 4 |
5 |
4 |
5 |
2 |
3 |
4 |
5 |
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
6 | 7 | 同:[链表:链表相交](https://programmercarl.com/面试题02.07.链表相交.html) 8 |
9 |
10 |  11 |
12 |
--------------------------------------------------------------------------------
/problems/前序/编程素养部分的吹毛求疵.md:
--------------------------------------------------------------------------------
1 | ## 代码风格
2 |
3 | - `不甚了解`是不能更了解的意思,这个地方应该使用存疑。
4 | - `后期在不断优化`,'在'应为'再'。
5 | - `googlec++编程规范`,Google拼写错误
6 |
7 | ## 代码本地编译
8 |
9 | - `粘到本例来运行`存疑,应为本地
10 | - `本题运行`存疑,应为本地
11 |
12 | ## ACM二叉树
13 |
14 | - 左孩子和右孩子的下标不太好理解。我给出证明过程:
15 |
16 | 如果父节点在第k层,第$m,m \in [0,2^k]$个节点,则其左孩子所在的位置必然为$k+1$层,第$2*(m-1)+1$个节点。
17 |
18 | - 计算父节点在数组中的索引:
19 | $$
20 | index_{father}=(\sum_{i=0}^{i=k-1}2^i)+m-1=2^k-1+m-1
21 | $$
22 |
23 | - 计算左子节点在数组的索引:
24 | $$
25 | index_{left}=(\sum_{i=0}^{i=k}2^i)+2*m-1-1=2^{k+1}+2m-3
26 | $$
27 |
28 | - 故左孩子的下表为$index_{left}=index_{father}\times2+1$,同理可得到右子孩子的索引关系。也可以直接在左子孩子的基础上`+1`。
29 |
30 |
31 |
32 |
--------------------------------------------------------------------------------
/problems/前序/刷力扣用不用库函数.md:
--------------------------------------------------------------------------------
1 | # 究竟什么时候用库函数,什么时候要自己实现
2 |
3 | 在[知识星球](https://programmercarl.com/other/kstar.html)里有录友问我,刷题究竟要不要用库函数? 刷题的时候总是禁不住库函数的诱惑,如果都不用库函数一些题目做起来还很麻烦。
4 |
5 | 估计不少录友都有这个困惑,我来说一说对于库函数的使用。
6 |
7 | 一些同学可能比较喜欢看力扣上直接调用库函数的评论和题解,**其实我感觉娱乐一下还是可以的,但千万别当真,别沉迷!**
8 |
9 | 例如:[字符串:151. 翻转字符串里的单词](https://programmercarl.com/0151.%E7%BF%BB%E8%BD%AC%E5%AD%97%E7%AC%A6%E4%B8%B2%E9%87%8C%E7%9A%84%E5%8D%95%E8%AF%8D.html)这道题目本身是综合考察同学们对字符串的处理能力,如果 split + reverse的话,那就失去了题目的意义了。
10 |
11 | 有的同学可能不屑于实现这么简单的功能,直接调库函数完事,把字符串分成一个个单词,一想就是那么一回事,多简单。
12 |
13 | 相信我,很多面试题都是一想很简单,实现起来一堆问题。 所以刷力扣本来就是为面试,也为了提高自己的代码能力,扎实一点没坏处。
14 |
15 | **那么平时写算法题目就全都不用库函数了么?**
16 |
17 | 当然也不是,这里我给大家提供一个标准。
18 |
19 | **如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数**。
20 |
21 | **如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,那么直接用库函数。**
22 |
23 | 使用库函数最大的忌讳就是不知道这个库函数怎么实现的,也不知道其时间复杂度,上来就用,这样写出来的算法,时间复杂度自己都掌握不好的。
24 |
25 | 例如for循环里套一个字符串的insert,erase之类的操作,你说时间复杂度是多少呢,很明显是O(n^2)的时间复杂度了。
26 |
27 | 在刷题的时候本着我说的标准来使用库函数,详细对大家回有所帮助!
28 |
29 |
--------------------------------------------------------------------------------
/problems/前序/成都互联网公司总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 成都互联网公司总结
3 |
11 |
12 |
--------------------------------------------------------------------------------
/problems/前序/编程素养部分的吹毛求疵.md:
--------------------------------------------------------------------------------
1 | ## 代码风格
2 |
3 | - `不甚了解`是不能更了解的意思,这个地方应该使用存疑。
4 | - `后期在不断优化`,'在'应为'再'。
5 | - `googlec++编程规范`,Google拼写错误
6 |
7 | ## 代码本地编译
8 |
9 | - `粘到本例来运行`存疑,应为本地
10 | - `本题运行`存疑,应为本地
11 |
12 | ## ACM二叉树
13 |
14 | - 左孩子和右孩子的下标不太好理解。我给出证明过程:
15 |
16 | 如果父节点在第k层,第$m,m \in [0,2^k]$个节点,则其左孩子所在的位置必然为$k+1$层,第$2*(m-1)+1$个节点。
17 |
18 | - 计算父节点在数组中的索引:
19 | $$
20 | index_{father}=(\sum_{i=0}^{i=k-1}2^i)+m-1=2^k-1+m-1
21 | $$
22 |
23 | - 计算左子节点在数组的索引:
24 | $$
25 | index_{left}=(\sum_{i=0}^{i=k}2^i)+2*m-1-1=2^{k+1}+2m-3
26 | $$
27 |
28 | - 故左孩子的下表为$index_{left}=index_{father}\times2+1$,同理可得到右子孩子的索引关系。也可以直接在左子孩子的基础上`+1`。
29 |
30 |
31 |
32 |
--------------------------------------------------------------------------------
/problems/前序/刷力扣用不用库函数.md:
--------------------------------------------------------------------------------
1 | # 究竟什么时候用库函数,什么时候要自己实现
2 |
3 | 在[知识星球](https://programmercarl.com/other/kstar.html)里有录友问我,刷题究竟要不要用库函数? 刷题的时候总是禁不住库函数的诱惑,如果都不用库函数一些题目做起来还很麻烦。
4 |
5 | 估计不少录友都有这个困惑,我来说一说对于库函数的使用。
6 |
7 | 一些同学可能比较喜欢看力扣上直接调用库函数的评论和题解,**其实我感觉娱乐一下还是可以的,但千万别当真,别沉迷!**
8 |
9 | 例如:[字符串:151. 翻转字符串里的单词](https://programmercarl.com/0151.%E7%BF%BB%E8%BD%AC%E5%AD%97%E7%AC%A6%E4%B8%B2%E9%87%8C%E7%9A%84%E5%8D%95%E8%AF%8D.html)这道题目本身是综合考察同学们对字符串的处理能力,如果 split + reverse的话,那就失去了题目的意义了。
10 |
11 | 有的同学可能不屑于实现这么简单的功能,直接调库函数完事,把字符串分成一个个单词,一想就是那么一回事,多简单。
12 |
13 | 相信我,很多面试题都是一想很简单,实现起来一堆问题。 所以刷力扣本来就是为面试,也为了提高自己的代码能力,扎实一点没坏处。
14 |
15 | **那么平时写算法题目就全都不用库函数了么?**
16 |
17 | 当然也不是,这里我给大家提供一个标准。
18 |
19 | **如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数**。
20 |
21 | **如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,那么直接用库函数。**
22 |
23 | 使用库函数最大的忌讳就是不知道这个库函数怎么实现的,也不知道其时间复杂度,上来就用,这样写出来的算法,时间复杂度自己都掌握不好的。
24 |
25 | 例如for循环里套一个字符串的insert,erase之类的操作,你说时间复杂度是多少呢,很明显是O(n^2)的时间复杂度了。
26 |
27 | 在刷题的时候本着我说的标准来使用库函数,详细对大家回有所帮助!
28 |
29 |
--------------------------------------------------------------------------------
/problems/前序/成都互联网公司总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 成都互联网公司总结
3 |
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
4 | 5 | 6 | **排名不分先后,个人总结难免有所疏漏,欢迎补充!** 7 | 8 | ## 一线互联网 9 | * 腾讯(成都) 游戏,王者荣耀就在成都! 10 | * 阿里(成都) 11 | * 蚂蚁金服(成都) 12 | * 字节跳动(成都) 13 | 14 | ## 硬件巨头 (有软件/互联网业务) 15 | 16 | * 华为(成都) 17 | * OPPO(成都) 18 | 19 | ## 二线互联网 20 | 21 | * 京东(成都) 22 | * 美团(成都) 23 | * 滴滴(成都) 24 | 25 | ## 三线互联网 26 | 27 | * 完美世界 (成都)游戏 28 | * 聚美优品 (成都) 29 | * 陌陌 (成都) 30 | * 爱奇艺(成都) 31 | 32 | ## 外企互联网 33 | 34 | * NAVER China (成都)搜索引擎公司,主要针对韩国市场 35 | 36 | ## 创业公司 37 | 38 | * tap4fun(总部)游戏 39 | * 趣乐多(总部)游戏 40 | * 天上友嘉(总部)游戏 41 | * 三七互娱(成都)游戏 42 | * 咕咚(总部)智能运动 43 | * 百词斩(总部)在线教育 44 | * 晓多科技(总部)AI方向 45 | * 萌想科技(总部)实习僧 46 | * Camera360(总部)移动影像社区 47 | * 医联 (总部)医疗解决方案提供商 48 | * 小明太极 (总部)原创漫画文娱内容网站以及相关APP 49 | * 小鸡叫叫(总部)致力于儿童教育的智慧解决方案 50 | 51 | 52 | ## AI独角兽公司 53 | 54 | * 科大讯飞(成都) 55 | * 商汤(成都) 56 | 57 | ## 总结 58 | 59 | 可以看出成都相对一线城市的互联网氛围确实差了很多。**但是!成都已经是在内陆城市中甚至二线城市中的佼佼者了!** 60 | 61 | 从公司的情况上也可以看出:**成都互联网行业目前的名片是“游戏”**,腾讯、完美世界等大厂,还有无数小厂都在成都搞游戏,可能成都的天然属性就是娱乐,这里是游戏的沃土吧。 62 | 63 | 相信大家如果在一些招聘平台上去搜,其实很多公司都在成都,但都是把客服之类的工作安排在成都,而我在列举的时候尽量把研发相关在成都的公司列出来,这样对大家更有帮助。 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | ----------------------- 72 |
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
5 | 6 | **个人总结难免有所疏忽,欢迎大家补充,公司好坏没有排名哈!** 7 | 8 | ## 一线互联网 9 | 10 | * 腾讯(总部深圳) 11 | * 百度(深圳) 12 | * 阿里(深圳) 13 | * 字节跳动(深圳) 14 | 15 | ## 硬件巨头 (有软件/互联网业务) 16 | 17 | * 华为(总部深圳) 18 | * 中兴(总部深圳) 19 | * 海能达(总部深圳) 20 | * oppo(总部深圳) 21 | * vivo(总部深圳) 22 | * 深信服(总部深圳) 23 | * 大疆(总部深圳,无人机巨头) 24 | * 一加手机(总部深圳) 25 | * 柔宇科技(最近口碑急转直下) 26 | 27 | ## 二线大厂 28 | 29 | * 快手(深圳) 30 | * 京东(深圳) 31 | * 顺丰(总部深圳) 32 | 33 | ## 三线大厂 34 | 35 | * 富途证券(2020年成功赴美上市,主要经营港股美股) 36 | * 微众银行(总部深圳) 37 | * 招银科技(总部深圳) 38 | * 平安系列(平安科技、平安寿险、平安产险、平安金融、平安好医生等) 39 | * Shopee(东南亚最大的电商平台,最近发展势头非常强劲) 40 | * 有赞(深圳) 41 | * 迅雷(总部深圳) 42 | * 金蝶(总部深圳) 43 | * 随手记(总部深圳) 44 | 45 | ## AI独角兽公司 46 | 47 | * 商汤科技(人工智能领域的独角兽) 48 | * 追一科技(一家企业级智能服务AI公司) 49 | * 超多维科技 (计算机视觉、裸眼3D) 50 | * 优必选科技 (智能机器人、人脸识别) 51 | 52 | ## 明星创业公司 53 | 54 | * 丰巢科技(让生活更简单) 55 | * 人人都是产品经理(全球领先的产品经理和运营人 学习、交流、分享平台) 56 | * 大丰收(综合农业互联网服务平台) 57 | * 小鹅通(专注新教育的技术服务商) 58 | * 货拉拉(拉货就找货拉拉) 59 | * 编程猫(少儿编程教育头部企业) 60 | * HelloTalk(全球最大的语言学习社交社区) 61 | * 大宇无限( 拥有SnapTube, Lark Player 等多款广受海外新兴市场用户欢迎的产品) 62 | * 知识星球(深圳大成天下公司出品) 63 | * XMind(隶属深圳市爱思软件技术有限公司,思维导图软件) 64 | * 小赢科技(以技术重塑人类的金融体验) 65 | 66 | ## 其他行业(有软件/互联网业务) 67 | 68 | * 三大电信运营商:中国移动、中国电信、中国联通 69 | * 房产企业:恒大(暴雷)、万科 70 | * 中信深圳 71 | * 广发证券,深交所 72 | * 珍爱网(珍爱网是国内知名的婚恋服务网站之一) 73 | 74 | 75 | 76 | 77 | 78 | ----------------------- 79 | 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
4 | 5 | 6 | **个人总结难免有所疏忽,欢迎大家补充,公司好坏没有排名哈!** 7 | 8 | ## 一线互联网 9 | 10 | * 阿里巴巴(总部) 11 | * 蚂蚁金服(总部)阿里旗下 12 | * 阿里云(总部)阿里旗下 13 | * 网易(杭州) 网易云音乐 14 | * 字节跳动(杭州)抖音分部 15 | 16 | ## 外企 17 | 18 | * ZOOM (杭州研发中心)全球知名云视频会议服务提供商 19 | * infosys(杭州)印度公司,据说工资相对不高 20 | * 思科(杭州) 21 | 22 | ## 二线互联网 23 | 24 | * 滴滴(杭州) 25 | * 快手(杭州) 26 | 27 | ## 硬件巨头 (有软件/互联网业务) 28 | 29 | * 海康威视(总部)安防三巨头 30 | * 浙江大华(总部)安防三巨头 31 | * 杭州宇视(总部) 安防三巨头 32 | * 萤石 33 | * 华为(杭州) 34 | * vivo(杭州) 35 | * oppo(杭州) 36 | * 魅族(杭州) 37 | 38 | ## 三线互联网 39 | 40 | * 蘑菇街(总部)女性消费者的电子商务网站 41 | * 有赞(总部)帮助商家进行网上开店、社交营销 42 | * 菜鸟网络(杭州) 43 | * 花瓣网(总部)图片素材领导者 44 | * 兑吧(总部)用户运营服务平台 45 | * 同花顺(总部)网上股票证券交易分析软件 46 | * 51信用卡(总部)信用卡管理 47 | * 虾米(总部)已被阿里收购 48 | * 曹操出行(总部) 49 | * 口碑网 (总部) 50 | 51 | ## AI独角兽公司 52 | 53 | * 旷视科技(杭州) 54 | * 商汤(杭州) 55 | 56 | ## 创业公司 57 | 58 | * e签宝(总部)做电子签名 59 | * 婚礼纪(总部)好多结婚的朋友都用 60 | * 大搜车(总部)中国领先的汽车交易服务供应商 61 | * 二更(总部)自媒体 62 | * 丁香园(总部) 63 | 64 | ## 总结 65 | 66 | 杭州距离上海非常近,难免不了和上海做对比,上海是金融之都,如果看了[上海有这些互联网公司,你都知道么?](https://programmercarl.com/前序/上海互联网公司总结.html)就会发现上海互联网也是仅次于北京的。 67 | 68 | 而杭州是阿里的大本营,到处都有阿里的影子,虽然有网易在,但是也基本是盖过去了,很多中小公司也都是阿里某某高管出来创业的。 69 | 70 | 杭州的阿里带动了杭州的电子商务领域热度非常高,如果你想做电商想做直播带货想做互联网营销,杭州都是圣地! 71 | 72 | 如果要是写代码的话,每年各种节日促销,加班996应该是常态,电商公司基本都是这样,当然如果赶上一个好领导的话,回报也是很丰厚的。 73 | 74 | 「代码随想录」一直都是干活满满,值得介绍给每一位学习算法的同学! 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | ----------------------- 83 | 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
4 | 5 | 6 | **个人总结难免有所疏忽,欢迎大家补充,公司好坏没有排名哈!** 7 | 8 | ## 一线互联网 9 | 10 | * 微信(总部) 有点难进! 11 | * 字节跳动(广州) 12 | 13 | ## 二线 14 | * 网易(总部)主要是游戏 15 | 16 | ## 三线 17 | 18 | * 唯品会(总部) 19 | * 欢聚时代(总部)旗下YY,虎牙,YY最近被浑水做空,不知百度还要不要收购了 20 | * 酷狗音乐(总部) 21 | * UC浏览器(总部)现在隶属阿里创始人何小鹏现在搞小鹏汽车 22 | * 荔枝FM(总部)用户可以在手机上开设自己的电台和录制节目 23 | * 映客直播(总部)股票已经跌成渣了 24 | * 爱范儿(总部) 25 | * 三七互娱(总部)游戏公司 26 | * 君海游戏(总部)游戏公司 27 | * 4399游戏(总部)游戏公司 28 | * 多益网络(总部)游戏公司 29 | 30 | ## 硬件巨头 (有软件/互联网业务) 31 | * 小鹏汽车(总部)新能源汽车小霸王 32 | 33 | ## 创业公司 34 | 35 | * 妈妈网(总部)母婴行业互联网公司 36 | * 云徙科技(总部)数字商业云服务提供商 37 | * Fordeal(总部)中东领先跨境电商平台 38 | * Mobvista(总部)移动数字营销 39 | * 久邦GOMO(总部)游戏 40 | * 深海游戏(总部)游戏 41 | 42 | ## 国企 43 | 44 | * 中国电信广州研发(听说没有996) 45 | 46 | 47 | ## 总结 48 | 49 | 同在广东省,难免不了要和深圳对比,大家如果看了这篇:[深圳原来有这么多互联网公司,你都知道么?](https://programmercarl.com/前序/深圳互联网公司总结.html)就能感受到鲜明的对比了。 50 | 51 | 广州大厂高端岗位其实比较少,本土只有微信和网易,微信呢毕竟还是腾讯的分部,而网易被很多人认为是杭州企业,其实网易总部在广州。 52 | 53 | 广州是唯一一个一线城市没有自己本土互联网巨头的城市,所以网易选择在广州扎根还是很正确的,毕竟杭州是阿里的天下,广州也应该扶持一把本土的互联网公司。 54 | 55 | 虽然对于互联网从业人员来说,广州的岗位要比深圳少很多,**但是!!广州的房价整体要比深圳低30%左右,而且广州的教育,医疗,公共资源完全碾压深圳**。 56 | 57 | 教育方面:大学广州有两个985,四个211,深圳这方面就不用说了,大家懂得。 58 | 59 | 基础教育方面深圳的小学初中高中学校数量远远不够用,小孩上学竞争很激烈,我也是经常听同事们说,耳濡目染了。 60 | 61 | 而医疗上基本深圳看不了的病都要往广州跑,深圳的医院数量也不够用。 62 | 63 | 在生活节奏上,广州更慢一些,更有生活的气息,而深圳生存下去的气息更浓烈一些。 64 | 65 | 所以很多在深圳打拼多年的IT从业者选择去广州安家也是有原因的。 66 | 67 | 但也有很多从广州跑到深圳的,深圳发展的机会更多,而广州教育医疗更丰富,房价不高(相对深圳)。 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | ----------------------- 77 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
' -cx $i 21 | # ex -sc '1i|' -cx $i 22 | # ex -sc '1i|' -cx $i
23 | # ex -sc '1i|' -cx $i
24 | # ex -sc '1i|' -cx $i 25 | # echo '## 其他语言版本' >> $i 26 | # echo '\n' >> $i 27 | # echo 'Java:' >> $i 28 | # echo '\n' >> $i 29 | # echo 'Python:' >> $i 30 | # echo '\n' >> $i 31 | # echo 'Go:' >> $i 32 | # echo '\n' >> $i 33 | # echo '\n' >> $i 34 | 35 | # 添加结尾 36 | 37 | echo '
' >> $i
38 | echo '' >> $i
39 | echo ' ' >> $i
40 | echo '' >> $i
41 |
42 | # echo '-----------------------' >> $i
43 |
44 | # echo '
49 | #
50 | #  51 | #
52 |
53 | #
51 | #
52 |
53 | #
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
54 | 55 | 56 | 57 | -------------------------------------------------------------------------------- /problems/前序/北京互联网公司总结.md: -------------------------------------------------------------------------------- 1 | # 北京互联网公司总结 2 | 3 |欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
4 | 5 | 6 | **个人总结难免有所疏忽,欢迎大家补充,公司好坏没有排名哈!** 7 | 8 | 如果要在北京找工作,这份list可以作为一个大纲,寻找自己合适的公司。 9 | 10 | ## 一线互联网 11 | 12 | * 百度(总部) 13 | * 阿里(北京) 14 | * 腾讯(北京) 15 | * 字节跳动(总部) 16 | 17 | ## 外企 18 | 19 | * 微软(北京)微软中国主要就是北京和苏州 20 | * Hulu(北京)美国的视频网站,听说福利待遇超级棒 21 | * Airbnb(北京)房屋租赁平台 22 | * Grab(北京)东南亚第一大出行 App 23 | * 印象笔记(北京)evernote在中国的独立品牌 24 | * FreeWheel(北京)美国最大的视频广告管理和投放平台 25 | * amazon(北京)全球最大的电商平台 26 | 27 | ## 二线互联网 28 | 29 | * 美团点评(总部) 30 | * 京东(总部) 31 | * 网易(北京) 32 | * 滴滴出行(总部) 33 | * 新浪(总部) 34 | * 快手(总部) 35 | * 搜狐(总部) 36 | * 搜狗(总部) 37 | * 360(总部) 38 | 39 | ## 硬件巨头 (有软件/互联网业务) 40 | 41 | * 华为(北京) 42 | * 联想(总部) 43 | * 小米(总部)后序要搬到武汉,互联网业务也是小米重头 44 | 45 | ## 三线互联网 46 | 47 | * 爱奇艺(总部) 48 | * 去哪儿网(总部) 49 | * 知乎(总部) 50 | * 豆瓣(总部) 51 | * 当当网(总部) 52 | * 完美世界(总部)游戏公司 53 | * 昆仑万维(总部)游戏公司 54 | * 58同城(总部) 55 | * 陌陌(总部) 56 | * 金山软件(北京)包括金山办公软件 57 | * 用友网络科技(总部)企业服务ERP提供商 58 | * 映客直播(总部) 59 | * 猎豹移动(总部) 60 | * 一点资讯(总部) 61 | * 国双(总部)企业级大数据和人工智能解决方案提供商 62 | 63 | ## 明星创业公司 64 | 65 | 可以发现北京一堆在线教育的公司,可能教育要紧盯了政策变化,所以都要在北京吧 66 | 67 | * 好未来(总部)在线教育 68 | * 猿辅导(总部)在线教育 69 | * 跟谁学(总部)在线教育 70 | * 作业帮(总部)在线教育 71 | * VIPKID(总部)在线教育 72 | * 雪球(总部)股市资讯 73 | * 唱吧(总部) 74 | * 每日优鲜(总部)让每个人随时随地享受食物的美好 75 | * 微店(总部) 76 | * 罗辑思维(总部)得到APP 77 | * 值得买科技(总部)让每一次消费产生幸福感 78 | * 拉勾网(总部)互联网招聘 79 | 80 | ## AI独角兽公司 81 | 82 | * 商汤科技(总部)专注于计算机视觉和深度学习 83 | * 旷视科技(总部)人工智能产品和解决方案公司 84 | * 第四范式(总部)人工智能技术与服务提供商 85 | * 地平线机器人(总部)边缘人工智能芯片的全球领导者 86 | * 寒武纪(总部)全球智能芯片领域的先行者 87 | 88 | ## 互联网媒体 89 | 90 | * 央视网 91 | * 搜房网 92 | * 易车网 93 | * 链家网 94 | * 自如网 95 | * 汽车之家 96 | 97 | ## 总结 98 | 99 | 可能是我写总结写习惯了,什么文章都要有一个总结,哈哈,那么我就总结一下。 100 | 101 | 北京的互联网氛围绝对是最好的(暂不讨论户口和房价问题),大家如果看了[深圳原来有这么多互联网公司,你都知道么?](https://programmercarl.com/前序/深圳互联网公司总结.html)这篇之后,**会发现北京互联网外企和二线互联网公司数量多的优势,在深圳的互联网公司断档比较严重,如果去不了为数不多的一线公司,可选择的余地就非常少了,而北京选择的余地就很多!** 102 | 103 | 相对来说,深圳的硬件企业更多一些,因为珠三角制造业配套比较完善。而大多数互联网公司其实就是媒体公司,当然要靠近政治文化中心,这也是有原因的。 104 | 105 | 就酱,我也会陆续整理其他城市的互联网公司,希望对大家有所帮助。 106 | 107 | 108 | 109 | 110 | 111 | ----------------------- 112 |
2 |
3 |
4 |
5 |
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
6 | 7 | 8 | # 关于贪心算法,你该了解这些! 9 | 10 | 题目分类大纲如下: 11 | 12 |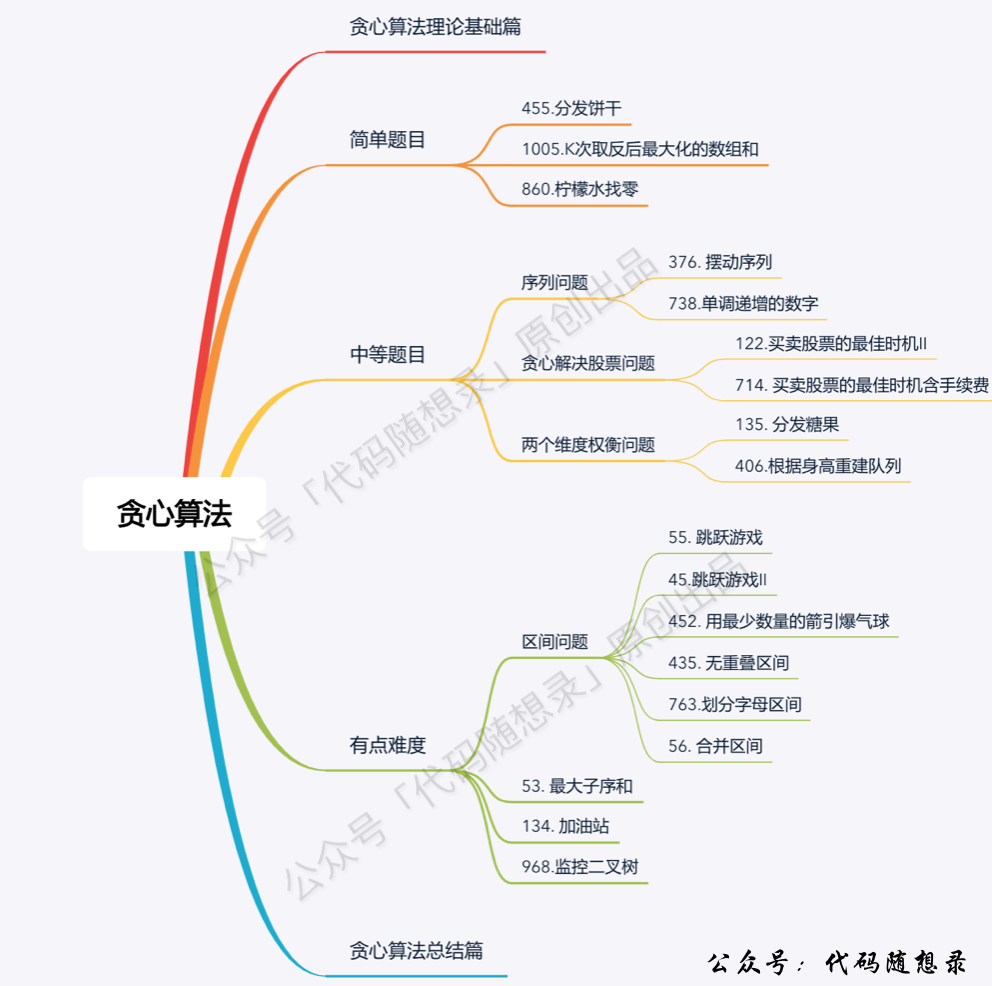 13 |
14 |
15 | ## 什么是贪心
16 |
17 | **贪心的本质是选择每一阶段的局部最优,从而达到全局最优**。
18 |
19 | 这么说有点抽象,来举一个例子:
20 |
21 | 例如,有一堆钞票,你可以拿走十张,如果想达到最大的金额,你要怎么拿?
22 |
23 | 指定每次拿最大的,最终结果就是拿走最大数额的钱。
24 |
25 | 每次拿最大的就是局部最优,最后拿走最大数额的钱就是推出全局最优。
26 |
27 | 再举一个例子如果是 有一堆盒子,你有一个背包体积为n,如何把背包尽可能装满,如果还每次选最大的盒子,就不行了。这时候就需要动态规划。动态规划的问题在下一个系列会详细讲解。
28 |
29 |
30 | ## 贪心的套路(什么时候用贪心)
31 |
32 | 很多同学做贪心的题目的时候,想不出来是贪心,想知道有没有什么套路可以一看就看出来是贪心。
33 |
34 | **说实话贪心算法并没有固定的套路**。
35 |
36 | 所以唯一的难点就是如何通过局部最优,推出整体最优。
37 |
38 | 那么如何能看出局部最优是否能推出整体最优呢?有没有什么固定策略或者套路呢?
39 |
40 | **不好意思,也没有!** 靠自己手动模拟,如果模拟可行,就可以试一试贪心策略,如果不可行,可能需要动态规划。
41 |
42 | 有同学问了如何验证可不可以用贪心算法呢?
43 |
44 | **最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧**。
45 |
46 | 可有有同学认为手动模拟,举例子得出的结论不靠谱,想要严格的数学证明。
47 |
48 | 一般数学证明有如下两种方法:
49 |
50 | * 数学归纳法
51 | * 反证法
52 |
53 | 看教课书上讲解贪心可以是一堆公式,估计大家连看都不想看,所以数学证明就不在我要讲解的范围内了,大家感兴趣可以自行查找资料。
54 |
55 | **面试中基本不会让面试者现场证明贪心的合理性,代码写出来跑过测试用例即可,或者自己能自圆其说理由就行了**。
56 |
57 | 举一个不太恰当的例子:我要用一下1+1 = 2,但我要先证明1+1 为什么等于2。严谨是严谨了,但没必要。
58 |
59 | 虽然这个例子很极端,但可以表达这么个意思:**刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心**。
60 |
61 | **例如刚刚举的拿钞票的例子,就是模拟一下每次拿做大的,最后就能拿到最多的钱,这还要数学证明的话,其实就不在算法面试的范围内了,可以看看专业的数学书籍!**
62 |
63 | 所以这也是为什么很多同学通过(accept)了贪心的题目,但都不知道自己用了贪心算法,**因为贪心有时候就是常识性的推导,所以会认为本应该就这么做!**
64 |
65 | **那么刷题的时候什么时候真的需要数学推导呢?**
66 |
67 | 例如这道题目:[链表:环找到了,那入口呢?](https://programmercarl.com/0142.环形链表II.html),这道题不用数学推导一下,就找不出环的起始位置,想试一下就不知道怎么试,这种题目确实需要数学简单推导一下。
68 |
69 | ## 贪心一般解题步骤
70 |
71 | 贪心算法一般分为如下四步:
72 |
73 | * 将问题分解为若干个子问题
74 | * 找出适合的贪心策略
75 | * 求解每一个子问题的最优解
76 | * 将局部最优解堆叠成全局最优解
77 |
78 | 这个四步其实过于理论化了,我们平时在做贪心类的题目 很难去按照这四步去思考,真是有点“鸡肋”。
79 |
80 | 做题的时候,只要想清楚 局部最优 是什么,如果推导出全局最优,其实就够了。
81 |
82 |
83 | ## 总结
84 |
85 | 本篇给出了什么是贪心以及大家关心的贪心算法固定套路。
86 |
87 | **不好意思了,贪心没有套路,说白了就是常识性推导加上举反例**。
88 |
89 | 最后给出贪心的一般解题步骤,大家可以发现这个解题步骤也是比较抽象的,不像是二叉树,回溯算法,给出了那么具体的解题套路和模板。
90 |
91 |
92 |
13 |
14 |
15 | ## 什么是贪心
16 |
17 | **贪心的本质是选择每一阶段的局部最优,从而达到全局最优**。
18 |
19 | 这么说有点抽象,来举一个例子:
20 |
21 | 例如,有一堆钞票,你可以拿走十张,如果想达到最大的金额,你要怎么拿?
22 |
23 | 指定每次拿最大的,最终结果就是拿走最大数额的钱。
24 |
25 | 每次拿最大的就是局部最优,最后拿走最大数额的钱就是推出全局最优。
26 |
27 | 再举一个例子如果是 有一堆盒子,你有一个背包体积为n,如何把背包尽可能装满,如果还每次选最大的盒子,就不行了。这时候就需要动态规划。动态规划的问题在下一个系列会详细讲解。
28 |
29 |
30 | ## 贪心的套路(什么时候用贪心)
31 |
32 | 很多同学做贪心的题目的时候,想不出来是贪心,想知道有没有什么套路可以一看就看出来是贪心。
33 |
34 | **说实话贪心算法并没有固定的套路**。
35 |
36 | 所以唯一的难点就是如何通过局部最优,推出整体最优。
37 |
38 | 那么如何能看出局部最优是否能推出整体最优呢?有没有什么固定策略或者套路呢?
39 |
40 | **不好意思,也没有!** 靠自己手动模拟,如果模拟可行,就可以试一试贪心策略,如果不可行,可能需要动态规划。
41 |
42 | 有同学问了如何验证可不可以用贪心算法呢?
43 |
44 | **最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧**。
45 |
46 | 可有有同学认为手动模拟,举例子得出的结论不靠谱,想要严格的数学证明。
47 |
48 | 一般数学证明有如下两种方法:
49 |
50 | * 数学归纳法
51 | * 反证法
52 |
53 | 看教课书上讲解贪心可以是一堆公式,估计大家连看都不想看,所以数学证明就不在我要讲解的范围内了,大家感兴趣可以自行查找资料。
54 |
55 | **面试中基本不会让面试者现场证明贪心的合理性,代码写出来跑过测试用例即可,或者自己能自圆其说理由就行了**。
56 |
57 | 举一个不太恰当的例子:我要用一下1+1 = 2,但我要先证明1+1 为什么等于2。严谨是严谨了,但没必要。
58 |
59 | 虽然这个例子很极端,但可以表达这么个意思:**刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心**。
60 |
61 | **例如刚刚举的拿钞票的例子,就是模拟一下每次拿做大的,最后就能拿到最多的钱,这还要数学证明的话,其实就不在算法面试的范围内了,可以看看专业的数学书籍!**
62 |
63 | 所以这也是为什么很多同学通过(accept)了贪心的题目,但都不知道自己用了贪心算法,**因为贪心有时候就是常识性的推导,所以会认为本应该就这么做!**
64 |
65 | **那么刷题的时候什么时候真的需要数学推导呢?**
66 |
67 | 例如这道题目:[链表:环找到了,那入口呢?](https://programmercarl.com/0142.环形链表II.html),这道题不用数学推导一下,就找不出环的起始位置,想试一下就不知道怎么试,这种题目确实需要数学简单推导一下。
68 |
69 | ## 贪心一般解题步骤
70 |
71 | 贪心算法一般分为如下四步:
72 |
73 | * 将问题分解为若干个子问题
74 | * 找出适合的贪心策略
75 | * 求解每一个子问题的最优解
76 | * 将局部最优解堆叠成全局最优解
77 |
78 | 这个四步其实过于理论化了,我们平时在做贪心类的题目 很难去按照这四步去思考,真是有点“鸡肋”。
79 |
80 | 做题的时候,只要想清楚 局部最优 是什么,如果推导出全局最优,其实就够了。
81 |
82 |
83 | ## 总结
84 |
85 | 本篇给出了什么是贪心以及大家关心的贪心算法固定套路。
86 |
87 | **不好意思了,贪心没有套路,说白了就是常识性推导加上举反例**。
88 |
89 | 最后给出贪心的一般解题步骤,大家可以发现这个解题步骤也是比较抽象的,不像是二叉树,回溯算法,给出了那么具体的解题套路和模板。
90 |
91 |
92 |
93 |
94 |
95 |
96 |
--------------------------------------------------------------------------------
/problems/1791.找出星型图的中心节点.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
6 | # 1791.找出星型图的中心节点 7 | 8 | [题目链接](https://leetcode.cn/problems/find-center-of-star-graph/) 9 | 10 | 本题思路就是统计各个节点的度(这里没有区别入度和出度),如果某个节点的度等于这个图边的数量。 那么这个节点一定是中心节点。 11 | 12 | 什么是度,可以理解为,链接节点的边的数量。 题目中度如图所示: 13 | 14 | 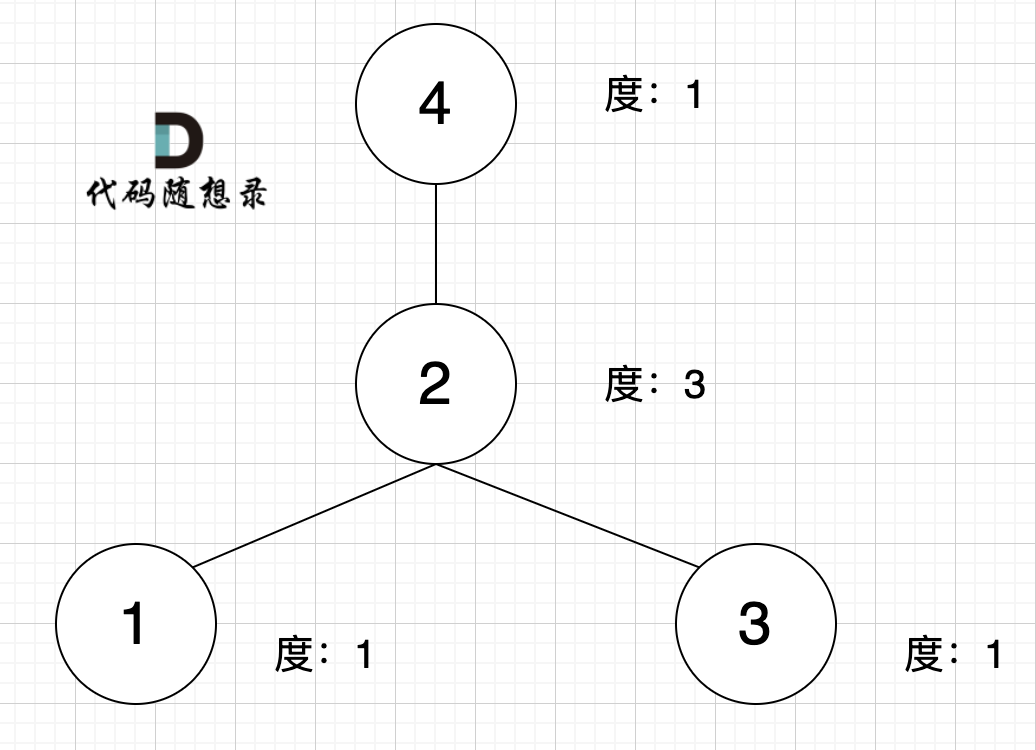 15 | 16 | 至于出度和入度,那就是在有向图里的概念了,本题是无向图。 17 | 18 | 本题代码如下: 19 | 20 | ```c++ 21 | 22 | class Solution { 23 | public: 24 | int findCenter(vector
80 |
81 |
82 |
83 |
--------------------------------------------------------------------------------
/problems/前序/上海互联网公司总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 上海互联网公司总结
3 |
4 | **个人总结难免有所疏忽,欢迎大家补充,公司好坏没有排名哈!**
5 |
6 | ## 一线互联网
7 |
8 | * 百度(上海)
9 | * 阿里(上海)
10 | * 腾讯(上海)
11 | * 字节跳动(上海)
12 | * 蚂蚁金服(上海)
13 |
14 | ## 外企IT/互联网/硬件
15 |
16 | * 互联网
17 | * Google(上海)
18 | * 微软(上海)
19 | * LeetCode/力扣(上海)
20 | * unity(上海)游戏引擎
21 | * SAP(上海)主要产品是ERP
22 | * PayPal(上海)在线支付鼻祖
23 | * eBay(上海)电子商务公司
24 | * 偏硬件
25 | * IBM(上海)
26 | * Tesla(上海)特斯拉
27 | * Cisco(上海)思科
28 | * Intel(上海)
29 | * AMD(上海)半导体产品领域
30 | * EMC(上海)易安信是美国信息存储资讯科技公司
31 | * NVIDIA(上海)英伟达是GPU(图形处理器)的发明者,人工智能计算的引领者
32 |
33 | ## 二线互联网
34 |
35 | * 拼多多(总部)
36 | * 饿了么(总部)阿里旗下。
37 | * 哈啰出行(总部)阿里旗下
38 | * 盒马(总部)阿里旗下
39 | * 哔哩哔哩(总部)
40 | * 阅文集团(总部)腾讯旗下
41 | * 爱奇艺(上海)百度旗下
42 | * 携程(总部)
43 | * 京东(上海)
44 | * 网易(上海)
45 | * 美团点评(上海)
46 | * 唯品会(上海)
47 |
48 | ## 硬件巨头 (有软件/互联网业务)
49 |
50 | 华为(上海)
51 |
52 | ## 三线互联网
53 |
54 | * PPTV(总部)
55 | * 微盟(总部)企业云端商业及营销解决方案提供商
56 | * 喜马拉雅(总部)
57 | * 陆金所(总部)全球领先的线上财富管理平台
58 | * 口碑(上海)阿里旗下。
59 | * 三七互娱(上海)
60 | * 趣头条(总部)
61 | * 巨人网络(总部)游戏公司
62 | * 盛大网络(总部)游戏公司
63 | * UCloud(总部)云服务提供商
64 | * 达达集团(总部)本地即时零售与配送平台
65 | * 众安保险(总部)在线财产保险
66 | * 触宝(总部)触宝输入法等多款APP
67 | * 平安系列
68 |
69 | ## 明星创业公司
70 |
71 | * 小红书(总部)
72 | * 叮咚买菜(总部)
73 | * 蔚来汽车(总部)
74 | * 七牛云(总部)
75 | * 得物App(总部)品潮流尖货装备交易、球鞋潮品鉴别查验、互动潮流社区
76 | * 收钱吧(总部)开创了中国移动支付市场“一站式收款”
77 | * 蜻蜓FM(总部)音频内容聚合平台
78 | * 流利说(总部)在线教育
79 | * Soul(总部)社交软件
80 | * 美味不用等(总部)智慧餐饮服务商
81 | * 微鲸科技(总部)专注于智能家居领域
82 | * 途虎养车(总部)
83 | * 米哈游(总部)游戏公司
84 | * 莉莉丝游戏(总部)游戏公司
85 | * 樊登读书(总部)在线教育
86 |
87 | ## AI独角兽公司
88 |
89 | * 依图科技(总部)和旷视,商汤对标,都是做安防视觉
90 | * 深兰科技(总部)致力于人工智能基础研究和应用开发
91 |
92 | ## 其他行业,涉及互联网
93 | * 花旗、摩根大通等一些列金融巨头
94 | * 百姓网
95 | * 找钢网
96 | * 安居客
97 | * 前程无忧
98 | * 东方财富
99 | * 三大电信运营商:中国移动、中国电信、中国联通
100 | * 沪江英语
101 | * 各大银行
102 |
103 | 通知:很多同学感觉自己基础还比较薄弱,想循序渐进的从头学一遍数据结构与算法,那你来对地方了。在公众号左下角「算法汇总」里已经按照各个系列难易程度排好顺序了,大家跟着文章顺序打卡学习就可以了,留言区有很多录友都在从头打卡!「算法汇总」会持续更新,大家快去看看吧!
