├── .gitignore
├── .idea
├── inspectionProfiles
│ ├── Project_Default.xml
│ └── profiles_settings.xml
├── misc.xml
├── modules.xml
├── seqGAN.iml
├── vcs.xml
└── workspace.xml
├── README.md
├── discriminator.py
├── generator.py
├── helpers.py
├── learning_curve.png
├── main.py
├── oracle_EMBDIM32_HIDDENDIM32_VOCAB5000_MAXSEQLEN20.trc
└── oracle_samples.trc
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/Project_Default.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/seqGAN.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 | Python
127 |
128 |
129 |
130 |
131 | PyCompatibilityInspection
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
256 |
257 |
258 |
259 |
260 |
261 |
262 |
263 |
264 |
265 |
266 |
267 |
268 |
269 |
270 |
271 |
272 |
273 |
274 |
275 |
276 |
277 |
278 |
279 |
280 |
281 |
282 |
283 |
284 |
285 |
286 |
287 |
288 |
289 |
290 |
291 |
292 |
293 |
294 |
295 |
296 |
297 |
298 |
299 |
300 |
301 |
302 |
303 |
304 |
305 |
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
331 |
332 |
333 |
334 |
335 |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
352 |
353 |
354 |
355 | 1500059530491
356 |
357 |
358 | 1500059530491
359 |
360 |
361 |
362 |
363 |
364 |
365 |
366 |
367 |
368 |
369 |
370 |
371 |
372 |
373 |
374 |
375 |
376 |
377 |
378 |
379 |
380 |
381 |
382 |
383 |
384 |
385 |
386 |
389 |
392 |
393 |
394 |
395 |
396 |
397 |
398 |
399 |
400 |
401 |
402 |
403 |
404 |
405 |
406 |
407 |
408 |
409 |
410 |
411 |
412 |
413 |
414 |
415 |
416 |
417 |
418 |
419 |
420 |
421 |
422 |
423 |
424 |
425 |
426 |
427 |
428 |
429 |
430 |
431 |
432 |
433 |
434 |
435 |
436 |
437 |
438 |
439 |
440 |
441 |
442 |
443 |
444 |
445 |
446 |
447 |
448 |
449 |
450 |
451 |
452 |
453 |
454 |
455 |
456 |
457 |
458 |
459 |
460 |
461 |
462 |
463 |
464 |
465 |
466 |
467 |
468 |
469 |
470 |
471 |
472 |
473 |
474 |
475 |
476 |
477 |
478 |
479 |
480 |
481 |
482 |
483 |
484 |
485 |
486 |
487 |
488 |
489 |
490 |
491 |
492 |
493 |
494 |
495 |
496 |
497 |
498 |
499 |
500 |
501 |
502 |
503 |
504 |
505 |
506 |
507 |
508 |
509 |
510 |
511 |
512 |
513 |
514 |
515 |
516 |
517 |
518 |
519 |
520 |
521 |
522 |
523 |
524 |
525 |
526 |
527 |
528 |
529 |
530 |
531 |
532 |
533 |
534 |
535 |
536 |
537 |
538 |
539 |
540 |
541 |
542 |
543 |
544 |
545 |
546 |
547 |
548 |
549 |
550 |
551 |
552 |
553 |
554 |
555 |
556 |
557 |
558 |
559 |
560 |
561 |
562 |
563 |
564 |
565 |
566 |
567 |
568 |
569 |
570 |
571 |
572 |
573 |
574 |
575 |
576 |
577 |
578 |
579 |
580 |
581 |
582 |
583 |
584 |
585 |
586 |
587 |
588 |
589 |
590 |
591 |
592 |
593 |
594 |
595 |
596 |
597 |
598 |
599 |
600 |
601 |
602 |
603 |
604 |
605 |
606 |
607 |
608 |
609 |
610 |
611 |
612 |
613 |
614 |
615 |
616 |
617 |
618 |
619 |
620 |
621 |
622 |
623 |
624 |
625 |
626 |
627 |
628 |
629 |
630 |
631 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # seqGAN
2 | A PyTorch implementation of "SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient." (Yu, Lantao, et al.). The code is highly simplified, commented and (hopefully) straightforward to understand. The policy gradients implemented are also much simpler than in the original work (https://github.com/LantaoYu/SeqGAN/) and do not involve rollouts- a single reward is used for the entire sentence (inspired by the examples in http://karpathy.github.io/2016/05/31/rl/).
