├── Images
├── Readme.md
├── RDD-1.png
├── Components.png
├── SparkSQL-1.png
├── Spark ecosystem.png
└── RDD_dependency_graph.PNG
├── _config.yml
├── Spark-with-Python-writeup
└── Readme.md
├── Data
├── chinook.db
├── chinook.zip
├── ContainsNull.csv
├── people.json
├── sqlite_latest.jar
└── sales_info.csv
├── Python-and-Spark-for-Big-Data-master
├── Spark_DataFrames
│ ├── ContainsNull.csv
│ ├── people.json
│ ├── sales_info.csv
│ └── Missing_Data.ipynb
├── Course_Notes.zip
├── Spark_for_Machine_Learning
│ ├── Clustering
│ │ ├── sample_kmeans_data.txt
│ │ ├── Clustering_Consulting_Project.ipynb
│ │ ├── Clustering_Code_Example.ipynb
│ │ ├── Clustering Code Along.ipynb
│ │ ├── seeds_dataset.csv
│ │ └── seeds_dataset.txt
│ ├── Natural_Language_Processing
│ │ └── smsspamcollection
│ │ │ └── readme
│ ├── Linear_Regression
│ │ ├── fake_customers.csv
│ │ ├── Linear_Regression_Consulting_Project.ipynb
│ │ ├── cruise_ship_info.csv
│ │ └── Data_Transformations.ipynb
│ ├── Logistic_Regression
│ │ ├── new_customers.csv
│ │ ├── Logistic_Regression_Consulting_Project.ipynb
│ │ ├── Titanic_Log_Regression_Code_Along.ipynb
│ │ └── Logistic_Regression_Example.ipynb
│ └── Tree_Methods
│ │ ├── Tree_Methods_Consulting_Project.ipynb
│ │ ├── dog_food.csv
│ │ └── Tree_Methods_Consulting_Project_SOLUTION.ipynb
├── Data Set Generator (remove me the future!)
│ ├── DataSets
│ │ ├── Facebook_metrics.txt
│ │ └── dog_food.csv
│ ├── new_customers.csv
│ └── fake_customers.csv
├── Spark Streaming
│ └── TweetRead.py
├── README.md
└── Python-Crash-Course
│ ├── Python Crash Course Exercises.ipynb
│ └── Python Crash Course Exercises - Solutions.ipynb
├── LICENSE
├── .gitignore
├── Key-Value RDD basics.ipynb
├── RDD_Chaining_Execution.ipynb
├── Partioning and Gloming.ipynb
├── README.md
├── SparkContext_Workers_Lazy_Evaluations.ipynb
└── Row_column_objects.ipynb
/Images/Readme.md:
--------------------------------------------------------------------------------
1 | ## Images
2 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-slate
--------------------------------------------------------------------------------
/Spark-with-Python-writeup/Readme.md:
--------------------------------------------------------------------------------
1 | ## Spark with Python writeup
2 |
--------------------------------------------------------------------------------
/Data/chinook.db:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Data/chinook.db
--------------------------------------------------------------------------------
/Data/chinook.zip:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Data/chinook.zip
--------------------------------------------------------------------------------
/Images/RDD-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Images/RDD-1.png
--------------------------------------------------------------------------------
/Data/ContainsNull.csv:
--------------------------------------------------------------------------------
1 | Id,Name,Sales
2 | emp1,John,
3 | emp2,,
4 | emp3,,345.0
5 | emp4,Cindy,456.0
6 |
--------------------------------------------------------------------------------
/Data/people.json:
--------------------------------------------------------------------------------
1 | {"name":"Michael"}
2 | {"name":"Andy", "age":30}
3 | {"name":"Justin", "age":19}
4 |
--------------------------------------------------------------------------------
/Images/Components.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Images/Components.png
--------------------------------------------------------------------------------
/Images/SparkSQL-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Images/SparkSQL-1.png
--------------------------------------------------------------------------------
/Data/sqlite_latest.jar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Data/sqlite_latest.jar
--------------------------------------------------------------------------------
/Images/Spark ecosystem.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Images/Spark ecosystem.png
--------------------------------------------------------------------------------
/Images/RDD_dependency_graph.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Images/RDD_dependency_graph.PNG
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_DataFrames/ContainsNull.csv:
--------------------------------------------------------------------------------
1 | Id,Name,Sales
2 | emp1,John,
3 | emp2,,
4 | emp3,,345.0
5 | emp4,Cindy,456.0
6 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_DataFrames/people.json:
--------------------------------------------------------------------------------
1 | {"name":"Michael"}
2 | {"name":"Andy", "age":30}
3 | {"name":"Justin", "age":19}
4 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Course_Notes.zip:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Python-and-Spark-for-Big-Data-master/Course_Notes.zip
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Clustering/sample_kmeans_data.txt:
--------------------------------------------------------------------------------
1 | 0 1:0.0 2:0.0 3:0.0
2 | 1 1:0.1 2:0.1 3:0.1
3 | 2 1:0.2 2:0.2 3:0.2
4 | 3 1:9.0 2:9.0 3:9.0
5 | 4 1:9.1 2:9.1 3:9.1
6 | 5 1:9.2 2:9.2 3:9.2
7 |
--------------------------------------------------------------------------------
/Data/sales_info.csv:
--------------------------------------------------------------------------------
1 | Company,Person,Sales
2 | GOOG,Sam,200
3 | GOOG,Charlie,120
4 | GOOG,Frank,340
5 | MSFT,Tina,600
6 | MSFT,Amy,124
7 | MSFT,Vanessa,243
8 | FB,Carl,870
9 | FB,Sarah,350
10 | APPL,John,250
11 | APPL,Linda, 130
12 | APPL,Mike, 750
13 | APPL, Chris, 350
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Data Set Generator (remove me the future!)/DataSets/Facebook_metrics.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Python-and-Spark-for-Big-Data-master/Data Set Generator (remove me the future!)/DataSets/Facebook_metrics.txt
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Natural_Language_Processing/smsspamcollection/readme:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tirthajyoti/Spark-with-Python/HEAD/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Natural_Language_Processing/smsspamcollection/readme
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_DataFrames/sales_info.csv:
--------------------------------------------------------------------------------
1 | Company,Person,Sales
2 | GOOG,Sam,200
3 | GOOG,Charlie,120
4 | GOOG,Frank,340
5 | MSFT,Tina,600
6 | MSFT,Amy,124
7 | MSFT,Vanessa,243
8 | FB,Carl,870
9 | FB,Sarah,350
10 | APPL,John,250
11 | APPL,Linda, 130
12 | APPL,Mike, 750
13 | APPL, Chris, 350
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Linear_Regression/fake_customers.csv:
--------------------------------------------------------------------------------
1 | Name,Phone,Group
2 | John,4085552424,A
3 | Mike,3105552738,B
4 | Cassie,4085552424,B
5 | Laura,3105552438,B
6 | Sarah,4085551234,A
7 | David,3105557463,C
8 | Zach,4085553987,C
9 | Kiera,3105552938,A
10 | Alexa,4085559467,C
11 | Karissa,3105553475,A
12 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Logistic_Regression/new_customers.csv:
--------------------------------------------------------------------------------
1 | Names,Age,Total_Purchase,Account_Manager,Years,Num_Sites,Onboard_date,Location,Company
2 | Andrew Mccall,37.0,9935.53,1,7.71,8.0,2011-08-29 18:37:54,"38612 Johnny Stravenue Nataliebury, WI 15717-8316",King Ltd,
3 | Michele Wright,23.0,7526.94,1,9.28,15.0,2013-07-22 18:19:54,"21083 Nicole Junction Suite 332, Youngport, ME 23686-4381",Cannon-Benson
4 | Jeremy Chang,65.0,100.0,1,1.0,15.0,2006-12-11 07:48:13,"085 Austin Views Lake Julialand, WY 63726-4298",Barron-Robertson
5 | Megan Ferguson,32.0,6487.5,0,9.4,14.0,2016-10-28 05:32:13,"922 Wright Branch North Cynthialand, NC 64721",Sexton-Golden
6 | Taylor Young,32.0,13147.71,1,10.0,8.0,2012-03-20 00:36:46,"Unit 0789 Box 0734 DPO AP 39702",Wood LLC,
7 | Jessica Drake,22.0,8445.26,1,3.46,14.0,2011-02-04 19:29:27,"1148 Tina Stravenue Apt. 978 South Carlos TX 21222 9221",Parks-Robbins
8 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Data Set Generator (remove me the future!)/new_customers.csv:
--------------------------------------------------------------------------------
1 | Names,Age,Total_Purchase,Account_Manager,Years,Num_Sites,Onboard_date,Location,Company
2 | Andrew Mccall,37.0,9935.53,1,7.71,8.0,2011-08-29 18:37:54,"38612 Johnny Stravenue
3 | Nataliebury, WI 15717-8316",King Ltd,
4 | Michele Wright,23.0,7526.94,1,9.28,15.0,2013-07-22 18:19:54,"21083 Nicole Junction Suite 332
5 | Youngport, ME 23686-4381",Cannon-Benson
6 | Jeremy Chang,65.0,100.0,1,1.0,15.0,2006-12-11 07:48:13,"085 Austin Views
7 | Lake Julialand, WY 63726-4298",Barron-Robertson
8 | Megan Ferguson,32.0,6487.5,0,9.4,14.0,2016-10-28 05:32:13,"922 Wright Branch
9 | North Cynthialand, NC 64721",Sexton-Golden
10 | Taylor Young,32.0,13147.71,1,10.0,8.0,2012-03-20 00:36:46,"Unit 0789 Box 0734
11 | DPO AP 39702",Wood LLC,
12 | Jessica Drake,22.0,8445.26,1,3.46,14.0,2011-02-04 19:29:27,"1148 Tina Stravenue Apt. 978
13 | South Carlos, TX 21222-9221",Parks-Robbins,
14 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2018 Tirthajyoti Sarkar
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark Streaming/TweetRead.py:
--------------------------------------------------------------------------------
1 | import tweepy
2 | from tweepy import OAuthHandler
3 | from tweepy import Stream
4 | from tweepy.streaming import StreamListener
5 | import socket
6 | import json
7 |
8 |
9 | # Set up your credentials
10 | consumer_key=''
11 | consumer_secret=''
12 | access_token =''
13 | access_secret=''
14 |
15 |
16 | class TweetsListener(StreamListener):
17 |
18 | def __init__(self, csocket):
19 | self.client_socket = csocket
20 |
21 | def on_data(self, data):
22 | try:
23 | msg = json.loads( data )
24 | print( msg['text'].encode('utf-8') )
25 | self.client_socket.send( msg['text'].encode('utf-8') )
26 | return True
27 | except BaseException as e:
28 | print("Error on_data: %s" % str(e))
29 | return True
30 |
31 | def on_error(self, status):
32 | print(status)
33 | return True
34 |
35 | def sendData(c_socket):
36 | auth = OAuthHandler(consumer_key, consumer_secret)
37 | auth.set_access_token(access_token, access_secret)
38 |
39 | twitter_stream = Stream(auth, TweetsListener(c_socket))
40 | twitter_stream.filter(track=['soccer'])
41 |
42 | if __name__ == "__main__":
43 | s = socket.socket() # Create a socket object
44 | host = "127.0.0.1" # Get local machine name
45 | port = 5555 # Reserve a port for your service.
46 | s.bind((host, port)) # Bind to the port
47 |
48 | print("Listening on port: %s" % str(port))
49 |
50 | s.listen(5) # Now wait for client connection.
51 | c, addr = s.accept() # Establish connection with client.
52 |
53 | print( "Received request from: " + str( addr ) )
54 |
55 | sendData( c )
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | *.egg-info/
24 | .installed.cfg
25 | *.egg
26 | MANIFEST
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 | .pytest_cache/
49 |
50 | # Translations
51 | *.mo
52 | *.pot
53 |
54 | # Django stuff:
55 | *.log
56 | local_settings.py
57 | db.sqlite3
58 |
59 | # Flask stuff:
60 | instance/
61 | .webassets-cache
62 |
63 | # Scrapy stuff:
64 | .scrapy
65 |
66 | # Sphinx documentation
67 | docs/_build/
68 |
69 | # PyBuilder
70 | target/
71 |
72 | # Jupyter Notebook
73 | .ipynb_checkpoints
74 |
75 | # pyenv
76 | .python-version
77 |
78 | # celery beat schedule file
79 | celerybeat-schedule
80 |
81 | # SageMath parsed files
82 | *.sage.py
83 |
84 | # Environments
85 | .env
86 | .venv
87 | env/
88 | venv/
89 | ENV/
90 | env.bak/
91 | venv.bak/
92 |
93 | # Spyder project settings
94 | .spyderproject
95 | .spyproject
96 |
97 | # Rope project settings
98 | .ropeproject
99 |
100 | # mkdocs documentation
101 | /site
102 |
103 | # mypy
104 | .mypy_cache/
105 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Data Set Generator (remove me the future!)/fake_customers.csv:
--------------------------------------------------------------------------------
1 | Names,Age,Phone,Location,Company,Lot,Sales
2 | Chelsea Taylor,46.0,1-431-660-1615x8629,"064 Stone Neck Apt. 766
3 | East Debrabury, FM 63246",Bentley-Waller,07 bz,0
4 | Pamela Williams,38.0,(101)883-0724x491,"5182 Emily Spurs
5 | West Lindsey, PA 79975",Gomez Group,21 cB,0
6 | Kristi Sandoval,41.0,+99(4)3518374928,"367 Nelson Gardens Apt. 209
7 | Ochoaview, MT 25437","Thomas, Brown and Stewart",25 to,0
8 | Ashley Morris,45.0,939-770-5901x336,"66532 Harris Loop
9 | West Susan, PR 68272-6257","Banks, Mendez and Reyes",46 rn,0
10 | Dwayne Nguyen,48.0,468-328-7711,"418 Martin Mall
11 | New John, MN 64235",Phelps-Bentley,97 lr,0
12 | Benjamin Nelson,43.0,257.443.9817x9922,"Unit 2069 Box 9542
13 | DPO AA 81875-0608",Madden-Murphy,76 YB,0
14 | Tanya Mcdonald,40.0,985.525.6864x365,"PSC 1888, Box 7629
15 | APO AE 68066-4189",Morgan-Wilson,74 HU,0
16 | Ashley Mullins,34.0,231-482-7034x4744,"9819 Flores Orchard Apt. 954
17 | Markchester, NE 71752-6833","Hall, Romero and Marshall",75 Ty,0
18 | David Hutchinson,39.0,932.142.2276,"Unit 8564 Box 6806
19 | DPO AE 41715",Hanna Ltd,84 Ho,0
20 | Kayla Arnold,31.0,550.464.0343x938,"9296 Matthew Oval Apt. 429
21 | Thomasborough, NJ 22056-5974",Bradley-Schwartz,74 lz,0
22 | Nathan Castaneda,37.0,498.517.0898x258,"02452 Dawn Tunnel Apt. 012
23 | Rodriguezmouth, MA 80967-6806",Young and Sons,51 AM,0
24 | Keith Nelson,46.0,1-434-023-4677,"6309 Dustin Heights
25 | Joseville, UT 00298-1977",Rodriguez Ltd,32 yr,0
26 | Kathleen Weaver,22.0,920-001-7389,"822 Smith Lodge Apt. 921
27 | Tonichester, KY 49154","Key, Johnson and Hunt",72 Uv,0
28 | Kevin Thomas,37.0,(536)901-0070x33732,"Unit 8732 Box 8363
29 | DPO AA 80979-6530",Patterson-Burton,69 mk,0
30 | Seth Lutz,38.0,1-689-306-8881x37712,"510 Michael Field
31 | East Kimberly, DE 21409",Kelley Inc,29 Ts,0
32 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Tree_Methods/Tree_Methods_Consulting_Project.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Tree Methods Consulting Project "
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "You've been hired by a dog food company to try to predict why some batches of their dog food are spoiling much quicker than intended! Unfortunately this Dog Food company hasn't upgraded to the latest machinery, meaning that the amounts of the five preservative chemicals they are using can vary a lot, but which is the chemical that has the strongest effect? The dog food company first mixes up a batch of preservative that contains 4 different preservative chemicals (A,B,C,D) and then is completed with a \"filler\" chemical. The food scientists beelive one of the A,B,C, or D preservatives is causing the problem, but need your help to figure out which one!\n",
15 | "Use Machine Learning with RF to find out which parameter had the most predicitive power, thus finding out which chemical causes the early spoiling! So create a model and then find out how you can decide which chemical is the problem!\n",
16 | "\n",
17 | "* Pres_A : Percentage of preservative A in the mix\n",
18 | "* Pres_B : Percentage of preservative B in the mix\n",
19 | "* Pres_C : Percentage of preservative C in the mix\n",
20 | "* Pres_D : Percentage of preservative D in the mix\n",
21 | "* Spoiled: Label indicating whether or not the dog food batch was spoiled.\n",
22 | "___\n",
23 | "\n",
24 | "**Think carefully about what this problem is really asking you to solve. While we will use Machine Learning to solve this, it won't be with your typical train/test split workflow. If this confuses you, skip ahead to the solution code along walk-through!**\n",
25 | "____"
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {},
31 | "source": [
32 | "# Good Luck!"
33 | ]
34 | }
35 | ],
36 | "metadata": {
37 | "anaconda-cloud": {},
38 | "kernelspec": {
39 | "display_name": "Python [conda root]",
40 | "language": "python",
41 | "name": "conda-root-py"
42 | },
43 | "language_info": {
44 | "codemirror_mode": {
45 | "name": "ipython",
46 | "version": 3
47 | },
48 | "file_extension": ".py",
49 | "mimetype": "text/x-python",
50 | "name": "python",
51 | "nbconvert_exporter": "python",
52 | "pygments_lexer": "ipython3",
53 | "version": "3.5.3"
54 | }
55 | },
56 | "nbformat": 4,
57 | "nbformat_minor": 0
58 | }
59 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/README.md:
--------------------------------------------------------------------------------
1 | # Python-and-Spark-for-Big-Data
2 | Course Notebooks for Python and Spark for Big Data
3 |
4 | Course Outline:
5 |
6 | * Course Introduction
7 | * Promo/Intro Video
8 | * Course Curriculum Overview
9 | * Introduction to Spark, RDDs, and Spark 2.0
10 |
11 | * Course Set-up
12 | * Set-up Overview
13 | * EC2 Installation Guide
14 | * Local Installation Guide with VirtualBox
15 | * Databricks Notebooks
16 | * Unix Command Line Basics and Jupyter Notebook Overview
17 |
18 | * Spark DataFrames
19 | * Spark DataFrames Section Introduction
20 | * Spark DataFrame Basics
21 | * Spark DataFrame Operations
22 | * Groupby and Aggregate Functions
23 | * Missing Data
24 | * Dates and Timestamps
25 |
26 | * Spark DataFrame Project
27 | * DataFrame Project Exercise
28 | * DataFrame Project Exercise Solutions
29 |
30 | * Machine Learning
31 | * Introduction to Machine Learning and ISLR
32 | * Machine Learning with Spark and Python and MLlib
33 | * Consulting Project Approach Overview
34 |
35 | * Linear Regression
36 | * Introduction to Linear Regression
37 | * Discussion on Data Transformations
38 | * Linear Regression with PySpark Example (Car Data)
39 | * Linear Regression Consulting Project (Housing Data)
40 | * Linear Regression Consulting Project Solution
41 |
42 | * Logistic Regression
43 | * Introduction to Logisitic Regression
44 | * Logistic Regression Example
45 | * Logistic Regression Consulting Project (Customer Churn)
46 | * Logistic Regression Consluting Project Solution
47 |
48 | * Tree Methods
49 | * Introduction to Tree Methods
50 | * Decision Tree and Random Forest Example
51 | * Random Forest Classification Consulting Project - Dog Food Data
52 | * RF Classification Consulting Project Solutions
53 | * RF Regression Project - (Facebook Data)
54 |
55 | * Clustering
56 | * Introduction to K-means Clustering
57 | * Clustering Example - Iris Dataset
58 | * Clustering Consulting Project - Customer Segmentation (Fake Data)
59 | * Clustering Consulting Project Solutions
60 |
61 | * Recommender System
62 | * Introduction to Recommender Systems and Collaborative Filtering
63 | * Code Along Project - MovieLens Dataset
64 | * Possible Consulting Project ? Company Service Reviews
65 |
66 | * Natural Language Processing
67 | * Introduction to Project/NLP/Naive Bayes Model
68 | * What are pipelines?
69 | * Code Along
70 |
71 | * Spark Streaming
72 | * Introduction to Spark Streaming
73 | * Spark Streaming Code-along!
74 |
75 |
76 |
77 |
78 |
79 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Logistic_Regression/Logistic_Regression_Consulting_Project.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Logistic Regression Consulting Project"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {
13 | "collapsed": true
14 | },
15 | "source": [
16 | "## Binary Customer Churn\n",
17 | "\n",
18 | "A marketing agency has many customers that use their service to produce ads for the client/customer websites. They've noticed that they have quite a bit of churn in clients. They basically randomly assign account managers right now, but want you to create a machine learning model that will help predict which customers will churn (stop buying their service) so that they can correctly assign the customers most at risk to churn an account manager. Luckily they have some historical data, can you help them out? Create a classification algorithm that will help classify whether or not a customer churned. Then the company can test this against incoming data for future customers to predict which customers will churn and assign them an account manager.\n",
19 | "\n",
20 | "The data is saved as customer_churn.csv. Here are the fields and their definitions:\n",
21 | "\n",
22 | " Name : Name of the latest contact at Company\n",
23 | " Age: Customer Age\n",
24 | " Total_Purchase: Total Ads Purchased\n",
25 | " Account_Manager: Binary 0=No manager, 1= Account manager assigned\n",
26 | " Years: Totaly Years as a customer\n",
27 | " Num_sites: Number of websites that use the service.\n",
28 | " Onboard_date: Date that the name of the latest contact was onboarded\n",
29 | " Location: Client HQ Address\n",
30 | " Company: Name of Client Company\n",
31 | " \n",
32 | "Once you've created the model and evaluated it, test out the model on some new data (you can think of this almost like a hold-out set) that your client has provided, saved under new_customers.csv. The client wants to know which customers are most likely to churn given this data (they don't have the label yet)."
33 | ]
34 | }
35 | ],
36 | "metadata": {
37 | "anaconda-cloud": {},
38 | "kernelspec": {
39 | "display_name": "Python [conda root]",
40 | "language": "python",
41 | "name": "conda-root-py"
42 | },
43 | "language_info": {
44 | "codemirror_mode": {
45 | "name": "ipython",
46 | "version": 3
47 | },
48 | "file_extension": ".py",
49 | "mimetype": "text/x-python",
50 | "name": "python",
51 | "nbconvert_exporter": "python",
52 | "pygments_lexer": "ipython3",
53 | "version": "3.5.3"
54 | }
55 | },
56 | "nbformat": 4,
57 | "nbformat_minor": 0
58 | }
59 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Clustering/Clustering_Consulting_Project.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Clustering Consulting Project \n",
8 | "\n",
9 | "A large technology firm needs your help, they've been hacked! Luckily their forensic engineers have grabbed valuable data about the hacks, including information like session time,locations, wpm typing speed, etc. The forensic engineer relates to you what she has been able to figure out so far, she has been able to grab meta data of each session that the hackers used to connect to their servers. These are the features of the data:\n",
10 | "\n",
11 | "* 'Session_Connection_Time': How long the session lasted in minutes\n",
12 | "* 'Bytes Transferred': Number of MB transferred during session\n",
13 | "* 'Kali_Trace_Used': Indicates if the hacker was using Kali Linux\n",
14 | "* 'Servers_Corrupted': Number of server corrupted during the attack\n",
15 | "* 'Pages_Corrupted': Number of pages illegally accessed\n",
16 | "* 'Location': Location attack came from (Probably useless because the hackers used VPNs)\n",
17 | "* 'WPM_Typing_Speed': Their estimated typing speed based on session logs.\n",
18 | "\n",
19 | "\n",
20 | "The technology firm has 3 potential hackers that perpetrated the attack. Their certain of the first two hackers but they aren't very sure if the third hacker was involved or not. They have requested your help! Can you help figure out whether or not the third suspect had anything to do with the attacks, or was it just two hackers? It's probably not possible to know for sure, but maybe what you've just learned about Clustering can help!\n",
21 | "\n",
22 | "**One last key fact, the forensic engineer knows that the hackers trade off attacks. Meaning they should each have roughly the same amount of attacks. For example if there were 100 total attacks, then in a 2 hacker situation each should have about 50 hacks, in a three hacker situation each would have about 33 hacks. The engineer believes this is the key element to solving this, but doesn't know how to distinguish this unlabeled data into groups of hackers.**"
23 | ]
24 | }
25 | ],
26 | "metadata": {
27 | "anaconda-cloud": {},
28 | "kernelspec": {
29 | "display_name": "Python [conda root]",
30 | "language": "python",
31 | "name": "conda-root-py"
32 | },
33 | "language_info": {
34 | "codemirror_mode": {
35 | "name": "ipython",
36 | "version": 3
37 | },
38 | "file_extension": ".py",
39 | "mimetype": "text/x-python",
40 | "name": "python",
41 | "nbconvert_exporter": "python",
42 | "pygments_lexer": "ipython3",
43 | "version": "3.5.3"
44 | }
45 | },
46 | "nbformat": 4,
47 | "nbformat_minor": 0
48 | }
49 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Linear_Regression/Linear_Regression_Consulting_Project.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Linear Regression Consulting Project"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {
13 | "collapsed": true
14 | },
15 | "source": [
16 | "Congratulations! You've been contracted by Hyundai Heavy Industries to help them build a predictive model for some ships. [Hyundai Heavy Industries](http://www.hyundai.eu/en) is one of the world's largest ship manufacturing companies and builds cruise liners.\n",
17 | "\n",
18 | "You've been flown to their headquarters in Ulsan, South Korea to help them give accurate estimates of how many crew members a ship will require.\n",
19 | "\n",
20 | "They are currently building new ships for some customers and want you to create a model and use it to predict how many crew members the ships will need.\n",
21 | "\n",
22 | "Here is what the data looks like so far:\n",
23 | "\n",
24 | " Description: Measurements of ship size, capacity, crew, and age for 158 cruise\n",
25 | " ships.\n",
26 | "\n",
27 | "\n",
28 | " Variables/Columns\n",
29 | " Ship Name 1-20\n",
30 | " Cruise Line 21-40\n",
31 | " Age (as of 2013) 46-48\n",
32 | " Tonnage (1000s of tons) 50-56\n",
33 | " passengers (100s) 58-64\n",
34 | " Length (100s of feet) 66-72\n",
35 | " Cabins (100s) 74-80\n",
36 | " Passenger Density 82-88\n",
37 | " Crew (100s) 90-96\n",
38 | " \n",
39 | "It is saved in a csv file for you called \"cruise_ship_info.csv\". Your job is to create a regression model that will help predict how many crew members will be needed for future ships. The client also mentioned that they have found that particular cruise lines will differ in acceptable crew counts, so it is most likely an important feature to include in your analysis! \n",
40 | "\n",
41 | "Once you've created the model and tested it for a quick check on how well you can expect it to perform, make sure you take a look at why it performs so well!"
42 | ]
43 | }
44 | ],
45 | "metadata": {
46 | "anaconda-cloud": {},
47 | "kernelspec": {
48 | "display_name": "Python [conda root]",
49 | "language": "python",
50 | "name": "conda-root-py"
51 | },
52 | "language_info": {
53 | "codemirror_mode": {
54 | "name": "ipython",
55 | "version": 3
56 | },
57 | "file_extension": ".py",
58 | "mimetype": "text/x-python",
59 | "name": "python",
60 | "nbconvert_exporter": "python",
61 | "pygments_lexer": "ipython3",
62 | "version": "3.5.3"
63 | }
64 | },
65 | "nbformat": 4,
66 | "nbformat_minor": 0
67 | }
68 |
--------------------------------------------------------------------------------
/Key-Value RDD basics.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "### Import libraries"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from pyspark import SparkContext\n",
17 | "import numpy as np"
18 | ]
19 | },
20 | {
21 | "cell_type": "markdown",
22 | "metadata": {},
23 | "source": [
24 | "### Initialize a `SparkContext` (main abstraction to the cluster) object"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": 2,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "sc=SparkContext(\"local[4]\")"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "### Create two random lists, zip them up, and initialize a `RDD` with the zipped list"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 6,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "a=np.random.randint(1,10,12)\n",
50 | "b=np.random.randint(1,10,12)"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 22,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "c=list(zip(a,b))"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 23,
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "kv_rdd=sc.parallelize(c)"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 24,
74 | "metadata": {},
75 | "outputs": [
76 | {
77 | "data": {
78 | "text/plain": [
79 | "[(6, 5),\n",
80 | " (2, 9),\n",
81 | " (4, 1),\n",
82 | " (3, 2),\n",
83 | " (4, 4),\n",
84 | " (5, 7),\n",
85 | " (4, 5),\n",
86 | " (1, 3),\n",
87 | " (3, 9),\n",
88 | " (9, 4),\n",
89 | " (2, 6),\n",
90 | " (4, 1)]"
91 | ]
92 | },
93 | "execution_count": 24,
94 | "metadata": {},
95 | "output_type": "execute_result"
96 | }
97 | ],
98 | "source": [
99 | "kv_rdd.collect()"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "### `Lookup` values corresponding to a key"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 26,
112 | "metadata": {},
113 | "outputs": [
114 | {
115 | "data": {
116 | "text/plain": [
117 | "[1, 4, 5, 1]"
118 | ]
119 | },
120 | "execution_count": 26,
121 | "metadata": {},
122 | "output_type": "execute_result"
123 | }
124 | ],
125 | "source": [
126 | "kv_rdd.lookup(4)"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": null,
132 | "metadata": {},
133 | "outputs": [],
134 | "source": []
135 | }
136 | ],
137 | "metadata": {
138 | "kernelspec": {
139 | "display_name": "Python 3",
140 | "language": "python",
141 | "name": "python3"
142 | },
143 | "language_info": {
144 | "codemirror_mode": {
145 | "name": "ipython",
146 | "version": 3
147 | },
148 | "file_extension": ".py",
149 | "mimetype": "text/x-python",
150 | "name": "python",
151 | "nbconvert_exporter": "python",
152 | "pygments_lexer": "ipython3",
153 | "version": "3.6.6"
154 | }
155 | },
156 | "nbformat": 4,
157 | "nbformat_minor": 2
158 | }
159 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Clustering/Clustering_Code_Example.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Clustering Documentation Example\n",
8 | "\n",
9 | "K-means
\n",
10 | "\n",
11 | "k-means is one of the\n",
12 | "most commonly used clustering algorithms that clusters the data points into a\n",
13 | "predefined number of clusters. The MLlib implementation includes a parallelized\n",
14 | "variant of the k-means++ method\n",
15 | "called kmeans||.
\n",
16 | "\n",
17 | "KMeans is implemented as an Estimator and generates a KMeansModel as the base model.
\n",
18 | "\n",
19 | "\n",
20 | "\n",
21 | "\n",
22 | " \n",
23 | " \n",
24 | " | Param name | \n",
25 | " Type(s) | \n",
26 | " Default | \n",
27 | " Description | \n",
28 | "
\n",
29 | " \n",
30 | " \n",
31 | " \n",
32 | " | featuresCol | \n",
33 | " Vector | \n",
34 | " \"features\" | \n",
35 | " Feature vector | \n",
36 | "
\n",
37 | " \n",
38 | "
\n",
39 | "\n",
40 | "Output Columns
\n",
41 | "\n",
42 | "\n",
43 | " \n",
44 | " \n",
45 | " | Param name | \n",
46 | " Type(s) | \n",
47 | " Default | \n",
48 | " Description | \n",
49 | "
\n",
50 | " \n",
51 | " \n",
52 | " \n",
53 | " | predictionCol | \n",
54 | " Int | \n",
55 | " \"prediction\" | \n",
56 | " Predicted cluster center | \n",
57 | "
\n",
58 | " \n",
59 | "
"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 2,
65 | "metadata": {
66 | "collapsed": true
67 | },
68 | "outputs": [],
69 | "source": [
70 | "#Cluster methods Example\n",
71 | "from pyspark.sql import SparkSession\n",
72 | "spark = SparkSession.builder.appName('cluster').getOrCreate()"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 3,
78 | "metadata": {
79 | "collapsed": false
80 | },
81 | "outputs": [
82 | {
83 | "name": "stdout",
84 | "output_type": "stream",
85 | "text": [
86 | "Within Set Sum of Squared Errors = 0.11999999999994547\n",
87 | "Cluster Centers: \n",
88 | "[ 9.1 9.1 9.1]\n",
89 | "[ 0.1 0.1 0.1]\n"
90 | ]
91 | }
92 | ],
93 | "source": [
94 | "from pyspark.ml.clustering import KMeans\n",
95 | "\n",
96 | "# Loads data.\n",
97 | "dataset = spark.read.format(\"libsvm\").load(\"sample_kmeans_data.txt\")\n",
98 | "\n",
99 | "# Trains a k-means model.\n",
100 | "kmeans = KMeans().setK(2).setSeed(1)\n",
101 | "model = kmeans.fit(dataset)\n",
102 | "\n",
103 | "# Evaluate clustering by computing Within Set Sum of Squared Errors.\n",
104 | "wssse = model.computeCost(dataset)\n",
105 | "print(\"Within Set Sum of Squared Errors = \" + str(wssse))\n",
106 | "\n",
107 | "# Shows the result.\n",
108 | "centers = model.clusterCenters()\n",
109 | "print(\"Cluster Centers: \")\n",
110 | "for center in centers:\n",
111 | " print(center)"
112 | ]
113 | },
114 | {
115 | "cell_type": "markdown",
116 | "metadata": {},
117 | "source": [
118 | "Alright let's code through our own example!"