104 |
105 | ## 总结
106 |
107 | 大家如果看了[北京有这些互联网公司,你都知道么?](https://programmercarl.com/前序/北京互联网公司总结.html)和[深圳原来有这么多互联网公司,你都知道么?](https://programmercarl.com/前序/深圳互联网公司总结.html)就可以看出中国互联网氛围最浓的当然是北京,其次就是上海!
108 |
109 | 很多人说深圳才是第二,上海没有产生BAT之类的企业。
110 |
111 | **那么来看看上海在垂直领域上是如何独领风骚的,视频领域B站,电商领域拼多多小红书,生活周边有饿了么,大众点评(现与美团合并),互联网金融有蚂蚁金服和陆金所,出行领域有行业老大携程,而且BAT在上海都有部门还是很大的团队,再加上上海众多的外企,以及金融公司(有互联网业务)**。
112 |
113 | 此时就能感受出来,上海的互联网氛围要比深圳强很多!
114 |
115 | 好了,希望这份list可以帮助到想在上海发展的录友们。
116 |
117 | 相对于北京和上海,深圳互联网公司断层很明显,腾讯一家独大,二线三线垂直行业的公司很少,所以说深圳腾讯的员工流动性相对是较低的,因为基本没得选。
118 |
119 |
120 |
121 |
122 |
123 |
124 | -----------------------
125 |
2 |
3 |
4 |
5 |
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
6 | 7 | > 来看看栈和队列不为人知的一面 8 | 9 | 我想栈和队列的原理大家应该很熟悉了,队列是先进先出,栈是先进后出。 10 | 11 | 如图所示: 12 | 13 | 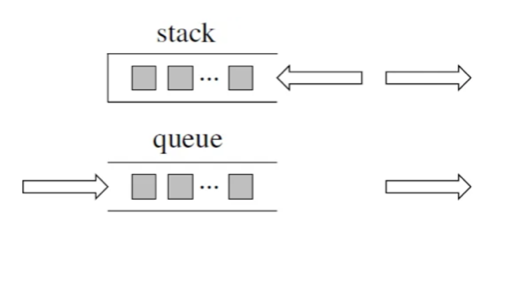 14 | 15 | 那么我这里再列出四个关于栈的问题,大家可以思考一下。以下是以C++为例,使用其他编程语言的同学也对应思考一下,自己使用的编程语言里栈和队列是什么样的。 16 | 17 | 1. C++中stack 是容器么? 18 | 2. 我们使用的stack是属于哪个版本的STL? 19 | 3. 我们使用的STL中stack是如何实现的? 20 | 4. stack 提供迭代器来遍历stack空间么? 21 | 22 | 相信这四个问题并不那么好回答, 因为一些同学使用数据结构会停留在非常表面上的应用,稍稍往深一问,就会有好像懂,好像也不懂的感觉。 23 | 24 | 有的同学可能仅仅知道有栈和队列这么个数据结构,却不知道底层实现,也不清楚所使用栈和队列和STL是什么关系。 25 | 26 | 所以这里我再给大家扫一遍基础知识, 27 | 28 | 首先大家要知道 栈和队列是STL(C++标准库)里面的两个数据结构。 29 | 30 | C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。 31 | 32 | 那么来介绍一下,三个最为普遍的STL版本: 33 | 34 | 1. HP STL 35 | 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。 36 | 37 | 2. P.J.Plauger STL 38 | 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。 39 | 40 | 3. SGI STL 41 | 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。 42 | 43 | 接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。 44 | 45 | 来说一说栈,栈先进后出,如图所示: 46 | 47 | 48 | 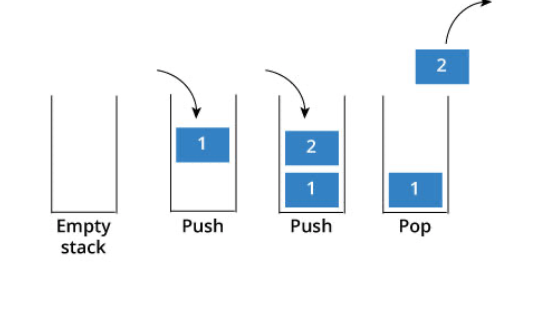 49 | 50 | 栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。 51 | 52 | **栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。** 53 | 54 | 所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。 55 | 56 | 那么问题来了,STL 中栈是用什么容器实现的? 57 | 58 | 从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。 59 | 60 | 61 | 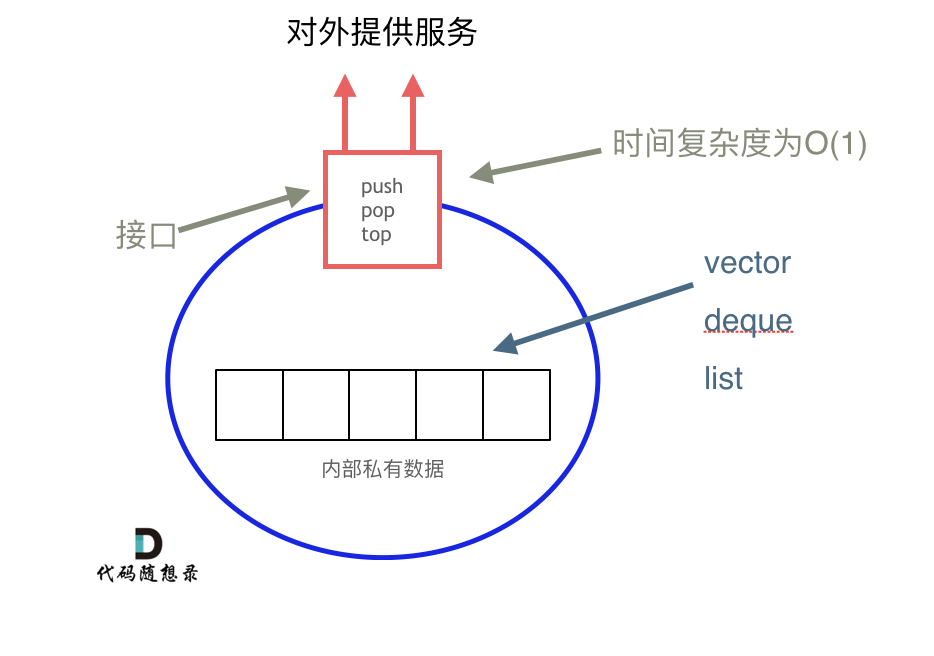 62 | 63 | **我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为缺省情况下栈的底层结构。** 64 | 65 | deque是一个双向队列,只要封住一段,只开通另一端就可以实现栈的逻辑了。 66 | 67 | **SGI STL中 队列底层实现缺省情况下一样使用deque实现的。** 68 | 69 | 我们也可以指定vector为栈的底层实现,初始化语句如下: 70 | 71 | ```cpp 72 | std::stack
93 |
94 |
95 |
96 |
--------------------------------------------------------------------------------
/problems/周总结/20201203贪心周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(贪心算法系列二)
3 |
4 | ## 周一
5 |
6 | 一说到股票问题,一般都会想到动态规划,其实有时候贪心更有效!
7 |
8 | 在[贪心算法:买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II.html)中,讲到只能多次买卖一支股票,如何获取最大利润。
9 |
10 | **这道题目理解利润拆分是关键点!** 不要整块的去看,而是把整体利润拆为每天的利润,就很容易想到贪心了。
11 |
12 | **局部最优:只收集每天的正利润,全局最优:得到最大利润**。
13 |
14 | 如果正利润连续上了,相当于连续持有股票,而本题并不需要计算具体的区间。
15 |
16 | 如图:
17 |
18 | 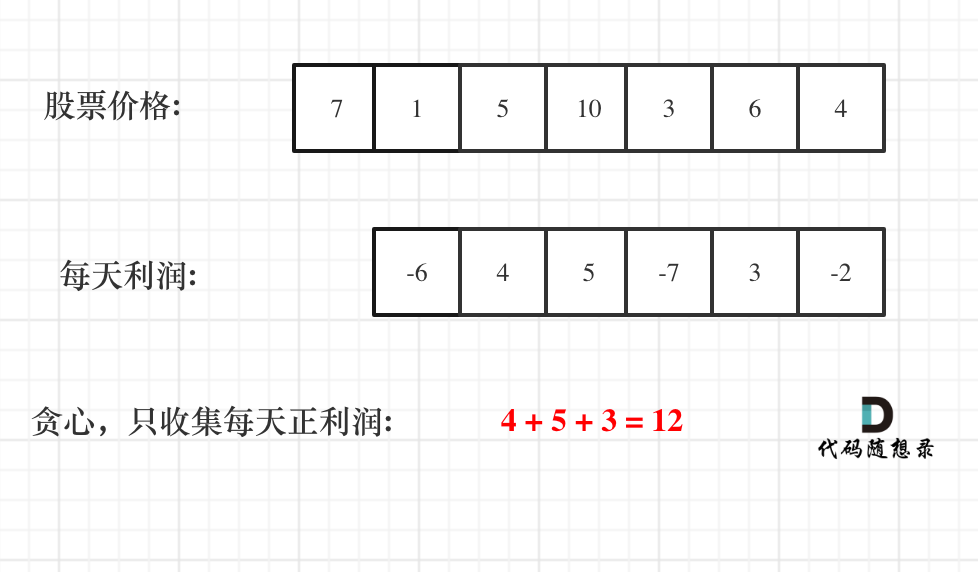
19 |
20 | ## 周二
21 |
22 | 在[贪心算法:跳跃游戏](https://programmercarl.com/0055.跳跃游戏.html)中是给你一个数组看能否跳到终点。
23 |
24 | 本题贪心的关键是:**不用拘泥于每次究竟跳几步,而是看覆盖范围,覆盖范围内一定是可以跳过来的,不用管是怎么跳的**。
25 |
26 | **那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!**
27 |
28 | 贪心算法局部最优解:移动下标每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点
29 |
30 | 如果覆盖范围覆盖到了终点,就表示一定可以跳过去。
31 |
32 | 如图:
33 |
34 | 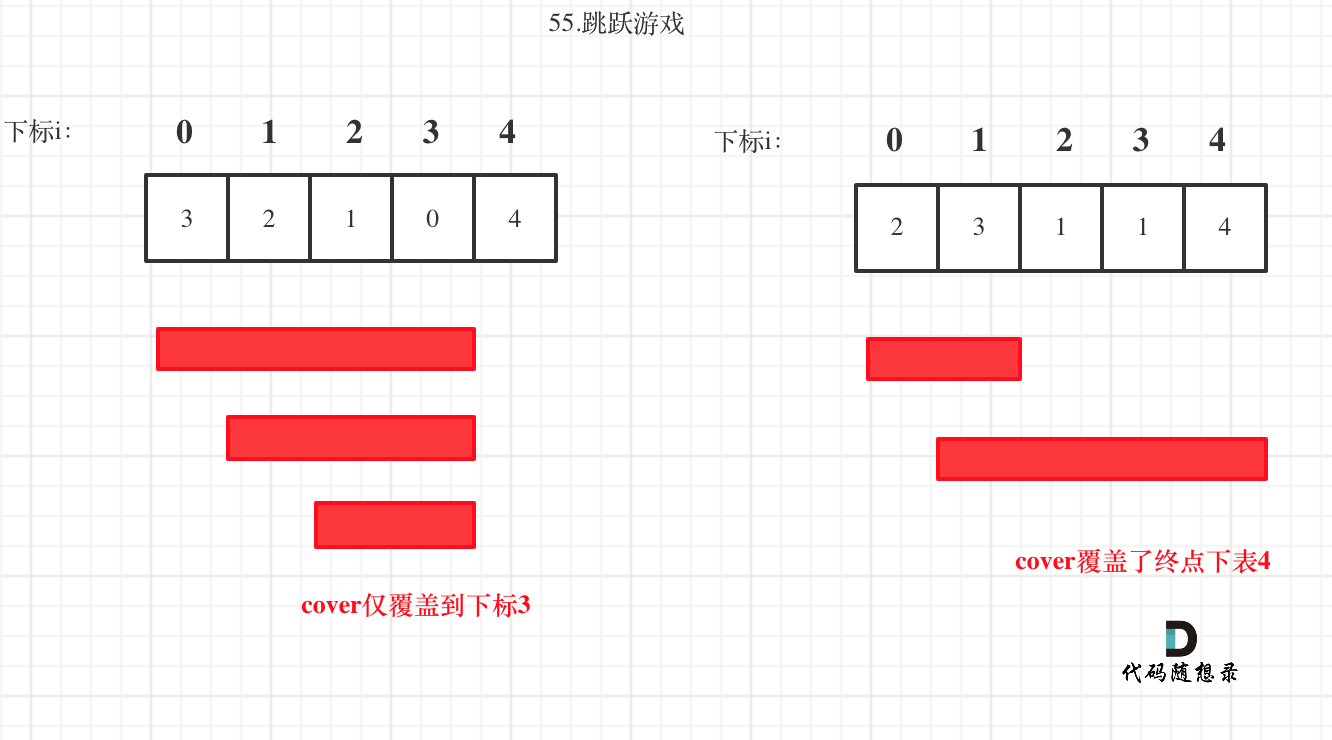
35 |
36 |
37 | ## 周三
38 |
39 | 这道题目:[贪心算法:跳跃游戏II](https://programmercarl.com/0045.跳跃游戏II.html)可就有点难了。
40 |
41 | 本题解题关键在于:**以最小的步数增加最大的覆盖范围,直到覆盖范围覆盖了终点**。
42 |
43 | 那么局部最优:求当前这步的最大覆盖,那么尽可能多走,到达覆盖范围的终点,只需要一步。整体最优:达到终点,步数最少。
44 |
45 | 如图:
46 |
47 | 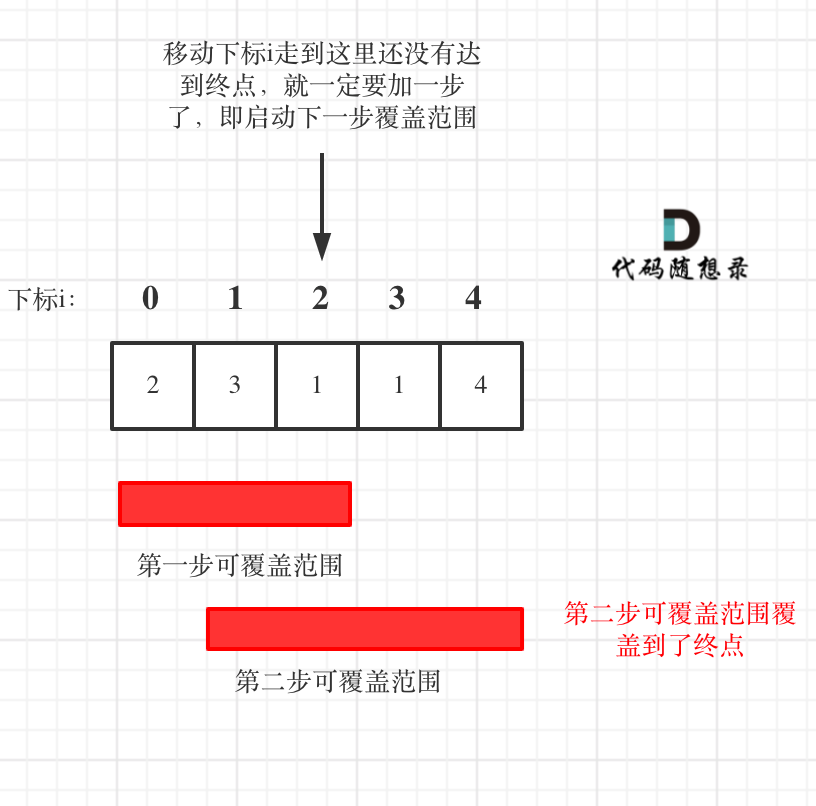
48 |
49 | 注意:**图中的移动下标是到当前这步覆盖的最远距离(下标2的位置),此时没有到终点,只能增加第二步来扩大覆盖范围**。
50 |
51 | 在[贪心算法:跳跃游戏II](https://programmercarl.com/0045.跳跃游戏II.html)中我给出了两个版本的代码。
52 |
53 | 其实本质都是超过当前覆盖范围,步数就加一,但版本一需要考虑当前覆盖最远距离下标是不是数组终点的情况。
54 |
55 | 而版本二就比较统一的,超过范围,步数就加一,但在移动下标的范围了做了文章。
56 |
57 | 即如果覆盖最远距离下标是倒数第二点:直接加一就行,默认一定可以到终点。如图:
58 | 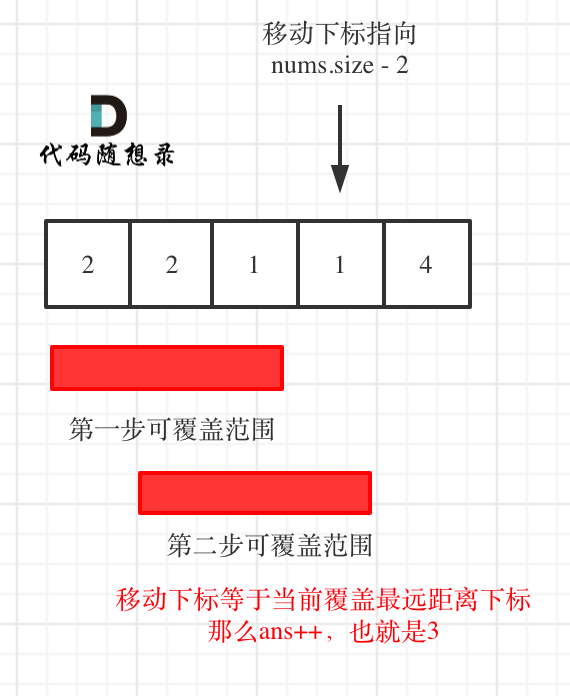
59 |
60 | 如果覆盖最远距离下标不是倒数第二点,说明本次覆盖已经到终点了。如图:
61 | 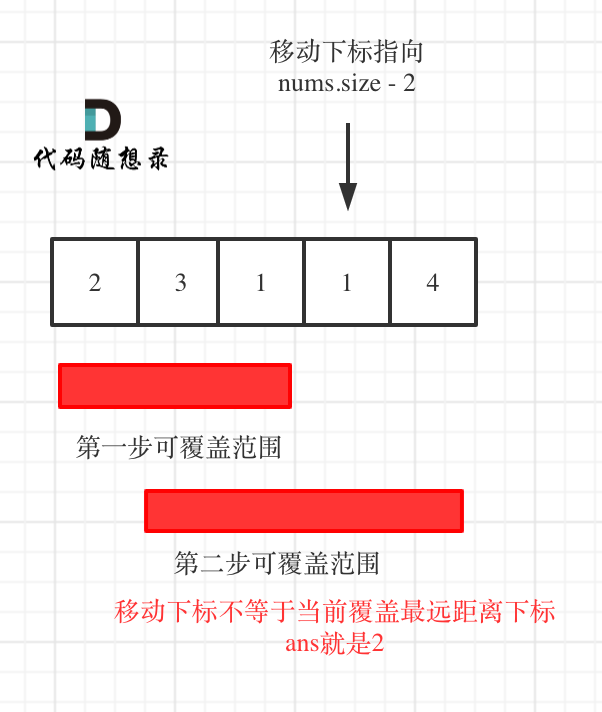
62 |
63 | 有的录友认为版本一好理解,有的录友认为版本二好理解,其实掌握一种就可以了,也不用非要比拼一下代码的简洁性,简洁程度都差不多了。
64 |
65 | 我个人倾向于版本一的写法,思路清晰一点,版本二会有点绕。
66 |
67 | ## 周四
68 |
69 | 这道题目:[贪心算法:K次取反后最大化的数组和](https://programmercarl.com/1005.K次取反后最大化的数组和.html)就比较简单了,哈哈,用简单题来讲一讲贪心的思想。
70 |
71 | **这里其实用了两次贪心!**
72 |
73 | 第一次贪心:局部最优:让绝对值大的负数变为正数,当前数值达到最大,整体最优:整个数组和达到最大。
74 |
75 | 处理之后,如果K依然大于0,此时的问题是一个有序正整数序列,如何转变K次正负,让 数组和 达到最大。
76 |
77 | 第二次贪心:局部最优:只找数值最小的正整数进行反转,当前数值可以达到最大(例如正整数数组{5, 3, 1},反转1 得到-1 比 反转5得到的-5 大多了),全局最优:整个 数组和 达到最大。
78 |
79 | [贪心算法:K次取反后最大化的数组和](https://programmercarl.com/1005.K次取反后最大化的数组和.html)中的代码,最后while处理K的时候,其实直接判断奇偶数就可以了,文中给出的方式太粗暴了,哈哈,Carl大意了。
80 |
81 | 例外一位录友留言给出一个很好的建议,因为文中是使用快排,仔细看题,**题目中限定了数据范围是正负一百,所以可以使用桶排序**,这样时间复杂度就可以优化为$O(n)$了。但可能代码要复杂一些了。
82 |
83 |
84 | ## 总结
85 |
86 | 大家会发现本周的代码其实都简单,但思路却很巧妙,并不容易写出来。
87 |
88 | 如果是第一次接触的话,其实很难想出来,就是接触过之后就会了,所以大家不用感觉自己想不出来而烦躁,哈哈。
89 |
90 | 相信此时大家现在对贪心算法又有一个新的认识了,加油💪
91 |
92 |
93 |
94 |
95 |
96 |
97 |
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
5 | 6 | 7 | 8 | Carl平时写东西,都是统一使用markdown,包括题解啊,笔记啊,所以这里给大家安利一波markdown对程序员的重要性! 9 | 10 | 程序员为什么要学习markdown呢? 11 | 12 | **一个让你难以拒绝的理由:markdown可以让你养成了记录的习惯**。 13 | 14 | 自从使用了markdown之后,就喜欢了写文档无法自拔,包括记录工作日志,记录周会,记录季度计划,记录学习目标,写各种设计文档。 15 | 16 | 有一种写代码一样的舒爽,markdown 和vim 一起用,简直绝配! 17 | 18 | 那来说一说markdown的好处。 19 | 20 | ## 为什么需要markdown 21 | 22 | 大家可能想为什么要使用markdown来写文档,而不用各种可以点击鼠标点点的那种所见即所得的工具来记笔记,例如word,云笔记之类的。 23 | 24 | 首先有如下几点: 25 | 26 | 1. Markdown可以在任何地方使用 27 | 28 | **可以使用它来创建网站,笔记,电子书,演讲稿,邮件信息和各种技术文档** 29 | 30 | 2. Markdown很轻便 31 | 32 | 事实上,**包含Markdown格式文本的文件可以被任何一个应用打开**。 33 | 34 | 如果感觉不喜欢当前使用的Markdown渲染应用,可以使用其他渲染应用来打开。 35 | 36 | 而鲜明对比的就是Microsoft Word,必须要使用特定的软件才能打开 .doc 或者 .docx的文档 而且可能还是乱码或者格式乱位。 37 | 38 | 3. Markdown是独立的平台 39 | 40 | **你可以创建Markdown格式文本的文件在任何一个可以运行的操作系统上** 41 | 42 | 4. Markdown已经无处不在 43 | 44 | **程序员的世界到处都是Markdown**,像简书,GitChat, GitHub,csdn等等都支持Markdown文档,正宗的官方技术文档都是使用Markdown来写的。 45 | 46 | 使用Markdown不仅可以非常方便的记录笔记,而且可以直接导出对应的网站内容,导出可打印的文档 47 | 48 | 至于markdown的语法,真的非常简单,不需要花费很长的时间掌握! 49 | 50 | 而且一旦你掌握了它,你就可以在任何地方任何平台使用Markdown来记录笔记,文档甚至写书。 51 | 52 | 很多人使用Markdown来创建网站的内容,但是Markdown更加擅长于格式化的文本内容,**使用Markdown 根部不用担心格式问题,兼容问题**。 53 | 54 | 很多后台开发程序员的工作环境是linux,linux下写文档最佳选择也是markdown。 55 | 56 | **我平时写代码,写文档都习惯在linux系统下进行(包括我的mac),所以我更喜欢vim + markdown**。 57 | 58 | 关于vim的话,后面我也可以单独介绍一波! 59 | 60 | ## Markdown常用语法 61 | 62 | 我这里就简单列举一些最基本的语法。 63 | 64 | ### 标题 65 | 66 | 使用'#' 可以展现1-6级别的标题 67 | 68 | ``` 69 | # 一级标题 70 | ## 二级标题 71 | ### 三级标题 72 | ``` 73 | 74 | ### 列表 75 | 76 | 使用 `*` 或者 `+` 或者 `-` 或者 `1. ` `2. ` 来表示列表 77 | 78 | 例如: 79 | 80 | ``` 81 | * 列表1 82 | * 列表2 83 | * 列表3 84 | ``` 85 | 86 | 效果: 87 | * 列表1 88 | * 列表2 89 | * 列表3 90 | 91 | ### 链接 92 | 93 | 使用 `[名字](url)` 表示连接,例如`[Github地址](https://github.com/youngyangyang04/Markdown-Resume-Template)` 94 | 95 | 96 | ### 添加图片 97 | 98 | 添加图片`` 例如`` 99 | 100 | ### html 标签 101 | 102 | Markdown支持部分html,例如这样 103 | 104 | ``` 105 |
2 |
3 |
4 |
5 |
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
6 | 7 | 8 | 9 | ## 链表的理论基础 10 | 11 | 在这篇文章[关于链表,你该了解这些!](https://programmercarl.com/链表理论基础.html)中,介绍了如下几点: 12 | 13 | * 链表的种类主要为:单链表,双链表,循环链表 14 | * 链表的存储方式:链表的节点在内存中是分散存储的,通过指针连在一起。 15 | * 链表是如何进行增删改查的。 16 | * 数组和链表在不同场景下的性能分析。 17 | 18 | **可以说把链表基础的知识都概括了,但又不像教科书那样的繁琐**。 19 | 20 | ## 链表经典题目 21 | 22 | ### 虚拟头结点 23 | 24 | 在[链表:听说用虚拟头节点会方便很多?](https://programmercarl.com/0203.移除链表元素.html)中,我们讲解了链表操作中一个非常总要的技巧:虚拟头节点。 25 | 26 | 链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点了。 27 | 28 | **每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决这个问题**。 29 | 30 | 在[链表:听说用虚拟头节点会方便很多?](https://programmercarl.com/0203.移除链表元素.html)中,我给出了用虚拟头结点和没用虚拟头结点的代码,大家对比一下就会发现,使用虚拟头结点的好处。 31 | 32 | ### 链表的基本操作 33 | 34 | 在[链表:一道题目考察了常见的五个操作!](https://programmercarl.com/0707.设计链表.html)中,我们通设计链表把链表常见的五个操作练习了一遍。 35 | 36 | 这是练习链表基础操作的非常好的一道题目,考察了: 37 | 38 | * 获取链表第index个节点的数值 39 | * 在链表的最前面插入一个节点 40 | * 在链表的最后面插入一个节点 41 | * 在链表第index个节点前面插入一个节点 42 | * 删除链表的第index个节点的数值 43 | 44 | **可以说把这道题目做了,链表基本操作就OK了,再也不用担心链表增删改查整不明白了**。 45 | 46 | 这里我依然使用了虚拟头结点的技巧,大家复习的时候,可以去看一下代码。 47 | 48 | ### 反转链表 49 | 50 | 在[链表:听说过两天反转链表又写不出来了?](https://programmercarl.com/0206.翻转链表.html)中,讲解了如何反转链表。 51 | 52 | 因为反转链表的代码相对简单,有的同学可能直接背下来了,但一写还是容易出问题。 53 | 54 | 反转链表是面试中高频题目,很考察面试者对链表操作的熟练程度。 55 | 56 | 我在[文章](https://programmercarl.com/0206.翻转链表.html)中,给出了两种反转的方式,迭代法和递归法。 57 | 58 | 建议大家先学透迭代法,然后再看递归法,因为递归法比较绕,如果迭代还写不明白,递归基本也写不明白了。 59 | 60 | **可以先通过迭代法,彻底弄清楚链表反转的过程!** 61 | 62 | ### 删除倒数第N个节点 63 | 64 | 在[链表:删除链表倒数第N个节点,怎么删?](https://programmercarl.com/0019.删除链表的倒数第N个节点.html)中我们结合虚拟头结点 和 双指针法来移除链表倒数第N个节点。 65 | 66 | 67 | ### 链表相交 68 | 69 | [链表:链表相交](https://programmercarl.com/面试题02.07.链表相交.html)使用双指针来找到两个链表的交点(引用完全相同,即:内存地址完全相同的交点) 70 | 71 | ## 环形链表 72 | 73 | 在[链表:环找到了,那入口呢?](https://programmercarl.com/0142.环形链表II.html)中,讲解了在链表如何找环,以及如何找环的入口位置。 74 | 75 | 这道题目可以说是链表的比较难的题目了。 但代码却十分简洁,主要在于一些数学证明。 76 | 77 | ## 总结 78 | 79 | 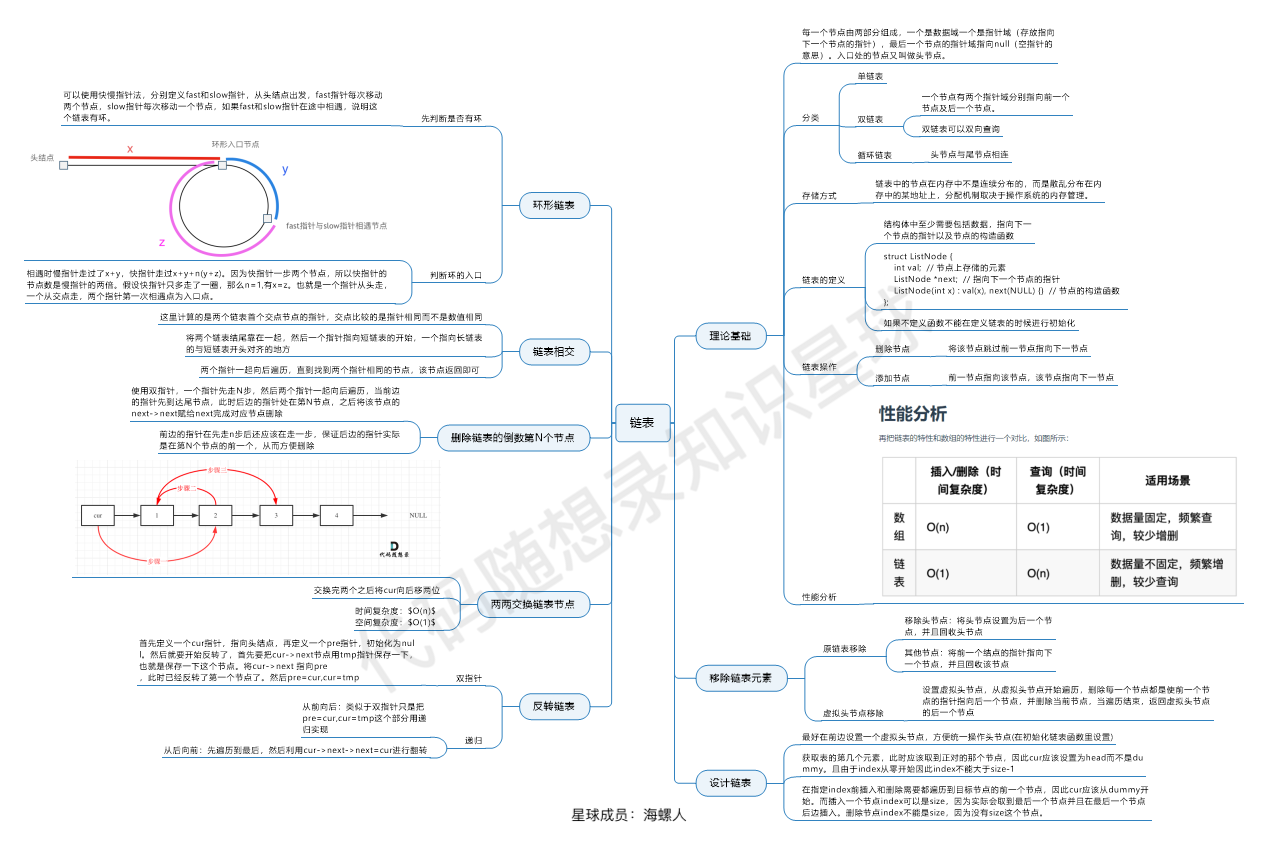 80 | 81 | 这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[海螺人](https://wx.zsxq.com/dweb2/index/footprint/844412858822412),所画,总结的非常好,分享给大家。 82 | 83 | 考察链表的操作其实就是考察指针的操作,是面试中的常见类型。 84 | 85 | 链表篇中开头介绍[链表理论知识](https://programmercarl.com/0203.移除链表元素.html),然后分别通过经典题目介绍了如下知识点: 86 | 87 | 1. [关于链表,你该了解这些!](https://programmercarl.com/链表理论基础.html) 88 | 2. [虚拟头结点的技巧](https://programmercarl.com/0203.移除链表元素.html) 89 | 3. [链表的增删改查](https://programmercarl.com/0707.设计链表.html) 90 | 4. [反转一个链表](https://programmercarl.com/0206.翻转链表.html) 91 | 5. [删除倒数第N个节点](https://programmercarl.com/0019.删除链表的倒数第N个节点.html) 92 | 6. [链表相交](https://programmercarl.com/面试题02.07.链表相交.html) 93 | 7. [有否环形,以及环的入口](https://programmercarl.com/0142.环形链表II.html) 94 | 95 | 96 | 97 | 98 | 99 |
100 |
101 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
124 |
125 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
130 |
131 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
98 |
99 |
5 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
130 |
131 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
106 |
107 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
128 |
129 |
4 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
161 |
162 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
132 |
133 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
173 |
174 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
129 |
130 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
128 |
129 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
159 |
160 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
163 |
164 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
138 |
139 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
163 |
164 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
185 |
186 |
3 |
4 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
133 |
134 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
162 |
163 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
175 |
176 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
153 |
154 |
2 |
3 | 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
154 |
155 |
102 |
103 |
--------------------------------------------------------------------------------
/problems/周总结/20201126贪心周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(贪心算法系列一)
3 |
4 | ## 周一
5 |
6 | 本周正式开始了贪心算法,在[关于贪心算法,你该了解这些!](https://programmercarl.com/贪心算法理论基础.html)中,我们介绍了什么是贪心以及贪心的套路。
7 |
8 | **贪心的本质是选择每一阶段的局部最优,从而达到全局最优。**
9 |
10 | 有没有啥套路呢?
11 |
12 | **不好意思,贪心没套路,就刷题而言,如果感觉好像局部最优可以推出全局最优,然后想不到反例,那就试一试贪心吧!**
13 |
14 | 而严格的数据证明一般有如下两种:
15 |
16 | * 数学归纳法
17 | * 反证法
18 |
19 | 数学就不在讲解范围内了,感兴趣的同学可以自己去查一查资料。
20 |
21 | 正是因为贪心算法有时候会感觉这是常识,本就应该这么做! 所以大家经常看到网上有人说这是一道贪心题目,有人说这不是。
22 |
23 | 这里说一下我的依据:**如果找到局部最优,然后推出整体最优,那么就是贪心**,大家可以参考哈。
24 |
25 | ## 周二
26 |
27 |
28 | 在[贪心算法:分发饼干](https://programmercarl.com/0455.分发饼干.html)中讲解了贪心算法的第一道题目。
29 |
30 | 这道题目很明显能看出来是用贪心,也是入门好题。
31 |
32 | 我在文中给出**局部最优:大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优:喂饱尽可能多的小孩**。
33 |
34 | 很多录友都是用小饼干优先先喂饱小胃口的。
35 |
36 | 后来我想一想,虽然结果是一样的,但是大家的这个思考方式更好一些。
37 |
38 | **因为用小饼干优先喂饱小胃口的 这样可以尽量保证最后省下来的是大饼干(虽然题目没有这个要求)!**
39 |
40 | 所以还是小饼干优先先喂饱小胃口更好一些,也比较直观。
41 |
42 | 一些录友不清楚[贪心算法:分发饼干](https://programmercarl.com/0455.分发饼干.html)中时间复杂度是怎么来的?
43 |
44 | 就是快排O(nlog n),遍历O(n),加一起就是还是O(nlogn)。
45 |
46 | ## 周三
47 |
48 | 接下来就要上一点难度了,要不然大家会误以为贪心算法就是常识判断一下就行了。
49 |
50 | 在[贪心算法:摆动序列](https://programmercarl.com/0376.摆动序列.html)中,需要计算最长摇摆序列。
51 |
52 | 其实就是让序列有尽可能多的局部峰值。
53 |
54 | 局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值。
55 |
56 | 整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列。
57 |
58 | 在计算峰值的时候,还是有一些代码技巧的,例如序列两端的峰值如何处理。
59 |
60 | 这些技巧,其实还是要多看多用才会掌握。
61 |
62 |
63 | ## 周四
64 |
65 | 在[贪心算法:最大子序和](https://programmercarl.com/0053.最大子序和.html)中,详细讲解了用贪心的方式来求最大子序列和,其实这道题目是一道动态规划的题目。
66 |
67 | **贪心的思路为局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。从而推出全局最优:选取最大“连续和”**
68 |
69 | 代码很简单,但是思路却比较难。还需要反复琢磨。
70 |
71 | 针对[贪心算法:最大子序和](https://programmercarl.com/0053.最大子序和.html)文章中给出的贪心代码如下;
72 | ```
73 | class Solution {
74 | public:
75 | int maxSubArray(vector
116 |
--------------------------------------------------------------------------------
/problems/数组理论基础.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
126 |
127 |
--------------------------------------------------------------------------------
/problems/周总结/20201224贪心周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(贪心算法系列四)
3 |
4 | ## 周一
5 |
6 | 在[贪心算法:用最少数量的箭引爆气球](https://programmercarl.com/0452.用最少数量的箭引爆气球.html)中,我们开始讲解了重叠区间问题,用最少的弓箭射爆所有气球,其本质就是找到最大的重叠区间。
7 |
8 | 按照左边界进行排序后,如果气球重叠了,重叠气球中右边边界的最小值 之前的区间一定需要一个弓箭
9 |
10 | 如图:
11 |
12 | 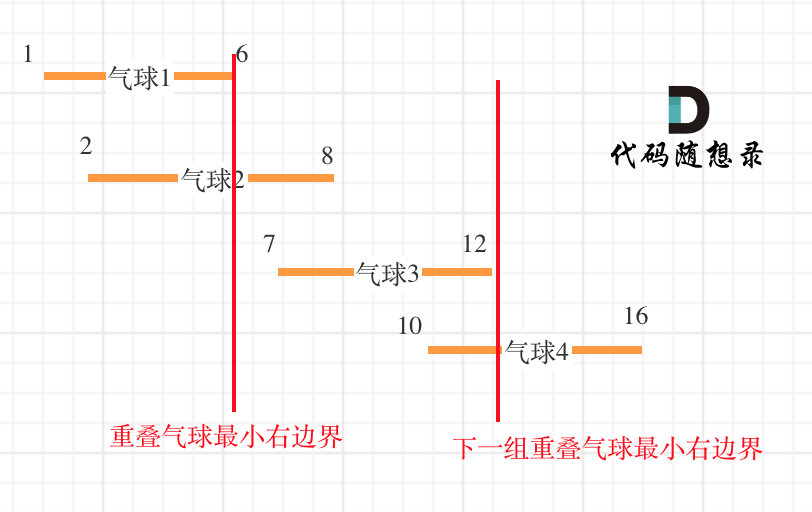
13 |
14 | 模拟射气球的过程,很多同学真的要去模拟了,实时把气球从数组中移走,这么写的话就复杂了,从前向后遍历重复的只要跳过就可以的。
15 |
16 | ## 周二
17 |
18 | 在[贪心算法:无重叠区间](https://programmercarl.com/0435.无重叠区间.html)中要去掉最少的区间,来让所有区间没有重叠。
19 |
20 | 我来按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉区间的个数就是需要移除的区间个数了。
21 |
22 | 如图:
23 |
24 | 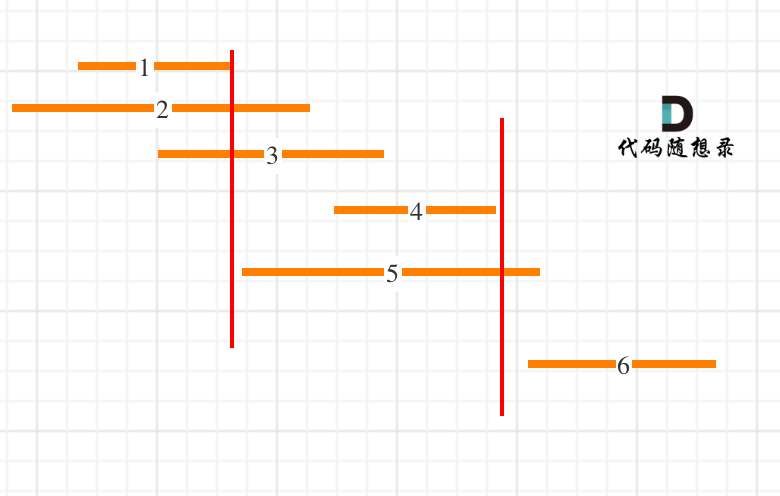
25 |
26 | 细心的同学就发现了,此题和 [贪心算法:用最少数量的箭引爆气球](https://programmercarl.com/0452.用最少数量的箭引爆气球.html)非常像。
27 |
28 | 弓箭的数量就相当于是非交叉区间的数量,只要把弓箭那道题目代码里射爆气球的判断条件加个等号(认为[0,1][1,2]不是相邻区间),然后用总区间数减去弓箭数量 就是要移除的区间数量了。
29 |
30 | 把[贪心算法:用最少数量的箭引爆气球](https://programmercarl.com/0452.用最少数量的箭引爆气球.html)代码稍做修改,就可以AC本题。
31 |
32 | 修改后的C++代码如下:
33 |
34 | ```CPP
35 | class Solution {
36 | public:
37 | // 按照区间左边界从大到小排序
38 | static bool cmp (const vector
106 |
--------------------------------------------------------------------------------
/problems/前序/vim.md:
--------------------------------------------------------------------------------
1 | # 人生苦短,我用VIM!| 最强vim配置
2 |
3 | > Github地址:[https://github.com/youngyangyang04/PowerVim](https://github.com/youngyangyang04/PowerVim)
4 | > Gitee地址:[https://gitee.com/programmercarl/power-vim](https://gitee.com/programmercarl/power-vim)
5 |
6 | 熟悉我的录友,应该都知道我是vim流,无论是写代码还是写文档(Markdown),都是vim,都没用IDE。
7 |
8 | 但这里我并不是说IDE不好用,IDE在 代码跟踪,引用跳转等等其实是很给力的,效率比vim高。
9 |
10 | 我用vim的话,如果需要跟踪代码的话,就用ctag去跳转,虽然很不智能(是基于规则匹配,不是语义匹配),但加上我自己的智能就也能用(这里真的要看对代码的把握程度了,哈哈哈)
11 |
12 | 所以连跟踪代码都不用IDE的话,其他方面那我就更用不上IDE了。
13 |
14 | ## 为什么用VIM
15 |
16 | **至于写代码的效率,VIM完爆IDE**,其他不说,就使用IDE每次还要去碰鼠标,就很让人烦心!(真凸显了程序员的执着)
17 |
18 | 这里说一说vim的方便之处吧,搞后端开发的同学,都得玩linux吧,在linux下写代码,如果不会vim的话,会非常难受。
19 |
20 | 日常我们的开发机,线上服务器,预发布服务器,都是远端linux,需要跳板机连上去,进行操作,如果不会vim,每次都把代码拷贝到本地,修改编译,在传到远端服务器,还真的麻烦。
21 |
22 | 使用VIM的话,本地,服务器,开发机,一刀流,无缝切换,爽不。
23 |
24 | IDE那么很吃内存,打开个IDE卡半天,用VIM就很轻便了,秒开有木有!
