├── .gitignore
├── README.md
├── data_set
└── README.md
├── main.py
└── util
├── __init__.py
├── image_augmenter.py
├── loader.py
├── model.py
└── repoter.py
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea/
2 | data_set/VOCdevkit/
3 | result/
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Semantic Segmentation using U-Net on Pascal VOC 2012
2 | This repository implements semantic segmentation on Pascal VOC2012 using U-Net.
3 |
4 | An article about this implementation is [here](https://qiita.com/tktktks10/items/0f551aea27d2f62ef708).
5 |
6 | Semantic segmentation is a kind of image processing as below.
7 |
8 | 
 9 |
10 | This package includes modules of data loader, reporter(creates reports of experiments), data augmenter, u-net model, and training it.
11 |
12 | # Usage
13 | To show how to run.
14 |
15 | `python main.py --help`
16 |
17 |
18 | To run with data augmentation using GPUs.
19 |
20 | `python main.py --gpu --augmentation`
21 |
22 |
23 | # U-Net
24 | U-Net is an encoder-decoder model consisted of only convolutions, without fully connected layers.
25 |
26 | U-Net has a shape like "U" as below, that's why it is called U-Net.
27 |
28 |
9 |
10 | This package includes modules of data loader, reporter(creates reports of experiments), data augmenter, u-net model, and training it.
11 |
12 | # Usage
13 | To show how to run.
14 |
15 | `python main.py --help`
16 |
17 |
18 | To run with data augmentation using GPUs.
19 |
20 | `python main.py --gpu --augmentation`
21 |
22 |
23 | # U-Net
24 | U-Net is an encoder-decoder model consisted of only convolutions, without fully connected layers.
25 |
26 | U-Net has a shape like "U" as below, that's why it is called U-Net.
27 |
28 | 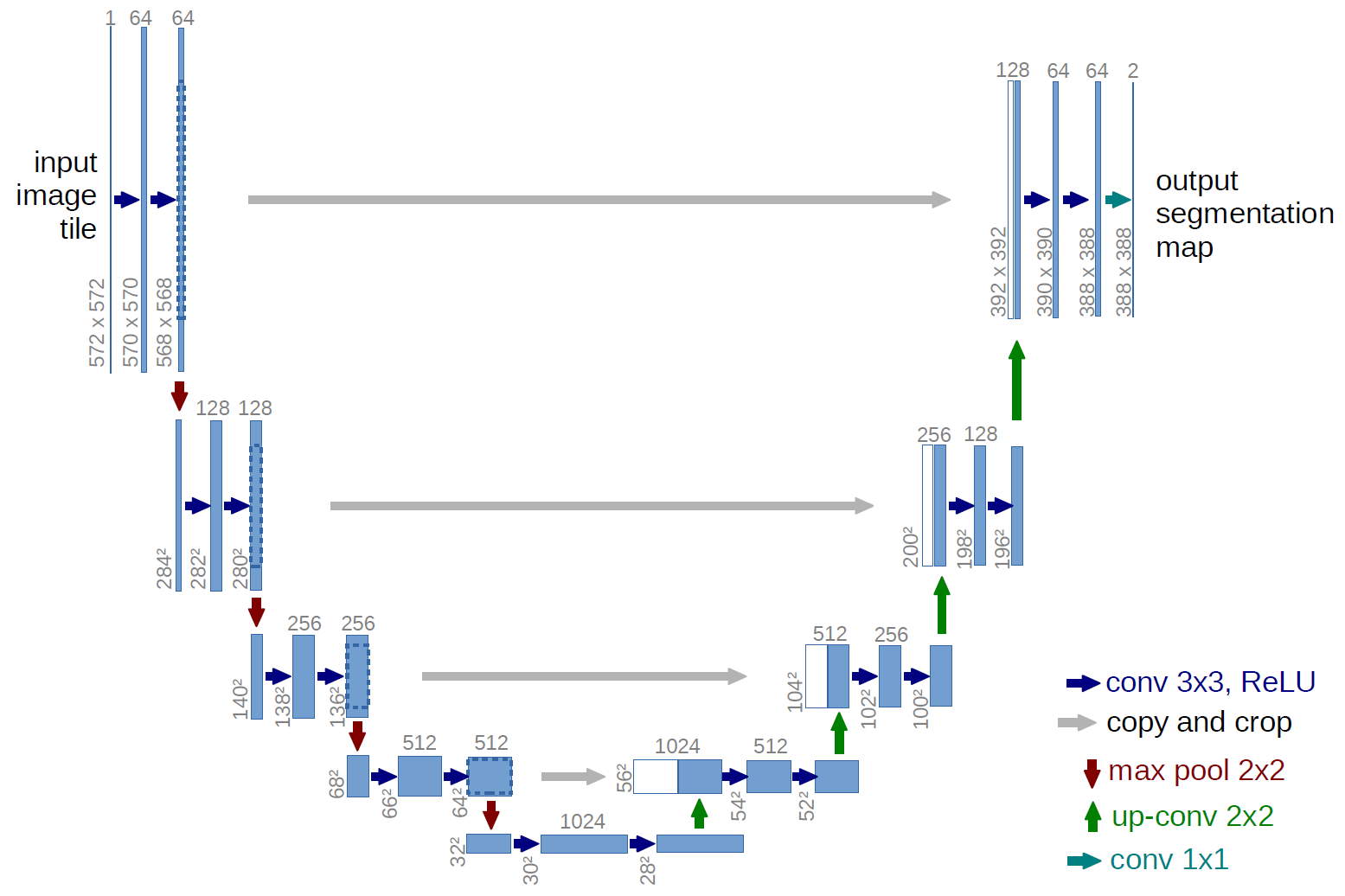 29 |
30 |
31 | # Experiments
32 |
33 | The following results is got by default settings.
34 |
35 | ## Results of segmentation
36 | ### For the training set
37 | 
38 |
39 | 
40 |
41 | ### For the test set
42 | 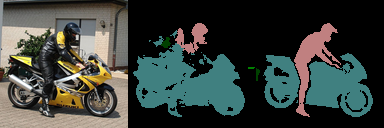
43 |
44 | 
45 |
46 | 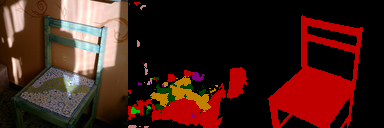
47 |
48 |
49 |
50 | ## Accuracy and Loss
51 |
29 |
30 |
31 | # Experiments
32 |
33 | The following results is got by default settings.
34 |
35 | ## Results of segmentation
36 | ### For the training set
37 | 
38 |
39 | 
40 |
41 | ### For the test set
42 | 
43 |
44 | 
45 |
46 | 
47 |
48 |
49 |
50 | ## Accuracy and Loss
51 | 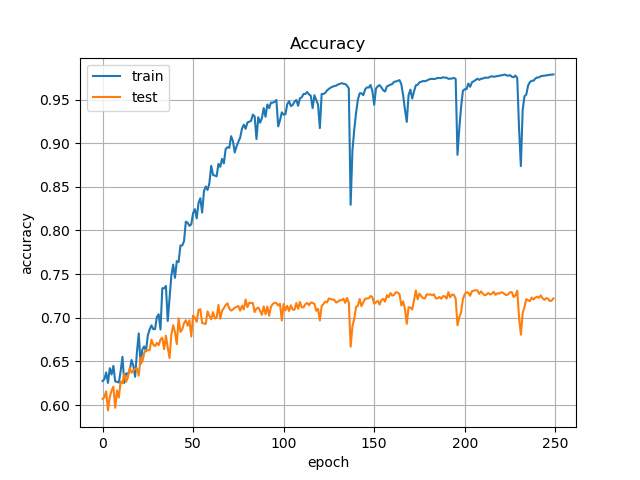
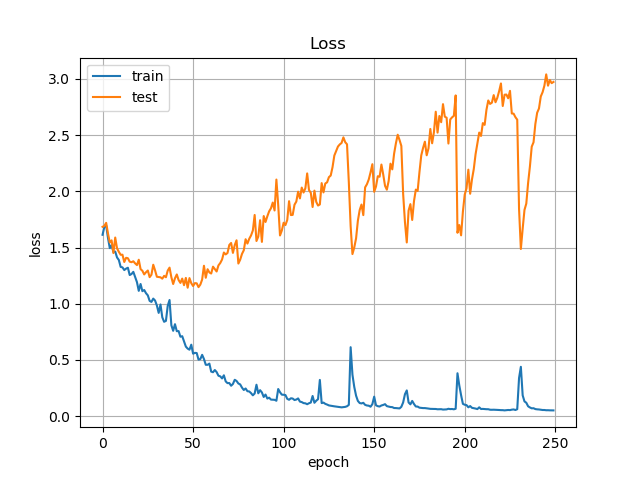 52 |
53 |
54 |
55 |
56 |
57 |
--------------------------------------------------------------------------------
/data_set/README.md:
--------------------------------------------------------------------------------
1 | You should store VOCdevkit here.
