├── output.png
├── AzureSearchOCR
├── AzureSearchOCR
│ ├── pdf
│ │ └── sample.pdf
│ ├── DataModel.cs
│ ├── App.config
│ ├── packages.config
│ ├── Properties
│ │ └── AssemblyInfo.cs
│ ├── AzureSearch.cs
│ ├── AzureSearchOCR.csproj
│ ├── Program.cs
│ ├── VisionHelper.cs
│ └── ImageExtractor.cs
├── AzureSearchOCRwithKeywordExtraction
│ ├── pdf
│ │ └── sample.pdf
│ ├── DataModel.cs
│ ├── packages.config
│ ├── App.config
│ ├── Properties
│ │ └── AssemblyInfo.cs
│ ├── AzureSearch.cs
│ ├── AzureSearchOCRwithKeywordExtraction.csproj
│ ├── TextExtractionHelper.cs
│ ├── Program.cs
│ ├── VisionHelper.cs
│ └── ImageExtractor.cs
└── AzureSearchOCR.sln
├── LICENSE
├── README.md
└── .gitignore
/output.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tikyau/AzureSearchOCR/master/output.png
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/pdf/sample.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tikyau/AzureSearchOCR/master/AzureSearchOCR/AzureSearchOCR/pdf/sample.pdf
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/pdf/sample.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tikyau/AzureSearchOCR/master/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/pdf/sample.pdf
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/DataModel.cs:
--------------------------------------------------------------------------------
1 | using Microsoft.Azure.Search.Models;
2 | using System;
3 | using System.Collections.Generic;
4 | using System.Linq;
5 | using System.Text;
6 | using System.Threading.Tasks;
7 |
8 | namespace AzureSearchOCR
9 | {
10 | [SerializePropertyNamesAsCamelCase]
11 | public class OCRTextIndex
12 | {
13 | public string fileId { get; set; }
14 |
15 | public string fileName { get; set; }
16 |
17 | public string ocrText { get; set; }
18 |
19 | }
20 | }
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/DataModel.cs:
--------------------------------------------------------------------------------
1 | using Microsoft.Azure.Search.Models;
2 | using System;
3 | using System.Collections.Generic;
4 | using System.Linq;
5 | using System.Text;
6 | using System.Threading.Tasks;
7 |
8 | namespace AzureSearchOCRwithKeywordExtraction
9 | {
10 | [SerializePropertyNamesAsCamelCase]
11 | public class OCRTextIndex
12 | {
13 | public string fileId { get; set; }
14 |
15 | public string fileName { get; set; }
16 |
17 | public string ocrText { get; set; }
18 |
19 | public string[] keyPhrases { get; set; }
20 |
21 | }
22 | }
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/App.config:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/packages.config:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/packages.config:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/App.config:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | The MIT License (MIT)
2 |
3 | Copyright (c) 2016 Liam Cavanagh
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/Properties/AssemblyInfo.cs:
--------------------------------------------------------------------------------
1 | using System.Reflection;
2 | using System.Runtime.CompilerServices;
3 | using System.Runtime.InteropServices;
4 |
5 | // General Information about an assembly is controlled through the following
6 | // set of attributes. Change these attribute values to modify the information
7 | // associated with an assembly.
8 | [assembly: AssemblyTitle("AzureSearchOCR")]
9 | [assembly: AssemblyDescription("")]
10 | [assembly: AssemblyConfiguration("")]
11 | [assembly: AssemblyCompany("")]
12 | [assembly: AssemblyProduct("AzureSearchOCR")]
13 | [assembly: AssemblyCopyright("Copyright © 2016")]
14 | [assembly: AssemblyTrademark("")]
15 | [assembly: AssemblyCulture("")]
16 |
17 | // Setting ComVisible to false makes the types in this assembly not visible
18 | // to COM components. If you need to access a type in this assembly from
19 | // COM, set the ComVisible attribute to true on that type.
20 | [assembly: ComVisible(false)]
21 |
22 | // The following GUID is for the ID of the typelib if this project is exposed to COM
23 | [assembly: Guid("d4d3696d-1c16-4d8f-a952-34c36e314ff5")]
24 |
25 | // Version information for an assembly consists of the following four values:
26 | //
27 | // Major Version
28 | // Minor Version
29 | // Build Number
30 | // Revision
31 | //
32 | // You can specify all the values or you can default the Build and Revision Numbers
33 | // by using the '*' as shown below:
34 | // [assembly: AssemblyVersion("1.0.*")]
35 | [assembly: AssemblyVersion("1.0.0.0")]
36 | [assembly: AssemblyFileVersion("1.0.0.0")]
37 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/Properties/AssemblyInfo.cs:
--------------------------------------------------------------------------------
1 | using System.Reflection;
2 | using System.Runtime.CompilerServices;
3 | using System.Runtime.InteropServices;
4 |
5 | // General Information about an assembly is controlled through the following
6 | // set of attributes. Change these attribute values to modify the information
7 | // associated with an assembly.
8 | [assembly: AssemblyTitle("AzureSearchOCRwithKeywordExtraction")]
9 | [assembly: AssemblyDescription("")]
10 | [assembly: AssemblyConfiguration("")]
11 | [assembly: AssemblyCompany("")]
12 | [assembly: AssemblyProduct("AzureSearchOCRwithKeywordExtraction")]
13 | [assembly: AssemblyCopyright("Copyright © 2016")]
14 | [assembly: AssemblyTrademark("")]
15 | [assembly: AssemblyCulture("")]
16 |
17 | // Setting ComVisible to false makes the types in this assembly not visible
18 | // to COM components. If you need to access a type in this assembly from
19 | // COM, set the ComVisible attribute to true on that type.
20 | [assembly: ComVisible(false)]
21 |
22 | // The following GUID is for the ID of the typelib if this project is exposed to COM
23 | [assembly: Guid("36c9d113-34ae-4690-a54f-bc754b0f6bc6")]
24 |
25 | // Version information for an assembly consists of the following four values:
26 | //
27 | // Major Version
28 | // Minor Version
29 | // Build Number
30 | // Revision
31 | //
32 | // You can specify all the values or you can default the Build and Revision Numbers
33 | // by using the '*' as shown below:
34 | // [assembly: AssemblyVersion("1.0.*")]
35 | [assembly: AssemblyVersion("1.0.0.0")]
36 | [assembly: AssemblyFileVersion("1.0.0.0")]
37 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR.sln:
--------------------------------------------------------------------------------
1 |
2 | Microsoft Visual Studio Solution File, Format Version 12.00
3 | # Visual Studio 2013
4 | VisualStudioVersion = 12.0.31101.0
5 | MinimumVisualStudioVersion = 10.0.40219.1
6 | Project("{FAE04EC0-301F-11D3-BF4B-00C04F79EFBC}") = "AzureSearchOCR", "AzureSearchOCR\AzureSearchOCR.csproj", "{9D100F4D-BA20-49F6-A080-79908F8E7D76}"
7 | EndProject
8 | Project("{FAE04EC0-301F-11D3-BF4B-00C04F79EFBC}") = "AzureSearchOCRwithKeywordExtraction", "AzureSearchOCRwithKeywordExtraction\AzureSearchOCRwithKeywordExtraction.csproj", "{5CE9F461-CAB2-4476-8E37-92BDDF0DF95C}"
9 | EndProject
10 | Global
11 | GlobalSection(SolutionConfigurationPlatforms) = preSolution
12 | Debug|Any CPU = Debug|Any CPU
13 | Release|Any CPU = Release|Any CPU
14 | EndGlobalSection
15 | GlobalSection(ProjectConfigurationPlatforms) = postSolution
16 | {9D100F4D-BA20-49F6-A080-79908F8E7D76}.Debug|Any CPU.ActiveCfg = Debug|Any CPU
17 | {9D100F4D-BA20-49F6-A080-79908F8E7D76}.Debug|Any CPU.Build.0 = Debug|Any CPU
18 | {9D100F4D-BA20-49F6-A080-79908F8E7D76}.Release|Any CPU.ActiveCfg = Release|Any CPU
19 | {9D100F4D-BA20-49F6-A080-79908F8E7D76}.Release|Any CPU.Build.0 = Release|Any CPU
20 | {5CE9F461-CAB2-4476-8E37-92BDDF0DF95C}.Debug|Any CPU.ActiveCfg = Debug|Any CPU
21 | {5CE9F461-CAB2-4476-8E37-92BDDF0DF95C}.Debug|Any CPU.Build.0 = Debug|Any CPU
22 | {5CE9F461-CAB2-4476-8E37-92BDDF0DF95C}.Release|Any CPU.ActiveCfg = Release|Any CPU
23 | {5CE9F461-CAB2-4476-8E37-92BDDF0DF95C}.Release|Any CPU.Build.0 = Release|Any CPU
24 | EndGlobalSection
25 | GlobalSection(SolutionProperties) = preSolution
26 | HideSolutionNode = FALSE
27 | EndGlobalSection
28 | EndGlobal
29 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | services: search
3 | platforms: dotnet
4 | author: liamca
5 | ---
6 |
7 | # Azure Search Optical Character Recognition Sample (OCR)
8 |
9 | This is a sample of how to leverage Optical Character Recognition (OCR) to extract text from images to enable Full Text Search over it, from within Azure Search. In this sample, we take the [following PDF](https://github.com/liamca/AzureSearchOCR/blob/master/AzureSearchOCR/AzureSearchOCR/pdf/sample.pdf) that has an embedded image, extract any of the images within the PDF using [iTextSharp](https://www.nuget.org/packages/iTextSharp/), apply OCR to extract the text using [Project Oxford's Vision API](https://www.projectoxford.ai/vision), and then upload the resulting text to an Azure Search index.
