├── README.md
├── feat
└── README.md
├── input
└── README.md
├── output
├── README.md
├── m1
│ ├── catboost03
│ │ └── .gitkeep
│ ├── inferSent1
│ │ └── .gitkeep
│ └── nn02
│ │ └── .gitkeep
└── m3
│ ├── lgb_m3_32-50-0
│ └── .gitkeep
│ ├── lgb_m3_37-0
│ └── .gitkeep
│ └── lgb_m3_38-0
│ └── .gitkeep
├── src
├── ensemble
│ └── .gitkeep
├── feature
│ ├── .gitkeep
│ ├── .ipynb_checkpoints
│ │ └── gen_dict-checkpoint.ipynb
│ ├── data_preprocess.py
│ ├── feat30-50.py
│ ├── feat31-50.py
│ ├── feat32-50.py
│ ├── feat37-pairwise.py
│ ├── feat38-stk.py
│ ├── feat40.py
│ ├── gen_dict.ipynb
│ ├── gen_samples.py
│ └── tfidf_recall_30.py
├── rank
│ ├── m1
│ │ ├── catboost03.py
│ │ ├── glove
│ │ │ ├── .gitignore
│ │ │ ├── .travis.yml
│ │ │ ├── LICENSE
│ │ │ ├── Makefile
│ │ │ ├── README.md
│ │ │ ├── demo.sh
│ │ │ ├── eval
│ │ │ │ ├── matlab
│ │ │ │ │ ├── WordLookup.m
│ │ │ │ │ ├── evaluate_vectors.m
│ │ │ │ │ └── read_and_evaluate.m
│ │ │ │ ├── octave
│ │ │ │ │ ├── WordLookup_octave.m
│ │ │ │ │ ├── evaluate_vectors_octave.m
│ │ │ │ │ └── read_and_evaluate_octave.m
│ │ │ │ ├── python
│ │ │ │ │ ├── distance.py
│ │ │ │ │ ├── evaluate.py
│ │ │ │ │ └── word_analogy.py
│ │ │ │ └── question-data
│ │ │ │ │ ├── capital-common-countries.txt
│ │ │ │ │ ├── capital-world.txt
│ │ │ │ │ ├── city-in-state.txt
│ │ │ │ │ ├── currency.txt
│ │ │ │ │ ├── family.txt
│ │ │ │ │ ├── gram1-adjective-to-adverb.txt
│ │ │ │ │ ├── gram2-opposite.txt
│ │ │ │ │ ├── gram3-comparative.txt
│ │ │ │ │ ├── gram4-superlative.txt
│ │ │ │ │ ├── gram5-present-participle.txt
│ │ │ │ │ ├── gram6-nationality-adjective.txt
│ │ │ │ │ ├── gram7-past-tense.txt
│ │ │ │ │ ├── gram8-plural.txt
│ │ │ │ │ └── gram9-plural-verbs.txt
│ │ │ └── src
│ │ │ │ ├── README.md
│ │ │ │ ├── cooccur.c
│ │ │ │ ├── glove.c
│ │ │ │ ├── shuffle.c
│ │ │ │ └── vocab_count.c
│ │ ├── inferSent1-5-fold_predict.py
│ │ ├── inferSent1-5-fold_train.py
│ │ ├── nn02_predict.py
│ │ ├── nn02_train.py
│ │ ├── prepare_rank_train.py
│ │ ├── run.sh
│ │ └── w2v_training.py
│ ├── m2
│ │ ├── bert_5_fold_predict.py
│ │ ├── bert_5_fold_train.py
│ │ ├── bert_preprocessing.py
│ │ ├── change_formatting4stk.py
│ │ ├── final_blend.py
│ │ ├── fold_result_integration.py
│ │ ├── gen_w2v.sh
│ │ ├── mk_submission.py
│ │ ├── model.py
│ │ ├── nn_5_fold_predict.py
│ │ ├── nn_5_fold_train.py
│ │ ├── nn_preprocessing.py
│ │ ├── preprocessing.py
│ │ ├── run.sh
│ │ └── utils.py
│ └── m3
│ │ ├── convert.py
│ │ ├── eval.py
│ │ ├── flow.py
│ │ ├── kfold_merge.py
│ │ ├── lgb_train_32-50-0.py
│ │ ├── lgb_train_37-0.py
│ │ ├── lgb_train_38-0.py
│ │ ├── lgb_train_38-1.py
│ │ └── lgb_train_40-0.py
├── recall
│ └── tfidf_recall_30.py
└── utils
│ └── .gitkeep
├── stk_feat
└── README.md
└── tools
├── __pycache__
├── basic_learner.cpython-37.pyc
├── custom_bm25.cpython-37.pyc
├── custom_metrics.cpython-37.pyc
├── feat_utils.cpython-37.pyc
├── lgb_learner.cpython-37.pyc
├── loader.cpython-37.pyc
├── nlp_preprocess.cpython-37.pyc
└── pandas_util.cpython-37.pyc
├── basic_learner.py
├── basic_learner.pyc
├── custom_bm25.py
├── custom_bm25.pyc
├── custom_metrics.py
├── custom_metrics.pyc
├── feat_utils.py
├── lgb_learner.py
├── lgb_learner.pyc
├── loader.py
├── loader.pyc
├── nlp_preprocess.py
├── pandas_util.py
└── pandas_util.pyc
/README.md:
--------------------------------------------------------------------------------
1 | # WSDM2020-solution
2 | ## Team Name: funny
3 | Team Member: just4fun, greedisgood, slowdown, funny
4 | ## No Data Leak
5 | We achieve map@3 score 0.37458 at part 1 and 0.38020 at part 2 without using any data leak in the competition. During the recall process we search the related papers from the whole dataset without tricky data screening.
6 |
7 | ## Our Basic Solution
8 | data preprocess -> recall by text similarity-> single model (LGB + NN) -> model stacking -> linear ensemble -> final result
9 |
10 |
--------------------------------------------------------------------------------
/feat/README.md:
--------------------------------------------------------------------------------
1 | ## Dir of generated features
2 |
--------------------------------------------------------------------------------
/input/README.md:
--------------------------------------------------------------------------------
1 | ## Dir of input
2 |
--------------------------------------------------------------------------------
/output/README.md:
--------------------------------------------------------------------------------
1 | ## Dir of cv results and results.
2 |
--------------------------------------------------------------------------------
/output/m1/catboost03/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/output/m1/catboost03/.gitkeep
--------------------------------------------------------------------------------
/output/m1/inferSent1/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/output/m1/inferSent1/.gitkeep
--------------------------------------------------------------------------------
/output/m1/nn02/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/output/m1/nn02/.gitkeep
--------------------------------------------------------------------------------
/output/m3/lgb_m3_32-50-0/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/output/m3/lgb_m3_32-50-0/.gitkeep
--------------------------------------------------------------------------------
/output/m3/lgb_m3_37-0/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/output/m3/lgb_m3_37-0/.gitkeep
--------------------------------------------------------------------------------
/output/m3/lgb_m3_38-0/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/output/m3/lgb_m3_38-0/.gitkeep
--------------------------------------------------------------------------------
/src/ensemble/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/src/ensemble/.gitkeep
--------------------------------------------------------------------------------
/src/feature/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/src/feature/.gitkeep
--------------------------------------------------------------------------------
/src/feature/data_preprocess.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import time
8 | from tqdm import tqdm
9 | from datetime import datetime
10 |
11 | # 数据处理
12 | import re
13 | import pickle
14 | import numpy as np
15 | import pandas as pd
16 | from multiprocessing import Pool
17 |
18 | # 自定义工具包
19 | sys.path.append('../../tools/')
20 | import loader
21 | import pandas_util
22 | from nlp_preprocess import preprocess
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | PROCESS_NUM, PARTITION_NUM = 32, 32
27 |
28 | input_root_path = '../../input/'
29 | output_root_path = '../../input/'
30 |
31 | postfix = 'final_all'
32 | file_type = 'ftr'
33 |
34 | tr_out_path = output_root_path + 'tr_input_{}.{}'.format(postfix, file_type)
35 | te_out_path = output_root_path + 'te_input_{}.{}'.format(postfix, file_type)
36 | paper_out_path = output_root_path + 'paper_input_{}.{}'.format(postfix, file_type)
37 |
38 | # 获取关键句函数
39 | def digest(text):
40 | backup = text[:]
41 | text = text.replace('al.', '').split('. ')
42 | t=''
43 | pre_text=[]
44 | len_text=len(text)-1
45 | add=True
46 | pre=''
47 | while len_text>=0:
48 | index=text[len_text]
49 | index+=pre
50 | if len(index.split(' '))<=3 :
51 | add=False
52 | pre=index+pre
53 | else:
54 | add=True
55 | pre=''
56 | if add:
57 | pre_text.append(index)
58 | len_text-=1
59 | if len(pre_text)==0:
60 | pre_text=text
61 | pre_text.reverse()
62 | for index in pre_text:
63 | if index.find('[**##**]') != -1:
64 | index = re.sub(r'[\[|,]+\*\*\#\#\*\*[\]|,]+','',index)
65 | index+='. '
66 | t+=index
67 | return t
68 |
69 | def partition(df, num):
70 | df_partitions, step = [], int(np.ceil(df.shape[0]/num))
71 | for i in range(0, df.shape[0], step):
72 | df_partitions.append(df.iloc[i:i+step])
73 | return df_partitions
74 |
75 | def tr_single_process(params=None):
76 | (tr, i) = params
77 | print (i, 'start', datetime.now())
78 | tr['quer_key'] = tr['description_text'].fillna('').progress_apply(lambda s: preprocess(digest(s)))
79 | tr['quer_all'] = tr['description_text'].fillna('').progress_apply(lambda s: preprocess(s))
80 | print (i, 'completed', datetime.now())
81 | return tr
82 |
83 | def paper_single_process(params=None):
