├── .clang-format
├── .gitattributes
├── .gitignore
├── Benchmark1.png
├── Benchmarks
├── Benchmarks.vcxproj
├── Benchmarks.vcxproj.filters
├── EigenBenchmark.cpp
├── IntrinASMDotBenchmark.cpp
├── IntrinsicSumBenchmarks.cpp
└── NumpyBenchmark.py
├── MatrixGenerator
├── MatrixGenerator.cpp
├── MatrixGenerator.vcxproj
└── MatrixGenerator.vcxproj.filters
├── MatrixMult.sln
├── MatrixMult
├── CPUUtil.cpp
├── CPUUtil.h
├── MatrixMul.cpp
├── MatrixMult.vcxproj
├── MatrixMult.vcxproj.filters
└── ThreadPool.h
├── README.md
├── benchmark.xlsx
└── run.bat
/.clang-format:
--------------------------------------------------------------------------------
1 | # SPDX-License-Identifier: GPL-2.0
2 | #
3 | # clang-format configuration file. Intended for clang-format >= 4.
4 | #
5 | # For more information, see:
6 | #
7 | # Documentation/process/clang-format.rst
8 | # https://clang.llvm.org/docs/ClangFormat.html
9 | # https://clang.llvm.org/docs/ClangFormatStyleOptions.html
10 | #
11 | ---
12 | AccessModifierOffset: -4
13 | AlignAfterOpenBracket: Align
14 | AlignConsecutiveAssignments: false
15 | AlignConsecutiveDeclarations: false
16 | #AlignEscapedNewlines: Left # Unknown to clang-format-4.0
17 | AlignOperands: true
18 | AlignTrailingComments: false
19 | AllowAllParametersOfDeclarationOnNextLine: false
20 | AllowShortBlocksOnASingleLine: false
21 | AllowShortCaseLabelsOnASingleLine: false
22 | AllowShortFunctionsOnASingleLine: None
23 | AllowShortIfStatementsOnASingleLine: false
24 | AllowShortLoopsOnASingleLine: false
25 | AlwaysBreakAfterDefinitionReturnType: None
26 | AlwaysBreakAfterReturnType: None
27 | AlwaysBreakBeforeMultilineStrings: false
28 | AlwaysBreakTemplateDeclarations: false
29 | BinPackArguments: true
30 | BinPackParameters: true
31 | BraceWrapping:
32 | AfterClass: false
33 | AfterControlStatement: false
34 | AfterEnum: false
35 | AfterFunction: true
36 | AfterNamespace: true
37 | AfterObjCDeclaration: false
38 | AfterStruct: false
39 | AfterUnion: false
40 | #AfterExternBlock: false # Unknown to clang-format-5.0
41 | BeforeCatch: false
42 | BeforeElse: false
43 | IndentBraces: false
44 | #SplitEmptyFunction: true # Unknown to clang-format-4.0
45 | #SplitEmptyRecord: true # Unknown to clang-format-4.0
46 | #SplitEmptyNamespace: true # Unknown to clang-format-4.0
47 | BreakBeforeBinaryOperators: None
48 | BreakBeforeBraces: Custom
49 | #BreakBeforeInheritanceComma: false # Unknown to clang-format-4.0
50 | BreakBeforeTernaryOperators: false
51 | BreakConstructorInitializersBeforeComma: false
52 | #BreakConstructorInitializers: BeforeComma # Unknown to clang-format-4.0
53 | BreakAfterJavaFieldAnnotations: false
54 | BreakStringLiterals: false
55 | ColumnLimit: 88
56 | CommentPragmas: '^ IWYU pragma:'
57 | #CompactNamespaces: false # Unknown to clang-format-4.0
58 | ConstructorInitializerAllOnOneLineOrOnePerLine: false
59 | ConstructorInitializerIndentWidth: 4
60 | ContinuationIndentWidth: 2
61 | Cpp11BracedListStyle: true
62 | DerivePointerAlignment: false
63 | DisableFormat: false
64 | ExperimentalAutoDetectBinPacking: false
65 | #FixNamespaceComments: false # Unknown to clang-format-4.0
66 |
67 | # Taken from:
68 | # git grep -h '^#define [^[:space:]]*for_each[^[:space:]]*(' include/ \
69 | # | sed "s,^#define \([^[:space:]]*for_each[^[:space:]]*\)(.*$, - '\1'," \
70 | # | sort | uniq
71 | ForEachMacros:
72 | - 'apei_estatus_for_each_section'
73 | - 'ata_for_each_dev'
74 | - 'ata_for_each_link'
75 | - 'ax25_for_each'
76 | - 'ax25_uid_for_each'
77 | - 'bio_for_each_integrity_vec'
78 | - '__bio_for_each_segment'
79 | - 'bio_for_each_segment'
80 | - 'bio_for_each_segment_all'
81 | - 'bio_list_for_each'
82 | - 'bip_for_each_vec'
83 | - 'blkg_for_each_descendant_post'
84 | - 'blkg_for_each_descendant_pre'
85 | - 'blk_queue_for_each_rl'
86 | - 'bond_for_each_slave'
87 | - 'bond_for_each_slave_rcu'
88 | - 'btree_for_each_safe128'
89 | - 'btree_for_each_safe32'
90 | - 'btree_for_each_safe64'
91 | - 'btree_for_each_safel'
92 | - 'card_for_each_dev'
93 | - 'cgroup_taskset_for_each'
94 | - 'cgroup_taskset_for_each_leader'
95 | - 'cpufreq_for_each_entry'
96 | - 'cpufreq_for_each_entry_idx'
97 | - 'cpufreq_for_each_valid_entry'
98 | - 'cpufreq_for_each_valid_entry_idx'
99 | - 'css_for_each_child'
100 | - 'css_for_each_descendant_post'
101 | - 'css_for_each_descendant_pre'
102 | - 'device_for_each_child_node'
103 | - 'drm_atomic_crtc_for_each_plane'
104 | - 'drm_atomic_crtc_state_for_each_plane'
105 | - 'drm_atomic_crtc_state_for_each_plane_state'
106 | - 'drm_for_each_connector_iter'
107 | - 'drm_for_each_crtc'
108 | - 'drm_for_each_encoder'
109 | - 'drm_for_each_encoder_mask'
110 | - 'drm_for_each_fb'
111 | - 'drm_for_each_legacy_plane'
112 | - 'drm_for_each_plane'
113 | - 'drm_for_each_plane_mask'
114 | - 'drm_mm_for_each_hole'
115 | - 'drm_mm_for_each_node'
116 | - 'drm_mm_for_each_node_in_range'
117 | - 'drm_mm_for_each_node_safe'
118 | - 'for_each_active_drhd_unit'
119 | - 'for_each_active_iommu'
120 | - 'for_each_available_child_of_node'
121 | - 'for_each_bio'
122 | - 'for_each_board_func_rsrc'
123 | - 'for_each_bvec'
124 | - 'for_each_child_of_node'
125 | - 'for_each_clear_bit'
126 | - 'for_each_clear_bit_from'
127 | - 'for_each_cmsghdr'
128 | - 'for_each_compatible_node'
129 | - 'for_each_console'
130 | - 'for_each_cpu'
131 | - 'for_each_cpu_and'
132 | - 'for_each_cpu_not'
133 | - 'for_each_cpu_wrap'
134 | - 'for_each_dev_addr'
135 | - 'for_each_dma_cap_mask'
136 | - 'for_each_drhd_unit'
137 | - 'for_each_dss_dev'
138 | - 'for_each_efi_memory_desc'
139 | - 'for_each_efi_memory_desc_in_map'
140 | - 'for_each_endpoint_of_node'
141 | - 'for_each_evictable_lru'
142 | - 'for_each_fib6_node_rt_rcu'
143 | - 'for_each_fib6_walker_rt'
144 | - 'for_each_free_mem_range'
145 | - 'for_each_free_mem_range_reverse'
146 | - 'for_each_func_rsrc'
147 | - 'for_each_hstate'
148 | - 'for_each_if'
149 | - 'for_each_iommu'
150 | - 'for_each_ip_tunnel_rcu'
151 | - 'for_each_irq_nr'
152 | - 'for_each_lru'
153 | - 'for_each_matching_node'
154 | - 'for_each_matching_node_and_match'
155 | - 'for_each_memblock'
156 | - 'for_each_memblock_type'
157 | - 'for_each_memcg_cache_index'
158 | - 'for_each_mem_pfn_range'
159 | - 'for_each_mem_range'
160 | - 'for_each_mem_range_rev'
161 | - 'for_each_migratetype_order'
162 | - 'for_each_msi_entry'
163 | - 'for_each_net'
164 | - 'for_each_netdev'
165 | - 'for_each_netdev_continue'
166 | - 'for_each_netdev_continue_rcu'
167 | - 'for_each_netdev_feature'
168 | - 'for_each_netdev_in_bond_rcu'
169 | - 'for_each_netdev_rcu'
170 | - 'for_each_netdev_reverse'
171 | - 'for_each_netdev_safe'
172 | - 'for_each_net_rcu'
173 | - 'for_each_new_connector_in_state'
174 | - 'for_each_new_crtc_in_state'
175 | - 'for_each_new_plane_in_state'
176 | - 'for_each_new_private_obj_in_state'
177 | - 'for_each_node'
178 | - 'for_each_node_by_name'
179 | - 'for_each_node_by_type'
180 | - 'for_each_node_mask'
181 | - 'for_each_node_state'
182 | - 'for_each_node_with_cpus'
183 | - 'for_each_node_with_property'
184 | - 'for_each_of_allnodes'
185 | - 'for_each_of_allnodes_from'
186 | - 'for_each_of_pci_range'
187 | - 'for_each_old_connector_in_state'
188 | - 'for_each_old_crtc_in_state'
189 | - 'for_each_oldnew_connector_in_state'
190 | - 'for_each_oldnew_crtc_in_state'
191 | - 'for_each_oldnew_plane_in_state'
192 | - 'for_each_oldnew_private_obj_in_state'
193 | - 'for_each_old_plane_in_state'
194 | - 'for_each_old_private_obj_in_state'
195 | - 'for_each_online_cpu'
196 | - 'for_each_online_node'
197 | - 'for_each_online_pgdat'
198 | - 'for_each_pci_bridge'
199 | - 'for_each_pci_dev'
200 | - 'for_each_pci_msi_entry'
201 | - 'for_each_populated_zone'
202 | - 'for_each_possible_cpu'
203 | - 'for_each_present_cpu'
204 | - 'for_each_prime_number'
205 | - 'for_each_prime_number_from'
206 | - 'for_each_process'
207 | - 'for_each_process_thread'
208 | - 'for_each_property_of_node'
209 | - 'for_each_reserved_mem_region'
210 | - 'for_each_resv_unavail_range'
211 | - 'for_each_rtdcom'
212 | - 'for_each_rtdcom_safe'
213 | - 'for_each_set_bit'
214 | - 'for_each_set_bit_from'
215 | - 'for_each_sg'
216 | - 'for_each_sg_page'
217 | - '__for_each_thread'
218 | - 'for_each_thread'
219 | - 'for_each_zone'
220 | - 'for_each_zone_zonelist'
221 | - 'for_each_zone_zonelist_nodemask'
222 | - 'fwnode_for_each_available_child_node'
223 | - 'fwnode_for_each_child_node'
224 | - 'fwnode_graph_for_each_endpoint'
225 | - 'gadget_for_each_ep'
226 | - 'hash_for_each'
227 | - 'hash_for_each_possible'
228 | - 'hash_for_each_possible_rcu'
229 | - 'hash_for_each_possible_rcu_notrace'
230 | - 'hash_for_each_possible_safe'
231 | - 'hash_for_each_rcu'
232 | - 'hash_for_each_safe'
233 | - 'hctx_for_each_ctx'
234 | - 'hlist_bl_for_each_entry'
235 | - 'hlist_bl_for_each_entry_rcu'
236 | - 'hlist_bl_for_each_entry_safe'
237 | - 'hlist_for_each'
238 | - 'hlist_for_each_entry'
239 | - 'hlist_for_each_entry_continue'
240 | - 'hlist_for_each_entry_continue_rcu'
241 | - 'hlist_for_each_entry_continue_rcu_bh'
242 | - 'hlist_for_each_entry_from'
243 | - 'hlist_for_each_entry_from_rcu'
244 | - 'hlist_for_each_entry_rcu'
245 | - 'hlist_for_each_entry_rcu_bh'
246 | - 'hlist_for_each_entry_rcu_notrace'
247 | - 'hlist_for_each_entry_safe'
248 | - '__hlist_for_each_rcu'
249 | - 'hlist_for_each_safe'
250 | - 'hlist_nulls_for_each_entry'
251 | - 'hlist_nulls_for_each_entry_from'
252 | - 'hlist_nulls_for_each_entry_rcu'
253 | - 'hlist_nulls_for_each_entry_safe'
254 | - 'ide_host_for_each_port'
255 | - 'ide_port_for_each_dev'
256 | - 'ide_port_for_each_present_dev'
257 | - 'idr_for_each_entry'
258 | - 'idr_for_each_entry_continue'
259 | - 'idr_for_each_entry_ul'
260 | - 'inet_bind_bucket_for_each'
261 | - 'inet_lhash2_for_each_icsk_rcu'
262 | - 'iov_for_each'
263 | - 'key_for_each'
264 | - 'key_for_each_safe'
265 | - 'klp_for_each_func'
266 | - 'klp_for_each_object'
267 | - 'kvm_for_each_memslot'
268 | - 'kvm_for_each_vcpu'
269 | - 'list_for_each'
270 | - 'list_for_each_entry'
271 | - 'list_for_each_entry_continue'
272 | - 'list_for_each_entry_continue_rcu'
273 | - 'list_for_each_entry_continue_reverse'
274 | - 'list_for_each_entry_from'
275 | - 'list_for_each_entry_from_reverse'
276 | - 'list_for_each_entry_lockless'
277 | - 'list_for_each_entry_rcu'
278 | - 'list_for_each_entry_reverse'
279 | - 'list_for_each_entry_safe'
280 | - 'list_for_each_entry_safe_continue'
281 | - 'list_for_each_entry_safe_from'
282 | - 'list_for_each_entry_safe_reverse'
283 | - 'list_for_each_prev'
284 | - 'list_for_each_prev_safe'
285 | - 'list_for_each_safe'
286 | - 'llist_for_each'
287 | - 'llist_for_each_entry'
288 | - 'llist_for_each_entry_safe'
289 | - 'llist_for_each_safe'
290 | - 'media_device_for_each_entity'
291 | - 'media_device_for_each_intf'
292 | - 'media_device_for_each_link'
293 | - 'media_device_for_each_pad'
294 | - 'netdev_for_each_lower_dev'
295 | - 'netdev_for_each_lower_private'
296 | - 'netdev_for_each_lower_private_rcu'
297 | - 'netdev_for_each_mc_addr'
298 | - 'netdev_for_each_uc_addr'
299 | - 'netdev_for_each_upper_dev_rcu'
300 | - 'netdev_hw_addr_list_for_each'
301 | - 'nft_rule_for_each_expr'
302 | - 'nla_for_each_attr'
303 | - 'nla_for_each_nested'
304 | - 'nlmsg_for_each_attr'
305 | - 'nlmsg_for_each_msg'
306 | - 'nr_neigh_for_each'
307 | - 'nr_neigh_for_each_safe'
308 | - 'nr_node_for_each'
309 | - 'nr_node_for_each_safe'
310 | - 'of_for_each_phandle'
311 | - 'of_property_for_each_string'
312 | - 'of_property_for_each_u32'
313 | - 'pci_bus_for_each_resource'
314 | - 'ping_portaddr_for_each_entry'
315 | - 'plist_for_each'
316 | - 'plist_for_each_continue'
317 | - 'plist_for_each_entry'
318 | - 'plist_for_each_entry_continue'
319 | - 'plist_for_each_entry_safe'
320 | - 'plist_for_each_safe'
321 | - 'pnp_for_each_card'
322 | - 'pnp_for_each_dev'
323 | - 'protocol_for_each_card'
324 | - 'protocol_for_each_dev'
325 | - 'queue_for_each_hw_ctx'
326 | - 'radix_tree_for_each_slot'
327 | - 'radix_tree_for_each_tagged'
328 | - 'rbtree_postorder_for_each_entry_safe'
329 | - 'resource_list_for_each_entry'
330 | - 'resource_list_for_each_entry_safe'
331 | - 'rhl_for_each_entry_rcu'
332 | - 'rhl_for_each_rcu'
333 | - 'rht_for_each'
334 | - 'rht_for_each_continue'
335 | - 'rht_for_each_entry'
336 | - 'rht_for_each_entry_continue'
337 | - 'rht_for_each_entry_rcu'
338 | - 'rht_for_each_entry_rcu_continue'
339 | - 'rht_for_each_entry_safe'
340 | - 'rht_for_each_rcu'
341 | - 'rht_for_each_rcu_continue'
342 | - '__rq_for_each_bio'
343 | - 'rq_for_each_segment'
344 | - 'scsi_for_each_prot_sg'
345 | - 'scsi_for_each_sg'
346 | - 'sctp_for_each_hentry'
347 | - 'sctp_skb_for_each'
348 | - 'shdma_for_each_chan'
349 | - '__shost_for_each_device'
350 | - 'shost_for_each_device'
351 | - 'sk_for_each'
352 | - 'sk_for_each_bound'
353 | - 'sk_for_each_entry_offset_rcu'
354 | - 'sk_for_each_from'
355 | - 'sk_for_each_rcu'
356 | - 'sk_for_each_safe'
357 | - 'sk_nulls_for_each'
358 | - 'sk_nulls_for_each_from'
359 | - 'sk_nulls_for_each_rcu'
360 | - 'snd_pcm_group_for_each_entry'
361 | - 'snd_soc_dapm_widget_for_each_path'
362 | - 'snd_soc_dapm_widget_for_each_path_safe'
363 | - 'snd_soc_dapm_widget_for_each_sink_path'
364 | - 'snd_soc_dapm_widget_for_each_source_path'
365 | - 'tb_property_for_each'
366 | - 'udp_portaddr_for_each_entry'
367 | - 'udp_portaddr_for_each_entry_rcu'
368 | - 'usb_hub_for_each_child'
369 | - 'v4l2_device_for_each_subdev'
370 | - 'v4l2_m2m_for_each_dst_buf'
371 | - 'v4l2_m2m_for_each_dst_buf_safe'
372 | - 'v4l2_m2m_for_each_src_buf'
373 | - 'v4l2_m2m_for_each_src_buf_safe'
374 | - 'zorro_for_each_dev'
375 |
376 | #IncludeBlocks: Preserve # Unknown to clang-format-5.0
377 | IncludeCategories:
378 | - Regex: '.*'
379 | Priority: 1
380 | IncludeIsMainRegex: '(Test)?$'
381 | IndentCaseLabels: false
382 | #IndentPPDirectives: None # Unknown to clang-format-5.0
383 | IndentWidth: 4
384 | IndentWrappedFunctionNames: false
385 | JavaScriptQuotes: Leave
386 | JavaScriptWrapImports: true
387 | KeepEmptyLinesAtTheStartOfBlocks: false
388 | MacroBlockBegin: ''
389 | MacroBlockEnd: ''
390 | MaxEmptyLinesToKeep: 1
391 | NamespaceIndentation: All
392 | #ObjCBinPackProtocolList: Auto # Unknown to clang-format-5.0
393 | ObjCBlockIndentWidth: 4
394 | ObjCSpaceAfterProperty: true
395 | ObjCSpaceBeforeProtocolList: true
396 |
397 | # Taken from git's rules
398 | #PenaltyBreakAssignment: 10 # Unknown to clang-format-4.0
399 | PenaltyBreakBeforeFirstCallParameter: 30
400 | PenaltyBreakComment: 10
401 | PenaltyBreakFirstLessLess: 0
402 | PenaltyBreakString: 10
403 | PenaltyExcessCharacter: 100
404 | PenaltyReturnTypeOnItsOwnLine: 60
405 |
406 | PointerAlignment: Left
407 | ReflowComments: false
408 | SortIncludes: false
409 | #SortUsingDeclarations: false # Unknown to clang-format-4.0
410 | SpaceAfterCStyleCast: false
411 | SpaceAfterTemplateKeyword: true
412 | SpaceBeforeAssignmentOperators: true
413 | #SpaceBeforeCtorInitializerColon: true # Unknown to clang-format-5.0
414 | #SpaceBeforeInheritanceColon: true # Unknown to clang-format-5.0
415 | SpaceBeforeParens: ControlStatements
416 | #SpaceBeforeRangeBasedForLoopColon: true # Unknown to clang-format-5.0
417 | SpaceInEmptyParentheses: false
418 | SpacesBeforeTrailingComments: 1
419 | SpacesInAngles: false
420 | SpacesInContainerLiterals: false
421 | SpacesInCStyleCastParentheses: false
422 | SpacesInParentheses: false
423 | SpacesInSquareBrackets: false
424 | Standard: Cpp11
425 | TabWidth: 4
426 | UseTab: Never
427 | ...
