├── LICENSE
├── README.md
├── anyup
├── __init__.py
├── layers
│ ├── __init__.py
│ ├── attention
│ │ ├── __init__.py
│ │ ├── attention_masking.py
│ │ └── chunked_attention.py
│ ├── convolutions.py
│ ├── feature_unification.py
│ └── positional_encoding.py
├── model.py
└── utils
│ ├── __init__.py
│ ├── img.py
│ └── visualization
│ ├── __init__.py
│ └── attention_visualization.py
├── example_usage.ipynb
└── hubconf.py
/LICENSE:
--------------------------------------------------------------------------------
1 | Attribution 4.0 International
2 |
3 | =======================================================================
4 |
5 | Creative Commons Corporation ("Creative Commons") is not a law firm and
6 | does not provide legal services or legal advice. Distribution of
7 | Creative Commons public licenses does not create a lawyer-client or
8 | other relationship. Creative Commons makes its licenses and related
9 | information available on an "as-is" basis. Creative Commons gives no
10 | warranties regarding its licenses, any material licensed under their
11 | terms and conditions, or any related information. Creative Commons
12 | disclaims all liability for damages resulting from their use to the
13 | fullest extent possible.
14 |
15 | Using Creative Commons Public Licenses
16 |
17 | Creative Commons public licenses provide a standard set of terms and
18 | conditions that creators and other rights holders may use to share
19 | original works of authorship and other material subject to copyright
20 | and certain other rights specified in the public license below. The
21 | following considerations are for informational purposes only, are not
22 | exhaustive, and do not form part of our licenses.
23 |
24 | Considerations for licensors: Our public licenses are
25 | intended for use by those authorized to give the public
26 | permission to use material in ways otherwise restricted by
27 | copyright and certain other rights. Our licenses are
28 | irrevocable. Licensors should read and understand the terms
29 | and conditions of the license they choose before applying it.
30 | Licensors should also secure all rights necessary before
31 | applying our licenses so that the public can reuse the
32 | material as expected. Licensors should clearly mark any
33 | material not subject to the license. This includes other CC-
34 | licensed material, or material used under an exception or
35 | limitation to copyright. More considerations for licensors:
36 | wiki.creativecommons.org/Considerations_for_licensors
37 |
38 | Considerations for the public: By using one of our public
39 | licenses, a licensor grants the public permission to use the
40 | licensed material under specified terms and conditions. If
41 | the licensor's permission is not necessary for any reason--for
42 | example, because of any applicable exception or limitation to
43 | copyright--then that use is not regulated by the license. Our
44 | licenses grant only permissions under copyright and certain
45 | other rights that a licensor has authority to grant. Use of
46 | the licensed material may still be restricted for other
47 | reasons, including because others have copyright or other
48 | rights in the material. A licensor may make special requests,
49 | such as asking that all changes be marked or described.
50 | Although not required by our licenses, you are encouraged to
51 | respect those requests where reasonable. More considerations
52 | for the public:
53 | wiki.creativecommons.org/Considerations_for_licensees
54 |
55 | =======================================================================
56 |
57 | Creative Commons Attribution 4.0 International Public License
58 |
59 | By exercising the Licensed Rights (defined below), You accept and agree
60 | to be bound by the terms and conditions of this Creative Commons
61 | Attribution 4.0 International Public License ("Public License"). To the
62 | extent this Public License may be interpreted as a contract, You are
63 | granted the Licensed Rights in consideration of Your acceptance of
64 | these terms and conditions, and the Licensor grants You such rights in
65 | consideration of benefits the Licensor receives from making the
66 | Licensed Material available under these terms and conditions.
67 |
68 |
69 | Section 1 -- Definitions.
70 |
71 | a. Adapted Material means material subject to Copyright and Similar
72 | Rights that is derived from or based upon the Licensed Material
73 | and in which the Licensed Material is translated, altered,
74 | arranged, transformed, or otherwise modified in a manner requiring
75 | permission under the Copyright and Similar Rights held by the
76 | Licensor. For purposes of this Public License, where the Licensed
77 | Material is a musical work, performance, or sound recording,
78 | Adapted Material is always produced where the Licensed Material is
79 | synched in timed relation with a moving image.
80 |
81 | b. Adapter's License means the license You apply to Your Copyright
82 | and Similar Rights in Your contributions to Adapted Material in
83 | accordance with the terms and conditions of this Public License.
84 |
85 | c. Copyright and Similar Rights means copyright and/or similar rights
86 | closely related to copyright including, without limitation,
87 | performance, broadcast, sound recording, and Sui Generis Database
88 | Rights, without regard to how the rights are labeled or
89 | categorized. For purposes of this Public License, the rights
90 | specified in Section 2(b)(1)-(2) are not Copyright and Similar
91 | Rights.
92 |
93 | d. Effective Technological Measures means those measures that, in the
94 | absence of proper authority, may not be circumvented under laws
95 | fulfilling obligations under Article 11 of the WIPO Copyright
96 | Treaty adopted on December 20, 1996, and/or similar international
97 | agreements.
98 |
99 | e. Exceptions and Limitations means fair use, fair dealing, and/or
100 | any other exception or limitation to Copyright and Similar Rights
101 | that applies to Your use of the Licensed Material.
102 |
103 | f. Licensed Material means the artistic or literary work, database,
104 | or other material to which the Licensor applied this Public
105 | License.
106 |
107 | g. Licensed Rights means the rights granted to You subject to the
108 | terms and conditions of this Public License, which are limited to
109 | all Copyright and Similar Rights that apply to Your use of the
110 | Licensed Material and that the Licensor has authority to license.
111 |
112 | h. Licensor means the individual(s) or entity(ies) granting rights
113 | under this Public License.
114 |
115 | i. Share means to provide material to the public by any means or
116 | process that requires permission under the Licensed Rights, such
117 | as reproduction, public display, public performance, distribution,
118 | dissemination, communication, or importation, and to make material
119 | available to the public including in ways that members of the
120 | public may access the material from a place and at a time
121 | individually chosen by them.
122 |
123 | j. Sui Generis Database Rights means rights other than copyright
124 | resulting from Directive 96/9/EC of the European Parliament and of
125 | the Council of 11 March 1996 on the legal protection of databases,
126 | as amended and/or succeeded, as well as other essentially
127 | equivalent rights anywhere in the world.
