├── soft_intro_vae_3d
├── datasets
│ ├── __init__.py
│ ├── transforms.py
│ ├── shapenet.py
│ └── modelnet40.py
├── metrics
│ ├── __init__.py
│ └── jsd.py
├── utils
│ ├── __init__.py
│ ├── util.py
│ ├── data.py
│ └── pcutil.py
├── requirements.txt
├── render
│ ├── LICENSE
│ ├── README.md
│ └── render_mitsuba2_pc.py
├── losses
│ └── chamfer_loss.py
├── config
│ └── soft_intro_vae_hp.json
├── test_model.py
├── evaluation
│ ├── generate_data_for_metrics.py
│ └── find_best_epoch_on_validation_soft.py
├── generate_for_rendering.py
└── README.md
├── style_soft_intro_vae
├── training_artifacts
│ ├── ffhq
│ │ └── last_checkpoint
│ └── celeba-hq256
│ │ └── last_checkpoint
├── requirements.txt
├── registry.py
├── split_train_test_dirs.py
├── configs
│ ├── celeba-hq256.yaml
│ └── ffhq256.yaml
├── defaults.py
├── environment.yml
├── utils.py
├── scheduler.py
├── custom_adam.py
├── make_figures
│ ├── generate_samples.py
│ ├── make_generation_figure.py
│ ├── make_recon_figure_ffhq.py
│ ├── make_recon_figure_interpolation_2_images.py
│ ├── make_recon_figure_paged.py
│ └── make_recon_figure_interpolation.py
├── launcher.py
├── lod_driver.py
├── tracker.py
├── checkpointer.py
├── dataset_preparation
│ └── split_tfrecords_ffhq.py
└── README.md
├── soft_intro_vae_tutorial
└── README.md
├── soft_intro_vae_2d
├── main.py
└── README.md
├── soft_intro_vae
├── main.py
├── README.md
└── dataset.py
├── soft_intro_vae_bootstrap
├── main.py
├── README.md
└── dataset.py
├── environment.yml
└── README.md
/soft_intro_vae_3d/datasets/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/metrics/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/utils/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/training_artifacts/ffhq/last_checkpoint:
--------------------------------------------------------------------------------
1 | training_artifacts/ffhq/ffhq_fid_17.55_epoch_270.pth
--------------------------------------------------------------------------------
/style_soft_intro_vae/training_artifacts/celeba-hq256/last_checkpoint:
--------------------------------------------------------------------------------
1 | training_artifacts/celeba-hq256/celebahq_fid_18.63_epoch_230.pth
--------------------------------------------------------------------------------
/soft_intro_vae_3d/requirements.txt:
--------------------------------------------------------------------------------
1 | h5py
2 | matplotlib
3 | numpy
4 | pandas
5 | git+https://github.com/szagoruyko/pyinn.git@master
6 | torch==0.4.1
--------------------------------------------------------------------------------
/style_soft_intro_vae/requirements.txt:
--------------------------------------------------------------------------------
1 | packaging
2 | imageio
3 | numpy
4 | scipy
5 | tqdm
6 | dlutils
7 | bimpy
8 | torch >= 1.3
9 | torchvision
10 | sklearn
11 | yacs
12 | matplotlib
13 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/registry.py:
--------------------------------------------------------------------------------
1 | from utils import Registry
2 |
3 | MODELS = Registry()
4 | ENCODERS = Registry()
5 | GENERATORS = Registry()
6 | MAPPINGS = Registry()
7 | DISCRIMINATORS = Registry()
8 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/split_train_test_dirs.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | import os
3 | import shutil
4 |
5 | if __name__ == '__main__':
6 | all_data_dir = str(Path.home()) + '/../../mnt/data/tal/celebhq_256'
7 | train_dir = str(Path.home()) + '/../../mnt/data/tal/celebhq_256_train'
8 | test_dir = str(Path.home()) + '/../../mnt/data/tal/celebhq_256_test'
9 | os.makedirs(train_dir, exist_ok=True)
10 | os.makedirs(test_dir, exist_ok=True)
11 | num_train = 29000
12 | num_test = 1000
13 | images = []
14 | for i, filename in enumerate(os.listdir(all_data_dir)):
15 | if i < num_train:
16 | shutil.copyfile(os.path.join(all_data_dir, filename), os.path.join(train_dir, filename))
17 | else:
18 | shutil.copyfile(os.path.join(all_data_dir, filename), os.path.join(test_dir, filename))
19 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/render/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Tolga Birdal
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/losses/chamfer_loss.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | class ChamferLoss(nn.Module):
6 |
7 | def __init__(self):
8 | super(ChamferLoss, self).__init__()
9 | self.use_cuda = torch.cuda.is_available()
10 |
11 | def forward(self, preds, gts):
12 | P = self.batch_pairwise_dist(gts, preds)
13 | mins, _ = torch.min(P, 1)
14 | loss_1 = torch.sum(mins, 1)
15 | mins, _ = torch.min(P, 2)
16 | loss_2 = torch.sum(mins, 1)
17 | return loss_1 + loss_2
18 |
19 | def batch_pairwise_dist(self, x, y):
20 | bs, num_points_x, points_dim = x.size()
21 | _, num_points_y, _ = y.size()
22 | xx = torch.bmm(x, x.transpose(2, 1))
23 | yy = torch.bmm(y, y.transpose(2, 1))
24 | zz = torch.bmm(x, y.transpose(2, 1))
25 | if self.use_cuda:
26 | dtype = torch.cuda.LongTensor
27 | else:
28 | dtype = torch.LongTensor
29 | diag_ind_x = torch.arange(0, num_points_x).type(dtype)
30 | diag_ind_y = torch.arange(0, num_points_y).type(dtype)
31 | rx = xx[:, diag_ind_x, diag_ind_x].unsqueeze(1).expand_as(
32 | zz.transpose(2, 1))
33 | ry = yy[:, diag_ind_y, diag_ind_y].unsqueeze(1).expand_as(zz)
34 | P = rx.transpose(2, 1) + ry - 2 * zz
35 | return P
36 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/config/soft_intro_vae_hp.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment_name": "soft_intro_vae",
3 | "results_root": "./results",
4 | "clean_results_dir": false,
5 |
6 | "cuda": true,
7 | "gpu": 0,
8 |
9 | "reconstruction_loss": "chamfer",
10 |
11 | "metrics": [
12 | ],
13 |
14 | "dataset": "shapenet",
15 | "data_dir": "./datasets/shapenet_data",
16 | "classes": ["car", "airplane"],
17 | "shuffle": true,
18 | "transforms": [],
19 | "num_workers": 8,
20 | "n_points": 2048,
21 |
22 | "max_epochs": 2000,
23 | "batch_size": 32,
24 | "beta_rec": 20.0,
25 | "beta_kl": 1.0,
26 | "beta_neg": 256,
27 | "z_size": 128,
28 | "gamma_r": 1e-8,
29 | "num_vae": 0,
30 | "prior_std": 0.2,
31 |
32 |
33 | "seed": -1,
34 | "save_frequency": 50,
35 | "valid_frequency": 2,
36 |
37 | "arch": "vae",
38 | "model": {
39 | "D": {
40 | "use_bias": true,
41 | "relu_slope": 0.2
42 | },
43 | "E": {
44 | "use_bias": true,
45 | "relu_slope": 0.2
46 | }
47 | },
48 | "optimizer": {
49 | "D": {
50 | "type": "Adam",
51 | "hyperparams": {
52 | "lr": 0.0005,
53 | "weight_decay": 0,
54 | "betas": [0.9, 0.999],
55 | "amsgrad": false
56 | }
57 | },
58 | "E": {
59 | "type": "Adam",
60 | "hyperparams": {
61 | "lr": 0.0005,
62 | "weight_decay": 0,
63 | "betas": [0.9, 0.999],
64 | "amsgrad": false
65 | }
66 | }
67 | }
68 | }
--------------------------------------------------------------------------------
/style_soft_intro_vae/configs/celeba-hq256.yaml:
--------------------------------------------------------------------------------
1 | # Config for training SoftIntroVAE on CelebA-HQ at resolution 256x256
2 |
3 | NAME: celeba-hq256
4 | DATASET:
5 | PART_COUNT: 16
6 | SIZE: 29000
7 | SIZE_TEST: 1000
8 | PATH: /mnt/data/tal/celebhq_256_tfrecords/celeba-r%02d.tfrecords.%03d
9 | PATH_TEST: /mnt/data/tal/celebhq_256_test_tfrecords/celeba-r%02d.tfrecords.%03d
10 | MAX_RESOLUTION_LEVEL: 8
11 | SAMPLES_PATH: /mnt/data/tal/celebhq_256_test/
12 | STYLE_MIX_PATH: /home/tal/tmp/SoftIntroVAE/style_mixing/test_images/set_ffhq
13 | MODEL:
14 | LATENT_SPACE_SIZE: 512
15 | LAYER_COUNT: 7
16 | MAX_CHANNEL_COUNT: 512
17 | START_CHANNEL_COUNT: 64
18 | DLATENT_AVG_BETA: 0.995
19 | MAPPING_LAYERS: 8
20 | BETA_KL: 0.2
21 | BETA_REC: 0.05
22 | BETA_NEG: [2048, 2048, 2048, 1024, 512, 512, 512, 512, 512]
23 | SCALE: 0.000005
24 | OUTPUT_DIR: /home/tal/tmp/SoftIntroVAE/training_artifacts/celeba-hq256
25 | TRAIN:
26 | BASE_LEARNING_RATE: 0.002
27 | EPOCHS_PER_LOD: 30
28 | NUM_VAE: 1
29 | LEARNING_DECAY_RATE: 0.1
30 | LEARNING_DECAY_STEPS: []
31 | TRAIN_EPOCHS: 300
32 | # 4 8 16 32 64 128 256 512 1024
33 | LOD_2_BATCH_8GPU: [512, 256, 128, 64, 32, 32, 32, 32, 24]
34 | LOD_2_BATCH_4GPU: [512, 256, 128, 64, 32, 32, 16, 8, 4]
35 | LOD_2_BATCH_2GPU: [128, 128, 128, 64, 32, 16, 8]
36 | LOD_2_BATCH_1GPU: [128, 128, 128, 32, 16, 8, 4]
37 |
38 | LEARNING_RATES: [0.0015, 0.0015, 0.0015, 0.0015, 0.0015, 0.0015, 0.0015, 0.003, 0.003]
39 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/configs/ffhq256.yaml:
--------------------------------------------------------------------------------
1 | # Config for training SoftIntroVAE on FFHQ at resolution 1256x256
2 |
3 | NAME: ffhq
4 | DATASET:
5 | PART_COUNT: 16
6 | SIZE: 60000
7 | FFHQ_SOURCE: /mnt/data/tal/ffhq_ds/ffhq-dataset/tfrecords_custom/ffhq-r%02d.tfrecords
8 | PATH: /mnt/data/tal/ffhq_ds/ffhq-dataset/tfrecords_custom/splitted/ffhq-r%02d.tfrecords.%03d
9 |
10 | PART_COUNT_TEST: 2
11 | PATH_TEST: /mnt/data/tal/ffhq_ds/ffhq-dataset/tfrecords_custom/splitted/ffhq-r%02d.tfrecords.%03d
12 |
13 | SAMPLES_PATH: /mnt/data/tal/ffhq_ds/ffhq-dataset/images1024x1024/69000
14 | STYLE_MIX_PATH: style_mixing/test_images/set_ffhq
15 |
16 | MAX_RESOLUTION_LEVEL: 8
17 | MODEL:
18 | LATENT_SPACE_SIZE: 512
19 | LAYER_COUNT: 7
20 | MAX_CHANNEL_COUNT: 512
21 | START_CHANNEL_COUNT: 64
22 | DLATENT_AVG_BETA: 0.995
23 | MAPPING_LAYERS: 8
24 | BETA_KL: 0.2
25 | BETA_REC: 0.1
26 | BETA_NEG: [2048, 2048, 2048, 1024, 512, 512, 512, 512, 512]
27 | SCALE: 0.000005
28 | OUTPUT_DIR: /home/tal/tmp/SoftIntroVAE/training_artifacts/ffhq
29 | TRAIN:
30 | BASE_LEARNING_RATE: 0.002
31 | EPOCHS_PER_LOD: 16
32 | NUM_VAE: 1
33 | LEARNING_DECAY_RATE: 0.1
34 | LEARNING_DECAY_STEPS: []
35 | TRAIN_EPOCHS: 300
36 | # 4 8 16 32 64 128 256
37 | LOD_2_BATCH_8GPU: [512, 256, 128, 64, 32, 32, 32, 32, 32] # If GPU memory ~16GB reduce last number from 32 to 24
38 | LOD_2_BATCH_4GPU: [ 512, 256, 128, 64, 32, 32, 16, 8, 4 ]
39 | LOD_2_BATCH_2GPU: [ 128, 128, 128, 64, 32, 16, 8 ]
40 | LOD_2_BATCH_1GPU: [ 128, 128, 128, 32, 16, 8, 4 ]
41 |
42 | LEARNING_RATES: [0.0015, 0.0015, 0.0015, 0.0015, 0.0015, 0.0015, 0.002, 0.003, 0.003]
43 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/render/README.md:
--------------------------------------------------------------------------------
1 | # Rendering Beautiful Point Clouds with Mitsuba Renderer
2 | This code was adapted from the code by [tolgabirdal](https://github.com/tolgabirdal/Mitsuba2PointCloudRenderer)
3 | and modified to work with Soft-IntroVAE output.
4 |
5 | # Installing Mitsuba 2 (on a Linux machine)
6 | Follow the following steps:
7 | 1. Follow https://mitsuba2.readthedocs.io/en/latest/src/getting_started/compiling.html#linux
8 | 2. Clone mitsuba2: git clone --recursive https://github.com/mitsuba-renderer/mitsuba2
9 | 3. Install `openEXR`: `sudo apt-get install libopenexr-dev`
10 | 4. `pip install openexr`
11 | 5. Replace 'PATH_TO_MITSUBA2' in the 'render_mitsuba2_pc.py' with the path to your local 'mitsuba' file.
12 |
13 |
14 | # Multiple Point Cloud Renderer using Mitsuba 2
15 |
16 | Calling the script **render_mitsuba2_pc.py** automatically performs the following in order:
17 |
18 | 1. generates an XML file, which describes a 3D scene in the format used by Mitsuba.
19 | 2. calls Mitsuba2 to render the point cloud into an EXR
20 | 3. processes the EXR into a jpg file.
21 | 4. iterates for multiple point clouds present in the tensor (.npy)
22 |
23 | It could process both plys and npy. The script is heavily inspired by [PointFlow renderer](https://github.com/zekunhao1995/PointFlowRenderer) and here is how the outputs can look like:
24 |
25 |
26 | ## Dependencies
27 | * Python >= 3.6
28 | * [Mitsuba 2](http://www.mitsuba-renderer.org/)
29 | * Used python packages for 'render_mitsuba2_pc' : OpenEXR, Imath, PIL
30 |
31 | Ensure that Mitsuba 2 can be called as 'mitsuba' by following the [instructions here](https://mitsuba2.readthedocs.io/en/latest/src/getting_started/compiling.html#linux).
32 | Also make sure that the 'PATH_TO_MITSUBA2' in the code is replaced by the path to your local 'mitsuba' file.
33 |
34 | ## Instructions
35 |
36 | Replace 'PATH_TO_MITSUBA2' in the 'render_mitsuba2_pc.py' with the path to your local 'mitsuba' file. Then call:
37 | ```bash
38 | # Render a single or multiple JPG file(s) as:
39 | python render_mitsuba2_pc.py interpolations.npy
40 |
41 | # It could also render a ply file
42 | python render_mitsuba2_pc.py chair.ply
43 | ```
44 |
45 | All the outputs including the resulting JPG files will be saved in the directory of the input point cloud. The intermediate EXR/XML files will remain in the folder and has to be removed by the user.
46 |
47 | * To animate a sequence of images in a `gif` format, it is recommended to use `imageio`.
48 |
--------------------------------------------------------------------------------
/soft_intro_vae_tutorial/README.md:
--------------------------------------------------------------------------------
1 | # soft-intro-vae-pytorch-tutorials
2 |
3 | Step-by-step Jupyter Notebook tutorials for Soft-IntroVAE
4 |
5 |
6 |
7 |  8 |
8 |
9 |
10 |
11 | 
12 |
13 |
14 |  15 |
15 |
16 |
17 | - [soft-intro-vae-pytorch-tutorials](#soft-intro-vae-pytorch-tutorials)
18 | * [Running Instructions](#running-instructions)
19 | * [Files and directories in the repository](#files-and-directories-in-the-repository)
20 | * [But Wait, There is More...](#but-wait--there-is-more)
21 |
22 | ## Running Instructions
23 | * This Jupyter Notebook can be opened locally with Anaconda, or online via Google Colab.
24 | * To run online, go to https://colab.research.google.com/ and drag-and-drop the `soft_intro_vae_code_tutorial.ipynb` file.
25 | * On Colab, note the "directory" icon on the left, figures and checkpoints are saved in this directory.
26 | * To run the training on the image dataset, it is better to have a GPU. In Google Colab select `Runtime->Change runtime type->GPU`.
27 | * You can also use NBViewer to render the notebooks: [Open with Jupyter NBviewer](https://nbviewer.jupyter.org/github/taldatech/soft-intro-vae-pytorch/tree/main/)
28 |
29 | ## Files and directories in the repository
30 |
31 | |File name | Purpose |
32 | |----------------------|------|
33 | |`soft_intro_vae_2d_code_tutorial.ipynb`| Soft-IntroVAE tutorial for 2D datasets|
34 | |`soft_intro_vae_image_code_tutorial.ipynb`| Soft-IntroVAE tutorial for image datasets|
35 | |`soft_intro_vae_bootstrap_code_tutorial.ipynb`| Bootstrap Soft-IntroVAE tutorial for image datasets (not used in the paper)|
36 |
37 |
38 | ## But Wait, There is More...
39 | * General Tutorials (Jupyter Notebooks with code)
40 | * [CS236756 - Intro to Machine Learning](https://github.com/taldatech/cs236756-intro-to-ml)
41 | * [EE046202 - Unsupervised Learning and Data Analysis](https://github.com/taldatech/ee046202-unsupervised-learning-data-analysis)
42 | * [EE046746 - Computer Vision](https://github.com/taldatech/ee046746-computer-vision)
--------------------------------------------------------------------------------
/soft_intro_vae_3d/utils/util.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import re
3 | from os import listdir, makedirs
4 | from os.path import join, exists
5 | from shutil import rmtree
6 | from time import sleep
7 |
8 | import torch
9 |
10 |
11 | def setup_logging(log_dir):
12 | makedirs(log_dir, exist_ok=True)
13 |
14 | logpath = join(log_dir, 'log.txt')
15 | filemode = 'a' if exists(logpath) else 'w'
16 |
17 | # set up logging to file - see previous section for more details
18 | logging.basicConfig(level=logging.DEBUG,
19 | format='%(asctime)s %(message)s',
20 | datefmt='%m-%d %H:%M:%S',
21 | filename=logpath,
22 | filemode=filemode)
23 | # define a Handler which writes INFO messages or higher to the sys.stderr
24 | console = logging.StreamHandler()
25 | console.setLevel(logging.DEBUG)
26 | # set a format which is simpler for console use
27 | formatter = logging.Formatter('%(asctime)s: %(levelname)-8s %(message)s')
28 | # tell the handler to use this format
29 | console.setFormatter(formatter)
30 | # add the handler to the root logger
31 | logging.getLogger('').addHandler(console)
32 |
33 |
34 | def prepare_results_dir(config):
35 | output_dir = join(config['results_root'], config['arch'],
36 | config['experiment_name'])
37 | if config['clean_results_dir']:
38 | if exists(output_dir):
39 | print('Attention! Cleaning results directory in 10 seconds!')
40 | sleep(10)
41 | rmtree(output_dir, ignore_errors=True)
42 | makedirs(output_dir, exist_ok=True)
43 | makedirs(join(output_dir, 'weights'), exist_ok=True)
44 | makedirs(join(output_dir, 'samples'), exist_ok=True)
45 | makedirs(join(output_dir, 'results'), exist_ok=True)
46 | return output_dir
47 |
48 |
49 | def find_latest_epoch(dirpath):
50 | # Files with weights are in format ddddd_{D,E,G}.pth
51 | epoch_regex = re.compile(r'^(?P\d+)_[DEG]\.pth$')
52 | epochs_completed = []
53 | if exists(join(dirpath, 'weights')):
54 | dirpath = join(dirpath, 'weights')
55 | for f in listdir(dirpath):
56 | m = epoch_regex.match(f)
57 | if m:
58 | epochs_completed.append(int(m.group('n_epoch')))
59 | return max(epochs_completed) if epochs_completed else 0
60 |
61 |
62 | def cuda_setup(cuda=False, gpu_idx=0):
63 | if cuda and torch.cuda.is_available():
64 | device = torch.device('cuda')
65 | torch.cuda.set_device(gpu_idx)
66 | else:
67 | device = torch.device('cpu')
68 | return device
69 |
70 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/defaults.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | from yacs.config import CfgNode as CN
17 |
18 |
19 | _C = CN()
20 |
21 | _C.NAME = ""
22 | _C.PPL_CELEBA_ADJUSTMENT = False
23 | _C.OUTPUT_DIR = "results"
24 |
25 | _C.DATASET = CN()
26 | _C.DATASET.PATH = 'celeba/data_fold_%d_lod_%d.pkl'
27 | _C.DATASET.PATH_TEST = ''
28 | _C.DATASET.FFHQ_SOURCE = '/data/datasets/ffhq-dataset/tfrecords/ffhq/ffhq-r%02d.tfrecords'
29 | _C.DATASET.PART_COUNT = 1
30 | _C.DATASET.PART_COUNT_TEST = 1
31 | _C.DATASET.SIZE = 70000
32 | _C.DATASET.SIZE_TEST = 10000
33 | _C.DATASET.FLIP_IMAGES = True
34 | _C.DATASET.SAMPLES_PATH = 'dataset_samples/faces/realign128x128'
35 |
36 | _C.DATASET.STYLE_MIX_PATH = 'style_mixing/test_images/set_celeba/'
37 |
38 | _C.DATASET.MAX_RESOLUTION_LEVEL = 10
39 |
40 | _C.MODEL = CN()
41 |
42 | _C.MODEL.LAYER_COUNT = 6
43 | _C.MODEL.START_CHANNEL_COUNT = 64
44 | _C.MODEL.MAX_CHANNEL_COUNT = 512
45 | _C.MODEL.LATENT_SPACE_SIZE = 256
46 | _C.MODEL.DLATENT_AVG_BETA = 0.995
47 | _C.MODEL.TRUNCATIOM_PSI = 0.7
48 | _C.MODEL.TRUNCATIOM_CUTOFF = 8
49 | _C.MODEL.STYLE_MIXING_PROB = 0.9
50 | _C.MODEL.MAPPING_LAYERS = 5
51 | _C.MODEL.CHANNELS = 3
52 | _C.MODEL.GENERATOR = "GeneratorDefault"
53 | _C.MODEL.ENCODER = "EncoderDefault"
54 | _C.MODEL.MAPPING_TO_LATENT = "MappingToLatent"
55 | _C.MODEL.MAPPING_FROM_LATENT = "MappingFromLatent"
56 | _C.MODEL.Z_REGRESSION = False
57 | _C.MODEL.BETA_KL = 1.0
58 | _C.MODEL.BETA_REC = 1.0
59 | _C.MODEL.BETA_NEG = [2048, 2048, 1024, 512, 512, 128, 128, 64, 64]
60 | _C.MODEL.SCALE = 1 / (3 * 256 ** 2)
61 |
62 | _C.TRAIN = CN()
63 |
64 | _C.TRAIN.EPOCHS_PER_LOD = 15
65 |
66 | _C.TRAIN.BASE_LEARNING_RATE = 0.0015
67 | _C.TRAIN.ADAM_BETA_0 = 0.0
68 | _C.TRAIN.ADAM_BETA_1 = 0.99
69 | _C.TRAIN.LEARNING_DECAY_RATE = 0.1
70 | _C.TRAIN.LEARNING_DECAY_STEPS = []
71 | _C.TRAIN.TRAIN_EPOCHS = 110
72 | _C.TRAIN.NUM_VAE = 1
73 |
74 | _C.TRAIN.LOD_2_BATCH_8GPU = [512, 256, 128, 64, 32, 32]
75 | _C.TRAIN.LOD_2_BATCH_4GPU = [512, 256, 128, 64, 32, 16]
76 | _C.TRAIN.LOD_2_BATCH_2GPU = [256, 256, 128, 64, 32, 16]
77 | _C.TRAIN.LOD_2_BATCH_1GPU = [128, 128, 128, 64, 32, 16]
78 |
79 |
80 | _C.TRAIN.SNAPSHOT_FREQ = [300, 300, 300, 100, 50, 30, 20, 20, 10]
81 |
82 | _C.TRAIN.REPORT_FREQ = [100, 80, 60, 30, 20, 10, 10, 5, 5]
83 |
84 | _C.TRAIN.LEARNING_RATES = [0.002]
85 |
86 |
87 | def get_cfg_defaults():
88 | return _C.clone()
89 |
--------------------------------------------------------------------------------
/soft_intro_vae_2d/main.py:
--------------------------------------------------------------------------------
1 | """
2 | Main function for arguments parsing
3 | Author: Tal Daniel
4 | """
5 | # imports
6 | import torch
7 | import argparse
8 | from train_soft_intro_vae_2d import train_soft_intro_vae_toy
9 |
10 | if __name__ == "__main__":
11 | """
12 | Recommended hyper-parameters:
13 | - 8Gaussians: beta_kl: 0.3, beta_rec: 0.2, beta_neg: 0.9, z_dim: 2, batch_size: 512
14 | - 2spirals: beta_kl: 0.5, beta_rec: 0.2, beta_neg: 1.0, z_dim: 2, batch_size: 512
15 | - checkerboard: beta_kl: 0.1, beta_rec: 0.2, beta_neg: 0.2, z_dim: 2, batch_size: 512
16 | - rings: beta_kl: 0.2, beta_rec: 0.2, beta_neg: 1.0, z_dim: 2, batch_size: 512
17 | """
18 | parser = argparse.ArgumentParser(description="train Soft-IntroVAE 2D")
19 | parser.add_argument("-d", "--dataset", type=str,
20 | help="dataset to train on: ['8Gaussians', '2spirals', 'checkerboard', rings']")
21 | parser.add_argument("-n", "--num_iter", type=int, help="total number of iterations to run", default=30_000)
22 | parser.add_argument("-z", "--z_dim", type=int, help="latent dimensions", default=2)
23 | parser.add_argument("-l", "--lr", type=float, help="learning rate", default=2e-4)
24 | parser.add_argument("-b", "--batch_size", type=int, help="batch size", default=512)
25 | parser.add_argument("-v", "--num_vae", type=int, help="number of iterations for vanilla vae training", default=2000)
26 | parser.add_argument("-r", "--beta_rec", type=float, help="beta coefficient for the reconstruction loss",
27 | default=0.2)
28 | parser.add_argument("-k", "--beta_kl", type=float, help="beta coefficient for the kl divergence",
29 | default=0.3)
30 | parser.add_argument("-e", "--beta_neg", type=float,
31 | help="beta coefficient for the kl divergence in the expELBO function", default=0.9)
32 | parser.add_argument("-g", "--gamma_r", type=float,
33 | help="coefficient for the reconstruction loss for fake data in the decoder", default=1e-8)
34 | parser.add_argument("-s", "--seed", type=int, help="seed", default=-1)
35 | parser.add_argument("-p", "--pretrained", type=str, help="path to pretrained model, to continue training",
36 | default="None")
37 | parser.add_argument("-c", "--device", type=int, help="device: -1 for cpu, 0 and up for specific cuda device",
38 | default=-1)
39 | args = parser.parse_args()
40 |
41 | device = torch.device("cpu") if args.device <= -1 else torch.device("cuda:" + str(args.device))
42 | pretrained = None if args.pretrained == "None" else args.pretrained
43 | if args.dataset == '8Gaussians':
44 | scale = 1
45 | else:
46 | scale = 2
47 | # train
48 | model = train_soft_intro_vae_toy(z_dim=args.z_dim, lr_e=args.lr, lr_d=args.lr, batch_size=args.batch_size,
49 | n_iter=args.num_iter, num_vae=args.num_vae, save_interval=5000,
50 | recon_loss_type="mse", beta_kl=args.beta_kl, beta_rec=args.beta_rec,
51 | beta_neg=args.beta_neg, test_iter=5000, seed=args.seed, scale=scale,
52 | device=device, dataset=args.dataset)
53 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/environment.yml:
--------------------------------------------------------------------------------
1 | name: tf_torch
2 | channels:
3 | - pytorch
4 | - conda-forge
5 | - defaults
6 | dependencies:
7 | - _libgcc_mutex=0.1=main
8 | - blas=1.0=mkl
9 | - ca-certificates=2020.6.24=0
10 | - certifi=2020.6.20=py36_0
11 | - cffi=1.14.0=py36he30daa8_1
12 | - cudatoolkit=10.1.243=h6bb024c_0
13 | - cycler=0.10.0=py_2
14 | - dbus=1.13.6=he372182_0
15 | - expat=2.2.9=he1b5a44_2
16 | - fontconfig=2.13.1=he4413a7_1000
17 | - freetype=2.10.2=he06d7ca_0
18 | - glib=2.65.0=h3eb4bd4_0
19 | - gst-plugins-base=1.14.0=hbbd80ab_1
20 | - gstreamer=1.14.0=hb31296c_0
21 | - icu=58.2=hf484d3e_1000
22 | - imageio=2.8.0=py_0
23 | - intel-openmp=2020.1=217
24 | - joblib=0.16.0=py_0
25 | - jpeg=9d=h516909a_0
26 | - kiwisolver=1.2.0=py36hdb11119_0
27 | - ld_impl_linux-64=2.33.1=h53a641e_7
28 | - libedit=3.1.20191231=h7b6447c_0
29 | - libffi=3.3=he6710b0_1
30 | - libgcc-ng=9.1.0=hdf63c60_0
31 | - libgfortran-ng=7.5.0=hdf63c60_6
32 | - libopenblas=0.3.7=h5ec1e0e_6
33 | - libpng=1.6.37=hed695b0_1
34 | - libstdcxx-ng=9.1.0=hdf63c60_0
35 | - libtiff=4.1.0=hc7e4089_6
36 | - libuuid=2.32.1=h14c3975_1000
37 | - libwebp-base=1.1.0=h516909a_3
38 | - libxcb=1.13=h14c3975_1002
39 | - libxml2=2.9.10=he19cac6_1
40 | - lz4-c=1.9.2=he1b5a44_1
41 | - matplotlib=3.2.2=0
42 | - matplotlib-base=3.2.2=py36hef1b27d_0
43 | - mkl=2020.1=217
44 | - mkl-service=2.3.0=py36he904b0f_0
45 | - mkl_fft=1.1.0=py36h23d657b_0
46 | - mkl_random=1.1.1=py36h0573a6f_0
47 | - ncurses=6.2=he6710b0_1
48 | - ninja=1.9.0=py36hfd86e86_0
49 | - olefile=0.46=py_0
50 | - openssl=1.1.1g=h516909a_0
51 | - packaging=20.4=pyh9f0ad1d_0
52 | - pcre=8.44=he1b5a44_0
53 | - pillow=7.2.0=py36h8328e55_0
54 | - pip=20.1.1=py36_1
55 | - pthread-stubs=0.4=h14c3975_1001
56 | - pycparser=2.20=py_0
57 | - pyparsing=2.4.7=pyh9f0ad1d_0
58 | - pyqt=5.9.2=py36hcca6a23_4
59 | - python=3.6.10=h7579374_2
60 | - python-dateutil=2.8.1=py_0
61 | - python_abi=3.6=1_cp36m
62 | - pytorch=1.5.1=py3.6_cuda10.1.243_cudnn7.6.3_0
63 | - pyyaml=5.3.1=py36h8c4c3a4_0
64 | - qt=5.9.7=h5867ecd_1
65 | - readline=8.0=h7b6447c_0
66 | - scikit-learn=0.23.1=py36h423224d_0
67 | - scipy=1.5.0=py36h0b6359f_0
68 | - sip=4.19.8=py36hf484d3e_0
69 | - six=1.15.0=pyh9f0ad1d_0
70 | - sqlite=3.32.3=h62c20be_0
71 | - threadpoolctl=2.1.0=pyh5ca1d4c_0
72 | - tk=8.6.10=hbc83047_0
73 | - torchvision=0.6.1=py36_cu101
74 | - tornado=6.0.4=py36h8c4c3a4_1
