├── .gitignore
├── .travis.yml
├── days
├── 20.md
├── 17.md
├── 4.md
├── 13.md
├── 0.md
├── 24.md
├── 18.md
├── 12.md
├── 22.md
├── 9.md
├── 19.md
├── 7.md
├── 11.md
├── 21.md
├── 5.md
├── 2.md
├── 3.md
├── 1.md
├── 10.md
├── 23.md
├── 15.md
├── 16.md
├── 14.md
├── 8.md
└── 6.md
├── script
└── modify.js
├── book.json
├── README.md
└── SUMMARY.md
/.gitignore:
--------------------------------------------------------------------------------
1 | _book
2 | node_modules
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | sudo: true
2 | language: node_js
3 | node_js:
4 | - "9"
5 |
6 | cache:
7 | directories:
8 | - $HOME/.npm
9 | - /usr/local/lib/node_modules
10 | - ./node_modules
11 |
12 | before_script:
13 | - npm install -g gitbook-cli
14 | - gitbook install
15 |
16 | script:
17 | - gitbook build
18 | - node script/modify.js
19 |
20 | deploy:
21 | provider: pages
22 | skip_cleanup: true
23 | github_token: $GH_TOKEN
24 | local_dir: _book
25 | target_branch: gh-pages
26 | on:
27 | branch: master
28 | notifications:
29 | email:
30 | on_success: never
31 | on_failure: never
32 |
--------------------------------------------------------------------------------
/days/20.md:
--------------------------------------------------------------------------------
1 | # 20: Parser Implementation (4)
2 |
3 | 2018/11/4
4 |
5 | I am thinking what is the next step. Probably looks like:
6 |
7 | !FILENAME sql/parser.rs
8 |
9 | ```rust
10 | fn parse(&self) {
11 | let mut iter = self.tokens.iter();
12 | let category = iter.next().unwrap().token;
13 |
14 | match category {
15 | Token::CreateDatabase => {}
16 | Token::CreateTable => {}
17 | // ...
18 | // ...
19 | _ => {}
20 | }
21 | }
22 | ```
23 |
24 | !FILENAME sql/create.rs
25 |
26 | ```rust
27 | struct CreateDatabase {
28 | // ...
29 | }
30 |
31 | struct CreateTable {
32 | // ...
33 | }
34 | ```
--------------------------------------------------------------------------------
/script/modify.js:
--------------------------------------------------------------------------------
1 | const fs = require('fs');
2 | const path = require('path');
3 |
4 | const dirPaths = [
5 | path.join(__dirname, '../_book/'),
6 | path.join(__dirname, '../_book/days/'),
7 | ]
8 |
9 | dirPaths.forEach(dirPath => {
10 | const dirCont = fs.readdirSync(dirPath);
11 | const files = dirCont.filter((elm) => elm.match(/\.html$/));
12 | files.forEach(file => {
13 | const filePath = path.join(dirPath, file);
14 | let data = fs.readFileSync(filePath, 'utf-8');
15 | data = data.replace("Published with GitBook", '');
16 | tmp = data.split("");
17 | data = tmp[0] + `` +
18 | tmp[1];
19 | fs.writeFileSync(filePath, data, 'utf-8');
20 | console.log(file, "has been modified.");
21 | });
22 | })
--------------------------------------------------------------------------------
/book.json:
--------------------------------------------------------------------------------
1 | {
2 | "title": "Let's build a DBMS: StellarSQL -- a minimal SQL DBMS written in Rust ",
3 | "description": "",
4 | "author": "tigercosmos",
5 | "plugins": [
6 | "expandable-chapters",
7 | "github-buttons@3.0.0",
8 | "github",
9 | "disqus",
10 | "codeblock-filename",
11 | "custom-favicon"
12 | ],
13 | "pluginsConfig": {
14 | "github-buttons": {
15 | "buttons": [{
16 | "user": "tigercosmos",
17 | "repo": "lets-build-dbms",
18 | "type": "star",
19 | "size": "small",
20 | "count": true
21 | }, {
22 | "user": "tigercosmos",
23 | "type": "follow",
24 | "width": "180",
25 | "size": "small",
26 | "count": true
27 | }]
28 | },
29 | "github": {
30 | "url": "https://github.com/tigercosmos/"
31 | },
32 | "disqus": {
33 | "shortName": "lets-build-dbms"
34 | },
35 | "favicon": "./favicon.ico"
36 | }
37 | }
--------------------------------------------------------------------------------
/days/17.md:
--------------------------------------------------------------------------------
1 | # 17: Parser Implementation (1)
2 |
3 | 2018/11/1
4 |
5 | I have done the lexical scanner. So, now I can get tokens from a message (SQL command).
6 |
7 | The parser should do several things, including syntax checking, semantics checking and worker.
8 |
9 | The syntax of a language is a set of rules that describes the words to make meaningful statements.
10 |
11 | For example, a SQL query:
12 |
13 | ```sql
14 | select from table t1
15 | ```
16 |
17 | This is a wrong syntax. As you can see, there is no identifier in the middle of `select` and `from`. Also, `table` is not a keyword.
18 |
19 | So, the correct one should be:
20 |
21 | ```sql
22 | select user_id from table_t1
23 | ```
24 |
25 | That's what syntax checking doing -- Find the wrong usage of SQL.
26 |
27 | The semantics of a language specifies a statement to have an actual meaning.
28 |
29 | For instance,
30 |
31 | ```sql
32 | select user_id from table_t1
33 | ```
34 |
35 | However, is `user_id` a field name? or is `table_t1` the name of tables? Is the name ambiguous? Is the type of field correct?
36 |
37 | The semantics should check for these things.
38 |
39 | Finally, if everything okay? The parser will pass the result to worker, and the worker will execute the tasks to finish the command.
40 |
--------------------------------------------------------------------------------
/days/4.md:
--------------------------------------------------------------------------------
1 | # 4: Client/Server Communication Implementation(1)
2 |
3 | 2018/10/19
4 |
5 | Before today's article, let's recall what I wrote in these days.
6 |
7 | First, you should know DBMS is based on servers. A well designed DBMS such as MySQL or PostgreSQL, would implement very underlying layers by themselves for high quality and well performance. As I said before, I will focus on database and SQL, so I just use `Tokio.rs` for handling server tasks, including task scheduler, thread, I/O, etc. Of course, it would be great if I have time implement these modules in my own way in the future.
8 |
9 | Then, I talked about client/server protocol yesterday, and I will implement the remaining part today.
10 |
11 | A message would probably includes header, metadata, and payload. A header is about information of connection. A metadata is the description of payload. A payload is the part of transmitted data that is the actual intended message.
12 |
13 | A message will be encoded according to the protocol. The protocol is the format of message. I will just implement message transmission in raw bytes first, and leave the part of the protocol, because the definition of protocol is much more complicated.
14 |
15 | > about the implementation, please see [day 6 article](https://tigercosmos.xyz/lets-build-dbms/days/6.html).
16 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Let's build a DBMS: StellarSQL -- a minimal SQL DBMS written in Rust
2 |
3 | [](https://travis-ci.org/tigercosmos/lets-build-dbms)
4 |
5 | ## Introduce
6 |
7 | Database management systems (DBMS) are used in everywhere. There are many DBMSs, including MySQL, MongoDB, etc. I would implement a minimal DBMS supporting SQL in Rust, with a new project, "[StellarSQL](https://github.com/tigercosmos/StellarSQL)", from scratch. I will work on it everyday since 2018/10/15, and record the process in this series articles, until I finish StellarSQL.
8 |
9 | ## Author
10 |
11 | Liu, An-Chi (劉安齊). A software engineer, who loves writing code and promoting CS to people. Welcome to follow me at [Facebook Page](https://www.facebook.com/pg/CodingNeutrino). More information on [Personal Site](https://tigercosmos.xyz/) and [Github](https://github.com/tigercosmos).
12 |
13 | ## License
14 |
15 | 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
16 |
--------------------------------------------------------------------------------
/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Summary
2 |
3 | * [Let's build a DBMS](README.md)
4 | * [0: Introduction to the Series Articles](days/0.md)
5 | * [1: Preparation & Basic Infrastructure](days/1.md)
6 | * [2: Basic Concept of Server](days/2.md)
7 | * [3: Frontend/Backend Protocol](days/3.md)
8 | * [4: Client/Server Communication Implementation (1)](days/4.md)
9 | * [5: Introduce to RDBMS and SQL](days/5.md)
10 | * [6: Client/Server Communication Implementation (2)](days/6.md)
11 | * [7: SQL Parser](days/7.md)
12 | * [8: SQL Parser - Lexical Scanner](days/8.md)
13 | * [9: Lexical Scanner Implementation (1)](days/9.md)
14 | * [10: Lexical Scanner Implementation (2)](days/10.md)
15 | * [11: Lexical Scanner Implementation (3)](days/11.md)
16 | * [12: Lexical Scanner Case Study](days/12.md)
17 | * [13: Recursive Descent Parser](days/13.md)
18 | * [14: Lexical Scanner Implementation (4)](days/14.md)
19 | * [15: Lexical Scanner Implementation (5)](days/15.md)
20 | * [16: Good RDB Design with the Concept of Normal Forms](days/16.md)
21 | * [17: Parser Implementation (1)](days/17.md)
22 | * [18: Parser Implementation (2)](days/18.md)
23 | * [19: Parser Implementation (3): Understand SQL grammar](days/19.md)
24 | * [20: Parser Implementation (4)](days/20.md)
25 | * [21: First Implementation for Database Components](days/21.md)
26 | * [22: Update Components of Database](days/22.md)
27 | * [23: Implement Table `insert_row`](days/23.md)
28 | * [24: Different Client Design of DBMS](days/24.md)
29 |
--------------------------------------------------------------------------------
/days/13.md:
--------------------------------------------------------------------------------
1 | # 13: Recursive Descent Parser
2 |
3 | 2018/10/28
4 |
5 | I am confused in these days about how to implement the parser. PhD candidate [Yushan Lin](https://github.com/SLMT) suggest me to see how [VanillaDB](https://github.com/vanilladb/vanillacore/) implement, which is a DBMS developed by his lab.
6 |
7 | There are many document about `VanillaDB` in its [official website](http://www.vanilladb.org/), including [the parser one](http://www.vanilladb.org/slides/core/Query_Processing.pdf). It is worth and enlightening to read the parser slide, because it is professional but not complicated.
8 |
9 | The most important part is that `VanillaDB` adopt [recursive descent parser](https://en.wikipedia.org/wiki/Recursive_descent_parser). You can check out more via google the keyword. I decide to use this method to implement grammar rule parser.
10 |
11 | > A recursive-descent parser has a method for each grammar rule, and calls these methods recursively to traverse the parse tree in prefix order.
12 |
13 | In the end, let's update the status of the previous code. In order to lexically scan messages, I add another types in `Group`, which are `Operator`, `Number`, and `Identifier`.
14 |
15 | ``` rust
16 | pub enum Group {
17 | DataType,
18 | DoubleKeyword,
19 | MultiKeyword,
20 | Function,
21 | Keyword,
22 | Operator, // >, >=, ==, !=, <, <=
23 | Number,
24 | Identifier, // t1, a, b
25 | }
26 | ```
27 |
28 | So, `Token` is also updated.
29 |
30 | ```rust
31 | pub enum Token {
32 |
33 | // ...
34 |
35 | /* Operator */
36 | LT, // <
37 | LE, // <=
38 | EQ, // ==
39 | NE, // !=
40 | GT, // >
41 | GE, // >=
42 | }
43 | ```
44 |
--------------------------------------------------------------------------------
/days/0.md:
--------------------------------------------------------------------------------
1 | # 0: Introduction to the Series Articles
2 |
3 | 2018/10/15
4 |
5 | This is a series articles for participating the [ITHelp Ironman Competition](https://ithelp.ithome.com.tw/ironman) hosted by ITHome in Taiwan. The participator of the competition needs to write technical articles for 30 days without any day break.
