├── .gitignore
├── .idea
├── .gitignore
├── SSLDPCA-IL-FaultDetection.iml
├── inspectionProfiles
│ ├── Project_Default.xml
│ └── profiles_settings.xml
├── misc.xml
├── modules.xml
└── vcs.xml
├── README.md
├── SSLDPCA
├── __init__.py
├── __pycache__
│ └── __init__.cpython-36.pyc
├── images
│ ├── areas.png
│ ├── data.png
│ └── digits_tsne1.png
├── ssl_dpca_1d.py
├── ssl_dpca_2d.py
└── toy_dataset.py
├── __pycache__
└── config.cpython-36.pyc
├── config.py
├── data
├── CWRU_data
│ ├── annotations.txt
│ └── annotations.xls
├── CWRU_data_1d
│ └── README.txt
├── CWRU_data_2d
│ └── README.txt
├── GramianAngularField.pdf
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ └── dataset.cpython-36.pyc
├── data_process.py
├── dataset.py
└── matrix.xlsx
├── main.py
├── models
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-36.pyc
│ ├── basic_module.cpython-36.pyc
│ └── resnet34.cpython-36.pyc
├── autoencoder.py
├── basic_module.py
├── cnn1d.py
├── resnet.py
└── resnet34.py
├── pic
├── 1.png
├── 2.png
├── 3.png
├── 4.png
├── 5.png
├── DS7-data.png
├── con-A.png
├── con-B.png
├── con-C.png
├── confusion-A.png
├── confusion-B.png
├── confusion-C.png
└── point.png
└── utils
├── __init__.py
├── __pycache__
├── __init__.cpython-36.pyc
└── visualize.cpython-36.pyc
├── plot.py
└── visualize.py
/.gitignore:
--------------------------------------------------------------------------------
1 | /data/CWRU_data
2 | /data/*.h5
3 | /data/CWRU_data_2d/DE
4 | /data/CWRU_data_2d/FE
5 | /data/CWRU_data_1d/*.h5
6 | /data/CWRU_data/*.mat
7 |
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 | # Datasource local storage ignored files
5 | /../../../../:\working_space\SSLDPCA-IL-FaultDetection\.idea/dataSources/
6 | /dataSources.local.xml
7 | # Editor-based HTTP Client requests
8 | /httpRequests/
9 |
--------------------------------------------------------------------------------
/.idea/SSLDPCA-IL-FaultDetection.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/Project_Default.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 基于密度峰值聚类和共享最近邻的IIOT机械半监督自训练故障诊断
2 |
3 | ## 简介
4 |
5 | 在工业系统中,机械设备在运行过程中会产生数据流,不断变化且缺乏标签,使得基于深度学习的故障诊断方法难以在这种环境下有效工作。增量学习是解决这个问题的有效方法,但它严重依赖标记数据并且无法检测数据中的新类别,这使得它在实际应用中并不理想。
6 |
7 | 鉴于此,设计了一种基于半监督式增量学习的工业物联网设备故障诊断系统,该系统包括:故障诊断模块、半监督标记模块、增量更新模块。
8 |
9 | 该系统针对传统数据驱动的故障诊断方法存在的增量更新能力与学习无标签样本数据能力不足的问题做出了改进。在面对数据时变与缺乏标签的情况时,保证故障诊断模型能够有效训练,及时更新,保持较高的故障诊断准确率。
10 |
11 | ## 整体架构
12 |
13 | - 故障诊断模块
14 | - 半监督标记模块
15 | - 增量更新模块
16 |
17 | 故障诊断模块读取设备监测数据,根据数据判断设备是否处于正常状态,如果出现故障,判断设备发生何种故障;
18 |
19 | 半监督标记模块首先判断设备监测数据中是否存在未知的故障类别样本,并对所有无标签的设备监测数据(包括已知故障类别与未知故障类别样本)标记伪标签,最后输出带有伪标签的样本以辅助增量更新模块对故障诊断模块进行更新;
20 |
21 | 增量更新模块使用半监督标记模块输出的伪标签样本对故障诊断模块进行增量地更新。
22 |
23 | 流程图:
24 |
25 | 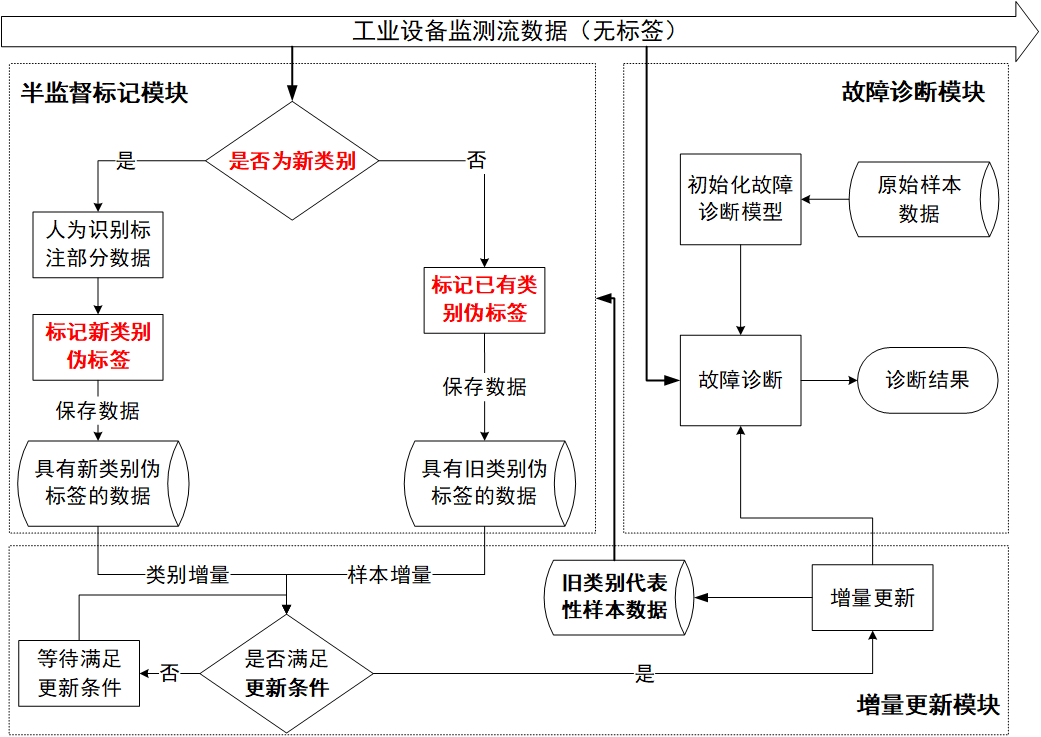
26 |
27 | ## 环境配置
28 |
29 | - python3.6
30 | - tslearn 0.5.0.5 `tslearn`是一个Python软件包,提供了用于分析时间序列的机器学习工具。
31 | - scikit-learn 0.23.2 机器学习库
32 | - pytorch 1.7.0 深度学习库
33 | - dcipy 科学计算
34 | - numpy 1.19.2 矩阵计算
35 | - h5py 2.10.0 用来存储使用h5文件
36 | - pandas 1.1.3 存储(好像没用到)
37 | - matplotlib 3.3.2 绘图
38 | - seaborn 0.11.1 绘图
39 | - tqdm 4.54.1 进度条
40 | - xlrd,xlwt 处理表格
--------------------------------------------------------------------------------
/SSLDPCA/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/9 19:19
3 | # @Author : wb
4 | # @File : __init__.py.py
5 |
6 |
--------------------------------------------------------------------------------
/SSLDPCA/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/SSLDPCA/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/SSLDPCA/images/areas.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/SSLDPCA/images/areas.png
--------------------------------------------------------------------------------
/SSLDPCA/images/data.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/SSLDPCA/images/data.png
--------------------------------------------------------------------------------
/SSLDPCA/images/digits_tsne1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/SSLDPCA/images/digits_tsne1.png
--------------------------------------------------------------------------------
/SSLDPCA/ssl_dpca_1d.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/16 21:28
3 | # @Author : wb
4 | # @File : ssl_dpca_1d.py
5 | import datetime
6 | import os
7 | import h5py
8 | from tqdm import tqdm
9 | import random
10 | import numpy as np
11 | from tslearn import neighbors
12 | from tslearn.utils import to_time_series_dataset
13 | from scipy.spatial.distance import pdist
14 | from collections import Counter
15 |
16 | from config import opt
17 | from utils import plot
18 |
19 | '''
20 | 半监督(SSL)的密度峰值聚类(DPCA),此文件用于1d数据
21 | '''
22 |
23 | class SslDpca1D(object):
24 | '''
25 | 半监督的DPCA,在原始的DPCA的基础上加入半监督(小部分有标签数据)
26 | 步骤:
27 | 1.注入部分的有标签数据
28 | 2.计算密度与间隔
29 | 3.计算数据点的分数
30 | 4.选取分数高的作为簇中心
31 | 5.根据规则在 密度-间隔决策图 上划分区域
32 | 6.对每个区域内的数据点分配标签
33 | 6.1 簇中心点的标签由簇中心点到带有真实标签样本数据的距离决定
34 | 6.2 核心区域中的主干点分配给距离最近的簇中心点,并且主干点的标签与所属簇中心点的标签保持一致
35 | 6.3 边缘区域内的边缘点选择与它距离最近K个主干点的标签值,K是人为设定值
36 | 6.4 新类别的样本数据点需要人为标注一部分的标签,然后使用Kmeans聚类传递标签
37 | 7.调整数据格式,输出所有的数据(大量伪标签,少量真实标签)
38 | density distance
39 | 重新修改方案,主要改动:
40 | 1.首先对注入的数据进行类型划分,划分为主干点,边界点,噪声点
41 | 2.保留主干点和边界点,删除噪声点
42 | 3.修改间隔定义公式,现在间隔定义公式与有标签样本无关
43 | 4.在计算完每个节点的分数之后,采用动态选择簇头(不太好用,还是直接赋一个固定值作为类别数)
44 |
45 | '''
46 |
47 | def __init__(self):
48 | '''
49 | 读取处理好的1d数据文件
50 | ../data/CWRU_data_1d/CWRU_DE.h5
51 | 设定一些全局变量作为参数
52 | '''
53 | # h5文件路径
54 | file_path = '../data/CWRU_data_1d/CWRU_mini_0_DE.h5'
55 | # 读取数据
56 | f = h5py.File(file_path, 'r')
57 | # 数据,取值,可以用f['data'].value,不过包自己推荐使用f['data'][()]这种方式
58 | self.data = f['data'][()]
59 | # 标签
60 | self.label = f['label'][()]
61 | # 每个类别的数据块数量
62 | self.data_num = f['data_num'][()]
63 | # 数据中每个数据点的SNN数量
64 | # 这里可以减少一次计算SNN的计算量,不过暂时还没用上
65 | self.snn_num = []
66 |
67 | # 有标签数据的占比
68 | self.label_fraction = opt.label_fraction
69 | # 有标签数据保存的文件
70 | self.labeled_data_file = './labeled_data.npy'
71 | self.label_file = './label.npy'
72 | # 故障的类别
73 | self.category = opt.CWRU_category
74 | # 邻居数量,因为计算的K邻居的第一个是自己,所以需要+1
75 | self.neighbor_num = opt.K + 1
76 | # 数据的维度
77 | self.dim = opt.CWRU_dim
78 | # K邻居模型保存路径
79 | self.K_neighbor = './K-neighbor_mini.h5'
80 |
81 | def make_labeled_data(self):
82 | '''
83 | 处理有标签的数据,选择其中的一部分作为标签数据输入算法,其他数据的标签全部清除
84 | 这里选择数据是随机选择的
85 | 所以每次运行此函数得到的有标签样本是变化的
86 | 考虑保存选出的数据,因为原始数据中需要删除这一部分的数据
87 | :return: labeled_datas,每个类别的有标签的数据集合 [[],[],...,[]]
88 | '''
89 | # 选取一定比例的有标签数据(这个是仿真中可以调整的参数)
90 | # 为了实验起见,选取平衡的数据,即每个类分配相同比例的有标签数据集
91 | # (33693,400)(33693)
92 | # 各个类别的数据
93 | category_data = []
94 | # 各个类别的标签
95 | category_label = []
96 | # 有标签的数据
97 | labeled_datas = []
98 | # 有标签的标签
99 | labels = []
100 |
101 | # 把每个类别的数据切分出来
102 | point = 0
103 | for i in range(len(self.data_num)):
104 | data = self.data[point:point + self.data_num[i]]
105 | label = self.label[point:point + self.data_num[i]]
106 |
107 | category_data.append(data)
108 | category_label.append(label)
109 |
110 | point = point + self.data_num[i]
111 |
112 | # 选出有标签的index
113 | for data, label in tqdm(zip(category_data, category_label)):
114 | # 有标签的数量
115 | label_data_num = int(len(data) * self.label_fraction)
116 | # 对category的格式为(609,400)
117 | # 随机从数据中取出需要数量的值,需要先转换为list
118 | data_ = random.sample(data.tolist(), label_data_num)
119 | label_ = random.sample(label.tolist(), label_data_num)
120 |
121 | # label_data为list,每个list是(400,)的数据
122 | # 再把list转换为ndarray
123 | labeled_datas.append(np.array(data_))
124 | # labeled_data为list,list中为[(121,400),(xxx,400)...]
