├── .env.sample
├── .gitignore
├── LICENSE
├── README.md
├── examples
├── Add Music to Sora Videos.ipynb
├── Adding_Brand_Elements.ipynb
├── Audio_Overlay.ipynb
├── Beep Curse Words.ipynb
├── Clip with Faces Rekognition.ipynb
├── Content Moderation AWS Rekognition.ipynb
├── Content Moderation.ipynb
├── Create Clip Faces.ipynb
├── Dubbing - Replace Soundtrack with New Audio.ipynb
├── Elevenlabs_Voiceover_1.ipynb
├── Elevenlabs_Voiceover_2.ipynb
├── GenAI_Storyboard.ipynb
├── Insert Inline Video.ipynb
├── Intro_Outro_Inline.ipynb
├── Keyword_Search_1.ipynb
├── Keyword_Search_Counter.ipynb
├── Lovo_Voiceover_1.ipynb
├── Programmatic_Streams_1.ipynb
├── Subtitle_Styling.ipynb
├── Wellsaid_Voiceover_1.ipynb
├── beep.wav
├── conference_slide_scraper.ipynb
└── lecture_notes_1.ipynb
├── guides
├── Cleanup.ipynb
├── Subtitle.ipynb
├── TextAsset.ipynb
├── VideoDB_Search_and_Evaluation.ipynb
├── genai.ipynb
├── multimodal
│ └── Prompt_Experiments_and_Benchmarking.ipynb
└── scene-index
│ ├── advanced_visual_search.ipynb
│ ├── custom_annotations.ipynb
│ └── playground_scene_extraction.ipynb
├── images
├── Audio_Overlay
│ └── image.png
├── Elevenlabs_Voiceover_1
│ └── image.png
├── Intro_Outro_Inline copy
│ └── image.png
├── assemblyai_labels1.png
├── assemblyai_labels2.png
├── director_architecture.png
├── director_reasoning_engine.png
├── scene_index
│ ├── VSF.png
│ └── intro.png
└── videodb.png
├── integrations
└── llama-index
│ └── simple_video_rag.ipynb
├── quickstart
├── Multimodal_Quickstart.ipynb
├── Scene Index QuickStart.ipynb
├── VideoDB Quickstart.ipynb
└── scene_level_metadata_indexing.ipynb
└── real_time_streaming
├── Baby_Crib_Monitoring.ipynb
├── Cricket_Match_Monitoring.ipynb
├── Flash_Flood_Detection.ipynb
├── Intrusion_Detection.ipynb
└── Road_Monitoring.ipynb
/.env.sample:
--------------------------------------------------------------------------------
1 | VIDEO_DB_API_KEY=
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | venv
2 | .venv
3 | personal
4 | **/.DS_Store
5 | **/.ipynb_checkpoints/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
6 |
7 |
8 | [![PyPI version][pypi-shield]][pypi-url]
9 | [![Website][website-shield]][website-url]
10 |
11 |
12 |
20 | Video Database for your AI Applications
21 |
22 | Explore the docs »
23 |
24 |
25 |
26 |
27 | ## Videodb Cookbook
28 | This repo has example code and quick tutorials for solving common tasks with the [VideoDB SDK](). To run these examples, you'll need to signup for VideoDB and get the API key ([create a free account here](https://console.videodb.io)).
29 |
30 | Most of the code examples are written in Python, though the concepts can be applied in any language.
31 |
32 | ## Contents
33 | | Cookbook| Colab |
34 | |:-----:|:-----:|
35 | | [Quickstart: VideoDB](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/VideoDB%20Quickstart.ipynb) | |
36 | | [Quickstart: Scene Index](https://colab.research.google.com/github/video-db/videodb-cookbook/blob/main/quickstart/Scene%20Index%20QuickStart.ipynb) | |
37 |
38 | ## Contributing
39 |
40 | The VideoDB Cookbook is a community-driven resource. Whether you're submitting an idea, fixing a typo, adding a new guide, or improving an existing one, your contributions are greatly appreciated!
41 |
42 | Before contributing, read through the existing issues and pull requests to see if someone else is already working on something similar. That way you can avoid duplicating efforts.
43 |
44 | If there are examples or guides you'd like to see, feel free to suggest them on the [issues page](https://github.com/video-db/videodb-cookbook/issues).
45 |
46 | [pypi-shield]: https://img.shields.io/pypi/v/videodb?style=for-the-badge
47 | [pypi-url]: https://pypi.org/project/videodb/
48 | [website-shield]: https://img.shields.io/website?url=https%3A%2F%2Fvideodb.io%2F&style=for-the-badge&label=videodb.io
49 | [website-url]: https://videodb.io/
50 |
--------------------------------------------------------------------------------
/examples/Add Music to Sora Videos.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "f31ba199-2675-4c94-b555-bff2945dbdf4",
7 | "metadata": {},
8 | "outputs": [
9 | {
10 | "name": "stdout",
11 | "output_type": "stream",
12 | "text": [
13 | "Requirement already satisfied: videodb in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (0.0.3)\n",
14 | "Requirement already satisfied: requests>=2.25.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.31.0)\n",
15 | "Requirement already satisfied: backoff>=2.2.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.2.1)\n",
16 | "Requirement already satisfied: tqdm>=4.66.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (4.66.1)\n",
17 | "Requirement already satisfied: charset-normalizer<4,>=2 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.3.2)\n",
18 | "Requirement already satisfied: idna<4,>=2.5 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.6)\n",
19 | "Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2.2.0)\n",
20 | "Requirement already satisfied: certifi>=2017.4.17 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2024.2.2)\n"
21 | ]
22 | }
23 | ],
24 | "source": [
25 | "# install latest version\n",
26 | "!pip install -U videodb"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 57,
32 | "id": "543dd0e9-abb0-423e-add7-058f2415f97d",
33 | "metadata": {},
34 | "outputs": [],
35 | "source": [
36 | "# create a new connection with your API ket\n",
37 | "from videodb import connect, play_stream\n",
38 | "from videodb import MediaType\n",
39 | "conn = connect(api_key=\"\")"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 43,
45 | "id": "7c09774b-c869-48a1-b05e-45153fa1a7af",
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "video = conn.upload(file_path=\"tokyo-walk.mp4\")"
50 | ]
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": 44,
55 | "id": "fd70719d-d278-4aa1-8809-e278bd9abb4e",
56 | "metadata": {},
57 | "outputs": [
58 | {
59 | "data": {
60 | "text/plain": [
61 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/c89aa854-91f4-4e3b-b477-32aabb05f7d6.m3u8'"
62 | ]
63 | },
64 | "execution_count": 44,
65 | "metadata": {},
66 | "output_type": "execute_result"
67 | }
68 | ],
69 | "source": [
70 | "video.player_url"
71 | ]
72 | },
73 | {
74 | "cell_type": "code",
75 | "execution_count": 3,
76 | "id": "f0eb8ac9-d8aa-4685-b331-dd1fe4adf235",
77 | "metadata": {},
78 | "outputs": [],
79 | "source": [
80 | "#choose music \n",
81 | "\n",
82 | "#links to dumb money soundtrack\n",
83 | "\n",
84 | "# https://www.youtube.com/watch?v=UBMbSYhelh0\n",
85 | "# https://www.youtube.com/watch?v=RCITj_yGIBA\n",
86 | "# https://www.youtube.com/watch?v=zkO0zrkt35Q"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 35,
92 | "id": "41ea9464-9ad7-4366-b8fa-a4978fd60a06",
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "audio = conn.upload(url=\"https://www.youtube.com/watch?v=zkO0zrkt35Q\", media_type=MediaType.audio)"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 36,
102 | "id": "ec9107a3-47ef-45d9-9eec-80c423f0cfbe",
103 | "metadata": {},
104 | "outputs": [],
105 | "source": [
106 | "from videodb.asset import VideoAsset, AudioAsset\n",
107 | "from videodb.timeline import Timeline\n",
108 | "from videodb import play_stream"
109 | ]
110 | },
111 | {
112 | "cell_type": "code",
113 | "execution_count": 51,
114 | "id": "d074fd74-5fdb-4ece-a146-0392cfef6e6d",
115 | "metadata": {},
116 | "outputs": [],
117 | "source": [
118 | "sound_track = AudioAsset(asset_id=audio.id, start=12)"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 52,
124 | "id": "dc930966-fd71-4332-9ef4-8461a9e361f9",
125 | "metadata": {},
126 | "outputs": [],
127 | "source": [
128 | "# create a new timeline\n",
129 | "timeline = Timeline(conn)\n",
130 | "# add the main video inline\n",
131 | "video_asset = VideoAsset(asset_id=video.id)"
132 | ]
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": 53,
137 | "id": "c9f97c6c-41c3-4289-94ba-3a8461f0cc30",
138 | "metadata": {},
139 | "outputs": [],
140 | "source": [
141 | "timeline.add_inline(video_asset)\n",
142 | "timeline.add_overlay(1, sound_track)"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 54,
148 | "id": "8c3e4faa-53ed-471b-b325-e7593d131324",
149 | "metadata": {},
150 | "outputs": [],
151 | "source": [
152 | "stream = timeline.generate_stream()"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 55,
158 | "id": "00d30688-4c6a-49cb-87e5-eb480d57ab80",
159 | "metadata": {},
160 | "outputs": [
161 | {
162 | "data": {
163 | "text/plain": [
164 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/ca6ec310-a857-4e50-b4ce-f4aab9bfcb1f.m3u8'"
165 | ]
166 | },
167 | "execution_count": 55,
168 | "metadata": {},
169 | "output_type": "execute_result"
170 | }
171 | ],
172 | "source": [
173 | "timeline.player_url"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 56,
179 | "id": "bdd505ea-8f69-4bd3-9ab9-e2cb4359a163",
180 | "metadata": {},
181 | "outputs": [
182 | {
183 | "data": {
184 | "text/plain": [
185 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/ca6ec310-a857-4e50-b4ce-f4aab9bfcb1f.m3u8'"
186 | ]
187 | },
188 | "execution_count": 56,
189 | "metadata": {},
190 | "output_type": "execute_result"
191 | }
192 | ],
193 | "source": [
194 | "play_stream(stream)"
195 | ]
196 | }
197 | ],
198 | "metadata": {
199 | "kernelspec": {
200 | "display_name": "Python 3 (ipykernel)",
201 | "language": "python",
202 | "name": "python3"
203 | },
204 | "language_info": {
205 | "codemirror_mode": {
206 | "name": "ipython",
207 | "version": 3
208 | },
209 | "file_extension": ".py",
210 | "mimetype": "text/x-python",
211 | "name": "python",
212 | "nbconvert_exporter": "python",
213 | "pygments_lexer": "ipython3",
214 | "version": "3.12.0"
215 | }
216 | },
217 | "nbformat": 4,
218 | "nbformat_minor": 5
219 | }
220 |
--------------------------------------------------------------------------------
/examples/Adding_Brand_Elements.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🖥️ Adding Brand Elements with VideoDB"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Introduction\n",
22 | "\n",
23 | "Adding brand elements like logo, overlays styles, elevate your video content to a new levels of professionalism. This tutorial will guide you through the process of integrating logos and custom text assets, ensuring your brand shines through in every frame."
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "## Setup\n",
31 | "---"
32 | ]
33 | },
34 | {
35 | "cell_type": "markdown",
36 | "metadata": {},
37 | "source": [
38 | "### 📦 Installing packages "
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": null,
44 | "metadata": {},
45 | "outputs": [],
46 | "source": [
47 | "%pip install videodb"
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "metadata": {},
53 | "source": [
54 | "### 🔑 API Keys\n",
55 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. If not, sign up for API access on the respective platforms.\n",
56 | "\n",
57 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 1,
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "import os\n",
67 | "\n",
68 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
69 | ]
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "metadata": {},
74 | "source": [
75 | "## Implementation\n",
76 | "\n",
77 | "---"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### 🌐 Step 1: Connect to VideoDB\n",
85 | "Begin by establishing a connection to VideoDB using your API key:"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 2,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "from videodb import connect\n",
95 | "\n",
96 | "# Connect to VideoDB using your API key\n",
97 | "conn = connect()\n",
98 | "coll = conn.get_collection()"
99 | ]
100 | },
101 | {
102 | "cell_type": "markdown",
103 | "metadata": {},
104 | "source": [
105 | "### 🎬 Step 2: Upload Video and Image Assets\n",
106 | "\n",
107 | "Begin the branding process by uploading your video and image assets (base video and logo image) to VideoDB:\n",
108 | "\n",
109 | "Refer to [this document](https://docs.videodb.io/timeline-and-assets-44) if you require any assistance with using image assets."
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 3,
115 | "metadata": {},
116 | "outputs": [],
117 | "source": [
118 | "from videodb import MediaType\n",
119 | "\n",
120 | "# Upload Video to VideoDB\n",
121 | "video = coll.upload(url=\"https://youtu.be/ps3cNAcPEMs\")\n",
122 | "\n",
123 | "# Upload Image asset for branding\n",
124 | "image = coll.upload(url=\"https://raw.githubusercontent.com/video-db/videodb-cookbook-assets/main/images/examples/Kyvos_Logo.png\", media_type=MediaType.image)"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "### 🎨 Step 3: Add Brand Elements to Video"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "We shall begin by defining the text asset (custom text: “Visit kyvosinsights.com today!”) and specifications about the image overlay (logo) and video.\n",
139 | "\n",
140 | "For details about the text customisation parameters, refer to the documentation for Text Assets."
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 4,
146 | "metadata": {},
147 | "outputs": [],
148 | "source": [
149 | "from videodb import TextStyle\n",
150 | "from videodb.asset import VideoAsset, TextAsset, ImageAsset\n",
151 | "\n",
152 | "text_asset = TextAsset(\n",
153 | " text=\"Visit kyvosinsights.com today!\",\n",
154 | " duration=2,\n",
155 | " style=TextStyle(\n",
156 | " fontsize=38,\n",
157 | " fontcolor=\"F58C29\",\n",
158 | " font=\"PT Sans\",\n",
159 | " box=True,\n",
160 | " boxcolor=\"29272D\",\n",
161 | " boxborderw=6,\n",
162 | " borderw=1,\n",
163 | " bordercolor=\"1D1C21\",\n",
164 | " y=600,\n",
165 | " ),\n",
166 | ")\n",
167 | "\n",
168 | "# Specify the duration for the video and image asset\n",
169 | "video_asset = VideoAsset(asset_id=video.id, start=0, end=44)\n",
170 | "\n",
171 | "image_asset = ImageAsset(\n",
172 | " asset_id=image.id, width=200, height=56, x=1050, y=625, duration=36\n",
173 | ")"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {},
179 | "source": [
180 | "### 🔍 Step 4: Add Brand Elements to Video\n",
181 | "\n"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "Lastly, we shall bring all these assets together by creating a timeline, and using the video asset as the base."
189 | ]
190 | },
191 | {
192 | "cell_type": "code",
193 | "execution_count": 5,
194 | "metadata": {},
195 | "outputs": [],
196 | "source": [
197 | "from videodb.timeline import Timeline\n",
198 | "\n",
199 | "timeline = Timeline(conn)\n",
200 | "\n",
201 | "timeline.add_inline(video_asset)\n",
202 | "\n",
203 | "# Create timeline with the logo & text assets\n",
204 | "timeline.add_overlay(2.5, image_asset)\n",
205 | "timeline.add_overlay(42, text_asset)"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "### 🎥 Step 5: Review and Share"
213 | ]
214 | },
215 | {
216 | "cell_type": "markdown",
217 | "metadata": {},
218 | "source": [
219 | "Review your branded video to ensure it aligns perfectly with your brand identity, then share it with your audience"
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 1,
225 | "metadata": {},
226 | "outputs": [],
227 | "source": [
228 | "from videodb import play_stream\n",
229 | "\n",
230 | "# Preview the branded video\n",
231 | "stream_url = timeline.generate_stream()\n",
232 | "play_stream(stream_url)"
233 | ]
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "metadata": {},
238 | "source": [
239 | "## 🎉 Conclusion\n",
240 | "---"
241 | ]
242 | },
243 | {
244 | "cell_type": "markdown",
245 | "metadata": {},
246 | "source": [
247 | "Congratulations on mastering the art of branding with VideoDB! By seamlessly integrating brand elements into your videos, you've enhanced their professionalism and engagement. Experiment with different branding techniques to ensure your brand shines through in every frame.\n",
248 | "\n",
249 | "For more information and advanced features, explore the [VideoDB Documentation](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration. Share your branded videos proudly and inspire others in the professional branding sphe"
250 | ]
251 | },
252 | {
253 | "cell_type": "markdown",
254 | "metadata": {},
255 | "source": []
256 | }
257 | ],
258 | "metadata": {
259 | "kernelspec": {
260 | "display_name": "Python 3 (ipykernel)",
261 | "language": "python",
262 | "name": "python3"
263 | },
264 | "language_info": {
265 | "codemirror_mode": {
266 | "name": "ipython",
267 | "version": 3
268 | },
269 | "file_extension": ".py",
270 | "mimetype": "text/x-python",
271 | "name": "python",
272 | "nbconvert_exporter": "python",
273 | "pygments_lexer": "ipython3",
274 | "version": "3.12.0"
275 | }
276 | },
277 | "nbformat": 4,
278 | "nbformat_minor": 4
279 | }
280 |
--------------------------------------------------------------------------------
/examples/Audio_Overlay.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🔊 Audio overlay + Video + Timeline"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## 💬 Overview\n",
22 | "Welcome to the groovy world of audio overlays with VideoDB! 🎶 In this tutorial, we're diving into the magic of adding audio overlays to your video assets. Picture this: you've got your video content all set, but it's missing that extra oomph. That's where audio overlay swoops in to save the day! With VideoDB's easy-to-use feature, you can seamlessly weave in background music, voiceovers, or funky sound effects, transforming your videos from ordinary to extraordinary. Let's crank up the volume and get ready to rock and roll!\n",
23 | "\n",
24 | "\n",
25 | "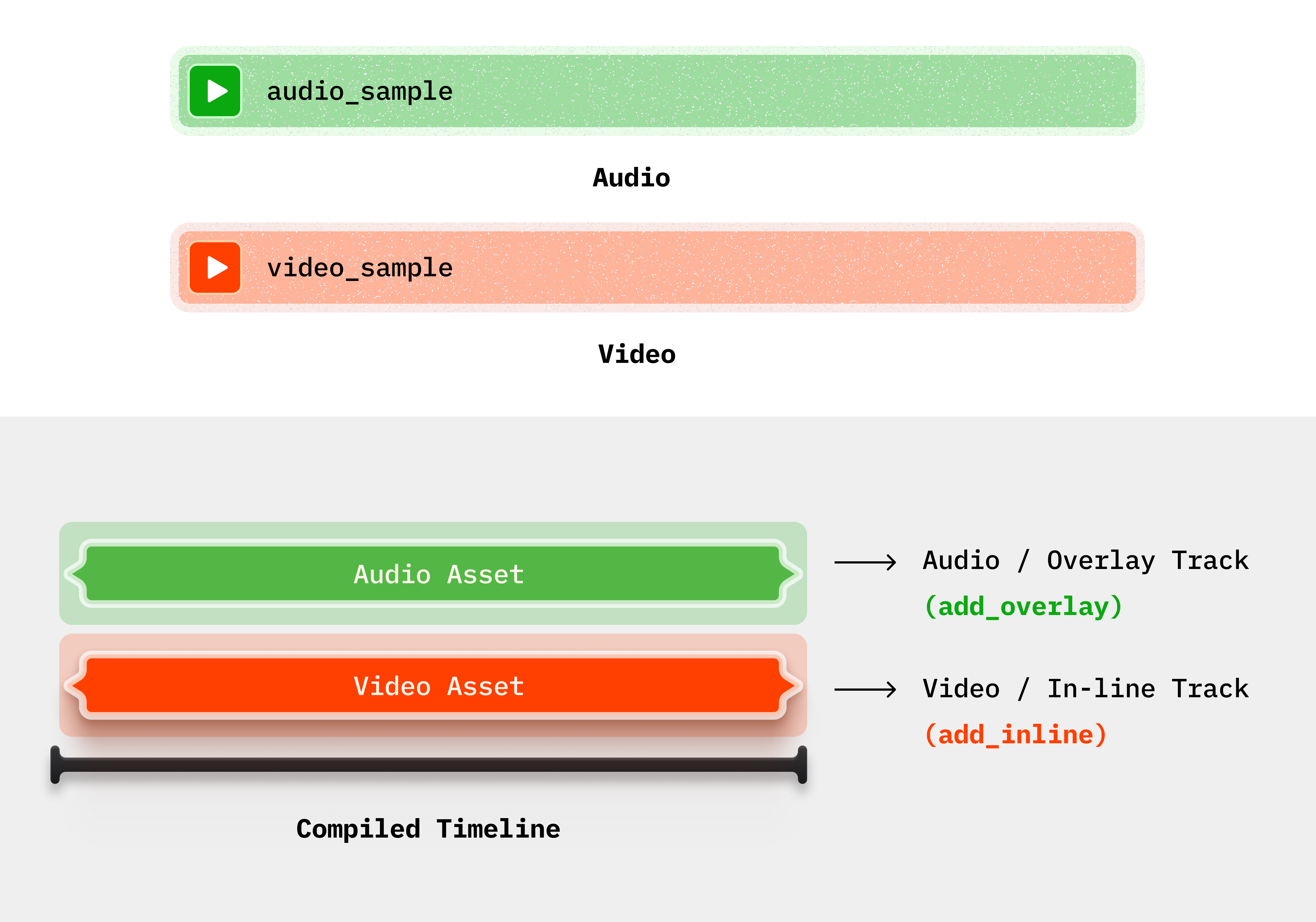"
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {},
31 | "source": [
32 | "## Setup\n",
33 | "---"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "### 📦 Installing packages "
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": null,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "%pip install videodb"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "### 🔑 API Keys\n",
57 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. If not, sign up for API access on the respective platforms.\n",
58 | "\n",
59 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": null,
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "import os\n",
69 | "\n",
70 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "## Implementation"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### 🌐 Step 1: Connect to VideoDB\n",
85 | "Connect to VideoDB to establish a session for uploading and manipulating video files. Import the necessary modules from VideoDB library to access functionalities."
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "from videodb import connect\n",
95 | "\n",
96 | "# Connect to VideoDB using your API key\n",
97 | "conn = connect()\n",
98 | "coll = conn.get_collection()"
99 | ]
100 | },
101 | {
102 | "cell_type": "markdown",
103 | "metadata": {},
104 | "source": [
105 | "### 🎥 Step 2: Upload Video\n",
106 | "Upload the video to VideoDB collection. You can upload the video asset from your local device or from a YouTube URL to upload the video from its source.Upload the video to VideoDB collection. You can upload the video asset from your local device or from a YouTube URL to upload the video from its source."