119 | ]
120 | }
121 | ],
122 | "metadata": {
123 | "anaconda-cloud": {},
124 | "kernelspec": {
125 | "display_name": "Python [conda root]",
126 | "language": "python",
127 | "name": "conda-root-py"
128 | },
129 | "language_info": {
130 | "codemirror_mode": {
131 | "name": "ipython",
132 | "version": 3
133 | },
134 | "file_extension": ".py",
135 | "mimetype": "text/x-python",
136 | "name": "python",
137 | "nbconvert_exporter": "python",
138 | "pygments_lexer": "ipython3",
139 | "version": "3.5.3"
140 | }
141 | },
142 | "nbformat": 4,
143 | "nbformat_minor": 0
144 | }
145 |
--------------------------------------------------------------------------------
/RDD_Chaining_Execution.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Chaining\n",
8 | "We can **chain** transformations and aaction to create a computation **pipeline**\n",
9 | "Suppose we want to compute the sum of the squares\n",
10 | "$$ \\sum_{i=1}^n x_i^2 $$\n",
11 | "where the elements $x_i$ are stored in an RDD."
12 | ]
13 | },
14 | {
15 | "cell_type": "markdown",
16 | "metadata": {},
17 | "source": [
18 | "### Start the `SparkContext`"
19 | ]
20 | },
21 | {
22 | "cell_type": "code",
23 | "execution_count": 1,
24 | "metadata": {},
25 | "outputs": [],
26 | "source": [
27 | "import numpy as np\n",
28 | "from pyspark import SparkContext\n",
29 | "sc = SparkContext(master=\"local[4]\")"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 2,
35 | "metadata": {},
36 | "outputs": [
37 | {
38 | "name": "stdout",
39 | "output_type": "stream",
40 | "text": [
41 | "7, 6, 4, 7, 9, 0, 3, 7, 6, 2, 7, 7, 1, 5, 3, 0, 3, 9, 2, 4, 4, 9, 5, 8, 9, 8, 3, 9, 3, 5, 1, 1, 9, 9, 0, 0, 5, 9, 2, 1, 1, 6, 9, 6, 3, 0, 4, 1, 3, 4, 1, 6, 3, 9, 1, 3, 7, 7, 1, 3, 3, 8, 6, 5, 5, 8, 3, 0, 6, 2, 7, 7, 7, 2, 0, 3, 7, 4, 4, 4, 7, 1, 9, 2, 7, 8, 8, 4, 7, 1, 9, 9, 9, 6, 5, 2, 7, 7, 3, 3, 0, 0, 9, 9, 7, 3, 6, 5, 1, 5, 9, 4, 8, 3, 2, 6, 7, 4, 8, 6, 8, 7, 5, 2, 5, 5, 9, 0, 6, 4, 7, 8, 2, 6, 6, 0, 7, 7, 1, 7, 6, 0, 8, 8, 1, 8, 0, 3, 9, 1, 1, 8, 4, 6, 0, 1, 4, 8, 0, 0, 6, 4, 4, 4, 8, 4, 1, 0, 0, 1, 5, 1, 1, 6, 6, 4, 7, 8, 2, 1, 6, 6, 1, 7, 9, 0, 3, 9, 3, 6, 7, 1, 5, 2, 3, 9, 1, 0, 9, 6, 3, 7, 9, 4, 2, 0, 5, 0, 8, 2, 8, 5, 8, 8, 1, 0, 3, 9, 2, 3, 6, 0, 0, 7, 6, 6, 5, 4, 2, 4, 8, 0, 4, 2, 6, 7, 8, 5, 9, 7, 0, 2, 0, 6, 1, 0, 0, 6, 3, 9, 1, 8, 7, 9, 5, 9, 0, 2, 9, 3, 7, 3, 3, 4, 8, 3, 5, 6, 5, 4, 4, 3, 9, 0, 0, 4, 1, 9, 9, 7, 9, 7, 0, 9, 8, 2, 6, 1, 4, 3, 3, 7, 8, 1, 1, 9, 1, 8, 4, 1, 3, 0, 3, 3, 1, 2, 2, 5, 9, 9, 1, 9, 4, 1, 4, 7, 8, 5, 8, 3, 9, 4, 6, 0, 5, 3, 6, 1, 6, 3, 8, 7, 3, 9, 0, 5, 9, 8, 5, 0, 7, 2, 8, 7, 6, 5, 2, 9, 3, 5, 6, 3, 4, 9, 3, 4, 3, 9, 9, 0, 5, 0, 2, 5, 7, 6, 7, 6, 7, 7, 6, 6, 0, 3, 5, 3, 7, 5, 9, 6, 3, 9, 2, 5, 1, 5, 7, 0, 5, 8, 5, 9, 0, 8, 0, 2, 5, 5, 1, 2, 9, 3, 1, 7, 2, 2, 6, 2, 9, 4, 0, 7, 9, 8, 9, 4, 2, 0, 7, 5, 5, 4, 2, 4, 8, 0, 3, 8, 0, 2, 3, 8, 5, 1, 5, 9, 4, 6, 8, 5, 8, 4, 0, 0, 0, 6, 1, 1, 8, 8, 5, 9, 0, 5, 9, 2, 8, 9, 4, 2, 4, 6, 2, 2, 6, 4, 4, 8, 1, 9, 6, 0, 7, 0, 5, 9, 1, 0, 6, 1, 6, 8, 7, 1, 8, 4, 8, 7, 1, 0, 8, 4, 8, 1, 9, 9, 1, 5, 4, 6, 7, 4, 4, 0, 1, 3, 0, 0, 1, 8, 8, 4, 5, 5, 4, 4, 8, 2, 0, 5, 1, 8, 5, 2, 0, 9, 8, 8, 7, 1, 0, 8, 6, 8, 3, 3, 6, 7, 6, 6, 6, 6, 9, 8, 6, 8, 5, 8, 6, 9, 2, 1, 0, 6, 8, 7, 6, 5, 8, 3, 3, 4, 3, 7, 9, 3, 8, 7, 8, 7, 5, 0, 3, 4, 7, 6, 5, 8, 9, 9, 5, 4, 0, 8, 4, 7, 5, 8, 7, 1, 4, 2, 6, 5, 8, 5, 7, 9, 8, 6, 0, 0, 8, 6, 1, 0, 0, 6, 4, 6, 1, 7, 7, 9, 0, 8, 7, 8, 0, 8, 8, 6, 3, 3, 8, 7, 3, 2, 1, 7, 7, 5, 7, 8, 3, 1, 7, 2, 7, 8, 5, 6, 3, 7, 8, 0, 6, 8, 7, 7, 3, 7, 0, 7, 7, 8, 5, 6, 4, 2, 0, 8, 7, 6, 3, 2, 3, 9, 4, 2, 3, 1, 1, 0, 1, 9, 3, 2, 6, 4, 8, 7, 0, 4, 2, 1, 2, 5, 4, 8, 6, 2, 2, 7, 7, 8, 6, 8, 2, 8, 9, 4, 7, 2, 1, 5, 5, 1, 9, 2, 1, 1, 4, 2, 2, 1, 6, 8, 2, 4, 2, 3, 7, 8, 9, 8, 6, 1, 1, 1, 9, 3, 6, 8, 2, 1, 2, 4, 1, 9, 4, 9, 6, 1, 0, 0, 1, 3, 8, 1, 3, 9, 8, 9, 5, 4, 9, 1, 6, 6, 3, 1, 2, 7, 5, 4, 7, 7, 4, 7, 1, 0, 0, 3, 4, 5, 4, 4, 5, 4, 1, 5, 2, 8, 1, 8, 0, 0, 2, 5, 5, 2, 2, 0, 3, 4, 3, 6, 0, 2, 6, 7, 7, 6, 7, 9, 6, 3, 6, 2, 4, 5, 0, 6, 7, 6, 4, 6, 5, 1, 1, 6, 9, 7, 6, 7, 6, 5, 2, 2, 7, 3, 7, 7, 2, 7, 1, 1, 2, 1, 9, 3, 8, 4, 5, 1, 7, 0, 3, 6, 5, 1, 2, 1, 8, 8, 0, 7, 2, 4, 6, 6, 8, 0, 5, 4, 6, 4, 2, 3, 2, 2, 8, 5, 2, 8, 2, 8, 2, 2, 4, 0, 4, 2, 9, 7, 9, 1, 2, 0, 4, 4, 9, 6, 3, 5, 3, 7, 1, 2, 6, 0, 7, 8, 7, 8, 1, 6, 9, 4, 1, 5, 5, 9, 3, 6, 9, 5, 1, 7, 3, 0, 8, 7, 5, 5, 2, 4, 2, 0, 9, 6, 0, 1, 5, 9, 2, 7, 1, 8, 3, 2, 9, 8, 6, 9, 4, 5, 0, 0, 5, 7, 0, 7, 0, 9, 1, 4, 7, 1, 7, 8, 6, 3, 8, 1, 1, 1, 7, 1, 6, 4, 3, 7, 7, 4, 1, 0, 5, 2, 1, 8, 4, 7, 2, 8, 1, 4, 6, 8, 8, 5, 2, 6, 2, 9, 7, 1, 6, 2, "
42 | ]
43 | }
44 | ],
45 | "source": [
46 | "B=sc.parallelize(np.random.randint(0,10,size=1000))\n",
47 | "lst = B.collect()\n",
48 | "for i in lst: \n",
49 | " print(i,end=', ')"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "### Sequential syntax for chaining\n",
57 | "Perform assignment after each computation"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 3,
63 | "metadata": {},
64 | "outputs": [
65 | {
66 | "name": "stdout",
67 | "output_type": "stream",
68 | "text": [
69 | "CPU times: user 15.2 ms, sys: 11.9 ms, total: 27.1 ms\n",
70 | "Wall time: 1.01 s\n"
71 | ]
72 | }
73 | ],
74 | "source": [
75 | "%%time\n",
76 | "Squares=B.map(lambda x:x*x)\n",
77 | "summation = Squares.reduce(lambda x,y:x+y)"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 5,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "name": "stdout",
87 | "output_type": "stream",
88 | "text": [
89 | "29395\n"
90 | ]
91 | }
92 | ],
93 | "source": [
94 | "print(summation)"
95 | ]
96 | },
97 | {
98 | "cell_type": "markdown",
99 | "metadata": {},
100 | "source": [
101 | "### Cascaded syntax for chaining\n",
102 | "Combine computations into a single cascaded command"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 6,
108 | "metadata": {},
109 | "outputs": [
110 | {
111 | "name": "stdout",
112 | "output_type": "stream",
113 | "text": [
114 | "CPU times: user 13.9 ms, sys: 13 ms, total: 26.9 ms\n",
115 | "Wall time: 304 ms\n"
116 | ]
117 | },
118 | {
119 | "data": {
120 | "text/plain": [
121 | "29395"
122 | ]
123 | },
124 | "execution_count": 6,
125 | "metadata": {},
126 | "output_type": "execute_result"
127 | }
128 | ],
129 | "source": [
130 | "%%time\n",
131 | "B.map(lambda x:x*x).reduce(lambda x,y:x+y)"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "### Both syntaxes mean exactly the same thing\n",
139 | "The only difference:\n",
140 | "* In the sequential syntax the intermediate RDD has a name `Squares`\n",
141 | "* In the cascaded syntax the intermediate RDD is *anonymous*\n",
142 | "\n",
143 | "The execution is identical!\n",
144 | "\n",
145 | "### Sequential execution\n",
146 | "The standard way that the map and reduce are executed is\n",
147 | "* perform the map\n",
148 | "* store the resulting RDD in memory\n",
149 | "* perform the reduce\n",
150 | "\n",
151 | "### Disadvantages of Sequential execution\n",
152 | "\n",
153 | "1. Intermediate result (`Squares`) requires memory space.\n",
154 | "2. Two scans of memory (of `B`, then of `Squares`) - double the cache-misses.\n",
155 | "\n",
156 | "### Pipelined execution\n",
157 | "Perform the whole computation in a single pass. For each element of **`B`**\n",
158 | "1. Compute the square\n",
159 | "2. Enter the square as input to the `reduce` operation.\n",
160 | "\n",
161 | "### Advantages of Pipelined execution\n",
162 | "\n",
163 | "1. Less memory required - intermediate result is not stored.\n",
164 | "2. Faster - only one pass through the Input RDD."
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": 7,
170 | "metadata": {},
171 | "outputs": [],
172 | "source": [
173 | "sc.stop()"
174 | ]
175 | }
176 | ],
177 | "metadata": {
178 | "kernelspec": {
179 | "display_name": "Python 3",
180 | "language": "python",
181 | "name": "python3"
182 | },
183 | "language_info": {
184 | "codemirror_mode": {
185 | "name": "ipython",
186 | "version": 3
187 | },
188 | "file_extension": ".py",
189 | "mimetype": "text/x-python",
190 | "name": "python",
191 | "nbconvert_exporter": "python",
192 | "pygments_lexer": "ipython3",
193 | "version": "3.6.6"
194 | }
195 | },
196 | "nbformat": 4,
197 | "nbformat_minor": 2
198 | }
199 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Data Set Generator (remove me the future!)/DataSets/dog_food.csv:
--------------------------------------------------------------------------------
1 | A,B,C,D,Spoiled
2 | 4,2,12.0,3,1
3 | 5,6,12.0,7,1
4 | 6,2,13.0,6,1
5 | 4,2,12.0,1,1
6 | 4,2,12.0,3,1
7 | 10,3,13.0,9,1
8 | 8,5,14.0,5,1
9 | 5,8,12.0,8,1
10 | 6,5,12.0,9,1
11 | 3,3,12.0,1,1
12 | 9,8,11.0,3,1
13 | 1,10,12.0,3,1
14 | 1,5,13.0,10,1
15 | 2,10,12.0,6,1
16 | 1,10,11.0,4,1
17 | 5,3,12.0,2,1
18 | 4,9,11.0,8,1
19 | 5,1,11.0,1,1
20 | 4,9,12.0,10,1
21 | 5,8,10.0,9,1
22 | 5,7,11.0,9,1
23 | 4,10,13.0,8,1
24 | 10,5,12.0,9,1
25 | 2,4,13.0,4,1
26 | 1,4,13.0,10,1
27 | 1,8,12.0,1,1
28 | 2,10,13.0,4,1
29 | 6,2,12.0,4,1
30 | 8,2,13.0,3,1
31 | 6,4,12.0,2,1
32 | 3,2,11.0,9,1
33 | 10,6,12.0,10,1
34 | 9,5,13.0,3,1
35 | 9,2,12.0,5,1
36 | 2,6,13.0,9,1
37 | 4,2,12.0,10,1
38 | 4,3,12.0,6,1
39 | 7,1,12.0,1,1
40 | 1,7,11.0,10,1
41 | 9,2,11.0,10,1
42 | 2,6,12.0,2,1
43 | 9,4,11.0,5,1
44 | 6,2,11.0,10,1
45 | 3,10,11.0,4,1
46 | 6,9,11.0,2,1
47 | 10,6,11.0,9,1
48 | 6,7,11.0,9,1
49 | 7,2,13.0,8,1
50 | 9,2,13.0,5,1
51 | 8,7,12.0,6,1
52 | 9,1,12.0,9,1
53 | 3,5,14.0,3,1
54 | 7,1,11.0,3,1
55 | 5,9,12.0,7,1
56 | 3,10,12.0,7,1
57 | 9,8,13.0,9,1
58 | 10,9,12.0,9,1
59 | 10,7,11.0,2,1
60 | 10,3,11.0,1,1
61 | 2,4,11.0,8,1
62 | 10,3,13.0,4,1
63 | 5,1,14.0,8,1
64 | 8,8,11.0,4,1
65 | 4,8,14.0,1,1
66 | 5,1,12.0,7,1
67 | 6,8,11.0,2,1
68 | 1,1,13.0,3,1
69 | 9,3,12.0,10,1
70 | 6,1,11.0,7,1
71 | 7,5,10.0,1,1
72 | 10,2,12.0,2,1
73 | 2,3,13.0,1,1
74 | 5,8,12.0,2,1
75 | 10,6,12.0,10,1
76 | 9,1,11.0,6,1
77 | 10,10,14.0,7,1
78 | 1,5,12.0,10,1
79 | 10,1,11.0,2,1
80 | 1,1,12.0,2,1
81 | 10,3,13.0,7,1
82 | 1,6,11.0,10,1
83 | 9,4,12.0,3,1
84 | 10,9,12.0,5,1
85 | 10,8,11.0,2,1
86 | 5,3,9.0,2,1
87 | 3,7,12.0,10,1
88 | 4,9,12.0,8,1
89 | 5,1,11.0,2,1
90 | 10,9,11.0,9,1
91 | 10,7,11.0,6,1
92 | 8,2,13.0,10,1
93 | 7,7,11.0,3,1
94 | 9,10,11.0,5,1
95 | 5,2,12.0,8,1
96 | 1,1,10.0,8,1
97 | 5,5,12.0,8,1
98 | 9,6,12.0,1,1
99 | 4,6,12.0,2,1
100 | 1,1,12.0,4,1
101 | 9,3,11.0,10,1
102 | 3,2,12.0,6,1
103 | 2,4,11.0,9,1
104 | 8,1,12.0,10,1
105 | 10,6,11.0,6,1
106 | 8,9,12.0,2,1
107 | 2,3,12.0,3,1
108 | 4,6,14.0,4,1
109 | 3,4,12.0,4,1
110 | 9,5,12.0,5,1
111 | 10,5,13.0,2,1
112 | 8,2,10.0,6,1
113 | 10,5,11.0,2,1
114 | 10,1,11.0,3,1
115 | 7,6,13.0,3,1
116 | 8,9,14.0,4,1
117 | 8,8,14.0,7,1
118 | 1,9,11.0,10,1
119 | 2,9,10.0,3,1
120 | 4,9,13.0,4,1
121 | 10,10,12.0,7,1
122 | 8,9,12.0,7,1
123 | 9,7,12.0,1,1
124 | 3,6,13.0,5,1
125 | 4,5,12.0,3,1
126 | 1,7,11.0,9,1
127 | 4,6,12.0,9,1
128 | 8,10,13.0,3,1
129 | 5,4,12.0,5,1
130 | 9,4,12.0,6,1
131 | 3,4,12.0,5,1
132 | 7,7,11.0,4,1
133 | 6,2,12.0,6,1
134 | 2,8,11.0,1,1
135 | 4,4,10.0,3,1
136 | 3,7,12.0,9,1
137 | 10,3,12.0,7,1
138 | 3,1,12.0,7,1
139 | 2,4,13.0,10,1
140 | 6,3,12.0,2,1
141 | 7,2,14.0,4,1
142 | 4,2,8.0,9,0
143 | 4,8,9.0,1,0
144 | 10,8,8.0,6,0
145 | 8,6,9.0,4,0
146 | 7,2,7.0,8,0
147 | 3,3,9.0,5,0
148 | 4,10,8.0,9,0
149 | 4,7,10.0,7,0
150 | 1,7,8.0,2,0
151 | 10,7,8.0,5,0
152 | 10,5,9.0,1,0
153 | 5,7,10.0,10,0
154 | 2,8,6.0,9,0
155 | 4,1,7.0,5,0
156 | 4,6,9.0,7,0
157 | 2,2,9.0,8,0
158 | 6,7,6.0,9,0
159 | 5,7,7.0,2,0
160 | 7,1,7.0,5,0
161 | 8,1,8.0,3,0
162 | 1,6,8.0,1,0
163 | 4,5,9.0,8,0
164 | 8,10,8.0,3,0
165 | 4,9,8.0,2,0
166 | 2,9,6.0,4,0
167 | 8,10,8.0,9,0
168 | 3,6,8.0,1,0
169 | 5,6,9.0,8,0
170 | 5,2,8.0,10,0
171 | 9,7,6.0,7,0
172 | 3,8,6.0,10,0
173 | 3,3,8.0,9,0
174 | 3,4,10.0,2,0
175 | 6,8,8.0,9,0
176 | 1,4,8.0,7,0
177 | 6,9,7.0,10,0
178 | 10,6,8.0,6,0
179 | 9,4,7.0,10,0
180 | 9,2,10.0,3,0
181 | 6,8,8.0,6,0
182 | 10,5,7.0,4,0
183 | 4,8,8.0,7,0
184 | 5,6,6.0,9,0
185 | 2,1,10.0,7,0
186 | 6,4,7.0,4,0
187 | 6,8,9.0,4,0
188 | 3,3,8.0,3,0
189 | 3,5,10.0,6,0
190 | 3,3,9.0,9,0
191 | 7,7,8.0,9,0
192 | 6,8,7.0,10,0
193 | 7,3,7.0,7,0
194 | 5,7,9.0,2,0
195 | 4,9,8.0,10,0
196 | 9,9,7.0,4,0
197 | 6,9,6.0,1,0
198 | 4,2,10.0,10,0
199 | 8,10,8.0,3,0
200 | 1,7,8.0,4,0
201 | 3,2,9.0,1,0
202 | 9,9,9.0,6,0
203 | 4,10,5.0,4,0
204 | 9,3,7.0,5,0
205 | 9,1,9.0,3,0
206 | 4,6,7.0,2,0
207 | 4,5,8.0,5,0
208 | 5,7,6.0,6,0
209 | 10,6,9.0,3,0
210 | 6,6,8.0,10,0
211 | 3,7,9.0,7,0
212 | 8,10,8.0,2,0
213 | 5,2,8.0,3,0
214 | 5,7,7.0,5,0
215 | 10,9,8.0,2,0
216 | 4,4,8.0,7,0
217 | 1,4,9.0,6,0
218 | 8,2,9.0,10,0
219 | 9,6,9.0,5,0
220 | 7,6,7.0,7,0
221 | 1,2,9.0,4,0
222 | 1,8,7.0,10,0
223 | 6,2,8.0,9,0
224 | 9,5,7.0,8,0
225 | 8,7,8.0,6,0
226 | 5,7,8.0,9,0
227 | 8,4,9.0,1,0
228 | 6,1,9.0,3,0
229 | 9,7,8.0,9,0
230 | 2,9,7.0,10,0
231 | 2,4,8.0,5,0
232 | 10,3,8.0,8,0
233 | 7,9,8.0,8,0
234 | 6,6,8.0,2,0
235 | 1,5,8.0,10,0
236 | 10,1,9.0,9,0
237 | 8,1,9.0,2,0
238 | 10,9,8.0,6,0
239 | 5,10,7.0,1,0
240 | 3,6,7.0,8,0
241 | 4,10,10.0,5,0
242 | 2,1,7.0,9,0
243 | 9,2,9.0,9,0
244 | 3,9,8.0,9,0
245 | 2,3,6.0,9,0
246 | 3,9,8.0,6,0
247 | 10,7,9.0,1,0
248 | 10,10,6.0,4,0
249 | 8,5,9.0,5,0
250 | 7,2,8.0,1,0
251 | 7,2,8.0,9,0
252 | 6,9,7.0,2,0
253 | 1,4,9.0,3,0
254 | 10,9,9.0,10,0
255 | 4,3,8.0,8,0
256 | 8,7,6.0,6,0
257 | 5,7,8.0,3,0
258 | 8,6,8.0,3,0
259 | 3,2,6.0,10,0
260 | 4,2,6.0,5,0
261 | 10,6,8.0,7,0
262 | 3,6,8.0,3,0
263 | 2,2,8.0,1,0
264 | 1,9,10.0,6,0
265 | 9,6,8.0,7,0
266 | 4,5,9.0,5,0
267 | 3,5,8.0,6,0
268 | 4,5,8.0,10,0
269 | 9,4,9.0,4,0
270 | 9,4,7.0,6,0
271 | 7,6,8.0,10,0
272 | 9,10,11.0,2,0
273 | 3,4,9.0,5,0
274 | 2,10,9.0,2,0
275 | 10,9,8.0,2,0
276 | 4,6,9.0,4,0
277 | 4,10,7.0,10,0
278 | 9,1,9.0,8,0
279 | 3,10,8.0,6,0
280 | 8,5,9.0,3,0
281 | 8,5,7.0,5,0
282 | 1,8,6.0,6,0
283 | 8,8,6.0,8,0
284 | 4,8,7.0,3,0
285 | 9,3,8.0,7,0
286 | 10,8,7.0,3,0
287 | 2,10,6.0,4,0
288 | 2,5,9.0,5,0
289 | 10,7,9.0,4,0
290 | 3,10,9.0,8,0
291 | 9,2,7.0,3,0
292 | 7,4,6.0,4,0
293 | 3,4,8.0,7,0
294 | 4,7,8.0,3,0
295 | 10,9,8.0,10,0
296 | 4,6,5.0,6,0
297 | 10,2,9.0,7,0
298 | 9,8,9.0,10,0
299 | 7,10,8.0,2,0
300 | 5,5,6.0,1,0
301 | 8,4,7.0,6,0
302 | 5,5,7.0,9,0
303 | 7,2,9.0,9,0
304 | 9,4,9.0,3,0
305 | 5,5,7.0,3,0
306 | 2,7,7.0,4,0
307 | 4,5,9.0,8,0
308 | 1,8,8.0,6,0
309 | 5,6,9.0,5,0
310 | 3,6,8.0,3,0
311 | 7,2,9.0,5,0
312 | 10,9,10.0,6,0
313 | 4,7,10.0,6,0
314 | 1,9,9.0,7,0
315 | 1,7,7.0,2,0
316 | 1,9,7.0,5,0
317 | 2,8,9.0,4,0
318 | 5,4,8.0,2,0
319 | 1,7,7.0,6,0
320 | 2,1,8.0,9,0
321 | 2,6,9.0,4,0
322 | 1,6,8.0,9,0
323 | 1,4,8.0,5,0
324 | 10,6,8.0,5,0
325 | 6,4,6.0,4,0
326 | 2,1,9.0,1,0
327 | 8,6,9.0,10,0
328 | 5,6,7.0,9,0
329 | 10,10,7.0,1,0
330 | 2,9,10.0,6,0
331 | 9,6,10.0,2,0
332 | 3,5,9.0,3,0
333 | 5,10,8.0,3,0
334 | 1,3,9.0,8,0
335 | 8,8,8.0,7,0
336 | 6,1,8.0,3,0
337 | 4,9,9.0,2,0
338 | 2,9,10.0,3,0
339 | 1,5,8.0,5,0
340 | 5,6,8.0,8,0
341 | 6,10,9.0,2,0
342 | 9,6,8.0,9,0
343 | 1,8,8.0,7,0
344 | 8,2,8.0,8,0
345 | 3,6,8.0,5,0
346 | 9,2,9.0,6,0
347 | 7,10,5.0,6,0
348 | 2,5,8.0,3,0
349 | 9,2,10.0,7,0
350 | 5,9,8.0,9,0
351 | 1,6,8.0,3,0
352 | 7,4,8.0,3,0
353 | 8,5,8.0,5,0
354 | 5,9,7.0,3,0
355 | 9,6,8.0,5,0
356 | 3,1,8.0,5,0
357 | 5,8,9.0,9,0
358 | 2,5,8.0,3,0
359 | 5,6,8.0,6,0
360 | 2,5,8.0,1,0
361 | 6,2,11.0,10,0
362 | 2,6,6.0,9,0
363 | 4,4,6.0,8,0
364 | 2,7,8.0,9,0
365 | 5,2,7.0,9,0
366 | 6,10,8.0,3,0
367 | 4,6,7.0,5,0
368 | 2,8,8.0,6,0
369 | 6,2,8.0,3,0
370 | 8,10,9.0,8,0
371 | 5,9,8.0,5,0
372 | 9,2,9.0,8,0
373 | 5,10,8.0,6,0
374 | 10,6,8.0,3,0
375 | 6,6,9.0,6,0
376 | 6,3,10.0,5,0
377 | 1,3,8.0,5,0
378 | 2,3,9.0,3,0
379 | 2,6,8.0,8,0
380 | 8,4,9.0,10,0
381 | 8,7,6.0,7,0
382 | 2,6,8.0,10,0
383 | 7,2,9.0,3,0
384 | 7,9,6.0,2,0
385 | 2,10,8.0,8,0
386 | 5,2,9.0,9,0
387 | 2,8,9.0,10,0
388 | 8,4,6.0,8,0
389 | 7,3,10.0,7,0
390 | 9,9,8.0,7,0
391 | 8,4,8.0,1,0
392 | 9,2,6.0,8,0
393 | 8,6,8.0,2,0
394 | 9,7,8.0,2,0
395 | 4,3,9.0,6,0
396 | 2,1,8.0,9,0
397 | 9,4,7.0,9,0
398 | 4,2,9.0,2,0
399 | 10,3,8.0,2,0
400 | 9,2,10.0,5,0
401 | 10,7,7.0,7,0
402 | 2,3,7.0,10,0
403 | 10,1,7.0,4,0
404 | 3,3,7.0,5,0
405 | 10,1,7.0,4,0
406 | 5,4,8.0,7,0
407 | 7,3,7.0,8,0
408 | 10,9,7.0,4,0
409 | 5,7,8.0,9,0
410 | 5,9,7.0,5,0
411 | 4,6,7.0,5,0
412 | 4,2,8.0,9,0
413 | 8,3,7.0,4,0
414 | 3,5,9.0,6,0
415 | 4,3,8.0,10,0
416 | 1,6,7.0,8,0
417 | 8,5,8.0,6,0
418 | 9,10,7.0,6,0
419 | 8,9,8.0,1,0
420 | 9,10,8.0,8,0
421 | 3,10,8.0,2,0
422 | 8,10,10.0,7,0
423 | 2,1,10.0,7,0
424 | 5,10,8.0,8,0
425 | 4,9,7.0,7,0
426 | 9,3,7.0,7,0
427 | 5,7,8.0,6,0
428 | 8,7,9.0,3,0
429 | 2,2,7.0,8,0
430 | 6,6,9.0,9,0
431 | 4,2,8.0,4,0
432 | 3,9,7.0,9,0
433 | 7,9,6.0,5,0
434 | 5,3,7.0,5,0
435 | 4,4,9.0,1,0
436 | 6,9,8.0,5,0
437 | 10,10,8.0,1,0
438 | 2,6,8.0,6,0
439 | 10,10,9.0,5,0
440 | 5,9,9.0,6,0
441 | 3,2,8.0,9,0
442 | 10,10,9.0,3,0
443 | 4,7,9.0,4,0
444 | 4,4,7.0,1,0
445 | 5,8,8.0,5,0
446 | 2,3,8.0,3,0
447 | 6,4,9.0,2,0
448 | 2,9,9.0,10,0
449 | 3,6,8.0,2,0
450 | 3,2,10.0,10,0
451 | 2,2,8.0,1,0
452 | 9,6,9.0,1,0
453 | 6,5,6.0,2,0
454 | 3,6,8.0,1,0
455 | 3,3,8.0,6,0
456 | 2,10,9.0,2,0
457 | 8,9,8.0,9,0
458 | 7,4,10.0,4,0
459 | 6,6,7.0,8,0
460 | 5,3,7.0,7,0
461 | 6,7,7.0,6,0
462 | 9,1,9.0,5,0
463 | 10,9,9.0,1,0
464 | 10,4,8.0,3,0
465 | 1,2,9.0,1,0
466 | 2,1,9.0,1,0
467 | 6,1,7.0,9,0
468 | 1,5,8.0,3,0
469 | 2,8,8.0,4,0
470 | 1,8,8.0,8,0
471 | 3,1,9.0,7,0
472 | 3,9,7.0,6,0
473 | 8,1,7.0,4,0
474 | 10,4,9.0,8,0
475 | 2,5,7.0,6,0
476 | 10,6,8.0,5,0
477 | 6,1,9.0,7,0
478 | 6,10,7.0,10,0
479 | 2,10,8.0,3,0
480 | 1,4,8.0,1,0
481 | 8,9,9.0,4,0
482 | 10,10,7.0,4,0
483 | 8,3,7.0,9,0
484 | 2,2,9.0,8,0
485 | 9,5,10.0,10,0
486 | 2,2,6.0,10,0
487 | 8,3,6.0,6,0
488 | 6,4,9.0,10,0
489 | 1,3,8.0,3,0
490 | 6,6,8.0,3,0
491 | 1,9,7.0,4,0
492 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Linear_Regression/cruise_ship_info.csv:
--------------------------------------------------------------------------------
1 | Ship_name,Cruise_line,Age,Tonnage,passengers,length,cabins,passenger_density,crew
2 | Journey,Azamara,6,30.276999999999997,6.94,5.94,3.55,42.64,3.55
3 | Quest,Azamara,6,30.276999999999997,6.94,5.94,3.55,42.64,3.55
4 | Celebration,Carnival,26,47.262,14.86,7.22,7.43,31.8,6.7
5 | Conquest,Carnival,11,110.0,29.74,9.53,14.88,36.99,19.1
6 | Destiny,Carnival,17,101.353,26.42,8.92,13.21,38.36,10.0
7 | Ecstasy,Carnival,22,70.367,20.52,8.55,10.2,34.29,9.2
8 | Elation,Carnival,15,70.367,20.52,8.55,10.2,34.29,9.2
9 | Fantasy,Carnival,23,70.367,20.56,8.55,10.22,34.23,9.2
10 | Fascination,Carnival,19,70.367,20.52,8.55,10.2,34.29,9.2
11 | Freedom,Carnival,6,110.23899999999999,37.0,9.51,14.87,29.79,11.5
12 | Glory,Carnival,10,110.0,29.74,9.51,14.87,36.99,11.6
13 | Holiday,Carnival,28,46.052,14.52,7.27,7.26,31.72,6.6
14 | Imagination,Carnival,18,70.367,20.52,8.55,10.2,34.29,9.2
15 | Inspiration,Carnival,17,70.367,20.52,8.55,10.2,34.29,9.2
16 | Legend,Carnival,11,86.0,21.24,9.63,10.62,40.49,9.3
17 | Liberty*,Carnival,8,110.0,29.74,9.51,14.87,36.99,11.6
18 | Miracle,Carnival,9,88.5,21.24,9.63,10.62,41.67,10.3
19 | Paradise,Carnival,15,70.367,20.52,8.55,10.2,34.29,9.2
20 | Pride,Carnival,12,88.5,21.24,9.63,11.62,41.67,9.3
21 | Sensation,Carnival,20,70.367,20.52,8.55,10.2,34.29,9.2
22 | Spirit,Carnival,12,88.5,21.24,9.63,10.56,41.67,10.29
23 | Triumph,Carnival,14,101.509,27.58,8.93,13.21,36.81,10.0
24 | Valor,Carnival,9,110.0,29.74,9.52,14.87,36.99,11.6
25 | Victory,Carnival,13,101.509,27.58,8.93,13.79,36.81,11.5
26 | Century,Celebrity,18,70.60600000000001,17.7,8.15,8.75,39.89,8.58
27 | Constellation,Celebrity,11,91.0,20.32,9.65,9.75,44.78,9.99
28 | Galaxy,Celebrity,17,77.71300000000001,18.9,8.66,9.35,41.12,9.09
29 | Infinity,Celebrity,12,91.0,20.32,9.65,9.75,44.78,9.99
30 | Mercury,Celebrity,16,77.71300000000001,18.82,8.66,9.35,41.29,9.09
31 | Millenium,Celebrity,13,91.0,20.32,9.65,9.75,44.78,9.99
32 | Solstice,Celebrity,5,122.0,28.5,10.33,6.87,34.57,6.7
33 | Summit,Celebrity,12,91.0,20.32,9.65,9.75,44.78,9.99
34 | Xpedition,Celebrity,12,2.329,0.94,2.96,0.45,24.78,0.6
35 | Zenith,Celebrity,21,47.225,13.66,6.82,6.87,34.57,6.7
36 | Allegra,Costa,21,28.43,8.08,6.16,4.1,35.19,4.0
37 | Atlantica,Costa,13,85.619,21.14,9.57,10.56,40.5,9.2
38 | Classica,Costa,22,52.926,13.02,7.18,6.54,40.65,6.17
39 | Europa,Costa,27,53.872,14.94,7.98,7.67,36.06,6.36
40 | Fortuna,Costa,10,105.0,27.2,8.9,13.56,38.6,10.68
41 | Magica,Costa,9,105.0,27.2,8.9,13.56,38.6,10.68
42 | Marina,Costa,23,25.0,7.76,6.22,3.86,32.22,3.85
43 | Mediterranea,Costa,10,86.0,21.14,9.6,10.56,40.68,9.2
44 | Romantica,Costa,20,53.049,13.44,7.22,6.78,39.47,6.0
45 | Serena,Costa,6,112.0,38.0,9.51,15.0,29.47,10.9
46 | Victoria,Costa,17,75.166,19.28,8.28,9.64,38.99,7.66
47 | Serenity,Crystal,10,68.0,10.8,7.9,5.5,62.96,6.36
48 | Symphony,Crystal,18,51.004,9.4,7.81,4.8,54.26,5.45
49 | QueenElizabethII,Cunard,44,70.327,17.91,9.63,9.5,39.27,9.21
50 | QueenMary2,Cunard,10,151.4,26.2,11.32,11.34,57.79,12.53
51 | QueenVictoria,Cunard,6,90.0,20.0,9.64,10.29,45.0,9.0
52 | Magic,Disney,15,83.338,17.5,9.64,8.75,47.62,9.45
53 | Wonder,Disney,14,83.0,17.5,9.64,8.75,47.43,9.45
54 | Amsterdam,Holland_American,13,61.0,13.8,7.8,6.88,44.2,6.0
55 | Eurodam,Holland_American,5,86.0,21.04,9.36,10.22,40.87,8.0
56 | Maasdam,Holland_American,20,55.451,12.64,7.19,6.32,43.87,5.57
57 | Noordam,Holland_American,29,33.92,12.14,7.04,6.07,27.94,5.3
58 | Oosterdam,Holland_American,10,81.76899999999999,18.48,9.59,9.24,44.25,8.42
59 | Prinsendam,Holland_American,25,38.0,7.49,6.74,3.96,50.73,4.6
60 | Rotterdam,Holland_American,16,59.652,13.2,7.77,6.6,45.19,6.44
61 | Ryndam,Holland_American,19,55.451,12.66,7.19,6.33,43.8,5.88
62 | Statendam,Holland_American,20,55.451,12.66,7.19,6.33,43.8,5.88
63 | Veendam,Holland_American,17,55.451,12.66,7.19,6.33,43.8,5.88
64 | Volendam,Holland_American,14,63.0,14.4,7.77,7.2,43.75,5.61
65 | Westerdam,Holland_American,27,53.872,14.94,7.98,7.47,36.06,6.12
66 | Zaandam,Holland_American,13,63.0,14.4,7.77,7.2,43.75,5.31
67 | Zuiderdam,Holland_American,11,85.0,18.48,9.51,9.24,46.0,8.0
68 | Armonia,MSC,12,58.6,15.66,8.24,7.83,37.42,7.0
69 | Fantasia,MSC,5,133.5,39.59,10.93,16.37,33.72,13.13
70 | Lirica,MSC,10,58.825,15.6,8.23,7.65,37.71,7.0
71 | Melody,MSC,31,35.143,12.5,6.69,5.32,28.11,5.35
72 | Musica,MSC,7,89.6,25.5,9.61,12.75,35.14,9.87
73 | Opera,MSC,9,59.058,17.0,7.63,8.5,34.74,7.4
74 | Rhapsody,MSC,36,16.852,9.52,5.41,3.83,17.7,2.97
75 | Sinfonia,MSC,11,58.6,15.66,8.23,7.83,37.42,7.6
76 | Crown,Norwegian,25,34.25,10.52,6.15,5.26,32.56,4.7
77 | Dawn,Norwegian,11,90.0,22.4,9.65,11.2,40.18,11.0
78 | Dream,Norwegian,21,50.76,17.48,7.54,8.74,29.04,6.14
79 | Gem,Norwegian,6,93.0,23.94,9.65,11.97,38.85,11.09
80 | Jewel,Norwegian,8,91.0,22.44,9.65,11.22,40.55,11.0
81 | Majesty,Norwegian,21,38.0,10.56,5.67,5.28,35.98,4.38
82 | PrideofAloha,Norwegian,14,77.104,20.02,8.53,10.01,38.51,8.0
83 | PrideofAmerica,Norwegian,9,81.0,21.44,9.21,10.72,37.78,10.0
84 | Sea,Norwegian,25,42.0,15.04,7.08,7.52,27.93,6.3
85 | Spirit,Norwegian,15,75.33800000000001,19.56,8.79,9.83,38.52,13.0
86 | Star,Norwegian,40,28.0,11.5,6.74,4.0,24.35,3.8
87 | Sun,Norwegian,12,77.104,20.02,8.53,10.01,38.51,9.59
88 | Wind,Norwegian,20,50.76,17.48,7.54,8.74,29.04,6.14
89 | Insignia,Oceania,15,30.276999999999997,6.84,5.94,3.42,44.26,4.0
90 | Nautica,Oceania,13,30.276999999999997,6.84,5.94,3.42,44.26,4.0