428 |
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | ###############################################################################
2 | # Set default behavior to automatically normalize line endings.
3 | ###############################################################################
4 | * text=auto
5 |
6 | ###############################################################################
7 | # Set default behavior for command prompt diff.
8 | #
9 | # This is need for earlier builds of msysgit that does not have it on by
10 | # default for csharp files.
11 | # Note: This is only used by command line
12 | ###############################################################################
13 | #*.cs diff=csharp
14 |
15 | ###############################################################################
16 | # Set the merge driver for project and solution files
17 | #
18 | # Merging from the command prompt will add diff markers to the files if there
19 | # are conflicts (Merging from VS is not affected by the settings below, in VS
20 | # the diff markers are never inserted). Diff markers may cause the following
21 | # file extensions to fail to load in VS. An alternative would be to treat
22 | # these files as binary and thus will always conflict and require user
23 | # intervention with every merge. To do so, just uncomment the entries below
24 | ###############################################################################
25 | #*.sln merge=binary
26 | #*.csproj merge=binary
27 | #*.vbproj merge=binary
28 | #*.vcxproj merge=binary
29 | #*.vcproj merge=binary
30 | #*.dbproj merge=binary
31 | #*.fsproj merge=binary
32 | #*.lsproj merge=binary
33 | #*.wixproj merge=binary
34 | #*.modelproj merge=binary
35 | #*.sqlproj merge=binary
36 | #*.wwaproj merge=binary
37 |
38 | ###############################################################################
39 | # behavior for image files
40 | #
41 | # image files are treated as binary by default.
42 | ###############################################################################
43 | #*.jpg binary
44 | #*.png binary
45 | #*.gif binary
46 |
47 | ###############################################################################
48 | # diff behavior for common document formats
49 | #
50 | # Convert binary document formats to text before diffing them. This feature
51 | # is only available from the command line. Turn it on by uncommenting the
52 | # entries below.
53 | ###############################################################################
54 | #*.doc diff=astextplain
55 | #*.DOC diff=astextplain
56 | #*.docx diff=astextplain
57 | #*.DOCX diff=astextplain
58 | #*.dot diff=astextplain
59 | #*.DOT diff=astextplain
60 | #*.pdf diff=astextplain
61 | #*.PDF diff=astextplain
62 | #*.rtf diff=astextplain
63 | #*.RTF diff=astextplain
64 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | ## Ignore Visual Studio temporary files, build results, and
2 | ## files generated by popular Visual Studio add-ons.
3 |
4 | # User-specific files
5 | *.suo
6 | *.user
7 | *.userosscache
8 | *.sln.docstates
9 |
10 | # User-specific files (MonoDevelop/Xamarin Studio)
11 | *.userprefs
12 |
13 | # Build results
14 | [Dd]ebug/
15 | [Dd]ebugPublic/
16 | [Rr]elease/
17 | [Rr]eleases/
18 | x64/
19 | x86/
20 | bld/
21 | [Bb]in/
22 | [Oo]bj/
23 | [Ll]og/
24 |
25 | # Visual Studio 2015 cache/options directory
26 | .vs/
27 | # Uncomment if you have tasks that create the project's static files in wwwroot
28 | #wwwroot/
29 |
30 | # MSTest test Results
31 | [Tt]est[Rr]esult*/
32 | [Bb]uild[Ll]og.*
33 |
34 | # NUNIT
35 | *.VisualState.xml
36 | TestResult.xml
37 |
38 | # Build Results of an ATL Project
39 | [Dd]ebugPS/
40 | [Rr]eleasePS/
41 | dlldata.c
42 |
43 | # DNX
44 | project.lock.json
45 | project.fragment.lock.json
46 | artifacts/
47 |
48 | *_i.c
49 | *_p.c
50 | *_i.h
51 | *.ilk
52 | *.meta
53 | *.obj
54 | *.pch
55 | *.pdb
56 | *.pgc
57 | *.pgd
58 | *.rsp
59 | *.sbr
60 | *.tlb
61 | *.tli
62 | *.tlh
63 | *.tmp
64 | *.tmp_proj
65 | *.log
66 | *.vspscc
67 | *.vssscc
68 | .builds
69 | *.pidb
70 | *.svclog
71 | *.scc
72 |
73 | # Chutzpah Test files
74 | _Chutzpah*
75 |
76 | # Visual C++ cache files
77 | ipch/
78 | *.aps
79 | *.ncb
80 | *.opendb
81 | *.opensdf
82 | *.sdf
83 | *.cachefile
84 | *.VC.db
85 | *.VC.VC.opendb
86 |
87 | # Visual Studio profiler
88 | *.psess
89 | *.vsp
90 | *.vspx
91 | *.sap
92 |
93 | # TFS 2012 Local Workspace
94 | $tf/
95 |
96 | # Guidance Automation Toolkit
97 | *.gpState
98 |
99 | # ReSharper is a .NET coding add-in
100 | _ReSharper*/
101 | *.[Rr]e[Ss]harper
102 | *.DotSettings.user
103 |
104 | # JustCode is a .NET coding add-in
105 | .JustCode
106 |
107 | # TeamCity is a build add-in
108 | _TeamCity*
109 |
110 | # DotCover is a Code Coverage Tool
111 | *.dotCover
112 |
113 | # NCrunch
114 | _NCrunch_*
115 | .*crunch*.local.xml
116 | nCrunchTemp_*
117 |
118 | # MightyMoose
119 | *.mm.*
120 | AutoTest.Net/
121 |
122 | # Web workbench (sass)
123 | .sass-cache/
124 |
125 | # Installshield output folder
126 | [Ee]xpress/
127 |
128 | # DocProject is a documentation generator add-in
129 | DocProject/buildhelp/
130 | DocProject/Help/*.HxT
131 | DocProject/Help/*.HxC
132 | DocProject/Help/*.hhc
133 | DocProject/Help/*.hhk
134 | DocProject/Help/*.hhp
135 | DocProject/Help/Html2
136 | DocProject/Help/html
137 |
138 | # Click-Once directory
139 | publish/
140 |
141 | # Publish Web Output
142 | *.[Pp]ublish.xml
143 | *.azurePubxml
144 | # TODO: Comment the next line if you want to checkin your web deploy settings
145 | # but database connection strings (with potential passwords) will be unencrypted
146 | #*.pubxml
147 | *.publishproj
148 |
149 | # Microsoft Azure Web App publish settings. Comment the next line if you want to
150 | # checkin your Azure Web App publish settings, but sensitive information contained
151 | # in these scripts will be unencrypted
152 | PublishScripts/
153 |
154 | # NuGet Packages
155 | *.nupkg
156 | # The packages folder can be ignored because of Package Restore
157 | **/packages/*
158 | # except build/, which is used as an MSBuild target.
159 | !**/packages/build/
160 | # Uncomment if necessary however generally it will be regenerated when needed
161 | #!**/packages/repositories.config
162 | # NuGet v3's project.json files produces more ignoreable files
163 | *.nuget.props
164 | *.nuget.targets
165 |
166 | # Microsoft Azure Build Output
167 | csx/
168 | *.build.csdef
169 |
170 | # Microsoft Azure Emulator
171 | ecf/
172 | rcf/
173 |
174 | # Windows Store app package directories and files
175 | AppPackages/
176 | BundleArtifacts/
177 | Package.StoreAssociation.xml
178 | _pkginfo.txt
179 |
180 | # Visual Studio cache files
181 | # files ending in .cache can be ignored
182 | *.[Cc]ache
183 | # but keep track of directories ending in .cache
184 | !*.[Cc]ache/
185 |
186 | # Others
187 | ClientBin/
188 | ~$*
189 | *~
190 | *.dbmdl
191 | *.dbproj.schemaview
192 | *.jfm
193 | *.pfx
194 | *.publishsettings
195 | node_modules/
196 | orleans.codegen.cs
197 |
198 | # Since there are multiple workflows, uncomment next line to ignore bower_components
199 | # (https://github.com/github/gitignore/pull/1529#issuecomment-104372622)
200 | #bower_components/
201 |
202 | # RIA/Silverlight projects
203 | Generated_Code/
204 |
205 | # Backup & report files from converting an old project file
206 | # to a newer Visual Studio version. Backup files are not needed,
207 | # because we have git ;-)
208 | _UpgradeReport_Files/
209 | Backup*/
210 | UpgradeLog*.XML
211 | UpgradeLog*.htm
212 |
213 | # SQL Server files
214 | *.mdf
215 | *.ldf
216 |
217 | # Business Intelligence projects
218 | *.rdl.data
219 | *.bim.layout
220 | *.bim_*.settings
221 |
222 | # Microsoft Fakes
223 | FakesAssemblies/
224 |
225 | # GhostDoc plugin setting file
226 | *.GhostDoc.xml
227 |
228 | # Node.js Tools for Visual Studio
229 | .ntvs_analysis.dat
230 |
231 | # Visual Studio 6 build log
232 | *.plg
233 |
234 | # Visual Studio 6 workspace options file
235 | *.opt
236 |
237 | # Visual Studio LightSwitch build output
238 | **/*.HTMLClient/GeneratedArtifacts
239 | **/*.DesktopClient/GeneratedArtifacts
240 | **/*.DesktopClient/ModelManifest.xml
241 | **/*.Server/GeneratedArtifacts
242 | **/*.Server/ModelManifest.xml
243 | _Pvt_Extensions
244 |
245 | # Paket dependency manager
246 | .paket/paket.exe
247 | paket-files/
248 |
249 | # FAKE - F# Make
250 | .fake/
251 |
252 | # JetBrains Rider
253 | .idea/
254 | *.sln.iml
255 |
256 | # CodeRush
257 | .cr/
258 |
259 | # Python Tools for Visual Studio (PTVS)
260 | __pycache__/
261 | *.pyc
262 | /MatrixMult/matrixB.bin
263 | /MatrixMult/matrixA.bin
264 | /matrixB.bin
265 | /matrixAB.bin
266 | /matrixA.bin
267 | /MatrixMult/matrixAB.bin
268 | /MatrixMult/matrixAB-out.bin
269 | /Benchmarks/My Inspector Results - Benchmarks/My Inspector Results - Benchmarks.inspxeproj
270 | /matrixAB-out.bin
271 | /MatrixMult/My Advisor Results - MatrixMult
272 | /MatrixMult/My Amplifier Results - MatrixMult
273 | /Benchmarks/matrixB.bin
274 | /Benchmarks/matrixAB.bin
275 | /Benchmarks/matrixA.bin
276 | /Benchmarks/My Advisor Results - Benchmarks
277 | /Benchmarks/My Amplifier Results - Benchmarks
278 | /MatrixGenerator/My Amplifier Results - MatrixGenerator
279 | /MatrixMult/matrixB11000.bin
280 | /MatrixMult/matrixAB11000.bin
281 | /MatrixMult/matrixA11000.bin
282 | /MatrixMult/matrixB9000.bin
283 | /MatrixMult/matrixA9000.bin
284 | /MatrixMult/My Inspector Results - MatrixMult
285 | /MatrixMult/matrixB1000.bin
286 | /MatrixMult/matrixA1000.bin
287 | /MatrixMult/matrixBx.bin
288 | /MatrixMult/matrixAx.bin
289 | /MatrixMult/matrixABx.bin
290 |
--------------------------------------------------------------------------------
/Benchmark1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/talhasaruhan/cpp-matmul/e1ef1edf935d5af6d79de15b127d1e8ad13f284c/Benchmark1.png
--------------------------------------------------------------------------------
/Benchmarks/Benchmarks.vcxproj:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | Debug
6 | Win32
7 |
8 |
9 | Release
10 | Win32
11 |
12 |
13 | Debug
14 | x64
15 |
16 |
17 | Release
18 | x64
19 |
20 |
21 |
22 | 15.0
23 | {5895928A-FD77-4426-9588-36399A75D082}
24 | Benchmarks
25 | 10.0.16299.0
26 |
27 |
28 |
29 | Application
30 | true
31 | v141
32 | MultiByte
33 |
34 |
35 | Application
36 | false
37 | v141
38 | true
39 | MultiByte
40 |
41 |
42 | Application
43 | true
44 | v141
45 | MultiByte
46 |
47 |
48 | Application
49 | false
50 | v141
51 | true
52 | MultiByte
53 | true
54 | Parallel
55 | true
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 | $(ExecutablePath)
77 | $(SourcePath)
78 |
79 |
80 |
81 | Level3
82 | MaxSpeed
83 | true
84 | true
85 | true
86 | true
87 | C:\eigen;
88 | Speed
89 | true
90 | AdvancedVectorExtensions2
91 | Fast
92 | true
93 | /DMKL_ILP64 -I"%MKLROOT%"\include %(AdditionalOptions)
94 | MultiThreaded
95 | true
96 | true
97 | true
98 | No
99 | false
100 | false
101 |
102 |
103 | true
104 | true
105 | mkl_intel_ilp64.lib; mkl_tbb_thread.lib; mkl_core.lib; tbb.lib
106 | C:\Program Files (x86)\IntelSWTools\compilers_and_libraries_2019.0.117\windows\mkl\lib\intel64_win;C:\Program Files (x86)\IntelSWTools\compilers_and_libraries_2019\windows\tbb\lib\intel64_win\vc14_uwp
107 | /DMKL_ILP64 -I"%MKLROOT%"\include %(AdditionalOptions)
108 | Console
109 |
110 |
111 |
112 |
113 | Level3
114 | Disabled
115 | true
116 | true
117 |
118 |
119 |
120 |
121 | Level3
122 | Disabled
123 | true
124 | true
125 |
126 |
127 |
128 |
129 | Level3
130 | MaxSpeed
131 | true
132 | true
133 | true
134 | true
135 |
136 |
137 | true
138 | true
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
--------------------------------------------------------------------------------
/Benchmarks/Benchmarks.vcxproj.filters:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | {4FC737F1-C7A5-4376-A066-2A32D752A2FF}
6 | cpp;c;cc;cxx;def;odl;idl;hpj;bat;asm;asmx
7 |
8 |
9 | {93995380-89BD-4b04-88EB-625FBE52EBFB}
10 | h;hh;hpp;hxx;hm;inl;inc;ipp;xsd
11 |
12 |
13 | {67DA6AB6-F800-4c08-8B7A-83BB121AAD01}
14 | rc;ico;cur;bmp;dlg;rc2;rct;bin;rgs;gif;jpg;jpeg;jpe;resx;tiff;tif;png;wav;mfcribbon-ms
15 |
16 |
17 |
18 |
19 | Source Files
20 |
21 |
22 | Source Files
23 |
24 |
25 | Source Files
26 |
27 |
28 |
--------------------------------------------------------------------------------
/Benchmarks/EigenBenchmark.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 |
8 | #define EIGEN_USE_MKL_ALL
9 | #include
10 |
11 | using namespace std;
12 | using namespace Eigen;
13 |
14 | int main(int argc, char* argv[])
15 | {
16 | int K;
17 | if (argc == 1) {
18 | K = 10000;
19 | } else if (argc == 2) {
20 | /* 2 NxN */
21 | K = atoi(argv[1]);
22 | assert(K > 0);
23 | }
24 |
25 | mkl_set_num_threads(12);
26 | setNbThreads(12);
27 |
28 | MatrixXd matA = MatrixXd::Random(K, K);
29 | MatrixXd matB = MatrixXd::Random(K, K);
30 |
31 | auto start = std::chrono::high_resolution_clock::now();
32 | MatrixXd matC = matA * matB;
33 | auto end = std::chrono::high_resolution_clock::now();
34 |
35 | std::cout
36 | << "Matrix Multiplication: "
37 | << std::chrono::duration_cast(end - start).count()
38 | << " microseconds.\n";
39 | }
40 |
--------------------------------------------------------------------------------
/Benchmarks/IntrinASMDotBenchmark.cpp:
--------------------------------------------------------------------------------
1 | //#include
2 | //#include
3 | //#include
4 | //#include
5 | //#include
6 | //#include
7 | //#include
8 | //#include
9 | //#include
10 | //#include
11 | //#include
12 | //
13 | //using namespace std;
14 | //
15 | //#define AVX_ALIGNMENT 32
16 | //
17 | //float VecDotIntrinsicExplicit1(float* const a, float* const b, const unsigned N)
18 | //{
19 | // float* vsum = (float*)aligned_alloc(8 * sizeof(float), AVX_ALIGNMENT);
20 | // for (int i = 0; i<8; ++i) vsum[i] = 0;
21 | //
22 | // __m256 sum = _mm256_setzero_ps();
23 | // __m256 a1, a2, a3, a4, a5, a6, a7, a8;
24 | // __m256 b1, b2, b3, b4, b5, b6, b7, b8;
25 | //
26 | // for (int i = 0; i(end - start).count() << " milliseconds.\n";
327 | //
328 | // /*****************************************************/
329 | //
330 | // cout << t1 << endl;
331 | //}
332 | //
333 | ////int main() {
334 | //// ILPSum();
335 | ////}
--------------------------------------------------------------------------------
/Benchmarks/IntrinsicSumBenchmarks.cpp:
--------------------------------------------------------------------------------
1 | //#include
2 | //#include
3 | //#include
4 | //#include
5 | //#include
6 | //#include
7 | //#include
8 | //
9 | //using namespace std;
10 | //
11 | //#define AVX_ALIGNMENT 32
12 | //
13 | ///* naive sum using intrinsics */
14 | //float VecSumIntrinsicNaiveLoop(const float* const __restrict c, const unsigned N)
15 | //{
16 | // _declspec(align(32)) float vsum[8];
17 | // for (int i = 0; i<8; ++i) vsum[i] = 0;
18 | //
19 | // __m256 sum = _mm256_setzero_ps();
20 | // __m256 x0, x1;
21 | //
22 | // for (int i = 0; i> 1;
282 | // _mm256_store_ps(&c[j + 0], c1);
283 | // _mm256_store_ps(&c[j + 8], c2);
284 | // _mm256_store_ps(&c[j + 16], c3);
285 | // _mm256_store_ps(&c[j + 24], c4);
286 | // _mm256_store_ps(&c[j + 32], c5);
287 | // _mm256_store_ps(&c[j + 40], c6);
288 | // _mm256_store_ps(&c[j + 48], c7);
289 | // _mm256_store_ps(&c[j + 56], c8);
290 | // }
291 | // }
292 | //
293 | // return VecSumIntrinsicNaiveLoop(c, 64);
294 | //}
295 | //
296 | ///* scalar sum */
297 | //float VecSumScalarAccumulate(const float* const __restrict c, const unsigned N) {
298 | // /*
299 | // * compiler optimizes this by keeping t in an xmm register
300 | // * s.t at every iteration, we do 1 load and 1 add
301 | // * but t <- add(t, ai) is obviously dependent on t
302 | // * so there goes the ILP.
