3 |
4 |
8 |
9 |
3 |
4 |
8 |
9 |
10 |
14 |
15 |
3 |
15 |
16 | ## CSVLoader
17 | ::: tip
18 | [CSVLoader 文档](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.csv_loader.CSVLoader.html)
19 | :::
20 |
21 | ```py
22 | from langchain_community.document_loaders import CSVLoader
23 |
24 | data_loader = CSVLoader(
25 | file_path="data/黑悟空/黑神话悟空.csv",
26 | encoding="utf-8",
27 | content_columns=("名称", "描述"), # 只加载这两列
28 | csv_args={
29 | "fieldnames": ["名称", "描述"] # 自定义列名
30 | }
31 | )
32 |
33 | documents = data_loader.load()
34 |
35 | for document in documents[:3]:
36 | print(document.page_content)
37 | print("=" * 50)
38 | ```
39 | 输出结果:
40 | ```text
41 | 名称: Category
42 | 描述: Name
43 | ==================================================
44 | 名称: 装备
45 | 描述: 铜云棒
46 | ==================================================
47 | 名称: 装备
48 | 描述: 百戏衬钱衣
49 | ==================================================
50 | ```
51 |
52 | ## DirectoryLoader
53 | ::: tip
54 | [DirectoryLoader 文档](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.directory.DirectoryLoader.html)
55 | :::
56 | 可以使用`DirectoryLoader` + `CSVLoader`批量加载`.csv`文件。
57 |
58 | ```py
59 | from langchain_community.document_loaders import DirectoryLoader, CSVLoader
60 |
61 | data_loader = DirectoryLoader(
62 | path="./data/灭神纪",
63 | glob="**/*.csv",
64 | loader_cls=lambda path: CSVLoader(
65 | path,
66 | encoding="utf-8"
67 | )
68 | )
69 |
70 | documents = data_loader.load()
71 |
72 | print(f"文档数据总数:{len(documents)}")
73 | ```
74 |
75 | ## UnstructuredCSVLoader
76 | ::: tip
77 | [UnstructuredCSVLoader 文档](https://python.langchain.com/api_reference/community/document_loaders/langchain_community.document_loaders.csv_loader.UnstructuredCSVLoader.html)
78 | :::
79 | 可以使用`UnstructuredCSVLoader`把`.csv`文件转换为`html`结构:
80 |
81 | ```py
82 | from langchain_community.document_loaders import UnstructuredCSVLoader
83 |
84 | data_loader = UnstructuredCSVLoader(
85 | file_path="./data/黑悟空/黑神话悟空.csv",
86 | encoding="utf-8",
87 | mode="elements"
88 | )
89 |
90 | documents = data_loader.load()
91 |
92 | print(documents[0].metadata.get('text_as_html'))
93 | ```
94 | 输出结果:
95 | ```py
96 | 原始CSV内容:
4 | 5 | ```csv 6 | Category,Name,Description,PowerLevel 7 | 装备,铜云棒,一根结实的青铜棒,挥舞时能发出破空之声,适合近战攻击。,85 8 | 装备,百戏衬钱衣,一件精美的战斗铠甲,能够提供强大的防御并抵御剧毒伤害。,90 9 | 技能,天雷击,召唤天雷攻击敌人,造成大范围雷电伤害。,95 10 | 技能,火焰舞,施展火焰舞步,将敌人包围在炽热的火焰之中。,92 11 | 人物,悟空,主角,拥有七十二变和腾云驾雾的能力,行侠仗义。,100 12 | 人物,银角大王,强大的妖王之一,擅长操控各种法宝,具有极高的战斗力。,88 13 | ``` 14 || Category | 99 |Name | 100 |Description | 101 |PowerLevel | 102 |
| 装备 | 105 |铜云棒 | 106 |一根结实的青铜棒,挥舞时能发出破空之声,适合近战攻击。 | 107 |85 | 108 |
| 装备 | 111 |百戏衬钱 衣 | 112 |一件精美的战斗铠甲,能够提供强大的防御并抵御剧毒伤害。 | 113 |90 | 114 |
| 技能 | 117 |天雷击 | 118 |召唤天雷攻击敌人,造成大范围雷电伤害。 | 119 |95 | 120 |
| 技能 | 123 |火焰舞 | 124 |施展火焰 舞步,将敌人包围在炽热的火焰之中。 | 125 |92 | 126 |
| 人物 | 129 |悟空 | 130 |主角,拥有七十二变和腾云驾雾的能力,行侠仗义。 | 131 |100 | 132 |
| 人物 | 135 |银角大王 | 136 |强大的妖王之一,擅长操控各种法 宝,具有极高的战斗力。 | 137 |88 | 138 |
72 | [向量数据库Benchmark对比](https://ann-benchmarks.com/index.html) 73 | ::: 74 | | 向量数据库 | 原生向量支持 | 是否开源 | 是否分布式 | 特点/优势 | 缺陷不足 | 典型适用场景 | 75 | | --- | --- | --- | --- | --- | --- | --- | 76 | | **Milvus** | 是 | 是 | 是 | 企业级、分布式、支持亿级数据量 | 资源需求高,部署复杂 | 图像搜索、推荐系统 | 77 | | **Qdrant** | 是 | 是 | 是 | REST/gRPC、支持过滤、异步搜索 | 较新项目、生态不如 Milvus 全 | 向量+元数据混合过滤 | 78 | | **Weaviate** | 是 | 是 | 是 | GraphQL 接口,支持嵌入生成和元数据联查 | 容器部署稍重 | 语义搜索、问答系统 | 79 | | **Pinecone** | 是 | 否 | 是 | 商业实现,全托管、免维护、上线快 | 付费、不可私有部署 | 快速开发、MVP、原型验证 | 80 | | **Faiss** | 是 | 是 | 否 | 高性能 ANN 算法库,支持多种索引,学术界流行 | 无服务层、不分布式 | 离线处理、研究、原型验证 | 81 | | **Chroma** | 是 | 是 | 否 | 零配置、本地知识库友好 | 不支持 ANN、大数据不适用 | 轻量 RAG、个人项目 | 82 | | **Redis** | `7.0+`支持 | 是 | 是 | 极低延迟,实时向量搜索 | 内存占用高、不适合超大规模 | 实时推荐、个性化问答 | 83 | | **MongoDB** | `5.0+`支持 | 是 | 是 | 适合文档+语义联合搜索 | 向量维度限制、功能有限 | 文档搜索、轻量语义搜索 | 84 | | **PGVector** | 扩展形式 | 是 | 否 | 原生 SQL 接口 | 单机性能有限,写入慢 | 企业集成、轻量向量搜索 | 85 | | **Elasticsearch** | `8.0+`支持 | 是 | 是 | 全文+向量混合检索 | 向量维度低(768 默认)、性能中等 | 多模态搜索、有 ES 基础场景 | 86 | -------------------------------------------------------------------------------- /docs/rag/vectorStore/chroma/README.md: -------------------------------------------------------------------------------- 1 | # Chroma 2 | ::: tip 3 | [Chroma 文档](https://docs.trychroma.com/docs/overview/introduction) 4 | ::: 5 | 6 | ## 安装 7 | 8 | 执行此命令安装`chroma`包: 9 | ```sh 10 | $ pip install chromadb 11 | ``` 12 | 13 | ## 客户端 14 | `Chroma`中的客户端一份分为如下几种类型: 15 | * **临时客户端(Ephemeral Client)**:数据存储在本地内存中,适合快速严重一些特性。 16 | * **持久化客户端(Persistent Client)**:数据存储在本地硬盘中,在`Chroma`其中时自动加载硬盘已经存储的数据。 17 | * **客户端-服务端模式(Client Server Mode)**:服务端和客户端可分离。 18 | 19 | ### 临时客户端 20 | 通过如下代码创建临时客户端: 21 | ```py 22 | import chromadb 23 | 24 | client = chromadb.EphemeralClient() 25 | ``` 26 | 27 | ### 持久化客户端 28 | 通过如下代码创建持久化客户端: 29 | ```py 30 | import chromadb 31 | 32 | client = chromadb.PersistentClient( 33 | path="./data" 34 | ) 35 | ``` 36 | 上述代码执行后会创建一个本地`db`: 37 | ```sh 38 | | - data 39 | | - | - chroma.sqlite3 40 | ``` 41 | 42 | ### 服务端-客户端模式 43 | 通过如下代码启动服务端: 44 | ```sh 45 | # 默认端口和host 46 | $ chroma run --path /db_path 47 | 48 | # 自定义端口和host 49 | $ chroma run --host localhost --port 80000 --path /db_path 50 | ``` 51 |  52 | 53 | 通过如下代码链接服务端: 54 | ```py 55 | import chromadb 56 | 57 | client = chromadb.HttpClient( 58 | host="localhost", 59 | port=8080, 60 | ) 61 | ``` 62 | 63 | ## 集合(Collection) 64 | ::: tip 65 | `Collection`是向量数据库中存储一组相似数据的逻辑单元,类似于传统数据库中的表`Table` 66 | ::: 67 | 68 | 集合相关操作如下: 69 | ```py 70 | # 创建集合(仅创建) 71 | collection = client.create_collection( 72 | name="test_collection" 73 | ) 74 | # 创建集合(如果存在则返回,如果不存在则创建) 75 | collection = client.get_or_create_collection( 76 | name="test_collection" 77 | ) 78 | 79 | 80 | # 修改集合名称 81 | collection.modify(name="dev") 82 | 83 | # 删除集合(不可逆,谨慎操作) 84 | client.delete_collection( 85 | name="test_collection" 86 | ) 87 | 88 | # 集合其它方法 89 | print(collection.peek()) # 返回一组items列表 90 | print(collection.count()) # 返回items的数量 91 | ``` 92 | 93 | ## 集合数据(Collection Data) 94 | 在操作集合数据时,有如下几个关键参数: 95 | * **documents**: 可选,与`embeddings`不能同时为空,原始文档对象的列表。 