128 |
129 | k. You means the individual or entity exercising the Licensed Rights
130 | under this Public License. Your has a corresponding meaning.
131 |
132 |
133 | Section 2 -- Scope.
134 |
135 | a. License grant.
136 |
137 | 1. Subject to the terms and conditions of this Public License,
138 | the Licensor hereby grants You a worldwide, royalty-free,
139 | non-sublicensable, non-exclusive, irrevocable license to
140 | exercise the Licensed Rights in the Licensed Material to:
141 |
142 | a. reproduce and Share the Licensed Material, in whole or
143 | in part; and
144 |
145 | b. produce, reproduce, and Share Adapted Material.
146 |
147 | 2. Exceptions and Limitations. For the avoidance of doubt, where
148 | Exceptions and Limitations apply to Your use, this Public
149 | License does not apply, and You do not need to comply with
150 | its terms and conditions.
151 |
152 | 3. Term. The term of this Public License is specified in Section
153 | 6(a).
154 |
155 | 4. Media and formats; technical modifications allowed. The
156 | Licensor authorizes You to exercise the Licensed Rights in
157 | all media and formats whether now known or hereafter created,
158 | and to make technical modifications necessary to do so. The
159 | Licensor waives and/or agrees not to assert any right or
160 | authority to forbid You from making technical modifications
161 | necessary to exercise the Licensed Rights, including
162 | technical modifications necessary to circumvent Effective
163 | Technological Measures. For purposes of this Public License,
164 | simply making modifications authorized by this Section 2(a)
165 | (4) never produces Adapted Material.
166 |
167 | 5. Downstream recipients.
168 |
169 | a. Offer from the Licensor -- Licensed Material. Every
170 | recipient of the Licensed Material automatically
171 | receives an offer from the Licensor to exercise the
172 | Licensed Rights under the terms and conditions of this
173 | Public License.
174 |
175 | b. No downstream restrictions. You may not offer or impose
176 | any additional or different terms or conditions on, or
177 | apply any Effective Technological Measures to, the
178 | Licensed Material if doing so restricts exercise of the
179 | Licensed Rights by any recipient of the Licensed
180 | Material.
181 |
182 | 6. No endorsement. Nothing in this Public License constitutes or
183 | may be construed as permission to assert or imply that You
184 | are, or that Your use of the Licensed Material is, connected
185 | with, or sponsored, endorsed, or granted official status by,
186 | the Licensor or others designated to receive attribution as
187 | provided in Section 3(a)(1)(A)(i).
188 |
189 | b. Other rights.
190 |
191 | 1. Moral rights, such as the right of integrity, are not
192 | licensed under this Public License, nor are publicity,
193 | privacy, and/or other similar personality rights; however, to
194 | the extent possible, the Licensor waives and/or agrees not to
195 | assert any such rights held by the Licensor to the limited
196 | extent necessary to allow You to exercise the Licensed
197 | Rights, but not otherwise.
198 |
199 | 2. Patent and trademark rights are not licensed under this
200 | Public License.
201 |
202 | 3. To the extent possible, the Licensor waives any right to
203 | collect royalties from You for the exercise of the Licensed
204 | Rights, whether directly or through a collecting society
205 | under any voluntary or waivable statutory or compulsory
206 | licensing scheme. In all other cases the Licensor expressly
207 | reserves any right to collect such royalties.
208 |
209 |
210 | Section 3 -- License Conditions.
211 |
212 | Your exercise of the Licensed Rights is expressly made subject to the
213 | following conditions.
214 |
215 | a. Attribution.
216 |
217 | 1. If You Share the Licensed Material (including in modified
218 | form), You must:
219 |
220 | a. retain the following if it is supplied by the Licensor
221 | with the Licensed Material:
222 |
223 | i. identification of the creator(s) of the Licensed
224 | Material and any others designated to receive
225 | attribution, in any reasonable manner requested by
226 | the Licensor (including by pseudonym if
227 | designated);
228 |
229 | ii. a copyright notice;
230 |
231 | iii. a notice that refers to this Public License;
232 |
233 | iv. a notice that refers to the disclaimer of
234 | warranties;
235 |
236 | v. a URI or hyperlink to the Licensed Material to the
237 | extent reasonably practicable;
238 |
239 | b. indicate if You modified the Licensed Material and
240 | retain an indication of any previous modifications; and
241 |
242 | c. indicate the Licensed Material is licensed under this
243 | Public License, and include the text of, or the URI or
244 | hyperlink to, this Public License.
245 |
246 | 2. You may satisfy the conditions in Section 3(a)(1) in any
247 | reasonable manner based on the medium, means, and context in
248 | which You Share the Licensed Material. For example, it may be
249 | reasonable to satisfy the conditions by providing a URI or
250 | hyperlink to a resource that includes the required
251 | information.
252 |
253 | 3. If requested by the Licensor, You must remove any of the
254 | information required by Section 3(a)(1)(A) to the extent
255 | reasonably practicable.
256 |
257 | 4. If You Share Adapted Material You produce, the Adapter's
258 | License You apply must not prevent recipients of the Adapted
259 | Material from complying with this Public License.
260 |
261 |
262 | Section 4 -- Sui Generis Database Rights.
263 |
264 | Where the Licensed Rights include Sui Generis Database Rights that
265 | apply to Your use of the Licensed Material:
266 |
267 | a. for the avoidance of doubt, Section 2(a)(1) grants You the right
268 | to extract, reuse, reproduce, and Share all or a substantial
269 | portion of the contents of the database;
270 |
271 | b. if You include all or a substantial portion of the database
272 | contents in a database in which You have Sui Generis Database
273 | Rights, then the database in which You have Sui Generis Database
274 | Rights (but not its individual contents) is Adapted Material; and
275 |
276 | c. You must comply with the conditions in Section 3(a) if You Share
277 | all or a substantial portion of the contents of the database.
278 |
279 | For the avoidance of doubt, this Section 4 supplements and does not
280 | replace Your obligations under this Public License where the Licensed
281 | Rights include other Copyright and Similar Rights.
282 |
283 |
284 | Section 5 -- Disclaimer of Warranties and Limitation of Liability.
