├── .gitignore
├── Contents.ipynb
├── README.md
├── exercises
├── Unit 3 Exercise Calculating Pi.ipynb
├── Unit 3 Working with meteorological data 1.ipynb
├── Unit 4 KMeans.ipynb
├── Unit 4 WordCount.ipynb
├── Unit 4 Working with meteorological data 2.ipynb
├── Unit 5 Working with meteorological data.ipynb
├── Unit 7 KMeans.ipynb
├── Unit_5_sentiment_analysis_amazon_books-short_version.ipynb
├── Unit_6_working_with_meteorological_data-using_dataframes.py
├── Unit_6_working_with_meteorological_data-using_rdds.py
└── unit_1_plotting_data.ipynb
├── solutions
├── Unit 3 Exercise Calculating Pi.ipynb
├── Unit 3 Working with meteorological data 1.ipynb
├── Unit 4 KMeans.ipynb
├── Unit 4 WordCount.ipynb
├── Unit 4 Working with meteorological data 2.ipynb
├── Unit 5 Working with meteorological data - SQL version.ipynb
├── Unit 5 Working with meteorological data.ipynb
├── Unit 7 KMeans.ipynb
├── Unit_5_sentiment_analysis_amazon_books-short_version.ipynb
├── Unit_6_WordCount.py
├── Unit_6_working_with_meteorological_data-using_dataframes.py
├── Unit_6_working_with_meteorological_data-using_rdds.py
└── unit_1_plotting_data.ipynb
├── unit_1_tools.ipynb
├── unit_2_basic_spark_concepts.ipynb
├── unit_3_programming_with_RDDs.ipynb
├── unit_4_programming_with_PairRDDs.ipynb
├── unit_5_programming_with_the_structured_api.ipynb
├── unit_6_launching_applications.ipynb
└── unit_7_optimizing_monitoring_and_debugging_applications.ipynb
/.gitignore:
--------------------------------------------------------------------------------
1 | private_material/*
2 | Contact.ipynb
3 | sync.sh
4 |
--------------------------------------------------------------------------------
/Contents.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# CONTENTS"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Unit 1: Basic tools\n",
15 | "## Unit 2: Basic Spark Concepts\n",
16 | "## Unit 3: Programming with RDDs\n",
17 | "## Unit 4: Programming with PairRDDs\n",
18 | "## Unit 5: Programming with the Structured API\n",
19 | "## Unit 6: Launching Applications\n",
20 | "## Unit 7: Monitoring and Debugging Applications"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "# ABOUT THE INSTRUCTOR\n",
28 | "\n",
29 | "Javier Cacheiro López / @javicacheiro / jlopez@cesga.es\n",
30 | "* Leads the Big Data team at CESGA\n",
31 | "* Big Data architect: Undertanding the technology and creating effective solutions for each problem\n",
32 | "* Cloudera Certified Developer for Apache Hadoop (CCDH)\n",
33 | "* Cloudera Certified Spark and Hadoop Developer (CCA175)\n",
34 | "* Cloudera Certified Administrator (CCA131)\n",
35 | "\n",
36 | " \n",
37 | "\n",
38 | "\n"
39 | ]
40 | }
41 | ],
42 | "metadata": {
43 | "kernelspec": {
44 | "display_name": "Python 2",
45 | "language": "python",
46 | "name": "python2"
47 | },
48 | "language_info": {
49 | "codemirror_mode": {
50 | "name": "ipython",
51 | "version": 2
52 | },
53 | "file_extension": ".py",
54 | "mimetype": "text/x-python",
55 | "name": "python",
56 | "nbconvert_exporter": "python",
57 | "pygments_lexer": "ipython2",
58 | "version": "2.7.15"
59 | }
60 | },
61 | "nbformat": 4,
62 | "nbformat_minor": 4
63 | }
64 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Using Spark Course
2 | The repo contains the notebooks used in the **Using Spark** course.
3 |
--------------------------------------------------------------------------------
/exercises/Unit 3 Exercise Calculating Pi.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Calculating $\\pi$ using Monte Carlo"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "To estimate the value of Pi using the Monte Carlo method we generate a large number of random points (similar to **launching darts**) and see how many fall in the circle enclosed by the unit square:"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "$\\pi = 4 * \\frac{N_{hits}}{N_{total}}$"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | ""
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "You can see a demo here: [Estimating Pi with Monte Carlo demo](https://academo.org/demos/estimating-pi-monte-carlo/)"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "# Implementation"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": null,
48 | "metadata": {},
49 | "outputs": [],
50 | "source": [
51 | "from __future__ import print_function\n",
52 | "from random import random\n",
53 | "from operator import add"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {},
60 | "outputs": [],
61 | "source": [
62 | "# Number of points to generate\n",
63 | "POINTS = 1000000\n",
64 | "# Number of partitions to use in the Spark program\n",
65 | "PARTITIONS = 2"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def launch_dart(_):\n",
75 | " \"Shoot a new random dart in the (1, 1) cuadrant and return 1 if it is inside the circle, 0 otherwise\"\n",
76 | " x = random() * 2 - 1\n",
77 | " y = random() * 2 - 1\n",
78 | " return 1 if x ** 2 + y ** 2 < 1 else 0"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "metadata": {},
84 | "source": [
85 | "## Serial implementation using Python"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "hits = 0\n",
95 | "for i in xrange(POINTS):\n",
96 | " hits += launch_dart(_)\n",
97 | "print('Pi is roughly', 4.0 * hits / POINTS)"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "NOTE: If you are using Python 3 instead of the `xrange` function you would use `range`."
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "## Parallel implementation using Spark"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": null,
117 | "metadata": {},
118 | "outputs": [],
119 | "source": [
120 | "# Complete the code below, you can make use of the launch_dart function\n",
121 | "hits = sc.parallelize(..., PARTITIONS).map(...).reduce(...)\n",
122 | "print('Pi is roughly', 4.0 * hits / POINTS)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## Explore the paralellism"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "Explore how changing the number of points and the number partitions affects the elapsed time of each implementation."
137 | ]
138 | }
139 | ],
140 | "metadata": {
141 | "kernelspec": {
142 | "display_name": "Python 2",
143 | "language": "python",
144 | "name": "python2"
145 | },
146 | "language_info": {
147 | "codemirror_mode": {
148 | "name": "ipython",
149 | "version": 2
150 | },
151 | "file_extension": ".py",
152 | "mimetype": "text/x-python",
153 | "name": "python",
154 | "nbconvert_exporter": "python",
155 | "pygments_lexer": "ipython2",
156 | "version": "2.7.15"
157 | }
158 | },
159 | "nbformat": 4,
160 | "nbformat_minor": 4
161 | }
162 |
--------------------------------------------------------------------------------
/exercises/Unit 3 Working with meteorological data 1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Filtering meteorological data"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "Load the data in `datasets/meteogalicia.txt` into an RDD:"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": null,
34 | "metadata": {
35 | "collapsed": true
36 | },
37 | "outputs": [],
38 | "source": [
39 | "rdd = ???"
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "## Filter temperature data"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "Filter data from the RDD keeping only \"Temperatura media\" lines."
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {
60 | "collapsed": true
61 | },
62 | "outputs": [],
63 | "source": [
64 | "temperature_lines = rdd.filter(???)"
65 | ]
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "metadata": {},
70 | "source": [
71 | "## Count the number of points"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": null,
77 | "metadata": {
78 | "collapsed": true
79 | },
80 | "outputs": [],
81 | "source": [
82 | "temperature_lines.???"
83 | ]
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "## Find the maximum temperature of the month"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "metadata": {},
95 | "source": [
96 | "Extract the column with the temperature strings:"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": null,
102 | "metadata": {
103 | "collapsed": true
104 | },
105 | "outputs": [],
106 | "source": [
107 | "temperature_strings = temperature_lines.map(lambda line: line.split()[6])"
108 | ]
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "metadata": {},
113 | "source": [
114 | "The temperature_strings contain strings of the form \"21,55\", in order to use them we have to convert them to floats we have to first replace the \",\" with a \".\":"
115 | ]
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": null,
120 | "metadata": {
121 | "collapsed": true
122 | },
123 | "outputs": [],
124 | "source": [
125 | "values = ???"
126 | ]
127 | },
128 | {
129 | "cell_type": "markdown",
130 | "metadata": {},
131 | "source": [
132 | "And now we can convert them to floats:"
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": null,
138 | "metadata": {
139 | "collapsed": true
140 | },
141 | "outputs": [],
142 | "source": [
143 | "temperatures = ???"
144 | ]
145 | },
146 | {
147 | "cell_type": "markdown",
148 | "metadata": {},
149 | "source": [
150 | "Finally we can calculate the maximum temperature:"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": null,
156 | "metadata": {
157 | "collapsed": true
158 | },
159 | "outputs": [],
160 | "source": [
161 | "temperatures.reduce(???)"
162 | ]
163 | },
164 | {
165 | "cell_type": "markdown",
166 | "metadata": {},
167 | "source": [
168 | "Sometimes it is useful to explore the API to find more direct ways to do what we want.\n",
169 | "\n",
170 | "In this case we can see that there is a **max()** built-in function in the RDD object just to do this, so we can also do:"
171 | ]
172 | },
173 | {
174 | "cell_type": "code",
175 | "execution_count": null,
176 | "metadata": {
177 | "collapsed": true
178 | },
179 | "outputs": [],
180 | "source": [
181 | "temperatures.max()"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "## Find the minimum temperature of the month"
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": null,
194 | "metadata": {
195 | "collapsed": true
196 | },
197 | "outputs": [],
198 | "source": [
199 | "temperatures.???"
200 | ]
201 | },
202 | {
203 | "cell_type": "markdown",
204 | "metadata": {},
205 | "source": [
206 | "Reading the header of the dataset file we can see that -9999 is used as a code to indicate N/A values.\n",
207 | "\n",
208 | "So we have to filter out -9999 and repeat:"
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "execution_count": null,
214 | "metadata": {
215 | "collapsed": true
216 | },
217 | "outputs": [],
218 | "source": [
219 | "temperatures.???"
220 | ]
221 | }
222 | ],
223 | "metadata": {
224 | "kernelspec": {
225 | "display_name": "Python 2",
226 | "language": "python",
227 | "name": "python2"
228 | },
229 | "language_info": {
230 | "codemirror_mode": {
231 | "name": "ipython",
232 | "version": 2
233 | },
234 | "file_extension": ".py",
235 | "mimetype": "text/x-python",
236 | "name": "python",
237 | "nbconvert_exporter": "python",
238 | "pygments_lexer": "ipython2",
239 | "version": "2.7.15"
240 | }
241 | },
242 | "nbformat": 4,
243 | "nbformat_minor": 1
244 | }
245 |
--------------------------------------------------------------------------------
/exercises/Unit 4 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "In this exercise we will be implementing the k-means clustering algorithm. For an introduction on how this algorithm works I recommend you to read:\n",
15 | "- [K-Means Clustering Algorithm Overview](https://stanford.edu/~cpiech/cs221/handouts/kmeans.html)\n",
16 | "\n",
17 | "The following figures illustrate the steps the algorithm follows to find two centroids (taken from the previous link):\n",
18 | "\n",
19 | "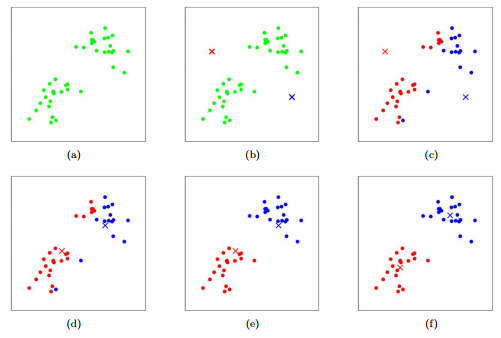"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "## Dependencies"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": null,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "from __future__ import print_function\n",
36 | "import math\n",
37 | "from collections import namedtuple"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## Parameters"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "# Number of clusters to find\n",
54 | "K = 5\n",
55 | "# Convergence threshold\n",
56 | "THRESHOLD = 0.1\n",
57 | "# Maximum number of iterations\n",
58 | "MAX_ITERS = 20"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## Load data"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def parse_coordinates(line):\n",
75 | " fields = line.split(',')\n",
76 | " return (float(fields[3]), float(fields[4]))"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": null,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "data = sc.textFile('datasets/locations')"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "metadata": {
92 | "scrolled": true
93 | },
94 | "outputs": [],
95 | "source": [
96 | "points = data.map(parse_coordinates)"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "## Useful functions"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": null,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "def distance(p1, p2): \n",
113 | " \"Calculate the squared distance between two given points\"\n",
114 | " return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2\n",
115 | "\n",
116 | "def closest_centroid(point, centroids): \n",
117 | " \"Calculate the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
118 | " distances = [distance(point, c) for c in centroids]\n",
119 | " shortest = min(distances)\n",
120 | " return distances.index(shortest)\n",
121 | "\n",
122 | "def add_points(p1,p2):\n",
123 | " \"Add two points of the same cluster in order to calculate later the new centroids\"\n",
124 | " return [p1[0] + p2[0], p1[1] + p2[1]]"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Iteratively calculate the centroids"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": null,
137 | "metadata": {},
138 | "outputs": [],
139 | "source": [
140 | "%%time\n",
141 | "# Initial centroids: we just take K randomly selected points\n",
142 | "centroids = points.takeSample(False, K, 42)\n",
143 | "\n",
144 | "# Just make sure the first iteration is always run\n",
145 | "variation = THRESHOLD + 1\n",
146 | "iteration = 0\n",
147 | "\n",
148 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
149 | " # Map each point to (centroid, (point, 1))\n",
150 | " with_centroids = points.map(???)\n",
151 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
152 | " # and keeping track of the number of points\n",
153 | " cluster_stats = with_centroids.reduceByKey(???)\n",
154 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
155 | " new_centroids = cluster_stats.map(???).collect()\n",
156 | " # Calculate the variation between old and new centroids\n",
157 | " variation = 0\n",
158 | " for (c, point) in new_centroids: variation += distance(centroids[c], point)\n",
159 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
160 | " # Replace old centroids with the new values\n",
161 | " for (c, point) in new_centroids: centroids[c] = point\n",
162 | " iteration += 1\n",
163 | " \n",
164 | "print('Final centroids: {}'.format(centroids))"
165 | ]
166 | }
167 | ],
168 | "metadata": {
169 | "kernelspec": {
170 | "display_name": "Python 2",
171 | "language": "python",
172 | "name": "python2"
173 | },
174 | "language_info": {
175 | "codemirror_mode": {
176 | "name": "ipython",
177 | "version": 2
178 | },
179 | "file_extension": ".py",
180 | "mimetype": "text/x-python",
181 | "name": "python",
182 | "nbconvert_exporter": "python",
183 | "pygments_lexer": "ipython2",
184 | "version": "2.7.15"
185 | }
186 | },
187 | "nbformat": 4,
188 | "nbformat_minor": 1
189 | }
190 |
--------------------------------------------------------------------------------
/exercises/Unit 4 WordCount.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# WordCount"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Load data"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": null,
20 | "metadata": {
21 | "collapsed": true,
22 | "jupyter": {
23 | "outputs_hidden": true
24 | }
25 | },
26 | "outputs": [],
27 | "source": [
28 | "lines = sc.textFile('datasets/slurmd/slurmd.log.c6601')"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "## Split lines into words"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": null,
41 | "metadata": {
42 | "collapsed": true,
43 | "jupyter": {
44 | "outputs_hidden": true
45 | },
46 | "scrolled": true
47 | },
48 | "outputs": [],
49 | "source": [
50 | "words = lines.???"
51 | ]
52 | },
53 | {
54 | "cell_type": "markdown",
55 | "metadata": {},
56 | "source": [
57 | "## Transform in a Pair RDD: word -> (word, 1)"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": null,
63 | "metadata": {
64 | "collapsed": true,
65 | "jupyter": {
66 | "outputs_hidden": true
67 | }
68 | },
69 | "outputs": [],
70 | "source": [
71 | "counts = words.???"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "metadata": {},
77 | "source": [
78 | "## Aggregate counts"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": null,
84 | "metadata": {
85 | "collapsed": true,
86 | "jupyter": {
87 | "outputs_hidden": true
88 | }
89 | },
90 | "outputs": [],
91 | "source": [
92 | "aggregated = counts.???"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## Show the 10 most common words"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "Invert the tuple contents so that the key is the number of occurrences"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": null,
112 | "metadata": {
113 | "collapsed": true,
114 | "jupyter": {
115 | "outputs_hidden": true
116 | }
117 | },
118 | "outputs": [],
119 | "source": [
120 | "result = aggregated.???"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "Sort and take the 10 first elements:"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": null,
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "result.???"
137 | ]
138 | }
139 | ],
140 | "metadata": {
141 | "kernelspec": {
142 | "display_name": "Python 3",
143 | "language": "python",
144 | "name": "python3"
145 | },
146 | "language_info": {
147 | "codemirror_mode": {
148 | "name": "ipython",
149 | "version": 2
150 | },
151 | "file_extension": ".py",
152 | "mimetype": "text/x-python",
153 | "name": "python",
154 | "nbconvert_exporter": "python",
155 | "pygments_lexer": "ipython2",
156 | "version": "2.7.15"
157 | }
158 | },
159 | "nbformat": 4,
160 | "nbformat_minor": 4
161 | }
162 |
--------------------------------------------------------------------------------
/exercises/Unit 4 Working with meteorological data 2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data 2"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorological data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Extract date and temperature information"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Filter data from the RDD keeping only \"Temperatura media\" lines and keeping the date information."
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "temperatures = ???"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "Take 5 elements of the dataset to verify the contents of the RDD:"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": null,
66 | "metadata": {},
67 | "outputs": [],
68 | "source": [
69 | "temperatures.take(5)"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "## Calculate the average temperature per day"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": null,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "averages = ???"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "## Show the results sorted by date"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": null,
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "averages.???"
102 | ]
103 | }
104 | ],
105 | "metadata": {
106 | "kernelspec": {
107 | "display_name": "Python 2",
108 | "language": "python",
109 | "name": "python2"
110 | },
111 | "language_info": {
112 | "codemirror_mode": {
113 | "name": "ipython",
114 | "version": 2
115 | },
116 | "file_extension": ".py",
117 | "mimetype": "text/x-python",
118 | "name": "python",
119 | "nbconvert_exporter": "python",
120 | "pygments_lexer": "ipython2",
121 | "version": "2.7.15"
122 | }
123 | },
124 | "nbformat": 4,
125 | "nbformat_minor": 2
126 | }
127 |
--------------------------------------------------------------------------------
/exercises/Unit 5 Working with meteorological data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data using DataFrames"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Convert to a DataFrame"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": null,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "from pyspark.sql import Row\n",
47 | "\n",
48 | "def parse_row(line):\n",
49 | " \"\"\"If the line is a data line convert it into a Row, otherwise return an empty list\"\"\"\n",
50 | " # All data lines start with 6 spaces\n",
51 | " if line.startswith(' '):\n",
52 | " codigo = int(line[:17].strip())\n",
53 | " datahora = line[17:40]\n",
54 | " data, hora = datahora.split()\n",
55 | " parametro = line[40:82].strip()\n",
56 | " valor = float(line[82:].replace(',', '.'))\n",
57 | " return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]\n",
58 | " return []"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "Using flatMap we have the flexibility to return nothing from a call to the function, this is accomplished returning and empty array."
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "data = rdd.flatMap(parse_row).toDF()"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "## Count the number of points"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": null,
87 | "metadata": {},
88 | "outputs": [],
89 | "source": [
90 | "data.???"
91 | ]
92 | },
93 | {
94 | "cell_type": "markdown",
95 | "metadata": {},
96 | "source": [
97 | "## Filter temperature data"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": null,
103 | "metadata": {},
104 | "outputs": [],
105 | "source": [
106 | "t = data.???"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "## Find the maximum temperature of the month"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": null,
119 | "metadata": {},
120 | "outputs": [],
121 | "source": [
122 | "t.???"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## Find the minimum temperature of the month"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": null,
135 | "metadata": {},
136 | "outputs": [],
137 | "source": [
138 | "t.???"
139 | ]
140 | },
141 | {
142 | "cell_type": "markdown",
143 | "metadata": {},
144 | "source": [
145 | "The value -9999 is a code used to indicate a non registered value (N/A).\n",
146 | "\n",
147 | "If we look to the possible values of \"Códigos de validación\" we see valid points have the code 1, so we can concentrate our efforts on data with code 1."
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": null,
153 | "metadata": {},
154 | "outputs": [],
155 | "source": [
156 | "t.???"
157 | ]
158 | },
159 | {
160 | "cell_type": "markdown",
161 | "metadata": {},
162 | "source": [
163 | "## Calculate the average temperature per day"
164 | ]
165 | },
166 | {
167 | "cell_type": "code",
168 | "execution_count": null,
169 | "metadata": {},
170 | "outputs": [],
171 | "source": [
172 | "t.???"
173 | ]
174 | },
175 | {
176 | "cell_type": "markdown",
177 | "metadata": {},
178 | "source": [
179 | "## Show the results sorted by date"
180 | ]
181 | },
182 | {
183 | "cell_type": "code",
184 | "execution_count": null,
185 | "metadata": {},
186 | "outputs": [],
187 | "source": [
188 | "t.???"
189 | ]
190 | }
191 | ],
192 | "metadata": {
193 | "kernelspec": {
194 | "display_name": "Python 2",
195 | "language": "python",
196 | "name": "python2"
197 | },
198 | "language_info": {
199 | "codemirror_mode": {
200 | "name": "ipython",
201 | "version": 2
202 | },
203 | "file_extension": ".py",
204 | "mimetype": "text/x-python",
205 | "name": "python",
206 | "nbconvert_exporter": "python",
207 | "pygments_lexer": "ipython2",
208 | "version": "2.7.15"
209 | }
210 | },
211 | "nbformat": 4,
212 | "nbformat_minor": 1
213 | }
214 |
--------------------------------------------------------------------------------
/exercises/Unit 7 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans (optimized version)"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": null,
13 | "metadata": {
14 | "collapsed": true
15 | },
16 | "outputs": [],
17 | "source": [
18 | "from __future__ import print_function\n",
19 | "import math\n",
20 | "from collections import namedtuple"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "## Parameters"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": null,
33 | "metadata": {
34 | "collapsed": true
35 | },
36 | "outputs": [],
37 | "source": [
38 | "# Number of clusters to find\n",
39 | "K = 5\n",
40 | "# Convergence threshold\n",
41 | "THRESHOLD = 0.1\n",
42 | "# Maximum number of iterations\n",
43 | "MAX_ITERS = 20"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "## Load data"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": null,
56 | "metadata": {
57 | "collapsed": true
58 | },
59 | "outputs": [],
60 | "source": [
61 | "def parse_coordinates(line):\n",
62 | " fields = line.split(',')\n",
63 | " return (float(fields[3]), float(fields[4]))"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {
70 | "collapsed": true
71 | },
72 | "outputs": [],
73 | "source": [
74 | "data = sc.textFile('datasets/locations')"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {
81 | "collapsed": true
82 | },
83 | "outputs": [],
84 | "source": [
85 | "points = data.map(parse_coordinates)"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "## Useful functions"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": null,
98 | "metadata": {
99 | "collapsed": true
100 | },
101 | "outputs": [],
102 | "source": [
103 | "def distance(p1, p2): \n",
104 | " \"Calculate the squared distance between two given points\"\n",
105 | " return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2\n",
106 | "\n",
107 | "def closest_centroid(point, centroids): \n",
108 | " \"Calculate the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
109 | " distances = [distance(point, c) for c in centroids]\n",
110 | " shortest = min(distances)\n",
111 | " return distances.index(shortest)\n",
112 | "\n",
113 | "def add_points(p1,p2):\n",
114 | " \"Add two points of the same cluster in order to calculate later the new centroids\"\n",
115 | " return [p1[0] + p2[0], p1[1] + p2[1]]"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "## Iteratively calculate the centroids"
123 | ]
124 | },
125 | {
126 | "cell_type": "code",
127 | "execution_count": null,
128 | "metadata": {},
129 | "outputs": [],
130 | "source": [
131 | "%%time\n",
132 | "# Initial centroids: we just take K randomly selected points\n",
133 | "centroids = points.takeSample(False, K, 42)\n",
134 | "\n",
135 | "# Just make sure the first iteration is always run\n",
136 | "variation = THRESHOLD + 1\n",
137 | "iteration = 0\n",
138 | "\n",
139 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
140 | " # Map each point to (centroid, (point, 1))\n",
141 | " with_centroids = points.map(lambda p : (closest_centroid(p, centroids), (p, 1)))\n",
142 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
143 | " # and keeping track of the number of points\n",
144 | " cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
145 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
146 | " new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, [x/n, y/n])).collect()\n",
147 | " # Calculate the variation between old and new centroids\n",
148 | " variation = 0\n",
149 | " for (c, point) in new_centroids: variation += distance(centroids[c], point)\n",
150 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
151 | " # Replace old centroids with the new values\n",
152 | " for (c, point) in new_centroids: centroids[c] = point\n",
153 | " iteration += 1\n",
154 | " \n",
155 | "print('Final centroids: {}'.format(centroids))"
156 | ]
157 | }
158 | ],
159 | "metadata": {
160 | "kernelspec": {
161 | "display_name": "Python 2",
162 | "language": "python",
163 | "name": "python2"
164 | },
165 | "language_info": {
166 | "codemirror_mode": {
167 | "name": "ipython",
168 | "version": 2
169 | },
170 | "file_extension": ".py",
171 | "mimetype": "text/x-python",
172 | "name": "python",
173 | "nbconvert_exporter": "python",
174 | "pygments_lexer": "ipython2",
175 | "version": "2.7.15"
176 | }
177 | },
178 | "nbformat": 4,
179 | "nbformat_minor": 1
180 | }
181 |
--------------------------------------------------------------------------------
/exercises/Unit_5_sentiment_analysis_amazon_books-short_version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# SENTIMENT ANALYSIS WITH SPARK ML"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "# Spark ML Main Concepts\n",
15 | "\n",
16 | "The Spark Machine learning API in the **spark.ml** package is based on DataFrames, there is also another Spark Machine learning API based on RDDs in the **spark.mllib** package, but as of Spark 2.0, the RDD-based API has entered maintenance mode. The primary Machine Learning API for Spark is now the DataFrame-based API.\n",
17 | "\n",
18 | "Main concepts of Spark ML:\n",
19 | "\n",
20 | "- **Transformer**: transforms one DataFrame into another DataFrame\n",
21 | "\n",
22 | "- **Estimator**: eg. a learning algorithm that trains on a DataFrame and produces a Model\n",
23 | "\n",
24 | "- **Pipeline**: chains Transformers and Estimators to produce a Model\n",
25 | "\n",
26 | "- **Evaluator**: measures how well a fitted Model does on held-out test data\n"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "# Amazon product data\n",
34 | "We will use a [dataset](http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Books_5.json.gz)[1] that contains 8.9M book reviews from Amazon, spanning May 1996 - July 2014.\n",
35 | "\n",
36 | "Dataset characteristics:\n",
37 | "- Number of reviews: 8.9M\n",
38 | "- Size: 8.8GB (uncompressed)\n",
39 | "- HDFS blocks: 70 (each with 3 replicas)\n",
40 | "\n",
41 | "\n",
42 | "[1] Image-based recommendations on styles and substitutes\n",
43 | "J. McAuley, C. Targett, J. Shi, A. van den Hengel\n",
44 | "SIGIR, 2015\n",
45 | "http://jmcauley.ucsd.edu/data/amazon/"
46 | ]
47 | },
48 | {
49 | "cell_type": "markdown",
50 | "metadata": {},
51 | "source": [
52 | "# Load Data"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": null,
58 | "metadata": {},
59 | "outputs": [],
60 | "source": [
61 | "%%time\n",
62 | "raw_reviews = spark.read.json('/tmp/reviews_Books_5_small.json')"
63 | ]
64 | },
65 | {
66 | "cell_type": "code",
67 | "execution_count": 2,
68 | "metadata": {},
69 | "outputs": [
70 | {
71 | "data": {
72 | "text/plain": [
73 | "10000"
74 | ]
75 | },
76 | "execution_count": 2,
77 | "metadata": {},
78 | "output_type": "execute_result"
79 | }
80 | ],
81 | "source": [
82 | "raw_reviews.count()"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 3,
88 | "metadata": {},
89 | "outputs": [
90 | {
91 | "name": "stdout",
92 | "output_type": "stream",
93 | "text": [
94 | "CPU times: user 6.46 ms, sys: 4.72 ms, total: 11.2 ms\n",
95 | "Wall time: 41.8 s\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "%%time\n",
101 | "raw_reviews = spark.read.json('data/amazon/reviews_Books_5.json')"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 2,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "name": "stdout",
111 | "output_type": "stream",
112 | "text": [
113 | "+--------------------+-------+\n",
114 | "| reviewText|overall|\n",
115 | "+--------------------+-------+\n",
116 | "|Spiritually and m...| 5.0|\n",
117 | "|This is one my mu...| 5.0|\n",
118 | "+--------------------+-------+\n",
119 | "only showing top 2 rows\n",
120 | "\n",
121 | "CPU times: user 3.91 ms, sys: 935 µs, total: 4.84 ms\n",
122 | "Wall time: 3.77 s\n"
123 | ]
124 | }
125 | ],
126 | "source": [
127 | "%%time\n",
128 | "all_reviews = raw_reviews.select('reviewText', 'overall')\n",
129 | "all_reviews.cache()\n",
130 | "all_reviews.show(2)"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "metadata": {},
136 | "source": [
137 | "# Prepare data\n",
138 | "We will avoid neutral reviews by keeping only reviews with 1 or 5 stars overall score.\n",
139 | "We will also filter out the reviews that contain no text."
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 3,
145 | "metadata": {},
146 | "outputs": [],
147 | "source": [
148 | "nonneutral_reviews = all_reviews.filter(\n",
149 | " (all_reviews.overall == 1.0) | (all_reviews.overall == 5.0))\n",
150 | "reviews = nonneutral_reviews.filter(all_reviews.reviewText != '')"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": 4,
156 | "metadata": {},
157 | "outputs": [
158 | {
159 | "data": {
160 | "text/plain": [
161 | "DataFrame[reviewText: string, overall: double]"
162 | ]
163 | },
164 | "execution_count": 4,
165 | "metadata": {},
166 | "output_type": "execute_result"
167 | }
168 | ],
169 | "source": [
170 | "reviews.cache()\n",
171 | "all_reviews.unpersist()"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "# Split Data"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 5,
184 | "metadata": {},
185 | "outputs": [],
186 | "source": [
187 | "trainingData, testData = reviews.randomSplit([0.8, 0.2])"
188 | ]
189 | },
190 | {
191 | "cell_type": "markdown",
192 | "metadata": {},
193 | "source": [
194 | "# Generate Pipeline\n",
195 | "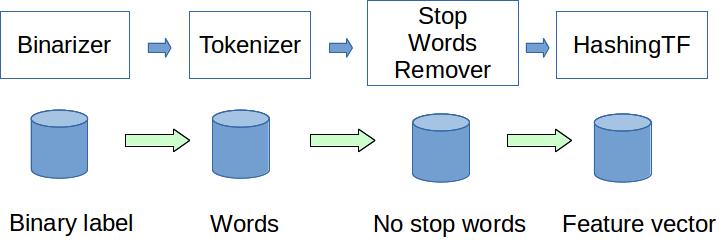"
196 | ]
197 | },
198 | {
199 | "cell_type": "markdown",
200 | "metadata": {},
201 | "source": [
202 | "## Binarizer\n",
203 | "A transformer to convert numerical features to binary (0/1) features"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 6,
209 | "metadata": {},
210 | "outputs": [],
211 | "source": [
212 | "from pyspark.ml.feature import Binarizer\n",
213 | "\n",
214 | "binarizer = Binarizer(threshold=2.5, inputCol='overall', outputCol='label')"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "## Tokenizer\n",
222 | "A transformer that converts the input string to lowercase and then splits it by white spaces."
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 7,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "from pyspark.ml.feature import Tokenizer\n",
232 | "tokenizer = Tokenizer(inputCol=\"reviewText\", outputCol=\"words\")"
233 | ]
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "metadata": {},
238 | "source": [
239 | "## StopWordsRemover\n",
240 | "A transformer that filters out stop words from input. Note: null values from input array are preserved unless adding null to stopWords explicitly."
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 8,
246 | "metadata": {},
247 | "outputs": [],
248 | "source": [
249 | "from pyspark.ml.feature import StopWordsRemover\n",
250 | "remover = StopWordsRemover(inputCol=tokenizer.getOutputCol(), outputCol=\"filtered\")"
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "## HashingTF\n",
258 | "A Transformer that converts a sequence of words into a fixed-length feature Vector. It maps a sequence of terms to their term frequencies using a hashing function."
259 | ]
260 | },
261 | {
262 | "cell_type": "code",
263 | "execution_count": 9,
264 | "metadata": {},
265 | "outputs": [],
266 | "source": [
267 | "from pyspark.ml.feature import HashingTF\n",
268 | "hashingTF = HashingTF(inputCol=remover.getOutputCol(), outputCol=\"features\")"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "# Estimator\n",
276 | "## LogisticRegression"
277 | ]
278 | },
279 | {
280 | "cell_type": "code",
281 | "execution_count": 10,
282 | "metadata": {},
283 | "outputs": [],
284 | "source": [
285 | "from pyspark.ml.classification import LogisticRegression\n",
286 | "lr = LogisticRegression(maxIter=10, regParam=0.01)"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "# Pipeline"
294 | ]
295 | },
296 | {
297 | "cell_type": "code",
298 | "execution_count": 11,
299 | "metadata": {},
300 | "outputs": [],
301 | "source": [
302 | "from pyspark.ml import Pipeline\n",
303 | "pipeline = Pipeline(stages=[binarizer, tokenizer, remover, hashingTF, lr])"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 12,
309 | "metadata": {},
310 | "outputs": [
311 | {
312 | "name": "stdout",
313 | "output_type": "stream",
314 | "text": [
315 | "CPU times: user 37 ms, sys: 13.2 ms, total: 50.2 ms\n",
316 | "Wall time: 58.1 s\n"
317 | ]
318 | }
319 | ],
320 | "source": [
321 | "%%time\n",
322 | "pipeLineModel = pipeline.fit(trainingData)"
323 | ]
324 | },
325 | {
326 | "cell_type": "markdown",
327 | "metadata": {},
328 | "source": [
329 | "# Evaluation"
330 | ]
331 | },
332 | {
333 | "cell_type": "code",
334 | "execution_count": 13,
335 | "metadata": {
336 | "scrolled": true
337 | },
338 | "outputs": [
339 | {
340 | "name": "stdout",
341 | "output_type": "stream",
342 | "text": [
343 | "Area under ROC: 0.967783441159\n",
344 | "CPU times: user 31.8 ms, sys: 4.17 ms, total: 36 ms\n",
345 | "Wall time: 16.7 s\n"
346 | ]
347 | }
348 | ],
349 | "source": [
350 | "%%time\n",
351 | "from pyspark.ml.evaluation import BinaryClassificationEvaluator\n",
352 | "evaluator = BinaryClassificationEvaluator()\n",
353 | "\n",
354 | "predictions = pipeLineModel.transform(testData)\n",
355 | "\n",
356 | "aur = evaluator.evaluate(predictions)\n",
357 | "\n",
358 | "print 'Area under ROC: ', aur"
359 | ]
360 | },
361 | {
362 | "cell_type": "markdown",
363 | "metadata": {},
364 | "source": [
365 | "# Hyperparameter Tuning"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 14,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "name": "stdout",
375 | "output_type": "stream",
376 | "text": [
377 | "CPU times: user 3.9 s, sys: 1.11 s, total: 5.01 s\n",
378 | "Wall time: 12min 49s\n"
379 | ]
380 | }
381 | ],
382 | "source": [
383 | "%%time\n",
384 | "from pyspark.ml.tuning import ParamGridBuilder, CrossValidator\n",
385 | "param_grid = ParamGridBuilder() \\\n",
386 | " .addGrid(hashingTF.numFeatures, [10000, 100000]) \\\n",
387 | " .addGrid(lr.regParam, [0.01, 0.1, 1.0]) \\\n",
388 | " .addGrid(lr.maxIter, [10, 20]) \\\n",
389 | " .build()\n",
390 | " \n",
391 | "cv = (CrossValidator()\n",
392 | " .setEstimator(pipeline)\n",
393 | " .setEvaluator(evaluator)\n",
394 | " .setEstimatorParamMaps(param_grid)\n",
395 | " .setNumFolds(3))\n",
396 | "\n",
397 | "cv_model = cv.fit(trainingData)"
398 | ]
399 | },
400 | {
401 | "cell_type": "code",
402 | "execution_count": 15,
403 | "metadata": {},
404 | "outputs": [
405 | {
406 | "name": "stdout",
407 | "output_type": "stream",
408 | "text": [
409 | "Area under ROC: 0.96977328792\n",
410 | "CPU times: user 28.3 ms, sys: 8.81 ms, total: 37.1 ms\n",
411 | "Wall time: 5.12 s\n"
412 | ]
413 | }
414 | ],
415 | "source": [
416 | "%%time\n",
417 | "new_predictions = cv_model.transform(testData)\n",
418 | "new_aur = evaluator.evaluate(new_predictions)\n",
419 | "print 'Area under ROC: ', new_aur"
420 | ]
421 | }
422 | ],
423 | "metadata": {
424 | "kernelspec": {
425 | "display_name": "Python 2",
426 | "language": "python",
427 | "name": "python2"
428 | },
429 | "language_info": {
430 | "codemirror_mode": {
431 | "name": "ipython",
432 | "version": 2
433 | },
434 | "file_extension": ".py",
435 | "mimetype": "text/x-python",
436 | "name": "python",
437 | "nbconvert_exporter": "python",
438 | "pygments_lexer": "ipython2",
439 | "version": "2.7.15"
440 | }
441 | },
442 | "nbformat": 4,
443 | "nbformat_minor": 1
444 | }
445 |
--------------------------------------------------------------------------------
/exercises/Unit_6_working_with_meteorological_data-using_dataframes.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 |
4 | if __name__ == '__main__':
5 | ???
6 |
--------------------------------------------------------------------------------
/exercises/Unit_6_working_with_meteorological_data-using_rdds.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 |
4 | if __name__ == '__main__':
5 | ????
6 |
--------------------------------------------------------------------------------
/exercises/unit_1_plotting_data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Exercise 1.4.1: Plotting Data"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": null,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from bokeh.io import show, output_notebook\n",
17 | "from bokeh.plotting import figure\n",
18 | "output_notebook()"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "Given the following data:"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "import pandas as pd\n",
35 | "X = range(100)\n",
36 | "Y = [0.01*n**3 for n in X]\n",
37 | "data = pd.DataFrame(zip(X,Y), columns=['Seconds', 'Connections'])"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Check the Bokeh documentation for [bokeh.plotting](https://bokeh.pydata.org/en/1.4.0/docs/reference/plotting.html) and generate a scatter plot representing 'Seconds' in the X axis and 'Connections' in the Y axis using squares as markers:"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "p = figure(title='Total Connections', x_axis_label='Seconds', y_axis_label='Connections')\n",
54 | "# Complete the line below\n",
55 | "...\n",
56 | "show(p)"
57 | ]
58 | }
59 | ],
60 | "metadata": {
61 | "kernelspec": {
62 | "display_name": "Python 3",
63 | "language": "python",
64 | "name": "python3"
65 | },
66 | "language_info": {
67 | "codemirror_mode": {
68 | "name": "ipython",
69 | "version": 3
70 | },
71 | "file_extension": ".py",
72 | "mimetype": "text/x-python",
73 | "name": "python",
74 | "nbconvert_exporter": "python",
75 | "pygments_lexer": "ipython3",
76 | "version": "3.7.6"
77 | }
78 | },
79 | "nbformat": 4,
80 | "nbformat_minor": 4
81 | }
82 |
--------------------------------------------------------------------------------
/solutions/Unit 3 Exercise Calculating Pi.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Calculating $\\pi$ using Monte Carlo"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "To estimate the value of Pi using the Monte Carlo method we generate a large number of random points (similar to **launching darts**) and see how many fall in the circle enclosed by the unit square:"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "$\\pi = 4 * \\frac{N_{hits}}{N_{total}}$"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | ""
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "You can see a demo here: [Estimating Pi with Monte Carlo demo](https://academo.org/demos/estimating-pi-monte-carlo/)"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "# Implementation"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 1,
48 | "metadata": {},
49 | "outputs": [],
50 | "source": [
51 | "from __future__ import print_function\n",
52 | "from random import random\n",
53 | "from operator import add\n",
54 | "import time"
55 | ]
56 | },
57 | {
58 | "cell_type": "code",
59 | "execution_count": 2,
60 | "metadata": {},
61 | "outputs": [],
62 | "source": [
63 | "# Number of points to generate\n",
64 | "POINTS = 10**8\n",
65 | "# Number of partitions to use in the Spark program\n",
66 | "PARTITIONS = 20"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 3,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "def launch_dart(_):\n",
76 | " \"Shoot a new random dart in the (1, 1) cuadrant and return 1 if it is inside the circle, 0 otherwise\"\n",
77 | " x = random() * 2 - 1\n",
78 | " y = random() * 2 - 1\n",
79 | " return 1 if x ** 2 + y ** 2 < 1 else 0"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "## Serial implementation using Python"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 4,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "Elapsed time: 59.5995240211\n",
99 | "Pi is roughly 3.14194192\n"
100 | ]
101 | }
102 | ],
103 | "source": [
104 | "start = time.time()\n",
105 | "hits = 0\n",
106 | "for i in xrange(POINTS):\n",
107 | " hits += launch_dart(_)\n",
108 | "end = time.time()\n",
109 | "print('Elapsed time:', end - start)\n",
110 | "print('Pi is roughly', 4.0 * hits / POINTS)"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "NOTE: If you are using Python 3 instead of the `xrange` function you would use `range`."
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "## Parallel implementation using Spark"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 8,
130 | "metadata": {},
131 | "outputs": [
132 | {
133 | "name": "stdout",
134 | "output_type": "stream",
135 | "text": [
136 | "Elapsed time: 9.7909719944\n",
137 | "Pi is roughly 3.14167076\n"
138 | ]
139 | }
140 | ],
141 | "source": [
142 | "start = time.time()\n",
143 | "hits = sc.parallelize(xrange(POINTS), PARTITIONS).map(launch_dart).reduce(add)\n",
144 | "end = time.time()\n",
145 | "print('Elapsed time:', end - start)\n",
146 | "print('Pi is roughly', 4.0 * hits / POINTS)"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "NOTE: If you are using Python 3 instead of the `xrange` function you would use `range`."
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "## Explore the paralellism"
161 | ]
162 | },
163 | {
164 | "cell_type": "markdown",
165 | "metadata": {},
166 | "source": [
167 | "Explore how changing the number of points and the number partitions affects the elapsed time of each implementation.\n",
168 | "\n",
169 | "- We can increase POINTS from `10**6` to `10**8`, in this case the sequential execution will need more than 60 seconds.\n",
170 | "- Take into account that just re-running again the spark calculation reduces the time because the executors are already launched so the application startup time is shorter."
171 | ]
172 | }
173 | ],
174 | "metadata": {
175 | "kernelspec": {
176 | "display_name": "Python 2",
177 | "language": "python",
178 | "name": "python2"
179 | },
180 | "language_info": {
181 | "codemirror_mode": {
182 | "name": "ipython",
183 | "version": 2
184 | },
185 | "file_extension": ".py",
186 | "mimetype": "text/x-python",
187 | "name": "python",
188 | "nbconvert_exporter": "python",
189 | "pygments_lexer": "ipython2",
190 | "version": "2.7.15"
191 | }
192 | },
193 | "nbformat": 4,
194 | "nbformat_minor": 4
195 | }
196 |
--------------------------------------------------------------------------------
/solutions/Unit 3 Working with meteorological data 1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Filtering meteorological data"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Filter temperature data"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Filter data from the RDD keeping only \"Temperatura media\" lines."
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 2,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "temperature_lines = rdd.filter(lambda line: 'Temperatura media' in line)"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "## Count the number of points"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 3,
66 | "metadata": {},
67 | "outputs": [
68 | {
69 | "data": {
70 | "text/plain": [
71 | "4176"
72 | ]
73 | },
74 | "execution_count": 3,
75 | "metadata": {},
76 | "output_type": "execute_result"
77 | }
78 | ],
79 | "source": [
80 | "temperature_lines.count()"
81 | ]
82 | },
83 | {
84 | "cell_type": "markdown",
85 | "metadata": {},
86 | "source": [
87 | "## Find the maximum temperature of the month"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 4,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "temperature_strings = temperature_lines.map(lambda line: line.split()[6])"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "The temperature_strings contain strings of the form \"21,55\", in order to use them we have to convert them to floats we have to first replace the \",\" with a \".\":"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 5,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "values = temperature_strings.map(lambda value: value.replace(',', '.'))"
