├── .gitignore
├── LICENSE
├── README.md
├── SummaC - Additional Experiments.ipynb
├── SummaC - Main Results.ipynb
├── requirements.txt
├── script.sh
├── setup.py
├── summac
├── __init__.py
├── benchmark.py
├── model_baseline.py
├── model_guardrails.py
├── model_summac.py
├── run_baseline.py
├── train_summac.py
├── utils_misc.py
├── utils_optim.py
├── utils_scorer.py
└── utils_scoring.py
└── summac_conv_vitc_sent_perc_e.bin
/.gitignore:
--------------------------------------------------------------------------------
1 | env/
2 | __pycache__/
3 | .vscode/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # SummaC: Summary Consistency Detection
2 |
3 | This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
4 |
5 | We release: (1) the trained SummaC models, (2) the SummaC Benchmark and data loaders, (3) training and evaluation scripts.
6 |
7 |
8 | 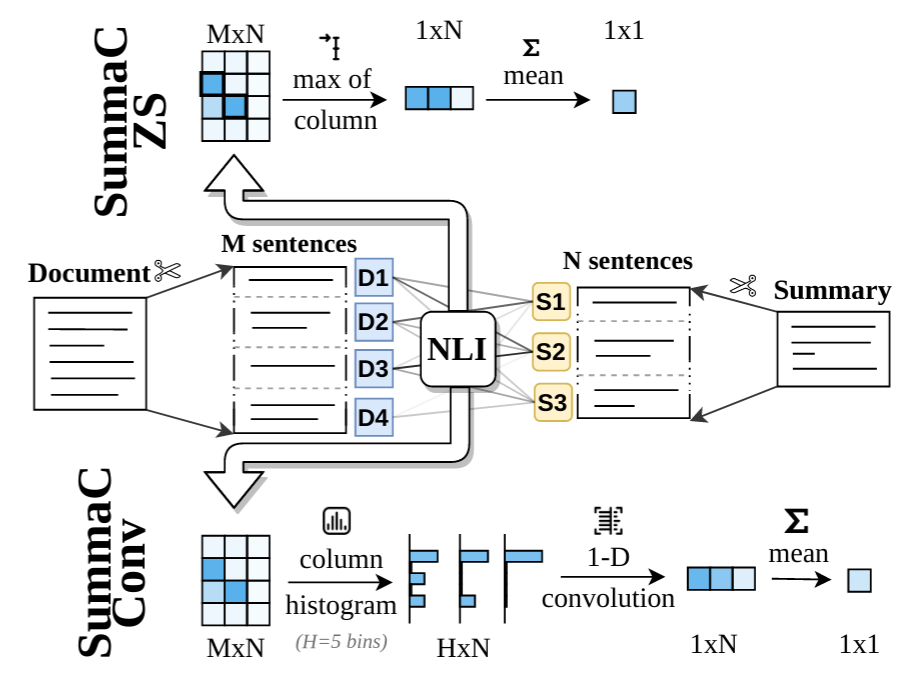 9 |
9 |
10 |
11 | ## Installing/Using SummaC
12 |
13 | [Update] Thanks to @Aktsvigun for the help, we now have a pip package, making it easy to install the SummaC models:
14 | ```
15 | pip install summac
16 | ```
17 |
18 | Requirement issues: in v0.0.4, we've reduced package dependencies to facilitate installation. We recommend you install `torch` first and verify it works before installing `summac`.
19 |
20 | The two trained models SummaC-ZS and SummaC-Conv are implemented in `model_summac` ([link](https://github.com/tingofurro/summac/blob/master/model_summac.py)). Once the package is installed, the models can be used like this:
21 |
22 | ### Example use
23 |
24 | ```python
25 | from summac.model_summac import SummaCZS, SummaCConv
26 |
27 | model_zs = SummaCZS(granularity="sentence", model_name="vitc", device="cpu") # If you have a GPU: switch to: device="cuda"
28 | model_conv = SummaCConv(models=["vitc"], bins='percentile', granularity="sentence", nli_labels="e", device="cpu", start_file="default", agg="mean")
29 |
30 | document = """Scientists are studying Mars to learn about the Red Planet and find landing sites for future missions.
31 | One possible site, known as Arcadia Planitia, is covered instrange sinuous features.
32 | The shapes could be signs that the area is actually made of glaciers, which are large masses of slow-moving ice.
33 | Arcadia Planitia is in Mars' northern lowlands."""
34 |
35 | summary1 = "There are strange shape patterns on Arcadia Planitia. The shapes could indicate the area might be made of glaciers. This makes Arcadia Planitia ideal for future missions."
36 | score_zs1 = model_zs.score([document], [summary1])
37 | score_conv1 = model_conv.score([document], [summary1])
38 | print("[Summary 1] SummaCZS Score: %.3f; SummacConv score: %.3f" % (score_zs1["scores"][0], score_conv1["scores"][0])) # [Summary 1] SummaCZS Score: 0.582; SummacConv score: 0.536
39 |
40 | summary2 = "There are strange shape patterns on Arcadia Planitia. The shapes could indicate the area might be made of glaciers."
41 | score_zs2 = model_zs.score([document], [summary2])
42 | score_conv2 = model_conv.score([document], [summary2])
43 | print("[Summary 2] SummaCZS Score: %.3f; SummacConv score: %.3f" % (score_zs2["scores"][0], score_conv2["scores"][0])) # [Summary 2] SummaCZS Score: 0.877; SummacConv score: 0.709
44 | ```
45 |
46 | We recommend using the SummaCConv models, as experiments from the paper show it provides better predictions. Two notebooks provide experimental details: [SummaC - Main Results.ipynb](https://github.com/tingofurro/summac/blob/master/SummaC%20-%20Main%20Results.ipynb) for the main results (Table 2) and [SummaC - Additional Experiments.ipynb](https://github.com/tingofurro/summac/blob/master/SummaC%20-%20Additional%20Experiments.ipynb) for additional experiments (Tables 1, 3, 4, 5, 6) from the paper.
47 |
48 | ### SummaC Benchmark
49 |
50 | The SummaC Benchmark consists of 6 summary consistency datasets that have been standardized to a binary classification task. The datasets included are:
51 |
52 |
53 | 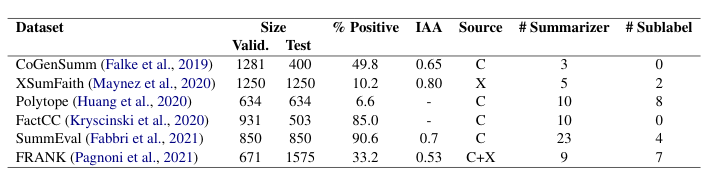
54 | % Positive is the percentage of positive (consistent) summaries. IAA is the inter-annotator agreement (Fleiss Kappa). Source is the dataset used for the source documents (CNN/DM or XSum). # Summarizers is the number of summarizers (extractive and abstractive) included in the dataset. # Sublabel is the number of labels in the typology used to label summary errors.
55 |
56 |
57 | The data-loaders for the benchmark are included in `benchmark.py` ([link](https://github.com/tingofurro/summac/blob/master/summac/benchmark.py)). Each dataset in the benchmark downloads automatically on first run. To load the benchmark:
58 | ```py
59 | from summac.benchmark import SummaCBenchmark
60 | benchmark_val = SummaCBenchmark(benchmark_folder="/path/to/summac_benchmark/", cut="val", hf_datasets_cache_dir = "/path/to/huggingface_datasets_cache_dir/")
61 | frank_dataset = benchmark_val.get_dataset("frank")
62 | print(frank_dataset[300]) # {"document: "A Darwin woman has become a TV [...]", "claim": "natalia moon , 23 , has become a tv sensation [...]", "label": 0, "cut": "val", "model_name": "s2s", "error_type": "LinkE"}
63 | ```
64 |
65 |
66 |
67 | ## Cite the work
68 |
69 | If you make use of the code, models, or algorithm, please cite our paper.
70 | ```
71 | @article{Laban2022SummaCRN,
72 | title={SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization},
73 | author={Philippe Laban and Tobias Schnabel and Paul N. Bennett and Marti A. Hearst},
74 | journal={Transactions of the Association for Computational Linguistics},
75 | year={2022},
76 | volume={10},
77 | pages={163-177}
78 | }
79 | ```
80 |
81 | ## Contributing
82 |
83 | If you'd like to contribute, or have questions or suggestions, you can contact us at phillab@berkeley.edu. All contributions welcome, for example helping make the benchmark more easily downloadable, or improving model performance on the benchmark.
84 |
--------------------------------------------------------------------------------
/SummaC - Additional Experiments.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "name": "stderr",
10 | "output_type": "stream",
11 | "text": [
12 | "2021-10-31 22:47:43,882 [3845] WARNING datasets.builder:355: [JupyterRequire] Using custom data configuration default\n",
13 | "2021-10-31 22:47:43,888 [3845] WARNING datasets.builder:510: [JupyterRequire] Reusing dataset xsum (/home/phillab/.cache/huggingface/datasets/xsum/default/1.2.0/4957825a982999fbf80bca0b342793b01b2611e021ef589fb7c6250b3577b499)\n",
14 | "2021-10-31 22:47:48,828 [3845] WARNING datasets.builder:510: [JupyterRequire] Reusing dataset cnn_dailymail (/home/phillab/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234)\n"
15 | ]
16 | },
17 | {
18 | "name": "stdout",
19 | "output_type": "stream",
20 | "text": [
21 | " name N N_pos N_neg frac_pos\n",
22 | "0 cogensumm 400 312 88 0.780000\n",
23 | "1 xsumfaith 1250 130 1120 0.104000\n",
24 | "2 polytope 634 41 593 0.064669\n",
25 | "3 factcc 503 441 62 0.876740\n",
26 | "4 summeval 850 770 80 0.905882\n",
27 | "5 frank 1575 529 1046 0.335873\n"
28 | ]
29 | }
30 | ],
31 | "source": [
32 | "import sklearn, torch, numpy as np, json, os, tqdm, pandas as pd, nltk, utils_misc, seaborn as sns, sys, glob\n",
33 | "sys.path.insert(0, \"/home/phillab/summac/\")\n",
34 | "from model_summac import SummaCConv, SummaCZS, model_map\n",
35 | "from utils_summac_benchmark import SummaCBenchmark\n",
36 | "from utils_scoring import ScorerWrapper\n",
37 | "import utils_summac_benchmark\n",
38 | "\n",
39 | "cm = sns.light_palette(\"green\", as_cmap=True)\n",
40 | "benchmark = SummaCBenchmark(cut=\"test\")\n",
41 | "benchmark.print_stats()\n",
42 | "\n",
43 | "def path_to_model_info(file_path):\n",
44 | " toks = file_path.split(\"/\")\n",
45 | " file_name = toks[-1].replace(\".bin\", \"\")\n",
46 | " model_type = \"histo\"\n",
47 | " model_card, granularity, bins, nli_labels, acc = file_name.split(\"_\")\n",
48 | " acc = float(acc.replace(\"bacc\", \"\").replace(\"f1\", \"\"))\n",
49 | " return {\"model_type\": model_type, \"model_card\": model_card, \"granularity\": granularity, \"bins\": bins, \"acc\": acc, \"model_path\": file_path, \"nli_labels\": nli_labels}"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {
55 | "heading_collapsed": true
56 | },
57 | "source": [
58 | "# Table 3: NLI Model Selection\n"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 2,
64 | "metadata": {
65 | "hidden": true,
66 | "scrolled": false
67 | },
68 | "outputs": [
69 | {
70 | "name": "stdout",
71 | "output_type": "stream",
72 | "text": [
73 | "\n",
74 | "\n",
75 | "\n",
76 | "\n",
77 | "\n",
78 | "\n",
79 | "\n",
80 | "\n"
81 | ]
82 | }
83 | ],
84 | "source": [
85 | "scorers = []\n",
86 | "model_keys = list(model_map.keys())#+ [\"decomp\"]\n",
87 | "# model_keys = [\"decomp\"]\n",
88 | "\n",
89 | "for model_key in model_keys:\n",
90 | " scorers.append({\"name\": \"ZS-%s\" % (model_key.upper().replace(\"-\", \"_\")), \"model\": SummaCZS(granularity=\"sentence\", model_name=model_key), \"sign\": 1, \"only_doc\": True})\n",
91 | " \n",
92 | " # Add a histogram based-model\n",
93 | " model_files = glob.glob(\"/home/phillab/models/summac/%s_sentence*\" % (model_key))\n",
94 | " if len(model_files) == 0:\n",
95 | " print(\"No model for [%s] was found\" % (model_key))\n",
96 | " continue\n",
97 | " best = sorted([path_to_model_info(mf) for mf in model_files], key=lambda m: m[\"acc\"])[-1]\n",
98 | " scorers.append({\"name\": \"Histo-%s\" % (model_key.upper().replace(\"-\", \"_\")), \"model\": SummaCConv(bins=best[\"bins\"], nli_labels=best[\"nli_labels\"], models=[model_key], granularity=\"sentence\", start_file=best[\"model_path\"]), \"sign\": 1})\n",
99 | "\n",
100 | "scorer_doc = ScorerWrapper(scorers, scoring_method=\"sum\", max_batch_size=20, use_caching=True)"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 3,
106 | "metadata": {
107 | "hidden": true,
108 | "scrolled": false
109 | },
110 | "outputs": [
111 | {
112 | "name": "stderr",
113 | "output_type": "stream",
114 | "text": [
115 | "Using custom data configuration default\n",
116 | "Reusing dataset xsum (/home/phillab/.cache/huggingface/datasets/xsum/default/1.2.0/4957825a982999fbf80bca0b342793b01b2611e021ef589fb7c6250b3577b499)\n",
117 | "Reusing dataset cnn_dailymail (/home/phillab/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234)\n",
118 | " 0%| | 0/400 [00:00\n",
232 | "Balanced Accuracy | | score |
| nli_name | model_type | |
\n",
233 | " \n",
234 | " | ANLI | \n",
235 | " Histo | \n",
236 | " 0.699 | \n",
237 | "
\n",
238 | " \n",
239 | " | ZS | \n",
240 | " 0.717 | \n",
241 | "
\n",
242 | " \n",
243 | " | MNLI | \n",
244 | " Histo | \n",
245 | " 0.73 | \n",
246 | "
\n",
247 | " \n",
248 | " | ZS | \n",
249 | " 0.709 | \n",
250 | "
\n",
251 | " \n",
252 | " | MNLI_BASE | \n",
253 | " Histo | \n",
254 | " 0.698 | \n",
255 | "
\n",
256 | " \n",
257 | " | ZS | \n",
258 | " 0.695 | \n",
259 | "
\n",
260 | " \n",
261 | " | SNLI_BASE | \n",
262 | " Histo | \n",
263 | " 0.64 | \n",
264 | "
\n",
265 | " \n",
266 | " | ZS | \n",
267 | " 0.666 | \n",
268 | "
\n",
269 | " \n",
270 | " | SNLI_LARGE | \n",
271 | " Histo | \n",
272 | " 0.624 | \n",
273 | "
\n",
274 | " \n",
275 | " | ZS | \n",
276 | " 0.666 | \n",
277 | "
\n",
278 | " \n",
279 | " | VITC | \n",
280 | " Histo | \n",
281 | " 0.74 | \n",
282 | "
\n",
283 | " \n",
284 | " | ZS | \n",
285 | " 0.721 | \n",
286 | "
\n",
287 | " \n",
288 | " | VITC_BASE | \n",
289 | " Histo | \n",
290 | " 0.712 | \n",
291 | "
\n",
292 | " \n",
293 | " | ZS | \n",
294 | " 0.679 | \n",
295 | "
\n",
296 | " \n",
297 | " | VITC_ONLY | \n",
298 | " Histo | \n",
299 | " 0.728 | \n",
300 | "
\n",
301 | " \n",
302 | " | ZS | \n",
303 | " 0.711 | \n",
304 | "
\n",
305 | "
"
306 | ],
307 | "text/plain": [
308 | ""
309 | ]
310 | },
311 | "execution_count": 3,
312 | "metadata": {},
313 | "output_type": "execute_result"
314 | }
315 | ],
316 | "source": [
317 | "benchmark = SummaCBenchmark(cut=\"test\")\n",
318 | "\n",
319 | "results = {}\n",
320 | "for dataset in benchmark.tasks:\n",
321 | " print(\"======= %s ========\" % (dataset[\"name\"]))\n",
322 | " datas = dataset[\"task\"]\n",
323 | " labels = [d[\"label\"] for d in datas]\n",
324 | " utils_summac_benchmark.compute_doc_level(scorer_doc, datas)\n",
325 | " \n",
326 | " for pred_label in datas[0].keys():\n",
327 | " if \"pred_\" not in pred_label or \"total\" in pred_label: continue\n",
328 | " balanced_acc = sklearn.metrics.balanced_accuracy_score(labels, [d[pred_label] for d in datas])\n",
329 | " model_name, input_type = pred_label.replace(\"pred_\", \"\").split(\"|\")\n",
330 | " model_type, nli_name = model_name.split(\"-\")\n",
331 | " k = (model_type, nli_name)\n",
332 | " if k not in results:\n",
333 | " results[k] = []\n",
334 | " results[k].append(balanced_acc)\n",
335 | "\n",
336 | "cleaned_results = []\n",
337 | "for (model_type, nli), vs in results.items():\n",
338 | " cleaned_results.append({\"nli_name\": nli, \"model_type\": model_type, \"score\": np.mean(vs)})\n",
339 | " \n",
340 | "pd.DataFrame(cleaned_results).groupby([\"nli_name\", \"model_type\"]).agg({\"score\": \"sum\"}).style.set_precision(3).set_caption(\"Balanced Accuracy\")"
341 | ]
342 | },
343 | {
344 | "cell_type": "code",
345 | "execution_count": 4,
346 | "metadata": {
347 | "hidden": true
348 | },
349 | "outputs": [],
350 | "source": [
351 | "for scorer in scorers:\n",
352 | " scorer[\"model\"].save_imager_cache()"
353 | ]
354 | },
355 | {
356 | "cell_type": "markdown",
357 | "metadata": {
358 | "heading_collapsed": true
359 | },
360 | "source": [
361 | "# Table 4: Choice of NLI Category"
362 | ]
363 | },
364 | {
365 | "cell_type": "code",
366 | "execution_count": null,
367 | "metadata": {
368 | "hidden": true
369 | },
370 | "outputs": [],
371 | "source": [
372 | "scorers = []\n",
373 | "for model_key in [\"vitc\", \"mnli\", \"anli\"]:\n",
374 | " for nli_labels in [\"e\", \"c\", \"n\", \"ec\", \"en\", \"cn\", \"ecn\"]:\n",
375 | " \n",
376 | " model_files = glob.glob(\"/home/phillab/models/summac/%s_sentence_percentile_%s*\" % (model_key, nli_labels))\n",
377 | " if len(model_files) == 0:\n",
378 | " print(\"No model for [%s, %s] was found\" % (model_key, nli_labels))\n",
379 | " continue\n",
380 | " best = sorted([path_to_model_info(mf) for mf in model_files], key=lambda m: m[\"acc\"])[-1]\n",
381 | " scorers.append({\"name\": \"Histo-%s-%s\" % (model_key.upper().replace(\"-\", \"_\"), nli_labels), \"model\": SummaCConv(bins=best[\"bins\"], nli_labels=best[\"nli_labels\"], models=[model_key], granularity=\"sentence\", start_file=best[\"model_path\"]), \"sign\": 1})\n",
382 | "\n",
383 | "scorer_doc = ScorerWrapper(scorers, max_batch_size=20, use_caching=True)\n",
384 | "print(\"%d scorers loaded\" % (len(scorers)))\n",
385 | "\n",
386 | "benchmark = SummaCBenchmark(cut=\"test\")\n",
387 | "\n",
388 | "results = {}\n",
389 | "for dataset in benchmark.tasks:\n",
390 | " print(\"======= %s ========\" % (dataset[\"name\"]))\n",
391 | " datas = dataset[\"task\"]\n",
392 | " labels = [d[\"label\"] for d in datas]\n",
393 | " utils_summac_benchmark.compute_doc_level(scorer_doc, datas)\n",
394 | " \n",
395 | " for pred_label in datas[0].keys():\n",
396 | " if \"pred_\" not in pred_label or \"total\" in pred_label: continue\n",
397 | " balanced_acc = sklearn.metrics.balanced_accuracy_score(labels, [d[pred_label] for d in datas])\n",
398 | " model_name, input_type = pred_label.replace(\"pred_\", \"\").split(\"|\")\n",
399 | " model_type, nli_name, nli_labels = model_name.split(\"-\")\n",
400 | " k = (nli_name, nli_labels)\n",
401 | " if k not in results:\n",
402 | " results[k] = []\n",
403 | " results[k].append(balanced_acc)\n",
404 | "\n",
405 | "cleaned_results = []\n",
406 | "for (nli, nli_labels), vs in results.items():\n",
407 | " cleaned_results.append({\"nli_name\": nli, \"nli_labels\": nli_labels, \"model_type\": model_type, \"score\": np.mean(vs)})\n",
408 | " \n",
409 | "pd.DataFrame(cleaned_results).groupby([\"nli_name\", \"nli_labels\"]).agg({\"score\": \"sum\"}).style.set_precision(3).set_caption(\"Balanced Accuracy\")"
410 | ]
411 | },
412 | {
413 | "cell_type": "markdown",
414 | "metadata": {
415 | "heading_collapsed": true
416 | },
417 | "source": [
418 | "# Table 5: Granularity Selection\n"
419 | ]
420 | },
421 | {
422 | "cell_type": "code",
423 | "execution_count": 2,
424 | "metadata": {
425 | "hidden": true
426 | },
427 | "outputs": [
428 | {
429 | "name": "stdout",
430 | "output_type": "stream",
431 | "text": [
432 | "\n",
433 | "\n",
434 | "\n",
435 | "\n",
436 | "\n",
437 | "\n",
438 | "\n",
439 | "\n",
440 | "\n",
441 | "\n",
442 | "\n",
443 | "\n",
444 | "28 scorers loaded\n"
445 | ]
446 | }
447 | ],
448 | "source": [
449 | "scorers = []\n",
450 | "granularities = [\"document\", \"document-sentence\", \"paragraph-document\", \"paragraph-sentence\", \"2sents-document\", \"2sents-sentence\", \"sentence-document\", \"sentence\"]\n",
451 | "\n",
452 | "for model_key in [\"mnli\", \"vitc\"]:\n",
453 | "# for granularity in [\"document\", \"document-sentence\", \"paragraph-document\", \"paragraph-sentence\", \"2sents-sentence\", \"sentence-document\", \"sentence\"]:\n",
454 | " for granularity in granularities:\n",
455 | "# for granularity in [\"sentence-document\"]:\n",
456 | " scorers.append({\"name\": \"ZS-%s-%s\" % (model_key.upper().replace(\"-\", \"_\"), granularity.replace(\"-\", \"_\")), \"model\": SummaCZS(granularity=granularity, model_name=model_key), \"sign\": 1})\n",
457 | " if granularity.startswith(\"document\"):\n",
458 | " continue\n",
459 | " model_files = glob.glob(\"/home/phillab/models/summac/%s_%s*\" % (model_key, granularity))\n",
460 | " if len(model_files) == 0:\n",
461 | " print(\"No model for [%s, %s] was found\" % (model_key, granularity))\n",
462 | " continue\n",
463 | " best = sorted([path_to_model_info(mf) for mf in model_files], key=lambda m: m[\"acc\"])[-1]\n",
464 | " scorers.append({\"name\": \"Histo-%s-%s\" % (model_key.upper().replace(\"-\", \"_\"), granularity.replace(\"-\", \"_\")), \"model\": SummaCConv(bins=best[\"bins\"], nli_labels=best[\"nli_labels\"], models=[model_key], granularity=granularity, start_file=best[\"model_path\"]), \"sign\": 1})\n",
465 | "\n",
466 | "scorer_doc = ScorerWrapper(scorers, max_batch_size=20, use_caching=True)\n",