84 | (df, i) = params
85 | print (i, 'start', datetime.now())
86 | df['titl'] = df['title'].fillna('').progress_apply(lambda s: preprocess(s))
87 | df['abst'] = df['abstract'].fillna('').progress_apply(lambda s: preprocess(s))
88 | print (i, 'completed', datetime.now())
89 | return df
90 |
91 | def multi_text_process(df, task, process_num=30):
92 | pool = Pool(process_num)
93 | df_parts = partition(df, process_num)
94 | print ('{} processes init and partition to {} parts' \
95 | .format(process_num, process_num))
96 | param_list = [(df_parts[i], i) for i in range(process_num)]
97 | if task in ['tr', 'te']:
98 | dfs = pool.map(tr_single_process, param_list)
99 | elif task in ['paper']:
100 | dfs = pool.map(paper_single_process, param_list)
101 | df = pd.concat(dfs, axis=0)
102 | print (task, 'multi process completed')
103 | print (df.columns)
104 | return df
105 |
106 | if __name__ == "__main__":
107 |
108 | ts = time.time()
109 | tqdm.pandas()
110 | print('start time: %s' % datetime.now())
111 | # load data
112 | df = loader.load_df(input_root_path + 'candidate_paper_for_wsdm2020.ftr')
113 | tr = loader.load_df(input_root_path + 'train_release.csv')
114 | te = loader.load_df(input_root_path + 'test.csv')
115 | cv = loader.load_df(input_root_path + 'cv_ids_0109.csv')
116 |
117 | # 过滤重复数据 & 异常数据
118 | tr = tr[tr['description_id'].isin(cv['description_id'].tolist())]
119 | tr = tr[tr.description_id != '6.45E+04']
120 |
121 | df = df[~pd.isnull(df['paper_id'])]
122 | tr = tr[~pd.isnull(tr['description_id'])]
123 | print ('pre', te.shape)
124 | te = te[~pd.isnull(te['description_id'])]
125 | print ('post', te.shape)
126 |
127 | #df = df.head(1000)
128 | #tr = tr.head(1000)
129 | #te = te.head(1000)
130 |
131 | tr = multi_text_process(tr, task='tr')
132 | te = multi_text_process(te, task='te')
133 | df = multi_text_process(df, task='paper')
134 |
135 | tr.drop(['description_text'], axis=1, inplace=True)
136 | te.drop(['description_text'], axis=1, inplace=True)
137 | df.drop(['abstract', 'title'], axis=1, inplace=True)
138 | print ('text preprocess completed')
139 |
140 | loader.save_df(tr, tr_out_path)
141 | print (tr.columns)
142 | print (tr.head())
143 |
144 | loader.save_df(te, te_out_path)
145 | print (te.columns)
146 | print (te.head())
147 |
148 | loader.save_df(df, paper_out_path)
149 | print (df.columns)
150 | print (df.head())
151 |
152 | print('all completed: {}, cost {}s'.format(datetime.now(), np.round(time.time() - ts, 2)))
153 |
154 |
155 |
156 |
--------------------------------------------------------------------------------
/src/feature/feat31-50.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # 生成词向量距离特征
5 |
6 | # 基础模块
7 | import os
8 | import gc
9 | import sys
10 | import time
11 | import pickle
12 | from datetime import datetime
13 | from tqdm import tqdm
14 |
15 | # 数据处理
16 | import numpy as np
17 | import pandas as pd
18 | from tqdm import tqdm
19 | from multiprocessing import Pool
20 |
21 | # 自定义工具包
22 | sys.path.append('../../tools/')
23 | import loader
24 | import pandas_util
25 | import custom_bm25 as bm25
26 | from feat_utils import try_divide, dump_feat_name
27 |
28 | # 开源工具包
29 | import nltk
30 | import gensim
31 | from gensim.models import Word2Vec
32 | from gensim.models.word2vec import LineSentence
33 | from gensim import corpora, models, similarities
34 | from gensim.similarities import SparseMatrixSimilarity
35 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
36 |
37 | # 设置随机种子
38 | SEED = 2020
39 |
40 | input_root_path = '../../input/'
41 | output_root_path = '../../feat/'
42 |
43 | postfix = '31-50'
44 | file_type = 'ftr'
45 |
46 | # 当前特征
47 | tr_fea_out_path = output_root_path + 'tr_fea_{}.{}'.format(postfix, file_type)
48 | te_fea_out_path = output_root_path + 'te_fea_{}.{}'.format(postfix, file_type)
49 |
50 | # 当前特征 + 之前特征 merge 之后的完整训练数据
51 | tr_out_path = output_root_path + 'tr_s0_{}.{}'.format(postfix, file_type)
52 | te_out_path = output_root_path + 'te_s0_{}.{}'.format(postfix, file_type)
53 |
54 | ID_NAMES = ['description_id', 'paper_id']
55 | PROCESS_NUM = 15
56 |
57 | # load data
58 | ts = time.time()
59 | dictionary = corpora.Dictionary.load('../../feat/corpus.dict')
60 | tfidf = models.TfidfModel.load('../../feat/tfidf.model')
61 |
62 | print ('load data completed, cost {}s'.format(np.round(time.time() - ts, 2)))
63 |
64 | def sum_score(x, y):
65 | return max(x, 0) + max(y, 0)
66 |
67 | def cos_dis(vec_x, vec_y, norm=False):
68 | if vec_x == None or vec_y == None:
69 | return -1
70 | dic_x = {v[0]: v[1] for v in vec_x}
71 | dic_y = {v[0]: v[1] for v in vec_y}
72 |
73 | dot_prod = 0
74 | for k, x in dic_x.items():
75 | y = dic_y.get(k, 0)
76 | dot_prod += x * y
77 | norm_x = np.linalg.norm([v[1] for v in vec_x])
78 | norm_y = np.linalg.norm([v[1] for v in vec_y])
79 |
80 | cos = dot_prod / (norm_x * norm_y)
81 | return 0.5 * cos + 0.5 if norm else cos # 归一化到[0, 1]区间内
82 |
83 | def eucl_dis(vec_x, vec_y):
84 | if vec_x == None or vec_y == None:
85 | return -1
86 | dic_x = {v[0]: v[1] for v in vec_x}
87 | dic_y = {v[0]: v[1] for v in vec_y}
88 | lis_i = list(set(list(dic_x.keys()) + list(dic_y.keys())))
89 | squa_sum = 0
90 | for i in lis_i:
91 | x, y = dic_x.get(i, 0), dic_y.get(i, 0)
92 | squa_sum += np.square(x - y)
93 | return np.sqrt(squa_sum)
94 |
95 | def manh_dis(vec_x, vec_y):
96 | if vec_x == None or vec_y == None:
97 | return -1
98 | dic_x = {v[0]: v[1] for v in vec_x}
99 | dic_y = {v[0]: v[1] for v in vec_y}
100 | lis_i = list(set(list(dic_x.keys()) + list(dic_y.keys())))
101 | abs_sum = 0
102 | for i in lis_i:
103 | x, y = dic_x.get(i, 0), dic_y.get(i, 0)
104 | abs_sum += np.abs(x - y)
105 | return abs_sum
106 |
107 | def get_bm25_corp(quer, paper_id):
108 | quer_vec = dictionary.doc2bow(quer.split(' '))
109 | corp_score = bm25_corp.get_score(quer_vec, paper_ids.index(paper_id))
110 | return corp_score
111 |
112 | def get_bm25_abst(quer, paper_id):
113 | quer_vec = dictionary.doc2bow(quer.split(' '))
114 | abst_score = bm25_abst.get_score(quer_vec, paper_ids.index(paper_id))
115 | return abst_score
116 |
117 | def get_bm25_titl(quer, paper_id):
118 | quer_vec = dictionary.doc2bow(quer.split(' '))
119 | titl_score = bm25_titl.get_score(quer_vec, paper_ids.index(paper_id))
120 | return titl_score
121 |
122 | def single_process_feat(params=None):
123 | ts = time.time()
124 | (df, i) = params
125 |
126 | ts = time.time()
127 | print (i, 'start', datetime.now())
128 | # tfidf vec dis
129 | df['quer_key_vec'] = df['quer_key'].progress_apply(lambda s: tfidf[dictionary.doc2bow(s.split(' '))])
130 | df['quer_all_vec'] = df['quer_all'].progress_apply(lambda s: tfidf[dictionary.doc2bow(s.split(' '))])
131 | df['titl_vec'] = df['titl'].progress_apply(lambda s: tfidf[dictionary.doc2bow(s.split(' '))])
132 | df['abst_vec'] = df['abst'].progress_apply(lambda s: tfidf[dictionary.doc2bow(s.split(' '))])
133 | df['corp_vec'] = df['corp'].progress_apply(lambda s: tfidf[dictionary.doc2bow(s.split(' '))])
134 | print (i, 'load vec completed, cost {}s'.format(np.round(time.time() - ts), 2))
135 |
136 | ts = time.time()
137 | vec_type = 'tfidf'
138 | for vec_x in ['quer_key', 'quer_all']:
139 | for vec_y in ['abst', 'titl', 'corp']:
140 | df['{}_{}_{}_cos_dis'.format(vec_x, vec_type, vec_y)] = df.progress_apply(lambda row: \
141 | cos_dis(row['{}_vec'.format(vec_x)], row['{}_vec'.format(vec_y)]), axis=1)
142 | df['{}_{}_{}_eucl_dis'.format(vec_x, vec_type, vec_y)] = df.progress_apply(lambda row: \
143 | eucl_dis(row['{}_vec'.format(vec_x)], row['{}_vec'.format(vec_y)]), axis=1)
144 | df['{}_{}_{}_manh_dis'.format(vec_x, vec_type, vec_y)] = df.progress_apply(lambda row: \
145 | manh_dis(row['{}_vec'.format(vec_x)], row['{}_vec'.format(vec_y)]), axis=1)
146 |
147 | print (i, vec_x, 'tfidf completed, cost {}s'.format(np.round(time.time() - ts), 2))
148 |
149 | del_cols = [col for col in df.columns if df[col].dtype == 'O' and col not in ID_NAMES]
150 | print ('del cols', del_cols)
151 | df.drop(del_cols, axis=1, inplace=True)
152 | return df
153 |
154 | def partition(df, num):
155 | df_partitions, step = [], int(np.ceil(df.shape[0]/num))
156 | for i in range(0, df.shape[0], step):
157 | df_partitions.append(df.iloc[i:i+step])