113 | ]
114 | },
115 | {
116 | "cell_type": "markdown",
117 | "metadata": {},
118 | "source": [
119 | "And now we can convert them to floats:"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 6,
125 | "metadata": {},
126 | "outputs": [],
127 | "source": [
128 | "temperatures = values.map(lambda value: float(value))"
129 | ]
130 | },
131 | {
132 | "cell_type": "markdown",
133 | "metadata": {},
134 | "source": [
135 | "Finally we can calculate the maximum temperature:"
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 7,
141 | "metadata": {},
142 | "outputs": [
143 | {
144 | "data": {
145 | "text/plain": [
146 | "34.4"
147 | ]
148 | },
149 | "execution_count": 7,
150 | "metadata": {},
151 | "output_type": "execute_result"
152 | }
153 | ],
154 | "source": [
155 | "temperatures.reduce(max)"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "Sometimes it is useful to explore the API to find more direct ways to do what we want.\n",
163 | "\n",
164 | "In this case we can see that there is a **max()** built-in function in the RDD object just to do this, so we can also do:"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": 8,
170 | "metadata": {},
171 | "outputs": [
172 | {
173 | "data": {
174 | "text/plain": [
175 | "34.4"
176 | ]
177 | },
178 | "execution_count": 8,
179 | "metadata": {},
180 | "output_type": "execute_result"
181 | }
182 | ],
183 | "source": [
184 | "temperatures.max()"
185 | ]
186 | },
187 | {
188 | "cell_type": "markdown",
189 | "metadata": {},
190 | "source": [
191 | "## Find the minimum temperature of the month"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 9,
197 | "metadata": {},
198 | "outputs": [
199 | {
200 | "data": {
201 | "text/plain": [
202 | "-9999.0"
203 | ]
204 | },
205 | "execution_count": 9,
206 | "metadata": {},
207 | "output_type": "execute_result"
208 | }
209 | ],
210 | "source": [
211 | "temperatures.min()"
212 | ]
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "metadata": {},
217 | "source": [
218 | "Reading the header of the dataset file we can see that -9999 is used as a code to indicate N/A values.\n",
219 | "\n",
220 | "So we have to filter out -9999 and repeat:"
221 | ]
222 | },
223 | {
224 | "cell_type": "code",
225 | "execution_count": 10,
226 | "metadata": {},
227 | "outputs": [
228 | {
229 | "data": {
230 | "text/plain": [
231 | "9.09"
232 | ]
233 | },
234 | "execution_count": 10,
235 | "metadata": {},
236 | "output_type": "execute_result"
237 | }
238 | ],
239 | "source": [
240 | "temperatures.filter(lambda value: value != -9999).min()"
241 | ]
242 | }
243 | ],
244 | "metadata": {
245 | "kernelspec": {
246 | "display_name": "Python 3",
247 | "language": "python",
248 | "name": "python3"
249 | },
250 | "language_info": {
251 | "codemirror_mode": {
252 | "name": "ipython",
253 | "version": 3
254 | },
255 | "file_extension": ".py",
256 | "mimetype": "text/x-python",
257 | "name": "python",
258 | "nbconvert_exporter": "python",
259 | "pygments_lexer": "ipython3",
260 | "version": "3.7.6"
261 | }
262 | },
263 | "nbformat": 4,
264 | "nbformat_minor": 4
265 | }
266 |
--------------------------------------------------------------------------------
/solutions/Unit 4 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "In this exercise we will be implementing the k-means clustering algorithm. For an introduction on how this algorithm works I recommend you to read:\n",
15 | "- [K-Means Clustering Algorithm Overview](https://stanford.edu/~cpiech/cs221/handouts/kmeans.html)\n",
16 | "\n",
17 | "The following figures illustrate the steps the algorithm follows to find two centroids (taken from the previous link):\n",
18 | "\n",
19 | ""
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "## Dependencies"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "from __future__ import print_function\n",
36 | "import math\n",
37 | "from collections import namedtuple"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## Parameters"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 2,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "# Number of clusters to find\n",
54 | "K = 5\n",
55 | "# Convergence threshold\n",
56 | "THRESHOLD = 0.1\n",
57 | "# Maximum number of iterations\n",
58 | "MAX_ITERS = 20"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## Load data"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def parse_coordinates(line):\n",
75 | " fields = line.split(',')\n",
76 | " return (float(fields[3]), float(fields[4]))"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "data = sc.textFile('datasets/locations')"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 5,
91 | "metadata": {
92 | "scrolled": true
93 | },
94 | "outputs": [],
95 | "source": [
96 | "points = data.map(parse_coordinates)"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "## Useful functions"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 6,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "def distance(p1, p2): \n",
113 | " \"Returns the squared distance between two given points\"\n",
114 | " return (p1[0] - p2[0])** 2 + (p1[1] - p2[1])** 2\n",
115 | "\n",
116 | "def closest_centroid(point, centroids): \n",
117 | " \"Returns the index of the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
118 | " distances = [distance(point, c) for c in centroids]\n",
119 | " shortest = min(distances)\n",
120 | " return distances.index(shortest)\n",
121 | "\n",
122 | "def add_points(p1, p2):\n",
123 | " \"Returns the sum of two points\"\n",
124 | " return (p1[0] + p2[0], p1[1] + p2[1])"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Iteratively calculate the centroids"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 7,
137 | "metadata": {},
138 | "outputs": [
139 | {
140 | "name": "stdout",
141 | "output_type": "stream",
142 | "text": [
143 | "Variation in iteration 0: 4989.32008451\n",
144 | "Variation in iteration 1: 2081.17551268\n",
145 | "Variation in iteration 2: 1.6011620119\n",
146 | "Variation in iteration 3: 2.55059475168\n",
147 | "Variation in iteration 4: 0.994848416636\n",
148 | "Variation in iteration 5: 0.0381850235415\n",
149 | "Final centroids: [(35.08592000544936, -112.57643826547803), (0.0, 0.0), (38.05200414101911, -121.20324355675143), (43.891507710205694, -121.32350131512835), (34.28939789970032, -117.77840744773651)]\n",
150 | "CPU times: user 84.9 ms, sys: 9.17 ms, total: 94.1 ms\n",
151 | "Wall time: 21 s\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "%%time\n",
157 | "# Initial centroids: we just take K randomly selected points\n",
158 | "centroids = points.takeSample(False, K, 42)\n",
159 | "\n",
160 | "# The first iteration should always run\n",
161 | "variation = THRESHOLD + 1\n",
162 | "iteration = 0\n",
163 | "\n",
164 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
165 | " # Map each point to (centroid, (point, 1))\n",
166 | " with_centroids = points.map(lambda p: (closest_centroid(p, centroids), (p, 1)))\n",
167 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
168 | " # and keeping track of the number of points\n",
169 | " cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
170 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
171 | " new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, (x/n, y/n))).collect()\n",
172 | " # Calculate the variation between old and new centroids\n",
173 | " variation = 0\n",
174 | " for (old_centroid_id, new_centroid) in new_centroids: \n",
175 | " variation += distance(centroids[old_centroid_id], new_centroid)\n",
176 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
177 | " # Replace old centroids with the new values\n",
178 | " for (old_centroid_id, new_centroid) in new_centroids: \n",
179 | " centroids[old_centroid_id] = new_centroid\n",
180 | " iteration += 1\n",
181 | " \n",
182 | "print('Final centroids: {}'.format(centroids))"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {},
188 | "source": [
189 | "## Reviewing the steps we have done"
190 | ]
191 | },
192 | {
193 | "cell_type": "markdown",
194 | "metadata": {},
195 | "source": [
196 | "We start with lines of text:"
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": 8,
202 | "metadata": {},
203 | "outputs": [
204 | {
205 | "name": "stdout",
206 | "output_type": "stream",
207 | "text": [
208 | "2017-03-15:10:10:20,Motorola F41L,8cc3b47e-bd01-4482-b500-28f2342679af,33.6894754264,-117.543308253\n"
209 | ]
210 | }
211 | ],
212 | "source": [
213 | "line = data.first()\n",
214 | "print(line)"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "We have to convert them to points:"
222 | ]
223 | },
224 | {
225 | "cell_type": "code",
226 | "execution_count": 9,
227 | "metadata": {},
228 | "outputs": [
229 | {
230 | "data": {
231 | "text/plain": [
232 | "(33.6894754264, -117.543308253)"
233 | ]
234 | },
235 | "execution_count": 9,
236 | "metadata": {},
237 | "output_type": "execute_result"
238 | }
239 | ],
240 | "source": [
241 | "parse_coordinates(line)"
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "execution_count": 10,
247 | "metadata": {},
248 | "outputs": [
249 | {
250 | "name": "stdout",
251 | "output_type": "stream",
252 | "text": [
253 | "(33.6894754264, -117.543308253)\n"
254 | ]
255 | }
256 | ],
257 | "source": [
258 | "points = data.map(parse_coordinates)\n",
259 | "point = points.first()\n",
260 | "print(point)"
261 | ]
262 | },
263 | {
264 | "cell_type": "markdown",
265 | "metadata": {},
266 | "source": [
267 | "We select some arbitrary points from our RDD of points as the initial centroids:"
268 | ]
269 | },
270 | {
271 | "cell_type": "code",
272 | "execution_count": 11,
273 | "metadata": {},
274 | "outputs": [
275 | {
276 | "name": "stdout",
277 | "output_type": "stream",
278 | "text": [
279 | "[(33.4898547489, -111.63617776), (33.5505811202, -111.243243255), (36.5697673035, -120.79623245), (37.7152004069, -121.473355818), (34.3743073814, -117.184154207)]\n"
280 | ]
281 | }
282 | ],
283 | "source": [
284 | "# Initial centroids: we just take K randomly selected points\n",
285 | "centroids = points.takeSample(False, K, 42)\n",
286 | "print(centroids)"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "NOTE: Using the closest_centroid() funtion, we are able so calculate the **index of the closest centroid** to a given point:"
294 | ]
295 | },
296 | {
297 | "cell_type": "code",
298 | "execution_count": 12,
299 | "metadata": {},
300 | "outputs": [
301 | {
302 | "name": "stdout",
303 | "output_type": "stream",
304 | "text": [
305 | "4\n"
306 | ]
307 | }
308 | ],
309 | "source": [
310 | "closest_centroid_index = closest_centroid(point, centroids)\n",
311 | "print(closest_centroid_index)"
312 | ]
313 | },
314 | {
315 | "cell_type": "code",
316 | "execution_count": 13,
317 | "metadata": {},
318 | "outputs": [
319 | {
320 | "data": {
321 | "text/plain": [
322 | "(34.3743073814, -117.184154207)"
323 | ]
324 | },
325 | "execution_count": 13,
326 | "metadata": {},
327 | "output_type": "execute_result"
328 | }
329 | ],
330 | "source": [
331 | "centroids[closest_centroid_index]"
332 | ]
333 | },
334 | {
335 | "cell_type": "markdown",
336 | "metadata": {},
337 | "source": [
338 | "#### STEP 1: Assign a point to its centroid\n",
339 | "**point -> (closest_centroid_id, (point, 1))**"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 14,
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stdout",
349 | "output_type": "stream",
350 | "text": [
351 | "(4, ((33.6894754264, -117.543308253), 1))\n"
352 | ]
353 | }
354 | ],
355 | "source": [
356 | "with_centroids = points.map(lambda p: (closest_centroid(p, centroids), (p, 1)))\n",
357 | "print(with_centroids.first())"
358 | ]
359 | },
360 | {
361 | "cell_type": "markdown",
362 | "metadata": {},
363 | "source": [
364 | "#### STEP 2: Preparation to calculate new centroids\n",
365 | "**(closest_centroid_id, (point, 1)) -> (closest_centroid_id, (sum(points), total_number_of_points)**"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 15,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "name": "stdout",
375 | "output_type": "stream",
376 | "text": [
377 | "(0, ((841812.50940875, -2768072.601871161), 24640))\n"
378 | ]
379 | }
380 | ],
381 | "source": [
382 | "cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
383 | "print(cluster_stats.first())"
384 | ]
385 | },
386 | {
387 | "cell_type": "markdown",
388 | "metadata": {},
389 | "source": [
390 | "#### STEP 3: We calculate the new centroids\n",
391 | "**closest_centroid_id, (sum(points), total_number_of_points) -> (centroid_id, new_centroid)** \n",
392 | "\n",
393 | "where `new_centroid = (sum_x/total, sum_y/total)`."
394 | ]
395 | },
396 | {
397 | "cell_type": "code",
398 | "execution_count": 16,
399 | "metadata": {},
400 | "outputs": [
401 | {
402 | "name": "stdout",
403 | "output_type": "stream",
404 | "text": [
405 | "(0, (34.164468726004465, -112.34060884217374))\n"
406 | ]
407 | }
408 | ],
409 | "source": [
410 | "new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, (x/n, y/n))).collect()\n",
411 | "print(new_centroids[0])"
412 | ]
413 | },
414 | {
415 | "cell_type": "markdown",
416 | "metadata": {},
417 | "source": [
418 | "#### STEP 4: We calculate the variation\n",
419 | "Finally we just calculate the variation between old and new centroids to verify if we have to continue iterating."
420 | ]
421 | },
422 | {
423 | "cell_type": "code",
424 | "execution_count": 17,
425 | "metadata": {},
426 | "outputs": [
427 | {
428 | "name": "stdout",
429 | "output_type": "stream",
430 | "text": [
431 | "4989.32008451\n"
432 | ]
433 | }
434 | ],
435 | "source": [
436 | "variation = 0\n",
437 | "for (old_centroid_id, new_centroid) in new_centroids:\n",
438 | " variation += distance(centroids[old_centroid_id], new_centroid)\n",
439 | "print(variation)"
440 | ]
441 | }
442 | ],
443 | "metadata": {
444 | "kernelspec": {
445 | "display_name": "Python 2",
446 | "language": "python",
447 | "name": "python2"
448 | },
449 | "language_info": {
450 | "codemirror_mode": {
451 | "name": "ipython",
452 | "version": 2
453 | },
454 | "file_extension": ".py",
455 | "mimetype": "text/x-python",
456 | "name": "python",
457 | "nbconvert_exporter": "python",
458 | "pygments_lexer": "ipython2",
459 | "version": "2.7.15"
460 | }
461 | },
462 | "nbformat": 4,
463 | "nbformat_minor": 4
464 | }
465 |
--------------------------------------------------------------------------------
/solutions/Unit 4 WordCount.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# WordCount"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Load data"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "lines = sc.textFile('datasets/slurmd/slurmd.log.c6601')"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "## Split lines into words"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 2,
36 | "metadata": {
37 | "scrolled": true
38 | },
39 | "outputs": [],
40 | "source": [
41 | "words = lines.flatMap(lambda line: line.split())"
42 | ]
43 | },
44 | {
45 | "cell_type": "markdown",
46 | "metadata": {},
47 | "source": [
48 | "## Transform in a Pair RDD: word -> (word, 1)"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 3,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "counts = words.map(lambda word: (word, 1))"
58 | ]
59 | },
60 | {
61 | "cell_type": "markdown",
62 | "metadata": {},
63 | "source": [
64 | "## Aggregate counts"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 4,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "aggregated = counts.reduceByKey(lambda a, b: a + b)"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "## Show the 10 most common words"
81 | ]
82 | },
83 | {
84 | "cell_type": "markdown",
85 | "metadata": {},
86 | "source": [
87 | "Invert the tuple contents so that the key is the number of occurrences"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 5,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "result = aggregated.map(lambda (x, y): (y, x))"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "NOTE: In Python 3 tuple parameter unpacking has been removed as explained in [PEP 3113](https://www.python.org/dev/peps/pep-3113/) so the syntax for lambda functions gets ugly, especially when the lambda functions become more complex:\n",
104 | "\n",
105 | " result = aggregated.map(lambda x_y: (x_y[1], x_y[0]))\n",
106 | "\n"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "Sort and take the 10 first elements:"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 6,
119 | "metadata": {},
120 | "outputs": [
121 | {
122 | "data": {
123 | "text/plain": [
124 | "[(29478, 'c6601'),\n",
125 | " (27084, '2017'),\n",
126 | " (19924, 'info'),\n",
127 | " (15476, 'slurmstepd'),\n",
128 | " (15446, 'user'),\n",
129 | " (12439, 'slurmd'),\n",
130 | " (12384, 'daemon'),\n",
131 | " (9285, 'job'),\n",
132 | " (7911, 'err'),\n",
133 | " (7905, 'error:')]"
134 | ]
135 | },
136 | "execution_count": 6,
137 | "metadata": {},
138 | "output_type": "execute_result"
139 | }
140 | ],
141 | "source": [
142 | "result.sortByKey(ascending=False).take(10)"
143 | ]
144 | }
145 | ],
146 | "metadata": {
147 | "kernelspec": {
148 | "display_name": "Python 2",
149 | "language": "python",
150 | "name": "python2"
151 | },
152 | "language_info": {
153 | "codemirror_mode": {
154 | "name": "ipython",
155 | "version": 2
156 | },
157 | "file_extension": ".py",
158 | "mimetype": "text/x-python",
159 | "name": "python",
160 | "nbconvert_exporter": "python",
161 | "pygments_lexer": "ipython2",
162 | "version": "2.7.15"
163 | }
164 | },
165 | "nbformat": 4,
166 | "nbformat_minor": 4
167 | }
168 |
--------------------------------------------------------------------------------
/solutions/Unit 4 Working with meteorological data 2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data 2"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorological data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Extract date and temperature information"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Filter data from the RDD keeping only \"Temperatura media\" lines and keeping the date information."
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 2,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "def parse_temperature(line):\n",
54 | " (_, date, hour, _, _, _, value) = line.split()\n",
55 | " return (date, float(value.replace(',', '.')))"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 3,
61 | "metadata": {},
62 | "outputs": [],
63 | "source": [
64 | "temperatures = (rdd.filter(lambda line: 'Temperatura media' in line)\n",
65 | " .map(parse_temperature))"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 4,
71 | "metadata": {},
72 | "outputs": [
73 | {
74 | "data": {
75 | "text/plain": [
76 | "[(u'2017-06-01', 13.82),\n",
77 | " (u'2017-06-01', 13.71),\n",
78 | " (u'2017-06-01', 13.61),\n",
79 | " (u'2017-06-01', 13.52),\n",
80 | " (u'2017-06-01', 13.33)]"
81 | ]
82 | },
83 | "execution_count": 4,
84 | "metadata": {},
85 | "output_type": "execute_result"
86 | }
87 | ],
88 | "source": [
89 | "temperatures.take(5)"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "metadata": {},
95 | "source": [
96 | "## Filter out invalid values"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "As we saw in part 1, a temperature value of -9999 indicates a non existing value, so we filter out these values before performing calculations on the data:"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 5,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "temperatures_clean = temperatures.filter(lambda (date, temp): temp != -9999)"
113 | ]
114 | },
115 | {
116 | "cell_type": "markdown",
117 | "metadata": {},
118 | "source": [
119 | "NOTE: In Python 3 tuple parameter unpacking has been removed as explained in [PEP 3113](https://www.python.org/dev/peps/pep-3113/) so we would rewrite it as:\n",
120 | "\n",
121 | " temperatures_clean = temperatures.filter(lambda date_temp: date_temp[1] != -9999)"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "## Calculate the average temperature per day"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": 6,
134 | "metadata": {},
135 | "outputs": [],
136 | "source": [
137 | "def sum_pairs(a, b):\n",
138 | " return (a[0]+b[0], a[1]+b[1])"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 7,
144 | "metadata": {},
145 | "outputs": [],
146 | "source": [
147 | "averages = (temperatures_clean.map(lambda (date, temp): (date, (temp, 1)))\n",
148 | " .reduceByKey(sum_pairs)\n",
149 | " .map(lambda (date, (temp, count)): (date, temp/count)))"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "NOTE: In Python 3 the syntax gets ugly especially in cases like this where there are nested structures. The code above in Python 3 will look like:\n",
157 | "\n",
158 | " averages = (temperatures_clean.map(lambda date_temp: (date_temp[0], (date_temp[1], 1)))\n",
159 | " .reduceByKey(sum_pairs)\n",
160 | " .map(lambda date__temp_count: (date__temp_count[0], date__temp_count[1][0]/date__temp_count[1][1])))\n",
161 | "\n"
162 | ]
163 | },
164 | {
165 | "cell_type": "markdown",
166 | "metadata": {},
167 | "source": [
168 | "## Show the results sorted by date"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": 8,
174 | "metadata": {},
175 | "outputs": [
176 | {
177 | "data": {
178 | "text/plain": [
179 | "[(u'2017-06-01', 17.179580419580425),\n",
180 | " (u'2017-06-02', 16.007500000000004),\n",
181 | " (u'2017-06-03', 14.511736111111105),\n",
182 | " (u'2017-06-04', 14.889375000000005),\n",
183 | " (u'2017-06-05', 13.67486111111111),\n",
184 | " (u'2017-06-06', 14.901041666666666),\n",
185 | " (u'2017-06-07', 17.76305555555556),\n",
186 | " (u'2017-06-08', 17.49979166666667),\n",
187 | " (u'2017-06-09', 17.86694444444445),\n",
188 | " (u'2017-06-10', 19.207222222222224),\n",
189 | " (u'2017-06-11', 17.806250000000006),\n",
190 | " (u'2017-06-12', 20.020138888888884),\n",
191 | " (u'2017-06-13', 18.769027777777776),\n",
192 | " (u'2017-06-14', 17.93489510489511),\n",
193 | " (u'2017-06-15', 18.135486111111103),\n",
194 | " (u'2017-06-16', 22.042708333333337),\n",
195 | " (u'2017-06-17', 25.475902777777772),\n",
196 | " (u'2017-06-18', 26.350069444444443),\n",
197 | " (u'2017-06-19', 25.422708333333333),\n",
198 | " (u'2017-06-20', 26.977916666666665),\n",
199 | " (u'2017-06-21', 23.28430555555555),\n",
200 | " (u'2017-06-22', 19.56493055555555),\n",
201 | " (u'2017-06-23', 18.57861111111111),\n",
202 | " (u'2017-06-24', 17.6775),\n",
203 | " (u'2017-06-25', 19.57138888888889),\n",
204 | " (u'2017-06-26', 18.298125000000002),\n",
205 | " (u'2017-06-27', 17.025555555555556),\n",
206 | " (u'2017-06-28', 15.242361111111105),\n",
207 | " (u'2017-06-29', 13.477083333333331),\n",
208 | " (u'2017-06-30', 11.59)]"
209 | ]
210 | },
211 | "execution_count": 8,
212 | "metadata": {},
213 | "output_type": "execute_result"
214 | }
215 | ],
216 | "source": [
217 | "averages.sortByKey().collect()"
218 | ]
219 | }
220 | ],
221 | "metadata": {
222 | "kernelspec": {
223 | "display_name": "Python 2",
224 | "language": "python",
225 | "name": "python2"
226 | },
227 | "language_info": {
228 | "codemirror_mode": {
229 | "name": "ipython",
230 | "version": 2
231 | },
232 | "file_extension": ".py",
233 | "mimetype": "text/x-python",
234 | "name": "python",
235 | "nbconvert_exporter": "python",
236 | "pygments_lexer": "ipython2",
237 | "version": "2.7.15"
238 | }
239 | },
240 | "nbformat": 4,
241 | "nbformat_minor": 4
242 | }
243 |
--------------------------------------------------------------------------------
/solutions/Unit 5 Working with meteorological data - SQL version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data using DataFrames (SQL version)"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Convert to a DataFrame"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "from pyspark.sql import Row\n",
47 | "\n",
48 | "def parse_row(line):\n",
49 | " \"\"\"Convert a line into a Row\"\"\"\n",
50 | " # All data lines start with 6 spaces\n",
51 | " if line.startswith(' '):\n",
52 | " codigo = int(line[:17].strip())\n",
53 | " datahora = line[17:40]\n",
54 | " data, hora = datahora.split()\n",
55 | " parametro = line[40:82].strip()\n",
56 | " valor = float(line[82:].replace(',', '.'))\n",
57 | " return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]\n",
58 | " return []"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "Using flatMap we have the flexibility to return nothing from a call to the function, this is accomplished returning and empty array."
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "data = rdd.flatMap(parse_row).toDF()"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "## Create Temporary View"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "To launch SQL queries we have first to create a temporary view:"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 4,
94 | "metadata": {},
95 | "outputs": [],
96 | "source": [
97 | "data.createOrReplaceTempView('data')"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "## Count the number of points"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 5,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "name": "stdout",
114 | "output_type": "stream",
115 | "text": [
116 | "+--------+\n",
117 | "|count(1)|\n",
118 | "+--------+\n",
119 | "| 16704|\n",
120 | "+--------+\n",
121 | "\n"
122 | ]
123 | }
124 | ],
125 | "source": [
126 | "# data.count()\n",
127 | "spark.sql('select count(*) from data').show()"
128 | ]
129 | },
130 | {
131 | "cell_type": "markdown",
132 | "metadata": {},
133 | "source": [
134 | "## Filter temperature data"
135 | ]
136 | },
137 | {
138 | "cell_type": "code",
139 | "execution_count": 6,
140 | "metadata": {},
141 | "outputs": [],
142 | "source": [
143 | "# t = data.where(data.parametro.like('Temperatura media %'))\n",
144 | "t = spark.sql('select * from data where parametro like \"Temperatura media %\"')\n",
145 | "t.createOrReplaceTempView('t')"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "## Find the maximum temperature of the month"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 7,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "+----------+\n",
165 | "|max(valor)|\n",
166 | "+----------+\n",
167 | "| 34.4|\n",
168 | "+----------+\n",
169 | "\n"
170 | ]
171 | }
172 | ],
173 | "source": [
174 | "# t.groupBy().max('valor').show()\n",
175 | "spark.sql('select max(valor) from t').show()"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "## Find the minimum temperature of the month"
183 | ]
184 | },
185 | {
186 | "cell_type": "code",
187 | "execution_count": 8,
188 | "metadata": {},
189 | "outputs": [
190 | {
191 | "name": "stdout",
192 | "output_type": "stream",
193 | "text": [
194 | "+----------+\n",
195 | "|min(valor)|\n",
196 | "+----------+\n",
197 | "| -9999.0|\n",
198 | "+----------+\n",
199 | "\n"
200 | ]
201 | }
202 | ],
203 | "source": [
204 | "# t.groupBy().min('valor').show()\n",
205 | "spark.sql('select min(valor) from t').show()"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "The value -9999 is a code used to indicate a non registered value (N/A).\n",
213 | "\n",
214 | "If we look to the possible values of \"Códigos de validación\" we see valid points have the code 1, so we can concentrate our efforts on data with code 1."
215 | ]
216 | },
217 | {
218 | "cell_type": "code",
219 | "execution_count": 9,
220 | "metadata": {},
221 | "outputs": [
222 | {
223 | "name": "stdout",
224 | "output_type": "stream",
225 | "text": [
226 | "+----------+\n",
227 | "|min(valor)|\n",
228 | "+----------+\n",
229 | "| 9.09|\n",
230 | "+----------+\n",
231 | "\n"
232 | ]
233 | }
234 | ],
235 | "source": [
236 | "# t.where(t.codigo == 1).groupBy().min('valor').show()\n",
237 | "spark.sql('select min(valor) from t where codigo=1').show()"
238 | ]
239 | },
240 | {
241 | "cell_type": "markdown",
242 | "metadata": {},
243 | "source": [
244 | "## Calculate the average temperature per day"
245 | ]
246 | },
247 | {
248 | "cell_type": "code",
249 | "execution_count": 10,
250 | "metadata": {},
251 | "outputs": [
252 | {
253 | "name": "stdout",
254 | "output_type": "stream",
255 | "text": [
256 | "+----------+------------------+\n",
257 | "| data| avg(valor)|\n",
258 | "+----------+------------------+\n",
259 | "|2017-06-22| 19.56493055555555|\n",
260 | "|2017-06-07| 17.76305555555556|\n",
261 | "|2017-06-24| 17.6775|\n",
262 | "|2017-06-29|13.477083333333331|\n",
263 | "|2017-06-19|25.422708333333333|\n",
264 | "|2017-06-03|14.511736111111105|\n",
265 | "|2017-06-23| 18.57861111111111|\n",
266 | "|2017-06-28|15.242361111111105|\n",
267 | "|2017-06-12|20.020138888888884|\n",
268 | "|2017-06-30| 11.59|\n",
269 | "|2017-06-26|18.298125000000002|\n",
270 | "|2017-06-04|14.889375000000005|\n",
271 | "|2017-06-18|26.350069444444443|\n",
272 | "|2017-06-06|14.901041666666666|\n",
273 | "|2017-06-09| 17.86694444444445|\n",
274 | "|2017-06-21| 23.28430555555555|\n",
275 | "|2017-06-25| 19.57138888888889|\n",
276 | "|2017-06-14| -51.6271527777778|\n",
277 | "|2017-06-16|22.042708333333337|\n",
278 | "|2017-06-11|17.806250000000006|\n",
279 | "|2017-06-08| 17.49979166666667|\n",
280 | "|2017-06-13|18.769027777777776|\n",
281 | "|2017-06-01|17.179580419580425|\n",
282 | "|2017-06-02|16.007500000000004|\n",
283 | "|2017-06-27|17.025555555555556|\n",
284 | "|2017-06-17|25.475902777777772|\n",
285 | "|2017-06-15|18.135486111111103|\n",
286 | "|2017-06-20|26.977916666666665|\n",
287 | "|2017-06-05| 13.67486111111111|\n",
288 | "|2017-06-10|19.207222222222224|\n",
289 | "+----------+------------------+\n",
290 | "\n"
291 | ]
292 | }
293 | ],
294 | "source": [
295 | "# t.groupBy(t.data).mean('valor').show(30)\n",
296 | "spark.sql('select data, mean(valor) from t group by data').show(30)"
297 | ]
298 | },
299 | {
300 | "cell_type": "markdown",
301 | "metadata": {},
302 | "source": [
303 | "## Show the results sorted by date"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 11,
309 | "metadata": {},
310 | "outputs": [
311 | {
312 | "name": "stdout",
313 | "output_type": "stream",
314 | "text": [
315 | "+----------+------------------+\n",
316 | "| data| avg(valor)|\n",
317 | "+----------+------------------+\n",
318 | "|2017-06-01|17.179580419580425|\n",
319 | "|2017-06-02|16.007500000000004|\n",
320 | "|2017-06-03|14.511736111111105|\n",
321 | "|2017-06-04|14.889375000000005|\n",
322 | "|2017-06-05| 13.67486111111111|\n",
323 | "|2017-06-06|14.901041666666666|\n",
324 | "|2017-06-07| 17.76305555555556|\n",
325 | "|2017-06-08| 17.49979166666667|\n",
326 | "|2017-06-09| 17.86694444444445|\n",
327 | "|2017-06-10|19.207222222222224|\n",
328 | "|2017-06-11|17.806250000000006|\n",
329 | "|2017-06-12|20.020138888888884|\n",
330 | "|2017-06-13|18.769027777777776|\n",
331 | "|2017-06-14| -51.6271527777778|\n",
332 | "|2017-06-15|18.135486111111103|\n",
333 | "|2017-06-16|22.042708333333337|\n",
334 | "|2017-06-17|25.475902777777772|\n",
335 | "|2017-06-18|26.350069444444443|\n",
336 | "|2017-06-19|25.422708333333333|\n",
337 | "|2017-06-20|26.977916666666665|\n",
338 | "|2017-06-21| 23.28430555555555|\n",
339 | "|2017-06-22| 19.56493055555555|\n",
340 | "|2017-06-23| 18.57861111111111|\n",
341 | "|2017-06-24| 17.6775|\n",
342 | "|2017-06-25| 19.57138888888889|\n",
343 | "|2017-06-26|18.298125000000002|\n",
344 | "|2017-06-27|17.025555555555556|\n",
345 | "|2017-06-28|15.242361111111105|\n",
346 | "|2017-06-29|13.477083333333331|\n",
347 | "|2017-06-30| 11.59|\n",
348 | "+----------+------------------+\n",
349 | "\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "# t.groupBy(t.data).mean('valor').sort('data').show(30)\n",
355 | "spark.sql('select data, mean(valor) from t group by data order by data').show(30)"
356 | ]
357 | }
358 | ],
359 | "metadata": {
360 | "kernelspec": {
361 | "display_name": "Python 2",
362 | "language": "python",
363 | "name": "python2"
364 | },
365 | "language_info": {
366 | "codemirror_mode": {
367 | "name": "ipython",
368 | "version": 2
369 | },
370 | "file_extension": ".py",
371 | "mimetype": "text/x-python",
372 | "name": "python",
373 | "nbconvert_exporter": "python",
374 | "pygments_lexer": "ipython2",
375 | "version": "2.7.15"
376 | }
377 | },
378 | "nbformat": 4,
379 | "nbformat_minor": 1
380 | }
381 |
--------------------------------------------------------------------------------
/solutions/Unit 5 Working with meteorological data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data using DataFrames"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Convert to a DataFrame"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "from pyspark.sql import Row\n",
47 | "\n",
48 | "def parse_row(line):\n",
49 | " \"\"\"Convert a line into a Row\"\"\"\n",
50 | " # All data lines start with 6 spaces\n",
51 | " if line.startswith(' '):\n",
52 | " codigo = int(line[:17].strip())\n",
53 | " datahora = line[17:40]\n",
54 | " data, hora = datahora.split()\n",
55 | " parametro = line[40:82].strip()\n",
56 | " valor = float(line[82:].replace(',', '.'))\n",
57 | " return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]\n",
58 | " return []"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "Using flatMap we have the flexibility to return nothing from a call to the function, this is accomplished returning and empty array."
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "data = rdd.flatMap(parse_row).toDF()"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "## Count the number of points"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 4,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "data": {
91 | "text/plain": [
92 | "16704"
93 | ]
94 | },
95 | "execution_count": 4,
96 | "metadata": {},
97 | "output_type": "execute_result"
98 | }
99 | ],
100 | "source": [
101 | "data.count()"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "## Filter temperature data"
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 5,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "t = data.where(data.parametro.like('Temperatura media %'))"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "## Find the maximum temperature of the month"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 6,
130 | "metadata": {},
131 | "outputs": [
132 | {
133 | "name": "stdout",
134 | "output_type": "stream",
135 | "text": [
136 | "+----------+\n",
137 | "|max(valor)|\n",
138 | "+----------+\n",
139 | "| 34.4|\n",
140 | "+----------+\n",
141 | "\n"
142 | ]
143 | }
144 | ],
145 | "source": [
146 | "t.groupBy().max('valor').show()"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "## Find the minimum temperature of the month"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 7,
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "name": "stdout",
163 | "output_type": "stream",
164 | "text": [
165 | "+----------+\n",
166 | "|min(valor)|\n",
167 | "+----------+\n",
168 | "| -9999.0|\n",
169 | "+----------+\n",
170 | "\n"
171 | ]
172 | }
173 | ],
174 | "source": [
175 | "t.groupBy().min('valor').show()"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "The value -9999 is a code used to indicate a non registered value (N/A).\n",
183 | "\n",
184 | "If we look to the possible values of \"Códigos de validación\" we see valid points have the code 1, so we can concentrate our efforts on data with code 1."
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 8,
190 | "metadata": {},
191 | "outputs": [
192 | {
193 | "name": "stdout",
194 | "output_type": "stream",
195 | "text": [
196 | "+----------+\n",
197 | "|min(valor)|\n",
198 | "+----------+\n",
199 | "| 9.09|\n",
200 | "+----------+\n",
201 | "\n"
202 | ]
203 | }
204 | ],
205 | "source": [
206 | "t.where(t.codigo == 1).groupBy().min('valor').show()"
207 | ]
208 | },
209 | {
210 | "cell_type": "markdown",
211 | "metadata": {},
212 | "source": [
213 | "## Calculate the average temperature per day"
214 | ]
215 | },
216 | {
217 | "cell_type": "code",
218 | "execution_count": 9,
219 | "metadata": {},
220 | "outputs": [
221 | {
222 | "name": "stdout",
223 | "output_type": "stream",
224 | "text": [
225 | "+----------+------------------+\n",
226 | "| data| avg(valor)|\n",
227 | "+----------+------------------+\n",
228 | "|2017-06-22| 19.56493055555555|\n",
229 | "|2017-06-07| 17.76305555555556|\n",
230 | "|2017-06-24| 17.6775|\n",
231 | "|2017-06-29|13.477083333333331|\n",
232 | "|2017-06-19|25.422708333333333|\n",
233 | "|2017-06-03|14.511736111111105|\n",
234 | "|2017-06-23| 18.57861111111111|\n",
235 | "|2017-06-28|15.242361111111105|\n",
236 | "|2017-06-12|20.020138888888884|\n",
237 | "|2017-06-30| 11.59|\n",
238 | "|2017-06-26|18.298125000000002|\n",
239 | "|2017-06-04|14.889375000000005|\n",
240 | "|2017-06-18|26.350069444444443|\n",
241 | "|2017-06-06|14.901041666666666|\n",
242 | "|2017-06-09| 17.86694444444445|\n",
243 | "|2017-06-21| 23.28430555555555|\n",
244 | "|2017-06-25| 19.57138888888889|\n",
245 | "|2017-06-14| -51.6271527777778|\n",
246 | "|2017-06-16|22.042708333333337|\n",
247 | "|2017-06-11|17.806250000000006|\n",
248 | "|2017-06-08| 17.49979166666667|\n",
249 | "|2017-06-13|18.769027777777776|\n",
250 | "|2017-06-01|17.179580419580425|\n",
251 | "|2017-06-02|16.007500000000004|\n",
252 | "|2017-06-27|17.025555555555556|\n",
253 | "|2017-06-17|25.475902777777772|\n",
254 | "|2017-06-15|18.135486111111103|\n",
255 | "|2017-06-20|26.977916666666665|\n",
256 | "|2017-06-05| 13.67486111111111|\n",
257 | "|2017-06-10|19.207222222222224|\n",
258 | "+----------+------------------+\n",
259 | "\n"
260 | ]
261 | }
262 | ],
263 | "source": [
264 | "t.groupBy(t.data).mean('valor').show(30)"
265 | ]
266 | },
267 | {
268 | "cell_type": "markdown",
269 | "metadata": {},
270 | "source": [
271 | "## Show the results sorted by date"
272 | ]
273 | },
274 | {
275 | "cell_type": "code",
276 | "execution_count": 10,
277 | "metadata": {},
278 | "outputs": [
279 | {
280 | "name": "stdout",
281 | "output_type": "stream",
282 | "text": [
283 | "+----------+------------------+\n",
284 | "| data| avg(valor)|\n",
285 | "+----------+------------------+\n",
286 | "|2017-06-01|17.179580419580425|\n",
287 | "|2017-06-02|16.007500000000004|\n",
288 | "|2017-06-03|14.511736111111105|\n",
289 | "|2017-06-04|14.889375000000005|\n",
290 | "|2017-06-05| 13.67486111111111|\n",
291 | "|2017-06-06|14.901041666666666|\n",
292 | "|2017-06-07| 17.76305555555556|\n",
293 | "|2017-06-08| 17.49979166666667|\n",
294 | "|2017-06-09| 17.86694444444445|\n",
295 | "|2017-06-10|19.207222222222224|\n",
296 | "|2017-06-11|17.806250000000006|\n",
297 | "|2017-06-12|20.020138888888884|\n",
298 | "|2017-06-13|18.769027777777776|\n",
299 | "|2017-06-14| -51.6271527777778|\n",
300 | "|2017-06-15|18.135486111111103|\n",
301 | "|2017-06-16|22.042708333333337|\n",
302 | "|2017-06-17|25.475902777777772|\n",
303 | "|2017-06-18|26.350069444444443|\n",
304 | "|2017-06-19|25.422708333333333|\n",
305 | "|2017-06-20|26.977916666666665|\n",
306 | "|2017-06-21| 23.28430555555555|\n",
307 | "|2017-06-22| 19.56493055555555|\n",
308 | "|2017-06-23| 18.57861111111111|\n",
309 | "|2017-06-24| 17.6775|\n",
310 | "|2017-06-25| 19.57138888888889|\n",
311 | "|2017-06-26|18.298125000000002|\n",
312 | "|2017-06-27|17.025555555555556|\n",
313 | "|2017-06-28|15.242361111111105|\n",
314 | "|2017-06-29|13.477083333333331|\n",
315 | "|2017-06-30| 11.59|\n",
316 | "+----------+------------------+\n",
317 | "\n"
318 | ]
319 | }
320 | ],
321 | "source": [
322 | "t.groupBy(t.data).mean('valor').sort('data').show(30)"
323 | ]
324 | }
325 | ],
326 | "metadata": {
327 | "kernelspec": {
328 | "display_name": "Python 2",
329 | "language": "python",
330 | "name": "python2"
331 | },
332 | "language_info": {
333 | "codemirror_mode": {
334 | "name": "ipython",
335 | "version": 2
336 | },
337 | "file_extension": ".py",
338 | "mimetype": "text/x-python",
339 | "name": "python",
340 | "nbconvert_exporter": "python",
341 | "pygments_lexer": "ipython2",
342 | "version": "2.7.15"
343 | }
344 | },
345 | "nbformat": 4,
346 | "nbformat_minor": 1
347 | }
348 |
--------------------------------------------------------------------------------
/solutions/Unit 7 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans (optimized version)"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from __future__ import print_function\n",
17 | "import math\n",
18 | "from collections import namedtuple"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "## Parameters"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 2,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "# Number of clusters to find\n",
35 | "K = 5\n",
36 | "# Convergence threshold\n",
37 | "THRESHOLD = 0.1\n",
38 | "# Maximum number of iterations\n",
39 | "MAX_ITERS = 20"
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "## Load data"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 3,
52 | "metadata": {},
53 | "outputs": [],
54 | "source": [
55 | "def parse_coordinates(line):\n",
56 | " fields = line.split(',')\n",
57 | " return (float(fields[3]), float(fields[4]))"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 4,
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "data = sc.textFile('datasets/locations')"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 5,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "points = data.map(parse_coordinates)"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "metadata": {},
81 | "source": [
82 | "Let's **cache the points** because the algorithm will be reusing them:"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 6,
88 | "metadata": {
89 | "scrolled": true
90 | },
91 | "outputs": [
92 | {
93 | "data": {
94 | "text/plain": [
95 | "PythonRDD[2] at RDD at PythonRDD.scala:53"
96 | ]
97 | },
98 | "execution_count": 6,
99 | "metadata": {},
100 | "output_type": "execute_result"
101 | }
102 | ],
103 | "source": [
104 | "points.cache()"
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "## Useful functions"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": 7,
117 | "metadata": {},
118 | "outputs": [],
119 | "source": [
120 | "def distance(p1, p2): \n",
121 | " \"Calculate the squared distance between two given points\"\n",
122 | " return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2\n",
123 | "\n",
124 | "def closest_centroid(point, centroidsBC): \n",
125 | " \"Calculate the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
126 | " distances = [distance(point, c) for c in centroidsBC.value]\n",
127 | " shortest = min(distances)\n",
128 | " return distances.index(shortest)\n",
129 | "\n",
130 | "def add_points(p1,p2):\n",
131 | " \"Add two points of the same cluster in order to calculate later the new centroids\"\n",
132 | " return [p1[0] + p2[0], p1[1] + p2[1]]"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "## Iteratively calculate the centroids"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 8,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "name": "stdout",
149 | "output_type": "stream",
150 | "text": [
151 | "Variation in iteration 0: 4989.32008451\n",
152 | "Variation in iteration 1: 2081.17551268\n",
153 | "Variation in iteration 2: 1.6011620119\n",
154 | "Variation in iteration 3: 2.55059475168\n",
155 | "Variation in iteration 4: 0.994848416636\n",
156 | "Variation in iteration 5: 0.0381850235415\n",
157 | "Final centroids: [[35.08592000544936, -112.57643826547803], [0.0, 0.0], [38.05200414101911, -121.20324355675143], [43.891507710205694, -121.32350131512835], [34.28939789970032, -117.77840744773651]]\n",
158 | "CPU times: user 84 ms, sys: 26.9 ms, total: 111 ms\n",
159 | "Wall time: 18.3 s\n"
160 | ]
161 | }
162 | ],
163 | "source": [
164 | "%%time\n",
165 | "# Initial centroids: we just take K randomly selected points\n",
166 | "centroids = points.takeSample(False, K, 42)\n",
167 | "# Broadcast var\n",
168 | "centroidsBC = sc.broadcast(centroids)\n",
169 | "\n",
170 | "# Just make sure the first iteration is always run\n",
171 | "variation = THRESHOLD + 1\n",
172 | "iteration = 0\n",
173 | "\n",
174 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
175 | " # Map each point to (centroid, (point, 1))\n",
176 | " with_centroids = points.map(lambda p : (closest_centroid(p, centroidsBC), (p, 1)))\n",
177 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
178 | " # and keeping track of the number of points\n",
179 | " cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
180 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
181 | " new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, [x/n, y/n])).collect()\n",
182 | " # Calculate the variation between old and new centroids\n",
183 | " variation = 0\n",
184 | " for (c, point) in new_centroids: variation += distance(centroids[c], point)\n",
185 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
186 | " # Replace old centroids with the new values\n",
187 | " for (c, point) in new_centroids: centroids[c] = point\n",
188 | " # Replace the centroids broadcast var with the new values\n",
189 | " centroidsBC = sc.broadcast(centroids)\n",
190 | " iteration += 1\n",
191 | " \n",
192 | "print('Final centroids: {}'.format(centroids))"
193 | ]
194 | }
195 | ],
196 | "metadata": {
197 | "kernelspec": {
198 | "display_name": "Python 2",
199 | "language": "python",
200 | "name": "python2"
201 | },
202 | "language_info": {
203 | "codemirror_mode": {
204 | "name": "ipython",
205 | "version": 2
206 | },
207 | "file_extension": ".py",
208 | "mimetype": "text/x-python",
209 | "name": "python",
210 | "nbconvert_exporter": "python",
211 | "pygments_lexer": "ipython2",
212 | "version": "2.7.15"
213 | }
214 | },
215 | "nbformat": 4,
216 | "nbformat_minor": 1
217 | }
218 |
--------------------------------------------------------------------------------
/solutions/Unit_5_sentiment_analysis_amazon_books-short_version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# SENTIMENT ANALYSIS WITH SPARK ML"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "# Spark ML Main Concepts\n",
15 | "\n",
16 | "The Spark Machine learning API in the **spark.ml** package is based on DataFrames, there is also another Spark Machine learning API based on RDDs in the **spark.mllib** package, but as of Spark 2.0, the RDD-based API has entered maintenance mode. The primary Machine Learning API for Spark is now the DataFrame-based API.\n",
17 | "\n",
18 | "Main concepts of Spark ML:\n",
19 | "\n",
20 | "- **Transformer**: transforms one DataFrame into another DataFrame\n",
21 | "\n",
22 | "- **Estimator**: eg. a learning algorithm that trains on a DataFrame and produces a Model\n",
23 | "\n",
24 | "- **Pipeline**: chains Transformers and Estimators to produce a Model\n",
25 | "\n",
26 | "- **Evaluator**: measures how well a fitted Model does on held-out test data\n",
27 | "\n"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "# Amazon product data\n",
35 | "We will use a [dataset](http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Books_5.json.gz)[1] that contains 8.9M book reviews from Amazon, spanning May 1996 - July 2014.\n",
36 | "\n",
37 | "Dataset characteristics:\n",
38 | "- Number of reviews: 8.9M\n",
39 | "- Size: 8.8GB (uncompressed)\n",
40 | "- HDFS blocks: 70 (each with 3 replicas)\n",
41 | "\n",
42 | "\n",
43 | "[1] Image-based recommendations on styles and substitutes\n",
44 | "J. McAuley, C. Targett, J. Shi, A. van den Hengel\n",
45 | "SIGIR, 2015\n",
46 | "http://jmcauley.ucsd.edu/data/amazon/"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "# Load Data"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 1,
59 | "metadata": {},
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "CPU times: user 6.25 ms, sys: 1.29 ms, total: 7.54 ms\n",
66 | "Wall time: 25.1 s\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "%%time\n",
72 | "raw_reviews = spark.read.json('data/amazon/reviews_Books_5.json')"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 2,
78 | "metadata": {},
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "+--------------------+-------+\n",
85 | "| reviewText|overall|\n",
86 | "+--------------------+-------+\n",
87 | "|Spiritually and m...| 5.0|\n",
88 | "|This is one my mu...| 5.0|\n",
89 | "+--------------------+-------+\n",
90 | "only showing top 2 rows\n",
91 | "\n",
92 | "CPU times: user 2.64 ms, sys: 2.37 ms, total: 5 ms\n",
93 | "Wall time: 4.12 s\n"
94 | ]
95 | }
96 | ],
97 | "source": [
98 | "%%time\n",
99 | "all_reviews = raw_reviews.select('reviewText', 'overall')\n",
100 | "all_reviews.cache()\n",
101 | "all_reviews.show(2)"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "# Prepare data\n",
109 | "We will avoid neutral reviews by keeping only reviews with 1 or 5 stars overall score.\n",
110 | "We will also filter out the reviews that contain no text."
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 3,
116 | "metadata": {},
117 | "outputs": [],
118 | "source": [
119 | "nonneutral_reviews = all_reviews.filter(\n",
120 | " (all_reviews.overall == 1.0) | (all_reviews.overall == 5.0))\n",
121 | "reviews = nonneutral_reviews.filter(all_reviews.reviewText != '')"
122 | ]
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": 4,
127 | "metadata": {},
128 | "outputs": [
129 | {
130 | "data": {
131 | "text/plain": [
132 | "DataFrame[reviewText: string, overall: double]"
133 | ]
134 | },
135 | "execution_count": 4,
136 | "metadata": {},
137 | "output_type": "execute_result"
138 | }
139 | ],
140 | "source": [
141 | "reviews.cache()\n",
142 | "all_reviews.unpersist()"
143 | ]
144 | },
145 | {
146 | "cell_type": "markdown",
147 | "metadata": {},
148 | "source": [
149 | "# Split Data"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 5,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": [
158 | "trainingData, testData = reviews.randomSplit([0.8, 0.2])"
159 | ]
160 | },
161 | {
162 | "cell_type": "markdown",
163 | "metadata": {},
164 | "source": [
165 | "# Generate Pipeline\n",
166 | ""
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "## Binarizer\n",
174 | "A transformer to convert numerical features to binary (0/1) features"
175 | ]
176 | },
177 | {
178 | "cell_type": "code",
179 | "execution_count": 6,
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "from pyspark.ml.feature import Binarizer\n",
184 | "\n",
185 | "binarizer = Binarizer(threshold=2.5, inputCol='overall', outputCol='label')"
186 | ]
187 | },
188 | {
189 | "cell_type": "markdown",
190 | "metadata": {},
191 | "source": [
192 | "## Tokenizer\n",
193 | "A transformer that converts the input string to lowercase and then splits it by white spaces."
194 | ]
195 | },
196 | {
197 | "cell_type": "code",
198 | "execution_count": 7,
199 | "metadata": {},
200 | "outputs": [],
201 | "source": [
202 | "from pyspark.ml.feature import Tokenizer\n",
203 | "tokenizer = Tokenizer(inputCol='reviewText', outputCol='words')"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "## StopWordsRemover\n",
211 | "A transformer that filters out stop words from input."