303 | // */
304 | //
305 | // float t = 0;
306 | // for (int i = 0; i(end - start).count() << " milliseconds.\n";
350 | //
351 | // /*****************************************************/
352 | //
353 | // //memcpy(ar_cpy, ar, N * sizeof(float));
354 | //
355 | // //start = std::chrono::high_resolution_clock::now();
356 | // //t2 = VecSumScalarBinary(ar_cpy, N, K);
357 | // //end = std::chrono::high_resolution_clock::now();
358 | // //std::cout << "C++ Binary sum: " << std::chrono::duration_cast(end - start).count() << " milliseconds.\n";
359 | //
360 | // /*****************************************************/
361 | //
362 | // start = std::chrono::high_resolution_clock::now();
363 | // for (int i = 0; i(end - start).count() << " milliseconds.\n";
367 | //
368 | // /*****************************************************/
369 | //
370 | // start = std::chrono::high_resolution_clock::now();
371 | // for (int i = 0; i(end - start).count() << " milliseconds.\n";
375 | //
376 | // /*****************************************************/
377 | //
378 | // start = std::chrono::high_resolution_clock::now();
379 | // for (int i = 0; i(end - start).count() << " milliseconds.\n";
383 | //
384 | // /*****************************************************/
385 | //
386 | // start = std::chrono::high_resolution_clock::now();
387 | // for (int i = 0; i(end - start).count() << " milliseconds.\n";
391 | //
392 | // /*****************************************************/
393 | //
394 | // cout << t1 << endl;
395 | // cout << t3 << endl;
396 | // cout << t4 << endl;
397 | // cout << t5 << endl;
398 | // cout << t6 << endl;
399 | //}
400 | //
401 | //int main() {
402 | // ILPSum();
403 | //}
--------------------------------------------------------------------------------
/Benchmarks/NumpyBenchmark.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import time
3 |
4 | n = 1000
5 | a = np.random.randn(n, n)*50
6 |
7 | start = time.time()
8 | b = np.dot(a, a)
9 | end = time.time()
10 |
11 | print(end-start)
--------------------------------------------------------------------------------
/MatrixGenerator/MatrixGenerator.cpp:
--------------------------------------------------------------------------------
1 | #define WIN32_LEAN_AND_MEAN
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 | #include
9 | #include
10 | #include
11 | #include
12 | #include
13 | #include
14 | #include
15 | #include
16 | #include
17 | #include
18 | #include
19 | #include
20 | #include
21 | #include
22 |
23 | #define AVX_ALIGN 32
24 |
25 | typedef struct Mat
26 | {
27 | unsigned width;
28 | unsigned height;
29 | unsigned rowSpan;
30 | float *mat;
31 | } Mat;
32 |
33 | template
34 | static void RandInitMat(Mat *m, Rand &r)
35 | {
36 | for(unsigned y=0; yheight; ++y)
37 | for(unsigned x=0; xwidth; ++x)
38 | m->mat[y*m->rowSpan + x] = r();
39 | }
40 |
41 | const Mat LoadMat(const char * const filename) {
42 | Mat mat;
43 | uint32_t matSize;
44 |
45 | std::ifstream in(filename, std::ios::binary | std::ios::in);
46 |
47 | if (!in.is_open()) {
48 | std::cerr << "Err loading!\n";
49 | return {};
50 | }
51 |
52 | in.read((char*)&mat, 3 * sizeof(uint32_t));
53 | in.read((char*)&matSize, sizeof(uint32_t));
54 | in.seekg(12*sizeof(uint32_t), std::ios::cur);
55 | mat.mat = (float*)malloc(matSize);
56 | in.read((char*)mat.mat, matSize);
57 |
58 | in.close();
59 |
60 | return mat;
61 | }
62 |
63 | static void DumpMat(const char *filename, const Mat &m)
64 | {
65 | uint32_t header[16];
66 | std::ofstream out(filename, std::ofstream::binary | std::ofstream::out);
67 |
68 | header[0] = m.width;
69 | header[1] = m.height;
70 | header[2] = m.rowSpan;
71 | header[3] = m.height * m.rowSpan * sizeof(float);
72 |
73 | out.write(reinterpret_cast(header), sizeof(header));
74 | out.write(reinterpret_cast(m.mat), header[3]);
75 |
76 | out.close();
77 | }
78 |
79 | static unsigned RoundUpPwr2(unsigned val, unsigned pwr2)
80 | {
81 | return (val + (pwr2 - 1)) & (~(pwr2 - 1));
82 | }
83 |
84 | /* This function prints the given matrix to given std::ostream */
85 | static void PrintMat(const Mat& mat, std::ostream& stream)
86 | {
87 | stream << "w, h, rS: " << mat.width << " " << mat.height << " " << mat.rowSpan
88 | << "\n";
89 | for (int i = 0; i < mat.height; i++) {
90 | for (int j = 0; j < mat.width; ++j) {
91 | stream << mat.mat[i * mat.rowSpan + j] << " ";
92 | }
93 | stream << "\n";
94 | }
95 | }
96 |
97 |
98 | /* Single threaded, do i need to multithread this as well?
99 | Honestly, I don't think it will have any significant effect. n^2 vs n^3 */
100 | __declspec(noalias) const Mat TransposeMat(const Mat& mat)
101 | {
102 | const unsigned tRowSpan = RoundUpPwr2(mat.height, 64 / sizeof(float));
103 | float* __restrict const tData =
104 | (float*)_aligned_malloc(mat.width * tRowSpan * sizeof(float), AVX_ALIGN);
105 |
106 | Mat T{ mat.height, mat.width, tRowSpan, tData };
107 |
108 | // hah, the loops are truly interchangable as we encounter a cache miss either ways
109 | for (int rowT = 0; rowT < T.height; ++rowT) {
110 | for (int colT = 0; colT < T.width; ++colT) {
111 | tData[rowT * tRowSpan + colT] = mat.mat[colT * mat.rowSpan + rowT];
112 | }
113 | }
114 |
115 | return T;
116 | }
117 |
118 | const Mat ST_TransposedBMatMul(const Mat& matA, const Mat& matB)
119 | {
120 | /* Now, I thought transposing B and then traversing it row order would help and it does!
121 | * Also, note that, if we manually unrolled the loop here, compiler wouldn't vectorize the loop for some reason
122 | * (1301: Loop stride is not +1.) is the exact compiler message. */
123 | float* __restrict const matData =
124 | (float*)_aligned_malloc(matA.height * matB.rowSpan * sizeof(float), AVX_ALIGN);
125 |
126 | Mat matC{ matB.width, matA.height, matB.rowSpan, matData };
127 |
128 | const Mat matBT = TransposeMat(matB);
129 | for (int rowC = 0; rowC < matA.height; ++rowC) {
130 | for (int colC = 0; colC < matB.width; ++colC) {
131 | float accumulate = 0;
132 | for (int pos = 0; pos < matA.width; ++pos) {
133 | accumulate += matA.mat[rowC * matA.rowSpan + pos] *
134 | matBT.mat[colC * matBT.rowSpan + pos];
135 | }
136 | matData[rowC * matB.rowSpan + colC] = accumulate;
137 | }
138 | }
139 |
140 | _aligned_free(matBT.mat);
141 |
142 | return matC;
143 | }
144 |
145 | int _cdecl main(int argc, char *argv[])
146 | {
147 | static const unsigned ALIGN = 64;
148 | static const unsigned FLT_ALIGN = ALIGN / sizeof(float);
149 |
150 | std::random_device rd;
151 | std::uniform_real_distribution matValDist(-50.0f, 50.0f);
152 | auto matRand = std::bind(matValDist, std::ref(rd));
153 | Mat a, b;
154 | std::string suffix;
155 |
156 | if (argc == 1) {
157 | /* randomly generated */
158 | std::uniform_int_distribution matSizeDist(100, 1000);
159 | auto sizeRand = std::bind(matSizeDist, std::ref(rd));
160 | a.width = sizeRand();
161 | a.height = sizeRand();
162 | a.rowSpan = RoundUpPwr2(a.width, FLT_ALIGN);
163 |
164 | b.width = sizeRand();
165 | b.height = a.width;
166 |
167 | suffix = "";
168 | }
169 | else if (argc == 2) {
170 | /* 2 NxN */
171 | const int N = atoi(argv[1]);
172 | assert(N > 0);
173 | a.width = N;
174 | a.height = N;
175 | b.width = N;
176 | b.height = N;
177 |
178 | suffix = "";
179 | }
180 | else if (argc == 3) {
181 | /* 2 NxN */
182 | const int N = atoi(argv[1]);
183 | assert(N > 0);
184 | a.width = N;
185 | a.height = N;
186 | b.width = N;
187 | b.height= N;
188 |
189 | suffix = std::string(argv[2]);
190 | }
191 | else if (argc == 4) {
192 | /* NxM, MxN */
193 | const int N = atoi(argv[1]);
194 | const int M = atoi(argv[2]);
195 | assert(N > 0 && M > 0);
196 | a.width = M;
197 | a.height = N;
198 | b.width = N;
199 | b.height = M;
200 |
201 | suffix = std::string(argv[3]);
202 | }
203 | else if (argc == 5) {
204 | /* NxM, MxK */
205 | const int N = atoi(argv[1]);
206 | const int M = atoi(argv[2]);
207 | const int K = atoi(argv[3]);
208 | assert(N > 0 && M > 0);
209 | a.width = M;
210 | a.height = N;
211 | b.width = K;
212 | b.height = M;
213 |
214 | suffix = std::string(argv[4]);
215 | }
216 | else {
217 | std::cerr << "Invalid arguments!\n";
218 | return 2;
219 | }
220 |
221 |
222 | a.rowSpan = RoundUpPwr2(a.width, FLT_ALIGN);
223 | b.rowSpan = RoundUpPwr2(b.width, FLT_ALIGN);
224 |
225 | a.mat = new float[a.rowSpan*a.height];
226 | b.mat = new float[b.rowSpan*b.height];
227 |
228 | RandInitMat(&a, matRand);
229 | RandInitMat(&b, matRand);
230 |
231 | printf("a: [%d %d] | b: [%d %d]\n", a.width, a.height, b.width, b.height);
232 |
233 | auto start = std::chrono::high_resolution_clock::now();
234 | const Mat c = ST_TransposedBMatMul(a, b);
235 | auto end = std::chrono::high_resolution_clock::now();
236 | std::cout << "Generation w/ tranposed mult. took: "
237 | << std::chrono::duration_cast(end - start).count()
238 | << " microseconds.\n";
239 |
240 | DumpMat(("matrixA" + suffix + ".bin").c_str(), a);
241 | DumpMat(("matrixB" + suffix + ".bin").c_str(), b);
242 | DumpMat(("matrixAB" + suffix + ".bin").c_str(), c);
243 |
244 | delete[] a.mat;
245 | delete[] b.mat;
246 | _aligned_free(c.mat);
247 |
248 | return 0;
249 | }
250 |
--------------------------------------------------------------------------------
/MatrixGenerator/MatrixGenerator.vcxproj:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | Debug
6 | Win32
7 |
8 |
9 | Release
10 | Win32
11 |
12 |
13 | Debug
14 | x64
15 |
16 |
17 | Release
18 | x64
19 |
20 |
21 |
22 |
23 |
24 |
25 | 15.0
26 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}
27 | MatrixGenerator
28 | 10.0.16299.0
29 |
30 |
31 |
32 | Application
33 | true
34 | v141
35 | MultiByte
36 |
37 |
38 | Application
39 | false
40 | v141
41 | true
42 | MultiByte
43 |
44 |
45 | Application
46 | true
47 | v141
48 | MultiByte
49 |
50 |
51 | Application
52 | false
53 | v141
54 | true
55 | MultiByte
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 | Level3
79 | Disabled
80 | true
81 | true
82 |
83 |
84 | Console
85 |
86 |
87 |
88 |
89 | Level3
90 | Disabled
91 | true
92 | true
93 |
94 |
95 |
96 |
97 | Level3
98 | MaxSpeed
99 | true
100 | true
101 | true
102 | true
103 |
104 |
105 | true
106 | true
107 |
108 |
109 |
110 |
111 | Level3
112 | MaxSpeed
113 | true
114 | true
115 | true
116 | true
117 | Speed
118 | AdvancedVectorExtensions2
119 | Fast
120 | false
121 | false
122 | true
123 | false
124 | false
125 |
126 |
127 | true
128 | true
129 |
130 |
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/MatrixGenerator/MatrixGenerator.vcxproj.filters:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | {4FC737F1-C7A5-4376-A066-2A32D752A2FF}
6 | cpp;c;cc;cxx;def;odl;idl;hpj;bat;asm;asmx
7 |
8 |
9 | {93995380-89BD-4b04-88EB-625FBE52EBFB}
10 | h;hh;hpp;hxx;hm;inl;inc;ipp;xsd
11 |
12 |
13 | {67DA6AB6-F800-4c08-8B7A-83BB121AAD01}
14 | rc;ico;cur;bmp;dlg;rc2;rct;bin;rgs;gif;jpg;jpeg;jpe;resx;tiff;tif;png;wav;mfcribbon-ms
15 |
16 |
17 |
18 |
19 | Source Files
20 |
21 |
22 |
--------------------------------------------------------------------------------
/MatrixMult.sln:
--------------------------------------------------------------------------------
1 |
2 | Microsoft Visual Studio Solution File, Format Version 12.00
3 | # Visual Studio 15
4 | VisualStudioVersion = 15.0.27428.2015
5 | MinimumVisualStudioVersion = 10.0.40219.1
6 | Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "MatrixMult", "MatrixMult\MatrixMult.vcxproj", "{54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}"
7 | EndProject
8 | Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "MatrixMulTester", "MatrixMulTester\MatrixMulTester.vcxproj", "{0417B0D4-F0BF-4218-945C-C139C9498728}"
9 | EndProject
10 | Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "MatrixGenerator", "MatrixGenerator\MatrixGenerator.vcxproj", "{C6A23610-8F92-418E-8BC6-2CEFA194CE78}"
11 | EndProject
12 | Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "Benchmarks", "Benchmarks\Benchmarks.vcxproj", "{5895928A-FD77-4426-9588-36399A75D082}"
13 | EndProject
14 | Global
15 | GlobalSection(SolutionConfigurationPlatforms) = preSolution
16 | Debug|x64 = Debug|x64
17 | Debug|x86 = Debug|x86
18 | Release|x64 = Release|x64
19 | Release|x86 = Release|x86
20 | EndGlobalSection
21 | GlobalSection(ProjectConfigurationPlatforms) = postSolution
22 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Debug|x64.ActiveCfg = Debug|x64
23 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Debug|x64.Build.0 = Debug|x64
24 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Debug|x86.ActiveCfg = Debug|Win32
25 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Debug|x86.Build.0 = Debug|Win32
26 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Release|x64.ActiveCfg = Release|x64
27 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Release|x64.Build.0 = Release|x64
28 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Release|x86.ActiveCfg = Release|Win32
29 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}.Release|x86.Build.0 = Release|Win32
30 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Debug|x64.ActiveCfg = Debug|x64
31 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Debug|x64.Build.0 = Debug|x64
32 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Debug|x86.ActiveCfg = Debug|Win32
33 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Debug|x86.Build.0 = Debug|Win32
34 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Release|x64.ActiveCfg = Release|x64
35 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Release|x64.Build.0 = Release|x64
