├── nlprep
├── test
│ ├── __init__.py
│ ├── test_sentutil.py
│ ├── test_dataset.py
│ ├── test_main.py
│ ├── test_middleformat.py
│ └── test_pairutil.py
├── datasets
│ ├── __init__.py
│ ├── clas_csv
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── qa_zh
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── tag_cged
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── clas_cosmosqa
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── clas_lihkgcat
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── clas_mathqa
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── clas_snli
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── clas_udicstm
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_dream
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_lcccbase
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_masklm
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_pttchat
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_squadqg
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_storyend
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_sumcnndm
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── gen_wmt17news
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── tag_clner
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── tag_cnername
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── tag_conllpp
│ │ ├── __init__.py
│ │ └── dataset.py
│ ├── tag_msraname
│ │ ├── __init__.py
│ │ └── dataset.py
│ └── tag_weiboner
│ │ ├── __init__.py
│ │ └── dataset.py
├── utils
│ ├── __init__.py
│ ├── sentlevel.py
│ └── pairslevel.py
├── __init__.py
├── main.py
├── middleformat.py
└── file_utils.py
├── template
└── dataset
│ └── task_datasetname
│ ├── __init__.py
│ └── dataset.py
├── docs
├── img
│ ├── nlprep.png
│ ├── nlprep-icon.png
│ └── example_report.png
├── utility.md
├── installation.md
├── datasets.md
├── usage.md
└── index.md
├── pyproject.toml
├── .pre-commit-config.yaml
├── requirements.txt
├── .github
└── workflows
│ └── python-package.yml
├── setup.py
├── CONTRIBUTING.md
├── mkdocs.yml
├── README.md
├── .gitignore
└── LICENSE
/nlprep/test/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/nlprep/datasets/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/template/dataset/task_datasetname/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_csv/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/qa_zh/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/tag_cged/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/clas_cosmosqa/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/clas_lihkgcat/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/clas_mathqa/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/clas_snli/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/clas_udicstm/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_dream/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_lcccbase/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_masklm/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_pttchat/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_squadqg/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_storyend/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_sumcnndm/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/gen_wmt17news/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/tag_clner/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/tag_cnername/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/tag_conllpp/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/tag_msraname/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/nlprep/datasets/tag_weiboner/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset import *
--------------------------------------------------------------------------------
/docs/img/nlprep.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/voidful/NLPrep/HEAD/docs/img/nlprep.png
--------------------------------------------------------------------------------
/nlprep/utils/__init__.py:
--------------------------------------------------------------------------------
1 | import nlprep.utils.sentlevel
2 | import nlprep.utils.pairslevel
3 |
--------------------------------------------------------------------------------
/docs/img/nlprep-icon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/voidful/NLPrep/HEAD/docs/img/nlprep-icon.png
--------------------------------------------------------------------------------
/docs/img/example_report.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/voidful/NLPrep/HEAD/docs/img/example_report.png
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.commitizen]
2 | name = "cz_conventional_commits"
3 | version = "0.1.1"
4 | tag_format = "v$version"
5 |
--------------------------------------------------------------------------------
/.pre-commit-config.yaml:
--------------------------------------------------------------------------------
1 | repos:
2 | - hooks:
3 | - id: commitizen
4 | stages:
5 | - commit-msg
6 | repo: https://github.com/commitizen-tools/commitizen
7 | rev: v2.1.0
8 |
--------------------------------------------------------------------------------
/nlprep/__init__.py:
--------------------------------------------------------------------------------
1 | __version__ = "2.4.1"
2 |
3 | import nlprep.file_utils
4 | from nlprep.main import load_utilities, load_dataset, list_all_utilities, list_all_datasets, convert_middleformat
5 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | boto3
2 | filelock
3 | requests
4 | inquirer
5 | BeautifulSoup4
6 | tqdm >= 4.27
7 | opencc-python-reimplemented
8 | pandas-profiling >= 2.8.0
9 | nlp2 >= 1.8.27
10 | phraseg >= 1.1.8
11 | transformers
12 | lxml
13 | datasets
--------------------------------------------------------------------------------
/docs/utility.md:
--------------------------------------------------------------------------------
1 | ::: nlprep.utils
2 |
3 | ## Add a new utility
4 | - sentence level: add function into utils/sentlevel.py, function name will be --util parameter
5 | - paris level - add function into utils/parislevel.py, function name will be --util parameter
6 |
--------------------------------------------------------------------------------
/nlprep/test/test_sentutil.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import os
3 | import unittest
4 | import nlprep
5 |
6 |
7 | class TestDataset(unittest.TestCase):
8 |
9 | def testS2T(self):
10 | sent_util = nlprep.utils.sentlevel
11 | self.assertTrue(sent_util.s2t("快乐") == "快樂")
12 |
13 | def testT2S(self):
14 | sent_util = nlprep.utils.sentlevel
15 | self.assertTrue(sent_util.t2s("快樂") == "快乐")
16 |
--------------------------------------------------------------------------------
/docs/installation.md:
--------------------------------------------------------------------------------
1 | ## Installation
2 | nlprep is tested on Python 3.6+, and PyTorch 1.1.0+.
3 |
4 | ### Installing via pip
5 | ```bash
6 | pip install nlprep
7 | ```
8 | ### Installing via source
9 | ```bash
10 | git clone https://github.com/voidful/nlprep.git
11 | python setup.py install
12 | ```
13 |
14 | ## Running nlprep
15 |
16 | Once you've installed nlprep, you can run with
17 |
18 | ### pip installed version:
19 | `nlprep`
20 |
21 | ### local version:
22 | `python -m nlprep.main`
--------------------------------------------------------------------------------
/nlprep/test/test_dataset.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import unittest
3 |
4 | import nlprep
5 |
6 |
7 | class TestDataset(unittest.TestCase):
8 |
9 | def testType(self):
10 | datasets = nlprep.list_all_datasets()
11 | for dataset in datasets:
12 | print(dataset)
13 | ds = importlib.import_module('.' + dataset, 'nlprep.datasets')
14 | self.assertTrue("DATASETINFO" in dir(ds))
15 | self.assertTrue("load" in dir(ds))
16 | self.assertTrue(ds.DATASETINFO['TASK'] in ['clas', 'tag', 'qa', 'gen'])
17 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_csv/dataset.py:
--------------------------------------------------------------------------------
1 | import csv
2 |
3 | from nlprep.middleformat import MiddleFormat
4 |
5 | DATASETINFO = {
6 | 'TASK': "clas"
7 | }
8 |
9 |
10 | def load(data):
11 | return data
12 |
13 |
14 | def toMiddleFormat(path):
15 | dataset = MiddleFormat(DATASETINFO)
16 | with open(path, encoding='utf8') as csvfile:
17 | spamreader = csv.reader(csvfile)
18 | for row in spamreader:
19 | if len(row[0].strip()) > 2 and len(row[1].strip()) > 2:
20 | dataset.add_data(row[0], row[1])
21 | return dataset
22 |
--------------------------------------------------------------------------------
/nlprep/utils/sentlevel.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import inspect
3 |
4 | from opencc import OpenCC
5 |
6 | cc_t2s = OpenCC('t2s')
7 | cc_s2t = OpenCC('s2t')
8 |
9 |
10 | def s2t(convt):
11 | """simplify chines to traditional chines"""
12 | return cc_s2t.convert(convt)
13 |
14 |
15 | def t2s(convt):
16 | """traditional chines to simplify chines"""
17 | return cc_t2s.convert(convt)
18 |
19 |
20 | SentUtils = dict(inspect.getmembers(sys.modules[__name__],
21 | predicate=lambda f: inspect.isfunction(f) and f.__module__ == __name__))
22 |
--------------------------------------------------------------------------------
/template/dataset/task_datasetname/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | 'DATASET_FILE_MAP': {
5 | "dataset_name": "dataset path" # list for multiple detests in one tag
6 | },
7 | 'TASK': ["gen", "tag", "clas", "qa"],
8 | 'FULLNAME': "Dataset Full Name",
9 | 'REF': {"Some dataset reference": "useful link"},
10 | 'DESCRIPTION': 'Dataset description'
11 | }
12 |
13 |
14 | def load(data):
15 | return data
16 |
17 |
18 | def toMiddleFormat(path):
19 | dataset = MiddleFormat(DATASETINFO)
20 | # some file reading and processing
21 | dataset.add_data("input", "target")
22 | return dataset
23 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_lihkgcat/dataset.py:
--------------------------------------------------------------------------------
1 | import csv
2 |
3 | from nlprep.middleformat import MiddleFormat
4 |
5 | DATASETINFO = {
6 | 'DATASET_FILE_MAP': {
7 | "lihkgcat": ["https://media.githubusercontent.com/media/voidful/lihkg_dataset/master/lihkg_posts_title_cat.csv"]
8 | },
9 | 'TASK': "clas",
10 | 'FULLNAME': "LIHKG Post Title 分類資料",
11 | 'REF': {"Source": "https://github.com/ylchan87/LiHKG_Post_NLP"},
12 | 'DESCRIPTION': '根據title去分析屬於邊一個台'
13 | }
14 |
15 |
16 | def load(data):
17 | return data
18 |
19 |
20 | def toMiddleFormat(paths):
21 | dataset = MiddleFormat(DATASETINFO)
22 | for path in paths:
23 | with open(path, encoding='utf8') as csvfile:
24 | rows = csv.reader(csvfile)
25 | for row in rows:
26 | input = row[0]
27 | target = row[1]
28 | dataset.add_data(input.strip(), target.strip())
29 | return dataset
30 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_mathqa/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 | import datasets
3 |
4 | DATASETINFO = {
5 | 'DATASET_FILE_MAP': {
6 | "mathqa-train": 'train',
7 | "mathqa-validation": 'validation',
8 | "mathqa-test": 'test'
9 | },
10 | 'TASK': "clas",
11 | 'FULLNAME': "Math QA",
12 | 'REF': {"Source url": "https://math-qa.github.io/math-QA/data/MathQA.zip"},
13 | 'DESCRIPTION': 'Our dataset is gathered by using a new representation language to annotate over the AQuA-RAT dataset. AQuA-RAT has provided the questions, options, rationale, and the correct options.'
14 | }
15 |
16 |
17 | def load(data):
18 | return datasets.load_dataset('math_qa')[data]
19 |
20 |
21 | def toMiddleFormat(data):
22 | dataset = MiddleFormat(DATASETINFO)
23 | for d in data:
24 | input = d['Problem'] + " [SEP] " + d['options']
25 | target = d['correct']
26 | dataset.add_data(input, target)
27 | return dataset
28 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_pttchat/dataset.py:
--------------------------------------------------------------------------------
1 | import csv
2 |
3 | from nlprep.middleformat import MiddleFormat
4 |
5 | DATASETINFO = {
6 | 'DATASET_FILE_MAP': {
7 | "pttchat": [
8 | "https://raw.githubusercontent.com/zake7749/Gossiping-Chinese-Corpus/master/data/Gossiping-QA-Dataset-2_0.csv"]
9 | },
10 | 'TASK': "gen",
11 | 'FULLNAME': "PTT八卦版中文對話語料",
12 | 'REF': {"Source": "https://github.com/zake7749/Gossiping-Chinese-Corpus"},
13 | 'DESCRIPTION': """
14 | 嗨,這裡是 PTT 中文語料集,我透過某些假設與方法 將每篇文章化簡為問答配對,其中問題來自文章的標題,而回覆是該篇文章的推文。
15 | """
16 | }
17 |
18 |
19 | def load(data):
20 | return data
21 |
22 |
23 | def toMiddleFormat(paths):
24 | mf = MiddleFormat(DATASETINFO)
25 | for path in paths:
26 | with open(path, encoding='utf8') as csvfile:
27 | rows = csv.reader(csvfile)
28 | next(rows, None)
29 | for row in rows:
30 | input = row[0]
31 | target = row[1]
32 | mf.add_data(input, target)
33 | return mf
34 |
--------------------------------------------------------------------------------
/nlprep/test/test_main.py:
--------------------------------------------------------------------------------
1 | import unittest
2 |
3 | from nlprep.main import *
4 |
5 |
6 | class TestMain(unittest.TestCase):
7 |
8 | def testListAllDataset(self):
9 | self.assertTrue(isinstance(list_all_datasets(), list))
10 |
11 | def testListAllUtilities(self):
12 | self.assertTrue(isinstance(list_all_utilities(), list))
13 |
14 | def testLoadUtility(self):
15 | sent_utils, pairs_utils = load_utilities(list_all_utilities(), disable_input_panel=True)
16 | self.assertTrue(len(sent_utils + pairs_utils), len(list_all_utilities()))
17 | for func, parma in sent_utils:
18 | print(func, parma)
19 | self.assertTrue(isinstance(parma, dict))
20 | for func, parma in pairs_utils:
21 | print(func, parma)
22 | self.assertTrue(isinstance(parma, dict))
23 |
24 | def testConvertMiddleformat(self):
25 | mf_dict = convert_middleformat(load_dataset('clas_udicstm'))
26 | for mf_key, mf in mf_dict.items():
27 | self.assertTrue(isinstance(mf_key, str))
28 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_dream/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 | import json
3 | import nlp2
4 |
5 | DATASETINFO = {
6 | 'DATASET_FILE_MAP': {
7 | "dream": "https://raw.githubusercontent.com/voidful/dream_gen/master/data.csv"
8 | },
9 | 'TASK': "gen",
10 | 'FULLNAME': "周公解夢資料集",
11 | 'REF': {"Source": "https://github.com/saiwaiyanyu/tensorflow-bert-seq2seq-dream-decoder"},
12 | 'DESCRIPTION': '透過夢境解析徵兆'
13 | }
14 |
15 |
16 | def load(data):
17 | return data
18 |
19 |
20 | def toMiddleFormat(path):
21 | dataset = MiddleFormat(DATASETINFO)
22 | with open(path, encoding='utf8') as f:
23 | for _ in list(f.readlines()):
24 | data = json.loads(_)
25 | input = nlp2.split_sentence_to_array(data['dream'], True)
26 | target = nlp2.split_sentence_to_array(data["decode"], True)
27 | if len(input) + len(target) < 512:
28 | input = " ".join(input)
29 | target = " ".join(target)
30 | dataset.add_data(input, target)
31 | return dataset
32 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_squadqg/dataset.py:
--------------------------------------------------------------------------------
1 | import datasets
2 | import nlp2
3 | from nlprep.middleformat import MiddleFormat
4 |
5 | DATASETINFO = {
6 | 'DATASET_FILE_MAP': {
7 | "squad-qg-train": "train",
8 | "squad-qg-dev": "validation"
9 | },
10 | 'TASK': "gen",
11 | 'FULLNAME': "The Stanford Question Answering Dataset 2.0",
12 | 'REF': {"Source": "https://rajpurkar.github.io/SQuAD-explorer/"},
13 | 'DESCRIPTION': 'Question Generate For SQuAD 2.0'
14 | }
15 |
16 |
17 | def load(data):
18 | return datasets.load_dataset('squad')[data]
19 |
20 |
21 | def toMiddleFormat(data, context_max_len=450, answer_max_len=50):
22 | dataset = MiddleFormat(DATASETINFO)
23 | for d in data:
24 | context = nlp2.split_sentence_to_array(d['context'])
25 | answer = nlp2.split_sentence_to_array(d['answers']['text'][0])
26 | input_data = " ".join(context[:context_max_len]) + " [SEP] " + " ".join(answer[:answer_max_len])
27 | target_data = d['question']
28 | dataset.add_data(input_data, target_data)
29 |
30 | return dataset
31 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_snli/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 | import datasets
3 |
4 | DATASETINFO = {
5 | 'DATASET_FILE_MAP': {
6 | "snli-train": 'train',
7 | "snli-validation": 'validation',
8 | "snli-test": 'test'
9 | },
10 | 'TASK': "clas",
11 | 'FULLNAME': "Stanford Natural Language Inference (SNLI) Corpus",
12 | 'REF': {"Home page": "https://nlp.stanford.edu/projects/snli/"},
13 | 'DESCRIPTION': 'The SNLI corpus (version 1.0) is a collection of 570k human-written English sentence pairs manually labeled for balanced classification with the labels entailment, contradiction, and neutral, supporting the task of natural language inference (NLI), also known as recognizing textual entailment (RTE).'