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import random
3 | import tensorflow as tf
4 |
5 | from util import loader as ld
6 | from util import model
7 | from util import repoter as rp
8 |
9 |
10 | def load_dataset(train_rate):
11 | loader = ld.Loader(dir_original="data_set/VOCdevkit/VOC2012/JPEGImages",
12 | dir_segmented="data_set/VOCdevkit/VOC2012/SegmentationClass")
13 | return loader.load_train_test(train_rate=train_rate, shuffle=False)
14 |
15 |
16 | def train(parser):
17 | # 訓練とテストデータを読み込みます
18 | # Load train and test datas
19 | train, test = load_dataset(train_rate=parser.trainrate)
20 | valid = train.perm(0, 30)
21 | test = test.perm(0, 150)
22 |
23 | # 結果保存用のインスタンスを作成します
24 | # Create Reporter Object
25 | reporter = rp.Reporter(parser=parser)
26 | accuracy_fig = reporter.create_figure("Accuracy", ("epoch", "accuracy"), ["train", "test"])
27 | loss_fig = reporter.create_figure("Loss", ("epoch", "loss"), ["train", "test"])
28 |
29 | # GPUを使用するか
30 | # Whether or not using a GPU
31 | gpu = parser.gpu
32 |
33 | # モデルの生成
34 | # Create a model
35 | model_unet = model.UNet(l2_reg=parser.l2reg).model
36 |
37 | # 誤差関数とオプティマイザの設定をします
38 | # Set a loss function and an optimizer
39 | cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=model_unet.teacher,
40 | logits=model_unet.outputs))
41 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
42 | with tf.control_dependencies(update_ops):
43 | train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
44 |
45 | # 精度の算出をします
46 | # Calculate accuracy
47 | correct_prediction = tf.equal(tf.argmax(model_unet.outputs, 3), tf.argmax(model_unet.teacher, 3))
48 | accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
49 |
50 | # セッションの初期化をします
51 | # Initialize session
52 | gpu_config = tf.ConfigProto(gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.7), device_count={'GPU': 1},
53 | log_device_placement=False, allow_soft_placement=True)
54 | sess = tf.InteractiveSession(config=gpu_config) if gpu else tf.InteractiveSession()
55 | tf.global_variables_initializer().run()
56 |
57 | # モデルの訓練
58 | # Train the model
59 | epochs = parser.epoch
60 | batch_size = parser.batchsize
61 | is_augment = parser.augmentation
62 | train_dict = {model_unet.inputs: valid.images_original, model_unet.teacher: valid.images_segmented,
63 | model_unet.is_training: False}
64 | test_dict = {model_unet.inputs: test.images_original, model_unet.teacher: test.images_segmented,
65 | model_unet.is_training: False}
66 |
67 | for epoch in range(epochs):
68 | for batch in train(batch_size=batch_size, augment=is_augment):
69 | # バッチデータの展開
70 | inputs = batch.images_original
71 | teacher = batch.images_segmented
72 | # Training
73 | sess.run(train_step, feed_dict={model_unet.inputs: inputs, model_unet.teacher: teacher,
74 | model_unet.is_training: True})
75 |
76 | # 評価
77 | # Evaluation
78 | if epoch % 1 == 0:
79 | loss_train = sess.run(cross_entropy, feed_dict=train_dict)
80 | loss_test = sess.run(cross_entropy, feed_dict=test_dict)
81 | accuracy_train = sess.run(accuracy, feed_dict=train_dict)
82 | accuracy_test = sess.run(accuracy, feed_dict=test_dict)
83 | print("Epoch:", epoch)
84 | print("[Train] Loss:", loss_train, " Accuracy:", accuracy_train)
85 | print("[Test] Loss:", loss_test, "Accuracy:", accuracy_test)
86 | accuracy_fig.add([accuracy_train, accuracy_test], is_update=True)
87 | loss_fig.add([loss_train, loss_test], is_update=True)
88 | if epoch % 3 == 0:
89 | idx_train = random.randrange(10)
90 | idx_test = random.randrange(100)
91 | outputs_train = sess.run(model_unet.outputs,
92 | feed_dict={model_unet.inputs: [train.images_original[idx_train]],
93 | model_unet.is_training: False})
94 | outputs_test = sess.run(model_unet.outputs,
95 | feed_dict={model_unet.inputs: [test.images_original[idx_test]],
96 | model_unet.is_training: False})
97 | train_set = [train.images_original[idx_train], outputs_train[0], train.images_segmented[idx_train]]
98 | test_set = [test.images_original[idx_test], outputs_test[0], test.images_segmented[idx_test]]
99 | reporter.save_image_from_ndarray(train_set, test_set, train.palette, epoch,
100 | index_void=len(ld.DataSet.CATEGORY)-1)
101 |
102 | # 訓練済みモデルの評価
103 | # Test the trained model
104 | loss_test = sess.run(cross_entropy, feed_dict=test_dict)
105 | accuracy_test = sess.run(accuracy, feed_dict=test_dict)
106 | print("Result")
107 | print("[Test] Loss:", loss_test, "Accuracy:", accuracy_test)
108 |
109 | sess.close()
110 |
111 |
112 | def get_parser():
113 | parser = argparse.ArgumentParser(
114 | prog='Image segmentation using U-Net',
115 | usage='python main.py',
116 | description='This module demonstrates image segmentation using U-Net.',
117 | add_help=True
118 | )
119 |
120 | parser.add_argument('-g', '--gpu', action='store_true', help='Using GPUs')
121 | parser.add_argument('-e', '--epoch', type=int, default=250, help='Number of epochs')
122 | parser.add_argument('-b', '--batchsize', type=int, default=32, help='Batch size')
123 | parser.add_argument('-t', '--trainrate', type=float, default=0.85, help='Training rate')
124 | parser.add_argument('-a', '--augmentation', action='store_true', help='Number of epochs')
125 | parser.add_argument('-r', '--l2reg', type=float, default=0.0001, help='L2 regularization')
126 |
127 | return parser
128 |
129 |
130 | if __name__ == '__main__':
131 | parser = get_parser().parse_args()
132 | train(parser)
133 |
--------------------------------------------------------------------------------
/util/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tks10/segmentation_unet/8dd6d951b3c56ff706eb3b0684b99736c7ce83dd/util/__init__.py
--------------------------------------------------------------------------------
/util/image_augmenter.py:
--------------------------------------------------------------------------------
1 | import random
2 | import tensorflow as tf
3 | import numpy as np
4 | from util import loader as ld
5 |
6 |
7 | class ImageAugmenter:
8 | NONE = 0
9 | FLIP = 1
10 | BRIGHTNESS = 2
11 | HUE = 3
12 | SATURATION = 4
13 |
14 | NUMBER_OF_AUGMENT = 5
15 |
16 | def __init__(self, size, class_count):
17 | self._sess = tf.Session()
18 | self._class_count = class_count
19 | self._width, self._height = size[0], size[1]
20 | self._ph_original = tf.placeholder(tf.float32, [size[0], size[1], 3])
21 | self._ph_segmented = tf.placeholder(tf.float32, [size[0], size[1], class_count])
22 | self._operation = {}
23 | self.init_graph()
24 |
25 | def augment_dataset(self, dataset, method=None):
26 | input_processed = []
27 | output_processed = []
28 | for ori, seg in zip(dataset.images_original, dataset.images_segmented):
29 | ori_processed, seg_processed = self.augment(ori, seg, method)
30 | input_processed.append(ori_processed)
31 | output_processed.append(seg_processed)
32 |
33 | return ld.DataSet(np.asarray(input_processed), np.asarray(output_processed), dataset.palette)
34 |
35 | def augment(self, image_in, image_out, method=None):
36 | if method is None:
37 | idx = random.randrange(ImageAugmenter.NUMBER_OF_AUGMENT)
38 | else:
39 | assert len(method) <= ImageAugmenter.NUMBER_OF_AUGMENT, "method is too many."
40 | if ImageAugmenter.NONE not in method:
41 | method.append(ImageAugmenter.NONE)
42 | idx = random.choice(method)
43 |
44 | op = self._operation[idx]
45 | return self._sess.run([op["original"], op["segmented"]], feed_dict={self._ph_original: image_in,
46 | self._ph_segmented: image_out})
47 |
48 | def init_graph(self):
49 | self._operation[ImageAugmenter.NONE] = {"original": self._ph_original, "segmented": self._ph_segmented}
50 | self._operation[ImageAugmenter.FLIP] = self.flip()
51 | self._operation[ImageAugmenter.BRIGHTNESS] = self.brightness()
52 | self._operation[ImageAugmenter.HUE] = self.hue()
53 | self._operation[ImageAugmenter.SATURATION] = self.saturation()
54 |
55 | def flip(self):
56 | image_out_index = tf.argmax(self._ph_segmented, axis=2)
57 | image_out_index = tf.reshape(image_out_index, (self._width, self._height, 1))
58 | image_in_processed = tf.image.flip_left_right(self._ph_original)
59 | image_out_processed = tf.image.flip_left_right(image_out_index)
60 | image_out_processed = tf.one_hot(image_out_processed, depth=len(ld.DataSet.CATEGORY), dtype=tf.float32)
61 | image_out_processed = tf.reshape(image_out_processed, (self._width, self._height, len(ld.DataSet.CATEGORY)))
62 | return {"original": image_in_processed, "segmented": image_out_processed}
63 |
64 | def brightness(self):
65 | max_delta = 0.3
66 | image_in_processed = tf.image.random_brightness(self._ph_original, max_delta)
67 | return {"original": image_in_processed, "segmented": self._ph_segmented}
68 |
69 | def hue(self):
70 | max_delta = 0.5
71 | image_in_processed = tf.image.random_hue(self._ph_original, max_delta)
72 | return {"original": image_in_processed, "segmented": self._ph_segmented}
73 |
74 | def saturation(self):
75 | lower, upper = 0.0, 1.2
76 | image_in_processed = tf.image.random_saturation(self._ph_original, lower, upper)
77 | return {"original": image_in_processed, "segmented": self._ph_segmented}
78 |
79 |
80 | if __name__ == "__main__":
81 | pass
82 |
--------------------------------------------------------------------------------
/util/loader.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 | import numpy as np
3 | import glob
4 | import os
5 | from util import image_augmenter as ia
6 |
7 |
8 | class Loader(object):
9 | def __init__(self, dir_original, dir_segmented, init_size=(128, 128), one_hot=True):
10 | self._data = Loader.import_data(dir_original, dir_segmented, init_size, one_hot)
11 |
12 | def get_all_dataset(self):
13 | return self._data
14 |
15 | def load_train_test(self, train_rate=0.85, shuffle=True, transpose_by_color=False):
16 | """
17 | `Load datasets splited into training set and test set.