36 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Release|x86.ActiveCfg = Release|Win32
37 | {0417B0D4-F0BF-4218-945C-C139C9498728}.Release|x86.Build.0 = Release|Win32
38 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Debug|x64.ActiveCfg = Debug|x64
39 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Debug|x64.Build.0 = Debug|x64
40 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Debug|x86.ActiveCfg = Debug|Win32
41 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Debug|x86.Build.0 = Debug|Win32
42 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Release|x64.ActiveCfg = Release|x64
43 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Release|x64.Build.0 = Release|x64
44 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Release|x86.ActiveCfg = Release|Win32
45 | {C6A23610-8F92-418E-8BC6-2CEFA194CE78}.Release|x86.Build.0 = Release|Win32
46 | {5895928A-FD77-4426-9588-36399A75D082}.Debug|x64.ActiveCfg = Debug|x64
47 | {5895928A-FD77-4426-9588-36399A75D082}.Debug|x64.Build.0 = Debug|x64
48 | {5895928A-FD77-4426-9588-36399A75D082}.Debug|x86.ActiveCfg = Debug|Win32
49 | {5895928A-FD77-4426-9588-36399A75D082}.Debug|x86.Build.0 = Debug|Win32
50 | {5895928A-FD77-4426-9588-36399A75D082}.Release|x64.ActiveCfg = Release|x64
51 | {5895928A-FD77-4426-9588-36399A75D082}.Release|x64.Build.0 = Release|x64
52 | {5895928A-FD77-4426-9588-36399A75D082}.Release|x86.ActiveCfg = Release|Win32
53 | {5895928A-FD77-4426-9588-36399A75D082}.Release|x86.Build.0 = Release|Win32
54 | EndGlobalSection
55 | GlobalSection(SolutionProperties) = preSolution
56 | HideSolutionNode = FALSE
57 | EndGlobalSection
58 | GlobalSection(ExtensibilityGlobals) = postSolution
59 | SolutionGuid = {D568E00C-A8ED-41CB-B719-B116D29D421F}
60 | EndGlobalSection
61 | GlobalSection(Performance) = preSolution
62 | HasPerformanceSessions = true
63 | EndGlobalSection
64 | EndGlobal
65 |
--------------------------------------------------------------------------------
/MatrixMult/CPUUtil.cpp:
--------------------------------------------------------------------------------
1 | #include "CPUUtil.h"
2 | #include
3 | #include
4 |
5 | namespace CPUUtil
6 | {
7 | namespace
8 | {
9 | static int logicalProcInfoCached = 0;
10 | static unsigned numHWCores, numLogicalProcessors;
11 | static ULONG_PTR* physLogicalProcessorMap = NULL;
12 |
13 | void PrintSysLPInfoArr(_SYSTEM_LOGICAL_PROCESSOR_INFORMATION* const sysLPInf,
14 | const DWORD& retLen)
15 | {
16 | unsigned numPhysicalCores = 0;
17 | for (int i = 0; i * sizeof(_SYSTEM_LOGICAL_PROCESSOR_INFORMATION) <= retLen;
18 | ++i) {
19 | if (sysLPInf[i].Relationship != RelationProcessorCore)
20 | continue;
21 |
22 | printf(
23 | "PHYSICAL CPU[%d]\n\t_SYSTEM_LOGICAL_PROCESSOR_INFORMATION_EX:\n",
24 | numPhysicalCores);
25 | printf("\t\tProcessorMask:%s\n",
26 | BitmaskToStr(sysLPInf[i].ProcessorMask));
27 | printf("\t\tRelationship:%u | RelationProcessorCore\n",
28 | (uint8_t)sysLPInf[i].Relationship);
29 | printf("\t\tProcessorCore:\n");
30 | printf("\t\t\tFlags(HT?):%d\n",
31 | (uint8_t)sysLPInf[i].ProcessorCore.Flags);
32 | ++numPhysicalCores;
33 | }
34 | }
35 |
36 | int TestPrintCPUCores()
37 | {
38 | const unsigned N = 30;
39 | _SYSTEM_LOGICAL_PROCESSOR_INFORMATION sysLPInf[N];
40 | DWORD retLen = N * sizeof(_SYSTEM_LOGICAL_PROCESSOR_INFORMATION);
41 | LOGICAL_PROCESSOR_RELATIONSHIP lpRel = RelationProcessorCore;
42 |
43 | BOOL retCode = GetLogicalProcessorInformation(&sysLPInf[0], &retLen);
44 |
45 | if (!retCode) {
46 | DWORD errCode = GetLastError();
47 | printf("ERR: %d\n", errCode);
48 | if (errCode == ERROR_INSUFFICIENT_BUFFER) {
49 | printf("Buffer is not large enough! Buffer length required: %d\n",
50 | retLen);
51 | } else {
52 | printf("CHECK MSDN SYSTEM ERROR CODES LIST.\n");
53 | }
54 | return errCode;
55 | }
56 |
57 | PrintSysLPInfoArr(sysLPInf, retLen);
58 |
59 | return 0;
60 | }
61 |
62 | template
63 | int NumSetBits(T n) {
64 | int count = 0;
65 | while (n) {
66 | count += (n & 1) > 0 ? 1 : 0;
67 | n >>= 1;
68 | }
69 | return count;
70 | }
71 |
72 | DWORD _GetSysLPMap(unsigned& numHWCores)
73 | {
74 | // These assumptions should never fail on desktop
75 | const unsigned N = 48, M = 48;
76 |
77 | _SYSTEM_LOGICAL_PROCESSOR_INFORMATION sysLPInf[N];
78 | DWORD retLen = N * sizeof(_SYSTEM_LOGICAL_PROCESSOR_INFORMATION);
79 | LOGICAL_PROCESSOR_RELATIONSHIP lpRel = RelationProcessorCore;
80 |
81 | static BOOL retCode = GetLogicalProcessorInformation(&sysLPInf[0], &retLen);
82 |
83 | if (!retCode) {
84 | return GetLastError();
85 | }
86 |
87 | ULONG_PTR* const lMap = (ULONG_PTR*)malloc(M * sizeof(ULONG_PTR));
88 |
89 | numHWCores = 0;
90 | for (int i = 0; i * sizeof(_SYSTEM_LOGICAL_PROCESSOR_INFORMATION) <= retLen;
91 | ++i) {
92 | if (sysLPInf[i].Relationship != RelationProcessorCore)
93 | continue;
94 |
95 | ULONG_PTR logicalProcessorMask = sysLPInf[i].ProcessorMask;
96 | lMap[numHWCores++] = logicalProcessorMask;
97 | numLogicalProcessors += NumSetBits(logicalProcessorMask);
98 | }
99 |
100 | physLogicalProcessorMap = (ULONG_PTR*)malloc(numHWCores * sizeof(ULONG_PTR));
101 | memcpy(physLogicalProcessorMap, lMap, numHWCores * sizeof(ULONG_PTR));
102 | free(lMap);
103 |
104 | return 0;
105 | }
106 | } // private namespace
107 |
108 | const char* BitmaskToStr(WORD bitmask)
109 | {
110 | const unsigned N = sizeof(WORD) * 8;
111 | char* const str = new char[N + 1];
112 | str[N] = 0;
113 | for (int i = 0; i < N; ++i) {
114 | str[N - i - 1] = '0' + ((bitmask)&1);
115 | bitmask >>= 1;
116 | }
117 | return str;
118 | }
119 |
120 | int GetNumHWCores()
121 | {
122 | if (!logicalProcInfoCached) {
123 | DWORD retCode = _GetSysLPMap(numHWCores);
124 | if (!retCode)
125 | logicalProcInfoCached = 1;
126 | else
127 | return -1;
128 | }
129 | return numHWCores;
130 | }
131 |
132 | int GetNumLogicalProcessors() {
133 | if (!logicalProcInfoCached) {
134 | DWORD retCode = _GetSysLPMap(numHWCores);
135 | if (!retCode)
136 | logicalProcInfoCached = 1;
137 | else
138 | return -1;
139 | }
140 | return numLogicalProcessors;
141 | }
142 |
143 | int GetProcessorMask(unsigned n, ULONG_PTR& mask)
144 | {
145 | if (!logicalProcInfoCached) {
146 | DWORD retCode = _GetSysLPMap(numHWCores);
147 | if (!retCode)
148 | logicalProcInfoCached = 1;
149 | else
150 | return retCode;
151 | }
152 |
153 | if (n >= numHWCores)
154 | return -1;
155 |
156 | mask = physLogicalProcessorMap[n];
157 |
158 | return 0;
159 | }
160 |
161 | /* Returns decimal value for a 32 bit mask at compile time, [i:j] set to 1, rest are 0. */
162 | constexpr int GenerateMask(int i, int j)
163 | {
164 | if (i > j)
165 | return (1 << (i + 1)) - (1 << j);
166 | else
167 | return (1 << (j + 1)) - (1 << i);
168 | }
169 |
170 | void GetCacheInfo(int* dCaches, int& iCache)
171 | {
172 | /*
173 | * From Intel's Processor Identification CPUID Instruction Notes:
174 | * EAX := 0x04, ECX := (0, 1, 2 .. until EAX[4:0]==0)
175 | * cpuid(memaddr, n, k) sets eax to n, ecx to k,
176 | * writes EAX, EBX, ECX, and EDX to memaddr[0:4] respectively.
177 | * Cache size in bytes = (Ways + 1) * (Partitions + 1)
178 | * * (Line size + 1) * (Sets + 1)
179 | * = (EBX[31:22]+1) * (EBX[21:12]+1)
180 | * * (EBX[11:0]+1) * (ECX+1)
181 | * For now, this function assumes we're on a modern Intel CPU
182 | * So we have L1,2,3 data caches and first level instruction cache
183 | */
184 |
185 | int cpui[4];
186 |
187 | for (int i = 0, dc = 0; i < 4; ++i) {
188 | __cpuidex(cpui, 4, i);
189 | int sz = (((cpui[1] & GenerateMask(31, 22)) >> 22) + 1) *
190 | (((cpui[1] & GenerateMask(21, 12)) >> 12) + 1) *
191 | ((cpui[1] & GenerateMask(11, 0)) + 1) * (cpui[2] + 1);
192 | int cacheType = (cpui[0] & 31);
193 | if (cacheType == 1 || cacheType == 3) {
194 | dCaches[dc++] = sz;
195 | } else if (cacheType == 2) {
196 | iCache = sz;
197 | }
198 | }
199 | }
200 |
201 | int GetCacheLineSize()
202 | {
203 | /*
204 | * From Intel's Processor Identification CPUID Instruction Notes:
205 | * Executing CPUID with EAX=1, fills EAX, EBX, ECX, EDX
206 | * EBX[15:8] : CLFLUSHSIZE, val*8 = cache line size
207 | */
208 | int cpui[4];
209 | __cpuid(cpui, 1);
210 | return (cpui[1] & GenerateMask(15, 8)) >> (8 - 3);
211 | }
212 |
213 | int GetHTTStatus() {
214 | int cpui[4];
215 | __cpuid(cpui, 1);
216 | return ((cpui[3] & (1<<28)) >> 28) ? 1 : 0;
217 | }
218 |
219 | int GetSIMDSupport() {
220 | int cpui[4];
221 | __cpuid(cpui, 1);
222 | int fma = (cpui[2] & (1 << 12)) >> 12;
223 | int avx = (cpui[2] & (1 << 28)) >> 28;
224 | return fma & avx;
225 | }
226 |
227 | }; // namespace CPUUtil
228 |
--------------------------------------------------------------------------------
/MatrixMult/CPUUtil.h:
--------------------------------------------------------------------------------
1 | #pragma once
2 | #define WIN32_LEAN_AND_MEAN
3 | #include
4 | #include
5 | #include
6 |
7 | namespace CPUUtil
8 | {
9 | /* Utility, convert given bitmask to const char* */
10 | const char* BitmaskToStr(WORD bitmask);
11 |
12 | /* Get number of physical processors on the runtime system */
13 | int GetNumHWCores();
14 |
15 | /* Get number of logical processors on the runtime system */
16 | int GetNumLogicalProcessors();
17 |
18 | /* Get the logical processor mask corresponding to the Nth hardware core */
19 | int GetProcessorMask(unsigned n, ULONG_PTR& mask);
20 |
21 | /* Fill dCaches with L1,2,3 data cache sizes,
22 | * and iCache with L1 dedicated instruction cache size. */
23 | void GetCacheInfo(int* dCaches, int& iCache);
24 |
25 | /* Query cache line size on the current system. */
26 | int GetCacheLineSize();
27 |
28 | /* Query whether or not the runtime system supports HTT */
29 | int GetHTTStatus();
30 |
31 | /* Query if the runtime system supports AVX and FMA instruction sets. */
32 | int GetSIMDSupport();
33 |
34 | }; // namespace CPUUtil
35 |
--------------------------------------------------------------------------------
/MatrixMult/MatrixMul.cpp:
--------------------------------------------------------------------------------
1 | #define WIN32_LEAN_AND_MEAN
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 | #include
9 | #include
10 | #include
11 | #include
12 | #include
13 | #include
14 | #include
15 | #include
16 | #include
17 | #include
18 | #include "ThreadPool.h"
19 |
20 | /* Define for AVX alignment requirements */
21 | #define AVX_ALIGN 32
22 |
23 | /* Define CPU related variables, actual values will be queried on runtime. */
24 | int CPUInfoQueried = 0;
25 | int L2Size = 256 * 1024;
26 | int L3Size = 12 * 1024 * 1024;
27 | int cacheLineSz = 64;
28 | int numHWCores = 6;
29 |
30 | /* Prefetching switches, if multiple MatMul operations are intended to run in parallel,
31 | * individual mutexes should be created for each one. */
32 | constexpr int doL3Prefetch = 0;
33 | constexpr int doL12Prefetch = 0;
34 | int prefetched[1024][1024];
35 | std::mutex prefetchMutex;
36 |
37 | /* Matrix structure */
38 | typedef struct Mat {
39 | unsigned width;
40 | unsigned height;
41 | unsigned rowSpan;
42 | /* guarantee that mat will not be aliased (__restrict),
43 | no need for two matrices to point at sama data */
44 | float* __restrict mat;
45 | } Mat;
46 |
47 | /*
48 | * This struct holds the information for multiple levels of block sizes.
49 | * It's used to keep function parameters short and readable
50 | * Constraints on block sizes:
51 | * L2BlockX % 3 == L2BlockY % 4 == 0,
52 | * L3BlockX % 2 == L3BlockY % 2 == 0,
53 | * (L3BlockX / 2) % L2BlockX == 0
54 | */
55 | typedef struct MMBlockInfo {
56 | const unsigned L3BlockX, L3BlockY;
57 | const unsigned L2BlockX, L2BlockY;
58 | const unsigned issuedBlockSzX, issuedBlockSzY;
59 | } MMBlockInfo;
60 |
61 | /* Load a previously saved matrix from disk */
62 | const Mat LoadMat(const char* const filename)
63 | {
64 | Mat mat;
65 | uint32_t matSize;
66 |
67 | std::ifstream in(filename, std::ios::binary | std::ios::in);
68 |
69 | if (!in.is_open()) {
70 | std::cout << "Err loading!\n";
71 | in.close();
72 | return {0, 0, 0, NULL};
73 | }
74 |
75 | in.read((char*)&mat, 3 * sizeof(uint32_t));
76 | in.read((char*)&matSize, sizeof(uint32_t));
77 | in.seekg(12 * sizeof(uint32_t), std::ios::cur);
78 | mat.mat = (float*)_aligned_malloc(matSize, AVX_ALIGN);
79 | in.read((char*)mat.mat, matSize);
80 |
81 | in.close();
82 |
83 | return mat;
84 | }
85 |
86 | /* Dump the given matrix to the disk. */
87 | static void DumpMat(const char* filename, const Mat& m)
88 | {
89 | uint32_t header[16];
90 | std::ofstream out(filename, std::ofstream::binary | std::ofstream::out);
91 |
92 | header[0] = m.width;
93 | header[1] = m.height;
94 | header[2] = m.rowSpan;
95 | header[3] = m.height * m.rowSpan * sizeof(float);
96 |
97 | out.write(reinterpret_cast(header), sizeof(header));
98 | out.write(reinterpret_cast(m.mat), header[3]);
99 |
100 | out.close();
101 | }
102 |
103 | /* Deallocate matrix data */
104 | void FreeMat(Mat& mat)
105 | {
106 | if (!mat.mat)
107 | return;
108 | _aligned_free(mat.mat);
109 | mat.mat = NULL;
110 | }
111 | void FreeMat(const Mat& mat)
112 | {
113 | if (!mat.mat)
114 | return;
115 | _aligned_free(mat.mat);
116 | }
117 |
118 | /* Round a given number to the nearest multiple of K,
119 | * where K is a parameter and is a power of 2 */
120 | static unsigned RoundUpPwr2(unsigned val, unsigned pwr2)
121 | {
122 | return (val + (pwr2 - 1)) & (~(pwr2 - 1));
123 | }
124 |
125 | /* Compute the transpose of a given matrix.