285 |
286 | a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
287 | EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
288 | AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
289 | ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
290 | IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
291 | WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
292 | PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
293 | ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
294 | KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
295 | ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
296 |
297 | b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
298 | TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
299 | NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
300 | INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
301 | COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
302 | USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
303 | ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
304 | DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
305 | IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
306 |
307 | c. The disclaimer of warranties and limitation of liability provided
308 | above shall be interpreted in a manner that, to the extent
309 | possible, most closely approximates an absolute disclaimer and
310 | waiver of all liability.
311 |
312 |
313 | Section 6 -- Term and Termination.
314 |
315 | a. This Public License applies for the term of the Copyright and
316 | Similar Rights licensed here. However, if You fail to comply with
317 | this Public License, then Your rights under this Public License
318 | terminate automatically.
319 |
320 | b. Where Your right to use the Licensed Material has terminated under
321 | Section 6(a), it reinstates:
322 |
323 | 1. automatically as of the date the violation is cured, provided
324 | it is cured within 30 days of Your discovery of the
325 | violation; or
326 |
327 | 2. upon express reinstatement by the Licensor.
328 |
329 | For the avoidance of doubt, this Section 6(b) does not affect any
330 | right the Licensor may have to seek remedies for Your violations
331 | of this Public License.
332 |
333 | c. For the avoidance of doubt, the Licensor may also offer the
334 | Licensed Material under separate terms or conditions or stop
335 | distributing the Licensed Material at any time; however, doing so
336 | will not terminate this Public License.
337 |
338 | d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
339 | License.
340 |
341 |
342 | Section 7 -- Other Terms and Conditions.
343 |
344 | a. The Licensor shall not be bound by any additional or different
345 | terms or conditions communicated by You unless expressly agreed.
346 |
347 | b. Any arrangements, understandings, or agreements regarding the
348 | Licensed Material not stated herein are separate from and
349 | independent of the terms and conditions of this Public License.
350 |
351 |
352 | Section 8 -- Interpretation.
353 |
354 | a. For the avoidance of doubt, this Public License does not, and
355 | shall not be interpreted to, reduce, limit, restrict, or impose
356 | conditions on any use of the Licensed Material that could lawfully
357 | be made without permission under this Public License.
358 |
359 | b. To the extent possible, if any provision of this Public License is
360 | deemed unenforceable, it shall be automatically reformed to the
361 | minimum extent necessary to make it enforceable. If the provision
362 | cannot be reformed, it shall be severed from this Public License
363 | without affecting the enforceability of the remaining terms and
364 | conditions.
365 |
366 | c. No term or condition of this Public License will be waived and no
367 | failure to comply consented to unless expressly agreed to by the
368 | Licensor.
369 |
370 | d. Nothing in this Public License constitutes or may be interpreted
371 | as a limitation upon, or waiver of, any privileges and immunities
372 | that apply to the Licensor or You, including from the legal
373 | processes of any jurisdiction or authority.
374 |
375 |
376 | =======================================================================
377 |
378 | Creative Commons is not a party to its public licenses.
379 | Notwithstanding, Creative Commons may elect to apply one of its public
380 | licenses to material it publishes and in those instances will be
381 | considered the “Licensor.” The text of the Creative Commons public
382 | licenses is dedicated to the public domain under the CC0 Public Domain
383 | Dedication. Except for the limited purpose of indicating that material
384 | is shared under a Creative Commons public license or as otherwise
385 | permitted by the Creative Commons policies published at
386 | creativecommons.org/policies, Creative Commons does not authorize the
387 | use of the trademark "Creative Commons" or any other trademark or logo
