 9 |
10 | `NeuralQA` provides an easy to use api and visual interface for Extractive Question Answering (QA),
11 | on large datasets. The QA process is comprised of two main stages - **Passage retrieval (Retriever)** is implemented using [ElasticSearch](https://www.elastic.co/downloads/elasticsearch)
12 | and **Document Reading (Reader)** is implemented using pretrained BERT models via the
13 | Huggingface [Transformers](https://github.com/huggingface/transformers) api.
14 |
15 | ## Usage
16 |
17 | ```shell
18 | pip3 install neuralqa
19 | ```
20 |
21 | Create (or navigate to) a folder you would like to use with NeuralQA. Run the following command line instruction within that folder.
22 |
23 | ```shell
24 | neuralqa ui --port 4000
25 | ```
26 |
27 | navigate to [http://localhost:4000/#/](http://localhost:4000/#/) to view the NeuralQA interface. Learn about other command line options in the documentation [here](https://victordibia.github.io/neuralqa/usage.html#command-line-options) or how to [configure](https://victordibia.github.io/neuralqa/configuration.html) NeuralQA to use your own reader models or retriever instances.
28 |
29 | > Note: To use NeuralQA with a retriever such as ElasticSearch, follow the [instructions here](https://www.elastic.co/downloads/elasticsearch) to download, install, and launch a local elasticsearch instance and add it to your config.yaml file.
30 |
31 | ### How Does it Work?
32 |
33 |
9 |
10 | `NeuralQA` provides an easy to use api and visual interface for Extractive Question Answering (QA),
11 | on large datasets. The QA process is comprised of two main stages - **Passage retrieval (Retriever)** is implemented using [ElasticSearch](https://www.elastic.co/downloads/elasticsearch)
12 | and **Document Reading (Reader)** is implemented using pretrained BERT models via the
13 | Huggingface [Transformers](https://github.com/huggingface/transformers) api.
14 |
15 | ## Usage
16 |
17 | ```shell
18 | pip3 install neuralqa
19 | ```
20 |
21 | Create (or navigate to) a folder you would like to use with NeuralQA. Run the following command line instruction within that folder.
22 |
23 | ```shell
24 | neuralqa ui --port 4000
25 | ```
26 |
27 | navigate to [http://localhost:4000/#/](http://localhost:4000/#/) to view the NeuralQA interface. Learn about other command line options in the documentation [here](https://victordibia.github.io/neuralqa/usage.html#command-line-options) or how to [configure](https://victordibia.github.io/neuralqa/configuration.html) NeuralQA to use your own reader models or retriever instances.
28 |
29 | > Note: To use NeuralQA with a retriever such as ElasticSearch, follow the [instructions here](https://www.elastic.co/downloads/elasticsearch) to download, install, and launch a local elasticsearch instance and add it to your config.yaml file.
30 |
31 | ### How Does it Work?
32 |
33 | 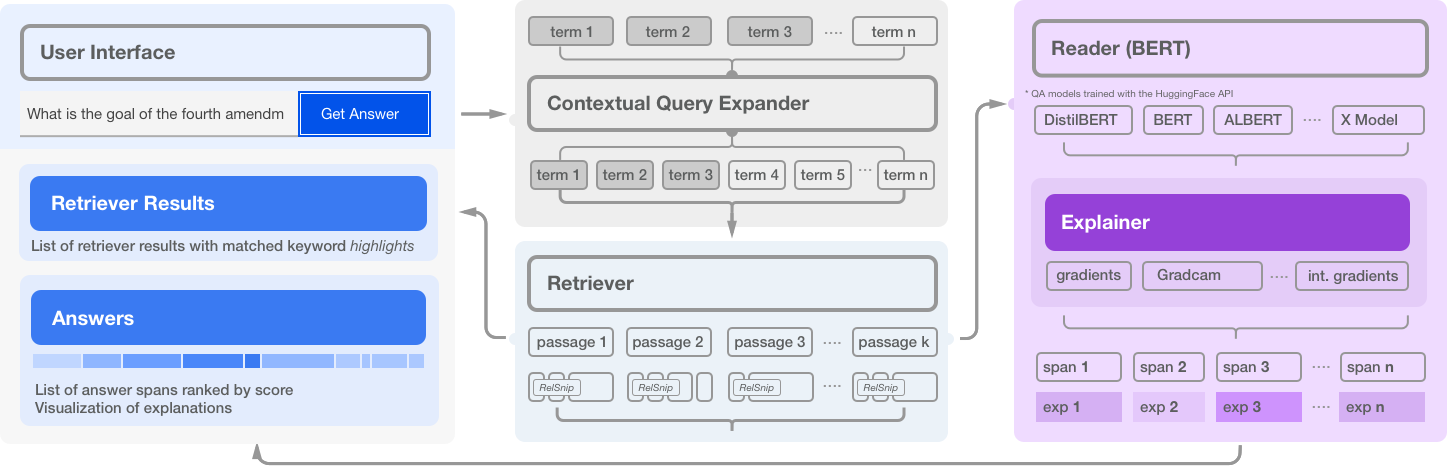 34 |
35 | NeuralQA is comprised of several high level modules:
36 |
37 | - **Retriever**: For each search query (question), scan an index (elasticsearch), and retrieve a list of candidate matched passages.
38 |
39 | - **Reader**: For each retrieved passage, a BERT based model predicts a span that contains the answer to the question. In practice, retrieved passages may be lengthy and BERT based models can process a maximum of 512 tokens at a time. NeuralQA handles this in two ways. Lengthy passages are chunked into smaller sections with a configurable stride. Secondly, NeuralQA offers the option of extracting a subset of relevant snippets (RelSnip) which a BERT reader can then scan to find answers. Relevant snippets are portions of the retrieved document that contain exact match results for the search query.
40 |
41 | - **Expander**: Methods for generating additional (relevant) query terms to improve recall. Currently, we implement Contextual Query Expansion using finetuned Masked Language Models. This is implemented via a user in the loop flow where the user can choose to include any suggested expansion terms.
42 |
43 |
34 |
35 | NeuralQA is comprised of several high level modules:
36 |
37 | - **Retriever**: For each search query (question), scan an index (elasticsearch), and retrieve a list of candidate matched passages.
38 |
39 | - **Reader**: For each retrieved passage, a BERT based model predicts a span that contains the answer to the question. In practice, retrieved passages may be lengthy and BERT based models can process a maximum of 512 tokens at a time. NeuralQA handles this in two ways. Lengthy passages are chunked into smaller sections with a configurable stride. Secondly, NeuralQA offers the option of extracting a subset of relevant snippets (RelSnip) which a BERT reader can then scan to find answers. Relevant snippets are portions of the retrieved document that contain exact match results for the search query.
40 |
41 | - **Expander**: Methods for generating additional (relevant) query terms to improve recall. Currently, we implement Contextual Query Expansion using finetuned Masked Language Models. This is implemented via a user in the loop flow where the user can choose to include any suggested expansion terms.
42 |
43 |  44 |
45 | - **User Interface**: NeuralQA provides a visual user interface for performing queries (manual queries where question and context are provided as well as queries over a search index), viewing results and also sensemaking of results (reranking of passages based on answer scores, highlighting keyword match, model explanations).
46 |
47 | ## Configuration
48 |
49 | Properties of modules within NeuralQA (ui, retriever, reader, expander) can be specified via a [yaml configuration](neuralqa/config_default.yaml) file. When you launch the ui, you can specify the path to your config file `--config-path`. If this is not provided, NeuralQA will search for a config.yaml in the current folder or create a [default copy](neuralqa/config_default.yaml)) in the current folder. Sample configuration shown below:
50 |
51 | ```yaml
52 | ui:
53 | queryview:
54 | intro:
55 | title: "NeuralQA: Question Answering on Large Datasets"
56 | subtitle: "Subtitle of your choice"
57 | views: # select sections of the ui to hide or show
58 | intro: True
59 | advanced: True
60 | samples: False
61 | passages: True
62 | explanations: True
63 | allanswers: True
64 | options: # values for advanced options
65 | stride: ..
66 | maxpassages: ..
67 | highlightspan: ..
68 |
69 | header: # header tile for ui
70 | appname: NeuralQA
71 | appdescription: Question Answering on Large Datasets
72 |
73 | reader:
74 | title: Reader
75 | selected: twmkn9/distilbert-base-uncased-squad2
76 | options:
77 | - name: DistilBERT SQUAD2
78 | value: twmkn9/distilbert-base-uncased-squad2
79 | type: distilbert
80 | - name: BERT SQUAD2
81 | value: deepset/bert-base-cased-squad2
82 | type: bert
83 | ```
84 |
85 | ## Documentation
86 |
87 | An attempt is being made to better document NeuralQA here - [https://victordibia.github.io/neuralqa/](https://victordibia.github.io/neuralqa/).
88 |
89 | ## Citation
90 |
91 | A paper introducing NeuralQA and its components can be [found here](https://arxiv.org/abs/2007.15211).
92 |
93 | ```
94 | @article{dibia2020neuralqa,
95 | title={NeuralQA: A Usable Library for Question Answering (Contextual Query Expansion + BERT) on Large Datasets},
96 | author={Victor Dibia},
97 | year={2020},
98 | journal={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations}
99 | }
100 | ```
101 |
--------------------------------------------------------------------------------
/docker-compose.yml:
--------------------------------------------------------------------------------
1 | version: "3"
2 | services:
3 | neuralqa_docker:
4 | build: .
5 | expose:
6 | - 80
7 |
--------------------------------------------------------------------------------
/docs/.nojekyll:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/victordibia/neuralqa/fb48f4d45d5856195baef25b4707e7b282cc364d/docs/.nojekyll
--------------------------------------------------------------------------------
/docs/Makefile:
--------------------------------------------------------------------------------
1 | # Minimal makefile for Sphinx documentation
2 | #
3 |
4 | # You can set these variables from the command line, and also
5 | # from the environment for the first two.
6 | SPHINXOPTS ?=
7 | SPHINXBUILD ?= sphinx-build
8 | SOURCEDIR = .
9 | BUILDDIR = _build
10 |
11 | # Put it first so that "make" without argument is like "make help".
12 | help:
13 | @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
14 |
15 | .PHONY: help Makefile
16 |
17 | # Catch-all target: route all unknown targets to Sphinx using the new
18 | # "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
19 | %: Makefile
20 | @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
21 |
--------------------------------------------------------------------------------
/docs/conf.py:
--------------------------------------------------------------------------------
1 | # Configuration file for the Sphinx documentation builder.
2 | #
3 | # This file only contains a selection of the most common options. For a full
4 | # list see the documentation:
5 | # https://www.sphinx-doc.org/en/master/usage/configuration.html
6 |
7 | # -- Path setup --------------------------------------------------------------
8 |
9 | # If extensions (or modules to document with autodoc) are in another directory,
10 | # add these directories to sys.path here. If the directory is relative to the
11 | # documentation root, use os.path.abspath to make it absolute, like shown here.
