7 | {% if page.title %}
8 |
19 | {{page.title}}
9 | {% endif %} 10 | {% if page.date %} 11 |
12 | {% if page.categories.size > 0 %}
13 | 分类于:{{ page.categories[0] }}
14 | {% endif %}
15 | 发布于:{{ page.date|date:"%Y-%m-%d" }}
16 |
17 | {% endif %}
18 |
20 | {% if page.cover %}
21 |
27 |
22 |  23 |
23 |
24 | {% endif %}
25 | {{ content }}
26 | 
 74 |
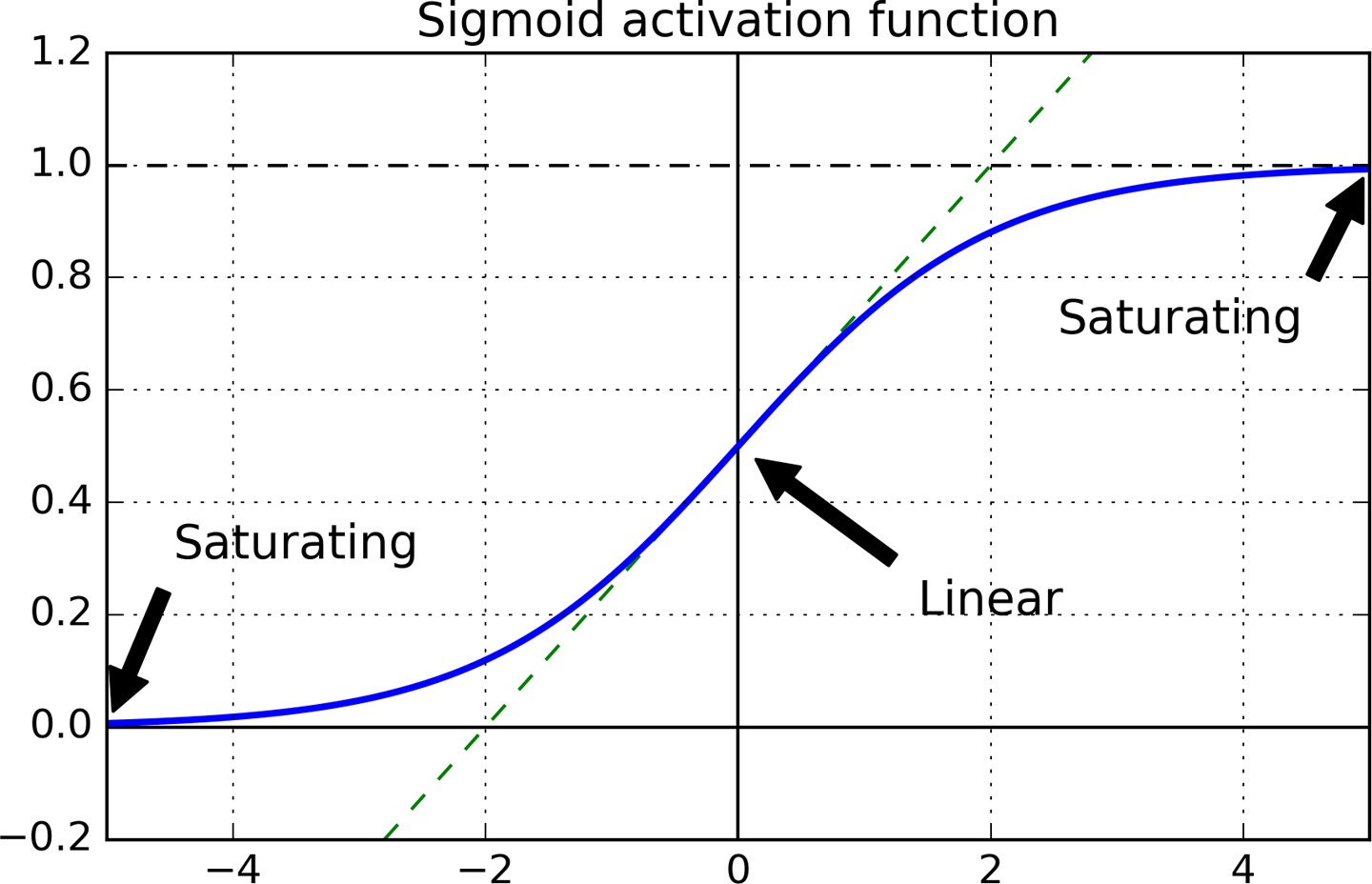
75 | 梯度消失的原因主要是使用 sigmoid 作为激活函数导致的,sigmoid 函数当输入很大或很小时,其梯度都接近于 0。
76 |
77 | Relu 激活函数的问题在于,一旦某个 unit 输出小于 0,那么它之后就只会输出 0,而且梯度也会是 0,即 ReLU 也可能出现梯度消失的问题,此 unit 的权重将得不到更新。这个问题称为 Dead ReLUs。
78 |
79 | 梯度爆炸常常出现在循环神经网络中。_为啥_
80 |
81 | ## Batch Normalization
82 |
83 | 使用 ReLU 及其变种,加上合适的参数初始化策略,在训练的初期可以很好地消除梯度消失/爆炸的问题,但不能保证在整个训练过程中都不出现梯度消失/爆炸的问题。Batch Normalization 对输入的整个 batch 的数据做标准化,可以持续减缓梯度消失/爆炸的问题。
84 |
85 | Batch Normalization 需要调整的参数不多,`momentum` 用于计算动态调整的均值,它的值应该接近于 1。样本集越大,或者 batch-size 越小时,`momentum` 应该越接近于 1。
86 |
87 | 如果在输入层之后紧接一个 batch normalization 层,对数据做标准化操作就可以不用显式地完成了。
88 |
89 | ## 梯度裁剪
90 |
91 | 梯度裁剪是限制梯度的大小不超过某个阈值。在 RNN 中梯度裁剪尤其重要,因为 RNN 常常出现梯度爆炸的问题。
92 |
93 | ```python
94 | optimizer = keras.optimizers.SGD(clipvalue=1.0)
95 | model.compile(loss="mse", optimizer=optimizer)
96 | ```
97 |
98 | 在 keras 中设置梯度裁剪尤其简单,以上代码将限制梯度的绝对值小于 1.0。对梯度的某个分量进行裁剪,会导致梯度方向的改变,比如原梯度为 `[100, 1]`, 裁剪后变为 `[1, 1]`,这极大地改变了梯度方向。要想保证梯度方向不变,可以对梯度的 L2 范数做限制,即限制梯度向量的模长。下面的设置保证梯度的模长不大于 1,否则各个分量都进行缩减,保证梯度方向不变。
99 |