10 |
11 | Once the text is uploaded to Azure Search, we can then do full text search over the text in the images.
12 |
13 | 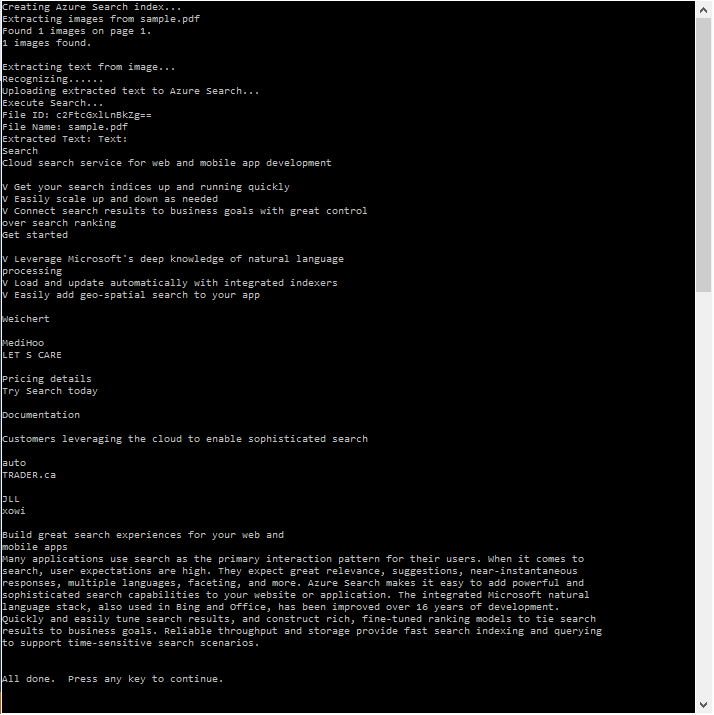
14 |
15 | ## Requirements
16 |
17 | Here are some things that you will need to run this sample:
18 | * **Project Oxford Vision API** which you can get [from here](https://www.projectoxford.ai/vision)
19 | * **Azure Search** Service and subscription. You might want to simply create one of the [free Azure Search service](https://azure.microsoft.com/en-us/pricing/details/search/)
20 |
21 | ## Special Thanks
22 | Special thanks to Jerome Viveiros who wrote a great sample on how to use iTextSharp on [his blog](https://psycodedeveloper.wordpress.com/2013/01/10/how-to-extract-images-from-pdf-files-using-c-and-itextsharp/) which formed a basis of much of what I used in my sample that extracts the images from the PDF file.
23 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/AzureSearch.cs:
--------------------------------------------------------------------------------
1 | using Microsoft.Azure.Search;
2 | using Microsoft.Azure.Search.Models;
3 | using System;
4 | using System.Collections.Generic;
5 | using System.Configuration;
6 | using System.Linq;
7 | using System.Text;
8 | using System.Threading.Tasks;
9 |
10 | namespace AzureSearchOCR
11 | {
12 | public class AzureSearch
13 | {
14 | public static void CreateIndex(SearchServiceClient serviceClient, string indexName)
15 | {
16 |
17 | if (serviceClient.Indexes.Exists(indexName))
18 | {
19 | serviceClient.Indexes.Delete(indexName);
20 | }
21 |
22 | var definition = new Index()
23 | {
24 | Name = indexName,
25 | Fields = new[]
26 | {
27 | new Field("fileId", DataType.String) { IsKey = true },
28 | new Field("fileName", DataType.String) { IsSearchable = true, IsFilterable = false, IsSortable = false, IsFacetable = false },
29 | new Field("ocrText", DataType.String) { IsSearchable = true, IsFilterable = false, IsSortable = false, IsFacetable = false }
30 | }
31 | };
32 |
33 | serviceClient.Indexes.Create(definition);
34 | }
35 |
36 | public static void UploadDocuments(SearchIndexClient indexClient, string fileId, string fileName, string ocrText)
37 | {
38 | List indexOperations = new List();
39 | var doc = new Document();
40 | doc.Add("fileId", fileId);
41 | doc.Add("fileName", fileName);
42 | doc.Add("ocrText", ocrText);
43 | indexOperations.Add(IndexAction.Upload(doc));
44 |
45 | try
46 | {
47 | indexClient.Documents.Index(new IndexBatch(indexOperations));
48 | }
49 | catch (IndexBatchException e)
50 | {
51 | // Sometimes when your Search service is under load, indexing will fail for some of the documents in
52 | // the batch. Depending on your application, you can take compensating actions like delaying and
53 | // retrying. For this simple demo, we just log the failed document keys and continue.
54 | Console.WriteLine(
55 | "Failed to index some of the documents: {0}",
56 | String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key)));
57 | }
58 |
59 | }
60 |
61 |
62 | public static void SearchDocuments(SearchIndexClient indexClient, string searchText)
63 | {
64 | // Search using the supplied searchText and output documents that match
65 | try
66 | {
67 | var sp = new SearchParameters();
68 |
69 | DocumentSearchResult response = indexClient.Documents.Search(searchText, sp);
70 | foreach (SearchResult result in response.Results)
71 | {
72 | Console.WriteLine("File ID: {0}", result.Document.fileId);
73 | Console.WriteLine("File Name: {0}", result.Document.fileName);
74 | Console.WriteLine("Extracted Text: {0}", result.Document.ocrText);
75 | }
76 | }
77 | catch (Exception e)
78 | {
79 | Console.WriteLine("Failed search: {0}", e.Message.ToString());
80 | }
81 |
82 | }
83 |
84 | }
85 | }
86 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/AzureSearch.cs:
--------------------------------------------------------------------------------
1 | using Microsoft.Azure.Search;
2 | using Microsoft.Azure.Search.Models;
3 | using System;
4 | using System.Collections.Generic;
5 | using System.Configuration;
6 | using System.Linq;
7 | using System.Text;
8 | using System.Threading.Tasks;
9 |
10 | namespace AzureSearchOCRwithKeywordExtraction
11 | {
12 | public class AzureSearch
13 | {
14 | public static void CreateIndex(SearchServiceClient serviceClient, string indexName)
15 | {
16 |
17 | if (serviceClient.Indexes.Exists(indexName))
18 | {
19 | serviceClient.Indexes.Delete(indexName);
20 | }
21 |
22 | var definition = new Index()
23 | {
24 | Name = indexName,
25 | Fields = new[]
26 | {
27 | new Field("fileId", DataType.String) { IsKey = true },
28 | new Field("fileName", DataType.String) { IsSearchable = true, IsFilterable = false, IsSortable = false, IsFacetable = false },
29 | new Field("ocrText", DataType.String) { IsSearchable = true, IsFilterable = false, IsSortable = false, IsFacetable = false },
30 | new Field("keyPhrases", DataType.Collection(DataType.String)) { IsSearchable = true, IsFilterable = true, IsFacetable = true }
31 | }
32 | };
33 |
34 | serviceClient.Indexes.Create(definition);
35 | }
36 |
37 | public static void UploadDocuments(SearchIndexClient indexClient, string fileId, string fileName, string ocrText, KeyPhraseResult keyPhraseResult)
38 | {
39 | List indexOperations = new List();
40 | var doc = new Document();
41 | doc.Add("fileId", fileId);
42 | doc.Add("fileName", fileName);
43 | doc.Add("ocrText", ocrText);
44 | doc.Add("keyPhrases", keyPhraseResult.KeyPhrases.ToList());
45 | indexOperations.Add(IndexAction.Upload(doc));
46 |
47 | try
48 | {
49 | indexClient.Documents.Index(new IndexBatch(indexOperations));
50 | }
51 | catch (IndexBatchException e)
52 | {
53 | // Sometimes when your Search service is under load, indexing will fail for some of the documents in
54 | // the batch. Depending on your application, you can take compensating actions like delaying and
55 | // retrying. For this simple demo, we just log the failed document keys and continue.