12 | #
13 | import os
14 | import sys
15 |
16 | sys.path.insert(0, os.path.abspath('../../neuralqa/'))
17 |
18 |
19 | # -- Project information -----------------------------------------------------
20 |
21 | project = 'NeuralQA'
22 | copyright = '2020, Victor Dibia'
23 | author = 'Victor Dibia'
24 |
25 | # The full version, including alpha/beta/rc tags
26 | release = '0.0.16a'
27 |
28 | # set master doc
29 | master_doc = 'index'
30 |
31 | # -- General configuration ---------------------------------------------------
32 |
33 | # Add any Sphinx extension module names here, as strings. They can be
34 | # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 | # ones.
36 | extensions = ['sphinx.ext.autodoc']
37 |
38 | # Add any paths that contain templates here, relative to this directory.
39 | templates_path = ['_templates']
40 |
41 | # List of patterns, relative to source directory, that match files and
42 | # directories to ignore when looking for source files.
43 | # This pattern also affects html_static_path and html_extra_path.
44 | exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
45 |
46 |
47 | # -- Options for HTML output -------------------------------------------------
48 |
49 | # The theme to use for HTML and HTML Help pages. See the documentation for
50 | # a list of builtin themes.
51 | #
52 | html_theme = 'sphinx_rtd_theme'
53 |
54 | # Add any paths that contain custom static files (such as style sheets) here,
55 | # relative to this directory. They are copied after the builtin static files,
56 | # so a file named "default.css" will overwrite the builtin "default.css".
57 | html_static_path = []
58 |
--------------------------------------------------------------------------------
/docs/configuration.rst:
--------------------------------------------------------------------------------
1 | Configuration
2 | ================
3 |
4 |
5 | ``NeuralQA`` provides an interface to specify properties of each module (ui, retriever, reader, expander) via a `yaml configuration
44 |
45 | - **User Interface**: NeuralQA provides a visual user interface for performing queries (manual queries where question and context are provided as well as queries over a search index), viewing results and also sensemaking of results (reranking of passages based on answer scores, highlighting keyword match, model explanations).
46 |
47 | ## Configuration
48 |
49 | Properties of modules within NeuralQA (ui, retriever, reader, expander) can be specified via a [yaml configuration](neuralqa/config_default.yaml) file. When you launch the ui, you can specify the path to your config file `--config-path`. If this is not provided, NeuralQA will search for a config.yaml in the current folder or create a [default copy](neuralqa/config_default.yaml)) in the current folder. Sample configuration shown below:
50 |
51 | ```yaml
52 | ui:
53 | queryview:
54 | intro:
55 | title: "NeuralQA: Question Answering on Large Datasets"
56 | subtitle: "Subtitle of your choice"
57 | views: # select sections of the ui to hide or show
58 | intro: True
59 | advanced: True
60 | samples: False
61 | passages: True
62 | explanations: True
63 | allanswers: True
64 | options: # values for advanced options
65 | stride: ..
66 | maxpassages: ..
67 | highlightspan: ..
68 |
69 | header: # header tile for ui
70 | appname: NeuralQA
71 | appdescription: Question Answering on Large Datasets
72 |
73 | reader:
74 | title: Reader
75 | selected: twmkn9/distilbert-base-uncased-squad2
76 | options:
77 | - name: DistilBERT SQUAD2
78 | value: twmkn9/distilbert-base-uncased-squad2
79 | type: distilbert
80 | - name: BERT SQUAD2
81 | value: deepset/bert-base-cased-squad2
82 | type: bert
83 | ```
84 |
85 | ## Documentation
86 |
87 | An attempt is being made to better document NeuralQA here - [https://victordibia.github.io/neuralqa/](https://victordibia.github.io/neuralqa/).
88 |
89 | ## Citation
90 |
91 | A paper introducing NeuralQA and its components can be [found here](https://arxiv.org/abs/2007.15211).
92 |
93 | ```
94 | @article{dibia2020neuralqa,
95 | title={NeuralQA: A Usable Library for Question Answering (Contextual Query Expansion + BERT) on Large Datasets},
96 | author={Victor Dibia},
97 | year={2020},
98 | journal={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations}
99 | }
100 | ```
101 |
--------------------------------------------------------------------------------
/docker-compose.yml:
--------------------------------------------------------------------------------
1 | version: "3"
2 | services:
3 | neuralqa_docker:
4 | build: .
5 | expose:
6 | - 80
7 |
--------------------------------------------------------------------------------
/docs/.nojekyll:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/victordibia/neuralqa/fb48f4d45d5856195baef25b4707e7b282cc364d/docs/.nojekyll
--------------------------------------------------------------------------------
/docs/Makefile:
--------------------------------------------------------------------------------
1 | # Minimal makefile for Sphinx documentation
2 | #
3 |
4 | # You can set these variables from the command line, and also
5 | # from the environment for the first two.
6 | SPHINXOPTS ?=
7 | SPHINXBUILD ?= sphinx-build
8 | SOURCEDIR = .
9 | BUILDDIR = _build
10 |
11 | # Put it first so that "make" without argument is like "make help".
12 | help:
13 | @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
14 |
15 | .PHONY: help Makefile
16 |
17 | # Catch-all target: route all unknown targets to Sphinx using the new
18 | # "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
19 | %: Makefile
20 | @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
21 |
--------------------------------------------------------------------------------
/docs/conf.py:
--------------------------------------------------------------------------------
1 | # Configuration file for the Sphinx documentation builder.
2 | #
3 | # This file only contains a selection of the most common options. For a full
4 | # list see the documentation:
5 | # https://www.sphinx-doc.org/en/master/usage/configuration.html
6 |
7 | # -- Path setup --------------------------------------------------------------
8 |
9 | # If extensions (or modules to document with autodoc) are in another directory,
10 | # add these directories to sys.path here. If the directory is relative to the
11 | # documentation root, use os.path.abspath to make it absolute, like shown here.
12 | #
13 | import os
14 | import sys
15 |
16 | sys.path.insert(0, os.path.abspath('../../neuralqa/'))
17 |
18 |
19 | # -- Project information -----------------------------------------------------
20 |
21 | project = 'NeuralQA'
22 | copyright = '2020, Victor Dibia'
23 | author = 'Victor Dibia'
24 |
25 | # The full version, including alpha/beta/rc tags
26 | release = '0.0.16a'
27 |
28 | # set master doc
29 | master_doc = 'index'
30 |
31 | # -- General configuration ---------------------------------------------------
32 |
33 | # Add any Sphinx extension module names here, as strings. They can be
34 | # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 | # ones.
36 | extensions = ['sphinx.ext.autodoc']
37 |
38 | # Add any paths that contain templates here, relative to this directory.
39 | templates_path = ['_templates']
40 |
41 | # List of patterns, relative to source directory, that match files and
42 | # directories to ignore when looking for source files.
43 | # This pattern also affects html_static_path and html_extra_path.
44 | exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
45 |
46 |
47 | # -- Options for HTML output -------------------------------------------------
48 |
49 | # The theme to use for HTML and HTML Help pages. See the documentation for
50 | # a list of builtin themes.
51 | #
52 | html_theme = 'sphinx_rtd_theme'
53 |
54 | # Add any paths that contain custom static files (such as style sheets) here,
55 | # relative to this directory. They are copied after the builtin static files,
56 | # so a file named "default.css" will overwrite the builtin "default.css".
57 | html_static_path = []
58 |
--------------------------------------------------------------------------------
/docs/configuration.rst:
--------------------------------------------------------------------------------
1 | Configuration
2 | ================
3 |
4 |
5 | ``NeuralQA`` provides an interface to specify properties of each module (ui, retriever, reader, expander) via a `yaml configuration
90 |
92 |
95 |
96 | )}
97 |
98 |
101 |
292 |
297 | );
298 | }
299 | }
300 |
301 | export default BarViz;
302 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/barviz/barviz.css:
--------------------------------------------------------------------------------
1 | .d3brush {
2 | /* border: 1px solid black; */
3 | }
4 |
5 | .yticktext {
6 | border: 1px solid green;
7 | }
8 |
9 | .barviz {
10 | /* border: 1px solid pink; */
11 | background-image: repeating-linear-gradient(
12 | 180deg,
13 | #ccc 29.5px,
14 | #ccc 30px,
15 | transparent 30px,
16 | transparent 55px
17 | );
18 | }
19 |
20 | .barvizcontent {
21 | background-color: rgb(235, 235, 235);
22 | padding: 10px 10px 8px 10px;
23 | }
24 |
25 | .strokedbarrect {
26 | /* stroke-width: 1px;
27 | stroke: rgba(44, 44, 44, 0.199); */
28 | }
29 |
30 | .textlabel {
31 | text-anchor: end;
32 | /* transform: rotate(20deg); */
33 | writing-mode: vertical-rl;
34 | cursor: default;
35 | text-shadow: 0.5px 0.5px 1px white;
36 | /* stroke: grey; */
37 | fill: black;
38 | stroke-width: 1px;
39 | pointer-events: none;
40 | }
41 |
42 | .tooltiptext {
43 | font-weight: bold;
44 | border: 1px solid black;
45 | pointer-events: none;
46 | font-size: 1.2em;
47 | text-anchor: start;
48 | }
49 |
50 | .tooltiprect {
51 | height: 1.7em;
52 | fill: white;
53 | opacity: 0.65;
54 | }
55 |
56 | .textinvisible {
57 | visibility: hidden;
58 | }
59 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/expandview/ExpandView.jsx:
--------------------------------------------------------------------------------
1 | import React, { Component } from "react";
2 | import { Modal } from "carbon-components-react";
3 | import "./expandview.css";
4 | import { LeaderLine, animOptions } from "../helperfunctions/HelperFunctions";
5 |
6 | class ExpandView extends Component {
7 | constructor(props) {
8 | super(props);
9 | this.data = props.data;
10 |
11 | // console.log(this.props);
12 |
13 | this.state = {
14 | data: this.data,
15 | showInfoModal: false,
16 | };
17 | this.blueColor = "#0062ff";
18 | this.greyColor = "#c4c3c3";
19 | }
20 |
21 | componentDidUpdate(prevProps, prevState) {
22 | if (this.props.data !== prevProps.data) {
23 | this.removeAllLines();
24 | this.drawLines();
25 | // console.log(this.lineHolder.length, " num lines");
26 | }
27 | if (this.props.viewChanged !== prevProps.viewChanged) {
28 | this.redrawAllLines();
29 | }
30 | }
31 |
32 | clickTerm(e) {
33 | // console.log(e.target.innerHTML);