75 | - tqdm=4.47.0=pyh9f0ad1d_0
76 | - wheel=0.34.2=py36_0
77 | - xorg-libxau=1.0.9=h14c3975_0
78 | - xorg-libxdmcp=1.1.3=h516909a_0
79 | - xz=5.2.5=h7b6447c_0
80 | - yacs=0.1.6=py_0
81 | - yaml=0.2.5=h516909a_0
82 | - zlib=1.2.11=h7b6447c_3
83 | - zstd=1.4.4=h6597ccf_3
84 | - pip:
85 | - absl-py==0.9.0
86 | - astor==0.8.1
87 | - bimpy==0.0.13
88 | - dareblopy==0.0.3
89 | - gast==0.3.3
90 | - grpcio==1.30.0
91 | - h5py==2.10.0
92 | - importlib-metadata==1.7.0
93 | - keras-applications==1.0.8
94 | - keras-preprocessing==1.1.2
95 | - markdown==3.2.2
96 | - mock==4.0.2
97 | - numpy==1.14.5
98 | - protobuf==3.12.2
99 | - setuptools==39.1.0
100 | - tensorboard==1.13.1
101 | - tensorflow-estimator==1.13.0
102 | - tensorflow-gpu==1.13.1
103 | - termcolor==1.1.0
104 | - werkzeug==1.0.1
105 | - zipp==3.1.0
106 | prefix: /home/tal/anaconda3/envs/tf_torch
107 |
108 |
--------------------------------------------------------------------------------
/soft_intro_vae/main.py:
--------------------------------------------------------------------------------
1 | """
2 | Main function for arguments parsing
3 | Author: Tal Daniel
4 | """
5 | # imports
6 | import torch
7 | import argparse
8 | from train_soft_intro_vae import train_soft_intro_vae
9 |
10 | if __name__ == "__main__":
11 | """
12 | Recommended hyper-parameters:
13 | - CIFAR10: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 128, batch_size: 32
14 | - SVHN: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 128, batch_size: 32
15 | - MNIST: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 32, batch_size: 128
16 | - FashionMNIST: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 32, batch_size: 128
17 | - Monsters: beta_kl: 0.2, beta_rec: 0.2, beta_neg: 256, z_dim: 128, batch_size: 16
18 | - CelebA-HQ: beta_kl: 1.0, beta_rec: 0.5, beta_neg: 1024, z_dim: 256, batch_size: 8
19 | """
20 | parser = argparse.ArgumentParser(description="train Soft-IntroVAE")
21 | parser.add_argument("-d", "--dataset", type=str,
22 | help="dataset to train on: ['cifar10', 'mnist', 'fmnist', 'svhn', 'monsters128', 'celeb128', "
23 | "'celeb256', 'celeb1024']")
24 | parser.add_argument("-n", "--num_epochs", type=int, help="total number of epochs to run", default=250)
25 | parser.add_argument("-z", "--z_dim", type=int, help="latent dimensions", default=128)
26 | parser.add_argument("-l", "--lr", type=float, help="learning rate", default=2e-4)
27 | parser.add_argument("-b", "--batch_size", type=int, help="batch size", default=32)
28 | parser.add_argument("-v", "--num_vae", type=int, help="number of epochs for vanilla vae training", default=0)
29 | parser.add_argument("-r", "--beta_rec", type=float, help="beta coefficient for the reconstruction loss",
30 | default=1.0)
31 | parser.add_argument("-k", "--beta_kl", type=float, help="beta coefficient for the kl divergence",
32 | default=1.0)
33 | parser.add_argument("-e", "--beta_neg", type=float,
34 | help="beta coefficient for the kl divergence in the expELBO function", default=1.0)
35 | parser.add_argument("-g", "--gamma_r", type=float,
36 | help="coefficient for the reconstruction loss for fake data in the decoder", default=1e-8)
37 | parser.add_argument("-s", "--seed", type=int, help="seed", default=-1)
38 | parser.add_argument("-p", "--pretrained", type=str, help="path to pretrained model, to continue training",
39 | default="None")
40 | parser.add_argument("-c", "--device", type=int, help="device: -1 for cpu, 0 and up for specific cuda device",
41 | default=-1)
42 | parser.add_argument('-f', "--fid", action='store_true', help="if specified, FID wil be calculated during training")
43 | args = parser.parse_args()
44 |
45 | device = torch.device("cpu") if args.device <= -1 else torch.device("cuda:" + str(args.device))
46 | pretrained = None if args.pretrained == "None" else args.pretrained
47 | train_soft_intro_vae(dataset=args.dataset, z_dim=args.z_dim, batch_size=args.batch_size, num_workers=0,
48 | num_epochs=args.num_epochs,
49 | num_vae=args.num_vae, beta_kl=args.beta_kl, beta_neg=args.beta_neg, beta_rec=args.beta_rec,
50 | device=device, save_interval=50, start_epoch=0, lr_e=args.lr, lr_d=args.lr,
51 | pretrained=pretrained, seed=args.seed,
52 | test_iter=1000, with_fid=args.fid)
53 |
--------------------------------------------------------------------------------
/soft_intro_vae_bootstrap/main.py:
--------------------------------------------------------------------------------
1 | """
2 | Main function for arguments parsing
3 | Author: Tal Daniel
4 | """
5 | # imports
6 | import torch
7 | import argparse
8 | from train_soft_intro_vae_bootstrap import train_soft_intro_vae
9 |
10 | if __name__ == "__main__":
11 | """
12 | Recommended hyper-parameters:
13 | - CIFAR10: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 128, batch_size: 32
14 | - SVHN: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 128, batch_size: 32
15 | - MNIST: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 32, batch_size: 128
16 | - FashionMNIST: beta_kl: 1.0, beta_rec: 1.0, beta_neg: 256, z_dim: 32, batch_size: 128
17 | - Monsters: beta_kl: 0.2, beta_rec: 0.2, beta_neg: 256, z_dim: 128, batch_size: 16
18 | """
19 | parser = argparse.ArgumentParser(description="train Soft-IntroVAE")
20 | parser.add_argument("-d", "--dataset", type=str,
21 | help="dataset to train on: ['cifar10', 'mnist', 'fmnist', 'svhn', 'monsters128', 'celeb128', "
22 | "'celeb256', 'celeb1024']")
23 | parser.add_argument("-n", "--num_epochs", type=int, help="total number of epochs to run", default=250)
24 | parser.add_argument("-z", "--z_dim", type=int, help="latent dimensions", default=128)
25 | parser.add_argument("-l", "--lr", type=float, help="learning rate", default=2e-4)
26 | parser.add_argument("-b", "--batch_size", type=int, help="batch size", default=32)
27 | parser.add_argument("-v", "--num_vae", type=int, help="number of epochs for vanilla vae training", default=0)
28 | parser.add_argument("-r", "--beta_rec", type=float, help="beta coefficient for the reconstruction loss",
29 | default=1.0)
30 | parser.add_argument("-k", "--beta_kl", type=float, help="beta coefficient for the kl divergence",
31 | default=1.0)
32 | parser.add_argument("-e", "--beta_neg", type=float,
33 | help="beta coefficient for the kl divergence in the expELBO function", default=1.0)
34 | parser.add_argument("-g", "--gamma_r", type=float,
35 | help="coefficient for the reconstruction loss for fake data in the decoder", default=1.0)
36 | parser.add_argument("-s", "--seed", type=int, help="seed", default=-1)
37 | parser.add_argument("-p", "--pretrained", type=str, help="path to pretrained model, to continue training",
38 | default="None")
39 | parser.add_argument("-c", "--device", type=int, help="device: -1 for cpu, 0 and up for specific cuda device",
40 | default=-1)
41 | parser.add_argument('-f', "--fid", action='store_true', help="if specified, FID wil be calculated during training")
42 | parser.add_argument("-o", "--freq", type=int, help="epochs between copying weights from decoder to target decoder",
43 | default=1)
44 | args = parser.parse_args()
45 |
46 | device = torch.device("cpu") if args.device <= -1 else torch.device("cuda:" + str(args.device))
47 | pretrained = None if args.pretrained == "None" else args.pretrained
48 | train_soft_intro_vae(dataset=args.dataset, z_dim=args.z_dim, batch_size=args.batch_size, num_workers=0,
49 | num_epochs=args.num_epochs, copy_to_target_freq=args.freq,
50 | num_vae=args.num_vae, beta_kl=args.beta_kl, beta_neg=args.beta_neg, beta_rec=args.beta_rec,
51 | device=device, save_interval=50, start_epoch=0, lr_e=args.lr, lr_d=args.lr,
52 | pretrained=pretrained, seed=args.seed,
53 | test_iter=1000, with_fid=args.fid)
54 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/utils.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | from torch import nn
17 | import torch
18 | import threading
19 | import hashlib
20 | import pickle
21 | import os
22 |
23 |
24 | class cache:
25 | def __init__(self, function):
26 | self.function = function
27 | self.pickle_name = self.function.__name__
28 |
29 | def __call__(self, *args, **kwargs):
30 | m = hashlib.sha256()
31 | m.update(pickle.dumps((self.function.__name__, args, frozenset(kwargs.items()))))
32 | output_path = os.path.join('.cache', "%s_%s" % (m.hexdigest(), self.pickle_name))
33 | try:
34 | with open(output_path, 'rb') as f:
35 | data = pickle.load(f)
36 | except (FileNotFoundError, pickle.PickleError):
37 | data = self.function(*args, **kwargs)
38 | os.makedirs(os.path.dirname(output_path), exist_ok=True)
39 | with open(output_path, 'wb') as f:
40 | pickle.dump(data, f)
41 | return data
42 |
43 |
44 | def save_model(x, name):
45 | if isinstance(x, nn.DataParallel):
46 | torch.save(x.module.state_dict(), name)
47 | else:
48 | torch.save(x.state_dict(), name)
49 |
50 |
51 | class AsyncCall(object):
52 | def __init__(self, fnc, callback=None):
53 | self.Callable = fnc
54 | self.Callback = callback
55 | self.result = None
56 |
57 | def __call__(self, *args, **kwargs):
58 | self.Thread = threading.Thread(target=self.run, name=self.Callable.__name__, args=args, kwargs=kwargs)
59 | self.Thread.start()
60 | return self
61 |
62 | def wait(self, timeout=None):
63 | self.Thread.join(timeout)
64 | if self.Thread.isAlive():
65 | raise TimeoutError
66 | else:
67 | return self.result
68 |
69 | def run(self, *args, **kwargs):
70 | self.result = self.Callable(*args, **kwargs)
71 | if self.Callback:
72 | self.Callback(self.result)
73 |
74 |
75 | class AsyncMethod(object):
76 | def __init__(self, fnc, callback=None):
77 | self.Callable = fnc
78 | self.Callback = callback
79 |
80 | def __call__(self, *args, **kwargs):
81 | return AsyncCall(self.Callable, self.Callback)(*args, **kwargs)
82 |
83 |
84 | def async_func(fnc=None, callback=None):
85 | if fnc is None:
86 | def add_async_callback(f):
87 | return AsyncMethod(f, callback)
88 | return add_async_callback
89 | else:
90 | return AsyncMethod(fnc, callback)
91 |
92 |
93 | class Registry(dict):
94 | def __init__(self, *args, **kwargs):
95 | super(Registry, self).__init__(*args, **kwargs)
96 |
97 | def register(self, module_name):
98 | def register_fn(module):
99 | assert module_name not in self
100 | self[module_name] = module
101 | return module
102 | return register_fn
103 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/test_model.py:
--------------------------------------------------------------------------------
1 | """
2 | Test a trained model (on the test split of the data)
3 | """
4 |
5 | import json
6 | import numpy as np
7 |
8 | import torch
9 | import torch.nn.parallel
10 | import torch.utils.data
11 | from torch.utils.data import DataLoader
12 |
13 | from utils.util import cuda_setup
14 | from metrics.jsd import jsd_between_point_cloud_sets
15 |
16 | from models.vae import SoftIntroVAE
17 |
18 |
19 | def prepare_model(config, path_to_weights, device=torch.device("cpu")):
20 | model = SoftIntroVAE(config).to(device)
21 | model.load_state_dict(torch.load(path_to_weights, map_location=device))
22 | model.eval()
23 | return model
24 |
25 |
26 | def prepare_data(config, split='train', batch_size=32):
27 | dataset_name = config['dataset'].lower()
28 | if dataset_name == 'shapenet':
29 | from datasets.shapenet import ShapeNetDataset
30 | dataset = ShapeNetDataset(root_dir=config['data_dir'],
31 | classes=config['classes'], split=split)
32 | else:
33 | raise ValueError(f'Invalid dataset name. Expected `shapenet` or '
34 | f'`faust`. Got: `{dataset_name}`')
35 | data_loader = DataLoader(dataset, batch_size=batch_size,
36 | shuffle=False, num_workers=4,
37 | drop_last=False, pin_memory=True)
38 | return data_loader
39 |
40 |
41 | def calc_jsd_valid(model, config, prior_std=1.0, split='valid'):
42 | model.eval()
43 | device = cuda_setup(config['cuda'], config['gpu'])
44 | dataset_name = config['dataset'].lower()
45 | if dataset_name == 'shapenet':
46 | from datasets.shapenet import ShapeNetDataset
47 | dataset = ShapeNetDataset(root_dir=config['data_dir'],
48 | classes=config['classes'], split=split)
49 | else:
50 | raise ValueError(f'Invalid dataset name. Expected `shapenet` or '
51 | f'`faust`. Got: `{dataset_name}`')
52 | classes_selected = ('all' if not config['classes']
53 | else ','.join(config['classes']))
54 | num_samples = len(dataset.point_clouds_names_valid)
55 | data_loader = DataLoader(dataset, batch_size=num_samples,
56 | shuffle=False, num_workers=4,
57 | drop_last=False, pin_memory=True)
58 | # We take 3 times as many samples as there are in test data in order to
59 | # perform JSD calculation in the same manner as in the reference publication
60 |
61 | x, _ = next(iter(data_loader))
62 | x = x.to(device)
63 |
64 | # We average JSD computation from 3 independent trials.
65 | js_results = []
66 | for _ in range(3):
67 | noise = prior_std * torch.randn(3 * num_samples, model.zdim)
68 | noise = noise.to(device)
69 |
70 | with torch.no_grad():
71 | x_g = model.decode(noise)
72 | if x_g.shape[-2:] == (3, 2048):
73 | x_g.transpose_(1, 2)
74 |
75 | jsd = jsd_between_point_cloud_sets(x, x_g, voxels=28)
76 | js_results.append(jsd)
77 | js_result = np.mean(js_results)
78 | return js_result
79 |
80 |
81 | if __name__ == "__main__":
82 | path_to_weights = './results/vae/soft_intro_vae_chair/weights/00350_jsd_0.106.pth'
83 | config_path = 'config/soft_intro_vae_hp.json'
84 | config = None
85 | if config_path is not None and config_path.endswith('.json'):
86 | with open(config_path) as f:
87 | config = json.load(f)
88 | assert config is not None
89 | device = cuda_setup(config['cuda'], config['gpu'])
90 | print("using device: ", device)
91 | model = prepare_model(config, path_to_weights, device=device)
92 | test_jsd = calc_jsd_valid(model, config, prior_std=config["prior_std"], split='test')
93 | print(f'test jsd: {test_jsd}')
94 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/evaluation/generate_data_for_metrics.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | import logging
4 | import random
5 | from importlib import import_module
6 | from os.path import join
7 |
8 | import numpy as np
9 | import torch
10 | from torch.distributions import Beta
11 | from torch.utils.data import DataLoader
12 |
13 | from datasets.shapenet.shapenet import ShapeNetDataset
14 | from models.vae import SoftIntroVAE, reparameterize
15 | from utils.util import cuda_setup
16 |
17 |
18 | def prepare_model(config, path_to_weights, device=torch.device("cpu")):
19 | model = SoftIntroVAE(config).to(device)
20 | model.load_state_dict(torch.load(path_to_weights, map_location=device))
21 | model.eval()
22 | return model
23 |
24 |
25 | def main(eval_config):
26 | # Load hyperparameters as they were during training
27 | train_results_path = join(eval_config['results_root'], eval_config['arch'],
28 | eval_config['experiment_name'])
29 | with open(join(train_results_path, 'config.json')) as f:
30 | train_config = json.load(f)
31 |
32 | random.seed(train_config['seed'])
33 | torch.manual_seed(train_config['seed'])
34 | torch.cuda.manual_seed_all(train_config['seed'])
35 |
36 | device = cuda_setup(config['cuda'], config['gpu'])
37 | print("using device: ", device)
38 |
39 | #
40 | # Dataset
41 | #
42 | dataset_name = train_config['dataset'].lower()
43 | if dataset_name == 'shapenet':
44 | dataset = ShapeNetDataset(root_dir=train_config['data_dir'],
45 | classes=train_config['classes'], split='test')
46 | else:
47 | raise ValueError(f'Invalid dataset name. Expected `shapenet` or '
48 | f'`faust`. Got: `{dataset_name}`')
49 | classes_selected = ('all' if not train_config['classes']
50 | else ','.join(train_config['classes']))
51 |
52 | #
53 | # Models
54 | #
55 |
56 | model = prepare_model(config, path_to_weights, device=device)
57 | model.eval()
58 |
59 | num_samples = len(dataset.point_clouds_names_test)
60 | data_loader = DataLoader(dataset, batch_size=num_samples,
61 | shuffle=False, num_workers=4,
62 | drop_last=False, pin_memory=True)
63 |
64 | # We take 3 times as many samples as there are in test data in order to
65 | # perform JSD calculation in the same manner as in the reference publication
66 |
67 | x, _ = next(iter(data_loader))
68 | x = x.to(device)
69 |
70 | np.save(join(train_results_path, 'results', f'_X'), x)
71 |
72 | prior_std = config["prior_std"]
73 |
74 | for i in range(3):
75 | noise = prior_std * torch.randn(3 * num_samples, model.zdim)
76 | noise = noise.to(device)
77 |
78 | with torch.no_grad():
79 | x_g = model.decode(noise)
80 | if x_g.shape[-2:] == (3, 2048):
81 | x_g.transpose_(1, 2)
82 | np.save(join(train_results_path, 'results', f'_Xg_{i}'), x_g)
83 |
84 | with torch.no_grad():
85 | mu_z, logvar_z = model.encode(x)
86 | data_z = reparameterize(mu_z, logvar_z)
87 | # x_rec = model.decode(data_z) # stochastic
88 | x_rec = model.decode(mu_z) # deterministic
89 | if x_rec.shape[-2:] == (3, 2048):
90 | x_rec.transpose_(1, 2)
91 |
92 | np.save(join(train_results_path, 'results', f'_Xrec'), x_rec)
93 |
94 |
95 | if __name__ == '__main__':
96 | path_to_weights = './results/vae/soft_intro_vae_chair/weights/00350_jsd_0.106.pth'
97 | config_path = 'config/soft_intro_vae_hp.json'
98 | config = None
99 | if config_path is not None and config_path.endswith('.json'):
100 | with open(config_path) as f:
101 | config = json.load(f)
102 | assert config is not None
103 |
104 | main(config)
105 |
--------------------------------------------------------------------------------
/environment.yml:
--------------------------------------------------------------------------------
1 | name: torch
2 | channels:
3 | - pytorch
4 | - conda-forge
5 | - defaults
6 | dependencies:
7 | - _libgcc_mutex=0.1=main
8 | - blas=1.0=mkl
9 | - bzip2=1.0.8=h516909a_3
10 | - ca-certificates=2020.12.5=ha878542_0
11 | - cairo=1.16.0=h18b612c_1001
12 | - certifi=2020.12.5=py36h5fab9bb_0
13 | - cudatoolkit=10.1.243=h6bb024c_0
14 | - cycler=0.10.0=py_2
15 | - dataclasses=0.7=py36_0
16 | - dbus=1.13.6=he372182_0
17 | - expat=2.2.9=he1b5a44_2
18 | - ffmpeg=4.0=hcdf2ecd_0
19 | - fontconfig=2.13.1=he4413a7_1000
20 | - freeglut=3.2.1=h58526e2_0
21 | - freetype=2.10.4=h5ab3b9f_0
22 | - glib=2.66.1=h92f7085_0
23 | - graphite2=1.3.13=h58526e2_1001
24 | - gst-plugins-base=1.14.0=hbbd80ab_1
25 | - gstreamer=1.14.0=hb31296c_0
26 | - harfbuzz=1.8.8=hffaf4a1_0
27 | - hdf5=1.10.2=hc401514_3
28 | - icu=58.2=hf484d3e_1000
29 | - intel-openmp=2020.2=254
30 | - jasper=2.0.14=h07fcdf6_1
31 | - joblib=0.17.0=py_0
32 | - jpeg=9b=h024ee3a_2
33 | - kiwisolver=1.3.1=py36h51d7077_0
34 | - lcms2=2.11=h396b838_0
35 | - ld_impl_linux-64=2.33.1=h53a641e_7
36 | - libblas=3.9.0=1_h6e990d7_netlib
37 | - libcblas=3.9.0=3_h893e4fe_netlib
38 | - libedit=3.1.20191231=h14c3975_1
39 | - libffi=3.3=he6710b0_2
40 | - libgcc-ng=9.1.0=hdf63c60_0
41 | - libgfortran=3.0.0=1
42 | - libgfortran-ng=7.5.0=hae1eefd_17
43 | - libgfortran4=7.5.0=hae1eefd_17
44 | - libglu=9.0.0=he1b5a44_1001
45 | - liblapack=3.9.0=3_h893e4fe_netlib
46 | - libopencv=3.4.2=hb342d67_1
47 | - libopus=1.3.1=h7b6447c_0
48 | - libpng=1.6.37=hbc83047_0
49 | - libstdcxx-ng=9.1.0=hdf63c60_0
50 | - libtiff=4.1.0=h2733197_1
51 | - libuuid=2.32.1=h14c3975_1000
52 | - libuv=1.40.0=h7b6447c_0
53 | - libvpx=1.7.0=h439df22_0
54 | - libxcb=1.13=h14c3975_1002
55 | - libxml2=2.9.10=hb55368b_3
56 | - lz4-c=1.9.2=heb0550a_3
57 | - matplotlib=3.3.3=py36h5fab9bb_0
58 | - matplotlib-base=3.3.3=py36he12231b_0
59 | - mkl=2020.2=256
60 | - mkl-service=2.3.0=py36he8ac12f_0
61 | - mkl_fft=1.2.0=py36h23d657b_0
62 | - mkl_random=1.1.1=py36h0573a6f_0
63 | - ncurses=6.2=he6710b0_1
64 | - ninja=1.10.2=py36hff7bd54_0
65 | - numpy=1.19.2=py36h54aff64_0
66 | - numpy-base=1.19.2=py36hfa32c7d_0
67 | - olefile=0.46=py36_0
68 | - opencv=3.4.2=py36h6fd60c2_1
69 | - openssl=1.1.1h=h516909a_0
70 | - pcre=8.44=he1b5a44_0
71 | - pillow=8.0.1=py36he98fc37_0
72 | - pip=20.3=py36h06a4308_0
73 | - pixman=0.38.0=h516909a_1003
74 | - pthread-stubs=0.4=h36c2ea0_1001
75 | - py-opencv=3.4.2=py36hb342d67_1
76 | - pyparsing=2.4.7=pyh9f0ad1d_0
77 | - pyqt=5.9.2=py36hcca6a23_4
78 | - python=3.6.12=hcff3b4d_2
79 | - python-dateutil=2.8.1=py_0
80 | - python_abi=3.6=1_cp36m
81 | - pytorch=1.7.0=py3.6_cuda10.1.243_cudnn7.6.3_0
82 | - qt=5.9.7=h5867ecd_1
83 | - readline=8.0=h7b6447c_0
84 | - scikit-learn=0.23.2=py36hb6e6923_3
85 | - scipy=1.5.3=py36h976291a_0
86 | - setuptools=50.3.2=py36h06a4308_2
87 | - sip=4.19.8=py36hf484d3e_0
88 | - six=1.15.0=py36h06a4308_0
89 | - sqlite=3.33.0=h62c20be_0
90 | - threadpoolctl=2.1.0=pyh5ca1d4c_0
91 | - tk=8.6.10=hbc83047_0
92 | - torchaudio=0.7.0=py36
93 | - torchvision=0.8.1=py36_cu101
94 | - tornado=6.1=py36h1d69622_0
95 | - tqdm=4.54.1=pyhd8ed1ab_0
96 | - typing_extensions=3.7.4.3=py_0
97 | - wheel=0.36.0=pyhd3eb1b0_0
98 | - xorg-fixesproto=5.0=h14c3975_1002
99 | - xorg-inputproto=2.3.2=h14c3975_1002
100 | - xorg-kbproto=1.0.7=h14c3975_1002
101 | - xorg-libice=1.0.10=h516909a_0
102 | - xorg-libsm=1.2.3=h84519dc_1000
103 | - xorg-libx11=1.6.12=h516909a_0
104 | - xorg-libxau=1.0.9=h14c3975_0
105 | - xorg-libxdmcp=1.1.3=h516909a_0
106 | - xorg-libxext=1.3.4=h516909a_0
107 | - xorg-libxfixes=5.0.3=h516909a_1004
108 | - xorg-libxi=1.7.10=h516909a_0
109 | - xorg-libxrender=0.9.10=h516909a_1002
110 | - xorg-renderproto=0.11.1=h14c3975_1002
111 | - xorg-xextproto=7.3.0=h14c3975_1002
112 | - xorg-xproto=7.0.31=h14c3975_1007
113 | - xz=5.2.5=h7b6447c_0
114 | - zlib=1.2.11=h7b6447c_3
115 | - zstd=1.4.5=h9ceee32_0
116 | - pip:
117 | - future==0.18.2
118 | - kornia==0.4.1
119 | - protobuf==3.14.0
120 | - tensorboardx==2.1
121 |
122 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/scheduler.py:
--------------------------------------------------------------------------------
1 | from bisect import bisect_right
2 | import torch
3 | import numpy as np
4 |
5 |
6 | class WarmupMultiStepLR(torch.optim.lr_scheduler._LRScheduler):
7 | def __init__(
8 | self,
9 | optimizer,
10 | milestones,
11 | gamma=0.1,
12 | warmup_factor=1.0 / 1.0,
13 | warmup_iters=1,
14 | last_epoch=-1,
15 | reference_batch_size=128,
16 | lr=[]
17 | ):
18 | if not list(milestones) == sorted(milestones):
19 | raise ValueError(
20 | "Milestones should be a list of" " increasing integers. Got {}",
21 | milestones,
22 | )
23 | self.milestones = milestones
24 | self.gamma = gamma
25 | self.warmup_factor = warmup_factor
26 | self.warmup_iters = warmup_iters
27 | self.batch_size = 1
28 | self.lod = 0
29 | self.reference_batch_size = reference_batch_size
30 |
31 | self.optimizer = optimizer
32 | self.base_lrs = []
33 | for _ in self.optimizer.param_groups:
34 | self.base_lrs.append(lr)
35 |
36 | self.last_epoch = last_epoch
37 |
38 | if not isinstance(optimizer, torch.optim.Optimizer):
39 | raise TypeError('{} is not an Optimizer'.format(
40 | type(optimizer).__name__))
41 | self.optimizer = optimizer
42 |
43 | if last_epoch == -1:
44 | for group in optimizer.param_groups:
45 | group.setdefault('initial_lr', group['lr'])
46 | last_epoch = 0
47 |
48 | self.last_epoch = last_epoch
49 |
50 | self.optimizer._step_count = 0
51 | self._step_count = 0
52 | # self.step(last_epoch)
53 | self.step()
54 |
55 | def set_batch_size(self, batch_size, lod):
56 | self.batch_size = batch_size
57 | self.lod = lod
58 | for param_group, lr in zip(self.optimizer.param_groups, self.get_lr()):
59 | param_group['lr'] = lr
60 |
61 | def get_lr(self):
62 | warmup_factor = 1
63 | if self.last_epoch < self.warmup_iters:
64 | alpha = float(self.last_epoch) / self.warmup_iters
65 | warmup_factor = self.warmup_factor * (1 - alpha) + alpha
66 | return [
67 | base_lr[self.lod]
68 | * warmup_factor
69 | * self.gamma ** bisect_right(self.milestones, self.last_epoch)
70 | # * float(self.batch_size)
71 | # / float(self.reference_batch_size)
72 | for base_lr in self.base_lrs
73 | ]
74 |
75 | def state_dict(self):
76 | return {
77 | "last_epoch": self.last_epoch
78 | }
79 |
80 | def load_state_dict(self, state_dict):
81 | self.__dict__.update(dict(last_epoch=state_dict["last_epoch"]))
82 |
83 |
84 | class ComboMultiStepLR:
85 | def __init__(
86 | self,
87 | optimizers, base_lr,
88 | **kwargs
89 | ):
90 | self.schedulers = dict()
91 | for name, opt in optimizers.items():
92 | self.schedulers[name] = WarmupMultiStepLR(opt, lr=base_lr, **kwargs)
93 | self.last_epoch = 0
94 |
95 | def set_batch_size(self, batch_size, lod):
96 | for x in self.schedulers.values():
97 | x.set_batch_size(batch_size, lod)
98 |
99 | def step(self, epoch=None):
100 | for x in self.schedulers.values():
101 | # x.step(epoch)
102 | x.step()
103 | if epoch is None:
104 | epoch = self.last_epoch + 1
105 | self.last_epoch = epoch
106 |
107 | def state_dict(self):
108 | return {key: value.state_dict() for key, value in self.schedulers.items()}
109 |
110 | def load_state_dict(self, state_dict):
111 | for k, x in self.schedulers.items():
112 | x.load_state_dict(state_dict[k])
113 |
114 | last_epochs = [x.last_epoch for k, x in self.schedulers.items()]
115 | assert np.all(np.asarray(last_epochs) == last_epochs[0])
116 | self.last_epoch = last_epochs[0]
117 |
118 | def start_epoch(self):
119 | return self.last_epoch
120 |
--------------------------------------------------------------------------------
/soft_intro_vae_2d/README.md:
--------------------------------------------------------------------------------
1 | # soft-intro-vae-pytorch-2d
2 |
3 | Implementation of Soft-IntroVAE for tabular (2D) data.