388 | of Creative Commons without its prior written consent including,
389 | without limitation, in connection with any unauthorized modifications
390 | to any of its public licenses or any other arrangements,
391 | understandings, or agreements concerning use of licensed material. For
392 | the avoidance of doubt, this paragraph does not form part of the public
393 | licenses.
394 |
395 | Creative Commons may be contacted at creativecommons.org.
396 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ### AnyUp: Universal Feature Upsampling
2 |
3 | [**Thomas Wimmer**](https://wimmerth.github.io/)1,2,
4 | [Prune Truong](https://prunetruong.com/)3,
5 | [Marie-Julie Rakotosaona](https://scholar.google.com/citations?user=eQ0om98AAAAJ&hl=en)3,
6 | [Michael Oechsle](https://moechsle.github.io/)3,
7 | [Federico Tombari](https://federicotombari.github.io/)3,4,
8 | [Bernt Schiele](https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/people/bernt-schiele)1
9 | [Jan Eric Lenssen](https://janericlenssen.github.io/)1
10 |
11 | 1Max Planck Institute for Informatics, 2ETH Zurich, 3Google, 4TU Munich
12 |
13 | [](https://wimmerth.github.io/anyup/)
14 | [](https://arxiv.org/abs/2510.12764)
15 | [](https://colab.research.google.com/github/wimmerth/anyup/blob/main/example_usage.ipynb)
16 |
17 | [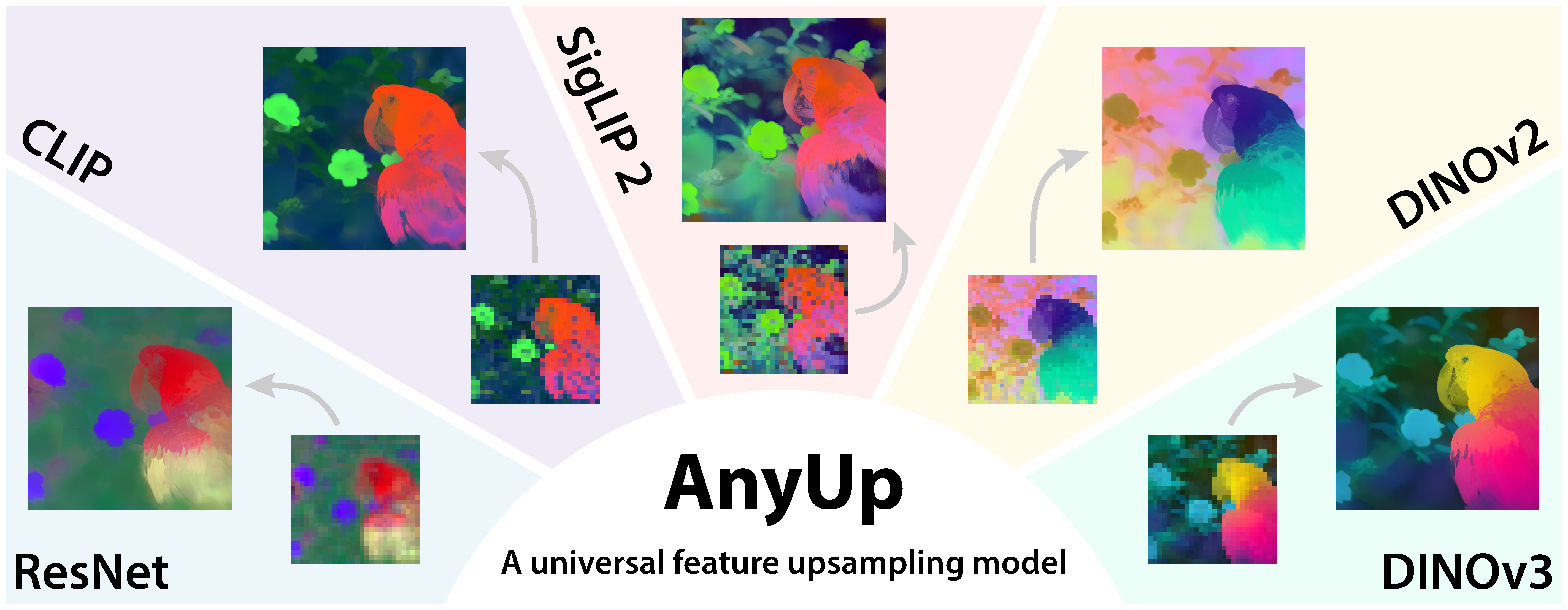](https://wimmerth.github.io/anyup/)
18 |
19 | **Abstract:**
20 |
21 | We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without
22 | encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for
23 | every feature extractor and thus do not generalize to different feature types at inference time. In this work, we
24 | propose an _inference-time_ feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling
25 | quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature
26 | types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.
27 |
28 | ---
29 |
30 | ### Use AnyUp to upsample your features!
31 |
32 | Upsample features from any model, at any layer without having to retrain the upsampler. It's as easy as this:
33 |
34 | ```python
35 | import torch
36 | # high-resolution image (B, 3, H, W)
37 | hr_image = ...
38 | # low-resolution features (B, C, h, w)
39 | lr_features = ...
40 | # load the AnyUp upsampler model
41 | upsampler = torch.hub.load('wimmerth/anyup', 'anyup')
42 | # upsampled high-resolution features (B, C, H, W)
43 | hr_features = upsampler(hr_image, lr_features)
44 | ```
45 |
46 | **Notes:**
47 | - The `hr_image` should be normalized to ImageNet mean and std as usual for most vision encoders.
48 | - The `lr_features` can be any features from any encoder, e.g. DINO, CLIP, or ResNet.
49 |
50 | The `hr_features` will have the same spatial resolution as the `hr_image` by default.
51 | If you want a different output resolution, you can specify it with the `output_size` argument:
52 |
53 | ```python
54 | # upsampled features with custom output size (B, C, H', W')
55 | hr_features = upsampler(hr_image, lr_features, output_size=(H_prime, W_prime))
56 | ```
57 |
58 | If you have limited compute resources and run into OOM issues when upsampling to high resolutions, you can use the
59 | `q_chunk_size` argument to trade off speed for memory:
60 |
61 | ```python
62 | # upsampled features using chunking to save memory (B, C, H, W)
63 | hr_features = upsampler(hr_image, lr_features, q_chunk_size=128)
64 | ```
65 |
66 | If you are interested in the attention that is used by AnyUp to upsample the features, we included an optional
67 | visualization thereof in the forward pass:
68 |
69 | ```python
70 | # matplotlib must be installed to use this feature
71 | # upsampled features and display attention map visualization (B, C, H, W)
72 | hr_features = upsampler(hr_image, lr_features, vis_attn=True)
73 | ```
74 |
75 | ---
76 |
77 | **Training code** for AnyUp will be released soon!
78 |
79 | We are also planning to integrate FlexAttention support to speed up the window attention and reduce memory consumption.
80 | We are always happy for a helping hand, so feel free to reach out if you want to contribute!
81 |
82 | ---
83 |
84 | **Evaluation** followed the protocols of [JAFAR](https://github.com/PaulCouairon/JAFAR) for semantic segmentation and
85 | [Probe3D](https://github.com/mbanani/probe3d) for surface normal and depth estimation. Note that we applied a small fix
86 | to the probe training in JAFAR (updating LR scheduling to per epoch instead of per iteration). Therefore, we re-ran all
87 | experiments with baselines to ensure a fair comparison.
88 |
89 | **Acknowledgements:**
90 | We built our implementation on top of the [JAFAR repository](https://github.com/PaulCouairon/JAFAR) and thank the
91 | authors for open-sourcing their code. Other note-worthy open-source repositories include:
92 | [LoftUp](https://github.com/andrehuang/loftup), [FeatUp](https://github.com/mhamilton723/FeatUp), and
93 | [Probe3D](https://github.com/mbanani/probe3d).