25 |
26 | 而且在我们日常开发中,工作年头多了,都会发现没有纯粹的C++,Java开发啥的,就是 C++也得写,Java也得写,有时候写Go起个http服务,写Python处理一下数据,写shell搞个自动部署,编译啥的。 **总是就是啥语言就得写,一些以项目需求为导向!**
27 |
28 | 写语言还要切换不同的IDE,熟悉不同的操作姿势,想想是不是很麻烦。
29 |
30 | 听说好像现在有的IDE可以支持很多语言了,这个我还不太了解,但能确定的是,IDE支持的语言再多,也不会有vim多。
31 |
32 | **因为vim是编辑器!**,什么都可以写,不同的语言做一下相应的配置就好,写起来都是一样的顺畅。
33 |
34 | 应该不少录友感觉vim上快捷键太多了,根本记不过来,其实这和我看IDE是一样的想法,我看IDE上哪些按钮一排一排的也太多了,我都记不过来,所以索性一套vim流 扫遍所有代码,它不香么。
35 |
36 | 而且IDE集成编译、调试、智能补全、语法高亮、工程管理等等,隐藏了太多细节,使用vim,就都自己配置,想支持什么语言就自己配置,想怎么样就怎么样,需要什么就补什么,这不是很酷么?
37 |
38 | 可能有的同学感觉什么都要自己配置,有点恐惧。但一旦配置好的就非常舒服了。
39 |
40 | **其实工程师就要逢山开路遇水搭桥,这也是最基本的素质!**
41 |
42 | 从头打在一个自己的开发利器,再舒服不过了。
43 |
44 | ## PowerVim
45 |
46 | 这里给大家介绍一下我的vim配置吧,**这套vim配置我已经打磨了将近四年**,不断调整优化,已经可以完全满足工业级打开的需求了。
47 |
48 | 所以我给它起名为PowerVim。一个真正强大的vim。
49 |
50 | ```
51 | _____ __ ___
52 | | __ \ \ \ / (_)
53 | | |__) |____ _____ _ _\ \ / / _ _ __ ___
54 | | ___/ _ \ \ /\ / / _ \ '__\ \/ / | | '_ ` _ \
55 | | | | (_) \ V V / __/ | \ / | | | | | | |
56 | |_| \___/ \_/\_/ \___|_| \/ |_|_| |_| |_|
57 | ```
58 |
59 | 这个配置我开源在Github上,地址:[https://github.com/youngyangyang04/PowerVim](https://github.com/youngyangyang04/PowerVim)
60 |
61 |
62 |
63 | 来感受一下PowerVim的使用体验,看起来很酷吧!注意这些操作都不用鼠标的,一波键盘控制流!所以我平时写代码是不碰鼠标的!
64 |
65 | 
66 |
67 | ## 安装
68 |
69 | PowerVim的安装非常简单,我已经写好了安装脚本,只要执行以下就可以安装,而且不会影响你之前的vim配置,之前的配置都给做了备份,大家看一下脚本就知道备份在哪里了。
70 |
71 | 安装过程非常简单:
72 | ```bash
73 | git clone https://github.com/youngyangyang04/PowerVim.git
74 | cd PowerVim
75 | sh install.sh
76 | ```
77 |
78 | ## 特性
79 |
80 | 目前PowerVim支持如下功能,这些都是自己配置的:
81 |
82 | * CPP、PHP、JAVA代码补全,如果需要其他语言补全,可自行配置关键字列表在PowerVim/.vim/dictionary目录下
83 | * 显示文件函数变量列表
84 | * MiniBuf显示打开过的文件
85 | * 语法高亮支持C++ (including C++11)、 Go、Java、 Php、 Html、 Json 和 Markdown
86 | * 显示git状态,和主干或分支的添加修改删除的情况
87 | * 显示项目文件目录,方便快速打开
88 | * 快速注释,使用gcc注释当前行,gc注释选中的块
89 | * 项目内搜索关键字和文件夹
90 | * 漂亮的颜色搭配和状态栏显示
91 |
92 | ## 最后
93 |
94 | 当然 还有很多,我还详细写了PowerVim的快捷键,使用方法,插件,配置,等等,都在Github主页的README上。当时我的Github上写的都是英文README,这次为了方便大家阅读,我又翻译成中文README。
95 |
96 | 
97 |
98 | Github地址:[https://github.com/youngyangyang04/PowerVim](https://github.com/youngyangyang04/PowerVim)
99 |
100 | Gitee地址:[https://gitee.com/programmercarl/power-vim](https://gitee.com/programmercarl/power-vim)
101 |
102 | 最后,因为这个vim配置因为我一直没有宣传,所以star数量很少,哈哈哈,录友们去给个star吧,真正的开发利器,值得顶起来!
103 |
104 |
--------------------------------------------------------------------------------
/problems/1971.寻找图中是否存在路径.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
132 |
133 |
--------------------------------------------------------------------------------
/problems/qita/server.md:
--------------------------------------------------------------------------------
1 |
2 | # 一台服务器有什么用!
3 |
4 | * [阿里云活动期间服务器购买](https://www.aliyun.com/minisite/goods?taskCode=shareNew2205&recordId=3641992&userCode=roof0wob)
5 | * [腾讯云活动期间服务器购买](https://curl.qcloud.com/EiaMXllu)
6 |
7 | 但在组织这场活动的时候,了解到大家都有一个共同的问题: **这个服务器究竟有啥用??**
8 |
9 | 这真是一个好问题,而且我一句两句还说不清楚,所以就专门发文来讲一讲。
10 |
11 | 同时我还录制的一期视频,哈哈我的视频号,大家可以关注一波。
12 |
13 |
14 | 一说到服务器,可能很多人都说搞分布式,做计算,搞爬虫,做程序后台服务,多人合作等等。
15 |
16 | 其实这些普通人都用不上,我来说一说大家能用上的吧。
17 |
18 | ## 搭建git私服
19 |
20 | 大家平时工作的时候一定有一个自己的工作文件夹,学生的话就是自己的课件,考试,准备面试的资料等等。
21 |
22 | 已经工作的录友,会有一个文件夹放着自己重要的文档,Markdown,图片,简历等等。
23 |
24 | 这么重要的文件夹,而且我们每天都要更新,也担心哪天电脑丢了,或者坏了,突然这些都不见了。
25 |
26 | 所以我们想备份嘛。
27 |
28 | 还有就是我们经常个人电脑和工作电脑要同步一些私人资料,而不是用微信传来传去。
29 |
30 | 这些都是git私服的使用场景,而且很好用。
31 |
32 | 大家也知道 github,gitee也可以搞私人仓库 用来备份,同步文件,但自己的文档可能放着很多重要的信息,包括自己的各种密码,密钥之类的,放到上面未必安全。你就不怕哪些重大bug把你的信息都泄漏了么[机智]
33 |
34 | 更关键的是,github 和 gitee都限速的。毕竟人家的功能定位并不是网盘。
35 |
36 | 项目里有大文件(几百M以上),例如pdf,ppt等等 其上传和下载速度会让你窒息。
37 |
38 | **后面我会发文专门来讲一讲,如何大家git私服!**
39 |
40 | ## 搞一个文件存储
41 |
42 | 这个可以用来生成文件的下载链接,也可以把本地文件传到服务器上。
43 |
44 | 相当于自己做一个对象存储,其实云厂商也有对象存储的产品。
45 |
46 | 不过我们自己也可以做一个,不够很多很同学应该都不知道对象存储怎么用吧,其实我们用服务器可以自己做一个类似的公司。
47 |
48 | 我现在就用自己用go写的一个工具,部署在服务器上。 用来和服务器传文件,或者生成一些文件的临时下载链接。
49 |
50 | 这些都是直接命令行操作的,
51 |
52 | 操作方式这样,我把命令包 包装成一个shell命令,想传那个文件,直接 uploadtomyserver,然后就返回可以下载的链接,这个文件也同时传到了我的服务器上。
53 |
54 | 
55 |
56 | 我也把我的项目代码放在了github上:
57 |
58 | https://github.com/youngyangyang04/fileHttpServer
59 |
60 | 感兴趣的录友可以去学习一波,顺便给个star 哈哈
61 |
62 |
63 | ## 网站
64 |
65 | 做网站,例如 大家知道用html 写几行代码,就可以生成一个网页,但怎么给别人展示呢?
66 |
67 | 大家如果用自己的电脑做服务器,只能同一个路由器下的设备可以访问你的网站,可能这个设备出了这个屋子 都访问不了你的网站了。
68 |
69 | 因为你的IP不是公网IP。
70 |
71 | 如果有了一台云服务器,都是配公网IP,你的网站就可以让任何人访问了。
72 |
73 | 或者说 你提供的一个服务就可以让任何人使用。
74 |
75 | 例如第二个例子中,我们可以自己开发一个文件存储,这个服务,我只把把命令行给其他人,其他人都可以使用我的服务来生成链接,当然他们的文件也都传到了我的服务器上。
76 |
77 | 再说一个使用场景。
78 |
79 | 我之前在组织免费里服务器的活动的时候,阿里云给我一个excel,让面就是从我这里买服务器录友的名单,我直接把这个名单甩到群里,让大家自己检查,出现在名单里就可以找我返现,这样做是不是也可以。
80 |
81 | 这么做有几个很大的问题:
82 | * 大家都要去下载excel,做对比,会有人改excel的内容然后就说是从你这里买的,我不可能挨个去比较excel有没有改动
83 | * excel有其他人的个人信息,这是不能暴漏的。
84 | * 如果每个人自己用excel查询,私信我返现,一个将近两千人找我返现,我微信根本处理不过来,这就变成体力活了。
85 |
86 | 那应该怎么做呢,
87 |
88 | 我就简单写一个查询的页面,后端逻辑就是读一个execel表格,大家在查询页面输入自己的阿里云ID,如果在excel里,页面就会返回返现群的二维码,大家就可以自主扫码加群了。
89 |
90 | 这样,我最后就直接在返现群里 发等额红包就好了,是不是极大降低人力成本了
91 |
92 | 当然我是把 17个返现群的二维码都生成好了,按照一定的规则,展现给查询通过的录友。
93 |
94 | 就是这样一个非常普通的查询页面。
95 |
96 | 
97 |
98 | 查询通过之后,就会展现返现群二维码。
99 |
100 | 
101 |
102 | 但要部署在服务器上,因为没有公网IP,别人用不了你的服务。
103 |
104 |
105 | ## 学习linux
106 |
107 | 学习linux其实在自己的电脑上搞一台虚拟机,或者安装双系统也可以学习,不过这很考验你的电脑性能如何了。
108 |
109 | 如果你有一个服务器,那就是独立的一台电脑,你怎么霍霍就怎么霍霍,而且一年都不用关机的,可以一直跑你的任务,和你本地电脑也完全隔离。
110 |
111 | 更方便的是,你目前系统假如是CentOS,想做一个实验需要在Ubuntu上,如果是云服务器,更换系统就是在 后台点一下,一键重装,云厂商基本都是支持所有系统一件安装的。
112 |
113 | 我们平时自己玩linux经常是配各种环境,然后这个linux就被自己玩坏了(一般都是毫无节制使用root权限导致的),总之就是环境配不起来了,基本就要重装了。
114 |
115 | 那云服务器重装系统可太方便了。
116 |
117 | 还有就是加入你好不容易配好的环境,如果以后把这个环境玩坏了,你先回退这之前配好的环境而不是重装系统在重新配一遍吧。
118 |
119 | 那么可以用云服务器的镜像保存功能,就是你配好环境的那一刻就可以打一个镜像包,以后如果环境坏了,直接回退到上次镜像包的状态,这是不是就很香了。
120 |
121 |
122 | ## 总结
123 |
124 | 其实云服务器还有很多其他用处,不过我就说一说大家普遍能用的上的。
125 |
126 |
127 | * [阿里云活动期间服务器购买](https://www.aliyun.com/minisite/goods?taskCode=shareNew2205&recordId=3641992&userCode=roof0wob)
128 | * [腾讯云活动期间服务器购买](https://curl.qcloud.com/EiaMXllu)
129 |
130 |
--------------------------------------------------------------------------------
/problems/周总结/20201112回溯周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(回溯算法系列三)
3 |
4 | ## 周一
5 |
6 | 在[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)中,开始针对子集问题进行去重。
7 |
8 | 本题就是[回溯算法:求子集问题!](https://programmercarl.com/0078.子集.html)的基础上加上了去重,去重我们在[回溯算法:求组合总和(三)](https://programmercarl.com/0040.组合总和II.html)也讲过了。
9 |
10 | 所以本题对大家应该并不难。
11 |
12 | 树形结构如下:
13 |
14 | 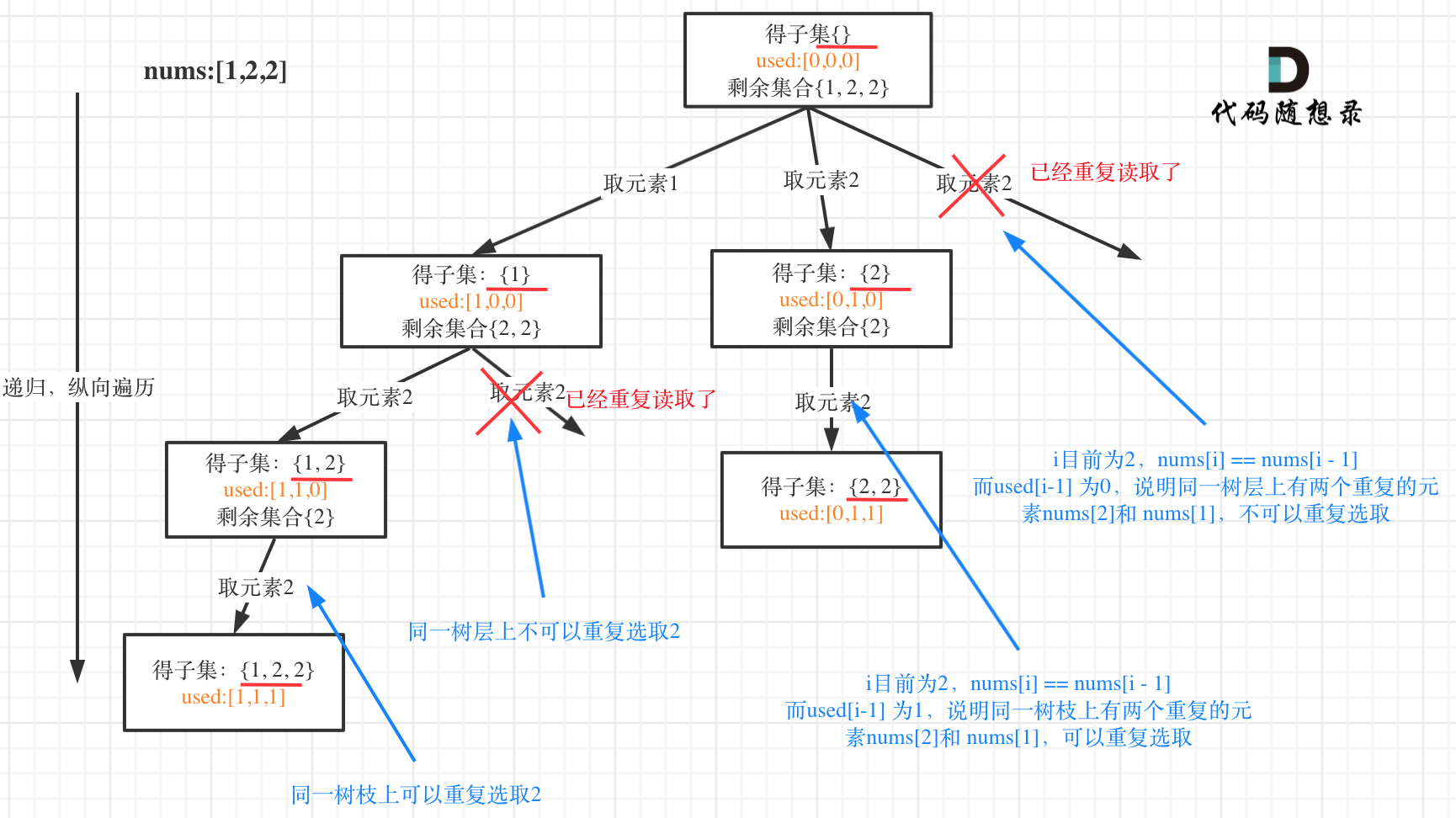
15 |
16 | ## 周二
17 |
18 | 在[回溯算法:递增子序列](https://programmercarl.com/0491.递增子序列.html)中,处处都能看到子集的身影,但处处是陷阱,值得好好琢磨琢磨!
19 |
20 | 树形结构如下:
21 | 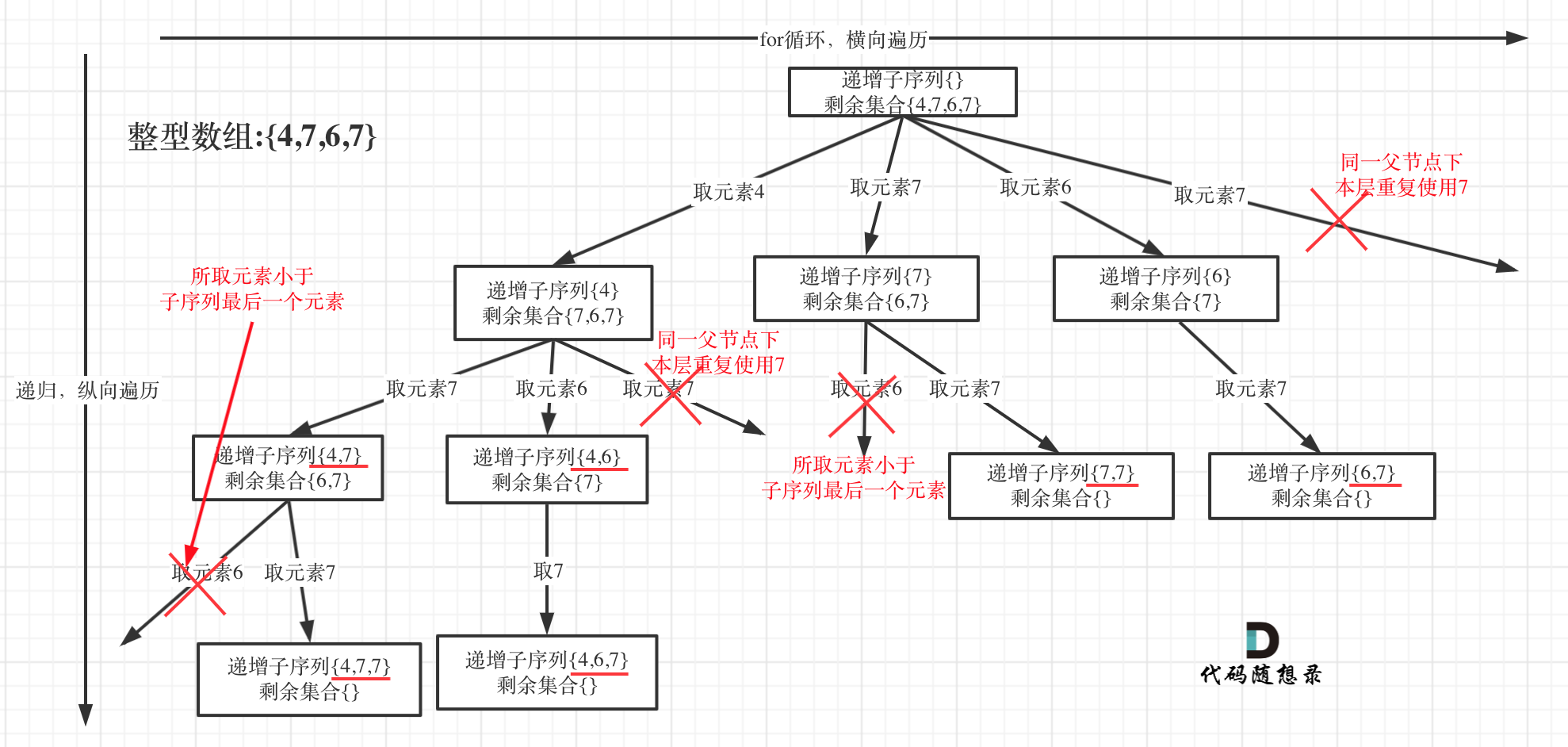
22 |
23 | [回溯算法:递增子序列](https://programmercarl.com/0491.递增子序列.html)留言区大家有很多疑问,主要还是和[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)混合在了一起。
24 |
25 | 详细在[本周小结!(回溯算法系列三)续集](https://mp.weixin.qq.com/s/kSMGHc_YpsqL2j-jb_E_Ag)中给出了介绍!
26 |
27 | ## 周三
28 |
29 | 我们已经分析了组合问题,分割问题,子集问题,那么[回溯算法:排列问题!](https://programmercarl.com/0046.全排列.html) 又不一样了。
30 |
31 | 排列是有序的,也就是说[1,2] 和[2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
32 |
33 | 可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
34 |
35 | 如图:
36 | 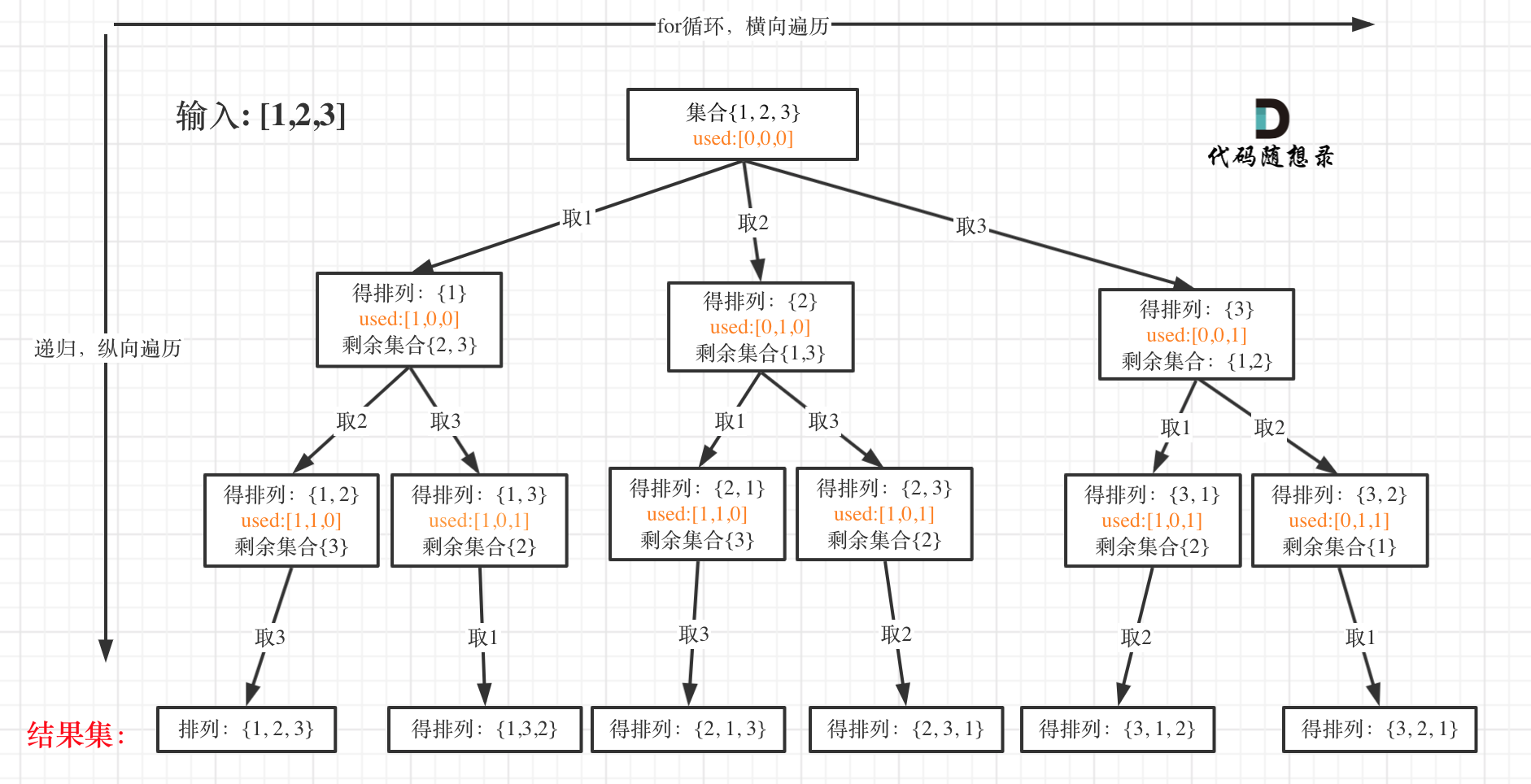
37 |
38 | **大家此时可以感受出排列问题的不同:**
39 |
40 | * 每层都是从0开始搜索而不是startIndex
41 | * 需要used数组记录path里都放了哪些元素了
42 |
43 | ## 周四
44 |
45 | 排列问题也要去重了,在[回溯算法:排列问题(二)](https://programmercarl.com/0047.全排列II.html)中又一次强调了“树层去重”和“树枝去重”。
46 |
47 | 树形结构如下:
48 |
49 | 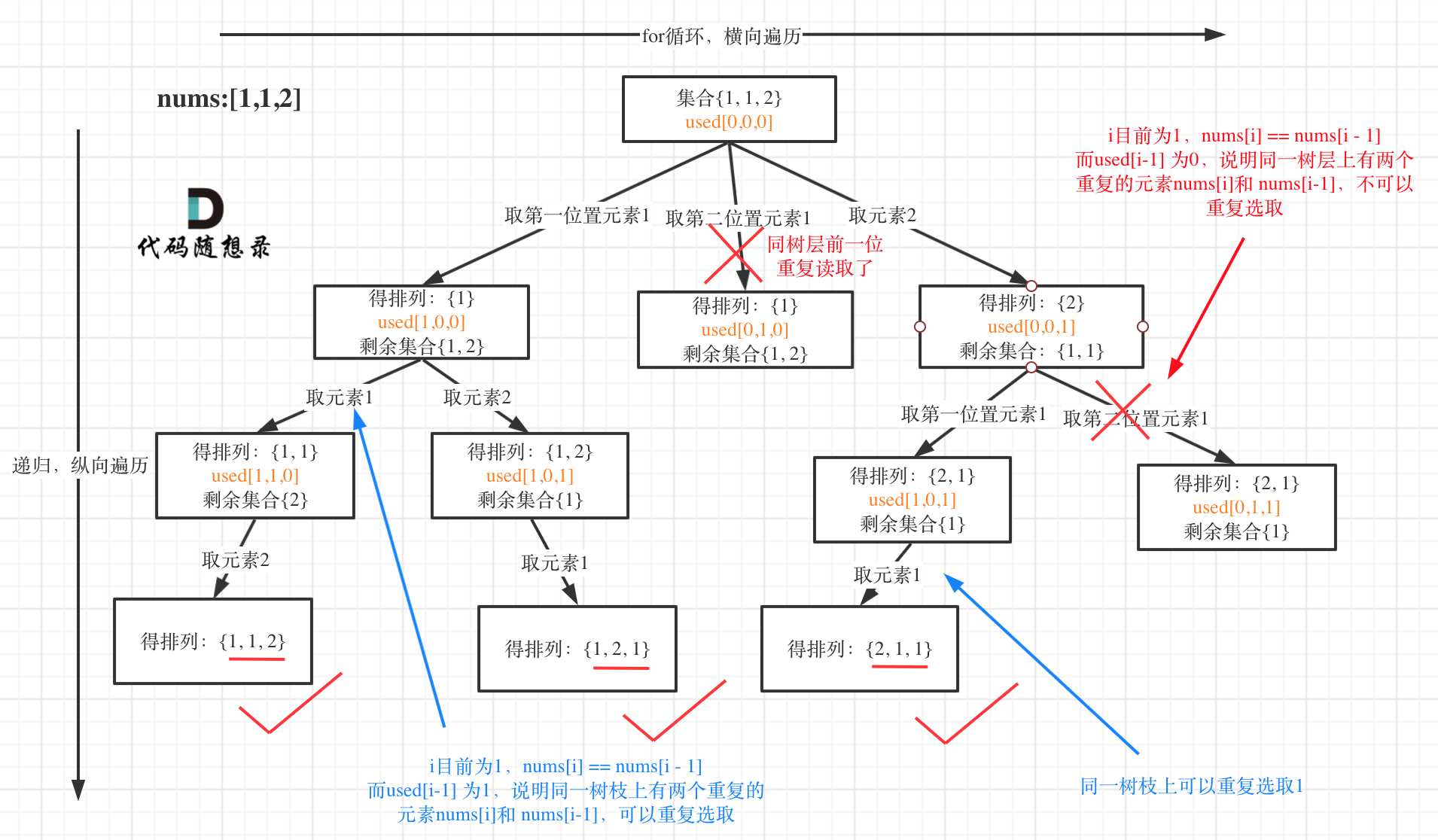
50 |
51 | **这道题目神奇的地方就是used[i - 1] == false也可以,used[i - 1] == true也可以!**
52 |
53 | 我就用输入: [1,1,1] 来举一个例子。
54 |
55 | 树层上去重(used[i - 1] == false),的树形结构如下:
56 |
57 | 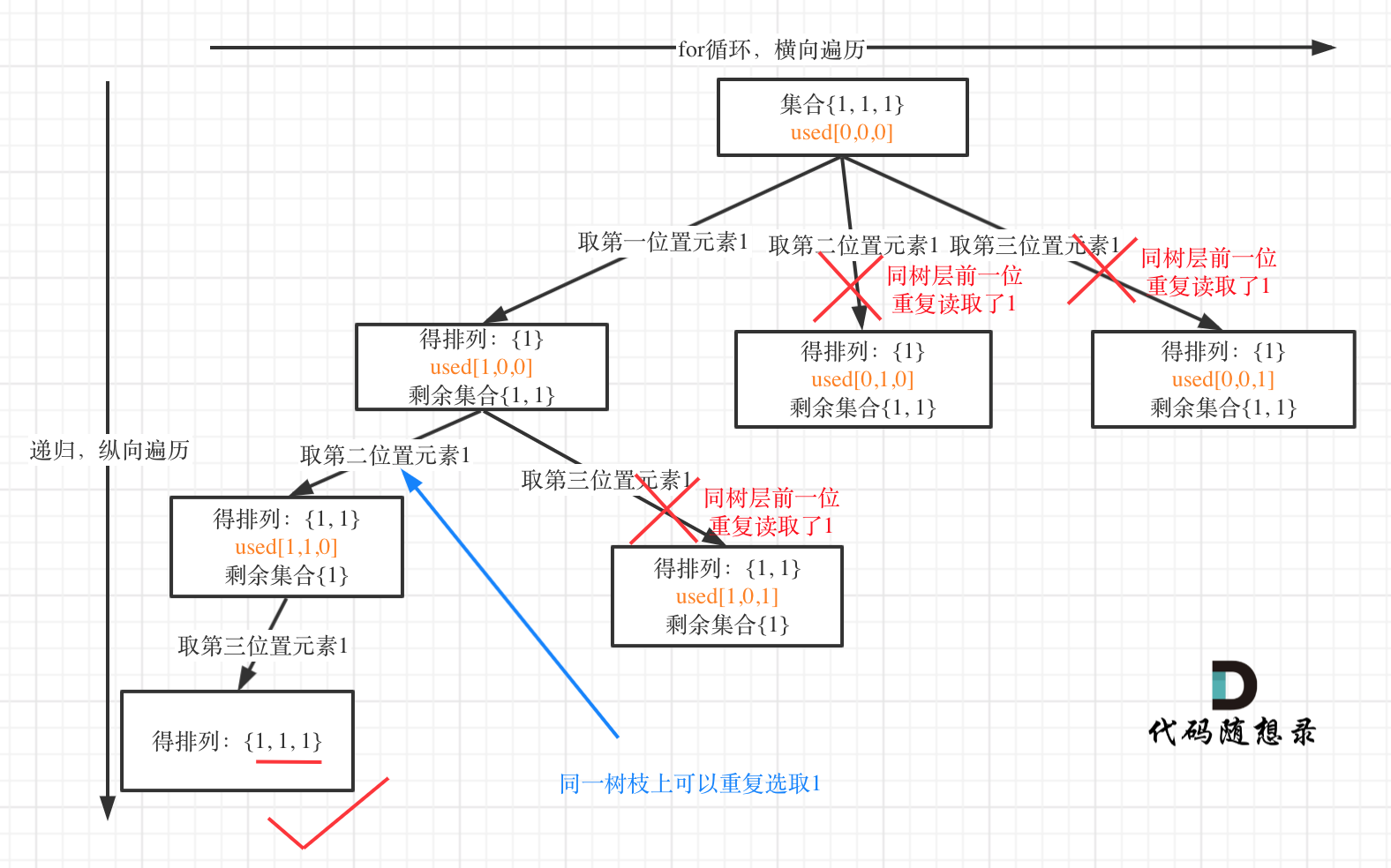
58 |
59 | 树枝上去重(used[i - 1] == true)的树型结构如下:
60 |
61 | 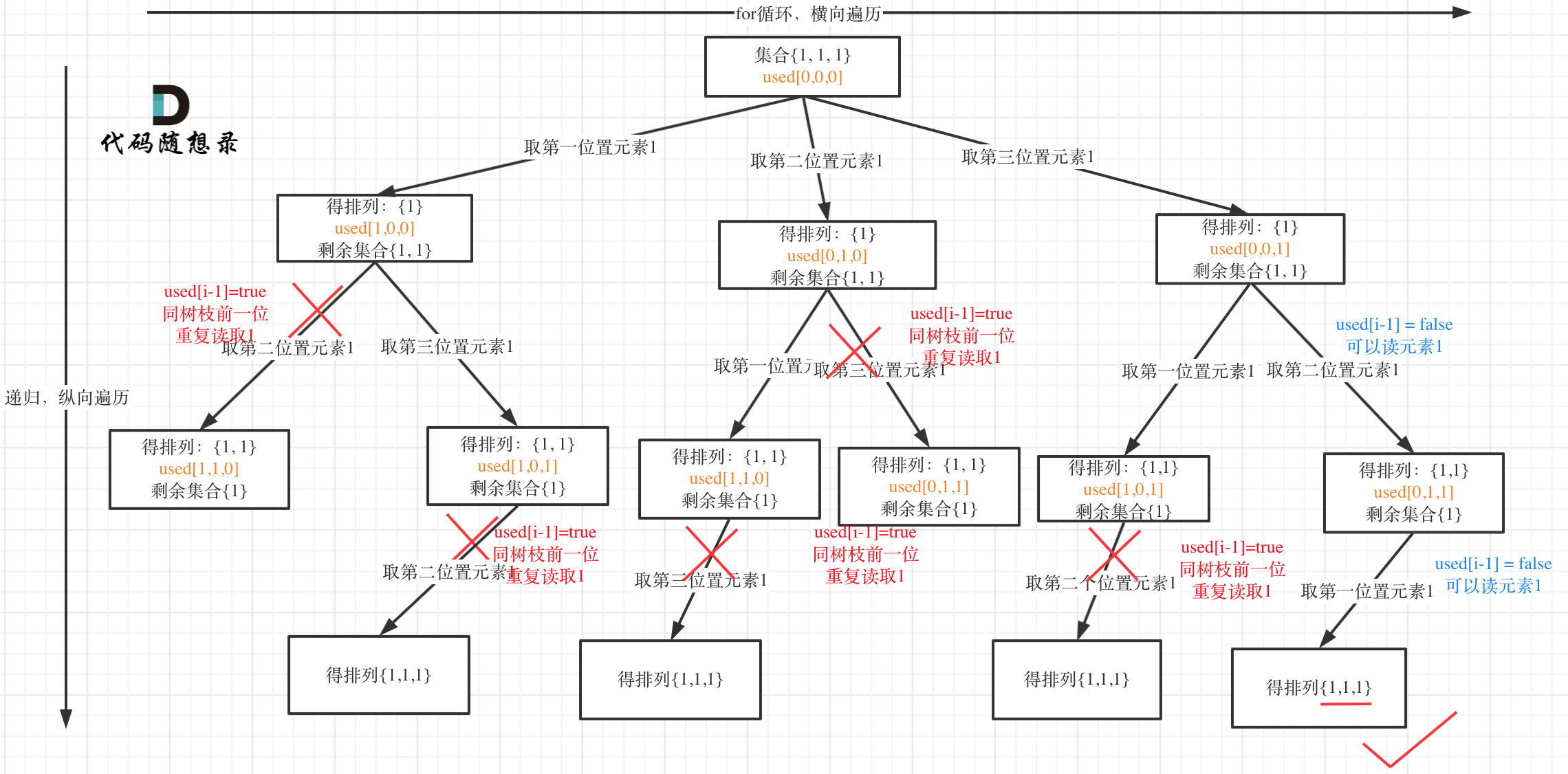
62 |
63 | **可以清晰的看到使用(used[i - 1] == false),即树层去重,效率更高!**
64 |
65 | ## 性能分析
66 |
67 | 之前并没有分析各个问题的时间复杂度和空间复杂度,这次来说一说。
68 |
69 | 这块网上的资料鱼龙混杂,一些所谓的经典面试书籍根本不讲回溯算法,算法书籍对这块也避而不谈,感觉就像是算法里模糊的边界。
70 |
71 | **所以这块就说一说我个人理解,对内容持开放态度,集思广益,欢迎大家来讨论!**
72 |
73 | 子集问题分析:
74 |
75 | * 时间复杂度:$O(n × 2^n)$,因为每一个元素的状态无外乎取与不取,所以时间复杂度为$O(2^n)$,构造每一组子集都需要填进数组,又有需要$O(n)$,最终时间复杂度:$O(n × 2^n)$。
76 | * 空间复杂度:$O(n)$,递归深度为n,所以系统栈所用空间为$O(n)$,每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为$O(n)$。
77 |
78 | 排列问题分析:
79 |
80 | * 时间复杂度:$O(n!)$,这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。每个叶子节点都会有一个构造全排列填进数组的操作(对应的代码:`result.push_back(path)`),该操作的复杂度为$O(n)$。所以,最终时间复杂度为:n * n!,简化为$O(n!)$。
81 | * 空间复杂度:$O(n)$,和子集问题同理。
82 |
83 | 组合问题分析:
84 |
85 | * 时间复杂度:$O(n × 2^n)$,组合问题其实就是一种子集的问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
86 | * 空间复杂度:$O(n)$,和子集问题同理。
87 |
88 | **一般说道回溯算法的复杂度,都说是指数级别的时间复杂度,这也算是一个概括吧!**
89 |
90 | ## 总结
91 |
92 | 本周我们对[子集问题进行了去重](https://programmercarl.com/0090.子集II.html),然后介绍了和子集问题非常像的[递增子序列](https://programmercarl.com/0491.递增子序列.html),如果还保持惯性思维,这道题就可以掉坑里。
93 |
94 | 接着介绍了[排列问题!](https://programmercarl.com/0046.全排列.html),以及对[排列问题如何进行去重](https://programmercarl.com/0047.全排列II.html)。
95 |
96 | 最后我补充了子集问题,排列问题和组合问题的性能分析,给大家提供了回溯算法复杂度的分析思路。
97 |
98 |
99 |
100 |
101 |
--------------------------------------------------------------------------------
/problems/双指针总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
100 |
101 |
--------------------------------------------------------------------------------
/problems/周总结/20210128动规周末总结.md:
--------------------------------------------------------------------------------
1 | # 本周小结!(动态规划系列四)
2 |
3 | ## 周一
4 |
5 | [动态规划:目标和!](https://programmercarl.com/0494.目标和.html)要求在数列之间加入+ 或者 -,使其和为S。
6 |
7 | 所有数的总和为sum,假设加法的总和为x,那么可以推出x = (S + sum) / 2。
8 |
9 | S 和 sum都是固定的,那此时问题就转化为01背包问题(数列中的数只能使用一次): 给你一些物品(数字),装满背包(就是x)有几种方法。
10 |
11 | 1. 确定dp数组以及下标的含义
12 |
13 | **dp[j] 表示:填满j(包括j)这么大容积的包,有dp[j]种方法**
14 |
15 | 2. 确定递推公式
16 |
17 | dp[j] += dp[j - nums[i]]
18 |
19 | **注意:求装满背包有几种方法类似的题目,递推公式基本都是这样的**。
20 |
21 | 3. dp数组如何初始化
22 |
23 | dp[0] 初始化为1 ,dp[j]其他下标对应的数值应该初始化为0。
24 |
25 | 4. 确定遍历顺序
26 |
27 | 01背包问题一维dp的遍历,nums放在外循环,target在内循环,且内循环倒序。
28 |
29 |
30 | 5. 举例推导dp数组
31 |
32 | 输入:nums: [1, 1, 1, 1, 1], S: 3
33 |
34 | bagSize = (S + sum) / 2 = (3 + 5) / 2 = 4
35 |
36 | dp数组状态变化如下:
37 |
38 | 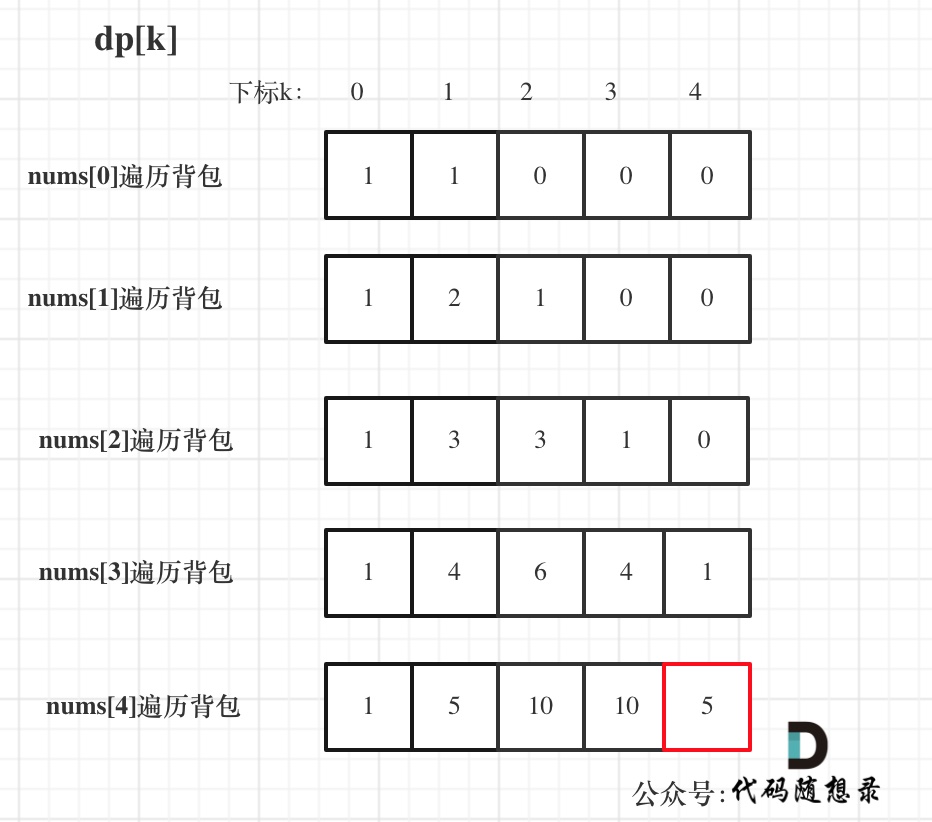
39 |
40 | ## 周二
41 |
42 | 这道题目[动态规划:一和零!](https://programmercarl.com/0474.一和零.html)算有点难度。
43 |
44 | **不少同学都以为是多重背包,其实这是一道标准的01背包**。
45 |
46 | 这不过这个背包有两个维度,一个是m 一个是n,而不同长度的字符串就是不同大小的待装物品。
47 |
48 | **所以这是一个二维01背包!**
49 |
50 | 1. 确定dp数组(dp table)以及下标的含义
51 |
52 | **dp[i][j]:最多有i个0和j个1的strs的最大子集的大小为dp[i][j]。**
53 |
54 |
55 | 2. 确定递推公式
56 |
57 | dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
58 |
59 | 字符串集合中的一个字符串0的数量为zeroNum,1的数量为oneNum。
60 |
61 | 3. dp数组如何初始化
62 |
63 | 因为物品价值不会是负数,初始为0,保证递推的时候dp[i][j]不会被初始值覆盖。
64 |
65 | 4. 确定遍历顺序
66 |
67 | 01背包一定是外层for循环遍历物品,内层for循环遍历背包容量且从后向前遍历!