125 | labels.append(np.array(label_))
126 |
127 | # # 保存为h5文件
128 | # f = h5py.File(self.labeled_data_file, 'w') # 创建一个h5文件,文件指针是f
129 | # f['labeled_data'] = np.array(labeled_data) # 将数据写入文件的主键data下面
130 | # f.close() # 关闭文件
131 |
132 | # 使用np的保存,不过保存下来是ndarray
133 | np.save(self.labeled_data_file, labeled_datas)
134 | np.save(self.label_file, labels)
135 | return labeled_datas
136 |
137 | def del_labeled_data(self):
138 | '''
139 | 从self.data,也就是原始数据中删除有标签的数据
140 | :return:
141 | '''
142 | # 从文件中读取保存好的有标签的样本
143 | # 读取出来是ndarray,需要转换成list
144 | labeled_datas = np.load(self.labeled_data_file, allow_pickle=True).tolist()
145 | labels = np.load(self.label_file, allow_pickle=True).tolist()
146 | # 为了从self.data中删除元素,需要先把ndarray转换为list
147 | data_list = self.data.tolist()
148 | label_list = self.label.tolist()
149 | # 读取每个类别的有标签样本
150 | for data, label in zip(labeled_datas, labels):
151 | # 遍历
152 | for category_data, category_label in zip(data, label):
153 | # 根据样本值从原始数据中删除样本
154 | # 使用np的ndarray删除
155 | data_list.remove(category_data.tolist())
156 | label_list.remove(category_label.tolist())
157 | # 最后还得把data转化为ndarray
158 | self.data = np.array(data_list)
159 | self.label = np.array(label_list)
160 |
161 | def neighbors_model(self):
162 | '''
163 | 计算数据的K邻居
164 | :return:
165 | '''
166 | # 把数据凑成需要的维度
167 | # tslearn的三个维度,分别对应于时间序列的数量、每个时间序列的测量数量和维度的数量
168 | # 使用tslearn计算K邻居
169 | train_time_series = to_time_series_dataset(self.data)
170 | knn_model = neighbors.KNeighborsTimeSeries(n_neighbors=self.neighbor_num,
171 | metric='euclidean',
172 | n_jobs=-1)
173 | knn_model.fit(train_time_series)
174 | if not os.path.exists(self.K_neighbor):
175 | knn_model.to_hdf5(self.K_neighbor)
176 |
177 | return knn_model
178 |
179 | def neighbors(self):
180 | '''
181 | 对输入的data进行计算邻居与距离
182 | :param data: 输入数据,data形式为[[],[],...,[]]
183 | :return: neigh_dist,邻居之间的距离;neigh_ind,邻居的ID
184 | '''
185 | starttime = datetime.datetime.now()
186 | # 在导入h5模型之前还是需要构建一下模型
187 | knn_model = neighbors.KNeighborsTimeSeries(n_neighbors=self.neighbor_num,
188 | metric='euclidean',
189 | n_jobs=-1)
190 | # 如果存在保存好的模型,h5
191 | if os.path.exists(self.K_neighbor):
192 | knn_model = knn_model.from_hdf5(self.K_neighbor)
193 | # 还是需要数据拟合一下
194 | knn_model.fit(self.data)
195 | else:
196 | # 没有保存模型那就去模型函数那边训练模型
197 | knn_model = self.neighbors_model()
198 | # 需要计算邻居的数据
199 | test_time_series = to_time_series_dataset(self.data)
200 | # K邻居的距离和邻居的id
201 | neigh_dist, neigh_ind = knn_model.kneighbors(test_time_series, return_distance=True)
202 |
203 | endtime = datetime.datetime.now()
204 | print('计算邻居用时', (endtime - starttime).seconds)
205 | return neigh_dist, neigh_ind
206 |
207 | def divide_type(self, neigh_ind, param_lambda_low, param_lambda_high):
208 | '''
209 | 获得每个点的邻居列表之后即可以为所有的无标签样本划分类型,分为主干点,边界点,噪声点
210 | :param neigh_ind: 邻居表
211 | :param param_lambda_low: 噪声点与边界点阈值
212 | :param param_lambda_high: 边界点和主干点的阈值
213 | :return:backbone_point, border_point, noise_point
214 | 主干点,边界点,噪声点的ID值,在data中的index值
215 | '''
216 |
217 | starttime = datetime.datetime.now()
218 |
219 | # 主干点
220 | backbone_point = []
221 | # 边界点
222 | border_point = []
223 | # 噪声点
224 | noise_point = []
225 |
226 | # r值
227 | r_list = []
228 | # 共享邻居数量
229 | for index in neigh_ind:
230 | # enumerate neigh_index[0]是id neigh_index[1]是值
231 | snn_list = []
232 | # 这个点的邻居列表
233 | for neighbor in index:
234 | # 求该数据点的邻居与其邻居的邻居有多少是重复邻居
235 | snn = list(set(index).intersection(set(neigh_ind[neighbor])))
236 | # 共享邻居的数量
237 | snn_num = len(snn)
238 | # 把每个邻居的共享邻居保存起来
239 | snn_list.append(snn_num)
240 | # 每个点的平均邻居数
241 | snn_avg = np.mean(snn_list)
242 | # 计算r值
243 | # 这里没有使用self.neighbor_num,因为这个数值+1了
244 | r = snn_avg / opt.K
245 | r_list.append(r)
246 |
247 | print('r均值', np.mean(r_list))
248 | print('r中位数', np.median(r_list))
249 | # return r_list
250 |
251 | # 设置para_lambda为均值
252 | # para_lambda = np.mean(r_list)
253 | # 划分点,并输出点的id
254 | for r in enumerate(r_list):
255 | # 主干点 backbone
256 | if (r[1] >= param_lambda_high and r[1] <= 1):
257 | backbone_point.append(r[0])
258 | # 边界点
259 | elif (r[1] >= param_lambda_low and r[1] <= param_lambda_high):
260 | border_point.append(r[0])
261 | # 噪声点
262 | elif (r[1] >= 0 and r[1] < param_lambda_low):
263 | noise_point.append(r[0])
264 | else:
265 | print('出错了')
266 |
267 | endtime = datetime.datetime.now()
268 | print('节点划分类型用时', (endtime - starttime).seconds)
269 |
270 | return backbone_point, border_point, noise_point
271 |
272 | def del_noise(self, noise_point, neigh_dist, neigh_ind):
273 | '''
274 | 从self.data,也就是原始数据中删除noise_point
275 | :param noise_point: 噪声点的idx
276 | :return:
277 | '''
278 | # 从self.data,neigh_dist,neigh_ind中删除noise_point
279 | for noise_node in noise_point:
280 | # np 删除行
281 | np.delete(self.data, noise_node, axis=0)
282 | # python list 删除,使用pop
283 | neigh_dist.pop(noise_node)
284 | neigh_ind.pop(noise_node)
285 |
286 | return neigh_dist, neigh_ind
287 |
288 | def build_density(self, neigh_dist, neigh_ind):
289 | '''
290 | 计算每个数据点的密度
291 | 使用SNN的方式,共享邻居数据点
292 | 两个邻居数据点才有相似度,相似度公式为S/d(i)+d(j),每个数据点的密度是K邻居的相似度之和
293 | dis和nei的第一个点都是自己本身,需要去掉
294 | :param: distance,[[],[],[]]数据点的距离
295 | :param: neighbors_index,[[],[],[]]数据点的邻居列表
296 | :return: density,密度列表,[, ,...,]
297 | '''
298 | starttime = datetime.datetime.now()
299 | # 每个数据点的密度
300 | density = []
301 | for index in range(len(neigh_dist)):
302 | # 该数据点的平均邻居距离,去掉第一个点,第一个是本身数据点
303 | node_distance_avg = np.mean(neigh_dist[index][1:])
304 |
305 | # 数据点的密度
306 | node_density = 0
307 |
308 | # 从一个数据点的邻居内开始计算,neighbor是邻居的ID
309 | for neighbor in neigh_ind[index]:
310 | # 求该数据点的邻居与其邻居的邻居有多少是重复邻居
311 | snn = list(set(neigh_ind[index][1:]).intersection(set(neigh_ind[neighbor][1:])))
312 | # 共享邻居的数量
313 | snn_num = len(snn)
314 | # 邻居数据点的平均距离
315 | neighbors_distance_avg = np.mean(neigh_dist[neighbor][1:])
316 |
317 | # 两个数据点的相似度
318 | sim = snn_num / (node_distance_avg + neighbors_distance_avg)
319 | # 数据点的密度是每个邻居的相似度的和
320 | node_density += sim
321 |
322 | # 所有数据点的密度
323 | density.append(node_density)
324 |
325 | endtime = datetime.datetime.now()
326 | print('计算密度用时', (endtime - starttime).seconds)
327 |
328 | return density
329 |
330 | def build_interval(self, density, neigh_dist):
331 | '''
332 | 这个函数是与有标签样本无关的版本,目前函数修改为无有标签样本
333 | :param density: 密度
334 | :param neigh_dist: 邻居之间的距离
335 | :return: interval,间隔列表 []
336 | '''
337 | # 1.首先需要寻找到比数据点密度更高的数据点
338 | # 2.然后计算dij,i的平均邻居距离,j的平均邻居距离
339 | # 3.密度最大值的数据点需要成为最大的间隔值
340 |
341 | starttime = datetime.datetime.now()
342 |
343 | # 数据点的间隔值
344 | interval = []
345 | # 因为排序过,所以得换一种dict
346 | interval_dict = {}
347 |
348 | # 排序,获得排序的ID[]
349 | sort_density_idx = np.argsort(density)
350 | # 数据点node的index
351 | for node_i in range(len(sort_density_idx)):
352 |
353 | # node_i的平均邻居距离
354 | node_i_distance_avg = np.mean(neigh_dist[sort_density_idx[node_i]])
355 |
356 | # 数据点的全部间隔
357 | node_intervals = []
358 | # 密度比node更大的数据点
359 | for node_j in range(node_i + 1, len(sort_density_idx)):
360 | # i,j的距离
361 | dij = self.euclidean_distance(self.data[sort_density_idx[node_i]], self.data[sort_density_idx[node_j]])
362 | # 数据点j的平均邻居距离
363 | node_j_distance_avg = np.mean(neigh_dist[sort_density_idx[node_j]])
364 | delta = dij * (node_i_distance_avg + node_j_distance_avg)
365 | node_intervals.append(delta)
366 |
367 | # 添加到interval
368 | # 判断node_intervals是否为空
369 | if node_intervals:
370 | # 不为空就是正常的间隔值
371 | # 因为排序过,所以不能是直接append,而是要找到位置入座
372 | interval_dict[sort_density_idx[node_i]] = np.min(node_intervals)
373 | else:
374 | # 如果为空,应该是密度最大值,先设置为-1,后面会为他设置为间隔最高值
375 | interval_dict[sort_density_idx[node_i]] = -1
376 |
377 | # 密度最高的数据点的间隔必须为间隔最大值
378 | # 这里用的是dict,所以需要先取出values,然后转换成list,才能使用np.max
379 | interval_dict[sort_density_idx[-1]] = np.max(list(interval_dict.values()))
380 |
381 | # 然后将dict按key排序,也就是回到从1-n的原序状态
382 | # 然后就可以把dict中的value输入到interval
383 | for key, value in sorted(interval_dict.items()):
384 | interval.append(value)
385 |
386 | endtime = datetime.datetime.now()
387 | print('计算间隔用时', (endtime - starttime).seconds)
388 | return interval
389 |
390 | def euclidean_distance(self, data1, data2):
391 | '''
392 | 计算两个数据点之间的欧几里得距离
393 | :param data1: 数据1
394 | :param data2: 数据2
395 | :return: 距离
396 | '''
397 |
398 | X = np.vstack([data1, data2])
399 | distance = pdist(X, 'euclidean')[0]
400 | return distance
401 |
402 | def build_score(self, density, interval):
403 | '''
404 | 根据数据点的密度与间隔,计算分数
405 | :param density: 数据点密度列表 []
406 | :param interval: 数据点间隔列表 []
407 | :return: node_scores [] 数据点的分数
408 | '''
409 |
410 | starttime = datetime.datetime.now()
411 |
412 | node_scores = []
413 | max_rho = np.max(density)
414 | max_delta = np.max(interval)
415 |
416 | for rho, delta in zip(density, interval):
417 | # 每个数据点的得分计算
418 | score = (rho / max_rho) * (delta / max_delta)
419 | node_scores.append(score)
420 |
421 | endtime = datetime.datetime.now()
422 | print('计算得分用时', (endtime - starttime).seconds)
423 |
424 | return node_scores
425 |
426 | def detect_jump_point(self, node_scores, param_alpha):
427 | '''
428 | 动态选择簇头
429 | f(x, a, k) = akax−(a + 1)
430 | logf(x, a, k) = alog(k) + log(a) − (a + 1)log(x)
431 | 本函数全部按照论文中伪代码编写而成
432 | 主要的流程就是,通过阈值找跳变点,因为score排序过,所以找到跳变的k,k前面的就全部是簇头
433 | 不过没有理解论文中的操作,可能是代码有问题,可能是参数设置的问题,反正这玩意不好用
434 | 最后还是直接设置给定值的类别数
435 | :param node_scores: 数组node_score的元素按升序排列
436 | :param param_alpha: 置信度参数 alpha
437 | :return: e 跳点e的对应索引
438 | '''
439 | # 长度
440 | n = len(node_scores)
441 | # 返回的簇的数量
442 | e = -1
443 | # 阈值
444 | w_n = 0
445 | # score_index = np.argsort(-np.array(scores))
446 | # 因为先取反进行降序排序的,所以最后需要取绝对值
447 | # sorted_scores = abs(np.sort(-np.array(scores)))
448 | # 论文中需要升序排序
449 | sorted_scores = np.sort(np.array(node_scores))
450 | for k in range(int(n / 2), n - 3):
451 | m_a = np.mean(sorted_scores[0:k])
452 | m_b = np.mean(sorted_scores[k:n])
453 | if m_a < param_alpha * m_b:
454 | # a的参数,shape就是k,scale就是a
455 | shape_a = sorted_scores[0]
456 | sum_a = 0
457 | for i in range(0, k):
458 | sum_a += np.log(sorted_scores[i] / shape_a)
459 | scale_a = k / sum_a
460 | # b的参数
461 | shape_b = sorted_scores[k]
462 | sum_b = 0
463 | for i in range(k, n):
464 | sum_b += np.log(sorted_scores[i] / shape_b)
465 | scale_b = (n - k + 1) / sum_b
466 | sk = 0
467 | for i in range(k, n):
468 | ta = scale_a * np.log(shape_a) + np.log(scale_a) - (scale_a + 1) * np.log(sorted_scores[i])
469 | tb = scale_b * np.log(shape_b) + np.log(scale_b) - (scale_b + 1) * np.log(sorted_scores[i])
470 | sk += np.log(tb / ta)
471 | if sk > w_n:
472 | w_n = sk
473 | e = k
474 | return e
475 |
476 | def select_head(self, node_scores):
477 | '''
478 | 根据每个数据点的分数,选择簇头
479 | 本来是应该使用跳变点动态选择类别的,不过还是用这个混混吧
480 | :param node_scores: 数据点分数
481 | :return: 簇节点的ID heads []
482 | '''
483 | starttime = datetime.datetime.now()
484 |
485 | # 降序排序,需要选取分数最大的作为簇头
486 | score_index = np.argsort(-np.array(node_scores))
487 | # 有多少个故障类别,就有多少个簇头
488 | head_nodes = score_index[:self.category].tolist()
489 |
490 | endtime = datetime.datetime.now()
491 | print('计算簇头用时', (endtime - starttime).seconds)
492 |
493 | return head_nodes
494 |
495 | def assign_labels(self, head_nodes, type_point, labeled_data):
496 | '''
497 | 为无标签样本标注伪标签,也就是对聚类中心,主干点,边界点分别标注标签
498 | 聚类中心:哪个已知类别的真实标签样本与聚类中心的平均距离最近,那么聚类中心的标签就是该已知类的标签
499 | 主干点:主干点分配给距离最近的聚类中心,也就是与聚类中心保持一致
500 | 边界点:边界点与距离他最近的K个主干点的标签值保持一致
501 | :param head_nodes: 簇中心点
502 | :param type_point: 不同区域的数据ID [[backbone_point],[border_point]]
503 | :param labeled_data: 有标签样本
504 | :return: 样本的伪标签值 []
505 | '''
506 | starttime = datetime.datetime.now()
507 |
508 | # 主干点
509 | backbone_point = type_point[0]
510 | # 边界点
511 | border_point = type_point[1]
512 |
513 | # 簇中心点的标签
514 | heads_labels = []
515 | # 簇中心点分配标签的过程
516 | for head_node in head_nodes:
517 | # 计算数据点node到有标签样本的平均距离,然后取最小的平均类别距离
518 | label_dis = []
519 | # 每个类别的有标签样本
520 | for category in labeled_data:
521 | category_dis = []
522 | for i in range(len(category)):
523 | # 两点间的距离
524 | dis = self.euclidean_distance(self.data[head_node], category[i])
525 | category_dis.append(dis)
526 | # 每个类别的平均距离
527 | label_dis.append(np.mean(category_dis))
528 | # 最近的类别
529 | min_label = np.argmin(label_dis)