18 | 訓練とテストに分けられたデータセットをロードします.
19 | Args:
20 | train_rate (float): Training rate.
21 | shuffle (bool): If true, shuffle dataset.
22 | transpose_by_color (bool): If True, transpose images for chainer. [channel][width][height]
23 | Returns:
24 | Training Set (Dataset), Test Set (Dataset)
25 | """
26 | if train_rate < 0.0 or train_rate > 1.0:
27 | raise ValueError("train_rate must be from 0.0 to 1.0.")
28 | if transpose_by_color:
29 | self._data.transpose_by_color()
30 | if shuffle:
31 | self._data.shuffle()
32 |
33 | train_size = int(self._data.images_original.shape[0] * train_rate)
34 | data_size = int(len(self._data.images_original))
35 | train_set = self._data.perm(0, train_size)
36 | test_set = self._data.perm(train_size, data_size)
37 |
38 | return train_set, test_set
39 |
40 | @staticmethod
41 | def import_data(dir_original, dir_segmented, init_size=None, one_hot=True):
42 | # Generate paths of images to load
43 | # 読み込むファイルのパスリストを作成
44 | paths_original, paths_segmented = Loader.generate_paths(dir_original, dir_segmented)
45 |
46 | # Extract images to ndarray using paths
47 | # 画像データをndarrayに展開
48 | images_original, images_segmented = Loader.extract_images(paths_original, paths_segmented, init_size, one_hot)
49 |
50 | # Get a color palette
51 | # カラーパレットを取得
52 | image_sample_palette = Image.open(paths_segmented[0])
53 | palette = image_sample_palette.getpalette()
54 |
55 | return DataSet(images_original, images_segmented, palette,
56 | augmenter=ia.ImageAugmenter(size=init_size, class_count=len(DataSet.CATEGORY)))
57 |
58 | @staticmethod
59 | def generate_paths(dir_original, dir_segmented):
60 | paths_original = glob.glob(dir_original + "/*")
61 | paths_segmented = glob.glob(dir_segmented + "/*")
62 | if len(paths_original) == 0 or len(paths_segmented) == 0:
63 | raise FileNotFoundError("Could not load images.")
64 | filenames = list(map(lambda path: path.split(os.sep)[-1].split(".")[0], paths_segmented))
65 | paths_original = list(map(lambda filename: dir_original + "/" + filename + ".jpg", filenames))
66 |
67 | return paths_original, paths_segmented
68 |
69 | @staticmethod
70 | def extract_images(paths_original, paths_segmented, init_size, one_hot):
71 | images_original, images_segmented = [], []
72 |
73 | # Load images from directory_path using generator
74 | print("Loading original images", end="", flush=True)
75 | for image in Loader.image_generator(paths_original, init_size, antialias=True):
76 | images_original.append(image)
77 | if len(images_original) % 200 == 0:
78 | print(".", end="", flush=True)
79 | print(" Completed", flush=True)
80 | print("Loading segmented images", end="", flush=True)
81 | for image in Loader.image_generator(paths_segmented, init_size, normalization=False):
82 | images_segmented.append(image)
83 | if len(images_segmented) % 200 == 0:
84 | print(".", end="", flush=True)
85 | print(" Completed")
86 | assert len(images_original) == len(images_segmented)
87 |
88 | # Cast to ndarray
89 | images_original = np.asarray(images_original, dtype=np.float32)
90 | images_segmented = np.asarray(images_segmented, dtype=np.uint8)
91 |
92 | # Change indices which correspond to "void" from 255
93 | images_segmented = np.where(images_segmented == 255, len(DataSet.CATEGORY)-1, images_segmented)
94 |
95 | # One hot encoding using identity matrix.
96 | if one_hot:
97 | print("Casting to one-hot encoding... ", end="", flush=True)
98 | identity = np.identity(len(DataSet.CATEGORY), dtype=np.uint8)
99 | images_segmented = identity[images_segmented]
100 | print("Done")
101 | else:
102 | pass
103 |
104 | return images_original, images_segmented
105 |
106 | @staticmethod
107 | def cast_to_index(ndarray):
108 | return np.argmax(ndarray, axis=2)
109 |
110 | @staticmethod
111 | def cast_to_onehot(ndarray):
112 | identity = np.identity(len(DataSet.CATEGORY), dtype=np.uint8)
113 | return identity[ndarray]
114 |
115 | @staticmethod
116 | def image_generator(file_paths, init_size=None, normalization=True, antialias=False):
117 | """
118 | `A generator which yields images deleted an alpha channel and resized.
119 | アルファチャネル削除、リサイズ(任意)処理を行った画像を返します
120 | Args:
121 | file_paths (list[string]): File paths you want load.
122 | init_size (tuple(int, int)): If having a value, images are resized by init_size.
123 | normalization (bool): If true, normalize images.
124 | antialias (bool): Antialias.
125 | Yields:
126 | image (ndarray[width][height][channel]): Processed image
127 | """
128 | for file_path in file_paths:
129 | if file_path.endswith(".png") or file_path.endswith(".jpg"):
130 | # open a image
131 | image = Image.open(file_path)
132 | # to square
133 | image = Loader.crop_to_square(image)
134 | # resize by init_size
135 | if init_size is not None and init_size != image.size:
136 | if antialias:
137 | image = image.resize(init_size, Image.ANTIALIAS)
138 | else:
139 | image = image.resize(init_size)
140 | # delete alpha channel
141 | if image.mode == "RGBA":
142 | image = image.convert("RGB")
143 | image = np.asarray(image)
144 | if normalization:
145 | image = image / 255.0
146 | yield image
147 |
148 | @staticmethod
149 | def crop_to_square(image):
150 | size = min(image.size)
151 | left, upper = (image.width - size) // 2, (image.height - size) // 2
152 | right, bottom = (image.width + size) // 2, (image.height + size) // 2
153 | return image.crop((left, upper, right, bottom))
154 |
155 |
156 | class DataSet(object):
157 | CATEGORY = (
158 | "ground",
159 | "aeroplane",
160 | "bicycle",
161 | "bird",
162 | "boat",
163 | "bottle",
164 | "bus",
165 | "car",
166 | "cat",
167 | "chair",
168 | "cow",
169 | "dining table",
170 | "dog",
171 | "horse",
172 | "motorbike",
173 | "person",
174 | "potted plant",
175 | "sheep",
176 | "sofa",
177 | "train",
178 | "tv/monitor",
179 | "void"
180 | )
181 |
182 | def __init__(self, images_original, images_segmented, image_palette, augmenter=None):
183 | assert len(images_original) == len(images_segmented), "images and labels must have same length."
184 | self._images_original = images_original
185 | self._images_segmented = images_segmented
186 | self._image_palette = image_palette
187 | self._augmenter = augmenter
188 |
189 | @property
190 | def images_original(self):
191 | return self._images_original
192 |
193 | @property
194 | def images_segmented(self):
195 | return self._images_segmented
196 |
197 | @property
198 | def palette(self):
199 | return self._image_palette
200 |
201 | @property
202 | def length(self):
203 | return len(self._images_original)
204 |
205 | @staticmethod
206 | def length_category():
207 | return len(DataSet.CATEGORY)
208 |
209 | def print_information(self):
210 | print("****** Dataset Information ******")
211 | print("[Number of Images]", len(self._images_original))
212 |
213 | def __add__(self, other):
214 | images_original = np.concatenate([self.images_original, other.images_original])
215 | images_segmented = np.concatenate([self.images_segmented, other.images_segmented])
216 | return DataSet(images_original, images_segmented, self._image_palette, self._augmenter)
217 |
218 | def shuffle(self):
219 | idx = np.arange(self._images_original.shape[0])
220 | np.random.shuffle(idx)
221 | self._images_original, self._images_segmented = self._images_original[idx], self._images_segmented[idx]
222 |
223 | def transpose_by_color(self):
224 | self._images_original = self._images_original.transpose(0, 3, 1, 2)
225 | self._images_segmented = self._images_segmented.transpose(0, 3, 1, 2)
226 |
227 | def perm(self, start, end):
228 | end = min(end, len(self._images_original))
229 | return DataSet(self._images_original[start:end], self._images_segmented[start:end], self._image_palette,
230 | self._augmenter)
231 |
232 | def __call__(self, batch_size=20, shuffle=True, augment=True):
233 | """
234 | `A generator which yields a batch. The batch is shuffled as default.
235 | バッチを返すジェネレータです。 デフォルトでバッチはシャッフルされます。
236 | Args:
237 | batch_size (int): batch size.
238 | shuffle (bool): If True, randomize batch datas.
239 | Yields:
240 | batch (ndarray[][][]): A batch data.
241 | """
242 |
243 | if batch_size < 1:
244 | raise ValueError("batch_size must be more than 1.")