14 | }
15 |
16 |
17 | def load(data):
18 | return datasets.load_dataset('snli')[data]
19 |
20 |
21 | def toMiddleFormat(data):
22 | dataset = MiddleFormat(DATASETINFO)
23 | for d in data:
24 | input = d['premise'] + " [SEP] " + d['hypothesis']
25 | target = d['label']
26 | dataset.add_data(input, target)
27 | return dataset
28 |
--------------------------------------------------------------------------------
/docs/datasets.md:
--------------------------------------------------------------------------------
1 | ## Browse All Available Dataset
2 | ### Online Explorer
3 | [https://voidful.github.io/NLPrep-Datasets/](https://voidful.github.io/NLPrep-Datasets/)
4 |
5 | ## Add a new dataset
6 | follow template from `template/dataset`
7 |
8 | 1. edit task_datasetname to your task. eg: /tag_clner
9 | 2. edit dataset.py in `template/dataset/task_datasetname`
10 | Edit DATASETINFO
11 | ```python
12 | DATASETINFO = {
13 | 'DATASET_FILE_MAP': {
14 | "dataset_name": "dataset path" # list for multiple detests in one tag
15 | },
16 | 'TASK': ["gen", "tag", "clas", "qa"],
17 | 'FULLNAME': "Dataset Full Name",
18 | 'REF': {"Some dataset reference": "useful link"},
19 | 'DESCRIPTION': 'Dataset description'
20 | }
21 | ```
22 | Implement `load` for pre-loading `'DATASET_FILE_MAP'`'s data
23 | ```python
24 | def load(data):
25 | return data
26 | ```
27 | Implement `toMiddleFormat` for converting file to input and target
28 | ```python
29 | def toMiddleFormat(path):
30 | dataset = MiddleFormat(DATASETINFO)
31 | # some file reading and processing
32 | dataset.add_data("input", "target")
33 | return dataset
34 | ```
35 | 3. move `task_datasetname` folder to `nlprep/datasets`
36 |
--------------------------------------------------------------------------------
/nlprep/datasets/tag_conllpp/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 | import datasets
3 |
4 | DATASETINFO = {
5 | 'DATASET_FILE_MAP': {
6 | "conllpp-train": 'train',
7 | "conllpp-validation": 'validation',
8 | "conllpp-test": 'test'
9 | },
10 | 'TASK': "tag",
11 | 'FULLNAME': "CoNLLpp is a corrected version of the CoNLL2003 NER dataset",
12 | 'REF': {"Home page": "https://huggingface.co/datasets/conllpp"},
13 | 'DESCRIPTION': 'CoNLLpp is a corrected version of the CoNLL2003 NER dataset where labels of 5.38% of the sentences in the test set have been manually corrected. The training set and development set from CoNLL2003 is included for completeness.'
14 | }
15 |
16 | ner_tag = {
17 | 0: "O",
18 | 1: "B-PER",
19 | 2: "I-PER",
20 | 3: "B-ORG",
21 | 4: "I-ORG",
22 | 5: "B-LOC",
23 | 6: "I-LOC",
24 | 7: "B-MISC",
25 | 8: "I-MISC"
26 | }
27 |
28 |
29 | def load(data):
30 | return datasets.load_dataset('conllpp')[data]
31 |
32 |
33 | def toMiddleFormat(data):
34 | dataset = MiddleFormat(DATASETINFO)
35 | for d in data:
36 | input = d['tokens']
37 | target = [ner_tag[i] for i in d['ner_tags']]
38 | dataset.add_data(input, target)
39 | return dataset
40 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_udicstm/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | 'DATASET_FILE_MAP': {
5 | "udicstm": [
6 | "https://raw.githubusercontent.com/UDICatNCHU/UdicOpenData/master/udicOpenData/Snownlp訓練資料/twpos.txt",
7 | "https://raw.githubusercontent.com/UDICatNCHU/UdicOpenData/master/udicOpenData/Snownlp訓練資料/twneg.txt"]
8 | },
9 | 'TASK': "clas",
10 | 'FULLNAME': "UDIC Sentiment Analysis Dataset",
11 | 'REF': {"Source": "https://github.com/UDICatNCHU/UdicOpenData"},
12 | 'DESCRIPTION': '正面情緒:約有309163筆,44M / 負面情緒:約有320456筆,15M'
13 | }
14 |
15 |
16 | def load(data):
17 | return data
18 |
19 |
20 | def toMiddleFormat(paths):
21 | dataset = MiddleFormat(DATASETINFO)
22 | for path in paths:
23 | added_data = []
24 | with open(path, encoding='utf8') as f:
25 | if "失望" in f.readline():
26 | sentiment = "negative"
27 | else:
28 | sentiment = "positive"
29 | for i in list(f.readlines()):
30 | input_data = i.strip().replace(" ", "")
31 | if input_data not in added_data:
32 | dataset.add_data(i.strip(), sentiment)
33 | added_data.append(input_data)
34 | return dataset
35 |
--------------------------------------------------------------------------------
/nlprep/datasets/clas_cosmosqa/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 | import datasets
3 |
4 | DATASETINFO = {
5 | 'DATASET_FILE_MAP': {
6 | "cosmosqa-train": 'train',
7 | "cosmosqa-validation": 'validation',
8 | "cosmosqa-test": 'test'
9 | },
10 | 'TASK': "clas",
11 | 'FULLNAME': "Cosmos QA",
12 | 'REF': {"HomePage": "https://wilburone.github.io/cosmos/",
13 | "Dataset": " https://github.com/huggingface/nlp/blob/master/datasets/cosmos_qa/cosmos_qa.py"},
14 | 'DESCRIPTION': "Cosmos QA is a large-scale dataset of 35.6K problems that require commonsense-based reading comprehension, formulated as multiple-choice questions. It focuses on reading between the lines over a diverse collection of people's everyday narratives, asking questions concerning on the likely causes or effects of events that require reasoning beyond the exact text spans in the context"
15 | }
16 |
17 |
18 | def load(data):
19 | return datasets.load_dataset('cosmos_qa')[data]
20 |
21 |
22 | def toMiddleFormat(data):
23 | dataset = MiddleFormat(DATASETINFO)
24 | for d in data:
25 | input = d['context'] + " [SEP] " + d['question'] + " [SEP] " + d['answer0'] + " [SEP] " + d[
26 | 'answer1'] + " [SEP] " + d['answer2'] + " [SEP] " + d['answer3']
27 | target = d['label']
28 | dataset.add_data(input, target)
29 | return dataset
30 |
--------------------------------------------------------------------------------
/nlprep/datasets/tag_cnername/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | 'DATASET_FILE_MAP': {
5 | "cnername-train": "https://raw.githubusercontent.com/zjy-ucas/ChineseNER/master/data/example.train",
6 | "cnername-test": "https://raw.githubusercontent.com/zjy-ucas/ChineseNER/master/data/example.test",
7 | "cnername-dev": "https://raw.githubusercontent.com/zjy-ucas/ChineseNER/master/data/example.dev",
8 | },
9 | 'TASK': "tag",
10 | 'FULLNAME': "ChineseNER with only name",
11 | 'REF': {"Source": "https://github.com/zjy-ucas/ChineseNER"},
12 | 'DESCRIPTION': 'From https://github.com/zjy-ucas/ChineseNER/tree/master/data, source unknown.'
13 | }
14 |
15 |
16 | def load(data):
17 | return data
18 |
19 |
20 | def toMiddleFormat(path):
21 | dataset = MiddleFormat(DATASETINFO)
22 | with open(path, encoding='utf8') as f:
23 | sent_input = []
24 | sent_target = []
25 | for i in list(f.readlines()):
26 | i = i.strip()
27 | if len(i) > 1:
28 | sent, tar = i.split(' ')
29 | sent_input.append(sent)
30 | if "PER" not in tar:
31 | tar = 'O'
32 | sent_target.append(tar)
33 | else:
34 | dataset.add_data(sent_input, sent_target)
35 | sent_input = []
36 | sent_target = []
37 | return dataset
38 |
--------------------------------------------------------------------------------
/nlprep/datasets/tag_weiboner/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | 'DATASET_FILE_MAP': {
5 | "weiboner-train": "https://raw.githubusercontent.com/hltcoe/golden-horse/master/data/weiboNER.conll.train",
6 | "weiboner-test": "https://raw.githubusercontent.com/hltcoe/golden-horse/master/data/weiboNER.conll.test",
7 | "weiboner-dev": "https://raw.githubusercontent.com/hltcoe/golden-horse/master/data/weiboNER.conll.dev",
8 | },
9 | 'TASK': "tag",
10 | 'FULLNAME': "Weibo NER dataset",
11 | 'REF': {"Source": "https://github.com/hltcoe/golden-horse"},
12 | 'DESCRIPTION': 'Entity Recognition (NER) for Chinese Social Media (Weibo). This dataset contains messages selected from Weibo and annotated according to the DEFT ERE annotation guidelines.'
13 | }
14 |
15 |
16 | def load(data):
17 | return data
18 |
19 |
20 | def toMiddleFormat(path):
21 | dataset = MiddleFormat(DATASETINFO)
22 | with open(path, encoding='utf8', errors='replace') as f:
23 | sent_input = []
24 | sent_target = []
25 | for i in list(f.readlines()):
26 | i = i.strip()
27 | if len(i) > 1:
28 | sent, tar = i.split(' ')
29 | sent_input.append(sent)
30 | sent_target.append(tar)
31 | else:
32 | dataset.add_data(sent_input, sent_target)
33 | sent_input = []
34 | sent_target = []
35 | return dataset
36 |
--------------------------------------------------------------------------------
/.github/workflows/python-package.yml:
--------------------------------------------------------------------------------
1 | # This workflow will install Python dependencies, run tests and lint with a variety of Python versions
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: Python package
5 |
6 | on:
7 | push:
8 | branches: [ master ]
9 | pull_request:
10 | branches: [ master ]
11 |
12 | jobs:
13 | build:
14 |
15 | runs-on: ubuntu-latest
16 | strategy:
17 | matrix:
18 | python-version: [3.6, 3.7, 3.8]
19 |
20 | steps:
21 | - uses: actions/checkout@v2
22 | - name: Set up Python ${{ matrix.python-version }}
23 | uses: actions/setup-python@v2
24 | with:
25 | python-version: ${{ matrix.python-version }}
26 | - name: Install dependencies
27 | run: |
28 | python -m pip install --upgrade pip
29 | pip install flake8 pytest
30 | pip install -r requirements.txt
31 | - name: Lint with flake8
32 | run: |
33 | # stop the build if there are Python syntax errors or undefined names
34 | flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
35 | - name: Test with pytest
36 | run: |
37 | pytest
38 | - name: Generate coverage report
39 | run: |
40 | pip install pytest-cov
41 | pytest --cov=./ --cov-report=xml
42 | - name: Upload coverage to Codecov
43 | uses: codecov/codecov-action@v1
44 | - name: Build
45 | run: |
46 | python setup.py install
47 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(
4 | name='nlprep',
5 | version='0.2.01',
6 | description='Download and pre-processing data for nlp tasks',
7 | url='https://github.com/voidful/nlprep',
8 | author='Voidful',
9 | author_email='voidful.stack@gmail.com',
10 | long_description=open("README.md", encoding="utf8").read(),
11 | long_description_content_type="text/markdown",
12 | keywords='nlp tfkit classification generation tagging deep learning machine reading',
13 | packages=find_packages(),
14 | install_requires=[
15 | # accessing files from S3 directly
16 | "boto3",
17 | # filesystem locks e.g. to prevent parallel downloads
18 | "filelock",
19 | # for downloading models over HTTPS
20 | "requests",
21 | # progress bars in model download and training scripts
22 | "tqdm >= 4.27",
23 | # Open Chinese convert (OpenCC) in pure Python.