34 | this.props.addQueryTerm(e.target.innerHTML);
35 | }
36 |
37 | updateGraph(data) {}
38 |
39 | drawLeaderLine(startElement, endElement, startAnchor, endAnchor) {
40 | let lineColor = this.blueColor;
41 | let lineWidth = 1.5;
42 | let plugType = "square";
43 | let endPlugType = "arrow2";
44 |
45 | let line = new LeaderLine(
46 | LeaderLine.pointAnchor(startElement, startAnchor),
47 | LeaderLine.pointAnchor(endElement, endAnchor),
48 | {
49 | color: lineColor,
50 | startPlug: plugType,
51 | endPlug: endPlugType,
52 | startPlugColor: lineColor,
53 | endSocketGravity: 400,
54 | path: "arc",
55 | size: lineWidth,
56 | hide: true,
57 | }
58 | );
59 | // document.querySelector('.leader-line').style.zIndex = -100
60 | animOptions.duration = this.state.animationDuration;
61 | line.show("draw", animOptions);
62 | this.lineHolder.push({
63 | line: line,
64 | });
65 | }
66 |
67 | removeAllLines(line) {
68 | this.lineHolder.forEach(function (each) {
69 | each.line.remove();
70 | });
71 | this.lineHolder = [];
72 | }
73 |
74 | redrawAllLines() {
75 | this.lineHolder.forEach(function (each) {
76 | each.line.position();
77 | });
78 | }
79 | getElement(attributeName, attributeValue) {
80 | return document
81 | .querySelector("div")
82 | .querySelector("[" + attributeName + "=" + attributeValue + "]");
83 | }
84 | componentDidMount() {
85 | this.lineHolder = [];
86 | this.topAnchor = { x: "50%", y: 0 };
87 | this.bottomAnchor = { x: "50%", y: "100%" };
88 | this.leftAnchor = { x: "0%", y: "50%" };
89 | this.rightAnchor = { x: "100%", y: "50%" };
90 |
91 | this.drawLines();
92 | }
93 |
94 | drawLines() {
95 | for (const ex of this.props.data.expansions) {
96 | if (ex.expansion) {
97 | for (let i = 0; i < ex.expansion.length; i++) {
98 | const startId = "term" + ex.token_index;
99 | const endId = "subterm" + ex.token_index + i;
100 | const startEl = this.getElement("id", startId);
101 | const endEl = this.getElement("id", endId);
102 | this.drawLeaderLine(startEl, endEl, this.leftAnchor, this.leftAnchor);
103 | }
104 | }
105 | }
106 | }
107 |
108 | componentWillUnmount() {
109 | this.removeAllLines();
110 | }
111 |
112 | clickInfo(e) {
113 | this.setState({ showInfoModal: !this.state.showInfoModal });
114 | }
115 |
116 | render() {
117 | let suggestedTermList = [];
118 | const data = this.props.data;
119 | if (data.expansions && data.terms) {
120 | suggestedTermList = data.terms.map((data, index) => {
121 | return (
122 |
293 |
294 |
295 |
296 |
126 | {data.token}
127 |
128 | );
129 | });
130 | }
131 | const expansionTermsList = data.expansions.map((expansionData, index) => {
132 | const terms = (expansionData.expansion || []).map((data, index) => {
133 | return (
134 |
140 | {data.token}
141 |
142 | );
143 | });
144 | const boxColor = terms.length > 0 ? this.blueColor : this.greyColor;
145 |
146 | return (
147 |
148 |
185 | );
186 | });
187 |
188 | // const subTermsList = this.data.expansions
189 | // .filter((data) => {
190 | // if (data.expansion) {
191 | // return true;
192 | // }
193 | // return false;
194 | // })
195 | // .map((expansionData, termIndex) => {
196 | // const terms = expansionData.expansion.map((data, index) => {
197 | // return (
198 | //
149 |
170 |
171 |
150 | {expansionData.pos}
151 |
152 |
158 |
153 | PART OF SPEECH
154 |
155 | {(expansionData.pos_desc || "").toUpperCase()}
156 |
157 |
159 | {expansionData.named_entity !== ""
160 | ? "| " + expansionData.named_entity
161 | : ""}
162 |
163 |
169 |
164 | NAMED ENTITY
165 |
166 | {(expansionData.ent_desc || "").toUpperCase()}
167 |
168 | 0 ? "mb5" : "")
175 | }
176 | style={{
177 | color: terms.length > 0 ? "white" : "",
178 | backgroundColor: boxColor,
179 | }}
180 | >
181 | {expansionData.token}
182 |
183 | {terms}
184 |
203 | // {data.token}
204 | //
205 | // );
206 | // });
207 | // return (
208 | //
209 | //
211 | // );
212 | // });
213 |
214 | return (
215 | {terms}
210 | //
216 |
227 |
258 |
293 | );
294 | }
295 | }
296 |
297 | export default ExpandView;
298 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/expandview/ex.json:
--------------------------------------------------------------------------------
1 | {
2 | "terms": [
3 | { "token": "personal", "probability": 0.2398897111415863 },
4 | { "token": "word", "probability": 0.04981723055243492 },
5 | { "token": "ii", "probability": 0.11301881819963455 },
6 | { "token": "macintosh", "probability": 0.09222493320703506 }
7 | ],
8 | "query": [
9 | "Steve",
10 | "jobs",
11 | "created",
12 | "the",
13 | "apple",
14 | "computer",
15 | "in",
16 | "which",
17 | "year"
18 | ],
19 | "expansions": [
20 | {
21 | "token": "Steve",
22 | "expansion": null,
23 | "token_index": 0,
24 | "pos": "PROPN",
25 | "pos_desc": "proper noun",
26 | "named_entity": "PERSON",
27 | "ent_desc": "People, including fictional"
28 | },
29 | {
30 | "token": "jobs",
31 | "expansion": null,
32 | "token_index": 1,
33 | "pos": "NOUN",
34 | "pos_desc": "noun",
35 | "named_entity": "PERSON",
36 | "ent_desc": "People, including fictional"
37 | },
38 | {
39 | "token": "created",
40 | "expansion": null,
41 | "token_index": 2,
42 | "pos": "VERB",
43 | "pos_desc": "verb",
44 | "named_entity": "",
45 | "ent_desc": null
46 | },
47 | {
48 | "token": "the",
49 | "expansion": null,
50 | "token_index": 3,
51 | "pos": "DET",
52 | "pos_desc": "determiner",
53 | "named_entity": "",
54 | "ent_desc": null
55 | },
56 | {
57 | "token": "apple",
58 | "expansion": [
59 | { "token": "apple", "probability": 0.29380887746810913 },
60 | { "token": "personal", "probability": 0.2398897111415863 },
61 | { "token": "word", "probability": 0.04981723055243492 }
62 | ],
63 | "token_index": 4,
64 | "pos": "NOUN",
65 | "pos_desc": "noun",
66 | "named_entity": "",
67 | "ent_desc": null
68 | },
69 | {
70 | "token": "computer",
71 | "expansion": [
72 | { "token": ",", "probability": 0.4731844961643219 },
73 | { "token": "ii", "probability": 0.11301881819963455 },
74 | { "token": "macintosh", "probability": 0.09222493320703506 }
75 | ],
76 | "token_index": 5,
77 | "pos": "NOUN",
78 | "pos_desc": "noun",
79 | "named_entity": "",
80 | "ent_desc": null
81 | },
82 | {
83 | "token": "in",
84 | "expansion": null,
85 | "token_index": 6,
86 | "pos": "ADP",
87 | "pos_desc": "adposition",
88 | "named_entity": "",
89 | "ent_desc": null
90 | },
91 | {
92 | "token": "which",
93 | "expansion": null,
94 | "token_index": 7,
95 | "pos": "DET",
96 | "pos_desc": "determiner",
97 | "named_entity": "",
98 | "ent_desc": null
99 | },
100 | {
101 | "token": "year",
102 | "expansion": [
103 | { "token": "?", "probability": 0.7166592478752136 },
104 | { "token": ".", "probability": 0.18741711974143982 },
105 | { "token": ";", "probability": 0.06785053759813309 }
106 | ],
107 | "token_index": 8,
108 | "pos": "NOUN",
109 | "pos_desc": "noun",
110 | "named_entity": "",
111 | "ent_desc": null
112 | }
113 | ],
114 | "took": 0.5484719276428223
115 | }
116 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/expandview/expandview.css:
--------------------------------------------------------------------------------
1 | .termcontainer {
2 | background-color: rgb(238, 238, 238);
3 | padding: 7px;
4 | margin: 5px 5px 0px 0px;
5 | vertical-align: top;
6 | }
7 | .termbox {
8 | padding: 6px;
9 | text-align: center;
10 | background-color: rgb(211, 211, 211);
11 | }
12 | .subtermbox {
13 | background-color: rgb(233, 233, 233);
14 | margin: 3px 0px 0px 0px;
15 | border: 1px solid #0062ff;
16 | }
17 | .subtermbox:hover {
18 | background-color: rgb(199, 199, 199);
19 | /* color: white; */
20 | }
21 | .subtermgroupbox {
22 | padding-right: 3px;
23 | border: 1px solid rgb(243, 243, 243);
24 | margin-right: 5px;
25 | }
26 | .expandview {
27 | border: 1px solid #c4c3c3;
28 | /* background-color: #f0efef; */
29 | padding-left: 10px;
30 | /* padding-right: 10px; */
31 | padding-bottom: 10px;
32 | }
33 |
34 | .tooltip {
35 | position: relative;
36 | display: inline-block;
37 | cursor: default;
38 | }
39 |
40 | .tooltip .expandtooltiptext {
41 | visibility: hidden;
42 | padding: 5px;
43 | /* width: 120px; */
44 | background-color: rgb(114, 114, 114);
45 | color: #fff;
46 | text-align: center;
47 | /* border-radius: 6px; */
48 | /* padding: 5px 0; */
49 | /* border: 1px solid black; */
50 |
51 | /* Position the tooltip */
52 | position: absolute;
53 | z-index: 1;
54 | bottom: 140%;
55 | left: 0%;
56 | /* margin-left: -60px; */
57 | }
58 |
59 | .tooltip:hover .expandtooltiptext {
60 | visibility: visible;
61 | }
62 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/explainview/ExplainView.jsx:
--------------------------------------------------------------------------------
1 | import React, { Component } from "react";
2 | import { Tabs, Tab } from "carbon-components-react";
3 | import "./explainview.css";
4 | import BarViz from "../barviz/BarViz";
5 |
6 | class ExplainView extends Component {
7 | constructor(props) {
8 | super(props);
9 |
10 | // console.log(props);
11 | this.state = {
12 | minCharWidth: null,
13 | };
14 | }
15 |
16 | getLabel(d, i) {
17 | return i + "*.*" + d.token + " *.* (" + d.gradient.toFixed(2) + ")";
18 | }
19 |
20 | componentDidUpdate(prevProps, prevState) {
21 | // this.data = prevProps.explanationData;
22 | // if (
23 | // prevProps.explanationData &&
24 | // prevProps.explanationData.answer !== this.state.data.answer
25 | // ) {
26 | // console.log("updating .. ", this.data);
27 | // this.updateGraph(this.data.gradients);
28 | // this.setState({
29 | // data: prevProps.explanationData,
30 | // });
31 | // }
32 | // // this.setState({
33 | // // data: prevProps.explanationData[prevProps.selectedExplanation],
34 | // // });
35 | }
36 |
37 | componentDidMount() {
38 | this.setState({
39 | minCharWidth: document.getElementById("barvizcontainer").offsetWidth - 40,
40 | });
41 | }
42 | render() {
43 | const denseViz = this.props.data.gradients.map((xdata, xindex) => {
44 | return (
45 |
52 | {xdata.token}
53 |
54 | );
55 | });
56 |
57 | return (
58 |
228 |
254 | *Note contextual query expansion works best when the model is 255 | trained on the target (open-domain) dataset. 256 |
257 |
229 | {" "}
230 | What is Contextual Query Expansion?{" "}
231 |
232 | Query expansion works as follows. First, a set of rules are used to
233 | determine which token in the query to expand. These rules are chosen
234 | to improve recall (surface relevant queries) without altering the
235 | semantics of the original query. Example rules include only
236 | expanding ADJECTIVES AND ADVERBS ; other parts of speech such as
237 | nouns, proper nouns or even named entities are not expanded. Once
238 | expansion candidates are selected, they are then iteratively masked
239 | and a masked language model is used to predict tokens that best
240 | complete the sentence given the surrounding tokens. Additional
241 | details are provided in the{" "}
242 |
243 | {" "}
244 | NeuralQA paper.