91 | Regatta,Oceania,15,30.276999999999997,6.84,5.94,3.42,44.26,4.0
92 | MarcoPolo,Orient,48,22.08,8.26,5.78,4.25,26.73,3.5
93 | Arcadia,P&O,9,85.0,19.68,9.35,9.84,43.19,8.69
94 | Artemis,P&O,29,45.0,11.78,7.54,5.3,38.2,5.2
95 | Aurora,P&O,13,76.0,18.74,8.86,9.39,40.55,8.5
96 | Oceana,P&O,10,77.0,20.16,8.56,9.75,38.19,9.0
97 | Oriana,P&O,18,69.153,18.82,8.53,9.14,36.74,7.94
98 | Ventura,P&O,5,115.0,35.74,9.0,15.32,32.18,12.2
99 | Caribbean,Princess,9,116.0,26.0,9.51,13.0,44.62,11.0
100 | Coral,Princess,11,91.62700000000001,19.74,9.64,9.87,46.42,9.0
101 | Crown,Princess,7,116.0,31.0,9.51,15.57,37.42,12.0
102 | Dawn,Princess,16,77.499,19.5,8.56,10.5,39.74,9.0
103 | Diamond,Princess,9,113.0,26.74,9.51,13.37,42.26,12.38
104 | Emerald,Princess,6,113.0,37.82,9.51,15.57,29.88,12.0
105 | Golden,Princess,12,108.865,27.58,9.51,13.0,39.47,11.0
106 | Grand,Princess,15,108.806,26.0,9.51,13.0,41.85,11.1
107 | Island,Princess,10,91.62700000000001,19.74,9.64,9.87,46.42,9.0
108 | Pacific,Princess,14,30.276999999999997,6.86,5.93,3.44,44.14,3.73
109 | Regal,Princess,22,69.845,15.9,8.03,7.95,43.93,6.96
110 | Royal,Princess,29,44.348,12.0,7.54,6.0,36.96,5.2
111 | Saphire,Princess,9,113.0,26.74,9.51,13.37,42.26,12.38
112 | Sea,Princess,8,77.499,19.5,8.56,9.75,39.74,9.0
113 | Star,Princess,11,108.977,26.02,9.51,13.01,41.88,12.0
114 | Sun,Princess,18,77.499,19.5,8.56,9.75,39.74,9.0
115 | Tahitian,Princess,14,30.276999999999997,6.88,5.93,3.44,44.01,3.73
116 | ExplorerII,Regent_Seven_Seas,27,12.5,3.94,4.36,0.88,31.73,1.46
117 | Mariner,Regent_Seven_Seas,12,50.0,7.0,7.09,3.54,71.43,4.45
118 | Navigator,Regent_Seven_Seas,14,33.0,4.9,5.6,2.45,67.35,3.24
119 | PaulGauguin,Regent_Seven_Seas,16,19.2,3.2,5.13,1.6,60.0,2.11
120 | Voyager,Regent_Seven_Seas,10,46.0,7.0,6.7,1.82,65.71,4.47
121 | Adventure,Royal_Caribbean,12,138.0,31.14,10.2,15.57,44.32,11.85
122 | Brilliance,Royal_Caribbean,11,90.09,25.01,9.62,10.5,36.02,8.48
123 | Empress,Royal_Caribbean,23,48.563,20.2,6.92,8.0,24.04,6.71
124 | Enchantment,Royal_Caribbean,16,74.137,19.5,9.16,9.75,38.02,7.6
125 | Explorer,Royal_Caribbean,13,138.0,31.14,10.2,15.57,44.32,11.76
126 | Freedom,Royal_Caribbean,7,158.0,43.7,11.12,18.0,36.16,13.6
127 | Grandeur,Royal_Caribbean,17,74.137,19.5,9.16,9.75,38.02,7.6
128 | Independence,Royal_Caribbean,5,160.0,36.34,11.12,18.17,44.03,13.6
129 | Jewel,Royal_Caribbean,9,90.09,25.01,9.62,10.94,36.02,8.69
130 | Legend,Royal_Caribbean,18,70.0,18.0,8.67,9.0,38.89,7.2
131 | Liberty,Royal_Caribbean,6,158.0,43.7,11.25,18.0,36.16,13.6
132 | Majesty,Royal_Caribbean,21,73.941,27.44,8.8,11.75,26.95,8.22
133 | Mariner,Royal_Caribbean,10,138.0,31.14,10.2,15.57,44.32,11.85
134 | Monarch,Royal_Caribbean,22,73.941,27.44,8.8,11.77,30.94,8.22
135 | Navigator,Royal_Caribbean,11,138.0,31.14,10.2,15.57,44.32,11.85
136 | Oasis,Royal_Caribbean,4,220.0,54.0,11.82,27.0,40.74,21.0
137 | Radiance,Royal_Caribbean,12,90.09,25.01,9.62,10.5,36.02,8.68
138 | Rhapsody,Royal_Caribbean,16,78.491,24.35,9.15,10.0,32.23,7.65
139 | Serenade,Royal_Caribbean,10,90.09,25.01,9.62,10.5,36.02,8.58
140 | Sovreign,Royal_Caribbean,25,73.192,28.52,8.8,11.38,25.66,8.08
141 | Splendour,Royal_Caribbean,17,70.0,20.76,8.67,9.02,33.72,7.2
142 | Vision,Royal_Caribbean,15,78.491,24.35,9.15,10.0,32.23,6.6
143 | Voyager,Royal_Caribbean,14,138.0,31.14,10.2,15.57,44.32,11.76
144 | Legend,Seabourn,21,10.0,2.08,4.4,1.04,48.08,1.6
145 | Pride,Seabourn,27,10.0,2.08,4.4,1.04,48.08,1.6
146 | Spirit,Seabourn,24,10.0,2.08,4.4,1.04,48.08,1.6
147 | Cloud,Silversea,19,16.8,2.96,5.14,1.48,56.76,2.1
148 | Shadow,Silversea,13,25.0,3.82,5.97,1.94,65.45,2.95
149 | Whisper,Silversea,12,25.0,3.88,5.97,1.94,64.43,2.87
150 | Wind,Silversea,19,16.8,2.96,5.14,1.48,56.76,1.97
151 | Aries,Star,22,3.341,0.66,2.8,0.33,50.62,0.59
152 | Gemini,Star,21,19.093,8.0,5.37,4.0,23.87,4.7
153 | Libra,Star,12,42.0,14.8,7.13,7.4,28.38,6.8
154 | Pisces,Star,24,40.053000000000004,12.87,5.79,7.76,31.12,7.5
155 | Taurus,Star,22,3.341,0.66,2.79,0.33,50.62,0.59
156 | Virgo,Star,14,76.8,19.6,8.79,9.67,39.18,12.0
157 | Spirit,Windstar,25,5.35,1.58,4.4,0.74,33.86,0.88
158 | Star,Windstar,27,5.35,1.67,4.4,0.74,32.04,0.88
159 | Surf,Windstar,23,14.745,3.08,6.17,1.56,47.87,1.8
160 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Linear_Regression/Data_Transformations.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Data Transformations\n",
8 | "\n",
9 | "You won't always get data in a convienent format, often you will have to deal with data that is non-numerical, such as customer names, or zipcodes, country names, etc...\n",
10 | "\n",
11 | "A big part of working with data is using your own domain knowledge to build an intuition of how to deal with the data, sometimes the best course of action is to drop the data, other times feature-engineering is a good way to go, or you could try to transform the data into something the Machine Learning Algorithms will understand.\n",
12 | "\n",
13 | "Spark has several built in methods of dealing with thse transformations, check them all out here: http://spark.apache.org/docs/latest/ml-features.html\n",
14 | "\n",
15 | "Let's see some examples of all of this!"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 2,
21 | "metadata": {
22 | "collapsed": true
23 | },
24 | "outputs": [],
25 | "source": [
26 | "from pyspark.sql import SparkSession"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 3,
32 | "metadata": {
33 | "collapsed": true
34 | },
35 | "outputs": [],
36 | "source": [
37 | "spark = SparkSession.builder.appName('data').getOrCreate()"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 4,
43 | "metadata": {
44 | "collapsed": true
45 | },
46 | "outputs": [],
47 | "source": [
48 | "df = spark.read.csv('fake_customers.csv',inferSchema=True,header=True)"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 5,
54 | "metadata": {
55 | "collapsed": false
56 | },
57 | "outputs": [
58 | {
59 | "name": "stdout",
60 | "output_type": "stream",
61 | "text": [
62 | "+-------+----------+-----+\n",
63 | "| Name| Phone|Group|\n",
64 | "+-------+----------+-----+\n",
65 | "| John|4085552424| A|\n",
66 | "| Mike|3105552738| B|\n",
67 | "| Cassie|4085552424| B|\n",
68 | "| Laura|3105552438| B|\n",
69 | "| Sarah|4085551234| A|\n",
70 | "| David|3105557463| C|\n",
71 | "| Zach|4085553987| C|\n",
72 | "| Kiera|3105552938| A|\n",
73 | "| Alexa|4085559467| C|\n",
74 | "|Karissa|3105553475| A|\n",
75 | "+-------+----------+-----+\n",
76 | "\n"
77 | ]
78 | }
79 | ],
80 | "source": [
81 | "df.show()"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## Data Features\n",
89 | "\n",
90 | "### StringIndexer\n",
91 | "\n",
92 | "We often have to convert string information into numerical information as a categorical feature. This is easily done with the StringIndexer Method:"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": 6,
98 | "metadata": {
99 | "collapsed": false
100 | },
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "+-------+--------+-------------+\n",
107 | "|user_id|category|categoryIndex|\n",
108 | "+-------+--------+-------------+\n",
109 | "| 0| a| 0.0|\n",
110 | "| 1| b| 2.0|\n",
111 | "| 2| c| 1.0|\n",
112 | "| 3| a| 0.0|\n",
113 | "| 4| a| 0.0|\n",
114 | "| 5| c| 1.0|\n",
115 | "+-------+--------+-------------+\n",
116 | "\n"
117 | ]
118 | }
119 | ],
120 | "source": [
121 | "from pyspark.ml.feature import StringIndexer\n",
122 | "\n",
123 | "df = spark.createDataFrame(\n",
124 | " [(0, \"a\"), (1, \"b\"), (2, \"c\"), (3, \"a\"), (4, \"a\"), (5, \"c\")],\n",
125 | " [\"user_id\", \"category\"])\n",
126 | "\n",
127 | "indexer = StringIndexer(inputCol=\"category\", outputCol=\"categoryIndex\")\n",
128 | "indexed = indexer.fit(df).transform(df)\n",
129 | "indexed.show()"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "The next step would be to encode these categories into \"dummy\" variables."
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": null,
142 | "metadata": {
143 | "collapsed": true
144 | },
145 | "outputs": [],
146 | "source": []
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "### VectorIndexer\n",
153 | "\n",
154 | "VectorAssembler is a transformer that combines a given list of columns into a single vector column. It is useful for combining raw features and features generated by different feature transformers into a single feature vector, in order to train ML models like logistic regression and decision trees. VectorAssembler accepts the following input column types: all numeric types, boolean type, and vector type. In each row, the values of the input columns will be concatenated into a vector in the specified order. \n",
155 | "\n",
156 | "Assume that we have a DataFrame with the columns id, hour, mobile, userFeatures, and clicked:\n",
157 | "\n",
158 | " id | hour | mobile | userFeatures | clicked\n",
159 | " ----|------|--------|------------------|---------\n",
160 | " 0 | 18 | 1.0 | [0.0, 10.0, 0.5] | 1.0\n",
161 | " \n",
162 | "userFeatures is a vector column that contains three user features. We want to combine hour, mobile, and userFeatures into a single feature vector called features and use it to predict clicked or not. If we set VectorAssembler’s input columns to hour, mobile, and userFeatures and output column to features, after transformation we should get the following DataFrame:\n",
163 | "\n",
164 | " id | hour | mobile | userFeatures | clicked | features\n",
165 | " ----|------|--------|------------------|---------|-----------------------------\n",
166 | " 0 | 18 | 1.0 | [0.0, 10.0, 0.5] | 1.0 | [18.0, 1.0, 0.0, 10.0, 0.5]"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 14,
172 | "metadata": {
173 | "collapsed": false
174 | },
175 | "outputs": [
176 | {
177 | "name": "stdout",
178 | "output_type": "stream",
179 | "text": [
180 | "+---+----+------+--------------+-------+\n",
181 | "| id|hour|mobile| userFeatures|clicked|\n",
182 | "+---+----+------+--------------+-------+\n",
183 | "| 0| 18| 1.0|[0.0,10.0,0.5]| 1.0|\n",
184 | "+---+----+------+--------------+-------+\n",
185 | "\n"
186 | ]
187 | }
188 | ],
189 | "source": [
190 | "from pyspark.ml.linalg import Vectors\n",
191 | "from pyspark.ml.feature import VectorAssembler\n",
192 | "\n",
193 | "dataset = spark.createDataFrame(\n",
194 | " [(0, 18, 1.0, Vectors.dense([0.0, 10.0, 0.5]), 1.0)],\n",
195 | " [\"id\", \"hour\", \"mobile\", \"userFeatures\", \"clicked\"])\n",
196 | "dataset.show()"
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": 15,
202 | "metadata": {
203 | "collapsed": false
204 | },
205 | "outputs": [
206 | {
207 | "name": "stdout",
208 | "output_type": "stream",
209 | "text": [
210 | "Assembled columns 'hour', 'mobile', 'userFeatures' to vector column 'features'\n",
211 | "+--------------------+-------+\n",
212 | "| features|clicked|\n",
213 | "+--------------------+-------+\n",
214 | "|[18.0,1.0,0.0,10....| 1.0|\n",
215 | "+--------------------+-------+\n",
216 | "\n"
217 | ]
218 | }
219 | ],
220 | "source": [
221 | "assembler = VectorAssembler(\n",
222 | " inputCols=[\"hour\", \"mobile\", \"userFeatures\"],\n",
223 | " outputCol=\"features\")\n",
224 | "\n",
225 | "output = assembler.transform(dataset)\n",
226 | "print(\"Assembled columns 'hour', 'mobile', 'userFeatures' to vector column 'features'\")\n",
227 | "output.select(\"features\", \"clicked\").show()"
228 | ]
229 | },
230 | {
231 | "cell_type": "markdown",
232 | "metadata": {},
233 | "source": [
234 | "There ar emany more data transformations available, we will cover them once we encounter a need for them, for now these were the most important ones.\n",
235 | "\n",
236 | "Let's continue on to Linear Regression!"
237 | ]
238 | },
239 | {
240 | "cell_type": "code",
241 | "execution_count": null,
242 | "metadata": {
243 | "collapsed": true
244 | },
245 | "outputs": [],
246 | "source": []
247 | }
248 | ],
249 | "metadata": {
250 | "anaconda-cloud": {},
251 | "kernelspec": {
252 | "display_name": "Python [conda root]",
253 | "language": "python",
254 | "name": "conda-root-py"
255 | },
256 | "language_info": {
257 | "codemirror_mode": {
258 | "name": "ipython",
259 | "version": 3
260 | },
261 | "file_extension": ".py",
262 | "mimetype": "text/x-python",
263 | "name": "python",
264 | "nbconvert_exporter": "python",
265 | "pygments_lexer": "ipython3",
266 | "version": "3.5.3"
267 | }
268 | },
269 | "nbformat": 4,
270 | "nbformat_minor": 0
271 | }
272 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Tree_Methods/dog_food.csv:
--------------------------------------------------------------------------------
1 | A,B,C,D,Spoiled
2 | 4,2,12.0,3,1.0
3 | 5,6,12.0,7,1.0
4 | 6,2,13.0,6,1.0
5 | 4,2,12.0,1,1.0
6 | 4,2,12.0,3,1.0
7 | 10,3,13.0,9,1.0
8 | 8,5,14.0,5,1.0
9 | 5,8,12.0,8,1.0
10 | 6,5,12.0,9,1.0
11 | 3,3,12.0,1,1.0
12 | 9,8,11.0,3,1.0
13 | 1,10,12.0,3,1.0
14 | 1,5,13.0,10,1.0
15 | 2,10,12.0,6,1.0
16 | 1,10,11.0,4,1.0
17 | 5,3,12.0,2,1.0
18 | 4,9,11.0,8,1.0
19 | 5,1,11.0,1,1.0
20 | 4,9,12.0,10,1.0
21 | 5,8,10.0,9,1.0
22 | 5,7,11.0,9,1.0
23 | 4,10,13.0,8,1.0
24 | 10,5,12.0,9,1.0
25 | 2,4,13.0,4,1.0
26 | 1,4,13.0,10,1.0
27 | 1,8,12.0,1,1.0
28 | 2,10,13.0,4,1.0
29 | 6,2,12.0,4,1.0
30 | 8,2,13.0,3,1.0
31 | 6,4,12.0,2,1.0
32 | 3,2,11.0,9,1.0
33 | 10,6,12.0,10,1.0
34 | 9,5,13.0,3,1.0
35 | 9,2,12.0,5,1.0
36 | 2,6,13.0,9,1.0
37 | 4,2,12.0,10,1.0
38 | 4,3,12.0,6,1.0
39 | 7,1,12.0,1,1.0
40 | 1,7,11.0,10,1.0
41 | 9,2,11.0,10,1.0
42 | 2,6,12.0,2,1.0
43 | 9,4,11.0,5,1.0
44 | 6,2,11.0,10,1.0
45 | 3,10,11.0,4,1.0
46 | 6,9,11.0,2,1.0
47 | 10,6,11.0,9,1.0
48 | 6,7,11.0,9,1.0
49 | 7,2,13.0,8,1.0
50 | 9,2,13.0,5,1.0
51 | 8,7,12.0,6,1.0
52 | 9,1,12.0,9,1.0
53 | 3,5,14.0,3,1.0
54 | 7,1,11.0,3,1.0
55 | 5,9,12.0,7,1.0
56 | 3,10,12.0,7,1.0
57 | 9,8,13.0,9,1.0
58 | 10,9,12.0,9,1.0
59 | 10,7,11.0,2,1.0
60 | 10,3,11.0,1,1.0
61 | 2,4,11.0,8,1.0
62 | 10,3,13.0,4,1.0
63 | 5,1,14.0,8,1.0
64 | 8,8,11.0,4,1.0
65 | 4,8,14.0,1,1.0
66 | 5,1,12.0,7,1.0
67 | 6,8,11.0,2,1.0
68 | 1,1,13.0,3,1.0
69 | 9,3,12.0,10,1.0
70 | 6,1,11.0,7,1.0
71 | 7,5,10.0,1,1.0
72 | 10,2,12.0,2,1.0
73 | 2,3,13.0,1,1.0
74 | 5,8,12.0,2,1.0
75 | 10,6,12.0,10,1.0
76 | 9,1,11.0,6,1.0
77 | 10,10,14.0,7,1.0
78 | 1,5,12.0,10,1.0
79 | 10,1,11.0,2,1.0
80 | 1,1,12.0,2,1.0
81 | 10,3,13.0,7,1.0
82 | 1,6,11.0,10,1.0
83 | 9,4,12.0,3,1.0
84 | 10,9,12.0,5,1.0
85 | 10,8,11.0,2,1.0
86 | 5,3,9.0,2,1.0
87 | 3,7,12.0,10,1.0
88 | 4,9,12.0,8,1.0
89 | 5,1,11.0,2,1.0
90 | 10,9,11.0,9,1.0
91 | 10,7,11.0,6,1.0
92 | 8,2,13.0,10,1.0
93 | 7,7,11.0,3,1.0
94 | 9,10,11.0,5,1.0
95 | 5,2,12.0,8,1.0
96 | 1,1,10.0,8,1.0
97 | 5,5,12.0,8,1.0
98 | 9,6,12.0,1,1.0
99 | 4,6,12.0,2,1.0
100 | 1,1,12.0,4,1.0
101 | 9,3,11.0,10,1.0
102 | 3,2,12.0,6,1.0
103 | 2,4,11.0,9,1.0
104 | 8,1,12.0,10,1.0
105 | 10,6,11.0,6,1.0
106 | 8,9,12.0,2,1.0
107 | 2,3,12.0,3,1.0
108 | 4,6,14.0,4,1.0
109 | 3,4,12.0,4,1.0
110 | 9,5,12.0,5,1.0
111 | 10,5,13.0,2,1.0
112 | 8,2,10.0,6,1.0
113 | 10,5,11.0,2,1.0
114 | 10,1,11.0,3,1.0
115 | 7,6,13.0,3,1.0
116 | 8,9,14.0,4,1.0
117 | 8,8,14.0,7,1.0
118 | 1,9,11.0,10,1.0
119 | 2,9,10.0,3,1.0
120 | 4,9,13.0,4,1.0
121 | 10,10,12.0,7,1.0
122 | 8,9,12.0,7,1.0
123 | 9,7,12.0,1,1.0
124 | 3,6,13.0,5,1.0
125 | 4,5,12.0,3,1.0
126 | 1,7,11.0,9,1.0
127 | 4,6,12.0,9,1.0
128 | 8,10,13.0,3,1.0
129 | 5,4,12.0,5,1.0
130 | 9,4,12.0,6,1.0
131 | 3,4,12.0,5,1.0
132 | 7,7,11.0,4,1.0
133 | 6,2,12.0,6,1.0
134 | 2,8,11.0,1,1.0
135 | 4,4,10.0,3,1.0
136 | 3,7,12.0,9,1.0
137 | 10,3,12.0,7,1.0
138 | 3,1,12.0,7,1.0
139 | 2,4,13.0,10,1.0
140 | 6,3,12.0,2,1.0
141 | 7,2,14.0,4,1.0
142 | 4,2,8.0,9,0.0
143 | 4,8,9.0,1,0.0
144 | 10,8,8.0,6,0.0
145 | 8,6,9.0,4,0.0
146 | 7,2,7.0,8,0.0
147 | 3,3,9.0,5,0.0
148 | 4,10,8.0,9,0.0
149 | 4,7,10.0,7,0.0
150 | 1,7,8.0,2,0.0
151 | 10,7,8.0,5,0.0
152 | 10,5,9.0,1,0.0
153 | 5,7,10.0,10,0.0
154 | 2,8,6.0,9,0.0
155 | 4,1,7.0,5,0.0
156 | 4,6,9.0,7,0.0
157 | 2,2,9.0,8,0.0
158 | 6,7,6.0,9,0.0
159 | 5,7,7.0,2,0.0
160 | 7,1,7.0,5,0.0
161 | 8,1,8.0,3,0.0
162 | 1,6,8.0,1,0.0
163 | 4,5,9.0,8,0.0
164 | 8,10,8.0,3,0.0
165 | 4,9,8.0,2,0.0
166 | 2,9,6.0,4,0.0
167 | 8,10,8.0,9,0.0
168 | 3,6,8.0,1,0.0
169 | 5,6,9.0,8,0.0
170 | 5,2,8.0,10,0.0
171 | 9,7,6.0,7,0.0
172 | 3,8,6.0,10,0.0
173 | 3,3,8.0,9,0.0
174 | 3,4,10.0,2,0.0
175 | 6,8,8.0,9,0.0
176 | 1,4,8.0,7,0.0
177 | 6,9,7.0,10,0.0
178 | 10,6,8.0,6,0.0
179 | 9,4,7.0,10,0.0
180 | 9,2,10.0,3,0.0
181 | 6,8,8.0,6,0.0
182 | 10,5,7.0,4,0.0
183 | 4,8,8.0,7,0.0
184 | 5,6,6.0,9,0.0
185 | 2,1,10.0,7,0.0
186 | 6,4,7.0,4,0.0
187 | 6,8,9.0,4,0.0
188 | 3,3,8.0,3,0.0
189 | 3,5,10.0,6,0.0
190 | 3,3,9.0,9,0.0
191 | 7,7,8.0,9,0.0
192 | 6,8,7.0,10,0.0
193 | 7,3,7.0,7,0.0
194 | 5,7,9.0,2,0.0
195 | 4,9,8.0,10,0.0
196 | 9,9,7.0,4,0.0
197 | 6,9,6.0,1,0.0
198 | 4,2,10.0,10,0.0
199 | 8,10,8.0,3,0.0
200 | 1,7,8.0,4,0.0
201 | 3,2,9.0,1,0.0
202 | 9,9,9.0,6,0.0
203 | 4,10,5.0,4,0.0
204 | 9,3,7.0,5,0.0
205 | 9,1,9.0,3,0.0
206 | 4,6,7.0,2,0.0
207 | 4,5,8.0,5,0.0
208 | 5,7,6.0,6,0.0
209 | 10,6,9.0,3,0.0
210 | 6,6,8.0,10,0.0
211 | 3,7,9.0,7,0.0
212 | 8,10,8.0,2,0.0
213 | 5,2,8.0,3,0.0
214 | 5,7,7.0,5,0.0
215 | 10,9,8.0,2,0.0
216 | 4,4,8.0,7,0.0
217 | 1,4,9.0,6,0.0
218 | 8,2,9.0,10,0.0
219 | 9,6,9.0,5,0.0
220 | 7,6,7.0,7,0.0
221 | 1,2,9.0,4,0.0
222 | 1,8,7.0,10,0.0
223 | 6,2,8.0,9,0.0
224 | 9,5,7.0,8,0.0
225 | 8,7,8.0,6,0.0
226 | 5,7,8.0,9,0.0
227 | 8,4,9.0,1,0.0
228 | 6,1,9.0,3,0.0
229 | 9,7,8.0,9,0.0
230 | 2,9,7.0,10,0.0
231 | 2,4,8.0,5,0.0
232 | 10,3,8.0,8,0.0
233 | 7,9,8.0,8,0.0
234 | 6,6,8.0,2,0.0
235 | 1,5,8.0,10,0.0
236 | 10,1,9.0,9,0.0
237 | 8,1,9.0,2,0.0
238 | 10,9,8.0,6,0.0
239 | 5,10,7.0,1,0.0
240 | 3,6,7.0,8,0.0
241 | 4,10,10.0,5,0.0
242 | 2,1,7.0,9,0.0
243 | 9,2,9.0,9,0.0
244 | 3,9,8.0,9,0.0
245 | 2,3,6.0,9,0.0
246 | 3,9,8.0,6,0.0
247 | 10,7,9.0,1,0.0
248 | 10,10,6.0,4,0.0
249 | 8,5,9.0,5,0.0
250 | 7,2,8.0,1,0.0
251 | 7,2,8.0,9,0.0
252 | 6,9,7.0,2,0.0
253 | 1,4,9.0,3,0.0
254 | 10,9,9.0,10,0.0
255 | 4,3,8.0,8,0.0
256 | 8,7,6.0,6,0.0
257 | 5,7,8.0,3,0.0
258 | 8,6,8.0,3,0.0
259 | 3,2,6.0,10,0.0
260 | 4,2,6.0,5,0.0
261 | 10,6,8.0,7,0.0
262 | 3,6,8.0,3,0.0
263 | 2,2,8.0,1,0.0
264 | 1,9,10.0,6,0.0
265 | 9,6,8.0,7,0.0
266 | 4,5,9.0,5,0.0
267 | 3,5,8.0,6,0.0
268 | 4,5,8.0,10,0.0
269 | 9,4,9.0,4,0.0
270 | 9,4,7.0,6,0.0
271 | 7,6,8.0,10,0.0
272 | 9,10,11.0,2,0.0
273 | 3,4,9.0,5,0.0
274 | 2,10,9.0,2,0.0
275 | 10,9,8.0,2,0.0
276 | 4,6,9.0,4,0.0
277 | 4,10,7.0,10,0.0
278 | 9,1,9.0,8,0.0
279 | 3,10,8.0,6,0.0
280 | 8,5,9.0,3,0.0
281 | 8,5,7.0,5,0.0
282 | 1,8,6.0,6,0.0
283 | 8,8,6.0,8,0.0
284 | 4,8,7.0,3,0.0
285 | 9,3,8.0,7,0.0
286 | 10,8,7.0,3,0.0
287 | 2,10,6.0,4,0.0
288 | 2,5,9.0,5,0.0
289 | 10,7,9.0,4,0.0
290 | 3,10,9.0,8,0.0
291 | 9,2,7.0,3,0.0
292 | 7,4,6.0,4,0.0
293 | 3,4,8.0,7,0.0
294 | 4,7,8.0,3,0.0
295 | 10,9,8.0,10,0.0
296 | 4,6,5.0,6,0.0
297 | 10,2,9.0,7,0.0
298 | 9,8,9.0,10,0.0
299 | 7,10,8.0,2,0.0
300 | 5,5,6.0,1,0.0
301 | 8,4,7.0,6,0.0
302 | 5,5,7.0,9,0.0
303 | 7,2,9.0,9,0.0
304 | 9,4,9.0,3,0.0
305 | 5,5,7.0,3,0.0
306 | 2,7,7.0,4,0.0
307 | 4,5,9.0,8,0.0
308 | 1,8,8.0,6,0.0
309 | 5,6,9.0,5,0.0
310 | 3,6,8.0,3,0.0
311 | 7,2,9.0,5,0.0
312 | 10,9,10.0,6,0.0
313 | 4,7,10.0,6,0.0
314 | 1,9,9.0,7,0.0
315 | 1,7,7.0,2,0.0
316 | 1,9,7.0,5,0.0
317 | 2,8,9.0,4,0.0
318 | 5,4,8.0,2,0.0
319 | 1,7,7.0,6,0.0
320 | 2,1,8.0,9,0.0
321 | 2,6,9.0,4,0.0
322 | 1,6,8.0,9,0.0
323 | 1,4,8.0,5,0.0
324 | 10,6,8.0,5,0.0
325 | 6,4,6.0,4,0.0
326 | 2,1,9.0,1,0.0
327 | 8,6,9.0,10,0.0
328 | 5,6,7.0,9,0.0
329 | 10,10,7.0,1,0.0
330 | 2,9,10.0,6,0.0
331 | 9,6,10.0,2,0.0
332 | 3,5,9.0,3,0.0
333 | 5,10,8.0,3,0.0
334 | 1,3,9.0,8,0.0
335 | 8,8,8.0,7,0.0
336 | 6,1,8.0,3,0.0
337 | 4,9,9.0,2,0.0
338 | 2,9,10.0,3,0.0
339 | 1,5,8.0,5,0.0
340 | 5,6,8.0,8,0.0
341 | 6,10,9.0,2,0.0
342 | 9,6,8.0,9,0.0
343 | 1,8,8.0,7,0.0
344 | 8,2,8.0,8,0.0
345 | 3,6,8.0,5,0.0
346 | 9,2,9.0,6,0.0
347 | 7,10,5.0,6,0.0
348 | 2,5,8.0,3,0.0
349 | 9,2,10.0,7,0.0
350 | 5,9,8.0,9,0.0
351 | 1,6,8.0,3,0.0
352 | 7,4,8.0,3,0.0
353 | 8,5,8.0,5,0.0
354 | 5,9,7.0,3,0.0
355 | 9,6,8.0,5,0.0
356 | 3,1,8.0,5,0.0
357 | 5,8,9.0,9,0.0
358 | 2,5,8.0,3,0.0
359 | 5,6,8.0,6,0.0
360 | 2,5,8.0,1,0.0
361 | 6,2,11.0,10,0.0
362 | 2,6,6.0,9,0.0
363 | 4,4,6.0,8,0.0
364 | 2,7,8.0,9,0.0
365 | 5,2,7.0,9,0.0
366 | 6,10,8.0,3,0.0
367 | 4,6,7.0,5,0.0
368 | 2,8,8.0,6,0.0
369 | 6,2,8.0,3,0.0
370 | 8,10,9.0,8,0.0
371 | 5,9,8.0,5,0.0
372 | 9,2,9.0,8,0.0
373 | 5,10,8.0,6,0.0
374 | 10,6,8.0,3,0.0
375 | 6,6,9.0,6,0.0
376 | 6,3,10.0,5,0.0
377 | 1,3,8.0,5,0.0
378 | 2,3,9.0,3,0.0
379 | 2,6,8.0,8,0.0
380 | 8,4,9.0,10,0.0
381 | 8,7,6.0,7,0.0
382 | 2,6,8.0,10,0.0
383 | 7,2,9.0,3,0.0
384 | 7,9,6.0,2,0.0
385 | 2,10,8.0,8,0.0
386 | 5,2,9.0,9,0.0
387 | 2,8,9.0,10,0.0
388 | 8,4,6.0,8,0.0
389 | 7,3,10.0,7,0.0
390 | 9,9,8.0,7,0.0
391 | 8,4,8.0,1,0.0
392 | 9,2,6.0,8,0.0
393 | 8,6,8.0,2,0.0
394 | 9,7,8.0,2,0.0
395 | 4,3,9.0,6,0.0
396 | 2,1,8.0,9,0.0
397 | 9,4,7.0,9,0.0
398 | 4,2,9.0,2,0.0
399 | 10,3,8.0,2,0.0
400 | 9,2,10.0,5,0.0
401 | 10,7,7.0,7,0.0
402 | 2,3,7.0,10,0.0
403 | 10,1,7.0,4,0.0
404 | 3,3,7.0,5,0.0
405 | 10,1,7.0,4,0.0
406 | 5,4,8.0,7,0.0
407 | 7,3,7.0,8,0.0
408 | 10,9,7.0,4,0.0
409 | 5,7,8.0,9,0.0
410 | 5,9,7.0,5,0.0
411 | 4,6,7.0,5,0.0
412 | 4,2,8.0,9,0.0
413 | 8,3,7.0,4,0.0
414 | 3,5,9.0,6,0.0
415 | 4,3,8.0,10,0.0
416 | 1,6,7.0,8,0.0
417 | 8,5,8.0,6,0.0
418 | 9,10,7.0,6,0.0
419 | 8,9,8.0,1,0.0
420 | 9,10,8.0,8,0.0
421 | 3,10,8.0,2,0.0
422 | 8,10,10.0,7,0.0
423 | 2,1,10.0,7,0.0
424 | 5,10,8.0,8,0.0
425 | 4,9,7.0,7,0.0
426 | 9,3,7.0,7,0.0
427 | 5,7,8.0,6,0.0
428 | 8,7,9.0,3,0.0
429 | 2,2,7.0,8,0.0
430 | 6,6,9.0,9,0.0
431 | 4,2,8.0,4,0.0
432 | 3,9,7.0,9,0.0
433 | 7,9,6.0,5,0.0
434 | 5,3,7.0,5,0.0
435 | 4,4,9.0,1,0.0
436 | 6,9,8.0,5,0.0
437 | 10,10,8.0,1,0.0
438 | 2,6,8.0,6,0.0
439 | 10,10,9.0,5,0.0
440 | 5,9,9.0,6,0.0
441 | 3,2,8.0,9,0.0
442 | 10,10,9.0,3,0.0
443 | 4,7,9.0,4,0.0
444 | 4,4,7.0,1,0.0
445 | 5,8,8.0,5,0.0
446 | 2,3,8.0,3,0.0
447 | 6,4,9.0,2,0.0
448 | 2,9,9.0,10,0.0
449 | 3,6,8.0,2,0.0
450 | 3,2,10.0,10,0.0
451 | 2,2,8.0,1,0.0
452 | 9,6,9.0,1,0.0
453 | 6,5,6.0,2,0.0
454 | 3,6,8.0,1,0.0
455 | 3,3,8.0,6,0.0
456 | 2,10,9.0,2,0.0
457 | 8,9,8.0,9,0.0
458 | 7,4,10.0,4,0.0
459 | 6,6,7.0,8,0.0
460 | 5,3,7.0,7,0.0
461 | 6,7,7.0,6,0.0
462 | 9,1,9.0,5,0.0
463 | 10,9,9.0,1,0.0
464 | 10,4,8.0,3,0.0
465 | 1,2,9.0,1,0.0
466 | 2,1,9.0,1,0.0
467 | 6,1,7.0,9,0.0
468 | 1,5,8.0,3,0.0
469 | 2,8,8.0,4,0.0
470 | 1,8,8.0,8,0.0
471 | 3,1,9.0,7,0.0
472 | 3,9,7.0,6,0.0
473 | 8,1,7.0,4,0.0
474 | 10,4,9.0,8,0.0
475 | 2,5,7.0,6,0.0
476 | 10,6,8.0,5,0.0
477 | 6,1,9.0,7,0.0
478 | 6,10,7.0,10,0.0
479 | 2,10,8.0,3,0.0
480 | 1,4,8.0,1,0.0
481 | 8,9,9.0,4,0.0
482 | 10,10,7.0,4,0.0
483 | 8,3,7.0,9,0.0
484 | 2,2,9.0,8,0.0
485 | 9,5,10.0,10,0.0
486 | 2,2,6.0,10,0.0
487 | 8,3,6.0,6,0.0
488 | 6,4,9.0,10,0.0
489 | 1,3,8.0,3,0.0
490 | 6,6,8.0,3,0.0
491 | 1,9,7.0,4,0.0