4 |
5 | A step-by-step tutorial can be found in [Soft-IntroVAE Jupyter Notebook Tutorials](https://github.com/taldatech/soft-intro-vae-pytorch/tree/main/soft_intro_vae_tutorial).
6 |
7 |
8 | 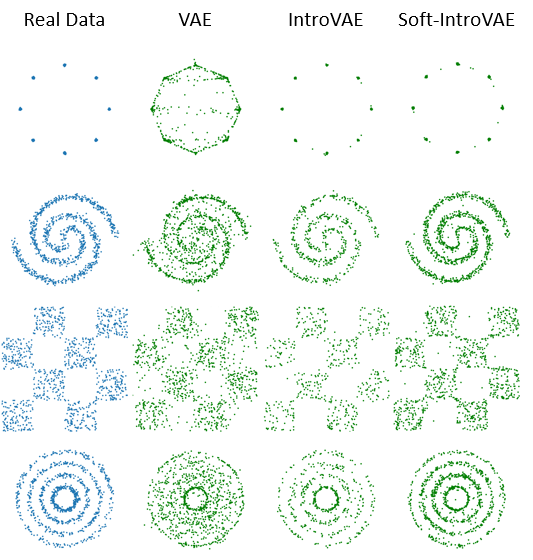 9 |
9 | 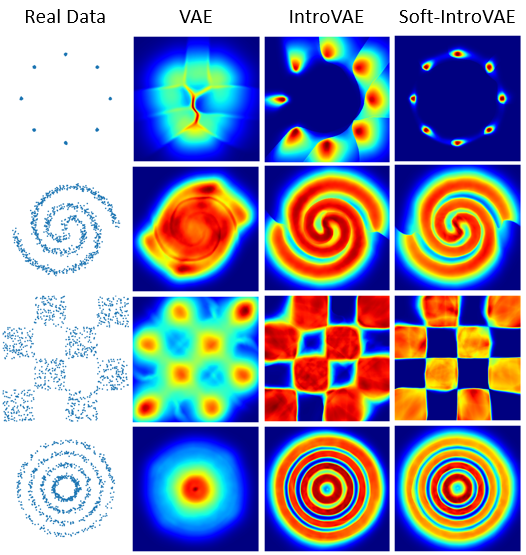 10 |
10 |
11 |
12 | - [soft-intro-vae-pytorch-2d](#soft-intro-vae-pytorch-2d)
13 | * [Training](#training)
14 | * [Recommended hyperparameters](#recommended-hyperparameters)
15 | * [What to expect](#what-to-expect)
16 | * [Files and directories in the repository](#files-and-directories-in-the-repository)
17 | * [Tutorial](#tutorial)
18 |
19 | ## Training
20 |
21 | `main.py --help`
22 |
23 |
24 | You should use the `main.py` file with the following arguments:
25 |
26 | |Argument | Description |Legal Values |
27 | |-------------------------|---------------------------------------------|-------------|
28 | |-h, --help | shows arguments description | |
29 | |-d, --dataset | dataset to train on |str: '8Gaussians', '2spirals', 'checkerboard', rings' |
30 | |-n, --num_iter | total number of iterations to run | int: default=30000|
31 | |-z, --z_dim| latent dimensions | int: default=2|
32 | |-s, --seed| random state to use. for random: -1 | int: -1 , 0, 1, 2 ,....|
33 | |-v, --num_vae| number of iterations for vanilla vae training | int: default=2000|
34 | |-l, --lr| learning rate | float: defalut=2e-4 |
35 | |-r, --beta_rec | beta coefficient for the reconstruction loss |float: default=0.2|
36 | |-k, --beta_kl| beta coefficient for the kl divergence | float: default=0.3|
37 | |-e, --beta_neg| beta coefficient for the kl divergence in the expELBO function | float: default=0.9|
38 | |-g, --gamma_r| coefficient for the reconstruction loss for fake data in the decoder | float: default=1e-8|
39 | |-b, --batch_size| batch size | int: default=512 |
40 | |-p, --pretrained | path to pretrained model, to continue training |str: default="None" |
41 | |-c, --device| device: -1 for cpu, 0 and up for specific cuda device |int: default=-1|
42 |
43 |
44 | Examples:
45 |
46 | `python main.py --dataset 8Gaussians --device 0 --seed 92 --lr 2e-4 --num_vae 2000 --num_iter 30000 --beta_kl 0.3 --beta_rec 0.2 --beta_neg 0.9`
47 |
48 | `python main.py --dataset rings --device -1 --seed -1 --lr 2e-4 --num_vae 2000 --num_iter 30000 --beta_kl 0.2 --beta_rec 0.2 --beta_neg 1.0`
49 |
50 | ## Recommended hyperparameters
51 |
52 | |Dataset | `beta_kl` | `beta_rec`| `beta_neg`|
53 | |------------|------|----|---|
54 | |`8Gaussians`|0.3|0.2| 0.9|
55 | |`2spirals`|0.5|0.2|1.0|
56 | |`checkerboard`|0.1|0.2|0.2|
57 | |`rings`|0.2|0.2|1.0|
58 |
59 |
60 | ## What to expect
61 |
62 | * During the training, figures of samples and density plots are saved locally.
63 | * During training, statistics are printed (reconstruction error, KLD, expELBO).
64 | * At the end of the training, the following quantities are calculated, printed and saved to a `.txt` file: grid-normalized ELBO (gnELBO), KL, JSD
65 | * Tips:
66 | * KL of fake/rec samples should be >= KL of real data
67 | * You will see that the deterministic reconstruction error is printed in parenthesis, it should be lower than the stochastic reconstruction error.
68 | * We found that for the 2D datasets, it better to initialize the networks with vanilla vae training (about 2000 iterations is good).
69 |
70 |
71 | ## Files and directories in the repository
72 |
73 | |File name | Purpose |
74 | |----------------------|------|
75 | |`main.py`| general purpose main application for training Soft-IntroVAE for 2D data|
76 | |`train_soft_intro_vae_2d.py`| main training function, datasets and architectures|
77 |
78 |
79 | ## Tutorial
80 | * [Jupyter Notebook tutorial for 2D datasets](https://github.com/taldatech/soft-intro-vae-pytorch/blob/main/soft_intro_vae_tutorial/soft_intro_vae_2d_code_tutorial.ipynb)
81 | * [Open in Colab](https://colab.research.google.com/github/taldatech/soft-intro-vae-pytorch/blob/main/soft_intro_vae_tutorial/soft_intro_vae_2d_code_tutorial.ipynb)
--------------------------------------------------------------------------------
/style_soft_intro_vae/custom_adam.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | # lr_equalization_coef was added for LREQ
3 |
4 | # Copyright (c) 2016- Facebook, Inc (Adam Paszke)
5 | # Copyright (c) 2014- Facebook, Inc (Soumith Chintala)
6 | # Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
7 | # Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
8 | # Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
9 | # Copyright (c) 2011-2013 NYU (Clement Farabet)
10 | # Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
11 | # Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
12 | # Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
13 |
14 | # https://github.com/pytorch/pytorch/blob/master/LICENSE
15 |
16 |
17 | import math
18 | import torch
19 | from torch.optim.optimizer import Optimizer
20 |
21 |
22 | class LREQAdam(Optimizer):
23 | def __init__(self, params, lr=1e-3, betas=(0.0, 0.99), eps=1e-8,
24 | weight_decay=0):
25 | beta_2 = betas[1]
26 | if not 0.0 <= lr:
27 | raise ValueError("Invalid learning rate: {}".format(lr))
28 | if not 0.0 <= eps:
29 | raise ValueError("Invalid epsilon value: {}".format(eps))
30 | if not 0.0 == betas[0]:
31 | raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
32 | if not 0.0 <= beta_2 < 1.0:
33 | raise ValueError("Invalid beta parameter at index 1: {}".format(beta_2))
34 | defaults = dict(lr=lr, beta_2=beta_2, eps=eps,
35 | weight_decay=weight_decay)
36 | super(LREQAdam, self).__init__(params, defaults)
37 |
38 | def __setstate__(self, state):
39 | super(LREQAdam, self).__setstate__(state)
40 |
41 | def step(self, closure=None):
42 | """Performs a single optimization step.
43 |
44 | Arguments:
45 | closure (callable, optional): A closure that reevaluates the model
46 | and returns the loss.
47 | """
48 | loss = None
49 | if closure is not None:
50 | loss = closure()
51 |
52 | for group in self.param_groups:
53 | for p in group['params']:
54 | if p.grad is None:
55 | continue
56 | grad = p.grad.data
57 | if grad.is_sparse:
58 | raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
59 |
60 | state = self.state[p]
61 |
62 | # State initialization
63 | if len(state) == 0:
64 | state['step'] = 0
65 | # Exponential moving average of gradient values
66 | # state['exp_avg'] = torch.zeros_like(p.data)
67 | # Exponential moving average of squared gradient values
68 | state['exp_avg_sq'] = torch.zeros_like(p.data)
69 |
70 | # exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
71 | exp_avg_sq = state['exp_avg_sq']
72 | beta_2 = group['beta_2']
73 |
74 | state['step'] += 1
75 |
76 | if group['weight_decay'] != 0:
77 | grad.add_(group['weight_decay'], p.data / p.coef)
78 |
79 | # Decay the first and second moment running average coefficient
80 | # exp_avg.mul_(beta1).add_(1 - beta1, grad)
81 | # exp_avg_sq.mul_(beta_2).addcmul_(1 - beta_2, grad, grad)
82 | exp_avg_sq.mul_(beta_2).addcmul_(grad, grad, value=1 - beta_2)
83 | denom = exp_avg_sq.sqrt().add_(group['eps'])
84 |
85 | # bias_correction1 = 1 - beta1 ** state['step'] # 1
86 | bias_correction2 = 1 - beta_2 ** state['step']
87 | # step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1
88 | step_size = group['lr'] * math.sqrt(bias_correction2)
89 |
90 | # p.data.addcdiv_(-step_size, exp_avg, denom)
91 | if hasattr(p, 'lr_equalization_coef'):
92 | step_size *= p.lr_equalization_coef
93 |
94 | # p.data.addcdiv_(-step_size, grad, denom)
95 | p.data.addcdiv_(grad, denom, value=-step_size)
96 |
97 | return loss
98 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/utils/data.py:
--------------------------------------------------------------------------------
1 | import math
2 | import numpy as np
3 | import os
4 | import pandas as pd
5 | import pickle
6 |
7 | from decimal import Decimal
8 | from itertools import accumulate, tee, chain
9 | from typing import List, Tuple, Dict, Optional, Any, Set
10 |
11 | from utils.plyfile import load_ply
12 |
13 | READERS = {
14 | '.ply': load_ply,
15 | '.np': lambda file_path: pickle.load(open(file_path, 'rb')),
16 | }
17 |
18 |
19 | def load_file(file_path):
20 | _, ext = os.path.splitext(file_path)
21 | return READERS[ext](file_path)
22 |
23 |
24 | def add_float(a, b):
25 | return float(Decimal(str(a)) + Decimal(str(b)))
26 |
27 |
28 | def ranges(values: List[float]) -> List[Tuple[float]]:
29 | lower, upper = tee(accumulate(values, add_float))
30 | lower = chain([0], lower)
31 |
32 | return zip(lower, upper)
33 |
34 |
35 | def make_slices(values: List[float], N: int):
36 | slices = [slice(int(N * s), int(N * e)) for s, e in ranges(values)]
37 | return slices
38 |
39 |
40 | def make_splits(
41 | data: pd.DataFrame,
42 | splits: Dict[str, float],
43 | seed: Optional[int] = None):
44 |
45 | # assert correctness
46 | if not math.isclose(sum(splits.values()), 1.0):
47 | values = " ".join([f"{k} : {v}" for k, v in splits.items()])
48 | raise ValueError(f"{values} should sum up to 1")
49 |
50 | # shuffle with random seed
51 | data = data.iloc[np.random.permutation(len(data))]
52 | slices = make_slices(list(splits.values()), len(data))
53 |
54 | return {
55 | name: data[idxs].reset_index(drop=True) for name, idxs in zip(splits.keys(), slices)
56 | }
57 |
58 |
59 | def sample_other_than(black_list: Set[int], x: np.ndarray) -> int:
60 | res = np.random.randint(0, len(x))
61 | while res in black_list:
62 | res = np.random.randint(0, len(x))
63 |
64 | return res
65 |
66 |
67 | def clip_cloud(p: np.ndarray) -> np.ndarray:
68 | # create list of extreme points
69 | black_list = set(np.hstack([
70 | np.argmax(p, axis=0), np.argmin(p, axis=0)
71 | ]))
72 |
73 | # swap any other point
74 | for idx in black_list:
75 | p[idx] = p[sample_other_than(black_list, p)]
76 |
77 | return p
78 |
79 |
80 | def find_extrema(xs, n_cols: int=3, clip: bool=True) -> Dict[Any, List[float]]:
81 | from collections import defaultdict
82 |
83 | mins = defaultdict(lambda: [np.inf for _ in range(n_cols)])
84 | maxs = defaultdict(lambda: [-np.inf for _ in range(n_cols)])
85 |
86 | for x, c in xs:
87 | x = clip_cloud(x) if clip else x
88 | mins[c] = [min(old, new) for old, new in zip(mins[c], np.min(x, axis=0))]
89 | maxs[c] = [max(old, new) for old, new in zip(maxs[c], np.max(x, axis=0))]
90 |
91 | return mins, maxs
92 |
93 |
94 | def merge_dicts(
95 | dict_old: Dict[Any, List[float]],
96 | dict_new: Dict[Any, List[float]], op=min) -> Dict[Any, List[float]]:
97 | '''
98 | Simply takes values on List of floats for given key
99 | '''
100 | d_out = {** dict_old}
101 | for k, v in dict_new.items():
102 | if k in dict_old:
103 | d_out[k] = [op(new, old) for old, new in zip(dict_new[k], dict_old[k])]
104 | else:
105 | d_out[k] = dict_new[k]
106 |
107 | return d_out
108 |
109 |
110 | def save_extrema(clazz, root_dir, splits=('train', 'test', 'valid')):
111 | '''
112 | Maybe this should be class dependent normalization?
113 | '''
114 | min_dict, max_dict = {}, {}
115 | for split in splits:
116 | data = clazz(root_dir=root_dir, split=split, remap=False)
117 | mins, maxs = find_extrema(data)
118 | min_dict = merge_dicts(min_dict, mins, min)
119 | max_dict = merge_dicts(max_dict, maxs, max)
120 |
121 | # vectorzie values
122 | for d in (min_dict, max_dict):
123 | for k in d:
124 | d[k] = np.array(d[k])
125 |
126 | with open(os.path.join(root_dir, 'extrema.np'), 'wb') as f:
127 | pickle.dump((min_dict, max_dict), f)
128 |
129 |
130 | def remap(old_value: np.ndarray,
131 | old_min: np.ndarray, old_max: np.ndarray,
132 | new_min: float = -0.5, new_max: float = 0.5) -> np.ndarray:
133 | '''
134 | Remap reange
135 | '''
136 | old_range = (old_max - old_min)
137 | new_range = (new_max - new_min)
138 | new_value = (((old_value - old_min) * new_range) / old_range) + new_min
139 |
140 | return new_value
141 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/make_figures/generate_samples.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020-2021 Tal Daniel
2 | # Copyright 2019-2020 Stanislav Pidhorskyi
3 | #
4 | # Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
5 | #
6 | # This work is licensed under the Creative Commons Attribution-NonCommercial
7 | # 4.0 International License. To view a copy of this license, visit
8 | # http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
9 | # Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
10 |
11 | from net import *
12 | from model import SoftIntroVAEModelTL
13 | from launcher import run
14 | from dataloader import *
15 | from checkpointer import Checkpointer
16 | # from dlutils.pytorch import count_parameters
17 | from defaults import get_cfg_defaults
18 | from PIL import Image
19 | import PIL
20 | from pathlib import Path
21 | from tqdm import tqdm
22 |
23 |
24 | def millify(n):
25 | millnames = ['', 'k', 'M', 'G', 'T', 'P']
26 | n = float(n)
27 | millidx = max(0, min(len(millnames) - 1, int(math.floor(0 if n == 0 else math.log10(abs(n)) / 3))))
28 |
29 | return '{:.1f}{}'.format(n / 10 ** (3 * millidx), millnames[millidx])
30 |
31 |
32 | def count_parameters(model, print_func=print, verbose=False):
33 | for n, p in model.named_parameters():
34 | if p.requires_grad and verbose:
35 | print_func(n, millify(p.numel()))
36 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
37 |
38 |
39 | def generate_samples(cfg, model, save_dir, num_samples, device=torch.device("cpu")):
40 | for i in tqdm(range(num_samples)):
41 | samplez = torch.randn(size=(1, cfg.MODEL.LATENT_SPACE_SIZE)).float().to(device)
42 | image = model.generate(cfg.DATASET.MAX_RESOLUTION_LEVEL - 2, 1, samplez, 1, mixing=True)[0]
43 | im = image.data.cpu().numpy()
44 | im = im.transpose(1, 2, 0)
45 | im = im * 0.5 + 0.5
46 | image = PIL.Image.fromarray(np.clip(im * 255, 0, 255).astype(np.uint8), 'RGB')
47 | image.save(os.path.join(save_dir, 'image_{}.jpg'.format(i)))
48 |
49 |
50 | def sample(cfg, logger):
51 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
52 | torch.cuda.set_device(2)
53 | model = SoftIntroVAEModelTL(
54 | startf=cfg.MODEL.START_CHANNEL_COUNT,
55 | layer_count=cfg.MODEL.LAYER_COUNT,
56 | maxf=cfg.MODEL.MAX_CHANNEL_COUNT,
57 | latent_size=cfg.MODEL.LATENT_SPACE_SIZE,
58 | dlatent_avg_beta=cfg.MODEL.DLATENT_AVG_BETA,
59 | style_mixing_prob=cfg.MODEL.STYLE_MIXING_PROB,
60 | mapping_layers=cfg.MODEL.MAPPING_LAYERS,
61 | channels=cfg.MODEL.CHANNELS,
62 | generator=cfg.MODEL.GENERATOR,
63 | encoder=cfg.MODEL.ENCODER,
64 | beta_kl=cfg.MODEL.BETA_KL,
65 | beta_rec=cfg.MODEL.BETA_REC,
66 | beta_neg=cfg.MODEL.BETA_NEG[cfg.MODEL.LAYER_COUNT - 1],
67 | scale=cfg.MODEL.SCALE
68 | )
69 |
70 | model.to(device)
71 | model.eval()
72 | model.requires_grad_(False)
73 |
74 | decoder = model.decoder
75 | encoder = model.encoder
76 | mapping_tl = model.mapping_tl
77 | mapping_fl = model.mapping_fl
78 |
79 | dlatent_avg = model.dlatent_avg
80 |
81 | logger.info("Trainable parameters decoder:")
82 | print(count_parameters(decoder))
83 |
84 | logger.info("Trainable parameters encoder:")
85 | print(count_parameters(encoder))
86 |
87 | arguments = dict()
88 | arguments["iteration"] = 0
89 |
90 | model_dict = {
91 | 'discriminator_s': encoder,
92 | 'generator_s': decoder,
93 | 'mapping_tl_s': mapping_tl,
94 | 'mapping_fl_s': mapping_fl,
95 | 'dlatent_avg': dlatent_avg
96 | }
97 |
98 | checkpointer = Checkpointer(cfg,
99 | model_dict,
100 | {},
101 | logger=logger,
102 | save=False)
103 |
104 | checkpointer.load()
105 |
106 | model.eval()
107 |
108 | path = './make_figures/output'
109 | os.makedirs(path, exist_ok=True)
110 | os.makedirs(os.path.join(path, cfg.NAME), exist_ok=True)
111 | with torch.no_grad():
112 | generate_samples(cfg, model, path, 5, device=device)
113 |
114 |
115 | if __name__ == "__main__":
116 | gpu_count = 1
117 | run(sample, get_cfg_defaults(), description='SoftIntroVAEVAE-generations',
118 | default_config='./configs/ffhq256.yaml',
119 | world_size=gpu_count, write_log=False)
120 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/launcher.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | import os
17 | import sys
18 | import argparse
19 | import logging
20 | import torch
21 | import torch.multiprocessing as mp
22 | from torch import distributed
23 | import inspect
24 |
25 |
26 | def setup(rank, world_size):
27 | os.environ['MASTER_ADDR'] = 'localhost'
28 | os.environ['MASTER_PORT'] = '12355'
29 | distributed.init_process_group("nccl", rank=rank, world_size=world_size)
30 |
31 |
32 | def cleanup():
33 | distributed.destroy_process_group()
34 |
35 |
36 | def _run(rank, world_size, fn, defaults, write_log, no_cuda, args):
37 | if world_size > 1:
38 | setup(rank, world_size)
39 | if not no_cuda:
40 | torch.cuda.set_device(rank)
41 |
42 | cfg = defaults
43 | config_file = args.config_file
44 | if len(os.path.splitext(config_file)[1]) == 0:
45 | config_file += '.yaml'
46 | if not os.path.exists(config_file) and os.path.exists(os.path.join('configs', config_file)):
47 | config_file = os.path.join('configs', config_file)
48 | cfg.merge_from_file(config_file)
49 | cfg.merge_from_list(args.opts)
50 | cfg.freeze()
51 |
52 | logger = logging.getLogger("logger")
53 | logger.setLevel(logging.DEBUG)
54 |
55 | output_dir = cfg.OUTPUT_DIR
56 | os.makedirs(output_dir, exist_ok=True)
57 |
58 | if rank == 0:
59 | ch = logging.StreamHandler(stream=sys.stdout)
60 | ch.setLevel(logging.DEBUG)
61 | formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s: %(message)s")
62 | ch.setFormatter(formatter)
63 | logger.addHandler(ch)
64 |
65 | if write_log:
66 | filepath = os.path.join(output_dir, 'log.txt')
67 | if isinstance(write_log, str):
68 | filepath = write_log
69 | fh = logging.FileHandler(filepath)
70 | fh.setLevel(logging.DEBUG)
71 | fh.setFormatter(formatter)
72 | logger.addHandler(fh)
73 |
74 | logger.info(args)
75 |
76 | logger.info("World size: {}".format(world_size))
77 |
78 | logger.info("Loaded configuration file {}".format(config_file))
79 | with open(config_file, "r") as cf:
80 | config_str = "\n" + cf.read()
81 | logger.info(config_str)
82 | logger.info("Running with config:\n{}".format(cfg))
83 |
84 | if not no_cuda:
85 | torch.set_default_tensor_type('torch.cuda.FloatTensor')
86 | device = torch.cuda.current_device()
87 | print("Running on ", torch.cuda.get_device_name(device))
88 |
89 | args.distributed = world_size > 1
90 | args_to_pass = dict(cfg=cfg, logger=logger, local_rank=rank, world_size=world_size, distributed=args.distributed)
91 | signature = inspect.signature(fn)
92 | matching_args = {}
93 | for key in args_to_pass.keys():
94 | if key in signature.parameters.keys():
95 | matching_args[key] = args_to_pass[key]
96 | fn(**matching_args)
97 |
98 | if world_size > 1:
99 | cleanup()
100 |
101 |
102 | def run(fn, defaults, description='', default_config='configs/experiment.yaml', world_size=1, write_log=True, no_cuda=False):
103 | parser = argparse.ArgumentParser(description=description)
104 | parser.add_argument(
105 | "-c", "--config-file",
106 | default=default_config,
107 | metavar="FILE",
108 | help="path to config file",
109 | type=str,
110 | )
111 | parser.add_argument(
112 | "opts",
113 | help="Modify config options using the command-line",
114 | default=None,
115 | nargs=argparse.REMAINDER,
116 | )
117 |
118 | import multiprocessing
119 | cpu_count = multiprocessing.cpu_count()
120 | os.environ["OMP_NUM_THREADS"] = str(max(1, int(cpu_count / world_size)))
121 | del multiprocessing
122 |
123 | args = parser.parse_args()
124 |
125 | if world_size > 1:
126 | mp.spawn(_run,
127 | args=(world_size, fn, defaults, write_log, no_cuda, args),
128 | nprocs=world_size,
129 | join=True)
130 | else:
131 | _run(0, world_size, fn, defaults, write_log, no_cuda, args)
132 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/lod_driver.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | import torch
17 | import math
18 | import time
19 | from collections import defaultdict
20 |
21 |
22 | class LODDriver:
23 | def __init__(self, cfg, logger, world_size, dataset_size):
24 | if world_size == 8:
25 | self.lod_2_batch = cfg.TRAIN.LOD_2_BATCH_8GPU
26 | if world_size == 4:
27 | self.lod_2_batch = cfg.TRAIN.LOD_2_BATCH_4GPU
28 | if world_size == 2:
29 | self.lod_2_batch = cfg.TRAIN.LOD_2_BATCH_2GPU
30 | if world_size == 1:
31 | self.lod_2_batch = cfg.TRAIN.LOD_2_BATCH_1GPU
32 |
33 | self.world_size = world_size
34 | self.minibatch_base = 16
35 | self.cfg = cfg
36 | self.dataset_size = dataset_size
37 | self.current_epoch = 0
38 | self.lod = -1
39 | self.in_transition = False
40 | self.logger = logger
41 | self.iteration = 0
42 | self.epoch_end_time = 0
43 | self.epoch_start_time = 0
44 | self.per_epoch_ptime = 0
45 | self.reports = cfg.TRAIN.REPORT_FREQ
46 | self.snapshots = cfg.TRAIN.SNAPSHOT_FREQ
47 | self.tick_start_nimg_report = 0
48 | self.tick_start_nimg_snapshot = 0
49 |
50 | def get_lod_power2(self):
51 | return self.lod + 2
52 |
53 | def get_batch_size(self):
54 | return self.lod_2_batch[min(self.lod, len(self.lod_2_batch) - 1)]
55 |
56 | def get_dataset_size(self):
57 | return self.dataset_size
58 |
59 | def get_per_GPU_batch_size(self):
60 | return self.get_batch_size() // self.world_size
61 |
62 | def get_blend_factor(self):
63 | if self.cfg.TRAIN.EPOCHS_PER_LOD == 0:
64 | return 1
65 | blend_factor = float((self.current_epoch % self.cfg.TRAIN.EPOCHS_PER_LOD) * self.dataset_size + self.iteration)
66 | blend_factor /= float(self.cfg.TRAIN.EPOCHS_PER_LOD // 2 * self.dataset_size)
67 | blend_factor = math.sin(blend_factor * math.pi - 0.5 * math.pi) * 0.5 + 0.5
68 |
69 | if not self.in_transition:
70 | blend_factor = 1
71 |
72 | return blend_factor
73 |
74 | def is_time_to_report(self):
75 | if self.iteration >= self.tick_start_nimg_report + self.reports[min(self.lod, len(self.reports) - 1)] * 1000:
76 | self.tick_start_nimg_report = self.iteration
77 | return True
78 | return False
79 |
80 | def is_time_to_save(self):
81 | if self.iteration >= self.tick_start_nimg_snapshot + self.snapshots[
82 | min(self.lod, len(self.snapshots) - 1)] * 1000:
83 | self.tick_start_nimg_snapshot = self.iteration
84 | return True
85 | return False
86 |
87 | def step(self):
88 | self.iteration += self.get_batch_size()
89 | self.epoch_end_time = time.time()
90 | self.per_epoch_ptime = self.epoch_end_time - self.epoch_start_time
91 |
92 | def set_epoch(self, epoch, optimizers):
93 | self.current_epoch = epoch
94 | self.iteration = 0