24 | "opencc-python-reimplemented",
25 | # tool for handling textinquirer
26 | "nlp2 >= 1.8.27",
27 | # generate report
28 | "pandas-profiling >= 2.8.0",
29 | # dataset
30 | "datasets",
31 | # phrase segmentation
32 | "phraseg >= 1.1.8",
33 | # tokenizer support
34 | "transformers>=3.3.0",
35 | # input panel
36 | "inquirer",
37 | "BeautifulSoup4",
38 | "lxml"
39 | ],
40 | entry_points={
41 | 'console_scripts': ['nlprep=nlprep.main:main']
42 | },
43 | zip_safe=False,
44 | )
45 |
--------------------------------------------------------------------------------
/nlprep/test/test_middleformat.py:
--------------------------------------------------------------------------------
1 | import unittest
2 |
3 | from nlprep.middleformat import MiddleFormat
4 |
5 |
6 | class TestDataset(unittest.TestCase):
7 | DATASETINFO = {
8 | 'DATASET_FILE_MAP': {
9 | "dataset_name": "dataset path" # list for multiple detests in one tag
10 | },
11 | 'TASK': ["gen", "tag", "clas", "qa"],
12 | 'FULLNAME': "Dataset Full Name",
13 | 'REF': {"Some dataset reference": "useful link"},
14 | 'DESCRIPTION': 'Dataset description'
15 | }
16 |
17 | def testQA(self):
18 | mf = MiddleFormat(self.DATASETINFO)
19 | input, target = mf.convert_to_taskformat(input="okkkkkk", target=[0, 2], sentu_func=[])
20 | row = [input] + target if isinstance(target, list) else [input, target]
21 | print(row)
22 |
23 | def testNormalize(self):
24 | mf = MiddleFormat(self.DATASETINFO)
25 | norm_input, norm_target = mf._normalize_input_target("fas[SEP]df", "fasdf")
26 | self.assertTrue("[SEP]" in norm_input)
27 | norm_input, norm_target = mf._normalize_input_target("我[SEP]df", "fasdf")
28 | self.assertTrue(len(norm_input.split(" ")) == 3)
29 | norm_input, norm_target = mf._normalize_input_target("how [SEP] you", "fasdf")
30 | self.assertTrue(len(norm_input.split(" ")) == 3)
31 |
32 | def testConvertToTaskFormat(self):
33 | mf = MiddleFormat(self.DATASETINFO)
34 | mf.task = 'qa'
35 | _, norm_target = mf.convert_to_taskformat("how [SEP] you", [3, 4], sentu_func=[])
36 | self.assertTrue(isinstance(norm_target, list))
37 |
--------------------------------------------------------------------------------
/nlprep/datasets/tag_msraname/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | "DATASET_FILE_MAP": {
5 | "msraner": "https://raw.githubusercontent.com/InsaneLife/ChineseNLPCorpus/master/NER/MSRA/train1.txt",
6 | },
7 | "TASK": "tag",
8 | "FULLNAME": "MSRA simplified character corpora for WS and NER",
9 | "REF": {
10 | "Source": "https://github.com/InsaneLife/ChineseNLPCorpus",
11 | "Paper": "https://faculty.washington.edu/levow/papers/sighan06.pdf",
12 | },
13 | "DESCRIPTION": "50k+ of Chinese naming entities including Location, Organization, and Person",
14 | }
15 |
16 |
17 | def load(data):
18 | return data
19 |
20 |
21 | def toMiddleFormat(path):
22 | dataset = MiddleFormat(DATASETINFO)
23 | with open(path, encoding="utf8") as f:
24 | for sentence in list(f.readlines()):
25 | sent_input = []
26 | sent_target = []
27 | word_tags = sentence.split()
28 | for word_tag in word_tags:
29 | context, tag = word_tag.split("/")
30 | if tag == "nr" and len(context) > 1:
31 | sent_input.append(context[0])
32 | sent_target.append("B-PER")
33 | for char in context[1:]:
34 | sent_input.append(char)
35 | sent_target.append("I-PER")
36 | else:
37 | for char in context:
38 | sent_input.append(char)
39 | sent_target.append("O")
40 | dataset.add_data(sent_input, sent_target)
41 | return dataset
42 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_masklm/dataset.py:
--------------------------------------------------------------------------------
1 | import re
2 | import nlp2
3 | import random
4 |
5 | from tqdm import tqdm
6 |
7 | from nlprep.middleformat import MiddleFormat
8 |
9 | DATASETINFO = {
10 | 'TASK': "gen"
11 | }
12 |
13 |
14 | def load(data):
15 | return data
16 |
17 |
18 | def toMiddleFormat(path):
19 | from phraseg import Phraseg
20 | punctuations = r"[.﹑︰〈〉─《﹖﹣﹂﹁﹔!?。。"#$%&'()*+,﹐-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏..!\"#$%&()*+,\-.\:;<=>?@\[\]\\\/^_`{|}~]+"
21 | MASKTOKEN = "[MASK]"
22 | dataset = MiddleFormat(DATASETINFO, [MASKTOKEN])
23 | phraseg = Phraseg(path)
24 |
25 | for line in tqdm(nlp2.read_files_yield_lines(path)):
26 | line = nlp2.clean_all(line).strip()
27 |
28 | if len(nlp2.split_sentence_to_array(line)) > 1:
29 | phrases = list((phraseg.extract(sent=line, merge_overlap=False)).keys())
30 | reg = "[0-9]+|[a-zA-Z]+\'*[a-z]*|[\w]" + "|" + punctuations
31 | reg = "|".join(phrases) + "|" + reg
32 | input_sent = re.findall(reg, line, re.UNICODE)
33 | target_sent = re.findall(reg, line, re.UNICODE)
34 | for ind, word in enumerate(input_sent):
35 | prob = random.random()
36 | if prob <= 0.15 and len(word) > 0:
37 | input_sent[ind] = MASKTOKEN
38 | if len(input_sent) > 2 and len(target_sent) > 2 and len("".join(input_sent).strip()) > 2 and len(
39 | "".join(target_sent).strip()) > 2:
40 | dataset.add_data(nlp2.join_words_to_sentence(input_sent), nlp2.join_words_to_sentence(target_sent))
41 |
42 | return dataset
43 |
--------------------------------------------------------------------------------
/nlprep/datasets/tag_clner/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | 'DATASET_FILE_MAP': {
5 | "clner-train": "https://raw.githubusercontent.com/lancopku/Chinese-Literature-NER-RE-Dataset/master/ner/train.txt",
6 | "clner-test": "https://raw.githubusercontent.com/lancopku/Chinese-Literature-NER-RE-Dataset/master/ner/test.txt",
7 | "clner-validation": "https://raw.githubusercontent.com/lancopku/Chinese-Literature-NER-RE-Dataset/master/ner/validation.txt",
8 | },
9 | 'TASK': "tag",
10 | 'FULLNAME': "Chinese-Literature-NER-RE-Dataset",
11 | 'REF': {"Source": "https://github.com/lancopku/Chinese-Literature-NER-RE-Dataset",
12 | "Paper": "https://arxiv.org/pdf/1711.07010.pdf"},
13 | 'DESCRIPTION': 'We provide a new Chinese literature dataset for Named Entity Recognition (NER) and Relation Extraction (RE). We define 7 entity tags and 9 relation tags based on several available NER and RE datasets but with some additional categories specific to Chinese literature text. '
14 | }
15 |
16 |
17 | def load(data):
18 | return data
19 |
20 |
21 | def toMiddleFormat(path):
22 | dataset = MiddleFormat(DATASETINFO)
23 | with open(path, encoding='utf8') as f:
24 | sent_input = []
25 | sent_target = []
26 | for i in list(f.readlines()):
27 | i = i.strip()
28 | if len(i) > 1:
29 | sent, tar = i.split(' ')
30 | sent_input.append(sent)
31 | sent_target.append(tar)
32 | else:
33 | dataset.add_data(sent_input, sent_target)
34 | sent_input = []
35 | sent_target = []
36 | return dataset
37 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_storyend/dataset.py:
--------------------------------------------------------------------------------
1 | from nlprep.middleformat import MiddleFormat
2 |
3 | DATASETINFO = {
4 | 'DATASET_FILE_MAP': {
5 | "storyend-train": ["https://raw.githubusercontent.com/JianGuanTHU/StoryEndGen/master/data/train.post",
6 | "https://raw.githubusercontent.com/JianGuanTHU/StoryEndGen/master/data/train.response"],
7 | "storyend-test": ["https://raw.githubusercontent.com/JianGuanTHU/StoryEndGen/master/data/test.post",
8 | "https://raw.githubusercontent.com/JianGuanTHU/StoryEndGen/master/data/test.response"],
9 | "storyend-val": ["https://raw.githubusercontent.com/JianGuanTHU/StoryEndGen/master/data/val.post",
10 | "https://raw.githubusercontent.com/JianGuanTHU/StoryEndGen/master/data/val.response"]
11 | },
12 | 'TASK': "gen",
13 | 'FULLNAME': "Five-sentence stories from ROCStories corpus ",
14 | 'REF': {"Source": "https://github.com/JianGuanTHU/StoryEndGen",
15 | "ROCStories corpus": "http://cs.rochester.edu/nlp/rocstories/"},
16 | 'DESCRIPTION': 'This corpus is unique in two ways: (1) it captures a rich set of causal and temporal commonsense relations between daily events, and (2) it is a high quality collection of everyday life stories that can also be used for story generation.'
17 | }
18 |
19 |
20 | def load(data):
21 | return data
22 |
23 |
24 | def toMiddleFormat(paths):
25 | dataset = MiddleFormat(DATASETINFO)
26 | with open(paths[0], 'r', encoding='utf8', errors='ignore') as posts:
27 | with open(paths[1], 'r', encoding='utf8', errors='ignore') as resps:
28 | for p, r in zip(posts.readlines(), resps.readlines()):
29 | p = p.replace('\t', " [SEP] ").replace('\n', "")
30 | r = r.replace('\n', "")
31 | dataset.add_data(p, r)
32 | return dataset
33 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_lcccbase/dataset.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | import re
4 |
5 | from nlprep.file_utils import cached_path
6 | from nlprep.middleformat import MiddleFormat
7 | import nlp2
8 |
9 | DATASETINFO = {
10 | 'DATASET_FILE_MAP': {
11 | "lccc-base": "https://coai-dataset.oss-cn-beijing.aliyuncs.com/LCCC-base.zip"
12 | },
13 | 'TASK': "gen",
14 | 'FULLNAME': "LCCC(Large-scale Cleaned Chinese Conversation) base",
15 | 'REF': {"paper": "https://arxiv.org/abs/2008.03946",
16 | "download source": "https://github.com/thu-coai/CDial-GPT#Dataset-zh"},
17 | 'DESCRIPTION': '我們所提供的數據集LCCC(Large-scale Cleaned Chinese Conversation)主要包含兩部分: LCCC-base 和 LCCC-large. 我們設計了一套嚴格的數據過濾流程來確保該數據集中對話數據的質量。這一數據過濾流程中包括一系列手工規則以及若干基於機器學習算法所構建的分類器。我們所過濾掉的噪聲包括:髒字臟詞、特殊字符、顏表情、語法不通的語句、上下文不相關的對話等。該數據集的統計信息如下表所示。其中,我們將僅包含兩個語句的對話稱為“單輪對話”,我們將包含兩個以上語句的對話稱為“多輪對話”。'