492 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Tree_Methods/Tree_Methods_Consulting_Project_SOLUTION.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Tree Methods Consulting Project - SOLUTION"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "You've been hired by a dog food company to try to predict why some batches of their dog food are spoiling much quicker than intended! Unfortunately this Dog Food company hasn't upgraded to the latest machinery, meaning that the amounts of the five preservative chemicals they are using can vary a lot, but which is the chemical that has the strongest effect? The dog food company first mixes up a batch of preservative that contains 4 different preservative chemicals (A,B,C,D) and then is completed with a \"filler\" chemical. The food scientists beelive one of the A,B,C, or D preservatives is causing the problem, but need your help to figure out which one!\n",
15 | "Use Machine Learning with RF to find out which parameter had the most predicitive power, thus finding out which chemical causes the early spoiling! So create a model and then find out how you can decide which chemical is the problem!\n",
16 | "\n",
17 | "* Pres_A : Percentage of preservative A in the mix\n",
18 | "* Pres_B : Percentage of preservative B in the mix\n",
19 | "* Pres_C : Percentage of preservative C in the mix\n",
20 | "* Pres_D : Percentage of preservative D in the mix\n",
21 | "* Spoiled: Label indicating whether or not the dog food batch was spoiled.\n",
22 | "___\n",
23 | "\n",
24 | "**Think carefully about what this problem is really asking you to solve. While we will use Machine Learning to solve this, it won't be with your typical train/test split workflow. If this confuses you, skip ahead to the solution code along walk-through!**\n",
25 | "____"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 46,
31 | "metadata": {
32 | "collapsed": true
33 | },
34 | "outputs": [],
35 | "source": [
36 | "#Tree methods Example\n",
37 | "from pyspark.sql import SparkSession\n",
38 | "spark = SparkSession.builder.appName('dogfood').getOrCreate()"
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": 47,
44 | "metadata": {
45 | "collapsed": true
46 | },
47 | "outputs": [],
48 | "source": [
49 | "# Load training data\n",
50 | "data = spark.read.csv('dog_food.csv',inferSchema=True,header=True)"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 48,
56 | "metadata": {
57 | "collapsed": false
58 | },
59 | "outputs": [
60 | {
61 | "name": "stdout",
62 | "output_type": "stream",
63 | "text": [
64 | "root\n",
65 | " |-- A: integer (nullable = true)\n",
66 | " |-- B: integer (nullable = true)\n",
67 | " |-- C: double (nullable = true)\n",
68 | " |-- D: integer (nullable = true)\n",
69 | " |-- Spoiled: double (nullable = true)\n",
70 | "\n"
71 | ]
72 | }
73 | ],
74 | "source": [
75 | "data.printSchema()"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 49,
81 | "metadata": {
82 | "collapsed": false
83 | },
84 | "outputs": [
85 | {
86 | "data": {
87 | "text/plain": [
88 | "Row(A=4, B=2, C=12.0, D=3, Spoiled=1.0)"
89 | ]
90 | },
91 | "execution_count": 49,
92 | "metadata": {},
93 | "output_type": "execute_result"
94 | }
95 | ],
96 | "source": [
97 | "data.head()"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 50,
103 | "metadata": {
104 | "collapsed": false
105 | },
106 | "outputs": [
107 | {
108 | "name": "stdout",
109 | "output_type": "stream",
110 | "text": [
111 | "+-------+------------------+------------------+------------------+------------------+-------------------+\n",
112 | "|summary| A| B| C| D| Spoiled|\n",
113 | "+-------+------------------+------------------+------------------+------------------+-------------------+\n",
114 | "| count| 490| 490| 490| 490| 490|\n",
115 | "| mean| 5.53469387755102| 5.504081632653061| 9.126530612244897| 5.579591836734694| 0.2857142857142857|\n",
116 | "| stddev|2.9515204234399057|2.8537966089662063|2.0555451971054275|2.8548369309982857|0.45221563164613465|\n",
117 | "| min| 1| 1| 5.0| 1| 0.0|\n",
118 | "| max| 10| 10| 14.0| 10| 1.0|\n",
119 | "+-------+------------------+------------------+------------------+------------------+-------------------+\n",
120 | "\n"
121 | ]
122 | }
123 | ],
124 | "source": [
125 | "data.describe().show()"
126 | ]
127 | },
128 | {
129 | "cell_type": "code",
130 | "execution_count": 51,
131 | "metadata": {
132 | "collapsed": true
133 | },
134 | "outputs": [],
135 | "source": [
136 | "# Import VectorAssembler and Vectors\n",
137 | "from pyspark.ml.linalg import Vectors\n",
138 | "from pyspark.ml.feature import VectorAssembler"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 52,
144 | "metadata": {
145 | "collapsed": false
146 | },
147 | "outputs": [
148 | {
149 | "data": {
150 | "text/plain": [
151 | "['A', 'B', 'C', 'D', 'Spoiled']"
152 | ]
153 | },
154 | "execution_count": 52,
155 | "metadata": {},
156 | "output_type": "execute_result"
157 | }
158 | ],
159 | "source": [
160 | "data.columns"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 53,
166 | "metadata": {
167 | "collapsed": false
168 | },
169 | "outputs": [],
170 | "source": [
171 | "assembler = VectorAssembler(inputCols=['A', 'B', 'C', 'D'],outputCol=\"features\")"
172 | ]
173 | },
174 | {
175 | "cell_type": "code",
176 | "execution_count": 54,
177 | "metadata": {
178 | "collapsed": true
179 | },
180 | "outputs": [],
181 | "source": [
182 | "output = assembler.transform(data)"
183 | ]
184 | },
185 | {
186 | "cell_type": "code",
187 | "execution_count": 55,
188 | "metadata": {
189 | "collapsed": true
190 | },
191 | "outputs": [],
192 | "source": [
193 | "from pyspark.ml.classification import RandomForestClassifier,DecisionTreeClassifier"
194 | ]
195 | },
196 | {
197 | "cell_type": "code",
198 | "execution_count": 56,
199 | "metadata": {
200 | "collapsed": true
201 | },
202 | "outputs": [],
203 | "source": [
204 | "rfc = DecisionTreeClassifier(labelCol='Spoiled',featuresCol='features')"
205 | ]
206 | },
207 | {
208 | "cell_type": "code",
209 | "execution_count": 57,
210 | "metadata": {
211 | "collapsed": false
212 | },
213 | "outputs": [
214 | {
215 | "name": "stdout",
216 | "output_type": "stream",
217 | "text": [
218 | "root\n",
219 | " |-- A: integer (nullable = true)\n",
220 | " |-- B: integer (nullable = true)\n",
221 | " |-- C: double (nullable = true)\n",
222 | " |-- D: integer (nullable = true)\n",
223 | " |-- Spoiled: double (nullable = true)\n",
224 | " |-- features: vector (nullable = true)\n",
225 | "\n"
226 | ]
227 | }
228 | ],
229 | "source": [
230 | "output.printSchema()"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": 58,
236 | "metadata": {
237 | "collapsed": false
238 | },
239 | "outputs": [
240 | {
241 | "data": {
242 | "text/plain": [
243 | "Row(features=DenseVector([4.0, 2.0, 12.0, 3.0]), Spoiled=1.0)"
244 | ]
245 | },
246 | "execution_count": 58,
247 | "metadata": {},
248 | "output_type": "execute_result"
249 | }
250 | ],
251 | "source": [
252 | "final_data = output.select('features','Spoiled')\n",
253 | "final_data.head()"
254 | ]
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": 59,
259 | "metadata": {
260 | "collapsed": false
261 | },
262 | "outputs": [],
263 | "source": [
264 | "rfc_model = rfc.fit(final_data)"
265 | ]
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": 60,
270 | "metadata": {
271 | "collapsed": false
272 | },
273 | "outputs": [
274 | {
275 | "data": {
276 | "text/plain": [
277 | "SparseVector(4, {0: 0.0026, 1: 0.0089, 2: 0.9686, 3: 0.0199})"
278 | ]
279 | },
280 | "execution_count": 60,
281 | "metadata": {},
282 | "output_type": "execute_result"
283 | }
284 | ],
285 | "source": [
286 | "rfc_model.featureImportances"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "Bingo! Feature at index 2 (Chemical C) is by far the most important feature, meaning it is causing the early spoilage! This is a pretty interesting use of a machine learning model in an alternative way!\n",
294 | "\n",
295 | "# Great Job"
296 | ]
297 | }
298 | ],
299 | "metadata": {
300 | "anaconda-cloud": {},
301 | "kernelspec": {
302 | "display_name": "Python [conda root]",
303 | "language": "python",
304 | "name": "conda-root-py"
305 | },
306 | "language_info": {
307 | "codemirror_mode": {
308 | "name": "ipython",
309 | "version": 3
310 | },
311 | "file_extension": ".py",
312 | "mimetype": "text/x-python",
313 | "name": "python",
314 | "nbconvert_exporter": "python",
315 | "pygments_lexer": "ipython3",
316 | "version": "3.5.3"
317 | }
318 | },
319 | "nbformat": 4,
320 | "nbformat_minor": 0
321 | }
322 |
--------------------------------------------------------------------------------
/Partioning and Gloming.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Partitioning\n",
8 | "\n",
9 | "When an RDD is created, you can specify the number of partitions.\n",
10 | "
The default is the number of workers defined when you setu th `SparkContext`"
11 | ]
12 | },
13 | {
14 | "cell_type": "code",
15 | "execution_count": 1,
16 | "metadata": {},
17 | "outputs": [],
18 | "source": [
19 | "from pyspark import SparkContext"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "### Creating `SparkContext` with 2 workers"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 2,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "sc = SparkContext(master=\"local[2]\")"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 3,
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "A = sc.parallelize(range(1000000))"
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {},
50 | "source": [
51 | "### Use `getNumPartition` to retrive the number of partitions created"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": 4,
57 | "metadata": {},
58 | "outputs": [
59 | {
60 | "name": "stdout",
61 | "output_type": "stream",
62 | "text": [
63 | "2\n"
64 | ]
65 | }
66 | ],
67 | "source": [
68 | "print(A.getNumPartitions())"
69 | ]
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "metadata": {},
74 | "source": [
75 | "### We can repartition _A_ in any number of partitions we want"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 5,
81 | "metadata": {},
82 | "outputs": [],
83 | "source": [
84 | "D = A.repartition(10)"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 6,
90 | "metadata": {},
91 | "outputs": [
92 | {
93 | "name": "stdout",
94 | "output_type": "stream",
95 | "text": [
96 | "10\n"
97 | ]
98 | }
99 | ],
100 | "source": [
101 | "print(D.getNumPartitions())"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "### We can also set the number of partitions while creating the RDD with `numSlices` argument "
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 7,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "A = sc.parallelize(range(1000000),numSlices=8)"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 8,
123 | "metadata": {},
124 | "outputs": [
125 | {
126 | "name": "stdout",
127 | "output_type": "stream",
128 | "text": [
129 | "8\n"
130 | ]
131 | }
132 | ],
133 | "source": [
134 | "print(A.getNumPartitions())"
135 | ]
136 | },
137 | {
138 | "cell_type": "markdown",
139 | "metadata": {},
140 | "source": [
141 | "### Why partitions are important?\n",
142 | "\n",
143 | "* They define the unit the executor works on\n",
144 | "* You should have at least as many partitions as the number of worker nodes\n",
145 | "* Smaller partitions may allow more parallelization"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "## Repartitioning for Load Balancing"
153 | ]
154 | },
155 | {
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "Suppose we start with 10 partitions, all with exactly the same number of elements"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 9,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "[100000, 100000, 100000, 100000, 100000, 100000, 100000, 100000, 100000, 100000]\n"
172 | ]
173 | }
174 | ],
175 | "source": [
176 | "A=sc.parallelize(range(1000000)).map(lambda x:(x,x)).partitionBy(10)\n",
177 | "print(A.glom().map(len).collect())"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "Suppose we want to use **`filter()`** to select some of the elements in A.
\n",
185 | "Some partitions might have more elements remaining than others."
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 10,
191 | "metadata": {},
192 | "outputs": [
193 | {
194 | "name": "stdout",
195 | "output_type": "stream",
196 | "text": [
197 | "[100000, 0, 0, 0, 0, 100000, 0, 0, 0, 0]\n"
198 | ]
199 | }
200 | ],
201 | "source": [
202 | "#select 10% of the entries\n",
203 | "# A bad filter for numbers divisable by 5\n",
204 | "B=A.filter(lambda pair: pair[0]%5==0)\n",
205 | "# get no. of partitions\n",
206 | "print(B.glom().map(len).collect())"
207 | ]
208 | },
209 | {
210 | "cell_type": "markdown",
211 | "metadata": {},
212 | "source": [
213 | "Future operations on B will use only two workers.
\n",
214 | "The other workers will do nothing, because their partitions are empty."
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "### To fix the situation we need to repartition the unbalanced RDD.
One way to do that is to repartition using a new key using the method `partitionBy()`\n",
222 | "\n",
223 | "* The method **`.partitionBy(k)`** expects to get a **`(key,value)`** RDD where keys are integers.\n",
224 | "* Partitions the RDD into **`k`** partitions.\n",
225 | "* The element **`(key,value)`** is placed into partition no. **`key % k`**"
226 | ]
227 | },
228 | {
229 | "cell_type": "code",
230 | "execution_count": 11,
231 | "metadata": {},
232 | "outputs": [
233 | {
234 | "name": "stdout",
235 | "output_type": "stream",
236 | "text": [
237 | "[20000, 20000, 20000, 20000, 20000, 20000, 20000, 20000, 20000, 20000]\n"
238 | ]
239 | }
240 | ],
241 | "source": [
242 | "C=B.map(lambda pair:(pair[1]/10,pair[1])).partitionBy(10) \n",
243 | "print(C.glom().map(len).collect())"
244 | ]
245 | },
246 | {
247 | "cell_type": "markdown",
248 | "metadata": {},
249 | "source": [
250 | "Note, how **`C`** consists of only 200,000 elements from the unbalanced **`B`** partition but redistributes them in equal partitions of 20,000 elements each."
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "### Another approach is to use random partitioning using **`repartition(k)`**\n",
258 | "* An **advantage** of random partitioning is that it does not require defining a key.\n",
259 | "* A **disadvantage** of random partitioning is that you have no control on the partitioning i.e. which elements go to which partition."
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 12,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "name": "stdout",
269 | "output_type": "stream",
270 | "text": [
271 | "[20000, 20000, 20000, 20000, 20000, 20000, 20000, 20000, 20000, 20000]\n"
272 | ]
273 | }
274 | ],
275 | "source": [
276 | "C=B.repartition(10)\n",
277 | "print(C.glom().map(len).collect())"
278 | ]
279 | },
280 | {
281 | "cell_type": "markdown",
282 | "metadata": {},
283 | "source": [
284 | "## `Glom()`\n",
285 | "* In general, spark does not allow the worker to refer to specific elements of the RDD.\n",
286 | "* Keeps the language clean, but can be a major limitation.\n",
287 | "\n",
288 | "#### `glom()` transforms each partition into a tuple (immutabe list) of elements.
Creates an RDD of tules. One tuple per partition.
Workers can refer to elements of the partition by index but you cannot assign values to the elements, the RDD is still immutable.\n",
289 | "\n",
290 | "* Consider **the command used above to count the number of elements in each partition.**: `print(C.glom().map(len).collect())`\n",
291 | "* We used `glom()` to make each partition into a tuple.\n",
292 | "* We used `len` on each partition to get the length of the tuple - size of the partition.\n",
293 | "* We `collect`ed the results to print them out."
294 | ]
295 | },
296 | {
297 | "cell_type": "markdown",
298 | "metadata": {},
299 | "source": [
300 | "### A more elaborate example\n",
301 | "There are many things that you can do using `glom()`.\n",
302 | "
\n",
303 | "For example, suppose we want to get the first element, the number of elements, and the sum of the elements of the unbalanced partitions we made from `A` into `B`. Of the partition is empty we just return `None`."
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 14,
309 | "metadata": {},
310 | "outputs": [
311 | {
312 | "name": "stdout",
313 | "output_type": "stream",
314 | "text": [
315 | "[(0, 100000, 999990), None, None, None, None, (5, 100000, 999990), None, None, None, None]\n"
316 | ]
317 | }
318 | ],
319 | "source": [
320 | "def getPartitionInfo(G):\n",
321 | " d=0\n",
322 | " if len(G)>1: \n",
323 | " for i in range(len(G)-1):\n",
324 | " d+=abs(G[i+1][1]-G[i][1]) # access the glomed RDD that is now a tuple (immutable list)\n",
325 | " return (G[0][0],len(G),d)\n",
326 | " else:\n",
327 | " return(None)\n",
328 | "\n",
329 | "output=B.glom().map(lambda B: getPartitionInfo(B)).collect()\n",
330 | "print(output)"
331 | ]
332 | }
333 | ],
334 | "metadata": {
335 | "kernelspec": {
336 | "display_name": "Python 3",
337 | "language": "python",
338 | "name": "python3"
339 | },
340 | "language_info": {
341 | "codemirror_mode": {
342 | "name": "ipython",
343 | "version": 3
344 | },
345 | "file_extension": ".py",
346 | "mimetype": "text/x-python",
347 | "name": "python",
348 | "nbconvert_exporter": "python",
349 | "pygments_lexer": "ipython3",
350 | "version": "3.6.6"
351 | }
352 | },
353 | "nbformat": 4,
354 | "nbformat_minor": 2
355 | }
356 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Spark with Python
2 |
3 | ## Apache Spark
4 | Apache Spark is one of the hottest new trends in the technology domain. It is the framework with probably the **highest potential to realize the fruit of the marriage between Big Data and Machine Learning**. It runs fast (up to 100x faster than traditional Hadoop MapReduce due to in-memory operation, offers robust, distributed, fault-tolerant data objects (called RDD), and integrates beautifully with the world of machine learning and graph analytics through supplementary packages like Mlib and GraphX.
5 |
6 |
7 |  8 |
8 |
9 | Spark is implemented on Hadoop/HDFS and written mostly in Scala, a functional programming language, similar to Java. In fact, Scala needs the latest Java installation on your system and runs on JVM. However, for most of the beginners, Scala is not a language that they learn first to venture into the world of data science. Fortunately, Spark provides a wonderful Python integration, called PySpark, which lets Python programmers to interface with the Spark framework and learn how to manipulate data at scale and work with objects and algorithms over a distributed file system.
10 |
11 | ## Notebooks
12 | ### RDD and basics
13 | * [SparkContext and RDD basiscs](https://github.com/tirthajyoti/Spark-with-Python/blob/master/SparkContext%20and%20RDD%20Basics.ipynb)
14 | * [SparkContext workers lazy evaluations](https://github.com/tirthajyoti/Spark-with-Python/blob/master/SparkContext_Workers_Lazy_Evaluations.ipynb)
15 | * [RDD chaining executions](https://github.com/tirthajyoti/Spark-with-Python/blob/master/RDD_Chaining_Execution.ipynb)
16 | * [Word count example with RDD](https://github.com/tirthajyoti/Spark-with-Python/blob/master/Word_Count.ipynb)
17 | * [Partitioning and Gloming](https://github.com/tirthajyoti/Spark-with-Python/blob/master/Partioning%20and%20Gloming.ipynb)
18 | ### Dataframe
19 | * [Dataframe basics](https://github.com/tirthajyoti/Spark-with-Python/blob/master/Dataframe_basics.ipynb)
20 | * [Dataframe simple operations](https://github.com/tirthajyoti/Spark-with-Python/blob/master/DataFrame_operations_basics.ipynb)
21 | * [Dataframe row and column objects](https://github.com/tirthajyoti/Spark-with-Python/blob/master/Row_column_objects.ipynb)
22 | * [Dataframe groupBy and aggregrate](https://github.com/tirthajyoti/Spark-with-Python/blob/master/GroupBy_aggregrate.ipynb)
23 | * [Dataframe SQL operations](https://github.com/tirthajyoti/Spark-with-Python/blob/master/Dataframe_SQL_query.ipynb)
24 |
25 | ## Setting up Apache Spark with Python 3 and Jupyter notebook
26 | Unlike most Python libraries, getting PySpark to start working properly is not as straightforward as `pip install ...` and `import ...` Most of us with Python-based data science and Jupyter/IPython background take this workflow as granted for all popular Python packages. We tend to just head over to our CMD or BASH shell, type the pip install command, launch a Jupyter notebook and import the library to start practicing.
27 | > But, PySpark+Jupyter combo needs a little bit more love :-)
28 |
29 |
30 |  31 |
31 |
32 |
33 | #### Check which version of Python is running. Python 3.4+ is needed.
34 | `python3 --version`
35 |
36 | #### Update apt-get
37 | `sudo apt-get update`
38 |
39 | #### Install pip3 (or pip for Python3)
40 | `sudo apt install python3-pip`
41 |
42 | #### Install Jupyter for Python3
43 | `pip3 install jupyter`
44 |
45 | #### Augment the PATH variable to launch Jupyter notebook
46 | `export PATH=$PATH:~/.local/bin`
47 |
48 | #### Java 8 is shown to work with UBUNTU 18.04 LTS/SPARK-2.3.1-BIN-HADOOP2.7
49 | ```
50 | sudo add-apt-repository ppa:webupd8team/java
51 | sudo apt-get install oracle-java8-installer
52 | sudo apt-get install oracle-java8-set-default
53 | ```
54 | #### Set Java related PATH variables
55 | ```
56 | export JAVA_HOME=/usr/lib/jvm/java-8-oracle
57 | export JRE_HOME=/usr/lib/jvm/java-8-oracle/jre
58 | ```
59 | #### Install Scala
60 | `sudo apt-get install scala`
61 |
62 | #### Install py4j for Python-Java integration
63 | `pip3 install py4j`
64 |
65 | #### Download latest Apache Spark (with pre-built Hadoop) from [Apache download server](https://spark.apache.org/downloads.html). Unpack Apache Spark after downloading
66 | `sudo tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz`
67 |
68 | #### Set variables to launch PySpark with Python3 and enable it to be called from Jupyter notebook. Add all the following lines to the end of your .bashrc file
69 | ```
70 | export SPARK_HOME='/home/tirtha/Spark/spark-2.3.1-bin-hadoop2.7'
71 | export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
72 | export PYSPARK_DRIVER_PYTHON="jupyter"
73 | export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
74 | export PYSPARK_PYTHON=python3
75 | export PATH=$SPARK_HOME:$PATH:~/.local/bin:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
76 | ```
77 | #### Source .bashrc
78 | `source .bashrc`
79 |
80 | ## Basics of `RDD`
81 | Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
82 |
83 | Spark makes use of the concept of RDD to achieve **faster and efficient MapReduce operations.**
84 |
85 |  86 |
87 | Formally, an RDD is a read-only, partitioned collection of records. RDDs can be created through deterministic operations on either data on stable storage or other RDDs. RDD is a fault-tolerant collection of elements that can be operated on in parallel.
88 |
89 | There are two ways to create RDDs,
90 | * parallelizing an existing collection in your driver program,
91 | * referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
92 |
93 | ## Basics of the `Dataframe`
94 |
86 |
87 | Formally, an RDD is a read-only, partitioned collection of records. RDDs can be created through deterministic operations on either data on stable storage or other RDDs. RDD is a fault-tolerant collection of elements that can be operated on in parallel.
