├── .gitignore
├── LICENSE.txt
├── VAE-GAN-multi-gpu-celebA.ipynb
├── VAE-GAN-multi-gpu-celebA_files
├── VAE-GAN-multi-gpu-celebA_14_1.png
├── VAE-GAN-multi-gpu-celebA_16_1.png
├── VAE-GAN-multi-gpu-celebA_22_1.png
├── VAE-GAN-multi-gpu-celebA_49_1.png
├── VAE-GAN-multi-gpu-celebA_50_1.png
├── VAE-GAN-multi-gpu-celebA_50_2.png
├── VAE-GAN-multi-gpu-celebA_55_0.png
├── VAE-GAN-multi-gpu-celebA_60_0.png
├── VAE-GAN-multi-gpu-celebA_62_0.png
├── VAE-GAN-multi-gpu-celebA_69_1.png
├── VAE-GAN-multi-gpu-celebA_74_1.png
└── VAE-GAN-multi-gpu-celebA_78_1.png
├── celeba_make_dataset.ipynb
├── deconv.py
├── network_outline.png
└── readme.md
/.gitignore:
--------------------------------------------------------------------------------
1 | datasets/*
2 | models/*
3 | img_align_celeba/
4 | list_attr_celeba.txt
5 | img_align_celeba.zip
6 | *.pyc
7 | .ipynb_checkpoints/
8 |
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | The MIT License (MIT)
2 |
3 | Copyright (c) 2016 Tim Sainburg
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_14_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_14_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_16_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_16_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_22_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_22_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_49_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_49_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_50_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_50_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_50_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_50_2.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_55_0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_55_0.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_60_0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_60_0.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_62_0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_62_0.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_69_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_69_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_74_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_74_1.png
--------------------------------------------------------------------------------
/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_78_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/VAE-GAN-multi-gpu-celebA_files/VAE-GAN-multi-gpu-celebA_78_1.png
--------------------------------------------------------------------------------
/deconv.py:
--------------------------------------------------------------------------------
1 | # Copyright 2015 Google Inc. All Rights Reserved.
2 | # Licensed under the Apache License, Version 2.0 (the "License");
3 | # you may not use this file except in compliance with the License.
4 | # You may obtain a copy of the License at
5 | # http://www.apache.org/licenses/LICENSE-2.0
6 | # Unless required by applicable law or agreed to in writing, software
7 | # distributed under the License is distributed on an "AS IS" BASIS,
8 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 | # See the License for the specific language governing permissions and
10 | # limitations under the License.
11 | """A quick hack to try deconv out."""
12 |
13 | import collections
14 |
15 | import tensorflow as tf
16 | from tensorflow.python.framework import tensor_shape
17 |
18 | from prettytensor import layers
19 | from prettytensor import pretty_tensor_class as prettytensor
20 | from prettytensor.pretty_tensor_class import PAD_SAME
21 | from prettytensor.pretty_tensor_class import Phase
22 | from prettytensor.pretty_tensor_class import PROVIDED
23 |
24 | # pylint: disable=redefined-outer-name,invalid-name
25 | @prettytensor.Register(
26 | assign_defaults=('activation_fn', 'l2loss', 'stddev', 'batch_normalize'))
27 | class deconv2d(prettytensor.VarStoreMethod):
28 |
29 | def __call__(self,
30 | input_layer,
31 | kernel,
32 | depth,
33 | name=PROVIDED,
34 | stride=None,
35 | activation_fn=None,
36 | l2loss=None,
37 | init=None,
38 | stddev=None,
39 | bias=True,
40 | edges=PAD_SAME,
41 | batch_normalize=False):
42 | """Adds a convolution to the stack of operations.
43 | The current head must be a rank 4 Tensor.
44 | Args:
45 | input_layer: The chainable object, supplied.
46 | kernel: The size of the patch for the pool, either an int or a length 1 or
47 | 2 sequence (if length 1 or int, it is expanded).
48 | depth: The depth of the new Tensor.
49 | name: The name for this operation is also used to create/find the
50 | parameter variables.
51 | stride: The strides as a length 1, 2 or 4 sequence or an integer. If an
52 | int, length 1 or 2, the stride in the first and last dimensions are 1.
53 | activation_fn: A tuple of (activation_function, extra_parameters). Any
54 | function that takes a tensor as its first argument can be used. More
55 | common functions will have summaries added (e.g. relu).
56 | l2loss: Set to a value greater than 0 to use L2 regularization to decay
57 | the weights.
58 | init: An optional initialization. If not specified, uses Xavier
59 | initialization.
60 | stddev: A standard deviation to use in parameter initialization.
61 | bias: Set to False to not have a bias.
62 | edges: Either SAME to use 0s for the out of bounds area or VALID to shrink
63 | the output size and only uses valid input pixels.
64 | batch_normalize: Set to True to batch_normalize this layer.
65 | Returns:
66 | Handle to the generated layer.
67 | Raises:
68 | ValueError: If head is not a rank 4 tensor or the depth of the input
69 | (4th dim) is not known.
70 | """
71 | if len(input_layer.shape) != 4:
72 | raise ValueError(
73 | 'Cannot perform conv2d on tensor with shape %s' % input_layer.shape)
74 | if input_layer.shape[3] is None:
75 | raise ValueError('Input depth must be known')
76 | kernel = _kernel(kernel)
77 | stride = _stride(stride)
78 | size = [kernel[0], kernel[1], depth, input_layer.shape[3]]
79 |
80 | books = input_layer.bookkeeper
81 | if init is None:
82 | if stddev is None:
83 | patch_size = size[0] * size[1]
84 | init = layers.xavier_init(size[2] * patch_size, size[3] * patch_size)
85 | elif stddev:
86 | init = tf.truncated_normal_initializer(stddev=stddev)
87 | else:
88 | init = tf.zeros_initializer
89 | elif stddev is not None:
90 | raise ValueError('Do not set both init and stddev.')