158 | return df_partitions
159 |
160 | def multi_process_feat(df):
161 | pool = Pool(PROCESS_NUM)
162 | df = df[ID_NAMES + ['quer_key', 'quer_all', 'abst', 'titl', 'corp']]
163 | df_parts = partition(df, PROCESS_NUM)
164 | print ('{} processes init and partition to {} parts' \
165 | .format(PROCESS_NUM, PROCESS_NUM))
166 | ts = time.time()
167 |
168 | param_list = [(df_parts[i], i) \
169 | for i in range(PROCESS_NUM)]
170 | dfs = pool.map(single_process_feat, param_list)
171 | df_out = pd.concat(dfs, axis=0)
172 | return df_out
173 |
174 | def gen_samples(paper, tr_desc_path, tr_recall_path, fea_out_path):
175 | tr_desc = loader.load_df(tr_desc_path)
176 | tr = loader.load_df(tr_recall_path)
177 | # tr = tr.head(1000)
178 |
179 | tr = tr.merge(paper, on=['paper_id'], how='left')
180 | tr = tr.merge(tr_desc[['description_id', 'quer_key', 'quer_all']], on=['description_id'], how='left')
181 |
182 | print (tr.columns)
183 | print (tr.head())
184 |
185 | tr_feat = multi_process_feat(tr)
186 | loader.save_df(tr_feat, fea_out_path)
187 |
188 | tr = tr.merge(tr_feat, on=ID_NAMES, how='left')
189 | del_cols = [col for col in tr.columns if tr[col].dtype == 'O' and col not in ID_NAMES]
190 | print ('tr del cols', del_cols)
191 | return tr.drop(del_cols, axis=1)
192 |
193 |
194 | # 增加 vec sim 特征
195 |
196 | if __name__ == "__main__":
197 |
198 | ts = time.time()
199 | tqdm.pandas()
200 | print('start time: %s' % datetime.now())
201 | paper = loader.load_df('../../input/paper_input_final.ftr')
202 | paper['abst'] = paper['abst'].apply(lambda s: s.replace('no_content', ''))
203 | paper['corp'] = paper['abst'] + ' ' + paper['titl'] + ' ' + paper['keywords'].fillna('').replace(';', ' ')
204 |
205 | tr_desc_path = '../../input/tr_input_final.ftr'
206 | te_desc_path = '../../input/te_input_final.ftr'
207 |
208 | tr_recall_path = '../../feat/tr_s0_30-50.ftr'
209 | te_recall_path = '../../feat/te_s0_30-50.ftr'
210 |
211 | tr = gen_samples(paper, tr_desc_path, tr_recall_path, tr_fea_out_path)
212 | print (tr.columns)
213 | print ([col for col in tr.columns if tr[col].dtype == 'O'])
214 | loader.save_df(tr, tr_out_path)
215 |
216 | te = gen_samples(paper, te_desc_path, te_recall_path, te_fea_out_path)
217 | print (te.columns)
218 | loader.save_df(te, te_out_path)
219 | print('all completed: {}, cost {}s'.format(datetime.now(), np.round(time.time() - ts, 2)))
220 |
221 |
222 |
223 |
224 |
--------------------------------------------------------------------------------
/src/feature/feat37-pairwise.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # 生成词向量距离特征
5 |
6 | # 基础模块
7 | import os
8 | import gc
9 | import sys
10 | import time
11 | import pickle
12 | from datetime import datetime
13 | from tqdm import tqdm
14 |
15 | # 数据处理
16 | import numpy as np
17 | import pandas as pd
18 | from tqdm import tqdm
19 | from multiprocessing import Pool
20 |
21 | # 自定义工具包
22 | sys.path.append('../../tools/')
23 | import loader
24 | import pandas_util
25 | import custom_bm25 as bm25
26 | from feat_utils import try_divide, dump_feat_name
27 |
28 | # 开源工具包
29 | import nltk
30 | import gensim
31 | from gensim.models import Word2Vec
32 | from gensim.models.word2vec import LineSentence
33 | from gensim import corpora, models, similarities
34 | from gensim.similarities import SparseMatrixSimilarity
35 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
36 |
37 | # 设置随机种子
38 | SEED = 2020
39 |
40 | input_root_path = '../../input/'
41 | output_root_path = '../../feat/'
42 |
43 | FEA_NUM = '37'
44 | postfix = 's0_{}'.format(FEA_NUM)
45 | file_type = 'ftr'
46 |
47 | # 当前特征
48 | tr_fea_out_path = output_root_path + 'tr_fea_{}.{}'.format(postfix, file_type)
49 | te_fea_out_path = output_root_path + 'te_fea_{}.{}'.format(postfix, file_type)
50 |
51 | # 当前特征 + 之前特征 merge 之后的完整训练数据
52 | tr_out_path = output_root_path + 'tr_{}.{}'.format(postfix, file_type)
53 | te_out_path = output_root_path + 'te_{}.{}'.format(postfix, file_type)
54 |
55 | ID_NAMES = ['description_id', 'paper_id']
56 | PROCESS_NUM = 20
57 |
58 | # load data
59 | ts = time.time()
60 |
61 | def feat_extract(df, is_te=False):
62 | if is_te:
63 | df_pred = loader.load_df('../../output/m3/lgb_m3_32-50-0/lgb_m3_32-50-0.ftr')
64 | else:
65 | df_pred = loader.load_df('../../output/m3/lgb_m3_32-50-0/lgb_m3_32-50-0_cv.ftr')
66 | df_pred = df_pred[ID_NAMES + ['target']]
67 |
68 | df_pred = df_pred.sort_values(by=['target'], ascending=False)
69 | df_pred['pred_rank'] = df_pred.groupby(['description_id']).cumcount().values
70 | df_pred = df_pred.sort_values(by=['description_id', 'target'])
71 | print (df_pred.shape)
72 | print (df_pred.head(10))
73 |
74 | pred_top1 = df_pred[df_pred['pred_rank'] == 0] \
75 | .drop_duplicates(subset='description_id', keep='first')
76 | pred_top1 = pred_top1[['description_id', 'target']]
77 | pred_top1.columns = ['description_id', 'top1_pred']
78 |
79 | pred_top2 = df_pred[df_pred['pred_rank'] < 2]
80 | pred_top2['top2_pred_avg'] = pred_top2.groupby('description_id')['target'].transform('mean')
81 | pred_top2['top2_pred_std'] = pred_top2.groupby('description_id')['target'].transform('std')
82 | pred_top2 = pred_top2[['description_id', 'top2_pred_avg', \
83 | 'top2_pred_std']].drop_duplicates(subset=['description_id'])
84 |
85 | pred_top3 = df_pred[df_pred['pred_rank'] < 3]
86 | pred_top3['top3_pred_avg'] = pred_top3.groupby('description_id')['target'].transform('mean')
87 | pred_top3['top3_pred_std'] = pred_top3.groupby('description_id')['target'].transform('std')
88 | pred_top3 = pred_top3[['description_id', 'top3_pred_avg', \
89 | 'top3_pred_std']].drop_duplicates(subset=['description_id'])
90 |
91 | pred_top5 = df_pred[df_pred['pred_rank'] < 5]
92 | pred_top5['top5_pred_avg'] = pred_top5.groupby('description_id')['target'].transform('mean')
93 | pred_top5['top5_pred_std'] = pred_top5.groupby('description_id')['target'].transform('std')
94 | pred_top5 = pred_top5[['description_id', 'top5_pred_avg', \
95 | 'top5_pred_std']].drop_duplicates(subset=['description_id'])
96 |
97 | df_pred.rename(columns={'target': 'pred'}, inplace=True)
98 | df = df.merge(df_pred, on=ID_NAMES, how='left')
99 | df = df.merge(pred_top1, on=['description_id'], how='left')
100 | df = df.merge(pred_top2, on=['description_id'], how='left')
101 | df = df.merge(pred_top3, on=['description_id'], how='left')
102 | df = df.merge(pred_top5, on=['description_id'], how='left')
103 |
104 | df['pred_sub_top1'] = df['pred'] - df['top1_pred']
105 | df['pred_sub_top2_avg'] = df['pred'] - df['top2_pred_avg']
106 | df['pred_sub_top3_avg'] = df['pred'] - df['top3_pred_avg']
107 | df['pred_sub_top5_avg'] = df['pred'] - df['top5_pred_avg']
108 |
109 | del_cols = ['paper_id', 'pred', 'pred_rank']
110 | df.drop(del_cols, axis=1, inplace=True)
111 | df_feat = df.drop_duplicates(subset=['description_id'])
112 |
113 | print ('df_feat info')
114 | print (df_feat.shape)
115 | print (df_feat.head())
116 | print (df_feat.columns.tolist())
117 |
118 | return df_feat
119 |
120 | def output_fea(tr, te):
121 | print (tr.head())
122 | print (te.head())
123 |
124 | loader.save_df(tr, tr_fea_out_path)
125 | loader.save_df(te, te_fea_out_path)
126 |
127 | def gen_fea():
128 | tr = loader.load_df('../../feat/tr_s0_32-50.ftr')
129 | te = loader.load_df('../../feat/te_s0_32-50.ftr')
130 |
131 | tr_feat = feat_extract(tr[ID_NAMES])
132 | te_feat = feat_extract(te[ID_NAMES], is_te=True)
133 |
134 | tr = tr[ID_NAMES].merge(tr_feat, on=['description_id'], how='left')
135 | te = te[ID_NAMES].merge(te_feat, on=['description_id'], how='left')
136 |
137 | print (tr.shape, te.shape)
138 | print (tr.head())
139 | print (te.head())
140 | print (tr.columns)
141 |
142 | output_fea(tr, te)
143 |
144 | # merge 已有特征
145 | def merge_fea(tr_list, te_list):
146 | tr = loader.merge_fea(tr_list, primary_keys=ID_NAMES)
147 | te = loader.merge_fea(te_list, primary_keys=ID_NAMES)
148 |
149 | print (tr.head())
150 | print (te.head())
151 | print (tr.columns.tolist())
152 |
153 | loader.save_df(tr, tr_out_path)
154 | loader.save_df(te, te_out_path)
155 |
156 | if __name__ == "__main__":
157 |
158 | print('start time: %s' % datetime.now())
159 | root_path = '../../feat/'
160 | base_tr_path = root_path + 'tr_s0_32-50.ftr'