68 |
69 | 5. 举例推导dp数组
70 |
71 | 以输入:["10","0001","111001","1","0"],m = 3,n = 3为例
72 |
73 | 最后dp数组的状态如下所示:
74 |
75 |
76 | 
77 |
78 | ## 周三
79 |
80 | 此时01背包我们就讲完了,正式开始完全背包。
81 |
82 | 在[动态规划:关于完全背包,你该了解这些!](https://programmercarl.com/背包问题理论基础完全背包.html)中我们讲解了完全背包的理论基础。
83 |
84 | 其实完全背包和01背包区别就是完全背包的物品是无限数量。
85 |
86 | 递推公式也是一样的,但难点在于遍历顺序上!
87 |
88 | 完全背包的物品是可以添加多次的,所以遍历背包容量要从小到大去遍历,即:
89 |
90 | ```CPP
91 | // 先遍历物品,再遍历背包
92 | for(int i = 0; i < weight.size(); i++) { // 遍历物品
93 | for(int j = weight[i]; j < bagWeight ; j++) { // 遍历背包容量
94 | dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
95 |
96 | }
97 | }
98 | ```
99 |
100 | 基本网上题的题解介绍到这里就到此为止了。
101 |
102 | **那么为什么要先遍历物品,在遍历背包呢?** (灵魂拷问)
103 |
104 | 其实对于纯完全背包,先遍历物品,再遍历背包 与 先遍历背包,再遍历物品都是可以的。我在文中[动态规划:关于完全背包,你该了解这些!](https://programmercarl.com/背包问题理论基础完全背包.html)也给出了详细的解释。
105 |
106 | 这个细节是很多同学忽略掉的点,其实也不算细节了,**相信不少同学在写背包的时候,两层for循环的先后循序搞不清楚,靠感觉来的**。
107 |
108 | 所以理解究竟是先遍历啥,后遍历啥非常重要,这也体现出遍历顺序的重要性!
109 |
110 | 在文中,我也强调了是对纯完全背包,两个for循环先后循序无所谓,那么题目稍有变化,可就有所谓了。
111 |
112 | ## 周四
113 |
114 | 在[动态规划:给你一些零钱,你要怎么凑?](https://programmercarl.com/0518.零钱兑换II.html)中就是给你一堆零钱(零钱个数无限),为凑成amount的组合数有几种。
115 |
116 | **注意这里组合数和排列数的区别!**
117 |
118 | 看到无限零钱个数就知道是完全背包,
119 |
120 | 但本题不是纯完全背包了(求是否能装满背包),而是求装满背包有几种方法。
121 |
122 | 这里在遍历顺序上可就有说法了。
123 |
124 | * 如果求组合数就是外层for循环遍历物品,内层for遍历背包。
125 | * 如果求排列数就是外层for遍历背包,内层for循环遍历物品。
126 |
127 | 这里同学们需要理解一波,我在文中也给出了详细的解释,下周我们将介绍求排列数的完全背包题目来加深对这个遍历顺序的理解。
128 |
129 |
130 | ## 总结
131 |
132 | 相信通过本周的学习,大家已经初步感受到遍历顺序的重要性!
133 |
134 | 很多对动规理解不深入的同学都会感觉:动规嘛,就是把递推公式推出来其他都easy了。
135 |
136 | 其实这是一种错觉,或者说对动规理解的不够深入!
137 |
138 | 我在动规专题开篇介绍[关于动态规划,你该了解这些!](https://programmercarl.com/动态规划理论基础.html)中就强调了 **递推公式仅仅是 动规五部曲里的一小部分, dp数组的定义、初始化、遍历顺序,哪一点没有搞透的话,即使知道递推公式,遇到稍稍难一点的动规题目立刻会感觉写不出来了**。
139 |
140 | 此时相信大家对动规五部曲也有更深的理解了,同样也验证了Carl之前讲过的:**简单题是用来学习方法论的,而遇到难题才体现出方法论的重要性!**
141 |
142 |
143 |
144 |
--------------------------------------------------------------------------------
/problems/前序/代码风格.md:
--------------------------------------------------------------------------------
1 |
2 | # 看了这么多代码,谈一谈代码风格!
3 |
4 | 最近看了很多录友在[leetcode-master](https://mp.weixin.qq.com/s/wZRTrA9Rbvgq1yEkSw4vfQ)上提交的代码,发现很多录友的代码其实并不规范,这一点平时在交流群和知识星球里也能看出来。
5 |
6 | 很多录友对代码规范应该了解得不多,代码看起来并不舒服。
7 |
8 | 所以呢,我给大家讲一讲代码规范,我主要以C++代码为例。
9 |
10 | 需要强调一下,代码规范并不是仅仅是让代码看着舒服,这是一个很重要的习惯。
11 |
12 | ## 题外话
13 |
14 | 工作之后,**特别是在大厂,看谁的技术牛不牛逼,不用看谁写出多牛逼的代码,就代码风格扫一眼,立刻就能看出来是正规军还是野生程序员**。
15 |
16 | 很多人甚至不屑于了解代码规范,认为实现功能就行,这种观点其实在上个世纪是很普遍的,因为那时候一般写代码不需要合作,自己一个人撸整个项目,想怎么写就怎么写。
17 |
18 | 现在一些小公司,甚至大公司里的某些技术团队也不注重代码规范,赶进度撸出功能就完事,这种情况就要分两方面看:
19 |
20 | * 第一种情况:这个项目在业务上具有巨大潜力,需要抢占市场,只要先站住市场就能赚到钱,每年年终好几十万,那项目前期还关心啥代码风格,赶进度把功能撸出来,赚钱就完事了,例如12年的微信,15年的王者荣耀。这些项目都是后期再不断优化的。
21 |
22 | * 第二种情况:这个项目没赚到钱,半死不活的,代码还没有设计也没有规范,这样对技术人员的伤害就非常大了。
23 |
24 | **而不注重代码风格的团队,99.99%都是第二种情况**,如果你赶上了第一种情况,那就恭喜你了,本文下面的内容可以不用看了,哈哈。
25 |
26 | ## 代码规范
27 |
28 | ### 变量命名
29 |
30 | 这里我简单说一说规范问题。
31 |
32 | **权威的C++规范以Google为主**,我给大家下载了一份中文版本,在公众号「代码随想录」后台回复:googlec++编程规范,就可以领取。(涉及到微信后台的回复,没更改)
33 |
34 | **具体的规范要以自己团队风格为主**,融入团队才是最重要的。
35 |
36 | 我先来说说变量的命名。
37 |
38 | 主流有如下三种变量规则:
39 |
40 | * 小驼峰、大驼峰命名法
41 | * 下划线命名法
42 | * 匈牙利命名法
43 |
44 | 小驼峰,第一个单词首字母小写,后面其他单词首字母大写。例如 `int myAge;`
45 |
46 | 大驼峰法把第一个单词的首字母也大写了。例如:``int MyAge;``
47 |
48 | 通常来讲 java和go都使用驼峰,C++的函数和结构体命名也是用大驼峰,**大家可以看到题解中我的C++代码风格就是小驼峰,因为leetcode上给出的默认函数的命名就是小驼峰,所以我入乡随俗**。
49 |
50 | 下划线命名法是名称中的每一个逻辑断点都用一个下划线来标记,例如:`int my_age`,**下划线命名法是随着C语言的出现流行起来的,如果大家看过UNIX高级编程或者UNIX网络编程,就会发现大量使用这种命名方式**。
51 |
52 | 匈牙利命名法是:变量名 = 属性 + 类型 + 对象描述,例如:`int iMyAge`,这种命名是一个来此匈牙利的程序员在微软内部推广起来,然后推广给了全世界的Windows开发人员。
53 |
54 | 这种命名方式在没有IDE的时代,可以很好的提醒开发人员遍历的意义,例如看到iMyAge,就知道它是一个int型的变量,而不用找它的定义,缺点是一旦改变变量的属性,那么整个项目里这个变量名字都要改动,所以带来代码维护困难。
55 |
56 | **目前IDE已经很发达了,都不用标记变量属性了,IDE就会帮我们识别了,所以基本没人用匈牙利命名法了**,虽然我不用IDE,VIM大法好。
57 |
58 | 我做了一下总结如图:
59 |
60 | 
61 |
62 | ### 水平留白(代码空格)
63 |
64 | 经常看到有的同学的代码都堆在一起,看起来都费劲,或者是有的间隔有空格,有的没有空格,很不统一,有的同学甚至为了让代码精简,把所有空格都省略掉了。
65 |
66 | 大家如果注意我题解上的代码风格,我的空格都是有统一规范的。
67 |
68 | **我所有题解的C++代码,都是严格按照Google C++编程规范来的,这样代码看起来就让人感觉清爽一些**。
69 |
70 | 我举一些例子:
71 |
72 | 操作符左右一定有空格,例如
73 | ```
74 | i = i + 1;
75 | ```
76 |
77 | 分隔符(`,` 和`;`)前一位没有空格,后一位保持空格,例如:
78 |
79 | ```
80 | int i, j;
81 | for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++)
82 | ```
83 |
84 | 大括号和函数保持同一行,并有一个空格例如:
85 |
86 | ```
87 | while (n) {
88 | n--;
89 | }
90 | ```
91 |
92 | 控制语句(while,if,for)后都有一个空格,例如:
93 | ```
94 | while (n) {
95 | if (k > 0) return 9;
96 | n--;
97 | }
98 | ```
99 |
100 | 以下是我刚写的力扣283.移动零的代码,大家可以看一下整体风格,注意空格的细节!
101 | ```CPP
102 | class Solution {
103 | public:
104 | void moveZeroes(vector
138 |
--------------------------------------------------------------------------------
/problems/周总结/20201017二叉树周末总结.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 本周小结!(二叉树系列四)
4 |
5 | > 这已经是二叉树的第四周总结了,二叉树是非常重要的数据结构,也是面试中的常客,所以有必要一步一步帮助大家彻底掌握二叉树!
6 |
7 | ## 周一
8 |
9 | 在[二叉树:合并两个二叉树](https://programmercarl.com/0617.合并二叉树.html)中讲解了如何合并两个二叉树,平时我们都习惯了操作一个二叉树,一起操作两个树可能还有点陌生。
10 |
11 | 其实套路是一样,只不过一起操作两个树的指针,我们之前讲过求 [二叉树:我对称么?](https://programmercarl.com/0101.对称二叉树.html)的时候,已经初步涉及到了 一起遍历两棵二叉树了。
12 |
13 | **迭代法中,一般一起操作两个树都是使用队列模拟类似层序遍历,同时处理两个树的节点,这种方式最好理解,如果用模拟递归的思路的话,要复杂一些。**
14 |
15 | ## 周二
16 |
17 | 周二开始讲解一个新的树,二叉搜索树,开始要换一个思路了,如果没有利用好二叉搜索树的特性,就容易把简单题做成了难题了。
18 |
19 | 学习[二叉搜索树的特性](https://programmercarl.com/0700.二叉搜索树中的搜索.html),还是比较容易的。
20 |
21 | 大多是二叉搜索树的题目,其实都离不开中序遍历,因为这样就是有序的。
22 |
23 | 至于迭代法,相信大家看到文章中如此简单的迭代法的时候,都会感动的痛哭流涕。
24 |
25 | ## 周三
26 |
27 | 了解了二搜索树的特性之后, 开始验证[一棵二叉树是不是二叉搜索树](https://programmercarl.com/0098.验证二叉搜索树.html)。
28 |
29 | 首先在此强调一下二叉搜索树的特性:
30 |
31 | * 节点的左子树只包含小于当前节点的数。
32 | * 节点的右子树只包含大于当前节点的数。
33 | * 所有左子树和右子树自身必须也是二叉搜索树。
34 |
35 | 那么我们在验证二叉搜索树的时候,有两个陷阱:
36 |
37 | * 陷阱一
38 |
39 | **不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**,而是左子树都小于中间节点,右子树都大于中间节点。
40 |
41 | * 陷阱二
42 |
43 | 在一个有序序列求最值的时候,不要定义一个全局遍历,然后遍历序列更新全局变量求最值。因为最值可能就是int 或者 longlong的最小值。
44 |
45 | 推荐要通过前一个数值(pre)和后一个数值比较(cur),得出最值。
46 |
47 | **在二叉树中通过两个前后指针作比较,会经常用到**。
48 |
49 | 本文[二叉树:我是不是一棵二叉搜索树](https://programmercarl.com/0098.验证二叉搜索树.html)中迭代法中为什么没有周一那篇那么简洁了呢,因为本篇是验证二叉搜索树,前提默认它是一棵普通二叉树,所以还是要回归之前老办法。
50 |
51 | ## 周四
52 |
53 | 了解了[二叉搜索树](https://programmercarl.com/0700.二叉搜索树中的搜索.html),并且知道[如何判断二叉搜索树](https://programmercarl.com/0098.验证二叉搜索树.html),本篇就很简单了。
54 |
55 | **要知道二叉搜索树和中序遍历是好朋友!**
56 |
57 | 在[二叉树:搜索树的最小绝对差](https://programmercarl.com/0530.二叉搜索树的最小绝对差.html)中强调了要利用搜索树的特性,把这道题目想象成在一个有序数组上求两个数最小差值,这就是一道送分题了。
58 |
59 | **需要明确:在有序数组求任意两数最小值差等价于相邻两数的最小值差**。
60 |
61 | 同样本题也需要用pre节点记录cur节点的前一个节点。(这种写法一定要掌握)
62 |
63 | ## 周五
64 |
65 | 此时大家应该知道遇到二叉搜索树,就想是有序数组,那么在二叉搜索树中求二叉搜索树众数就很简单了。
66 |
67 | 在[二叉树:我的众数是多少?](https://programmercarl.com/0501.二叉搜索树中的众数.html)中我给出了如果是普通二叉树,应该如何求众数的集合,然后进一步讲解了二叉搜索树应该如何求众数集合。
68 |
69 | 在求众数集合的时候有一个技巧,因为题目中众数是可以有多个的,所以一般的方法需要遍历两遍才能求出众数的集合。
70 |
71 | **但可以遍历一遍就可以求众数集合,使用了适时清空结果集的方法**,这个方法还是很巧妙的。相信仔细读了文章的同学会惊呼其巧妙!
72 |
73 | **所以大家不要看题目简单了,就不动手做了,我选的题目,一般不会简单到不用动手的程度,哈哈**。
74 |
75 | ## 周六
76 |
77 | 在[二叉树:公共祖先问题](https://programmercarl.com/0236.二叉树的最近公共祖先.html)中,我们开始讲解如何在二叉树中求公共祖先的问题,本来是打算和二叉搜索树一起讲的,但发现篇幅过长,所以先讲二叉树的公共祖先问题。
78 |
79 | **如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。**
80 |
81 | 这道题目的看代码比较简单,而且好像也挺好理解的,但是如果把每一个细节理解到位,还是不容易的。
82 |
83 | 主要思考如下几点:
84 |
85 | * 如何从底向上遍历?
86 | * 遍历整棵树,还是遍历局部树?
87 | * 如何把结果传到根节点的?
88 |
89 | 这些问题都需要弄清楚,上来直接看代码的话,是可能想不到这些细节的。
90 |
91 | 公共祖先问题,还是有难度的,初学者还是需要慢慢消化!
92 |
93 | ## 总结
94 |
95 | 本周我们讲了[如何合并两个二叉树](https://programmercarl.com/0617.合并二叉树.html),了解了如何操作两个二叉树。
96 |
97 | 然后开始另一种树:二叉搜索树,了解[二叉搜索树的特性](https://programmercarl.com/0700.二叉搜索树中的搜索.html),然后[判断一棵二叉树是不是二叉搜索树](https://programmercarl.com/0098.验证二叉搜索树.html)。
98 |
99 | 了解以上知识之后,就开始利用其特性,做一些二叉搜索树上的题目,[求最小绝对差](https://programmercarl.com/0530.二叉搜索树的最小绝对差.html),[求众数集合](https://programmercarl.com/0501.二叉搜索树中的众数.html)。
100 |
101 | 接下来,开始求二叉树与二叉搜索树的公共祖先问题,单篇篇幅原因,先单独介绍[普通二叉树如何求最近公共祖先](https://programmercarl.com/0236.二叉树的最近公共祖先.html)。
102 |
103 | 现在已经讲过了几种二叉树了,二叉树,二叉平衡树,完全二叉树,二叉搜索树,后面还会有平衡二叉搜索树。 那么一些同学难免会有混乱了,我针对如下三个问题,帮大家在捋顺一遍:
104 |
105 | 1. 平衡二叉搜索树是不是二叉搜索树和平衡二叉树的结合?
106 |
107 | 是的,是二叉搜索树和平衡二叉树的结合。
108 |
109 | 2. 平衡二叉树与完全二叉树的区别在于底层节点的位置?
110 |
111 | 是的,完全二叉树底层必须是从左到右连续的,且次底层是满的。
112 |
113 | 3. 堆是完全二叉树和排序的结合,而不是平衡二叉搜索树?
114 |
115 | 堆是一棵完全二叉树,同时保证父子节点的顺序关系(有序)。 **但完全二叉树一定是平衡二叉树,堆的排序是父节点大于子节点,而搜索树是父节点大于左孩子,小于右孩子,所以堆不是平衡二叉搜索树**。
116 |
117 | 大家如果每天坚持跟下来,会发现又是充实的一周![机智]
118 |
119 |
120 |
--------------------------------------------------------------------------------
/problems/周总结/20201210复杂度分析周末总结.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
6 |
7 |
8 |
9 |
124 |
--------------------------------------------------------------------------------
/problems/动态规划理论基础.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |  12 |
13 | ## 什么是动态规划
14 |
15 | 动态规划,英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
16 |
17 | 所以动态规划中每一个状态一定是由上一个状态推导出来的,**这一点就区分于贪心**,贪心没有状态推导,而是从局部直接选最优的,
18 |
19 | 在[关于贪心算法,你该了解这些!](https://programmercarl.com/%E8%B4%AA%E5%BF%83%E7%AE%97%E6%B3%95%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html)中我举了一个背包问题的例子。
20 |
21 | 例如:有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。**每件物品只能用一次**,求解将哪些物品装入背包里物品价值总和最大。
22 |
23 | 动态规划中dp[j]是由dp[j-weight[i]]推导出来的,然后取max(dp[j], dp[j - weight[i]] + value[i])。
24 |
25 | 但如果是贪心呢,每次拿物品选一个最大的或者最小的就完事了,和上一个状态没有关系。
26 |
27 | 所以贪心解决不了动态规划的问题。
28 |
29 | **其实大家也不用死扣动规和贪心的理论区别,后面做做题目自然就知道了**。
30 |
31 | 而且很多讲解动态规划的文章都会讲最优子结构啊和重叠子问题啊这些,这些东西都是教科书的上定义,晦涩难懂而且不实用。
32 |
33 | 大家知道动规是由前一个状态推导出来的,而贪心是局部直接选最优的,对于刷题来说就够用了。
34 |
35 | 上述提到的背包问题,后序会详细讲解。
36 |
37 | ## 动态规划的解题步骤
38 |
39 | 做动规题目的时候,很多同学会陷入一个误区,就是以为把状态转移公式背下来,照葫芦画瓢改改,就开始写代码,甚至把题目AC之后,都不太清楚dp[i]表示的是什么。
40 |
41 | **这就是一种朦胧的状态,然后就把题给过了,遇到稍稍难一点的,可能直接就不会了,然后看题解,然后继续照葫芦画瓢陷入这种恶性循环中**。
42 |
43 | 状态转移公式(递推公式)是很重要,但动规不仅仅只有递推公式。
44 |
45 | **对于动态规划问题,我将拆解为如下五步曲,这五步都搞清楚了,才能说把动态规划真的掌握了!**
46 |
47 | 1. 确定dp数组(dp table)以及下标的含义
48 | 2. 确定递推公式
49 | 3. dp数组如何初始化
50 | 4. 确定遍历顺序
51 | 5. 举例推导dp数组
52 |
53 | 一些同学可能想为什么要先确定递推公式,然后在考虑初始化呢?
54 |
55 | **因为一些情况是递推公式决定了dp数组要如何初始化!**
56 |
57 | 后面的讲解中我都是围绕着这五点来进行讲解。
58 |
59 | 可能刷过动态规划题目的同学可能都知道递推公式的重要性,感觉确定了递推公式这道题目就解出来了。
60 |
61 | 其实 确定递推公式 仅仅是解题里的一步而已!
62 |
63 | 一些同学知道递推公式,但搞不清楚dp数组应该如何初始化,或者正确的遍历顺序,以至于记下来公式,但写的程序怎么改都通过不了。
64 |
65 | 后序的讲解的大家就会慢慢感受到这五步的重要性了。
66 |
67 | ## 动态规划应该如何debug
68 |
69 |
70 | 相信动规的题目,很大部分同学都是这样做的。
71 |
72 | 看一下题解,感觉看懂了,然后照葫芦画瓢,如果能正好画对了,万事大吉,一旦要是没通过,就怎么改都通过不了,对 dp数组的初始化,递推公式,遍历顺序,处于一种黑盒的理解状态。
73 |
74 | 写动规题目,代码出问题很正常!
75 |
76 | **找问题的最好方式就是把dp数组打印出来,看看究竟是不是按照自己思路推导的!**
77 |
78 | 一些同学对于dp的学习是黑盒的状态,就是不清楚dp数组的含义,不懂为什么这么初始化,递推公式背下来了,遍历顺序靠习惯就是这么写的,然后一鼓作气写出代码,如果代码能通过万事大吉,通过不了的话就凭感觉改一改。
79 |
80 | 这是一个很不好的习惯!
81 |
82 | **做动规的题目,写代码之前一定要把状态转移在dp数组的上具体情况模拟一遍,心中有数,确定最后推出的是想要的结果**。
83 |
84 | 然后再写代码,如果代码没通过就打印dp数组,看看是不是和自己预先推导的哪里不一样。
85 |
86 | 如果打印出来和自己预先模拟推导是一样的,那么就是自己的递归公式、初始化或者遍历顺序有问题了。
87 |
88 | 如果和自己预先模拟推导的不一样,那么就是代码实现细节有问题。
89 |
90 | **这样才是一个完整的思考过程,而不是一旦代码出问题,就毫无头绪的东改改西改改,最后过不了,或者说是稀里糊涂的过了**。
91 |
92 | 这也是我为什么在动规五步曲里强调推导dp数组的重要性。
93 |
94 | 举个例子哈:在「代码随想录」刷题小分队微信群里,一些录友可能代码通过不了,会把代码抛到讨论群里问:我这里代码都已经和题解一模一样了,为什么通过不了呢?
95 |
96 | 发出这样的问题之前,其实可以自己先思考这三个问题:
97 |
98 | * 这道题目我举例推导状态转移公式了么?
99 | * 我打印dp数组的日志了么?
100 | * 打印出来了dp数组和我想的一样么?
101 |
102 | **如果这灵魂三问自己都做到了,基本上这道题目也就解决了**,或者更清晰的知道自己究竟是哪一点不明白,是状态转移不明白,还是实现代码不知道该怎么写,还是不理解遍历dp数组的顺序。
103 |
104 | 然后在问问题,目的性就很强了,群里的小伙伴也可以快速知道提问者的疑惑了。
105 |
106 | **注意这里不是说不让大家问问题哈, 而是说问问题之前要有自己的思考,问题要问到点子上!**
107 |
108 | **大家工作之后就会发现,特别是大厂,问问题是一个专业活,是的,问问题也要体现出专业!**
109 |
110 | 如果问同事很不专业的问题,同事们会懒的回答,领导也会认为你缺乏思考能力,这对职场发展是很不利的。
111 |
112 | 所以大家在刷题的时候,就锻炼自己养成专业提问的好习惯。
113 |
114 | ## 总结
115 |
116 | 这一篇是动态规划的整体概述,讲解了什么是动态规划,动态规划的解题步骤,以及如何debug。
117 |
118 | 动态规划是一个很大的领域,今天这一篇讲解的内容是整个动态规划系列中都会使用到的一些理论基础。
119 |
120 | 在后序讲解中针对某一具体问题,还会讲解其对应的理论基础,例如背包问题中的01背包,leetcode上的题目都是01背包的应用,而没有纯01背包的问题,那么就需要在把对应的理论知识讲解一下。
121 |
122 | 大家会发现,我讲解的理论基础并不是教科书上各种动态规划的定义,错综复杂的公式。
123 |
124 | 这里理论基础篇已经是非常偏实用的了,每个知识点都是在解题实战中非常有用的内容,大家要重视起来哈。
125 |
126 | 今天我们开始新的征程了,你准备好了么?
127 |
128 |
129 |
132 |
133 |
--------------------------------------------------------------------------------
/problems/背包总结篇.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
108 |
109 |
--------------------------------------------------------------------------------
/problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md:
--------------------------------------------------------------------------------
1 |
2 | # 刷了这么多题,你了解自己代码的内存消耗么?
3 |
4 | 理解代码的内存消耗,最关键是要知道自己所用编程语言的内存管理。
5 |
6 | ## 不同语言的内存管理
7 |
8 | 不同的编程语言各自的内存管理方式。
9 |
10 | * C/C++这种内存堆空间的申请和释放完全靠自己管理
11 | * Java 依赖JVM来做内存管理,不了解jvm内存管理的机制,很可能会因一些错误的代码写法而导致内存泄漏或内存溢出
12 | * Python内存管理是由私有堆空间管理的,所有的python对象和数据结构都存储在私有堆空间中。程序员没有访问堆的权限,只有解释器才能操作。
13 |
14 | 例如Python万物皆对象,并且将内存操作封装的很好,**所以python的基本数据类型所用的内存会要远大于存放纯数据类型所占的内存**,例如,我们都知道存储int型数据需要四个字节,但是使用Python 申请一个对象来存放数据的话,所用空间要远大于四个字节。
15 |
16 | ## C++的内存管理
17 |
18 | 以C++为例来介绍一下编程语言的内存管理。
19 |
20 | 如果我们写C++的程序,就要知道栈和堆的概念,程序运行时所需的内存空间分为 固定部分,和可变部分,如下:
21 |
22 | 
23 |
24 | 固定部分的内存消耗 是不会随着代码运行产生变化的, 可变部分则是会产生变化的
25 |
26 | 更具体一些,一个由C/C++编译的程序占用的内存分为以下几个部分:
27 |
28 | * 栈区(Stack) :由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈。
29 | * 堆区(Heap) :一般由程序员分配释放,若程序员不释放,程序结束时可能由OS收回
30 | * 未初始化数据区(Uninitialized Data): 存放未初始化的全局变量和静态变量
31 | * 初始化数据区(Initialized Data):存放已经初始化的全局变量和静态变量
32 | * 程序代码区(Text):存放函数体的二进制代码
33 |
34 | 代码区和数据区所占空间都是固定的,而且占用的空间非常小,那么看运行时消耗的内存主要看可变部分。
35 |
36 | 在可变部分中,栈区间的数据在代码块执行结束之后,系统会自动回收,而堆区间数据是需要程序员自己回收,所以也就是造成内存泄漏的发源地。
37 |
38 | **而Java、Python的话则不需要程序员去考虑内存泄漏的问题,虚拟机都做了这些事情**。
39 |
40 | ## 如何计算程序占用多大内存
41 |
42 | 想要算出自己程序会占用多少内存就一定要了解自己定义的数据类型的大小,如下:
43 |
44 | 
45 |
46 | 注意图中有两个不一样的地方,为什么64位的指针就占用了8个字节,而32位的指针占用4个字节呢?
47 |
48 | 1个字节占8个比特,那么4个字节就是32个比特,可存放数据的大小为2^32,也就是4G空间的大小,即:可以寻找4G空间大小的内存地址。
49 |
50 | 大家现在使用的计算机一般都是64位了,所以编译器也都是64位的。
51 |
52 | 安装64位的操作系统的计算机内存都已经超过了4G,也就是指针大小如果还是4个字节的话,就已经不能寻址全部的内存地址,所以64位编译器使用8个字节的指针才能寻找所有的内存地址。
53 |
54 | 注意2^64是一个非常巨大的数,对于寻找地址来说已经足够用了。
55 |
56 | ## 内存对齐
57 |
58 | 再介绍一下内存管理中另一个重要的知识点:**内存对齐**。
59 |
60 | **不要以为只有C/C++才会有内存对齐,只要可以跨平台的编程语言都需要做内存对齐,Java、Python都是一样的**。
61 |
62 | 而且这是面试中面试官非常喜欢问到的问题,就是:**为什么会有内存对齐?**
63 |
64 | 主要是两个原因
65 |
66 | 1. 平台原因:不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
67 |
68 | 2. 硬件原因:经过内存对齐后,CPU访问内存的速度大大提升。
69 |
70 | 可以看一下这段C++代码输出的各个数据类型大小是多少?
71 |
72 | ```CPP
73 | struct node{
74 | int num;
75 | char cha;
76 | }st;
77 | int main() {
78 | int a[100];
79 | char b[100];
80 | cout << sizeof(int) << endl;
81 | cout << sizeof(char) << endl;
82 | cout << sizeof(a) << endl;
83 | cout << sizeof(b) << endl;
84 | cout << sizeof(st) << endl;
85 | }
86 | ```
87 |
88 | 看一下和自己想的结果一样么, 我们来逐一分析一下。
89 |
90 | 其输出的结果依次为:
91 |
92 | ```
93 | 4
94 | 1
95 | 400
96 | 100
97 | 8
98 | ```
99 |
100 | 此时会发现,和单纯计算字节数的话是有一些误差的。
101 |
102 | 这就是因为内存对齐的原因。
103 |
104 | 来看一下内存对齐和非内存对齐产生的效果区别。
105 |
106 | CPU读取内存不是一次读取单个字节,而是一块一块的来读取内存,块的大小可以是2,4,8,16个字节,具体取多少个字节取决于硬件。
107 |
108 | 假设CPU把内存划分为4字节大小的块,要读取一个4字节大小的int型数据,来看一下这两种情况下CPU的工作量:
109 |
110 | 第一种就是内存对齐的情况,如图:
111 |
112 | 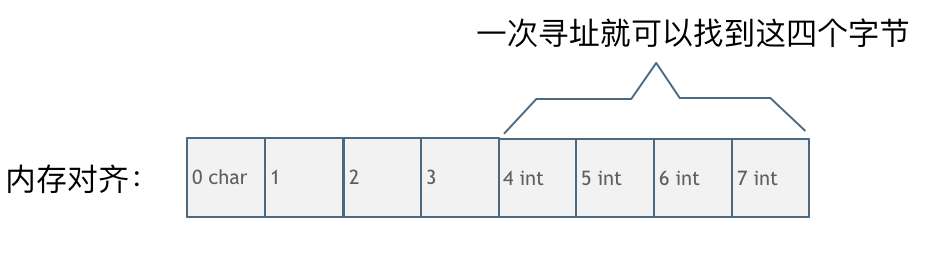
113 |
114 | 一字节的char占用了四个字节,空了三个字节的内存地址,int数据从地址4开始。
115 |
116 | 此时,直接将地址4,5,6,7处的四个字节数据读取到即可。
117 |
118 | 第二种是没有内存对齐的情况如图:
119 |
120 | 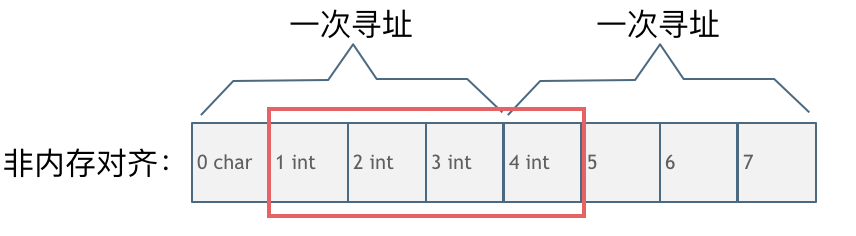
121 |
122 | char型的数据和int型的数据挨在一起,该int数据从地址1开始,那么CPU想要读这个数据的话来看看需要几步操作:
123 |
124 | 1. 因为CPU是四个字节四个字节来寻址,首先CPU读取0,1,2,3处的四个字节数据
125 | 2. CPU读取4,5,6,7处的四个字节数据
126 | 3. 合并地址1,2,3,4处四个字节的数据才是本次操作需要的int数据
127 |
128 | 此时一共需要两次寻址,一次合并的操作。
129 |
130 | **大家可能会发现内存对齐岂不是浪费的内存资源么?**
131 |
132 | 是这样的,但事实上,相对来说计算机内存资源一般都是充足的,我们更希望的是提高运行速度。
133 |
134 | **编译器一般都会做内存对齐的优化操作,也就是说当考虑程序真正占用的内存大小的时候,也需要认识到内存对齐的影响**。
135 |
136 |
137 | ## 总结
138 |
139 | 不少同学对这方面的知识很欠缺,基本处于盲区,通过这一篇大家可以初步补齐一下这块。
140 |
141 | 之后也可以有意识的去学习自己所用的编程语言是如何管理内存的,这些也是程序员的内功。
142 |
143 |
144 |
145 |
146 | -----------------------
147 |
148 |
149 |
--------------------------------------------------------------------------------
/problems/字符串总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
130 |
131 |
--------------------------------------------------------------------------------
/problems/周总结/20201030回溯周末总结.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
12 |
13 | ## 什么是动态规划
14 |
15 | 动态规划,英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。
16 |
17 | 所以动态规划中每一个状态一定是由上一个状态推导出来的,**这一点就区分于贪心**,贪心没有状态推导,而是从局部直接选最优的,
18 |
19 | 在[关于贪心算法,你该了解这些!](https://programmercarl.com/%E8%B4%AA%E5%BF%83%E7%AE%97%E6%B3%95%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html)中我举了一个背包问题的例子。
20 |
21 | 例如:有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。**每件物品只能用一次**,求解将哪些物品装入背包里物品价值总和最大。
22 |
23 | 动态规划中dp[j]是由dp[j-weight[i]]推导出来的,然后取max(dp[j], dp[j - weight[i]] + value[i])。
24 |
25 | 但如果是贪心呢,每次拿物品选一个最大的或者最小的就完事了,和上一个状态没有关系。
26 |
27 | 所以贪心解决不了动态规划的问题。
28 |
29 | **其实大家也不用死扣动规和贪心的理论区别,后面做做题目自然就知道了**。
30 |
31 | 而且很多讲解动态规划的文章都会讲最优子结构啊和重叠子问题啊这些,这些东西都是教科书的上定义,晦涩难懂而且不实用。
32 |
33 | 大家知道动规是由前一个状态推导出来的,而贪心是局部直接选最优的,对于刷题来说就够用了。
34 |
35 | 上述提到的背包问题,后序会详细讲解。
36 |
37 | ## 动态规划的解题步骤
38 |
39 | 做动规题目的时候,很多同学会陷入一个误区,就是以为把状态转移公式背下来,照葫芦画瓢改改,就开始写代码,甚至把题目AC之后,都不太清楚dp[i]表示的是什么。
40 |
41 | **这就是一种朦胧的状态,然后就把题给过了,遇到稍稍难一点的,可能直接就不会了,然后看题解,然后继续照葫芦画瓢陷入这种恶性循环中**。
42 |
43 | 状态转移公式(递推公式)是很重要,但动规不仅仅只有递推公式。
44 |
45 | **对于动态规划问题,我将拆解为如下五步曲,这五步都搞清楚了,才能说把动态规划真的掌握了!**
46 |
47 | 1. 确定dp数组(dp table)以及下标的含义
48 | 2. 确定递推公式
49 | 3. dp数组如何初始化
50 | 4. 确定遍历顺序
51 | 5. 举例推导dp数组
52 |
53 | 一些同学可能想为什么要先确定递推公式,然后在考虑初始化呢?
54 |
55 | **因为一些情况是递推公式决定了dp数组要如何初始化!**
56 |
57 | 后面的讲解中我都是围绕着这五点来进行讲解。
58 |
59 | 可能刷过动态规划题目的同学可能都知道递推公式的重要性,感觉确定了递推公式这道题目就解出来了。
60 |
61 | 其实 确定递推公式 仅仅是解题里的一步而已!
62 |
63 | 一些同学知道递推公式,但搞不清楚dp数组应该如何初始化,或者正确的遍历顺序,以至于记下来公式,但写的程序怎么改都通过不了。
64 |
65 | 后序的讲解的大家就会慢慢感受到这五步的重要性了。
66 |
67 | ## 动态规划应该如何debug
68 |
69 |
70 | 相信动规的题目,很大部分同学都是这样做的。
71 |
72 | 看一下题解,感觉看懂了,然后照葫芦画瓢,如果能正好画对了,万事大吉,一旦要是没通过,就怎么改都通过不了,对 dp数组的初始化,递推公式,遍历顺序,处于一种黑盒的理解状态。
73 |
74 | 写动规题目,代码出问题很正常!
75 |
76 | **找问题的最好方式就是把dp数组打印出来,看看究竟是不是按照自己思路推导的!**
77 |
78 | 一些同学对于dp的学习是黑盒的状态,就是不清楚dp数组的含义,不懂为什么这么初始化,递推公式背下来了,遍历顺序靠习惯就是这么写的,然后一鼓作气写出代码,如果代码能通过万事大吉,通过不了的话就凭感觉改一改。
79 |
80 | 这是一个很不好的习惯!
81 |
82 | **做动规的题目,写代码之前一定要把状态转移在dp数组的上具体情况模拟一遍,心中有数,确定最后推出的是想要的结果**。
83 |
84 | 然后再写代码,如果代码没通过就打印dp数组,看看是不是和自己预先推导的哪里不一样。
85 |
86 | 如果打印出来和自己预先模拟推导是一样的,那么就是自己的递归公式、初始化或者遍历顺序有问题了。
87 |
88 | 如果和自己预先模拟推导的不一样,那么就是代码实现细节有问题。
89 |
90 | **这样才是一个完整的思考过程,而不是一旦代码出问题,就毫无头绪的东改改西改改,最后过不了,或者说是稀里糊涂的过了**。
91 |
92 | 这也是我为什么在动规五步曲里强调推导dp数组的重要性。
93 |
94 | 举个例子哈:在「代码随想录」刷题小分队微信群里,一些录友可能代码通过不了,会把代码抛到讨论群里问:我这里代码都已经和题解一模一样了,为什么通过不了呢?
95 |
96 | 发出这样的问题之前,其实可以自己先思考这三个问题:
97 |
98 | * 这道题目我举例推导状态转移公式了么?
99 | * 我打印dp数组的日志了么?
100 | * 打印出来了dp数组和我想的一样么?
101 |
102 | **如果这灵魂三问自己都做到了,基本上这道题目也就解决了**,或者更清晰的知道自己究竟是哪一点不明白,是状态转移不明白,还是实现代码不知道该怎么写,还是不理解遍历dp数组的顺序。
103 |
104 | 然后在问问题,目的性就很强了,群里的小伙伴也可以快速知道提问者的疑惑了。
105 |
106 | **注意这里不是说不让大家问问题哈, 而是说问问题之前要有自己的思考,问题要问到点子上!**
107 |
108 | **大家工作之后就会发现,特别是大厂,问问题是一个专业活,是的,问问题也要体现出专业!**
109 |
110 | 如果问同事很不专业的问题,同事们会懒的回答,领导也会认为你缺乏思考能力,这对职场发展是很不利的。
111 |
112 | 所以大家在刷题的时候,就锻炼自己养成专业提问的好习惯。
113 |
114 | ## 总结
115 |
116 | 这一篇是动态规划的整体概述,讲解了什么是动态规划,动态规划的解题步骤,以及如何debug。
117 |
118 | 动态规划是一个很大的领域,今天这一篇讲解的内容是整个动态规划系列中都会使用到的一些理论基础。
119 |
120 | 在后序讲解中针对某一具体问题,还会讲解其对应的理论基础,例如背包问题中的01背包,leetcode上的题目都是01背包的应用,而没有纯01背包的问题,那么就需要在把对应的理论知识讲解一下。
121 |
122 | 大家会发现,我讲解的理论基础并不是教科书上各种动态规划的定义,错综复杂的公式。
123 |
124 | 这里理论基础篇已经是非常偏实用的了,每个知识点都是在解题实战中非常有用的内容,大家要重视起来哈。
125 |
126 | 今天我们开始新的征程了,你准备好了么?
127 |
128 |
129 |
132 |
133 |
--------------------------------------------------------------------------------
/problems/背包总结篇.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
108 |
109 |
--------------------------------------------------------------------------------
/problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md:
--------------------------------------------------------------------------------
1 |
2 | # 刷了这么多题,你了解自己代码的内存消耗么?
3 |
4 | 理解代码的内存消耗,最关键是要知道自己所用编程语言的内存管理。
5 |
6 | ## 不同语言的内存管理
7 |
8 | 不同的编程语言各自的内存管理方式。
9 |
10 | * C/C++这种内存堆空间的申请和释放完全靠自己管理
11 | * Java 依赖JVM来做内存管理,不了解jvm内存管理的机制,很可能会因一些错误的代码写法而导致内存泄漏或内存溢出
12 | * Python内存管理是由私有堆空间管理的,所有的python对象和数据结构都存储在私有堆空间中。程序员没有访问堆的权限,只有解释器才能操作。
13 |
14 | 例如Python万物皆对象,并且将内存操作封装的很好,**所以python的基本数据类型所用的内存会要远大于存放纯数据类型所占的内存**,例如,我们都知道存储int型数据需要四个字节,但是使用Python 申请一个对象来存放数据的话,所用空间要远大于四个字节。
15 |
16 | ## C++的内存管理
17 |
18 | 以C++为例来介绍一下编程语言的内存管理。
19 |
20 | 如果我们写C++的程序,就要知道栈和堆的概念,程序运行时所需的内存空间分为 固定部分,和可变部分,如下:
21 |
22 | 
23 |
24 | 固定部分的内存消耗 是不会随着代码运行产生变化的, 可变部分则是会产生变化的
25 |
26 | 更具体一些,一个由C/C++编译的程序占用的内存分为以下几个部分:
27 |
28 | * 栈区(Stack) :由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈。
29 | * 堆区(Heap) :一般由程序员分配释放,若程序员不释放,程序结束时可能由OS收回
30 | * 未初始化数据区(Uninitialized Data): 存放未初始化的全局变量和静态变量
31 | * 初始化数据区(Initialized Data):存放已经初始化的全局变量和静态变量
32 | * 程序代码区(Text):存放函数体的二进制代码
33 |
34 | 代码区和数据区所占空间都是固定的,而且占用的空间非常小,那么看运行时消耗的内存主要看可变部分。
35 |
36 | 在可变部分中,栈区间的数据在代码块执行结束之后,系统会自动回收,而堆区间数据是需要程序员自己回收,所以也就是造成内存泄漏的发源地。
37 |
38 | **而Java、Python的话则不需要程序员去考虑内存泄漏的问题,虚拟机都做了这些事情**。
39 |
40 | ## 如何计算程序占用多大内存
41 |
42 | 想要算出自己程序会占用多少内存就一定要了解自己定义的数据类型的大小,如下:
43 |
44 | 
45 |
46 | 注意图中有两个不一样的地方,为什么64位的指针就占用了8个字节,而32位的指针占用4个字节呢?
