绝对
1433 | 绝非
1434 | 绝顶
1435 | 继之
1436 | 继后
1437 | 继续
1438 | 继而
1439 | 维持
1440 | 综上所述
1441 | 缕缕
1442 | 罢了
1443 | 老
1444 | 老大
1445 | 老是
1446 | 老老实实
1447 | 考虑
1448 | 者
1449 | 而
1450 | 而且
1451 | 而况
1452 | 而又
1453 | 而后
1454 | 而外
1455 | 而已
1456 | 而是
1457 | 而言
1458 | 而论
1459 | 联系
1460 | 联袂
1461 | 背地里
1462 | 背靠背
1463 | 能
1464 | 能否
1465 | 能够
1466 | 腾
1467 | 自
1468 | 自个儿
1469 | 自从
1470 | 自各儿
1471 | 自后
1472 | 自家
1473 | 自己
1474 | 自打
1475 | 自身
1476 | 臭
1477 | 至
1478 | 至于
1479 | 至今
1480 | 至若
1481 | 致
1482 | 般的
1483 | 良好
1484 | 若
1485 | 若夫
1486 | 若是
1487 | 若果
1488 | 若非
1489 | 范围
1490 | 莫
1491 | 莫不
1492 | 莫不然
1493 | 莫如
1494 | 莫若
1495 | 莫非
1496 | 获得
1497 | 藉以
1498 | 虽
1499 | 虽则
1500 | 虽然
1501 | 虽说
1502 | 蛮
1503 | 行为
1504 | 行动
1505 | 表明
1506 | 表示
1507 | 被
1508 | 要
1509 | 要不
1510 | 要不是
1511 | 要不然
1512 | 要么
1513 | 要是
1514 | 要求
1515 | 见
1516 | 规定
1517 | 觉得
1518 | 譬喻
1519 | 譬如
1520 | 认为
1521 | 认真
1522 | 认识
1523 | 让
1524 | 许多
1525 | 论
1526 | 论说
1527 | 设使
1528 | 设或
1529 | 设若
1530 | 诚如
1531 | 诚然
1532 | 话说
1533 | 该
1534 | 该当
1535 | 说明
1536 | 说来
1537 | 说说
1538 | 请勿
1539 | 诸
1540 | 诸位
1541 | 诸如
1542 | 谁
1543 | 谁人
1544 | 谁料
1545 | 谁知
1546 | 谨
1547 | 豁然
1548 | 贼死
1549 | 赖以
1550 | 赶
1551 | 赶快
1552 | 赶早不赶晚
1553 | 起
1554 | 起先
1555 | 起初
1556 | 起头
1557 | 起来
1558 | 起见
1559 | 起首
1560 | 趁
1561 | 趁便
1562 | 趁势
1563 | 趁早
1564 | 趁机
1565 | 趁热
1566 | 趁着
1567 | 越是
1568 | 距
1569 | 跟
1570 | 路经
1571 | 转动
1572 | 转变
1573 | 转贴
1574 | 轰然
1575 | 较
1576 | 较为
1577 | 较之
1578 | 较比
1579 | 边
1580 | 达到
1581 | 达旦
1582 | 迄
1583 | 迅速
1584 | 过
1585 | 过于
1586 | 过去
1587 | 过来
1588 | 运用
1589 | 近
1590 | 近几年来
1591 | 近年来
1592 | 近来
1593 | 还
1594 | 还是
1595 | 还有
1596 | 还要
1597 | 这
1598 | 这一来
1599 | 这个
1600 | 这么
1601 | 这么些
1602 | 这么样
1603 | 这么点儿
1604 | 这些
1605 | 这会儿
1606 | 这儿
1607 | 这就是说
1608 | 这时
1609 | 这样
1610 | 这次
1611 | 这点
1612 | 这种
1613 | 这般
1614 | 这边
1615 | 这里
1616 | 这麽
1617 | 进入
1618 | 进去
1619 | 进来
1620 | 进步
1621 | 进而
1622 | 进行
1623 | 连
1624 | 连同
1625 | 连声
1626 | 连日
1627 | 连日来
1628 | 连袂
1629 | 连连
1630 | 迟早
1631 | 迫于
1632 | 适应
1633 | 适当
1634 | 适用
1635 | 逐步
1636 | 逐渐
1637 | 通常
1638 | 通过
1639 | 造成
1640 | 逢
1641 | 遇到
1642 | 遭到
1643 | 遵循
1644 | 遵照
1645 | 避免
1646 | 那
1647 | 那个
1648 | 那么
1649 | 那么些
1650 | 那么样
1651 | 那些
1652 | 那会儿
1653 | 那儿
1654 | 那时
1655 | 那末
1656 | 那样
1657 | 那般
1658 | 那边
1659 | 那里
1660 | 那麽
1661 | 部分
1662 | 都
1663 | 鄙人
1664 | 采取
1665 | 里面
1666 | 重大
1667 | 重新
1668 | 重要
1669 | 鉴于
1670 | 针对
1671 | 长期以来
1672 | 长此下去
1673 | 长线
1674 | 长话短说
1675 | 问题
1676 | 间或
1677 | 防止
1678 | 阿
1679 | 附近
1680 | 陈年
1681 | 限制
1682 | 陡然
1683 | 除
1684 | 除了
1685 | 除却
1686 | 除去
1687 | 除外
1688 | 除开
1689 | 除此
1690 | 除此之外
1691 | 除此以外
1692 | 除此而外
1693 | 除非
1694 | 随
1695 | 随后
1696 | 随时
1697 | 随着
1698 | 随著
1699 | 隔夜
1700 | 隔日
1701 | 难得
1702 | 难怪
1703 | 难说
1704 | 难道
1705 | 难道说
1706 | 集中
1707 | 零
1708 | 需要
1709 | 非但
1710 | 非常
1711 | 非徒
1712 | 非得
1713 | 非特
1714 | 非独
1715 | 靠
1716 | 顶多
1717 | 顷
1718 | 顷刻
1719 | 顷刻之间
1720 | 顷刻间
1721 | 顺
1722 | 顺着
1723 | 顿时
1724 | 颇
1725 | 风雨无阻
1726 | 饱
1727 | 首先
1728 | 马上
1729 | 高低
1730 | 高兴
1731 | 默然
1732 | 默默地
1733 | 齐
1734 | ︿
1735 | !
1736 | #
1737 | $
1738 | %
1739 | &
1740 | '
1741 | (
1742 | )
1743 | )÷(1-
1744 | )、
1745 | *
1746 | +
1747 | +ξ
1748 | ++
1749 | ,
1750 | ,也
1751 | -
1752 | -β
1753 | --
1754 | -[*]-
1755 | .
1756 | /
1757 | 0
1758 | 0:2
1759 | 1
1760 | 1.
1761 | 12%
1762 | 2
1763 | 2.3%
1764 | 3
1765 | 4
1766 | 5
1767 | 5:0
1768 | 6
1769 | 7
1770 | 8
1771 | 9
1772 | :
1773 | ;
1774 | <
1775 | <±
1776 | <Δ
1777 | <λ
1778 | <φ
1779 | <<
1780 | =
1781 | =″
1782 | =☆
1783 | =(
1784 | =-
1785 | =[
1786 | ={
1787 | >
1788 | >λ
1789 | ?
1790 | @
1791 | A
1792 | LI
1793 | R.L.
1794 | ZXFITL
1795 | [
1796 | [①①]
1797 | [①②]
1798 | [①③]
1799 | [①④]
1800 | [①⑤]
1801 | [①⑥]
1802 | [①⑦]
1803 | [①⑧]
1804 | [①⑨]
1805 | [①A]
1806 | [①B]
1807 | [①C]
1808 | [①D]
1809 | [①E]
1810 | [①]
1811 | [①a]
1812 | [①c]
1813 | [①d]
1814 | [①e]
1815 | [①f]
1816 | [①g]
1817 | [①h]
1818 | [①i]
1819 | [①o]
1820 | [②
1821 | [②①]
1822 | [②②]
1823 | [②③]
1824 | [②④
1825 | [②⑤]
1826 | [②⑥]
1827 | [②⑦]
1828 | [②⑧]
1829 | [②⑩]
1830 | [②B]
1831 | [②G]
1832 | [②]
1833 | [②a]
1834 | [②b]
1835 | [②c]
1836 | [②d]
1837 | [②e]
1838 | [②f]
1839 | [②g]
1840 | [②h]
1841 | [②i]
1842 | [②j]
1843 | [③①]
1844 | [③⑩]
1845 | [③F]
1846 | [③]
1847 | [③a]
1848 | [③b]
1849 | [③c]
1850 | [③d]
1851 | [③e]
1852 | [③g]
1853 | [③h]
1854 | [④]
1855 | [④a]
1856 | [④b]
1857 | [④c]
1858 | [④d]
1859 | [④e]
1860 | [⑤]
1861 | [⑤]]
1862 | [⑤a]
1863 | [⑤b]
1864 | [⑤d]
1865 | [⑤e]
1866 | [⑤f]
1867 | [⑥]
1868 | [⑦]
1869 | [⑧]
1870 | [⑨]
1871 | [⑩]
1872 | [*]
1873 | [-
1874 | []
1875 | ]
1876 | ]∧′=[
1877 | ][
1878 | _
1879 | a]
1880 | b]
1881 | c]
1882 | e]
1883 | f]
1884 | ng昉
1885 | {
1886 | {-
1887 | |
1888 | }
1889 | }>
1890 | ~
1891 | ~±
1892 | ~+
1893 | ¥
1894 |
--------------------------------------------------------------------------------
/Chapter 5 文本数据增强/文本截断.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 5 文本数据增强/文本截断.jpg
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/LSTM公式.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/LSTM公式.jpeg
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/RNN.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/RNN.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/RNN公式.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/RNN公式.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/Rnn_formula_1.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/TextRNN.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/TextRNN.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/apple_onehot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/Chapter 6 循环神经网络(RNN LSTM)/apple_onehot.png
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/中文停用词表.txt:
--------------------------------------------------------------------------------
1 | !
2 | "
3 | #
4 | $
5 | %
6 | &
7 | '
8 | (
9 | )
10 | *
11 | +
12 | ,
13 | -
14 | --
15 | .
16 | ..
17 | ...
18 | ......
19 | ...................
20 | ./
21 | .一
22 | .数
23 | .日
24 | /
25 | //
26 | 0
27 | 1
28 | 2
29 | 3
30 | 4
31 | 5
32 | 6
33 | 7
34 | 8
35 | 9
36 | :
37 | ://
38 | ::
39 | ;
40 | <
41 | =
42 | >
43 | >>
44 | ?
45 | @
46 | A
47 | Lex
48 | [
49 | \
50 | ]
51 | ^
52 | _
53 | `
54 | exp
55 | sub
56 | sup
57 | |
58 | }
59 | ~
60 | ~~~~
61 | ·
62 | ×
63 | ×××
64 | Δ
65 | Ψ
66 | γ
67 | μ
68 | φ
69 | φ.
70 | В
71 | —
72 | ——
73 | ———
74 | ‘
75 | ’
76 | ’‘
77 | “
78 | ”
79 | ”,
80 | …
81 | ……
82 | …………………………………………………③
83 | ′∈
84 | ′|
85 | ℃
86 | Ⅲ
87 | ↑
88 | →
89 | ∈[
90 | ∪φ∈
91 | ≈
92 | ①
93 | ②
94 | ②c
95 | ③
96 | ③]
97 | ④
98 | ⑤
99 | ⑥
100 | ⑦
101 | ⑧
102 | ⑨
103 | ⑩
104 | ──
105 | ■
106 | ▲
107 |
108 | 、
109 | 。
110 | 〈
111 | 〉
112 | 《
113 | 》
114 | 》),
115 | 」
116 | 『
117 | 』
118 | 【
119 | 】
120 | 〔
121 | 〕
122 | 〕〔
123 | ㈧
124 | 一
125 | 一.