3 |
4 | The architectures used are different than those in the orignal work. Specifically, a recurrent bidirectional GRU network is used as the discriminator.
5 |
6 | The code performs the experiment on synthetic data as described in the paper.
7 |
8 | You are encouraged to raise any doubts regarding the working of the code as Issues.
9 |
10 | To run the code:
11 | ```bash
12 | python main.py
13 | ```
14 | main.py should be your entry point into the code.
15 |
16 | ## Hacks and Observations
17 | The following hacks (borrowed from https://github.com/soumith/ganhacks) seem to have worked in this case:
18 | - Training Discriminator a lot more than Generator (Generator is trained only for one batch of examples, and increasing the batch size hurts stability)
19 | - Using Adam for Generator and Adagrad for Discriminator
20 | - Tweaking learning rate for Generator in GAN phase
21 | - Using dropout in both training and testing phase
22 |
23 | - Stablity is extremely sensitive to almost every parameter :/
24 | - The GAN phase may not always lead to massive drops in NLL (sometimes very minimal) - I suspect this is due to the very crude nature of the policy gradients implemented (without rollouts).
25 |
26 | ## Sample Learning Curve
27 | Learning curve obtained after MLE training for 100 epochs followed by adversarial training. (Your results may vary!)
28 |
29 | 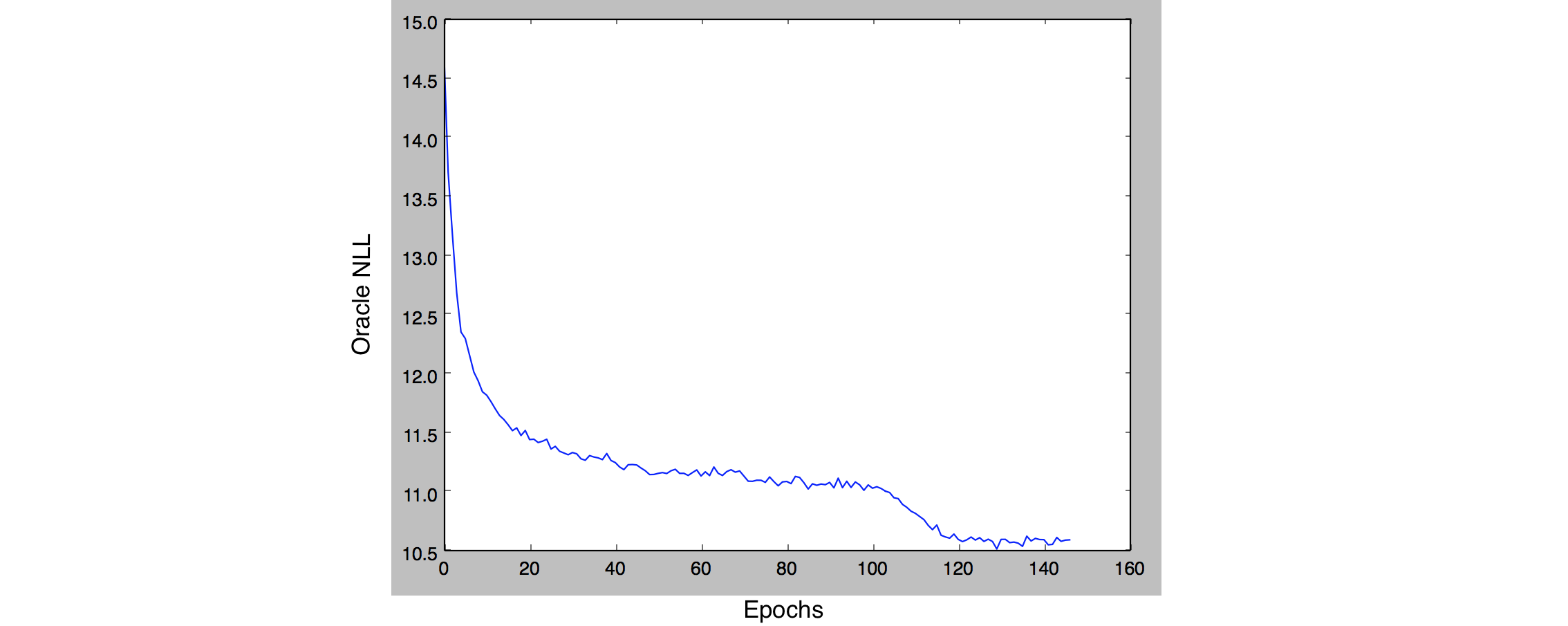
30 |
--------------------------------------------------------------------------------
/discriminator.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.autograd as autograd
3 | import torch.nn as nn
4 | import pdb
5 |
6 | class Discriminator(nn.Module):
7 |
8 | def __init__(self, embedding_dim, hidden_dim, vocab_size, max_seq_len, gpu=False, dropout=0.2):