467 | "print(\"%d scorers loaded\" % (len(scorers)))"
468 | ]
469 | },
470 | {
471 | "cell_type": "code",
472 | "execution_count": 3,
473 | "metadata": {
474 | "hidden": true
475 | },
476 | "outputs": [
477 | {
478 | "name": "stderr",
479 | "output_type": "stream",
480 | "text": [
481 | " 10%|█ | 40/400 [00:00<00:01, 304.49it/s]"
482 | ]
483 | },
484 | {
485 | "name": "stdout",
486 | "output_type": "stream",
487 | "text": [
488 | "======= cogensumm ========\n"
489 | ]
490 | },
491 | {
492 | "name": "stderr",
493 | "output_type": "stream",
494 | "text": [
495 | "100%|██████████| 400/400 [00:01<00:00, 326.26it/s]\n",
496 | " 3%|▎ | 40/1250 [00:00<00:03, 326.44it/s]"
497 | ]
498 | },
499 | {
500 | "name": "stdout",
501 | "output_type": "stream",
502 | "text": [
503 | "======= xsumfaith ========\n"
504 | ]
505 | },
506 | {
507 | "name": "stderr",
508 | "output_type": "stream",
509 | "text": [
510 | "100%|██████████| 1250/1250 [00:02<00:00, 462.43it/s]\n",
511 | " 6%|▋ | 40/634 [00:00<00:01, 330.76it/s]"
512 | ]
513 | },
514 | {
515 | "name": "stdout",
516 | "output_type": "stream",
517 | "text": [
518 | "======= polytope ========\n"
519 | ]
520 | },
521 | {
522 | "name": "stderr",
523 | "output_type": "stream",
524 | "text": [
525 | "100%|██████████| 634/634 [00:01<00:00, 386.73it/s]\n",
526 | " 8%|▊ | 40/503 [00:00<00:01, 341.95it/s]"
527 | ]
528 | },
529 | {
530 | "name": "stdout",
531 | "output_type": "stream",
532 | "text": [
533 | "======= factcc ========\n"
534 | ]
535 | },
536 | {
537 | "name": "stderr",
538 | "output_type": "stream",
539 | "text": [
540 | "100%|██████████| 503/503 [00:01<00:00, 441.78it/s]\n",
541 | " 5%|▍ | 40/850 [00:00<00:02, 356.76it/s]"
542 | ]
543 | },
544 | {
545 | "name": "stdout",
546 | "output_type": "stream",
547 | "text": [
548 | "======= summeval ========\n"
549 | ]
550 | },
551 | {
552 | "name": "stderr",
553 | "output_type": "stream",
554 | "text": [
555 | "100%|██████████| 850/850 [00:02<00:00, 350.46it/s]\n",
556 | " 4%|▍ | 60/1575 [00:00<00:03, 423.98it/s]"
557 | ]
558 | },
559 | {
560 | "name": "stdout",
561 | "output_type": "stream",
562 | "text": [
563 | "======= frank ========\n"
564 | ]
565 | },
566 | {
567 | "name": "stderr",
568 | "output_type": "stream",
569 | "text": [
570 | "100%|██████████| 1575/1575 [00:03<00:00, 394.82it/s]\n"
571 | ]
572 | },
573 | {
574 | "data": {
575 | "text/html": [
576 | "Balanced Accuracy | | | score |
| nli_name | granularity | model_type | |
\n",
578 | " \n",
579 | " | MNLI | \n",
580 | " 2sents_document | \n",
581 | " Histo | \n",
582 | " 0.638 | \n",
583 | "
\n",
584 | " \n",
585 | " | ZS | \n",
586 | " 0.64 | \n",
587 | "
\n",
588 | " \n",
589 | " | 2sents_sentence | \n",
590 | " Histo | \n",
591 | " 0.737 | \n",
592 | "
\n",
593 | " \n",
594 | " | ZS | \n",
595 | " 0.712 | \n",
596 | "
\n",
597 | " \n",
598 | " | document | \n",
599 | " ZS | \n",
600 | " 0.564 | \n",
601 | "
\n",
602 | " \n",
603 | " | document_sentence | \n",
604 | " ZS | \n",
605 | " 0.574 | \n",
606 | "
\n",
607 | " \n",
608 | " | paragraph_document | \n",
609 | " Histo | \n",
610 | " 0.616 | \n",
611 | "
\n",
612 | " \n",
613 | " | ZS | \n",
614 | " 0.598 | \n",
615 | "
\n",
616 | " \n",
617 | " | paragraph_sentence | \n",
618 | " Histo | \n",
619 | " 0.647 | \n",
620 | "
\n",
621 | " \n",
622 | " | ZS | \n",
623 | " 0.652 | \n",
624 | "
\n",
625 | " \n",
626 | " | sentence | \n",
627 | " Histo | \n",
628 | " 0.73 | \n",
629 | "
\n",
630 | " \n",
631 | " | ZS | \n",
632 | " 0.703 | \n",
633 | "
\n",
634 | " \n",
635 | " | sentence_document | \n",
636 | " Histo | \n",
637 | " 0.62 | \n",
638 | "
\n",
639 | " \n",
640 | " | ZS | \n",
641 | " 0.587 | \n",
642 | "
\n",
643 | " \n",
644 | " | VITC | \n",
645 | " 2sents_document | \n",
646 | " Histo | \n",
647 | " 0.713 | \n",
648 | "
\n",
649 | " \n",
650 | " | ZS | \n",
651 | " 0.697 | \n",
652 | "
\n",
653 | " \n",
654 | " | 2sents_sentence | \n",
655 | " Histo | \n",
656 | " 0.741 | \n",
657 | "
\n",
658 | " \n",
659 | " | ZS | \n",
660 | " 0.725 | \n",
661 | "
\n",
662 | " \n",
663 | " | document | \n",
664 | " ZS | \n",
665 | " 0.721 | \n",
666 | "
\n",
667 | " \n",
668 | " | document_sentence | \n",
669 | " ZS | \n",
670 | " 0.731 | \n",
671 | "
\n",
672 | " \n",
673 | " | paragraph_document | \n",
674 | " Histo | \n",
675 | " 0.712 | \n",
676 | "
\n",
677 | " \n",
678 | " | ZS | \n",
679 | " 0.698 | \n",
680 | "
\n",
681 | " \n",
682 | " | paragraph_sentence | \n",
683 | " Histo | \n",
684 | " 0.743 | \n",
685 | "
\n",
686 | " \n",
687 | " | ZS | \n",
688 | " 0.726 | \n",
689 | "
\n",
690 | " \n",
691 | " | sentence | \n",
692 | " Histo | \n",
693 | " 0.74 | \n",
694 | "
\n",
695 | " \n",
696 | " | ZS | \n",
697 | " 0.718 | \n",
698 | "
\n",
699 | " \n",
700 | " | sentence_document | \n",
701 | " Histo | \n",
702 | " 0.697 | \n",
703 | "
\n",
704 | " \n",
705 | " | ZS | \n",
706 | " 0.684 | \n",
707 | "
\n",
708 | "
"
709 | ],
710 | "text/plain": [
711 | ""
712 | ]
713 | },
714 | "execution_count": 3,
715 | "metadata": {},
716 | "output_type": "execute_result"
717 | }
718 | ],
719 | "source": [
720 | "results = {}\n",
721 | "for dataset in benchmark.tasks:\n",
722 | " print(\"======= %s ========\" % (dataset[\"name\"]))\n",
723 | " datas = dataset[\"task\"]\n",
724 | " labels = [d[\"label\"] for d in datas]\n",
725 | " utils_summac_benchmark.compute_doc_level(scorer_doc, datas)\n",
726 | " \n",
727 | " # Can be removed if re-running\n",
728 | " for scorer in scorers:\n",
729 | " scorer[\"model\"].save_imager_cache()\n",
730 | " \n",
731 | " for pred_label in datas[0].keys():\n",
732 | " if \"pred_\" not in pred_label or \"total\" in pred_label: continue\n",
733 | " balanced_acc = sklearn.metrics.balanced_accuracy_score(labels, [d[pred_label] for d in datas])\n",
734 | " model_name, input_type = pred_label.replace(\"pred_\", \"\").split(\"|\")\n",
735 | " \n",
736 | " model_type, nli_name, gran = model_name.split(\"-\")\n",
737 | " k = (model_type, nli_name, gran)\n",
738 | " if k not in results:\n",
739 | " results[k] = []\n",
740 | " results[k].append(balanced_acc)\n",
741 | "\n",
742 | "cleaned_results = []\n",
743 | "for (model_type, nli, gran), vs in results.items():\n",
744 | " cleaned_results.append({\"nli_name\": nli, \"granularity\": gran, \"model_type\": model_type, \"score\": np.mean(vs)})\n",
745 | " \n",
746 | "pd.DataFrame(cleaned_results).groupby([\"nli_name\", \"granularity\", \"model_type\"]).agg({\"score\": \"sum\"}).style.set_precision(3).set_caption(\"Balanced Accuracy\")"
747 | ]
748 | },
749 | {
750 | "cell_type": "markdown",
751 | "metadata": {},
752 | "source": [
753 | "# Table 6: SummaCZS Operator Choice"
754 | ]
755 | },
756 | {
757 | "cell_type": "code",
758 | "execution_count": 7,
759 | "metadata": {},
760 | "outputs": [
761 | {
762 | "name": "stdout",
763 | "output_type": "stream",
764 | "text": [
765 | "9 scorers loaded\n"
766 | ]
767 | }
768 | ],
769 | "source": [
770 | "scorers = []\n",
771 | "for op1 in [\"min\", \"mean\", \"max\"]:\n",
772 | " for op2 in [\"min\", \"mean\", \"max\"]:\n",
773 | " scorers.append({\"name\": \"ZS-%s-%s\" % (op1, op2), \"model\": SummaCZS(granularity=\"sentence\", model_name=\"vitc\", op1=op1, op2=op2), \"sign\": 1})\n",
774 | " \n",
775 | "scorer_doc = ScorerWrapper(scorers, max_batch_size=20, use_caching=True)\n",
776 | "print(\"%d scorers loaded\" % (len(scorers)))"
777 | ]
778 | },
779 | {
780 | "cell_type": "code",
781 | "execution_count": 8,
782 | "metadata": {},
783 | "outputs": [
784 | {
785 | "name": "stderr",
786 | "output_type": "stream",
787 | "text": [
788 | "2021-07-31 14:15:34,909 [6185] WARNING datasets.builder:355: [JupyterRequire] Using custom data configuration default\n",
789 | "2021-07-31 14:15:34,912 [6185] WARNING datasets.builder:510: [JupyterRequire] Reusing dataset xsum (/home/phillab/.cache/huggingface/datasets/xsum/default/1.2.0/4957825a982999fbf80bca0b342793b01b2611e021ef589fb7c6250b3577b499)\n",
790 | "2021-07-31 14:15:39,162 [6185] WARNING datasets.builder:510: [JupyterRequire] Reusing dataset cnn_dailymail (/home/phillab/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234)\n",
791 | "100%|██████████| 400/400 [00:00<00:00, 4027.15it/s]"
792 | ]
793 | },
794 | {
795 | "name": "stdout",
796 | "output_type": "stream",
797 | "text": [
798 | "======= cogensumm ========\n"
799 | ]
800 | },
801 | {
802 | "name": "stderr",
803 | "output_type": "stream",
804 | "text": [
805 | "\n",
806 | " 38%|███▊ | 480/1250 [00:00<00:00, 4655.20it/s]"
807 | ]
808 | },
809 | {
810 | "name": "stdout",
811 | "output_type": "stream",
812 | "text": [
813 | "======= xsumfaith ========\n"
814 | ]
815 | },
816 | {
817 | "name": "stderr",
818 | "output_type": "stream",
819 | "text": [
820 | "100%|██████████| 1250/1250 [00:00<00:00, 4622.31it/s]\n",
821 | "100%|██████████| 634/634 [00:00<00:00, 4340.38it/s]"
822 | ]
823 | },
824 | {
825 | "name": "stdout",
826 | "output_type": "stream",
827 | "text": [
828 | "======= polytope ========\n"
829 | ]
830 | },
831 | {
832 | "name": "stderr",
833 | "output_type": "stream",
834 | "text": [
835 | "\n",
836 | "100%|██████████| 503/503 [00:00<00:00, 4521.10it/s]"
837 | ]
838 | },
839 | {
840 | "name": "stdout",
841 | "output_type": "stream",
842 | "text": [
843 | "======= factcc ========\n"
844 | ]
845 | },
846 | {
847 | "name": "stderr",
848 | "output_type": "stream",
849 | "text": [
850 | "\n",
851 | " 52%|█████▏ | 440/850 [00:00<00:00, 4396.31it/s]"
852 | ]
853 | },
854 | {
855 | "name": "stdout",
856 | "output_type": "stream",
857 | "text": [
858 | "======= summeval ========\n"
859 | ]
860 | },
861 | {
862 | "name": "stderr",
863 | "output_type": "stream",
864 | "text": [
865 | "100%|██████████| 850/850 [00:00<00:00, 3651.48it/s]\n",
866 | " 30%|███ | 480/1575 [00:00<00:00, 4628.48it/s]"
867 | ]
868 | },
869 | {
870 | "name": "stdout",
871 | "output_type": "stream",
872 | "text": [
873 | "======= frank ========\n"
874 | ]
875 | },
876 | {
877 | "name": "stderr",
878 | "output_type": "stream",
879 | "text": [
880 | "100%|██████████| 1575/1575 [00:00<00:00, 4369.67it/s]\n"
881 | ]
882 | },
883 | {
884 | "data": {
885 | "text/html": [
886 | "Balanced Accuracy | | score |
| op1 | op2 | |
\n",
888 | " \n",
889 | " | max | \n",
890 | " max | \n",
891 | " 0.691 | \n",
892 | "
\n",
893 | " \n",
894 | " | mean | \n",
895 | " 0.718 | \n",
896 | "
\n",
897 | " \n",
898 | " | min | \n",
899 | " 0.72 | \n",
900 | "
\n",
901 | " \n",
902 | " | mean | \n",
903 | " max | \n",
904 | " 0.62 | \n",
905 | "
\n",
906 | " \n",
907 | " | mean | \n",
908 | " 0.628 | \n",
909 | "
\n",
910 | " \n",
911 | " | min | \n",
912 | " 0.605 | \n",
913 | "
\n",
914 | " \n",
915 | " | min | \n",
916 | " max | \n",
917 | " 0.574 | \n",
918 | "
\n",
919 | " \n",
920 | " | mean | \n",
921 | " 0.557 | \n",
922 | "
\n",
923 | " \n",
924 | " | min | \n",
925 | " 0.531 | \n",
926 | "
\n",
927 | "
"
928 | ],
929 | "text/plain": [
930 | ""
931 | ]
932 | },
933 | "execution_count": 8,
934 | "metadata": {},
935 | "output_type": "execute_result"
936 | }
937 | ],
938 | "source": [
939 | "benchmark = SummaCBenchmark(cut=\"test\")\n",
940 | "\n",
941 | "results = {}\n",
942 | "for dataset in benchmark.tasks:\n",
943 | " print(\"======= %s ========\" % (dataset[\"name\"]))\n",
944 | " datas = dataset[\"task\"]\n",
945 | " labels = [d[\"label\"] for d in datas]\n",
946 | " utils_summac_benchmark.compute_doc_level(scorer_doc, datas)\n",
947 | " \n",
948 | " for pred_label in datas[0].keys():\n",
949 | " if \"pred_\" not in pred_label or \"total\" in pred_label: continue\n",
950 | " balanced_acc = sklearn.metrics.balanced_accuracy_score(labels, [d[pred_label] for d in datas])\n",
951 | " model_name, input_type = pred_label.replace(\"pred_\", \"\").split(\"|\")\n",
952 | " model_type, op1, op2 = model_name.split(\"-\")\n",
953 | " k = (op1, op2)\n",
954 | " if k not in results:\n",
955 | " results[k] = []\n",
956 | " results[k].append(balanced_acc)\n",
957 | "\n",
958 | "cleaned_results = []\n",
959 | "for (op1, op2), vs in results.items():\n",
960 | " cleaned_results.append({\"op1\": op1, \"op2\": op2, \"score\": np.mean(vs)})\n",
961 | " \n",
962 | "pd.DataFrame(cleaned_results).groupby([\"op1\", \"op2\"]).agg({\"score\": \"sum\"}).style.set_precision(3).set_caption(\"Balanced Accuracy\")"
963 | ]
964 | }
965 | ],
966 | "metadata": {
967 | "finalized": {
968 | "timestamp": 1625710190289,
969 | "trusted": true
970 | },
971 | "kernelspec": {
972 | "display_name": "Python 3",
973 | "language": "python",
974 | "name": "python3"
975 | },
976 | "language_info": {
977 | "codemirror_mode": {
978 | "name": "ipython",
979 | "version": 3
980 | },
981 | "file_extension": ".py",
982 | "mimetype": "text/x-python",
983 | "name": "python",
984 | "nbconvert_exporter": "python",
985 | "pygments_lexer": "ipython3",
986 | "version": "3.7.6"
987 | }
988 | },
989 | "nbformat": 4,
990 | "nbformat_minor": 4
991 | }
992 |
--------------------------------------------------------------------------------
/SummaC - Main Results.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [
8 | {
9 | "name": "stderr",
10 | "output_type": "stream",
11 | "text": [
12 | "Using custom data configuration default\n",
13 | "Reusing dataset xsum (/home/phillab/.cache/huggingface/datasets/xsum/default/1.2.0/4957825a982999fbf80bca0b342793b01b2611e021ef589fb7c6250b3577b499)\n",
14 | "Reusing dataset cnn_dailymail (/home/phillab/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0/3cb851bf7cf5826e45d49db2863f627cba583cbc32342df7349dfe6c38060234)\n"
15 | ]
16 | },
17 | {
18 | "name": "stdout",
19 | "output_type": "stream",
20 | "text": [
21 | " name N N_pos N_neg frac_pos\n",
22 | "0 cogensumm 400 312 88 0.780000\n",
23 | "1 xsumfaith 1250 130 1120 0.104000\n",
24 | "2 polytope 634 41 593 0.064669\n",
25 | "3 factcc 503 441 62 0.876740\n",
26 | "4 summeval 850 770 80 0.905882\n",
27 | "5 frank 1575 529 1046 0.335873\n"
28 | ]
29 | }
30 | ],
31 | "source": [
32 | "from utils_summac_benchmark import SummaCBenchmark\n",
33 | "import utils_summac_benchmark, random\n",
34 | "\n",
35 | "benchmark = SummaCBenchmark(benchmark_folder=\"/home/phillab/data/summac_benchmark/\", cut=\"test\")\n",
36 | "benchmark.print_stats()"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "metadata": {},
42 | "source": [
43 | "# Table 2: Main Table of Results\n"
44 | ]
45 | },
46 | {
47 | "cell_type": "code",
48 | "execution_count": 2,
49 | "metadata": {},
50 | "outputs": [
51 | {
52 | "name": "stdout",
53 | "output_type": "stream",
54 | "text": [
55 | "\n"
56 | ]
57 | }
58 | ],
59 | "source": [
60 | "import sklearn, torch, numpy as np, json, os, tqdm, pandas as pd, nltk, seaborn as sns\n",
61 | "from model_guardrails import NERInaccuracyPenalty\n",
62 | "from model_summac import SummaCConv, SummaCZS\n",
63 | "from model_baseline import BaselineScorer\n",
64 | "# from model_entailment import EntailmentScorer\n",
65 | "from model_classifier import Classifier\n",
66 | "from utils_scoring import ScorerWrapper\n",
67 | "\n",
68 | "use_cache = True\n",
69 | "scorers = [\n",
70 | " {\"name\": \"NER\", \"model\": NERInaccuracyPenalty(flipped=True), \"only_doc\": True, \"sign\": 1},\n",
71 | "# {\"name\": \"MNLI\", \"model\": EntailmentScorer(model_card=\"roberta-large-mnli\", contradiction_idx=0), \"sign\": 1},\n",
72 | " # {\"name\": \"FactCC-CLS\", \"model\": Classifier(model_card=\"roberta-base\", score_class=1, model_file=\"/home/phillab/models/cls_roberta-base_factcc_first_0_f1_0.4766.bin\"), \"sign\": 1, \"only_doc\": True},\n",
73 | " {\"name\": \"DAE\", \"model\": BaselineScorer(model=\"dae\"), \"only_doc\": True, \"sign\": 1},\n",
74 | " {\"name\": \"FEQA\", \"model\": BaselineScorer(model=\"feqa\"), \"only_doc\": True, \"sign\": 1},\n",
75 | " {\"name\": \"QuestEval\", \"model\": BaselineScorer(model=\"questeval\"), \"only_doc\": True, \"sign\": 1},\n",
76 | " {\"name\": \"SummaC-ZS-VITC-L\", \"model\": SummaCZS(granularity=\"sentence\", model_name=\"vitc\", imager_load_cache=use_cache), \"sign\": 1, \"only_doc\": True},\n",
77 | " {\"name\": \"SummaC-Histo-VITC-L\", \"model\": SummaCConv(models=[\"vitc\"], granularity=\"sentence\", start_file=\"/home/phillab/models/summac/vitc_sentence_percentile_e_bacc0.744.bin\", bins=\"percentile\", imager_load_cache=use_cache, device=\"cpu\"), \"sign\": 1, \"only_doc\": True},\n",
78 | "]\n",
79 | "\n",
80 | "scorer_doc = ScorerWrapper(scorers, scoring_method=\"sum\", max_batch_size=20, use_caching=True)\n",
81 | "scorer_para = ScorerWrapper([s for s in scorers if \"only_doc\" not in s], scoring_method=\"sum\", max_batch_size=20, use_caching=True)"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "metadata": {
88 | "scrolled": false
89 | },
90 | "outputs": [
91 | {
92 | "name": "stderr",
93 | "output_type": "stream",
94 | "text": [
95 | "\r",
96 | " 0%| | 0/400 [00:00\n",
248 | " #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col0 {\n",
249 | " : ;\n",
250 | " background-color: #9ece9e;\n",
251 | " color: #000000;\n",
252 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col1 {\n",
253 | " : ;\n",
254 | " background-color: #ebf3eb;\n",
255 | " color: #000000;\n",
256 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col2 {\n",
257 | " : ;\n",
258 | " background-color: #a5d1a5;\n",
259 | " color: #000000;\n",
260 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col3 {\n",
261 | " : ;\n",
262 | " background-color: #9dcd9d;\n",
263 | " color: #000000;\n",
264 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col4 {\n",
265 | " : ;\n",
266 | " background-color: #a5d1a5;\n",
267 | " color: #000000;\n",
268 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col5 {\n",
269 | " : ;\n",
270 | " background-color: #e7f1e7;\n",
271 | " color: #000000;\n",
272 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow0_col6 {\n",
273 | " : ;\n",
274 | " background-color: #b4d8b4;\n",
275 | " color: #000000;\n",
276 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col0 {\n",
277 | " : ;\n",
278 | " background-color: #acd4ac;\n",
279 | " color: #000000;\n",
280 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col1 {\n",
281 | " : ;\n",
282 | " background-color: #c4e0c4;\n",
283 | " color: #000000;\n",
284 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col2 {\n",