6 |
7 | ## About the series
8 |
9 | This is my third time entering this competition. According to my experience, the page design of ITHelp is not easy for finding old articles in a series, and the most important thing is that ITHelp cannot support `Rust` syntax highlight well. Therefore I also put the series in a [gitbook](https://tigercosmos.xyz/lets-build-dbms/) on my website. It's recommended to read the version of gitbook. You can still read articles on [ITHelp](https://ithelp.ithome.com.tw/users/20103745/ironman/1913).
10 |
11 | ## Why I write it
12 |
13 | I am not an expert of database management systems (DBMS) or SQL languages. This series is for a proof of concept on DBMS on the purpose of practicing, but not a textbook for the concept of DBMS. I am learning by doing. For doing that, I create the project, [StellarSQL](https://github.com/tigercosmos/StellarSQL), which is a minimal DBMS implemented in Rust. I will start working on StellarSQL from scratch. In the meanwhile, I will also introduce some concepts of DBMS and explain why I am doing that way on the project in articles. The series is just following the process of StellarSQL.
14 |
15 | ## Expectation
16 |
17 | Practicing makes better. I am just a junior on DBMS, I am not familiar with Rust programing, and I am also not a native English speaker. I am studying through writing this series, and hope you can learn something from the articles.
18 |
--------------------------------------------------------------------------------
/days/24.md:
--------------------------------------------------------------------------------
1 | # 24: Different Client Design of DBMS
2 |
3 | 2018/11/8
4 |
5 | When you want to fetch the DBMS, you would need a client. A client could be a user interface application, or embed in programs written in JS, C++, JAVA, ect.
6 |
7 | In earlier times, the DBMS is really simple. There is just a DBMS and a client on the same device. When a program want to connect and manipulate a DBMS, it could use functions or macro.
8 |
9 | the code might look like:
10 |
11 | 
12 |
13 | As you can see, `EXEC SQL` is the macro, and the program could call the DBMS.
14 |
15 | This design is old-fashioned, but still could be seen at embedded device, which runs a local DBMS.
16 |
17 | The more modern way of design would like:
18 |
19 | ```java
20 | String conUrl = "jdbc:sqlserver://portNumber:1234;serverName=test;databaseName=test_db;user=tester;password=12345;";
21 | Connection connection = DriverManager.getConnection(conUrl);
22 |
23 | try {
24 | String sql = "SELECT user_id FROM user_table";
25 | Statement stmt = connection.createStatement();
26 |
27 | ResultSet rs = stmt.executeQuery(sql); // query result
28 | ResultSetMetaData rsmd = rs.getMetaData(); // get data from query
29 |
30 | // ...
31 | }
32 | ```
33 |
34 | The biggest improvement is not the object-oriented design, but rather the concept of `connection`. In this design, the `connection` needs to set the ip, port, and the server name, which means there are more than one DBMS the program could reach for. In other words, there are more data and servers in the age of this design becoming to be used.
35 |
36 | In the end, advance in technology, there will be more and more high level designs of DBMS and clients for big data and distributed system being being created and adopted.
37 |
--------------------------------------------------------------------------------
/days/18.md:
--------------------------------------------------------------------------------
1 | # 18: Parser Implementation (2)
2 |
3 | 2018/11/2
4 |
5 | Working on the parser. When I write the following function `Parser::new`, I encounter lifetime issue. No matter how I add lifetime syntax `'a`, '`b` in the function. I cannot pass the compiler.
6 |
7 | !FILENAME sql/parser.rs
8 |
9 | ```rust
10 | // The old version
11 | struct Parser<'a> {
12 | tokens: Vec>,
13 | }
14 |
15 | impl<'a> Parser<'a> {
16 | fn new(message: &'a str) -> Parser<'a> {
17 | let mut s: Scanner<'a> = Scanner::new(message);
18 | let tokens = s.scan_tokens();
19 | Parser { tokens }
20 | }
21 | }
22 | ```
23 |
24 | The error is:
25 |
26 | ```log
27 | error[E0597]: `s` does not live long enough
28 | --> src/sql/parser.rs:12:39
29 | |
30 | 12 | let tokens = s.scan_tokens();
31 | | ^ borrowed value does not live long enough
32 | ...
33 | 15 | }
34 | | - borrowed value only lives until here
35 | |
36 | ```
37 |
38 | That's very wierd, because I expect the lifetime is correct. Anyway, I give up fighting with lifetime.
39 |
40 | Therefore, I change the type of `Symbol::name` to `String` rather than `&str`. Then all errors exist, and I don't need to add lifetime syntax anymore.
41 |
42 | !FILENAME sql/parser.rs
43 |
44 | ```rust
45 | use sql::lexer::Scanner;
46 | use sql::symbol::Symbol;
47 |
48 | struct Parser {
49 | tokens: Vec,
50 | }
51 |
52 | impl Parser {
53 | fn new(message: &str) -> Parser {
54 | let mut s: Scanner = Scanner::new(message);
55 | let tokens: Vec = s.scan_tokens();
56 | Parser { tokens }
57 | }
58 | }
59 | ```
60 |
61 | It works very well.
62 |
63 | This story tells us, when you implement a `struct` in Rust, it is better to let the type `String` in the fields. Though it will be stored at heap, but it will be easier with lifetime handling -- once using `&str` as type, you must add `'a` lifetime for the `struct`, and all other `fn` or `struct` that use this `struct`. Also, all objects related to this `struct` in lifetime `'a`, will all live as long as `'a`, and it seems not a good idea. So, `String` next time.
--------------------------------------------------------------------------------
/days/12.md:
--------------------------------------------------------------------------------
1 | # 12: Lexical Scanner Case Study
2 |
3 | 2018/10/27
4 |
5 | I found it becomes more and more difficult to programing some and record the process on this series. The reason is that it costs huge time for studying and thinking about the next steps. I expected I could write some code every day, but it seems that I would take two or three days for studying on a topic and then implementing functions.
6 |
7 | So, let's talked about my studying today. I spend some time studying the implementation of [TiDB](https://github.com/pingcap/tidb) that I talked about yesterday. I have some reflection on its methods.
8 |
9 | It uses "trie" to identify tokens. [Trie](https://en.wikipedia.org/wiki/Trie) is a data structure. It is good at searching words in a dictionary. So, in this case, `TiDB` searches tokens in a symbols dictionary.
10 |
11 | I am thinking why it uses trie, but I still don't understand why. As far as I am concerned, I would rather use hash. The searching complexity of trie and hash are both O(N). In this case, we only need to look up tokens, so no need to considering inserting and deleting data. In the condition that with a large amount of words, trie would use less space. However, in our case, symbols are only about a hundred, and adopting hash is much easy and straightforward for me.
12 |
13 | No matter `MySQL` or `TiDB`, they both use `Yacc`, and their scanners are just the interface for `Yacc`. I would not use `Yacc`, on one hand it is written in C++ (I want StellarSQL is pure Rust. Though in fact, `Yacc` is run to create codes before the runtime of the program), and the other hand I would like to doing any parts by myself (less third party modules as possible), so the term, "from scratch", would make sense.
14 |
15 | Further, considering the performance, many DBMS implement their own bytes or strings handler for the scanner. I have not designed the protocol of the message yet, and I am just thinking about converting the string to bytes as protocol to make it simple. Anyway, handling bytes by well designed protocol would optimize the performance, but I would just process strings and using the Rust standard library for now. Maybe I will rewrite and refactor this part in the future, but now it's fine to "keep it simple, keep it stupid".
--------------------------------------------------------------------------------
/days/22.md:
--------------------------------------------------------------------------------
1 | # 22: Update Components of Database
2 |
3 | 2018/11/6
4 |
5 | I modify some parts that I did yesterday.
6 |
7 | `Table` in `Database` should be stored in `HashMap`. So checking the table is convenient.
8 |
9 | !FILENAME component/database.rs
10 |
11 | ```rust
12 | pub struct Database {
13 | pub name: String,
14 | pub tables: HashMap,
15 | }
16 | ```
17 |
18 | I decide to store all value in `String`. For the reasons that, (1) the `Field` has defined the `DataType`, so we can format the value if we want, (2) DBMS will not use the real value so frequently (only when processing `where`, but that's fine to deal in `String`), and (3) loading and saving data are all in `String` (actually, string to binary).
19 |
20 | Therefore I only remain `DataType`:
21 |
22 | !FILENAME component/datatype.rs
23 |
24 | ```rust
25 | pub enum DataType {
26 | Char(u8),
27 | Double,
28 | Float,
29 | Int,
30 | Varchar(u8),
31 | }
32 | ```
33 |
34 | Also, I forget that attributes could have default values. So I add a `default` in `Field`. Also, I remove `DataValue`, because `Field` is only the definition of a table. Therefore I also update table.
35 |
36 | !FILENAME component/field.rs
37 |
38 | ```rust
39 | pub struct Field {
40 | pub name: String,
41 | pub datatype: DataType,
42 | pub not_null: bool,
43 | pub default: Option,
44 | pub check: Checker,
45 | }
46 | ```
47 |
48 | I also update `Table` a lot. A `Table` should be able to store `rows`, and it might be just a part of data from a huge set of table files. So, it needs to know where is the data from, including which `page` and which range by the `cursors`.
49 |
50 | !FILENAME component/table.rs
51 |
52 | ```rust
53 | pub struct Table {
54 | /* definition */
55 | pub name: String,
56 | pub fields: HashMap, // aka attributes
57 | pub primary_key: Vec,
58 | pub foreign_key: Vec,
59 | pub reference_table: Option,
60 |
61 | /* value */
62 | pub rows: Vec,
63 |
64 | /* storage */
65 | pub page: u64, // which page of this table
66 | pub cursors: (u64, u64), // cursors of range in a page
67 | }
68 | ```
69 |
70 | I cannot design very well at the moment, so I would find more that should be modified as time goes by. In real practice, I believe I am on the right way.
--------------------------------------------------------------------------------
/days/9.md:
--------------------------------------------------------------------------------
1 | # 9: Lexical Scanner Implementation (1)
2 |
3 | 2018/10/24
4 |
5 | Today, I am going to implement the lexical scanner for StellarSQL. It would be a quite big engineering, so I could only do the part 1 today. I don't even know how many parts it would be, but I would do my best.
6 |
7 | There is a standard for SQL by ISO, which is "ISO/IEC 9075". Moreover, every DBMS have their own SQL syntax. Those DBMS follow the standard and add the extension syntax. An extension is only for a certain DBMS which define and implement it, and would not work on another one.
8 |
9 | The full list of keywords is too long and we usually do not use most of all. More syntax supported, more complicated a DBMS is. To keep StellarSQL simple, I use the [keywords list](https://www.w3schools.com/sql/sql_ref_keywords.asp) in W3C SQL Tutorial, which is a basic version.
10 |
11 | 
12 |
13 | Basically, these keywords are enough for normal usage.
14 |
15 | So, I define these keywords in file [src/sql/symbol.rs](https://github.com/tigercosmos/StellarSQL/tree/master/src/sql/symbol.rs).
16 |
17 | !FILENAME src/sql/symbol.rs
18 |
19 | ```rust
20 | struct Symbol {
21 | name: String,
22 | len: u32,
23 | token: Token,
24 | group: Group,
25 | }
26 |
27 | enum Group {
28 | Keyword,
29 | Function,
30 | }
31 |
32 | enum Token {
33 | Add,
34 | AddConstraint,
35 | Alter,
36 | AlterColumn,
37 | AlterTable,
38 | All,
39 | And,
40 | Any,
41 | As,
42 | Asc,
43 | Between,
44 | Case,
45 | Check,
46 | // ...