126 | 一一
127 | 一下
128 | 一个
129 | 一些
130 | 一何
131 | 一切
132 | 一则
133 | 一则通过
134 | 一天
135 | 一定
136 | 一方面
137 | 一旦
138 | 一时
139 | 一来
140 | 一样
141 | 一次
142 | 一片
143 | 一番
144 | 一直
145 | 一致
146 | 一般
147 | 一起
148 | 一转眼
149 | 一边
150 | 一面
151 | 七
152 | 万一
153 | 三
154 | 三天两头
155 | 三番两次
156 | 三番五次
157 | 上
158 | 上下
159 | 上升
160 | 上去
161 | 上来
162 | 上述
163 | 上面
164 | 下
165 | 下列
166 | 下去
167 | 下来
168 | 下面
169 | 不
170 | 不一
171 | 不下
172 | 不久
173 | 不了
174 | 不亦乐乎
175 | 不仅
176 | 不仅...而且
177 | 不仅仅
178 | 不仅仅是
179 | 不会
180 | 不但
181 | 不但...而且
182 | 不光
183 | 不免
184 | 不再
185 | 不力
186 | 不单
187 | 不变
188 | 不只
189 | 不可
190 | 不可开交
191 | 不可抗拒
192 | 不同
193 | 不外
194 | 不外乎
195 | 不够
196 | 不大
197 | 不如
198 | 不妨
199 | 不定
200 | 不对
201 | 不少
202 | 不尽
203 | 不尽然
204 | 不巧
205 | 不已
206 | 不常
207 | 不得
208 | 不得不
209 | 不得了
210 | 不得已
211 | 不必
212 | 不怎么
213 | 不怕
214 | 不惟
215 | 不成
216 | 不拘
217 | 不择手段
218 | 不敢
219 | 不料
220 | 不断
221 | 不日
222 | 不时
223 | 不是
224 | 不曾
225 | 不止
226 | 不止一次
227 | 不比
228 | 不消
229 | 不满
230 | 不然
231 | 不然的话
232 | 不特
233 | 不独
234 | 不由得
235 | 不知不觉
236 | 不管
237 | 不管怎样
238 | 不经意
239 | 不胜
240 | 不能
241 | 不能不
242 | 不至于
243 | 不若
244 | 不要
245 | 不论
246 | 不起
247 | 不足
248 | 不过
249 | 不迭
250 | 不问
251 | 不限
252 | 与
253 | 与其
254 | 与其说
255 | 与否
256 | 与此同时
257 | 专门
258 | 且
259 | 且不说
260 | 且说
261 | 两者
262 | 严格
263 | 严重
264 | 个
265 | 个人
266 | 个别
267 | 中小
268 | 中间
269 | 丰富
270 | 串行
271 | 临
272 | 临到
273 | 为
274 | 为主
275 | 为了
276 | 为什么
277 | 为什麽
278 | 为何
279 | 为止
280 | 为此
281 | 为着
282 | 主张
283 | 主要
284 | 举凡
285 | 举行
286 | 乃
287 | 乃至
288 | 乃至于
289 | 么
290 | 之
291 | 之一
292 | 之前
293 | 之后
294 | 之後
295 | 之所以
296 | 之类
297 | 乌乎
298 | 乎
299 | 乒
300 | 乘
301 | 乘势
302 | 乘机
303 | 乘胜
304 | 乘虚
305 | 乘隙
306 | 九
307 | 也
308 | 也好
309 | 也就是说
310 | 也是
311 | 也罢
312 | 了
313 | 了解
314 | 争取
315 | 二
316 | 二来
317 | 二话不说
318 | 二话没说
319 | 于
320 | 于是
321 | 于是乎
322 | 云云
323 | 云尔
324 | 互
325 | 互相
326 | 五
327 | 些
328 | 交口
329 | 亦
330 | 产生
331 | 亲口
332 | 亲手
333 | 亲眼
334 | 亲自
335 | 亲身
336 | 人
337 | 人人
338 | 人们
339 | 人家
340 | 人民
341 | 什么
342 | 什么样
343 | 什麽
344 | 仅
345 | 仅仅
346 | 今
347 | 今后
348 | 今天
349 | 今年
350 | 今後
351 | 介于
352 | 仍
353 | 仍旧
354 | 仍然
355 | 从
356 | 从不
357 | 从严
358 | 从中
359 | 从事
360 | 从今以后
361 | 从优
362 | 从古到今
363 | 从古至今
364 | 从头
365 | 从宽
366 | 从小
367 | 从新
368 | 从无到有
369 | 从早到晚
370 | 从未
371 | 从来
372 | 从此
373 | 从此以后
374 | 从而
375 | 从轻
376 | 从速
377 | 从重
378 | 他
379 | 他人
380 | 他们
381 | 他是
382 | 他的
383 | 代替
384 | 以
385 | 以上
386 | 以下
387 | 以为
388 | 以便
389 | 以免
390 | 以前
391 | 以及
392 | 以后
393 | 以外
394 | 以後
395 | 以故
396 | 以期
397 | 以来
398 | 以至
399 | 以至于
400 | 以致
401 | 们
402 | 任
403 | 任何
404 | 任凭
405 | 任务
406 | 企图
407 | 伙同
408 | 会
409 | 伟大
410 | 传
411 | 传说
412 | 传闻
413 | 似乎
414 | 似的
415 | 但
416 | 但凡
417 | 但愿
418 | 但是
419 | 何
420 | 何乐而不为
421 | 何以
422 | 何况
423 | 何处
424 | 何妨
425 | 何尝
426 | 何必
427 | 何时
428 | 何止
429 | 何苦
430 | 何须
431 | 余外
432 | 作为
433 | 你
434 | 你们
435 | 你是
436 | 你的
437 | 使
438 | 使得
439 | 使用
440 | 例如
441 | 依
442 | 依据
443 | 依照
444 | 依靠
445 | 便
446 | 便于
447 | 促进
448 | 保持
449 | 保管
450 | 保险
451 | 俺
452 | 俺们
453 | 倍加
454 | 倍感
455 | 倒不如
456 | 倒不如说
457 | 倒是
458 | 倘
459 | 倘使
460 | 倘或
461 | 倘然
462 | 倘若
463 | 借
464 | 借以
465 | 借此
466 | 假使
467 | 假如
468 | 假若
469 | 偏偏
470 | 做到
471 | 偶尔
472 | 偶而
473 | 傥然
474 | 像
475 | 儿
476 | 允许
477 | 元/吨
478 | 充其极
479 | 充其量
480 | 充分
481 | 先不先
482 | 先后
483 | 先後
484 | 先生
485 | 光
486 | 光是
487 | 全体
488 | 全力
489 | 全年
490 | 全然
491 | 全身心
492 | 全部
493 | 全都
494 | 全面
495 | 八
496 | 八成
497 | 公然
498 | 六
499 | 兮
500 | 共
501 | 共同
502 | 共总
503 | 关于
504 | 其
505 | 其一
506 | 其中
507 | 其二
508 | 其他
509 | 其余
510 | 其后
511 | 其它
512 | 其实
513 | 其次
514 | 具体
515 | 具体地说
516 | 具体来说
517 | 具体说来
518 | 具有
519 | 兼之
520 | 内
521 | 再
522 | 再其次
523 | 再则
524 | 再有
525 | 再次
526 | 再者
527 | 再者说
528 | 再说
529 | 冒
530 | 冲
531 | 决不
532 | 决定
533 | 决非
534 | 况且
535 | 准备
536 | 凑巧
537 | 凝神
538 | 几
539 | 几乎
540 | 几度
541 | 几时
542 | 几番
543 | 几经
544 | 凡
545 | 凡是
546 | 凭
547 | 凭借
548 | 出
549 | 出于
550 | 出去
551 | 出来
552 | 出现
553 | 分别
554 | 分头
555 | 分期
556 | 分期分批
557 | 切
558 | 切不可
559 | 切切
560 | 切勿
561 | 切莫
562 | 则
563 | 则甚
564 | 刚
565 | 刚好
566 | 刚巧
567 | 刚才
568 | 初
569 | 别
570 | 别人
571 | 别处
572 | 别是
573 | 别的
574 | 别管
575 | 别说
576 | 到
577 | 到了儿
578 | 到处
579 | 到头
580 | 到头来
581 | 到底
582 | 到目前为止
583 | 前后
584 | 前此
585 | 前者
586 | 前进
587 | 前面
588 | 加上
589 | 加之
590 | 加以
591 | 加入
592 | 加强
593 | 动不动
594 | 动辄
595 | 勃然
596 | 匆匆
597 | 十分
598 | 千
599 | 千万
600 | 千万千万
601 | 半
602 | 单
603 | 单单
604 | 单纯
605 | 即
606 | 即令
607 | 即使
608 | 即便
609 | 即刻
610 | 即如
611 | 即将
612 | 即或
613 | 即是说
614 | 即若
615 | 却
616 | 却不
617 | 历
618 | 原来
619 | 去
620 | 又
621 | 又及
622 | 及
623 | 及其
624 | 及时
625 | 及至
626 | 双方
627 | 反之
628 | 反之亦然
629 | 反之则
630 | 反倒
631 | 反倒是
632 | 反应
633 | 反手
634 | 反映
635 | 反而
636 | 反过来
637 | 反过来说
638 | 取得
639 | 取道
640 | 受到
641 | 变成
642 | 古来
643 | 另
644 | 另一个
645 | 另一方面
646 | 另外
647 | 另悉
648 | 另方面
649 | 另行
650 | 只
651 | 只当
652 | 只怕
653 | 只是
654 | 只有
655 | 只消
656 | 只要
657 | 只限
658 | 叫
659 | 叫做
660 | 召开
661 | 叮咚
662 | 叮当
663 | 可
664 | 可以
665 | 可好
666 | 可是
667 | 可能
668 | 可见
669 | 各
670 | 各个
671 | 各人
672 | 各位
673 | 各地
674 | 各式
675 | 各种
676 | 各级
677 | 各自
678 | 合理
679 | 同
680 | 同一
681 | 同时
682 | 同样
683 | 后
684 | 后来
685 | 后者
686 | 后面
687 | 向
688 | 向使
689 | 向着
690 | 吓
691 | 吗
692 | 否则
693 | 吧
694 | 吧哒
695 | 吱
696 | 呀
697 | 呃
698 | 呆呆地
699 | 呐
700 | 呕
701 | 呗
702 | 呜
703 | 呜呼
704 | 呢
705 | 周围
706 | 呵
707 | 呵呵
708 | 呸
709 | 呼哧
710 | 呼啦
711 | 咋
712 | 和
713 | 咚
714 | 咦
715 | 咧
716 | 咱
717 | 咱们
718 | 咳
719 | 哇
720 | 哈
721 | 哈哈
722 | 哉
723 | 哎
724 | 哎呀
725 | 哎哟
726 | 哗
727 | 哗啦
728 | 哟
729 | 哦
730 | 哩
731 | 哪
732 | 哪个
733 | 哪些
734 | 哪儿
735 | 哪天
736 | 哪年
737 | 哪怕
738 | 哪样
739 | 哪边
740 | 哪里
741 | 哼
742 | 哼唷
743 | 唉
744 | 唯有
745 | 啊
746 | 啊呀
747 | 啊哈
748 | 啊哟
749 | 啐
750 | 啥
751 | 啦
752 | 啪达
753 | 啷当
754 | 喀
755 | 喂
756 | 喏
757 | 喔唷
758 | 喽
759 | 嗡
760 | 嗡嗡
761 | 嗬
762 | 嗯
763 | 嗳
764 | 嘎
765 | 嘎嘎
766 | 嘎登
767 | 嘘
768 | 嘛
769 | 嘻
770 | 嘿
771 | 嘿嘿
772 | 四
773 | 因
774 | 因为
775 | 因了
776 | 因此
777 | 因着
778 | 因而
779 | 固
780 | 固然
781 | 在
782 | 在下
783 | 在于
784 | 地
785 | 均
786 | 坚决
787 | 坚持
788 | 基于
789 | 基本
790 | 基本上
791 | 处在
792 | 处处
793 | 处理
794 | 复杂
795 | 多
796 | 多么
797 | 多亏
798 | 多多
799 | 多多少少
800 | 多多益善
801 | 多少
802 | 多年前
803 | 多年来
804 | 多数
805 | 多次
806 | 够瞧的
807 | 大
808 | 大不了
809 | 大举
810 | 大事
811 | 大体
812 | 大体上
813 | 大凡
814 | 大力
815 | 大多
816 | 大多数
817 | 大大
818 | 大家
819 | 大张旗鼓
820 | 大批
821 | 大抵
822 | 大概
823 | 大略
824 | 大约
825 | 大致
826 | 大都
827 | 大量
828 | 大面儿上
829 | 失去
830 | 奇
831 | 奈
832 | 奋勇
833 | 她
834 | 她们
835 | 她是
836 | 她的
837 | 好
838 | 好在
839 | 好的
840 | 好象
841 | 如
842 | 如上
843 | 如上所述
844 | 如下
845 | 如今
846 | 如何
847 | 如其
848 | 如前所述
849 | 如同
850 | 如常
851 | 如是
852 | 如期
853 | 如果
854 | 如次
855 | 如此
856 | 如此等等
857 | 如若
858 | 始而
859 | 姑且
860 | 存在
861 | 存心
862 | 孰料
863 | 孰知
864 | 宁
865 | 宁可
866 | 宁愿
867 | 宁肯
868 | 它
869 | 它们
870 | 它们的
871 | 它是
872 | 它的
873 | 安全
874 | 完全
875 | 完成
876 | 定
877 | 实现
878 | 实际
879 | 宣布
880 | 容易
881 | 密切
882 | 对
883 | 对于
884 | 对应
885 | 对待
886 | 对方
887 | 对比
888 | 将
889 | 将才
890 | 将要
891 | 将近
892 | 小
893 | 少数
894 | 尔
895 | 尔后
896 | 尔尔
897 | 尔等
898 | 尚且
899 | 尤其
900 | 就
901 | 就地
902 | 就是
903 | 就是了
904 | 就是说
905 | 就此
906 | 就算
907 | 就要
908 | 尽
909 | 尽可能
910 | 尽如人意
911 | 尽心尽力
912 | 尽心竭力
913 | 尽快
914 | 尽早
915 | 尽然