47 |
48 | 1个字节占8个比特,那么4个字节就是32个比特,可存放数据的大小为2^32,也就是4G空间的大小,即:可以寻找4G空间大小的内存地址。
49 |
50 | 大家现在使用的计算机一般都是64位了,所以编译器也都是64位的。
51 |
52 | 安装64位的操作系统的计算机内存都已经超过了4G,也就是指针大小如果还是4个字节的话,就已经不能寻址全部的内存地址,所以64位编译器使用8个字节的指针才能寻找所有的内存地址。
53 |
54 | 注意2^64是一个非常巨大的数,对于寻找地址来说已经足够用了。
55 |
56 | ## 内存对齐
57 |
58 | 再介绍一下内存管理中另一个重要的知识点:**内存对齐**。
59 |
60 | **不要以为只有C/C++才会有内存对齐,只要可以跨平台的编程语言都需要做内存对齐,Java、Python都是一样的**。
61 |
62 | 而且这是面试中面试官非常喜欢问到的问题,就是:**为什么会有内存对齐?**
63 |
64 | 主要是两个原因
65 |
66 | 1. 平台原因:不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
67 |
68 | 2. 硬件原因:经过内存对齐后,CPU访问内存的速度大大提升。
69 |
70 | 可以看一下这段C++代码输出的各个数据类型大小是多少?
71 |
72 | ```CPP
73 | struct node{
74 | int num;
75 | char cha;
76 | }st;
77 | int main() {
78 | int a[100];
79 | char b[100];
80 | cout << sizeof(int) << endl;
81 | cout << sizeof(char) << endl;
82 | cout << sizeof(a) << endl;
83 | cout << sizeof(b) << endl;
84 | cout << sizeof(st) << endl;
85 | }
86 | ```
87 |
88 | 看一下和自己想的结果一样么, 我们来逐一分析一下。
89 |
90 | 其输出的结果依次为:
91 |
92 | ```
93 | 4
94 | 1
95 | 400
96 | 100
97 | 8
98 | ```
99 |
100 | 此时会发现,和单纯计算字节数的话是有一些误差的。
101 |
102 | 这就是因为内存对齐的原因。
103 |
104 | 来看一下内存对齐和非内存对齐产生的效果区别。
105 |
106 | CPU读取内存不是一次读取单个字节,而是一块一块的来读取内存,块的大小可以是2,4,8,16个字节,具体取多少个字节取决于硬件。
107 |
108 | 假设CPU把内存划分为4字节大小的块,要读取一个4字节大小的int型数据,来看一下这两种情况下CPU的工作量:
109 |
110 | 第一种就是内存对齐的情况,如图:
111 |
112 | 
113 |
114 | 一字节的char占用了四个字节,空了三个字节的内存地址,int数据从地址4开始。
115 |
116 | 此时,直接将地址4,5,6,7处的四个字节数据读取到即可。
117 |
118 | 第二种是没有内存对齐的情况如图:
119 |
120 | 
121 |
122 | char型的数据和int型的数据挨在一起,该int数据从地址1开始,那么CPU想要读这个数据的话来看看需要几步操作:
123 |
124 | 1. 因为CPU是四个字节四个字节来寻址,首先CPU读取0,1,2,3处的四个字节数据
125 | 2. CPU读取4,5,6,7处的四个字节数据
126 | 3. 合并地址1,2,3,4处四个字节的数据才是本次操作需要的int数据
127 |
128 | 此时一共需要两次寻址,一次合并的操作。
129 |
130 | **大家可能会发现内存对齐岂不是浪费的内存资源么?**
131 |
132 | 是这样的,但事实上,相对来说计算机内存资源一般都是充足的,我们更希望的是提高运行速度。
133 |
134 | **编译器一般都会做内存对齐的优化操作,也就是说当考虑程序真正占用的内存大小的时候,也需要认识到内存对齐的影响**。
135 |
136 |
137 | ## 总结
138 |
139 | 不少同学对这方面的知识很欠缺,基本处于盲区,通过这一篇大家可以初步补齐一下这块。
140 |
141 | 之后也可以有意识的去学习自己所用的编程语言是如何管理内存的,这些也是程序员的内功。
142 |
143 |
144 |
145 |
146 | -----------------------
147 |
148 |
149 |
--------------------------------------------------------------------------------
/problems/字符串总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
130 |
131 |
--------------------------------------------------------------------------------
/problems/周总结/20201030回溯周末总结.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
5 |
6 |
7 |
8 |
116 |
--------------------------------------------------------------------------------
/problems/1221.分割平衡字符串.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
163 |
164 |
--------------------------------------------------------------------------------
/problems/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.md:
--------------------------------------------------------------------------------
1 |
2 | # 通过一道面试题目,讲一讲递归算法的时间复杂度!
3 |
4 | > 本篇通过一道面试题,一个面试场景,来好好分析一下如何求递归算法的时间复杂度。
5 |
6 | 相信很多同学对递归算法的时间复杂度都很模糊,那么这篇来给大家通透的讲一讲。
7 |
8 | **同一道题目,同样使用递归算法,有的同学会写出了O(n)的代码,有的同学就写出了O(logn)的代码**。
9 |
10 | 这是为什么呢?
11 |
12 | 如果对递归的时间复杂度理解的不够深入的话,就会这样!
13 |
14 | 那么我通过一道简单的面试题,模拟面试的场景,来带大家逐步分析递归算法的时间复杂度,最后找出最优解,来看看同样是递归,怎么就写成了O(n)的代码。
15 |
16 | 面试题:求x的n次方
17 |
18 | 想一下这么简单的一道题目,代码应该如何写呢。最直观的方式应该就是,一个for循环求出结果,代码如下:
19 |
20 | ```CPP
21 | int function1(int x, int n) {
22 | int result = 1; // 注意 任何数的0次方等于1
23 | for (int i = 0; i < n; i++) {
24 | result = result * x;
25 | }
26 | return result;
27 | }
28 | ```
29 | 时间复杂度为O(n),此时面试官会说,有没有效率更好的算法呢。
30 |
31 | **如果此时没有思路,不要说:我不会,我不知道了等等**。
32 |
33 | 可以和面试官探讨一下,询问:“可不可以给点提示”。面试官提示:“考虑一下递归算法”。
34 |
35 | 那么就可以写出了如下这样的一个递归的算法,使用递归解决了这个问题。
36 |
37 | ```CPP
38 | int function2(int x, int n) {
39 | if (n == 0) {
40 | return 1; // return 1 同样是因为0次方是等于1的
41 | }
42 | return function2(x, n - 1) * x;
43 | }
44 | ```
45 | 面试官问:“那么这个代码的时间复杂度是多少?”。
46 |
47 | 一些同学可能一看到递归就想到了O(log n),其实并不是这样,递归算法的时间复杂度本质上是要看: **递归的次数 * 每次递归中的操作次数**。
48 |
49 | 那再来看代码,这里递归了几次呢?
50 |
51 | 每次n-1,递归了n次时间复杂度是O(n),每次进行了一个乘法操作,乘法操作的时间复杂度一个常数项O(1),所以这份代码的时间复杂度是 n × 1 = O(n)。
52 |
53 | 这个时间复杂度就没有达到面试官的预期。于是又写出了如下的递归算法的代码:
54 |
55 | ```CPP
56 | int function3(int x, int n) {
57 | if (n == 0) {
58 | return 1;
59 | }
60 | if (n % 2 == 1) {
61 | return function3(x, n / 2) * function3(x, n / 2)*x;
62 | }
63 | return function3(x, n / 2) * function3(x, n / 2);
64 | }
65 |
66 | ```
67 |
68 | 面试官看到后微微一笑,问:“这份代码的时间复杂度又是多少呢?” 此刻有些同学可能要陷入了沉思了。
69 |
70 | 我们来分析一下,首先看递归了多少次呢,可以把递归抽象出一棵满二叉树。刚刚同学写的这个算法,可以用一棵满二叉树来表示(为了方便表示,选择n为偶数16),如图:
71 |
72 | 
73 |
74 | 当前这棵二叉树就是求x的n次方,n为16的情况,n为16的时候,进行了多少次乘法运算呢?
75 |
76 | 这棵树上每一个节点就代表着一次递归并进行了一次相乘操作,所以进行了多少次递归的话,就是看这棵树上有多少个节点。
77 |
78 | 熟悉二叉树话应该知道如何求满二叉树节点数量,这棵满二叉树的节点数量就是`2^3 + 2^2 + 2^1 + 2^0 = 15`,可以发现:**这其实是等比数列的求和公式,这个结论在二叉树相关的面试题里也经常出现**。
79 |
80 | 这么如果是求x的n次方,这个递归树有多少个节点呢,如下图所示:(m为深度,从0开始)
81 |
82 | 
83 |
84 | **时间复杂度忽略掉常数项`-1`之后,这个递归算法的时间复杂度依然是O(n)**。对,你没看错,依然是O(n)的时间复杂度!
85 |
86 | 此时面试官就会说:“这个递归的算法依然还是O(n)啊”, 很明显没有达到面试官的预期。
87 |
88 | 那么O(logn)的递归算法应该怎么写呢?
89 |
90 | 想一想刚刚给出的那份递归算法的代码,是不是有哪里比较冗余呢,其实有重复计算的部分。
91 |
92 | 于是又写出如下递归算法的代码:
93 |
94 | ```CPP
95 | int function4(int x, int n) {
96 | if (n == 0) {
97 | return 1;
98 | }
99 | int t = function4(x, n / 2);// 这里相对于function3,是把这个递归操作抽取出来
100 | if (n % 2 == 1) {
101 | return t * t * x;
102 | }
103 | return t * t;
104 | }
105 | ```
106 |
107 | 再来看一下现在这份代码时间复杂度是多少呢?
108 |
109 | 依然还是看他递归了多少次,可以看到这里仅仅有一个递归调用,且每次都是n/2 ,所以这里我们一共调用了log以2为底n的对数次。
110 |
111 | **每次递归了做都是一次乘法操作,这也是一个常数项的操作,那么这个递归算法的时间复杂度才是真正的O(logn)**。
112 |
113 | 此时大家最后写出了这样的代码并且将时间复杂度分析的非常清晰,相信面试官是比较满意的。
114 |
115 | # 总结
116 |
117 | 对于递归的时间复杂度,毕竟初学者有时候会迷糊,刷过很多题的老手依然迷糊。
118 |
119 | **本篇我用一道非常简单的面试题目:求x的n次方,来逐步分析递归算法的时间复杂度,注意不要一看到递归就想到了O(logn)!**
120 |
121 | 同样使用递归,有的同学可以写出O(logn)的代码,有的同学还可以写出O(n)的代码。
122 |
123 | 对于function3 这样的递归实现,很容易让人感觉这是O(log n)的时间复杂度,其实这是O(n)的算法!
124 |
125 | ```CPP
126 | int function3(int x, int n) {
127 | if (n == 0) {
128 | return 1;
129 | }
130 | if (n % 2 == 1) {
131 | return function3(x, n / 2) * function3(x, n / 2)*x;
132 | }
133 | return function3(x, n / 2) * function3(x, n / 2);
134 | }
135 | ```
136 | 可以看出这道题目非常简单,但是又很考究算法的功底,特别是对递归的理解,这也是我面试别人的时候用过的一道题,所以整个情景我才写的如此逼真,哈哈。
137 |
138 | 大厂面试的时候最喜欢用“简单题”来考察候选人的算法功底,注意这里的“简单题”可并不一定真的简单哦!
139 |
140 | 如果认真读完本篇,相信大家对递归算法的有一个新的认识的,同一道题目,同样是递归,效率可是不一样的!
141 |
142 |
143 |
144 | -----------------------
145 |
146 |
--------------------------------------------------------------------------------
/problems/数组总结篇.md:
--------------------------------------------------------------------------------
1 |
4 |
5 | 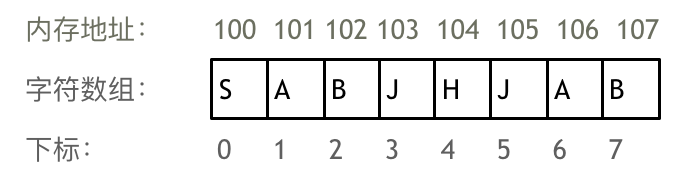 24 |
25 | 需要两点注意的是
26 |
27 | * **数组下标都是从0开始的。**
28 | * **数组内存空间的地址是连续的**
29 |
30 | 正是**因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。**
31 |
32 | 例如删除下标为3的元素,需要对下标为3的元素后面的所有元素都要做移动操作,如图所示:
33 |
34 |
24 |
25 | 需要两点注意的是
26 |
27 | * **数组下标都是从0开始的。**
28 | * **数组内存空间的地址是连续的**
29 |
30 | 正是**因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。**
31 |
32 | 例如删除下标为3的元素,需要对下标为3的元素后面的所有元素都要做移动操作,如图所示:
33 |
34 | 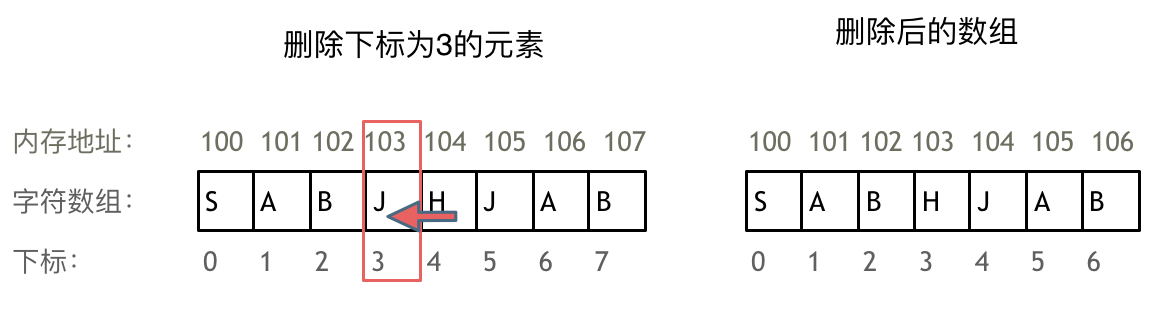 35 |
36 | 而且大家如果使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。
37 |
38 | **数组的元素是不能删的,只能覆盖。**
39 |
40 | 那么二维数组直接上图,大家应该就知道怎么回事了
41 |
42 |
35 |
36 | 而且大家如果使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。
37 |
38 | **数组的元素是不能删的,只能覆盖。**
39 |
40 | 那么二维数组直接上图,大家应该就知道怎么回事了
41 |
42 | 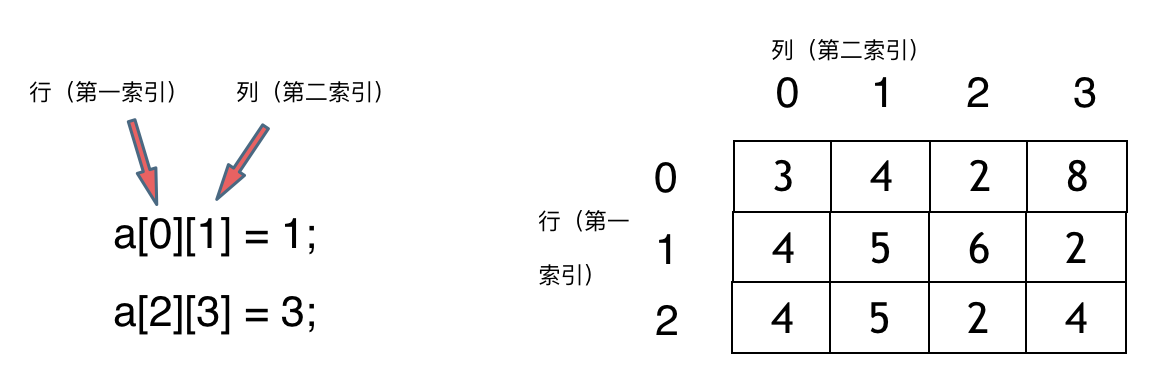 43 |
44 | **那么二维数组在内存的空间地址是连续的么?**
45 |
46 | 我们来举一个Java的例子,例如: `int[][] rating = new int[3][4];` , 这个二维数组在内存空间可不是一个 `3*4` 的连续地址空间
47 |
48 | 看了下图,就应该明白了:
49 |
50 |
43 |
44 | **那么二维数组在内存的空间地址是连续的么?**
45 |
46 | 我们来举一个Java的例子,例如: `int[][] rating = new int[3][4];` , 这个二维数组在内存空间可不是一个 `3*4` 的连续地址空间
47 |
48 | 看了下图,就应该明白了:
49 |
50 | 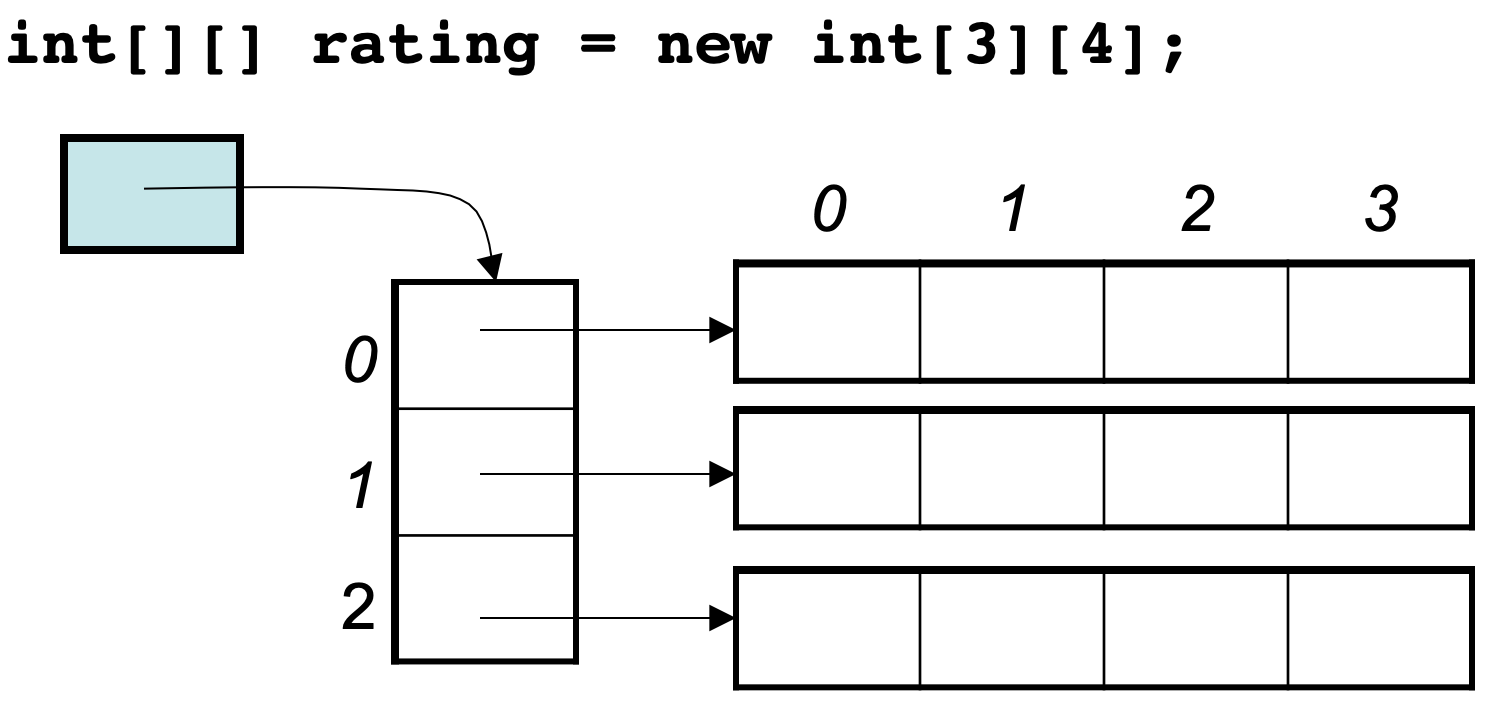 51 |
52 | 所以**Java的二维数组在内存中不是 `3*4` 的连续地址空间,而是四条连续的地址空间组成!**
53 |
54 | # 数组的经典题目
55 |
56 | 在面试中,数组是必考的基础数据结构。
57 |
58 | 其实数组的题目在思想上一般比较简单的,但是如果想高效,并不容易。
59 |
60 | 我们之前一共讲解了四道经典数组题目,每一道题目都代表一个类型,一种思想。
61 |
62 | ## 二分法
63 |
64 | [数组:每次遇到二分法,都是一看就会,一写就废](https://programmercarl.com/0704.二分查找.html)
65 |
66 | 这道题目呢,考察数组的基本操作,思路很简单,但是通过率在简单题里并不高,不要轻敌。
67 |
68 | 可以使用暴力解法,通过这道题目,如果追求更优的算法,建议试一试用二分法,来解决这道题目
69 |
70 | * 暴力解法时间复杂度:O(n)
71 | * 二分法时间复杂度:O(logn)
72 |
73 | 在这道题目中我们讲到了**循环不变量原则**,只有在循环中坚持对区间的定义,才能清楚的把握循环中的各种细节。
74 |
75 | **二分法是算法面试中的常考题,建议通过这道题目,锻炼自己手撕二分的能力**。
76 |
77 |
78 | ## 双指针法
79 |
80 | * [数组:就移除个元素很难么?](https://programmercarl.com/0027.移除元素.html)
81 |
82 | 双指针法(快慢指针法):**通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
83 |
84 | * 暴力解法时间复杂度:O(n^2)
85 | * 双指针时间复杂度:O(n)
86 |
87 | 这道题目迷惑了不少同学,纠结于数组中的元素为什么不能删除,主要是因为以下两点:
88 |
89 | * 数组在内存中是连续的地址空间,不能释放单一元素,如果要释放,就是全释放(程序运行结束,回收内存栈空间)。
90 | * C++中vector和array的区别一定要弄清楚,vector的底层实现是array,封装后使用更友好。
91 |
92 | 双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。
93 |
94 | ## 滑动窗口
95 |
96 | * [数组:滑动窗口拯救了你](https://programmercarl.com/0209.长度最小的子数组.html)
97 |
98 | 本题介绍了数组操作中的另一个重要思想:滑动窗口。
99 |
100 | * 暴力解法时间复杂度:O(n^2)
101 | * 滑动窗口时间复杂度:O(n)
102 |
103 | 本题中,主要要理解滑动窗口如何移动 窗口起始位置,达到动态更新窗口大小的,从而得出长度最小的符合条件的长度。
104 |
105 | **滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。**
106 |
107 | 如果没有接触过这一类的方法,很难想到类似的解题思路,滑动窗口方法还是很巧妙的。
108 |
109 |
110 | ## 模拟行为
111 |
112 | * [数组:这个循环可以转懵很多人!](https://programmercarl.com/0059.螺旋矩阵II.html)
113 |
114 | 模拟类的题目在数组中很常见,不涉及到什么算法,就是单纯的模拟,十分考察大家对代码的掌控能力。
115 |
116 | 在这道题目中,我们再一次介绍到了**循环不变量原则**,其实这也是写程序中的重要原则。
117 |
118 | 相信大家有遇到过这种情况: 感觉题目的边界调节超多,一波接着一波的判断,找边界,拆了东墙补西墙,好不容易运行通过了,代码写的十分冗余,毫无章法,其实**真正解决题目的代码都是简洁的,或者有原则性的**,大家可以在这道题目中体会到这一点。
119 |
120 |
121 | # 总结
122 |
123 | 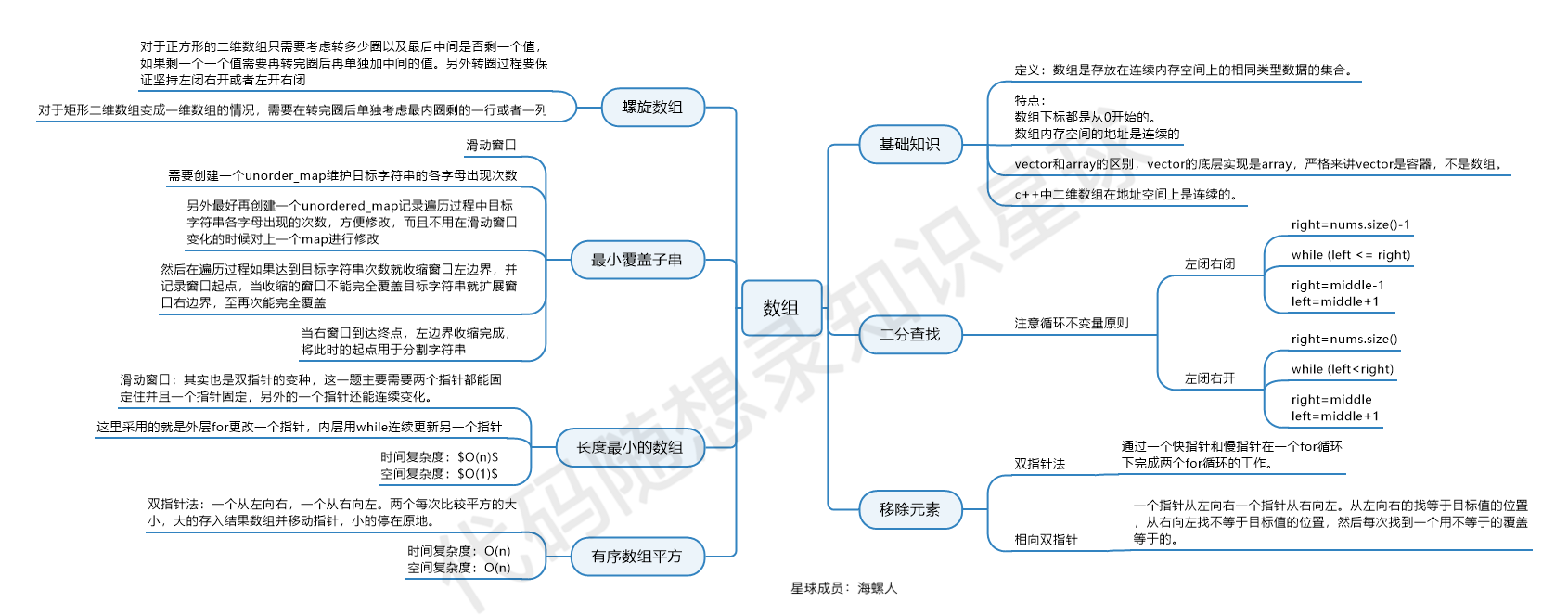
124 |
125 | 这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[海螺人](https://wx.zsxq.com/dweb2/index/footprint/844412858822412),所画,总结的非常好,分享给大家。
126 |
127 | 从二分法到双指针,从滑动窗口到螺旋矩阵,相信如果大家真的认真做了「代码随想录」每日推荐的题目,定会有所收获。
128 |
129 | 推荐的题目即使大家之前做过了,再读一遍文章,也会帮助你提炼出解题的精髓所在。
130 |
131 |
134 |
135 |
--------------------------------------------------------------------------------
/problems/前序/程序员简历.md:
--------------------------------------------------------------------------------
1 | # 程序员的简历应该这么写!!(附简历模板)
2 |
3 | Carl校招社招都拿过大厂的offer,同时也看过很多应聘者的简历,这里把自己总结的简历技巧以及常见问题给大家梳理一下。
4 |
5 | ## 简历篇幅
6 |
7 | 首先程序员的简历力求简洁明了,不用设计上要过于复杂。
8 |
9 | 对于校招生,一页简历就够了,社招的话两页简历便可。
10 |
11 | 有的校招生说自己的经历太多了,简历要写出两三页,实际上基本是无关内容太多或者描述太啰唆,例如多过的校园活动,学生会经历等等。
12 |
13 | 既然是面试技术岗位,其他的方面一笔带过就好。
14 |
15 |
16 | ## 谨慎使用“精通”两字
17 |
18 | 应届生或者刚毕业的程序员在写简历的时候 **切记不要写精通某某语言**,如果真的学的很好,**推荐写“熟悉”或者“掌握”**。
19 |
20 | 但是有的同学可能仅仅使用一些语言例如go或者python写了一些小东西,或者了解一些语言的语法,就直接写上熟悉C++、JAVA、GO、PYTHON ,这也是大忌,如果C++更了解的话,建议写熟悉C++,了解JAVA、GO、PYTHON。
21 |
22 | **词语的强烈程度:精通 > 熟悉(推荐使用)> 掌握(推荐使用)> 了解(推荐使用)**
23 |
24 | 还有做好心理准备,一旦我们写了熟悉某某语言,这门语言就一定是面试中重点考察的一个点。
25 |
26 | 例如写了熟悉C++, 那么继承、多态、封装、虚函数、C++11的一些特性、STL就一定会被问道。
27 |
28 | **所以简历上写着熟悉哪一门语言,在准备面试的时候重点准备,其他语言几乎可以不用看了,面试官在面试中通常只会考察一门编程语言**。
29 |
30 |
31 | ## 拿不准的绝对不要写在简历上
32 |
33 | **不要为了简历上看上去很丰富,就写很多内容上去,内容越多,面试中考点就越多**。
34 |
35 | 简历中突出自己技能的几个点,而不是面面俱到。
36 |
37 | 想想看,面试官一定是拿着你的简历开始问问题的,**如果因为仅仅想展示自己多会一点点的东西就都写在简历上,等于给自己挖了一个“大坑”**。
38 |
39 | 例如仅仅部署过nginx服务器,就在简历上写熟悉nginx,那面试官可能上来就围绕着nginx问很多问题,同学们如果招架不住,然后说:“我仅仅部署过,底层实现我都不了解。这样就是让面试官有些失望”。
40 |
41 | **同时尽量不要写代码行数10万+ 在简历上**,这就相当于提高了面试官的期望。
42 |
43 | 首先就是代码行数10W+ 无从考证,而且这无疑大大提高的面试官的期望和面试官问问题的范围,这相当于告诉面试官“我写代码没问题,你就尽管问吧”。
44 |
45 | 如果简历上再没有侧重点的话,面试官就开始铺天盖地问起来,恐怕大家回答的效果也不会太好。
46 |
47 | ## 项目经验应该如何写
48 |
49 | **项目经验中要突出自己的贡献**,不要描述一遍项目就完事,要突出自己的贡献,是添加了哪些功能,还是优化了那些性能指数,最后再说说受益怎么样。
50 |
51 | 例如这个功能被多少人使用,例如性能提升了多少倍。
52 |
53 | 其实很多同学的一个通病就是在面试中说不出自己项目的难点,项目经历写了一大堆,各种框架数据库的使用都写上了,却答不出自己项目中的难点。
54 |
55 | 有的同学可能心里会想:“自己的项目没有什么难点,就是按照功能来做,遇到不会配置的不会调节的,就百度一下”。
56 |
57 | 其实大多数人做项目的时候都是这样的,不是每个项目都有什么难点,可是为什么一样的项目经验,别人就可以在难点上说出一二三来呢?
58 |
59 | 这里还是有一些技巧的,首先是**做项目的时候时刻保持着对难点的敏感程度**,很多我们费尽周折解决了一个问题,然后自己也不做记录,就忘掉了,**此时如果及时将自己的思考过程记录下来,就是面试中的重要素材,养成这样的习惯非常重要**。
60 |
61 | 很多同学埋怨自己的项目没难点,其实不然,**找到项目中的一点,深挖下去就会遇到难点,解决它,这种经历就可以拿来在面试中来说了**。
62 |
63 | 例如使用java完成的项目,在深挖一下Java内存管理,看看是不是可以减少一些虚拟机上内存的压力。
64 |
65 | 所以很多时候 **不是自己的项目没有难点,而是自己准备的不充分**。
66 |
67 | 项目经验是面试官一定会问的,那么不是每一个面试都是主动问项目中有哪些亮点或者难点,这时候就需要我们自己主动去说自己项目中的难点。
68 |
69 | ## 变被动为主动
70 |
71 | 再说一个面试中如何变被动为主动的技巧,例如自己的项目是一套分布式系统,我们在介绍项目的时候主动说:“项目中的难点就是分布式数据一致性的问题。”。
72 |
73 | **此时就应该知道面试官定会问:“你是如何解决数据一致性的?”**。
74 |
75 | 如果你对数据一致性协议的使用和原理足够的了解的话,就可以和面试官侃侃而谈了。
76 |
77 | 我们在简历中突出项目的难点在于数据一致性,并且**我们之前就精心准备一致性协议,数据一致性相关的知识,就等着面试官来问**,这样准备面试更有效率,这些写出来的简历也才是好的简历,而不是简历上泛泛而谈什么都说一些,最后都不太了解。
78 |
79 | 面试一共就三十分钟或者一个小时,说两个两个项目中的难点,既凸显出自己技术上的深度,同时项目中的难点是最好被我们自己掌控的,**因为这块是面试官必问的,就是我们可以变被动为主动的关键**。
80 |
81 | **真正好的简历是 当同学们把自己的简历递给面试官的时候,基本都知道面试官看着简历都会问什么问题**,然后将面试官的引导到自己最熟悉的领域,这样大家才会占有主动权。
82 |
83 |
84 | ## 博客的重要性
85 |
86 | 简历上可以放上自己的博客地址、Github地址甚至微博(如果发了很多关于技术的内容),**通过博客和github 面试官就可以快速判断同学们对技术的热情,以及学习的态度**,可以让面试官快速的了解同学们的技术水平。
87 |
88 | 如果有很多高质量博客和漂亮的github的话,即使面试现场发挥的不好,面试官通过博客也会知道这位同学基础还是很扎实,只是发挥的不好而已。
89 |
90 | 可以看出记录和总结的重要性。
91 |
92 | 写博客,不一定非要是技术大牛才写博客,大家都可以写博客来记录自己的收获,每一个知识点大家都可以写一篇技术博客,这方面要切忌懒惰!
93 |
94 | **我是欢迎录友们参考我的文章写博客来记录自己收获的,但一定要注明来自公众号「代码随想录」呀!**
95 |
96 | 同时大家对github不要畏惧,可以很容易找到一些小的项目来练手。
97 |
98 | 这里贴出我的Github,上面有一些我自己写的小项目,大家可以参考:https://github.com/youngyangyang04
99 |
100 | 面试只有短短的30分钟或者一个小时,如何把自己掌握的技术更好的展现给面试官呢,博客、github都是很好的选择,如果把这些放在简历上,面试官一定会看的,这都是加分项。
101 |
102 | ## 简历模板
103 |
104 | 最后福利,把我的简历模板贡献出来!如下图所示。
105 |
106 | 
107 |
108 | 这里是简历模板中Markdown的代码:[https://github.com/youngyangyang04/Markdown-Resume-Template](https://github.com/youngyangyang04/Markdown-Resume-Template) ,可以fork到自己Github仓库上,按照这个模板来修改自己的简历。
109 |
110 | **Word版本的简历,大家可以在公众号「代码随想录」后台回复:简历模板,就可以获取!**
111 |
112 | ## 总结
113 |
114 | **好的简历是敲门砖,同时也不要在简历上花费过多的精力,好的简历以及面试技巧都是锦上添花**,真的求得心得的offer靠的还是真才实学。
115 |
116 | 如何真才实学呢? 跟着「代码随想录」一起刷题呀,哈哈
117 |
118 | 大家此时可以再重审一遍自己的简历,如果发现哪里的不足,面试前要多准备多练习。
119 |
120 | 就酱,「代码随想录」就是这么干货,Carl多年积累的简历技巧都毫不保留的写出来了,如果感觉对你有帮助,就宣传一波「代码随想录」吧,值得大家的关注!
121 |
122 |
123 |
124 | -----------------------
125 |
126 |
--------------------------------------------------------------------------------
/problems/周总结/20210107动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | 这周我们正式开始动态规划的学习!
3 |
4 | ## 周一
5 |
6 | 在[关于动态规划,你该了解这些!](https://programmercarl.com/动态规划理论基础.html)中我们讲解了动态规划的基础知识。
7 |
8 | 首先讲一下动规和贪心的区别,其实大家不用太强调理论上的区别,做做题,就感受出来了。
9 |
10 | 然后我们讲了动规的五部曲:
11 |
12 | 1. 确定dp数组(dp table)以及下标的含义
13 | 2. 确定递推公式
14 | 3. dp数组如何初始化
15 | 4. 确定遍历顺序
16 | 5. 举例推导dp数组
17 |
18 | 后序我们在讲解动规的题目时候,都离不开这五步!
19 |
20 | 本周都是简单题目,大家可能会感觉 按照这五部来好麻烦,凭感觉随手一写,直接就过,越到后面越会感觉,凭感觉这个事还是不靠谱的,哈哈。
21 |
22 | 最后我们讲了动态规划题目应该如何debug,相信一些录友做动规的题目,一旦报错也是凭感觉来改。
23 |
24 | 其实只要把dp数组打印出来,哪里有问题一目了然!
25 |
26 | **如果代码写出来了,一直AC不了,灵魂三问:**
27 |
28 | 1. 这道题目我举例推导状态转移公式了么?
29 | 2. 我打印dp数组的日志了么?
30 | 3. 打印出来了dp数组和我想的一样么?
31 |
32 | 哈哈,专治各种代码写出来了但AC不了的疑难杂症。
33 |
34 | ## 周二
35 |
36 | 这道题目[动态规划:斐波那契数](https://programmercarl.com/0509.斐波那契数.html)是当之无愧的动规入门题。
37 |
38 | 简单题,我们就是用来了解方法论的,用动规五部曲走一遍,题目其实已经把递推公式,和dp数组如何初始化都给我们了。
39 |
40 | ## 周三
41 |
42 | [动态规划:爬楼梯](https://programmercarl.com/0070.爬楼梯.html) 这道题目其实就是斐波那契数列。
43 |
44 | 但正常思考过程应该是推导完递推公式之后,发现这是斐波那契,而不是上来就知道这是斐波那契。
45 |
46 | 在这道题目的第三步,确认dp数组如何初始化,其实就可以看出来,对dp[i]定义理解的深度。
47 |
48 | dp[0]其实就是一个无意义的存在,不用去初始化dp[0]。
49 |
50 | 有的题解是把dp[0]初始化为1,然后遍历的时候i从2开始遍历,这样是可以解题的,然后强行解释一波dp[0]应该等于1的含义。
51 |
52 | 一个严谨的思考过程,应该是初始化dp[1] = 1,dp[2] = 2,然后i从3开始遍历,代码如下:
53 |
54 | ```CPP
55 | dp[1] = 1;
56 | dp[2] = 2;
57 | for (int i = 3; i <= n; i++) { // 注意i是从3开始的
58 | dp[i] = dp[i - 1] + dp[i - 2];
59 | }
60 | ```
61 |
62 | 这个可以是面试的一个小问题,哈哈,考察候选人对dp[i]定义的理解程度。
63 |
64 | 这道题目还可以继续深化,就是一步一个台阶,两个台阶,三个台阶,直到 m个台阶,有多少种方法爬到n阶楼顶。
65 |
66 | 这又有难度了,这其实是一个完全背包问题,但力扣上没有这种题目,所以后续我在讲解背包问题的时候,今天这道题还会拿从背包问题的角度上来再讲一遍。
67 |
68 | 这里我先给出我的实现代码:
69 |
70 | ```CPP
71 | class Solution {
72 | public:
73 | int climbStairs(int n) {
74 | vector
153 |
--------------------------------------------------------------------------------
/problems/回溯算法理论基础.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
51 |
52 | 所以**Java的二维数组在内存中不是 `3*4` 的连续地址空间,而是四条连续的地址空间组成!**
53 |
54 | # 数组的经典题目
55 |
56 | 在面试中,数组是必考的基础数据结构。
57 |
58 | 其实数组的题目在思想上一般比较简单的,但是如果想高效,并不容易。
59 |
60 | 我们之前一共讲解了四道经典数组题目,每一道题目都代表一个类型,一种思想。
61 |
62 | ## 二分法
63 |
64 | [数组:每次遇到二分法,都是一看就会,一写就废](https://programmercarl.com/0704.二分查找.html)
65 |
66 | 这道题目呢,考察数组的基本操作,思路很简单,但是通过率在简单题里并不高,不要轻敌。
67 |
68 | 可以使用暴力解法,通过这道题目,如果追求更优的算法,建议试一试用二分法,来解决这道题目
69 |
70 | * 暴力解法时间复杂度:O(n)
71 | * 二分法时间复杂度:O(logn)
72 |
73 | 在这道题目中我们讲到了**循环不变量原则**,只有在循环中坚持对区间的定义,才能清楚的把握循环中的各种细节。
74 |
75 | **二分法是算法面试中的常考题,建议通过这道题目,锻炼自己手撕二分的能力**。
76 |
77 |
78 | ## 双指针法
79 |
80 | * [数组:就移除个元素很难么?](https://programmercarl.com/0027.移除元素.html)
81 |
82 | 双指针法(快慢指针法):**通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
83 |
84 | * 暴力解法时间复杂度:O(n^2)
85 | * 双指针时间复杂度:O(n)
86 |
87 | 这道题目迷惑了不少同学,纠结于数组中的元素为什么不能删除,主要是因为以下两点:
88 |
89 | * 数组在内存中是连续的地址空间,不能释放单一元素,如果要释放,就是全释放(程序运行结束,回收内存栈空间)。
90 | * C++中vector和array的区别一定要弄清楚,vector的底层实现是array,封装后使用更友好。
91 |
92 | 双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。
93 |
94 | ## 滑动窗口
95 |
96 | * [数组:滑动窗口拯救了你](https://programmercarl.com/0209.长度最小的子数组.html)
97 |
98 | 本题介绍了数组操作中的另一个重要思想:滑动窗口。
99 |
100 | * 暴力解法时间复杂度:O(n^2)
101 | * 滑动窗口时间复杂度:O(n)
102 |
103 | 本题中,主要要理解滑动窗口如何移动 窗口起始位置,达到动态更新窗口大小的,从而得出长度最小的符合条件的长度。
104 |
105 | **滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。**
106 |
107 | 如果没有接触过这一类的方法,很难想到类似的解题思路,滑动窗口方法还是很巧妙的。
108 |
109 |
110 | ## 模拟行为
111 |
112 | * [数组:这个循环可以转懵很多人!](https://programmercarl.com/0059.螺旋矩阵II.html)
113 |
114 | 模拟类的题目在数组中很常见,不涉及到什么算法,就是单纯的模拟,十分考察大家对代码的掌控能力。
115 |
116 | 在这道题目中,我们再一次介绍到了**循环不变量原则**,其实这也是写程序中的重要原则。
117 |
118 | 相信大家有遇到过这种情况: 感觉题目的边界调节超多,一波接着一波的判断,找边界,拆了东墙补西墙,好不容易运行通过了,代码写的十分冗余,毫无章法,其实**真正解决题目的代码都是简洁的,或者有原则性的**,大家可以在这道题目中体会到这一点。
119 |
120 |
121 | # 总结
122 |
123 | 
124 |
125 | 这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[海螺人](https://wx.zsxq.com/dweb2/index/footprint/844412858822412),所画,总结的非常好,分享给大家。
126 |
127 | 从二分法到双指针,从滑动窗口到螺旋矩阵,相信如果大家真的认真做了「代码随想录」每日推荐的题目,定会有所收获。
128 |
129 | 推荐的题目即使大家之前做过了,再读一遍文章,也会帮助你提炼出解题的精髓所在。
130 |
131 |
134 |
135 |
--------------------------------------------------------------------------------
/problems/前序/程序员简历.md:
--------------------------------------------------------------------------------
1 | # 程序员的简历应该这么写!!(附简历模板)
2 |
3 | Carl校招社招都拿过大厂的offer,同时也看过很多应聘者的简历,这里把自己总结的简历技巧以及常见问题给大家梳理一下。
4 |
5 | ## 简历篇幅
6 |
7 | 首先程序员的简历力求简洁明了,不用设计上要过于复杂。
8 |
9 | 对于校招生,一页简历就够了,社招的话两页简历便可。
10 |
11 | 有的校招生说自己的经历太多了,简历要写出两三页,实际上基本是无关内容太多或者描述太啰唆,例如多过的校园活动,学生会经历等等。
12 |
13 | 既然是面试技术岗位,其他的方面一笔带过就好。
14 |
15 |
16 | ## 谨慎使用“精通”两字
17 |
18 | 应届生或者刚毕业的程序员在写简历的时候 **切记不要写精通某某语言**,如果真的学的很好,**推荐写“熟悉”或者“掌握”**。
19 |
20 | 但是有的同学可能仅仅使用一些语言例如go或者python写了一些小东西,或者了解一些语言的语法,就直接写上熟悉C++、JAVA、GO、PYTHON ,这也是大忌,如果C++更了解的话,建议写熟悉C++,了解JAVA、GO、PYTHON。
21 |
22 | **词语的强烈程度:精通 > 熟悉(推荐使用)> 掌握(推荐使用)> 了解(推荐使用)**
23 |
24 | 还有做好心理准备,一旦我们写了熟悉某某语言,这门语言就一定是面试中重点考察的一个点。
25 |
26 | 例如写了熟悉C++, 那么继承、多态、封装、虚函数、C++11的一些特性、STL就一定会被问道。
27 |
28 | **所以简历上写着熟悉哪一门语言,在准备面试的时候重点准备,其他语言几乎可以不用看了,面试官在面试中通常只会考察一门编程语言**。
29 |
30 |
31 | ## 拿不准的绝对不要写在简历上
32 |
33 | **不要为了简历上看上去很丰富,就写很多内容上去,内容越多,面试中考点就越多**。
34 |
35 | 简历中突出自己技能的几个点,而不是面面俱到。
36 |
37 | 想想看,面试官一定是拿着你的简历开始问问题的,**如果因为仅仅想展示自己多会一点点的东西就都写在简历上,等于给自己挖了一个“大坑”**。
38 |
39 | 例如仅仅部署过nginx服务器,就在简历上写熟悉nginx,那面试官可能上来就围绕着nginx问很多问题,同学们如果招架不住,然后说:“我仅仅部署过,底层实现我都不了解。这样就是让面试官有些失望”。
40 |
41 | **同时尽量不要写代码行数10万+ 在简历上**,这就相当于提高了面试官的期望。
42 |
43 | 首先就是代码行数10W+ 无从考证,而且这无疑大大提高的面试官的期望和面试官问问题的范围,这相当于告诉面试官“我写代码没问题,你就尽管问吧”。
44 |
45 | 如果简历上再没有侧重点的话,面试官就开始铺天盖地问起来,恐怕大家回答的效果也不会太好。
46 |
47 | ## 项目经验应该如何写
48 |
49 | **项目经验中要突出自己的贡献**,不要描述一遍项目就完事,要突出自己的贡献,是添加了哪些功能,还是优化了那些性能指数,最后再说说受益怎么样。
50 |
51 | 例如这个功能被多少人使用,例如性能提升了多少倍。
52 |
53 | 其实很多同学的一个通病就是在面试中说不出自己项目的难点,项目经历写了一大堆,各种框架数据库的使用都写上了,却答不出自己项目中的难点。
54 |
55 | 有的同学可能心里会想:“自己的项目没有什么难点,就是按照功能来做,遇到不会配置的不会调节的,就百度一下”。
56 |
57 | 其实大多数人做项目的时候都是这样的,不是每个项目都有什么难点,可是为什么一样的项目经验,别人就可以在难点上说出一二三来呢?
