.*?
您好!(.*?)您有未读提醒 1 条
',
44 | html, re.S)[0]
45 | print(data)
46 |
47 |
48 | if __name__ == '__main__':
49 | username = input('请输入账户:')
50 | pwd = input('请输入密码:')
51 | sign = main(pwd)
52 | print('正在登录....')
53 | login(sign, username)
54 | home()
55 |
--------------------------------------------------------------------------------
/其他实战/【谷雨】数字解密/GuYu.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-09-25 Python: 3.7
4 |
5 | import requests
6 | import os
7 | from fontTools.ttLib import TTFont
8 |
9 |
10 | class Font:
11 | """
12 | https://guyujiezi.com/
13 | 谷雨解字的 数字解密
14 | 现在版本的 雨谷字体加的xml 会有一个移位操作
15 | """
16 | def __init__(self, uri):
17 | self.url = uri
18 | self.filename = uri.split('/')[-1]
19 | self.font = None
20 | self._list = []
21 |
22 | def check(self):
23 | """检查目录
24 | """
25 | if not os.path.isfile(self.filename):
26 | resp = requests.get(self.url)
27 | with open(self.filename, 'wb') as f:
28 | f.write(resp.content)
29 | # TTFont 存为 xml
30 | self.font = TTFont(self.filename)
31 | self.font.saveXML(self.filename.replace(self.filename.split('.')[-1], 'xml'))
32 |
33 | def get_wo(self):
34 | """获取 woff
35 | """
36 | self.check()
37 | ph = self.font['cmap']
38 | _dict = ph.tables[0].cmap
39 | # 1. 字典取 value 列表化
40 | # 2. str 取最后 2 位,并转为 int
41 | # 3. 减去 17 并从新组装列表
42 | self._list = [int(i[-2:])-17 for i in list(_dict.values())]
43 | """
44 | 处理移位
45 | """
46 | print(list(_dict.values()))
47 | print(self._list)
48 |
49 | def parse(self, number):
50 | _str = ''
51 | for num in number:
52 | _str += str(self._list[int(num)])
53 | print('最终展示字', int(_str))
54 |
55 |
56 | if __name__ == '__main__':
57 | ft = Font("https://guyujiezi.com/fonts/2DLw9u/3iZbr8.woff")
58 | ft.get_wo()
59 | # 输入页面数字测试
60 | ft.parse('947')
61 |
62 |
63 |
--------------------------------------------------------------------------------
/其他实战/【豆瓣】自动登录/DouBan.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2020-01-08 Python: 3.7
4 |
5 | import requests
6 | import re
7 |
8 |
9 | class DouBan:
10 | def __init__(self, name, pwd):
11 | self.name = name.strip()
12 | self.pwd = pwd.strip()
13 | self.session = requests.session()
14 | self.headers = {
15 | 'Origin': 'https://accounts.douban.com',
16 | 'Host': 'accounts.douban.com',
17 | 'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony',
18 | 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
19 | }
20 | self.login_url = 'https://accounts.douban.com/j/mobile/login/basic'
21 | self.index_url = "https://www.douban.com/"
22 | self.session = requests.session()
23 |
24 | def login(self):
25 | data = {
26 | 'ck': '',
27 | 'name': self.name,
28 | 'password': self.pwd,
29 | 'remember': 'false',
30 | 'ticket': '',
31 | }
32 | self.session.post(self.login_url, data=data, headers=self.headers)
33 |
34 | def check(self):
35 | self.headers['Host'] = 'www.douban.com'
36 | response = self.session.get("https://www.douban.com/", headers=self.headers)
37 | try:
38 | title = re.search(r'
(.*?)的帐号', response.text).group(1)
39 | print('【登录成功】', title)
40 | except:
41 | print('【登录失败】')
42 |
43 |
44 | if __name__ == '__main__':
45 | username = input('豆瓣用户名 >>>')
46 | password = input('密码 >>>')
47 | db = DouBan(username, password)
48 | db.login()
49 | db.check()
50 |
--------------------------------------------------------------------------------
/其他实战/【逗游】自动登录/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-10-06 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/其他实战/【逗游】自动登录/douyou.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-08-01 Python: 3.7
4 |
5 | import js2py
6 | import requests
7 | import json
8 |
9 |
10 | class DouYou:
11 | headers = {
12 | 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
13 | 'Referer': 'http://www.doyo.cn/passport/login'
14 | }
15 |
16 | def __init__(self, username, password):
17 | self.context = js2py.EvalJs() # python中使用js
18 | self.username = username
19 | self.password = password
20 |
21 | def make_password(self):
22 | """取加密后的字符串
23 | """
24 | try:
25 | nonce, ts = self.get_token()
26 | with open("encryp.js", "r", encoding="utf-8") as f:
27 | self.context.execute(f.read())
28 | pwd_hash = self.context.get_value(self.password, nonce, ts)
29 | return pwd_hash # 打印加密之后的密码
30 | except:
31 | print('获取token失败')
32 |
33 | def get_token(self):
34 | """获取 token
35 | """
36 | get_token_url = 'http://www.doyo.cn/User/Passport/token?username={user}&random=0.1428378278012199'.format(user=self.username)
37 | result = json.loads(requests.get(get_token_url).text)
38 | if result.get('result'):
39 | nonce = result.get('nonce')
40 | ts = result.get('ts')
41 | return nonce, ts
42 | else:
43 | print('获取token失败')
44 | exit()
45 |
46 | def login(self):
47 | """登陆
48 | """
49 | # decode('unicode_escape')
50 | login_url = 'http://www.doyo.cn/passport/login'
51 | data = {
52 | 'username': self.username,
53 | 'password': self.make_password(),
54 | 'remberme': '1',
55 | 'next': 'aHR0cCUzQSUyRiUyRnd3dy5kb3lvLmNuJTJG'
56 | }
57 | response = requests.post(login_url, data=data, headers=self.headers)
58 | info = json.loads(response.text)
59 | if info.get('result'):
60 | print('登陆成功 | 用户等级:{level} 用户id:{uid}'.format(level=info.get('level'), uid=info.get('uid')))
61 | else:
62 | print('登陆失败')
63 |
64 |
65 | if __name__ == '__main__':
66 | user = input('输入逗游账号')
67 | pwd = input('输入密码')
68 | dy = DouYou(user, pwd)
69 | dy.login()
70 |
--------------------------------------------------------------------------------
/其他实战/【金逸电影】自动注册/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-10-06 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/其他实战/【金逸电影】自动注册/register.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/其他实战/【金逸电影】自动注册/register.png
--------------------------------------------------------------------------------
/其他实战/【金逸电影】自动注册/register.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-09-04 Python: 3.7
4 |
5 | import requests
6 | import execjs.runtime_names
7 |
8 |
9 | class JinYiRegister:
10 | """
11 | 金逸电影注册
12 | http://www.jycinema.com/wap/#/register
13 | """
14 | def __init__(self, phone):
15 | self.headers = {
16 | 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
17 | }
18 | self.url = 'http://www.jycinema.com/frontUIWebapp/appserver/photoMessageService/newsSendMessage'
19 | self.phone = phone
20 |
21 | @staticmethod
22 | def js_make(json_data):
23 | with open('encryp.js', 'r', encoding='utf-8') as f:
24 | js = execjs.compile(f.read())
25 | try:
26 | result = js.call("getEncryption", json_data)
27 | return result
28 | except Exception:
29 | print('js 异常')
30 |
31 | def register(self):
32 | data = '{"mobileNumber": ' + self.phone + ', "channelId": 7, "channelCode": "J0005", "memberId": ""}'
33 | data = {
34 | 'params': self.js_make(data),
35 | 'Origin': 'http://www.jycinema.com',
36 | 'Referer': 'http://www.jycinema.com/wap/',
37 | }
38 | response = requests.post(self.url, data=data, headers=self.headers)
39 | print(response.content.decode('utf-8'))
40 |
41 |
42 | if __name__ == '__main__':
43 | your_phone = input('请输入待注册手机号')
44 | jy = JinYiRegister(your_phone)
45 | jy.register()
46 |
--------------------------------------------------------------------------------
/其他实战/【青海移动】登陆参数生成/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-10-06 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/其他实战/【青海移动】登陆参数生成/make_param.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-09-12 Python: 3.7
4 | import execjs.runtime_names
5 |
6 |
7 | class QinHaiYiDong:
8 | """
9 | 青海移动
10 | 参数加密
11 | https://www.iqhmall.cn/shopweb/logon/logon
12 | """
13 | def __init__(self, user, pwd):
14 | self.js = None
15 | self.user = user
16 | self.pwd = pwd
17 | self.init_js()
18 |
19 | def init_js(self):
20 | print('引擎', execjs.get().name)
21 | with open("encryp.js", "r", encoding="utf-8") as f:
22 | self.js = execjs.compile(f.read())
23 |
24 | def make_param(self):
25 | print(self.js.call('test', self.pwd))
26 |
27 |
28 | if __name__ == '__main__':
29 | yd = QinHaiYiDong('17327362817', '123123123')
30 | yd.make_param()
31 |
--------------------------------------------------------------------------------
/其他实战/【餐饮】查询信息/FoodInfo.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | # Time : 2020/01/16
3 | # Author : Zok
4 | # Email : 362416272@qq.com
5 |
6 | import requests
7 | import re
8 | import json
9 | from copyheaders import headers_raw_to_dict
10 |
11 |
12 | class Food:
13 | """
14 | 根据输入美团餐馆名,解析参观基础信息
15 | """
16 | def __init__(self):
17 | self.headers = headers_raw_to_dict(b"""
18 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
19 | Accept-Encoding: gzip, deflate, br
20 | Accept-Language: zh-CN,zh;q=0.9
21 | Cache-Control: max-age=0
22 | Connection: keep-alive
23 | Cookie: _lxsdk_s=16fb0ce3a0d-4cf-d9e-cf2%7C%7C1
24 | Host: www.meituan.com
25 | Sec-Fetch-Mode: navigate
26 | Sec-Fetch-Site: none
27 | Sec-Fetch-User: ?1
28 | Upgrade-Insecure-Requests: 1
29 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
30 | """)
31 |
32 | def get_info(self, url):
33 | response = requests.get(url, headers=self.headers)
34 | data = json.loads(re.search(r'
{ Object.defineProperties(navigator,'
23 | '{ webdriver:{ get: () => false } }) }') # 本页刷新后值不变
24 |
25 | await page.goto(self.login_url)
26 | await page.type('input#login-email', username)