530 | heads_labels.append(min_label)
531 |
532 | # 主干点的标签分配
533 | backbone_labels = []
534 | for backbone_node in backbone_point:
535 | head_dis = []
536 | for head_node in head_nodes:
537 | # 主干点与簇中心点的距离
538 | dis = self.euclidean_distance(self.data[backbone_node], self.data[head_node])
539 | head_dis.append(dis)
540 | # 核心区域点的标签值与最近的簇中心点保持一致
541 | backbone_label = heads_labels[int(np.argmin(head_dis))]
542 | backbone_labels.append(backbone_label)
543 |
544 | # 边缘区域的标签分配
545 | border_labels = []
546 | for border_node in border_point:
547 | # 计算距离
548 | border_node_dis = []
549 | for backbone_node in backbone_point:
550 | # 边缘区域中的点与核心区域内点的距离
551 | dis = self.euclidean_distance(self.data[border_node], self.data[backbone_node])
552 | border_node_dis.append(dis)
553 | # 保存K邻居的标签值
554 | K_labels = []
555 | # 找到距离边缘点最近的核心点
556 | for i in np.argsort(border_node_dis)[:opt.K]:
557 | K_labels.append(backbone_labels[i])
558 |
559 | # 这里是dict,Counter({3: 2, 10: 2, 1: 1, 0: 1})
560 | max_K_labels = Counter(K_labels)
561 | # 按value对dict排序,逆序排序
562 | max_K_labels = sorted(max_K_labels.items(), key=lambda item: item[1], reverse=True)
563 | # max_K_labels[0]为最大值,max_K_labels[0][0]为最大值的key
564 | border_labels.append(max_K_labels[0][0])
565 |
566 | # 新类别区域的标签分配
567 | # new_category_labels = []
568 | # new_category_labels = self.new_category_label(new_category_region)
569 |
570 | # 最后需要把标签按顺序摆好,然后输出
571 | pseudo_labels = []
572 | # 把几个list合并一下
573 | data_index = head_nodes + backbone_point + border_point
574 | data_labels = heads_labels + backbone_labels + border_labels
575 | # 设置一个dict
576 | pseudo_labels_dict = {}
577 | for i in range(len(data_index)):
578 | # 给这个dict赋值
579 | pseudo_labels_dict[data_index[i]] = data_labels[i]
580 |
581 | # 然后将dict按key排序,也就是回到从1-n的原序状态
582 | # 然后就可以把dict中的value输入到pseudo_labels
583 | for key, value in sorted(pseudo_labels_dict.items()):
584 | pseudo_labels.append(value)
585 |
586 | endtime = datetime.datetime.now()
587 | print('分配标签用时', (endtime - starttime).seconds)
588 |
589 | return pseudo_labels
590 |
591 | if __name__ == '__main__':
592 | ssldpca = SslDpca1D()
593 |
594 | # 绘制原始数据的t-sne图
595 | plot = plot.Plot()
596 | plot.plot_data(ssldpca.data, ssldpca.label)
597 | # # 选出有标签的数据,准备注入
598 | # labeled_data = ssldpca.make_labeled_data()
599 | # # 删除有标签数据
600 | # ssldpca.del_labeled_data()
601 | # # # 构建邻居模型
602 | # # ssldpca.neighbors_model()
603 | # # 计算邻居,取得邻居距离和邻居idx
604 | # neigh_dist, neigh_ind = ssldpca.neighbors()
605 | # # 给所有节点划分类型
606 | # param_lambda_low = 0.52311
607 | # para_lambda_high = 0.57111
608 | # # 三种类型,backbon_point 主干点;border_point 边界点;noise_point 噪声点
609 | # backbone_point, border_point, noise_point = ssldpca.divide_type(neigh_ind, param_lambda_low, para_lambda_high)
610 | # print(len(backbone_point), len(border_point), len(noise_point))
611 | #
612 | # # 删除噪声点,self.data,neigh_dist,neigh_ind,都删除
613 | # neigh_dist, neigh_ind = ssldpca.del_noise(noise_point, neigh_dist, neigh_ind)
614 | # # 计算密度
615 | # density = ssldpca.build_density(neigh_dist, neigh_ind)
616 | # # 计算间隔
617 | # interval = ssldpca.build_interval(density, neigh_dist)
618 | #
619 | # # 计算节点分数
620 | # node_scores = ssldpca.build_score(density, interval)
621 | # head_nodes = ssldpca.select_head(node_scores)
622 | #
623 | # # 获取数据的伪标签
624 | # pseudo_labels = ssldpca.assign_labels(head_nodes, [backbone_point, border_point], labeled_data)
625 | # # print(pseudo_labels)
626 |
627 |
628 |
629 |
630 |
631 |
--------------------------------------------------------------------------------
/SSLDPCA/ssl_dpca_2d.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/9 19:25
3 | # @Author : wb
4 | # @File : ssl_dpca_2d.py
5 | import os
6 | import random
7 | import numpy as np
8 | from PIL import Image
9 | from scipy.spatial.distance import pdist
10 | from tqdm import tqdm
11 | import itertools
12 | import h5py
13 |
14 | from config import opt
15 |
16 | '''
17 | 半监督(SSL)的密度峰值聚类(DPCA),此文件用于2d数据
18 | '''
19 |
20 | class SslDpca2D(object):
21 | '''
22 | 半监督的DPCA,在原始的DPCA的基础上加入半监督(小部分有标签数据)
23 | 步骤:
24 | 1.注入部分的有标签数据
25 | 2.计算密度与间隔
26 | 3.计算数据点的分数
27 | 4.选取分数高的作为簇中心
28 | 5.根据规则在 密度-间隔决策图 上划分区域
29 | 6.对每个区域内的数据点分配标签
30 | 6.1 簇中心点的标签由簇中心点到带有真实标签样本数据的距离决定
31 | 6.2 核心区域中的主干点分配给距离最近的簇中心点,并且主干点的标签与所属簇中心点的标签保持一致
32 | 6.3 边缘区域内的边缘点选择与它距离最近K个主干点的标签值,K是人为设定值
33 | 6.4 新类别的样本数据点需要人为标注一部分的标签,然后使用Kmeans聚类传递标签
34 | 7.输出所有的数据(大量伪标签,少量真实标签)
35 | density distance
36 | '''
37 | def __init__(self, root):
38 | '''
39 | 初始化,读取图片
40 | :param root: 图像数据的目录
41 | '''
42 | # 有标签数据的占比
43 | self.label_fraction = opt.label_fraction
44 | # 故障的类别
45 | self.category = opt.CWRU_category
46 | # 邻居数量
47 | self.neighbor = opt.K
48 | # 全部的图片的ID
49 | self.imgs_path = [os.path.join(root, img) for img in os.listdir(root)]
50 | # 图像的ID
51 | self.category_imgs_index = []
52 |
53 | def label_data_index(self):
54 | '''
55 | 处理有标签的数据,选择其中的一部分作为标签数据输入算法,其他数据的标签全部清除
56 |
57 | :return: input_label_index,每个类别的有标签的数据的ID集合
58 | '''
59 | # 选取一定比例的有标签数据(这个是仿真中可以调整的参数)
60 | # 为了实验起见,选取平衡的数据,即每个类分配相同比例的有标签数据集
61 | for category in range(self.category):
62 | category_img_index = []
63 | # 读取图片的编号
64 | for index in range(len(self.imgs_path)):
65 | # 提取出每一个图像的标签
66 | label = int(self.imgs_path[index].split('/')[-1].split('\\')[-1].split('.')[0])
67 | if label == category:
68 | category_img_index.append(index)
69 | # 将每个类别的图片分别保存
70 | self.category_imgs_index.append(category_img_index)
71 |
72 | input_label_index = []
73 | # 选取每个类中一定比例的数据作为有标签数据
74 | for category_index in self.category_imgs_index:
75 | category_label_index = []
76 | for _ in range(int(len(category_index)*self.label_fraction)):
77 | category_label_index.append(category_index[random.randint(0, len(category_index)-1)])
78 | input_label_index.append(category_label_index)
79 | return input_label_index
80 |
81 | def local_density(self):
82 | '''
83 | 计算数据点的密度
84 | :return:
85 | '''
86 | share_neighbor = []
87 |
88 | def build_distance(self):
89 | '''
90 | 根据图片之间的相互距离,选出每个数据点的K邻居列表,计算出K邻居平均距离
91 | :return:
92 | '''
93 | node_K_neighbor = []
94 |
95 | # 两两组合
96 | img_iter_path = itertools.combinations(self.imgs_path, 2)
97 | for node_i_path, node_j_path in img_iter_path:
98 | node_i = Image.open(node_i_path)
99 | node_j = Image.open(node_j_path)
100 | # 两个数据点之间的距离
101 | distance = self.euclidean_distance(node_i, node_j)
102 | # 记录每个数据点与其他数据点的距离
103 |
104 | # 从中选出最近的K个,就是K邻居
105 |
106 | # 计算K邻居的平均距离
107 |
108 | return node_K_neighbor
109 |
110 | def build_distance_all(self):
111 | '''
112 | 上面那个函数主要是进行了组合,减少了需要计算的数量,增加了工作量
113 | 但是据观察发现,其实大部分的时间都是花费在了读取图片的工作上,所以这个是全部读取的函数
114 |
115 | 根据图片之间的相互距离,选出每个数据点的K邻居列表,计算出K邻居平均距离
116 | :return:
117 | '''
118 |
119 | # 这边我的理解出了一点问题,我完全可以把每个图片读取进来,然后在进行计算
120 | # 而不是重复的读取,这样浪费了很多时间
121 |
122 | # 所有的图片
123 | imgs = []
124 | # 数据点的K邻居的路径
125 | node_K_neighbor_path = []
126 | for path in tqdm(self.imgs_path):
127 | img = Image.open(path)
128 | imgs.append(np.asarray(img, dtype='uint8'))
129 | img.close()
130 |
131 | #
132 | # 开始计算
133 | for node_i in tqdm(imgs):
134 | # 数据点间的距离合集
135 | node_distance = np.empty(len(self.imgs_path))
136 | for node_j in imgs:
137 | # 计算两个图像之间的距离
138 | distance = self.euclidean_distance(node_i, node_j)
139 | np.append(node_distance, distance)
140 |
141 | # 排序
142 | order_node_distance = np.argsort(node_distance)
143 | # 选取其中K个
144 | neighbor = order_node_distance[:self.neighbor]
145 | # 邻居的路径
146 | neighbor_path = []
147 | # 保存所有数据点邻居的K邻居
148 | for nei in neighbor:
149 | neighbor_path.append(self.imgs_path[nei])
150 | node_K_neighbor_path.append(neighbor_path)
151 |
152 | f = open('neighbor.txt', 'w') # output.txt - 文件名称及格式 w - writing
153 | # 以这种模式打开文件,原来文件内容会被新写入的内容覆盖,如文件不存在会自动创建
154 | for i in range(len(self.imgs_path)):
155 | f.write(self.imgs_path[i])
156 | f.write(':')
157 | for j in node_K_neighbor_path[i]:
158 | f.write(j)
159 | f.write('||')
160 | f.write('\n')
161 | f.close()
162 |
163 | return node_K_neighbor
164 |
165 | def euclidean_distance(self, node_i, node_j):
166 | '''
167 | 计算两个数据点之间的欧几里得距离
168 | :param node_i: 输入图片的image对象
169 | :param node_j: 输入图片
170 | :return: distance,距离
171 | '''
172 | # 先对image对象进行ndarry化,然后展平
173 | node_i = node_i.flatten()
174 | node_j = node_j.flatten()
175 |
176 | # 统一大小
177 | # img_j = img_j.resize(img_i.size)
178 |
179 | # 计算距离
180 | X = np.vstack([node_i, node_j])
181 | # 距离的值有点太精确了
182 | distance = pdist(X, 'euclidean')[0]
183 |
184 | return distance
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 | if __name__ == '__main__':
193 | root = os.path.join('../', opt.train_data_root)
194 | ssldpca = SslDpca2D(root)
195 | node_K_neighbor = ssldpca.build_distance_all()
196 | print(node_K_neighbor)
197 |
198 |
199 |
--------------------------------------------------------------------------------
/SSLDPCA/toy_dataset.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/4/14 9:51
3 | # @Author : wb
4 | # @File : toy_dataset.py
5 | import datetime
6 |
7 | import numpy as np
8 | import matplotlib.pyplot as plt
9 |
10 | from sklearn.preprocessing import StandardScaler
11 | from sklearn.neighbors import NearestNeighbors
12 | from itertools import cycle, islice
13 | from scipy.spatial.distance import pdist
14 |
15 | from sklearn.datasets import make_moons, make_blobs, make_circles
16 |
17 | class ToyDataset():
18 |
19 | def moon_data(self):
20 | '''
21 | 读取sklearn two_moons数据集
22 | :return: X n*2 y
23 | '''
24 |
25 | # noise 噪声,高斯噪声的标准偏差
26 | X, y = make_moons(n_samples=1000, noise=0.06)
27 | X = StandardScaler().fit_transform(X)
28 | return X, y
29 |
30 | def blobs_data(self):
31 | '''
32 | 读取sklearn blobs数据集
33 | :return: X n*2 y
34 | '''
35 | # n_features 特征维度
36 | X, y = make_blobs(n_samples=1800, n_features=2, centers=6, cluster_std=0.6, center_box=(-7, 15))
37 | X = StandardScaler().fit_transform(X)
38 | return X, y
39 |
40 | def circles_data(self):
41 | '''
42 | 读取sklearn circles数据集
43 | :return:
44 | '''
45 | # factor 内圆和外圆之间的比例因子,范围为(0,1)。
46 | X, y = make_circles(n_samples=2000, noise=0.07, factor=0.5)
47 | X = StandardScaler().fit_transform(X)
48 | return X, y
49 |
50 | def jain_data(self):
51 | '''
52 | 读取Jain的数据
53 | :return:
54 | '''
55 | X = []
56 | y = []
57 | file_path = '../data/toy_data/Jain.txt'
58 | with open(file_path, 'r') as f:
59 | lines = f.readlines()
60 |
61 | for line in lines:
62 | split = line.split()
63 | X.append([float(split[0]), float(split[1])])
64 | y.append(int(split[2]))
65 |
66 | return np.array(X), np.array(y)
67 |
68 | def pathbased_data(self):
69 | '''
70 | 读取 Pathbased 数据集
71 | :return:
72 | '''
73 | X = []
74 | y = []
75 | file_path = '../data/toy_data/Pathbased.txt'
76 | with open(file_path, 'r') as f:
77 | lines = f.readlines()
78 |
79 | for line in lines:
80 | split = line.split()
81 | X.append([float(split[0]), float(split[1])])
82 | y.append(int(split[2]))
83 |
84 | return np.array(X), np.array(y)
85 |
86 | def ds_data(self, type='DS4'):
87 | '''
88 | DS数据集,4578
89 | :param type: DS4,DS5,DS7,DS8
90 | :return:
91 | '''
92 | X = []
93 | # y = []
94 | if type == 'DS4':
95 | file_path = '../data/toy_data/t4.8k.dat'
96 | elif type == 'DS5':
97 | file_path = '../data/toy_data/t5.8k.dat'
98 | elif type == 'DS7':
99 | file_path = '../data/toy_data/t7.10k.dat'
100 | elif type == 'DS8':
101 | file_path = '../data/toy_data/t8.8k.dat'
102 | else:
103 | file_path = '../data/toy_data/t4.8k.dat'
104 |
105 | with open(file_path, 'r') as f:
106 | lines = f.readlines()
107 |
108 | for line in lines:
109 | split = line.split()
110 | X.append([float(split[0]), float(split[1])])
111 |
112 | return np.array(X)
113 |
114 | def neighbors(self, data, n_neighbors):
115 | '''
116 | 从输入数据中找到邻居点
117 | :param data: 数据
118 | :n_neighbors: 邻居数量
119 | :return: neigh_ind 邻居的ID;neigh_dist 邻居的距离
120 | '''
121 | neigh = NearestNeighbors(n_neighbors=n_neighbors, radius=0.4, n_jobs=-1)
122 | neigh.fit(data)
123 | neigh_dist, neigh_ind = neigh.kneighbors()
124 |
125 | return neigh_ind, neigh_dist
126 |
127 | def divide_type(self, neigh_ind, n_neighbors, param_lambda_low, param_lambda_high):
128 | '''
129 | 为所有的无标签样本划分类型,分为主干点,边界点,噪声点
130 | :param neigh_ind: 邻居表
131 | :param param_lambda_low: 噪声点与边界点阈值
132 | :param param_lambda_high: 边界点和主干点的阈值