285 | " : ;\n",
286 | " background-color: #c5e0c5;\n",
287 | " color: #000000;\n",
288 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col3 {\n",
289 | " : ;\n",
290 | " background-color: #e0eee0;\n",
291 | " color: #000000;\n",
292 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col4 {\n",
293 | " : ;\n",
294 | " background-color: #ebf3eb;\n",
295 | " color: #000000;\n",
296 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col5 {\n",
297 | " : ;\n",
298 | " background-color: #b9dbb9;\n",
299 | " color: #000000;\n",
300 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow1_col6 {\n",
301 | " : ;\n",
302 | " background-color: #d6e9d6;\n",
303 | " color: #000000;\n",
304 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col0 {\n",
305 | " : ;\n",
306 | " background-color: #ebf3eb;\n",
307 | " color: #000000;\n",
308 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col1 {\n",
309 | " : ;\n",
310 | " background-color: #94c994;\n",
311 | " color: #000000;\n",
312 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col2 {\n",
313 | " : ;\n",
314 | " background-color: #ebf3eb;\n",
315 | " color: #000000;\n",
316 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col3 {\n",
317 | " : ;\n",
318 | " background-color: #ebf3eb;\n",
319 | " color: #000000;\n",
320 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col4 {\n",
321 | " : ;\n",
322 | " background-color: #dfeddf;\n",
323 | " color: #000000;\n",
324 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col5 {\n",
325 | " : ;\n",
326 | " background-color: #ebf3eb;\n",
327 | " color: #000000;\n",
328 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow2_col6 {\n",
329 | " : ;\n",
330 | " background-color: #ebf3eb;\n",
331 | " color: #000000;\n",
332 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col0 {\n",
333 | " : ;\n",
334 | " background-color: #a3d0a3;\n",
335 | " color: #000000;\n",
336 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col1 {\n",
337 | " : ;\n",
338 | " background-color: #96c996;\n",
339 | " color: #000000;\n",
340 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col2 {\n",
341 | " font-weight: bold;\n",
342 | " background-color: #75b975;\n",
343 | " color: #000000;\n",
344 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col3 {\n",
345 | " : ;\n",
346 | " background-color: #badbba;\n",
347 | " color: #000000;\n",
348 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col4 {\n",
349 | " : ;\n",
350 | " background-color: #9bcc9b;\n",
351 | " color: #000000;\n",
352 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col5 {\n",
353 | " font-weight: bold;\n",
354 | " background-color: #76ba76;\n",
355 | " color: #000000;\n",
356 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow3_col6 {\n",
357 | " : ;\n",
358 | " background-color: #94c994;\n",
359 | " color: #000000;\n",
360 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col0 {\n",
361 | " : ;\n",
362 | " background-color: #97ca97;\n",
363 | " color: #000000;\n",
364 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col1 {\n",
365 | " font-weight: bold;\n",
366 | " background-color: #75b975;\n",
367 | " color: #000000;\n",
368 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col2 {\n",
369 | " : ;\n",
370 | " background-color: #a6d1a6;\n",
371 | " color: #000000;\n",
372 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col3 {\n",
373 | " font-weight: bold;\n",
374 | " background-color: #75b975;\n",
375 | " color: #000000;\n",
376 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col4 {\n",
377 | " font-weight: bold;\n",
378 | " background-color: #75b975;\n",
379 | " color: #000000;\n",
380 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col5 {\n",
381 | " : ;\n",
382 | " background-color: #78bb78;\n",
383 | " color: #000000;\n",
384 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow4_col6 {\n",
385 | " font-weight: bold;\n",
386 | " background-color: #75b975;\n",
387 | " color: #000000;\n",
388 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col0 {\n",
389 | " font-weight: bold;\n",
390 | " background-color: #75b975;\n",
391 | " color: #000000;\n",
392 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col1 {\n",
393 | " : ;\n",
394 | " background-color: #b2d7b1;\n",
395 | " color: #000000;\n",
396 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col2 {\n",
397 | " : ;\n",
398 | " background-color: #a9d3a9;\n",
399 | " color: #000000;\n",
400 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col3 {\n",
401 | " : ;\n",
402 | " background-color: #86c286;\n",
403 | " color: #000000;\n",
404 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col4 {\n",
405 | " : ;\n",
406 | " background-color: #82c082;\n",
407 | " color: #000000;\n",
408 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col5 {\n",
409 | " : ;\n",
410 | " background-color: #86c286;\n",
411 | " color: #000000;\n",
412 | " } #T_a290bb2c_3a8a_11ec_b554_d587d49477ferow5_col6 {\n",
413 | " : ;\n",
414 | " background-color: #84c084;\n",
415 | " color: #000000;\n",
416 | " }Balanced Accuracy | | cogensumm | xsumfaith | polytope | factcc | summeval | frank | overall |
| model_name | input | | | | | | | |
\n",
417 | " \n",
418 | " | DAE | \n",
419 | " doc | \n",
420 | " 0.634 | \n",
421 | " 0.508 | \n",
422 | " 0.628 | \n",
423 | " 0.759 | \n",
424 | " 0.703 | \n",
425 | " 0.617 | \n",
426 | " 0.642 | \n",
427 | "
\n",
428 | " \n",
429 | " | FEQA | \n",
430 | " doc | \n",
431 | " 0.61 | \n",
432 | " 0.56 | \n",
433 | " 0.578 | \n",
434 | " 0.536 | \n",
435 | " 0.538 | \n",
436 | " 0.699 | \n",
437 | " 0.587 | \n",
438 | "
\n",
439 | " \n",
440 | " | NER | \n",
441 | " doc | \n",
442 | " 0.502 | \n",
443 | " 0.623 | \n",
444 | " 0.517 | \n",
445 | " 0.5 | \n",
446 | " 0.568 | \n",
447 | " 0.609 | \n",
448 | " 0.553 | \n",
449 | "
\n",
450 | " \n",
451 | " | QuestEval | \n",
452 | " doc | \n",
453 | " 0.626 | \n",
454 | " 0.621 | \n",
455 | " 0.703 | \n",
456 | " 0.666 | \n",
457 | " 0.725 | \n",
458 | " 0.821 | \n",
459 | " 0.694 | \n",
460 | "
\n",
461 | " \n",
462 | " | SummaC-Histo-VITC-L | \n",
463 | " doc | \n",
464 | " 0.647 | \n",
465 | " 0.664 | \n",
466 | " 0.627 | \n",
467 | " 0.895 | \n",
468 | " 0.817 | \n",
469 | " 0.816 | \n",
470 | " 0.744 | \n",
471 | "
\n",
472 | " \n",
473 | " | SummaC-ZS-VITC-L | \n",
474 | " doc | \n",
475 | " 0.704 | \n",
476 | " 0.584 | \n",
477 | " 0.62 | \n",
478 | " 0.838 | \n",
479 | " 0.787 | \n",
480 | " 0.79 | \n",
481 | " 0.721 | \n",
482 | "
\n",
483 | "
"
484 | ],
485 | "text/plain": [
486 | ""
487 | ]
488 | },
489 | "execution_count": 4,
490 | "metadata": {},
491 | "output_type": "execute_result"
492 | }
493 | ],
494 | "source": [
495 | "cm = sns.light_palette(\"green\", as_cmap=True)\n",
496 | "\n",
497 | "def highlight_max(data):\n",
498 | " is_max = data == data.max()\n",
499 | " return ['font-weight: bold' if v else '' for v in is_max]\n",
500 | "\n",
501 | "df = pd.DataFrame(results)\n",
502 | "df = df.groupby([\"model_name\", \"input\"]).agg({\"%s_bacc\" % (d): \"mean\" for d in benchmark.task_name_to_task})\n",
503 | "df.rename(columns={k: k.replace(\"_bacc\", \"\") for k in df.keys()}, inplace=True)\n",
504 | "df.drop(\"total\",inplace=True)\n",
505 | "df[\"overall\"] = (df[\"factcc\"]+df[\"frank\"]+df[\"polytope\"]+df[\"cogensumm\"]+df[\"summeval\"]+df[\"xsumfaith\"]) / (6.0)\n",
506 | "\n",
507 | "df.style.apply(highlight_max).background_gradient(cmap=cm, high=1.0, low=0.0).set_precision(3).set_caption(\"Balanced Accuracy\")"
508 | ]
509 | },
510 | {
511 | "cell_type": "code",
512 | "execution_count": 16,
513 | "metadata": {},
514 | "outputs": [
515 | {
516 | "name": "stdout",
517 | "output_type": "stream",
518 | "text": [
519 | "DATASET NAME MODEL NAME \n",
520 | "cogensumm DAE - 0.634 (0.598 - 0.677) (0.594 - 0.688)\n",
521 | "--------------\n",
522 | "cogensumm SummaC-ZS-VITC-L - 0.704 (0.668 - 0.745) (0.654 - 0.749)\n",
523 | "cogensumm SummaC-Histo-VITC-L - 0.647 (0.618 - 0.680) (0.612 - 0.684)\n",
524 | "==================================================\n",
525 | "xsumfaith NER - 0.623 (0.610 - 0.640) (0.607 - 0.644)\n",
526 | "--------------\n",
527 | "xsumfaith SummaC-ZS-VITC-L - 0.584 (0.561 - 0.606) (0.553 - 0.614)\n",
528 | "xsumfaith SummaC-Histo-VITC-L - 0.664 (0.643 - 0.694) (0.638 - 0.704)\n",
529 | "Significant difference (p < 0.05)\n",
530 | "==================================================\n",
531 | "polytope QuestEval - 0.703 (0.672 - 0.742) (0.657 - 0.745)\n",
532 | "--------------\n",
533 | "polytope SummaC-ZS-VITC-L - 0.620 (0.570 - 0.667) (0.557 - 0.684)\n",
534 | "polytope SummaC-Histo-VITC-L - 0.627 (0.552 - 0.680) (0.547 - 0.690)\n",
535 | "==================================================\n",
536 | "factcc DAE - 0.759 (0.720 - 0.797) (0.708 - 0.808)\n",
537 | "--------------\n",
538 | "factcc SummaC-ZS-VITC-L - 0.838 (0.809 - 0.870) (0.803 - 0.880)\n",
539 | "Significant difference (p < 0.05)\n",
540 | "factcc SummaC-Histo-VITC-L - 0.895 (0.878 - 0.916) (0.875 - 0.926)\n",
541 | "Significant difference (p < 0.05)\n",
542 | "Significant difference (p < 0.01)\n",
543 | "==================================================\n",
544 | "summeval QuestEval - 0.725 (0.702 - 0.758) (0.697 - 0.764)\n",
545 | "--------------\n",
546 | "summeval SummaC-ZS-VITC-L - 0.787 (0.755 - 0.823) (0.748 - 0.829)\n",
547 | "summeval SummaC-Histo-VITC-L - 0.817 (0.793 - 0.851) (0.788 - 0.858)\n",
548 | "Significant difference (p < 0.05)\n",
549 | "Significant difference (p < 0.01)\n",
550 | "==================================================\n",
551 | "frank QuestEval - 0.821 (0.809 - 0.835) (0.808 - 0.836)\n",
552 | "--------------\n",
553 | "frank SummaC-ZS-VITC-L - 0.790 (0.776 - 0.803) (0.775 - 0.807)\n",
554 | "frank SummaC-Histo-VITC-L - 0.816 (0.804 - 0.827) (0.801 - 0.830)\n",
555 | "==================================================\n",
556 | "==========================\n",
557 | "==========================\n",
558 | "==========================\n",
559 | "OVERALL QuestEval - (0.684 - 0.709) (0.682 - 0.711)\n",
560 | "OVERALL SummaC-ZS-VITC-L - (0.709 - 0.735) (0.707 - 0.737)\n",
561 | "OVERALL SummaC-Histo-VITC-L - (0.734 - 0.757) (0.730 - 0.760)\n"
562 | ]
563 | }
564 | ],
565 | "source": [
566 | "# Analysis with confidence interval\n",
567 | "strongest_baseline = {\"cogensumm\": \"DAE\", \"xsumfaith\": \"NER\", \"polytope\": \"QuestEval\", \"factcc\": \"DAE\", \"summeval\": \"QuestEval\", \"frank\": \"QuestEval\"}\n",
568 | "\n",
569 | "P5 = 5 / 2 # Correction due to the fact that we are running 2 tests with the same data\n",
570 | "P1 = 1 / 2 # Correction due to the fact that we are running 2 tests with the same data\n",
571 | "\n",
572 | "def resample_balanced_acc(preds, labels, n_samples=100, sample_ratio=0.7):\n",
573 | " N = len(preds)\n",
574 | " idxs = list(range(N))\n",
575 | " N_batch = int(sample_ratio*N)\n",
576 | "\n",
577 | " bal_accs = []\n",
578 | " for _ in range(n_samples):\n",
579 | " random.shuffle(idxs)\n",
580 | " batch_preds = [preds[i] for i in idxs[:N_batch]]\n",
581 | " batch_labels = [labels[i] for i in idxs[:N_batch]]\n",
582 | " \n",
583 | " bal_accs.append(sklearn.metrics.balanced_accuracy_score(batch_labels, batch_preds))\n",
584 | " return bal_accs\n",
585 | "\n",
586 | "print(\"DATASET NAME\".ljust(15), \"MODEL NAME\".ljust(20))\n",
587 | "\n",
588 | "sampled_batch_preds = {res[\"model_name\"]: [] for res in results}\n",
589 | "for res in results:\n",
590 | " if res[\"model_name\"] == \"total\":\n",
591 | " print(\"==================================================\")\n",
592 | " continue\n",
593 | " \n",
594 | " samples = resample_balanced_acc(res[\"preds\"], res[\"labels\"])\n",
595 | " sampled_batch_preds[res[\"model_name\"]].append(samples)\n",
596 | " low5, high5 = np.percentile(samples, P5), np.percentile(samples, 100-P5)\n",
597 | " low1, high1 = np.percentile(samples, P1), np.percentile(samples, 100-P1)\n",
598 | " bacc = sklearn.metrics.balanced_accuracy_score(res[\"labels\"], res[\"preds\"])\n",
599 | " if \"SummaC\" in res[\"model_name\"] or res[\"model_name\"] == strongest_baseline[res[\"dataset_name\"]]:\n",
600 | " \n",
601 | " print(res[\"dataset_name\"].ljust(15), res[\"model_name\"].ljust(20), \" - %.3f (%.3f - %.3f) (%.3f - %.3f)\" % (bacc, low5, high5, low1, high1))\n",
602 | " if res[\"model_name\"] == strongest_baseline[res[\"dataset_name\"]]:\n",
603 | " bl5, bh5, bl1, bh1 = low5, high5, low1, high1\n",
604 | " print(\"--------------\")\n",
605 | " else:\n",
606 | " if low5 >= bh5:\n",
607 | " print(\"Significant difference (p < 0.05)\")\n",
608 | " if low1 >= bh1:\n",
609 | " print(\"Significant difference (p < 0.01)\")\n",
610 | "\n",
611 | "print(\"==========================\")\n",
612 | "print(\"==========================\")\n",
613 | "print(\"==========================\")\n",
614 | "\n",
615 | "baseline = np.mean(np.array(sampled_batch_preds[\"QuestEval\"]), axis=0)\n",
616 | "summaczs = np.mean(np.array(sampled_batch_preds[\"SummaC-ZS-VITC-L\"]), axis=0)\n",
617 | "summacconv = np.mean(np.array(sampled_batch_preds[\"SummaC-Histo-VITC-L\"]), axis=0)\n",
618 | "\n",
619 | "for model in [\"QuestEval\", \"SummaC-ZS-VITC-L\", \"SummaC-Histo-VITC-L\"]:\n",
620 | " samples = np.mean(np.array(sampled_batch_preds[model]), axis=0)\n",
621 | " low5, high5 = np.percentile(samples, P5), np.percentile(samples, 100-P5)\n",
622 | " low1, high1 = np.percentile(samples, P1), np.percentile(samples, 100-P1)\n",
623 | " \n",
624 | " print(\"OVERALL\".ljust(15), model.ljust(20), \" - (%.3f - %.3f) (%.3f - %.3f)\" % (low5, high5, low1, high1))"
625 | ]
626 | },
627 | {
628 | "cell_type": "markdown",
629 | "metadata": {},
630 | "source": [
631 | "## ROC AUC score"
632 | ]
633 | },
634 | {
635 | "cell_type": "code",
636 | "execution_count": 6,
637 | "metadata": {},
638 | "outputs": [
639 | {
640 | "data": {
641 | "text/html": [
642 | "ROC AUC | | cogensumm | xsumfaith | polytope | factcc | summeval | frank | overall |
| model_name | input | | | | | | | |
\n",
812 | " \n",
813 | " | DAE | \n",
814 | " doc | \n",
815 | " 0.678 | \n",
816 | " 0.413 | \n",
817 | " 0.641 | \n",
818 | " 0.827 | \n",
819 | " 0.774 | \n",
820 | " 0.643 | \n",
821 | " 0.663 | \n",
822 | "
\n",
823 | " \n",
824 | " | FEQA | \n",
825 | " doc | \n",
826 | " 0.608 | \n",
827 | " 0.534 | \n",
828 | " 0.546 | \n",
829 | " 0.507 | \n",
830 | " 0.522 | \n",
831 | " 0.748 | \n",
832 | " 0.577 | \n",
833 | "
\n",
834 | " \n",
835 | " | NER | \n",
836 | " doc | \n",
837 | " 0.502 | \n",
838 | " 0.623 | \n",
839 | " 0.517 | \n",
840 | " 0.5 | \n",
841 | " 0.568 | \n",
842 | " 0.609 | \n",
843 | " 0.553 | \n",
844 | "
\n",
845 | " \n",
846 | " | QuestEval | \n",
847 | " doc | \n",
848 | " 0.644 | \n",
849 | " 0.664 | \n",
850 | " 0.722 | \n",
851 | " 0.715 | \n",
852 | " 0.79 | \n",
853 | " 0.879 | \n",
854 | " 0.736 | \n",
855 | "
\n",
856 | " \n",
857 | " | SummaC-Histo-VITC-L | \n",
858 | " doc | \n",
859 | " 0.676 | \n",
860 | " 0.702 | \n",
861 | " 0.624 | \n",
862 | " 0.922 | \n",
863 | " 0.86 | \n",
864 | " 0.884 | \n",
865 | " 0.778 | \n",
866 | "
\n",
867 | " \n",
868 | " | SummaC-ZS-VITC-L | \n",
869 | " doc | \n",
870 | " 0.731 | \n",
871 | " 0.58 | \n",
872 | " 0.603 | \n",
873 | " 0.837 | \n",
874 | " 0.855 | \n",
875 | " 0.853 | \n",
876 | " 0.743 | \n",
877 | "
\n",
878 | "
"
879 | ],
880 | "text/plain": [
881 | ""
882 | ]
883 | },
884 | "execution_count": 6,
885 | "metadata": {},
886 | "output_type": "execute_result"
887 | }
888 | ],
889 | "source": [
890 | "df = pd.DataFrame(results)\n",
891 | "df = df.groupby([\"model_name\", \"input\"]).agg({\"%s_roc_auc\" % (d): \"mean\" for d in benchmark.task_name_to_task})\n",
892 | "df.rename(columns={k: k.replace(\"_roc_auc\", \"\") for k in df.keys()}, inplace=True)\n",
893 | "df.drop(\"total\",inplace=True)\n",
894 | "df[\"overall\"] = (df[\"factcc\"]+df[\"frank\"]+df[\"polytope\"]+df[\"cogensumm\"]+df[\"summeval\"]+df[\"xsumfaith\"]) / (6.0)\n",
895 | "\n",
896 | "df.style.apply(highlight_max).background_gradient(cmap=cm, high=1.0, low=0.0).set_precision(3).set_caption(\"ROC AUC\")"
897 | ]
898 | },
899 | {
900 | "cell_type": "code",
901 | "execution_count": 17,
902 | "metadata": {},
903 | "outputs": [
904 | {
905 | "name": "stdout",
906 | "output_type": "stream",
907 | "text": [
908 | "DATASET NAME MODEL NAME \n",
909 | "cogensumm DAE - 0.678 (0.639 - 0.726) (0.632 - 0.735)\n",
910 | "--------------\n",
911 | "cogensumm SummaC-ZS-VITC-L - 0.731 (0.697 - 0.767) (0.685 - 0.778)\n",
912 | "cogensumm SummaC-Histo-VITC-L - 0.676 (0.633 - 0.716) (0.627 - 0.720)\n",
913 | "==================================================\n",
914 | "xsumfaith QuestEval - 0.664 (0.631 - 0.688) (0.626 - 0.699)\n",
915 | "--------------\n",
916 | "xsumfaith SummaC-ZS-VITC-L - 0.580 (0.552 - 0.615) (0.547 - 0.616)\n",
917 | "xsumfaith SummaC-Histo-VITC-L - 0.702 (0.675 - 0.733) (0.666 - 0.740)\n",
918 | "==================================================\n",
919 | "polytope QuestEval - 0.722 (0.683 - 0.762) (0.682 - 0.766)\n",
920 | "--------------\n",
921 | "polytope SummaC-ZS-VITC-L - 0.603 (0.529 - 0.667) (0.524 - 0.685)\n",
922 | "polytope SummaC-Histo-VITC-L - 0.624 (0.560 - 0.679) (0.530 - 0.696)\n",
923 | "==================================================\n",
924 | "factcc DAE - 0.827 (0.793 - 0.863) (0.787 - 0.881)\n",
925 | "--------------\n",
926 | "factcc SummaC-ZS-VITC-L - 0.837 (0.800 - 0.879) (0.786 - 0.891)\n",
927 | "factcc SummaC-Histo-VITC-L - 0.922 (0.899 - 0.945) (0.895 - 0.952)\n",
928 | "Significant difference (p < 0.05)\n",
929 | "Significant difference (p < 0.01)\n",
930 | "==================================================\n",
931 | "summeval QuestEval - 0.790 (0.751 - 0.836) (0.750 - 0.843)\n",
932 | "--------------\n",
933 | "summeval SummaC-ZS-VITC-L - 0.855 (0.829 - 0.879) (0.817 - 0.887)\n",
934 | "summeval SummaC-Histo-VITC-L - 0.860 (0.837 - 0.883) (0.832 - 0.886)\n",
935 | "Significant difference (p < 0.05)\n",
936 | "==================================================\n",
937 | "frank QuestEval - 0.879 (0.870 - 0.888) (0.868 - 0.892)\n",
938 | "--------------\n",
939 | "frank SummaC-ZS-VITC-L - 0.853 (0.842 - 0.865) (0.839 - 0.867)\n",
940 | "frank SummaC-Histo-VITC-L - 0.884 (0.875 - 0.895) (0.869 - 0.898)\n",
941 | "==================================================\n",