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 8,
217 | "metadata": {},
218 | "outputs": [],
219 | "source": [
220 | "from pyspark.ml.feature import StopWordsRemover\n",
221 | "remover = StopWordsRemover(inputCol=tokenizer.getOutputCol(), outputCol='filtered')"
222 | ]
223 | },
224 | {
225 | "cell_type": "markdown",
226 | "metadata": {},
227 | "source": [
228 | "## HashingTF\n",
229 | "A Transformer that converts a sequence of words into a fixed-length feature Vector. It maps a sequence of terms to their term frequencies using a hashing function."
230 | ]
231 | },
232 | {
233 | "cell_type": "code",
234 | "execution_count": 9,
235 | "metadata": {},
236 | "outputs": [],
237 | "source": [
238 | "from pyspark.ml.feature import HashingTF\n",
239 | "hashingTF = HashingTF(inputCol=remover.getOutputCol(), outputCol='features')"
240 | ]
241 | },
242 | {
243 | "cell_type": "markdown",
244 | "metadata": {},
245 | "source": [
246 | "# Estimator\n",
247 | "## LogisticRegression"
248 | ]
249 | },
250 | {
251 | "cell_type": "code",
252 | "execution_count": 10,
253 | "metadata": {},
254 | "outputs": [],
255 | "source": [
256 | "from pyspark.ml.classification import LogisticRegression\n",
257 | "lr = LogisticRegression(maxIter=10, regParam=0.01)"
258 | ]
259 | },
260 | {
261 | "cell_type": "markdown",
262 | "metadata": {},
263 | "source": [
264 | "# Pipeline"
265 | ]
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": 11,
270 | "metadata": {},
271 | "outputs": [],
272 | "source": [
273 | "from pyspark.ml import Pipeline\n",
274 | "pipeline = Pipeline(stages=[binarizer, tokenizer, remover, hashingTF, lr])"
275 | ]
276 | },
277 | {
278 | "cell_type": "code",
279 | "execution_count": 12,
280 | "metadata": {},
281 | "outputs": [
282 | {
283 | "name": "stdout",
284 | "output_type": "stream",
285 | "text": [
286 | "CPU times: user 38.1 ms, sys: 16.3 ms, total: 54.3 ms\n",
287 | "Wall time: 1min 3s\n"
288 | ]
289 | }
290 | ],
291 | "source": [
292 | "%%time\n",
293 | "pipeLineModel = pipeline.fit(trainingData)"
294 | ]
295 | },
296 | {
297 | "cell_type": "markdown",
298 | "metadata": {},
299 | "source": [
300 | "# Evaluation"
301 | ]
302 | },
303 | {
304 | "cell_type": "code",
305 | "execution_count": 13,
306 | "metadata": {
307 | "scrolled": true
308 | },
309 | "outputs": [
310 | {
311 | "name": "stdout",
312 | "output_type": "stream",
313 | "text": [
314 | "Area under ROC: 0.967867334409\n",
315 | "CPU times: user 26.3 ms, sys: 11.4 ms, total: 37.7 ms\n",
316 | "Wall time: 17.8 s\n"
317 | ]
318 | }
319 | ],
320 | "source": [
321 | "%%time\n",
322 | "from pyspark.ml.evaluation import BinaryClassificationEvaluator\n",
323 | "evaluator = BinaryClassificationEvaluator()\n",
324 | "\n",
325 | "predictions = pipeLineModel.transform(testData)\n",
326 | "\n",
327 | "aur = evaluator.evaluate(predictions)\n",
328 | "\n",
329 | "print 'Area under ROC: ', aur"
330 | ]
331 | },
332 | {
333 | "cell_type": "markdown",
334 | "metadata": {},
335 | "source": [
336 | "# Hyperparameter Tuning"
337 | ]
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": 14,
342 | "metadata": {},
343 | "outputs": [
344 | {
345 | "name": "stdout",
346 | "output_type": "stream",
347 | "text": [
348 | "CPU times: user 3.77 s, sys: 1.09 s, total: 4.86 s\n",
349 | "Wall time: 11min 48s\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "%%time\n",
355 | "from pyspark.ml.tuning import ParamGridBuilder, CrossValidator\n",
356 | "param_grid = ParamGridBuilder() \\\n",
357 | " .addGrid(hashingTF.numFeatures, [10000, 100000]) \\\n",
358 | " .addGrid(lr.regParam, [0.01, 0.1, 1.0]) \\\n",
359 | " .addGrid(lr.maxIter, [10, 20]) \\\n",
360 | " .build()\n",
361 | " \n",
362 | "cv = (CrossValidator()\n",
363 | " .setEstimator(pipeline)\n",
364 | " .setEvaluator(evaluator)\n",
365 | " .setEstimatorParamMaps(param_grid)\n",
366 | " .setNumFolds(3))\n",
367 | "\n",
368 | "cv_model = cv.fit(trainingData)"
369 | ]
370 | },
371 | {
372 | "cell_type": "code",
373 | "execution_count": 15,
374 | "metadata": {},
375 | "outputs": [
376 | {
377 | "name": "stdout",
378 | "output_type": "stream",
379 | "text": [
380 | "Area under ROC: 0.97005045743\n",
381 | "CPU times: user 29.1 ms, sys: 6.17 ms, total: 35.2 ms\n",
382 | "Wall time: 5.89 s\n"
383 | ]
384 | }
385 | ],
386 | "source": [
387 | "%%time\n",
388 | "new_predictions = cv_model.transform(testData)\n",
389 | "new_aur = evaluator.evaluate(new_predictions)\n",
390 | "print 'Area under ROC: ', new_aur"
391 | ]
392 | }
393 | ],
394 | "metadata": {
395 | "kernelspec": {
396 | "display_name": "Python 2",
397 | "language": "python",
398 | "name": "python2"
399 | },
400 | "language_info": {
401 | "codemirror_mode": {
402 | "name": "ipython",
403 | "version": 2
404 | },
405 | "file_extension": ".py",
406 | "mimetype": "text/x-python",
407 | "name": "python",
408 | "nbconvert_exporter": "python",
409 | "pygments_lexer": "ipython2",
410 | "version": "2.7.15"
411 | }
412 | },
413 | "nbformat": 4,
414 | "nbformat_minor": 2
415 | }
416 |
--------------------------------------------------------------------------------
/solutions/Unit_6_WordCount.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from pyspark.sql import SparkSession
3 |
4 | if __name__ == '__main__':
5 | spark = SparkSession\
6 | .builder \
7 | .appName("WordCount") \
8 | .config('spark.driver.memory', '2g') \
9 | .config('spark.executor.cores', 1) \
10 | .config('spark.executor.memory', '2g') \
11 | .config('spark.executor.memoryOverhead', '1g') \
12 | .config('spark.dynamicAllocation.enabled', False) \
13 | .getOrCreate()
14 | sc = spark.sparkContext
15 |
16 | lines = sc.textFile('datasets/slurmd/slurmd.log.c6601')
17 | words = lines.flatMap(lambda line: line.split())
18 | counts = words.map(lambda word: (word, 1))
19 | aggregated = counts.reduceByKey(lambda a, b: a + b)
20 | result = aggregated.map(lambda (x, y): (y, x))
21 | print(result.sortByKey(ascending=False).take(10))
22 |
23 | spark.stop()
24 |
--------------------------------------------------------------------------------
/solutions/Unit_6_working_with_meteorological_data-using_dataframes.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from pyspark.sql import SparkSession, Row
3 |
4 |
5 | def parse_row(line):
6 | """Convert a line into a Row"""
7 | # All data lines start with 6 spaces
8 | if line.startswith(' '):
9 | codigo = int(line[:17].strip())
10 | datahora = line[17:40]
11 | data, hora = datahora.split()
12 | parametro = line[40:82].strip()
13 | valor = float(line[82:].replace(',', '.'))
14 | return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]
15 | return []
16 |
17 |
18 | if __name__ == '__main__':
19 | spark = SparkSession\
20 | .builder \
21 | .appName("Meteo-using-DF") \
22 | .config('spark.driver.memory', '2g') \
23 | .config('spark.executor.cores', 1) \
24 | .config('spark.executor.memory', '2g') \
25 | .config('spark.executor.memoryOverhead', '1g') \
26 | .config('spark.dynamicAllocation.enabled', False) \
27 | .getOrCreate()
28 | sc = spark.sparkContext
29 |
30 | rdd = sc.textFile('datasets/meteogalicia.txt')
31 | data = rdd.flatMap(parse_row).toDF()
32 | count = data.count()
33 | print('Total count:', count)
34 | t = data.where(data.parametro.like('Temperatura media %'))
35 | print('Maximum temperature')
36 | t.groupBy().max('valor').show()
37 | print('Minimum temperature')
38 | t.where(t.codigo == 1).groupBy().min('valor').show()
39 | print('Average temperatures per day')
40 | t.groupBy(t.data).mean('valor').sort('data').show(30)
41 |
42 | spark.stop()
43 |
--------------------------------------------------------------------------------
/solutions/Unit_6_working_with_meteorological_data-using_rdds.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from pyspark import SparkContext
3 |
4 |
5 | def parse_temperature(line):
6 | (_, date, hour, _, _, _, value) = line.split()
7 | return (date, float(value.replace(',', '.')))
8 |
9 |
10 | def sum_pairs(a, b):
11 | return (a[0]+b[0], a[1]+b[1])
12 |
13 |
14 | if __name__ == '__main__':
15 | sc = SparkContext(appName='Meteo analysis')
16 |
17 | rdd = sc.textFile('datasets/meteogalicia.txt')
18 |
19 | temperatures = (rdd.filter(lambda line: 'Temperatura media' in line)
20 | .map(parse_temperature))
21 |
22 | averages = (temperatures.map(lambda (date, t): (date, (t, 1)))
23 | .reduceByKey(sum_pairs)
24 | .mapValues(lambda (temp, count): temp/count))
25 |
26 | result = averages.sortByKey().collect()
27 | print('Average temperature per day')
28 | for date, temp in result:
29 | print('{} {}'.format(date, temp))
30 |
31 | sc.stop()
32 |
--------------------------------------------------------------------------------
/unit_2_basic_spark_concepts.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 2: Basic Spark Concepts"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "\n",
16 | "2.1 Spark Components\n",
17 | "\n",
18 | "2.2 RDD\n",
19 | "\n",
20 | "2.3 Partitioning\n",
21 | "\n",
22 | "2.4 Transformations vs Actions\n",
23 | "\n",
24 | "2.5 DAG\n",
25 | "\n",
26 | "2.6 Available APIs"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "## Spark Components\n",
34 | "\n",
35 | "A Spark application consists of a driver program that runs the main code of the program, distributing the operations to the rest of executors assigned by YARN to the application.\n",
36 | "\n",
37 | "\n",
38 | "\n",
39 | "Diagram taken from the [Spark Cluster Mode Overview](https://spark.apache.org/docs/2.4.0/cluster-overview.html)."
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "For further information check our [Spark Tutorial](http://bigdata.cesga.es/tutorials/spark.html#/) and the [Spark Cluster Mode Overview](https://spark.apache.org/docs/2.4.0/cluster-overview.html)."
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "## RDD\n",
54 | "A Resilient Distributed Dataset (RDD) is an abstraction that represents a collection of elements **distributed** across the nodes of the cluster.\n",
55 | "\n",
56 | "A RDD provides a series of methods that allow to operate with its underlying data in parallel in a very transparent way:\n"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 1,
62 | "metadata": {},
63 | "outputs": [],
64 | "source": [
65 | "rdd = sc.parallelize([1, 2, 3, 4, 5, 6])\n"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 2,
71 | "metadata": {},
72 | "outputs": [
73 | {
74 | "data": {
75 | "text/plain": [
76 | "6"
77 | ]
78 | },
79 | "execution_count": 2,
80 | "metadata": {},
81 | "output_type": "execute_result"
82 | }
83 | ],
84 | "source": [
85 | "rdd.count()"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "RDDs are **resilient** because they can automatically recover in case some of the nodes fails."
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## Partitioning"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "The elements in a RDD are splitted between the nodes of the cluster, dividing the collection in partitions. Each partition is then processed by a given executor.\n",
107 | "\n",
108 | ""
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 3,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6])"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 4,
123 | "metadata": {},
124 | "outputs": [
125 | {
126 | "data": {
127 | "text/plain": [
128 | "'(2) ParallelCollectionRDD[2] at parallelize at PythonRDD.scala:195 []'"
129 | ]
130 | },
131 | "execution_count": 4,
132 | "metadata": {},
133 | "output_type": "execute_result"
134 | }
135 | ],
136 | "source": [
137 | "rdd1.toDebugString()"
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 5,
143 | "metadata": {},
144 | "outputs": [
145 | {
146 | "data": {
147 | "text/plain": [
148 | "[[1, 2, 3], [4, 5, 6]]"
149 | ]
150 | },
151 | "execution_count": 5,
152 | "metadata": {},
153 | "output_type": "execute_result"
154 | }
155 | ],
156 | "source": [
157 | "rdd1.glom().collect()"
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 6,
163 | "metadata": {},
164 | "outputs": [],
165 | "source": [
166 | "rdd2 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 7,
172 | "metadata": {},
173 | "outputs": [
174 | {
175 | "data": {
176 | "text/plain": [
177 | "[[1, 2], [3, 4], [5, 6]]"
178 | ]
179 | },
180 | "execution_count": 7,
181 | "metadata": {},
182 | "output_type": "execute_result"
183 | }
184 | ],
185 | "source": [
186 | "rdd2.glom().collect()"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 8,
192 | "metadata": {},
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "(3) ParallelCollectionRDD[4] at parallelize at PythonRDD.scala:195 []\n"
199 | ]
200 | }
201 | ],
202 | "source": [
203 | "print rdd2.toDebugString()"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "In general, each task of an application runs against a different partition of the RDD.\n",
211 | "\n",
212 | "When using **large files** in HDFS (with many blocks) the partitions can be considered equivalent to the HDFS blocks of the given file.\n",
213 | "\n",
214 | "For **small files** (smaller than 128MB) by default spark will create two partitions, so initally only two tasks can be executed in parallel, independently of how many resources YARN has allocated to the application."
215 | ]
216 | },
217 | {
218 | "cell_type": "code",
219 | "execution_count": 9,
220 | "metadata": {},
221 | "outputs": [],
222 | "source": [
223 | "rdd3 = sc.textFile('datasets/meteogalicia.txt')"
224 | ]
225 | },
226 | {
227 | "cell_type": "code",
228 | "execution_count": 10,
229 | "metadata": {},
230 | "outputs": [
231 | {
232 | "name": "stdout",
233 | "output_type": "stream",
234 | "text": [
235 | "(2) datasets/meteogalicia.txt MapPartitionsRDD[7] at textFile at NativeMethodAccessorImpl.java:0 []\n",
236 | " | datasets/meteogalicia.txt HadoopRDD[6] at textFile at NativeMethodAccessorImpl.java:0 []\n"
237 | ]
238 | }
239 | ],
240 | "source": [
241 | "print rdd3.toDebugString()"
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "execution_count": 11,
247 | "metadata": {},
248 | "outputs": [],
249 | "source": [
250 | "rdd4 = sc.textFile('datasets/meteogalicia.txt', 4)"
251 | ]
252 | },
253 | {
254 | "cell_type": "code",
255 | "execution_count": 12,
256 | "metadata": {},
257 | "outputs": [
258 | {
259 | "name": "stdout",
260 | "output_type": "stream",
261 | "text": [
262 | "(4) datasets/meteogalicia.txt MapPartitionsRDD[9] at textFile at NativeMethodAccessorImpl.java:0 []\n",
263 | " | datasets/meteogalicia.txt HadoopRDD[8] at textFile at NativeMethodAccessorImpl.java:0 []\n"
264 | ]
265 | }
266 | ],
267 | "source": [
268 | "print rdd4.toDebugString()"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "## Transformations vs Actions"
276 | ]
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "metadata": {},
281 | "source": [
282 | "### Transformations\n",
283 | "Create a new RDD from an existing one.\n",
284 | "\n",
285 | "All transformations in Spark are **lazy**, in the sense that they do not actually do anything until an action is executed.\n",
286 | "\n",
287 | "Examples:\n",
288 | "* map\n",
289 | "* filter\n",
290 | "\n",
291 | "### Actions\n",
292 | "Return the result to the driver program.\n",
293 | "\n",
294 | "Examples:\n",
295 | "* reduce\n",
296 | "* collect"
297 | ]
298 | },
299 | {
300 | "cell_type": "markdown",
301 | "metadata": {},
302 | "source": [
303 | "## DAG"
304 | ]
305 | },
306 | {
307 | "cell_type": "markdown",
308 | "metadata": {},
309 | "source": [
310 | "Each job is represented by a graph (specifically a [directed acyclic graph (DAG)](https://en.wikipedia.org/wiki/Directed_acyclic_graph)):\n",
311 | "\n",
312 | ""
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "metadata": {},
318 | "source": [
319 | "## Available APIs "
320 | ]
321 | },
322 | {
323 | "cell_type": "markdown",
324 | "metadata": {},
325 | "source": [
326 | "Currently there are different options to use Spark in Python:\n",
327 | "\n",
328 | "* Low-Level API: Using **RDDs and PairRDDs**: the original API, low level, great flexibility\n",
329 | "\n",
330 | "* Structured API: Using **Spark SQL and DataFrames**: newer, higher level, better performance\n",
331 | "\n",
332 | "In the case of Java and Scala there is also the option of using **DataSets**: a generalization of DataFrames that allows to use typed data instead of generic Row objects."
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "## Useful Reference Resources"
340 | ]
341 | },
342 | {
343 | "cell_type": "markdown",
344 | "metadata": {},
345 | "source": [
346 | "* [Spark RDD Programming Guide](https://spark.apache.org/docs/2.4.0/rdd-programming-guide.html)\n",
347 | "* [Spark SQL, DataFrames and Datasets Guide](https://spark.apache.org/docs/2.4.0/sql-programming-guide.html)\n",
348 | "* [Spark Python API](https://spark.apache.org/docs/2.4.0/api/python/index.html)"
349 | ]
350 | },
351 | {
352 | "cell_type": "markdown",
353 | "metadata": {},
354 | "source": [
355 | "## Questionaire\n",
356 | "Complete the [Unit 2 questionaire](https://forms.gle/xSErFivLyu3uxY7r6)."
357 | ]
358 | }
359 | ],
360 | "metadata": {
361 | "kernelspec": {
362 | "display_name": "Python 2",
363 | "language": "python",
364 | "name": "python2"
365 | },
366 | "language_info": {
367 | "codemirror_mode": {
368 | "name": "ipython",
369 | "version": 2
370 | },
371 | "file_extension": ".py",
372 | "mimetype": "text/x-python",
373 | "name": "python",
374 | "nbconvert_exporter": "python",
375 | "pygments_lexer": "ipython2",
376 | "version": "2.7.15"
377 | }
378 | },
379 | "nbformat": 4,
380 | "nbformat_minor": 4
381 | }
382 |
--------------------------------------------------------------------------------
/unit_3_programming_with_RDDs.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 3: Programming with RDDs"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "```\n",
16 | "3.1 Before we begin: Passing funtions to Spark\n",
17 | "3.2 Transformations\n",
18 | "3.3 Actions\n",
19 | "3.4 Loading data from HDFS\n",
20 | "3.5 Saving results back to HDFS\n",
21 | "```"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "## Before we begin: Passing functions to Spark"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "Using lambda functions:"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 1,
41 | "metadata": {},
42 | "outputs": [
43 | {
44 | "data": {
45 | "text/plain": [
46 | "[0, 1, 2, 3]"
47 | ]
48 | },
49 | "execution_count": 1,
50 | "metadata": {},
51 | "output_type": "execute_result"
52 | }
53 | ],
54 | "source": [
55 | "rdd1 = sc.parallelize(range(4))\n",
56 | "rdd1.collect()"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 2,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "data": {
66 | "text/plain": [
67 | "[0, 2, 4, 6]"
68 | ]
69 | },
70 | "execution_count": 2,
71 | "metadata": {},
72 | "output_type": "execute_result"
73 | }
74 | ],
75 | "source": [
76 | "rdd2 = rdd1.map(lambda x: 2*x)\n",
77 | "rdd2.collect()"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "Using normal functions:"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 3,
90 | "metadata": {},
91 | "outputs": [],
92 | "source": [
93 | "def double(x):\n",
94 | " return 2*x"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 4,
100 | "metadata": {
101 | "scrolled": true
102 | },
103 | "outputs": [
104 | {
105 | "data": {
106 | "text/plain": [
107 | "[0, 2, 4, 6]"
108 | ]
109 | },
110 | "execution_count": 4,
111 | "metadata": {},
112 | "output_type": "execute_result"
113 | }
114 | ],
115 | "source": [
116 | "rdd3 = rdd1.map(double)\n",
117 | "rdd3.collect()"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "Sometimes it is tricky to understand the scope and life cycle of variables and methods when running in a cluster. The main part of the code executes in the driver, but when parallel operations are done the functions passed are executed in the executors and data is passed around using **closures**."
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Transformations"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "### map"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 5,
144 | "metadata": {},
145 | "outputs": [
146 | {
147 | "data": {
148 | "text/plain": [
149 | "[0, 1, 2, 3]"
150 | ]
151 | },
152 | "execution_count": 5,
153 | "metadata": {},
154 | "output_type": "execute_result"
155 | }
156 | ],
157 | "source": [
158 | "rdd1 = sc.parallelize(range(4))\n",
159 | "rdd1.collect()"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 6,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "data": {
169 | "text/plain": [
170 | "[5, 6, 7, 8]"
171 | ]
172 | },
173 | "execution_count": 6,
174 | "metadata": {},
175 | "output_type": "execute_result"
176 | }
177 | ],
178 | "source": [
179 | "rdd2 = rdd1.map(lambda x: x + 5)\n",
180 | "rdd2.collect()"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 7,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "data": {
190 | "text/plain": [
191 | "[5, 6, 7, 8]"
192 | ]
193 | },
194 | "execution_count": 7,
195 | "metadata": {},
196 | "output_type": "execute_result"
197 | }
198 | ],
199 | "source": [
200 | "def plus_five(x):\n",
201 | " return x + 5\n",
202 | "\n",
203 | "rdd1.map(plus_five).collect()"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "### filter"
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": 8,
216 | "metadata": {},
217 | "outputs": [
218 | {
219 | "data": {
220 | "text/plain": [
221 | "['a1', 'a2', 'b1', 'b2']"
222 | ]
223 | },
224 | "execution_count": 8,
225 | "metadata": {},
226 | "output_type": "execute_result"
227 | }
228 | ],
229 | "source": [
230 | "rdd1 = sc.parallelize(['a1', 'a2', 'b1', 'b2'])\n",
231 | "rdd1.collect()"
232 | ]
233 | },
234 | {
235 | "cell_type": "code",
236 | "execution_count": 9,
237 | "metadata": {},
238 | "outputs": [
239 | {
240 | "data": {
241 | "text/plain": [
242 | "['a1', 'a2']"
243 | ]
244 | },
245 | "execution_count": 9,
246 | "metadata": {},
247 | "output_type": "execute_result"
248 | }
249 | ],
250 | "source": [
251 | "rdd2 = rdd1.filter(lambda x: 'a' in x)\n",
252 | "rdd2.collect()"
253 | ]
254 | },
255 | {
256 | "cell_type": "markdown",
257 | "metadata": {},
258 | "source": [
259 | "### flatMap"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 10,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "data": {
269 | "text/plain": [
270 | "['Space: the final frontier.',\n",
271 | " 'These are the voyages of the starship Enterprise.']"
272 | ]
273 | },
274 | "execution_count": 10,
275 | "metadata": {},
276 | "output_type": "execute_result"
277 | }
278 | ],
279 | "source": [
280 | "rdd1 = sc.parallelize(['Space: the final frontier.',\n",
281 | " 'These are the voyages of the starship Enterprise.'])\n",
282 | "rdd1.collect()"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": 11,
288 | "metadata": {},
289 | "outputs": [
290 | {
291 | "data": {
292 | "text/plain": [
293 | "[['Space:', 'the', 'final', 'frontier.'],\n",
294 | " ['These', 'are', 'the', 'voyages', 'of', 'the', 'starship', 'Enterprise.']]"
295 | ]
296 | },
297 | "execution_count": 11,
298 | "metadata": {},
299 | "output_type": "execute_result"
300 | }
301 | ],
302 | "source": [
303 | "rdd2 = rdd1.map(lambda line: line.split())\n",
304 | "rdd2.collect()"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": 12,
310 | "metadata": {},
311 | "outputs": [
312 | {
313 | "data": {
314 | "text/plain": [
315 | "['Space:',\n",
316 | " 'the',\n",
317 | " 'final',\n",
318 | " 'frontier.',\n",
319 | " 'These',\n",
320 | " 'are',\n",
321 | " 'the',\n",
322 | " 'voyages',\n",
323 | " 'of',\n",
324 | " 'the',\n",
325 | " 'starship',\n",
326 | " 'Enterprise.']"
327 | ]
328 | },
329 | "execution_count": 12,
330 | "metadata": {},
331 | "output_type": "execute_result"
332 | }
333 | ],
334 | "source": [
335 | "rdd3 = rdd1.flatMap(lambda line: line.split())\n",
336 | "rdd3.collect()"
337 | ]
338 | },
339 | {
340 | "cell_type": "markdown",
341 | "metadata": {},
342 | "source": [
343 | "### distinct"
344 | ]
345 | },
346 | {
347 | "cell_type": "code",
348 | "execution_count": 13,
349 | "metadata": {},
350 | "outputs": [
351 | {
352 | "data": {
353 | "text/plain": [
354 | "[1, 1, 1, 2, 2]"
355 | ]
356 | },
357 | "execution_count": 13,
358 | "metadata": {},
359 | "output_type": "execute_result"
360 | }
361 | ],
362 | "source": [
363 | "rdd1 = sc.parallelize([1, 1, 1, 2, 2])\n",
364 | "rdd1.collect()"
365 | ]
366 | },
367 | {
368 | "cell_type": "code",
369 | "execution_count": 14,
370 | "metadata": {},
371 | "outputs": [
372 | {
373 | "data": {
374 | "text/plain": [
375 | "[2, 1]"
376 | ]
377 | },
378 | "execution_count": 14,
379 | "metadata": {},
380 | "output_type": "execute_result"
381 | }
382 | ],
383 | "source": [
384 | "rdd2 = rdd1.distinct()\n",
385 | "rdd2.collect()"
386 | ]
387 | },
388 | {
389 | "cell_type": "markdown",
390 | "metadata": {},
391 | "source": [
392 | "## Actions"
393 | ]
394 | },
395 | {
396 | "cell_type": "code",
397 | "execution_count": 15,
398 | "metadata": {},
399 | "outputs": [],
400 | "source": [
401 | "rdd1 = sc.parallelize([1, 1, 1, 2, 2])"
402 | ]
403 | },
404 | {
405 | "cell_type": "markdown",
406 | "metadata": {},
407 | "source": [
408 | "### reduce"
409 | ]
410 | },
411 | {
412 | "cell_type": "code",
413 | "execution_count": 16,
414 | "metadata": {},
415 | "outputs": [
416 | {
417 | "data": {
418 | "text/plain": [
419 | "7"
420 | ]
421 | },
422 | "execution_count": 16,
423 | "metadata": {},
424 | "output_type": "execute_result"
425 | }
426 | ],
427 | "source": [
428 | "rdd1.reduce(lambda a, b: a + b)"
429 | ]
430 | },
431 | {
432 | "cell_type": "markdown",
433 | "metadata": {},
434 | "source": [
435 | "### count"
436 | ]
437 | },
438 | {
439 | "cell_type": "code",
440 | "execution_count": 17,
441 | "metadata": {},
442 | "outputs": [
443 | {
444 | "data": {
445 | "text/plain": [
446 | "5"
447 | ]
448 | },
449 | "execution_count": 17,
450 | "metadata": {},
451 | "output_type": "execute_result"
452 | }
453 | ],
454 | "source": [
455 | "rdd1.count()"
456 | ]
457 | },
458 | {
459 | "cell_type": "markdown",
460 | "metadata": {},
461 | "source": [
462 | "### collect"
463 | ]
464 | },
465 | {
466 | "cell_type": "code",
467 | "execution_count": 18,
468 | "metadata": {},
469 | "outputs": [
470 | {
471 | "data": {
472 | "text/plain": [
473 | "[1, 1, 1, 2, 2]"
474 | ]
475 | },
476 | "execution_count": 18,
477 | "metadata": {},
478 | "output_type": "execute_result"
479 | }
480 | ],
481 | "source": [
482 | "rdd1.collect()"
483 | ]
484 | },
485 | {
486 | "cell_type": "markdown",
487 | "metadata": {},
488 | "source": [
489 | "### first"
490 | ]
491 | },
492 | {
493 | "cell_type": "code",
494 | "execution_count": 19,
495 | "metadata": {},
496 | "outputs": [
497 | {
498 | "data": {
499 | "text/plain": [
500 | "1"
501 | ]
502 | },
503 | "execution_count": 19,
504 | "metadata": {},
505 | "output_type": "execute_result"
506 | }
507 | ],
508 | "source": [
509 | "rdd1.first()"
510 | ]
511 | },
512 | {
513 | "cell_type": "markdown",
514 | "metadata": {},
515 | "source": [
516 | "### take"
517 | ]
518 | },
519 | {
520 | "cell_type": "code",
521 | "execution_count": 20,
522 | "metadata": {
523 | "scrolled": true
524 | },
525 | "outputs": [
526 | {
527 | "data": {
528 | "text/plain": [
529 | "[1, 1]"
530 | ]
531 | },
532 | "execution_count": 20,
533 | "metadata": {},
534 | "output_type": "execute_result"
535 | }
536 | ],
537 | "source": [
538 | "rdd1.take(2)"
539 | ]
540 | },
541 | {
542 | "cell_type": "markdown",
543 | "metadata": {},
544 | "source": [
545 | "### takeSample"
546 | ]
547 | },
548 | {
549 | "cell_type": "code",
550 | "execution_count": 21,
551 | "metadata": {},
552 | "outputs": [
553 | {
554 | "data": {
555 | "text/plain": [
556 | "[2, 1, 1, 2, 1]"
557 | ]
558 | },
559 | "execution_count": 21,
560 | "metadata": {},
561 | "output_type": "execute_result"
562 | }
563 | ],
564 | "source": [
565 | "rdd1.takeSample(withReplacement=False, num=10)"
566 | ]
567 | },
568 | {
569 | "cell_type": "code",
570 | "execution_count": 22,
571 | "metadata": {},
572 | "outputs": [
573 | {
574 | "data": {
575 | "text/plain": [
576 | "[1, 2, 1, 1, 1, 1, 1, 1, 1, 2]"
577 | ]
578 | },
579 | "execution_count": 22,
580 | "metadata": {},
581 | "output_type": "execute_result"
582 | }
583 | ],
584 | "source": [
585 | "rdd1.takeSample(withReplacement=True, num=10)"
586 | ]
587 | },
588 | {
589 | "cell_type": "markdown",
590 | "metadata": {},
591 | "source": [
592 | "## Loading data from HDFS"
593 | ]
594 | },
595 | {
596 | "cell_type": "markdown",
597 | "metadata": {},
598 | "source": [
599 | "### textFile"
600 | ]
601 | },
602 | {
603 | "cell_type": "code",
604 | "execution_count": 23,
605 | "metadata": {},
606 | "outputs": [],
607 | "source": [
608 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
609 | ]
610 | },
611 | {
612 | "cell_type": "code",
613 | "execution_count": 24,
614 | "metadata": {
615 | "scrolled": true
616 | },
617 | "outputs": [
618 | {
619 | "data": {
620 | "text/plain": [
621 | "[u'',\n",
622 | " u'',\n",
623 | " u'ESTACI\\ufffdN AUTOM\\ufffdTICA:Santiago-EOAS',\n",
624 | " u'CONCELLO:Santiago de Compostela',\n",
625 | " u'PROVINCIA:A Coru\\ufffda']"
626 | ]
627 | },
628 | "execution_count": 24,
629 | "metadata": {},
630 | "output_type": "execute_result"
631 | }
632 | ],
633 | "source": [
634 | "\n",
635 | "rdd.take(5)"
636 | ]
637 | },
638 | {
639 | "cell_type": "markdown",
640 | "metadata": {},
641 | "source": [
642 | "Several files can also be loaded together at the same time but **be careful with the number of partitions generated**:"
643 | ]
644 | },
645 | {
646 | "cell_type": "code",
647 | "execution_count": 25,
648 | "metadata": {},
649 | "outputs": [],
650 | "source": [
651 | "rdd1 = sc.textFile('datasets/slurmd/slurmd.log.*')"
652 | ]
653 | },
654 | {
655 | "cell_type": "code",
656 | "execution_count": 26,
657 | "metadata": {},
658 | "outputs": [
659 | {
660 | "name": "stdout",
661 | "output_type": "stream",
662 | "text": [
663 | "(10) datasets/slurmd/slurmd.log.* MapPartitionsRDD[29] at textFile at NativeMethodAccessorImpl.java:0 []\n",
664 | " | datasets/slurmd/slurmd.log.* HadoopRDD[28] at textFile at NativeMethodAccessorImpl.java:0 []\n"
665 | ]
666 | }
667 | ],
668 | "source": [
669 | "print rdd1.toDebugString()"
670 | ]
671 | },
672 | {
673 | "cell_type": "code",
674 | "execution_count": 27,
675 | "metadata": {},
676 | "outputs": [
677 | {
678 | "data": {
679 | "text/plain": [
680 | "[u'1488161034 2017 Feb 27 03:03:54 c6610 daemon info slurmd Launching batch job 467165 for UID 1053',\n",
681 | " u'1494997188 2017 May 17 06:59:48 c6603 user info slurmstepd task/cgroup: /slurm/uid_12329/job_706187/step_batch: alloc=16384MB mem.limit=16384MB memsw.limit=unlimited',\n",
682 | " u'1486762787 2017 Feb 10 22:39:47 c6604 daemon info slurmd _run_prolog: run job script took usec=39335',\n",
683 | " u'1492284836 2017 Apr 15 21:33:56 c6609 user info slurmstepd done with job',\n",
684 | " u'1489949176 2017 Mar 19 19:46:16 c6604 user info slurmstepd done with job']"
685 | ]
686 | },
687 | "execution_count": 27,
688 | "metadata": {},
689 | "output_type": "execute_result"
690 | }
691 | ],
692 | "source": [
693 | "rdd1.takeSample(withReplacement=False, num=5)"
694 | ]
695 | },
696 | {
697 | "cell_type": "markdown",
698 | "metadata": {},
699 | "source": [
700 | "### wholeTextFiles"
701 | ]
702 | },
703 | {
704 | "cell_type": "markdown",
705 | "metadata": {},
706 | "source": [
707 | "wholeTextFiles lets you read a directory containing multiple small text files, and returns each of them as (filename, content) pairs. This is in contrast with textFile, which would return one record per line in each file."
708 | ]
709 | },
710 | {
711 | "cell_type": "code",
712 | "execution_count": 28,
713 | "metadata": {},
714 | "outputs": [],
715 | "source": [
716 | "rdd2 = sc.wholeTextFiles('datasets/slurmd/slurmd.log.*')"
717 | ]
718 | },
719 | {
720 | "cell_type": "code",
721 | "execution_count": 29,
722 | "metadata": {},
723 | "outputs": [
724 | {
725 | "data": {
726 | "text/plain": [
727 | "'(2) datasets/slurmd/slurmd.log.* MapPartitionsRDD[33] at wholeTextFiles at NativeMethodAccessorImpl.java:0 []\\n | WholeTextFileRDD[32] at wholeTextFiles at NativeMethodAccessorImpl.java:0 []'"
728 | ]
729 | },
730 | "execution_count": 29,
731 | "metadata": {},
732 | "output_type": "execute_result"
733 | }
734 | ],
735 | "source": [
736 | "rdd2.toDebugString()"
737 | ]
738 | },
739 | {
740 | "cell_type": "code",
741 | "execution_count": 30,
742 | "metadata": {},
743 | "outputs": [
744 | {
745 | "data": {
746 | "text/plain": [
747 | "[(u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6601',\n",
748 | " u'1482336831 2016 Dec 21 17:13:51 c6601 daemon info slurmd launch task 387796.0 re'),\n",
749 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6602',\n",
750 | " u'1482485639 2016 Dec 23 10:33:59 c6602 daemon info slurmd Slurmd shutdown complet'),\n",
751 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6603',\n",
752 | " u'1482485628 2016 Dec 23 10:33:48 c6603 daemon info slurmd Slurmd shutdown complet'),\n",
753 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6604',\n",
754 | " u'1482485636 2016 Dec 23 10:33:56 c6604 daemon info slurmd Slurmd shutdown complet'),\n",
755 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6605',\n",
756 | " u'1482485640 2016 Dec 23 10:34:00 c6605 daemon info slurmd Slurmd shutdown complet'),\n",
757 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6606',\n",
758 | " u'1482485652 2016 Dec 23 10:34:12 c6606 daemon info slurmd Slurmd shutdown complet'),\n",
759 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6607',\n",
760 | " u'1482485637 2016 Dec 23 10:33:57 c6607 daemon info slurmd Slurmd shutdown complet'),\n",
761 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6608',\n",
762 | " u'1482484569 2016 Dec 23 10:16:09 c6608 daemon err slurmd error: gres/mic unable t'),\n",
763 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6609',\n",
764 | " u'1482485648 2016 Dec 23 10:34:08 c6609 daemon info slurmd Slurmd shutdown complet'),\n",
765 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6610',\n",
766 | " u'1482485646 2016 Dec 23 10:34:06 c6610 daemon info slurmd Slurmd shutdown complet')]"
767 | ]
768 | },
769 | "execution_count": 30,
770 | "metadata": {},
771 | "output_type": "execute_result"
772 | }
773 | ],
774 | "source": [
775 | "rdd2.map(lambda (filename, content): (filename, content[:80])).collect()"
776 | ]
777 | },
778 | {
779 | "cell_type": "markdown",
780 | "metadata": {},
781 | "source": [
782 | "### binaryRecords"
783 | ]
784 | },
785 | {
786 | "cell_type": "code",
787 | "execution_count": 31,
788 | "metadata": {},
789 | "outputs": [],
790 | "source": [
791 | "import struct\n",
792 | "from collections import namedtuple\n",
793 | "\n",
794 | "AcctRecord = namedtuple('AcctRecord',\n",
795 | " 'flag version tty exitcode uid gid pid ppid '\n",
796 | " 'btime etime utime stime mem io rw minflt majflt swaps '\n",
797 | " 'command')\n",
798 | "\n",
799 | "def read_record(data):\n",
800 | " values = struct.unpack(\"2BH6If8H16s\", data)\n",
801 | " return AcctRecord(*values)"
802 | ]
803 | },
804 | {
805 | "cell_type": "code",
806 | "execution_count": 32,
807 | "metadata": {},
808 | "outputs": [
809 | {
810 | "data": {
811 | "text/plain": [
812 | "[AcctRecord(flag=2, version=3, tty=0, exitcode=0, uid=0, gid=0, pid=24150, ppid=24144, btime=1474162981, etime=0.0, utime=0, stime=0, mem=3924, io=0, rw=0, minflt=482, majflt=0, swaps=0, command='accton\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00'),\n",
813 | " AcctRecord(flag=0, version=3, tty=0, exitcode=0, uid=0, gid=0, pid=24151, ppid=24144, btime=1474162981, etime=0.0, utime=0, stime=0, mem=4300, io=0, rw=0, minflt=199, majflt=0, swaps=0, command='gzip\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00')]"
814 | ]
815 | },
816 | "execution_count": 32,
817 | "metadata": {},
818 | "output_type": "execute_result"
819 | }
820 | ],
821 | "source": [
822 | "raw_rdd = sc.binaryRecords('datasets/pacct-20160919', recordLength=64)\n",
823 | "records = raw_rdd.map(read_record)\n",
824 | "records.take(2)"
825 | ]
826 | },
827 | {
828 | "cell_type": "markdown",
829 | "metadata": {},
830 | "source": [
831 | "## Saving results back to HDFS"
832 | ]
833 | },
834 | {
835 | "cell_type": "code",
836 | "execution_count": 33,
837 | "metadata": {},
838 | "outputs": [],
839 | "source": [
840 | "rdd.saveAsTextFile('results_directory')"
841 | ]
842 | },
843 | {
844 | "cell_type": "markdown",
845 | "metadata": {},
846 | "source": [
847 | "It will create a separate file for each partition of the RDD."
848 | ]
849 | },
850 | {
851 | "cell_type": "markdown",
852 | "metadata": {},
853 | "source": [
854 | "## Pipe RDDs to System Commands"
855 | ]
856 | },
857 | {
858 | "cell_type": "markdown",
859 | "metadata": {},
860 | "source": [
861 | "A very interesting functionality of RDDs is that you can pipe the contents of the RDD to system commands, so you can easily parallelize the execution of common tasks in multiple nodes.\n",
862 | "\n",
863 | "For each partition, all elements inside the partition are passed together (separated by newlines) as the stdin of the command, and each line of the stdout of the command will be transformed in one element of the output partition."
864 | ]
865 | },
866 | {
867 | "cell_type": "code",
868 | "execution_count": 34,
869 | "metadata": {},
870 | "outputs": [],
871 | "source": [
872 | "rdd = sc.parallelize(range(10), 4)"
873 | ]
874 | },
875 | {
876 | "cell_type": "code",
877 | "execution_count": 35,
878 | "metadata": {},
879 | "outputs": [
880 | {
881 | "data": {
882 | "text/plain": [
883 | "[[0, 1], [2, 3], [4, 5], [6, 7, 8, 9]]"
884 | ]
885 | },
886 | "execution_count": 35,
887 | "metadata": {},
888 | "output_type": "execute_result"
889 | }
890 | ],
891 | "source": [
892 | "rdd.glom().collect()"
893 | ]
894 | },
895 | {
896 | "cell_type": "code",
897 | "execution_count": 36,
898 | "metadata": {},
899 | "outputs": [
900 | {
901 | "data": {
902 | "text/plain": [
903 | "[u'2', u'2', u'2', u'4']"
904 | ]
905 | },
906 | "execution_count": 36,
907 | "metadata": {},
908 | "output_type": "execute_result"
909 | }
910 | ],
911 | "source": [
912 | "rdd.pipe('wc -l').collect()"
913 | ]
914 | },
915 | {
916 | "cell_type": "code",
917 | "execution_count": 37,
918 | "metadata": {},
919 | "outputs": [
920 | {
921 | "data": {
922 | "text/plain": [
923 | "[u'0', u'1', u'2', u'3', u'4', u'5', u'6', u'7', u'8', u'9']"
924 | ]
925 | },
926 | "execution_count": 37,
927 | "metadata": {},
928 | "output_type": "execute_result"
929 | }
930 | ],
931 | "source": [
932 | "rdd.pipe('cat').collect()"
933 | ]
934 | },
935 | {
936 | "cell_type": "markdown",
937 | "metadata": {},
938 | "source": [
939 | "## Exercises\n",
940 | "Now you can try to apply the above concepts to solve the following problems:\n",
941 | "* Unit 3 Working with meteorological data 1\n",
942 | "* Unit 3 Calculating Pi"
943 | ]
944 | }
945 | ],
946 | "metadata": {
947 | "kernelspec": {
948 | "display_name": "Python 2",
949 | "language": "python",
950 | "name": "python2"
951 | },
952 | "language_info": {
953 | "codemirror_mode": {
954 | "name": "ipython",
955 | "version": 2
956 | },
957 | "file_extension": ".py",
958 | "mimetype": "text/x-python",
959 | "name": "python",
960 | "nbconvert_exporter": "python",
961 | "pygments_lexer": "ipython2",
962 | "version": "2.7.15"
963 | }
964 | },
965 | "nbformat": 4,
966 | "nbformat_minor": 4
967 | }
968 |
--------------------------------------------------------------------------------
/unit_4_programming_with_PairRDDs.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 4: Programming with Pair RDDs"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "```\n",
16 | "4.1 Pair RDDs\n",
17 | "4.2 Transformations\n",
18 | "4.3 Actions\n",
19 | "4.4 Considerations about performance\n",
20 | "```"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "## Pair RDDs"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "We have seen that a normal RDD is just a collection of elements."
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 1,
40 | "metadata": {},
41 | "outputs": [],
42 | "source": [
43 | "normal_rdd = sc.parallelize(['a', 'b', 'c'])"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "A Pair RDDs is a special type of RDD which elements are tuples (*pairs*):"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 2,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "pair_rdd = sc.parallelize([('a', 1), ('b', 1), ('c', 1)])"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "The interesting part about Pair RDDs is that they provide additional transformations and actions."
