├── .gitignore
├── .gitattributes
├── 6871657625761_.pic.jpg
├── docs
├── extra
│ └── image.js
├── index.md
├── chapter00-前言.md
├── chapter26-vscode调试Node.js.md
├── chapter31-Node.js 的 perf_hooks.md
├── chapter28-Node.js底层原理(架构篇).md
├── chapter22-events模块.md
├── chapter20-拓展Node.js.md
├── chapter09-Unix域.md
├── chapter03-事件循环.md
├── chapter29-Node.js底层原理(实现篇).md
├── chapter11-setImmediate和nextTick.md
├── chapter02-Libuv数据结构和通用逻辑.md
├── chapter10-定时器.md
├── chapter04-线程池.md
└── chapter27-深入理解 Node.js 的 Buffer.md
├── requirements.txt
├── .github
├── workflows
│ └── ci.yml
└── FUNDING.yml
├── README.md
├── LICENSE
└── mkdocs.yml
/.gitignore:
--------------------------------------------------------------------------------
1 | site/
2 |
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | *.md diff
2 |
--------------------------------------------------------------------------------
/6871657625761_.pic.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/theanarkh/understand-nodejs/HEAD/6871657625761_.pic.jpg
--------------------------------------------------------------------------------
/docs/extra/image.js:
--------------------------------------------------------------------------------
1 | const images = document.querySelectorAll('img');
2 |
3 | for (const image of images) {
4 | image.setAttribute('referrerpolicy', 'no-referrer');
5 | }
6 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 |
2 | mkdocs-material
3 | mkdocs-minify-plugin>=0.3.0
4 | mkdocs-git-revision-date-localized-plugin>=0.8
5 | mkdocs-git-revision-date-plugin>=0.3.1
6 | mkdocs-awesome-pages-plugin>=2.5.0
7 | mkdocs-redirects>=1.0.1
8 | mkdocs-macros-plugin>=0.5.0
--------------------------------------------------------------------------------
/.github/workflows/ci.yml:
--------------------------------------------------------------------------------
1 | name: ci
2 | on:
3 | push:
4 | branches:
5 | - master
6 | - main
7 | - docs
8 | jobs:
9 | deploy:
10 | runs-on: ubuntu-latest
11 | steps:
12 | - uses: actions/checkout@v2
13 | - uses: actions/setup-python@v2
14 | with:
15 | python-version: 3.x
16 | - run: |
17 | pip install -r requirements.txt
18 | - run: |
19 | mkdocs gh-deploy --force
20 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 | # 通过源码分析nodejs原理
2 |
3 | * 知乎:[Node.js源码分析](https://www.zhihu.com/column/c_1094251741922619392)
4 | * [为什么要读Node.js源码?](https://zhuanlan.zhihu.com/p/350625461)
5 | * [Node.js的底层原理](https://zhuanlan.zhihu.com/p/375276722)
6 | * [《Node.js源码解析1.0.0带标签版》](https://11111-1252105172.cos.ap-shanghai.myqcloud.com/understand-nodejs%EF%BC%88%E5%B8%A6%E6%A0%87%E7%AD%BE%E7%89%88%EF%BC%89.pdf)
7 |
8 |
9 | 让我们开始学习[Node.js](chapter00-前言.md)吧🔥
10 |
11 | ---
12 |
13 | 最后更新: {{ git.date.strftime('%Y-%m-%d') }}
14 |
--------------------------------------------------------------------------------
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | # These are supported funding model platforms
2 |
3 | github: # Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [user1, user2]
4 | patreon: # Replace with a single Patreon username
5 | open_collective: # Replace with a single Open Collective username
6 | ko_fi: # Replace with a single Ko-fi username
7 | tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
8 | community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
9 | liberapay: # Replace with a single Liberapay username
10 | issuehunt: # Replace with a single IssueHunt username
11 | otechie: # Replace with a single Otechie username
12 | lfx_crowdfunding: # Replace with a single LFX Crowdfunding project-name e.g., cloud-foundry
13 | custom: https://github.com/theanarkh/understand-nodejs
14 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 通过源码分析 Node.js 原理
2 |
3 | * [官网](https://theanarkh.github.io/understand-nodejs)
4 | * [Node.js 源码分析系列文章](https://www.zhihu.com/column/c_1094251741922619392)
5 | * [深入剖析 Node.js 底层原理](https://juejin.cn/book/7171733571638738952) 和 [示例代码](https://github.com/theanarkh/nodejs-book)
6 | * [JavaScript 运行时 Demo](https://github.com/theanarkh/js-runtime-demo)
7 | * [No.js: 基于 V8 和 io_uring 的 JavaScript 运行时](https://github.com/theanarkh/No.js)
8 | * [Deer: 基于 V8 和 kqueue 的 JavaScript 运行时](https://github.com/theanarkh/Deer)
9 | * [No.js: 基于 V8 和 Libuv 的 JavaScript 运行时](https://github.com/theanarkh/nojs)
10 | * [Node.js V10.x 源码注释](https://github.com/theanarkh/read-nodejs-code)
11 | * [Libuv 源码注释](https://github.com/theanarkh/read-libuv-code)
12 |
13 |  14 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 theanarkh
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/mkdocs.yml:
--------------------------------------------------------------------------------
1 | site_name: Node.js 源码剖析
2 | site_url: https://github.com/theanarkh/understand-nodejs
3 | site_author: theanarkh
4 | site_description: 通过源码分析 Node.js 原理
5 |
6 | repo_name: understand-nodejs
7 | repo_url: https://github.com/theanarkh/understand-nodejs
8 | edit_uri: edit/master/docs/
9 |
10 | copyright: Copyright © 2021 theanarkh
11 |
12 | theme:
13 | name: material
14 | language: zh
15 | icon:
16 | logo: material/book-open-page-variant
17 | repo: fontawesome/brands/github
18 | features:
19 | # https://squidfunk.github.io/mkdocs-material/reference/code-blocks/#adding-annotations
20 | - content.code.annotate
21 | - navigation.indexes
22 | - navigation.instant
23 | - navigation.tabs
24 | - navigation.tabs.sticky
25 | - navigation.sections
26 | - navigation.top
27 | - navigation.tracking
28 | - search.highlight
29 | - search.share
30 | - search.suggest
31 | palette:
32 | - scheme: default
33 | primary: indigo
34 | accent: indigo
35 | toggle:
36 | icon: material/toggle-switch-off-outline
37 | name: Switch to dark mode
38 | - scheme: slate
39 | primary: blue
40 | accent: blue
41 | toggle:
42 | icon: material/toggle-switch
43 | name: Switch to light mode
44 |
45 | markdown_extensions:
46 | - admonition
47 | - codehilite
48 | - footnotes
49 | - toc:
50 | permalink: true
51 | - pymdownx.arithmatex
52 | - pymdownx.betterem:
53 | smart_enable: all
54 | - pymdownx.caret
55 | - pymdownx.critic
56 | - pymdownx.details
57 | - pymdownx.highlight:
58 | linenums: true
59 | - pymdownx.superfences
60 | - pymdownx.emoji:
61 | emoji_index: !!python/name:materialx.emoji.twemoji
62 | emoji_generator: !!python/name:materialx.emoji.to_svg
63 | - pymdownx.inlinehilite
64 | - pymdownx.magiclink
65 | - pymdownx.mark
66 | - pymdownx.smartsymbols
67 | - pymdownx.superfences
68 | - pymdownx.tasklist:
69 | custom_checkbox: true
70 | - pymdownx.tabbed
71 | - pymdownx.tilde
72 |
73 | plugins:
74 | - search
75 | - minify:
76 | minify_html: true
77 | - awesome-pages
78 | - macros
79 | # https://squidfunk.github.io/mkdocs-material/setup/setting-up-tags/
80 | # - tags:
81 | # tags_file: tags.md
82 |
83 | extra:
84 |
85 | social:
86 | - icon: fontawesome/brands/github
87 | link: https://github.com/theanarkh
88 | - icon: fontawesome/brands/zhihu
89 | link: https://www.zhihu.com/people/theanarkh
90 | # - icon: fontawesome/brands/blog
91 | # link: https://xkx9431.github.io/xkx_blog/
92 | spark:
93 | version: 3.2.0 (RC2)
94 | github: https://github.com/apache/spark/tree/v3.2.0-rc2
95 |
96 |
97 | nav:
98 | - Home: index.md
99 | - 前言: chapter00-前言.md
100 | - Node.js基础和架构:
101 | - 01-Node.js组成和原理: chapter01-Node.js组成和原理.md
102 | - 02-Libuv数据结构和通用逻辑: chapter02-Libuv数据结构和通用逻辑.md
103 | - 03-事件循环: chapter03-事件循环.md
104 | - 04-线程池: chapter04-线程池.md
105 | - 05-Libuv流: chapter05-Libuv流.md
106 | - 06-C++层: chapter06-C++层.md
107 | - Node.js核心模块的实现:
108 | - 07-信号处理: chapter07-信号处理.md
109 | - 08-DNS: chapter08-DNS.md
110 | - 09-Unix域: chapter09-Unix域.md
111 | - 10-定时器: chapter10-定时器.md
112 | - 11-setImmediate和nextTick: chapter11-setImmediate和nextTick.md
113 | - 12-文件: chapter12-文件.md
114 | - 13-进程: chapter13-进程.md
115 | - 14-线程: chapter14-线程.md
116 | - 15-Cluster: chapter15-Cluster.md
117 | - 16-UDP: chapter16-UDP.md
118 | - 17-TCP: chapter17-TCP.md
119 | - 18-HTTP: chapter18-HTTP.md
120 | - 19-模块加载: chapter19-模块加载.md
121 | - 20-JS Stream: chapter21-JS Stream.md
122 | - 21-events模块: chapter22-events模块.md
123 | - 22-Async hooks: chapter23-Async hooks.md
124 | - 23-Inspector: chapter24-Inspector.md
125 | - 27-深入理解 Node.js 的 Buffer: chapter27-深入理解 Node.js 的 Buffer.md
126 | - 30-Node.js 的 trace events 架构: chapter30-Node.js 的 trace events 架构.md
127 | - 31-Node.js 的 perf_hooks: chapter31-Node.js 的 perf_hooks.md
128 | - 其他:
129 | - 24-拓展Node.js: chapter20-拓展Node.js.md
130 | - 25-Node.js子线程调试和诊断指南: chapter25-Node.js子线程调试和诊断指南
131 | - 26-vscode调试Node.js: chapter26-vscode调试Node.js.md
132 | - 28-Node.js底层原理(架构篇): chapter28-Node.js底层原理(架构篇).md
133 | - 29-Node.js底层原理(实现篇): chapter29-Node.js底层原理(实现篇).md
134 |
135 | extra_javascript:
136 | - path: extra/image.js
137 | defer: true
--------------------------------------------------------------------------------
/docs/chapter00-前言.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 我很喜欢JS这门语言,感觉它和C语言一样,在C语言里,很多东西都需要自己实现,让我们可以发挥无限的创造力和想象力。在JS中,虽然很多东西在V8里已经提供,但是用JS,依然可以创造很多好玩的东西,还有好玩的写法。另外,JS应该我见过唯一的一门没有实现网络和文件功能的语言,网络和文件,是一个很重要的能力,对于程序员来说,也是很核心很基础的知识。很幸运,Node.js被创造出来了,Node.js在JS的基础上,使用V8和Libuv提供的能力,极大地拓展、丰富了JS的能力,尤其是网络和文件,这样我就不仅可以使用JS,还可以使用网络、文件等功能,这是我逐渐转向Node.js方向的原因之一,也是我开始研究Node.js源码的原因之一。虽然Node.js满足了我喜好和技术上的需求,不过一开始的时候,我并没有全身心地投入代码的研究,只是偶尔会看一下某些模块的实现,真正的开始,是为了做《Node.js是如何利用Libuv实现事件循环和异步》的分享,从那时候起,大部分业余时间和精力都投入源码的研究。
4 | 我首先从Libuv开始研究,因为Libuv是Node.js的核心之一。由于曾经研究过一些Linux的源码,也一直在学习操作系统的一些原理和实现,所以在阅读Libuv的时候,算是没有遇到太大的困难,C语言函数的使用和原理,基本都可以看明白,重点在于需要把各个逻辑捋清楚。我使用的方法就是注释和画图,我个人比较喜欢写注释。虽然说代码是最好的注释,但是我还是愿意花时间用注释去把代码的背景和意义阐述一下,而且注释会让大部分人更快地能读懂代码的含义。读Libuv的时候,也穿插地读了一些JS和C++层的代码。我阅读Node.js源码的方式是,选择一个模块,垂直地从JS层分析到C++层,然后到Libuv层。
5 | 读完Libuv,接下来读的是JS层的代码,JS虽然容易看懂,但是JS层的代码非常多,而且我感觉逻辑上也非常绕,所以至今,我还有很多没有细读,这个作为后续的计划。Node.js中,C++算是胶水层,很多时候,不会C++,其实也不影响Node.js源码的阅读,因为C++很多时候,只是一种透传的功能,它把JS层的请求,通过V8,传给Libuv,然后再反过来,所以C++层我是放到最后才细读。C++层我觉得是最难的,这时候,我又不得不开始读V8的源码了,理解V8非常难,我选取的几乎是最早的版本0.1.5,然后结合8.x版本。通过早期版本,先学习V8的大概原理和一些早期实现上的细节。因为后续的版本虽然变化很大,但是更多只是功能的增强和优化,有很多核心的概念还是没有变化的,这是我选取早期版本的原因,避免一开始就陷入无穷无尽的代码中,迷失了方向,失去了动力。但是哪怕是早期的版本,有很多内容依然非常复杂,结合新版本是因为有些功能在早期版本里没有实现,这时候要明白它的原理,就只能看新版的代码,有了早期版本的经验,阅读新版的代码也有一定的好处,多少也知道了一些阅读技巧。
6 | Node.js的大部分代码都在C++和JS层,所以目前仍然是在不断地阅读这两层的代码。还是按照模块垂直分析。阅读Node.js代码,让我更了解Node.js的原理,也更了解JS。不过代码量非常大,需要源源不断的时间和精力投入。但是做技术,知其然知其所以然的感觉是非常美妙的,你靠着一门技术谋生,却对它知之甚少,这种感觉并不好。阅读源码,虽然不会为你带来直接的、迅速的收益,但是有几个好处是必然的。第一是它会决定你的高度,第二你写代码的时候,你看到的不再是一些冰冷冷、无生命的字符。这可能有点夸张,但是你了解了技术的原理,你在使用技术的时候,的确会有不同的体验,你的思维也会有了更多的变化。第三是提高了你的学习能力,当你对底层原理有了更多的了解和理解,你在学习其它技术的时候,就会更快地学会,比如你了解了epoll的原理,那你看Nginx、Redis、Libuv等源码的时候,关于事件驱动的逻辑,基本上很快就能看懂。很高兴有这些经历,也投入了很多时间和经精力,希望以后对Node.js有更多的理解和了解,也希望在Node.js方向有更多的实践。
7 |
8 | ## 本书的目的
9 | 阅读Node.js源码的初衷是让自己深入理解Node.js的原理,但是我发现有很多同学对Node.js原理也非常感兴趣,因为业余时间里也一直在写一些关于Node.js源码分析的文章(基于Node.js V10和V14),所以就打算把这些内容整理成一本有体系的书,让感兴趣的同学能系统地去了解和理解Node.js的原理。不过我更希望的是,读者从书中不仅学到Node.js的知识,而且也学到如何阅读Node.js源码,可以自己独立完成源码的研究。也希望更多同学分享自己的心得。本书不是Node.js的全部,但是尽量去讲得更多,源码非常多,错综复杂,理解上可能有不对之处,欢迎交流。因为看过Linux早期内核(0.11和1.2.13)和早期V8(0.1.5)的一些实现,文章会引用其中的一些代码,目的在于让读者可以更了解一个知识点的大致实现原理,如果读者有兴趣,可以自行阅读相关代码。
10 |
11 | ## 本书结构
12 | 本书共分为二十二章,讲解的代码都是基于Linux系统的。
13 |
14 | 1. 主要介绍了Node.js的组成和整体的工作原理,另外分析了Node.js启动的过程,最后介绍了服务器架构的演变和Node.js的所选取的架构。
15 | 2. 主要介绍了Node.js中的基础数据结构和通用的逻辑,在后面的章节会用到。
16 | 3. 主要介绍了Libuv的事件循环,这是Node.js的核心所在,本章具体介绍了事件循环中每个阶段的实现。
17 | 4. 主要分析了Libuv中线程池的实现,Libuv线程池对Node.js来说是非常重要的,Node.js中很多模块都需要使用线程池,包括crypto、fs、dns等。如果没有线程池,Node.js的功能将会大打折扣。同时分析了Libuv中子线程和主线程的通信机制。同样适合其它子线程和主线程通信。
18 | 5. 主要分析了Libuv中流的实现,流在Node.js源码中很多地方都用到,可以说是非常核心的概念。
19 | 6. 主要分析了Node.js中C++层的一些重要模块和通用逻辑。
20 | 7. 主要分析了Node.js的信号处理机制,信号是进程间通信的另一种方式。
21 | 8. 主要分析了Node.js的dns模块的实现,包括cares的使用和原理。
22 | 9. 主要分析了Node.js中pipe模块(Unix域)的实现和使用,Unix域是实现进程间通信的方式,它解决了没有继承的进程无法通信的问题。而且支持传递文件描述符,极大地增强了Node.js的能力。
23 | 10. 主要分析了Node.js中定时器模块的实现。定时器是定时处理任务的利器。
24 | 11. 主要分析了Node.js setImmediate和nextTick的实现。
25 | 12. 主要介绍了Node.js中文件模块的实现,文件操作是我们经常会用到的功能。
26 | 13. 主要介绍了Node.js中进程模块的实现,多进程使得Node.js可以利用多核能力。
27 | 14. 主要介绍了Node.js中线程模块的实现,多进程和多线程有类似的功能但是也有一些差异。
28 | 15. 主要介绍了Node.js中cluster模块的使用和实现原理,cluster模块封装了多进程能力,使得Node.j是可以使用多进程的服务器架构,利用了多核的能力。
29 | 16. 主要分析了Node.js中UDP的实现和相关内容。
30 | 17. 主要分析了Node.js中TCP模块的实现,TCP是Node.js的核心模块,我们常用的HTTP,HTTPS都是基于net模块。
31 | 18. 主要介绍了HTTP模块的实现以及HTTP协议的一些原理。
32 | 19. 主要分析了Node.js中各种模块加载的原理,深入理解Node.js的require函数所做的事情。
33 | 20. 主要介绍了一些拓展Node.js的方法,使用Node.js,拓展Node.js。
34 | 21. 主要介绍了JS层Stream的实现,Stream模块的逻辑很绕,大概讲解了一下。