56 | Console.WriteLine(
57 | "Failed to index some of the documents: {0}",
58 | String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key)));
59 | }
60 |
61 | }
62 |
63 |
64 | public static void SearchDocuments(SearchIndexClient indexClient, string searchText)
65 | {
66 | // Search using the supplied searchText and output documents that match
67 | try
68 | {
69 | var sp = new SearchParameters();
70 |
71 | DocumentSearchResult response = indexClient.Documents.Search(searchText, sp);
72 | foreach (SearchResult result in response.Results)
73 | {
74 | Console.WriteLine("File ID: {0}", result.Document.fileId);
75 | Console.WriteLine("File Name: {0}", result.Document.fileName);
76 | Console.WriteLine("Extracted Text: {0}", result.Document.ocrText);
77 | Console.WriteLine("Key Phrases: {0}", string.Join(",", result.Document.keyPhrases));
78 |
79 | }
80 | }
81 | catch (Exception e)
82 | {
83 | Console.WriteLine("Failed search: {0}", e.Message.ToString());
84 | }
85 |
86 | }
87 |
88 | }
89 | }
90 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/AzureSearchOCRwithKeywordExtraction.csproj:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | Debug
6 | AnyCPU
7 | {5CE9F461-CAB2-4476-8E37-92BDDF0DF95C}
8 | Exe
9 | Properties
10 | AzureSearchOCRwithKeywordExtraction
11 | AzureSearchOCRwithKeywordExtraction
12 | v4.5
13 | 512
14 |
15 |
16 | AnyCPU
17 | true
18 | full
19 | false
20 | bin\Debug\
21 | DEBUG;TRACE
22 | prompt
23 | 4
24 |
25 |
26 | AnyCPU
27 | pdbonly
28 | true
29 | bin\Release\
30 | TRACE
31 | prompt
32 | 4
33 |
34 |
35 |
36 | ..\packages\iTextSharp.5.5.8\lib\itextsharp.dll
37 |
38 |
39 | ..\packages\Microsoft.Azure.Search.1.1.1\lib\net45\Microsoft.Azure.Search.dll
40 |
41 |
42 | ..\packages\Microsoft.ProjectOxford.Vision.0.5.0.1\lib\portable-net45+dnxcore50+wp80\Microsoft.ProjectOxford.Vision.dll
43 |
44 |
45 | ..\packages\Microsoft.Rest.ClientRuntime.1.8.1\lib\net45\Microsoft.Rest.ClientRuntime.dll
46 |
47 |
48 | ..\packages\Microsoft.Rest.ClientRuntime.Azure.2.5.2\lib\net45\Microsoft.Rest.ClientRuntime.Azure.dll
49 |
50 |
51 | ..\packages\Microsoft.Spatial.6.13.0\lib\portable-net40+sl5+wp8+win8+wpa\Microsoft.Spatial.dll
52 |
53 |
54 | ..\packages\Newtonsoft.Json.7.0.1\lib\net45\Newtonsoft.Json.dll
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 | PreserveNewest
84 |
85 |
86 |
87 |
94 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | ## Ignore Visual Studio temporary files, build results, and
2 | ## files generated by popular Visual Studio add-ons.
3 |
4 | # User-specific files
5 | *.suo
6 | *.user
7 | *.userosscache
8 | *.sln.docstates
9 |
10 | # User-specific files (MonoDevelop/Xamarin Studio)
11 | *.userprefs
12 |
13 | # Build results
14 | [Dd]ebug/
15 | [Dd]ebugPublic/
16 | [Rr]elease/
17 | [Rr]eleases/
18 | x64/
19 | x86/
20 | bld/
21 | [Bb]in/
22 | [Oo]bj/
23 |
24 | # Visual Studio 2015 cache/options directory
25 | .vs/
26 | # Uncomment if you have tasks that create the project's static files in wwwroot
27 | #wwwroot/
28 |
29 | # MSTest test Results
30 | [Tt]est[Rr]esult*/
31 | [Bb]uild[Ll]og.*
32 |
33 | # NUNIT
34 | *.VisualState.xml
35 | TestResult.xml
36 |
37 | # Build Results of an ATL Project
38 | [Dd]ebugPS/
39 | [Rr]eleasePS/
40 | dlldata.c
41 |
42 | # DNX
43 | project.lock.json
44 | artifacts/
45 |
46 | *_i.c
47 | *_p.c
48 | *_i.h
49 | *.ilk
50 | *.meta
51 | *.obj
52 | *.pch
53 | *.pdb
54 | *.pgc
55 | *.pgd
56 | *.rsp
57 | *.sbr
58 | *.tlb
59 | *.tli
60 | *.tlh
61 | *.tmp
62 | *.tmp_proj
63 | *.log
64 | *.vspscc
65 | *.vssscc
66 | .builds
67 | *.pidb
68 | *.svclog
69 | *.scc
70 |
71 | # Chutzpah Test files
72 | _Chutzpah*
73 |
74 | # Visual C++ cache files
75 | ipch/
76 | *.aps
77 | *.ncb
78 | *.opendb
79 | *.opensdf
80 | *.sdf
81 | *.cachefile
82 |
83 | # Visual Studio profiler
84 | *.psess
85 | *.vsp
86 | *.vspx
87 | *.sap
88 |
89 | # TFS 2012 Local Workspace
90 | $tf/
91 |
92 | # Guidance Automation Toolkit
93 | *.gpState
94 |
95 | # ReSharper is a .NET coding add-in
96 | _ReSharper*/
97 | *.[Rr]e[Ss]harper
98 | *.DotSettings.user
99 |
100 | # JustCode is a .NET coding add-in
101 | .JustCode
102 |
103 | # TeamCity is a build add-in
104 | _TeamCity*
105 |
106 | # DotCover is a Code Coverage Tool
107 | *.dotCover
108 |
109 | # NCrunch
110 | _NCrunch_*
111 | .*crunch*.local.xml
112 | nCrunchTemp_*
113 |
114 | # MightyMoose
115 | *.mm.*
116 | AutoTest.Net/
117 |
118 | # Web workbench (sass)
119 | .sass-cache/
120 |
121 | # Installshield output folder
122 | [Ee]xpress/
123 |
124 | # DocProject is a documentation generator add-in
125 | DocProject/buildhelp/
126 | DocProject/Help/*.HxT
127 | DocProject/Help/*.HxC
128 | DocProject/Help/*.hhc
129 | DocProject/Help/*.hhk
130 | DocProject/Help/*.hhp
131 | DocProject/Help/Html2
132 | DocProject/Help/html
133 |
134 | # Click-Once directory
135 | publish/
136 |
137 | # Publish Web Output
138 | *.[Pp]ublish.xml
139 | *.azurePubxml
140 | # TODO: Comment the next line if you want to checkin your web deploy settings
141 | # but database connection strings (with potential passwords) will be unencrypted
142 | *.pubxml
143 | *.publishproj
144 |
145 | # NuGet Packages
146 | *.nupkg
147 | # The packages folder can be ignored because of Package Restore
148 | **/packages/*
149 | # except build/, which is used as an MSBuild target.