95 | self.tick_start_nimg_report = 0
96 | self.tick_start_nimg_snapshot = 0
97 | self.epoch_start_time = time.time()
98 |
99 | if self.cfg.TRAIN.EPOCHS_PER_LOD == 0:
100 | self.lod = self.cfg.MODEL.LAYER_COUNT - 1
101 | return
102 |
103 | new_lod = min(self.cfg.MODEL.LAYER_COUNT - 1, epoch // self.cfg.TRAIN.EPOCHS_PER_LOD)
104 | if new_lod != self.lod:
105 | self.lod = new_lod
106 | self.logger.info("#" * 80)
107 | self.logger.info("# Switching LOD to %d" % self.lod)
108 | self.logger.info("# Starting transition")
109 | self.logger.info("#" * 80)
110 | self.in_transition = True
111 | for opt in optimizers:
112 | opt.state = defaultdict(dict)
113 |
114 | is_in_first_half_of_cycle = (epoch % self.cfg.TRAIN.EPOCHS_PER_LOD) < (self.cfg.TRAIN.EPOCHS_PER_LOD // 2)
115 | is_growing = epoch // self.cfg.TRAIN.EPOCHS_PER_LOD == self.lod > 0
116 | new_in_transition = is_in_first_half_of_cycle and is_growing
117 |
118 | if new_in_transition != self.in_transition:
119 | self.in_transition = new_in_transition
120 | self.logger.info("#" * 80)
121 | self.logger.info("# Transition ended")
122 | self.logger.info("#" * 80)
123 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/tracker.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | import csv
17 | from collections import OrderedDict
18 | import matplotlib
19 | matplotlib.use('Agg')
20 | import matplotlib.pyplot as plt
21 | import numpy as np
22 | import torch
23 | import os
24 |
25 |
26 | class RunningMean:
27 | def __init__(self):
28 | self.mean = 0.0
29 | self.n = 0
30 |
31 | def __iadd__(self, value):
32 | self.mean = (float(value) + self.mean * self.n)/(self.n + 1)
33 | self.n += 1
34 | return self
35 |
36 | def reset(self):
37 | self.mean = 0.0
38 | self.n = 0
39 |
40 | def mean(self):
41 | return self.mean
42 |
43 |
44 | class RunningMeanTorch:
45 | def __init__(self):
46 | self.values = []
47 |
48 | def __iadd__(self, value):
49 | with torch.no_grad():
50 | self.values.append(value.detach().cpu().unsqueeze(0))
51 | return self
52 |
53 | def reset(self):
54 | self.values = []
55 |
56 | def mean(self):
57 | with torch.no_grad():
58 | if len(self.values) == 0:
59 | return 0.0
60 | return float(torch.cat(self.values).mean().item())
61 |
62 |
63 | class LossTracker:
64 | def __init__(self, output_folder='.'):
65 | self.tracks = OrderedDict()
66 | self.epochs = []
67 | self.means_over_epochs = OrderedDict()
68 | self.output_folder = output_folder
69 |
70 | def update(self, d):
71 | for k, v in d.items():
72 | if k not in self.tracks:
73 | self.add(k)
74 | self.tracks[k] += v
75 |
76 | def add(self, name, pytorch=True):
77 | assert name not in self.tracks, "Name is already used"
78 | if pytorch:
79 | track = RunningMeanTorch()
80 | else:
81 | track = RunningMean()
82 | self.tracks[name] = track
83 | self.means_over_epochs[name] = []
84 | return track
85 |
86 | def register_means(self, epoch):
87 | self.epochs.append(epoch)
88 |
89 | for key in self.means_over_epochs.keys():
90 | if key in self.tracks:
91 | value = self.tracks[key]
92 | self.means_over_epochs[key].append(value.mean())
93 | value.reset()
94 | else:
95 | self.means_over_epochs[key].append(None)
96 |
97 | with open(os.path.join(self.output_folder, 'log.csv'), mode='w') as csv_file:
98 | fieldnames = ['epoch'] + list(self.tracks.keys())
99 | writer = csv.writer(csv_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
100 | writer.writerow(fieldnames)
101 | for i in range(len(self.epochs)):
102 | writer.writerow([self.epochs[i]] + [self.means_over_epochs[x][i] for x in self.tracks.keys()])
103 |
104 | def __str__(self):
105 | result = ""
106 | for key, value in self.tracks.items():
107 | result += "%s: %.7f, " % (key, value.mean())
108 | return result[:-2]
109 |
110 | def plot(self):
111 | plt.figure(figsize=(12, 8))
112 | for key in self.tracks.keys():
113 | plt.plot(self.epochs, self.means_over_epochs[key], label=key)
114 |
115 | plt.xlabel('Epoch')
116 | plt.ylabel('Loss')
117 |
118 | plt.legend(loc=2)
119 | plt.grid(True)
120 | plt.tight_layout()
121 |
122 | plt.savefig(os.path.join(self.output_folder, 'plot.png'))
123 | plt.close()
124 |
125 | def state_dict(self):
126 | return {
127 | 'tracks': self.tracks,
128 | 'epochs': self.epochs,
129 | 'means_over_epochs': self.means_over_epochs}
130 |
131 | def load_state_dict(self, state_dict):
132 | self.tracks = state_dict['tracks']
133 | self.epochs = state_dict['epochs']
134 | self.means_over_epochs = state_dict['means_over_epochs']
135 |
136 | counts = list(map(len, self.means_over_epochs.values()))
137 |
138 | if len(counts) == 0:
139 | counts = [0]
140 | m = min(counts)
141 |
142 | if m < len(self.epochs):
143 | self.epochs = self.epochs[:m]
144 |
145 | for key in self.means_over_epochs.keys():
146 | if len(self.means_over_epochs[key]) > m:
147 | self.means_over_epochs[key] = self.means_over_epochs[key][:m]
148 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/generate_for_rendering.py:
--------------------------------------------------------------------------------
1 | """
2 | Generate point clouds from a trained model for rendering using Mitsuba
3 | """
4 |
5 | import json
6 | import numpy as np
7 | import os
8 |
9 | import torch
10 | import torch.nn.parallel
11 | import torch.utils.data
12 | from torch.utils.data import DataLoader
13 |
14 | from utils.util import cuda_setup
15 | from models.vae import SoftIntroVAE, reparameterize
16 |
17 |
18 | def generate_from_model(model, num_samples, prior_std=0.2, device=torch.device("cpu")):
19 | model.eval()
20 | noise = prior_std * torch.randn(size=(num_samples, model.zdim)).to(device)
21 | with torch.no_grad():
22 | x_g = model.decode(noise)
23 | if x_g.shape[-2:] == (3, 2048):
24 | x_g.transpose_(1, 2)
25 | return x_g
26 |
27 |
28 | def interpolate(model, data, num_steps=20, device=torch.device("cpu")):
29 | assert data.shape[0] >= 2, "must supply at least 2 data points"
30 | model.eval()
31 | steps = np.linspace(0, 1, num_steps)
32 | data = data[:2].to(device)
33 | # Change dim [BATCH, N_POINTS, N_DIM] -> [BATCH, N_DIM, N_POINTS]
34 | if data.size(-1) == 3:
35 | data.transpose_(data.dim() - 2, data.dim() - 1)
36 | mu_z, logvar_z = model.encode(data)
37 | data_z = reparameterize(mu_z, logvar_z)
38 | interpolations = [data_z[0][None,]]
39 | for step in steps:
40 | interpolation = step * data_z[1] + (1 - step) * data_z[0]
41 | interpolations.append(interpolation[None,])
42 | interpolations.append(data_z[1][None,])
43 | interpolations = torch.cat(interpolations, dim=0)
44 | data_interpolation = model.decode(interpolations)
45 | return data_interpolation
46 |
47 |
48 | def save_point_cloud_np(save_path, data_tensor):
49 | # Change dim
50 | if data_tensor.size(-1) != 3:
51 | data_tensor.transpose_(data_tensor.dim() - 1, data_tensor.dim() - 2)
52 | data_np = data_tensor.data.cpu().numpy()
53 | np.save(save_path, data_np)
54 | print(f'saved data @ {save_path}')
55 |
56 |
57 | def prepare_model(config, path_to_weights, device=torch.device("cpu")):
58 | model = SoftIntroVAE(config).to(device)
59 | model.load_state_dict(torch.load(path_to_weights, map_location=device))
60 | model.eval()
61 | return model
62 |
63 |
64 | def prepare_data(config, split='train', batch_size=32):
65 | dataset_name = config['dataset'].lower()
66 | if dataset_name == 'shapenet':
67 | from datasets.shapenet import ShapeNetDataset
68 | dataset = ShapeNetDataset(root_dir=config['data_dir'],
69 | classes=config['classes'], split=split)
70 | else:
71 | raise ValueError(f'Invalid dataset name. Expected `shapenet` or '
72 | f'`faust`. Got: `{dataset_name}`')
73 | data_loader = DataLoader(dataset, batch_size=batch_size,
74 | shuffle=True, num_workers=4,
75 | drop_last=False, pin_memory=True)
76 | return data_loader
77 |
78 |
79 | def prepare_dataset(config, split='train', batch_size=32):
80 | dataset_name = config['dataset'].lower()
81 | if dataset_name == 'shapenet':
82 | from datasets.shapenet import ShapeNetDataset
83 | dataset = ShapeNetDataset(root_dir=config['data_dir'],
84 | classes=config['classes'], split=split)
85 | else:
86 | raise ValueError(f'Invalid dataset name. Expected `shapenet` or '
87 | f'`faust`. Got: `{dataset_name}`')
88 | return dataset
89 |
90 |
91 | if __name__ == "__main__":
92 | """
93 | cars + airplane: cars:[60, 5150], planes: [6450, 6550, 6950]
94 | """
95 | save_path = './results/generated_data'
96 | os.makedirs(save_path, exist_ok=True)
97 | path_generated = os.path.join(save_path, 'generated.npy')
98 | path_interpolated = os.path.join(save_path, 'interpolations.npy')
99 | path_to_weights = './results/vae/soft_intro_vae_chair/weights/01618_jsd_0.0175.pth'
100 | config_path = 'config/soft_intro_vae_hp.json'
101 | config = None
102 | if config_path is not None and config_path.endswith('.json'):
103 | with open(config_path) as f:
104 | config = json.load(f)
105 | assert config is not None
106 | device = cuda_setup(config['cuda'], config['gpu'])
107 | print("using device: ", device)
108 | model = prepare_model(config, path_to_weights, device=device)
109 | dataset = prepare_dataset(config, split='train', batch_size=config['batch_size'])
110 | batch = torch.stack([torch.from_numpy(dataset[60][0]), torch.from_numpy(dataset[6450][0])], dim=0)
111 | # generate
112 | x_g = generate_from_model(model, num_samples=5, device=device)
113 | save_point_cloud_np(path_generated, x_g)
114 | print(f'save generations in {path_generated}')
115 | # interpolate
116 | x_interpolated = interpolate(model, batch, num_steps=50, device=device)
117 | save_point_cloud_np(path_interpolated, x_interpolated)
118 | print(f'save interpolations in {path_interpolated}')
119 | print("use these .npy files to render beautiful point clouds with Mitsuba, see the 'render' directory for instructions")
120 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/checkpointer.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | import os
17 | from torch import nn
18 | import torch
19 | import utils
20 |
21 |
22 | def get_model_dict(x):
23 | if x is None:
24 | return None
25 | if isinstance(x, nn.DataParallel):
26 | return x.module.state_dict()
27 | else:
28 | return x.state_dict()
29 |
30 |
31 | def load_model(x, state_dict):
32 | if isinstance(x, nn.DataParallel):
33 | x.module.load_state_dict(state_dict)
34 | else:
35 | x.load_state_dict(state_dict)
36 |
37 |
38 | class Checkpointer(object):
39 | def __init__(self, cfg, models, auxiliary=None, logger=None, save=True):
40 | self.models = models
41 | self.auxiliary = auxiliary
42 | self.cfg = cfg
43 | self.logger = logger
44 | self._save = save
45 |
46 | def save(self, _name, **kwargs):
47 | if not self._save:
48 | return
49 | data = dict()
50 | data["models"] = dict()
51 | data["auxiliary"] = dict()
52 | for name, model in self.models.items():
53 | data["models"][name] = get_model_dict(model)
54 |
55 | if self.auxiliary is not None:
56 | for name, item in self.auxiliary.items():
57 | data["auxiliary"][name] = item.state_dict()
58 | data.update(kwargs)
59 |
60 | @utils.async_func
61 | def save_data():
62 | save_file = os.path.join(self.cfg.OUTPUT_DIR, "%s.pth" % _name)
63 | self.logger.info("Saving checkpoint to %s" % save_file)
64 | torch.save(data, save_file)
65 | self.tag_last_checkpoint(save_file)
66 |
67 | return save_data()
68 |
69 | def load(self, ignore_last_checkpoint=False, file_name=None):
70 | save_file = os.path.join(self.cfg.OUTPUT_DIR, "last_checkpoint")
71 | try:
72 | with open(save_file, "r") as last_checkpoint:
73 | f = last_checkpoint.read().strip()
74 | except IOError:
75 | self.logger.info("No checkpoint found. Initializing model from scratch")
76 | if file_name is None:
77 | return {}
78 |
79 | if ignore_last_checkpoint:
80 | self.logger.info("Forced to Initialize model from scratch")
81 | return {}
82 | if file_name is not None:
83 | f = file_name
84 |
85 | self.logger.info("Loading checkpoint from {}".format(f))
86 | checkpoint = torch.load(f, map_location=torch.device("cpu"))
87 | for name, model in self.models.items():
88 | if name in checkpoint["models"]:
89 | try:
90 | model_dict = checkpoint["models"].pop(name)
91 | if model_dict is not None:
92 | self.models[name].load_state_dict(model_dict, strict=False)
93 | else:
94 | self.logger.warning("State dict for model \"%s\" is None " % name)
95 | except RuntimeError as e:
96 | self.logger.warning('%s\nFailed to load: %s\n%s' % ('!' * 160, name, '!' * 160))
97 | self.logger.warning('\nFailed to load: %s' % str(e))
98 | else:
99 | self.logger.warning("No state dict for model: %s" % name)
100 | checkpoint.pop('models')
101 | if "auxiliary" in checkpoint and self.auxiliary:
102 | self.logger.info("Loading auxiliary from {}".format(f))
103 | for name, item in self.auxiliary.items():
104 | try:
105 | if name in checkpoint["auxiliary"]:
106 | self.auxiliary[name].load_state_dict(checkpoint["auxiliary"].pop(name))
107 | if "optimizers" in checkpoint and name in checkpoint["optimizers"]:
108 | self.auxiliary[name].load_state_dict(checkpoint["optimizers"].pop(name))
109 | if name in checkpoint:
110 | self.auxiliary[name].load_state_dict(checkpoint.pop(name))
111 | except IndexError:
112 | self.logger.warning('%s\nFailed to load: %s\n%s' % ('!' * 160, name, '!' * 160))
113 | checkpoint.pop('auxiliary')
114 |
115 | return checkpoint
116 |
117 | def tag_last_checkpoint(self, last_filename):
118 | save_file = os.path.join(self.cfg.OUTPUT_DIR, "last_checkpoint")
119 | with open(save_file, "w") as f:
120 | f.write(last_filename)
121 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/make_figures/make_generation_figure.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020-2021 Tal Daniel
2 | # Copyright 2019-2020 Stanislav Pidhorskyi
3 | #
4 | # Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
5 | #
6 | # This work is licensed under the Creative Commons Attribution-NonCommercial
7 | # 4.0 International License. To view a copy of this license, visit
8 | # http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
9 | # Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
10 |
11 | from net import *
12 | from model import SoftIntroVAEModelTL
13 | from launcher import run
14 | from dataloader import *
15 | from checkpointer import Checkpointer
16 | from defaults import get_cfg_defaults
17 | from PIL import Image
18 | import PIL
19 | import os
20 |
21 |
22 | def millify(n):
23 | millnames = ['', 'k', 'M', 'G', 'T', 'P']
24 | n = float(n)
25 | millidx = max(0, min(len(millnames) - 1, int(math.floor(0 if n == 0 else math.log10(abs(n)) / 3))))
26 |
27 | return '{:.1f}{}'.format(n / 10 ** (3 * millidx), millnames[millidx])
28 |
29 |
30 | def count_parameters(model, print_func=print, verbose=False):
31 | for n, p in model.named_parameters():
32 | if p.requires_grad and verbose:
33 | print_func(n, millify(p.numel()))
34 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
35 |
36 |
37 | def draw_uncurated_result_figure(cfg, png, model, cx, cy, cw, ch, rows, lods, seed):
38 | print(png)
39 | N = sum(rows * 2 ** lod for lod in lods)
40 | images = []
41 |
42 | rnd = np.random.RandomState(5)
43 | for i in range(N):
44 | latents = rnd.randn(1, cfg.MODEL.LATENT_SPACE_SIZE)
45 | samplez = torch.tensor(latents).float().cuda()
46 | image = model.generate(cfg.DATASET.MAX_RESOLUTION_LEVEL - 2, 1, samplez, 1, mixing=True)
47 | images.append(image[0])
48 |
49 | canvas = PIL.Image.new('RGB', (sum(cw // 2 ** lod for lod in lods), ch * rows), 'white')
50 | image_iter = iter(list(images))
51 | for col, lod in enumerate(lods):
52 | for row in range(rows * 2 ** lod):
53 | im = next(image_iter).cpu().numpy()
54 | im = im.transpose(1, 2, 0)
55 | im = im * 0.5 + 0.5
56 | image = PIL.Image.fromarray(np.clip(im * 255, 0, 255).astype(np.uint8), 'RGB')
57 | image = image.crop((cx, cy, cx + cw, cy + ch))
58 | image = image.resize((cw // 2 ** lod, ch // 2 ** lod), PIL.Image.ANTIALIAS)
59 | canvas.paste(image, (sum(cw // 2 ** lod for lod in lods[:col]), row * ch // 2 ** lod))
60 | canvas.save(png)
61 |
62 |
63 | def sample(cfg, logger):
64 | torch.cuda.set_device(0)
65 | model = SoftIntroVAEModelTL(
66 | startf=cfg.MODEL.START_CHANNEL_COUNT,
67 | layer_count=cfg.MODEL.LAYER_COUNT,
68 | maxf=cfg.MODEL.MAX_CHANNEL_COUNT,
69 | latent_size=cfg.MODEL.LATENT_SPACE_SIZE,
70 | dlatent_avg_beta=cfg.MODEL.DLATENT_AVG_BETA,
71 | style_mixing_prob=cfg.MODEL.STYLE_MIXING_PROB,
72 | mapping_layers=cfg.MODEL.MAPPING_LAYERS,
73 | channels=cfg.MODEL.CHANNELS,
74 | generator=cfg.MODEL.GENERATOR,
75 | encoder=cfg.MODEL.ENCODER,
76 | beta_kl=cfg.MODEL.BETA_KL,
77 | beta_rec=cfg.MODEL.BETA_REC,
78 | beta_neg=cfg.MODEL.BETA_NEG[cfg.MODEL.LAYER_COUNT - 1],
79 | scale=cfg.MODEL.SCALE
80 | )
81 |
82 | model.cuda(0)
83 | model.eval()
84 | model.requires_grad_(False)
85 |
86 | decoder = model.decoder
87 | encoder = model.encoder
88 | mapping_tl = model.mapping_tl
89 | mapping_fl = model.mapping_fl
90 |
91 | dlatent_avg = model.dlatent_avg
92 |
93 | logger.info("Trainable parameters decoder:")
94 | print(count_parameters(decoder))
95 |
96 | logger.info("Trainable parameters encoder:")
97 | print(count_parameters(encoder))
98 |
99 | arguments = dict()
100 | arguments["iteration"] = 0
101 |
102 | model_dict = {
103 | 'discriminator_s': encoder,
104 | 'generator_s': decoder,
105 | 'mapping_tl_s': mapping_tl,
106 | 'mapping_fl_s': mapping_fl,
107 | 'dlatent_avg': dlatent_avg
108 | }
109 |
110 | checkpointer = Checkpointer(cfg,
111 | model_dict,
112 | {},
113 | logger=logger,
114 | save=False)
115 |
116 | checkpointer.load()
117 |
118 | model.eval()
119 |
120 | im_size = 2 ** (cfg.MODEL.LAYER_COUNT + 1)
121 | seed = np.random.randint(0, 999999)
122 | print("seed:", seed)
123 | with torch.no_grad():
124 | path = './make_figures/output'
125 | os.makedirs(path, exist_ok=True)
126 | os.makedirs(os.path.join(path, cfg.NAME), exist_ok=True)
127 | draw_uncurated_result_figure(cfg, './make_figures/output/%s/generations.jpg' % cfg.NAME,
128 | model, cx=0, cy=0, cw=im_size, ch=im_size, rows=6, lods=[0, 0, 0, 1, 1, 2], seed=seed)
129 |
130 |
131 | if __name__ == "__main__":
132 | gpu_count = 1
133 | run(sample, get_cfg_defaults(), description='SoftIntroVAE-generations', default_config='./configs/ffhq256.yaml',
134 | world_size=gpu_count, write_log=False)
135 |
--------------------------------------------------------------------------------
/soft_intro_vae/README.md:
--------------------------------------------------------------------------------
1 | # soft-intro-vae-pytorch-images
2 |
3 | Implementation of Soft-IntroVAE for image data.
4 |
5 | A step-by-step tutorial can be found in [Soft-IntroVAE Jupyter Notebook Tutorials](https://github.com/taldatech/soft-intro-vae-pytorch/tree/main/soft_intro_vae_tutorial).
6 |
7 |
8 |  9 |
9 |
10 |
11 | - [soft-intro-vae-pytorch-images](#soft-intro-vae-pytorch-images)
12 | * [Training](#training)
13 | * [Datasets](#datasets)
14 | * [Recommended hyperparameters](#recommended-hyperparameters)
15 | * [What to expect](#what-to-expect)
16 | * [Files and directories in the repository](#files-and-directories-in-the-repository)
17 | * [Tutorial](#tutorial)
18 |
19 | ## Training
20 |
21 | `main.py --help`
22 |
23 |
24 | You should use the `main.py` file with the following arguments:
25 |
26 | |Argument | Description |Legal Values |
27 | |-------------------------|---------------------------------------------|-------------|
28 | |-h, --help | shows arguments description | |
29 | |-d, --dataset | dataset to train on |str: 'cifar10', 'mnist', 'fmnist', 'svhn', 'monsters128', 'celeb128', 'celeb256', 'celeb1024' |
30 | |-n, --num_epochs | total number of epochs to run | int: default=250|
31 | |-z, --z_dim| latent dimensions | int: default=128|
32 | |-s, --seed| random state to use. for random: -1 | int: -1 , 0, 1, 2 ,....|
33 | |-v, --num_vae| number of iterations for vanilla vae training | int: default=0|
34 | |-l, --lr| learning rate | float: defalut=2e-4 |
35 | |-r, --beta_rec | beta coefficient for the reconstruction loss |float: default=1.0|
36 | |-k, --beta_kl| beta coefficient for the kl divergence | float: default=1.0|
37 | |-e, --beta_neg| beta coefficient for the kl divergence in the expELBO function | float: default=256.0|
38 | |-g, --gamma_r| coefficient for the reconstruction loss for fake data in the decoder | float: default=1e-8|
39 | |-b, --batch_size| batch size | int: default=32 |
40 | |-p, --pretrained | path to pretrained model, to continue training |str: default="None" |
41 | |-c, --device| device: -1 for cpu, 0 and up for specific cuda device |int: default=-1|
42 | |-f, --fid| if specified, FID wil be calculated during training |bool: default=False|
43 |
44 | Examples:
45 |
46 | `python main.py --dataset cifar10 --device 0 --lr 2e-4 --num_epochs 250 --beta_kl 1.0 --beta_rec 1.0 --beta_neg 256 --z_dim 128 --batch_size 32`
47 |
48 | `python main.py --dataset mnist --device 0 --lr 2e-4 --num_epochs 200 --beta_kl 1.0 --beta_rec 1.0 --beta_neg 256 --z_dim 32 --batch_size 128`
49 |
50 | ## Datasets
51 | * CelebHQ: please follow [ALAE](https://github.com/podgorskiy/ALAE#datasets) instructions.
52 | * Digital-Monsters dataset: we curated a “Digital Monsters” dataset: ~4000 images of Pokemon, Digimon and Nexomon (yes, it’s a thing). We currently don't provide a download link for this dataset (not because we are bad people), but please contact us if you wish to create it yourself.
53 |
54 | On the left is a sample from the (very diverse) Digital-Monsters dataset (we used augmentations to enrich it), and on the right, samples generated from S-IntroVAE.
55 | We hope this does not give you nightmares.
56 |
57 |
58 |  59 |
59 |  60 |
60 |
61 |
62 | ## Recommended hyperparameters
63 |
64 | |Dataset | `beta_kl` | `beta_rec`| `beta_neg`|`z_dim`|`batch_size`|
65 | |------------|------|----|---|----|---|
66 | |CIFAR10 (`cifar10`)|1.0|1.0| 256|128| 32|
67 | |SVHN (`svhn`)|1.0|1.0| 256|128| 32|
68 | |MNIST (`mnist`)|1.0|1.0|256|32|128|
69 | |FashionMNIST (`fmnist`)|1.0|1.0|256|32|128|
70 | |Monsters (`monsters128`)|0.2|0.2|256|128|16|
71 | |CelebA-HQ (`celeb256`)|0.5|1.0|1024|256|8|
72 |
73 |
74 | ## What to expect
75 |
76 | * During the training, figures of samples and reconstructions are saved locally.
77 | * During training, statistics are printed (reconstruction error, KLD, expELBO).
78 | * At the end of each epoch, a summary of statistics will be printed.
79 | * Tips:
80 | * KL of fake/rec samples should be >= KL of real data.