126 | * A singlethreaded implementation without block tiling. */
127 | __declspec(noalias) const Mat TransposeMat(const Mat& mat)
128 | {
129 | const unsigned tRowSpan = RoundUpPwr2(mat.height, 64 / sizeof(float));
130 | float* __restrict const tData =
131 | (float*)_aligned_malloc(mat.width * tRowSpan * sizeof(float), AVX_ALIGN);
132 |
133 | Mat T{mat.height, mat.width, tRowSpan, tData};
134 |
135 | // the loops are truly interchangable as we encounter a cache miss either ways
136 | for (int rowT = 0; rowT < T.height; ++rowT) {
137 | for (int colT = 0; colT < T.width; ++colT) {
138 | tData[rowT * tRowSpan + colT] = mat.mat[colT * mat.rowSpan + rowT];
139 | }
140 | }
141 |
142 | return T;
143 | }
144 |
145 | /* Print the given matrix to given std::ostream */
146 | static void PrintMat(const Mat& mat, std::ostream& stream)
147 | {
148 | stream << "w, h, rS: " << mat.width << " " << mat.height << " " << mat.rowSpan
149 | << "\n";
150 | for (int i = 0; i < mat.height; i++) {
151 | for (int j = 0; j < mat.width; ++j) {
152 | stream << mat.mat[i * mat.rowSpan + j] << " ";
153 | }
154 | stream << "\n";
155 | }
156 | }
157 |
158 | /**************** Naive, initial implementations ****************/
159 |
160 | /* Naive MatMul */
161 | const Mat ST_NaiveMatMul(const Mat& matA, const Mat& matB)
162 | {
163 | /* First : naive solution with but with some tricks to make compiler (MSVC) behave
164 | * Note that, in this case, manually unrolling the loop helps
165 | * as the compiler can't auto-vectorize non-contagious memory access */
166 | float* __restrict const matData =
167 | (float*)_aligned_malloc(matA.height * matB.rowSpan * sizeof(float), AVX_ALIGN);
168 |
169 | Mat matC{matB.width, matA.height, matB.rowSpan, matData};
170 |
171 | for (int rowC = 0; rowC < matA.height; ++rowC) {
172 | for (int colC = 0; colC < matB.width; ++colC) {
173 | /* an independent, local accumulator. */
174 | float accumulate = 0;
175 | int pos = 0;
176 | /* manual unrolling IS helpful in this case */
177 | for (; pos < matA.width - 4; pos += 4) {
178 | accumulate += matA.mat[rowC * matA.rowSpan + pos] *
179 | matB.mat[pos * matB.rowSpan + colC] +
180 | matA.mat[rowC * matA.rowSpan + pos + 1] *
181 | matB.mat[(pos + 1) * matB.rowSpan + colC] +
182 | matA.mat[rowC * matA.rowSpan + pos + 2] *
183 | matB.mat[(pos + 2) * matB.rowSpan + colC] +
184 | matA.mat[rowC * matA.rowSpan + pos + 3] *
185 | matB.mat[(pos + 3) * matB.rowSpan + colC];
186 | }
187 | for (; pos < matA.width; ++pos) {
188 | accumulate += matA.mat[rowC * matA.rowSpan + pos] *
189 | matB.mat[pos * matB.rowSpan + colC];
190 | }
191 | matData[rowC * matB.rowSpan + colC] = accumulate;
192 | }
193 | }
194 |
195 | return matC;
196 | }
197 |
198 | /* MatMul with transposed B for improved cache behavior. */
199 | const Mat ST_TransposedBMatMul(const Mat& matA, const Mat& matB)
200 | {
201 | /*
202 | * Now, transposing B and then traversing it row order seemed promising!
203 | * Also, note that, if we manually unrolled the loop here,
204 | * compiler wouldn't vectorize the loop,
205 | * so we keep it simple and let MSVC auto vectorize this.
206 | */
207 | float* __restrict const matData =
208 | (float*)_aligned_malloc(matA.height * matB.rowSpan * sizeof(float), AVX_ALIGN);
209 |
210 | Mat matC{matB.width, matA.height, matB.rowSpan, matData};
211 |
212 | const Mat matBT = TransposeMat(matB);
213 | for (int rowC = 0; rowC < matA.height; ++rowC) {
214 | for (int colC = 0; colC < matB.width; ++colC) {
215 | float accumulate = 0;
216 | for (int pos = 0; pos < matA.width; ++pos) {
217 | accumulate += matA.mat[rowC * matA.rowSpan + pos] *
218 | matBT.mat[colC * matBT.rowSpan + pos];
219 | }
220 | matData[rowC * matB.rowSpan + colC] = accumulate;
221 | }
222 | }
223 |
224 | _aligned_free(matBT.mat);
225 |
226 | return matC;
227 | }
228 |
229 | /*
230 | * MatMul with a different traversal order.
231 | * Instead of linearly running thru whole rows of output matrix C,
232 | * calculate blocks of a certain size at a time.
233 | */
234 | const Mat ST_BlockMult(const Mat& matA, const Mat& matB)
235 | {
236 | /* Now, once we fetch column col from B, we use these cached values
237 | * to populate C(row, col:col+8), Any more than that,
238 | * and we lose the old cached values. But notice that,
239 | * the C(row+1, col:col+8) uses the exact same columns.
240 | * So instead of traversing in row order, we could do blocks!
241 | * Notice that I'm using transposed B,
242 | * That's because MSVC refuses to vectorize the loop with
243 | * non-contagious memory access.
244 | * So even though the floats themselves will be in the cache,
245 | * we won't have SIMD, which kills the performance.
246 | *
247 | * Also, I had to assign offsets to temporary constants,
248 | * because otherwise MSVC can't auto-vectorize. */
249 | float* __restrict const matData =
250 | (float*)_aligned_malloc(matA.height * matB.rowSpan * sizeof(float), AVX_ALIGN);
251 |
252 | Mat matC{matB.width, matA.height, matB.rowSpan, matData};
253 |
254 | const unsigned blockX = 16, blockY = 16;
255 |
256 | const Mat matBT = TransposeMat(matB);
257 |
258 | int rowC = 0;
259 | for (; rowC < matA.height - blockY; rowC += blockY) {
260 | int colC = 0;
261 | for (; colC < matB.width - blockX; colC += blockX) {
262 | for (int blockRow = 0; blockRow < blockY; ++blockRow) {
263 | for (int blockCol = 0; blockCol < blockX; ++blockCol) {
264 | const unsigned r = rowC + blockRow;
265 | const unsigned c = colC + blockCol;
266 | const unsigned matAoffset = r * matA.rowSpan;
267 | const unsigned matBoffset = c * matBT.rowSpan;
268 |
269 | float accumulate = 0;
270 | for (int pos = 0; pos < matA.width; ++pos) {
271 | accumulate +=
272 | matA.mat[matAoffset + pos] * matBT.mat[matBoffset + pos];
273 | }
274 | matData[r * matB.rowSpan + c] = accumulate;
275 | }
276 | }
277 | }
278 | for (int blockRow = 0; blockRow < blockY; ++blockRow) {
279 | for (int c = colC; c < matB.width; ++c) {
280 | const unsigned r = rowC + blockRow;
281 | const unsigned matAoffset = r * matA.rowSpan;
282 | const unsigned matBoffset = c * matBT.rowSpan;
283 | float accumulate = 0;
284 | for (int pos = 0; pos < matA.width; ++pos) {
285 | accumulate +=
286 | matA.mat[matAoffset + pos] * matBT.mat[matBoffset + pos];
287 | }
288 | matData[r * matB.rowSpan + c] = accumulate;
289 | }
290 | }
291 | }
292 | for (; rowC < matA.height; ++rowC) {
293 | for (int colC = 0; colC < matB.width; ++colC) {
294 | const unsigned matAoffset = rowC * matA.rowSpan;
295 | const unsigned matBoffset = colC * matBT.rowSpan;
296 | float accumulate = 0;
297 | for (int pos = 0; pos < matA.width; ++pos) {
298 | accumulate += matA.mat[matAoffset + pos] * matBT.mat[matBoffset + pos];
299 | }
300 | matData[rowC * matB.rowSpan + colC] = accumulate;
301 | }
302 | }
303 |
304 | _aligned_free(matBT.mat);
305 |
306 | return matC;
307 | }
308 |
309 | /************** ~~Naive, initial implementations~~ **************/
310 |
311 | /* Declerations for helper functions for the final implementation */
312 |
313 | __declspec(noalias) void MMHelper_MultAnyBlocks(float* __restrict const matData,
314 | const unsigned rowSpan, const Mat& matA,
315 | const Mat& matBT, const unsigned colC,
316 | const unsigned rowC, const int blockX,
317 | const int blockY,
318 | const MMBlockInfo& mmBlockInfo);
319 |
320 | __declspec(noalias) void MMHelper_MultL2Blocks(float* __restrict const matData,
321 | const unsigned rowSpan, const Mat& matA,
322 | const Mat& matBT, const unsigned col,
323 | const unsigned row,
324 | const unsigned L2BlockX,
325 | const unsigned L2BlockY);
326 |
327 | __declspec(noalias) void MMHelper_MultFullBlocks(float* __restrict const matData,
328 | const unsigned rowSpan,
329 | const Mat& matA, const Mat& matBT,
330 | const unsigned colC,
331 | const unsigned rowC,
332 | const MMBlockInfo& mmBlockInfo);
333 |
334 | /* Declarations for helper functions that handle NxM blocks */
335 |
336 | __declspec(noalias) void MMHelper_Mult4x3Blocks(float* __restrict const matData,
337 | const unsigned rowSpan, const Mat& matA,
338 | const Mat& matBT, const unsigned col,
339 | const unsigned row);
340 | __declspec(noalias) void MMHelper_Mult4x1Blocks(float* __restrict const matData,
341 | const unsigned rowSpan, const Mat& matA,
342 | const Mat& matBT, const unsigned col,
343 | const unsigned row);
344 | __declspec(noalias) void MMHelper_Mult1x3Blocks(float* __restrict const matData,
345 | const unsigned rowSpan, const Mat& matA,
346 | const Mat& matBT, const unsigned col,
347 | const unsigned row);
348 | __declspec(noalias) void MMHelper_Mult1x1Blocks(float* __restrict const matData,
349 | const unsigned rowSpan, const Mat& matA,
350 | const Mat& matBT, const unsigned col,
351 | const unsigned row);
352 |
353 | /*
354 | * Helper function for computing a block out of the output matrix C.
355 | * This function is used for the residues at the edges
356 | * after the majority of the matrix is computed as KxK sized blocks.
357 | * (t,l,b,r)->(row, col, row+blockY, col+blockX).
358 | */
359 | __declspec(noalias) void MMHelper_MultAnyBlocks(float* __restrict const matData,
360 | const unsigned rowSpan, const Mat& matA,
361 | const Mat& matBT, const unsigned colC,
362 | const unsigned rowC, const int blockX,
363 | const int blockY,
364 | const MMBlockInfo& mmBlockInfo)
365 | {
366 | /* if no work to be done, exit */
367 | if (blockX <= 0 || blockY <= 0)
368 | return;
369 |
370 | /* shorthand for some parameters */
371 | const unsigned L2BlockX = mmBlockInfo.L2BlockX, L2BlockY = mmBlockInfo.L2BlockY,
372 | L3BlockX = mmBlockInfo.L3BlockX, L3BlockY = mmBlockInfo.L3BlockY;
373 |
374 | int blockRowC = rowC;
375 | /* handle full L2Y sized rows */
376 | for (; blockRowC <= rowC + blockY - L2BlockY; blockRowC += L2BlockY) {
377 | int blockColC = colC;
378 | /* handle (L2X x L2Y) blocks */
379 | for (; blockColC <= colC + blockX - L2BlockX; blockColC += L2BlockX) {
380 | MMHelper_MultL2Blocks(matData, rowSpan, matA, matBT, blockColC, blockRowC,
381 | L2BlockX, L2BlockY);
382 | }
383 | /* handle the remaining columns, (w 4) {
387 | for (; blockCol <= colC + blockX - 3; blockCol += 3) {
388 | MMHelper_Mult4x3Blocks(matData, rowSpan, matA, matBT, blockCol,
389 | blockRow);
390 | }
391 | }
392 | for (; blockCol < colC + blockX; ++blockCol) {
393 | MMHelper_Mult4x1Blocks(matData, rowSpan, matA, matBT, blockCol,
394 | blockRow);
395 | }
396 | }
397 | }
398 | /* handle rest of the rows, h
450 | * [---- [a1] [a2] ---- ]
451 | * [---- [b1] [b2] ---- ]
452 | */
453 |
454 | for (int pos = 0; pos < matA.width; pos += 16) {
455 | a1 = _mm256_load_ps(&matA.mat[matAoffset + pos]);
456 | a2 = _mm256_load_ps(&matA.mat[matAoffset + pos + 8]);
457 |
458 | b1 = _mm256_load_ps(&matBT.mat[matBToffset + pos]);
459 | b2 = _mm256_load_ps(&matBT.mat[matBToffset + pos + 8]);
460 |
461 | c1 = _mm256_fmadd_ps(a1, b1, c1);
462 | c2 = _mm256_fmadd_ps(a2, b2, c2);
463 | }
464 |
465 | c1 = _mm256_add_ps(c1, c2);
466 | _mm256_store_ps(&fps[0], c1);
467 |
468 | accumulate = 0;
469 | for (int i = 0; i < 8; ++i) {
470 | accumulate += fps[i];
471 | }
472 |
473 | /* store */
474 | matData[row * rowSpan + col] = accumulate;
475 | }
476 |
477 | /* Calculates a 1x3 block on the matrix C, (t,l,b,r)->(row,col,row+1,col+3) */
478 | __declspec(noalias) void MMHelper_Mult1x3Blocks(float* __restrict const matData,
479 | const unsigned rowSpan, const Mat& matA,
480 | const Mat& matBT, const unsigned col,
481 | const unsigned row)
482 | {
483 | /* set up scalar array and accumulators for doing the horizontal sum (__m256 -> f32)
484 | * and storing its value. Horizontal sum is auto-vectorized by the compiler anyways. */
485 | __declspec(align(32)) float fps[8 * 3];
486 | __declspec(align(32)) float accumulate[3];
487 |
488 | /* we will be reusing these */
489 | const unsigned matAoffset = row * matA.rowSpan;
490 | const unsigned matBToffset1 = (col + 0) * matBT.rowSpan,
491 | matBToffset2 = (col + 1) * matBT.rowSpan,
492 | matBToffset3 = (col + 2) * matBT.rowSpan;
493 |
494 | /* set up accumulators */
495 | __m256 a1, b1, b2, b3;
496 | __m256 c1 = _mm256_setzero_ps();
497 | __m256 c2 = _mm256_setzero_ps();
498 | __m256 c3 = _mm256_setzero_ps();
499 |
500 | for (int pos = 0; pos < matA.width; pos += 8) {
501 | a1 = _mm256_load_ps(&matA.mat[matAoffset + pos]);
502 |
503 | b1 = _mm256_load_ps(&matBT.mat[matBToffset1 + pos]);
504 | b2 = _mm256_load_ps(&matBT.mat[matBToffset2 + pos]);
505 | b3 = _mm256_load_ps(&matBT.mat[matBToffset3 + pos]);
506 |
507 | c1 = _mm256_fmadd_ps(a1, b1, c1);
508 | c2 = _mm256_fmadd_ps(a1, b2, c2);
509 | c3 = _mm256_fmadd_ps(a1, b3, c3);
510 | }
511 |
512 | /* horizontal sum */
513 |
514 | memset(&accumulate[0], 0, 3 * sizeof(float));
515 |
516 | _mm256_store_ps(&fps[0], c1);
517 | _mm256_store_ps(&fps[8], c2);
518 | _mm256_store_ps(&fps[16], c3);
519 |
520 | /* autovectorized */
521 | for (int i = 0; i < 3; ++i) {
522 | for (int j = 0; j < 8; ++j) {
523 | accumulate[i] += fps[i * 8 + j];
524 | }
525 | }
526 |
527 | /* stores */
528 | matData[row * rowSpan + col + 0] = accumulate[0];
529 | matData[row * rowSpan + col + 1] = accumulate[1];
530 | matData[row * rowSpan + col + 2] = accumulate[2];
531 | }
532 |
533 | /* Calculates a 4x1 block on output matrix C. (t,l,b,r)->(row,col,row+4,col+1) */
534 | __declspec(noalias) void MMHelper_Mult4x1Blocks(float* __restrict const matData,
535 | const unsigned rowSpan, const Mat& matA,
536 | const Mat& matBT, const unsigned col,
537 | const unsigned row)
538 | {
539 | /* set up scalar array and accumulators for doing the horizontal sum (__m256 -> f32)
540 | * and storing its value. Horizontal sum is auto-vectorized by the compiler anyways. */
541 | __declspec(align(32)) float fps[8 * 12];
542 | __declspec(align(32)) float accumulate[8 * 12];
543 |
544 | const unsigned matAoffset1 = (row + 0) * matA.rowSpan,
545 | matAoffset2 = (row + 1) * matA.rowSpan,
546 | matAoffset3 = (row + 2) * matA.rowSpan,
547 | matAoffset4 = (row + 3) * matA.rowSpan;
548 |
549 | const unsigned matBToffset = col * matBT.rowSpan;
550 |
551 | /* set up accumulators */
552 | __m256 a11, a12, a21, a22, a31, a32, a41, a42, b1, b2;
553 | __m256 c1 = _mm256_setzero_ps();
554 | __m256 c2 = _mm256_setzero_ps();
555 | __m256 c3 = _mm256_setzero_ps();
556 | __m256 c4 = _mm256_setzero_ps();
557 | __m256 c5 = _mm256_setzero_ps();
558 | __m256 c6 = _mm256_setzero_ps();
559 | __m256 c7 = _mm256_setzero_ps();
560 | __m256 c8 = _mm256_setzero_ps();
561 |
562 | for (int pos = 0; pos < matA.width; pos += 16) {
563 | a11 = _mm256_load_ps(&matA.mat[matAoffset1 + pos]);
564 | a12 = _mm256_load_ps(&matA.mat[matAoffset1 + pos + 8]);
565 |
566 | a21 = _mm256_load_ps(&matA.mat[matAoffset2 + pos]);
567 | a22 = _mm256_load_ps(&matA.mat[matAoffset2 + pos + 8]);
568 |
569 | a31 = _mm256_load_ps(&matA.mat[matAoffset3 + pos]);
570 | a32 = _mm256_load_ps(&matA.mat[matAoffset3 + pos + 8]);
571 |
572 | a41 = _mm256_load_ps(&matA.mat[matAoffset4 + pos]);
573 | a42 = _mm256_load_ps(&matA.mat[matAoffset4 + pos + 8]);
574 |
575 | b1 = _mm256_load_ps(&matBT.mat[matBToffset + pos]);
576 | b2 = _mm256_load_ps(&matBT.mat[matBToffset + pos + 8]);
577 |
578 | c1 = _mm256_fmadd_ps(a11, b1, c1);
579 | c2 = _mm256_fmadd_ps(a21, b1, c2);
580 | c3 = _mm256_fmadd_ps(a31, b1, c3);
581 | c4 = _mm256_fmadd_ps(a41, b1, c4);
582 |
583 | c5 = _mm256_fmadd_ps(a12, b2, c5);
584 | c6 = _mm256_fmadd_ps(a22, b2, c6);
585 | c7 = _mm256_fmadd_ps(a32, b2, c7);
586 | c8 = _mm256_fmadd_ps(a42, b2, c8);
587 | }
588 |
589 | /* horizontal sum */
590 |
591 | memset(&accumulate[0], 0, 4 * sizeof(float));
592 |
593 | c1 = _mm256_add_ps(c1, c5);
594 | c2 = _mm256_add_ps(c2, c6);
595 | c3 = _mm256_add_ps(c3, c7);
596 | c4 = _mm256_add_ps(c4, c8);
597 |
598 | _mm256_store_ps(&fps[0], c1);
599 | _mm256_store_ps(&fps[8], c2);
600 | _mm256_store_ps(&fps[16], c3);
601 | _mm256_store_ps(&fps[24], c4);
602 |
603 | /* autovectorized */
604 | for (int i = 0; i < 4; ++i) {
605 | for (int j = 0; j < 8; ++j) {
606 | accumulate[i] += fps[i * 8 + j];
607 | }
608 | }
609 |
610 | /* stores */
611 | matData[(row + 0) * rowSpan + col] = accumulate[0];
612 | matData[(row + 1) * rowSpan + col] = accumulate[1];
613 | matData[(row + 2) * rowSpan + col] = accumulate[2];
614 | matData[(row + 3) * rowSpan + col] = accumulate[3];
615 | }
616 |
617 | /* Calculates a 4x3 block on output matrix C. (t,l,b,r)->(row,col,row+4,col+3) */
618 | __declspec(noalias) void MMHelper_Mult4x3Blocks(float* __restrict const matData,
619 | const unsigned rowSpan, const Mat& matA,
620 | const Mat& matBT, const unsigned col,
621 | const unsigned row)
622 | {
623 | /* aligned placeholders and accumulators */
624 | __declspec(align(32)) float fps[8 * 12];
625 | __declspec(align(32)) float accumulate[12];
626 |
627 | const unsigned matAoffset1 = (row + 0) * matA.rowSpan,
628 | matAoffset2 = (row + 1) * matA.rowSpan,
629 | matAoffset3 = (row + 2) * matA.rowSpan,
630 | matAoffset4 = (row + 3) * matA.rowSpan,
631 | matBToffset1 = (col + 0) * matBT.rowSpan,
632 | matBToffset2 = (col + 1) * matBT.rowSpan,
633 | matBToffset3 = (col + 2) * matBT.rowSpan;
634 |
635 | /*
636 | * <-----A.w----> <-----A.w---->
637 | * [----[a1]----] [----[b1]----]
638 | * [----[a2]----] [----[b2]----]
639 | * [----[a3]----] [----[b3]----]
640 | * [----[a4]----] ^col
641 | * ^ row
642 | *
643 | * we are now computing dot product of 3 rows and 3 columns
644 | * at the same time, 1x8f vectors at a time.