133 | :param n_neighbors: 邻居数量K
134 | :return:
135 | '''
136 |
137 | starttime = datetime.datetime.now()
138 |
139 | # 主干点
140 | backbone_point = []
141 | # 边界点
142 | border_point = []
143 | # 噪声点
144 | noise_point = []
145 |
146 | # r值
147 | r_list = []
148 | # 共享邻居数量
149 | for index in neigh_ind:
150 | # enumerate neigh_index[0]是id neigh_index[1]是值
151 | snn_list = []
152 | # 这个点的邻居列表
153 | for neighbor in index:
154 | # 求该数据点的邻居与邻居的邻居有多少是重复邻居
155 | snn = list(set(index).intersection(set(neigh_ind[neighbor])))
156 | # 共享邻居的数量
157 | snn_num = len(snn)
158 | # 把每个邻居的共享邻居保存起来
159 | snn_list.append(snn_num)
160 | # 每个点的平均邻居数
161 | snn_avg = np.mean(snn_list)
162 | # 计算r值
163 | r = snn_avg / n_neighbors
164 | r_list.append(r)
165 |
166 | print('r均值', np.mean(r_list))
167 | print('r中位数', np.median(r_list))
168 | # return r_list
169 |
170 | # 设置para_lambda为均值
171 | # para_lambda = np.mean(r_list)
172 | # 划分点,并输出点的id
173 | for r in enumerate(r_list):
174 | # 主干点 backbone
175 | if (r[1] >= param_lambda_high and r[1] <= 1):
176 | backbone_point.append(r[0])
177 | elif (r[1] >= param_lambda_low and r[1] <= param_lambda_high):
178 | border_point.append(r[0])
179 | elif (r[1] >= 0 and r[1] < param_lambda_low):
180 | noise_point.append(r[0])
181 | else:
182 | print('出错了')
183 |
184 | endtime = datetime.datetime.now()
185 | print('节点划分类型用时', (endtime - starttime).seconds)
186 |
187 | return backbone_point, border_point, noise_point
188 |
189 | def build_density(self, neigh_ind, neigh_dist):
190 | '''
191 | 计算每个数据点的密度
192 | 使用SNN的方式,共享邻居数据点
193 | 两个邻居数据点才有相似度,相似度公式为S/d(i)+d(j),每个数据点的密度是K邻居的相似度之和
194 | :param neigh_ind: 邻居id
195 | :param neigh_dist: 邻居的距离
196 | :return: density 每个点的密度值
197 | '''
198 | density = []
199 |
200 | # 平均邻居距离
201 | neigh_dist_avg = []
202 | for dist in neigh_dist:
203 | neigh_dist_avg.append(np.mean(dist))
204 |
205 | # 共享邻居数量
206 | for neigh_index in enumerate(neigh_ind):
207 | # 每个节点的密度值,是相似度的和
208 | node_density = 0
209 | # 这个点的邻居列表
210 | for neighbor in neigh_index[1]:
211 | # 求该数据点的邻居与邻居的邻居有多少是重复邻居
212 | snn = list(set(neigh_index[1]).intersection(set(neigh_ind[neighbor])))
213 | # 共享邻居的数量
214 | snn_num = len(snn)
215 | # 求个平方
216 | snn_num = np.square(snn_num)
217 |
218 | # 两个数据点的相似度
219 | sim = snn_num / (neigh_dist_avg[neigh_index[0]] + neigh_dist_avg[neighbor])
220 | # 数据点的密度是每个邻居的相似度的和
221 | node_density += sim
222 |
223 | # 所有数据点的密度
224 | density.append(node_density)
225 |
226 | return density
227 |
228 | def build_interval(self, data, density, neigh_dist):
229 | '''
230 | 计算每个数据点的间隔
231 | :param data: 数据
232 | :param density: 密度
233 | :param neigh_dist: 邻居距离
234 | :return:
235 | '''
236 | # 数据点的间隔值
237 | interval = []
238 | # 因为排序过,所以得换一种dict
239 | interval_dict = {}
240 |
241 | # 平均邻居距离
242 | neigh_dist_avg = []
243 | for dist in neigh_dist:
244 | neigh_dist_avg.append(np.mean(dist))
245 |
246 | # 排序,获得排序的ID[]
247 | sort_density_idx = np.argsort(density)
248 |
249 | # 数据点node的index
250 | for node_i in range(len(sort_density_idx)):
251 | # 数据点的全部间隔
252 | node_intervals = []
253 | # 密度比node更大的数据点
254 | for node_j in range(node_i + 1, len(sort_density_idx)):
255 | # i,j的距离
256 | dij = self.euclidean_distance(data[sort_density_idx[node_i]], data[sort_density_idx[node_j]])
257 | # dij*(node_i的平均邻居值+node_j的平均邻居值)
258 | delta = (dij + (neigh_dist_avg[sort_density_idx[node_i]] + neigh_dist_avg[sort_density_idx[node_j]]))
259 | node_intervals.append(delta)
260 |
261 | # 添加到interval
262 | # 判断node_intervals是否为空
263 | if node_intervals:
264 | # 不为空就是正常的间隔值
265 | # 因为排序过,所以不能是直接append,而是要找到位置入座
266 | interval_dict[sort_density_idx[node_i]] = np.min(node_intervals)
267 | else:
268 | # 如果为空,应该是密度最大值,先设置为-1,后面会为他设置为间隔最高值
269 | interval_dict[sort_density_idx[node_i]] = -1
270 |
271 | # 密度最高的数据点的间隔必须为间隔最大值
272 | # 这里用的是dict,所以需要先取出values,然后转换成list,才能使用np.max
273 | interval_dict[sort_density_idx[-1]] = np.max(list(interval_dict.values()))
274 |
275 | # 然后将dict按key排序,也就是回到从1-n的原序状态
276 | # 然后就可以把dict中的value输入到interval
277 | for key, value in sorted(interval_dict.items()):
278 | interval.append(value)
279 |
280 | return interval
281 |
282 | def score(self, density, interval):
283 | '''
284 | 计算数据点的得分
285 | :param density: 密度
286 | :param interval: 间隔
287 | :return: scores 每个节点的得分
288 | '''
289 | scores = []
290 | max_rho = np.max(density)
291 | max_delta = np.max(interval)
292 |
293 | for rho, delta in zip(density, interval):
294 | # 每个数据点的得分计算
295 | score = (rho / max_rho) * (delta / max_delta)
296 | # score = rho * delta
297 | scores.append(score)
298 | return scores
299 |
300 | def detect_jump_point(self, scores, param_alpha):
301 | '''
302 | 动态选择簇头
303 | f(x, a, k) = akax−(a + 1)
304 | logf(x, a, k) = alog(k) + log(a) − (a + 1)log(x)
305 | 本函数全部按照论文中伪代码编写而成
306 | 主要的流程就是,通过阈值找跳变点,因为score排序过,所以找到跳变的k,k前面的就全部是簇头
307 | :param scores: 数组scores的元素按升序排列
308 | :param param_alpha: 置信度参数 alpha
309 | :return: e 跳点e的对应索引
310 | '''
311 | # 长度
312 | n = len(scores)
313 | # 返回的簇的数量
314 | e = -1
315 | # 阈值
316 | w_n = 0
317 | # score_index = np.argsort(-np.array(scores))
318 | # 因为先取反进行降序排序的,所以最后需要取绝对值
319 | # sorted_scores = abs(np.sort(-np.array(scores)))
320 | # 论文中需要升序排序
321 | sorted_scores = np.sort(np.array(scores))
322 | for k in range(int(n/2), n-3):
323 | m_a = np.mean(sorted_scores[0:k])
324 | m_b = np.mean(sorted_scores[k:n])
325 | if m_a <= param_alpha * m_b:
326 | # a的参数,shape就是k,scale就是a
327 | shape_a = sorted_scores[0]
328 | sum_a = 0
329 | for i in range(0, k):
330 | sum_a += np.log(sorted_scores[i] / shape_a)
331 | scale_a = k / sum_a
332 | # b的参数
333 | shape_b = sorted_scores[k]
334 | sum_b = 0
335 | for i in range(k, n):
336 | sum_b += np.log(sorted_scores[i] / shape_b)
337 | scale_b = (n - k + 1) / sum_b
338 | sk = 0
339 | for i in range(k, n):
340 | ta = scale_a * np.log(shape_a) + np.log(scale_a) - (scale_a + 1) * np.log(sorted_scores[i])
341 | tb = scale_b * np.log(shape_b) + np.log(scale_b) - (scale_b + 1) * np.log(sorted_scores[i])
342 | sk += np.log(tb / ta)
343 | if sk > w_n:
344 | w_n = sk
345 | e = k
346 | return e
347 |
348 | # def select_head(self, scores, class_num):
349 | # '''
350 | # 根据每个数据点的分数,选择簇头
351 | # :param scores: 数据点分数
352 | # :param class_num: 类别数
353 | # :return: 簇节点的ID heads []
354 | # '''
355 | #
356 | # # 降序排序,需要选取分数最大的作为簇头
357 | # score_index = np.argsort(-np.array(scores))
358 | # # 有多少个故障类别,就有多少个簇头
359 | # heads = score_index[:class_num].tolist()
360 | #
361 | # return heads
362 |
363 | # def divide_area(self, density, interval, param_lambda):
364 | # '''
365 | # 划分区域
366 | # :param density: 密度
367 | # :param interval: 间隔
368 | # :param param_lambda: 划分区域的参数lambda
369 | # :return: areas [[core_region], [border_region], [new_category_region]]
370 | # '''
371 | # # 1.在rho和delta的决策图中划分区域
372 | # # 2.把所有的无标签点分配到这些区域
373 | # # 3.输出每个区域内的数据点ID
374 | #
375 | # # 密度的分割线,平均密度
376 | # rho_split_line = np.mean(density)
377 | # # 间隔的分割线,lambda*间隔的方差
378 | # delta_split_line = param_lambda * np.var(interval)
379 | #
380 | # # 根据分割线划分区域
381 | # # 核心区域
382 | # core_region = []
383 | # # 边缘区域
384 | # border_region = []
385 | # # 新类别区域
386 | # new_category_region = []
387 | # # 数据ID
388 | # index = 0
389 | # for rho, delta in zip(density, interval):
390 | #
391 | # if rho >= rho_split_line:
392 | # core_region.append(index)
393 | # elif rho < rho_split_line and delta < delta_split_line:
394 | # border_region.append(index)
395 | # elif rho < rho_split_line and delta >= delta_split_line:
396 | # new_category_region.append(index)
397 | # else:
398 | # print('没这种数据')
399 | #
400 | # index = index + 1
401 | #
402 | # # 最后输出的三个区域的值
403 | # areas = [core_region, border_region, new_category_region]
404 | #
405 | # return areas
406 |
407 | def euclidean_distance(self, data1, data2):
408 | '''
409 | 计算两个数据点之间的欧几里得距离
410 | :param n1: 数据1
411 | :param n2: 数据2
412 | :return: 距离
413 | '''
414 |
415 | X = np.vstack([data1, data2])
416 | distance = pdist(X, 'euclidean')[0]
417 | return distance
418 |
419 | def plot_data(self, X, y):
420 | '''
421 | 绘制二维数据,是二维
422 | :param X: 数据X
423 | :param y: 标签y
424 | :return:
425 | '''
426 | plt.rcParams['savefig.dpi'] = 300 # 图片像素
427 | plt.rcParams['figure.dpi'] = 300 # 分辨率
428 | colors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a',
429 | '#f781bf', '#a65628', '#984ea3',
430 | '#999999', '#e41a1c', '#dede00']),
431 | int(max(y) + 1))))
432 |
433 | # 添加X/Y轴描述
434 | plt.xlabel('x')
435 | plt.ylabel('y')
436 |
437 | plt.scatter(X[:, 0], X[:, 1], s=3, color=colors[y])
438 | plt.show()
439 |
440 | def plot_heads(self, X, y, heads):
441 | '''
442 | 绘制带簇头的二维数据
443 | :param X: 数据X
444 | :param y: 标签y
445 | :param heads: 簇头
446 | :return:
447 | '''
448 | plt.rcParams['savefig.dpi'] = 200 # 图片像素
449 | plt.rcParams['figure.dpi'] = 200 # 分辨率
450 | colors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a',
451 | '#f781bf', '#a65628', '#984ea3',
452 | '#999999', '#e41a1c', '#dede00']),
453 | int(max(y) + 1))))
454 |
455 | plt.scatter(X[:, 0], X[:, 1], s=3, color=colors[y])
456 | for head in heads:
457 | plt.scatter(X[head, 0], X[head, 1], s=10, color='k', marker='*')
458 |
459 | plt.show()
460 |
461 | def plot_rho_delta(self, density, interval, y, heads):
462 | '''
463 | 绘制rho-delta 密度间隔决策图
464 | :param density: 密度
465 | :param interval: 间隔
466 | :param y: 类别标签,帮助绘制颜色的
467 | :param heads: 簇头
468 | :return:
469 | '''
470 | plt.rcParams['savefig.dpi'] = 200 # 图片像素
471 | plt.rcParams['figure.dpi'] = 200 # 分辨率
472 | colors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a',
473 | '#f781bf', '#a65628', '#984ea3',
474 | '#999999', '#e41a1c', '#dede00']),
475 | int(max(y) + 1))))
476 |
477 | # 添加X/Y轴描述
478 | plt.xlabel('rho')
479 | plt.ylabel('delta')
480 |
481 | plt.scatter(density, interval, s=3, color=colors[y])
482 | for head in heads:
483 | plt.scatter(density[head], interval[head], s=15, color='k', marker='^')
484 |
485 | plt.show()
486 |
487 | def plot_scores(self, scores):
488 | '''
489 | 绘制分数图
490 | :param scores: 节点的分数
491 | :return:
492 | '''
493 | # sorted_scores = abs(np.sort(-np.array(scores)))
494 | sorted_scores = np.sort(np.array(scores))
495 | index = [i for i in range(len(scores))]
496 | plt.rcParams['savefig.dpi'] = 300 # 图片像素
497 | plt.rcParams['figure.dpi'] = 300 # 分辨率
498 |
499 | # 添加X/Y轴描述
500 | plt.xlabel('n')
501 | plt.ylabel('rho*delta')
502 | plt.scatter(index, sorted_scores, s=3)
503 |
504 | plt.show()
505 |
506 | # def plot_pointwithtype(self):
507 | # '''
508 | # 绘制数据点的type
509 | # :return:
510 | # '''
511 |
512 | if __name__ == '__main__':
513 | toy = ToyDataset()
514 | # 普通数据集的情况
515 | X, y = toy.blobs_data()
516 | # toy.plot_data(X, y)
517 | # 获取邻居
518 | n_neighbors = int(len(X) * 0.05)
519 | neigh_ind, neigh_dist = toy.neighbors(X, n_neighbors)
520 | # print(neigh_dist)
521 |
522 | # 计算密度与间隔
523 | density = toy.build_density(neigh_ind, neigh_dist)
524 | # print(density)
525 | interval = toy.build_interval(X, density, neigh_dist)
526 | # print(interval)
527 |
528 | # 计算得分
529 | scores = toy.score(density, interval)
530 | # toy.plot_scores(scores)
531 |
532 | # 自动获取聚类中心
533 | # 在论文SAND中的alpha为0.05.这里的alpha为SAND中的1-alpha,所以设置为0.95
534 |
535 | param_alpha = 0.95
536 | k = toy.detect_jump_point(scores, param_alpha)
537 |
538 | print('K值', k)
539 |
540 | # # 找到聚类中心
541 | # heads = toy.select_head(scores, class_num=3)
542 | # # 绘制聚类中心
543 | # toy.plot_heads(X, y, heads)
544 | # # 绘制密度与间隔
545 | # toy.plot_rho_delta(density, interval, y, heads)
546 |
547 | # '#377eb8', '#ff7f00', '#4daf4a'
548 |
549 | #######################################################################################
550 | # 无标签数据集
551 | # X = toy.ds_data(type='DS7')
552 | # n_neighbors = 50
553 | # # n_neighbors = int(len(X) * 0.05)
554 | # # 获取邻居
555 | # neigh_ind, neigh_dist = toy.neighbors(X, n_neighbors)
556 | # print(len(neigh_ind))
557 |
558 | # 划分节点类型
559 | # param_lambda_low = 0.52311
560 | # para_lambda_high = 0.57111
561 | # backbone_point, border_point, noise_point = toy.divide_type(neigh_ind, n_neighbors,
562 | # param_lambda_low, para_lambda_high)
563 | # print(len(backbone_point), len(border_point), len(noise_point))
564 |
565 | # # 计算密度与间隔
566 | # density = toy.build_density(neigh_ind, neigh_dist)