88 |
89 | There are two ways to create RDDs,
90 | * parallelizing an existing collection in your driver program,
91 | * referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
92 |
93 | ## Basics of the `Dataframe`
94 | 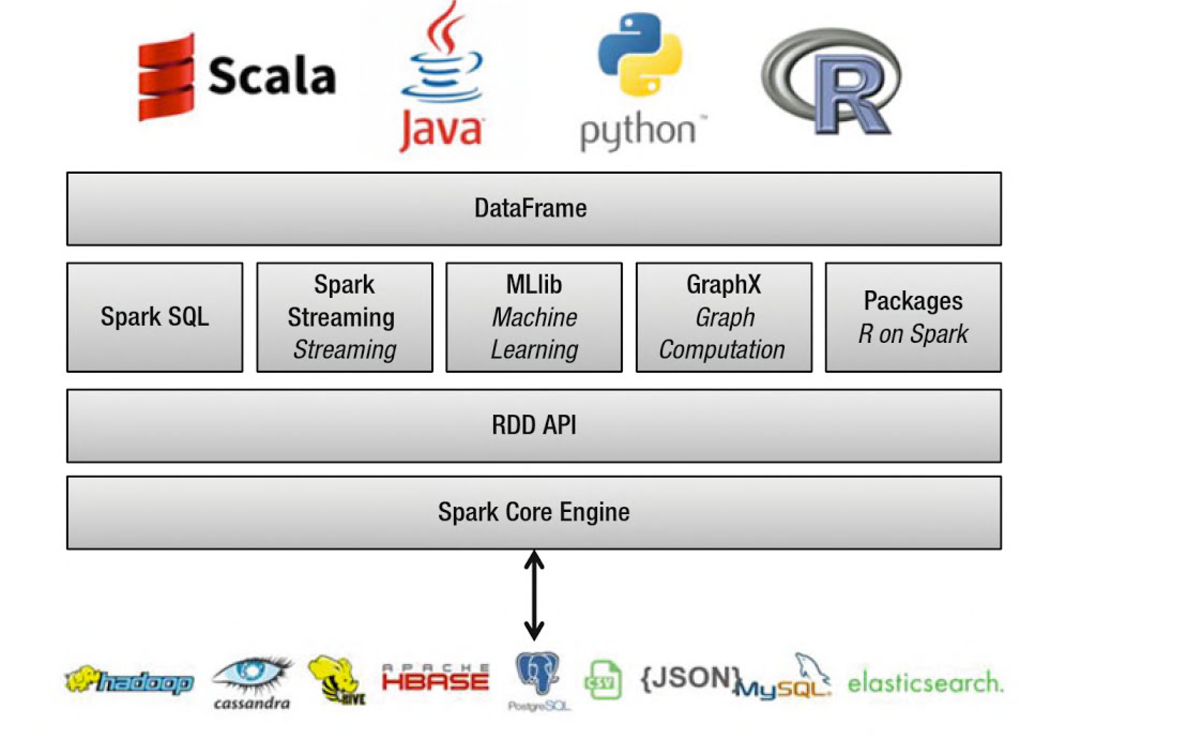
95 |
96 | ### DataFrame
97 |
98 | In Apache Spark, a DataFrame is a distributed collection of rows under named columns. It is conceptually equivalent to a table in a relational database, an Excel sheet with Column headers, or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. It also shares some common characteristics with RDD:
99 |
100 | * __Immutable in nature__ : We can create DataFrame / RDD once but can’t change it. And we can transform a DataFrame / RDD after applying transformations.
101 | * __Lazy Evaluations__: Which means that a task is not executed until an action is performed.
102 | * __Distributed__: RDD and DataFrame both are distributed in nature.
103 |
104 | ### Advantages of the Dataframe
105 |
106 | * DataFrames are designed for processing large collection of structured or semi-structured data.
107 | * Observations in Spark DataFrame are organised under named columns, which helps Apache Spark to understand the schema of a DataFrame. This helps Spark optimize execution plan on these queries.
108 | * DataFrame in Apache Spark has the ability to handle petabytes of data.
109 | * DataFrame has a support for wide range of data format and sources.
110 | * It has API support for different languages like Python, R, Scala, Java.
111 |
112 | ## Spark SQL
113 | Spark SQL provides a DataFrame API that can perform relational operations on both external data sources and Spark's built-in distributed collections—at scale!
114 |
115 | To support a wide variety of diverse data sources and algorithms in Big Data, Spark SQL introduces a novel extensible optimizer called Catalyst, which makes it easy to add data sources, optimization rules, and data types for advanced analytics such as machine learning.
116 | Essentially, Spark SQL leverages the power of Spark to perform distributed, robust, in-memory computations at massive scale on Big Data.
117 |
118 | Spark SQL provides state-of-the-art SQL performance and also maintains compatibility with all existing structures and components supported by Apache Hive (a popular Big Data warehouse framework) including data formats, user-defined functions (UDFs), and the metastore. Besides this, it also helps in ingesting a wide variety of data formats from Big Data sources and enterprise data warehouses like JSON, Hive, Parquet, and so on, and performing a combination of relational and procedural operations for more complex, advanced analytics.
119 |
120 | 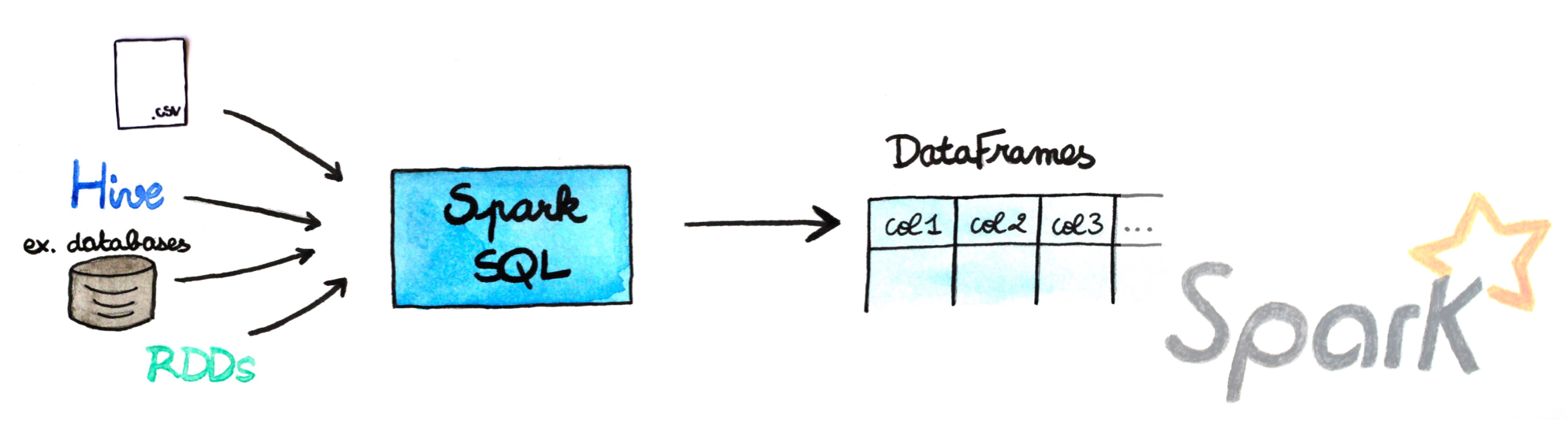
121 |
122 | ### Speed of Spark SQL
123 | Spark SQL has been shown to be extremely fast, even comparable to C++ based engines such as Impala.
124 |
125 | 
126 |
127 | Following graph shows a nice benchmark result of DataFrames vs. RDDs in different languages, which gives an interesting perspective on how optimized DataFrames can be.
128 |
129 | 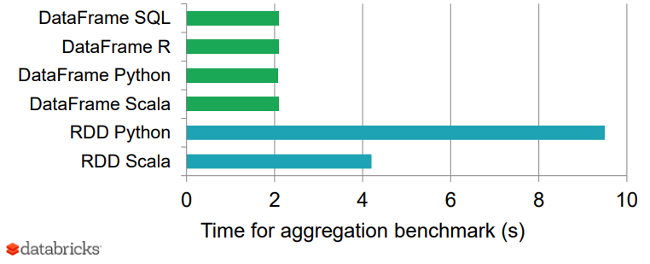
130 |
131 | Why is Spark SQL so fast and optimized? The reason is because of a new extensible optimizer, **Catalyst**, based on functional programming constructs in Scala.
132 |
133 | Catalyst's extensible design has two purposes.
134 |
135 | * Makes it easy to add new optimization techniques and features to Spark SQL, especially to tackle diverse problems around Big Data, semi-structured data, and advanced analytics
136 | * Ease of being able to extend the optimizer—for example, by adding data source-specific rules that can push filtering or aggregation into external storage systems or support for new data types
137 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Python-Crash-Course/Python Crash Course Exercises.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python Crash Course Exercises \n",
8 | "\n",
9 | "This is an optional exercise to test your understanding of Python Basics. If you find this extremely challenging, then you probably are not ready for the rest of this course yet and don't have enough programming experience to continue. I would suggest you take another course more geared towards complete beginners, such as [Complete Python Bootcamp]()"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "## Exercises\n",
17 | "\n",
18 | "Answer the questions or complete the tasks outlined in bold below, use the specific method described if applicable."
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "** What is 7 to the power of 4?**"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 1,
31 | "metadata": {
32 | "collapsed": false
33 | },
34 | "outputs": [
35 | {
36 | "data": {
37 | "text/plain": [
38 | "2401"
39 | ]
40 | },
41 | "execution_count": 1,
42 | "metadata": {},
43 | "output_type": "execute_result"
44 | }
45 | ],
46 | "source": []
47 | },
48 | {
49 | "cell_type": "markdown",
50 | "metadata": {},
51 | "source": [
52 | "** Split this string:**\n",
53 | "\n",
54 | " s = \"Hi there Sam!\"\n",
55 | " \n",
56 | "**into a list. **"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 4,
62 | "metadata": {
63 | "collapsed": true
64 | },
65 | "outputs": [],
66 | "source": []
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {
72 | "collapsed": false
73 | },
74 | "outputs": [
75 | {
76 | "data": {
77 | "text/plain": [
78 | "['Hi', 'there', 'dad!']"
79 | ]
80 | },
81 | "execution_count": 3,
82 | "metadata": {},
83 | "output_type": "execute_result"
84 | }
85 | ],
86 | "source": []
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "** Given the variables:**\n",
93 | "\n",
94 | " planet = \"Earth\"\n",
95 | " diameter = 12742\n",
96 | "\n",
97 | "** Use .format() to print the following string: **\n",
98 | "\n",
99 | " The diameter of Earth is 12742 kilometers."
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 5,
105 | "metadata": {
106 | "collapsed": true
107 | },
108 | "outputs": [],
109 | "source": [
110 | "planet = \"Earth\"\n",
111 | "diameter = 12742"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": 6,
117 | "metadata": {
118 | "collapsed": false
119 | },
120 | "outputs": [
121 | {
122 | "name": "stdout",
123 | "output_type": "stream",
124 | "text": [
125 | "The diameter of Earth is 12742 kilometers.\n"
126 | ]
127 | }
128 | ],
129 | "source": []
130 | },
131 | {
132 | "cell_type": "markdown",
133 | "metadata": {},
134 | "source": [
135 | "** Given this nested list, use indexing to grab the word \"hello\" **"
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 7,
141 | "metadata": {
142 | "collapsed": true
143 | },
144 | "outputs": [],
145 | "source": [
146 | "lst = [1,2,[3,4],[5,[100,200,['hello']],23,11],1,7]"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 14,
152 | "metadata": {
153 | "collapsed": false
154 | },
155 | "outputs": [
156 | {
157 | "data": {
158 | "text/plain": [
159 | "'hello'"
160 | ]
161 | },
162 | "execution_count": 14,
163 | "metadata": {},
164 | "output_type": "execute_result"
165 | }
166 | ],
167 | "source": []
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "** Given this nest dictionary grab the word \"hello\". Be prepared, this will be annoying/tricky **"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 16,
179 | "metadata": {
180 | "collapsed": false
181 | },
182 | "outputs": [],
183 | "source": [
184 | "d = {'k1':[1,2,3,{'tricky':['oh','man','inception',{'target':[1,2,3,'hello']}]}]}"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 22,
190 | "metadata": {
191 | "collapsed": false
192 | },
193 | "outputs": [
194 | {
195 | "data": {
196 | "text/plain": [
197 | "'hello'"
198 | ]
199 | },
200 | "execution_count": 22,
201 | "metadata": {},
202 | "output_type": "execute_result"
203 | }
204 | ],
205 | "source": []
206 | },
207 | {
208 | "cell_type": "markdown",
209 | "metadata": {},
210 | "source": [
211 | "** What is the main difference between a tuple and a list? **"
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 23,
217 | "metadata": {
218 | "collapsed": true
219 | },
220 | "outputs": [],
221 | "source": [
222 | "# Just answer with text, no code necessary"
223 | ]
224 | },
225 | {
226 | "cell_type": "markdown",
227 | "metadata": {},
228 | "source": [
229 | "** Create a function that grabs the email website domain from a string in the form: **\n",
230 | "\n",
231 | " user@domain.com\n",
232 | " \n",
233 | "**So for example, passing \"user@domain.com\" would return: domain.com**"
234 | ]
235 | },
236 | {
237 | "cell_type": "code",
238 | "execution_count": 24,
239 | "metadata": {
240 | "collapsed": true
241 | },
242 | "outputs": [],
243 | "source": []
244 | },
245 | {
246 | "cell_type": "code",
247 | "execution_count": 26,
248 | "metadata": {
249 | "collapsed": false
250 | },
251 | "outputs": [
252 | {
253 | "data": {
254 | "text/plain": [
255 | "'domain.com'"
256 | ]
257 | },
258 | "execution_count": 26,
259 | "metadata": {},
260 | "output_type": "execute_result"
261 | }
262 | ],
263 | "source": []
264 | },
265 | {
266 | "cell_type": "markdown",
267 | "metadata": {},
268 | "source": [
269 | "** Create a basic function that returns True if the word 'dog' is contained in the input string. Don't worry about edge cases like a punctuation being attached to the word dog, but do account for capitalization. **"
270 | ]
271 | },
272 | {
273 | "cell_type": "code",
274 | "execution_count": 27,
275 | "metadata": {
276 | "collapsed": true
277 | },
278 | "outputs": [],
279 | "source": []
280 | },
281 | {
282 | "cell_type": "code",
283 | "execution_count": 28,
284 | "metadata": {
285 | "collapsed": false
286 | },
287 | "outputs": [
288 | {
289 | "data": {
290 | "text/plain": [
291 | "True"
292 | ]
293 | },
294 | "execution_count": 28,
295 | "metadata": {},
296 | "output_type": "execute_result"
297 | }
298 | ],
299 | "source": []
300 | },
301 | {
302 | "cell_type": "markdown",
303 | "metadata": {},
304 | "source": [
305 | "** Create a function that counts the number of times the word \"dog\" occurs in a string. Again ignore edge cases. **"
306 | ]
307 | },
308 | {
309 | "cell_type": "code",
310 | "execution_count": 30,
311 | "metadata": {
312 | "collapsed": false
313 | },
314 | "outputs": [],
315 | "source": []
316 | },
317 | {
318 | "cell_type": "code",
319 | "execution_count": 31,
320 | "metadata": {
321 | "collapsed": false
322 | },
323 | "outputs": [
324 | {
325 | "data": {
326 | "text/plain": [
327 | "2"
328 | ]
329 | },
330 | "execution_count": 31,
331 | "metadata": {},
332 | "output_type": "execute_result"
333 | }
334 | ],
335 | "source": []
336 | },
337 | {
338 | "cell_type": "markdown",
339 | "metadata": {},
340 | "source": [
341 | "### Final Problem\n",
342 | "**You are driving a little too fast, and a police officer stops you. Write a function\n",
343 | " to return one of 3 possible results: \"No ticket\", \"Small ticket\", or \"Big Ticket\". \n",
344 | " If your speed is 60 or less, the result is \"No Ticket\". If speed is between 61 \n",
345 | " and 80 inclusive, the result is \"Small Ticket\". If speed is 81 or more, the result is \"Big Ticket\". Unless it is your birthday (encoded as a boolean value in the parameters of the function) -- on your birthday, your speed can be 5 higher in all \n",
346 | " cases. **"
347 | ]
348 | },
349 | {
350 | "cell_type": "code",
351 | "execution_count": 4,
352 | "metadata": {
353 | "collapsed": true
354 | },
355 | "outputs": [],
356 | "source": []
357 | },
358 | {
359 | "cell_type": "code",
360 | "execution_count": 5,
361 | "metadata": {
362 | "collapsed": false
363 | },
364 | "outputs": [
365 | {
366 | "data": {
367 | "text/plain": [
368 | "'Small Ticket'"
369 | ]
370 | },
371 | "execution_count": 5,
372 | "metadata": {},
373 | "output_type": "execute_result"
374 | }
375 | ],
376 | "source": []
377 | },
378 | {
379 | "cell_type": "code",
380 | "execution_count": 6,
381 | "metadata": {
382 | "collapsed": false
383 | },
384 | "outputs": [
385 | {
386 | "data": {
387 | "text/plain": [
388 | "'Big Ticket'"
389 | ]
390 | },
391 | "execution_count": 6,
392 | "metadata": {},
393 | "output_type": "execute_result"
394 | }
395 | ],
396 | "source": []
397 | },
398 | {
399 | "cell_type": "markdown",
400 | "metadata": {},
401 | "source": [
402 | "# Great job!"
403 | ]
404 | }
405 | ],
406 | "metadata": {
407 | "anaconda-cloud": {},
408 | "kernelspec": {
409 | "display_name": "Python [default]",
410 | "language": "python",
411 | "name": "python3"
412 | },
413 | "language_info": {
414 | "codemirror_mode": {
415 | "name": "ipython",
416 | "version": 3
417 | },
418 | "file_extension": ".py",
419 | "mimetype": "text/x-python",
420 | "name": "python",
421 | "nbconvert_exporter": "python",
422 | "pygments_lexer": "ipython3",
423 | "version": "3.5.3"
424 | }
425 | },
426 | "nbformat": 4,
427 | "nbformat_minor": 0
428 | }
429 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Logistic_Regression/Titanic_Log_Regression_Code_Along.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Logistic Regression Code Along\n",
8 | "This is a code along of the famous titanic dataset, its always nice to start off with this dataset because it is an example you will find across pretty much every data analysis language."
9 | ]
10 | },
11 | {
12 | "cell_type": "code",
13 | "execution_count": 1,
14 | "metadata": {
15 | "collapsed": true
16 | },
17 | "outputs": [],
18 | "source": [
19 | "from pyspark.sql import SparkSession"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 2,
25 | "metadata": {
26 | "collapsed": true
27 | },
28 | "outputs": [],
29 | "source": [
30 | "spark = SparkSession.builder.appName('myproj').getOrCreate()"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 3,
36 | "metadata": {
37 | "collapsed": true
38 | },
39 | "outputs": [],
40 | "source": [
41 | "data = spark.read.csv('titanic.csv',inferSchema=True,header=True)"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 4,
47 | "metadata": {
48 | "collapsed": false
49 | },
50 | "outputs": [
51 | {
52 | "name": "stdout",
53 | "output_type": "stream",
54 | "text": [
55 | "root\n",
56 | " |-- PassengerId: integer (nullable = true)\n",
57 | " |-- Survived: integer (nullable = true)\n",
58 | " |-- Pclass: integer (nullable = true)\n",
59 | " |-- Name: string (nullable = true)\n",
60 | " |-- Sex: string (nullable = true)\n",
61 | " |-- Age: double (nullable = true)\n",
62 | " |-- SibSp: integer (nullable = true)\n",
63 | " |-- Parch: integer (nullable = true)\n",
64 | " |-- Ticket: string (nullable = true)\n",
65 | " |-- Fare: double (nullable = true)\n",
66 | " |-- Cabin: string (nullable = true)\n",
67 | " |-- Embarked: string (nullable = true)\n",
68 | "\n"
69 | ]
70 | }
71 | ],
72 | "source": [
73 | "data.printSchema()"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 7,
79 | "metadata": {
80 | "collapsed": false
81 | },
82 | "outputs": [
83 | {
84 | "data": {
85 | "text/plain": [
86 | "['PassengerId',\n",
87 | " 'Survived',\n",
88 | " 'Pclass',\n",
89 | " 'Name',\n",
90 | " 'Sex',\n",
91 | " 'Age',\n",
92 | " 'SibSp',\n",
93 | " 'Parch',\n",
94 | " 'Ticket',\n",
95 | " 'Fare',\n",
96 | " 'Cabin',\n",
97 | " 'Embarked']"
98 | ]
99 | },
100 | "execution_count": 7,
101 | "metadata": {},
102 | "output_type": "execute_result"
103 | }
104 | ],
105 | "source": [
106 | "data.columns"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 8,
112 | "metadata": {
113 | "collapsed": true
114 | },
115 | "outputs": [],
116 | "source": [
117 | "my_cols = data.select(['Survived',\n",
118 | " 'Pclass',\n",
119 | " 'Sex',\n",
120 | " 'Age',\n",
121 | " 'SibSp',\n",
122 | " 'Parch',\n",
123 | " 'Fare',\n",
124 | " 'Embarked'])"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 29,
130 | "metadata": {
131 | "collapsed": false
132 | },
133 | "outputs": [],
134 | "source": [
135 | "my_final_data = my_cols.na.drop()"
136 | ]
137 | },
138 | {
139 | "cell_type": "markdown",
140 | "metadata": {},
141 | "source": [
142 | "### Working with Categorical Columns\n",
143 | "\n",
144 | "Let's break this down into multiple steps to make it all clear."
145 | ]
146 | },
147 | {
148 | "cell_type": "code",
149 | "execution_count": 12,
150 | "metadata": {
151 | "collapsed": true
152 | },
153 | "outputs": [],
154 | "source": [
155 | "from pyspark.ml.feature import (VectorAssembler,VectorIndexer,\n",
156 | " OneHotEncoder,StringIndexer)"
157 | ]
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": 13,
162 | "metadata": {
163 | "collapsed": true
164 | },
165 | "outputs": [],
166 | "source": [
167 | "gender_indexer = StringIndexer(inputCol='Sex',outputCol='SexIndex')\n",
168 | "gender_encoder = OneHotEncoder(inputCol='SexIndex',outputCol='SexVec')"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": 14,
174 | "metadata": {
175 | "collapsed": true
176 | },
177 | "outputs": [],
178 | "source": [
179 | "embark_indexer = StringIndexer(inputCol='Embarked',outputCol='EmbarkIndex')\n",
180 | "embark_encoder = OneHotEncoder(inputCol='EmbarkIndex',outputCol='EmbarkVec')"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 15,
186 | "metadata": {
187 | "collapsed": true
188 | },
189 | "outputs": [],
190 | "source": [
191 | "assembler = VectorAssembler(inputCols=['Pclass',\n",
192 | " 'SexVec',\n",
193 | " 'Age',\n",
194 | " 'SibSp',\n",
195 | " 'Parch',\n",
196 | " 'Fare',\n",
197 | " 'EmbarkVec'],outputCol='features')"
198 | ]
199 | },
200 | {
201 | "cell_type": "code",
202 | "execution_count": 30,
203 | "metadata": {
204 | "collapsed": true
205 | },
206 | "outputs": [],
207 | "source": [
208 | "from pyspark.ml.classification import LogisticRegression"
209 | ]
210 | },
211 | {
212 | "cell_type": "markdown",
213 | "metadata": {},
214 | "source": [
215 | "## Pipelines \n",
216 | "\n",
217 | "Let's see an example of how to use pipelines (we'll get a lot more practice with these later!)"
218 | ]
219 | },
220 | {
221 | "cell_type": "code",
222 | "execution_count": 17,
223 | "metadata": {
224 | "collapsed": true
225 | },
226 | "outputs": [],
227 | "source": [
228 | "from pyspark.ml import Pipeline"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 18,
234 | "metadata": {
235 | "collapsed": true
236 | },
237 | "outputs": [],
238 | "source": [
239 | "log_reg_titanic = LogisticRegression(featuresCol='features',labelCol='Survived')"
240 | ]
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": 19,
245 | "metadata": {
246 | "collapsed": true
247 | },
248 | "outputs": [],
249 | "source": [
250 | "pipeline = Pipeline(stages=[gender_indexer,embark_indexer,\n",
251 | " gender_encoder,embark_encoder,\n",
252 | " assembler,log_reg_titanic])"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 20,
258 | "metadata": {
259 | "collapsed": true
260 | },
261 | "outputs": [],
262 | "source": [
263 | "train_titanic_data, test_titanic_data = my_final_data.randomSplit([0.7,.3])"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": 21,
269 | "metadata": {
270 | "collapsed": true
271 | },
272 | "outputs": [],
273 | "source": [
274 | "fit_model = pipeline.fit(train_titanic_data)"
275 | ]
276 | },
277 | {
278 | "cell_type": "code",
279 | "execution_count": 22,
280 | "metadata": {
281 | "collapsed": true
282 | },
283 | "outputs": [],
284 | "source": [
285 | "results = fit_model.transform(test_titanic_data)"
286 | ]
287 | },
288 | {
289 | "cell_type": "code",
290 | "execution_count": 23,
291 | "metadata": {
292 | "collapsed": true
293 | },
294 | "outputs": [],
295 | "source": [
296 | "from pyspark.ml.evaluation import BinaryClassificationEvaluator"
297 | ]
298 | },
299 | {
300 | "cell_type": "code",
301 | "execution_count": 24,
302 | "metadata": {
303 | "collapsed": true
304 | },
305 | "outputs": [],
306 | "source": [
307 | "my_eval = BinaryClassificationEvaluator(rawPredictionCol='prediction',\n",
308 | " labelCol='Survived')"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 26,
314 | "metadata": {
315 | "collapsed": false
316 | },
317 | "outputs": [
318 | {
319 | "name": "stdout",
320 | "output_type": "stream",
321 | "text": [
322 | "+--------+----------+\n",
323 | "|Survived|prediction|\n",
324 | "+--------+----------+\n",
325 | "| 0| 1.0|\n",
326 | "| 0| 1.0|\n",
327 | "| 0| 1.0|\n",
328 | "| 0| 1.0|\n",
329 | "| 0| 0.0|\n",
330 | "| 0| 1.0|\n",
331 | "| 0| 1.0|\n",
332 | "| 0| 0.0|\n",
333 | "| 0| 0.0|\n",
334 | "| 0| 0.0|\n",
335 | "| 0| 0.0|\n",
336 | "| 0| 0.0|\n",
337 | "| 0| 0.0|\n",
338 | "| 0| 0.0|\n",
339 | "| 0| 0.0|\n",
340 | "| 0| 0.0|\n",
341 | "| 0| 0.0|\n",
342 | "| 0| 1.0|\n",
343 | "| 0| 1.0|\n",
344 | "| 0| 1.0|\n",
345 | "+--------+----------+\n",
346 | "only showing top 20 rows\n",
347 | "\n"
348 | ]
349 | }
350 | ],
351 | "source": [
352 | "results.select('Survived','prediction').show()"
353 | ]
354 | },
355 | {
356 | "cell_type": "code",
357 | "execution_count": 27,
358 | "metadata": {
359 | "collapsed": true
360 | },
361 | "outputs": [],
362 | "source": [
363 | "AUC = my_eval.evaluate(results)"
364 | ]
365 | },
366 | {
367 | "cell_type": "code",
368 | "execution_count": 28,
369 | "metadata": {
370 | "collapsed": false
371 | },
372 | "outputs": [
373 | {
374 | "data": {
375 | "text/plain": [
376 | "0.7918269230769232"
377 | ]
378 | },
379 | "execution_count": 28,
380 | "metadata": {},
381 | "output_type": "execute_result"
382 | }
383 | ],
384 | "source": [
385 | "AUC"
386 | ]
387 | },
388 | {
389 | "cell_type": "markdown",
390 | "metadata": {},
391 | "source": [
392 | "## Great Job!"
393 | ]
394 | }
395 | ],
396 | "metadata": {
397 | "anaconda-cloud": {},
398 | "kernelspec": {
399 | "display_name": "Python [conda root]",
400 | "language": "python",
401 | "name": "conda-root-py"
402 | },
403 | "language_info": {
404 | "codemirror_mode": {
405 | "name": "ipython",
406 | "version": 3
407 | },
408 | "file_extension": ".py",
409 | "mimetype": "text/x-python",
410 | "name": "python",
411 | "nbconvert_exporter": "python",
412 | "pygments_lexer": "ipython3",
413 | "version": "3.5.3"
414 | }
415 | },
416 | "nbformat": 4,
417 | "nbformat_minor": 0
418 | }
419 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Clustering/Clustering Code Along.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Clustering Code Along\n",
8 | "\n",
9 | "We'll be working with a real data set about seeds, from UCI repository: https://archive.ics.uci.edu/ml/datasets/seeds."
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "The examined group comprised kernels belonging to three different varieties of wheat: Kama, Rosa and Canadian, 70 elements each, randomly selected for \n",
17 | "the experiment. High quality visualization of the internal kernel structure was detected using a soft X-ray technique. It is non-destructive and considerably cheaper than other more sophisticated imaging techniques like scanning microscopy or laser technology. The images were recorded on 13x18 cm X-ray KODAK plates. Studies were conducted using combine harvested wheat grain originating from experimental fields, explored at the Institute of Agrophysics of the Polish Academy of Sciences in Lublin. \n",
18 | "\n",
19 | "The data set can be used for the tasks of classification and cluster analysis.\n",
20 | "\n",
21 | "\n",
22 | "Attribute Information:\n",
23 | "\n",
24 | "To construct the data, seven geometric parameters of wheat kernels were measured: \n",
25 | "1. area A, \n",
26 | "2. perimeter P, \n",
27 | "3. compactness C = 4*pi*A/P^2, \n",
28 | "4. length of kernel, \n",
29 | "5. width of kernel, \n",
30 | "6. asymmetry coefficient \n",
31 | "7. length of kernel groove. \n",
32 | "All of these parameters were real-valued continuous.\n",
33 | "\n",
34 | "Let's see if we can cluster them in to 3 groups with K-means!"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 53,
40 | "metadata": {
41 | "collapsed": true
42 | },
43 | "outputs": [],
44 | "source": [
45 | "from pyspark.sql import SparkSession\n",
46 | "spark = SparkSession.builder.appName('cluster').getOrCreate()"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 54,
52 | "metadata": {
53 | "collapsed": false
54 | },
55 | "outputs": [],
56 | "source": [
57 | "from pyspark.ml.clustering import KMeans\n",
58 | "\n",
59 | "# Loads data.\n",
60 | "dataset = spark.read.csv(\"seeds_dataset.csv\",header=True,inferSchema=True)"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 55,
66 | "metadata": {
67 | "collapsed": false
68 | },
69 | "outputs": [
70 | {
71 | "data": {
72 | "text/plain": [
73 | "Row(area=15.26, perimeter=14.84, compactness=0.871, length_of_kernel=5.763, width_of_kernel=3.312, asymmetry_coefficient=2.221, length_of_groove=5.22)"
74 | ]
75 | },
76 | "execution_count": 55,
77 | "metadata": {},
78 | "output_type": "execute_result"
79 | }
80 | ],
81 | "source": [
82 | "dataset.head()"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 56,
88 | "metadata": {
89 | "collapsed": false
90 | },
91 | "outputs": [
92 | {
93 | "name": "stdout",
94 | "output_type": "stream",
95 | "text": [
96 | "+-------+------------------+------------------+--------------------+-------------------+------------------+---------------------+-------------------+\n",
97 | "|summary| area| perimeter| compactness| length_of_kernel| width_of_kernel|asymmetry_coefficient| length_of_groove|\n",
98 | "+-------+------------------+------------------+--------------------+-------------------+------------------+---------------------+-------------------+\n",
99 | "| count| 210| 210| 210| 210| 210| 210| 210|\n",
100 | "| mean|14.847523809523816|14.559285714285718| 0.8709985714285714| 5.628533333333335| 3.258604761904762| 3.7001999999999997| 5.408071428571429|\n",
101 | "| stddev|2.9096994306873647|1.3059587265640225|0.023629416583846364|0.44306347772644983|0.3777144449065867| 1.5035589702547392|0.49148049910240543|\n",
102 | "| min| 10.59| 12.41| 0.8081| 4.899| 2.63| 0.765| 4.519|\n",
103 | "| max| 21.18| 17.25| 0.9183| 6.675| 4.033| 8.456| 6.55|\n",
104 | "+-------+------------------+------------------+--------------------+-------------------+------------------+---------------------+-------------------+\n",
105 | "\n"
106 | ]
107 | }
108 | ],
109 | "source": [
110 | "dataset.describe().show()"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "## Format the Data"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 57,
123 | "metadata": {
124 | "collapsed": true
125 | },
126 | "outputs": [],
127 | "source": [
128 | "from pyspark.ml.linalg import Vectors\n",
129 | "from pyspark.ml.feature import VectorAssembler"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 58,
135 | "metadata": {
136 | "collapsed": false
137 | },
138 | "outputs": [
139 | {
140 | "data": {
141 | "text/plain": [
142 | "['area',\n",
143 | " 'perimeter',\n",
144 | " 'compactness',\n",
145 | " 'length_of_kernel',\n",
146 | " 'width_of_kernel',\n",
147 | " 'asymmetry_coefficient',\n",
148 | " 'length_of_groove']"
149 | ]
150 | },
151 | "execution_count": 58,
152 | "metadata": {},
153 | "output_type": "execute_result"
154 | }
155 | ],
156 | "source": [
157 | "dataset.columns"
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 59,
163 | "metadata": {
164 | "collapsed": true
165 | },
166 | "outputs": [],
167 | "source": [
168 | "vec_assembler = VectorAssembler(inputCols = dataset.columns, outputCol='features')"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": 60,
174 | "metadata": {
175 | "collapsed": true
176 | },
177 | "outputs": [],
178 | "source": [
179 | "final_data = vec_assembler.transform(dataset)"
180 | ]
181 | },
182 | {
183 | "cell_type": "markdown",
184 | "metadata": {},
185 | "source": [
186 | "## Scale the Data\n",
187 | "It is a good idea to scale our data to deal with the curse of dimensionality: https://en.wikipedia.org/wiki/Curse_of_dimensionality"
188 | ]
189 | },
190 | {
191 | "cell_type": "code",
192 | "execution_count": 61,
193 | "metadata": {
194 | "collapsed": true
195 | },
196 | "outputs": [],
197 | "source": [
198 | "from pyspark.ml.feature import StandardScaler"
199 | ]
200 | },
201 | {
202 | "cell_type": "code",
203 | "execution_count": 62,
204 | "metadata": {
205 | "collapsed": false
206 | },
207 | "outputs": [],
208 | "source": [
209 | "scaler = StandardScaler(inputCol=\"features\", outputCol=\"scaledFeatures\", withStd=True, withMean=False)"
210 | ]
211 | },
212 | {
213 | "cell_type": "code",
214 | "execution_count": 63,
215 | "metadata": {
216 | "collapsed": true
217 | },
218 | "outputs": [],
219 | "source": [
220 | "# Compute summary statistics by fitting the StandardScaler\n",
221 | "scalerModel = scaler.fit(final_data)"
222 | ]
223 | },
224 | {
225 | "cell_type": "code",
226 | "execution_count": 64,
227 | "metadata": {
228 | "collapsed": false
229 | },
230 | "outputs": [],
231 | "source": [
232 | "# Normalize each feature to have unit standard deviation.\n",
233 | "final_data = scalerModel.transform(final_data)"
234 | ]
235 | },
236 | {
237 | "cell_type": "markdown",
238 | "metadata": {},
239 | "source": [
240 | "## Train the Model and Evaluate"
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 76,
246 | "metadata": {
247 | "collapsed": true
248 | },
249 | "outputs": [],
250 | "source": [
251 | "# Trains a k-means model.\n",
252 | "kmeans = KMeans(featuresCol='scaledFeatures',k=3)\n",
253 | "model = kmeans.fit(final_data)"
254 | ]
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": 77,
259 | "metadata": {
260 | "collapsed": false
261 | },
262 | "outputs": [
263 | {
264 | "name": "stdout",
265 | "output_type": "stream",
266 | "text": [
267 | "Within Set Sum of Squared Errors = 429.07559671506715\n"
268 | ]
269 | }
270 | ],
271 | "source": [
272 | "# Evaluate clustering by computing Within Set Sum of Squared Errors.\n",
273 | "wssse = model.computeCost(final_data)\n",
274 | "print(\"Within Set Sum of Squared Errors = \" + str(wssse))"
275 | ]
276 | },
277 | {
278 | "cell_type": "code",
279 | "execution_count": 79,
280 | "metadata": {
281 | "collapsed": false
282 | },
283 | "outputs": [
284 | {
285 | "name": "stdout",
286 | "output_type": "stream",
287 | "text": [
288 | "Cluster Centers: \n",
289 | "[ 6.31670546 12.37109759 37.39491396 13.91155062 9.748067\n",
290 | " 2.39849968 12.2661748 ]\n",
291 | "[ 4.87257659 10.88120146 37.27692543 12.3410157 8.55443412\n",
292 | " 1.81649011 10.32998598]\n",
293 | "[ 4.06105916 10.13979506 35.80536984 11.82133095 7.50395937\n",
294 | " 3.27184732 10.42126018]\n"
295 | ]
296 | }
297 | ],
298 | "source": [
299 | "# Shows the result.\n",
300 | "centers = model.clusterCenters()\n",
301 | "print(\"Cluster Centers: \")\n",
302 | "for center in centers:\n",
303 | " print(center)"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 80,
309 | "metadata": {
310 | "collapsed": false
311 | },
312 | "outputs": [
313 | {
314 | "name": "stdout",
315 | "output_type": "stream",
316 | "text": [
317 | "+----------+\n",
318 | "|prediction|\n",
319 | "+----------+\n",
320 | "| 1|\n",
321 | "| 1|\n",
322 | "| 1|\n",
323 | "| 1|\n",
324 | "| 1|\n",
325 | "| 1|\n",
326 | "| 1|\n",
327 | "| 1|\n",
328 | "| 0|\n",
329 | "| 0|\n",
330 | "| 1|\n",
331 | "| 1|\n",
332 | "| 1|\n",
333 | "| 1|\n",
334 | "| 1|\n",
335 | "| 1|\n",
336 | "| 1|\n",
337 | "| 1|\n",
338 | "| 1|\n",
339 | "| 2|\n",
340 | "+----------+\n",
341 | "only showing top 20 rows\n",
342 | "\n"
343 | ]
344 | }
345 | ],
346 | "source": [
347 | "model.transform(final_data).select('prediction').show()"
348 | ]
349 | },
350 | {
351 | "cell_type": "markdown",
352 | "metadata": {},
353 | "source": [
354 | "Now you are ready for your consulting Project!\n",
355 | "# Great Job!"