96 | * **embeddings**:可选,与`documents`不能同时为空,一组向量列表。 97 | * **metadatas**:可选,元数据列表,需要和`documents` 和 `embeddings`在维度上相同。 98 | * **ids**:必填,一组唯一`id`的列表,需要和`documents` 和 `embeddings`在维度上相同。 99 | 100 | 101 | ### 添加集合数据 102 | ```py 103 | # 添加数据 104 | collection.add( 105 | documents=["Vue.js", "React.js", "Svelte.js"], 106 | metadatas=[ 107 | { "framework": "FE", "version": "2.7" }, 108 | { "framework": "FE", "version": "18.0" }, 109 | { "framework": "FE", "version": "5.0" } 110 | ], 111 | ids=["id1", "id2", "id3"] 112 | ) 113 | print(collection.count()) 114 | ``` 115 | 116 | ### 更新集合数据 117 | ```py 118 | # 同时更新document和metadata 119 | collection.update( 120 | ids=["id1"], 121 | documents=["Vue.js"] 122 | metadatas=[ 123 | { "framework": "FE", "version": "3.0" } 124 | ] 125 | ) 126 | 127 | # 插入数据 128 | collection.upsert( 129 | documents=["Angular.js"], 130 | metadatas=[ 131 | { "framework": "FE", "version": "20.0" } 132 | ], 133 | ids=["id4"] 134 | ) 135 | ``` 136 | 137 | ### 删除集合数据 138 | ```py 139 | # ids可选,如果不提供,则删除满足where条件所有的数据 140 | collection.delete( 141 | ids=["id3"], 142 | where={ 143 | "version": "5.0" 144 | } 145 | ) 146 | ``` 147 | 148 | ## 查询集合(Query Collection) 149 | ::: tip 150 | [Collection Query API 文档](https://docs.trychroma.com/reference/python/collection#query)
151 | [Collection Get API 文档](https://docs.trychroma.com/reference/python/collection#get) 152 | ::: 153 | ```py 154 | # 根据查询内容查询 155 | result = collection.query( 156 | query_texts=["Vue.js"], 157 | n_results=1 # 仅返回最匹配的一项 158 | ) 159 | 160 | # 根据id查询 161 | result = collection.get( 162 | ids=["id1", "id2", "id3"], 163 | where={ 164 | "version": "3.0" 165 | } 166 | ) 167 | ``` 168 | 169 | ## 元数据过滤(Metadata Filter) 170 | 171 | ## 自定义Embedding 172 | 173 | ## 多模态(MultiModal) -------------------------------------------------------------------------------- /docs/rag/vectorStore/milvus/README.md: -------------------------------------------------------------------------------- 1 | # Milvus 2 | ::: tip 3 | [Milvus 文档](https://milvus.io/docs/zh/quickstart.md) 4 | ::: 5 | 撰写中。。。 -------------------------------------------------------------------------------- /docs/rollup/README.md: -------------------------------------------------------------------------------- 1 | 2 | # Rollup介绍
{{msg}}
'
35 | })
36 |
37 | // 不需要使用带编译的版本
38 | new Vue({
39 | data: {
40 | msg: 'hello,world'
41 | },
42 | render (h) {
43 | return h('div', this.msg)
44 | }
45 | })
46 | ```
47 | * `src/core`:此目录包含了`Vue.js`的核心代码,包括:内置组件`keep-alive`、全局 API(`Vue.use`、`Vue.mixin`和`Vue.extend`等)、实例化、响应式相关、虚拟 DOM 和工具函数等。
48 |
49 | ```sh
50 | |-- core
51 | | |-- components # 内助组件
52 | | |-- global-api # 全局API
53 | | |-- instance # 实例化
54 | | |-- observer # 响应式
55 | | |-- util # 工具函数
56 | | |-- vdom # 虚拟DOM
57 | ```
58 | * `src/platform`:`Vue2.0`提供了跨平台的能力,在`React`中有`React Native`跨平台客户端,而在`Vue2.0`中其对应的跨平台就是`Weex`。
59 |
60 | ```js
61 | |-- platform
62 | | |-- web # web浏览器端
63 | | |-- weex # native客户端
64 | ```
65 |
66 | * `src/server`: `Vue2.0`提供服务端渲染的能力,所有跟服务端渲染相关的代码都在`server`目录下,此部分代码是运行在服务端,而非 Web 浏览器端。
67 |
68 | * `src/sfc`:此目录的主要作用是如何把`.vue`文件解析成一个`JavaScript`对象。
69 |
70 | * `src/shared`:此目录下存放了一些在 Web 浏览器端和服务端都会用到的共享代码。
71 |
72 |
73 | ## 架构设计
74 | 我们通过以上目录结构可以很容易的发现,`Vue.js`整体分为三个部分:**核心代码**、**跨平台相关**和**公共工具函数**。
75 |
76 | 同时其架构是分层的,最底层是一个构造函数(普通的函数),最上层是一个入口,也就是将一个完整的构造函数导出给用户使用。在中间层,我们需要逐渐添加一些方法和属性,主要是原型`prototype`相关和全局API相关。
77 |
78 | 
79 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/dom/README.md:
--------------------------------------------------------------------------------
1 | # 虚拟DOM
2 |
3 | ## 虚拟DOM介绍
4 | 我们在最开始提到过,`Vue`从`2.0+`版本开始就引入了虚拟`DOM`,也知道`Vue`中的虚拟DOM借鉴了开源库[snabbdom](https://github.com/snabbdom/snabbdom)的实现,并根据自身特色添加了许多特性。
5 |
6 | `Vue`在`1.0+`版本还没有引入虚拟`DOM`的时候,当某一个状态发生变化时,它在一定程度上是知道哪些节点使用到了这个状态,从而可以准确的针对这些节点进行更新操作,不需要进行对比。但这种做法是有一定的代价的,因为更新的粒度太细,每一次节点的绑定都需要一个`Watcher`去观察状态的变化,这样会增加更多的内存开销。当一个状态被越多的节点使用,它的内存开销就越大。
7 |
8 | 因此在`Vue`的`2.0+`版本中,引入了虚拟`DOM`将更新粒度调整为组件级别,当状态发生变化的时候,只派发更新到组件级别,然后组件内部再进行对比和渲染。这样做以后,当一个状态在同一个组件内被引用多次的时候,它们只需要一个`render watcher`去观察状态的变化即可。
9 |
10 | ## Vue中的虚拟DOM
11 |
12 | 虚拟`DOM`解决`DOM`更新的方式是:通过状态生成一个虚拟节点树,然后使用虚拟节点树进行渲染,在渲染之前会使用新生成的虚拟节点树和上一次生成的虚拟节点树进行对比,然后只渲染其不相同的部分(包括新增和删除的)。
13 |
14 | 在`Vue`中,根实例就是虚拟节点树的根节点,各种组件就是`children`孩子节点,树节点使用`VNode`类来表示。它使用`template`模板来描述状态与`DOM`之间的映射关系,然后通过`parse`编译将`template`模板转换成渲染函数`render`,执行渲染函数`render`就可以得到一个虚拟节点树,最后使用这个虚拟节点树渲染到视图上。
15 |
16 | 因此根据上面这段话,我们可以得到`Vue`使用虚拟`DOM`进行模板转视图的一个流程。
17 |
18 |
19 |  20 |
20 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/dom/diff.md:
--------------------------------------------------------------------------------
1 | # Diff算法
2 | Diff算法介绍
--------------------------------------------------------------------------------
/docs/vueAnalysis/entry/README.md:
--------------------------------------------------------------------------------
1 | # 整体流程
2 |
3 | 在之前的介绍中,我们知道`Vue.js`内部会根据`Web`浏览器、`Weex`跨平台和`SSR`服务端渲染,不同的环境寻找不同的入口文件,但其核心代码是在`src/core`目录下,我们这一节的主要目标是为了搞清楚从入口文件到`Vue`构造函数执行,这期间的整体流程。
4 |
5 | 在分析完从入口到构造函数的各个部分的流程后,我们可以得到一份大的流程图:
6 |
20 |
7 |  8 |
8 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/entry/global.md:
--------------------------------------------------------------------------------
1 | # initGlobalAPI流程
2 | 我们会在`src/core/index.js`文件中看到如下精简代码:
3 | ```js
4 | import Vue from './instance/index'
5 | import { initGlobalAPI } from './global-api/index'
6 | initGlobalAPI(Vue)
7 |
8 | export default Vue
9 | ```
10 | 在以上代码中,我们发现它引入了`Vue`随后调用了`initGlobalAPI()`函数,此函数的作用是挂载一些全局`API`方法。