645 | *
646 | * 3 ymm registers for b1:3,
647 | * 4*3 = 12 registers for the accumulators
648 | * 1 register for the temporary ai value loaded.
649 | * All 16 registers are used.
650 | * High arithmetic density: 7 loads -> 12 fma instructions
651 | *
652 | */
653 |
654 | /* set up SIMD variables */
655 | __m256 a, b1, b2, b3;
656 | __m256 c1 = _mm256_setzero_ps();
657 | __m256 c2 = _mm256_setzero_ps();
658 | __m256 c3 = _mm256_setzero_ps();
659 | __m256 c4 = _mm256_setzero_ps();
660 | __m256 c5 = _mm256_setzero_ps();
661 | __m256 c6 = _mm256_setzero_ps();
662 | __m256 c7 = _mm256_setzero_ps();
663 | __m256 c8 = _mm256_setzero_ps();
664 | __m256 c9 = _mm256_setzero_ps();
665 | __m256 c10 = _mm256_setzero_ps();
666 | __m256 c11 = _mm256_setzero_ps();
667 | __m256 c12 = _mm256_setzero_ps();
668 |
669 | /* if prefetch switch is set,
670 | * prefetch first sections, one cache line at a time */
671 | if constexpr (doL12Prefetch) {
672 | _mm_prefetch((const char*)&matA.mat[matAoffset1], _MM_HINT_T0);
673 | _mm_prefetch((const char*)&matA.mat[matAoffset2], _MM_HINT_T0);
674 | _mm_prefetch((const char*)&matA.mat[matAoffset3], _MM_HINT_T0);
675 | _mm_prefetch((const char*)&matA.mat[matAoffset4], _MM_HINT_T0);
676 |
677 | _mm_prefetch((const char*)&matBT.mat[matBToffset1], _MM_HINT_T0);
678 | _mm_prefetch((const char*)&matBT.mat[matBToffset2], _MM_HINT_T0);
679 | _mm_prefetch((const char*)&matBT.mat[matBToffset3], _MM_HINT_T0);
680 | }
681 |
682 | /* do the dot products */
683 | for (int pos = 0; pos < matA.width; pos += 8) {
684 | if constexpr (doL12Prefetch) {
685 | if ((pos & (unsigned)15)) {
686 | _mm_prefetch((const char*)&matA.mat[matAoffset1 + pos + 8],
687 | _MM_HINT_T0);
688 | }
689 | }
690 |
691 | b1 = _mm256_load_ps(&matBT.mat[matBToffset1 + pos]);
692 | b2 = _mm256_load_ps(&matBT.mat[matBToffset2 + pos]);
693 | b3 = _mm256_load_ps(&matBT.mat[matBToffset3 + pos]);
694 |
695 | if constexpr (doL12Prefetch) {
696 | if ((pos & (unsigned)15)) {
697 | _mm_prefetch((const char*)&matA.mat[matAoffset2 + pos + 8],
698 | _MM_HINT_T0);
699 | }
700 | }
701 |
702 | a = _mm256_load_ps(&matA.mat[matAoffset1 + pos]);
703 | c1 = _mm256_fmadd_ps(a, b1, c1);
704 | c2 = _mm256_fmadd_ps(a, b2, c2);
705 | c3 = _mm256_fmadd_ps(a, b3, c3);
706 |
707 | if constexpr (doL12Prefetch) {
708 | if ((pos & (unsigned)15)) {
709 | _mm_prefetch((const char*)&matA.mat[matAoffset3 + pos + 8],
710 | _MM_HINT_T0);
711 | }
712 | }
713 | a = _mm256_load_ps(&matA.mat[matAoffset2 + pos]);
714 | c4 = _mm256_fmadd_ps(a, b1, c4);
715 | c5 = _mm256_fmadd_ps(a, b2, c5);
716 | c6 = _mm256_fmadd_ps(a, b3, c6);
717 |
718 | if constexpr (doL12Prefetch) {
719 | if ((pos & (unsigned)15)) {
720 | _mm_prefetch((const char*)&matA.mat[matAoffset4 + pos + 8],
721 | _MM_HINT_T0);
722 | }
723 | }
724 |
725 | a = _mm256_load_ps(&matA.mat[matAoffset3 + pos]);
726 | c7 = _mm256_fmadd_ps(a, b1, c7);
727 | c8 = _mm256_fmadd_ps(a, b2, c8);
728 | c9 = _mm256_fmadd_ps(a, b3, c9);
729 |
730 | if constexpr (doL12Prefetch) {
731 | if ((pos & (unsigned)15)) {
732 | _mm_prefetch((const char*)&matBT.mat[matBToffset1 + pos + 8],
733 | _MM_HINT_T0);
734 | _mm_prefetch((const char*)&matBT.mat[matBToffset2 + pos + 8],
735 | _MM_HINT_T0);
736 | _mm_prefetch((const char*)&matBT.mat[matBToffset3 + pos + 8],
737 | _MM_HINT_T0);
738 | }
739 | }
740 |
741 | a = _mm256_load_ps(&matA.mat[matAoffset4 + pos]);
742 | c10 = _mm256_fmadd_ps(a, b1, c10);
743 | c11 = _mm256_fmadd_ps(a, b2, c11);
744 | c12 = _mm256_fmadd_ps(a, b3, c12);
745 | }
746 |
747 | /* horizontal sum */
748 | memset(&accumulate[0], 0, 12 * sizeof(float));
749 |
750 | _mm256_store_ps(&fps[0], c1);
751 | _mm256_store_ps(&fps[8], c2);
752 | _mm256_store_ps(&fps[16], c3);
753 | _mm256_store_ps(&fps[24], c4);
754 | _mm256_store_ps(&fps[32], c5);
755 | _mm256_store_ps(&fps[40], c6);
756 | _mm256_store_ps(&fps[48], c7);
757 | _mm256_store_ps(&fps[56], c8);
758 | _mm256_store_ps(&fps[64], c9);
759 | _mm256_store_ps(&fps[72], c10);
760 | _mm256_store_ps(&fps[80], c11);
761 | _mm256_store_ps(&fps[88], c12);
762 |
763 | for (int i = 0; i < 12; ++i) {
764 | for (int j = 0; j < 8; ++j) {
765 | accumulate[i] += fps[i * 8 + j];
766 | }
767 | }
768 |
769 | /* stores */
770 | matData[(row + 0) * rowSpan + col + 0] = accumulate[0];
771 | matData[(row + 0) * rowSpan + col + 1] = accumulate[1];
772 | matData[(row + 0) * rowSpan + col + 2] = accumulate[2];
773 |
774 | matData[(row + 1) * rowSpan + col + 0] = accumulate[3];
775 | matData[(row + 1) * rowSpan + col + 1] = accumulate[4];
776 | matData[(row + 1) * rowSpan + col + 2] = accumulate[5];
777 |
778 | matData[(row + 2) * rowSpan + col + 0] = accumulate[6];
779 | matData[(row + 2) * rowSpan + col + 1] = accumulate[7];
780 | matData[(row + 2) * rowSpan + col + 2] = accumulate[8];
781 |
782 | matData[(row + 3) * rowSpan + col + 0] = accumulate[9];
783 | matData[(row + 3) * rowSpan + col + 1] = accumulate[10];
784 | matData[(row + 3) * rowSpan + col + 2] = accumulate[11];
785 | }
786 |
787 | /*
788 | * Compute L2Y x L2X sized blocks from the output matrix C.
789 | * In order to keep this code nice and hot in instruction cache,
790 | * keep it restricted to full blocks of L2X x L2Y.
791 | */
792 | __declspec(noalias) void MMHelper_MultL2Blocks(float* __restrict const matData,
793 | const unsigned rowSpan, const Mat& matA,
794 | const Mat& matBT, const unsigned col,
795 | const unsigned row,
796 | const unsigned L2BlockX,
797 | const unsigned L2BlockY)
798 | {
799 | /* multiply 4x3 blocks, L2blockX == 3*k, L2blockY == 4*m */
800 | for (int blockRow = row; blockRow < row + L2BlockY; blockRow += 4) {
801 | for (int blockCol = col; blockCol < col + L2BlockX; blockCol += 3) {
802 | MMHelper_Mult4x3Blocks(matData, rowSpan, matA, matBT, blockCol, blockRow);
803 | }
804 | }
805 | }
806 |
807 | /* Compute K x K sized blocks from the output matrix C. see struct mmBlockInfo */
808 | __declspec(noalias) void MMHelper_MultFullBlocks(float* __restrict const matData,
809 | const unsigned rowSpan,
810 | const Mat& matA, const Mat& matBT,
811 | const unsigned colC,
812 | const unsigned rowC,
813 | const MMBlockInfo& mmBlockInfo)
814 | {
815 | const unsigned L2BlockX = mmBlockInfo.L2BlockX, L2BlockY = mmBlockInfo.L2BlockY,
816 | L3BlockX = mmBlockInfo.L3BlockX, L3BlockY = mmBlockInfo.L3BlockY,
817 | issuedBlockSzX = mmBlockInfo.issuedBlockSzX,
818 | issuedBlockSzY = mmBlockInfo.issuedBlockSzY;
819 |
820 | /* try to prefetch next bit of block into memory while still handling this one */
821 | {
822 | if constexpr (doL3Prefetch) {
823 | std::unique_lock lock(prefetchMutex);
824 | int alreadyPrefetchedCol =
825 | prefetched[rowC / L3BlockY][colC / issuedBlockSzX];
826 | lock.unlock();
827 | if (!alreadyPrefetchedCol) {
828 | for (int c = colC + issuedBlockSzX; c < colC + issuedBlockSzX; ++c) {
829 | for (int pos = 0; pos < matA.rowSpan;
830 | pos += cacheLineSz / sizeof(float)) {
831 | _mm_prefetch((const char*)&matBT.mat[c * matBT.rowSpan + pos],
832 | _MM_HINT_T2);
833 | }
834 | }
835 | lock.lock();
836 | prefetched[rowC / L3BlockY][colC / issuedBlockSzX]++;
837 | lock.unlock();
838 | }
839 | }
840 | }
841 |
842 | /* multiply L2YxL2X blocks */
843 | for (int blockColC = colC; blockColC < colC + issuedBlockSzX;
844 | blockColC += L2BlockX) {
845 | for (int blockRowC = rowC; blockRowC < rowC + issuedBlockSzY;
846 | blockRowC += L2BlockY) {
847 | MMHelper_MultL2Blocks(matData, rowSpan, matA, matBT, blockColC, blockRowC,
848 | L2BlockX, L2BlockY);
849 | }
850 | }
851 | }
852 |
853 | /*
854 | * This function divides the matrix multiplication into segments and
855 | * issues commands for a cache aware thread pool to handle them.
856 | * Uses the helper functions above.
857 | */
858 | __declspec(noalias) const Mat MTMatMul(const Mat& matA, const Mat& matB)
859 | {
860 | /* if CPU information is not already queried, do so */
861 | if (!CPUInfoQueried) {
862 | int dCaches[3];
863 | int iCache;
864 |
865 | CPUUtil::GetCacheInfo(&dCaches[0], iCache);
866 |
867 | L2Size = dCaches[1];
868 | L3Size = dCaches[2];
869 |
870 | cacheLineSz = CPUUtil::GetCacheLineSize();
871 |
872 | CPUInfoQueried++;
873 | }
874 |
875 | /* allocate the aligned float array for our new matrix C */
876 | float* __restrict const matData =
877 | (float*)_aligned_malloc(matA.height * matB.rowSpan * sizeof(float), AVX_ALIGN);
878 |
879 | /* construct matrix C */
880 | Mat matC{matB.width, matA.height, matB.rowSpan, matData};
881 |
882 | /* for the sake of cache, we'll be working with transposed B */
883 | const Mat matBT = TransposeMat(matB);
884 |
885 | /* initialize the HWLocalThreadPool with 1 or 2 threads per physical core
886 | * for all physical cores. Number of threads per core depends on HTT status. */
887 | const int HTTEnabled = CPUUtil::GetHTTStatus();
888 | const int jobStride = (1 << HTTEnabled);
889 | HWLocalThreadPool tp(0, jobStride);
890 |
891 | /* decide the block sizes for the given matrix and CPU */
892 | const float invN = 1.0 / matA.rowSpan;
893 |
894 | int QL2 = invN * L2Size / sizeof(float);
895 | int QL3 = invN * L3Size / sizeof(float);
896 | int k = min(max(QL2 / 6, 1), 10);
897 | int m = min(max(QL2 / 8, 1), 10);
898 | int L2BlockX = 3 * k;
899 | int L2BlockY = 4 * m;
900 | int lcmMN = std::lcm(k, m);
901 | int L3BlockX = min(max(QL3 / 120 / lcmMN * lcmMN * 60, 12*L2BlockX), 360);
902 | int L3BlockY = L3BlockX;
903 | int issuedBlockSzX = L3BlockX / 4;
904 | int issuedBlockSzY = L3BlockY / 3;
905 |
906 | /*printf("%d %d\n%d %d %d %d %d %d\n", matC.height, matC.width, L2BlockX, L2BlockY, issuedBlockSzX, issuedBlockSzY,
907 | L3BlockX, L3BlockY);*/
908 |
909 | MMBlockInfo mmBlockInfo{L3BlockX, L3BlockY, L2BlockX,
910 | L2BlockY, issuedBlockSzX, issuedBlockSzY};
911 |
912 | /* before we begin, start prefetching the first L3 level block */
913 | /* reset the prefetched flags */
914 | memset(&prefetched[0][0], 0, 1024 * 1024 * sizeof(int));
915 | /* prefetch rows of A and columns of B, one cache line at a time */
916 | for (int r = 0; r < L3BlockY; ++r) {
917 | for (int pos = 0; pos < matA.rowSpan; pos += cacheLineSz / sizeof(float)) {
918 | _mm_prefetch((const char*)&matA.mat[r * matA.rowSpan + pos], _MM_HINT_T2);
919 | }
920 | }
921 | for (int c = 0; c < L3BlockX; ++c) {
922 | for (int pos = 0; pos < matA.rowSpan; pos += cacheLineSz / sizeof(float)) {
923 | _mm_prefetch((const char*)&matBT.mat[c * matBT.rowSpan + pos], _MM_HINT_T2);
924 | }
925 | }
926 | /* prefetch is called for the first block, mark it. */
927 | prefetched[0][0]++;
928 |
929 | /* start issuing jobs for the thread pool */
930 |
931 | /*
932 | * We incorporate multiple levels of tiling into our traversal.