58 |
59 | 这里还是有一些技巧的,首先是**做项目的时候时刻保持着对难点的敏感程度**,很多我们费尽周折解决了一个问题,然后自己也不做记录,就忘掉了,**此时如果及时将自己的思考过程记录下来,就是面试中的重要素材,养成这样的习惯非常重要**。
60 |
61 | 很多同学埋怨自己的项目没难点,其实不然,**找到项目中的一点,深挖下去就会遇到难点,解决它,这种经历就可以拿来在面试中来说了**。
62 |
63 | 例如使用java完成的项目,在深挖一下Java内存管理,看看是不是可以减少一些虚拟机上内存的压力。
64 |
65 | 所以很多时候 **不是自己的项目没有难点,而是自己准备的不充分**。
66 |
67 | 项目经验是面试官一定会问的,那么不是每一个面试都是主动问项目中有哪些亮点或者难点,这时候就需要我们自己主动去说自己项目中的难点。
68 |
69 | ## 变被动为主动
70 |
71 | 再说一个面试中如何变被动为主动的技巧,例如自己的项目是一套分布式系统,我们在介绍项目的时候主动说:“项目中的难点就是分布式数据一致性的问题。”。
72 |
73 | **此时就应该知道面试官定会问:“你是如何解决数据一致性的?”**。
74 |
75 | 如果你对数据一致性协议的使用和原理足够的了解的话,就可以和面试官侃侃而谈了。
76 |
77 | 我们在简历中突出项目的难点在于数据一致性,并且**我们之前就精心准备一致性协议,数据一致性相关的知识,就等着面试官来问**,这样准备面试更有效率,这些写出来的简历也才是好的简历,而不是简历上泛泛而谈什么都说一些,最后都不太了解。
78 |
79 | 面试一共就三十分钟或者一个小时,说两个两个项目中的难点,既凸显出自己技术上的深度,同时项目中的难点是最好被我们自己掌控的,**因为这块是面试官必问的,就是我们可以变被动为主动的关键**。
80 |
81 | **真正好的简历是 当同学们把自己的简历递给面试官的时候,基本都知道面试官看着简历都会问什么问题**,然后将面试官的引导到自己最熟悉的领域,这样大家才会占有主动权。
82 |
83 |
84 | ## 博客的重要性
85 |
86 | 简历上可以放上自己的博客地址、Github地址甚至微博(如果发了很多关于技术的内容),**通过博客和github 面试官就可以快速判断同学们对技术的热情,以及学习的态度**,可以让面试官快速的了解同学们的技术水平。
87 |
88 | 如果有很多高质量博客和漂亮的github的话,即使面试现场发挥的不好,面试官通过博客也会知道这位同学基础还是很扎实,只是发挥的不好而已。
89 |
90 | 可以看出记录和总结的重要性。
91 |
92 | 写博客,不一定非要是技术大牛才写博客,大家都可以写博客来记录自己的收获,每一个知识点大家都可以写一篇技术博客,这方面要切忌懒惰!
93 |
94 | **我是欢迎录友们参考我的文章写博客来记录自己收获的,但一定要注明来自公众号「代码随想录」呀!**
95 |
96 | 同时大家对github不要畏惧,可以很容易找到一些小的项目来练手。
97 |
98 | 这里贴出我的Github,上面有一些我自己写的小项目,大家可以参考:https://github.com/youngyangyang04
99 |
100 | 面试只有短短的30分钟或者一个小时,如何把自己掌握的技术更好的展现给面试官呢,博客、github都是很好的选择,如果把这些放在简历上,面试官一定会看的,这都是加分项。
101 |
102 | ## 简历模板
103 |
104 | 最后福利,把我的简历模板贡献出来!如下图所示。
105 |
106 | 
107 |
108 | 这里是简历模板中Markdown的代码:[https://github.com/youngyangyang04/Markdown-Resume-Template](https://github.com/youngyangyang04/Markdown-Resume-Template) ,可以fork到自己Github仓库上,按照这个模板来修改自己的简历。
109 |
110 | **Word版本的简历,大家可以在公众号「代码随想录」后台回复:简历模板,就可以获取!**
111 |
112 | ## 总结
113 |
114 | **好的简历是敲门砖,同时也不要在简历上花费过多的精力,好的简历以及面试技巧都是锦上添花**,真的求得心得的offer靠的还是真才实学。
115 |
116 | 如何真才实学呢? 跟着「代码随想录」一起刷题呀,哈哈
117 |
118 | 大家此时可以再重审一遍自己的简历,如果发现哪里的不足,面试前要多准备多练习。
119 |
120 | 就酱,「代码随想录」就是这么干货,Carl多年积累的简历技巧都毫不保留的写出来了,如果感觉对你有帮助,就宣传一波「代码随想录」吧,值得大家的关注!
121 |
122 |
123 |
124 | -----------------------
125 |
126 |
--------------------------------------------------------------------------------
/problems/周总结/20210107动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | 这周我们正式开始动态规划的学习!
3 |
4 | ## 周一
5 |
6 | 在[关于动态规划,你该了解这些!](https://programmercarl.com/动态规划理论基础.html)中我们讲解了动态规划的基础知识。
7 |
8 | 首先讲一下动规和贪心的区别,其实大家不用太强调理论上的区别,做做题,就感受出来了。
9 |
10 | 然后我们讲了动规的五部曲:
11 |
12 | 1. 确定dp数组(dp table)以及下标的含义
13 | 2. 确定递推公式
14 | 3. dp数组如何初始化
15 | 4. 确定遍历顺序
16 | 5. 举例推导dp数组
17 |
18 | 后序我们在讲解动规的题目时候,都离不开这五步!
19 |
20 | 本周都是简单题目,大家可能会感觉 按照这五部来好麻烦,凭感觉随手一写,直接就过,越到后面越会感觉,凭感觉这个事还是不靠谱的,哈哈。
21 |
22 | 最后我们讲了动态规划题目应该如何debug,相信一些录友做动规的题目,一旦报错也是凭感觉来改。
23 |
24 | 其实只要把dp数组打印出来,哪里有问题一目了然!
25 |
26 | **如果代码写出来了,一直AC不了,灵魂三问:**
27 |
28 | 1. 这道题目我举例推导状态转移公式了么?
29 | 2. 我打印dp数组的日志了么?
30 | 3. 打印出来了dp数组和我想的一样么?
31 |
32 | 哈哈,专治各种代码写出来了但AC不了的疑难杂症。
33 |
34 | ## 周二
35 |
36 | 这道题目[动态规划:斐波那契数](https://programmercarl.com/0509.斐波那契数.html)是当之无愧的动规入门题。
37 |
38 | 简单题,我们就是用来了解方法论的,用动规五部曲走一遍,题目其实已经把递推公式,和dp数组如何初始化都给我们了。
39 |
40 | ## 周三
41 |
42 | [动态规划:爬楼梯](https://programmercarl.com/0070.爬楼梯.html) 这道题目其实就是斐波那契数列。
43 |
44 | 但正常思考过程应该是推导完递推公式之后,发现这是斐波那契,而不是上来就知道这是斐波那契。
45 |
46 | 在这道题目的第三步,确认dp数组如何初始化,其实就可以看出来,对dp[i]定义理解的深度。
47 |
48 | dp[0]其实就是一个无意义的存在,不用去初始化dp[0]。
49 |
50 | 有的题解是把dp[0]初始化为1,然后遍历的时候i从2开始遍历,这样是可以解题的,然后强行解释一波dp[0]应该等于1的含义。
51 |
52 | 一个严谨的思考过程,应该是初始化dp[1] = 1,dp[2] = 2,然后i从3开始遍历,代码如下:
53 |
54 | ```CPP
55 | dp[1] = 1;
56 | dp[2] = 2;
57 | for (int i = 3; i <= n; i++) { // 注意i是从3开始的
58 | dp[i] = dp[i - 1] + dp[i - 2];
59 | }
60 | ```
61 |
62 | 这个可以是面试的一个小问题,哈哈,考察候选人对dp[i]定义的理解程度。
63 |
64 | 这道题目还可以继续深化,就是一步一个台阶,两个台阶,三个台阶,直到 m个台阶,有多少种方法爬到n阶楼顶。
65 |
66 | 这又有难度了,这其实是一个完全背包问题,但力扣上没有这种题目,所以后续我在讲解背包问题的时候,今天这道题还会拿从背包问题的角度上来再讲一遍。
67 |
68 | 这里我先给出我的实现代码:
69 |
70 | ```CPP
71 | class Solution {
72 | public:
73 | int climbStairs(int n) {
74 | vector
153 |
--------------------------------------------------------------------------------
/problems/回溯算法理论基础.md:
--------------------------------------------------------------------------------
1 |
4 |
5 | 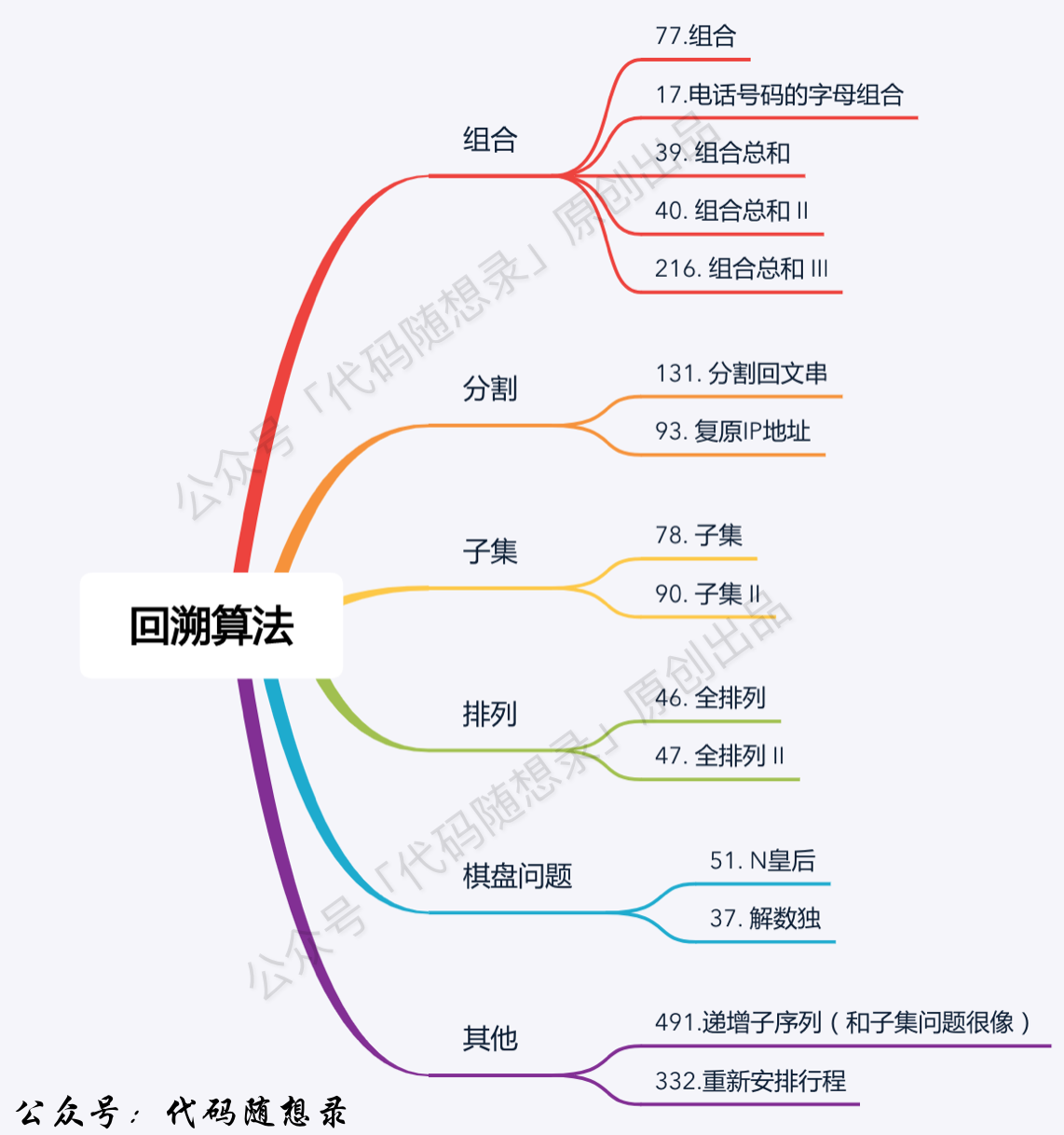 12 |
13 | 可以配合我的B站视频:[带你学透回溯算法(理论篇)](https://www.bilibili.com/video/BV1cy4y167mM/) 一起学习!
14 |
15 | ## 什么是回溯法
16 |
17 | 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
18 |
19 | 在二叉树系列中,我们已经不止一次,提到了回溯,例如[二叉树:以为使用了递归,其实还隐藏着回溯](https://programmercarl.com/二叉树中递归带着回溯.html)。
20 |
21 | 回溯是递归的副产品,只要有递归就会有回溯。
22 |
23 | **所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数**。
24 |
25 | ## 回溯法的效率
26 |
27 | 回溯法的性能如何呢,这里要和大家说清楚了,**虽然回溯法很难,很不好理解,但是回溯法并不是什么高效的算法**。
28 |
29 | **因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案**,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
30 |
31 | 那么既然回溯法并不高效为什么还要用它呢?
32 |
33 | 因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
34 |
35 | 此时大家应该好奇了,都什么问题,这么牛逼,只能暴力搜索。
36 |
37 | ## 回溯法解决的问题
38 |
39 | 回溯法,一般可以解决如下几种问题:
40 |
41 | * 组合问题:N个数里面按一定规则找出k个数的集合
42 | * 切割问题:一个字符串按一定规则有几种切割方式
43 | * 子集问题:一个N个数的集合里有多少符合条件的子集
44 | * 排列问题:N个数按一定规则全排列,有几种排列方式
45 | * 棋盘问题:N皇后,解数独等等
46 |
47 | **相信大家看着这些之后会发现,每个问题,都不简单!**
48 |
49 |
50 | 另外,会有一些同学可能分不清什么是组合,什么是排列?
51 |
52 | **组合是不强调元素顺序的,排列是强调元素顺序**。
53 |
54 | 例如:{1, 2} 和 {2, 1} 在组合上,就是一个集合,因为不强调顺序,而要是排列的话,{1, 2} 和 {2, 1} 就是两个集合了。
55 |
56 | 记住组合无序,排列有序,就可以了。
57 |
58 | ## 如何理解回溯法
59 |
60 | **回溯法解决的问题都可以抽象为树形结构**,是的,我指的是所有回溯法的问题都可以抽象为树形结构!
61 |
62 | 因为回溯法解决的都是在集合中递归查找子集,**集合的大小就构成了树的宽度,递归的深度,都构成的树的深度**。
63 |
64 | 递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
65 |
66 | 这块可能初学者还不太理解,后面的回溯算法解决的所有题目中,我都会强调这一点并画图举相应的例子,现在有一个印象就行。
67 |
68 |
69 | ## 回溯法模板
70 |
71 | 这里给出Carl总结的回溯算法模板。
72 |
73 | 在讲[二叉树的递归](https://programmercarl.com/二叉树的递归遍历.html)中我们说了递归三部曲,这里我再给大家列出回溯三部曲。
74 |
75 | * 回溯函数模板返回值以及参数
76 |
77 | 在回溯算法中,我的习惯是函数起名字为backtracking,这个起名大家随意。
78 |
79 | 回溯算法中函数返回值一般为void。
80 |
81 | 再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
82 |
83 | 但后面的回溯题目的讲解中,为了方便大家理解,我在一开始就帮大家把参数确定下来。
84 |
85 | 回溯函数伪代码如下:
86 |
87 | ```
88 | void backtracking(参数)
89 | ```
90 |
91 | * 回溯函数终止条件
92 |
93 | 既然是树形结构,那么我们在讲解[二叉树的递归](https://programmercarl.com/二叉树的递归遍历.html)的时候,就知道遍历树形结构一定要有终止条件。
94 |
95 | 所以回溯也有要终止条件。
96 |
97 | 什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
98 |
99 | 所以回溯函数终止条件伪代码如下:
100 | ```
101 | if (终止条件) {
102 | 存放结果;
103 | return;
104 | }
105 | ```
106 |
107 | * 回溯搜索的遍历过程
108 |
109 | 在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
110 |
111 | 如图:
112 |
113 | 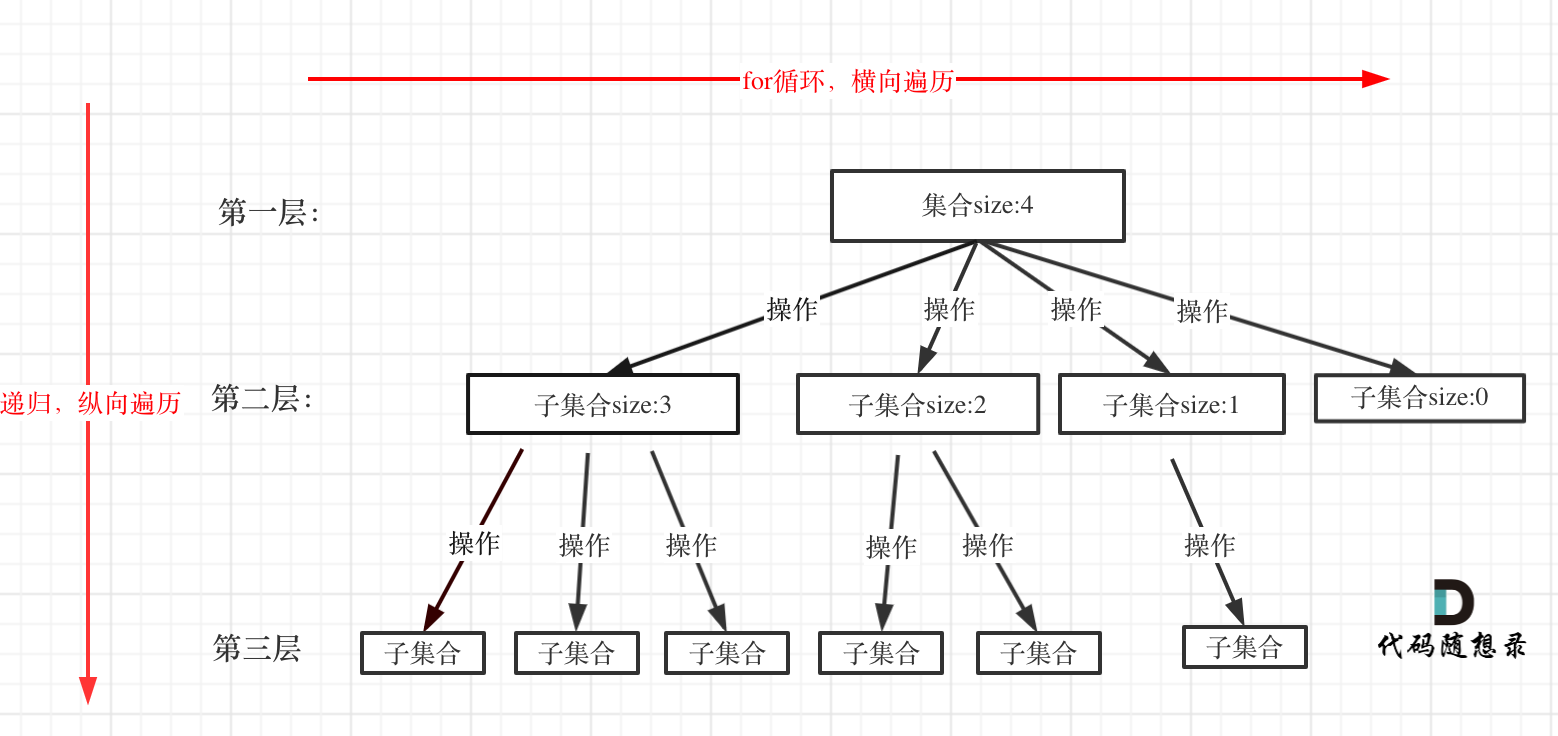
114 |
115 | 注意图中,我特意举例集合大小和孩子的数量是相等的!
116 |
117 | 回溯函数遍历过程伪代码如下:
118 | ```
119 | for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
120 | 处理节点;
121 | backtracking(路径,选择列表); // 递归
122 | 回溯,撤销处理结果
123 | }
124 | ```
125 |
126 |
127 | for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
128 |
129 | backtracking这里自己调用自己,实现递归。
130 |
131 | 大家可以从图中看出**for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历**,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
132 |
133 | 分析完过程,回溯算法模板框架如下:
134 |
135 | ```
136 | void backtracking(参数) {
137 | if (终止条件) {
138 | 存放结果;
139 | return;
140 | }
141 |
142 | for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
143 | 处理节点;
144 | backtracking(路径,选择列表); // 递归
145 | 回溯,撤销处理结果
146 | }
147 | }
148 |
149 | ```
150 |
151 | **这份模板很重要,后面做回溯法的题目都靠它了!**
152 |
153 | 如果从来没有学过回溯算法的录友们,看到这里会有点懵,后面开始讲解具体题目的时候就会好一些了,已经做过回溯法题目的录友,看到这里应该会感同身受了。
154 |
155 | ## 总结
156 |
157 | 本篇我们讲解了,什么是回溯算法,知道了回溯和递归是相辅相成的。
158 |
159 | 接着提到了回溯法的效率,回溯法其实就是暴力查找,并不是什么高效的算法。
160 |
161 | 然后列出了回溯法可以解决几类问题,可以看出每一类问题都不简单。
162 |
163 | 最后我们讲到回溯法解决的问题都可以抽象为树形结构(N叉树),并给出了回溯法的模板。
164 |
165 | 今天是回溯算法的第一天,按照惯例Carl都是先概述一波,然后在开始讲解具体题目,没有接触过回溯法的同学刚学起来有点看不懂很正常,后面和具体题目结合起来会好一些。
166 |
167 |
168 |
169 |
170 |
171 |
172 |
175 |
176 |
--------------------------------------------------------------------------------
/problems/周总结/20210121动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(动态规划系列三)
3 |
4 | 本周我们正式开始讲解背包问题,也是动规里非常重要的一类问题。
5 |
6 | 背包问题其实有很多细节,如果了解个大概,然后也能一气呵成把代码写出来,但稍稍变变花样可能会陷入迷茫了。
7 |
8 | 开始回顾一下本周的内容吧!
9 |
10 | ## 周一
11 |
12 | [动态规划:关于01背包问题,你该了解这些!](https://programmercarl.com/背包理论基础01背包-1.html)中,我们开始介绍了背包问题。
13 |
14 | 首先对于背包的所有问题中,01背包是最最基础的,其他背包也是在01背包的基础上稍作变化。
15 |
16 | 所以我才花费这么大精力去讲解01背包。
17 |
18 | 关于其他几种常用的背包,大家看这张图就了然于胸了:
19 |
20 | 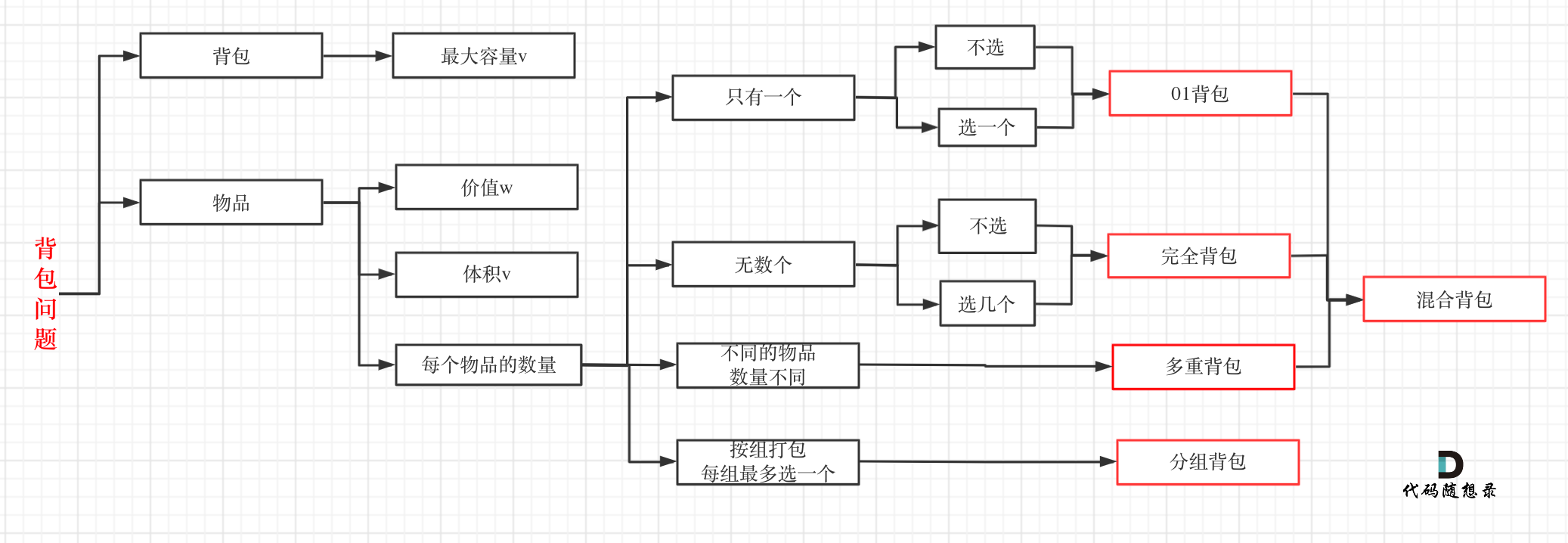
21 |
22 | 本文用动规五部曲详细讲解了01背包的二维dp数组的实现方法,大家其实可以发现最简单的是推导公式了,推导公式估计看一遍就记下来了,但难就难在确定初始化和遍历顺序上。
23 |
24 | 1. 确定dp数组以及下标的含义
25 |
26 | dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
27 |
28 | 2. 确定递推公式
29 |
30 | dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
31 |
32 | 3. dp数组如何初始化
33 |
34 | ```CPP
35 | // 初始化 dp
36 | vector
164 |
--------------------------------------------------------------------------------
/problems/哈希表总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
131 |
132 |
--------------------------------------------------------------------------------
/problems/图论广索理论基础.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
130 |
131 |
--------------------------------------------------------------------------------
/problems/0283.移动零.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
161 |
162 |
--------------------------------------------------------------------------------
/problems/0724.寻找数组的中心索引.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
165 |
166 |
--------------------------------------------------------------------------------
/problems/周总结/20210114动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | ## 周一
3 |
4 | [动态规划:不同路径](https://programmercarl.com/0062.不同路径.html)中求从出发点到终点有几种路径,只能向下或者向右移动一步。
5 |
6 | 我们提供了三种方法,但重点讲解的还是动规,也是需要重点掌握的。
7 |
8 | **dp[i][j]定义 :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径**。
9 |
10 | 本题在初始化的时候需要点思考了,即:
11 |
12 | dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理。
13 |
14 | 所以初始化为:
15 |
16 | ```
17 | for (int i = 0; i < m; i++) dp[i][0] = 1;
18 | for (int j = 0; j < n; j++) dp[0][j] = 1;
19 | ```
20 |
21 | 这里已经不像之前做过的题目,随便赋个0就行的。
22 |
23 | 遍历顺序以及递推公式:
24 |
25 | ```
26 | for (int i = 1; i < m; i++) {
27 | for (int j = 1; j < n; j++) {
28 | dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
29 | }
30 | }
31 | ```
32 |
33 | 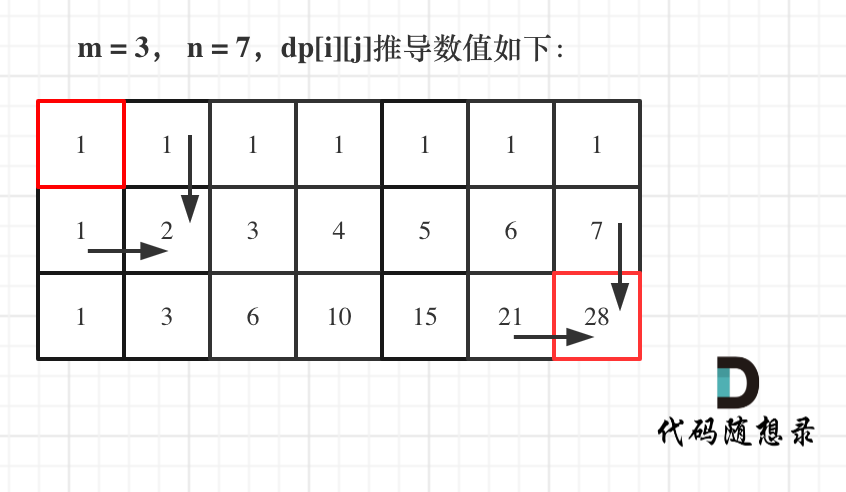
34 |
35 |
36 | ## 周二
37 |
38 | [动态规划:不同路径还不够,要有障碍!](https://programmercarl.com/0063.不同路径II.html)相对于[动态规划:不同路径](https://programmercarl.com/0062.不同路径.html)添加了障碍。
39 |
40 | dp[i][j]定义依然是:表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
41 |
42 |
43 | 本题难点在于初始化,如果(i, 0) 这条边有了障碍之后,障碍之后(包括障碍)都是走不到的位置了,所以障碍之后的dp[i][0]应该还是初始值0。
44 |
45 | 如图:
46 |
47 | 
48 |
49 |
50 | 这里难住了不少同学,代码如下:
51 |
52 | ```
53 | vector
162 |
--------------------------------------------------------------------------------
/problems/1254.统计封闭岛屿的数目.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
140 |
141 |
142 |
143 |
--------------------------------------------------------------------------------
/problems/0141.环形链表.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
12 |
13 | 可以配合我的B站视频:[带你学透回溯算法(理论篇)](https://www.bilibili.com/video/BV1cy4y167mM/) 一起学习!
14 |
15 | ## 什么是回溯法
16 |
17 | 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
18 |
19 | 在二叉树系列中,我们已经不止一次,提到了回溯,例如[二叉树:以为使用了递归,其实还隐藏着回溯](https://programmercarl.com/二叉树中递归带着回溯.html)。
20 |
21 | 回溯是递归的副产品,只要有递归就会有回溯。
22 |
23 | **所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数**。
24 |
25 | ## 回溯法的效率
26 |
27 | 回溯法的性能如何呢,这里要和大家说清楚了,**虽然回溯法很难,很不好理解,但是回溯法并不是什么高效的算法**。
28 |
29 | **因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案**,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
30 |
31 | 那么既然回溯法并不高效为什么还要用它呢?
32 |
33 | 因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
34 |
35 | 此时大家应该好奇了,都什么问题,这么牛逼,只能暴力搜索。
36 |
37 | ## 回溯法解决的问题
38 |
39 | 回溯法,一般可以解决如下几种问题:
40 |
41 | * 组合问题:N个数里面按一定规则找出k个数的集合
42 | * 切割问题:一个字符串按一定规则有几种切割方式
43 | * 子集问题:一个N个数的集合里有多少符合条件的子集
44 | * 排列问题:N个数按一定规则全排列,有几种排列方式
45 | * 棋盘问题:N皇后,解数独等等
46 |
47 | **相信大家看着这些之后会发现,每个问题,都不简单!**
48 |
49 |
50 | 另外,会有一些同学可能分不清什么是组合,什么是排列?
51 |
52 | **组合是不强调元素顺序的,排列是强调元素顺序**。
53 |
54 | 例如:{1, 2} 和 {2, 1} 在组合上,就是一个集合,因为不强调顺序,而要是排列的话,{1, 2} 和 {2, 1} 就是两个集合了。
55 |
56 | 记住组合无序,排列有序,就可以了。
57 |
58 | ## 如何理解回溯法
59 |
60 | **回溯法解决的问题都可以抽象为树形结构**,是的,我指的是所有回溯法的问题都可以抽象为树形结构!
61 |
62 | 因为回溯法解决的都是在集合中递归查找子集,**集合的大小就构成了树的宽度,递归的深度,都构成的树的深度**。
63 |
64 | 递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
65 |
66 | 这块可能初学者还不太理解,后面的回溯算法解决的所有题目中,我都会强调这一点并画图举相应的例子,现在有一个印象就行。
67 |
68 |
69 | ## 回溯法模板
70 |
71 | 这里给出Carl总结的回溯算法模板。
72 |
73 | 在讲[二叉树的递归](https://programmercarl.com/二叉树的递归遍历.html)中我们说了递归三部曲,这里我再给大家列出回溯三部曲。
74 |
75 | * 回溯函数模板返回值以及参数
76 |
77 | 在回溯算法中,我的习惯是函数起名字为backtracking,这个起名大家随意。
78 |
79 | 回溯算法中函数返回值一般为void。
80 |
81 | 再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
82 |
83 | 但后面的回溯题目的讲解中,为了方便大家理解,我在一开始就帮大家把参数确定下来。
84 |
85 | 回溯函数伪代码如下:
86 |
87 | ```
88 | void backtracking(参数)
89 | ```
90 |
91 | * 回溯函数终止条件
92 |
93 | 既然是树形结构,那么我们在讲解[二叉树的递归](https://programmercarl.com/二叉树的递归遍历.html)的时候,就知道遍历树形结构一定要有终止条件。
94 |
95 | 所以回溯也有要终止条件。
96 |
97 | 什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
98 |
99 | 所以回溯函数终止条件伪代码如下:
100 | ```
101 | if (终止条件) {
102 | 存放结果;
103 | return;
104 | }
105 | ```
106 |
107 | * 回溯搜索的遍历过程
108 |
109 | 在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
110 |
111 | 如图:
112 |
113 | 
114 |
115 | 注意图中,我特意举例集合大小和孩子的数量是相等的!
116 |
117 | 回溯函数遍历过程伪代码如下:
118 | ```
119 | for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
120 | 处理节点;
121 | backtracking(路径,选择列表); // 递归
122 | 回溯,撤销处理结果
123 | }
124 | ```
125 |
126 |
127 | for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
128 |
129 | backtracking这里自己调用自己,实现递归。
130 |
131 | 大家可以从图中看出**for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历**,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
132 |
133 | 分析完过程,回溯算法模板框架如下:
134 |
135 | ```
136 | void backtracking(参数) {
137 | if (终止条件) {
138 | 存放结果;
139 | return;
140 | }
141 |
142 | for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
143 | 处理节点;
144 | backtracking(路径,选择列表); // 递归
145 | 回溯,撤销处理结果
146 | }
147 | }
148 |
149 | ```
150 |
151 | **这份模板很重要,后面做回溯法的题目都靠它了!**
152 |
153 | 如果从来没有学过回溯算法的录友们,看到这里会有点懵,后面开始讲解具体题目的时候就会好一些了,已经做过回溯法题目的录友,看到这里应该会感同身受了。
154 |
155 | ## 总结
156 |
157 | 本篇我们讲解了,什么是回溯算法,知道了回溯和递归是相辅相成的。
158 |
159 | 接着提到了回溯法的效率,回溯法其实就是暴力查找,并不是什么高效的算法。
160 |
161 | 然后列出了回溯法可以解决几类问题,可以看出每一类问题都不简单。
162 |
163 | 最后我们讲到回溯法解决的问题都可以抽象为树形结构(N叉树),并给出了回溯法的模板。
164 |
165 | 今天是回溯算法的第一天,按照惯例Carl都是先概述一波,然后在开始讲解具体题目,没有接触过回溯法的同学刚学起来有点看不懂很正常,后面和具体题目结合起来会好一些。
166 |
167 |
168 |
169 |
170 |
171 |
172 |
175 |
176 |
--------------------------------------------------------------------------------
/problems/周总结/20210121动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(动态规划系列三)
3 |
4 | 本周我们正式开始讲解背包问题,也是动规里非常重要的一类问题。
5 |
6 | 背包问题其实有很多细节,如果了解个大概,然后也能一气呵成把代码写出来,但稍稍变变花样可能会陷入迷茫了。
7 |
8 | 开始回顾一下本周的内容吧!