150 | !**/packages/build/
151 | # Uncomment if necessary however generally it will be regenerated when needed
152 | #!**/packages/repositories.config
153 |
154 | # Microsoft Azure Build Output
155 | csx/
156 | *.build.csdef
157 |
158 | # Microsoft Azure Emulator
159 | ecf/
160 | rcf/
161 |
162 | # Microsoft Azure ApplicationInsights config file
163 | ApplicationInsights.config
164 |
165 | # Windows Store app package directory
166 | AppPackages/
167 | BundleArtifacts/
168 |
169 | # Visual Studio cache files
170 | # files ending in .cache can be ignored
171 | *.[Cc]ache
172 | # but keep track of directories ending in .cache
173 | !*.[Cc]ache/
174 |
175 | # Others
176 | ClientBin/
177 | ~$*
178 | *~
179 | *.dbmdl
180 | *.dbproj.schemaview
181 | *.pfx
182 | *.publishsettings
183 | node_modules/
184 | orleans.codegen.cs
185 |
186 | # RIA/Silverlight projects
187 | Generated_Code/
188 |
189 | # Backup & report files from converting an old project file
190 | # to a newer Visual Studio version. Backup files are not needed,
191 | # because we have git ;-)
192 | _UpgradeReport_Files/
193 | Backup*/
194 | UpgradeLog*.XML
195 | UpgradeLog*.htm
196 |
197 | # SQL Server files
198 | *.mdf
199 | *.ldf
200 |
201 | # Business Intelligence projects
202 | *.rdl.data
203 | *.bim.layout
204 | *.bim_*.settings
205 |
206 | # Microsoft Fakes
207 | FakesAssemblies/
208 |
209 | # GhostDoc plugin setting file
210 | *.GhostDoc.xml
211 |
212 | # Node.js Tools for Visual Studio
213 | .ntvs_analysis.dat
214 |
215 | # Visual Studio 6 build log
216 | *.plg
217 |
218 | # Visual Studio 6 workspace options file
219 | *.opt
220 |
221 | # Visual Studio LightSwitch build output
222 | **/*.HTMLClient/GeneratedArtifacts
223 | **/*.DesktopClient/GeneratedArtifacts
224 | **/*.DesktopClient/ModelManifest.xml
225 | **/*.Server/GeneratedArtifacts
226 | **/*.Server/ModelManifest.xml
227 | _Pvt_Extensions
228 |
229 | # Paket dependency manager
230 | .paket/paket.exe
231 |
232 | # FAKE - F# Make
233 | .fake/
234 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/AzureSearchOCR.csproj:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | Debug
6 | AnyCPU
7 | {9D100F4D-BA20-49F6-A080-79908F8E7D76}
8 | Exe
9 | Properties
10 | AzureSearchOCR
11 | AzureSearchOCR
12 | v4.5
13 | 512
14 | e47e02a0
15 |
16 |
17 | AnyCPU
18 | true
19 | full
20 | false
21 | bin\Debug\
22 | DEBUG;TRACE
23 | prompt
24 | 4
25 |
26 |
27 | AnyCPU
28 | pdbonly
29 | true
30 | bin\Release\
31 | TRACE
32 | prompt
33 | 4
34 |
35 |
36 |
37 | ..\packages\iTextSharp.5.5.8\lib\itextsharp.dll
38 |
39 |
40 | False
41 | ..\packages\Microsoft.Azure.Search.1.1.1\lib\net45\Microsoft.Azure.Search.dll
42 |
43 |
44 | ..\packages\Microsoft.ProjectOxford.Vision.0.5.0.1\lib\portable-net45+dnxcore50+wp80\Microsoft.ProjectOxford.Vision.dll
45 |
46 |
47 | ..\packages\Microsoft.Rest.ClientRuntime.1.8.1\lib\net45\Microsoft.Rest.ClientRuntime.dll
48 |
49 |
50 | ..\packages\Microsoft.Rest.ClientRuntime.Azure.2.5.2\lib\net45\Microsoft.Rest.ClientRuntime.Azure.dll
51 |
52 |
53 | False
54 | ..\packages\Microsoft.Spatial.6.15.0-beta\lib\portable-net40+sl5+wp8+win8+wpa\Microsoft.Spatial.dll
55 |
56 |
57 | False
58 | ..\packages\Newtonsoft.Json.8.0.3\lib\net45\Newtonsoft.Json.dll
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 | PreserveNewest
86 |
87 |
88 |
89 |
90 |
97 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/Program.cs:
--------------------------------------------------------------------------------
1 | // This sample will open a PDF file that includes an image where the image is then extracted,
2 | // sent to Project Oxford Vision API for OCR analysis. The resulting text is then sent to an
3 | // Azure Search index.
4 |
5 | // Sample Code used based from the PDF Image extraction sample provided by
6 | // https://psycodedeveloper.wordpress.com/2013/01/10/how-to-extract-images-from-pdf-files-using-c-and-itextsharp/
7 | // PDF Extraction done using iTextSharp
8 | // These libraries may have different licenses then those for this sample
9 |
10 | // Copyright (c) Microsoft. All rights reserved.
11 | // Licensed under the MIT license.
12 | //
13 | // Azure Search: http://azure.com
14 | // Project Oxford: http://ProjectOxford.ai
15 | //
16 | // Copyright (c) Microsoft Corporation
17 | // All rights reserved.
18 | //
19 | // MIT License:
20 | // Permission is hereby granted, free of charge, to any person obtaining
21 | // a copy of this software and associated documentation files (the
22 | // "Software"), to deal in the Software without restriction, including
23 | // without limitation the rights to use, copy, modify, merge, publish,
24 | // distribute, sublicense, and/or sell copies of the Software, and to
25 | // permit persons to whom the Software is furnished to do so, subject to
26 | // the following conditions:
27 | //
28 | // The above copyright notice and this permission notice shall be
29 | // included in all copies or substantial portions of the Software.
30 | //
31 | // THE SOFTWARE IS PROVIDED ""AS IS"", WITHOUT WARRANTY OF ANY KIND,
32 | // EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
33 | // MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
34 | // NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
35 | // LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
36 | // OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
37 | // WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
38 | //
39 |
40 | using AzureSearchOCR.AzureSearchOCR;
41 | using Microsoft.Azure.Search;
42 | using Microsoft.ProjectOxford.Vision.Contract;
43 | using System;
44 | using System.Configuration;
45 | using System.IO;
46 |
47 | namespace AzureSearchOCR
48 | {
49 | class Program
50 | {
51 | static string oxfordSubscriptionKey = ConfigurationManager.AppSettings["oxfordSubscriptionKey"];
52 | static string searchServiceName = ConfigurationManager.AppSettings["searchServiceName"];
53 | static string searchServiceAPIKey = ConfigurationManager.AppSettings["searchServiceAPIKey"];
54 | static string indexName = "ocrtest";
55 | static SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(searchServiceAPIKey));
56 | static SearchIndexClient indexClient = serviceClient.Indexes.GetClient(indexName);
57 | static VisionHelper vision = new VisionHelper(oxfordSubscriptionKey);
58 |
59 | static void Main(string[] args)
60 | {
61 | var searchPath = "pdf";
62 | var outPath = "image";
63 |
64 | // Note, this will create a new Azure Search Index for the OCR text
65 | Console.WriteLine("Creating Azure Search index...");
66 | AzureSearch.CreateIndex(serviceClient, indexName);
67 |
68 | // Creating an image directory
69 | if (Directory.Exists(outPath) == false)
70 | Directory.CreateDirectory(outPath);
71 |
72 | foreach (var filename in Directory.GetFiles(searchPath, "*.pdf", SearchOption.TopDirectoryOnly))
73 | {
74 | Console.WriteLine("Extracting images from {0}", System.IO.Path.GetFileName(filename));
75 | var images = PdfImageExtractor.ExtractImages(filename);
76 | Console.WriteLine("{0} images found.", images.Count);
77 | Console.WriteLine();
78 |
79 | var directory = System.IO.Path.GetDirectoryName(filename);
80 | foreach (var name in images.Keys)
81 | {
82 | //if there is a filetype save the file
83 | if (name.LastIndexOf(".") + 1 != name.Length)
84 | images[name].Save(System.IO.Path.Combine(outPath, name));
85 | }
86 |
87 | // Read in all the images and convert to text creating one big text string
88 | string ocrText = string.Empty;
89 | Console.WriteLine("Extracting text from image...");
90 | foreach (var imagefilename in Directory.GetFiles(outPath))
91 | {
92 | OcrResults ocr = vision.RecognizeText(imagefilename);
93 | ocrText += vision.GetRetrieveText(ocr);
94 | File.Delete(imagefilename);
95 | }
96 |
97 | // Take the resulting orcText and upload to a new Azure Search Index
98 | // It is highly recommended that you upload documents in batches rather
99 | // individually like is done here
100 | if (ocrText.Length > 0)
101 | {
102 | Console.WriteLine("Uploading extracted text to Azure Search...");
103 | string fileNameOnly = System.IO.Path.GetFileName(filename);
104 | string fileId = System.Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes(fileNameOnly));
105 | AzureSearch.UploadDocuments(indexClient, fileId, fileNameOnly, ocrText);
106 | }
107 |
108 | }
109 |
110 | // Execute a test search
111 | Console.WriteLine("Execute Search...");
112 | AzureSearch.SearchDocuments(indexClient, "Azure Search");
113 |
114 | Console.WriteLine("All done. Press any key to continue.");
115 | Console.ReadLine();
116 |
117 | }
118 | }
119 | }
120 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/TextExtractionHelper.cs:
--------------------------------------------------------------------------------
1 | using System;
2 | using System.Collections.Generic;
3 | using System.Linq;
4 | using System.Net.Http;
5 | using System.Net.Http.Headers;
6 | using System.Text;
7 | using System.Threading.Tasks;
8 | using System.Web;
9 | using Newtonsoft.Json;
10 | using System.Configuration; // get it from http://www.newtonsoft.com/json
11 | namespace AzureSearchOCRwithKeywordExtraction
12 | {
13 | ///
14 | /// This is a sample program that shows how to use the Azure ML Text Analytics app (https://datamarket.azure.com/dataset/amla/text-analytics)
15 | ///
16 | public class TextExtraction
17 | {
18 | private const string ServiceBaseUri = "https://api.datamarket.azure.com/";
19 | public static KeyPhraseResult ProcessText(string inputText)
20 | {
21 | string accountKey = ConfigurationManager.AppSettings["textExtractionAccountKey"];
22 | KeyPhraseResult keyPhraseResult = new KeyPhraseResult();
23 | using (var httpClient = new HttpClient())
24 | {
25 | string inputTextEncoded = HttpUtility.UrlEncode(inputText);
26 | httpClient.BaseAddress = new Uri(ServiceBaseUri);