942 | "==========================\n",
943 | "==========================\n",
944 | "==========================\n",
945 | "OVERALL QuestEval - (0.721 - 0.750) (0.715 - 0.751)\n",
946 | "OVERALL SummaC-ZS-VITC-L - (0.723 - 0.756) (0.719 - 0.764)\n",
947 | "OVERALL SummaC-Histo-VITC-L - (0.763 - 0.791) (0.762 - 0.792)\n"
948 | ]
949 | }
950 | ],
951 | "source": [
952 | "# Analysis with confidence interval\n",
953 | "strongest_baseline = {\"cogensumm\": \"DAE\", \"xsumfaith\": \"QuestEval\", \"polytope\": \"QuestEval\", \"factcc\": \"DAE\", \"summeval\": \"QuestEval\", \"frank\": \"QuestEval\"}\n",
954 | "\n",
955 | "P5 = 5 / 2 # Correction due to the fact that we are running 2 tests with the same data\n",
956 | "P1 = 1 / 2 # Correction due to the fact that we are running 2 tests with the same data\n",
957 | "\n",
958 | "def resample_roc_auc(scores, labels, n_samples=100, sample_ratio=0.7):\n",
959 | " N = len(scores)\n",
960 | " idxs = list(range(N))\n",
961 | " N_batch = int(sample_ratio*N)\n",
962 | "\n",
963 | " roc_aucs = []\n",
964 | " for _ in range(n_samples):\n",
965 | " random.shuffle(idxs)\n",
966 | " batch_scores = [scores[i] for i in idxs[:N_batch]]\n",
967 | " batch_labels = [labels[i] for i in idxs[:N_batch]]\n",
968 | " roc_aucs.append(sklearn.metrics.roc_auc_score(batch_labels, batch_scores))\n",
969 | " return roc_aucs\n",
970 | "\n",
971 | "sampled_batch_preds = {res[\"model_name\"]: [] for res in results}\n",
972 | "print(\"DATASET NAME\".ljust(15), \"MODEL NAME\".ljust(20))\n",
973 | "for res in results:\n",
974 | " if res[\"model_name\"] == \"total\":\n",
975 | " print(\"==================================================\")\n",
976 | " continue\n",
977 | " samples = resample_roc_auc(res[\"scores\"], res[\"labels\"])\n",
978 | " sampled_batch_preds[res[\"model_name\"]].append(samples)\n",
979 | " low5, high5 = np.percentile(samples, P5), np.percentile(samples, 100-P5)\n",
980 | " low1, high1 = np.percentile(samples, P1), np.percentile(samples, 100-P1)\n",
981 | " roc_auc = sklearn.metrics.roc_auc_score(res[\"labels\"], res[\"scores\"])\n",
982 | " if \"SummaC\" in res[\"model_name\"] or res[\"model_name\"] == strongest_baseline[res[\"dataset_name\"]]:\n",
983 | " print(res[\"dataset_name\"].ljust(15), res[\"model_name\"].ljust(20), \" - %.3f (%.3f - %.3f) (%.3f - %.3f)\" % (roc_auc, low5, high5, low1, high1))\n",
984 | " if res[\"model_name\"] == strongest_baseline[res[\"dataset_name\"]]:\n",
985 | " bl5, bh5, bl1, bh1 = low5, high5, low1, high1\n",
986 | " print(\"--------------\")\n",
987 | " else:\n",
988 | " if low5 >= bh5:\n",
989 | " print(\"Significant difference (p < 0.05)\")\n",
990 | " if low1 >= bh1:\n",
991 | " print(\"Significant difference (p < 0.01)\")\n",
992 | "\n",
993 | "print(\"==========================\")\n",
994 | "print(\"==========================\")\n",
995 | "print(\"==========================\")\n",
996 | "\n",
997 | "baseline = np.mean(np.array(sampled_batch_preds[\"QuestEval\"]), axis=0)\n",
998 | "summaczs = np.mean(np.array(sampled_batch_preds[\"SummaC-ZS-VITC-L\"]), axis=0)\n",
999 | "summacconv = np.mean(np.array(sampled_batch_preds[\"SummaC-Histo-VITC-L\"]), axis=0)\n",
1000 | "\n",
1001 | "for model in [\"QuestEval\", \"SummaC-ZS-VITC-L\", \"SummaC-Histo-VITC-L\"]:\n",
1002 | " samples = np.mean(np.array(sampled_batch_preds[model]), axis=0)\n",
1003 | " low5, high5 = np.percentile(samples, P5), np.percentile(samples, 100-P5)\n",
1004 | " low1, high1 = np.percentile(samples, P1), np.percentile(samples, 100-P1)\n",
1005 | " \n",
1006 | " print(\"OVERALL\".ljust(15), model.ljust(20), \" - (%.3f - %.3f) (%.3f - %.3f)\" % (low5, high5, low1, high1))"
1007 | ]
1008 | }
1009 | ],
1010 | "metadata": {
1011 | "finalized": {
1012 | "timestamp": 1625710190289,
1013 | "trusted": true
1014 | },
1015 | "interpreter": {
1016 | "hash": "c723e9d1a9662a11de23e7914e75631adbad784f516bc181f2c98a6790ee4bb2"
1017 | },
1018 | "kernelspec": {
1019 | "display_name": "Python 3",
1020 | "language": "python",
1021 | "name": "python3"
1022 | },
1023 | "language_info": {
1024 | "codemirror_mode": {
1025 | "name": "ipython",
1026 | "version": 3
1027 | },
1028 | "file_extension": ".py",
1029 | "mimetype": "text/x-python",
1030 | "name": "python",
1031 | "nbconvert_exporter": "python",
1032 | "pygments_lexer": "ipython3",
1033 | "version": "3.7.6"
1034 | }
1035 | },
1036 | "nbformat": 4,
1037 | "nbformat_minor": 4
1038 | }
1039 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | transformers>=4.8.1
3 | nltk>=3.6.6
4 | huggingface-hub<=0.28.0 # Updated
5 | sentencepiece
6 | protobuf
7 |
--------------------------------------------------------------------------------
/script.sh:
--------------------------------------------------------------------------------
1 | python run_summac_precomp.py --model vitc --granularity sentence
2 | python train_summac.py --model vitc --granularity sentence --train_batch_size 16 --num_epochs 10 --nli_labels e
3 |
4 |
5 | # python run_summac_precomp.py --model mnli-base --granularity paragraph
6 | # python run_summac_precomp.py --model mnli-base --granularity 2sents
7 |
8 | # python train_summac.py --model mnli-base --granularity paragraph --train_batch_size 8 --nli_labels e
9 | # python train_summac.py --model mnli-base --granularity 2sents --train_batch_size 8 --nli_labels e
10 |
11 |
12 | # python train_summac.py --model mnli --granularity sentence --train_batch_size 8 --nli_labels n
13 | # python train_summac.py --model mnli --granularity sentence --train_batch_size 8 --nli_labels ec
14 | # python train_summac.py --model mnli --granularity sentence --train_batch_size 8 --nli_labels en
15 | # python train_summac.py --model mnli --granularity sentence --train_batch_size 8 --nli_labels cn
16 | # python train_summac.py --model mnli --granularity sentence --train_batch_size 8 --nli_labels ecn
17 |
18 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels e
19 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels c
20 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels n
21 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels ec
22 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels en
23 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels cn
24 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels ecn
25 |
26 |
27 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels e
28 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels c
29 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels n
30 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels ec
31 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels en
32 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels cn
33 | # python train_summac.py --model anli --granularity sentence --train_batch_size 8 --nli_labels ecn
34 |
35 | # conda init bash
36 |
37 | # conda activate feqa
38 | # python run_baseline.py --model feqa --cut test
39 | # conda activate questeval
40 | # python run_baseline.py --model questeval --cut test
41 | # conda deactivate
42 |
43 | # python train_summac.py --model anli --bins even100 --granularity sentence --train_batch_size 8 --nli_labels e
44 | # python train_summac.py --model snli-base --bins even100 --granularity sentence --train_batch_size 8 --nli_labels e
45 | # python train_summac.py --model snli-large --bins even100 --granularity sentence --train_batch_size 8 --nli_labels e
46 | # python train_summac.py --model mnli-base --bins even100 --granularity sentence --train_batch_size 8 --nli_labels e
47 | # python train_summac.py --model vitc-base --bins even100 --granularity sentence --train_batch_size 8 --nli_labels e
48 | # python train_summac.py --model vitc-only --bins even100 --granularity sentence --train_batch_size 8 --nli_labels e
49 |
50 | # python run_summac_precomp.py --model decomp --granularity sentence
51 | # python train_summac.py --model decomp --granularity sentence --train_batch_size 8 --nli_labels e
52 |
53 | # python run_summac_precomp.py --model anli --granularity sentence
54 | # python run_summac_precomp.py --model snli-large --granularity sentence
55 | # python run_summac_precomp.py --model snli-base --granularity sentence
56 | # python run_summac_precomp.py --model mnli-base --granularity sentence
57 | # python run_summac_precomp.py --model vitc-base --granularity sentence
58 | # python run_summac_precomp.py --model vitc-only --granularity sentence
59 |
60 | # python train_summac.py --model vitc --bins even100 --granularity sentence --train_batch_size 8 --nli_labels c
61 | # python train_summac.py --model vitc --bins even100 --granularity sentence --train_batch_size 8 --nli_labels n
62 | # python train_summac.py --model vitc --bins even100 --granularity sentence --train_batch_size 8 --nli_labels ec
63 | # python train_summac.py --model vitc --bins even100 --granularity sentence --train_batch_size 8 --nli_labels en
64 | # python train_summac.py --model vitc --bins even100 --granularity sentence --train_batch_size 8 --nli_labels cn
65 | # python train_summac.py --model vitc --bins even100 --granularity sentence --train_batch_size 8 --nli_labels ecn
66 |
67 |
68 |
69 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels e
70 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels c
71 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels n
72 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels ec
73 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels en
74 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels cn
75 | # python train_summac.py --model vitc --granularity sentence --train_batch_size 8 --nli_labels ecn
76 |
77 |
78 | # python run_ec_precompute.py --model mnli --granularity 2sents
79 | # python run_ec_precompute.py --model vitc --granularity 2sents
80 |
81 | # python train_summac.py --model snli-large --granularity sentence
82 | # python train_summac.py --model snli-large --granularity sentence --bins even100
83 | # python train_summac.py --model snli-large --granularity paragraph
84 | # python train_summac.py --model snli-large --granularity paragraph --bins even100
85 | # python train_summac.py --model mnli-base --granularity sentence
86 | # python train_summac.py --model mnli-base --granularity sentence --bins even100
87 | # python train_summac.py --model mnli-base --granularity paragraph
88 | # python train_summac.py --model mnli-base --granularity paragraph --bins even100
89 | # python train_summac.py --model mnli --granularity sentence
90 | # python train_summac.py --model mnli --granularity sentence --bins even100
91 | # python train_summac.py --model mnli --granularity paragraph
92 | # python train_summac.py --model mnli --granularity paragraph --bins even100
93 | # python train_summac.py --model anli --granularity sentence
94 | # python train_summac.py --model anli --granularity sentence --bins even100
95 | # python train_summac.py --model anli --granularity paragraph
96 | # python train_summac.py --model anli --granularity paragraph --bins even100
97 | # python train_summac.py --model vitc-base --granularity sentence
98 | # python train_summac.py --model vitc-base --granularity sentence --bins even100
99 | # python train_summac.py --model vitc-base --granularity paragraph
100 | # python train_summac.py --model vitc-base --granularity paragraph --bins even100
101 | # python train_summac.py --model vitc --granularity sentence
102 | # python train_summac.py --model vitc --granularity sentence --bins even100
103 | # python train_summac.py --model vitc --granularity paragraph
104 | # python train_summac.py --model vitc --granularity paragraph --bins even100
105 | # python train_summac.py --model vitc-only --granularity sentence
106 | # python train_summac.py --model vitc-only --granularity sentence --bins even100
107 | # python train_summac.py --model vitc-only --granularity paragraph
108 | # python train_summac.py --model vitc-only --granularity paragraph --bins even100
109 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 | from pathlib import Path
3 |
4 |
5 | REQUIREMENTS_PATH = Path(__file__).resolve().parent / "requirements.txt"
6 |
7 | with open(str(REQUIREMENTS_PATH), "r", encoding="utf-8") as f:
8 | requirements = f.read().splitlines()
9 |
10 | setup(
11 | name="summac",
12 | packages=find_packages(include=["summac"]),
13 | version="0.0.4",
14 | license="Apache",
15 | long_description=open("README.md").read(),
16 | long_description_content_type="text/markdown",
17 | install_requires=requirements,
18 | # extras_require={},
19 | include_package_data=True,
20 | )
21 |
--------------------------------------------------------------------------------
/summac/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tingofurro/summac/c1f3da93cd074c24d8033eb27a88b5a7cc5c08fa/summac/__init__.py
--------------------------------------------------------------------------------
/summac/benchmark.py:
--------------------------------------------------------------------------------
1 | import json, os, pandas as pd, numpy as np, csv
2 | from datasets import load_dataset
3 | from collections import Counter
4 | import requests, zipfile, tarfile
5 | from .utils_scorer import choose_best_threshold
6 | from .utils_misc import download_file_from_google_drive
7 | from tqdm import tqdm
8 | from itertools import islice
9 |
10 |
11 |
12 | # SummaC Benchmark
13 | class SummaCBenchmark:
14 |
15 | def __init__(self,
16 | benchmark_folder="/home/phillab/data/summac_benchmark/",
17 | dataset_names=["cogensumm", "xsumfaith", "polytope", "factcc", "summeval", "frank"],
18 | cut="val",
19 | hf_datasets_cache_dir = os.environ.get("HF_DATASETS_CACHE", None),
20 | debug=False):
21 | assert cut in ["val", "test"], "Unrecognized cut for the Fact Checking Benchmark"
22 | if not os.path.exists(benchmark_folder):
23 | os.makedirs(benchmark_folder)
24 |
25 | self.cut = cut
26 | self.benchmark_folder = benchmark_folder
27 | self.cnndm_id2reference = None
28 | self.cnndm = None
29 | self.xsum = None
30 | self.hf_datasets_cache_dir = hf_datasets_cache_dir
31 | self.debug = debug
32 |
33 | self.datasets = []
34 | for dataset_name in dataset_names:
35 | print ("Loading dataset %s" % (dataset_name))
36 | if dataset_name == "cogensumm":
37 | self.load_cogensumm()
38 | elif dataset_name == "xsumfaith":
39 | self.load_xsumfaith()
40 | elif dataset_name == "polytope":
41 | self.load_polytope()
42 | elif dataset_name == "factcc":
43 | self.load_factcc()
44 | elif dataset_name == "summeval":
45 | self.load_summeval()
46 | elif dataset_name == "frank":
47 | self.load_frank()
48 | else:
49 | raise ValueError("Unrecognized dataset name: %s" % (dataset_name))
50 |
51 | # Underlying dataset loader: CNN/DM and XSum
52 | def get_cnndm_document(self, aid):
53 | if self.cnndm is None:
54 | self.cnndm= load_dataset("cnn_dailymail", "3.0.0", cache_dir=self.hf_datasets_cache_dir)
55 | self.cnndm_id2article = {}
56 | for cut in ["test", "validation"]:
57 | self.cnndm_id2article.update({d["id"]: d["article"] for d in self.cnndm[cut]})
58 | return self.cnndm_id2article[aid]
59 |
60 | def get_cnndm_reference(self, aid):
61 | if self.cnndm is None:
62 | self.cnndm= load_dataset("cnn_dailymail", "3.0.0", cache_dir=self.hf_datasets_cache_dir)
63 | if self.cnndm_id2reference is None:
64 | self.cnndm_id2reference = {}
65 | for cut in ["test", "validation"]:
66 | self.cnndm_id2reference.update({d["id"]: d["highlights"] for d in self.cnndm[cut]})
67 | return self.cnndm_id2reference[aid]
68 |
69 |
70 | def get_xsum_document(self, aid):
71 | if self.xsum is None:
72 | self.xsum = load_dataset("xsum", cache_dir=self.hf_datasets_cache_dir, trust_remote_code=True)["test"]
73 | self.xsumid2article = {d["id"]: d["document"] for d in self.xsum}
74 |
75 | return self.xsumid2article[aid]
76 |
77 | # Individual dataset loaders
78 | def load_cogensumm(self):
79 | # Correctness of Generated Summaries: https://www.aclweb.org/anthology/P19-1213.pdf
80 | # CoGenSumm: https://tudatalib.ulb.tu-darmstadt.de/handle/tudatalib/2002
81 |
82 | dataset_folder = os.path.join(self.benchmark_folder, "cogensumm/")
83 | if not os.path.exists(dataset_folder):
84 | print("==== CoGenSumm dataset not found, downloading from scratch")
85 | os.makedirs(dataset_folder)
86 | data = requests.get("https://tudatalib.ulb.tu-darmstadt.de/bitstream/handle/tudatalib/2002/summary-correctness-v1.0.zip?sequence=3&isAllowed=y")
87 | zip_file = os.path.join(dataset_folder, "summary-correctness-v1.0.zip")
88 | with open(zip_file, "wb") as f:
89 | f.write(data.content)
90 |
91 | with zipfile.ZipFile(zip_file, "r") as zip_ref:
92 | zip_ref.extractall(dataset_folder)
93 | os.remove(zip_file)
94 |
95 | clean_dataset = []
96 | for fn in os.listdir(dataset_folder):
97 | if self.cut not in fn:
98 | continue
99 |
100 | with open(os.path.join(dataset_folder, fn), "r") as f:
101 | dataset = json.load(f)
102 |
103 | if self.debug:
104 | if type(dataset) == dict:
105 | dataset = dict(islice(dataset.items(), 4))
106 | elif type(dataset) == list:
107 | dataset = dataset[:4]
108 |
109 | if "_org" in fn or fn == "test_chen18_reranked.json":
110 | for aid in tqdm(dataset):
111 | document = self.get_cnndm_document(aid)
112 | label = 0 if dataset[aid]["label"] == "Incorrect" else 1
113 | sents = dataset[aid]["sents"]
114 | summary = " ".join([sents[str(i)]["text"] for i in range(len(sents))])
115 | clean_dataset.append({"filename": fn, "label": label, "document": document, "claim": summary, "cnndm_id": aid, "annotations": [label], "dataset": "cogensumm", "origin": "cnndm"})
116 | elif fn == "val_reranking.json":
117 | for aid in tqdm(dataset):
118 | document = self.get_cnndm_document(aid)
119 | for idx, data in dataset[aid].items():
120 | label = 0 if data["label"] == "Incorrect" else 1
121 | summary = " ".join([data["sents"][str(i)]["text"] for i in range(len(data["sents"]))])
122 | clean_dataset.append({"filename": fn, "label": label, "document": document, "claim": summary, "cnndm_id": aid, "annotations": [label], "dataset": "cogensumm", "origin": "cnndm"})
123 | elif fn == "val_sentence_pairs.json":
124 | for d in tqdm(dataset):
125 | aid = d["article_id"]
126 | document = self.get_cnndm_document(aid)
127 | clean_dataset.append({"filename": fn, "label": 1, "document": document, "claim": d["correct_sent"], "cnndm_id": aid, "annotations": [1], "dataset": "cogensumm", "origin": "cnndm"})