916 | 尽管
917 | 尽管如此
918 | 尽量
919 | 局外
920 | 居然
921 | 届时
922 | 属于
923 | 屡
924 | 屡屡
925 | 屡次
926 | 屡次三番
927 | 岂
928 | 岂但
929 | 岂止
930 | 岂非
931 | 川流不息
932 | 左右
933 | 巨大
934 | 巩固
935 | 差一点
936 | 差不多
937 | 己
938 | 已
939 | 已矣
940 | 已经
941 | 巴
942 | 巴巴
943 | 带
944 | 帮助
945 | 常
946 | 常常
947 | 常言说
948 | 常言说得好
949 | 常言道
950 | 平素
951 | 年复一年
952 | 并
953 | 并不
954 | 并不是
955 | 并且
956 | 并排
957 | 并无
958 | 并没
959 | 并没有
960 | 并肩
961 | 并非
962 | 广大
963 | 广泛
964 | 应当
965 | 应用
966 | 应该
967 | 庶乎
968 | 庶几
969 | 开外
970 | 开始
971 | 开展
972 | 引起
973 | 弗
974 | 弹指之间
975 | 强烈
976 | 强调
977 | 归
978 | 归根到底
979 | 归根结底
980 | 归齐
981 | 当
982 | 当下
983 | 当中
984 | 当儿
985 | 当前
986 | 当即
987 | 当口儿
988 | 当地
989 | 当场
990 | 当头
991 | 当庭
992 | 当时
993 | 当然
994 | 当真
995 | 当着
996 | 形成
997 | 彻夜
998 | 彻底
999 | 彼
1000 | 彼时
1001 | 彼此
1002 | 往
1003 | 往往
1004 | 待
1005 | 待到
1006 | 很
1007 | 很多
1008 | 很少
1009 | 後来
1010 | 後面
1011 | 得
1012 | 得了
1013 | 得出
1014 | 得到
1015 | 得天独厚
1016 | 得起
1017 | 心里
1018 | 必
1019 | 必定
1020 | 必将
1021 | 必然
1022 | 必要
1023 | 必须
1024 | 快
1025 | 快要
1026 | 忽地
1027 | 忽然
1028 | 怎
1029 | 怎么
1030 | 怎么办
1031 | 怎么样
1032 | 怎奈
1033 | 怎样
1034 | 怎麽
1035 | 怕
1036 | 急匆匆
1037 | 怪
1038 | 怪不得
1039 | 总之
1040 | 总是
1041 | 总的来看
1042 | 总的来说
1043 | 总的说来
1044 | 总结
1045 | 总而言之
1046 | 恍然
1047 | 恐怕
1048 | 恰似
1049 | 恰好
1050 | 恰如
1051 | 恰巧
1052 | 恰恰
1053 | 恰恰相反
1054 | 恰逢
1055 | 您
1056 | 您们
1057 | 您是
1058 | 惟其
1059 | 惯常
1060 | 意思
1061 | 愤然
1062 | 愿意
1063 | 慢说
1064 | 成为
1065 | 成年
1066 | 成年累月
1067 | 成心
1068 | 我
1069 | 我们
1070 | 我是
1071 | 我的
1072 | 或
1073 | 或则
1074 | 或多或少
1075 | 或是
1076 | 或曰
1077 | 或者
1078 | 或许
1079 | 战斗
1080 | 截然
1081 | 截至
1082 | 所
1083 | 所以
1084 | 所在
1085 | 所幸
1086 | 所有
1087 | 所谓
1088 | 才
1089 | 才能
1090 | 扑通
1091 | 打
1092 | 打从
1093 | 打开天窗说亮话
1094 | 扩大
1095 | 把
1096 | 抑或
1097 | 抽冷子
1098 | 拦腰
1099 | 拿
1100 | 按
1101 | 按时
1102 | 按期
1103 | 按照
1104 | 按理
1105 | 按说
1106 | 挨个
1107 | 挨家挨户
1108 | 挨次
1109 | 挨着
1110 | 挨门挨户
1111 | 挨门逐户
1112 | 换句话说
1113 | 换言之
1114 | 据
1115 | 据实
1116 | 据悉
1117 | 据我所知
1118 | 据此
1119 | 据称
1120 | 据说
1121 | 掌握
1122 | 接下来
1123 | 接着
1124 | 接著
1125 | 接连不断
1126 | 放量
1127 | 故
1128 | 故意
1129 | 故此
1130 | 故而
1131 | 敞开儿
1132 | 敢
1133 | 敢于
1134 | 敢情
1135 | 数/
1136 | 整个
1137 | 断然
1138 | 方
1139 | 方便
1140 | 方才
1141 | 方能
1142 | 方面
1143 | 旁人
1144 | 无
1145 | 无宁
1146 | 无法
1147 | 无论
1148 | 既
1149 | 既...又
1150 | 既往
1151 | 既是
1152 | 既然
1153 | 日复一日
1154 | 日渐
1155 | 日益
1156 | 日臻
1157 | 日见
1158 | 时候
1159 | 昂然
1160 | 明显
1161 | 明确
1162 | 是
1163 | 是不是
1164 | 是以
1165 | 是否
1166 | 是的
1167 | 显然
1168 | 显著
1169 | 普通
1170 | 普遍
1171 | 暗中
1172 | 暗地里
1173 | 暗自
1174 | 更
1175 | 更为
1176 | 更加
1177 | 更进一步
1178 | 曾
1179 | 曾经
1180 | 替
1181 | 替代
1182 | 最
1183 | 最后
1184 | 最大
1185 | 最好
1186 | 最後
1187 | 最近
1188 | 最高
1189 | 有
1190 | 有些
1191 | 有关
1192 | 有利
1193 | 有力
1194 | 有及
1195 | 有所
1196 | 有效
1197 | 有时
1198 | 有点
1199 | 有的
1200 | 有的是
1201 | 有着
1202 | 有著
1203 | 望
1204 | 朝
1205 | 朝着
1206 | 末##末
1207 | 本
1208 | 本人
1209 | 本地
1210 | 本着
1211 | 本身
1212 | 权时
1213 | 来
1214 | 来不及
1215 | 来得及
1216 | 来看
1217 | 来着
1218 | 来自
1219 | 来讲
1220 | 来说
1221 | 极
1222 | 极为
1223 | 极了
1224 | 极其
1225 | 极力
1226 | 极大
1227 | 极度
1228 | 极端
1229 | 构成
1230 | 果然
1231 | 果真
1232 | 某
1233 | 某个
1234 | 某些
1235 | 某某
1236 | 根据
1237 | 根本
1238 | 格外
1239 | 梆
1240 | 概
1241 | 次第
1242 | 欢迎
1243 | 欤
1244 | 正值
1245 | 正在
1246 | 正如
1247 | 正巧
1248 | 正常
1249 | 正是
1250 | 此
1251 | 此中
1252 | 此后
1253 | 此地
1254 | 此处
1255 | 此外
1256 | 此时
1257 | 此次
1258 | 此间
1259 | 殆
1260 | 毋宁
1261 | 每
1262 | 每个
1263 | 每天
1264 | 每年
1265 | 每当
1266 | 每时每刻
1267 | 每每
1268 | 每逢
1269 | 比
1270 | 比及
1271 | 比如
1272 | 比如说
1273 | 比方
1274 | 比照
1275 | 比起
1276 | 比较
1277 | 毕竟
1278 | 毫不
1279 | 毫无
1280 | 毫无例外
1281 | 毫无保留地
1282 | 汝
1283 | 沙沙
1284 | 没
1285 | 没奈何
1286 | 没有
1287 | 沿
1288 | 沿着
1289 | 注意
1290 | 活
1291 | 深入
1292 | 清楚
1293 | 满
1294 | 满足
1295 | 漫说
1296 | 焉
1297 | 然
1298 | 然则
1299 | 然后
1300 | 然後
1301 | 然而
1302 | 照
1303 | 照着
1304 | 牢牢
1305 | 特别是
1306 | 特殊
1307 | 特点
1308 | 犹且
1309 | 犹自
1310 | 独
1311 | 独自
1312 | 猛然
1313 | 猛然间
1314 | 率尔
1315 | 率然
1316 | 现代
1317 | 现在
1318 | 理应
1319 | 理当
1320 | 理该
1321 | 瑟瑟
1322 | 甚且
1323 | 甚么
1324 | 甚或
1325 | 甚而
1326 | 甚至
1327 | 甚至于
1328 | 用
1329 | 用来
1330 | 甫
1331 | 甭
1332 | 由
1333 | 由于
1334 | 由是
1335 | 由此
1336 | 由此可见
1337 | 略
1338 | 略为
1339 | 略加
1340 | 略微
1341 | 白
1342 | 白白
1343 | 的
1344 | 的确
1345 | 的话
1346 | 皆可
1347 | 目前
1348 | 直到
1349 | 直接
1350 | 相似
1351 | 相信
1352 | 相反
1353 | 相同
1354 | 相对
1355 | 相对而言
1356 | 相应
1357 | 相当
1358 | 相等
1359 | 省得
1360 | 看
1361 | 看上去
1362 | 看出
1363 | 看到
1364 | 看来
1365 | 看样子
1366 | 看看
1367 | 看见
1368 | 看起来
1369 | 真是
1370 | 真正
1371 | 眨眼
1372 | 着
1373 | 着呢
1374 | 矣
1375 | 矣乎
1376 | 矣哉
1377 | 知道
1378 | 砰
1379 | 确定
1380 | 碰巧
1381 | 社会主义
1382 | 离
1383 | 种
1384 | 积极
1385 | 移动
1386 | 究竟
1387 | 穷年累月
1388 | 突出
1389 | 突然
1390 | 窃
1391 | 立
1392 | 立刻
1393 | 立即
1394 | 立地
1395 | 立时
1396 | 立马
1397 | 竟
1398 | 竟然
1399 | 竟而
1400 | 第
1401 | 第二
1402 | 等
1403 | 等到
1404 | 等等
1405 | 策略地
1406 | 简直
1407 | 简而言之
1408 | 简言之
1409 | 管
1410 | 类如
1411 | 粗
1412 | 精光
1413 | 紧接着
1414 | 累年
1415 | 累次
1416 | 纯
1417 | 纯粹
1418 | 纵
1419 | 纵令
1420 | 纵使
1421 | 纵然
1422 | 练习
1423 | 组成
1424 | 经
1425 | 经常
1426 | 经过
1427 | 结合
1428 | 结果
1429 | 给
1430 | 绝
1431 | 绝不
1432 | 绝对
1433 | 绝非
1434 | 绝顶
1435 | 继之
1436 | 继后
1437 | 继续
1438 | 继而
1439 | 维持
1440 | 综上所述
1441 | 缕缕
1442 | 罢了
1443 | 老
1444 | 老大
1445 | 老是
1446 | 老老实实
1447 | 考虑
1448 | 者
1449 | 而
1450 | 而且
1451 | 而况
1452 | 而又
1453 | 而后
1454 | 而外
1455 | 而已
1456 | 而是
1457 | 而言
1458 | 而论
1459 | 联系
1460 | 联袂
1461 | 背地里
1462 | 背靠背
1463 | 能
1464 | 能否
1465 | 能够
1466 | 腾
1467 | 自
1468 | 自个儿
1469 | 自从
1470 | 自各儿
1471 | 自后
1472 | 自家
1473 | 自己
1474 | 自打
1475 | 自身
1476 | 臭
1477 | 至
1478 | 至于
1479 | 至今
1480 | 至若
1481 | 致
1482 | 般的
1483 | 良好
1484 | 若
1485 | 若夫
1486 | 若是
1487 | 若果
1488 | 若非
1489 | 范围
1490 | 莫
1491 | 莫不
1492 | 莫不然
1493 | 莫如
1494 | 莫若
1495 | 莫非
1496 | 获得
1497 | 藉以
1498 | 虽
1499 | 虽则
1500 | 虽然
1501 | 虽说
1502 | 蛮
1503 | 行为
1504 | 行动
1505 | 表明
1506 | 表示
1507 | 被
1508 | 要
1509 | 要不
1510 | 要不是
1511 | 要不然
1512 | 要么
1513 | 要是
1514 | 要求
1515 | 见
1516 | 规定
1517 | 觉得
1518 | 譬喻
1519 | 譬如
1520 | 认为
1521 | 认真
1522 | 认识
1523 | 让
1524 | 许多
1525 | 论
1526 | 论说
1527 | 设使
1528 | 设或
1529 | 设若
1530 | 诚如
1531 | 诚然
1532 | 话说
1533 | 该
1534 | 该当
1535 | 说明
1536 | 说来
1537 | 说说
1538 | 请勿
1539 | 诸
1540 | 诸位
1541 | 诸如
1542 | 谁
1543 | 谁人
1544 | 谁料
1545 | 谁知
1546 | 谨
1547 | 豁然
1548 | 贼死
1549 | 赖以
1550 | 赶
1551 | 赶快
1552 | 赶早不赶晚
1553 | 起
1554 | 起先
1555 | 起初
1556 | 起头
1557 | 起来
1558 | 起见
1559 | 起首
1560 | 趁
1561 | 趁便
1562 | 趁势
1563 | 趁早
1564 | 趁机
1565 | 趁热
1566 | 趁着
1567 | 越是
1568 | 距
1569 | 跟
1570 | 路经
1571 | 转动
1572 | 转变
1573 | 转贴
1574 | 轰然
1575 | 较
1576 | 较为
1577 | 较之
1578 | 较比
1579 | 边
1580 | 达到
1581 | 达旦
1582 | 迄
1583 | 迅速
1584 | 过
1585 | 过于
1586 | 过去
1587 | 过来
1588 | 运用
1589 | 近
1590 | 近几年来
1591 | 近年来
1592 | 近来
1593 | 还
1594 | 还是
1595 | 还有
1596 | 还要
1597 | 这
1598 | 这一来
1599 | 这个
1600 | 这么
1601 | 这么些
1602 | 这么样
1603 | 这么点儿
1604 | 这些
1605 | 这会儿
1606 | 这儿
1607 | 这就是说
1608 | 这时
1609 | 这样
1610 | 这次
1611 | 这点
1612 | 这种
1613 | 这般
1614 | 这边
1615 | 这里
1616 | 这麽
1617 | 进入
1618 | 进去
1619 | 进来
1620 | 进步
1621 | 进而
1622 | 进行
1623 | 连
1624 | 连同
1625 | 连声
1626 | 连日
1627 | 连日来
1628 | 连袂
1629 | 连连
1630 | 迟早
1631 | 迫于
1632 | 适应