9 | super(Discriminator, self).__init__()
10 | self.hidden_dim = hidden_dim
11 | self.embedding_dim = embedding_dim
12 | self.max_seq_len = max_seq_len
13 | self.gpu = gpu
14 |
15 | self.embeddings = nn.Embedding(vocab_size, embedding_dim)
16 | self.gru = nn.GRU(embedding_dim, hidden_dim, num_layers=2, bidirectional=True, dropout=dropout)
17 | self.gru2hidden = nn.Linear(2*2*hidden_dim, hidden_dim)
18 | self.dropout_linear = nn.Dropout(p=dropout)
19 | self.hidden2out = nn.Linear(hidden_dim, 1)
20 |
21 | def init_hidden(self, batch_size):
22 | h = autograd.Variable(torch.zeros(2*2*1, batch_size, self.hidden_dim))
23 |
24 | if self.gpu:
25 | return h.cuda()
26 | else:
27 | return h
28 |
29 | def forward(self, input, hidden):
30 | # input dim # batch_size x seq_len
31 | emb = self.embeddings(input) # batch_size x seq_len x embedding_dim
32 | emb = emb.permute(1, 0, 2) # seq_len x batch_size x embedding_dim
33 | _, hidden = self.gru(emb, hidden) # 4 x batch_size x hidden_dim
34 | hidden = hidden.permute(1, 0, 2).contiguous() # batch_size x 4 x hidden_dim
35 | out = self.gru2hidden(hidden.view(-1, 4*self.hidden_dim)) # batch_size x 4*hidden_dim
36 | out = torch.tanh(out)
37 | out = self.dropout_linear(out)
38 | out = self.hidden2out(out) # batch_size x 1
39 | out = torch.sigmoid(out)
40 | return out
41 |
42 | def batchClassify(self, inp):
43 | """
44 | Classifies a batch of sequences.
45 |
46 | Inputs: inp
47 | - inp: batch_size x seq_len
48 |
49 | Returns: out
50 | - out: batch_size ([0,1] score)
51 | """
52 |
53 | h = self.init_hidden(inp.size()[0])
54 | out = self.forward(inp, h)
55 | return out.view(-1)
56 |
57 | def batchBCELoss(self, inp, target):
58 | """
59 | Returns Binary Cross Entropy Loss for discriminator.