245 | if shuffle:
246 | self.shuffle()
247 |
248 | for start in range(0, self.length, batch_size):
249 | batch = self.perm(start, start+batch_size)
250 | if augment:
251 | assert self._augmenter is not None, "you have to set an augmenter."
252 | yield self._augmenter.augment_dataset(batch, method=[ia.ImageAugmenter.NONE, ia.ImageAugmenter.FLIP])
253 | else:
254 | yield batch
255 |
256 |
257 | if __name__ == "__main__":
258 | dataset_loader = Loader(dir_original="../data_set/VOCdevkit/VOC2012/JPEGImages",
259 | dir_segmented="../data_set/VOCdevkit/VOC2012/SegmentationClass")
260 | train, test = dataset_loader.load_train_test()
261 | train.print_information()
262 | test.print_information()
--------------------------------------------------------------------------------
/util/model.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from util import loader as ld
3 |
4 |
5 | class UNet:
6 | def __init__(self, size=(128, 128), l2_reg=None):
7 | self.model = self.create_model(size, l2_reg)
8 |
9 | @staticmethod
10 | def create_model(size, l2_reg):
11 | inputs = tf.placeholder(tf.float32, [None, size[0], size[1], 3])
12 | teacher = tf.placeholder(tf.float32, [None, size[0], size[1], len(ld.DataSet.CATEGORY)])
13 | is_training = tf.placeholder(tf.bool)
14 |
15 | # 1, 1, 3
16 | conv1_1 = UNet.conv(inputs, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
17 | conv1_2 = UNet.conv(conv1_1, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
18 | pool1 = UNet.pool(conv1_2)
19 |
20 | # 1/2, 1/2, 64
21 | conv2_1 = UNet.conv(pool1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
22 | conv2_2 = UNet.conv(conv2_1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
23 | pool2 = UNet.pool(conv2_2)
24 |
25 | # 1/4, 1/4, 128
26 | conv3_1 = UNet.conv(pool2, filters=256, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
27 | conv3_2 = UNet.conv(conv3_1, filters=256, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
28 | pool3 = UNet.pool(conv3_2)
29 |
30 | # 1/8, 1/8, 256
31 | conv4_1 = UNet.conv(pool3, filters=512, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
32 | conv4_2 = UNet.conv(conv4_1, filters=512, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
33 | pool4 = UNet.pool(conv4_2)
34 |
35 | # 1/16, 1/16, 512
36 | conv5_1 = UNet.conv(pool4, filters=1024, l2_reg_scale=l2_reg)
37 | conv5_2 = UNet.conv(conv5_1, filters=1024, l2_reg_scale=l2_reg)
38 | concated1 = tf.concat([UNet.conv_transpose(conv5_2, filters=512, l2_reg_scale=l2_reg), conv4_2], axis=3)
39 |
40 | conv_up1_1 = UNet.conv(concated1, filters=512, l2_reg_scale=l2_reg)
41 | conv_up1_2 = UNet.conv(conv_up1_1, filters=512, l2_reg_scale=l2_reg)
42 | concated2 = tf.concat([UNet.conv_transpose(conv_up1_2, filters=256, l2_reg_scale=l2_reg), conv3_2], axis=3)
43 |
44 | conv_up2_1 = UNet.conv(concated2, filters=256, l2_reg_scale=l2_reg)
45 | conv_up2_2 = UNet.conv(conv_up2_1, filters=256, l2_reg_scale=l2_reg)
46 | concated3 = tf.concat([UNet.conv_transpose(conv_up2_2, filters=128, l2_reg_scale=l2_reg), conv2_2], axis=3)
47 |
48 | conv_up3_1 = UNet.conv(concated3, filters=128, l2_reg_scale=l2_reg)
49 | conv_up3_2 = UNet.conv(conv_up3_1, filters=128, l2_reg_scale=l2_reg)
50 | concated4 = tf.concat([UNet.conv_transpose(conv_up3_2, filters=64, l2_reg_scale=l2_reg), conv1_2], axis=3)
51 |
52 | conv_up4_1 = UNet.conv(concated4, filters=64, l2_reg_scale=l2_reg)
53 | conv_up4_2 = UNet.conv(conv_up4_1, filters=64, l2_reg_scale=l2_reg)
54 | outputs = UNet.conv(conv_up4_2, filters=ld.DataSet.length_category(), kernel_size=[1, 1], activation=None)
55 |
56 | return Model(inputs, outputs, teacher, is_training)
57 |
58 | @staticmethod
59 | def conv(inputs, filters, kernel_size=[3, 3], activation=tf.nn.relu, l2_reg_scale=None, batchnorm_istraining=None):
60 | if l2_reg_scale is None:
61 | regularizer = None
62 | else:
63 | regularizer = tf.contrib.layers.l2_regularizer(scale=l2_reg_scale)
64 | conved = tf.layers.conv2d(
65 | inputs=inputs,
66 | filters=filters,
67 | kernel_size=kernel_size,
68 | padding="same",
69 | activation=activation,
70 | kernel_regularizer=regularizer
71 | )
72 | if batchnorm_istraining is not None:
73 | conved = UNet.bn(conved, batchnorm_istraining)
74 |
75 | return conved
76 |
77 | @staticmethod
78 | def bn(inputs, is_training):
79 | normalized = tf.layers.batch_normalization(
80 | inputs=inputs,
81 | axis=-1,
82 | momentum=0.9,
83 | epsilon=0.001,
84 | center=True,
85 | scale=True,
86 | training=is_training,
87 | )
88 | return normalized
89 |
90 | @staticmethod
91 | def pool(inputs):
92 | pooled = tf.layers.max_pooling2d(inputs=inputs, pool_size=[2, 2], strides=2)
93 | return pooled
94 |
95 | @staticmethod
96 | def conv_transpose(inputs, filters, l2_reg_scale=None):
97 | if l2_reg_scale is None:
98 | regularizer = None
99 | else:
100 | regularizer = tf.contrib.layers.l2_regularizer(scale=l2_reg_scale)
101 | conved = tf.layers.conv2d_transpose(
102 | inputs=inputs,
103 | filters=filters,
104 | strides=[2, 2],
105 | kernel_size=[2, 2],
106 | padding='same',
107 | activation=tf.nn.relu,
108 | kernel_regularizer=regularizer
109 | )
110 | return conved
111 |
112 |
113 | class Model:
114 | def __init__(self, inputs, outputs, teacher, is_training):
115 | self.inputs = inputs
116 | self.outputs = outputs
117 | self.teacher = teacher
118 | self.is_training = is_training
119 |
--------------------------------------------------------------------------------
/util/repoter.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 | import numpy as np
3 | import datetime
4 | import os
5 | import matplotlib.pyplot as plt
6 |
7 |
8 | class Reporter:
9 | ROOT_DIR = "result"
10 | IMAGE_DIR = "image"
11 | LEARNING_DIR = "learning"
12 | INFO_DIR = "info"
13 | MODEL_DIR = "model"
14 | PARAMETER = "parameter.txt"
15 | IMAGE_PREFIX = "epoch_"
16 | IMAGE_EXTENSION = ".png"
17 | MODEL_NAME = "model.ckpt"
18 |
19 | def __init__(self, result_dir=None, parser=None):
20 | if result_dir is None:
21 | result_dir = Reporter.generate_dir_name()
22 | self._root_dir = self.ROOT_DIR
23 | self._result_dir = os.path.join(self._root_dir, result_dir)
24 | self._image_dir = os.path.join(self._result_dir, self.IMAGE_DIR)
25 | self._image_train_dir = os.path.join(self._image_dir, "train")
26 | self._image_test_dir = os.path.join(self._image_dir, "test")
27 | self._learning_dir = os.path.join(self._result_dir, self.LEARNING_DIR)
28 | self._info_dir = os.path.join(self._result_dir, self.INFO_DIR)
29 | self._model_dir = os.path.join(self._result_dir, self.MODEL_DIR)
30 | self._parameter = os.path.join(self._info_dir, self.PARAMETER)
31 | self.create_dirs()
32 |
33 | self._matplot_manager = MatPlotManager(self._learning_dir)
34 | if parser is not None:
35 | self.save_params(self._parameter, parser)
36 |
37 | @staticmethod
38 | def generate_dir_name():
39 | return datetime.datetime.today().strftime("%Y%m%d_%H%M")
40 |
41 | def create_dirs(self):
42 | os.makedirs(self._root_dir, exist_ok=True)
43 | os.makedirs(self._result_dir)
44 | os.makedirs(self._image_dir)
45 | os.makedirs(self._image_train_dir)
46 | os.makedirs(self._image_test_dir)
47 | os.makedirs(self._learning_dir)
48 | os.makedirs(self._info_dir)
49 |
50 | @staticmethod
51 | def save_params(filename, parser):
52 | parameters = list()
53 | parameters.append("Number of epochs:" + str(parser.epoch))
54 | parameters.append("Batch size:" + str(parser.batchsize))
55 | parameters.append("Training rate:" + str(parser.trainrate))
56 | parameters.append("Augmentation:" + str(parser.augmentation))
57 | parameters.append("L2 regularization:" + str(parser.l2reg))
58 | output = "\n".join(parameters)
59 |
60 | with open(filename, mode='w') as f:
61 | f.write(output)
62 |
63 | def save_image(self, train, test, epoch):
64 | file_name = self.IMAGE_PREFIX + str(epoch) + self.IMAGE_EXTENSION
65 | train_filename = os.path.join(self._image_train_dir, file_name)
66 | test_filename = os.path.join(self._image_test_dir, file_name)
67 | train.save(train_filename)
68 | test.save(test_filename)
69 |
70 | def save_image_from_ndarray(self, train_set, test_set, palette, epoch, index_void=None):
71 | assert len(train_set) == len(test_set) == 3
72 | train_image = Reporter.get_imageset(train_set[0], train_set[1], train_set[2], palette, index_void)
73 | test_image = Reporter.get_imageset(test_set[0], test_set[1], test_set[2], palette, index_void)
74 | self.save_image(train_image, test_image, epoch)
75 |
76 | def create_figure(self, title, xylabels, labels, filename=None):
77 | return self._matplot_manager.add_figure(title, xylabels, labels, filename=filename)
78 |
79 | @staticmethod
80 | def concat_images(im1, im2, palette, mode):
81 | if mode == "P":
82 | assert palette is not None
83 | dst = Image.new("P", (im1.width + im2.width, im1.height))
84 | dst.paste(im1, (0, 0))
85 | dst.paste(im2, (im1.width, 0))
86 | dst.putpalette(palette)
87 | elif mode == "RGB":
88 | dst = Image.new("RGB", (im1.width + im2.width, im1.height))
89 | dst.paste(im1, (0, 0))
90 | dst.paste(im2, (im1.width, 0))
91 | else:
92 | raise NotImplementedError
93 |
94 | return dst
95 |
96 | @staticmethod
97 | def cast_to_pil(ndarray, palette, index_void=None):
98 | assert len(ndarray.shape) == 3
99 | res = np.argmax(ndarray, axis=2)
100 | if index_void is not None:
101 | res = np.where(res == index_void, 0, res)
102 | image = Image.fromarray(np.uint8(res), mode="P")
103 | image.putpalette(palette)
104 | return image
105 |
106 | @staticmethod
107 | def get_imageset(image_in_np, image_out_np, image_tc_np, palette, index_void=None):
108 | assert image_in_np.shape[:2] == image_out_np.shape[:2] == image_tc_np.shape[:2]
109 | image_out, image_tc = Reporter.cast_to_pil(image_out_np, palette, index_void),\
110 | Reporter.cast_to_pil(image_tc_np, palette, index_void)
111 | image_concated = Reporter.concat_images(image_out, image_tc, palette, "P").convert("RGB")
112 | image_in_pil = Image.fromarray(np.uint8(image_in_np * 255), mode="RGB")
113 | image_result = Reporter.concat_images(image_in_pil, image_concated, None, "RGB")
114 | return image_result
115 |
116 | def save_model(self, saver, sess):
117 | saver.save(sess, os.path.join(self._model_dir, self.MODEL_NAME))
118 |
119 |
120 | class MatPlotManager:
121 | def __init__(self, root_dir):
122 | self._root_dir = root_dir
123 | self._figures = {}
124 |
125 | def add_figure(self, title, xylabels, labels, filename=None):
126 | assert not(title in self._figures.keys()), "This title already exists."