18 | }
19 |
20 |
21 | def load(data_path):
22 | import zipfile
23 | cache_path = cached_path(data_path)
24 | cache_dir = os.path.abspath(os.path.join(cache_path, os.pardir))
25 | data_folder = os.path.join(cache_dir, 'lccc_data')
26 | if nlp2.is_dir_exist(data_folder) is False:
27 | with zipfile.ZipFile(cache_path, 'r') as zip_ref:
28 | zip_ref.extractall(data_folder)
29 | path = [f for f in nlp2.get_files_from_dir(data_folder) if
30 | '.json' in f]
31 | return path
32 |
33 |
34 | def toMiddleFormat(path):
35 | dataset = MiddleFormat(DATASETINFO)
36 | with open(path[0], encoding='utf8') as f:
37 | pairs = json.load(f)
38 | for pair in pairs:
39 | input_s = []
40 | for p in pair[:-1]:
41 | input_s.append(nlp2.join_words_to_sentence(nlp2.split_sentence_to_array(p)))
42 | dataset.add_data(" [SEP] ".join(input_s),
43 | nlp2.join_words_to_sentence(nlp2.split_sentence_to_array(pair[-1])))
44 | return dataset
45 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_sumcnndm/dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 |
4 | from nlprep.file_utils import cached_path
5 | from nlprep.middleformat import MiddleFormat
6 | import nlp2
7 |
8 | DATASETINFO = {
9 | 'DATASET_FILE_MAP': {
10 | "cnndm-train": "train.txt",
11 | "cnndm-test": "test.txt",
12 | "cnndm-val": "val.txt"
13 | },
14 | 'TASK': "gen",
15 | 'FULLNAME': "CNN/DM Abstractive Summary Dataset",
16 | 'REF': {"Source": "https://github.com/harvardnlp/sent-summary"},
17 | 'DESCRIPTION': 'Abstractive Text Summarization on CNN / Daily Mail'
18 | }
19 |
20 |
21 | def load(data):
22 | import tarfile
23 | cache_path = cached_path("https://s3.amazonaws.com/opennmt-models/Summary/cnndm.tar.gz")
24 | cache_dir = os.path.abspath(os.path.join(cache_path, os.pardir))
25 | data_folder = os.path.join(cache_dir, 'cnndm_data')
26 | if nlp2.is_dir_exist(data_folder) is False:
27 | tar = tarfile.open(cache_path, "r:gz")
28 | tar.extractall(data_folder)
29 | tar.close()
30 | return [os.path.join(data_folder, data + ".src"), os.path.join(data_folder, data + ".tgt.tagged")]
31 |
32 |
33 | REMAP = {"-lrb-": "(", "-rrb-": ")", "-lcb-": "{", "-rcb-": "}",
34 | "-lsb-": "[", "-rsb-": "]", "``": '"', "''": '"'}
35 |
36 |
37 | def clean_text(text):
38 | text = re.sub(
39 | r"-lrb-|-rrb-|-lcb-|-rcb-|-lsb-|-rsb-|``|''",
40 | lambda m: REMAP.get(m.group()), text)
41 | return nlp2.clean_all(text.strip().replace('``', '"').replace('\'\'', '"').replace('`', '\''))
42 |
43 |
44 | def toMiddleFormat(path):
45 | dataset = MiddleFormat(DATASETINFO)
46 | with open(path[0], 'r', encoding='utf8') as src:
47 | with open(path[1], 'r', encoding='utf8') as tgt:
48 | for ori, sum in zip(src, tgt):
49 | ori = clean_text(ori)
50 | sum = clean_text(sum)
51 | dataset.add_data(ori, sum)
52 | return dataset
53 |
--------------------------------------------------------------------------------
/docs/usage.md:
--------------------------------------------------------------------------------
1 | #Usage
2 | ## Overview
3 | ```
4 | $ nlprep
5 | arguments:
6 | --dataset which dataset to use
7 | --outdir processed result output directory
8 |
9 | optional arguments:
10 | -h, --help show this help message and exit
11 | --util data preprocessing utility, multiple utility are supported
12 | --cachedir dir for caching raw dataset
13 | --infile local dataset path
14 | --report generate a html statistics report
15 | ```
16 | ## Python
17 | ```python
18 | import os
19 | import nlprep
20 | datasets = nlprep.list_all_datasets()
21 | ds = nlprep.load_dataset(datasets[0])
22 | ds_info = ds.DATASETINFO
23 | for ds_name, mf in nlprep.convert_middleformat(ds).items():
24 | print(ds_name, ds_info, mf.dump_list()[:3])
25 | profile = mf.get_report(ds_name)
26 | profile.to_file(os.path.join('./', ds_name + "_report.html"))
27 | ```
28 |
29 | ## Example
30 | Download udicstm dataset that
31 | ```bash
32 | nlprep --dataset clas_udicstm --outdir sentiment --util splitData --report
33 | ```
34 | Show result file
35 | ```text
36 | !head -10 ./sentiment/udicstm_valid.csv
37 |
38 | 會生孩子不等於會當父母,這可能讓許多人無法接受,不少父母打着“愛孩子”的旗號做了許多阻礙孩子心智發展的事,甚至傷害了孩子卻還不知道,反而怪孩子。看了這本書我深受教育,我慶幸在寶寶才七個月就看到了這本書,而不是七歲或者十七歲,可能會讓我在教育孩子方面少走許多彎路。非常感謝尹建莉老師,希望她再寫出更好的書。也希望衆多的年輕父母好好看看這本書。我已向許多朋友推薦此書。,positive
39 | 第一,一插入無線上網卡(usb接口)就自動關機;第二,待機時間沒有宣稱的那麼長久;第三,比較容易沾手印。,negative
40 | "小巧實用,外觀好看;而且系統盤所在的區和其它區已經分開,儘管只有兩個區,不過已經足夠了",positive
41 | 特價房非常小 四步走到房間牆角 基本是用不隔音的板材隔出來的 隔壁的電視聲音 還有臨近房間夜晚男女做事的呻吟和同浴的聲音都能很清楚的聽見 簡直就是網友見面的炮房 房間裏空氣質量很差 且無法通過換氣排出 攜程價格與門市價相同 主要考慮辦事地點在附近 纔去住的,negative
42 | 在同等價位上來講配置不錯,品牌知名度高,品質也有保證。商務機型,外觀一般,按鍵手感很好,戴爾的電源適配器造型很好,也比較輕巧。,positive
43 | 一般的書。。。。。。。。。。。。。,negative
44 | "有點重,是個遺憾。能買這麼小的筆記本,就是希望可以方便攜帶。尺寸是OK了,要是再輕薄些就更完美了。沒有光驅的說,所以華碩有待改善。然後就是外殼雖然是烤漆的,很漂亮(請勿觸摸),因爲一觸摸就會留下指紋",negative
45 | 自帶了一個白色的包包,不用額外買了,positive
46 | "剛收到,發現鍵盤有些鬆,觸摸屏太難按了,最主要的是開機的時候打開和關上光驅導致系統藍屏,不知道是不是這個原因 , 其他的到目前爲止正常.",negative
47 | "酒店地理位置不錯,門口時高速和輕軌.",negative
48 | ```
49 | Report will be at `sentiment/udicstm_valid_report.html`
50 | 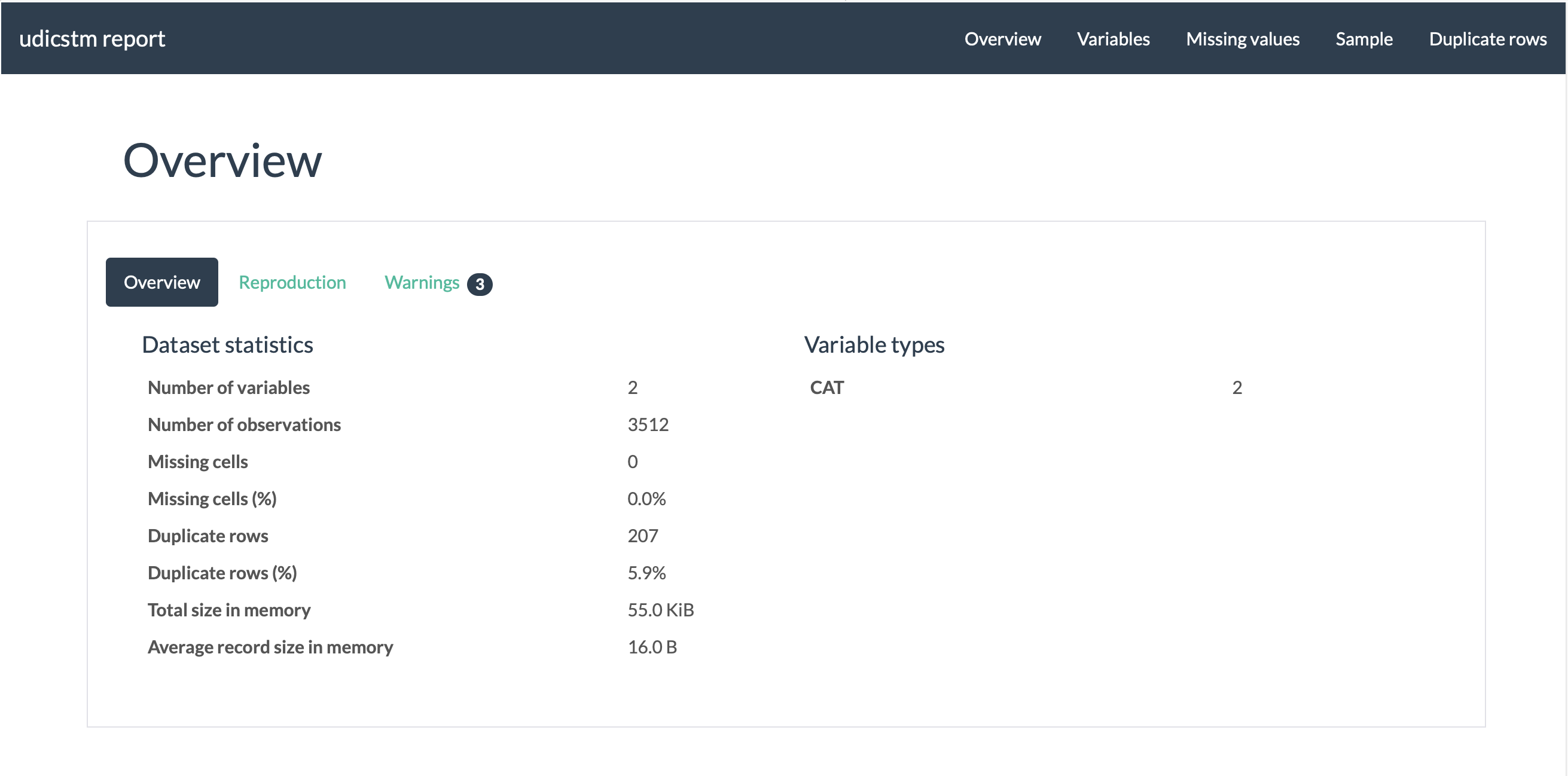
51 |
52 |
--------------------------------------------------------------------------------
/nlprep/datasets/tag_cged/dataset.py:
--------------------------------------------------------------------------------
1 | from bs4 import BeautifulSoup
2 |
3 | from nlprep.middleformat import MiddleFormat
4 |
5 | DATASETINFO = {
6 | 'DATASET_FILE_MAP': {
7 | "cged": [
8 | "https://raw.githubusercontent.com/voidful/ChineseErrorDataset/master/CGED/CGED16_HSK_TrainingSet.xml",
9 | "https://raw.githubusercontent.com/voidful/ChineseErrorDataset/master/CGED/CGED17_HSK_TrainingSet.xml",
10 | "https://raw.githubusercontent.com/voidful/ChineseErrorDataset/master/CGED/CGED18_HSK_TrainingSet.xml"]
11 | },
12 | 'TASK': "tag",
13 | 'FULLNAME': "中文語法錯誤診斷 - Chinese Grammatical Error Diagnosis",
14 | 'REF': {"Project Page": "http://nlp.ee.ncu.edu.tw/resource/cged.html"},
15 | 'DESCRIPTION': 'The grammatical errors are broadly categorized into 4 error types: word ordering, redundant, missing, and incorrect selection of linguistic components (also called PADS error types, denoting errors of Permutation, Addition, Deletion, and Selection, correspondingly).'
16 | }
17 |
18 |
19 | def load(data):
20 | return data
21 |
22 |
23 | def toMiddleFormat(paths):
24 | dataset = MiddleFormat(DATASETINFO)
25 | for path in paths:
26 | soup = BeautifulSoup(open(path, 'r', encoding='utf8'), features="lxml")
27 | temp = soup.root.find_all('doc')
28 |
29 | for i in temp:
30 | tag_s = i.find('text').string
31 | error_temp = i.find_all('error')
32 |
33 | tag_s = tag_s.strip(' ')
34 | tag_s = tag_s.strip('\n')
35 |
36 | if (len(tag_s)) >= 2:
37 | try:
38 | empty_tag = list()
39 |
40 | for i in range(len(tag_s)):
41 | empty_tag.append('O')
42 |
43 | for e in error_temp:
44 | for i in range(int(e['start_off']), int(e['end_off'])):
45 | empty_tag[i] = str(e['type'])
46 | except:
47 | pass
48 |
49 | if len(tag_s) == len(empty_tag):
50 | dataset.add_data(tag_s, empty_tag)
51 |
52 | return dataset
53 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing to nlprep
2 | We love your input! We want to make contributing to this project as easy and transparent as possible, whether it's:
3 |
4 | - Reporting a bug
5 | - Discussing the current state of the code
6 | - Submitting a fix
7 | - Proposing new features
8 | - Becoming a maintainer
9 |
10 | ## We Develop with Github
11 | We use github to host code, to track issues and feature requests, as well as accept pull requests.
12 |
13 | ## We Use [Github Flow](https://guides.github.com/introduction/flow/index.html), So All Code Changes Happen Through Pull Requests
14 | Pull requests are the best way to propose changes to the codebase (we use [Github Flow](https://guides.github.com/introduction/flow/index.html)). We actively welcome your pull requests:
15 |
16 | 1. Fork the repo and create your branch from `master`.
17 | 2. If you've added code that should be tested, add tests.
18 | 3. If you've changed APIs, update the documentation.
19 | 4. Ensure the test suite passes.
20 | 5. Make sure your code lints.
21 | 6. Issue that pull request!
22 |
23 | ## Any contributions you make will be under the Apache 2.0 Software License
24 | In short, when you submit code changes, your submissions are understood to be under the same [Apache 2.0 License](https://choosealicense.com/licenses/apache-2.0/) that covers the project. Feel free to contact the maintainers if that's a concern.
25 |
26 | ## Report bugs using Github's [issues](https://github.com/voidful/nlprep/issues)
27 | We use GitHub issues to track public bugs. Report a bug by [opening a new issue](); it's that easy!
28 |
29 | ## Write bug reports with detail, background, and sample code
30 | **Great Bug Reports** tend to have:
31 |
32 | - A quick summary and/or background
33 | - Steps to reproduce
34 | - Be specific!
35 | - Give sample code if you can.
36 | - What you expected would happen
37 | - What actually happens
38 | - Notes (possibly including why you think this might be happening, or stuff you tried that didn't work)
39 |
40 | People *love* thorough bug reports. I'm not even kidding.
41 |
42 | ## License
43 | By contributing, you agree that your contributions will be licensed under its Apache 2.0 License.