567 | # print(density)
568 | # interval = toy.build_interval(X, density, neigh_dist)
569 | # print(interval)
570 |
571 | # # 计算节点的得分
572 | # scores = toy.score(density, interval)
573 |
574 | # # 自动获取聚类中心
575 | # param_alpha = 2
576 | # k = toy.detect_jump_point(scores, param_alpha)
577 | #
578 | # print('K值', k)
579 |
580 | # 设置分辨率
581 | # plt.rcParams['savefig.dpi'] = 300 # 图片像素
582 | # plt.rcParams['figure.dpi'] = 300 # 分辨率
583 |
584 | # 绘制密度图
585 | # colors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a',
586 | # '#f781bf', '#a65628', '#984ea3',
587 | # '#999999', '#e41a1c', '#dede00']),
588 | # int(max(y) + 1))))
589 | # # 添加X/Y轴描述
590 | # plt.xlabel('rho')
591 | # plt.ylabel('delta')
592 | #
593 | # plt.scatter(density, interval, s=3, color=colors[y])
594 | # plt.show()
595 |
596 | # 绘制节点邻居
597 | # plt.scatter(X[:, 0], X[:, 1], s=2)
598 | # plt.scatter(X[0, 0], X[0, 1], s=5, c='#4daf4a', marker='^')
599 | # for neigh in neigh_ind[0]:
600 | # plt.scatter(X[neigh, 0], X[neigh, 1], s=2, c='#ff7f00')
601 |
602 | # 添加X/Y轴描述
603 | # plt.xlabel('x')
604 | # plt.ylabel('y')
605 |
606 | # 绘制数据图像
607 | # plt.scatter(X[:, 0], X[:, 1], s=3)
608 |
609 | # 绘制节点类型
610 | # for backbone in backbone_point:
611 | # plt.scatter(X[backbone, 0], X[backbone, 1], s=3, c='#377eb8')
612 | # for border in border_point:
613 | # plt.scatter(X[border, 0], X[border, 1], s=3, c='#ff7f00')
614 | # for noise in noise_point:
615 | # plt.scatter(X[noise, 0], X[noise, 1], s=3, c='#4daf4a')
616 |
617 | # plt.show()
618 |
619 |
620 |
--------------------------------------------------------------------------------
/__pycache__/config.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/__pycache__/config.cpython-36.pyc
--------------------------------------------------------------------------------
/config.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/2 15:44
3 | # @Author : wb
4 | # @File : config.py
5 |
6 | '''
7 | 配置文件,配置项目的超参数
8 | '''
9 |
10 | import warnings
11 | import torch as t
12 |
13 | class DefaultConfig(object):
14 | '''
15 | 各种参数
16 | 以__开头的为默认参数,不显示
17 | '''
18 | env = 'default' # visdom 环境
19 | model = 'cnn1d' # 使用的模型,名字必须与models/__init__.py中的名字一致
20 | __vis_port = 8097 # visdom 端口
21 |
22 | train_data_root = './data/CWRU_data_1d/CWRU_mini_DE10.h5' # 训练集存放路径,测试集从训练集中划出来
23 | load_model_path = None # 加载预训练的模型的路径,为None代表不加载
24 |
25 | __CWRU_data_root = './CWRU_data' # CWRU的数据列表
26 | __read_file_directory = 'annotations_mini.txt' # 读取文件的目录,也就是从CWRU数据集中读取哪些数据
27 | __CWRU_data_1d_root = './CWRU_data_1d' # CWRU数据1d的保存路径,h5文件
28 | __CWRU_data_2d_root = './CWRU_data_2d' # CWRU数据2d的根目录保存路径
29 |
30 | CWRU_dim = 400 # CWRU的数据维度
31 | CWRU_category = 10 # CWRU总共有101个类别
32 |
33 | train_fraction = 0.8 # 训练集数据的占比
34 | test_fraction = 0.2 # 测试集
35 |
36 | batch_size = 64 # batch size
37 | use_gpu = True # user GPU or not
38 | num_workers = 4 # how many workers for loading data
39 | print_freq = 1 # print info every N batch
40 |
41 | __debug_file = './tmp/debug' # if os.path.exists(debug_file): enter ipdb
42 | __result_file = './result/result.csv'
43 | __model_file = './checkpoints'
44 |
45 | max_epoch = 10
46 | lr = 0.1 # initial learning rate
47 | lr_decay = 0.95 # when val_loss increase, lr = lr*lr_decay
48 | weight_decay = 1e-4 # 损失函数
49 |
50 | # 下面是半监督的部分参数
51 | label_fraction = 0.2 # 选取有标签样本的占比
52 | K = 10 # KNN的K值
53 | lambda_delta = 0.6 # 间隔的参数
54 |
55 | def parse(self, kwargs):
56 | '''
57 | 根据字典kwargs 更新 config参数
58 | '''
59 | for k, v in kwargs.items():
60 | if not hasattr(self, k):
61 | warnings.warn("Warning: opt has not attribut %s" % k)
62 | setattr(self, k, v)
63 | opt.device = t.device('cuda') if opt.use_gpu else t.device('cpu')
64 |
65 | print('user config:')
66 | for k, v in self.__class__.__dict__.items():
67 | if not k.startswith('__'):
68 | print(k, getattr(self, k))
69 |
70 |
71 | opt = DefaultConfig()
72 |
--------------------------------------------------------------------------------
/data/CWRU_data/annotations.txt:
--------------------------------------------------------------------------------
1 | file_name label
2 | 97.mat 1
3 | 98.mat 2
4 | 99.mat 3
5 | 100.mat 4
6 | 105.mat 5
7 | 106.mat 6
8 | 107.mat 7
9 | 108.mat 8
10 | 118.mat 9
11 | 119.mat 10
12 | 120.mat 11
13 | 121.mat 12
14 | 130.mat 13
15 | 131.mat 14
16 | 132.mat 15
17 | 133.mat 16
18 | 144.mat 17
19 | 145.mat 18
20 | 146.mat 19
21 | 147.mat 20
22 | 156.mat 21
23 | 158.mat 22
24 | 159.mat 23
25 | 160.mat 24
26 | 169.mat 25
27 | 170.mat 26
28 | 171.mat 27
29 | 172.mat 28
30 | 185.mat 29
31 | 186.mat 30
32 | 187.mat 31
33 | 188.mat 32
34 | 197.mat 33
35 | 198.mat 34
36 | 199.mat 35
37 | 200.mat 36
38 | 209.mat 37
39 | 210.mat 38
40 | 211.mat 39
41 | 212.mat 40
42 | 222.mat 41
43 | 223.mat 42
44 | 224.mat 43
45 | 225.mat 44
46 | 234.mat 45
47 | 235.mat 46
48 | 236.mat 47
49 | 237.mat 48
50 | 246.mat 49
51 | 247.mat 50
52 | 248.mat 51
53 | 249.mat 52
54 | 258.mat 53
55 | 259.mat 54
56 | 260.mat 55
57 | 261.mat 56
58 | 270.mat 57
59 | 271.mat 58
60 | 272.mat 59
61 | 273.mat 60
62 | 274.mat 61
63 | 275.mat 62
64 | 276.mat 63
65 | 277.mat 64
66 | 278.mat 65
67 | 279.mat 66
68 | 280.mat 67
69 | 281.mat 68
70 | 282.mat 69
71 | 283.mat 70
72 | 284.mat 71
73 | 285.mat 72
74 | 286.mat 73
75 | 287.mat 74
76 | 288.mat 75
77 | 289.mat 76
78 | 290.mat 77
79 | 291.mat 78
80 | 292.mat 79
81 | 293.mat 80
82 | 294.mat 81
83 | 295.mat 82
84 | 296.mat 83
85 | 297.mat 84
86 | 298.mat 85
87 | 299.mat 86
88 | 300.mat 87
89 | 301.mat 88
90 | 302.mat 89
91 | 305.mat 90
92 | 306.mat 91
93 | 307.mat 92
94 | 309.mat 93
95 | 310.mat 94
96 | 311.mat 95
97 | 312.mat 96
98 | 313.mat 97
99 | 315.mat 98
100 | 316.mat 99
101 | 317.mat 100
102 | 318.mat 101
--------------------------------------------------------------------------------
/data/CWRU_data/annotations.xls:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/data/CWRU_data/annotations.xls
--------------------------------------------------------------------------------
/data/CWRU_data_1d/README.txt:
--------------------------------------------------------------------------------
1 | CWRU一维数据
--------------------------------------------------------------------------------
/data/CWRU_data_2d/README.txt:
--------------------------------------------------------------------------------
1 | CWRU二维数据
--------------------------------------------------------------------------------
/data/GramianAngularField.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/data/GramianAngularField.pdf
--------------------------------------------------------------------------------
/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/data/__init__.py
--------------------------------------------------------------------------------
/data/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/data/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/data/__pycache__/dataset.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/data/__pycache__/dataset.cpython-36.pyc
--------------------------------------------------------------------------------
/data/data_process.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/2 15:44
3 | # @Author : wb
4 | # @File : data_process.py
5 |
6 | '''
7 | 数据处理页面,将数据处理成需要的格式
8 | '''
9 |
10 | import h5py
11 | import pandas as pd
12 | import numpy as np
13 | import os
14 | import scipy.io as scio
15 | import matplotlib.pyplot as plt
16 | from PIL import Image
17 | from matplotlib import image
18 | from pyts.image import GramianAngularField
19 | from tqdm import tqdm
20 | from tslearn.piecewise import PiecewiseAggregateApproximation
21 |
22 | from config import opt
23 |
24 | class DataProcess(object):
25 | '''
26 | 处理CWRU,凯斯西储大学轴承数据
27 | CWRU原始数据分为驱动端与风扇端(DE,FE)
28 | 正常 4个
29 | 12K采样频率下的驱动端轴承故障数据 52个 没有第四种载荷的情况
30 | 48K采样频率下的驱动端轴承故障数据*(删除不用)
31 | 12K采样频率下的风扇端轴承故障数据 45个
32 | 每个采样频率下面三种故障直径,每种故障直径下面四种电机载荷,每种载荷有三种故障
33 | 内圈故障,外圈故障(三个位置),滚动体故障
34 | 总共101个数据文件
35 | '''
36 |
37 | def CWRU_data_1d(self, type='DE'):
38 | '''
39 | 直接处理1d的时序数据
40 | :type: DE或者FE,驱动端还是风扇端
41 | :return: 保存为h5文件
42 | '''
43 |
44 | # 维度
45 | dim = opt.CWRU_dim
46 | # CWRU原始数据
47 | CWRU_data_path = opt.CWRU_data_root
48 | read_file_directory = opt.read_file_directory
49 | # 一维数据保存路径
50 | save_path = opt.CWRU_data_1d_root
51 |
52 | # 读取文件列表
53 | frame_name = os.path.join(CWRU_data_path, read_file_directory)
54 | frame = pd.read_table(frame_name)
55 |
56 | # 数据
57 | signals = []
58 | # 标签
59 | labels = []
60 | # 数据块数量
61 | data_num = []
62 |
63 | for idx in range(len(frame)):
64 | mat_name = os.path.join(CWRU_data_path, frame['file_name'][idx])
65 | raw_data = scio.loadmat(mat_name)
66 | # raw_data.items() X097_DE_time 所以选取5:7为DE的
67 | for key, value in raw_data.items():
68 | if key[5:7] == type:
69 | # 以dim的长度划分,有多少个数据块
70 | sample_num = value.shape[0] // dim
71 | # print('sample_num', sample_num)
72 |
73 | # 数据取整
74 | signal = value[0:dim * sample_num].reshape(1, -1)
75 | # print('signals', signals.shape)
76 | # 把数据分割成sample_num个数据块,(609,400,1)
77 | signal_split = np.array(np.split(signal, sample_num, axis=1))
78 |
79 | # 保存行向量
80 | signals.append(signal_split)
81 | # (123,)一维的label
82 | labels.append(idx * np.ones(sample_num))
83 | # 保存每个类别数据块的数量
84 | data_num.append(sample_num)
85 |
86 | # squeeze删除维度为1的维度,(1,123)->(123,)
87 | # axis=0为纵向的拼接,axis=1为纵向的拼接
88 | # (13477200,)
89 | signals_np = np.concatenate(signals).squeeze()
90 | # (33693,)
91 | labels_np = np.concatenate(np.array(labels)).astype('uint8')
92 | data_num_np = np.array(data_num).astype('uint8')
93 | print(signals_np.shape, labels_np.shape, data_num_np.shape)
94 |
95 | # 保存为h5的文件
96 | file_name = os.path.join(save_path, 'CWRU_mini_' + type + str(len(frame)) + '.h5')
97 | f = h5py.File(file_name, 'w')
98 | # 数据
99 | f.create_dataset('data', data=signals_np)
100 | # 标签
101 | f.create_dataset('label', data=labels_np)
102 | # 每个类别的数据块数量
103 | f.create_dataset('data_num', data=data_num_np)
104 | f.close()
105 |
106 | def CWRU_data_2d_gaf(self, type='DE'):
107 | '''
108 | 把CWRU数据集做成2d图像,使用Gramian Angular Field (GAF),保存为png图片
109 | 因为GAF将n的时序信号转换为n*n,这样导致数据量过大,采用分段聚合近似(PAA)转换压缩时序数据的长度
110 | 97:243938
111 | :type: DE还是FE
112 | :return: 保存为2d图像
113 | '''
114 |
115 | # CWRU原始数据
116 | CWRU_data_path = opt.CWRU_data_root
117 | # 维度
118 | dim = opt.CWRU_dim
119 |
120 | # 读取文件列表
121 | frame_name = os.path.join(CWRU_data_path, 'annotations.txt')
122 | frame = pd.read_table(frame_name)
123 |
124 | # 保存路径
125 | save_path = os.path.join(opt.CWRU_data_2d_root, type)
126 | if not os.path.exists(save_path):
127 | os.makedirs(save_path)
128 |
129 | # gasf文件目录
130 | gasf_path = os.path.join(save_path, 'gasf')
131 | if not os.path.exists(gasf_path):
132 | os.makedirs(gasf_path)
133 | # gadf文件目录
134 | gadf_path = os.path.join(save_path, 'gadf')
135 | if not os.path.exists(gadf_path):
136 | os.makedirs(gadf_path)
137 |
138 | for idx in tqdm(range(len(frame))):
139 | # mat文件名
140 | mat_name = os.path.join(CWRU_data_path, frame['file_name'][idx])
141 | # 读取mat文件中的原始数据
142 | raw_data = scio.loadmat(mat_name)
143 | # raw_data.items() X097_DE_time 所以选取5:7为DE的
144 | for key, value in raw_data.items():
145 | if key[5:7] == type:
146 | # dim个数据点一个划分,计算数据块的数量
147 | sample_num = value.shape[0] // dim
148 |
149 | # 数据取整,把列向量转换成行向量
150 | signal = value[0:dim * sample_num].reshape(1, -1)
151 | # PAA 分段聚合近似(PAA)转换
152 | # paa = PiecewiseAggregateApproximation(n_segments=100)
153 | # paa_signal = paa.fit_transform(signal)
154 |
155 | # 按sample_num切分,每个dim大小
156 | signals = np.split(signal, sample_num, axis=1)
157 |
158 | for i in tqdm(range(len(signals))):
159 | # 将每个dim的数据转换为2d图像
160 | gasf = GramianAngularField(image_size=dim, method='summation')
161 | signals_gasf = gasf.fit_transform(signals[i])
162 | gadf = GramianAngularField(image_size=dim, method='difference')
163 | signals_gadf = gadf.fit_transform(signals[i])
164 |
165 | # 保存图像
166 | filename_gasf = os.path.join(gasf_path, str(idx) + '.%d.png' % i)
167 | image.imsave(filename_gasf, signals_gasf[0])
168 | filename_gadf = os.path.join(gadf_path, str(idx) + '.%d.png' % i)
169 | image.imsave(filename_gadf, signals_gadf[0])
170 |
171 | # 展示图片
172 | # images = [signals_gasf[0], signals_gadf[0]]