161 | base_te_path = root_path + 'te_s0_32-50.ftr'
162 |
163 | gen_fea()
164 |
165 | # merge fea
166 | prefix = 's0'
167 | fea_list = [FEA_NUM]
168 |
169 | tr_list = [base_tr_path] + \
170 | [root_path + 'tr_fea_{}_{}.ftr'.format(prefix, i) for i in fea_list]
171 | te_list = [base_te_path] + \
172 | [root_path + 'te_fea_{}_{}.ftr'.format(prefix, i) for i in fea_list]
173 |
174 | merge_fea(tr_list, te_list)
175 |
176 | print('all completed: %s' % datetime.now())
177 |
178 |
179 |
--------------------------------------------------------------------------------
/src/feature/feat38-stk.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # 生成词向量距离特征
5 |
6 | # 基础模块
7 | import os
8 | import gc
9 | import sys
10 | import time
11 | import pickle
12 | from datetime import datetime
13 | from tqdm import tqdm
14 |
15 | # 数据处理
16 | import numpy as np
17 | import pandas as pd
18 | from tqdm import tqdm
19 | from multiprocessing import Pool
20 |
21 | # 自定义工具包
22 | sys.path.append('../../tools/')
23 | import loader
24 | import pandas_util
25 | import custom_bm25 as bm25
26 | from preprocess import preprocess
27 | from feat_utils import try_divide, dump_feat_name
28 |
29 | # 开源工具包
30 | import nltk
31 | import gensim
32 | from gensim.models import Word2Vec
33 | from gensim.models.word2vec import LineSentence
34 | from gensim import corpora, models, similarities
35 | from gensim.similarities import SparseMatrixSimilarity
36 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
37 |
38 | # 设置随机种子
39 | SEED = 2020
40 |
41 | input_root_path = '../../input/'
42 | output_root_path = '../../feat/'
43 |
44 | FEA_NUM = 38
45 |
46 | postfix = 's0_{}'.format(FEA_NUM)
47 | file_type = 'ftr'
48 |
49 | # 当前特征
50 | tr_fea_out_path = output_root_path + 'tr_fea_{}.{}'.format(postfix, file_type)
51 | te_fea_out_path = output_root_path + 'te_fea_{}.{}'.format(postfix, file_type)
52 |
53 | # 当前特征 + 之前特征 merge 之后的完整训练数据
54 | tr_out_path = output_root_path + 'tr_{}.{}'.format(postfix, file_type)
55 | te_out_path = output_root_path + 'te_{}.{}'.format(postfix, file_type)
56 |
57 | ID_NAMES = ['description_id', 'paper_id']
58 | PROCESS_NUM = 20
59 |
60 | # load data
61 | ts = time.time()
62 |
63 | def feat_extract(tr_path, te_path, prefix):
64 | tr_sample = loader.load_df('../../feat/tr_s0_37.ftr')
65 | te_sample = loader.load_df('../../feat/te_s0_37.ftr')
66 |
67 | tr = loader.load_df(tr_path)
68 | te = loader.load_df(te_path)
69 |
70 | del_cols = ['label']
71 | del_cols = [col for col in tr.columns if col in del_cols]
72 | tr.drop(del_cols, axis=1, inplace=True)
73 |
74 | tr = tr_sample[ID_NAMES].merge(tr, on=ID_NAMES, how='left')
75 | te = te_sample[ID_NAMES].merge(te, on=ID_NAMES, how='left')
76 |
77 | tr.columns = ID_NAMES + [prefix]
78 | te.columns = ID_NAMES + [prefix]
79 |
80 | print (prefix)
81 | print (tr.shape, te.shape)
82 | print (tr.head())
83 |
84 | tr = tr[prefix]
85 | te = te[prefix]
86 |
87 | return tr, te
88 |
89 | def output_fea(tr, te):
90 | print (tr.head())
91 | print (te.head())
92 |
93 | loader.save_df(tr, tr_fea_out_path)
94 | loader.save_df(te, te_fea_out_path)
95 |
96 | # 生成特征
97 | def gen_fea(base_tr_path=None, base_te_path=None):
98 |
99 | tr_sample = loader.load_df('../../feat/tr_s0_37.ftr')
100 | te_sample = loader.load_df('../../feat/te_s0_37.ftr')
101 |
102 | prefixs = ['m1_cat_03', 'm1_infesent_simple', 'm1_nn_02', \
103 | 'm2_ESIM_001', 'm2_ESIMplus_001', 'lgb_m3_37-0']
104 |
105 | tr_paths = ['{}_tr.ftr'.format(prefix) for prefix in prefixs]
106 | te_paths = ['final_{}_te.ftr'.format(prefix) for prefix in prefixs]
107 |
108 | tr_paths = ['../../stk_feat/{}'.format(p) for p in tr_paths]
109 | te_paths = ['../../stk_feat/{}'.format(p) for p in te_paths]
110 |
111 |
112 | trs, tes = [], []
113 | for i, prefix in enumerate(prefixs):
114 | tr, te = feat_extract(tr_paths[i], te_paths[i], prefix + '_prob')
115 | trs.append(tr)
116 | tes.append(te)
117 | tr = pd.concat([tr_sample[ID_NAMES]] + trs, axis=1)
118 | te = pd.concat([te_sample[ID_NAMES]] + tes, axis=1)
119 |
120 | float_cols = [c for c in tr.columns if tr[c].dtype == 'float']
121 | tr[float_cols] = tr[float_cols].astype('float32')
122 | te[float_cols] = te[float_cols].astype('float32')
123 |
124 | print (tr.shape, te.shape)
125 | print (tr.head())
126 | print (te.head())
127 | print (tr.columns)
128 |
129 | output_fea(tr, te)
130 |
131 | # merge 已有特征
132 | def merge_fea(tr_list, te_list):
133 | tr = loader.merge_fea(tr_list, primary_keys=ID_NAMES)
134 | te = loader.merge_fea(te_list, primary_keys=ID_NAMES)
135 |
136 | print (tr.head())
137 | print (te.head())
138 | print (tr.columns.tolist())
139 |
140 | loader.save_df(tr, tr_out_path)
141 | loader.save_df(te, te_out_path)
142 |
143 | if __name__ == "__main__":
144 |
145 | print('start time: %s' % datetime.now())
146 | root_path = '../../feat/'
147 | base_tr_path = root_path + 'tr_s0_37.ftr'
148 | base_te_path = root_path + 'te_s0_37.ftr'
149 |
150 | gen_fea()
151 |
152 | # merge fea
153 | prefix = 's0'
154 | fea_list = [FEA_NUM]
155 |
156 | tr_list = [base_tr_path] + \
157 | [root_path + 'tr_fea_{}_{}.ftr'.format(prefix, i) for i in fea_list]
158 | te_list = [base_te_path] + \
159 | [root_path + 'te_fea_{}_{}.ftr'.format(prefix, i) for i in fea_list]
160 |
161 | merge_fea(tr_list, te_list)
162 |
163 | print('all completed: %s' % datetime.now())
164 |
165 |
166 |
167 |
--------------------------------------------------------------------------------
/src/feature/gen_samples.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | import warnings
5 | warnings.filterwarnings('always')
6 | warnings.filterwarnings('ignore')
7 |
8 | # 基础模块
9 | import os
10 | import sys
11 | import time
12 | from datetime import datetime
13 | from tqdm import tqdm
14 |
15 | # 数据处理
16 | import numpy as np
17 | import pandas as pd
18 |
19 | # 自定义工具包
20 | sys.path.append('../../tools/')
21 | import loader
22 | import pandas_util
23 |
24 | # 开源工具包
25 | from gensim.models import Word2Vec
26 | from gensim.models.word2vec import LineSentence
27 | from gensim import corpora, models, similarities
28 | from gensim.similarities import SparseMatrixSimilarity
29 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
30 |
31 | # 设置随机种子
32 | SEED = 2020
33 |
34 | def topk_lines(df, k):
35 | df.loc[:, 'rank'] = df.groupby(['description_id']).cumcount().values
36 | df = df[df['rank'] < k]
37 | df.drop(['rank'], axis=1, inplace=True)
38 | return df
39 |
40 | def process(in_path, k):
41 | ID_NAMES = ['description_id', 'paper_id']
42 |
43 | df = loader.load_df(in_path)
44 | df = topk_lines(df, k)
45 | df['sim_score'] = df['sim_score'].astype('float')
46 | df.rename(columns={'sim_score': 'corp_sim_score'}, inplace=True)
47 | return df
48 |
49 |
50 | if __name__ == "__main__":
51 |
52 | ts = time.time()
53 | tr_path = '../../feat/tr_tfidf_30.ftr'
54 | te_path = '../../feat/te_tfidf_30.ftr'
55 |
56 | cv = loader.load_df('../../input/cv_ids_0109.csv')[['description_id', 'cv']]
57 |
58 | tr = process(tr_path, k=50)
59 | tr = tr.merge(cv, on=['description_id'], how='left')
60 |
61 | te = process(te_path, k=50)
62 | te['cv'] = 0
63 |
64 | loader.save_df(tr, '../../feat/tr_samples_30-50.ftr')
65 | loader.save_df(te, '../../feat/te_samples_30-50.ftr')
66 | print('all completed: {}, cost {}s'.format(datetime.now(), np.round(time.time() - ts, 2)))
67 |
68 |
69 |
70 |
71 |
72 |
--------------------------------------------------------------------------------
/src/feature/tfidf_recall_30.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # bm25 recall
5 |
6 | # 基础模块
7 | import os
8 | import gc
9 | import sys
10 | import time
11 | import functools
12 | from tqdm import tqdm
13 | from six import iteritems
14 | from datetime import datetime
15 |
16 | # 数据处理
17 | import re
18 | import math
19 | import pickle
20 | import numpy as np
21 | import pandas as pd
22 | from multiprocessing import Pool
23 |
24 | # 自定义工具包
25 | sys.path.append('../../tools/')
26 | import loader
27 | import pandas_util
28 | import custom_bm25 as bm25
29 |
30 | # 开源工具包
31 | from gensim.models import Word2Vec
32 | from gensim.models.word2vec import LineSentence
33 | from gensim import corpora, models, similarities
34 | from gensim.similarities import SparseMatrixSimilarity