60 |
61 | Inputs: inp, target
62 | - inp: batch_size x seq_len
63 | - target: batch_size (binary 1/0)
64 | """
65 |
66 | loss_fn = nn.BCELoss()
67 | h = self.init_hidden(inp.size()[0])
68 | out = self.forward(inp, h)
69 | return loss_fn(out, target)
70 |
71 |
--------------------------------------------------------------------------------
/generator.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.autograd as autograd
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | import numpy as np
6 | import pdb
7 | import math
8 | import torch.nn.init as init
9 |
10 |
11 | class Generator(nn.Module):
12 |
13 | def __init__(self, embedding_dim, hidden_dim, vocab_size, max_seq_len, gpu=False, oracle_init=False):
14 | super(Generator, self).__init__()
15 | self.hidden_dim = hidden_dim
16 | self.embedding_dim = embedding_dim
17 | self.max_seq_len = max_seq_len
18 | self.vocab_size = vocab_size
19 | self.gpu = gpu
20 |
21 | self.embeddings = nn.Embedding(vocab_size, embedding_dim)
22 | self.gru = nn.GRU(embedding_dim, hidden_dim)
23 | self.gru2out = nn.Linear(hidden_dim, vocab_size)
24 |
25 | # initialise oracle network with N(0,1)
26 | # otherwise variance of initialisation is very small => high NLL for data sampled from the same model
27 | if oracle_init:
28 | for p in self.parameters():
29 | init.normal(p, 0, 1)
30 |
31 | def init_hidden(self, batch_size=1):
32 | h = autograd.Variable(torch.zeros(1, batch_size, self.hidden_dim))
33 |
34 | if self.gpu:
35 | return h.cuda()
36 | else:
37 | return h
38 |
39 | def forward(self, inp, hidden):
40 | """
41 | Embeds input and applies GRU one token at a time (seq_len = 1)
42 | """
43 | # input dim # batch_size
44 | emb = self.embeddings(inp) # batch_size x embedding_dim
45 | emb = emb.view(1, -1, self.embedding_dim) # 1 x batch_size x embedding_dim
46 | out, hidden = self.gru(emb, hidden) # 1 x batch_size x hidden_dim (out)
47 | out = self.gru2out(out.view(-1, self.hidden_dim)) # batch_size x vocab_size
48 | out = F.log_softmax(out, dim=1)
49 | return out, hidden
50 |
51 | def sample(self, num_samples, start_letter=0):
52 | """
53 | Samples the network and returns num_samples samples of length max_seq_len.
54 |
55 | Outputs: samples, hidden
56 | - samples: num_samples x max_seq_length (a sampled sequence in each row)
57 | """
58 |
59 | samples = torch.zeros(num_samples, self.max_seq_len).type(torch.LongTensor)
60 |
61 | h = self.init_hidden(num_samples)
62 | inp = autograd.Variable(torch.LongTensor([start_letter]*num_samples))
63 |
64 | if self.gpu:
65 | samples = samples.cuda()
66 | inp = inp.cuda()
67 |
68 | for i in range(self.max_seq_len):
69 | out, h = self.forward(inp, h) # out: num_samples x vocab_size
70 | out = torch.multinomial(torch.exp(out), 1) # num_samples x 1 (sampling from each row)
71 | samples[:, i] = out.view(-1).data
72 |
73 | inp = out.view(-1)
74 |
75 | return samples
76 |
77 | def batchNLLLoss(self, inp, target):
78 | """
79 | Returns the NLL Loss for predicting target sequence.