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "# Transformations"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "### keyBy"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 3,
86 | "metadata": {},
87 | "outputs": [
88 | {
89 | "data": {
90 | "text/plain": [
91 | "['cat', 'lion', 'dog', 'tiger', 'elephant']"
92 | ]
93 | },
94 | "execution_count": 3,
95 | "metadata": {},
96 | "output_type": "execute_result"
97 | }
98 | ],
99 | "source": [
100 | "rdd1 = sc.parallelize(['cat', 'lion', 'dog', 'tiger', 'elephant'])\n",
101 | "rdd1.collect()"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 4,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "data": {
111 | "text/plain": [
112 | "[(3, 'cat'), (4, 'lion'), (3, 'dog'), (5, 'tiger'), (8, 'elephant')]"
113 | ]
114 | },
115 | "execution_count": 4,
116 | "metadata": {},
117 | "output_type": "execute_result"
118 | }
119 | ],
120 | "source": [
121 | "rdd2 = rdd1.keyBy(lambda line: len(line))\n",
122 | "rdd2.collect()"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "### groupByKey"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | ""
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 5,
142 | "metadata": {},
143 | "outputs": [],
144 | "source": [
145 | "rdd1 = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('a', 1), ('b', 1), ('b', 1), ('a', 1), ('a', 1), ('a', 1), ('b', 1), ('b',1), ('b', 1)])"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 6,
151 | "metadata": {
152 | "scrolled": true
153 | },
154 | "outputs": [
155 | {
156 | "data": {
157 | "text/plain": [
158 | "[('a', ),\n",
159 | " ('b', )]"
160 | ]
161 | },
162 | "execution_count": 6,
163 | "metadata": {},
164 | "output_type": "execute_result"
165 | }
166 | ],
167 | "source": [
168 | "rdd2 = rdd1.groupByKey()\n",
169 | "rdd2.collect()"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "### reduceByKey"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | "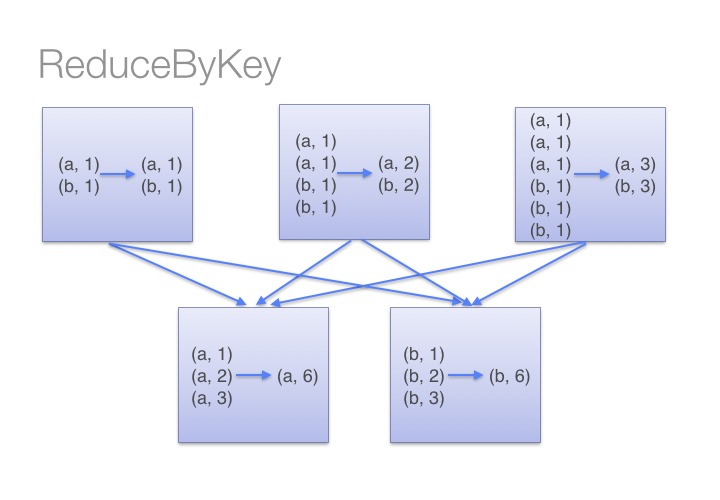"
184 | ]
185 | },
186 | {
187 | "cell_type": "code",
188 | "execution_count": 7,
189 | "metadata": {},
190 | "outputs": [],
191 | "source": [
192 | "rdd1 = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('a', 1), ('b', 1), ('b', 1), ('a', 1), ('a', 1), ('a', 1), ('b', 1), ('b',1), ('b', 1)])"
193 | ]
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": 8,
198 | "metadata": {
199 | "scrolled": true
200 | },
201 | "outputs": [
202 | {
203 | "data": {
204 | "text/plain": [
205 | "[('a', 6), ('b', 6)]"
206 | ]
207 | },
208 | "execution_count": 8,
209 | "metadata": {},
210 | "output_type": "execute_result"
211 | }
212 | ],
213 | "source": [
214 | "rdd2 = rdd1.reduceByKey(lambda x, y: x + y)\n",
215 | "rdd2.collect()"
216 | ]
217 | },
218 | {
219 | "cell_type": "markdown",
220 | "metadata": {},
221 | "source": [
222 | "### sortByKey"
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 9,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "rdd1 = sc.parallelize([('c', 1), ('b', 1), ('a', 1)])"
232 | ]
233 | },
234 | {
235 | "cell_type": "code",
236 | "execution_count": 10,
237 | "metadata": {},
238 | "outputs": [
239 | {
240 | "data": {
241 | "text/plain": [
242 | "[('a', 1), ('b', 1), ('c', 1)]"
243 | ]
244 | },
245 | "execution_count": 10,
246 | "metadata": {},
247 | "output_type": "execute_result"
248 | }
249 | ],
250 | "source": [
251 | "rdd2 = rdd1.sortByKey()\n",
252 | "rdd2.collect()"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 11,
258 | "metadata": {},
259 | "outputs": [
260 | {
261 | "data": {
262 | "text/plain": [
263 | "[('c', 1), ('b', 1), ('a', 1)]"
264 | ]
265 | },
266 | "execution_count": 11,
267 | "metadata": {},
268 | "output_type": "execute_result"
269 | }
270 | ],
271 | "source": [
272 | "rdd2 = rdd1.sortByKey(ascending=False)\n",
273 | "rdd2.collect()"
274 | ]
275 | },
276 | {
277 | "cell_type": "markdown",
278 | "metadata": {},
279 | "source": [
280 | "### join"
281 | ]
282 | },
283 | {
284 | "cell_type": "code",
285 | "execution_count": 12,
286 | "metadata": {},
287 | "outputs": [],
288 | "source": [
289 | "rdd1 = sc.parallelize([('a', 1), ('b', 2), ('c', 3)])\n",
290 | "rdd2 = sc.parallelize([('a', 4), ('b', 5), ('c', 6)])"
291 | ]
292 | },
293 | {
294 | "cell_type": "code",
295 | "execution_count": 13,
296 | "metadata": {
297 | "scrolled": true
298 | },
299 | "outputs": [
300 | {
301 | "data": {
302 | "text/plain": [
303 | "[('a', (1, 4)), ('c', (3, 6)), ('b', (2, 5))]"
304 | ]
305 | },
306 | "execution_count": 13,
307 | "metadata": {},
308 | "output_type": "execute_result"
309 | }
310 | ],
311 | "source": [
312 | "rdd3 = rdd1.join(rdd2)\n",
313 | "rdd3.collect()"
314 | ]
315 | },
316 | {
317 | "cell_type": "markdown",
318 | "metadata": {},
319 | "source": [
320 | "The join transformation performs an **inner join**. In case there is no match between the keys or any of them are repeated this would be the situation:"
321 | ]
322 | },
323 | {
324 | "cell_type": "code",
325 | "execution_count": 14,
326 | "metadata": {},
327 | "outputs": [],
328 | "source": [
329 | "rdd1 = sc.parallelize([('a', 1), ('b', 2)])\n",
330 | "rdd2 = sc.parallelize([('a', 4), ('a', 5), ('c', 6)])"
331 | ]
332 | },
333 | {
334 | "cell_type": "code",
335 | "execution_count": 15,
336 | "metadata": {},
337 | "outputs": [
338 | {
339 | "data": {
340 | "text/plain": [
341 | "[('a', (1, 5)), ('a', (1, 4))]"
342 | ]
343 | },
344 | "execution_count": 15,
345 | "metadata": {},
346 | "output_type": "execute_result"
347 | }
348 | ],
349 | "source": [
350 | "rdd3 = rdd1.join(rdd2)\n",
351 | "rdd3.collect()"
352 | ]
353 | },
354 | {
355 | "cell_type": "markdown",
356 | "metadata": {},
357 | "source": [
358 | "### leftOuterJoin"
359 | ]
360 | },
361 | {
362 | "cell_type": "code",
363 | "execution_count": 16,
364 | "metadata": {},
365 | "outputs": [],
366 | "source": [
367 | "rdd1 = sc.parallelize([('a', 1), ('b', 2)])\n",
368 | "rdd2 = sc.parallelize([('a', 4), ('a', 5), ('c', 6)])"
369 | ]
370 | },
371 | {
372 | "cell_type": "code",
373 | "execution_count": 17,
374 | "metadata": {
375 | "scrolled": true
376 | },
377 | "outputs": [
378 | {
379 | "data": {
380 | "text/plain": [
381 | "[('a', (1, 5)), ('a', (1, 4)), ('b', (2, None))]"
382 | ]
383 | },
384 | "execution_count": 17,
385 | "metadata": {},
386 | "output_type": "execute_result"
387 | }
388 | ],
389 | "source": [
390 | "rdd3 = rdd1.leftOuterJoin(rdd2)\n",
391 | "rdd3.collect()"
392 | ]
393 | },
394 | {
395 | "cell_type": "markdown",
396 | "metadata": {},
397 | "source": [
398 | "## Actions"
399 | ]
400 | },
401 | {
402 | "cell_type": "markdown",
403 | "metadata": {},
404 | "source": [
405 | "### countByKey"
406 | ]
407 | },
408 | {
409 | "cell_type": "code",
410 | "execution_count": 18,
411 | "metadata": {},
412 | "outputs": [
413 | {
414 | "data": {
415 | "text/plain": [
416 | "defaultdict(int, {'a': 3, 'b': 2})"
417 | ]
418 | },
419 | "execution_count": 18,
420 | "metadata": {},
421 | "output_type": "execute_result"
422 | }
423 | ],
424 | "source": [
425 | "rdd1 = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('a', 1), ('b', 1)])\n",
426 | "rdd1.countByKey()"
427 | ]
428 | },
429 | {
430 | "cell_type": "markdown",
431 | "metadata": {},
432 | "source": [
433 | "## Considerations about performance"
434 | ]
435 | },
436 | {
437 | "cell_type": "markdown",
438 | "metadata": {},
439 | "source": [
440 | "In general [avoid using GroupByKey](https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html).\n",
441 | "\n",
442 | "If you want to perform an aggregation inside each group it is more efficient to use the reduceByKey, aggregateByKey or combineByKey alternatives because they make use of **combiners** to reduce the amount of data passed between the nodes (it is the same concept of combiners as in Hadoop MapReduce)."
443 | ]
444 | },
445 | {
446 | "cell_type": "markdown",
447 | "metadata": {},
448 | "source": [
449 | "## Exercises\n",
450 | "Now you can try to apply the above concepts to solve the following problems:\n",
451 | "* Unit 4 WordCount\n",
452 | "* Unit 4 Working with meteorological data 2\n",
453 | "* Unit 4 KMeans"
454 | ]
455 | }
456 | ],
457 | "metadata": {
458 | "kernelspec": {
459 | "display_name": "Python 2",
460 | "language": "python",
461 | "name": "python2"
462 | },
463 | "language_info": {
464 | "codemirror_mode": {
465 | "name": "ipython",
466 | "version": 2
467 | },
468 | "file_extension": ".py",
469 | "mimetype": "text/x-python",
470 | "name": "python",
471 | "nbconvert_exporter": "python",
472 | "pygments_lexer": "ipython2",
473 | "version": "2.7.15"
474 | }
475 | },
476 | "nbformat": 4,
477 | "nbformat_minor": 4
478 | }
479 |
--------------------------------------------------------------------------------
/unit_6_launching_applications.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 6 Launching Spark Applications"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "\n",
16 | "```\n",
17 | "6.1 Creating a Spark application\n",
18 | "6.2 Submitting an application to YARN\n",
19 | "6.3 Simple application submission example\n",
20 | "6.4 Cluster vs Client mode\n",
21 | "6.5 Adding dependencies\n",
22 | "6.6 Complex application submission example\n",
23 | "6.7 How-to install additional Python packages\n",
24 | "6.8 Native Compression Libraries\n",
25 | "6.9 Sending the application in the background\n",
26 | "6.10 Dynamic resource allocation\n",
27 | "6.11 Overriding configuration directory\n",
28 | "6.12 Run an interactive shell\n",
29 | "```"
30 | ]
31 | },
32 | {
33 | "cell_type": "markdown",
34 | "metadata": {},
35 | "source": [
36 | "## Creating a Spark application\n",
37 | "An application is very similar to a notebook, but there are some minor changes that must be applied.\n",
38 | "\n",
39 | "The interactive notebook creates automatically the SparkContext (sc) and a SparkSession (spark) but in a standard application you must take care of creating them manually:"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {
46 | "collapsed": true
47 | },
48 | "outputs": [],
49 | "source": [
50 | "from pyspark.sql import SparkSession\n",
51 | "from pyspark import SparkContext\n",
52 | "\n",
53 | "if __name__ == '__main__':\n",
54 | " spark = SparkSession \\\n",
55 | " .builder \\\n",
56 | " .appName('My Application') \\\n",
57 | " .getOrCreate()\n",
58 | " sc = spark.sparkContext\n",
59 | " # ...\n",
60 | " # Application specific code\n",
61 | " # ..\n",
62 | " spark.stop()"
63 | ]
64 | },
65 | {
66 | "cell_type": "markdown",
67 | "metadata": {},
68 | "source": [
69 | "## Submitting an application to YARN\n",
70 | "\n",
71 | "To submit an application to YARN you use the **spark-submit** utility:\n",
72 | "\n",
73 | "```\n",
74 | "spark-submit\n",
75 | " --name NAME A name of your application.\n",
76 | "\n",
77 | " --master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.\n",
78 | " --deploy-mode DEPLOY_MODE Whether to launch the driver program locally (\"client\") or\n",
79 | " on one of the worker machines inside the cluster (\"cluster\")\n",
80 | " (Default: client).\n",
81 | " --queue QUEUE_NAME The YARN queue to submit to (Default: \"default\").\n",
82 | "\n",
83 | " --num-executors NUM Number of executors to launch (Default: 2).\n",
84 | " \n",
85 | " --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).\n",
86 | " --driver-cores NUM Number of cores used by the driver, only in cluster mode\n",
87 | " (Default: 1).\n",
88 | " \n",
89 | " --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).\n",
90 | " --executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,\n",
91 | " or all available cores on the worker in standalone mode)\n",
92 | "```\n",
93 | "\n",
94 | "The main options to take into account for resource allocation are:\n",
95 | "\n",
96 | "* The `--num-executors` (spark.executor.instances as configuration property) option controls how many executors it will allocate for the application on the cluster .\n",
97 | "* The `--executor-memory` (spark.executor.memory configuration property) option controls the memory allocated per executor.\n",
98 | "* The `--executor-cores` (spark.executor.cores configuration property) option controls the cores allocated per executor.\n",
99 | "\n"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "## Simple application submission example\n",
107 | "\n",
108 | " spark-submit --master yarn --name testWC test.py\n",
109 | " spark-submit --master yarn --deploy-mode cluster --name testWC test.py\n",
110 | "\n"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "## Cluster vs Client mode\n",
118 | "\n",
119 | "\n",
120 | "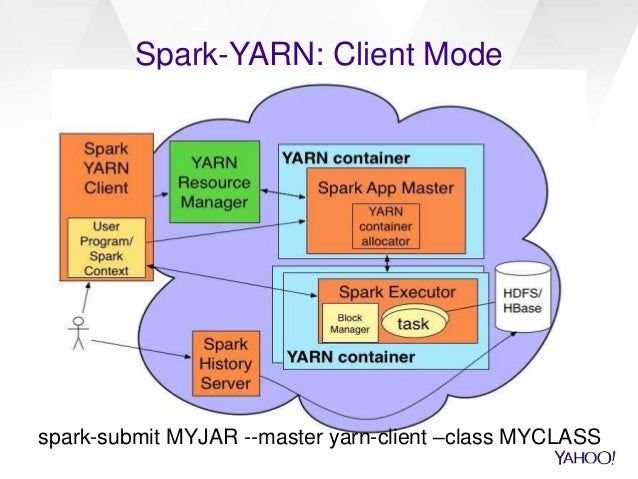\n",
121 | "\n",
122 | "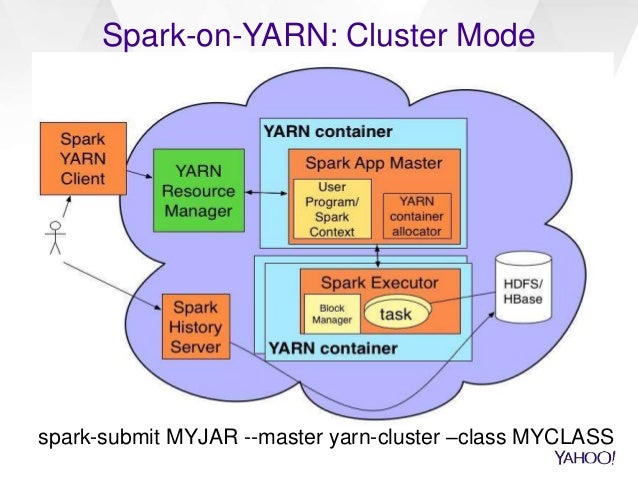\n",
123 | "\n",
124 | "Image Source: [Spark-on-YARN: Empower Spark Applications on Hadoop Cluster](https://www.slideshare.net/Hadoop_Summit/sparkonyarn-empower-spark-applications-on-hadoop-cluster)"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Adding dependencies\n",
132 | "\n",
133 | "To add dependencies we have to distinguish two different cases, when we need to extend Spark code itself which is written in Scala, or when we need to add the of our Python code.\n",
134 | "\n",
135 | "When you need to add dependencies for Spark itself we can use:\n",
136 | "- The **--packages** option pulls directly the packages from the Central Maven Repository. This approach requires an internet connection.\n",
137 | "- The **--jars** option transfers associated jar files to the cluster.\n",
138 | "\n",
139 | "\n",
140 | "To include the dependencies of our Python program we can use:\n",
141 | "- The **--py-files** option adds .zip, .egg, or .py files to the PYTHONPATH."
142 | ]
143 | },
144 | {
145 | "cell_type": "markdown",
146 | "metadata": {},
147 | "source": [
148 | "### Adding Spark dependencies: packages\n",
149 | "You can add Spark dependencies directly using the maven coordinates:\n",
150 | "\n",
151 | " spark-submit --packages com.databricks:spark-avro_2.10:2.0.1 ...\n",
152 | " \n",
153 | "The usual place to look for plublic packages is the Maven Central Repository:\n",
154 | "\n",
155 | " https://search.maven.org/"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "### Adding Spark dependencies: jar files\n",
163 | "You can also add exising jar files directly as dependencies:\n",
164 | "\n",
165 | " spark-submit --jars /jar_path/spark-streaming-kafka-assembly_2.10-1.6.1.2.4.2.0-258.jar ..."
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "metadata": {},
171 | "source": [
172 | "### Adding Python dependencies: zip files\n",
173 | "The easiest way to add our Python dependencies is to package all the dependencies in a zip file.\n",
174 | "If our program is more than a simple script and it defines its own modules and packages, then it is also needed to package and distribute them so the executors can access them.\n",
175 | "\n",
176 | "If we have a `requirements.txt` file we can generate a `dependencies.zip` file including all the dependencies with the following commands:\n",
177 | "```\n",
178 | "pip install -t dependencies -r requirements.txt\n",
179 | "```\n",
180 | "\n",
181 | "If the package we need it is not in PyPI but we have its `setup.py` then we can generate easily a zip with it and its dependencies running from the directory where the setup.py is located:\n",
182 | "```\n",
183 | "pip install -t dependencies .\n",
184 | "```\n",
185 | "\n",
186 | "Then we just package all the dependencies in a zip file:\n",
187 | "```\n",
188 | "cd dependencies\n",
189 | "zip -r ../dependencies.zip .\n",
190 | "```\n",
191 | "\n",
192 | "And then we need to package also the code of our application:\n",
193 | "```\n",
194 | "zip -r my_program.zip my_program\n",
195 | "```\n",
196 | "\n",
197 | "Finally to submit your application you will use:\n",
198 | "\n",
199 | " spark-submit --py-files dependencies.zip,my_program.zip ..."
200 | ]
201 | },
202 | {
203 | "cell_type": "markdown",
204 | "metadata": {},
205 | "source": [
206 | "### Adding Python dependencies: egg files\n",
207 | "\n",
208 | "In case you have an egg file of a package you want to use, you can add it directly to the `--py-files` option of spark-submit or to the `sc.addPyFile()` method to make it available to the application. After that you can make use of it in your application in the standard way.\n",
209 | "\n",
210 | " spark-submit --py-files /egg_path/avro-1.8.1-py2.7.egg ..."
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": null,
216 | "metadata": {
217 | "collapsed": true
218 | },
219 | "outputs": [],
220 | "source": [
221 | "# First we add the egg file to the application environment\n",
222 | "sc.addPyFile('/home/cesga/jlopez/packages/ClusterShell-1.7.3-py2.7.egg')\n",
223 | "# Then we can import and use it in the standard way\n",
224 | "from ClusterShell.NodeSet import NodeSet\n",
225 | "nodeset = NodeSet('c[6601-6610]')"
226 | ]
227 | },
228 | {
229 | "cell_type": "markdown",
230 | "metadata": {},
231 | "source": [
232 | "### Adding Python dependencies: wheel files\n",
233 | "Unfortunately wheel files are not yet supported.\n",
234 | "\n",
235 | "There was a feature request by it has been recently closed because no progress had been made since 2016:\n",
236 | "\n",
237 | "https://issues.apache.org/jira/browse/SPARK-6764"
238 | ]
239 | },
240 | {
241 | "cell_type": "markdown",
242 | "metadata": {},
243 | "source": [
244 | "## Complex application submission example"
245 | ]
246 | },
247 | {
248 | "cell_type": "markdown",
249 | "metadata": {},
250 | "source": [
251 | "Here you can see a real example of how to submit a real application that consumes data from Kafka in avro format using Spark Streaming:\n",
252 | "\n",
253 | "```\n",
254 | "spark-submit --master yarn --deploy-mode cluster \\\n",
255 | " --num-executors 2 \\\n",
256 | " --conf spark.yarn.submit.waitAppCompletion=false \\\n",
257 | " --packages com.databricks:spark-avro_2.10:2.0.1 \\\n",
258 | " --jars /home/cesga/jlopez/packages/spark-streaming-kafka-assembly_2.10-1.6.1.2.4.2.0-258.jar \\\n",
259 | " --py-files /home/cesga/jlopez/packages/avro-1.8.1-py2.7.egg \\\n",
260 | " --name 'SSH attack detector' \\ \n",
261 | " ssh_attack_detector.py\n",
262 | "```"
263 | ]
264 | },
265 | {
266 | "cell_type": "markdown",
267 | "metadata": {},
268 | "source": [
269 | "## How-to install additional Python packages\n",
270 | "The simplest way is to use **pip** with the `--user` option:\n",
271 | "\n",
272 | " pip install --user pymongo\n",
273 | " \n",
274 | "You can also create a **virtualenv** and use it to install all your dependencies:\n",
275 | "\n",
276 | " virtualenv venv\n",
277 | " . venv/bin/activate\n",
278 | " \n",
279 | "In case you are using a virtualenv you have to point spark to the appropriate python interpreter for your virtualenv:\n",
280 | "\n",
281 | " export PYSPARK_DRIVER_PYTHON=/home/cesga/jlopez/my_app/venv/bin/python\n",
282 | " export PYSPARK_PYTHON=/home/cesga/jlopez/my_app/venv/bin/python\n",
283 | "\n",
284 | "You will also need to adjust the permissions of your HOME directory so the spark user can access this virtualenv.\n",
285 | "\n",
286 | "This a quick & dirty way that you can use during development but, for production, I would recommend the zip file alternative."
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "## Native Compression Libraries\n",
294 | "\n",
295 | "To check native Hadoop and compression libraries availability you can run the `hadoop checknative` command:\n",
296 | "\n",
297 | "```\n",
298 | "[jlopez@cdh61-login6 ~]$ hadoop checknative\n",
299 | "...\n",
300 | "Native library checking:\n",
301 | "hadoop: true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libhadoop.so.1.0.0\n",
302 | "zlib: true /lib64/libz.so.1\n",
303 | "zstd : true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libzstd.so.1\n",
304 | "snappy: true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libsnappy.so.1\n",
305 | "lz4: true revision:10301\n",
306 | "bzip2: true /lib64/libbz2.so.1\n",
307 | "openssl: true /lib64/libcrypto.so\n",
308 | "ISA-L: true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libisal.so.2\n",
309 | "```"
310 | ]
311 | },
312 | {
313 | "cell_type": "markdown",
314 | "metadata": {},
315 | "source": [
316 | "## How-to submit the application in the background\n",
317 | "\n",
318 | "By default when you submit an application the spark-submit command keeps active waiting for application output. To avoid this behaviour use spark.yarn.submit.waitAppCompletion=false:\n",
319 | "\n",
320 | " spark-submit --conf spark.yarn.submit.waitAppCompletion=false ...\n",
321 | "\n"
322 | ]
323 | },
324 | {
325 | "cell_type": "markdown",
326 | "metadata": {},
327 | "source": [
328 | "## Dynamic resource allocation\n",
329 | "Spark provides a mechanism to dynamically adjust the resources your application occupies based on the workload. This means that your application may give resources back to the cluster if they are no longer used and request them again later when there is demand. This feature is particularly useful if multiple applications share resources in your Spark cluster.\n",
330 | "\n",
331 | "Our cluster has this feature enabled so it **automatically expands new executors when they are needed**, instead of fixing them at launch time with --num-executors.\n",
332 | "\n",
333 | "This allows that interactive jobs dynamically add and remove executors during execution.\n",
334 | "\n",
335 | "It is important to notice that when you specify the `--num-executors` option without explicitly disabling dynamic resource allocation, then num-executors indicates the initial number of executors to allocate (by default it is 2).\n",
336 | "\n",
337 | "If you want to **disable dynamic resource allocation** and request a fixed number of executors you have to use the following spark-submit options:\n",
338 | "\n",
339 | " spark-submit --conf spark.dynamicAllocation.enabled=false --num-executors 4 ..."
340 | ]
341 | },
342 | {
343 | "cell_type": "markdown",
344 | "metadata": {},
345 | "source": [
346 | "## Overriding configuration directory\n",
347 | "To specify a different configuration directory other than the default “SPARK_HOME/conf”, you can set SPARK_CONF_DIR. Spark will use the configuration files (spark-defaults.conf, spark-env.sh, log4j.properties, etc) from this directory.\n",
348 | "\n",
349 | "Example:\n",
350 | "\n",
351 | " export SPARK_CONF_DIR=/home/cesga/jlopez/conf/\n"
352 | ]
353 | },
354 | {
355 | "cell_type": "markdown",
356 | "metadata": {},
357 | "source": [
358 | "## Running an interactive shell\n",
359 | "Additionally to Jupyter notebooks you can also use the command line interactive shell provided by Spark:\n",
360 | "\n",
361 | " pyspark --master yarn --num-executors 4 --executor-cores 6 --queue interactive\n",
362 | "\n",
363 | " --num-executors NUM Number of executors to launch (Default: 2).\n",
364 | " --executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode)\n",
365 | " --driver-cores NUM Number of cores used by the driver, only in cluster mode (Default: 1).\n",
366 | " --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).\n",
367 | " --queue QUEUE_NAME The YARN queue to submit to (Default: \"default\"). \n",
368 | "\n",
369 | "\n",
370 | "To use ipython instead of python for an interactive session use:\n",
371 | "\n",
372 | " module load anaconda2\n",
373 | " PYSPARK_DRIVER_PYTHON=$(which ipython) pyspark --queue interactive\n"
374 | ]
375 | },
376 | {
377 | "cell_type": "markdown",
378 | "metadata": {},
379 | "source": [
380 | "## Exercises\n",
381 | "\n",
382 | "* Exercise: Modify the \"Unit 4 Working with meteorological data 2\" notebook and submit it to YARN\n",
383 | "* Exercise: Modify the \"Unit 5 Working with meteorological data\" notebook and submit it to YARN"
384 | ]
385 | }
386 | ],
387 | "metadata": {
388 | "kernelspec": {
389 | "display_name": "Python 2",
390 | "language": "python",
391 | "name": "python2"
392 | },
393 | "language_info": {
394 | "codemirror_mode": {
395 | "name": "ipython",
396 | "version": 2
397 | },
398 | "file_extension": ".py",
399 | "mimetype": "text/x-python",
400 | "name": "python",
401 | "nbconvert_exporter": "python",
402 | "pygments_lexer": "ipython2",
403 | "version": "2.7.15"
404 | }
405 | },
406 | "nbformat": 4,
407 | "nbformat_minor": 1
408 | }
409 |
--------------------------------------------------------------------------------
/unit_7_optimizing_monitoring_and_debugging_applications.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 7 Optimizing, Monitoring and Debugging Applications"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "```\n",
16 | "7.1. Performance considerations\n",
17 | " 7.1.1 RDD lineage\n",
18 | " 7.1.2 RDD persistance\n",
19 | " 7.1.3 Broadcast variables\n",
20 | " 7.1.4 Accumulators\n",
21 | " 7.1.5 Repartition and coalesce\n",
22 | " \n",
23 | "7.2. Monitoring and Debugging\n",
24 | " 7.2.1. HUE/YARN UI\n",
25 | " 7.2.2. Spark UI and Spark History\n",
26 | " 7.2.2.1. Spark Event Timeline\n",
27 | " 7.2.2.2. Spark DAG Visualization\n",
28 | " 7.2.2.3. How to interprate the DAG\n",
29 | " 7.2.3. How to see the logs of a job\n",
30 | " 7.2.4. How to change the log level\n",
31 | " 7.2.5. Understanding how to configure memory limits\n",
32 | " 7.2.6. How to tune the partitioner\n",
33 | "```"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "# Performance considerations"
41 | ]
42 | },
43 | {
44 | "cell_type": "markdown",
45 | "metadata": {},
46 | "source": [
47 | "### RDD lineage\n",
48 | "Each time you do a transformation in an RDD, Spark does not execute it immediately, instead it creates what is called an RDD lineage.\n",
49 | "\n",
50 | "This lineage keeps track of what are all transformations that has to be applied to produce the final RDD, from reading the data from HDFS to the different transformations that have to be applied and in which order.\n",
51 | "\n",
52 | "The lineage allows to add fault tolerance to the RDD, because in the case that something goes wrong and a executor is lost it is able to re-compute the RDD from the HDFS original data."
53 | ]
54 | },
55 | {
56 | "cell_type": "markdown",
57 | "metadata": {},
58 | "source": [
59 | "### RDD persistance"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "In case there is an RDD that you are going to reuse it is very useful to persist it so it does not need to re-compute it each time you operate on it (by default it is persisted in memory)."
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "metadata": {
73 | "collapsed": true
74 | },
75 | "outputs": [],
76 | "source": [
77 | "rdd.cache()"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "The same can be done for a DataFrame:"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": null,
90 | "metadata": {
91 | "collapsed": true
92 | },
93 | "outputs": [],
94 | "source": [
95 | "df.cache()"
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "metadata": {},
101 | "source": [
102 | "In a similar way when you no longer need it you can unpersist it:"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": null,
108 | "metadata": {
109 | "collapsed": true
110 | },
111 | "outputs": [],
112 | "source": [
113 | "rdd.unpersist()"
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "metadata": {},
119 | "source": [
120 | "It is also possible to indicate a the storage location:"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": null,
126 | "metadata": {
127 | "collapsed": true
128 | },
129 | "outputs": [],
130 | "source": [
131 | "from pyspark import StorageLevel\n",
132 | "# The following is equivalent to rdd.cache()\n",
133 | "rdd.persist(StorageLevel.MEMORY_ONLY)\n",
134 | "# Use disk instead of memory\n",
135 | "rdd.persist(StorageLevel.DISK_ONLY)\n",
136 | "# Use disk if it does not fit in memory (spilling)\n",
137 | "rdd.persist(StorageLevel.MEMORY_AND_DISK)"
138 | ]
139 | },
140 | {
141 | "cell_type": "markdown",
142 | "metadata": {},
143 | "source": [
144 | "If you want to know more about why persistance is important and the different persistance options you can read:\n",
145 | "* [RDD persistance](https://spark.apache.org/docs/2.4.0/programming-guide.html#rdd-persistence)"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "### Broadcast variables\n",
153 | "If you have a **read-only** variable that must be shared between all the tasks you can do it more efficiently using a broadcast variable:"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": null,
159 | "metadata": {
160 | "collapsed": true
161 | },
162 | "outputs": [],
163 | "source": [
164 | "# You create a broadcast variable in the driver\n",
165 | "centroidsBC = sc.broadcast([1, 2, 3])\n",
166 | "\n",
167 | "# And then you can read it in the different tasks with\n",
168 | "centroidsBC.value"
169 | ]
170 | },
171 | {
172 | "cell_type": "markdown",
173 | "metadata": {},
174 | "source": [
175 | "\"Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.\" Source: [Spark Programming Guide](https://spark.apache.org/docs/2.4.0/programming-guide.html#broadcast-variables)"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "### Accumulators"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {},
188 | "source": [
189 | "Accumulators are **write-only** variables (only the driver can read it) that can be used to implement counters (as in MapReduce) or sums."
190 | ]
191 | },
192 | {
193 | "cell_type": "code",
194 | "execution_count": null,
195 | "metadata": {
196 | "collapsed": true
197 | },
198 | "outputs": [],
199 | "source": [
200 | "# Integer accumulator\n",
201 | "events = sc.accumulator(0)\n",
202 | "# Float accumulator\n",
203 | "amount = sc.accumulator(0.0)"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "The accumulator will be incremented once per task."
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": null,
216 | "metadata": {
217 | "collapsed": true,
218 | "scrolled": true
219 | },
220 | "outputs": [],
221 | "source": [
222 | "# On the executors\n",
223 | "events += 1"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "metadata": {},
229 | "source": [
230 | "Only the driver can access the value:"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": null,
236 | "metadata": {
237 | "collapsed": true
238 | },
239 | "outputs": [],
240 | "source": [
241 | "# Only works in the driver\n",
242 | "total.value"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "For more information: [Spark Programming Guide](https://spark.apache.org/docs/1.6.1/programming-guide.html#accumulators)"
250 | ]
251 | },
252 | {
253 | "cell_type": "markdown",
254 | "metadata": {},
255 | "source": [
256 | "### Repartitition and Coalesce"
257 | ]
258 | },
259 | {
260 | "cell_type": "markdown",
261 | "metadata": {},
262 | "source": [
263 | "You can change the number of partitions of an RDD using:"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": null,
269 | "metadata": {
270 | "collapsed": true
271 | },
272 | "outputs": [],
273 | "source": [
274 | "rdd.repartition(10)"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "You can also reduce the number of partitions, this is done more efficiently using:"
282 | ]
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": null,
287 | "metadata": {
288 | "collapsed": true
289 | },
290 | "outputs": [],
291 | "source": [
292 | "rdd.coalesce(4)"
293 | ]
294 | },
295 | {
296 | "cell_type": "markdown",
297 | "metadata": {},
298 | "source": [
299 | "**coalesce()** is an optimized version of repartition() that allows avoiding data movement, but only if you are decreasing the number of RDD partitions."
300 | ]
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {},
305 | "source": [
306 | "# Monitoring and Debugging"
307 | ]
308 | },
309 | {
310 | "cell_type": "markdown",
311 | "metadata": {},
312 | "source": [
313 | "## Big Data WebUI\n",
314 | "To see the status of the cluster you can connect to the Big Data Web UI and from there you connect to HUE Web Interface.\n",
315 | "\n",
316 | "This interface will allow you to monitor your applications from a graphical interface and to access the Spark UI information.\n",
317 | "\n",
318 | "\n",
319 | "## Spark UI and Spark History\n",
320 | "From HUE by looking at the Properties tab and following the `trackingURL` link you can access the Spark UI of the running application or the Spark History server in case the application has finished.\n",
321 | "\n",
322 | "### Understanding your Apache Spark Application Through Visualization\n",
323 | "A Spark application is composed of:\n",
324 | "* jobs\n",
325 | "* stages\n",
326 | "* tasks\n",
327 | "\n",
328 | "#### Spark Event Timeline\n",
329 | "The timeline view is available on three levels: across all jobs, within one job, and within one stage.\n",
330 | "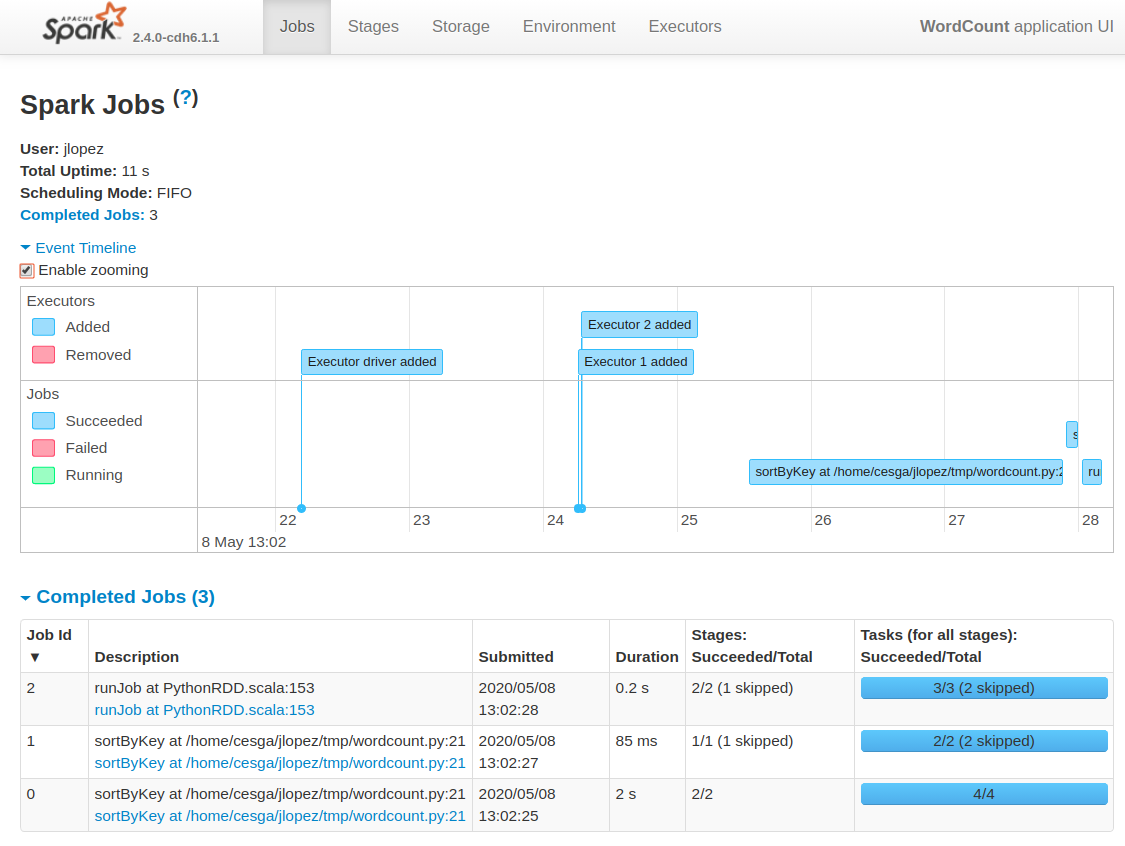\n",
331 | "\n",
332 | "We can get more details about a specific, for example Job 0:\n",
333 | "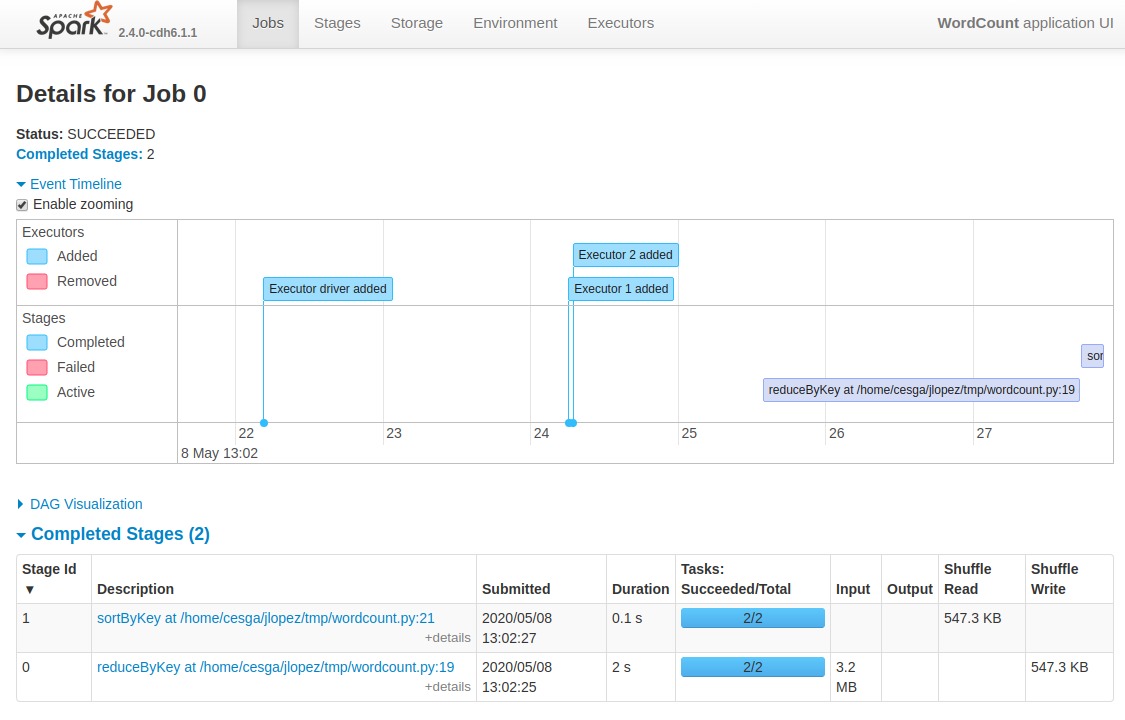\n",
334 | "\n",
335 | "And finally we can go deeper selecting a specific stage:\n",
336 | "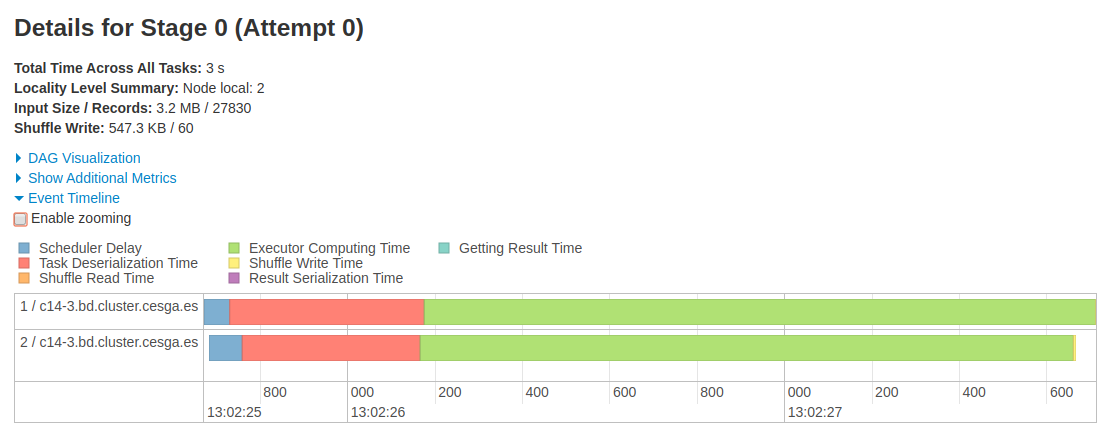\n",
337 | "\n",
338 | "#### Execution DAG\n",
339 | "A job is associated with a chain of RDD dependencies organized in a direct acyclic graph (DAG) that we can also visualize in the Spark UI:\n",
340 | "\n",
341 | "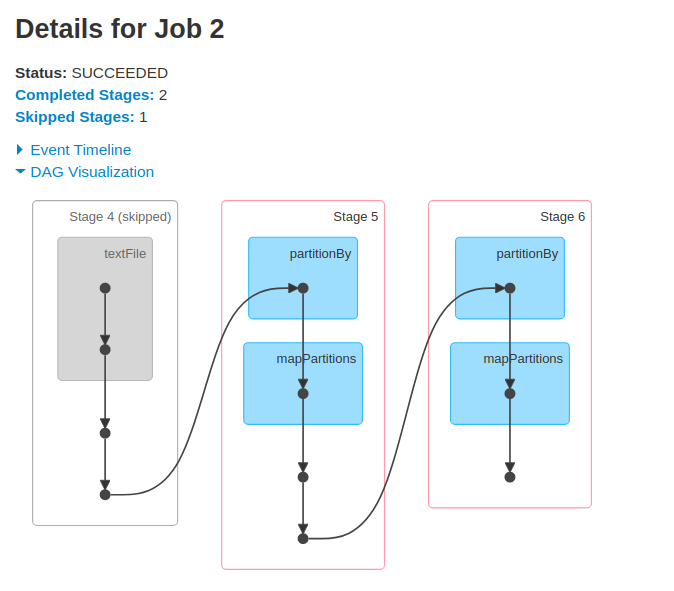\n",
342 | "\n",
343 | "The greyed stage indicates that data was fetched from cache so it was not needed to re-execute that given stage: for that reason it appears as **skipped**. Whenever there is shuffling involved Spark automatically caches generated data.\n",
344 | "\n",
345 | "\n",
346 | "More information: [Understanding your Apache Spark Application Through Visualization](https://databricks.com/blog/2015/06/22/understanding-your-spark-application-through-visualization.html)"
347 | ]
348 | },
349 | {
350 | "cell_type": "markdown",
351 | "metadata": {},
352 | "source": [
353 | "## How-to see the logs of a job\n",
354 | "YARN has the aggregated logs produced by the job.\n",
355 | "\n",
356 | " yarn logs -applicationId application_1489083567361_0070 | less\n",
357 | "\n",
358 | "## Configuring the log level\n",
359 | "For debugging it can be useful to modify the debug level.\n",
360 | "\n",
361 | "Spark uses log4j for logging so the more versatile way to do it is changing the log4j.properties file.\n",
362 | "\n",
363 | "In some cases it can be useful to set the log level from the SparkContext:\n",
364 | " sc.setLogLevel(\"INFO\")\n",
365 | " sc.setLogLevel(\"WARN\")\n",
366 | " \n",
367 | "This allows you to tune the information shown in order to debug your application."