245 | {" "}
246 |
247 | {" "}
248 | How is this Implemented?{" "}
249 |
250 | Part of speech detection is implemented using Spacy NLP. A BERT
251 | based masked language model is used for predicting expansion terms
252 | (can be selected under advanced options).
253 | 254 | *Note contextual query expansion works best when the model is 255 | trained on the target (open-domain) dataset. 256 |
259 |
260 | {" "}
261 | {suggestedTermList.length} Suggested Expansion Terms{" "}
262 |
263 |
264 | {" "}
265 | {this.props.data.took.toFixed(3)} seconds
266 |
267 | .
268 |
269 |
270 | {/* suggested terms:
271 | {suggestedTermList} */}
272 |
292 |
273 |
284 |
285 |
274 | Click any of the expansion candidate terms below to append it to
275 | your query
276 |
277 |
281 | ? info
282 |
283 | {expansionTermsList}
286 |
287 | {" "}
288 | The visualization above indicates how the expansion terms were
289 | generated.
290 |
291 | 290 |
59 |
60 |
61 | {/* {answerText} */}
62 |
71 |
72 | {/* {answerText} */}
73 |
85 |
86 |
91 | );
92 | }
93 | }
94 |
95 | export default ExplainView;
96 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/explainview/ex.json:
--------------------------------------------------------------------------------
1 | {
2 | "gradients": [
3 | {
4 | "gradient": 0.7776244878768921,
5 | "token": "what",
6 | "token_type": 0
7 | },
8 | {
9 | "gradient": 0.3813329041004181,
10 | "token": "is",
11 | "token_type": 0
12 | },
13 | {
14 | "gradient": 0.4833911657333374,
15 | "token": "the",
16 | "token_type": 0
17 | },
18 | {
19 | "gradient": 1,
20 | "token": "goal",
21 | "token_type": 0
22 | },
23 | {
24 | "gradient": 0.4539879858493805,
25 | "token": "of",
26 | "token_type": 0
27 | },
28 | {
29 | "gradient": 0.2254873514175415,
30 | "token": "the",
31 | "token_type": 0
32 | },
33 | {
34 | "gradient": 0.5164986252784729,
35 | "token": "fourth",
36 | "token_type": 0
37 | },
38 | {
39 | "gradient": 0.577403724193573,
40 | "token": "amendment",
41 | "token_type": 0
42 | },
43 | {
44 | "gradient": 0.4014101028442383,
45 | "token": "?",
46 | "token_type": 0
47 | },
48 | {
49 | "gradient": 0.08653245866298676,
50 | "token": "the",
51 | "token_type": 1
52 | },
53 | {
54 | "gradient": 0.4406398832798004,
55 | "token": "fourth",
56 | "token_type": 1
57 | },
58 | {
59 | "gradient": 0.4501516819000244,
60 | "token": "amendment",
61 | "token_type": 1
62 | },
63 | {
64 | "gradient": 0.09730638563632965,
65 | "token": "of",
66 | "token_type": 1
67 | },
68 | {
69 | "gradient": 0.05219580605626106,
70 | "token": "the",
71 | "token_type": 1
72 | },
73 | {
74 | "gradient": 0.10632430016994476,
75 | "token": "u",
76 | "token_type": 1
77 | },
78 | {
79 | "gradient": 0.08209715783596039,
80 | "token": ".",
81 | "token_type": 1
82 | },
83 | {
84 | "gradient": 0.11832378804683685,
85 | "token": "s",
86 | "token_type": 1
87 | },
88 | {
89 | "gradient": 0.12593649327754974,
90 | "token": ".",
91 | "token_type": 1
92 | },
93 | {
94 | "gradient": 0.18220987915992737,
95 | "token": "constitution",
96 | "token_type": 1
97 | },
98 | {
99 | "gradient": 0.2233753353357315,
100 | "token": "provides",
101 | "token_type": 1
102 | },
103 | {
104 | "gradient": 0.09926070272922516,
105 | "token": "that",
106 | "token_type": 1
107 | },
108 | {
109 | "gradient": 0.04957512393593788,
110 | "token": "the",
111 | "token_type": 1
112 | },
113 | {
114 | "gradient": 0.06091616675257683,
115 | "token": "right",
116 | "token_type": 1
117 | },
118 | {
119 | "gradient": 0.0487910620868206,
120 | "token": "of",
121 | "token_type": 1
122 | },
123 | {
124 | "gradient": 0.03942923620343208,
125 | "token": "the",
126 | "token_type": 1
127 | },
128 | {
129 | "gradient": 0.07061353325843811,
130 | "token": "people",
131 | "token_type": 1
132 | },
133 | {
134 | "gradient": 0.035968974232673645,
135 | "token": "to",
136 | "token_type": 1
137 | },
138 | {
139 | "gradient": 0.05321967601776123,
140 | "token": "be",
141 | "token_type": 1
142 | },
143 | {
144 | "gradient": 0.08256877958774567,
145 | "token": "secure",
146 | "token_type": 1
147 | },
148 | {
149 | "gradient": 0.06096402183175087,
150 | "token": "in",
151 | "token_type": 1
152 | },
153 | {
154 | "gradient": 0.0372462272644043,
155 | "token": "their",
156 | "token_type": 1
157 | },
158 | {
159 | "gradient": 0.06295276433229446,
160 | "token": "persons",
161 | "token_type": 1
162 | },
163 | {
164 | "gradient": 0.04519972205162048,
165 | "token": ",",
166 | "token_type": 1
167 | },
168 | {
169 | "gradient": 0.06783878803253174,
170 | "token": "houses",
171 | "token_type": 1
172 | },
173 | {
174 | "gradient": 0.040804315358400345,
175 | "token": ",",
176 | "token_type": 1
177 | },
178 | {
179 | "gradient": 0.06289402395486832,
180 | "token": "papers",
181 | "token_type": 1
182 | },
183 | {
184 | "gradient": 0.03958067297935486,
185 | "token": ",",
186 | "token_type": 1
187 | },
188 | {
189 | "gradient": 0.05112042650580406,
190 | "token": "and",
191 | "token_type": 1
192 | },
193 | {
194 | "gradient": 0.07284298539161682,
195 | "token": "effects",
196 | "token_type": 1
197 | },
198 | {
199 | "gradient": 0.05123045668005943,
200 | "token": ",",
201 | "token_type": 1
202 | },
203 | {
204 | "gradient": 0.05624000355601311,
205 | "token": "against",
206 | "token_type": 1
207 | },
208 | {
209 | "gradient": 0.1851975917816162,
210 | "token": "unreasonable",
211 | "token_type": 1
212 | },
213 | {
214 | "gradient": 0.06078457459807396,
215 | "token": "searches",
216 | "token_type": 1
217 | },
218 | {
219 | "gradient": 0.07405952364206314,
220 | "token": "and",
221 | "token_type": 1
222 | },
223 | {
224 | "gradient": 0.07777296006679535,
225 | "token": "seizures",
226 | "token_type": 1
227 | },
228 | {
229 | "gradient": 0.0655774474143982,
230 | "token": ",",
231 | "token_type": 1
232 | },
233 | {
234 | "gradient": 0.09869317710399628,
235 | "token": "shall",
236 | "token_type": 1
237 | },
238 | {
239 | "gradient": 0.07527285069227219,
240 | "token": "not",
241 | "token_type": 1
242 | },
243 | {
244 | "gradient": 0.0456937812268734,
245 | "token": "be",
246 | "token_type": 1
247 | },
248 | {
249 | "gradient": 0.10462962836027145,
250 | "token": "violated",
251 | "token_type": 1
252 | },
253 | {
254 | "gradient": 0.06425818055868149,
255 | "token": ",",
256 | "token_type": 1
257 | },
258 | {
259 | "gradient": 0.05537235736846924,
260 | "token": "and",
261 | "token_type": 1
262 | },
263 | {
264 | "gradient": 0.0633930191397667,
265 | "token": "no",
266 | "token_type": 1
267 | },
268 | {
269 | "gradient": 0.04549432918429375,
270 | "token": "warrants",
271 | "token_type": 1
272 | },
273 | {
274 | "gradient": 0.0779174342751503,
275 | "token": "shall",
276 | "token_type": 1
277 | },
278 | {
279 | "gradient": 0.047900501638650894,
280 | "token": "issue",
281 | "token_type": 1
282 | },
283 | {
284 | "gradient": 0.05423515662550926,
285 | "token": ",",
286 | "token_type": 1
287 | },
288 | {
289 | "gradient": 0.054544754326343536,
290 | "token": "but",
291 | "token_type": 1
292 | },
293 | {
294 | "gradient": 0.04602174833416939,
295 | "token": "upon",
296 | "token_type": 1
297 | },
298 | {
299 | "gradient": 0.07888579368591309,
300 | "token": "probable",
301 | "token_type": 1
302 | },
303 | {
304 | "gradient": 0.07856228202581406,
305 | "token": "cause",
306 | "token_type": 1
307 | },
308 | {
309 | "gradient": 0.11361091583967209,
310 | "token": ",",
311 | "token_type": 1
312 | },
313 | {
314 | "gradient": 0.062142688781023026,
315 | "token": "supported",
316 | "token_type": 1
317 | },
318 | {
319 | "gradient": 0.05307861790060997,
320 | "token": "by",
321 | "token_type": 1
322 | },
323 | {
324 | "gradient": 0.09184946864843369,
325 | "token": "oath",
326 | "token_type": 1
327 | },
328 | {
329 | "gradient": 0.060711491852998734,
330 | "token": "or",
331 | "token_type": 1
332 | },
333 | {
334 | "gradient": 0.047539242853720985,
335 | "token": "affirmation",
336 | "token_type": 1
337 | },
338 | {
339 | "gradient": 0.07517780363559723,
340 | "token": ",",
341 | "token_type": 1
342 | },
343 | {
344 | "gradient": 0.06382681429386139,
345 | "token": "and",
346 | "token_type": 1
347 | },
348 | {
349 | "gradient": 0.10078483819961548,
350 | "token": "particularly",
351 | "token_type": 1
352 | },
353 | {
354 | "gradient": 0.07376561313867569,
355 | "token": "describing",