81 | * It is usually better to choose `beta_kl` >= `beta_rec`.
82 | * FID calculation is not so fast, so turn it off if you don't care about it.
83 |
84 | ## Files and directories in the repository
85 |
86 | |File name | Purpose |
87 | |----------------------|------|
88 | |`main.py`| general purpose main application for training Soft-IntroVAE for image data|
89 | |`train_soft_intro_vae.py`| main training function, datasets and architectures|
90 | |`datasets.py`| classes for creating PyTorch dataset classes from images|
91 | |`metrics/fid.py`, `metrics/inception.py`| functions for FID calculation from datasets, using the pretrained Inception network|
92 |
93 |
94 | ## Tutorial
95 | * [Jupyter Notebook tutorial for image datasets](https://github.com/taldatech/soft-intro-vae-pytorch/blob/main/soft_intro_vae_tutorial/soft_intro_vae_image_code_tutorial.ipynb)
96 | * [Open in Colab](https://colab.research.google.com/github/taldatech/soft-intro-vae-pytorch/blob/main/soft_intro_vae_tutorial/soft_intro_vae_image_code_tutorial.ipynb)
97 |
98 |
99 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/datasets/transforms.py:
--------------------------------------------------------------------------------
1 | # https://pytorch-geometric.readthedocs.io/en/latest/modules/transforms.html
2 |
3 | import numbers
4 | import random
5 | import math
6 | import numpy as np
7 | import torch
8 |
9 |
10 | class LinearTransformation(object):
11 | r"""Transforms node positions with a square transformation matrix computed
12 | offline.
13 |
14 | Args:
15 | matrix (Tensor): tensor with shape :math:`[D, D]` where :math:`D`
16 | corresponds to the dimensionality of node positions.
17 | """
18 |
19 | def __init__(self, matrix):
20 | assert matrix.dim() == 2, (
21 | 'Transformation matrix should be two-dimensional.')
22 | assert matrix.size(0) == matrix.size(1), (
23 | 'Transformation matrix should be square. Got [{} x {}] rectangular'
24 | 'matrix.'.format(*matrix.size()))
25 |
26 | self.matrix = matrix
27 |
28 | def __call__(self, data):
29 | pos = data.pos.view(-1, 1) if data.pos.dim() == 1 else data.pos
30 |
31 | assert pos.size(-1) == self.matrix.size(-2), (
32 | 'Node position matrix and transformation matrix have incompatible '
33 | 'shape.')
34 |
35 | data.pos = torch.matmul(pos, self.matrix.to(pos.dtype).to(pos.device))
36 |
37 | return data
38 |
39 | def __repr__(self):
40 | return '{}({})'.format(self.__class__.__name__, self.matrix.tolist())
41 |
42 |
43 | class RandomRotate(object):
44 | r"""Rotates node positions around a specific axis by a randomly sampled
45 | factor within a given interval.
46 |
47 | Args:
48 | degrees (tuple or float): Rotation interval from which the rotation
49 | angle is sampled. If :obj:`degrees` is a number instead of a
50 | tuple, the interval is given by :math:`[-\mathrm{degrees},
51 | \mathrm{degrees}]`.
52 | axis (int, optional): The rotation axis. (default: :obj:`0`)
53 | """
54 |
55 | def __init__(self, degrees, axis=0):
56 | if isinstance(degrees, numbers.Number):
57 | degrees = (-abs(degrees), abs(degrees))
58 | assert isinstance(degrees, (tuple, list)) and len(degrees) == 2
59 | self.degrees = degrees
60 | self.axis = axis
61 |
62 | def __call__(self, data):
63 | degree = math.pi * random.uniform(*self.degrees) / 180.0
64 | sin, cos = math.sin(degree), math.cos(degree)
65 |
66 | if data.pos.size(-1) == 2:
67 | matrix = [[cos, sin], [-sin, cos]]
68 | else:
69 | if self.axis == 0:
70 | matrix = [[1, 0, 0], [0, cos, sin], [0, -sin, cos]]
71 | elif self.axis == 1:
72 | matrix = [[cos, 0, -sin], [0, 1, 0], [sin, 0, cos]]
73 | else:
74 | matrix = [[cos, sin, 0], [-sin, cos, 0], [0, 0, 1]]
75 | return LinearTransformation(torch.tensor(matrix))(data)
76 |
77 | def __repr__(self):
78 | return '{}({}, axis={})'.format(self.__class__.__name__, self.degrees,
79 | self.axis)
80 |
81 |
82 | # https://github.com/hxdengBerkeley/PointCNN.Pytorch/blob/master/provider.py
83 |
84 | def rotate_point_cloud(batch_data):
85 | """ Randomly rotate the point clouds to augument the dataset
86 | rotation is per shape based along up direction
87 | Input:
88 | BxNx3 array, original batch of point clouds
89 | Return:
90 | BxNx3 array, rotated batch of point clouds
91 | """
92 | rotated_data = np.zeros(batch_data.shape, dtype=np.float32)
93 | for k in range(batch_data.shape[0]):
94 | rotation_angle = np.random.uniform() * 2 * np.pi
95 | cosval = np.cos(rotation_angle)
96 | sinval = np.sin(rotation_angle)
97 | rotation_matrix = np.array([[cosval, 0, sinval],
98 | [0, 1, 0],
99 | [-sinval, 0, cosval]])
100 | shape_pc = batch_data[k, ...]
101 | rotated_data[k, ...] = np.dot(shape_pc.reshape((-1, 3)), rotation_matrix)
102 | return rotated_data
103 |
104 |
105 | def rotate_point_cloud_by_angle(batch_data, rotation_angle):
106 | """ Rotate the point cloud along up direction with certain angle.
107 | Input:
108 | BxNx3 array, original batch of point clouds
109 | Return:
110 | BxNx3 array, rotated batch of point clouds
111 | """
112 | rotated_data = np.zeros(batch_data.shape, dtype=np.float32)
113 | for k in range(batch_data.shape[0]):
114 | # rotation_angle = np.random.uniform() * 2 * np.pi
115 | cosval = np.cos(rotation_angle)
116 | sinval = np.sin(rotation_angle)
117 | rotation_matrix = np.array([[cosval, 0, sinval],
118 | [0, 1, 0],
119 | [-sinval, 0, cosval]])
120 | shape_pc = batch_data[k, ...]
121 | rotated_data[k, ...] = np.dot(shape_pc.reshape((-1, 3)), rotation_matrix)
122 | return rotated_data
123 |
124 |
125 | def jitter_point_cloud(batch_data, sigma=0.01, clip=0.05):
126 | """ Randomly jitter points. jittering is per point.
127 | Input:
128 | BxNx3 array, original batch of point clouds
129 | Return:
130 | BxNx3 array, jittered batch of point clouds
131 | """
132 | B, N, C = batch_data.shape
133 | assert (clip > 0)
134 | jittered_data = np.clip(sigma * np.random.randn(B, N, C), -1 * clip, clip)
135 | jittered_data += batch_data
136 | return jittered_data
137 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/utils/pcutil.py:
--------------------------------------------------------------------------------
1 | import matplotlib
2 | import matplotlib.pyplot as plt
3 | import numpy as np
4 | from numpy.linalg import norm
5 | # Don't delete this line, even if PyCharm says it's an unused import.
6 | # It is required for projection='3d' in add_subplot()
7 | from mpl_toolkits.mplot3d import Axes3D
8 | matplotlib.use('Agg')
9 |
10 |
11 | def rand_rotation_matrix(deflection=1.0, seed=None):
12 | """Creates a random rotation matrix.
13 |
14 | Args:
15 | deflection: the magnitude of the rotation. For 0, no rotation; for 1,
16 | completely random rotation. Small deflection => small
17 | perturbation.
18 |
19 | DOI: http://www.realtimerendering.com/resources/GraphicsGems/gemsiii/rand_rotation.c
20 | http://blog.lostinmyterminal.com/python/2015/05/12/random-rotation-matrix.html
21 | """
22 | if seed is not None:
23 | np.random.seed(seed)
24 |
25 | theta, phi, z = np.random.uniform(size=(3,))
26 |
27 | theta = theta * 2.0 * deflection * np.pi # Rotation about the pole (Z).
28 | phi = phi * 2.0 * np.pi # For direction of pole deflection.
29 | z = z * 2.0 * deflection # For magnitude of pole deflection.
30 |
31 | # Compute a vector V used for distributing points over the sphere
32 | # via the reflection I - V Transpose(V). This formulation of V
33 | # will guarantee that if x[1] and x[2] are uniformly distributed,
34 | # the reflected points will be uniform on the sphere. Note that V
35 | # has length sqrt(2) to eliminate the 2 in the Householder matrix.
36 |
37 | r = np.sqrt(z)
38 | V = (np.sin(phi) * r,
39 | np.cos(phi) * r,
40 | np.sqrt(2.0 - z))
41 |
42 | st = np.sin(theta)
43 | ct = np.cos(theta)
44 |
45 | R = np.array(((ct, st, 0), (-st, ct, 0), (0, 0, 1)))
46 |
47 | # Construct the rotation matrix ( V Transpose(V) - I ) R.
48 | M = (np.outer(V, V) - np.eye(3)).dot(R)
49 | return M
50 |
51 |
52 | def add_gaussian_noise_to_pcloud(pcloud, mu=0, sigma=1):
53 | gnoise = np.random.normal(mu, sigma, pcloud.shape[0])
54 | gnoise = np.tile(gnoise, (3, 1)).T
55 | pcloud += gnoise
56 | return pcloud
57 |
58 |
59 | def add_rotation_to_pcloud(pcloud):
60 | r_rotation = rand_rotation_matrix()
61 |
62 | if len(pcloud.shape) == 2:
63 | return pcloud.dot(r_rotation)
64 | else:
65 | return np.asarray([e.dot(r_rotation) for e in pcloud])
66 |
67 |
68 | def apply_augmentations(batch, conf):
69 | if conf.gauss_augment is not None or conf.z_rotate:
70 | batch = batch.copy()
71 |
72 | if conf.gauss_augment is not None:
73 | mu = conf.gauss_augment['mu']
74 | sigma = conf.gauss_augment['sigma']
75 | batch += np.random.normal(mu, sigma, batch.shape)
76 |
77 | if conf.z_rotate:
78 | r_rotation = rand_rotation_matrix()
79 | r_rotation[0, 2] = 0
80 | r_rotation[2, 0] = 0
81 | r_rotation[1, 2] = 0
82 | r_rotation[2, 1] = 0
83 | r_rotation[2, 2] = 1
84 | batch = batch.dot(r_rotation)
85 | return batch
86 |
87 |
88 | def unit_cube_grid_point_cloud(resolution, clip_sphere=False):
89 | """Returns the center coordinates of each cell of a 3D grid with
90 | resolution^3 cells, that is placed in the unit-cube.
91 | If clip_sphere it True it drops the "corner" cells that lie outside
92 | the unit-sphere.
93 | """
94 | grid = np.ndarray((resolution, resolution, resolution, 3), np.float32)
95 | spacing = 1.0 / float(resolution - 1)
96 | for i in range(resolution):
97 | for j in range(resolution):
98 | for k in range(resolution):
99 | grid[i, j, k, 0] = i * spacing - 0.5
100 | grid[i, j, k, 1] = j * spacing - 0.5
101 | grid[i, j, k, 2] = k * spacing - 0.5
102 |
103 | if clip_sphere:
104 | grid = grid.reshape(-1, 3)
105 | grid = grid[norm(grid, axis=1) <= 0.5]
106 |
107 | return grid, spacing
108 |
109 |
110 | def plot_3d_point_cloud(x, y, z, show=True, show_axis=True, in_u_sphere=False,
111 | marker='.', s=8, alpha=.8, figsize=(5, 5), elev=10,
112 | azim=240, axis=None, title=None, *args, **kwargs):
113 | # plt.switch_backend('agg')
114 | if axis is None:
115 | fig = plt.figure(figsize=figsize)
116 | ax = fig.add_subplot(111, projection='3d')
117 | else:
118 | ax = axis
119 | fig = axis
120 |
121 | if title is not None:
122 | plt.title(title)
123 |
124 | sc = ax.scatter(x, y, z, marker=marker, s=s, alpha=alpha, *args, **kwargs)
125 | ax.view_init(elev=elev, azim=azim)
126 |
127 | if in_u_sphere:
128 | ax.set_xlim3d(-0.5, 0.5)
129 | ax.set_ylim3d(-0.5, 0.5)
130 | ax.set_zlim3d(-0.5, 0.5)
131 | else:
132 | # Multiply with 0.7 to squeeze free-space.
133 | miv = 0.7 * np.min([np.min(x), np.min(y), np.min(z)])
134 | mav = 0.7 * np.max([np.max(x), np.max(y), np.max(z)])
135 | ax.set_xlim(miv, mav)
136 | ax.set_ylim(miv, mav)
137 | ax.set_zlim(miv, mav)
138 | plt.tight_layout()
139 |
140 | if not show_axis:
141 | # plt.axis('off')
142 | ax.set_axis_off()
143 |
144 | if 'c' in kwargs:
145 | plt.colorbar(sc)
146 |
147 | if show:
148 | plt.show()
149 |
150 | return fig
151 |
152 |
153 | def transform_point_clouds(X, only_z_rotation=False, deflection=1.0):
154 | r_rotation = rand_rotation_matrix(deflection)
155 | if only_z_rotation:
156 | r_rotation[0, 2] = 0
157 | r_rotation[2, 0] = 0
158 | r_rotation[1, 2] = 0
159 | r_rotation[2, 1] = 0
160 | r_rotation[2, 2] = 1
161 | X = X.dot(r_rotation).astype(np.float32)
162 | return X
163 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # soft-intro-vae-pytorch
2 |
3 |
4 |
5 | [CVPR 2021 Oral] Soft-IntroVAE: Analyzing and Improving Introspective Variational Autoencoders
6 |
7 |
8 |
9 | Tal Daniel •
10 | Aviv Tamar
11 |
12 |
13 | Official repository of the paper
14 |
15 | CVPR 2021 Oral
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |  26 |
26 |  27 |
27 |
28 |
29 |  30 |
31 |
30 |
31 |
32 |
33 | # Soft-IntroVAE
34 |
35 | > **Soft-IntroVAE: Analyzing and Improving Introspective Variational Autoencoders**
36 | > Tal Daniel, Aviv Tamar
37 | >
38 | > **Abstract:** *The recently introduced introspective variational autoencoder (IntroVAE) exhibits outstanding image generations, and allows for amortized inference using an image encoder. The main idea in IntroVAE is to train a VAE adversarially, using the VAE encoder to discriminate between generated and real data samples. However, the original IntroVAE loss function relied on a particular hinge-loss formulation that is very hard to stabilize in practice, and its theoretical convergence analysis ignored important terms in the loss. In this work, we take a step towards better understanding of the IntroVAE model, its practical implementation, and its applications. We propose the Soft-IntroVAE, a modified IntroVAE that replaces the hinge-loss terms with a smooth exponential loss on generated samples. This change significantly improves training stability, and also enables theoretical analysis of the complete algorithm. Interestingly, we show that the IntroVAE converges to a distribution that minimizes a sum of KL distance from the data distribution and an entropy term. We discuss the implications of this result, and demonstrate that it induces competitive image generation and reconstruction. Finally, we describe two applications of Soft-IntroVAE to unsupervised image translation and out-of-distribution detection, and demonstrate compelling results.*
39 |
40 | ## Citation
41 | Daniel, Tal, and Aviv Tamar. "Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder." arXiv preprint arXiv:2012.13253 (2020).
42 | >
43 | @InProceedings{Daniel_2021_CVPR,
44 | author = {Daniel, Tal and Tamar, Aviv},
45 | title = {Soft-IntroVAE: Analyzing and Improving the Introspective Variational Autoencoder},
46 | booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
47 | month = {June},
48 | year = {2021},
49 | pages = {4391-4400}
50 | }
51 |
52 |
53 |
54 |
55 | - [soft-intro-vae-pytorch](#soft-intro-vae-pytorch)
56 | - [Soft-IntroVAE](#soft-introvae)
57 | * [Citation](#citation)
58 | * [Prerequisites](#prerequisites)
59 | * [Repository Organization](#repository-organization)
60 | * [Credits](#credits)
61 |
62 |
63 | ## Prerequisites
64 |
65 | * For your convenience, we provide an `environemnt.yml` file which installs the required packages in a `conda` environment name `torch`.
66 | * Use the terminal or an Anaconda Prompt and run the following command `conda env create -f environment.yml`.
67 | * For Style-SoftIntroVAE, more packages are required, and we provide them in the `style_soft_intro_vae` directory.
68 |
69 |
70 | |Library | Version |
71 | |----------------------|----|
72 | |`Python`| `3.6 (Anaconda)`|
73 | |`torch`| >= `1.2` (tested on `1.7`)|
74 | |`torchvision`| >= `0.4`|
75 | |`matplotlib`| >= `2.2.2`|
76 | |`numpy`| >= `1.17`|
77 | |`opencv`| >= `3.4.2`|
78 | |`tqdm`| >= `4.36.1`|
79 | |`scipy`| >= `1.3.1`|
80 |
81 |
82 |
83 | ## Repository Organization
84 |
85 | |File name | Content |
86 | |----------------------|------|
87 | |`/soft_intro_vae`| directory containing implementation for image data|
88 | |`/soft_intro_vae_2d`| directory containing implementations for 2D datasets|
89 | |`/soft_intro_vae_3d`| directory containing implementations for 3D point clouds data|
90 | |`/soft_intro_vae_bootstrap`| directory containing implementation for image data using bootstrapping (using a target decoder)|
91 | |`/style_soft_intro_vae`| directory containing implementation for image data using ALAE's style-based architecture|
92 | |`/soft_intro_vae_tutorials`| directory containing Jupyter Noteboook tutorials for the various types of Soft-IntroVAE|
93 |
94 | ## Related Projects
95 |
96 | * March 2022: `augmentation-enhanced-soft-intro-vae` - GitHub - using differentiable augmentations to improve image generation FID score.
97 |
98 |
99 | ## Credits
100 | * Adversarial Latent Autoencoders, Pidhorskyi et al., CVPR 2020 - [Code](https://github.com/podgorskiy/ALAE), [Paper](https://arxiv.org/abs/2004.04467).
101 | * FID is calculated natively in PyTorch using Seitzer implementation - [Code](https://github.com/mseitzer/pytorch-fid)
102 |
103 |
104 |
105 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/metrics/jsd.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from numpy.linalg import norm
4 | from scipy.stats import entropy
5 | from sklearn.neighbors import NearestNeighbors
6 |
7 |
8 | __all__ = ['js_divercence_between_pc', 'jsd_between_point_cloud_sets']
9 |
10 |
11 | #
12 | # Compute JS divergence
13 | #
14 |
15 |
16 | def js_divercence_between_pc(pc1: torch.Tensor, pc2: torch.Tensor,
17 | voxels: int = 64) -> float:
18 | """Method for computing JSD from 2 sets of point clouds."""
19 | pc1_ = _pc_to_voxel_distribution(pc1, voxels)
20 | pc2_ = _pc_to_voxel_distribution(pc2, voxels)
21 | jsd = _js_divergence(pc1_, pc2_)
22 | return jsd
23 |
24 |
25 | def _js_divergence(P, Q):
26 | # Ensure probabilities.
27 | P_ = P / np.sum(P)
28 | Q_ = Q / np.sum(Q)
29 |
30 | # Calculate JSD using scipy.stats.entropy()
31 | e1 = entropy(P_, base=2)
32 | e2 = entropy(Q_, base=2)
33 | e_sum = entropy((P_ + Q_) / 2.0, base=2)
34 | res1 = e_sum - ((e1 + e2) / 2.0)
35 |
36 | # Calcujate JS-Div using manually defined KL divergence.
37 | # res2 = _jsdiv(P_, Q_)
38 | #
39 | # if not np.allclose(res1, res2, atol=10e-5, rtol=0):
40 | # warnings.warn('Numerical values of two JSD methods don\'t agree.')
41 |
42 | return res1
43 |
44 |
45 | def _jsdiv(P, Q):
46 | """Another way of computing JSD to check numerical stability."""
47 | def _kldiv(A, B):
48 | a = A.copy()
49 | b = B.copy()
50 | idx = np.logical_and(a > 0, b > 0)
51 | a = a[idx]
52 | b = b[idx]
53 | return np.sum([v for v in a * np.log2(a / b)])
54 |
55 | P_ = P / np.sum(P)
56 | Q_ = Q / np.sum(Q)
57 |
58 | M = 0.5 * (P_ + Q_)
59 |
60 | return 0.5 * (_kldiv(P_, M) + _kldiv(Q_, M))
61 |
62 |
63 | def _pc_to_voxel_distribution(pc: torch.Tensor, n_voxels: int = 64) -> np.ndarray:
64 | pc_ = pc.clamp(-0.5, 0.4999) + 0.5
65 | # Because points are in range [0, 1], simple multiplication will bin them.
66 | pc_ = (pc_ * n_voxels).int()
67 | pc_ = pc_[:, :, 0] * n_voxels ** 2 + pc_[:, :, 1] * n_voxels + pc_[:, :, 2]
68 |
69 | B = np.zeros(n_voxels**3, dtype=np.int32)
70 | values, amounts = np.unique(pc_, return_counts=True)
71 | B[values] = amounts
72 | return B
73 |
74 |
75 | #
76 | # Stanford way to calculate JSD
77 | #
78 |
79 |
80 | def jsd_between_point_cloud_sets(sample_pcs, ref_pcs, voxels=28,
81 | in_unit_sphere=True):
82 | """Computes the JSD between two sets of point-clouds, as introduced in the
83 | paper ```Learning Representations And Generative Models For 3D Point
84 | Clouds```.
85 | Args:
86 | sample_pcs: (np.ndarray S1xR2x3) S1 point-clouds, each of R1 points.
87 | ref_pcs: (np.ndarray S2xR2x3) S2 point-clouds, each of R2 points.
88 | voxels: (int) grid-resolution. Affects granularity of measurements.
89 | """
90 | sample_grid_var = _entropy_of_occupancy_grid(sample_pcs, voxels,
91 | in_unit_sphere)[1]
92 | ref_grid_var = _entropy_of_occupancy_grid(ref_pcs, voxels,
93 | in_unit_sphere)[1]
94 | return _js_divergence(sample_grid_var, ref_grid_var)
95 |
96 |
97 | def _entropy_of_occupancy_grid(pclouds, grid_resolution, in_sphere=False):
98 | """Given a collection of point-clouds, estimate the entropy of the random
99 | variables corresponding to occupancy-grid activation patterns.
100 | Inputs:
101 | pclouds: (numpy array) #point-clouds x points per point-cloud x 3
102 | grid_resolution (int) size of occupancy grid that will be used.
103 | """
104 | pclouds = pclouds.cpu().numpy()
105 | epsilon = 10e-4
106 | bound = 0.5 + epsilon
107 | # if abs(np.max(pclouds)) > bound or abs(np.min(pclouds)) > bound:
108 | # warnings.warn('Point-clouds are not in unit cube.')
109 | #
110 | # if in_sphere and np.max(np.sqrt(np.sum(pclouds ** 2, axis=2))) > bound:
111 | # warnings.warn('Point-clouds are not in unit sphere.')
112 |
113 | grid_coordinates, _ = _unit_cube_grid_point_cloud(grid_resolution, in_sphere)
114 | grid_coordinates = grid_coordinates.reshape(-1, 3)
115 | grid_counters = np.zeros(len(grid_coordinates))
116 | grid_bernoulli_rvars = np.zeros(len(grid_coordinates))
117 | nn = NearestNeighbors(n_neighbors=1).fit(grid_coordinates)
118 |
119 | for pc in pclouds:
120 | _, indices = nn.kneighbors(pc)
121 | indices = np.squeeze(indices)
122 | for i in indices:
123 | grid_counters[i] += 1
124 | indices = np.unique(indices)
125 | for i in indices:
126 | grid_bernoulli_rvars[i] += 1
127 |
128 | acc_entropy = 0.0
129 | n = float(len(pclouds))
130 | for g in grid_bernoulli_rvars:
131 | p = 0.0
132 | if g > 0:
133 | p = float(g) / n
134 | acc_entropy += entropy([p, 1.0 - p])
135 |
136 | return acc_entropy / len(grid_counters), grid_counters
137 |
138 |
139 | def _unit_cube_grid_point_cloud(resolution, clip_sphere=False):
140 | """Returns the center coordinates of each cell of a 3D grid with resolution^3 cells,
141 | that is placed in the unit-cube.
142 | If clip_sphere it True it drops the "corner" cells that lie outside the unit-sphere.
143 | """
144 | grid = np.ndarray((resolution, resolution, resolution, 3), np.float32)
145 | spacing = 1.0 / float(resolution - 1)
146 | for i in range(resolution):
147 | for j in range(resolution):
148 | for k in range(resolution):
149 | grid[i, j, k, 0] = i * spacing - 0.5
150 | grid[i, j, k, 1] = j * spacing - 0.5
151 | grid[i, j, k, 2] = k * spacing - 0.5
152 |
153 | if clip_sphere:
154 | grid = grid.reshape(-1, 3)
155 | grid = grid[norm(grid, axis=1) <= 0.5]
156 |
157 | return grid, spacing
158 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/README.md:
--------------------------------------------------------------------------------
1 | # 3d-soft-intro-vae-pytorch
2 |
3 | Implementation of 3D Soft-IntroVAE for point clouds.
4 |
5 | This codes builds upon the code base of [3D-AAE](https://github.com/MaciejZamorski/3d-AAE)
6 | from the paper "Adversarial Autoencoders for Compact Representations of 3D Point Clouds"
7 | by Maciej Zamorski, Maciej Zięba, Piotr Klukowski, Rafał Nowak, Karol Kurach, Wojciech Stokowiec, and Tomasz Trzciński
8 |
9 |  10 |
10 |  11 |
11 |
12 |
13 |
14 |
15 |
16 |
17 | - [3d-soft-intro-vae-pytorch](#3d-soft-intro-vae-pytorch)
18 | * [Requirements](#requirements)
19 | * [Training](#training)
20 | * [Testing](#testing)
21 | * [Rendering](#rendering)
22 | * [Datasets](#datasets)
23 | * [Pretrained models](#pretrained-models)
24 | * [Recommended hyperparameters](#recommended-hyperparameters)
25 | * [What to expect](#what-to-expect)
26 | * [Files and directories in the repository](#files-and-directories-in-the-repository)
27 | * [Credits](#credits)
28 |
29 | ## Requirements
30 |
31 | * The required packages are located in the `requirements.txt` file, nothing special.
32 | * `pip install -r requirements.txt`
33 | * We provide an `environment.yml` file for `conda` (at the repo's root), which installs all that is needed to run the files.
34 | * `conda env create -f environment.yml`
35 |
36 | ## Training
37 |
38 | To run training:
39 |
40 | * Modify the hyperparameters in `/config/soft_intro_vae_hp.json`
41 |
42 | * Run: `python train_soft_intro_vae_3d.py`
43 |
44 | ## Testing
45 |
46 | * To test the generations from a trained model in terms of JSD, modify `path_to_weights` and `config_path` in `test_model.py` and run it: `python test_model.py`.
47 | * To produce reconstructed and generated point clouds in a form of NumPy array to be used with validation methods from ["Learning Representations and Generative Models For 3D Point Clouds" repository](https://github.com/optas/latent_3d_points/blob/master/notebooks/compute_evaluation_metrics.ipynb)
48 | modify `path_to_weights` and `config_path` in `evaluation/generate_data_for_metrics.py` and run: `python evaluation/generate_data_for_metrics.py`
49 |
50 | ## Rendering
51 | * To render beautiful point clouds from a trained model, we provide a script that uses Mitsuba 2 renderer. Instructions can be found in `/render`.
52 |
53 | ## Datasets
54 | * We currently support [ShapeNet](https://shapenet.org/), which will be downloaded automatically on first run.
55 |
56 | ## Pretrained models
57 | |Dataset/Class | Filename | Validation Sample JSD| Links|
58 | |------------|------|----|---|
59 | |ShapeNet-Chair|`chair_01618_jsd_0.0175.pth` |0.0175|[MEGA.co.nz](https://mega.nz/file/RJ8mmIjL#DKuvWImRZdzKL_JN9JwwsvZw3F4Iv0i5g0qaLiSL84Q), [Mediafire](http://www.mediafire.com/file/i9ozb2yv4bv1i76/chair_01618_jsd_0.0175.pth/file) |
60 | |ShapeNet-Table|`table_01592_jsd_0.0143.pth` |0.0143 | [MEGA.co.nz](https://mega.nz/file/ZQ8GjSQB#ctGaJXgvUsgaMYQm1R3bfMUzKld7nGO-oUAGGA9EOX8), [Mediafire](http://www.mediafire.com/file/hvygeusesaa58y2/table_01592_jsd_0.0143.pth/file) |
61 | |ShapeNet-Car|`car_01344_jsd_0.0113.pth` |0.0113 | [MEGA.co.nz](https://mega.nz/file/kZ0AQQQL#hecHNlPyh0ww3_RZOvrXCE48yr5ZmfL3RZ01MSz2NwU), [Mediafire](http://www.mediafire.com/file/ja1p9wjnc58uab4/car_01344_jsd_0.0113.pth/file) |
62 | |ShapeNet-Airplane|`airplane_00536_jsd_0.0191.pth` |0.0191 | [MEGA.co.nz](https://mega.nz/file/xA9g0ajA#jyhBgPQC4VxLwgDPfk-xo_xAbCUQofzVz9jdP0OUvDc), [Mediafire](http://www.mediafire.com/file/79ett5dhhwm2yl8/airplane_00536_jsd_0.0191.pth/file) |
63 |
64 |
65 | ## Recommended hyperparameters
66 |
67 | |Dataset | `beta_kl` | `beta_rec`| `beta_neg`|`z_dim`|
68 | |------------|------|----|---|----|
69 | |ShapeNet|0.2|1.0| 20.0|128|
70 |
71 |
72 | ## What to expect
73 |
74 | * During the training, figures of samples and reconstructions are saved locally.