94 |
95 | ---
96 | ### Citation
97 |
98 | If you find our work useful in your research, please cite it as:
99 | ```
100 | @article{wimmer2025anyup,
101 | title={AnyUp: Universal Feature Upsampling},
102 | author={Wimmer, Thomas and Truong, Prune and Rakotosaona, Marie-Julie and Oechsle, Michael and Tombari, Federico and Schiele, Bernt and Lenssen, Jan Eric},
103 | journal={arXiv preprint arXiv:2510.12764},
104 | year={2025}
105 | }
106 | ```
--------------------------------------------------------------------------------
/anyup/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wimmerth/anyup/0dbfc182cb3481abcb090253b86dc5f652f7a537/anyup/__init__.py
--------------------------------------------------------------------------------
/anyup/layers/__init__.py:
--------------------------------------------------------------------------------
1 | from .convolutions import ResBlock
2 | from .feature_unification import LearnedFeatureUnification
3 | from .attention import CrossAttentionBlock
4 | from .positional_encoding import RoPE
--------------------------------------------------------------------------------
/anyup/layers/attention/__init__.py:
--------------------------------------------------------------------------------
1 | from .chunked_attention import CrossAttentionBlock
--------------------------------------------------------------------------------
/anyup/layers/attention/attention_masking.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from typing import Tuple
3 | from functools import lru_cache
4 |
5 |
6 | def window2d(
7 | low_res: int | Tuple[int, int],
8 | high_res: int | Tuple[int, int],
9 | ratio: float,
10 | *,
11 | device: str = "cpu"
12 | ) -> torch.Tensor:
13 | # unpack
14 | if isinstance(high_res, int):
15 | H = W = high_res
16 | else:
17 | H, W = high_res
18 | if isinstance(low_res, int):
19 | Lh = Lw = low_res
20 | else:
21 | Lh, Lw = low_res
22 |
23 | # pixel-centers in [0,1)
24 | r_pos = (torch.arange(H, device=device, dtype=torch.float32) + 0.5) / H # (H,)
25 | c_pos = (torch.arange(W, device=device, dtype=torch.float32) + 0.5) / W # (W,)
26 | pos_r, pos_c = torch.meshgrid(r_pos, c_pos, indexing="ij") # (H,W)
27 |
28 | # clamp before scaling
29 | r_lo = (pos_r - ratio).clamp(0.0, 1.0)
30 | r_hi = (pos_r + ratio).clamp(0.0, 1.0)
31 | c_lo = (pos_c - ratio).clamp(0.0, 1.0)
32 | c_hi = (pos_c + ratio).clamp(0.0, 1.0)
33 |
34 | # quantise symmetrically
35 | r0 = (r_lo * Lh).floor().long() # inclusive start
36 | r1 = (r_hi * Lh).ceil().long() # exclusive end
37 | c0 = (c_lo * Lw).floor().long()
38 | c1 = (c_hi * Lw).ceil().long()
39 |
40 | return torch.stack([r0, r1, c0, c1], dim=2)
41 |
42 |
43 | @lru_cache
44 | def compute_attention_mask(high_res_h, high_res_w, low_res_h, low_res_w, window_size_ratio, device="cpu"):
45 | h, w = high_res_h, high_res_w
46 | h_, w_ = low_res_h, low_res_w
47 |
48 | windows = window2d(
49 | low_res=(h_, w_),
50 | high_res=(h, w),
51 | ratio=window_size_ratio,
52 | device=device
53 | )
54 |
55 | q = h * w # number of high-res query locations
56 |
57 | # flatten window bounds: (q, 1)
58 | r0 = windows[..., 0].reshape(q, 1)
59 | r1 = windows[..., 1].reshape(q, 1) # exclusive
60 | c0 = windows[..., 2].reshape(q, 1)
61 | c1 = windows[..., 3].reshape(q, 1) # exclusive
62 |
63 | # row / column indices on low-res grid
64 | rows = torch.arange(h_, device=device) # (h_,)
65 | cols = torch.arange(w_, device=device) # (w_,)
66 |
67 | row_ok = (rows >= r0) & (rows < r1) # (q, h_)
68 | col_ok = (cols >= c0) & (cols < c1) # (q, w_)
69 |
70 | # broadcast to (q, h_, w_) and flatten last two dims
71 | attention_mask = (row_ok.unsqueeze(2) & col_ok.unsqueeze(1)) \
72 | .reshape(q, h_ * w_).to(dtype=torch.bool)
73 |
74 | return ~attention_mask
75 |
--------------------------------------------------------------------------------
/anyup/layers/attention/chunked_attention.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from torch import einsum
4 | from typing import Optional
5 | from .attention_masking import compute_attention_mask
6 |
7 |
8 | class CrossAttention(nn.Module):
9 | def __init__(self, qk_dim, num_heads,
10 | q_chunk_size: Optional[int] = None,
11 | store_attn: bool = False):
12 | super().__init__()
13 | self.norm_q = nn.RMSNorm(qk_dim)
14 | self.norm_k = nn.RMSNorm(qk_dim)
15 | self.q_chunk_size = q_chunk_size
16 | self.store_attn = store_attn
17 | self.attention = nn.MultiheadAttention(
18 | embed_dim=qk_dim,
19 | num_heads=num_heads,
20 | dropout=0.0,
21 | batch_first=True,
22 | )
23 |
24 | @torch.no_grad()
25 | def _slice_mask(self, mask, start, end):
26 | if mask is None:
27 | return None
28 | # 2D: (tgt_len, src_len), 3D: (B*num_heads or B, tgt_len, src_len)
29 | if mask.dim() == 2:
30 | return mask[start:end, :]
31 | elif mask.dim() == 3:
32 | return mask[:, start:end, :]
33 | else:
34 | raise ValueError("attn_mask must be 2D or 3D")
35 |
36 | def forward(self, query, key, value, mask=None,
37 | q_chunk_size: Optional[int] = None,
38 | store_attn: Optional[bool] = None):
39 | q_chunk_size = self.q_chunk_size if q_chunk_size is None else q_chunk_size
40 | store_attn = self.store_attn if store_attn is None else store_attn
41 |
42 | val = key
43 |
44 | query = self.norm_q(query)
45 | key = self.norm_k(key)
46 |
47 | # Fast path: no chunking
48 | if q_chunk_size is None or query.size(1) <= q_chunk_size:
49 | _, attn = self.attention(query, key, val,
50 | average_attn_weights=True,
51 | attn_mask=mask)
52 | features = einsum("b i j, b j d -> b i d", attn, value)
53 | return features, (attn if store_attn else None)
54 |
55 | # Chunked over the query length (tgt_len)
56 | B, Q, _ = query.shape
57 | outputs = []
58 | attns = [] if store_attn else None
59 |
60 | for start in range(0, Q, q_chunk_size):
61 | end = min(start + q_chunk_size, Q)
62 | q_chunk = query[:, start:end, :]
63 | mask_chunk = self._slice_mask(mask, start, end)
64 |
65 | # We ignore the MHA output as in JAFAR:
66 | # use the averaged attention to weight the unprojected V.
