├── .gitignore
├── LICENSE
├── README.md
├── SLD_benchmark.py
├── SLD_demo.py
├── benchmark_config.ini
├── demo
├── image_editing
│ ├── data.json
│ ├── results
│ │ ├── dalle3_banana
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_dalle3_banana.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_dalle3_banana.png
│ │ ├── dalle3_dog
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_dalle3_dog.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_dalle3_dog.png
│ │ ├── indoor_scene_attr_mod
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_scene.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_scene.png
│ │ ├── indoor_scene_move
│ │ │ ├── corrected_result.png
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_scene.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_scene.png
│ │ ├── indoor_scene_replace
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_scene.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_scene.png
│ │ ├── indoor_scene_resize
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_scene.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_scene.png
│ │ ├── indoor_scene_swap
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_scene.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_scene.png
│ │ ├── indoor_table_attr_mod
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_table.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_table.png
│ │ ├── indoor_table_move
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_table.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_table.png
│ │ ├── indoor_table_replace
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_table.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_table.png
│ │ ├── indoor_table_resize
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_table.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_table.png
│ │ └── indoor_table_swap
│ │ │ ├── det_result_obj.png
│ │ │ ├── final_indoor_table.png
│ │ │ ├── initial_image.png
│ │ │ └── intermediate_indoor_table.png
│ └── src_image
│ │ ├── dalle3_banana.png
│ │ ├── dalle3_dog.png
│ │ ├── indoor_scene.png
│ │ └── indoor_table.png
└── self_correction
│ ├── data.json
│ ├── results
│ ├── dalle3_beach
│ │ ├── det_result_obj.png
│ │ ├── final_dalle3_beach.png
│ │ ├── initial_image.png
│ │ └── intermediate_dalle3_beach.png
│ ├── dalle3_clown
│ │ ├── det_result_obj.png
│ │ ├── final_dalle3_clown.png
│ │ ├── initial_image.png
│ │ └── intermediate_dalle3_clown.png
│ ├── dalle3_motor
│ │ ├── det_result_obj.png
│ │ ├── final_dalle3_motor.png
│ │ ├── initial_image.png
│ │ └── intermediate_dalle3_motor.png
│ ├── dalle3_snowwhite
│ │ ├── det_result_obj.png
│ │ ├── final_dalle3_snowwhite.png
│ │ ├── initial_image.png
│ │ └── intermediate_dalle3_snowwhite.png
│ ├── lmdplus_beach
│ │ ├── det_result_obj.png
│ │ ├── final_lmdplus_beach.png
│ │ ├── initial_image.png
│ │ └── intermediate_lmdplus_beach.png
│ ├── lmdplus_motor
│ │ ├── det_result_obj.png
│ │ ├── final_lmdplus_motor.png
│ │ ├── initial_image.png
│ │ └── intermediate_lmdplus_motor.png
│ ├── sdxl_beach
│ │ ├── det_result_obj.png
│ │ ├── final_sdxl_beach.png
│ │ ├── initial_image.png
│ │ └── intermediate_sdxl_beach.png
│ └── sdxl_motor
│ │ ├── det_result_obj.png
│ │ ├── final_sdxl_motor.png
│ │ ├── initial_image.png
│ │ └── intermediate_sdxl_motor.png
│ └── src_image
│ ├── dalle3_beach.png
│ ├── dalle3_car.png
│ ├── dalle3_clown.png
│ ├── dalle3_motor.png
│ ├── dalle3_snowwhite.png
│ ├── lmdplus_beach.png
│ ├── lmdplus_motor.png
│ ├── sdxl_beach.png
│ └── sdxl_motor.png
├── demo_config.ini
├── eval
├── __init__.py
├── eval.py
├── lmd.py
└── utils.py
├── lmd_benchmark_eval.py
├── models
├── __init__.py
├── attention.py
├── attention_processor.py
├── models.py
├── pipelines.py
├── sam.py
├── transformer_2d.py
├── unet_2d_blocks.py
└── unet_2d_condition.py
├── requirements.txt
├── sld
├── detector.py
├── image_generator.py
├── llm_chat.py
├── llm_template.py
├── sdxl_refine.py
└── utils.py
└── utils
├── __init__.py
├── attn.py
├── boxdiff.py
├── guidance.py
├── latents.py
├── parse.py
├── schedule.py
├── utils.py
└── vis.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # poetry
98 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
99 | # This is especially recommended for binary packages to ensure reproducibility, and is more
100 | # commonly ignored for libraries.