128 | clean_dataset.append({"filename": fn, "label": 0, "document": document, "claim": d["incorrect_sent"], "cnndm_id": aid, "annotations": [0], "dataset": "cogensumm", "origin": "cnndm"})
129 | self.datasets.append({"name": "cogensumm", "dataset": clean_dataset})
130 |
131 | def load_xsumfaith(self):
132 | # On Faithfulness and Factuality in Abstractive Summarization - ACL 2020
133 | # https://github.com/google-research-datasets/xsum_hallucination_annotations
134 | # https://aclanthology.org/2020.acl-main.173.pdf
135 |
136 | dataset_folder = os.path.join(self.benchmark_folder, "xsumfaith/")
137 | if not os.path.exists(dataset_folder):
138 | print("==== XSum dataset not found, downloading from scratch")
139 | os.makedirs(dataset_folder)
140 |
141 | csv_file = requests.get("https://github.com/google-research-datasets/xsum_hallucination_annotations/raw/master/hallucination_annotations_xsum_summaries.csv")
142 | with open(os.path.join(dataset_folder, "hallucination_annotations_xsum_summaries.csv"), "wb") as f:
143 | f.write(csv_file.content)
144 |
145 | path_to_annotation = os.path.join(dataset_folder, "hallucination_annotations_xsum_summaries.csv")
146 |
147 | with open(path_to_annotation, "r") as f:
148 | raw_data = list(csv.reader(f))
149 | dataset = []
150 | keys = raw_data[0]
151 | for line in raw_data[1:]:
152 | dataset.append({k: v for k, v in zip(keys, line)})
153 |
154 | groups = {}
155 | for d in dataset:
156 | k = (d["bbcid"], d["system"])
157 | if k not in groups:
158 | groups[k] = []
159 | groups[k].append(d)
160 |
161 | clean_dataset = []
162 |
163 | if self.debug:
164 | groups = dict(islice(groups.items(), 4))
165 | for k, vs in tqdm(groups.items()):
166 | A = vs[0]
167 | document = self.get_xsum_document(A["bbcid"])
168 | labels = [v["hallucination_type"] for v in vs]
169 | annotations = [1 if label == "NULL" else 0 for label in labels]
170 | most_common_label = Counter(labels).most_common(1)[0][0]
171 | label = 1 if most_common_label == "NULL" else 0
172 | c = "val" if len(clean_dataset) % 2 == 0 else "test"
173 |
174 | clean_dataset.append({"document": document, "claim": A["summary"], "bbcid": A["bbcid"], "model_name": A["system"], "label": label, "cut": c, "annotations": annotations, "dataset": "xsumfaith", "origin": "xsum"})
175 | final_dataset = [d for d in clean_dataset if d["cut"]==self.cut]
176 | self.datasets.append({"name": "xsumfaith", "dataset": final_dataset})
177 |
178 | def load_polytope(self, which_label="overall"):
179 | # What Have We Achieved on Text Summarization? [https://arxiv.org/abs/2010.04529]
180 | # Dataset must be downloaded from the Github repo: https://github.com/hddbang/polytope
181 |
182 | assert which_label in ["overall", "omission", "addition", "duplication", "inaccuracy"], "Unrecognized `which label`"
183 |
184 | dataset_folder = os.path.join(self.benchmark_folder, "polytope")
185 | if not os.path.exists(dataset_folder):
186 | print("==== Polytope dataset not found, downloading from scratch")
187 | os.makedirs(dataset_folder)
188 |
189 | for model_name in ["BART", "Bert_Ext", "Bert_Ext_Abs", "BottomUp", "PG", "PG_Coverage", "Summa", "TextRank", "seq2seq"]:
190 | url = "https://github.com/hddbang/PolyTope/raw/master/outputs_with_human_annotation/Human_Annotation_Summarization_%s.xlsm" % (model_name)
191 | r = requests.get(url)
192 | with open(os.path.join(dataset_folder, "Human_Annotation_Summarization_%s.xlsm" % (model_name)), "wb") as f:
193 | f.write(r.content)
194 |
195 | full_dataset = []
196 | for fn in os.listdir(dataset_folder):
197 | fn = os.path.join(dataset_folder, fn)
198 |
199 | all_segments = pd.read_excel(fn, sheet_name="Scores per segment")
200 | ID2row = {}
201 | for i, segment in all_segments.iterrows():
202 | c = "val" if i % 2 == 0 else "test"
203 | if str(segment["ID"]) != "nan":
204 | ID2row[segment["ID"]] = {"ID": segment["ID"], "document": segment["Source"], "claim": segment["Target"], "errors": [], "cut": c}
205 |
206 | for i, row in pd.read_excel(fn, sheet_name="Error Log").iterrows():
207 | if str(row["Subtypes"]) != "nan":
208 | ID2row[row["ID"]]["errors"].append(row["Subtypes"])
209 |
210 | if self.debug:
211 | ID2row = dict(islice(ID2row.items(), 4))
212 | for ID in tqdm(ID2row):
213 | d = ID2row[ID]
214 | d["overall_label"] = 1 if len(d["errors"]) == 0 else 0
215 | d["omission_label"] = 0 if "Omission" in d["errors"] else 1
216 | d["addition_label"] = 0 if "Addition" in d["errors"] else 1
217 | d["duplication_label"] = 0 if "Duplication" in d["errors"] else 1
218 | d["inaccuracy_label"] = 0 if "Inaccuracy_internal" in d["errors"] or "Inaccuracy_external" in d["errors"] else 1
219 | if which_label is not None:
220 | d["label"] = d["%s_label" % (which_label)]
221 | d["dataset"] = "polytope"
222 | d["annotations"] = [d["label"]]
223 | d["origin"] = "cnndm"
224 |
225 | full_dataset.append(d)
226 | cut_dataset = [d for d in full_dataset if d["cut"]==self.cut]
227 | self.datasets.append({"name": "polytope", "dataset": cut_dataset})
228 |
229 | def load_factcc(self, max_entries=-1):
230 | # Evaluating the Factual Consistency of Abstractive Text Summarization [https://arxiv.org/abs/1910.12840]
231 | # Dataset for each split must be downloaded from the Github repo: https://github.com/salesforce/factCC
232 |
233 | dataset_folder = os.path.join(self.benchmark_folder, "factcc/")
234 | if not os.path.exists(dataset_folder):
235 | print("==== FactCC dataset not found, downloading from scratch")
236 | os.makedirs(dataset_folder)
237 |
238 | urls = ["https://storage.googleapis.com/sfr-factcc-data-research/unpaired_generated_data.tar.gz", "https://storage.googleapis.com/sfr-factcc-data-research/unpaired_annotated_data.tar.gz"]
239 | for url in urls:
240 | zip_name = url.split("/")[-1]
241 | r = requests.get(url)
242 | with open(os.path.join(dataset_folder, zip_name), "wb") as f:
243 | f.write(r.content)
244 |
245 | with tarfile.open(os.path.join(dataset_folder, zip_name), "r:gz") as f:
246 | f.extractall(dataset_folder)
247 | os.remove(os.path.join(dataset_folder, zip_name))
248 |
249 | if self.cut == "train":
250 | dataset = []
251 | with open(os.path.join(dataset_folder, "unpaired_generated_data/data-original/data-train.jsonl"), "r") as f:
252 | for i, line in enumerate(f):
253 | if max_entries > 0 and i >= max_entries:
254 | break
255 | D = json.loads(line)
256 | aid = D["filepath"].split("/")[-1].replace(".story", "")
257 | full_text = self.get_cnndm_document(aid)
258 |
259 | label = 1 if D["label"]=="CORRECT" else 0
260 | datum = {"document": full_text, "claim": D["claim"], "cnndm_id": D["id"], "label": label, "dataset": "factcc", "origin": "cnndm"}
261 | dataset.append(datum)
262 |
263 | if self.cut in ["val", "test"]:
264 | factcc_file = os.path.join(dataset_folder, "unpaired_annotated_data/%s/data-dev.jsonl" % (self.cut))
265 | dataset = []
266 | with open(factcc_file, "r") as f:
267 | for line in f:
268 | dataset.append(json.loads(line))
269 |
270 | if self.debug:
271 | dataset = dataset[:4]
272 | for d in tqdm(dataset):
273 | aid = d["filepath"].split("/")[-1].replace(".story", "")
274 | d["document"] = self.get_cnndm_document(aid)
275 | d["label"] = 1 if d["label"] == "CORRECT" else 0
276 | d["annotations"] = [d["label"]]
277 | d["dataset"] = "factcc"
278 | d["origin"] = "cnndm"
279 |
280 | self.datasets.append({"name": "factcc", "dataset": dataset})
281 |
282 | def load_summeval(self, key_focus="consistency"):
283 | assert key_focus in ["consistency", "coherence", "fluency", "relevance"]
284 | # SummEval: Re-evaluating Summarization Evaluation [https://arxiv.org/abs/2007.12626]
285 | # Data files must be downloaded from the following Github repository: https://github.com/Yale-LILY/SummEval
286 | raw_dataset = []
287 |
288 | dataset_folder = os.path.join(self.benchmark_folder, "summeval/")
289 | fn = os.path.join(dataset_folder, "model_annotations.aligned.scored.jsonl")
290 | if not os.path.exists(dataset_folder):
291 | print("==== SummEval dataset not found, downloading from scratch")
292 | os.makedirs(dataset_folder)
293 |
294 | # From the 4/19/2020 update on the README: https://github.com/Yale-LILY/SummEval
295 | download_file_from_google_drive("1d2Iaz3jNraURP1i7CfTqPIj8REZMJ3tS", fn)
296 |
297 | with open(fn, "r") as f:
298 | for line in f:
299 | raw_dataset.append(json.loads(line))
300 |
301 | clean_dataset = []
302 |
303 | if self.debug:
304 | raw_dataset = raw_dataset[:4]
305 | for i, d in enumerate(tqdm(raw_dataset)):
306 | c = "val" if i % 2 == 0 else "test"
307 | _, _, article_id = d["id"].split("-")
308 | document = self.get_cnndm_document(article_id)
309 | annotations = d["expert_annotations"]
310 |
311 | consistencies = [a[key_focus] for a in annotations]
312 | final_label = 1 if len([cons for cons in consistencies if cons==5]) > len(annotations)/2 else 0
313 |
314 | # annotations = [1 if cons == 5 else 0 for cons in consistencies]
315 | annotations = consistencies
316 | error_type = "no error" if final_label == 1 else "error"
317 |
318 | clean_dataset.append({"document": document, "claim": d["decoded"], "label": final_label, "model_name": d["model_id"], "cnndm_id": d["id"], "cut": c, "annotations": annotations, "dataset": "summeval", "origin": "cnndm", "error_type": error_type})
319 | final_dataset = [d for d in clean_dataset if d["cut"] == self.cut]
320 | self.datasets.append({"name": "summeval", "dataset": final_dataset})
321 |
322 | def load_frank(self):
323 | # FRANK: Factuality Evaluation Benchmark [https://aclanthology.org/2021.naacl-main.383.pdf]
324 | # Files must be downloaded from the Github repository: https://github.com/artidoro/frank
325 |
326 | dataset_folder = os.path.join(self.benchmark_folder, "frank/")
327 | if not os.path.exists(dataset_folder):
328 | print("==== Frank dataset not found, downloading from scratch")
329 | os.makedirs(dataset_folder)
330 |
331 | fns = ["human_annotations_sentence.json", "validation_split.txt", "test_split.txt"]
332 | for fn in fns:
333 | data = requests.get("https://raw.githubusercontent.com/artidoro/frank/main/data/%s" % fn)
334 | with open(os.path.join(dataset_folder, fn), "w") as f:
335 | f.write(data.text)
336 |
337 | raw_file = os.path.join(dataset_folder, "human_annotations_sentence.json")
338 | val_hash_file = os.path.join(dataset_folder, "validation_split.txt")
339 | test_hash_file = os.path.join(dataset_folder, "test_split.txt")
340 | with open(val_hash_file if self.cut=="val" else test_hash_file, "r") as f:
341 | valid_hashes = set([line.strip() for line in f])
342 |
343 | with open(raw_file, "r") as f:
344 | raw_dataset = json.load(f)
345 | dataset = []
346 |
347 | if self.debug:
348 | raw_dataset = raw_dataset[:100]
349 | for d in tqdm(raw_dataset):
350 | article = d["article"]
351 | origin = "cnndm" if len(d["hash"]) >= 40 else "xsum"
352 |
353 | if d["hash"] not in valid_hashes:
354 | continue
355 |
356 | summ_labels = []
357 | annotator_labels = {}
358 | for annot in d["summary_sentences_annotations"]:
359 | annot_vals = [an for ans in annot.values() for an in ans]
360 | noerror_count = len([an for an in annot_vals if an=="NoE"])
361 | label = 1 if noerror_count >= 2 else 0
362 | summ_labels.append(label)
363 | for anno_name, anno in annot.items():
364 | if anno_name not in annotator_labels:
365 | annotator_labels[anno_name] = []
366 | annotator_labels[anno_name] += anno
367 |
368 | annotations = [1 if all(a=="NoE" for a in annos) else 0 for annos in annotator_labels.values()]
369 | label = 0 if any(sl==0 for sl in summ_labels) else 1
370 |
371 | error_type = "NoE"
372 | if label == 0:
373 | errors = [anno for annos in annotator_labels.values() for anno in annos if anno != "NoE"]
374 | error_type = Counter(errors).most_common(1)[0][0]
375 |
376 | summary = d["summary"]
377 | dataset.append({"document": article, "claim": summary, "label": label, "cut": self.cut, "hash": d["hash"], "model_name": d["model_name"], "annotations": annotations, "dataset": "frank", "origin": origin, "error_type": error_type})
378 | self.datasets.append({"name": "frank", "dataset": dataset})
379 |
380 | def get_dataset(self, dataset_name):
381 | for dataset in self.datasets:
382 | if dataset["name"] == dataset_name:
383 | return dataset["dataset"]
384 | raise ValueError("Unrecognized dataset name: %s" % (dataset_name))
385 |
386 | def print_stats(self):
387 | dataset_stats = []
388 | for dataset in self.datasets:
389 | N_pos, N_neg = len([d for d in dataset["dataset"] if d["label"]==1]), len([d for d in dataset["dataset"] if d["label"]==0])
390 | dataset_stats.append({"name": dataset["name"], "N": len(dataset["dataset"]), "N_pos": N_pos, "N_neg": N_neg, "frac_pos": N_pos/(N_pos+N_neg)})
391 | print(pd.DataFrame(dataset_stats))
392 |
393 | def evaluate(self, scorer):
394 | benchmark = []
395 |
396 | for dataset in self.datasets:
397 | dataset_labels = [d["label"] for d in dataset["dataset"]]
398 | dataset_preds = scorer.score([d["document"] for d in dataset["dataset"]], [d["claim"] for d in dataset["dataset"]])["scores"]
399 |
400 | dataset_thresh, dataset_f1 = choose_best_threshold(dataset_labels, dataset_preds)
401 | benchmark.append({"name": dataset["name"], "score": dataset_f1, "threshold": dataset_thresh})
402 | return {"overall_score": np.mean([t["score"] for t in benchmark]), "benchmark": benchmark}
403 |
404 |
405 | if __name__ == "__main__":
406 | import random
407 |
408 | for cut in ["val", "test"]:
409 | summac_benchmark = SummaCBenchmark(benchmark_folder="/home/tingu/data/summac_benchmark2/", cut=cut)
410 | print("============= SUMMAC %s ===============" % (cut.upper()))
411 | summac_benchmark.print_stats()
412 | for dataset in summac_benchmark.datasets:
413 | print("\n============= %s ===============" % (dataset["name"]))
414 | random.shuffle(dataset["dataset"])
415 | print(dataset["dataset"][0]["document"][:400])
416 | print("-------------")
417 | print(dataset["dataset"][0]["claim"])
418 | print("-------------")
419 | print(dataset["dataset"][0]["label"])
420 |
--------------------------------------------------------------------------------
/summac/model_baseline.py:
--------------------------------------------------------------------------------
1 | import datasets, nltk, numpy as np
2 | import json, os, sys, argparse
3 |
4 | class BaselineScorer:
5 | def __init__(self, model="questeval", do_weighter=False, load_cache=True):
6 | assert model in ["questeval", "feqa", "dae"], "Unrecognized baseline model"
7 | self.model = model
8 | self.do_weighter = do_weighter
9 | self.model_loaded = False
10 | self.cache = {}
11 | self.cache_file = "/export/share/plaban/summac_cache/cache_%s.json" % (self.model)
12 | if load_cache:
13 | self.load_cache()
14 |
15 | def load_model(self):
16 | if self.model == "questeval":
17 | from questeval.questeval_metric import QuestEval
18 | self.questeval = QuestEval(isCuda=True, do_weighter=self.do_weighter)
19 | elif self.model == "feqa":
20 | # import benepar, nltk
21 | # benepar.download('benepar_en2')
22 | # nltk.download('stopwords')
23 | from feqa import FEQA
24 | self.scorer = FEQA(use_gpu=True)
25 | elif self.model == "dae":
26 | sys.path.insert(0, "/home/phillab/dae-factuality/")
27 | from evaluate_factuality import MODEL_CLASSES, score_example_single_context
28 |
29 | parser = argparse.ArgumentParser()
30 | args = parser.parse_args()
31 | args.device = "cuda:0"
32 | args.per_gpu_eval_batch_size = 8
33 | args.max_seq_length = 128
34 | args.dependency_type = "enhancedDependencies"
35 | self.args = args
36 |
37 | model_dir = "/home/phillab/models/dae_basic/"
38 | model_type = "electra_dae"
39 | config_class, model_class, tokenizer_class = MODEL_CLASSES[model_type]
40 |
41 | self.tokenizer = tokenizer_class.from_pretrained(model_dir)
42 | self.dae_model = model_class.from_pretrained(model_dir)
43 | self.dae_model.to(args.device)
44 |
45 | self.model_loaded = True
46 |
47 | def load_cache(self):
48 | if os.path.isfile(self.cache_file):
49 | with open(self.cache_file, "r") as f:
50 | self.cache = json.load(f)
51 |
52 | def save_cache(self):
53 | with open(self.cache_file, "w") as f:
54 | json.dump(self.cache, f)
55 |
56 | def get_sample_key(self, document, generated):
57 | return "%s|%%%%|%%|%s" % (document, generated)
58 |
59 | def score_questeval(self, documents, generateds, **kwargs):
60 | scores = []
61 | for document, generated in zip(documents, generateds):
62 | score = self.questeval.compute_all(document, generated)
63 | scores.append(score["scores"]["fscore"])
64 | return {"scores": scores}
65 |
66 | def score_feqa(self, documents, generateds, **kwargs):
67 | scores = self.scorer.compute_score(documents, generateds, aggregate=False)
68 | self.save_cache()
69 | return {"scores": scores}
70 |
71 | def score_dae(self, documents, generateds, **kwargs):
72 | from evaluate_factuality import score_example_single_context
73 |
74 | scores = []
75 | for document, generated in zip(documents, generateds):
76 | document = " ".join(document.split(" ")[:250])
77 | score = score_example_single_context(generated, document, self.dae_model, self.tokenizer, self.args).item()
78 | scores.append(score)
79 |
80 | # self.save_cache()
81 | return {"scores": scores}
82 |
83 | def score(self, documents, generateds, **kwargs):
84 | new_samples = []
85 | for d, g in zip(documents, generateds):
86 | k = self.get_sample_key(d, g)
87 | if k not in self.cache:
88 | new_samples.append((k, d, g))
89 |
90 | if len(new_samples) > 0:
91 | if not self.model_loaded:
92 | self.load_model()
93 |
94 | if self.model == "questeval":
95 | new_scores = self.score_questeval([d[1] for d in new_samples], [d[2] for d in new_samples])
96 | elif self.model == "feqa":
97 | new_scores = self.score_feqa([d[1] for d in new_samples], [d[2] for d in new_samples])
98 | elif self.model == "dae":
99 | new_scores = self.score_dae([d[1] for d in new_samples], [d[2] for d in new_samples])
100 |
101 | for (k, d, g), score in zip(new_samples, new_scores["scores"]):
102 | self.cache[k] = score
103 |
104 | return {"scores": [self.cache[self.get_sample_key(d, g)] for d, g in zip(documents, generateds)]}
105 |
106 |
107 | if __name__ == "__main__":
108 | hypothesis = """After wildfires consumed an entire town, students and teachers who had planned for remote classes found some comfort in staying connected amid the chaos."""