27 | string creds = "AccountKey:" + accountKey;
28 | string authorizationHeader = "Basic " + Convert.ToBase64String(Encoding.ASCII.GetBytes(creds));
29 | httpClient.DefaultRequestHeaders.Add("Authorization", authorizationHeader);
30 | httpClient.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
31 | // get key phrases
32 | string keyPhrasesRequest = "data.ashx/amla/text-analytics/v1/GetKeyPhrases?Text=" + inputTextEncoded;
33 | Task responseTask = httpClient.GetAsync(keyPhrasesRequest);
34 | responseTask.Wait();
35 | HttpResponseMessage response = responseTask.Result;
36 | Task contentTask = response.Content.ReadAsStringAsync();
37 | contentTask.Wait();
38 | string content = contentTask.Result;
39 | if (!response.IsSuccessStatusCode)
40 | {
41 | throw new Exception("Call to get key phrases failed with HTTP status code: " +
42 | response.StatusCode + " and contents: " + content);
43 | }
44 | keyPhraseResult = JsonConvert.DeserializeObject(content);
45 | Console.WriteLine("Key phrases: {0} \r\n", string.Join(",", keyPhraseResult.KeyPhrases));
46 |
47 | // Uncomment the following if you want to retrieve additional details on this text
48 |
49 | //// get sentiment
50 | //string sentimentRequest = "data.ashx/amla/text-analytics/v1/GetSentiment?Text=" + inputTextEncoded;
51 | //responseTask = httpClient.GetAsync(sentimentRequest);
52 | //responseTask.Wait();
53 | //response = responseTask.Result;
54 | //contentTask = response.Content.ReadAsStringAsync();
55 | //contentTask.Wait();
56 | //content = contentTask.Result;
57 | //if (!response.IsSuccessStatusCode)
58 | //{
59 | // throw new Exception("Call to get sentiment failed with HTTP status code: " +
60 | // response.StatusCode + " and contents: " + content);
61 | //}
62 | //SentimentResult sentimentResult = JsonConvert.DeserializeObject(content);
63 | //Console.WriteLine("Sentiment score: " + sentimentResult.Score);
64 |
65 | //// get the language in text
66 | //string languageRequest = "data.ashx/amla/text-analytics/v1/GetLanguage?Text=" + inputTextEncoded;
67 | //responseTask = httpClient.GetAsync(languageRequest);
68 | //responseTask.Wait();
69 | //response = responseTask.Result;
70 | //contentTask = response.Content.ReadAsStringAsync();
71 | //contentTask.Wait();
72 | //content = contentTask.Result;
73 | //if (!response.IsSuccessStatusCode)
74 | //{
75 | // throw new Exception("Call to get language failed with HTTP status code: " +
76 | // response.StatusCode + " and contents: " + content);
77 | //}
78 | //LanguageResult languageResult = JsonConvert.DeserializeObject(content);
79 | //Console.WriteLine("Detected Languages: " + string.Join(",", languageResult.DetectedLanguages.Select(language => language.Name).ToArray()));
80 |
81 | }
82 | return keyPhraseResult;
83 | }
84 | }
85 | ///
86 | /// Class to hold result of Key Phrases call
87 | ///
88 | public class KeyPhraseResult
89 | {
90 | public List KeyPhrases { get; set; }
91 | }
92 | ///
93 | /// Class to hold result of Sentiment call
94 | ///
95 | public class SentimentResult
96 | {
97 | public double Score { get; set; }
98 | }
99 |
100 | ///
101 | /// Class to hold result of Language detection call
102 | ///
103 | public class LanguageResult
104 | {
105 | public bool UnknownLanguage { get; set; }
106 | public IList DetectedLanguages { get; set; }
107 | }
108 | ///
109 | /// Class to hold information about a single detected language
110 | ///
111 | public class DetectedLanguage
112 | {
113 | public string Name { get; set; }
114 |
115 | ///
116 | /// This is the short ISO 639-1 standard form of representing
117 | /// all languages. The short form is a 2 letter representation of the language.
118 | /// en = English, fr = French for example
119 | ///
120 | public string Iso6391Name { get; set; }
121 | public double Score { get; set; }
122 | }
123 | }
124 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/Program.cs:
--------------------------------------------------------------------------------
1 | // This sample will open a PDF file that includes an image where the image is then extracted,
2 | // sent to Project Oxford Vision API for OCR analysis. The resulting text is then sent to an
3 | // Azure Search index.
4 |
5 | // Sample Code used based from the PDF Image extraction sample provided by
6 | // https://psycodedeveloper.wordpress.com/2013/01/10/how-to-extract-images-from-pdf-files-using-c-and-itextsharp/
7 | // PDF Extraction done using iTextSharp
8 | // These libraries may have different licenses then those for this sample
9 |
10 | // Copyright (c) Microsoft. All rights reserved.
11 | // Licensed under the MIT license.
12 | //
13 | // Azure Search: http://azure.com
14 | // Project Oxford: http://ProjectOxford.ai
15 | //
16 | // Copyright (c) Microsoft Corporation
17 | // All rights reserved.
18 | //
19 | // MIT License:
20 | // Permission is hereby granted, free of charge, to any person obtaining
21 | // a copy of this software and associated documentation files (the
22 | // "Software"), to deal in the Software without restriction, including
23 | // without limitation the rights to use, copy, modify, merge, publish,
24 | // distribute, sublicense, and/or sell copies of the Software, and to
25 | // permit persons to whom the Software is furnished to do so, subject to
26 | // the following conditions:
27 | //
28 | // The above copyright notice and this permission notice shall be
29 | // included in all copies or substantial portions of the Software.
30 | //
31 | // THE SOFTWARE IS PROVIDED ""AS IS"", WITHOUT WARRANTY OF ANY KIND,
32 | // EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
33 | // MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
34 | // NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
35 | // LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
36 | // OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
37 | // WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
38 | //
39 |
40 | using AzureSearchOCRwithKeywordExtraction.AzureSearchOCR;
41 | using Microsoft.Azure.Search;
42 | using Microsoft.ProjectOxford.Vision.Contract;
43 | using System;
44 | using System.Configuration;
45 | using System.IO;
46 |
47 | namespace AzureSearchOCRwithKeywordExtraction
48 | {
49 | class Program
50 | {
51 | static string oxfordSubscriptionKey = ConfigurationManager.AppSettings["oxfordSubscriptionKey"];
52 | static string searchServiceName = ConfigurationManager.AppSettings["searchServiceName"];
53 | static string searchServiceAPIKey = ConfigurationManager.AppSettings["searchServiceAPIKey"];
54 | static string indexName = "ocrtest";
55 | static SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(searchServiceAPIKey));
56 | static SearchIndexClient indexClient = serviceClient.Indexes.GetClient(indexName);
57 | static VisionHelper vision = new VisionHelper(oxfordSubscriptionKey);
58 |
59 | static void Main(string[] args)
60 | {
61 | var searchPath = "pdf";
62 | var outPath = "image";
63 |
64 | // Note, this will create a new Azure Search Index for the OCR text
65 | Console.WriteLine("Creating Azure Search index...");
66 | AzureSearch.CreateIndex(serviceClient, indexName);
67 |
68 | // Creating an image directory
69 | if (Directory.Exists(outPath) == false)
70 | Directory.CreateDirectory(outPath);
71 |
72 | foreach (var filename in Directory.GetFiles(searchPath, "*.pdf", SearchOption.TopDirectoryOnly))
73 | {
74 | Console.WriteLine("Extracting images from {0} \r\n", System.IO.Path.GetFileName(filename));
75 | var images = PdfImageExtractor.ExtractImages(filename);
76 | Console.WriteLine("{0} images found.", images.Count);
77 | Console.WriteLine();
78 |
79 | var directory = System.IO.Path.GetDirectoryName(filename);
80 | foreach (var name in images.Keys)
81 | {
82 | //if there is a filetype save the file
83 | if (name.LastIndexOf(".") + 1 != name.Length)
84 | images[name].Save(System.IO.Path.Combine(outPath, name));
85 | }
86 |
87 | // Read in all the images and convert to text creating one big text string
88 | string ocrText = string.Empty;
89 | Console.WriteLine("Extracting text from image... \r\n");
90 | foreach (var imagefilename in Directory.GetFiles(outPath))
91 | {
92 | OcrResults ocr = vision.RecognizeText(imagefilename);
93 | ocrText += vision.GetRetrieveText(ocr);
94 | File.Delete(imagefilename);
95 | }
96 |
97 | // Taking the ocrText we will now apply the Machine Learning Text Extraction to
98 | // retrieve only the key phrases
99 | Console.WriteLine("Extracting key phrases from processed text... \r\n");
100 | KeyPhraseResult keyPhraseResult = TextExtraction.ProcessText(ocrText);
101 |
102 | // Take the resulting orcText and upload to a new Azure Search Index
103 | // It is highly recommended that you upload documents in batches rather
104 | // individually like is done here
105 | if (ocrText.Length > 0)
106 | {
107 | Console.WriteLine("Uploading extracted text to Azure Search...\r\n");
108 | string fileNameOnly = System.IO.Path.GetFileName(filename);
109 | string fileId = System.Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes(fileNameOnly));
110 | AzureSearch.UploadDocuments(indexClient, fileId, fileNameOnly, ocrText, keyPhraseResult);
111 | }
112 |
113 | }
114 |
115 | // Execute a test search
116 | Console.WriteLine("Execute Search...");
117 | AzureSearch.SearchDocuments(indexClient, "Azure Search");
118 |
119 | Console.WriteLine("All done. Press any key to continue.");
120 | Console.ReadLine();
121 |
122 | }
123 | }
124 | }
125 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/VisionHelper.cs:
--------------------------------------------------------------------------------
1 | using System;
2 | using System.Collections.Generic;
3 | using System.Linq;
4 | using System.Text;
5 | using System.Threading.Tasks;
6 |
7 | namespace AzureSearchOCR
8 | {
9 | //
10 | // Copyright (c) Microsoft. All rights reserved.