1633 | 适当
1634 | 适用
1635 | 逐步
1636 | 逐渐
1637 | 通常
1638 | 通过
1639 | 造成
1640 | 逢
1641 | 遇到
1642 | 遭到
1643 | 遵循
1644 | 遵照
1645 | 避免
1646 | 那
1647 | 那个
1648 | 那么
1649 | 那么些
1650 | 那么样
1651 | 那些
1652 | 那会儿
1653 | 那儿
1654 | 那时
1655 | 那末
1656 | 那样
1657 | 那般
1658 | 那边
1659 | 那里
1660 | 那麽
1661 | 部分
1662 | 都
1663 | 鄙人
1664 | 采取
1665 | 里面
1666 | 重大
1667 | 重新
1668 | 重要
1669 | 鉴于
1670 | 针对
1671 | 长期以来
1672 | 长此下去
1673 | 长线
1674 | 长话短说
1675 | 问题
1676 | 间或
1677 | 防止
1678 | 阿
1679 | 附近
1680 | 陈年
1681 | 限制
1682 | 陡然
1683 | 除
1684 | 除了
1685 | 除却
1686 | 除去
1687 | 除外
1688 | 除开
1689 | 除此
1690 | 除此之外
1691 | 除此以外
1692 | 除此而外
1693 | 除非
1694 | 随
1695 | 随后
1696 | 随时
1697 | 随着
1698 | 随著
1699 | 隔夜
1700 | 隔日
1701 | 难得
1702 | 难怪
1703 | 难说
1704 | 难道
1705 | 难道说
1706 | 集中
1707 | 零
1708 | 需要
1709 | 非但
1710 | 非常
1711 | 非徒
1712 | 非得
1713 | 非特
1714 | 非独
1715 | 靠
1716 | 顶多
1717 | 顷
1718 | 顷刻
1719 | 顷刻之间
1720 | 顷刻间
1721 | 顺
1722 | 顺着
1723 | 顿时
1724 | 颇
1725 | 风雨无阻
1726 | 饱
1727 | 首先
1728 | 马上
1729 | 高低
1730 | 高兴
1731 | 默然
1732 | 默默地
1733 | 齐
1734 | ︿
1735 | !
1736 | #
1737 | $
1738 | %
1739 | &
1740 | '
1741 | (
1742 | )
1743 | )÷(1-
1744 | )、
1745 | *
1746 | +
1747 | +ξ
1748 | ++
1749 | ,
1750 | ,也
1751 | -
1752 | -β
1753 | --
1754 | -[*]-
1755 | .
1756 | /
1757 | 0
1758 | 0:2
1759 | 1
1760 | 1.
1761 | 12%
1762 | 2
1763 | 2.3%
1764 | 3
1765 | 4
1766 | 5
1767 | 5:0
1768 | 6
1769 | 7
1770 | 8
1771 | 9
1772 | :
1773 | ;
1774 | <
1775 | <±
1776 | <Δ
1777 | <λ
1778 | <φ
1779 | <<
1780 | =
1781 | =″
1782 | =☆
1783 | =(
1784 | =-
1785 | =[
1786 | ={
1787 | >
1788 | >λ
1789 | ?
1790 | @
1791 | A
1792 | LI
1793 | R.L.
1794 | ZXFITL
1795 | [
1796 | [①①]
1797 | [①②]
1798 | [①③]
1799 | [①④]
1800 | [①⑤]
1801 | [①⑥]
1802 | [①⑦]
1803 | [①⑧]
1804 | [①⑨]
1805 | [①A]
1806 | [①B]
1807 | [①C]
1808 | [①D]
1809 | [①E]
1810 | [①]
1811 | [①a]
1812 | [①c]
1813 | [①d]
1814 | [①e]
1815 | [①f]
1816 | [①g]
1817 | [①h]
1818 | [①i]
1819 | [①o]
1820 | [②
1821 | [②①]
1822 | [②②]
1823 | [②③]
1824 | [②④
1825 | [②⑤]
1826 | [②⑥]
1827 | [②⑦]
1828 | [②⑧]
1829 | [②⑩]
1830 | [②B]
1831 | [②G]
1832 | [②]
1833 | [②a]
1834 | [②b]
1835 | [②c]
1836 | [②d]
1837 | [②e]
1838 | [②f]
1839 | [②g]
1840 | [②h]
1841 | [②i]
1842 | [②j]
1843 | [③①]
1844 | [③⑩]
1845 | [③F]
1846 | [③]
1847 | [③a]
1848 | [③b]
1849 | [③c]
1850 | [③d]
1851 | [③e]
1852 | [③g]
1853 | [③h]
1854 | [④]
1855 | [④a]
1856 | [④b]
1857 | [④c]
1858 | [④d]
1859 | [④e]
1860 | [⑤]
1861 | [⑤]]
1862 | [⑤a]
1863 | [⑤b]
1864 | [⑤d]
1865 | [⑤e]
1866 | [⑤f]
1867 | [⑥]
1868 | [⑦]
1869 | [⑧]
1870 | [⑨]
1871 | [⑩]
1872 | [*]
1873 | [-
1874 | []
1875 | ]
1876 | ]∧′=[
1877 | ][
1878 | _
1879 | a]
1880 | b]
1881 | c]
1882 | e]
1883 | f]
1884 | ng昉
1885 | {
1886 | {-
1887 | |
1888 | }
1889 | }>
1890 | ~
1891 | ~±
1892 | ~+
1893 | ¥
--------------------------------------------------------------------------------
/Chapter 6 循环神经网络(RNN LSTM)/循环神经网络(RNN LSTM).ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "
"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "# ![]()
 \n",
71 | ""
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "metadata": {},
78 | "source": [
79 | " 举一个简单的文本例子:假设我们输入的序列为**“我 爱 西 财”**这一句话,$x_0$是第$0$步循环时的输入,也就是“我”字,$h_0$为一个包含了“我”字向量信息的输出,那么$x_1$是第$1$步循环时的输入,也就是“爱”字;$h_1$不仅包含了“爱”字向量信息,也包含了上一步“我”字的向量信息;同理,依次循环,最后的$h_3$其实是一个包含“我 爱 西 财”向量信息的输出,这样就实现了序列的**“记忆”**。"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | " 用数学公式表示为:"
87 | ]
88 | },
89 | {
90 | "cell_type": "markdown",
91 | "metadata": {},
92 | "source": [
93 | ""
94 | ]
95 | },
96 | {
97 | "cell_type": "markdown",
98 | "metadata": {},
99 | "source": [
100 | " 其中$W$为权重矩阵,$b$为偏置,都为**模型参数**,也是后续训练优化的对象;$tanh$为**激活函数**,也可以使用$relu$等其他激活函数。\n",
101 | "以上就是循环神经网络RNN最基本的一个**循环单元**,现在我们利用上面“我爱西财”的例子,用纯python的代码去解析它。假设不存在偏置项的情况下,那么首先我们定义了一个方法`RNNstep`,来完成上面公式的计算,即RNN循环的一步。"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "### 1.2 RNN基本代码实现(拆分版)"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | " RNN的代码本质上就是在一个普通的神经网络基础上,多加一个**hidden_state**来保存历史信息。用公式来表示的话就是:\n",
116 | "$h_t=tanh(w_h$$x_t+b_t+w_h+b_h)$,而普通的神经网络只有$w_h$$x_t+b_h$,少了隐藏状态的信息。那么我们可以通过构建一个`RNNstep`方法来存储隐藏状态信息:"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": 1,
122 | "metadata": {},
123 | "outputs": [],
124 | "source": [
125 | "import numpy as np\n",
126 | "\n",
127 | "def RNNstep(x, hidden):\n",
128 | " # 更新隐藏状态\n",
129 | " hidden = np.tanh(np.dot(W_hh, hidden) + np.dot(W_xh, x)) # 注意看,其实实现的就是上面的公式(无偏置项)\n",
130 | " return hidden # 当前inpu和隐藏状态作为输入,得到下一步的隐藏状态"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "metadata": {},
136 | "source": [
137 | "给定我们的输入文本数据**“我 爱 西 财”**,这里作一个最简单的onehot处理:"
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 2,
143 | "metadata": {},
144 | "outputs": [
145 | {
146 | "name": "stdout",
147 | "output_type": "stream",
148 | "text": [
149 | "输入的向量形状为:(4, 4)\n",
150 | "句子长度为:4\n"
151 | ]
152 | }
153 | ],
154 | "source": [
155 | "# 我 爱 西 财\n",
156 | "text_data = np.array([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]])\n",
157 | "print(f\"输入的向量形状为:{text_data.shape}\") # [seq_len * input_size]\n",
158 | "seq_len = text_data.shape[1]\n",
159 | "print(f\"句子长度为:{seq_len}\")"
160 | ]
161 | },
162 | {
163 | "cell_type": "markdown",
164 | "metadata": {},
165 | "source": [
166 | "从第0步开始,我们需要输入“我”字($x_0$ = [1,0,0,0]),此时不存在**hidden_state**,也就是$h_0$,可以手动随机初始化的hidden_state;除此之外,我们还应该初始化参数,这里为$W$:"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 3,
172 | "metadata": {},
173 | "outputs": [
174 | {
175 | "name": "stdout",
176 | "output_type": "stream",
177 | "text": [
178 | "初始隐藏状态:\n",
179 | "[[0.23615902 0.44332739 0.52193922 0.46863795]\n",
180 | " [0.74552592 0.44449781 0.97458196 0.29072798]\n",
181 | " [0.18527842 0.31399347 0.97185445 0.04075662]\n",
182 | " [0.1519588 0.88534927 0.49714817 0.85433517]]\n",
183 | "初始权重矩阵:\n",
184 | "[[0.37018877 0.9345049 0.43001064 0.3104593 ]\n",
185 | " [0.16109335 0.11693149 0.21544091 0.77692601]\n",
186 | " [0.58470632 0.66477251 0.98469315 0.07241005]\n",
187 | " [0.90195891 0.18030394 0.05723204 0.42469328]]\n"
188 | ]
189 | }
190 | ],
191 | "source": [
192 | "hidden_state = np.random.random((4,4))\n",
193 | " # 这里的hidden_state的维度设置本质上为序列长度,即循环输入时应该用到多少个隐藏单元\n",
194 | "print(f\"初始隐藏状态:\\n{hidden_state}\")\n",
195 | "\n",
196 | "W_hh = W_xh = np.random.random((4,4))\n",
197 | "print(f\"初始权重矩阵:\\n{W_hh}\")"
198 | ]
199 | },
200 | {
201 | "cell_type": "markdown",
202 | "metadata": {},
203 | "source": [
204 | "一共4个字,那么我们应该循环计算4步,最终得到的**hidden_state**为最后的隐藏状态$h_3$。"
205 | ]
206 | },
207 | {
208 | "cell_type": "code",
209 | "execution_count": 4,
210 | "metadata": {},
211 | "outputs": [
212 | {
213 | "name": "stdout",
214 | "output_type": "stream",
215 | "text": [
216 | "最终隐藏状态:\n",
217 | "[[0.97885185 0.9902648 0.96978843 0.97910535]\n",
218 | " [0.91175181 0.96153125 0.86889499 0.92129702]\n",
219 | " [0.9878806 0.99458351 0.98220887 0.98853489]\n",
220 | " [0.94988961 0.97819583 0.92491659 0.95506927]]\n"
221 | ]
222 | }
223 | ],
224 | "source": [
225 | "for i in range(seq_len):\n",
226 | " hidden_state = RNNstep(text_data[i,:], hidden_state) \n",
227 | "print(f\"最终隐藏状态:\\n{hidden_state}\")"