109 |
110 | source = """Ash fell from an apocalyptic orange sky as Jennifer Willin drove home last week from the only school in tiny Berry Creek, Calif., where she had picked up a pair of Wi-Fi hot spots for her daughters’ remote classes. Hours later,
111 | her cellphone erupted with an emergency alert: Evacuate immediately. By the next morning, what one official described as a “massive wall of fire” had swept through the entire Northern California town of about 1,200 people, killing nine residents,
112 | including a 16-year-old boy, and destroying the school and almost every home and business. Ms. Willin and her family escaped to a cramped hotel room 60 miles away.
113 | In her panic, she had forgotten to grab masks, but she had the hot spots, along with her daughters’ laptops and school books. On Monday, the two girls plan to meet with their teachers on Zoom, seeking some comfort amid the chaos.
114 | They’re still able to be in school,” Ms. Willin said, “even though the school burned to the ground.”
115 | As the worst wildfire season in decades scorches the West amid a still raging pandemic, families and educators who were already starting the strangest and most challenging school year of their lifetimes have been traumatized all over again.
116 | Tens of thousands of people have been forced to flee their homes, with some mourning the loss of their entire communities.
117 | But amid the twin disasters, the remote learning preparations that schools made for the coronavirus are providing a strange
118 | modicum of stability for teachers and students, letting many stay connected and take comfort in an unexpected form of virtual community."""
119 |
120 | qe_score = BaselineScorer(model="dae")
121 | print(qe_score.score([source], [hypothesis]))
122 |
--------------------------------------------------------------------------------
/summac/model_guardrails.py:
--------------------------------------------------------------------------------
1 | import nltk, spacy
2 |
3 | def doc2ents(doc, black_list_types=[]):
4 | ents = [{"type": ent.label_, "entity": ent.text, "sent_idx": sent_idx} for sent_idx, sent in enumerate(doc.sents) for ent in sent.ents]
5 | ents = [e for e in ents if e["type"] not in black_list_types]
6 | return ents
7 |
8 |
9 | class NERInaccuracyPenalty:
10 | def __init__(self, spacy_model="en_core_web_sm"):
11 |
12 | common_ents = ["one", "united states", "army"]
13 | self.common_ents = set([cent.lower() for cent in common_ents])
14 | self.spacy_model = spacy.load(spacy_model)
15 | self.word2num = {}
16 | self.black_list_types = set(["ORDINAL", "WORK_OF_ART", "EVENT","PRODUCT", "LAW", "LANGUAGE"])
17 | self.number_words_to_remove = set(["the", "a", "an", "at", "of", "in", "than", "several", "few", "only", "about", "another", "least", "most", "last", "first", "early", "earlier", "later", "over", "fewer", "row", "every", "late", "ago", "only", "about", "around", "within", "more", "less"])
18 |
19 | self.string2digits = {"zero": 0, "one": 1, "two": 2, "three": 3, "four": 4, "five": 5, "six": 6, "seven": 7, "eight": 8, "nine": 9, "ten": 10, "eleven": 11, "twelve": 12, "thirteen": 13, "fourteen": 14, "fifteen": 15, "sixteen": 16, "seventeen": 17, "eighteen": 18, "nineteen": 19, "twenty": 20, "thirty": 30, "forty": 40, "fifty": 50, "sixty": 60, "seventy": 70, "eighty": 80, "ninety": 90, "a hundred": 100, "hundred": 100, "a thousand": 1000, "thousand": 1000}
20 | self.string2digits = {k: str(v) for k, v in self.string2digits.items()}
21 | self.digits2string = {v:k for k,v in self.string2digits.items()}
22 |
23 | def common_ents_no_problem(self, ent_text):
24 | return ent_text in self.common_ents
25 |
26 | def clean_entity_text(self, ent_text):
27 | ent_text = ent_text.lower().replace("-", " ").replace('"', '').strip().replace("'s", "")
28 | if ent_text[:4] == "the ":
29 | ent_text = ent_text[4:]
30 | return ent_text.strip()
31 |
32 | def singular(self, ent_text):
33 | if len(ent_text) == 0:
34 | return ent_text
35 | if ent_text[-1] == "s":
36 | return ent_text[:-1]
37 | else:
38 | return ent_text
39 |
40 | def quantifier_cleaning(self, quantifier_text):
41 | words = nltk.tokenize.word_tokenize(quantifier_text.lower())
42 | words = sorted([w for w in words if len(w) >= 2 and w not in self.number_words_to_remove])
43 | return set(words)
44 |
45 | def quantifier_matching(self, quantifier, entity_list):
46 | quantifier_clean = self.quantifier_cleaning(quantifier)
47 | entity_list_clean = [self.quantifier_cleaning(ent["text"]) for ent in entity_list]
48 | return any([quantifier_clean in ent2_clean for ent2_clean in entity_list_clean])
49 |
50 | def remove_common_entities(self, ent_list_new, ent_list_old, source_text):
51 | source_text = source_text.lower()
52 |
53 | ent_set = set([self.clean_entity_text(e["text"]) for e in ent_list_old])
54 | finals = []
55 |
56 | for ent_new in ent_list_new:
57 | raw_entity_lower = ent_new["text"].lower()
58 | entity_text = self.clean_entity_text(ent_new["text"])
59 | if self.common_ents_no_problem(entity_text): # The entity is too common and could added anywhere
60 | continue
61 | if entity_text in ent_set or self.singular(entity_text) in ent_set: # Exact match with some entity
62 | continue
63 | if entity_text in source_text or self.singular(entity_text).lower() in source_text or raw_entity_lower in source_text: # Sometimes the NER model won't tag the exact same thing in the original paragraph, but we can just do string matching
64 | continue
65 | # Starting the entity-specific matching
66 | if ent_new["type"] in ["DATE", "CARDINAL", "MONEY", "PERCENT"]:
67 | # For dates:
68 | # a subset match is allowed: "several months" -> "months", "only a few weeks" -> "a few weeks"
69 | quantifier_clean = self.quantifier_cleaning(ent_new["text"])
70 | if self.quantifier_matching(ent_new["text"], ent_list_old):
71 | # if any([clean_string in ent_text2 for ent_text2 in ent_set]):
72 | continue
73 |
74 | if all([w in source_text for w in quantifier_clean]):
75 | # A bit more desperate: remove additional words, and check that what's left is in the original
76 | continue
77 | if ent_new["type"] == "CARDINAL":
78 | if raw_entity_lower in self.string2digits and self.string2digits[raw_entity_lower] in source_text:
79 | continue # They wrote "nineteen" instead of 19
80 | elif raw_entity_lower in self.digits2string and self.digits2string[raw_entity_lower] in source_text.replace(",", ""):
81 | continue # They wrote 19 instead of "nineteen"
82 |
83 | if ent_new["type"] == "GPE":
84 | if entity_text+"n" in ent_set or entity_text[:-1] in ent_set:
85 | # If you say india instead of indian, or indian instead of india.
86 | # Definitely doesn't work with every country, could use a lookup table
87 | continue
88 | if ent_new["type"] in ["ORG", "PERSON"]:
89 | # Saying a smaller thing is fine: Barack Obama -> Obama. University of California, Berkeley -> University of California
90 | if any([entity_text in ent_text2 for ent_text2 in ent_set]):
91 | continue
92 | finals.append(ent_new)
93 | return finals
94 |
95 | def score_one(self, ents1, ents2, source):
96 | new_ents2 = self.remove_common_entities(ents2, ents1, source)
97 | score = 1.0 if len(new_ents2) > 0 else 0.0
98 | return {"score": score, "new_ents": new_ents2, "gen_entities": ents2, "source_entities": ents1}
99 |
100 | def extract_entities(self, text):
101 | doc = self.spacy_model(text)
102 | return [{"text": ent.text, "type": ent.label_} for ent in doc.ents]
103 |
104 | def score(self, sources, generateds, printing=False, **kwargs):
105 | source_ents = [self.extract_entities(text) for text in sources]
106 | generated_ents = [self.extract_entities(text) for text in generateds]
107 |
108 | scores, all_new_ents = [], []
109 | for source_ent, generated_ent, source in zip(source_ents, generated_ents, sources):
110 | out = self.score_one(source_ent, generated_ent, source)
111 | scores.append(out["score"])
112 | all_new_ents.append(out["new_ents"])
113 | # gen_ents.append(out["gen_entities"])
114 | # source_ents.append(out["source_entities"])
115 | # if printing:
116 | # print("NER Inaccuracy:", out["new_ents"])
117 | return {"scores": scores, "source_ents": source_ents, "gen_ents": generated_ents, "new_ents": all_new_ents}
118 |
119 |
120 | if __name__ == "__main__":
121 | start = "Increases the amount of such credit to 50 percent for contributions to schools or public libraries in empowerment zones, enterprise communities, and Indian reservations."
122 | end = "Increases the blabla of such credit to 50 percent."