44 |
45 |
--------------------------------------------------------------------------------
/mkdocs.yml:
--------------------------------------------------------------------------------
1 | # Project information
2 | site_name: nlprep
3 | site_description: 🍳 dataset tool for many natural language processing task
4 | site_author: Voidful
5 | site_url: https://github.com/voidful/nlprep
6 | repo_name: nlprep
7 | repo_url: https://github.com/voidful/nlprep
8 | copyright: Copyright © Voidful
9 |
10 | nav:
11 | - Home: index.md
12 | - Installation: installation.md
13 | - Usage: usage.md
14 | - Datasets: datasets.md
15 | - Utilities: utility.md
16 |
17 | plugins:
18 | - search
19 | - mkdocstrings:
20 | default_handler: python
21 | handlers:
22 | python:
23 | setup_commands:
24 | - import sys
25 | - sys.path.append("docs")
26 | watch:
27 | - nlprep
28 |
29 | theme:
30 | name: material
31 | language: en
32 | palette:
33 | primary: blue grey
34 | accent: blue grey
35 | font:
36 | text: Roboto
37 | code: Roboto Mono
38 | logo: img/nlprep-icon.png
39 | favicon: img/nlprep-icon.png
40 |
41 | # Extras
42 | extra:
43 | social:
44 | - icon: fontawesome/brands/github-alt
45 | link: https://github.com/voidful/nlprep
46 | - icon: fontawesome/brands/twitter
47 | link: https://twitter.com/voidful_stack
48 | - icon: fontawesome/brands/linkedin
49 | link: https://www.linkedin.com/in/voidful/
50 |
51 | # Google Analytics
52 | google_analytics:
53 | - UA-127062540-4
54 | - auto
55 |
56 | # Extensions
57 | markdown_extensions:
58 | - markdown.extensions.admonition
59 | - markdown.extensions.attr_list
60 | - markdown.extensions.codehilite:
61 | guess_lang: false
62 | - markdown.extensions.def_list
63 | - markdown.extensions.footnotes
64 | - markdown.extensions.meta
65 | - markdown.extensions.toc:
66 | permalink: true
67 | - pymdownx.arithmatex
68 | - pymdownx.betterem:
69 | smart_enable: all
70 | - pymdownx.caret
71 | - pymdownx.critic
72 | - pymdownx.details
73 | - pymdownx.emoji:
74 | emoji_index: !!python/name:materialx.emoji.twemoji
75 | emoji_generator: !!python/name:materialx.emoji.to_svg
76 | # - pymdownx.highlight:
77 | # linenums_style: pymdownx-inline
78 | - pymdownx.inlinehilite
79 | - pymdownx.keys
80 | - pymdownx.magiclink:
81 | repo_url_shorthand: true
82 | user: squidfunk
83 | repo: mkdocs-material
84 | - pymdownx.mark
85 | - pymdownx.smartsymbols
86 | - pymdownx.snippets:
87 | check_paths: true
88 | - pymdownx.superfences
89 | - pymdownx.tabbed
90 | - pymdownx.tasklist:
91 | custom_checkbox: true
92 | - pymdownx.tilde
93 |
--------------------------------------------------------------------------------
/nlprep/test/test_pairutil.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import os
3 | import unittest
4 | import nlprep
5 |
6 |
7 | class TestDataset(unittest.TestCase):
8 |
9 | def testReverse(self):
10 | pair_util = nlprep.utils.pairslevel
11 | dummyPath = "path"
12 | dummyPair = [["a", "b"]]
13 | rev_pair = pair_util.reverse(dummyPath, dummyPair)[0][1]
14 | dummyPair.reverse()
15 | self.assertTrue(rev_pair == dummyPair)
16 |
17 | def testSplitData(self):
18 | pair_util = nlprep.utils.pairslevel
19 | dummyPath = "path"
20 | dummyPair = [[1, 1], [2, 2], [3, 3], [4, 4], [5, 5], [6, 6], [7, 7], [8, 8], [9, 9], [10, 10]]
21 |
22 | splited = pair_util.splitData(dummyPath, dummyPair, train_ratio=0.7, test_ratio=0.2, valid_ratio=0.1)
23 | print(splited)
24 | for s in splited:
25 | if "train" in s[0]:
26 | self.assertTrue(len(s[1]) == 7)
27 | elif "test" in s[0]:
28 | self.assertTrue(len(s[1]) == 2)
29 | elif "valid" in s[0]:
30 | self.assertTrue(len(s[1]) == 1)
31 |
32 | def testSetSepToken(self):
33 | pair_util = nlprep.utils.pairslevel
34 | dummyPath = "path"
35 | dummyPair = [["a [SEP] b", "c"]]
36 | processed = pair_util.setSepToken(dummyPath, dummyPair, sep_token="QAQ")
37 | print(processed[0][1][0])
38 | self.assertTrue("QAQ" in processed[0][1][0][0])
39 |
40 | def testSetMaxLen(self):
41 | pair_util = nlprep.utils.pairslevel
42 | dummyPath = "path"
43 | dummyPair = [["a" * 513, "c"]]
44 | processed = pair_util.setMaxLen(dummyPath, dummyPair, maxlen=512, tokenizer="char",
45 | with_target=False, handle_over='remove')
46 | self.assertTrue(0 == len(processed[0][1]))
47 | processed = pair_util.setMaxLen(dummyPath, dummyPair, maxlen=512, tokenizer="char",
48 | with_target=False, handle_over='slice')
49 | self.assertTrue(len(processed[0][1][0][0]) < 512)
50 | processed = pair_util.setMaxLen(dummyPath, dummyPair, maxlen=514, tokenizer="char",
51 | with_target=True, handle_over='remove')
52 | self.assertTrue(0 == len(processed[0][1]))
53 |
54 | def testsplitDataIntoPart(self):
55 | pair_util = nlprep.utils.pairslevel
56 | dummyPath = "path"
57 | dummyPair = [["a", "b"]] * 10
58 | processed = pair_util.splitDataIntoPart(dummyPath, dummyPair, part=4)
59 | print(processed)
60 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |  4 |
4 |
5 |
6 |
7 |
8 |  9 |
10 |
11 |
9 |
10 |
11 |  12 |
13 |
14 |
12 |
13 |
14 |  15 |
16 |
17 |
15 |
16 |
17 |  18 |
19 |
18 |
19 |
20 |
21 | ## Feature
22 |
23 | - handle over 100 dataset
24 | - generate statistic report about processed dataset
25 | - support many pre-processing ways
26 | - Provide a panel for entering your parameters at runtime
27 | - easy to adapt your own dataset and pre-processing utility
28 |
29 | ## Online Explorer
30 | [https://voidful.github.io/NLPrep-Datasets/](https://voidful.github.io/NLPrep-Datasets/)
31 |
32 | ## Quick Start
33 | ### Installing via pip
34 | ```bash
35 | pip install nlprep
36 | ```
37 | ### get one of the dataset
38 | ```bash
39 | nlprep --dataset clas_udicstm --outdir sentiment --util
40 | ```
41 |
42 | **You can also try nlprep in Google Colab: [](https://colab.research.google.com/drive/1EfVXa0O1gtTZ1xEAPDyvXMnyjcHxO7Jk?usp=sharing)**
43 |
44 | ## Overview
45 | ```
46 | $ nlprep
47 | arguments:
48 | --dataset which dataset to use
49 | --outdir processed result output directory
50 |
51 | optional arguments:
52 | -h, --help show this help message and exit
53 | --util data preprocessing utility, multiple utility are supported
54 | --cachedir dir for caching raw dataset
55 | --infile local dataset path
56 | --report generate a html statistics report
57 | ```
58 |
59 | ## Contributing
60 | Thanks for your interest.There are many ways to contribute to this project. Get started [here](https://github.com/voidful/nlprep/blob/master/CONTRIBUTING.md).
61 |
62 | ## License 
63 |
64 | * [License](https://github.com/voidful/nlprep/blob/master/LICENSE)
65 |
66 | ## Icons reference
67 | Icons modify from Darius Dan from www.flaticon.com
68 | Icons modify from Freepik from www.flaticon.com
69 |
70 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 | ## Feature
22 | - handle over 100 dataset
23 | - generate statistic report about processed dataset
24 | - support many pre-processing ways
25 | - Provide a panel for entering your parameters at runtime
26 | - easy to adapt your own dataset and pre-processing utility
27 |
28 | # Online Explorer
29 | [https://voidful.github.io/NLPrep-Datasets/](https://voidful.github.io/NLPrep-Datasets/)
30 |
31 | # Documentation
32 | Learn more from the [docs](https://voidful.github.io/NLPrep/).
33 |
34 | ## Quick Start
35 | ### Installing via pip
36 | ```bash
37 | pip install nlprep
38 | ```
39 | ### get one of the dataset
40 | ```bash
41 | nlprep --dataset clas_udicstm --outdir sentiment
42 | ```
43 |
44 | **You can also try nlprep in Google Colab: [](https://colab.research.google.com/drive/1EfVXa0O1gtTZ1xEAPDyvXMnyjcHxO7Jk?usp=sharing)**
45 |
46 | ## Overview
47 | ```
48 | $ nlprep
49 | arguments:
50 | --dataset which dataset to use
51 | --outdir processed result output directory
52 |
53 | optional arguments:
54 | -h, --help show this help message and exit
55 | --util data preprocessing utility, multiple utility are supported
56 | --cachedir dir for caching raw dataset
57 | --infile local dataset path
58 | --report generate a html statistics report
59 | ```
60 |
61 | ## Contributing
62 | Thanks for your interest.There are many ways to contribute to this project. Get started [here](https://github.com/voidful/nlprep/blob/master/CONTRIBUTING.md).
63 |
64 | ## License 
65 |
66 | * [License](https://github.com/voidful/nlprep/blob/master/LICENSE)
67 |
68 | ## Icons reference
69 | Icons modify from Darius Dan from www.flaticon.com
70 | Icons modify from Freepik from www.flaticon.com
71 |
--------------------------------------------------------------------------------
/nlprep/main.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import importlib
3 | import datasets
4 |
5 | from nlprep.file_utils import cached_path
6 | from nlprep.utils.sentlevel import *
7 | from nlprep.utils.pairslevel import *
8 |
9 | import os
10 |
11 | os.environ["PYTHONIOENCODING"] = "utf-8"
12 |
13 |
14 | def list_all_datasets(ignore_list=[]):
15 | dataset_dir = os.path.dirname(__file__) + '/datasets'
16 | return list(filter(
17 | lambda x: os.path.isdir(os.path.join(dataset_dir, x)) and '__pycache__' not in x and x not in ignore_list,
18 | os.listdir(dataset_dir)))
19 |
20 |
21 | def list_all_utilities():
22 | return list(SentUtils.keys()) + list(PairsUtils.keys())
23 |
24 |
25 | def load_dataset(dataset_name):
26 | return importlib.import_module('.' + dataset_name, 'nlprep.datasets')
27 |
28 |
29 | def load_utilities(util_name_list, disable_input_panel=False):
30 | sent_utils = [SentUtils[i] for i in util_name_list if i in SentUtils]
31 | pairs_utils = [PairsUtils[i] for i in util_name_list if i in PairsUtils]
32 | # handle utility argument input
33 | for util_list in [pairs_utils, sent_utils]:
34 | for ind, util in enumerate(util_list):
35 | util_arg = nlp2.function_argument_panel(util, disable_input_panel=disable_input_panel)
36 | util_list[ind] = [util, util_arg]
37 | return sent_utils, pairs_utils
38 |
39 |
40 | def convert_middleformat(dataset, input_file_map=None, cache_dir=None, dataset_arg={}):
41 | sets = {}
42 | dataset_map = input_file_map if input_file_map else dataset.DATASETINFO['DATASET_FILE_MAP']
43 | for map_name, map_dataset in dataset_map.items():
44 | loaded_dataset = dataset.load(map_dataset)
45 | if isinstance(loaded_dataset, list):
46 | for i, path in enumerate(loaded_dataset):
47 | loaded_dataset[i] = cached_path(path, cache_dir=cache_dir)
48 | dataset_path = loaded_dataset
49 | elif isinstance(loaded_dataset, datasets.arrow_dataset.Dataset):
50 | dataset_path = loaded_dataset
51 | else:
52 | dataset_path = cached_path(loaded_dataset, cache_dir=cache_dir)
53 | sets[map_name] = dataset.toMiddleFormat(dataset_path, **dataset_arg)
54 | return sets
55 |
56 |
57 | def main():
58 | parser = argparse.ArgumentParser()
59 | parser.add_argument("--dataset", type=str,
60 | choices=list_all_datasets(),
61 | required=True)
62 | parser.add_argument("--infile", type=str)
63 | parser.add_argument("--outdir", type=str, required=True)
64 | parser.add_argument("--cachedir", type=str)
65 | parser.add_argument("--report", action='store_true', help='dataset statistic report')
66 | parser.add_argument("--util", type=str, default=[], nargs='+',
67 | choices=list_all_utilities())
68 | global arg
69 | arg = parser.parse_args()
70 |
71 | # creat dir if not exist
72 | nlp2.get_dir_with_notexist_create(arg.outdir)
73 |
74 | # load dataset and utility
75 | dataset = load_dataset(arg.dataset)
76 | sent_utils, pairs_utils = load_utilities(arg.util)
77 |
78 | # handle local file1
79 | if arg.infile:
80 | fname = nlp2.get_filename_from_path(arg.infile)
81 | input_map = {
82 | fname: arg.infile
83 | }
84 | else:
85 | input_map = None
86 |
87 | print("Start processing data...")
88 | dataset_arg = nlp2.function_argument_panel(dataset.toMiddleFormat, ignore_empty=True)
89 | for k, middleformat in convert_middleformat(dataset, input_file_map=input_map, cache_dir=arg.cachedir,
90 | dataset_arg=dataset_arg).items():
91 | middleformat.dump_csvfile(os.path.join(arg.outdir, k), pairs_utils, sent_utils)
92 | if arg.report:
93 | profile = middleformat.get_report(k)
94 | profile.to_file(os.path.join(arg.outdir, k + "_report.html"))
95 |
96 |
97 | if __name__ == "__main__":
98 | main()
99 |
--------------------------------------------------------------------------------
/nlprep/datasets/qa_zh/dataset.py:
--------------------------------------------------------------------------------
1 | import json
2 |
3 | import nlp2
4 |
5 | from nlprep.middleformat import MiddleFormat
6 |
7 | DATASETINFO = {
8 | 'DATASET_FILE_MAP': {
9 | "drcd-train": "https://raw.githubusercontent.com/voidful/zh_mrc/master/drcd/DRCD_training.json",
10 | "drcd-test": "https://raw.githubusercontent.com/voidful/zh_mrc/master/drcd/DRCD_test.json",
11 | "drcd-dev": "https://raw.githubusercontent.com/voidful/zh_mrc/master/drcd/DRCD_dev.json",
12 | "cmrc-train": "https://raw.githubusercontent.com/voidful/zh_mrc/master/cmrc2018/train.json",
13 | "cmrc-test": "https://raw.githubusercontent.com/voidful/zh_mrc/master/cmrc2018/test.json",
14 | "cmrc-dev": "https://raw.githubusercontent.com/voidful/zh_mrc/master/cmrc2018/dev.json",
15 | "cail-train": "https://raw.githubusercontent.com/voidful/zh_mrc/master/cail/big_train_data.json",