80 |
81 | Inputs: inp, target
82 | - inp: batch_size x seq_len
83 | - target: batch_size x seq_len
84 |
85 | inp should be target with (start letter) prepended
86 | """
87 |
88 | loss_fn = nn.NLLLoss()
89 | batch_size, seq_len = inp.size()
90 | inp = inp.permute(1, 0) # seq_len x batch_size
91 | target = target.permute(1, 0) # seq_len x batch_size
92 | h = self.init_hidden(batch_size)
93 |
94 | loss = 0
95 | for i in range(seq_len):
96 | out, h = self.forward(inp[i], h)
97 | loss += loss_fn(out, target[i])
98 |
99 | return loss # per batch
100 |
101 | def batchPGLoss(self, inp, target, reward):
102 | """
103 | Returns a pseudo-loss that gives corresponding policy gradients (on calling .backward()).
104 | Inspired by the example in http://karpathy.github.io/2016/05/31/rl/
105 |
106 | Inputs: inp, target
107 | - inp: batch_size x seq_len
108 | - target: batch_size x seq_len
109 | - reward: batch_size (discriminator reward for each sentence, applied to each token of the corresponding
110 | sentence)
111 |
112 | inp should be target with (start letter) prepended
113 | """
114 |
115 | batch_size, seq_len = inp.size()
116 | inp = inp.permute(1, 0) # seq_len x batch_size
117 | target = target.permute(1, 0) # seq_len x batch_size
118 | h = self.init_hidden(batch_size)
119 |
120 | loss = 0
121 | for i in range(seq_len):
122 | out, h = self.forward(inp[i], h)
123 | # TODO: should h be detached from graph (.detach())?
124 | for j in range(batch_size):
125 | loss += -out[j][target.data[i][j]]*reward[j] # log(P(y_t|Y_1:Y_{t-1})) * Q
126 |
127 | return loss/batch_size
128 |
129 |
--------------------------------------------------------------------------------
/helpers.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.autograd import Variable
3 | from math import ceil
4 |
5 | def prepare_generator_batch(samples, start_letter=0, gpu=False):
6 | """
7 | Takes samples (a batch) and returns
8 |
9 | Inputs: samples, start_letter, cuda
10 | - samples: batch_size x seq_len (Tensor with a sample in each row)
11 |
12 | Returns: inp, target
13 | - inp: batch_size x seq_len (same as target, but with start_letter prepended)
14 | - target: batch_size x seq_len (Variable same as samples)
15 | """
16 |
17 | batch_size, seq_len = samples.size()
18 |
19 | inp = torch.zeros(batch_size, seq_len)
20 | target = samples
21 | inp[:, 0] = start_letter
22 | inp[:, 1:] = target[:, :seq_len-1]
23 |
24 | inp = Variable(inp).type(torch.LongTensor)
25 | target = Variable(target).type(torch.LongTensor)
26 |
27 | if gpu:
28 | inp = inp.cuda()
29 | target = target.cuda()
30 |
31 | return inp, target
32 |
33 |
34 | def prepare_discriminator_data(pos_samples, neg_samples, gpu=False):
35 | """
36 | Takes positive (target) samples, negative (generator) samples and prepares inp and target data for discriminator.
37 |
38 | Inputs: pos_samples, neg_samples
39 | - pos_samples: pos_size x seq_len
40 | - neg_samples: neg_size x seq_len
41 |
42 | Returns: inp, target
43 | - inp: (pos_size + neg_size) x seq_len
44 | - target: pos_size + neg_size (boolean 1/0)
45 | """
46 |
47 | inp = torch.cat((pos_samples, neg_samples), 0).type(torch.LongTensor)
48 | target = torch.ones(pos_samples.size()[0] + neg_samples.size()[0])
49 | target[pos_samples.size()[0]:] = 0
50 |
51 | # shuffle
52 | perm = torch.randperm(target.size()[0])
53 | target = target[perm]
54 | inp = inp[perm]
55 |
56 | inp = Variable(inp)
57 | target = Variable(target)
58 |
59 | if gpu:
60 | inp = inp.cuda()
61 | target = target.cuda()
62 |
63 | return inp, target
64 |
65 |
66 | def batchwise_sample(gen, num_samples, batch_size):
67 | """
68 | Sample num_samples samples batch_size samples at a time from gen.