47 | // ...
48 | // ...
49 | SelectTop,
50 | Set,
51 | Table,
52 | Top,
53 | TruncateTable,
54 | Union,
55 | UnionAll,
56 | Unique,
57 | Update,
58 | Values,
59 | View,
60 | Where,
61 | }
62 | ```
63 |
64 | The `Symbol` structure stores information for tokens, which includes `name`, `token`, and `group`. For example, a Symbol of "CREATE" keyword is `Symbol{ name: "CREATE", token: Token::CREATE, group: Group::keyword }`.
65 |
66 | `Token` stores all keywords of SQL that the scanner needs to know.
67 |
68 | `Group` classify the symbol a keywords or a function.
69 |
70 | I am studying the code of MySQL for more than 4 hours. That's why it looks like I don't write too much code. I will continue tomorrow.
--------------------------------------------------------------------------------
/days/19.md:
--------------------------------------------------------------------------------
1 | # 19: Parser Implementation (3): Understand SQL grammar
2 |
3 | 2018/11/3
4 |
5 | A parse need to recognize and check the grammar. So, let's see the grammar of SQL.
6 |
7 | There are four basic SQL grammar with fundamental operations:
8 |
9 | - Read the data -- `SELECT`
10 | - Insert new data -- `INSERT`
11 | - Update existing data -- `UPDATE`
12 | - Remove data -- `DELETE`
13 |
14 | It's a CRUD (Create, Read, Update, Delete) schema, and it's very like HTTP requests -- `POST`, `GET`, `PUT`, `DELETE`.
15 |
16 | Also, there are two syntax `CREATE` and `DELETE`, which are for creating and deleting databases, tables.
17 |
18 | ## General Forms of SQL syntax
19 |
20 | SQL is not a complicated language, so there are general forms for the `2 + 4` grammar.
21 |
22 | ### CREATE
23 |
24 | ```sql
25 | CREATE DATABASE database_name
26 |
27 | CREATE TABLE table_name (
28 | column1 datatype,
29 | column2 datatype,
30 | column3 datatype,
31 | ....
32 | )
33 | ```
34 |
35 | ```sql
36 | CREATE DATABASE testDB
37 |
38 | CREATE TABLE Persons (
39 | PersonID int,
40 | LastName varchar(255),
41 | FirstName varchar(255),
42 | Address varchar(255),
43 | City varchar(255)
44 | );
45 | ```
46 |
47 | ### SELECT
48 |
49 | ```sql
50 | SELECT column-names
51 | FROM table-name
52 | WHERE condition
53 | ORDER BY sort-order
54 | ```
55 |
56 | ```sql
57 | SELECT FirstName, LastName, City, Country
58 | FROM Customer
59 | WHERE City = 'Tokio'
60 | ORDER BY LastName
61 | ```
62 |
63 | ### INSERT
64 |
65 | ```sql
66 | INSERT table-name (column-names)
67 | VALUES (column-values)
68 | ```
69 |
70 | ```sql
71 | INSERT Supplier (Name, City, Country)
72 | VALUES ('National Taiwan University', 'Taipei', 'Taiwan')
73 | ```
74 |
75 | ### UPDATE
76 |
77 | ```sql
78 | UPDATE table-name
79 | SET column-name = column-value
80 | WHERE condition
81 | ```
82 |
83 | ```sql
84 | UPDATE OrderItem
85 | SET Quantity = 22
86 | WHERE Id = 38833
87 | ```
88 |
89 | ### DELETE
90 |
91 | ```sql
92 | DELETE table-name
93 | WHERE condition
94 | ```
95 |
96 | ```sql
97 | DELETE User
98 | WHERE Email = 'phy.tiger@gmail.com'
99 | ```
100 |
101 | ### DROP
102 |
103 | ```sql
104 | DROP DATABASE database_name
105 |
106 | DROP TABLE table_name
107 | ```
108 |
109 | ```sql
110 | DROP DATABASE testDB
111 |
112 | DROP TABLE Shippers
113 | ```
--------------------------------------------------------------------------------
/days/7.md:
--------------------------------------------------------------------------------
1 | # 7: SQL Parser
2 |
3 | 2018/10/22
4 |
5 | Until now, StellarSQL has been able to receive message from and send answer back to clients. That's good. It is a server, but it still cannot do works of database management.
6 |
7 | Further, only with SQL parser, storage engine, and data engine, StellarSQL could be called a real DBMS.
8 |
9 | These modules should be implemented in order, so let's talk about the SQL parser first.
10 |
11 | For any message sent from client, it must be a query in SQL format. The query could be "create table", "insert data", "delete date", etc. In order to understand the query, we need a SQL parser.
12 |
13 | Generally speaking, DBMS has a parser includes a lexical scanner and a grammar rule module. The lexical scanner splits the entire query into tokens (keywords or domain name), and the grammar rule module finds a combination of SQL grammar rules that produce this sequence, and process the code associated with those rules.
14 |
15 | For example:
16 |
17 | ```sql
18 | SELECT * FROM Customers WHERE Country = 'Mexico';
19 | ```
20 |
21 | The lexical scanner breaks a SQL query above into tokens as:
22 |
23 | - `SELECT`
24 | - `*`
25 | - `FROM`
26 | - `Customers`
27 | - `WHERE`
28 | - `Country`
29 | - `=`
30 | - `Mexico`
31 |
32 | A semicolon means the end of a query, so not it is not counted here.
33 |
34 | Furthermore, the grammar rule module applies rules for these tokens, such as:
35 |
36 | - `SELECT` keyword is before columns
37 | - `From` keyword is before tables
38 | - `Where` keyword stands for conditions
39 |
40 | A mature DBMS also does lots of optimizations. As you can imagine, the complexity of a SQL query requires an equally complex structure that efficiently stores the information needed for executing every possible SQL statement.
41 |
42 | For example, according to the book, "[Understanding MySQL Internals](https://www.safaribooksonline.com/library/view/understanding-mysql-internals/0596009577/ch09s02.html)", MySQL optimizer does some important tasks (I just list a few):
43 |
44 | - Determine which keys can be used to retrieve the records from tables, and choose the best one for each table.
45 |
46 | - Determine the order in which tables should be joined when more than one table is present in the query.
47 |
48 | - Eliminate unused tables from the join.
49 |
50 | - Determine whether keys can be used for ORDER BY and GROUP BY.
51 |
52 | In the next days, I am going to implement the SQL parser. However, I am afraid that I could only implement it with basic algorithm. The optimizer is a huge engineering, not to mention my lack of time due to preparing midterm exams.
53 |
54 | The good news is that StellarSQL can parse SQL soon. :)
55 |
56 | ***Reference***
57 |
58 | - [MySQL Reference Manual](https://dev.mysql.com/doc/refman/8.0/en)
59 | - [Understanding MySQL Internals CH9](https://www.safaribooksonline.com/library/view/understanding-mysql-internals/0596009577/ch09.html)
--------------------------------------------------------------------------------
/days/11.md:
--------------------------------------------------------------------------------
1 | # 11: Lexical Scanner Implementation (3)
2 |
3 | 2018/10/26
4 |
5 | I found a cool project -- [TiDB](https://github.com/pingcap/tidb), which has more than 15k stars.
6 |
7 | > TiDB is an open-source distributed scalable Hybrid Transactional and Analytical Processing (HTAP) database. It features infinite horizontal scalability, strong consistency, and high availability. TiDB is MySQL compatible and serves as a one-stop data warehouse for both OLTP (Online Transactional Processing) and OLAP (Online Analytical Processing) workloads. -- From Github
8 |
9 | I found this project because an article [*"How TiDB SQL Parser implement (TiDB SQL Parser 的实现)"*](https://pingcap.com/blog-cn/tidb-source-code-reading-5/)(Written in Chinese). The article introduces the parser of TiDB, and it's quite helpful for me. The parser source code is at [pingcap/parser](https://github.com/pingcap/parser). I refer partly from `lexer.go`, which implement the scanner, and `misc.go`, which implements the token identifier with trie.
10 |
11 | Let's see some snippets from `TiDB`:
12 |
13 | !FILENAME pingcap/parser/lexer.go
14 |
15 | ```go
16 | // Scanner implements the yyLexer interface.
17 | type Scanner struct {
18 | r reader
19 | buf bytes.Buffer
20 |
21 | errs []error
22 | stmtStartPos int
23 |
24 | // For scanning such kind of comment: /*! MySQL-specific code */ or /*+ optimizer hint */
25 | specialComment specialCommentScanner
26 |
27 | sqlMode mysql.SQLMode
28 | }
29 | ```
30 |
31 | !FILENAME pingcap/parser/misc.go
32 |
33 | ```go
34 | func (s *Scanner) isTokenIdentifier(lit string, offset int) int {
35 | // An identifier before or after '.' means it is part of a qualified identifier.
36 | // We do not parse it as keyword.
37 | if s.r.peek() == '.' {
38 | return 0
39 | }
40 | if offset > 0 && s.r.s[offset-1] == '.' {
41 | return 0
42 | }
43 | buf := &s.buf
44 | buf.Reset()
45 | buf.Grow(len(lit))
46 | data := buf.Bytes()[:len(lit)]
47 | for i := 0; i < len(lit); i++ {
48 | if lit[i] >= 'a' && lit[i] <= 'z' {
49 | data[i] = lit[i] + 'A' - 'a'
50 | } else {
51 | data[i] = lit[i]
52 | }
53 | }
54 |
55 | checkBtFuncToken, tokenStr := false, string(data)
56 | if s.r.peek() == '(' {
57 | checkBtFuncToken = true
58 | } else if s.sqlMode.HasIgnoreSpaceMode() {
59 | s.skipWhitespace()
60 | if s.r.peek() == '(' {
61 | checkBtFuncToken = true
62 | }
63 | }
64 | if checkBtFuncToken {
65 | if tok := btFuncTokenMap[tokenStr]; tok != 0 {
66 | return tok
67 | }
68 | }
69 | tok := tokenMap[tokenStr]
70 | return tok
71 | }
72 | ```
73 |
74 | It is interesting and enlightening to read these code, but not just copy-and-parse. `TiDB` use `Yacc` to find the hierarchical structure of the program. The `Scanner` structure is following the interface of `Yacc`. However, I would implement all by myself without any other tools.
75 |
76 | I spend too much time reading `TiDB` source code, so I just program a little bit today. I think it's fine that I show the code tomorrow, and it would be more complete.
77 |
--------------------------------------------------------------------------------
/days/21.md:
--------------------------------------------------------------------------------
1 | # 21: First Implementation for Database Components
2 |
3 | 2018/11/5
4 |
5 | I found that, before I finish the parser and the worker of SQL. I should implement the components of a database first.
6 |
7 | So, other modules could use components. No matter the parser or the worker, if there are no information and data of components, they cannot do anything.
8 |
9 | There are four layers of a database, which are `database`, `table`, `field`, and `datatype`.
10 |
11 | - `Database` has many `table`s.
12 | - `Table` has many `field`s, and some traits, which are `primary_key`, `foreign_key`, and `reference_table`.