228 | ]
229 | },
230 | {
231 | "cell_type": "markdown",
232 | "metadata": {},
233 | "source": [
234 | "RNN的循环单元部分比较抽象,不过也是最重要的部分,让我们再回顾以下流程:"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | "
\n",
71 | ""
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "metadata": {},
78 | "source": [
79 | " 举一个简单的文本例子:假设我们输入的序列为**“我 爱 西 财”**这一句话,$x_0$是第$0$步循环时的输入,也就是“我”字,$h_0$为一个包含了“我”字向量信息的输出,那么$x_1$是第$1$步循环时的输入,也就是“爱”字;$h_1$不仅包含了“爱”字向量信息,也包含了上一步“我”字的向量信息;同理,依次循环,最后的$h_3$其实是一个包含“我 爱 西 财”向量信息的输出,这样就实现了序列的**“记忆”**。"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | " 用数学公式表示为:"
87 | ]
88 | },
89 | {
90 | "cell_type": "markdown",
91 | "metadata": {},
92 | "source": [
93 | ""
94 | ]
95 | },
96 | {
97 | "cell_type": "markdown",
98 | "metadata": {},
99 | "source": [
100 | " 其中$W$为权重矩阵,$b$为偏置,都为**模型参数**,也是后续训练优化的对象;$tanh$为**激活函数**,也可以使用$relu$等其他激活函数。\n",
101 | "以上就是循环神经网络RNN最基本的一个**循环单元**,现在我们利用上面“我爱西财”的例子,用纯python的代码去解析它。假设不存在偏置项的情况下,那么首先我们定义了一个方法`RNNstep`,来完成上面公式的计算,即RNN循环的一步。"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "### 1.2 RNN基本代码实现(拆分版)"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | " RNN的代码本质上就是在一个普通的神经网络基础上,多加一个**hidden_state**来保存历史信息。用公式来表示的话就是:\n",
116 | "$h_t=tanh(w_h$$x_t+b_t+w_h+b_h)$,而普通的神经网络只有$w_h$$x_t+b_h$,少了隐藏状态的信息。那么我们可以通过构建一个`RNNstep`方法来存储隐藏状态信息:"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": 1,
122 | "metadata": {},
123 | "outputs": [],
124 | "source": [
125 | "import numpy as np\n",
126 | "\n",
127 | "def RNNstep(x, hidden):\n",
128 | " # 更新隐藏状态\n",
129 | " hidden = np.tanh(np.dot(W_hh, hidden) + np.dot(W_xh, x)) # 注意看,其实实现的就是上面的公式(无偏置项)\n",
130 | " return hidden # 当前inpu和隐藏状态作为输入,得到下一步的隐藏状态"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "metadata": {},
136 | "source": [
137 | "给定我们的输入文本数据**“我 爱 西 财”**,这里作一个最简单的onehot处理:"
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 2,
143 | "metadata": {},
144 | "outputs": [
145 | {
146 | "name": "stdout",
147 | "output_type": "stream",
148 | "text": [
149 | "输入的向量形状为:(4, 4)\n",
150 | "句子长度为:4\n"
151 | ]
152 | }
153 | ],
154 | "source": [
155 | "# 我 爱 西 财\n",
156 | "text_data = np.array([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]])\n",
157 | "print(f\"输入的向量形状为:{text_data.shape}\") # [seq_len * input_size]\n",
158 | "seq_len = text_data.shape[1]\n",
159 | "print(f\"句子长度为:{seq_len}\")"
160 | ]
161 | },
162 | {
163 | "cell_type": "markdown",
164 | "metadata": {},
165 | "source": [
166 | "从第0步开始,我们需要输入“我”字($x_0$ = [1,0,0,0]),此时不存在**hidden_state**,也就是$h_0$,可以手动随机初始化的hidden_state;除此之外,我们还应该初始化参数,这里为$W$:"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 3,
172 | "metadata": {},
173 | "outputs": [
174 | {
175 | "name": "stdout",
176 | "output_type": "stream",
177 | "text": [
178 | "初始隐藏状态:\n",
179 | "[[0.23615902 0.44332739 0.52193922 0.46863795]\n",
180 | " [0.74552592 0.44449781 0.97458196 0.29072798]\n",
181 | " [0.18527842 0.31399347 0.97185445 0.04075662]\n",
182 | " [0.1519588 0.88534927 0.49714817 0.85433517]]\n",
183 | "初始权重矩阵:\n",
184 | "[[0.37018877 0.9345049 0.43001064 0.3104593 ]\n",
185 | " [0.16109335 0.11693149 0.21544091 0.77692601]\n",
186 | " [0.58470632 0.66477251 0.98469315 0.07241005]\n",
187 | " [0.90195891 0.18030394 0.05723204 0.42469328]]\n"
188 | ]
189 | }
190 | ],
191 | "source": [
192 | "hidden_state = np.random.random((4,4))\n",
193 | " # 这里的hidden_state的维度设置本质上为序列长度,即循环输入时应该用到多少个隐藏单元\n",
194 | "print(f\"初始隐藏状态:\\n{hidden_state}\")\n",
195 | "\n",
196 | "W_hh = W_xh = np.random.random((4,4))\n",
197 | "print(f\"初始权重矩阵:\\n{W_hh}\")"
198 | ]
199 | },
200 | {
201 | "cell_type": "markdown",
202 | "metadata": {},
203 | "source": [
204 | "一共4个字,那么我们应该循环计算4步,最终得到的**hidden_state**为最后的隐藏状态$h_3$。"
205 | ]
206 | },
207 | {
208 | "cell_type": "code",
209 | "execution_count": 4,
210 | "metadata": {},
211 | "outputs": [
212 | {
213 | "name": "stdout",
214 | "output_type": "stream",
215 | "text": [
216 | "最终隐藏状态:\n",
217 | "[[0.97885185 0.9902648 0.96978843 0.97910535]\n",
218 | " [0.91175181 0.96153125 0.86889499 0.92129702]\n",
219 | " [0.9878806 0.99458351 0.98220887 0.98853489]\n",
220 | " [0.94988961 0.97819583 0.92491659 0.95506927]]\n"
221 | ]
222 | }
223 | ],
224 | "source": [
225 | "for i in range(seq_len):\n",
226 | " hidden_state = RNNstep(text_data[i,:], hidden_state) \n",
227 | "print(f\"最终隐藏状态:\\n{hidden_state}\")"
228 | ]
229 | },
230 | {
231 | "cell_type": "markdown",
232 | "metadata": {},
233 | "source": [
234 | "RNN的循环单元部分比较抽象,不过也是最重要的部分,让我们再回顾以下流程:"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | " \n",
72 | "\n",
242 | ""
244 | ]
245 | },
246 | {
247 | "cell_type": "markdown",
248 | "metadata": {},
249 | "source": [
250 | ""
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "### 1.3利用Pytorch实现RNN模型"
258 | ]
259 | },
260 | {
261 | "cell_type": "markdown",
262 | "metadata": {},
263 | "source": [
264 | "上面已经介绍了RNN的基本源码,让我们使用pytorch的RNN模块来快速搭建循环神经网络:"
265 | ]
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": 5,
270 | "metadata": {},
271 | "outputs": [],
272 | "source": [
273 | "import torch\n",
274 | "import torch.nn as nn"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "定义`exampleRNN`,输入为**[input_size :输入特征维数(特征向量的长度)\n",
282 | ";hidden_size:隐层状态的维数]:**"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": 6,
288 | "metadata": {},
289 | "outputs": [],
290 | "source": [
291 | "class exampleRNN(object):\n",
292 | " def __init__(self,input_size,hidden_size):\n",
293 | " super().__init__()\n",
294 | " self.W_xh = torch.nn.Linear(input_size, hidden_size) #因为最后的操作是相加 所以hidden要和output的shape一致\n",
295 | " self.W_hh = torch.nn.Linear(hidden_size, hidden_size)\n",
296 | "\n",
297 | " def __call__(self, x, hidden):\n",
298 | " return self.step(x, hidden)\n",
299 | " \n",
300 | " def step(self, x, hidden):\n",
301 | " #前向传播的一步\n",
302 | " h1 = self.W_hh(hidden)\n",
303 | " w1 = self.W_xh(x)\n",
304 | " out = torch.tanh(h1 + w1)\n",
305 | " hidden = self.W_hh.weight #隐藏状态权重\n",
306 | " return out, hidden"
307 | ]
308 | },
309 | {
310 | "cell_type": "markdown",
311 | "metadata": {},
312 | "source": [
313 | "给定input_text(我 爱 西 财),利用`exampleRNN`建立rnn模型:"
314 | ]
315 | },
316 | {
317 | "cell_type": "code",
318 | "execution_count": 7,
319 | "metadata": {},
320 | "outputs": [],
321 | "source": [
322 | "input_text = torch.from_numpy(text_data).float() # [seq_len * input_size],从numpy转化为tensor.float格式\n",
323 | "rnn = exampleRNN(4, 4) #[input_size*hidden_size] \n",
324 | "h_0 = torch.randn(4, 4) # [seq_len*hidden_size]\n",
325 | "seq_len = input_text.shape[0] # 4,句子长度"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "metadata": {},
331 | "source": [
332 | "注:因为文本向量one_hot输入的形状是4*4,且只有一句话,没有考虑batch_size,所以这里input_size、hidden_size、seq_len都为4,容易混淆原本的维度含义,请参照注释理解"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "循环得到最终输出"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 8,
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stdout",
349 | "output_type": "stream",
350 | "text": [
351 | "torch.Size([4, 4]) tensor([[ 0.1478, 0.3786, 0.4213, -0.3913],\n",
352 | " [ 0.1763, 0.7221, -0.8491, -0.4117],\n",
353 | " [-0.0558, 0.4432, 0.3692, 0.1021],\n",