35 | 22. 主要介绍了Node.js中event模块的实现,event模块虽然简单,但是是Node.js的核心模块。
36 |
37 | ## 面对的读者
38 | 本书面向有一定Node.js使用经验并对Node.js原理感兴趣的同学,因为本书是Node.js源码的角度去分析Node.js的原理,其中部分是C、C++,所以需要读者有一定的C、C++基础,另外,有一定的操作系统、计算机网络、V8基础会更好。
39 |
40 | ## 阅读建议
41 | 建议首先阅读前面几种基础和通用的内容,然后再阅读单个模块的实现,最后有兴趣的话,再阅读如何拓展Node.js章节。如果你已经比较熟悉Node.js,只是对某个模块或内容比较感兴趣,则可以直接阅读某个章节。刚开始阅读Node.js源码时,选取的是V10.x的版本,后来Node.js已经更新到了V14,所以书中的代码有的是V10有的是V14的。Libuv是V1.23。可以到我的github上获取。
42 |
43 | ## 源码阅读建议
44 | Node.js的源码由JS、C++、C组成。
45 | 1 Libuv是C语言编写。理解Libuv除了需要了解C语法外,更多的是对操作系统和网络的理解,有些经典的书籍可以参考,比如《Unix网络编程》1,2两册,《Linux系统编程手册》上下两册,《TCP/IP权威指南》等等。还有Linux的API文档以及网上优秀的文章都可以参考一下。
46 |
47 | 2 C++主要是利用V8提供的能力对JS进行拓展,也有一部分功能使用C++实现,总的来说C++的作用更多是胶水层,利用V8作为桥梁,连接Libuv和JS。不会C++,也不完全影响源码的阅读,但是会C++会更好。阅读C++层代码,除了语法外,还需要对V8的概念和使用有一定的了解和理解。
48 |
49 | 3 JS代码相信学习Node.js的同学都没什么问题。
50 |
51 | ## 其它资源
52 | 个人博客
53 | csdn [https://blog.csdn.net/THEANARKH](https://blog.csdn.net/THEANARKH)
54 | 知乎[https://www.zhihu.com/people/theanarkh](https://www.zhihu.com/people/theanarkh)
55 | github [https://github.com/theanarkh](https://github.com/theanarkh)
56 | 阅读Node.js源码时,所用到的基础知识、所作积累和记录几乎都在上面的博客中。 如果你有任何问题可以到[https://github.com/theanarkh/understand-nodejs](https://github.com/theanarkh/understand-nodejs)提issue或者联系我。
57 |
--------------------------------------------------------------------------------
/docs/chapter26-vscode调试Node.js.md:
--------------------------------------------------------------------------------
1 | 前言:调试代码不管对于开发还是学习源码都是非常重要的技能,本文简单介绍vscode调试Node.js相关代码的调试技巧。
2 | # 1 调试业务JS
3 | 调试业务JS可能是普遍的场景,随着Node.js和调试工具的成熟,调试也变得越来越简单。下面是vscode的lauch.json配置。
4 | ```json
5 | {
6 | "version": "0.2.0",
7 | "configurations": [
8 | {
9 | "type": "node",
10 | "request": "attach",
11 | "name": "Attact Program",
12 | "port": 9229
13 | }
14 | ]
15 | }
16 | ```
17 | 1 在JS里设置断点,执行node --inspect index.js 启动进程,会输出调试地址。
18 | 
19 | 2 点击虫子,然后点击绿色的三角形。
20 | 3 vscode会连接Node.js的WebSocket服务。
21 | 4 开始调试(或者使用Chrome Dev Tools调试)。
22 |
23 | # 2 调试Addon的C++
24 | 写Addon的场景可能不多,但是当你需要的时候,你就会需要调试它。下面的配置只可以调试C++代码。
25 | ```json
26 | {
27 | "version": "0.2.0",
28 | "configurations": [
29 | {
30 | "name": "Debug node C++ addon",
31 | "type": "lldb",
32 | "request": "launch",
33 | "program": "node",
34 | "args": ["${workspaceFolder}/node-addon-examples/1_hello_world/napi/hello.js"],
35 | "cwd": "${workspaceFolder}/node-addon-examples/1_hello_world/napi"
36 | },
37 | ]
38 | }
39 | ```
40 | 1 在C++代码设置断点。
41 | 
42 | 2 执行node-gyp configure && node-gyp build --debug编译debug版本的Addon。
43 | 3 JS里加载debug版本的Addon。
44 | 
45 | 4 点击小虫子开始调试。
46 | 
47 |
48 | # 3 调试Addon的C++和JS
49 | Addon通常需要通过JS暴露出来使用,如果我们需要调试C++和JS,那么就可以使用以下配置。
50 | ```json
51 | {
52 | "version": "0.2.0",
53 | "configurations": [
54 | {
55 | "name": "Debug node C++ addon",
56 | "type": "node",
57 | "request": "launch",
58 | "program": "${workspaceFolder}/node-addon-examples/1_hello_world/napi/hello.js",
59 | "cwd": "${workspaceFolder}/node-addon-examples/1_hello_world/napi"
60 | },
61 | {
62 | "name": "Attach node C/C++ Addon",
63 | "type": "lldb",
64 | "request": "attach",
65 | "pid": "${command:pickMyProcess}"
66 | }
67 | ]
68 | }
69 | ```
70 | 和2的过程类似,点三角形开始调试,再选择Attach node C/C++ Addon,然后再次点击三角形。
71 | 选择attach到hello.js中。
72 | 
73 | 开始调试。
74 |
75 | # 4 调试Node.js源码C++
76 | 我们不仅用Node.js,我们可能还会学习Node.js源码,学习源码的时候就少不了调试。可以通过下面的方式调试Node.js的C++源码。
77 | ```text
78 | ./configure --debug && make
79 | ```
80 | 使用以下配置
81 | ```json
82 | {
83 | "version": "0.2.0",
84 | "configurations": [
85 | {
86 | "name": "(lldb) 启动",
87 | "type": "cppdbg",
88 | "request": "launch",
89 | "program": "${workspaceFolder}/out/Debug/node",
90 | "args": [],
91 | "stopAtEntry": false,
92 | "cwd": "${fileDirname}",
93 | "environment": [],
94 | "externalConsole": false,
95 | "MIMode": "lldb"
96 | }
97 | ]
98 | }
99 | ```
100 | 在node_main.cc的main函数或任何C++代码里打断点,点击小虫子开始调试。
101 |
102 | # 5 调试Node.js源码C++和JS代码
103 | Node.js的源码不仅仅有C++,还有JS,如果我们想同时调试,那么就使用以下配置。
104 | ```json
105 | {
106 | "version": "0.2.0",
107 | "configurations": [
108 | {
109 | "name": "(lldb) 启动",
110 | "type": "cppdbg",
111 | "request": "launch",
112 | "program": "${workspaceFolder}/out/Debug/node",
113 | "args": ["--inspect-brk", "${workspaceFolder}/out/Debug/index.js"],
114 | "stopAtEntry": false,
115 | "cwd": "${fileDirname}",
116 | "environment": [],
117 | "externalConsole": false,
118 | "MIMode": "lldb"
119 | }
120 | ]
121 | }
122 | ```
123 | 1 点击调试。
124 | 
125 | 2 在vscode调试C++,执行完Node.js启动的流程后会输出调试JS的地址。
126 | 
127 | 3 在浏览器连接WebSocket服务调试JS。
128 | 
129 | 
130 |
131 |
132 |
--------------------------------------------------------------------------------
/docs/chapter31-Node.js 的 perf_hooks.md:
--------------------------------------------------------------------------------
1 | 前言:perf_hooks 是 Node.js 中用于收集性能数据的模块,Node.js 本身基于 perf_hooks 提供了性能数据,同时也提供了机制给用户上报性能数据。文本介绍一下 perk_hooks。
2 |
3 | # 1 使用
4 | 首先看一下 perf_hooks 的基本使用。
5 | ```c
6 | const { PerformanceObserver } = require('perf_hooks');
7 | const obs = new PerformanceObserver((items) => {
8 | //
9 | };
10 |
11 | obs.observe({ type: 'http' });
12 | ```
13 | 通过 PerformanceObserver 可以创建一个观察者,然后调用 observe 可以订阅对哪种类型的性能数据感兴趣。
14 |
15 | 下面看一下 C++ 层的实现,C++ 层的实现首先是为了支持 C++ 层的代码进行数据的上报,同时也为了支持 JS 层的功能。
16 | # 2 C++ 层实现
17 | ## 2.1 PerformanceEntry
18 | PerformanceEntry 是 perf_hooks 里的一个核心数据结构,PerformanceEntry 代表一次性能数据。下面来看一下它的定义。
19 | ```c
20 | template
21 | struct PerformanceEntry {
22 | using Details = typename Traits::Details;
23 | std::string name;
24 | double start_time;
25 | double duration;
26 | Details details;
27 |
28 | static v8::MaybeLocal GetDetails(
29 | Environment* env,
30 | const PerformanceEntry& entry) {
31 | return Traits::GetDetails(env, entry);
32 | }
33 | };
34 | ```
35 | PerformanceEntry 里面记录了一次性能数据的信息,从定义中可以看到,里面记录了类型,开始时间,持续时间,比如一个 HTTP 请求的开始时间,处理耗时。除了这些信息之外,性能数据还包括一些额外的信息,由 details 字段保存,比如 HTTP 请求的 url,不过目前还不支持这个能力,不同的性能数据会包括不同的额外信息,所以 PerformanceEntry 是一个类模版,具体的 details 由具体的性能数据生产者实现。下面我们看一个具体的例子。
36 | ```c
37 | struct GCPerformanceEntryTraits {
38 | static constexpr PerformanceEntryType kType = NODE_PERFORMANCE_ENTRY_TYPE_GC;
39 | struct Details {
40 | PerformanceGCKind kind;
41 | PerformanceGCFlags flags;
42 |
43 | Details(PerformanceGCKind kind_, PerformanceGCFlags flags_)
44 | : kind(kind_), flags(flags_) {}
45 | };
46 |
47 | static v8::MaybeLocal GetDetails(
48 | Environment* env,
49 | const PerformanceEntry& entry);
50 | };
51 |
52 | using GCPerformanceEntry = PerformanceEntry;
53 | ```
54 | 这是关于 gc 性能数据的实现,我们看到它的 details 里包括了 kind 和 flags。接下来看一下 perf_hooks 是如何收集 gc 的性能数据的。首先通过 InstallGarbageCollectionTracking 注册 gc 钩子。
55 | ```c
56 | static void InstallGarbageCollectionTracking(const FunctionCallbackInfo& args) {
57 | Environment* env = Environment::GetCurrent(args);
58 |
59 | env->isolate()->AddGCPrologueCallback(MarkGarbageCollectionStart,
60 | static_cast(env));
61 | env->isolate()->AddGCEpilogueCallback(MarkGarbageCollectionEnd,
62 | static_cast(env));
63 | env->AddCleanupHook(GarbageCollectionCleanupHook, env);
64 | }
65 | ```
66 | InstallGarbageCollectionTracking 主要是使用了 V8 提供的两个函数注册了 gc 开始和 gc 结束阶段的钩子。我们看一下这两个钩子的逻辑。
67 | ```c
68 | void MarkGarbageCollectionStart(
69 | Isolate* isolate,
70 | GCType type,
71 | GCCallbackFlags flags,
72 | void* data) {
73 | Environment* env = static_cast(data);
74 | env->performance_state()->performance_last_gc_start_mark = PERFORMANCE_NOW();
75 | }
76 | ```
77 | MarkGarbageCollectionStart 在开始 gc 时被执行,逻辑很简单,主要是记录了 gc 的开始时间。接着看 MarkGarbageCollectionEnd。
78 | ```c
79 | void MarkGarbageCollectionEnd(
80 | Isolate* isolate,
81 | GCType type,
82 | GCCallbackFlags flags,
83 | void* data) {
84 | Environment* env = static_cast(data);
85 | PerformanceState* state = env->performance_state();
86 |
87 | double start_time = state->performance_last_gc_start_mark / 1e6;
88 | double duration = (PERFORMANCE_NOW() / 1e6) - start_time;
89 |
90 | std::unique_ptr entry =
91 | std::make_unique(
92 | "gc",
93 | start_time,
94 | duration,
95 | GCPerformanceEntry::Details(
96 | static_cast(type),
97 | static_cast(flags)));
98 |
99 | env->SetImmediate([entry = std::move(entry)](Environment* env) {
100 | entry->Notify(env);
101 | }, CallbackFlags::kUnrefed);
102 | }
103 | ```
104 | MarkGarbageCollectionEnd 根据刚才记录 gc 开始时间,计算出 gc 的持续时间。然后产生一个性能数据 GCPerformanceEntry。然后在事件循环的 check 阶段通过 Notify 进行上报。
105 | ```c
106 | void Notify(Environment* env) {
107 | v8::Local detail;
108 | if (!Traits::GetDetails(env, *this).ToLocal(&detail)) {
109 | // TODO(@jasnell): Handle the error here
110 | return;
111 | }
112 |
113 | v8::Local argv[] = {
114 | OneByteString(env->isolate(), name.c_str()),
115 | OneByteString(env->isolate(), GetPerformanceEntryTypeName(Traits::kType)),
116 | v8::Number::New(env->isolate(), start_time),
117 | v8::Number::New(env->isolate(), duration),
118 | detail
119 | };
120 |
121 | node::MakeSyncCallback(
122 | env->isolate(),
123 | env->context()->Global(),
124 | env->performance_entry_callback(),
125 | arraysize(argv),
126 | argv);
127 | }
128 | };
129 | ```
130 | Notify 进行进一步的处理,然后执行 JS 的回调进行数据的上报。env->performance_entry_callback() 对应的回调在 JS 设置。
131 |
132 | ## 2.2 PerformanceState
133 | PerformanceState 是 perf_hooks 的另一个核心数据结构,负责管理 perf_hooks 模块的一些公共数据。
134 | ```c
135 | class PerformanceState {
136 | public:
137 | explicit PerformanceState(v8::Isolate* isolate, const SerializeInfo* info);
138 | AliasedUint8Array root;
139 | AliasedFloat64Array milestones;
140 | AliasedUint32Array observers;
141 |
142 | uint64_t performance_last_gc_start_mark = 0;
143 |
144 | void Mark(enum PerformanceMilestone milestone,uint64_t ts = PERFORMANCE_NOW());
145 |
146 | private:
147 | struct performance_state_internal {
148 | // Node.js 初始化时的性能数据
149 | double milestones[NODE_PERFORMANCE_MILESTONE_INVALID];
150 | // 记录对不同类型性能数据感兴趣的观察者个数
151 | uint32_t observers[NODE_PERFORMANCE_ENTRY_TYPE_INVALID];
152 | };
153 | };
154 | ```
155 | PerformanceState 主要是记录了 Node.js 初始化时的性能数据,比如 Node.js 初始化完毕的时间,事件循环的开始时间等。还有就是记录了观察者的数据结构,比如对 HTTP 性能数据感兴趣的观察者,主要用于控制要不要上报相关类型的性能数据。比如如果没有观察者的话,那么就不需要上报这个数据。
156 |
157 | # 3 JS 层实现
158 | 接下来看一下 JS 的实现。首先看一下观察者的实现。
159 |
160 | ```c
161 | class PerformanceObserver {
162 | constructor(callback) {
163 | // 性能数据
164 | this[kBuffer] = [];
165 | // 观察者订阅的性能数据类型
166 | this[kEntryTypes] = new SafeSet();
167 | // 观察者对一个还是多个性能数据类型感兴趣
168 | this[kType] = undefined;
169 | // 观察者回调
170 | this[kCallback] = callback;
171 | }
172 |
173 | observe(options = {}) {
174 | const {
175 | entryTypes,
176 | type,
177 | buffered,
178 | } = { ...options };
179 | // 清除之前的数据
180 | maybeDecrementObserverCounts(this[kEntryTypes]);
181 | this[kEntryTypes].clear();
182 | // 重新订阅当前设置的类型
183 | for (let n = 0; n < entryTypes.length; n++) {
184 | if (ArrayPrototypeIncludes(kSupportedEntryTypes, entryTypes[n])) {
185 | this[kEntryTypes].add(entryTypes[n]);
186 | maybeIncrementObserverCount(entryTypes[n]);
187 | }
188 | }
189 | // 插入观察者队列
190 | kObservers.add(this);
191 | }
192 |
193 | takeRecords() {
194 | const list = this[kBuffer];
195 | this[kBuffer] = [];
196 | return list;
197 | }
198 |
199 | static get supportedEntryTypes() {
200 | return kSupportedEntryTypes;
201 | }
202 | // 产生性能数据时被执行的函数
203 | [kMaybeBuffer](entry) {
204 | if (!this[kEntryTypes].has(entry.entryType))
205 | return;
206 | // 保存性能数据,迟点上报
207 | ArrayPrototypePush(this[kBuffer], entry);
208 | // 插入待上报队列
209 | kPending.add(this);
210 | if (kPending.size)
211 | queuePending();
212 | }
213 | // 执行观察者回调
214 | [kDispatch]() {
215 | this[kCallback](new PerformanceObserverEntryList(this.takeRecords()),
216 | this);
217 | }
218 | }
219 | ```
220 | 观察者的实现比较简单,首先有一个全局的变量记录了所有的观察者,然后每个观察者记录了自己订阅的类型。当产生性能数据时,生产者就会通知观察者,接着观察者执行回调。这里需要额外介绍的一个是 maybeDecrementObserverCounts 和 maybeIncrementObserverCount。
221 | ```c
222 | function getObserverType(type) {
223 | switch (type) {
224 | case 'gc': return NODE_PERFORMANCE_ENTRY_TYPE_GC;
225 | case 'http2': return NODE_PERFORMANCE_ENTRY_TYPE_HTTP2;
226 | case 'http': return NODE_PERFORMANCE_ENTRY_TYPE_HTTP;
227 | }
228 | }
229 |
230 | function maybeDecrementObserverCounts(entryTypes) {
231 | for (const type of entryTypes) {
232 | const observerType = getObserverType(type);
233 |
234 | if (observerType !== undefined) {
235 | observerCounts[observerType]--;
236 |
237 | if (observerType === NODE_PERFORMANCE_ENTRY_TYPE_GC &&
238 | observerCounts[observerType] === 0) {