11 | // Licensed under the MIT license.
12 | //
13 | // Project Oxford: http://ProjectOxford.ai
14 | //
15 | // ProjectOxford SDK Github:
16 | // https://github.com/Microsoft/ProjectOxfordSDK-Windows
17 | //
18 | // Copyright (c) Microsoft Corporation
19 | // All rights reserved.
20 | //
21 | // MIT License:
22 | // Permission is hereby granted, free of charge, to any person obtaining
23 | // a copy of this software and associated documentation files (the
24 | // "Software"), to deal in the Software without restriction, including
25 | // without limitation the rights to use, copy, modify, merge, publish,
26 | // distribute, sublicense, and/or sell copies of the Software, and to
27 | // permit persons to whom the Software is furnished to do so, subject to
28 | // the following conditions:
29 | //
30 | // The above copyright notice and this permission notice shall be
31 | // included in all copies or substantial portions of the Software.
32 | //
33 | // THE SOFTWARE IS PROVIDED ""AS IS"", WITHOUT WARRANTY OF ANY KIND,
34 | // EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
35 | // MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
36 | // NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
37 | // LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
38 | // OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
39 | // WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
40 | //
41 |
42 | using System;
43 | using System.IO;
44 | using System.Text;
45 |
46 | using Microsoft.ProjectOxford.Vision;
47 | using Microsoft.ProjectOxford.Vision.Contract;
48 |
49 | namespace AzureSearchOCR
50 | {
51 |
52 | ///
53 | /// The class is used to access vision APIs.
54 | ///
55 | public class VisionHelper
56 | {
57 | ///
58 | /// The vision service client.
59 | ///
60 | private readonly IVisionServiceClient visionClient;
61 |
62 | ///
63 | /// Initializes a new instance of the class.
64 | ///
65 | /// The subscription key.
66 | public VisionHelper(string subscriptionKey)
67 | {
68 | this.visionClient = new VisionServiceClient(subscriptionKey);
69 | }
70 |
71 | ///
72 | /// Recognize text from given image.
73 | ///
74 | /// The image path or url.
75 | /// if set to true [detect orientation].
76 | /// The language code.
77 | public OcrResults RecognizeText(string imagePathOrUrl, bool detectOrientation = true, string languageCode = LanguageCodes.AutoDetect)
78 | {
79 | this.ShowInfo("Recognizing");
80 | OcrResults ocrResult = null;
81 | string resultStr = string.Empty;
82 |
83 | try
84 | {
85 | if (File.Exists(imagePathOrUrl))
86 | {
87 | using (FileStream stream = File.Open(imagePathOrUrl, FileMode.Open))
88 | {
89 | ocrResult = this.visionClient.RecognizeTextAsync(stream, languageCode, detectOrientation).Result;
90 | }
91 | }
92 | else
93 | {
94 | this.ShowError("Invalid image path or Url");
95 | }
96 | }
97 | catch (ClientException e)
98 | {
99 | if (e.Error != null)
100 | {
101 | this.ShowError(e.Error.Message);
102 | }
103 | else
104 | {
105 | this.ShowError(e.Message);
106 | }
107 |
108 | return null;
109 | }
110 | catch (Exception ex)
111 | {
112 | this.ShowError("Error: " + ex.Message.ToString());
113 | return null;
114 | }
115 |
116 | return ocrResult;
117 | }
118 |
119 |
120 | ///
121 | /// Retrieve text from the given OCR results object.
122 | ///
123 | /// The OCR results.
124 | /// Return the text.
125 | public string GetRetrieveText(OcrResults results)
126 | {
127 | StringBuilder stringBuilder = new StringBuilder();
128 |
129 | if (results != null && results.Regions != null)
130 | {
131 | stringBuilder.Append("Text: ");
132 | stringBuilder.AppendLine();
133 | foreach (var item in results.Regions)
134 | {
135 | foreach (var line in item.Lines)
136 | {
137 | foreach (var word in line.Words)
138 | {
139 | stringBuilder.Append(word.Text);
140 | stringBuilder.Append(" ");
141 | }
142 |
143 | stringBuilder.AppendLine();
144 | }
145 |
146 | stringBuilder.AppendLine();
147 | }
148 | }
149 |
150 | return stringBuilder.ToString();
151 | }
152 |
153 | ///
154 | /// Show the working item.
155 | ///
156 | /// The work item's string.
157 | private void ShowInfo(string workStr)
158 | {
159 | Console.WriteLine(string.Format("{0}......", workStr));
160 | Console.ResetColor();
161 | }
162 |
163 | ///
164 | /// Show error message.
165 | ///
166 | /// The error message.
167 | private void ShowError(string errorMessage)
168 | {
169 | Console.ForegroundColor = ConsoleColor.Red;
170 | Console.WriteLine(errorMessage);
171 | Console.ResetColor();
172 | }
173 |
174 | ///
175 | /// Show result message.
176 | ///
177 | /// The result message.
178 | private void ShowResult(string resultMessage)
179 | {
180 | Console.ForegroundColor = ConsoleColor.Green;
181 | Console.WriteLine(resultMessage);
182 | Console.ResetColor();
183 | }
184 |
185 | }
186 | }
187 | }
188 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/VisionHelper.cs:
--------------------------------------------------------------------------------
1 | using System;
2 | using System.Collections.Generic;
3 | using System.Linq;
4 | using System.Text;
5 | using System.Threading.Tasks;
6 |
7 | namespace AzureSearchOCRwithKeywordExtraction
8 | {
9 | //
10 | // Copyright (c) Microsoft. All rights reserved.
11 | // Licensed under the MIT license.
12 | //
13 | // Project Oxford: http://ProjectOxford.ai
14 | //
15 | // ProjectOxford SDK Github:
16 | // https://github.com/Microsoft/ProjectOxfordSDK-Windows
17 | //
18 | // Copyright (c) Microsoft Corporation
19 | // All rights reserved.
20 | //
21 | // MIT License:
22 | // Permission is hereby granted, free of charge, to any person obtaining
23 | // a copy of this software and associated documentation files (the
24 | // "Software"), to deal in the Software without restriction, including
25 | // without limitation the rights to use, copy, modify, merge, publish,
26 | // distribute, sublicense, and/or sell copies of the Software, and to
27 | // permit persons to whom the Software is furnished to do so, subject to
28 | // the following conditions:
29 | //
30 | // The above copyright notice and this permission notice shall be
31 | // included in all copies or substantial portions of the Software.
32 | //
33 | // THE SOFTWARE IS PROVIDED ""AS IS"", WITHOUT WARRANTY OF ANY KIND,
34 | // EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
35 | // MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
36 | // NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
37 | // LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
38 | // OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
39 | // WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
40 | //
41 |
42 | using System;
43 | using System.IO;
44 | using System.Text;
45 |
46 | using Microsoft.ProjectOxford.Vision;
47 | using Microsoft.ProjectOxford.Vision.Contract;
48 |
49 | namespace AzureSearchOCR
50 | {
51 |
52 | ///
53 | /// The class is used to access vision APIs.
54 | ///
55 | public class VisionHelper
56 | {
57 | ///
58 | /// The vision service client.
59 | ///
60 | private readonly IVisionServiceClient visionClient;
61 |
62 | ///
63 | /// Initializes a new instance of the class.
64 | ///
65 | /// The subscription key.
66 | public VisionHelper(string subscriptionKey)
67 | {
68 | this.visionClient = new VisionServiceClient(subscriptionKey);
69 | }
70 |
71 | ///
72 | /// Recognize text from given image.
73 | ///
74 | /// The image path or url.
75 | /// if set to true [detect orientation].
76 | /// The language code.