356 | ]
357 | }
358 | ],
359 | "metadata": {
360 | "anaconda-cloud": {},
361 | "kernelspec": {
362 | "display_name": "Python [conda root]",
363 | "language": "python",
364 | "name": "conda-root-py"
365 | },
366 | "language_info": {
367 | "codemirror_mode": {
368 | "name": "ipython",
369 | "version": 3
370 | },
371 | "file_extension": ".py",
372 | "mimetype": "text/x-python",
373 | "name": "python",
374 | "nbconvert_exporter": "python",
375 | "pygments_lexer": "ipython3",
376 | "version": "3.5.3"
377 | }
378 | },
379 | "nbformat": 4,
380 | "nbformat_minor": 0
381 | }
382 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Python-Crash-Course/Python Crash Course Exercises - Solutions.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python Crash Course Exercises - Solutions\n",
8 | "\n",
9 | "This is an optional exercise to test your understanding of Python Basics. If you find this extremely challenging, then you probably are not ready for the rest of this course yet and don't have enough programming experience to continue. I would suggest you take another course more geared towards complete beginners, such as [Complete Python Bootcamp]()"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "## Exercises\n",
17 | "\n",
18 | "Answer the questions or complete the tasks outlined in bold below, use the specific method described if applicable."
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "** What is 7 to the power of 4?**"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 1,
31 | "metadata": {
32 | "collapsed": false
33 | },
34 | "outputs": [
35 | {
36 | "data": {
37 | "text/plain": [
38 | "2401"
39 | ]
40 | },
41 | "execution_count": 1,
42 | "metadata": {},
43 | "output_type": "execute_result"
44 | }
45 | ],
46 | "source": [
47 | "7 **4"
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "metadata": {},
53 | "source": [
54 | "** Split this string:**\n",
55 | "\n",
56 | " s = \"Hi there Sam!\"\n",
57 | " \n",
58 | "**into a list. **"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 4,
64 | "metadata": {
65 | "collapsed": true
66 | },
67 | "outputs": [],
68 | "source": [
69 | "s = 'Hi there Sam!'"
70 | ]
71 | },
72 | {
73 | "cell_type": "code",
74 | "execution_count": 3,
75 | "metadata": {
76 | "collapsed": false
77 | },
78 | "outputs": [
79 | {
80 | "data": {
81 | "text/plain": [
82 | "['Hi', 'there', 'dad!']"
83 | ]
84 | },
85 | "execution_count": 3,
86 | "metadata": {},
87 | "output_type": "execute_result"
88 | }
89 | ],
90 | "source": [
91 | "s.split()"
92 | ]
93 | },
94 | {
95 | "cell_type": "markdown",
96 | "metadata": {},
97 | "source": [
98 | "** Given the variables:**\n",
99 | "\n",
100 | " planet = \"Earth\"\n",
101 | " diameter = 12742\n",
102 | "\n",
103 | "** Use .format() to print the following string: **\n",
104 | "\n",
105 | " The diameter of Earth is 12742 kilometers."
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 5,
111 | "metadata": {
112 | "collapsed": true
113 | },
114 | "outputs": [],
115 | "source": [
116 | "planet = \"Earth\"\n",
117 | "diameter = 12742"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 6,
123 | "metadata": {
124 | "collapsed": false
125 | },
126 | "outputs": [
127 | {
128 | "name": "stdout",
129 | "output_type": "stream",
130 | "text": [
131 | "The diameter of Earth is 12742 kilometers.\n"
132 | ]
133 | }
134 | ],
135 | "source": [
136 | "print(\"The diameter of {} is {} kilometers.\".format(planet,diameter))"
137 | ]
138 | },
139 | {
140 | "cell_type": "markdown",
141 | "metadata": {},
142 | "source": [
143 | "** Given this nested list, use indexing to grab the word \"hello\" **"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": 7,
149 | "metadata": {
150 | "collapsed": true
151 | },
152 | "outputs": [],
153 | "source": [
154 | "lst = [1,2,[3,4],[5,[100,200,['hello']],23,11],1,7]"
155 | ]
156 | },
157 | {
158 | "cell_type": "code",
159 | "execution_count": 14,
160 | "metadata": {
161 | "collapsed": false
162 | },
163 | "outputs": [
164 | {
165 | "data": {
166 | "text/plain": [
167 | "'hello'"
168 | ]
169 | },
170 | "execution_count": 14,
171 | "metadata": {},
172 | "output_type": "execute_result"
173 | }
174 | ],
175 | "source": [
176 | "lst[3][1][2][0]"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | "** Given this nest dictionary grab the word \"hello\". Be prepared, this will be annoying/tricky **"
184 | ]
185 | },
186 | {
187 | "cell_type": "code",
188 | "execution_count": 16,
189 | "metadata": {
190 | "collapsed": false
191 | },
192 | "outputs": [],
193 | "source": [
194 | "d = {'k1':[1,2,3,{'tricky':['oh','man','inception',{'target':[1,2,3,'hello']}]}]}"
195 | ]
196 | },
197 | {
198 | "cell_type": "code",
199 | "execution_count": 22,
200 | "metadata": {
201 | "collapsed": false
202 | },
203 | "outputs": [
204 | {
205 | "data": {
206 | "text/plain": [
207 | "'hello'"
208 | ]
209 | },
210 | "execution_count": 22,
211 | "metadata": {},
212 | "output_type": "execute_result"
213 | }
214 | ],
215 | "source": [
216 | "d['k1'][3]['tricky'][3]['target'][3]"
217 | ]
218 | },
219 | {
220 | "cell_type": "markdown",
221 | "metadata": {},
222 | "source": [
223 | "** What is the main difference between a tuple and a list? **"
224 | ]
225 | },
226 | {
227 | "cell_type": "code",
228 | "execution_count": 23,
229 | "metadata": {
230 | "collapsed": true
231 | },
232 | "outputs": [],
233 | "source": [
234 | "# Just answer with text, no code necessary"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | "** Create a function that grabs the email website domain from a string in the form: **\n",
242 | "\n",
243 | " user@domain.com\n",
244 | " \n",
245 | "**So for example, passing \"user@domain.com\" would return: domain.com**"
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": 24,
251 | "metadata": {
252 | "collapsed": true
253 | },
254 | "outputs": [],
255 | "source": [
256 | "def domainGet(email):\n",
257 | " return email.split('@')[-1]"
258 | ]
259 | },
260 | {
261 | "cell_type": "code",
262 | "execution_count": 26,
263 | "metadata": {
264 | "collapsed": false
265 | },
266 | "outputs": [
267 | {
268 | "data": {
269 | "text/plain": [
270 | "'domain.com'"
271 | ]
272 | },
273 | "execution_count": 26,
274 | "metadata": {},
275 | "output_type": "execute_result"
276 | }
277 | ],
278 | "source": [
279 | "domainGet('user@domain.com')"
280 | ]
281 | },
282 | {
283 | "cell_type": "markdown",
284 | "metadata": {},
285 | "source": [
286 | "** Create a basic function that returns True if the word 'dog' is contained in the input string. Don't worry about edge cases like a punctuation being attached to the word dog, but do account for capitalization. **"
287 | ]
288 | },
289 | {
290 | "cell_type": "code",
291 | "execution_count": 27,
292 | "metadata": {
293 | "collapsed": true
294 | },
295 | "outputs": [],
296 | "source": [
297 | "def findDog(st):\n",
298 | " return 'dog' in st.lower().split()"
299 | ]
300 | },
301 | {
302 | "cell_type": "code",
303 | "execution_count": 28,
304 | "metadata": {
305 | "collapsed": false
306 | },
307 | "outputs": [
308 | {
309 | "data": {
310 | "text/plain": [
311 | "True"
312 | ]
313 | },
314 | "execution_count": 28,
315 | "metadata": {},
316 | "output_type": "execute_result"
317 | }
318 | ],
319 | "source": [
320 | "findDog('Is there a dog here?')"
321 | ]
322 | },
323 | {
324 | "cell_type": "markdown",
325 | "metadata": {},
326 | "source": [
327 | "** Create a function that counts the number of times the word \"dog\" occurs in a string. Again ignore edge cases. **"
328 | ]
329 | },
330 | {
331 | "cell_type": "code",
332 | "execution_count": 30,
333 | "metadata": {
334 | "collapsed": false
335 | },
336 | "outputs": [],
337 | "source": [
338 | "def countDog(st):\n",
339 | " count = 0\n",
340 | " for word in st.lower().split():\n",
341 | " if word == 'dog':\n",
342 | " count += 1\n",
343 | " return count"
344 | ]
345 | },
346 | {
347 | "cell_type": "code",
348 | "execution_count": 31,
349 | "metadata": {
350 | "collapsed": false
351 | },
352 | "outputs": [
353 | {
354 | "data": {
355 | "text/plain": [
356 | "2"
357 | ]
358 | },
359 | "execution_count": 31,
360 | "metadata": {},
361 | "output_type": "execute_result"
362 | }
363 | ],
364 | "source": [
365 | "countDog('This dog runs faster than the other dog dude!')"
366 | ]
367 | },
368 | {
369 | "cell_type": "markdown",
370 | "metadata": {},
371 | "source": [
372 | "### Final Problem\n",
373 | "**You are driving a little too fast, and a police officer stops you. Write a function\n",
374 | " to return one of 3 possible results: \"No ticket\", \"Small ticket\", or \"Big Ticket\". \n",
375 | " If your speed is 60 or less, the result is \"No Ticket\". If speed is between 61 \n",
376 | " and 80 inclusive, the result is \"Small Ticket\". If speed is 81 or more, the result is \"Big Ticket\". Unless it is your birthday (encoded as a boolean value in the parameters of the function) -- on your birthday, your speed can be 5 higher in all \n",
377 | " cases. **"
378 | ]
379 | },
380 | {
381 | "cell_type": "code",
382 | "execution_count": 4,
383 | "metadata": {
384 | "collapsed": true
385 | },
386 | "outputs": [],
387 | "source": [
388 | "def caught_speeding(speed, is_birthday):\n",
389 | " \n",
390 | " if is_birthday:\n",
391 | " speeding = speed - 5\n",
392 | " else:\n",
393 | " speeding = speed\n",
394 | " \n",
395 | " if speeding > 80:\n",
396 | " return 'Big Ticket'\n",
397 | " elif speeding > 60:\n",
398 | " return 'Small Ticket'\n",
399 | " else:\n",
400 | " return 'No Ticket'"
401 | ]
402 | },
403 | {
404 | "cell_type": "code",
405 | "execution_count": 5,
406 | "metadata": {
407 | "collapsed": false
408 | },
409 | "outputs": [
410 | {
411 | "data": {
412 | "text/plain": [
413 | "'Small Ticket'"
414 | ]
415 | },
416 | "execution_count": 5,
417 | "metadata": {},
418 | "output_type": "execute_result"
419 | }
420 | ],
421 | "source": [
422 | "caught_speeding(81,True)"
423 | ]
424 | },
425 | {
426 | "cell_type": "code",
427 | "execution_count": 6,
428 | "metadata": {
429 | "collapsed": false
430 | },
431 | "outputs": [
432 | {
433 | "data": {
434 | "text/plain": [
435 | "'Big Ticket'"
436 | ]
437 | },
438 | "execution_count": 6,
439 | "metadata": {},
440 | "output_type": "execute_result"
441 | }
442 | ],
443 | "source": [
444 | "caught_speeding(81,False)"
445 | ]
446 | },
447 | {
448 | "cell_type": "markdown",
449 | "metadata": {},
450 | "source": [
451 | "# Great job!"
452 | ]
453 | }
454 | ],
455 | "metadata": {
456 | "anaconda-cloud": {},
457 | "kernelspec": {
458 | "display_name": "Python [default]",
459 | "language": "python",
460 | "name": "python3"
461 | },
462 | "language_info": {
463 | "codemirror_mode": {
464 | "name": "ipython",
465 | "version": 3
466 | },
467 | "file_extension": ".py",
468 | "mimetype": "text/x-python",
469 | "name": "python",
470 | "nbconvert_exporter": "python",
471 | "pygments_lexer": "ipython3",
472 | "version": "3.5.3"
473 | }
474 | },
475 | "nbformat": 4,
476 | "nbformat_minor": 0
477 | }
478 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_DataFrames/Missing_Data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Missing Data\n",
8 | "\n",
9 | "Often data sources are incomplete, which means you will have missing data, you have 3 basic options for filling in missing data (you will personally have to make the decision for what is the right approach:\n",
10 | "\n",
11 | "* Just keep the missing data points.\n",
12 | "* Drop them missing data points (including the entire row)\n",
13 | "* Fill them in with some other value.\n",
14 | "\n",
15 | "Let's cover examples of each of these methods!"
16 | ]
17 | },
18 | {
19 | "cell_type": "markdown",
20 | "metadata": {
21 | "collapsed": true
22 | },
23 | "source": [
24 | "## Keeping the missing data\n",
25 | "A few machine learning algorithms can easily deal with missing data, let's see what it looks like:"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 1,
31 | "metadata": {
32 | "collapsed": true
33 | },
34 | "outputs": [],
35 | "source": [
36 | "from pyspark.sql import SparkSession\n",
37 | "# May take a little while on a local computer\n",
38 | "spark = SparkSession.builder.appName(\"missingdata\").getOrCreate()"
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": 2,
44 | "metadata": {
45 | "collapsed": true
46 | },
47 | "outputs": [],
48 | "source": [
49 | "df = spark.read.csv(\"ContainsNull.csv\",header=True,inferSchema=True)"
50 | ]
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": 3,
55 | "metadata": {
56 | "collapsed": false
57 | },
58 | "outputs": [
59 | {
60 | "name": "stdout",
61 | "output_type": "stream",
62 | "text": [
63 | "+----+-----+-----+\n",
64 | "| Id| Name|Sales|\n",
65 | "+----+-----+-----+\n",
66 | "|emp1| John| null|\n",
67 | "|emp2| null| null|\n",
68 | "|emp3| null|345.0|\n",
69 | "|emp4|Cindy|456.0|\n",
70 | "+----+-----+-----+\n",
71 | "\n"
72 | ]
73 | }
74 | ],
75 | "source": [
76 | "df.show()"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {},
82 | "source": [
83 | "Notice how the data remains as a null."
84 | ]
85 | },
86 | {
87 | "cell_type": "markdown",
88 | "metadata": {},
89 | "source": [
90 | "## Drop the missing data\n",
91 | "\n",
92 | "You can use the .na functions for missing data. The drop command has the following parameters:\n",
93 | "\n",
94 | " df.na.drop(how='any', thresh=None, subset=None)\n",
95 | " \n",
96 | " * param how: 'any' or 'all'.\n",
97 | " \n",
98 | " If 'any', drop a row if it contains any nulls.\n",
99 | " If 'all', drop a row only if all its values are null.\n",
100 | " \n",
101 | " * param thresh: int, default None\n",
102 | " \n",
103 | " If specified, drop rows that have less than `thresh` non-null values.\n",
104 | " This overwrites the `how` parameter.\n",
105 | " \n",
106 | " * param subset: \n",
107 | " optional list of column names to consider."
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 6,
113 | "metadata": {
114 | "collapsed": false
115 | },
116 | "outputs": [
117 | {
118 | "name": "stdout",
119 | "output_type": "stream",
120 | "text": [
121 | "+----+-----+-----+\n",
122 | "| Id| Name|Sales|\n",
123 | "+----+-----+-----+\n",
124 | "|emp4|Cindy|456.0|\n",
125 | "+----+-----+-----+\n",
126 | "\n"
127 | ]
128 | }
129 | ],
130 | "source": [
131 | "# Drop any row that contains missing data\n",
132 | "df.na.drop().show()"
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": 8,
138 | "metadata": {
139 | "collapsed": false
140 | },
141 | "outputs": [
142 | {
143 | "name": "stdout",
144 | "output_type": "stream",
145 | "text": [
146 | "+----+-----+-----+\n",
147 | "| Id| Name|Sales|\n",
148 | "+----+-----+-----+\n",
149 | "|emp1| John| null|\n",
150 | "|emp3| null|345.0|\n",
151 | "|emp4|Cindy|456.0|\n",
152 | "+----+-----+-----+\n",
153 | "\n"
154 | ]
155 | }
156 | ],
157 | "source": [
158 | "# Has to have at least 2 NON-null values\n",
159 | "df.na.drop(thresh=2).show()"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 9,
165 | "metadata": {
166 | "collapsed": false
167 | },
168 | "outputs": [
169 | {
170 | "name": "stdout",
171 | "output_type": "stream",
172 | "text": [
173 | "+----+-----+-----+\n",
174 | "| Id| Name|Sales|\n",
175 | "+----+-----+-----+\n",
176 | "|emp3| null|345.0|\n",
177 | "|emp4|Cindy|456.0|\n",
178 | "+----+-----+-----+\n",
179 | "\n"
180 | ]
181 | }
182 | ],
183 | "source": [
184 | "df.na.drop(subset=[\"Sales\"]).show()"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 10,
190 | "metadata": {
191 | "collapsed": false
192 | },
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "+----+-----+-----+\n",
199 | "| Id| Name|Sales|\n",
200 | "+----+-----+-----+\n",
201 | "|emp4|Cindy|456.0|\n",
202 | "+----+-----+-----+\n",
203 | "\n"
204 | ]
205 | }
206 | ],
207 | "source": [
208 | "df.na.drop(how='any').show()"
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "execution_count": 11,
214 | "metadata": {
215 | "collapsed": false
216 | },
217 | "outputs": [
218 | {
219 | "name": "stdout",
220 | "output_type": "stream",
221 | "text": [
222 | "+----+-----+-----+\n",
223 | "| Id| Name|Sales|\n",
224 | "+----+-----+-----+\n",
225 | "|emp1| John| null|\n",
226 | "|emp2| null| null|\n",
227 | "|emp3| null|345.0|\n",
228 | "|emp4|Cindy|456.0|\n",
229 | "+----+-----+-----+\n",
230 | "\n"
231 | ]
232 | }
233 | ],
234 | "source": [
235 | "df.na.drop(how='all').show()"
236 | ]
237 | },
238 | {
239 | "cell_type": "markdown",
240 | "metadata": {},
241 | "source": [
242 | "## Fill the missing values\n",
243 | "\n",
244 | "We can also fill the missing values with new values. If you have multiple nulls across multiple data types, Spark is actually smart enough to match up the data types. For example:"
245 | ]
246 | },
247 | {
248 | "cell_type": "code",
249 | "execution_count": 15,
250 | "metadata": {
251 | "collapsed": false
252 | },
253 | "outputs": [
254 | {
255 | "name": "stdout",
256 | "output_type": "stream",
257 | "text": [
258 | "+----+---------+-----+\n",
259 | "| Id| Name|Sales|\n",
260 | "+----+---------+-----+\n",
261 | "|emp1| John| null|\n",
262 | "|emp2|NEW VALUE| null|\n",
263 | "|emp3|NEW VALUE|345.0|\n",
264 | "|emp4| Cindy|456.0|\n",
265 | "+----+---------+-----+\n",
266 | "\n"
267 | ]
268 | }
269 | ],
270 | "source": [
271 | "df.na.fill('NEW VALUE').show()"
272 | ]
273 | },
274 | {
275 | "cell_type": "code",
276 | "execution_count": 16,
277 | "metadata": {
278 | "collapsed": false
279 | },
280 | "outputs": [
281 | {
282 | "name": "stdout",
283 | "output_type": "stream",
284 | "text": [
285 | "+----+-----+-----+\n",
286 | "| Id| Name|Sales|\n",
287 | "+----+-----+-----+\n",
288 | "|emp1| John| 0.0|\n",
289 | "|emp2| null| 0.0|\n",
290 | "|emp3| null|345.0|\n",
291 | "|emp4|Cindy|456.0|\n",
292 | "+----+-----+-----+\n",
293 | "\n"
294 | ]
295 | }
296 | ],
297 | "source": [
298 | "df.na.fill(0).show()"
299 | ]
300 | },
301 | {
302 | "cell_type": "markdown",
303 | "metadata": {},
304 | "source": [
305 | "Usually you should specify what columns you want to fill with the subset parameter"
306 | ]
307 | },
308 | {
309 | "cell_type": "code",
310 | "execution_count": 17,
311 | "metadata": {
312 | "collapsed": false
313 | },
314 | "outputs": [
315 | {
316 | "name": "stdout",
317 | "output_type": "stream",
318 | "text": [
319 | "+----+-------+-----+\n",
320 | "| Id| Name|Sales|\n",
321 | "+----+-------+-----+\n",
322 | "|emp1| John| null|\n",
323 | "|emp2|No Name| null|\n",
324 | "|emp3|No Name|345.0|\n",
325 | "|emp4| Cindy|456.0|\n",
326 | "+----+-------+-----+\n",
327 | "\n"
328 | ]
329 | }
330 | ],
331 | "source": [
332 | "df.na.fill('No Name',subset=['Name']).show()"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "A very common practice is to fill values with the mean value for the column, for example:"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 23,
345 | "metadata": {
346 | "collapsed": false
347 | },
348 | "outputs": [
349 | {
350 | "data": {
351 | "text/plain": [
352 | "400.5"
353 | ]
354 | },
355 | "execution_count": 23,
356 | "metadata": {},
357 | "output_type": "execute_result"
358 | }
359 | ],
360 | "source": [
361 | "from pyspark.sql.functions import mean\n",
362 | "mean_val = df.select(mean(df['Sales'])).collect()\n",
363 | "\n",
364 | "# Weird nested formatting of Row object!\n",
365 | "mean_val[0][0]"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 24,
371 | "metadata": {
372 | "collapsed": true
373 | },
374 | "outputs": [],
375 | "source": [
376 | "mean_sales = mean_val[0][0]"
377 | ]
378 | },
379 | {
380 | "cell_type": "code",
381 | "execution_count": 26,
382 | "metadata": {
383 | "collapsed": false
384 | },
385 | "outputs": [
386 | {
387 | "name": "stdout",
388 | "output_type": "stream",
389 | "text": [
390 | "+----+-----+-----+\n",
391 | "| Id| Name|Sales|\n",
392 | "+----+-----+-----+\n",
393 | "|emp1| John|400.5|\n",
394 | "|emp2| null|400.5|\n",
395 | "|emp3| null|345.0|\n",
396 | "|emp4|Cindy|456.0|\n",
397 | "+----+-----+-----+\n",
398 | "\n"
399 | ]
400 | }
401 | ],
402 | "source": [
403 | "df.na.fill(mean_sales,[\"Sales\"]).show()"
404 | ]
405 | },
406 | {
407 | "cell_type": "code",
408 | "execution_count": 28,
409 | "metadata": {
410 | "collapsed": false
411 | },
412 | "outputs": [
413 | {
414 | "name": "stdout",
415 | "output_type": "stream",
416 | "text": [
417 | "+----+-----+-----+\n",
418 | "| Id| Name|Sales|\n",
419 | "+----+-----+-----+\n",
420 | "|emp1| John|400.5|\n",
421 | "|emp2| null|400.5|\n",
422 | "|emp3| null|345.0|\n",
423 | "|emp4|Cindy|456.0|\n",
424 | "+----+-----+-----+\n",
425 | "\n"
426 | ]
427 | }
428 | ],
429 | "source": [
430 | "# One (very ugly) one-liner\n",
431 | "df.na.fill(df.select(mean(df['Sales'])).collect()[0][0],['Sales']).show()"
432 | ]
433 | },
434 | {
435 | "cell_type": "markdown",
436 | "metadata": {},
437 | "source": [
438 | "That is all we need to know for now!"
439 | ]
440 | }
441 | ],
442 | "metadata": {
443 | "anaconda-cloud": {},
444 | "kernelspec": {
445 | "display_name": "Python [conda root]",
446 | "language": "python",
447 | "name": "conda-root-py"
448 | },
449 | "language_info": {
450 | "codemirror_mode": {
451 | "name": "ipython",
452 | "version": 3
453 | },
454 | "file_extension": ".py",
455 | "mimetype": "text/x-python",
456 | "name": "python",
457 | "nbconvert_exporter": "python",
458 | "pygments_lexer": "ipython3",
459 | "version": "3.5.3"
460 | }
461 | },
462 | "nbformat": 4,
463 | "nbformat_minor": 0
464 | }
465 |
--------------------------------------------------------------------------------
/SparkContext_Workers_Lazy_Evaluations.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# SparkContext - number of workers and lazy evaluation"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Checking the impact of number of workers\n",
15 | "While initializing the `SparkContext`, we can specify number of worker nodes. Generally, it is recommended to have one worker per core of the machine. But it can be smaller or larger. In the following code, we will examine the impact of number of worker cores on some parallelized operation."
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "from time import time\n",
25 | "from pyspark import SparkContext"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 2,
31 | "metadata": {},
32 | "outputs": [
33 | {
34 | "name": "stdout",
35 | "output_type": "stream",
36 | "text": [
37 | "1 executors, time = 4.308391571044922\n",
38 | "2 executors, time = 2.318211793899536\n",
39 | "3 executors, time = 2.5603320598602295\n",
40 | "4 executors, time = 2.663661003112793\n"
41 | ]
42 | }
43 | ],
44 | "source": [
45 | "for j in range(1,5):\n",
46 | " sc= SparkContext(master = \"local[%d]\"%(j))\n",
47 | " t0=time()\n",
48 | " for i in range(10):\n",
49 | " sc.parallelize([1,2]*10000).reduce(lambda x,y:x+y)\n",
50 | " print(f\"{j} executors, time = {time()-t0}\")\n",
51 | " sc.stop()"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "#### We observe that it takes almost double time for 1 worker, and after that time reduces to a flat level for 2,3,4 workers etc. This is because this code run on a Linux virtual box using only 2 cores from the host machine. If you run this code on a machine with 4 cores, you will see benefit upto 4 cores and then the flattening out of the time taken. It also become clear that using more than one worker per core is not beneficial as it just does context-switching in that case and does not speed up the parallel computation."
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## Showing the essence of _lazy_ evaluation\n",
66 | ""
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 3,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "sc = SparkContext(master=\"local[2]\")"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "metadata": {},
81 | "source": [
82 | "### Make a RDD with 1 million elements"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 19,
88 | "metadata": {},
89 | "outputs": [
90 | {
91 | "name": "stdout",
92 | "output_type": "stream",
93 | "text": [
94 | "CPU times: user 316 µs, sys: 5.13 ms, total: 5.45 ms\n",
95 | "Wall time: 24.6 ms\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "%%time\n",
101 | "rdd1 = sc.parallelize(range(1000000))"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "### Some computing function - `taketime`"
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 20,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "from math import cos\n",
118 | "def taketime(x):\n",
119 | " [cos(j) for j in range(100)]\n",
120 | " return cos(x)"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "### Check how much time is taken by `taketime` function"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": 25,
133 | "metadata": {},
134 | "outputs": [
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "CPU times: user 21 µs, sys: 7 µs, total: 28 µs\n",
140 | "Wall time: 31.5 µs\n"
141 | ]
142 | },
143 | {
144 | "data": {
145 | "text/plain": [
146 | "-0.4161468365471424"
147 | ]
148 | },
149 | "execution_count": 25,
150 | "metadata": {},
151 | "output_type": "execute_result"
152 | }
153 | ],
154 | "source": [
155 | "%%time\n",
156 | "taketime(2)"
157 | ]
158 | },
159 | {
160 | "cell_type": "markdown",
161 | "metadata": {},
162 | "source": [
163 | "### Now do the `map` operation on the function"
164 | ]
165 | },
166 | {
167 | "cell_type": "code",
168 | "execution_count": 26,
169 | "metadata": {},
170 | "outputs": [
171 | {
172 | "name": "stdout",
173 | "output_type": "stream",
174 | "text": [
175 | "CPU times: user 23 µs, sys: 8 µs, total: 31 µs\n",
176 | "Wall time: 34.8 µs\n"
177 | ]
178 | }
179 | ],
180 | "source": [
181 | "%%time\n",
182 | "interim = rdd1.map(lambda x: taketime(x))"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {},
188 | "source": [
189 | "#### How come each taketime function takes 45.8 us but the map operation with a 10000 element RDD also took similar time?
Because of _lazy_ evaluation i.e. nothing was computed in the previous step, just a plan of execution was made. The variable `interim` does not point to a data structure, instead it points to a plan of execution, expressed as a dependency graph. The dependency graph defines how RDDs are computed from each other."
190 | ]
191 | },
192 | {
193 | "cell_type": "markdown",
194 | "metadata": {},
195 | "source": [
196 | "### Let's see the \"Dependency Graph\" using `toDebugString` method"
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": 27,
202 | "metadata": {},
203 | "outputs": [
204 | {
205 | "name": "stdout",
206 | "output_type": "stream",
207 | "text": [
208 | "(2) PythonRDD[10] at RDD at PythonRDD.scala:49 []\n",
209 | " | ParallelCollectionRDD[7] at parallelize at PythonRDD.scala:184 []\n"
210 | ]
211 | }
212 | ],
213 | "source": [
214 | "print(interim.toDebugString().decode())"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | ""
222 | ]
223 | },
224 | {
225 | "cell_type": "markdown",
226 | "metadata": {},
227 | "source": [
228 | "### The actual execution by `reduce` method"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 28,
234 | "metadata": {},
235 | "outputs": [
236 | {
237 | "name": "stdout",
238 | "output_type": "stream",
239 | "text": [
240 | "output = -0.28870546796843666\n",
241 | "CPU times: user 11.6 ms, sys: 5.56 ms, total: 17.2 ms\n",
242 | "Wall time: 15.6 s\n"
243 | ]
244 | }
245 | ],
246 | "source": [
247 | "%%time\n",
248 | "print('output =',interim.reduce(lambda x,y:x+y))"
249 | ]
250 | },
251 | {
252 | "cell_type": "code",
253 | "execution_count": 29,
254 | "metadata": {},
255 | "outputs": [
256 | {
257 | "data": {
258 | "text/plain": [
259 | "31.0"
260 | ]
261 | },
262 | "execution_count": 29,
263 | "metadata": {},
264 | "output_type": "execute_result"
265 | }
266 | ],
267 | "source": [
268 | "1000000*31e-6"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "#### It is less than what we would have expected considering 1 million operations with the `taketime` function. This is the result of parallel operation of 2 cores."