101 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
102 | #poetry.lock
103 |
104 | # pdm
105 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
106 | #pdm.lock
107 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
108 | # in version control.
109 | # https://pdm.fming.dev/#use-with-ide
110 | .pdm.toml
111 |
112 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
113 | __pypackages__/
114 |
115 | # Celery stuff
116 | celerybeat-schedule
117 | celerybeat.pid
118 |
119 | # SageMath parsed files
120 | *.sage.py
121 |
122 | # Environments
123 | .env
124 | .venv
125 | env/
126 | venv/
127 | ENV/
128 | env.bak/
129 | venv.bak/
130 |
131 | # Spyder project settings
132 | .spyderproject
133 | .spyproject
134 |
135 | # Rope project settings
136 | .ropeproject
137 |
138 | # mkdocs documentation
139 | /site
140 |
141 | # mypy
142 | .mypy_cache/
143 | .dmypy.json
144 | dmypy.json
145 |
146 | # Pyre type checker
147 | .pyre/
148 |
149 | # pytype static type analyzer
150 | .pytype/
151 |
152 | # Cython debug symbols
153 | cython_debug/
154 |
155 | # PyCharm
156 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
157 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
158 | # and can be added to the global gitignore or merged into this file. For a more nuclear
159 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
160 | #.idea/
161 |
162 | .vscode
163 | *tmp_imgs
164 | # Never upload you secret token to github!!!
165 | config.ini
166 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Tsung-Han Wu
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Self-correcting LLM-controlled Diffusion Models
2 |
3 | This repo provides the PyTorch source code of our paper: [Self-correcting LLM-controlled Diffusion Models (CVPR 2024)](https://arxiv.org/abs/2311.16090). Check out project page [here](https://self-correcting-llm-diffusion.github.io/)!
4 |
5 | [](https://lbesson.mit-license.org/) [](https://arxiv.org/abs/2311.16090)
6 |
7 |
8 | **Authors**: [Tsung-Han Wu\*](https://tsunghan-wu.github.io/), [Long Lian\*](https://tonylian.com/), [Joseph E. Gonzalez](https://people.eecs.berkeley.edu/~jegonzal/), [Boyi Li†](https://sites.google.com/site/boyilics/home), [Trevor Darrell†](https://people.eecs.berkeley.edu/~trevor/) at UC Berkeley.
9 |
10 |
11 | ## :rocket: The Self-correcting LLM-controlled Diffusion (SLD) Framework Highlights:
12 | 1. **Self-correction**: Enhances generative models with LLM-integrated detectors for precise text-to-image alignment.