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": null,
112 | "metadata": {},
113 | "outputs": [],
114 | "source": [
115 | "video = coll.upload(url=\"https://youtu.be/e49VEpWg61M\")\n",
116 | "\n",
117 | "video.play()"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "> You can upload from your local file system too by passing `file_path` in `upload()`"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "### 🎥 Step 3: Upload Audio \n",
132 | "Upload the audio file to VideoDB collection. You can upload the audio asset from your local device or from a YouTube URL to upload the audio from its source. Make sure to mention `media_type` if you want to use audio track of a video. "
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": null,
138 | "metadata": {},
139 | "outputs": [],
140 | "source": [
141 | "audio = coll.upload(url=\"https://youtu.be/_Gd8mbQ3-mI\", media_type=\"audio\")"
142 | ]
143 | },
144 | {
145 | "cell_type": "markdown",
146 | "metadata": {},
147 | "source": [
148 | "### 🎼 Step 4: Create Assets\n",
149 | "Create assets for Audio and Video using `AudioAsset` and `VideoAsset` class"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": [
158 | "from videodb.asset import VideoAsset, AudioAsset\n",
159 | "\n",
160 | "video_asset = VideoAsset(\n",
161 | " asset_id=video.id\n",
162 | ")\n",
163 | "\n",
164 | "audio_asset = AudioAsset(asset_id=audio.id, fade_out_duration=0, disable_other_tracks=True)"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "### Step 5: Create timeline\n",
172 | "Finally, add audio as an overlay to the video using VideoDB's timeline feature.\n",
173 | "\n",
174 | "Add the main `video asset inline` and `overlay audio assets` onto the timeline. Generate a stream URL for the timeline, incorporating all assets and overlays, for playback or further processing"
175 | ]
176 | },
177 | {
178 | "cell_type": "code",
179 | "execution_count": null,
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "from videodb.timeline import Timeline\n",
184 | "\n",
185 | "# create a new timeline\n",
186 | "timeline = Timeline(conn)\n",
187 | "\n",
188 | "# add the main video inline\n",
189 | "timeline.add_inline(video_asset)\n",
190 | "\n",
191 | "# add asset overlay\n",
192 | "timeline.add_overlay(start=0, asset=audio_asset)"
193 | ]
194 | },
195 | {
196 | "cell_type": "markdown",
197 | "metadata": {},
198 | "source": [
199 | "### 🪄 Final Step: Review and Share\n",
200 | "Preview the video with the integrated voiceover to ensure it functions correctly. Once satisfied, generate a stream of the video and share the link for others to view and enjoy this wholesome creation!"
201 | ]
202 | },
203 | {
204 | "cell_type": "code",
205 | "execution_count": null,
206 | "metadata": {},
207 | "outputs": [],
208 | "source": [
209 | "from videodb import play_stream\n",
210 | "\n",
211 | "stream = timeline.generate_stream()\n",
212 | "play_stream(stream)"
213 | ]
214 | },
215 | {
216 | "cell_type": "markdown",
217 | "metadata": {},
218 | "source": [
219 | ""
220 | ]
221 | },
222 | {
223 | "cell_type": "markdown",
224 | "metadata": {},
225 | "source": [
226 | "## 🎉 Conclusion\n",
227 | "In this tutorial, we've learned how to enhance video content by adding audio overlays using VideoDB's intuitive features. By seamlessly integrating background music, voiceovers, or sound effects into video assets, users can elevate the quality and engagement of their videos.\n",
228 | "\n",
229 | "Start exploring the power of audio overlays today with VideoDB and take your video content to the next level!\n",
230 | "\n",
231 | "For more information and advanced features, explore the [VideoDB Documentation](https://docs.videodb.io) and join the VideoDB community on [GitHub](https://github.com) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration."
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {},
237 | "source": []
238 | }
239 | ],
240 | "metadata": {
241 | "kernelspec": {
242 | "display_name": "Python 3 (ipykernel)",
243 | "language": "python",
244 | "name": "python3"
245 | },
246 | "language_info": {
247 | "codemirror_mode": {
248 | "name": "ipython",
249 | "version": 3
250 | },
251 | "file_extension": ".py",
252 | "mimetype": "text/x-python",
253 | "name": "python",
254 | "nbconvert_exporter": "python",
255 | "pygments_lexer": "ipython3",
256 | "version": "3.12.0"
257 | }
258 | },
259 | "nbformat": 4,
260 | "nbformat_minor": 4
261 | }
262 |
--------------------------------------------------------------------------------
/examples/Content Moderation AWS Rekognition.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## AWS Rekognition and VideoDB - Effortlessly Remove Inappropriate Content from Video\n",
8 | "---\n",
9 | "\n",
10 | "This section of our cookbook demonstrates a method for using video analysis to identify sections of inappropriate content, then remove them from video \n",
11 | "\n",
12 | "🥡 Key components of this technique include::\n",
13 | "- **AWS Rekognition API**: The [StartContentModeration](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_StartContentModeration.html) endpoint of the AWS Rekognition API will be used to scan the video and detect inappropriate content.\n",
14 | "- **VideoDB**: This tool will be used for storing the video in a database specifically designed for videos. It also aids in extracting clips an removing section of video.\n",
15 | "\n",
16 | "\n",
17 | "We will collect timestamps where inappropriate content is present in video, then using videodb to filter out inappropriate content, **without needing to touch video editor, waiting in render queue and instantly playable**\n"
18 | ]
19 | },
20 | {
21 | "cell_type": "markdown",
22 | "metadata": {},
23 | "source": [
24 | "## Setup\n",
25 | "---"
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {
31 | "id": "jREYq-aUBkaz"
32 | },
33 | "source": [
34 | "### Installing Required Packages\n",
35 | "\n",
36 | "To ensure our Python environment has the necessary tools, we need to install following packages:\n",
37 | "- boto3: to use aws services such as [S3](https://docs.aws.amazon.com/s3/) and [AWS rekognition api](https://docs.aws.amazon.com/rekognition/)\n",
38 | "- pytube: for downloading YouTube Videos.\n",
39 | "- VideoDB : to access videodb"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "!pip install -U boto3 pytube requests videodb"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "metadata": {},
54 | "source": [
55 | "### Helper functions"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 3,
61 | "metadata": {
62 | "id": "w6OjXNT4RzvJ"
63 | },
64 | "outputs": [],
65 | "source": [
66 | "import requests\n",
67 | "import pytube\n",
68 | "import os\n",
69 | "import datetime\n",
70 | "import time\n",
71 | "import json\n",
72 | "\n",
73 | "#Downlaods Youtube video\n",
74 | "def download_video_yt(youtube_url, output_file=\"video.mp4\"):\n",
75 | " youtube_object = pytube.YouTube(youtube_url)\n",
76 | " video_stream = youtube_object.streams.get_highest_resolution()\n",
77 | " video_stream.download(filename=output_file)\n",
78 | " print(f\"Downloaded video to: {output_file}\")\n",
79 | " return output_file"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "## ⚙️ Configuartion\n",
87 | "We must set up AWS and the VideoDB api keys."
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {},
93 | "source": [
94 | "### 🔗 Setting Up a connection to db\n",
95 | "\n",
96 | "To connect to `VideoDB`, simply create a `Connection` object.\n",
97 | "\n",
98 | "This can be done by either providing your VideoDB API key directly to the constructor or by setting the `VIDEO_DB_API_KEY` environment variable with your API key.\n",
99 | "\n",
100 | "> 💡 Your API key is available in the [VideoDB dashboard](https://console.videodb.io)"
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 1,
106 | "metadata": {},
107 | "outputs": [],
108 | "source": [
109 | "from videodb import connect, play_stream\n",
110 | "conn = connect(api_key=\"\")"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "### AWS Configuration\n",
118 | "\n",
119 | "- AWS secrets like `aws_secret_key_id`, `aws_secret_access_key` and `aws_reigon` \n",
120 | "- Ensure your AWS user has access to necessary policies like : `AmazonRekognitionFullAccess` and `AmazonS3FullAccess`"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": null,
126 | "metadata": {
127 | "id": "XZyx_7Q4R7WH"
128 | },
129 | "outputs": [],
130 | "source": [
131 | "import boto3\n",
132 | "\n",
133 | "aws_access_key_id= \"YOUR_AWS_KEY_ID\"\n",
134 | "aws_secret_access_key = \"YOUR_AWS_SECRET_KEY\" \n",
135 | "region_name = \"YOUR_AWS_REIGON\"\n",
136 | "\n",
137 | "bucket_name = \"videorekog\"\n",
138 | "\n",
139 | "rekognition_client = boto3.client(\n",
140 | " \"rekognition\",\n",
141 | " aws_access_key_id=aws_access_key_id,\n",
142 | " aws_secret_access_key=aws_secret_access_key,\n",
143 | " region_name=region_name,\n",
144 | ")\n",
145 | "s3 = boto3.client('s3',\n",
146 | " aws_access_key_id=aws_access_key_id,\n",
147 | " aws_secret_access_key=aws_secret_access_key,\n",
148 | " region_name=region_name,\n",
149 | ")"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "### Downloading media\n",
157 | "\n",
158 | "Our task involves downloading a YouTube video, with a focus on removing any parts that might not be suitable for all audiences, commonly known as Content Moderation.\n",
159 | "\n",
160 | "In this demonstration, we're going to download a 10-minute clip from the TV show \"The Breaking Bad,\" aiming to remove violence, gore, and inappropriate content from the video.\n",
161 | "\n",
162 | "
\n",
163 | " Note: Please be mindful in selecting your YouTube video, as we are utilizing a premium API service. Opting for a longer video could result in extra charges.\n",
164 | "
"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": 5,
170 | "metadata": {},
171 | "outputs": [
172 | {
173 | "name": "stdout",
174 | "output_type": "stream",
175 | "text": [
176 | "Downloaded video to: video.mp4\n"
177 | ]
178 | },
179 | {
180 | "data": {
181 | "text/plain": [
182 | "'video.mp4'"
183 | ]
184 | },
185 | "execution_count": 5,
186 | "metadata": {},
187 | "output_type": "execute_result"
188 | }
189 | ],
190 | "source": [
191 | "video_url_yt = \"https://www.youtube.com/watch?v=Xa7UaHgOGfM\"\n",
192 | "video_output = \"video.mp4\"\n",
193 | "\n",
194 | "download_video_yt(video_url_yt, video_output)\n"
195 | ]
196 | },
197 | {
198 | "cell_type": "markdown",
199 | "metadata": {},
200 | "source": [
201 | "## Rekognition API Workflow\n",
202 | "\n",
203 | "- Upload a video to S3 Bucket and Start Content moderation using [StartContentModeration](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_StartContentModeration.html)"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": null,
209 | "metadata": {
210 | "id": "5xYXGQDIR-s-"
211 | },
212 | "outputs": [],
213 | "source": [
214 | "# Define function to start face search in video\n",
215 | "def start_content_moderation(video_path, bucket_name):\n",
216 | " response = rekognition_client.start_content_moderation(\n",
217 | " Video={\"S3Object\": {\"Bucket\": bucket_name, \"Name\": video_path}}\n",
218 | " )\n",
219 | "\n",
220 | " return response[\"JobId\"]\n",
221 | "\n",
222 | "\n",
223 | "# Define function to get face search results\n",
224 | "def get_content_moderation(job_id):\n",
225 | " wait_for = 5\n",
226 | " pagination_finished = False\n",
227 | " next_token = \"\"\n",
228 | " response = {\n",
229 | " \"ModerationLabels\" : []\n",
230 | " }\n",
231 | " while not pagination_finished:\n",
232 | " print(next_token)\n",
233 | " moderation_res = rekognition_client.get_content_moderation(JobId=job_id, NextToken = next_token)\n",
234 | " status = moderation_res[\"JobStatus\"]\n",
235 | " next_token = moderation_res.get(\"NextToken\", \"\")\n",
236 | " if status == \"IN_PROGRESS\":\n",
237 | " time.sleep(wait_for)\n",
238 | " elif status == \"SUCCEEDED\" :\n",
239 | " print(moderation_res)\n",
240 | " if (not next_token):\n",
241 | " pagination_finished = True\n",
242 | " response[\"ModerationLabels\"].extend(moderation_res[\"ModerationLabels\"])\n",
243 | " return response\n",
244 | "\n",
245 | "#Upload Target video to S3 Bucket\n",
246 | "s3.create_bucket(Bucket=bucket_name)\n",
247 | "s3.upload_file(video_output, bucket_name, video_output)\n",
248 | "\n",
249 | "#Start Content Moderation using Rekognition API \n",
250 | "job_id = start_content_moderation(video_output, bucket_name )\n",
251 | "print(job_id)\n",
252 | "moderation_res = get_content_moderation(job_id)\n",
253 | "print(moderation_res)\n"
254 | ]
255 | },
256 | {
257 | "cell_type": "markdown",
258 | "metadata": {},
259 | "source": [
260 | "### Preparing clips timestamps\n",
261 | "\n",
262 | "The Rekognition API flags moments in a video that are inappropriate, unwanted, or offensive by providing timestamps. Our objective is to consolidate timestamps that belong to the same sequence.\n",
263 | "\n",
264 | "Though the [AWS Segment API](https://docs.aws.amazon.com/rekognition/latest/dg/segment-api.html) offers a method for this, we will employ a more straightforward strategy.\n",
265 | "\n",
266 | "If the gap between two consecutive timestamps is less than a `threshold`, they will be combined into a single continuous scene. To ensure thorough coverage, we'll also introduce a `padding` on both the right and left sides of each scene.\n",
267 | "\n",
268 | "Then, we need to do a compliment operation on video from inappropriate clips to get appropriate and safe content clips.\n",
269 | "\n",
270 | "Feel free to adjust the `threshold` and `padding` settings to optimize the results."
271 | ]
272 | },
273 | {
274 | "cell_type": "code",
275 | "execution_count": 20,
276 | "metadata": {},
277 | "outputs": [
278 | {
279 | "name": "stdout",
280 | "output_type": "stream",
281 | "text": [
282 | "[[0, 102], [104, 119], [122, 188], [192, 197], [202, 202], [207, 209], [223, 225], [231, 234], [245, 273], [275, 275], [277, 280], [282, 291], [293, 382], [384, 396], [398, 402], [405, 438], [440, 473], [475, 532], [534, 545], [547, 558]]\n"
283 | ]
284 | }
285 | ],
286 | "source": [
287 | "timestamps = []\n",
288 | "threshold = 1\n",
289 | "padding = 1\n",
290 | "\n",
291 | "for label in moderation_res[\"ModerationLabels\"]:\n",
292 | " timestamp = label[\"Timestamp\"]/1000\n",
293 | " timestamps.append(round(timestamp))\n",
294 | "\n",
295 | "def merge_timestamps(numbers, threshold, padding):\n",
296 | " grouped_numbers = []\n",
297 | " end_last_segment = 0\n",
298 | " current_group = [numbers[0]]\n",
299 | "\n",
300 | " for i in range(1, len(numbers)):\n",
301 | " # if timestamp is with threshold from previous timestamp, consolidate them under same group\n",
302 | " if numbers[i] - numbers[i-1] <= threshold:\n",
303 | " current_group.append(numbers[i])\n",
304 | " \n",
305 | " # else put last group's end and this group's start in result clips \n",
306 | " else:\n",
307 | " start_segment = current_group[0] - padding\n",
308 | " end_segment = current_group[-1] + padding\n",
309 | " grouped_numbers.append([end_last_segment, start_segment])\n",
310 | " end_last_segment = end_segment\n",
311 | " current_group = [numbers[i]]\n",
312 | "\n",
313 | " grouped_numbers.append([end_last_segment, numbers[-1]])\n",
314 | " return grouped_numbers\n",
315 | "\n",
316 | "shots = merge_timestamps(timestamps,threshold=threshold,padding=padding)\n",
317 | "print(shots)"
318 | ]
319 | },
320 | {
321 | "cell_type": "markdown",
322 | "metadata": {},
323 | "source": [
324 | "\n",
325 | "### Removing inappropriate content from video Using VideoDB \n",
326 | "\n",
327 | "The idea behind VideoDB is straightforward: it functions as a database specifically for videos. Similar to how you upload tables or JSON data to a standard database, you can upload your videos to videodb. You can also retrieve your videos through queries, much like accessing regular data from a database.\n",
328 | "\n",
329 | "Additionally, VideoDB enables you to swiftly create clips from your videos, ensuring a ⚡️ process, just like retreiving text data from a db.\n",
330 | "\n",
331 | "For this demo, we'll be uploading our clip from \"The Breaking Bad\" to `VideoDB`.\n",
332 | "\n",
333 | "Following this, we will compile a master clip composed of smaller segments that depict appropriate contents only (i.e excluding inappropriate portions of clips from video)"
334 | ]
335 | },
336 | {
337 | "cell_type": "code",
338 | "execution_count": 22,
339 | "metadata": {},
340 | "outputs": [
341 | {
342 | "name": "stdout",
343 | "output_type": "stream",
344 | "text": [
345 | "https://console.dev.videodb.io/player?url=https://dseetlpshk2tb.cloudfront.net/v3/published/manifests/9ec3d1e9-499f-488a-b8b2-f2880f35d1a6.m3u8\n"
346 | ]
347 | }
348 | ],
349 | "source": [
350 | "video = conn.upload(url=video_url_yt)\n",
351 | "stream_link = video.generate_stream(timeline=shots)\n",
352 | "play_stream(stream_link)"
353 | ]
354 | }
355 | ],
356 | "metadata": {
357 | "colab": {
358 | "provenance": []
359 | },
360 | "kernelspec": {
361 | "display_name": "Python 3 (ipykernel)",
362 | "language": "python",
363 | "name": "python3"
364 | },
365 | "language_info": {
366 | "codemirror_mode": {
367 | "name": "ipython",
368 | "version": 3
369 | },
370 | "file_extension": ".py",
371 | "mimetype": "text/x-python",
372 | "name": "python",
373 | "nbconvert_exporter": "python",
374 | "pygments_lexer": "ipython3",
375 | "version": "3.12.0"
376 | }
377 | },
378 | "nbformat": 4,
379 | "nbformat_minor": 4
380 | }
381 |
--------------------------------------------------------------------------------
/examples/Content Moderation.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "### Effortlessly Remove Unwanted Content from videos with VideoDB: Say Goodbye to Inappropriate Sections\n",
8 | "\n",
9 | "[VideoDB](https://videodb.io) gives you power to choose any bits from any video in an instant. If you are streaming a content that has unwanted section for minors and NSFW content, you can easily skip that by just identifying the timeline where unwanted content exists and videoDB would take care of your stream to skip those secions."
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "### Workflow\n",
17 | "---\n",
18 | "\n",
19 | "1. Let's use a 10-minute video from the TV show \"The Breaking Bad,\" aiming to remove sections from video which might not be appropriate for all viewers. You can view the clip [here](https://www.youtube.com/watch?v=Xa7UaHgOGfM)\n",
20 | "2. We've identified specific times when inappropriate video content appears. This was achieved using AWS Rekognition API. If you're curious about the full process, including how to find visual inappropriate content in a video, check out our [blog](https://docs.videodb.io/ensure-a-safe-and-family-friendly-viewing-experience-with-videod-6) where we walk through the entire process.\n",
21 | "3. In this notebook, we're going to skip the details of video analysis and jump straight to the timestamps.\n",
22 | "4. We've identified the appearances of visually inappropriate content, and then relatively computed the section of video which are safe.\n",
23 | "5. Next, we'll upload the video to VideoDB and use these timestamps to clip the video. "
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "\n",
31 | "\n",
32 | "### Setup\n",
33 | "--- "
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "#### 🔧 Installing VideoDB in your environment\n",
41 | "\n",
42 | "VideoDB is available as [python package 📦](https://pypi.org/project/videodb) \n",
43 | "Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, No credit card required ) 🎉"
44 | ]
45 | },
46 | {
47 | "cell_type": "code",
48 | "execution_count": 1,
49 | "metadata": {},
50 | "outputs": [
51 | {
52 | "name": "stdout",
53 | "output_type": "stream",
54 | "text": [
55 | "Requirement already satisfied: videodb in /Users/ashu/videodb/videodb-python (0.0.2)\n",
56 | "Requirement already satisfied: requests>=2.25.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.31.0)\n",
57 | "Requirement already satisfied: backoff>=2.2.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.2.1)\n",
58 | "Requirement already satisfied: charset-normalizer<4,>=2 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.3.2)\n",
59 | "Requirement already satisfied: idna<4,>=2.5 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.6)\n",
60 | "Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2.1.0)\n",
61 | "Requirement already satisfied: certifi>=2017.4.17 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2023.11.17)\n"
62 | ]
63 | }
64 | ],
65 | "source": [
66 | "!pip install videodb"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "#### 🔗 Setting Up a connection to db\n",
74 | "To connect to VideoDB, simply create a `Connection` object. \n",
75 | "\n",
76 | "This can be done by either providing your VideoDB API key directly to the constructor or by setting the `VIDEO_DB_API_KEY` environment variable with your API key. \n",
77 | "\n",
78 | ">💡\n",
79 | ">Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, No credit card required ) 🎉."