173 | # titles = ['Summation', 'Difference']
174 | #
175 | # fig, axs = plt.subplots(1, 2, constrained_layout=True)
176 | # for image, title, ax in zip(images, titles, axs):
177 | # ax.imshow(image)
178 | # ax.set_title(title)
179 | # fig.suptitle('GramianAngularField', y=0.94, fontsize=16)
180 | # plt.margins(0, 0)
181 | # plt.savefig("GramianAngularField.pdf", pad_inches=0)
182 | # plt.show()
183 |
184 | # 此函数未完成
185 | def CWRU_data_2d_transform(self, type='DE'):
186 | '''
187 | 使用数据拼接的方式,将一个长的时序数据拆分成小段,将小段按按行拼接
188 | 如果直接进行拼接的话样本数量比较少,采用时间窗移动切割,也就是很多数据会重复
189 | 这样可以提高图片的数量
190 | 未完成
191 | :param type:DE or FE
192 | :return:
193 | '''
194 | # CWRU原始数据
195 | CWRU_data_path = opt.CWRU_data_root
196 | # 维度
197 | dim = opt.CWRU_dim
198 |
199 | # 读取文件列表
200 | frame_name = os.path.join(CWRU_data_path, 'annotations.txt')
201 | frame = pd.read_table(frame_name)
202 |
203 | # 保存路径
204 | save_path = os.path.join(opt.CWRU_data_2d_root, type)
205 | if not os.path.exists(save_path):
206 | os.makedirs(save_path)
207 |
208 | # 转换生成的图像文件目录
209 | transform_path = os.path.join(save_path, 'transform')
210 | if not os.path.exists(transform_path):
211 | os.makedirs(transform_path)
212 |
213 | for idx in tqdm(range(len(frame))):
214 | # mat文件名
215 | mat_name = os.path.join(CWRU_data_path, frame['file_name'][idx])
216 | # 读取mat文件中的原始数据
217 | raw_data = scio.loadmat(mat_name)
218 | # raw_data.items() X097_DE_time 所以选取5:7为DE的
219 | for key, value in raw_data.items():
220 | if key[5:7] == type:
221 | # dim个数据点一个划分,计算数据块的数量
222 | sample_num = value.shape[0] // dim
223 |
224 | # 数据取整,并转换为行向量
225 | signal = value[0:dim * sample_num].reshape(1, -1)
226 | # 归一化到[-1,1],生成灰度图
227 | signal = self.normalization(signal)
228 |
229 | # 按sample_num切分,每一个块dim大小
230 | signals = np.split(signal, sample_num, axis=1)
231 |
232 | # 生成正方形的图片,正方形面积小,能生成多张图片
233 | pic_num = sample_num // dim
234 | pic_data = []
235 | for i in range(pic_num-1):
236 | pic_data.append(signals[i * dim:(i + 1) * dim])
237 |
238 | # pic = np.concatenate(pic_data).squeeze()
239 |
240 | # 展示图片
241 | plt.imshow(pic_data)
242 | plt.show()
243 |
244 | def normalization(self, data):
245 | '''
246 | 归一化
247 | :param data:
248 | :return:
249 | '''
250 | _range = np.max(abs(data))
251 | return data / _range
252 |
253 | def png2h5(self):
254 | '''
255 | 将保存好的png图片保存到h5文件中,需要大量内存
256 | :return: h5文件
257 | '''
258 | # 根目录
259 | img_root = opt.CWRU_data_2d_DE
260 | # 全部的图片的ID
261 | imgs_path = [os.path.join(img_root, img) for img in os.listdir(img_root)]
262 | # 图片数据
263 | imgs = []
264 | # 标签值
265 | labels = []
266 | for path in tqdm(imgs_path):
267 | img = Image.open(path)
268 | # img是Image内部的类文件,还需转换
269 | img_PIL = np.asarray(img, dtype='uint8')
270 | labels.append(path.split('/')[-1].split('\\')[-1].split('.')[0])
271 | imgs.append(img_PIL)
272 | # 关闭文件,防止多线程读取文件太多
273 | img.close()
274 |
275 | imgs = np.asarray(imgs).astype('uint8')
276 | labels = np.asarray(labels).astype('uint8')
277 | # 创建h5文件
278 | file = h5py.File(opt.CWRU_data_2d_h5, "w")
279 | # 在文件中创建数据集
280 | file.create_dataset("image", np.shape(imgs), dtype='uint8', data=imgs)
281 | # 标签
282 | file.create_dataset("label", np.shape(labels), dtype='uint8', data=labels)
283 | file.close()
284 |
285 | '''
286 | 考虑下也导入田纳西-伊斯曼Tennessee Eastman(TE过程)的数据
287 | TE过程有21个故障,也就是21个dat文件(21个训练,21个测试)
288 | 有53个变量,41个+12个
289 | '''
290 | # 此函数未完成
291 | def TE_data_1d(self):
292 | '''
293 | 1D的TE过程数据处理
294 | :return:
295 | '''
296 |
297 |
298 |
299 | if __name__ == '__main__':
300 | data = DataProcess()
301 | data.CWRU_data_1d(type='DE')
302 |
303 | # DE(33693, 400) (33693,)
304 | # FE(33693, 400) (33693,)
305 |
306 |
307 |
308 |
309 |
310 |
--------------------------------------------------------------------------------
/data/dataset.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/8 15:40
3 | # @Author : wb
4 | # @File : dataset.py
5 |
6 | '''
7 | pytorch 读取数据
8 | '''
9 |
10 | import h5py
11 | import os
12 | from torchvision import transforms as T
13 | from PIL import Image
14 | import torch.utils.data as data
15 | from tqdm import tqdm
16 | import numpy as np
17 | from sklearn.model_selection import train_test_split
18 |
19 | from config import opt
20 |
21 | class CWRUDataset1D(data.Dataset):
22 |
23 | def __init__(self, filename, train=True):
24 | '''
25 | pytorch读取训练数据
26 | :param filename: 数据集文件,这边是h5py文件
27 | :param train: 是否为训练,还是测试
28 | '''
29 | f = h5py.File(filename, 'r')
30 | # 数据,取值,可以用f['data'].value,不过包自己推荐使用f['data'][()]这种方式
31 | data = f['data'][()]
32 | # 标签
33 | label = f['label'][()]
34 | # 每个类别的数据块数量
35 | data_num = f['data_num'][()]
36 |
37 | print(label)
38 |
39 | # 各个类别的数据
40 | category_data = []
41 | # 各个类别的标签
42 | category_label = []
43 |
44 | # 手动拆分下数据集
45 | # 把每个类别的数据切分出来,就是根据每个类别数据块的数量将数据拆分过来
46 | point = 0
47 | for i in range(len(data_num)):
48 | data_ = data[point:point + data_num[i]]
49 | label_ = label[point:point + data_num[i]]
50 |
51 | category_data.append(data_)
52 | category_label.append(label_)
53 |
54 | point = point + data_num[i]
55 |
56 | # 训练集与测试集
57 | train_X = np.empty(shape=(1, 400))
58 | train_y = np.empty(shape=(1,))
59 | test_X = np.empty(shape=(1, 400))
60 | test_y = np.empty(shape=(1,))
61 | # 选出有标签的index
62 | for data, label in tqdm(zip(category_data, category_label)):
63 | # 拆分训练集与测试集,需要打乱
64 | X_train, X_test, y_train, y_test = train_test_split(data, label, test_size=opt.test_fraction, shuffle=True)
65 | # print(X_train.shape, y_train.shape)
66 | # print(X_test.shape, y_test.shape)
67 |
68 | np.concatenate((train_X, X_train), axis=0)
69 | np.concatenate((train_y, y_train), axis=0)
70 | np.concatenate((test_X, X_test), axis=0)
71 | np.concatenate((test_y, y_test), axis=0)
72 |
73 | # 训练数据集
74 | if train:
75 | # 最后需要的数据X与对应的标签y
76 | self.X = train_X
77 | self.y = train_y
78 | # print(self.X.shape)
79 |
80 | else: # 测试数据集
81 | self.X = test_X
82 | self.y = test_y
83 |
84 | def __getitem__(self, idx):
85 | '''
86 | 返回一条数据
87 | :param idx:
88 | :return:
89 | '''
90 | return self.X[idx], self.y[idx]
91 |
92 | def __len__(self):
93 | '''
94 | 数据长度
95 | :return:
96 | '''
97 | return len(self.X)
98 |
99 | class CWRUDataset2D(data.Dataset):
100 |
101 | def __init__(self, root, train=True):
102 | '''
103 | 获取所有图片的地址,并根据训练,测试划分数据(就不搞验证集了)
104 | :param root: 图片目录
105 | :param train: 是否为训练
106 | :param test: 是否为测试
107 | '''
108 | self.train_fraction = opt.train_fraction
109 | # 输出全部的图片
110 | imgs = [os.path.join(root, img) for img in os.listdir(root)]
111 |
112 | # train: data/CWRU_data_2d/DE/gadf/0.35.png
113 | # test: test文件从train里面分出来的
114 |
115 | # 对图片的id进行排序 ['0', '35', 'png']
116 | imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2]))
117 | imgs_num = len(imgs)
118 |
119 | # 训练数据集
120 | if train:
121 | self.imgs = imgs[:int(self.train_fraction * imgs_num)]
122 | else:
123 | self.imgs = imgs[int(self.train_fraction * imgs_num):]
124 |
125 | self.transforms = T.Compose([T.ToTensor()])
126 |
127 | def __getitem__(self, index):
128 | """
129 | 一次返回一张图片的数据
130 | 如果是测试集,没有图片id
131 | """
132 | img_path = self.imgs[index]
133 | # self.imgs[index] == ./data/CWRU_data_2d/DE/gadf\97.62.png
134 | label = int(self.imgs[index].split('/')[-1].split('\\')[-1].split('.')[0])
135 | # 图片数据
136 | data = Image.open(img_path)
137 | # 这里需要将Image对象转换成tensor
138 | data = self.transforms(data)
139 |
140 | return data, label
141 |
142 | def __len__(self):
143 | return len(self.imgs)
--------------------------------------------------------------------------------
/data/matrix.xlsx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/data/matrix.xlsx
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/8 15:06
3 | # @Author : wb
4 | # @File : main.py
5 |
6 | '''
7 | 主文件,用于训练,测试等
8 | '''
9 | import torch
10 | from torch.utils.data import DataLoader
11 | from torchnet import meter
12 | from tqdm import tqdm
13 | import os
14 |
15 | import models
16 | from config import opt
17 | from utils.visualize import Visualizer
18 | from data.dataset import CWRUDataset1D, CWRUDataset2D
19 |
20 |
21 | def train(**kwargs):
22 | '''
23 | 训练
24 | :param kwargs: 可调整参数,默认是config中的默认参数
25 | :return:训练出完整模型
26 | '''
27 |
28 | # 根据命令行参数更新配置
29 | opt.parse(kwargs)
30 | # visdom绘图程序,需要启动visdom服务器
31 | vis = Visualizer(opt.env, port=opt.vis_port)
32 |
33 | # step:1 构建模型
34 | # 选取配置中名字为model的模型
35 | model = getattr(models, opt.model)()
36 | # 是否读取保存好的模型参数
37 | if opt.load_model_path:
38 | model = model.load(opt.load_model_path)
39 |
40 | # 设置GPU
41 | if torch.cuda.is_available():
42 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
43 | model = model.to(opt.device)
44 |
45 | # step2: 数据
46 | train_data = CWRUDataset1D(opt.train_data_root, train=True)
47 | # 测试数据集和验证数据集是一样的,这些数据是没有用于训练的
48 | test_data = CWRUDataset1D(opt.train_data_root, train=False)
49 |
50 | # 使用DataLoader一条一条读取数据
51 | train_dataloader = DataLoader(train_data, opt.batch_size, shuffle=True)
52 | test_dataloader = DataLoader(test_data, opt.batch_size, shuffle=False)
53 |
54 | # step3: 目标函数和优化器
55 | # 损失函数,交叉熵
56 | criterion = torch.nn.CrossEntropyLoss()
57 | lr = opt.lr
58 | # 优化函数,Adam
59 | optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=opt.weight_decay)
60 | scheduler = torch.optim.lr_scheduler.StepLR(optimizer, opt.lr_decay_iters,
61 | opt.lr_decay) # regulation rate decay
62 |
63 | # step4: 统计指标,平滑处理之后的损失,还有混淆矩阵
64 | # 损失进行取平均及方差计算。
65 | loss_meter = meter.AverageValueMeter()
66 | # 混淆矩阵
67 | confusion_matrix = meter.ConfusionMeter(opt.CWRU_category)
68 | previous_loss = 1e10
69 |
70 | # 训练
71 | for epoch in range(opt.max_epoch):
72 |
73 | # 重置
74 | loss_meter.reset()
75 | confusion_matrix.reset()
76 |
77 | for ii, (data, label) in tqdm(enumerate(train_dataloader)):
78 | # print('data', data)
79 | # print('label', label)
80 |
81 | # 改变形状
82 | data.resize_(data.size()[0], 1, data.size()[1])
83 | # 训练模型
84 | # 转换成float
85 | input = data.type(torch.FloatTensor).to(opt.device)
86 | target = label.type(torch.LongTensor).to(opt.device)
87 |
88 | optimizer.zero_grad()
89 | score = model(input)
90 | # 计算loss
91 | loss = criterion(score, target)
92 |
93 | loss.backward()
94 | # 优化参数
95 | optimizer.step()
96 | # 修改学习率
97 | scheduler.step()
98 |
99 |
100 | # 更新统计指标以及可视化
101 | loss_meter.add(loss.item())
102 | # detach 一下更安全保险
103 | confusion_matrix.add(score.detach(), target.detach())
104 |
105 | if (ii + 1) % opt.print_freq == 0:
106 | # vis绘图
107 | vis.plot('loss', loss_meter.value()[0])
108 | # 打印出信息
109 | print('t = %d, loss = %.4f' % (ii + 1, loss.item()))
110 |
111 | # 进入debug模式
112 | if os.path.exists(opt.debug_file):
113 | import ipdb;
114 | ipdb.set_trace()
115 |
116 | # 每个batch保存模型
117 | model.save()
118 |
119 | # 计算测试集上的指标和可视化
120 | val_cm, val_accuracy = val(model, test_dataloader)
121 |
122 | vis.plot('val_accuracy', val_accuracy)
123 | vis.log("epoch:{epoch},lr:{lr},loss:{loss},train_cm:{train_cm},val_cm:{val_cm}".format(
124 | epoch=epoch, loss=loss_meter.value()[0], val_cm=str(val_cm.value()), train_cm=str(confusion_matrix.value()),
125 | lr=lr))
126 |
127 | # 如果损失不在下降,那么就降低学习率
128 | if loss_meter.value()[0] > previous_loss:
129 | lr = lr * opt.lr_decay
130 | # 第二种降低学习率的方法:不会有moment等信息的丢失
131 | for param_group in optimizer.param_groups:
132 | param_group['lr'] = lr
133 |
134 | previous_loss = loss_meter.value()[0]
135 |
136 | def val(model, dataloader):
137 | """
138 | 计算模型在验证集上的准确率等信息
139 | """
140 | # pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值
141 | model.eval()
142 | confusion_matrix = meter.ConfusionMeter(opt.CWRU_category)
143 | for ii, (data, label) in tqdm(enumerate(dataloader)):
144 | # 改变形状
145 | data.resize_(data.size()[0], 1, data.size()[1])
146 | # 训练模型
147 | # 转换成float
148 | test_input = data.type(torch.FloatTensor).to(opt.device)
149 | target = label.type(torch.LongTensor).to(opt.device)
150 |
151 | score = model(test_input)
152 | confusion_matrix.add(score.detach(), target)
153 |
154 | model.train()
155 | cm_value = confusion_matrix.value()
156 | accuracy = 100. * (cm_value[0][0] + cm_value[1][1]) / (cm_value.sum())
157 | return confusion_matrix, accuracy
158 |
159 |
160 | def test(**kwargs):
161 | opt._parse(kwargs)
162 |
163 | # 构建模型
164 | model = getattr(models, opt.model)().eval()