354 | " [-0.2990, 0.5833, -0.0143, 0.2127]], grad_fn=
\n",
72 | "\n",
242 | ""
244 | ]
245 | },
246 | {
247 | "cell_type": "markdown",
248 | "metadata": {},
249 | "source": [
250 | ""
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "### 1.3利用Pytorch实现RNN模型"
258 | ]
259 | },
260 | {
261 | "cell_type": "markdown",
262 | "metadata": {},
263 | "source": [
264 | "上面已经介绍了RNN的基本源码,让我们使用pytorch的RNN模块来快速搭建循环神经网络:"
265 | ]
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": 5,
270 | "metadata": {},
271 | "outputs": [],
272 | "source": [
273 | "import torch\n",
274 | "import torch.nn as nn"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "定义`exampleRNN`,输入为**[input_size :输入特征维数(特征向量的长度)\n",
282 | ";hidden_size:隐层状态的维数]:**"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": 6,
288 | "metadata": {},
289 | "outputs": [],
290 | "source": [
291 | "class exampleRNN(object):\n",
292 | " def __init__(self,input_size,hidden_size):\n",
293 | " super().__init__()\n",
294 | " self.W_xh = torch.nn.Linear(input_size, hidden_size) #因为最后的操作是相加 所以hidden要和output的shape一致\n",
295 | " self.W_hh = torch.nn.Linear(hidden_size, hidden_size)\n",
296 | "\n",
297 | " def __call__(self, x, hidden):\n",
298 | " return self.step(x, hidden)\n",
299 | " \n",
300 | " def step(self, x, hidden):\n",
301 | " #前向传播的一步\n",
302 | " h1 = self.W_hh(hidden)\n",
303 | " w1 = self.W_xh(x)\n",
304 | " out = torch.tanh(h1 + w1)\n",
305 | " hidden = self.W_hh.weight #隐藏状态权重\n",
306 | " return out, hidden"
307 | ]
308 | },
309 | {
310 | "cell_type": "markdown",
311 | "metadata": {},
312 | "source": [
313 | "给定input_text(我 爱 西 财),利用`exampleRNN`建立rnn模型:"
314 | ]
315 | },
316 | {
317 | "cell_type": "code",
318 | "execution_count": 7,
319 | "metadata": {},
320 | "outputs": [],
321 | "source": [
322 | "input_text = torch.from_numpy(text_data).float() # [seq_len * input_size],从numpy转化为tensor.float格式\n",
323 | "rnn = exampleRNN(4, 4) #[input_size*hidden_size] \n",
324 | "h_0 = torch.randn(4, 4) # [seq_len*hidden_size]\n",
325 | "seq_len = input_text.shape[0] # 4,句子长度"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "metadata": {},
331 | "source": [
332 | "注:因为文本向量one_hot输入的形状是4*4,且只有一句话,没有考虑batch_size,所以这里input_size、hidden_size、seq_len都为4,容易混淆原本的维度含义,请参照注释理解"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "循环得到最终输出"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 8,
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stdout",
349 | "output_type": "stream",
350 | "text": [
351 | "torch.Size([4, 4]) tensor([[ 0.1478, 0.3786, 0.4213, -0.3913],\n",
352 | " [ 0.1763, 0.7221, -0.8491, -0.4117],\n",
353 | " [-0.0558, 0.4432, 0.3692, 0.1021],\n",
354 | " [-0.2990, 0.5833, -0.0143, 0.2127]], grad_fn= \n",
243 | "
\n",
243 | "
\n",
432 | " **梯度爆炸**:同理,越靠后的网络层权重矩阵更新会使用前面网络层权重信息,如果靠近输入层的网络层的梯度信息变得极大,那么更新后的权重信息也会变得极大,称为梯度爆炸
\n",
433 | " **为了更好的理解梯度消失和梯度爆炸,将通过下面的例子进行说明:**"
434 | ]
435 | },
436 | {
437 | "cell_type": "markdown",
438 | "metadata": {},
439 | "source": [
440 | "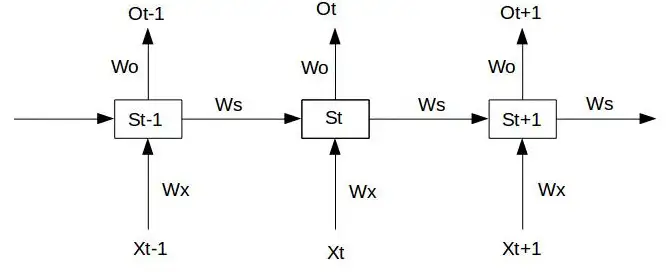"
441 | ]
442 | },
443 | {
444 | "cell_type": "markdown",
445 | "metadata": {},
446 | "source": [
447 | " 上图中是一个标准的RNN模型,Xt表示在t时刻的输入,Wx表示输入的权重矩阵,Ws表示隐藏层上一时刻传递的权重矩阵,Wo表示隐藏层到输出层的权重矩阵,Ot表示t时刻的输出。假设我们的序列只有三段:s1、s2、s3。其中s0表示的是一个固定值,使用的激活函数为tanh,则RNN的前向传播过程如下:"
448 | ]
449 | },
450 | {
451 | "cell_type": "markdown",
452 | "metadata": {},
453 | "source": [
454 | "\\begin{align}\n",
455 | "\\mathrm{S}_1&= tanh(W_xX_1 + W_sS_0 + b_1)\\\\ \n",
456 | "\\mathrm{S}_2&= tanh(W_xX_2 + W_sS_1 + b_1)\\\\\n",
457 | "\\mathrm{S}_3&= tanh(W_xX_3 + W_sS_2 + b_1)\\\\\n",
458 | "\\mathrm{O}_1&= W_oS_1 + b_2\\\\\n",
459 | "\\mathrm{O}_2&= W_oS_2 + b_2\\\\\n",
460 | "\\mathrm{O}_3&= W_oS_3 + b_2\\\\\n",
461 | "\\end{align}"
462 | ]
463 | },
464 | {
465 | "cell_type": "markdown",
466 | "metadata": {},
467 | "source": [
468 | " 假设在t = 3的时候,我们的损失函数为$L_3 = \\frac{1}{2}(Y_3 - O_3)^2$,使用梯度下降法求解$L_3$的最小值的过程就是对$W_x,W_s,W_o$求偏导,不断的调整三个权重的值,然后使得$L_3$变得最小,下面列出对$W_o,W_x,W_s$的求偏导过程:"
469 | ]
470 | },
471 | {
472 | "cell_type": "markdown",
473 | "metadata": {},
474 | "source": [
475 | "\\begin{align}\n",
476 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{W_o}}}&=\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{W_o}}}\\\\\n",
477 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{W_x}}}&=\\frac{\\partial{\\mathrm{L_3}}}\n",
478 | "{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{S_3}}}\\frac{\\partial{\\mathrm{S_3}}}{\\partial{\\mathrm{W_x}}}+\n",
479 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{S_3}}}\\frac{\\partial{\\mathrm{S_3}}}{\\partial{\\mathrm{S_2}}}\\frac{\\partial{\\mathrm{S_2}}}{\\partial{\\mathrm{W_x}}}+\n",
480 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{S_3}}}\\frac{\\partial{\\mathrm{S_3}}}{\\partial{\\mathrm{S_2}}}\\frac{\\partial{\\mathrm{S_2}}}{\\partial{\\mathrm{S_1}}}\\frac{\\partial{\\mathrm{S_1}}}{\\partial{\\mathrm{W_x}}}\\\\\n",
481 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{W_s}}}&=\\frac{\\partial{\\mathrm{L_3}}}\n",
482 | "{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{S_3}}}\\frac{\\partial{\\mathrm{S_3}}}{\\partial{\\mathrm{W_s}}}+\n",
483 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{S_3}}}\\frac{\\partial{\\mathrm{S_3}}}{\\partial{\\mathrm{S_2}}}\\frac{\\partial{\\mathrm{S_2}}}{\\partial{\\mathrm{W_s}}}+\n",
484 | "\\frac{\\partial{\\mathrm{L_3}}}{\\partial{\\mathrm{O_3}}}\\frac{\\partial{\\mathrm{O_3}}}{\\partial{\\mathrm{S_3}}}\\frac{\\partial{\\mathrm{S_3}}}{\\partial{\\mathrm{S_2}}}\\frac{\\partial{\\mathrm{S_2}}}{\\partial{\\mathrm{S_1}}}\\frac{\\partial{\\mathrm{S_1}}}{\\partial{\\mathrm{W_s}}}\n",
485 | "\\end{align}"
486 | ]
487 | },
488 | {
489 | "cell_type": "markdown",
490 | "metadata": {},
491 | "source": [
492 | " **注意:在上面求$W_x$偏导的表达式中,从左往右的$W_x$分别表示的是t=3,t=2,t=1时刻下的权重信息,$W_s$同理**"
493 | ]
494 | },
495 | {
496 | "cell_type": "markdown",
497 | "metadata": {},
498 | "source": [
499 | " 从上面的求导过程中,我们在t3时刻对$W_x,W_s$求偏导的过程中,会不断的使用到t2和t1时刻的$W_x,W_s$权重信息,即随着时间序列会产生**长期依赖**,一旦时间序列变得较长的情况下,那么对$W_x,W_s$的计算将变的非常的冗长,由于$W_x,W_s$计算过程十分相似,于是以$W_x$为例归纳权重矩阵的偏导计算公式:"
500 | ]
501 | },
502 | {
503 | "cell_type": "markdown",
504 | "metadata": {},
505 | "source": [
506 | "\\begin{align}\n",
507 | "\\frac{\\partial{\\mathrm{L}_{t}}}{\\partial{\\mathrm{W}_{x}}}=\\sum_{k=0}^{t}\\frac{\\partial{\\mathrm{L_t}}}{\\partial{\\mathrm{O_t}}}\n",
508 | "\\frac{\\partial{\\mathrm{O_t}}}{\\partial{\\mathrm{S_t}}}(\\prod_{j=k+1}^{t}\\frac{\\partial{\\mathrm{S_j}}}{\\partial{\\mathrm{S}_{j-1}}})\\frac{\\partial{\\mathrm{S_k}}}{\\partial{\\mathrm{W_x}}}\\\\\n",
509 | "\\end{align}"
510 | ]
511 | },
512 | {
513 | "cell_type": "markdown",
514 | "metadata": {},
515 | "source": [
516 | "\\begin{align}\n",
517 | "\\frac{\\partial{\\mathrm{Sj}}}{\\partial{\\mathrm{S_j-1}}}=tanh'* W_x\n",
518 | "\\end{align}"
519 | ]
520 | },
521 | {
522 | "cell_type": "markdown",
523 | "metadata": {},
524 | "source": [
525 | " 通过上面的两个归纳的公式可以看到,在对$W_x$进行求偏导的过程中,$W_x$将会以指数程度进行增长,其表现形式为$(W_x)^{t-k}$,当t变得非常大(靠后的时间序列),而k变的非常小的时候(靠前的时间序列),**t-k将变得非常大**,而我们知道权重矩阵在初始化时是随机分配的,当$W_x < 1$时就会出现梯度消失的情况,而当$W_x > 1$时就会出现梯度爆炸的情况。针对RNN存在的这种缺陷,于是提出了RNN的变体,LSTM。"