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 2,
85 | "metadata": {},
86 | "outputs": [],
87 | "source": [
88 | "import videodb\n",
89 | "conn = videodb.connect(api_key=\"\")"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "metadata": {},
95 | "source": [
96 | "\n",
97 | "\n",
98 | "### Idenfied Sections\n",
99 | "---\n",
100 | "Here’s the list of safe timestamps of the 10-minute video from the TV show \"The Breaking Bad\". check out our 👉 [blog](https://docs.videodb.io/ensure-a-safe-and-family-friendly-viewing-experience-with-videod-6) where we walk through the entire process of using AWS Rekognition API, you can also look for other solutions. "
101 | ]
102 | },
103 | {
104 | "cell_type": "code",
105 | "execution_count": 3,
106 | "metadata": {},
107 | "outputs": [],
108 | "source": [
109 | "safe_shots = [[0, 102], [104, 119], [122, 188], [192, 197], [202, 202], [207, 209], [223, 225], [231, 234], [245, 273], [275, 275], [277, 280], [282, 291], [293, 382], [384, 396], [398, 402], [405, 438], [440, 473], [475, 532], [534, 545], [547, 558]]"
110 | ]
111 | },
112 | {
113 | "cell_type": "markdown",
114 | "metadata": {},
115 | "source": [
116 | "\n",
117 | "\n",
118 | "### Removing unsafe visual sections using VideoDB\n",
119 | "---\n",
120 | "\n",
121 | "* First, We will upload our video to VideoDB \n",
122 | "* Then create a clip which contains only Safe Shots from the video by passing timeline in `Video.generate_stream()` \n",
123 | "* you can use `play_stream()` to play the video"
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "execution_count": 4,
129 | "metadata": {},
130 | "outputs": [],
131 | "source": [
132 | "video_url_yt = \"https://www.youtube.com/watch?v=Xa7UaHgOGfM\"\n",
133 | "video = conn.upload(url=video_url_yt)"
134 | ]
135 | },
136 | {
137 | "cell_type": "markdown",
138 | "metadata": {},
139 | "source": [
140 | "### Let's play the video"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 5,
146 | "metadata": {},
147 | "outputs": [
148 | {
149 | "data": {
150 | "text/plain": [
151 | "'https://console.videodb.io/player?url=https://d27qzqw9ehjjni.cloudfront.net/v3/published/manifests/75da6b6d-03db-4bb1-a937-88b78871aa00.m3u8'"
152 | ]
153 | },
154 | "execution_count": 5,
155 | "metadata": {},
156 | "output_type": "execute_result"
157 | }
158 | ],
159 | "source": [
160 | "video.play()"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 7,
166 | "metadata": {},
167 | "outputs": [],
168 | "source": [
169 | "### Remove unsafe sections and generate stream"
170 | ]
171 | },
172 | {
173 | "cell_type": "code",
174 | "execution_count": 8,
175 | "metadata": {},
176 | "outputs": [],
177 | "source": [
178 | "stream_link = video.generate_stream(timeline=safe_shots) "
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | "\n",
186 | "\n",
187 | "### View the Results in VideoDB Player\n",
188 | "---\n",
189 | "\n",
190 | "`stream_link` is viewable by `play_stream()`. "
191 | ]
192 | },
193 | {
194 | "cell_type": "code",
195 | "execution_count": 9,
196 | "metadata": {},
197 | "outputs": [
198 | {
199 | "data": {
200 | "text/plain": [
201 | "'https://console.videodb.io/player?url=https://d27qzqw9ehjjni.cloudfront.net/v3/published/manifests/a00eebb4-a751-4807-83c5-c0eab7bdbf04.m3u8'"
202 | ]
203 | },
204 | "execution_count": 9,
205 | "metadata": {},
206 | "output_type": "execute_result"
207 | }
208 | ],
209 | "source": [
210 | "from videodb import play_stream\n",
211 | "play_stream(stream_link)"
212 | ]
213 | }
214 | ],
215 | "metadata": {
216 | "kernelspec": {
217 | "display_name": "Python 3 (ipykernel)",
218 | "language": "python",
219 | "name": "python3"
220 | },
221 | "language_info": {
222 | "codemirror_mode": {
223 | "name": "ipython",
224 | "version": 3
225 | },
226 | "file_extension": ".py",
227 | "mimetype": "text/x-python",
228 | "name": "python",
229 | "nbconvert_exporter": "python",
230 | "pygments_lexer": "ipython3",
231 | "version": "3.12.0"
232 | }
233 | },
234 | "nbformat": 4,
235 | "nbformat_minor": 4
236 | }
237 |
--------------------------------------------------------------------------------
/examples/Create Clip Faces.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "### Create Instant Clips of Your Favorite Characters with VideoDB: Effortless Video Editing at Your Fingertip\n",
8 | "\n",
9 | "We all have our favorite characters in TV shows the we love. What if you can create the clips of the scenes when they appear. You can use it in your content creation, analysis workflow or just watch how they talk, dress or act in an episode. \n",
10 | "\n",
11 | "[VideoDB](https://videodb.io) is the database for your AI applicaitons and enables it with ease. No need for fancy editing software or waiting around – you get to see your video right away. ⚡️"
12 | ]
13 | },
14 | {
15 | "cell_type": "markdown",
16 | "metadata": {},
17 | "source": [
18 | "\n",
19 | "\n",
20 | "### Workflow\n",
21 | "--- \n",
22 | "\n",
23 | "Here’s a [15-minute video](https://www.youtube.com/watch?v=NNAgJ5p4CIY) from HBO's Silicon Valley show. We've done the pre work of finding, instances when `Gilfoyle`, `Jian Yang`, `Erlich`, `Jared`, `Dinesh` and `Richard` make appearances. (This was achieved using [AWS Rekognition API](https://docs.aws.amazon.com/rekognition/). If you're curious about the full process, including how to index faces and pinpoint timestamps in videos, check out our blog where we walk through the entire process)"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "\n",
31 | "\n",
32 | "### Setup\n",
33 | "---\n",
34 | "#### 🔧 Installing VideoDB in your environment\n",
35 | "\n",
36 | "VideoDB is available as [python package 📦](https://pypi.org/project/videodb/)"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": 1,
42 | "metadata": {},
43 | "outputs": [
44 | {
45 | "name": "stdout",
46 | "output_type": "stream",
47 | "text": [
48 | "Requirement already satisfied: videodb in /Users/ashu/videodb/videodb-python (0.0.2)\n",
49 | "Requirement already satisfied: requests>=2.25.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.31.0)\n",
50 | "Requirement already satisfied: backoff>=2.2.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.2.1)\n",
51 | "Requirement already satisfied: charset-normalizer<4,>=2 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.3.2)\n",
52 | "Requirement already satisfied: idna<4,>=2.5 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.6)\n",
53 | "Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2.1.0)\n",
54 | "Requirement already satisfied: certifi>=2017.4.17 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2023.11.17)\n"
55 | ]
56 | }
57 | ],
58 | "source": [
59 | "!pip install videodb"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "#### 🔗 Setting Up a connection to db\n",
67 | "\n",
68 | "To connect to `VideoDB`, simply create a `Connection` object.\n",
69 | "\n",
70 | "This can be done by either providing your VideoDB API key directly to the constructor or by setting the `VIDEO_DB_API_KEY` environment variable with your API key.\n",
71 | "\n",
72 | ">💡\n",
73 | ">Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, No credit card required ) 🎉."
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 2,
79 | "metadata": {},
80 | "outputs": [],
81 | "source": [
82 | "import videodb\n",
83 | "conn = videodb.connect(api_key=\"\")"
84 | ]
85 | },
86 | {
87 | "cell_type": "markdown",
88 | "metadata": {},
89 | "source": [
90 | "\n",
91 | "\n",
92 | "### 🔍 Video Analysis data\n",
93 | "---\n",
94 | "\n",
95 | "The `persons_data` contains timeline for each character, representing the timestamps of shots when they were present in the video."
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": 11,
101 | "metadata": {},
102 | "outputs": [],
103 | "source": [
104 | "persons_data = [\n",
105 | " {\n",
106 | " \"name\":\"gilfoyle\",\n",
107 | " \"timeline\": [[0, 4], [160, 185], [330, 347], [370, 378], [382, 391], [391, 400]]\n",
108 | " },\n",
109 | " {\n",
110 | " \"name\": \"jinyang\",\n",
111 | " \"timeline\": [[232, 271], [271, 283], [284, 308], [312, 343], [398, 407]]\n",
112 | " },\n",
113 | " {\n",
114 | " \"name\" : \"erlic\",\n",
115 | " \"timeline\": [[0, 8], [12, 30], [31, 41], [44, 52], [56, 97], [97, 124], [147, 165], [185, 309], [316, 336], [336, 345], [348, 398], [398, 408]]\n",
116 | " },\n",
117 | " {\n",
118 | " \"name\" : \"jared\",\n",
119 | " \"timeline\": [[0, 15], [148, 165], [182, 190], [343, 355], [358, 381], [384, 393]]\n",
120 | " },\n",
121 | " {\n",
122 | " \"name\": \"dinesh\" ,\n",
123 | " \"timeline\": [[0, 4], [160, 189], [343, 354], [374, 383], [392, 402]]\n",
124 | " },\n",
125 | " {\n",
126 | " \"name\" : \"richard\" ,\n",
127 | " \"timeline\": [[12, 41], [127, 137], [137, 154], [159, 167], [360, 378], [381, 398], [399, 407]]\n",
128 | " }\n",
129 | "]"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "\n",
137 | "\n",
138 | "\n",
139 | "### 🎬️ Clips \n",
140 | "---\n",
141 | "\n",
142 | "\n",
143 | "#### Generate Clip for each character using VideoDB\n",
144 | "\n",
145 | "For this step,\n",
146 | "\n",
147 | "* We will upload our video to VideoDB using `conn.upload()`\n",
148 | "* Create clips of each character from our analyzed data by passing `timeline` in `video.generate_stream()`"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 4,
154 | "metadata": {},
155 | "outputs": [],
156 | "source": [
157 | "video_url_yt = \"https://www.youtube.com/watch?v=NNAgJ5p4CIY\"\n",
158 | "video = conn.upload(url=video_url_yt)"
159 | ]
160 | },
161 | {
162 | "cell_type": "code",
163 | "execution_count": 15,
164 | "metadata": {},
165 | "outputs": [],
166 | "source": [
167 | "for person in persons_data:\n",
168 | " stream_link = video.generate_stream(timeline=person[\"timeline\"]) \n",
169 | " person[\"clip\"] = stream_link"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "### View the results in Videodb Player \n",
177 | "Now, it's time to check out our results.\n",
178 | "\n",
179 | "Let's take a look at a clip featuring Gilfoyle (or, feel free to choose your favorite character)."
180 | ]
181 | },
182 | {
183 | "cell_type": "code",
184 | "execution_count": 16,
185 | "metadata": {},
186 | "outputs": [],
187 | "source": [
188 | "from videodb import play_stream \n",
189 | "\n",
190 | "for person in persons_data:\n",
191 | " if person['name'] == \"gilfoyle\":\n",
192 | " play_stream(person['clip'])"
193 | ]
194 | }
195 | ],
196 | "metadata": {
197 | "kernelspec": {
198 | "display_name": "Python 3 (ipykernel)",
199 | "language": "python",
200 | "name": "python3"
201 | },
202 | "language_info": {
203 | "codemirror_mode": {
204 | "name": "ipython",
205 | "version": 3
206 | },
207 | "file_extension": ".py",
208 | "mimetype": "text/x-python",
209 | "name": "python",
210 | "nbconvert_exporter": "python",
211 | "pygments_lexer": "ipython3",
212 | "version": "3.12.0"
213 | }
214 | },
215 | "nbformat": 4,
216 | "nbformat_minor": 4
217 | }
218 |
--------------------------------------------------------------------------------
/examples/Dubbing - Replace Soundtrack with New Audio.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "2ee616dc-4bb4-4f79-aab4-26c8995a62e7",
6 | "metadata": {},
7 | "source": [
8 | "### Overview\n",
9 | "\n",
10 | "Dubbing videos is a great strategy for your existing content. This guide is here to help you explore localizing content or just enjoy remixing your favorite videos into new versions.\n",
11 | "\n",
12 | "Focus is on how to replace the soundtrack with ease if you alerady have the dubbed content. \n",
13 | "\n",
14 | "If you are looking for AI solutions for dubbing the soundtrack, please wait for part-2 of this tutorial. \n"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "id": "fc962a65-26be-4d46-bbc4-7fa85cfac170",
20 | "metadata": {},
21 | "source": [
22 | "### Prerequisites\n",
23 | "Ensure you have VideoDB installed in your environment. If not, simply run `!pip install videodb` in your terminal. \n",
24 | "\n",
25 | "You'll also need a `VideoDB API key`, which can be obtained from the VideoDB console."
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "id": "8c5307d0-9717-47f0-97e1-e8f611ff9e83",
31 | "metadata": {},
32 | "source": [
33 | "### Step 1: Source Your Videos\n",
34 | "First, identify the original video and the new audio track you wish to overlay. For this tutorial, we're using an English video and a Hindi audio track:"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 35,
40 | "id": "f3f423a4-47d8-4d76-b999-7bd774b0fd12",
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "# Original video in English\n",
45 | "english_audio = 'https://www.youtube.com/watch?v=0e3GPea1Tyg'\n",
46 | "\n",
47 | "# New audio track in Hindi\n",
48 | "hindi_audio = 'https://www.youtube.com/watch?v=IoDVfXFq5cU'\n"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "id": "4c8132ac-247f-44a6-b6de-d0c7acd22a03",
54 | "metadata": {},
55 | "source": [
56 | "### Step 2: Connect to VideoDB\n",
57 | "Connect to VideoDB using your API key. This establishes a session for uploading and manipulating video and audio files:\n",
58 | "\n"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 36,
64 | "id": "3aa868ec-58dc-4334-89c0-c4b21e8ef12b",
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "#connect to videodb\n",
69 | "from videodb import connect\n",
70 | "from videodb import MediaType\n",
71 | "conn = connect(api_key=\" \")"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "id": "a4f48e4d-14cc-4fde-ab18-8d4ca44013e9",
77 | "metadata": {},
78 | "source": [
79 | "### Step 3: Upload and Prepare Media\n",
80 | "Upload both the original video and the new audio track to VideoDB. Specify the `media_type` for the audio to ensure only the soundtrack is used:"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 37,
86 | "id": "8d4d4220-94e9-457c-9bd3-625a128c6d5b",
87 | "metadata": {},
88 | "outputs": [],
89 | "source": [
90 | "# Upload the original video\n",
91 | "video = conn.upload(url=english_audio)\n",
92 | "\n",
93 | "# Upload and extract audio from the new track\n",
94 | "audio = conn.upload(url=hindi_audio, media_type=MediaType.audio)\n"
95 | ]
96 | },
97 | {
98 | "cell_type": "markdown",
99 | "id": "d8d4a5c3-190c-4160-ab1e-cd244301ae20",
100 | "metadata": {},
101 | "source": [
102 | "### Step 4: Create and Customize Your Timeline\n",
103 | "Create a new timeline and add your video. Then, overlay the new audio track, replacing the original audio:"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 38,
109 | "id": "85e48e11-076f-437a-94c7-aa62c9f32e9a",
110 | "metadata": {},
111 | "outputs": [],
112 | "source": [
113 | "from videodb.asset import VideoAsset, AudioAsset\n",
114 | "from videodb.timeline import Timeline\n",
115 | "\n",
116 | "# create a new timeline\n",
117 | "timeline = Timeline(conn)\n",
118 | "\n",
119 | "#create video asset with full length\n",
120 | "video_asset = VideoAsset(asset_id=video.id)\n",
121 | "\n",
122 | "# add original video inline\n",
123 | "timeline.add_inline(video_asset)"
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "execution_count": 39,
129 | "id": "a73f4303-bfef-46cd-b151-a35ee78fd8a9",
130 | "metadata": {},
131 | "outputs": [],
132 | "source": [
133 | "# create an audio asset from 0 sec to the full length of the video .\n",
134 | "hindi_audio_asset = AudioAsset(asset_id=audio.id, disable_other_tracks=True)\n",
135 | "\n",
136 | "# add overlay starting from 0 sec in the timeline as we want to replace the full track.\n",
137 | "timeline.add_overlay(0, hindi_audio_asset)"
138 | ]
139 | },
140 | {
141 | "cell_type": "markdown",
142 | "id": "6da18992-f453-4ba0-b26a-83f83365598d",
143 | "metadata": {},
144 | "source": [
145 | "### Step 5: Review and Share Your Dubbed Video\n",
146 | "Finally, generate a stream of your newly dubbed video and share the link for others to view:"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 40,
152 | "id": "30caa500-c565-4ae5-ae3a-d7b5541b077d",
153 | "metadata": {},
154 | "outputs": [
155 | {
156 | "data": {
157 | "text/plain": [
158 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/5dd7e078-0ecb-4b23-89bd-968e557c98a6.m3u8'"
159 | ]
160 | },
161 | "execution_count": 40,
162 | "metadata": {},
163 | "output_type": "execute_result"
164 | }
165 | ],
166 | "source": [
167 | "from videodb import play_stream\n",
168 | "play_stream(hindi_dub_stream)"
169 | ]
170 | },
171 | {
172 | "cell_type": "markdown",
173 | "id": "34e390f2-084e-430d-b62c-e425735c3ba5",
174 | "metadata": {},
175 | "source": [
176 | "### Generating Dubbed Audio with AI\n",
177 | "If you don't have a ready-made audio track, consider using AI solutions like Eleven Labs to generate dubbed audio in various languages and voices.\n",
178 | "\n",
179 | "With VideoDB, dubbing videos is as straightforward as querying a database. Enjoy creating and sharing your dubbed video content!"
180 | ]
181 | }
182 | ],
183 | "metadata": {
184 | "kernelspec": {
185 | "display_name": "Python 3 (ipykernel)",
186 | "language": "python",
187 | "name": "python3"
188 | },
189 | "language_info": {
190 | "codemirror_mode": {
191 | "name": "ipython",
192 | "version": 3
193 | },
194 | "file_extension": ".py",
195 | "mimetype": "text/x-python",
196 | "name": "python",
197 | "nbconvert_exporter": "python",
198 | "pygments_lexer": "ipython3",
199 | "version": "3.12.0"
200 | }
201 | },
202 | "nbformat": 4,
203 | "nbformat_minor": 5
204 | }
205 |
--------------------------------------------------------------------------------
/examples/Elevenlabs_Voiceover_1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🔊 Eleven Labs x VideoDB: Adding AI Generated voiceovers to silent footage"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Overview\n",
22 | "Voiceovers are the secret sauce that turns silent footage into captivating stories. They add depth, emotion, and excitement, elevating the viewing experience to new heights. With [VideoDB](https://videodb.io)'s cutting-edge technology, creating dynamic voiceovers for your videos is easier and more thrilling than ever before.\n",
23 | "\n",
24 | "Creating AI content and merging outputs from different tools can be tough and time-consuming. Doing it manually is even harder! What if you could do it all- in just a few lines of code? \n",
25 | "\n",
26 | "[VideoDB](https://videodb.io)'s cool tech helps you generate intelligent AI content and combine outputs from various tools quickly and automatically. No more long and tedious processes. Just simple, efficient, and awesome results"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "\n",
34 | "Let’s try adding an automatically generated voiceover to [this silent footage](https://youtu.be/RcRjY5kzia8) in the style and voice of Sir David Attenborough. We shall do this using the powerful tech provided by `Open AI`, `ElevenLabs` and `VideoDB`\n",
35 | "\n"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | ""
43 | ]
44 | },
45 | {
46 | "cell_type": "markdown",
47 | "metadata": {},
48 | "source": [
49 | "---"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "## Setup"
57 | ]
58 | },
59 | {
60 | "cell_type": "markdown",
61 | "metadata": {},
62 | "source": [
63 | "### 📦 Installing packages "
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {},
70 | "outputs": [],
71 | "source": [
72 | "%pip install openai\n",
73 | "%pip install videodb"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "### 🔑 API Keys\n",
81 | "Before proceeding, ensure access to [VideoDB](https://videodb.io), [OpenAI](https://openai.com), and [ElevenLabs](https://elevenlabs.io) API key. If not, sign up for API access on the respective platforms.\n",
82 | "\n",
83 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
84 | ]
85 | },
86 | {
87 | "cell_type": "code",
88 | "execution_count": null,
89 | "metadata": {},
90 | "outputs": [],
91 | "source": [
92 | "import os\n",
93 | "\n",
94 | "os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
95 | "os.environ[\"ELEVEN_LABS_API_KEY\"] = \"\"\n",
96 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "### 🎙️ ElevenLab's Voice ID \n",
104 | "You will also need ElevenLab's VoiceID of a Voice that you want to use.\n",
105 | "\n",
106 | "For this demo, we will be using [David Attenborough's Voice](https://elevenlabs.io/app/voice-lab/share/2ee40b08feb5b536baa392b1efc25f1cbbf432099b40982407990f4aa0dfe8a7/iJVpwDOsPQAptMKoj1ea). ElevenLabs has a large variety of voices to choose from (browse them [here](https://elevenlabs.io/voice-library)). Once finalized, copy the Voice ID from ElevenLabs and link it here."
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": null,
112 | "metadata": {},
113 | "outputs": [],
114 | "source": [
115 | "voiceover_artist_id = \"VOICEOVER_ARTIST_ID\""
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "---"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## Implementation"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "\n",
137 | "### 🌐 Step 1: Connect to VideoDB\n",
138 | "Connect to VideoDB using your API key to establish a session for uploading and manipulating video files."
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": null,
144 | "metadata": {},
145 | "outputs": [],
146 | "source": [
147 | "from videodb import connect\n",
148 | "\n",
149 | "# Connect to VideoDB using your API key\n",
150 | "conn = connect()"
151 | ]
152 | },
153 | {
154 | "cell_type": "markdown",
155 | "metadata": {},
156 | "source": [
157 | "### 🎥 Step 2: Upload Video"
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": null,
163 | "metadata": {},
164 | "outputs": [],
165 | "source": [
166 | "# Upload a video by URL (replace the url with your video)\n",
167 | "video = conn.upload(url='https://youtu.be/RcRjY5kzia8')"
168 | ]
169 | },
170 | {
171 | "cell_type": "markdown",
172 | "metadata": {},
173 | "source": [
174 | "### 🔍 Step 3: Analyze Scenes and Generate Scene Descriptions\n",
175 | "\n",
176 | "Start by analyzing the scenes within your Video using VideoDB's scene indexing capabilities. This will provide context for generating the script prompt."
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": null,
182 | "metadata": {},
183 | "outputs": [],
184 | "source": [
185 | "video.index_scenes()"
186 | ]
187 | },
188 | {
189 | "cell_type": "markdown",
190 | "metadata": {},
191 | "source": [
192 | "Let's view the description of first scene of the video"
193 | ]
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": 8,
198 | "metadata": {},
199 | "outputs": [
200 | {
201 | "name": "stdout",
202 | "output_type": "stream",
203 | "text": [
204 | "0 - 9.033333333333333\n",
205 | "The image displays an abstract array of blue shades forming a textured pattern resembling overlapping petals or scales. The hues range from deep cobalt to turquoise, intimating a fluid or organic essence reminiscent of natural elements like water or foliage. The amalgamation of shapes and colors creates a vibrant mosaic, without any discernible figures or familiar forms. It conveys a sense of calmness and depth, akin to peering into a cerulean sea or a cluster of exotic flowers. This image could be interpreted as a close-up of scales, artistic rendering, or a digitally altered photograph, with its focus on the interplay of color and form.\n"
206 | ]
207 | }
208 | ],
209 | "source": [
210 | "scenes = video.get_scenes()\n",
211 | "print(f\"{scenes[0]['start']} - {scenes[0]['end']}\")\n",
212 | "print(scenes[0][\"response\"])"
213 | ]
214 | },
215 | {
216 | "cell_type": "markdown",
217 | "metadata": {},
218 | "source": [
219 | "### Step 4: Generate Voiceover Script with LLM\n",
220 | "Combine scene descriptions with the script prompt, instructing LLM to create a voiceover script in David Attenborough's style.\n",
221 | "\n",
222 | "This script prompt can be refined and tweaked to generate the most suitable output. Check out [these examples](https://www.youtube.com/playlist?list=PLhxAMFLSSK03rsPTjRv1LbAXHQpNN6BS0) to explore more use cases."
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": null,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "import openai\n",
232 | "\n",
233 | "client = openai.OpenAI()\n",
234 | "\n",
235 | "script_prompt = \"Here's the data from a scene index for a video about the underwater world. Study this and then generate a synced script based on the description below. Make sure the script is in the language, voice and style of Sir David Attenborough\"\n",
236 | "\n",
237 | "full_prompt = script_prompt + \"\\n\\n\"\n",
238 | "for scene in scenes:\n",
239 | " full_prompt += f\"- {scene}\\n\"\n",
240 | "\n",
241 | "openai_res = client.chat.completions.create(\n",
242 | " model=\"gpt-3.5-turbo\",\n",
243 | " messages=[{\"role\": \"system\", \"content\": full_prompt}],\n",
244 | ")\n",
245 | "voiceover_script = openai_res.choices[0].message.content\n",
246 | "\n",
247 | "# If you have ElevenLab's paid plan remove this\n",
248 | "voiceover_script = voiceover_script[:2500]"
249 | ]
250 | },
251 | {
252 | "cell_type": "markdown",
253 | "metadata": {},
254 | "source": [
255 | "### 🎤 Step 5: Generate Voiceover Audio with ElevenLabs\n",
256 | "Utilize the generated script to synthesize AI-generated voiceover narration in David Attenborough's voice using ElevenLabs API."