356 | "token_type": 1
357 | },
358 | {
359 | "gradient": 0.03218426927924156,
360 | "token": "the",
361 | "token_type": 1
362 | },
363 | {
364 | "gradient": 0.04783613234758377,
365 | "token": "place",
366 | "token_type": 1
367 | },
368 | {
369 | "gradient": 0.051581379026174545,
370 | "token": "to",
371 | "token_type": 1
372 | },
373 | {
374 | "gradient": 0.03697739914059639,
375 | "token": "be",
376 | "token_type": 1
377 | },
378 | {
379 | "gradient": 0.08481930196285248,
380 | "token": "searched",
381 | "token_type": 1
382 | },
383 | {
384 | "gradient": 0.0867309644818306,
385 | "token": ",",
386 | "token_type": 1
387 | },
388 | {
389 | "gradient": 0.06060314550995827,
390 | "token": "and",
391 | "token_type": 1
392 | },
393 | {
394 | "gradient": 0.042602699249982834,
395 | "token": "the",
396 | "token_type": 1
397 | },
398 | {
399 | "gradient": 0.056840281933546066,
400 | "token": "persons",
401 | "token_type": 1
402 | },
403 | {
404 | "gradient": 0.061877764761447906,
405 | "token": "or",
406 | "token_type": 1
407 | },
408 | {
409 | "gradient": 0.04903039708733559,
410 | "token": "things",
411 | "token_type": 1
412 | },
413 | {
414 | "gradient": 0.04995288327336311,
415 | "token": "to",
416 | "token_type": 1
417 | },
418 | {
419 | "gradient": 0.06450371444225311,
420 | "token": "be",
421 | "token_type": 1
422 | },
423 | {
424 | "gradient": 0.1317097693681717,
425 | "token": "seized",
426 | "token_type": 1
427 | },
428 | {
429 | "gradient": 0.27072301506996155,
430 | "token": ".",
431 | "token_type": 1
432 | },
433 | {
434 | "gradient": 0.3593496084213257,
435 | "token": "'",
436 | "token_type": 1
437 | },
438 | {
439 | "gradient": 0.20046266913414001,
440 | "token": "the",
441 | "token_type": 1
442 | },
443 | {
444 | "gradient": 0.5591774582862854,
445 | "token": "ultimate",
446 | "token_type": 1
447 | },
448 | {
449 | "gradient": 0.6059514284133911,
450 | "token": "goal",
451 | "token_type": 1
452 | },
453 | {
454 | "gradient": 0.22130441665649414,
455 | "token": "of",
456 | "token_type": 1
457 | },
458 | {
459 | "gradient": 0.21139739453792572,
460 | "token": "this",
461 | "token_type": 1
462 | },
463 | {
464 | "gradient": 0.22913874685764313,
465 | "token": "provision",
466 | "token_type": 1
467 | },
468 | {
469 | "gradient": 0.3722269535064697,
470 | "token": "is",
471 | "token_type": 1
472 | },
473 | {
474 | "gradient": 0.37132930755615234,
475 | "token": "to",
476 | "token_type": 1
477 | },
478 | {
479 | "gradient": 0.3717334270477295,
480 | "token": "protect",
481 | "token_type": 1
482 | },
483 | {
484 | "gradient": 0.16041798889636993,
485 | "token": "people",
486 | "token_type": 1
487 | },
488 | {
489 | "gradient": 0.1518508344888687,
490 | "token": "’",
491 | "token_type": 1
492 | },
493 | {
494 | "gradient": 0.0807218924164772,
495 | "token": "s",
496 | "token_type": 1
497 | },
498 | {
499 | "gradient": 0.15385906398296356,
500 | "token": "right",
501 | "token_type": 1
502 | },
503 | {
504 | "gradient": 0.050815142691135406,
505 | "token": "to",
506 | "token_type": 1
507 | },
508 | {
509 | "gradient": 0.16720698773860931,
510 | "token": "privacy",
511 | "token_type": 1
512 | },
513 | {
514 | "gradient": 0.14042364060878754,
515 | "token": "and",
516 | "token_type": 1
517 | },
518 | {
519 | "gradient": 0.15495635569095612,
520 | "token": "freedom",
521 | "token_type": 1
522 | },
523 | {
524 | "gradient": 0.16938212513923645,
525 | "token": "from",
526 | "token_type": 1
527 | },
528 | {
529 | "gradient": 0.11007372289896011,
530 | "token": "unreasonable",
531 | "token_type": 1
532 | },
533 | {
534 | "gradient": 0.11692224815487862,
535 | "token": "intrusions",
536 | "token_type": 1
537 | },
538 | {
539 | "gradient": 0.10463482141494751,
540 | "token": "by",
541 | "token_type": 1
542 | },
543 | {
544 | "gradient": 0.10229557752609253,
545 | "token": "the",
546 | "token_type": 1
547 | },
548 | {
549 | "gradient": 0.4751121699810028,
550 | "token": "government",
551 | "token_type": 1
552 | },
553 | {
554 | "gradient": 0.480056494474411,
555 | "token": ".",
556 | "token_type": 1
557 | },
558 | {
559 | "gradient": 0.37309250235557556,
560 | "token": "however",
561 | "token_type": 1
562 | },
563 | {
564 | "gradient": 0.2522304356098175,
565 | "token": ",",
566 | "token_type": 1
567 | },
568 | {
569 | "gradient": 0.1848718523979187,
570 | "token": "the",
571 | "token_type": 1
572 | },
573 | {
574 | "gradient": 0.3077230453491211,
575 | "token": "fourth",
576 | "token_type": 1
577 | },
578 | {
579 | "gradient": 0.2492513805627823,
580 | "token": "amendment",
581 | "token_type": 1
582 | },
583 | {
584 | "gradient": 0.11481970548629761,
585 | "token": "does",
586 | "token_type": 1
587 | },
588 | {
589 | "gradient": 0.12900979816913605,
590 | "token": "not",
591 | "token_type": 1
592 | },
593 | {
594 | "gradient": 0.16723977029323578,
595 | "token": "guarantee",
596 | "token_type": 1
597 | },
598 | {
599 | "gradient": 0.08052156865596771,
600 | "token": "protection",
601 | "token_type": 1
602 | },
603 | {
604 | "gradient": 0.0599604956805706,
605 | "token": "from",
606 | "token_type": 1
607 | },
608 | {
609 | "gradient": 0.0466151125729084,
610 | "token": "all",
611 | "token_type": 1
612 | },
613 | {
614 | "gradient": 0.0796627625823021,
615 | "token": "searches",
616 | "token_type": 1
617 | },
618 | {
619 | "gradient": 0.09778217226266861,
620 | "token": "and",
621 | "token_type": 1
622 | },
623 | {
624 | "gradient": 0.13690105080604553,
625 | "token": "seizures",
626 | "token_type": 1
627 | },
628 | {
629 | "gradient": 0.1097775250673294,
630 | "token": ",",
631 | "token_type": 1
632 | },
633 | {
634 | "gradient": 0.14515969157218933,
635 | "token": "but",
636 | "token_type": 1
637 | },
638 | {
639 | "gradient": 0.07196320593357086,
640 | "token": "only",
641 | "token_type": 1
642 | },
643 | {
644 | "gradient": 0.09799671918153763,
645 | "token": "those",
646 | "token_type": 1
647 | },
648 | {
649 | "gradient": 0.05541221424937248,
650 | "token": "done",
651 | "token_type": 1
652 | },
653 | {
654 | "gradient": 0.054436687380075455,
655 | "token": "by",
656 | "token_type": 1
657 | },
658 | {
659 | "gradient": 0.06119629368185997,
660 | "token": "the",
661 | "token_type": 1
662 | },
663 | {
664 | "gradient": 0.11526178568601608,
665 | "token": "government",
666 | "token_type": 1
667 | },
668 | {
669 | "gradient": 0.07573369145393372,
670 | "token": "and",
671 | "token_type": 1
672 | },
673 | {
674 | "gradient": 0.09001221507787704,
675 | "token": "deemed",
676 | "token_type": 1
677 | },
678 | {
679 | "gradient": 0.0890301913022995,
680 | "token": "unreasonable",
681 | "token_type": 1
682 | },
683 | {
684 | "gradient": 0.07160922139883041,
685 | "token": "under",
686 | "token_type": 1
687 | },
688 | {
689 | "gradient": 0.05608946084976196,
690 | "token": "the",
691 | "token_type": 1
692 | },
693 | {
694 | "gradient": 0.05668415129184723,
695 | "token": "law",
696 | "token_type": 1
697 | },
698 | {
699 | "gradient": 0.13379965722560883,
700 | "token": ".",
701 | "token_type": 1
702 | }
703 | ],
704 | "answer": "to protect people ’ s right to privacy and freedom from unreasonable intrusions by the government",
705 | "question": "what is the goal of the fourth amendment? "
706 | }
707 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/explainview/explainview.css:
--------------------------------------------------------------------------------
1 | .explanationspan {
2 | /* border: 1px solid green; */
3 | padding: 2px;
4 | display: inline;
5 | /* line-height: 1.5em; */
6 | }
7 |
8 | .barviz {
9 | /* border: 2px solid green; */
10 | /* background: green; */
11 | overflow: scroll;
12 | }
13 |
14 | .viztabcontent {
15 | background-color: rgb(235, 235, 235);
16 | }
17 |
18 | .brushbox {
19 | /* border: 1px solid green; */
20 | width: 100%;
21 | }
22 |
23 | .graphsvgpath {
24 | /* transform: rotate(90deg); */
25 | fill: #686868;
26 | stroke: #070707;
27 | }
28 | .brushhandle {
29 | position: absolute;
30 | height: 100%;
31 | background-color: #b4b4b48e;
32 | border: 1px solid white;
33 | border-radius: 2px;
34 | cursor: grab;
35 | }
36 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/footer/Footer.jsx:
--------------------------------------------------------------------------------
1 | /**
2 | * @license
3 | * Copyright 2019 Fast Forward Labs.