67 | _, attn_chunk = self.attention(q_chunk, key, val,
68 | average_attn_weights=True,
69 | attn_mask=mask_chunk)
70 | out_chunk = einsum("b i j, b j d -> b i d", attn_chunk, value)
71 | outputs.append(out_chunk)
72 | if store_attn:
73 | attns.append(attn_chunk)
74 |
75 | features = torch.cat(outputs, dim=1)
76 | attn_scores = torch.cat(attns, dim=1) if store_attn else None
77 | return features, attn_scores
78 |
79 |
80 | class CrossAttentionBlock(nn.Module):
81 | def __init__(self, qk_dim, num_heads, window_ratio: float = 0.1,
82 | q_chunk_size: Optional[int] = None, **kwargs):
83 | super().__init__()
84 | self.cross_attn = CrossAttention(
85 | qk_dim, num_heads,
86 | q_chunk_size=q_chunk_size
87 | )
88 | self.window_ratio = window_ratio
89 | self.conv2d = nn.Conv2d(qk_dim, qk_dim, kernel_size=3, stride=1, padding=1, bias=False)
90 |
91 | def forward(self, q, k, v, q_chunk_size: Optional[int] = None, store_attn: Optional[bool] = None, vis_attn=False,
92 | **kwargs):
93 | store_attn = store_attn or vis_attn
94 | q = self.conv2d(q)
95 | if self.window_ratio > 0:
96 | attn_mask = compute_attention_mask(
97 | *q.shape[-2:], *k.shape[-2:], window_size_ratio=self.window_ratio
98 | ).to(q.device)
99 | else:
100 | attn_mask = None
101 | b, _, h, w = q.shape
102 | _, _, h_k, w_k = k.shape
103 | c = v.shape[1]
104 | q = q.permute(0, 2, 3, 1).view(b, h * w, -1)
105 | k = k.permute(0, 2, 3, 1).view(b, h_k * w_k, -1)
106 | v = v.permute(0, 2, 3, 1).view(b, h_k * w_k, -1)
107 |
108 | features, attn = self.cross_attn(q, k, v, mask=attn_mask,
109 | q_chunk_size=q_chunk_size,
110 | store_attn=store_attn)
111 | features = features.view(b, h, w, c).permute(0, 3, 1, 2)
112 | if vis_attn:
113 | from anyup.utils.visualization import visualize_attention_oklab
114 | import matplotlib.pyplot as plt
115 |
116 | ref, out = visualize_attention_oklab(attn[0], h, w, h_k, w_k)
117 |
118 | fig, ax = plt.subplots(1, 2, figsize=(10, 5))
119 | ax[0].imshow(ref.cpu().numpy())
120 | ax[0].set_title("Reference (Values)")
121 | ax[0].set_xticks([-.5, w_k - .5], labels=[0, w_k])
122 | ax[0].set_yticks([-.5, h_k - .5], labels=[0, h_k])
123 |
124 | ax[1].imshow(out.cpu().numpy())
125 | ax[1].set_title("Attention Output")
126 | ax[1].set_xticks([-.5, w - .5], labels=[0, w])
127 | ax[1].set_yticks([-.5, h - .5], labels=[0, h])
128 | plt.show()
129 |
130 | return features
131 |
--------------------------------------------------------------------------------
/anyup/layers/convolutions.py:
--------------------------------------------------------------------------------
1 | from torch import nn
2 |
3 |
4 | class ResBlock(nn.Module):
5 | def __init__(self, in_channels, out_channels, kernel_size=3, num_groups=8,
6 | pad_mode="zeros", norm_fn=None, activation_fn=nn.SiLU, use_conv_shortcut=False):
7 | super().__init__()
8 | N = (lambda c: norm_fn(num_groups, c)) if norm_fn else (lambda c: nn.Identity())
9 | p = kernel_size // 2
10 | self.block = nn.Sequential(
11 | N(in_channels),
12 | activation_fn(),
13 | nn.Conv2d(in_channels, out_channels, kernel_size, padding=p, padding_mode=pad_mode, bias=False),
14 | N(out_channels),
15 | activation_fn(),
16 | nn.Conv2d(out_channels, out_channels, kernel_size, padding=p, padding_mode=pad_mode, bias=False),
17 | )
18 | self.shortcut = (
19 | nn.Conv2d(in_channels, out_channels, 1, bias=False, padding_mode=pad_mode)
20 | if use_conv_shortcut or in_channels != out_channels else nn.Identity()
21 | )
22 |
23 | def forward(self, x):
24 | return self.block(x) + self.shortcut(x)
25 |
--------------------------------------------------------------------------------
/anyup/layers/feature_unification.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torch.nn.functional as F
4 |
5 | compute_basis_size = {"gauss_deriv": lambda order, mirror: ((order + 1) * (order + 2)) // (1 if mirror else 2)}
6 |
7 |
8 | def herme_vander_torch(z, m):
9 | He0 = z.new_ones(z.shape)
10 | if m == 0: return He0[:, None]
11 | H = [He0, z]
12 | for n in range(1, m):
13 | H.append(z * H[-1] - n * H[-2])
14 | return torch.stack(H, 1)
15 |
16 |
17 | def gauss_deriv(max_order, device, dtype, kernel_size, sigma=None, include_negations=False, scale_magnitude=True):
18 | sigma = (kernel_size // 2) / 1.645 if sigma is None else sigma
19 | if kernel_size % 2 == 0: raise ValueError("ksize must be odd")
20 | half = kernel_size // 2
21 | x = torch.arange(-half, half + 1, dtype=dtype, device=device)
22 | z = x / sigma
23 | g = torch.exp(-0.5 * z ** 2) / (sigma * (2.0 * torch.pi) ** 0.5)
24 | He = herme_vander_torch(z, max_order)
25 | derivs_1d = [(((-1) ** n) / (sigma ** n) if scale_magnitude else (-1) ** n) * He[:, n] * g for n in
26 | range(max_order + 1)]
27 | bank = []
28 | for o in range(max_order + 1):
29 | for i in range(o + 1):
30 | K = torch.outer(derivs_1d[o - i], derivs_1d[i])
31 | bank.append(K)
32 | if include_negations: bank.append(-K)
33 | return torch.stack(bank, 0)
34 |
35 |
36 | class LearnedFeatureUnification(nn.Module):