257 | ]
258 | },
259 | {
260 | "cell_type": "code",
261 | "execution_count": null,
262 | "metadata": {},
263 | "outputs": [],
264 | "source": [
265 | "import requests\n",
266 | "\n",
267 | "\n",
268 | "# Call ElevenLabs API to generate voiceover\n",
269 | "url = f\"https://api.elevenlabs.io/v1/text-to-speech/{voiceover_artist_id}\"\n",
270 | "headers = {\n",
271 | " \"xi-api-key\": os.environ.get(\"ELEVEN_LABS_API_KEY\"),\n",
272 | " \"Content-Type\": \"application/json\"\n",
273 | "}\n",
274 | "payload = {\n",
275 | " \"model_id\": \"eleven_monolingual_v1\",\n",
276 | " \"text\": voiceover_script,\n",
277 | " \"voice_settings\": {\n",
278 | " \"stability\": 0.5,\n",
279 | " \"similarity_boost\": 0.5\n",
280 | " }\n",
281 | "}\n",
282 | "elevenlabs_res = requests.request(\"POST\", url, json=payload, headers=headers)\n",
283 | "\n",
284 | "# Save the audio file\n",
285 | "audio_file = \"audio.mp3\"\n",
286 | "CHUNK_SIZE = 1024\n",
287 | "with open(audio_file, 'wb') as f:\n",
288 | " for chunk in elevenlabs_res.iter_content(chunk_size=CHUNK_SIZE):\n",
289 | " if chunk:\n",
290 | " f.write(chunk)"
291 | ]
292 | },
293 | {
294 | "cell_type": "markdown",
295 | "metadata": {},
296 | "source": [
297 | "### 🎬 Step 6: Add Voiceover to Video with VideoDB"
298 | ]
299 | },
300 | {
301 | "cell_type": "markdown",
302 | "metadata": {},
303 | "source": [
304 | "In order to use the voiceover generated above, let's upload the audio file (voiceover) to VideoDB first"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": null,
310 | "metadata": {},
311 | "outputs": [],
312 | "source": [
313 | "audio = conn.upload(file_path=audio_file)"
314 | ]
315 | },
316 | {
317 | "cell_type": "markdown",
318 | "metadata": {},
319 | "source": [
320 | "Finally, add the AI-generated voiceover to the original footage using VideoDB's [timeline feature](https://docs.videodb.io/version-0-0-3-timeline-and-assets-44)"
321 | ]
322 | },
323 | {
324 | "cell_type": "code",
325 | "execution_count": null,
326 | "metadata": {},
327 | "outputs": [],
328 | "source": [
329 | "from videodb.timeline import Timeline\n",
330 | "from videodb.asset import VideoAsset, AudioAsset\n",
331 | "\n",
332 | "# Create a timeline object\n",
333 | "timeline = Timeline(conn)\n",
334 | "\n",
335 | "# Add the video asset to the timeline for playback\n",
336 | "video_asset = VideoAsset(asset_id=video.id)\n",
337 | "timeline.add_inline(asset=video_asset)\n",
338 | "\n",
339 | "# Add the audio asset to the timeline for playback\n",
340 | "audio_asset = AudioAsset(asset_id=audio.id)\n",
341 | "timeline.add_overlay(start=0, asset=audio_asset)"
342 | ]
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "metadata": {},
347 | "source": [
348 | "### 🪄 Step 7: Review and Share\n",
349 | "Preview the video with the integrated voiceover to ensure it functions correctly. \n",
350 | "Once satisfied, generate a stream of the video and share the link for others to view and enjoy this wholesome creation!\n"
351 | ]
352 | },
353 | {
354 | "cell_type": "code",
355 | "execution_count": 1,
356 | "metadata": {},
357 | "outputs": [],
358 | "source": [
359 | "from videodb import play_stream\n",
360 | "\n",
361 | "stream_url = timeline.generate_stream()\n",
362 | "play_stream(stream_url)"
363 | ]
364 | },
365 | {
366 | "cell_type": "markdown",
367 | "metadata": {},
368 | "source": [
369 | "---"
370 | ]
371 | },
372 | {
373 | "cell_type": "markdown",
374 | "metadata": {},
375 | "source": [
376 | "### 🎉 Conclusion:\n",
377 | "Congratulations! You have successfully automated the process of creating custom and personalized voiceovers based on a simple prompt and raw video footage using VideoDB, OpenAI, and ElevenLabs.\n",
378 | "\n",
379 | "By leveraging advanced AI technologies, you can enhance the storytelling and immersive experience of your video content. Experiment with different prompts and scene analysis techniques to further improve the quality and accuracy of the voiceovers. Enjoy creating captivating narratives with AI-powered voiceovers using VideoDB! \n",
380 | "\n",
381 | "For more such explorations, refer to the [documentation of VideoDB](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration.\n",
382 | "\n",
383 | "We're excited to see your creations, so we welcome you to share your creations via [Discord](https://discord.com/invite/py9P639jGz), [LinkedIn](https://www.linkedin.com/company/videodb) or [Twitter](https://twitter.com/videodb_io)."
384 | ]
385 | }
386 | ],
387 | "metadata": {
388 | "kernelspec": {
389 | "display_name": "Python 3 (ipykernel)",
390 | "language": "python",
391 | "name": "python3"
392 | },
393 | "language_info": {
394 | "codemirror_mode": {
395 | "name": "ipython",
396 | "version": 3
397 | },
398 | "file_extension": ".py",
399 | "mimetype": "text/x-python",
400 | "name": "python",
401 | "nbconvert_exporter": "python",
402 | "pygments_lexer": "ipython3",
403 | "version": "3.12.0"
404 | }
405 | },
406 | "nbformat": 4,
407 | "nbformat_minor": 4
408 | }
409 |
--------------------------------------------------------------------------------
/examples/Elevenlabs_Voiceover_2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🔊 Elevating Trailers with Automated Narration"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Introduction \n",
22 | "\n",
23 | "Narration is the heartbeat of trailers, injecting excitement and intrigue into every frame ▶️ With [VideoDB](https://videodb.io), [OpenAI](https://openai.com), and [ElevenLabs](https://elevenlabs.io) at your fingertips, adding narration to trailers becomes a creative process. This tutorial will guide you through the simple process of seamlessly integrating narration into trailers using these powerful tools."
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "## Setup"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "---"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "### 📦 Installing packages "
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "metadata": {},
51 | "outputs": [],
52 | "source": [
53 | "%pip install openai\n",
54 | "%pip install videodb"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {},
60 | "source": [
61 | "### 🔑 API keys\n",
62 | "Before proceeding, ensure access to [VideoDB](https://videodb.io), [OpenAI](https://openai.com), and [ElevenLabs](https://elevenlabs.io) API key. If not, sign up for API access on the respective platforms.\n",
63 | "\n",
64 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 13,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "import os\n",
74 | "\n",
75 | "os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
76 | "os.environ[\"ELEVEN_LABS_API_KEY\"] = \"\"\n",
77 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### 🎙️ ElevenLab's Voice ID \n",
85 | "You will also need ElevenLab's VoiceID of a Voice that you want to use.\n",
86 | "\n",
87 | "For this demo, we will be using [Sam Elliot's Voice](https://elevenlabs.io/app/voice-lab/share/bcf1f77ee30ba698ec2808b47188b4189a69c862c073d704fde7034608eeaec5/nRjJQMMnjuyMXVyDw9TC). ElevenLabs has a large variety of voices to choose from (browse them [here](https://elevenlabs.io/voice-library)). Once finalized, copy the Voice ID from ElevenLabs and link it here."
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 15,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "voiceover_artist_id = \"VOICEOVER_ARTIST_ID\""
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "## Tutorial Walkthrough"
104 | ]
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "metadata": {},
109 | "source": [
110 | "---"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "\n",
118 | "### 📋 Step 1: Connect to VideoDB\n",
119 | "Gear up by establishing a connection to VideoDB using your API key to manage and make the most of you video library with unparalleled efficiency."
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 4,
125 | "metadata": {},
126 | "outputs": [],
127 | "source": [
128 | "from videodb import connect\n",
129 | "\n",
130 | "# Connect to VideoDB using your API key\n",
131 | "conn = connect()"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "### 🎬 Step 2: Upload the Trailer\n",
139 | "Upload the trailer video to VideoDB for further processing. This creates the base video asset that we shall use later in this tutorial."
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 5,
145 | "metadata": {},
146 | "outputs": [],
147 | "source": [
148 | "video = conn.upload(url='https://www.youtube.com/watch?v=WQmGwmc-XUY')"
149 | ]
150 | },
151 | {
152 | "cell_type": "markdown",
153 | "metadata": {},
154 | "source": [
155 | "### 🔍 Step 3: Analyze Scenes and Generate Scene Descriptions\n",
156 | "\n",
157 | "Start by analyzing the scenes within your Video using VideoDB's scene indexing capabilities. This will provide context for generating the script prompt."
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 6,
163 | "metadata": {},
164 | "outputs": [],
165 | "source": [
166 | "video.index_scenes()"
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "Let's view the description of first scene from the video"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 8,
179 | "metadata": {},
180 | "outputs": [
181 | {
182 | "name": "stdout",
183 | "output_type": "stream",
184 | "text": [
185 | "0 - 0.7090416666666666\n",
186 | "The image captures a fiery blaze, a dynamic dance of flames in vivid shades of orange, gold, and red. Light flickers intensely, radiance expanding, contracting with the fire's rhythm. No specific source is visible; the fire dominates entirely, filling the frame with energetic movement. The luminosity suggests a fierce heat, powerful enough to demand respect and caution. Each tongue of flame is seemingly alive, almost writhing against a darker, indistinct background. This could be a natural fire or a controlled blaze—there’s no context to indicate its origin. Amidst the searing heat, the flames create a mesmeric, albeit destructive, spectacle.\n"
187 | ]
188 | }
189 | ],
190 | "source": [
191 | "scenes = video.get_scenes()\n",
192 | "print(f\"{scenes[0]['start']} - {scenes[0]['end']}\")\n",
193 | "print(scenes[0][\"response\"])"
194 | ]
195 | },
196 | {
197 | "cell_type": "markdown",
198 | "metadata": {},
199 | "source": [
200 | "### 🔊 Step 4: Generate Narration Script with LLM\n",
201 | "Here, we use OpenAI’s GPT to build context around the scene descriptions above, and generate a fitting narration script for the visuals."
202 | ]
203 | },
204 | {
205 | "cell_type": "code",
206 | "execution_count": 9,
207 | "metadata": {},
208 | "outputs": [],
209 | "source": [
210 | "# Generate narration script with ChatGPT\n",
211 | "import openai\n",
212 | "\n",
213 | "client = openai.OpenAI()\n",
214 | "\n",
215 | "script_prompt = \"Craft a dynamic narration script for this trailer, incorporating scene descriptions to enhance storytelling. Ensure that the narration aligns seamlessly with the timestamps provided in the scene index. Do not include any annotations in the output script\"\n",
216 | "\n",
217 | "full_prompt = script_prompt + \"\\n\\n\"\n",
218 | "for scene in scenes:\n",
219 | " full_prompt += f\"- {scene}\\n\"\n",
220 | "\n",
221 | "openai_res = client.chat.completions.create(\n",
222 | " model=\"gpt-3.5-turbo\",\n",
223 | " messages=[{\"role\": \"system\", \"content\": full_prompt}],\n",
224 | ")\n",
225 | "voiceover_script = openai_res.choices[0].message.content\n",
226 | "\n",
227 | "# If you have ElevenLab's paid plan remove the :2500 limit on voiceover script.\n",
228 | "voiceover_script = voiceover_script[:2500]"
229 | ]
230 | },
231 | {
232 | "cell_type": "markdown",
233 | "metadata": {},
234 | "source": [
235 | "You can refine the narration script prompt to ensure synchronization with timestamps in the scene index, optimizing the storytelling experience."
236 | ]
237 | },
238 | {
239 | "cell_type": "markdown",
240 | "metadata": {},
241 | "source": [
242 | "### 🎙️ Step 5: Generate Narration Audio with elevenlabs.io\n",
243 | "Prepare to be dazzled as you synthesize the narration audio using elevenlabs.io API, tailored to match the trailer's pulse-pounding rhythm.\n",
244 | "\n",
245 | "Note: for this step, you will need a specific voice ID that fits perfectly with the vibe of your trailer. In our example, we have used this voice that resembles the vocal quality and style that of Sam Elliott. You can find a voice suitable for your trailer in the ElevenLabs Voice Library."
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": null,
251 | "metadata": {},
252 | "outputs": [],
253 | "source": [
254 | "import requests\n",
255 | "\n",
256 | "\n",
257 | "# Call ElevenLabs API to generate voiceover\n",
258 | "url = f\"https://api.elevenlabs.io/v1/text-to-speech/{voiceover_artist_id}\"\n",
259 | "headers = {\n",
260 | " \"xi-api-key\": os.environ.get(\"ELEVEN_LABS_API_KEY\"),\n",
261 | " \"Content-Type\": \"application/json\"\n",
262 | "}\n",
263 | "payload = {\n",
264 | " \"model_id\": \"eleven_monolingual_v1\",\n",
265 | " \"text\": voiceover_script,\n",
266 | " \"voice_settings\": {\n",
267 | " \"stability\": 0.5,\n",
268 | " \"similarity_boost\": 0.5\n",
269 | " }\n",
270 | "}\n",
271 | "elevenlabs_res = requests.request(\"POST\", url, json=payload, headers=headers)\n",
272 | "\n",
273 | "# Save the audio file\n",
274 | "audio_file = \"audio.mp3\"\n",
275 | "CHUNK_SIZE = 1024\n",
276 | "with open(audio_file, 'wb') as f:\n",
277 | " for chunk in elevenlabs_res.iter_content(chunk_size=CHUNK_SIZE):\n",
278 | " if chunk:\n",
279 | " f.write(chunk)"
280 | ]
281 | },
282 | {
283 | "cell_type": "markdown",
284 | "metadata": {},
285 | "source": [
286 | "### 🎬 Step 6: Add Voiceover to Video with VideoDB"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": [
293 | "Upload the audio file (voiceover) to VideoDB"
294 | ]
295 | },
296 | {
297 | "cell_type": "code",
298 | "execution_count": null,
299 | "metadata": {},
300 | "outputs": [],
301 | "source": [
302 | "audio = conn.upload(file_path=audio_file)"
303 | ]
304 | },
305 | {
306 | "cell_type": "markdown",
307 | "metadata": {},
308 | "source": [
309 | "### 🎥 Step 7: Add Narration to Trailer with VideoDB\n",
310 | "Combine the narration audio with the trailer using VideoDB's timeline feature."
311 | ]
312 | },
313 | {
314 | "cell_type": "code",
315 | "execution_count": null,
316 | "metadata": {},
317 | "outputs": [],
318 | "source": [
319 | "from videodb.timeline import Timeline\n",
320 | "from videodb.asset import VideoAsset, AudioAsset\n",
321 | "\n",
322 | "timeline = Timeline(conn)\n",
323 | "\n",
324 | "video_asset = VideoAsset(asset_id=video.id, start=0)\n",
325 | "\n",
326 | "audio_asset1 = AudioAsset(asset_id=audio.id, start=5, end=25.5, disable_other_tracks=False)\n",
327 | "audio_asset2 = AudioAsset(asset_id=audio.id, start=35, end=49, disable_other_tracks=False)\n",
328 | "\n",
329 | "# add asset overlay\n",
330 | "timeline.add_inline(asset=video_asset)\n",
331 | "timeline.add_overlay(start=4, asset=audio_asset1)\n",
332 | "timeline.add_overlay(start=35, asset=audio_asset2)\n"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "### 🪄 Step 8: Review and Share\n",
340 | "Preview the trailer with the integrated narration to ensure it aligns with your vision. Once satisfied, share the trailer with others to experience the enhanced storytelling.\n"
341 | ]
342 | },
343 | {
344 | "cell_type": "code",
345 | "execution_count": 15,
346 | "metadata": {},
347 | "outputs": [
348 | {
349 | "data": {
350 | "text/plain": [
351 | "'https://console.videodb.io/player?url=https://dseetlpshk2tb.cloudfront.net/v3/published/manifests/fea6943a-0ac6-4a13-9309-4df35e41f6f7.m3u8'"
352 | ]
353 | },
354 | "execution_count": 15,
355 | "metadata": {},
356 | "output_type": "execute_result"
357 | }
358 | ],
359 | "source": [
360 | "from videodb import play_stream\n",
361 | "\n",
362 | "stream_url = timeline.generate_stream()\n",
363 | "play_stream(stream_url)"
364 | ]
365 | },
366 | {
367 | "cell_type": "markdown",
368 | "metadata": {},
369 | "source": [
370 | "## 🎬 Bonus\n",
371 | "-----"
372 | ]
373 | },
374 | {
375 | "cell_type": "markdown",
376 | "metadata": {},
377 | "source": [
378 | "Add Movie Poster at the End\n",
379 | "\n",
380 | "To incorporate adding a movie poster as a bonus section at the end of the trailer using VideoDB, you can follow these steps (you’ll find the code snippet for the same below):\n",
381 | "\n",
382 | "1. We first import the necessary module for handling Image Assets. \n",
383 | "2. Then, we upload the movie poster image to VideoDB. \n",
384 | "3. Next, we create an Image Asset with the uploaded poster image, specifying its dimensions and duration. \n",
385 | "4. Finally, we add the movie poster as an overlay at the end of the video timeline."
386 | ]
387 | },
388 | {
389 | "cell_type": "code",
390 | "execution_count": null,
391 | "metadata": {},
392 | "outputs": [],
393 | "source": [
394 | "from videodb.asset import ImageAsset\n",
395 | "from videodb import MediaType, play_stream\n",
396 | "\n",
397 | "image = conn.upload(url=\"https://raw.githubusercontent.com/video-db/videodb-cookbook/dev/images/chase_trailer.png\", media_type=MediaType.image)\n",
398 | "\n",
399 | "image_asset = ImageAsset(\n",
400 | " asset_id=image.id,\n",
401 | " width=1392,\n",
402 | " height=783,\n",
403 | " x=0,\n",
404 | " y=0,\n",
405 | " duration=13\n",
406 | ")\n",
407 | "\n",
408 | "timeline.add_overlay(start=67.5, asset=image_asset)\n",
409 | "\n",
410 | "stream_url = timeline.generate_stream()\n",
411 | "play_stream(stream_url)"
412 | ]
413 | },
414 | {
415 | "cell_type": "markdown",
416 | "metadata": {},
417 | "source": [
418 | "### 🎉 Conclusion\n",
419 | "____\n",
420 | "Try out various narration styles and prompts to personalize your trailers and keep viewers hooked. \n",
421 | "\n",
422 | "For more creative experiments and support, refer to the [VideoDB docs](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration.\n",
423 | "\n",
424 | "We're excited to see your creations, so we welcome you to share your creations via [Discord](https://discord.com/invite/py9P639jGz), [LinkedIn](https://www.linkedin.com/company/videodb) or [Twitter](https://twitter.com/videodb_io)."
425 | ]
426 | }
427 | ],
428 | "metadata": {
429 | "kernelspec": {
430 | "display_name": "Python 3 (ipykernel)",
431 | "language": "python",
432 | "name": "python3"
433 | },
434 | "language_info": {
435 | "codemirror_mode": {
436 | "name": "ipython",
437 | "version": 3
438 | },
439 | "file_extension": ".py",
440 | "mimetype": "text/x-python",
441 | "name": "python",
442 | "nbconvert_exporter": "python",
443 | "pygments_lexer": "ipython3",
444 | "version": "3.12.0"
445 | }
446 | },
447 | "nbformat": 4,
448 | "nbformat_minor": 4
449 | }
450 |
--------------------------------------------------------------------------------
/examples/Insert Inline Video.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "### Insert Dynamic Ads Seamlessly and Effortlessly\n",
8 | "\n",
9 | "\n",
10 | "\n",
11 | "Video files are not very flexible if we want to change the flow and insert another video at a certain place. Imagine putting a video advertisement on your video stream for your customers. You don’t need to edit the video file and create another one.\n",
12 | "\n",
13 | "`VideoDB` simplifies it for you. It gives you power to build contextualize Ad insertion and personalized Ad insertion on your videos. \n",
14 | "\n"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "\n",
22 | "\n",
23 | "### Setup\n",
24 | "---\n",
25 | "#### 🔧 Installing VideoDB in your environment\n",
26 | "\n",
27 | "VideoDB is available as [python package 📦](https://pypi.org/project/videodb/)"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": 1,
33 | "metadata": {},
34 | "outputs": [
35 | {
36 | "name": "stdout",
37 | "output_type": "stream",
38 | "text": [
39 | "Requirement already satisfied: videodb in /Users/ashu/videodb/videodb-python (0.0.2)\n",
40 | "Requirement already satisfied: requests>=2.25.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.31.0)\n",
41 | "Requirement already satisfied: backoff>=2.2.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from videodb) (2.2.1)\n",
42 | "Requirement already satisfied: charset-normalizer<4,>=2 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.3.2)\n",
43 | "Requirement already satisfied: idna<4,>=2.5 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (3.6)\n",
44 | "Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2.1.0)\n",
45 | "Requirement already satisfied: certifi>=2017.4.17 in /Users/ashu/opt/anaconda3/envs/videoDB/lib/python3.12/site-packages (from requests>=2.25.1->videodb) (2023.11.17)\n"
46 | ]
47 | }
48 | ],
49 | "source": [
50 | "!pip install videodb"
51 | ]
52 | },
53 | {
54 | "cell_type": "markdown",
55 | "metadata": {},
56 | "source": [
57 | "#### 🔗 Setting Up a connection to db\n",
58 | "\n",
59 | "To connect to `VideoDB`, simply create a `Connection` object.\n",
60 | "\n",
61 | "This can be done by either providing your VideoDB API key directly to the constructor or by setting the `VIDEO_DB_API_KEY` environment variable with your API key.\n",
62 | "\n",
63 | ">💡\n",
64 | ">Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, No credit card required ) 🎉."
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 4,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "import videodb\n",
74 | "conn = videodb.connect(api_key=\"\")"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "\n",
82 | "\n",
83 | "### Uploading our videos to VideoDB\n",
84 | "---\n",
85 | "\n",
86 | "Let’s have a base video as Sam Altman’s conversation on OpenAI and AGI. We’ll choose another video to insert in this 👉 ( let’s get IBM’s Advertisement) . We are going to insert the Ad video into the base video at a specific timestamp. \n",
87 | "\n",
88 | "For this, we will need to first upload both the videos to VideoDB"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 5,
94 | "metadata": {},
95 | "outputs": [],
96 | "source": [
97 | "base_video_url = \"https://www.youtube.com/watch?v=e1cf58VWzt8\"\n",
98 | "ad_video_url = \"https://www.youtube.com/watch?v=jtwduf2lh08\"\n",
99 | "\n",
100 | "base_video = conn.upload(url=base_video_url)\n",
101 | "ad_video = conn.upload(url=ad_video_url)"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "\n",
109 | "\n",
110 | "### Inserting Ad in our Base Video\n",
111 | "---\n",
112 | "Now that we have both the videos uploaded, Inserting into another becomes incredibly straightforward using VideoDB \n",
113 | "\n",
114 | "For instance, let's say we wish to insert our clip at the 10-second mark in the video's timeline. "
115 | ]
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": 6,
120 | "metadata": {},
121 | "outputs": [],
122 | "source": [
123 | "stream_link = base_video.insert_video(ad_video, 10)"
124 | ]
125 | },
126 | {
127 | "cell_type": "markdown",
128 | "metadata": {},
129 | "source": [
130 | "\n",
131 | "\n",
132 | "### View the Results in VideoDB Player\n",
133 | "---\n",
134 | "\n",
135 | "`stream_link` is viewable by `play_stream()`. "
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 7,
141 | "metadata": {},
142 | "outputs": [
143 | {
144 | "data": {
145 | "text/plain": [
146 | "'https://console.videodb.io/player?url=https://d27qzqw9ehjjni.cloudfront.net/v3/published/manifests/86976631-abdf-48da-8ac4-a55bb55f4831.m3u8'"
147 | ]
148 | },
149 | "execution_count": 7,
150 | "metadata": {},
151 | "output_type": "execute_result"
152 | }
153 | ],
154 | "source": [
155 | "from videodb import play_stream\n",
156 | "play_stream(stream_link)"
157 | ]
158 | }
159 | ],
160 | "metadata": {
161 | "kernelspec": {
162 | "display_name": "Python 3 (ipykernel)",
163 | "language": "python",
164 | "name": "python3"
165 | },
166 | "language_info": {
167 | "codemirror_mode": {
168 | "name": "ipython",
169 | "version": 3
170 | },
171 | "file_extension": ".py",
172 | "mimetype": "text/x-python",
173 | "name": "python",
174 | "nbconvert_exporter": "python",
175 | "pygments_lexer": "ipython3",
176 | "version": "3.12.0"
177 | }
178 | },
179 | "nbformat": 4,
180 | "nbformat_minor": 4
181 | }
182 |
--------------------------------------------------------------------------------
/examples/Intro_Outro_Inline.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 📹 Intro/Outro video Inline"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## 💬 Overview\n",
22 | "--- \n",
23 | "Imagine a virtual DJ mixing deck where you can seamlessly blend multiple videos into one epic timeline. Whether you're adding flashy intros, snazzy outros, or even splicing in some behind-the-scenes footage, this feature lets you take your video content to the next level!\n",
24 | "\n",
25 | "In this tutorial, let’s dive into how you can seamlessly integrate multiple videos onto a single timeline. Users can easily enhance their video content by appending intros, outros, or supplementary segments. The workflow is straightforward and scalable."