75 | * First row - real, second row - reconstructions, third row - random samples
76 | * During training, statistics are printed (reconstruction error, KLD, expELBO).
77 | * Checkpoint is saved every epoch, and JSD is calculated on the validation split.
78 | * Tips:
79 | * KL of fake/rec samples should be > KL of real data (by a fair margin).
80 | * Currently, this code only supports the Chamfer Distance loss, which requires high `beta_rec`.
81 | * Since the practice is to train on a single class, it is usually better to use a narrower Gaussian for the prior (e.g., N(0, 0.2)).
82 |
83 |
84 | ## Files and directories in the repository
85 |
86 | |File name | Purpose |
87 | |----------------------|------|
88 | |`train_soft_intro_vae_3d.py`| main training function.|
89 | |`generate_for_rendering.py`| generate samples (+interpolation) from a trained model for rendering with Mitsuba.|
90 | |`test_model.py`| test sampling JSD of a trained model (w.r.t the test split).|
91 | |`config/soft_intro_vae_hp.json`| contains the hyperparmeters of the model.|
92 | |`/datasets`| directory containing various datasets files (e.g., data loader for ShapeNet).|
93 | |`/evaluations`| directory containing evaluation scrips (e.g., generating data for evaluation metrics).|
94 | |`/losses/chamfer_loss.py`| PyTorch implementation of the Chamfer distance loss function.|
95 | |`/metrics/jsd.py`| functions to measure JSD between point clouds.|
96 | |`/models/vae.py`| VAE module and architecture.|
97 | |`/render`| directory containing scripts and instructions to render point clouds with Mitsuba 2 renderer.|
98 | |`/utils`| various utility functions to process the data|
99 |
100 | ## Credits
101 | * Adversarial Autoencoders for Compact Representations of 3D Point Clouds, Zamorski et al., 2018 - [Code](https://github.com/MaciejZamorski/3d-AAE), [Paper](https://arxiv.org/abs/1811.07605).
102 |
103 |
--------------------------------------------------------------------------------
/soft_intro_vae_bootstrap/README.md:
--------------------------------------------------------------------------------
1 | # soft-intro-vae-pytorch-images-bootstrap
2 |
3 | Implementation of Soft-IntroVAE for image data, using "bootstrapping". This version was not used in the paper.
4 |
5 | A step-by-step tutorial can be found in [Soft-IntroVAE Jupyter Notebook Tutorials](https://github.com/taldatech/soft-intro-vae-pytorch/tree/main/soft_intro_vae_tutorial).
6 |
7 |
8 |  9 |
9 |
10 |
11 | - [soft-intro-vae-pytorch-images-bootstrap](#soft-intro-vae-pytorch-images-bootstrap)
12 | * [What is different?](#what-is-different-)
13 | * [Training](#training)
14 | * [Datasets](#datasets)
15 | * [Recommended hyperparameters](#recommended-hyperparameters)
16 | * [What to expect](#what-to-expect)
17 | * [Files and directories in the repository](#files-and-directories-in-the-repository)
18 | * [Tutorial](#tutorial)
19 |
20 | ## What is different?
21 |
22 | The idea is to use a `target` decoder to update both encoder and decoder. This makes
23 | the optimization a bit simpler, and allows more flexible values for `gamma_r` (e.g. 1.0 instead of 1e-8),
24 | the coefficient of the reconstruction error for the fake data in the decoder.
25 | Implementation-wise, the `target` decoder is not trained, but uses the weights of the original
26 | decoder, and it lags 1 epoch behind (so we just copy the weights of the decoder to the target decoder every 1 epoch).
27 |
28 | * In `train_soft_intro_vae_bootstrap.py`:
29 | * In the `SoftIntroVAE` class, another decoder is added (`self.target_decoder`), the `forward()` function uses the target decoder by default.
30 | * In the decoder training step: no need to `detach()` the reconstructions of fake data.
31 | * At the end of each epoch, weights are copied from `model.decoder` to `model.target_decoder`.
32 |
33 | ## Training
34 |
35 | `main.py --help`
36 |
37 |
38 | You should use the `main.py` file with the following arguments:
39 |
40 | |Argument | Description |Legal Values |
41 | |-------------------------|---------------------------------------------|-------------|
42 | |-h, --help | shows arguments description | |
43 | |-d, --dataset | dataset to train on |str: 'cifar10', 'mnist', 'fmnist', 'svhn', 'monsters128', 'celeb128', 'celeb256', 'celeb1024' |
44 | |-n, --num_epochs | total number of epochs to run | int: default=250|
45 | |-z, --z_dim| latent dimensions | int: default=128|
46 | |-s, --seed| random state to use. for random: -1 | int: -1 , 0, 1, 2 ,....|
47 | |-v, --num_vae| number of iterations for vanilla vae training | int: default=0|
48 | |-l, --lr| learning rate | float: defalut=2e-4 |
49 | |-r, --beta_rec | beta coefficient for the reconstruction loss |float: default=1.0|
50 | |-k, --beta_kl| beta coefficient for the kl divergence | float: default=1.0|
51 | |-e, --beta_neg| beta coefficient for the kl divergence in the expELBO function | float: default=256.0|
52 | |-g, --gamma_r| coefficient for the reconstruction loss for fake data in the decoder | float: default=1e-8|
53 | |-b, --batch_size| batch size | int: default=32 |
54 | |-p, --pretrained | path to pretrained model, to continue training |str: default="None" |
55 | |-c, --device| device: -1 for cpu, 0 and up for specific cuda device |int: default=-1|
56 | |-f, --fid| if specified, FID wil be calculated during training |bool: default=False|
57 | |-o, --freq| epochs between copying weights from decoder to target decoder |int: default=1|
58 |
59 | Examples:
60 |
61 | `python main.py --dataset cifar10 --device 0 --lr 2e-4 --num_epochs 250 --beta_kl 1.0 --beta_rec 1.0 --beta_neg 256 --z_dim 128 --batch_size 32`
62 |
63 | `python main.py --dataset mnist --device 0 --lr 2e-4 --num_epochs 200 --beta_kl 1.0 --beta_rec 1.0 --beta_neg 256 --z_dim 32 --batch_size 128`
64 |
65 | ## Datasets
66 | * CelebHQ: please follow [ALAE](https://github.com/podgorskiy/ALAE#datasets) instructions.
67 |
68 | ## Recommended hyperparameters
69 |
70 | |Dataset | `beta_kl` | `beta_rec`| `beta_neg`|`z_dim`|`batch_size`|
71 | |------------|------|----|---|----|---|
72 | |CIFAR10 (`cifar10`)|1.0|1.0| 256|128| 32|
73 | |SVHN (`svhn`)|1.0|1.0| 256|128| 32|
74 | |MNIST (`mnist`)|1.0|1.0|256|32|128|
75 | |FashionMNIST (`fmnist`)|1.0|1.0|256|32|128|
76 | |Monsters (`monsters128`)|0.2|0.2|256|128|16|
77 | |CelebA-HQ (`celeb256`)|0.5|1.0|1024|256|8|
78 |
79 |
80 | ## What to expect
81 |
82 | * During the training, figures of samples and reconstructions are saved locally.
83 | * During training, statistics are printed (reconstruction error, KLD, expELBO).
84 | * At the end of each epoch, a summary of statistics will be printed.
85 | * Tips:
86 | * KL of fake/rec samples should be >= KL of real data.
87 | * It is usually better to choose `beta_kl` >= `beta_rec`.
88 | * FID calculation is not so fast, so turn it off if you don't care about it.
89 | * `gamma_r` can be set to values such as 0.5, 1.0, and etc...
90 |
91 | ## Files and directories in the repository
92 |
93 | |File name | Purpose |
94 | |----------------------|------|
95 | |`main.py`| general purpose main application for training Soft-IntroVAE for image data|
96 | |`train_soft_intro_vae_bootstrap.py`| main training function, datasets and architectures|
97 | |`datasets.py`| classes for creating PyTorch dataset classes from images|
98 | |`metrics/fid.py`, `metrics/inception.py`| functions for FID calculation from datasets, using the pretrained Inception network|
99 |
100 |
101 | ## Tutorial
102 | * [Jupyter Notebook tutorial for image datasets with bootstrapping](https://github.com/taldatech/soft-intro-vae-pytorch/blob/main/soft_intro_vae_tutorial/soft_intro_vae_bootstrap_code_tutorial.ipynb)
103 | * [Open in Colab](https://colab.research.google.com/github/taldatech/soft-intro-vae-pytorch/blob/main/soft_intro_vae_tutorial/soft_intro_vae_bootstrap_code_tutorial.ipynb)
104 |
105 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/datasets/shapenet.py:
--------------------------------------------------------------------------------
1 | import urllib
2 | import shutil
3 | from os import listdir, makedirs, remove
4 | from os.path import exists, join
5 | from zipfile import ZipFile
6 |
7 | import pandas as pd
8 | from torch.utils.data import Dataset
9 |
10 | from utils.plyfile import load_ply
11 |
12 | synth_id_to_category = {
13 | '02691156': 'airplane', '02773838': 'bag', '02801938': 'basket',
14 | '02808440': 'bathtub', '02818832': 'bed', '02828884': 'bench',
15 | '02834778': 'bicycle', '02843684': 'birdhouse', '02871439': 'bookshelf',
16 | '02876657': 'bottle', '02880940': 'bowl', '02924116': 'bus',
17 | '02933112': 'cabinet', '02747177': 'can', '02942699': 'camera',
18 | '02954340': 'cap', '02958343': 'car', '03001627': 'chair',
19 | '03046257': 'clock', '03207941': 'dishwasher', '03211117': 'monitor',
20 | '04379243': 'table', '04401088': 'telephone', '02946921': 'tin_can',
21 | '04460130': 'tower', '04468005': 'train', '03085013': 'keyboard',
22 | '03261776': 'earphone', '03325088': 'faucet', '03337140': 'file',
23 | '03467517': 'guitar', '03513137': 'helmet', '03593526': 'jar',
24 | '03624134': 'knife', '03636649': 'lamp', '03642806': 'laptop',
25 | '03691459': 'speaker', '03710193': 'mailbox', '03759954': 'microphone',
26 | '03761084': 'microwave', '03790512': 'motorcycle', '03797390': 'mug',
27 | '03928116': 'piano', '03938244': 'pillow', '03948459': 'pistol',
28 | '03991062': 'pot', '04004475': 'printer', '04074963': 'remote_control',
29 | '04090263': 'rifle', '04099429': 'rocket', '04225987': 'skateboard',
30 | '04256520': 'sofa', '04330267': 'stove', '04530566': 'vessel',
31 | '04554684': 'washer', '02858304': 'boat', '02992529': 'cellphone'
32 | }
33 |
34 | category_to_synth_id = {v: k for k, v in synth_id_to_category.items()}
35 | synth_id_to_number = {k: i for i, k in enumerate(synth_id_to_category.keys())}
36 |
37 |
38 | class ShapeNetDataset(Dataset):
39 | def __init__(self, root_dir='/home/datasets/shapenet', classes=[],
40 | transform=None, split='train'):
41 | """
42 | Args:
43 | root_dir (string): Directory with all the point clouds.
44 | transform (callable, optional): Optional transform to be applied
45 | on a sample.
46 | """
47 | self.root_dir = root_dir
48 | self.transform = transform
49 | self.split = split
50 |
51 | self._maybe_download_data()
52 |
53 | pc_df = self._get_names()
54 | if classes:
55 | if classes[0] not in synth_id_to_category.keys():
56 | classes = [category_to_synth_id[c] for c in classes]
57 | pc_df = pc_df[pc_df.category.isin(classes)].reset_index(drop=True)
58 | else:
59 | classes = synth_id_to_category.keys()
60 |
61 | self.point_clouds_names_train = pd.concat([pc_df[pc_df['category'] == c][:int(0.85*len(pc_df[pc_df['category'] == c]))].reset_index(drop=True) for c in classes])
62 | self.point_clouds_names_valid = pd.concat([pc_df[pc_df['category'] == c][int(0.85*len(pc_df[pc_df['category'] == c])):int(0.9*len(pc_df[pc_df['category'] == c]))].reset_index(drop=True) for c in classes])
63 | self.point_clouds_names_test = pd.concat([pc_df[pc_df['category'] == c][int(0.9*len(pc_df[pc_df['category'] == c])):].reset_index(drop=True) for c in classes])
64 |
65 | def __len__(self):
66 | if self.split == 'train':
67 | pc_names = self.point_clouds_names_train
68 | elif self.split == 'valid':
69 | pc_names = self.point_clouds_names_valid
70 | elif self.split == 'test':
71 | pc_names = self.point_clouds_names_test
72 | else:
73 | raise ValueError('Invalid split. Should be train, valid or test.')
74 | return len(pc_names)
75 |
76 | def __getitem__(self, idx):
77 | if self.split == 'train':
78 | pc_names = self.point_clouds_names_train
79 | elif self.split == 'valid':
80 | pc_names = self.point_clouds_names_valid
81 | elif self.split == 'test':
82 | pc_names = self.point_clouds_names_test
83 | else:
84 | raise ValueError('Invalid split. Should be train, valid or test.')
85 |
86 | pc_category, pc_filename = pc_names.iloc[idx].values
87 |
88 | pc_filepath = join(self.root_dir, pc_category, pc_filename)
89 | sample = load_ply(pc_filepath)
90 |
91 | if self.transform:
92 | sample = self.transform(sample)
93 |
94 | return sample, synth_id_to_number[pc_category]
95 |
96 | def _get_names(self) -> pd.DataFrame:
97 | filenames = []
98 | for category_id in synth_id_to_category.keys():
99 | for f in listdir(join(self.root_dir, category_id)):
100 | if f not in ['.DS_Store']:
101 | filenames.append((category_id, f))
102 | return pd.DataFrame(filenames, columns=['category', 'filename'])
103 |
104 | def _maybe_download_data(self):
105 | if exists(self.root_dir):
106 | return
107 |
108 | print(f'ShapeNet doesn\'t exist in root directory {self.root_dir}. '
109 | f'Downloading...')
110 | makedirs(self.root_dir)
111 |
112 | url = 'https://www.dropbox.com/s/vmsdrae6x5xws1v/shape_net_core_uniform_samples_2048.zip?dl=1'
113 |
114 | data = urllib.request.urlopen(url)
115 | filename = url.rpartition('/')[2][:-5]
116 | file_path = join(self.root_dir, filename)
117 | with open(file_path, mode='wb') as f:
118 | d = data.read()
119 | f.write(d)
120 |
121 | print('Extracting...')
122 | with ZipFile(file_path, mode='r') as zip_f:
123 | zip_f.extractall(self.root_dir)
124 |
125 | remove(file_path)
126 |
127 | extracted_dir = join(self.root_dir,
128 | 'shape_net_core_uniform_samples_2048')
129 | for d in listdir(extracted_dir):
130 | shutil.move(src=join(extracted_dir, d),
131 | dst=self.root_dir)
132 |
133 | shutil.rmtree(extracted_dir)
134 |
135 |
--------------------------------------------------------------------------------
/soft_intro_vae/dataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.utils.data as data
3 |
4 | from os import listdir
5 | from os.path import join
6 | from PIL import Image, ImageOps
7 | import random
8 | import torchvision.transforms as transforms
9 | import os
10 |
11 |
12 | def load_image(file_path, input_height=128, input_width=None, output_height=128, output_width=None,
13 | crop_height=None, crop_width=None, is_random_crop=True, is_mirror=True, is_gray=False):
14 | if input_width is None:
15 | input_width = input_height
16 | if output_width is None:
17 | output_width = output_height
18 | if crop_width is None:
19 | crop_width = crop_height
20 |
21 | img = Image.open(file_path)
22 | if is_gray is False and img.mode is not 'RGB':
23 | img = img.convert('RGB')
24 | if is_gray and img.mode is not 'L':
25 | img = img.convert('L')
26 |
27 | if is_mirror and random.randint(0, 1) is 0:
28 | img = ImageOps.mirror(img)
29 |
30 | if input_height is not None:
31 | img = img.resize((input_width, input_height), Image.BICUBIC)
32 |
33 | if crop_height is not None:
34 | [w, h] = img.size
35 | if is_random_crop:
36 | # print([w,cropSize])
37 | cx1 = random.randint(0, w - crop_width)
38 | cx2 = w - crop_width - cx1
39 | cy1 = random.randint(0, h - crop_height)
40 | cy2 = h - crop_height - cy1
41 | else:
42 | cx2 = cx1 = int(round((w - crop_width) / 2.))
43 | cy2 = cy1 = int(round((h - crop_height) / 2.))
44 | img = ImageOps.crop(img, (cx1, cy1, cx2, cy2))
45 |
46 | img = img.resize((output_width, output_height), Image.BICUBIC)
47 | return img
48 |
49 |
50 | class ImageDatasetFromFile(data.Dataset):
51 | def __init__(self, image_list, root_path,
52 | input_height=128, input_width=None, output_height=128, output_width=None,
53 | crop_height=None, crop_width=None, is_random_crop=False, is_mirror=True, is_gray=False):
54 | super(ImageDatasetFromFile, self).__init__()
55 |
56 | self.image_filenames = image_list
57 | self.is_random_crop = is_random_crop
58 | self.is_mirror = is_mirror
59 | self.input_height = input_height
60 | self.input_width = input_width
61 | self.output_height = output_height
62 | self.output_width = output_width
63 | self.root_path = root_path
64 | self.crop_height = crop_height
65 | self.crop_width = crop_width
66 | self.is_gray = is_gray
67 |
68 | self.input_transform = transforms.Compose([
69 | transforms.ToTensor()
70 | ])
71 |
72 | def __getitem__(self, index):
73 | img = load_image(join(self.root_path, self.image_filenames[index]),
74 | self.input_height, self.input_width, self.output_height, self.output_width,
75 | self.crop_height, self.crop_width, self.is_random_crop, self.is_mirror, self.is_gray)
76 |
77 | img = self.input_transform(img)
78 |
79 | return img
80 |
81 | def __len__(self):
82 | return len(self.image_filenames)
83 |
84 |
85 | def list_images_in_dir(path):
86 | valid_images = [".jpg", ".gif", ".png"]
87 | img_list = []
88 | for f in os.listdir(path):
89 | ext = os.path.splitext(f)[1]
90 | if ext.lower() not in valid_images:
91 | continue
92 | img_list.append(os.path.join(path, f))
93 | return img_list
94 |
95 |
96 | class DigitalMonstersDataset(data.Dataset):
97 | def __init__(self, root_path,
98 | input_height=None, input_width=None, output_height=128, output_width=None, is_gray=False, pokemon=True,
99 | digimon=True, nexomon=True):
100 | super(DigitalMonstersDataset, self).__init__()
101 | image_list = []
102 | if pokemon:
103 | print("collecting pokemon...")
104 | image_list.extend(list_images_in_dir(os.path.join(root_path, 'pokemon')))
105 | if digimon:
106 | print("collecting digimon...")
107 | image_list.extend(list_images_in_dir(os.path.join(root_path, 'digimon', '200')))
108 | if nexomon:
109 | print("collecting nexomon...")
110 | image_list.extend(list_images_in_dir(os.path.join(root_path, 'nexomon')))
111 | print(f'total images: {len(image_list)}')
112 |
113 | self.image_filenames = image_list
114 | self.input_height = input_height
115 | self.input_width = input_width
116 | self.output_height = output_height
117 | self.output_width = output_width
118 | self.root_path = root_path
119 | self.is_gray = is_gray
120 |
121 | # self.input_transform = transforms.Compose([
122 | # transforms.RandomAffine(0, translate=(5 / output_height, 5 / output_height), fillcolor=(255, 255, 255)),
123 | # transforms.ColorJitter(hue=0.5),
124 | # transforms.RandomHorizontalFlip(p=0.5),
125 | # transforms.ToTensor(),
126 | # transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,))
127 | # ])
128 |
129 | self.input_transform = transforms.Compose([
130 | transforms.RandomAffine(0, translate=(5 / output_height, 5 / output_height), fillcolor=(255, 255, 255)),
131 | transforms.ColorJitter(hue=0.5),
132 | transforms.RandomHorizontalFlip(p=0.5),
133 | transforms.ToTensor()
134 | ])
135 |
136 | # self.input_transform = transforms.Compose([
137 | # transforms.ToTensor()
138 | # ])
139 |
140 | def __getitem__(self, index):
141 | img = load_image(self.image_filenames[index], input_height=self.input_height, input_width=self.input_width,
142 | output_height=self.output_height, output_width=self.output_width,
143 | crop_height=None, crop_width=None, is_random_crop=False, is_mirror=False, is_gray=False)
144 | img = self.input_transform(img)
145 |
146 | return img
147 |
148 | def __len__(self):
149 | return len(self.image_filenames)
150 |
151 |
152 | if __name__ == "__main__":
153 | ds = DigitalMonstersDataset(root_path='./pokemon_ds')
154 | print(ds)
155 |
--------------------------------------------------------------------------------
/soft_intro_vae_bootstrap/dataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.utils.data as data
3 |
4 | from os import listdir
5 | from os.path import join
6 | from PIL import Image, ImageOps
7 | import random
8 | import torchvision.transforms as transforms
9 | import os
10 |
11 |
12 | def load_image(file_path, input_height=128, input_width=None, output_height=128, output_width=None,
13 | crop_height=None, crop_width=None, is_random_crop=True, is_mirror=True, is_gray=False):
14 | if input_width is None:
15 | input_width = input_height
16 | if output_width is None:
17 | output_width = output_height
18 | if crop_width is None:
19 | crop_width = crop_height
20 |
21 | img = Image.open(file_path)
22 | if is_gray is False and img.mode is not 'RGB':
23 | img = img.convert('RGB')
24 | if is_gray and img.mode is not 'L':
25 | img = img.convert('L')
26 |
27 | if is_mirror and random.randint(0, 1) is 0:
28 | img = ImageOps.mirror(img)
29 |
30 | if input_height is not None:
31 | img = img.resize((input_width, input_height), Image.BICUBIC)
32 |
33 | if crop_height is not None:
34 | [w, h] = img.size
35 | if is_random_crop:
36 | # print([w,cropSize])
37 | cx1 = random.randint(0, w - crop_width)
38 | cx2 = w - crop_width - cx1
39 | cy1 = random.randint(0, h - crop_height)
40 | cy2 = h - crop_height - cy1
41 | else:
42 | cx2 = cx1 = int(round((w - crop_width) / 2.))
43 | cy2 = cy1 = int(round((h - crop_height) / 2.))
44 | img = ImageOps.crop(img, (cx1, cy1, cx2, cy2))
45 |
46 | img = img.resize((output_width, output_height), Image.BICUBIC)
47 | return img
48 |
49 |
50 | class ImageDatasetFromFile(data.Dataset):
51 | def __init__(self, image_list, root_path,
52 | input_height=128, input_width=None, output_height=128, output_width=None,
53 | crop_height=None, crop_width=None, is_random_crop=False, is_mirror=True, is_gray=False):
54 | super(ImageDatasetFromFile, self).__init__()
55 |
56 | self.image_filenames = image_list
57 | self.is_random_crop = is_random_crop
58 | self.is_mirror = is_mirror
59 | self.input_height = input_height
60 | self.input_width = input_width
61 | self.output_height = output_height
62 | self.output_width = output_width
63 | self.root_path = root_path
64 | self.crop_height = crop_height
65 | self.crop_width = crop_width
66 | self.is_gray = is_gray
67 |
68 | self.input_transform = transforms.Compose([
69 | transforms.ToTensor()
70 | ])
71 |
72 | def __getitem__(self, index):
73 | img = load_image(join(self.root_path, self.image_filenames[index]),
74 | self.input_height, self.input_width, self.output_height, self.output_width,
75 | self.crop_height, self.crop_width, self.is_random_crop, self.is_mirror, self.is_gray)
76 |
77 | img = self.input_transform(img)
78 |
79 | return img
80 |
81 | def __len__(self):
82 | return len(self.image_filenames)
83 |
84 |
85 | def list_images_in_dir(path):
86 | valid_images = [".jpg", ".gif", ".png"]
87 | img_list = []
88 | for f in os.listdir(path):
89 | ext = os.path.splitext(f)[1]
90 | if ext.lower() not in valid_images:
91 | continue
92 | img_list.append(os.path.join(path, f))
93 | return img_list
94 |
95 |
96 | class DigitalMonstersDataset(data.Dataset):
97 | def __init__(self, root_path,
98 | input_height=None, input_width=None, output_height=128, output_width=None, is_gray=False, pokemon=True,
99 | digimon=True, nexomon=True):
100 | super(DigitalMonstersDataset, self).__init__()
101 | image_list = []
102 | if pokemon:
103 | print("collecting pokemon...")
104 | image_list.extend(list_images_in_dir(os.path.join(root_path, 'pokemon')))
105 | if digimon:
106 | print("collecting digimon...")
107 | image_list.extend(list_images_in_dir(os.path.join(root_path, 'digimon', '200')))
108 | if nexomon:
109 | print("collecting nexomon...")