127 | self._figures[title] = MatPlot(title, xylabels, labels, self._root_dir, filename=filename)
128 | return self._figures[title]
129 |
130 | def get_figure(self, title):
131 | return self._figures[title]
132 |
133 |
134 | class MatPlot:
135 | EXTENSION = ".png"
136 |
137 | def __init__(self, title, xylabels, labels, root_dir, filename=None):
138 | assert len(labels) > 0 and len(xylabels) == 2
139 | if filename is None:
140 | self._filename = title
141 | else:
142 | self._filename = filename
143 | self._title = title
144 | self._xlabel, self._ylabel = xylabels[0], xylabels[1]
145 | self._labels = labels
146 | self._root_dir = root_dir
147 | self._series = np.zeros((len(labels), 0))
148 |
149 | def add(self, series, is_update=False):
150 | series = np.asarray(series).reshape((len(series), 1))
151 | assert series.shape[0] == self._series.shape[0], "series must have same length."
152 | self._series = np.concatenate([self._series, series], axis=1)
153 | if is_update:
154 | self.save()
155 |
156 | def save(self):
157 | plt.cla()
158 | for s, l in zip(self._series, self._labels):
159 | plt.plot(s, label=l)
160 | plt.legend()
161 | plt.grid()
162 | plt.xlabel(self._xlabel)
163 | plt.ylabel(self._ylabel)
164 | plt.title(self._title)
165 | plt.savefig(os.path.join(self._root_dir, self._filename+self.EXTENSION))
166 |
167 |
168 | if __name__ == "__main__":
169 | pass
170 |
--------------------------------------------------------------------------------
52 |
53 |
54 |
55 |
56 |
57 |
--------------------------------------------------------------------------------
/data_set/README.md:
--------------------------------------------------------------------------------
1 | You should store VOCdevkit here.
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import random
3 | import tensorflow as tf
4 |
5 | from util import loader as ld
6 | from util import model
7 | from util import repoter as rp
8 |
9 |
10 | def load_dataset(train_rate):
11 | loader = ld.Loader(dir_original="data_set/VOCdevkit/VOC2012/JPEGImages",
12 | dir_segmented="data_set/VOCdevkit/VOC2012/SegmentationClass")
13 | return loader.load_train_test(train_rate=train_rate, shuffle=False)
14 |
15 |
16 | def train(parser):
17 | # 訓練とテストデータを読み込みます
18 | # Load train and test datas
19 | train, test = load_dataset(train_rate=parser.trainrate)
20 | valid = train.perm(0, 30)
21 | test = test.perm(0, 150)
22 |
23 | # 結果保存用のインスタンスを作成します
24 | # Create Reporter Object
25 | reporter = rp.Reporter(parser=parser)
26 | accuracy_fig = reporter.create_figure("Accuracy", ("epoch", "accuracy"), ["train", "test"])
27 | loss_fig = reporter.create_figure("Loss", ("epoch", "loss"), ["train", "test"])
28 |
29 | # GPUを使用するか
30 | # Whether or not using a GPU
31 | gpu = parser.gpu
32 |
33 | # モデルの生成
34 | # Create a model
35 | model_unet = model.UNet(l2_reg=parser.l2reg).model
36 |
37 | # 誤差関数とオプティマイザの設定をします
38 | # Set a loss function and an optimizer
39 | cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=model_unet.teacher,
40 | logits=model_unet.outputs))
41 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
42 | with tf.control_dependencies(update_ops):
43 | train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
44 |
45 | # 精度の算出をします
46 | # Calculate accuracy
47 | correct_prediction = tf.equal(tf.argmax(model_unet.outputs, 3), tf.argmax(model_unet.teacher, 3))
48 | accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
49 |
50 | # セッションの初期化をします
51 | # Initialize session
52 | gpu_config = tf.ConfigProto(gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.7), device_count={'GPU': 1},
53 | log_device_placement=False, allow_soft_placement=True)
54 | sess = tf.InteractiveSession(config=gpu_config) if gpu else tf.InteractiveSession()
55 | tf.global_variables_initializer().run()
56 |
57 | # モデルの訓練
58 | # Train the model
59 | epochs = parser.epoch
60 | batch_size = parser.batchsize
61 | is_augment = parser.augmentation
62 | train_dict = {model_unet.inputs: valid.images_original, model_unet.teacher: valid.images_segmented,
63 | model_unet.is_training: False}
64 | test_dict = {model_unet.inputs: test.images_original, model_unet.teacher: test.images_segmented,
65 | model_unet.is_training: False}
66 |
67 | for epoch in range(epochs):
68 | for batch in train(batch_size=batch_size, augment=is_augment):
69 | # バッチデータの展開
70 | inputs = batch.images_original
71 | teacher = batch.images_segmented
72 | # Training
73 | sess.run(train_step, feed_dict={model_unet.inputs: inputs, model_unet.teacher: teacher,
74 | model_unet.is_training: True})
75 |
76 | # 評価
77 | # Evaluation
78 | if epoch % 1 == 0:
79 | loss_train = sess.run(cross_entropy, feed_dict=train_dict)
80 | loss_test = sess.run(cross_entropy, feed_dict=test_dict)
81 | accuracy_train = sess.run(accuracy, feed_dict=train_dict)
82 | accuracy_test = sess.run(accuracy, feed_dict=test_dict)
83 | print("Epoch:", epoch)
84 | print("[Train] Loss:", loss_train, " Accuracy:", accuracy_train)
85 | print("[Test] Loss:", loss_test, "Accuracy:", accuracy_test)
86 | accuracy_fig.add([accuracy_train, accuracy_test], is_update=True)
87 | loss_fig.add([loss_train, loss_test], is_update=True)
88 | if epoch % 3 == 0:
89 | idx_train = random.randrange(10)
90 | idx_test = random.randrange(100)
91 | outputs_train = sess.run(model_unet.outputs,
92 | feed_dict={model_unet.inputs: [train.images_original[idx_train]],
93 | model_unet.is_training: False})
94 | outputs_test = sess.run(model_unet.outputs,
95 | feed_dict={model_unet.inputs: [test.images_original[idx_test]],
96 | model_unet.is_training: False})
97 | train_set = [train.images_original[idx_train], outputs_train[0], train.images_segmented[idx_train]]
98 | test_set = [test.images_original[idx_test], outputs_test[0], test.images_segmented[idx_test]]
99 | reporter.save_image_from_ndarray(train_set, test_set, train.palette, epoch,
100 | index_void=len(ld.DataSet.CATEGORY)-1)
101 |
102 | # 訓練済みモデルの評価
103 | # Test the trained model
104 | loss_test = sess.run(cross_entropy, feed_dict=test_dict)
105 | accuracy_test = sess.run(accuracy, feed_dict=test_dict)
106 | print("Result")
107 | print("[Test] Loss:", loss_test, "Accuracy:", accuracy_test)
108 |
109 | sess.close()
110 |
111 |
112 | def get_parser():
113 | parser = argparse.ArgumentParser(
114 | prog='Image segmentation using U-Net',
115 | usage='python main.py',
116 | description='This module demonstrates image segmentation using U-Net.',
117 | add_help=True
118 | )
119 |
120 | parser.add_argument('-g', '--gpu', action='store_true', help='Using GPUs')
121 | parser.add_argument('-e', '--epoch', type=int, default=250, help='Number of epochs')
122 | parser.add_argument('-b', '--batchsize', type=int, default=32, help='Batch size')
123 | parser.add_argument('-t', '--trainrate', type=float, default=0.85, help='Training rate')
124 | parser.add_argument('-a', '--augmentation', action='store_true', help='Number of epochs')
125 | parser.add_argument('-r', '--l2reg', type=float, default=0.0001, help='L2 regularization')
126 |
127 | return parser
128 |
129 |
130 | if __name__ == '__main__':
131 | parser = get_parser().parse_args()
132 | train(parser)
133 |
--------------------------------------------------------------------------------
/util/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/tks10/segmentation_unet/8dd6d951b3c56ff706eb3b0684b99736c7ce83dd/util/__init__.py
--------------------------------------------------------------------------------