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {},
31 | "source": [
32 | ""
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "## Setup\n",
40 | "---"
41 | ]
42 | },
43 | {
44 | "cell_type": "markdown",
45 | "metadata": {},
46 | "source": [
47 | "### 📦 Installing packages "
48 | ]
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": null,
53 | "metadata": {},
54 | "outputs": [],
55 | "source": [
56 | "%pip install videodb"
57 | ]
58 | },
59 | {
60 | "cell_type": "markdown",
61 | "metadata": {},
62 | "source": [
63 | "### 🔑 API Keys\n",
64 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. \n",
65 | "\n",
66 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 2,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "import os\n",
76 | "\n",
77 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "## Implementation\n",
85 | "---"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "### 🌐 Step 1: Connect to VideoDB\n",
93 | "Connect to VideoDB using your API key to establish a session for uploading and manipulating video files. Import the necessary modules from VideoDB library to access functionalities."
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 3,
99 | "metadata": {},
100 | "outputs": [],
101 | "source": [
102 | "from videodb import connect\n",
103 | "\n",
104 | "# Connect to VideoDB using your API key\n",
105 | "conn = connect()\n",
106 | "coll = conn.get_collection()"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "### 🎥 Step 2: Upload Videos\n",
114 | "Firstly, we upload an introductory video (`intro.mp4`) and an outro video (`outro.mp4`) into the collection, followed by the base video (`sugar_craving.mp4`). This approach allows us to efficiently reuse the intro and outro videos for other projects by simply changing the base video, thereby saving time and streamlining the video creation process. \n",
115 | "\n",
116 | "You can upload the video asset from your local device or from a YouTube URL to upload the video from its source."
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": 4,
122 | "metadata": {},
123 | "outputs": [],
124 | "source": [
125 | "intro = coll.upload(url=\"https://github.com/video-db/videodb-cookbook-assets/raw/main/videos/intro.mp4\")\n",
126 | "outro = coll.upload(url=\"https://github.com/video-db/videodb-cookbook-assets/raw/main/videos/outro.mp4\")\n",
127 | "base = coll.upload(url=\"https://github.com/video-db/videodb-cookbook-assets/raw/main/videos/sugar_craving.mp4\")"
128 | ]
129 | },
130 | {
131 | "cell_type": "markdown",
132 | "metadata": {},
133 | "source": [
134 | "### 🎼 Step 3: Create Assets\n",
135 | "Adjust parameters for all the video assets according to your preference, such as start and end times."
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 5,
141 | "metadata": {},
142 | "outputs": [],
143 | "source": [
144 | "from videodb.asset import VideoAsset\n",
145 | "\n",
146 | "intro_asset = VideoAsset(asset_id=intro.id, start=0, end=3)\n",
147 | "base_asset = VideoAsset(asset_id=base.id, start=0, end=90)\n",
148 | "outro_asset = VideoAsset(asset_id=outro.id, start=0, end=3)"
149 | ]
150 | },
151 | {
152 | "cell_type": "markdown",
153 | "metadata": {},
154 | "source": [
155 | "### Step 4: Create timeline\n",
156 | "Combine all video assets onto a single timeline using VideoDB's timeline feature."
157 | ]
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": 6,
162 | "metadata": {},
163 | "outputs": [],
164 | "source": [
165 | "from videodb.timeline import Timeline\n",
166 | "\n",
167 | "timeline = Timeline(conn)\n",
168 | "\n",
169 | "timeline.add_inline(intro_asset)\n",
170 | "timeline.add_inline(base_asset)\n",
171 | "timeline.add_inline(outro_asset)"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "### Step 5: Play the generated video stream"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 1,
184 | "metadata": {},
185 | "outputs": [],
186 | "source": [
187 | "from videodb import play_stream\n",
188 | "\n",
189 | "stream = timeline.generate_stream()\n",
190 | "play_stream(stream)"
191 | ]
192 | },
193 | {
194 | "cell_type": "markdown",
195 | "metadata": {},
196 | "source": [
197 | "Preview the video to ensure it functions correctly. Once satisfied, generate a stream of the video and share the link for others to view and enjoy this wholesome creation!"
198 | ]
199 | },
200 | {
201 | "cell_type": "markdown",
202 | "metadata": {},
203 | "source": [
204 | "## 🎉 Conclusion\n",
205 | "---\n",
206 | "With VideoDB's intuitive workflow, the possibilities for video creation are endless, empowering developers to bring their visions to life effortlessly.\n",
207 | "\n",
208 | "For more such explorations, refer to the [VideoDB Docs](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration."
209 | ]
210 | }
211 | ],
212 | "metadata": {
213 | "kernelspec": {
214 | "display_name": "Python 3 (ipykernel)",
215 | "language": "python",
216 | "name": "python3"
217 | },
218 | "language_info": {
219 | "codemirror_mode": {
220 | "name": "ipython",
221 | "version": 3
222 | },
223 | "file_extension": ".py",
224 | "mimetype": "text/x-python",
225 | "name": "python",
226 | "nbconvert_exporter": "python",
227 | "pygments_lexer": "ipython3",
228 | "version": "3.12.0"
229 | }
230 | },
231 | "nbformat": 4,
232 | "nbformat_minor": 4
233 | }
234 |
--------------------------------------------------------------------------------
/examples/Keyword_Search_1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🔍 Fun with Keyword Search using VideoDB"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## 💬 Overview\n",
22 | "--- \n",
23 | "\n",
24 | "\n",
25 | "In this tutorial, let’s explore the powerful functionality of Keyword Search in VideoDB. This feature enables users to efficiently locate any keyword or phrase within their video assets, streamlining the process of content discovery.\n",
26 | "\n",
27 | ""
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | ""
35 | ]
36 | },
37 | {
38 | "cell_type": "markdown",
39 | "metadata": {},
40 | "source": [
41 | "## Setup\n",
42 | "---"
43 | ]
44 | },
45 | {
46 | "cell_type": "markdown",
47 | "metadata": {},
48 | "source": [
49 | "### 📦 Installing packages "
50 | ]
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": 2,
55 | "metadata": {},
56 | "outputs": [
57 | {
58 | "name": "stdout",
59 | "output_type": "stream",
60 | "text": [
61 | "Requirement already satisfied: videodb in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (0.1.0)\n",
62 | "Requirement already satisfied: requests>=2.25.1 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from videodb) (2.31.0)\n",
63 | "Requirement already satisfied: backoff>=2.2.1 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from videodb) (2.2.1)\n",
64 | "Requirement already satisfied: tqdm>=4.66.1 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from videodb) (4.66.2)\n",
65 | "Requirement already satisfied: charset-normalizer<4,>=2 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from requests>=2.25.1->videodb) (3.3.2)\n",
66 | "Requirement already satisfied: idna<4,>=2.5 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from requests>=2.25.1->videodb) (3.6)\n",
67 | "Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from requests>=2.25.1->videodb) (2.2.1)\n",
68 | "Requirement already satisfied: certifi>=2017.4.17 in /Users/rohit/Spext/videodb/videodb-cookbook/.venv/lib/python3.11/site-packages (from requests>=2.25.1->videodb) (2024.2.2)\n",
69 | "\n",
70 | "\u001b[1m[\u001b[0m\u001b[34;49mnotice\u001b[0m\u001b[1;39;49m]\u001b[0m\u001b[39;49m A new release of pip is available: \u001b[0m\u001b[31;49m23.2.1\u001b[0m\u001b[39;49m -> \u001b[0m\u001b[32;49m24.0\u001b[0m\n",
71 | "\u001b[1m[\u001b[0m\u001b[34;49mnotice\u001b[0m\u001b[1;39;49m]\u001b[0m\u001b[39;49m To update, run: \u001b[0m\u001b[32;49mpip install --upgrade pip\u001b[0m\n",
72 | "Note: you may need to restart the kernel to use updated packages.\n"
73 | ]
74 | }
75 | ],
76 | "source": [
77 | "%pip install videodb"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### 🔑 API Keys\n",
85 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. \n",
86 | "\n",
87 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 3,
93 | "metadata": {},
94 | "outputs": [],
95 | "source": [
96 | "import os\n",
97 | "\n",
98 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
99 | ]
100 | },
101 | {
102 | "cell_type": "markdown",
103 | "metadata": {},
104 | "source": [
105 | "## Steps\n",
106 | "---"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "### 🌐 Step 1: Connect to VideoDB\n",
114 | "Begin by establishing a connection to VideoDB using your API key"
115 | ]
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": 4,
120 | "metadata": {},
121 | "outputs": [],
122 | "source": [
123 | "from videodb import connect\n",
124 | "\n",
125 | "# Connect to VideoDB using your API key\n",
126 | "conn = connect()\n",
127 | "coll = conn.get_collection()"
128 | ]
129 | },
130 | {
131 | "cell_type": "markdown",
132 | "metadata": {},
133 | "source": [
134 | "### 🎥 Step 2: Upload Videos\n",
135 | "\n",
136 | "Upload the video to your VideoDB collection. You can upload the video asset from your local device or from a YouTube URL to upload the video from its source. This works as the base video for all the Keyword Search queries."
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 5,
142 | "metadata": {},
143 | "outputs": [
144 | {
145 | "data": {
146 | "text/plain": [
147 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/5205a412-3574-403f-b1cc-2be5479d872a.m3u8'"
148 | ]
149 | },
150 | "execution_count": 5,
151 | "metadata": {},
152 | "output_type": "execute_result"
153 | }
154 | ],
155 | "source": [
156 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=Uvufun6xer8\")\n",
157 | "video.play()"
158 | ]
159 | },
160 | {
161 | "cell_type": "markdown",
162 | "metadata": {},
163 | "source": [
164 | ">You can upload from your local file system too by passing `file_path` in `upload()` "
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "### 🔊 Step 3: Index Spoken Words\n",
172 | "\n",
173 | "Index the spoken words in your video to enable keyword search.\n"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 6,
179 | "metadata": {},
180 | "outputs": [
181 | {
182 | "name": "stderr",
183 | "output_type": "stream",
184 | "text": [
185 | "100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [01:05<00:00, 1.52it/s]\n"
186 | ]
187 | }
188 | ],
189 | "source": [
190 | "video.index_spoken_words()"
191 | ]
192 | },
193 | {
194 | "cell_type": "markdown",
195 | "metadata": {},
196 | "source": [
197 | "### 🔎 Step 4: Search for any keyword\n",
198 | "\n",
199 | "Utilize the keyword search by using `Video.search()` method with following parameters.\n",
200 | "\n",
201 | "* pass search query in `query` parameter\n",
202 | "* pass `SearchType.keyword` in `search_type`"
203 | ]
204 | },
205 | {
206 | "cell_type": "code",
207 | "execution_count": 7,
208 | "metadata": {},
209 | "outputs": [],
210 | "source": [
211 | "from videodb import SearchType\n",
212 | "\n",
213 | "results = video.search(query='metaverse', search_type=SearchType.keyword)"
214 | ]
215 | },
216 | {
217 | "cell_type": "markdown",
218 | "metadata": {},
219 | "source": [
220 | "### 👀 Step 5: Preview and Share\n",
221 | "\n",
222 | "Preview your video with a compilation of all the clips matching your search query. You can access the stream link alongside the preview to share the Keyword Search result with others."
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 8,
228 | "metadata": {},
229 | "outputs": [
230 | {
231 | "data": {
232 | "text/plain": [
233 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/5e946b7d-e4f8-431c-913d-bc0315502a75.m3u8'"
234 | ]
235 | },
236 | "execution_count": 8,
237 | "metadata": {},
238 | "output_type": "execute_result"
239 | }
240 | ],
241 | "source": [
242 | "results.play()"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "## 🔎 Bonus : Refining Keyword Search results by adding padding."
250 | ]
251 | },
252 | {
253 | "cell_type": "markdown",
254 | "metadata": {},
255 | "source": [
256 | "Some keyword search results/ compilations may appear slightly choppy, or the cuts may feel abrupt. We can solve this issue by using VideoDB’s padding controls. Here’s how it works:"
257 | ]
258 | },
259 | {
260 | "cell_type": "markdown",
261 | "metadata": {},
262 | "source": [
263 | "\n",
264 | ""
265 | ]
266 | },
267 | {
268 | "cell_type": "markdown",
269 | "metadata": {},
270 | "source": [
271 | "The resulting shots can be made smoother by including a little more context from before and after the matching timestamps. That’s exactly what padding controls enable: "
272 | ]
273 | },
274 | {
275 | "cell_type": "markdown",
276 | "metadata": {},
277 | "source": [
278 | "1. Create a timeline, just like we did previously, by using the `Timeline()` function.\n",
279 | "2. Create VideoAsset of each result shot using VideoAsset() with following parameters\n",
280 | " * `asset_id` : Video ID of the Video to which result belongs to [base video]\n",
281 | " * `start` : To adjust the beginning of the resulting shot, we subtract the padding duration from the original start timestamp. This ensures the resulting shot starts earlier in relation to the base video. \n",
282 | " * `end`: Likewise, we extend the resulting shot's end timestamp by adding the padding duration. This gives the resulting shot additional context from the base video.\n",
283 | "\n",
284 | "Finally, we will add these freshly created assets in our Timeline by using `Timeline.add_inline()`"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": 11,
290 | "metadata": {},
291 | "outputs": [
292 | {
293 | "data": {
294 | "text/plain": [
295 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/57c576c9-8a00-4952-bdf3-323fdab7ed37.m3u8'"
296 | ]
297 | },
298 | "execution_count": 11,
299 | "metadata": {},
300 | "output_type": "execute_result"
301 | }
302 | ],
303 | "source": [
304 | "from videodb import play_stream\n",
305 | "from videodb.timeline import Timeline\n",
306 | "from videodb.asset import VideoAsset\n",
307 | "\n",
308 | "timeline = Timeline(conn)\n",
309 | "\n",
310 | "# Add padding\n",
311 | "padding = 0.4\n",
312 | "\n",
313 | "# Compile Video \n",
314 | "for shot in results.shots:\n",
315 | " asset = VideoAsset(\n",
316 | " asset_id=shot.video_id, start=shot.start-padding, end=shot.end+padding\n",
317 | " )\n",
318 | " timeline.add_inline(asset)\n",
319 | "\n",
320 | "stream_url = timeline.generate_stream()\n",
321 | "play_stream(stream_url)"
322 | ]
323 | },
324 | {
325 | "cell_type": "markdown",
326 | "metadata": {},
327 | "source": [
328 | "## 🎉 Conclusion\n",
329 | "---\n",
330 | "Keyword Search in VideoDB empowers users to extract valuable insights from their video assets with ease. For more information and advanced features, explore the [VideoDB Documentation](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration.\n"
331 | ]
332 | },
333 | {
334 | "cell_type": "markdown",
335 | "metadata": {},
336 | "source": []
337 | }
338 | ],
339 | "metadata": {
340 | "kernelspec": {
341 | "display_name": "Python 3 (ipykernel)",
342 | "language": "python",
343 | "name": "python3"
344 | },
345 | "language_info": {
346 | "codemirror_mode": {
347 | "name": "ipython",
348 | "version": 3
349 | },
350 | "file_extension": ".py",
351 | "mimetype": "text/x-python",
352 | "name": "python",
353 | "nbconvert_exporter": "python",
354 | "pygments_lexer": "ipython3",
355 | "version": "3.11.7"
356 | }
357 | },
358 | "nbformat": 4,
359 | "nbformat_minor": 4
360 | }
361 |
--------------------------------------------------------------------------------
/examples/Keyword_Search_Counter.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# ⏱️ Building a Word-Counter Video with VideoDB"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Introduction\n",
22 | "With an endless stream of new video content on our feeds, engaging the audience with dynamic visual elements can make educational and promotional videos much more impactful. VideoDB's suite of features allows you to enhance videos with programmatic editing.\n",
23 | "\n",
24 | "In this tutorial, we'll explore how to create a video that visually counts and displays instances of a specified word as it's spoken. We'll use VideoDB’s [Keyword Search ](https://docs.videodb.io)to index spoken words, and then apply audio and [text overlays](https://docs.videodb.io) to show a counter updating in real-time with synchronized audio cues."
25 | ]
26 | },
27 | {
28 | "cell_type": "markdown",
29 | "metadata": {},
30 | "source": [
31 | "## Setup\n",
32 | "---"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "\n",
40 | "### 📦 Installing packages "
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": null,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "%pip install videodb"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "### 🔑 API Keys\n",
57 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. \n",
58 | "\n",
59 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": 22,
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "import os\n",
69 | "\n",
70 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "## Steps\n",
78 | "---"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "metadata": {},
84 | "source": [
85 | "### 🔗 Step 1: Connect to VideoDB"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 23,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "import videodb\n",
95 | "\n",
96 | "conn = videodb.connect()\n",
97 | "coll = conn.get_collection()"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "### 🎥 Step 2: Upload Video\n",
105 | "Upload and play the video to ensure it's correctly loaded. We’ll be using [this video](https://www.youtube.com/watch?v=Js4rTM2Z1Eg) for the purpose of this tutorial."
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 24,
111 | "metadata": {},
112 | "outputs": [
113 | {
114 | "data": {
115 | "text/plain": [
116 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/09b866a6-ccf8-4d11-b37c-0a2b9edc78aa.m3u8'"
117 | ]
118 | },
119 | "execution_count": 24,
120 | "metadata": {},
121 | "output_type": "execute_result"
122 | }
123 | ],
124 | "source": [
125 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=Js4rTM2Z1Eg\")\n",
126 | "video.play()"
127 | ]
128 | },
129 | {
130 | "cell_type": "markdown",
131 | "metadata": {},
132 | "source": [
133 | "### 📝 Step 3: Indexing Spoken Words\n",
134 | "Index the video to identify and timestamp all spoken words."
135 | ]
136 | },
137 | {
138 | "cell_type": "code",
139 | "execution_count": 25,
140 | "metadata": {},
141 | "outputs": [
142 | {
143 | "name": "stderr",
144 | "output_type": "stream",
145 | "text": [
146 | "100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:34<00:00, 2.92it/s]\n"
147 | ]
148 | }
149 | ],
150 | "source": [
151 | "video.index_spoken_words()"
152 | ]
153 | },
154 | {
155 | "cell_type": "markdown",
156 | "metadata": {},
157 | "source": [
158 | "### 🔍 Step 4: Keyword Search\n",
159 | "\n",
160 | "Search within the video for the keyword (\"education\" in this example), and note each occurrence.\n"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 26,
166 | "metadata": {},
167 | "outputs": [],
168 | "source": [
169 | "from videodb import SearchType\n",
170 | "\n",
171 | "result = video.search(query='education', search_type=SearchType.keyword)"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "### 🎼 Step 5: Setup Timeline \n",
179 | "\n",
180 | "Initialize the timeline and retrieve an audio asset to use for each word occurrence."
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 31,
186 | "metadata": {},
187 | "outputs": [],
188 | "source": [
189 | "from videodb.timeline import Timeline\n",
190 | "from videodb.asset import AudioAsset\n",
191 | "from videodb import MediaType\n",
192 | "\n",
193 | "timeline = Timeline(conn)\n",
194 | "\n",
195 | "\n",
196 | "audio = conn.upload(url=\"https://github.com/video-db/videodb-cookbook-assets/raw/main/audios/twink.mp3\", media_type=MediaType.audio)\n",
197 | "\n",
198 | "audio_asset = AudioAsset(asset_id=audio.id,\n",
199 | " start=0,\n",
200 | " end=1.7,\n",
201 | " disable_other_tracks=False,\n",
202 | " fade_in_duration=1,\n",
203 | " fade_out_duration=0,\n",
204 | ")"
205 | ]
206 | },
207 | {
208 | "cell_type": "markdown",
209 | "metadata": {},
210 | "source": [
211 | "### 💬 Step 6: Overlay Text and Audio\n",
212 | "\n",
213 | "Add text and audio overlays at each instance where the word is spoken."
214 | ]
215 | },
216 | {
217 | "cell_type": "markdown",
218 | "metadata": {},
219 | "source": [
220 | ">\n",
221 | ">Note: Adding the ‘padding’ is an optional step. It helps in adding a little more context to the exact instance identified, thus resulting in a better compiled output.\n",
222 | ">"
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 32,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "from videodb.asset import TextAsset, TextStyle, VideoAsset, AudioAsset\n",
232 | "\n",
233 | "seeker = 0\n",
234 | "counter = 0\n",
235 | "padding = 1.5\n",
236 | "\n",
237 | "for shot in result.shots:\n",
238 | " duration = shot.end - shot.start + 2 * padding\n",
239 | " \n",
240 | " # VideoAsset for each Shot\n",
241 | " video_asset = VideoAsset(\n",
242 | " asset_id=shot.video_id, start=shot.start - padding, end=shot.end + padding\n",
243 | " )\n",
244 | "\n",
245 | " # TextAsset that displays count\n",
246 | " text_asset = TextAsset(\n",
247 | " text=f\"Count-{counter}\",\n",
248 | " duration=duration,\n",
249 | " style=TextStyle(\n",
250 | " font=\"Do Hyeon\",\n",
251 | " fontsize = \"(h/10)\",\n",
252 | " x=\"w-1.5*text_w\",\n",
253 | " y=\"0+(2*text_h)\",\n",
254 | " fontcolor=\"#000100\",\n",
255 | " box=True,\n",
256 | " boxcolor=\"F702A4\"\n",
257 | " ),\n",
258 | " )\n",
259 | "\n",
260 | "\n",
261 | " timeline.add_inline(asset=video_asset)\n",
262 | " timeline.add_overlay(asset=text_asset, start=seeker - padding)\n",
263 | " timeline.add_overlay(asset=audio_asset, start=seeker + padding)\n",
264 | "\n",
265 | " seeker += duration\n",
266 | " counter += 1"
267 | ]
268 | },
269 | {
270 | "cell_type": "markdown",
271 | "metadata": {},
272 | "source": []
273 | },
274 | {
275 | "cell_type": "markdown",
276 | "metadata": {},
277 | "source": [
278 | "### ⚡️ Step 7: Generate and Play the Stream"
279 | ]
280 | },
281 | {
282 | "cell_type": "markdown",
283 | "metadata": {},
284 | "source": [
285 | "Finally, generate a streaming URL for your edited video and play it."
286 | ]
287 | },
288 | {
289 | "cell_type": "code",
290 | "execution_count": 33,
291 | "metadata": {},
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | "'https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/de823df2-b6a8-4384-937b-77767d666c99.m3u8'"
297 | ]
298 | },
299 | "execution_count": 33,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | }
303 | ],
304 | "source": [
305 | "from videodb import play_stream\n",
306 | "\n",
307 | "stream_url = timeline.generate_stream()\n",
308 | "play_stream(stream_url)\n"
309 | ]
310 | },
311 | {
312 | "cell_type": "markdown",
313 | "metadata": {},
314 | "source": [
315 | "## Conclusion\n",
316 | "---\n",
317 | "\n",
318 | "This tutorial showcases VideoDB's capabilities to create a video that programmatically counts and displays the frequency of a specific keyword spoken throughout the video. This method can be adapted for various applications where dynamic text overlays add significant value to video content.\n",
319 | "\n",
320 | "### Tips and Tricks\n",
321 | "\n",
322 | "* Use different text styles and positions based on your video's theme.\n",
323 | "* Add background sounds or effects to enhance the viewer's experience."