110 | image_list.extend(list_images_in_dir(os.path.join(root_path, 'nexomon')))
111 | print(f'total images: {len(image_list)}')
112 |
113 | self.image_filenames = image_list
114 | self.input_height = input_height
115 | self.input_width = input_width
116 | self.output_height = output_height
117 | self.output_width = output_width
118 | self.root_path = root_path
119 | self.is_gray = is_gray
120 |
121 | # self.input_transform = transforms.Compose([
122 | # transforms.RandomAffine(0, translate=(5 / output_height, 5 / output_height), fillcolor=(255, 255, 255)),
123 | # transforms.ColorJitter(hue=0.5),
124 | # transforms.RandomHorizontalFlip(p=0.5),
125 | # transforms.ToTensor(),
126 | # transforms.Normalize((0.5, 0.5, 0.5,), (0.5, 0.5, 0.5,))
127 | # ])
128 |
129 | self.input_transform = transforms.Compose([
130 | transforms.RandomAffine(0, translate=(5 / output_height, 5 / output_height), fillcolor=(255, 255, 255)),
131 | transforms.ColorJitter(hue=0.5),
132 | transforms.RandomHorizontalFlip(p=0.5),
133 | transforms.ToTensor()
134 | ])
135 |
136 | # self.input_transform = transforms.Compose([
137 | # transforms.ToTensor()
138 | # ])
139 |
140 | def __getitem__(self, index):
141 | img = load_image(self.image_filenames[index], input_height=self.input_height, input_width=self.input_width,
142 | output_height=self.output_height, output_width=self.output_width,
143 | crop_height=None, crop_width=None, is_random_crop=False, is_mirror=False, is_gray=False)
144 | img = self.input_transform(img)
145 |
146 | return img
147 |
148 | def __len__(self):
149 | return len(self.image_filenames)
150 |
151 |
152 | if __name__ == "__main__":
153 | ds = DigitalMonstersDataset(root_path='./pokemon_ds')
154 | print(ds)
155 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/make_figures/make_recon_figure_ffhq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020-2021 Tal Daniel
2 | # Copyright 2019-2020 Stanislav Pidhorskyi
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | # ==============================================================================
16 |
17 | import torch.utils.data
18 | from torchvision.utils import save_image
19 | from net import *
20 | from model import SoftIntroVAEModelTL
21 | from launcher import run
22 | from checkpointer import Checkpointer
23 | from defaults import get_cfg_defaults
24 | import lreq
25 | from dataloader import *
26 |
27 | lreq.use_implicit_lreq.set(True)
28 |
29 |
30 | def millify(n):
31 | millnames = ['', 'k', 'M', 'G', 'T', 'P']
32 | n = float(n)
33 | millidx = max(0, min(len(millnames) - 1, int(math.floor(0 if n == 0 else math.log10(abs(n)) / 3))))
34 |
35 | return '{:.1f}{}'.format(n / 10 ** (3 * millidx), millnames[millidx])
36 |
37 |
38 | def count_parameters(model, print_func=print, verbose=False):
39 | for n, p in model.named_parameters():
40 | if p.requires_grad and verbose:
41 | print_func(n, millify(p.numel()))
42 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
43 |
44 |
45 | def place(canvas, image, x, y):
46 | im_size = image.shape[2]
47 | if len(image.shape) == 4:
48 | image = image[0]
49 | canvas[:, y: y + im_size, x: x + im_size] = image * 0.5 + 0.5
50 |
51 |
52 | def save_sample(model, sample, i):
53 | os.makedirs('results', exist_ok=True)
54 |
55 | with torch.no_grad():
56 | model.eval()
57 | x_rec = model.generate(model.generator.layer_count - 1, 1, z=sample)
58 |
59 | def save_pic(x_rec):
60 | resultsample = x_rec * 0.5 + 0.5
61 | resultsample = resultsample.cpu()
62 | save_image(resultsample,
63 | 'sample_%i_lr.png' % i, nrow=16)
64 |
65 | save_pic(x_rec)
66 |
67 |
68 | def sample(cfg, logger):
69 | torch.cuda.set_device(0)
70 | model = SoftIntroVAEModelTL(
71 | startf=cfg.MODEL.START_CHANNEL_COUNT,
72 | layer_count=cfg.MODEL.LAYER_COUNT,
73 | maxf=cfg.MODEL.MAX_CHANNEL_COUNT,
74 | latent_size=cfg.MODEL.LATENT_SPACE_SIZE,
75 | dlatent_avg_beta=cfg.MODEL.DLATENT_AVG_BETA,
76 | style_mixing_prob=cfg.MODEL.STYLE_MIXING_PROB,
77 | mapping_layers=cfg.MODEL.MAPPING_LAYERS,
78 | channels=cfg.MODEL.CHANNELS,
79 | generator=cfg.MODEL.GENERATOR,
80 | encoder=cfg.MODEL.ENCODER,
81 | beta_kl=cfg.MODEL.BETA_KL,
82 | beta_rec=cfg.MODEL.BETA_REC,
83 | beta_neg=cfg.MODEL.BETA_NEG[cfg.MODEL.LAYER_COUNT - 1],
84 | scale=cfg.MODEL.SCALE
85 | )
86 | model.cuda(0)
87 | model.eval()
88 | model.requires_grad_(False)
89 |
90 | decoder = model.decoder
91 | encoder = model.encoder
92 | mapping_tl = model.mapping_tl
93 | mapping_fl = model.mapping_fl
94 | dlatent_avg = model.dlatent_avg
95 |
96 | logger.info("Trainable parameters decoder:")
97 | print(count_parameters(decoder))
98 |
99 | logger.info("Trainable parameters encoder:")
100 | print(count_parameters(encoder))
101 |
102 | arguments = dict()
103 | arguments["iteration"] = 0
104 |
105 | model_dict = {
106 | 'discriminator_s': encoder,
107 | 'generator_s': decoder,
108 | 'mapping_tl_s': mapping_tl,
109 | 'mapping_fl_s': mapping_fl,
110 | 'dlatent_avg': dlatent_avg
111 | }
112 |
113 | checkpointer = Checkpointer(cfg,
114 | model_dict,
115 | {},
116 | logger=logger,
117 | save=False)
118 |
119 | extra_checkpoint_data = checkpointer.load()
120 |
121 | model.eval()
122 |
123 | layer_count = cfg.MODEL.LAYER_COUNT
124 |
125 | def encode(x):
126 | z, mu, _ = model.encode(x, layer_count - 1, 1)
127 | styles = model.mapping_fl(mu)
128 | return styles
129 |
130 | def decode(x):
131 | return model.decoder(x, layer_count - 1, 1, noise=True)
132 |
133 | rnd = np.random.RandomState(5)
134 |
135 | dataset = TFRecordsDataset(cfg, logger, rank=0, world_size=1, buffer_size_mb=10, channels=cfg.MODEL.CHANNELS,
136 | train=False)
137 |
138 | dataset.reset(cfg.DATASET.MAX_RESOLUTION_LEVEL, 10)
139 | b = iter(make_dataloader(cfg, logger, dataset, 10, 0, numpy=True))
140 |
141 | def make(sample):
142 | canvas = []
143 | with torch.no_grad():
144 | for img in sample:
145 | x = torch.tensor(np.asarray(img, dtype=np.float32), device='cpu',
146 | requires_grad=True).cuda() / 127.5 - 1.
147 | if x.shape[0] == 4:
148 | x = x[:3]
149 | latents = encode(x[None, ...].cuda())
150 | f = decode(latents)
151 | r = torch.cat([x[None, ...].detach().cpu(), f.detach().cpu()], dim=3)
152 | canvas.append(r)
153 | return canvas
154 |
155 | sample = next(b)
156 | canvas = make(sample)
157 | canvas = torch.cat(canvas, dim=0)
158 |
159 | save_image(canvas * 0.5 + 0.5, './make_figures/reconstructions_ffhq_real_1.png', nrow=2, pad_value=1.0)
160 |
161 | sample = next(b)
162 | canvas = make(sample)
163 | canvas = torch.cat(canvas, dim=0)
164 |
165 | save_image(canvas * 0.5 + 0.5, './make_figures/reconstructions_ffhq_real_2.png', nrow=2, pad_value=1.0)
166 |
167 |
168 | if __name__ == "__main__":
169 | gpu_count = 1
170 | run(sample, get_cfg_defaults(), description='SoftIntroVAE-reconstruction-ffhq',
171 | default_config='./configs/ffhq256.yaml',
172 | world_size=gpu_count, write_log=False)
173 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/datasets/modelnet40.py:
--------------------------------------------------------------------------------
1 | import urllib
2 | import shutil
3 | from os import listdir, makedirs, remove
4 | from os.path import exists, join
5 | from zipfile import ZipFile
6 |
7 | import h5py
8 | import numpy as np
9 | import pandas as pd
10 | from torch.utils.data import Dataset
11 |
12 | from utils.pcutil import rand_rotation_matrix
13 |
14 | all_classes = ['airplane', 'bathtub', 'bed', 'bench', 'bookshelf', 'bottle',
15 | 'bowl', 'car', 'chair', 'cone', 'cup', 'curtain', 'desk', 'door',
16 | 'dresser', 'flower_pot', 'glass_box', 'guitar', 'keyboard',
17 | 'lamp', 'laptop', 'mantel', 'monitor', 'night_stand', 'person',
18 | 'piano', 'plant', 'radio', 'range_hood', 'sink', 'sofa',
19 | 'stairs', 'stool', 'table', 'tent', 'toilet', 'tv_stand', 'vase',
20 | 'wardrobe', 'xbox']
21 |
22 | number_to_category = {i: c for i, c in enumerate(all_classes)}
23 | category_to_number = {c: i for i, c in enumerate(all_classes)}
24 |
25 |
26 | class ModelNet40(Dataset):
27 | def __init__(self, root_dir='/home/datasets/modelnet40', classes=[],
28 | transform=[], split='train', valid_percent=10, percent_supervised=0.0):
29 | """
30 | Args:
31 | root_dir (string): Directory with all the point clouds.
32 | transform (callable, optional): Optional transform to be applied
33 | on a sample.
34 | split (string): `train` or `test`
35 | valid_percent (int): Percent of train (from the end) to use as valid set.
36 | """
37 | self.root_dir = root_dir
38 | self.transform = transform
39 | self.split = split.lower()
40 | self.valid_percent = valid_percent
41 | self.percent_supervised = percent_supervised
42 |
43 | self._maybe_download_data()
44 |
45 | if self.split in ('train', 'valid'):
46 | self.files_list = join(self.root_dir, 'train_files.txt')
47 | elif self.split == 'test':
48 | self.files_list = join(self.root_dir, 'test_files.txt')
49 | else:
50 | raise ValueError('Incorrect split')
51 |
52 | data, labels = self._load_files()
53 |
54 | if classes:
55 | if classes[0] in all_classes:
56 | classes = np.asarray([category_to_number[c] for c in classes])
57 | filter = [label in classes for label in labels]
58 | data = data[filter]
59 | labels = labels[filter]
60 | else:
61 | classes = np.arange(len(all_classes))
62 |
63 | if self.split in ('train', 'valid'):
64 | new_data, new_labels = [], []
65 | if self.percent_supervised > 0.0:
66 | data_sup, labels_sub = [], []
67 | for c in classes:
68 | pc_in_class = sum(labels.flatten() == c)
69 |
70 | if self.split == 'train':
71 | portion = slice(0, int(pc_in_class * (1 - (self.valid_percent / 100))))
72 | else:
73 | portion = slice(int(pc_in_class * (1 - (self.valid_percent / 100))), pc_in_class)
74 |
75 | new_data.append(data[labels.flatten() == c][portion])
76 | new_labels.append(labels[labels.flatten() == c][portion])
77 |
78 | if self.percent_supervised > 0.0:
79 | n_max = int(self.percent_supervised * (portion.stop - 1))
80 | data_sup.append(data[labels.flatten() == c][:n_max])
81 | labels_sub.append(labels[labels.flatten() == c][:n_max])
82 | data = np.vstack(new_data)
83 | labels = np.vstack(new_labels)
84 | if self.percent_supervised > 0.0:
85 | self.data_sup = np.vstack(data_sup)
86 | self.labels_sup = np.vstack(labels_sub)
87 | self.data = data
88 | self.labels = labels
89 |
90 | def _load_files(self) -> pd.DataFrame:
91 |
92 | with open(self.files_list) as f:
93 | files = [join(self.root_dir, line.rstrip().rsplit('/', 1)[1]) for line in f]
94 |
95 | data, labels = [], []
96 | for file in files:
97 | with h5py.File(file) as f:
98 | data.extend(f['data'][:])
99 | labels.extend(f['label'][:])
100 |
101 | return np.asarray(data), np.asarray(labels)
102 |
103 | def __len__(self):
104 | return len(self.data)
105 |
106 | def __getitem__(self, idx):
107 | sample = self.data[idx]
108 | sample /= 2 # Scale to [-0.5, 0.5] range
109 | label = self.labels[idx]
110 |
111 | if 'rotate'.lower() in self.transform:
112 | r_rotation = rand_rotation_matrix()
113 | r_rotation[0, 2] = 0
114 | r_rotation[2, 0] = 0
115 | r_rotation[1, 2] = 0
116 | r_rotation[2, 1] = 0
117 | r_rotation[2, 2] = 1
118 |
119 | sample = sample.dot(r_rotation).astype(np.float32)
120 | if self.percent_supervised > 0.0:
121 | id_sup = np.random.randint(self.data_sup.shape[0])
122 | sample_sup = self.data_sup[id_sup]
123 | sample_sup /= 2
124 | label_sup = self.labels_sup[id_sup]
125 | return sample, label, sample_sup, label_sup
126 | else:
127 | return sample, label
128 |
129 | def _maybe_download_data(self):
130 | if exists(self.root_dir):
131 | return
132 |
133 | print(f'ModelNet40 doesn\'t exist in root directory {self.root_dir}. '
134 | f'Downloading...')
135 | makedirs(self.root_dir)
136 |
137 | url = 'https://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip'
138 |
139 | data = urllib.request.urlopen(url)
140 | filename = url.rpartition('/')[2][:-5]
141 | file_path = join(self.root_dir, filename)
142 | with open(file_path, mode='wb') as f:
143 | d = data.read()
144 | f.write(d)
145 |
146 | print('Extracting...')
147 | with ZipFile(file_path, mode='r') as zip_f:
148 | zip_f.extractall(self.root_dir)
149 |
150 | remove(file_path)
151 |
152 | extracted_dir = join(self.root_dir, 'modelnet40_ply_hdf5_2048')
153 | for d in listdir(extracted_dir):
154 | shutil.move(src=join(extracted_dir, d),
155 | dst=self.root_dir)
156 |
157 | shutil.rmtree(extracted_dir)
158 |
159 |
160 | if __name__ == '__main__':
161 | ModelNet40()
162 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/dataset_preparation/split_tfrecords_ffhq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 Stanislav Pidhorskyi
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ==============================================================================
15 |
16 | import os
17 | import sys
18 | import argparse
19 | import logging
20 | import tensorflow as tf
21 | # from defaults import get_cfg_defaults
22 |
23 | from yacs.config import CfgNode as CN
24 |
25 | _C = CN()
26 |
27 | _C.NAME = ""
28 | _C.PPL_CELEBA_ADJUSTMENT = False
29 | _C.OUTPUT_DIR = "results"
30 |
31 | _C.DATASET = CN()
32 | _C.DATASET.PATH = 'celeba/data_fold_%d_lod_%d.pkl'
33 | _C.DATASET.PATH_TEST = ''
34 | _C.DATASET.FFHQ_SOURCE = '/data/datasets/ffhq-dataset/tfrecords/ffhq/ffhq-r%02d.tfrecords'
35 | _C.DATASET.PART_COUNT = 1
36 | _C.DATASET.PART_COUNT_TEST = 1
37 | _C.DATASET.SIZE = 70000
38 | _C.DATASET.SIZE_TEST = 10000
39 | _C.DATASET.FLIP_IMAGES = True
40 | _C.DATASET.SAMPLES_PATH = 'dataset_samples/faces/realign128x128'
41 |
42 | _C.DATASET.STYLE_MIX_PATH = 'style_mixing/test_images/set_celeba/'
43 |
44 | _C.DATASET.MAX_RESOLUTION_LEVEL = 10
45 |
46 | _C.MODEL = CN()
47 |
48 | _C.MODEL.LAYER_COUNT = 6
49 | _C.MODEL.START_CHANNEL_COUNT = 64
50 | _C.MODEL.MAX_CHANNEL_COUNT = 512
51 | _C.MODEL.LATENT_SPACE_SIZE = 256
52 | _C.MODEL.DLATENT_AVG_BETA = 0.995
53 | _C.MODEL.TRUNCATIOM_PSI = 0.7
54 | _C.MODEL.TRUNCATIOM_CUTOFF = 8
55 | _C.MODEL.STYLE_MIXING_PROB = 0.9
56 | _C.MODEL.MAPPING_LAYERS = 5
57 | _C.MODEL.CHANNELS = 3
58 | _C.MODEL.GENERATOR = "GeneratorDefault"
59 | _C.MODEL.ENCODER = "EncoderDefault"
60 | _C.MODEL.MAPPING_TO_LATENT = "MappingToLatent"
61 | _C.MODEL.MAPPING_FROM_LATENT = "MappingFromLatent"
62 | _C.MODEL.Z_REGRESSION = False
63 | _C.MODEL.BETA_KL = 1.0
64 | _C.MODEL.BETA_REC = 1.0
65 | _C.MODEL.BETA_NEG = [2048, 2048, 1024, 512, 512, 128, 128, 64, 64]
66 | _C.MODEL.SCALE = 1 / (3 * 256 ** 2)
67 |
68 | _C.TRAIN = CN()
69 |
70 | _C.TRAIN.EPOCHS_PER_LOD = 15
71 |
72 | _C.TRAIN.BASE_LEARNING_RATE = 0.0015
73 | _C.TRAIN.ADAM_BETA_0 = 0.0
74 | _C.TRAIN.ADAM_BETA_1 = 0.99
75 | _C.TRAIN.LEARNING_DECAY_RATE = 0.1
76 | _C.TRAIN.LEARNING_DECAY_STEPS = []
77 | _C.TRAIN.TRAIN_EPOCHS = 110
78 | _C.TRAIN.NUM_VAE = 1
79 |
80 | _C.TRAIN.LOD_2_BATCH_8GPU = [512, 256, 128, 64, 32, 32]
81 | _C.TRAIN.LOD_2_BATCH_4GPU = [512, 256, 128, 64, 32, 16]
82 | _C.TRAIN.LOD_2_BATCH_2GPU = [256, 256, 128, 64, 32, 16]
83 | _C.TRAIN.LOD_2_BATCH_1GPU = [128, 128, 128, 64, 32, 16]
84 |
85 | _C.TRAIN.SNAPSHOT_FREQ = [300, 300, 300, 100, 50, 30, 20, 20, 10]
86 |
87 | _C.TRAIN.REPORT_FREQ = [100, 80, 60, 30, 20, 10, 10, 5, 5]
88 |
89 | _C.TRAIN.LEARNING_RATES = [0.002]
90 |
91 | def get_cfg_defaults():
92 | return _C.clone()
93 |
94 |
95 | def split_tfrecord(cfg, logger):
96 | tfrecord_path = cfg.DATASET.FFHQ_SOURCE
97 |
98 | ffhq_train_size = 60000
99 |
100 | part_size = ffhq_train_size // cfg.DATASET.PART_COUNT
101 |
102 | logger.info("Splitting into % size parts" % part_size)
103 |
104 | for i in range(2, cfg.DATASET.MAX_RESOLUTION_LEVEL + 1):
105 | with tf.Graph().as_default(), tf.Session() as sess:
106 | ds = tf.data.TFRecordDataset(tfrecord_path % i)
107 | ds = ds.batch(part_size)
108 | batch = ds.make_one_shot_iterator().get_next()
109 | part_num = 0
110 | while True:
111 | try:
112 | records = sess.run(batch)
113 | if part_num < cfg.DATASET.PART_COUNT:
114 | part_path = cfg.DATASET.PATH % (i, part_num)
115 | os.makedirs(os.path.dirname(part_path), exist_ok=True)
116 | with tf.python_io.TFRecordWriter(part_path) as writer:
117 | for record in records:
118 | writer.write(record)
119 | else:
120 | part_path = cfg.DATASET.PATH_TEST % (i, part_num - cfg.DATASET.PART_COUNT)
121 | os.makedirs(os.path.dirname(part_path), exist_ok=True)
122 | with tf.python_io.TFRecordWriter(part_path) as writer:
123 | for record in records:
124 | writer.write(record)
125 | part_num += 1
126 | except tf.errors.OutOfRangeError:
127 | break
128 |
129 |
130 | def run():
131 | parser = argparse.ArgumentParser(description="ALAE. Split FFHQ into parts for training and testing")
132 | parser.add_argument(
133 | "--config-file",
134 | default="/home/tal/tmp/StyleSandwichVAE2/configs/ffhq256.yaml",
135 | metavar="FILE",
136 | help="path to config file",
137 | type=str,
138 | )
139 | parser.add_argument(
140 | "opts",
141 | help="Modify config options using the command-line",
142 | default=None,
143 | nargs=argparse.REMAINDER,
144 | )
145 |
146 | args = parser.parse_args()
147 | cfg = get_cfg_defaults()
148 | cfg.merge_from_file(args.config_file)
149 | cfg.merge_from_list(args.opts)
150 | cfg.freeze()
151 |
152 | logger = logging.getLogger("logger")
153 | logger.setLevel(logging.DEBUG)
154 |
155 | output_dir = cfg.OUTPUT_DIR
156 | os.makedirs(output_dir, exist_ok=True)
157 |
158 | ch = logging.StreamHandler(stream=sys.stdout)
159 | ch.setLevel(logging.DEBUG)
160 | formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s: %(message)s")
161 | ch.setFormatter(formatter)
162 | logger.addHandler(ch)
163 |
164 | fh = logging.FileHandler(os.path.join(output_dir, 'log.txt'))
165 | fh.setLevel(logging.DEBUG)
166 | fh.setFormatter(formatter)
167 | logger.addHandler(fh)
168 |
169 | logger.info(args)
170 |
171 | logger.info("Loaded configuration file {}".format(args.config_file))
172 | with open(args.config_file, "r") as cf:
173 | config_str = "\n" + cf.read()
174 | logger.info(config_str)
175 | logger.info("Running with config:\n{}".format(cfg))
176 |
177 | split_tfrecord(cfg, logger)
178 |
179 |
180 | if __name__ == '__main__':
181 | run()
182 |
183 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/make_figures/make_recon_figure_interpolation_2_images.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020-2021 Tal Daniel
2 | # Copyright 2019-2020 Stanislav Pidhorskyi
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | # ==============================================================================
16 |
17 | import torch.utils.data
18 | from torchvision.utils import save_image
19 | from net import *
20 | from model import SoftIntroVAEModelTL
21 | from launcher import run
22 | from checkpointer import Checkpointer
23 | from defaults import get_cfg_defaults
24 | import lreq
25 | from PIL import Image
26 |
27 | lreq.use_implicit_lreq.set(True)
28 |
29 |
30 | def millify(n):
31 | millnames = ['', 'k', 'M', 'G', 'T', 'P']
32 | n = float(n)
33 | millidx = max(0, min(len(millnames) - 1, int(math.floor(0 if n == 0 else math.log10(abs(n)) / 3))))
34 |
35 | return '{:.1f}{}'.format(n / 10 ** (3 * millidx), millnames[millidx])
36 |
37 |
38 | def count_parameters(model, print_func=print, verbose=False):
39 | for n, p in model.named_parameters():
40 | if p.requires_grad and verbose:
41 | print_func(n, millify(p.numel()))
42 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
43 |
44 |
45 | def place(canvas, image, x, y):
46 | im_size = image.shape[2]
47 | if len(image.shape) == 4:
48 | image = image[0]
49 | canvas[:, y: y + im_size, x: x + im_size] = image * 0.5 + 0.5
50 |
51 |
52 | def save_sample(model, sample, i):
53 | os.makedirs('results', exist_ok=True)
54 |
55 | with torch.no_grad():
56 | model.eval()
57 | x_rec = model.generate(model.generator.layer_count - 1, 1, z=sample)
58 |
59 | def save_pic(x_rec):
60 | resultsample = x_rec * 0.5 + 0.5
61 | resultsample = resultsample.cpu()
62 | save_image(resultsample,
63 | 'sample_%i_lr.png' % i, nrow=16)
64 |
65 | save_pic(x_rec)
66 |
67 |
68 | def sample(cfg, logger):
69 | torch.cuda.set_device(0)
70 | model = SoftIntroVAEModelTL(
71 | startf=cfg.MODEL.START_CHANNEL_COUNT,
72 | layer_count=cfg.MODEL.LAYER_COUNT,
73 | maxf=cfg.MODEL.MAX_CHANNEL_COUNT,
74 | latent_size=cfg.MODEL.LATENT_SPACE_SIZE,
75 | dlatent_avg_beta=cfg.MODEL.DLATENT_AVG_BETA,
76 | style_mixing_prob=cfg.MODEL.STYLE_MIXING_PROB,
77 | mapping_layers=cfg.MODEL.MAPPING_LAYERS,
78 | channels=cfg.MODEL.CHANNELS,
79 | generator=cfg.MODEL.GENERATOR,
80 | encoder=cfg.MODEL.ENCODER,
81 | beta_kl=cfg.MODEL.BETA_KL,
82 | beta_rec=cfg.MODEL.BETA_REC,
83 | beta_neg=cfg.MODEL.BETA_NEG[cfg.MODEL.LAYER_COUNT - 1],
84 | scale=cfg.MODEL.SCALE
85 | )
86 | model.cuda(0)
87 | model.eval()
88 | model.requires_grad_(False)
89 |
90 | decoder = model.decoder
91 | encoder = model.encoder
92 | mapping_tl = model.mapping_tl
93 | mapping_fl = model.mapping_fl
94 | dlatent_avg = model.dlatent_avg
95 |
96 | logger.info("Trainable parameters decoder:")
97 | print(count_parameters(decoder))
98 |
99 | logger.info("Trainable parameters encoder:")
100 | print(count_parameters(encoder))
101 |
102 | arguments = dict()
103 | arguments["iteration"] = 0
104 |
105 | model_dict = {
106 | 'discriminator_s': encoder,
107 | 'generator_s': decoder,
108 | 'mapping_tl_s': mapping_tl,
109 | 'mapping_fl_s': mapping_fl,
110 | 'dlatent_avg': dlatent_avg
111 | }
112 |
113 | checkpointer = Checkpointer(cfg,
114 | model_dict,
115 | {},
116 | logger=logger,
117 | save=False)
118 |
119 | extra_checkpoint_data = checkpointer.load()
120 |
121 | model.eval()
122 |
123 | layer_count = cfg.MODEL.LAYER_COUNT
124 |
125 | def encode(x):
126 | z, mu, _ = model.encode(x, layer_count - 1, 1)
127 | styles = model.mapping_fl(mu)
128 | return styles
129 |
130 | def decode(x):
131 | return model.decoder(x, layer_count - 1, 1, noise=True)
132 |
133 | rnd = np.random.RandomState(4)
134 |
135 | path = cfg.DATASET.SAMPLES_PATH
136 | im_size = 2 ** (cfg.MODEL.LAYER_COUNT + 1)
137 |
138 | pathA = '17460.jpg'
139 | pathB = '02973.jpg'
140 |
141 | def open_image(filename):
142 | img = np.asarray(Image.open(path + '/' + filename))
143 | if img.shape[2] == 4:
144 | img = img[:, :, :3]
145 | im = img.transpose((2, 0, 1))
146 | x = torch.tensor(np.asarray(im, dtype=np.float32), device='cpu', requires_grad=True).cuda() / 127.5 - 1.
147 | if x.shape[0] == 4:
148 | x = x[:3]
149 | factor = x.shape[2] // im_size
150 | if factor != 1:
151 | x = torch.nn.functional.avg_pool2d(x[None, ...], factor, factor)[0]
152 | assert x.shape[2] == im_size
153 | _latents = encode(x[None, ...].cuda())
154 | latents = _latents[0, 0]
155 | return latents
156 |
157 | def make(w):
158 | with torch.no_grad():
159 | w = w[None, None, ...].repeat(1, model.mapping_fl.num_layers, 1)
160 | x_rec = decode(w)
161 | return x_rec
162 |
163 | wa = open_image(pathA)
164 | wb = open_image(pathB)
165 |
166 | width = 7
167 |
168 | images = []
169 |
170 | for j in range(width):
171 | kh = j / (width - 1.0)
172 |
173 | ka = (1.0 - kh)
174 | kb = kh
175 | w = ka * wa + kb * wb
176 |
177 | interpolated = make(w)
178 | images.append(interpolated)
179 |
180 | images = torch.cat(images)
181 |
182 | path = './make_figures/output'
183 | os.makedirs(path, exist_ok=True)
184 | os.makedirs(os.path.join(path, cfg.NAME), exist_ok=True)
185 | save_image(images * 0.5 + 0.5, './make_figures/output/%s/interpolations.png' % cfg.NAME, nrow=width)
186 | save_image(images * 0.5 + 0.5, './make_figures/output/%s/interpolations.jpg' % cfg.NAME, nrow=width)
187 |
188 |
189 | if __name__ == "__main__":
190 | gpu_count = 1
191 | run(sample, get_cfg_defaults(), description='SoftIntroVAE-interpolations',
192 | default_config='./configs/ffhq256.yaml',
193 | world_size=gpu_count, write_log=False)
194 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/evaluation/find_best_epoch_on_validation_soft.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | import logging
4 | import random
5 | import re
6 | from datetime import datetime
7 | from os import listdir
8 | from os.path import join
9 |
10 | import numpy as np
11 | import pandas as pd
12 | import torch
13 | from torch.utils.data import DataLoader
14 |
15 | from datasets.shapenet import ShapeNetDataset
16 | from metrics.jsd import jsd_between_point_cloud_sets
17 | from utils.util import cuda_setup, setup_logging
18 | from models.vae import SoftIntroVAE, reparameterize
19 |
20 |
21 | def _get_epochs_by_regex(path, regex):
22 | reg = re.compile(regex)
23 | return {int(w[:5]) for w in listdir(path) if reg.match(w)}
24 |
25 |
26 | def main(eval_config):
27 | # Load hyperparameters as they were during training
28 | train_results_path = join(eval_config['results_root'], eval_config['arch'],
29 | eval_config['experiment_name'])
30 | with open(join(train_results_path, 'config.json')) as f:
31 | train_config = json.load(f)
32 |
33 | if train_config['seed'] >= 0:
34 | random.seed(train_config['seed'])
35 | torch.manual_seed(train_config['seed'])
36 | torch.cuda.manual_seed(train_config['seed'])
37 | np.random.seed(train_config['seed'])
38 | torch.backends.cudnn.deterministic = True
39 | print("random seed: ", train_config['seed'])
40 |
41 | setup_logging(join(train_results_path, 'results'))
42 | log = logging.getLogger(__name__)
43 |
44 | log.debug('Evaluating Jensen-Shannon divergences on validation set on all '
45 | 'saved epochs.')
46 |
47 | weights_path = join(train_results_path, 'weights')
48 |
49 | # Find all epochs that have saved model weights
50 | v_epochs = _get_epochs_by_regex(weights_path, r'(?P\d{5})\.pth')
51 | epochs = sorted(v_epochs)
52 | log.debug(f'Testing epochs: {epochs}')
53 |
54 | device = cuda_setup(eval_config['cuda'], eval_config['gpu'])
55 | log.debug(f'Device variable: {device}')
56 | if device.type == 'cuda':
57 | log.debug(f'Current CUDA device: {torch.cuda.current_device()}')
58 |
59 | #
60 | # Dataset
61 | #
62 | dataset_name = train_config['dataset'].lower()
63 | if dataset_name == 'shapenet':
64 | dataset = ShapeNetDataset(root_dir=train_config['data_dir'],
65 | classes=train_config['classes'], split='valid')
66 | # elif dataset_name == 'faust':
67 | # from datasets.dfaust import DFaustDataset
68 | # dataset = DFaustDataset(root_dir=train_config['data_dir'],
69 | # classes=train_config['classes'], split='valid')
70 | # elif dataset_name == 'mcgill':
71 | # from datasets.mcgill import McGillDataset
72 | # dataset = McGillDataset(root_dir=train_config['data_dir'],
73 | # classes=train_config['classes'], split='valid')
74 | else:
75 | raise ValueError(f'Invalid dataset name. Expected `shapenet` or '
76 | f'`faust`. Got: `{dataset_name}`')
77 | classes_selected = ('all' if not train_config['classes']
78 | else ','.join(train_config['classes']))
79 | log.debug(f'Selected {classes_selected} classes. Loaded {len(dataset)} '
80 | f'samples.')