16 | "cail-test": "https://raw.githubusercontent.com/voidful/zh_mrc/master/cail/test_ground_truth.json",
17 | "cail-dev": "https://raw.githubusercontent.com/voidful/zh_mrc/master/cail/dev_ground_truth.json",
18 | "combine-train": ["https://raw.githubusercontent.com/voidful/zh_mrc/master/drcd/DRCD_training.json",
19 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/cmrc2018/train.json",
20 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/cail/big_train_data.json"],
21 | "combine-test": ["https://raw.githubusercontent.com/voidful/zh_mrc/master/drcd/DRCD_test.json",
22 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/drcd/DRCD_dev.json",
23 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/cmrc2018/test.json",
24 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/cmrc2018/dev.json",
25 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/cail/test_ground_truth.json",
26 | "https://raw.githubusercontent.com/voidful/zh_mrc/master/cail/dev_ground_truth.json"
27 | ]
28 | },
29 | 'TASK': "qa",
30 | 'FULLNAME': "多個抽取式的中文閱讀理解資料集",
31 | 'REF': {"DRCD Source": "https://github.com/DRCKnowledgeTeam/DRCD",
32 | "CMRC2018 Source": "https://github.com/ymcui/cmrc2018",
33 | "CAIL2019 Source": "https://github.com/iFlytekJudiciary/CAIL2019_CJRC"},
34 | 'DESCRIPTION': '有DRCD/CMRC/CAIL三個資料集'
35 | }
36 |
37 |
38 | def load(data):
39 | return data
40 |
41 |
42 | def toMiddleFormat(paths):
43 | dataset = MiddleFormat(DATASETINFO)
44 | if not isinstance(paths, list):
45 | paths = [paths]
46 |
47 | for path in paths:
48 | with open(path, encoding="utf-8", errors='replace') as dataset_file:
49 | dataset_json = json.loads(dataset_file.read())
50 | dataset_json = dataset_json['data']
51 | for item in dataset_json:
52 | for paragraph in item['paragraphs']:
53 | for qas in paragraph['qas']:
54 | question = replace_s(qas['question'])
55 | for answers in qas['answers'][:1]:
56 | context = replace_s(paragraph['context'])
57 | ans = replace_s(str(answers['text']))
58 | ori_start = start = answers['answer_start']
59 |
60 | ans = nlp2.split_sentence_to_array(ans)
61 | context = nlp2.split_sentence_to_array(context)
62 | question = nlp2.split_sentence_to_array(question)
63 |
64 | pos = -1
65 | for tok in context:
66 | pos += len(tok)
67 | if len(tok) != 1:
68 | if pos <= ori_start:
69 | start -= len(tok) - 1
70 | end = start + len(ans)
71 |
72 | if 'YES' in ans or 'NO' in ans:
73 | input_sent = " ".join(ans + context) + " [SEP] " + " ".join(question)
74 | dataset.add_data(input_sent, [0, 1])
75 | elif 'FAKE' in ans:
76 | input_sent = " ".join(context) + " [SEP] " + " ".join(question)
77 | dataset.add_data(input_sent, [0, 0])
78 | elif context[start:end] == ans:
79 | input_sent = " ".join(context) + " [SEP] " + " ".join(question)
80 | dataset.add_data(input_sent, [start, end])
81 | else:
82 | print("input_sent", context[start:end], "ans", ans)
83 | return dataset
84 |
85 |
86 | def replace_s(s):
87 | return s.replace(" ", "_").replace("", "_").replace('\t', "_").replace('\n', "_"). \
88 | replace('\r', "_").replace('\v', "_").replace('\f', "_").replace(' ', "_").replace(' ', "_").replace(" ", "_")
89 |
--------------------------------------------------------------------------------
/nlprep/utils/pairslevel.py:
--------------------------------------------------------------------------------
1 | import json
2 | import random
3 | import sys
4 | import inspect
5 | import nlp2
6 | from transformers import BertTokenizer, AutoTokenizer
7 |
8 | separate_token = "[SEP]"
9 |
10 |
11 | def splitData(path, pair, seed=612, train_ratio=0.7, test_ratio=0.2, valid_ratio=0.1):
12 | """split data into training testing and validation"""
13 | random.seed(seed)
14 | random.shuffle(pair)
15 | train_ratio = float(train_ratio)
16 | test_ratio = float(test_ratio)
17 | valid_ratio = float(valid_ratio)
18 | assert train_ratio > test_ratio >= valid_ratio and round(train_ratio + test_ratio + valid_ratio) == 1.0
19 | train_num = int(len(pair) * train_ratio)
20 | test_num = train_num + int(len(pair) * test_ratio)
21 | valid_num = test_num + int(len(pair) * valid_ratio)
22 | return [[path + "_train", pair[:train_num]],
23 | [path + "_test", pair[train_num:test_num]],
24 | [path + "_valid", pair[test_num:valid_num]]]
25 |
26 |
27 | def splitDataIntoPart(path, pair, seed=712, part=4):
28 | """split data into part because of not enough memory"""
29 | random.seed(seed)
30 | random.shuffle(pair)
31 | part = int(len(pair) / part) + 1
32 | return [[path + "_" + str(int(i / part)), pair[i:i + part]] for i in range(0, len(pair), part)]
33 |
34 |
35 | def setSepToken(path, pair, sep_token="[SEP]"):
36 | """set SEP token for different pre-trained model"""
37 | global separate_token
38 | separate_token = sep_token
39 | for ind, p in enumerate(pair):
40 | input_sent = p[0]
41 | if isinstance(input_sent, str):
42 | pair[ind][0] = input_sent.replace("[SEP]", sep_token)
43 | else:
44 | pair[ind][0] = [sep_token if word == "[SEP]" else word for word in pair[ind][0]]
45 | return [[path, pair]]
46 |
47 |
48 | def setMaxLen(path, pair, maxlen=512, tokenizer="word", with_target=False, handle_over=['remove', 'slice']):
49 | """set model maximum length"""
50 | global separate_token
51 | maxlen = int(maxlen)
52 | with_target = json.loads(str(with_target).lower())
53 | if tokenizer == 'word':
54 | sep_func = nlp2.split_sentence_to_array
55 | elif tokenizer == 'char':
56 | sep_func = list
57 | else:
58 | if 'voidful/albert' in tokenizer:
59 | tok = BertTokenizer.from_pretrained(tokenizer)
60 | else:
61 | tok = AutoTokenizer.from_pretrained(tokenizer)
62 | sep_func = tok.tokenize
63 | new_sep_token = " ".join(sep_func(separate_token)).strip()
64 | small_than_max_pairs = []
65 | for ind, p in enumerate(pair):
66 | tok_input = sep_func(p[0] + " " + p[1]) if with_target and isinstance(p[0], str) and isinstance(p[1], str) \
67 | else sep_func(p[0])
68 | if len(tok_input) < maxlen:
69 | small_than_max_pairs.append(p)
70 | elif handle_over == 'slice':
71 | exceed = len(tok_input) - maxlen + 3 # +3 for more flexible space to further avoid exceed
72 | first_sep_index = tok_input.index(new_sep_token) if new_sep_token in tok_input else len(tok_input)
73 | limit_len = first_sep_index - exceed
74 | if limit_len > 0:
75 | tok_input = tok_input[:limit_len] + tok_input[first_sep_index:]
76 | if tokenizer == 'char':
77 | small_than_max_pairs.append([("".join(tok_input)).replace(new_sep_token, separate_token), p[1]])
78 | else:
79 | small_than_max_pairs.append([(" ".join(tok_input)).replace(new_sep_token, separate_token), p[1]])
80 | print("Num of data before handle max len :", len(pair))
81 | print("Num of data after handle max len :", len(small_than_max_pairs))
82 | return [[path, small_than_max_pairs]]
83 |
84 |
85 | def setAllSameTagRate(path, pair, seed=612, rate=0.27):
86 | """set all same tag data ratio in tagging dataset"""
87 | random.seed(seed)
88 | allsame_pair = []
89 | notsame_pair = []
90 | for p in pair:
91 | if len(set(p[1])) < 2:
92 | allsame_pair.append(p)
93 | else:
94 | notsame_pair.append(p)
95 |
96 | asnum = min(int(len(notsame_pair) * rate), len(allsame_pair))
97 | print("all same pair:", len(allsame_pair), "have diff pair:", len(notsame_pair), "ratio:", rate, "take:", asnum)
98 | random.shuffle(allsame_pair)
99 | result = allsame_pair[:asnum] + notsame_pair
100 | random.shuffle(result)
101 | return [[path, result]]
102 |
103 |
104 | def rmAllSameTag(path, pair):
105 | """remove all same tag in tagging dataset"""
106 | result_pair = []
107 | for p in pair:
108 | if len(set(p[1])) > 1:
109 | result_pair.append(p)
110 | return [[path, result_pair]]
111 |
112 |
113 | def reverse(path, pair):
114 | """swap input and target data"""
115 | for p in pair:
116 | p.reverse()
117 | return [[path, pair]]
118 |
119 |
120 | PairsUtils = dict(inspect.getmembers(sys.modules[__name__],
121 | predicate=lambda f: inspect.isfunction(f) and f.__module__ == __name__))
122 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by .ignore support plugin (hsz.mobi)
2 | ### Python template
3 | # Byte-compiled / optimized / DLL files
4 | __pycache__/
5 | *.py[cod]
6 | *$py.class
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | pip-wheel-metadata/
26 | share/python-wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .nox/
46 | .coverage
47 | .coverage.*
48 | .cache
49 | nosetests.xml
50 | coverage.xml
51 | *.cover
52 | *.py,cover
53 | .hypothesis/
54 | .pytest_cache/
55 |
56 | # Translations
57 | *.mo
58 | *.pot
59 |
60 | # Django stuff:
61 | *.log
62 | local_settings.py
63 | db.sqlite3
64 | db.sqlite3-journal
65 |
66 | # Flask stuff:
67 | instance/
68 | .webassets-cache
69 |
70 | # Scrapy stuff:
71 | .scrapy
72 |
73 | # Sphinx documentation
74 | docs/_build/
75 |
76 | # PyBuilder
77 | target/
78 |
79 | # Jupyter Notebook
80 | .ipynb_checkpoints
81 |
82 | # IPython
83 | profile_default/
84 | ipython_config.py
85 |
86 | # pyenv
87 | .python-version
88 |
89 | # pipenv
90 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
91 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
92 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
93 | # install all needed dependencies.
94 | #Pipfile.lock
95 |
96 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
97 | __pypackages__/
98 |
99 | # Celery stuff
100 | celerybeat-schedule
101 | celerybeat.pid
102 |
103 | # SageMath parsed files
104 | *.sage.py
105 |
106 | # Environments
107 | .env
108 | .venv
109 | env/
110 | venv/
111 | ENV/
112 | env.bak/
113 | venv.bak/
114 |
115 | # Spyder project settings
116 | .spyderproject
117 | .spyproject
118 |
119 | # Rope project settings
120 | .ropeproject
121 |
122 | # mkdocs documentation
123 | /site
124 |
125 | # mypy
126 | .mypy_cache/
127 | .dmypy.json
128 | dmypy.json
129 |
130 | # Pyre type checker
131 | .pyre/
132 |
133 | ### Example user template template
134 | ### Example user template
135 |
136 | # IntelliJ project files
137 | .idea
138 | *.iml
139 | out
140 | gen
141 | ### JetBrains template
142 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
143 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
144 |
145 | # User-specific stuff
146 | .idea/**/workspace.xml
147 | .idea/**/tasks.xml
148 | .idea/**/usage.statistics.xml
149 | .idea/**/dictionaries
150 | .idea/**/shelf
151 |
152 | # Generated files
153 | .idea/**/contentModel.xml
154 |
155 | # Sensitive or high-churn files
156 | .idea/**/dataSources/
157 | .idea/**/dataSources.ids
158 | .idea/**/dataSources.local.xml
159 | .idea/**/sqlDataSources.xml
160 | .idea/**/dynamic.xml
161 | .idea/**/uiDesigner.xml
162 | .idea/**/dbnavigator.xml
163 |
164 | # Gradle
165 | .idea/**/gradle.xml
166 | .idea/**/libraries
167 |
168 | # Gradle and Maven with auto-import
169 | # When using Gradle or Maven with auto-import, you should exclude module files,
170 | # since they will be recreated, and may cause churn. Uncomment if using
171 | # auto-import.
172 | # .idea/artifacts
173 | # .idea/compiler.xml
174 | # .idea/modules.xml
175 | # .idea/*.iml
176 | # .idea/modules
177 | # *.iml
178 | # *.ipr
179 |
180 | # CMake
181 | cmake-build-*/
182 |
183 | # Mongo Explorer plugin
184 | .idea/**/mongoSettings.xml
185 |
186 | # File-based project format
187 | *.iws
188 |
189 | # IntelliJ
190 | out/
191 |
192 | # mpeltonen/sbt-idea plugin
193 | .idea_modules/
194 |
195 | # JIRA plugin
196 | atlassian-ide-plugin.xml
197 |
198 | # Cursive Clojure plugin
199 | .idea/replstate.xml
200 |
201 | # Crashlytics plugin (for Android Studio and IntelliJ)
202 | com_crashlytics_export_strings.xml
203 | crashlytics.properties
204 | crashlytics-build.properties
205 | fabric.properties
206 |
207 | # Editor-based Rest Client
208 | .idea/httpRequests
209 |
210 | # Android studio 3.1+ serialized cache file
211 | .idea/caches/build_file_checksums.ser
212 |
213 | ### macOS template
214 | # General
215 | .DS_Store
216 | .AppleDouble
217 | .LSOverride
218 |
219 | # Icon must end with two \r
220 | Icon
221 |
222 | # Thumbnails
223 | ._*
224 |
225 | # Files that might appear in the root of a volume
226 | .DocumentRevisions-V100
227 | .fseventsd
228 | .Spotlight-V100
229 | .TemporaryItems
230 | .Trashes
231 | .VolumeIcon.icns
232 | .com.apple.timemachine.donotpresent
233 |
234 | # Directories potentially created on remote AFP share
235 | .AppleDB
236 | .AppleDesktop
237 | Network Trash Folder
238 | Temporary Items
239 | .apdisk
240 |
241 | # how2
242 | .how2
243 | how2
244 | /how2
245 |
246 | ./cache
247 | cache
248 | /cache/
249 |
250 | ./backup_dataset
251 | backup_dataset
252 | /backup_dataset/
253 |
254 | ./pytest_cache
255 | pytest_cache
256 | /pytest_cache/
--------------------------------------------------------------------------------
/nlprep/middleformat.py:
--------------------------------------------------------------------------------
1 | import csv
2 | from tqdm import tqdm
3 | import nlp2
4 |
5 | from pandas_profiling import ProfileReport
6 | import pandas as pd
7 |
8 | # {
9 | # "input": [
10 | # example1 input,
11 | # example2 input,
12 | # ...
13 | # ],
14 | # "target": [
15 | # example1 target,
16 | # example2 target,
17 | # ...