9 |
10 | ## 周一
11 |
12 | [动态规划:关于01背包问题,你该了解这些!](https://programmercarl.com/背包理论基础01背包-1.html)中,我们开始介绍了背包问题。
13 |
14 | 首先对于背包的所有问题中,01背包是最最基础的,其他背包也是在01背包的基础上稍作变化。
15 |
16 | 所以我才花费这么大精力去讲解01背包。
17 |
18 | 关于其他几种常用的背包,大家看这张图就了然于胸了:
19 |
20 | 
21 |
22 | 本文用动规五部曲详细讲解了01背包的二维dp数组的实现方法,大家其实可以发现最简单的是推导公式了,推导公式估计看一遍就记下来了,但难就难在确定初始化和遍历顺序上。
23 |
24 | 1. 确定dp数组以及下标的含义
25 |
26 | dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
27 |
28 | 2. 确定递推公式
29 |
30 | dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
31 |
32 | 3. dp数组如何初始化
33 |
34 | ```CPP
35 | // 初始化 dp
36 | vector
164 |
--------------------------------------------------------------------------------
/problems/哈希表总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
131 |
132 |
--------------------------------------------------------------------------------
/problems/图论广索理论基础.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
130 |
131 |
--------------------------------------------------------------------------------
/problems/0283.移动零.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
161 |
162 |
--------------------------------------------------------------------------------
/problems/0724.寻找数组的中心索引.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
165 |
166 |
--------------------------------------------------------------------------------
/problems/周总结/20210114动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | ## 周一
3 |
4 | [动态规划:不同路径](https://programmercarl.com/0062.不同路径.html)中求从出发点到终点有几种路径,只能向下或者向右移动一步。
5 |
6 | 我们提供了三种方法,但重点讲解的还是动规,也是需要重点掌握的。
7 |
8 | **dp[i][j]定义 :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径**。
9 |
10 | 本题在初始化的时候需要点思考了,即:
11 |
12 | dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理。
13 |
14 | 所以初始化为:
15 |
16 | ```
17 | for (int i = 0; i < m; i++) dp[i][0] = 1;
18 | for (int j = 0; j < n; j++) dp[0][j] = 1;
19 | ```
20 |
21 | 这里已经不像之前做过的题目,随便赋个0就行的。
22 |
23 | 遍历顺序以及递推公式:
24 |
25 | ```
26 | for (int i = 1; i < m; i++) {
27 | for (int j = 1; j < n; j++) {
28 | dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
29 | }
30 | }
31 | ```
32 |
33 | 
34 |
35 |
36 | ## 周二
37 |
38 | [动态规划:不同路径还不够,要有障碍!](https://programmercarl.com/0063.不同路径II.html)相对于[动态规划:不同路径](https://programmercarl.com/0062.不同路径.html)添加了障碍。
39 |
40 | dp[i][j]定义依然是:表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
41 |
42 |
43 | 本题难点在于初始化,如果(i, 0) 这条边有了障碍之后,障碍之后(包括障碍)都是走不到的位置了,所以障碍之后的dp[i][0]应该还是初始值0。
44 |
45 | 如图:
46 |
47 | 
48 |
49 |
50 | 这里难住了不少同学,代码如下:
51 |
52 | ```
53 | vector
162 |
--------------------------------------------------------------------------------
/problems/1254.统计封闭岛屿的数目.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
140 |
141 |
142 |
143 |
--------------------------------------------------------------------------------
/problems/0141.环形链表.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |  35 |
36 | fast和slow各自再走一步, fast和slow就相遇了
37 |
38 | 这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
39 |
40 | 动画如下:
41 |
42 |
43 | 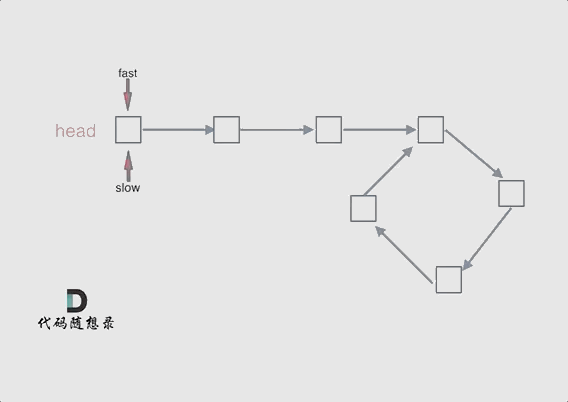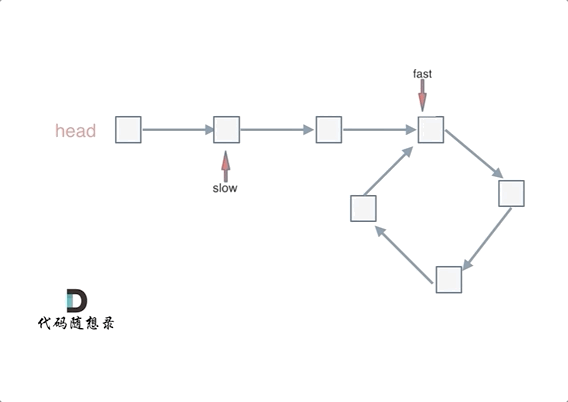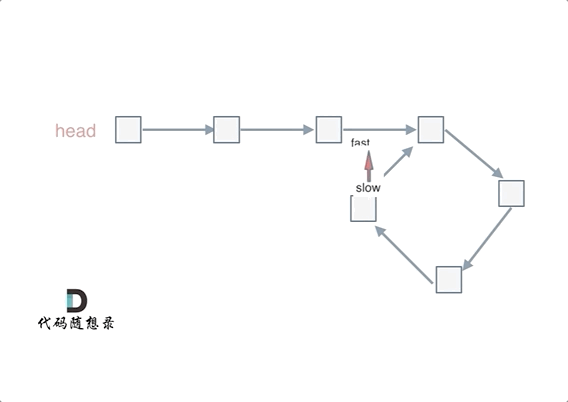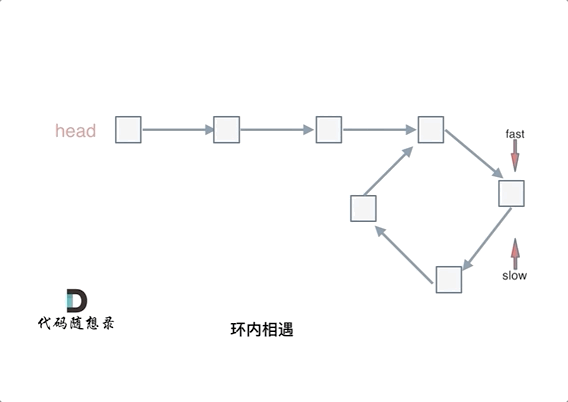
44 |
45 |
46 | C++代码如下
47 |
48 | ```CPP
49 | class Solution {
50 | public:
51 | bool hasCycle(ListNode *head) {
52 | ListNode* fast = head;
53 | ListNode* slow = head;
54 | while(fast != NULL && fast->next != NULL) {
55 | slow = slow->next;
56 | fast = fast->next->next;
57 | // 快慢指针相遇,说明有环
58 | if (slow == fast) return true;
59 | }
60 | return false;
61 | }
62 | };
63 | ```
64 |
65 | ## 扩展
66 |
67 | 做完这道题目,可以在做做[142.环形链表II](https://programmercarl.com/0142.%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A8II.html),不仅仅要找环,还要找环的入口。
68 |
69 |
70 |
71 | ## 其他语言版本
72 |
73 | ### Java
74 |
75 | ```java
76 | public class Solution {
77 | public boolean hasCycle(ListNode head) {
78 | ListNode fast = head;
79 | ListNode slow = head;
80 | // 空链表、单节点链表一定不会有环
81 | while (fast != null && fast.next != null) {
82 | fast = fast.next.next; // 快指针,一次移动两步
83 | slow = slow.next; // 慢指针,一次移动一步
84 | if (fast == slow) { // 快慢指针相遇,表明有环
85 | return true;
86 | }
87 | }
88 | return false; // 正常走到链表末尾,表明没有环
89 | }
90 | }
91 | ```
92 |
93 | ### Python
94 |
95 | ```python
96 | class Solution:
97 | def hasCycle(self, head: ListNode) -> bool:
98 | if not head: return False
99 | slow, fast = head, head
100 | while fast and fast.next:
101 | slow = slow.next
102 | fast = fast.next.next
103 | if fast == slow:
104 | return True
105 | return False
106 | ```
107 |
108 | ### Go
109 |
110 | ```go
111 | func hasCycle(head *ListNode) bool {
112 | if head==nil{
113 | return false
114 | } //空链表一定不会有环
115 | fast:=head
116 | slow:=head //快慢指针
117 | for fast.Next!=nil&&fast.Next.Next!=nil{
118 | fast=fast.Next.Next
119 | slow=slow.Next
120 | if fast==slow{
121 | return true //快慢指针相遇则有环
122 | }
123 | }
124 | return false
125 | }
126 | ```
127 |
128 | ### JavaScript
129 |
130 | ```js
131 | var hasCycle = function(head) {
132 | let fast = head;
133 | let slow = head;
134 | // 空链表、单节点链表一定不会有环
135 | while(fast != null && fast.next != null){
136 | fast = fast.next.next; // 快指针,一次移动两步
137 | slow = slow.next; // 慢指针,一次移动一步
138 | if(fast === slow) return true; // 快慢指针相遇,表明有环
139 | }
140 | return false; // 正常走到链表末尾,表明没有环
141 | };
142 | ```
143 |
144 | ### TypeScript
145 |
146 | ```typescript
147 | function hasCycle(head: ListNode | null): boolean {
148 | let slowNode: ListNode | null = head,
149 | fastNode: ListNode | null = head;
150 | while (fastNode !== null && fastNode.next !== null) {
151 | slowNode = slowNode!.next;
152 | fastNode = fastNode.next.next;
153 | if (slowNode === fastNode) return true;
154 | }
155 | return false;
156 | };
157 | ```
158 |
159 |
160 |
161 |
162 |
165 |
166 |
--------------------------------------------------------------------------------
/problems/0657.机器人能否返回原点.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
35 |
36 | fast和slow各自再走一步, fast和slow就相遇了
37 |
38 | 这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
39 |
40 | 动画如下:
41 |
42 |
43 | 
44 |
45 |
46 | C++代码如下
47 |
48 | ```CPP
49 | class Solution {
50 | public:
51 | bool hasCycle(ListNode *head) {
52 | ListNode* fast = head;
53 | ListNode* slow = head;
54 | while(fast != NULL && fast->next != NULL) {
55 | slow = slow->next;
56 | fast = fast->next->next;
57 | // 快慢指针相遇,说明有环
58 | if (slow == fast) return true;
59 | }
60 | return false;
61 | }
62 | };
63 | ```
64 |
65 | ## 扩展
66 |
67 | 做完这道题目,可以在做做[142.环形链表II](https://programmercarl.com/0142.%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A8II.html),不仅仅要找环,还要找环的入口。
68 |
69 |
70 |
71 | ## 其他语言版本
72 |
73 | ### Java
74 |
75 | ```java
76 | public class Solution {
77 | public boolean hasCycle(ListNode head) {
78 | ListNode fast = head;
79 | ListNode slow = head;
80 | // 空链表、单节点链表一定不会有环
81 | while (fast != null && fast.next != null) {
82 | fast = fast.next.next; // 快指针,一次移动两步
83 | slow = slow.next; // 慢指针,一次移动一步
84 | if (fast == slow) { // 快慢指针相遇,表明有环
85 | return true;
86 | }
87 | }
88 | return false; // 正常走到链表末尾,表明没有环
89 | }
90 | }
91 | ```
92 |
93 | ### Python
94 |
95 | ```python
96 | class Solution:
97 | def hasCycle(self, head: ListNode) -> bool:
98 | if not head: return False
99 | slow, fast = head, head
100 | while fast and fast.next:
101 | slow = slow.next
102 | fast = fast.next.next
103 | if fast == slow:
104 | return True
105 | return False
106 | ```
107 |
108 | ### Go
109 |
110 | ```go
111 | func hasCycle(head *ListNode) bool {
112 | if head==nil{
113 | return false
114 | } //空链表一定不会有环
115 | fast:=head
116 | slow:=head //快慢指针
117 | for fast.Next!=nil&&fast.Next.Next!=nil{
118 | fast=fast.Next.Next
119 | slow=slow.Next
120 | if fast==slow{
121 | return true //快慢指针相遇则有环
122 | }
123 | }
124 | return false
125 | }
126 | ```
127 |
128 | ### JavaScript
129 |
130 | ```js
131 | var hasCycle = function(head) {
132 | let fast = head;
133 | let slow = head;
134 | // 空链表、单节点链表一定不会有环
135 | while(fast != null && fast.next != null){
136 | fast = fast.next.next; // 快指针,一次移动两步
137 | slow = slow.next; // 慢指针,一次移动一步
138 | if(fast === slow) return true; // 快慢指针相遇,表明有环
139 | }
140 | return false; // 正常走到链表末尾,表明没有环
141 | };
142 | ```
143 |
144 | ### TypeScript
145 |
146 | ```typescript
147 | function hasCycle(head: ListNode | null): boolean {
148 | let slowNode: ListNode | null = head,
149 | fastNode: ListNode | null = head;
150 | while (fastNode !== null && fastNode.next !== null) {
151 | slowNode = slowNode!.next;
152 | fastNode = fastNode.next.next;
153 | if (slowNode === fastNode) return true;
154 | }
155 | return false;
156 | };
157 | ```
158 |
159 |
160 |
161 |
162 |
165 |
166 |
--------------------------------------------------------------------------------
/problems/0657.机器人能否返回原点.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |  46 |
47 | C++代码如下:
48 |
49 | ```CPP
50 | class Solution {
51 | public:
52 | bool judgeCircle(string moves) {
53 | int x = 0, y = 0;
54 | for (int i = 0; i < moves.size(); i++) {
55 | if (moves[i] == 'U') y++;
56 | if (moves[i] == 'D') y--;
57 | if (moves[i] == 'L') x--;
58 | if (moves[i] == 'R') x++;
59 | }
60 | if (x == 0 && y == 0) return true;
61 | return false;
62 | }
63 | };
64 | ```
65 |
66 |
67 | # 其他语言版本
68 |
69 | ## Java
70 |
71 | ```java
72 | // 时间复杂度:O(n)
73 | // 空间复杂度:如果采用 toCharArray,则是 O(n);如果使用 charAt,则是 O(1)
74 | class Solution {
75 | public boolean judgeCircle(String moves) {
76 | int x = 0;
77 | int y = 0;
78 | for (char c : moves.toCharArray()) {
79 | if (c == 'U') y++;
80 | if (c == 'D') y--;
81 | if (c == 'L') x++;
82 | if (c == 'R') x--;
83 | }
84 | return x == 0 && y == 0;
85 | }
86 | }
87 | ```
88 |
89 | ## Python
90 |
91 | ```python
92 | # 时间复杂度:O(n)
93 | # 空间复杂度:O(1)
94 | class Solution:
95 | def judgeCircle(self, moves: str) -> bool:
96 | x = 0 # 记录当前位置
97 | y = 0
98 | for i in range(len(moves)):
99 | if (moves[i] == 'U'):
100 | y += 1
101 | if (moves[i] == 'D'):
102 | y -= 1
103 | if (moves[i] == 'L'):
104 | x += 1
105 | if (moves[i] == 'R'):
106 | x -= 1
107 | return x == 0 and y == 0
108 | ```
109 |
110 | ## Go
111 |
112 | ```go
113 | func judgeCircle(moves string) bool {
114 | x := 0
115 | y := 0
116 | for i := 0; i < len(moves); i++ {
117 | if moves[i] == 'U' {
118 | y++
119 | }
120 | if moves[i] == 'D' {
121 | y--
122 | }
123 | if moves[i] == 'L' {
124 | x++
125 | }
126 | if moves[i] == 'R' {
127 | x--
128 | }
129 | }
130 | return x == 0 && y == 0;
131 | }
132 | ```
133 |
134 | ## JavaScript
135 |
136 | ```js
137 | // 时间复杂度:O(n)
138 | // 空间复杂度:O(1)
139 | var judgeCircle = function(moves) {
140 | var x = 0; // 记录当前位置
141 | var y = 0;
142 | for (var i = 0; i < moves.length; i++) {
143 | if (moves[i] == 'U') y++;
144 | if (moves[i] == 'D') y--;
145 | if (moves[i] == 'L') x++;
146 | if (moves[i] == 'R') x--;
147 | }
148 | return x == 0 && y == 0;
149 | };
150 | ```
151 |
152 |
153 | ## TypeScript
154 |
155 | ```ts
156 | var judgeCircle = function (moves) {
157 | let x = 0
158 | let y = 0
159 | for (let i = 0; i < moves.length; i++) {
160 | switch (moves[i]) {
161 | case 'L': {
162 | x--
163 | break
164 | }
165 | case 'R': {
166 | x++
167 | break
168 | }
169 | case 'U': {
170 | y--
171 | break
172 | }
173 | case 'D': {
174 | y++
175 | break
176 | }
177 | }
178 | }
179 | return x === 0 && y === 0
180 | };
181 | ```
182 |
183 |
184 |
187 |
188 |
--------------------------------------------------------------------------------
/problems/0377.组合总和IV二维dp数组.md:
--------------------------------------------------------------------------------
1 | # 完全背包的排列问题模拟
2 |
3 | #### Problem
4 |
5 | 1. 排列问题是完全背包中十分棘手的问题。
6 | 2. 其在迭代过程中需要先迭代背包容量,再迭代物品个数,使得其在代码理解上较难入手。
7 |
8 | #### Contribution
9 |
10 | 本文档以力扣上[组合总和IV](https://leetcode.cn/problems/combination-sum-iv/)为例,提供一个二维dp的代码例子,并提供模拟过程以便于理解
11 |
12 | #### Code
13 |
14 | ```cpp
15 | int combinationSum4(vector
168 |
--------------------------------------------------------------------------------
/problems/哈希表理论基础.md:
--------------------------------------------------------------------------------
1 |
2 |
5 |
6 |
135 |
136 |
--------------------------------------------------------------------------------
/problems/周总结/20210304动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | 本周的主题就是股票系列,来一起回顾一下吧
3 |
4 | ## 周一
5 |
6 | [动态规划:买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II(动态规划).html)中股票可以买卖多次了!
7 |
8 | 这也是和[121. 买卖股票的最佳时机](https://programmercarl.com/0121.买卖股票的最佳时机.html)的唯一区别(注意只有一只股票,所以再次购买前要出售掉之前的股票)
9 |
10 | 重点在于递推公式的不同。
11 |
12 | 在回顾一下dp数组的含义:
13 |
14 | * dp[i][0] 表示第i天持有股票所得现金。
15 | * dp[i][1] 表示第i天不持有股票所得最多现金
16 |
17 |
18 | 递推公式:
19 |
20 | ```
21 | dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
22 | dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
23 | ```
24 |
25 | 大家可以发现本题和[121. 买卖股票的最佳时机](https://programmercarl.com/0121.买卖股票的最佳时机.html)的代码几乎一样,唯一的区别在:
26 |
27 | ```
28 | dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
29 | ```
30 |
31 | **这正是因为本题的股票可以买卖多次!** 所以买入股票的时候,可能会有之前买卖的利润即:dp[i - 1][1],所以dp[i - 1][1] - prices[i]。
32 |
33 | ## 周二
34 |
35 | [动态规划:买卖股票的最佳时机III](https://programmercarl.com/0123.买卖股票的最佳时机III.html)中最多只能完成两笔交易。
36 |
37 | **这意味着可以买卖一次,可以买卖两次,也可以不买卖**。
38 |
39 |
40 | 1. 确定dp数组以及下标的含义
41 |
42 | 一天一共就有五个状态,
43 |
44 | 0. 没有操作
45 | 1. 第一次买入
46 | 2. 第一次卖出
47 | 3. 第二次买入
48 | 4. 第二次卖出
49 |
50 | **dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金**。
51 |
52 | 2. 确定递推公式
53 |
54 | 需要注意:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。
55 |
56 | ```
57 | dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
58 | dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2]);
59 | dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
60 | dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
61 | ```
62 |
63 | 3. dp数组如何初始化
64 |
65 | dp[0][0] = 0;
66 | dp[0][1] = -prices[0];
67 | dp[0][2] = 0;
68 | dp[0][3] = -prices[0];
69 | dp[0][4] = 0;
70 |
71 | 4. 确定遍历顺序
72 |
73 | 从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
74 |
75 | 5. 举例推导dp数组
76 |
77 | 以输入[1,2,3,4,5]为例
78 |
79 | 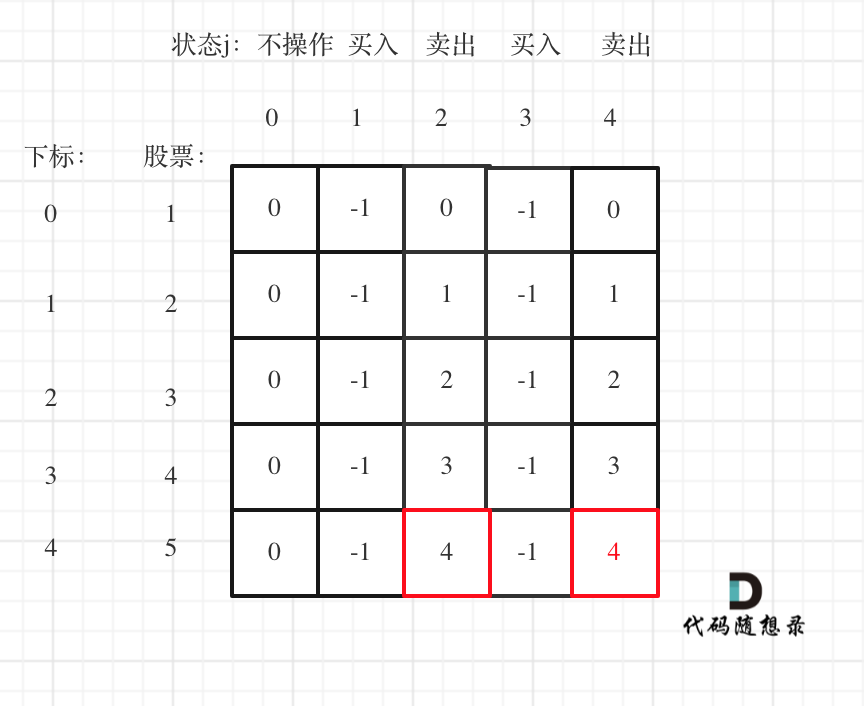
80 |
81 | 可以看到红色框为最后两次卖出的状态。
82 |
83 | 现在最大的时候一定是卖出的状态,而两次卖出的状态现金最大一定是最后一次卖出。
84 |
85 | 所以最终最大利润是dp[4][4]
86 |
87 | ## 周三
88 |
89 | [动态规划:买卖股票的最佳时机IV](https://programmercarl.com/0188.买卖股票的最佳时机IV.html)最多可以完成 k 笔交易。
90 |
91 | 相对于上一道[动态规划:123.买卖股票的最佳时机III](https://programmercarl.com/0123.买卖股票的最佳时机III.html),本题需要通过前两次的交易,来类比前k次的交易
92 |
93 |
94 | 1. 确定dp数组以及下标的含义
95 |
96 | 使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
97 |
98 | j的状态表示为:
99 |
100 | * 0 表示不操作
101 | * 1 第一次买入
102 | * 2 第一次卖出
103 | * 3 第二次买入
104 | * 4 第二次卖出
105 | * .....
106 |
107 | **除了0以外,偶数就是卖出,奇数就是买入**。
108 |
109 |
110 | 2. 确定递推公式
111 |
112 | 还要强调一下:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。
113 |
114 | ```CPP
115 | for (int j = 0; j < 2 * k - 1; j += 2) {
116 | dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
117 | dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
118 | }
119 | ```
120 |
121 | **本题和[动态规划:123.买卖股票的最佳时机III](https://programmercarl.com/0123.买卖股票的最佳时机III.html)最大的区别就是这里要类比j为奇数是买,偶数是卖的状态**。
122 |
123 | 3. dp数组如何初始化
124 |
125 | **dp[0][j]当j为奇数的时候都初始化为 -prices[0]**
126 |
127 | 代码如下:
128 |
129 | ```CPP
130 | for (int j = 1; j < 2 * k; j += 2) {
131 | dp[0][j] = -prices[0];
132 | }
133 | ```
134 |
135 | **在初始化的地方同样要类比j为奇数是买、偶数是卖的状态**。
136 |
137 | 4. 确定遍历顺序
138 |
139 | 从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
140 |
141 | 5. 举例推导dp数组
142 |
143 | 以输入[1,2,3,4,5],k=2为例。
144 |
145 |
146 | 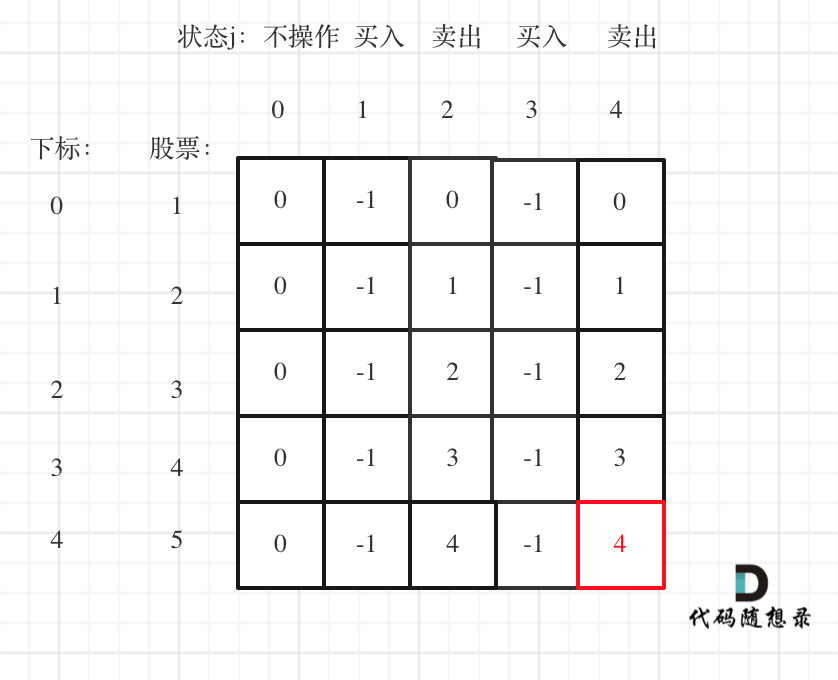
147 |
148 | 最后一次卖出,一定是利润最大的,dp[prices.size() - 1][2 * k]即红色部分就是最后求解。
149 |
150 | ## 周四
151 |
152 | [动态规划:最佳买卖股票时机含冷冻期](https://programmercarl.com/0309.最佳买卖股票时机含冷冻期.html)尽可能地完成更多的交易(多次买卖一支股票),但有冷冻期,冷冻期为1天
153 |
154 | 相对于[动态规划:122.买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II(动态规划).html),本题加上了一个冷冻期
155 |
156 |
157 | **本题则需要第三个状态:不持有股票(冷冻期)的最多现金**。
158 |
159 | 动规五部曲,分析如下:
160 |
161 | 1. 确定dp数组以及下标的含义
162 |
163 | **dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]**。
164 |
165 | j的状态为:
166 |
167 | * 0:持有股票后的最多现金
168 | * 1:不持有股票(能购买)的最多现金
169 | * 2:不持有股票(冷冻期)的最多现金
170 |
171 | 2. 确定递推公式
172 |
173 | ```
174 | dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
175 | dp[i][1] = max(dp[i - 1][1], dp[i - 1][2]);
176 | dp[i][2] = dp[i - 1][0] + prices[i];
177 | ```
178 |
179 | 3. dp数组如何初始化
180 |
181 | 可以统一都初始为0了。
182 |
183 | 代码如下:
184 | ```CPP
185 | vector
209 |
--------------------------------------------------------------------------------
/problems/栈与队列总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
164 |
165 |
--------------------------------------------------------------------------------
/problems/关于时间复杂度,你不知道的都在这里!.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
177 |
178 |
--------------------------------------------------------------------------------
/problems/1020.飞地的数量.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
155 |
156 |
--------------------------------------------------------------------------------
/problems/周总结/20201107回溯周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(回溯算法系列二)
3 |
4 | > 例行每周小结
5 |
6 | ## 周一
7 |
8 | 在[回溯算法:求组合总和(二)](https://programmercarl.com/0039.组合总和.html)中讲解的组合总和问题,和以前的组合问题还都不一样。
9 |
10 | 本题和[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html),[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
11 |
12 | 不少录友都是看到可以重复选择,就义无反顾的把startIndex去掉了。
13 |
14 | **本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?**
15 |
16 | 我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html),[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)。
17 |
18 | 如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[回溯算法:电话号码的字母组合](https://programmercarl.com/0017.电话号码的字母组合.html)
19 |
20 | **注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我再讲解排列的时候就重点介绍**。
21 |
22 | 最后还给出了本题的剪枝优化,如下:
23 |
24 | ```
25 | for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
26 | ```
27 |
28 | 这个优化如果是初学者的话并不容易想到。
29 |
30 | **在求和问题中,排序之后加剪枝是常见的套路!**
31 |
32 | 在[回溯算法:求组合总和(二)](https://programmercarl.com/0039.组合总和.html)第一个树形结构没有画出startIndex的作用,**这里这里纠正一下,准确的树形结构如图所示:**
33 |
34 | 
35 |
36 | ## 周二
37 |
38 | 在[回溯算法:求组合总和(三)](https://programmercarl.com/0040.组合总和II.html)中依旧讲解组合总和问题,本题集合元素会有重复,但要求解集不能包含重复的组合。
39 |
40 | **所以难就难在去重问题上了**。
41 |
42 | 这个去重问题,相信做过的录友都知道有多么的晦涩难懂。网上的题解一般就说“去掉重复”,但说不清怎么个去重,代码一甩就完事了。
43 |
44 | 为了讲解这个去重问题,**我自创了两个词汇,“树枝去重”和“树层去重”**。
45 |
46 | 都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上“使用过”,一个维度是同一树层上“使用过”。**没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因**。
47 |
48 | 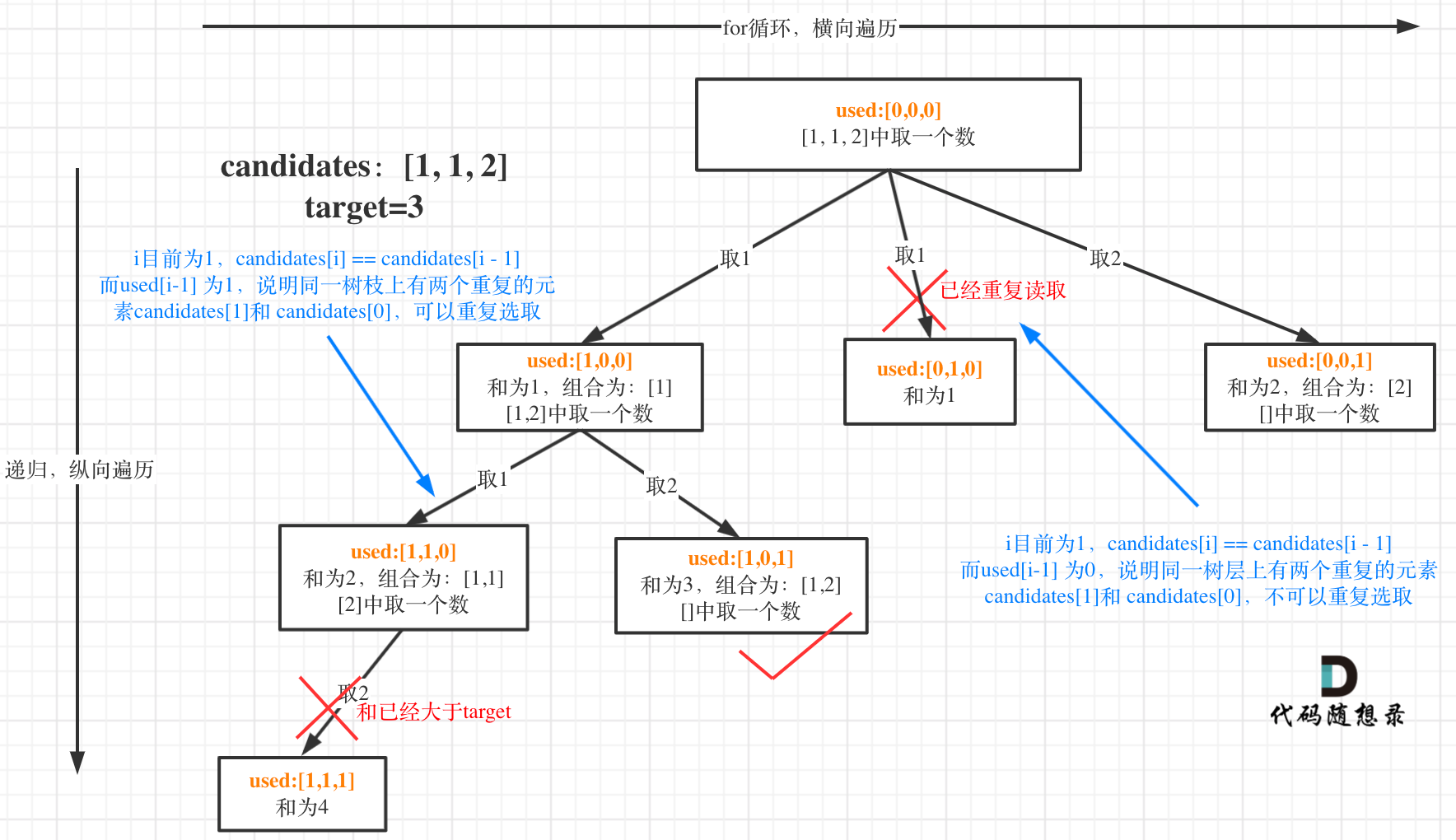
49 |
50 | 我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
51 |
52 | * used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
53 | * used[i - 1] == false,说明同一树层candidates[i - 1]使用过
54 |
55 | **这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!**
56 |
57 | 对于去重,其实排列问题也是一样的道理,后面我会讲到。
58 |
59 |
60 | ## 周三
61 |
62 | 在[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)中,我们开始讲解切割问题,虽然最后代码看起来好像是一道模板题,但是从分析到学会套用这个模板,是比较难的。
63 |
64 | 我列出如下几个难点:
65 |
66 | * 切割问题其实类似组合问题
67 | * 如何模拟那些切割线
68 | * 切割问题中递归如何终止
69 | * 在递归循环中如何截取子串
70 | * 如何判断回文
71 |
72 | 如果想到了**用求解组合问题的思路来解决 切割问题本题就成功一大半了**,接下来就可以对着模板照葫芦画瓢。
73 |
74 | **但后序如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了**。
75 |
76 | 除了这些难点,**本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1**。
77 |
78 | 所以本题应该是一个道hard题目了。
79 |
80 | **本题的树形结构中,和代码的逻辑有一个小出入,已经判断不是回文的子串就不会进入递归了,纠正如下:**
81 |
82 | 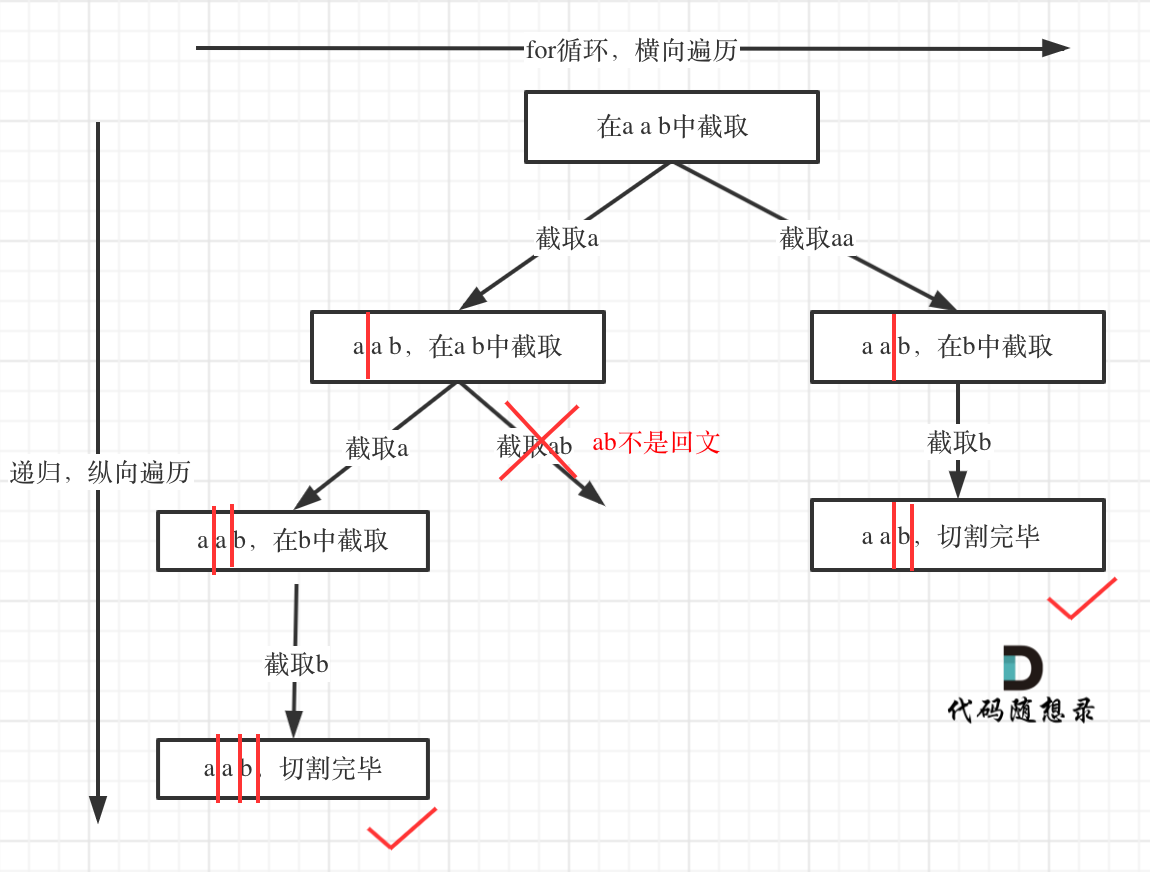
83 |
84 |
85 | ## 周四
86 |
87 | 如果没有做过[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)的话,[回溯算法:复原IP地址](https://programmercarl.com/0093.复原IP地址.html)这道题目应该是比较难的。
88 |
89 | 复原IP照[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)就多了一些限制,例如只能分四段,而且还是更改字符串,插入逗点。
90 |
91 | 树形图如下:
92 |
93 | 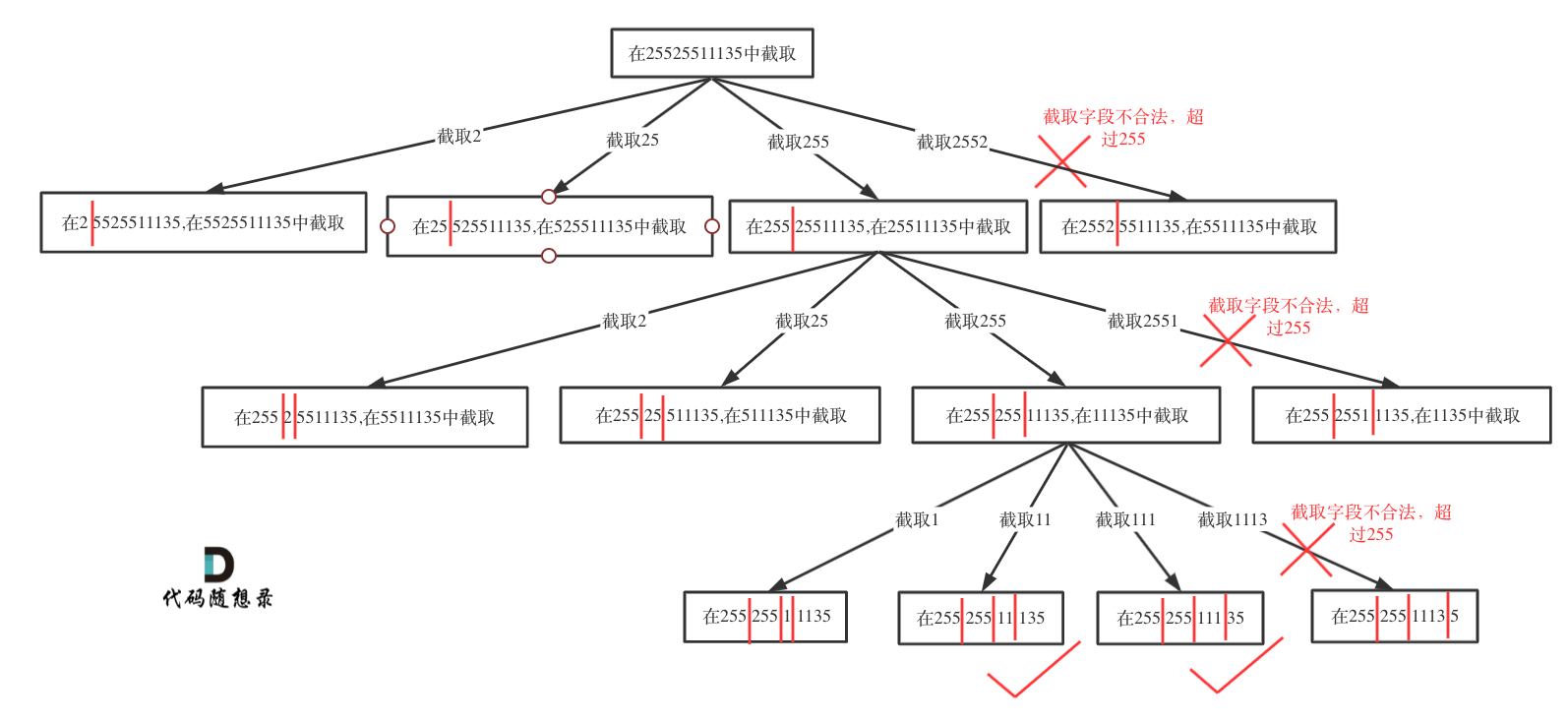
94 |
95 | 在本文的树形结构图中,我已经把详细的分析思路都画了出来,相信大家看了之后一定会思路清晰不少!
96 |
97 | 本题还可以有一个剪枝,合法ip长度为12,如果s的长度超过了12就不是有效IP地址,直接返回!
98 |
99 | 代码如下:
100 |
101 | ```
102 | if (s.size() > 12) return result; // 剪枝
103 |
104 | ```
105 |
106 | 我之前给出的C++代码没有加这个限制,也没有超时,因为在第四段超过长度之后,就会截止了,所以就算给出特别长的字符串,搜索的范围也是有限的(递归只会到第三层),及时就会返回了。
107 |
108 |
109 | ## 周五
110 |
111 | 在[回溯算法:求子集问题!](https://programmercarl.com/0078.子集.html)中讲解了子集问题,**在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果**。
112 |
113 | 如图:
114 |
115 | 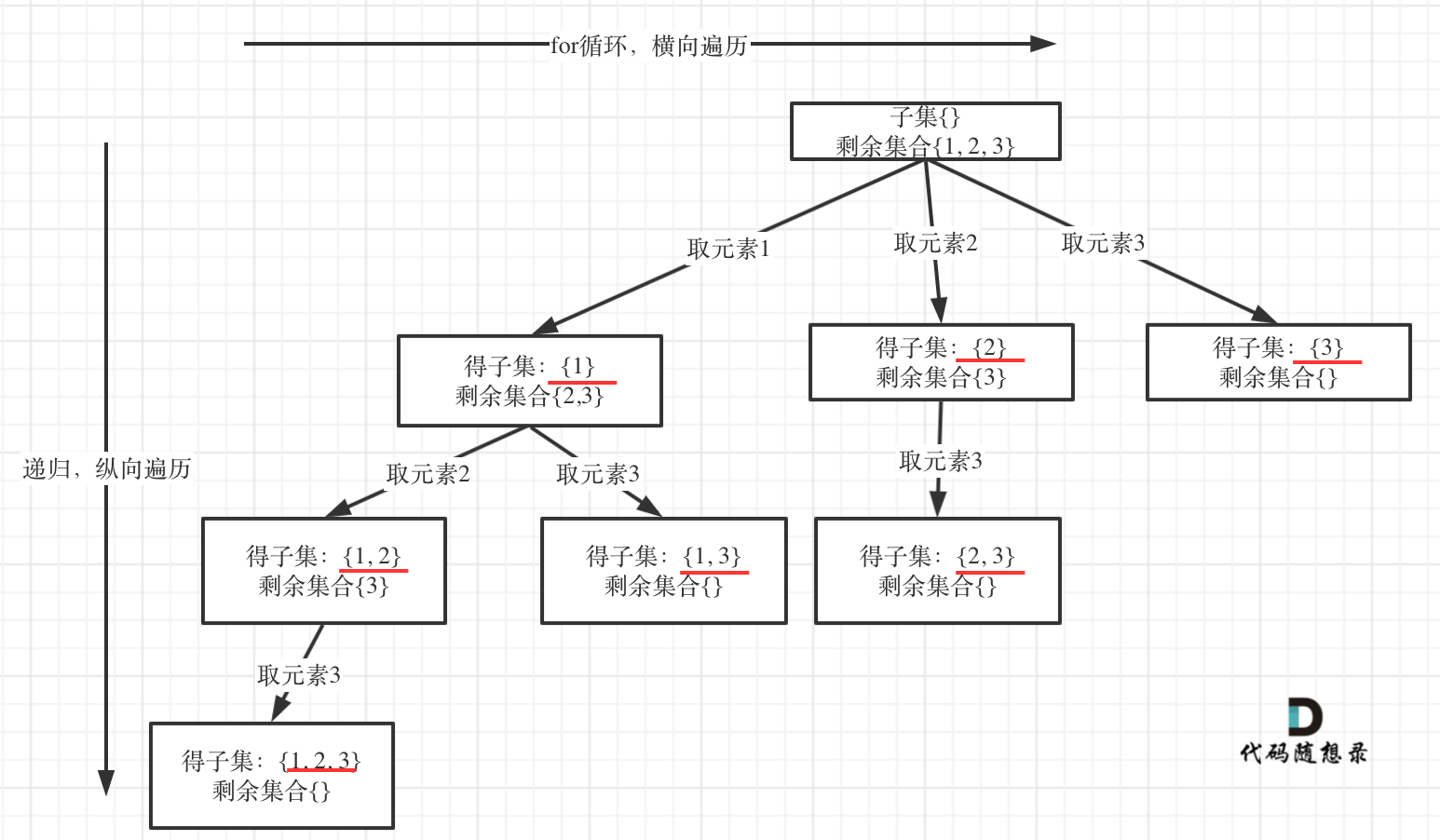
116 |
117 |
118 | 认清这个本质之后,今天的题目就是一道模板题了。
119 |
120 | 其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了,本来我们就要遍历整棵树。
121 |
122 | 有的同学可能担心不写终止条件会不会无限递归?