35 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
36 |
37 | # 设置随机种子
38 | SEED = 2020
39 | PROCESS_NUM, PARTITION_NUM = 18, 18
40 |
41 | input_root_path = '../../input/'
42 | output_root_path = '../../feat/'
43 |
44 | postfix = '30'
45 | file_type = 'ftr'
46 |
47 | train_out_path = output_root_path + 'tr_tfidf_{}.{}'.format(postfix, file_type)
48 | test_out_path = output_root_path + 'te_tfidf_{}.{}'.format(postfix, file_type)
49 |
50 | def topk_sim_samples(desc, desc_ids, paper_ids, bm25_model, k=10):
51 | desc_id2papers = {}
52 | for desc_i in tqdm(range(len(desc))):
53 | query_vec, query_desc_id = desc[desc_i], desc_ids[desc_i]
54 | sims = bm25_model.get_scores(query_vec)
55 | sort_sims = sorted(enumerate(sims), key=lambda item: -item[1])
56 | sim_papers = [paper_ids[val[0]] for val in sort_sims[:k]]
57 | sim_scores = [str(val[1]) for val in sort_sims[:k]]
58 | desc_id2papers[query_desc_id] = ['|'.join(sim_papers), '|'.join(sim_scores)]
59 | sim_df = pd.DataFrame.from_dict(desc_id2papers, orient='index', columns=['paper_id', 'sim_score'])
60 | sim_df = sim_df.reset_index().rename(columns={'index':'description_id'})
61 | return sim_df
62 |
63 | def partition(queries, num):
64 | queries_partitions, step = [], int(np.ceil(len(queries)/num))
65 | for i in range(0, len(queries), step):
66 | queries_partitions.append(queries[i:i+step])
67 | return queries_partitions
68 |
69 | def single_process_search(params=None):
70 | (query_vecs, desc_ids, paper_ids, bm25_model, k, i) = params
71 | print (i, 'start', datetime.now())
72 | gc.collect()
73 | sim_df = topk_sim_samples(query_vecs, desc_ids, paper_ids, bm25_model, k)
74 | print (i, 'completed', datetime.now())
75 | return sim_df
76 |
77 | def multi_process_search(query_vecs, desc_ids, paper_ids, bm25_model, k):
78 | pool = Pool(PROCESS_NUM)
79 | queries_parts = partition(query_vecs, PARTITION_NUM)
80 | desc_ids_parts = partition(desc_ids, PARTITION_NUM)
81 | print ('{} processes init and partition to {} parts' \
82 | .format(PROCESS_NUM, PARTITION_NUM))
83 |
84 | param_list = [(queries_parts[i], desc_ids_parts[i], \
85 | paper_ids, bm25_model, k, i) for i in range(PARTITION_NUM)]
86 | sim_dfs = pool.map(single_process_search, param_list)
87 | sim_df = pd.concat(sim_dfs, axis=0)
88 | return sim_df
89 |
90 | def gen_samples(df, desc, desc_ids, corpus_list, paper_ids_list, k):
91 | df_samples_list = []
92 | for i, corpus in enumerate(corpus_list):
93 | bm25_model = bm25.BM25(corpus[0])
94 | cur_df_sample = multi_process_search(desc, desc_ids, \
95 | paper_ids_list[i], bm25_model, k)
96 | cur_df_sample_out = pandas_util.explode(cur_df_sample, ['paper_id', 'sim_score'])
97 | cur_df_sample_out['type'] = corpus[1] # recall_name
98 | df_samples_list.append(cur_df_sample_out)
99 | df_samples = pd.concat(df_samples_list, axis=0)
100 | df_samples.drop_duplicates(subset=['description_id', 'paper_id'], inplace=True)
101 | df_samples['target'] = 0
102 | return df_samples
103 |
104 | if __name__ == "__main__":
105 |
106 | ts = time.time()
107 | tqdm.pandas()
108 | print('start time: %s' % datetime.now())
109 | # load data
110 | df = loader.load_df(input_root_path + 'paper_input_final.ftr')
111 | df = df[~pd.isnull(df['paper_id'])]
112 |
113 | # gen tfidf vecs
114 | dictionary = pickle.load(open('../../feat/corpus.dict', 'rb'))
115 | print ('dic len', len(dictionary))
116 |
117 | df['corp'] = df['abst'] + ' ' + df['titl'] + ' ' + df['keywords'].fillna('').replace(';', ' ')
118 | df_corp, corp_paper_ids = [dictionary.doc2bow(line.split(' ')) for line in df['corp'].tolist()], \
119 | df['paper_id'].tolist()
120 |
121 | # gen topk sim samples
122 | paper_ids_list = [corp_paper_ids]
123 | corpus_list = [(df_corp, 'corp_bm25')]
124 | out_cols = ['description_id', 'paper_id', 'sim_score', 'target', 'type']
125 |
126 | if sys.argv[1] in ['tr']:
127 | # for tr ins
128 | tr = loader.load_df(input_root_path + 'tr_input_final.ftr')
129 | tr = tr[~pd.isnull(tr['description_id'])]
130 |
131 | # tr = tr.head(1000)
132 | tr_desc, tr_desc_ids = [dictionary.doc2bow(line.split(' ')) for line in tr['quer_all'].tolist()], \
133 | tr['description_id'].tolist()
134 | print ('gen tf completed, cost {}s'.format(np.round(time.time() - ts, 2)))
135 |
136 | tr_samples = gen_samples(tr, tr_desc, tr_desc_ids, \
137 | corpus_list, paper_ids_list, k=50)
138 | tr_samples = tr.rename(columns={'paper_id': 'target_paper_id'}) \
139 | .merge(tr_samples, on='description_id', how='left')
140 | tr_samples.loc[tr_samples['target_paper_id'] == tr_samples['paper_id'], 'target'] = 1
141 | loader.save_df(tr_samples[out_cols], train_out_path)
142 | print ('recall succ {} from {}'.format(tr_samples['target'].sum(), tr.shape[0]))
143 | print (tr.shape, tr_samples.shape)
144 |
145 | if sys.argv[1] in ['te']:
146 | # for te ins
147 | te = loader.load_df(input_root_path + 'te_input_final.ftr')
148 | te = te[~pd.isnull(te['description_id'])]
149 |
150 | # te = te.head(1000)
151 | te_desc, te_desc_ids = [dictionary.doc2bow(line.split(' ')) for line in te['quer_all'].tolist()], \
152 | te['description_id'].tolist()
153 | print ('gen tf completed, cost {}s'.format(np.round(time.time() - ts, 2)))
154 |
155 | te_samples = gen_samples(te, te_desc, te_desc_ids, \
156 | corpus_list, paper_ids_list, k=50)
157 | te_samples = te.merge(te_samples, on='description_id', how='left')
158 | loader.save_df(te_samples[out_cols], test_out_path)
159 | print (te.shape, te_samples.shape)
160 |
161 | print('all completed: {}, cost {}s'.format(datetime.now(), np.round(time.time() - ts, 2)))
162 |
163 |
164 |
165 |
--------------------------------------------------------------------------------
/src/rank/m1/catboost03.py:
--------------------------------------------------------------------------------
1 |
2 | # coding: utf-8
3 |
4 | # In[1]:
5 |
6 |
7 | import numpy as np
8 | import pandas as pd
9 | import datetime
10 | from catboost import CatBoostClassifier
11 | from time import time
12 | from tqdm import tqdm_notebook as tqdm
13 |
14 |
15 | # In[2]:
16 |
17 |
18 | feat_dir = "../../../feat/"
19 | input_dir = "../../../input/"
20 | cv_id = pd.read_csv("../../../input/cv_ids_0109.csv")
21 |
22 |
23 | # In[3]:
24 |
25 |
26 | train = pd.read_feather(f'{feat_dir}/tr_s0_32-50.ftr')
27 | train.drop(columns=['cv'],axis=1,inplace=True)
28 | train = train.merge(cv_id,on=['description_id'],how='left')
29 | train = train.dropna(subset=['cv']).reset_index(drop=True)
30 | # test = pd.read_feather(f'{feat_dir}/te_s0_20-50.ftr')
31 | test = pd.read_feather(f'{feat_dir}/te_s0_32-50.ftr')
32 |
33 |
34 | # In[4]:
35 |
36 |
37 | ID_NAMES = ['description_id', 'paper_id']
38 | TARGET_NAME = 'target'
39 |
40 |
41 | # In[5]:
42 |
43 |
44 | def get_feas(data):
45 | cols = data.columns.tolist()
46 | del_cols = ID_NAMES + ['target', 'cv']
47 | #sub_cols = ['year', 'corp_cos', 'corp_eucl', 'corp_manh', 'quer_all']
48 | sub_cols = ['year', 'corp_sim_score']
49 | sub_cols = ['year', 'pos_of_corp', 'pos_of_abst', 'pos_of_titl']
50 | for col in data.columns:
51 | for sub_col in sub_cols:
52 | if sub_col in col:
53 | del_cols.append(col)
54 |
55 | cols = [val for val in cols if val not in del_cols]
56 | print ('del_cols', del_cols)
57 | return cols
58 |
59 |
60 | # In[6]:
61 |
62 |
63 | feas = get_feas(train)
64 |
65 |
66 | # In[7]:
67 |
68 |
69 | def make_classifier():
70 | clf = CatBoostClassifier(
71 | loss_function='Logloss',
72 | eval_metric="AUC",
73 | # task_type="CPU",
74 | learning_rate=0.1, ###0.01
75 | iterations=2500, ###2000
76 | od_type="Iter",
77 | # depth=8,
78 | thread_count=10,
79 | early_stopping_rounds=100, ###100
80 | # l2_leaf_reg=1,
81 | # border_count=96,
82 | random_seed=42
83 | )
84 |
85 | return clf
86 |
87 |
88 | # In[8]:
89 |
90 |
91 | # 开源工具包
92 | import ml_metrics as metrics
93 | def cal_map(pred_valid,cv,train_df,tr_data):
94 | df_pred = train_df[train_df['cv']==cv].copy()
95 | df_pred['pred'] = pred_valid
96 | df_pred = df_pred[['description_id','paper_id','pred']]
97 | sort_df_pred = df_pred.sort_values(['description_id', 'pred'], ascending=False)
98 | df_pred = df_pred[['description_id']].drop_duplicates() .merge(sort_df_pred, on=['description_id'], how='left')
99 | df_pred['rank'] = df_pred.groupby('description_id').cumcount().values