91 | dtype = input_layer.tensor.dtype
92 | params = self.variable('weights', size, init, dt=dtype)
93 |
94 | input_height = input_layer.shape[1]
95 | input_width = input_layer.shape[2]
96 |
97 | filter_height = kernel[0]
98 | filter_width = kernel[1]
99 |
100 | row_stride = stride[1]
101 | col_stride = stride[2]
102 |
103 | out_rows, out_cols = get2d_deconv_output_size(input_height, input_width, filter_height,
104 | filter_width, row_stride, col_stride, edges)
105 |
106 | output_shape = [input_layer.shape[0], out_rows, out_cols, depth]
107 | y = tf.nn.conv2d_transpose(input_layer, params, output_shape, stride, edges)
108 | layers.add_l2loss(books, params, l2loss)
109 | if bias:
110 | y += self.variable(
111 | 'bias',
112 | [size[-2]],
113 | tf.zeros_initializer,
114 | dt=dtype)
115 | books.add_scalar_summary(
116 | tf.reduce_mean(
117 | layers.spatial_slice_zeros(y)), '%s/zeros_spatial' % y.op.name)
118 | if batch_normalize:
119 | y = input_layer.with_tensor(y).batch_normalize()
120 | if activation_fn is not None:
121 | if not isinstance(activation_fn, collections.Sequence):
122 | activation_fn = (activation_fn,)
123 | y = layers.apply_activation(
124 | books,
125 | y,
126 | activation_fn[0],
127 | activation_args=activation_fn[1:])
128 | return input_layer.with_tensor(y)
129 | # pylint: enable=redefined-outer-name,invalid-name
130 |
131 | # Helper methods
132 |
133 | def get2d_deconv_output_size(input_height, input_width, filter_height,
134 | filter_width, row_stride, col_stride, padding_type):
135 | """Returns the number of rows and columns in a convolution/pooling output."""
136 | input_height = tensor_shape.as_dimension(input_height)
137 | input_width = tensor_shape.as_dimension(input_width)
138 | filter_height = tensor_shape.as_dimension(filter_height)
139 | filter_width = tensor_shape.as_dimension(filter_width)
140 | row_stride = int(row_stride)
141 | col_stride = int(col_stride)
142 |
143 | # Compute number of rows in the output, based on the padding.
144 | if input_height.value is None or filter_height.value is None:
145 | out_rows = None
146 | elif padding_type == "VALID":
147 | out_rows = (input_height.value - 1) * row_stride + filter_height.value
148 | elif padding_type == "SAME":
149 | out_rows = input_height.value * row_stride
150 | else:
151 | raise ValueError("Invalid value for padding: %r" % padding_type)
152 |
153 | # Compute number of columns in the output, based on the padding.
154 | if input_width.value is None or filter_width.value is None:
155 | out_cols = None
156 | elif padding_type == "VALID":
157 | out_cols = (input_width.value - 1) * col_stride + filter_width.value
158 | elif padding_type == "SAME":
159 | out_cols = input_width.value * col_stride
160 |
161 | return out_rows, out_cols
162 |
163 | def _kernel(kernel_spec):
164 | """Expands the kernel spec into a length 2 list.
165 | Args:
166 | kernel_spec: An integer or a length 1 or 2 sequence that is expanded to a
167 | list.
168 | Returns:
169 | A length 2 list.
170 | """
171 | if isinstance(kernel_spec, int):
172 | return [kernel_spec, kernel_spec]
173 | elif len(kernel_spec) == 1:
174 | return [kernel_spec[0], kernel_spec[0]]
175 | else:
176 | assert len(kernel_spec) == 2
177 | return kernel_spec
178 |
179 |
180 | def _stride(stride_spec):
181 | """Expands the stride spec into a length 4 list.
182 | Args:
183 | stride_spec: None, an integer or a length 1, 2, or 4 sequence.
184 | Returns:
185 | A length 4 list.
186 | """
187 | if stride_spec is None:
188 | return [1, 1, 1, 1]
189 | elif isinstance(stride_spec, int):
190 | return [1, stride_spec, stride_spec, 1]
191 | elif len(stride_spec) == 1:
192 | return [1, stride_spec[0], stride_spec[0], 1]
193 | elif len(stride_spec) == 2:
194 | return [1, stride_spec[0], stride_spec[1], 1]
195 | else:
196 | assert len(stride_spec) == 4
197 | return stride_spec
--------------------------------------------------------------------------------
/network_outline.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/timsainb/Tensorflow-MultiGPU-VAE-GAN/453c02c4439aa7fb3b741e38d19d324e1f237ef1/network_outline.png
--------------------------------------------------------------------------------
/readme.md:
--------------------------------------------------------------------------------
1 | ## UPDATE: See [Generative Models in Tensorflow 2](https://github.com/timsainb/tensorflow2-generative-models) for a Tensorflow 2.X version of VAEGAN.
2 |
3 | # Tensorflow Multi-GPU VAE-GAN implementation
4 |
5 | - This is an implementation of the VAE-GAN based on the implementation described in *Autoencoding beyond pixels using a learned similarity metric*
6 | - I implement a few useful things like
7 | - Visualizing Movement Through Z-Space
8 | - Latent Space Algebra
9 | - Spike Triggered Average Style Receptive Fields
10 |
11 | ### How does a VAE-GAN work?
12 | - We have three networks, an Encoder,
13 | a Generator, and a Discriminator.
14 | - The Encoder learns to map input x onto z space (latent space)
15 | - The Generator learns to generate x from z space
16 | - The Discriminator learns to discriminate whether the image being put in is real, or generated
17 |
18 | ### Diagram of basic network input and output
19 |
20 | 
21 |
22 | ### `l_x_tilde` and `l_x` here become layers of *high level features* that the discriminator learns.
23 | - we train the network to minimize the difference between the high level features of `x` and `x_tilde`
24 | - This is basically an autoencoder that works on *high level features* rather than pixels
25 | - Adding this *autoencoder* to a GAN helps to stabilize the GAN
26 |
27 | ### Training
28 | Train Encoder on minimization of:
29 | - `kullback_leibler_loss(z_x, gaussian)`
30 | - `mean_squared_error(l_x_tilde_, l_x)`
31 |
32 | Train Generator on minimization of:
33 | - `kullback_leibler_loss(z_x, gaussian)`
34 | - `mean_squared_error(l_x_tilde_, l_x)`
35 | - `-1*log(d_x_p)`
36 |
37 | Train Discriminator on minimization of:
38 | - `-1*log(d_x) + log(1 - d_x_p)`
39 |
40 |
41 |
42 | ```
43 | # Import all of our packages
44 |
45 | import os
46 | import numpy as np
47 | import prettytensor as pt
48 | import tensorflow as tf
49 | from tensorflow.examples.tutorials.mnist import input_data
50 | import matplotlib.pyplot as plt
51 | from deconv import deconv2d
52 | import IPython.display
53 | import math
54 | import tqdm # making loops prettier
55 | import h5py # for reading our dataset
56 | import ipywidgets as widgets
57 | from ipywidgets import interact, interactive, fixed
58 |
59 | %matplotlib inline
60 | ```
61 |
62 | ## Parameters
63 |
64 |
65 |
66 | ```
67 | dim1 = 64 # first dimension of input data
68 | dim2 = 64 # second dimension of input data
69 | dim3 = 3 # third dimension of input data (colors)
70 | batch_size = 32 # size of batches to use (per GPU)
71 | hidden_size = 2048 # size of hidden (z) layer to use
72 | num_examples = 60000 # how many examples are in your training set
73 | num_epochs = 10000 # number of epochs to run
74 | ### we can train our different networks with different learning rates if we want to
75 | e_learning_rate = 1e-3
76 | g_learning_rate = 1e-3
77 | d_learning_rate = 1e-3
78 | ```
79 |
80 | ### Which GPUs are we using?