13 | - `Field` has `datatype`, `value`, `not_null`, and `check`
14 | - `Datatype` are the same enum as in `Symbol`
15 |
16 | Let's take a look:
17 |
18 | !FILENAME component/database.rs
19 |
20 | ```rust
21 | use component::table::Table;
22 | #[derive(Debug, Clone)]
23 | pub struct Database {
24 | name: String,
25 | tables: Vec
26 | }
27 | impl Database {
28 | fn new(name: &str) -> Database {
29 | Database {
30 | name: name.to_string(),
31 | tables: vec![],
32 | }
33 | }
34 | }
35 | ```
36 |
37 | !FILENAME component/table.rs
38 |
39 | ```rust
40 | use std::collections::HashMap;
41 | use component::field::Field;
42 | #[derive(Debug, Clone)]
43 | pub struct Table {
44 | name: String,
45 | fields: HashMap,
46 | primary_key: Vec,
47 | foreign_key: Vec,
48 | reference_table: Option,
49 | }
50 | impl Table {
51 | fn new(name: &str) -> Table {
52 | Table {
53 | name: name.to_string(),
54 | fields: HashMap::new(),
55 | primary_key: vec![],
56 | foreign_key: vec![],
57 | reference_table: None,
58 | }
59 | }
60 | }
61 | ```
62 |
63 | !FILENAME component/field.rs
64 |
65 | ```rust
66 | use component::datatype::DataType;
67 | use component::datatype::Value;
68 | #[derive(Debug, Clone)]
69 | pub struct Field {
70 | name: String,
71 | datatype: DataType,
72 | value: Value,
73 | not_null: bool,
74 | check: Checker,
75 | }
76 | #[derive(Debug, Clone)]
77 | pub enum Checker {
78 | None,
79 | Some(Operator, Value)
80 | }
81 | #[derive(Debug, Clone)]
82 | enum Operator {
83 | LT, // <
84 | LE, // <=
85 | EQ, // =
86 | NE, // !=
87 | GT, // >
88 | GE, // >=
89 | }
90 | impl Field {
91 | fn new(name: &str, datatype: DataType, value: Value, not_null: bool, check: Checker) -> Field {
92 | Field {
93 | name: name.to_string(),
94 | datatype,
95 | value,
96 | not_null,
97 | check,
98 | }
99 | }
100 | }
101 | ```
102 |
103 | !FILENAME component/datatype.rs
104 |
105 | ```rust
106 | #[derive(Debug, Clone)]
107 | pub enum DataType {
108 | Char,
109 | Double,
110 | Float,
111 | Int,
112 | Varchar,
113 | }
114 | #[derive(Debug, Clone)]
115 | pub enum Value{
116 | Char(u8, String),
117 | Double(f64),
118 | Float(f32),
119 | Int(i32),
120 | Varchar(u8, String),
121 | }
122 | ```
123 |
124 | This is just the initialization. I will implement methods later.
125 |
--------------------------------------------------------------------------------
/days/5.md:
--------------------------------------------------------------------------------
1 | # 5: Introduce to RDBMS and SQL
2 |
3 | 2018/10/20
4 |
5 | It is very sad to say that, I have spent more than ten hours fighting with `Tokio.rs` from yesterday. I am going to write today's article and go back to continue programming.
6 |
7 | Today, I will talk about RDBMS and SQL.
8 |
9 | ## Entity Model
10 |
11 | Before SQL, you should understand what is entity relationship (ER) model. The ER model is first introduced by 陳品山 (Peter P.S Chen) in 1976. In short, it is a model for organizing data with many relationships. There is an introduction on [Wikipedia](https://en.wikipedia.org/wiki/Entity%E2%80%93relationship_model). A ER diagram is a visualization way for a ER model.
12 |
13 | A ER diagram looks like (source: Wikipedia):
14 |
15 | 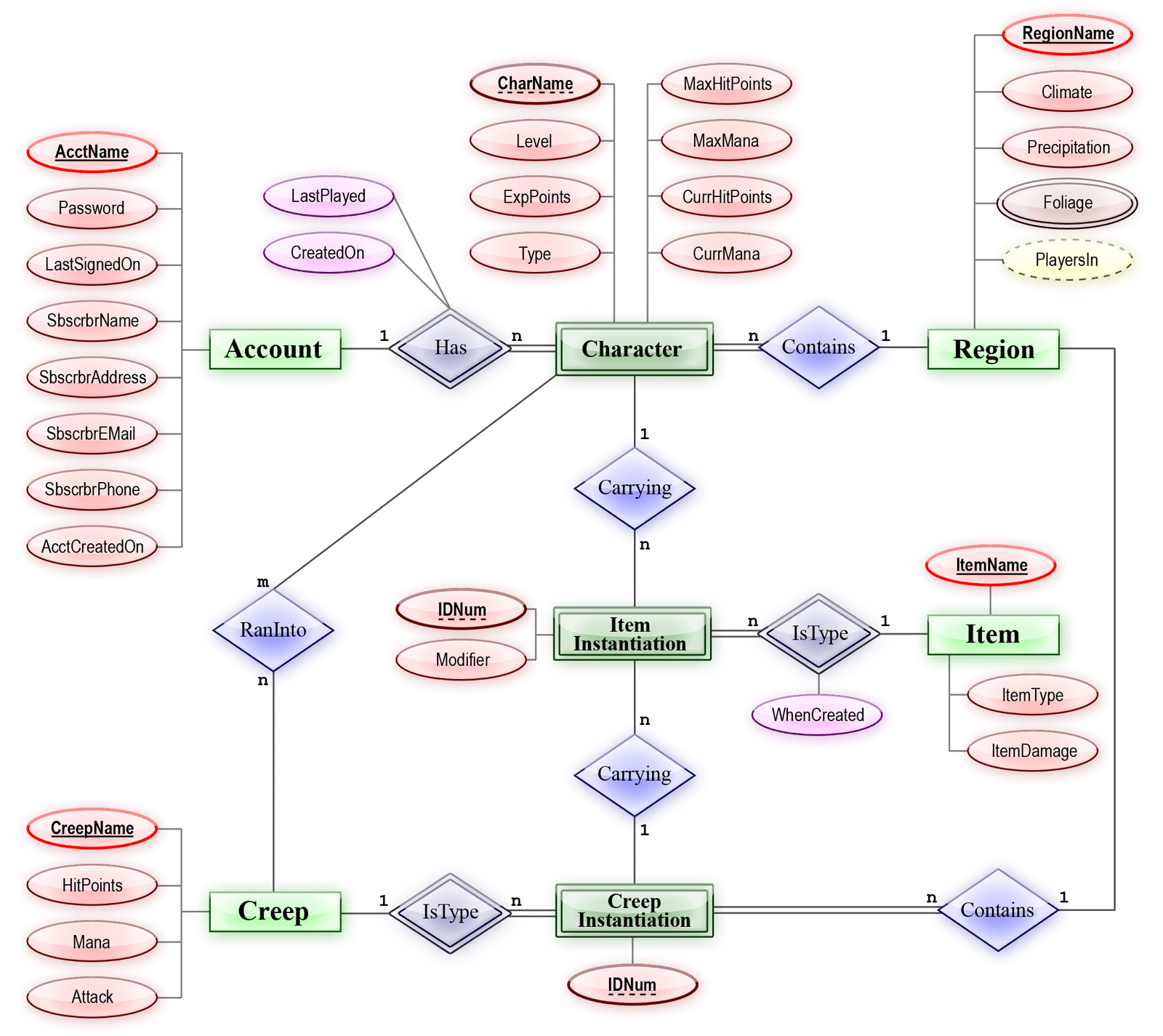
16 |
17 | As you can see, there the rectangles are entities, and entities have relationships which are diamonds. There are also ovals which are attributes for entities.
18 |
19 | For example in the figure, `Character` is a entity, it has a relationship `Has` to an another entity `Account`. `Account` has many attributes, and one is `AccName`.
20 |
21 | ## RDBMS
22 |
23 | With ER model, we can define all data in the real world into a model. Then, we can use the model to create a database. A relational database is based on ER model, and a RDBMS is a DBMS for relational database.
24 |
25 | Assume we have a ER model (maybe a model for a company), we will transfer the model into the format of relational database. Generally speaking for RDBMS, a `database` is for a model. There would be `table`s in a `database`. A table is a partial relationship of entities in the model, and all tables can make up a complete model.
26 |
27 | It will somehow looks like this (source: Wikipedia):
28 |
29 | 
30 |
31 | You can see there are tables in a database which is for a model.
32 |
33 | This series is just for implementing a RDBMS, StellarSQL.
34 |
35 | ## SQL
36 |
37 | Now we know what is a RDBMS. However, we need a method for creating database, reading data, searching data, or creating relationships for data. So we introduce the SQL, which means Structured Query Language. SQL is designed for programs and management systems processing data. It is particularly useful in handling structured data where there are relations between different entities/variables of the data.
38 |
39 | There is a math for supporting SQL, which is [relational algebra](https://en.wikipedia.org/wiki/Relational_algebra). It is because the math that we can ensure SQL could handle data well.
40 |
41 | SQL is a language. I will talk about the syntax later. Just take a look for now.
42 |
43 | For example, the following SQL statement selects all the `customers` from the country `"Mexico"`, in the `customers` table.
44 |
45 | ```SQL
46 | SELECT * FROM customers
47 | WHERE country='Mexico';
48 | ```
49 |
50 | Note that SQL is just like human speaking, so it is quite straightforward.
51 |
52 | The modules for parsing SQL and processing SQL command on StellarSQL will be very important and also not easy, so I would need spend many time on it in the following days. (I am afraid that I don't have enough time)
53 |
54 | That's all for today. If you have some time, I recommend you search some articles about ER model and ER diagram.
55 |
--------------------------------------------------------------------------------
/days/2.md:
--------------------------------------------------------------------------------
1 | # 2: Basic Concept of Server
2 |
3 | 2018/10/17
4 |
5 | I would like to enforce me spending at most 3 hours on this series and developing StellarSQL each day. I am still studying in college now, so I cannot spend too much time on this. I cannot write too much words because it costs lots of time reading the source code of other DBMS and thinking about how to implement on StellarSQL.
6 |
7 | As I mentioned yesterday, DBMS runs on servers. Therefore, before we develop modules of SQL parsing or database handling, we need to implement server functions.
8 |
9 | The server part of a DBMS isn't different too much from any other backend services. You can just think we are going to develop a server and add some DBMS modules on it.
10 |
11 | ## Shoulders of Giants
12 |
13 | Let's take a glimpse at how MySQL does on the server part. It is always good to stand on the shoulders of giants. The "[The Skeleton of the Server Code](https://dev.mysql.com/doc/internals/en/guided-tour-skeleton.html)" in the internal guide of MySQL shows the underlying concepts about what a server of DBMS does. It's recommended to read that guide before reading the following parts.
14 |
15 | Basically, I would like to follow MySQL architecture when I implement StellarSQL, but in a simplified way. I would refers some good parts in other open sources projects when I develop the project.
16 |
17 | The following snippet is the simplified server code of MySQL:
18 |
19 | !FILENAME /sql/mysqld.cc
20 |
21 | ```cc
22 | int main(int argc, char **argv)
23 | {
24 | _cust_check_startup();
25 | (void) thr_setconcurrency(concurrency);
26 | init_ssl();
27 | server_init(); // 'bind' + 'listen'
28 | init_server_components();
29 | start_signal_handler();
30 | acl_init((THD *)0, opt_noacl);
31 | init_slave();
32 | create_shutdown_thread();
33 | create_maintenance_thread();
34 | handle_connections_sockets(0);
35 | DBUG_PRINT("quit",("Exiting main thread"));
36 | exit(0);
37 | }
38 | ```
39 |
40 | All functions are very straightforward. `init_ssl` runs OpenSSL. `server_init` and `init_server_components` are just doing as their names. `start_signal_handler` is for interrupt and (a)synchronous procedures. `handle_connections_sockets` is for the connections.
41 |
42 | Now we have the idea of how to do. So let's work on StellarSQL.
43 |
44 | ## Tokio.rs in StellarSQL
45 |
46 | As you can see the source code of MySQL has implemented lots of underlying functions by themselves, including lock, signal, IPC, socket and others. I am just going to do a proof of concept project of DBMS, so I would not implement such detail modules.