77 | public OcrResults RecognizeText(string imagePathOrUrl, bool detectOrientation = true, string languageCode = LanguageCodes.AutoDetect)
78 | {
79 | this.ShowInfo("Recognizing");
80 | OcrResults ocrResult = null;
81 | string resultStr = string.Empty;
82 |
83 | try
84 | {
85 | if (File.Exists(imagePathOrUrl))
86 | {
87 | using (FileStream stream = File.Open(imagePathOrUrl, FileMode.Open))
88 | {
89 | ocrResult = this.visionClient.RecognizeTextAsync(stream, languageCode, detectOrientation).Result;
90 | }
91 | }
92 | else
93 | {
94 | this.ShowError("Invalid image path or Url");
95 | }
96 | }
97 | catch (ClientException e)
98 | {
99 | if (e.Error != null)
100 | {
101 | this.ShowError(e.Error.Message);
102 | }
103 | else
104 | {
105 | this.ShowError(e.Message);
106 | }
107 |
108 | return null;
109 | }
110 | catch (Exception ex)
111 | {
112 | this.ShowError("Error: " + ex.Message.ToString());
113 | return null;
114 | }
115 |
116 | return ocrResult;
117 | }
118 |
119 |
120 | ///
121 | /// Retrieve text from the given OCR results object.
122 | ///
123 | /// The OCR results.
124 | /// Return the text.
125 | public string GetRetrieveText(OcrResults results)
126 | {
127 | StringBuilder stringBuilder = new StringBuilder();
128 |
129 | if (results != null && results.Regions != null)
130 | {
131 | stringBuilder.Append("Text: ");
132 | stringBuilder.AppendLine();
133 | foreach (var item in results.Regions)
134 | {
135 | foreach (var line in item.Lines)
136 | {
137 | foreach (var word in line.Words)
138 | {
139 | stringBuilder.Append(word.Text);
140 | stringBuilder.Append(" ");
141 | }
142 |
143 | stringBuilder.AppendLine();
144 | }
145 |
146 | stringBuilder.AppendLine();
147 | }
148 | }
149 |
150 | return stringBuilder.ToString();
151 | }
152 |
153 | ///
154 | /// Show the working item.
155 | ///
156 | /// The work item's string.
157 | private void ShowInfo(string workStr)
158 | {
159 | Console.WriteLine(string.Format("{0}......", workStr));
160 | Console.ResetColor();
161 | }
162 |
163 | ///
164 | /// Show error message.
165 | ///
166 | /// The error message.
167 | private void ShowError(string errorMessage)
168 | {
169 | Console.ForegroundColor = ConsoleColor.Red;
170 | Console.WriteLine(errorMessage);
171 | Console.ResetColor();
172 | }
173 |
174 | ///
175 | /// Show result message.
176 | ///
177 | /// The result message.
178 | private void ShowResult(string resultMessage)
179 | {
180 | Console.ForegroundColor = ConsoleColor.Green;
181 | Console.WriteLine(resultMessage);
182 | Console.ResetColor();
183 | }
184 |
185 | }
186 | }
187 | }
188 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCR/ImageExtractor.cs:
--------------------------------------------------------------------------------
1 | // Sample Code used based from the PDF Image extraction sample provided by
2 | // https://psycodedeveloper.wordpress.com/2013/01/10/how-to-extract-images-from-pdf-files-using-c-and-itextsharp/
3 | // PDF Extraction done using iTextSharp
4 |
5 | using iTextSharp.text.pdf;
6 | using iTextSharp.text.pdf.parser;
7 | using System;
8 | using System.Collections.Generic;
9 | using System.IO;
10 |
11 | namespace AzureSearchOCR
12 | {
13 | /// Helper class to extract images from a PDF file. Works with the most
14 | /// common image types embedded in PDF files, as far as I can tell.
15 | ///
16 | /// Usage example:
17 | ///
18 | /// foreach (var filename in Directory.GetFiles(searchPath, "*.pdf", SearchOption.TopDirectoryOnly))
19 | /// {
20 | /// var images = ImageExtractor.ExtractImages(filename);
21 | /// var directory = Path.GetDirectoryName(filename);
22 | ///
23 | /// foreach (var name in images.Keys)
24 | /// {
25 | /// images[name].Save(Path.Combine(directory, name));
26 | /// }
27 | /// }
28 | ///
29 | public static class PdfImageExtractor
30 | {
31 | #region Methods
32 |
33 | #region Public Methods
34 |
35 | /// Checks whether a specified page of a PDF file contains images.
36 | /// True if the page contains at least one image; false otherwise.
37 | public static bool PageContainsImages(string filename, int pageNumber)
38 | {
39 | using (var reader = new PdfReader(filename))
40 | {
41 | var parser = new PdfReaderContentParser(reader);
42 | ImageRenderListener listener = null;
43 | parser.ProcessContent(pageNumber, (listener = new ImageRenderListener()));
44 | return listener.Images.Count > 0;
45 | }
46 | }
47 |
48 | /// Extracts all images (of types that iTextSharp knows how to decode) from a PDF file.
49 | public static Dictionary ExtractImages(string filename)
50 | {
51 | var images = new Dictionary();
52 |
53 | using (var reader = new PdfReader(filename))
54 | {
55 | var parser = new PdfReaderContentParser(reader);
56 | ImageRenderListener listener = null;
57 |
58 | for (var i = 1; i <= reader.NumberOfPages; i++)
59 | {
60 | parser.ProcessContent(i, (listener = new ImageRenderListener()));
61 | var index = 1;
62 |
63 | if (listener.Images.Count > 0)
64 | {
65 | Console.WriteLine("Found {0} images on page {1}.", listener.Images.Count, i);
66 |
67 | foreach (var pair in listener.Images)
68 | {
69 | images.Add(string.Format("{0}_Page_{1}_Image_{2}{3}",
70 | System.IO.Path.GetFileNameWithoutExtension(filename), i.ToString("D4"), index.ToString("D4"), pair.Value), pair.Key);
71 | index++;
72 | }
73 | }
74 | }
75 | return images;
76 | }
77 | }
78 |
79 | /// Extracts all images (of types that iTextSharp knows how to decode)
80 | /// from a specified page of a PDF file.
81 | /// Returns a generic ,
82 | /// where the key is a suggested file name, in the format: PDF filename without extension,
83 | /// page number and image index in the page.
84 | public static Dictionary ExtractImages(string filename, int pageNumber)
85 | {
86 | Dictionary images = new Dictionary();
87 | PdfReader reader = new PdfReader(filename);
88 | PdfReaderContentParser parser = new PdfReaderContentParser(reader);
89 | ImageRenderListener listener = null;
90 |
91 | parser.ProcessContent(pageNumber, (listener = new ImageRenderListener()));
92 | int index = 1;
93 |
94 | if (listener.Images.Count > 0)
95 | {
96 | Console.WriteLine("Found {0} images on page {1}.", listener.Images.Count, pageNumber);
97 |
98 | foreach (KeyValuePair pair in listener.Images)
99 | {
100 | images.Add(string.Format("{0}_Page_{1}_Image_{2}{3}",
101 | System.IO.Path.GetFileNameWithoutExtension(filename), pageNumber.ToString("D4"), index.ToString("D4"), pair.Value), pair.Key);
102 | index++;
103 | }
104 | }
105 | return images;
106 | }
107 |
108 | #endregion Public Methods
109 |
110 | #endregion Methods
111 | }
112 |
113 | internal class ImageRenderListener : IRenderListener
114 | {
115 | #region Fields
116 |
117 | Dictionary images = new Dictionary();
118 |
119 | #endregion Fields
120 |
121 | #region Properties
122 |
123 | public Dictionary Images
124 | {
125 | get { return images; }
126 | }
127 |
128 | #endregion Properties
129 |
130 | #region Methods
131 |
132 | #region Public Methods
133 |
134 | public void BeginTextBlock() { }
135 |
136 | public void EndTextBlock() { }
137 |
138 | public void RenderImage(ImageRenderInfo renderInfo)
139 | {
140 | PdfImageObject image = renderInfo.GetImage();
141 | PdfName filter = (PdfName)image.Get(PdfName.FILTER);
142 |
143 | //int width = Convert.ToInt32(image.Get(PdfName.WIDTH).ToString());
144 | //int bitsPerComponent = Convert.ToInt32(image.Get(PdfName.BITSPERCOMPONENT).ToString());
145 | //string subtype = image.Get(PdfName.SUBTYPE).ToString();
146 | //int height = Convert.ToInt32(image.Get(PdfName.HEIGHT).ToString());
147 | //int length = Convert.ToInt32(image.Get(PdfName.LENGTH).ToString());
148 | //string colorSpace = image.Get(PdfName.COLORSPACE).ToString();
149 |
150 | /* It appears to be safe to assume that when filter == null, PdfImageObject
151 | * does not know how to decode the image to a System.Drawing.Image.