239 | removeGarbageCollectionTracking();
240 | gcTrackingInstalled = false;
241 | }
242 | }
243 | }
244 | }
245 | ```
246 | maybeDecrementObserverCounts 主要用于操作 C++ 层的逻辑,首先根据订阅类型判断是不是 C++ 层支持的类型,因为 perf_hooks 在 C++ 和 JS 层都定义了不同的性能类型,如果是涉及到底层的类型,就会操作 observerCounts 记录当前类型的观察者数量,observerCounts 就是刚才分析 C++ 层的 observers 变量,它是一个数组,每个索引对应一个类型,数组元素的值是观察者的个数。另外如果订阅的是 gc 类型,并且是第一个订阅者,那就 JS 层就会操作 C++ 层往 V8 里注册 gc 回调。
247 |
248 | 了解了 perf_hooks 提供的机制后,我们来看一个具体的性能数据上报例子。这里以 HTTP Server 处理请求的耗时为例。
249 | ```c
250 | function emitStatistics(statistics) {
251 | const startTime = statistics.startTime;
252 | const diff = process.hrtime(startTime);
253 | const entry = new InternalPerformanceEntry(
254 | statistics.type,
255 | 'http',
256 | startTime[0] * 1000 + startTime[1] / 1e6,
257 | diff[0] * 1000 + diff[1] / 1e6,
258 | undefined,
259 | );
260 | enqueue(entry);
261 | }
262 | ```
263 | 下面是 HTTP Server 处理完一个请求时上报性能数据的逻辑。首先创建一个 InternalPerformanceEntry 对象,这个和刚才介绍的 C++ 对象是一样的,是表示一个性能数据的对象。接着调用 enqueue 函数。
264 | ```c
265 | function enqueue(entry) {
266 | // 通知观察者有性能数据,观察者自己判断是否订阅了这个类型的数据
267 | for (const obs of kObservers) {
268 | obs[kMaybeBuffer](entry);
269 | }
270 | // 如果是 mark 或 measure 类型,则插入一个全局队列。
271 | const entryType = entry.entryType;
272 | let buffer;
273 | if (entryType === 'mark') {
274 | buffer = markEntryBuffer; // mark 性能数据队列
275 | } else if (entryType === 'measure') {
276 | buffer = measureEntryBuffer; // measure 性能数据队列
277 | } else {
278 | return;
279 | }
280 |
281 | ArrayPrototypePush(buffer, entry);
282 | }
283 | ```
284 | enqueue 会把性能数据上报到观察者,然后观察者如果订阅这个类型的数据则执行用户回调通知用户。我们看一下 obs[kMaybeBuffer] 的逻辑。
285 | ```c
286 | [kMaybeBuffer](entry) {
287 | if (!this[kEntryTypes].has(entry.entryType))
288 | return;
289 | ArrayPrototypePush(this[kBuffer], entry);
290 | // this 是观察者实例
291 | kPending.add(this);
292 | if (kPending.size)
293 | queuePending();
294 | }
295 |
296 |
297 | function queuePending() {
298 | if (isPending) return;
299 | isPending = true;
300 | setImmediate(() => {
301 | isPending = false;
302 | const pendings = ArrayFrom(kPending.values());
303 | kPending.clear();
304 | // 遍历观察者队列,执行 kDispatch
305 | for (const pending of pendings)
306 | pending[kDispatch]();
307 | });
308 | }
309 | // 下面是观察者中的逻辑,观察者把当前保存的数据上报给用户
310 | [kDispatch]() {
311 | this[kCallback](new PerformanceObserverEntryList(this.takeRecords()),this);
312 | }
313 | ```
314 | 另外 mark 和 measure 类型的性能数据比较特殊,它不仅会通知观察者,还会插入到全局的一个队列中。所以对于其他类型的性能数据,如果没有观察者的话就会被丢弃(通常在调用 enqueue 之前会先判断是否有观察者),对于 mark 和 measure 类型的性能数据,不管有没有观察者都会被保存下来,所以我们需要显式清除。
315 |
316 | # 4 总结
317 | 以上就是 perf_hooks 中核心的实现,除此之外,perf_hooks 还提供了其他的功能,本文就先不介绍了。可以看到 perf_hooks 的实现是一个订阅发布的模式,看起来貌似没什么特别的。但是它的强大之处在于是由 Node.js 内置实现的, 这样 Node.js 的其他模块就可以基于 perf_hooks 这个框架上报各种类型的性能数据。相比来说虽然我们也能在用户层实现这样的逻辑,但是我们拿不到或者没有办法优雅地方法拿到 Node.js 内核里面的数据,比如我们想拿到 gc 的性能数据,我们只能写 addon 实现。又比如我们想拿到 HTTP Server 处理请求的耗时,虽然可以通过监听 reqeust 或者 response 对象的事件实现,但是这样一来我们就会耦合到业务代码里,每个开发者都需要处理这样的逻辑,如果我们想收拢这个逻辑,就只能劫持 HTTP 模块来实现,这些不是优雅但是是不得已的解决方案。有了 perf_hooks 机制,我们就可以以一种结耦的方式来收集这些性能数据,实现写一个 SDK,大家只需要简单引入就行。
318 |
319 | 最近在研究 perf_hooks 代码的时候发现目前 perf_hooks 的功能还不算完善,很多性能数据并没有上报,目前只支持 HTTP Server 的请求耗时、HTTP 2 和 gc 耗时这些性能数据。所以最近提交了两个 PR 支持了更多性能数据的上报。第一个 PR 是用于支持收集 HTTP Client 的耗时,第二个 PR 是用于支持收集 TCP 连接和 DNS 解析的耗时。在第二个 PR 里,实现了两个通用的方法,方便后续其他模块做性能上报。另外后续有时间的话,希望可以去不断完善 perf_hooks 机制和性能数据收集这块的能力。在从事 Node.js 调试和诊断这个方向的这段时间里,深感到应用层能力的局限,因为我们不是业务方,而是基础能力的提供者,就像前面提到的,哪怕想提供一个收集 HTTP 请求耗时的数据都是非常困难的,而作为基础能力的提供者,我们一直希望我们的能力对业务来说是无感知,无侵入并且是稳定可靠的。所以我们需要不断深入地了解 Node.js 在这方面提供的能力,如果 Node.js 没有提供我们想要的功能,我们只能写 addon 或者尝试给社区提交 PR 来解决。另外我们也在慢慢了解和学习 ebpf,希望能利用 ebpf 从另外一个层面帮助我们解决所碰到的问题。
320 |
--------------------------------------------------------------------------------
/docs/chapter28-Node.js底层原理(架构篇).md:
--------------------------------------------------------------------------------
1 | 前言:之前分享了 Node.js 的底层原理,主要是简单介绍了 Node.js 的一些基础原理和一些核心模块的实现,本文从 Node.js 整体方面介绍 Node.js 的底层原理。
2 |
3 | 内容主要包括五个部分。第一部分是首先介绍一下 Node.js 的组成和代码架构。然后介绍一下 Node.js 中的 Libuv, 还有 V8 和模块加载器。最后介绍一下 Node.js 的服务器架构。
4 |
5 | # 1 Node.js 的组成和代码架构
6 | 下面先来看一下Node.js 的组成。Node.js 主要是由 V8、Libuv 和一些第三方库组成。
7 | 1. V8 我们都比较熟悉,它是一个 JS 引擎。但是它不仅实现了 JS 解析和执行,它还是自定义拓展。比如说我们可以通过 V8 提供一些 C++ API 去定义一些全局变量,这样话我们在 JS 里面去使用这个变量了。正是因为 V8 支持这个自定义的拓展,所以才有了 Node.js 等 JS 运行时。
8 | 2. Libuv 是一个跨平台的异步 IO 库。它主要的功能是它封装了各个操作系统的一些 API, 提供网络还有文件进程的这些功能。我们知道在 JS 里面是没有网络文件这些功能的,在前端时,是由浏览器提供的,而在 Node.js 里,这些功能是由 Libuv 提供的。
9 | 3. 另外 Node.js 里面还引用了很多第三方库,比如 DNS 解析库,还有 HTTP 解析器等等。
10 |
11 | 接下来看一下 Node.js 代码整体的架构。
12 | 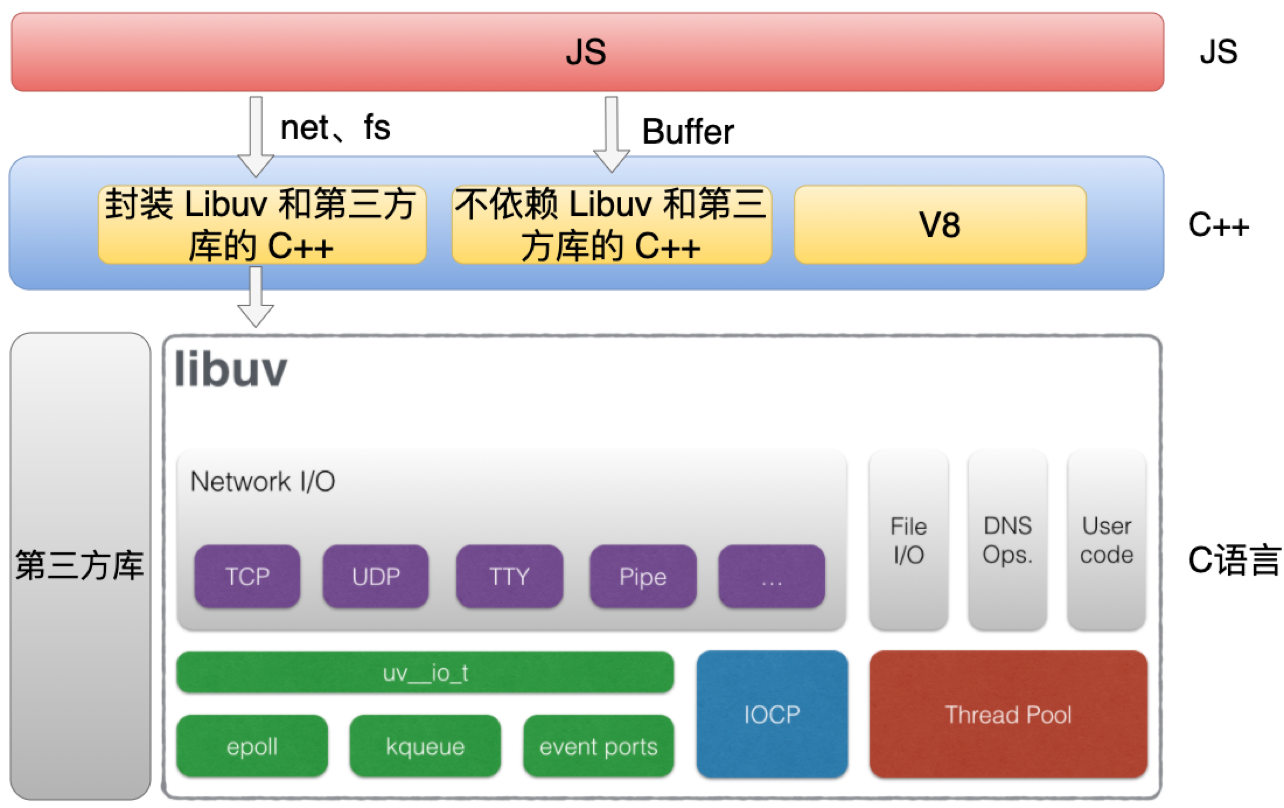
13 | Node.js 代码主要是分为三个部分,分别是C、C++ 和 JS。
14 | 1. JS 代码就是我们平时在使用的那些 JS 的模块,比方说像 http 和 fs 这些模块。
15 | 2. C++ 代码主要分为三个部分,第一部分主要是封装 Libuv 和第三方库的 C++ 代码,比如net 和 fs 这些模块都会对应一个 C++ 模块,它主要是对底层的一些封装。第二部分是不依赖 Libuv 和第三方库的 C++ 代码,比方像 Buffer 模块的实现。第三部分 C++ 代码是 V8 本身的代码。
16 | 3. C 语言代码主要是包括 Libuv 和第三方库的代码,它们都是纯 C 语言实现的代码。
17 |
18 | 了解了 Nodejs 的组成和代码架构之后,再来看一下 Node.js 中各个主要部分的实现。
19 | # 2 Node.js 中的 Libuv
20 | 首先来看一下 Node.js 中的 Libuv,下面从三个方面介绍 Libuv。
21 | 1. 介绍 Libuv 的模型和限制
22 | 2. 介绍线程池解决的问题和带来的问题
23 | 3. 介绍事件循环
24 |
25 | ## 2.1 Libuv 的模型和限制
26 | Libuv 本质上是一个生产者消费者的模型。
27 | 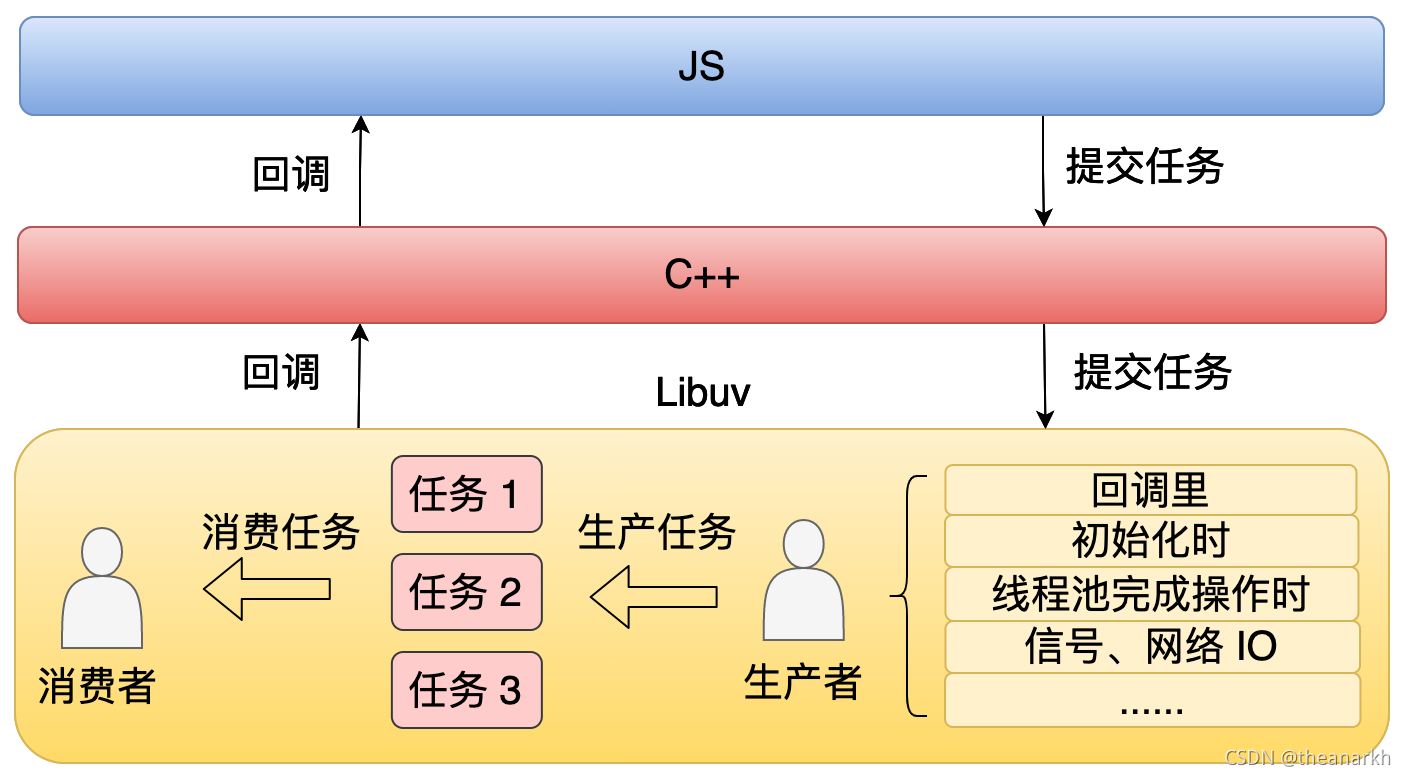
28 | 从上面这个图中,我们可以看到在 Libuv 中有很多种生产任务的方式,比如说在一个回调里,在 Node.js 初始化的时候,或者在线程池完成一些操作的时候,这些方式都可以生产任务。然后 Libuv 会不断的去消费这些任务,从而驱动着整个进程的运行,这就是我们一直说的事件循环。
29 |
30 | 但是生产者的消费者模型存在一个问题,就是消费者和生产者之间,怎么去同步?比如说在没有任务消费的时候,这个消费者他应该在干嘛?第一种方式是消费者可以睡眠一段时间,睡醒之后,他会去判断有没有任务需要消费,如果有的话就继续消费,如果没有的话他就继续睡眠。很显然这种方式其实是比较低效的。第二种方式是消费者会把自己挂起,也就是说这个消费所在的进程会被挂起,然后等到有任务的时候,操作系统就会唤醒它,相对来说,这种方式是更高效的,Libuv 里也正是使用这种方式。
31 | 
32 | 这个逻辑主要是由事件驱动模块实现的,下面看一下事件驱动的大致的流程。
33 | 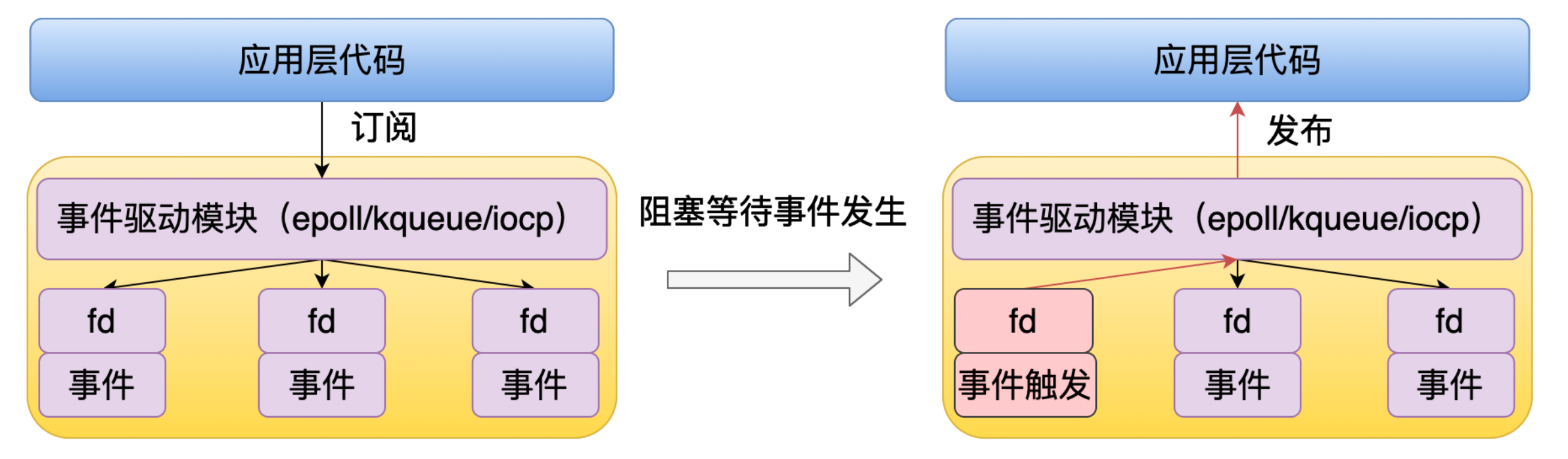
34 | 应用层代码可以通过事件驱动模块订阅 fd 的事件,如果这个事件还没有准备好的话,那么这个进程就会被挂起。然后等到这个 fd 所对应的事件触发了之后,就会通过事件驱动模块回调应用层的代码。
35 |
36 | 下面以 Linux 的 事件驱动模块 epoll 为例,来看一下使用流程。
37 | 1. 首先通过 epoll_create 去创建一个epoll 实例。
38 | 2. 然后通过 epoll_ctl 这个函数订阅、修改或者取消订阅一个 fd 的一些事件。
39 | 3. 最后通过 epoll_wait 去判断当前订阅的事件有没有发生,如果有事情要发生的话,那么就直接执行上层回调,如果没有事件发生的话,这种时候可以选择不阻塞,定时阻塞或者一直阻塞,直到有事件发生。要不要阻塞或者说阻塞多久,是根据当前系统的情况。比如 Node.js 里面如果有定时器的节点的话,那么 Node.js 就会定时阻塞,这样就可以保证定时器可以按时执行。
40 |
41 | 接下来再深入一点去看一下 epoll 的大致的实现。
42 | 
43 | 当应用层代码调用事件驱动模块订阅 fd 的事件时,比如说这里是订阅一个可读事件。那么事件驱动模块它就会往这个 fd 的队列里面注册一个回调,如果当前这个事件还没有触发,这个进程它就会被阻塞。等到有一块数据写入了这个 fd 时,也就是说这个 fd 有可读事件了,操作系统就会执行事件驱动模块的回调,事件驱动模块就会相应的执行用层代码的回调。
44 |
45 | 但是 epoll 存在一些限制。首先第一个是不支持文件操作的,比方说文件读写这些,因为操作系统没有实现。第二个是不适合执行耗时操作,比如大量 CPU 计算、引起进程阻塞的任务,因为 epoll 通常是搭配单线程的,如果在单线程里执行耗时任务,就会导致后面的任务无法执行。
46 | ## 2.2 线程池解决的问题和带来的问题
47 | 针对这个问题,Libuv 提供的解决方案就是使用线程池。下面来看一下引入了线程池之后, 线程池和主线程的关系。
48 | 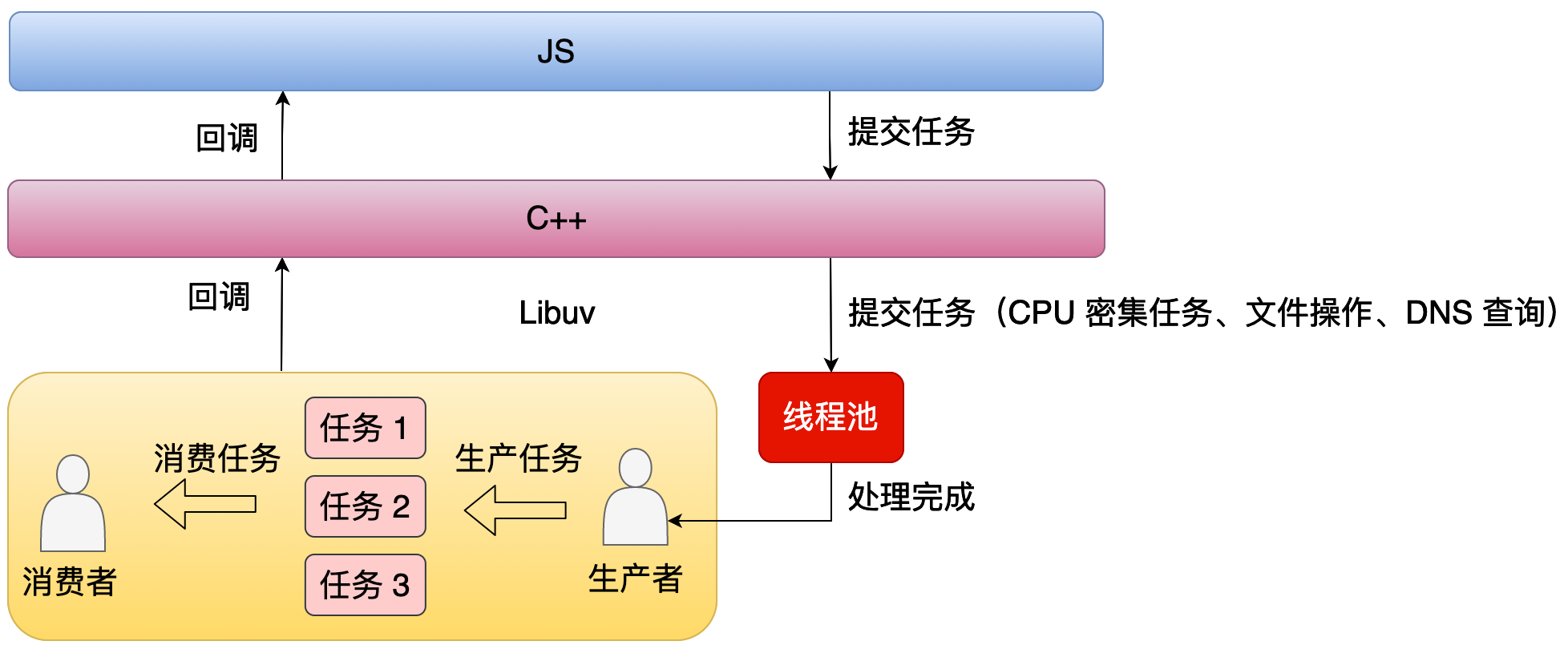
49 | 从这个图中我们可以看到,当应用层提交任务时,比方说像 CPU 计算还有文件操作,这种时候不是交给主线程去处理的,而是直接交给线程池处理的。线程池处理完之后它会通知主线程。
50 |
51 | 但是引入了多线程后会带来一个问题,就是怎么去保证上层代码跑在单个线程里面。因为我们知道 JS 它是单线程的,如果线程池处理完一个任务之后,直接执行上层回调,那么上层代码就会完全乱了。这种时候就需要一个异步通知的机制,也就是说当一个线程它处理完任务的时候,它不是直接去执行上程回调的,而是通过异步机制去通知主线程来执行这个回调。
52 | 
53 | Libuv 中具体通过 fd 的方式去实现的。当线程池完成任务时,它会以原子的方式去修改这个 fd 为可读的,然后在主线程事件循环的 Poll IO 阶段时,它就会执行这个可读事件的回调,从而执行上层的回调。可以看到,Node.js 虽然是跑在多线程上面的,但是所有的 JS 代码都是跑在单个线程里的,这也是我们经常讨论的 Node.js 是单线程还是多线程的,从不同的角度去看就会得到不同的答案。
54 |
55 |
56 | 下面的图就是异步任务处理的一个大致过程。
57 | 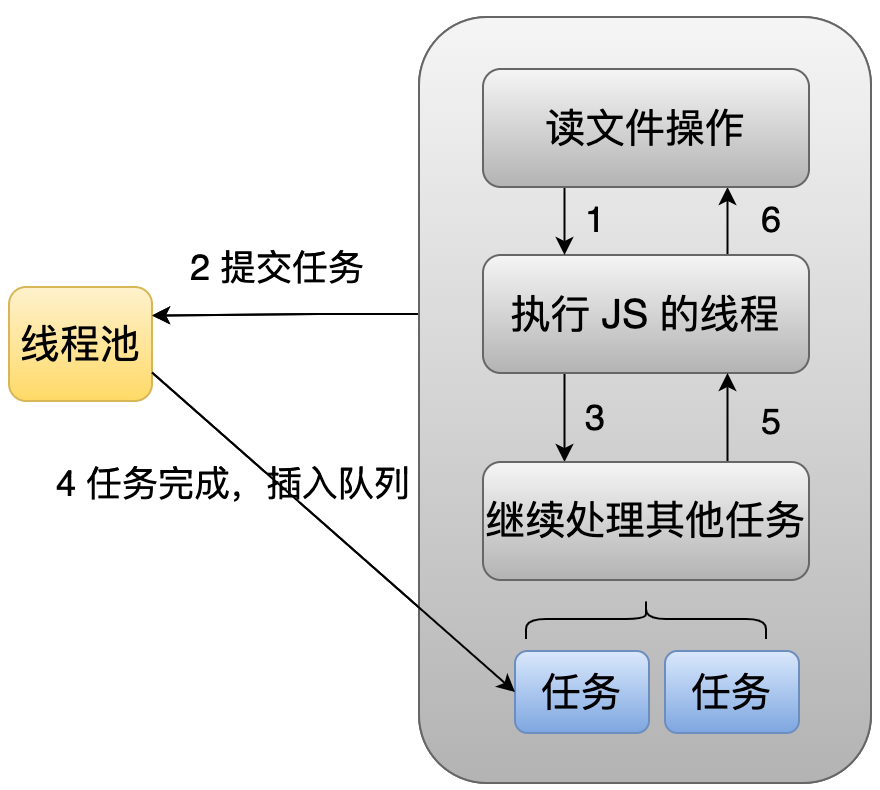
58 | 比如我们想读一个文件的时候,这时候主线程会把这个任务直接提交到线程池里面去处理,然后主线程就可以继续去做自己的事情了。当在线程池里面的线程完成这个任务之后,它就会往这个主线程的队列里面插入一个节点,然后主线程在 Poll IO 阶段时,它就会去执行这个节点里面的回调。
59 | ## 2.3 事件循环
60 | 了解 Libuv 的一些核心实现之后,下面我们再看一下 Libuv 中一个著名的事件循环。事件循环主要分为七个阶段,
61 | 1. 第一是 timer 阶段,timer 阶段是处理定时器相关的一些任务,比如 Node.js 中的 setTimeout和 setInterval。
62 | 2. 第二是 pending 的阶段, pending 阶段主要处理 Poll IO 阶段执行回调时产生的回调。
63 | 3. 第三是 check、prepare 和 idle 三个阶段,这三个阶段主要处理一些自定义的任务。setImmediate 属于 check 阶段。
64 | 4. 第四是 Poll IO 阶段,Poll IO 阶段主要要处理跟文件描述符相关的一些事件。
65 | 5. 第五是 close 阶段, 它主要是处理,调用了 uv_close 时传入的回调。比如关闭一个 TCP 连接时传入的回调,它就会在这个阶段被执行。
66 |
67 | 下面这个图是各个阶段在事件循环的顺序图。
68 | 
69 | 下面我们来看一下每个阶段的实现。
70 |
71 | 1. 定时器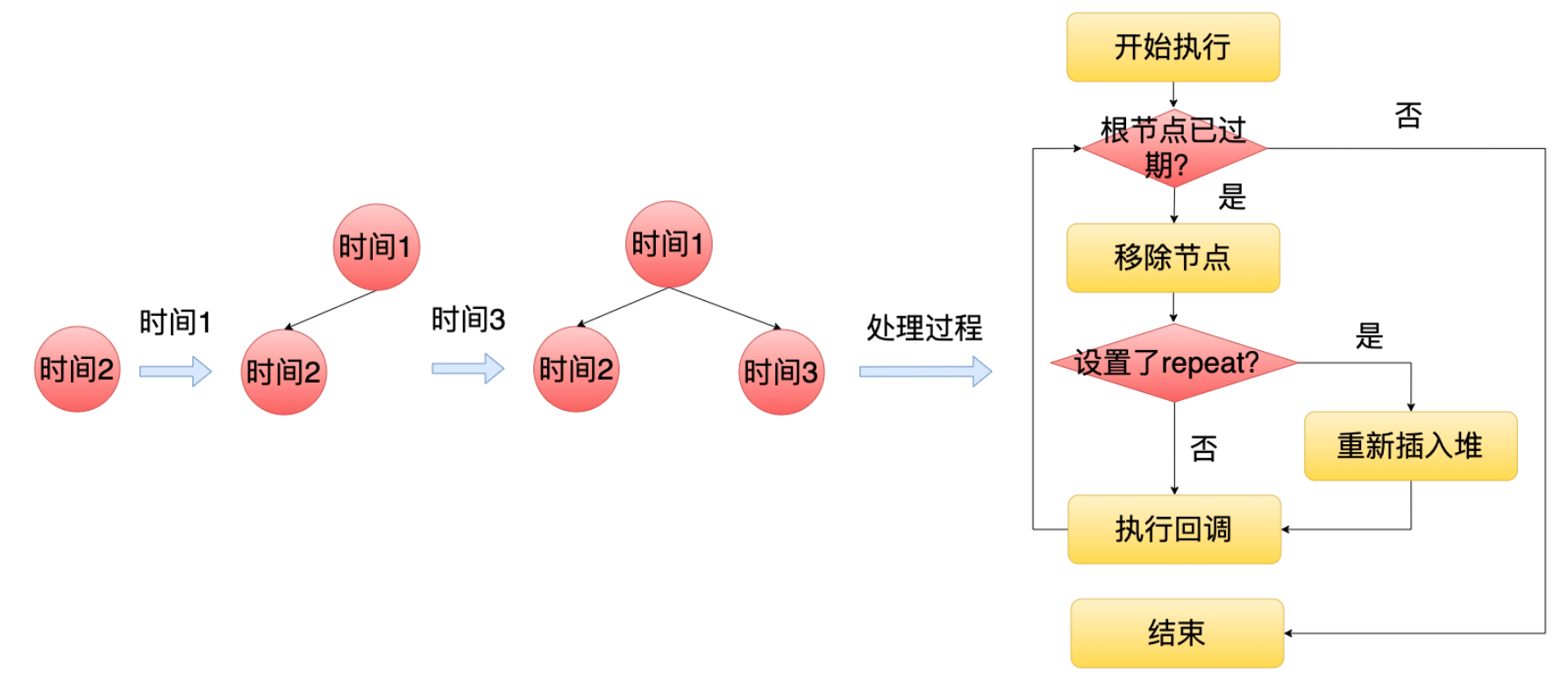
72 | Libuv 在底层里面维护了一个最小堆,每个定时节点就是堆里面的一个节点(Node.js 只用了 Libuv 的一个定时器节点),越早超时的节点就在越上面。然后等到定时期阶段的时候, Libuv 就会从上往下去遍历这个最小堆判断当前节点有没有超时,如果没有到期的话,那么后面节点也不需要去判断了,因为最早到期的节点都没到期,那么它后面节点也显然不会到期。如果当前节点到期了,那么就会执行它的回调,并且把它移出这个最小堆。但是为了支持类似 setInterval 这种场景。如果这个节点设置了repeat 标记,那么这个节点它会被重新插入到最小堆中,等待下一次的超时。
73 |
74 | 2. check、idle、prepare 阶段和 pending、close 阶段。
75 | 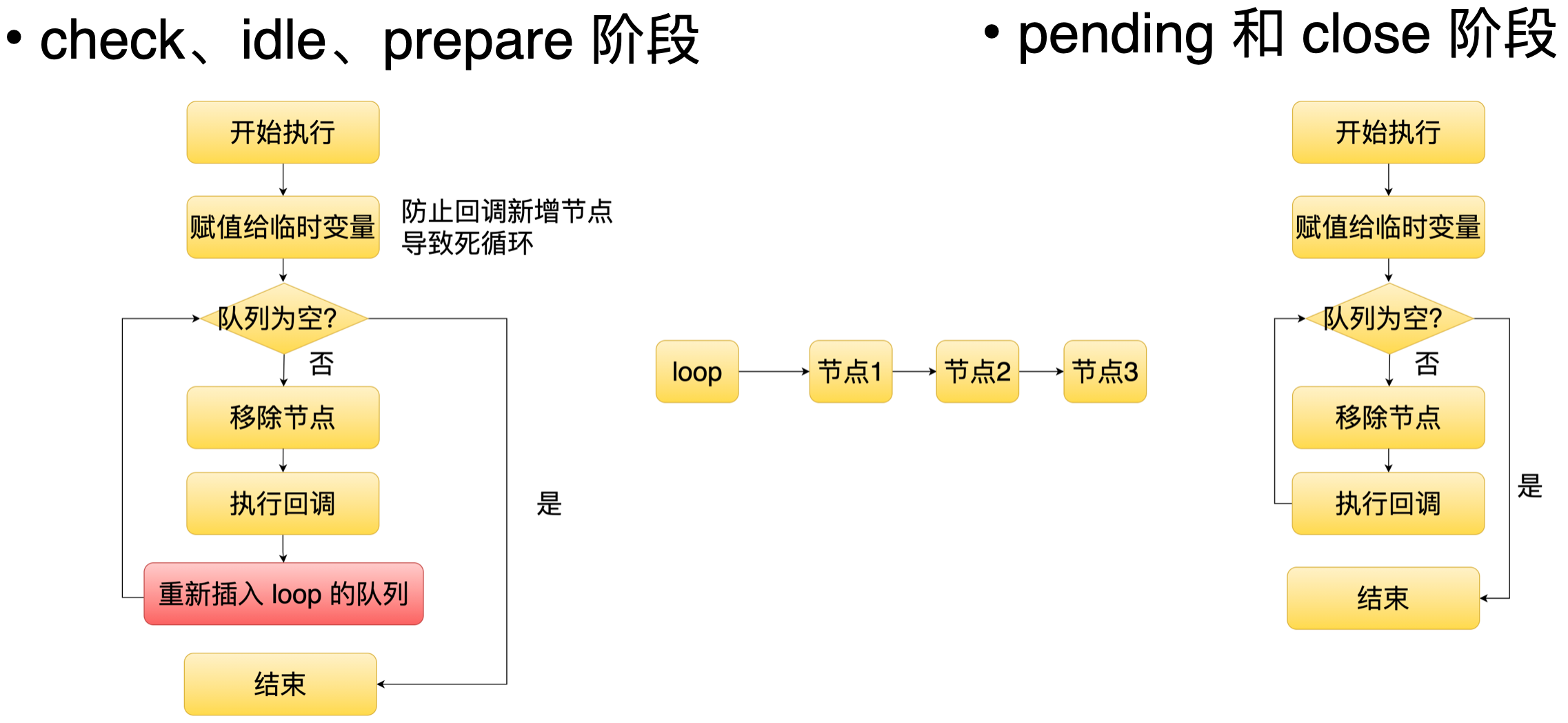
76 | 这五个阶段的实现其实类似的,它们都对应自己的一个任务队列。当产生任务的时候,它就会往这个队列里面插入一个节点,等到相应的阶段时,它就会去遍历这个队列里面的每个节点,并且执行它的回调。但是 check idle 还有 prepare 阶段有一个比较特别的地方,就是当这些阶段的节点回调被执行之后,它还会重新插入队列里面,也是说这三个阶段它对应的任务在每一轮的事件循环都会被执行。
77 |
78 | 3. Poll IO 阶段
79 | Poll IO 本质上是对前面讲的事件驱动模块的封装。下面来看一下整体的流程。
80 | 
81 |
82 | 当我们订阅一个 fd 的事件时,Libuv 就会通过 epoll 去注册这个 fd 对应的事件。如果这时候事件没有就绪,那么进程就会阻塞在 epoll_wait 中。等到这事件触发的时候,进程就会被唤醒,唤醒之后,它就遍历 epoll 返回了事件列表,并执行上层回调。
83 |
84 | 现在有一个底层能力,那么这个底层能力是怎么暴露给上层的 JS 去使用呢?这种时候就需要用到 JS 引擎 V8了。
85 |
86 | # 3. Node.js 中的 V8
87 | 下面从三个方面介绍 V8。
88 | 1. 介绍 V8 在 Node.js 的作用和 V8 的一些基础概念
89 | 2. 介绍如何通过 V8 执行 JS 和拓展 JS
90 | 3. 介绍如何通过 V8 实现 JS 和 C++ 通信
91 |
92 | ## 3.1 V8 在 Node.js 的作用和基础概念
93 | V8 在 Node.js 里面主要是有两个作用,第一个是负责解析和执行 JS。第二个是支持拓展 JS 能力,作为这个 JS 和 C++ 的桥梁。下面我们先来看一下 V8 里面那些重要的概念。
94 |
95 | Isolate:首先第一个是 Isolate 它是代表一个 V8 的实例,它相当于这一个容器。通常一个线程里面会有一个这样的实例。比如说在 Node.js主线程里面,它就会有一个 Isolate 实例。
96 |
97 | Context:Context 是代表我们执行代码的一个上下文,它主要是保存像 Object,Function 这些我们平时经常会用到的内置的类型。如果我们想拓展 JS 功能,就可以通过这个对象实现。
98 |
99 | ObjectTemplate:ObjectTemplate 是用于定义对象的模板,然后我们就可以基于这个模板去创建对象。
100 |
101 | FunctionTemplate:FunctionTemplate 和 ObjectTemplate 是类似的,它主要是用于定义一个函数的模板,然后就可以基于这个函数模板去创建一个函数。
102 |
103 | FunctionCallbackInfo: 用于实现 JS 和 C++ 通信的对象。
104 |
105 | Handle:Handle 是用管理在 V8 堆里面那些对象,因为像我们平时定义的对象和数组,它是存在 V8 堆内存里面的。Handle 就是用于管理这些对象。
106 |
107 | HandleScope:HandleScope 是一个 Handle 容器,HandleScope 里面可以定义很多 Handle,它主要是利用自己的生命周期管理多个 Handle。
108 |
109 | 下面我们通过一个代码来看一下 HandleScope 和 Handle 它们之间的关系。
110 | 
111 | 首先第一步新建一个 HandleScope,就会在一个栈里面定义一个 HandleScope 对象。然后第二步新建了一个 Handle 并且把它指向一个堆对象。这时候就会在栈里面分配一个叫 Local 对象,然后在堆里面分配一块 slot 所代表的内存和一个 Object 对象,并且建立关联关系。当执行完这个函数的时候,这个栈就会被清空,相应的这个 slot 代表的内存也会被释放,但是 Object 所代表这个对象,它是不会立马被释放的,它会等待 GC 的回收。
112 |
113 | ## 3.2 通过 V8 执行 JS 和拓展 JS
114 | 了解了 V8 的基础概念之后,来看一下怎么通过 V8 执行一段 JS 的代码。
115 | 
116 | 首先第一步新建一个 Isolate,它这表示一个隔离的实例。第二步定义一个 HandleScope 对象,因为我们下面需要定义 Handle。第三步定义一个 Context,这是代码执行所在的上下文。第四步定义一些需要被执行的 JS 代码。第五步通过 Script 对象的 Compile 函数编译 JS 代码。编译完之后,我们会得到一个 Script 对象,然后执行这个对象的 Run 函数就可以完成代码的执行。
117 |
118 | 接下来再看一下怎么去拓展 JS 原有的一些能力。
119 | 
120 | 首先第一步是通过 Context 上下文对象拿到一个全局的对象,类似于在前端里面的 window 对象。第二步通过 ObjectTemplate 新建一个对象的模板,然后接着会给这个对象模板设置一个 test 属性, 值是函数。接着通过这个对象模板新建一个对象,并且把这个对象设置到一个全局变量里面去。这样我们就可以在 JS 层去访问这个全局对象。
121 |
122 | 下面我们通过使用刚才定义那个全局对象来看一下 JS 和 C++ 是怎么通信的。
123 |
124 | ## 3.3 通过 V8 实现 JS 和 C++ 层通信
125 | 
126 | 当在 JS 层调用刚才定义 test 函数时,就会相应的执行 C++ 层的 test 函数。这个函数有一个入参是 FunctionCallbackInfo,在 C++ 中可以通过这个对象拿到 JS 传来一些参数,这样就完成了 JS 层到 C++ 层通信。经过一系列处理之后,还是可以通过这个对象给 JS 层设置需要返回给 JS 的内容,这样可以完成了 C++ 层到 JS 层的通信。
127 |
128 | 现在有了底层能力,有了这一层的接口,但是我们是怎么去加载后执行 JS 代码呢?这时候就需要模块加载器。
129 | # 4 Node.js 中的模块加载器
130 | Node.js 中有五种模块加载器。
131 | 1. JSON 模块加载器
132 | 2. 用户 JS 模块加载器
133 | 3. 原生 JS 模块加载器
134 | 4. 内置 C++ 模块加载器
135 | 5. Addon 模块加载器
136 |
137 | 现在来看下每种模块加载器。
138 | ## 4.1 JSON 模块加载器
139 | JSON 模块加载器实现比较简单,Node.js 从硬盘里面把 JSON 文件读到内存里面去,然后通过 JSON.parse 函数进行解析,就可以拿到里面的数据。
140 | 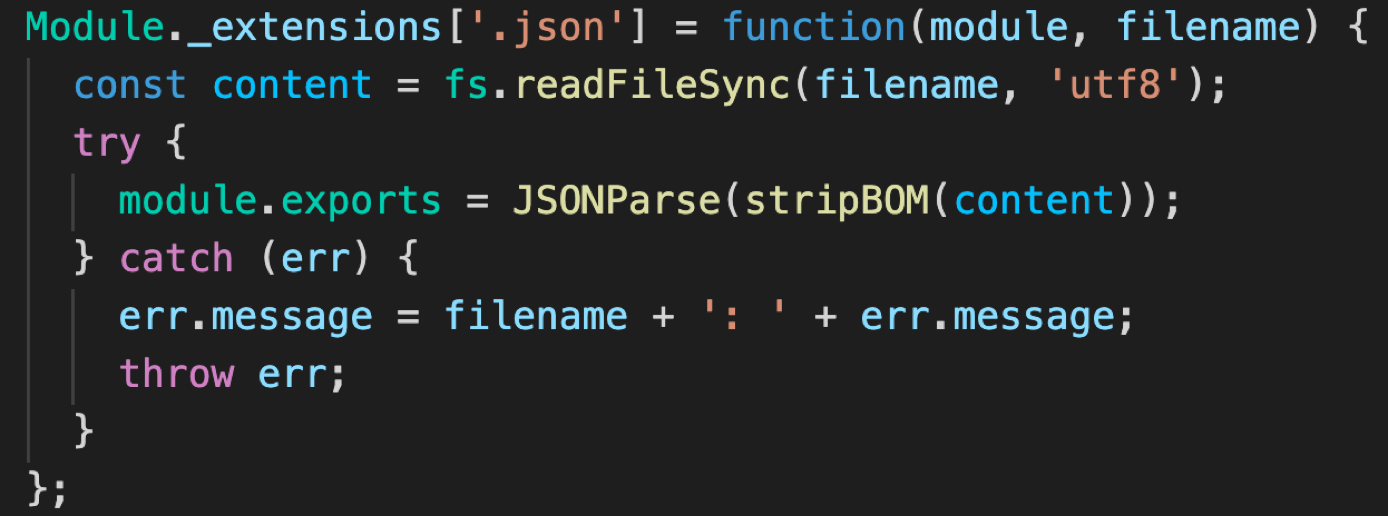
141 |
142 | ## 4.2 用户 JS 模块
143 | 
144 | 用户 JS 模块就是我们平时写的一些 JS 代码。当通过 require 函数加载一个用户 JS 模块时,Node.js 就会从硬盘读取这个模块的内容到内存中,然后通过 V8 提供了一个函数叫 CompileFunctionInContext 把读取的代码封装成一个函数,接着新建立一个 Module 对象。这个对象里面有两个属性叫 exports 和 require 函数,这两个对象就是我们平时在代码里面所使用的变量,接着会把这个对象作为函数的参数,并且执行这个函数,执行完这个函数的时候,就可以通过 module.exports 拿到这个函数(模块)里面导出的内容。这里需要注意的是这里的 require 函数是可以加载原生 JS 模块和用户模块的,所以我们平时在我们代码里面,可以通过require 加载我们自己写的模块,或者 Node.js 本身提供的 JS 模块。
145 |
146 | ## 4.3 原生 JS 模块
147 | 
148 | 接下来看下原生 JS 模块加载器。原生JS 模块是 Node.js 本身提供了一些 JS 模块,比如经常使用的 http 和 fs。当通过 require 函数加载 http 这个模块的时候,Node.js 就会从内存里读取这个模块所对应内容。因为原生 JS 模块默认是打包进内存里面的,所以直接从内存里面读就可以了,不需要从硬盘里面去读。然后还是通过 V8 提供的 CompileFunctionInContext 这个函数把读取的代码封装成一个函数,接着新建一个 NativeModule 对象,同样这个对象里面也是有个 exports 属性,接着它会把这个对象传到这个函数里面去执行,执行完这函数之后,就可以通过 module.exports 拿到这个函数里面导出的内容。需要注意是这里传入的 require 函数是一个叫 NativeModuleRequire 函数,这个函数它就只能加载原生 JS 模块。另外这里还传了另外一个 internalBinding 函数,这个函数是用于加载 C++ 模块的,所以在原生 JS 模块里面,是可以加载 C++ 模块的。
149 |
150 | ## 4.4 C++ 模块
151 | 
152 | Node.js 在初始化的时候会注册 C++ 模块,并且形成一个 C++ 模块链表。当加载 C++ 模块时,Node.js 就通过模块名,从这个链表里面找到对应的节点,然后去执行它里面的钩子函数,执行完之后就可以拿到 C++ 模块导出的内容。
153 |
154 | ## 4.5 Addon 模块
155 | 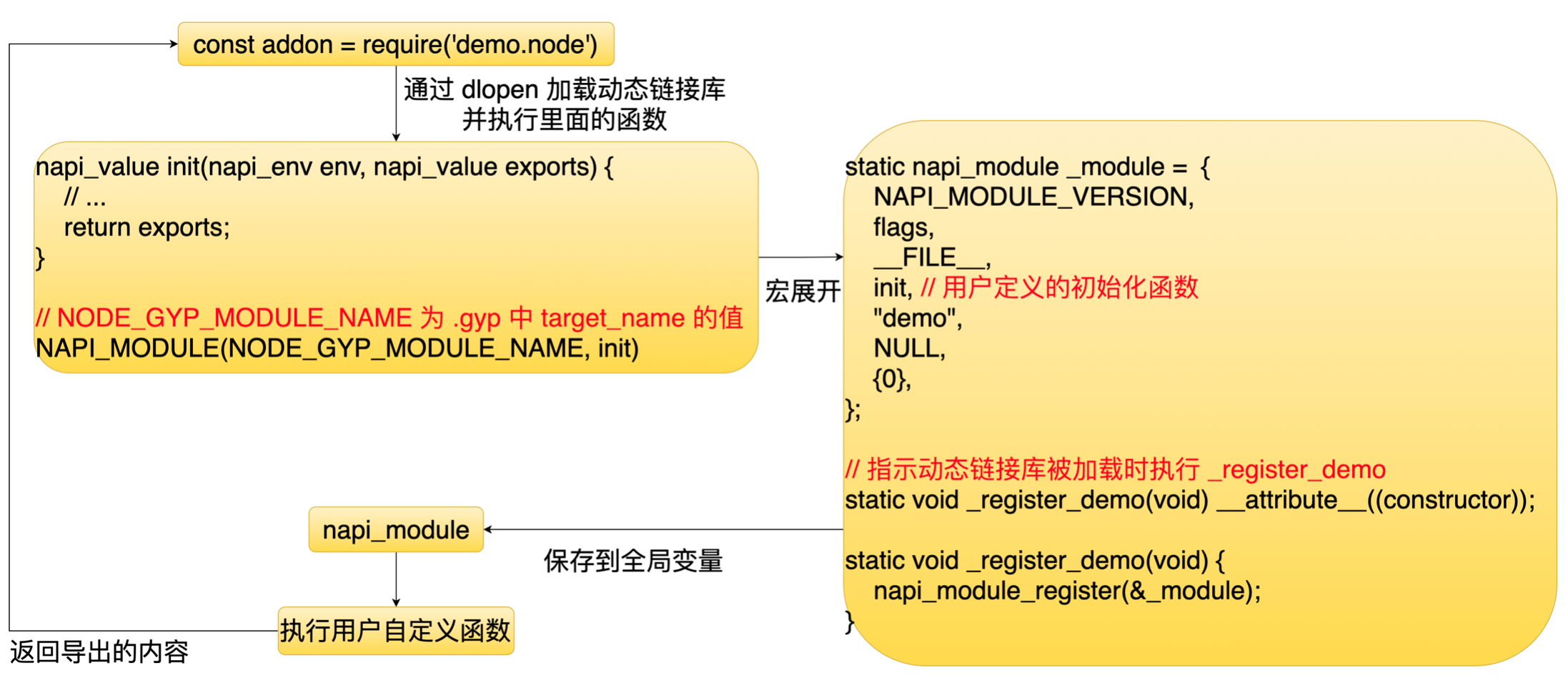