526 | ]
527 | },
528 | {
529 | "cell_type": "markdown",
530 | "metadata": {},
531 | "source": [
532 | "### 2.2 LSTM模型与RNN联系与区别"
533 | ]
534 | },
535 | {
536 | "cell_type": "markdown",
537 | "metadata": {},
538 | "source": [
539 | " **LSTM(Long-short-term-Memory 长短时记忆网路)** 是RNN模型的一种变体,通过上面的分析我们知道RNN只包含了一个隐藏层状态h,并且仅仅**对于短期记忆敏感**,而容易丢失长期记忆,因此我们增加一个状态来保存长期记忆。LSTM 通过加入**细胞状态(Cell State)和门控思想(gate)** 对过往的信息进行选择的记忆。\n",
540 | "\n",
541 | " 和RNN模型进行比较理解,RNN得到的**hidden_state**是上一层的**hidden_state**和当前**input**信息的**直接**向量运算。简单而直接的保留了**全部的信息**,随着序列的不断加长,循环的不断进行,之前的信息可能会发生**遗忘**;而LSTM模型在RNN的基础上加入**细胞状态(Cell State)和门控思想(gate)**,这些都是基于上一层**hidden_state**,通过很多**间接**操作得到当前**hidden_state**,这样就可以选择哪些信息**被保留**而传入下一个循环,哪些信息直接被**主动遗忘**,达到筛选和保留重要信息的作用。"
542 | ]
543 | },
544 | {
545 | "cell_type": "markdown",
546 | "metadata": {},
547 | "source": [
548 | "**RNN:**"
549 | ]
550 | },
551 | {
552 | "cell_type": "markdown",
553 | "metadata": {},
554 | "source": [
555 | "\n",
556 | ""
558 | ]
559 | },
560 | {
561 | "cell_type": "markdown",
562 | "metadata": {},
563 | "source": [
564 | "**LSTM:**"
565 | ]
566 | },
567 | {
568 | "cell_type": "markdown",
569 | "metadata": {},
570 | "source": [
571 | ""
572 | ]
573 | },
574 | {
575 | "cell_type": "markdown",
576 | "metadata": {},
577 | "source": [
578 | " 将上面的LSTM模型和RNN模型对比,可以发现不同的是状态信息从**单通道输入变成了双通道输入**,并且**增添了许多门(gate)和运算**来对输入信息进行处理,即对信息进行有选择性的记忆。下面将对上图涉及到的门和运算一一解释。"
579 | ]
580 | },
581 | {
582 | "cell_type": "markdown",
583 | "metadata": {},
584 | "source": [
585 | "### 2.3 LSTM模型详解"
586 | ]
587 | },
588 | {
589 | "cell_type": "markdown",
590 | "metadata": {},
591 | "source": [
592 | "#### 2.3.1 门思想和符号介绍\n",
593 | " **门思想**:门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1的实数向量。门思想类似于过滤器,对于输入的信息进行过滤和选择,这里用到的是sigmoid函数,sigmoid函数的输出介于0-1,表示对于输入的数据按照怎样的比率通过该道门。**如果得到的值为0表示任何内容都不通过该门,如果得到的值为1表示所有的内容通过该门**\n",
557 | "
"
594 | ]
595 | },
596 | {
597 | "cell_type": "markdown",
598 | "metadata": {},
599 | "source": [
600 | ""
601 | ]
602 | },
603 | {
604 | "cell_type": "markdown",
605 | "metadata": {},
606 | "source": [
607 | "**符号介绍**:
\n",
608 | "* $X_t$表示在t时刻输入的信息\n",
609 | "* ${h}_{t-1}$表示在t-1时刻的状态信息\n",
610 | "* ${C}_{t-1}$表示在t-1时刻的细胞残留的信息\n",
611 | "* ${σ、tanh}$的黄色方框,表示的是神经网络层,\n",
612 | "* ${×}$的圆圈表示的是哈达玛积,运算规则为对应的位置元素相乘\n",
613 | "* ${+}$表示的是向量相加\n",
614 | "* ${f_t}$表示的是遗忘门,可以理解为以怎样的比例来遗忘之前的信息\n",
615 | "* ${i_t}$表示的是输入门,可以理解为对于当前的输入信息以怎样的比例来保留\n",
616 | "* ${\\tilde{C_t}}$可以理解为对输入内容创建候选值向量,其中的东西就是最后加入细胞状态的内容\n",
617 | "* ${O_t}$表示的是输出门,可以理解为以怎样的比例将当前的值进行输出"
618 | ]
619 | },
620 | {
621 | "cell_type": "markdown",
622 | "metadata": {},
623 | "source": [
624 | "#### **遗忘门(${f_t}$)**\n",
625 | "\n",
626 | " 遗忘门通过查看**当前**的输入以及**之前**的状态信息,通过遗忘门的权重矩阵${W_f}$,乘上当前的输入矩阵$[{h}_{t-1},{x_t}]$,经过sigmoid函数得到每一个输入的**遗忘比例**,然后会在之后将输入的**遗忘比例**作用到${C}_{t-1}$上,决定了上一时刻的单元状态${C}_{t-1}$有多少内容**保留**到当前时刻${C_t}$。如果输入项的维度是${d_x}$,隐藏层的维度是${d_h}$,单元状态的维度是${d_c}$(通常${d_c}$ = ${d_h}$),则输入矩阵的维度为$({d_h}$ + ${d_x})*$${d_c}$,权重矩阵${W_f}$由两部分构成,分别是$W_{fh}$和$W_{fx}$,其中$W_{fh}$的维度是${d_c}*{d_h}$,$W_{fx}$的维度是${d_c}*{d_x}$,因此${W_f}$的维度是${d_c}*$$({d_h} + {d_x})$"
627 | ]
628 | },
629 | {
630 | "cell_type": "markdown",
631 | "metadata": {},
632 | "source": [
633 | "#### **输入门(${i_t}$)**\n",
634 | "\n",
635 | " 输入门与以遗忘门的作用原理比较类似,通过${W_i}$乘上当前的输入矩阵,经过sigmoid函数得到一个输入的**保留比例**,${\\tilde{C_t}}$描述的是当前的输入状态,通过tanh函数得到一个候选向量(实际要加入到细胞状态的内容,类似于**数据拷贝**,但是不是简单的复制,而是经过tanh作用),之后将**保存的比例**,乘上候选向量得到要新加入的内容。"
636 | ]
637 | },
638 | {
639 | "cell_type": "markdown",
640 | "metadata": {},
641 | "source": [
642 | "#### **细胞状态的更新**\n",
643 | "\n",
644 | " 通过之前的解释,这里就比较好理解了,将t-1时刻的细胞状态(Cell State)中的部分内容**遗忘**,再加入t时刻经过**筛选**的新的内容,从而得到了t时刻的细胞状态${C_t}$。这样就将**长期的记忆**${C}_{t-1}$与**当前的记忆**${\\tilde{C_t}}$组合在了一起,形成了新的细胞状态。由于**遗忘门**的控制,它可以保存很久很久之前的信息,由于**输入门**的控制,它又可以避免当前无关紧要的内容进入记忆。"
645 | ]
646 | },
647 | {
648 | "cell_type": "markdown",
649 | "metadata": {},
650 | "source": [
651 | "#### **输出门(${O_t}$)**"
652 | ]
653 | },
654 | {
655 | "cell_type": "markdown",
656 | "metadata": {},
657 | "source": [
658 | "\n",
659 | " 与前面同理,输出门计算中要输出内容的比例${O_t}$,控制了**长期记忆**对当前输出的影响,表示要输出${C_t}$的哪些部分,然后将经过tanh变化的候选向量乘上对应的**输出比例**得到最终的输出。"
660 | ]
661 | },
662 | {
663 | "cell_type": "markdown",
664 | "metadata": {},
665 | "source": [
666 | "### 2.4 LSTM代码实现"
667 | ]
668 | },
669 | {
670 | "cell_type": "markdown",
671 | "metadata": {},
672 | "source": [
673 | "#### 2.4.1 LSTM代码拆分版"
674 | ]
675 | },
676 | {
677 | "cell_type": "markdown",
678 | "metadata": {},
679 | "source": [
680 | " LSTM的代码本质上就是在一个RNN循环神经单元基础上(建议再回看一下RNN的代码拆分,与LSTM的代码对比加强理解),加入**细胞状态(Cell State)和遗忘门,输入门,输出门**来选择性的将信息存入hidden_state。用公式来表示的话就是:"
681 | ]
682 | },
683 | {
684 | "cell_type": "markdown",
685 | "metadata": {},
686 | "source": [
687 | "
![]() 3 |
4 | ## 课件简介
5 | 西南财经大学金融科技国际联合实验室《利用Python学习NLP》系列课件针对0基础的NLP(Natural Language Processing)学习者,通过代码实践,详细的注释与示意图讲解,让初学者一步步从最基础的文本处理开始,进阶到当前主流的预训练**BERT**、**GPT**等,并在实践中完成**情感分析**,**语义理解**,**文本生成**等经典NLP任务,掌握使用对应模型来解决现实中各类问题的能力。
6 |
7 | 本课件使用**python**进行编写,面向实践应用,尽量调用主流的库例如`Pytorch`和`transformer`,为了加强理解和应用,同时针对难点重点详解对应的源代码。
8 | 课件中使用的示例问题与数据选自实际应用中金融相关的算法比赛,论文代码复现等场景。
9 |
10 | ## 章节简介
11 |
12 | ### 1. Chapter 1 NLP简介 - [NLP简介.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%201%20NLP%E7%AE%80%E4%BB%8B/Chapter%201%20NLP%E7%AE%80%E4%BB%8B.ipynb)
13 | 此章节将介绍自然语言文本的内涵和当前的主要任务,例如**文本分类**、**情绪分析**、**命名实体识别 (NER)**、**文本摘要**、**文本生成**。并直接调用简单的代码直观实现当前的一些NLP任务。
14 |
15 | - 1-1. 自然语言的性质
16 | - 1-2. 自然语言处理的流程
17 | - 1-3. 自然语言处理的主要任务
18 |
19 | ### 2. Chapter 2 文本的基本处理 - [文本的基本处理.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%202%20%E6%96%87%E6%9C%AC%E7%9A%84%E5%9F%BA%E6%9C%AC%E5%A4%84%E7%90%86/Chapter%202%20%E6%96%87%E6%9C%AC%E7%9A%84%E5%9F%BA%E6%9C%AC%E5%A4%84%E7%90%86.ipynb)
20 | 此章节将使用中文例子利用代码实现基本的文本字符串处理,文本清洗,简单的正则表达式,切词分词,词频统计,词云图等操作,掌握python处理文本的基本方法。
21 |
22 | - 2-1. 基本的文本字符串处理方法
23 | - 2-2. 文本清洗与正则表达式
24 | - 2-3. 中文切词分词方法
25 | - 2-4. 词频统计
26 | - 2-5. 绘制词云图
27 |
28 | ### 3. Chapter 3 经典文本向量化方法 - [经典文本向量化方法.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%203%20%E7%BB%8F%E5%85%B8%E6%96%87%E6%9C%AC%E5%90%91%E9%87%8F%E5%8C%96%E6%96%B9%E6%B3%95/Chapter%203%20%E7%BB%8F%E5%85%B8%E6%96%87%E6%9C%AC%E5%90%91%E9%87%8F%E5%8C%96%E6%96%B9%E6%B3%95.ipynb)
29 | 此章节介绍文本向量化的基本概念并利用代码实现经典的文本向量化表示方法:one-hot,tfidf,基于语料库的词典方法。
30 |
31 | - 3-1. one-hot
32 | - 3-2. TF-IDF
33 | - 3-3. 基于语料库的词典方法
34 |
35 | ### 4. Chapter 4 词嵌入与word2vec - [词嵌入与word2vec.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%204%20%E8%AF%8D%E5%B5%8C%E5%85%A5%E4%B8%8Eword2vec/Chapter%204%20%E8%AF%8D%E5%B5%8C%E5%85%A5%E4%B8%8Eword2vec.ipynb)
36 | 此章节介绍将单词映射到向量表示的内涵并利用使用经典word2vec例子完成代码学习,降维并作图。
37 |
38 | - 4-1. 词嵌入的概念与简单实现
39 | - 4-2. 利用python实现word2vec方法
40 | - 4-3. 利用PCA方法对词嵌入向量降至二维并可视化
41 |
42 | ### 5. Chapter 5 文本数据增强 - [文本数据增强.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%205%20%E6%96%87%E6%9C%AC%E6%95%B0%E6%8D%AE%E5%A2%9E%E5%BC%BA/Chapter%205%20%E6%96%87%E6%9C%AC%E6%95%B0%E6%8D%AE%E5%A2%9E%E5%BC%BA.ipynb)
43 | 此章节介绍词汇替换,反译,噪声数据等文本增强技术的概念并利用中文实例使用代码掌握实现方法。
44 |
45 | - 5-1. 文本截断