933 | *
934 | * If we issue commands linearly, we'll have poor L3 cache utilization.
935 | * [ [C0T0 | C0T1] [C1T0 | C1T1] ... [C5T0 | C5T1] ] covering a rows, b columns,
936 | * (a+b)N floats of data is needed to compute a*b sized block.
937 | * So, instead, we issue commands in the blocked manner, like:
938 | * [ [C0T0 | C0T1] [C1T0 | C1T1]
939 | * [C2T0 | C5T1] [C2T0 | C2T1] ]
940 | *
941 | * Traverse L3 sized blocks,
942 | * inside each, issue issuedBlockSz sized blocks.
943 | */
944 |
945 | int rowC = 0;
946 | /* handle L3Y sized rows
947 | * cast unsigned dimensions to signed to avoid UB */
948 | for (; rowC <= (int)matA.height - L3BlockY; rowC += L3BlockY) {
949 | int colC = 0;
950 | /* handle L3Y x L3X sized blocks */
951 | for (; colC <= (int)matB.width - L3BlockX; colC += L3BlockX) {
952 | /* Issue issuedBlockSzY x issuedBlockSzX sized blocks */
953 | for (int blockRowC = rowC; blockRowC < rowC + L3BlockY;
954 | blockRowC += issuedBlockSzY) {
955 | for (int blockColC = colC; blockColC < colC + L3BlockX;
956 | blockColC += jobStride * issuedBlockSzX) {
957 | tp.Add({
958 | HWLocalThreadPool::WrapFunc(MMHelper_MultFullBlocks, matData,
959 | matB.rowSpan, matA, matBT, blockColC,
960 | blockRowC, mmBlockInfo),
961 | HWLocalThreadPool::WrapFunc(MMHelper_MultFullBlocks, matData,
962 | matB.rowSpan, matA, matBT,
963 | blockColC + issuedBlockSzX,
964 | blockRowC, mmBlockInfo)
965 | });
966 | }
967 | }
968 | }
969 | /* handle the block w < L3X, h = L3Y at the end of the row */
970 | if (matB.width > colC) {
971 | const unsigned remSubX = (matB.width - colC) >> HTTEnabled;
972 | tp.Add({
973 | HWLocalThreadPool::WrapFunc(MMHelper_MultAnyBlocks, matData,
974 | matB.rowSpan, matA, matBT, colC, rowC,
975 | remSubX, L3BlockY, mmBlockInfo),
976 | HWLocalThreadPool::WrapFunc(MMHelper_MultAnyBlocks, matData,
977 | matB.rowSpan, matA, matBT,
978 | colC + remSubX, rowC,
979 | matB.width - colC - remSubX, L3BlockY,
980 | mmBlockInfo)
981 | });
982 | }
983 | }
984 | /* handle last row, h < L3Y */
985 | int colC = 0;
986 | /* first handle blocks of w = L3X, h < L3Y */
987 | for (; colC <= (int)matB.width - L3BlockX; colC += jobStride * issuedBlockSzX) {
988 | tp.Add({
989 | HWLocalThreadPool::WrapFunc(MMHelper_MultAnyBlocks, matData,
990 | matB.rowSpan, matA, matBT, colC,
991 | rowC, issuedBlockSzX, matA.height - rowC,
992 | mmBlockInfo),
993 | HWLocalThreadPool::WrapFunc(MMHelper_MultAnyBlocks, matData,
994 | matB.rowSpan, matA, matBT,
995 | colC + issuedBlockSzX, rowC, issuedBlockSzX,
996 | matA.height - rowC, mmBlockInfo)});
997 | }
998 | /* now handle the rightmost block of w < L3X, h < L3Y */
999 | tp.Add({HWLocalThreadPool::WrapFunc(MMHelper_MultAnyBlocks, matData, matB.rowSpan,
1000 | matA, matBT, colC, rowC, matB.width - colC,
1001 | matA.height - rowC, mmBlockInfo),
1002 | []() {}});
1003 |
1004 | /* -- commands issued -- */
1005 |
1006 | /* wait for the thread pool to finish */
1007 | tp.Close();
1008 | /* free the temporary bT matrix */
1009 | _aligned_free(matBT.mat);
1010 |
1011 | return matC;
1012 | }
1013 |
1014 | /* MatMul function, a simple branch that calls the proper implementation
1015 | * based on the complexity of the input matrix. */
1016 | const Mat MatMul(const Mat& matA, const Mat& matB)
1017 | {
1018 | /*
1019 | * If complexity is low enough,
1020 | * use the single threaded, transposed B method.
1021 | * A(N, M) B(M, K) => # of ops ~= 2*N*K*M
1022 | */
1023 | if (matA.height * matA.width * matB.width < 350 * 350 * 350) {
1024 | return ST_TransposedBMatMul(matA, matB);
1025 | }
1026 | return MTMatMul(matA, matB);
1027 | }
1028 |
1029 | int __cdecl main(int argc, char* argv[])
1030 | {
1031 | if (argc < 4) {
1032 | std::cout << "No args\n";
1033 | return 0;
1034 | }
1035 |
1036 | /* make sure the runtime system supports AVX and FMA ISAs */
1037 | assert(CPUUtil::GetSIMDSupport());
1038 |
1039 | const char* inputMtxAFile = argv[1];
1040 | const char* inputMtxBFile = argv[2];
1041 | const char* outMtxABFile = argv[3];
1042 |
1043 | //const char* inputMtxAFile = "matrixAx.bin";
1044 | //const char* inputMtxBFile = "matrixBx.bin";
1045 | //const char* outMtxABFile = "matrixAB-out.bin";
1046 |
1047 | const Mat inputMtxA = LoadMat(inputMtxAFile);
1048 | const Mat inputMtxB = LoadMat(inputMtxBFile);
1049 |
1050 | /*printf("%d %d %d %d\n", inputMtxA.height, inputMtxA.width, inputMtxB.height,
1051 | inputMtxB.width);*/
1052 |
1053 | auto start = std::chrono::high_resolution_clock::now();
1054 | const Mat outMtxAB = MatMul(inputMtxA, inputMtxB);
1055 | auto end = std::chrono::high_resolution_clock::now();
1056 |
1057 | std::cout
1058 | << "Matrix Multiplication: "
1059 | << std::chrono::duration_cast(end - start).count()
1060 | << " microseconds.\n";
1061 |
1062 | DumpMat(outMtxABFile, outMtxAB);
1063 |
1064 | FreeMat(inputMtxA);
1065 | FreeMat(inputMtxB);
1066 | FreeMat(outMtxAB);
1067 |
1068 | return 0;
1069 | }
1070 |
--------------------------------------------------------------------------------
/MatrixMult/MatrixMult.vcxproj:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | Debug
6 | Win32
7 |
8 |
9 | Release
10 | Win32
11 |
12 |
13 | Debug
14 | x64
15 |
16 |
17 | Release
18 | x64
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 | 15.0
31 | {54F1A74A-017A-4CF8-9D98-BE6E04DD2DE7}
32 | MatrixMult
33 | 10.0.16299.0
34 |
35 |
36 |
37 | Application
38 | true
39 | v141
40 | MultiByte
41 |
42 |
43 | Application
44 | false
45 | v141
46 | true
47 | MultiByte
48 |
49 |
50 | Application
51 | true
52 | v141
53 | MultiByte
54 |
55 |
56 | Application
57 | false
58 | v141
59 | true
60 | MultiByte
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 | Level3
84 | MaxSpeed
85 | true
86 | true
87 | true
88 | Speed
89 | Default
90 |
91 |
92 | Console
93 |
94 |
95 |
96 |
97 | Level3
98 | Disabled
99 | true
100 | true
101 | true
102 | Default
103 | false
104 | AdvancedVectorExtensions2
105 | Speed
106 | false
107 | false
108 | true
109 | Fast
110 | /Qvec-report:2 %(AdditionalOptions)
111 | false
112 | stdcpp17
113 | SyncCThrow
114 |
115 |
116 | Console
117 |
118 |
119 |
120 |
121 | Level3
122 | MaxSpeed
123 | true
124 | true
125 | true
126 | true
127 |
128 |
129 | true
130 | true
131 | true
132 |
133 |
134 |
135 |
136 | Level3
137 | true
138 | true
139 | true
140 | true
141 | Speed
142 | AdvancedVectorExtensions2
143 | Fast
144 | true
145 | true
146 | /Qvec-report:2 /Qpar-report:2 %(AdditionalOptions)
147 | false
148 | false
149 | false
150 | stdcpp17
151 | true
152 | false
153 | true
154 | true
155 | No
156 | false
157 | false
158 |
159 | COFFEELAKE
160 | COFFEELAKE
161 | Coffeelake
162 |
163 |
164 | true
165 | true
166 | Console
167 | true
168 |
169 |
170 |
171 |
172 |
173 |
--------------------------------------------------------------------------------
/MatrixMult/MatrixMult.vcxproj.filters:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | {4FC737F1-C7A5-4376-A066-2A32D752A2FF}
6 | cpp;c;cc;cxx;def;odl;idl;hpj;bat;asm;asmx
7 |
8 |
9 | {93995380-89BD-4b04-88EB-625FBE52EBFB}
10 | h;hh;hpp;hxx;hm;inl;inc;ipp;xsd
11 |
12 |
13 | {67DA6AB6-F800-4c08-8B7A-83BB121AAD01}
14 | rc;ico;cur;bmp;dlg;rc2;rct;bin;rgs;gif;jpg;jpeg;jpe;resx;tiff;tif;png;wav;mfcribbon-ms
15 |
16 |
17 |
18 |
19 | Source Files
20 |
21 |
22 | Source Files
23 |
24 |
25 |
26 |
27 | Header Files
28 |
29 |
30 | Header Files
31 |
32 |
33 |
--------------------------------------------------------------------------------
/MatrixMult/ThreadPool.h:
--------------------------------------------------------------------------------
1 | #pragma once
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 | #include
9 | #include
10 | #include
11 | #include
12 | #include
13 | #include "CPUUtil.h"
14 |
15 | /*
16 | * Thread pool that respects cache locality on HyperThreaded CPUs (WIN32 API dependent)
17 | *
18 | * Each job is described as an array of N functions. (ideal N=2 for HT)
19 | * For each job, N threads are created and assigned respective functions.
20 | * For a given job, all threads are guaranteed to be on the same physical core.
21 | * No two threads from different jobs are allowed on the same physical core.
22 | *
23 | *
24 | * Why?
25 | * When doing multithreading on cache sensitive tasks,
26 | * we want to keep threads that operate on same or contiguous memory region
27 | * on the same physical core s.t they share the same L2 cache.
28 | *
29 | * Reference: This code is influenced by writeup that explains thread pools at
30 | * https://github.com/mtrebi/thread-pool/blob/master/README.md
31 | *
32 | * Structure:
33 | * CPUUtil:
34 | * Uses Windows API to detect the number of physical cores, cache sizes
35 | * and mapping between physical and logical processors.
36 | *
37 | * HWLocalThreadPool:
38 | * Submission:
39 | * initializer list or vector of (void function (void)) of length N
40 | * where N is the num of threads that will spawn on the same core,
41 | * and, the length of the std::function array.
42 | * ith thread handles repective ith function
43 | *
44 | * Core Handlers:
45 | * We create NumHWCores many CoreHandler objects.
46 | * These objects are responsible for managing their cores.
47 | * They check the main pool for jobs, when a job is found,
48 | * if N==1 , they call the only function in the job description.
49 | * if N>1 , they assign N-1 threads on the same physical core to,
50 | * respective functions in the array. The CoreHandler is
51 | * assigned to the first function.
52 | * Once CoreHandler finishes its own task, it waits for other threads,
53 | * Then its available for new jobs, waiting to be notified by the pool manager.
54 | *
55 | * Thread Handlers:
56 | * Responsible for handling tasks handed away by the CoreHandler.
57 | * When they finish execution, they signal to notify CoreHandler
58 | * Then, they wait for a new task to run until they are terminated.
59 | *
60 | * Notes:
61 | *
62 | * DON'T KEEP THESE TASKS TOO SMALL.
63 | * We don't want our CoreHandler to check its childrens states constantly,
64 | * So, when a thread finishes a task, we signal the CoreHandler.
65 | * This might become a overhead if the task itself is trivial.
66 | * In that case you probably shouldn't be using this structure anyways,
67 | * But if you want to, you can change it so that,
68 | * CoreHandler periodically checks m_childThreadOnline array and sleeps in between.