37 | def __init__(self, out_channels: int, kernel_size: int = 3, init_gaussian_derivatives: bool = False):
38 | super().__init__()
39 | self.out_channels = out_channels
40 | self.kernel_size = kernel_size
41 | if init_gaussian_derivatives:
42 | # find smallest order that gives at least out_channels basis functions
43 | order = 0
44 | while compute_basis_size["gauss_deriv"](order, False) < out_channels:
45 | order += 1
46 | print(f"FeatureUnification: initializing with Gaussian derivative basis of order {order}")
47 | self.basis = nn.Parameter(
48 | gauss_deriv(
49 | order, device='cpu', dtype=torch.float32, kernel_size=kernel_size, scale_magnitude=False
50 | )[:out_channels, None]
51 | )
52 | else:
53 | self.basis = nn.Parameter(
54 | torch.randn(out_channels, 1, kernel_size, kernel_size)
55 | )
56 |
57 | def forward(self, features: torch.Tensor) -> torch.Tensor:
58 | b, c, h, w = features.shape
59 | x = self._depthwise_conv(features, self.basis, self.kernel_size).view(b, self.out_channels, c, h, w)
60 | attn = F.softmax(x, dim=1)
61 | return attn.mean(dim=2)
62 |
63 | @staticmethod
64 | def _depthwise_conv(feats, basis, k):
65 | b, c, h, w = feats.shape
66 | p = k // 2
67 | x = F.pad(feats, (p, p, p, p), value=0)
68 | x = F.conv2d(x, basis.repeat(c, 1, 1, 1), groups=c)
69 | mask = torch.ones(1, 1, h, w, dtype=x.dtype, device=x.device)
70 | denom = F.conv2d(F.pad(mask, (p, p, p, p), value=0), torch.ones(1, 1, k, k, device=x.device))
71 | return x / denom # (B, out_channels*C, H, W)
72 |
--------------------------------------------------------------------------------
/anyup/layers/positional_encoding.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | def rotate_half(x):
5 | x1, x2 = x.chunk(2, dim=-1)
6 | return torch.cat((-x2, x1), dim=-1)
7 |
8 |
9 | class RoPE(nn.Module):
10 | def __init__(
11 | self,
12 | dim: int,
13 | theta: int = 100,
14 | ):
15 | super().__init__()
16 | self.dim = dim
17 | self.theta = theta
18 | self.freqs = nn.Parameter(torch.empty(2, self.dim))
19 |
20 | def _device_weight_init(self):
21 | freqs_1d = self.theta ** torch.linspace(0, -1, self.dim // 4)
22 | freqs_1d = torch.cat([freqs_1d, freqs_1d])
23 | freqs_2d = torch.zeros(2, self.dim)
24 | freqs_2d[0, : self.dim // 2] = freqs_1d
25 | freqs_2d[1, -self.dim // 2 :] = freqs_1d
26 | self.freqs.data.copy_(freqs_2d * 2 * torch.pi)
27 |
28 | def forward(self, x: torch.Tensor, coords: torch.Tensor) -> torch.Tensor:
29 | angle = coords @ self.freqs
30 | return x * angle.cos() + rotate_half(x) * angle.sin()
31 |
--------------------------------------------------------------------------------
/anyup/model.py:
--------------------------------------------------------------------------------
1 | from torch import nn
2 | import torch.nn.functional as F
3 | import torch
4 |
5 | from .layers import ResBlock
6 | from .layers import LearnedFeatureUnification
7 | from .layers import CrossAttentionBlock
8 | from .layers import RoPE
9 | from .utils.img import create_coordinate
10 |
11 |
12 | class AnyUp(nn.Module):
13 | def __init__(
14 | self,
15 | input_dim=3,
16 | qk_dim=128,
17 | kernel_size=1,
18 | kernel_size_lfu=5,
19 | window_ratio=0.1,
20 | num_heads=4,
21 | init_gaussian_derivatives=False,
22 | **kwargs,
23 | ):
24 | super().__init__()
25 | self.qk_dim = qk_dim
26 | self.window_ratio = window_ratio
27 | self._rb_args = dict(kernel_size=1, num_groups=8, pad_mode="reflect", norm_fn=nn.GroupNorm,
28 | activation_fn=nn.SiLU)
29 |
30 | # Encoders
31 | self.image_encoder = self._make_encoder(input_dim, kernel_size)
32 | self.key_encoder = self._make_encoder(qk_dim, 1)
33 | self.query_encoder = self._make_encoder(qk_dim, 1)
34 | self.key_features_encoder = self._make_encoder(None, 1, first_layer_k=kernel_size_lfu,
35 | init_gaussian_derivatives=init_gaussian_derivatives)
36 |
37 | # Cross-attention
38 | self.cross_decode = CrossAttentionBlock(qk_dim=qk_dim, num_heads=num_heads, window_ratio=window_ratio)
39 | self.aggregation = self._make_encoder(2 * qk_dim, 3)
40 |
41 | # RoPE for (H*W, C)
42 | self.rope = RoPE(qk_dim)
43 | self.rope._device_weight_init()
44 |
45 | def _make_encoder(self, in_ch, k, layers=2, first_layer_k=0, init_gaussian_derivatives=False):
46 | pre = (
47 | nn.Conv2d(in_ch, self.qk_dim, k, padding=k // 2, padding_mode="reflect", bias=False)
48 | if first_layer_k == 0 else
49 | LearnedFeatureUnification(self.qk_dim, first_layer_k, init_gaussian_derivatives=init_gaussian_derivatives)
50 | )
51 | blocks = [ResBlock(self.qk_dim, self.qk_dim, **self._rb_args) for _ in range(layers)]
52 | return nn.Sequential(pre, *blocks)
53 |
54 | def upsample(self, enc_img, feats, out_size, vis_attn=False, q_chunk_size=None):
55 | b, c, h, w = feats.shape
56 |
57 | # Q
58 | q = F.adaptive_avg_pool2d(self.query_encoder(enc_img), output_size=out_size)
59 |
60 | # K
61 | k = F.adaptive_avg_pool2d(self.key_encoder(enc_img), output_size=(h, w))
62 | k = torch.cat([k, self.key_features_encoder(F.normalize(feats, dim=1))], dim=1)