123 |
124 | 并不会,因为每次递归的下一层就是从i+1开始的。
125 |
126 | 如果要写终止条件,注意:`result.push_back(path);`要放在终止条件的上面,如下:
127 |
128 | ```
129 | result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
130 | if (startIndex >= nums.size()) { // 终止条件可以不加
131 | return;
132 | }
133 | ```
134 |
135 | ## 周六
136 |
137 | 早起的哈希表系列没有总结,所以[哈希表:总结篇!(每逢总结必经典)](https://programmercarl.com/哈希表总结.html)如约而至。
138 |
139 | 可能之前大家做过很多哈希表的题目,但是没有串成线,总结篇来帮你串成线,捋顺哈希表的整个脉络。
140 |
141 | 大家对什么时候各种set与map比较疑惑,想深入了解红黑树,哈希之类的。
142 |
143 | **如果真的只是想清楚什么时候使用各种set与map,不用看那么多,把[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html)看了就够了**。
144 |
145 | ## 总结
146 |
147 | 本周我们依次介绍了组合问题,分割问题以及子集问题,子集问题还没有讲完,下周还会继续。
148 |
149 | **我讲解每一种问题,都会和其他问题作对比,做分析,所以只要跟着细心琢磨相信对回溯又有新的认识**。
150 |
151 | 最近这两天题目有点难度,刚刚开始学回溯算法的话,按照现在这个每天一题的速度来,确实有点快,学起来吃力非常正常,这些题目都是我当初学了好几个月才整明白的,哈哈。
152 |
153 | **所以大家能跟上的话,已经很优秀了!**
154 |
155 | 还有一些录友会很关心leetcode上的耗时统计。
156 |
157 | 这个是很不准确的,相同的代码多提交几次,大家就知道怎么回事了。
158 |
159 | leetcode上的计时应该是以4ms为单位,有的多提交几次,多个4ms就多击败50%,所以比较夸张,如果程序运行是几百ms的级别,可以看看leetcode上的耗时,因为它的误差10几ms对最终影响不大。
160 |
161 | **所以我的题解基本不会写击败百分之多少多少,没啥意义,时间复杂度分析清楚了就可以了**,至于回溯算法不用分析时间复杂度了,都是一样的爆搜,就看谁剪枝厉害了。
162 |
163 | 一些录友表示最近回溯算法看的实在是有点懵,回溯算法确实是晦涩难懂,可能视频的话更直观一些,我最近应该会在B站(同名:「代码随想录」)出回溯算法的视频,大家也可以看视频在回顾一波。
164 |
165 | **就酱,又是充实的一周,做好本周总结,迎接下一周,冲!**
166 |
167 |
168 |
169 |
170 |
--------------------------------------------------------------------------------
/problems/贪心算法总结篇.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
156 |
157 |
--------------------------------------------------------------------------------
/problems/前序/BAT级别技术面试流程和注意事项都在这里了.md:
--------------------------------------------------------------------------------
1 |
2 | # 大厂技术面试流程和注意事项
3 |
4 | 大型互联网企业一般通过几轮技术面试来考察大家的各项能力,一般流程如下:
5 |
6 | * 一面机试:一般会考选择题和编程题
7 | * 二面基础算法面:就是基础的算法都是该专栏要讲的
8 | * 三面综合技术面:会考察编程语言,计算机基础知识 ,以及了解项目经历等等
9 | * 四面技术boss面:会问一些比较范范的内容,考察大家解决问题和快速学习的能力
10 | * 最后hr面:主要了解面试者与企业文化相不相符,面试者的职业发展,offer的选择以及介绍一下企业提供的薪资待遇等等
11 |
12 | 并不是说一定是这五轮面试,不同的公司情况都不一样,甚至同一个公司不同事业群面试的流程都是不一样的
13 |
14 | 可能 一面和二面放到一起,可能三面和四面放到一起,这里尽量将各个维度拆开,让同学们了解 技术面试需要做哪方面的准备。
15 |
16 | 我们来逐一展开分析各个面试环节面试官是从哪些维度来考察大家的
17 |
18 |
19 | ## 一面 机试
20 |
21 | 一面的话通常是 选择题 + 编程题,还有些公司机试都是编程题。
22 |
23 | * 选择题:计算机基础知识涉及计算机网络,操作系统,数据库,编程语言等等
24 | * 编程题:一般是代码量比较大的题目
25 |
26 | 一面机试,**通常校招生的话,BAT的级别的企业 都会提前发笔试题,发到邮箱里然后指定时间内做完,一定要慎重对待,机试没有过,后面就没有面试机会了**
27 |
28 | 机试通常是 **选择题 + 编程题,还有些公司机试都是编程题**
29 |
30 | 选择题则是计算机基础知识涉及计算机网络,操作系统,数据库,编程语言等等,这里如果有些同学对计算机基础心里没有底的话,可以去牛客网上找一找 历年各大公司的机试题目找找感觉。
31 |
32 | 编程题则一般是代码量比较大的题目,图、复杂数据结构或者一些模拟类的题目,编程题目都是我们这门课程会讲述的重点
33 |
34 | 所以也给同学们也推荐一个编程学习的网站,也就是leetcode
35 |
36 | leetcode是专门针对算法练习的题库,leetcode现在也推出了中文网站,所以更方面中国的算法爱好者在上面刷题。 这门课程也是主要在leetcode上选择经典题目。
37 |
38 | 牛客网上涉及到程序员面试的各个环节,有很多国内互联网公司历年面试的题目还是很不错的。
39 |
40 | **建议学习计算机基础知识可以在牛客网上,刷算法题可以选择leetcode。**
41 |
42 | ## 二面 基础算法面
43 |
44 | ### 更注意考察的是思维方式
45 |
46 | 这一块和机试对算法的考察又不一样,机试仅仅就是要一个结果,对了就是对了不对就是不对,
47 |
48 | 而二面的算法面试**面试官更想看到同学们的思考过程**,而不仅仅是一个答案。
49 |
50 | 通常一面机试的题目是代码量比较大的题目,而二面而是一些基础算法
51 |
52 | 面试官会让面试者在白纸上写代码或者给面试者一台电脑来写代码,
53 |
54 | **一般面试官倾向于使用白纸,这样更好看到同学们的思考方式**
55 |
56 | ### 应该用什么语言写算法题呢?
57 |
58 | 应该用什么语言写算法题呢? **用自己最熟悉什么语言,但最好是JAVA或者C++**
59 |
60 | 如果不会JAVA或C++的话,那更建议通过做算法题,顺便学习一下。
61 |
62 | 如果想在编程的路上走得更远,掌握一门重语言是十分重要的,学好了C++或者Java在学脚本语言会非常的快,相当于降维打击
63 |
64 | 反而如果只会脚本语言,工作之后在学习高级语言会很困难,很多东西回不理解。
65 |
66 | 所以这里建议特别是应届生,大家有时间就要打好语言的基础, 不要太迷信用10行代码调用一个包解决100行代码的事,
67 |
68 | 因为这样也不会清楚省略掉的90行做了哪些工作。
69 |
70 | 这里建议大家 **在打基础的时候 最好不要上来就走捷径。**
71 |
72 | **简单代码一定要可以手写出来,不要过于依赖IDE的自动补全 。**
73 |
74 | 例如写一个翻转二叉树的函数, 很多同学在刷了很多leetcode 上面的题目
75 |
76 | 但是leetcode上一般都把二叉树的结构已经定义好了,所以可以上来直接写函数的实现
77 |
78 | 但是面试的时候要在白纸上写代码,一些同学一下子不知道二叉树的定义应该如何写,不是结构体定义的不对,就是忘了如何写指针。
79 |
80 | 总之,错漏百出。 **所以基本结构的定义以及代码一定要训练在白纸上写出来**
81 |
82 | 后面我在讲解各个知识点的时候 会在给同学们在强调一遍哪些代码是一定要手写出来的
83 |
84 | ## 三面 综合技术面
85 |
86 | 综合技术面 一般从如下三点考察大家。
87 |
88 | ### 编程语言
89 |
90 | 编程语言,这里是面试官**考察编程语言掌握程度**,如果是C++的话, 会问STL,继承,多态,指针等等 这里还可以问很多问题。
91 |
92 | ### 计算机基础知识
93 |
94 | **考察计算机方面的综合知识**,这里不同方向考察的侧重点不一样,如果是后台开发,Linux , TCP, 进程线程这些是一定要问的。
95 |
96 | ### 项目经验
97 |
98 | 在项目经验中 面试官想考察什么呢
99 |
100 | 项目经验主要从这三方面进行考察 **技术原理、 技术深度、应变能力**
101 |
102 | 考察技术原理, 做了一个项目,是不是仅仅调一调接口就完事,之后接口背后做了些什么么? 这些还是要了解的
103 |
104 | 考察技术深度,如果是后台开发的话,可以从系统的扩容、缓存、数据存储等多方面进行考察
105 |
106 | 考察应变能力,如果面试官针对项目问同学们一个场景,**最为忌讳的回答是什么?“我没考虑过这种情况”。** 这会让面试官对同学们的印象大打折扣。
107 |
108 | 这个时候,面试官最欣赏的候选人,就是尽管没考虑过,但也会思考出一个方案,然后跟面试官进行讨论。
109 |
110 | 最终讨论出一个可行的方案,这个会让面试官对同学们的好感倍增。
111 |
112 | 通常应届生没有什么项目经验,特备是本科生,其实可以自己做一些的小项目。
113 |
114 | 例如做一个 可以联机的五子棋游戏,这里就涉及到了网络知识,可以结合着自己网络知识来介绍自己的项目。
115 |
116 | 已经工作的人,就要找出自己工作项目的亮点,其实一个项目不是每一个人都有机会参与核心的开发。
117 |
118 | 也不是每个人都有解决难题的机会,这也是我们在工作中 遇到难点,要勇往直前的动力,因为这个就是自己项目经验最值钱的一部分。
119 |
120 |
121 | ## 四面 boss面
122 |
123 | 技术leader面试主要考察面试者两个能力, **解决问题的能力和快速学习的能力**
124 |
125 | ### 考察解决问题的能力
126 |
127 | 面试官最喜欢问的相关问题:
128 | * **在项目中遇到的最大的技术挑战是什么,而你是如果解决的**
129 | * **给出一个项目问题来让面试者分析**
130 |
131 | 如果你是学生,就会问在你学习中遇到哪些挑战, 这些都是面试官经常问的问题。
132 |
133 | 面试官可能还会给出一个具体的项目场景,问同学们如何去解决。
134 |
135 | 例如微信朋友圈的后台设计,如果是你应该怎么设计,这种问题大家也不必惊慌
136 |
137 | 因为面试官也知道你没有设计过,所以大家只要大胆说出自己的设计方案就好
138 |
139 | 面试官会在进一步指引你的方案可能那里有问题,最终讨论出一个看似合理的结果。
140 |
141 | **这里面试官考察的主要是针对项目问题,同学们是如何思考的,如何解决的。**
142 |
143 | ### 考察快速学习的能力
144 |
145 | 面试官最喜欢问的相关问题:
146 | * **快速学习的能力 如果快速学习一门新的技术或者语言?**
147 | * **读研之后发现自己和本科毕业有什么差别?**
148 |
149 | 在具体一点 面试官会问,如果有个项目这两天就要启动,而这个项目使用了你没有用过的语言或者技术,你将怎么完成这个项目?
150 |
151 | 换句话说,面试官会问:你如果快速学习一门新的编程语言或技术,这里同学们就要好好总结一下自己学习的技巧
152 |
153 | 如果你是研究生,面试官还喜欢问: 读研之后发现自己和本科毕业有什么差别?
154 |
155 | **这里要体现出自己思维方式和学习方法上的进步,而不是用了两三年的时间有多学了那些技术,因为互联网是不断变化的。**
156 |
157 | 面试官更喜欢考察是同学们的快速学习的能力。
158 |
159 | ## 五面 hr面
160 |
161 | 终于到了HR面了,大家是不是感觉完事万事大吉了,这里万万不可大意,否则到手的offer就飞掉了。
162 |
163 | 要知道HR那里如果有十个名额,技术面留给通常留给HR的人数是大于十个的,也就是HR有选择权,HR会选择符合公司文化的价值观的候选人。
164 |
165 | 这里呢给大家列举一些关键问题
166 |
167 | ### 为什么选择我们公司?
168 |
169 | 这个大家一定要有所准备,不能被问到了之后一脸茫然,然后说 就是想找个工作,那基本就没戏了
170 |
171 | 要从技术氛围,职业发展,公司潜力等等方面来说自己为什么选择这家公司
172 |
173 | ### 有没有职业规划?
174 |
175 | 其实如果刚刚毕业并没有明确的职业规划,这里建议大家不要说 自己想工作几年想做项目经理,工作几年想做产品经理的
176 |
177 | 这样会被HR认为 职业规划不清晰,尽量从技术的角度规划自己。
178 |
179 | ### 是否接受加班?
180 |
181 | 虽然大家都不喜欢加班,但是这个问题 我还是建议如果手头没有offer的话,大家尽量选择接受了
182 |
183 | 除非是超级大牛手头N多高新offer,可以直接说不接受,然后起身潇洒离去
184 |
185 | ### 坚持最长的一件事情是什么?
186 |
187 | 这里大家最好之前就想好,有一些同学可能印象里自己没有坚持很长的事情,也没有好好想过这个问题,在HR面的时候被问到的时候,一脸茫然
188 |
189 | 憋了半天说出一个不痛不痒的事情。这就是一个减分项了
190 |
191 | ### 如果校招,直接会问:期望薪资XXX是否接受?
192 |
193 | 这里大家如果感觉自己表现的很好 给面试官留下的很好的印象,**可以在这里争取 special offer,或者ssp offer**
194 |
195 | 这都是可以的,但是要真的对自己信心十足。
196 |
197 | ### 如果社招,则会了解前一家目前公司薪水多少 ?
198 |
199 | **这里大家切记不要虚报工资,因为入职前是要查流水的,这个是比较严肃的问题。**
200 |
201 | 其实HR也不会只聊很严肃的话题, 也会聊一聊家常之类的,问一问 家在哪里?在介绍一下公司薪酬福利待遇,这些就比较放松了
202 |
203 | ## 总结
204 |
205 | 这里面试流程就是这样了, 还是那句话 不是所有公司都按照这个流程来面试,但是如果是一线互联网公司,一般都会从我说的这几方面来考察大家
206 | 大家加油!
207 |
208 |
209 |
210 |
211 |
212 |
213 | -----------------------
214 |
215 |
--------------------------------------------------------------------------------
46 |
47 | C++代码如下:
48 |
49 | ```CPP
50 | class Solution {
51 | public:
52 | bool judgeCircle(string moves) {
53 | int x = 0, y = 0;
54 | for (int i = 0; i < moves.size(); i++) {
55 | if (moves[i] == 'U') y++;
56 | if (moves[i] == 'D') y--;
57 | if (moves[i] == 'L') x--;
58 | if (moves[i] == 'R') x++;
59 | }
60 | if (x == 0 && y == 0) return true;
61 | return false;
62 | }
63 | };
64 | ```
65 |
66 |
67 | # 其他语言版本
68 |
69 | ## Java
70 |
71 | ```java
72 | // 时间复杂度:O(n)
73 | // 空间复杂度:如果采用 toCharArray,则是 O(n);如果使用 charAt,则是 O(1)
74 | class Solution {
75 | public boolean judgeCircle(String moves) {
76 | int x = 0;
77 | int y = 0;
78 | for (char c : moves.toCharArray()) {
79 | if (c == 'U') y++;
80 | if (c == 'D') y--;
81 | if (c == 'L') x++;
82 | if (c == 'R') x--;
83 | }
84 | return x == 0 && y == 0;
85 | }
86 | }
87 | ```
88 |
89 | ## Python
90 |
91 | ```python
92 | # 时间复杂度:O(n)
93 | # 空间复杂度:O(1)
94 | class Solution:
95 | def judgeCircle(self, moves: str) -> bool:
96 | x = 0 # 记录当前位置
97 | y = 0
98 | for i in range(len(moves)):
99 | if (moves[i] == 'U'):
100 | y += 1
101 | if (moves[i] == 'D'):
102 | y -= 1
103 | if (moves[i] == 'L'):
104 | x += 1
105 | if (moves[i] == 'R'):
106 | x -= 1
107 | return x == 0 and y == 0
108 | ```
109 |
110 | ## Go
111 |
112 | ```go
113 | func judgeCircle(moves string) bool {
114 | x := 0
115 | y := 0
116 | for i := 0; i < len(moves); i++ {
117 | if moves[i] == 'U' {
118 | y++
119 | }
120 | if moves[i] == 'D' {
121 | y--
122 | }
123 | if moves[i] == 'L' {
124 | x++
125 | }
126 | if moves[i] == 'R' {
127 | x--
128 | }
129 | }
130 | return x == 0 && y == 0;
131 | }
132 | ```
133 |
134 | ## JavaScript
135 |
136 | ```js
137 | // 时间复杂度:O(n)
138 | // 空间复杂度:O(1)
139 | var judgeCircle = function(moves) {
140 | var x = 0; // 记录当前位置
141 | var y = 0;
142 | for (var i = 0; i < moves.length; i++) {
143 | if (moves[i] == 'U') y++;
144 | if (moves[i] == 'D') y--;
145 | if (moves[i] == 'L') x++;
146 | if (moves[i] == 'R') x--;
147 | }
148 | return x == 0 && y == 0;
149 | };
150 | ```
151 |
152 |
153 | ## TypeScript
154 |
155 | ```ts
156 | var judgeCircle = function (moves) {
157 | let x = 0
158 | let y = 0
159 | for (let i = 0; i < moves.length; i++) {
160 | switch (moves[i]) {
161 | case 'L': {
162 | x--
163 | break
164 | }
165 | case 'R': {
166 | x++
167 | break
168 | }
169 | case 'U': {
170 | y--
171 | break
172 | }
173 | case 'D': {
174 | y++
175 | break
176 | }
177 | }
178 | }
179 | return x === 0 && y === 0
180 | };
181 | ```
182 |
183 |
184 |
187 |
188 |
--------------------------------------------------------------------------------
/problems/0377.组合总和IV二维dp数组.md:
--------------------------------------------------------------------------------
1 | # 完全背包的排列问题模拟
2 |
3 | #### Problem
4 |
5 | 1. 排列问题是完全背包中十分棘手的问题。
6 | 2. 其在迭代过程中需要先迭代背包容量,再迭代物品个数,使得其在代码理解上较难入手。
7 |
8 | #### Contribution
9 |
10 | 本文档以力扣上[组合总和IV](https://leetcode.cn/problems/combination-sum-iv/)为例,提供一个二维dp的代码例子,并提供模拟过程以便于理解
11 |
12 | #### Code
13 |
14 | ```cpp
15 | int combinationSum4(vector
168 |
--------------------------------------------------------------------------------
/problems/哈希表理论基础.md:
--------------------------------------------------------------------------------
1 |
2 |
5 |
6 |
135 |
136 |
--------------------------------------------------------------------------------
/problems/周总结/20210304动规周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | 本周的主题就是股票系列,来一起回顾一下吧
3 |
4 | ## 周一
5 |
6 | [动态规划:买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II(动态规划).html)中股票可以买卖多次了!
7 |
8 | 这也是和[121. 买卖股票的最佳时机](https://programmercarl.com/0121.买卖股票的最佳时机.html)的唯一区别(注意只有一只股票,所以再次购买前要出售掉之前的股票)
9 |
10 | 重点在于递推公式的不同。
11 |
12 | 在回顾一下dp数组的含义:
13 |
14 | * dp[i][0] 表示第i天持有股票所得现金。
15 | * dp[i][1] 表示第i天不持有股票所得最多现金
16 |
17 |
18 | 递推公式:
19 |
20 | ```
21 | dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
22 | dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
23 | ```
24 |
25 | 大家可以发现本题和[121. 买卖股票的最佳时机](https://programmercarl.com/0121.买卖股票的最佳时机.html)的代码几乎一样,唯一的区别在:
26 |
27 | ```
28 | dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
29 | ```
30 |
31 | **这正是因为本题的股票可以买卖多次!** 所以买入股票的时候,可能会有之前买卖的利润即:dp[i - 1][1],所以dp[i - 1][1] - prices[i]。
32 |
33 | ## 周二
34 |
35 | [动态规划:买卖股票的最佳时机III](https://programmercarl.com/0123.买卖股票的最佳时机III.html)中最多只能完成两笔交易。
36 |
37 | **这意味着可以买卖一次,可以买卖两次,也可以不买卖**。
38 |
39 |
40 | 1. 确定dp数组以及下标的含义
41 |
42 | 一天一共就有五个状态,
43 |
44 | 0. 没有操作
45 | 1. 第一次买入
46 | 2. 第一次卖出
47 | 3. 第二次买入
48 | 4. 第二次卖出
49 |
50 | **dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金**。
51 |
52 | 2. 确定递推公式
53 |
54 | 需要注意:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。
55 |
56 | ```
57 | dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
58 | dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2]);
59 | dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
60 | dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
61 | ```
62 |
63 | 3. dp数组如何初始化
64 |
65 | dp[0][0] = 0;
66 | dp[0][1] = -prices[0];
67 | dp[0][2] = 0;
68 | dp[0][3] = -prices[0];
69 | dp[0][4] = 0;
70 |
71 | 4. 确定遍历顺序
72 |
73 | 从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
74 |
75 | 5. 举例推导dp数组
76 |
77 | 以输入[1,2,3,4,5]为例
78 |
79 | 
80 |
81 | 可以看到红色框为最后两次卖出的状态。
82 |
83 | 现在最大的时候一定是卖出的状态,而两次卖出的状态现金最大一定是最后一次卖出。
84 |
85 | 所以最终最大利润是dp[4][4]
86 |
87 | ## 周三
88 |
89 | [动态规划:买卖股票的最佳时机IV](https://programmercarl.com/0188.买卖股票的最佳时机IV.html)最多可以完成 k 笔交易。
90 |
91 | 相对于上一道[动态规划:123.买卖股票的最佳时机III](https://programmercarl.com/0123.买卖股票的最佳时机III.html),本题需要通过前两次的交易,来类比前k次的交易
92 |
93 |
94 | 1. 确定dp数组以及下标的含义
95 |
96 | 使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
97 |
98 | j的状态表示为:
99 |
100 | * 0 表示不操作
101 | * 1 第一次买入
102 | * 2 第一次卖出
103 | * 3 第二次买入
104 | * 4 第二次卖出
105 | * .....
106 |
107 | **除了0以外,偶数就是卖出,奇数就是买入**。
108 |
109 |
110 | 2. 确定递推公式
111 |
112 | 还要强调一下:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。
113 |
114 | ```CPP
115 | for (int j = 0; j < 2 * k - 1; j += 2) {
116 | dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
117 | dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
118 | }
119 | ```
120 |
121 | **本题和[动态规划:123.买卖股票的最佳时机III](https://programmercarl.com/0123.买卖股票的最佳时机III.html)最大的区别就是这里要类比j为奇数是买,偶数是卖的状态**。
122 |
123 | 3. dp数组如何初始化
124 |
125 | **dp[0][j]当j为奇数的时候都初始化为 -prices[0]**
126 |
127 | 代码如下:
128 |
129 | ```CPP
130 | for (int j = 1; j < 2 * k; j += 2) {
131 | dp[0][j] = -prices[0];
132 | }
133 | ```
134 |
135 | **在初始化的地方同样要类比j为奇数是买、偶数是卖的状态**。
136 |
137 | 4. 确定遍历顺序
138 |
139 | 从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
140 |
141 | 5. 举例推导dp数组
142 |
143 | 以输入[1,2,3,4,5],k=2为例。
144 |
145 |
146 | 
147 |
148 | 最后一次卖出,一定是利润最大的,dp[prices.size() - 1][2 * k]即红色部分就是最后求解。
149 |
150 | ## 周四
151 |
152 | [动态规划:最佳买卖股票时机含冷冻期](https://programmercarl.com/0309.最佳买卖股票时机含冷冻期.html)尽可能地完成更多的交易(多次买卖一支股票),但有冷冻期,冷冻期为1天
153 |
154 | 相对于[动态规划:122.买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II(动态规划).html),本题加上了一个冷冻期
155 |
156 |
157 | **本题则需要第三个状态:不持有股票(冷冻期)的最多现金**。
158 |
159 | 动规五部曲,分析如下:
160 |
161 | 1. 确定dp数组以及下标的含义
162 |
163 | **dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]**。
164 |
165 | j的状态为:
166 |
167 | * 0:持有股票后的最多现金
168 | * 1:不持有股票(能购买)的最多现金
169 | * 2:不持有股票(冷冻期)的最多现金
170 |
171 | 2. 确定递推公式
172 |
173 | ```
174 | dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
175 | dp[i][1] = max(dp[i - 1][1], dp[i - 1][2]);
176 | dp[i][2] = dp[i - 1][0] + prices[i];
177 | ```
178 |
179 | 3. dp数组如何初始化
180 |
181 | 可以统一都初始为0了。
182 |
183 | 代码如下:
184 | ```CPP
185 | vector
209 |
--------------------------------------------------------------------------------
/problems/栈与队列总结.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
164 |
165 |
--------------------------------------------------------------------------------
/problems/关于时间复杂度,你不知道的都在这里!.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
177 |
178 |
--------------------------------------------------------------------------------
/problems/1020.飞地的数量.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
155 |
156 |
--------------------------------------------------------------------------------
/problems/周总结/20201107回溯周末总结.md:
--------------------------------------------------------------------------------
1 |
2 | # 本周小结!(回溯算法系列二)
3 |
4 | > 例行每周小结
5 |
6 | ## 周一
7 |
8 | 在[回溯算法:求组合总和(二)](https://programmercarl.com/0039.组合总和.html)中讲解的组合总和问题,和以前的组合问题还都不一样。
9 |
10 | 本题和[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html),[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
11 |
12 | 不少录友都是看到可以重复选择,就义无反顾的把startIndex去掉了。
13 |
14 | **本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?**
15 |
16 | 我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html),[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)。
17 |
18 | 如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[回溯算法:电话号码的字母组合](https://programmercarl.com/0017.电话号码的字母组合.html)
19 |
20 | **注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我再讲解排列的时候就重点介绍**。
21 |
22 | 最后还给出了本题的剪枝优化,如下:
23 |
24 | ```
25 | for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
26 | ```
27 |
28 | 这个优化如果是初学者的话并不容易想到。
29 |
30 | **在求和问题中,排序之后加剪枝是常见的套路!**
31 |
32 | 在[回溯算法:求组合总和(二)](https://programmercarl.com/0039.组合总和.html)第一个树形结构没有画出startIndex的作用,**这里这里纠正一下,准确的树形结构如图所示:**
33 |
34 | 
35 |
36 | ## 周二
37 |
38 | 在[回溯算法:求组合总和(三)](https://programmercarl.com/0040.组合总和II.html)中依旧讲解组合总和问题,本题集合元素会有重复,但要求解集不能包含重复的组合。
39 |
40 | **所以难就难在去重问题上了**。
41 |
42 | 这个去重问题,相信做过的录友都知道有多么的晦涩难懂。网上的题解一般就说“去掉重复”,但说不清怎么个去重,代码一甩就完事了。
43 |
44 | 为了讲解这个去重问题,**我自创了两个词汇,“树枝去重”和“树层去重”**。
45 |
46 | 都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上“使用过”,一个维度是同一树层上“使用过”。**没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因**。
47 |
48 | 
49 |
50 | 我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
51 |
52 | * used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
53 | * used[i - 1] == false,说明同一树层candidates[i - 1]使用过
54 |
55 | **这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!**
56 |
57 | 对于去重,其实排列问题也是一样的道理,后面我会讲到。
58 |
59 |
60 | ## 周三
61 |
62 | 在[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)中,我们开始讲解切割问题,虽然最后代码看起来好像是一道模板题,但是从分析到学会套用这个模板,是比较难的。
63 |
64 | 我列出如下几个难点:
65 |
66 | * 切割问题其实类似组合问题
67 | * 如何模拟那些切割线
68 | * 切割问题中递归如何终止
69 | * 在递归循环中如何截取子串
70 | * 如何判断回文
71 |
72 | 如果想到了**用求解组合问题的思路来解决 切割问题本题就成功一大半了**,接下来就可以对着模板照葫芦画瓢。
73 |
74 | **但后序如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了**。
75 |
76 | 除了这些难点,**本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1**。
77 |
78 | 所以本题应该是一个道hard题目了。
79 |
80 | **本题的树形结构中,和代码的逻辑有一个小出入,已经判断不是回文的子串就不会进入递归了,纠正如下:**
81 |
82 | 
83 |
84 |
85 | ## 周四
86 |
87 | 如果没有做过[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)的话,[回溯算法:复原IP地址](https://programmercarl.com/0093.复原IP地址.html)这道题目应该是比较难的。
88 |
89 | 复原IP照[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)就多了一些限制,例如只能分四段,而且还是更改字符串,插入逗点。
90 |
91 | 树形图如下:
92 |
93 | 
94 |
95 | 在本文的树形结构图中,我已经把详细的分析思路都画了出来,相信大家看了之后一定会思路清晰不少!
96 |
97 | 本题还可以有一个剪枝,合法ip长度为12,如果s的长度超过了12就不是有效IP地址,直接返回!
98 |
99 | 代码如下:
100 |
101 | ```
102 | if (s.size() > 12) return result; // 剪枝
103 |
104 | ```
105 |
106 | 我之前给出的C++代码没有加这个限制,也没有超时,因为在第四段超过长度之后,就会截止了,所以就算给出特别长的字符串,搜索的范围也是有限的(递归只会到第三层),及时就会返回了。
107 |
108 |
109 | ## 周五
110 |
111 | 在[回溯算法:求子集问题!](https://programmercarl.com/0078.子集.html)中讲解了子集问题,**在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果**。
112 |
113 | 如图:
114 |
115 | 
116 |
117 |
118 | 认清这个本质之后,今天的题目就是一道模板题了。
119 |
120 | 其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了,本来我们就要遍历整棵树。
121 |
122 | 有的同学可能担心不写终止条件会不会无限递归?
123 |
124 | 并不会,因为每次递归的下一层就是从i+1开始的。
125 |
126 | 如果要写终止条件,注意:`result.push_back(path);`要放在终止条件的上面,如下:
127 |
128 | ```
129 | result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
130 | if (startIndex >= nums.size()) { // 终止条件可以不加
131 | return;
132 | }
133 | ```
134 |
135 | ## 周六
136 |
137 | 早起的哈希表系列没有总结,所以[哈希表:总结篇!(每逢总结必经典)](https://programmercarl.com/哈希表总结.html)如约而至。
138 |
139 | 可能之前大家做过很多哈希表的题目,但是没有串成线,总结篇来帮你串成线,捋顺哈希表的整个脉络。
140 |
141 | 大家对什么时候各种set与map比较疑惑,想深入了解红黑树,哈希之类的。
142 |
143 | **如果真的只是想清楚什么时候使用各种set与map,不用看那么多,把[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html)看了就够了**。
144 |
145 | ## 总结
146 |
147 | 本周我们依次介绍了组合问题,分割问题以及子集问题,子集问题还没有讲完,下周还会继续。
148 |
149 | **我讲解每一种问题,都会和其他问题作对比,做分析,所以只要跟着细心琢磨相信对回溯又有新的认识**。
150 |
151 | 最近这两天题目有点难度,刚刚开始学回溯算法的话,按照现在这个每天一题的速度来,确实有点快,学起来吃力非常正常,这些题目都是我当初学了好几个月才整明白的,哈哈。
152 |
153 | **所以大家能跟上的话,已经很优秀了!**
154 |
155 | 还有一些录友会很关心leetcode上的耗时统计。
156 |
157 | 这个是很不准确的,相同的代码多提交几次,大家就知道怎么回事了。
158 |
159 | leetcode上的计时应该是以4ms为单位,有的多提交几次,多个4ms就多击败50%,所以比较夸张,如果程序运行是几百ms的级别,可以看看leetcode上的耗时,因为它的误差10几ms对最终影响不大。
160 |
161 | **所以我的题解基本不会写击败百分之多少多少,没啥意义,时间复杂度分析清楚了就可以了**,至于回溯算法不用分析时间复杂度了,都是一样的爆搜,就看谁剪枝厉害了。
162 |
163 | 一些录友表示最近回溯算法看的实在是有点懵,回溯算法确实是晦涩难懂,可能视频的话更直观一些,我最近应该会在B站(同名:「代码随想录」)出回溯算法的视频,大家也可以看视频在回顾一波。
164 |
165 | **就酱,又是充实的一周,做好本周总结,迎接下一周,冲!**
166 |
167 |
168 |
169 |
170 |
--------------------------------------------------------------------------------
/problems/贪心算法总结篇.md:
--------------------------------------------------------------------------------
1 |
4 |
5 |
156 |
157 |
--------------------------------------------------------------------------------
/problems/前序/BAT级别技术面试流程和注意事项都在这里了.md:
--------------------------------------------------------------------------------
1 |
2 | # 大厂技术面试流程和注意事项
3 |
4 | 大型互联网企业一般通过几轮技术面试来考察大家的各项能力,一般流程如下:
5 |
6 | * 一面机试:一般会考选择题和编程题
7 | * 二面基础算法面:就是基础的算法都是该专栏要讲的
8 | * 三面综合技术面:会考察编程语言,计算机基础知识 ,以及了解项目经历等等
9 | * 四面技术boss面:会问一些比较范范的内容,考察大家解决问题和快速学习的能力
10 | * 最后hr面:主要了解面试者与企业文化相不相符,面试者的职业发展,offer的选择以及介绍一下企业提供的薪资待遇等等
11 |
12 | 并不是说一定是这五轮面试,不同的公司情况都不一样,甚至同一个公司不同事业群面试的流程都是不一样的
13 |
14 | 可能 一面和二面放到一起,可能三面和四面放到一起,这里尽量将各个维度拆开,让同学们了解 技术面试需要做哪方面的准备。
15 |
16 | 我们来逐一展开分析各个面试环节面试官是从哪些维度来考察大家的
17 |
18 |
19 | ## 一面 机试
20 |
21 | 一面的话通常是 选择题 + 编程题,还有些公司机试都是编程题。
22 |
23 | * 选择题:计算机基础知识涉及计算机网络,操作系统,数据库,编程语言等等
24 | * 编程题:一般是代码量比较大的题目
25 |
26 | 一面机试,**通常校招生的话,BAT的级别的企业 都会提前发笔试题,发到邮箱里然后指定时间内做完,一定要慎重对待,机试没有过,后面就没有面试机会了**
27 |
28 | 机试通常是 **选择题 + 编程题,还有些公司机试都是编程题**
29 |
30 | 选择题则是计算机基础知识涉及计算机网络,操作系统,数据库,编程语言等等,这里如果有些同学对计算机基础心里没有底的话,可以去牛客网上找一找 历年各大公司的机试题目找找感觉。
31 |
32 | 编程题则一般是代码量比较大的题目,图、复杂数据结构或者一些模拟类的题目,编程题目都是我们这门课程会讲述的重点
33 |
34 | 所以也给同学们也推荐一个编程学习的网站,也就是leetcode
35 |
36 | leetcode是专门针对算法练习的题库,leetcode现在也推出了中文网站,所以更方面中国的算法爱好者在上面刷题。 这门课程也是主要在leetcode上选择经典题目。
37 |
38 | 牛客网上涉及到程序员面试的各个环节,有很多国内互联网公司历年面试的题目还是很不错的。
39 |
40 | **建议学习计算机基础知识可以在牛客网上,刷算法题可以选择leetcode。**
41 |
42 | ## 二面 基础算法面
43 |
44 | ### 更注意考察的是思维方式
45 |
46 | 这一块和机试对算法的考察又不一样,机试仅仅就是要一个结果,对了就是对了不对就是不对,
47 |
48 | 而二面的算法面试**面试官更想看到同学们的思考过程**,而不仅仅是一个答案。
49 |
50 | 通常一面机试的题目是代码量比较大的题目,而二面而是一些基础算法
51 |
52 | 面试官会让面试者在白纸上写代码或者给面试者一台电脑来写代码,
53 |
54 | **一般面试官倾向于使用白纸,这样更好看到同学们的思考方式**
55 |
56 | ### 应该用什么语言写算法题呢?
57 |
58 | 应该用什么语言写算法题呢? **用自己最熟悉什么语言,但最好是JAVA或者C++**
59 |
60 | 如果不会JAVA或C++的话,那更建议通过做算法题,顺便学习一下。
61 |
62 | 如果想在编程的路上走得更远,掌握一门重语言是十分重要的,学好了C++或者Java在学脚本语言会非常的快,相当于降维打击
63 |
64 | 反而如果只会脚本语言,工作之后在学习高级语言会很困难,很多东西回不理解。
65 |
66 | 所以这里建议特别是应届生,大家有时间就要打好语言的基础, 不要太迷信用10行代码调用一个包解决100行代码的事,
67 |
68 | 因为这样也不会清楚省略掉的90行做了哪些工作。
69 |
70 | 这里建议大家 **在打基础的时候 最好不要上来就走捷径。**
71 |
72 | **简单代码一定要可以手写出来,不要过于依赖IDE的自动补全 。**
73 |
74 | 例如写一个翻转二叉树的函数, 很多同学在刷了很多leetcode 上面的题目
75 |
76 | 但是leetcode上一般都把二叉树的结构已经定义好了,所以可以上来直接写函数的实现
77 |
78 | 但是面试的时候要在白纸上写代码,一些同学一下子不知道二叉树的定义应该如何写,不是结构体定义的不对,就是忘了如何写指针。
79 |
80 | 总之,错漏百出。 **所以基本结构的定义以及代码一定要训练在白纸上写出来**
81 |
82 | 后面我在讲解各个知识点的时候 会在给同学们在强调一遍哪些代码是一定要手写出来的
83 |
84 | ## 三面 综合技术面
85 |
86 | 综合技术面 一般从如下三点考察大家。
87 |
88 | ### 编程语言
89 |
90 | 编程语言,这里是面试官**考察编程语言掌握程度**,如果是C++的话, 会问STL,继承,多态,指针等等 这里还可以问很多问题。
91 |
92 | ### 计算机基础知识
93 |
94 | **考察计算机方面的综合知识**,这里不同方向考察的侧重点不一样,如果是后台开发,Linux , TCP, 进程线程这些是一定要问的。
95 |
96 | ### 项目经验
97 |
98 | 在项目经验中 面试官想考察什么呢
99 |
100 | 项目经验主要从这三方面进行考察 **技术原理、 技术深度、应变能力**
101 |
102 | 考察技术原理, 做了一个项目,是不是仅仅调一调接口就完事,之后接口背后做了些什么么? 这些还是要了解的
103 |
104 | 考察技术深度,如果是后台开发的话,可以从系统的扩容、缓存、数据存储等多方面进行考察
105 |
106 | 考察应变能力,如果面试官针对项目问同学们一个场景,**最为忌讳的回答是什么?“我没考虑过这种情况”。** 这会让面试官对同学们的印象大打折扣。
107 |
108 | 这个时候,面试官最欣赏的候选人,就是尽管没考虑过,但也会思考出一个方案,然后跟面试官进行讨论。
109 |
110 | 最终讨论出一个可行的方案,这个会让面试官对同学们的好感倍增。
111 |
112 | 通常应届生没有什么项目经验,特备是本科生,其实可以自己做一些的小项目。
113 |
114 | 例如做一个 可以联机的五子棋游戏,这里就涉及到了网络知识,可以结合着自己网络知识来介绍自己的项目。
115 |
116 | 已经工作的人,就要找出自己工作项目的亮点,其实一个项目不是每一个人都有机会参与核心的开发。
117 |
118 | 也不是每个人都有解决难题的机会,这也是我们在工作中 遇到难点,要勇往直前的动力,因为这个就是自己项目经验最值钱的一部分。
119 |
120 |
121 | ## 四面 boss面
122 |
123 | 技术leader面试主要考察面试者两个能力, **解决问题的能力和快速学习的能力**
124 |
125 | ### 考察解决问题的能力
126 |
127 | 面试官最喜欢问的相关问题:
128 | * **在项目中遇到的最大的技术挑战是什么,而你是如果解决的**
129 | * **给出一个项目问题来让面试者分析**
130 |
131 | 如果你是学生,就会问在你学习中遇到哪些挑战, 这些都是面试官经常问的问题。
132 |
133 | 面试官可能还会给出一个具体的项目场景,问同学们如何去解决。
134 |
135 | 例如微信朋友圈的后台设计,如果是你应该怎么设计,这种问题大家也不必惊慌
136 |
137 | 因为面试官也知道你没有设计过,所以大家只要大胆说出自己的设计方案就好
138 |
139 | 面试官会在进一步指引你的方案可能那里有问题,最终讨论出一个看似合理的结果。
140 |
141 | **这里面试官考察的主要是针对项目问题,同学们是如何思考的,如何解决的。**
142 |
143 | ### 考察快速学习的能力
144 |
145 | 面试官最喜欢问的相关问题:
146 | * **快速学习的能力 如果快速学习一门新的技术或者语言?**
147 | * **读研之后发现自己和本科毕业有什么差别?**
148 |
149 | 在具体一点 面试官会问,如果有个项目这两天就要启动,而这个项目使用了你没有用过的语言或者技术,你将怎么完成这个项目?
150 |
151 | 换句话说,面试官会问:你如果快速学习一门新的编程语言或技术,这里同学们就要好好总结一下自己学习的技巧
152 |
153 | 如果你是研究生,面试官还喜欢问: 读研之后发现自己和本科毕业有什么差别?
154 |
155 | **这里要体现出自己思维方式和学习方法上的进步,而不是用了两三年的时间有多学了那些技术,因为互联网是不断变化的。**
156 |
157 | 面试官更喜欢考察是同学们的快速学习的能力。
158 |
159 | ## 五面 hr面
160 |
161 | 终于到了HR面了,大家是不是感觉完事万事大吉了,这里万万不可大意,否则到手的offer就飞掉了。
162 |
163 | 要知道HR那里如果有十个名额,技术面留给通常留给HR的人数是大于十个的,也就是HR有选择权,HR会选择符合公司文化的价值观的候选人。
164 |
165 | 这里呢给大家列举一些关键问题
166 |
167 | ### 为什么选择我们公司?
168 |
169 | 这个大家一定要有所准备,不能被问到了之后一脸茫然,然后说 就是想找个工作,那基本就没戏了
170 |
171 | 要从技术氛围,职业发展,公司潜力等等方面来说自己为什么选择这家公司
172 |
173 | ### 有没有职业规划?
174 |
175 | 其实如果刚刚毕业并没有明确的职业规划,这里建议大家不要说 自己想工作几年想做项目经理,工作几年想做产品经理的
176 |
177 | 这样会被HR认为 职业规划不清晰,尽量从技术的角度规划自己。
178 |
179 | ### 是否接受加班?
180 |
181 | 虽然大家都不喜欢加班,但是这个问题 我还是建议如果手头没有offer的话,大家尽量选择接受了
182 |
183 | 除非是超级大牛手头N多高新offer,可以直接说不接受,然后起身潇洒离去
184 |
185 | ### 坚持最长的一件事情是什么?
186 |
187 | 这里大家最好之前就想好,有一些同学可能印象里自己没有坚持很长的事情,也没有好好想过这个问题,在HR面的时候被问到的时候,一脸茫然
188 |
189 | 憋了半天说出一个不痛不痒的事情。这就是一个减分项了
190 |
191 | ### 如果校招,直接会问:期望薪资XXX是否接受?
192 |
193 | 这里大家如果感觉自己表现的很好 给面试官留下的很好的印象,**可以在这里争取 special offer,或者ssp offer**
194 |
195 | 这都是可以的,但是要真的对自己信心十足。
196 |
197 | ### 如果社招,则会了解前一家目前公司薪水多少 ?
198 |
199 | **这里大家切记不要虚报工资,因为入职前是要查流水的,这个是比较严肃的问题。**
200 |
201 | 其实HR也不会只聊很严肃的话题, 也会聊一聊家常之类的,问一问 家在哪里?在介绍一下公司薪酬福利待遇,这些就比较放松了
202 |
203 | ## 总结
204 |
205 | 这里面试流程就是这样了, 还是那句话 不是所有公司都按照这个流程来面试,但是如果是一线互联网公司,一般都会从我说的这几方面来考察大家
206 | 大家加油!
207 |
208 |
209 |
210 |
211 |
212 |
213 | -----------------------
214 |
215 |
--------------------------------------------------------------------------------