69 | *
70 | */
71 |
72 | class HWLocalThreadPool {
73 | public:
74 | HWLocalThreadPool(int _numOfCoresToUse, int _numThreadsPerCore) : m_terminate(false)
75 | {
76 | m_numHWCores = CPUUtil::GetNumHWCores();
77 |
78 | if (_numOfCoresToUse <= 0) {
79 | m_numCoreHandlers = m_numHWCores;
80 | } else {
81 | m_numCoreHandlers = _numOfCoresToUse;
82 | }
83 |
84 | if (_numThreadsPerCore <= 0) {
85 | m_numThreadsPerCore =
86 | CPUUtil::GetNumLogicalProcessors() / m_numCoreHandlers;
87 | } else {
88 | m_numThreadsPerCore = _numThreadsPerCore;
89 | }
90 |
91 | /* malloc m_coreHandlers s.t no default initialization takes place,
92 | we construct every object with placement new */
93 | m_coreHandlers = (CoreHandler*)malloc(m_numCoreHandlers * sizeof(CoreHandler));
94 | m_coreHandlerThreads = new std::thread[m_numCoreHandlers];
95 |
96 | for (int i = 0; i < m_numCoreHandlers; ++i) {
97 | ULONG_PTR processAffinityMask;
98 | int maskQueryRetCode = CPUUtil::GetProcessorMask(i, processAffinityMask);
99 | if (maskQueryRetCode) {
100 | assert(0, "Can't query processor relations.");
101 | return;
102 | }
103 | CoreHandler* coreHandler =
104 | new (&m_coreHandlers[i]) CoreHandler(this, i, processAffinityMask);
105 | m_coreHandlerThreads[i] = std::thread(std::ref(m_coreHandlers[i]));
106 | }
107 | }
108 |
109 | ~HWLocalThreadPool()
110 | {
111 | if (!m_terminate)
112 | Close();
113 | }
114 |
115 | void Add(std::vector> const& F)
116 | {
117 | m_queue.Push(F);
118 | m_queueToCoreNotifier.notify_one();
119 | }
120 |
121 | /* if finishQueue is set, cores will termianate after handling every job at the queue
122 | if not, they will finish the current job they have and terminate. */
123 | void Close(const bool finishQueue = true)
124 | {
125 | {
126 | std::unique_lock lock(m_queueMutex);
127 | m_terminate = 1;
128 | m_waitToFinish = finishQueue;
129 | m_queueToCoreNotifier.notify_all();
130 | }
131 |
132 | for (int i = 0; i < m_numCoreHandlers; ++i) {
133 | if (m_coreHandlerThreads[i].joinable())
134 | m_coreHandlerThreads[i].join();
135 | }
136 |
137 | /* free doesn't call the destructor, so */
138 | for (int i = 0; i < m_numCoreHandlers; ++i) {
139 | m_coreHandlers[i].~CoreHandler();
140 | }
141 | free(m_coreHandlers);
142 | delete[] m_coreHandlerThreads;
143 | }
144 |
145 | const unsigned NumCores()
146 | {
147 | return m_numHWCores;
148 | }
149 |
150 | const unsigned NumThreadsPerCore()
151 | {
152 | return m_numThreadsPerCore;
153 | }
154 |
155 | template
156 | static std::function WrapFunc(F&& f, Args&&... args)
157 | {
158 | std::function func =
159 | std::bind(std::forward(f), std::forward(args)...);
160 | auto task_ptr =
161 | std::make_shared>(func);
162 |
163 | std::function wrapper_func = [task_ptr]() { (*task_ptr)(); };
164 |
165 | return wrapper_func;
166 | }
167 |
168 | protected:
169 | template class Queue {
170 | public:
171 | Queue()
172 | {
173 | }
174 | ~Queue()
175 | {
176 | }
177 |
178 | void Push(T const& element)
179 | {
180 | std::unique_lock lock(m_mutex);
181 | m_queue.push(std::move(element));
182 | }
183 |
184 | bool Pop(T& function)
185 | {
186 | std::unique_lock lock(m_mutex);
187 | if (!m_queue.empty()) {
188 | function = std::move(m_queue.front());
189 | m_queue.pop();
190 | return true;
191 | }
192 | return false;
193 | }
194 |
195 | int Size()
196 | {
197 | std::unique_lock lock(m_mutex);
198 | return m_queue.size();
199 | }
200 |
201 | private:
202 | std::queue m_queue;
203 | std::mutex m_mutex;
204 | };
205 |
206 | class CoreHandler {
207 | public:
208 | CoreHandler(HWLocalThreadPool* const _parent, const unsigned _id,
209 | const ULONG_PTR& _processorMask)
210 | : m_parent(_parent), m_id(_id), m_processorAffinityMask(_processorMask),
211 | m_terminate(false), m_numChildThreads(_parent->m_numThreadsPerCore - 1)
212 | {
213 | if (m_numChildThreads > 0) {
214 | m_childThreads = new std::thread[m_numChildThreads];
215 | m_childThreadOnline = new bool[m_numChildThreads];
216 | std::unique_lock lock(m_threadMutex);
217 | for (int i = 0; i < m_numChildThreads; ++i) {
218 | m_childThreadOnline[i] = 0;
219 | m_childThreads[i] =
220 | std::thread(ThreadHandler(this, i, m_processorAffinityMask));
221 | }
222 | }
223 | }
224 |
225 | void WaitForChildThreads()
226 | {
227 | if (!m_childThreads || m_numChildThreads < 1)
228 | return;
229 |
230 | std::unique_lock lock(m_threadMutex);
231 | bool anyOnline = 1;
232 | while (anyOnline) {
233 | anyOnline = 0;
234 | for (int i = 0; i < m_numChildThreads; ++i) {
235 | anyOnline |= m_childThreadOnline[i];
236 | }
237 | if (anyOnline) {
238 | m_threadToCoreNotifier.wait(lock);
239 | }
240 | }
241 | }
242 |
243 | void CloseChildThreads()
244 | {
245 | if (m_terminate || m_numChildThreads < 1)
246 | return;
247 |
248 | {
249 | std::unique_lock lock(m_threadMutex);
250 | m_terminate = 1;
251 | m_coreToThreadNotifier.notify_all();
252 | }
253 |
254 | /* Core closing threads */
255 | for (int i = 0; i < m_numChildThreads; ++i) {
256 | if (m_childThreads[i].joinable()) {
257 | m_childThreads[i].join();
258 | }
259 | }
260 |
261 | delete[] m_childThreads;
262 | delete[] m_childThreadOnline;
263 | }
264 |
265 | void operator()()
266 | {
267 | SetThreadAffinityMask(GetCurrentThread(), m_processorAffinityMask);
268 | bool dequeued;
269 | while (1) {
270 | {
271 | std::unique_lock lock(m_parent->m_queueMutex);
272 | if (m_parent->m_terminate &&
273 | !(m_parent->m_waitToFinish && m_parent->m_queue.Size() > 0)) {
274 | break;
275 | }
276 | if (m_parent->m_queue.Size() == 0) {
277 | m_parent->m_queueToCoreNotifier.wait(lock);
278 | }
279 | dequeued = m_parent->m_queue.Pop(m_job);
280 | }
281 | if (dequeued) {
282 | m_ownJob = std::move(m_job[0]);
283 | if (m_numChildThreads < 1) {
284 | m_ownJob();
285 | } else {
286 | {
287 | std::unique_lock lock(m_threadMutex);
288 | for (int i = 0; i < m_numChildThreads; ++i) {
289 | m_childThreadOnline[i] = 1;
290 | }
291 | m_coreToThreadNotifier.notify_all();
292 | }
293 |
294 | m_ownJob();
295 |
296 | WaitForChildThreads();
297 | }
298 | }
299 | }
300 | CloseChildThreads();
301 | }
302 |
303 | class ThreadHandler {
304 | public:
305 | ThreadHandler(CoreHandler* _parent, const unsigned _id,
306 | const ULONG_PTR& _processorAffinityMask)
307 | : m_parent(_parent), m_processorAffinityMask(_processorAffinityMask),
308 | m_id(_id), m_jobSlot(_id + 1)
309 | {
310 | }
311 |
312 | void operator()()
313 | {
314 | SetThreadAffinityMask(GetCurrentThread(), m_processorAffinityMask);
315 | while (1) {
316 | {
317 | std::unique_lock lock(m_parent->m_threadMutex);
318 | if (m_parent->m_terminate)
319 | break;
320 | if (!m_parent->m_childThreadOnline[m_id]) {
321 | m_parent->m_coreToThreadNotifier.wait(lock);
322 | }
323 | }
324 | bool online = 0;
325 | {
326 | std::unique_lock lock(m_parent->m_threadMutex);
327 | online = m_parent->m_childThreadOnline[m_id];
328 | }
329 | if (online) {
330 | func = std::move(m_parent->m_job[m_jobSlot]);
331 | func();
332 | std::unique_lock lock(m_parent->m_threadMutex);
333 | m_parent->m_childThreadOnline[m_id] = 0;
334 | m_parent->m_threadToCoreNotifier.notify_one();
335 | }
336 | }
337 | }
338 |
339 | const unsigned m_id;
340 | const unsigned m_jobSlot;
341 | CoreHandler* m_parent;
342 | ULONG_PTR m_processorAffinityMask;
343 | std::function func;
344 | };
345 |
346 | const unsigned m_id;
347 | HWLocalThreadPool* const m_parent;
348 | const ULONG_PTR m_processorAffinityMask;
349 | const unsigned m_numChildThreads;
350 |
351 | std::thread* m_childThreads;
352 | bool* m_childThreadOnline;
353 | bool m_terminate;
354 |
355 | std::vector> m_job;
356 | std::function m_ownJob;
357 |
358 | std::mutex m_threadMutex;
359 | std::condition_variable m_coreToThreadNotifier;
360 | std::condition_variable m_threadToCoreNotifier;
361 | };
362 |
363 | private:
364 | unsigned m_numHWCores, m_numCoreHandlers, m_numThreadsPerCore;
365 | CoreHandler* m_coreHandlers;
366 | std::thread* m_coreHandlerThreads;
367 |
368 | Queue>> m_queue;
369 |
370 | bool m_terminate, m_waitToFinish;
371 |
372 | std::mutex m_queueMutex;
373 | std::condition_variable m_queueToCoreNotifier;
374 | };
375 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Multithreaded, Lightning fast Matrix-Matrix Multiplication
2 |
3 | [See CHANGELOG](#changelog)
4 |
5 | [What's next?](#whats-next)
6 |
7 | In this project, I’ve implemented multiple methods for multiplying
8 | matrices, and relevant utilities. My prime focuses were:
9 |
10 | - Cache locality, memory access patterns.
11 |
12 | - SIMD, hand optimized AVX/FMA intrinsics.
13 |
14 | - Software prefetching to maximize pipeline utilization.
15 |
16 | - Cache friendly multithreading.
17 |
18 | I didn’t implement the Strassen’s algorithm, this code runs on O(N^3).
19 |
20 | # How to run
21 |
22 | **Requirements:**
23 | * Windows platform
24 | * 64-bit Intel CPU with AVX / FMA support
25 |
26 | Currently, if you're looking to use this code, just copy and include CPUUtils.\* ThreadPool.h and copy the contents of MatrixMul.cpp except main() into a namespace, the code should be ready to compile as a header only library. Will tidy up the code into a proper library soon.
27 |
28 | Note that this program relies on Intel specifix cpuid responses and intrinsics and Win32 API for logical-physical processor mapping and setting thread affinity.
29 |
30 | Running the example code:
31 | Build the solution (see build options), then navigate to *x64\\Release\\* and run this command or call “run.bat”. If
32 | you don’t have “tee” command, just delete the last part or install
33 | GnuWin32 CoreUtils.
34 |
35 | ``` bash
36 | for /l %x in (1, 1, 100) do echo %x && (MatrixGenerator.exe && printf "Generated valid output. Testing...\n" && MatrixMult.exe matrixA.bin matrixB.bin matrixAB-out.bin && printf \n\n ) | tee -a out.txt
37 | ```
38 |
39 | # Benchmarks
40 |
41 | On my machine (6 core i7-8700K), I’ve compared my implementation against:
42 |
43 | * Eigen library (with all the compiler optimizations turned on)
44 | * I've tested both Eigen's own implementation and Eigen compiled with MKL+TBB backend, runtime analysis shows that the benchmark indeed uses MKL kernel for matrix multiplication and Eigen doesn't introduce any overheads.
45 | * Multithreaded python-numpy which uses C/C++ backend and Intel MKL BLAS
46 | library. The code can be found under the Benchmarks folder, however the graph below doesn't include it as it was consistently slower than Eigen(MKL+TBB)
47 |
48 | ## Comparison
49 |
50 | Current implementation runs identically or slightly faster than Eigen (MKL+TBB) for all test cases (tested up to N=15K)! Intel Advisor and VTune clearly shows that MKL kernel *avx2_dgemm_kernel_0* is used and no abnormal overheads are present.
51 |
52 | 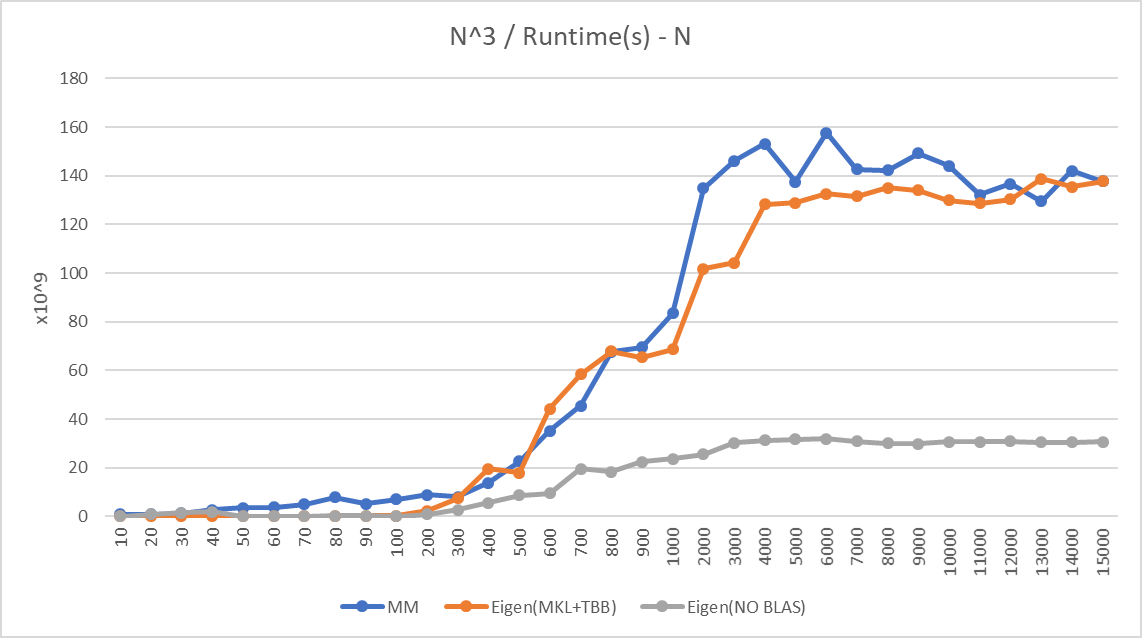
53 |
54 | ## Multithreading utilities ([ThreadPool.h](https://github.com/talhasaruhan/cpp-matmul/blob/master/MatrixMult/ThreadPool.h))
55 |
56 | ``` c++
57 | Namespace CPUUtil,
58 | HWLocalThreadPool(NumOfCoresToUse, NumThreadsPerCore)
59 | ```
60 |
61 | CPUUtil namespace has utility functions for querying runtime system for logical-physical processor mapping, cache sizes, cache line size, hyperthreading, AVX/FMA instruction set support and few more.
62 |
63 | I’ve also implemented a hardware local thread pool to handle jobs for multithreaded
64 | *MTMatMul* function. The pool runs every thread corresponding to a job
65 | on the same physical core. Idea is that, on hyperthreaded systems such
66 | as mine, 2 threads that work on contiguous parts of memory should live
67 | on the same core and share the same L1 and L2 cache.
68 |
69 | - Each job is described as an array of N functions. (N=2)
70 |
71 | - For each job, N threads (that were already created) are assigned respective
72 | functions.
73 |
74 | - For a given job, all threads are guaranteed to be on the same
75 | physical core.
76 |
77 | - No two threads from different jobs are allowed on the same physical
78 | core.
79 |
80 | ## MSVC2017 Build options (over default x64 Release build settings)
81 |
82 | - Maximum optimization: /O2
83 |
84 | - Favor fast code /Ot
85 |
86 | - Enable function level linking: /Gy
87 |
88 | - Enable enhanced instruction set: /arch:AVX2
89 |
90 | - Floating point model: /fp:fast
91 |
92 | - Language: /std:c++17 (for several “if constexpr”s, and one std::lcm. otherwise can be
93 | compiled with C++ 11)
94 |
95 | # What's next?
96 | * ~~Still a factor of 2 to achieve MKL performance.~~ Achieved and surpassed Eigen(MKL+TBB) performance for most test cases N<15K. Test and optimize for larger matrices.
97 | * Right now, when the prefetch switches are enabled, instruction retirement rate is about 88%, and the program is neither front-end nor back-end bound, it has excellent pipeline utilization. When the switches are disabled, the retirement rate drops to about 50%, and the program is heavily memory bound, pipelines are heavily stalled due to these bounds. However, on my current system (i7 8700K), binary without prefetching actually computes the output significantly faster (15%). I think this behaviour will heavily rely on the specific CPU, its cache size and performance. Try this on other hardware with different cache performances and varying matrix sizes.
98 | * Wrap the functionality in a replicable and distributable framework that's easy to use.
99 |
100 | # Changelog
101 |
102 | **Note:** Debugging builds will have arguments pre-set on the MatrixMul.cpp, you can ignore or revert those to accept argument from command line.
103 |
104 | ### 27/11/2018
105 | * Cleaned up the code. Split some behaviours into seperate functions.
106 | * Implemented runtime detection for best block size parameters for the runtime system.
107 | * Tuned software prefetching, now we do multiple smaller prefetches in between arithmetic operations and with a stride between prefetches.
108 | * More arithmetically dense inner loop. Instead of 3x3 blocks, do 4x3 blocks (3b + 12c + 1 temporary a == 16 registers used), 7 loads, 12 arithmetic operations.
109 | * HWLocalThreadPool takes number of cores and threads per core as contructor arguments and is not templated anymore. It never should have been.
110 | * Renamed QueryHWCores namespace to CPUUtils and extended it to support querying cache sizes, HTT/AVX/FMA support etc. using \_\_cpuid.
111 |
112 | ### 15/11/2018
113 | * Implemented **one more level of blocking**, first block holds data in L3 while the second holds the data in L2. To avoid the "job" overhead in thread pool system and to allow for explicit software prefetching, threads groups handle the highest level of blocks. (If the job was issued on lower level blocks, the threads need explicit syncing so that they only issue prefetch command once per L3 block.)
114 | * Implemented **software prefetching**. Now while an L3 block is being computed, next one is loaded into the memory in an asynchronous manner. May implement a similar feature for L2 level blocks later on.
115 | * **Removed** all but one of the *MMHelper_MultBlocks* implementations.
116 | * **Converted** AVX multiply and add intrinsics to **fused multiply add intrinsics** from FMA set.
117 | * **Now the MultBlocks use the loaded __m256 vectors as long as possible without unloading and loading a new one.** Just like we keep same values in cache and use them as much as possible without unloading, this is the the same idea applied to **YMM registers**. This increased Arithmetic Intensity (FLOP/L1 Transferred Bytes) metric from 0.25 to 0.67, speeding up the entire matrix multiplication by the same ratio.
118 | * Now fully integrated **VTune** into my workflow to analyze the application.
119 |
120 | ### 13/11/2018
121 | Long and detailed work journal, click to expand
122 |
123 |
124 | - Added a couple of vector sum implementations in benchmark project to compare different intrinsic approaches. The aim is to achieve maximum throughput with ILP minded design. However compiler optimizes away different ways in which I try to maximize the throughput for my own specific CPU architecture.
125 | - In order to address this issue, I wrote another benchmark with inline assembly and compiled it with GCC (as MSVC doesn't support inline assembly in x64 architecture). First of all, I tested GCC's behaviour with intrinsics and found it to be same as MSVC's for our purposes. Having shown that, I've written volatile inline assembly to force compiler to use my implementation. The tests showed that the compiler optimized the intrinsics to almost the same level when the optimizations are enabled. But compiler optimized versions, and my ASM code, is still not fast enough to compete with BLAS packages. So I'm doing something wrong in the first place and writing ASM is not the answer.
126 | - Benchmarked auto vectorization, naive intrinsics and other 2 intrinsic based block multiplication implementations, last 2 methods are about 15% faster than naive intrinsics and auto vectorized code. But arithmetic intensity (FLOPs / memory accesses) is still quite low.
127 | - Started analyzing the bottlenecks further using **Intel's VTune and Advisor**. It now became apparent that while I was getting similar results from different approaches, each had **different bottlenecks** which at first I couldn't see. So with this detailed information I should be able to address those bottlenecks.
128 | - Added another intrinsic based block multiplication method, changed a few implementations to use **FMA** intructions rather than seperate multiply-adds, to achieve higher throughput.
129 | - When profiling my program I noticed that small block sizes that can fit into L2 cache yielded a lot of L3 misses and large blocks that utilized L3 well and cut down the DRAM fetches, ran into L2 misses. So applying the idea that led to blocking to begin with, I will implement **one more level of blocking** to better utilize multiple layers of cache.
130 |
131 |
132 | Screenshot of memory usage analysis
138 |  139 |
139 |