123 |
124 | ner_hallu = NERInaccuracyPenalty()
125 |
126 | print(ner_hallu.score([start], [end]))
127 |
--------------------------------------------------------------------------------
/summac/model_summac.py:
--------------------------------------------------------------------------------
1 | from transformers import AutoTokenizer, AutoModelForSequenceClassification
2 | import nltk, numpy as np, torch, os, json
3 | from .utils_misc import batcher
4 |
5 | model_map = {
6 | "snli-base": {"model_card": "boychaboy/SNLI_roberta-base", "entailment_idx": 0, "contradiction_idx": 2},
7 | "snli-large": {"model_card": "boychaboy/SNLI_roberta-large", "entailment_idx": 0, "contradiction_idx": 2},
8 | "mnli-base": {"model_card": "microsoft/deberta-base-mnli", "entailment_idx": 2, "contradiction_idx": 0},
9 | "mnli": {"model_card": "roberta-large-mnli", "entailment_idx": 2, "contradiction_idx": 0},
10 | "anli": {"model_card": "ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli", "entailment_idx": 0, "contradiction_idx": 2},
11 | "vitc-base": {"model_card": "tals/albert-base-vitaminc-mnli", "entailment_idx": 0, "contradiction_idx": 1},
12 | "vitc": {"model_card": "tals/albert-xlarge-vitaminc-mnli", "entailment_idx": 0, "contradiction_idx": 1},
13 | "vitc-only": {"model_card": "tals/albert-xlarge-vitaminc", "entailment_idx": 0, "contradiction_idx": 1},
14 | # "decomp": 0,
15 | }
16 |
17 |
18 | def card_to_name(card):
19 | card2name = {v["model_card"]: k for k, v in model_map.items()}
20 | if card in card2name:
21 | return card2name[card]
22 | return card
23 |
24 |
25 | def name_to_card(name):
26 | if name in model_map:
27 | return model_map[name]["model_card"]
28 | return name
29 |
30 |
31 | def get_neutral_idx(ent_idx, con_idx):
32 | return list(set([0, 1, 2]) - set([ent_idx, con_idx]))[0]
33 |
34 |
35 | class SummaCImager:
36 | def __init__(self, model_name="mnli", granularity="paragraph", use_cache=True, max_doc_sents=100, device="cuda", **kwargs):
37 |
38 | self.grans = granularity.split("-")
39 |
40 | assert all(gran in ["paragraph", "sentence", "document", "2sents", "mixed"] for gran in self.grans) and len(self.grans) <= 2, "Unrecognized `granularity` %s" % (granularity)
41 | assert model_name in model_map.keys(), "Unrecognized model name: `%s`" % (model_name)
42 |
43 | self.model_name = model_name
44 | if model_name != "decomp":
45 | self.model_card = name_to_card(model_name)
46 | self.entailment_idx = model_map[model_name]["entailment_idx"]
47 | self.contradiction_idx = model_map[model_name]["contradiction_idx"]
48 | self.neutral_idx = get_neutral_idx(self.entailment_idx, self.contradiction_idx)
49 |
50 | self.granularity = granularity
51 | self.use_cache = use_cache
52 | self.cache_folder = "/export/share/plaban/summac_cache/"
53 |
54 | self.max_doc_sents = max_doc_sents
55 | self.max_input_length = 500
56 | self.device = device
57 | self.cache = {}
58 | self.model = None # Lazy loader
59 |
60 | def load_nli(self):
61 | self.tokenizer = AutoTokenizer.from_pretrained(self.model_card)
62 | self.model = AutoModelForSequenceClassification.from_pretrained(self.model_card).eval()
63 | self.model.to(self.device)
64 | if self.device == "cuda":
65 | self.model.half()
66 |
67 | def split_sentences(self, text):
68 | sentences = nltk.tokenize.sent_tokenize(text)
69 | sentences = [sent for sent in sentences if len(sent)>10]
70 | return sentences
71 |
72 | def split_2sents(self, text):
73 | sentences = nltk.tokenize.sent_tokenize(text)
74 | sentences = [sent for sent in sentences if len(sent)>10]
75 | two_sents = [" ".join(sentences[i:(i+2)]) for i in range(len(sentences))]
76 | return two_sents
77 |
78 | def split_paragraphs(self, text):
79 | if text.count("\n\n") > 0:
80 | paragraphs = [p.strip() for p in text.split("\n\n")]
81 | else:
82 | paragraphs = [p.strip() for p in text.split("\n")]
83 | return [p for p in paragraphs if len(p) > 10]
84 |
85 | def split_text(self, text, granularity="sentence"):
86 | if granularity == "document":
87 | return [text]
88 | elif granularity == "paragraph":
89 | return self.split_paragraphs(text)
90 | elif granularity == "sentence":
91 | return self.split_sentences(text)
92 | elif granularity == "2sents":
93 | return self.split_2sents(text)
94 | elif granularity == "mixed":
95 | return self.split_sentences(text) + self.split_paragraphs(text)
96 |
97 | def build_chunk_dataset(self, original, generated, pair_idx=None):
98 | if len(self.grans) == 1:
99 | gran_doc, gran_sum = self.grans[0], self.grans[0]
100 | else:
101 | gran_doc, gran_sum = self.grans[0], self.grans[1]
102 |
103 | original_chunks = self.split_text(original, granularity=gran_doc)[:self.max_doc_sents]
104 | generated_chunks = self.split_text(generated, granularity=gran_sum)
105 |
106 | N_ori, N_gen = len(original_chunks), len(generated_chunks)
107 | dataset = [{"premise": original_chunks[i], "hypothesis": generated_chunks[j], "doc_i": i, "gen_i": j, "pair_idx": pair_idx} for i in range(N_ori) for j in range(N_gen)]
108 | return dataset, N_ori, N_gen
109 |
110 | def build_image(self, original, generated):
111 | cache_key = (original, generated)
112 | if self.use_cache and cache_key in self.cache:
113 | cached_image = self.cache[cache_key]
114 | cached_image = cached_image[:, :self.max_doc_sents, :]
115 | return cached_image
116 |
117 | dataset, N_ori, N_gen = self.build_chunk_dataset(original, generated)
118 |
119 | if len(dataset) == 0:
120 | return np.zeros((3, 1, 1))
121 |
122 | image = np.zeros((3, N_ori, N_gen))
123 |
124 | if self.model is None:
125 | self.load_nli()
126 |
127 | for batch in batcher(dataset, batch_size=20):
128 | batch_prems = [b["premise"] for b in batch]
129 | batch_hypos = [b["hypothesis"] for b in batch]
130 | batch_tokens = self.tokenizer.batch_encode_plus(list(zip(batch_prems, batch_hypos)), padding=True, truncation=True, max_length=self.max_input_length, return_tensors="pt", truncation_strategy="only_first")
131 | with torch.no_grad():
132 | model_outputs = self.model(**{k: v.to(self.device) for k, v in batch_tokens.items()})
133 |
134 | batch_probs = torch.nn.functional.softmax(model_outputs["logits"], dim=-1)
135 | batch_evids = batch_probs[:, self.entailment_idx].tolist()
136 | batch_conts = batch_probs[:, self.contradiction_idx].tolist()
137 | batch_neuts = batch_probs[:, self.neutral_idx].tolist()
138 |
139 | for b, evid, cont, neut in zip(batch, batch_evids, batch_conts, batch_neuts):
140 | image[0, b["doc_i"], b["gen_i"]] = evid
141 | image[1, b["doc_i"], b["gen_i"]] = cont
142 | image[2, b["doc_i"], b["gen_i"]] = neut
143 |
144 | if self.use_cache:
145 | self.cache[cache_key] = image
146 | return image
147 |
148 | def build_images(self, originals, generateds, batch_size=128):
149 | todo_originals, todo_generateds = [], []
150 | for ori, gen in zip(originals, generateds):
151 | cache_key = (ori, gen)
152 | if cache_key not in self.cache:
153 | todo_originals.append(ori)
154 | todo_generateds.append(gen)
155 |
156 | total_dataset = []
157 | todo_images = []
158 | for pair_idx, (ori, gen) in enumerate(zip(todo_originals, todo_generateds)):
159 | dataset, N_ori, N_gen = self.build_chunk_dataset(ori, gen, pair_idx=pair_idx)
160 | if len(dataset) == 0:
161 | image = np.zeros((3, 1, 1))
162 | else:
163 | image = np.zeros((3, N_ori, N_gen))
164 | todo_images.append(image)
165 | total_dataset += dataset
166 | if len(total_dataset) > 0 and self.model is None: # Can't just rely on the cache
167 | self.load_nli()
168 |
169 | for batch in batcher(total_dataset, batch_size=batch_size):
170 | batch_prems = [b["premise"] for b in batch]
171 | batch_hypos = [b["hypothesis"] for b in batch]
172 | batch_tokens = self.tokenizer.batch_encode_plus(list(zip(batch_prems, batch_hypos)), padding=True, truncation=True, max_length=self.max_input_length, return_tensors="pt", truncation_strategy="only_first")
173 | with torch.no_grad():
174 | model_outputs = self.model(**{k: v.to(self.device) for k, v in batch_tokens.items()})
175 |
176 | batch_probs = torch.nn.functional.softmax(model_outputs["logits"], dim=-1)
177 | batch_evids = batch_probs[:, self.entailment_idx].tolist()
178 | batch_conts = batch_probs[:, self.contradiction_idx].tolist()
179 | batch_neuts = batch_probs[:, self.neutral_idx].tolist()
180 |
181 | for b, evid, cont, neut in zip(batch, batch_evids, batch_conts, batch_neuts):
182 | image = todo_images[b["pair_idx"]]
183 | image[0, b["doc_i"], b["gen_i"]] = evid
184 | image[1, b["doc_i"], b["gen_i"]] = cont
185 | image[2, b["doc_i"], b["gen_i"]] = neut
186 |
187 | for pair_idx, (ori, gen) in enumerate(zip(todo_originals, todo_generateds)):
188 | cache_key = (ori, gen)
189 | self.cache[cache_key] = todo_images[pair_idx]
190 |
191 | images = [self.cache[(ori, gen)] for ori, gen in zip(originals, generateds)]
192 | return images
193 |
194 | def get_cache_file(self):
195 | return os.path.join(self.cache_folder, "cache_%s_%s.json" % (self.model_name, self.granularity))
196 |
197 | def save_cache(self):
198 | cache_cp = {"[///]".join(k): v.tolist() for k, v in self.cache.items()}
199 | with open(self.get_cache_file(), "w") as f:
200 | json.dump(cache_cp, f)
201 |
202 | def load_cache(self):
203 | cache_file = self.get_cache_file()
204 | if os.path.isfile(cache_file):
205 | with open(cache_file, "r") as f:
206 | cache_cp = json.load(f)
207 | self.cache = {tuple(k.split("[///]")): np.array(v) for k, v in cache_cp.items()}
208 |
209 | class SummaCConv(torch.nn.Module):
210 | def __init__(self, models=["mnli", "anli", "vitc"], bins='even50', granularity="sentence", nli_labels="e", device="cuda", start_file=None, imager_load_cache=True, agg="mean", **kwargs):
211 | # `bins` should be `even%d` or `percentiles`
212 | assert nli_labels in ["e", "c", "n", "ec", "en", "cn", "ecn"], "Unrecognized nli_labels argument %s" % (nli_labels)
213 |
214 | super(SummaCConv, self).__init__()
215 | self.device = device
216 | self.models = models
217 |
218 | self.imagers = []
219 | for model_name in models:
220 | self.imagers.append(SummaCImager(model_name=model_name, granularity=granularity, device=self.device, **kwargs))
221 | if imager_load_cache:
222 | for imager in self.imagers:
223 | imager.load_cache()
224 | assert len(self.imagers)>0, "Imager names were empty or unrecognized"
225 |
226 | if "even" in bins:
227 | n_bins = int(bins.replace("even", ""))
228 | self.bins = list(np.arange(0, 1, 1/n_bins)) + [1.0]
229 | elif bins == "percentile":
230 | self.bins = [0.0, 0.01, 0.02, 0.03, 0.04, 0.07, 0.13, 0.37, 0.90, 0.91, 0.92, 0.93, 0.94, 0.95, 0.955, 0.96, 0.965, 0.97, 0.975, 0.98, 0.985, 0.99, 0.995, 1.0] # Based on the percentile of the distribution on some large number of summaries
231 |
232 | self.nli_labels = nli_labels
233 | self.n_bins = len(self.bins) - 1
234 | self.n_rows = 10
235 | self.n_labels = 2
236 | self.n_depth = len(self.imagers)*len(self.nli_labels)
237 | self.full_size = self.n_depth*self.n_bins
238 |
239 | self.agg = agg
240 |
241 | self.mlp = torch.nn.Linear(self.full_size, 1).to(device)
242 | self.layer_final = torch.nn.Linear(3, self.n_labels).to(device)
243 |
244 | if start_file == "default":
245 | start_file = "summac_conv_vitc_sent_perc_e.bin"
246 | if not os.path.isfile("summac_conv_vitc_sent_perc_e.bin"):
247 | os.system("wget https://github.com/tingofurro/summac/raw/master/summac_conv_vitc_sent_perc_e.bin")
248 | assert bins == "percentile", "bins mode should be set to percentile if using the default 1-d convolution weights."
249 | if start_file is not None:
250 | print(self.load_state_dict(torch.load(start_file)))
251 |
252 | def build_image(self, original, generated):
253 | images = [imager.build_image(original, generated) for imager in self.imagers]
254 | image = np.concatenate(images, axis=0)
255 | return image
256 |
257 | def compute_histogram(self, original=None, generated=None, image=None):
258 | # Takes the two texts, and generates a (n_rows, 2*n_bins)
259 |
260 | if image is None:
261 | image = self.build_image(original, generated)
262 |
263 | N_depth, N_ori, N_gen = image.shape
264 |
265 | full_histogram = []
266 | for i_gen in range(N_gen):
267 | histos = []
268 |
269 | for i_depth in range(N_depth):
270 | if (i_depth % 3 == 0 and "e" in self.nli_labels) or (i_depth % 3 == 1 and "c" in self.nli_labels) or (i_depth % 3 == 2 and "n" in self.nli_labels):
271 | histo, X = np.histogram(image[i_depth, :, i_gen], range=(0, 1), bins=self.bins, density=False)
272 | histos.append(histo)
273 |
274 | histogram_row = np.concatenate(histos)
275 | full_histogram.append(histogram_row)
276 |
277 | n_rows_missing = self.n_rows - len(full_histogram)
278 | full_histogram += [[0.0] * self.full_size] * n_rows_missing
279 | full_histogram = full_histogram[:self.n_rows]
280 | full_histogram = np.array(full_histogram)
281 | return image, full_histogram
282 |
283 | def forward(self, originals, generateds, images=None):
284 | if images is not None:
285 | # In case they've been pre-computed.
286 | histograms = []
287 | for image in images:
288 | _, histogram = self.compute_histogram(image=image)
289 | histograms.append(histogram)
290 | else:
291 | images, histograms = [], []
292 | for original, generated in zip(originals, generateds):
293 | image, histogram = self.compute_histogram(original=original, generated=generated)
294 | images.append(image)
295 | histograms.append(histogram)
296 |
297 | N = len(histograms)
298 | histograms = torch.FloatTensor(histograms).to(self.device)
299 |
300 | non_zeros = (torch.sum(histograms, dim=-1) != 0.0).long()
301 | seq_lengths = non_zeros.sum(dim=-1).tolist()
302 |
303 | mlp_outs = self.mlp(histograms).reshape(N, self.n_rows)
304 | features = []
305 |
306 | for mlp_out, seq_length in zip(mlp_outs, seq_lengths):
307 | if seq_length > 0:
308 | Rs = mlp_out[:seq_length]
309 | if self.agg == "mean":
310 | features.append(torch.cat([torch.mean(Rs).unsqueeze(0), torch.mean(Rs).unsqueeze(0), torch.mean(Rs).unsqueeze(0)]).unsqueeze(0))
311 | elif self.agg == "min":
312 | features.append(torch.cat([torch.min(Rs).unsqueeze(0), torch.min(Rs).unsqueeze(0), torch.min(Rs).unsqueeze(0)]).unsqueeze(0))
313 | elif self.agg == "max":
314 | features.append(torch.cat([torch.max(Rs).unsqueeze(0), torch.max(Rs).unsqueeze(0), torch.max(Rs).unsqueeze(0)]).unsqueeze(0))
315 | elif self.agg == "all":
316 | features.append(torch.cat([torch.min(Rs).unsqueeze(0), torch.mean(Rs).unsqueeze(0), torch.max(Rs).unsqueeze(0)]).unsqueeze(0))
317 | else:
318 | features.append(torch.FloatTensor([0.0, 0.0, 0.0]).unsqueeze(0)) # .cuda()
319 | features = torch.cat(features)
320 | logits = self.layer_final(features)
321 | histograms_out = [histogram.cpu().numpy() for histogram in histograms]
322 | return logits, histograms_out, images
323 |
324 | def save_imager_cache(self):
325 | for imager in self.imagers:
326 | imager.save_cache()
327 |
328 | def score(self, originals, generateds, **kwargs):
329 | with torch.no_grad():
330 | logits, histograms, images = self.forward(originals, generateds)
331 | probs = torch.nn.functional.softmax(logits, dim=-1)
332 | batch_scores = probs[:, 1].tolist()
333 | return {"scores": batch_scores} # , "histograms": histograms, "images": images
334 |
335 |
336 | class SummaCZS:
337 | def __init__(self, model_name="mnli", granularity="paragraph", op1="max", op2="mean", use_ent=True, use_con=True, imager_load_cache=True, device="cuda", **kwargs):
338 | assert op2 in ["min", "mean", "max"], "Unrecognized `op2`"
339 | assert op1 in ["max", "mean", "min"], "Unrecognized `op1`"
340 | self.device = device
341 | self.imager = SummaCImager(model_name=model_name, granularity=granularity, device=self.device, **kwargs)
342 | if imager_load_cache:
343 | self.imager.load_cache()
344 | self.op2 = op2
345 | self.op1 = op1
346 | self.use_ent = use_ent
347 | self.use_con = use_con
348 |
349 | def save_imager_cache(self):
350 | self.imager.save_cache()
351 |
352 | def score_one(self, original, generated):
353 | image = self.imager.build_image(original, generated)
354 | score = self.image2score(image)
355 | return {"image": image, "score": score}
356 |
357 | def image2score(self, image):
358 | ent_scores = np.max(image[0], axis=0)
359 | co_scores = np.max(image[1], axis=0)
360 | if self.op1 == "mean":
361 | ent_scores = np.mean(image[0], axis=0)
362 | co_scores = np.mean(image[1], axis=0)
363 | elif self.op1 == "min":
364 | ent_scores = np.min(image[0], axis=0)
365 | co_scores = np.min(image[1], axis=0)
366 |
367 | if self.use_ent and self.use_con:
368 | scores = ent_scores - co_scores
369 | elif self.use_ent:
370 | scores = ent_scores
371 | elif self.use_con:
372 | scores = 1.0 - co_scores
373 |
374 | final_score = np.mean(scores)
375 | if self.op2 == "min":
376 | final_score = np.min(scores)
377 | elif self.op2 == "max":
378 | final_score = np.max(scores)
379 | return final_score
380 |
381 | def score(self, sources, generateds, batch_size=128, **kwargs):
382 | images = self.imager.build_images(sources, generateds, batch_size=batch_size)
383 | scores = [self.image2score(image) for image in images]
384 | return {"scores": scores, "images": images}
385 |
386 |
387 | if __name__ == "__main__":
388 | model = SummaCZS(granularity="document", model_name="vitc", imager_load_cache=True, device="cpu") # Device can be `cpu` or `cuda` when GPU is available
389 |
390 | document = "Jeff joined Microsoft in 1992 to lead corporate developer evangelism for Windows NT."
391 | summary1 = "Jeff joined Microsoft in 1992."
392 | summary2 = "Jeff joined Microsoft."
393 |
394 | print(model.score([document, document], [summary1, summary2])["scores"])
395 |
396 | # document = """Jeff joined Microsoft in 1992 to lead corporate developer evangelism for Windows NT. He then served as a Group Program manager in Microsoft's Internet Business Unit. In 1998, he led the creation of SharePoint Portal Server, which became one of Microsoft’s fastest-growing businesses, exceeding $2 billion in revenues. Jeff next served as Corporate Vice President for Program Management across Office 365 Services and Servers, which is the foundation of Microsoft's enterprise cloud leadership. He then led Corporate Strategy supporting Satya Nadella and Amy Hood on Microsoft's mobile-first/cloud-first transformation and acquisitions. Prior to joining Microsoft, Jeff was vice president for software development for an investment firm in New York. He leads Office shared experiences and core applications, as well as OneDrive and SharePoint consumer and business services in Office 365. Jeff holds a Master of Business Administration degree from Harvard Business School and a Bachelor of Science degree in information systems and finance from New York University."""
397 | # summary = "Jeff joined Microsoft in 1992 to lead the company's corporate evangelism. He then served as a Group Manager in Microsoft's Internet Business Unit. In 1998, Jeff led Sharepoint Portal Server, which became the company's fastest-growing business, surpassing $3 million in revenue. Jeff next leads corporate strategy for SharePoint and Servers which is the basis of Microsoft's cloud-first strategy. He leads corporate strategy for Satya Nadella and Amy Hood on Microsoft's mobile-first."
398 |
399 | # scores = model.score([document], [summary])["images"][0][0].T
400 | # summary_sentences = model.imager.split_text(summary)
401 |
402 | # print(np.array2string(scores, precision=2))
403 | # for score_row, sentence in zip(scores, summary_sentences):
404 | # print("-----------")
405 | # print("[SummaC score: %.3f; supporting sentence: %d] %s " % (np.max(score_row), np.argmax(score_row)+1, sentence))
406 |
--------------------------------------------------------------------------------
/summac/run_baseline.py:
--------------------------------------------------------------------------------
1 | # This code does not work as is, but was kept for reference, if others are interested in re-running baselines.