11 |
12 | 
13 |
14 | 我们首先能在`src/core/global-api`文件夹下看到如下目录结构:
15 | ```sh
16 | |-- global-api
17 | | |-- index.js # 入口文件
18 | | |-- assets.js # 挂载filter、component和directive
19 | | |-- extend.js # 挂载extend方法
20 | | |-- mixin.js # 挂载mixin方法
21 | | |-- use.js # 挂载use方法
22 | ```
23 |
24 | 随后在`index.js`入口文件中,我们能看到如下精简代码:
25 | ```js
26 | import { initUse } from './use'
27 | import { initMixin } from './mixin'
28 | import { initExtend } from './extend'
29 | import { initAssetRegisters } from './assets'
30 | import { set, del } from '../observer/index'
31 | import { observe } from 'core/observer/index'
32 | import { extend, nextTick } from '../util/index'
33 |
34 | export function initGlobalAPI (Vue: GlobalAPI) {
35 | Vue.set = set
36 | Vue.delete = del
37 | Vue.nextTick = nextTick
38 |
39 | Vue.observable = (obj) => {
40 | observe(obj)
41 | return obj
42 | }
43 |
44 | initUse(Vue)
45 | initMixin(Vue)
46 | initExtend(Vue)
47 | initAssetRegisters(Vue)
48 | }
49 | ```
50 | 从以上代码能够很清晰的看到在`index.js`入口文件中,会在`Vue`构造函数上挂载各种全局`API`函数,其中`set`、`delete`、`nextTick`和`observable`直接赋值为一个函数,而其他几种`API`则是调用了一个以`init`开头的方法,我们以`initAssetRegisters()`方法为例,它的精简代码如下:
51 | ```js
52 | // ['component','directive', 'filter']
53 | import { ASSET_TYPES } from 'shared/constants'
54 |
55 | export function initAssetRegisters (Vue: GlobalAPI) {
56 | ASSET_TYPES.forEach(type => {
57 | Vue[type] = function () {
58 | // 省略了函数的参数和函数实现代码
59 | }
60 | })
61 | }
62 | ```
63 | 其中`ASSET_TYPES`是一个定义在`src/shared/constants.js`中的一个数组,然后在`initAssetRegisters()`方法中遍历这个数组,依次在`Vue`构造函数上挂载`Vue.component()`、`Vue.directive()`和`Vue.filter()`方法,另外三种`init`开头的方法挂载对应的全局`API`是一样的道理:
64 | ```js
65 | // initUse
66 | export function initUse(Vue) {
67 | Vue.use = function () {}
68 | }
69 |
70 | // initMixin
71 | export function initMixin(Vue) {
72 | Vue.mixin = function () {}
73 | }
74 |
75 | // initExtend
76 | export function initExtend(Vue) {
77 | Vue.extend = function () {}
78 | }
79 | ```
80 |
81 | 最后,我们发现还差一个`Vue.compile()`方法,它其实是在`runtime+compile`版本才会有的一个全局方法,因此它在`src/platforms/web/entry-runtime-with-compile.js`中被定义:
82 | ```js
83 | import Vue from './runtime/index'
84 | import { compileToFunctions } from './compiler/index'
85 | Vue.compile = compileToFunctions
86 | export default Vue
87 | ```
88 |
89 | 根据`initGlobalAPI()`方法的逻辑,可以得到如下流程图:
90 | 
91 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/entry/lifecycle.md:
--------------------------------------------------------------------------------
1 | # lifecycleMixin流程
2 | 和以上其它几种方法一样,`lifecycleMixin`主要是定义实例方法和生命周期,例如:`$forceUpdate()`、`$destroy`,另外它还定义一个`_update`的私有方法,其中当调用`$forceUpdate()`方法强制组件重新渲染时会调用这个方法,`lifecycleMixin`精简代码如下:
3 | ```js
4 | export function lifecycleMixin (Vue) {
5 | // 私有方法
6 | Vue.prototype._update = function () {}
7 |
8 | // 实例方法
9 | Vue.prototype.$forceUpdate = function () {
10 | if (this._watcher) {
11 | this._watcher.update()
12 | }
13 | }
14 | Vue.prototype.$destroy = function () {}
15 | }
16 | ```
17 | 代码分析:
18 | * `_update()`会在组件渲染的时候调用,其具体的实现我们会在组件章节详细介绍。
19 | * `$forceUpdate()`为一个强制`Vue`实例重新渲染的方法,它的内部调用了`_update`,也就是强制组件重新编译渲染。
20 | * `$destroy()`为组件销毁方法,在其具体的实现中,会处理父子组件的关系,事件监听,触发生命周期等操作。
21 |
22 | `lifecycleMixin()`方法的代码不是很多,我们也能很容易的得到如下流程图:
23 |
8 |
24 |  25 |
25 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/entry/render.md:
--------------------------------------------------------------------------------
1 | # renderMixin流程
2 | 相比于以上几种方法,`renderMixin`是最简单的,它主要在`Vue.prototype`上定义各种私有方法和一个非常重要的实例方法:`$nextTick`,其精简代码如下:
3 | ```js
4 | export function renderMixin (Vue) {
5 | // 挂载各种私有方法,例如this._c,this._v等
6 | installRenderHelpers(Vue.prototype)
7 | Vue.prototype._render = function () {}
8 |
9 | // 实例方法
10 | Vue.prototype.$nextTick = function (fn) {
11 | return nextTick(fn, this)
12 | }
13 | }
14 | ```
15 | 代码分析:
16 | * `installRenderHelpers`:它会在`Vue.prototype`上挂载各种私有方法,例如`this._n = toNumber`、`this._s = toString`、`this._v = createTextVNode`和`this._e = createEmptyVNode`。
17 | * `_render()`:`_render()`方法会把模板编译成`VNode`,我们会在其后的编译章节详细介绍。
18 | * `nextTick`:就像我们之前介绍过的,`nextTick`会在`Vue`构造函数上挂载一个全局的`nextTick()`方法,而此处为实例方法,本质上引用的是同一个`nextTick`。
19 |
20 | 在以上代码分析完毕后,我们可以得到`renderMixin`如下流程图:
21 |
25 |
22 |  23 |
23 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/entry/state.md:
--------------------------------------------------------------------------------
1 | # stateMixin流程
2 | `stateMixin`主要是处理跟实例相关的属性和方法,它会在`Vue.prototype`上定义实例会使用到的属性或者方法,这一节我们主要任务是弄清楚`stateMixin`的主要流程。在`src/core/instance/state.js`代码中,它精简后如下所示:
3 | ```js
4 | import { set, del } from '../observer/index'
5 | export function stateMixin (Vue) {
6 | // 定义$data, $props
7 | const dataDef = {}
8 | dataDef.get = function () { return this._data }
9 | const propsDef = {}
10 | propsDef.get = function () { return this._props }
11 | Object.defineProperty(Vue.prototype, '$data', dataDef)
12 | Object.defineProperty(Vue.prototype, '$props', propsDef)
13 |
14 | // 定义$set, $delete, $watch
15 | Vue.prototype.$set = set
16 | Vue.prototype.$delete = del
17 | Vue.prototype.$watch = function() {}
18 | }
19 | ```
20 | 我们可以从上面代码中发现,`stateMixin()`方法中在`Vue.prototype`上定义的几个属性或者方法,全部都是和响应式相关的,我们来简要分析一下以上代码:
21 | * `$data和$props`:根据以上代码,我们发现`$data`和`$props`分别是`_data`和`_props`的访问代理,从命名中我们可以推测,以下划线开头的变量,我们一般认为是私有变量,然后通过`$data`和`$props`来提供一个对外的访问接口,虽然可以通过属性的`get()`方法去取,但对于这两个私有变量来说是并不能随意`set`,对于`data`来说不能替换根实例,而对于`props`来说它是只读的。因此在原版源码中,还劫持了`set()`方法,当设置`$data`或者`$props`时会报错:
22 | ```js
23 | if (process.env.NODE_ENV !== 'production') {
24 | dataDef.set = function () {
25 | warn(
26 | 'Avoid replacing instance root $data. ' +
27 | 'Use nested data properties instead.',
28 | this
29 | )
30 | }
31 | propsDef.set = function () {
32 | warn(`$props is readonly.`, this)
33 | }