276 | ]
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "metadata": {},
281 | "source": [
282 | "### Now, we have not saved (materialized) any intermediate results in `interim`, so another simple operation (e.g. counting elements > 0) will take almost same time"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": 31,
288 | "metadata": {},
289 | "outputs": [
290 | {
291 | "name": "stdout",
292 | "output_type": "stream",
293 | "text": [
294 | "500000\n",
295 | "CPU times: user 10.6 ms, sys: 8.55 ms, total: 19.2 ms\n",
296 | "Wall time: 12.1 s\n"
297 | ]
298 | }
299 | ],
300 | "source": [
301 | "%%time\n",
302 | "print(interim.filter(lambda x:x>0).count())"
303 | ]
304 | },
305 | {
306 | "cell_type": "markdown",
307 | "metadata": {},
308 | "source": [
309 | "## Caching to reduce computation time on similar operation (spending memory)"
310 | ]
311 | },
312 | {
313 | "cell_type": "markdown",
314 | "metadata": {},
315 | "source": [
316 | "### Run the same computation as before with `cache` method to tell the dependency graph to plan for caching"
317 | ]
318 | },
319 | {
320 | "cell_type": "code",
321 | "execution_count": 32,
322 | "metadata": {},
323 | "outputs": [
324 | {
325 | "name": "stdout",
326 | "output_type": "stream",
327 | "text": [
328 | "CPU times: user 7.22 ms, sys: 4.29 ms, total: 11.5 ms\n",
329 | "Wall time: 63 ms\n"
330 | ]
331 | }
332 | ],
333 | "source": [
334 | "%%time\n",
335 | "interim = rdd1.map(lambda x: taketime(x)).cache()"
336 | ]
337 | },
338 | {
339 | "cell_type": "code",
340 | "execution_count": 33,
341 | "metadata": {},
342 | "outputs": [
343 | {
344 | "name": "stdout",
345 | "output_type": "stream",
346 | "text": [
347 | "(2) PythonRDD[14] at RDD at PythonRDD.scala:49 [Memory Serialized 1x Replicated]\n",
348 | " | ParallelCollectionRDD[7] at parallelize at PythonRDD.scala:184 [Memory Serialized 1x Replicated]\n"
349 | ]
350 | }
351 | ],
352 | "source": [
353 | "print(interim.toDebugString().decode())"
354 | ]
355 | },
356 | {
357 | "cell_type": "code",
358 | "execution_count": 34,
359 | "metadata": {},
360 | "outputs": [
361 | {
362 | "name": "stdout",
363 | "output_type": "stream",
364 | "text": [
365 | "output = -0.28870546796843666\n",
366 | "CPU times: user 16.4 ms, sys: 2.24 ms, total: 18.7 ms\n",
367 | "Wall time: 15.3 s\n"
368 | ]
369 | }
370 | ],
371 | "source": [
372 | "%%time\n",
373 | "print('output =',interim.reduce(lambda x,y:x+y))"
374 | ]
375 | },
376 | {
377 | "cell_type": "markdown",
378 | "metadata": {},
379 | "source": [
380 | "### Now run the same `filter` method with the help of cached result"
381 | ]
382 | },
383 | {
384 | "cell_type": "code",
385 | "execution_count": 35,
386 | "metadata": {},
387 | "outputs": [
388 | {
389 | "name": "stdout",
390 | "output_type": "stream",
391 | "text": [
392 | "500000\n",
393 | "CPU times: user 14.2 ms, sys: 3.27 ms, total: 17.4 ms\n",
394 | "Wall time: 811 ms\n"
395 | ]
396 | }
397 | ],
398 | "source": [
399 | "%%time\n",
400 | "print(interim.filter(lambda x:x>0).count())"
401 | ]
402 | },
403 | {
404 | "cell_type": "markdown",
405 | "metadata": {},
406 | "source": [
407 | "#### This time it took much shorter time due to cached result, which it could use to compare to 0 and count easily."
408 | ]
409 | }
410 | ],
411 | "metadata": {
412 | "kernelspec": {
413 | "display_name": "Python 3",
414 | "language": "python",
415 | "name": "python3"
416 | },
417 | "language_info": {
418 | "codemirror_mode": {
419 | "name": "ipython",
420 | "version": 3
421 | },
422 | "file_extension": ".py",
423 | "mimetype": "text/x-python",
424 | "name": "python",
425 | "nbconvert_exporter": "python",
426 | "pygments_lexer": "ipython3",
427 | "version": "3.6.6"
428 | }
429 | },
430 | "nbformat": 4,
431 | "nbformat_minor": 2
432 | }
433 |
--------------------------------------------------------------------------------
/Row_column_objects.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Row and column objects\n",
8 | "### Dr. Tirthajyoti Sarkar, Fremont, CA 94536\n",
9 | "In this notebook, we will talk about row and column objects of a Spark dataframe."
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [],
17 | "source": [
18 | "from pyspark.sql import SparkSession"
19 | ]
20 | },
21 | {
22 | "cell_type": "code",
23 | "execution_count": 2,
24 | "metadata": {},
25 | "outputs": [],
26 | "source": [
27 | "spark1 = SparkSession.builder.appName('row_col').getOrCreate()"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "### Column objects"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 3,
40 | "metadata": {},
41 | "outputs": [],
42 | "source": [
43 | "df = spark1.read.json('Data/people.json')"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "#### What is the type of a single column?"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 4,
56 | "metadata": {},
57 | "outputs": [
58 | {
59 | "data": {
60 | "text/plain": [
61 | "pyspark.sql.column.Column"
62 | ]
63 | },
64 | "execution_count": 4,
65 | "metadata": {},
66 | "output_type": "execute_result"
67 | }
68 | ],
69 | "source": [
70 | "type(df['age'])"
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "#### But how to extract a single column as a DataFrame? Use `select()`"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 5,
83 | "metadata": {},
84 | "outputs": [
85 | {
86 | "data": {
87 | "text/plain": [
88 | "DataFrame[age: bigint]"
89 | ]
90 | },
91 | "execution_count": 5,
92 | "metadata": {},
93 | "output_type": "execute_result"
94 | }
95 | ],
96 | "source": [
97 | "df.select('age')"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": 6,
103 | "metadata": {},
104 | "outputs": [
105 | {
106 | "name": "stdout",
107 | "output_type": "stream",
108 | "text": [
109 | "+----+\n",
110 | "| age|\n",
111 | "+----+\n",
112 | "|null|\n",
113 | "| 30|\n",
114 | "| 19|\n",
115 | "+----+\n",
116 | "\n"
117 | ]
118 | }
119 | ],
120 | "source": [
121 | "df.select('age').show()"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "### Row objects\n",
129 | "Note, we get back a list of row objects with `head`"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 7,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "data": {
139 | "text/plain": [
140 | "[Row(age=None, name='Michael'), Row(age=30, name='Andy')]"
141 | ]
142 | },
143 | "execution_count": 7,
144 | "metadata": {},
145 | "output_type": "execute_result"
146 | }
147 | ],
148 | "source": [
149 | "df.head(2)"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 8,
155 | "metadata": {},
156 | "outputs": [
157 | {
158 | "data": {
159 | "text/plain": [
160 | "Row(age=None, name='Michael')"
161 | ]
162 | },
163 | "execution_count": 8,
164 | "metadata": {},
165 | "output_type": "execute_result"
166 | }
167 | ],
168 | "source": [
169 | "df.head(2)[0]"
170 | ]
171 | },
172 | {
173 | "cell_type": "code",
174 | "execution_count": 10,
175 | "metadata": {},
176 | "outputs": [],
177 | "source": [
178 | "row0=(df.head(2)[0])"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 11,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "data": {
188 | "text/plain": [
189 | "pyspark.sql.types.Row"
190 | ]
191 | },
192 | "execution_count": 11,
193 | "metadata": {},
194 | "output_type": "execute_result"
195 | }
196 | ],
197 | "source": [
198 | "type(row0)"
199 | ]
200 | },
201 | {
202 | "cell_type": "markdown",
203 | "metadata": {},
204 | "source": [
205 | "#### Row object has a very useful `asDict` method"
206 | ]
207 | },
208 | {
209 | "cell_type": "code",
210 | "execution_count": 12,
211 | "metadata": {},
212 | "outputs": [
213 | {
214 | "data": {
215 | "text/plain": [
216 | "{'age': None, 'name': 'Michael'}"
217 | ]
218 | },
219 | "execution_count": 12,
220 | "metadata": {},
221 | "output_type": "execute_result"
222 | }
223 | ],
224 | "source": [
225 | "row0.asDict()"
226 | ]
227 | },
228 | {
229 | "cell_type": "markdown",
230 | "metadata": {},
231 | "source": [
232 | "Remember that in Pandas DataFrame we have pandas.series object as either column or row.
\n",
233 | "The reason Spark offers separate Column or Row object is the ability to work over a distributed file system where this distinction will come handy."
234 | ]
235 | },
236 | {
237 | "cell_type": "markdown",
238 | "metadata": {},
239 | "source": [
240 | "### Create new columns (after some processing of existing columns)"
241 | ]
242 | },
243 | {
244 | "cell_type": "markdown",
245 | "metadata": {},
246 | "source": [
247 | "#### You cannot think like Pandas. Following will produce error"
248 | ]
249 | },
250 | {
251 | "cell_type": "code",
252 | "execution_count": 13,
253 | "metadata": {},
254 | "outputs": [
255 | {
256 | "ename": "TypeError",
257 | "evalue": "'DataFrame' object does not support item assignment",
258 | "output_type": "error",
259 | "traceback": [
260 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
261 | "\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
262 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mdf\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m'newage'\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0;36m2\u001b[0m\u001b[0;34m*\u001b[0m\u001b[0mdf\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m'age'\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
263 | "\u001b[0;31mTypeError\u001b[0m: 'DataFrame' object does not support item assignment"
264 | ]
265 | }
266 | ],
267 | "source": [
268 | "df['newage']=2*df['age']"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "#### Use `useColumn()` method instead"
276 | ]
277 | },
278 | {
279 | "cell_type": "code",
280 | "execution_count": 14,
281 | "metadata": {},
282 | "outputs": [
283 | {
284 | "name": "stdout",
285 | "output_type": "stream",
286 | "text": [
287 | "+----+-------+----------+\n",
288 | "| age| name|double_age|\n",
289 | "+----+-------+----------+\n",
290 | "|null|Michael| null|\n",
291 | "| 30| Andy| 60|\n",
292 | "| 19| Justin| 38|\n",
293 | "+----+-------+----------+\n",
294 | "\n"
295 | ]
296 | }
297 | ],
298 | "source": [
299 | "df.withColumn('double_age',df['age']*2).show()"
300 | ]
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {},
305 | "source": [
306 | "#### Just for renaming, use `withColumnRenamed()` method"
307 | ]
308 | },
309 | {
310 | "cell_type": "code",
311 | "execution_count": 15,
312 | "metadata": {},
313 | "outputs": [
314 | {
315 | "name": "stdout",
316 | "output_type": "stream",
317 | "text": [
318 | "+----------+-------+\n",
319 | "|my_new_age| name|\n",
320 | "+----------+-------+\n",
321 | "| null|Michael|\n",
322 | "| 30| Andy|\n",
323 | "| 19| Justin|\n",
324 | "+----------+-------+\n",
325 | "\n"
326 | ]
327 | }
328 | ],
329 | "source": [
330 | "df.withColumnRenamed('age','my_new_age').show()"
331 | ]
332 | },
333 | {
334 | "cell_type": "markdown",
335 | "metadata": {},
336 | "source": [
337 | "#### You can do operation with multiple columns, like a vector sum"
338 | ]
339 | },
340 | {
341 | "cell_type": "code",
342 | "execution_count": 16,
343 | "metadata": {},
344 | "outputs": [
345 | {
346 | "name": "stdout",
347 | "output_type": "stream",
348 | "text": [
349 | "+----+-------+--------+\n",
350 | "| age| name|half_age|\n",
351 | "+----+-------+--------+\n",
352 | "|null|Michael| null|\n",
353 | "| 30| Andy| 15.0|\n",
354 | "| 19| Justin| 9.5|\n",
355 | "+----+-------+--------+\n",
356 | "\n"
357 | ]
358 | }
359 | ],
360 | "source": [
361 | "df2=df.withColumn('half_age',df['age']/2)\n",
362 | "df2.show()"
363 | ]
364 | },
365 | {
366 | "cell_type": "code",
367 | "execution_count": 17,
368 | "metadata": {},
369 | "outputs": [
370 | {
371 | "name": "stdout",
372 | "output_type": "stream",
373 | "text": [
374 | "+----+-------+--------+-------+\n",
375 | "| age| name|half_age|new_age|\n",
376 | "+----+-------+--------+-------+\n",
377 | "|null|Michael| null| null|\n",
378 | "| 30| Andy| 15.0| 45.0|\n",
379 | "| 19| Justin| 9.5| 28.5|\n",
380 | "+----+-------+--------+-------+\n",
381 | "\n"
382 | ]
383 | }
384 | ],
385 | "source": [
386 | "df2=df2.withColumn('new_age',df2['age']+df2['half_age'])\n",
387 | "df2.show()"
388 | ]
389 | },
390 | {
391 | "cell_type": "markdown",
392 | "metadata": {},
393 | "source": [
394 | "#### Now if you print the schema, you will see that the data type of `half_age` and `new_age` are automaically set to `double` (due to floating point operation performed)"
395 | ]
396 | },
397 | {
398 | "cell_type": "code",
399 | "execution_count": 18,
400 | "metadata": {},
401 | "outputs": [
402 | {
403 | "name": "stdout",
404 | "output_type": "stream",
405 | "text": [
406 | "root\n",
407 | " |-- age: long (nullable = true)\n",
408 | " |-- name: string (nullable = true)\n",
409 | " |-- half_age: double (nullable = true)\n",
410 | " |-- new_age: double (nullable = true)\n",
411 | "\n"
412 | ]
413 | }
414 | ],
415 | "source": [
416 | "df2.printSchema()"
417 | ]
418 | },
419 | {
420 | "cell_type": "markdown",
421 | "metadata": {},
422 | "source": [
423 | "#### DataFrame is immutable and there is no inplace choice like Pandas! So the original DataFrame has not changed"
424 | ]
425 | },
426 | {
427 | "cell_type": "code",
428 | "execution_count": 20,
429 | "metadata": {},
430 | "outputs": [
431 | {
432 | "name": "stdout",
433 | "output_type": "stream",
434 | "text": [
435 | "+----+-------+\n",
436 | "| age| name|\n",
437 | "+----+-------+\n",
438 | "|null|Michael|\n",
439 | "| 30| Andy|\n",
440 | "| 19| Justin|\n",
441 | "+----+-------+\n",
442 | "\n"
443 | ]
444 | }
445 | ],
446 | "source": [
447 | "df.show()"
448 | ]
449 | }
450 | ],
451 | "metadata": {
452 | "kernelspec": {
453 | "display_name": "Python 3",
454 | "language": "python",
455 | "name": "python3"
456 | },
457 | "language_info": {
458 | "codemirror_mode": {
459 | "name": "ipython",
460 | "version": 3
461 | },
462 | "file_extension": ".py",
463 | "mimetype": "text/x-python",
464 | "name": "python",
465 | "nbconvert_exporter": "python",
466 | "pygments_lexer": "ipython3",
467 | "version": "3.6.8"
468 | }
469 | },
470 | "nbformat": 4,
471 | "nbformat_minor": 2
472 | }
473 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Clustering/seeds_dataset.csv:
--------------------------------------------------------------------------------
1 | area,perimeter,compactness,length_of_kernel,width_of_kernel,asymmetry_coefficient,length_of_groove
2 | 15.26,14.84,0.871,5.763,3.312,2.221,5.22
3 | 14.88,14.57,0.8811,5.553999999999999,3.333,1.018,4.956
4 | 14.29,14.09,0.905,5.291,3.3369999999999997,2.699,4.825
5 | 13.84,13.94,0.8955,5.324,3.3789999999999996,2.259,4.805
6 | 16.14,14.99,0.9034,5.6579999999999995,3.562,1.355,5.175
7 | 14.38,14.21,0.8951,5.386,3.312,2.4619999999999997,4.956
8 | 14.69,14.49,0.8799,5.563,3.259,3.5860000000000003,5.218999999999999
9 | 14.11,14.1,0.8911,5.42,3.302,2.7,5.0
10 | 16.63,15.46,0.8747,6.053,3.465,2.04,5.877000000000001
11 | 16.44,15.25,0.888,5.8839999999999995,3.505,1.969,5.5329999999999995
12 | 15.26,14.85,0.8696,5.7139999999999995,3.242,4.543,5.314
13 | 14.03,14.16,0.8796,5.438,3.201,1.7169999999999999,5.001
14 | 13.89,14.02,0.888,5.439,3.199,3.986,4.738
15 | 13.78,14.06,0.8759,5.479,3.156,3.136,4.872
16 | 13.74,14.05,0.8744,5.482,3.114,2.932,4.825
17 | 14.59,14.28,0.8993,5.351,3.333,4.185,4.781000000000001
18 | 13.99,13.83,0.9183,5.119,3.383,5.234,4.781000000000001
19 | 15.69,14.75,0.9058,5.527,3.514,1.599,5.046
20 | 14.7,14.21,0.9153,5.205,3.466,1.767,4.649
21 | 12.72,13.57,0.8686,5.226,3.049,4.102,4.914
22 | 14.16,14.4,0.8584,5.6579999999999995,3.1289999999999996,3.072,5.176
23 | 14.11,14.26,0.8722,5.52,3.168,2.688,5.218999999999999
24 | 15.88,14.9,0.8988,5.617999999999999,3.5069999999999997,0.765,5.091
25 | 12.08,13.23,0.8664,5.099,2.9360000000000004,1.415,4.961
26 | 15.01,14.76,0.8657,5.789,3.245,1.791,5.001
27 | 16.19,15.16,0.8849,5.832999999999999,3.4210000000000003,0.903,5.307
28 | 13.02,13.76,0.8641,5.395,3.0260000000000002,3.373,4.825
29 | 12.74,13.67,0.8564,5.395,2.9560000000000004,2.504,4.869
30 | 14.11,14.18,0.882,5.541,3.221,2.7539999999999996,5.038
31 | 13.45,14.02,0.8604,5.516,3.065,3.531,5.0969999999999995
32 | 13.16,13.82,0.8662,5.454,2.975,0.855,5.056
33 | 15.49,14.94,0.8724,5.757000000000001,3.3710000000000004,3.412,5.228
34 | 14.09,14.41,0.8529,5.7170000000000005,3.1860000000000004,3.92,5.2989999999999995
35 | 13.94,14.17,0.8728,5.585,3.15,2.124,5.012
36 | 15.05,14.68,0.8779,5.712000000000001,3.3280000000000003,2.129,5.36
37 | 16.12,15.0,0.9,5.709,3.485,2.27,5.443
38 | 16.2,15.27,0.8734,5.8260000000000005,3.464,2.823,5.527
39 | 17.08,15.38,0.9079,5.832000000000001,3.6830000000000003,2.9560000000000004,5.484
40 | 14.8,14.52,0.8823,5.656000000000001,3.2880000000000003,3.112,5.309
41 | 14.28,14.17,0.8944,5.397,3.298,6.685,5.001
42 | 13.54,13.85,0.8871,5.348,3.156,2.5869999999999997,5.178
43 | 13.5,13.85,0.8852,5.351,3.158,2.249,5.176
44 | 13.16,13.55,0.9009,5.138,3.201,2.461,4.783
45 | 15.5,14.86,0.882,5.877000000000001,3.3960000000000004,4.711,5.528
46 | 15.11,14.54,0.8986,5.579,3.4619999999999997,3.128,5.18
47 | 13.8,14.04,0.8794,5.376,3.155,1.56,4.961
48 | 15.36,14.76,0.8861,5.7010000000000005,3.3930000000000002,1.367,5.132000000000001
49 | 14.99,14.56,0.8883,5.57,3.377,2.958,5.175
50 | 14.79,14.52,0.8819,5.545,3.2910000000000004,2.7039999999999997,5.111000000000001
51 | 14.86,14.67,0.8676,5.678,3.258,2.129,5.351
52 | 14.43,14.4,0.8751,5.585,3.272,3.975,5.144
53 | 15.78,14.91,0.8923,5.6739999999999995,3.4339999999999997,5.593,5.136
54 | 14.49,14.61,0.8538,5.715,3.113,4.1160000000000005,5.396
55 | 14.33,14.28,0.8831,5.504,3.199,3.3280000000000003,5.224
56 | 14.52,14.6,0.8557,5.7410000000000005,3.113,1.4809999999999999,5.487
57 | 15.03,14.77,0.8658,5.702000000000001,3.2119999999999997,1.933,5.439
58 | 14.46,14.35,0.8818,5.388,3.377,2.802,5.044
59 | 14.92,14.43,0.9006,5.3839999999999995,3.412,1.1420000000000001,5.088
60 | 15.38,14.77,0.8857,5.662000000000001,3.4189999999999996,1.999,5.222
61 | 12.11,13.47,0.8392,5.159,3.032,1.5019999999999998,4.519
62 | 11.42,12.86,0.8683,5.008,2.85,2.7,4.607
63 | 11.23,12.63,0.884,4.902,2.8789999999999996,2.269,4.703
64 | 12.36,13.19,0.8923,5.0760000000000005,3.042,3.22,4.605
65 | 13.22,13.84,0.868,5.395,3.07,4.157,5.088
66 | 12.78,13.57,0.8716,5.2620000000000005,3.0260000000000002,1.176,4.782
67 | 12.88,13.5,0.8879,5.138999999999999,3.1189999999999998,2.352,4.607
68 | 14.34,14.37,0.8726,5.63,3.19,1.3130000000000002,5.15
69 | 14.01,14.29,0.8625,5.609,3.158,2.217,5.132000000000001
70 | 14.37,14.39,0.8726,5.569,3.153,1.464,5.3
71 | 12.73,13.75,0.8458,5.412000000000001,2.8819999999999997,3.533,5.067
72 | 17.63,15.98,0.8673,6.191,3.5610000000000004,4.0760000000000005,6.06
73 | 16.84,15.67,0.8623,5.997999999999999,3.484,4.675,5.877000000000001
74 | 17.26,15.73,0.8763,5.978,3.594,4.539,5.791
75 | 19.11,16.26,0.9081,6.154,3.93,2.9360000000000004,6.079
76 | 16.82,15.51,0.8786,6.017,3.486,4.004,5.841
77 | 16.77,15.62,0.8638,5.9270000000000005,3.438,4.92,5.795
78 | 17.32,15.91,0.8599,6.064,3.403,3.824,5.922000000000001
79 | 20.71,17.23,0.8763,6.579,3.8139999999999996,4.4510000000000005,6.4510000000000005
80 | 18.94,16.49,0.875,6.445,3.639,5.064,6.362
81 | 17.12,15.55,0.8892,5.85,3.5660000000000003,2.858,5.746
82 | 16.53,15.34,0.8823,5.875,3.467,5.532,5.88
83 | 18.72,16.19,0.8977,6.006,3.8569999999999998,5.324,5.879
84 | 20.2,16.89,0.8894,6.285,3.864,5.172999999999999,6.187
85 | 19.57,16.74,0.8779,6.3839999999999995,3.772,1.472,6.273
86 | 19.51,16.71,0.878,6.3660000000000005,3.801,2.9619999999999997,6.185
87 | 18.27,16.09,0.887,6.172999999999999,3.6510000000000002,2.443,6.197
88 | 18.88,16.26,0.8969,6.084,3.764,1.649,6.109
89 | 18.98,16.66,0.8590000000000001,6.5489999999999995,3.67,3.6910000000000003,6.497999999999999
90 | 21.18,17.21,0.8989,6.5729999999999995,4.033,5.78,6.231
91 | 20.88,17.05,0.9031,6.45,4.032,5.016,6.321000000000001
92 | 20.1,16.99,0.8746,6.581,3.785,1.955,6.449
93 | 18.76,16.2,0.8984,6.172000000000001,3.7960000000000003,3.12,6.053
94 | 18.81,16.29,0.8906,6.272,3.693,3.237,6.053
95 | 18.59,16.05,0.9066,6.037000000000001,3.86,6.001,5.877000000000001
96 | 18.36,16.52,0.8452,6.666,3.485,4.933,6.4479999999999995
97 | 16.87,15.65,0.8648,6.138999999999999,3.463,3.696,5.9670000000000005
98 | 19.31,16.59,0.8815,6.341,3.81,3.477,6.2379999999999995
99 | 18.98,16.57,0.8687,6.449,3.552,2.144,6.452999999999999
100 | 18.17,16.26,0.8637,6.271,3.512,2.853,6.273
101 | 18.72,16.34,0.8809999999999999,6.218999999999999,3.6839999999999997,2.188,6.097
102 | 16.41,15.25,0.8866,5.718,3.525,4.217,5.617999999999999
103 | 17.99,15.86,0.8992,5.89,3.694,2.068,5.837000000000001
104 | 19.46,16.5,0.8985,6.1129999999999995,3.892,4.308,6.0089999999999995
105 | 19.18,16.63,0.8717,6.369,3.681,3.3569999999999998,6.229
106 | 18.95,16.42,0.8829,6.247999999999999,3.755,3.3680000000000003,6.148
107 | 18.83,16.29,0.8917,6.037000000000001,3.786,2.553,5.879
108 | 18.85,16.17,0.9056,6.152,3.806,2.843,6.2
109 | 17.63,15.86,0.88,6.0329999999999995,3.573,3.747,5.928999999999999
110 | 19.94,16.92,0.8752,6.675,3.763,3.252,6.55
111 | 18.55,16.22,0.8865,6.153,3.674,1.7380000000000002,5.894
112 | 18.45,16.12,0.8921,6.107,3.7689999999999997,2.235,5.794
113 | 19.38,16.72,0.8716,6.303,3.7910000000000004,3.678,5.965
114 | 19.13,16.31,0.9035,6.183,3.9019999999999997,2.109,5.9239999999999995
115 | 19.14,16.61,0.8722,6.2589999999999995,3.737,6.682,6.053
116 | 20.97,17.25,0.8859,6.563,3.991,4.677,6.316
117 | 19.06,16.45,0.8854,6.416,3.719,2.248,6.162999999999999
118 | 18.96,16.2,0.9077,6.051,3.897,4.334,5.75
119 | 19.15,16.45,0.889,6.245,3.815,3.0839999999999996,6.185
120 | 18.89,16.23,0.9008,6.227,3.7689999999999997,3.639,5.966
121 | 20.03,16.9,0.8811,6.492999999999999,3.8569999999999998,3.063,6.32
122 | 20.24,16.91,0.8897,6.315,3.9619999999999997,5.901,6.188
123 | 18.14,16.12,0.8772,6.059,3.563,3.6189999999999998,6.011
124 | 16.17,15.38,0.8588,5.7620000000000005,3.387,4.2860000000000005,5.702999999999999
125 | 18.43,15.97,0.9077,5.98,3.7710000000000004,2.984,5.905
126 | 15.99,14.89,0.9064,5.3629999999999995,3.582,3.3360000000000003,5.144
127 | 18.75,16.18,0.8999,6.111000000000001,3.8689999999999998,4.188,5.992000000000001
128 | 18.65,16.41,0.8698,6.285,3.594,4.391,6.102
129 | 17.98,15.85,0.8993,5.979,3.687,2.2569999999999997,5.919
130 | 20.16,17.03,0.8735,6.513,3.773,1.91,6.185
131 | 17.55,15.66,0.8991,5.791,3.69,5.3660000000000005,5.6610000000000005
132 | 18.3,15.89,0.9108,5.979,3.755,2.8369999999999997,5.962000000000001
133 | 18.94,16.32,0.8942,6.144,3.825,2.908,5.949
134 | 15.38,14.9,0.8706,5.8839999999999995,3.2680000000000002,4.462,5.795
135 | 16.16,15.33,0.8644,5.845,3.395,4.266,5.795
136 | 15.56,14.89,0.8823,5.776,3.408,4.9719999999999995,5.847
137 | 15.38,14.66,0.899,5.477,3.465,3.6,5.439
138 | 17.36,15.76,0.8785,6.145,3.574,3.5260000000000002,5.971
139 | 15.57,15.15,0.8527,5.92,3.2310000000000003,2.64,5.879
140 | 15.6,15.11,0.858,5.832000000000001,3.286,2.725,5.752000000000001
141 | 16.23,15.18,0.885,5.872000000000001,3.472,3.7689999999999997,5.922000000000001
142 | 13.07,13.92,0.848,5.472,2.9939999999999998,5.303999999999999,5.395
143 | 13.32,13.94,0.8613,5.541,3.073,7.035,5.44
144 | 13.34,13.95,0.862,5.388999999999999,3.074,5.995,5.307
145 | 12.22,13.32,0.8652,5.224,2.967,5.468999999999999,5.221
146 | 11.82,13.4,0.8274,5.314,2.7769999999999997,4.471,5.178
147 | 11.21,13.13,0.8167,5.279,2.687,6.169,5.275
148 | 11.43,13.13,0.8335,5.176,2.719,2.221,5.132000000000001
149 | 12.49,13.46,0.8658,5.267,2.967,4.421,5.002
150 | 12.7,13.71,0.8491,5.386,2.911,3.26,5.316
151 | 10.79,12.93,0.8107,5.317,2.648,5.462000000000001,5.194
152 | 11.83,13.23,0.8496,5.263,2.84,5.195,5.307
153 | 12.01,13.52,0.8249,5.405,2.7760000000000002,6.992000000000001,5.27
154 | 12.26,13.6,0.8333,5.4079999999999995,2.833,4.756,5.36
155 | 11.18,13.04,0.8266,5.22,2.693,3.332,5.001
156 | 11.36,13.05,0.8382,5.175,2.755,4.048,5.263
157 | 11.19,13.05,0.8253,5.25,2.675,5.813,5.218999999999999
158 | 11.34,12.87,0.8596,5.053,2.8489999999999998,3.347,5.003
159 | 12.13,13.73,0.8081,5.394,2.745,4.825,5.22
160 | 11.75,13.52,0.8082,5.444,2.678,4.378,5.31
161 | 11.49,13.22,0.8263,5.303999999999999,2.695,5.388,5.31
162 | 12.54,13.67,0.8425,5.4510000000000005,2.8789999999999996,3.082,5.4910000000000005
163 | 12.02,13.33,0.8503,5.35,2.81,4.271,5.308
164 | 12.05,13.41,0.8416,5.267,2.847,4.988,5.046
165 | 12.55,13.57,0.8558,5.332999999999999,2.968,4.419,5.176
166 | 11.14,12.79,0.8558,5.011,2.7939999999999996,6.388,5.0489999999999995
167 | 12.1,13.15,0.8793,5.105,2.9410000000000003,2.201,5.056
168 | 12.44,13.59,0.8462,5.319,2.897,4.9239999999999995,5.27
169 | 12.15,13.45,0.8443,5.417000000000001,2.8369999999999997,3.638,5.337999999999999
170 | 11.35,13.12,0.8291,5.176,2.668,4.337,5.132000000000001
171 | 11.24,13.0,0.8359,5.09,2.715,3.5210000000000004,5.088
172 | 11.02,13.0,0.8189,5.325,2.701,6.735,5.162999999999999
173 | 11.55,13.1,0.8455,5.167000000000001,2.845,6.715,4.956
174 | 11.27,12.97,0.8419,5.088,2.763,4.309,5.0
175 | 11.4,13.08,0.8375,5.136,2.763,5.587999999999999,5.0889999999999995
176 | 10.83,12.96,0.8099,5.278,2.641,5.182,5.185
177 | 10.8,12.57,0.8590000000000001,4.981,2.821,4.773,5.063
178 | 11.26,13.01,0.8355,5.186,2.71,5.335,5.092
179 | 10.74,12.73,0.8329,5.145,2.642,4.702,4.963
180 | 11.48,13.05,0.8473,5.18,2.758,5.876,5.002
181 | 12.21,13.47,0.8453,5.357,2.8930000000000002,1.661,5.178
182 | 11.41,12.95,0.856,5.09,2.775,4.957,4.825
183 | 12.46,13.41,0.8706,5.236000000000001,3.017,4.987,5.147
184 | 12.19,13.36,0.8579,5.24,2.909,4.857,5.1579999999999995
185 | 11.65,13.07,0.8575,5.1080000000000005,2.85,5.209,5.135
186 | 12.89,13.77,0.8541,5.495,3.0260000000000002,6.185,5.316
187 | 11.56,13.31,0.8198,5.3629999999999995,2.6830000000000003,4.062,5.182