4 | * Written by Victor Dibia / Contact : https://github.com/victordibia
5 | * CaseQA - CaseQA: Question Answering on Large Datasets with BERT.
6 | * Licensed under the MIT License (the "License");
7 | * =============================================================================
8 | */
9 |
10 |
11 | import React, { Component } from "react";
12 | import "./footer.css"
13 |
14 | class Footer extends Component {
15 | render() {
16 | return (
17 |
63 |
70 |
64 | * Darker words indicate larger impact on answer span selection.
65 |
66 |
67 |
69 | {denseViz}
68 |
74 |
84 |
75 | * Darker bars indicate larger impact on answer span selection.
76 |
77 | {this.state.minCharWidth && (
78 |
87 | The visualizations above indicate how each word in the query and
88 | context contributes to the model's selection of an answer span.
89 |
90 |
18 | © NeuralQA 2020. Learn more on Github.
19 |
20 | );
21 | }
22 | }
23 |
24 | export default Footer;
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/footer/footer.css:
--------------------------------------------------------------------------------
1 |
2 |
3 | #footer {
4 | position: fixed;
5 | bottom: 0;
6 | width: 100%;
7 | border-top: 1px solid #f0f3f6;
8 | padding: 14px;
9 | background: #fff;
10 | z-index: 10;
11 | }
12 |
13 | #footer a {
14 | text-decoration: none;
15 | }
16 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/header/Header.jsx:
--------------------------------------------------------------------------------
1 | /**
2 | * @license
3 | * Copyright 2019 Fast Forward Labs.
4 | * Written by / Contact : https://github.com/victordibia
5 | * NeuralQA - NeuralQA: Question Answering on Large Datasets with BERT.
6 | * Licensed under the MIT License (the "License");
7 | * =============================================================================
8 | */
9 |
10 |
11 | import React, { Component } from "react";
12 | import {
13 | // NavLink
14 | } from "react-router-dom";
15 | // import { LogoGithub16 } from '@carbon/icons-react';
16 |
17 | import "./header.css"
18 |
19 | class Header extends Component {
20 | constructor(props) {
21 | super(props)
22 | this.appName = props.data.appname || "NeuralQA"
23 | this.appDescription = props.data.appdescription || " Question Answering on Large Datasets."
24 | }
25 | render() {
26 | return (
27 |
28 |
61 |
62 |
63 | );
64 | }
65 | }
66 |
67 | export default Header;
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/header/header.css:
--------------------------------------------------------------------------------
1 |
2 | .navbarlinks a.active:hover, .navbarlinks a.active, .navbarlinks.selected {
3 | border-bottom: 4px #0062FF solid;
4 | }
5 | .navbarlinks a{
6 | text-decoration: none;
7 | color: #fff;
8 | width: 100%;
9 | /* height: 100%; */
10 | /* border: 1px solid pink; */
11 | line-height: 3.1em;
12 | border-bottom: 4px solid rgb(36, 36, 36) ;
13 | padding: 0px 12px 0px 12px;
14 | }
15 |
16 | .navbarlinks a:hover{
17 | background-color: #3D3D3D;
18 | border-bottom: 4px solid #3D3D3D ;
19 | }
20 |
21 | .headerboost{
22 | height: 38px;
23 | }
24 |
25 | .headerrow{
26 | height: 48px;
27 | }
28 | .headericonbox{
29 | padding-top: 8px;
30 | }
31 | .headericon{
32 | height: 2.0em;
33 | }
34 | /* .bx--header{
35 | background-color: rgb(199, 29, 29);
36 | border: 10px solid green;
37 | } */
38 |
39 | .headermain{
40 | background: #161616 ;
41 | position: fixed;
42 | top: 0;
43 | width: 100%;
44 | z-index: 5000;
45 | }
46 |
47 | .gitlogo{
48 | position: absolute;
49 | top: 14px;
50 | }
51 | .gitlogotext{
52 | margin: 0px 0px 0px 20px;
53 | }
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/helperfunctions/HelperFunctions.jsx:
--------------------------------------------------------------------------------
1 | export function abbreviateString(value, maxLength) {
2 | if (value.length <= maxLength) {
3 | return value;
4 | } else {
5 | let retval = value.substring(0, maxLength) + "..";
6 | return retval;
7 | }
8 | }
9 |
10 | function intlFormat(num) {
11 | return new Intl.NumberFormat().format(Math.round(num * 10) / 10);
12 | }
13 | export function makeFriendly(num) {
14 | if (num < 1 && num > 0) {
15 | return num;
16 | }
17 | if (Math.abs(num) >= 1000000) return intlFormat(num / 1000000) + "M";
18 | if (Math.abs(num) >= 1000) return intlFormat(num / 1000) + "k";
19 | return intlFormat(num);
20 | }
21 |
22 | export function getJSONData(url) {
23 | return fetch(url)
24 | .then(function (response) {
25 | if (response.status !== 200) {
26 | console.log(
27 | "Looks like there was a problem. Status Code: " + response.status
28 | );
29 | return Promise.reject(response.status);
30 | }
31 | return response.json().then(function (data) {
32 | return data;
33 | });
34 | })
35 | .catch(function (err) {
36 | return Promise.reject(err);
37 | });
38 | }
39 |
40 | export function postJSONData(url, postData) {
41 | return fetch(url, {
42 | method: "post",
43 | body: JSON.stringify(postData),
44 | headers: {
45 | "Content-Type": "application/json",
46 | },
47 | })
48 | .then(function (response) {
49 | if (response.status !== 200) {
50 | console.log(
51 | "Looks like there was a problem. Status Code: " + response.status
52 | );
53 | return Promise.reject(response.status);
54 | }
55 | return response.json().then(function (data) {
56 | return data;
57 | });
58 | })
59 | .catch(function (err) {
60 | return Promise.reject(err);
61 | });
62 | }
63 |
64 | export function sampleConfig() {
65 | return {
66 | header: {
67 | appname: "NeuralQA",
68 | appdescription: "Question Answering on Large Datasets",
69 | },
70 | queryview: {
71 | intro: {
72 | title: "NeuralQA: Question Answering on Large Datasets",
73 | subtitle:
74 | "NeuralQA is an interactive tool for question answering (passage retrieval + document reading). You can manually provide a passage or select a search index from (e.g. case.law ) dataset under the QA configuration settings below. To begin, type in a question query below.",
75 | disclaimer: " .. ",
76 | },
77 | views: {
78 | intro: true,
79 | advanced: true,
80 | samples: true,
81 | passages: true,
82 | explanations: true,
83 | allanswers: false,
84 | expander: false,
85 | },
86 | options: {
87 | stride: {
88 | title: "Token Stride",
89 | selected: 0,
90 | options: [
91 | { name: 0, value: 0 },
92 | { name: 50, value: 50 },
93 | { name: 100, value: 100 },
94 | { name: 200, value: 200 },
95 | ],
96 | },
97 | maxdocuments: {
98 | title: "Max Documents",
99 | selected: 5,
100 | options: [
101 | { name: 5, value: 5 },
102 | { name: 10, value: 10 },
103 | { name: 15, value: 15 },
104 | ],
105 | },
106 | fragmentsize: {
107 | title: "Fragment Size",
108 | selected: 350,
109 | options: [
110 | { name: 350, value: 350 },
111 | { name: 450, value: 450 },
112 | { name: 650, value: 650 },
113 | { name: 850, value: 850 },
114 | ],
115 | },
116 | relsnip: {
117 | title: "Relsnip",
118 | selected: true,
119 | options: [
120 | { name: true, value: true },
121 | { name: false, value: false },
122 | ],
123 | },
124 | samples: [
125 | {
126 | question: "what is the goal of the fourth amendment? ",
127 | context:
128 | "The Fourth Amendment of the U.S. Constitution provides that the right of the people to be secure in their persons, houses, papers, and effects, against unreasonable searches and seizures, shall not be violated, and no Warrants shall issue, but upon probable cause, supported by Oath or affirmation, and particularly describing the place to be searched, and the persons or things to be seized.'The ultimate goal of this provision is to protect people’s right to privacy and freedom from unreasonable intrusions by the government. However, the Fourth Amendment does not guarantee protection from all searches and seizures, but only those done by the government and deemed unreasonable under the law.",
129 | },
130 | {
131 | question:
132 | "Who was the first woman to serve on the supreme court in America",
133 | context:
134 | "Sandra Day O’Connor, née Sandra Day, (born March 26, 1930, El Paso, Texas, U.S.), associate justice of the Supreme Court of the United States from 1981 to 2006. She was the first woman to serve on the Supreme Court. A moderate conservative, she was known for her dispassionate and meticulously researched opinions. Sandra Day grew up on a large family ranch near Duncan, Arizona. She received undergraduate (1950) and law (1952) degrees from Stanford University, where she met the future chief justice of the United States William Rehnquist.",
135 | },
136 | {
137 | question: "Where did Sandra Day grow up?",
138 | context:
139 | "Sandra Day O’Connor, née Sandra Day, (born March 26, 1930, El Paso, Texas, U.S.), associate justice of the Supreme Court of the United States from 1981 to 2006. She was the first woman to serve on the Supreme Court. A moderate conservative, she was known for her dispassionate and meticulously researched opinions. Sandra Day grew up on a large family ranch near Duncan, Arizona. She received undergraduate (1950) and law (1952) degrees from Stanford University, where she met the future chief justice of the United States William Rehnquist.",