100 | ```python
101 | optimizer = keras.optimizers.SGD(clipnorm=1.0)
102 | ```
--------------------------------------------------------------------------------
/_posts/web/2016-09-08-css-center.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: CSS 垂直居中
4 | category: Web
5 | ---
6 |
7 |
8 |
9 | - *
10 | {:toc}
11 |
12 |
24 |
25 |
26 | 垂直居中,这是任何前端开发者都遇到的场景,也是大多数人都为之困惑的问题。记得当时来公司后,进行了一次笔试,其中一个便是用 CSS 实现垂直居中,我突然发现自己竟不能写出一种自信无误的实现方式。
27 |
28 | 下面来总结一下 CSS 垂直居中的方式,对于 hack 气息较重的方法(比如使用 table,button 等)这里不再讨论了,这里主要谈谈现代 CSS 中实现垂直居中的方式。
29 |
30 |
31 | 下面的示例中均采用下面这样的 HTML 结构:
32 |
33 | ```html
34 |
74 |
75 | 梯度消失的原因主要是使用 sigmoid 作为激活函数导致的,sigmoid 函数当输入很大或很小时,其梯度都接近于 0。
76 |
77 | Relu 激活函数的问题在于,一旦某个 unit 输出小于 0,那么它之后就只会输出 0,而且梯度也会是 0,即 ReLU 也可能出现梯度消失的问题,此 unit 的权重将得不到更新。这个问题称为 Dead ReLUs。
78 |
79 | 梯度爆炸常常出现在循环神经网络中。_为啥_
80 |
81 | ## Batch Normalization
82 |
83 | 使用 ReLU 及其变种,加上合适的参数初始化策略,在训练的初期可以很好地消除梯度消失/爆炸的问题,但不能保证在整个训练过程中都不出现梯度消失/爆炸的问题。Batch Normalization 对输入的整个 batch 的数据做标准化,可以持续减缓梯度消失/爆炸的问题。
84 |
85 | Batch Normalization 需要调整的参数不多,`momentum` 用于计算动态调整的均值,它的值应该接近于 1。样本集越大,或者 batch-size 越小时,`momentum` 应该越接近于 1。
86 |
87 | 如果在输入层之后紧接一个 batch normalization 层,对数据做标准化操作就可以不用显式地完成了。
88 |
89 | ## 梯度裁剪
90 |
91 | 梯度裁剪是限制梯度的大小不超过某个阈值。在 RNN 中梯度裁剪尤其重要,因为 RNN 常常出现梯度爆炸的问题。
92 |
93 | ```python
94 | optimizer = keras.optimizers.SGD(clipvalue=1.0)
95 | model.compile(loss="mse", optimizer=optimizer)
96 | ```