100 | df_pred = df_pred[df_pred['rank'] < 3]
101 | df_pred = df_pred.groupby(['description_id'])['paper_id'] .apply(lambda s : ','.join((s))).reset_index()
102 | df_pred = df_pred.merge(tr_data, on=['description_id'], how='left')
103 | df_pred.rename(columns={'paper_id': 'paper_ids'}, inplace=True)
104 | df_pred['paper_ids'] = df_pred['paper_ids'].apply(lambda s: s.split(','))
105 | df_pred['target_id'] = df_pred['target_id'].apply(lambda s: [s])
106 | return metrics.mapk(df_pred['target_id'].tolist(), df_pred['paper_ids'].tolist(), 3)
107 |
108 |
109 | # In[9]:
110 |
111 |
112 | import os
113 | model_dir = "./m1_model/catboost03"
114 | if not os.path.exists(model_dir):
115 | os.makedirs(model_dir)
116 |
117 |
118 | # In[10]:
119 |
120 |
121 | tr_data = pd.read_csv(f'{input_dir}/train_release.csv')
122 | tr_data = tr_data[['description_id', 'paper_id']].rename(columns={'paper_id': 'target_id'})
123 |
124 |
125 | # In[13]:
126 |
127 |
128 | for fea in feas:
129 | if fea not in test.columns:
130 | print(fea)
131 |
132 |
133 | # In[14]:
134 |
135 |
136 | CV_RESULT_OUT=True
137 |
138 |
139 | # In[15]:
140 |
141 |
142 | def train_one_fold(type_train_df,type_test_df,model_dir,cv,pi=False):
143 | print(" fold " + str(cv))
144 | train_data = type_train_df[(type_train_df['cv']!=cv)]
145 | valid_data = type_train_df[(type_train_df['cv']==cv)]
146 |
147 | des_id = valid_data['description_id']
148 | paper_id = valid_data['paper_id']
149 |
150 | idx_train = train_data.index
151 | idx_val = valid_data.index
152 | des_id = valid_data['description_id']
153 | paper_id = valid_data['paper_id']
154 | model_name = "fold_{}_cbt_best.model".format(str(cv))
155 | model_name_wrt = os.path.join(model_dir,model_name)
156 | clf = make_classifier()
157 | imp=pd.DataFrame()
158 | if not os.path.exists(model_name_wrt):
159 | clf.fit(train_data[feas], train_data[['target']], eval_set=(valid_data[feas],valid_data[['target']]),
160 | use_best_model=True, verbose=100)
161 | clf.save_model(model_name_wrt)
162 | fea_ = clf.feature_importances_
163 | fea_name = clf.feature_names_
164 | imp = pd.DataFrame({'name':fea_name,'imp':fea_})
165 | else:
166 | clf.load_model(model_name_wrt)
167 | cv_predict=clf.predict_proba(valid_data[feas])[:,1]
168 | # print(cv_predict.shape)
169 | cv_score_fold = cal_map(cv_predict,cv,type_train_df,tr_data)
170 | if CV_RESULT_OUT:
171 | cv_preds = cv_predict
172 | rdf = pd.DataFrame()
173 | rdf = rdf.reindex(columns=['description_id','paper_id','pred'])
174 | rdf['description_id'] = des_id
175 | rdf['paper_id'] = paper_id
176 | rdf['pred'] = cv_preds
177 | test_des_id = type_test_df['description_id']
178 | test_paper_id = type_test_df['paper_id']
179 | test_preds = clf.predict_proba(type_test_df[feas])[:,1]
180 | test_df = pd.DataFrame()
181 | test_df = test_df.reindex(columns=['description_id','paper_id','pred'])
182 | test_df['description_id'] = test_des_id
183 | test_df['paper_id'] = test_paper_id
184 | test_df['pred'] = test_preds
185 | return rdf,test_df,cv_score_fold,imp
186 |
187 |
188 | # In[16]:
189 |
190 |
191 | kfold = 5
192 | type_scores = []
193 | type_cv_results = []
194 | type_test_results = []
195 | model_name = '../../../output/m1/catboost03/'
196 | fold_scores = []
197 | fold_cv_results = []
198 | fold_test_results = []
199 | imps=[]
200 | # test_preds = np.zeros(len(test))
201 | for cv in range(1,kfold+1):#####这里是因为cv是1~5
202 | cv_df,test_df,cv_score,imp = train_one_fold(train,test,model_dir,cv)
203 | # fold_cv_results.append(cv_df)
204 | # fold_test_results.append(test_df)
205 | cv_df.to_csv(f"{model_name}_cv_{cv}.csv",index=False)
206 | test_df.to_csv(f"{model_name}_result_{cv}.csv",index=False)
207 | imp.to_csv(f"{model_name}_imp_{cv}.csv",index=False)
208 | print("fold {} finished".format(cv))
209 | print(cv_score)
210 | fold_scores.append(cv_score)
211 | imps.append(imp)
212 |
213 |
214 | # In[1]:
215 |
216 |
217 | np.mean(fold_scores)
218 |
219 | #0.35309347230573923
220 | #0.3522860689007414
221 | #0.3585175465159315
222 | #0.35720084429290466
223 | #0.34729405401751007
224 |
225 |
226 | # In[ ]:
227 |
228 |
229 | result = []
230 | for i in range(1,6):
231 | re_csv = f"{model_name}_result_{i}.csv"
232 | test_df = pd.read_csv(re_csv)
233 | result.append(test_df)
234 |
235 |
236 | # In[ ]:
237 |
238 |
239 | final_test = result[0].copy()
240 |
241 |
242 | # In[ ]:
243 |
244 |
245 | for i in range(1,5):
246 | final_test['pred']+=result[i]['pred']
247 |
248 |
249 | # In[ ]:
250 |
251 |
252 | final_test['pred'] = final_test['pred']/5
253 |
254 |
255 | # In[ ]:
256 |
257 |
258 | final_test.to_csv("../../../output/m1/nn02/te_catboost03newtest.csv",index=False)
259 |
260 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/.gitignore:
--------------------------------------------------------------------------------
1 | # Object files
2 | *.o
3 | *.ko
4 | *.obj
5 | *.elf
6 |
7 | # Precompiled Headers
8 | *.gch
9 | *.pch
10 |
11 | # Libraries
12 | *.lib
13 | *.a
14 | *.la
15 | *.lo
16 |
17 | # Shared objects (inc. Windows DLLs)
18 | *.dll
19 | *.so
20 | *.so.*
21 | *.dylib
22 |
23 | # Executables
24 | *.exe
25 | *.out
26 | *.app
27 | *.i*86
28 | *.x86_64
29 | *.hex
30 |
31 | # Debug files
32 | *.dSYM/
33 |
34 |
35 | build/*
36 | *.swp
37 |
38 | # OS X stuff
39 | ._*
40 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/.travis.yml:
--------------------------------------------------------------------------------
1 | language: c
2 | dist: trusty
3 | sudo: required
4 | before_install:
5 | - sudo apt-get install python2.7 python-numpy python-pip
6 | script: pip install numpy && ./demo.sh | tee results.txt && [[ `cat results.txt | egrep "Total accuracy. 2[23]" | wc -l` = "1" ]] && echo test-passed
7 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/Makefile:
--------------------------------------------------------------------------------
1 | CC = gcc
2 | #For older gcc, use -O3 or -O2 instead of -Ofast
3 | # CFLAGS = -lm -pthread -Ofast -march=native -funroll-loops -Wno-unused-result
4 | CFLAGS = -lm -pthread -Ofast -march=native -funroll-loops -Wall -Wextra -Wpedantic
5 | BUILDDIR := build
6 | SRCDIR := src
7 |
8 | all: dir glove shuffle cooccur vocab_count
9 |
10 | dir :
11 | mkdir -p $(BUILDDIR)
12 | glove : $(SRCDIR)/glove.c
13 | $(CC) $(SRCDIR)/glove.c -o $(BUILDDIR)/glove $(CFLAGS)
14 | shuffle : $(SRCDIR)/shuffle.c
15 | $(CC) $(SRCDIR)/shuffle.c -o $(BUILDDIR)/shuffle $(CFLAGS)
16 | cooccur : $(SRCDIR)/cooccur.c
17 | $(CC) $(SRCDIR)/cooccur.c -o $(BUILDDIR)/cooccur $(CFLAGS)
18 | vocab_count : $(SRCDIR)/vocab_count.c
19 | $(CC) $(SRCDIR)/vocab_count.c -o $(BUILDDIR)/vocab_count $(CFLAGS)
20 |
21 | clean:
22 | rm -rf glove shuffle cooccur vocab_count build
23 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/README.md:
--------------------------------------------------------------------------------
1 | ## GloVe: Global Vectors for Word Representation
2 |
3 |
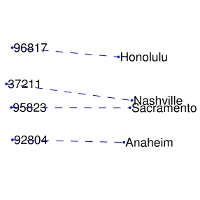
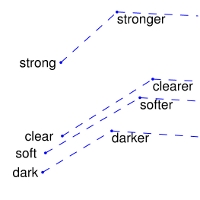
4 | | nearest neighbors of
frog | Litoria | Leptodactylidae | Rana | Eleutherodactylus |
5 | | --- | ------------------------------- | ------------------- | ---------------- | ------------------- |
6 | | Pictures |  |
|  |
|  |
|  |
7 |
8 | | Comparisons | man -> woman | city -> zip | comparative -> superlative |
9 | | --- | ------------------------|-------------------------|-------------------------|
10 | | GloVe Geometry |
|
7 |
8 | | Comparisons | man -> woman | city -> zip | comparative -> superlative |
9 | | --- | ------------------------|-------------------------|-------------------------|
10 | | GloVe Geometry | 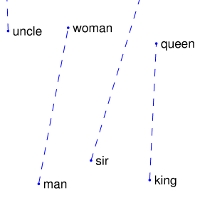 |
|  |
|  |
11 |
12 | We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the [project page](http://nlp.stanford.edu/projects/glove/) or the [paper](http://nlp.stanford.edu/pubs/glove.pdf) for more information on glove vectors.
13 |
14 | ## Download pre-trained word vectors
15 | The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
16 |
|
11 |
12 | We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the [project page](http://nlp.stanford.edu/projects/glove/) or the [paper](http://nlp.stanford.edu/pubs/glove.pdf) for more information on glove vectors.