81 | - Set `gpus` to a list of the GPUs you're using. The network will then split up the work between those gpus
82 |
83 |
84 | ```
85 | gpus = [2] # Here I set CUDA to only see one GPU
86 | os.environ["CUDA_VISIBLE_DEVICES"]=','.join([str(i) for i in gpus])
87 | num_gpus = len(gpus) # number of GPUs to use
88 | ```
89 |
90 | ### Reading the dataset from HDF5 format
91 | - open `makedataset.ipynb' for instructions on how to build the dataset
92 |
93 |
94 | ```
95 | with h5py.File(''.join(['datasets/faces_dataset_new.h5']), 'r') as hf:
96 | faces = hf['images'].value
97 | headers = hf['headers'].value
98 | labels = hf['label_input'].value
99 | ```
100 |
101 |
102 | ```
103 | # Normalize the dataset between 0 and 1
104 | faces = (faces/255.)
105 | ```
106 |
107 |
108 | ```
109 | # Just taking a look and making sure everything works
110 | plt.imshow(np.reshape(faces[1], (64,64,3)), interpolation='nearest')
111 | ```
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 | 
122 |
123 |
124 |
125 | ```
126 | # grab the faces back out after we've flattened them
127 | def create_image(im):
128 | return np.reshape(im,(dim1,dim2,dim3))
129 | ```
130 |
131 |
132 | ```
133 | # Lets just take a look at our channels
134 | cm = plt.cm.hot
135 | test_face = faces[0].reshape(dim1,dim2,dim3)
136 | fig, ax = plt.subplots(nrows=1,ncols=4, figsize=(20,8))
137 | ax[0].imshow(create_image(test_face), interpolation='nearest')
138 | ax[1].imshow(create_image(test_face)[:,:,0], interpolation='nearest', cmap=cm)
139 | ax[2].imshow(create_image(test_face)[:,:,1], interpolation='nearest', cmap=cm)
140 | ax[3].imshow(create_image(test_face)[:,:,2], interpolation='nearest', cmap=cm)
141 | ```
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 | 
152 |
153 |
154 | ### A data iterator for batching (drawn up by Luke Metz)
155 | - https://indico.io/blog/tensorflow-data-inputs-part1-placeholders-protobufs-queues/
156 |
157 |
158 |
159 | ```
160 | def data_iterator():
161 | """ A simple data iterator """
162 | batch_idx = 0
163 | while True:
164 | idxs = np.arange(0, len(faces))
165 | np.random.shuffle(idxs)
166 | for batch_idx in range(0, len(faces), batch_size):
167 | cur_idxs = idxs[batch_idx:batch_idx+batch_size]
168 | images_batch = faces[cur_idxs]
169 | #images_batch = images_batch.astype("float32")
170 | labels_batch = labels[cur_idxs]
171 | yield images_batch, labels_batch
172 |
173 |
174 | iter_ = data_iterator()
175 | ```
176 |
177 |
178 | ```
179 | iter_ = data_iterator()
180 | ```
181 |
182 |
183 | ```
184 | #face_batch, label_batch
185 | ```
186 |
187 | ### Bald people
188 |
189 |
190 | ```
191 | fig, ax = plt.subplots(nrows=1,ncols=4, figsize=(20,8))
192 | ax[0].imshow(create_image(faces[labels[:,4] == 1][0]), interpolation='nearest')
193 | ax[1].imshow(create_image(faces[labels[:,4] == 1][1]), interpolation='nearest')
194 | ax[2].imshow(create_image(faces[labels[:,4] == 1][2]), interpolation='nearest')
195 | ax[3].imshow(create_image(faces[labels[:,4] == 1][3]), interpolation='nearest')
196 | ```
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 | 
207 |
208 |
209 | ### Draw out the architecture of our network
210 | - Each of these functions represent the Encoder,
211 | Generator, and Discriminator described above.
212 | - It would be interesting to try and implement the inception architecture to do the same thing, next time around:
213 |
214 | 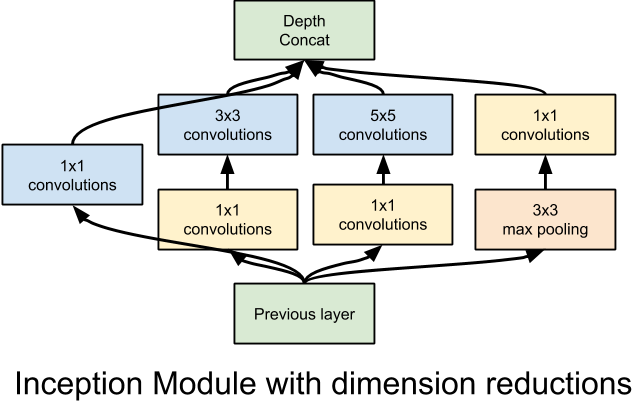
215 | - They describe how to implement inception, in prettytensor, here: https://github.com/google/prettytensor
216 |
217 |
218 | ```
219 | def encoder(X):
220 | '''Create encoder network.
221 | Args:
222 | x: a batch of flattened images [batch_size, 28*28]
223 | Returns:
224 | A tensor that expresses the encoder network
225 | # The transformation is parametrized and can be learned.
226 | # returns network output, mean, setd
227 | '''
228 | lay_end = (pt.wrap(X).
229 | reshape([batch_size, dim1, dim2, dim3]).
230 | conv2d(5, 64, stride=2).
231 | conv2d(5, 128, stride=2).
232 | conv2d(5, 256, stride=2).
233 | flatten())
234 | z_mean = lay_end.fully_connected(hidden_size, activation_fn=None)
235 | z_log_sigma_sq = lay_end.fully_connected(hidden_size, activation_fn=None)
236 | return z_mean, z_log_sigma_sq
237 |
238 |
239 | def generator(Z):
240 | '''Create generator network.
241 | If input tensor is provided then decodes it, otherwise samples from
242 | a sampled vector.
243 | Args:
244 | x: a batch of vectors to decode
245 | Returns:
246 | A tensor that expresses the generator network
247 | '''
248 | return (pt.wrap(Z).
249 | fully_connected(8*8*256).reshape([batch_size, 8, 8, 256]). #(128, 4 4, 256)
250 | deconv2d(5, 256, stride=2).
251 | deconv2d(5, 128, stride=2).
252 | deconv2d(5, 32, stride=2).