/util/image_augmenter.py:
--------------------------------------------------------------------------------
1 | import random
2 | import tensorflow as tf
3 | import numpy as np
4 | from util import loader as ld
5 |
6 |
7 | class ImageAugmenter:
8 | NONE = 0
9 | FLIP = 1
10 | BRIGHTNESS = 2
11 | HUE = 3
12 | SATURATION = 4
13 |
14 | NUMBER_OF_AUGMENT = 5
15 |
16 | def __init__(self, size, class_count):
17 | self._sess = tf.Session()
18 | self._class_count = class_count
19 | self._width, self._height = size[0], size[1]
20 | self._ph_original = tf.placeholder(tf.float32, [size[0], size[1], 3])
21 | self._ph_segmented = tf.placeholder(tf.float32, [size[0], size[1], class_count])
22 | self._operation = {}
23 | self.init_graph()
24 |
25 | def augment_dataset(self, dataset, method=None):
26 | input_processed = []
27 | output_processed = []
28 | for ori, seg in zip(dataset.images_original, dataset.images_segmented):
29 | ori_processed, seg_processed = self.augment(ori, seg, method)
30 | input_processed.append(ori_processed)
31 | output_processed.append(seg_processed)
32 |
33 | return ld.DataSet(np.asarray(input_processed), np.asarray(output_processed), dataset.palette)
34 |
35 | def augment(self, image_in, image_out, method=None):
36 | if method is None:
37 | idx = random.randrange(ImageAugmenter.NUMBER_OF_AUGMENT)
38 | else:
39 | assert len(method) <= ImageAugmenter.NUMBER_OF_AUGMENT, "method is too many."
40 | if ImageAugmenter.NONE not in method:
41 | method.append(ImageAugmenter.NONE)
42 | idx = random.choice(method)
43 |
44 | op = self._operation[idx]
45 | return self._sess.run([op["original"], op["segmented"]], feed_dict={self._ph_original: image_in,
46 | self._ph_segmented: image_out})
47 |
48 | def init_graph(self):
49 | self._operation[ImageAugmenter.NONE] = {"original": self._ph_original, "segmented": self._ph_segmented}
50 | self._operation[ImageAugmenter.FLIP] = self.flip()
51 | self._operation[ImageAugmenter.BRIGHTNESS] = self.brightness()
52 | self._operation[ImageAugmenter.HUE] = self.hue()
53 | self._operation[ImageAugmenter.SATURATION] = self.saturation()
54 |
55 | def flip(self):
56 | image_out_index = tf.argmax(self._ph_segmented, axis=2)
57 | image_out_index = tf.reshape(image_out_index, (self._width, self._height, 1))
58 | image_in_processed = tf.image.flip_left_right(self._ph_original)
59 | image_out_processed = tf.image.flip_left_right(image_out_index)
60 | image_out_processed = tf.one_hot(image_out_processed, depth=len(ld.DataSet.CATEGORY), dtype=tf.float32)
61 | image_out_processed = tf.reshape(image_out_processed, (self._width, self._height, len(ld.DataSet.CATEGORY)))
62 | return {"original": image_in_processed, "segmented": image_out_processed}
63 |
64 | def brightness(self):
65 | max_delta = 0.3
66 | image_in_processed = tf.image.random_brightness(self._ph_original, max_delta)
67 | return {"original": image_in_processed, "segmented": self._ph_segmented}
68 |
69 | def hue(self):
70 | max_delta = 0.5
71 | image_in_processed = tf.image.random_hue(self._ph_original, max_delta)
72 | return {"original": image_in_processed, "segmented": self._ph_segmented}
73 |
74 | def saturation(self):
75 | lower, upper = 0.0, 1.2
76 | image_in_processed = tf.image.random_saturation(self._ph_original, lower, upper)
77 | return {"original": image_in_processed, "segmented": self._ph_segmented}
78 |
79 |
80 | if __name__ == "__main__":
81 | pass
82 |
--------------------------------------------------------------------------------
/util/loader.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 | import numpy as np
3 | import glob
4 | import os
5 | from util import image_augmenter as ia
6 |
7 |
8 | class Loader(object):
9 | def __init__(self, dir_original, dir_segmented, init_size=(128, 128), one_hot=True):
10 | self._data = Loader.import_data(dir_original, dir_segmented, init_size, one_hot)
11 |
12 | def get_all_dataset(self):
13 | return self._data
14 |
15 | def load_train_test(self, train_rate=0.85, shuffle=True, transpose_by_color=False):
16 | """
17 | `Load datasets splited into training set and test set.
18 | 訓練とテストに分けられたデータセットをロードします.
19 | Args:
20 | train_rate (float): Training rate.
21 | shuffle (bool): If true, shuffle dataset.
22 | transpose_by_color (bool): If True, transpose images for chainer. [channel][width][height]
23 | Returns:
24 | Training Set (Dataset), Test Set (Dataset)
25 | """
26 | if train_rate < 0.0 or train_rate > 1.0:
27 | raise ValueError("train_rate must be from 0.0 to 1.0.")
28 | if transpose_by_color:
29 | self._data.transpose_by_color()
30 | if shuffle:
31 | self._data.shuffle()
32 |
33 | train_size = int(self._data.images_original.shape[0] * train_rate)
34 | data_size = int(len(self._data.images_original))
35 | train_set = self._data.perm(0, train_size)
36 | test_set = self._data.perm(train_size, data_size)
37 |
38 | return train_set, test_set
39 |
40 | @staticmethod
41 | def import_data(dir_original, dir_segmented, init_size=None, one_hot=True):
42 | # Generate paths of images to load
43 | # 読み込むファイルのパスリストを作成
44 | paths_original, paths_segmented = Loader.generate_paths(dir_original, dir_segmented)
45 |
46 | # Extract images to ndarray using paths
47 | # 画像データをndarrayに展開
48 | images_original, images_segmented = Loader.extract_images(paths_original, paths_segmented, init_size, one_hot)
49 |
50 | # Get a color palette
51 | # カラーパレットを取得
52 | image_sample_palette = Image.open(paths_segmented[0])
53 | palette = image_sample_palette.getpalette()
54 |
55 | return DataSet(images_original, images_segmented, palette,
56 | augmenter=ia.ImageAugmenter(size=init_size, class_count=len(DataSet.CATEGORY)))
57 |
58 | @staticmethod
59 | def generate_paths(dir_original, dir_segmented):
60 | paths_original = glob.glob(dir_original + "/*")
61 | paths_segmented = glob.glob(dir_segmented + "/*")
62 | if len(paths_original) == 0 or len(paths_segmented) == 0:
63 | raise FileNotFoundError("Could not load images.")
64 | filenames = list(map(lambda path: path.split(os.sep)[-1].split(".")[0], paths_segmented))
65 | paths_original = list(map(lambda filename: dir_original + "/" + filename + ".jpg", filenames))
66 |
67 | return paths_original, paths_segmented
68 |
69 | @staticmethod
70 | def extract_images(paths_original, paths_segmented, init_size, one_hot):
71 | images_original, images_segmented = [], []
72 |
73 | # Load images from directory_path using generator
74 | print("Loading original images", end="", flush=True)
75 | for image in Loader.image_generator(paths_original, init_size, antialias=True):
76 | images_original.append(image)
77 | if len(images_original) % 200 == 0:
78 | print(".", end="", flush=True)
79 | print(" Completed", flush=True)
80 | print("Loading segmented images", end="", flush=True)
81 | for image in Loader.image_generator(paths_segmented, init_size, normalization=False):
82 | images_segmented.append(image)
83 | if len(images_segmented) % 200 == 0:
84 | print(".", end="", flush=True)
85 | print(" Completed")
86 | assert len(images_original) == len(images_segmented)
87 |
88 | # Cast to ndarray
89 | images_original = np.asarray(images_original, dtype=np.float32)
90 | images_segmented = np.asarray(images_segmented, dtype=np.uint8)
91 |
92 | # Change indices which correspond to "void" from 255
93 | images_segmented = np.where(images_segmented == 255, len(DataSet.CATEGORY)-1, images_segmented)
94 |
95 | # One hot encoding using identity matrix.