156 | 接着再来看一下 Addon 模块, Addon 模块本质上是一个动态链接库。当通过 require 加载Addon 模块的时候,Node.js 会通过 dlopen 这个函数去加载这个动态链接库。
157 | 下图是我们定义一个 Addon 模块时的一个标准格式。
158 | 
159 | 它里面有一些 C语言宏,宏展开之后里面内容像下图所示。
160 | 
161 | 里面主要定义了一个结构体和一个函数,这个函数会把这个结构体赋值给 Node.js 的一个全局变量,然后 Nodejs 它就可以通过全局变量拿到这个结构体,并且执行它里面的一个钩子函数,执行完之后就可以拿到它里面要导出的一些内容。
162 |
163 | 现在有了底层的能力,也有了这一次层的接口,也有了代码加载器。最后我们来看一下 Node.js 作为一个服务器的时候,它的架构是怎么样的?
164 | # 5 Node.js 的服务器架构
165 | 下面从两个方面介绍 Node.js 的服务器架构
166 | 1. 介绍服务器处理 TCP 连接的模型
167 | 2. 介绍 Node.js 中的实现和存在的问题
168 |
169 | ## 5.1 处理 TCP 连接的模型
170 |
171 | 首先来看一下网络编程中怎么去创建一个 TCP 服务器。
172 | ```c
173 | int fd = socket(…);
174 | bind(fd, 监听地址);
175 | listen(fd);
176 | ```
177 | 首先建一个 socket, 然后把需要监听的地址绑定到这个 socket 中,最后通过 listen 函数启动服务器。启动服务器之后,那么怎么去处理 TCP 连接呢?
178 |
179 | 1. 串行处理(accept 和 handle 都会引起进程阻塞)
180 | 
181 | 第一种处理方式是串行处理,串行方式就是在一个 while 循环里面,通过 accept 函数不断地摘取 TCP 连接,然后处理它。这种方式的缺点就是它每次只能处理一个连接,处理完一个连接之后,才能继续处理下一个连接。
182 |
183 | 2. 多进程/多线程
184 | 
185 | 第二种方式是多进程或者多线程的方式。这种方式主要是利用多个进程或者线程同时处理多个连接。但这种模式它的缺点就是当流量非常大的时候,进程数或者线程数它会成为这种架构下面的一个瓶颈,因为我们不能无限的创建进程或者线程,像 Apache 还有 PHP 就是这种架构的。
186 |
187 | 3. 单进程单线程 + 事件驱动( Reactor & Proactor )
188 | 第三种就是单线程 + 事件驱动的模式。这种模式下有两种类型,第一种叫 Reactor, 第二种叫 Proactor。
189 | Reactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写事件,然后事件触发的时候,它就会通过事件驱动模块回调上层的代码。
190 | 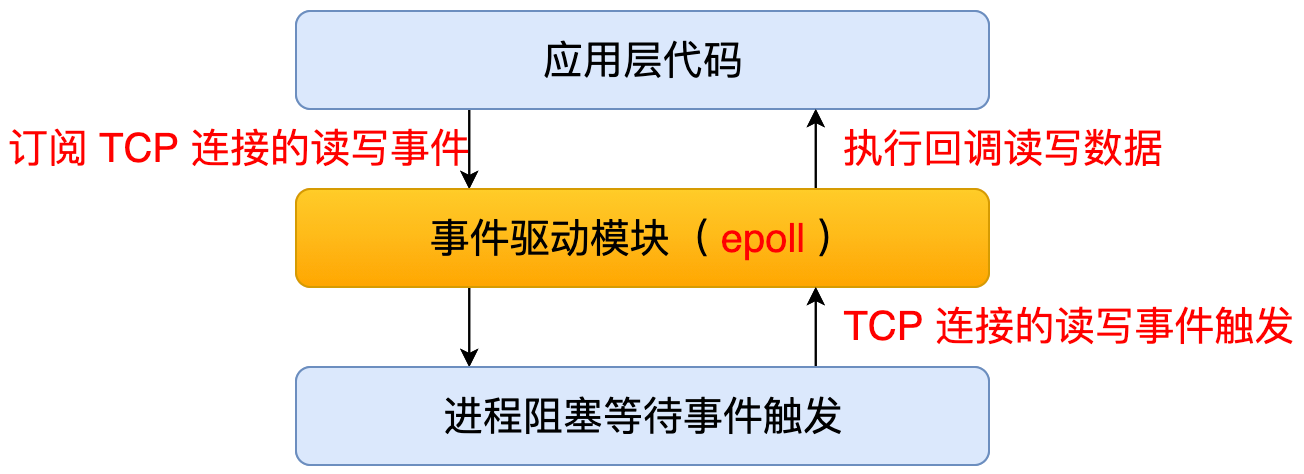
191 | Proactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写完成事件,然后这个读写完成事件后就会通过事件驱动模块回调上层代码。
192 | 
193 | 我们看到这两种模式的区别是,数据读写是由内核完成的,还是由应用程序完成的。很显然,通过内核去完成是更高效的,但是因为 Proactor 这种模式它兼容性还不是很好,所以目前用的还不算太多,主要目前主流的一些服务器,它用的都是 Reactor 模式。比方说像 Node.js、Redis 和 Nginx 这些服务器用的都是这种模式。
194 |
195 | 刚才提到 Node.js 是单进程单线程加事件驱动的架构。那么单线程的架构它怎么去利用多核呢?这种时候就需要用到多进程的这种模式了,每一个进程里面会包含一个Reactor 模式。但是引入多进程之后,它会带来一个问题,就是多进程之间它怎么去监听同一个端口。
196 |
197 | ## 5.2 Node.js 的实现和问题
198 | 下面来看下针对多进程监听同一个端口的一些解决方式。
199 | 1. 主进程监听端口并接收请求,轮询分发(轮询模式)
200 | 2. 子进程竞争接收请求(共享模式)
201 | 3. 子进程负载均衡处理连接(SO_REUSEPORT 模式)
202 |
203 | 第一种方式就是主进程去监听这个端口,并且接收连接。它接收连接之后,通过一定的算法(比如轮询)分发给各个子进程。这种模式。它的一个缺点就是当流量非常大的时候,这个主进程就会成为瓶颈,因为它可能都来不及接收或者分发这个连接给子进程去处理。
204 | 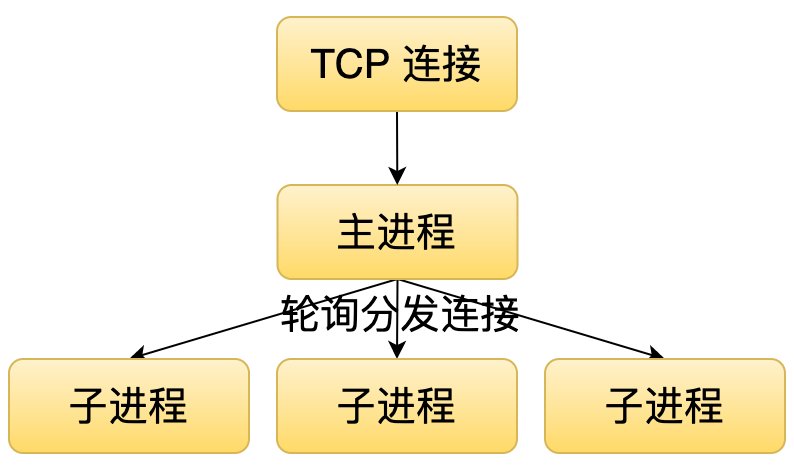
205 |
206 | 第二种就是主进程创建监听 socket, 然后子进程通过 fork 的方式继承这个监听的 socket, 当有一个连接到来的时候,操作系统就唤醒所有的子进程,所有子进程会以竞争的方式接收连接。这种模式,它的缺点主要是有两个,第一个就是负载均衡的问题,因为操作系统唤醒了所有的进程,可能会导致某一个进程一直在处理连接,其他其它进程都没机会处理连接。然后另外一个问题就是惊群的问题,因为操作系统唤起了所有的进程,但是只有一个进程它会处理这个连接,然后剩下进程就会被无效地唤醒。这种方式会造成一定的性能的损失。
207 | 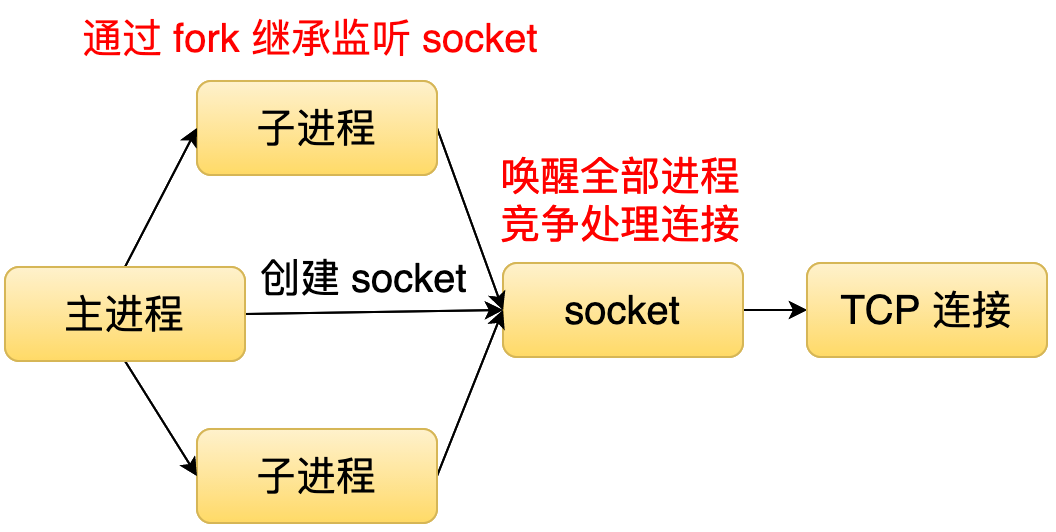
208 |
209 | 第三种通过 SO_REUSEPORT 这个标记来解决刚才提到的两个问题。在这种模式下,每个子进程都会有一个独立的监听 socket 和连接队列。当有一个连接到来的时候,操作系统会把这个连接分发给某一个子进程并且唤醒它。这样就可以解决惊群的问题,因为它只会唤醒一个子进程。又因为操作系统分发这个连接的时候,内部是有一个负载均衡的算法。所以这样的话又可以解决负载均衡的问题。
210 | 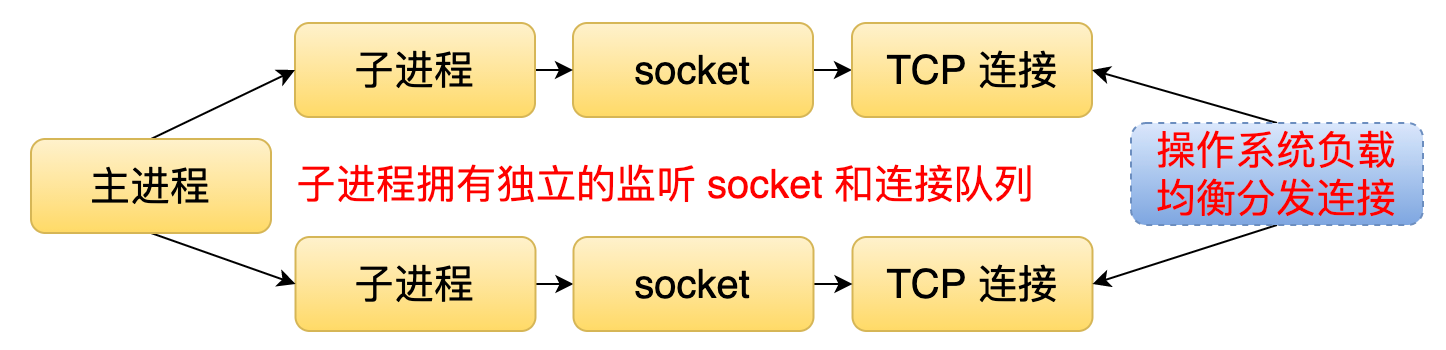
211 |
212 |
213 | 接下来我们看一下 Node.js 中的实现。
214 | 1. 轮询模式。
215 | 在这种模式下,主进程会 fork 多个子进程,然后每个子进程里面都会调用 listen 函数。但是 listen 函数不会监听一个端口,它会请求主进程监听这个端口,当有连接到来的时候,这个主进程就会接收这个连接,然后通过文件描述符的方式传给各个子进程去处理。
216 | 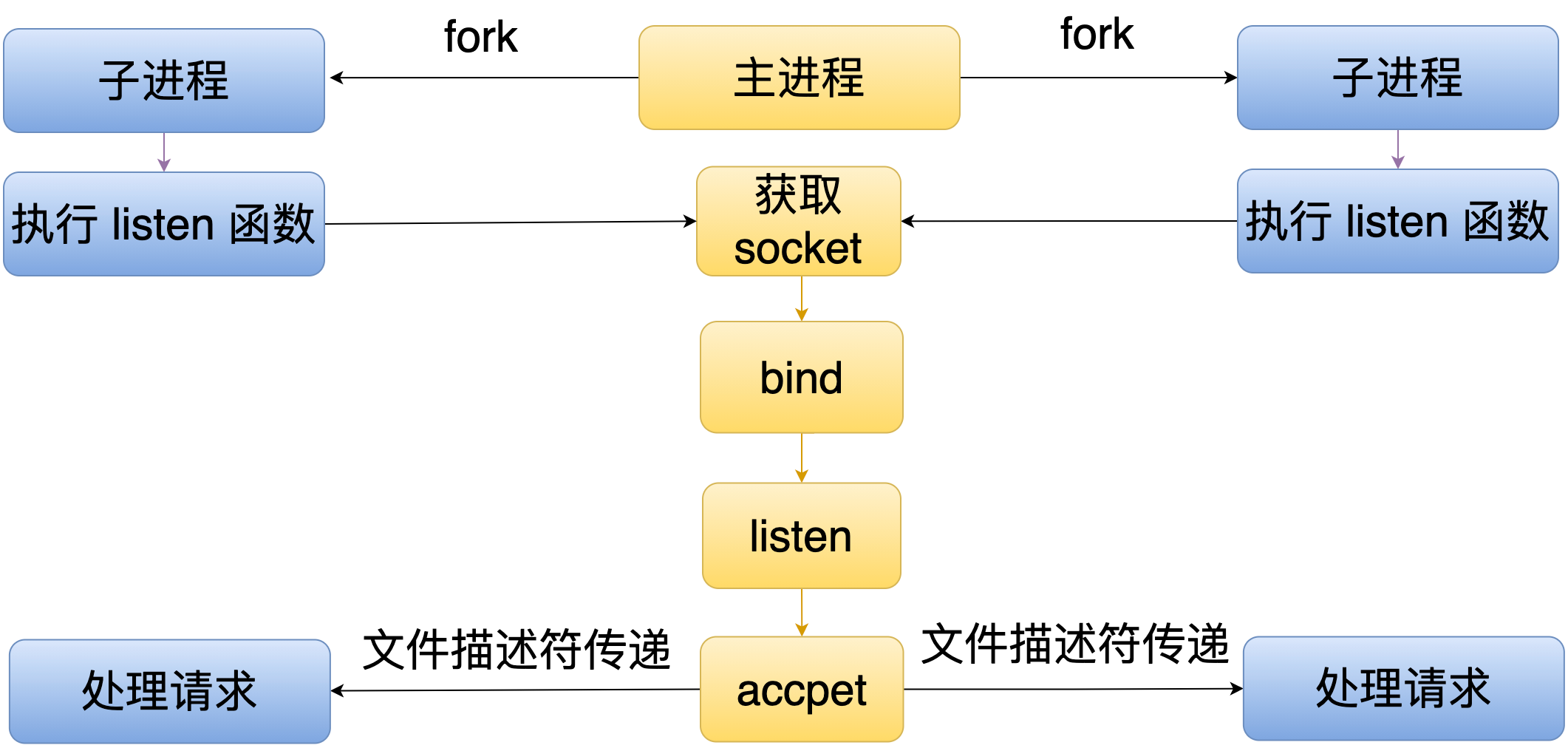
217 | 2. 共享模式
218 | 共享模式下,主进程同样还是会 fork 多个子进程,然后每个子进程里面还是会执行 listen 函数,但同样的这个 listen 函数不会监听一个端口,它会请求主进程创建一个 socket 并绑定到一个需要监听的地址,接着主进程会把这个 socket 通过文件描述符传递的方式传给多个子进程,这样就可以达到多个子进程同时监听同一个端口的效果。
219 | 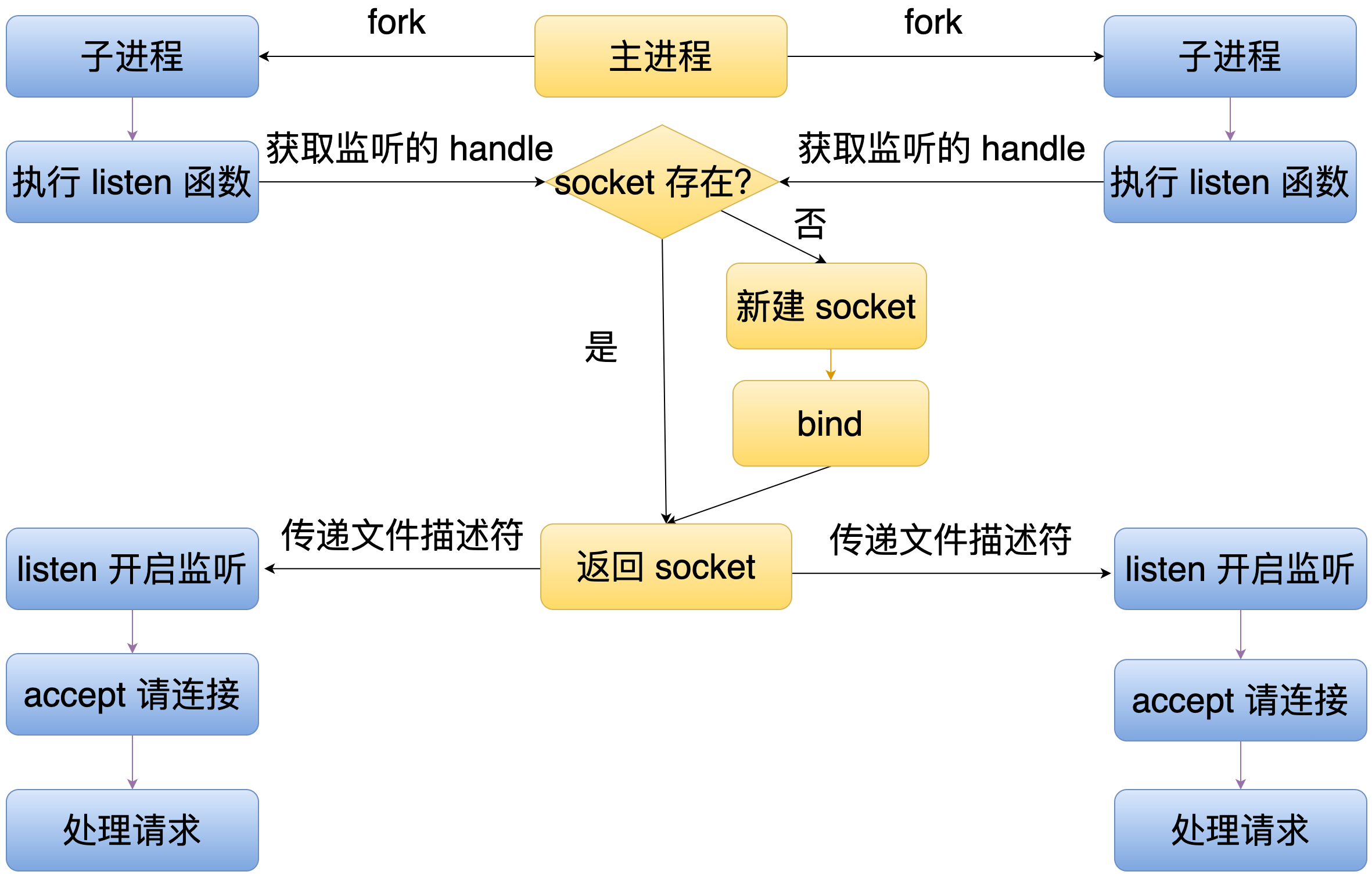
220 | 通过刚才介绍,我们可以知道 Node.js 的服务器架构存在的问题。如果我们使用轮询模式,当流量比较大的时候,那么这个主进程就会成为系统瓶颈。如果我们使用共享模式,就会存在惊群和负载均衡的问题。不过在 Libuv 里面,可以通过设置 UV_TCP_SINGLE_ACCEPT 环境变量来一定程度缓解这个问题。当我们设置了这个环境变量。Libuv 在接收完一个连接的时候,它就会休眠一会,让其它进程也有接收连接的机会。
221 |
222 | 最后来总结一下,本文的内容。Node.js 里面通过 Libuv 解决了操作系统相关的问题。通过 V8 解决了执行 JS 和拓展 JS 功能的问题。通过模块加载器解决了代码加载还有组织的问题。通过多进程的服务器架构,使得 Node.js 可以利用多核,并且解决了多个进程监听同一个端口的问题。
223 |
224 | 下面是一些资料,有兴趣的同学也可以看一下。
225 | 1. 基于 epoll + V8 的JS 运行时 Just:
226 | https://github.com/theanarkh/read-just-0.1.4-code
227 | 2. 基于 io_uring+ V8 的 JS 运行时 No.js:
228 | https://github.com/theanarkh/No.js
229 | 3. 理解 Node.js 原理:
230 | https://github.com/theanarkh/understand-nodejs
231 |
--------------------------------------------------------------------------------
/docs/chapter22-events模块.md:
--------------------------------------------------------------------------------
1 |
2 | events模块是Node.js中比较简单但是却非常核心的模块,Node.js中,很多模块都继承于events模块,events模块是发布、订阅模式的实现。我们首先看一个如果使用events模块。
3 |
4 | ```js
5 | const { EventEmitter } = require('events');
6 | class Events extends EventEmitter {}
7 | const events = new Events();
8 | events.on('demo', () => {
9 | console.log('emit demo event');
10 | });
11 | events.emit('demo');
12 | ```
13 |
14 | 接下来我们看一下events模块的具体实现。
15 | ## 22.1 初始化
16 | 当new一个EventEmitter或者他的子类时,就会进入EventEmitter的逻辑。
17 |
18 | ```js
19 | function EventEmitter(opts) {
20 | EventEmitter.init.call(this, opts);
21 | }
22 |
23 | EventEmitter.init = function(opts) {
24 | // 如果是未初始化或者没有自定义_events,则初始化
25 | if (this._events === undefined ||
26 | this._events === ObjectGetPrototypeOf(this)._events) {
27 | this._events = ObjectCreate(null);
28 | this._eventsCount = 0;
29 | }
30 | // 初始化处理函数个数的阈值
31 | this._maxListeners = this._maxListeners || undefined;
32 |
33 | // 是否开启捕获promise reject,默认false
34 | if (opts && opts.captureRejections) {
35 | this[kCapture] = Boolean(opts.captureRejections);
36 | } else {
37 | this[kCapture] = EventEmitter.prototype[kCapture];
38 | }
39 | };
40 | ```
41 |
42 | EventEmitter的初始化主要是初始化了一些数据结构和属性。唯一支持的一个参数就是captureRejections,captureRejections表示当触发事件,执行处理函数时,EventEmitter是否捕获处理函数中的异常。后面我们会详细讲解。
43 | ## 22.2 订阅事件
44 | 初始化完EventEmitter之后,我们就可以开始使用订阅、发布的功能。我们可以通过addListener、prependListener、on、once订阅事件。addListener和on是等价的,prependListener的区别在于处理函数会被插入到队首,而默认是追加到队尾。once注册的处理函数,最多被执行一次。四个API都是通过_addListener函数实现的。下面我们看一下具体实现。
45 |
46 | ```js
47 | function _addListener(target, type, listener, prepend) {
48 | let m;
49 | let events;
50 | let existing;
51 | events = target._events;
52 | // 还没有初始化_events则初始化
53 | if (events === undefined) {
54 | events = target._events = ObjectCreate(null);
55 | target._eventsCount = 0;
56 | } else {
57 | /*
58 | 是否定义了newListener事件,是的话先触发,如果监听了newListener事件,
59 | 每次注册其他事件时都会触发newListener,相当于钩子
60 | */
61 | if (events.newListener !== undefined) {
62 | target.emit('newListener', type,
63 | listener.listener ? listener.listener : listener);
64 | // 可能会修改_events,这里重新赋值
65 | events = target._events;
66 | }
67 | // 判断是否已经存在处理函数
68 | existing = events[type];
69 | }
70 | // 不存在则以函数的形式存储,否则是数组
71 | if (existing === undefined) {
72 | events[type] = listener;
73 | ++target._eventsCount;
74 | } else {
75 | if (typeof existing === 'function') {
76 | existing = events[type] =
77 | prepend ? [listener, existing] : [existing, listener];
78 | } else if (prepend) {
79 | existing.unshift(listener);
80 | } else {
81 | existing.push(listener);
82 | }
83 |
84 | // 处理告警,处理函数过多可能是因为之前的没有删除,造成内存泄漏
85 | m = _getMaxListeners(target);
86 | if (m > 0 && existing.length > m && !existing.warned) {
87 | existing.warned = true;
88 | const w = new Error('Possible EventEmitter memory leak detected. ' +
89 | `${existing.length} ${String(type)} listeners ` +
90 | `added to ${inspect(target, { depth: -1 })}. Use ` +
91 | 'emitter.setMaxListeners() to increase limit');
92 | w.name = 'MaxListenersExceededWarning';
93 | w.emitter = target;
94 | w.type = type;
95 | w.count = existing.length;
96 | process.emitWarning(w);
97 | }
98 | }
99 |
100 | return target;
101 | }
102 | ```
103 |
104 | 接下来我们看一下once的实现,对比其他几种api,once的实现相对比较难,因为我们要控制处理函数最多执行一次,所以我们需要坚持用户定义的函数,保证在事件触发的时候,执行用户定义函数的同时,还需要删除注册的事件。
105 |
106 | ```js
107 | EventEmitter.prototype.once = function once(type, listener) {
108 | this.on(type, _onceWrap(this, type, listener));
109 | return this;
110 | };
111 |
112 | function onceWrapper() {
113 | // 还没有触发过
114 | if (!this.fired) {
115 | // 删除他
116 | this.target.removeListener(this.type, this.wrapFn);
117 | // 触发了
118 | this.fired = true;
119 | // 执行
120 | if (arguments.length === 0)
121 | return this.listener.call(this.target);
122 | return this.listener.apply(this.target, arguments);
123 | }
124 | }
125 | // 支持once api
126 | function _onceWrap(target, type, listener) {
127 | // fired是否已执行处理函数,wrapFn包裹listener的函数
128 | const state = { fired: false, wrapFn: undefined, target, type, listener };
129 | // 生成一个包裹listener的函数
130 | const wrapped = onceWrapper.bind(state);
131 | // 把原函数listener也挂到包裹函数中,用于事件没有触发前,用户主动删除,见removeListener
132 | wrapped.listener = listener;
133 | // 保存包裹函数,用于执行完后删除,见onceWrapper
134 | state.wrapFn = wrapped;
135 | return wrapped;
136 | }
137 | ```
138 |
139 | ## 22.3 触发事件
140 | 分析完事件的订阅,接着我们看一下事件的触发。
141 |
142 | ```js
143 | EventEmitter.prototype.emit = function emit(type, ...args) {
144 | // 触发的事件是否是error,error事件需要特殊处理
145 | let doError = (type === 'error');
146 |
147 | const events = this._events;
148 | // 定义了处理函数(不一定是type事件的处理函数)
149 | if (events !== undefined) {
150 | // 如果触发的事件是error,并且监听了kErrorMonitor事件则触发kErrorMonitor事件
151 | if (doError && events[kErrorMonitor] !== undefined)
152 | this.emit(kErrorMonitor, ...args);
153 | // 触发的是error事件但是没有定义处理函数
154 | doError = (doError && events.error === undefined);
155 | } else if (!doError) // 没有定义处理函数并且触发的不是error事件则不需要处理,
156 | return false;
157 |
158 | // If there is no 'error' event listener then throw.
159 | // 触发的是error事件,但是没有定义处理error事件的函数,则报错
160 | if (doError) {
161 | let er;
162 | if (args.length > 0)
163 | er = args[0];
164 | // 第一个入参是Error的实例
165 | if (er instanceof Error) {
166 | try {
167 | const capture = {};
168 | /*
169 | 给capture对象注入stack属性,stack的值是执行Error.captureStackTrace
170 | 语句的当前栈信息,但是不包括emit的部分
171 | */
172 | Error.captureStackTrace(capture, EventEmitter.prototype.emit);
173 | ObjectDefineProperty(er, kEnhanceStackBeforeInspector, {
174 | value: enhanceStackTrace.bind(this, er, capture),
175 | configurable: true
176 | });
177 | } catch {}
178 | throw er; // Unhandled 'error' event
179 | }
180 |
181 | let stringifiedEr;
182 | const { inspect } = require('internal/util/inspect');
183 | try {
184 | stringifiedEr = inspect(er);
185 | } catch {
186 | stringifiedEr = er;
187 | }
188 | const err = new ERR_UNHANDLED_ERROR(stringifiedEr);
189 | err.context = er;
190 | throw err; // Unhandled 'error' event
191 | }
192 | // 获取type事件对应的处理函数
193 | const handler = events[type];
194 | // 没有则不处理
195 | if (handler === undefined)
196 | return false;
197 | // 等于函数说明只有一个
198 | if (typeof handler === 'function') {
199 | // 直接执行
200 | const result = ReflectApply(handler, this, args);
201 | // 非空判断是不是promise并且是否需要处理,见addCatch
202 | if (result !== undefined && result !== null) {
203 | addCatch(this, result, type, args);
204 | }
205 | } else {
206 | // 多个处理函数,同上
207 | const len = handler.length;
208 | const listeners = arrayClone(handler, len);
209 | for (let i = 0; i < len; ++i) {
210 | const result = ReflectApply(listeners[i], this, args);
211 | if (result !== undefined && result !== null) {
212 | addCatch(this, result, type, args);
213 | }
214 | }
215 | }
216 |
217 | return true;
218 | }
219 | ```
220 |
221 | 我们看到在Node.js中,对于error事件是特殊处理的,如果用户没有注册error事件的处理函数,可能会导致程序挂掉,另外我们看到有一个addCatch的逻辑,addCatch是为了支持事件处理函数为异步模式的情况,比如async函数或者返回Promise的函数。
222 |
223 | ```js
224 | function addCatch(that, promise, type, args) {
225 | // 没有开启捕获则不需要处理
226 | if (!that[kCapture]) {
227 | return;
228 | }
229 | // that throws on second use.
230 | try {
231 | const then = promise.then;
232 |
233 | if (typeof then === 'function') {
234 | // 注册reject的处理函数
235 | then.call(promise, undefined, function(err) {
236 | process.nextTick(emitUnhandledRejectionOrErr, that, err, type, args);
237 | });
238 | }
239 | } catch (err) {
240 | that.emit('error', err);
241 | }
242 | }
243 |
244 | function emitUnhandledRejectionOrErr(ee, err, type, args) {
245 | // 用户实现了kRejection则执行
246 | if (typeof ee[kRejection] === 'function') {
247 | ee[kRejection](err, type, ...args);
248 | } else {
249 | // 保存当前值
250 | const prev = ee[kCapture];
251 | try {
252 | /*
253 | 关闭然后触发error事件,意义
254 | 1 防止error事件处理函数也抛出error,导致死循环
255 | 2 如果用户处理了error,则进程不会退出,所以需要恢复kCapture的值
256 | 如果用户没有处理error,则nodejs会触发uncaughtException,如果用户
257 | 处理了uncaughtException则需要灰度kCapture的值
258 | */
259 | ee[kCapture] = false;
260 | ee.emit('error', err);
261 | } finally {
262 | ee[kCapture] = prev;
263 | }
264 | }
265 | }
266 | ```
267 |
268 | ## 22.4 取消订阅
269 | 我们接着看一下删除事件处理函数的逻辑。
270 |
271 | ```js
272 | function removeAllListeners(type) {
273 | const events = this._events;
274 | if (events === undefined)
275 | return this;
276 |
277 | // 没有注册removeListener事件,则只需要删除数据,否则还需要触发removeListener事件
278 | if (events.removeListener === undefined) {
279 | // 等于0说明是删除全部
280 | if (arguments.length === 0) {