47 |
48 | I would use [Tokio.rs](https://tokio.rs/docs/overview/) in StellarSQL. This framework has done some underlying modules already, so I can focus on implementation parts of SQL and database.
49 |
50 | According to the official website of Tokio.rs:
51 |
52 | > Tokio is an event-driven, non-blocking I/O platform for writing asynchronous applications with Rust. At a high level, it provides a few major components:
53 | > - A multithreaded, work-stealing based task scheduler.
54 | > - A reactor backed by the operating system’s event queue (epoll, kqueue, IOCP, etc…).
55 | > - Asynchronous TCP and UDP sockets.
56 | > These components provide the runtime components necessary for building an asynchronous application.
57 |
58 | Looks like Tokio.rs is so powerful, isn't it?
59 |
60 | Then, I will use Tokio.rs to implement the basic parts of StellarSQL tomorrow.
61 |
62 | I have run out the time today (remember the rule of 3-hours limitation?), so see you tomorrow!
63 |
--------------------------------------------------------------------------------
/days/3.md:
--------------------------------------------------------------------------------
1 | # 3: Frontend/Backend Protocol
2 |
3 | 2018/10/18
4 |
5 | StellarSQL is a relational DBMS (RDBMS). Usually, RDBMS is 2-tier client/server architecture, which includes a server and a client. A client might be any devices which wants to access databases, and a server is running a DBMS for handling requests from clients.
6 |
7 | There must be a protocol between client and server, in order to communication and data transmission. MySQL and PostgreSQL apply message stream communication as their protocol. MySQL and PostgreSQL do talk about protocol on their document:
8 |
9 | - MySQL: [Client/Server Protocol](https://dev.mysql.com/doc/dev/mysql-server/8.0.2/PAGE_PROTOCOL.html)
10 | - PostgreSQL: [Chapter 50. Frontend/Backend Protocol](https://www.postgresql.org/docs/9.5/static/protocol-overview.html#PROTOCOL-MESSAGE-CONCEPTS)
11 |
12 | Of course, you can also use HTTP protocol. Firebase is a NoSQL cloud database, and clients send HTTP requests for querying data. However HTTP is somehow too "fat" for the purpose of data querying, so message stream might be suitable in the case of DBMS.
13 |
14 | Now, we can start to develop a little about Tokio.rs for StellarSQL, which we talked about on yesterday.
15 |
16 | ## Create server
17 |
18 | Based on the reason above, I would also use message stream communication as the protocol for StellarSQL.
19 |
20 | I will think about the detail of the protocol in the following days. But now, we can implement the part of TCP stream by using `Tokio.rs` first.
21 |
22 | We create a server first:
23 |
24 | !FILENAME src/main.rs
25 |
26 | ```rust
27 | let addr = format!("127.0.0.1:{}", port).parse().unwrap();
28 |
29 | // Bind a TCP listener to the socket address.
30 | // Note that this is the Tokio TcpListener, which is fully async.
31 | let listener = TcpListener::bind(&addr).unwrap();
32 |
33 | // The server task asynchronously iterates over and processes each
34 | // incoming connection.
35 | let server = listener
36 | .incoming()
37 | .for_each(move |socket| {
38 | // Spawn a task to process the connection
39 | // TODO process()
40 | Ok(())
41 | }).map_err(|err| {
42 | println!("accept error = {:?}", err);
43 | });
44 |
45 | tokio::run(server);
46 | println!("StellarSQL running on {} port", port);
47 | ```
48 |
49 | Continue to the day before yesterday, we let address use the port from arguments or configuration. So the server will serve at `127.0.0.1:PORT`.
50 |
51 | Then we let server listen to any sockets input from connections. For servers or DBMS, it is always that clients ask requests and servers answer responses. So, you could see there is a `listener` that will handles any sockets, which I remain it as TODO.
52 |
53 | Finally, we run the server with `tokio::run(server)`. According to the document, the Tokio is a pre-configured "out of the box" runtime for building asynchronous applications. It includes both a reactor and a task scheduler. This means applications are multi-threaded by default. In this case, we just use the default setting by Tokio.
54 |
55 | ## Message
56 |
57 | I also define the `Message` for message streaming. The `Message` struct is really basic and straightforward now. I will finish it and define the protocol in the following days. Then, we could use it for client/server communication later.
58 |
59 | ```rust
60 | pub struct Message {
61 | /// The TCP socket.
62 | socket: TcpStream,
63 |
64 | /// Buffer used when reading from the socket. Data is not returned from this
65 | /// buffer until an entire message has been read.
66 | rd: BytesMut,
67 |
68 | /// Buffer used to stage data before writing it to the socket.
69 | wr: BytesMut,
70 | }
71 |
72 | impl Message {
73 | /// Create a new `Message` codec backed by the socket
74 | fn new(socket: TcpStream) -> Self {
75 | Message {
76 | socket,
77 | rd: BytesMut::new(),
78 | wr: BytesMut::new(),
79 | }
80 | }
81 | }
82 | ```
83 |
--------------------------------------------------------------------------------
/days/1.md:
--------------------------------------------------------------------------------
1 | # 1: Preparation & Basic Infrastructure
2 |
3 | 2018/10/16
4 |
5 | ## Introduction to DBMS
6 |
7 | A database management system (DBMS) is a software run on server, which controls many databases. MongoDB, MySQL, Oracle, PostgreSQL, etc., all are DBMS.
8 |
9 | A DBMS verifies authenticity of connections. It schedules tasks of requests, including inserting, deleting, or searching in a DB. It enforces rules, which defined by the users, for each transactions, such as specified types of data.
10 |
11 | There are some materials good to read: "[Database Management System – Introduction](https://www.geeksforgeeks.org/database-management-system-introduction-set-1/)" on GeeksforGeeks, or "[Database — Introduction](https://medium.com/omarelgabrys-blog/database-introduction-part-1-4844fada1fb0)" by Omar El Gabry on Medium. There are also many good articles that introduce to DBMS on the Internet, so I would not talk too much about it.
12 |
13 | Once you know what is a DBMS, you would have an overview about what we are going to implement on StellarSQL. DBMS is a server service. It should be able to do any things on databases. It should be able to parse SQL languages. It needs a storage systems. It might have good algorithms for searching DB, storing data, or scheduling tasks. There might be much more functions for a DBMS, and I would finish them one by one.
14 |
15 | ## Setup Environment
16 |
17 | Ok, we are ready to program the StellarSQL!
18 |
19 | First of all, we need to setup our programming environment.
20 |
21 | Since StellarSQL is written in Rust language, you must install Rust via Rustup. Rustup is a version manager of Rust.
22 |
23 | Enter the command in terminal to install Rust:
24 |
25 | ```bash
26 | curl https://sh.rustup.rs -sSf | sh
27 | ```
28 |
29 | Once installing Rust, it will also installed Cargo for you. Cargo is a tool for running Rust and installing packages. It's recommended to read the [Rust book](https://doc.rust-lang.org/book/2018-edition/index.html) if you have not learned Rust before. It's fine if you just read the rust code directly, because you still can understand the logic of the code in StellarSQL.
30 |
31 | ## Code
32 |
33 | StellarSQL is on Github. You could get the source code of StellarSQL
34 |
35 | ```bash
36 | git clone https://github.com/tigercosmos/StellarSQL
37 | cd StellarSQL
38 | ```
39 |
40 | The series is based on the project. I would only select the vital part of function ins articles while explaining a certain concept. You might want to know the full code, and you could browser the source code.
41 |
42 | ## Build and Run
43 |
44 | You could build and run the program simply run:
45 |
46 | ```bash
47 | cargo run
48 | ```
49 |
50 | With the progress of developing, it might be more steps to build and run, but all information would update on README.
51 |
52 | ## CI
53 |
54 | I use travis as CI. CI will check the code can build and run, and check the format of code is OK.
55 |
56 | ## Basic Infrastructure
57 |
58 | The StellarSQL program might have some configuration and arguments.
59 |
60 | If the user doesn't give arguments to run the program, the program should adopt the default value from configuration.
61 |
62 | There are some settings would be covered in configuration and arguments. So far I could think of is that, the settings include the port of the server and whether the server runs in daemon mode. There might be more, and I will add others later.
63 |
64 | For configuration, you can see there is a `.env` file, which is for configuration. The `dotenv_codegen` crate helps us to parse the value from `.env`. There is also a `cli.yml` file, which is the schema of arguments of the program, powered by `clap` crate.
65 |
66 | You could run the program with the argument `-h` to see how to set arguments for StellarSQL once you `cargo build` an executable file. Assume it is a debug build, the file is at `target/debug/stellar_sql`.
67 |
68 | ```bash
69 | ./stellar_sql -h
70 | ```
71 |
72 | Then you can see the introduction for the program, and all information is based on the `cli.yml` file.
73 |
74 | We have added some code in the main program.
75 |
76 | ```rust
77 | let yml = load_yaml!("../cli.yml");
78 | let m = App::from_yaml(yml).get_matches();
79 |
80 | let port = if let Some(port_) = m.value_of("port") {
81 | port_
82 | } else {
83 | dotenv!("PORT")
84 | };
85 | println!("StellarSQL running on {} port", port);
86 | ```
87 |
88 | Now we can parse arguments and read values from configuration! In this example, if `PORT` is not in the arguments, it would use the default value from `.env`.
89 |
90 | That's all for today!
91 |
--------------------------------------------------------------------------------
/days/10.md:
--------------------------------------------------------------------------------
1 | # 10: Lexical Scanner Implementation (2)
2 |
3 | 2018/10/25
4 |
5 | I modify some part that I wrote yesterday.
6 |
7 | !FILENAME src/sql/symbol.rs
8 |
9 | ```rust
10 | pub struct Symbol<'a> {
11 | name: &'a str,
12 | len: usize,
13 | token: Token,
14 | group: Group,
15 | }
16 | ```
17 |
18 | I change `Symbol.name` from `String` to `&str` type, because `String` type stores data in the heap and `&str` stores at the stack. There is no reason we should store `name` in heap, since `name` is a fixed value and put it in the stack would be faster.
19 |
20 | You would notice the `<'a>` syntax, it is the lifetime syntax in rust. The `&str` usually live only in the scope, so I need to tell the compiler that `name` should live as long as `Symbol`.
21 |
22 | !FILENAME src/sql/symbol.rs
23 |
24 | ```rust
25 | pub enum Group {
26 | DataType,
27 | DoubleKeyword,
28 | MultiKeyword,
29 | Function,
30 | Keyword,
31 | }
32 | ```
33 |
34 | I add more enums in `Group`, where `DataType` includes `Int`, `Char`, etc., and `DoubleKeyword` means the a two-word keywords.
35 |
36 | !FILENAME src/sql/symbol.rs
37 |
38 | ```rust
39 | pub enum Token {
40 | /* SQL Keywords */
41 |
42 | //...
43 | //...
44 |
45 | /* SQL Function */
46 | AVG,
47 | COUNT,
48 | MAX,
49 | MIN,
50 | SUM,
51 |
52 | /* SQL Data Type */
53 | Char,
54 | Double,
55 | Float,
56 | Int,
57 | Varchar,
58 | }
59 | ```
60 |
61 | I update struct `Token`. There is only `Keywords` part yesterday, and I fill up `Function` and `Data Type`. I just plan to implement `Functions` and `Data Type` listed in `Token`, though other DBMS implement more.
62 |
63 | You might wonder what is the difference between `Varchar` and `Char`. According to MySQL document, the `Char` and `Varchar` types are similar, but differ in the way they are stored and retrieved. They also differ in maximum length and in whether trailing spaces are retained.
64 |
65 | The `Char` and `Varchar` types are declared with a length that indicates the maximum number of characters you want to store. For example, `CHAR(30)` can hold up to `30` characters.