18 | # ]
19 | # }
20 | import nlprep.utils.pairslevel as pltool
21 |
22 |
23 | class MiddleFormat:
24 |
25 | def __init__(self, dataset_info, special_token=[]):
26 | self.pairs = []
27 | self.processed_pairs = []
28 |
29 | self.task = dataset_info['TASK']
30 | self.file_map = dataset_info.get('DATASET_FILE_MAP', {})
31 | self.fullname = dataset_info.get('FULLNAME', "")
32 | self.ref = dataset_info.get('REF', "")
33 | self.desc = dataset_info.get('DESCRIPTION', "")
34 | self.spe_tok = special_token
35 |
36 | def add_data(self, input, target):
37 | self.pairs.append([input, target])
38 |
39 | def _run_pair_utility(self, path, pairsu_func=[]):
40 | processed_pair = []
41 | if len(pairsu_func) > 0:
42 | for func_pack in pairsu_func:
43 | func, func_arg = func_pack
44 | if len(processed_pair) > 0:
45 | new_pp = []
46 | for pp in processed_pair:
47 | path, pairs = pp
48 | new_pp.extend(func(path, pairs, **func_arg))
49 | processed_pair = new_pp
50 | else:
51 | processed_pair = func(path, self.pairs, **func_arg)
52 | else:
53 | processed_pair = [[path, self.pairs]]
54 | return processed_pair
55 |
56 | def _run_sent_utility(self, sents, sentu_func=[]):
57 | for ind, sent in enumerate(sents):
58 | for func, func_arg in sentu_func:
59 | sents[ind] = func(sent, **func_arg)
60 | return sents
61 |
62 | def _normalize_input_target(self, input, target=None):
63 | if isinstance(input, str) and not nlp2.is_all_english(input):
64 | input = " ".join(nlp2.split_sentence_to_array(input))
65 | input = input.replace(" ".join(nlp2.split_sentence_to_array(pltool.separate_token)), pltool.separate_token)
66 | for t in self.spe_tok:
67 | input = input.replace(" ".join(nlp2.split_sentence_to_array(t)), t)
68 |
69 | if isinstance(target, str) and not nlp2.is_all_english(target):
70 | target = " ".join(nlp2.split_sentence_to_array(target))
71 |
72 | if isinstance(input, list):
73 | input = " ".join(input)
74 | if isinstance(target, list):
75 | target = " ".join(target)
76 |
77 | return input, target
78 |
79 | def convert_to_taskformat(self, input, target, sentu_func):
80 | if self.task == "tag":
81 | input, target = self._normalize_input_target(input, target)
82 | input = self._run_sent_utility([input], sentu_func)[0]
83 | elif self.task == "gen":
84 | input, target = self._normalize_input_target(input, target)
85 | input, target = self._run_sent_utility([input, target], sentu_func)
86 | elif self.task == "clas":
87 | input, target = self._normalize_input_target(input, target)
88 | input, target = self._run_sent_utility([input, target], sentu_func)
89 | elif self.task == "qa":
90 | input = self._run_sent_utility([input], sentu_func)[0]
91 | return input, target
92 |
93 | def dump_list(self, pairsu_func=[], sentu_func=[], path=''):
94 | self.processed_pairs = []
95 | processed_pair = self._run_pair_utility(path, pairsu_func)
96 | for pp in processed_pair:
97 | path, pairs = pp
98 | result_list = []
99 | for input, target in tqdm(pairs):
100 | input, target = self.convert_to_taskformat(input, target, sentu_func)
101 | res = [input] + target if isinstance(target, list) else [input, target]
102 | result_list.append(res)
103 | yield path, result_list
104 | self.processed_pairs.extend(result_list)
105 |
106 | def dump_csvfile(self, path, pairsu_func=[], sentu_func=[]):
107 | for dump_path, dump_pairs in self.dump_list(pairsu_func=pairsu_func, sentu_func=sentu_func, path=path):
108 | with open(dump_path + ".csv", 'w', encoding='utf-8') as outfile:
109 | writer = csv.writer(outfile)
110 | writer.writerows(dump_pairs)
111 |
112 | def get_report(self, report_name):
113 | if len(self.processed_pairs) == 0:
114 | [_ for _ in self.dump_list()]
115 | df = pd.DataFrame(self.processed_pairs)
116 |
117 | df.columns = ['input'] + ['target_' + str(i) for i in range(len(df.columns) - 1)] \
118 | if len(df.columns) > 2 else ['input', 'target']
119 | profile = ProfileReport(df,
120 | html={'style': {'primary_color': '#999999', 'full_width': True}, 'minify_html': True},
121 | vars={'cat': {'unicode': True}},
122 | title=report_name + " report")
123 | return profile
124 |
--------------------------------------------------------------------------------
/nlprep/datasets/gen_wmt17news/dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 |
4 | from nlprep.file_utils import cached_path
5 | from nlprep.middleformat import MiddleFormat
6 | import nlp2
7 |
8 | DATASETINFO = {
9 | 'DATASET_FILE_MAP': {
10 | # zh
11 | "wmt17-news-enzh-train": ["http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz",
12 | 'training', 'zh'],
13 | "wmt17-news-enzh-dev": ["http://data.statmt.org/wmt17/translation-task/dev.tgz", 'dev', 'zh'],
14 | "wmt17-news-enzh-test": ["http://data.statmt.org/wmt17/translation-task/test.tgz", 'test', 'zh'],
15 | # cs
16 | "wmt17-news-encs-train": ["http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz",
17 | 'training', 'cs'],
18 | "wmt17-news-encs-dev": ["http://data.statmt.org/wmt17/translation-task/dev.tgz", 'dev', 'cs'],
19 | "wmt17-news-encs-test": ["http://data.statmt.org/wmt17/translation-task/test.tgz", 'test', 'cs'],
20 | # de
21 | "wmt17-news-ende-train": ["http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz",
22 | 'training', 'de'],
23 | "wmt17-news-ende-dev": ["http://data.statmt.org/wmt17/translation-task/dev.tgz", 'dev', 'de'],
24 | "wmt17-news-ende-test": ["http://data.statmt.org/wmt17/translation-task/test.tgz", 'test', 'de'],
25 | # es
26 | "wmt17-news-enes-train": ["http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz",
27 | 'training', 'es'],
28 | "wmt17-news-enes-dev": ["http://data.statmt.org/wmt17/translation-task/dev.tgz", 'dev', 'es'],
29 | "wmt17-news-enes-test": ["http://data.statmt.org/wmt17/translation-task/test.tgz", 'test', 'es'],
30 | # fr
31 | "wmt17-news-enfr-train": ["http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz",
32 | 'training', 'fr'],
33 | "wmt17-news-enfr-dev": ["http://data.statmt.org/wmt17/translation-task/dev.tgz", 'dev', 'fr'],
34 | # ru
35 | "wmt17-news-enru-train": ["http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz",
36 | 'training', 'ru'],
37 | "wmt17-news-enru-dev": ["http://data.statmt.org/wmt17/translation-task/dev.tgz", 'dev', 'ru'],
38 | "wmt17-news-enru-test": ["http://data.statmt.org/wmt17/translation-task/test.tgz", 'test', 'ru'],
39 |
40 | },
41 | 'TASK': "gen",
42 | 'FULLNAME': "WMT17 NEWS TRANSLATION TASK",
43 | 'REF': {"homepage": "http://www.statmt.org/wmt17/",
44 | "download source": "http://data.statmt.org/wmt17/translation-task",
45 | "reference preprocess": "https://github.com/twairball/fairseq-zh-en/blob/master/preprocess/prepare.py"},
46 | 'DESCRIPTION': 'The text for all the test sets will be drawn from news articles. Participants may submit translations for any or all of the language directions. In addition to the common test sets the conference organizers will provide optional training resources.'
47 | }
48 |
49 |
50 | def load(data_list):
51 | import tarfile
52 | path, task, lang = data_list
53 | cache_path = cached_path(path)
54 | cache_dir = os.path.abspath(os.path.join(cache_path, os.pardir))
55 | data_folder = os.path.join(cache_dir, 'wmt17_data')
56 | task_folder = os.path.join(data_folder, task)
57 | if nlp2.is_dir_exist(task_folder) is False:
58 | tar = tarfile.open(cache_path, "r:gz")
59 | tar.extractall(data_folder)
60 | tar.close()
61 |
62 | pairs = [f for f in nlp2.get_files_from_dir(task_folder) if
63 | lang in f and 'en' in f]
64 | return pairs
65 |
66 |
67 | def _preprocess_sgm(line, is_sgm):
68 | """Preprocessing to strip tags in SGM files."""
69 | if not is_sgm:
70 | return line
71 | # In SGM files, remove , , lines.
72 | if line.startswith("") or line.startswith("
"):
79 | return ""
80 | # Strip tags.
81 | line = line.strip()
82 | if line.startswith(""):
83 | i = line.index(">")
84 | return line[i + 1:-6] # Strip first and last .
85 |
86 |
87 | def _preprocess(line, is_sgm=False):
88 | line = _preprocess_sgm(line, is_sgm=is_sgm)
89 | line = line.replace("\xa0", " ").strip()
90 | return line
91 |
92 |
93 | def _merge_blanks(src, targ, verbose=False):
94 | """Read parallel corpus 2 lines at a time.
95 | Merge both sentences if only either source or target has blank 2nd line.
96 | If both have blank 2nd lines, then ignore.
97 |
98 | Returns tuple (src_lines, targ_lines), arrays of strings sentences.
99 | """
100 | merges_done = [] # array of indices of rows merged
101 | sub = None # replace sentence after merge
102 | with open(src, 'rb') as src_file, open(targ, 'rb') as targ_file:
103 | src_lines = src_file.readlines()
104 | targ_lines = targ_file.readlines()
105 |
106 | print("src: %d, targ: %d" % (len(src_lines), len(targ_lines)))
107 | print("=" * 30)
108 | for i in range(0, len(src_lines) - 1):
109 | s = src_lines[i].decode().rstrip()
110 | s_next = src_lines[i + 1].decode().rstrip()
111 |
112 | t = targ_lines[i].decode().rstrip()
113 | t_next = targ_lines[i + 1].decode().rstrip()
114 |
115 | if t == '.':
116 | t = ''
117 | if t_next == '.':
118 | t_next = ''
119 |
120 | if (len(s_next) == 0) and (len(t_next) > 0):
121 | targ_lines[i] = "%s %s" % (t, t_next) # assume it has punctuation
122 | targ_lines[i + 1] = b''
123 | src_lines[i] = s if len(s) > 0 else sub
124 |
125 | merges_done.append(i)
126 | if verbose:
127 | print("t [%d] src: %s\n targ: %s" % (i, src_lines[i], targ_lines[i]))
128 | print()
129 |
130 | elif (len(s_next) > 0) and (len(t_next) == 0):
131 | src_lines[i] = "%s %s" % (s, s_next) # assume it has punctuation
132 | src_lines[i + 1] = b''
133 | targ_lines[i] = t if len(t) > 0 else sub
134 |
135 | merges_done.append(i)
136 | if verbose:
137 | print("s [%d] src: %s\n targ: %s" % (i, src_lines[i], targ_lines[i]))
138 | print()
139 | elif (len(s) == 0) and (len(t) == 0):
140 | # both blank -- remove
141 | merges_done.append(i)
142 | else:
143 | src_lines[i] = s if len(s) > 0 else sub
144 | targ_lines[i] = t if len(t) > 0 else sub
145 |
146 | # handle last line
147 | s_last = src_lines[-1].decode().strip()
148 | t_last = targ_lines[-1].decode().strip()
149 | if (len(s_last) == 0) and (len(t_last) == 0):
150 | merges_done.append(len(src_lines) - 1)
151 | else:
152 | src_lines[-1] = s_last
153 | targ_lines[-1] = t_last
154 |
155 | # remove empty sentences
156 | for m in reversed(merges_done):
157 | del src_lines[m]
158 | del targ_lines[m]
159 |
160 | print("merges done: %d" % len(merges_done))
161 | return (src_lines, targ_lines)
162 |
163 |
164 | def toMiddleFormat(pairs):
165 | dataset = MiddleFormat(DATASETINFO)
166 | if 'news-commentary-v12' in pairs[0]: ## training data
167 | pairs = [[p, p.replace('.en', "." + re.search("v12.(.+)+-", p).group(1))] for p in pairs if '-en.en' in p]
168 | else:
169 | pairs = [[p, p.replace('src', "ref").replace(re.search("\.\w+\.", p).group(0),
170 | "." + re.search("-\w{2}(\w{2})-", p).group(1) + ".")]
171 | for p in pairs if 'src.en' in p and re.search("-\w{4}-", p)]
172 |
173 | for pair in pairs:
174 | is_sgm = 'sgm' in pair[0]
175 | src_lines, targ_lines = _merge_blanks(pair[0], pair[1], verbose=False)
176 | for src, targ in zip(src_lines, targ_lines):
177 | src = _preprocess(src, is_sgm)
178 | targ = _preprocess(targ, is_sgm)
179 | if len(src) > 0 and len(targ) > 0:
180 | dataset.add_data(src, targ)
181 | return dataset
182 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright voidful
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/nlprep/file_utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Utilities for working with the local dataset cache.
3 | This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
4 | Copyright by the AllenNLP authors.
5 | """
6 | """
7 | Utilities for working with the local dataset cache.
8 | """
9 |
10 | import glob
11 | import os
12 | import logging
13 | import tempfile
14 | import json
15 | from os import PathLike
16 | from urllib.parse import urlparse
17 | from pathlib import Path
18 | from typing import Optional, Tuple, Union, IO, Callable, Set, List, Iterator, Iterable
19 | from hashlib import sha256
20 | from functools import wraps
21 | from zipfile import ZipFile, is_zipfile
22 | import tarfile
23 | import shutil
24 |
25 | import boto3
26 | import botocore
27 | from botocore.exceptions import ClientError, EndpointConnectionError
28 | from filelock import FileLock
29 | import requests
30 | from requests.adapters import HTTPAdapter
31 | from requests.exceptions import ConnectionError
32 | from requests.packages.urllib3.util.retry import Retry
33 | from tqdm import tqdm
34 |
35 | logger = logging.getLogger(__name__)
36 |
37 | CACHE_ROOT = Path(os.getenv("NLPREP_CACHE_ROOT", Path.home() / ".nlprep"))
38 | CACHE_DIRECTORY = str(CACHE_ROOT / "cache")
39 | DEPRECATED_CACHE_DIRECTORY = str(CACHE_ROOT / "datasets")
40 |
41 | # This variable was deprecated in 0.7.2 since we use a single folder for caching
42 | # all types of files (datasets, models, etc.)
43 | DATASET_CACHE = CACHE_DIRECTORY
44 |
45 | # Warn if the user is still using the deprecated cache directory.
46 | if os.path.exists(DEPRECATED_CACHE_DIRECTORY):
47 | logger = logging.getLogger(__name__)
48 | logger.warning(
49 | f"Deprecated cache directory found ({DEPRECATED_CACHE_DIRECTORY}). "
50 | f"Please remove this directory from your system to free up space."
51 | )
52 |
53 |
54 | def url_to_filename(url: str, etag: str = None) -> str:
55 | """
56 | Convert `url` into a hashed filename in a repeatable way.
57 | If `etag` is specified, append its hash to the url's, delimited
58 | by a period.
59 | """
60 | url_bytes = url.encode("utf-8")
61 | url_hash = sha256(url_bytes)
62 | filename = url_hash.hexdigest()
63 |
64 | if etag:
65 | etag_bytes = etag.encode("utf-8")
66 | etag_hash = sha256(etag_bytes)
67 | filename += "." + etag_hash.hexdigest()
68 |
69 | return filename
70 |
71 |
72 | def filename_to_url(filename: str, cache_dir: Union[str, Path] = None) -> Tuple[str, str]:
73 | """
74 | Return the url and etag (which may be `None`) stored for `filename`.
75 | Raise `FileNotFoundError` if `filename` or its stored metadata do not exist.
76 | """
77 | if cache_dir is None:
78 | cache_dir = CACHE_DIRECTORY
79 |
80 | cache_path = os.path.join(cache_dir, filename)
81 | if not os.path.exists(cache_path):
82 | raise FileNotFoundError("file {} not found".format(cache_path))
83 |
84 | meta_path = cache_path + ".json"
85 | if not os.path.exists(meta_path):
86 | raise FileNotFoundError("file {} not found".format(meta_path))
87 |
88 | with open(meta_path) as meta_file:
89 | metadata = json.load(meta_file)
90 | url = metadata["url"]
91 | etag = metadata["etag"]
92 |
93 | return url, etag
94 |
95 |
96 | def cached_path(
97 | url_or_filename: Union[str, PathLike],
98 | cache_dir: Union[str, Path] = None,
99 | extract_archive: bool = False,
100 | force_extract: bool = False,
101 | ) -> str:
102 | """
103 | Given something that might be a URL (or might be a local path),
104 | determine which. If it's a URL, download the file and cache it, and
105 | return the path to the cached file. If it's already a local path,
106 | make sure the file exists and then return the path.
107 |
108 | # Parameters
109 |
110 | url_or_filename : `Union[str, Path]`
111 | A URL or local file to parse and possibly download.