165 | if opt.load_model_path:
166 | model.load(opt.load_model_path)
167 | model.to(opt.device)
168 |
169 | # data
170 | train_data = CWRUDataset2D(opt.train_data_root, test=True)
171 | test_dataloader = DataLoader(train_data, batch_size=opt.batch_size, shuffle=False, num_workers=opt.num_workers)
172 | results = []
173 | for ii, (data, path) in tqdm(enumerate(test_dataloader)):
174 | input = data.to(opt.device)
175 | score = model(input)
176 | probability = torch.nn.functional.softmax(score, dim=1)[:, 0].detach().tolist()
177 | # label = score.max(dim = 1)[1].detach().tolist()
178 |
179 | batch_results = [(path_.item(), probability_) for path_, probability_ in zip(path, probability)]
180 |
181 | results += batch_results
182 | write_csv(results, opt.result_file)
183 |
184 | return results
185 |
186 | def write_csv(results, file_name):
187 | import csv
188 | with open(file_name, 'w') as f:
189 | writer = csv.writer(f)
190 | writer.writerow(['id', 'label'])
191 | writer.writerows(results)
192 |
193 | def build_pseudo_label():
194 | '''
195 | 构建伪标签
196 | :return: 伪标签集合
197 | '''
198 |
199 | def help():
200 | """
201 | 打印帮助的信息: python file.py help
202 | """
203 |
204 | print("""
205 | usage : python file.py [--args=value]
206 | := train | test | help
207 | example:
208 | python {0} train --env='env0701' --lr=0.01
209 | python {0} test --dataset='path/to/dataset/root/'
210 | python {0} help
211 | avaiable args:""".format(__file__))
212 |
213 | from inspect import getsource
214 | source = (getsource(opt.__class__))
215 | # print(source)
216 |
217 | if __name__ == '__main__':
218 | train()
219 |
220 |
221 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | from .resnet34 import ResNet34
2 | from .cnn1d import cnn1d
--------------------------------------------------------------------------------
/models/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/models/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/models/__pycache__/basic_module.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/models/__pycache__/basic_module.cpython-36.pyc
--------------------------------------------------------------------------------
/models/__pycache__/resnet34.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/models/__pycache__/resnet34.cpython-36.pyc
--------------------------------------------------------------------------------
/models/autoencoder.py:
--------------------------------------------------------------------------------
1 | # !/usr/bin/env python
2 | # -*-coding:utf-8 -*-
3 | '''
4 | # Time :2022/3/15 16:42
5 | # Author :wb
6 | # File : autoencoder.py
7 | '''
8 | from torch import nn
9 | from .basic_module import BasicModule
10 |
11 | class Flatten(nn.Module):
12 | '''
13 | 把输入reshape成(batch_size,dim_length)
14 | '''
15 |
16 | def __init__(self):
17 | super(Flatten, self).__init__()
18 |
19 | def forward(self, x):
20 | return x.view(x.size(0), -1)
21 |
22 | # 自动编码器
23 | class autoencoder(BasicModule):
24 | '''
25 | 自动编码器
26 | '''
27 | def __init__(self, kernel1=27, kernel2=36, kernel_size=10, pad=0, ms1=4, ms2=4):
28 | super(autoencoder, self).__init__()
29 | self.model_name = 'autoencoder'
30 |
31 | # 输入 [batch size, channels, length] [N, 1, L]
32 | # 编码器 卷积层
33 | self.conv = nn.Sequential(
34 | nn.Conv1d(1, kernel1, kernel_size, padding=pad),
35 | nn.BatchNorm1d(kernel1),
36 | nn.ReLU(),
37 | nn.MaxPool1d(ms1),
38 | nn.Conv1d(kernel1, kernel1, kernel_size, padding=pad),
39 | nn.BatchNorm1d(kernel1),
40 | nn.ReLU(),
41 | nn.Dropout(),
42 | nn.Conv1d(kernel1, kernel2, kernel_size, padding=pad),
43 | nn.BatchNorm1d(kernel2),
44 | nn.ReLU(),
45 | nn.MaxPool1d(ms2),
46 | nn.Conv1d(kernel2, kernel2, kernel_size, padding=pad),
47 | nn.BatchNorm1d(kernel2),
48 | nn.ReLU(),
49 | nn.Dropout(),
50 | )
51 |
52 | # 解码器 反卷积
53 | self.transconv = nn.Sequential(
54 | nn.ConvTranspose1d(kernel2, kernel2, kernel_size, padding=pad),
55 | nn.BatchNorm1d(kernel2),
56 | nn.ReLU(),
57 | nn.MaxUnpool1d(ms2),
58 | nn.ConvTranspose1d(kernel2, kernel1, kernel_size, padding=pad),
59 | nn.BatchNorm1d(kernel1),
60 | nn.ReLU(),
61 | nn.Dropout(),
62 | nn.ConvTranspose1d(kernel1, kernel1, kernel_size, padding=pad),
63 | nn.BatchNorm1d(kernel1),
64 | nn.ReLU(),
65 | nn.MaxUnpool1d(ms1),
66 | nn.ConvTranspose1d(kernel1, 1, kernel_size, padding=pad),
67 | nn.ReLU(),
68 | nn.Dropout(),
69 | )
70 |
71 | def forward(self, x):
72 | x = self.conv(x)
73 | x = self.transconv(x)
74 | return x
75 |
76 |
77 |
--------------------------------------------------------------------------------
/models/basic_module.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/8 10:31
3 | # @Author : wb
4 | # @File : basic_module.py
5 |
6 | '''
7 | 封装了nn.Module,主要提供save和load两个方法
8 | '''
9 |
10 | import torch
11 | import time
12 |
13 | class BasicModule(torch.nn.Module):
14 | '''
15 | 封装了nn.Module,主要是提供了save和load两个方法
16 | '''
17 |
18 | def __init__(self):
19 | super(BasicModule, self).__init__()
20 | self.model_name = str(self) # 默认名字
21 | # print(self.model_name)
22 |
23 | def load(self, path):
24 | '''
25 | 可加载指定路径的模型
26 | '''
27 | self.load_state_dict(torch.load(path))
28 |
29 | def save(self, name=None):
30 | '''
31 | 保存模型,默认使用“模型名字+时间”作为文件名
32 | '''
33 | if name is None:
34 | prefix = './models/checkpoints/' + self.model_name + '_'
35 | name = time.strftime(prefix + '%m%d_%H_%M_%S.pth')
36 | else:
37 | prefix = './models/checkpoints/' + name + '_'
38 | name = time.strftime(prefix + '%m%d_%H_%M_%S.pth')
39 | torch.save(self.state_dict(), name)
40 | return name
--------------------------------------------------------------------------------
/models/cnn1d.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2020/7/8 15:47
3 | # @Author : wb
4 | # @File : cnn1d.py
5 |
6 | from torch import nn
7 | import torchsnooper
8 | from .basic_module import BasicModule
9 |
10 | '''
11 | 1D的CNN,用于处理1d的时序信号
12 | 可以用于构建基础的故障诊断(分类)模块
13 | '''
14 |
15 | class Flatten(nn.Module):
16 | '''
17 | 把输入reshape成(batch_size,dim_length)
18 | '''
19 |
20 | def __init__(self):
21 | super(Flatten, self).__init__()
22 |
23 | def forward(self, x):
24 | return x.view(x.size(0), -1)
25 |
26 |
27 | class cnn1d(BasicModule):
28 | '''
29 | 1dCNN,用于处理时序信号
30 | '''
31 |
32 | def __init__(self, kernel1=27, kernel2=36, kernel_size=10, pad=0, ms1=4, ms2=4):
33 | super(cnn1d, self).__init__()
34 | self.model_name = 'cnn1d'
35 |
36 | # 输入 [batch size, channels, length] [N, 1, L]
37 | self.conv = nn.Sequential(
38 | nn.Conv1d(1, kernel1, kernel_size, padding=pad),
39 | nn.BatchNorm1d(kernel1),
40 | nn.ReLU(),
41 | nn.MaxPool1d(ms1),
42 | nn.Conv1d(kernel1, kernel1, kernel_size, padding=pad),
43 | nn.BatchNorm1d(kernel1),
44 | nn.ReLU(),
45 | nn.Dropout(),
46 | nn.Conv1d(kernel1, kernel2, kernel_size, padding=pad),
47 | nn.BatchNorm1d(kernel2),
48 | nn.ReLU(),
49 | nn.MaxPool1d(ms2),
50 | nn.Dropout(),
51 | nn.Conv1d(kernel2, kernel2, kernel_size, padding=pad),
52 | nn.BatchNorm1d(kernel2),
53 | nn.ReLU(),
54 | Flatten()
55 | )
56 |
57 | self.fc = nn.Sequential(
58 | nn.Linear(360, 180),
59 | nn.ReLU(),
60 | nn.Linear(180, 90),
61 | nn.ReLU(),
62 | nn.Linear(90, 10),
63 | )
64 |
65 | def forward(self, x):
66 | x = self.conv(x)
67 | x = self.fc(x)
68 | return x
--------------------------------------------------------------------------------
/models/resnet.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/8 14:26
3 | # @Author : wb
4 | # @File : resnet.py
5 |
6 | """
7 | 采用cifar100构建的ResNet
8 | 这个暂时没有用到
9 | """
10 |
11 | import torch.nn as nn
12 | from .basic_module import BasicModule
13 |
14 | class BasicBlock(nn.Module):
15 | """
16 | Basic Block for resnet 18 and resnet 34
17 | """
18 |
19 | # BasicBlock和BottleNeck块具有不同的输出大小,我们使用类属性扩展来区分
20 | expansion = 1
21 |
22 | def __init__(self, in_channels, out_channels, stride=1):
23 | super().__init__()
24 |
25 | # 残差网络(residual function)
26 | self.residual_function = nn.Sequential(
27 | nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
28 | nn.BatchNorm2d(out_channels),
29 | nn.ReLU(inplace=True),
30 | nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
31 | nn.BatchNorm2d(out_channels * BasicBlock.expansion)
32 | )
33 |
34 | # 直连(shortcut)
35 | self.shortcut = nn.Sequential()
36 |
37 | # 直连输出尺寸与残差函数使用1 * 1卷积匹配尺寸不相同
38 | if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
39 | self.shortcut = nn.Sequential(
40 | nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
41 | nn.BatchNorm2d(out_channels * BasicBlock.expansion)
42 | )
43 |
44 | def forward(self, x):
45 | return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
46 |
47 | class BottleNeck(nn.Module):
48 | """Residual block for resnet over 50 layers
49 |
50 | """
51 | expansion = 4
52 | def __init__(self, in_channels, out_channels, stride=1):
53 | super().__init__()
54 | self.residual_function = nn.Sequential(
55 | nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
56 | nn.BatchNorm2d(out_channels),
57 | nn.ReLU(inplace=True),
58 | nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
59 | nn.BatchNorm2d(out_channels),
60 | nn.ReLU(inplace=True),
61 | nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
62 | nn.BatchNorm2d(out_channels * BottleNeck.expansion),
63 | )
64 |
65 | self.shortcut = nn.Sequential()
66 |
67 | if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
68 | self.shortcut = nn.Sequential(
69 | nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
70 | nn.BatchNorm2d(out_channels * BottleNeck.expansion)
71 | )
72 |
73 | def forward(self, x):
74 | return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
75 |
76 | class ResNet(BasicModule):
77 |
78 | def __init__(self, block, num_block, name, num_classes=100):
79 | super(ResNet, self).__init__()
80 | self.model_name = name
81 |
82 | self.in_channels = 64
83 |
84 | self.conv1 = nn.Sequential(
85 | nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
86 | nn.BatchNorm2d(64),
87 | nn.ReLU(inplace=True))
88 | # 我们使用的输入大小与原始论文不同,因此conv2_x的步幅为1
89 | self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
90 | self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
91 | self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
92 | self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
93 | self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
94 | self.fc = nn.Linear(512 * block.expansion, num_classes)
95 |
96 | def _make_layer(self, block, out_channels, num_blocks, stride):
97 | """make resnet layers(by layer i didnt mean this 'layer' was the
98 | same as a neuron netowork layer, ex. conv layer), one layer may
99 | contain more than one residual block
100 |
101 | Args:
102 | block: block type, basic block or bottle neck block
103 | out_channels: output depth channel number of this layer
104 | num_blocks: how many blocks per layer
105 | stride: the stride of the first block of this layer
106 |
107 | Return:
108 | return a resnet layer
109 | """
110 |
111 | # 我们每层有num_block个块,第一个块可以是1或2,其他块始终是1
112 | strides = [stride] + [1] * (num_blocks - 1)
113 | layers = []
114 | for stride in strides:
115 | layers.append(block(self.in_channels, out_channels, stride))
116 | self.in_channels = out_channels * block.expansion
117 |
118 | return nn.Sequential(*layers)
119 |
120 | def forward(self, x):
121 | output = self.conv1(x)
122 | output = self.conv2_x(output)
123 | output = self.conv3_x(output)
124 | output = self.conv4_x(output)
125 | output = self.conv5_x(output)
126 | output = self.avg_pool(output)
127 | output = output.view(output.size(0), -1)
128 | output = self.fc(output)
129 |
130 | return output
131 |
132 | def resnet18():
133 | """ return a ResNet 18 object
134 | """
135 | return ResNet(BasicBlock, [2, 2, 2, 2], 'resnet18')
136 |
137 | def resnet34():
138 | """ return a ResNet 34 object
139 | """
140 | return ResNet(BasicBlock, [3, 4, 6, 3], 'resnet34')
141 |
142 | def resnet50():
143 | """ return a ResNet 50 object
144 | """
145 | return ResNet(BottleNeck, [3, 4, 6, 3], 'resnet50')
146 |
147 | def resnet101():
148 | """ return a ResNet 101 object
149 | """
150 | return ResNet(BottleNeck, [3, 4, 23, 3], 'resnet101')
151 |
152 | def resnet152():
153 | """ return a ResNet 152 object
154 | """
155 | return ResNet(BottleNeck, [3, 8, 36, 3], 'resnet152')