34 | }
35 | ```
36 | * `$set`和`$delete`:`set`和`delete`这两个方法被定义在跟`instance`目录平级的`observer`目录下,在`stateMixin()`中,它们分别赋值给了`$set`和`$delete`方法,而在`initGlobalAPI`中,也同样使用到了这两个方法,只不过一个是全局方法,一个是实例方法。
37 |
38 | * `$watch`:在`stateMixin()`方法中,详细实现了`$watch()`方法,此方法实现的核心是通过一个`watcher`实例来监听。当取消监听时,同样是使用`watcher`实例相关的方法,关于`watcher`我们会在后续响应式章节详细介绍。
39 | ```js
40 | Vue.prototype.$watch = function (
41 | expOrFn: string | Function,
42 | cb: any,
43 | options?: Object
44 | ): Function {
45 | const vm: Component = this
46 | if (isPlainObject(cb)) {
47 | return createWatcher(vm, expOrFn, cb, options)
48 | }
49 | options = options || {}
50 | options.user = true
51 | const watcher = new Watcher(vm, expOrFn, cb, options)
52 | if (options.immediate) {
53 | try {
54 | cb.call(vm, watcher.value)
55 | } catch (error) {
56 | handleError(error, vm, `callback for immediate watcher "${watcher.expression}"`)
57 | }
58 | }
59 | return function () {
60 | watcher.teardownunwatchFn()
61 | }
62 | }
63 | ```
64 | 在以上代码分析完毕后,我们可以得到`stateMixin`如下流程图:
65 |
23 |
66 |  67 |
67 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/expand/README.md:
--------------------------------------------------------------------------------
1 | # 扩展
2 | 在前面的几个章节中,我们介绍了响应式原理、虚拟DOM、组件化以及编译原理等相关知识,这几章里面的内容几乎涵盖了`Vue`大部分核心知识。但依然有一些知识,我们在前面几个章节中没有提到的:包括指令、过滤器、内置组件,事件处理,`v-model`以及插槽等。
3 |
4 | 在扩展这个大章节中,我们将对这些概念一一进行详细的解读,以便更好的理解`Vue`原理。
--------------------------------------------------------------------------------
/docs/vueAnalysis/expand/plugin.md:
--------------------------------------------------------------------------------
1 | # Vue.use插件机制
2 |
3 | 在使用`Vue`开发应用程序的时候,我们经常使用第三方插件库来方便我们开发,例如:`Vue-Router`、`Vuex`和`element-ui`等等。
4 |
5 | ```js
6 | // main.js
7 | import Vue from 'vue'
8 | import Router from 'vue-router'
9 | import Vuex from 'vuex'
10 | import ElementUI from 'element-ui'
11 |
12 | Vue.use(Router)
13 | Vue.use(Vuex)
14 | Vue.use(ElementUI)
15 |
16 | new Vue({})
17 | ```
18 |
19 | 在`new Vue`之前,我们使用`Vue.use`方法来注册这些插件。其中,`Vue.use`作为一个全局方法,它是在`initGlobalAPI`方法内部通过调用`initUse`来注册这个全局方法的。
20 | ```js
21 | import { initUse } from './use'
22 | export function initGlobalAPI (Vue: GlobalAPI) {
23 | // ...省略代码
24 | initUse(Vue)
25 | // ...省略代码
26 | }
27 | ```
28 | `initUse`方法的代码并不复杂,如下:
29 | ```js
30 | import { toArray } from '../util/index'
31 | export function initUse (Vue: GlobalAPI) {
32 | Vue.use = function (plugin: Function | Object) {
33 | // 1.检测是否已经注册了插件
34 | const installedPlugins = (this._installedPlugins || (this._installedPlugins = []))
35 | if (installedPlugins.indexOf(plugin) > -1) {
36 | return this
37 | }
38 |
39 | // 2.处理参数
40 | const args = toArray(arguments, 1)
41 | args.unshift(this)
42 |
43 | // 3.调用install方法
44 | if (typeof plugin.install === 'function') {
45 | plugin.install.apply(plugin, args)
46 | } else if (typeof plugin === 'function') {
47 | plugin.apply(null, args)
48 | }
49 | installedPlugins.push(plugin)
50 | return this
51 | }
52 | }
53 | ```
54 | 我们可以从以上代码中看出,当调用`Vue.use`时,它只要做三件事情:**检查插件是否重复注册**、**处理插件参数**和**调用插件的install方法**。
55 |
56 | 代码分析:
57 | * **检查插件是否重复注册**:首先通过判断大`Vue`上的`_installedPlugins`属性是否已经存在当前插件,如果已经存在则直接返回;如果不存在才会执行后面的逻辑,假如我们有如下案例:
58 | ```js
59 | import Vue from 'vue'
60 | import Router from 'vue-router'
61 |
62 | Vue.use(Router)
63 | Vue.use(Router)
64 | ```
65 | 多次调用`Vue.use()`方法注册同一个组件,只有第一个生效。
66 |
67 | * **处理插件参数**:有些插件在注册的时候,可能需要我们额外的传递一些参数,例如`element-ui`。
68 | ```js
69 | import Vue from 'vue'
70 | import ElementUI from 'element-ui'
71 | Vue.use(ElementUI, {
72 | size: 'small',
73 | zIndex: 3000
74 | })
75 | ```
76 | 按照上面的例子,`Vue.use()`方法的`arguments`数组的第一项为我们传递的插件,剩下的参数才是我们需要的,因此通过`toArray`方法把`arguments`类数组转成一个真正的数组。注意,此时`args`变量不包含插件这个元素,随后再把当前`this`也就是大`Vue`也传递进数组中。
77 | ```js
78 | // 演示使用,实际为大Vue的构造函数
79 | const args = ['Vue', { size: 'small', zIndex: 3000}]
80 | ```
81 |
82 | * **调用插件的install方法**:从官网[插件](https://cn.vuejs.org/v2/guide/plugins.html)我们知道,如果我们在开发一个`Vue`插件,必须为这个插件提供一个`install`方法,当调用`Vue.use()`方法的时候会自动调用此插件的`install`方法,并把第二步处理好的参数传递进去。假如,我们有如下插件代码:
83 | ```js
84 | // plugins.js
85 | const plugin = {
86 | install (Vue, options) {
87 | console.log(options) // {msg: 'test use plugin'}
88 |
89 | // 其它逻辑
90 | }
91 | }
92 |
93 |
94 | // main.js
95 | import Vue from 'vue'
96 | import MyPlugin from './plugins.js'
97 | Vue.use(MyPlugin, { msg: 'test use plugin' })
98 | ```
99 | 在`install`方法中,我们成功获取到了大`Vue`构造函数以及我们传递的参数,在随后我们就可以做一些其它事情,例如:注册公共组件、注册指令、添加公共方法以及全局`Mixin`混入等等。
100 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/expand/transition-group.md:
--------------------------------------------------------------------------------
1 | # Transition-Group
2 |
3 | Transition-Group介绍
--------------------------------------------------------------------------------
/docs/vueAnalysis/expand/transition.md:
--------------------------------------------------------------------------------
1 | # Transition
2 |
3 | Transition介绍
--------------------------------------------------------------------------------
/docs/vueAnalysis/introduction/README.md:
--------------------------------------------------------------------------------
1 | # 介绍和参考
2 | 本篇`Vue2.6.11`源码分析文章由观看[Vue.js源码全方位深入解析](https://coding.imooc.com/class/228.html)视频,阅读[深入浅出Vue.js](https://www.ituring.com.cn/book/2675)书籍以及参考其他`Vue`源码分析博客而来,阅读视频和书籍请支持正版。
3 |
4 | ## Vue发展简史
5 | * 2013年7月,`Vue.js`在`Github`上第一次提交,此时名字叫做`Element`,后来被改名为`Seed.js`,到现在的`Vue.js`。
6 | * 2013年12月,`Github`发布`0.6`版本,并正式更名为`Vue.js`。
7 | * 2014年2月,在`Hacker News`网站上时候首次公开。
8 | * 2015年10月,`Vue.js`发布`1.0.0`版本。
9 | * 2016年10月,`Vue.js`发布`2.0`版本。
10 | * 2020年9月18日,`Vue.js`发布`3.0`版本。
11 |
12 | ## Vue版本变化
13 | `Vue2.0`版本和`Vue1.0`版本之间虽然内部变化非常大,整个渲染层都重写了,但`API`层面的变化却很小,对开发者来说非常友好,另外`Vue2.0`版本还引入了很多特性:
14 | * `Virtual DOM`虚拟DOM。
15 | * 支持`JSX`语法。