81 |
82 | # if 'distribution' in train_config:
83 | # distribution = train_config['distribution']
84 | # elif 'distribution' in eval_config:
85 | # distribution = eval_config['distribution']
86 | # else:
87 | # log.warning('No distribution type specified. Assumed normal = N(0, 0.2)')
88 | # distribution = 'normal'
89 |
90 | #
91 | # Models
92 |
93 | model = SoftIntroVAE(train_config).to(device)
94 | model.eval()
95 |
96 | num_samples = len(dataset.point_clouds_names_valid)
97 | data_loader = DataLoader(dataset, batch_size=num_samples,
98 | shuffle=False, num_workers=4,
99 | drop_last=False, pin_memory=True)
100 |
101 | # We take 3 times as many samples as there are in test data in order to
102 | # perform JSD calculation in the same manner as in the reference publication
103 | # noise = torch.FloatTensor(3 * num_samples, train_config['z_size'], 1)
104 | noise = torch.randn(3 * num_samples, model.zdim)
105 | noise = noise.to(device)
106 |
107 | x, _ = next(iter(data_loader))
108 | x = x.to(device)
109 |
110 | results = {}
111 |
112 | for epoch in reversed(epochs):
113 | try:
114 | model.load_state_dict(torch.load(
115 | join(weights_path, f'{epoch:05}.pth')))
116 |
117 | start_clock = datetime.now()
118 |
119 | # We average JSD computation from 3 independet trials.
120 | js_results = []
121 | for _ in range(3):
122 | # if distribution == 'normal':
123 | # noise.normal_(0, 0.2)
124 | # elif distribution == 'beta':
125 | # noise_np = np.random.beta(train_config['z_beta_a'],
126 | # train_config['z_beta_b'],
127 | # noise.shape)
128 | # noise = torch.tensor(noise_np).float().round().to(device)
129 |
130 | with torch.no_grad():
131 | x_g = model.decode(noise)
132 | if x_g.shape[-2:] == (3, 2048):
133 | x_g.transpose_(1, 2)
134 |
135 | jsd = jsd_between_point_cloud_sets(x, x_g, voxels=28)
136 | js_results.append(jsd)
137 |
138 | js_result = np.mean(js_results)
139 | log.debug(f'Epoch: {epoch} JSD: {js_result: .6f} '
140 | f'Time: {datetime.now() - start_clock}')
141 | results[epoch] = js_result
142 | except KeyboardInterrupt:
143 | log.debug(f'Interrupted during epoch: {epoch}')
144 | break
145 |
146 | results = pd.DataFrame.from_dict(results, orient='index', columns=['jsd'])
147 | log.debug(f"Minimum JSD at epoch {results.idxmin()['jsd']}: "
148 | f"{results.min()['jsd']: .6f}")
149 |
150 |
151 | if __name__ == '__main__':
152 | logger = logging.getLogger()
153 |
154 | parser = argparse.ArgumentParser()
155 | parser.add_argument('-c', '--config', default=None, type=str,
156 | help='File path for evaluation config')
157 | args = parser.parse_args()
158 |
159 | args.config = './config/soft_intro_vae_hp.json'
160 | evaluation_config = None
161 | if args.config is not None and args.config.endswith('.json'):
162 | with open(args.config) as f:
163 | evaluation_config = json.load(f)
164 | assert evaluation_config is not None
165 |
166 | main(evaluation_config)
167 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/make_figures/make_recon_figure_paged.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020-2021 Tal Daniel
2 | # Copyright 2019-2020 Stanislav Pidhorskyi
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | # ==============================================================================
16 |
17 | import torch.utils.data
18 | from torchvision.utils import save_image
19 | import random
20 | from net import *
21 | from model import SoftIntroVAEModelTL
22 | from launcher import run
23 | from checkpointer import Checkpointer
24 | from defaults import get_cfg_defaults
25 | import lreq
26 | from PIL import Image
27 |
28 | lreq.use_implicit_lreq.set(True)
29 |
30 |
31 | def millify(n):
32 | millnames = ['', 'k', 'M', 'G', 'T', 'P']
33 | n = float(n)
34 | millidx = max(0, min(len(millnames) - 1, int(math.floor(0 if n == 0 else math.log10(abs(n)) / 3))))
35 |
36 | return '{:.1f}{}'.format(n / 10 ** (3 * millidx), millnames[millidx])
37 |
38 |
39 | def count_parameters(model, print_func=print, verbose=False):
40 | for n, p in model.named_parameters():
41 | if p.requires_grad and verbose:
42 | print_func(n, millify(p.numel()))
43 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
44 |
45 |
46 | def place(canvas, image, x, y):
47 | im_size = image.shape[2]
48 | if len(image.shape) == 4:
49 | image = image[0]
50 | canvas[:, y: y + im_size, x: x + im_size] = image * 0.5 + 0.5
51 |
52 |
53 | def save_sample(model, sample, i):
54 | os.makedirs('results', exist_ok=True)
55 |
56 | with torch.no_grad():
57 | model.eval()
58 | x_rec = model.generate(model.generator.layer_count - 1, 1, z=sample)
59 |
60 | def save_pic(x_rec):
61 | resultsample = x_rec * 0.5 + 0.5
62 | resultsample = resultsample.cpu()
63 | save_image(resultsample,
64 | 'sample_%i_lr.png' % i, nrow=16)
65 |
66 | save_pic(x_rec)
67 |
68 |
69 | def sample(cfg, logger):
70 | torch.cuda.set_device(0)
71 | model = SoftIntroVAEModelTL(
72 | startf=cfg.MODEL.START_CHANNEL_COUNT,
73 | layer_count=cfg.MODEL.LAYER_COUNT,
74 | maxf=cfg.MODEL.MAX_CHANNEL_COUNT,
75 | latent_size=cfg.MODEL.LATENT_SPACE_SIZE,
76 | dlatent_avg_beta=cfg.MODEL.DLATENT_AVG_BETA,
77 | style_mixing_prob=cfg.MODEL.STYLE_MIXING_PROB,
78 | mapping_layers=cfg.MODEL.MAPPING_LAYERS,
79 | channels=cfg.MODEL.CHANNELS,
80 | generator=cfg.MODEL.GENERATOR,
81 | encoder=cfg.MODEL.ENCODER,
82 | beta_kl=cfg.MODEL.BETA_KL,
83 | beta_rec=cfg.MODEL.BETA_REC,
84 | beta_neg=cfg.MODEL.BETA_NEG[cfg.MODEL.LAYER_COUNT - 1],
85 | scale=cfg.MODEL.SCALE
86 | )
87 | model.cuda(0)
88 | model.eval()
89 | model.requires_grad_(False)
90 |
91 | decoder = model.decoder
92 | encoder = model.encoder
93 | mapping_tl = model.mapping_tl
94 | mapping_fl = model.mapping_fl
95 | dlatent_avg = model.dlatent_avg
96 |
97 | logger.info("Trainable parameters decoder:")
98 | print(count_parameters(decoder))
99 |
100 | logger.info("Trainable parameters encoder:")
101 | print(count_parameters(encoder))
102 |
103 | arguments = dict()
104 | arguments["iteration"] = 0
105 |
106 | model_dict = {
107 | 'discriminator_s': encoder,
108 | 'generator_s': decoder,
109 | 'mapping_tl_s': mapping_tl,
110 | 'mapping_fl_s': mapping_fl,
111 | 'dlatent_avg': dlatent_avg
112 | }
113 |
114 | checkpointer = Checkpointer(cfg,
115 | model_dict,
116 | {},
117 | logger=logger,
118 | save=False)
119 |
120 | extra_checkpoint_data = checkpointer.load()
121 |
122 | model.eval()
123 |
124 | layer_count = cfg.MODEL.LAYER_COUNT
125 |
126 | def encode(x):
127 | z, mu, _ = model.encode(x, layer_count - 1, 1)
128 | styles = model.mapping_fl(mu)
129 | return styles
130 |
131 | def decode(x):
132 | return model.decoder(x, layer_count - 1, 1, noise=True)
133 |
134 | path = cfg.DATASET.SAMPLES_PATH
135 | im_size = 2 ** (cfg.MODEL.LAYER_COUNT + 1)
136 |
137 | paths = list(os.listdir(path))
138 |
139 | paths = sorted(paths)
140 | random.seed(1)
141 | random.shuffle(paths)
142 |
143 | def make(paths):
144 | canvas = []
145 | with torch.no_grad():
146 | for filename in paths:
147 | img = np.asarray(Image.open(path + '/' + filename))
148 | if img.shape[2] == 4:
149 | img = img[:, :, :3]
150 | im = img.transpose((2, 0, 1))
151 | x = torch.tensor(np.asarray(im, dtype=np.float32), device='cpu', requires_grad=True).cuda() / 127.5 - 1.
152 | if x.shape[0] == 4:
153 | x = x[:3]
154 | factor = x.shape[2] // im_size
155 | if factor != 1:
156 | x = torch.nn.functional.avg_pool2d(x[None, ...], factor, factor)[0]
157 | assert x.shape[2] == im_size
158 | latents = encode(x[None, ...].cuda())
159 | f = decode(latents)
160 | r = torch.cat([x[None, ...].detach().cpu(), f.detach().cpu()], dim=3)
161 | canvas.append(r)
162 | return canvas
163 |
164 | def chunker_list(seq, n):
165 | return [seq[i * n:(i + 1) * n] for i in range((len(seq) + n - 1) // n)]
166 |
167 | paths = chunker_list(paths, 8 * 3)
168 |
169 | path = './make_figures/output'
170 | os.makedirs(path, exist_ok=True)
171 | os.makedirs(os.path.join(path, cfg.NAME), exist_ok=True)
172 |
173 | for i, chunk in enumerate(paths):
174 | canvas = make(chunk)
175 | canvas = torch.cat(canvas, dim=0)
176 |
177 | save_path = './make_figures/output/%s/reconstructions_%d.png' % (cfg.NAME, i)
178 | os.makedirs(os.path.dirname(save_path), exist_ok=True)
179 | save_image(canvas * 0.5 + 0.5, save_path,
180 | nrow=3,
181 | pad_value=1.0)
182 |
183 |
184 | if __name__ == "__main__":
185 | gpu_count = 1
186 | run(sample, get_cfg_defaults(), description='SoftIntroVAE-figure-reconstructions-paged',
187 | default_config='./configs/ffhq256.yaml',
188 | world_size=gpu_count, write_log=False)
189 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/make_figures/make_recon_figure_interpolation.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020-2021 Tal Daniel
2 | # Copyright 2019-2020 Stanislav Pidhorskyi
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | # ==============================================================================
16 |
17 | import torch.utils.data
18 | from torchvision.utils import save_image
19 | from net import *
20 | from model import SoftIntroVAEModelTL
21 | from launcher import run
22 | from checkpointer import Checkpointer
23 | from defaults import get_cfg_defaults
24 | import lreq
25 | from PIL import Image
26 |
27 | lreq.use_implicit_lreq.set(True)
28 |
29 |
30 | def millify(n):
31 | millnames = ['', 'k', 'M', 'G', 'T', 'P']
32 | n = float(n)
33 | millidx = max(0, min(len(millnames) - 1, int(math.floor(0 if n == 0 else math.log10(abs(n)) / 3))))
34 |
35 | return '{:.1f}{}'.format(n / 10 ** (3 * millidx), millnames[millidx])
36 |
37 |
38 | def count_parameters(model, print_func=print, verbose=False):
39 | for n, p in model.named_parameters():
40 | if p.requires_grad and verbose:
41 | print_func(n, millify(p.numel()))
42 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
43 |
44 |
45 | def place(canvas, image, x, y):
46 | im_size = image.shape[2]
47 | if len(image.shape) == 4:
48 | image = image[0]
49 | canvas[:, y: y + im_size, x: x + im_size] = image * 0.5 + 0.5
50 |
51 |
52 | def save_sample(model, sample, i):
53 | os.makedirs('results', exist_ok=True)
54 |
55 | with torch.no_grad():
56 | model.eval()
57 | x_rec = model.generate(model.generator.layer_count - 1, 1, z=sample)
58 |
59 | def save_pic(x_rec):
60 | resultsample = x_rec * 0.5 + 0.5
61 | resultsample = resultsample.cpu()
62 | save_image(resultsample,
63 | 'sample_%i_lr.png' % i, nrow=16)
64 |
65 | save_pic(x_rec)
66 |
67 |
68 | def sample(cfg, logger):
69 | torch.cuda.set_device(0)
70 | model = SoftIntroVAEModelTL(
71 | startf=cfg.MODEL.START_CHANNEL_COUNT,
72 | layer_count=cfg.MODEL.LAYER_COUNT,
73 | maxf=cfg.MODEL.MAX_CHANNEL_COUNT,
74 | latent_size=cfg.MODEL.LATENT_SPACE_SIZE,
75 | dlatent_avg_beta=cfg.MODEL.DLATENT_AVG_BETA,
76 | style_mixing_prob=cfg.MODEL.STYLE_MIXING_PROB,
77 | mapping_layers=cfg.MODEL.MAPPING_LAYERS,
78 | channels=cfg.MODEL.CHANNELS,
79 | generator=cfg.MODEL.GENERATOR,
80 | encoder=cfg.MODEL.ENCODER,
81 | beta_kl=cfg.MODEL.BETA_KL,
82 | beta_rec=cfg.MODEL.BETA_REC,
83 | beta_neg=cfg.MODEL.BETA_NEG[cfg.MODEL.LAYER_COUNT - 1],
84 | scale=cfg.MODEL.SCALE
85 | )
86 | model.cuda(0)
87 | model.eval()
88 | model.requires_grad_(False)
89 |
90 | decoder = model.decoder
91 | encoder = model.encoder
92 | mapping_tl = model.mapping_tl
93 | mapping_fl = model.mapping_fl
94 | dlatent_avg = model.dlatent_avg
95 |
96 | logger.info("Trainable parameters decoder:")
97 | print(count_parameters(decoder))
98 |
99 | logger.info("Trainable parameters encoder:")
100 | print(count_parameters(encoder))
101 |
102 | arguments = dict()
103 | arguments["iteration"] = 0
104 |
105 | model_dict = {
106 | 'discriminator_s': encoder,
107 | 'generator_s': decoder,
108 | 'mapping_tl_s': mapping_tl,
109 | 'mapping_fl_s': mapping_fl,
110 | 'dlatent_avg': dlatent_avg
111 | }
112 |
113 | checkpointer = Checkpointer(cfg,
114 | model_dict,
115 | {},
116 | logger=logger,
117 | save=False)
118 |
119 | extra_checkpoint_data = checkpointer.load()
120 |
121 | model.eval()
122 |
123 | layer_count = cfg.MODEL.LAYER_COUNT
124 |
125 | def encode(x):
126 | z, mu, _ = model.encode(x, layer_count - 1, 1)
127 | styles = model.mapping_fl(mu)
128 | return styles
129 |
130 | def decode(x):
131 | return model.decoder(x, layer_count - 1, 1, noise=True)
132 |
133 | rnd = np.random.RandomState(4)
134 |
135 | path = cfg.DATASET.SAMPLES_PATH
136 | im_size = 2 ** (cfg.MODEL.LAYER_COUNT + 1)
137 |
138 | pathA = '00001.png'
139 | pathB = '00022.png'
140 | pathC = '00077.png'
141 | pathD = '00016.png'
142 |
143 | def open_image(filename):
144 | img = np.asarray(Image.open(path + '/' + filename))
145 | if img.shape[2] == 4:
146 | img = img[:, :, :3]
147 | im = img.transpose((2, 0, 1))
148 | x = torch.tensor(np.asarray(im, dtype=np.float32), device='cpu', requires_grad=True).cuda() / 127.5 - 1.
149 | if x.shape[0] == 4:
150 | x = x[:3]
151 | factor = x.shape[2] // im_size
152 | if factor != 1:
153 | x = torch.nn.functional.avg_pool2d(x[None, ...], factor, factor)[0]
154 | assert x.shape[2] == im_size
155 | _latents = encode(x[None, ...].cuda())
156 | latents = _latents[0, 0]
157 | return latents
158 |
159 | def make(w):
160 | with torch.no_grad():
161 | w = w[None, None, ...].repeat(1, model.mapping_fl.num_layers, 1)
162 | x_rec = decode(w)
163 | return x_rec
164 |
165 | wa = open_image(pathA)
166 | wb = open_image(pathB)
167 | wc = open_image(pathC)
168 | wd = open_image(pathD)
169 |
170 | height = 7
171 | width = 7
172 |
173 | images = []
174 |
175 | for i in range(height):
176 | for j in range(width):
177 | kv = i / (height - 1.0)
178 | kh = j / (width - 1.0)
179 |
180 | ka = (1.0 - kh) * (1.0 - kv)
181 | kb = kh * (1.0 - kv)
182 | kc = (1.0 - kh) * kv
183 | kd = kh * kv
184 |
185 | w = ka * wa + kb * wb + kc * wc + kd * wd
186 |
187 | interpolated = make(w)
188 | images.append(interpolated)
189 |
190 | images = torch.cat(images)
191 |
192 | path = './make_figures/output'
193 | os.makedirs(path, exist_ok=True)
194 | os.makedirs(os.path.join(path, cfg.NAME), exist_ok=True)
195 |
196 | save_image(images * 0.5 + 0.5, './make_figures/output/%s/interpolations.png' % cfg.NAME, nrow=width)
197 | save_image(images * 0.5 + 0.5, './make_figures/output/%s/interpolations.jpg' % cfg.NAME, nrow=width)
198 |
199 |
200 | if __name__ == "__main__":
201 | gpu_count = 1
202 | run(sample, get_cfg_defaults(), description='SoftIntroVAE-interpolations', default_config='./configs/ffhq256.yaml',
203 | world_size=gpu_count, write_log=False)
204 |
--------------------------------------------------------------------------------
/style_soft_intro_vae/README.md:
--------------------------------------------------------------------------------
1 | # style-soft-intro-vae-pytorch
2 |
3 | Implementation of Style Soft-IntroVAE for image data.
4 |
5 | This codes builds upon the original Adversarial Latent Autoencoders (ALAE) implementation by Stanislav Pidhorskyi.
6 | Please see the [official repository](https://github.com/podgorskiy/ALAE) for a more detailed explanation of the files and how to get the datasets.
7 | The authors would like to thank Stanislav Pidhorskyi, Donald A. Adjeroh and Gianfranco Doretto for their great work which inspired this implementation.
8 |
9 |
10 |  11 |
11 |  12 |
12 |
13 |
14 |
15 | 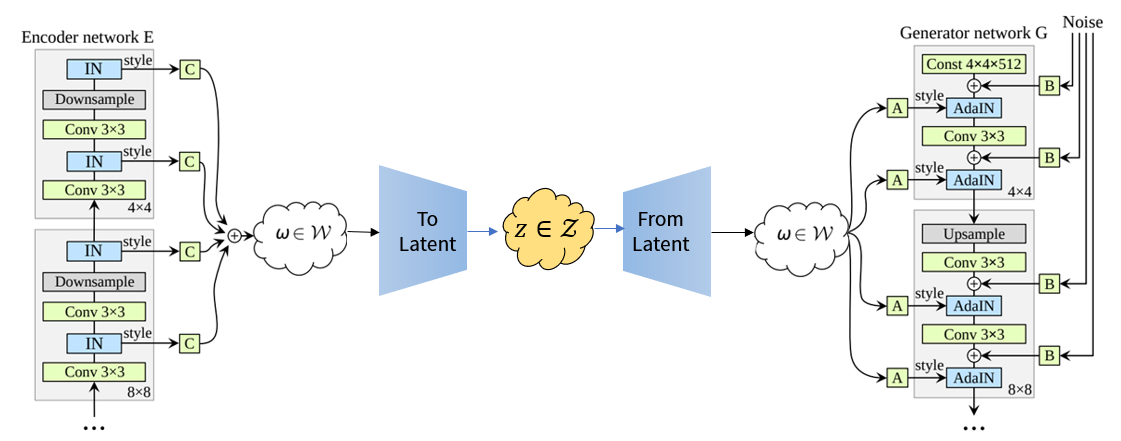 16 |
16 |
17 |
18 | - [style-soft-intro-vae-pytorch](#style-soft-intro-vae-pytorch)
19 | * [Requirements](#requirements)
20 | * [Training](#training)
21 | * [Datasets](#datasets)
22 | * [Pretrained models](#pretrained-models)
23 | * [Recommended hyperparameters](#recommended-hyperparameters)
24 | * [What to expect](#what-to-expect)
25 | * [Files and directories in the repository](#files-and-directories-in-the-repository)
26 | * [Credits](#credits)
27 |
28 | ## Requirements
29 |
30 | * Please see ALAE's repository for explanation of the requirements and how to get them.
31 | * We provide an `environment.yml` file for `conda`, which installs all that is needed to run the files, in an environment called `tf_torch`.
32 | * `conda env create -f environment.yml`
33 | * The required packages are located in the `requirements.txt` file.
34 | * `pip install -r requirements.txt`
35 | * If you installed the environment using the `environment.yml` file, there is no need to use the `requirements.txt` file.
36 | * As in the original ALAE repository, the code is organized in such a way that all scripts must be run from the root of the repository.
37 | * If you use an IDE (e.g. PyCharm or Visual Studio Code), just set Working Directory to point to the root of the repository.
38 | * If you want to run from the command line, then you also need to set PYTHONPATH variable to point to the root of the repository.
39 | * Run `$ export PYTHONPATH=$PYTHONPATH:$(pwd)` in the root directory.
40 |
41 | ## Training
42 |
43 | * This implementation uses the [DareBlopy](https://github.com/podgorskiy/DareBlopy) package to load the data.
44 | * `pip install dareblopy` (in addition to the `pip install -r requirements.txt`)
45 | * TL;DR: read TFRecords files in PyTorch, for better utilization of the data loading, train faster.
46 |
47 | To run training:
48 |
49 | `python train_style_soft_intro_vae.py -c `
50 |
51 | * Configs are located in the `configs` directory, edit them to change the hyperparameters.
52 | * It will run multi-GPU training on all available GPUs. It uses DistributedDataParallel for parallelism. If only one GPU available, it will run on single GPU, no special care is needed.
53 | * To modify the visible GPUs, edit the line: `os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1, 2, 3"` in the `train_style_soft_intro_vae.py` file.
54 |
55 | Examples:
56 |
57 | `python train_style_soft_intro_vae.py` (FFHQ)
58 |
59 | `python train_style_soft_intro_vae.py -c ./configs/celeba-hq256`
60 |
61 |
62 | ## Datasets
63 | * CelebHQ: please follow [ALAE](https://github.com/podgorskiy/ALAE#datasets) instructions.
64 | * FFHQ: please see the following repository [Flickr-Faces-HQ Dataset (FFHQ)](https://github.com/NVlabs/ffhq-dataset).
65 |
66 | ## Pretrained models
67 | |Dataset | Filename | Where to Put| Links|
68 | |------------|------|----|---|
69 | |CelebA-HQ (256x256)|`celebahq_fid_18.63_epoch_230.pth` |`training_artifacts/celeba-hq256`|[MEGA.co.nz](https://mega.nz/file/sJkS2BAC#aGFwJIPvOTIP147GwBGHOJgwRMC_NYKHT_QK7abb0VE), [Mediafire](https://www.mediafire.com/file/fgf0a85z5d0jtu5/celebahq_fid_18.63_epoch_230.pth/file) |
70 | |FFHQ (256x256)|`ffhq_fid_17.55_epoch_270.pth` |`training_artifacts/ffhq` | [MEGA.co.nz](https://mega.nz/file/YJ1SkBwI#9t0ZEZTC0WWG0NUsJg2OwZujOuUXKn_ehP6fba1pV7o), [Mediafire](https://www.mediafire.com/file/x6jkyg4rlkqc4hl/ffhq_fid_17.55_epoch_270.pth/file) |
71 |
72 | * In config files, `OUTPUT_DIR` points to where weights are saved to and read from. For example: `OUTPUT_DIR: training_artifacts/celeba-hq256`.
73 |
74 | * In `OUTPUT_DIR` it saves a file `last_checkpoint` which contains the path to the actual `.pth` pickle with model weight. If you want to test the model with a specific weight file, you can simply modify `last_checkpoint` file.
75 |
76 | ## Recommended hyperparameters
77 |
78 | |Dataset | `beta_kl` | `beta_rec`| `beta_neg`|`z_dim`|
79 | |------------|------|----|---|----|
80 | |FFHQ (256x256)|0.2|0.05| 512|512|
81 | |CelebA-HQ (256x256)|0.2|0.1| 512|512|
82 |
83 |
84 | ## What to expect
85 |
86 | * During the training, figures of samples and reconstructions are saved locally.
87 | * During training, statistics are printed (reconstruction error, KLD, expELBO).
88 | * In the final resolution stage (256x256), FID will be calculated every 10 epcohs.
89 | * Tips:
90 | * KL of fake/rec samples should be > KL of real data (by a fair margin).
91 | * It is usually better to choose `beta_kl` >= `beta_rec`.
92 | * We stick to ALAE's original architecture hyperparameters, and mostly didn't change their configs.
93 |
94 |
95 | ## Files and directories in the repository
96 |
97 | * For a full description, please ALAE's repository.
98 |
99 | |File name | Purpose |
100 | |----------------------|------|
101 | |`train_style_soft_intro_vae.py`| main training function|
102 | |`checkpointer.py`| module for saving/restoring model weights, optimizer state and loss history.|
103 | |`custom_adam.py`| customized adam optimizer for learning rate equalization and zero second beta.|
104 | |`dataloader.py`| module with dataset classes, loaders, iterators, etc.|
105 | |`defaults.py`| definition for config variables with default values.|
106 | |`launcher.py`| helper for running multi-GPU, multiprocess training. Sets up config and logging.|
107 | |`lod_driver.py`| helper class for managing growing/stabilizing network.|
108 | |`lreq.py`| custom `Linear`, `Conv2d` and `ConvTranspose2d` modules for learning rate equalization.|
109 | |`model.py`| module with high-level model definition.|
110 | |`net.py`| definition of all network blocks for multiple architectures.|
111 | |`registry.py`| registry of network blocks for selecting from config file.|
112 | |`scheduler.py`| custom schedulers with warm start and aggregating several optimizers.|
113 | |`tracker.py`| module for plotting losses.|
114 | |`utils.py`| decorator for async call, decorator for caching, registry for network blocks.|
115 | |`configs/celeba-hq256.yaml`, `configs/ffhq256.yaml`| config file for CelebA-HQ and FFHQ datasets at 256x256 resolution.|
116 | |`dataset_preparation/`| folder with scripts for dataset preparation (creating and splitting TFRecords files).|
117 | |`make_figures/`| scripts for making various figures.|
118 | |`metrics/fid_score.py`, `metrics/inception.py`| functions for FID calculation from datasets, using the pretrained Inception network|
119 | |` training_artifacts/`| default folder for saving checkpoints/sample outputs/plots.|
120 |
121 | ## Credits
122 | * Adversarial Latent Autoencoders, Pidhorskyi et al., CVPR 2020 - [Code](https://github.com/podgorskiy/ALAE), [Paper](https://arxiv.org/abs/2004.04467).
123 |
124 |
--------------------------------------------------------------------------------
/soft_intro_vae_3d/render/render_mitsuba2_pc.py:
--------------------------------------------------------------------------------
1 | """
2 | Render Point Clouds with Mitsuba Renderer.
3 | Adpated from: https://github.com/tolgabirdal/Mitsuba2PointCloudRenderer
4 | """
5 |
6 | import numpy as np
7 | import sys, os, subprocess
8 | import OpenEXR
9 | import Imath
10 | from PIL import Image
11 | from plyfile import PlyData, PlyElement
12 |
13 | # mitsuba exectuable - EDIT WITH YOUR OWN INSTALLATION PATH
14 | PATH_TO_MITSUBA2 = "/home/tal/mitsuba2/mitsuba2/build/dist/mitsuba"
15 |
16 | # replaced by command line arguments
17 | # PATH_TO_NPY = 'pcl_ex.npy' # the tensor to load
18 |
19 | # note that sampler is changed to 'independent' and the ldrfilm is changed to hdrfilm
20 | xml_head = \
21 | """
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 | """
51 |
52 | # I also use a smaller point size
53 | xml_ball_segment = \
54 | """
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 | """
65 |
66 | xml_tail = \
67 | """
68 |
69 |