188 | 11.81,13.45,0.8198,5.412999999999999,2.716,4.898,5.352
189 | 10.91,12.8,0.8372,5.088,2.675,4.178999999999999,4.956
190 | 11.23,12.82,0.8594,5.0889999999999995,2.821,7.524,4.957
191 | 10.59,12.41,0.8648,4.899,2.787,4.975,4.794
192 | 10.93,12.8,0.8390000000000001,5.046,2.717,5.398,5.045
193 | 11.27,12.86,0.8563,5.091,2.804,3.985,5.001
194 | 11.87,13.02,0.8795,5.132000000000001,2.9530000000000003,3.597,5.132000000000001
195 | 10.82,12.83,0.8256,5.18,2.63,4.853,5.0889999999999995
196 | 12.11,13.27,0.8639,5.236000000000001,2.975,4.132,5.012
197 | 12.8,13.47,0.8859999999999999,5.16,3.1260000000000003,4.873,4.914
198 | 12.79,13.53,0.8786,5.224,3.054,5.483,4.958
199 | 13.37,13.78,0.8849,5.32,3.128,4.67,5.091
200 | 12.62,13.67,0.8481,5.41,2.911,3.306,5.231
201 | 12.76,13.38,0.8964,5.073,3.155,2.8280000000000003,4.83
202 | 12.38,13.44,0.8609,5.218999999999999,2.989,5.472,5.045
203 | 12.67,13.32,0.8977,4.984,3.135,2.3,4.745
204 | 11.18,12.72,0.868,5.0089999999999995,2.81,4.051,4.828
205 | 12.7,13.41,0.8874,5.183,3.091,8.456,5.0
206 | 12.37,13.47,0.8567,5.204,2.96,3.9189999999999996,5.001
207 | 12.19,13.2,0.8783,5.1370000000000005,2.9810000000000003,3.6310000000000002,4.87
208 | 11.23,12.88,0.8511,5.14,2.795,4.325,5.003
209 | 13.2,13.66,0.8883,5.236000000000001,3.2319999999999998,8.315,5.056
210 | 11.84,13.21,0.8521,5.175,2.8360000000000003,3.5980000000000003,5.044
211 | 12.3,13.34,0.8684,5.242999999999999,2.9739999999999998,5.6370000000000005,5.063
212 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Clustering/seeds_dataset.txt:
--------------------------------------------------------------------------------
1 | area,perimeter,compactness,length of kernel,width of kernel,asymmetry coefficient,length of groove
2 | 15.26,14.84,0.871,5.763,3.312,2.221,5.22
3 | 14.88,14.57,0.8811,5.553999999999999,3.333,1.018,4.956
4 | 14.29,14.09,0.905,5.291,3.3369999999999997,2.699,4.825
5 | 13.84,13.94,0.8955,5.324,3.3789999999999996,2.259,4.805
6 | 16.14,14.99,0.9034,5.6579999999999995,3.562,1.355,5.175
7 | 14.38,14.21,0.8951,5.386,3.312,2.4619999999999997,4.956
8 | 14.69,14.49,0.8799,5.563,3.259,3.5860000000000003,5.218999999999999
9 | 14.11,14.1,0.8911,5.42,3.302,2.7,5.0
10 | 16.63,15.46,0.8747,6.053,3.465,2.04,5.877000000000001
11 | 16.44,15.25,0.888,5.8839999999999995,3.505,1.969,5.5329999999999995
12 | 15.26,14.85,0.8696,5.7139999999999995,3.242,4.543,5.314
13 | 14.03,14.16,0.8796,5.438,3.201,1.7169999999999999,5.001
14 | 13.89,14.02,0.888,5.439,3.199,3.986,4.738
15 | 13.78,14.06,0.8759,5.479,3.156,3.136,4.872
16 | 13.74,14.05,0.8744,5.482,3.114,2.932,4.825
17 | 14.59,14.28,0.8993,5.351,3.333,4.185,4.781000000000001
18 | 13.99,13.83,0.9183,5.119,3.383,5.234,4.781000000000001
19 | 15.69,14.75,0.9058,5.527,3.514,1.599,5.046
20 | 14.7,14.21,0.9153,5.205,3.466,1.767,4.649
21 | 12.72,13.57,0.8686,5.226,3.049,4.102,4.914
22 | 14.16,14.4,0.8584,5.6579999999999995,3.1289999999999996,3.072,5.176
23 | 14.11,14.26,0.8722,5.52,3.168,2.688,5.218999999999999
24 | 15.88,14.9,0.8988,5.617999999999999,3.5069999999999997,0.765,5.091
25 | 12.08,13.23,0.8664,5.099,2.9360000000000004,1.415,4.961
26 | 15.01,14.76,0.8657,5.789,3.245,1.791,5.001
27 | 16.19,15.16,0.8849,5.832999999999999,3.4210000000000003,0.903,5.307
28 | 13.02,13.76,0.8641,5.395,3.0260000000000002,3.373,4.825
29 | 12.74,13.67,0.8564,5.395,2.9560000000000004,2.504,4.869
30 | 14.11,14.18,0.882,5.541,3.221,2.7539999999999996,5.038
31 | 13.45,14.02,0.8604,5.516,3.065,3.531,5.0969999999999995
32 | 13.16,13.82,0.8662,5.454,2.975,0.855,5.056
33 | 15.49,14.94,0.8724,5.757000000000001,3.3710000000000004,3.412,5.228
34 | 14.09,14.41,0.8529,5.7170000000000005,3.1860000000000004,3.92,5.2989999999999995
35 | 13.94,14.17,0.8728,5.585,3.15,2.124,5.012
36 | 15.05,14.68,0.8779,5.712000000000001,3.3280000000000003,2.129,5.36
37 | 16.12,15.0,0.9,5.709,3.485,2.27,5.443
38 | 16.2,15.27,0.8734,5.8260000000000005,3.464,2.823,5.527
39 | 17.08,15.38,0.9079,5.832000000000001,3.6830000000000003,2.9560000000000004,5.484
40 | 14.8,14.52,0.8823,5.656000000000001,3.2880000000000003,3.112,5.309
41 | 14.28,14.17,0.8944,5.397,3.298,6.685,5.001
42 | 13.54,13.85,0.8871,5.348,3.156,2.5869999999999997,5.178
43 | 13.5,13.85,0.8852,5.351,3.158,2.249,5.176
44 | 13.16,13.55,0.9009,5.138,3.201,2.461,4.783
45 | 15.5,14.86,0.882,5.877000000000001,3.3960000000000004,4.711,5.528
46 | 15.11,14.54,0.8986,5.579,3.4619999999999997,3.128,5.18
47 | 13.8,14.04,0.8794,5.376,3.155,1.56,4.961
48 | 15.36,14.76,0.8861,5.7010000000000005,3.3930000000000002,1.367,5.132000000000001
49 | 14.99,14.56,0.8883,5.57,3.377,2.958,5.175
50 | 14.79,14.52,0.8819,5.545,3.2910000000000004,2.7039999999999997,5.111000000000001
51 | 14.86,14.67,0.8676,5.678,3.258,2.129,5.351
52 | 14.43,14.4,0.8751,5.585,3.272,3.975,5.144
53 | 15.78,14.91,0.8923,5.6739999999999995,3.4339999999999997,5.593,5.136
54 | 14.49,14.61,0.8538,5.715,3.113,4.1160000000000005,5.396
55 | 14.33,14.28,0.8831,5.504,3.199,3.3280000000000003,5.224
56 | 14.52,14.6,0.8557,5.7410000000000005,3.113,1.4809999999999999,5.487
57 | 15.03,14.77,0.8658,5.702000000000001,3.2119999999999997,1.933,5.439
58 | 14.46,14.35,0.8818,5.388,3.377,2.802,5.044
59 | 14.92,14.43,0.9006,5.3839999999999995,3.412,1.1420000000000001,5.088
60 | 15.38,14.77,0.8857,5.662000000000001,3.4189999999999996,1.999,5.222
61 | 12.11,13.47,0.8392,5.159,3.032,1.5019999999999998,4.519
62 | 11.42,12.86,0.8683,5.008,2.85,2.7,4.607
63 | 11.23,12.63,0.884,4.902,2.8789999999999996,2.269,4.703
64 | 12.36,13.19,0.8923,5.0760000000000005,3.042,3.22,4.605
65 | 13.22,13.84,0.868,5.395,3.07,4.157,5.088
66 | 12.78,13.57,0.8716,5.2620000000000005,3.0260000000000002,1.176,4.782
67 | 12.88,13.5,0.8879,5.138999999999999,3.1189999999999998,2.352,4.607
68 | 14.34,14.37,0.8726,5.63,3.19,1.3130000000000002,5.15
69 | 14.01,14.29,0.8625,5.609,3.158,2.217,5.132000000000001
70 | 14.37,14.39,0.8726,5.569,3.153,1.464,5.3
71 | 12.73,13.75,0.8458,5.412000000000001,2.8819999999999997,3.533,5.067
72 | 17.63,15.98,0.8673,6.191,3.5610000000000004,4.0760000000000005,6.06
73 | 16.84,15.67,0.8623,5.997999999999999,3.484,4.675,5.877000000000001
74 | 17.26,15.73,0.8763,5.978,3.594,4.539,5.791
75 | 19.11,16.26,0.9081,6.154,3.93,2.9360000000000004,6.079
76 | 16.82,15.51,0.8786,6.017,3.486,4.004,5.841
77 | 16.77,15.62,0.8638,5.9270000000000005,3.438,4.92,5.795
78 | 17.32,15.91,0.8599,6.064,3.403,3.824,5.922000000000001
79 | 20.71,17.23,0.8763,6.579,3.8139999999999996,4.4510000000000005,6.4510000000000005
80 | 18.94,16.49,0.875,6.445,3.639,5.064,6.362
81 | 17.12,15.55,0.8892,5.85,3.5660000000000003,2.858,5.746
82 | 16.53,15.34,0.8823,5.875,3.467,5.532,5.88
83 | 18.72,16.19,0.8977,6.006,3.8569999999999998,5.324,5.879
84 | 20.2,16.89,0.8894,6.285,3.864,5.172999999999999,6.187
85 | 19.57,16.74,0.8779,6.3839999999999995,3.772,1.472,6.273
86 | 19.51,16.71,0.878,6.3660000000000005,3.801,2.9619999999999997,6.185
87 | 18.27,16.09,0.887,6.172999999999999,3.6510000000000002,2.443,6.197
88 | 18.88,16.26,0.8969,6.084,3.764,1.649,6.109
89 | 18.98,16.66,0.8590000000000001,6.5489999999999995,3.67,3.6910000000000003,6.497999999999999
90 | 21.18,17.21,0.8989,6.5729999999999995,4.033,5.78,6.231
91 | 20.88,17.05,0.9031,6.45,4.032,5.016,6.321000000000001
92 | 20.1,16.99,0.8746,6.581,3.785,1.955,6.449
93 | 18.76,16.2,0.8984,6.172000000000001,3.7960000000000003,3.12,6.053
94 | 18.81,16.29,0.8906,6.272,3.693,3.237,6.053
95 | 18.59,16.05,0.9066,6.037000000000001,3.86,6.001,5.877000000000001
96 | 18.36,16.52,0.8452,6.666,3.485,4.933,6.4479999999999995
97 | 16.87,15.65,0.8648,6.138999999999999,3.463,3.696,5.9670000000000005
98 | 19.31,16.59,0.8815,6.341,3.81,3.477,6.2379999999999995
99 | 18.98,16.57,0.8687,6.449,3.552,2.144,6.452999999999999
100 | 18.17,16.26,0.8637,6.271,3.512,2.853,6.273
101 | 18.72,16.34,0.8809999999999999,6.218999999999999,3.6839999999999997,2.188,6.097
102 | 16.41,15.25,0.8866,5.718,3.525,4.217,5.617999999999999
103 | 17.99,15.86,0.8992,5.89,3.694,2.068,5.837000000000001
104 | 19.46,16.5,0.8985,6.1129999999999995,3.892,4.308,6.0089999999999995
105 | 19.18,16.63,0.8717,6.369,3.681,3.3569999999999998,6.229
106 | 18.95,16.42,0.8829,6.247999999999999,3.755,3.3680000000000003,6.148
107 | 18.83,16.29,0.8917,6.037000000000001,3.786,2.553,5.879
108 | 18.85,16.17,0.9056,6.152,3.806,2.843,6.2
109 | 17.63,15.86,0.88,6.0329999999999995,3.573,3.747,5.928999999999999
110 | 19.94,16.92,0.8752,6.675,3.763,3.252,6.55
111 | 18.55,16.22,0.8865,6.153,3.674,1.7380000000000002,5.894
112 | 18.45,16.12,0.8921,6.107,3.7689999999999997,2.235,5.794
113 | 19.38,16.72,0.8716,6.303,3.7910000000000004,3.678,5.965
114 | 19.13,16.31,0.9035,6.183,3.9019999999999997,2.109,5.9239999999999995
115 | 19.14,16.61,0.8722,6.2589999999999995,3.737,6.682,6.053
116 | 20.97,17.25,0.8859,6.563,3.991,4.677,6.316
117 | 19.06,16.45,0.8854,6.416,3.719,2.248,6.162999999999999
118 | 18.96,16.2,0.9077,6.051,3.897,4.334,5.75
119 | 19.15,16.45,0.889,6.245,3.815,3.0839999999999996,6.185
120 | 18.89,16.23,0.9008,6.227,3.7689999999999997,3.639,5.966
121 | 20.03,16.9,0.8811,6.492999999999999,3.8569999999999998,3.063,6.32
122 | 20.24,16.91,0.8897,6.315,3.9619999999999997,5.901,6.188
123 | 18.14,16.12,0.8772,6.059,3.563,3.6189999999999998,6.011
124 | 16.17,15.38,0.8588,5.7620000000000005,3.387,4.2860000000000005,5.702999999999999
125 | 18.43,15.97,0.9077,5.98,3.7710000000000004,2.984,5.905
126 | 15.99,14.89,0.9064,5.3629999999999995,3.582,3.3360000000000003,5.144
127 | 18.75,16.18,0.8999,6.111000000000001,3.8689999999999998,4.188,5.992000000000001
128 | 18.65,16.41,0.8698,6.285,3.594,4.391,6.102
129 | 17.98,15.85,0.8993,5.979,3.687,2.2569999999999997,5.919
130 | 20.16,17.03,0.8735,6.513,3.773,1.91,6.185
131 | 17.55,15.66,0.8991,5.791,3.69,5.3660000000000005,5.6610000000000005
132 | 18.3,15.89,0.9108,5.979,3.755,2.8369999999999997,5.962000000000001
133 | 18.94,16.32,0.8942,6.144,3.825,2.908,5.949
134 | 15.38,14.9,0.8706,5.8839999999999995,3.2680000000000002,4.462,5.795
135 | 16.16,15.33,0.8644,5.845,3.395,4.266,5.795
136 | 15.56,14.89,0.8823,5.776,3.408,4.9719999999999995,5.847
137 | 15.38,14.66,0.899,5.477,3.465,3.6,5.439
138 | 17.36,15.76,0.8785,6.145,3.574,3.5260000000000002,5.971
139 | 15.57,15.15,0.8527,5.92,3.2310000000000003,2.64,5.879
140 | 15.6,15.11,0.858,5.832000000000001,3.286,2.725,5.752000000000001
141 | 16.23,15.18,0.885,5.872000000000001,3.472,3.7689999999999997,5.922000000000001
142 | 13.07,13.92,0.848,5.472,2.9939999999999998,5.303999999999999,5.395
143 | 13.32,13.94,0.8613,5.541,3.073,7.035,5.44
144 | 13.34,13.95,0.862,5.388999999999999,3.074,5.995,5.307
145 | 12.22,13.32,0.8652,5.224,2.967,5.468999999999999,5.221
146 | 11.82,13.4,0.8274,5.314,2.7769999999999997,4.471,5.178
147 | 11.21,13.13,0.8167,5.279,2.687,6.169,5.275
148 | 11.43,13.13,0.8335,5.176,2.719,2.221,5.132000000000001
149 | 12.49,13.46,0.8658,5.267,2.967,4.421,5.002
150 | 12.7,13.71,0.8491,5.386,2.911,3.26,5.316
151 | 10.79,12.93,0.8107,5.317,2.648,5.462000000000001,5.194
152 | 11.83,13.23,0.8496,5.263,2.84,5.195,5.307
153 | 12.01,13.52,0.8249,5.405,2.7760000000000002,6.992000000000001,5.27
154 | 12.26,13.6,0.8333,5.4079999999999995,2.833,4.756,5.36
155 | 11.18,13.04,0.8266,5.22,2.693,3.332,5.001
156 | 11.36,13.05,0.8382,5.175,2.755,4.048,5.263
157 | 11.19,13.05,0.8253,5.25,2.675,5.813,5.218999999999999
158 | 11.34,12.87,0.8596,5.053,2.8489999999999998,3.347,5.003
159 | 12.13,13.73,0.8081,5.394,2.745,4.825,5.22
160 | 11.75,13.52,0.8082,5.444,2.678,4.378,5.31
161 | 11.49,13.22,0.8263,5.303999999999999,2.695,5.388,5.31
162 | 12.54,13.67,0.8425,5.4510000000000005,2.8789999999999996,3.082,5.4910000000000005
163 | 12.02,13.33,0.8503,5.35,2.81,4.271,5.308
164 | 12.05,13.41,0.8416,5.267,2.847,4.988,5.046
165 | 12.55,13.57,0.8558,5.332999999999999,2.968,4.419,5.176
166 | 11.14,12.79,0.8558,5.011,2.7939999999999996,6.388,5.0489999999999995
167 | 12.1,13.15,0.8793,5.105,2.9410000000000003,2.201,5.056
168 | 12.44,13.59,0.8462,5.319,2.897,4.9239999999999995,5.27
169 | 12.15,13.45,0.8443,5.417000000000001,2.8369999999999997,3.638,5.337999999999999
170 | 11.35,13.12,0.8291,5.176,2.668,4.337,5.132000000000001
171 | 11.24,13.0,0.8359,5.09,2.715,3.5210000000000004,5.088
172 | 11.02,13.0,0.8189,5.325,2.701,6.735,5.162999999999999
173 | 11.55,13.1,0.8455,5.167000000000001,2.845,6.715,4.956
174 | 11.27,12.97,0.8419,5.088,2.763,4.309,5.0
175 | 11.4,13.08,0.8375,5.136,2.763,5.587999999999999,5.0889999999999995
176 | 10.83,12.96,0.8099,5.278,2.641,5.182,5.185
177 | 10.8,12.57,0.8590000000000001,4.981,2.821,4.773,5.063
178 | 11.26,13.01,0.8355,5.186,2.71,5.335,5.092
179 | 10.74,12.73,0.8329,5.145,2.642,4.702,4.963
180 | 11.48,13.05,0.8473,5.18,2.758,5.876,5.002
181 | 12.21,13.47,0.8453,5.357,2.8930000000000002,1.661,5.178
182 | 11.41,12.95,0.856,5.09,2.775,4.957,4.825
183 | 12.46,13.41,0.8706,5.236000000000001,3.017,4.987,5.147
184 | 12.19,13.36,0.8579,5.24,2.909,4.857,5.1579999999999995
185 | 11.65,13.07,0.8575,5.1080000000000005,2.85,5.209,5.135
186 | 12.89,13.77,0.8541,5.495,3.0260000000000002,6.185,5.316
187 | 11.56,13.31,0.8198,5.3629999999999995,2.6830000000000003,4.062,5.182
188 | 11.81,13.45,0.8198,5.412999999999999,2.716,4.898,5.352
189 | 10.91,12.8,0.8372,5.088,2.675,4.178999999999999,4.956
190 | 11.23,12.82,0.8594,5.0889999999999995,2.821,7.524,4.957
191 | 10.59,12.41,0.8648,4.899,2.787,4.975,4.794
192 | 10.93,12.8,0.8390000000000001,5.046,2.717,5.398,5.045
193 | 11.27,12.86,0.8563,5.091,2.804,3.985,5.001
194 | 11.87,13.02,0.8795,5.132000000000001,2.9530000000000003,3.597,5.132000000000001
195 | 10.82,12.83,0.8256,5.18,2.63,4.853,5.0889999999999995
196 | 12.11,13.27,0.8639,5.236000000000001,2.975,4.132,5.012
197 | 12.8,13.47,0.8859999999999999,5.16,3.1260000000000003,4.873,4.914
198 | 12.79,13.53,0.8786,5.224,3.054,5.483,4.958
199 | 13.37,13.78,0.8849,5.32,3.128,4.67,5.091
200 | 12.62,13.67,0.8481,5.41,2.911,3.306,5.231
201 | 12.76,13.38,0.8964,5.073,3.155,2.8280000000000003,4.83
202 | 12.38,13.44,0.8609,5.218999999999999,2.989,5.472,5.045
203 | 12.67,13.32,0.8977,4.984,3.135,2.3,4.745
204 | 11.18,12.72,0.868,5.0089999999999995,2.81,4.051,4.828
205 | 12.7,13.41,0.8874,5.183,3.091,8.456,5.0
206 | 12.37,13.47,0.8567,5.204,2.96,3.9189999999999996,5.001
207 | 12.19,13.2,0.8783,5.1370000000000005,2.9810000000000003,3.6310000000000002,4.87
208 | 11.23,12.88,0.8511,5.14,2.795,4.325,5.003
209 | 13.2,13.66,0.8883,5.236000000000001,3.2319999999999998,8.315,5.056
210 | 11.84,13.21,0.8521,5.175,2.8360000000000003,3.5980000000000003,5.044
211 | 12.3,13.34,0.8684,5.242999999999999,2.9739999999999998,5.6370000000000005,5.063
212 |
--------------------------------------------------------------------------------
/Python-and-Spark-for-Big-Data-master/Spark_for_Machine_Learning/Logistic_Regression/Logistic_Regression_Example.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Logistic Regression\n",
8 | "\n",
9 | "Let's see an example of how to run a logistic regression with Python and Spark! This is documentation example, we will quickly run through this and then show a more realistic example, afterwards, you will have another consulting project!"
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 69,
15 | "metadata": {
16 | "collapsed": true
17 | },
18 | "outputs": [],
19 | "source": [
20 | "from pyspark.sql import SparkSession\n",
21 | "spark = SparkSession.builder.appName('logregdoc').getOrCreate()"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 70,
27 | "metadata": {
28 | "collapsed": true
29 | },
30 | "outputs": [],
31 | "source": [
32 | "from pyspark.ml.classification import LogisticRegression"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 86,
38 | "metadata": {
39 | "collapsed": false
40 | },
41 | "outputs": [],
42 | "source": [
43 | "# Load training data\n",
44 | "training = spark.read.format(\"libsvm\").load(\"sample_libsvm_data.txt\")\n",
45 | "\n",
46 | "lr = LogisticRegression()\n",
47 | "\n",
48 | "# Fit the model\n",
49 | "lrModel = lr.fit(training)\n",
50 | "\n",
51 | "trainingSummary = lrModel.summary"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": 87,
57 | "metadata": {
58 | "collapsed": false
59 | },
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "+-----+--------------------+--------------------+--------------------+----------+\n",
66 | "|label| features| rawPrediction| probability|prediction|\n",
67 | "+-----+--------------------+--------------------+--------------------+----------+\n",
68 | "| 0.0|(692,[127,128,129...|[19.8534775947479...|[0.99999999761359...| 0.0|\n",
69 | "| 1.0|(692,[158,159,160...|[-20.377398194909...|[1.41321555110962...| 1.0|\n",
70 | "| 1.0|(692,[124,125,126...|[-27.401459284891...|[1.25804865127002...| 1.0|\n",
71 | "| 1.0|(692,[152,153,154...|[-18.862741612668...|[6.42710509170470...| 1.0|\n",
72 | "| 1.0|(692,[151,152,153...|[-20.483011833009...|[1.27157209200655...| 1.0|\n",
73 | "| 0.0|(692,[129,130,131...|[19.8506078990277...|[0.99999999760673...| 0.0|\n",
74 | "| 1.0|(692,[158,159,160...|[-20.337256674834...|[1.47109814695468...| 1.0|\n",
75 | "| 1.0|(692,[99,100,101,...|[-19.595579753418...|[3.08850168102550...| 1.0|\n",
76 | "| 0.0|(692,[154,155,156...|[19.2708803215615...|[0.99999999572670...| 0.0|\n",
77 | "| 0.0|(692,[127,128,129...|[23.6202328360424...|[0.99999999994480...| 0.0|\n",
78 | "| 1.0|(692,[154,155,156...|[-24.385235147660...|[2.56818872776620...| 1.0|\n",
79 | "| 0.0|(692,[153,154,155...|[26.3082522490181...|[0.99999999999624...| 0.0|\n",
80 | "| 0.0|(692,[151,152,153...|[25.8329060318707...|[0.99999999999396...| 0.0|\n",
81 | "| 1.0|(692,[129,130,131...|[-19.794609139087...|[2.53110684529387...| 1.0|\n",
82 | "| 0.0|(692,[154,155,156...|[21.0260440948067...|[0.99999999926123...| 0.0|\n",
83 | "| 1.0|(692,[150,151,152...|[-22.764979942873...|[1.29806018790960...| 1.0|\n",
84 | "| 0.0|(692,[124,125,126...|[21.5049307193955...|[0.99999999954235...| 0.0|\n",
85 | "| 0.0|(692,[152,153,154...|[31.9927184226426...|[0.99999999999998...| 0.0|\n",
86 | "| 1.0|(692,[97,98,99,12...|[-20.521067180413...|[1.22409115616575...| 1.0|\n",
87 | "| 1.0|(692,[124,125,126...|[-22.245377742755...|[2.18250475400430...| 1.0|\n",
88 | "+-----+--------------------+--------------------+--------------------+----------+\n",
89 | "only showing top 20 rows\n",
90 | "\n"
91 | ]
92 | }
93 | ],
94 | "source": [
95 | "trainingSummary.predictions.show()"
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": 73,
101 | "metadata": {
102 | "collapsed": true
103 | },
104 | "outputs": [],
105 | "source": [
106 | "# May change soon!\n",
107 | "from pyspark.mllib.evaluation import MulticlassMetrics"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 74,
113 | "metadata": {
114 | "collapsed": false
115 | },
116 | "outputs": [
117 | {
118 | "data": {
119 | "text/plain": [
120 | ""
121 | ]
122 | },
123 | "execution_count": 74,
124 | "metadata": {},
125 | "output_type": "execute_result"
126 | }
127 | ],
128 | "source": [
129 | "lrModel.evaluate(training)"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 75,
135 | "metadata": {
136 | "collapsed": true
137 | },
138 | "outputs": [],
139 | "source": [
140 | "# Usually would do this on a separate test set!\n",
141 | "predictionAndLabels = lrModel.evaluate(training)"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 76,
147 | "metadata": {
148 | "collapsed": false
149 | },
150 | "outputs": [
151 | {
152 | "name": "stdout",
153 | "output_type": "stream",
154 | "text": [
155 | "+-----+--------------------+--------------------+--------------------+----------+\n",
156 | "|label| features| rawPrediction| probability|prediction|\n",
157 | "+-----+--------------------+--------------------+--------------------+----------+\n",
158 | "| 0.0|(692,[127,128,129...|[19.8534775947479...|[0.99999999761359...| 0.0|\n",
159 | "| 1.0|(692,[158,159,160...|[-20.377398194909...|[1.41321555110962...| 1.0|\n",
160 | "| 1.0|(692,[124,125,126...|[-27.401459284891...|[1.25804865127002...| 1.0|\n",
161 | "| 1.0|(692,[152,153,154...|[-18.862741612668...|[6.42710509170470...| 1.0|\n",
162 | "| 1.0|(692,[151,152,153...|[-20.483011833009...|[1.27157209200655...| 1.0|\n",
163 | "| 0.0|(692,[129,130,131...|[19.8506078990277...|[0.99999999760673...| 0.0|\n",
164 | "| 1.0|(692,[158,159,160...|[-20.337256674834...|[1.47109814695468...| 1.0|\n",
165 | "| 1.0|(692,[99,100,101,...|[-19.595579753418...|[3.08850168102550...| 1.0|\n",
166 | "| 0.0|(692,[154,155,156...|[19.2708803215615...|[0.99999999572670...| 0.0|\n",
167 | "| 0.0|(692,[127,128,129...|[23.6202328360424...|[0.99999999994480...| 0.0|\n",
168 | "| 1.0|(692,[154,155,156...|[-24.385235147660...|[2.56818872776620...| 1.0|\n",
169 | "| 0.0|(692,[153,154,155...|[26.3082522490181...|[0.99999999999624...| 0.0|\n",
170 | "| 0.0|(692,[151,152,153...|[25.8329060318707...|[0.99999999999396...| 0.0|\n",
171 | "| 1.0|(692,[129,130,131...|[-19.794609139087...|[2.53110684529387...| 1.0|\n",
172 | "| 0.0|(692,[154,155,156...|[21.0260440948067...|[0.99999999926123...| 0.0|\n",
173 | "| 1.0|(692,[150,151,152...|[-22.764979942873...|[1.29806018790960...| 1.0|\n",
174 | "| 0.0|(692,[124,125,126...|[21.5049307193955...|[0.99999999954235...| 0.0|\n",
175 | "| 0.0|(692,[152,153,154...|[31.9927184226426...|[0.99999999999998...| 0.0|\n",
176 | "| 1.0|(692,[97,98,99,12...|[-20.521067180413...|[1.22409115616575...| 1.0|\n",
177 | "| 1.0|(692,[124,125,126...|[-22.245377742755...|[2.18250475400430...| 1.0|\n",
178 | "+-----+--------------------+--------------------+--------------------+----------+\n",
179 | "only showing top 20 rows\n",
180 | "\n"
181 | ]
182 | }
183 | ],
184 | "source": [
185 | "predictionAndLabels.predictions.show()"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 77,
191 | "metadata": {
192 | "collapsed": false
193 | },
194 | "outputs": [],
195 | "source": [
196 | "predictionAndLabels = predictionAndLabels.predictions.select('label','prediction')"
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": 78,
202 | "metadata": {
203 | "collapsed": false
204 | },
205 | "outputs": [
206 | {
207 | "name": "stdout",
208 | "output_type": "stream",
209 | "text": [
210 | "+-----+----------+\n",
211 | "|label|prediction|\n",
212 | "+-----+----------+\n",
213 | "| 0.0| 0.0|\n",
214 | "| 1.0| 1.0|\n",
215 | "| 1.0| 1.0|\n",
216 | "| 1.0| 1.0|\n",
217 | "| 1.0| 1.0|\n",
218 | "| 0.0| 0.0|\n",
219 | "| 1.0| 1.0|\n",
220 | "| 1.0| 1.0|\n",
221 | "| 0.0| 0.0|\n",
222 | "| 0.0| 0.0|\n",
223 | "| 1.0| 1.0|\n",
224 | "| 0.0| 0.0|\n",
225 | "| 0.0| 0.0|\n",
226 | "| 1.0| 1.0|\n",
227 | "| 0.0| 0.0|\n",
228 | "| 1.0| 1.0|\n",
229 | "| 0.0| 0.0|\n",
230 | "| 0.0| 0.0|\n",
231 | "| 1.0| 1.0|\n",
232 | "| 1.0| 1.0|\n",
233 | "+-----+----------+\n",
234 | "only showing top 20 rows\n",
235 | "\n"
236 | ]
237 | }
238 | ],
239 | "source": [
240 | "predictionAndLabels.show()"
241 | ]
242 | },
243 | {
244 | "cell_type": "markdown",
245 | "metadata": {},
246 | "source": [
247 | "## Evaluators\n",
248 | "\n",
249 | "Evaluators will be a very important part of our pipline when working with Machine Learning, let's see some basics for Logistic Regression, useful links:\n",
250 | "\n",
251 | "https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.evaluation.BinaryClassificationEvaluator\n",
252 | "\n",
253 | "https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.evaluation.MulticlassClassificationEvaluator"
254 | ]
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": 79,
259 | "metadata": {
260 | "collapsed": false
261 | },
262 | "outputs": [],
263 | "source": [
264 | "from pyspark.ml.evaluation import BinaryClassificationEvaluator,MulticlassClassificationEvaluator"
265 | ]
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": 89,
270 | "metadata": {
271 | "collapsed": true
272 | },
273 | "outputs": [],
274 | "source": [
275 | "evaluator = BinaryClassificationEvaluator(rawPredictionCol='prediction', labelCol='label')"
276 | ]
277 | },
278 | {
279 | "cell_type": "code",
280 | "execution_count": 83,
281 | "metadata": {
282 | "collapsed": false
283 | },
284 | "outputs": [],
285 | "source": [
286 | "# For multiclass\n",
287 | "evaluator = MulticlassClassificationEvaluator(predictionCol='prediction', labelCol='label',\n",
288 | " metricName='accuracy')"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 90,
294 | "metadata": {
295 | "collapsed": true
296 | },
297 | "outputs": [],
298 | "source": [
299 | "acc = evaluator.evaluate(predictionAndLabels)"
300 | ]
301 | },
302 | {
303 | "cell_type": "code",
304 | "execution_count": 91,
305 | "metadata": {
306 | "collapsed": false
307 | },
308 | "outputs": [
309 | {
310 | "data": {
311 | "text/plain": [
312 | "1.0"
313 | ]
314 | },
315 | "execution_count": 91,
316 | "metadata": {},
317 | "output_type": "execute_result"
318 | }
319 | ],
320 | "source": [
321 | "acc"
322 | ]
323 | },
324 | {
325 | "cell_type": "markdown",
326 | "metadata": {},
327 | "source": [
328 | "Okay let's move on see some more examples!"
329 | ]
330 | }
331 | ],
332 | "metadata": {
333 | "anaconda-cloud": {},
334 | "kernelspec": {
335 | "display_name": "Python [conda root]",
336 | "language": "python",
337 | "name": "conda-root-py"
338 | },
339 | "language_info": {
340 | "codemirror_mode": {
341 | "name": "ipython",
342 | "version": 3
343 | },
344 | "file_extension": ".py",
345 | "mimetype": "text/x-python",
346 | "name": "python",
347 | "nbconvert_exporter": "python",
348 | "pygments_lexer": "ipython3",
349 | "version": "3.5.3"
350 | }
351 | },
352 | "nbformat": 4,
353 | "nbformat_minor": 0
354 | }
355 |
--------------------------------------------------------------------------------