368 | ]
369 | },
370 | {
371 | "cell_type": "markdown",
372 | "metadata": {},
373 | "source": [
374 | "## Understanding how to configure memory limits\n",
375 | "To increase performance Spark uses an off-heap memory through the [Project Tungsten](https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html).\n",
376 | "\n",
377 | "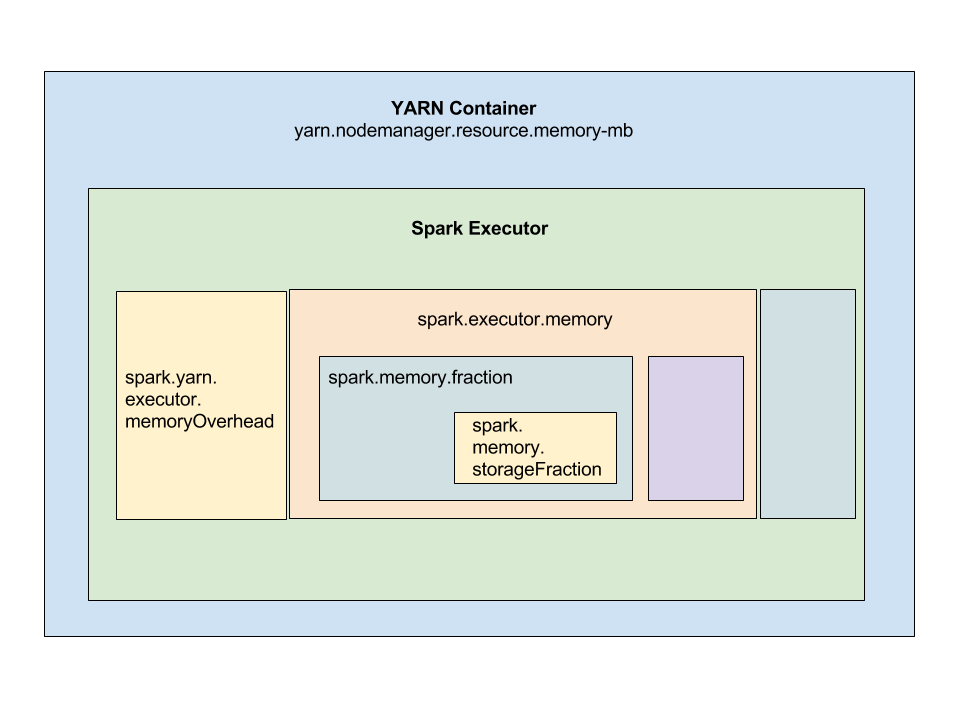\n",
378 | "\n",
379 | "In case you are facing a **memoryOverhead issue**:\n",
380 | "* The first thing to do, is to boost ‘spark.yarn.executor.memoryOverhead’ (Tungsten: off-heap memory, recommended 10% memory)\n",
381 | "* The second thing to take into account, is whether your data is balanced across the partitions\n",
382 | "\n",
383 | "When using Python, decreasing the value of **spark.executor.memory** will help since Python will be all off-heap memory and would not use the RAM we reserved for heap. So, by decreasing this value, you reserve less space for the heap, thus you get more space for the off-heap operations (we want that, since Python will operate there). ‘spark.executor.memory’ is for JVM heap only.\n",
384 | "\n",
385 | "Sources and further details:\n",
386 | "* [Memory Overhead](https://gsamaras.wordpress.com/code/memoryoverhead-issue-in-spark/)\n",
387 | "* [Understanding memory management in spark for fun and profit](https://www.slideshare.net/SparkSummit/understanding-memory-management-in-spark-for-fun-and-profit)\n",
388 | "* [Project Tungsten: Bringing Apache Spark Closer to Bare Metal](https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html)"
389 | ]
390 | },
391 | {
392 | "cell_type": "markdown",
393 | "metadata": {},
394 | "source": [
395 | "## Verifying Spark Configuration"
396 | ]
397 | },
398 | {
399 | "cell_type": "markdown",
400 | "metadata": {},
401 | "source": [
402 | "When debugging an application it can be useful to verify the values of all the Spark Properties.\n",
403 | "\n",
404 | "There are two options to do it:\n",
405 | "* Connecting to the Spark UI and checking the Environment tab\n",
406 | "* Programatically using:"
407 | ]
408 | },
409 | {
410 | "cell_type": "code",
411 | "execution_count": 1,
412 | "metadata": {},
413 | "outputs": [
414 | {
415 | "data": {
416 | "text/plain": [
417 | "[(u'spark.eventLog.enabled', u'true'),\n",
418 | " (u'spark.yarn.jars',\n",
419 | " u'local:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/jars/*,local:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/hive/*'),\n",
420 | " (u'spark.yarn.appMasterEnv.MKL_NUM_THREADS', u'1'),\n",
421 | " (u'spark.sql.queryExecutionListeners',\n",
422 | " u'com.cloudera.spark.lineage.NavigatorQueryListener'),\n",
423 | " (u'spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_HOSTS',\n",
424 | " u'c14-18.bd.cluster.cesga.es,c14-19.bd.cluster.cesga.es'),\n",
425 | " (u'spark.ui.killEnabled', u'true'),\n",
426 | " (u'spark.lineage.log.dir', u'/var/log/spark/lineage'),\n",
427 | " (u'spark.eventLog.dir', u'hdfs://nameservice1/user/spark/applicationHistory'),\n",
428 | " (u'spark.dynamicAllocation.executorIdleTimeout', u'60'),\n",
429 | " (u'spark.serializer', u'org.apache.spark.serializer.KryoSerializer'),\n",
430 | " (u'spark.io.encryption.enabled', u'false'),\n",
431 | " (u'spark.authenticate', u'false'),\n",
432 | " (u'spark.serializer.objectStreamReset', u'100'),\n",
433 | " (u'spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_URI_BASES',\n",
434 | " u'https://c14-18.bd.cluster.cesga.es:8090/proxy/application_1560154709544_0163,https://c14-19.bd.cluster.cesga.es:8090/proxy/application_1560154709544_0163'),\n",
435 | " (u'spark.submit.deployMode', u'client'),\n",
436 | " (u'spark.executor.extraLibraryPath',\n",
437 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native'),\n",
438 | " (u'spark.ui.filters',\n",
439 | " u'org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter'),\n",
440 | " (u'spark.driver.port', u'37717'),\n",
441 | " (u'spark.network.crypto.enabled', u'false'),\n",
442 | " (u'spark.yarn.historyServer.address',\n",
443 | " u'http://c14-18.bd.cluster.cesga.es:18088'),\n",
444 | " (u'spark.shuffle.service.enabled', u'true'),\n",
445 | " (u'spark.yarn.historyServer.allowTracking', u'true'),\n",
446 | " (u'spark.executorEnv.MKL_NUM_THREADS', u'1'),\n",
447 | " (u'spark.ui.enabled', u'true'),\n",
448 | " (u'spark.driver.appUIAddress',\n",
449 | " u'http://cdh61-login2.bd.cluster.cesga.es:4041'),\n",
450 | " (u'spark.yarn.am.extraLibraryPath',\n",
451 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native'),\n",
452 | " (u'spark.executor.id', u'driver'),\n",
453 | " (u'spark.dynamicAllocation.schedulerBacklogTimeout', u'1'),\n",
454 | " (u'spark.yarn.appMasterEnv.OPENBLAS_NUM_THREADS', u'1'),\n",
455 | " (u'spark.app.id', u'application_1560154709544_0163'),\n",
456 | " (u'spark.driver.host', u'cdh61-login2.bd.cluster.cesga.es'),\n",
457 | " (u'spark.yarn.queue', u'interactive'),\n",
458 | " (u'spark.app.name', u'PySparkShell'),\n",
459 | " (u'spark.executorEnv.PYTHONPATH',\n",
460 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/lib/py4j-0.10.7-src.zip:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/lib/py4j-0.10.7-src.zip/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/lib/pyspark.zip'),\n",
461 | " (u'spark.shuffle.service.port', u'7337'),\n",
462 | " (u'spark.lineage.enabled', u'true'),\n",
463 | " (u'spark.extraListeners', u'com.cloudera.spark.lineage.NavigatorAppListener'),\n",
464 | " (u'spark.yarn.config.gatewayPath', u'/opt/cloudera/parcels'),\n",
465 | " (u'spark.master', u'yarn'),\n",
466 | " (u'spark.sql.warehouse.dir', u'/user/hive/warehouse'),\n",
467 | " (u'spark.driver.extraLibraryPath',\n",
468 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native'),\n",
469 | " (u'spark.sql.catalogImplementation', u'hive'),\n",
470 | " (u'spark.rdd.compress', u'True'),\n",
471 | " (u'spark.dynamicAllocation.minExecutors', u'0'),\n",
472 | " (u'spark.yarn.config.replacementPath', u'{{HADOOP_COMMON_HOME}}/../../..'),\n",
473 | " (u'spark.dynamicAllocation.enabled', u'true'),\n",
474 | " (u'spark.yarn.isPython', u'true'),\n",
475 | " (u'spark.executorEnv.OPENBLAS_NUM_THREADS', u'1'),\n",
476 | " (u'spark.ui.showConsoleProgress', u'true'),\n",
477 | " (u'spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.RM_HA_URLS',\n",
478 | " u'c14-18.bd.cluster.cesga.es:8090,c14-19.bd.cluster.cesga.es:8090')]"
479 | ]
480 | },
481 | "execution_count": 1,
482 | "metadata": {},
483 | "output_type": "execute_result"
484 | }
485 | ],
486 | "source": [
487 | "sc._conf.getAll()"
488 | ]
489 | },
490 | {
491 | "cell_type": "markdown",
492 | "metadata": {},
493 | "source": [
494 | "## Tuning the partitioner\n",
495 | "\n",
496 | "The partitioner is the part that decides how to split the data into the different partitions. The default is to use the HashPartitioner but in some cases you may use other partitioners in order to produce a more balanced data distribution between partitions.\n",
497 | "\n",
498 | "Apart from the HashPartitioner Spark provides the [RangePartitioner](https://spark.apache.org/docs/2.4.0/api/java/org/apache/spark/RangePartitioner.html).\n",
499 | "\n",
500 | "You can also implement your own partitioner.\n"
501 | ]
502 | },
503 | {
504 | "cell_type": "markdown",
505 | "metadata": {},
506 | "source": [
507 | "## Exercises\n",
508 | "* Exercise: Optimize the KMeans exercise by making use of RDD caching and broadcast variables.\n",
509 | "* Exercise: Explore the monitoring information for your optimized KMeans notebook, comparing it with the information for the non-optimized version, and answer the following questions:\n",
510 | "\n",
511 | " * Explore the Jobs tab:\n",
512 | " * How many jobs were run by Spark?\n",
513 | " * What was the typical duration of each job? You can sort the jobs by Duration clicking in the \"Duration\" column label\n",
514 | " * Explore the global event timeline\n",
515 | " * Explore the job with Job Id 7:\n",
516 | " * Explore the Event Timeline\n",
517 | " * Explore the DAG: How many stages were run?\n",
518 | " \n",
519 | " * Explore the Stages tab:\n",
520 | " * What was the total number of stages for all jobs?\n",
521 | " * Explore the Stage 12:\n",
522 | " * What was the 75th percentile duration of the tasks? \n",
523 | " * What was the Input Size?\n",
524 | " * Expand the Event Timeline: \n",
525 | " * How was the time distributed?\n",
526 | " * Compare with Stage 0: In this case the percentage of computing time is reduced, compared to the scheduler delay and task deserialization parts.\n",
527 | "\n",
528 | " * Explore the Storage tab (notebook must be still running, it is blank for finished applications): \n",
529 | " * How much data is cached?\n",
530 | " * How many partitions are cached?\n",
531 | " * What is the fraction of the RDD cached in memory?\n",
532 | "\n",
533 | " * Explore the Environment tab: \n",
534 | " * Was dynamic resource allocation enabled? Look at the value of the spark.dynamicAllocation.enabled property.\n",
535 | " \n",
536 | " * Explore the Executors tab: \n",
537 | " * How many executors were used? The driver also appears in the list.\n",
538 | " * In which cluster node run executor 1?\n",
539 | " * Notice that, when using dynamic allocation, the executors not being used will be automatically shutdown\n",
540 | " * Could we take advantadge of more executors? Check if there are executors that did not run any task.\n",
541 | " "
542 | ]
543 | }
544 | ],
545 | "metadata": {
546 | "kernelspec": {
547 | "display_name": "Python 2",
548 | "language": "python",
549 | "name": "python2"
550 | },
551 | "language_info": {
552 | "codemirror_mode": {
553 | "name": "ipython",
554 | "version": 2
555 | },
556 | "file_extension": ".py",
557 | "mimetype": "text/x-python",
558 | "name": "python",
559 | "nbconvert_exporter": "python",
560 | "pygments_lexer": "ipython2",
561 | "version": "2.7.15"
562 | }
563 | },
564 | "nbformat": 4,
565 | "nbformat_minor": 2
566 | }
567 |
--------------------------------------------------------------------------------
\n",
37 | "\n",
38 | "\n"
39 | ]
40 | }
41 | ],
42 | "metadata": {
43 | "kernelspec": {
44 | "display_name": "Python 2",
45 | "language": "python",
46 | "name": "python2"
47 | },
48 | "language_info": {
49 | "codemirror_mode": {
50 | "name": "ipython",
51 | "version": 2
52 | },
53 | "file_extension": ".py",
54 | "mimetype": "text/x-python",
55 | "name": "python",
56 | "nbconvert_exporter": "python",
57 | "pygments_lexer": "ipython2",
58 | "version": "2.7.15"
59 | }
60 | },
61 | "nbformat": 4,
62 | "nbformat_minor": 4
63 | }
64 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Using Spark Course
2 | The repo contains the notebooks used in the **Using Spark** course.
3 |
--------------------------------------------------------------------------------
/exercises/Unit 3 Exercise Calculating Pi.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Calculating $\\pi$ using Monte Carlo"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "To estimate the value of Pi using the Monte Carlo method we generate a large number of random points (similar to **launching darts**) and see how many fall in the circle enclosed by the unit square:"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "$\\pi = 4 * \\frac{N_{hits}}{N_{total}}$"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | ""
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "You can see a demo here: [Estimating Pi with Monte Carlo demo](https://academo.org/demos/estimating-pi-monte-carlo/)"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "# Implementation"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": null,
48 | "metadata": {},
49 | "outputs": [],
50 | "source": [
51 | "from __future__ import print_function\n",
52 | "from random import random\n",
53 | "from operator import add"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {},
60 | "outputs": [],
61 | "source": [
62 | "# Number of points to generate\n",
63 | "POINTS = 1000000\n",
64 | "# Number of partitions to use in the Spark program\n",
65 | "PARTITIONS = 2"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def launch_dart(_):\n",
75 | " \"Shoot a new random dart in the (1, 1) cuadrant and return 1 if it is inside the circle, 0 otherwise\"\n",
76 | " x = random() * 2 - 1\n",
77 | " y = random() * 2 - 1\n",
78 | " return 1 if x ** 2 + y ** 2 < 1 else 0"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "metadata": {},
84 | "source": [
85 | "## Serial implementation using Python"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "hits = 0\n",
95 | "for i in xrange(POINTS):\n",
96 | " hits += launch_dart(_)\n",
97 | "print('Pi is roughly', 4.0 * hits / POINTS)"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "NOTE: If you are using Python 3 instead of the `xrange` function you would use `range`."
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "## Parallel implementation using Spark"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": null,
117 | "metadata": {},
118 | "outputs": [],
119 | "source": [
120 | "# Complete the code below, you can make use of the launch_dart function\n",
121 | "hits = sc.parallelize(..., PARTITIONS).map(...).reduce(...)\n",
122 | "print('Pi is roughly', 4.0 * hits / POINTS)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## Explore the paralellism"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "Explore how changing the number of points and the number partitions affects the elapsed time of each implementation."
137 | ]
138 | }
139 | ],
140 | "metadata": {
141 | "kernelspec": {
142 | "display_name": "Python 2",
143 | "language": "python",
144 | "name": "python2"
145 | },
146 | "language_info": {
147 | "codemirror_mode": {
148 | "name": "ipython",
149 | "version": 2
150 | },
151 | "file_extension": ".py",
152 | "mimetype": "text/x-python",
153 | "name": "python",
154 | "nbconvert_exporter": "python",
155 | "pygments_lexer": "ipython2",
156 | "version": "2.7.15"
157 | }
158 | },
159 | "nbformat": 4,
160 | "nbformat_minor": 4
161 | }
162 |
--------------------------------------------------------------------------------
/exercises/Unit 3 Working with meteorological data 1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Filtering meteorological data"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "Load the data in `datasets/meteogalicia.txt` into an RDD:"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": null,
34 | "metadata": {
35 | "collapsed": true
36 | },
37 | "outputs": [],
38 | "source": [
39 | "rdd = ???"
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "## Filter temperature data"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "Filter data from the RDD keeping only \"Temperatura media\" lines."
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {
60 | "collapsed": true
61 | },
62 | "outputs": [],
63 | "source": [
64 | "temperature_lines = rdd.filter(???)"
65 | ]
66 | },
67 | {
68 | "cell_type": "markdown",
69 | "metadata": {},
70 | "source": [
71 | "## Count the number of points"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": null,
77 | "metadata": {
78 | "collapsed": true
79 | },
80 | "outputs": [],
81 | "source": [
82 | "temperature_lines.???"
83 | ]
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "## Find the maximum temperature of the month"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "metadata": {},
95 | "source": [
96 | "Extract the column with the temperature strings:"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": null,
102 | "metadata": {
103 | "collapsed": true
104 | },
105 | "outputs": [],
106 | "source": [
107 | "temperature_strings = temperature_lines.map(lambda line: line.split()[6])"
108 | ]
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "metadata": {},
113 | "source": [
114 | "The temperature_strings contain strings of the form \"21,55\", in order to use them we have to convert them to floats we have to first replace the \",\" with a \".\":"
115 | ]
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": null,
120 | "metadata": {
121 | "collapsed": true
122 | },
123 | "outputs": [],
124 | "source": [
125 | "values = ???"
126 | ]
127 | },
128 | {
129 | "cell_type": "markdown",
130 | "metadata": {},
131 | "source": [
132 | "And now we can convert them to floats:"
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": null,
138 | "metadata": {
139 | "collapsed": true
140 | },
141 | "outputs": [],
142 | "source": [
143 | "temperatures = ???"
144 | ]
145 | },
146 | {
147 | "cell_type": "markdown",
148 | "metadata": {},
149 | "source": [
150 | "Finally we can calculate the maximum temperature:"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": null,
156 | "metadata": {
157 | "collapsed": true
158 | },
159 | "outputs": [],
160 | "source": [
161 | "temperatures.reduce(???)"
162 | ]
163 | },
164 | {
165 | "cell_type": "markdown",
166 | "metadata": {},
167 | "source": [
168 | "Sometimes it is useful to explore the API to find more direct ways to do what we want.\n",
169 | "\n",
170 | "In this case we can see that there is a **max()** built-in function in the RDD object just to do this, so we can also do:"
171 | ]
172 | },
173 | {
174 | "cell_type": "code",
175 | "execution_count": null,
176 | "metadata": {
177 | "collapsed": true
178 | },
179 | "outputs": [],
180 | "source": [
181 | "temperatures.max()"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "## Find the minimum temperature of the month"
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": null,
194 | "metadata": {
195 | "collapsed": true
196 | },
197 | "outputs": [],
198 | "source": [
199 | "temperatures.???"
200 | ]
201 | },
202 | {
203 | "cell_type": "markdown",
204 | "metadata": {},
205 | "source": [
206 | "Reading the header of the dataset file we can see that -9999 is used as a code to indicate N/A values.\n",
207 | "\n",
208 | "So we have to filter out -9999 and repeat:"
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "execution_count": null,
214 | "metadata": {
215 | "collapsed": true
216 | },
217 | "outputs": [],
218 | "source": [
219 | "temperatures.???"
220 | ]
221 | }
222 | ],
223 | "metadata": {
224 | "kernelspec": {
225 | "display_name": "Python 2",
226 | "language": "python",
227 | "name": "python2"
228 | },
229 | "language_info": {
230 | "codemirror_mode": {
231 | "name": "ipython",
232 | "version": 2
233 | },
234 | "file_extension": ".py",
235 | "mimetype": "text/x-python",
236 | "name": "python",
237 | "nbconvert_exporter": "python",
238 | "pygments_lexer": "ipython2",
239 | "version": "2.7.15"
240 | }
241 | },
242 | "nbformat": 4,
243 | "nbformat_minor": 1
244 | }
245 |
--------------------------------------------------------------------------------
/exercises/Unit 4 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "In this exercise we will be implementing the k-means clustering algorithm. For an introduction on how this algorithm works I recommend you to read:\n",
15 | "- [K-Means Clustering Algorithm Overview](https://stanford.edu/~cpiech/cs221/handouts/kmeans.html)\n",
16 | "\n",
17 | "The following figures illustrate the steps the algorithm follows to find two centroids (taken from the previous link):\n",
18 | "\n",
19 | ""
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "## Dependencies"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": null,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "from __future__ import print_function\n",
36 | "import math\n",
37 | "from collections import namedtuple"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## Parameters"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "# Number of clusters to find\n",
54 | "K = 5\n",
55 | "# Convergence threshold\n",
56 | "THRESHOLD = 0.1\n",
57 | "# Maximum number of iterations\n",
58 | "MAX_ITERS = 20"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## Load data"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def parse_coordinates(line):\n",
75 | " fields = line.split(',')\n",
76 | " return (float(fields[3]), float(fields[4]))"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": null,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "data = sc.textFile('datasets/locations')"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "metadata": {
92 | "scrolled": true
93 | },
94 | "outputs": [],
95 | "source": [
96 | "points = data.map(parse_coordinates)"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "## Useful functions"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": null,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "def distance(p1, p2): \n",
113 | " \"Calculate the squared distance between two given points\"\n",
114 | " return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2\n",
115 | "\n",
116 | "def closest_centroid(point, centroids): \n",
117 | " \"Calculate the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
118 | " distances = [distance(point, c) for c in centroids]\n",
119 | " shortest = min(distances)\n",
120 | " return distances.index(shortest)\n",
121 | "\n",
122 | "def add_points(p1,p2):\n",
123 | " \"Add two points of the same cluster in order to calculate later the new centroids\"\n",
124 | " return [p1[0] + p2[0], p1[1] + p2[1]]"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Iteratively calculate the centroids"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": null,
137 | "metadata": {},
138 | "outputs": [],
139 | "source": [
140 | "%%time\n",
141 | "# Initial centroids: we just take K randomly selected points\n",
142 | "centroids = points.takeSample(False, K, 42)\n",
143 | "\n",
144 | "# Just make sure the first iteration is always run\n",
145 | "variation = THRESHOLD + 1\n",
146 | "iteration = 0\n",
147 | "\n",
148 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
149 | " # Map each point to (centroid, (point, 1))\n",
150 | " with_centroids = points.map(???)\n",
151 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
152 | " # and keeping track of the number of points\n",
153 | " cluster_stats = with_centroids.reduceByKey(???)\n",
154 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
155 | " new_centroids = cluster_stats.map(???).collect()\n",
156 | " # Calculate the variation between old and new centroids\n",
157 | " variation = 0\n",
158 | " for (c, point) in new_centroids: variation += distance(centroids[c], point)\n",
159 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
160 | " # Replace old centroids with the new values\n",
161 | " for (c, point) in new_centroids: centroids[c] = point\n",
162 | " iteration += 1\n",
163 | " \n",
164 | "print('Final centroids: {}'.format(centroids))"
165 | ]
166 | }
167 | ],
168 | "metadata": {
169 | "kernelspec": {
170 | "display_name": "Python 2",
171 | "language": "python",
172 | "name": "python2"
173 | },
174 | "language_info": {
175 | "codemirror_mode": {
176 | "name": "ipython",
177 | "version": 2
178 | },
179 | "file_extension": ".py",
180 | "mimetype": "text/x-python",
181 | "name": "python",
182 | "nbconvert_exporter": "python",
183 | "pygments_lexer": "ipython2",
184 | "version": "2.7.15"
185 | }
186 | },
187 | "nbformat": 4,
188 | "nbformat_minor": 1
189 | }
190 |
--------------------------------------------------------------------------------
/exercises/Unit 4 WordCount.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# WordCount"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Load data"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": null,
20 | "metadata": {
21 | "collapsed": true,
22 | "jupyter": {
23 | "outputs_hidden": true
24 | }
25 | },
26 | "outputs": [],
27 | "source": [
28 | "lines = sc.textFile('datasets/slurmd/slurmd.log.c6601')"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "## Split lines into words"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": null,
41 | "metadata": {
42 | "collapsed": true,
43 | "jupyter": {
44 | "outputs_hidden": true
45 | },
46 | "scrolled": true
47 | },
48 | "outputs": [],
49 | "source": [
50 | "words = lines.???"
51 | ]
52 | },
53 | {
54 | "cell_type": "markdown",
55 | "metadata": {},
56 | "source": [
57 | "## Transform in a Pair RDD: word -> (word, 1)"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": null,
63 | "metadata": {
64 | "collapsed": true,
65 | "jupyter": {
66 | "outputs_hidden": true
67 | }
68 | },
69 | "outputs": [],
70 | "source": [
71 | "counts = words.???"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "metadata": {},
77 | "source": [
78 | "## Aggregate counts"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": null,
84 | "metadata": {
85 | "collapsed": true,
86 | "jupyter": {
87 | "outputs_hidden": true
88 | }
89 | },
90 | "outputs": [],
91 | "source": [
92 | "aggregated = counts.???"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## Show the 10 most common words"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "Invert the tuple contents so that the key is the number of occurrences"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": null,
112 | "metadata": {
113 | "collapsed": true,
114 | "jupyter": {
115 | "outputs_hidden": true
116 | }
117 | },
118 | "outputs": [],
119 | "source": [
120 | "result = aggregated.???"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "Sort and take the 10 first elements:"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": null,
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "result.???"
137 | ]
138 | }
139 | ],
140 | "metadata": {
141 | "kernelspec": {
142 | "display_name": "Python 3",
143 | "language": "python",
144 | "name": "python3"
145 | },
146 | "language_info": {
147 | "codemirror_mode": {
148 | "name": "ipython",
149 | "version": 2
150 | },
151 | "file_extension": ".py",
152 | "mimetype": "text/x-python",
153 | "name": "python",
154 | "nbconvert_exporter": "python",
155 | "pygments_lexer": "ipython2",
156 | "version": "2.7.15"
157 | }
158 | },
159 | "nbformat": 4,
160 | "nbformat_minor": 4
161 | }
162 |
--------------------------------------------------------------------------------
/exercises/Unit 4 Working with meteorological data 2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data 2"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorological data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Extract date and temperature information"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Filter data from the RDD keeping only \"Temperatura media\" lines and keeping the date information."
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "temperatures = ???"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "Take 5 elements of the dataset to verify the contents of the RDD:"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": null,
66 | "metadata": {},
67 | "outputs": [],
68 | "source": [
69 | "temperatures.take(5)"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "## Calculate the average temperature per day"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": null,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "averages = ???"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "## Show the results sorted by date"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": null,
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "averages.???"
102 | ]
103 | }
104 | ],
105 | "metadata": {
106 | "kernelspec": {
107 | "display_name": "Python 2",
108 | "language": "python",
109 | "name": "python2"
110 | },
111 | "language_info": {
112 | "codemirror_mode": {
113 | "name": "ipython",
114 | "version": 2
115 | },
116 | "file_extension": ".py",
117 | "mimetype": "text/x-python",
118 | "name": "python",
119 | "nbconvert_exporter": "python",
120 | "pygments_lexer": "ipython2",
121 | "version": "2.7.15"
122 | }
123 | },
124 | "nbformat": 4,
125 | "nbformat_minor": 2
126 | }
127 |
--------------------------------------------------------------------------------
/exercises/Unit 5 Working with meteorological data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data using DataFrames"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Convert to a DataFrame"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": null,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "from pyspark.sql import Row\n",
47 | "\n",
48 | "def parse_row(line):\n",
49 | " \"\"\"If the line is a data line convert it into a Row, otherwise return an empty list\"\"\"\n",
50 | " # All data lines start with 6 spaces\n",
51 | " if line.startswith(' '):\n",
52 | " codigo = int(line[:17].strip())\n",
53 | " datahora = line[17:40]\n",
54 | " data, hora = datahora.split()\n",
55 | " parametro = line[40:82].strip()\n",
56 | " valor = float(line[82:].replace(',', '.'))\n",
57 | " return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]\n",
58 | " return []"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "Using flatMap we have the flexibility to return nothing from a call to the function, this is accomplished returning and empty array."
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "data = rdd.flatMap(parse_row).toDF()"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "## Count the number of points"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": null,
87 | "metadata": {},
88 | "outputs": [],
89 | "source": [
90 | "data.???"
91 | ]
92 | },
93 | {
94 | "cell_type": "markdown",
95 | "metadata": {},
96 | "source": [
97 | "## Filter temperature data"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": null,
103 | "metadata": {},
104 | "outputs": [],
105 | "source": [
106 | "t = data.???"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "## Find the maximum temperature of the month"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": null,
119 | "metadata": {},
120 | "outputs": [],
121 | "source": [
122 | "t.???"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## Find the minimum temperature of the month"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": null,
135 | "metadata": {},
136 | "outputs": [],
137 | "source": [
138 | "t.???"
139 | ]
140 | },
141 | {
142 | "cell_type": "markdown",
143 | "metadata": {},
144 | "source": [
145 | "The value -9999 is a code used to indicate a non registered value (N/A).\n",
146 | "\n",
147 | "If we look to the possible values of \"Códigos de validación\" we see valid points have the code 1, so we can concentrate our efforts on data with code 1."
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": null,
153 | "metadata": {},
154 | "outputs": [],
155 | "source": [
156 | "t.???"
157 | ]
158 | },
159 | {
160 | "cell_type": "markdown",
161 | "metadata": {},
162 | "source": [
163 | "## Calculate the average temperature per day"
164 | ]
165 | },
166 | {
167 | "cell_type": "code",
168 | "execution_count": null,
169 | "metadata": {},
170 | "outputs": [],
171 | "source": [
172 | "t.???"
173 | ]
174 | },
175 | {
176 | "cell_type": "markdown",
177 | "metadata": {},
178 | "source": [
179 | "## Show the results sorted by date"
180 | ]
181 | },
182 | {
183 | "cell_type": "code",
184 | "execution_count": null,
185 | "metadata": {},
186 | "outputs": [],
187 | "source": [
188 | "t.???"
189 | ]
190 | }
191 | ],
192 | "metadata": {
193 | "kernelspec": {
194 | "display_name": "Python 2",
195 | "language": "python",
196 | "name": "python2"
197 | },
198 | "language_info": {
199 | "codemirror_mode": {
200 | "name": "ipython",
201 | "version": 2
202 | },
203 | "file_extension": ".py",
204 | "mimetype": "text/x-python",
205 | "name": "python",
206 | "nbconvert_exporter": "python",
207 | "pygments_lexer": "ipython2",
208 | "version": "2.7.15"
209 | }
210 | },
211 | "nbformat": 4,
212 | "nbformat_minor": 1
213 | }
214 |
--------------------------------------------------------------------------------
/exercises/Unit 7 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans (optimized version)"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": null,
13 | "metadata": {
14 | "collapsed": true
15 | },
16 | "outputs": [],
17 | "source": [
18 | "from __future__ import print_function\n",
19 | "import math\n",
20 | "from collections import namedtuple"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "## Parameters"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": null,
33 | "metadata": {
34 | "collapsed": true
35 | },
36 | "outputs": [],
37 | "source": [
38 | "# Number of clusters to find\n",
39 | "K = 5\n",
40 | "# Convergence threshold\n",
41 | "THRESHOLD = 0.1\n",
42 | "# Maximum number of iterations\n",
43 | "MAX_ITERS = 20"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "## Load data"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": null,
56 | "metadata": {
57 | "collapsed": true
58 | },
59 | "outputs": [],
60 | "source": [
61 | "def parse_coordinates(line):\n",
62 | " fields = line.split(',')\n",
63 | " return (float(fields[3]), float(fields[4]))"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {
70 | "collapsed": true
71 | },
72 | "outputs": [],
73 | "source": [
74 | "data = sc.textFile('datasets/locations')"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {
81 | "collapsed": true
82 | },
83 | "outputs": [],
84 | "source": [
85 | "points = data.map(parse_coordinates)"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "## Useful functions"
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": null,
98 | "metadata": {
99 | "collapsed": true
100 | },
101 | "outputs": [],
102 | "source": [
103 | "def distance(p1, p2): \n",
104 | " \"Calculate the squared distance between two given points\"\n",
105 | " return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2\n",
106 | "\n",
107 | "def closest_centroid(point, centroids): \n",
108 | " \"Calculate the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
109 | " distances = [distance(point, c) for c in centroids]\n",
110 | " shortest = min(distances)\n",
111 | " return distances.index(shortest)\n",
112 | "\n",
113 | "def add_points(p1,p2):\n",
114 | " \"Add two points of the same cluster in order to calculate later the new centroids\"\n",
115 | " return [p1[0] + p2[0], p1[1] + p2[1]]"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "## Iteratively calculate the centroids"
123 | ]
124 | },
125 | {
126 | "cell_type": "code",
127 | "execution_count": null,
128 | "metadata": {},
129 | "outputs": [],
130 | "source": [
131 | "%%time\n",
132 | "# Initial centroids: we just take K randomly selected points\n",
133 | "centroids = points.takeSample(False, K, 42)\n",
134 | "\n",
135 | "# Just make sure the first iteration is always run\n",
136 | "variation = THRESHOLD + 1\n",
137 | "iteration = 0\n",
138 | "\n",
139 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
140 | " # Map each point to (centroid, (point, 1))\n",
141 | " with_centroids = points.map(lambda p : (closest_centroid(p, centroids), (p, 1)))\n",
142 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
143 | " # and keeping track of the number of points\n",
144 | " cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
145 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
146 | " new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, [x/n, y/n])).collect()\n",
147 | " # Calculate the variation between old and new centroids\n",
148 | " variation = 0\n",
149 | " for (c, point) in new_centroids: variation += distance(centroids[c], point)\n",
150 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
151 | " # Replace old centroids with the new values\n",
152 | " for (c, point) in new_centroids: centroids[c] = point\n",
153 | " iteration += 1\n",
154 | " \n",
155 | "print('Final centroids: {}'.format(centroids))"
156 | ]
157 | }
158 | ],
159 | "metadata": {
160 | "kernelspec": {
161 | "display_name": "Python 2",
162 | "language": "python",
163 | "name": "python2"
164 | },
165 | "language_info": {
166 | "codemirror_mode": {
167 | "name": "ipython",
168 | "version": 2
169 | },
170 | "file_extension": ".py",
171 | "mimetype": "text/x-python",
172 | "name": "python",
173 | "nbconvert_exporter": "python",
174 | "pygments_lexer": "ipython2",
175 | "version": "2.7.15"
176 | }
177 | },
178 | "nbformat": 4,
179 | "nbformat_minor": 1
180 | }
181 |
--------------------------------------------------------------------------------
/exercises/Unit_5_sentiment_analysis_amazon_books-short_version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# SENTIMENT ANALYSIS WITH SPARK ML"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "# Spark ML Main Concepts\n",
15 | "\n",
16 | "The Spark Machine learning API in the **spark.ml** package is based on DataFrames, there is also another Spark Machine learning API based on RDDs in the **spark.mllib** package, but as of Spark 2.0, the RDD-based API has entered maintenance mode. The primary Machine Learning API for Spark is now the DataFrame-based API.\n",
17 | "\n",
18 | "Main concepts of Spark ML:\n",
19 | "\n",
20 | "- **Transformer**: transforms one DataFrame into another DataFrame\n",
21 | "\n",
22 | "- **Estimator**: eg. a learning algorithm that trains on a DataFrame and produces a Model\n",
23 | "\n",
24 | "- **Pipeline**: chains Transformers and Estimators to produce a Model\n",
25 | "\n",
26 | "- **Evaluator**: measures how well a fitted Model does on held-out test data\n"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "# Amazon product data\n",
34 | "We will use a [dataset](http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Books_5.json.gz)[1] that contains 8.9M book reviews from Amazon, spanning May 1996 - July 2014.\n",
35 | "\n",
36 | "Dataset characteristics:\n",
37 | "- Number of reviews: 8.9M\n",
38 | "- Size: 8.8GB (uncompressed)\n",
39 | "- HDFS blocks: 70 (each with 3 replicas)\n",
40 | "\n",
41 | "\n",
42 | "[1] Image-based recommendations on styles and substitutes\n",
43 | "J. McAuley, C. Targett, J. Shi, A. van den Hengel\n",
44 | "SIGIR, 2015\n",
45 | "http://jmcauley.ucsd.edu/data/amazon/"
46 | ]
47 | },
48 | {
49 | "cell_type": "markdown",
50 | "metadata": {},
51 | "source": [
52 | "# Load Data"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": null,
58 | "metadata": {},
59 | "outputs": [],
60 | "source": [
61 | "%%time\n",
62 | "raw_reviews = spark.read.json('/tmp/reviews_Books_5_small.json')"
63 | ]
64 | },
65 | {
66 | "cell_type": "code",
67 | "execution_count": 2,
68 | "metadata": {},
69 | "outputs": [
70 | {
71 | "data": {
72 | "text/plain": [
73 | "10000"
74 | ]
75 | },
76 | "execution_count": 2,
77 | "metadata": {},
78 | "output_type": "execute_result"
79 | }
80 | ],
81 | "source": [
82 | "raw_reviews.count()"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 3,
88 | "metadata": {},
89 | "outputs": [
90 | {
91 | "name": "stdout",
92 | "output_type": "stream",
93 | "text": [
94 | "CPU times: user 6.46 ms, sys: 4.72 ms, total: 11.2 ms\n",
95 | "Wall time: 41.8 s\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "%%time\n",
101 | "raw_reviews = spark.read.json('data/amazon/reviews_Books_5.json')"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 2,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "name": "stdout",
111 | "output_type": "stream",
112 | "text": [
113 | "+--------------------+-------+\n",
114 | "| reviewText|overall|\n",
115 | "+--------------------+-------+\n",
116 | "|Spiritually and m...| 5.0|\n",
117 | "|This is one my mu...| 5.0|\n",
118 | "+--------------------+-------+\n",
119 | "only showing top 2 rows\n",
120 | "\n",
121 | "CPU times: user 3.91 ms, sys: 935 µs, total: 4.84 ms\n",
122 | "Wall time: 3.77 s\n"
123 | ]
124 | }
125 | ],
126 | "source": [
127 | "%%time\n",
128 | "all_reviews = raw_reviews.select('reviewText', 'overall')\n",
129 | "all_reviews.cache()\n",
130 | "all_reviews.show(2)"
131 | ]
132 | },
133 | {
134 | "cell_type": "markdown",
135 | "metadata": {},
136 | "source": [
137 | "# Prepare data\n",
138 | "We will avoid neutral reviews by keeping only reviews with 1 or 5 stars overall score.\n",
139 | "We will also filter out the reviews that contain no text."
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 3,
145 | "metadata": {},
146 | "outputs": [],
147 | "source": [
148 | "nonneutral_reviews = all_reviews.filter(\n",
149 | " (all_reviews.overall == 1.0) | (all_reviews.overall == 5.0))\n",
150 | "reviews = nonneutral_reviews.filter(all_reviews.reviewText != '')"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": 4,
156 | "metadata": {},
157 | "outputs": [
158 | {
159 | "data": {
160 | "text/plain": [
161 | "DataFrame[reviewText: string, overall: double]"
162 | ]
163 | },
164 | "execution_count": 4,
165 | "metadata": {},
166 | "output_type": "execute_result"
167 | }
168 | ],
169 | "source": [
170 | "reviews.cache()\n",
171 | "all_reviews.unpersist()"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "# Split Data"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 5,
184 | "metadata": {},
185 | "outputs": [],
186 | "source": [
187 | "trainingData, testData = reviews.randomSplit([0.8, 0.2])"
188 | ]
189 | },
190 | {
191 | "cell_type": "markdown",
192 | "metadata": {},
193 | "source": [
194 | "# Generate Pipeline\n",
195 | ""
196 | ]
197 | },
198 | {
199 | "cell_type": "markdown",
200 | "metadata": {},
201 | "source": [
202 | "## Binarizer\n",
203 | "A transformer to convert numerical features to binary (0/1) features"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 6,
209 | "metadata": {},
210 | "outputs": [],
211 | "source": [
212 | "from pyspark.ml.feature import Binarizer\n",
213 | "\n",
214 | "binarizer = Binarizer(threshold=2.5, inputCol='overall', outputCol='label')"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "## Tokenizer\n",
222 | "A transformer that converts the input string to lowercase and then splits it by white spaces."
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 7,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "from pyspark.ml.feature import Tokenizer\n",
232 | "tokenizer = Tokenizer(inputCol=\"reviewText\", outputCol=\"words\")"
233 | ]
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "metadata": {},
238 | "source": [
239 | "## StopWordsRemover\n",
240 | "A transformer that filters out stop words from input. Note: null values from input array are preserved unless adding null to stopWords explicitly."
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 8,
246 | "metadata": {},
247 | "outputs": [],
248 | "source": [
249 | "from pyspark.ml.feature import StopWordsRemover\n",
250 | "remover = StopWordsRemover(inputCol=tokenizer.getOutputCol(), outputCol=\"filtered\")"
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {},
256 | "source": [
257 | "## HashingTF\n",
258 | "A Transformer that converts a sequence of words into a fixed-length feature Vector. It maps a sequence of terms to their term frequencies using a hashing function."
259 | ]
260 | },
261 | {
262 | "cell_type": "code",
263 | "execution_count": 9,
264 | "metadata": {},
265 | "outputs": [],
266 | "source": [
267 | "from pyspark.ml.feature import HashingTF\n",
268 | "hashingTF = HashingTF(inputCol=remover.getOutputCol(), outputCol=\"features\")"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "# Estimator\n",
276 | "## LogisticRegression"
277 | ]
278 | },
279 | {
280 | "cell_type": "code",
281 | "execution_count": 10,
282 | "metadata": {},
283 | "outputs": [],
284 | "source": [
285 | "from pyspark.ml.classification import LogisticRegression\n",
286 | "lr = LogisticRegression(maxIter=10, regParam=0.01)"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "# Pipeline"
294 | ]
295 | },
296 | {
297 | "cell_type": "code",
298 | "execution_count": 11,
299 | "metadata": {},
300 | "outputs": [],
301 | "source": [
302 | "from pyspark.ml import Pipeline\n",
303 | "pipeline = Pipeline(stages=[binarizer, tokenizer, remover, hashingTF, lr])"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 12,
309 | "metadata": {},
310 | "outputs": [
311 | {
312 | "name": "stdout",
313 | "output_type": "stream",
314 | "text": [
315 | "CPU times: user 37 ms, sys: 13.2 ms, total: 50.2 ms\n",
316 | "Wall time: 58.1 s\n"
317 | ]
318 | }
319 | ],
320 | "source": [
321 | "%%time\n",
322 | "pipeLineModel = pipeline.fit(trainingData)"
323 | ]
324 | },
325 | {
326 | "cell_type": "markdown",
327 | "metadata": {},
328 | "source": [
329 | "# Evaluation"
330 | ]
331 | },
332 | {
333 | "cell_type": "code",
334 | "execution_count": 13,
335 | "metadata": {
336 | "scrolled": true
337 | },
338 | "outputs": [
339 | {
340 | "name": "stdout",
341 | "output_type": "stream",
342 | "text": [
343 | "Area under ROC: 0.967783441159\n",
344 | "CPU times: user 31.8 ms, sys: 4.17 ms, total: 36 ms\n",
345 | "Wall time: 16.7 s\n"
346 | ]
347 | }
348 | ],
349 | "source": [
350 | "%%time\n",
351 | "from pyspark.ml.evaluation import BinaryClassificationEvaluator\n",
352 | "evaluator = BinaryClassificationEvaluator()\n",
353 | "\n",
354 | "predictions = pipeLineModel.transform(testData)\n",
355 | "\n",
356 | "aur = evaluator.evaluate(predictions)\n",
357 | "\n",
358 | "print 'Area under ROC: ', aur"
359 | ]
360 | },
361 | {
362 | "cell_type": "markdown",
363 | "metadata": {},
364 | "source": [
365 | "# Hyperparameter Tuning"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 14,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "name": "stdout",
375 | "output_type": "stream",
376 | "text": [
377 | "CPU times: user 3.9 s, sys: 1.11 s, total: 5.01 s\n",
378 | "Wall time: 12min 49s\n"
379 | ]
380 | }
381 | ],
382 | "source": [
383 | "%%time\n",
384 | "from pyspark.ml.tuning import ParamGridBuilder, CrossValidator\n",
385 | "param_grid = ParamGridBuilder() \\\n",
386 | " .addGrid(hashingTF.numFeatures, [10000, 100000]) \\\n",
387 | " .addGrid(lr.regParam, [0.01, 0.1, 1.0]) \\\n",
388 | " .addGrid(lr.maxIter, [10, 20]) \\\n",
389 | " .build()\n",
390 | " \n",
391 | "cv = (CrossValidator()\n",
392 | " .setEstimator(pipeline)\n",
393 | " .setEvaluator(evaluator)\n",
394 | " .setEstimatorParamMaps(param_grid)\n",
395 | " .setNumFolds(3))\n",
396 | "\n",
397 | "cv_model = cv.fit(trainingData)"
398 | ]
399 | },
400 | {
401 | "cell_type": "code",
402 | "execution_count": 15,
403 | "metadata": {},
404 | "outputs": [
405 | {
406 | "name": "stdout",
407 | "output_type": "stream",
408 | "text": [
409 | "Area under ROC: 0.96977328792\n",
410 | "CPU times: user 28.3 ms, sys: 8.81 ms, total: 37.1 ms\n",
411 | "Wall time: 5.12 s\n"
412 | ]
413 | }
414 | ],
415 | "source": [
416 | "%%time\n",
417 | "new_predictions = cv_model.transform(testData)\n",
418 | "new_aur = evaluator.evaluate(new_predictions)\n",
419 | "print 'Area under ROC: ', new_aur"
420 | ]
421 | }
422 | ],
423 | "metadata": {
424 | "kernelspec": {
425 | "display_name": "Python 2",
426 | "language": "python",
427 | "name": "python2"
428 | },
429 | "language_info": {
430 | "codemirror_mode": {
431 | "name": "ipython",
432 | "version": 2
433 | },
434 | "file_extension": ".py",
435 | "mimetype": "text/x-python",
436 | "name": "python",
437 | "nbconvert_exporter": "python",
438 | "pygments_lexer": "ipython2",
439 | "version": "2.7.15"
440 | }
441 | },
442 | "nbformat": 4,
443 | "nbformat_minor": 1
444 | }
445 |
--------------------------------------------------------------------------------
/exercises/Unit_6_working_with_meteorological_data-using_dataframes.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 |
4 | if __name__ == '__main__':
5 | ???
6 |
--------------------------------------------------------------------------------
/exercises/Unit_6_working_with_meteorological_data-using_rdds.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 |
4 | if __name__ == '__main__':
5 | ????
6 |
--------------------------------------------------------------------------------
/exercises/unit_1_plotting_data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Exercise 1.4.1: Plotting Data"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": null,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from bokeh.io import show, output_notebook\n",
17 | "from bokeh.plotting import figure\n",
18 | "output_notebook()"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "Given the following data:"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "import pandas as pd\n",
35 | "X = range(100)\n",
36 | "Y = [0.01*n**3 for n in X]\n",
37 | "data = pd.DataFrame(zip(X,Y), columns=['Seconds', 'Connections'])"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Check the Bokeh documentation for [bokeh.plotting](https://bokeh.pydata.org/en/1.4.0/docs/reference/plotting.html) and generate a scatter plot representing 'Seconds' in the X axis and 'Connections' in the Y axis using squares as markers:"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "p = figure(title='Total Connections', x_axis_label='Seconds', y_axis_label='Connections')\n",
54 | "# Complete the line below\n",
55 | "...\n",
56 | "show(p)"
57 | ]
58 | }
59 | ],
60 | "metadata": {
61 | "kernelspec": {
62 | "display_name": "Python 3",
63 | "language": "python",
64 | "name": "python3"
65 | },
66 | "language_info": {
67 | "codemirror_mode": {
68 | "name": "ipython",
69 | "version": 3
70 | },
71 | "file_extension": ".py",
72 | "mimetype": "text/x-python",
73 | "name": "python",
74 | "nbconvert_exporter": "python",
75 | "pygments_lexer": "ipython3",
76 | "version": "3.7.6"
77 | }
78 | },
79 | "nbformat": 4,
80 | "nbformat_minor": 4
81 | }
82 |
--------------------------------------------------------------------------------
/solutions/Unit 3 Exercise Calculating Pi.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Calculating $\\pi$ using Monte Carlo"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "To estimate the value of Pi using the Monte Carlo method we generate a large number of random points (similar to **launching darts**) and see how many fall in the circle enclosed by the unit square:"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "$\\pi = 4 * \\frac{N_{hits}}{N_{total}}$"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | ""
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "You can see a demo here: [Estimating Pi with Monte Carlo demo](https://academo.org/demos/estimating-pi-monte-carlo/)"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "# Implementation"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 1,
48 | "metadata": {},
49 | "outputs": [],
50 | "source": [
51 | "from __future__ import print_function\n",
52 | "from random import random\n",
53 | "from operator import add\n",
54 | "import time"
55 | ]
56 | },
57 | {
58 | "cell_type": "code",
59 | "execution_count": 2,
60 | "metadata": {},
61 | "outputs": [],
62 | "source": [
63 | "# Number of points to generate\n",
64 | "POINTS = 10**8\n",
65 | "# Number of partitions to use in the Spark program\n",
66 | "PARTITIONS = 20"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 3,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "def launch_dart(_):\n",
76 | " \"Shoot a new random dart in the (1, 1) cuadrant and return 1 if it is inside the circle, 0 otherwise\"\n",
77 | " x = random() * 2 - 1\n",
78 | " y = random() * 2 - 1\n",
79 | " return 1 if x ** 2 + y ** 2 < 1 else 0"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "## Serial implementation using Python"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 4,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "Elapsed time: 59.5995240211\n",
99 | "Pi is roughly 3.14194192\n"
100 | ]
101 | }
102 | ],
103 | "source": [
104 | "start = time.time()\n",
105 | "hits = 0\n",
106 | "for i in xrange(POINTS):\n",
107 | " hits += launch_dart(_)\n",
108 | "end = time.time()\n",
109 | "print('Elapsed time:', end - start)\n",
110 | "print('Pi is roughly', 4.0 * hits / POINTS)"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "NOTE: If you are using Python 3 instead of the `xrange` function you would use `range`."
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "## Parallel implementation using Spark"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 8,
130 | "metadata": {},
131 | "outputs": [
132 | {
133 | "name": "stdout",
134 | "output_type": "stream",
135 | "text": [
136 | "Elapsed time: 9.7909719944\n",
137 | "Pi is roughly 3.14167076\n"
138 | ]
139 | }
140 | ],
141 | "source": [
142 | "start = time.time()\n",
143 | "hits = sc.parallelize(xrange(POINTS), PARTITIONS).map(launch_dart).reduce(add)\n",
144 | "end = time.time()\n",
145 | "print('Elapsed time:', end - start)\n",
146 | "print('Pi is roughly', 4.0 * hits / POINTS)"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "NOTE: If you are using Python 3 instead of the `xrange` function you would use `range`."
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "## Explore the paralellism"
161 | ]
162 | },
163 | {
164 | "cell_type": "markdown",
165 | "metadata": {},
166 | "source": [
167 | "Explore how changing the number of points and the number partitions affects the elapsed time of each implementation.\n",
168 | "\n",
169 | "- We can increase POINTS from `10**6` to `10**8`, in this case the sequential execution will need more than 60 seconds.\n",
170 | "- Take into account that just re-running again the spark calculation reduces the time because the executors are already launched so the application startup time is shorter."
171 | ]
172 | }
173 | ],
174 | "metadata": {
175 | "kernelspec": {
176 | "display_name": "Python 2",
177 | "language": "python",
178 | "name": "python2"
179 | },
180 | "language_info": {
181 | "codemirror_mode": {
182 | "name": "ipython",
183 | "version": 2
184 | },
185 | "file_extension": ".py",
186 | "mimetype": "text/x-python",
187 | "name": "python",
188 | "nbconvert_exporter": "python",
189 | "pygments_lexer": "ipython2",
190 | "version": "2.7.15"
191 | }
192 | },
193 | "nbformat": 4,
194 | "nbformat_minor": 4
195 | }
196 |
--------------------------------------------------------------------------------
/solutions/Unit 3 Working with meteorological data 1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Filtering meteorological data"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Filter temperature data"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Filter data from the RDD keeping only \"Temperatura media\" lines."