253 | deconv2d(1, dim3, stride=1, activation_fn=tf.sigmoid).
254 | flatten()
255 | )
256 |
257 |
258 |
259 | def discriminator(D_I):
260 | ''' A encodes
261 | Create a network that discriminates between images from a dataset and
262 | generated ones.
263 | Args:
264 | input: a batch of real images [batch, height, width, channels]
265 | Returns:
266 | A tensor that represents the network
267 | '''
268 | descrim_conv = (pt.wrap(D_I). # This is what we're descriminating
269 | reshape([batch_size, dim1, dim2, dim3]).
270 | conv2d(5, 32, stride=1).
271 | conv2d(5, 128, stride=2).
272 | conv2d(5, 256, stride=2).
273 | conv2d(5, 256, stride=2).
274 | flatten()
275 | )
276 | lth_layer= descrim_conv.fully_connected(1024, activation_fn=tf.nn.elu)# this is the lth layer
277 | D =lth_layer.fully_connected(1, activation_fn=tf.nn.sigmoid) # this is the actual discrimination
278 | return D, lth_layer
279 |
280 | ```
281 |
282 | ### Defining the forward pass through the network
283 | - This function is based upon the inference function from tensorflows cifar tutorials
284 | - https://github.com/tensorflow/tensorflow/blob/r0.10/tensorflow/models/image/cifar10/cifar10.py
285 | - Notice I use `with tf.variable_scope("enc")`. This way, we can reuse these variables using `reuse=True`. We can also specify which variables to train using which error functions based upon the label `enc`
286 |
287 |
288 | ```
289 | def inference(x):
290 | """
291 | Run the models. Called inference because it does the same thing as tensorflow's cifar tutorial
292 | """
293 | z_p = tf.random_normal((batch_size, hidden_size), 0, 1) # normal dist for GAN
294 | eps = tf.random_normal((batch_size, hidden_size), 0, 1) # normal dist for VAE
295 |
296 | with pt.defaults_scope(activation_fn=tf.nn.elu,
297 | batch_normalize=True,
298 | learned_moments_update_rate=0.0003,
299 | variance_epsilon=0.001,
300 | scale_after_normalization=True):
301 |
302 | with tf.variable_scope("enc"):
303 | z_x_mean, z_x_log_sigma_sq = encoder(x) # get z from the input
304 | with tf.variable_scope("gen"):
305 | z_x = tf.add(z_x_mean,
306 | tf.mul(tf.sqrt(tf.exp(z_x_log_sigma_sq)), eps)) # grab our actual z
307 | x_tilde = generator(z_x)
308 | with tf.variable_scope("dis"):
309 | _, l_x_tilde = discriminator(x_tilde)
310 | with tf.variable_scope("gen", reuse=True):
311 | x_p = generator(z_p)
312 | with tf.variable_scope("dis", reuse=True):
313 | d_x, l_x = discriminator(x) # positive examples
314 | with tf.variable_scope("dis", reuse=True):
315 | d_x_p, _ = discriminator(x_p)
316 | return z_x_mean, z_x_log_sigma_sq, z_x, x_tilde, l_x_tilde, x_p, d_x, l_x, d_x_p, z_p
317 | ```
318 |
319 | ### Loss - define our various loss functions
320 | - **SSE** - we don't actually use this loss (also its the MSE), its just to see how close x is to x_tilde
321 | - **KL Loss** - our VAE gaussian distribution loss.
322 | - See https://arxiv.org/abs/1312.6114
323 | - **D_loss** - Our descriminator loss, how good the discriminator is at telling if something is real
324 | - **G_loss** - essentially the opposite of the D_loss, how good the generator is a tricking the discriminator
325 | - ***notice we clip our values to make sure learning rates don't explode***
326 |
327 |
328 | ```
329 | def loss(x, x_tilde, z_x_log_sigma_sq, z_x_mean, d_x, d_x_p, l_x, l_x_tilde, dim1, dim2, dim3):
330 | """
331 | Loss functions for SSE, KL divergence, Discrim, Generator, Lth Layer Similarity
332 | """
333 | ### We don't actually use SSE (MSE) loss for anything (but maybe pretraining)
334 | SSE_loss = tf.reduce_mean(tf.square(x - x_tilde)) # This is what a normal VAE uses
335 |
336 | # We clip gradients of KL divergence to prevent NANs
337 | KL_loss = tf.reduce_sum(-0.5 * tf.reduce_sum(1 + tf.clip_by_value(z_x_log_sigma_sq, -10.0, 10.0)
338 | - tf.square(tf.clip_by_value(z_x_mean, -10.0, 10.0) )
339 | - tf.exp(tf.clip_by_value(z_x_log_sigma_sq, -10.0, 10.0) ), 1))/dim1/dim2/dim3
340 | # Discriminator Loss
341 | D_loss = tf.reduce_mean(-1.*(tf.log(tf.clip_by_value(d_x,1e-5,1.0)) +
342 | tf.log(tf.clip_by_value(1.0 - d_x_p,1e-5,1.0))))
343 | # Generator Loss
344 | G_loss = tf.reduce_mean(-1.*(tf.log(tf.clip_by_value(d_x_p,1e-5,1.0))))# +
345 | #tf.log(tf.clip_by_value(1.0 - d_x,1e-5,1.0))))
346 | # Lth Layer Loss - the 'learned similarity measure'
347 | LL_loss = tf.reduce_sum(tf.square(l_x - l_x_tilde))/dim1/dim2/dim3
348 | return SSE_loss, KL_loss, D_loss, G_loss, LL_loss
349 | ```
350 |
351 | ### Average the gradients between towers
352 | - This function is taken directly from
353 | - https://github.com/tensorflow/tensorflow/blob/r0.10/tensorflow/models/image/cifar10/cifar10_multi_gpu_train.py
354 | - Basically we're taking a list of gradients from each tower, and averaging them together
355 |
356 |
357 | ```
358 | def average_gradients(tower_grads):
359 | """Calculate the average gradient for each shared variable across all towers.
360 | Note that this function provides a synchronization point across all towers.
361 | Args:
362 | tower_grads: List of lists of (gradient, variable) tuples. The outer list
363 | is over individual gradients. The inner list is over the gradient
364 | calculation for each tower.
365 | Returns:
366 | List of pairs of (gradient, variable) where the gradient has been averaged
367 | across all towers.
368 |
369 |
370 | """
371 | average_grads = []
372 | for grad_and_vars in zip(*tower_grads):
373 | # Note that each grad_and_vars looks like the following:
374 | # ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
375 | grads = []
376 | for g, _ in grad_and_vars:
377 | # Add 0 dimension to the gradients to represent the tower.