140 | },
141 | ],
142 | expander: {
143 | title: "Expander",
144 | selected: "none",
145 | options: [{ name: "None", value: "none", type: "none" }],
146 | },
147 | reader: {
148 | title: "Reader",
149 | selected: "twmkn9/distilbert-base-uncased-squad2",
150 | options: [
151 | {
152 | name: "DistilBERT SQUAD2",
153 | value: "twmkn9/distilbert-base-uncased-squad2",
154 | type: "distilbert",
155 | },
156 | {
157 | name: "BERT SQUAD2",
158 | value: "deepset/bert-base-cased-squad2",
159 | type: "bert",
160 | },
161 | ],
162 | },
163 | retriever: {
164 | title: "Retriever",
165 | selected: "none",
166 | options: [
167 | { name: "None", value: "none", type: "none" },
168 | {
169 | name: "Case Law",
170 | value: "cases",
171 | host: "localhost",
172 | port: 9200,
173 | username: "None",
174 | password: "None",
175 | type: "elasticsearch",
176 | fields: { body_field: "casebody.data.opinions.text" },
177 | },
178 | ],
179 | readtopn: 0,
180 | },
181 | },
182 | },
183 | };
184 | }
185 |
186 | export const LeaderLine = window.LeaderLine;
187 | export const animOptions = { duration: 800, timing: "ease" };
188 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/queryview/queryview.css:
--------------------------------------------------------------------------------
1 | .passagetitle {
2 | font-weight: bold;
3 | padding: 0px 0px 5px 0px;
4 | }
5 | .passagexcerpt {
6 | }
7 | .passagerow {
8 | background: rgb(243, 244, 245);
9 | padding: 10px;
10 | margin-bottom: 5px;
11 | }
12 |
13 | .rightbox {
14 | position: absolute;
15 | right: 10px;
16 | top: 10px;
17 | }
18 |
19 | .highlightsection > span > em,
20 | .contextrow > em {
21 | background-color: #fcfcaa;
22 | padding: 0px 5px 0px 5px;
23 | border: 1px solid rgb(197, 197, 197);
24 | }
25 | .underline {
26 | border-bottom: 1px dashed rgb(196, 193, 193);
27 | }
28 | .highlightsection {
29 | padding: 0px 0px 7px 0px;
30 | }
31 | .answerspan {
32 | padding: 8px;
33 | background-color: rgb(227, 227, 227);
34 | margin: 0px 0px 5px 0px;
35 | }
36 | .loaderbox {
37 | /* border: 1px solid grey; */
38 | transition: width 0.7s, opacity 0.7s;
39 | -webkit-transition: width 0.7s, opacity 0.7s;
40 | /* width: 34px; */
41 | }
42 |
43 | .errormessage {
44 | padding: 5px;
45 | color: white;
46 | background-color: red;
47 | }
48 |
49 | .excerpttitle {
50 | padding: 2px 2px 2px 0px;
51 | color: rgb(97, 97, 97);
52 | font-weight: bold;
53 | }
54 |
55 | .answersubrow {
56 | padding: 5px 0px 5px 0px;
57 | line-height: 1.2em;
58 | }
59 | .topanswer {
60 | /* border: 2px solid rgb(253, 162, 42); */
61 | border: 2px solid #999898;
62 | }
63 | .answerrow {
64 | margin: 0px 0px 3px 0px;
65 | background-color: rgb(244, 244, 244);
66 | }
67 |
68 | .contextinputarea {
69 | min-height: 120px;
70 | }
71 | .samplequestionrow {
72 | background: rgb(210, 210, 210);
73 | padding: 5px;
74 | margin: 5px 5px 0px 0px;
75 | border-left: 1.5px solid white;
76 | }
77 | .samplequestionrow.selected {
78 | background-color: rgb(190, 213, 250);
79 | border-left: 1.5px solid rgb(157, 157, 157);
80 | }
81 |
82 | .lh2m {
83 | line-height: 2em;
84 | }
85 |
86 | .answerrowtitletag {
87 | font-size: 2.4em;
88 | color: grey;
89 | }
90 |
91 | .answerquote {
92 | font-size: 1.5em;
93 | color: rgb(14, 14, 68);
94 | }
95 |
96 | .sectionheading {
97 | line-height: 2em;
98 | }
99 |
100 | .explanationspan {
101 | /* border: 1px solid green; */
102 | padding: 2px;
103 | display: inline;
104 | /* line-height: 1.5em; */
105 | }
106 |
107 | .whatsthis {
108 | position: absolute;
109 | right: 0px;
110 | top: 0px;
111 | background-color: #807e7e;
112 | padding: 10px;
113 | color: white;
114 | }
115 | .whatsthis:hover {
116 | background-color: #0062ff;
117 | }
118 |
119 | .infodesctitle {
120 | /* font-weight: bold; */
121 | }
122 |
123 | .infodescrow {
124 | }
125 |
126 | .infocircle {
127 | border-radius: 50%;
128 | border: 1px solid white;
129 | padding: 0px 5px 0px 5px;
130 | }
131 |
132 | .exptermbox {
133 | margin-top: 5px;
134 | }
135 |
136 | .exptermboxdata {
137 | padding: 10px;
138 | border-left: 1px solid lightgrey;
139 | border-top: 1px solid lightgrey;
140 | border-bottom: 1px solid lightgrey;
141 | }
142 | .termboxclose {
143 | border: 1px solid lightgrey;
144 | padding: 10px;
145 | cursor: pointer;
146 | }
147 | .termboxclose:hover {
148 | background-color: lightgrey;
149 | }
150 | .selectedtermslabel {
151 | background-color: lightgrey;
152 | padding: 9px;
153 | }
154 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/template.css:
--------------------------------------------------------------------------------
1 | /* Text Highlights */
2 | .textalignright {
3 | text-align: right;
4 | }
5 | .textaligncenter {
6 | text-align: center;
7 | }
8 | .textvalignmiddle {
9 | vertical-align: middle;
10 | }
11 | .bluehightlight {
12 | padding: 10px;
13 | background: rgb(190, 213, 250);
14 | margin: 0px 0px 0px 0px;
15 | }
16 | .greyhighlight {
17 | background: rgba(209, 209, 209, 0.9);
18 | }
19 | .borderleftdash {
20 | border-left: 1px dashed grey;
21 | }
22 | .lightgreyhighlight {
23 | background: rgba(231, 231, 231, 0.9);
24 | }
25 | .justifycenter {
26 | justify-content: center;
27 | }
28 | .mynotif {
29 | border-left: 4px #054ada solid;
30 | }
31 | .unselectable {
32 | -webkit-touch-callout: none;
33 | -webkit-user-select: none;
34 | -khtml-user-select: none;
35 | -moz-user-select: none;
36 | -ms-user-select: none;
37 | user-select: none;
38 | }
39 | .mediumdesc {
40 | font-size: 0.9em;
41 | }
42 | .greymoreinfo {
43 | background: rgba(209, 209, 209, 0.9);
44 | }
45 | .greymoreinfo:hover {
46 | background: rgb(187, 187, 187);
47 | }
48 | .greymoreinfo:active {
49 | background: rgb(155, 155, 155);
50 | }
51 | .modelconfigdiv {
52 | background: rgba(209, 209, 209, 0.3);
53 | }
54 | .lightbluehightlight {
55 | padding: 10px;
56 | background: #edf4ff;
57 | margin: 0px 0px 0px 0px;
58 | }
59 |
60 | .orangehighlight {
61 | padding: 10px;
62 | background: rgb(240, 134, 3);
63 | margin: 0px 0px 0px 0px;
64 | color: white;
65 | }
66 |
67 | .topblueborder {
68 | border-top: 3px solid #0062ff;
69 | }
70 |
71 | .bottomblueborder {
72 | border-bottom: 3px solid #0062ff;
73 | }
74 |
75 | .lh10 {
76 | line-height: 1.25rem;
77 | }
78 |
79 | .lhmedium {
80 | line-height: 1rem;
81 | }
82 | .lhsmall {
83 | line-height: 0.8rem;
84 | }
85 | .smalldesc {
86 | font-size: 0.72em;
87 | }
88 |
89 | .sectiontitle {
90 | font-size: 1.2em;
91 | font-weight: bold;
92 | }
93 |
94 | .horrule {
95 | height: 1px;
96 | border-bottom: 1px solid rgba(145, 142, 142, 0.4);
97 | }
98 |
99 | .boldtext {
100 | font-weight: bold;
101 | }
102 |
103 | .boldmediumtext {
104 | font-weight: 600;
105 | }
106 | .whitetext {
107 | color: white;
108 | }
109 | .whitefill {
110 | fill: white;
111 | }
112 | .greentext {
113 | color: green;
114 | }
115 | /* Layout Spacing margin, etc */
116 | .iblock {
117 | display: inline-block;
118 | }
119 | .redcolor {
120 | color: red;
121 | }
122 | .border {
123 | border: 1px solid green;
124 | }
125 | .greyborder {
126 | border: 1px solid rgba(105, 105, 105, 0.8);
127 | }
128 |
129 | .floatleft {
130 | float: left;
131 | }
132 |
133 | .floatright {
134 | float: right;
135 | }
136 | .clearfix {
137 | overflow: auto;
138 | }
139 |
140 | .p10 {
141 | padding: 10px;
142 | }
143 | .m10 {
144 | margin: 10px;
145 | }
146 |
147 | .p20 {
148 | padding: 20px;
149 | }
150 | .m20 {
151 | margin: 20px;
152 | }
153 |
154 | .pb10 {
155 | padding-bottom: 10px;
156 | }
157 |
158 | .pb20 {
159 | padding-bottom: 20px;
160 | }
161 |
162 | .pb3 {
163 | padding-bottom: 3px;
164 | }
165 |
166 | .p5 {
167 | padding: 5px;
168 | }
169 | .p4 {
170 | padding: 4px;
171 | }
172 | .p3 {
173 | padding: 3px;
174 | }
175 | .pt10 {
176 | padding-top: 10px;
177 | }
178 | .pt2 {
179 | padding-top: 2px;
180 | }
181 |
182 | .pt3 {
183 | padding-top: 3px;
184 | }
185 | .pt4 {
186 | padding-top: 4px;
187 | }
188 | .pt5 {
189 | padding-top: 5px;
190 | }
191 | .pt7 {
192 | padding-top: 7px;
193 | }
194 |
195 | .pb5 {
196 | padding-bottom: 5px;
197 | }
198 | .pb7 {
199 | padding-bottom: 7px;
200 | }
201 |
202 | .pb2 {
203 | padding-bottom: 2px;
204 | }
205 |
206 | .pt20 {
207 | padding-top: 20px;
208 | }
209 |
210 | .pr5 {
211 | padding-right: 5px;
212 | }
213 | .pr10 {
214 | padding-right: 10px;
215 | }
216 | .pr20 {
217 | padding-right: 20px;
218 | }
219 |
220 | .pl4 {
221 | padding-left: 4px;
222 | }
223 |
224 | .pl5 {
225 | padding-left: 5px;
226 | }
227 |
228 | .pl10 {
229 | padding-left: 10px;
230 | }
231 | .pl20 {
232 | padding-left: 20px;
233 | }
234 |
235 | .mt10 {
236 | margin-top: 10px;
237 | }
238 | .mt5 {
239 | margin-top: 5px;
240 | }
241 |
242 | .mt20 {
243 | margin-top: 20px;
244 | }
245 |
246 | .mb10 {
247 | margin-bottom: 10px;
248 | }
249 |
250 | .mb20 {
251 | margin-bottom: 20px;
252 | }
253 |
254 | .mb3 {
255 | margin-bottom: 3px;
256 | }
257 |
258 | .mb5 {
259 | margin-bottom: 5px;
260 | }
261 |
262 | .mb7 {
263 | margin-bottom: 7px;
264 | }
265 |
266 | .mr10 {
267 | margin-right: 10px;
268 | }
269 | .mr5 {
270 | margin-right: 5px;
271 | }
272 | .mr3 {
273 | margin-right: 3px;