281 | this._events = ObjectCreate(null);
282 | this._eventsCount = 0;
283 | } else if (events[type] !== undefined) { // 否则是删除某个类型的事件,
284 | // 是唯一一个处理函数,则重置_events,否则删除对应的事件类型
285 | if (--this._eventsCount === 0)
286 | this._events = ObjectCreate(null);
287 | else
288 | delete events[type];
289 | }
290 | return this;
291 | }
292 |
293 | // 说明注册了removeListener事件,arguments.length === 0说明删除所有类型的事件
294 | if (arguments.length === 0) {
295 | // 逐个删除,除了removeListener事件,这里删除了非removeListener事件
296 | for (const key of ObjectKeys(events)) {
297 | if (key === 'removeListener') continue;
298 | this.removeAllListeners(key);
299 | }
300 | // 这里删除removeListener事件,见下面的逻辑
301 | this.removeAllListeners('removeListener');
302 | // 重置数据结构
303 | this._events = ObjectCreate(null);
304 | this._eventsCount = 0;
305 | return this;
306 | }
307 | // 删除某类型事件
308 | const listeners = events[type];
309 |
310 | if (typeof listeners === 'function') {
311 | this.removeListener(type, listeners);
312 | } else if (listeners !== undefined) {
313 | // LIFO order
314 | for (let i = listeners.length - 1; i >= 0; i--) {
315 | this.removeListener(type, listeners[i]);
316 | }
317 | }
318 |
319 | return this;
320 | }
321 | ```
322 |
323 | removeAllListeners函数主要的逻辑有两点,第一个是removeListener事件需要特殊处理,这类似一个钩子,每次用户删除事件处理函数的时候都会触发该事件。第二是removeListener函数。removeListener是真正删除事件处理函数的实现。removeAllListeners是封装了removeListener的逻辑。
324 |
325 | ```js
326 | function removeListener(type, listener) {
327 | let originalListener;
328 | const events = this._events;
329 | // 没有东西可删除
330 | if (events === undefined)
331 | return this;
332 |
333 | const list = events[type];
334 | // 同上
335 | if (list === undefined)
336 | return this;
337 | // list是函数说明只有一个处理函数,否则是数组,如果list.listener === listener说明是once注册的
338 | if (list === listener || list.listener === listener) {
339 | // type类型的处理函数就一个,并且也没有注册其他类型的事件,则初始化_events
340 | if (--this._eventsCount === 0)
341 | this._events = ObjectCreate(null);
342 | else {
343 | // 就一个执行完删除type对应的属性
344 | delete events[type];
345 | // 注册了removeListener事件,则先注册removeListener事件
346 | if (events.removeListener)
347 | this.emit('removeListener', type, list.listener || listener);
348 | }
349 | } else if (typeof list !== 'function') {
350 | // 多个处理函数
351 | let position = -1;
352 | // 找出需要删除的函数
353 | for (let i = list.length - 1; i >= 0; i--) {
354 | if (list[i] === listener || list[i].listener === listener) {
355 | // 保存原处理函数,如果有的话
356 | originalListener = list[i].listener;
357 | position = i;
358 | break;
359 | }
360 | }
361 |
362 | if (position < 0)
363 | return this;
364 | // 第一个则出队,否则删除一个
365 | if (position === 0)
366 | list.shift();
367 | else {
368 | if (spliceOne === undefined)
369 | spliceOne = require('internal/util').spliceOne;
370 | spliceOne(list, position);
371 | }
372 | // 如果只剩下一个,则值改成函数类型
373 | if (list.length === 1)
374 | events[type] = list[0];
375 | // 触发removeListener
376 | if (events.removeListener !== undefined)
377 | this.emit('removeListener', type, originalListener || listener);
378 | }
379 |
380 | return this;
381 | };
382 | ```
383 |
384 | 以上就是events模块的核心逻辑,另外还有一些工具函数就不一一分析。
385 |
--------------------------------------------------------------------------------
/docs/chapter20-拓展Node.js.md:
--------------------------------------------------------------------------------
1 |
2 | 拓展Node.js从宏观来说,有几种方式,包括直接修改Node.js内核重新编译分发、提供npm包。npm包又可以分为JS和C++拓展。本章主要是介绍修改Node.js内核和写C++插件。
3 | ## 20.1 修改Node.js内核
4 | 修改Node.js内核的方式也有很多种,我们可以修改JS层、C++、C语言层的代码,也可以新增一些功能或模块。本节分别介绍如何新增一个Node.js的C++模块和修改Node.js内核。相比修改Node.js内核代码,新增一个Node.js内置模块需要了解更多的知识。
5 | ### 20.1.1 新增一个内置C++模块
6 | 1.首先在src文件夹下新增两个文件。
7 | cyb.h
8 |
9 | ```cpp
10 | #ifndef SRC_CYB_H_
11 | #define SRC_CYB_H_
12 | #include "v8.h"
13 |
14 | namespace node {
15 | class Environment;
16 | class Cyb {
17 | public:
18 | static void Initialize(v8::Local target,
19 | v8::Local unused,
20 | v8::Local context,
21 | void* priv);
22 | private:
23 | static void Console(const v8::FunctionCallbackInfo& args);
24 | };
25 | } // namespace node
26 | #endif
27 | ```
28 |
29 | cyb.cc
30 |
31 | ```cpp
32 | #include "cyb.h"
33 | #include "env-inl.h"
34 | #include "util-inl.h"
35 | #include "node_internals.h"
36 |
37 | namespace node {
38 | using v8::Context;
39 | using v8::Function;
40 | using v8::FunctionCallbackInfo;
41 | using v8::FunctionTemplate;
42 | using v8::Local;
43 | using v8::Object;
44 | using v8::String;
45 | using v8::Value;
46 |
47 | void Cyb::Initialize(Local
14 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 theanarkh
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/mkdocs.yml:
--------------------------------------------------------------------------------
1 | site_name: Node.js 源码剖析
2 | site_url: https://github.com/theanarkh/understand-nodejs
3 | site_author: theanarkh
4 | site_description: 通过源码分析 Node.js 原理
5 |
6 | repo_name: understand-nodejs
7 | repo_url: https://github.com/theanarkh/understand-nodejs
8 | edit_uri: edit/master/docs/
9 |
10 | copyright: Copyright © 2021 theanarkh
11 |
12 | theme:
13 | name: material
14 | language: zh
15 | icon:
16 | logo: material/book-open-page-variant
17 | repo: fontawesome/brands/github
18 | features:
19 | # https://squidfunk.github.io/mkdocs-material/reference/code-blocks/#adding-annotations
20 | - content.code.annotate
21 | - navigation.indexes
22 | - navigation.instant
23 | - navigation.tabs
24 | - navigation.tabs.sticky
25 | - navigation.sections
26 | - navigation.top
27 | - navigation.tracking
28 | - search.highlight
29 | - search.share
30 | - search.suggest
31 | palette:
32 | - scheme: default
33 | primary: indigo
34 | accent: indigo
35 | toggle:
36 | icon: material/toggle-switch-off-outline
37 | name: Switch to dark mode
38 | - scheme: slate
39 | primary: blue
40 | accent: blue
41 | toggle:
42 | icon: material/toggle-switch
43 | name: Switch to light mode
44 |
45 | markdown_extensions:
46 | - admonition
47 | - codehilite
48 | - footnotes
49 | - toc:
50 | permalink: true
51 | - pymdownx.arithmatex
52 | - pymdownx.betterem:
53 | smart_enable: all
54 | - pymdownx.caret
55 | - pymdownx.critic
56 | - pymdownx.details
57 | - pymdownx.highlight:
58 | linenums: true
59 | - pymdownx.superfences
60 | - pymdownx.emoji:
61 | emoji_index: !!python/name:materialx.emoji.twemoji
62 | emoji_generator: !!python/name:materialx.emoji.to_svg
63 | - pymdownx.inlinehilite
64 | - pymdownx.magiclink
65 | - pymdownx.mark
66 | - pymdownx.smartsymbols
67 | - pymdownx.superfences
68 | - pymdownx.tasklist:
69 | custom_checkbox: true
70 | - pymdownx.tabbed
71 | - pymdownx.tilde
72 |
73 | plugins:
74 | - search
75 | - minify:
76 | minify_html: true
77 | - awesome-pages
78 | - macros
79 | # https://squidfunk.github.io/mkdocs-material/setup/setting-up-tags/
80 | # - tags:
81 | # tags_file: tags.md
82 |
83 | extra:
84 |
85 | social:
86 | - icon: fontawesome/brands/github
87 | link: https://github.com/theanarkh
88 | - icon: fontawesome/brands/zhihu
89 | link: https://www.zhihu.com/people/theanarkh
90 | # - icon: fontawesome/brands/blog
91 | # link: https://xkx9431.github.io/xkx_blog/
92 | spark:
93 | version: 3.2.0 (RC2)
94 | github: https://github.com/apache/spark/tree/v3.2.0-rc2
95 |
96 |
97 | nav:
98 | - Home: index.md
99 | - 前言: chapter00-前言.md
100 | - Node.js基础和架构:
101 | - 01-Node.js组成和原理: chapter01-Node.js组成和原理.md
102 | - 02-Libuv数据结构和通用逻辑: chapter02-Libuv数据结构和通用逻辑.md
103 | - 03-事件循环: chapter03-事件循环.md
104 | - 04-线程池: chapter04-线程池.md
105 | - 05-Libuv流: chapter05-Libuv流.md
106 | - 06-C++层: chapter06-C++层.md
107 | - Node.js核心模块的实现:
108 | - 07-信号处理: chapter07-信号处理.md
109 | - 08-DNS: chapter08-DNS.md
110 | - 09-Unix域: chapter09-Unix域.md
111 | - 10-定时器: chapter10-定时器.md
112 | - 11-setImmediate和nextTick: chapter11-setImmediate和nextTick.md
113 | - 12-文件: chapter12-文件.md
114 | - 13-进程: chapter13-进程.md
115 | - 14-线程: chapter14-线程.md
116 | - 15-Cluster: chapter15-Cluster.md
117 | - 16-UDP: chapter16-UDP.md
118 | - 17-TCP: chapter17-TCP.md
119 | - 18-HTTP: chapter18-HTTP.md
120 | - 19-模块加载: chapter19-模块加载.md
121 | - 20-JS Stream: chapter21-JS Stream.md
122 | - 21-events模块: chapter22-events模块.md
123 | - 22-Async hooks: chapter23-Async hooks.md
124 | - 23-Inspector: chapter24-Inspector.md
125 | - 27-深入理解 Node.js 的 Buffer: chapter27-深入理解 Node.js 的 Buffer.md
126 | - 30-Node.js 的 trace events 架构: chapter30-Node.js 的 trace events 架构.md
127 | - 31-Node.js 的 perf_hooks: chapter31-Node.js 的 perf_hooks.md
128 | - 其他:
129 | - 24-拓展Node.js: chapter20-拓展Node.js.md
130 | - 25-Node.js子线程调试和诊断指南: chapter25-Node.js子线程调试和诊断指南
131 | - 26-vscode调试Node.js: chapter26-vscode调试Node.js.md
132 | - 28-Node.js底层原理(架构篇): chapter28-Node.js底层原理(架构篇).md
133 | - 29-Node.js底层原理(实现篇): chapter29-Node.js底层原理(实现篇).md
134 |
135 | extra_javascript:
136 | - path: extra/image.js
137 | defer: true
--------------------------------------------------------------------------------
/docs/chapter00-前言.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 我很喜欢JS这门语言,感觉它和C语言一样,在C语言里,很多东西都需要自己实现,让我们可以发挥无限的创造力和想象力。在JS中,虽然很多东西在V8里已经提供,但是用JS,依然可以创造很多好玩的东西,还有好玩的写法。另外,JS应该我见过唯一的一门没有实现网络和文件功能的语言,网络和文件,是一个很重要的能力,对于程序员来说,也是很核心很基础的知识。很幸运,Node.js被创造出来了,Node.js在JS的基础上,使用V8和Libuv提供的能力,极大地拓展、丰富了JS的能力,尤其是网络和文件,这样我就不仅可以使用JS,还可以使用网络、文件等功能,这是我逐渐转向Node.js方向的原因之一,也是我开始研究Node.js源码的原因之一。虽然Node.js满足了我喜好和技术上的需求,不过一开始的时候,我并没有全身心地投入代码的研究,只是偶尔会看一下某些模块的实现,真正的开始,是为了做《Node.js是如何利用Libuv实现事件循环和异步》的分享,从那时候起,大部分业余时间和精力都投入源码的研究。
4 | 我首先从Libuv开始研究,因为Libuv是Node.js的核心之一。由于曾经研究过一些Linux的源码,也一直在学习操作系统的一些原理和实现,所以在阅读Libuv的时候,算是没有遇到太大的困难,C语言函数的使用和原理,基本都可以看明白,重点在于需要把各个逻辑捋清楚。我使用的方法就是注释和画图,我个人比较喜欢写注释。虽然说代码是最好的注释,但是我还是愿意花时间用注释去把代码的背景和意义阐述一下,而且注释会让大部分人更快地能读懂代码的含义。读Libuv的时候,也穿插地读了一些JS和C++层的代码。我阅读Node.js源码的方式是,选择一个模块,垂直地从JS层分析到C++层,然后到Libuv层。
5 | 读完Libuv,接下来读的是JS层的代码,JS虽然容易看懂,但是JS层的代码非常多,而且我感觉逻辑上也非常绕,所以至今,我还有很多没有细读,这个作为后续的计划。Node.js中,C++算是胶水层,很多时候,不会C++,其实也不影响Node.js源码的阅读,因为C++很多时候,只是一种透传的功能,它把JS层的请求,通过V8,传给Libuv,然后再反过来,所以C++层我是放到最后才细读。C++层我觉得是最难的,这时候,我又不得不开始读V8的源码了,理解V8非常难,我选取的几乎是最早的版本0.1.5,然后结合8.x版本。通过早期版本,先学习V8的大概原理和一些早期实现上的细节。因为后续的版本虽然变化很大,但是更多只是功能的增强和优化,有很多核心的概念还是没有变化的,这是我选取早期版本的原因,避免一开始就陷入无穷无尽的代码中,迷失了方向,失去了动力。但是哪怕是早期的版本,有很多内容依然非常复杂,结合新版本是因为有些功能在早期版本里没有实现,这时候要明白它的原理,就只能看新版的代码,有了早期版本的经验,阅读新版的代码也有一定的好处,多少也知道了一些阅读技巧。
6 | Node.js的大部分代码都在C++和JS层,所以目前仍然是在不断地阅读这两层的代码。还是按照模块垂直分析。阅读Node.js代码,让我更了解Node.js的原理,也更了解JS。不过代码量非常大,需要源源不断的时间和精力投入。但是做技术,知其然知其所以然的感觉是非常美妙的,你靠着一门技术谋生,却对它知之甚少,这种感觉并不好。阅读源码,虽然不会为你带来直接的、迅速的收益,但是有几个好处是必然的。第一是它会决定你的高度,第二你写代码的时候,你看到的不再是一些冰冷冷、无生命的字符。这可能有点夸张,但是你了解了技术的原理,你在使用技术的时候,的确会有不同的体验,你的思维也会有了更多的变化。第三是提高了你的学习能力,当你对底层原理有了更多的了解和理解,你在学习其它技术的时候,就会更快地学会,比如你了解了epoll的原理,那你看Nginx、Redis、Libuv等源码的时候,关于事件驱动的逻辑,基本上很快就能看懂。很高兴有这些经历,也投入了很多时间和经精力,希望以后对Node.js有更多的理解和了解,也希望在Node.js方向有更多的实践。
7 |
8 | ## 本书的目的
9 | 阅读Node.js源码的初衷是让自己深入理解Node.js的原理,但是我发现有很多同学对Node.js原理也非常感兴趣,因为业余时间里也一直在写一些关于Node.js源码分析的文章(基于Node.js V10和V14),所以就打算把这些内容整理成一本有体系的书,让感兴趣的同学能系统地去了解和理解Node.js的原理。不过我更希望的是,读者从书中不仅学到Node.js的知识,而且也学到如何阅读Node.js源码,可以自己独立完成源码的研究。也希望更多同学分享自己的心得。本书不是Node.js的全部,但是尽量去讲得更多,源码非常多,错综复杂,理解上可能有不对之处,欢迎交流。因为看过Linux早期内核(0.11和1.2.13)和早期V8(0.1.5)的一些实现,文章会引用其中的一些代码,目的在于让读者可以更了解一个知识点的大致实现原理,如果读者有兴趣,可以自行阅读相关代码。
10 |
11 | ## 本书结构
12 | 本书共分为二十二章,讲解的代码都是基于Linux系统的。
13 |
14 | 1. 主要介绍了Node.js的组成和整体的工作原理,另外分析了Node.js启动的过程,最后介绍了服务器架构的演变和Node.js的所选取的架构。
15 | 2. 主要介绍了Node.js中的基础数据结构和通用的逻辑,在后面的章节会用到。
16 | 3. 主要介绍了Libuv的事件循环,这是Node.js的核心所在,本章具体介绍了事件循环中每个阶段的实现。
17 | 4. 主要分析了Libuv中线程池的实现,Libuv线程池对Node.js来说是非常重要的,Node.js中很多模块都需要使用线程池,包括crypto、fs、dns等。如果没有线程池,Node.js的功能将会大打折扣。同时分析了Libuv中子线程和主线程的通信机制。同样适合其它子线程和主线程通信。
18 | 5. 主要分析了Libuv中流的实现,流在Node.js源码中很多地方都用到,可以说是非常核心的概念。
19 | 6. 主要分析了Node.js中C++层的一些重要模块和通用逻辑。
20 | 7. 主要分析了Node.js的信号处理机制,信号是进程间通信的另一种方式。
21 | 8. 主要分析了Node.js的dns模块的实现,包括cares的使用和原理。
22 | 9. 主要分析了Node.js中pipe模块(Unix域)的实现和使用,Unix域是实现进程间通信的方式,它解决了没有继承的进程无法通信的问题。而且支持传递文件描述符,极大地增强了Node.js的能力。
23 | 10. 主要分析了Node.js中定时器模块的实现。定时器是定时处理任务的利器。
24 | 11. 主要分析了Node.js setImmediate和nextTick的实现。
25 | 12. 主要介绍了Node.js中文件模块的实现,文件操作是我们经常会用到的功能。
26 | 13. 主要介绍了Node.js中进程模块的实现,多进程使得Node.js可以利用多核能力。
27 | 14. 主要介绍了Node.js中线程模块的实现,多进程和多线程有类似的功能但是也有一些差异。
28 | 15. 主要介绍了Node.js中cluster模块的使用和实现原理,cluster模块封装了多进程能力,使得Node.j是可以使用多进程的服务器架构,利用了多核的能力。
29 | 16. 主要分析了Node.js中UDP的实现和相关内容。
30 | 17. 主要分析了Node.js中TCP模块的实现,TCP是Node.js的核心模块,我们常用的HTTP,HTTPS都是基于net模块。
31 | 18. 主要介绍了HTTP模块的实现以及HTTP协议的一些原理。
32 | 19. 主要分析了Node.js中各种模块加载的原理,深入理解Node.js的require函数所做的事情。
33 | 20. 主要介绍了一些拓展Node.js的方法,使用Node.js,拓展Node.js。
34 | 21. 主要介绍了JS层Stream的实现,Stream模块的逻辑很绕,大概讲解了一下。