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 2,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "temperature_lines = rdd.filter(lambda line: 'Temperatura media' in line)"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "## Count the number of points"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 3,
66 | "metadata": {},
67 | "outputs": [
68 | {
69 | "data": {
70 | "text/plain": [
71 | "4176"
72 | ]
73 | },
74 | "execution_count": 3,
75 | "metadata": {},
76 | "output_type": "execute_result"
77 | }
78 | ],
79 | "source": [
80 | "temperature_lines.count()"
81 | ]
82 | },
83 | {
84 | "cell_type": "markdown",
85 | "metadata": {},
86 | "source": [
87 | "## Find the maximum temperature of the month"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 4,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "temperature_strings = temperature_lines.map(lambda line: line.split()[6])"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "The temperature_strings contain strings of the form \"21,55\", in order to use them we have to convert them to floats we have to first replace the \",\" with a \".\":"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 5,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "values = temperature_strings.map(lambda value: value.replace(',', '.'))"
113 | ]
114 | },
115 | {
116 | "cell_type": "markdown",
117 | "metadata": {},
118 | "source": [
119 | "And now we can convert them to floats:"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 6,
125 | "metadata": {},
126 | "outputs": [],
127 | "source": [
128 | "temperatures = values.map(lambda value: float(value))"
129 | ]
130 | },
131 | {
132 | "cell_type": "markdown",
133 | "metadata": {},
134 | "source": [
135 | "Finally we can calculate the maximum temperature:"
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 7,
141 | "metadata": {},
142 | "outputs": [
143 | {
144 | "data": {
145 | "text/plain": [
146 | "34.4"
147 | ]
148 | },
149 | "execution_count": 7,
150 | "metadata": {},
151 | "output_type": "execute_result"
152 | }
153 | ],
154 | "source": [
155 | "temperatures.reduce(max)"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "Sometimes it is useful to explore the API to find more direct ways to do what we want.\n",
163 | "\n",
164 | "In this case we can see that there is a **max()** built-in function in the RDD object just to do this, so we can also do:"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": 8,
170 | "metadata": {},
171 | "outputs": [
172 | {
173 | "data": {
174 | "text/plain": [
175 | "34.4"
176 | ]
177 | },
178 | "execution_count": 8,
179 | "metadata": {},
180 | "output_type": "execute_result"
181 | }
182 | ],
183 | "source": [
184 | "temperatures.max()"
185 | ]
186 | },
187 | {
188 | "cell_type": "markdown",
189 | "metadata": {},
190 | "source": [
191 | "## Find the minimum temperature of the month"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 9,
197 | "metadata": {},
198 | "outputs": [
199 | {
200 | "data": {
201 | "text/plain": [
202 | "-9999.0"
203 | ]
204 | },
205 | "execution_count": 9,
206 | "metadata": {},
207 | "output_type": "execute_result"
208 | }
209 | ],
210 | "source": [
211 | "temperatures.min()"
212 | ]
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "metadata": {},
217 | "source": [
218 | "Reading the header of the dataset file we can see that -9999 is used as a code to indicate N/A values.\n",
219 | "\n",
220 | "So we have to filter out -9999 and repeat:"
221 | ]
222 | },
223 | {
224 | "cell_type": "code",
225 | "execution_count": 10,
226 | "metadata": {},
227 | "outputs": [
228 | {
229 | "data": {
230 | "text/plain": [
231 | "9.09"
232 | ]
233 | },
234 | "execution_count": 10,
235 | "metadata": {},
236 | "output_type": "execute_result"
237 | }
238 | ],
239 | "source": [
240 | "temperatures.filter(lambda value: value != -9999).min()"
241 | ]
242 | }
243 | ],
244 | "metadata": {
245 | "kernelspec": {
246 | "display_name": "Python 3",
247 | "language": "python",
248 | "name": "python3"
249 | },
250 | "language_info": {
251 | "codemirror_mode": {
252 | "name": "ipython",
253 | "version": 3
254 | },
255 | "file_extension": ".py",
256 | "mimetype": "text/x-python",
257 | "name": "python",
258 | "nbconvert_exporter": "python",
259 | "pygments_lexer": "ipython3",
260 | "version": "3.7.6"
261 | }
262 | },
263 | "nbformat": 4,
264 | "nbformat_minor": 4
265 | }
266 |
--------------------------------------------------------------------------------
/solutions/Unit 4 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "In this exercise we will be implementing the k-means clustering algorithm. For an introduction on how this algorithm works I recommend you to read:\n",
15 | "- [K-Means Clustering Algorithm Overview](https://stanford.edu/~cpiech/cs221/handouts/kmeans.html)\n",
16 | "\n",
17 | "The following figures illustrate the steps the algorithm follows to find two centroids (taken from the previous link):\n",
18 | "\n",
19 | ""
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "## Dependencies"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "from __future__ import print_function\n",
36 | "import math\n",
37 | "from collections import namedtuple"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## Parameters"
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 2,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "# Number of clusters to find\n",
54 | "K = 5\n",
55 | "# Convergence threshold\n",
56 | "THRESHOLD = 0.1\n",
57 | "# Maximum number of iterations\n",
58 | "MAX_ITERS = 20"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## Load data"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def parse_coordinates(line):\n",
75 | " fields = line.split(',')\n",
76 | " return (float(fields[3]), float(fields[4]))"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "data = sc.textFile('datasets/locations')"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 5,
91 | "metadata": {
92 | "scrolled": true
93 | },
94 | "outputs": [],
95 | "source": [
96 | "points = data.map(parse_coordinates)"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "## Useful functions"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 6,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "def distance(p1, p2): \n",
113 | " \"Returns the squared distance between two given points\"\n",
114 | " return (p1[0] - p2[0])** 2 + (p1[1] - p2[1])** 2\n",
115 | "\n",
116 | "def closest_centroid(point, centroids): \n",
117 | " \"Returns the index of the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
118 | " distances = [distance(point, c) for c in centroids]\n",
119 | " shortest = min(distances)\n",
120 | " return distances.index(shortest)\n",
121 | "\n",
122 | "def add_points(p1, p2):\n",
123 | " \"Returns the sum of two points\"\n",
124 | " return (p1[0] + p2[0], p1[1] + p2[1])"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Iteratively calculate the centroids"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 7,
137 | "metadata": {},
138 | "outputs": [
139 | {
140 | "name": "stdout",
141 | "output_type": "stream",
142 | "text": [
143 | "Variation in iteration 0: 4989.32008451\n",
144 | "Variation in iteration 1: 2081.17551268\n",
145 | "Variation in iteration 2: 1.6011620119\n",
146 | "Variation in iteration 3: 2.55059475168\n",
147 | "Variation in iteration 4: 0.994848416636\n",
148 | "Variation in iteration 5: 0.0381850235415\n",
149 | "Final centroids: [(35.08592000544936, -112.57643826547803), (0.0, 0.0), (38.05200414101911, -121.20324355675143), (43.891507710205694, -121.32350131512835), (34.28939789970032, -117.77840744773651)]\n",
150 | "CPU times: user 84.9 ms, sys: 9.17 ms, total: 94.1 ms\n",
151 | "Wall time: 21 s\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "%%time\n",
157 | "# Initial centroids: we just take K randomly selected points\n",
158 | "centroids = points.takeSample(False, K, 42)\n",
159 | "\n",
160 | "# The first iteration should always run\n",
161 | "variation = THRESHOLD + 1\n",
162 | "iteration = 0\n",
163 | "\n",
164 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
165 | " # Map each point to (centroid, (point, 1))\n",
166 | " with_centroids = points.map(lambda p: (closest_centroid(p, centroids), (p, 1)))\n",
167 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
168 | " # and keeping track of the number of points\n",
169 | " cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
170 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
171 | " new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, (x/n, y/n))).collect()\n",
172 | " # Calculate the variation between old and new centroids\n",
173 | " variation = 0\n",
174 | " for (old_centroid_id, new_centroid) in new_centroids: \n",
175 | " variation += distance(centroids[old_centroid_id], new_centroid)\n",
176 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
177 | " # Replace old centroids with the new values\n",
178 | " for (old_centroid_id, new_centroid) in new_centroids: \n",
179 | " centroids[old_centroid_id] = new_centroid\n",
180 | " iteration += 1\n",
181 | " \n",
182 | "print('Final centroids: {}'.format(centroids))"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {},
188 | "source": [
189 | "## Reviewing the steps we have done"
190 | ]
191 | },
192 | {
193 | "cell_type": "markdown",
194 | "metadata": {},
195 | "source": [
196 | "We start with lines of text:"
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": 8,
202 | "metadata": {},
203 | "outputs": [
204 | {
205 | "name": "stdout",
206 | "output_type": "stream",
207 | "text": [
208 | "2017-03-15:10:10:20,Motorola F41L,8cc3b47e-bd01-4482-b500-28f2342679af,33.6894754264,-117.543308253\n"
209 | ]
210 | }
211 | ],
212 | "source": [
213 | "line = data.first()\n",
214 | "print(line)"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "We have to convert them to points:"
222 | ]
223 | },
224 | {
225 | "cell_type": "code",
226 | "execution_count": 9,
227 | "metadata": {},
228 | "outputs": [
229 | {
230 | "data": {
231 | "text/plain": [
232 | "(33.6894754264, -117.543308253)"
233 | ]
234 | },
235 | "execution_count": 9,
236 | "metadata": {},
237 | "output_type": "execute_result"
238 | }
239 | ],
240 | "source": [
241 | "parse_coordinates(line)"
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "execution_count": 10,
247 | "metadata": {},
248 | "outputs": [
249 | {
250 | "name": "stdout",
251 | "output_type": "stream",
252 | "text": [
253 | "(33.6894754264, -117.543308253)\n"
254 | ]
255 | }
256 | ],
257 | "source": [
258 | "points = data.map(parse_coordinates)\n",
259 | "point = points.first()\n",
260 | "print(point)"
261 | ]
262 | },
263 | {
264 | "cell_type": "markdown",
265 | "metadata": {},
266 | "source": [
267 | "We select some arbitrary points from our RDD of points as the initial centroids:"
268 | ]
269 | },
270 | {
271 | "cell_type": "code",
272 | "execution_count": 11,
273 | "metadata": {},
274 | "outputs": [
275 | {
276 | "name": "stdout",
277 | "output_type": "stream",
278 | "text": [
279 | "[(33.4898547489, -111.63617776), (33.5505811202, -111.243243255), (36.5697673035, -120.79623245), (37.7152004069, -121.473355818), (34.3743073814, -117.184154207)]\n"
280 | ]
281 | }
282 | ],
283 | "source": [
284 | "# Initial centroids: we just take K randomly selected points\n",
285 | "centroids = points.takeSample(False, K, 42)\n",
286 | "print(centroids)"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "NOTE: Using the closest_centroid() funtion, we are able so calculate the **index of the closest centroid** to a given point:"
294 | ]
295 | },
296 | {
297 | "cell_type": "code",
298 | "execution_count": 12,
299 | "metadata": {},
300 | "outputs": [
301 | {
302 | "name": "stdout",
303 | "output_type": "stream",
304 | "text": [
305 | "4\n"
306 | ]
307 | }
308 | ],
309 | "source": [
310 | "closest_centroid_index = closest_centroid(point, centroids)\n",
311 | "print(closest_centroid_index)"
312 | ]
313 | },
314 | {
315 | "cell_type": "code",
316 | "execution_count": 13,
317 | "metadata": {},
318 | "outputs": [
319 | {
320 | "data": {
321 | "text/plain": [
322 | "(34.3743073814, -117.184154207)"
323 | ]
324 | },
325 | "execution_count": 13,
326 | "metadata": {},
327 | "output_type": "execute_result"
328 | }
329 | ],
330 | "source": [
331 | "centroids[closest_centroid_index]"
332 | ]
333 | },
334 | {
335 | "cell_type": "markdown",
336 | "metadata": {},
337 | "source": [
338 | "#### STEP 1: Assign a point to its centroid\n",
339 | "**point -> (closest_centroid_id, (point, 1))**"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 14,
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stdout",
349 | "output_type": "stream",
350 | "text": [
351 | "(4, ((33.6894754264, -117.543308253), 1))\n"
352 | ]
353 | }
354 | ],
355 | "source": [
356 | "with_centroids = points.map(lambda p: (closest_centroid(p, centroids), (p, 1)))\n",
357 | "print(with_centroids.first())"
358 | ]
359 | },
360 | {
361 | "cell_type": "markdown",
362 | "metadata": {},
363 | "source": [
364 | "#### STEP 2: Preparation to calculate new centroids\n",
365 | "**(closest_centroid_id, (point, 1)) -> (closest_centroid_id, (sum(points), total_number_of_points)**"
366 | ]
367 | },
368 | {
369 | "cell_type": "code",
370 | "execution_count": 15,
371 | "metadata": {},
372 | "outputs": [
373 | {
374 | "name": "stdout",
375 | "output_type": "stream",
376 | "text": [
377 | "(0, ((841812.50940875, -2768072.601871161), 24640))\n"
378 | ]
379 | }
380 | ],
381 | "source": [
382 | "cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
383 | "print(cluster_stats.first())"
384 | ]
385 | },
386 | {
387 | "cell_type": "markdown",
388 | "metadata": {},
389 | "source": [
390 | "#### STEP 3: We calculate the new centroids\n",
391 | "**closest_centroid_id, (sum(points), total_number_of_points) -> (centroid_id, new_centroid)** \n",
392 | "\n",
393 | "where `new_centroid = (sum_x/total, sum_y/total)`."
394 | ]
395 | },
396 | {
397 | "cell_type": "code",
398 | "execution_count": 16,
399 | "metadata": {},
400 | "outputs": [
401 | {
402 | "name": "stdout",
403 | "output_type": "stream",
404 | "text": [
405 | "(0, (34.164468726004465, -112.34060884217374))\n"
406 | ]
407 | }
408 | ],
409 | "source": [
410 | "new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, (x/n, y/n))).collect()\n",
411 | "print(new_centroids[0])"
412 | ]
413 | },
414 | {
415 | "cell_type": "markdown",
416 | "metadata": {},
417 | "source": [
418 | "#### STEP 4: We calculate the variation\n",
419 | "Finally we just calculate the variation between old and new centroids to verify if we have to continue iterating."
420 | ]
421 | },
422 | {
423 | "cell_type": "code",
424 | "execution_count": 17,
425 | "metadata": {},
426 | "outputs": [
427 | {
428 | "name": "stdout",
429 | "output_type": "stream",
430 | "text": [
431 | "4989.32008451\n"
432 | ]
433 | }
434 | ],
435 | "source": [
436 | "variation = 0\n",
437 | "for (old_centroid_id, new_centroid) in new_centroids:\n",
438 | " variation += distance(centroids[old_centroid_id], new_centroid)\n",
439 | "print(variation)"
440 | ]
441 | }
442 | ],
443 | "metadata": {
444 | "kernelspec": {
445 | "display_name": "Python 2",
446 | "language": "python",
447 | "name": "python2"
448 | },
449 | "language_info": {
450 | "codemirror_mode": {
451 | "name": "ipython",
452 | "version": 2
453 | },
454 | "file_extension": ".py",
455 | "mimetype": "text/x-python",
456 | "name": "python",
457 | "nbconvert_exporter": "python",
458 | "pygments_lexer": "ipython2",
459 | "version": "2.7.15"
460 | }
461 | },
462 | "nbformat": 4,
463 | "nbformat_minor": 4
464 | }
465 |
--------------------------------------------------------------------------------
/solutions/Unit 4 WordCount.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# WordCount"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Load data"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "lines = sc.textFile('datasets/slurmd/slurmd.log.c6601')"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "## Split lines into words"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 2,
36 | "metadata": {
37 | "scrolled": true
38 | },
39 | "outputs": [],
40 | "source": [
41 | "words = lines.flatMap(lambda line: line.split())"
42 | ]
43 | },
44 | {
45 | "cell_type": "markdown",
46 | "metadata": {},
47 | "source": [
48 | "## Transform in a Pair RDD: word -> (word, 1)"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 3,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "counts = words.map(lambda word: (word, 1))"
58 | ]
59 | },
60 | {
61 | "cell_type": "markdown",
62 | "metadata": {},
63 | "source": [
64 | "## Aggregate counts"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 4,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "aggregated = counts.reduceByKey(lambda a, b: a + b)"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "## Show the 10 most common words"
81 | ]
82 | },
83 | {
84 | "cell_type": "markdown",
85 | "metadata": {},
86 | "source": [
87 | "Invert the tuple contents so that the key is the number of occurrences"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 5,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "result = aggregated.map(lambda (x, y): (y, x))"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "NOTE: In Python 3 tuple parameter unpacking has been removed as explained in [PEP 3113](https://www.python.org/dev/peps/pep-3113/) so the syntax for lambda functions gets ugly, especially when the lambda functions become more complex:\n",
104 | "\n",
105 | " result = aggregated.map(lambda x_y: (x_y[1], x_y[0]))\n",
106 | "\n"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "Sort and take the 10 first elements:"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 6,
119 | "metadata": {},
120 | "outputs": [
121 | {
122 | "data": {
123 | "text/plain": [
124 | "[(29478, 'c6601'),\n",
125 | " (27084, '2017'),\n",
126 | " (19924, 'info'),\n",
127 | " (15476, 'slurmstepd'),\n",
128 | " (15446, 'user'),\n",
129 | " (12439, 'slurmd'),\n",
130 | " (12384, 'daemon'),\n",
131 | " (9285, 'job'),\n",
132 | " (7911, 'err'),\n",
133 | " (7905, 'error:')]"
134 | ]
135 | },
136 | "execution_count": 6,
137 | "metadata": {},
138 | "output_type": "execute_result"
139 | }
140 | ],
141 | "source": [
142 | "result.sortByKey(ascending=False).take(10)"
143 | ]
144 | }
145 | ],
146 | "metadata": {
147 | "kernelspec": {
148 | "display_name": "Python 2",
149 | "language": "python",
150 | "name": "python2"
151 | },
152 | "language_info": {
153 | "codemirror_mode": {
154 | "name": "ipython",
155 | "version": 2
156 | },
157 | "file_extension": ".py",
158 | "mimetype": "text/x-python",
159 | "name": "python",
160 | "nbconvert_exporter": "python",
161 | "pygments_lexer": "ipython2",
162 | "version": "2.7.15"
163 | }
164 | },
165 | "nbformat": 4,
166 | "nbformat_minor": 4
167 | }
168 |
--------------------------------------------------------------------------------
/solutions/Unit 4 Working with meteorological data 2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data 2"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorological data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Extract date and temperature information"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "Filter data from the RDD keeping only \"Temperatura media\" lines and keeping the date information."
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 2,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "def parse_temperature(line):\n",
54 | " (_, date, hour, _, _, _, value) = line.split()\n",
55 | " return (date, float(value.replace(',', '.')))"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 3,
61 | "metadata": {},
62 | "outputs": [],
63 | "source": [
64 | "temperatures = (rdd.filter(lambda line: 'Temperatura media' in line)\n",
65 | " .map(parse_temperature))"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 4,
71 | "metadata": {},
72 | "outputs": [
73 | {
74 | "data": {
75 | "text/plain": [
76 | "[(u'2017-06-01', 13.82),\n",
77 | " (u'2017-06-01', 13.71),\n",
78 | " (u'2017-06-01', 13.61),\n",
79 | " (u'2017-06-01', 13.52),\n",
80 | " (u'2017-06-01', 13.33)]"
81 | ]
82 | },
83 | "execution_count": 4,
84 | "metadata": {},
85 | "output_type": "execute_result"
86 | }
87 | ],
88 | "source": [
89 | "temperatures.take(5)"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "metadata": {},
95 | "source": [
96 | "## Filter out invalid values"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "As we saw in part 1, a temperature value of -9999 indicates a non existing value, so we filter out these values before performing calculations on the data:"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 5,
109 | "metadata": {},
110 | "outputs": [],
111 | "source": [
112 | "temperatures_clean = temperatures.filter(lambda (date, temp): temp != -9999)"
113 | ]
114 | },
115 | {
116 | "cell_type": "markdown",
117 | "metadata": {},
118 | "source": [
119 | "NOTE: In Python 3 tuple parameter unpacking has been removed as explained in [PEP 3113](https://www.python.org/dev/peps/pep-3113/) so we would rewrite it as:\n",
120 | "\n",
121 | " temperatures_clean = temperatures.filter(lambda date_temp: date_temp[1] != -9999)"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "## Calculate the average temperature per day"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": 6,
134 | "metadata": {},
135 | "outputs": [],
136 | "source": [
137 | "def sum_pairs(a, b):\n",
138 | " return (a[0]+b[0], a[1]+b[1])"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 7,
144 | "metadata": {},
145 | "outputs": [],
146 | "source": [
147 | "averages = (temperatures_clean.map(lambda (date, temp): (date, (temp, 1)))\n",
148 | " .reduceByKey(sum_pairs)\n",
149 | " .map(lambda (date, (temp, count)): (date, temp/count)))"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "NOTE: In Python 3 the syntax gets ugly especially in cases like this where there are nested structures. The code above in Python 3 will look like:\n",
157 | "\n",
158 | " averages = (temperatures_clean.map(lambda date_temp: (date_temp[0], (date_temp[1], 1)))\n",
159 | " .reduceByKey(sum_pairs)\n",
160 | " .map(lambda date__temp_count: (date__temp_count[0], date__temp_count[1][0]/date__temp_count[1][1])))\n",
161 | "\n"
162 | ]
163 | },
164 | {
165 | "cell_type": "markdown",
166 | "metadata": {},
167 | "source": [
168 | "## Show the results sorted by date"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": 8,
174 | "metadata": {},
175 | "outputs": [
176 | {
177 | "data": {
178 | "text/plain": [
179 | "[(u'2017-06-01', 17.179580419580425),\n",
180 | " (u'2017-06-02', 16.007500000000004),\n",
181 | " (u'2017-06-03', 14.511736111111105),\n",
182 | " (u'2017-06-04', 14.889375000000005),\n",
183 | " (u'2017-06-05', 13.67486111111111),\n",
184 | " (u'2017-06-06', 14.901041666666666),\n",
185 | " (u'2017-06-07', 17.76305555555556),\n",
186 | " (u'2017-06-08', 17.49979166666667),\n",
187 | " (u'2017-06-09', 17.86694444444445),\n",
188 | " (u'2017-06-10', 19.207222222222224),\n",
189 | " (u'2017-06-11', 17.806250000000006),\n",
190 | " (u'2017-06-12', 20.020138888888884),\n",
191 | " (u'2017-06-13', 18.769027777777776),\n",
192 | " (u'2017-06-14', 17.93489510489511),\n",
193 | " (u'2017-06-15', 18.135486111111103),\n",
194 | " (u'2017-06-16', 22.042708333333337),\n",
195 | " (u'2017-06-17', 25.475902777777772),\n",
196 | " (u'2017-06-18', 26.350069444444443),\n",
197 | " (u'2017-06-19', 25.422708333333333),\n",
198 | " (u'2017-06-20', 26.977916666666665),\n",
199 | " (u'2017-06-21', 23.28430555555555),\n",
200 | " (u'2017-06-22', 19.56493055555555),\n",
201 | " (u'2017-06-23', 18.57861111111111),\n",
202 | " (u'2017-06-24', 17.6775),\n",
203 | " (u'2017-06-25', 19.57138888888889),\n",
204 | " (u'2017-06-26', 18.298125000000002),\n",
205 | " (u'2017-06-27', 17.025555555555556),\n",
206 | " (u'2017-06-28', 15.242361111111105),\n",
207 | " (u'2017-06-29', 13.477083333333331),\n",
208 | " (u'2017-06-30', 11.59)]"
209 | ]
210 | },
211 | "execution_count": 8,
212 | "metadata": {},
213 | "output_type": "execute_result"
214 | }
215 | ],
216 | "source": [
217 | "averages.sortByKey().collect()"
218 | ]
219 | }
220 | ],
221 | "metadata": {
222 | "kernelspec": {
223 | "display_name": "Python 2",
224 | "language": "python",
225 | "name": "python2"
226 | },
227 | "language_info": {
228 | "codemirror_mode": {
229 | "name": "ipython",
230 | "version": 2
231 | },
232 | "file_extension": ".py",
233 | "mimetype": "text/x-python",
234 | "name": "python",
235 | "nbconvert_exporter": "python",
236 | "pygments_lexer": "ipython2",
237 | "version": "2.7.15"
238 | }
239 | },
240 | "nbformat": 4,
241 | "nbformat_minor": 4
242 | }
243 |
--------------------------------------------------------------------------------
/solutions/Unit 5 Working with meteorological data - SQL version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data using DataFrames (SQL version)"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Convert to a DataFrame"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "from pyspark.sql import Row\n",
47 | "\n",
48 | "def parse_row(line):\n",
49 | " \"\"\"Convert a line into a Row\"\"\"\n",
50 | " # All data lines start with 6 spaces\n",
51 | " if line.startswith(' '):\n",
52 | " codigo = int(line[:17].strip())\n",
53 | " datahora = line[17:40]\n",
54 | " data, hora = datahora.split()\n",
55 | " parametro = line[40:82].strip()\n",
56 | " valor = float(line[82:].replace(',', '.'))\n",
57 | " return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]\n",
58 | " return []"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "Using flatMap we have the flexibility to return nothing from a call to the function, this is accomplished returning and empty array."
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "data = rdd.flatMap(parse_row).toDF()"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "## Create Temporary View"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "To launch SQL queries we have first to create a temporary view:"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 4,
94 | "metadata": {},
95 | "outputs": [],
96 | "source": [
97 | "data.createOrReplaceTempView('data')"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "## Count the number of points"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 5,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "name": "stdout",
114 | "output_type": "stream",
115 | "text": [
116 | "+--------+\n",
117 | "|count(1)|\n",
118 | "+--------+\n",
119 | "| 16704|\n",
120 | "+--------+\n",
121 | "\n"
122 | ]
123 | }
124 | ],
125 | "source": [
126 | "# data.count()\n",
127 | "spark.sql('select count(*) from data').show()"
128 | ]
129 | },
130 | {
131 | "cell_type": "markdown",
132 | "metadata": {},
133 | "source": [
134 | "## Filter temperature data"
135 | ]
136 | },
137 | {
138 | "cell_type": "code",
139 | "execution_count": 6,
140 | "metadata": {},
141 | "outputs": [],
142 | "source": [
143 | "# t = data.where(data.parametro.like('Temperatura media %'))\n",
144 | "t = spark.sql('select * from data where parametro like \"Temperatura media %\"')\n",
145 | "t.createOrReplaceTempView('t')"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "## Find the maximum temperature of the month"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 7,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "+----------+\n",
165 | "|max(valor)|\n",
166 | "+----------+\n",
167 | "| 34.4|\n",
168 | "+----------+\n",
169 | "\n"
170 | ]
171 | }
172 | ],
173 | "source": [
174 | "# t.groupBy().max('valor').show()\n",
175 | "spark.sql('select max(valor) from t').show()"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "## Find the minimum temperature of the month"
183 | ]
184 | },
185 | {
186 | "cell_type": "code",
187 | "execution_count": 8,
188 | "metadata": {},
189 | "outputs": [
190 | {
191 | "name": "stdout",
192 | "output_type": "stream",
193 | "text": [
194 | "+----------+\n",
195 | "|min(valor)|\n",
196 | "+----------+\n",
197 | "| -9999.0|\n",
198 | "+----------+\n",
199 | "\n"
200 | ]
201 | }
202 | ],
203 | "source": [
204 | "# t.groupBy().min('valor').show()\n",
205 | "spark.sql('select min(valor) from t').show()"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "The value -9999 is a code used to indicate a non registered value (N/A).\n",
213 | "\n",
214 | "If we look to the possible values of \"Códigos de validación\" we see valid points have the code 1, so we can concentrate our efforts on data with code 1."
215 | ]
216 | },
217 | {
218 | "cell_type": "code",
219 | "execution_count": 9,
220 | "metadata": {},
221 | "outputs": [
222 | {
223 | "name": "stdout",
224 | "output_type": "stream",
225 | "text": [
226 | "+----------+\n",
227 | "|min(valor)|\n",
228 | "+----------+\n",
229 | "| 9.09|\n",
230 | "+----------+\n",
231 | "\n"
232 | ]
233 | }
234 | ],
235 | "source": [
236 | "# t.where(t.codigo == 1).groupBy().min('valor').show()\n",
237 | "spark.sql('select min(valor) from t where codigo=1').show()"
238 | ]
239 | },
240 | {
241 | "cell_type": "markdown",
242 | "metadata": {},
243 | "source": [
244 | "## Calculate the average temperature per day"
245 | ]
246 | },
247 | {
248 | "cell_type": "code",
249 | "execution_count": 10,
250 | "metadata": {},
251 | "outputs": [
252 | {
253 | "name": "stdout",
254 | "output_type": "stream",
255 | "text": [
256 | "+----------+------------------+\n",
257 | "| data| avg(valor)|\n",
258 | "+----------+------------------+\n",
259 | "|2017-06-22| 19.56493055555555|\n",
260 | "|2017-06-07| 17.76305555555556|\n",
261 | "|2017-06-24| 17.6775|\n",
262 | "|2017-06-29|13.477083333333331|\n",
263 | "|2017-06-19|25.422708333333333|\n",
264 | "|2017-06-03|14.511736111111105|\n",
265 | "|2017-06-23| 18.57861111111111|\n",
266 | "|2017-06-28|15.242361111111105|\n",
267 | "|2017-06-12|20.020138888888884|\n",
268 | "|2017-06-30| 11.59|\n",
269 | "|2017-06-26|18.298125000000002|\n",
270 | "|2017-06-04|14.889375000000005|\n",
271 | "|2017-06-18|26.350069444444443|\n",
272 | "|2017-06-06|14.901041666666666|\n",
273 | "|2017-06-09| 17.86694444444445|\n",
274 | "|2017-06-21| 23.28430555555555|\n",
275 | "|2017-06-25| 19.57138888888889|\n",
276 | "|2017-06-14| -51.6271527777778|\n",
277 | "|2017-06-16|22.042708333333337|\n",
278 | "|2017-06-11|17.806250000000006|\n",
279 | "|2017-06-08| 17.49979166666667|\n",
280 | "|2017-06-13|18.769027777777776|\n",
281 | "|2017-06-01|17.179580419580425|\n",
282 | "|2017-06-02|16.007500000000004|\n",
283 | "|2017-06-27|17.025555555555556|\n",
284 | "|2017-06-17|25.475902777777772|\n",
285 | "|2017-06-15|18.135486111111103|\n",
286 | "|2017-06-20|26.977916666666665|\n",
287 | "|2017-06-05| 13.67486111111111|\n",
288 | "|2017-06-10|19.207222222222224|\n",
289 | "+----------+------------------+\n",
290 | "\n"
291 | ]
292 | }
293 | ],
294 | "source": [
295 | "# t.groupBy(t.data).mean('valor').show(30)\n",
296 | "spark.sql('select data, mean(valor) from t group by data').show(30)"
297 | ]
298 | },
299 | {
300 | "cell_type": "markdown",
301 | "metadata": {},
302 | "source": [
303 | "## Show the results sorted by date"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 11,
309 | "metadata": {},
310 | "outputs": [
311 | {
312 | "name": "stdout",
313 | "output_type": "stream",
314 | "text": [
315 | "+----------+------------------+\n",
316 | "| data| avg(valor)|\n",
317 | "+----------+------------------+\n",
318 | "|2017-06-01|17.179580419580425|\n",
319 | "|2017-06-02|16.007500000000004|\n",
320 | "|2017-06-03|14.511736111111105|\n",
321 | "|2017-06-04|14.889375000000005|\n",
322 | "|2017-06-05| 13.67486111111111|\n",
323 | "|2017-06-06|14.901041666666666|\n",
324 | "|2017-06-07| 17.76305555555556|\n",
325 | "|2017-06-08| 17.49979166666667|\n",
326 | "|2017-06-09| 17.86694444444445|\n",
327 | "|2017-06-10|19.207222222222224|\n",
328 | "|2017-06-11|17.806250000000006|\n",
329 | "|2017-06-12|20.020138888888884|\n",
330 | "|2017-06-13|18.769027777777776|\n",
331 | "|2017-06-14| -51.6271527777778|\n",
332 | "|2017-06-15|18.135486111111103|\n",
333 | "|2017-06-16|22.042708333333337|\n",
334 | "|2017-06-17|25.475902777777772|\n",
335 | "|2017-06-18|26.350069444444443|\n",
336 | "|2017-06-19|25.422708333333333|\n",
337 | "|2017-06-20|26.977916666666665|\n",
338 | "|2017-06-21| 23.28430555555555|\n",
339 | "|2017-06-22| 19.56493055555555|\n",
340 | "|2017-06-23| 18.57861111111111|\n",
341 | "|2017-06-24| 17.6775|\n",
342 | "|2017-06-25| 19.57138888888889|\n",
343 | "|2017-06-26|18.298125000000002|\n",
344 | "|2017-06-27|17.025555555555556|\n",
345 | "|2017-06-28|15.242361111111105|\n",
346 | "|2017-06-29|13.477083333333331|\n",
347 | "|2017-06-30| 11.59|\n",
348 | "+----------+------------------+\n",
349 | "\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "# t.groupBy(t.data).mean('valor').sort('data').show(30)\n",
355 | "spark.sql('select data, mean(valor) from t group by data order by data').show(30)"
356 | ]
357 | }
358 | ],
359 | "metadata": {
360 | "kernelspec": {
361 | "display_name": "Python 2",
362 | "language": "python",
363 | "name": "python2"
364 | },
365 | "language_info": {
366 | "codemirror_mode": {
367 | "name": "ipython",
368 | "version": 2
369 | },
370 | "file_extension": ".py",
371 | "mimetype": "text/x-python",
372 | "name": "python",
373 | "nbconvert_exporter": "python",
374 | "pygments_lexer": "ipython2",
375 | "version": "2.7.15"
376 | }
377 | },
378 | "nbformat": 4,
379 | "nbformat_minor": 1
380 | }
381 |
--------------------------------------------------------------------------------
/solutions/Unit 5 Working with meteorological data.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Working with meteorological data using DataFrames"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "We will use meteorolical data from Meteogalicia that contains the measurements of a weather station in Santiago during June 2017."
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Load data"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "## Convert to a DataFrame"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 2,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "from pyspark.sql import Row\n",
47 | "\n",
48 | "def parse_row(line):\n",
49 | " \"\"\"Convert a line into a Row\"\"\"\n",
50 | " # All data lines start with 6 spaces\n",
51 | " if line.startswith(' '):\n",
52 | " codigo = int(line[:17].strip())\n",
53 | " datahora = line[17:40]\n",
54 | " data, hora = datahora.split()\n",
55 | " parametro = line[40:82].strip()\n",
56 | " valor = float(line[82:].replace(',', '.'))\n",
57 | " return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]\n",
58 | " return []"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "Using flatMap we have the flexibility to return nothing from a call to the function, this is accomplished returning and empty array."
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 3,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "data = rdd.flatMap(parse_row).toDF()"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "## Count the number of points"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 4,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "data": {
91 | "text/plain": [
92 | "16704"
93 | ]
94 | },
95 | "execution_count": 4,
96 | "metadata": {},
97 | "output_type": "execute_result"
98 | }
99 | ],
100 | "source": [
101 | "data.count()"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "## Filter temperature data"
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 5,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "t = data.where(data.parametro.like('Temperatura media %'))"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "## Find the maximum temperature of the month"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 6,
130 | "metadata": {},
131 | "outputs": [
132 | {
133 | "name": "stdout",
134 | "output_type": "stream",
135 | "text": [
136 | "+----------+\n",
137 | "|max(valor)|\n",
138 | "+----------+\n",
139 | "| 34.4|\n",
140 | "+----------+\n",
141 | "\n"
142 | ]
143 | }
144 | ],
145 | "source": [
146 | "t.groupBy().max('valor').show()"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "## Find the minimum temperature of the month"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 7,
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "name": "stdout",
163 | "output_type": "stream",
164 | "text": [
165 | "+----------+\n",
166 | "|min(valor)|\n",
167 | "+----------+\n",
168 | "| -9999.0|\n",
169 | "+----------+\n",
170 | "\n"
171 | ]
172 | }
173 | ],
174 | "source": [
175 | "t.groupBy().min('valor').show()"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "The value -9999 is a code used to indicate a non registered value (N/A).\n",
183 | "\n",
184 | "If we look to the possible values of \"Códigos de validación\" we see valid points have the code 1, so we can concentrate our efforts on data with code 1."
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 8,
190 | "metadata": {},
191 | "outputs": [
192 | {
193 | "name": "stdout",
194 | "output_type": "stream",
195 | "text": [
196 | "+----------+\n",
197 | "|min(valor)|\n",
198 | "+----------+\n",
199 | "| 9.09|\n",
200 | "+----------+\n",
201 | "\n"
202 | ]
203 | }
204 | ],
205 | "source": [
206 | "t.where(t.codigo == 1).groupBy().min('valor').show()"
207 | ]
208 | },
209 | {
210 | "cell_type": "markdown",
211 | "metadata": {},
212 | "source": [
213 | "## Calculate the average temperature per day"
214 | ]
215 | },
216 | {
217 | "cell_type": "code",
218 | "execution_count": 9,
219 | "metadata": {},
220 | "outputs": [
221 | {
222 | "name": "stdout",
223 | "output_type": "stream",
224 | "text": [
225 | "+----------+------------------+\n",
226 | "| data| avg(valor)|\n",
227 | "+----------+------------------+\n",
228 | "|2017-06-22| 19.56493055555555|\n",
229 | "|2017-06-07| 17.76305555555556|\n",
230 | "|2017-06-24| 17.6775|\n",
231 | "|2017-06-29|13.477083333333331|\n",
232 | "|2017-06-19|25.422708333333333|\n",
233 | "|2017-06-03|14.511736111111105|\n",
234 | "|2017-06-23| 18.57861111111111|\n",
235 | "|2017-06-28|15.242361111111105|\n",
236 | "|2017-06-12|20.020138888888884|\n",
237 | "|2017-06-30| 11.59|\n",
238 | "|2017-06-26|18.298125000000002|\n",
239 | "|2017-06-04|14.889375000000005|\n",
240 | "|2017-06-18|26.350069444444443|\n",
241 | "|2017-06-06|14.901041666666666|\n",
242 | "|2017-06-09| 17.86694444444445|\n",
243 | "|2017-06-21| 23.28430555555555|\n",
244 | "|2017-06-25| 19.57138888888889|\n",
245 | "|2017-06-14| -51.6271527777778|\n",
246 | "|2017-06-16|22.042708333333337|\n",
247 | "|2017-06-11|17.806250000000006|\n",
248 | "|2017-06-08| 17.49979166666667|\n",
249 | "|2017-06-13|18.769027777777776|\n",
250 | "|2017-06-01|17.179580419580425|\n",
251 | "|2017-06-02|16.007500000000004|\n",
252 | "|2017-06-27|17.025555555555556|\n",
253 | "|2017-06-17|25.475902777777772|\n",
254 | "|2017-06-15|18.135486111111103|\n",
255 | "|2017-06-20|26.977916666666665|\n",
256 | "|2017-06-05| 13.67486111111111|\n",
257 | "|2017-06-10|19.207222222222224|\n",
258 | "+----------+------------------+\n",
259 | "\n"
260 | ]
261 | }
262 | ],
263 | "source": [
264 | "t.groupBy(t.data).mean('valor').show(30)"
265 | ]
266 | },
267 | {
268 | "cell_type": "markdown",
269 | "metadata": {},
270 | "source": [
271 | "## Show the results sorted by date"
272 | ]
273 | },
274 | {
275 | "cell_type": "code",
276 | "execution_count": 10,
277 | "metadata": {},
278 | "outputs": [
279 | {
280 | "name": "stdout",
281 | "output_type": "stream",
282 | "text": [
283 | "+----------+------------------+\n",
284 | "| data| avg(valor)|\n",
285 | "+----------+------------------+\n",
286 | "|2017-06-01|17.179580419580425|\n",
287 | "|2017-06-02|16.007500000000004|\n",
288 | "|2017-06-03|14.511736111111105|\n",
289 | "|2017-06-04|14.889375000000005|\n",
290 | "|2017-06-05| 13.67486111111111|\n",
291 | "|2017-06-06|14.901041666666666|\n",
292 | "|2017-06-07| 17.76305555555556|\n",
293 | "|2017-06-08| 17.49979166666667|\n",
294 | "|2017-06-09| 17.86694444444445|\n",
295 | "|2017-06-10|19.207222222222224|\n",
296 | "|2017-06-11|17.806250000000006|\n",
297 | "|2017-06-12|20.020138888888884|\n",
298 | "|2017-06-13|18.769027777777776|\n",
299 | "|2017-06-14| -51.6271527777778|\n",
300 | "|2017-06-15|18.135486111111103|\n",
301 | "|2017-06-16|22.042708333333337|\n",
302 | "|2017-06-17|25.475902777777772|\n",
303 | "|2017-06-18|26.350069444444443|\n",
304 | "|2017-06-19|25.422708333333333|\n",
305 | "|2017-06-20|26.977916666666665|\n",
306 | "|2017-06-21| 23.28430555555555|\n",
307 | "|2017-06-22| 19.56493055555555|\n",
308 | "|2017-06-23| 18.57861111111111|\n",
309 | "|2017-06-24| 17.6775|\n",
310 | "|2017-06-25| 19.57138888888889|\n",
311 | "|2017-06-26|18.298125000000002|\n",
312 | "|2017-06-27|17.025555555555556|\n",
313 | "|2017-06-28|15.242361111111105|\n",
314 | "|2017-06-29|13.477083333333331|\n",
315 | "|2017-06-30| 11.59|\n",
316 | "+----------+------------------+\n",
317 | "\n"
318 | ]
319 | }
320 | ],
321 | "source": [
322 | "t.groupBy(t.data).mean('valor').sort('data').show(30)"
323 | ]
324 | }
325 | ],
326 | "metadata": {
327 | "kernelspec": {
328 | "display_name": "Python 2",
329 | "language": "python",
330 | "name": "python2"
331 | },
332 | "language_info": {
333 | "codemirror_mode": {
334 | "name": "ipython",
335 | "version": 2
336 | },
337 | "file_extension": ".py",
338 | "mimetype": "text/x-python",
339 | "name": "python",
340 | "nbconvert_exporter": "python",
341 | "pygments_lexer": "ipython2",
342 | "version": "2.7.15"
343 | }
344 | },
345 | "nbformat": 4,
346 | "nbformat_minor": 1
347 | }
348 |
--------------------------------------------------------------------------------
/solutions/Unit 7 KMeans.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Implementing KMeans (optimized version)"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "from __future__ import print_function\n",
17 | "import math\n",
18 | "from collections import namedtuple"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "## Parameters"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 2,
31 | "metadata": {},
32 | "outputs": [],
33 | "source": [
34 | "# Number of clusters to find\n",
35 | "K = 5\n",
36 | "# Convergence threshold\n",
37 | "THRESHOLD = 0.1\n",
38 | "# Maximum number of iterations\n",
39 | "MAX_ITERS = 20"
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "## Load data"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 3,
52 | "metadata": {},
53 | "outputs": [],
54 | "source": [
55 | "def parse_coordinates(line):\n",
56 | " fields = line.split(',')\n",
57 | " return (float(fields[3]), float(fields[4]))"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 4,
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "data = sc.textFile('datasets/locations')"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 5,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "points = data.map(parse_coordinates)"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "metadata": {},
81 | "source": [
82 | "Let's **cache the points** because the algorithm will be reusing them:"
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 6,
88 | "metadata": {
89 | "scrolled": true
90 | },
91 | "outputs": [
92 | {
93 | "data": {
94 | "text/plain": [
95 | "PythonRDD[2] at RDD at PythonRDD.scala:53"
96 | ]
97 | },
98 | "execution_count": 6,
99 | "metadata": {},
100 | "output_type": "execute_result"
101 | }
102 | ],
103 | "source": [
104 | "points.cache()"
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "## Useful functions"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": 7,
117 | "metadata": {},
118 | "outputs": [],
119 | "source": [
120 | "def distance(p1, p2): \n",
121 | " \"Calculate the squared distance between two given points\"\n",
122 | " return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2\n",
123 | "\n",
124 | "def closest_centroid(point, centroidsBC): \n",
125 | " \"Calculate the closest centroid to the given point: eg. the cluster this point belongs to\"\n",
126 | " distances = [distance(point, c) for c in centroidsBC.value]\n",
127 | " shortest = min(distances)\n",
128 | " return distances.index(shortest)\n",
129 | "\n",
130 | "def add_points(p1,p2):\n",
131 | " \"Add two points of the same cluster in order to calculate later the new centroids\"\n",
132 | " return [p1[0] + p2[0], p1[1] + p2[1]]"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "## Iteratively calculate the centroids"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 8,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "name": "stdout",
149 | "output_type": "stream",
150 | "text": [
151 | "Variation in iteration 0: 4989.32008451\n",
152 | "Variation in iteration 1: 2081.17551268\n",
153 | "Variation in iteration 2: 1.6011620119\n",
154 | "Variation in iteration 3: 2.55059475168\n",
155 | "Variation in iteration 4: 0.994848416636\n",
156 | "Variation in iteration 5: 0.0381850235415\n",
157 | "Final centroids: [[35.08592000544936, -112.57643826547803], [0.0, 0.0], [38.05200414101911, -121.20324355675143], [43.891507710205694, -121.32350131512835], [34.28939789970032, -117.77840744773651]]\n",
158 | "CPU times: user 84 ms, sys: 26.9 ms, total: 111 ms\n",
159 | "Wall time: 18.3 s\n"
160 | ]
161 | }
162 | ],
163 | "source": [
164 | "%%time\n",
165 | "# Initial centroids: we just take K randomly selected points\n",
166 | "centroids = points.takeSample(False, K, 42)\n",
167 | "# Broadcast var\n",
168 | "centroidsBC = sc.broadcast(centroids)\n",
169 | "\n",
170 | "# Just make sure the first iteration is always run\n",
171 | "variation = THRESHOLD + 1\n",
172 | "iteration = 0\n",
173 | "\n",
174 | "while variation > THRESHOLD and iteration < MAX_ITERS:\n",
175 | " # Map each point to (centroid, (point, 1))\n",
176 | " with_centroids = points.map(lambda p : (closest_centroid(p, centroidsBC), (p, 1)))\n",
177 | " # For each centroid reduceByKey adding the coordinates of all the points\n",
178 | " # and keeping track of the number of points\n",
179 | " cluster_stats = with_centroids.reduceByKey(lambda (p1, n1), (p2, n2): (add_points(p1, p2), n1 + n2))\n",
180 | " # For each existing centroid find the new centroid location calculating the average of each closest point\n",
181 | " new_centroids = cluster_stats.map(lambda (c, ((x, y), n)): (c, [x/n, y/n])).collect()\n",
182 | " # Calculate the variation between old and new centroids\n",
183 | " variation = 0\n",
184 | " for (c, point) in new_centroids: variation += distance(centroids[c], point)\n",
185 | " print('Variation in iteration {}: {}'.format(iteration, variation))\n",
186 | " # Replace old centroids with the new values\n",
187 | " for (c, point) in new_centroids: centroids[c] = point\n",
188 | " # Replace the centroids broadcast var with the new values\n",
189 | " centroidsBC = sc.broadcast(centroids)\n",
190 | " iteration += 1\n",
191 | " \n",
192 | "print('Final centroids: {}'.format(centroids))"
193 | ]
194 | }
195 | ],
196 | "metadata": {
197 | "kernelspec": {
198 | "display_name": "Python 2",
199 | "language": "python",
200 | "name": "python2"
201 | },
202 | "language_info": {
203 | "codemirror_mode": {
204 | "name": "ipython",
205 | "version": 2
206 | },
207 | "file_extension": ".py",
208 | "mimetype": "text/x-python",
209 | "name": "python",
210 | "nbconvert_exporter": "python",
211 | "pygments_lexer": "ipython2",
212 | "version": "2.7.15"
213 | }
214 | },
215 | "nbformat": 4,
216 | "nbformat_minor": 1
217 | }
218 |
--------------------------------------------------------------------------------
/solutions/Unit_5_sentiment_analysis_amazon_books-short_version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# SENTIMENT ANALYSIS WITH SPARK ML"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "# Spark ML Main Concepts\n",
15 | "\n",
16 | "The Spark Machine learning API in the **spark.ml** package is based on DataFrames, there is also another Spark Machine learning API based on RDDs in the **spark.mllib** package, but as of Spark 2.0, the RDD-based API has entered maintenance mode. The primary Machine Learning API for Spark is now the DataFrame-based API.\n",
17 | "\n",
18 | "Main concepts of Spark ML:\n",
19 | "\n",
20 | "- **Transformer**: transforms one DataFrame into another DataFrame\n",
21 | "\n",
22 | "- **Estimator**: eg. a learning algorithm that trains on a DataFrame and produces a Model\n",
23 | "\n",
24 | "- **Pipeline**: chains Transformers and Estimators to produce a Model\n",
25 | "\n",
26 | "- **Evaluator**: measures how well a fitted Model does on held-out test data\n",
27 | "\n"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "# Amazon product data\n",
35 | "We will use a [dataset](http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Books_5.json.gz)[1] that contains 8.9M book reviews from Amazon, spanning May 1996 - July 2014.\n",
36 | "\n",
37 | "Dataset characteristics:\n",
38 | "- Number of reviews: 8.9M\n",
39 | "- Size: 8.8GB (uncompressed)\n",
40 | "- HDFS blocks: 70 (each with 3 replicas)\n",
41 | "\n",
42 | "\n",
43 | "[1] Image-based recommendations on styles and substitutes\n",
44 | "J. McAuley, C. Targett, J. Shi, A. van den Hengel\n",
45 | "SIGIR, 2015\n",
46 | "http://jmcauley.ucsd.edu/data/amazon/"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "# Load Data"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 1,
59 | "metadata": {},
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "CPU times: user 6.25 ms, sys: 1.29 ms, total: 7.54 ms\n",
66 | "Wall time: 25.1 s\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "%%time\n",
72 | "raw_reviews = spark.read.json('data/amazon/reviews_Books_5.json')"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 2,
78 | "metadata": {},
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "+--------------------+-------+\n",
85 | "| reviewText|overall|\n",
86 | "+--------------------+-------+\n",
87 | "|Spiritually and m...| 5.0|\n",
88 | "|This is one my mu...| 5.0|\n",
89 | "+--------------------+-------+\n",
90 | "only showing top 2 rows\n",
91 | "\n",
92 | "CPU times: user 2.64 ms, sys: 2.37 ms, total: 5 ms\n",
93 | "Wall time: 4.12 s\n"
94 | ]
95 | }
96 | ],
97 | "source": [
98 | "%%time\n",
99 | "all_reviews = raw_reviews.select('reviewText', 'overall')\n",
100 | "all_reviews.cache()\n",
101 | "all_reviews.show(2)"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "# Prepare data\n",
109 | "We will avoid neutral reviews by keeping only reviews with 1 or 5 stars overall score.\n",
110 | "We will also filter out the reviews that contain no text."