274 | }
275 | .mr2 {
276 | margin-right: 2px;
277 | }
278 |
279 | .ml5 {
280 | margin-left: 5px;
281 | }
282 |
283 | .mr20 {
284 | margin-right: 20px;
285 | }
286 |
287 | .ml10 {
288 | margin-left: 10px;
289 | }
290 |
291 | .rad5 {
292 | border-radius: 5px;
293 | }
294 |
295 | .rad4 {
296 | border-radius: 4px;
297 | }
298 |
299 | .rad3 {
300 | border-radius: 3px;
301 | }
302 |
303 | .rad2 {
304 | border-radius: 2px;
305 | }
306 |
307 | .opacity100 {
308 | opacity: 1;
309 | }
310 | .opacity50 {
311 | opacity: 0.5;
312 | }
313 | .opacity0 {
314 | opacity: 0;
315 | }
316 | .transitiono3s {
317 | transition: opacity 0.3s ease-in-out;
318 | -moz-transition: opacity 0.3s ease-in-out;
319 | -webkit-transition: opacity 0.3s ease-in-out;
320 | }
321 |
322 | .transitionoh4s {
323 | border: 1px solid pink;
324 | transition: opacity 0.4s ease-in-out;
325 | -webkit-transition: opacity 0.4s ease-in-out;
326 |
327 | /* transition: height .4s ease-in-out; */
328 | -webkit-transition: height 1.4s ease-in-out;
329 | }
330 |
331 | .transitionw6s {
332 | transition: width 0.4s ease-in-out;
333 | -moz-transition: width 0.4s ease-in-out;
334 | -webkit-transition: width 0.4s ease-in-out;
335 | }
336 | .notransition {
337 | -webkit-transition: none !important;
338 | -moz-transition: none !important;
339 | -o-transition: none !important;
340 | transition: none !important;
341 | }
342 |
343 | .clickable {
344 | cursor: pointer;
345 | }
346 | .decornone > a {
347 | text-decoration: none;
348 | color: white;
349 | }
350 | .w0 {
351 | width: 0%;
352 | }
353 | .w100 {
354 | width: 100%;
355 | }
356 |
357 | .h100 {
358 | height: 100%;
359 | }
360 | .h100v {
361 | height: 100vh;
362 | }
363 | .unclickable {
364 | pointer-events: none;
365 | }
366 |
367 | .flexcolumn {
368 | flex-direction: column;
369 | }
370 |
371 | .flexstretch {
372 | align-self: stretch;
373 | }
374 |
375 | .flexjustifycenter {
376 | justify-content: center;
377 | align-items: center;
378 | }
379 |
380 | .flexjustifyright {
381 | justify-content: right;
382 | align-items: right;
383 | }
384 |
385 | .flexjustifyleft {
386 | justify-content: left;
387 | align-items: left;
388 | }
389 |
390 | .flex {
391 | display: flex;
392 | }
393 |
394 | .displaynone {
395 | display: none;
396 | }
397 | .displayblock {
398 | display: block;
399 | }
400 |
401 | .flexwrap {
402 | flex-wrap: wrap;
403 | justify-content: space-around;
404 | }
405 |
406 | .flexpushout {
407 | display: none;
408 | }
409 |
410 | @media screen and (max-width: 600px) {
411 | .flexwrap {
412 | flex-wrap: wrap;
413 | }
414 | .flexwrapitem:first-child {
415 | flex-basis: 100%;
416 | margin-bottom: 5px;
417 | }
418 | .flexwrapitem:nth-child(n + 2) {
419 | flex-basis: 100%;
420 | margin-bottom: 5px;
421 | }
422 | .flexpushout {
423 | display: block;
424 | }
425 | }
426 |
427 | @media screen and (max-width: 400px) {
428 | .flexwrapitem:nth-child(n + 2) {
429 | flex-basis: 100%;
430 | margin-bottom: 5px;
431 | }
432 | }
433 |
434 | @media screen and (max-width: 500px) {
435 | .apptitle {
436 | display: none;
437 | }
438 | }
439 |
440 | @media screen and (max-width: 800px) {
441 | .flexwrap8 {
442 | flex-wrap: wrap;
443 | }
444 | .flexwrapitem8:first-child {
445 | flex-basis: 100%;
446 | margin-bottom: 5px;
447 | }
448 | }
449 |
450 | @media screen and (max-width: 1070px) {
451 | .smallhide {
452 | display: none;
453 | }
454 | }
455 |
456 | @media screen and (min-width: 1000px) {
457 | .smallshow {
458 | display: none;
459 | }
460 | }
461 |
462 | .errordiv {
463 | border: 1px solid red;
464 | border-left: 4px solid red;
465 | }
466 |
467 | .flexfull {
468 | flex: 1;
469 | }
470 |
471 | .flex1 {
472 | flex: 0.1;
473 | }
474 |
475 | .flex2 {
476 | flex: 0.2;
477 | }
478 |
479 | .flex20 {
480 | flex: 2;
481 | }
482 |
483 | .flex30 {
484 | flex: 3;
485 | }
486 | .flex40 {
487 | flex: 4;
488 | }
489 | .flex80 {
490 | flex: 8;
491 | }
492 |
493 | .flex3 {
494 | flex: 0.3;
495 | }
496 | .flex35 {
497 | flex: 0.35;
498 | }
499 |
500 | .flex4 {
501 | flex: 0.4;
502 | }
503 |
504 | .flex5 {
505 | flex: 0.5;
506 | }
507 |
508 | .flex6 {
509 | flex: 0.6;
510 | }
511 |
512 | .flex7 {
513 | flex: 0.7;
514 | }
515 |
516 | .flex8 {
517 | flex: 0.8;
518 | }
519 |
520 | .flex9 {
521 | flex: 0.9;
522 | }
523 |
524 | .positionrelative {
525 | position: relative;
526 | }
527 |
528 | .positionabsolute {
529 | position: absolute;
530 | }
531 | .bottomright {
532 | bottom: 0px;
533 | right: 0px;
534 | }
535 | .container-fluid {
536 | max-width: 1220px;
537 | margin: auto;
538 | }
539 |
540 | .centerpage {
541 | max-width: 1220px;
542 | margin: auto;
543 | }
544 |
545 | .scrollwindow {
546 | overflow: scroll;
547 | }
548 |
549 | .scrollwindow::-webkit-scrollbar {
550 | -webkit-appearance: none;
551 | }
552 |
553 | .scrollwindow::-webkit-scrollbar:vertical {
554 | width: 8px;
555 | }
556 |
557 | .scrollwindow::-webkit-scrollbar:horizontal {
558 | height: 8px;
559 | }
560 |
561 | .scrollwindow::-webkit-scrollbar-thumb {
562 | border-radius: 8px;
563 | border: 2px solid white; /* should match background, can't be transparent */
564 | background-color: rgba(0, 0, 0, 0.5);
565 | }
566 | ::-webkit-scrollbar-corner {
567 | background-color: rgba(0, 0, 0, 0);
568 | }
569 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/template.scss:
--------------------------------------------------------------------------------
1 | // @import 'carbon-components/scss/globals/scss/_styles.scss';
2 |
3 | //-------------------------
4 | // 🌍 Global
5 | //-------------------------
6 |
7 | $css--font-face: true;
8 | $css--helpers: true;
9 | $css--body: true;
10 | $css--use-layer: true;
11 | $css--reset: true;
12 | $css--typography: true;
13 | $css--plex: true;
14 |
15 | @import "carbon-components/scss/globals/scss/_typography";
16 | @import "carbon-components/scss/globals/scss/_css--font-face";
17 | @import "carbon-components/scss/globals/scss/_css--body";
18 |
19 | //-------------------------
20 | // 🍕 Components
21 | //-------------------------
22 |
23 | @import "carbon-components/scss/components/select/_select";
24 | @import "carbon-components/scss/components/tabs/_tabs";
25 | // @import "carbon-components/scss/components/tabs/_tab";
26 | // @import 'carbon-components/scss/components/data-table/_data-table';
27 | @import "carbon-components/scss/components/loading/_loading";
28 | @import "carbon-components/scss/components/modal/_modal";
29 | @import "carbon-components/scss/components/button/_button";
30 | @import "carbon-components/scss/components/checkbox/_checkbox";
31 | // @import 'carbon-components/scss/components/radio-button/_radio-button';
32 | @import "carbon-components/scss/components/toggle/_toggle";
33 | // @import 'carbon-components/scss/components/search/_search';
34 | @import "carbon-components/scss/components/tooltip/_tooltip";
35 | @import "carbon-components/scss/components/slider/_slider";
36 | @import "carbon-components/scss/components/text-area/_text-area";
37 |
38 | // @import 'carbon-components/scss/components/combo-box/_combo-box';
39 |
40 | // @import 'carbon-components/scss/components/list-box/_list-box';
41 |
42 | // .bx--toggle-input__label, .bx--toggle-input{
43 | // background-color: green;
44 | // margin: 0px;
45 | // padding: 0px;
46 | // height: 24px ;
47 | // }
48 |
49 | .bx--tab-content {
50 | padding: 10px 0px 0px 0px;
51 | }
52 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/testview/TestView.jsx:
--------------------------------------------------------------------------------
1 | import React, { Component } from "react";
2 | import "./testview.css";
3 | import BarViz from "../barviz/BarViz";
4 |
5 | class TestView extends Component {
6 | constructor(props) {
7 | super(props);
8 |
9 | this.data = require("./ex.json");
10 | // this.data.gradients = this.data.gradients.concat(this.data.gradients);
11 | // console.log(this.data);
12 | }
13 | componentDidMount() {
14 | this.barVizWidth = document.getElementById("barvizcontainer").offsetWidth;
15 | // console.log(this.barVizWidth);
16 | }
17 |
18 | render() {
19 | return (
20 |
29 |
59 |
60 |
30 |
58 |
31 |
56 |
57 |
32 |
33 |  34 |
35 |
36 |
34 |
35 |
36 |
37 |
38 |
40 | {/* {this.appName}
39 |
41 | NeuralQA
42 |
*/}
43 | {/*
44 |
45 |
*/}
49 | {/*
50 |
51 |
*/}
55 |
21 |
23 | );
24 | }
25 | }
26 |
27 | export default TestView;
28 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/components/testview/testview.css:
--------------------------------------------------------------------------------
1 | .d3brush {
2 | /* border: 1px solid black; */
3 | }
4 |
5 | .yticktext {
6 | border: 1px solid green;
7 | background-color: rgba(85, 85, 85, 0.986);
8 | }
9 |
10 | .barviz {
11 | overflow: hidden;
12 | }
13 |
--------------------------------------------------------------------------------
/neuralqa/server/ui/src/index.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import ReactDOM from 'react-dom';
3 | import './components/template.scss';
4 | import './components/template.css';
5 | import App from './components/Main';
6 | import * as serviceWorker from './serviceWorker';
7 |
8 | ReactDOM.render(