35 | 22. 主要介绍了Node.js中event模块的实现,event模块虽然简单,但是是Node.js的核心模块。
36 |
37 | ## 面对的读者
38 | 本书面向有一定Node.js使用经验并对Node.js原理感兴趣的同学,因为本书是Node.js源码的角度去分析Node.js的原理,其中部分是C、C++,所以需要读者有一定的C、C++基础,另外,有一定的操作系统、计算机网络、V8基础会更好。
39 |
40 | ## 阅读建议
41 | 建议首先阅读前面几种基础和通用的内容,然后再阅读单个模块的实现,最后有兴趣的话,再阅读如何拓展Node.js章节。如果你已经比较熟悉Node.js,只是对某个模块或内容比较感兴趣,则可以直接阅读某个章节。刚开始阅读Node.js源码时,选取的是V10.x的版本,后来Node.js已经更新到了V14,所以书中的代码有的是V10有的是V14的。Libuv是V1.23。可以到我的github上获取。
42 |
43 | ## 源码阅读建议
44 | Node.js的源码由JS、C++、C组成。
45 | 1 Libuv是C语言编写。理解Libuv除了需要了解C语法外,更多的是对操作系统和网络的理解,有些经典的书籍可以参考,比如《Unix网络编程》1,2两册,《Linux系统编程手册》上下两册,《TCP/IP权威指南》等等。还有Linux的API文档以及网上优秀的文章都可以参考一下。
46 |
47 | 2 C++主要是利用V8提供的能力对JS进行拓展,也有一部分功能使用C++实现,总的来说C++的作用更多是胶水层,利用V8作为桥梁,连接Libuv和JS。不会C++,也不完全影响源码的阅读,但是会C++会更好。阅读C++层代码,除了语法外,还需要对V8的概念和使用有一定的了解和理解。
48 |
49 | 3 JS代码相信学习Node.js的同学都没什么问题。
50 |
51 | ## 其它资源
52 | 个人博客
53 | csdn [https://blog.csdn.net/THEANARKH](https://blog.csdn.net/THEANARKH)
54 | 知乎[https://www.zhihu.com/people/theanarkh](https://www.zhihu.com/people/theanarkh)
55 | github [https://github.com/theanarkh](https://github.com/theanarkh)
56 | 阅读Node.js源码时,所用到的基础知识、所作积累和记录几乎都在上面的博客中。 如果你有任何问题可以到[https://github.com/theanarkh/understand-nodejs](https://github.com/theanarkh/understand-nodejs)提issue或者联系我。
57 |
--------------------------------------------------------------------------------
/docs/chapter26-vscode调试Node.js.md:
--------------------------------------------------------------------------------
1 | 前言:调试代码不管对于开发还是学习源码都是非常重要的技能,本文简单介绍vscode调试Node.js相关代码的调试技巧。
2 | # 1 调试业务JS
3 | 调试业务JS可能是普遍的场景,随着Node.js和调试工具的成熟,调试也变得越来越简单。下面是vscode的lauch.json配置。
4 | ```json
5 | {
6 | "version": "0.2.0",
7 | "configurations": [
8 | {
9 | "type": "node",
10 | "request": "attach",
11 | "name": "Attact Program",
12 | "port": 9229
13 | }
14 | ]
15 | }
16 | ```
17 | 1 在JS里设置断点,执行node --inspect index.js 启动进程,会输出调试地址。
18 | 
19 | 2 点击虫子,然后点击绿色的三角形。
20 | 3 vscode会连接Node.js的WebSocket服务。
21 | 4 开始调试(或者使用Chrome Dev Tools调试)。
22 |
23 | # 2 调试Addon的C++
24 | 写Addon的场景可能不多,但是当你需要的时候,你就会需要调试它。下面的配置只可以调试C++代码。
25 | ```json
26 | {
27 | "version": "0.2.0",
28 | "configurations": [
29 | {
30 | "name": "Debug node C++ addon",
31 | "type": "lldb",
32 | "request": "launch",
33 | "program": "node",
34 | "args": ["${workspaceFolder}/node-addon-examples/1_hello_world/napi/hello.js"],
35 | "cwd": "${workspaceFolder}/node-addon-examples/1_hello_world/napi"
36 | },
37 | ]
38 | }
39 | ```
40 | 1 在C++代码设置断点。
41 | 
42 | 2 执行node-gyp configure && node-gyp build --debug编译debug版本的Addon。
43 | 3 JS里加载debug版本的Addon。
44 | 
45 | 4 点击小虫子开始调试。
46 | 
47 |
48 | # 3 调试Addon的C++和JS
49 | Addon通常需要通过JS暴露出来使用,如果我们需要调试C++和JS,那么就可以使用以下配置。
50 | ```json
51 | {
52 | "version": "0.2.0",
53 | "configurations": [
54 | {
55 | "name": "Debug node C++ addon",
56 | "type": "node",
57 | "request": "launch",
58 | "program": "${workspaceFolder}/node-addon-examples/1_hello_world/napi/hello.js",
59 | "cwd": "${workspaceFolder}/node-addon-examples/1_hello_world/napi"
60 | },
61 | {
62 | "name": "Attach node C/C++ Addon",
63 | "type": "lldb",
64 | "request": "attach",
65 | "pid": "${command:pickMyProcess}"
66 | }
67 | ]
68 | }
69 | ```
70 | 和2的过程类似,点三角形开始调试,再选择Attach node C/C++ Addon,然后再次点击三角形。
71 | 选择attach到hello.js中。
72 | 
73 | 开始调试。
74 |
75 | # 4 调试Node.js源码C++
76 | 我们不仅用Node.js,我们可能还会学习Node.js源码,学习源码的时候就少不了调试。可以通过下面的方式调试Node.js的C++源码。
77 | ```text
78 | ./configure --debug && make
79 | ```
80 | 使用以下配置
81 | ```json
82 | {
83 | "version": "0.2.0",
84 | "configurations": [
85 | {
86 | "name": "(lldb) 启动",
87 | "type": "cppdbg",
88 | "request": "launch",
89 | "program": "${workspaceFolder}/out/Debug/node",
90 | "args": [],
91 | "stopAtEntry": false,
92 | "cwd": "${fileDirname}",
93 | "environment": [],
94 | "externalConsole": false,
95 | "MIMode": "lldb"
96 | }
97 | ]
98 | }
99 | ```
100 | 在node_main.cc的main函数或任何C++代码里打断点,点击小虫子开始调试。
101 |
102 | # 5 调试Node.js源码C++和JS代码
103 | Node.js的源码不仅仅有C++,还有JS,如果我们想同时调试,那么就使用以下配置。
104 | ```json
105 | {
106 | "version": "0.2.0",
107 | "configurations": [
108 | {
109 | "name": "(lldb) 启动",
110 | "type": "cppdbg",
111 | "request": "launch",
112 | "program": "${workspaceFolder}/out/Debug/node",
113 | "args": ["--inspect-brk", "${workspaceFolder}/out/Debug/index.js"],
114 | "stopAtEntry": false,
115 | "cwd": "${fileDirname}",
116 | "environment": [],
117 | "externalConsole": false,
118 | "MIMode": "lldb"
119 | }
120 | ]
121 | }
122 | ```
123 | 1 点击调试。
124 | 
125 | 2 在vscode调试C++,执行完Node.js启动的流程后会输出调试JS的地址。
126 | 
127 | 3 在浏览器连接WebSocket服务调试JS。
128 | 
129 | 
130 |
131 |
132 |
--------------------------------------------------------------------------------
/docs/chapter31-Node.js 的 perf_hooks.md:
--------------------------------------------------------------------------------
1 | 前言:perf_hooks 是 Node.js 中用于收集性能数据的模块,Node.js 本身基于 perf_hooks 提供了性能数据,同时也提供了机制给用户上报性能数据。文本介绍一下 perk_hooks。
2 |
3 | # 1 使用
4 | 首先看一下 perf_hooks 的基本使用。
5 | ```c
6 | const { PerformanceObserver } = require('perf_hooks');
7 | const obs = new PerformanceObserver((items) => {
8 | //
9 | };
10 |
11 | obs.observe({ type: 'http' });
12 | ```
13 | 通过 PerformanceObserver 可以创建一个观察者,然后调用 observe 可以订阅对哪种类型的性能数据感兴趣。
14 |
15 | 下面看一下 C++ 层的实现,C++ 层的实现首先是为了支持 C++ 层的代码进行数据的上报,同时也为了支持 JS 层的功能。
16 | # 2 C++ 层实现
17 | ## 2.1 PerformanceEntry
18 | PerformanceEntry 是 perf_hooks 里的一个核心数据结构,PerformanceEntry 代表一次性能数据。下面来看一下它的定义。
19 | ```c
20 | template
21 | struct PerformanceEntry {
22 | using Details = typename Traits::Details;
23 | std::string name;
24 | double start_time;
25 | double duration;
26 | Details details;
27 |
28 | static v8::MaybeLocal GetDetails(
29 | Environment* env,
30 | const PerformanceEntry& entry) {
31 | return Traits::GetDetails(env, entry);
32 | }
33 | };
34 | ```
35 | PerformanceEntry 里面记录了一次性能数据的信息,从定义中可以看到,里面记录了类型,开始时间,持续时间,比如一个 HTTP 请求的开始时间,处理耗时。除了这些信息之外,性能数据还包括一些额外的信息,由 details 字段保存,比如 HTTP 请求的 url,不过目前还不支持这个能力,不同的性能数据会包括不同的额外信息,所以 PerformanceEntry 是一个类模版,具体的 details 由具体的性能数据生产者实现。下面我们看一个具体的例子。
36 | ```c
37 | struct GCPerformanceEntryTraits {
38 | static constexpr PerformanceEntryType kType = NODE_PERFORMANCE_ENTRY_TYPE_GC;
39 | struct Details {
40 | PerformanceGCKind kind;
41 | PerformanceGCFlags flags;
42 |
43 | Details(PerformanceGCKind kind_, PerformanceGCFlags flags_)
44 | : kind(kind_), flags(flags_) {}
45 | };
46 |
47 | static v8::MaybeLocal GetDetails(
48 | Environment* env,
49 | const PerformanceEntry& entry);
50 | };
51 |
52 | using GCPerformanceEntry = PerformanceEntry;
53 | ```
54 | 这是关于 gc 性能数据的实现,我们看到它的 details 里包括了 kind 和 flags。接下来看一下 perf_hooks 是如何收集 gc 的性能数据的。首先通过 InstallGarbageCollectionTracking 注册 gc 钩子。
55 | ```c
56 | static void InstallGarbageCollectionTracking(const FunctionCallbackInfo& args) {
57 | Environment* env = Environment::GetCurrent(args);
58 |
59 | env->isolate()->AddGCPrologueCallback(MarkGarbageCollectionStart,
60 | static_cast(env));
61 | env->isolate()->AddGCEpilogueCallback(MarkGarbageCollectionEnd,
62 | static_cast(env));
63 | env->AddCleanupHook(GarbageCollectionCleanupHook, env);
64 | }
65 | ```
66 | InstallGarbageCollectionTracking 主要是使用了 V8 提供的两个函数注册了 gc 开始和 gc 结束阶段的钩子。我们看一下这两个钩子的逻辑。
67 | ```c
68 | void MarkGarbageCollectionStart(
69 | Isolate* isolate,
70 | GCType type,
71 | GCCallbackFlags flags,
72 | void* data) {
73 | Environment* env = static_cast(data);
74 | env->performance_state()->performance_last_gc_start_mark = PERFORMANCE_NOW();
75 | }
76 | ```
77 | MarkGarbageCollectionStart 在开始 gc 时被执行,逻辑很简单,主要是记录了 gc 的开始时间。接着看 MarkGarbageCollectionEnd。
78 | ```c
79 | void MarkGarbageCollectionEnd(
80 | Isolate* isolate,
81 | GCType type,
82 | GCCallbackFlags flags,
83 | void* data) {
84 | Environment* env = static_cast(data);
85 | PerformanceState* state = env->performance_state();
86 |
87 | double start_time = state->performance_last_gc_start_mark / 1e6;
88 | double duration = (PERFORMANCE_NOW() / 1e6) - start_time;
89 |
90 | std::unique_ptr entry =
91 | std::make_unique(
92 | "gc",
93 | start_time,
94 | duration,
95 | GCPerformanceEntry::Details(
96 | static_cast(type),
97 | static_cast(flags)));
98 |
99 | env->SetImmediate([entry = std::move(entry)](Environment* env) {
100 | entry->Notify(env);
101 | }, CallbackFlags::kUnrefed);
102 | }
103 | ```
104 | MarkGarbageCollectionEnd 根据刚才记录 gc 开始时间,计算出 gc 的持续时间。然后产生一个性能数据 GCPerformanceEntry。然后在事件循环的 check 阶段通过 Notify 进行上报。
105 | ```c
106 | void Notify(Environment* env) {
107 | v8::Local detail;
108 | if (!Traits::GetDetails(env, *this).ToLocal(&detail)) {
109 | // TODO(@jasnell): Handle the error here
110 | return;
111 | }
112 |
113 | v8::Local argv[] = {
114 | OneByteString(env->isolate(), name.c_str()),
115 | OneByteString(env->isolate(), GetPerformanceEntryTypeName(Traits::kType)),
116 | v8::Number::New(env->isolate(), start_time),
117 | v8::Number::New(env->isolate(), duration),
118 | detail
119 | };
120 |
121 | node::MakeSyncCallback(
122 | env->isolate(),
123 | env->context()->Global(),
124 | env->performance_entry_callback(),
125 | arraysize(argv),
126 | argv);
127 | }
128 | };
129 | ```
130 | Notify 进行进一步的处理,然后执行 JS 的回调进行数据的上报。env->performance_entry_callback() 对应的回调在 JS 设置。
131 |
132 | ## 2.2 PerformanceState
133 | PerformanceState 是 perf_hooks 的另一个核心数据结构,负责管理 perf_hooks 模块的一些公共数据。
134 | ```c
135 | class PerformanceState {
136 | public:
137 | explicit PerformanceState(v8::Isolate* isolate, const SerializeInfo* info);
138 | AliasedUint8Array root;
139 | AliasedFloat64Array milestones;
140 | AliasedUint32Array observers;
141 |
142 | uint64_t performance_last_gc_start_mark = 0;
143 |
144 | void Mark(enum PerformanceMilestone milestone,uint64_t ts = PERFORMANCE_NOW());
145 |
146 | private:
147 | struct performance_state_internal {
148 | // Node.js 初始化时的性能数据
149 | double milestones[NODE_PERFORMANCE_MILESTONE_INVALID];
150 | // 记录对不同类型性能数据感兴趣的观察者个数
151 | uint32_t observers[NODE_PERFORMANCE_ENTRY_TYPE_INVALID];
152 | };
153 | };
154 | ```
155 | PerformanceState 主要是记录了 Node.js 初始化时的性能数据,比如 Node.js 初始化完毕的时间,事件循环的开始时间等。还有就是记录了观察者的数据结构,比如对 HTTP 性能数据感兴趣的观察者,主要用于控制要不要上报相关类型的性能数据。比如如果没有观察者的话,那么就不需要上报这个数据。
156 |
157 | # 3 JS 层实现
158 | 接下来看一下 JS 的实现。首先看一下观察者的实现。
159 |
160 | ```c
161 | class PerformanceObserver {
162 | constructor(callback) {
163 | // 性能数据
164 | this[kBuffer] = [];
165 | // 观察者订阅的性能数据类型
166 | this[kEntryTypes] = new SafeSet();
167 | // 观察者对一个还是多个性能数据类型感兴趣
168 | this[kType] = undefined;
169 | // 观察者回调
170 | this[kCallback] = callback;
171 | }
172 |
173 | observe(options = {}) {
174 | const {
175 | entryTypes,
176 | type,
177 | buffered,
178 | } = { ...options };
179 | // 清除之前的数据
180 | maybeDecrementObserverCounts(this[kEntryTypes]);
181 | this[kEntryTypes].clear();
182 | // 重新订阅当前设置的类型
183 | for (let n = 0; n < entryTypes.length; n++) {
184 | if (ArrayPrototypeIncludes(kSupportedEntryTypes, entryTypes[n])) {
185 | this[kEntryTypes].add(entryTypes[n]);
186 | maybeIncrementObserverCount(entryTypes[n]);
187 | }
188 | }
189 | // 插入观察者队列
190 | kObservers.add(this);
191 | }
192 |
193 | takeRecords() {
194 | const list = this[kBuffer];
195 | this[kBuffer] = [];
196 | return list;
197 | }
198 |
199 | static get supportedEntryTypes() {
200 | return kSupportedEntryTypes;
201 | }
202 | // 产生性能数据时被执行的函数
203 | [kMaybeBuffer](entry) {
204 | if (!this[kEntryTypes].has(entry.entryType))
205 | return;
206 | // 保存性能数据,迟点上报
207 | ArrayPrototypePush(this[kBuffer], entry);
208 | // 插入待上报队列
209 | kPending.add(this);
210 | if (kPending.size)
211 | queuePending();
212 | }
213 | // 执行观察者回调
214 | [kDispatch]() {
215 | this[kCallback](new PerformanceObserverEntryList(this.takeRecords()),
216 | this);
217 | }
218 | }
219 | ```
220 | 观察者的实现比较简单,首先有一个全局的变量记录了所有的观察者,然后每个观察者记录了自己订阅的类型。当产生性能数据时,生产者就会通知观察者,接着观察者执行回调。这里需要额外介绍的一个是 maybeDecrementObserverCounts 和 maybeIncrementObserverCount。
221 | ```c
222 | function getObserverType(type) {
223 | switch (type) {
224 | case 'gc': return NODE_PERFORMANCE_ENTRY_TYPE_GC;
225 | case 'http2': return NODE_PERFORMANCE_ENTRY_TYPE_HTTP2;
226 | case 'http': return NODE_PERFORMANCE_ENTRY_TYPE_HTTP;
227 | }
228 | }
229 |
230 | function maybeDecrementObserverCounts(entryTypes) {
231 | for (const type of entryTypes) {
232 | const observerType = getObserverType(type);
233 |
234 | if (observerType !== undefined) {
235 | observerCounts[observerType]--;
236 |
237 | if (observerType === NODE_PERFORMANCE_ENTRY_TYPE_GC &&
238 | observerCounts[observerType] === 0) {
239 | removeGarbageCollectionTracking();