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 3,
116 | "metadata": {},
117 | "outputs": [],
118 | "source": [
119 | "nonneutral_reviews = all_reviews.filter(\n",
120 | " (all_reviews.overall == 1.0) | (all_reviews.overall == 5.0))\n",
121 | "reviews = nonneutral_reviews.filter(all_reviews.reviewText != '')"
122 | ]
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": 4,
127 | "metadata": {},
128 | "outputs": [
129 | {
130 | "data": {
131 | "text/plain": [
132 | "DataFrame[reviewText: string, overall: double]"
133 | ]
134 | },
135 | "execution_count": 4,
136 | "metadata": {},
137 | "output_type": "execute_result"
138 | }
139 | ],
140 | "source": [
141 | "reviews.cache()\n",
142 | "all_reviews.unpersist()"
143 | ]
144 | },
145 | {
146 | "cell_type": "markdown",
147 | "metadata": {},
148 | "source": [
149 | "# Split Data"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": 5,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": [
158 | "trainingData, testData = reviews.randomSplit([0.8, 0.2])"
159 | ]
160 | },
161 | {
162 | "cell_type": "markdown",
163 | "metadata": {},
164 | "source": [
165 | "# Generate Pipeline\n",
166 | ""
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "## Binarizer\n",
174 | "A transformer to convert numerical features to binary (0/1) features"
175 | ]
176 | },
177 | {
178 | "cell_type": "code",
179 | "execution_count": 6,
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "from pyspark.ml.feature import Binarizer\n",
184 | "\n",
185 | "binarizer = Binarizer(threshold=2.5, inputCol='overall', outputCol='label')"
186 | ]
187 | },
188 | {
189 | "cell_type": "markdown",
190 | "metadata": {},
191 | "source": [
192 | "## Tokenizer\n",
193 | "A transformer that converts the input string to lowercase and then splits it by white spaces."
194 | ]
195 | },
196 | {
197 | "cell_type": "code",
198 | "execution_count": 7,
199 | "metadata": {},
200 | "outputs": [],
201 | "source": [
202 | "from pyspark.ml.feature import Tokenizer\n",
203 | "tokenizer = Tokenizer(inputCol='reviewText', outputCol='words')"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "## StopWordsRemover\n",
211 | "A transformer that filters out stop words from input."
212 | ]
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": 8,
217 | "metadata": {},
218 | "outputs": [],
219 | "source": [
220 | "from pyspark.ml.feature import StopWordsRemover\n",
221 | "remover = StopWordsRemover(inputCol=tokenizer.getOutputCol(), outputCol='filtered')"
222 | ]
223 | },
224 | {
225 | "cell_type": "markdown",
226 | "metadata": {},
227 | "source": [
228 | "## HashingTF\n",
229 | "A Transformer that converts a sequence of words into a fixed-length feature Vector. It maps a sequence of terms to their term frequencies using a hashing function."
230 | ]
231 | },
232 | {
233 | "cell_type": "code",
234 | "execution_count": 9,
235 | "metadata": {},
236 | "outputs": [],
237 | "source": [
238 | "from pyspark.ml.feature import HashingTF\n",
239 | "hashingTF = HashingTF(inputCol=remover.getOutputCol(), outputCol='features')"
240 | ]
241 | },
242 | {
243 | "cell_type": "markdown",
244 | "metadata": {},
245 | "source": [
246 | "# Estimator\n",
247 | "## LogisticRegression"
248 | ]
249 | },
250 | {
251 | "cell_type": "code",
252 | "execution_count": 10,
253 | "metadata": {},
254 | "outputs": [],
255 | "source": [
256 | "from pyspark.ml.classification import LogisticRegression\n",
257 | "lr = LogisticRegression(maxIter=10, regParam=0.01)"
258 | ]
259 | },
260 | {
261 | "cell_type": "markdown",
262 | "metadata": {},
263 | "source": [
264 | "# Pipeline"
265 | ]
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": 11,
270 | "metadata": {},
271 | "outputs": [],
272 | "source": [
273 | "from pyspark.ml import Pipeline\n",
274 | "pipeline = Pipeline(stages=[binarizer, tokenizer, remover, hashingTF, lr])"
275 | ]
276 | },
277 | {
278 | "cell_type": "code",
279 | "execution_count": 12,
280 | "metadata": {},
281 | "outputs": [
282 | {
283 | "name": "stdout",
284 | "output_type": "stream",
285 | "text": [
286 | "CPU times: user 38.1 ms, sys: 16.3 ms, total: 54.3 ms\n",
287 | "Wall time: 1min 3s\n"
288 | ]
289 | }
290 | ],
291 | "source": [
292 | "%%time\n",
293 | "pipeLineModel = pipeline.fit(trainingData)"
294 | ]
295 | },
296 | {
297 | "cell_type": "markdown",
298 | "metadata": {},
299 | "source": [
300 | "# Evaluation"
301 | ]
302 | },
303 | {
304 | "cell_type": "code",
305 | "execution_count": 13,
306 | "metadata": {
307 | "scrolled": true
308 | },
309 | "outputs": [
310 | {
311 | "name": "stdout",
312 | "output_type": "stream",
313 | "text": [
314 | "Area under ROC: 0.967867334409\n",
315 | "CPU times: user 26.3 ms, sys: 11.4 ms, total: 37.7 ms\n",
316 | "Wall time: 17.8 s\n"
317 | ]
318 | }
319 | ],
320 | "source": [
321 | "%%time\n",
322 | "from pyspark.ml.evaluation import BinaryClassificationEvaluator\n",
323 | "evaluator = BinaryClassificationEvaluator()\n",
324 | "\n",
325 | "predictions = pipeLineModel.transform(testData)\n",
326 | "\n",
327 | "aur = evaluator.evaluate(predictions)\n",
328 | "\n",
329 | "print 'Area under ROC: ', aur"
330 | ]
331 | },
332 | {
333 | "cell_type": "markdown",
334 | "metadata": {},
335 | "source": [
336 | "# Hyperparameter Tuning"
337 | ]
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": 14,
342 | "metadata": {},
343 | "outputs": [
344 | {
345 | "name": "stdout",
346 | "output_type": "stream",
347 | "text": [
348 | "CPU times: user 3.77 s, sys: 1.09 s, total: 4.86 s\n",
349 | "Wall time: 11min 48s\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "%%time\n",
355 | "from pyspark.ml.tuning import ParamGridBuilder, CrossValidator\n",
356 | "param_grid = ParamGridBuilder() \\\n",
357 | " .addGrid(hashingTF.numFeatures, [10000, 100000]) \\\n",
358 | " .addGrid(lr.regParam, [0.01, 0.1, 1.0]) \\\n",
359 | " .addGrid(lr.maxIter, [10, 20]) \\\n",
360 | " .build()\n",
361 | " \n",
362 | "cv = (CrossValidator()\n",
363 | " .setEstimator(pipeline)\n",
364 | " .setEvaluator(evaluator)\n",
365 | " .setEstimatorParamMaps(param_grid)\n",
366 | " .setNumFolds(3))\n",
367 | "\n",
368 | "cv_model = cv.fit(trainingData)"
369 | ]
370 | },
371 | {
372 | "cell_type": "code",
373 | "execution_count": 15,
374 | "metadata": {},
375 | "outputs": [
376 | {
377 | "name": "stdout",
378 | "output_type": "stream",
379 | "text": [
380 | "Area under ROC: 0.97005045743\n",
381 | "CPU times: user 29.1 ms, sys: 6.17 ms, total: 35.2 ms\n",
382 | "Wall time: 5.89 s\n"
383 | ]
384 | }
385 | ],
386 | "source": [
387 | "%%time\n",
388 | "new_predictions = cv_model.transform(testData)\n",
389 | "new_aur = evaluator.evaluate(new_predictions)\n",
390 | "print 'Area under ROC: ', new_aur"
391 | ]
392 | }
393 | ],
394 | "metadata": {
395 | "kernelspec": {
396 | "display_name": "Python 2",
397 | "language": "python",
398 | "name": "python2"
399 | },
400 | "language_info": {
401 | "codemirror_mode": {
402 | "name": "ipython",
403 | "version": 2
404 | },
405 | "file_extension": ".py",
406 | "mimetype": "text/x-python",
407 | "name": "python",
408 | "nbconvert_exporter": "python",
409 | "pygments_lexer": "ipython2",
410 | "version": "2.7.15"
411 | }
412 | },
413 | "nbformat": 4,
414 | "nbformat_minor": 2
415 | }
416 |
--------------------------------------------------------------------------------
/solutions/Unit_6_WordCount.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from pyspark.sql import SparkSession
3 |
4 | if __name__ == '__main__':
5 | spark = SparkSession\
6 | .builder \
7 | .appName("WordCount") \
8 | .config('spark.driver.memory', '2g') \
9 | .config('spark.executor.cores', 1) \
10 | .config('spark.executor.memory', '2g') \
11 | .config('spark.executor.memoryOverhead', '1g') \
12 | .config('spark.dynamicAllocation.enabled', False) \
13 | .getOrCreate()
14 | sc = spark.sparkContext
15 |
16 | lines = sc.textFile('datasets/slurmd/slurmd.log.c6601')
17 | words = lines.flatMap(lambda line: line.split())
18 | counts = words.map(lambda word: (word, 1))
19 | aggregated = counts.reduceByKey(lambda a, b: a + b)
20 | result = aggregated.map(lambda (x, y): (y, x))
21 | print(result.sortByKey(ascending=False).take(10))
22 |
23 | spark.stop()
24 |
--------------------------------------------------------------------------------
/solutions/Unit_6_working_with_meteorological_data-using_dataframes.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from pyspark.sql import SparkSession, Row
3 |
4 |
5 | def parse_row(line):
6 | """Convert a line into a Row"""
7 | # All data lines start with 6 spaces
8 | if line.startswith(' '):
9 | codigo = int(line[:17].strip())
10 | datahora = line[17:40]
11 | data, hora = datahora.split()
12 | parametro = line[40:82].strip()
13 | valor = float(line[82:].replace(',', '.'))
14 | return [Row(codigo=codigo, data=data, hora=hora, parametro=parametro, valor=valor)]
15 | return []
16 |
17 |
18 | if __name__ == '__main__':
19 | spark = SparkSession\
20 | .builder \
21 | .appName("Meteo-using-DF") \
22 | .config('spark.driver.memory', '2g') \
23 | .config('spark.executor.cores', 1) \
24 | .config('spark.executor.memory', '2g') \
25 | .config('spark.executor.memoryOverhead', '1g') \
26 | .config('spark.dynamicAllocation.enabled', False) \
27 | .getOrCreate()
28 | sc = spark.sparkContext
29 |
30 | rdd = sc.textFile('datasets/meteogalicia.txt')
31 | data = rdd.flatMap(parse_row).toDF()
32 | count = data.count()
33 | print('Total count:', count)
34 | t = data.where(data.parametro.like('Temperatura media %'))
35 | print('Maximum temperature')
36 | t.groupBy().max('valor').show()
37 | print('Minimum temperature')
38 | t.where(t.codigo == 1).groupBy().min('valor').show()
39 | print('Average temperatures per day')
40 | t.groupBy(t.data).mean('valor').sort('data').show(30)
41 |
42 | spark.stop()
43 |
--------------------------------------------------------------------------------
/solutions/Unit_6_working_with_meteorological_data-using_rdds.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | from pyspark import SparkContext
3 |
4 |
5 | def parse_temperature(line):
6 | (_, date, hour, _, _, _, value) = line.split()
7 | return (date, float(value.replace(',', '.')))
8 |
9 |
10 | def sum_pairs(a, b):
11 | return (a[0]+b[0], a[1]+b[1])
12 |
13 |
14 | if __name__ == '__main__':
15 | sc = SparkContext(appName='Meteo analysis')
16 |
17 | rdd = sc.textFile('datasets/meteogalicia.txt')
18 |
19 | temperatures = (rdd.filter(lambda line: 'Temperatura media' in line)
20 | .map(parse_temperature))
21 |
22 | averages = (temperatures.map(lambda (date, t): (date, (t, 1)))
23 | .reduceByKey(sum_pairs)
24 | .mapValues(lambda (temp, count): temp/count))
25 |
26 | result = averages.sortByKey().collect()
27 | print('Average temperature per day')
28 | for date, temp in result:
29 | print('{} {}'.format(date, temp))
30 |
31 | sc.stop()
32 |
--------------------------------------------------------------------------------
/unit_2_basic_spark_concepts.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 2: Basic Spark Concepts"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "\n",
16 | "2.1 Spark Components\n",
17 | "\n",
18 | "2.2 RDD\n",
19 | "\n",
20 | "2.3 Partitioning\n",
21 | "\n",
22 | "2.4 Transformations vs Actions\n",
23 | "\n",
24 | "2.5 DAG\n",
25 | "\n",
26 | "2.6 Available APIs"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "## Spark Components\n",
34 | "\n",
35 | "A Spark application consists of a driver program that runs the main code of the program, distributing the operations to the rest of executors assigned by YARN to the application.\n",
36 | "\n",
37 | "\n",
38 | "\n",
39 | "Diagram taken from the [Spark Cluster Mode Overview](https://spark.apache.org/docs/2.4.0/cluster-overview.html)."
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "For further information check our [Spark Tutorial](http://bigdata.cesga.es/tutorials/spark.html#/) and the [Spark Cluster Mode Overview](https://spark.apache.org/docs/2.4.0/cluster-overview.html)."
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "## RDD\n",
54 | "A Resilient Distributed Dataset (RDD) is an abstraction that represents a collection of elements **distributed** across the nodes of the cluster.\n",
55 | "\n",
56 | "A RDD provides a series of methods that allow to operate with its underlying data in parallel in a very transparent way:\n"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 1,
62 | "metadata": {},
63 | "outputs": [],
64 | "source": [
65 | "rdd = sc.parallelize([1, 2, 3, 4, 5, 6])\n"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 2,
71 | "metadata": {},
72 | "outputs": [
73 | {
74 | "data": {
75 | "text/plain": [
76 | "6"
77 | ]
78 | },
79 | "execution_count": 2,
80 | "metadata": {},
81 | "output_type": "execute_result"
82 | }
83 | ],
84 | "source": [
85 | "rdd.count()"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "RDDs are **resilient** because they can automatically recover in case some of the nodes fails."
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## Partitioning"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "The elements in a RDD are splitted between the nodes of the cluster, dividing the collection in partitions. Each partition is then processed by a given executor.\n",
107 | "\n",
108 | ""
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 3,
114 | "metadata": {},
115 | "outputs": [],
116 | "source": [
117 | "rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6])"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 4,
123 | "metadata": {},
124 | "outputs": [
125 | {
126 | "data": {
127 | "text/plain": [
128 | "'(2) ParallelCollectionRDD[2] at parallelize at PythonRDD.scala:195 []'"
129 | ]
130 | },
131 | "execution_count": 4,
132 | "metadata": {},
133 | "output_type": "execute_result"
134 | }
135 | ],
136 | "source": [
137 | "rdd1.toDebugString()"
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 5,
143 | "metadata": {},
144 | "outputs": [
145 | {
146 | "data": {
147 | "text/plain": [
148 | "[[1, 2, 3], [4, 5, 6]]"
149 | ]
150 | },
151 | "execution_count": 5,
152 | "metadata": {},
153 | "output_type": "execute_result"
154 | }
155 | ],
156 | "source": [
157 | "rdd1.glom().collect()"
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 6,
163 | "metadata": {},
164 | "outputs": [],
165 | "source": [
166 | "rdd2 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 7,
172 | "metadata": {},
173 | "outputs": [
174 | {
175 | "data": {
176 | "text/plain": [
177 | "[[1, 2], [3, 4], [5, 6]]"
178 | ]
179 | },
180 | "execution_count": 7,
181 | "metadata": {},
182 | "output_type": "execute_result"
183 | }
184 | ],
185 | "source": [
186 | "rdd2.glom().collect()"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 8,
192 | "metadata": {},
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "(3) ParallelCollectionRDD[4] at parallelize at PythonRDD.scala:195 []\n"
199 | ]
200 | }
201 | ],
202 | "source": [
203 | "print rdd2.toDebugString()"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "In general, each task of an application runs against a different partition of the RDD.\n",
211 | "\n",
212 | "When using **large files** in HDFS (with many blocks) the partitions can be considered equivalent to the HDFS blocks of the given file.\n",
213 | "\n",
214 | "For **small files** (smaller than 128MB) by default spark will create two partitions, so initally only two tasks can be executed in parallel, independently of how many resources YARN has allocated to the application."
215 | ]
216 | },
217 | {
218 | "cell_type": "code",
219 | "execution_count": 9,
220 | "metadata": {},
221 | "outputs": [],
222 | "source": [
223 | "rdd3 = sc.textFile('datasets/meteogalicia.txt')"
224 | ]
225 | },
226 | {
227 | "cell_type": "code",
228 | "execution_count": 10,
229 | "metadata": {},
230 | "outputs": [
231 | {
232 | "name": "stdout",
233 | "output_type": "stream",
234 | "text": [
235 | "(2) datasets/meteogalicia.txt MapPartitionsRDD[7] at textFile at NativeMethodAccessorImpl.java:0 []\n",
236 | " | datasets/meteogalicia.txt HadoopRDD[6] at textFile at NativeMethodAccessorImpl.java:0 []\n"
237 | ]
238 | }
239 | ],
240 | "source": [
241 | "print rdd3.toDebugString()"
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "execution_count": 11,
247 | "metadata": {},
248 | "outputs": [],
249 | "source": [
250 | "rdd4 = sc.textFile('datasets/meteogalicia.txt', 4)"
251 | ]
252 | },
253 | {
254 | "cell_type": "code",
255 | "execution_count": 12,
256 | "metadata": {},
257 | "outputs": [
258 | {
259 | "name": "stdout",
260 | "output_type": "stream",
261 | "text": [
262 | "(4) datasets/meteogalicia.txt MapPartitionsRDD[9] at textFile at NativeMethodAccessorImpl.java:0 []\n",
263 | " | datasets/meteogalicia.txt HadoopRDD[8] at textFile at NativeMethodAccessorImpl.java:0 []\n"
264 | ]
265 | }
266 | ],
267 | "source": [
268 | "print rdd4.toDebugString()"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | "## Transformations vs Actions"
276 | ]
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "metadata": {},
281 | "source": [
282 | "### Transformations\n",
283 | "Create a new RDD from an existing one.\n",
284 | "\n",
285 | "All transformations in Spark are **lazy**, in the sense that they do not actually do anything until an action is executed.\n",
286 | "\n",
287 | "Examples:\n",
288 | "* map\n",
289 | "* filter\n",
290 | "\n",
291 | "### Actions\n",
292 | "Return the result to the driver program.\n",
293 | "\n",
294 | "Examples:\n",
295 | "* reduce\n",
296 | "* collect"
297 | ]
298 | },
299 | {
300 | "cell_type": "markdown",
301 | "metadata": {},
302 | "source": [
303 | "## DAG"
304 | ]
305 | },
306 | {
307 | "cell_type": "markdown",
308 | "metadata": {},
309 | "source": [
310 | "Each job is represented by a graph (specifically a [directed acyclic graph (DAG)](https://en.wikipedia.org/wiki/Directed_acyclic_graph)):\n",
311 | "\n",
312 | ""
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "metadata": {},
318 | "source": [
319 | "## Available APIs "
320 | ]
321 | },
322 | {
323 | "cell_type": "markdown",
324 | "metadata": {},
325 | "source": [
326 | "Currently there are different options to use Spark in Python:\n",
327 | "\n",
328 | "* Low-Level API: Using **RDDs and PairRDDs**: the original API, low level, great flexibility\n",
329 | "\n",
330 | "* Structured API: Using **Spark SQL and DataFrames**: newer, higher level, better performance\n",
331 | "\n",
332 | "In the case of Java and Scala there is also the option of using **DataSets**: a generalization of DataFrames that allows to use typed data instead of generic Row objects."
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "## Useful Reference Resources"
340 | ]
341 | },
342 | {
343 | "cell_type": "markdown",
344 | "metadata": {},
345 | "source": [
346 | "* [Spark RDD Programming Guide](https://spark.apache.org/docs/2.4.0/rdd-programming-guide.html)\n",
347 | "* [Spark SQL, DataFrames and Datasets Guide](https://spark.apache.org/docs/2.4.0/sql-programming-guide.html)\n",
348 | "* [Spark Python API](https://spark.apache.org/docs/2.4.0/api/python/index.html)"
349 | ]
350 | },
351 | {
352 | "cell_type": "markdown",
353 | "metadata": {},
354 | "source": [
355 | "## Questionaire\n",
356 | "Complete the [Unit 2 questionaire](https://forms.gle/xSErFivLyu3uxY7r6)."
357 | ]
358 | }
359 | ],
360 | "metadata": {
361 | "kernelspec": {
362 | "display_name": "Python 2",
363 | "language": "python",
364 | "name": "python2"
365 | },
366 | "language_info": {
367 | "codemirror_mode": {
368 | "name": "ipython",
369 | "version": 2
370 | },
371 | "file_extension": ".py",
372 | "mimetype": "text/x-python",
373 | "name": "python",
374 | "nbconvert_exporter": "python",
375 | "pygments_lexer": "ipython2",
376 | "version": "2.7.15"
377 | }
378 | },
379 | "nbformat": 4,
380 | "nbformat_minor": 4
381 | }
382 |
--------------------------------------------------------------------------------
/unit_3_programming_with_RDDs.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 3: Programming with RDDs"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "```\n",
16 | "3.1 Before we begin: Passing funtions to Spark\n",
17 | "3.2 Transformations\n",
18 | "3.3 Actions\n",
19 | "3.4 Loading data from HDFS\n",
20 | "3.5 Saving results back to HDFS\n",
21 | "```"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "## Before we begin: Passing functions to Spark"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "Using lambda functions:"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 1,
41 | "metadata": {},
42 | "outputs": [
43 | {
44 | "data": {
45 | "text/plain": [
46 | "[0, 1, 2, 3]"
47 | ]
48 | },
49 | "execution_count": 1,
50 | "metadata": {},
51 | "output_type": "execute_result"
52 | }
53 | ],
54 | "source": [
55 | "rdd1 = sc.parallelize(range(4))\n",
56 | "rdd1.collect()"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 2,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "data": {
66 | "text/plain": [
67 | "[0, 2, 4, 6]"
68 | ]
69 | },
70 | "execution_count": 2,
71 | "metadata": {},
72 | "output_type": "execute_result"
73 | }
74 | ],
75 | "source": [
76 | "rdd2 = rdd1.map(lambda x: 2*x)\n",
77 | "rdd2.collect()"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "Using normal functions:"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 3,
90 | "metadata": {},
91 | "outputs": [],
92 | "source": [
93 | "def double(x):\n",
94 | " return 2*x"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 4,
100 | "metadata": {
101 | "scrolled": true
102 | },
103 | "outputs": [
104 | {
105 | "data": {
106 | "text/plain": [
107 | "[0, 2, 4, 6]"
108 | ]
109 | },
110 | "execution_count": 4,
111 | "metadata": {},
112 | "output_type": "execute_result"
113 | }
114 | ],
115 | "source": [
116 | "rdd3 = rdd1.map(double)\n",
117 | "rdd3.collect()"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "Sometimes it is tricky to understand the scope and life cycle of variables and methods when running in a cluster. The main part of the code executes in the driver, but when parallel operations are done the functions passed are executed in the executors and data is passed around using **closures**."
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Transformations"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "### map"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 5,
144 | "metadata": {},
145 | "outputs": [
146 | {
147 | "data": {
148 | "text/plain": [
149 | "[0, 1, 2, 3]"
150 | ]
151 | },
152 | "execution_count": 5,
153 | "metadata": {},
154 | "output_type": "execute_result"
155 | }
156 | ],
157 | "source": [
158 | "rdd1 = sc.parallelize(range(4))\n",
159 | "rdd1.collect()"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 6,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "data": {
169 | "text/plain": [
170 | "[5, 6, 7, 8]"
171 | ]
172 | },
173 | "execution_count": 6,
174 | "metadata": {},
175 | "output_type": "execute_result"
176 | }
177 | ],
178 | "source": [
179 | "rdd2 = rdd1.map(lambda x: x + 5)\n",
180 | "rdd2.collect()"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 7,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "data": {
190 | "text/plain": [
191 | "[5, 6, 7, 8]"
192 | ]
193 | },
194 | "execution_count": 7,
195 | "metadata": {},
196 | "output_type": "execute_result"
197 | }
198 | ],
199 | "source": [
200 | "def plus_five(x):\n",
201 | " return x + 5\n",
202 | "\n",
203 | "rdd1.map(plus_five).collect()"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "### filter"
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": 8,
216 | "metadata": {},
217 | "outputs": [
218 | {
219 | "data": {
220 | "text/plain": [
221 | "['a1', 'a2', 'b1', 'b2']"
222 | ]
223 | },
224 | "execution_count": 8,
225 | "metadata": {},
226 | "output_type": "execute_result"
227 | }
228 | ],
229 | "source": [
230 | "rdd1 = sc.parallelize(['a1', 'a2', 'b1', 'b2'])\n",
231 | "rdd1.collect()"
232 | ]
233 | },
234 | {
235 | "cell_type": "code",
236 | "execution_count": 9,
237 | "metadata": {},
238 | "outputs": [
239 | {
240 | "data": {
241 | "text/plain": [
242 | "['a1', 'a2']"
243 | ]
244 | },
245 | "execution_count": 9,
246 | "metadata": {},
247 | "output_type": "execute_result"
248 | }
249 | ],
250 | "source": [
251 | "rdd2 = rdd1.filter(lambda x: 'a' in x)\n",
252 | "rdd2.collect()"
253 | ]
254 | },
255 | {
256 | "cell_type": "markdown",
257 | "metadata": {},
258 | "source": [
259 | "### flatMap"
260 | ]
261 | },
262 | {
263 | "cell_type": "code",
264 | "execution_count": 10,
265 | "metadata": {},
266 | "outputs": [
267 | {
268 | "data": {
269 | "text/plain": [
270 | "['Space: the final frontier.',\n",
271 | " 'These are the voyages of the starship Enterprise.']"
272 | ]
273 | },
274 | "execution_count": 10,
275 | "metadata": {},
276 | "output_type": "execute_result"
277 | }
278 | ],
279 | "source": [
280 | "rdd1 = sc.parallelize(['Space: the final frontier.',\n",
281 | " 'These are the voyages of the starship Enterprise.'])\n",
282 | "rdd1.collect()"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": 11,
288 | "metadata": {},
289 | "outputs": [
290 | {
291 | "data": {
292 | "text/plain": [
293 | "[['Space:', 'the', 'final', 'frontier.'],\n",
294 | " ['These', 'are', 'the', 'voyages', 'of', 'the', 'starship', 'Enterprise.']]"
295 | ]
296 | },
297 | "execution_count": 11,
298 | "metadata": {},
299 | "output_type": "execute_result"
300 | }
301 | ],
302 | "source": [
303 | "rdd2 = rdd1.map(lambda line: line.split())\n",
304 | "rdd2.collect()"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": 12,
310 | "metadata": {},
311 | "outputs": [
312 | {
313 | "data": {
314 | "text/plain": [
315 | "['Space:',\n",
316 | " 'the',\n",
317 | " 'final',\n",
318 | " 'frontier.',\n",
319 | " 'These',\n",
320 | " 'are',\n",
321 | " 'the',\n",
322 | " 'voyages',\n",
323 | " 'of',\n",
324 | " 'the',\n",
325 | " 'starship',\n",
326 | " 'Enterprise.']"
327 | ]
328 | },
329 | "execution_count": 12,
330 | "metadata": {},
331 | "output_type": "execute_result"
332 | }
333 | ],
334 | "source": [
335 | "rdd3 = rdd1.flatMap(lambda line: line.split())\n",
336 | "rdd3.collect()"
337 | ]
338 | },
339 | {
340 | "cell_type": "markdown",
341 | "metadata": {},
342 | "source": [
343 | "### distinct"
344 | ]
345 | },
346 | {
347 | "cell_type": "code",
348 | "execution_count": 13,
349 | "metadata": {},
350 | "outputs": [
351 | {
352 | "data": {
353 | "text/plain": [
354 | "[1, 1, 1, 2, 2]"
355 | ]
356 | },
357 | "execution_count": 13,
358 | "metadata": {},
359 | "output_type": "execute_result"
360 | }
361 | ],
362 | "source": [
363 | "rdd1 = sc.parallelize([1, 1, 1, 2, 2])\n",
364 | "rdd1.collect()"
365 | ]
366 | },
367 | {
368 | "cell_type": "code",
369 | "execution_count": 14,
370 | "metadata": {},
371 | "outputs": [
372 | {
373 | "data": {
374 | "text/plain": [
375 | "[2, 1]"
376 | ]
377 | },
378 | "execution_count": 14,
379 | "metadata": {},
380 | "output_type": "execute_result"
381 | }
382 | ],
383 | "source": [
384 | "rdd2 = rdd1.distinct()\n",
385 | "rdd2.collect()"
386 | ]
387 | },
388 | {
389 | "cell_type": "markdown",
390 | "metadata": {},
391 | "source": [
392 | "## Actions"
393 | ]
394 | },
395 | {
396 | "cell_type": "code",
397 | "execution_count": 15,
398 | "metadata": {},
399 | "outputs": [],
400 | "source": [
401 | "rdd1 = sc.parallelize([1, 1, 1, 2, 2])"
402 | ]
403 | },
404 | {
405 | "cell_type": "markdown",
406 | "metadata": {},
407 | "source": [
408 | "### reduce"
409 | ]
410 | },
411 | {
412 | "cell_type": "code",
413 | "execution_count": 16,
414 | "metadata": {},
415 | "outputs": [
416 | {
417 | "data": {
418 | "text/plain": [
419 | "7"
420 | ]
421 | },
422 | "execution_count": 16,
423 | "metadata": {},
424 | "output_type": "execute_result"
425 | }
426 | ],
427 | "source": [
428 | "rdd1.reduce(lambda a, b: a + b)"
429 | ]
430 | },
431 | {
432 | "cell_type": "markdown",
433 | "metadata": {},
434 | "source": [
435 | "### count"
436 | ]
437 | },
438 | {
439 | "cell_type": "code",
440 | "execution_count": 17,
441 | "metadata": {},
442 | "outputs": [
443 | {
444 | "data": {
445 | "text/plain": [
446 | "5"
447 | ]
448 | },
449 | "execution_count": 17,
450 | "metadata": {},
451 | "output_type": "execute_result"
452 | }
453 | ],
454 | "source": [
455 | "rdd1.count()"
456 | ]
457 | },
458 | {
459 | "cell_type": "markdown",
460 | "metadata": {},
461 | "source": [
462 | "### collect"
463 | ]
464 | },
465 | {
466 | "cell_type": "code",
467 | "execution_count": 18,
468 | "metadata": {},
469 | "outputs": [
470 | {
471 | "data": {
472 | "text/plain": [
473 | "[1, 1, 1, 2, 2]"
474 | ]
475 | },
476 | "execution_count": 18,
477 | "metadata": {},
478 | "output_type": "execute_result"
479 | }
480 | ],
481 | "source": [
482 | "rdd1.collect()"
483 | ]
484 | },
485 | {
486 | "cell_type": "markdown",
487 | "metadata": {},
488 | "source": [
489 | "### first"
490 | ]
491 | },
492 | {
493 | "cell_type": "code",
494 | "execution_count": 19,
495 | "metadata": {},
496 | "outputs": [
497 | {
498 | "data": {
499 | "text/plain": [
500 | "1"
501 | ]
502 | },
503 | "execution_count": 19,
504 | "metadata": {},
505 | "output_type": "execute_result"
506 | }
507 | ],
508 | "source": [
509 | "rdd1.first()"
510 | ]
511 | },
512 | {
513 | "cell_type": "markdown",
514 | "metadata": {},
515 | "source": [
516 | "### take"
517 | ]
518 | },
519 | {
520 | "cell_type": "code",
521 | "execution_count": 20,
522 | "metadata": {
523 | "scrolled": true
524 | },
525 | "outputs": [
526 | {
527 | "data": {
528 | "text/plain": [
529 | "[1, 1]"
530 | ]
531 | },
532 | "execution_count": 20,
533 | "metadata": {},
534 | "output_type": "execute_result"
535 | }
536 | ],
537 | "source": [
538 | "rdd1.take(2)"
539 | ]
540 | },
541 | {
542 | "cell_type": "markdown",
543 | "metadata": {},
544 | "source": [
545 | "### takeSample"
546 | ]
547 | },
548 | {
549 | "cell_type": "code",
550 | "execution_count": 21,
551 | "metadata": {},
552 | "outputs": [
553 | {
554 | "data": {
555 | "text/plain": [
556 | "[2, 1, 1, 2, 1]"
557 | ]
558 | },
559 | "execution_count": 21,
560 | "metadata": {},
561 | "output_type": "execute_result"
562 | }
563 | ],
564 | "source": [
565 | "rdd1.takeSample(withReplacement=False, num=10)"
566 | ]
567 | },
568 | {
569 | "cell_type": "code",
570 | "execution_count": 22,
571 | "metadata": {},
572 | "outputs": [
573 | {
574 | "data": {
575 | "text/plain": [
576 | "[1, 2, 1, 1, 1, 1, 1, 1, 1, 2]"
577 | ]
578 | },
579 | "execution_count": 22,
580 | "metadata": {},
581 | "output_type": "execute_result"
582 | }
583 | ],
584 | "source": [
585 | "rdd1.takeSample(withReplacement=True, num=10)"
586 | ]
587 | },
588 | {
589 | "cell_type": "markdown",
590 | "metadata": {},
591 | "source": [
592 | "## Loading data from HDFS"
593 | ]
594 | },
595 | {
596 | "cell_type": "markdown",
597 | "metadata": {},
598 | "source": [
599 | "### textFile"
600 | ]
601 | },
602 | {
603 | "cell_type": "code",
604 | "execution_count": 23,
605 | "metadata": {},
606 | "outputs": [],
607 | "source": [
608 | "rdd = sc.textFile('datasets/meteogalicia.txt')"
609 | ]
610 | },
611 | {
612 | "cell_type": "code",
613 | "execution_count": 24,
614 | "metadata": {
615 | "scrolled": true
616 | },
617 | "outputs": [
618 | {
619 | "data": {
620 | "text/plain": [
621 | "[u'',\n",
622 | " u'',\n",
623 | " u'ESTACI\\ufffdN AUTOM\\ufffdTICA:Santiago-EOAS',\n",
624 | " u'CONCELLO:Santiago de Compostela',\n",
625 | " u'PROVINCIA:A Coru\\ufffda']"
626 | ]
627 | },
628 | "execution_count": 24,
629 | "metadata": {},
630 | "output_type": "execute_result"
631 | }
632 | ],
633 | "source": [
634 | "\n",
635 | "rdd.take(5)"
636 | ]
637 | },
638 | {
639 | "cell_type": "markdown",
640 | "metadata": {},
641 | "source": [
642 | "Several files can also be loaded together at the same time but **be careful with the number of partitions generated**:"
643 | ]
644 | },
645 | {
646 | "cell_type": "code",
647 | "execution_count": 25,
648 | "metadata": {},
649 | "outputs": [],
650 | "source": [
651 | "rdd1 = sc.textFile('datasets/slurmd/slurmd.log.*')"
652 | ]
653 | },
654 | {
655 | "cell_type": "code",
656 | "execution_count": 26,
657 | "metadata": {},
658 | "outputs": [
659 | {
660 | "name": "stdout",
661 | "output_type": "stream",
662 | "text": [
663 | "(10) datasets/slurmd/slurmd.log.* MapPartitionsRDD[29] at textFile at NativeMethodAccessorImpl.java:0 []\n",
664 | " | datasets/slurmd/slurmd.log.* HadoopRDD[28] at textFile at NativeMethodAccessorImpl.java:0 []\n"
665 | ]
666 | }
667 | ],
668 | "source": [
669 | "print rdd1.toDebugString()"
670 | ]
671 | },
672 | {
673 | "cell_type": "code",
674 | "execution_count": 27,
675 | "metadata": {},
676 | "outputs": [
677 | {
678 | "data": {
679 | "text/plain": [
680 | "[u'1488161034 2017 Feb 27 03:03:54 c6610 daemon info slurmd Launching batch job 467165 for UID 1053',\n",
681 | " u'1494997188 2017 May 17 06:59:48 c6603 user info slurmstepd task/cgroup: /slurm/uid_12329/job_706187/step_batch: alloc=16384MB mem.limit=16384MB memsw.limit=unlimited',\n",
682 | " u'1486762787 2017 Feb 10 22:39:47 c6604 daemon info slurmd _run_prolog: run job script took usec=39335',\n",
683 | " u'1492284836 2017 Apr 15 21:33:56 c6609 user info slurmstepd done with job',\n",
684 | " u'1489949176 2017 Mar 19 19:46:16 c6604 user info slurmstepd done with job']"
685 | ]
686 | },
687 | "execution_count": 27,
688 | "metadata": {},
689 | "output_type": "execute_result"
690 | }
691 | ],
692 | "source": [
693 | "rdd1.takeSample(withReplacement=False, num=5)"
694 | ]
695 | },
696 | {
697 | "cell_type": "markdown",
698 | "metadata": {},
699 | "source": [
700 | "### wholeTextFiles"
701 | ]
702 | },
703 | {
704 | "cell_type": "markdown",
705 | "metadata": {},
706 | "source": [
707 | "wholeTextFiles lets you read a directory containing multiple small text files, and returns each of them as (filename, content) pairs. This is in contrast with textFile, which would return one record per line in each file."
708 | ]
709 | },
710 | {
711 | "cell_type": "code",
712 | "execution_count": 28,
713 | "metadata": {},
714 | "outputs": [],
715 | "source": [
716 | "rdd2 = sc.wholeTextFiles('datasets/slurmd/slurmd.log.*')"
717 | ]
718 | },
719 | {
720 | "cell_type": "code",
721 | "execution_count": 29,
722 | "metadata": {},
723 | "outputs": [
724 | {
725 | "data": {
726 | "text/plain": [
727 | "'(2) datasets/slurmd/slurmd.log.* MapPartitionsRDD[33] at wholeTextFiles at NativeMethodAccessorImpl.java:0 []\\n | WholeTextFileRDD[32] at wholeTextFiles at NativeMethodAccessorImpl.java:0 []'"
728 | ]
729 | },
730 | "execution_count": 29,
731 | "metadata": {},
732 | "output_type": "execute_result"
733 | }
734 | ],
735 | "source": [
736 | "rdd2.toDebugString()"
737 | ]
738 | },
739 | {
740 | "cell_type": "code",
741 | "execution_count": 30,
742 | "metadata": {},
743 | "outputs": [
744 | {
745 | "data": {
746 | "text/plain": [
747 | "[(u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6601',\n",
748 | " u'1482336831 2016 Dec 21 17:13:51 c6601 daemon info slurmd launch task 387796.0 re'),\n",
749 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6602',\n",
750 | " u'1482485639 2016 Dec 23 10:33:59 c6602 daemon info slurmd Slurmd shutdown complet'),\n",
751 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6603',\n",
752 | " u'1482485628 2016 Dec 23 10:33:48 c6603 daemon info slurmd Slurmd shutdown complet'),\n",
753 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6604',\n",
754 | " u'1482485636 2016 Dec 23 10:33:56 c6604 daemon info slurmd Slurmd shutdown complet'),\n",
755 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6605',\n",
756 | " u'1482485640 2016 Dec 23 10:34:00 c6605 daemon info slurmd Slurmd shutdown complet'),\n",
757 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6606',\n",
758 | " u'1482485652 2016 Dec 23 10:34:12 c6606 daemon info slurmd Slurmd shutdown complet'),\n",
759 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6607',\n",
760 | " u'1482485637 2016 Dec 23 10:33:57 c6607 daemon info slurmd Slurmd shutdown complet'),\n",
761 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6608',\n",
762 | " u'1482484569 2016 Dec 23 10:16:09 c6608 daemon err slurmd error: gres/mic unable t'),\n",
763 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6609',\n",
764 | " u'1482485648 2016 Dec 23 10:34:08 c6609 daemon info slurmd Slurmd shutdown complet'),\n",
765 | " (u'hdfs://nameservice1/user/jlopez/datasets/slurmd/slurmd.log.c6610',\n",
766 | " u'1482485646 2016 Dec 23 10:34:06 c6610 daemon info slurmd Slurmd shutdown complet')]"
767 | ]
768 | },
769 | "execution_count": 30,
770 | "metadata": {},
771 | "output_type": "execute_result"
772 | }
773 | ],
774 | "source": [
775 | "rdd2.map(lambda (filename, content): (filename, content[:80])).collect()"
776 | ]
777 | },
778 | {
779 | "cell_type": "markdown",
780 | "metadata": {},
781 | "source": [
782 | "### binaryRecords"
783 | ]
784 | },
785 | {
786 | "cell_type": "code",
787 | "execution_count": 31,
788 | "metadata": {},
789 | "outputs": [],
790 | "source": [
791 | "import struct\n",
792 | "from collections import namedtuple\n",
793 | "\n",
794 | "AcctRecord = namedtuple('AcctRecord',\n",
795 | " 'flag version tty exitcode uid gid pid ppid '\n",
796 | " 'btime etime utime stime mem io rw minflt majflt swaps '\n",
797 | " 'command')\n",
798 | "\n",
799 | "def read_record(data):\n",
800 | " values = struct.unpack(\"2BH6If8H16s\", data)\n",
801 | " return AcctRecord(*values)"
802 | ]
803 | },
804 | {
805 | "cell_type": "code",
806 | "execution_count": 32,
807 | "metadata": {},
808 | "outputs": [
809 | {
810 | "data": {
811 | "text/plain": [
812 | "[AcctRecord(flag=2, version=3, tty=0, exitcode=0, uid=0, gid=0, pid=24150, ppid=24144, btime=1474162981, etime=0.0, utime=0, stime=0, mem=3924, io=0, rw=0, minflt=482, majflt=0, swaps=0, command='accton\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00'),\n",
813 | " AcctRecord(flag=0, version=3, tty=0, exitcode=0, uid=0, gid=0, pid=24151, ppid=24144, btime=1474162981, etime=0.0, utime=0, stime=0, mem=4300, io=0, rw=0, minflt=199, majflt=0, swaps=0, command='gzip\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00')]"
814 | ]
815 | },
816 | "execution_count": 32,
817 | "metadata": {},
818 | "output_type": "execute_result"
819 | }
820 | ],
821 | "source": [
822 | "raw_rdd = sc.binaryRecords('datasets/pacct-20160919', recordLength=64)\n",
823 | "records = raw_rdd.map(read_record)\n",
824 | "records.take(2)"
825 | ]
826 | },
827 | {
828 | "cell_type": "markdown",
829 | "metadata": {},
830 | "source": [
831 | "## Saving results back to HDFS"
832 | ]
833 | },
834 | {
835 | "cell_type": "code",
836 | "execution_count": 33,
837 | "metadata": {},
838 | "outputs": [],
839 | "source": [
840 | "rdd.saveAsTextFile('results_directory')"
841 | ]
842 | },
843 | {
844 | "cell_type": "markdown",
845 | "metadata": {},
846 | "source": [
847 | "It will create a separate file for each partition of the RDD."
848 | ]
849 | },
850 | {
851 | "cell_type": "markdown",
852 | "metadata": {},
853 | "source": [
854 | "## Pipe RDDs to System Commands"
855 | ]
856 | },
857 | {
858 | "cell_type": "markdown",
859 | "metadata": {},
860 | "source": [
861 | "A very interesting functionality of RDDs is that you can pipe the contents of the RDD to system commands, so you can easily parallelize the execution of common tasks in multiple nodes.\n",
862 | "\n",
863 | "For each partition, all elements inside the partition are passed together (separated by newlines) as the stdin of the command, and each line of the stdout of the command will be transformed in one element of the output partition."