13 |
14 | ## Download pre-trained word vectors
15 | The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
16 |
17 |
18 | - Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip
19 | - Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip
20 | - Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 300d vectors, 822 MB download): glove.6B.zip
21 | - Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 200d vectors, 1.42 GB download): glove.twitter.27B.zip
22 |
23 |
 28 |
29 | If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
30 |
31 | $ git clone http://github.com/stanfordnlp/glove
32 | $ cd glove && make
33 | $ ./demo.sh
34 |
35 | The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading [demo.sh](https://github.com/stanfordnlp/GloVe/blob/master/demo.sh) or the [src/README.md](https://github.com/stanfordnlp/GloVe/tree/master/src)
36 |
37 | ### License
38 | All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.
39 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/demo.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | # Makes programs, downloads sample data, trains a GloVe model, and then evaluates it.
5 | # One optional argument can specify the language used for eval script: matlab, octave or [default] python
6 |
7 | make
8 | if [ ! -e text8 ]; then
9 | if hash wget 2>/dev/null; then
10 | wget http://mattmahoney.net/dc/text8.zip
11 | else
12 | curl -O http://mattmahoney.net/dc/text8.zip
13 | fi
14 | unzip text8.zip
15 | rm text8.zip
16 | fi
17 |
18 | CORPUS=../corpus.txt
19 | VOCAB_FILE=vocab.txt
20 | COOCCURRENCE_FILE=cooccurrence.bin
21 | COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
22 | BUILDDIR=build
23 | SAVE_FILE=vectors
24 | VERBOSE=2
25 | MEMORY=4.0
26 | VOCAB_MIN_COUNT=2
27 | VECTOR_SIZE=300
28 | MAX_ITER=15
29 | WINDOW_SIZE=15
30 | BINARY=2
31 | NUM_THREADS=8
32 | X_MAX=10
33 |
34 | echo
35 | echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
36 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
37 | echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE"
38 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE
39 | echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
40 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
41 | echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE"
42 | $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE
43 | if [ "$CORPUS" = 'text8' ]; then
44 | if [ "$1" = 'matlab' ]; then
45 | matlab -nodisplay -nodesktop -nojvm -nosplash < ./eval/matlab/read_and_evaluate.m 1>&2
46 | elif [ "$1" = 'octave' ]; then
47 | octave < ./eval/octave/read_and_evaluate_octave.m 1>&2
48 | else
49 | echo "$ python eval/python/evaluate.py"
50 | python eval/python/evaluate.py
51 | fi
52 | fi
53 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/matlab/WordLookup.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup(InputString)
2 | global wordMap
3 | if wordMap.isKey(InputString)
4 | index = wordMap(InputString);
5 | elseif wordMap.isKey('')
6 | index = wordMap('');
7 | else
8 | index = 0;
9 | end
10 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/matlab/evaluate_vectors.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 | if wordMap.isKey('')
21 | unkkey = wordMap('');
22 | else
23 | unkkey = 0;
24 | end
25 |
26 | for j=1:length(filenames);
27 |
28 | clear dist;
29 |
30 | fid=fopen([path filenames{j} '.txt']);
31 | temp=textscan(fid,'%s%s%s%s');
32 | fclose(fid);
33 | ind1 = cellfun(@WordLookup,temp{1}); %indices of first word in analogy
34 | ind2 = cellfun(@WordLookup,temp{2}); %indices of second word in analogy
35 | ind3 = cellfun(@WordLookup,temp{3}); %indices of third word in analogy
36 | ind4 = cellfun(@WordLookup,temp{4}); %indices of answer word in analogy
37 | full_count = full_count + length(ind1);
38 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
39 | ind1 = ind1(ind);
40 | ind2 = ind2(ind);
41 | ind3 = ind3(ind);
42 | ind4 = ind4(ind);
43 | disp([filenames{j} ':']);
44 | mx = zeros(1,length(ind1));
45 | num_iter = ceil(length(ind1)/split_size);
46 | for jj=1:num_iter
47 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
48 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
49 | for i=1:length(range)
50 | dist(ind1(range(i)),i) = -Inf;
51 | dist(ind2(range(i)),i) = -Inf;
52 | dist(ind3(range(i)),i) = -Inf;
53 | end
54 | [~, mx(range)] = max(dist); %predicted word index
55 | end
56 |
57 | val = (ind4 == mx'); %correct predictions
58 | count_tot = count_tot + length(ind1);
59 | correct_tot = correct_tot + sum(val);
60 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
61 | if j < 6
62 | count_sem = count_sem + length(ind1);
63 | correct_sem = correct_sem + sum(val);
64 | else
65 | count_syn = count_syn + length(ind1);
66 | correct_syn = correct_syn + sum(val);
67 | end
68 |
69 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
70 |
71 | end
72 | disp('________________________________________________________________________________');
73 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
74 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
75 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
76 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
77 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
78 |
79 | end
80 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/matlab/read_and_evaluate.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/matlab');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 | wordMap = containers.Map(words(1:vocab_size),1:vocab_size);
16 |
17 | fid = fopen(vectors_file,'r');
18 | fseek(fid,0,'eof');
19 | vector_size = ftell(fid)/16/vocab_size - 1;
20 | frewind(fid);
21 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
22 | fclose(fid);
23 |
24 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
25 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
26 |
27 | W = W1 + W2; %Evaluate on sum of word vectors
28 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
29 | evaluate_vectors(W);
30 | exit
31 |
32 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/octave/WordLookup_octave.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup_octave(InputString)
2 | global wordMap
3 |
4 | if isfield(wordMap, InputString)
5 | index = wordMap.(InputString);
6 | elseif isfield(wordMap, '')
7 | index = wordMap.('');
8 | else
9 | index = 0;
10 | end
11 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/octave/evaluate_vectors_octave.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors_octave(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 |
21 | if isfield(wordMap, '')
22 | unkkey = wordMap.('');
23 | else
24 | unkkey = 0;
25 | end
26 |
27 | for j=1:length(filenames);
28 |
29 | clear dist;
30 |
31 | fid=fopen([path filenames{j} '.txt']);
32 | temp=textscan(fid,'%s%s%s%s');
33 | fclose(fid);
34 | ind1 = cellfun(@WordLookup_octave,temp{1}); %indices of first word in analogy
35 | ind2 = cellfun(@WordLookup_octave,temp{2}); %indices of second word in analogy
36 | ind3 = cellfun(@WordLookup_octave,temp{3}); %indices of third word in analogy
37 | ind4 = cellfun(@WordLookup_octave,temp{4}); %indices of answer word in analogy
38 | full_count = full_count + length(ind1);
39 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
40 | ind1 = ind1(ind);
41 | ind2 = ind2(ind);
42 | ind3 = ind3(ind);
43 | ind4 = ind4(ind);
44 | disp([filenames{j} ':']);
45 | mx = zeros(1,length(ind1));
46 | num_iter = ceil(length(ind1)/split_size);
47 | for jj=1:num_iter
48 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
49 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
50 | for i=1:length(range)
51 | dist(ind1(range(i)),i) = -Inf;
52 | dist(ind2(range(i)),i) = -Inf;
53 | dist(ind3(range(i)),i) = -Inf;
54 | end
55 | [~, mx(range)] = max(dist); %predicted word index
56 | end
57 |
58 | val = (ind4 == mx'); %correct predictions
59 | count_tot = count_tot + length(ind1);
60 | correct_tot = correct_tot + sum(val);
61 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
62 | if j < 6
63 | count_sem = count_sem + length(ind1);
64 | correct_sem = correct_sem + sum(val);
65 | else
66 | count_syn = count_syn + length(ind1);
67 | correct_syn = correct_syn + sum(val);
68 | end
69 |
70 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
71 |
72 | end
73 | disp('________________________________________________________________________________');
74 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
75 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
76 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
77 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
78 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
79 |
80 | end
81 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/octave/read_and_evaluate_octave.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/octave');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 |
16 | wordMap = struct();
17 | for i=1:numel(words)
18 | wordMap.(words{i}) = i;
19 | end
20 |
21 | fid = fopen(vectors_file,'r');
22 | fseek(fid,0,'eof');
23 | vector_size = ftell(fid)/16/vocab_size - 1;
24 | frewind(fid);
25 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
26 | fclose(fid);
27 |
28 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
29 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
30 |
31 | W = W1 + W2; %Evaluate on sum of word vectors
32 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
33 | evaluate_vectors_octave(W);
34 | exit
35 |
36 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/python/distance.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import sys
4 |
5 | def generate():
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
8 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
9 | args = parser.parse_args()
10 |
11 | with open(args.vocab_file, 'r') as f:
12 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
13 | with open(args.vectors_file, 'r') as f:
14 | vectors = {}
15 | for line in f:
16 | vals = line.rstrip().split(' ')
17 | vectors[vals[0]] = [float(x) for x in vals[1:]]
18 |
19 | vocab_size = len(words)
20 | vocab = {w: idx for idx, w in enumerate(words)}
21 | ivocab = {idx: w for idx, w in enumerate(words)}
22 |
23 | vector_dim = len(vectors[ivocab[0]])
24 | W = np.zeros((vocab_size, vector_dim))
25 | for word, v in vectors.items():
26 | if word == '':
27 | continue
28 | W[vocab[word], :] = v
29 |
30 | # normalize each word vector to unit variance