16 | * 支持`TypeScript`。
17 | * 支持服务端渲染`ssr`。
18 | * 提供跨平台能力`weex`。
19 |
20 | **正确理解虚拟DOM**:`Vue`中的虚拟DOM借鉴了开源库[snabbdom](https://github.com/snabbdom/snabbdom)的实现,并根据自身特色添加了许多特性。引入虚拟DOM的一个很重要的好处是:绝大部分情况下,组件渲染变得更快了,而少部分情况下反而变慢了。引入虚拟DOM这项技术通常都是在解决一些问题,然而解决一个问题的同时也可能会引入其它问题,这种情况更多的是如何做权衡、如何做取舍。因此,一味的强调虚拟DOM在任何时候都能提高性能这种说法需要正确对待和理解。
21 |
22 | **核心思想**:`Vue`两大核心思想是**数据驱动**和**组件化**,因此我们在介绍完源码目录设计和整体流程后,会先介绍这两方面。
--------------------------------------------------------------------------------
/docs/vueAnalysis/reactive/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 | 在上一章节,我们分析过`initState()`方法的整体流程,知道它会处理`props`、`methods`和`data`等等相关的内容:
3 | ```js
4 | export function initState (vm: Component) {
5 | vm._watchers = []
6 | const opts = vm.$options
7 | if (opts.props) initProps(vm, opts.props)
8 | if (opts.methods) initMethods(vm, opts.methods)
9 | if (opts.data) {
10 | initData(vm)
11 | } else {
12 | observe(vm._data = {}, true /* asRootData */)
13 | }
14 | if (opts.computed) initComputed(vm, opts.computed)
15 | if (opts.watch && opts.watch !== nativeWatch) {
16 | initWatch(vm, opts.watch)
17 | }
18 | }
19 | ```
20 | 那么我们的深入响应式原理介绍会以`initState()`方法开始,逐步分析`Vue`中响应式的原理,下面这张图可以很好的展示响应式的原理。
21 |
22 |
67 |
23 |  24 |
24 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/reactive/methods.md:
--------------------------------------------------------------------------------
1 | # methods处理
2 | 在分析完`props`相关逻辑后,我们接下来分析与`methods`相关的逻辑,这部分相比于`props`要简单得多。
3 | ```js
4 | export function initState (vm: Component) {
5 | // 省略代码
6 | const opts = vm.$options
7 | if (opts.methods) initMethods(vm, opts.methods)
8 | }
9 | ```
10 | 在`initState()`方法中,调用了`initMethods()`并传入了当前实例`vm`和我们撰写的`methods`。接下来,我们看一下`initMethods`方法具体的实现:
11 | ```js
12 | function initMethods (vm: Component, methods: Object) {
13 | const props = vm.$options.props
14 | for (const key in methods) {
15 | if (process.env.NODE_ENV !== 'production') {
16 | if (typeof methods[key] !== 'function') {
17 | warn(
18 | `Method "${key}" has type "${typeof methods[key]}" in the component definition. ` +
19 | `Did you reference the function correctly?`,
20 | vm
21 | )
22 | }
23 | if (props && hasOwn(props, key)) {
24 | warn(
25 | `Method "${key}" has already been defined as a prop.`,
26 | vm
27 | )
28 | }
29 | if ((key in vm) && isReserved(key)) {
30 | warn(
31 | `Method "${key}" conflicts with an existing Vue instance method. ` +
32 | `Avoid defining component methods that start with _ or $.`
33 | )
34 | }
35 | }
36 | vm[key] = typeof methods[key] !== 'function' ? noop : bind(methods[key], vm)
37 | }
38 | }
39 | ```
40 | 在以上代码中可以看到,`initMethods()`方法实现中最重要的一段代码就是:
41 | ```js
42 | // 空函数
43 | function noop () {}
44 |
45 | vm[key] = typeof methods[key] !== 'function' ? noop : bind(methods[key], vm)
46 | ```
47 | 它首先判断了我们定义的`methods`是不是`function`类型,如果不是则赋值为一个`noop`空函数,如果是则把这个方法进行`bind`绑定,其中传入的`vm`为当前实例。这样做的目的是为了把`methods`方法中的`this`指向当前实例,使得我们能在`methods`方法中通过`this.xxx`的形式,很方便的访问到`props`、`data`以及`computed`等与实例相关的属性或方法。
48 |
49 | 在开发环境下,它还做了如下几种判断:
50 | * 必须为`function`类型。
51 | ```js
52 | // 抛出错误:Method sayHello has type null in the component definition.
53 | // Did you reference the function correctly?
54 | export default {
55 | methods: {
56 | sayHello: null
57 | }
58 | }
59 | ```
60 | * 命名不能和`props`冲突。
61 | ```js
62 | // 抛出错误:Method name has already been defined as a prop.
63 | export default {
64 | props: ['name']
65 | methods: {
66 | name () {
67 | console.log('name')
68 | }
69 | }
70 | }
71 | ```
72 | * 命名不能和已有的实例方法冲突。
73 | ```js
74 | // 抛出错误:Method $set conflicts with an existing Vue instance method.
75 | // Avoid defining component methods that start with _ or $.
76 | export default {
77 | methods: {
78 | $set () {
79 | console.log('$set')
80 | }
81 | }
82 | }
83 | ```
84 |
85 | 在分析完以上`initMethods`流程后,我们能得到如下流程图:
86 |
24 |
87 |  88 |
88 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/reactive/prepare.md:
--------------------------------------------------------------------------------
1 | # 前置核心概念
2 |
3 | ## Object.defineProperty介绍
4 | 也许你已经从很多地方了解到,`Vue.js`利用了`Object.defineProperty(obj, key, descriptor)`方法来实现响应式,其中`Object.defineProperty()`方法的参数介绍如下:
5 | * `obj`:要定义其属性的对象。
6 | * `key`:要定义或修改属性的名称。
7 | * `descriptor`:要定义或修改属性的描述符。
8 |
9 | 其中`descriptor`有很多可选的键值, 然而对`Vue`响应式来说最重要的是`get`和`set`方法,它们分别会在获取属性值的时候触发`getter`,设置属性值的时候触发`setter`。在介绍原理之前,我们使用`Object.defineProperty()`来实现一个简单的响应式例子:
10 | ```js
11 | function defineReactive (obj, key, val) {
12 | Object.defineProperty(obj, key, {
13 | enumerable: true,
14 | configurable: true,
15 | get: function reactiveGetter () {
16 | console.log('get msg')
17 | return val
18 | },
19 | set: function reactiveSetter (newVal) {
20 | console.log('set msg')
21 | val = newVal
22 | }
23 | })
24 | }
25 | const vm = {
26 | msg: 'hello, Vue.js'
27 | }
28 | let msg = ''
29 | defineReactive(vm, 'msg', vm.msg)
30 | msg = vm.msg // get msg
31 | vm.msg = 'Hello, Msg' // set msg
32 | msg = vm.msg // get msg
33 | ```
34 | 为了在别的地方方便的使用`Object.defineProperty()`方法,因此我们把其封装成一个`defineReactive`函数。
35 |
36 | ## proxy代理
37 | 在开发过程中,我们经常会使用`this.xxx`的形式直接访问`props`或者`data`中的值,这是因为`Vue`为`props`和`data`默认做了`proxy`代理。关于什么是`proxy`代理,请先看一个简单的例子:
38 | ```js
39 | this._data = {
40 | name: 'AAA',
41 | age: 23
42 | }
43 | // 代理前
44 | console.log(this._data.name) // AAA
45 | proxy(vm, '_data', 'name')
46 | // 代理后
47 | console.log(this.name) // AAA
48 | ```
49 | 接下来我们详细介绍`proxy()`方法是如何实现的,在`instance/state.js`文件中定义了`proxy`方法,它的代码也很简单:
50 | ```js
51 | const sharedPropertyDefinition = {
52 | enumerable: true,
53 | configurable: true,
54 | get: noop,
55 | set: noop
56 | }
57 | export function proxy (target: Object, sourceKey: string, key: string) {
58 | sharedPropertyDefinition.get = function proxyGetter () {