324 | ]
325 | },
326 | {
327 | "cell_type": "markdown",
328 | "metadata": {},
329 | "source": []
330 | }
331 | ],
332 | "metadata": {
333 | "kernelspec": {
334 | "display_name": ".venv",
335 | "language": "python",
336 | "name": "python3"
337 | },
338 | "language_info": {
339 | "codemirror_mode": {
340 | "name": "ipython",
341 | "version": 3
342 | },
343 | "file_extension": ".py",
344 | "mimetype": "text/x-python",
345 | "name": "python",
346 | "nbconvert_exporter": "python",
347 | "pygments_lexer": "ipython3",
348 | "version": "3.11.7"
349 | }
350 | },
351 | "nbformat": 4,
352 | "nbformat_minor": 2
353 | }
354 |
--------------------------------------------------------------------------------
/examples/Programmatic_Streams_1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "xEBvVSuzjxHh"
7 | },
8 | "source": [
9 | "# ↔️ Building Dynamic Video Streams with VideoDB: Integrating Custom Data and APIs"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {
15 | "id": "LCwBGclTjxHi"
16 | },
17 | "source": [
18 | ""
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {
24 | "id": "w8xeWTZkjxHi"
25 | },
26 | "source": [
27 | "## Introduction\n",
28 | "Imagine you're watching a captivating keynote session from your favorite conference, and you’re welcomed with a personalized stream just for you.\n",
29 | "\n",
30 | "This tutorial demonstrates how to create dynamic video streams by integrating data from custom databases and external APIs. We'll use a practical example: a recording of a [Config 2023](https://www.youtube.com/watch?v=Nmv8XdFiej0) keynote session. By using VideoDB, we'll show how companies like [Figma](https://www.figma.com/files/recents-and-sharing?fuid=940498258276625180) can personalize the viewing experience for their audience, delivering a richer and more engaging experience.\n",
31 | "\n",
32 | "We'll showcase how to:\n",
33 | "\n",
34 | "* Fetch data from a random user API to represent a hypothetical viewer.\n",
35 | "* Integrate this data into a custom VideoDB timeline.\n",
36 | "* Create a personalized stream that dynamically displays relevant information alongside the keynote video.\n",
37 | "\n",
38 | "This tutorial is your guide to unlocking the potential of dynamic video streams and transforming your video content with personalized experiences."
39 | ]
40 | },
41 | {
42 | "cell_type": "markdown",
43 | "metadata": {
44 | "id": "6Izs6lxqjxHi"
45 | },
46 | "source": [
47 | "## Setup\n",
48 | "---"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "metadata": {
54 | "id": "JiLgb86qjxHi"
55 | },
56 | "source": [
57 | "\n",
58 | "### 📦 Installing packages"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": null,
64 | "metadata": {
65 | "id": "VaSLRgz-jxHj"
66 | },
67 | "outputs": [],
68 | "source": [
69 | "%pip install videodb"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {
75 | "id": "8vQk4j1MjxHj"
76 | },
77 | "source": [
78 | "### 🔑 API Keys\n",
79 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key.\n",
80 | "\n",
81 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 1,
87 | "metadata": {
88 | "id": "DuhMNCgfjxHj"
89 | },
90 | "outputs": [],
91 | "source": [
92 | "import os\n",
93 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
94 | ]
95 | },
96 | {
97 | "cell_type": "markdown",
98 | "metadata": {
99 | "id": "s8RAYTtnjxHj"
100 | },
101 | "source": [
102 | "## Steps\n",
103 | "---"
104 | ]
105 | },
106 | {
107 | "cell_type": "markdown",
108 | "metadata": {
109 | "id": "TIwDr4SIjxHj"
110 | },
111 | "source": [
112 | "### 🔗 Step 1: Connect to VideoDB"
113 | ]
114 | },
115 | {
116 | "cell_type": "markdown",
117 | "metadata": {
118 | "id": "cegRs1devmg9"
119 | },
120 | "source": [
121 | "Establish a session for uploading videos. Import the necessary modules from VideoDB library to access functionalities."
122 | ]
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": 2,
127 | "metadata": {
128 | "id": "GvEF198HjxHj"
129 | },
130 | "outputs": [],
131 | "source": [
132 | "import videodb\n",
133 | "from videodb import connect\n",
134 | "\n",
135 | "conn = videodb.connect()\n",
136 | "coll = conn.get_collection()"
137 | ]
138 | },
139 | {
140 | "cell_type": "markdown",
141 | "metadata": {
142 | "id": "bMGnv3j0jxHj"
143 | },
144 | "source": [
145 | "### 🗳️ Step 2: Upload Base Video\n",
146 | "Upload and play the video to ensure it's correctly loaded. We’ll be using [this video](https://www.youtube.com/watch?v=Nmv8XdFiej0) for the purpose of this tutorial."
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 3,
152 | "metadata": {
153 | "id": "I4FukL25jxHj"
154 | },
155 | "outputs": [
156 | {
157 | "data": {
158 | "text/plain": [
159 | "'https://console.videodb.io/player?url=https://dseetlpshk2tb.cloudfront.net/v3/published/manifests/5035d388-3b20-48e8-8391-ad157d3784b5.m3u8'"
160 | ]
161 | },
162 | "execution_count": 3,
163 | "metadata": {},
164 | "output_type": "execute_result"
165 | }
166 | ],
167 | "source": [
168 | "# Upload and play a video from a URL\n",
169 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=Nmv8XdFiej0\")\n",
170 | "video.play()\n",
171 | "\n",
172 | "# Alternatively, get a video from your VideoDB collection\n",
173 | "# video = coll.get_video('VIDEO_ID_HERE')\n",
174 | "# video.play()"
175 | ]
176 | },
177 | {
178 | "cell_type": "markdown",
179 | "metadata": {
180 | "id": "dS6KesexjxHk"
181 | },
182 | "source": [
183 | "### 📥 Step 3: Fetch Data from a Random User API\n",
184 | "This code fetches a random user's data (name and picture) from the \"randomuser.me\" API. You can adapt this to retrieve data from any relevant API (e.g., product data, news articles) for your use case."
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 10,
190 | "metadata": {
191 | "id": "4yLqe4g0jxHk"
192 | },
193 | "outputs": [],
194 | "source": [
195 | "import requests\n",
196 | "\n",
197 | "# Make a request to the Randomizer API\n",
198 | "response = requests.get('https://randomuser.me/api/?results=1&nat=us,ca,gb,au')\n",
199 | "data = response.json()\n",
200 | "\n",
201 | "# Extract relevant information\n",
202 | "first_name = data['results'][0]['name']['first']\n",
203 | "medium_picture = data['results'][0]['picture']['medium']"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {
209 | "id": "5ML2q-OWjxHk"
210 | },
211 | "source": [
212 | "### 🚥 Step 4 (optional): Prepare Data for Integration\n",
213 | "\n",
214 | "No additional data transformation is required in this example since we are using the data directly from the API. However, in more complex scenarios, you may need to format the data to be suitable for VideoDB.\n"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {
220 | "id": "5c0fYqjXjxHk"
221 | },
222 | "source": [
223 | "### 🧱 Step 5: Create VideoDB Assets\n",
224 | "\n",
225 | "We create VideoDB assets for the base video, the user's name (text), and their picture (image). The `TextStyle` object allows us to customize the appearance of the text elements."
226 | ]
227 | },
228 | {
229 | "cell_type": "code",
230 | "execution_count": 5,
231 | "metadata": {
232 | "id": "fOBsa9pdjxHk"
233 | },
234 | "outputs": [],
235 | "source": [
236 | "from videodb import play_stream, TextStyle, MediaType\n",
237 | "from videodb.asset import VideoAsset, TextAsset, ImageAsset\n",
238 | "from videodb.timeline import Timeline\n",
239 | "\n",
240 | "# Video Asset\n",
241 | "video_asset = VideoAsset(asset_id=video.id, start=0)\n",
242 | "\n",
243 | "# Text Asset with First Name\n",
244 | "name_asset = TextAsset(\n",
245 | " text=f'Hi {first_name} !',\n",
246 | " duration=4,\n",
247 | " style=TextStyle(\n",
248 | " fontsize=32,\n",
249 | " font=\"montserrat\",\n",
250 | " borderw=1,\n",
251 | " boxcolor=\"#D2C11D\",\n",
252 | " boxborderw=\"20\",\n",
253 | " x=\"((w-tw)/2)\",\n",
254 | " y=\"(h-th)/4\"\n",
255 | " )\n",
256 | ")\n",
257 | "\n",
258 | "# Image Asset with Medium Picture\n",
259 | "image = coll.upload(url=medium_picture, media_type=MediaType.image)\n",
260 | "image_asset = ImageAsset(\n",
261 | " asset_id=image.id,\n",
262 | " width=80,\n",
263 | " height=80,\n",
264 | " x=\"275\",\n",
265 | " y=\"230\",\n",
266 | " duration=4\n",
267 | ")\n",
268 | "\n",
269 | "# Fixed Text Asset\n",
270 | "cmon_asset = TextAsset(\n",
271 | " text=\"Here are your favorite moments\",\n",
272 | " duration=4,\n",
273 | " style=TextStyle(\n",
274 | " fontsize=24,\n",
275 | " fontcolor=\"#D2C11D\",\n",
276 | " font=\"montserrat\",\n",
277 | " bordercolor=\"#D2C11D\",\n",
278 | " borderw=1,\n",
279 | " boxborderw=\"20\",\n",
280 | " x=\"((w-tw)/2)\",\n",
281 | " y=\"(h-200)\"\n",
282 | " )\n",
283 | ")\n"
284 | ]
285 | },
286 | {
287 | "cell_type": "markdown",
288 | "metadata": {
289 | "id": "48WrFjfDjxHk"
290 | },
291 | "source": [
292 | "### ↔️ Step 6: Create the VideoDB Timeline\n",
293 | "\n",
294 | "The VideoDB timeline allows you to arrange and layer your assets to create a dynamic video stream. In this example, we add the name and picture overlays at a specific time (5 seconds) within the base video."
295 | ]
296 | },
297 | {
298 | "cell_type": "code",
299 | "execution_count": 6,
300 | "metadata": {
301 | "id": "b291hycbjxHk"
302 | },
303 | "outputs": [],
304 | "source": [
305 | "# Create the timeline\n",
306 | "timeline = Timeline(conn)\n",
307 | "\n",
308 | "# Add the base video to the timeline\n",
309 | "timeline.add_inline(video_asset)\n",
310 | "\n",
311 | "# Add overlays to the timeline\n",
312 | "timeline.add_overlay(5, name_asset)\n",
313 | "timeline.add_overlay(5, cmon_asset)\n",
314 | "timeline.add_overlay(5, image_asset)"
315 | ]
316 | },
317 | {
318 | "cell_type": "markdown",
319 | "metadata": {
320 | "id": "K8pGqSZgjxHk"
321 | },
322 | "source": [
323 | "### ▶️ Step 7: Generate and Play the Personalized Stream"
324 | ]
325 | },
326 | {
327 | "cell_type": "markdown",
328 | "metadata": {
329 | "id": "CNq_yCwsjxHk"
330 | },
331 | "source": [
332 | "The `generate_stream()` method creates a streamable URL for your personalized video stream. You can then use `play_stream()` to preview it in your browser."
333 | ]
334 | },
335 | {
336 | "cell_type": "code",
337 | "execution_count": 7,
338 | "metadata": {
339 | "id": "96SYlAhQjxHk"
340 | },
341 | "outputs": [
342 | {
343 | "name": "stdout",
344 | "output_type": "stream",
345 | "text": [
346 | "https://dseetlpshk2tb.cloudfront.net/v3/published/manifests/52bedad7-2da2-4664-94a6-bb6d781e7471.m3u8\n"
347 | ]
348 | },
349 | {
350 | "data": {
351 | "text/plain": [
352 | "'https://console.videodb.io/player?url=https://dseetlpshk2tb.cloudfront.net/v3/published/manifests/52bedad7-2da2-4664-94a6-bb6d781e7471.m3u8'"
353 | ]
354 | },
355 | "execution_count": 7,
356 | "metadata": {},
357 | "output_type": "execute_result"
358 | }
359 | ],
360 | "source": [
361 | "from videodb import play_stream\n",
362 | "\n",
363 | "stream_url = timeline.generate_stream()\n",
364 | "print(stream_url)\n",
365 | "play_stream(stream_url)"
366 | ]
367 | },
368 | {
369 | "cell_type": "markdown",
370 | "metadata": {
371 | "id": "xiuqa7o9jxHl"
372 | },
373 | "source": [
374 | "## Conclusion\n",
375 | "---\n",
376 | "\n",
377 | "This tutorial showcased how to create personalized video streams using VideoDB. By integrating data from external APIs and custom databases, you can enhance your video content, personalize user experiences, and unlock new possibilities for engagement. Explore various data sources, experiment with different integrations, and customize your video streams to suit your specific needs."
378 | ]
379 | }
380 | ],
381 | "metadata": {
382 | "colab": {
383 | "provenance": []
384 | },
385 | "kernelspec": {
386 | "display_name": ".venv",
387 | "language": "python",
388 | "name": "python3"
389 | },
390 | "language_info": {
391 | "codemirror_mode": {
392 | "name": "ipython",
393 | "version": 3
394 | },
395 | "file_extension": ".py",
396 | "mimetype": "text/x-python",
397 | "name": "python",
398 | "nbconvert_exporter": "python",
399 | "pygments_lexer": "ipython3",
400 | "version": "3.11.7"
401 | }
402 | },
403 | "nbformat": 4,
404 | "nbformat_minor": 0
405 | }
406 |
--------------------------------------------------------------------------------
/examples/Subtitle_Styling.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🎥 Enhancing Video Captions with VideoDB Subtitle Styling"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Introduction\n",
22 | "\n",
23 | "Auto-generated captions on platforms like YouTube often lack precision, especially with specialized terminology, or context-specific information (like character names, literary references, etc.). VideoDB offers a solution by enabling more accurate identification, spelling, and formatting of spoken words in videos. In this tutorial, we'll explore how VideoDB's spoken word indexing feature and newly introduced [Subtitle Styling](https://docs.videodb.io/subtitle-styles-57) can significantly enhance the quality of captions in your videos."
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "### Comparative Analysis\n",
31 | "\n",
32 | "Let's start by comparing auto-generated captions from YouTube with those generated using VideoDB. We'll use an example from an explanatory tutorial on the complex literature of \"Dune.\"\n",
33 | "\n"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "[Here’s](https://youtu.be/geWcjgIojYk) what YouTube’s Auto-CC gives us \n",
41 | "\n",
42 | "[Here](https://www.youtube.com/watch?v=KOj9OxrUwIQ) is VideoDB’s styled subtitles:"
43 | ]
44 | },
45 | {
46 | "cell_type": "markdown",
47 | "metadata": {},
48 | "source": [
49 | "## Setup\n",
50 | "---"
51 | ]
52 | },
53 | {
54 | "cell_type": "markdown",
55 | "metadata": {},
56 | "source": [
57 | "### 📦 Installing packages "
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": null,
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "%pip install videodb"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "### 🔑 API Keys\n",
74 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. \n",
75 | "\n",
76 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 4,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "import os\n",
86 | "\n",
87 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {},
93 | "source": [
94 | "## 📝 Tutorial Walkthrough\n",
95 | "---"
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "metadata": {},
101 | "source": [
102 | "### 🔗 Step 1: Connect to VideoDB"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 5,
108 | "metadata": {},
109 | "outputs": [],
110 | "source": [
111 | "from videodb import connect\n",
112 | "\n",
113 | "# Connect to VideoDB using your API key\n",
114 | "conn = connect()\n",
115 | "coll = conn.get_collection()"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "### 🎥 Step 2: Upload Video\n",
123 | "Upload your video to VideoDB for processing."
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "execution_count": 6,
129 | "metadata": {},
130 | "outputs": [],
131 | "source": [
132 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=nHgoTNyY8w0\")"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "### 🧐 Step 3: Index Spoken Words\n",
140 | "Add subtitles to your video using default styling."
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": null,
146 | "metadata": {},
147 | "outputs": [],
148 | "source": [
149 | "video.index_spoken_words()"
150 | ]
151 | },
152 | {
153 | "cell_type": "markdown",
154 | "metadata": {},
155 | "source": [
156 | "### ️✏️ Step 4: Add Subtitles with Default Style\n",
157 | "Add subtitles to your video using default styling."
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 4,
163 | "metadata": {},
164 | "outputs": [],
165 | "source": [
166 | "from videodb import play_stream \n",
167 | "\n",
168 | "stream_url = video.add_subtitle()\n",
169 | "play_stream(stream_url)"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "### 🎨 Step 5: Customize Subtitle Style\n",
177 | "\n",
178 | "Utilize VideoDB's Subtitle Styling feature to customize the appearance of your subtitles.\n",
179 | "\n",
180 | "You can find details about VideoDB’s Subtitling release [here](https://docs.videodb.io/subtitle-styles-57)."
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 11,
186 | "metadata": {},
187 | "outputs": [],
188 | "source": [
189 | "from videodb import SubtitleStyle\n",
190 | "\n",
191 | "stream_url = video.add_subtitle(\n",
192 | " SubtitleStyle(\n",
193 | " font_size=16,\n",
194 | " font_name='Arial',\n",
195 | " primary_colour='&H0066ff',\n",
196 | " back_colour=\"&H40000000\",\n",
197 | " margin_l=12,\n",
198 | " margin_r=12,\n",
199 | " )\n",
200 | ")\n",
201 | "play_stream(stream_url)"
202 | ]
203 | },
204 | {
205 | "cell_type": "markdown",
206 | "metadata": {},
207 | "source": [
208 | "### 👁️🗨️ Step 6: Preview and Share\n",
209 | "Preview your video with enhanced subtitles to ensure they align with your vision. Share your video with others to showcase the improved captioning."
210 | ]
211 | },
212 | {
213 | "cell_type": "code",
214 | "execution_count": 3,
215 | "metadata": {},
216 | "outputs": [],
217 | "source": [
218 | "from videodb import play_stream\n",
219 | "play_stream(stream_url)"
220 | ]
221 | },
222 | {
223 | "cell_type": "markdown",
224 | "metadata": {},
225 | "source": [
226 | "Voila! Your video is now complete with well styled and accurate subtitles. Stream the complete experiment output [here](https://console.videodb.io/player?url=https://stream.videodb.io/v3/published/manifests/aa22191c-5bf7-4721-ab25-be2b113053e7.m3u8)."
227 | ]
228 | },
229 | {
230 | "cell_type": "markdown",
231 | "metadata": {},
232 | "source": [
233 | "## ⭐️ Conclusion\n",
234 | "---"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | "With VideoDB's spoken word indexing and [Subtitle Styling](https://docs.videodb.io/subtitle-styles-57), you can elevate the quality of captions in your videos, providing viewers with a more immersive and accurate viewing experience. Experiment with different styles and settings to tailor subtitles to your content and engage your audience effectively.\n",
242 | "\n",
243 | "\n",
244 | "For more such explorations, refer to the [documentation of VideoDB](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration.\n",
245 | "\n",
246 | "We're excited to see your creations, so we welcome you to share your creations via [Discord](https://discord.com/invite/py9P639jGz), [LinkedIn](https://www.linkedin.com/company/videodb) or [Twitter](https://twitter.com/videodb_io)."
247 | ]
248 | },
249 | {
250 | "cell_type": "markdown",
251 | "metadata": {},
252 | "source": []
253 | }
254 | ],
255 | "metadata": {
256 | "kernelspec": {
257 | "display_name": "Python 3 (ipykernel)",
258 | "language": "python",
259 | "name": "python3"
260 | },
261 | "language_info": {
262 | "codemirror_mode": {
263 | "name": "ipython",
264 | "version": 3
265 | },
266 | "file_extension": ".py",
267 | "mimetype": "text/x-python",
268 | "name": "python",
269 | "nbconvert_exporter": "python",
270 | "pygments_lexer": "ipython3",
271 | "version": "3.12.0"
272 | }
273 | },
274 | "nbformat": 4,
275 | "nbformat_minor": 4
276 | }
277 |
--------------------------------------------------------------------------------
/examples/Wellsaid_Voiceover_1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🔊 AI Generated Ad Films for Product Videography"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "## Overview"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "Crafting AI content and blending results from multiple tools can be incredibly powerful and time-efficient. Manual execution of these tasks is often cumbersome and time-consuming. However, with the right tools and techniques, you can automate various processes to achieve remarkable results effortlessly.\n",
29 | "\n",
30 | "In this tutorial, we will explore how to leverage the seamless integration between `Wellsaid`, `OpenAI` and `VideoDB` to create captivating voiceovers for product advertisements. By harnessing the advanced capabilities of these platforms, you can enhance the storytelling and engagement of your product videos with AI-generated voiceovers; all within a single environment. \n",
31 | "\n",
32 | "For this tutorial, we’ll be using a product footage from Youtube 👉🏼 https://www.youtube.com/watch?v=2DcAMbmmYNM and convert it into a professionally made advertisement for a jewellery brand; all using AI and programmatic scripting & editing."