156 |
157 |
--------------------------------------------------------------------------------
/models/resnet34.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/8 17:58
3 | # @Author : wb
4 | # @File : resnet34.py
5 |
6 | from .basic_module import BasicModule
7 | from torch import nn
8 | from torch.nn import functional as F
9 |
10 | '''
11 | 构建Resnet作为基础的CNN模块,用于处理2D的数据信号
12 | 可以用于构建基础的故障诊断(分类)模块
13 | 使用resnet34
14 | '''
15 |
16 | class ResidualBlock(nn.Module):
17 | """
18 | 实现子module: Residual Block
19 | """
20 |
21 | def __init__(self, inchannel, outchannel, stride=1, shortcut=None):
22 | super(ResidualBlock, self).__init__()
23 | self.left = nn.Sequential(
24 | nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
25 | nn.BatchNorm2d(outchannel),
26 | nn.ReLU(inplace=True),
27 | nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
28 | nn.BatchNorm2d(outchannel))
29 | self.right = shortcut
30 |
31 | def forward(self, x):
32 | out = self.left(x)
33 | residual = x if self.right is None else self.right(x)
34 | out += residual
35 | return F.relu(out)
36 |
37 |
38 | class ResNet34(BasicModule):
39 | """
40 | 实现主module:ResNet34
41 | ResNet34包含多个layer,每个layer又包含多个Residual block
42 | 用子module来实现Residual block,用_make_layer函数来实现layer
43 | """
44 |
45 | def __init__(self, num_classes=2):
46 | super(ResNet34, self).__init__()
47 | self.model_name = 'resnet34'
48 |
49 | # 前几层: 图像转换
50 | self.pre = nn.Sequential(
51 | nn.Conv2d(4, 64, 7, 2, 3, bias=False),
52 | nn.BatchNorm2d(64),
53 | nn.ReLU(inplace=True),
54 | nn.MaxPool2d(3, 2, 1))
55 |
56 | # 重复的layer,分别有3,4,6,3个residual block
57 | self.layer1 = self._make_layer(64, 128, 3)
58 | self.layer2 = self._make_layer(128, 256, 4, stride=2)
59 | self.layer3 = self._make_layer(256, 512, 6, stride=2)
60 | self.layer4 = self._make_layer(512, 512, 3, stride=2)
61 |
62 | # 分类用的全连接
63 | self.fc = nn.Linear(512, num_classes)
64 |
65 | def _make_layer(self, inchannel, outchannel, block_num, stride=1):
66 | """
67 | 构建layer,包含多个residual block
68 | """
69 | shortcut = nn.Sequential(
70 | nn.Conv2d(inchannel, outchannel, 1, stride, bias=False),
71 | nn.BatchNorm2d(outchannel))
72 |
73 | layers = []
74 | layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
75 |
76 | for i in range(1, block_num):
77 | layers.append(ResidualBlock(outchannel, outchannel))
78 | return nn.Sequential(*layers)
79 |
80 | def forward(self, x):
81 | x = self.pre(x)
82 |
83 | x = self.layer1(x)
84 | x = self.layer2(x)
85 | x = self.layer3(x)
86 | x = self.layer4(x)
87 |
88 | x = F.avg_pool2d(x, 7)
89 | x = x.view(x.size(0), -1)
90 | return self.fc(x)
--------------------------------------------------------------------------------
/pic/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/1.png
--------------------------------------------------------------------------------
/pic/2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/2.png
--------------------------------------------------------------------------------
/pic/3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/3.png
--------------------------------------------------------------------------------
/pic/4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/4.png
--------------------------------------------------------------------------------
/pic/5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/5.png
--------------------------------------------------------------------------------
/pic/DS7-data.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/DS7-data.png
--------------------------------------------------------------------------------
/pic/con-A.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/con-A.png
--------------------------------------------------------------------------------
/pic/con-B.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/con-B.png
--------------------------------------------------------------------------------
/pic/con-C.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/con-C.png
--------------------------------------------------------------------------------
/pic/confusion-A.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/confusion-A.png
--------------------------------------------------------------------------------
/pic/confusion-B.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/confusion-B.png
--------------------------------------------------------------------------------
/pic/confusion-C.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/confusion-C.png
--------------------------------------------------------------------------------
/pic/point.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/pic/point.png
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .visualize import Visualizer
--------------------------------------------------------------------------------
/utils/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/utils/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/utils/__pycache__/visualize.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wangfin/SSLDPCA-IL-FaultDetection/f0bc3d51414936482f8b910ea1e48e7bb7325d84/utils/__pycache__/visualize.cpython-36.pyc
--------------------------------------------------------------------------------
/utils/plot.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/23 15:52
3 | # @Author : wb
4 | # @File : plot.py
5 |
6 | import matplotlib.pyplot as plt
7 | from sklearn.manifold import TSNE
8 | import os
9 | import itertools
10 | import numpy as np
11 | import openpyxl
12 |
13 | '''
14 | 绘制图形
15 | '''
16 |
17 | class Plot(object):
18 | def plot_data(self, data, label):
19 | '''
20 | 绘制图形
21 | '''
22 |
23 | # 点图采用T-SNE
24 |
25 | X_tsne = TSNE(n_components=2,
26 | perplexity=20.0,
27 | early_exaggeration=12.0,
28 | learning_rate=300.0,
29 | init='pca').fit_transform(data, label)
30 |
31 | ckpt_dir = "../SSLDPCA/images"
32 | if not os.path.exists(ckpt_dir):
33 | os.makedirs(ckpt_dir)
34 |
35 | plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=label, cmap='Spectral', label=label)
36 |
37 | # plt.savefig('images/data.png', dpi=600)
38 | plt.show()
39 |
40 | def plot_areas(self, data, areas):
41 | '''
42 | 绘制区域示意图
43 | '''
44 | # 核心区域
45 | core = []
46 | for index in areas[0]:
47 | core.append(data[index])
48 | core_label = [0 for _ in range(len(core))]
49 | # 边缘区域
50 | border = []
51 | for index in areas[1]:
52 | border.append(data[index])
53 | border_label = [1 for _ in range(len(border))]
54 | # 新类别区域
55 | new_category = []
56 | for index in areas[2]:
57 | new_category.append(data[index])
58 | new_category_label = [2 for _ in range(len(new_category))]
59 |
60 | # 合并数据
61 | areas_data = core + border + new_category
62 | areas_label = core_label + border_label + new_category_label
63 |
64 | areas_sne = TSNE(n_components=2, random_state=0).fit_transform(areas_data, areas_label)
65 |
66 | plt.scatter(areas_sne[:, 0], areas_sne[:, 1], c=areas_label, cmap='Spectral', label=areas_label)
67 |
68 | plt.savefig('images/areas.png', dpi=600)
69 | plt.show()
70 |
71 | def plot_pseudo_labels(self, data, true_labels, pseudo_labels):
72 | '''
73 | 绘制伪标签示意图,将原有类别标签与伪标签对比展示
74 | '''
75 | plt.figure(dpi=600)
76 | ax1 = plt.subplot(121)
77 | ax2 = plt.subplot(122)
78 | true_sne = TSNE(n_components=2, random_state=0).fit_transform(data, true_labels)
79 | pseudo_sne = TSNE(n_components=2, random_state=0).fit_transform(data, pseudo_labels)
80 |
81 | ax1.scatter(true_sne[:, 0], true_sne[:, 1], c=true_labels, cmap='Spectral', label=true_labels)
82 | ax2.scatter(pseudo_sne[:, 0], pseudo_sne[:, 1], c=pseudo_labels, cmap='Spectral', label=pseudo_labels)
83 |
84 | plt.show()
85 |
86 | # 绘制混淆矩阵
87 | def plot_confusion_matrix(self, cm, save_fig, normalize=False, map='Blues'):
88 | """
89 | This function prints and plots the confusion matrix.
90 | Normalization can be applied by setting `normalize=True`.
91 | Input
92 | - cm : 计算出的混淆矩阵的值
93 | - save_fig : 想要把图片保存在哪个位置
94 | - classes : 混淆矩阵中每一行每一列对应的列
95 | - normalize : True:显示百分比, False:显示个数
96 | - map :Blues, Greens, Reds
97 | """
98 | plt.rcParams['savefig.dpi'] = 300 # 图片像素
99 | plt.rcParams['figure.dpi'] = 300 # 分辨率
100 | plt.rcParams["image.cmap"] = map
101 | plt.rcParams["savefig.bbox"] = 'tight'
102 | plt.rcParams["savefig.pad_inches"] = 0.2
103 |
104 | if normalize:
105 | cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
106 | print("Normalized confusion matrix")
107 | else:
108 | print('Confusion matrix, without normalization')
109 | print(cm)
110 | plt.imshow(cm, interpolation='nearest')
111 | # plt.title(title)
112 | # plt.colorbar()
113 | classes = ['NC', 'IF-1', 'OF-1', 'BF-1', 'IF-2', 'OF-2', 'BF-2', 'IF-3', 'OF-3', 'BF-3']
114 | tick_marks = np.arange(len(classes))
115 | plt.xticks(tick_marks, classes, rotation=45)
116 | plt.yticks(tick_marks, classes)
117 | fmt = '.1f' # if normalize else 'd'
118 | thresh = cm.max() / 2.
119 | for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
120 | plt.text(j, i, format(cm[i, j], fmt),
121 | horizontalalignment="center",
122 | color="white" if cm[i, j] > thresh else "black",
123 | fontsize=9)
124 | plt.tight_layout()
125 | plt.ylabel('True label')
126 | plt.xlabel('Predicted label')
127 | plt.savefig(save_fig, transparent=True)
128 | # plt.show()
129 |
130 | def excel2matrix(self, path, sheet=4):
131 | '''
132 | 读入excel数据,转换为矩阵
133 | :param path:
134 | :param sheet:1
135 | :return:
136 | '''
137 | data = openpyxl.load_workbook(path)
138 | table = data.worksheets[sheet]
139 | data = []
140 | for row in table.iter_rows(min_col=1, max_col=10, min_row=2, max_row=11):
141 | data.append([cell.value for cell in row])
142 |
143 | datamatrix = np.array(data)
144 | return datamatrix
145 |
146 |
147 | if __name__ == '__main__':
148 | plot = Plot()
149 | plot.plot_data()
150 | # cnf_matrix = plot.excel2matrix(path='../data/matrix.xlsx')
151 | # save_fig = '../pic/E.png'
152 | # plot.plot_confusion_matrix(cm=cnf_matrix, save_fig=save_fig)
153 |
154 |
155 |
156 |
157 |
158 |
--------------------------------------------------------------------------------
/utils/visualize.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # @Time : 2021/3/8 15:08
3 | # @Author : wb
4 | # @File : visualize.py
5 |
6 | import visdom
7 | import time
8 | import numpy as np
9 |
10 |
11 | class Visualizer(object):
12 | """
13 | 封装了visdom的基本操作,但是你仍然可以通过`self.vis.function`
14 | 调用原生的visdom接口
15 | visdom命令 python -m visdom.server
16 | """
17 |
18 | def __init__(self, env='default', **kwargs):
19 | self.vis = visdom.Visdom(env=env, use_incoming_socket=False, **kwargs)
20 |
21 | # 画的第几个数,相当于横座标
22 | # 保存(’loss',23) 即loss的第23个点
23 | self.index = {}
24 | self.log_text = ''
25 |
26 | def reinit(self, env='default', **kwargs):
27 | """
28 | 修改visdom的配置
29 | """
30 | self.vis = visdom.Visdom(env=env, **kwargs)
31 | return self
32 |
33 | def plot_many(self, d):
34 | """
35 | 一次plot多个
36 | @params d: dict (name,value) i.e. ('loss',0.11)
37 | """
38 | for k, v in d.items():
39 | self.plot(k, v)
40 |
41 | def img_many(self, d):
42 | for k, v in d.items():
43 | self.img(k, v)
44 |
45 | def plot(self, name, y, **kwargs):
46 | """
47 | self.plot('loss',1.00)
48 | """
49 | x = self.index.get(name, 0)
50 | self.vis.line(Y=np.array([y]), X=np.array([x]),
51 | win=name,
52 | opts=dict(title=name),
53 | update=None if x == 0 else 'append',
54 | **kwargs
55 | )
56 | self.index[name] = x + 1
57 |
58 | def img(self, name, img_, **kwargs):
59 | """
60 | self.img('input_img',t.Tensor(64,64))
61 | self.img('input_imgs',t.Tensor(3,64,64))
62 | self.img('input_imgs',t.Tensor(100,1,64,64))
63 | self.img('input_imgs',t.Tensor(100,3,64,64),nrows=10)
64 |
65 | !!!don‘t ~~self.img('input_imgs',t.Tensor(100,64,64),nrows=10)~~!!!
66 | """
67 | self.vis.images(img_.cpu().numpy(),
68 | win=name,
69 | opts=dict(title=name),
70 | **kwargs
71 | )
72 |
73 | def log(self, info, win='log_text'):
74 | """
75 | self.log({'loss':1,'lr':0.0001})
76 | """
77 |
78 | self.log_text += ('[{time}] {info}
'.format(
79 | time=time.strftime('%m%d_%H%M%S'),
80 | info=info))
81 | self.vis.text(self.log_text, win)
82 |
83 | def __getattr__(self, name):
84 | return getattr(self.vis, name)
--------------------------------------------------------------------------------