13 | 2. **Unified Generation and Editing**: Excels at both image generation and fine-grained editing.
14 | 3. **Universal Compatibility**: Works with ANY image generator, like DALL-E 3, requiring no extra training or data.
15 |
16 | 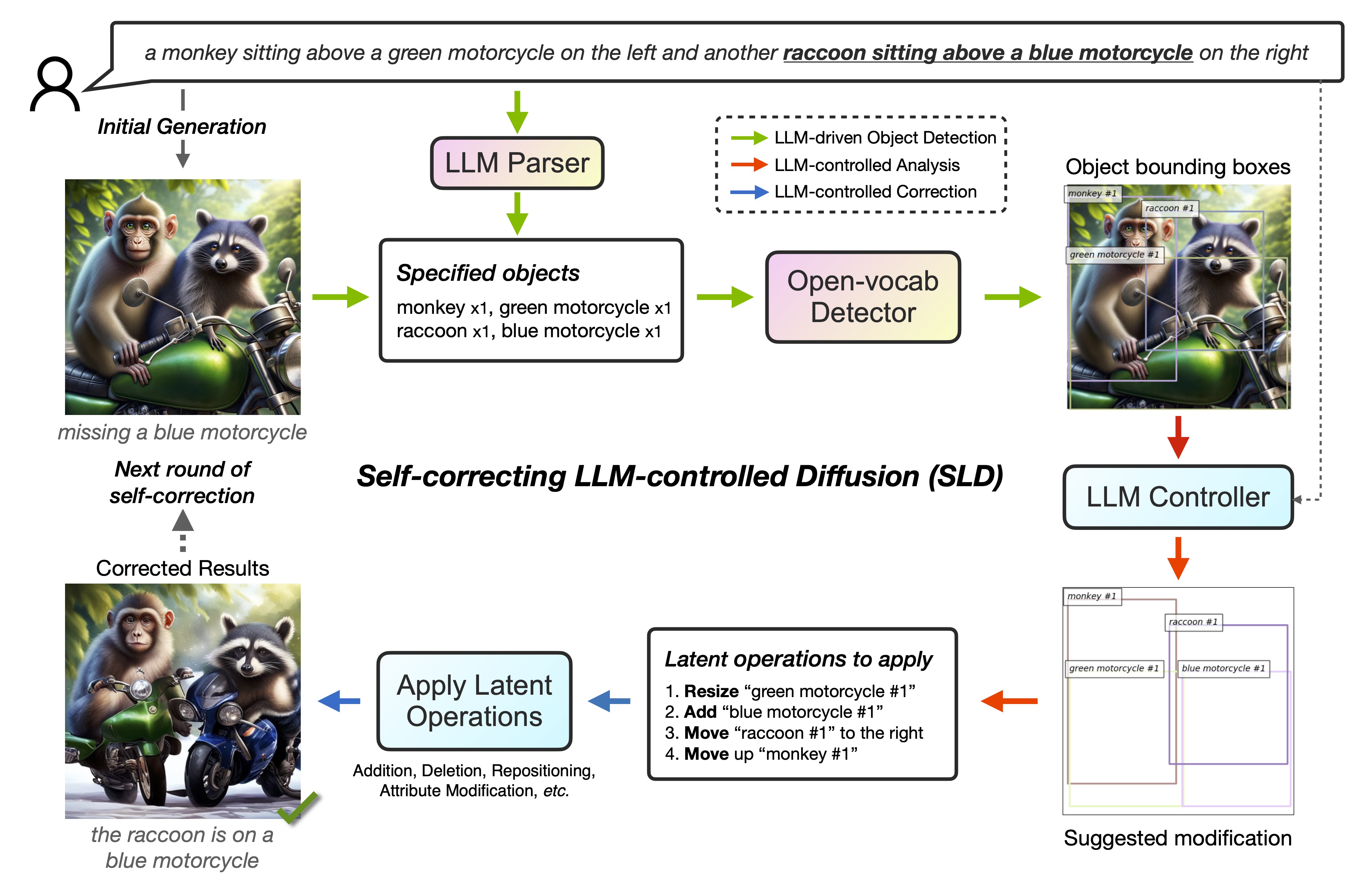
17 |
18 | ## :rotating_light: Update
19 | - 03/10/2024 - Add the all SLD scripts and results on the LMD T2I benchmark (all done!)
20 | - 02/13/2024 - Add self-correction and image editing scripts with a few demo examples
21 |
22 | ## :wrench: Installation Guide
23 |
24 | ### System Requirements
25 |
26 | - System Setup: Linux with a single A100 GPU (GPUs with more than 24 GB RAM are also compatible). For Mac or Windows, minor adjustments may be necessary.
27 |
28 | - Dependency Installation: Create a Python environment named "SLD" and install necessary dependencies:
29 |
30 |
31 | ```bash
32 | conda create -n SLD python=3.9
33 | pip3 install -r requirements.txt
34 | ```
35 |
36 | Note: Ensure the versions of transformers and diffusers match the requirements. Versions of `transformers` before 4.35 do not include `owlv2`, and our code is incompatible with some newer versions of diffusers with different API.
37 |
38 | ## :gear: Usage
39 |
40 | Execute the following command to process images from an input directory according to the instruction in the JSON file and save the transformed images to an output directory.
41 |
42 | ```
43 | CUDA_VISIBLE_DEVICES=X python3 SLD_demo.py \
44 | --json-file demo/self_correction/data.json \ # demo/image_editing/data.json
45 | --input-dir demo/self_correction/src_image \ # demo/image_editing/src_image
46 | --output-dir demo/self_correction/results \ # demo/image_editing/results
47 | --mode self_correction \ # image_editing
48 | --config demo_config.ini
49 | ```
50 |
51 | 1. This script supports both self-correction and image editing modes. Adjust the paths and --mode flag as needed.
52 | 2. We use `gligen/diffusers-generation-text-box` (SDv1.4) as the base diffusion model for image manipulation. For enhanced image quality, we incorporate SDXL refinement techniques similar to [LMD](https://github.com/TonyLianLong/LLM-groundedDiffusion).
53 |
54 |
55 | ## :briefcase: Applying to Your Own Images
56 |
57 | 1. Prepare a JSON File: Structure the file as follows, providing necessary information for each image you wish to process:
58 |
59 | ```
60 | [
61 | {
62 | "input_fname": "",
63 | "output_dir": "