46 | - 5-2. 文本数据扩充
47 | - 5-3. 噪声技术(EDA)
48 |
49 | ### 6. Chapter 6 循环神经网络(RNN LSTM) - [循环神经网络.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%206%20%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C(RNN%20LSTM)/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C(RNN%20LSTM).ipynb)
50 | 此章节将详细介绍经典的循环神经网络RNN与LSTM,并利用详细拆解的python代码实现其功能与架构,最后通过循环神经网络进行NLP任务示例。
51 |
52 | - 6-1. RNN
53 | - 6-2. LSTM
54 | - 6-3. 利用循环神经网络实现文本生成
55 |
56 | ### 7. Chapter 7 注意力机制与Transformer - [注意力机制与Transformer.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%207%20Attention%E6%9C%BA%E5%88%B6%E4%B8%8Etransformer/Attention%E6%9C%BA%E5%88%B6%E4%B8%8Etransformer_2_17.ipynb)
57 | 此章节通过代码学习当前NLP领域主流的注意力机制与Transformer模型,并利用Transformer模型完成虚假文本评论识别任务。
58 |
59 | - 7-1. 注意力机制(Attention)
60 | - 7-2. transformer结构
61 | - 7-3. 利用transformer结构实现文本分类任务(虚假评论识别)
62 |
63 | ### 8. Chapter 8 预训练模型BERT
64 | 此章节介绍经典NLP预训练模型BERT,并利用代码实现基于BERT模型的新闻文本多标签分类任务,掌握从网络上调用各种经典的预训练模型进行微调并完成下游任务的基本流程。
65 |
66 | ### 9. Chapter 9 生成式语言模型GPT
67 | 此章节介绍经典NLP生成模型GPT,并利用代码实现基于GPT框架的新闻摘要生成任务,掌握生成式模型的基本原理与技术细节。
68 |
69 | ### 10. Chapter 10 机器翻译模型
70 | (待补充)
71 |
72 | ### 11. Chapter 11 TTS文本到语音模型
73 | (待补充)
74 |
75 | ### 12. Chapter 12 基于人类喜好的NLP增强学习(chatgpt前身)
76 | (待补充)
77 |
78 | ### 13. Chapter 13 chatgpt流程复现
79 | (待补充)
80 |
81 | ## 相关文献
82 | - Word2Vec - [Distributed Representations of Words and Phrases
83 | and their Compositionality(2013)](https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf)
84 | - 数据增强(噪声技术) - [EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks](https://arxiv.org/pdf/1901.11196.pdf)
85 | - textRNN - [Finding Structure in Time(1990)](http://psych.colorado.edu/~kimlab/Elman1990.pdf)
86 | - textLSTM - [LONG SHORT-TERM MEMORY(1997)](https://www.bioinf.jku.at/publications/older/2604.pdf)
87 | - Transformer - [Attention Is All You Need(2017)](https://arxiv.org/abs/1706.03762)
88 | - BERT - [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)](https://arxiv.org/abs/1810.04805)
89 |
90 | (待补充)
91 |
92 | ## 交流反馈
93 | 感谢西南财经大学金融科技国际联合实验室的各位老师对本课件项目的帮助与支持。读者有任何问题反馈或是答疑交流,欢迎发送至邮箱2211201z5009@smail.swufe.edu.cn
94 |
--------------------------------------------------------------------------------
/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/logo.png
--------------------------------------------------------------------------------
3 |
4 | ## 课件简介
5 | 西南财经大学金融科技国际联合实验室《利用Python学习NLP》系列课件针对0基础的NLP(Natural Language Processing)学习者,通过代码实践,详细的注释与示意图讲解,让初学者一步步从最基础的文本处理开始,进阶到当前主流的预训练**BERT**、**GPT**等,并在实践中完成**情感分析**,**语义理解**,**文本生成**等经典NLP任务,掌握使用对应模型来解决现实中各类问题的能力。
6 |
7 | 本课件使用**python**进行编写,面向实践应用,尽量调用主流的库例如`Pytorch`和`transformer`,为了加强理解和应用,同时针对难点重点详解对应的源代码。
8 | 课件中使用的示例问题与数据选自实际应用中金融相关的算法比赛,论文代码复现等场景。
9 |
10 | ## 章节简介
11 |
12 | ### 1. Chapter 1 NLP简介 - [NLP简介.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%201%20NLP%E7%AE%80%E4%BB%8B/Chapter%201%20NLP%E7%AE%80%E4%BB%8B.ipynb)
13 | 此章节将介绍自然语言文本的内涵和当前的主要任务,例如**文本分类**、**情绪分析**、**命名实体识别 (NER)**、**文本摘要**、**文本生成**。并直接调用简单的代码直观实现当前的一些NLP任务。
14 |
15 | - 1-1. 自然语言的性质
16 | - 1-2. 自然语言处理的流程
17 | - 1-3. 自然语言处理的主要任务
18 |
19 | ### 2. Chapter 2 文本的基本处理 - [文本的基本处理.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%202%20%E6%96%87%E6%9C%AC%E7%9A%84%E5%9F%BA%E6%9C%AC%E5%A4%84%E7%90%86/Chapter%202%20%E6%96%87%E6%9C%AC%E7%9A%84%E5%9F%BA%E6%9C%AC%E5%A4%84%E7%90%86.ipynb)
20 | 此章节将使用中文例子利用代码实现基本的文本字符串处理,文本清洗,简单的正则表达式,切词分词,词频统计,词云图等操作,掌握python处理文本的基本方法。
21 |
22 | - 2-1. 基本的文本字符串处理方法
23 | - 2-2. 文本清洗与正则表达式
24 | - 2-3. 中文切词分词方法
25 | - 2-4. 词频统计
26 | - 2-5. 绘制词云图
27 |
28 | ### 3. Chapter 3 经典文本向量化方法 - [经典文本向量化方法.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%203%20%E7%BB%8F%E5%85%B8%E6%96%87%E6%9C%AC%E5%90%91%E9%87%8F%E5%8C%96%E6%96%B9%E6%B3%95/Chapter%203%20%E7%BB%8F%E5%85%B8%E6%96%87%E6%9C%AC%E5%90%91%E9%87%8F%E5%8C%96%E6%96%B9%E6%B3%95.ipynb)
29 | 此章节介绍文本向量化的基本概念并利用代码实现经典的文本向量化表示方法:one-hot,tfidf,基于语料库的词典方法。
30 |
31 | - 3-1. one-hot
32 | - 3-2. TF-IDF
33 | - 3-3. 基于语料库的词典方法
34 |
35 | ### 4. Chapter 4 词嵌入与word2vec - [词嵌入与word2vec.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%204%20%E8%AF%8D%E5%B5%8C%E5%85%A5%E4%B8%8Eword2vec/Chapter%204%20%E8%AF%8D%E5%B5%8C%E5%85%A5%E4%B8%8Eword2vec.ipynb)
36 | 此章节介绍将单词映射到向量表示的内涵并利用使用经典word2vec例子完成代码学习,降维并作图。
37 |
38 | - 4-1. 词嵌入的概念与简单实现
39 | - 4-2. 利用python实现word2vec方法
40 | - 4-3. 利用PCA方法对词嵌入向量降至二维并可视化
41 |
42 | ### 5. Chapter 5 文本数据增强 - [文本数据增强.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%205%20%E6%96%87%E6%9C%AC%E6%95%B0%E6%8D%AE%E5%A2%9E%E5%BC%BA/Chapter%205%20%E6%96%87%E6%9C%AC%E6%95%B0%E6%8D%AE%E5%A2%9E%E5%BC%BA.ipynb)
43 | 此章节介绍词汇替换,反译,噪声数据等文本增强技术的概念并利用中文实例使用代码掌握实现方法。
44 |
45 | - 5-1. 文本截断
46 | - 5-2. 文本数据扩充
47 | - 5-3. 噪声技术(EDA)
48 |
49 | ### 6. Chapter 6 循环神经网络(RNN LSTM) - [循环神经网络.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%206%20%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C(RNN%20LSTM)/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C(RNN%20LSTM).ipynb)
50 | 此章节将详细介绍经典的循环神经网络RNN与LSTM,并利用详细拆解的python代码实现其功能与架构,最后通过循环神经网络进行NLP任务示例。
51 |
52 | - 6-1. RNN
53 | - 6-2. LSTM
54 | - 6-3. 利用循环神经网络实现文本生成
55 |
56 | ### 7. Chapter 7 注意力机制与Transformer - [注意力机制与Transformer.ipynb](https://github.com/superlin30/NLP-with-Python/blob/main/Chapter%207%20Attention%E6%9C%BA%E5%88%B6%E4%B8%8Etransformer/Attention%E6%9C%BA%E5%88%B6%E4%B8%8Etransformer_2_17.ipynb)
57 | 此章节通过代码学习当前NLP领域主流的注意力机制与Transformer模型,并利用Transformer模型完成虚假文本评论识别任务。
58 |
59 | - 7-1. 注意力机制(Attention)
60 | - 7-2. transformer结构
61 | - 7-3. 利用transformer结构实现文本分类任务(虚假评论识别)
62 |
63 | ### 8. Chapter 8 预训练模型BERT
64 | 此章节介绍经典NLP预训练模型BERT,并利用代码实现基于BERT模型的新闻文本多标签分类任务,掌握从网络上调用各种经典的预训练模型进行微调并完成下游任务的基本流程。
65 |
66 | ### 9. Chapter 9 生成式语言模型GPT
67 | 此章节介绍经典NLP生成模型GPT,并利用代码实现基于GPT框架的新闻摘要生成任务,掌握生成式模型的基本原理与技术细节。
68 |
69 | ### 10. Chapter 10 机器翻译模型
70 | (待补充)
71 |
72 | ### 11. Chapter 11 TTS文本到语音模型
73 | (待补充)
74 |
75 | ### 12. Chapter 12 基于人类喜好的NLP增强学习(chatgpt前身)
76 | (待补充)
77 |
78 | ### 13. Chapter 13 chatgpt流程复现
79 | (待补充)
80 |
81 | ## 相关文献
82 | - Word2Vec - [Distributed Representations of Words and Phrases
83 | and their Compositionality(2013)](https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf)
84 | - 数据增强(噪声技术) - [EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks](https://arxiv.org/pdf/1901.11196.pdf)
85 | - textRNN - [Finding Structure in Time(1990)](http://psych.colorado.edu/~kimlab/Elman1990.pdf)
86 | - textLSTM - [LONG SHORT-TERM MEMORY(1997)](https://www.bioinf.jku.at/publications/older/2604.pdf)
87 | - Transformer - [Attention Is All You Need(2017)](https://arxiv.org/abs/1706.03762)
88 | - BERT - [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)](https://arxiv.org/abs/1810.04805)
89 |
90 | (待补充)
91 |
92 | ## 交流反馈
93 | 感谢西南财经大学金融科技国际联合实验室的各位老师对本课件项目的帮助与支持。读者有任何问题反馈或是答疑交流,欢迎发送至邮箱2211201z5009@smail.swufe.edu.cn
94 |
--------------------------------------------------------------------------------
/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/superlin30/NLP-with-Python/c2476598f286ed1a2450d0118e7394e154ed0747/logo.png
--------------------------------------------------------------------------------