66 |
67 | The table shows the difference.
68 |
69 | Value|CHAR(4)|Storage Required |VARCHAR(4)|Storage Required
70 | -|-|:-:|-|:-:
71 | ''|' '|4 bytes|''|1 byte
72 | 'ab'|'ab ' |4 bytes|'ab'|3 bytes
73 | 'abcd' |'abcd'| 4 bytes|'abcd'|5 bytes
74 | 'abcdefgh'|'abcd'|4 bytes|'abcd'|5 bytes
75 |
76 | !FILENAME src/sql/symbol.rs
77 |
78 | ```rust
79 | lazy_static! {
80 | /// A static struct of token hashmap storing all tokens
81 | pub static ref SYMBOLS: HashMap<&'static str, Symbol<'static>> = {
82 | let mut m = HashMap::new();
83 |
84 | // The following is maintained by hand according to `Token`
85 | /* SQL Keywords */
86 | m.insert("add", sym("add", Token::Add, Group::Keyword));
87 | m.insert(
88 | "add constraint",
89 | sym("add constraint", Token::AddConstraint, Group::Keyword),
90 | );
91 |
92 | // ...
93 | // ...
94 | // ...
95 |
96 | m // return m
97 | };
98 | }
99 | ```
100 |
101 | I store all `Symbol` to `SYMBOLS` hashmap for later use by the scanner.
102 |
103 | In C++, we can define and export a list, an array, or a map with value. Other file could simply `include` the `.h` or `.cc` to use the exported variable.
104 |
105 | However in Rust, we cannot do that without crates help (crate is a third party module). So, I use `lazy_static` here, it helps us to export the hashmap just like C++. Using the macro `lazy_static!` (You could see a macro as a decorator in Rust), it is possible to have statics that require code to be executed at runtime in order to be initialized.
106 |
107 | Note that the lifetime of the `SYMBOLS` should be `static`, which mean it and its content should live in the whole life of the program. So, you could see the type is `HashMap<&'static str, Symbol<'static>>`.
108 |
109 | All that remains to do are lots of "dirty works". As you could see, I need to `insert` all `Symbol` in `SYMBOLS`. This is a boring job by hand, but I still need to that. (Of course I write a simple script to make it easier)
110 |
111 | Today commits:
112 |
113 | - `74adcd01220e3b73947dcfa1d6ff83101953f843` sql: update Symbol, Group, Token. Implement SYMBOLS
114 | - `46a3ce29ab482197baebceb4197502e46e17b8ac` travis: add cargo test
115 | - `1257a38bdcb0f76e76f00ac70c5d5a4773462c1b` crate: add lazy_static
116 | - `7bf3f54b8ef0a6cfd3803d646fe7bb42a9d93307` sql: let symbol pub
--------------------------------------------------------------------------------
/days/23.md:
--------------------------------------------------------------------------------
1 | # 23: Implement Table `insert_row`
2 |
3 | 2018/11/7
4 |
5 | As I did the basic infrastructure of components, there are still lots of methods that I need to implement.
6 |
7 | I choose `Table` first, and I write the `insert_row` method for it. Note that it still stores data in memory. It should also write to file in the future.
8 |
9 | !FILENAME component/table.rs
10 |
11 | ```rust
12 | /// `insert` row into the table
13 | /// `key` and `value` are `&str`, and will be formated to the right type.
14 | pub fn insert(&mut self, row: Vec<(&str, &str)>) -> Result<(), TableError> {
15 | let mut new_row = Row::new();
16 |
17 | // insert data into row
18 | for (key, value) in row {
19 | match self.fields.get(key) {
20 | Some(field) => {
21 | if field.not_null && value == "null" {
22 | return Err(TableError::InsertFieldNotNullMismatched(field.clone().name));
23 | }
24 | new_row.0.insert(key.to_string(), value.to_string());
25 | }
26 | None => return Err(TableError::InsertFieldNotExisted(key.to_string())),
27 | }
28 | }
29 |
30 | // check if the row fits the field
31 | for (key, field) in self.fields.iter() {
32 | match new_row.0.get(key) {
33 | Some(_) => {}
34 | None => {
35 | match field.clone().default {
36 | // if the attribute has default value, then insert with the default value.
37 | Some(value) => new_row.0.insert(key.to_string(), value.to_string()),
38 | None => return Err(TableError::InsertFieldDefaultMismatched(key.to_string())),
39 | };
40 | }
41 | };
42 | }
43 |
44 | self.rows.push(new_row);
45 |
46 | Ok(())
47 | }
48 | ```
49 |
50 | there are also some tests for it.
51 |
52 | !FILENAME component/table.rs
53 |
54 | ```rust
55 | fn test_insert_row() {
56 | let mut table = Table::new("table_1");
57 | table.fields.insert(
58 | "attr_1".to_string(),
59 | Field::new(
60 | "attr_1",
61 | DataType::Int,
62 | true, // not_null is true
63 | Some("123".to_string()), // default is 123
64 | field::Checker::None,
65 | ),
66 | );
67 | table.fields.insert(
68 | "attr_2".to_string(),
69 | Field::new(
70 | "attr_2",
71 | DataType::Int,
72 | true, // not_null is true
73 | None, // no default
74 | field::Checker::None,
75 | ),
76 | );
77 | table.fields.insert(
78 | "attr_3".to_string(),
79 | Field::new(
80 | "attr_3",
81 | DataType::Int,
82 | false, // not null is false
83 | None, // no default
84 | field::Checker::None,
85 | ),
86 | );
87 |
88 | println!("correct data");
89 | let data = vec![("attr_1", "123"), ("attr_2", "123"), ("attr_3", "123")];
90 | assert!(table.insert_row(data).is_ok());
91 |
92 | println!("`attr_2` is null while its not_null is true");
93 | let data = vec![("attr_1", "123"), ("attr_2", "null"), ("attr_3", "123")];
94 | assert!(table.insert_row(data).is_err());
95 |
96 | println!("`attr_3` is null while its not_null is false");
97 | let data = vec![("attr_1", "123"), ("attr_2", "123"), ("attr_3", "null")];
98 | assert!(table.insert_row(data).is_ok());
99 |
100 | println!("none given value `attr_2` while its default is None");
101 | let data = vec![("attr_1", "123"), ("attr_3", "123")];
102 | assert!(table.insert_row(data).is_err());
103 |
104 | println!("none given value `attr_1` while it has default");
105 | let data = vec![("attr_2", "123"), ("attr_3", "123")];
106 | assert!(table.insert_row(data).is_ok());
107 |
108 | println!("fields mismatched");
109 | let data = vec![
110 | ("attr_1", "123"),
111 | ("attr_2", "123"),
112 | ("attr_3", "123"),
113 | ("attr_4", "123"),
114 | ];
115 | assert!(table.insert_row(data).is_err());
116 | let data = vec![("attr_1", "123")];
117 | assert!(table.insert_row(data).is_err());
118 | }
119 | ```
--------------------------------------------------------------------------------
/days/15.md:
--------------------------------------------------------------------------------
1 | # 15: Lexical Scanner Implementation (5)
2 |
3 | 2018/10/30
4 |
5 | Finally, the scanner could identify a multikeyword, such as `insert into`, `create table`.
6 |
7 | The algorithm for the scanner is really straightforward. Check the first word to see if the word could be a multikeyword. If the keyword has three words, read the following two words and check if the string match a multikeyword.
8 |
9 | The algorithm looks some how ugly. I would like to refactor it later.
10 |
11 | There are also tests for the scanner, just take a look at the bottom of `lexer.rs`.
12 |
13 | !FILENAME sql/lexer.rs
14 |
15 | ```rust
16 | // if this is possible a multikeyword, search the following chars
17 | match symbol::check_multi_keywords_front(word) {
18 | // parts for how many parts in this possible keyword
19 | Some(parts) => {
20 | println!("The word `{}` might be a multikeyword", word);
21 |
22 | for keyword_total_parts in parts {
23 | println!("Assume this keyword has {} parts", keyword_total_parts);
24 |
25 | // copy remaining chars for testing
26 | let mut test_chars = chars.as_str().chars();
27 | // for testing if the string a multikeyword. Insert the first word
28 | // and a space already. (because start scanning from next word)
29 | let mut test_str = String::from(format!("{} ", word));
30 |
31 | // for checking a new word
32 | let mut is_last_letter = false;
33 |
34 | // record the right cursor position when checking if multikeyword
35 | // if match a multikeyword, shift right cursor with steps
36 | let mut step_counter = 0;
37 |
38 | // How many words added in the test_str
39 | // if the keyword is 3 parts, the following_parts should be 2
40 | let mut following_parts = 0;
41 |
42 | loop {
43 | match test_chars.next() {
44 | Some(y) => {
45 | // A multikeyword should be all ASCII alphabetic character
46 | if y.is_ascii_alphabetic() {
47 | if !is_last_letter {
48 | is_last_letter = true;
49 | }
50 | test_str.push(y);
51 | } else {
52 | match y {
53 | ' ' | '\t' | '\r' | '\n' => {
54 | if is_last_letter {
55 | // from letter to space, count one
56 | following_parts += 1;
57 | // find enough parts, break earlier
58 | if following_parts
59 | == keyword_total_parts - 1
60 | {
61 | break; // loop
62 | }
63 | // add ` ` between words
64 | test_str.push(' ');
65 | is_last_letter = false
66 | }
67 | }
68 | // &, %, *, @, etc.
69 | // keywords must be letters
70 | _ => break, // loop
71 | }
72 | }
73 | }
74 | None => break, // loop
75 | }
76 | step_counter += 1;
77 | }
78 |
79 | println!("Checking `{}` ...", test_str);
80 | match symbol::SYMBOLS.get(test_str.as_str()) {
81 | // a multikeyword
82 | Some(token) => {
83 | println!("Found keyword `{}`", test_str);
84 | self.tokens.push(token.clone());
85 |
86 | // shift the right cursor to the right of multikeyword
87 | self.pos.cursor_r += step_counter;
88 | // skip the chars included in this multikeyword
89 | for _ in 0..step_counter {
90 | chars.next();
91 | }
92 |
93 | is_multi_keyword = true;
94 | break; // parts
95 | }
96 | None => println!("`{}` not a keyword", test_str),
97 | }
98 | }
99 | }
100 | None => {}
101 | }
102 | ```
--------------------------------------------------------------------------------
/days/16.md:
--------------------------------------------------------------------------------
1 | # 16: Good RDB Design with the Concept of Normal Forms
2 |
3 | 2018/10/31
4 |
5 | What is a good design for a relational database (RDB)?
6 |
7 | You might have seen an excel data sheet filled with lots of columns. I can imagine that kind of excel sheet is very messy. A well designed database should design and create a model, and then implement the model into database.
8 |
9 | For RDB, we use ER model. However, we might still design a model with deflects. For example, a table combines student information and department information.
10 |
11 | 
12 |
13 | In this case, `DNUM` is followed by `SID`, but `DNAME` and `D_HEAD` are followed by `DNUM`. That's dangerous, because it might cause anomalies while inserting, deleting, or modifying a tuple of data.
14 |
15 | This is an example of bad designs. So, I am going to introduce to 5 concept of normal forms.
16 |
17 | When we create a RDB, we should not only base on ER model, but also need to consider that if the database are normal forms. Then we will have a good design database.
18 |
19 | Concept of normal forms were first proposed by Codd in 1972.
20 |
21 | - functional dependencies
22 | - 1st normal form
23 | - 2nd normal form
24 | - 3rd normal form
25 | - multi-valued dependency
26 | - 4th normal form
27 | - join dependency
28 | - 5th normal form
29 |
30 | ## First Normal Form
31 |
32 | The value of an attribute should be an atomic value. It could not be multi-value, array, composite values, or any other relation. (ER model has already defined)
33 |
34 | ## Second Normal Form
35 |
36 | Primary key could be a combination of keys. If a key of the primary key, could determine an attributes in the table, it is a partial relationship between the primary key and non-prime attributes. Then, it violates the second normal form.