378 | expanded_g = tf.expand_dims(g, 0)
379 |
380 | # Append on a 'tower' dimension which we will average over below.
381 | grads.append(expanded_g)
382 |
383 | # Average over the 'tower' dimension.
384 | grad = tf.concat(0, grads)
385 | grad = tf.reduce_mean(grad, 0)
386 |
387 | # Keep in mind that the Variables are redundant because they are shared
388 | # across towers. So .. we will just return the first tower's pointer to
389 | # the Variable.
390 | v = grad_and_vars[0][1]
391 | grad_and_var = (grad, v)
392 | average_grads.append(grad_and_var)
393 | return average_grads
394 |
395 | ```
396 |
397 | ### Plot network output
398 | - This is just my ugly function to regularly plot the output of my network - tensorboard would probably be a better option for this
399 |
400 |
401 | ```
402 | def plot_network_output():
403 | """ Just plots the output of the network, error, reconstructions, etc
404 | """
405 | random_x, recon_z, all_d= sess.run((x_p, z_x_mean, d_x_p), {all_input: example_data})
406 | top_d = np.argsort(np.squeeze(all_d))
407 | recon_x = sess.run((x_tilde), {z_x: recon_z})
408 | examples = 8
409 | random_x = np.squeeze(random_x)
410 | recon_x = np.squeeze(recon_x)
411 | random_x = random_x[top_d]
412 |
413 | fig, ax = plt.subplots(nrows=3,ncols=examples, figsize=(18,6))
414 | for i in xrange(examples):
415 | ax[(0,i)].imshow(create_image(random_x[i]), cmap=plt.cm.gray, interpolation='nearest')
416 | ax[(1,i)].imshow(create_image(recon_x[i]), cmap=plt.cm.gray, interpolation='nearest')
417 | ax[(2,i)].imshow(create_image(example_data[i + (num_gpus-1)*batch_size]), cmap=plt.cm.gray, interpolation='nearest')
418 | ax[(0,i)].axis('off')
419 | ax[(1,i)].axis('off')
420 | ax[(2,i)].axis('off')
421 | fig.suptitle('Top: random points in z space | Bottom: inputs | Middle: reconstructions')
422 | plt.show()
423 | #fig.savefig(''.join(['imgs/test_',str(epoch).zfill(4),'.png']),dpi=100)
424 | fig, ax = plt.subplots(nrows=1,ncols=1, figsize=(20,10), linewidth = 4)
425 | KL_plt, = plt.semilogy((KL_loss_list), linewidth = 4, ls='-', color='r', alpha = .5, label='KL')
426 | D_plt, = plt.semilogy((D_loss_list),linewidth = 4, ls='-', color='b',alpha = .5, label='D')
427 | G_plt, = plt.semilogy((G_loss_list),linewidth = 4, ls='-', color='k',alpha = .5, label='G')
428 | SSE_plt, = plt.semilogy((SSE_loss_list),linewidth = 4,ls='-', color='g',alpha = .5, label='SSE')
429 | LL_plt, = plt.semilogy((LL_loss_list),linewidth = 4,ls='-', color='m',alpha = .5, label='LL')
430 |
431 | axes = plt.gca()
432 | leg = plt.legend(handles=[KL_plt, D_plt, G_plt, SSE_plt, LL_plt], fontsize=20)
433 | leg.get_frame().set_alpha(0.5)
434 | plt.show()
435 |
436 | ```
437 |
438 |
439 | ```
440 | graph = tf.Graph()
441 | ```
442 |
443 |
444 | ```
445 | # Make lists to save the losses to
446 | # You should probably just be using tensorboard to do any visualization(or just use tensorboard...)
447 | G_loss_list = []
448 | D_loss_list = []
449 | SSE_loss_list = []
450 | KL_loss_list = []
451 | LL_loss_list = []
452 | dxp_list = []
453 | dx_list = []
454 | ```
455 |
456 | ### With your graph, define what a step is (needed for multi-gpu), and what your optimizers are for each of your networks
457 |
458 |
459 | ```
460 | with graph.as_default():
461 | #with tf.Graph().as_default(), tf.device('/cpu:0'):
462 | # Create a variable to count number of train calls
463 | global_step = tf.get_variable(
464 | 'global_step', [],
465 | initializer=tf.constant_initializer(0), trainable=False)
466 |
467 |
468 | # different optimizers are needed for different learning rates (using the same learning rate seems to work fine though)
469 | lr_D = tf.placeholder(tf.float32, shape=[])
470 | lr_G = tf.placeholder(tf.float32, shape=[])
471 | lr_E = tf.placeholder(tf.float32, shape=[])
472 | opt_D = tf.train.AdamOptimizer(lr_D, epsilon=1.0)
473 | opt_G = tf.train.AdamOptimizer(lr_G, epsilon=1.0)
474 | opt_E = tf.train.AdamOptimizer(lr_E, epsilon=1.0)
475 | ```
476 |
477 | ### Run all of the functions we defined above
478 | - `tower_grads_e` defines the list of gradients for the encoder for each tower
479 | - For each GPU we grab parameters corresponding to each network, we then calculate the gradients, and add them to the twoers to be averaged
480 |
481 |
482 |
483 | ```
484 | with graph.as_default():
485 |
486 | # These are the lists of gradients for each tower
487 | tower_grads_e = []
488 | tower_grads_g = []
489 | tower_grads_d = []
490 |
491 | all_input = tf.placeholder(tf.float32, [batch_size*num_gpus, dim1*dim2*dim3])
492 | KL_param = tf.placeholder(tf.float32)
493 | LL_param = tf.placeholder(tf.float32)
494 | G_param = tf.placeholder(tf.float32)
495 |
496 |
497 | # Define the network for each GPU
498 | for i in xrange(num_gpus):
499 | with tf.device('/gpu:%d' % i):
500 | with tf.name_scope('Tower_%d' % (i)) as scope:
501 | # grab this portion of the input
502 | next_batch = all_input[i*batch_size:(i+1)*batch_size,:]
503 |
504 | # Construct the model
505 | z_x_mean, z_x_log_sigma_sq, z_x, x_tilde, l_x_tilde, x_p, d_x, l_x, d_x_p, z_p = inference(next_batch)
506 |
507 | # Calculate the loss for this tower
508 | SSE_loss, KL_loss, D_loss, G_loss, LL_loss = loss(next_batch, x_tilde, z_x_log_sigma_sq, z_x_mean, d_x, d_x_p, l_x, l_x_tilde, dim1, dim2, dim3)
509 |
510 | # specify loss to parameters
511 | params = tf.trainable_variables()
512 | E_params = [i for i in params if 'enc' in i.name]
513 | G_params = [i for i in params if 'gen' in i.name]
514 | D_params = [i for i in params if 'dis' in i.name]
515 |
516 | # Calculate the losses specific to encoder, generator, decoder
517 | L_e = tf.clip_by_value(KL_loss*KL_param + LL_loss, -100, 100)
518 | L_g = tf.clip_by_value(LL_loss*LL_param+G_loss*G_param, -100, 100)
519 | L_d = tf.clip_by_value(D_loss, -100, 100)
520 |
521 |
522 | # Reuse variables for the next tower.