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "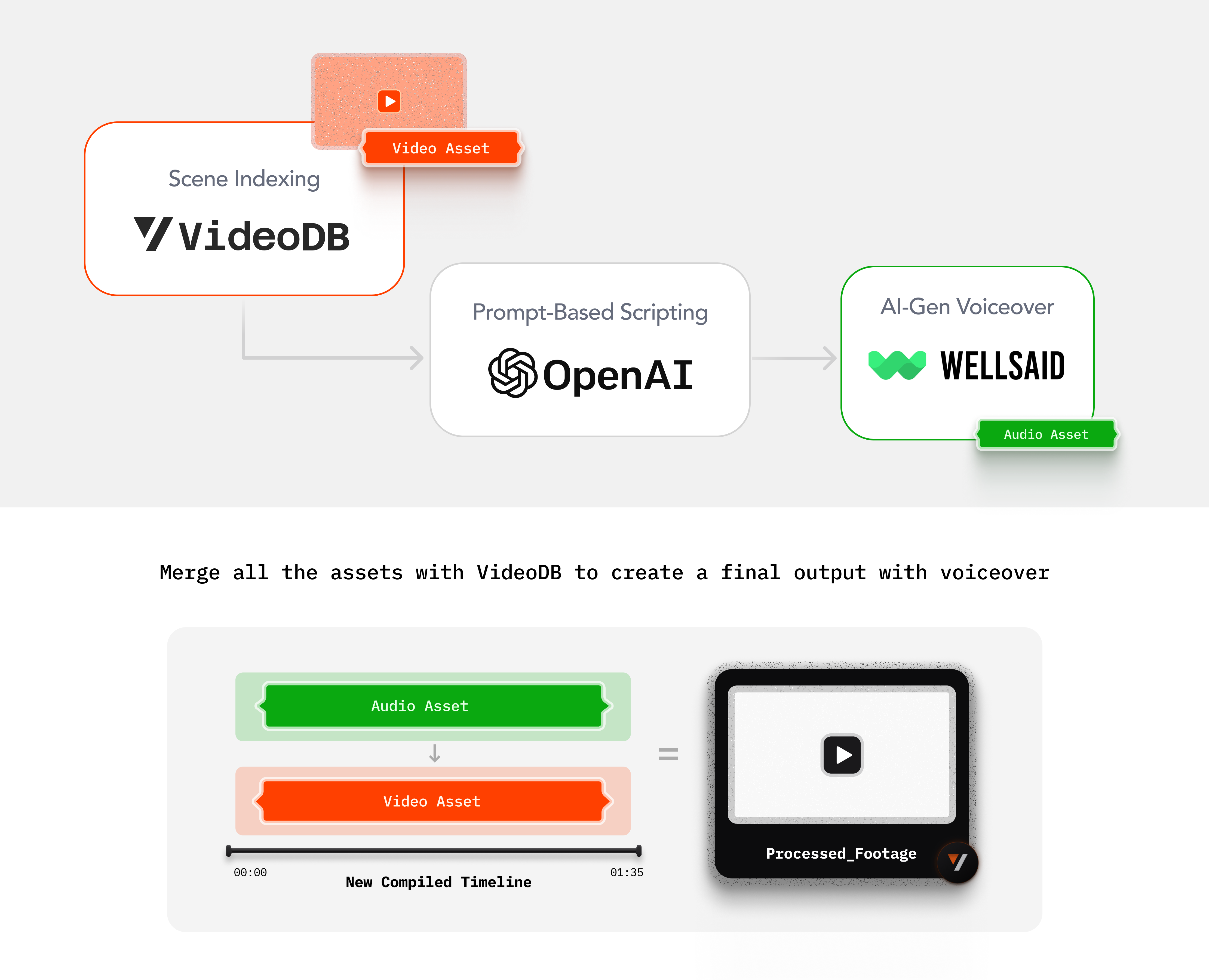"
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "## Setup"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "---"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "### 📦 Installing packages "
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "Ensure you have the necessary packages installed:"
68 | ]
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": null,
73 | "metadata": {},
74 | "outputs": [],
75 | "source": [
76 | "%pip install openai\n",
77 | "%pip install videodb"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### 🔑 API Keys"
85 | ]
86 | },
87 | {
88 | "cell_type": "markdown",
89 | "metadata": {},
90 | "source": [
91 | "Ensure you have access to [OpenAI](https://openai.com), [Wellsaid](https://wellsaidlabs.com/features/api/) and [VideoDB](https://videodb.io) API keys. If you haven't already, sign up for API access on the respective platforms.\n",
92 | "\n",
93 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 2,
99 | "metadata": {},
100 | "outputs": [],
101 | "source": [
102 | "import os\n",
103 | "\n",
104 | "os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
105 | "os.environ[\"WELLSAID_API_KEY\"] = \"\"\n",
106 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": [
113 | "### 🎙️ Wellsaid's Voice Avatar "
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "metadata": {},
119 | "source": [
120 | "\n",
121 | "You will also need Wellsaid's Voice Avatar that you want to use to generate your voiceover. \n",
122 | "\n",
123 | "For this demo, we’ll choose a slick, professional ads voiceover artist’s voice. Wellsaid has a wide range of options to choose from- you can check them out by signing up on their platform and accessing their [Voice Studio](https://docs.wellsaidlabs.com/reference/available-voice-avatars). Once finalized, copy the Speaker ID from Wellsaid and link it here."
124 | ]
125 | },
126 | {
127 | "cell_type": "code",
128 | "execution_count": 3,
129 | "metadata": {},
130 | "outputs": [],
131 | "source": [
132 | "speaker_id = \"109\""
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "## Implementation"
140 | ]
141 | },
142 | {
143 | "cell_type": "markdown",
144 | "metadata": {},
145 | "source": [
146 | "---"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "\n",
154 | "### 🌐 Step 1: Connect to VideoDB\n",
155 | "Begin by establishing a connection to VideoDB using your API key"
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": 4,
161 | "metadata": {},
162 | "outputs": [],
163 | "source": [
164 | "from videodb import connect\n",
165 | "\n",
166 | "# Connect to VideoDB using your API key\n",
167 | "conn = connect()\n",
168 | "coll = conn.get_collection()"
169 | ]
170 | },
171 | {
172 | "cell_type": "markdown",
173 | "metadata": {},
174 | "source": [
175 | "### 🎥 Step 2: Upload Video\n",
176 | "\n",
177 | "Upload your product video to VideoDB using its URL or file path."
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": 5,
183 | "metadata": {},
184 | "outputs": [],
185 | "source": [
186 | "# Upload a video by URL (replace the url with your video)\n",
187 | "video = conn.upload(url='https://www.youtube.com/watch?v=2DcAMbmmYNM')"
188 | ]
189 | },
190 | {
191 | "cell_type": "markdown",
192 | "metadata": {},
193 | "source": [
194 | "### 🔍 Step 3: Analyze Scenes and Generate Scene Descriptions\n",
195 | "\n",
196 | "Start by analyzing the scenes within your Video using VideoDB's scene indexing capabilities. This will provide context for the script prompt."
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": 6,
202 | "metadata": {},
203 | "outputs": [],
204 | "source": [
205 | "video.index_scenes()"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "Let's view the description of first scene of the video"
213 | ]
214 | },
215 | {
216 | "cell_type": "code",
217 | "execution_count": 7,
218 | "metadata": {},
219 | "outputs": [
220 | {
221 | "name": "stdout",
222 | "output_type": "stream",
223 | "text": [
224 | "0 - 0.5338666666666667\n",
225 | "The image presented is overwhelmingly dark, with different shades of black and deep blues blending into each other. There are no discernible objects, figures, or distinct shapes to provide context or detail. The top right corner holds a small watermark or icon with illegible text, suggesting some form of branding or ownership. This image conveys a sense of emptiness or perhaps an abstract concept, as it lacks visual content that would normally inform the viewer's interpretation. It could represent a darkroom, outer space, or even an image error. The nature of this image is enigmatic and open-ended, allowing for various interpretations.\n"
226 | ]
227 | }
228 | ],
229 | "source": [
230 | "scenes = video.get_scenes()\n",
231 | "print(f\"{scenes[0]['start']} - {scenes[0]['end']}\")\n",
232 | "print(scenes[0][\"response\"])"
233 | ]
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "metadata": {},
238 | "source": [
239 | "### Step 4: Generate Voiceover Script with LLM\n",
240 | "Combine scene descriptions with a script prompt, instructing LLM (OpenAI) to create a suitable voiceover for your product advertisement.\n",
241 | "\n",
242 | "This script prompt can be refined and tweaked to generate the most suitable output. Check out [these examples](https://www.youtube.com/playlist?list=PLhxAMFLSSK03rsPTjRv1LbAXHQpNN6BS0) to explore more use cases."
243 | ]
244 | },
245 | {
246 | "cell_type": "code",
247 | "execution_count": 8,
248 | "metadata": {},
249 | "outputs": [],
250 | "source": [
251 | "import openai\n",
252 | "\n",
253 | "client = openai.OpenAI()\n",
254 | "\n",
255 | "script_prompt = \"Here's the data from a scene index for a video from a jewellery product photoshoot. Study this and then generate a synced script based on the description below. Make sure the script is in the language, voice and style of a professional voiceover artist skilled at weaving beautiful storytelling in advertisements.\\n \\n\"\n",
256 | "\n",
257 | "full_prompt = script_prompt + \"\\n\\n\"\n",
258 | "for scene in scenes:\n",
259 | " full_prompt += f\"- {scene}\\n\"\n",
260 | "\n",
261 | "openai_res = client.chat.completions.create(\n",
262 | " model=\"gpt-3.5-turbo\",\n",
263 | " messages=[{\"role\": \"system\", \"content\": full_prompt}],\n",
264 | ")\n",
265 | "voiceover_script = openai_res.choices[0].message.content\n",
266 | "\n",
267 | "\n",
268 | "# Truncate first 1000 characters of script\n",
269 | "# If you have Wellsaid's paid plan remove this\n",
270 | "voiceover_script = voiceover_script[:1000]"
271 | ]
272 | },
273 | {
274 | "cell_type": "markdown",
275 | "metadata": {},
276 | "source": [
277 | "### 🎤 Step 5: Generate Voiceover Audio with Wellsaid "
278 | ]
279 | },
280 | {
281 | "cell_type": "markdown",
282 | "metadata": {},
283 | "source": [
284 | "Utilize the generated script to synthesize a professional voiceover for your product advertisement using Wellsaid's API."
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": 9,
290 | "metadata": {},
291 | "outputs": [],
292 | "source": [
293 | "import requests\n",
294 | "import time \n",
295 | "\n",
296 | "\n",
297 | "# Call Wellsaid API to generate voiceover\n",
298 | "url = \"https://api.wellsaidlabs.com/v1/tts/stream\"\n",
299 | "headers = {\n",
300 | " \"accept\": \"application/json\",\n",
301 | " \"content-type\": \"application/json\",\n",
302 | " \"X-Api-Key\": os.environ.get(\"WELLSAID_API_KEY\")\n",
303 | "}\n",
304 | "\n",
305 | "# Initiate TTS Job for each Chunk\n",
306 | "payload = {\n",
307 | " \"text\": voiceover_script,\n",
308 | " \"speaker_id\": speaker_id\n",
309 | "}\n",
310 | "wellsaid_res = requests.request(\"POST\", url, json=payload, headers=headers)\n",
311 | "\n",
312 | "# Save the audio file\n",
313 | "audio_file = \"audio.mp3\"\n",
314 | "CHUNK_SIZE = 1024\n",
315 | "with open(audio_file, 'wb') as f:\n",
316 | " for chunk in wellsaid_res.iter_content(chunk_size=CHUNK_SIZE):\n",
317 | " if chunk:\n",
318 | " f.write(chunk)"
319 | ]
320 | },
321 | {
322 | "cell_type": "markdown",
323 | "metadata": {},
324 | "source": [
325 | "### 🎬 Step 6: Add Voiceover to Video with VideoDB"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "metadata": {},
331 | "source": [
332 | "In order to use the voiceover generated above, let's upload the audio file (voiceover) to VideoDB first"
333 | ]
334 | },
335 | {
336 | "cell_type": "code",
337 | "execution_count": 10,
338 | "metadata": {},
339 | "outputs": [],
340 | "source": [
341 | "audio = conn.upload(file_path=audio_file)"
342 | ]
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "metadata": {},
347 | "source": [
348 | "Finally, add the AI-generated voiceover to the original footage using VideoDB's [timeline feature](https://docs.videodb.io/version-0-0-3-timeline-and-assets-44)"
349 | ]
350 | },
351 | {
352 | "cell_type": "code",
353 | "execution_count": 11,
354 | "metadata": {},
355 | "outputs": [],
356 | "source": [
357 | "from videodb.timeline import Timeline\n",
358 | "from videodb.asset import VideoAsset, AudioAsset\n",
359 | "\n",
360 | "# Create a timeline object\n",
361 | "timeline = Timeline(conn)\n",
362 | "\n",
363 | "# Add the video asset to the timeline for playback\n",
364 | "video_asset = VideoAsset(asset_id=video.id)\n",
365 | "timeline.add_inline(asset=video_asset)\n",
366 | "\n",
367 | "# Add the audio asset to the timeline for playback\n",
368 | "audio_asset = AudioAsset(asset_id=audio.id)\n",
369 | "timeline.add_overlay(start=0, asset=audio_asset)"
370 | ]
371 | },
372 | {
373 | "cell_type": "markdown",
374 | "metadata": {},
375 | "source": [
376 | "### 🪄 Step 7: Review and Share\n",
377 | "\n",
378 | "Preview the product video with the integrated voiceover to ensure it aligns with your vision. Once satisfied, share the video to showcase your product effectively.\n"
379 | ]
380 | },
381 | {
382 | "cell_type": "code",
383 | "execution_count": 1,
384 | "metadata": {},
385 | "outputs": [],
386 | "source": [
387 | "from videodb import play_stream\n",
388 | "\n",
389 | "stream_url = timeline.generate_stream()\n",
390 | "play_stream(stream_url)"
391 | ]
392 | },
393 | {
394 | "cell_type": "markdown",
395 | "metadata": {},
396 | "source": [
397 | "---"
398 | ]
399 | },
400 | {
401 | "cell_type": "markdown",
402 | "metadata": {},
403 | "source": [
404 | "### 🎉 Conclusion:\n",
405 | "Congratulations! You have successfully automated the process of creating AI-generated voiceovers for product videography using Wellsaid and VideoDB.\n",
406 | "\n",
407 | "Experiment with different script prompts and scene analysis techniques to tailor the voiceovers to your specific product and audience. We look forward to seeing your captivating product videos!\n",
408 | "\n",
409 | "For more such explorations, refer to the [documentation of VideoDB](https://docs.videodb.io/) and join the VideoDB community on [GitHub](https://github.com/video-db) or [Discord](https://discord.com/invite/py9P639jGz) for support and collaboration.\n",
410 | "\n",
411 | "We're excited to see your creations, so we welcome you to share your creations via [Discord](https://discord.com/invite/py9P639jGz), [LinkedIn](https://www.linkedin.com/company/videodb) or [Twitter](https://twitter.com/videodb_io)."
412 | ]
413 | },
414 | {
415 | "cell_type": "markdown",
416 | "metadata": {},
417 | "source": []
418 | }
419 | ],
420 | "metadata": {
421 | "kernelspec": {
422 | "display_name": "Python 3 (ipykernel)",
423 | "language": "python",
424 | "name": "python3"
425 | },
426 | "language_info": {
427 | "codemirror_mode": {
428 | "name": "ipython",
429 | "version": 3
430 | },
431 | "file_extension": ".py",
432 | "mimetype": "text/x-python",
433 | "name": "python",
434 | "nbconvert_exporter": "python",
435 | "pygments_lexer": "ipython3",
436 | "version": "3.12.0"
437 | }
438 | },
439 | "nbformat": 4,
440 | "nbformat_minor": 4
441 | }
442 |
--------------------------------------------------------------------------------
/examples/beep.wav:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/examples/beep.wav
--------------------------------------------------------------------------------
/guides/Cleanup.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## Guide: Cleanup \n",
8 | "\n",
9 | ""
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "\n",
17 | "⚠️ **WARNING** ⚠️\n",
18 | "\n",
19 | "🔴 **PROCEED WITH CAUTION: This notebook contains operations that will permanently delete media files from your VideoDB account.**\n",
20 | "\n",
21 | "🚨 **IMPORTANT: Make sure to carefully review all media files before deletion as this action cannot be undone.**\n",
22 | "\n",
23 | "This guide helps you delete media files and clean up storage from your VideoDB account. You'll learn how to:\n",
24 | "\n",
25 | "* Delete videos\n",
26 | "* Remove audio files\n",
27 | "* Clean up images\n",
28 | "\n"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "## 🛠️ Setup\n",
36 | "---"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "metadata": {},
42 | "source": [
43 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) API key. "
44 | ]
45 | },
46 | {
47 | "cell_type": "code",
48 | "execution_count": null,
49 | "metadata": {},
50 | "outputs": [],
51 | "source": [
52 | "%pip install videodb"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": 2,
58 | "metadata": {},
59 | "outputs": [],
60 | "source": [
61 | "import os\n",
62 | "from videodb import connect\n",
63 | "\n",
64 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"YOUR_KEY_HERE\"\n",
65 | "\n",
66 | "conn = connect()"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "## Review Collections \n",
74 | "---"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {},
81 | "outputs": [],
82 | "source": [
83 | "colls = conn.get_collections()\n",
84 | "\n",
85 | "print(f\"There are {len(colls)} collections\")\n",
86 | "print()\n",
87 | "\n",
88 | "for coll in colls:\n",
89 | " videos = coll.get_videos()\n",
90 | " audios = coll.get_images()\n",
91 | " images = coll.get_images()\n",
92 | " \n",
93 | " print(f\"Collection '{coll.name}' (id: {coll.id})\")\n",
94 | " print(f\" - Videos : {len(videos)}\")\n",
95 | " print(f\" - Audio : {len(audios)}\")\n",
96 | " print(f\" - Images : {len(images)}\")\n",
97 | " print()"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "## Set the Collection \n",
105 | "---"
106 | ]
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "metadata": {},
111 | "source": [
112 | "Set the Collection you wish to cleanup to this id"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": 6,
118 | "metadata": {},
119 | "outputs": [],
120 | "source": [
121 | "collection_id = \"YOUR_COLLECTION_ID_HERE\""
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "### ⚠️ Delete All Videos \n",
129 | "---"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": null,
135 | "metadata": {},
136 | "outputs": [],
137 | "source": [
138 | "coll = conn.get_collection(collection_id)\n",
139 | "videos = coll.get_videos()\n",
140 | "\n",
141 | "for video in videos:\n",
142 | " video.delete()\n",
143 | " print(f\"Deleted video {video.name} ({video.id})\")\n"
144 | ]
145 | },
146 | {
147 | "cell_type": "markdown",
148 | "metadata": {},
149 | "source": [
150 | "### ⚠️ Delete All Audios\n",
151 | "\n",
152 | "---"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": null,
158 | "metadata": {},
159 | "outputs": [],
160 | "source": [
161 | "coll = conn.get_collection(collection_id)\n",
162 | "audios = coll.get_audios()\n",
163 | "\n",
164 | "for audio in audios:\n",
165 | " audio.delete()\n",
166 | " print(f\"Deleted audio {audio.name} ({audio.id})\")"
167 | ]
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "metadata": {},
172 | "source": [
173 | "### ⚠️ Delete All Images \n",
174 | "\n",
175 | "---"
176 | ]
177 | },
178 | {
179 | "cell_type": "code",
180 | "execution_count": null,
181 | "metadata": {},
182 | "outputs": [],
183 | "source": [
184 | "coll = conn.get_collection(collection_id)\n",
185 | "images = coll.get_images()\n",
186 | "\n",
187 | "for image in images:\n",
188 | " image.delete()\n",
189 | " print(f\"Deleted image {image.name} ({image.id})\")"
190 | ]
191 | }
192 | ],
193 | "metadata": {
194 | "kernelspec": {
195 | "display_name": ".venv",
196 | "language": "python",
197 | "name": "python3"
198 | },
199 | "language_info": {
200 | "codemirror_mode": {
201 | "name": "ipython",
202 | "version": 3
203 | },
204 | "file_extension": ".py",
205 | "mimetype": "text/x-python",
206 | "name": "python",
207 | "nbconvert_exporter": "python",
208 | "pygments_lexer": "ipython3",
209 | "version": "3.11.7"
210 | }
211 | },
212 | "nbformat": 4,
213 | "nbformat_minor": 2
214 | }
215 |
--------------------------------------------------------------------------------
/guides/TextAsset.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Guide : TextAsset\n",
8 | "\n",
9 | ""
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "## Overview\n",
17 | "\n",
18 | "This guide gives you an introduction to `TextAssets` and how you can use them to overlay text elements on your videos.\n",
19 | "\n",
20 | "We will also explore the configurations available for the `TextAssets` class, such as:\n",
21 | "\n",
22 | "* Default Styling\n",
23 | "* Font Styling\n",
24 | "* Background box styling\n",
25 | "* Shadow for Text Element\n",
26 | "* Position and alignment\n"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "## Setup\n",
34 | "---"
35 | ]
36 | },
37 | {
38 | "cell_type": "markdown",
39 | "metadata": {},
40 | "source": [
41 | "### 📦 Installing packages "
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": null,
47 | "metadata": {},
48 | "outputs": [],
49 | "source": [
50 | "%pip install videodb"
51 | ]
52 | },
53 | {
54 | "cell_type": "markdown",
55 | "metadata": {},
56 | "source": [
57 | "### 🔑 API Keys\n",
58 | "Before proceeding, ensure access to [VideoDB](https://videodb.io) \n",
59 | "\n",
60 | "> Get your API key from [VideoDB Console](https://console.videodb.io). ( Free for first 50 uploads, **No credit card required** ) 🎉"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 4,
66 | "metadata": {},
67 | "outputs": [],
68 | "source": [
69 | "import os\n",
70 | "\n",
71 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "metadata": {},
77 | "source": [
78 | "### 🌐 Connect to VideoDB"
79 | ]
80 | },
81 | {
82 | "cell_type": "code",
83 | "execution_count": 5,
84 | "metadata": {},
85 | "outputs": [],
86 | "source": [
87 | "from videodb import connect\n",
88 | "\n",
89 | "conn = connect()\n",
90 | "coll = conn.get_collection()"
91 | ]
92 | },
93 | {
94 | "cell_type": "markdown",
95 | "metadata": {},
96 | "source": [
97 | "### 🎥 Upload Video\n",
98 | "VideoDB uses video as a base to create a timeline. Click here to learn more about how [Timelines and Assets](https://docs.videodb.io/timeline-and-assets-44) function."