864 | ]
865 | },
866 | {
867 | "cell_type": "code",
868 | "execution_count": 34,
869 | "metadata": {},
870 | "outputs": [],
871 | "source": [
872 | "rdd = sc.parallelize(range(10), 4)"
873 | ]
874 | },
875 | {
876 | "cell_type": "code",
877 | "execution_count": 35,
878 | "metadata": {},
879 | "outputs": [
880 | {
881 | "data": {
882 | "text/plain": [
883 | "[[0, 1], [2, 3], [4, 5], [6, 7, 8, 9]]"
884 | ]
885 | },
886 | "execution_count": 35,
887 | "metadata": {},
888 | "output_type": "execute_result"
889 | }
890 | ],
891 | "source": [
892 | "rdd.glom().collect()"
893 | ]
894 | },
895 | {
896 | "cell_type": "code",
897 | "execution_count": 36,
898 | "metadata": {},
899 | "outputs": [
900 | {
901 | "data": {
902 | "text/plain": [
903 | "[u'2', u'2', u'2', u'4']"
904 | ]
905 | },
906 | "execution_count": 36,
907 | "metadata": {},
908 | "output_type": "execute_result"
909 | }
910 | ],
911 | "source": [
912 | "rdd.pipe('wc -l').collect()"
913 | ]
914 | },
915 | {
916 | "cell_type": "code",
917 | "execution_count": 37,
918 | "metadata": {},
919 | "outputs": [
920 | {
921 | "data": {
922 | "text/plain": [
923 | "[u'0', u'1', u'2', u'3', u'4', u'5', u'6', u'7', u'8', u'9']"
924 | ]
925 | },
926 | "execution_count": 37,
927 | "metadata": {},
928 | "output_type": "execute_result"
929 | }
930 | ],
931 | "source": [
932 | "rdd.pipe('cat').collect()"
933 | ]
934 | },
935 | {
936 | "cell_type": "markdown",
937 | "metadata": {},
938 | "source": [
939 | "## Exercises\n",
940 | "Now you can try to apply the above concepts to solve the following problems:\n",
941 | "* Unit 3 Working with meteorological data 1\n",
942 | "* Unit 3 Calculating Pi"
943 | ]
944 | }
945 | ],
946 | "metadata": {
947 | "kernelspec": {
948 | "display_name": "Python 2",
949 | "language": "python",
950 | "name": "python2"
951 | },
952 | "language_info": {
953 | "codemirror_mode": {
954 | "name": "ipython",
955 | "version": 2
956 | },
957 | "file_extension": ".py",
958 | "mimetype": "text/x-python",
959 | "name": "python",
960 | "nbconvert_exporter": "python",
961 | "pygments_lexer": "ipython2",
962 | "version": "2.7.15"
963 | }
964 | },
965 | "nbformat": 4,
966 | "nbformat_minor": 4
967 | }
968 |
--------------------------------------------------------------------------------
/unit_4_programming_with_PairRDDs.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 4: Programming with Pair RDDs"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "```\n",
16 | "4.1 Pair RDDs\n",
17 | "4.2 Transformations\n",
18 | "4.3 Actions\n",
19 | "4.4 Considerations about performance\n",
20 | "```"
21 | ]
22 | },
23 | {
24 | "cell_type": "markdown",
25 | "metadata": {},
26 | "source": [
27 | "## Pair RDDs"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "We have seen that a normal RDD is just a collection of elements."
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 1,
40 | "metadata": {},
41 | "outputs": [],
42 | "source": [
43 | "normal_rdd = sc.parallelize(['a', 'b', 'c'])"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "A Pair RDDs is a special type of RDD which elements are tuples (*pairs*):"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 2,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "pair_rdd = sc.parallelize([('a', 1), ('b', 1), ('c', 1)])"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "The interesting part about Pair RDDs is that they provide additional transformations and actions."
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "# Transformations"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "### keyBy"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 3,
86 | "metadata": {},
87 | "outputs": [
88 | {
89 | "data": {
90 | "text/plain": [
91 | "['cat', 'lion', 'dog', 'tiger', 'elephant']"
92 | ]
93 | },
94 | "execution_count": 3,
95 | "metadata": {},
96 | "output_type": "execute_result"
97 | }
98 | ],
99 | "source": [
100 | "rdd1 = sc.parallelize(['cat', 'lion', 'dog', 'tiger', 'elephant'])\n",
101 | "rdd1.collect()"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 4,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "data": {
111 | "text/plain": [
112 | "[(3, 'cat'), (4, 'lion'), (3, 'dog'), (5, 'tiger'), (8, 'elephant')]"
113 | ]
114 | },
115 | "execution_count": 4,
116 | "metadata": {},
117 | "output_type": "execute_result"
118 | }
119 | ],
120 | "source": [
121 | "rdd2 = rdd1.keyBy(lambda line: len(line))\n",
122 | "rdd2.collect()"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "### groupByKey"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | ""
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 5,
142 | "metadata": {},
143 | "outputs": [],
144 | "source": [
145 | "rdd1 = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('a', 1), ('b', 1), ('b', 1), ('a', 1), ('a', 1), ('a', 1), ('b', 1), ('b',1), ('b', 1)])"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 6,
151 | "metadata": {
152 | "scrolled": true
153 | },
154 | "outputs": [
155 | {
156 | "data": {
157 | "text/plain": [
158 | "[('a', ),\n",
159 | " ('b', )]"
160 | ]
161 | },
162 | "execution_count": 6,
163 | "metadata": {},
164 | "output_type": "execute_result"
165 | }
166 | ],
167 | "source": [
168 | "rdd2 = rdd1.groupByKey()\n",
169 | "rdd2.collect()"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "### reduceByKey"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | ""
184 | ]
185 | },
186 | {
187 | "cell_type": "code",
188 | "execution_count": 7,
189 | "metadata": {},
190 | "outputs": [],
191 | "source": [
192 | "rdd1 = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('a', 1), ('b', 1), ('b', 1), ('a', 1), ('a', 1), ('a', 1), ('b', 1), ('b',1), ('b', 1)])"
193 | ]
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": 8,
198 | "metadata": {
199 | "scrolled": true
200 | },
201 | "outputs": [
202 | {
203 | "data": {
204 | "text/plain": [
205 | "[('a', 6), ('b', 6)]"
206 | ]
207 | },
208 | "execution_count": 8,
209 | "metadata": {},
210 | "output_type": "execute_result"
211 | }
212 | ],
213 | "source": [
214 | "rdd2 = rdd1.reduceByKey(lambda x, y: x + y)\n",
215 | "rdd2.collect()"
216 | ]
217 | },
218 | {
219 | "cell_type": "markdown",
220 | "metadata": {},
221 | "source": [
222 | "### sortByKey"
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 9,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "rdd1 = sc.parallelize([('c', 1), ('b', 1), ('a', 1)])"
232 | ]
233 | },
234 | {
235 | "cell_type": "code",
236 | "execution_count": 10,
237 | "metadata": {},
238 | "outputs": [
239 | {
240 | "data": {
241 | "text/plain": [
242 | "[('a', 1), ('b', 1), ('c', 1)]"
243 | ]
244 | },
245 | "execution_count": 10,
246 | "metadata": {},
247 | "output_type": "execute_result"
248 | }
249 | ],
250 | "source": [
251 | "rdd2 = rdd1.sortByKey()\n",
252 | "rdd2.collect()"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 11,
258 | "metadata": {},
259 | "outputs": [
260 | {
261 | "data": {
262 | "text/plain": [
263 | "[('c', 1), ('b', 1), ('a', 1)]"
264 | ]
265 | },
266 | "execution_count": 11,
267 | "metadata": {},
268 | "output_type": "execute_result"
269 | }
270 | ],
271 | "source": [
272 | "rdd2 = rdd1.sortByKey(ascending=False)\n",
273 | "rdd2.collect()"
274 | ]
275 | },
276 | {
277 | "cell_type": "markdown",
278 | "metadata": {},
279 | "source": [
280 | "### join"
281 | ]
282 | },
283 | {
284 | "cell_type": "code",
285 | "execution_count": 12,
286 | "metadata": {},
287 | "outputs": [],
288 | "source": [
289 | "rdd1 = sc.parallelize([('a', 1), ('b', 2), ('c', 3)])\n",
290 | "rdd2 = sc.parallelize([('a', 4), ('b', 5), ('c', 6)])"
291 | ]
292 | },
293 | {
294 | "cell_type": "code",
295 | "execution_count": 13,
296 | "metadata": {
297 | "scrolled": true
298 | },
299 | "outputs": [
300 | {
301 | "data": {
302 | "text/plain": [
303 | "[('a', (1, 4)), ('c', (3, 6)), ('b', (2, 5))]"
304 | ]
305 | },
306 | "execution_count": 13,
307 | "metadata": {},
308 | "output_type": "execute_result"
309 | }
310 | ],
311 | "source": [
312 | "rdd3 = rdd1.join(rdd2)\n",
313 | "rdd3.collect()"
314 | ]
315 | },
316 | {
317 | "cell_type": "markdown",
318 | "metadata": {},
319 | "source": [
320 | "The join transformation performs an **inner join**. In case there is no match between the keys or any of them are repeated this would be the situation:"
321 | ]
322 | },
323 | {
324 | "cell_type": "code",
325 | "execution_count": 14,
326 | "metadata": {},
327 | "outputs": [],
328 | "source": [
329 | "rdd1 = sc.parallelize([('a', 1), ('b', 2)])\n",
330 | "rdd2 = sc.parallelize([('a', 4), ('a', 5), ('c', 6)])"
331 | ]
332 | },
333 | {
334 | "cell_type": "code",
335 | "execution_count": 15,
336 | "metadata": {},
337 | "outputs": [
338 | {
339 | "data": {
340 | "text/plain": [
341 | "[('a', (1, 5)), ('a', (1, 4))]"
342 | ]
343 | },
344 | "execution_count": 15,
345 | "metadata": {},
346 | "output_type": "execute_result"
347 | }
348 | ],
349 | "source": [
350 | "rdd3 = rdd1.join(rdd2)\n",
351 | "rdd3.collect()"
352 | ]
353 | },
354 | {
355 | "cell_type": "markdown",
356 | "metadata": {},
357 | "source": [
358 | "### leftOuterJoin"
359 | ]
360 | },
361 | {
362 | "cell_type": "code",
363 | "execution_count": 16,
364 | "metadata": {},
365 | "outputs": [],
366 | "source": [
367 | "rdd1 = sc.parallelize([('a', 1), ('b', 2)])\n",
368 | "rdd2 = sc.parallelize([('a', 4), ('a', 5), ('c', 6)])"
369 | ]
370 | },
371 | {
372 | "cell_type": "code",
373 | "execution_count": 17,
374 | "metadata": {
375 | "scrolled": true
376 | },
377 | "outputs": [
378 | {
379 | "data": {
380 | "text/plain": [
381 | "[('a', (1, 5)), ('a', (1, 4)), ('b', (2, None))]"
382 | ]
383 | },
384 | "execution_count": 17,
385 | "metadata": {},
386 | "output_type": "execute_result"
387 | }
388 | ],
389 | "source": [
390 | "rdd3 = rdd1.leftOuterJoin(rdd2)\n",
391 | "rdd3.collect()"
392 | ]
393 | },
394 | {
395 | "cell_type": "markdown",
396 | "metadata": {},
397 | "source": [
398 | "## Actions"
399 | ]
400 | },
401 | {
402 | "cell_type": "markdown",
403 | "metadata": {},
404 | "source": [
405 | "### countByKey"
406 | ]
407 | },
408 | {
409 | "cell_type": "code",
410 | "execution_count": 18,
411 | "metadata": {},
412 | "outputs": [
413 | {
414 | "data": {
415 | "text/plain": [
416 | "defaultdict(int, {'a': 3, 'b': 2})"
417 | ]
418 | },
419 | "execution_count": 18,
420 | "metadata": {},
421 | "output_type": "execute_result"
422 | }
423 | ],
424 | "source": [
425 | "rdd1 = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('a', 1), ('b', 1)])\n",
426 | "rdd1.countByKey()"
427 | ]
428 | },
429 | {
430 | "cell_type": "markdown",
431 | "metadata": {},
432 | "source": [
433 | "## Considerations about performance"
434 | ]
435 | },
436 | {
437 | "cell_type": "markdown",
438 | "metadata": {},
439 | "source": [
440 | "In general [avoid using GroupByKey](https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/best_practices/prefer_reducebykey_over_groupbykey.html).\n",
441 | "\n",
442 | "If you want to perform an aggregation inside each group it is more efficient to use the reduceByKey, aggregateByKey or combineByKey alternatives because they make use of **combiners** to reduce the amount of data passed between the nodes (it is the same concept of combiners as in Hadoop MapReduce)."
443 | ]
444 | },
445 | {
446 | "cell_type": "markdown",
447 | "metadata": {},
448 | "source": [
449 | "## Exercises\n",
450 | "Now you can try to apply the above concepts to solve the following problems:\n",
451 | "* Unit 4 WordCount\n",
452 | "* Unit 4 Working with meteorological data 2\n",
453 | "* Unit 4 KMeans"
454 | ]
455 | }
456 | ],
457 | "metadata": {
458 | "kernelspec": {
459 | "display_name": "Python 2",
460 | "language": "python",
461 | "name": "python2"
462 | },
463 | "language_info": {
464 | "codemirror_mode": {
465 | "name": "ipython",
466 | "version": 2
467 | },
468 | "file_extension": ".py",
469 | "mimetype": "text/x-python",
470 | "name": "python",
471 | "nbconvert_exporter": "python",
472 | "pygments_lexer": "ipython2",
473 | "version": "2.7.15"
474 | }
475 | },
476 | "nbformat": 4,
477 | "nbformat_minor": 4
478 | }
479 |
--------------------------------------------------------------------------------
/unit_6_launching_applications.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 6 Launching Spark Applications"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "\n",
16 | "```\n",
17 | "6.1 Creating a Spark application\n",
18 | "6.2 Submitting an application to YARN\n",
19 | "6.3 Simple application submission example\n",
20 | "6.4 Cluster vs Client mode\n",
21 | "6.5 Adding dependencies\n",
22 | "6.6 Complex application submission example\n",
23 | "6.7 How-to install additional Python packages\n",
24 | "6.8 Native Compression Libraries\n",
25 | "6.9 Sending the application in the background\n",
26 | "6.10 Dynamic resource allocation\n",
27 | "6.11 Overriding configuration directory\n",
28 | "6.12 Run an interactive shell\n",
29 | "```"
30 | ]
31 | },
32 | {
33 | "cell_type": "markdown",
34 | "metadata": {},
35 | "source": [
36 | "## Creating a Spark application\n",
37 | "An application is very similar to a notebook, but there are some minor changes that must be applied.\n",
38 | "\n",
39 | "The interactive notebook creates automatically the SparkContext (sc) and a SparkSession (spark) but in a standard application you must take care of creating them manually:"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {
46 | "collapsed": true
47 | },
48 | "outputs": [],
49 | "source": [
50 | "from pyspark.sql import SparkSession\n",
51 | "from pyspark import SparkContext\n",
52 | "\n",
53 | "if __name__ == '__main__':\n",
54 | " spark = SparkSession \\\n",
55 | " .builder \\\n",
56 | " .appName('My Application') \\\n",
57 | " .getOrCreate()\n",
58 | " sc = spark.sparkContext\n",
59 | " # ...\n",
60 | " # Application specific code\n",
61 | " # ..\n",
62 | " spark.stop()"
63 | ]
64 | },
65 | {
66 | "cell_type": "markdown",
67 | "metadata": {},
68 | "source": [
69 | "## Submitting an application to YARN\n",
70 | "\n",
71 | "To submit an application to YARN you use the **spark-submit** utility:\n",
72 | "\n",
73 | "```\n",
74 | "spark-submit\n",
75 | " --name NAME A name of your application.\n",
76 | "\n",
77 | " --master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.\n",
78 | " --deploy-mode DEPLOY_MODE Whether to launch the driver program locally (\"client\") or\n",
79 | " on one of the worker machines inside the cluster (\"cluster\")\n",
80 | " (Default: client).\n",
81 | " --queue QUEUE_NAME The YARN queue to submit to (Default: \"default\").\n",
82 | "\n",
83 | " --num-executors NUM Number of executors to launch (Default: 2).\n",
84 | " \n",
85 | " --driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).\n",
86 | " --driver-cores NUM Number of cores used by the driver, only in cluster mode\n",
87 | " (Default: 1).\n",
88 | " \n",
89 | " --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).\n",
90 | " --executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,\n",
91 | " or all available cores on the worker in standalone mode)\n",
92 | "```\n",
93 | "\n",
94 | "The main options to take into account for resource allocation are:\n",
95 | "\n",
96 | "* The `--num-executors` (spark.executor.instances as configuration property) option controls how many executors it will allocate for the application on the cluster .\n",
97 | "* The `--executor-memory` (spark.executor.memory configuration property) option controls the memory allocated per executor.\n",
98 | "* The `--executor-cores` (spark.executor.cores configuration property) option controls the cores allocated per executor.\n",
99 | "\n"
100 | ]
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "metadata": {},
105 | "source": [
106 | "## Simple application submission example\n",
107 | "\n",
108 | " spark-submit --master yarn --name testWC test.py\n",
109 | " spark-submit --master yarn --deploy-mode cluster --name testWC test.py\n",
110 | "\n"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "## Cluster vs Client mode\n",
118 | "\n",
119 | "\n",
120 | "\n",
121 | "\n",
122 | "\n",
123 | "\n",
124 | "Image Source: [Spark-on-YARN: Empower Spark Applications on Hadoop Cluster](https://www.slideshare.net/Hadoop_Summit/sparkonyarn-empower-spark-applications-on-hadoop-cluster)"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "## Adding dependencies\n",
132 | "\n",
133 | "To add dependencies we have to distinguish two different cases, when we need to extend Spark code itself which is written in Scala, or when we need to add the of our Python code.\n",
134 | "\n",
135 | "When you need to add dependencies for Spark itself we can use:\n",
136 | "- The **--packages** option pulls directly the packages from the Central Maven Repository. This approach requires an internet connection.\n",
137 | "- The **--jars** option transfers associated jar files to the cluster.\n",
138 | "\n",
139 | "\n",
140 | "To include the dependencies of our Python program we can use:\n",
141 | "- The **--py-files** option adds .zip, .egg, or .py files to the PYTHONPATH."
142 | ]
143 | },
144 | {
145 | "cell_type": "markdown",
146 | "metadata": {},
147 | "source": [
148 | "### Adding Spark dependencies: packages\n",
149 | "You can add Spark dependencies directly using the maven coordinates:\n",
150 | "\n",
151 | " spark-submit --packages com.databricks:spark-avro_2.10:2.0.1 ...\n",
152 | " \n",
153 | "The usual place to look for plublic packages is the Maven Central Repository:\n",
154 | "\n",
155 | " https://search.maven.org/"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "### Adding Spark dependencies: jar files\n",
163 | "You can also add exising jar files directly as dependencies:\n",
164 | "\n",
165 | " spark-submit --jars /jar_path/spark-streaming-kafka-assembly_2.10-1.6.1.2.4.2.0-258.jar ..."
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "metadata": {},
171 | "source": [
172 | "### Adding Python dependencies: zip files\n",
173 | "The easiest way to add our Python dependencies is to package all the dependencies in a zip file.\n",
174 | "If our program is more than a simple script and it defines its own modules and packages, then it is also needed to package and distribute them so the executors can access them.\n",
175 | "\n",
176 | "If we have a `requirements.txt` file we can generate a `dependencies.zip` file including all the dependencies with the following commands:\n",
177 | "```\n",
178 | "pip install -t dependencies -r requirements.txt\n",
179 | "```\n",
180 | "\n",
181 | "If the package we need it is not in PyPI but we have its `setup.py` then we can generate easily a zip with it and its dependencies running from the directory where the setup.py is located:\n",
182 | "```\n",
183 | "pip install -t dependencies .\n",
184 | "```\n",
185 | "\n",
186 | "Then we just package all the dependencies in a zip file:\n",
187 | "```\n",
188 | "cd dependencies\n",
189 | "zip -r ../dependencies.zip .\n",
190 | "```\n",
191 | "\n",
192 | "And then we need to package also the code of our application:\n",
193 | "```\n",
194 | "zip -r my_program.zip my_program\n",
195 | "```\n",
196 | "\n",
197 | "Finally to submit your application you will use:\n",
198 | "\n",
199 | " spark-submit --py-files dependencies.zip,my_program.zip ..."
200 | ]
201 | },
202 | {
203 | "cell_type": "markdown",
204 | "metadata": {},
205 | "source": [
206 | "### Adding Python dependencies: egg files\n",
207 | "\n",
208 | "In case you have an egg file of a package you want to use, you can add it directly to the `--py-files` option of spark-submit or to the `sc.addPyFile()` method to make it available to the application. After that you can make use of it in your application in the standard way.\n",
209 | "\n",
210 | " spark-submit --py-files /egg_path/avro-1.8.1-py2.7.egg ..."
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": null,
216 | "metadata": {
217 | "collapsed": true
218 | },
219 | "outputs": [],
220 | "source": [
221 | "# First we add the egg file to the application environment\n",
222 | "sc.addPyFile('/home/cesga/jlopez/packages/ClusterShell-1.7.3-py2.7.egg')\n",
223 | "# Then we can import and use it in the standard way\n",
224 | "from ClusterShell.NodeSet import NodeSet\n",
225 | "nodeset = NodeSet('c[6601-6610]')"
226 | ]
227 | },
228 | {
229 | "cell_type": "markdown",
230 | "metadata": {},
231 | "source": [
232 | "### Adding Python dependencies: wheel files\n",
233 | "Unfortunately wheel files are not yet supported.\n",
234 | "\n",
235 | "There was a feature request by it has been recently closed because no progress had been made since 2016:\n",
236 | "\n",
237 | "https://issues.apache.org/jira/browse/SPARK-6764"
238 | ]
239 | },
240 | {
241 | "cell_type": "markdown",
242 | "metadata": {},
243 | "source": [
244 | "## Complex application submission example"
245 | ]
246 | },
247 | {
248 | "cell_type": "markdown",
249 | "metadata": {},
250 | "source": [
251 | "Here you can see a real example of how to submit a real application that consumes data from Kafka in avro format using Spark Streaming:\n",
252 | "\n",
253 | "```\n",
254 | "spark-submit --master yarn --deploy-mode cluster \\\n",
255 | " --num-executors 2 \\\n",
256 | " --conf spark.yarn.submit.waitAppCompletion=false \\\n",
257 | " --packages com.databricks:spark-avro_2.10:2.0.1 \\\n",
258 | " --jars /home/cesga/jlopez/packages/spark-streaming-kafka-assembly_2.10-1.6.1.2.4.2.0-258.jar \\\n",
259 | " --py-files /home/cesga/jlopez/packages/avro-1.8.1-py2.7.egg \\\n",
260 | " --name 'SSH attack detector' \\ \n",
261 | " ssh_attack_detector.py\n",
262 | "```"
263 | ]
264 | },
265 | {
266 | "cell_type": "markdown",
267 | "metadata": {},
268 | "source": [
269 | "## How-to install additional Python packages\n",
270 | "The simplest way is to use **pip** with the `--user` option:\n",
271 | "\n",
272 | " pip install --user pymongo\n",
273 | " \n",
274 | "You can also create a **virtualenv** and use it to install all your dependencies:\n",
275 | "\n",
276 | " virtualenv venv\n",
277 | " . venv/bin/activate\n",
278 | " \n",
279 | "In case you are using a virtualenv you have to point spark to the appropriate python interpreter for your virtualenv:\n",
280 | "\n",
281 | " export PYSPARK_DRIVER_PYTHON=/home/cesga/jlopez/my_app/venv/bin/python\n",
282 | " export PYSPARK_PYTHON=/home/cesga/jlopez/my_app/venv/bin/python\n",
283 | "\n",
284 | "You will also need to adjust the permissions of your HOME directory so the spark user can access this virtualenv.\n",
285 | "\n",
286 | "This a quick & dirty way that you can use during development but, for production, I would recommend the zip file alternative."
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "## Native Compression Libraries\n",
294 | "\n",
295 | "To check native Hadoop and compression libraries availability you can run the `hadoop checknative` command:\n",
296 | "\n",
297 | "```\n",
298 | "[jlopez@cdh61-login6 ~]$ hadoop checknative\n",
299 | "...\n",
300 | "Native library checking:\n",
301 | "hadoop: true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libhadoop.so.1.0.0\n",
302 | "zlib: true /lib64/libz.so.1\n",
303 | "zstd : true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libzstd.so.1\n",
304 | "snappy: true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libsnappy.so.1\n",
305 | "lz4: true revision:10301\n",
306 | "bzip2: true /lib64/libbz2.so.1\n",
307 | "openssl: true /lib64/libcrypto.so\n",
308 | "ISA-L: true /opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native/libisal.so.2\n",
309 | "```"
310 | ]
311 | },
312 | {
313 | "cell_type": "markdown",
314 | "metadata": {},
315 | "source": [
316 | "## How-to submit the application in the background\n",
317 | "\n",
318 | "By default when you submit an application the spark-submit command keeps active waiting for application output. To avoid this behaviour use spark.yarn.submit.waitAppCompletion=false:\n",
319 | "\n",
320 | " spark-submit --conf spark.yarn.submit.waitAppCompletion=false ...\n",
321 | "\n"
322 | ]
323 | },
324 | {
325 | "cell_type": "markdown",
326 | "metadata": {},
327 | "source": [
328 | "## Dynamic resource allocation\n",
329 | "Spark provides a mechanism to dynamically adjust the resources your application occupies based on the workload. This means that your application may give resources back to the cluster if they are no longer used and request them again later when there is demand. This feature is particularly useful if multiple applications share resources in your Spark cluster.\n",
330 | "\n",
331 | "Our cluster has this feature enabled so it **automatically expands new executors when they are needed**, instead of fixing them at launch time with --num-executors.\n",
332 | "\n",
333 | "This allows that interactive jobs dynamically add and remove executors during execution.\n",
334 | "\n",
335 | "It is important to notice that when you specify the `--num-executors` option without explicitly disabling dynamic resource allocation, then num-executors indicates the initial number of executors to allocate (by default it is 2).\n",
336 | "\n",
337 | "If you want to **disable dynamic resource allocation** and request a fixed number of executors you have to use the following spark-submit options:\n",
338 | "\n",
339 | " spark-submit --conf spark.dynamicAllocation.enabled=false --num-executors 4 ..."
340 | ]
341 | },
342 | {
343 | "cell_type": "markdown",
344 | "metadata": {},
345 | "source": [
346 | "## Overriding configuration directory\n",
347 | "To specify a different configuration directory other than the default “SPARK_HOME/conf”, you can set SPARK_CONF_DIR. Spark will use the configuration files (spark-defaults.conf, spark-env.sh, log4j.properties, etc) from this directory.\n",
348 | "\n",
349 | "Example:\n",
350 | "\n",
351 | " export SPARK_CONF_DIR=/home/cesga/jlopez/conf/\n"
352 | ]
353 | },
354 | {
355 | "cell_type": "markdown",
356 | "metadata": {},
357 | "source": [
358 | "## Running an interactive shell\n",
359 | "Additionally to Jupyter notebooks you can also use the command line interactive shell provided by Spark:\n",
360 | "\n",
361 | " pyspark --master yarn --num-executors 4 --executor-cores 6 --queue interactive\n",
362 | "\n",
363 | " --num-executors NUM Number of executors to launch (Default: 2).\n",
364 | " --executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode)\n",
365 | " --driver-cores NUM Number of cores used by the driver, only in cluster mode (Default: 1).\n",
366 | " --executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).\n",
367 | " --queue QUEUE_NAME The YARN queue to submit to (Default: \"default\"). \n",
368 | "\n",
369 | "\n",
370 | "To use ipython instead of python for an interactive session use:\n",
371 | "\n",
372 | " module load anaconda2\n",
373 | " PYSPARK_DRIVER_PYTHON=$(which ipython) pyspark --queue interactive\n"
374 | ]
375 | },
376 | {
377 | "cell_type": "markdown",
378 | "metadata": {},
379 | "source": [
380 | "## Exercises\n",
381 | "\n",
382 | "* Exercise: Modify the \"Unit 4 Working with meteorological data 2\" notebook and submit it to YARN\n",
383 | "* Exercise: Modify the \"Unit 5 Working with meteorological data\" notebook and submit it to YARN"
384 | ]
385 | }
386 | ],
387 | "metadata": {
388 | "kernelspec": {
389 | "display_name": "Python 2",
390 | "language": "python",
391 | "name": "python2"
392 | },
393 | "language_info": {
394 | "codemirror_mode": {
395 | "name": "ipython",
396 | "version": 2
397 | },
398 | "file_extension": ".py",
399 | "mimetype": "text/x-python",
400 | "name": "python",
401 | "nbconvert_exporter": "python",
402 | "pygments_lexer": "ipython2",
403 | "version": "2.7.15"
404 | }
405 | },
406 | "nbformat": 4,
407 | "nbformat_minor": 1
408 | }
409 |
--------------------------------------------------------------------------------
/unit_7_optimizing_monitoring_and_debugging_applications.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Unit 7 Optimizing, Monitoring and Debugging Applications"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Contents\n",
15 | "```\n",
16 | "7.1. Performance considerations\n",
17 | " 7.1.1 RDD lineage\n",
18 | " 7.1.2 RDD persistance\n",
19 | " 7.1.3 Broadcast variables\n",
20 | " 7.1.4 Accumulators\n",
21 | " 7.1.5 Repartition and coalesce\n",
22 | " \n",
23 | "7.2. Monitoring and Debugging\n",
24 | " 7.2.1. HUE/YARN UI\n",
25 | " 7.2.2. Spark UI and Spark History\n",
26 | " 7.2.2.1. Spark Event Timeline\n",
27 | " 7.2.2.2. Spark DAG Visualization\n",
28 | " 7.2.2.3. How to interprate the DAG\n",
29 | " 7.2.3. How to see the logs of a job\n",
30 | " 7.2.4. How to change the log level\n",
31 | " 7.2.5. Understanding how to configure memory limits\n",
32 | " 7.2.6. How to tune the partitioner\n",
33 | "```"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "# Performance considerations"
41 | ]
42 | },
43 | {
44 | "cell_type": "markdown",
45 | "metadata": {},
46 | "source": [
47 | "### RDD lineage\n",
48 | "Each time you do a transformation in an RDD, Spark does not execute it immediately, instead it creates what is called an RDD lineage.\n",
49 | "\n",
50 | "This lineage keeps track of what are all transformations that has to be applied to produce the final RDD, from reading the data from HDFS to the different transformations that have to be applied and in which order.\n",
51 | "\n",
52 | "The lineage allows to add fault tolerance to the RDD, because in the case that something goes wrong and a executor is lost it is able to re-compute the RDD from the HDFS original data."
53 | ]
54 | },
55 | {
56 | "cell_type": "markdown",
57 | "metadata": {},
58 | "source": [
59 | "### RDD persistance"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "In case there is an RDD that you are going to reuse it is very useful to persist it so it does not need to re-compute it each time you operate on it (by default it is persisted in memory)."
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "metadata": {
73 | "collapsed": true
74 | },
75 | "outputs": [],
76 | "source": [
77 | "rdd.cache()"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "The same can be done for a DataFrame:"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": null,
90 | "metadata": {
91 | "collapsed": true
92 | },
93 | "outputs": [],
94 | "source": [
95 | "df.cache()"
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "metadata": {},
101 | "source": [
102 | "In a similar way when you no longer need it you can unpersist it:"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": null,
108 | "metadata": {
109 | "collapsed": true
110 | },
111 | "outputs": [],
112 | "source": [
113 | "rdd.unpersist()"
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "metadata": {},
119 | "source": [
120 | "It is also possible to indicate a the storage location:"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": null,
126 | "metadata": {
127 | "collapsed": true
128 | },
129 | "outputs": [],
130 | "source": [
131 | "from pyspark import StorageLevel\n",
132 | "# The following is equivalent to rdd.cache()\n",
133 | "rdd.persist(StorageLevel.MEMORY_ONLY)\n",
134 | "# Use disk instead of memory\n",
135 | "rdd.persist(StorageLevel.DISK_ONLY)\n",
136 | "# Use disk if it does not fit in memory (spilling)\n",
137 | "rdd.persist(StorageLevel.MEMORY_AND_DISK)"
138 | ]
139 | },
140 | {
141 | "cell_type": "markdown",
142 | "metadata": {},
143 | "source": [
144 | "If you want to know more about why persistance is important and the different persistance options you can read:\n",
145 | "* [RDD persistance](https://spark.apache.org/docs/2.4.0/programming-guide.html#rdd-persistence)"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "### Broadcast variables\n",
153 | "If you have a **read-only** variable that must be shared between all the tasks you can do it more efficiently using a broadcast variable:"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": null,
159 | "metadata": {
160 | "collapsed": true
161 | },
162 | "outputs": [],
163 | "source": [
164 | "# You create a broadcast variable in the driver\n",
165 | "centroidsBC = sc.broadcast([1, 2, 3])\n",
166 | "\n",
167 | "# And then you can read it in the different tasks with\n",
168 | "centroidsBC.value"
169 | ]
170 | },
171 | {
172 | "cell_type": "markdown",
173 | "metadata": {},
174 | "source": [
175 | "\"Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.\" Source: [Spark Programming Guide](https://spark.apache.org/docs/2.4.0/programming-guide.html#broadcast-variables)"
176 | ]
177 | },
178 | {
179 | "cell_type": "markdown",
180 | "metadata": {},
181 | "source": [
182 | "### Accumulators"
183 | ]
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "metadata": {},
188 | "source": [
189 | "Accumulators are **write-only** variables (only the driver can read it) that can be used to implement counters (as in MapReduce) or sums."
190 | ]
191 | },
192 | {
193 | "cell_type": "code",
194 | "execution_count": null,
195 | "metadata": {
196 | "collapsed": true
197 | },
198 | "outputs": [],
199 | "source": [
200 | "# Integer accumulator\n",
201 | "events = sc.accumulator(0)\n",
202 | "# Float accumulator\n",
203 | "amount = sc.accumulator(0.0)"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "The accumulator will be incremented once per task."
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": null,
216 | "metadata": {
217 | "collapsed": true,
218 | "scrolled": true
219 | },
220 | "outputs": [],
221 | "source": [
222 | "# On the executors\n",
223 | "events += 1"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "metadata": {},
229 | "source": [
230 | "Only the driver can access the value:"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": null,
236 | "metadata": {
237 | "collapsed": true
238 | },
239 | "outputs": [],
240 | "source": [
241 | "# Only works in the driver\n",
242 | "total.value"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "For more information: [Spark Programming Guide](https://spark.apache.org/docs/1.6.1/programming-guide.html#accumulators)"
250 | ]
251 | },
252 | {
253 | "cell_type": "markdown",
254 | "metadata": {},
255 | "source": [
256 | "### Repartitition and Coalesce"
257 | ]
258 | },
259 | {
260 | "cell_type": "markdown",
261 | "metadata": {},
262 | "source": [
263 | "You can change the number of partitions of an RDD using:"
264 | ]
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": null,
269 | "metadata": {
270 | "collapsed": true
271 | },
272 | "outputs": [],
273 | "source": [
274 | "rdd.repartition(10)"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "You can also reduce the number of partitions, this is done more efficiently using:"
282 | ]
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": null,
287 | "metadata": {
288 | "collapsed": true
289 | },
290 | "outputs": [],
291 | "source": [
292 | "rdd.coalesce(4)"
293 | ]
294 | },
295 | {
296 | "cell_type": "markdown",
297 | "metadata": {},
298 | "source": [
299 | "**coalesce()** is an optimized version of repartition() that allows avoiding data movement, but only if you are decreasing the number of RDD partitions."
300 | ]
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {},
305 | "source": [
306 | "# Monitoring and Debugging"
307 | ]
308 | },
309 | {
310 | "cell_type": "markdown",
311 | "metadata": {},
312 | "source": [
313 | "## Big Data WebUI\n",
314 | "To see the status of the cluster you can connect to the Big Data Web UI and from there you connect to HUE Web Interface.\n",
315 | "\n",
316 | "This interface will allow you to monitor your applications from a graphical interface and to access the Spark UI information.\n",
317 | "\n",
318 | "\n",
319 | "## Spark UI and Spark History\n",
320 | "From HUE by looking at the Properties tab and following the `trackingURL` link you can access the Spark UI of the running application or the Spark History server in case the application has finished.\n",
321 | "\n",
322 | "### Understanding your Apache Spark Application Through Visualization\n",
323 | "A Spark application is composed of:\n",
324 | "* jobs\n",
325 | "* stages\n",
326 | "* tasks\n",
327 | "\n",
328 | "#### Spark Event Timeline\n",
329 | "The timeline view is available on three levels: across all jobs, within one job, and within one stage.\n",
330 | "\n",
331 | "\n",
332 | "We can get more details about a specific, for example Job 0:\n",
333 | "\n",
334 | "\n",
335 | "And finally we can go deeper selecting a specific stage:\n",
336 | "\n",
337 | "\n",
338 | "#### Execution DAG\n",
339 | "A job is associated with a chain of RDD dependencies organized in a direct acyclic graph (DAG) that we can also visualize in the Spark UI:\n",
340 | "\n",
341 | "\n",
342 | "\n",
343 | "The greyed stage indicates that data was fetched from cache so it was not needed to re-execute that given stage: for that reason it appears as **skipped**. Whenever there is shuffling involved Spark automatically caches generated data.\n",
344 | "\n",
345 | "\n",
346 | "More information: [Understanding your Apache Spark Application Through Visualization](https://databricks.com/blog/2015/06/22/understanding-your-spark-application-through-visualization.html)"
347 | ]
348 | },
349 | {
350 | "cell_type": "markdown",
351 | "metadata": {},
352 | "source": [
353 | "## How-to see the logs of a job\n",
354 | "YARN has the aggregated logs produced by the job.\n",
355 | "\n",
356 | " yarn logs -applicationId application_1489083567361_0070 | less\n",
357 | "\n",
358 | "## Configuring the log level\n",
359 | "For debugging it can be useful to modify the debug level.\n",
360 | "\n",
361 | "Spark uses log4j for logging so the more versatile way to do it is changing the log4j.properties file.\n",
362 | "\n",
363 | "In some cases it can be useful to set the log level from the SparkContext:\n",
364 | " sc.setLogLevel(\"INFO\")\n",
365 | " sc.setLogLevel(\"WARN\")\n",
366 | " \n",
367 | "This allows you to tune the information shown in order to debug your application."
368 | ]
369 | },
370 | {
371 | "cell_type": "markdown",
372 | "metadata": {},
373 | "source": [
374 | "## Understanding how to configure memory limits\n",
375 | "To increase performance Spark uses an off-heap memory through the [Project Tungsten](https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html).\n",
376 | "\n",
377 | "\n",
378 | "\n",
379 | "In case you are facing a **memoryOverhead issue**:\n",
380 | "* The first thing to do, is to boost ‘spark.yarn.executor.memoryOverhead’ (Tungsten: off-heap memory, recommended 10% memory)\n",
381 | "* The second thing to take into account, is whether your data is balanced across the partitions\n",
382 | "\n",
383 | "When using Python, decreasing the value of **spark.executor.memory** will help since Python will be all off-heap memory and would not use the RAM we reserved for heap. So, by decreasing this value, you reserve less space for the heap, thus you get more space for the off-heap operations (we want that, since Python will operate there). ‘spark.executor.memory’ is for JVM heap only.\n",
384 | "\n",
385 | "Sources and further details:\n",
386 | "* [Memory Overhead](https://gsamaras.wordpress.com/code/memoryoverhead-issue-in-spark/)\n",
387 | "* [Understanding memory management in spark for fun and profit](https://www.slideshare.net/SparkSummit/understanding-memory-management-in-spark-for-fun-and-profit)\n",
388 | "* [Project Tungsten: Bringing Apache Spark Closer to Bare Metal](https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html)"
389 | ]
390 | },
391 | {
392 | "cell_type": "markdown",
393 | "metadata": {},
394 | "source": [
395 | "## Verifying Spark Configuration"
396 | ]
397 | },
398 | {
399 | "cell_type": "markdown",
400 | "metadata": {},
401 | "source": [
402 | "When debugging an application it can be useful to verify the values of all the Spark Properties.\n",
403 | "\n",
404 | "There are two options to do it:\n",
405 | "* Connecting to the Spark UI and checking the Environment tab\n",
406 | "* Programatically using:"
407 | ]
408 | },
409 | {
410 | "cell_type": "code",
411 | "execution_count": 1,
412 | "metadata": {},
413 | "outputs": [
414 | {
415 | "data": {
416 | "text/plain": [
417 | "[(u'spark.eventLog.enabled', u'true'),\n",
418 | " (u'spark.yarn.jars',\n",
419 | " u'local:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/jars/*,local:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/hive/*'),\n",
420 | " (u'spark.yarn.appMasterEnv.MKL_NUM_THREADS', u'1'),\n",
421 | " (u'spark.sql.queryExecutionListeners',\n",
422 | " u'com.cloudera.spark.lineage.NavigatorQueryListener'),\n",
423 | " (u'spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_HOSTS',\n",
424 | " u'c14-18.bd.cluster.cesga.es,c14-19.bd.cluster.cesga.es'),\n",
425 | " (u'spark.ui.killEnabled', u'true'),\n",
426 | " (u'spark.lineage.log.dir', u'/var/log/spark/lineage'),\n",
427 | " (u'spark.eventLog.dir', u'hdfs://nameservice1/user/spark/applicationHistory'),\n",
428 | " (u'spark.dynamicAllocation.executorIdleTimeout', u'60'),\n",
429 | " (u'spark.serializer', u'org.apache.spark.serializer.KryoSerializer'),\n",
430 | " (u'spark.io.encryption.enabled', u'false'),\n",
431 | " (u'spark.authenticate', u'false'),\n",
432 | " (u'spark.serializer.objectStreamReset', u'100'),\n",
433 | " (u'spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_URI_BASES',\n",
434 | " u'https://c14-18.bd.cluster.cesga.es:8090/proxy/application_1560154709544_0163,https://c14-19.bd.cluster.cesga.es:8090/proxy/application_1560154709544_0163'),\n",
435 | " (u'spark.submit.deployMode', u'client'),\n",
436 | " (u'spark.executor.extraLibraryPath',\n",
437 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native'),\n",
438 | " (u'spark.ui.filters',\n",
439 | " u'org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter'),\n",
440 | " (u'spark.driver.port', u'37717'),\n",
441 | " (u'spark.network.crypto.enabled', u'false'),\n",
442 | " (u'spark.yarn.historyServer.address',\n",
443 | " u'http://c14-18.bd.cluster.cesga.es:18088'),\n",
444 | " (u'spark.shuffle.service.enabled', u'true'),\n",
445 | " (u'spark.yarn.historyServer.allowTracking', u'true'),\n",
446 | " (u'spark.executorEnv.MKL_NUM_THREADS', u'1'),\n",
447 | " (u'spark.ui.enabled', u'true'),\n",
448 | " (u'spark.driver.appUIAddress',\n",
449 | " u'http://cdh61-login2.bd.cluster.cesga.es:4041'),\n",
450 | " (u'spark.yarn.am.extraLibraryPath',\n",
451 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native'),\n",
452 | " (u'spark.executor.id', u'driver'),\n",
453 | " (u'spark.dynamicAllocation.schedulerBacklogTimeout', u'1'),\n",
454 | " (u'spark.yarn.appMasterEnv.OPENBLAS_NUM_THREADS', u'1'),\n",
455 | " (u'spark.app.id', u'application_1560154709544_0163'),\n",
456 | " (u'spark.driver.host', u'cdh61-login2.bd.cluster.cesga.es'),\n",
457 | " (u'spark.yarn.queue', u'interactive'),\n",
458 | " (u'spark.app.name', u'PySparkShell'),\n",
459 | " (u'spark.executorEnv.PYTHONPATH',\n",
460 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/lib/py4j-0.10.7-src.zip:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/:/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/lib/py4j-0.10.7-src.zip/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/spark/python/lib/pyspark.zip'),\n",
461 | " (u'spark.shuffle.service.port', u'7337'),\n",
462 | " (u'spark.lineage.enabled', u'true'),\n",
463 | " (u'spark.extraListeners', u'com.cloudera.spark.lineage.NavigatorAppListener'),\n",
464 | " (u'spark.yarn.config.gatewayPath', u'/opt/cloudera/parcels'),\n",
465 | " (u'spark.master', u'yarn'),\n",
466 | " (u'spark.sql.warehouse.dir', u'/user/hive/warehouse'),\n",
467 | " (u'spark.driver.extraLibraryPath',\n",
468 | " u'/opt/cloudera/parcels/CDH-6.1.1-1.cdh6.1.1.p0.875250/lib/hadoop/lib/native'),\n",
469 | " (u'spark.sql.catalogImplementation', u'hive'),\n",
470 | " (u'spark.rdd.compress', u'True'),\n",
471 | " (u'spark.dynamicAllocation.minExecutors', u'0'),\n",
472 | " (u'spark.yarn.config.replacementPath', u'{{HADOOP_COMMON_HOME}}/../../..'),\n",
473 | " (u'spark.dynamicAllocation.enabled', u'true'),\n",
474 | " (u'spark.yarn.isPython', u'true'),\n",
475 | " (u'spark.executorEnv.OPENBLAS_NUM_THREADS', u'1'),\n",
476 | " (u'spark.ui.showConsoleProgress', u'true'),\n",
477 | " (u'spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.RM_HA_URLS',\n",
478 | " u'c14-18.bd.cluster.cesga.es:8090,c14-19.bd.cluster.cesga.es:8090')]"
479 | ]
480 | },
481 | "execution_count": 1,
482 | "metadata": {},
483 | "output_type": "execute_result"
484 | }
485 | ],
486 | "source": [
487 | "sc._conf.getAll()"
488 | ]
489 | },
490 | {
491 | "cell_type": "markdown",
492 | "metadata": {},
493 | "source": [
494 | "## Tuning the partitioner\n",
495 | "\n",
496 | "The partitioner is the part that decides how to split the data into the different partitions. The default is to use the HashPartitioner but in some cases you may use other partitioners in order to produce a more balanced data distribution between partitions.\n",
497 | "\n",
498 | "Apart from the HashPartitioner Spark provides the [RangePartitioner](https://spark.apache.org/docs/2.4.0/api/java/org/apache/spark/RangePartitioner.html).\n",
499 | "\n",
500 | "You can also implement your own partitioner.\n"
501 | ]
502 | },
503 | {
504 | "cell_type": "markdown",
505 | "metadata": {},
506 | "source": [
507 | "## Exercises\n",
508 | "* Exercise: Optimize the KMeans exercise by making use of RDD caching and broadcast variables.\n",
509 | "* Exercise: Explore the monitoring information for your optimized KMeans notebook, comparing it with the information for the non-optimized version, and answer the following questions:\n",
510 | "\n",
511 | " * Explore the Jobs tab:\n",
512 | " * How many jobs were run by Spark?\n",
513 | " * What was the typical duration of each job? You can sort the jobs by Duration clicking in the \"Duration\" column label\n",
514 | " * Explore the global event timeline\n",
515 | " * Explore the job with Job Id 7:\n",
516 | " * Explore the Event Timeline\n",
517 | " * Explore the DAG: How many stages were run?\n",
518 | " \n",
519 | " * Explore the Stages tab:\n",
520 | " * What was the total number of stages for all jobs?\n",
521 | " * Explore the Stage 12:\n",
522 | " * What was the 75th percentile duration of the tasks? \n",
523 | " * What was the Input Size?\n",
524 | " * Expand the Event Timeline: \n",
525 | " * How was the time distributed?\n",
526 | " * Compare with Stage 0: In this case the percentage of computing time is reduced, compared to the scheduler delay and task deserialization parts.\n",
527 | "\n",
528 | " * Explore the Storage tab (notebook must be still running, it is blank for finished applications): \n",
529 | " * How much data is cached?\n",
530 | " * How many partitions are cached?\n",
531 | " * What is the fraction of the RDD cached in memory?\n",
532 | "\n",
533 | " * Explore the Environment tab: \n",
534 | " * Was dynamic resource allocation enabled? Look at the value of the spark.dynamicAllocation.enabled property.\n",
535 | " \n",
536 | " * Explore the Executors tab: \n",
537 | " * How many executors were used? The driver also appears in the list.\n",
538 | " * In which cluster node run executor 1?\n",
539 | " * Notice that, when using dynamic allocation, the executors not being used will be automatically shutdown\n",
540 | " * Could we take advantadge of more executors? Check if there are executors that did not run any task.\n",
541 | " "
542 | ]
543 | }
544 | ],
545 | "metadata": {
546 | "kernelspec": {
547 | "display_name": "Python 2",
548 | "language": "python",
549 | "name": "python2"
550 | },
551 | "language_info": {
552 | "codemirror_mode": {
553 | "name": "ipython",
554 | "version": 2
555 | },
556 | "file_extension": ".py",
557 | "mimetype": "text/x-python",
558 | "name": "python",
559 | "nbconvert_exporter": "python",
560 | "pygments_lexer": "ipython2",
561 | "version": "2.7.15"
562 | }
563 | },
564 | "nbformat": 4,
565 | "nbformat_minor": 2
566 | }
567 |
--------------------------------------------------------------------------------