59 | return this[sourceKey][key]
60 | }
61 | sharedPropertyDefinition.set = function proxySetter (val) {
62 | this[sourceKey][key] = val
63 | }
64 | Object.defineProperty(target, key, sharedPropertyDefinition)
65 | }
66 | ```
67 | 我们可以从上面的代码中发现,`proxy`方法主要是做了属性的`get`和`set`方法劫持。
68 | ```js
69 | const name = this.name
70 | this.name = 'BBB'
71 | // 等价于
72 | const name = this._data.name
73 | this._data.name = 'BBB'
74 | ```
75 | ## $options属性
76 | 在之前的介绍中,我们知道当初始化`Vue`实例的时候,传递的`options`会根据不同的情况进行配置合并,关于详细的`options`合并策略我们会在之后的章节详细介绍,现阶段我们只需要知道`$options`可以拿到合并后的所有属性,例如`props`、`methods`以及`data`等等。
77 |
78 | 假设我们定义了如下实例:
79 | ```js
80 | const vm = new Vue({
81 | el: '#app',
82 | props: {
83 | msg: ''
84 | },
85 | data () {
86 | return {
87 | firstName: 'AAA',
88 | lastName: 'BBB',
89 | age: 23
90 | }
91 | },
92 | methods: {
93 | sayHello () {
94 | console.log('Hello, Vue.js')
95 | }
96 | },
97 | computed: {
98 | fullName () {
99 | return this.firstName + this.lastName
100 | }
101 | }
102 | })
103 | ```
104 | 那么我们在之后可以通过下面的方式来取这些属性。
105 | ```js
106 | const opts = this.$options
107 | const props = opts.props
108 | const methods = opts.methods
109 | const data = opts.data
110 | const computed = opts.computed
111 | const watch = opts.watch
112 | // ...等等
113 | ```
--------------------------------------------------------------------------------
/docs/vueAnalysis/reactive/problem.md:
--------------------------------------------------------------------------------
1 | # 变化侦测注意事项
2 | 虽然`Object.defineProperty()`方法很好用,但也会存在一些例外情况,这些例外情况的变动不能触发`setter`。这种情况,我们分为对象和数组两类来分析。
3 |
4 | ## 对象
5 | 假设我们有如下例子:
6 | ```js
7 | export default {
8 | data () {
9 | return {
10 | obj: {
11 | a: 'a'
12 | }
13 | }
14 | },
15 | created () {
16 | // 1.新增属性b,属性b不是响应式的,不会触发obj的setter
17 | this.obj.b = 'b'
18 | // 2.delete删除已有属性,无法触发obj的setter
19 | delete this.obj.a
20 | }
21 | }
22 | ```
23 | 从以上例子我们可以看到:
24 | * 当为一个响应式对象新增一个属性的时候,新增的属性不是响应式的,后续对于这个新增属性的任何修改,都无法触发其`setter`。为了解决这种问题,`Vue.js`提供了一个全局的`Vue.set()`方法和实例`vm.$set()`方法,它们实际上都是同一个`set`方法,我们会在后续的章节中介绍与响应式相关的全局`API`的实现。
25 | * 当一个响应式对象删除一个已有属性的时候,不会触发`setter`。为了解决这个问题,`Vue.js`提供了一个全局的`vue.delete()`方法和实例`vm.$delete()`方法,它们实际上都是同一个`del`方法,我们会在后续的章节中介绍与响应式相关的全局`API`的实现。
26 |
27 | ## 数组
28 | 假设我们有如下例子:
29 | ```js
30 | export default {
31 | data () {
32 | return {
33 | arr: [1, 2, 3]
34 | }
35 | },
36 | created () {
37 | // 1.通过索引进行修改,无法捕获到数组的变动。
38 | this.arr[0] = 11
39 | // 2.通过修改数组长度,无法捕获到数组的变动。
40 | this.arr.length = 0
41 | }
42 | }
43 | ```
44 | 从以上例子我们可以看到:
45 | * 通过索引直接修改数组,无法捕捉到数组的变动。
46 | * 通过修改数组长度,无法捕获到数组的变动。
47 |
48 | 对于第一种情况,我们可以使用前面提到过的`Vue.set`或者`vm.$set`来解决,对于第二种方法,我们可以使用数组的`splice()`方法解决。
49 |
50 | 在最新版`Vue3.0`中,使用到了`Proxy`来代替`Object.defineProperty()`实现响应式,使用`Proxy`后以上问题全部可以解决,然而`Proxy`属于`ES6`的内容,因此对于浏览器兼容性方面有一定的要求。
--------------------------------------------------------------------------------
/docs/vueAnalysis/router/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 | Vue-Router介绍
--------------------------------------------------------------------------------
/docs/vueAnalysis/router/change.md:
--------------------------------------------------------------------------------
1 | # 路由切换
2 | 路由切换
--------------------------------------------------------------------------------
/docs/vueAnalysis/router/components.md:
--------------------------------------------------------------------------------
1 | # 内置组件
2 |
3 | ## RouterView
4 |
5 | ## RouterLink
6 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/router/hooks.md:
--------------------------------------------------------------------------------
1 | # 路由hooks钩子函数
2 | 路由hooks钩子函数
--------------------------------------------------------------------------------
/docs/vueAnalysis/router/install.md:
--------------------------------------------------------------------------------
1 | # 路由安装
2 |
3 | 路由安装
--------------------------------------------------------------------------------
/docs/vueAnalysis/router/matcher.md:
--------------------------------------------------------------------------------
1 | # matcher介绍
2 | matcher介绍
3 |
--------------------------------------------------------------------------------
/docs/vueAnalysis/vuex/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 |
3 | 在`Vuex`官网中它有这样一段话:**Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。**
4 |
5 | 借用一张`Vuex`官网中一张关于其状态管理的流程图:
6 |
7 |
88 |
8 | 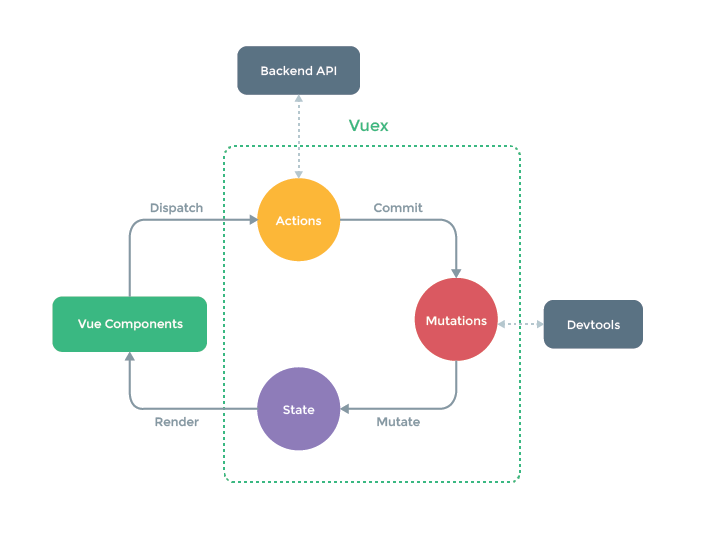 9 |
9 |
10 |
11 |
12 | 在分析`Vuex`源码章节,我们会按照`Vuex`的安装、`Vuex`的初始化、`Vuex`提供的辅助`API`以及`Store`实例`API`这几个模块来进行说明,其中最后几个模块是重点。
13 |
14 | **Vuex初始化**:
15 | 1. `State`初始化。
16 | 2. `Mutations`初始化。
17 | 3. `Actions`初始化。
18 | 4. `Getters`初始化和响应式。
19 | 5. `Modules`初始化。
20 |
21 |
22 | **Vuex**辅助`API`设计:
23 | 1. `createNamespacedHelpers`设计原理。
24 | 2. `mapState`设计原理。
25 | 3. `mapMutations`设计思想。
26 | 4. `mapActions`设计思想。
27 |
28 | **Store**实例`API`设计:
29 | 1. `commit`设计思想。
30 | 1. `dispatch`设计思想。
31 | 1. `subscribe`设计思想。
32 | 1. `subscribeAction`设计思想。
33 | 1. `registerModule`设计思想。
34 | 1. `unregisterModule`设计思想。
--------------------------------------------------------------------------------
/docs/vueAnalysis/vuex/install.md:
--------------------------------------------------------------------------------
1 | # Vuex安装
2 |
3 | 由于`Vuex`也属于`Vue`的插件,因此我们在使用`Vuex`的时候,需要使用`Vue.use()`方法进行注册。
4 |
5 | 在`store.js`中其代码如下:
6 | ```js
7 | // store.js
8 | import Vue from 'vue'
9 | import Vuex from 'vuex'
10 | Vue.use(Vuex)
11 | ```
12 | 根据`Vue`插件机制原理,插件需要提供一个`install`方法,在`Vuex`源码中,`install`的代码路径为`src/store.js`,其实现代码如下:
13 | ```js
14 | import applyMixin from './mixin'
15 |
16 | let Vue
17 | export function install (_Vue) {
18 | if (Vue && _Vue === Vue) {
19 | if (__DEV__) {
20 | console.error(
21 | '[vuex] already installed. Vue.use(Vuex) should be called only once.'