27 | await page.type('input#login-password', password)
28 | await page.click('input.btn')
29 | await self.get_cookie(page,username,password)
30 |
31 | async def get_cookie(self, page,username,password):
32 | """
33 | 获取 cookies
34 | :param page: 页面
35 | :return:
36 | """
37 | cookies_list = await page.cookies()
38 | cookies = ''
39 | for cookie in cookies_list:
40 | str_cookie = '{0}={1};'
41 | str_cookie = str_cookie.format(cookie.get('name'), cookie.get('value'))
42 | cookies += str_cookie
43 | # 储存cookies
44 | print(cookies)
45 | self.r.set(username, json.dumps({'password': password, 'cookies': cookies}))
46 |
47 |
48 | if __name__ == '__main__':
49 | mt = MeiTuanCookies()
50 |
51 | with open('账号.txt', 'r', encoding='utf-8') as f:
52 | # 账号|密码\n
53 | lines = f.readlines()
54 |
55 | tasks = []
56 | for line in lines:
57 | username, password = line.strip().split('|')
58 | tasks.append(mt.star(username, password))
59 |
60 | loop = asyncio.get_event_loop()
61 | loop.run_until_complete(asyncio.wait(tasks))
62 |
63 |
--------------------------------------------------------------------------------
/原创爬虫工具/Cookies/MeiTuan/账号.txt:
--------------------------------------------------------------------------------
1 | 账号1|密码1
2 | 账号2|密码2
3 | 账号3|密码3
--------------------------------------------------------------------------------
/原创爬虫工具/Cookies/README.md:
--------------------------------------------------------------------------------
1 | # 异步批量登陆美团获取cookies
2 |
3 | > pyppeteer 异步批量登陆美团并将cookies储存到redis 的hash表中
--------------------------------------------------------------------------------
/原创爬虫工具/Cookies/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-14 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/README.md:
--------------------------------------------------------------------------------
1 | # 工作中经常有这种需求
2 | > 将采集好的mongodb数据转存到mysql中,或者是redis数据转到mongodb,于是打算封装一个组件便于以后调用
3 |
4 | # mysql转存mongo
5 | 1. 在 config 中配置 mongo 与 mysql 连接
6 | 2. 在 `msyql_to_mongo.py` 下方实例化时填入 `需要转换mysql表名`, `mongo库名`, `mongo表名`
7 | 3. 调用 `mi.easy_to_mongo()` 即可将 mysql 中的 数据导入到 mongodb
8 |
9 | > 当然也支持自定义转换,在类中添加即可
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-15 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/config.py:
--------------------------------------------------------------------------------
1 | # mongodb链接
2 | MONGODB_URL = 'mongodb://localhost:27017'
3 |
4 | # Redis数据库地址
5 | REDIS_HOST = ''
6 |
7 | # Redis端口
8 | REDIS_PORT = 6379
9 |
10 | # Redis密码,如无填None
11 | REDIS_PASSWORD = None
12 |
13 | # Mysql地址
14 | MYSQL_HOST = '127.0.0.1'
15 |
16 | # Mysql端口
17 | MYSQL_PORT = 3306
18 |
19 | # Mysql用户名
20 | MYSQL_USER = 'root'
21 |
22 | # Mysql密码
23 | MYSQL_PASSWORD = ''
24 |
25 | # Mysql链接库
26 | MYSQL_DB_NAME = 'travel'
27 |
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/db/MongoDB.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-15 Python: 3.7
4 | from pymongo import MongoClient
5 |
6 | from DataMigration.config import MONGODB_URL
7 |
8 |
9 | class Mongo(object):
10 | def __init__(self, db_name, collection):
11 | client = MongoClient(MONGODB_URL)
12 | database = client[db_name]
13 | self.collection = database[collection]
14 |
15 | def delete(self, *args, del_one=True):
16 | """
17 | 删除复合条件的信息
18 | :param sql: sql 语句
19 | :param del_one: 默认删除第一条,否则删除复合条件的所有
20 | :return:
21 | """
22 | return self.collection.delete_one(*args) if del_one else self.collection.deleteMany(*args)
23 |
24 | @property
25 | def all(self):
26 | """
27 | 返回全部
28 | :return: 整表信息
29 | """
30 | return self.collection.find({})
31 |
32 | def find(self, *args):
33 | """
34 | 指定查找
35 | :param sql:
36 | :return:
37 | """
38 | return self.collection.find(*args)
39 |
40 | def update(self, *args, update_one=True):
41 | """
42 | 修改数据
43 | :param sql: 修改sql
44 | :param update_one: 默认修改第一个,否则修改复合条件所有
45 | :return:
46 | """
47 | return self.collection.update_one(*args) if update_one else self.collection.update_many(*args)
48 |
49 | def insert(self, *args, insert_one=True):
50 | """
51 | 插入数据
52 | :param sql: 新增sql
53 | :param insert_one: 默认插入一个
54 | :return:
55 | """
56 | return self.collection.insert_one(*args) if insert_one else self.collection.insert_many(*args)
57 |
58 |
59 | if __name__ == '__main__':
60 | # 测试
61 | mg = Mongo('meituan', 'user_info')
62 | # data = mg.all
63 | ret = mg.update({'用户名': '三丰948'}, {'$set': {'用户名': '三三风'}})
64 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/db/Mysql.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-15 Python: 3.7
4 | import pymysql
5 |
6 | from DataMigration.config import MYSQL_HOST, MYSQL_PORT, MYSQL_USER, MYSQL_PASSWORD, MYSQL_DB_NAME
7 |
8 |
9 | class Mysql(object):
10 | def __init__(self):
11 | """
12 | 链接数据库
13 | """
14 | self.conn = pymysql.Connect(
15 | host=MYSQL_HOST,
16 | port=MYSQL_PORT,
17 | user=MYSQL_USER,
18 | password=MYSQL_PASSWORD,
19 | db=MYSQL_DB_NAME,
20 | )
21 |
22 | def insert(self, sql):
23 | """
24 | 查找
25 | :param sql: sql语句
26 | :return:
27 | """
28 | # 创建游标对象
29 | cursor = self.conn.cursor()
30 | # 执行并提交
31 | try:
32 | cursor.execute(sql)
33 | self.conn.commit()
34 | except Exception as e:
35 | print('异常回滚')
36 | self.conn.rollback()
37 | finally:
38 | cursor.close()
39 |
40 | def select(self, sql):
41 | """
42 | 查找
43 | :param sql: sql 语句
44 | :return: 查找结果
45 | """
46 | cursor = self.conn.cursor() # 创建游标对象
47 | # 提交事务
48 | try:
49 | cursor.execute(sql)
50 | data = cursor.fetchall()
51 | except Exception as e:
52 | print('异常回滚')
53 | data = None
54 | self.conn.rollback()
55 | finally:
56 | cursor.close()
57 | return data
58 |
59 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/db/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-15 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/migration/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-15 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/migration/mongo_to_mysql.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-23 Python: 3.7
4 |
5 |
6 | from DataMigration.db.MongoDB import Mongo
7 | from DataMigration.db.Mysql import Mysql
8 | from DataMigration.config import MYSQL_DB_NAME
9 |
10 |
11 | class Migrate(object):
12 | def __init__(self,mysql_table_name, mongodb_name, mongodb_collection):
13 | self.mongo = Mongo(mongodb_name, mongodb_collection)
14 | self.mysql = Mysql()
15 | self.mysql_name = mysql_table_name
16 |
17 | def easy_to_mongo(self, column_comment=False):
18 | """
19 | 将输入插入 mongodb
20 | :return:
21 | """
22 | columns = self.get_column()
23 | nodes = self.all_mysql_data()
24 | data_list = []
25 |
26 | for node in nodes:
27 | data_dict = {}
28 | for index, column in enumerate(columns):
29 | if column_comment:
30 | data_dict[column[1]] = node[index]
31 | else:
32 | data_dict[column[0]] = node[index]
33 | data_list.append(data_dict)
34 | try:
35 | self.mongo.insert(data_list, insert_one=False)
36 | print('储存成功')
37 | except Exception:
38 | print('转存失败')
39 |
40 | def all_mysql_data(self):
41 | """
42 | 获取需要转换的数据
43 | :return: 所有 mysql 数据
44 | """
45 | sql = """SELECT * from {table_name};""".format(table_name=self.mysql_name)
46 | return self.mysql.select(sql)
47 |
48 | def get_column(self):
49 | """
50 | 取字段名
51 | :return: (字段名,字段描述)
52 | """
53 | sql = """select COLUMN_NAME,column_comment
54 | from INFORMATION_SCHEMA.Columns
55 | where table_name='{table_name}' and table_schema='{db_name}'""".format(
56 | table_name=self.mysql_name,
57 | db_name=MYSQL_DB_NAME,
58 | )
59 | return self.mysql.select(sql)
60 |
61 |
62 | if __name__ == '__main__':
63 | mi = Migrate('需要转换mysql表名', 'mongo库名', 'mongo表名')
64 | mi.easy_to_mongo(column_comment=True) # column_comment=True 使用注释的字段名, 默认不使用
65 |
--------------------------------------------------------------------------------
/原创爬虫工具/DataMigration/migration/mysql_to_mongo.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-20 Python: 3.7
4 |
5 |
6 | from DataMigration.db.MongoDB import Mongo
7 | from DataMigration.db.Mysql import Mysql
8 | from DataMigration.config import MYSQL_DB_NAME
9 |
10 |
11 | class Migrate(object):
12 | def __init__(self, mysql_table_name, mongodb_name, mongodb_collection):
13 | self.mongo = Mongo(mongodb_name, mongodb_collection)
14 | self.mysql = Mysql()
15 | self.mysql_name = mysql_table_name
16 |
17 | def easy_to_mongo(self, column_comment=False):
18 | """
19 | 将输入插入 mongodb
20 | :return:
21 | """
22 | columns = self.get_column()
23 | nodes = self.all_mysql_data()
24 | data_list = []
25 |
26 | for node in nodes:
27 | data_dict = {}
28 | for index, column in enumerate(columns):
29 | if column_comment:
30 | data_dict[column[1]] = node[index]
31 | else:
32 | data_dict[column[0]] = node[index]
33 | data_list.append(data_dict)
34 | try:
35 | self.mongo.insert(data_list, insert_one=False)
36 | print('储存成功')
37 | except Exception:
38 | print('转存失败')
39 |
40 | def all_mysql_data(self):
41 | """
42 | 获取需要转换的数据
43 | :return: 所有 mysql 数据
44 | """
45 | sql = """SELECT * from {table_name};""".format(table_name=self.mysql_name)
46 | return self.mysql.select(sql)
47 |
48 | def get_column(self):
49 | """
50 | 取字段名
51 | :return: (字段名,字段描述)
52 | """
53 | sql = """select COLUMN_NAME,column_comment
54 | from INFORMATION_SCHEMA.Columns
55 | where table_name='{table_name}' and table_schema='{db_name}'""".format(