152 | *
153 | * Uncomment the code above to verify, but when I've seen this happen,
154 | * width, height and bits per component all equal zero as well. */
155 | if (filter != null)
156 | {
157 | System.Drawing.Image drawingImage = image.GetDrawingImage();
158 |
159 | string extension = ".";
160 |
161 | if (filter == PdfName.DCTDECODE)
162 | {
163 | extension += PdfImageObject.ImageBytesType.JPG.FileExtension;
164 | }
165 | else if (filter == PdfName.JPXDECODE)
166 | {
167 | extension += PdfImageObject.ImageBytesType.JP2.FileExtension;
168 | }
169 | else if (filter == PdfName.FLATEDECODE)
170 | {
171 | extension += PdfImageObject.ImageBytesType.PNG.FileExtension;
172 | }
173 | else if (filter == PdfName.LZWDECODE)
174 | {
175 | extension += PdfImageObject.ImageBytesType.CCITT.FileExtension;
176 | }
177 |
178 | /* Rather than struggle with the image stream and try to figure out how to handle
179 | * BitMapData scan lines in various formats (like virtually every sample I've found
180 | * online), use the PdfImageObject.GetDrawingImage() method, which does the work for us. */
181 | this.Images.Add(drawingImage, extension);
182 | }
183 | }
184 |
185 | public void RenderText(TextRenderInfo renderInfo) { }
186 |
187 | #endregion Public Methods
188 |
189 | #endregion Methods
190 | }
191 | }
192 |
--------------------------------------------------------------------------------
/AzureSearchOCR/AzureSearchOCRwithKeywordExtraction/ImageExtractor.cs:
--------------------------------------------------------------------------------
1 | // Sample Code used based from the PDF Image extraction sample provided by
2 | // https://psycodedeveloper.wordpress.com/2013/01/10/how-to-extract-images-from-pdf-files-using-c-and-itextsharp/
3 | // PDF Extraction done using iTextSharp
4 |
5 | using iTextSharp.text.pdf;
6 | using iTextSharp.text.pdf.parser;
7 | using System;
8 | using System.Collections.Generic;
9 | using System.IO;
10 |
11 | namespace AzureSearchOCRwithKeywordExtraction
12 | {
13 | /// Helper class to extract images from a PDF file. Works with the most
14 | /// common image types embedded in PDF files, as far as I can tell.
15 | ///
16 | /// Usage example:
17 | ///
18 | /// foreach (var filename in Directory.GetFiles(searchPath, "*.pdf", SearchOption.TopDirectoryOnly))
19 | /// {
20 | /// var images = ImageExtractor.ExtractImages(filename);
21 | /// var directory = Path.GetDirectoryName(filename);
22 | ///
23 | /// foreach (var name in images.Keys)
24 | /// {
25 | /// images[name].Save(Path.Combine(directory, name));
26 | /// }
27 | /// }
28 | ///
29 | public static class PdfImageExtractor
30 | {
31 | #region Methods
32 |
33 | #region Public Methods
34 |
35 | /// Checks whether a specified page of a PDF file contains images.
36 | /// True if the page contains at least one image; false otherwise.
37 | public static bool PageContainsImages(string filename, int pageNumber)
38 | {
39 | using (var reader = new PdfReader(filename))
40 | {
41 | var parser = new PdfReaderContentParser(reader);
42 | ImageRenderListener listener = null;
43 | parser.ProcessContent(pageNumber, (listener = new ImageRenderListener()));
44 | return listener.Images.Count > 0;
45 | }
46 | }
47 |
48 | /// Extracts all images (of types that iTextSharp knows how to decode) from a PDF file.
49 | public static Dictionary ExtractImages(string filename)
50 | {
51 | var images = new Dictionary();
52 |
53 | using (var reader = new PdfReader(filename))
54 | {
55 | var parser = new PdfReaderContentParser(reader);
56 | ImageRenderListener listener = null;
57 |
58 | for (var i = 1; i <= reader.NumberOfPages; i++)
59 | {
60 | parser.ProcessContent(i, (listener = new ImageRenderListener()));
61 | var index = 1;
62 |
63 | if (listener.Images.Count > 0)
64 | {
65 | Console.WriteLine("Found {0} images on page {1}.", listener.Images.Count, i);
66 |
67 | foreach (var pair in listener.Images)
68 | {
69 | images.Add(string.Format("{0}_Page_{1}_Image_{2}{3}",
70 | System.IO.Path.GetFileNameWithoutExtension(filename), i.ToString("D4"), index.ToString("D4"), pair.Value), pair.Key);
71 | index++;
72 | }
73 | }
74 | }
75 | return images;
76 | }
77 | }
78 |
79 | /// Extracts all images (of types that iTextSharp knows how to decode)
80 | /// from a specified page of a PDF file.
81 | /// Returns a generic ,
82 | /// where the key is a suggested file name, in the format: PDF filename without extension,
83 | /// page number and image index in the page.
84 | public static Dictionary ExtractImages(string filename, int pageNumber)
85 | {
86 | Dictionary images = new Dictionary();
87 | PdfReader reader = new PdfReader(filename);
88 | PdfReaderContentParser parser = new PdfReaderContentParser(reader);
89 | ImageRenderListener listener = null;
90 |
91 | parser.ProcessContent(pageNumber, (listener = new ImageRenderListener()));
92 | int index = 1;
93 |
94 | if (listener.Images.Count > 0)
95 | {
96 | Console.WriteLine("Found {0} images on page {1}.", listener.Images.Count, pageNumber);
97 |
98 | foreach (KeyValuePair pair in listener.Images)
99 | {
100 | images.Add(string.Format("{0}_Page_{1}_Image_{2}{3}",
101 | System.IO.Path.GetFileNameWithoutExtension(filename), pageNumber.ToString("D4"), index.ToString("D4"), pair.Value), pair.Key);
102 | index++;
103 | }
104 | }
105 | return images;
106 | }
107 |
108 | #endregion Public Methods
109 |
110 | #endregion Methods
111 | }
112 |
113 | internal class ImageRenderListener : IRenderListener
114 | {
115 | #region Fields
116 |
117 | Dictionary images = new Dictionary();
118 |
119 | #endregion Fields
120 |
121 | #region Properties
122 |
123 | public Dictionary Images
124 | {
125 | get { return images; }
126 | }
127 |
128 | #endregion Properties
129 |
130 | #region Methods
131 |
132 | #region Public Methods
133 |
134 | public void BeginTextBlock() { }
135 |
136 | public void EndTextBlock() { }
137 |
138 | public void RenderImage(ImageRenderInfo renderInfo)
139 | {
140 | PdfImageObject image = renderInfo.GetImage();
141 | PdfName filter = (PdfName)image.Get(PdfName.FILTER);
142 |
143 | //int width = Convert.ToInt32(image.Get(PdfName.WIDTH).ToString());
144 | //int bitsPerComponent = Convert.ToInt32(image.Get(PdfName.BITSPERCOMPONENT).ToString());
145 | //string subtype = image.Get(PdfName.SUBTYPE).ToString();
146 | //int height = Convert.ToInt32(image.Get(PdfName.HEIGHT).ToString());
147 | //int length = Convert.ToInt32(image.Get(PdfName.LENGTH).ToString());
148 | //string colorSpace = image.Get(PdfName.COLORSPACE).ToString();
149 |
150 | /* It appears to be safe to assume that when filter == null, PdfImageObject
151 | * does not know how to decode the image to a System.Drawing.Image.
152 | *
153 | * Uncomment the code above to verify, but when I've seen this happen,
154 | * width, height and bits per component all equal zero as well. */
155 | if (filter != null)
156 | {
157 | System.Drawing.Image drawingImage = image.GetDrawingImage();
158 |
159 | string extension = ".";
160 |
161 | if (filter == PdfName.DCTDECODE)
162 | {
163 | extension += PdfImageObject.ImageBytesType.JPG.FileExtension;
164 | }
165 | else if (filter == PdfName.JPXDECODE)
166 | {
167 | extension += PdfImageObject.ImageBytesType.JP2.FileExtension;
168 | }
169 | else if (filter == PdfName.FLATEDECODE)
170 | {
171 | extension += PdfImageObject.ImageBytesType.PNG.FileExtension;
172 | }
173 | else if (filter == PdfName.LZWDECODE)
174 | {
175 | extension += PdfImageObject.ImageBytesType.CCITT.FileExtension;
176 | }
177 |
178 | /* Rather than struggle with the image stream and try to figure out how to handle
179 | * BitMapData scan lines in various formats (like virtually every sample I've found
180 | * online), use the PdfImageObject.GetDrawingImage() method, which does the work for us. */
181 | this.Images.Add(drawingImage, extension);
182 | }
183 | }
184 |
185 | public void RenderText(TextRenderInfo renderInfo) { }
186 |
187 | #endregion Public Methods
188 |
189 | #endregion Methods
190 | }
191 | }
192 |
--------------------------------------------------------------------------------