112 |
113 | cache_dir : `Union[str, Path]`, optional (default = `None`)
114 | The directory to cache downloads.
115 |
116 | extract_archive : `bool`, optional (default = `False`)
117 | If `True`, then zip or tar.gz archives will be automatically extracted.
118 | In which case the directory is returned.
119 |
120 | force_extract : `bool`, optional (default = `False`)
121 | If `True` and the file is an archive file, it will be extracted regardless
122 | of whether or not the extracted directory already exists.
123 | """
124 | if cache_dir is None:
125 | cache_dir = CACHE_DIRECTORY
126 |
127 | if isinstance(url_or_filename, PathLike):
128 | url_or_filename = str(url_or_filename)
129 |
130 | # If we're using the /a/b/foo.zip!c/d/file.txt syntax, handle it here.
131 | exclamation_index = url_or_filename.find("!")
132 | if extract_archive and exclamation_index >= 0:
133 | archive_path = url_or_filename[:exclamation_index]
134 | archive_path = cached_path(archive_path, cache_dir, True, force_extract)
135 | if not os.path.isdir(archive_path):
136 | raise ValueError(
137 | f"{url_or_filename} uses the ! syntax, but does not specify an archive file."
138 | )
139 | return os.path.join(archive_path, url_or_filename[exclamation_index + 1:])
140 |
141 | url_or_filename = os.path.expanduser(url_or_filename)
142 | parsed = urlparse(url_or_filename)
143 |
144 | file_path: str
145 | extraction_path: Optional[str] = None
146 |
147 | if parsed.scheme in ("http", "https", "s3"):
148 | # URL, so get it from the cache (downloading if necessary)
149 | file_path = get_from_cache(url_or_filename, cache_dir)
150 |
151 | if extract_archive and (is_zipfile(file_path) or tarfile.is_tarfile(file_path)):
152 | # This is the path the file should be extracted to.
153 | # For example ~/.allennlp/cache/234234.21341 -> ~/.allennlp/cache/234234.21341-extracted
154 | extraction_path = file_path + "-extracted"
155 |
156 | elif os.path.exists(url_or_filename):
157 | # File, and it exists.
158 | file_path = url_or_filename
159 |
160 | if extract_archive and (is_zipfile(file_path) or tarfile.is_tarfile(file_path)):
161 | # This is the path the file should be extracted to.
162 | # For example model.tar.gz -> model-tar-gz-extracted
163 | extraction_dir, extraction_name = os.path.split(file_path)
164 | extraction_name = extraction_name.replace(".", "-") + "-extracted"
165 | extraction_path = os.path.join(extraction_dir, extraction_name)
166 |
167 | elif parsed.scheme == "":
168 | # File, but it doesn't exist.
169 | raise FileNotFoundError("file {} not found".format(url_or_filename))
170 |
171 | else:
172 | # Something unknown
173 | raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
174 |
175 | if extraction_path is not None:
176 | # No need to extract again.
177 | if os.path.isdir(extraction_path) and os.listdir(extraction_path) and not force_extract:
178 | return extraction_path
179 |
180 | # Extract it.
181 | with FileLock(file_path + ".lock"):
182 | shutil.rmtree(extraction_path, ignore_errors=True)
183 | os.makedirs(extraction_path)
184 | if is_zipfile(file_path):
185 | with ZipFile(file_path, "r") as zip_file:
186 | zip_file.extractall(extraction_path)
187 | zip_file.close()
188 | else:
189 | tar_file = tarfile.open(file_path)
190 | tar_file.extractall(extraction_path)
191 | tar_file.close()
192 |
193 | return extraction_path
194 |
195 | return file_path
196 |
197 |
198 | def is_url_or_existing_file(url_or_filename: Union[str, Path, None]) -> bool:
199 | """
200 | Given something that might be a URL (or might be a local path),
201 | determine check if it's url or an existing file path.
202 | """
203 | if url_or_filename is None:
204 | return False
205 | url_or_filename = os.path.expanduser(str(url_or_filename))
206 | parsed = urlparse(url_or_filename)
207 | return parsed.scheme in ("http", "https", "s3") or os.path.exists(url_or_filename)
208 |
209 |
210 | def _split_s3_path(url: str) -> Tuple[str, str]:
211 | """Split a full s3 path into the bucket name and path."""
212 | parsed = urlparse(url)
213 | if not parsed.netloc or not parsed.path:
214 | raise ValueError("bad s3 path {}".format(url))
215 | bucket_name = parsed.netloc
216 | s3_path = parsed.path
217 | # Remove '/' at beginning of path.
218 | if s3_path.startswith("/"):
219 | s3_path = s3_path[1:]
220 | return bucket_name, s3_path
221 |
222 |
223 | def _s3_request(func: Callable):
224 | """
225 | Wrapper function for s3 requests in order to create more helpful error
226 | messages.
227 | """
228 |
229 | @wraps(func)
230 | def wrapper(url: str, *args, **kwargs):
231 | try:
232 | return func(url, *args, **kwargs)
233 | except ClientError as exc:
234 | if int(exc.response["Error"]["Code"]) == 404:
235 | raise FileNotFoundError("file {} not found".format(url))
236 | else:
237 | raise
238 |
239 | return wrapper
240 |
241 |
242 | def _get_s3_resource():
243 | session = boto3.session.Session()
244 | if session.get_credentials() is None:
245 | # Use unsigned requests.
246 | s3_resource = session.resource(
247 | "s3", config=botocore.client.Config(signature_version=botocore.UNSIGNED)
248 | )
249 | else:
250 | s3_resource = session.resource("s3")
251 | return s3_resource
252 |
253 |
254 | @_s3_request
255 | def _s3_etag(url: str) -> Optional[str]:
256 | """Check ETag on S3 object."""
257 | s3_resource = _get_s3_resource()
258 | bucket_name, s3_path = _split_s3_path(url)
259 | s3_object = s3_resource.Object(bucket_name, s3_path)
260 | return s3_object.e_tag
261 |
262 |
263 | @_s3_request
264 | def _s3_get(url: str, temp_file: IO) -> None:
265 | """Pull a file directly from S3."""
266 | s3_resource = _get_s3_resource()
267 | bucket_name, s3_path = _split_s3_path(url)
268 | s3_resource.Bucket(bucket_name).download_fileobj(s3_path, temp_file)
269 |
270 |
271 | def _session_with_backoff() -> requests.Session:
272 | """
273 | We ran into an issue where http requests to s3 were timing out,
274 | possibly because we were making too many requests too quickly.
275 | This helper function returns a requests session that has retry-with-backoff
276 | built in. See
277 | .
278 | """
279 | session = requests.Session()
280 | retries = Retry(total=5, backoff_factor=1, status_forcelist=[502, 503, 504])
281 | session.mount("http://", HTTPAdapter(max_retries=retries))
282 | session.mount("https://", HTTPAdapter(max_retries=retries))
283 |
284 | return session
285 |
286 |
287 | def _http_etag(url: str) -> Optional[str]:
288 | with _session_with_backoff() as session:
289 | response = session.head(url, allow_redirects=True)
290 | if response.status_code != 200:
291 | raise IOError(
292 | "HEAD request failed for url {} with status code {}".format(url, response.status_code)
293 | )
294 | return response.headers.get("ETag")
295 |
296 |
297 | def _http_get(url: str, temp_file: IO) -> None:
298 | with _session_with_backoff() as session:
299 | req = session.get(url, stream=True)
300 | content_length = req.headers.get("Content-Length")
301 | total = int(content_length) if content_length is not None else None
302 | progress = tqdm(unit="B", total=total, desc="downloading")
303 | for chunk in req.iter_content(chunk_size=1024):
304 | if chunk: # filter out keep-alive new chunks
305 | progress.update(len(chunk))
306 | temp_file.write(chunk)
307 | progress.close()
308 |
309 |
310 | def _find_latest_cached(url: str, cache_dir: Union[str, Path]) -> Optional[str]:
311 | filename = url_to_filename(url)
312 | cache_path = os.path.join(cache_dir, filename)
313 | candidates: List[Tuple[str, float]] = []
314 | for path in glob.glob(cache_path + "*"):
315 | if path.endswith(".json"):
316 | continue
317 | mtime = os.path.getmtime(path)
318 | candidates.append((path, mtime))
319 | # Sort candidates by modification time, neweste first.
320 | candidates.sort(key=lambda x: x[1], reverse=True)
321 | if candidates:
322 | return candidates[0][0]
323 | return None
324 |
325 |
326 | class CacheFile:
327 | """
328 | This is a context manager that makes robust caching easier.
329 |
330 | On `__enter__`, an IO handle to a temporarily file is returned, which can
331 | be treated as if it's the actual cache file.
332 |
333 | On `__exit__`, the temporarily file is renamed to the cache file. If anything
334 | goes wrong while writing to the temporary file, it will be removed.
335 | """
336 |
337 | def __init__(self, cache_filename: Union[Path, str], mode="w+b") -> None:
338 | self.cache_filename = (
339 | cache_filename if isinstance(cache_filename, Path) else Path(cache_filename)
340 | )
341 | self.cache_directory = os.path.dirname(self.cache_filename)
342 | self.mode = mode
343 | self.temp_file = tempfile.NamedTemporaryFile(
344 | self.mode, dir=self.cache_directory, delete=False, suffix=".tmp"
345 | )
346 |
347 | def __enter__(self):
348 | return self.temp_file
349 |
350 | def __exit__(self, exc_type, exc_value, traceback):
351 | self.temp_file.close()
352 | if exc_value is None:
353 | # Success.
354 | logger.debug(
355 | "Renaming temp file %s to cache at %s", self.temp_file.name, self.cache_filename
356 | )
357 | # Rename the temp file to the actual cache filename.
358 | os.replace(self.temp_file.name, self.cache_filename)
359 | return True
360 | # Something went wrong, remove the temp file.
361 | logger.debug("removing temp file %s", self.temp_file.name)
362 | os.remove(self.temp_file.name)
363 | return False
364 |
365 |
366 | # TODO(joelgrus): do we want to do checksums or anything like that?
367 | def get_from_cache(url: str, cache_dir: Union[str, Path] = None) -> str:
368 | """
369 | Given a URL, look for the corresponding dataset in the local cache.
370 | If it's not there, download it. Then return the path to the cached file.
371 | """
372 | if cache_dir is None:
373 | cache_dir = CACHE_DIRECTORY
374 |
375 | os.makedirs(cache_dir, exist_ok=True)
376 |
377 | # Get eTag to add to filename, if it exists.
378 | try:
379 | if url.startswith("s3://"):
380 | etag = _s3_etag(url)
381 | else:
382 | etag = _http_etag(url)
383 | except (ConnectionError, EndpointConnectionError):
384 | # We might be offline, in which case we don't want to throw an error
385 | # just yet. Instead, we'll try to use the latest cached version of the
386 | # target resource, if it exists. We'll only throw an exception if we
387 | # haven't cached the resource at all yet.
388 | logger.warning(
389 | "Connection error occured while trying to fetch ETag for %s. "
390 | "Will attempt to use latest cached version of resource",
391 | url,
392 | )
393 | latest_cached = _find_latest_cached(url, cache_dir)
394 | if latest_cached:
395 | logger.info(
396 | "ETag request failed with connection error, using latest cached "
397 | "version of %s: %s",
398 | url,
399 | latest_cached,
400 | )
401 | return latest_cached
402 | else:
403 | logger.error(
404 | "Connection failed while trying to fetch ETag, "
405 | "and no cached version of %s could be found",
406 | url,
407 | )
408 | raise
409 | except OSError:
410 | # OSError may be triggered if we were unable to fetch the eTag.
411 | # If this is the case, try to proceed without eTag check.
412 | etag = None
413 |
414 | filename = url_to_filename(url, etag)
415 |
416 | # Get cache path to put the file.
417 | cache_path = os.path.join(cache_dir, filename)
418 |
419 | # Multiple processes may be trying to cache the same file at once, so we need
420 | # to be a little careful to avoid race conditions. We do this using a lock file.
421 | # Only one process can own this lock file at a time, and a process will block
422 | # on the call to `lock.acquire()` until the process currently holding the lock
423 | # releases it.
424 | logger.debug("waiting to acquire lock on %s", cache_path)
425 | with FileLock(cache_path + ".lock"):
426 | if os.path.exists(cache_path):
427 | logger.info("cache of %s is up-to-date", url)
428 | else:
429 | with CacheFile(cache_path) as cache_file:
430 | logger.info("%s not found in cache, downloading to %s", url, cache_path)
431 |
432 | # GET file object
433 | if url.startswith("s3://"):
434 | _s3_get(url, cache_file)
435 | else:
436 | _http_get(url, cache_file)
437 |
438 | logger.debug("creating metadata file for %s", cache_path)
439 | meta = {"url": url, "etag": etag}
440 | meta_path = cache_path + ".json"
441 | with open(meta_path, "w") as meta_file:
442 | json.dump(meta, meta_file)
443 |
444 | return cache_path
445 |
446 |
447 | def read_set_from_file(filename: str) -> Set[str]:
448 | """
449 | Extract a de-duped collection (set) of text from a file.
450 | Expected file format is one item per line.
451 | """
452 | collection = set()
453 | with open(filename, "r") as file_:
454 | for line in file_:
455 | collection.add(line.rstrip())
456 | return collection
457 |
458 |
459 | def get_file_extension(path: str, dot=True, lower: bool = True):
460 | ext = os.path.splitext(path)[1]
461 | ext = ext if dot else ext[1:]
462 | return ext.lower() if lower else ext
463 |
464 |
465 | def open_compressed(
466 | filename: Union[str, Path], mode: str = "rt", encoding: Optional[str] = "UTF-8", **kwargs
467 | ):
468 | if isinstance(filename, Path):
469 | filename = str(filename)
470 | open_fn: Callable = open
471 |
472 | if filename.endswith(".gz"):
473 | import gzip
474 |
475 | open_fn = gzip.open
476 | elif filename.endswith(".bz2"):
477 | import bz2
478 |
479 | open_fn = bz2.open
480 | return open_fn(filename, mode=mode, encoding=encoding, **kwargs)
481 |
482 |
483 | def text_lines_from_file(filename: Union[str, Path], strip_lines: bool = True) -> Iterator[str]:
484 | with open_compressed(filename, "rt", encoding="UTF-8", errors="replace") as p:
485 | if strip_lines:
486 | for line in p:
487 | yield line.strip()
488 | else:
489 | yield from p
490 |
491 |
492 | def json_lines_from_file(filename: Union[str, Path]) -> Iterable[Union[list, dict]]:
493 | return (json.loads(line) for line in text_lines_from_file(filename))
494 |
--------------------------------------------------------------------------------