523 | tf.get_variable_scope().reuse_variables()
524 |
525 | # Calculate the gradients for the batch of data on this CIFAR tower.
526 | grads_e = opt_E.compute_gradients(L_e, var_list = E_params)
527 | grads_g = opt_G.compute_gradients(L_g, var_list = G_params)
528 | grads_d = opt_D.compute_gradients(L_d, var_list = D_params)
529 |
530 | # Keep track of the gradients across all towers.
531 | tower_grads_e.append(grads_e)
532 | tower_grads_g.append(grads_g)
533 | tower_grads_d.append(grads_d)
534 |
535 | ```
536 |
537 | ### Now lets average, and apply those gradients
538 |
539 |
540 | ```
541 | with graph.as_default():
542 | # Average the gradients
543 | grads_e = average_gradients(tower_grads_e)
544 | grads_g = average_gradients(tower_grads_g)
545 | grads_d = average_gradients(tower_grads_d)
546 |
547 | # apply the gradients with our optimizers
548 | train_E = opt_E.apply_gradients(grads_e, global_step=global_step)
549 | train_G = opt_G.apply_gradients(grads_g, global_step=global_step)
550 | train_D = opt_D.apply_gradients(grads_d, global_step=global_step)
551 | ```
552 |
553 | ### Now lets actually run our session
554 |
555 |
556 | ```
557 | with graph.as_default():
558 |
559 | # Start the Session
560 | init = tf.initialize_all_variables()
561 | saver = tf.train.Saver() # initialize network saver
562 | sess = tf.InteractiveSession(graph=graph,config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))
563 | sess.run(init)
564 | ```
565 |
566 | ### Get some example data to do visualizations with
567 |
568 |
569 | ```
570 | example_data, _ = iter_.next()
571 | np.shape(example_data)
572 | ```
573 |
574 |
575 |
576 |
577 | (32, 12288)
578 |
579 |
580 |
581 | ### Initialize our epoch number, and restore a saved network by uncommening `#tf.train...`
582 |
583 |
584 | ```
585 | epoch = 0
586 | tf.train.Saver.restore(saver, sess, 'models/faces_multiGPU_64_0000.tfmod')
587 | ```
588 |
589 | ### Now we actually run the network
590 | - Importantly, notice how we define the learning rates
591 | - `e_current_lr = e_learning_rate*sigmoid(np.mean(d_real),-.5,10)`
592 | - we calculate the sigmoid of how the network has been performing, and squash the learning rate using a sigmoid based on that. So if the discriminator has been winning, it's learning rate will be low, and if the generator is winning, it's learning rate will be lower on the next batch.
593 |
594 |
595 | ```
596 | def sigmoid(x,shift,mult):
597 | """
598 | Using this sigmoid to discourage one network overpowering the other
599 | """
600 | return 1 / (1 + math.exp(-(x+shift)*mult))
601 | ```
602 |
603 |
604 | ```
605 | fig, ax = plt.subplots(nrows=1,ncols=1, figsize=(18,4))
606 | plt.plot(np.arange(0,1,.01), [sigmoid(i/100.,-.5,10) for i in range(100)])
607 | ax.set_xlabel('Mean of Discriminator(Real) or Discriminator(Fake)')
608 | ax.set_ylabel('Multiplier for learning rate')
609 | plt.title('Squashing the Learning Rate to balance Discrim/Gen network performance')
610 | ```
611 |
612 |
613 |
614 |
615 |
616 |
617 |
618 |
619 |
620 | 
621 |
622 |
623 |
624 | ```
625 | total_batch = int(np.floor(num_examples / batch_size*num_gpus)) # how many batches are in an epoch
626 |
627 | # We balance of generator and discriminators learning rate by using a sigmoid function,
628 | # encouraging the generator and discriminator be about equal
629 | d_real = .5
630 | d_fake = .5
631 |
632 | while epoch < num_epochs:
633 | for i in tqdm.tqdm(range(total_batch)):
634 | iter_ = data_iterator()
635 | # balence gen and descrim
636 | e_current_lr = e_learning_rate*sigmoid(np.mean(d_real),-.5,15)
637 | g_current_lr = g_learning_rate*sigmoid(np.mean(d_real),-.5,15)
638 | d_current_lr = d_learning_rate*sigmoid(np.mean(d_fake),-.5,15)
639 | next_batches, _ = iter_.next()
640 |
641 | _, _, _, D_err, G_err, KL_err, SSE_err, LL_err, d_fake,d_real = sess.run([
642 | train_E, train_G, train_D,
643 | D_loss, G_loss, KL_loss, SSE_loss, LL_loss,
644 | d_x_p, d_x,
645 |
646 | ],
647 | {
648 | lr_E: e_current_lr,
649 | lr_G: g_current_lr,
650 | lr_D: d_current_lr,
651 | all_input: next_batches,
652 | KL_param: 1,
653 | G_param: 1,
654 | LL_param: 1
655 | }
656 | )
657 | #KL_err= SSE_err= LL_err = 1
658 | # Save our lists
659 | dxp_list.append(d_fake)
660 | dx_list.append(d_real)
661 | G_loss_list.append(G_err)
662 | D_loss_list.append(D_err)
663 | KL_loss_list.append(KL_err)
664 | SSE_loss_list.append(SSE_err)
665 | LL_loss_list.append(LL_err)
666 |
667 | if i%300 == 0:
668 | # print display network output
669 | IPython.display.clear_output()
670 | print('Epoch: '+str(epoch))
671 | plot_network_output()
672 |
673 | # save network
674 | saver.save(sess,''.join(['models/faces_multiGPU_64_',str(epoch).zfill(4),'.tfmod']))
675 | epoch +=1
676 |
677 | ```
678 |
679 | Epoch: 46
680 |
681 |
682 |
683 | 
684 |
685 |
686 |
687 | 
688 |
689 |
690 |
691 |
692 |
693 | ### This is how we save our network
694 | - Just uncomment, and name it.