56 | table_name=self.mysql_name,
57 | db_name=MYSQL_DB_NAME,
58 | )
59 | return self.mysql.select(sql)
60 |
61 |
62 | if __name__ == '__main__':
63 | mi = Migrate('需要转换mysql表名', 'mongo库名', 'mongo表名')
64 | mi.easy_to_mongo(column_comment=True) # column_comment=True 使用注释的字段名, 默认不使用
65 |
--------------------------------------------------------------------------------
/原创爬虫工具/Decode/README.md:
--------------------------------------------------------------------------------
1 | # 可拓展式解密器
2 | > 方便测试可连续转换重制的编码转换器,可灵活拓展解码规则
3 |
4 |
5 | # 说明博客
6 |
7 | [**博客地址**](https://www.zhangkunzhi.com/?p=241)
8 |
9 |
10 |
--------------------------------------------------------------------------------
/原创爬虫工具/Decode/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-01 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/Decode/translation.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-04-28 Python: 3.7
4 |
5 | import base64
6 | import zlib
7 |
8 | COLOR = {'red': 1, 'green': 2, 'yellow': 3, 'blue': 4}
9 |
10 |
11 | class TranslationMetaClass(type):
12 | """Meta 类"""
13 | def __new__(mcs, name, bases, attrs):
14 | count = 0
15 | attrs['__Decode__'] = {}
16 | for k, v in attrs.items():
17 | if 'decode_' in k:
18 | count += 1
19 | attrs['__Decode__'][str(count)] = k
20 | attrs['__TranslationFuncCount__'] = count
21 | return type.__new__(mcs, name, bases, attrs)
22 |
23 |
24 | class Util(object):
25 | """辅助类"""
26 |
27 | @staticmethod
28 | def _print(color, msg):
29 | """print color control
30 | """
31 | node = '\033[1;3{id}m{msg}\033[0m'
32 | if COLOR.get(color):
33 | print(node.format(id=COLOR.get(color), msg=msg))
34 | else:
35 | print(msg)
36 |
37 | def msg(self):
38 | """print decode func
39 | """
40 | for k in self.__Decode__:
41 | self._print('yellow', str(k) + ': ' + self.__Decode__[k][7:])
42 | self._print('yellow', 'r: 【重制】 e:【退出】')
43 | return input('请选择 >>>').lower()
44 |
45 |
46 | class Decode(Util, metaclass=TranslationMetaClass):
47 | """
48 | 将需要添加的转码类型按下列类似格式添加即可
49 | def decode_自定义名(self):
50 | self._key = 解密过程
51 | """
52 | def __init__(self, _key):
53 | self._key = _key
54 | self._copy = _key
55 | self.crumbs = ''
56 |
57 | def main(self):
58 | choice = self.msg()
59 | while choice != 'e':
60 | if choice == 'r': # 重制
61 | self._key, self.crumbs = self._copy, ''
62 | self._print('blue', '重制成功: ' + self._key)
63 | choice = self.msg()
64 | elif choice in self.__Decode__: # 选择是否在现有函数选项中
65 | try:
66 | eval("self.{}()".format(self.__Decode__[choice])) # 字符串转函数运行
67 | self._print('blue', self._key)
68 | self.crumbs += self.__Decode__[choice][7:] + ' > '
69 | self._print('green', self.crumbs)
70 | choice = self.msg()
71 | except Exception:
72 | choice = input('解码失败,换一种 >>>')
73 |
74 | self._print('red', '调试结束')
75 |
76 | def decode_base64(self):
77 | """解base64"""
78 | self._key = base64.b64decode(self._key)
79 |
80 | def decode_zlib(self):
81 | """解压串"""
82 | self._key = zlib.decompress(self._key)
83 |
84 | def decode_str(self):
85 | """转字符串"""
86 | self._key = str(self._key, encoding="utf-8")
87 |
88 | def decode_hex(self):
89 | """转到16进制"""
90 | self._key = self._key.hex()
91 |
92 |
93 | if __name__ == '__main__':
94 | # _key = 'eJyrVnqxZdnT/u1KVgpKpcWpRUo6CkpP17c9X9AIEilILC4uzy9KUaoFAGxTEMo=' # 测试
95 | _key = input('\033[1;31m输入解码内容>>> \033[0m')
96 | ts = Decode(_key)
97 | ts.main()
98 |
--------------------------------------------------------------------------------
/原创爬虫工具/Jsencrypt/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-29 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/Jsencrypt/make_encrypt.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-28 Python: 3.7
4 |
5 | import base64
6 |
7 | from Crypto.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
8 | from Crypto.PublicKey import RSA
9 |
10 |
11 | public_key = """
12 | -----BEGIN PUBLIC KEY-----
13 | Your PUBLIC KEY
14 | -----END PUBLIC KEY-----
15 | """
16 |
17 |
18 | def make_message(pwd):
19 | rsakey = RSA.importKey(public_key)
20 | cipher = Cipher_pkcs1_v1_5.new(rsakey)
21 | cipher_text = base64.b64encode(cipher.encrypt(pwd.encode(encoding="utf-8")))
22 | return cipher_text.decode('utf8')
23 |
24 |
25 | if __name__ == '__main__':
26 | print(make_message('hellow'))
27 |
--------------------------------------------------------------------------------
/原创爬虫工具/OSS/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-24 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/OSS/push_to_oss.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-24 Python: 3.7
4 |
5 | """
6 | 将图redis中储存的网络图片链接,并发直传到 OSS 上
7 | """
8 |
9 | import oss2
10 | import redis
11 | import requests
12 |
13 | from concurrent.futures import ThreadPoolExecutor # 线程池模块
14 |
15 | KEY = ''
16 | KEYSECRET = ''
17 | BUCKETNAME = ''
18 | ENDPOINT = 'http://oss-cn-hangzhou.aliyuncs.com'
19 |
20 | REDIS_HOST = "localhost"
21 | REDIS_USER = "root"
22 | REDIS_PASSWORD = ""
23 | REDIS_DB_NAME = 1
24 | REDIS_PORT = 6379
25 |
26 | list_name = 'restaurant' # 列队名
27 |
28 | # oss
29 | auth = oss2.Auth(KEY, KEYSECRET)
30 | bucket = oss2.Bucket(auth, ENDPOINT, BUCKETNAME)
31 |
32 | # redis 池
33 | pool = redis.ConnectionPool(host=REDIS_HOST, port=REDIS_PORT, db=REDIS_DB_NAME, password=REDIS_PASSWORD,
34 | decode_responses=True)
35 | r = redis.Redis(connection_pool=pool)
36 |
37 |
38 | def put_img():
39 | """上传逻辑,根据项目需求修改即可"""
40 | url = r.rpop(list_name)
41 | input = requests.get(url)
42 | if input.status_code == 200:
43 | file_name = url # this is file name
44 | obj = bucket.put_object(file_name, input)
45 | if obj.status == 200:
46 | print('OK', file_name)
47 | else:
48 | r.lpush(list_name)
49 |
50 |
51 | def get_len():
52 | return r.llen(list_name)
53 |
54 |
55 | if __name__ == '__main__':
56 | list_len = get_len()
57 | print('专辑总图数量', list_len)
58 | pool = ThreadPoolExecutor() # 设置线程池大小,默认等于cpu核数
59 | for i in range(list_len):
60 | pool.submit(put_img)
61 |
62 | pool.shutdown(wait=True)
63 | print('主进程')
64 |
--------------------------------------------------------------------------------
/原创爬虫工具/Proxy/KDLProxyPool.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-17 Python: 3.7
4 |
5 | """
6 | 快代理IP池
7 | https://www.kuaidaili.com/ 放代理API
8 | """
9 |
10 | import redis
11 | import requests
12 | import json
13 |
14 | from apscheduler.schedulers.blocking import BlockingScheduler
15 |
16 |
17 | class KDLProxyPool(object):
18 | """
19 | 快代理IP池
20 | 用的快代理开放代理API
21 | """
22 |
23 | def __init__(self, key, count):
24 | try:
25 | self.key = key # 订单号
26 | self.count = count # 代理池代理数量
27 | """redis数据库配置区"""
28 | pool = redis.ConnectionPool(decode_responses=True)
29 | self.r = redis.Redis(connection_pool=pool)
30 | except:
31 | print('请填入正确的API链接')
32 |
33 | def check_ip(self):
34 | """
35 | 监控 IP 分数、个数,对其进行增删
36 | """
37 | # 检查分数
38 | nodes = self.r.zrevrange('KDLProxy', 0, -1, withscores=True)
39 | for i in nodes:
40 | node = list(i)
41 | score = int(node[1])
42 | if score <= 0:
43 | print('\033[1;33m分数过低剔除\033[0m')
44 | self.r.zrem('KDLProxy', node[0])
45 |
46 | # 检查个数
47 | _sum = self.r.zcard('KDLProxy')
48 | if _sum < self.count:
49 | self.add_ip(self.count - _sum)
50 |
51 | def add_ip(self, num):
52 | """
53 | 提取IP
54 | """
55 | get_url = 'http://svip.kdlapi.com/api/getproxy/?orderid={key}&num={num}&protocol=2&method=2&an_ha=1&sp1=1&quality=2&format=json&sep=1'.format(
56 | key=self.key, num=num)
57 |
58 | # 返回的文本进行解析
59 | response = requests.get(get_url)
60 | if response.status_code == 200:
61 | ret = json.loads(response.text)
62 | if ret.get('code') == 0:
63 | self.parse(ret.get('data').get('proxy_list'))
64 | else:
65 | print(ret.get('msg'))
66 | else:
67 | print('提取失败')
68 |
69 | def parse(self, proxy_list):
70 | """
71 | 解析返回数据
72 | """
73 | for node in proxy_list:
74 | self.save_to_redis(node, 10) # 默认10分
75 |
76 | def save_to_redis(self, proxy, expire):
77 | """
78 | 推送到redis集合中
79 | """
80 | print('代理 %s 推入redis集合' % proxy)
81 | self.r.zadd('KDLProxy', {proxy: expire})
82 |
83 |
84 | def aps_run():
85 | """
86 | 监控
87 | """
88 | kdl.check_ip()
89 |
90 |
91 | kdl = KDLProxyPool('填写开放代理订单号', 20)
92 |
93 | # 循环监控
94 | scheduler = BlockingScheduler()
95 | scheduler.add_job(aps_run, 'cron', second='*/1') # 这里设置检测评论,推荐2s一次(默认)
96 | scheduler.start()
97 |
--------------------------------------------------------------------------------
/原创爬虫工具/Proxy/README.md:
--------------------------------------------------------------------------------
1 | [TOC]
2 |
3 | # 安装模块
4 |
5 | ```bush
6 | pip3 install redis
7 | pip3 install apscheduler
8 | pip3 install reuqest
9 | pip3 install python-dateutil
10 | ```
11 |
12 | # 讯代理池使用
13 | 1. 登陆讯代理 进入API页码将下面下方生成的API复制
14 | 
15 |
16 | 2. 将链接复制到项目该位置
17 | 
18 |
19 | 3. 配置redis, 默认是本机
20 | 
21 |
22 | 4. 启动程序,大功告成,只需要在调用ip的时候对其进行增减分操作即可
23 | 
24 | 
25 |
26 | # 芝麻代理池使用
27 |
28 | 1. 首先登陆你的芝麻代理后台管理,找到自己的key如图
29 | 
30 |
31 | 1. 在代码下方配置key
32 | 
33 |
34 | 1. 在代码中配置 redis库连接 **默认链接的本地**
35 | 
36 |
37 | 1. 启动程序
38 | > 如果在服务端可以使用后台运行命令
39 | `nohup python3 ProxyPool.py >my.log &`
40 |
41 | 1. 第一次启动芝麻代理会绑定你的ip白名单,稍等片刻就会开始提取
42 |
43 | 
44 |
45 | 1. 链接redis可以看到ip池了,大功告成
46 | 
47 |
48 | 1. 后续在使用代理ip时,根据访问结果对代理ip积分增减即可,后续会更新这个Demo继续关注Github即可。[**传送门**](https://github.com/wkunzhi/SpiderUtilPackage)
49 |
50 |
51 | # 额外配置
52 | - 可以自由配置,代理池上线值(默认20),实例化时配置即可