96 | if one_hot:
97 | print("Casting to one-hot encoding... ", end="", flush=True)
98 | identity = np.identity(len(DataSet.CATEGORY), dtype=np.uint8)
99 | images_segmented = identity[images_segmented]
100 | print("Done")
101 | else:
102 | pass
103 |
104 | return images_original, images_segmented
105 |
106 | @staticmethod
107 | def cast_to_index(ndarray):
108 | return np.argmax(ndarray, axis=2)
109 |
110 | @staticmethod
111 | def cast_to_onehot(ndarray):
112 | identity = np.identity(len(DataSet.CATEGORY), dtype=np.uint8)
113 | return identity[ndarray]
114 |
115 | @staticmethod
116 | def image_generator(file_paths, init_size=None, normalization=True, antialias=False):
117 | """
118 | `A generator which yields images deleted an alpha channel and resized.
119 | アルファチャネル削除、リサイズ(任意)処理を行った画像を返します
120 | Args:
121 | file_paths (list[string]): File paths you want load.
122 | init_size (tuple(int, int)): If having a value, images are resized by init_size.
123 | normalization (bool): If true, normalize images.
124 | antialias (bool): Antialias.
125 | Yields:
126 | image (ndarray[width][height][channel]): Processed image
127 | """
128 | for file_path in file_paths:
129 | if file_path.endswith(".png") or file_path.endswith(".jpg"):
130 | # open a image
131 | image = Image.open(file_path)
132 | # to square
133 | image = Loader.crop_to_square(image)
134 | # resize by init_size
135 | if init_size is not None and init_size != image.size:
136 | if antialias:
137 | image = image.resize(init_size, Image.ANTIALIAS)
138 | else:
139 | image = image.resize(init_size)
140 | # delete alpha channel
141 | if image.mode == "RGBA":
142 | image = image.convert("RGB")
143 | image = np.asarray(image)
144 | if normalization:
145 | image = image / 255.0
146 | yield image
147 |
148 | @staticmethod
149 | def crop_to_square(image):
150 | size = min(image.size)
151 | left, upper = (image.width - size) // 2, (image.height - size) // 2
152 | right, bottom = (image.width + size) // 2, (image.height + size) // 2
153 | return image.crop((left, upper, right, bottom))
154 |
155 |
156 | class DataSet(object):
157 | CATEGORY = (
158 | "ground",
159 | "aeroplane",
160 | "bicycle",
161 | "bird",
162 | "boat",
163 | "bottle",
164 | "bus",
165 | "car",
166 | "cat",
167 | "chair",
168 | "cow",
169 | "dining table",
170 | "dog",
171 | "horse",
172 | "motorbike",
173 | "person",
174 | "potted plant",
175 | "sheep",
176 | "sofa",
177 | "train",
178 | "tv/monitor",
179 | "void"
180 | )
181 |
182 | def __init__(self, images_original, images_segmented, image_palette, augmenter=None):
183 | assert len(images_original) == len(images_segmented), "images and labels must have same length."
184 | self._images_original = images_original
185 | self._images_segmented = images_segmented
186 | self._image_palette = image_palette
187 | self._augmenter = augmenter
188 |
189 | @property
190 | def images_original(self):
191 | return self._images_original
192 |
193 | @property
194 | def images_segmented(self):
195 | return self._images_segmented
196 |
197 | @property
198 | def palette(self):
199 | return self._image_palette
200 |
201 | @property
202 | def length(self):
203 | return len(self._images_original)
204 |
205 | @staticmethod
206 | def length_category():
207 | return len(DataSet.CATEGORY)
208 |
209 | def print_information(self):
210 | print("****** Dataset Information ******")
211 | print("[Number of Images]", len(self._images_original))
212 |
213 | def __add__(self, other):
214 | images_original = np.concatenate([self.images_original, other.images_original])
215 | images_segmented = np.concatenate([self.images_segmented, other.images_segmented])
216 | return DataSet(images_original, images_segmented, self._image_palette, self._augmenter)
217 |
218 | def shuffle(self):
219 | idx = np.arange(self._images_original.shape[0])
220 | np.random.shuffle(idx)
221 | self._images_original, self._images_segmented = self._images_original[idx], self._images_segmented[idx]
222 |
223 | def transpose_by_color(self):
224 | self._images_original = self._images_original.transpose(0, 3, 1, 2)
225 | self._images_segmented = self._images_segmented.transpose(0, 3, 1, 2)
226 |
227 | def perm(self, start, end):
228 | end = min(end, len(self._images_original))
229 | return DataSet(self._images_original[start:end], self._images_segmented[start:end], self._image_palette,
230 | self._augmenter)
231 |
232 | def __call__(self, batch_size=20, shuffle=True, augment=True):
233 | """
234 | `A generator which yields a batch. The batch is shuffled as default.
235 | バッチを返すジェネレータです。 デフォルトでバッチはシャッフルされます。
236 | Args:
237 | batch_size (int): batch size.
238 | shuffle (bool): If True, randomize batch datas.
239 | Yields:
240 | batch (ndarray[][][]): A batch data.
241 | """
242 |
243 | if batch_size < 1:
244 | raise ValueError("batch_size must be more than 1.")
245 | if shuffle:
246 | self.shuffle()
247 |
248 | for start in range(0, self.length, batch_size):
249 | batch = self.perm(start, start+batch_size)
250 | if augment:
251 | assert self._augmenter is not None, "you have to set an augmenter."
252 | yield self._augmenter.augment_dataset(batch, method=[ia.ImageAugmenter.NONE, ia.ImageAugmenter.FLIP])
253 | else:
254 | yield batch
255 |
256 |
257 | if __name__ == "__main__":
258 | dataset_loader = Loader(dir_original="../data_set/VOCdevkit/VOC2012/JPEGImages",
259 | dir_segmented="../data_set/VOCdevkit/VOC2012/SegmentationClass")
260 | train, test = dataset_loader.load_train_test()
261 | train.print_information()
262 | test.print_information()
--------------------------------------------------------------------------------
/util/model.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from util import loader as ld
3 |
4 |
5 | class UNet:
6 | def __init__(self, size=(128, 128), l2_reg=None):
7 | self.model = self.create_model(size, l2_reg)
8 |
9 | @staticmethod
10 | def create_model(size, l2_reg):
11 | inputs = tf.placeholder(tf.float32, [None, size[0], size[1], 3])
12 | teacher = tf.placeholder(tf.float32, [None, size[0], size[1], len(ld.DataSet.CATEGORY)])
13 | is_training = tf.placeholder(tf.bool)
14 |
15 | # 1, 1, 3
16 | conv1_1 = UNet.conv(inputs, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
17 | conv1_2 = UNet.conv(conv1_1, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
18 | pool1 = UNet.pool(conv1_2)
19 |
20 | # 1/2, 1/2, 64
21 | conv2_1 = UNet.conv(pool1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
22 | conv2_2 = UNet.conv(conv2_1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
23 | pool2 = UNet.pool(conv2_2)
24 |
25 | # 1/4, 1/4, 128
26 | conv3_1 = UNet.conv(pool2, filters=256, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
27 | conv3_2 = UNet.conv(conv3_1, filters=256, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
28 | pool3 = UNet.pool(conv3_2)
29 |
30 | # 1/8, 1/8, 256
31 | conv4_1 = UNet.conv(pool3, filters=512, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
32 | conv4_2 = UNet.conv(conv4_1, filters=512, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
33 | pool4 = UNet.pool(conv4_2)
34 |
35 | # 1/16, 1/16, 512
36 | conv5_1 = UNet.conv(pool4, filters=1024, l2_reg_scale=l2_reg)
37 | conv5_2 = UNet.conv(conv5_1, filters=1024, l2_reg_scale=l2_reg)
38 | concated1 = tf.concat([UNet.conv_transpose(conv5_2, filters=512, l2_reg_scale=l2_reg), conv4_2], axis=3)
39 |
40 | conv_up1_1 = UNet.conv(concated1, filters=512, l2_reg_scale=l2_reg)
41 | conv_up1_2 = UNet.conv(conv_up1_1, filters=512, l2_reg_scale=l2_reg)
42 | concated2 = tf.concat([UNet.conv_transpose(conv_up1_2, filters=256, l2_reg_scale=l2_reg), conv3_2], axis=3)
43 |
44 | conv_up2_1 = UNet.conv(concated2, filters=256, l2_reg_scale=l2_reg)
45 | conv_up2_2 = UNet.conv(conv_up2_1, filters=256, l2_reg_scale=l2_reg)
46 | concated3 = tf.concat([UNet.conv_transpose(conv_up2_2, filters=128, l2_reg_scale=l2_reg), conv2_2], axis=3)
47 |
48 | conv_up3_1 = UNet.conv(concated3, filters=128, l2_reg_scale=l2_reg)
49 | conv_up3_2 = UNet.conv(conv_up3_1, filters=128, l2_reg_scale=l2_reg)
50 | concated4 = tf.concat([UNet.conv_transpose(conv_up3_2, filters=64, l2_reg_scale=l2_reg), conv1_2], axis=3)
51 |
52 | conv_up4_1 = UNet.conv(concated4, filters=64, l2_reg_scale=l2_reg)
53 | conv_up4_2 = UNet.conv(conv_up4_1, filters=64, l2_reg_scale=l2_reg)
54 | outputs = UNet.conv(conv_up4_2, filters=ld.DataSet.length_category(), kernel_size=[1, 1], activation=None)