63 | k = self.aggregation(k)
64 |
65 | # V
66 | v = feats
67 |
68 | return self.cross_decode(q, k, v, vis_attn=vis_attn, q_chunk_size=q_chunk_size)
69 |
70 | def forward(self, image, features, output_size=None, vis_attn=False, q_chunk_size=None):
71 | output_size = output_size if output_size is not None else image.shape[-2:]
72 | enc = self.image_encoder(image)
73 | h = enc.shape[-2]
74 | coords = create_coordinate(h, enc.shape[-1], device=enc.device, dtype=enc.dtype)
75 | enc = enc.permute(0, 2, 3, 1).view(enc.shape[0], -1, enc.shape[1])
76 | enc = self.rope(enc, coords)
77 | enc = enc.view(enc.shape[0], h, -1, enc.shape[-1]).permute(0, 3, 1, 2)
78 | return self.upsample(enc, features, output_size, vis_attn=vis_attn, q_chunk_size=q_chunk_size)
79 |
--------------------------------------------------------------------------------
/anyup/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wimmerth/anyup/0dbfc182cb3481abcb090253b86dc5f652f7a537/anyup/utils/__init__.py
--------------------------------------------------------------------------------
/anyup/utils/img.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | def create_coordinate(h, w, start=0.0, end=1.0, device=None, dtype=None):
4 | x = torch.linspace(start, end, h, device=device, dtype=dtype)
5 | y = torch.linspace(start, end, w, device=device, dtype=dtype)
6 | xx, yy = torch.meshgrid(x, y, indexing="ij")
7 | return torch.stack((xx, yy), -1).view(1, h * w, 2)
8 |
--------------------------------------------------------------------------------
/anyup/utils/visualization/__init__.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from .attention_visualization import visualize_attention_oklab
3 |
4 | IMAGENET_MEAN = [0.485, 0.456, 0.406]
5 | IMAGENET_STD = [0.229, 0.224, 0.225]
6 |
7 | def unnormalize(t, mean=None, std=None):
8 | if mean is None: mean = IMAGENET_MEAN
9 | if std is None: std = IMAGENET_STD
10 | m = torch.as_tensor(mean, device=t.device, dtype=t.dtype).view(1, -1, 1, 1)
11 | s = torch.as_tensor(std, device=t.device, dtype=t.dtype).view(1, -1, 1, 1)
12 | return t * s + m
--------------------------------------------------------------------------------
/anyup/utils/visualization/attention_visualization.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def srgb_to_linear(c):
5 | a = 0.055
6 | return torch.where(c <= 0.04045, c / 12.92, ((c + a) / (1 + a)) ** 2.4)
7 |
8 |
9 | def linear_to_srgb(c):
10 | a = 0.055
11 | c = torch.clamp(c, 0.0, 1.0) # simple gamut clamp in linear light
12 | return torch.where(c <= 0.0031308, 12.92 * c, (1 + a) * torch.pow(c, 1 / 2.4) - a)
13 |
14 |
15 | def oklab_to_linear_srgb(L, a, b):
16 | l_ = L + 0.3963377774 * a + 0.2158037573 * b
17 | m_ = L - 0.1055613458 * a - 0.0638541728 * b
18 | s_ = L - 0.0894841775 * a - 1.2914855480 * b
19 | l, m, s = l_ ** 3, m_ ** 3, s_ ** 3
20 | R = +4.0767416621 * l - 3.3077115913 * m + 0.2309699292 * s
21 | G = -1.2684380046 * l + 2.6097574011 * m - 0.3413193965 * s
22 | B = -0.0041960863 * l - 0.7034186147 * m + 1.7076147010 * s
23 | return torch.stack([R, G, B], dim=-1)
24 |
25 |
26 | def oklch_grid(h_k, w_k, col_range=.7):
27 | i, j = torch.meshgrid(
28 | torch.arange(-col_range / 2, col_range / 2, col_range / h_k),
29 | torch.arange(-col_range / 2, col_range / 2, col_range / w_k),
30 | indexing='ij'
31 | )
32 | rgb = oklab_to_linear_srgb(torch.full_like(i, .7), i, j)
33 | return rgb
34 |
35 |
36 | def visualize_attention_oklab(attn, h_q, w_q, h_k=None, w_k=None):
37 | h_k = h_k or h_q
38 | w_k = w_k or w_q
39 |
40 | num_q, num_k = attn.shape
41 | assert 0 < h_q * w_q <= num_q
42 | assert 0 < h_k * w_k <= num_k
43 | if h_q * w_q < num_q: attn = attn[-h_q * w_q:]
44 | if h_k * w_k < num_k: attn = attn[:, -h_k * w_k:]
45 |
46 | # rows sum to 1
47 | attn = torch.nn.functional.normalize(attn, p=1, dim=1)
48 |
49 | ref_lin = oklch_grid(h_k, w_k).to(attn.device) # [h_k, w_k, 3]
50 | ref_rgb = linear_to_srgb(ref_lin)
51 | ref_lin = ref_lin.view(-1, 3)
52 |
53 | out_lin = attn @ ref_lin # [(h_q*w_q), 3]
54 | out_rgb = linear_to_srgb(out_lin.view(h_q, w_q, 3))
55 | return ref_rgb, out_rgb
56 |
--------------------------------------------------------------------------------
/hubconf.py:
--------------------------------------------------------------------------------
1 | dependencies = ['torch']
2 |
3 | from anyup.model import AnyUp
4 | import torch
5 |
6 |
7 | def anyup(pretrained: bool = True, device='cpu'):
8 | """
9 | AnyUp model trained on DINOv2 ViT-S/14 features, used in most experiments of the paper.
10 | Note: If you want to use vis_attn, you also need to install matplotlib.
11 | """
12 | model = AnyUp().to(device)
13 | if pretrained:
14 | checkpoint = "https://github.com/wimmerth/anyup/releases/download/checkpoint/anyup_paper.pth"
15 | model.load_state_dict(torch.hub.load_state_dict_from_url(checkpoint, progress=True, map_location=device))
16 | return model
17 |
--------------------------------------------------------------------------------