53 | ```python
54 | zm = ZhiMaPool('key', ip_sum=100)
55 | ```
56 | - 可以自由配置,只取可用时间xx以上的ip(默认1号套餐下的1000秒以上),实例化时配置即可
57 | ```python
58 | zm = ZhiMaPool('key', ttl=1000)
59 | ```
60 | - 还可以配置 每次提取数、提取套餐类型、提取ip HTTP或者HTTPS或者Sockets
61 |
--------------------------------------------------------------------------------
/原创爬虫工具/Proxy/XDLProxyPool.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-09 Python: 3.7
4 | import redis
5 | import requests
6 | import re
7 | import time
8 | import json
9 |
10 | from apscheduler.schedulers.blocking import BlockingScheduler
11 |
12 | """
13 | 可自型拓展其他的代理ip产品,只需修改调用接口即可
14 | """
15 |
16 |
17 | class XDLProxyPool(object):
18 | """
19 | 迅代理IP池
20 | """
21 |
22 | def __init__(self, api_url):
23 | try:
24 | """redis数据库配置区"""
25 | pool = redis.ConnectionPool(decode_responses=True)
26 | self.r = redis.Redis(connection_pool=pool)
27 |
28 | """白名单初始化"""
29 | ret = re.search(r'spiderId=(.*?)&orderno=(.*?)&returnType=\d+&count=(\d+)', api_url)
30 | self.spiderId, self.orderno, self.count = ret.group(1), ret.group(2), int(ret.group(3))
31 | self.init_proxy()
32 | except:
33 | print('请填入正确的API链接')
34 |
35 | def init_proxy(self):
36 | """
37 | 初始化代理
38 | """
39 | print('\033[1;35m初始化中...\033[0m')
40 |
41 | # 取出当前IP地址
42 | response = requests.get('http://pv.sohu.com/cityjson?ie=utf-8')
43 | address = re.search(r'"cip": "(.*?)", "cid', response.text).group(1)
44 |
45 | # 加入白名单
46 | url = 'http://www.xdaili.cn/ipagent/newWhilteList/updateByOrder?orderno={orderno}&ip={ip}&spiderId={spiderId}'.format(
47 | orderno=self.orderno, ip=address, spiderId=self.spiderId)
48 | status = requests.get(url=url).status_code
49 | if status == 200:
50 | print('\033[1;35m初始化成功,启动中稍等..\033[0m')
51 | time.sleep(2)
52 | print('监控已开启')
53 | else:
54 | print('初始化白名单失败')
55 |
56 | def check_ip(self):
57 | """
58 | 监控 IP 分数、个数,对其进行增删
59 | """
60 |
61 | # 检查分数
62 | nodes = self.r.zrevrange('XDLProxy', 0, -1, withscores=True)
63 | for i in nodes:
64 | node = list(i)
65 | score = int(node[1])
66 | if score <= 0:
67 | print('\033[1;33m分数过低剔除\033[0m')
68 | self.r.zrem('XDLProxy', node[0])
69 |
70 | # 检查个数
71 | _sum = self.r.zcard('XDLProxy')
72 | if _sum < self.count:
73 | self.add_ip(self.count - _sum)
74 |
75 | def add_ip(self, count):
76 | """
77 | 提取IP
78 | """
79 | get_url = 'http://api.xdaili.cn/xdaili-api//greatRecharge/getGreatIp?spiderId={spiderId}&orderno={orderno}&returnType=2&count={count}'.format(
80 | spiderId=self.spiderId, orderno=self.orderno, count=str(count))
81 |
82 | # 返回的文本进行解析
83 | response = requests.get(get_url)
84 | if response.status_code == 200:
85 | ret = json.loads(response.text)
86 | if ret.get('ERRORCODE') in ['10036', '10038', '10055']:
87 | print('提取速度过快5秒钟提取一次')
88 | elif ret.get('ERRORCODE') == '10032':
89 | print('余额不足或今日已到提取上线')
90 | else:
91 | self.parse(ret)
92 | else:
93 | print('提取失败')
94 |
95 | def parse(self, data):
96 | """
97 | 解析返回数据
98 | """
99 | proxy_list = data.get('RESULT')
100 | for node in proxy_list:
101 | proxy = node.get('ip') + ':' + node.get('port')
102 | self.save_to_redis(proxy, 10) # 默认10分
103 |
104 | def save_to_redis(self, proxy, expire):
105 | """
106 | 推送到redis集合中
107 | """
108 | print('代理 %s 推入redis集合' % proxy)
109 | self.r.zadd('XDLProxy', {proxy: expire})
110 |
111 |
112 | def aps_run():
113 | """
114 | 监控
115 | """
116 | xdl.check_ip()
117 |
118 |
119 | # 填入提取链接
120 | xdl = XDLProxyPool('填写讯代理api链接')
121 |
122 | # 循环监控
123 | scheduler = BlockingScheduler()
124 | scheduler.add_job(aps_run, 'cron', second='*/1') # 这里设置检测评论,推荐2s一次(默认)
125 | scheduler.start()
126 |
--------------------------------------------------------------------------------
/原创爬虫工具/Proxy/XDLProxyUseDemo.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-11 Python: 3.7
4 |
5 | import redis
6 | import random
7 |
8 | # 在scrapy中使用 代理池的demo
9 |
10 |
11 | """
12 | middleware中代码如下
13 | """
14 |
15 | pool = redis.ConnectionPool(decode_responses=True) # redis 池
16 | r = redis.Redis(connection_pool=pool)
17 |
18 |
19 |
20 |
21 | """
22 | middleware中配置代理中间键
23 | 注意,根据爬取网址是http 还是https 来设置
24 | """
25 |
26 | class MyProxy(object):
27 | """代理IP设置"""
28 | def process_request(self, request, spider):
29 | # 此处对接redis
30 | data = r.zrangebyscore('XDLProxy', 1, 100, withscores=True)
31 | ip, score = random.choice(data)
32 | request.meta['proxy'] = 'http://'+ip # 根据自己情况填写
33 |
34 |
35 |
36 |
37 | """
38 | 拦截中间键中配置如下,写入计分器,满分20分
39 | """
40 |
41 | class DownloaderMiddleware(object):
42 | def process_response(self, request, response, spider):
43 | # 对代理ip进行清洗
44 | proxy = request._meta.get('proxy')
45 | if not response.status == 200:
46 | print('IP访问失败')
47 | if proxy:
48 | proxy = proxy[proxy.find('/')+2:] # 提取当此访问proxy
49 | r.zincrby('XDLProxy', -1, proxy) # redis 命令修改
50 | else:
51 | if proxy:
52 | proxy = proxy[proxy.find('/') + 2:] # 提取当此访问proxy
53 | score = r.zscore('XDLProxy', proxy) # 取出分数
54 | if score < 20:
55 | r.zincrby('XDLProxy', 1, proxy) # redis 新版本命令更改这样了
56 | return response
57 |
58 | def process_exception(self, request, exception, spider): # 可能由于IP质量问题无法访问超时
59 | print('超时异常')
60 | proxy = request._meta.get('proxy')
61 | if proxy:
62 | proxy = proxy[proxy.find('/') + 2:]
63 | r.zincrby('XDLProxy', -1, proxy) # redis 新版本命令更改这样了
64 | return request
65 |
66 |
67 | """
68 | setting中配置
69 | """
70 | DOWNLOAD_TIMEOUT = 5 # 有的时候代理ip失效,会导致一直卡在那里 ,也有可能是用http 访问https
71 | DOWNLOADER_MIDDLEWARES = {
72 | 'middlewares.MyProxy': 543, # 自定义代理IP
73 | 'middlewares.spiderDownloaderMiddleware': 600, # 拦截301、302等跳转 必须设置到600
74 | }
--------------------------------------------------------------------------------
/原创爬虫工具/Proxy/ZhiMaProxyUseDemo.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-07 Python: 3.7
4 | import redis
5 | import random
6 |
7 | # 在scrapy中使用 代理池的demo
8 |
9 |
10 | """
11 | scrapy 中 middleware中代码如下
12 | """
13 |
14 | pool = redis.ConnectionPool(decode_responses=True)
15 | r = redis.Redis(connection_pool=pool)
16 |
17 |
18 |
19 |
20 | """
21 | middleware中配置代理中间键
22 | 注意,根据爬取网址是http 还是https 来设置
23 | """
24 |
25 | class MyProxy(object):
26 | """代理IP设置"""
27 | def process_request(self, request, spider):
28 | # 此处对接redis
29 | data = r.zrange('ZhiMaProxy', 0, -1, withscores=True)
30 | ip, score = random.choice(data)
31 | request.meta['proxy'] = 'http://'+ip
32 |
33 |
34 |
35 |
36 | """
37 | 拦截中间键中配置如下,写入计分器,满分20分
38 | """
39 |
40 | class DownloaderMiddleware(object):
41 | def process_response(self, request, response, spider):
42 | # 对代理ip进行清洗
43 | proxy = request._meta.get('proxy')
44 | if response.status == 302:
45 | print('IP访问失败')
46 | if proxy:
47 | proxy = proxy[proxy.find('/')+2:]
48 | r.zincrby('ZhiMaProxy', -10000000000, proxy) # redis 命令修改
49 | elif response.status == 200:
50 | if proxy:
51 | proxy = proxy[proxy.find('/') + 2:]
52 | score = r.zscore('ZhiMaProxy',proxy)
53 | if score < 200000000000:
54 | r.zincrby('ZhiMaProxy', 10000000000, proxy) # redis 新版本命令更改这样了
55 | return response
56 |
57 | def process_exception(self, request, exception, spider): # 可能由于IP质量问题无法访问超时,必须在这里捕获然后扣分
58 | print('超时异常')
59 | proxy = request._meta.get('proxy')
60 | if proxy:
61 | proxy = proxy[proxy.find('/') + 2:]
62 | r.zincrby('ZhiMaProxy', -10000000000, proxy) # redis 新版本命令更改这样了
63 | return request
64 |
65 |
66 | """
67 | setting中配置
68 | """
69 | DOWNLOAD_TIMEOUT = 5 # 有的时候代理ip失效,会导致一直卡在那里 ,也有可能是用http 访问https
70 | OWNLOADER_MIDDLEWARES = {
71 | 'middlewares.MyProxy': 543, # 自定义代理IP
72 | 'middlewares.spiderDownloaderMiddleware': 600, # 拦截301、302等跳转
73 | }
--------------------------------------------------------------------------------
/原创爬虫工具/README.md:
--------------------------------------------------------------------------------
1 | ## 工具表
2 | - [x] [解密工具-可拓展式解密器](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Decode)
3 | - [x] [自动注册-验证短信接收器](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Register)
4 | - [x] [代理IP-芝麻代理池监控器](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Proxy)
5 | - [x] [代理IP-芝麻代理池客户端Demo](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Proxy)
6 | - [x] [代理IP-讯代理池监控器](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Proxy)
7 | - [x] [代理IP-讯代理池客户端Demo](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Proxy)
8 | - [x] [代理IP-快代理池监控器](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Proxy)
9 | - [x] [cookies获取-pyppeteer获取美团登陆cookies](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Cookies)
10 | - [x] [跨数据库迁移器-开发中](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/DataMigration)
11 | - [x] [网络图片并发直传OSS](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/OSS)
12 | - [x] [生成encrypt加密参数器](https://github.com/wkunzhi/SpiderUtilPackage/tree/master/Jsencrypt)
13 |
14 |
15 |
16 |
17 |
18 | # 可拓展式解密器
19 |
20 | [**博客传送门**](https://blog.zhangkunzhi.com/2019/06/02/%E5%8E%9F%E5%88%9B%E5%B7%A5%E5%85%B7%E4%B9%8B%E5%8F%AF%E6%8B%93%E5%B1%95%E8%A7%A3%E7%A0%81%E5%99%A8/index.html)
21 |
22 | > 方便测试可连续转换重制的编码转换器,可灵活拓展解码规则
23 |
24 | 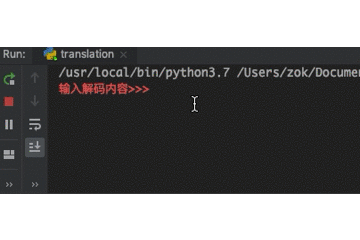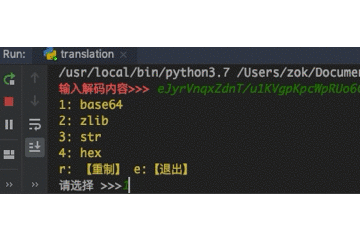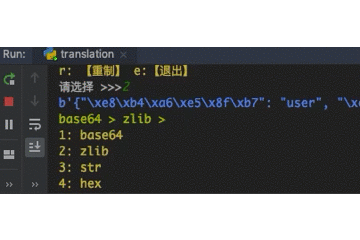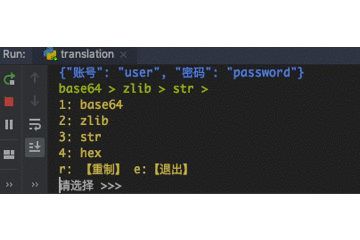
25 |
26 |
27 |
28 |
29 |
30 |
31 | # 代理池清洗工具
32 |