55 |
56 | return Model(inputs, outputs, teacher, is_training)
57 |
58 | @staticmethod
59 | def conv(inputs, filters, kernel_size=[3, 3], activation=tf.nn.relu, l2_reg_scale=None, batchnorm_istraining=None):
60 | if l2_reg_scale is None:
61 | regularizer = None
62 | else:
63 | regularizer = tf.contrib.layers.l2_regularizer(scale=l2_reg_scale)
64 | conved = tf.layers.conv2d(
65 | inputs=inputs,
66 | filters=filters,
67 | kernel_size=kernel_size,
68 | padding="same",
69 | activation=activation,
70 | kernel_regularizer=regularizer
71 | )
72 | if batchnorm_istraining is not None:
73 | conved = UNet.bn(conved, batchnorm_istraining)
74 |
75 | return conved
76 |
77 | @staticmethod
78 | def bn(inputs, is_training):
79 | normalized = tf.layers.batch_normalization(
80 | inputs=inputs,
81 | axis=-1,
82 | momentum=0.9,
83 | epsilon=0.001,
84 | center=True,
85 | scale=True,
86 | training=is_training,
87 | )
88 | return normalized
89 |
90 | @staticmethod
91 | def pool(inputs):
92 | pooled = tf.layers.max_pooling2d(inputs=inputs, pool_size=[2, 2], strides=2)
93 | return pooled
94 |
95 | @staticmethod
96 | def conv_transpose(inputs, filters, l2_reg_scale=None):
97 | if l2_reg_scale is None:
98 | regularizer = None
99 | else:
100 | regularizer = tf.contrib.layers.l2_regularizer(scale=l2_reg_scale)
101 | conved = tf.layers.conv2d_transpose(
102 | inputs=inputs,
103 | filters=filters,
104 | strides=[2, 2],
105 | kernel_size=[2, 2],
106 | padding='same',
107 | activation=tf.nn.relu,
108 | kernel_regularizer=regularizer
109 | )
110 | return conved
111 |
112 |
113 | class Model:
114 | def __init__(self, inputs, outputs, teacher, is_training):
115 | self.inputs = inputs
116 | self.outputs = outputs
117 | self.teacher = teacher
118 | self.is_training = is_training
119 |
--------------------------------------------------------------------------------
/util/repoter.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 | import numpy as np
3 | import datetime
4 | import os
5 | import matplotlib.pyplot as plt
6 |
7 |
8 | class Reporter:
9 | ROOT_DIR = "result"
10 | IMAGE_DIR = "image"
11 | LEARNING_DIR = "learning"
12 | INFO_DIR = "info"
13 | MODEL_DIR = "model"
14 | PARAMETER = "parameter.txt"
15 | IMAGE_PREFIX = "epoch_"
16 | IMAGE_EXTENSION = ".png"
17 | MODEL_NAME = "model.ckpt"
18 |
19 | def __init__(self, result_dir=None, parser=None):
20 | if result_dir is None:
21 | result_dir = Reporter.generate_dir_name()
22 | self._root_dir = self.ROOT_DIR
23 | self._result_dir = os.path.join(self._root_dir, result_dir)
24 | self._image_dir = os.path.join(self._result_dir, self.IMAGE_DIR)
25 | self._image_train_dir = os.path.join(self._image_dir, "train")
26 | self._image_test_dir = os.path.join(self._image_dir, "test")
27 | self._learning_dir = os.path.join(self._result_dir, self.LEARNING_DIR)
28 | self._info_dir = os.path.join(self._result_dir, self.INFO_DIR)
29 | self._model_dir = os.path.join(self._result_dir, self.MODEL_DIR)
30 | self._parameter = os.path.join(self._info_dir, self.PARAMETER)
31 | self.create_dirs()
32 |
33 | self._matplot_manager = MatPlotManager(self._learning_dir)
34 | if parser is not None:
35 | self.save_params(self._parameter, parser)
36 |
37 | @staticmethod
38 | def generate_dir_name():
39 | return datetime.datetime.today().strftime("%Y%m%d_%H%M")
40 |
41 | def create_dirs(self):
42 | os.makedirs(self._root_dir, exist_ok=True)
43 | os.makedirs(self._result_dir)
44 | os.makedirs(self._image_dir)
45 | os.makedirs(self._image_train_dir)
46 | os.makedirs(self._image_test_dir)
47 | os.makedirs(self._learning_dir)
48 | os.makedirs(self._info_dir)
49 |
50 | @staticmethod
51 | def save_params(filename, parser):
52 | parameters = list()
53 | parameters.append("Number of epochs:" + str(parser.epoch))
54 | parameters.append("Batch size:" + str(parser.batchsize))
55 | parameters.append("Training rate:" + str(parser.trainrate))
56 | parameters.append("Augmentation:" + str(parser.augmentation))
57 | parameters.append("L2 regularization:" + str(parser.l2reg))
58 | output = "\n".join(parameters)
59 |
60 | with open(filename, mode='w') as f:
61 | f.write(output)
62 |
63 | def save_image(self, train, test, epoch):
64 | file_name = self.IMAGE_PREFIX + str(epoch) + self.IMAGE_EXTENSION
65 | train_filename = os.path.join(self._image_train_dir, file_name)
66 | test_filename = os.path.join(self._image_test_dir, file_name)
67 | train.save(train_filename)
68 | test.save(test_filename)
69 |
70 | def save_image_from_ndarray(self, train_set, test_set, palette, epoch, index_void=None):
71 | assert len(train_set) == len(test_set) == 3
72 | train_image = Reporter.get_imageset(train_set[0], train_set[1], train_set[2], palette, index_void)
73 | test_image = Reporter.get_imageset(test_set[0], test_set[1], test_set[2], palette, index_void)
74 | self.save_image(train_image, test_image, epoch)
75 |
76 | def create_figure(self, title, xylabels, labels, filename=None):
77 | return self._matplot_manager.add_figure(title, xylabels, labels, filename=filename)
78 |
79 | @staticmethod
80 | def concat_images(im1, im2, palette, mode):
81 | if mode == "P":
82 | assert palette is not None
83 | dst = Image.new("P", (im1.width + im2.width, im1.height))
84 | dst.paste(im1, (0, 0))
85 | dst.paste(im2, (im1.width, 0))
86 | dst.putpalette(palette)
87 | elif mode == "RGB":
88 | dst = Image.new("RGB", (im1.width + im2.width, im1.height))
89 | dst.paste(im1, (0, 0))
90 | dst.paste(im2, (im1.width, 0))
91 | else:
92 | raise NotImplementedError
93 |
94 | return dst
95 |
96 | @staticmethod
97 | def cast_to_pil(ndarray, palette, index_void=None):
98 | assert len(ndarray.shape) == 3
99 | res = np.argmax(ndarray, axis=2)
100 | if index_void is not None:
101 | res = np.where(res == index_void, 0, res)
102 | image = Image.fromarray(np.uint8(res), mode="P")
103 | image.putpalette(palette)
104 | return image
105 |
106 | @staticmethod
107 | def get_imageset(image_in_np, image_out_np, image_tc_np, palette, index_void=None):
108 | assert image_in_np.shape[:2] == image_out_np.shape[:2] == image_tc_np.shape[:2]
109 | image_out, image_tc = Reporter.cast_to_pil(image_out_np, palette, index_void),\
110 | Reporter.cast_to_pil(image_tc_np, palette, index_void)
111 | image_concated = Reporter.concat_images(image_out, image_tc, palette, "P").convert("RGB")
112 | image_in_pil = Image.fromarray(np.uint8(image_in_np * 255), mode="RGB")
113 | image_result = Reporter.concat_images(image_in_pil, image_concated, None, "RGB")
114 | return image_result
115 |
116 | def save_model(self, saver, sess):
117 | saver.save(sess, os.path.join(self._model_dir, self.MODEL_NAME))
118 |
119 |
120 | class MatPlotManager:
121 | def __init__(self, root_dir):
122 | self._root_dir = root_dir
123 | self._figures = {}
124 |
125 | def add_figure(self, title, xylabels, labels, filename=None):
126 | assert not(title in self._figures.keys()), "This title already exists."
127 | self._figures[title] = MatPlot(title, xylabels, labels, self._root_dir, filename=filename)
128 | return self._figures[title]
129 |
130 | def get_figure(self, title):
131 | return self._figures[title]
132 |
133 |
134 | class MatPlot:
135 | EXTENSION = ".png"
136 |
137 | def __init__(self, title, xylabels, labels, root_dir, filename=None):
138 | assert len(labels) > 0 and len(xylabels) == 2
139 | if filename is None:
140 | self._filename = title
141 | else:
142 | self._filename = filename
143 | self._title = title
144 | self._xlabel, self._ylabel = xylabels[0], xylabels[1]
145 | self._labels = labels
146 | self._root_dir = root_dir
147 | self._series = np.zeros((len(labels), 0))
148 |
149 | def add(self, series, is_update=False):
150 | series = np.asarray(series).reshape((len(series), 1))
151 | assert series.shape[0] == self._series.shape[0], "series must have same length."
152 | self._series = np.concatenate([self._series, series], axis=1)
153 | if is_update:
154 | self.save()
155 |
156 | def save(self):
157 | plt.cla()
158 | for s, l in zip(self._series, self._labels):
159 | plt.plot(s, label=l)
160 | plt.legend()
161 | plt.grid()
162 | plt.xlabel(self._xlabel)
163 | plt.ylabel(self._ylabel)
164 | plt.title(self._title)
165 | plt.savefig(os.path.join(self._root_dir, self._filename+self.EXTENSION))
166 |
167 |
168 | if __name__ == "__main__":
169 | pass
170 |
--------------------------------------------------------------------------------