37 |
38 | 
39 |
40 | In this case, the primary key is `SID` and `PID`, and any attributes should be determined by the two. But, `SNAME` is only determined by `SID`, so it violates the rule. Therefore, this table should divide in three new tables to follow the concept.
41 |
42 | ## Third Normal Form
43 |
44 | If there are attributes that follow a non-primary key, these attributes should be an another table. Just as the example:
45 |
46 | 
47 |
48 | ## Forth Normal Form
49 |
50 | A table is in 4NF if and only if, for every one of its non-trivial multi-valued dependencies X ↠ Y, X is a superkey. That is, X is either a candidate key or a superset thereof.
51 |
52 | Removing “bad” multi-valued dependencies help us get into 4th normal.
53 | form, and into better design.
54 |
55 | Considering the following example:
56 |
57 | In this case, both `Pizza Variety` and `Delivery Area` are determined by `Restaurant`, and the two should be a combination.
58 |
59 | 
60 |
61 | If `Pizza Variety` and `Delivery Area` are independent to each other, it violates 4NF. Because, if restaurant `Pizza A1` add a new kind pizza `Cheese Pizza`, it need to add three rows for the three locations that in the table. (Because `Pizza Variety` is not binding `Delivery Area`, any `Delivery Area` should have this new `Pizza Variety`)
62 |
63 | In other words, adding a new kind of pizza, the table need to insert rows, which is the new pizza with each area, and it is easy to make errors when updating. To eliminate the possibility of these anomalies, 4NF suggests that the table should be split.
64 |
65 | 
66 |
67 | ## Fifth Normal Form
68 |
69 | Assume the table meets 1NF to 4NF.
70 |
71 | Considering a table that has `Traveling Salesman`(primary key), `Brand` and `Product`.
72 |
73 | Imagining a extreme case:
74 |
75 | A `Traveling Salesman` has certain `Brand`s and certain `Product` Types in their repertoire. If `Brand` B1 and `Brand` B2 are in their repertoire, and `Product` Type P is in their repertoire, then (assuming `Brand` B1 and `Brand` B2 both make Product Type P,) the `Traveling Salesman` must offer products of Product Type P those made by Brand B1 and those made by Brand B2.
76 |
77 | That is to say, the `Brand` and `Product` are combined (4NF), the `Salesman` is not able to only sale a certain `Brand` but exclude one of products of that `Brand`.
78 |
79 | Then to solve this, splitting the able to three would make sense.
80 |
81 | - `Traveling Salesman` with `Brand`
82 | - `Traveling Salesman` with `Product`
83 | - `Brand` with `Product`
84 |
85 | ## Conclusion
86 |
87 | ER model is good for RDB, but the database might easily makes error if we design not well.
88 |
89 | Following these concept of normal forms would reduce the possibility of anomalies, which makes the database more clear and reliable.
--------------------------------------------------------------------------------
/days/14.md:
--------------------------------------------------------------------------------
1 | # 14: Lexical Scanner Implementation (4)
2 |
3 | 2018/10/29
4 |
5 | I write a scanner to get tokens. The code is at `lexer.rs`.
6 |
7 | The algorithm is simple. The scanner will read char by char. There are two cursors, `cursor_l` and `cursor_r`. When the income char is one of separators or delimiters, the scanner will check the last word selected by two cursors. If the word is a keyword, add the keyword as the token. Otherwise, add the identifier with its name.
8 |
9 | There are some small parts need to fix, but the function is almost done.
10 |
11 | If we have a message:
12 |
13 | ```sql
14 | select customername, contactname, address from customers where address is null;
15 | ```
16 |
17 | then the scanner will get:
18 |
19 | ```rust
20 | [
21 | Symbol { name: "select", len: 6, token: Select, group: Keyword },
22 | Symbol { name: "customername", len: 12, token: Identifier, group: Identifier },
23 | Symbol { name: ",", len: 1, token: Comma, group: Delimiter },
24 | Symbol { name: "", len: 0, token: Identifier, group: Identifier },
25 | Symbol { name: "contactname", len: 11, token: Identifier, group: Identifier },
26 | Symbol { name: ",", len: 1, token: Comma, group: Delimiter },
27 | Symbol { name: "", len: 0, token: Identifier, group: Identifier },
28 | Symbol { name: "address", len: 7, token: Identifier, group: Identifier },
29 | Symbol { name: "from", len: 4, token: From, group: Keyword },
30 | Symbol { name: "customers", len: 9, token: Identifier, group: Identifier },
31 | Symbol { name: "where", len: 5, token: Where, group: Keyword },
32 | Symbol { name: "address", len: 7, token: Identifier, group: Identifier },
33 | Symbol { name: "is", len: 2, token: Identifier, group: Identifier },
34 | Symbol { name: "null", len: 4, token: Identifier, group: Identifier },
35 | Symbol { name: ";", len: 1, token: Semicolon, group: Delimiter }
36 | ]
37 | ```
38 |
39 | `is null` should be recognized as a token, so I will fix later.
40 |
41 | as you can see, we get the tokens and we can use these token to do the next step.
42 |
43 | !FILENAME sql/lexer.rs
44 |
45 | ```rust
46 | use sql::symbol;
47 |
48 | #[derive(Debug, Clone)]
49 | pub struct Scanner<'a> {
50 | message: String,
51 | tokens: Vec>,
52 | pos: Pos,
53 | }
54 |
55 | #[derive(Debug, Clone)]
56 | struct Pos {
57 | cursor_l: usize,
58 | cursor_r: usize,
59 | }
60 |
61 | impl<'a> Scanner<'a> {
62 | pub fn new(message: &str) -> Scanner {
63 | Scanner {
64 | message: message.to_lowercase().trim().to_string(),
65 | tokens: vec![],
66 | pos: Pos {
67 | cursor_l: 0,
68 | cursor_r: 0,
69 | },
70 | }
71 | }
72 | pub fn scan_tokens(&'a mut self) -> Vec> {
73 | println!("Starting scanning message: {}", self.message);
74 | let mut chars = self.message.chars();
75 | loop {
76 | match chars.next() {
77 | Some(x) => {
78 | if is_letter_or_number(x) {
79 | self.pos.cursor_r += 1;
80 | } else {
81 | match x {
82 | ' ' | '\t' | '\r' | '\n' | '(' | ')' | ','
83 | | ';' => {
84 | if self.pos.cursor_l != self.pos.cursor_r {
85 | let word = self
86 | .message
87 | .get(
88 | self.pos.cursor_l
89 | ..self.pos.cursor_r,
90 | ).unwrap();
91 | println!(
92 | "encounter `{}`, last word is {}",
93 | x, word
94 | );
95 | match symbol::SYMBOLS.get(word) {
96 | // either keyword
97 | Some(token) => {
98 | self.tokens.push(token.clone())
99 | }
100 | // or identifier
101 | None => {
102 | self.tokens.push(symbol::sym(
103 | word,
104 | symbol::Token::Identifier,
105 | symbol::Group::Identifier,
106 | ));
107 | }
108 | }
109 | if is_delimiter(x) {
110 | self.tokens.push(
111 | symbol::Symbol::match_delimiter(x)
112 | .unwrap(),
113 | );
114 | }
115 | }
116 | // set the cursor next to `x` in the right
117 | self.pos.cursor_r += 1;
118 | self.pos.cursor_l = self.pos.cursor_r;
119 | }
120 | _ => {
121 | // error
122 | }
123 | }
124 | }
125 | }
126 | // no remaining char in message
127 | None => break,
128 | };
129 | }
130 | self.tokens.clone()
131 | }
132 | }
133 |
134 | fn is_letter_or_number(ch: char) -> bool {
135 | ch.is_digit(10) || ch.is_ascii_alphabetic()
136 | }
137 |
138 | fn is_delimiter(ch: char) -> bool {
139 | ch == '(' || ch == ')' || ch == ',' || ch == ';'
140 | }
141 | ```
--------------------------------------------------------------------------------
/days/8.md:
--------------------------------------------------------------------------------
1 | # 8: SQL Parser - Lexical Scanner
2 |
3 | 2018/10/23
4 |
5 | As I introduced yesterday, there are a lexical scanner and a grammar rule parser in the SQL parser.
6 |
7 | I would implement a basic SQL first, which supports a simplified version of SQL syntax. How basic is it? I use [W3C SQL Tutorial](https://www.w3schools.com/sql/) as the standard, which means I will support most syntax in that tutorial. There are more syntax which are complex, and I would not support those for now.
8 |
9 | Today, I am studying how to implement the lexical scanner. There are many articles about how a lexical scanner works, so I skip the introduction here. Just mention a few good articles: "*[Gentle introduction into compilers. Part 1: Lexical analysis and Scanner](https://medium.com/dailyjs/733246be6738)*" by @maxim_koretskyi, "*[Lexical Analysis](https://hackernoon.com/861b8bfe4cb0)*" by Faiçal Tchirou.
10 |
11 | ## How MySQL Does
12 |
13 | Before we start, it's good to see how others compiler implement their lexical scanner. Finite state machines and finite automaton are helpful for processing lexical analysis. Most projects use tools like GNU Flex, however MySQL uses handwritten identifiers in lexical scanner for better performance and flexibility.
14 |
15 | MySQL puts their keywords in `sql/lex.h`:
16 |
17 | !FILENAME mysql_server/sql/lex.h
18 |
19 | ```h
20 | static const SYMBOL symbols[] = {
21 | /*
22 | Insert new SQL keywords after that commentary (by alphabetical order):
23 | */
24 | {SYM("&&", AND_AND_SYM)},
25 | {SYM("<", LT)},
26 | {SYM("<=", LE)},
27 | {SYM("<>", NE)},
28 | {SYM("!=", NE)},
29 | {SYM("=", EQ)},
30 | {SYM(">", GT_SYM)},
31 | {SYM(">=", GE)},
32 | {SYM("<<", SHIFT_LEFT)},
33 | {SYM(">>", SHIFT_RIGHT)},
34 | {SYM("<=>", EQUAL_SYM)},
35 | {SYM("ACCESSIBLE", ACCESSIBLE_SYM)},
36 | {SYM("ACCOUNT", ACCOUNT_SYM)},
37 | {SYM("ACTION", ACTION)},
38 | {SYM("ADD", ADD)},
39 | {SYM("ADMIN", ADMIN_SYM)},
40 | {SYM("AFTER", AFTER_SYM)},
41 | {SYM("AGAINST", AGAINST)},
42 | // ...
43 | // ...
44 | }
45 | ```
46 |
47 | The entry points for the lexical scanner of MySQL is `yylex()` in `sql/sql_lex.cc`, where `yy` is just a prefix.
48 |
49 | !FILENAME mysql_server/sql/sql_lex.cc
50 |
51 | ```c++
52 | static int lex_one_token(YYSTYPE *yylval, THD *thd) {
53 | uchar c = 0;
54 | bool comment_closed;
55 | int tokval, result_state;
56 | uint length;
57 | enum my_lex_states state;
58 | Lex_input_stream *lip = &thd->m_parser_state->m_lip;
59 | const CHARSET_INFO *cs = thd->charset();
60 | const my_lex_states *state_map = cs->state_maps->main_map;
61 | const uchar *ident_map = cs->ident_map;
62 |
63 | lip->yylval = yylval; // The global state
64 |
65 | lip->start_token();
66 | state = lip->next_state;
67 | lip->next_state = MY_LEX_START;
68 | for (;;) {
69 | switch (state) {
70 | case MY_LEX_START: // Start of token
71 | // Skip starting whitespace
72 | while (state_map[c = lip->yyPeek()] == MY_LEX_SKIP) {
73 | if (c == '\n') lip->yylineno++;
74 |
75 | lip->yySkip();
76 | }
77 |
78 | /* Start of real token */
79 | lip->restart_token();
80 | c = lip->yyGet();
81 | state = state_map[c];
82 | break;
83 | case MY_LEX_CHAR: // Unknown or single char token
84 | // ...