33 | [**博客传送门**](https://blog.zhangkunzhi.com/2019/05/02/%E6%90%AD%E5%BB%BA%E4%B8%80%E4%B8%AA%E8%B6%85%E7%AE%80%E5%8D%95%E7%9A%84%E5%AE%9E%E7%94%A8%E7%9A%84%E9%AB%98%E5%8F%AF%E7%94%A8%E4%BB%98%E8%B4%B9IP%E6%B1%A0/index.html)
34 |
35 | > 爬虫经常会用到代理ip,其中有很多收费ip,但是如何在scrapy中,高效使用这些ip是一个比较麻烦的事情,在这里基于[芝麻代理ip](http://h.zhimaruanjian.com/pay/)做一个代理池监控器,首先整理我们的需求再对其代理质量进行管理,从而保持高效IP使用率
36 |
37 | 
38 |
39 |
40 |
41 |
42 | # 验证码短信接收器
43 |
44 | > 基于短信接收平台的异步短信接收器,最大并发上限 20,Python3.5+。
45 | 启动后会根据设置的异步并发数进行获取手机号码并监听短信接收情况(60秒) 超过60秒后会将未收到短信的手机号拉入黑名单,并是释放。
46 |
47 | 若要配置具体某个网站使用,还需开发对应的账号注册器,配合调用本短信接收器来达到自动注册账号的功能
48 |
49 |
50 |
51 | # cookies获取Demo
52 |
53 | > 基于Pyppeteer 并发获取站点cookies
54 | - 美团登陆cookies
55 | 
56 |
57 |
58 | # 跨数据库迁移器
59 | **工作中经常有这种需求**
60 | > 将采集好的mongodb数据转存到mysql中,或者是redis数据转到mongodb,于是打算封装一个组件便于以后调用
61 |
62 | - [x] mysql 数据迁移 mongodb
63 | 
64 | 
--------------------------------------------------------------------------------
/原创爬虫工具/Register/README.md:
--------------------------------------------------------------------------------
1 | # 注册短信并发异步接收器
2 |
3 | > 基于短信接收平台的异步短信接收器,最大并发上限20,Python3.5+
4 |
5 | `pip3 install asyncio`
6 | `pip3 install aiohttp`
7 |
8 | [平台网址](http://www.51ym.me/User/Default.aspx)
9 |
10 | ## 使用步骤
11 | 1. 实例化对象时填入平台 token
12 | 2. 实例化对象时填入后台查询的项目 id
13 | 3. 实例化对象时填入手机短信并发上限(最大20并发)
14 |
15 | > 启动后会根据设置的异步并发数进行获取手机号码并监听短信接收情况(60秒) 超过60秒后会将未收到短信的手机号拉入黑名单,并是释放。
16 |
17 | 若要配置具体某个网站使用,还需开发对应的账号注册器,配合调用本短信接收器来达到自动注册账号的功能
--------------------------------------------------------------------------------
/原创爬虫工具/Register/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-05-13 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/README.md:
--------------------------------------------------------------------------------
1 | # Zok 组件使用说明
2 | > by: 362416272@qq.com 自用
3 |
4 | ### 目录
5 | - repetition 内容更新处理
6 | - save 通用持久化存储组件
7 | - random_UA 随机UA
8 | - proxies 阿布云代理组件
9 |
10 |
11 |
12 | **mysql储存**
13 | 1. 必须在zok_config中配置要持久化的数据库账户密码
14 | 2. 在爬虫项目文件pipelines管道中,引入并使用
15 | ```python
16 | from zok.save.to_mysql import SaveToMysqlBase
17 |
18 | class CityLandmarkListPipeline(SaveToMysqlBase):
19 | member = 'city' # redis集合名 如果是分布式无需设置
20 |
21 | @staticmethod
22 | def get_sql(item):
23 | sql = """INSERT INTO base_city_landmark(city, county, landmark) VALUES ("{city}","{county}","{landmark}") """.format(
24 | city=item['city'],
25 | county=item['county'],
26 | landmark=item['landmark'],
27 | )
28 | return sql
29 |
30 | '''必须调用 def_sql(item)方法,并返回sql语句即可'''
31 | ```
32 |
33 | **随机UA**
34 | ```python
35 | # setting.py中 加入即可
36 | DOWNLOADER_MIDDLEWARES = {
37 | 'zok.random_UA.ua_random.RandomUserAgentMiddleware': 20,
38 | }
39 | ```
40 |
41 | **代理ip设置**
42 | ```python
43 | # 在setting中配置即可
44 | DOWNLOADER_MIDDLEWARES = {
45 | 'zok.proxies.proxies.ProxyMiddleware': 15, # 自定义的中间件
46 | }
47 | ```
48 |
49 | **基于redis内容去重更新**
50 | > 原理: 在储存数据之前取到hash数据值,并加以对比,如果有值就跳过不储存,无值就set(md5, id)
51 | 1. 开启redis服务
52 | 2. 在 zok_config中配置 redis配置
53 | 3. 应用储存组件 mysql 就会自动启用去重增量更新功能
54 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/5 Python: 3.7
4 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/get_db/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/16 Python: 3.7
4 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/get_db/from_mongodb.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-04-23 Python: 3.7
4 | from pymongo import MongoClient
5 |
6 | from zok.zok_config import MONGODB_URL
7 |
8 | client = MongoClient(MONGODB_URL)
9 |
10 | database = client.meituan_db # 链接数据库
11 | collection = database.href_coolections # 链接结合
12 |
13 | data = collection.find({},{'_id': 0})
14 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/get_db/from_mysql.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 |
5 | import pymysql
6 |
7 | from zok.zok_config import *
8 |
9 |
10 | def get_data(sql):
11 | conn = pymysql.Connect(
12 | host=MYSQL_HOST,
13 | port=MYSQL_PORT,
14 | user=MYSQL_USER,
15 | password=MYSQL_PASSWORD,
16 | db=MYSQL_DB_NAME,
17 | )
18 | # 创建游标对象
19 | cursor = conn.cursor()
20 | # 提交事务
21 | try:
22 | cursor.execute(sql)
23 | data = cursor.fetchall()
24 | cursor.close()
25 | conn.close()
26 | return data
27 | except Exception as e:
28 | print(e)
29 | print('异常回滚')
30 | conn.rollback()
31 | cursor.close()
32 | conn.close()
33 | return None
34 |
35 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/proxies/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/proxies/proxies.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/5 Python: 3.7
4 |
5 | import base64
6 | from zok.zok_config import *
7 |
8 | # 代理服务器
9 | proxyServer = "http://http-dyn.abuyun.com:9020"
10 |
11 |
12 | proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((PROXY_USER + ":" + PROXY_PASS), "ascii")).decode("utf8")
13 |
14 |
15 | class ProxyMiddleware(object):
16 | """自定义中间件代理IP"""
17 | def process_request(self, request, spider):
18 | request.meta["proxy"] = proxyServer
19 | request.headers["Proxy-Authorization"] = proxyAuth
20 |
21 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/random_UA/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/random_UA/ua_random.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 | import os
5 |
6 | from fake_useragent import UserAgent
7 |
8 |
9 | class RandomUserAgentMiddleware(object):
10 | """
11 | first to use location because it is the fastest
12 | """
13 |
14 | def __init__(self):
15 | location = os.getcwd() + '/zok/random_UA/fake_useragent.json'
16 | self.agent = UserAgent(path=location) # 调用本地 ua池
17 | # self.agent = UserAgent(verify_ssl=False)
18 | # self.agent = UserAgent(use_cache_server=False)
19 |
20 | @classmethod
21 | def from_crawler(cls, crawler):
22 | return cls()
23 |
24 | def process_request(self, request, spider):
25 | request.headers.setdefault('User-Agent', self.agent.random)
26 |
27 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/repetition/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/5 Python: 3.7
4 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/repetition/update_cache.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 |
5 | import redis
6 | import hashlib
7 |
8 | from zok.zok_config import REDIS_PORT, REDIS_DB_NAME, REDIS_HOST, REDIS_USER, REDIS_PASSWORD
9 |
10 |
11 | class CacheRedis(object):
12 |
13 | pool = redis.ConnectionPool(host=REDIS_HOST, port=REDIS_PORT, db=REDIS_DB_NAME, password=REDIS_PASSWORD, decode_responses=True)
14 | r = redis.Redis(connection_pool=pool)
15 | # 加上decode_responses=True,写入的键值对中的value为str类型,不加这个参数写入的则为字节类型。
16 |
17 | # 1. 根据储存数据取值判断是否存在
18 | # 3. 不存在-已有数据: 需要更新
19 | # 4. 不存在-无数据: 需要插入
20 | # 5. 存在 直接跳过储存
21 |
22 | # BUG 在redis数据库丢失的情况下【会全体重新录入】
23 |
24 | @staticmethod
25 | def get_md5(data):
26 | md5 = hashlib.md5(data.encode('utf-8')).hexdigest()
27 | return md5
28 |
29 | def redis_exists(self, member, md5):
30 | """
31 | 验证hash是否存在, 有返回True,没有返回False
32 | :param member: 验证区域集合Key
33 | :param md5: 要储存的数据
34 | :return: True or False
35 | """
36 | print()
37 | if self.r.sismember(member, md5):
38 | return True
39 | else:
40 | return False
41 |
42 | def save_redis(self, member, md5):
43 | self.r.sadd(member, md5)
44 |
45 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/save/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/save/to_mysql.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 |
5 | import pymysql
6 |
7 | from zok.zok_config import *
8 | from zok.repetition.update_cache import CacheRedis
9 |
10 |
11 | class SaveToMysqlBase(object):
12 | """
13 | mysql储存基类
14 | 新增语法 INSERT INTO 表名(city, county, district) VALUES ("%s","%s","%s")
15 | 更新语法 UPDATE 表名 SET mail = "playstation.com" WHERE user_name = "Peter"
16 | """
17 | member = None # 不设置默认不开启 redis去重校验
18 | conn = None
19 | cursor = None # 游标对象
20 | redis = CacheRedis()
21 |
22 | def open_spider(self, spider):
23 | print('开始爬虫,链接数据库')
24 | self.conn = pymysql.Connect(
25 | host=MYSQL_HOST,
26 | port=MYSQL_PORT,
27 | user=MYSQL_USER,
28 | password=MYSQL_PASSWORD,
29 | db=MYSQL_DB_NAME,
30 | )
31 |
32 | def process_item(self, item, spider):
33 | # 写sql语句 插数据,没有表的话要先在数据库创建
34 | sql = self.get_sql(item)
35 | if self.member:
36 | sql_md5 = self.redis.get_md5(sql)
37 | if not self.redis.redis_exists(self.member, sql_md5):
38 | # 创建游标对象
39 | self.cursor = self.conn.cursor()
40 | # 提交事务
41 | try:
42 | self.cursor.execute(sql)
43 | self.conn.commit()
44 | self.redis.save_redis(self.member, sql_md5)
45 | # int(conn.insert_id()) # 最新插入行的主键ID,conn.insert_id()一定要在conn.commit()之前,否则会返回0
46 | except Exception as e:
47 | print(e)
48 | print('异常回滚')
49 | self.conn.rollback()
50 |
51 | self.cursor.close()
52 | return item
53 | else:
54 | print('已有相同数据无需插入')
55 | else:
56 | # 创建游标对象
57 | self.cursor = self.conn.cursor()
58 | # 提交事务
59 | try:
60 | self.cursor.execute(sql)
61 | self.conn.commit()
62 | except Exception as e:
63 | print(e)
64 | print('异常回滚')
65 | self.conn.rollback()
66 | self.cursor.close()
67 | return item
68 |
69 | def close_spider(self, spider):
70 | print('爬虫结束, 关闭通道')
71 | self.conn.close()
72 |
--------------------------------------------------------------------------------
/原创爬虫工具/zok/zok_config.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/5 Python: 3.7
4 | from urllib import parse
5 |
6 |
7 | MONGODB_URL = 'mongodb://localhost:27017'
8 |
9 |
10 | REDIS_HOST = "localhost"