695 |
696 |
697 | ```
698 | #saver.save(sess,''.join(['models/faces_multiGPU_64_',str(epoch).zfill(4),'.tfmod']))
699 | ```
700 |
701 | ### Visualize movement through z-space
702 | - we're using jupyter widgets to slide through z-space from one point to another
703 |
704 |
705 | ```
706 | n_steps = 20
707 | examples = 10
708 | all_x_recon = np.zeros((batch_size, dim1*dim2*dim3,n_steps))
709 | z_point_a= np.random.normal(0,1,(batch_size,hidden_size))
710 | z_point_b= np.random.normal(0,1,(batch_size,hidden_size))
711 | recon_z_step = (z_point_b - z_point_a)/n_steps
712 | for i in range(n_steps):
713 | z_point_a += recon_z_step
714 | all_x_recon[:,:,i] = sess.run((x_tilde), {z_x: z_point_a})
715 |
716 | canvas = np.zeros((dim1,dim2*examples,dim3, n_steps))
717 | print np.shape(canvas)
718 | for f in range(n_steps):
719 | for i in range(examples):
720 | canvas[:,dim2*i:dim2*(i+1),:,f] = create_image(all_x_recon[i,:,f])
721 |
722 | ```
723 |
724 | (64, 640, 3, 20)
725 |
726 |
727 |
728 | ```
729 | def plt_random_faces(f):
730 | fig, ax = plt.subplots(nrows=1,ncols=1, figsize=(18,12))
731 | plt.imshow(canvas[:,:,:,f],interpolation='nearest')
732 | plt.title('This slider won\.t work in Github')
733 | plt.show()
734 | interact(plt_random_faces, f = (0,n_steps-1,1))
735 | ```
736 |
737 |
738 | 
739 |
740 |
741 |
742 |
743 |
744 |
745 |
746 |
747 |
748 | ### 'Spike Triggered Average' style receptive fields.
749 | - We take a look at what makes a neuron respond, by taking a bunch of images, and averaging them based on how much the neuron was activated.
750 |
751 |
752 | ```
753 | def norm(x):
754 | return (x - np.min(x)) / np.max(x - np.min(x))
755 | ```
756 |
757 |
758 | ```
759 | # get a bunch of images and their corresponding z points in the network
760 | recon_z = np.random.normal(0,1,(batch_size,hidden_size))
761 | recon_x, recon_l = sess.run((x_tilde, l_x_tilde), {z_x: recon_z})
762 | for i in range(100):
763 | rz = np.random.normal(0,1,(batch_size,hidden_size))
764 | rx, rl = sess.run((x_tilde, l_x_tilde), {z_x: rz})
765 | recon_z= np.concatenate((recon_z,rz),axis = 0)
766 | recon_l = np.concatenate((recon_l,rl),axis = 0)
767 | recon_x = np.concatenate((recon_x,rx),axis = 0)
768 | ```
769 |
770 | #### Z-Neurons
771 |
772 |
773 | ```
774 | num_neurons = 25
775 |
776 | neuron = 0
777 | fig, ax = plt.subplots(nrows=int(np.sqrt(num_neurons)),ncols=int(np.sqrt(num_neurons)), figsize=(18,12))
778 | for a in range(int(np.sqrt(num_neurons))):
779 | for b in range(int(np.sqrt(num_neurons))):
780 | proportions = (recon_z[:,neuron] - min(recon_z[:,neuron])) / max((recon_z[:,neuron] - min(recon_z[:,neuron])))
781 | receptive_field = norm(np.sum(([proportions[i] * recon_x[i,:] for i in range(len(proportions))]),axis = 0)/np.sum(proportions)- np.mean(recon_x,axis = 0))
782 | ax[(a,b)].imshow(create_image(receptive_field), cmap=plt.cm.gray, interpolation='nearest')
783 | ax[(a,b)].axis('off')
784 | neuron+=1
785 | ```
786 |
787 |
788 | 
789 |
790 |
791 | #### Deep Descriminator Neurons
792 |
793 |
794 | ```
795 | num_neurons = 25
796 |
797 | neuron = 0
798 | fig, ax = plt.subplots(nrows=int(np.sqrt(num_neurons)),ncols=int(np.sqrt(num_neurons)), figsize=(18,12))
799 | for a in range(int(np.sqrt(num_neurons))):
800 | for b in range(int(np.sqrt(num_neurons))):
801 | proportions = (recon_l[:,neuron] - min(recon_l[:,neuron])) / max((recon_l[:,neuron] - min(recon_l[:,neuron])))
802 | receptive_field = norm(np.sum(([proportions[i] * recon_x[i,:] for i in range(len(proportions))]),axis = 0)/np.sum(proportions)- np.mean(recon_x,axis = 0))
803 | #test = norm(test/np.mean(test_list, axis = 0))
804 | ax[(a,b)].imshow(create_image(receptive_field), cmap=plt.cm.gray, interpolation='nearest')
805 | ax[(a,b)].axis('off')
806 | neuron+=1
807 | ```
808 |
809 |
810 | 
811 |
812 |
813 | ### Now lets try some latent space algebra
814 |
815 |
816 | ```
817 | # Here are the attribute types
818 | print [str(i) + ': ' + headers[i] for i in range(len(headers))]
819 | ```
820 |
821 | ['0: 5_o_Clock_Shadow', '1: Arched_Eyebrows', '2: Attractive', '3: Bags_Under_Eyes', '4: Bald', '5: Bangs', '6: Big_Lips', '7: Big_Nose', '8: Black_Hair', '9: Blond_Hair', '10: Blurry', '11: Brown_Hair', '12: Bushy_Eyebrows', '13: Chubby', '14: Double_Chin', '15: Eyeglasses', '16: Goatee', '17: Gray_Hair', '18: Heavy_Makeup', '19: High_Cheekbones', '20: Male', '21: Mouth_Slightly_Open', '22: Mustache', '23: Narrow_Eyes', '24: No_Beard', '25: Oval_Face', '26: Pale_Skin', '27: Pointy_Nose', '28: Receding_Hairline', '29: Rosy_Cheeks', '30: Sideburns', '31: Smiling', '32: Straight_Hair', '33: Wavy_Hair', '34: Wearing_Earrings', '35: Wearing_Hat', '36: Wearing_Lipstick', '37: Wearing_Necklace', '38: Wearing_Necktie', '39: Young']
822 |
823 |
824 |
825 | ```
826 | # Go through a bunch of inputs, get their z values and their attributes
827 | iter_ = data_iterator()
828 | all_batch, all_attrib = iter_.next()
829 | all_z = sess.run((z_x_mean), {all_input: all_batch})
830 | all_recon_x = sess.run((x_tilde), {z_x: all_z})
831 |
832 | for i in range(200):
833 | next_batch, next_attrib = iter_.next()
834 | recon_z = sess.run((z_x_mean), {all_input: next_batch})
835 | recon_x = sess.run((x_tilde), {z_x: recon_z})
836 |
837 | all_z = np.concatenate((all_z,recon_z),axis = 0)
838 | all_batch = np.concatenate((all_batch,next_batch),axis = 0)
839 | all_recon_x = np.concatenate((all_recon_x,recon_x),axis = 0)
840 | all_attrib = np.concatenate((all_attrib,next_attrib),axis = 0)
841 | ```
842 |
843 |
844 | ```