69 | Does not require gpu since gen.sample() takes care of that.
70 | """
71 |
72 | samples = []
73 | for i in range(int(ceil(num_samples/float(batch_size)))):
74 | samples.append(gen.sample(batch_size))
75 |
76 | return torch.cat(samples, 0)[:num_samples]
77 |
78 |
79 | def batchwise_oracle_nll(gen, oracle, num_samples, batch_size, max_seq_len, start_letter=0, gpu=False):
80 | s = batchwise_sample(gen, num_samples, batch_size)
81 | oracle_nll = 0
82 | for i in range(0, num_samples, batch_size):
83 | inp, target = prepare_generator_batch(s[i:i+batch_size], start_letter, gpu)
84 | oracle_loss = oracle.batchNLLLoss(inp, target) / max_seq_len
85 | oracle_nll += oracle_loss.data.item()
86 |
87 | return oracle_nll/(num_samples/batch_size)
88 |
--------------------------------------------------------------------------------
/learning_curve.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/suragnair/seqGAN/ae8ffcd54977bd9ee177994c751f86d34f5f7aa3/learning_curve.png
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from math import ceil
3 | import numpy as np
4 | import sys
5 | import pdb
6 |
7 | import torch
8 | import torch.optim as optim
9 | import torch.nn as nn
10 |
11 | import generator
12 | import discriminator
13 | import helpers
14 |
15 |
16 | CUDA = False
17 | VOCAB_SIZE = 5000
18 | MAX_SEQ_LEN = 20
19 | START_LETTER = 0
20 | BATCH_SIZE = 32
21 | MLE_TRAIN_EPOCHS = 100
22 | ADV_TRAIN_EPOCHS = 50
23 | POS_NEG_SAMPLES = 10000
24 |
25 | GEN_EMBEDDING_DIM = 32
26 | GEN_HIDDEN_DIM = 32
27 | DIS_EMBEDDING_DIM = 64
28 | DIS_HIDDEN_DIM = 64
29 |
30 | oracle_samples_path = './oracle_samples.trc'
31 | oracle_state_dict_path = './oracle_EMBDIM32_HIDDENDIM32_VOCAB5000_MAXSEQLEN20.trc'
32 | pretrained_gen_path = './gen_MLEtrain_EMBDIM32_HIDDENDIM32_VOCAB5000_MAXSEQLEN20.trc'
33 | pretrained_dis_path = './dis_pretrain_EMBDIM_64_HIDDENDIM64_VOCAB5000_MAXSEQLEN20.trc'
34 |
35 |
36 | def train_generator_MLE(gen, gen_opt, oracle, real_data_samples, epochs):
37 | """
38 | Max Likelihood Pretraining for the generator
39 | """
40 | for epoch in range(epochs):
41 | print('epoch %d : ' % (epoch + 1), end='')
42 | sys.stdout.flush()
43 | total_loss = 0
44 |
45 | for i in range(0, POS_NEG_SAMPLES, BATCH_SIZE):
46 | inp, target = helpers.prepare_generator_batch(real_data_samples[i:i + BATCH_SIZE], start_letter=START_LETTER,
47 | gpu=CUDA)
48 | gen_opt.zero_grad()
49 | loss = gen.batchNLLLoss(inp, target)
50 | loss.backward()
51 | gen_opt.step()
52 |
53 | total_loss += loss.data.item()
54 |
55 | if (i / BATCH_SIZE) % ceil(
56 | ceil(POS_NEG_SAMPLES / float(BATCH_SIZE)) / 10.) == 0: # roughly every 10% of an epoch
57 | print('.', end='')
58 | sys.stdout.flush()
59 |
60 | # each loss in a batch is loss per sample
61 | total_loss = total_loss / ceil(POS_NEG_SAMPLES / float(BATCH_SIZE)) / MAX_SEQ_LEN
62 |
63 | # sample from generator and compute oracle NLL
64 | oracle_loss = helpers.batchwise_oracle_nll(gen, oracle, POS_NEG_SAMPLES, BATCH_SIZE, MAX_SEQ_LEN,
65 | start_letter=START_LETTER, gpu=CUDA)
66 |
67 | print(' average_train_NLL = %.4f, oracle_sample_NLL = %.4f' % (total_loss, oracle_loss))
68 |
69 |
70 | def train_generator_PG(gen, gen_opt, oracle, dis, num_batches):
71 | """
72 | The generator is trained using policy gradients, using the reward from the discriminator.