11 | REDIS_USER = "root"
12 | REDIS_PASSWORD = ""
13 | REDIS_DB_NAME = 0
14 | REDIS_PORT = 6379
15 |
16 |
17 |
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-10-10 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/bg.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/bg.png
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/chache.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/chache.png
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/hk.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/hk.png
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/img/0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/img/0.png
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/img/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/img/1.png
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/img/2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/img/2.png
--------------------------------------------------------------------------------
/滑动验证码/【w3c】滑块验证/img/3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【w3c】滑块验证/img/3.png
--------------------------------------------------------------------------------
/滑动验证码/【腾讯】滑块验证/bg.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/滑动验证码/【腾讯】滑块验证/bg.jpeg
--------------------------------------------------------------------------------
/滑动验证码/【腾讯】滑块验证/discriminate.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-10-11 Python: 3.7
4 |
5 |
6 | """
7 | pip3 install opencv-python
8 | """
9 |
10 | import cv2 as cv
11 |
12 |
13 | def get_pos(image):
14 | """
15 | 缺口轮廓检测
16 | 对付腾讯滑块够用
17 | 该方法识别率 95% 左右
18 | """
19 | blurred = cv.GaussianBlur(image, (5, 5), 0)
20 | canny = cv.Canny(blurred, 200, 400)
21 | contours, hierarchy = cv.findContours(canny, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
22 | for i, contour in enumerate(contours):
23 | m = cv.moments(contour)
24 | if m['m00'] == 0:
25 | cx = cy = 0
26 | else:
27 | cx, cy = m['m10'] / m['m00'], m['m01'] / m['m00']
28 | if 6000 < cv.contourArea(contour) < 8000 and 370 < cv.arcLength(contour, True) < 390:
29 | if cx < 400:
30 | continue
31 | x, y, w, h = cv.boundingRect(contour) # 外接矩形
32 | cv.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
33 | cv.imshow('image', image)
34 | return x
35 | return 0
36 |
37 |
38 | if __name__ == '__main__':
39 | """
40 | 这里是滑块缺口识别
41 | 识别到后
42 | 1。可以通过自动化工具取拖动滑块
43 | 2。可以通过参数解析的形式生成参数提交通过验证
44 | """
45 | img0 = cv.imread('bg.jpeg')
46 | get_pos(img0)
47 | cv.waitKey(0)
48 | cv.destroyAllWindows()
49 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/requirements:
--------------------------------------------------------------------------------
1 | scrapy
2 | scrapy-redis
3 | pymysql
4 | redis>=3.2.1
5 | pymongo
--------------------------------------------------------------------------------
/项目/HouseScrapy/scrapy.cfg:
--------------------------------------------------------------------------------
1 | # Automatically created by: scrapy startproject
2 | #
3 | # For more information about the [deploy] section see:
4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html
5 |
6 | [settings]
7 | default = settings
8 |
9 | [deploy]
10 | #url = http://localhost:6800/
11 | project = HouseScrapy
12 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/settings.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | # 阿布云代理 IP
4 | PROXY_USER = ''
5 | PROXY_PASS = ''
6 |
7 | BOT_NAME = 'HouseScrapy'
8 |
9 | SPIDER_MODULES = ['spiders']
10 | NEWSPIDER_MODULE = 'spiders'
11 |
12 | # 否认协议
13 | ROBOTSTXT_OBEY = False
14 |
15 | # 随机延迟
16 | RANDOMIZE_DOWNLOAD_DELAY = True
17 |
18 | # 重试处理
19 | DOWNLOAD_FAIL_ON_DATALOSS = False
20 |
21 | # 设置超时时间
22 | DOWNLOAD_TIMEOUT = 5
23 |
24 | # MongoDB
25 | MONGODB_URL = 'mongodb://localhost:27017'
26 | MONGODB_DB = '房产'
27 | MONGODB_COLL = '地产数据'
28 |
29 |
30 | # Redis
31 | REDIS_HOST = '127.0.0.1' # 本机
32 | REDIS_WORD = None
33 | REDIS_PORT = 6379
34 |
35 | # 限流 秒/次
36 | DOWNLOAD_DELAY = 1 / 10
37 |
38 | # 禁止301
39 | # HTTPERROR_ALLOWED_CODES = [301]
40 |
41 | # 日志配置
42 | # LOG_LEVEL = 'WARNING'
43 | # LOG_FILE = 'log/error_log.txt'
44 |
45 |
46 | # Headers
47 | DEFAULT_REQUEST_HEADERS = {
48 | 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
49 | 'Host': 'www.funi.com'
50 | }
51 |
52 |
53 | """项目独立配置区"""
54 |
55 | # HOST
56 | HOST = 'http://www.funi.com'
57 |
58 |
59 | """===== 分布式配置区 ====="""
60 |
61 | # # 去重,利用set指纹去重
62 | # DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
63 | #
64 | # # 调度器
65 | # SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
66 | #
67 | # # 去重指纹的set
68 | # SCHEDULER_PERSIST = True
69 | #
70 | # # 配置密码
71 | # REDIS_PARAMS = {
72 | # 'password': REDIS_WORD,
73 | # }
74 | #
75 | #
--------------------------------------------------------------------------------
/项目/HouseScrapy/spiders/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-15 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/toolkits/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-15 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/toolkits/items.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | import scrapy
4 |
5 |
6 | class HousesItem(scrapy.Item):
7 | data = scrapy.Field()
8 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/toolkits/make_ua.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/7 Python: 3.7
4 | import os
5 |
6 | from fake_useragent import UserAgent
7 |
8 |
9 | class RandomUserAgentMiddleware(object):
10 | """
11 | first to use location because it is the fastest
12 | """
13 |
14 | def __init__(self):
15 | location = os.getcwd() + '/toolkits/fake_useragent.json'
16 | self.agent = UserAgent(path=location)
17 | # self.agent = UserAgent(verify_ssl=False)
18 | # self.agent = UserAgent(use_cache_server=False)
19 |
20 | @classmethod
21 | def from_crawler(cls, crawler):
22 | return cls()
23 |
24 | def process_request(self, request, spider):
25 | request.headers.setdefault('User-Agent', self.agent.random)
26 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/toolkits/middlewares.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | # Define here the models for your spider middleware
4 | #
5 | # See documentation in:
6 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html
7 |
8 | from scrapy import signals
9 |
10 |
11 | class HousescrapySpiderMiddleware(object):
12 | # Not all methods need to be defined. If a method is not defined,
13 | # scrapy acts as if the spider middleware does not modify the
14 | # passed objects.
15 |
16 | @classmethod
17 | def from_crawler(cls, crawler):
18 | # This method is used by Scrapy to create your spiders.
19 | s = cls()
20 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
21 | return s
22 |
23 | def process_spider_input(self, response, spider):
24 | # Called for each response that goes through the spider
25 | # middleware and into the spider.
26 |
27 | # Should return None or raise an exception.
28 | return None
29 |
30 | def process_spider_output(self, response, result, spider):
31 | # Called with the results returned from the Spider, after
32 | # it has processed the response.
33 |
34 | # Must return an iterable of Request, dict or Item objects.
35 | for i in result:
36 | yield i
37 |
38 | def process_spider_exception(self, response, exception, spider):
39 | # Called when a spider or process_spider_input() method
40 | # (from other spider middleware) raises an exception.
41 |
42 | # Should return either None or an iterable of Response, dict
43 | # or Item objects.
44 | pass
45 |
46 | def process_start_requests(self, start_requests, spider):
47 | # Called with the start requests of the spider, and works
48 | # similarly to the process_spider_output() method, except
49 | # that it doesn’t have a response associated.
50 |
51 | # Must return only requests (not items).
52 | for r in start_requests:
53 | yield r
54 |
55 | def spider_opened(self, spider):
56 | spider.logger.info('Spider opened: %s' % spider.name)
57 |
58 |
59 | class HousescrapyDownloaderMiddleware(object):
60 | # Not all methods need to be defined. If a method is not defined,
61 | # scrapy acts as if the downloader middleware does not modify the
62 | # passed objects.
63 |
64 | @classmethod
65 | def from_crawler(cls, crawler):
66 | # This method is used by Scrapy to create your spiders.
67 | s = cls()
68 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
69 | return s
70 |
71 | def process_request(self, request, spider):
72 | # Called for each request that goes through the downloader
73 | # middleware.
74 |
75 | # Must either:
76 | # - return None: continue processing this request
77 | # - or return a Response object
78 | # - or return a Request object
79 | # - or raise IgnoreRequest: process_exception() methods of
80 | # installed downloader middleware will be called
81 | return None
82 |
83 | def process_response(self, request, response, spider):
84 | # Called with the response returned from the downloader.
85 |
86 | # Must either;
87 | # - return a Response object
88 | # - return a Request object
89 | # - or raise IgnoreRequest
90 | return response
91 |
92 | def process_exception(self, request, exception, spider):
93 | # Called when a download handler or a process_request()
94 | # (from other downloader middleware) raises an exception.