240 | gcTrackingInstalled = false;
241 | }
242 | }
243 | }
244 | }
245 | ```
246 | maybeDecrementObserverCounts 主要用于操作 C++ 层的逻辑,首先根据订阅类型判断是不是 C++ 层支持的类型,因为 perf_hooks 在 C++ 和 JS 层都定义了不同的性能类型,如果是涉及到底层的类型,就会操作 observerCounts 记录当前类型的观察者数量,observerCounts 就是刚才分析 C++ 层的 observers 变量,它是一个数组,每个索引对应一个类型,数组元素的值是观察者的个数。另外如果订阅的是 gc 类型,并且是第一个订阅者,那就 JS 层就会操作 C++ 层往 V8 里注册 gc 回调。
247 |
248 | 了解了 perf_hooks 提供的机制后,我们来看一个具体的性能数据上报例子。这里以 HTTP Server 处理请求的耗时为例。
249 | ```c
250 | function emitStatistics(statistics) {
251 | const startTime = statistics.startTime;
252 | const diff = process.hrtime(startTime);
253 | const entry = new InternalPerformanceEntry(
254 | statistics.type,
255 | 'http',
256 | startTime[0] * 1000 + startTime[1] / 1e6,
257 | diff[0] * 1000 + diff[1] / 1e6,
258 | undefined,
259 | );
260 | enqueue(entry);
261 | }
262 | ```
263 | 下面是 HTTP Server 处理完一个请求时上报性能数据的逻辑。首先创建一个 InternalPerformanceEntry 对象,这个和刚才介绍的 C++ 对象是一样的,是表示一个性能数据的对象。接着调用 enqueue 函数。
264 | ```c
265 | function enqueue(entry) {
266 | // 通知观察者有性能数据,观察者自己判断是否订阅了这个类型的数据
267 | for (const obs of kObservers) {
268 | obs[kMaybeBuffer](entry);
269 | }
270 | // 如果是 mark 或 measure 类型,则插入一个全局队列。
271 | const entryType = entry.entryType;
272 | let buffer;
273 | if (entryType === 'mark') {
274 | buffer = markEntryBuffer; // mark 性能数据队列
275 | } else if (entryType === 'measure') {
276 | buffer = measureEntryBuffer; // measure 性能数据队列
277 | } else {
278 | return;
279 | }
280 |
281 | ArrayPrototypePush(buffer, entry);
282 | }
283 | ```
284 | enqueue 会把性能数据上报到观察者,然后观察者如果订阅这个类型的数据则执行用户回调通知用户。我们看一下 obs[kMaybeBuffer] 的逻辑。
285 | ```c
286 | [kMaybeBuffer](entry) {
287 | if (!this[kEntryTypes].has(entry.entryType))
288 | return;
289 | ArrayPrototypePush(this[kBuffer], entry);
290 | // this 是观察者实例
291 | kPending.add(this);
292 | if (kPending.size)
293 | queuePending();
294 | }
295 |
296 |
297 | function queuePending() {
298 | if (isPending) return;
299 | isPending = true;
300 | setImmediate(() => {
301 | isPending = false;
302 | const pendings = ArrayFrom(kPending.values());
303 | kPending.clear();
304 | // 遍历观察者队列,执行 kDispatch
305 | for (const pending of pendings)
306 | pending[kDispatch]();
307 | });
308 | }
309 | // 下面是观察者中的逻辑,观察者把当前保存的数据上报给用户
310 | [kDispatch]() {
311 | this[kCallback](new PerformanceObserverEntryList(this.takeRecords()),this);
312 | }
313 | ```
314 | 另外 mark 和 measure 类型的性能数据比较特殊,它不仅会通知观察者,还会插入到全局的一个队列中。所以对于其他类型的性能数据,如果没有观察者的话就会被丢弃(通常在调用 enqueue 之前会先判断是否有观察者),对于 mark 和 measure 类型的性能数据,不管有没有观察者都会被保存下来,所以我们需要显式清除。
315 |
316 | # 4 总结
317 | 以上就是 perf_hooks 中核心的实现,除此之外,perf_hooks 还提供了其他的功能,本文就先不介绍了。可以看到 perf_hooks 的实现是一个订阅发布的模式,看起来貌似没什么特别的。但是它的强大之处在于是由 Node.js 内置实现的, 这样 Node.js 的其他模块就可以基于 perf_hooks 这个框架上报各种类型的性能数据。相比来说虽然我们也能在用户层实现这样的逻辑,但是我们拿不到或者没有办法优雅地方法拿到 Node.js 内核里面的数据,比如我们想拿到 gc 的性能数据,我们只能写 addon 实现。又比如我们想拿到 HTTP Server 处理请求的耗时,虽然可以通过监听 reqeust 或者 response 对象的事件实现,但是这样一来我们就会耦合到业务代码里,每个开发者都需要处理这样的逻辑,如果我们想收拢这个逻辑,就只能劫持 HTTP 模块来实现,这些不是优雅但是是不得已的解决方案。有了 perf_hooks 机制,我们就可以以一种结耦的方式来收集这些性能数据,实现写一个 SDK,大家只需要简单引入就行。
318 |
319 | 最近在研究 perf_hooks 代码的时候发现目前 perf_hooks 的功能还不算完善,很多性能数据并没有上报,目前只支持 HTTP Server 的请求耗时、HTTP 2 和 gc 耗时这些性能数据。所以最近提交了两个 PR 支持了更多性能数据的上报。第一个 PR 是用于支持收集 HTTP Client 的耗时,第二个 PR 是用于支持收集 TCP 连接和 DNS 解析的耗时。在第二个 PR 里,实现了两个通用的方法,方便后续其他模块做性能上报。另外后续有时间的话,希望可以去不断完善 perf_hooks 机制和性能数据收集这块的能力。在从事 Node.js 调试和诊断这个方向的这段时间里,深感到应用层能力的局限,因为我们不是业务方,而是基础能力的提供者,就像前面提到的,哪怕想提供一个收集 HTTP 请求耗时的数据都是非常困难的,而作为基础能力的提供者,我们一直希望我们的能力对业务来说是无感知,无侵入并且是稳定可靠的。所以我们需要不断深入地了解 Node.js 在这方面提供的能力,如果 Node.js 没有提供我们想要的功能,我们只能写 addon 或者尝试给社区提交 PR 来解决。另外我们也在慢慢了解和学习 ebpf,希望能利用 ebpf 从另外一个层面帮助我们解决所碰到的问题。
320 |
--------------------------------------------------------------------------------
/docs/chapter28-Node.js底层原理(架构篇).md:
--------------------------------------------------------------------------------
1 | 前言:之前分享了 Node.js 的底层原理,主要是简单介绍了 Node.js 的一些基础原理和一些核心模块的实现,本文从 Node.js 整体方面介绍 Node.js 的底层原理。
2 |
3 | 内容主要包括五个部分。第一部分是首先介绍一下 Node.js 的组成和代码架构。然后介绍一下 Node.js 中的 Libuv, 还有 V8 和模块加载器。最后介绍一下 Node.js 的服务器架构。
4 |
5 | # 1 Node.js 的组成和代码架构
6 | 下面先来看一下Node.js 的组成。Node.js 主要是由 V8、Libuv 和一些第三方库组成。
7 | 1. V8 我们都比较熟悉,它是一个 JS 引擎。但是它不仅实现了 JS 解析和执行,它还是自定义拓展。比如说我们可以通过 V8 提供一些 C++ API 去定义一些全局变量,这样话我们在 JS 里面去使用这个变量了。正是因为 V8 支持这个自定义的拓展,所以才有了 Node.js 等 JS 运行时。
8 | 2. Libuv 是一个跨平台的异步 IO 库。它主要的功能是它封装了各个操作系统的一些 API, 提供网络还有文件进程的这些功能。我们知道在 JS 里面是没有网络文件这些功能的,在前端时,是由浏览器提供的,而在 Node.js 里,这些功能是由 Libuv 提供的。
9 | 3. 另外 Node.js 里面还引用了很多第三方库,比如 DNS 解析库,还有 HTTP 解析器等等。
10 |
11 | 接下来看一下 Node.js 代码整体的架构。
12 | 
13 | Node.js 代码主要是分为三个部分,分别是C、C++ 和 JS。
14 | 1. JS 代码就是我们平时在使用的那些 JS 的模块,比方说像 http 和 fs 这些模块。
15 | 2. C++ 代码主要分为三个部分,第一部分主要是封装 Libuv 和第三方库的 C++ 代码,比如net 和 fs 这些模块都会对应一个 C++ 模块,它主要是对底层的一些封装。第二部分是不依赖 Libuv 和第三方库的 C++ 代码,比方像 Buffer 模块的实现。第三部分 C++ 代码是 V8 本身的代码。
16 | 3. C 语言代码主要是包括 Libuv 和第三方库的代码,它们都是纯 C 语言实现的代码。
17 |
18 | 了解了 Nodejs 的组成和代码架构之后,再来看一下 Node.js 中各个主要部分的实现。
19 | # 2 Node.js 中的 Libuv
20 | 首先来看一下 Node.js 中的 Libuv,下面从三个方面介绍 Libuv。
21 | 1. 介绍 Libuv 的模型和限制
22 | 2. 介绍线程池解决的问题和带来的问题
23 | 3. 介绍事件循环
24 |
25 | ## 2.1 Libuv 的模型和限制
26 | Libuv 本质上是一个生产者消费者的模型。
27 | 
28 | 从上面这个图中,我们可以看到在 Libuv 中有很多种生产任务的方式,比如说在一个回调里,在 Node.js 初始化的时候,或者在线程池完成一些操作的时候,这些方式都可以生产任务。然后 Libuv 会不断的去消费这些任务,从而驱动着整个进程的运行,这就是我们一直说的事件循环。
29 |
30 | 但是生产者的消费者模型存在一个问题,就是消费者和生产者之间,怎么去同步?比如说在没有任务消费的时候,这个消费者他应该在干嘛?第一种方式是消费者可以睡眠一段时间,睡醒之后,他会去判断有没有任务需要消费,如果有的话就继续消费,如果没有的话他就继续睡眠。很显然这种方式其实是比较低效的。第二种方式是消费者会把自己挂起,也就是说这个消费所在的进程会被挂起,然后等到有任务的时候,操作系统就会唤醒它,相对来说,这种方式是更高效的,Libuv 里也正是使用这种方式。
31 | 
32 | 这个逻辑主要是由事件驱动模块实现的,下面看一下事件驱动的大致的流程。
33 | 
34 | 应用层代码可以通过事件驱动模块订阅 fd 的事件,如果这个事件还没有准备好的话,那么这个进程就会被挂起。然后等到这个 fd 所对应的事件触发了之后,就会通过事件驱动模块回调应用层的代码。
35 |
36 | 下面以 Linux 的 事件驱动模块 epoll 为例,来看一下使用流程。
37 | 1. 首先通过 epoll_create 去创建一个epoll 实例。
38 | 2. 然后通过 epoll_ctl 这个函数订阅、修改或者取消订阅一个 fd 的一些事件。
39 | 3. 最后通过 epoll_wait 去判断当前订阅的事件有没有发生,如果有事情要发生的话,那么就直接执行上层回调,如果没有事件发生的话,这种时候可以选择不阻塞,定时阻塞或者一直阻塞,直到有事件发生。要不要阻塞或者说阻塞多久,是根据当前系统的情况。比如 Node.js 里面如果有定时器的节点的话,那么 Node.js 就会定时阻塞,这样就可以保证定时器可以按时执行。
40 |
41 | 接下来再深入一点去看一下 epoll 的大致的实现。
42 | 
43 | 当应用层代码调用事件驱动模块订阅 fd 的事件时,比如说这里是订阅一个可读事件。那么事件驱动模块它就会往这个 fd 的队列里面注册一个回调,如果当前这个事件还没有触发,这个进程它就会被阻塞。等到有一块数据写入了这个 fd 时,也就是说这个 fd 有可读事件了,操作系统就会执行事件驱动模块的回调,事件驱动模块就会相应的执行用层代码的回调。
44 |
45 | 但是 epoll 存在一些限制。首先第一个是不支持文件操作的,比方说文件读写这些,因为操作系统没有实现。第二个是不适合执行耗时操作,比如大量 CPU 计算、引起进程阻塞的任务,因为 epoll 通常是搭配单线程的,如果在单线程里执行耗时任务,就会导致后面的任务无法执行。
46 | ## 2.2 线程池解决的问题和带来的问题
47 | 针对这个问题,Libuv 提供的解决方案就是使用线程池。下面来看一下引入了线程池之后, 线程池和主线程的关系。
48 | 
49 | 从这个图中我们可以看到,当应用层提交任务时,比方说像 CPU 计算还有文件操作,这种时候不是交给主线程去处理的,而是直接交给线程池处理的。线程池处理完之后它会通知主线程。
50 |
51 | 但是引入了多线程后会带来一个问题,就是怎么去保证上层代码跑在单个线程里面。因为我们知道 JS 它是单线程的,如果线程池处理完一个任务之后,直接执行上层回调,那么上层代码就会完全乱了。这种时候就需要一个异步通知的机制,也就是说当一个线程它处理完任务的时候,它不是直接去执行上程回调的,而是通过异步机制去通知主线程来执行这个回调。
52 | 
53 | Libuv 中具体通过 fd 的方式去实现的。当线程池完成任务时,它会以原子的方式去修改这个 fd 为可读的,然后在主线程事件循环的 Poll IO 阶段时,它就会执行这个可读事件的回调,从而执行上层的回调。可以看到,Node.js 虽然是跑在多线程上面的,但是所有的 JS 代码都是跑在单个线程里的,这也是我们经常讨论的 Node.js 是单线程还是多线程的,从不同的角度去看就会得到不同的答案。
54 |
55 |
56 | 下面的图就是异步任务处理的一个大致过程。
57 | 
58 | 比如我们想读一个文件的时候,这时候主线程会把这个任务直接提交到线程池里面去处理,然后主线程就可以继续去做自己的事情了。当在线程池里面的线程完成这个任务之后,它就会往这个主线程的队列里面插入一个节点,然后主线程在 Poll IO 阶段时,它就会去执行这个节点里面的回调。
59 | ## 2.3 事件循环
60 | 了解 Libuv 的一些核心实现之后,下面我们再看一下 Libuv 中一个著名的事件循环。事件循环主要分为七个阶段,
61 | 1. 第一是 timer 阶段,timer 阶段是处理定时器相关的一些任务,比如 Node.js 中的 setTimeout和 setInterval。
62 | 2. 第二是 pending 的阶段, pending 阶段主要处理 Poll IO 阶段执行回调时产生的回调。
63 | 3. 第三是 check、prepare 和 idle 三个阶段,这三个阶段主要处理一些自定义的任务。setImmediate 属于 check 阶段。
64 | 4. 第四是 Poll IO 阶段,Poll IO 阶段主要要处理跟文件描述符相关的一些事件。
65 | 5. 第五是 close 阶段, 它主要是处理,调用了 uv_close 时传入的回调。比如关闭一个 TCP 连接时传入的回调,它就会在这个阶段被执行。
66 |
67 | 下面这个图是各个阶段在事件循环的顺序图。
68 | 
69 | 下面我们来看一下每个阶段的实现。
70 |
71 | 1. 定时器
72 | Libuv 在底层里面维护了一个最小堆,每个定时节点就是堆里面的一个节点(Node.js 只用了 Libuv 的一个定时器节点),越早超时的节点就在越上面。然后等到定时期阶段的时候, Libuv 就会从上往下去遍历这个最小堆判断当前节点有没有超时,如果没有到期的话,那么后面节点也不需要去判断了,因为最早到期的节点都没到期,那么它后面节点也显然不会到期。如果当前节点到期了,那么就会执行它的回调,并且把它移出这个最小堆。但是为了支持类似 setInterval 这种场景。如果这个节点设置了repeat 标记,那么这个节点它会被重新插入到最小堆中,等待下一次的超时。
73 |
74 | 2. check、idle、prepare 阶段和 pending、close 阶段。
75 | 
76 | 这五个阶段的实现其实类似的,它们都对应自己的一个任务队列。当产生任务的时候,它就会往这个队列里面插入一个节点,等到相应的阶段时,它就会去遍历这个队列里面的每个节点,并且执行它的回调。但是 check idle 还有 prepare 阶段有一个比较特别的地方,就是当这些阶段的节点回调被执行之后,它还会重新插入队列里面,也是说这三个阶段它对应的任务在每一轮的事件循环都会被执行。
77 |
78 | 3. Poll IO 阶段
79 | Poll IO 本质上是对前面讲的事件驱动模块的封装。下面来看一下整体的流程。
80 | 
81 |
82 | 当我们订阅一个 fd 的事件时,Libuv 就会通过 epoll 去注册这个 fd 对应的事件。如果这时候事件没有就绪,那么进程就会阻塞在 epoll_wait 中。等到这事件触发的时候,进程就会被唤醒,唤醒之后,它就遍历 epoll 返回了事件列表,并执行上层回调。
83 |
84 | 现在有一个底层能力,那么这个底层能力是怎么暴露给上层的 JS 去使用呢?这种时候就需要用到 JS 引擎 V8了。
85 |
86 | # 3. Node.js 中的 V8
87 | 下面从三个方面介绍 V8。
88 | 1. 介绍 V8 在 Node.js 的作用和 V8 的一些基础概念
89 | 2. 介绍如何通过 V8 执行 JS 和拓展 JS
90 | 3. 介绍如何通过 V8 实现 JS 和 C++ 通信
91 |
92 | ## 3.1 V8 在 Node.js 的作用和基础概念
93 | V8 在 Node.js 里面主要是有两个作用,第一个是负责解析和执行 JS。第二个是支持拓展 JS 能力,作为这个 JS 和 C++ 的桥梁。下面我们先来看一下 V8 里面那些重要的概念。
94 |
95 | Isolate:首先第一个是 Isolate 它是代表一个 V8 的实例,它相当于这一个容器。通常一个线程里面会有一个这样的实例。比如说在 Node.js主线程里面,它就会有一个 Isolate 实例。
96 |
97 | Context:Context 是代表我们执行代码的一个上下文,它主要是保存像 Object,Function 这些我们平时经常会用到的内置的类型。如果我们想拓展 JS 功能,就可以通过这个对象实现。
98 |
99 | ObjectTemplate:ObjectTemplate 是用于定义对象的模板,然后我们就可以基于这个模板去创建对象。
100 |
101 | FunctionTemplate:FunctionTemplate 和 ObjectTemplate 是类似的,它主要是用于定义一个函数的模板,然后就可以基于这个函数模板去创建一个函数。
102 |
103 | FunctionCallbackInfo: 用于实现 JS 和 C++ 通信的对象。
104 |
105 | Handle:Handle 是用管理在 V8 堆里面那些对象,因为像我们平时定义的对象和数组,它是存在 V8 堆内存里面的。Handle 就是用于管理这些对象。
106 |
107 | HandleScope:HandleScope 是一个 Handle 容器,HandleScope 里面可以定义很多 Handle,它主要是利用自己的生命周期管理多个 Handle。
108 |
109 | 下面我们通过一个代码来看一下 HandleScope 和 Handle 它们之间的关系。
110 | 
111 | 首先第一步新建一个 HandleScope,就会在一个栈里面定义一个 HandleScope 对象。然后第二步新建了一个 Handle 并且把它指向一个堆对象。这时候就会在栈里面分配一个叫 Local 对象,然后在堆里面分配一块 slot 所代表的内存和一个 Object 对象,并且建立关联关系。当执行完这个函数的时候,这个栈就会被清空,相应的这个 slot 代表的内存也会被释放,但是 Object 所代表这个对象,它是不会立马被释放的,它会等待 GC 的回收。
112 |
113 | ## 3.2 通过 V8 执行 JS 和拓展 JS
114 | 了解了 V8 的基础概念之后,来看一下怎么通过 V8 执行一段 JS 的代码。
115 | 
116 | 首先第一步新建一个 Isolate,它这表示一个隔离的实例。第二步定义一个 HandleScope 对象,因为我们下面需要定义 Handle。第三步定义一个 Context,这是代码执行所在的上下文。第四步定义一些需要被执行的 JS 代码。第五步通过 Script 对象的 Compile 函数编译 JS 代码。编译完之后,我们会得到一个 Script 对象,然后执行这个对象的 Run 函数就可以完成代码的执行。
117 |
118 | 接下来再看一下怎么去拓展 JS 原有的一些能力。
119 | 
120 | 首先第一步是通过 Context 上下文对象拿到一个全局的对象,类似于在前端里面的 window 对象。第二步通过 ObjectTemplate 新建一个对象的模板,然后接着会给这个对象模板设置一个 test 属性, 值是函数。接着通过这个对象模板新建一个对象,并且把这个对象设置到一个全局变量里面去。这样我们就可以在 JS 层去访问这个全局对象。
121 |
122 | 下面我们通过使用刚才定义那个全局对象来看一下 JS 和 C++ 是怎么通信的。
123 |
124 | ## 3.3 通过 V8 实现 JS 和 C++ 层通信
125 | 
126 | 当在 JS 层调用刚才定义 test 函数时,就会相应的执行 C++ 层的 test 函数。这个函数有一个入参是 FunctionCallbackInfo,在 C++ 中可以通过这个对象拿到 JS 传来一些参数,这样就完成了 JS 层到 C++ 层通信。经过一系列处理之后,还是可以通过这个对象给 JS 层设置需要返回给 JS 的内容,这样可以完成了 C++ 层到 JS 层的通信。
127 |
128 | 现在有了底层能力,有了这一层的接口,但是我们是怎么去加载后执行 JS 代码呢?这时候就需要模块加载器。
129 | # 4 Node.js 中的模块加载器
130 | Node.js 中有五种模块加载器。
131 | 1. JSON 模块加载器
132 | 2. 用户 JS 模块加载器
133 | 3. 原生 JS 模块加载器
134 | 4. 内置 C++ 模块加载器
135 | 5. Addon 模块加载器
136 |
137 | 现在来看下每种模块加载器。
138 | ## 4.1 JSON 模块加载器
139 | JSON 模块加载器实现比较简单,Node.js 从硬盘里面把 JSON 文件读到内存里面去,然后通过 JSON.parse 函数进行解析,就可以拿到里面的数据。
140 | 
141 |
142 | ## 4.2 用户 JS 模块
143 | 
144 | 用户 JS 模块就是我们平时写的一些 JS 代码。当通过 require 函数加载一个用户 JS 模块时,Node.js 就会从硬盘读取这个模块的内容到内存中,然后通过 V8 提供了一个函数叫 CompileFunctionInContext 把读取的代码封装成一个函数,接着新建立一个 Module 对象。这个对象里面有两个属性叫 exports 和 require 函数,这两个对象就是我们平时在代码里面所使用的变量,接着会把这个对象作为函数的参数,并且执行这个函数,执行完这个函数的时候,就可以通过 module.exports 拿到这个函数(模块)里面导出的内容。这里需要注意的是这里的 require 函数是可以加载原生 JS 模块和用户模块的,所以我们平时在我们代码里面,可以通过require 加载我们自己写的模块,或者 Node.js 本身提供的 JS 模块。
145 |
146 | ## 4.3 原生 JS 模块
147 | 
148 | 接下来看下原生 JS 模块加载器。原生JS 模块是 Node.js 本身提供了一些 JS 模块,比如经常使用的 http 和 fs。当通过 require 函数加载 http 这个模块的时候,Node.js 就会从内存里读取这个模块所对应内容。因为原生 JS 模块默认是打包进内存里面的,所以直接从内存里面读就可以了,不需要从硬盘里面去读。然后还是通过 V8 提供的 CompileFunctionInContext 这个函数把读取的代码封装成一个函数,接着新建一个 NativeModule 对象,同样这个对象里面也是有个 exports 属性,接着它会把这个对象传到这个函数里面去执行,执行完这函数之后,就可以通过 module.exports 拿到这个函数里面导出的内容。需要注意是这里传入的 require 函数是一个叫 NativeModuleRequire 函数,这个函数它就只能加载原生 JS 模块。另外这里还传了另外一个 internalBinding 函数,这个函数是用于加载 C++ 模块的,所以在原生 JS 模块里面,是可以加载 C++ 模块的。
149 |
150 | ## 4.4 C++ 模块
151 | 
152 | Node.js 在初始化的时候会注册 C++ 模块,并且形成一个 C++ 模块链表。当加载 C++ 模块时,Node.js 就通过模块名,从这个链表里面找到对应的节点,然后去执行它里面的钩子函数,执行完之后就可以拿到 C++ 模块导出的内容。
153 |
154 | ## 4.5 Addon 模块
155 | 
156 | 接着再来看一下 Addon 模块, Addon 模块本质上是一个动态链接库。当通过 require 加载Addon 模块的时候,Node.js 会通过 dlopen 这个函数去加载这个动态链接库。
157 | 下图是我们定义一个 Addon 模块时的一个标准格式。
158 | 
159 | 它里面有一些 C语言宏,宏展开之后里面内容像下图所示。
160 | 
161 | 里面主要定义了一个结构体和一个函数,这个函数会把这个结构体赋值给 Node.js 的一个全局变量,然后 Nodejs 它就可以通过全局变量拿到这个结构体,并且执行它里面的一个钩子函数,执行完之后就可以拿到它里面要导出的一些内容。
162 |
163 | 现在有了底层的能力,也有了这一次层的接口,也有了代码加载器。最后我们来看一下 Node.js 作为一个服务器的时候,它的架构是怎么样的?