73 | Training is done for num_batches batches.
74 | """
75 |
76 | for batch in range(num_batches):
77 | s = gen.sample(BATCH_SIZE*2) # 64 works best
78 | inp, target = helpers.prepare_generator_batch(s, start_letter=START_LETTER, gpu=CUDA)
79 | rewards = dis.batchClassify(target)
80 |
81 | gen_opt.zero_grad()
82 | pg_loss = gen.batchPGLoss(inp, target, rewards)
83 | pg_loss.backward()
84 | gen_opt.step()
85 |
86 | # sample from generator and compute oracle NLL
87 | oracle_loss = helpers.batchwise_oracle_nll(gen, oracle, POS_NEG_SAMPLES, BATCH_SIZE, MAX_SEQ_LEN,
88 | start_letter=START_LETTER, gpu=CUDA)
89 |
90 | print(' oracle_sample_NLL = %.4f' % oracle_loss)
91 |
92 |
93 | def train_discriminator(discriminator, dis_opt, real_data_samples, generator, oracle, d_steps, epochs):
94 | """
95 | Training the discriminator on real_data_samples (positive) and generated samples from generator (negative).
96 | Samples are drawn d_steps times, and the discriminator is trained for epochs epochs.
97 | """
98 |
99 | # generating a small validation set before training (using oracle and generator)
100 | pos_val = oracle.sample(100)
101 | neg_val = generator.sample(100)
102 | val_inp, val_target = helpers.prepare_discriminator_data(pos_val, neg_val, gpu=CUDA)
103 |
104 | for d_step in range(d_steps):
105 | s = helpers.batchwise_sample(generator, POS_NEG_SAMPLES, BATCH_SIZE)
106 | dis_inp, dis_target = helpers.prepare_discriminator_data(real_data_samples, s, gpu=CUDA)
107 | for epoch in range(epochs):
108 | print('d-step %d epoch %d : ' % (d_step + 1, epoch + 1), end='')
109 | sys.stdout.flush()
110 | total_loss = 0
111 | total_acc = 0
112 |
113 | for i in range(0, 2 * POS_NEG_SAMPLES, BATCH_SIZE):
114 | inp, target = dis_inp[i:i + BATCH_SIZE], dis_target[i:i + BATCH_SIZE]
115 | dis_opt.zero_grad()
116 | out = discriminator.batchClassify(inp)
117 | loss_fn = nn.BCELoss()
118 | loss = loss_fn(out, target)
119 | loss.backward()
120 | dis_opt.step()
121 |
122 | total_loss += loss.data.item()
123 | total_acc += torch.sum((out>0.5)==(target>0.5)).data.item()
124 |
125 | if (i / BATCH_SIZE) % ceil(ceil(2 * POS_NEG_SAMPLES / float(
126 | BATCH_SIZE)) / 10.) == 0: # roughly every 10% of an epoch
127 | print('.', end='')
128 | sys.stdout.flush()
129 |
130 | total_loss /= ceil(2 * POS_NEG_SAMPLES / float(BATCH_SIZE))
131 | total_acc /= float(2 * POS_NEG_SAMPLES)
132 |
133 | val_pred = discriminator.batchClassify(val_inp)
134 | print(' average_loss = %.4f, train_acc = %.4f, val_acc = %.4f' % (
135 | total_loss, total_acc, torch.sum((val_pred>0.5)==(val_target>0.5)).data.item()/200.))