95 |
96 | # Must either:
97 | # - return None: continue processing this exception
98 | # - return a Response object: stops process_exception() chain
99 | # - return a Request object: stops process_exception() chain
100 | pass
101 |
102 | def spider_opened(self, spider):
103 | spider.logger.info('Spider opened: %s' % spider.name)
104 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/toolkits/pipelines.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | from pymongo import MongoClient
4 | from bson.objectid import ObjectId
5 | from settings import MONGODB_URL, MONGODB_DB, MONGODB_COLL
6 |
7 |
8 | class HousePipeline(object):
9 | """地产基础数据
10 | """
11 |
12 | def __init__(self):
13 | client = MongoClient(MONGODB_URL)
14 | self.coll = client[MONGODB_DB][MONGODB_COLL] # 地产链接
15 |
16 | def process_item(self, item, spider):
17 | self.coll.insert_one(item['data'])
18 |
--------------------------------------------------------------------------------
/项目/HouseScrapy/toolkits/proxies.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok"
3 | # Date: 2019/3/5 Python: 3.7
4 |
5 | import base64
6 | from settings import PROXY_USER, PROXY_PASS
7 |
8 | # 代理服务器
9 | proxyServer = "http://http-dyn.abuyun.com:9020"
10 |
11 |
12 | proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((PROXY_USER + ":" + PROXY_PASS), "ascii")).decode("utf8")
13 |
14 |
15 | class ProxyMiddleware(object):
16 | """自定义中间件代理IP"""
17 | def process_request(self, request, spider):
18 | request.meta["proxy"] = proxyServer
19 | request.headers["Proxy-Authorization"] = proxyAuth
20 |
21 |
22 |
23 |
--------------------------------------------------------------------------------
/项目/HouseSpider/README.md:
--------------------------------------------------------------------------------
1 | # 目前项目还在抽空更新中
2 | > 慢慢填坑
3 |
4 | # 概述
5 | > 对 `www.funi.com` 网站进行数据爬取
--------------------------------------------------------------------------------
/项目/HouseSpider/config.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-12 Python: 3.7
4 |
5 | # Redis
6 | REDIS_HOST = '127.0.0.1'
7 | REDIS_PORT = '6379'
8 | REDIS_PASSWORD = None
9 |
10 | # MongoDB
11 | MONGO_CLEAN = 'mongodb://localhost:27017'
12 |
13 | # TargetUrl
14 | TARGET_URL = "http://www.funi.com/loupan/region_0_0_0_0_{page}"
15 |
16 | # ProxyIP
17 | PROXY_USER = ""
18 | PROXY_PASS = ""
19 |
20 | # HOST
21 | HOST = 'http://www.funi.com'
22 |
--------------------------------------------------------------------------------
/项目/HouseSpider/db/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-12 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/项目/HouseSpider/main.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-12 Python: 3.7
4 |
5 | import asyncio
6 |
7 | from tool.parse import *
8 | from tool.toolkit import *
9 |
10 |
11 | async def get_max_page():
12 | """获取总页数
13 | """
14 | url = TARGET_URL.format(page=1)
15 | result = await get(url)
16 | return await parse_total_page(result)
17 |
18 |
19 | async def get_house_url(page):
20 | """获取地产链接
21 | """
22 | url = TARGET_URL.format(page=page)
23 | result = await get(url)
24 | await parse_house_url(result, page)
25 |
26 |
27 | @count_time
28 | def main():
29 | loop = asyncio.get_event_loop()
30 |
31 | # 1. 获取总页数
32 | task = loop.create_task(get_max_page())
33 | total_page = loop.run_until_complete(task)
34 |
35 | # 2. 获取链接
36 | house_url_func = [asyncio.ensure_future(get_house_url(_)) for _ in range(1, int(total_page))]
37 | loop.run_until_complete(asyncio.wait(house_url_func))
38 |
39 | # 3. 楼盘详情
40 |
41 |
42 | if __name__ == '__main__':
43 | main()
44 |
--------------------------------------------------------------------------------
/项目/HouseSpider/tool/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-12 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/项目/HouseSpider/tool/parse.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-12 Python: 3.7
4 |
5 | from pyquery import PyQuery as pq
6 | from config import *
7 |
8 |
9 | async def parse_total_page(result):
10 | """解析总页数
11 | """
12 | doc = pq(result)
13 | max_page = doc('.pages a').eq(-2).text()
14 | print('数据总: {total} 页'.format(total=max_page))
15 | return max_page
16 |
17 |
18 | async def parse_house_url(result, page):
19 | """页面解析链接
20 | """
21 | doc = pq(result)
22 | dls = doc('.fleft div').eq(-2)('dl')
23 | n = 0
24 | for dl in dls:
25 | href = pq(dl)('dt a').attr('href')
26 | href = HOST + href[: href.find(';')] # 清洗链接
27 | print(href)
28 | n += 1
29 | if not n:
30 | print('第 {page} 抽取链接失败'.format(page=page))
31 |
32 |
33 |
--------------------------------------------------------------------------------
/项目/HouseSpider/tool/proxy.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-12 Python: 3.7
4 |
5 |
6 | from config import PROXY_PASS, PROXY_USER
7 |
8 | # 代理服务器
9 | proxyHost = "http-dyn.abuyun.com"
10 | proxyPort = "9020"
11 |
12 |
13 | proxyServer = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
14 | "host": proxyHost,
15 | "port": proxyPort,
16 | "user": PROXY_USER,
17 | "pass": PROXY_PASS,
18 | }
19 |
20 | if not PROXY_USER or not PROXY_PASS:
21 | msg = """
22 | 请先在 config.py 配置文件内填入代理IP账号
23 | 阿布云代理IP:https://www.abuyun.com/http-proxy/products.html
24 | """
25 | print(msg)
26 | exit()
27 |
--------------------------------------------------------------------------------
/项目/HouseSpider/tool/toolkit.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-07-13 Python: 3.7
4 | import datetime
5 | import aiohttp
6 |
7 | from tool.proxy import proxyServer
8 |
9 |
10 | async def get(url):
11 | """请求页面
12 | """
13 | headers = {
14 | 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
15 | 'Host': 'www.funi.com'
16 | }
17 |
18 | try:
19 | """conn = aiohttp.TCPConnector(verify_ssl=False) connector=conn"""
20 | async with aiohttp.ClientSession(headers=headers) as session:
21 | async with session.get(url, proxy=proxyServer) as response:
22 | return await response.text("utf-8")
23 | except TimeoutError as te:
24 | print('超时', te)
25 |
26 |
27 | def count_time(func):
28 | """取运行时间
29 | """
30 | def int_time(*args, **kwargs):
31 | start_time = datetime.datetime.now() # 程序开始时间
32 | func()
33 | over_time = datetime.datetime.now() # 程序结束时间
34 | total_time = (over_time-start_time).total_seconds()
35 | print('程序耗时: %s 秒' % total_time)
36 | return int_time
37 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wkunzhi/Python3-Spider/5188ca4056bb94d956df9ddbeb42c765ebe9819a/项目/MeiTuanArea/MeiTuanArea/__init__.py
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/items.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | import scrapy
4 |
5 |
6 | class AreaItem(scrapy.Item):
7 | """地区"""
8 | type = scrapy.Field()
9 | id = scrapy.Field()
10 | pid = scrapy.Field()
11 | name = scrapy.Field()
12 | pinyin = scrapy.Field()
13 | first = scrapy.Field()
14 | haschild = scrapy.Field()
15 |
16 |
17 | class CoordItem(scrapy.Item):
18 | """坐标录入"""
19 | type = scrapy.Field()
20 | id = scrapy.Field()
21 | lng = scrapy.Field()
22 | lat = scrapy.Field()
23 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/middlewares.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | # Define here the models for your spider middleware
4 | #
5 | # See documentation in:
6 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html
7 |
8 | from scrapy import signals
9 |
10 |
11 | class MeituanareaSpiderMiddleware(object):
12 | # Not all methods need to be defined. If a method is not defined,
13 | # scrapy acts as if the spider middleware does not modify the
14 | # passed objects.
15 |
16 | @classmethod
17 | def from_crawler(cls, crawler):
18 | # This method is used by Scrapy to create your spiders.
19 | s = cls()
20 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
21 | return s
22 |
23 | def process_spider_input(self, response, spider):
24 | # Called for each response that goes through the spider
25 | # middleware and into the spider.
26 |
27 | # Should return None or raise an exception.
28 | return None
29 |
30 | def process_spider_output(self, response, result, spider):
31 | # Called with the results returned from the Spider, after
32 | # it has processed the response.
33 |
34 | # Must return an iterable of Request, dict or Item objects.
35 | for i in result:
36 | yield i
37 |
38 | def process_spider_exception(self, response, exception, spider):
39 | # Called when a spider or process_spider_input() method
40 | # (from other spider middleware) raises an exception.
41 |
42 | # Should return either None or an iterable of Response, dict
43 | # or Item objects.
44 | pass
45 |
46 | def process_start_requests(self, start_requests, spider):
47 | # Called with the start requests of the spider, and works
48 | # similarly to the process_spider_output() method, except
49 | # that it doesn’t have a response associated.
50 |
51 | # Must return only requests (not items).
52 | for r in start_requests:
53 | yield r
54 |
55 | def spider_opened(self, spider):
56 | spider.logger.info('Spider opened: %s' % spider.name)
57 |
58 |
59 | class MeituanareaDownloaderMiddleware(object):
60 | # Not all methods need to be defined. If a method is not defined,
61 | # scrapy acts as if the downloader middleware does not modify the
62 | # passed objects.
63 |
64 | @classmethod
65 | def from_crawler(cls, crawler):
66 | # This method is used by Scrapy to create your spiders.
67 | s = cls()
68 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
69 | return s
70 |
71 | def process_request(self, request, spider):
72 | # Called for each request that goes through the downloader
73 | # middleware.
74 |
75 | # Must either:
76 | # - return None: continue processing this request
77 | # - or return a Response object
78 | # - or return a Request object
79 | # - or raise IgnoreRequest: process_exception() methods of
80 | # installed downloader middleware will be called
81 | return None
82 |
83 | def process_response(self, request, response, spider):
84 | # Called with the response returned from the downloader.
85 |
86 | # Must either;
87 | # - return a Response object
88 | # - return a Request object
89 | # - or raise IgnoreRequest
90 | return response
91 |
92 | def process_exception(self, request, exception, spider):
93 | # Called when a download handler or a process_request()
94 | # (from other downloader middleware) raises an exception.
95 |
96 | # Must either:
97 | # - return None: continue processing this exception
98 | # - return a Response object: stops process_exception() chain
99 | # - return a Request object: stops process_exception() chain
100 | pass
101 |
102 | def spider_opened(self, spider):
103 | spider.logger.info('Spider opened: %s' % spider.name)
104 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/settings.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 |
4 | BOT_NAME = 'MeiTuanArea' # 爬虫项目名
5 |
6 | SPIDER_MODULES = ['MeiTuanArea.spiders'] # 爬虫目录设定
7 | NEWSPIDER_MODULE = 'MeiTuanArea.spiders' # 爬虫生成目录
8 |
9 | ROBOTSTXT_OBEY = False # 否认协议
10 |
11 | RANDOMIZE_DOWNLOAD_DELAY = True # 开启随机增加毫秒级延迟,增加访问成功率
12 |
13 | DOWNLOAD_FAIL_ON_DATALOSS = False # 重试处理
14 |
15 | DOWNLOAD_TIMEOUT = 5 # 设置超时时间,避免ip失效等待时间过长
16 |
17 | # HTTPERROR_ALLOWED_CODES = [301] # 禁止301
18 |
19 | # 指定终端输出日志、日志位置
20 | # LOG_LEVEL = 'WARNING'
21 | # LOG_FILE = 'error_log.txt'
22 |
23 | HTTPERROR_ALLOWED_CODES = [403]
24 |
25 | # UA
26 | USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
27 |
28 | # mysql
29 | MYSQL_HOST = '127.0.0.1'
30 | MYSQL_PORT = 3306
31 | MYSQL_USER = 'root'
32 | MYSQL_PASSWORD = 'mysql 密码'
33 | MYSQL_DB_NAME = 'mysql库'
34 |
35 | # API 百度地图坐标获取API,申请后填写即可
36 | API_AK = '百度地图 api ak'
37 |
38 |
39 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/spiders/__init__.py:
--------------------------------------------------------------------------------
1 | # This package will contain the spiders of your Scrapy project
2 | #
3 | # Please refer to the documentation for information on how to create and manage
4 | # your spiders.