22 | )
23 | }
24 | return
25 | }
26 | Vue = _Vue
27 | applyMixin(Vue)
28 | }
29 | ```
30 |
31 | 在这个方法中,它所做的事情很简单,第一个就是把我们传递的`Vue`实例缓存起来,以方便后续实例化`Store`的时候使用。第二件事情就是调用`applyMixin`方法,此方法代码路径为`src/mixin.js`。
32 | ```js
33 | // mixin.js文件
34 | export default function (Vue) {
35 | const version = Number(Vue.version.split('.')[0])
36 | if (version >= 2) {
37 | Vue.mixin({ beforeCreate: vuexInit })
38 | } else {
39 | // 省略Vue1.0+版本逻辑
40 | }
41 | }
42 | ```
43 | 因为我们`Vue`源码分析是基于`Vue2.6.11`,因此我们省略关于`else`分支的逻辑。
44 |
45 | 当`Vue`的版本高于`2.0`时,它会调用`Vue.mixin()`方法全局混入一个`beforeCreate`生命周期,当`beforeCreate`生命周期执行的时候,会调用`vuexInit`,其代码如下:
46 | ```js
47 | // vuexInit中的this代表当前Vue实例
48 | function vuexInit () {
49 | const options = this.$options
50 | // store injection
51 | if (options.store) {
52 | this.$store = typeof options.store === 'function'
53 | ? options.store()
54 | : options.store
55 | } else if (options.parent && options.parent.$store) {
56 | this.$store = options.parent.$store
57 | }
58 | }
59 | ```
60 |
61 | 在入口`main.js`文件中,我们有这样一段代码:
62 | ```js
63 | // main.js
64 | import store from './store'
65 |
66 | new Vue({
67 | el: '#app',
68 | store
69 | })
70 | ```
71 | 我们在`vuexInit`方法中拿到的`options.store`就是我们传入的`store`,我们再来把目光跳转到`store.js`文件中,其代码如下:
72 | ```js
73 | // store.js
74 | import Vuex from 'vuex'
75 |
76 | export default new Vuex.Store({})
77 | ```
78 | 原来我们在根实例中传递的是一个`Store`实例,这样我们就明白了`vuexInit`方法的主要作用了:**给每一个Vue实例都赋值一个$store属性。**
79 |
80 | 这样,我们在组件中就不用去手动引入`store`了,而是可以直接使用`$store`,例如:
81 | ```html
82 |
83 |
9 | {{$store.state.xxx}}
84 |
85 | ```
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/catalog/README.md:
--------------------------------------------------------------------------------
1 | # 源码目录
2 | 因为`Vue3`采用`Monorepo`进行项目代码管理,所以我们着重关注`packages`目录,其中比较关键的几个`package`如下:
3 | ```sh
4 | |-- packages
5 | | |-- compiler-core
6 | | |-- compiler-dom
7 | | |-- compiler-sfc
8 | | |-- compiler-ssr
9 | | |-- reactivity
10 | | |-- runtime-core
11 | | |-- runtime-dom
12 | | |-- vue
13 | ```
14 | `package`功能介绍:
15 | * `compiler-core`:跟环境无关的公共编译模块。
16 | * `compiler-dom`:针对`web`浏览器端编译模块。
17 | * `compiler-sfc`:`.vue`单文件解析模块,我们比较熟悉的`vue-loader`打包插件会使用到它。
18 | * `compiler-ssr`: 服务端渲染相关的编译模块。
19 | * `reactivity`:响应式模块,例如`ref`和`reactive`都定义在此模块中。
20 | * `runtime-core`:跟环境无关的公共运行时模块。
21 | * `runtime-dom`:针对`web`浏览器端的运行时模块。
22 | * `vue`: 集合几乎所有模块为一身的完整包。
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 | 组件化介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/createApp.md:
--------------------------------------------------------------------------------
1 | # createApp
2 | createApp介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/lifecycle.md:
--------------------------------------------------------------------------------
1 | # 组件生命周期
2 | 组件生命周期介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/mount.md:
--------------------------------------------------------------------------------
1 | # $mount
2 | $mount方法介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/register.md:
--------------------------------------------------------------------------------
1 | # 组件注册
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/render.md:
--------------------------------------------------------------------------------
1 | # render
2 | render介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/component/setup.md:
--------------------------------------------------------------------------------
1 | # setup
2 | setup介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/introduction/README.md:
--------------------------------------------------------------------------------
1 | # 参考和历史
2 |
3 | ## 参考
4 | 本篇`Vue3.4.33`源码分析文章由学习[Vue.js 3.0 核心源码解析](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=326&sid=20-h5Url-0#/sale)课程以及参考其它学习视频、博客而来,阅读视频、书籍请支持正版。
5 |
6 | ## 发展历史
7 | * 2013年7月,`Vue.js`在`Github`上第一次提交,此时名字叫做`Element`,后来被改名为`Seed.js`,到现在的`Vue.js`。
8 | * 2013年12月,`Github`发布`0.6`版本,并正式更名为`Vue.js`。
9 | * 2014年2月,在`Hacker News`网站上时候首次公开。
10 | * 2015年10月,`Vue.js`发布`1.0.0`版本。
11 | * 2016年10月,`Vue.js`发布`2.0`版本。
12 | * 2020年9月18日,`Vue.js`发布`3.0`版本。
13 |
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 | 在`Vue3`中,[@vue/reactivity](https://www.npmjs.com/package/@vue/reactivity)作为独立的`package`子包,可以脱离`Vue`在其他工具和库中进行使用,你甚至可以在`React`中使用。
3 |
4 | 之所以`Vue3`能够这样,而`Vue2`不行,这是因为`Vue3`采用`Monorepo`进行项目代码管理,它让各个模块之间,能够相互独立进行发包。
5 |
6 | 如果你对`Monorepo`还不是特别了解的话,你可以点击[Monorepo + Rollup](/vueNextAnalysis/monorepo/)这个章节去了解更多内容。
7 |
8 | 在这一章节,我们重点分析`reactivity`模块中各个`API`是如何实现的,包括:`ref`、`reactive`、`computed`以及`readonly`等等。
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/base.md:
--------------------------------------------------------------------------------
1 | # 基础概念
2 |
3 | ## Proxy
4 | Proxy介绍
5 |
6 | ## WeakSet
7 | WeakSet介绍
8 |
9 | ## WeakMap
10 | WeakMap介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/computed.md:
--------------------------------------------------------------------------------
1 | # computed
2 | computed介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/reactive.md:
--------------------------------------------------------------------------------
1 | # reactive
2 | reactive介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/readonly.md:
--------------------------------------------------------------------------------
1 | # readonly
2 | readonly介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/ref.md:
--------------------------------------------------------------------------------
1 | # ref
2 |
3 | ## ref和shallowRef
4 |
5 | ### 用法
6 |
7 | ### 实现方式
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/track.md:
--------------------------------------------------------------------------------
1 | # Track依赖收集
2 | Track依赖收集介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/trigger.md:
--------------------------------------------------------------------------------
1 | # Trigger派发更新
2 | Trigger派发更新介绍
--------------------------------------------------------------------------------
/docs/vueNextAnalysis/reactivity/watch.md:
--------------------------------------------------------------------------------
1 | # Watch
2 | Watch介绍
--------------------------------------------------------------------------------
/docs/webpack/tapable/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | sidebar: heading
3 | ---
4 |
5 | # Tapable事件流插件
6 |
7 | Tapable事件流插件
--------------------------------------------------------------------------------