845 | # for each attribute type, get the difference between the mean z-vector of faces with
846 | # the attribute, and without the attribute
847 | attr_vector_list = []
848 | avg_attr_list = []
849 | avg_not_attr_list = []
850 |
851 | for i in range(np.shape(all_attrib)[1]):
852 | has_attribute = all_attrib[:,i] == 1
853 | average_attribute = np.mean(all_z[has_attribute], axis=0)
854 | average_not_attribute = np.mean(all_z[has_attribute == False], axis=0)
855 | avg_attr_list.append(average_attribute)
856 | avg_not_attr_list.append(average_not_attribute)
857 | attr_vector_list.append(average_attribute - average_not_attribute)
858 | ```
859 |
860 |
861 | ```
862 | feature_to_look_at = 9 # specify the attribute we want to look at
863 | ```
864 |
865 | #### Look at some blonde people (bottom), and their reconstructions (top)
866 |
867 |
868 | ```
869 | # show some faces which have this attribute
870 | recon_faces = all_recon_x[all_attrib[:,feature_to_look_at] == 1,:]
871 | new_faces = all_batch[all_attrib[:,feature_to_look_at] == 1,:]
872 |
873 | examples = 4
874 | canvas = np.zeros((dim1*2,dim2*examples,dim3))
875 | for i in range(examples):
876 | canvas[0:dim1,dim2*i:dim2*(i+1),:] = create_image(recon_faces[i])
877 | canvas[dim1:,dim2*i:dim2*(i+1),:] = create_image(new_faces[i])
878 |
879 | fig, ax = plt.subplots(nrows=1,ncols=1, figsize=(18,6))
880 | ax.imshow(canvas)
881 | ax.axis('off')
882 | ```
883 |
884 |
885 |
886 |
887 | (-0.5, 255.5, 127.5, -0.5)
888 |
889 |
890 |
891 |
892 | 
893 |
894 |
895 | #### Take random z-points, and add the blonde vector
896 |
897 |
898 | ```
899 | recon_z = np.random.normal(0,1,(batch_size,hidden_size))
900 | recon_x = sess.run((x_tilde), {z_x: recon_z})
901 | ```
902 |
903 |
904 | ```
905 | recon_z_with_attribute = [recon_z[i] + attr_vector_list[feature_to_look_at] for i in range(len(recon_z))]
906 | recon_x_with_attribute = sess.run((x_tilde), {z_x: recon_z_with_attribute})
907 | ```
908 |
909 |
910 | ```
911 | examples = 12
912 | canvas = np.zeros((dim1*2,dim2*examples,dim3))
913 | for i in range(examples):
914 | canvas[:dim1,dim2*i:dim2*(i+1),:] = create_image(recon_x[i])
915 | canvas[dim1:,dim2*i:dim2*(i+1),:] = create_image(recon_x_with_attribute[i])
916 | ```
917 |
918 |
919 | ```
920 | fig, ax = plt.subplots(nrows=1,ncols=1, figsize=(18,6))
921 | ax.imshow(canvas)
922 | ax.axis('off')
923 | plt.title('Top: random points in z space | Bottom: random points + blonde vector')
924 | ```
925 |
926 |
927 |
928 |
929 |
930 |
931 |
932 |
933 |
934 | 
935 |
936 |
937 | #### Look at the average blonde person, the average not blonde person, and their difference
938 |
939 |
940 | ```
941 | recon_z = np.random.normal(0,1,(batch_size,hidden_size))
942 | recon_z[0] = avg_attr_list[feature_to_look_at]
943 | recon_z[1] = avg_not_attr_list[feature_to_look_at]
944 | recon_z[2] = attr_vector_list[feature_to_look_at]
945 |
946 | recon_x = sess.run((x_tilde), {z_x: recon_z})
947 | ```
948 |
949 |
950 | ```
951 | examples = 3
952 | canvas = np.zeros((dim1,dim2*examples,dim3))
953 | for i in range(examples):
954 | canvas[:,dim2*i:dim2*(i+1),:] = create_image(recon_x[i])
955 | ```
956 |
957 |
958 | ```
959 | fig, ax = plt.subplots(nrows=1,ncols=1, figsize=(18,6))
960 | ax.imshow(canvas)
961 | ax.axis('off')
962 | plt.title('Average Blonde Person | Average Not Blonde Person | ABP-ANBP')
963 | ```
964 |
965 |
966 |
967 |
968 |
969 |
970 |
971 |
972 |
973 | 
974 |
975 |
976 | ### This implementation is based on a few other things:
977 | - [Autoencoding beyond pixels](http://arxiv.org/abs/1512.09300) [*(Github)*](https://github.com/andersbll/autoencoding_beyond_pixels)
978 | - [VAE and GAN implementations in prettytensor/tensorflow (*Github*)](https://github.com/ikostrikov/TensorFlow-VAE-GAN-DRAW)
979 | - [Tensorflow VAE tutorial](https://jmetzen.github.io/2015-11-27/vae.html)
980 | - [DCGAN](https://arxiv.org/abs/1511.06434) [*(Github)*](https://github.com/Newmu/dcgan_code)
981 | - [Torch GAN tutorial](http://torch.ch/blog/2015/11/13/gan.html) [*(Github)*](https://github.com/skaae/torch-gan)
982 | - [Open AI improving GANS](https://openai.com/blog/generative-models/) [*(Github)*](https://github.com/openai/improved-gan)
983 | - Other things which I am probably forgetting...
984 |
985 |
986 |
987 | ```
988 | # this is just a little command to convert this as md for the github page
989 | !jupyter nbconvert --to markdown VAE-GAN-multi-gpu-celebA.ipynb
990 | !mv VAE-GAN-multi-gpu-celebA.md readme.md
991 | ```
992 |
993 | [NbConvertApp] Converting notebook VAE-GAN-multi-gpu-celebA.ipynb to markdown
994 | [NbConvertApp] Support files will be in VAE-GAN-multi-gpu-celebA_files/
995 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
996 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
997 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
998 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
999 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1000 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1001 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1002 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1003 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1004 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1005 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1006 | [NbConvertApp] Making directory VAE-GAN-multi-gpu-celebA_files
1007 | [NbConvertApp] Writing 34120 bytes to VAE-GAN-multi-gpu-celebA.md
1008 |
1009 |
1010 |
1011 | ```
1012 |
1013 | ```
1014 |
--------------------------------------------------------------------------------