2 | from utils_summac_benchmark import load_factcc, load_polytope, load_cogensumm, load_frank, load_summeval, load_xsumfaith
3 | import sklearn, numpy as np, os, pandas as pd, sys, argparse
4 | from model_baseline import BaselineScorer
5 | from utils_scoring import ScorerWrapper
6 | import utils_misc, seaborn as sns
7 | from collections import Counter
8 |
9 | sys.path.insert(0, "/home/phillab/feqa/")
10 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
11 |
12 | # For now, can't use argparse because it is hard-coded in DAE... very shitty
13 | # parser = argparse.ArgumentParser()
14 | # parser.add_argument("--model", type=str, choices=["questeval", "feqa", "dae"], default="questeval")
15 | # parser.add_argument("--questeval_weighter", action="store_true")
16 | # parser.add_argument("--cut", type=str, choices=["val", "test"], default="val")
17 | # args = parser.parse_args()
18 |
19 | model = "dae"
20 | cut = "test"
21 |
22 | utils_misc.DoublePrint("%s_%s.log" % (model, cut))
23 |
24 | def choose_best_threshold(labels, scores):
25 | best_bacc = 0.0
26 | best_thresh = 0.0
27 | thresholds = [np.percentile(scores, p) for p in np.arange(0, 100, 1)]
28 | for thresh in thresholds:
29 | preds = [1 if score > thresh else 0 for score in scores]
30 | bacc_score = sklearn.metrics.balanced_accuracy_score(labels, preds)
31 | if bacc_score >= best_bacc:
32 | best_bacc = bacc_score
33 | best_thresh = thresh
34 | return best_thresh
35 |
36 | def from_score_to_pred(dataset, score_key):
37 | scores = [d[score_key] for d in dataset]
38 | labels = [d["label"] for d in dataset]
39 | thresh = choose_best_threshold(labels, scores)
40 |
41 | pred_key = "pred_%s" % (score_key)
42 | for d in dataset:
43 | d[pred_key] = 1 if d[score_key]>thresh else 0
44 |
45 |
46 | datasets = [{"name": "factcc", "dataset": load_factcc(cut=cut)},
47 | {"name": "frank", "dataset": load_frank(cut=cut)},
48 | {"name": "pt_any", "dataset": load_polytope(which_label="overall", cut=cut)},
49 | {"name": "summ_corr", "dataset": load_cogensumm(cut=cut)},
50 | {"name": "summeval", "dataset": load_summeval(cut=cut)},
51 | {"name": "xsumfaith", "dataset": load_xsumfaith(cut=cut)}
52 | ]
53 |
54 | dataset_stats = []
55 | for dataset in datasets:
56 | N_pos, N_neg = len([d for d in dataset["dataset"] if d["label"]==1]), len([d for d in dataset["dataset"] if d["label"]==0])
57 | dataset_stats.append({"name": dataset["name"], "N": len(dataset["dataset"]), "N_pos": N_pos, "N_neg": N_neg, "frac_pos": N_pos/(N_pos+N_neg)})
58 |
59 | print(pd.DataFrame(dataset_stats))
60 |
61 | scorers = []
62 | if model == "questeval":
63 | scorers.append({"name": "QuestEval", "model": BaselineScorer(model="questeval", do_weighter=args.questeval_weighter), "sign": 1})
64 | elif model == "feqa":
65 | scorers.append({"name": "FEQA", "model": BaselineScorer(model="feqa"), "sign": 1})
66 | elif model == "dae":
67 | scorers.append({"name": "DAE", "model": BaselineScorer(model="dae"), "sign": 1})
68 |
69 |
70 | for scorer in scorers:
71 | scorer["model"].load_cache()
72 |
73 | batch_size = 100
74 | scorer_doc = ScorerWrapper(scorers, scoring_method="sum", max_batch_size=batch_size, use_caching=True)
75 |
76 | def compute_doc_level(dataset):
77 | documents = [d["document"] for d in dataset]
78 | summaries = [d["claim"] for d in dataset]
79 | doc_scores = scorer_doc(documents, summaries, progress=True)
80 | label_keys = [k for k in doc_scores.keys() if "_scores" in k]
81 |
82 | for label_key in label_keys:
83 | score_key = ("%s|doc" % (label_key)).replace("_scores", "")
84 | for d, score in zip(dataset, doc_scores[label_key]):
85 | d[score_key] = score
86 | from_score_to_pred(dataset, score_key)
87 |
88 |
89 | results = []
90 | for dataset in datasets:
91 | print("======= %s ========" % (dataset["name"]))
92 | datas = dataset["dataset"]
93 | compute_doc_level(datas)
94 | for scorer in scorers:
95 | scorer["model"].save_cache()
96 |
97 | pred_labels = [k for k in datas[0].keys() if "pred_" in k]
98 | for pred_label in pred_labels:
99 | preds = [d[pred_label] for d in datas]
100 | labels = [d["label"] for d in datas]
101 | model_name, input_type = pred_label.replace("pred_", "").split("|")
102 |
103 | label_counts = Counter([d["label"] for d in dataset["dataset"]])
104 | pos_label = 0 if label_counts[0] < label_counts[1] else 1
105 |
106 | f1 = sklearn.metrics.f1_score(labels, preds, pos_label=pos_label)
107 | balanced_acc = sklearn.metrics.balanced_accuracy_score(labels, preds)
108 |
109 | results.append({"model_name": model_name, "dataset_name": dataset["name"], "input": input_type, "%s_f1" % (dataset["name"]): f1, "%s_bacc" % (dataset["name"]): balanced_acc})
110 |
111 | cm = sns.light_palette("green", as_cmap=True)
112 |
113 | def highlight_max(data):
114 | is_max = data == data.max()
115 | return ['font-weight: bold' if v else '' for v in is_max]
116 |
117 |
118 | df = pd.DataFrame(results)
119 | df = df.groupby(["model_name", "input"]).agg({"%s_bacc" % (d["name"]): "mean" for d in datasets})
120 |
121 | df = df.rename(columns={k: k.replace("_bacc", "") for k in df.keys()})
122 | df.drop("total", inplace=True)
123 |
124 | print(df)
125 | df.to_csv("/home/phillab/%s_results.csv" % (model))
126 | # print(df.style.apply(highlight_max).background_gradient(cmap=cm, high=1.0, low=0.0).set_precision(3).set_caption("Weighed Accuracy"))
127 |
--------------------------------------------------------------------------------
/summac/train_summac.py:
--------------------------------------------------------------------------------
1 | from .utils_misc import select_freer_gpu
2 |
3 | select_freer_gpu()
4 | import torch, tqdm, nltk, numpy as np, argparse, json
5 | from torch.utils.data import DataLoader, RandomSampler
6 | from .utils_optim import build_optimizer
7 | from .benchmark import SummaCBenchmark, load_factcc
8 | from .model_summac import SummaCConv, model_map
9 | import os, time
10 |
11 | def train(model="mnli", granularity="sentence", nli_labels="e", pre_file="", num_epochs=5, optimizer="adam", train_batch_size=32, learning_rate=0.1, bins="even50", silent=False, norm_histo=False):
12 | experiment = "%s_%s_%s_%s" % (model, granularity, bins, nli_labels)
13 |
14 | if not silent:
15 | print("Experiment name: %s" % (experiment))
16 |
17 | if len(pre_file) == 0:
18 | standard_pre_file = "/home/phillab/data/summac_cache/train_%s_%s.jsonl" % (model, granularity)
19 | if os.path.isfile(standard_pre_file):
20 | pre_file = standard_pre_file
21 |
22 | precomputed = len(pre_file) > 0
23 | device = "cpu" if precomputed else "cuda"
24 |
25 | if model == "multi":
26 | models = ["mnli", "anli", "vitc"]
27 | elif model == "multi2":
28 | models = ["mnli", "vitc", "vitc-only", "vitc-base"]
29 | else:
30 | models = [model]
31 |
32 | model = SummaCConv(models=models, granularity=granularity, nli_labels=nli_labels, device=device, bins=bins, norm_histo=norm_histo)
33 |
34 | optimizer = build_optimizer(model, learning_rate=learning_rate, optimizer_name=optimizer)
35 | if not silent:
36 | print("Model Loaded")
37 |
38 | def sent_tok(text):
39 | sentences = nltk.tokenize.sent_tokenize(text)
40 | return [sent for sent in sentences if len(sent)>10]
41 |
42 | def collate_func(inps):
43 | documents, claims, labels = [], [], []
44 | for inp in inps:
45 | if len(sent_tok(inp["claim"])) > 0 and len(sent_tok(inp["document"])) > 0:
46 | documents.append(inp["document"])
47 | claims.append(inp["claim"])
48 | labels.append(inp["label"])
49 | labels = torch.LongTensor(labels).to(device)
50 | return documents, claims, labels
51 |
52 | def collate_pre(inps):
53 | documents = [inp["document"] for inp in inps]
54 | claims = [inp["claim"] for inp in inps]
55 | # images = [[np.array(im) for im in inp["image"]] for inp in inps]
56 | images = [np.array(inp["image"]) for inp in inps]
57 | labels = torch.LongTensor([inp["label"] for inp in inps]).to(device)
58 | return documents, claims, images, labels
59 |
60 | if precomputed:
61 | d_train = []
62 | with open(pre_file, "r") as f:
63 | for line in f:
64 | d_train.append(json.loads(line))
65 | dl_train = DataLoader(dataset=d_train, batch_size=train_batch_size, sampler=RandomSampler(d_train), collate_fn=collate_pre)
66 | else:
67 | d_train = load_factcc(cut="train")
68 | dl_train = DataLoader(dataset=d_train, batch_size=train_batch_size, sampler=RandomSampler(d_train), collate_fn=collate_func)
69 |
70 | fcb = SummaCBenchmark(cut="val")
71 |
72 | if not silent:
73 | print("Length of dataset. [Training: %d]" % (len(d_train)))
74 |
75 | crit = torch.nn.CrossEntropyLoss()
76 | eval_every = 200
77 | best_val_score = 0.0
78 | best_file = ""
79 |
80 | for epi in range(num_epochs):
81 | ite = enumerate(dl_train)
82 | if not silent:
83 | ite = tqdm.tqdm(ite, total=len(dl_train))
84 | for ib, batch in ite:
85 | if precomputed:
86 | documents, claims, images, batch_labels = batch
87 | logits, _, _ = model(documents, claims, images=images)
88 | else:
89 | documents, claims, batch_labels = batch
90 | logits, _, _ = model(originals=documents, generateds=claims)
91 | loss = crit(logits, batch_labels)
92 |
93 | loss.backward()
94 | optimizer.step()
95 | optimizer.zero_grad()
96 | # wandb.log({"loss": loss.item()})
97 |
98 | if ib % eval_every == eval_every-1:
99 |
100 | eval_time = time.time()
101 | benchmark = fcb.evaluate(model)
102 | val_score = benchmark["overall_score"]
103 | eval_time = time.time() - eval_time
104 | if eval_time > 10.0:
105 | model.save_imager_cache()
106 |
107 | if not silent:
108 | ite.set_description("[Benchmark Score: %.3f]" % (val_score))
109 | if val_score > best_val_score:
110 | best_val_score = val_score
111 | if len(best_file) > 0:
112 | os.remove(best_file)
113 | best_file = "/home/phillab/models/summac/%s_bacc%.3f.bin" % (experiment, best_val_score)
114 | torch.save(model.state_dict(), best_file)
115 | if not silent:
116 | for t in benchmark["benchmark"]:
117 | print("[%s] Score: %.3f (thresh: %.3f)" % (t["name"].ljust(10), t["score"], t["threshold"]))
118 | return best_val_score
119 |
120 |
121 | if __name__ == "__main__":
122 | parser = argparse.ArgumentParser()
123 |
124 | model_choices = list(model_map.keys()) + ["multi", "multi2"]
125 |
126 | parser.add_argument("--model", type=str, choices=model_choices, default="mnli")
127 | parser.add_argument("--granularity", type=str, default="sentence") # , choices=["sentence", "paragraph", "mixed", "2sents"]
128 | parser.add_argument("--pre_file", type=str, default="", help="If not empty, will use the precomputed instead of computing images on the fly. (useful for hyper-param tuning)")
129 | parser.add_argument("--bins", type=str, default="percentile", help="How should the bins of the histograms be decided (even%d or percentile)")
130 | parser.add_argument("--nli_labels", type=str, default="e", choices=["e", "c", "n", "ec", "en", "cn", "ecn"], help="Which of the three labels should be used in the creation of the histogram")
131 |
132 | parser.add_argument("--num_epochs", type=int, default=5, help="Number of passes over the data.")
133 | parser.add_argument("--optimizer", type=str, choices=["adam", "sgd"], default="adam")
134 | parser.add_argument("--train_batch_size", type=int, default=32, help="Training batch size.")
135 | parser.add_argument("--learning_rate", type=float, default=1e-2, help="Number of passes over the data.")
136 | parser.add_argument("--norm_histo", action="store_true", help="Normalize the histogram to be between 0 and 1, and include the explicit count")
137 |
138 | args = parser.parse_args()
139 | train(**args.__dict__)
140 |
--------------------------------------------------------------------------------
/summac/utils_misc.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import requests
3 | import tqdm
4 | import os
5 |
6 | # GPU-related business
7 |
8 | def get_freer_gpu():
9 | os.system('nvidia-smi -q -d Memory |grep -A4 GPU|grep Free >tmp_smi')
10 | memory_available = [int(x.split()[2])+5*i for i, x in enumerate(open('tmp_smi', 'r').readlines())]
11 | os.remove("tmp_smi")
12 | return np.argmax(memory_available)
13 |
14 | def select_freer_gpu():
15 | freer_gpu = str(get_freer_gpu())
16 | print("Will use GPU: %s" % (freer_gpu))
17 | os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
18 | os.environ["CUDA_VISIBLE_DEVICES"] = ""+freer_gpu
19 | return freer_gpu
20 |
21 | def batcher(iterator, batch_size=4, progress=False):
22 | if progress:
23 | iterator = tqdm.tqdm(iterator)
24 |
25 | batch = []
26 | for elem in iterator:
27 | batch.append(elem)
28 | if len(batch) == batch_size:
29 | final_batch = batch
30 | batch = []
31 | yield final_batch
32 | if len(batch) > 0: # Leftovers
33 | yield batch
34 |
35 | # Google Drive related
36 |
37 | def download_file_from_google_drive(id, destination):
38 | URL = "https://docs.google.com/uc?export=download"
39 |
40 | session = requests.Session()
41 |
42 | response = session.get(URL, params = { 'id' : id }, stream = True)
43 | token = get_confirm_token(response)
44 |
45 | if token:
46 | params = { 'id' : id, 'confirm' : token }
47 | response = session.get(URL, params = params, stream = True)
48 |
49 | save_response_content(response, destination)
50 |
51 | def get_confirm_token(response):
52 | for key, value in response.cookies.items():
53 | if key.startswith('download_warning'):
54 | return value
55 |
56 | return None
57 |
58 | def save_response_content(response, destination):
59 | CHUNK_SIZE = 32768
60 |
61 | with open(destination, "wb") as f:
62 | for chunk in response.iter_content(CHUNK_SIZE):
63 | if chunk: # filter out keep-alive new chunks
64 | f.write(chunk)
65 |
--------------------------------------------------------------------------------
/summac/utils_optim.py:
--------------------------------------------------------------------------------
1 | from transformers.optimization import AdamW
2 | from torch.optim.lr_scheduler import LambdaLR
3 | from torch.optim import Optimizer, SGD
4 | from torch import nn
5 | import math, torch
6 |
7 | def build_optimizer(model, optimizer_name="adam", learning_rate=1e-5):
8 | param_optimizer = list(model.named_parameters())
9 | no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
10 | optimizer_grouped_parameters = [
11 | {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
12 | {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
13 | ]
14 | if optimizer_name == "adam":
15 | optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
16 | elif optimizer_name == "sgd":
17 | optimizer = SGD(optimizer_grouped_parameters, lr=learning_rate)
18 | else:
19 | assert False, "optimizer_name = '%s' is not `adam` or `lamb`" % (optimizer_name)
20 | return optimizer
21 |
--------------------------------------------------------------------------------
/summac/utils_scorer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import sklearn
3 |
4 | # Choosing threshold
5 | def choose_best_threshold(labels, scores):
6 | best_f1 = 0.0
7 | best_thresh = 0.0
8 | thresholds = [np.percentile(scores, p) for p in np.arange(0, 100, 0.2)]
9 | for thresh in thresholds:
10 | preds = [1 if score > thresh else 0 for score in scores]
11 | f1_score = sklearn.metrics.balanced_accuracy_score(labels, preds)
12 |
13 | if f1_score >= best_f1:
14 | best_f1 = f1_score
15 | best_thresh = thresh
16 | return best_thresh, best_f1
17 |
18 | def from_score_to_pred(dataset, score_key):
19 | scores = [d[score_key] for d in dataset]
20 | labels = [d["label"] for d in dataset]
21 | thresh, _ = choose_best_threshold(labels, scores)
22 |
23 | pred_key = "pred_%s" % (score_key)
24 | for d in dataset:
25 | d[pred_key] = 1 if d[score_key] > thresh else 0
26 |
27 |
28 | # Score computation utility
29 | def compute_doc_level(scorer_doc, dataset):
30 | documents = [d["document"] for d in dataset]
31 | summaries = [d["claim"] for d in dataset]
32 | doc_scores = scorer_doc(documents, summaries, progress=True)
33 | label_keys = [k for k in doc_scores.keys() if "_scores" in k]
34 |
35 | for label_key in label_keys:
36 | score_key = ("%s|doc" % (label_key)).replace("_scores", "")
37 | for d, score in zip(dataset, doc_scores[label_key]):
38 | d[score_key] = score
39 | from_score_to_pred(dataset, score_key)
40 |
41 | def compute_paragraph_level(scorer_para, dataset):
42 | all_paragraphs = []
43 | all_summaries = []
44 | idx_map = []
45 | for i, d in enumerate(dataset):
46 | separator = "\n\n" if d["document"].count("\n\n")>0 else "\n"
47 | paragraphs = d["document"].split(separator)
48 | paragraphs = [p.strip() for p in paragraphs if len(p.strip()) > 0]
49 | all_paragraphs += paragraphs
50 | all_summaries += [d["claim"]] * len(paragraphs)
51 | idx_map += [i] * len(paragraphs)
52 |
53 | para_scores = scorer_para(all_paragraphs, all_summaries, progress=True)
54 | label_keys = [sname+"_scores" for sname in scorer_para.get_score_names()]
55 | for label_key in label_keys:
56 | score_key = ("%s|paras" % (label_key)).replace("_scores", "")
57 | for d in dataset:
58 | d[score_key] = []
59 | for j, score in enumerate(para_scores[label_key]):
60 | dataset[idx_map[j]][score_key].append(score)
61 |
62 | mean_k, max_k, min_k = score_key+"_mean", score_key+"_max", score_key+"_min"
63 | for d in dataset:
64 | d[mean_k] = np.mean(d[score_key])
65 | d[max_k] = np.max(d[score_key])
66 | d[min_k] = np.min(d[score_key])
67 | from_score_to_pred(dataset, mean_k)
68 | from_score_to_pred(dataset, max_k)
69 | from_score_to_pred(dataset, min_k)
70 |
--------------------------------------------------------------------------------
/summac/utils_scoring.py:
--------------------------------------------------------------------------------
1 | import torch, time, numpy as np
2 | from .utils_misc import batcher
3 |
4 | class ScorerWrapper:
5 | def __init__(self, scorers, scoring_method="logsum", max_batch_size=100, use_caching=False):
6 | assert scoring_method in ["sum", "product", "logsum"], "Unrecognized `scoring_method`"
7 |
8 | self.scorers = scorers
9 | self.scoring_method = scoring_method
10 | self.use_caching = use_caching
11 | self.cache = {}
12 |
13 | self.max_batch_size = max_batch_size
14 | if self.scoring_method == "logsum":
15 | self.score_func = logsum_score
16 | elif self.scoring_method == "product":
17 | self.score_func = product_score
18 | elif self.scoring_method == "sum":
19 | self.score_func = sum_score
20 |
21 | def get_score_names(self):
22 | return [s["name"] for s in self.scorers]
23 |
24 | def make_key(self, inp, gen):
25 | return "%s|||___|||%s" % (inp, gen)
26 |
27 | def score(self, inputs, generateds, partial=False, printing=False, timings=False, extras={}, progress=False):
28 | assert len(inputs) == len(generateds), "Input and output lengths don't match"
29 |
30 | if not self.use_caching:
31 | self.cache = {} # Reset the cache
32 |
33 | todo = []
34 | all_keys = []
35 | for inp, gen in zip(inputs, generateds):
36 | key = self.make_key(inp, gen)
37 | all_keys.append(key)
38 | if key not in self.cache:
39 | todo.append({"inp": inp, "gen": gen, "key": key})
40 |
41 | for d in todo:
42 | self.cache[d["key"]] = {}
43 |
44 | if self.use_caching and len(todo) < len(all_keys):
45 | print("With caching, only processing: %d / %d samples" % (len(todo), len(all_keys)))
46 |
47 | if len(todo) == 0:
48 | progress = False # Not needed, it's empty
49 |
50 | for batch_todo in batcher(todo, batch_size=self.max_batch_size, progress=progress):
51 | batch_inputs = [d["inp"] for d in batch_todo]
52 | batch_gens = [d["gen"] for d in batch_todo]
53 |
54 | batch_scores, timings_out = self.score_func(self.scorers, batch_inputs, batch_gens, partial=partial, printing=printing, extras=extras)
55 |
56 | for k, out in batch_scores.items():
57 | if type(out) in [torch.Tensor, np.array, np.ndarray]:
58 | out = out.tolist()
59 |
60 | for i, d in enumerate(batch_todo):
61 | self.cache[d["key"]][k] = out[i]
62 |
63 | if timings:
64 | print(timings_out)
65 |
66 | all_outputs = {}
67 | for k in self.cache[all_keys[0]].keys():
68 | all_outputs[k] = [self.cache[key][k] for key in all_keys]
69 |
70 | if printing:
71 | print("[total]", all_outputs["total_scores"])
72 | return all_outputs
73 |
74 | def __call__(self, inputs, generateds, **kwargs):
75 | return self.score(inputs, generateds, **kwargs)
76 |
77 | def sum_score(scorers, paragraphs, generateds, partial=False, printing=False, extras={}):
78 | total_scores = np.zeros((len(paragraphs)))
79 | scorer_returns, timings = {}, {}
80 | T = time.time()
81 |
82 | for scorer in scorers:
83 | scores = scorer['model'].score(paragraphs, generateds, partial=partial, printing=printing, **extras)
84 | weight = scorer.get("weight", 1.0)
85 | total_scores += scorer["sign"]*weight*np.array(scores['scores'])
86 |
87 | scorer_returns.update({scorer['name']+"_"+k: v for k, v in scores.items()})
88 | timings[scorer["name"]] = time.time()-T
89 | T = time.time()
90 |
91 | scorer_returns['total_scores'] = total_scores
92 | return scorer_returns, timings
93 |
94 | def product_score(scorers, paragraphs, generateds, partial=False, printing=False, extras={}):
95 | total_scores = np.ones((len(paragraphs)))
96 | scorer_returns, timings = {}, {}
97 | T = time.time()
98 |
99 | for scorer in scorers:
100 | scores = scorer['model'].score(paragraphs, generateds, partial=partial, printing=printing, **extras)
101 | if scorer['sign'] == 1:
102 | total_scores *= np.array(scores['scores'])
103 | else: # It's a binary penalty
104 | total_scores *= (1-np.array(scores['scores']))
105 |
106 | scorer_returns.update({scorer['name']+"_"+k: v for k, v in scores.items()})
107 | timings[scorer["name"]] = time.time()-T
108 | T = time.time()
109 |
110 | scorer_returns['total_scores'] = total_scores
111 | return scorer_returns, timings
112 |
113 | def logsum_score(scorers, paragraphs, generateds, partial=False, printing=False, extras={}):
114 | total_scores = np.zeros((len(paragraphs)))
115 | scorer_returns, timings = {}, {}
116 | T = time.time()
117 |
118 | for scorer in scorers:
119 | scores = scorer['model'].score(paragraphs, generateds, partial=partial, printing=printing, **extras)
120 | weight = scorer.get("weight", 1.0)
121 | scores["scores"] = np.clip(scores["scores"], 0.0001, 0.9999)
122 | if scorer['sign'] == 1:
123 | total_scores += weight*np.log(np.array(scores['scores']))
124 | else: # It's a binary penalty
125 | total_scores += np.log(1-np.array(scores["scores"]))
126 |
127 | scorer_returns.update({scorer['name']+"_"+k: v for k, v in scores.items()})
128 | timings[scorer["name"]] = time.time()-T
129 | T = time.time()
130 |
131 | scorer_returns['total_scores'] = total_scores
132 | return scorer_returns, timings
133 |
--------------------------------------------------------------------------------
/summac_conv_vitc_sent_perc_e.bin:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tingofurro/summac/c1f3da93cd074c24d8033eb27a88b5a7cc5c08fa/summac_conv_vitc_sent_perc_e.bin
--------------------------------------------------------------------------------