164 | # 5 Node.js 的服务器架构
165 | 下面从两个方面介绍 Node.js 的服务器架构
166 | 1. 介绍服务器处理 TCP 连接的模型
167 | 2. 介绍 Node.js 中的实现和存在的问题
168 |
169 | ## 5.1 处理 TCP 连接的模型
170 |
171 | 首先来看一下网络编程中怎么去创建一个 TCP 服务器。
172 | ```c
173 | int fd = socket(…);
174 | bind(fd, 监听地址);
175 | listen(fd);
176 | ```
177 | 首先建一个 socket, 然后把需要监听的地址绑定到这个 socket 中,最后通过 listen 函数启动服务器。启动服务器之后,那么怎么去处理 TCP 连接呢?
178 |
179 | 1. 串行处理(accept 和 handle 都会引起进程阻塞)
180 | 
181 | 第一种处理方式是串行处理,串行方式就是在一个 while 循环里面,通过 accept 函数不断地摘取 TCP 连接,然后处理它。这种方式的缺点就是它每次只能处理一个连接,处理完一个连接之后,才能继续处理下一个连接。
182 |
183 | 2. 多进程/多线程
184 | 
185 | 第二种方式是多进程或者多线程的方式。这种方式主要是利用多个进程或者线程同时处理多个连接。但这种模式它的缺点就是当流量非常大的时候,进程数或者线程数它会成为这种架构下面的一个瓶颈,因为我们不能无限的创建进程或者线程,像 Apache 还有 PHP 就是这种架构的。
186 |
187 | 3. 单进程单线程 + 事件驱动( Reactor & Proactor )
188 | 第三种就是单线程 + 事件驱动的模式。这种模式下有两种类型,第一种叫 Reactor, 第二种叫 Proactor。
189 | Reactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写事件,然后事件触发的时候,它就会通过事件驱动模块回调上层的代码。
190 | 
191 | Proactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写完成事件,然后这个读写完成事件后就会通过事件驱动模块回调上层代码。
192 | 
193 | 我们看到这两种模式的区别是,数据读写是由内核完成的,还是由应用程序完成的。很显然,通过内核去完成是更高效的,但是因为 Proactor 这种模式它兼容性还不是很好,所以目前用的还不算太多,主要目前主流的一些服务器,它用的都是 Reactor 模式。比方说像 Node.js、Redis 和 Nginx 这些服务器用的都是这种模式。
194 |
195 | 刚才提到 Node.js 是单进程单线程加事件驱动的架构。那么单线程的架构它怎么去利用多核呢?这种时候就需要用到多进程的这种模式了,每一个进程里面会包含一个Reactor 模式。但是引入多进程之后,它会带来一个问题,就是多进程之间它怎么去监听同一个端口。
196 |
197 | ## 5.2 Node.js 的实现和问题
198 | 下面来看下针对多进程监听同一个端口的一些解决方式。
199 | 1. 主进程监听端口并接收请求,轮询分发(轮询模式)
200 | 2. 子进程竞争接收请求(共享模式)
201 | 3. 子进程负载均衡处理连接(SO_REUSEPORT 模式)
202 |
203 | 第一种方式就是主进程去监听这个端口,并且接收连接。它接收连接之后,通过一定的算法(比如轮询)分发给各个子进程。这种模式。它的一个缺点就是当流量非常大的时候,这个主进程就会成为瓶颈,因为它可能都来不及接收或者分发这个连接给子进程去处理。
204 | 
205 |
206 | 第二种就是主进程创建监听 socket, 然后子进程通过 fork 的方式继承这个监听的 socket, 当有一个连接到来的时候,操作系统就唤醒所有的子进程,所有子进程会以竞争的方式接收连接。这种模式,它的缺点主要是有两个,第一个就是负载均衡的问题,因为操作系统唤醒了所有的进程,可能会导致某一个进程一直在处理连接,其他其它进程都没机会处理连接。然后另外一个问题就是惊群的问题,因为操作系统唤起了所有的进程,但是只有一个进程它会处理这个连接,然后剩下进程就会被无效地唤醒。这种方式会造成一定的性能的损失。
207 | 
208 |
209 | 第三种通过 SO_REUSEPORT 这个标记来解决刚才提到的两个问题。在这种模式下,每个子进程都会有一个独立的监听 socket 和连接队列。当有一个连接到来的时候,操作系统会把这个连接分发给某一个子进程并且唤醒它。这样就可以解决惊群的问题,因为它只会唤醒一个子进程。又因为操作系统分发这个连接的时候,内部是有一个负载均衡的算法。所以这样的话又可以解决负载均衡的问题。
210 | 
211 |
212 |
213 | 接下来我们看一下 Node.js 中的实现。
214 | 1. 轮询模式。
215 | 在这种模式下,主进程会 fork 多个子进程,然后每个子进程里面都会调用 listen 函数。但是 listen 函数不会监听一个端口,它会请求主进程监听这个端口,当有连接到来的时候,这个主进程就会接收这个连接,然后通过文件描述符的方式传给各个子进程去处理。
216 | 
217 | 2. 共享模式
218 | 共享模式下,主进程同样还是会 fork 多个子进程,然后每个子进程里面还是会执行 listen 函数,但同样的这个 listen 函数不会监听一个端口,它会请求主进程创建一个 socket 并绑定到一个需要监听的地址,接着主进程会把这个 socket 通过文件描述符传递的方式传给多个子进程,这样就可以达到多个子进程同时监听同一个端口的效果。
219 | 
220 | 通过刚才介绍,我们可以知道 Node.js 的服务器架构存在的问题。如果我们使用轮询模式,当流量比较大的时候,那么这个主进程就会成为系统瓶颈。如果我们使用共享模式,就会存在惊群和负载均衡的问题。不过在 Libuv 里面,可以通过设置 UV_TCP_SINGLE_ACCEPT 环境变量来一定程度缓解这个问题。当我们设置了这个环境变量。Libuv 在接收完一个连接的时候,它就会休眠一会,让其它进程也有接收连接的机会。
221 |
222 | 最后来总结一下,本文的内容。Node.js 里面通过 Libuv 解决了操作系统相关的问题。通过 V8 解决了执行 JS 和拓展 JS 功能的问题。通过模块加载器解决了代码加载还有组织的问题。通过多进程的服务器架构,使得 Node.js 可以利用多核,并且解决了多个进程监听同一个端口的问题。
223 |
224 | 下面是一些资料,有兴趣的同学也可以看一下。
225 | 1. 基于 epoll + V8 的JS 运行时 Just:
226 | https://github.com/theanarkh/read-just-0.1.4-code
227 | 2. 基于 io_uring+ V8 的 JS 运行时 No.js:
228 | https://github.com/theanarkh/No.js
229 | 3. 理解 Node.js 原理:
230 | https://github.com/theanarkh/understand-nodejs
231 |
--------------------------------------------------------------------------------
/docs/chapter22-events模块.md:
--------------------------------------------------------------------------------
1 |
2 | events模块是Node.js中比较简单但是却非常核心的模块,Node.js中,很多模块都继承于events模块,events模块是发布、订阅模式的实现。我们首先看一个如果使用events模块。
3 |
4 | ```js
5 | const { EventEmitter } = require('events');
6 | class Events extends EventEmitter {}
7 | const events = new Events();
8 | events.on('demo', () => {
9 | console.log('emit demo event');
10 | });
11 | events.emit('demo');
12 | ```
13 |
14 | 接下来我们看一下events模块的具体实现。
15 | ## 22.1 初始化
16 | 当new一个EventEmitter或者他的子类时,就会进入EventEmitter的逻辑。
17 |
18 | ```js
19 | function EventEmitter(opts) {
20 | EventEmitter.init.call(this, opts);
21 | }
22 |
23 | EventEmitter.init = function(opts) {
24 | // 如果是未初始化或者没有自定义_events,则初始化
25 | if (this._events === undefined ||
26 | this._events === ObjectGetPrototypeOf(this)._events) {
27 | this._events = ObjectCreate(null);
28 | this._eventsCount = 0;
29 | }
30 | // 初始化处理函数个数的阈值
31 | this._maxListeners = this._maxListeners || undefined;
32 |
33 | // 是否开启捕获promise reject,默认false
34 | if (opts && opts.captureRejections) {
35 | this[kCapture] = Boolean(opts.captureRejections);
36 | } else {
37 | this[kCapture] = EventEmitter.prototype[kCapture];
38 | }
39 | };
40 | ```
41 |
42 | EventEmitter的初始化主要是初始化了一些数据结构和属性。唯一支持的一个参数就是captureRejections,captureRejections表示当触发事件,执行处理函数时,EventEmitter是否捕获处理函数中的异常。后面我们会详细讲解。
43 | ## 22.2 订阅事件
44 | 初始化完EventEmitter之后,我们就可以开始使用订阅、发布的功能。我们可以通过addListener、prependListener、on、once订阅事件。addListener和on是等价的,prependListener的区别在于处理函数会被插入到队首,而默认是追加到队尾。once注册的处理函数,最多被执行一次。四个API都是通过_addListener函数实现的。下面我们看一下具体实现。
45 |
46 | ```js
47 | function _addListener(target, type, listener, prepend) {
48 | let m;
49 | let events;
50 | let existing;
51 | events = target._events;
52 | // 还没有初始化_events则初始化
53 | if (events === undefined) {
54 | events = target._events = ObjectCreate(null);
55 | target._eventsCount = 0;
56 | } else {
57 | /*
58 | 是否定义了newListener事件,是的话先触发,如果监听了newListener事件,
59 | 每次注册其他事件时都会触发newListener,相当于钩子
60 | */
61 | if (events.newListener !== undefined) {
62 | target.emit('newListener', type,
63 | listener.listener ? listener.listener : listener);
64 | // 可能会修改_events,这里重新赋值
65 | events = target._events;
66 | }
67 | // 判断是否已经存在处理函数
68 | existing = events[type];
69 | }
70 | // 不存在则以函数的形式存储,否则是数组
71 | if (existing === undefined) {
72 | events[type] = listener;
73 | ++target._eventsCount;
74 | } else {
75 | if (typeof existing === 'function') {
76 | existing = events[type] =
77 | prepend ? [listener, existing] : [existing, listener];
78 | } else if (prepend) {
79 | existing.unshift(listener);
80 | } else {
81 | existing.push(listener);
82 | }
83 |
84 | // 处理告警,处理函数过多可能是因为之前的没有删除,造成内存泄漏
85 | m = _getMaxListeners(target);
86 | if (m > 0 && existing.length > m && !existing.warned) {
87 | existing.warned = true;
88 | const w = new Error('Possible EventEmitter memory leak detected. ' +
89 | `${existing.length} ${String(type)} listeners ` +
90 | `added to ${inspect(target, { depth: -1 })}. Use ` +
91 | 'emitter.setMaxListeners() to increase limit');
92 | w.name = 'MaxListenersExceededWarning';
93 | w.emitter = target;
94 | w.type = type;
95 | w.count = existing.length;
96 | process.emitWarning(w);
97 | }
98 | }
99 |
100 | return target;
101 | }
102 | ```
103 |
104 | 接下来我们看一下once的实现,对比其他几种api,once的实现相对比较难,因为我们要控制处理函数最多执行一次,所以我们需要坚持用户定义的函数,保证在事件触发的时候,执行用户定义函数的同时,还需要删除注册的事件。
105 |
106 | ```js
107 | EventEmitter.prototype.once = function once(type, listener) {
108 | this.on(type, _onceWrap(this, type, listener));
109 | return this;
110 | };
111 |
112 | function onceWrapper() {
113 | // 还没有触发过
114 | if (!this.fired) {
115 | // 删除他
116 | this.target.removeListener(this.type, this.wrapFn);
117 | // 触发了
118 | this.fired = true;
119 | // 执行
120 | if (arguments.length === 0)
121 | return this.listener.call(this.target);
122 | return this.listener.apply(this.target, arguments);
123 | }
124 | }
125 | // 支持once api
126 | function _onceWrap(target, type, listener) {
127 | // fired是否已执行处理函数,wrapFn包裹listener的函数
128 | const state = { fired: false, wrapFn: undefined, target, type, listener };
129 | // 生成一个包裹listener的函数
130 | const wrapped = onceWrapper.bind(state);
131 | // 把原函数listener也挂到包裹函数中,用于事件没有触发前,用户主动删除,见removeListener
132 | wrapped.listener = listener;
133 | // 保存包裹函数,用于执行完后删除,见onceWrapper
134 | state.wrapFn = wrapped;
135 | return wrapped;
136 | }
137 | ```
138 |
139 | ## 22.3 触发事件
140 | 分析完事件的订阅,接着我们看一下事件的触发。
141 |
142 | ```js
143 | EventEmitter.prototype.emit = function emit(type, ...args) {
144 | // 触发的事件是否是error,error事件需要特殊处理
145 | let doError = (type === 'error');
146 |
147 | const events = this._events;
148 | // 定义了处理函数(不一定是type事件的处理函数)
149 | if (events !== undefined) {
150 | // 如果触发的事件是error,并且监听了kErrorMonitor事件则触发kErrorMonitor事件
151 | if (doError && events[kErrorMonitor] !== undefined)
152 | this.emit(kErrorMonitor, ...args);
153 | // 触发的是error事件但是没有定义处理函数
154 | doError = (doError && events.error === undefined);
155 | } else if (!doError) // 没有定义处理函数并且触发的不是error事件则不需要处理,
156 | return false;
157 |
158 | // If there is no 'error' event listener then throw.
159 | // 触发的是error事件,但是没有定义处理error事件的函数,则报错
160 | if (doError) {
161 | let er;
162 | if (args.length > 0)
163 | er = args[0];
164 | // 第一个入参是Error的实例
165 | if (er instanceof Error) {
166 | try {
167 | const capture = {};
168 | /*
169 | 给capture对象注入stack属性,stack的值是执行Error.captureStackTrace
170 | 语句的当前栈信息,但是不包括emit的部分
171 | */
172 | Error.captureStackTrace(capture, EventEmitter.prototype.emit);
173 | ObjectDefineProperty(er, kEnhanceStackBeforeInspector, {
174 | value: enhanceStackTrace.bind(this, er, capture),
175 | configurable: true
176 | });
177 | } catch {}
178 | throw er; // Unhandled 'error' event
179 | }
180 |
181 | let stringifiedEr;
182 | const { inspect } = require('internal/util/inspect');
183 | try {
184 | stringifiedEr = inspect(er);
185 | } catch {
186 | stringifiedEr = er;
187 | }
188 | const err = new ERR_UNHANDLED_ERROR(stringifiedEr);
189 | err.context = er;
190 | throw err; // Unhandled 'error' event
191 | }
192 | // 获取type事件对应的处理函数
193 | const handler = events[type];
194 | // 没有则不处理
195 | if (handler === undefined)
196 | return false;
197 | // 等于函数说明只有一个
198 | if (typeof handler === 'function') {
199 | // 直接执行
200 | const result = ReflectApply(handler, this, args);
201 | // 非空判断是不是promise并且是否需要处理,见addCatch
202 | if (result !== undefined && result !== null) {
203 | addCatch(this, result, type, args);
204 | }
205 | } else {
206 | // 多个处理函数,同上
207 | const len = handler.length;
208 | const listeners = arrayClone(handler, len);
209 | for (let i = 0; i < len; ++i) {
210 | const result = ReflectApply(listeners[i], this, args);
211 | if (result !== undefined && result !== null) {
212 | addCatch(this, result, type, args);
213 | }
214 | }
215 | }
216 |
217 | return true;
218 | }
219 | ```
220 |
221 | 我们看到在Node.js中,对于error事件是特殊处理的,如果用户没有注册error事件的处理函数,可能会导致程序挂掉,另外我们看到有一个addCatch的逻辑,addCatch是为了支持事件处理函数为异步模式的情况,比如async函数或者返回Promise的函数。
222 |
223 | ```js
224 | function addCatch(that, promise, type, args) {
225 | // 没有开启捕获则不需要处理
226 | if (!that[kCapture]) {
227 | return;
228 | }
229 | // that throws on second use.
230 | try {
231 | const then = promise.then;
232 |
233 | if (typeof then === 'function') {
234 | // 注册reject的处理函数
235 | then.call(promise, undefined, function(err) {
236 | process.nextTick(emitUnhandledRejectionOrErr, that, err, type, args);
237 | });
238 | }
239 | } catch (err) {
240 | that.emit('error', err);
241 | }
242 | }
243 |
244 | function emitUnhandledRejectionOrErr(ee, err, type, args) {
245 | // 用户实现了kRejection则执行
246 | if (typeof ee[kRejection] === 'function') {
247 | ee[kRejection](err, type, ...args);
248 | } else {
249 | // 保存当前值
250 | const prev = ee[kCapture];
251 | try {
252 | /*
253 | 关闭然后触发error事件,意义
254 | 1 防止error事件处理函数也抛出error,导致死循环
255 | 2 如果用户处理了error,则进程不会退出,所以需要恢复kCapture的值
256 | 如果用户没有处理error,则nodejs会触发uncaughtException,如果用户
257 | 处理了uncaughtException则需要灰度kCapture的值
258 | */
259 | ee[kCapture] = false;
260 | ee.emit('error', err);
261 | } finally {
262 | ee[kCapture] = prev;
263 | }
264 | }
265 | }
266 | ```
267 |
268 | ## 22.4 取消订阅
269 | 我们接着看一下删除事件处理函数的逻辑。
270 |
271 | ```js
272 | function removeAllListeners(type) {
273 | const events = this._events;
274 | if (events === undefined)
275 | return this;
276 |
277 | // 没有注册removeListener事件,则只需要删除数据,否则还需要触发removeListener事件
278 | if (events.removeListener === undefined) {
279 | // 等于0说明是删除全部
280 | if (arguments.length === 0) {
281 | this._events = ObjectCreate(null);
282 | this._eventsCount = 0;
283 | } else if (events[type] !== undefined) { // 否则是删除某个类型的事件,
284 | // 是唯一一个处理函数,则重置_events,否则删除对应的事件类型
285 | if (--this._eventsCount === 0)
286 | this._events = ObjectCreate(null);
287 | else
288 | delete events[type];
289 | }
290 | return this;
291 | }
292 |
293 | // 说明注册了removeListener事件,arguments.length === 0说明删除所有类型的事件
294 | if (arguments.length === 0) {
295 | // 逐个删除,除了removeListener事件,这里删除了非removeListener事件
296 | for (const key of ObjectKeys(events)) {
297 | if (key === 'removeListener') continue;
298 | this.removeAllListeners(key);
299 | }
300 | // 这里删除removeListener事件,见下面的逻辑
301 | this.removeAllListeners('removeListener');
302 | // 重置数据结构
303 | this._events = ObjectCreate(null);
304 | this._eventsCount = 0;
305 | return this;
306 | }
307 | // 删除某类型事件
308 | const listeners = events[type];
309 |
310 | if (typeof listeners === 'function') {
311 | this.removeListener(type, listeners);
312 | } else if (listeners !== undefined) {
313 | // LIFO order
314 | for (let i = listeners.length - 1; i >= 0; i--) {
315 | this.removeListener(type, listeners[i]);
316 | }
317 | }
318 |
319 | return this;
320 | }
321 | ```
322 |
323 | removeAllListeners函数主要的逻辑有两点,第一个是removeListener事件需要特殊处理,这类似一个钩子,每次用户删除事件处理函数的时候都会触发该事件。第二是removeListener函数。removeListener是真正删除事件处理函数的实现。removeAllListeners是封装了removeListener的逻辑。
324 |
325 | ```js
326 | function removeListener(type, listener) {
327 | let originalListener;
328 | const events = this._events;
329 | // 没有东西可删除
330 | if (events === undefined)
331 | return this;
332 |
333 | const list = events[type];
334 | // 同上
335 | if (list === undefined)
336 | return this;
337 | // list是函数说明只有一个处理函数,否则是数组,如果list.listener === listener说明是once注册的
338 | if (list === listener || list.listener === listener) {
339 | // type类型的处理函数就一个,并且也没有注册其他类型的事件,则初始化_events
340 | if (--this._eventsCount === 0)
341 | this._events = ObjectCreate(null);
342 | else {
343 | // 就一个执行完删除type对应的属性
344 | delete events[type];
345 | // 注册了removeListener事件,则先注册removeListener事件
346 | if (events.removeListener)
347 | this.emit('removeListener', type, list.listener || listener);
348 | }
349 | } else if (typeof list !== 'function') {
350 | // 多个处理函数
351 | let position = -1;
352 | // 找出需要删除的函数
353 | for (let i = list.length - 1; i >= 0; i--) {
354 | if (list[i] === listener || list[i].listener === listener) {
355 | // 保存原处理函数,如果有的话
356 | originalListener = list[i].listener;
357 | position = i;
358 | break;
359 | }
360 | }
361 |
362 | if (position < 0)
363 | return this;
364 | // 第一个则出队,否则删除一个
365 | if (position === 0)
366 | list.shift();
367 | else {
368 | if (spliceOne === undefined)
369 | spliceOne = require('internal/util').spliceOne;
370 | spliceOne(list, position);
371 | }
372 | // 如果只剩下一个,则值改成函数类型
373 | if (list.length === 1)
374 | events[type] = list[0];
375 | // 触发removeListener
376 | if (events.removeListener !== undefined)
377 | this.emit('removeListener', type, originalListener || listener);
378 | }
379 |
380 | return this;
381 | };
382 | ```
383 |
384 | 以上就是events模块的核心逻辑,另外还有一些工具函数就不一一分析。
385 |
--------------------------------------------------------------------------------
/docs/chapter20-拓展Node.js.md:
--------------------------------------------------------------------------------
1 |
2 | 拓展Node.js从宏观来说,有几种方式,包括直接修改Node.js内核重新编译分发、提供npm包。npm包又可以分为JS和C++拓展。本章主要是介绍修改Node.js内核和写C++插件。
3 | ## 20.1 修改Node.js内核
4 | 修改Node.js内核的方式也有很多种,我们可以修改JS层、C++、C语言层的代码,也可以新增一些功能或模块。本节分别介绍如何新增一个Node.js的C++模块和修改Node.js内核。相比修改Node.js内核代码,新增一个Node.js内置模块需要了解更多的知识。
5 | ### 20.1.1 新增一个内置C++模块
6 | 1.首先在src文件夹下新增两个文件。
7 | cyb.h
8 |
9 | ```cpp
10 | #ifndef SRC_CYB_H_
11 | #define SRC_CYB_H_
12 | #include "v8.h"
13 |
14 | namespace node {
15 | class Environment;
16 | class Cyb {
17 | public:
18 | static void Initialize(v8::Local target,
19 | v8::Local unused,
20 | v8::Local context,
21 | void* priv);
22 | private:
23 | static void Console(const v8::FunctionCallbackInfo& args);
24 | };
25 | } // namespace node
26 | #endif
27 | ```
28 |
29 | cyb.cc
30 |
31 | ```cpp
32 | #include "cyb.h"
33 | #include "env-inl.h"
34 | #include "util-inl.h"
35 | #include "node_internals.h"
36 |
37 | namespace node {
38 | using v8::Context;
39 | using v8::Function;
40 | using v8::FunctionCallbackInfo;
41 | using v8::FunctionTemplate;
42 | using v8::Local;
43 | using v8::Object;
44 | using v8::String;
45 | using v8::Value;
46 |
47 | void Cyb::Initialize(Local