136 |
137 | # MAIN
138 | if __name__ == '__main__':
139 | oracle = generator.Generator(GEN_EMBEDDING_DIM, GEN_HIDDEN_DIM, VOCAB_SIZE, MAX_SEQ_LEN, gpu=CUDA)
140 | oracle.load_state_dict(torch.load(oracle_state_dict_path))
141 | oracle_samples = torch.load(oracle_samples_path).type(torch.LongTensor)
142 | # a new oracle can be generated by passing oracle_init=True in the generator constructor
143 | # samples for the new oracle can be generated using helpers.batchwise_sample()
144 |
145 | gen = generator.Generator(GEN_EMBEDDING_DIM, GEN_HIDDEN_DIM, VOCAB_SIZE, MAX_SEQ_LEN, gpu=CUDA)
146 | dis = discriminator.Discriminator(DIS_EMBEDDING_DIM, DIS_HIDDEN_DIM, VOCAB_SIZE, MAX_SEQ_LEN, gpu=CUDA)
147 |
148 | if CUDA:
149 | oracle = oracle.cuda()
150 | gen = gen.cuda()
151 | dis = dis.cuda()
152 | oracle_samples = oracle_samples.cuda()
153 |
154 | # GENERATOR MLE TRAINING
155 | print('Starting Generator MLE Training...')
156 | gen_optimizer = optim.Adam(gen.parameters(), lr=1e-2)
157 | train_generator_MLE(gen, gen_optimizer, oracle, oracle_samples, MLE_TRAIN_EPOCHS)
158 |
159 | # torch.save(gen.state_dict(), pretrained_gen_path)
160 | # gen.load_state_dict(torch.load(pretrained_gen_path))
161 |
162 | # PRETRAIN DISCRIMINATOR
163 | print('\nStarting Discriminator Training...')
164 | dis_optimizer = optim.Adagrad(dis.parameters())
165 | train_discriminator(dis, dis_optimizer, oracle_samples, gen, oracle, 50, 3)
166 |
167 | # torch.save(dis.state_dict(), pretrained_dis_path)
168 | # dis.load_state_dict(torch.load(pretrained_dis_path))
169 |
170 | # ADVERSARIAL TRAINING
171 | print('\nStarting Adversarial Training...')
172 | oracle_loss = helpers.batchwise_oracle_nll(gen, oracle, POS_NEG_SAMPLES, BATCH_SIZE, MAX_SEQ_LEN,
173 | start_letter=START_LETTER, gpu=CUDA)
174 | print('\nInitial Oracle Sample Loss : %.4f' % oracle_loss)
175 |
176 | for epoch in range(ADV_TRAIN_EPOCHS):
177 | print('\n--------\nEPOCH %d\n--------' % (epoch+1))
178 | # TRAIN GENERATOR
179 | print('\nAdversarial Training Generator : ', end='')
180 | sys.stdout.flush()
181 | train_generator_PG(gen, gen_optimizer, oracle, dis, 1)
182 |
183 | # TRAIN DISCRIMINATOR
184 | print('\nAdversarial Training Discriminator : ')
185 | train_discriminator(dis, dis_optimizer, oracle_samples, gen, oracle, 5, 3)
--------------------------------------------------------------------------------
/oracle_EMBDIM32_HIDDENDIM32_VOCAB5000_MAXSEQLEN20.trc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/suragnair/seqGAN/ae8ffcd54977bd9ee177994c751f86d34f5f7aa3/oracle_EMBDIM32_HIDDENDIM32_VOCAB5000_MAXSEQLEN20.trc
--------------------------------------------------------------------------------
/oracle_samples.trc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/suragnair/seqGAN/ae8ffcd54977bd9ee177994c751f86d34f5f7aa3/oracle_samples.trc
--------------------------------------------------------------------------------