/docs/webpack/webpack/README.md:
--------------------------------------------------------------------------------
1 | # 说明
2 |
3 | ## 版本和参考说明
4 | ::: tip 说明
5 | 本篇博客由学习[从基础到实战手把手带你掌握新版Webpack4.0](https://coding.imooc.com/class/316.html)视频整理而来,观看视频请支持正版。
6 | :::
7 | ::: warning 注意
8 | 本篇博客 Webpack 版本是`4.0+`,请确保你安装了`Node.js`最新版本。
9 | :::
10 |
11 | ## Webpack概念
12 | Webpack 的核心概念是一个 **模块打包工具** ,它的主要目标是将`js`文件打包在一起,打包后的文件用于在目标环境中使用,但它也能胜任 **转换`transform`** 、**打包`bundle`** 或 **包裹`package`** 任何其他资源。
--------------------------------------------------------------------------------
/docs/webpack/webpack/install.md:
--------------------------------------------------------------------------------
1 | # 安装
2 |
3 | ## 全局安装
4 | ::: warning 注意
5 | 如果你只是想做一个 Webpack 的 Demo 案例,那么全局安装方法可能会比较适合你。如果你是在实际生产开发中使用,那么推荐你使用本地安装方法。
6 | :::
7 | ### 全局安装命令
8 | :::tip 参数说明
9 | `webpack4.0+`的版本,必须安装`webpack-cli`,`-g`命令代表全局安装的意思
10 | :::
11 | ``` sh
12 | $ npm install webpack webpack-cli -g
13 | ```
14 |
15 | ## 卸载
16 | ::: tip 参数说明
17 | 通过`npm install`安装的模块,对应的可通过`npm uninstall`进行卸载
18 | :::
19 | ```sh
20 | $ npm uninstall webpack webpack-cli -g
21 | ```
22 |
23 | ## 本地安装(推荐)
24 | ::: tip 参数说明
25 | 本地安装的`Webpack`意思是,只在你当前项目下有效,而通过全局安装的`Webpack`,如果两个项目的`Webpack`主版本不一致,则可能会造成其中一个项目无法正常打包。本地安装方式也是实际开发中推荐的一种`Webpack`安装方式。
26 | :::
27 | ```sh
28 | $ npm install webpack webpack-cli -D
29 | # 等价于
30 | $ npm install webpack webpack-cli --save-dev
31 | ```
32 |
33 | ## 版本号安装
34 | ::: tip 参数说明
35 | 如果你对`Webpack`的具体版本有严格要求,那么可以先去Github的`Webpack`仓库查看历史版本记录或者使用`npm view webpack versions`查看`Webpack`的`npm`包历史版本记录
36 | :::
37 | ```sh
38 | # 查看webpack的历史版本记录
39 | $ npm view webpack versions
40 |
41 | # 按版本号安装
42 | $ npm install webpack@4.25.0 -D
43 | ```
44 |
--------------------------------------------------------------------------------
/docs/webpack/webpack/plugin.md:
--------------------------------------------------------------------------------
1 |
2 | # 编写自己的Plugin
3 | 与`loader`一样,我们在使用 Webpack 的过程中,也经常使用`plugin`,那么我们学习如何编写自己的`plugin`是十分有必要的。
4 | ::: tip 场景
5 | 编写我们自己的`plugin`的场景是在打包后的`dist`目录下生成一个`copyright.txt`文件
6 | :::
7 | ## plugin基础
8 | `plugin`基础讲述了怎么编写自己的`plugin`以及如何使用,与创建自己的`loader`相似,我们需要创建如下的项目目录结构:
9 | ```js
10 | |-- plugins
11 | | -- copyWebpackPlugin.js
12 | |-- src
13 | | -- index.js
14 | |-- webpack.config.js
15 | |-- package.json
16 | ```
17 | `copyWebpackPlugins.js`中的代码:使用`npm run build`进行打包时,我们会看到控制台会输出`hello, my plugin`这段话。
18 | ::: tip 说明
19 | `plugin`与`loader`不同,`plugin`需要我们提供的是一个类,这也就解释了我们必须在使用插件时,为什么要进行`new`操作了。
20 | :::
21 | ```js
22 | class copyWebpackPlugin {
23 | constructor() {
24 | console.log('hello, my plugin');
25 | }
26 | apply(compiler) {
27 |
28 | }
29 | }
30 | module.exports = copyWebpackPlugin;
31 | ```
32 |
33 | `webpack.config.js`中的代码:
34 | ```js
35 | const path = require('path');
36 | // 引用自己的插件
37 | const copyWebpackPlugin = require('./plugins/copyWebpackPlugin.js');
38 | module.exports = {
39 | mode: 'development',
40 | entry: './src/index.js',
41 | output: {
42 | filename: '[name].js',
43 | path: path.resolve(__dirname, 'dist')
44 | },
45 | plugins: [
46 | // new自己的插件
47 | new copyWebpackPlugin()
48 | ]
49 | }
50 | ```
51 |
52 | ## 如何传递参数
53 | 在使用其他`plugin`插件时,我们经常需要传递一些参数进去,那么我们如何在自己的插件中传递参数呢?在哪里接受呢?54 | 其实,插件传参跟其他插件传参是一样的,都是在构造函数中传递一个对象,插件传参如下所示: 55 | ```js {13} 56 | const path = require('path'); 57 | const copyWebpackPlugin = require('./plugins/copyWebpackPlugin.js'); 58 | module.exports = { 59 | mode: 'development', 60 | entry: './src/index.js', 61 | output: { 62 | filename: '[name].js', 63 | path: path.resolve(__dirname, 'dist') 64 | }, 65 | plugins: [ 66 | // 向我们的插件传递参数 67 | new copyWebpackPlugin({ 68 | name: 'why' 69 | }) 70 | ] 71 | } 72 | ``` 73 | 在`plugin`的构造函数中调用:使用`npm run build`进行打包,在控制台可以打印出我们传递的参数值`why` 74 | ```js {3} 75 | class copyWebpackPlugin { 76 | constructor(options) { 77 | console.log(options.name); 78 | } 79 | apply(compiler) { 80 | 81 | } 82 | } 83 | module.exports = copyWebpackPlugin; 84 | ``` 85 | 86 | ## 如何编写及使用自己的Plugin 87 | ::: tip 说明 88 | * `apply`函数是我们插件在调用时,需要执行的函数 89 | * `apply`的参数,指的是 Webpack 的实例 90 | * `compilation.assets`打包的文件信息 91 | ::: 92 | 我们现在有这样一个需求:使用自己的插件,在打包目录下生成一个`copyright.txt`版权文件,那么该如何编写这样的插件呢? 93 | 首先我们需要知道`plugin`的钩子函数,符合我们规则钩子函数叫:`emit`,它的用法如下: 94 | ```js 95 | class CopyWebpackPlugin { 96 | constructor() { 97 | } 98 | apply(compiler) { 99 | compiler.hooks.emit.tapAsync('CopyWebpackPlugin', (compilation, cb) => { 100 | var copyrightText = 'copyright by why'; 101 | compilation.assets['copyright.txt'] = { 102 | source: function() { 103 | return copyrightText 104 | }, 105 | size: function() { 106 | return copyrightText.length; 107 | } 108 | } 109 | cb(); 110 | }) 111 | } 112 | } 113 | module.exports = CopyWebpackPlugin; 114 | ``` 115 | 使用`npm run build`命名打包后,我们可以看到`dist`目录下,确实生成了我们的`copyright.txt`文件。 116 | ```js 117 | |-- dist 118 | | |-- copyright.txt 119 | | |-- main.js 120 | |-- plugins 121 | | |-- copyWebpackPlugin.js 122 | |-- src 123 | | |-- index.js 124 | |-- webpack.config.js 125 | |-- package.json 126 | ``` 127 | 我们打开`copyright.txt`文件,它的内容如下: 128 | ``` html 129 | copyright by why 130 | ``` -------------------------------------------------------------------------------- /donate.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/wangtunan/blog/4cae81a7be7882437e8f42d6762dbb92aa7d76e8/donate.jpg -------------------------------------------------------------------------------- /package.json: -------------------------------------------------------------------------------- 1 | { 2 | "type": "module", 3 | "scripts": { 4 | "dev": "vuepress dev docs", 5 | "build": "vuepress build docs", 6 | "depoly": "depoly.sh" 7 | }, 8 | "keywords": [ 9 | "vue", 10 | "vue源码分析", 11 | "wangtunan", 12 | "汪图南的博客", 13 | "汪图南" 14 | ], 15 | "dependencies": { 16 | "vuepress": "^2.0.0-rc.21" 17 | }, 18 | "devDependencies": { 19 | "@vuepress/bundler-vite": "^2.0.0-rc.21", 20 | "@vuepress/plugin-baidu-analytics": "^2.0.0-rc.94", 21 | "@vuepress/plugin-comment": "^2.0.0-rc.94", 22 | "@vuepress/plugin-markdown-math": "^2.0.0-rc.94", 23 | "@vuepress/plugin-register-components": "^2.0.0-rc.94", 24 | "@vuepress/plugin-prismjs": "^2.0.0-rc.94", 25 | "@vuepress/theme-default": "^2.0.0-rc.94", 26 | "katex": "^0.16.22", 27 | "sass-embedded": "^1.86.3" 28 | } 29 | } --------------------------------------------------------------------------------