5 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/spiders/area_coord.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import scrapy
3 | import pymysql
4 | import json
5 |
6 | from MeiTuanArea.settings import API_AK
7 | from MeiTuanArea.settings import MYSQL_DB_NAME, MYSQL_HOST, MYSQL_PASSWORD, MYSQL_PORT, MYSQL_USER
8 | from MeiTuanArea.items import CoordItem
9 |
10 |
11 | class GetLngSpider(scrapy.Spider):
12 | name = 'area_coord'
13 |
14 | # 独立配置
15 | custom_settings = {
16 | 'ITEM_PIPELINES': {
17 | 'MeiTuanArea.pipelines.CoordPipeline': 300,
18 | },
19 | }
20 |
21 | # mysql 配置
22 | conn = pymysql.Connect(
23 | host=MYSQL_HOST,
24 | port=MYSQL_PORT,
25 | user=MYSQL_USER,
26 | password=MYSQL_PASSWORD,
27 | db=MYSQL_DB_NAME,
28 | )
29 |
30 | url = 'http://api.map.baidu.com/geocoder/v2/?address={address}&output=json&ak={ak}'
31 |
32 | def start_requests(self):
33 |
34 | # 一级区域 省市
35 | provinces = self.get_db("""SELECT id,`name` from province""")
36 | for _id, name in provinces:
37 | target_url = self.url.format(address=name, ak=API_AK)
38 | yield scrapy.Request(target_url, meta={'type': 'province', '_id': _id})
39 |
40 | # 二级区域 城市
41 | city = self.get_db("""SELECT id,`name` from city""")
42 | for _id, name in city:
43 | target_url = self.url.format(address=name, ak=API_AK)
44 | yield scrapy.Request(target_url, meta={'type': 'city', '_id': _id})
45 |
46 | # 三级区域 区域
47 | area = self.get_db("""select area.id, city.name, area.name from city LEFT JOIN area on city.id=area.pid""")
48 | for _id, name, address_name in area:
49 | address = str(name)+str(address_name)
50 | target_url = self.url.format(address=address, ak=API_AK)
51 | yield scrapy.Request(target_url, meta={'type': 'area', '_id': i[0]})
52 |
53 | # 四级区域 街道
54 | address = self.get_db("""select address.id,area.name, address.name from area LEFT JOIN address on address.pid=area.id""")
55 | for _id, name, address_name in address:
56 | target_url = self.url.format(address=str(name)+str(address_name), ak=API_AK)
57 | yield scrapy.Request(target_url, meta={'type': 'address', '_id': _id})
58 |
59 | def get_db(self, sql):
60 | """数据库查询"""
61 | # 创建游标对象
62 | cursor = self.conn.cursor()
63 | # 提交事务
64 | try:
65 | cursor.execute(sql)
66 | data = cursor.fetchall()
67 | cursor.close()
68 | self.conn.close()
69 | return data
70 | except Exception as e:
71 | print('异常回滚')
72 | self.conn.rollback()
73 | cursor.close()
74 | self.conn.close()
75 | return None
76 |
77 | def parse(self, response):
78 | """清洗数据"""
79 | item = CoordItem()
80 | data = json.loads(response.text)
81 | # 处理字符串 把闲杂符号去掉
82 | if data.get('status') == 0:
83 | # 坐标
84 | item['lng'] = data.get('result').get('location').get('lng')
85 | item['lat'] = data.get('result').get('location').get('lat')
86 | item['id'] = response.meta.get('_id')
87 | item['type'] = response.meta.get('type')
88 | yield item
89 |
90 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/MeiTuanArea/spiders/areas.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import scrapy
3 | import json
4 | import re
5 |
6 | from pypinyin import pinyin, lazy_pinyin
7 | from MeiTuanArea.items import AreaItem
8 |
9 |
10 | class GetAreaSpider(scrapy.Spider):
11 | name = 'areas'
12 |
13 | # 独立配置
14 | custom_settings = {
15 | 'ITEM_PIPELINES': {
16 | 'MeiTuanArea.pipelines.AreaPipeline': 300,
17 | },
18 | 'USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
19 | 'DOWNLOAD_DELAY': 0.5, # 限流 下载同一个网站下一个页面前需要等待的时间
20 | }
21 |
22 | def start_requests(self):
23 | start_url = 'https://www.meituan.com/ptapi/getprovincecityinfo/'
24 | yield scrapy.Request(start_url, callback=self.parse_province)
25 |
26 | def parse_province(self, response):
27 | """省市+市 1、2 级区域采集"""
28 | target_url = 'http://{acronym}.meituan.com/meishi/'
29 |
30 | item = AreaItem()
31 | data = json.loads(response.text)
32 | for node in data:
33 | name = node.get('provinceName')
34 | item['type'] = 'province'
35 | item['haschild'] = 1
36 | item['id'] = node.get('provinceCode')
37 | item['pid'] = 0
38 | item['name'] = name
39 | item['pinyin'] = ''.join(lazy_pinyin(name))
40 | item['first'] = self.get_acronym(name)
41 | yield item # 一级省市
42 |
43 | for i in node.get('cityInfoList'):
44 | item['type'] = 'city'
45 | item['id'] = i.get('id')
46 | item['pid'] = node.get('provinceCode')
47 | item['name'] = i.get('name')
48 | item['pinyin'] = i.get('pinyin')
49 | item['first'] = i.get('acronym')
50 | yield item # 二级市
51 |
52 | url = target_url.format(acronym=i.get('acronym'))
53 | yield scrapy.Request(url, callback=self.parse_area, meta={'pid': i.get('id')})
54 |
55 | def parse_area(self, response):
56 | """区域+街道 2、3 级区域采集"""
57 | info, areas = re.search(r',"areas":(.*?),"dinnerCountsAttr', response.text), None
58 | if info:
59 | areas = json.loads(info.group(1))
60 | if areas:
61 | city_id = response.meta.get('pid')
62 | item = AreaItem()
63 |
64 | # 解析区域 3 级
65 | for area in areas:
66 | item['type'] = 'area'
67 | item['id'] = area.get('id')
68 | item['pid'] = city_id
69 | item['name'] = area.get('name')
70 | item['pinyin'] = ''.join(lazy_pinyin(area.get('name')))
71 | item['first'] = self.get_acronym(area.get('name'))
72 |
73 | subs = area.get('subAreas')
74 | # 判断是否有下级,有的区域么有下级了
75 | if len(subs) > 1:
76 | item['haschild'] = 1
77 | else:
78 | item['haschild'] = 0
79 |
80 | yield item
81 |
82 | # 解析 4 级
83 | if len(subs) > 1:
84 | for sub in subs:
85 | if not sub.get('name') == '全部':
86 | item['haschild'] = 0
87 | item['type'] = 'address'
88 | item['id'] = sub.get('id')
89 | item['pid'] = area.get('id')
90 | item['name'] = sub.get('name')
91 | item['pinyin'] = ''.join(lazy_pinyin(sub.get('name')))
92 | item['first'] = self.get_acronym(sub.get('name'))
93 | yield item
94 |
95 | else:
96 | print('区域读取失败')
97 |
98 | @staticmethod
99 | def get_acronym(str_data):
100 | """
101 | 获取字符串的首字母
102 | :param str_data: 字符串
103 | :return: 字符串
104 | """
105 | return "".join([i[0][0] for i in pinyin(str_data)])
106 |
107 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/README.md:
--------------------------------------------------------------------------------
1 | # 美团城市采集
2 | > 因为全站爬取需要用到,区域基础数据。这里单独抽离出来。
3 |
4 | ## 配置
5 | 在 settings 内配置 mysql 与 百度api_ak 即可
6 |
7 | ## 数据库设计
8 | > 因为最终数据将会用到Mysql上,区域一共有4个层级,分别是省市、市、区域、街道,这里按照业务需求拆分到4张表中。
9 |
10 | 
11 |
12 | ## 坐标拾取
13 | > 通过百度API调用地址,获取坐标并存入库中
14 |
15 | ## 效果
16 | 
--------------------------------------------------------------------------------
/项目/MeiTuanArea/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # __author__ = "zok" 362416272@qq.com
3 | # Date: 2019-06-18 Python: 3.7
4 |
5 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/scrapy.cfg:
--------------------------------------------------------------------------------
1 | # Automatically created by: scrapy startproject
2 | #
3 | # For more information about the [deploy] section see:
4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html
5 |
6 | [settings]
7 | default = MeiTuanArea.settings
8 |
9 | [deploy]
10 | #url = http://localhost:6800/
11 | project = MeiTuanArea
12 |
--------------------------------------------------------------------------------
/项目/MeiTuanArea/初始化.sql:
--------------------------------------------------------------------------------
1 | /*
2 | Navicat Premium Data Transfer
3 |
4 | Source Server : LocalhostMysql
5 | Source Server Type : MySQL
6 | Source Server Version : 50725
7 | Source Host : localhost:3306
8 | Source Schema : nujiang
9 |
10 | Target Server Type : MySQL
11 | Target Server Version : 50725
12 | File Encoding : 65001
13 |
14 | Date: 23/05/2019 16:32:56
15 | */
16 |
17 | SET NAMES utf8mb4;
18 | SET FOREIGN_KEY_CHECKS = 0;
19 |
20 | -- ----------------------------
21 | -- Table structure for address
22 | -- ----------------------------
23 | DROP TABLE IF EXISTS `address`;
24 | CREATE TABLE `address` (
25 | `id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'ID',
26 | `pid` bigint(10) DEFAULT NULL COMMENT '父id',
27 | `name` varchar(100) DEFAULT NULL COMMENT '名称',
28 | `pinyin` varchar(100) DEFAULT NULL COMMENT '拼音',
29 | `code` varchar(100) DEFAULT NULL COMMENT '长途区号',
30 | `zip` varchar(100) DEFAULT NULL COMMENT '邮编',
31 | `first` varchar(50) DEFAULT NULL COMMENT '首字母',
32 | `lng` varchar(100) DEFAULT NULL COMMENT '经度',
33 | `lat` varchar(100) DEFAULT NULL COMMENT '纬度',
34 | PRIMARY KEY (`id`) USING BTREE,
35 | KEY `pid` (`pid`) USING BTREE
36 | ) ENGINE=InnoDB AUTO_INCREMENT=3749 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='四级区域 地址';
37 |
38 | -- ----------------------------
39 | -- Table structure for area
40 | -- ----------------------------
41 | DROP TABLE IF EXISTS `area`;
42 | CREATE TABLE `area` (
43 | `id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'ID',
44 | `pid` bigint(10) DEFAULT NULL COMMENT '父id',
45 | `name` varchar(100) DEFAULT NULL COMMENT '名称',
46 | `pinyin` varchar(100) DEFAULT NULL COMMENT '拼音',
47 | `code` varchar(100) DEFAULT NULL COMMENT '长途区号',
48 | `zip` varchar(100) DEFAULT NULL COMMENT '邮编',
49 | `first` varchar(50) DEFAULT NULL COMMENT '首字母',
50 | `lng` varchar(100) DEFAULT NULL COMMENT '经度',
51 | `lat` varchar(100) DEFAULT NULL COMMENT '纬度',
52 | `haschild` int(1) DEFAULT NULL COMMENT '是否有下级',
53 | PRIMARY KEY (`id`) USING BTREE,
54 | KEY `pid` (`pid`) USING BTREE
55 | ) ENGINE=InnoDB AUTO_INCREMENT=39793 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='三级区域 区域';
56 |
57 | -- ----------------------------
58 | -- Table structure for city
59 | -- ----------------------------
60 | DROP TABLE IF EXISTS `city`;
61 | CREATE TABLE `city` (
62 | `id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'ID',
63 | `pid` bigint(10) DEFAULT NULL COMMENT '父id',
64 | `name` varchar(100) DEFAULT NULL COMMENT '名称',
65 | `pinyin` varchar(100) DEFAULT NULL COMMENT '拼音',
66 | `code` varchar(100) DEFAULT NULL COMMENT '长途区号',
67 | `zip` varchar(100) DEFAULT NULL COMMENT '邮编',
68 | `first` varchar(50) DEFAULT NULL COMMENT '首字母',
69 | `lng` varchar(100) DEFAULT NULL COMMENT '经度',
70 | `lat` varchar(100) DEFAULT NULL COMMENT '纬度',
71 | PRIMARY KEY (`id`) USING BTREE,
72 | KEY `pid` (`pid`) USING BTREE
73 | ) ENGINE=InnoDB AUTO_INCREMENT=8002 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='二级区域 城市';
74 |
75 | -- ----------------------------
76 | -- Table structure for province
77 | -- ----------------------------
78 | DROP TABLE IF EXISTS `province`;
79 | CREATE TABLE `province` (
80 | `id` bigint(10) NOT NULL AUTO_INCREMENT COMMENT 'ID',
81 | `name` varchar(100) DEFAULT NULL COMMENT '名称',
82 | `pinyin` varchar(100) DEFAULT NULL COMMENT '拼音',
83 | `code` varchar(100) DEFAULT NULL COMMENT '长途区号',
84 | `zip` varchar(100) DEFAULT NULL COMMENT '邮编',
85 | `first` varchar(50) DEFAULT NULL COMMENT '首字母',
86 | `lng` varchar(100) DEFAULT NULL COMMENT '经度',
87 | `lat` varchar(100) DEFAULT NULL COMMENT '纬度',
88 | PRIMARY KEY (`id`) USING BTREE
89 | ) ENGINE=InnoDB AUTO_INCREMENT=820001 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='一级区域 省市';
90 |
91 | SET FOREIGN_KEY_CHECKS = 1;
92 |
--------------------------------------------------------------------------------
/项目/README.md:
--------------------------------------------------------------------------------
1 | # 该板块不定期更新
2 | > 因为工作中会经常开发重型的爬虫,并且也属于公司的资源,所以并不会将代码放到网上。尽量以一些实战demo形式发布一些个人小项目。
3 |
4 | ## MeiTuanArea
5 | 美团区域 Scrapy 爬虫
6 |
7 | ## HoseSpider
8 | 房地产爬虫 aiohttp 爬虫
--------------------------------------------------------------------------------