99 | ]
100 | },
101 | {
102 | "cell_type": "code",
103 | "execution_count": 1,
104 | "metadata": {},
105 | "outputs": [],
106 | "source": [
107 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=w4NEOTvstAc\")\n",
108 | "video.play()"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "## Creating assets\n",
116 | "---\n",
117 | "\n",
118 | "Now, we will create some assets that we are going to use in our Video Timeline\n",
119 | "\n",
120 | "* `VideoAsset` - A Video that will be used as a base for Video Timeline\n",
121 | "* `TextAsset` - A Text Element that will overlayed on our Video Timeline"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "> Checkout [Timeline and Assets](https://docs.videodb.io/timeline-and-assets-44)"
129 | ]
130 | },
131 | {
132 | "cell_type": "markdown",
133 | "metadata": {},
134 | "source": [
135 | "### 🎥 VideoAsset \n",
136 | "---"
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 106,
142 | "metadata": {},
143 | "outputs": [],
144 | "source": [
145 | "from videodb.asset import VideoAsset\n",
146 | "\n",
147 | "# Create a VideoAsset from Video\n",
148 | "video_asset = VideoAsset(\n",
149 | " asset_id = video.id,\n",
150 | " start = 0,\n",
151 | " end = 60 \n",
152 | ")"
153 | ]
154 | },
155 | {
156 | "cell_type": "markdown",
157 | "metadata": {},
158 | "source": [
159 | "### 🔠 TextAsset : Default Styling \n",
160 | "---\n",
161 | "To Create a TextAsset, use `TextAsset`\n",
162 | "\n",
163 | "Params: \n",
164 | "\n",
165 | "* `text` (required): The text that needs to be displayed\n",
166 | "* `duration` (optional): The duration for which the text element needs to be displayed"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 8,
172 | "metadata": {},
173 | "outputs": [],
174 | "source": [
175 | "from videodb.asset import TextAsset\n",
176 | "\n",
177 | "text_asset_1 = TextAsset(\n",
178 | " text=\"THIS IS A SENTENCE\",\n",
179 | " duration=5\n",
180 | ")"
181 | ]
182 | },
183 | {
184 | "cell_type": "markdown",
185 | "metadata": {},
186 | "source": [
187 | ""
188 | ]
189 | },
190 | {
191 | "cell_type": "markdown",
192 | "metadata": {},
193 | "source": [
194 | "### 🔡 TextAsset - Custom Styling \n",
195 | "\n",
196 | "To Create a `TextAsset`, with custom styling you can pass an additional parameter\n",
197 | "\n",
198 | "* style (optional): Accepts a `TextStyle` Instance, which contains styling configuration of a `TextAsset` \n",
199 | "\n",
200 | "> View API Reference for [`TextStyle`]()"
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {},
206 | "source": [
207 | "**𝟏.Font Styling**"
208 | ]
209 | },
210 | {
211 | "cell_type": "code",
212 | "execution_count": 9,
213 | "metadata": {},
214 | "outputs": [],
215 | "source": [
216 | "from videodb.asset import TextAsset, TextStyle\n",
217 | "\n",
218 | "\n",
219 | "# Create TextAsset with custom styling using TextStyle \n",
220 | "text_asset_2 = TextAsset(\n",
221 | " text=\"THIS IS A SENTENCE\",\n",
222 | " duration=5,\n",
223 | " style=TextStyle(\n",
224 | " font = \"Inter\",\n",
225 | " fontsize = 50,\n",
226 | " fontcolor = \"#FFCFA5\",\n",
227 | " bordercolor = \"#C14103\",\n",
228 | " borderw = \"2\",\n",
229 | " box = False \n",
230 | " )\n",
231 | ")\n"
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {},
237 | "source": [
238 | ""
239 | ]
240 | },
241 | {
242 | "cell_type": "markdown",
243 | "metadata": {},
244 | "source": [
245 | "**𝟐.Configuring Background box**"
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": 10,
251 | "metadata": {},
252 | "outputs": [],
253 | "source": [
254 | "from videodb.asset import TextAsset, TextStyle\n",
255 | "\n",
256 | "\n",
257 | "# Create TextAsset with custom styling using TextStyle \n",
258 | "text_asset_3 = TextAsset(\n",
259 | " text=\"THIS IS A SENTENCE\",\n",
260 | " duration=5,\n",
261 | " style=TextStyle(\n",
262 | " box = True,\n",
263 | " boxcolor = \"#FFCFA5\",\n",
264 | " boxborderw = 10,\n",
265 | " boxw = 0,\n",
266 | " boxh = 0, \n",
267 | " )\n",
268 | ")"
269 | ]
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "metadata": {},
274 | "source": [
275 | ""
276 | ]
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "metadata": {},
281 | "source": [
282 | "**𝟑.Configuring Shadows**"
283 | ]
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": 11,
288 | "metadata": {},
289 | "outputs": [],
290 | "source": [
291 | "from videodb.asset import TextAsset, TextStyle\n",
292 | "\n",
293 | "\n",
294 | "# Create TextAsset with custom styling using TextStyle \n",
295 | "text_asset_4 = TextAsset(\n",
296 | " text=\"THIS IS A SENTENCE\",\n",
297 | " duration=5,\n",
298 | " style=TextStyle(\n",
299 | " shadowcolor=\"#0AA910\",\n",
300 | " shadowx=\"2\",\n",
301 | " shadowy=\"3\",\n",
302 | " )\n",
303 | ")\n"
304 | ]
305 | },
306 | {
307 | "cell_type": "markdown",
308 | "metadata": {},
309 | "source": [
310 | ""
311 | ]
312 | },
313 | {
314 | "cell_type": "markdown",
315 | "metadata": {},
316 | "source": [
317 | "**3. Position and Alignment**\n"
318 | ]
319 | },
320 | {
321 | "cell_type": "code",
322 | "execution_count": 103,
323 | "metadata": {},
324 | "outputs": [],
325 | "source": [
326 | "from videodb.asset import TextAsset, TextStyle\n",
327 | "\n",
328 | "text_asset_5 = TextAsset(\n",
329 | " text=\"THIS IS A SENTENCE\",\n",
330 | " duration=5,\n",
331 | " style=TextStyle(\n",
332 | " x = 50, \n",
333 | " y = 50,\n",
334 | " y_align = \"text\",\n",
335 | " text_align = \"T+L\",\n",
336 | " boxcolor=\"#FFCFA5\",\n",
337 | " boxh=100,\n",
338 | " boxw=600\n",
339 | " )\n",
340 | ")\n",
341 | "\n",
342 | "text_asset_6 = TextAsset(\n",
343 | " text=\"THIS IS A SENTENCE\",\n",
344 | " duration=5,\n",
345 | " style=TextStyle(\n",
346 | " x = 50, \n",
347 | " y = 50,\n",
348 | " y_align = \"text\",\n",
349 | " text_align = \"M+C\",\n",
350 | " boxcolor=\"#FFCFA5\",\n",
351 | " boxh=100,\n",
352 | " boxw=600\n",
353 | " )\n",
354 | ")\n",
355 | "\n",
356 | "text_asset_7 = TextAsset(\n",
357 | " text=\"THIS IS A SENTENCE\",\n",
358 | " duration=5,\n",
359 | " style=TextStyle(\n",
360 | " x = 50, \n",
361 | " y = 50,\n",
362 | " y_align = \"text\",\n",
363 | " text_align = \"B+R\",\n",
364 | " boxcolor=\"#FFCFA5\",\n",
365 | " boxh=100,\n",
366 | " boxw=600\n",
367 | " )\n",
368 | ")"
369 | ]
370 | },
371 | {
372 | "cell_type": "markdown",
373 | "metadata": {},
374 | "source": [
375 | "\n",
376 | ""
377 | ]
378 | },
379 | {
380 | "cell_type": "markdown",
381 | "metadata": {},
382 | "source": [
383 | "## View Results\n",
384 | "--- "
385 | ]
386 | },
387 | {
388 | "cell_type": "markdown",
389 | "metadata": {},
390 | "source": [
391 | "### 🎼 Create a timeline using Timeline "
392 | ]
393 | },
394 | {
395 | "cell_type": "code",
396 | "execution_count": 104,
397 | "metadata": {},
398 | "outputs": [],
399 | "source": [
400 | "from videodb.timeline import Timeline\n",
401 | "\n",
402 | "# Initialize a Timeline\n",
403 | "timeline = Timeline(conn)\n",
404 | "\n",
405 | "# Add Our base VideoAsset inline\n",
406 | "timeline.add_inline(video_asset)\n",
407 | "\n",
408 | "# TextAsset with default Styling \n",
409 | "timeline.add_overlay(0, text_asset_1)\n",
410 | "\n",
411 | "# TextAsset with Custom Font Styling\n",
412 | "timeline.add_overlay(5, text_asset_2)\n",
413 | "\n",
414 | "# TextAsset with Custom Border Box \n",
415 | "timeline.add_overlay(10, text_asset_3)\n",
416 | "\n",
417 | "# TextAsset with Custom Shadow \n",
418 | "timeline.add_overlay(15, text_asset_4)\n",
419 | "\n",
420 | "# TextAsset with Custom Position and alignment \n",
421 | "timeline.add_overlay(20, text_asset_5)\n",
422 | "timeline.add_overlay(25, text_asset_6)\n",
423 | "timeline.add_overlay(30, text_asset_7)"
424 | ]
425 | },
426 | {
427 | "cell_type": "markdown",
428 | "metadata": {},
429 | "source": [
430 | "### ▶️ Play the Video"
431 | ]
432 | },
433 | {
434 | "cell_type": "code",
435 | "execution_count": 3,
436 | "metadata": {},
437 | "outputs": [],
438 | "source": [
439 | "from videodb import play_stream\n",
440 | "\n",
441 | "stream_url = timeline.generate_stream()\n",
442 | "play_stream(stream_url)"
443 | ]
444 | }
445 | ],
446 | "metadata": {
447 | "kernelspec": {
448 | "display_name": "Python 3 (ipykernel)",
449 | "language": "python",
450 | "name": "python3"
451 | },
452 | "language_info": {
453 | "codemirror_mode": {
454 | "name": "ipython",
455 | "version": 3
456 | },
457 | "file_extension": ".py",
458 | "mimetype": "text/x-python",
459 | "name": "python",
460 | "nbconvert_exporter": "python",
461 | "pygments_lexer": "ipython3",
462 | "version": "3.12.0"
463 | }
464 | },
465 | "nbformat": 4,
466 | "nbformat_minor": 4
467 | }
468 |
--------------------------------------------------------------------------------
/guides/scene-index/advanced_visual_search.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 🚀️ Scene Index: Advanced Visual Search"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "\n",
22 | "> This guide assumes you are already familiar with the concept of Scene Indexing. If you are not, please refer to our [Scene Index: QuickStart](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/quickstart.ipynb) Guide to get up to speed. \n",
23 | "\n",
24 | "\n",
25 | "We provide you with easy-to-use objects and functions to bring flexibility in designing your visual understanding pipeline. With these tools, you have the freedom to..\n",
26 | "\n",
27 | "1. Extract scene according to your use case.\n",
28 | "2. Go to frame level abstraction. \n",
29 | "3. Assign label, custom model description for each frame. \n",
30 | "4. Use of multiple models, prompts for each scene or frame to convert information to text. \n",
31 | "5. Send multiple frames to vision model for better temporal activity understanding."
32 | ]
33 | },
34 | {
35 | "cell_type": "markdown",
36 | "metadata": {},
37 | "source": [
38 | "## Setup\n",
39 | "---"
40 | ]
41 | },
42 | {
43 | "cell_type": "markdown",
44 | "metadata": {},
45 | "source": [
46 | "### 📦 Installing packages "
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": null,
52 | "metadata": {},
53 | "outputs": [],
54 | "source": [
55 | "!pip install videodb"
56 | ]
57 | },
58 | {
59 | "cell_type": "markdown",
60 | "metadata": {},
61 | "source": [
62 | "### 🔑 API Keys"
63 | ]
64 | },
65 | {
66 | "cell_type": "code",
67 | "execution_count": 2,
68 | "metadata": {},
69 | "outputs": [],
70 | "source": [
71 | "import os\n",
72 | "\n",
73 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "### 🌐 Connect to VideoDB"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 3,
86 | "metadata": {},
87 | "outputs": [],
88 | "source": [
89 | "from videodb import connect\n",
90 | "\n",
91 | "conn = connect()\n",
92 | "coll = conn.get_collection()"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "### 🎥 Upload Video"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 4,
105 | "metadata": {},
106 | "outputs": [],
107 | "source": [
108 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=LejnTJL173Y\")"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "## ✂️🎬 Extract Scenes\n",
116 | "---"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": 5,
122 | "metadata": {},
123 | "outputs": [],
124 | "source": [
125 | "from videodb import SceneExtractionType\n",
126 | "\n",
127 | "scene_collection = video.extract_scenes(\n",
128 | " extraction_type=SceneExtractionType.time_based,\n",
129 | " extraction_config={\"time\": 30, \"select_frames\": [\"middle\"]},\n",
130 | ")"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": null,
136 | "metadata": {},
137 | "outputs": [],
138 | "source": [
139 | "print(\"This is scene collection id\", scene_collection.id)\n",
140 | "print(\"This is scene collection config\", scene_collection.config)"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "**Note**: Image Upload might take time ranging from 5s-60s. Re-fetch the scene collection if image_url is None"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": null,
153 | "metadata": {},
154 | "outputs": [],
155 | "source": [
156 | "scene_collection = video.get_scene_collection(scene_collection.id)\n",
157 | "print(scene_collection.scenes[0].frames[0].url)"
158 | ]
159 | },
160 | {
161 | "cell_type": "markdown",
162 | "metadata": {},
163 | "source": [
164 | "\n",
165 | "## 📝 Annotating Scene\n",
166 | "---"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": null,
172 | "metadata": {},
173 | "outputs": [],
174 | "source": [
175 | "# get scene from collection\n",
176 | "scenes = scene_collection.scenes\n",
177 | "\n",
178 | "def describe_images(urls, start, end):\n",
179 | " # Plug your VLLM or CV model here\n",
180 | " return f\"This is a scene from {start}s-{end}s\" \n",
181 | "\n",
182 | "for scene in scenes:\n",
183 | " print(f\"Scene Duration {scene.start}-{scene.end}\")\n",
184 | "\n",
185 | " frames_url = [frame.url for frame in scene.frames]\n",
186 | " scene.description = describe_images(frames_url, start=scene.start, end=scene.end)"
187 | ]
188 | },
189 | {
190 | "cell_type": "markdown",
191 | "metadata": {},
192 | "source": [
193 | "## 📝 Annotating Frames \n",
194 | "---"
195 | ]
196 | },
197 | {
198 | "cell_type": "code",
199 | "execution_count": null,
200 | "metadata": {},
201 | "outputs": [],
202 | "source": [
203 | "def describe_image(url, time):\n",
204 | " # Plug your VLLM or CV model here\n",
205 | " return f\"This is a keyframe at {time}s\" \n",
206 | "\n",
207 | "\n",
208 | "# Iterate through each scene\n",
209 | "for scene in scenes:\n",
210 | " \n",
211 | " # Iterate through each frame in the scene\n",
212 | " for frame in scene.frames:\n",
213 | " print(f\"Frame at {frame.frame_time} {frame.url}\")\n",
214 | " frame.description = describe_image(frame.url, time=frame.frame_time) "
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "## Indexing the Annotated Scenes\n",
222 | "---"
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": null,
228 | "metadata": {},
229 | "outputs": [],
230 | "source": [
231 | "index_id = video.index_scenes(scenes=scenes, name=\"My Custom Annotation\")\n",
232 | "\n",
233 | "scene_index = video.get_scene_index(index_id)\n",
234 | "print(scene_index)"
235 | ]
236 | },
237 | {
238 | "cell_type": "markdown",
239 | "metadata": {},
240 | "source": [
241 | "## Searching the Index\n",
242 | "---"
243 | ]
244 | },
245 | {
246 | "cell_type": "markdown",
247 | "metadata": {},
248 | "source": [
249 | "> Note: it might take a additional 5-10 seconds for your index to become available for search"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": null,
255 | "metadata": {},
256 | "outputs": [],
257 | "source": [
258 | "from videodb import IndexType\n",
259 | "\n",
260 | "# search using the index_id\n",
261 | "res = video.search(query=\"first 29s\", index_type=IndexType.scene, index_id=index_id)\n",
262 | "res.play()"
263 | ]
264 | },
265 | {
266 | "cell_type": "markdown",
267 | "metadata": {},
268 | "source": [
269 | "## 🧑💻 Next Steps\n",
270 | "---"
271 | ]
272 | },
273 | {
274 | "cell_type": "markdown",
275 | "metadata": {},
276 | "source": [
277 | "\n",
278 | "Check out the other resources and tutorials using Scene Indexing\n",
279 | "* If you want to bring your own scene descriptions and annotations, explore the [Custom Annotations Pipeline](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/custom_annotations.ipynb)\n",
280 | "* Experiment with extraction algorithms, prompts, and search using the [Playground for Scene Extractions](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/playground_scene_extraction.ipynb)\n",
281 | "\n",
282 | "If you have any questions or feedback. Feel free to reach out to us 🙌🏼\n",
283 | "\n",
284 | "* [Discord](https://colab.research.google.com/corgiredirector?site=https%3A%2F%2Fdiscord.gg%2Fpy9P639jGz)\n",
285 | "* [GitHub](https://github.com/video-db)\n",
286 | "* [VideoDB](https://colab.research.google.com/corgiredirector?site=https%3A%2F%2Fvideodb.io)\n",
287 | "* [Email](ashu@videodb.io)"
288 | ]
289 | },
290 | {
291 | "cell_type": "markdown",
292 | "metadata": {},
293 | "source": []
294 | }
295 | ],
296 | "metadata": {
297 | "kernelspec": {
298 | "display_name": ".venv",
299 | "language": "python",
300 | "name": "python3"
301 | },
302 | "language_info": {
303 | "codemirror_mode": {
304 | "name": "ipython",
305 | "version": 3
306 | },
307 | "file_extension": ".py",
308 | "mimetype": "text/x-python",
309 | "name": "python",
310 | "nbconvert_exporter": "python",
311 | "pygments_lexer": "ipython3",
312 | "version": "3.11.7"
313 | }
314 | },
315 | "nbformat": 4,
316 | "nbformat_minor": 2
317 | }
318 |
--------------------------------------------------------------------------------
/guides/scene-index/custom_annotations.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 📝️ Scene Index: Custom Annotations"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "> This guide assumes you are already familiar with the concept of Scene Indexing. If you are not, please refer to our [Scene Index: QuickStart](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/quickstart.ipynb) Guide to get up to speed. \n",
22 | "\n",
23 | "You can enhance your understanding of videos by using our simple custom annotation and tagging pipeline. \n",
24 | "To enable this, you can create a new `Scene` object. Then, pass your annotations in the `Scene.description` and index them using `Video.index_scenes()` function. \n",
25 | "\n",
26 | "VideoDB allows multiple indexes on video objects. This is advantageous as it allows you to attach additional context to each scene, enhancing the search functionality.\n",
27 | "This guide walks you through Custom Annotations Pipeline\n"
28 | ]
29 | },
30 | {
31 | "cell_type": "markdown",
32 | "metadata": {},
33 | "source": [
34 | "## Setup\n",
35 | "---"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "### 📦 Installing packages "
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": null,
48 | "metadata": {},
49 | "outputs": [],
50 | "source": [
51 | "!pip install videodb"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "### 🔑 API Keys"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 4,
64 | "metadata": {},
65 | "outputs": [],
66 | "source": [
67 | "import os\n",
68 | "\n",
69 | "os.environ[\"VIDEO_DB_API_KEY\"] = \"\""
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "### 🌐 Connect to VideoDB"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 5,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "from videodb import connect\n",
86 | "\n",
87 | "conn = connect()\n",
88 | "coll = conn.get_collection()"
89 | ]
90 | },
91 | {
92 | "cell_type": "markdown",
93 | "metadata": {},
94 | "source": [
95 | "### 🎥 Upload Video"
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": 6,
101 | "metadata": {},
102 | "outputs": [],
103 | "source": [
104 | "video = coll.upload(url=\"https://www.youtube.com/watch?v=LejnTJL173Y\")"
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "## 📝 Annotating Scenes\n",
112 | "---"
113 | ]
114 | },
115 | {
116 | "cell_type": "markdown",
117 | "metadata": {},
118 | "source": [
119 | "To Anotate your Video with Custom Annotations, You can follow this workflow\n",
120 | "\n",
121 | "- Create a new `Scene` object \n",
122 | "- Pass your annotations in the `Scene.description` \n",
123 | "- Index them using `Video.index_scenes()` function. \n",
124 | "\n",
125 | "\n",
126 | "Let's understand `Scene` Object\n",
127 | "\n",
128 | "### 🎬 Scene\n",
129 | "\n",
130 | "A Scene object describes a unique event in the video. \n",
131 | "\n",
132 | "`video_id` : id of the video object\n",
133 | "\n",
134 | "`start` : seconds\n",
135 | "\n",
136 | "`end` : seconds\n",
137 | "\n",
138 | "`description` : string description\n",
139 | "\n",
140 | "\n",
141 | "Each scene object has another attribute, frames, which contains a list of `Frame` objects. \n",
142 | "However, we don't need them here for custom annotation pipelines because we are bringing the description from outside.\n",
143 | "\n",
144 | " \n",
145 | "\n",
146 | "### ✂️🎬 Create a new Scene\n",
147 | "\n",
148 | "Create new Scene objects and add your description"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": null,
154 | "metadata": {},
155 | "outputs": [],
156 | "source": [
157 | "from videodb.scene import Scene\n",
158 | "\n",
159 | "# create scene object and patch your description\n",
160 | "scene1 = Scene(\n",
161 | " video_id=video.id,\n",
162 | " start=0,\n",
163 | " end=10,\n",
164 | " description=\"Detective Martin is being interviewed by the police.\",\n",
165 | ")\n",
166 | "\n",
167 | "\n",
168 | "scene2 = Scene(\n",
169 | " video_id=video.id,\n",
170 | " start=10,\n",
171 | " end=100,\n",
172 | " description=\"A religious gathering. People are praying and singing.\",\n",
173 | ")\n",
174 | "\n",
175 | "# create a list of scene objects\n",
176 | "scenes = [scene1, scene2]"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | "### ️ 🗂️️ Index and search scenes\n",
184 | "\n",
185 | "Index using the list of scene objects and use the `index_id` for search"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": null,
191 | "metadata": {},
192 | "outputs": [],
193 | "source": [
194 | "#create new index and assign it a name\n",
195 | "index_id = video.index_scenes(scenes=scenes, name=\"My Custom Annotations#1\")\n",
196 | "\n",
197 | "custom_scene_index = video.get_scene_index(index_id)\n",
198 | "print(custom_scene_index)"
199 | ]
200 | },
201 | {
202 | "cell_type": "markdown",
203 | "metadata": {},
204 | "source": [
205 | "> Note: it might take a additional 5-10 seconds for your index to become available for search"
206 | ]
207 | },
208 | {
209 | "cell_type": "code",
210 | "execution_count": null,
211 | "metadata": {},
212 | "outputs": [],
213 | "source": [
214 | "from videodb import IndexType\n",
215 | "\n",
216 | "# search using the index_id\n",
217 | "res = video.search(query=\"religious gathering\", index_type=IndexType.scene, index_id=index_id)\n",
218 | "res.play()"
219 | ]
220 | },
221 | {
222 | "cell_type": "markdown",
223 | "metadata": {},
224 | "source": [
225 | "## 🧑💻 Deep Dive\n",
226 | "---"
227 | ]
228 | },
229 | {
230 | "cell_type": "markdown",
231 | "metadata": {},
232 | "source": [
233 | "\n",
234 | "Check out the other resources and tutorials using Scene Indexing\n",
235 | "* Experiment with extraction algorithms, prompts, and search using the [Playground for Scene Extractions](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/playground_scene_extraction.ipynb)\n",
236 | "* Check out our open and flexible [Advanced Visual Search Pipelines](https://github.com/video-db/videodb-cookbook/blob/main/guides/video/scene-index/advanced_visual_search.ipynb)\n",
237 | "\n",
238 | "\n",
239 | "If you have any questions or feedback. Feel free to reach out to us 🙌🏼\n",
240 | "\n",
241 | "* [Discord](https://colab.research.google.com/corgiredirector?site=https%3A%2F%2Fdiscord.gg%2Fpy9P639jGz)\n",
242 | "* [GitHub](https://github.com/video-db)\n",
243 | "* [VideoDB](https://colab.research.google.com/corgiredirector?site=https%3A%2F%2Fvideodb.io)\n",
244 | "* [Email](ashu@videodb.io)"
245 | ]
246 | },
247 | {
248 | "cell_type": "markdown",
249 | "metadata": {},
250 | "source": []
251 | }
252 | ],
253 | "metadata": {
254 | "kernelspec": {
255 | "display_name": ".venv",
256 | "language": "python",
257 | "name": "python3"
258 | },
259 | "language_info": {
260 | "codemirror_mode": {
261 | "name": "ipython",
262 | "version": 3
263 | },
264 | "file_extension": ".py",
265 | "mimetype": "text/x-python",
266 | "name": "python",
267 | "nbconvert_exporter": "python",
268 | "pygments_lexer": "ipython3",
269 | "version": "3.11.7"
270 | }
271 | },
272 | "nbformat": 4,
273 | "nbformat_minor": 2
274 | }
275 |
--------------------------------------------------------------------------------
/images/Audio_Overlay/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/Audio_Overlay/image.png
--------------------------------------------------------------------------------
/images/Elevenlabs_Voiceover_1/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/Elevenlabs_Voiceover_1/image.png
--------------------------------------------------------------------------------
/images/Intro_Outro_Inline copy/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/Intro_Outro_Inline copy/image.png
--------------------------------------------------------------------------------
/images/assemblyai_labels1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/assemblyai_labels1.png
--------------------------------------------------------------------------------
/images/assemblyai_labels2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/assemblyai_labels2.png
--------------------------------------------------------------------------------
/images/director_architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/director_architecture.png
--------------------------------------------------------------------------------
/images/director_reasoning_engine.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/director_reasoning_engine.png
--------------------------------------------------------------------------------
/images/scene_index/VSF.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/scene_index/VSF.png
--------------------------------------------------------------------------------
/images/scene_index/intro.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/scene_index/intro.png
--------------------------------------------------------------------------------
/images/videodb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/video-db/videodb-cookbook/ac868212ffde668fcf4abf7d4742498978650566/images/videodb.png
--------------------------------------------------------------------------------
 15 |
16 |
17 |
15 |
16 |
17 |