97 |
98 | 在 keras 中设置梯度裁剪尤其简单,以上代码将限制梯度的绝对值小于 1.0。对梯度的某个分量进行裁剪,会导致梯度方向的改变,比如原梯度为 `[100, 1]`, 裁剪后变为 `[1, 1]`,这极大地改变了梯度方向。要想保证梯度方向不变,可以对梯度的 L2 范数做限制,即限制梯度向量的模长。下面的设置保证梯度的模长不大于 1,否则各个分量都进行缩减,保证梯度方向不变。
99 |
100 | ```python
101 | optimizer = keras.optimizers.SGD(clipnorm=1.0)
102 | ```
--------------------------------------------------------------------------------
/_posts/web/2016-09-08-css-center.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: CSS 垂直居中
4 | category: Web
5 | ---
6 |
7 |
8 |
9 | - *
10 | {:toc}
11 |
12 |
24 |
25 |
26 | 垂直居中,这是任何前端开发者都遇到的场景,也是大多数人都为之困惑的问题。记得当时来公司后,进行了一次笔试,其中一个便是用 CSS 实现垂直居中,我突然发现自己竟不能写出一种自信无误的实现方式。
27 |
28 | 下面来总结一下 CSS 垂直居中的方式,对于 hack 气息较重的方法(比如使用 table,button 等)这里不再讨论了,这里主要谈谈现代 CSS 中实现垂直居中的方式。
29 |
30 |
31 | 下面的示例中均采用下面这样的 HTML 结构:
32 |
33 | ```html
34 |  75 | */
76 | img[src*=selector]
77 |
78 |
79 | /*
80 | 选择 class 属性中包含字符串单词 selector 的 img 标签,与前一个不同的是,这里要求是单词,前一个匹配的是子字符串
81 |
82 |
75 | */
76 | img[src*=selector]
77 |
78 |
79 | /*
80 | 选择 class 属性中包含字符串单词 selector 的 img 标签,与前一个不同的是,这里要求是单词,前一个匹配的是子字符串
81 |
82 |  99 | */
100 | img[src$=jpg]
101 | ```
102 |
103 |
104 | 注意:乍一看好像 `img[src^=http]` 和 `img[src|=http]` 是一样的,其实不然。前者匹配前缀字符串,后缀匹配第一个单词。举个不恰当的例子:
105 |
106 | ```html
107 |
99 | */
100 | img[src$=jpg]
101 | ```
102 |
103 |
104 | 注意:乍一看好像 `img[src^=http]` 和 `img[src|=http]` 是一样的,其实不然。前者匹配前缀字符串,后缀匹配第一个单词。举个不恰当的例子:
105 |
106 | ```html
107 |