85 | // ...
86 | // ...
87 | }
88 | }
89 | }
90 | ```
91 |
92 | ## How TypeScript Does
93 |
94 | It is also worth to read the scanner in TypeScript, in which is [TypeScript/src/compiler/scanner.ts](https://github.com/Microsoft/TypeScript/blob/fbd6cad437390693e69707928896d7da620a803e/src/compiler/scanner.ts)
95 |
96 | !FILENAME TypeScript/src/compiler/scanner.ts
97 |
98 | ```ts
99 | // ...
100 | // ...
101 |
102 | // ...
103 | // ...
104 |
105 | const textToToken = createMapFromTemplate({
106 | ...textToKeywordObj,
107 | "{": SyntaxKind.OpenBraceToken,
108 | "}": SyntaxKind.CloseBraceToken,
109 | "(": SyntaxKind.OpenParenToken,
110 | ")": SyntaxKind.CloseParenToken,
111 | "[": SyntaxKind.OpenBracketToken,
112 | "]": SyntaxKind.CloseBracketToken,
113 | ".": SyntaxKind.DotToken,
114 | "...": SyntaxKind.DotDotDotToken
115 | // ...
116 | // ...
117 | })
118 | // ...
119 | // ...
120 |
121 | // ...
122 | // ...
123 |
124 | // ...
125 | // ...
126 |
127 | // Creates a scanner over a (possibly unspecified) range of a piece of text.
128 | export function createScanner(languageVersion: ScriptTarget,
129 | skipTrivia: boolean,
130 | languageVariant = LanguageVariant.Standard,
131 | textInitial?: string,
132 | onError?: ErrorCallback,
133 | start?: number,
134 | length?: number): Scanner {
135 | let text = textInitial!;
136 |
137 | // Current position (end position of text of current token)
138 | let pos: number;
139 |
140 |
141 | // end of text
142 | let end: number;
143 |
144 | // Start position of whitespace before current token
145 | let startPos: number;
146 |
147 | // Start position of text of current token
148 | let tokenPos: number;
149 |
150 | let token: SyntaxKind;
151 | let tokenValue!: string;
152 | let tokenFlags: TokenFlags;
153 |
154 | let inJSDocType = 0;
155 |
156 | setText(text, start, length);
157 |
158 | return {
159 | getStartPos: () => startPos,
160 | getTextPos: () => pos,
161 | getToken: () => token,
162 | getTokenPos: () => tokenPos,
163 | getTokenText: () => text.substring(tokenPos, pos),
164 | getTokenValue: () => tokenValue,
165 | hasExtendedUnicodeEscape: () => (tokenFlags & TokenFlags.ExtendedUnicodeEscape) !== 0,
166 | hasPrecedingLineBreak: () => (tokenFlags & TokenFlags.PrecedingLineBreak) !== 0,
167 | isIdentifier: () => token === SyntaxKind.Identifier || token > SyntaxKind.LastReservedWord,
168 | isReservedWord: () => token >= SyntaxKind.FirstReservedWord && token <= SyntaxKind.LastReservedWord,
169 | isUnterminated: () => (tokenFlags & TokenFlags.Unterminated) !== 0,
170 | getTokenFlags: () => tokenFlags,
171 | reScanGreaterToken,
172 | reScanSlashToken,
173 | reScanTemplateToken,
174 | scanJsxIdentifier,
175 | scanJsxAttributeValue,
176 | reScanJsxToken,
177 | scanJsxToken,
178 | scanJSDocToken,
179 | scan,
180 | getText,
181 | setText,
182 | setScriptTarget,
183 | setLanguageVariant,
184 | setOnError,
185 | setTextPos,
186 | setInJSDocType,
187 | tryScan,
188 | lookAhead,
189 | scanRange,
190 | };
191 | // ...
192 | // ...
193 |
194 | // ...
195 | // ...
196 | // ...
197 | // ...
198 | ```
199 |
200 | Tomorrow I will start to implement the lexical scanner of StellarSQL.
201 |
--------------------------------------------------------------------------------
/days/6.md:
--------------------------------------------------------------------------------
1 | # 6: Client/Server Communication Implementation(2)
2 |
3 | 2018/10/21
4 |
5 | I have told you that I want to implement client/server communication two days ago. Unfortunately, I spend lots of hour for understanding `Tokio.rs` and `future`. So this is the part 2 of this topic.
6 |
7 | `Tokio.rs` is a framework based on `future`, and `future` makes writing asynchronous program easy.
8 |
9 | Asynchronous IO is always the most difficult part in an application, not to mention the fact that `Tokio.rs` is very new with few documents. Therefore, I need learn by programing, trying to make the code of `Tokio.rs` works.
10 |
11 | Finally, I have done the communication between client and server. So let's look at what I have written in StellarSQL.
12 |
13 | Each commits have their own meaning. I will explain the commits in order, and those commit also represent the process of my thoughts.
14 |
15 | ## Communication
16 |
17 | Think about how server and client communicate with each other, we talked there is a protocol doing that. A protocol could be HTTP or defined by ourselves. Protocols are based on TCP or UDP, and we will use TCP for DBMS due to the trait that TCP won't lose packets.
18 |
19 | Let's dig deeper for a communication.
20 |
21 | A client creates a socket and send some bytes to a server. The bytes are encode in the format of a protocol, which clients and server should all follow with. The server receive sockets and get bytes, and the server will parse the bytes to meaningful messages according to the protocol.
22 |
23 | Once the server get a message, which might be any commands, including searching, inserting, deleting, ect., the server will reply the result to client. In the same way, the server will give the answer in a response which is serialized by the protocol.
24 |
25 | ## Commits
26 |
27 | If you read this series after today for a long time, I believe most parts would be changed a lot. Though I am going to write down some code in the following part, you can check out commits if you like to read what the whole code looks like at this moment.
28 |
29 | These commits are done in today:
30 |
31 | - main: implement connection
32 | - connection: mod add `request` and `response`
33 | - response: enum Response and impl serialize
34 | - request: enum Request and impl parse
35 | - message: define struc and impl
36 |
37 | Or you can run the command to see the version in today:
38 |
39 | ```sh
40 | git checkout 569fd175824000d372370496949d487a87823a25
41 | ```
42 |
43 | ## Code
44 |
45 | Recall that we listen sockets and want to do `process()`
46 |
47 | !FILENAME src/main.rs
48 |
49 | ```rust
50 | let server = listener
51 | .incoming()
52 | .for_each(move |socket| {
53 | let addr = socket.peer_addr().unwrap();
54 | println!("New Connection: {}", addr);
55 |
56 | // Spawn a task to process the connection
57 | process(socket);
58 |
59 | Ok(())
60 | }).map_err(|err| {
61 | println!("accept error = {:?}", err);
62 | });
63 | ```
64 |
65 | The `process()` is doing the process of what I just talk about for communication above, and there are comments for explaining in the following snippet:
66 |
67 | !FILENAME src/main.rs
68 |
69 | ```rust
70 | fn process(socket: TcpStream) {
71 |
72 | // split socket into two parts
73 | let (reader, writer) = socket.split();
74 |
75 | // make stream bytes to a message
76 | let messages = message::new(BufReader::new(reader));
77 |
78 | // note the `move` keyword on the closure here which moves ownership
79 | // of the reference into the closure, which we'll need for spawning the
80 | // client below.
81 | //
82 | // The `map` function here means that we'll run some code for all
83 | // requests (lines) we receive from the client. The actual handling here
84 | // is pretty simple, first we parse the request and if it's valid we
85 | // generate a response.
86 | let responses =
87 | messages.map(move |message| match Request::parse(&message) {
88 | Ok(req) => req,
89 | Err(e) => return Response::Error { msg: e },
90 | });
91 |
92 | // At this point `responses` is a stream of `Response` types which we
93 | // now want to write back out to the client. To do that we use
94 | // `Stream::fold` to perform a loop here, serializing each response and
95 | // then writing it out to the client.
96 | let writes = responses.fold(writer, |writer, response| {
97 | let response = response.serialize().into_bytes();
98 | write_all(writer, response).map(|(w, _)| w)
99 | });
100 |
101 | // `spawn` this client to ensure it
102 | // runs concurrently with all other clients, for now ignoring any errors
103 | // that we see.
104 | let connection = writes.then(move |_| Ok(()));
105 |
106 | // Spawn the task. Internally, this submits the task to a thread pool.
107 | tokio::spawn(connection);
108 | }
109 | ```
110 |
111 | We see `message`, `response` and `request` in `main.rs`. These modules are defined in `connection` module.
112 |
113 | `message` is for parsing the stream into a `Message`, but I don't implement a well designed protocol. The `poll()` function will decode streams of each socket to messages, so we should implement our protocol here. Now it just see any "lines" sent from terminals entered by users as messages, so I delete `\n\r` in the function `poll()` (not showing here).
114 |
115 | Note that `impl Stream for Message` is needed if we want to use functions of `future` crate and spawn the task to thread pool. (Remember `Tokio.rs` is based on `future`?)
116 |
117 | !FILENAME src/connection/message.rs
118 |
119 | ```rust
120 | pub struct Message { /* ... */}
121 |
122 | pub fn new(a: A) -> Message { /* ... */}
123 |
124 | impl Stream for Message {
125 | fn poll(&mut self) -> Poll, io::Error> {/* ... */}
126 | }
127 | ```
128 |
129 | `request` and `response` define the types of requests and responses. Just like HTTP, you send request in `get`, `post`, or `put`, and get response with `code` 200, 300, 400. These modules are doing the same thing.
130 |
131 | There should be many types in `Request`, but I don't do it yet. `request.parse()` will parse the request. In this step, it will check if the request is valid, such as authentication, and then return the response. The logic here might changed, because some logic could be better.
132 |
133 | !FILENAME src/connection/request.rs
134 |
135 | ```rust
136 | use Response;
137 |
138 | pub enum Request {}
139 |
140 | impl Request {
141 | pub fn parse(input: &str) -> Result {
142 | Ok(Response::OK {
143 | msg: input.to_string(),
144 | })
145 | }
146 | }
147 | ```
148 |
149 | `Response` defines all response types, and it can `serialize()` the `Response` in order to send back to the client. There will be more types, and `serialize()` will follow the protocol.
150 |
151 | !FILENAME src/connection/response.rs
152 |
153 | ```rust
154 | pub enum Response {
155 | OK { msg: String },
156 | Error { msg: String },
157 | }
158 |
159 | impl Response {
160 | pub fn serialize(&self) -> String {
161 | match *self {
162 | Response::OK { ref msg } => format!("{}\n", msg),
163 | Response::Error { ref msg } => format!("Error: {}\n", msg),
164 | }
165 | }
166 | }
167 | ```
168 |
169 | So, the communication works. Clients can connect to StellarSQL. Now StellarSQL just echoes the request to response. When I finish the database and SQL parts, it will be a real DBMS.
170 |
171 | You can build and run with:
172 |
173 | ```sh
174 | cargo run
175 | ```
176 |
177 | then open another terminal run the command, and put any words:
178 |
179 | ```sh
180 | # A client connect to localhost 23333
181 | telnet localhost 23333
182 | ```
183 |
184 | StellarSQL will echoes what you enter. :)
185 |
--------------------------------------------------------------------------------