31 | W_norm = np.zeros(W.shape)
32 | d = (np.sum(W ** 2, 1) ** (0.5))
33 | W_norm = (W.T / d).T
34 | return (W_norm, vocab, ivocab)
35 |
36 |
37 | def distance(W, vocab, ivocab, input_term):
38 | for idx, term in enumerate(input_term.split(' ')):
39 | if term in vocab:
40 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
41 | if idx == 0:
42 | vec_result = np.copy(W[vocab[term], :])
43 | else:
44 | vec_result += W[vocab[term], :]
45 | else:
46 | print('Word: %s Out of dictionary!\n' % term)
47 | return
48 |
49 | vec_norm = np.zeros(vec_result.shape)
50 | d = (np.sum(vec_result ** 2,) ** (0.5))
51 | vec_norm = (vec_result.T / d).T
52 |
53 | dist = np.dot(W, vec_norm.T)
54 |
55 | for term in input_term.split(' '):
56 | index = vocab[term]
57 | dist[index] = -np.Inf
58 |
59 | a = np.argsort(-dist)[:N]
60 |
61 | print("\n Word Cosine distance\n")
62 | print("---------------------------------------------------------\n")
63 | for x in a:
64 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
65 |
66 |
67 | if __name__ == "__main__":
68 | N = 100; # number of closest words that will be shown
69 | W, vocab, ivocab = generate()
70 | while True:
71 | input_term = raw_input("\nEnter word or sentence (EXIT to break): ")
72 | if input_term == 'EXIT':
73 | break
74 | else:
75 | distance(W, vocab, ivocab, input_term)
76 |
77 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/python/evaluate.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 |
4 | def main():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
7 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
8 | args = parser.parse_args()
9 |
10 | with open(args.vocab_file, 'r') as f:
11 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
12 | with open(args.vectors_file, 'r') as f:
13 | vectors = {}
14 | for line in f:
15 | vals = line.rstrip().split(' ')
16 | vectors[vals[0]] = [float(x) for x in vals[1:]]
17 |
18 | vocab_size = len(words)
19 | vocab = {w: idx for idx, w in enumerate(words)}
20 | ivocab = {idx: w for idx, w in enumerate(words)}
21 |
22 | vector_dim = len(vectors[ivocab[0]])
23 | W = np.zeros((vocab_size, vector_dim))
24 | for word, v in vectors.items():
25 | if word == '':
26 | continue
27 | W[vocab[word], :] = v
28 |
29 | # normalize each word vector to unit length
30 | W_norm = np.zeros(W.shape)
31 | d = (np.sum(W ** 2, 1) ** (0.5))
32 | W_norm = (W.T / d).T
33 | evaluate_vectors(W_norm, vocab, ivocab)
34 |
35 | def evaluate_vectors(W, vocab, ivocab):
36 | """Evaluate the trained word vectors on a variety of tasks"""
37 |
38 | filenames = [
39 | 'capital-common-countries.txt', 'capital-world.txt', 'currency.txt',
40 | 'city-in-state.txt', 'family.txt', 'gram1-adjective-to-adverb.txt',
41 | 'gram2-opposite.txt', 'gram3-comparative.txt', 'gram4-superlative.txt',
42 | 'gram5-present-participle.txt', 'gram6-nationality-adjective.txt',
43 | 'gram7-past-tense.txt', 'gram8-plural.txt', 'gram9-plural-verbs.txt',
44 | ]
45 | prefix = './eval/question-data/'
46 |
47 | # to avoid memory overflow, could be increased/decreased
48 | # depending on system and vocab size
49 | split_size = 100
50 |
51 | correct_sem = 0; # count correct semantic questions
52 | correct_syn = 0; # count correct syntactic questions
53 | correct_tot = 0 # count correct questions
54 | count_sem = 0; # count all semantic questions
55 | count_syn = 0; # count all syntactic questions
56 | count_tot = 0 # count all questions
57 | full_count = 0 # count all questions, including those with unknown words
58 |
59 | for i in range(len(filenames)):
60 | with open('%s/%s' % (prefix, filenames[i]), 'r') as f:
61 | full_data = [line.rstrip().split(' ') for line in f]
62 | full_count += len(full_data)
63 | data = [x for x in full_data if all(word in vocab for word in x)]
64 |
65 | indices = np.array([[vocab[word] for word in row] for row in data])
66 | ind1, ind2, ind3, ind4 = indices.T
67 |
68 | predictions = np.zeros((len(indices),))
69 | num_iter = int(np.ceil(len(indices) / float(split_size)))
70 | for j in range(num_iter):
71 | subset = np.arange(j*split_size, min((j + 1)*split_size, len(ind1)))
72 |
73 | pred_vec = (W[ind2[subset], :] - W[ind1[subset], :]
74 | + W[ind3[subset], :])
75 | #cosine similarity if input W has been normalized
76 | dist = np.dot(W, pred_vec.T)
77 |
78 | for k in range(len(subset)):
79 | dist[ind1[subset[k]], k] = -np.Inf
80 | dist[ind2[subset[k]], k] = -np.Inf
81 | dist[ind3[subset[k]], k] = -np.Inf
82 |
83 | # predicted word index
84 | predictions[subset] = np.argmax(dist, 0).flatten()
85 |
86 | val = (ind4 == predictions) # correct predictions
87 | count_tot = count_tot + len(ind1)
88 | correct_tot = correct_tot + sum(val)
89 | if i < 5:
90 | count_sem = count_sem + len(ind1)
91 | correct_sem = correct_sem + sum(val)
92 | else:
93 | count_syn = count_syn + len(ind1)
94 | correct_syn = correct_syn + sum(val)
95 |
96 | print("%s:" % filenames[i])
97 | print('ACCURACY TOP1: %.2f%% (%d/%d)' %
98 | (np.mean(val) * 100, np.sum(val), len(val)))
99 |
100 | print('Questions seen/total: %.2f%% (%d/%d)' %
101 | (100 * count_tot / float(full_count), count_tot, full_count))
102 | print('Semantic accuracy: %.2f%% (%i/%i)' %
103 | (100 * correct_sem / float(count_sem), correct_sem, count_sem))
104 | print('Syntactic accuracy: %.2f%% (%i/%i)' %
105 | (100 * correct_syn / float(count_syn), correct_syn, count_syn))
106 | print('Total accuracy: %.2f%% (%i/%i)' % (100 * correct_tot / float(count_tot), correct_tot, count_tot))
107 |
108 |
109 | if __name__ == "__main__":
110 | main()
111 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/python/word_analogy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import sys
4 |
5 | def generate():
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
8 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
9 | args = parser.parse_args()
10 |
11 | with open(args.vocab_file, 'r') as f:
12 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
13 | with open(args.vectors_file, 'r') as f:
14 | vectors = {}
15 | for line in f:
16 | vals = line.rstrip().split(' ')
17 | vectors[vals[0]] = [float(x) for x in vals[1:]]
18 |
19 | vocab_size = len(words)
20 | vocab = {w: idx for idx, w in enumerate(words)}
21 | ivocab = {idx: w for idx, w in enumerate(words)}
22 |
23 | vector_dim = len(vectors[ivocab[0]])
24 | W = np.zeros((vocab_size, vector_dim))
25 | for word, v in vectors.items():
26 | if word == '':
27 | continue
28 | W[vocab[word], :] = v
29 |
30 | # normalize each word vector to unit variance
31 | W_norm = np.zeros(W.shape)
32 | d = (np.sum(W ** 2, 1) ** (0.5))
33 | W_norm = (W.T / d).T
34 | return (W_norm, vocab, ivocab)
35 |
36 |
37 | def distance(W, vocab, ivocab, input_term):
38 | vecs = {}
39 | if len(input_term.split(' ')) < 3:
40 | print("Only %i words were entered.. three words are needed at the input to perform the calculation\n" % len(input_term.split(' ')))
41 | return
42 | else:
43 | for idx, term in enumerate(input_term.split(' ')):
44 | if term in vocab:
45 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
46 | vecs[idx] = W[vocab[term], :]
47 | else:
48 | print('Word: %s Out of dictionary!\n' % term)
49 | return
50 |
51 | vec_result = vecs[1] - vecs[0] + vecs[2]
52 |
53 | vec_norm = np.zeros(vec_result.shape)
54 | d = (np.sum(vec_result ** 2,) ** (0.5))
55 | vec_norm = (vec_result.T / d).T
56 |
57 | dist = np.dot(W, vec_norm.T)
58 |
59 | for term in input_term.split(' '):
60 | index = vocab[term]
61 | dist[index] = -np.Inf
62 |
63 | a = np.argsort(-dist)[:N]
64 |
65 | print("\n Word Cosine distance\n")
66 | print("---------------------------------------------------------\n")
67 | for x in a:
68 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
69 |
70 |
71 | if __name__ == "__main__":
72 | N = 100; # number of closest words that will be shown
73 | W, vocab, ivocab = generate()
74 | while True:
75 | input_term = raw_input("\nEnter three words (EXIT to break): ")
76 | if input_term == 'EXIT':
77 | break
78 | else:
79 | distance(W, vocab, ivocab, input_term)
80 |
81 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/src/README.md:
--------------------------------------------------------------------------------
1 | ### Package Contents
2 |
3 | To train your own GloVe vectors, first you'll need to prepare your corpus as a single text file with all words separated by one or more spaces or tabs. If your corpus has multiple documents, the documents (only) should be separated by new line characters. Cooccurrence contexts for words do not extend past newline characters. Once you create your corpus, you can train GloVe vectors using the following 4 tools. An example is included in `demo.sh`, which you can modify as necessary.
4 |
5 | The four main tools in this package are:
6 |
7 | #### 1) vocab_count
8 | This tool requires an input corpus that should already consist of whitespace-separated tokens. Use something like the [Stanford Tokenizer](https://nlp.stanford.edu/software/tokenizer.html) first on raw text. From the corpus, it constructs unigram counts from a corpus, and optionally thresholds the resulting vocabulary based on total vocabulary size or minimum frequency count.
9 |
10 | #### 2) cooccur
11 | Constructs word-word cooccurrence statistics from a corpus. The user should supply a vocabulary file, as produced by `vocab_count`, and may specify a variety of parameters, as described by running `./build/cooccur`.
12 |
13 | #### 3) shuffle
14 | Shuffles the binary file of cooccurrence statistics produced by `cooccur`. For large files, the file is automatically split into chunks, each of which is shuffled and stored on disk before being merged and shuffled together. The user may specify a number of parameters, as described by running `./build/shuffle`.
15 |
16 | #### 4) glove
17 | Train the GloVe model on the specified cooccurrence data, which typically will be the output of the `shuffle` tool. The user should supply a vocabulary file, as given by `vocab_count`, and may specify a number of other parameters, which are described by running `./build/glove`.
18 |
--------------------------------------------------------------------------------
/src/rank/m1/prepare_rank_train.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | # In[1]:
5 |
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from tqdm import tqdm
10 |
11 |
12 | # In[2]:
13 |
14 |
15 | paper = pd.read_feather("../../../input/paper_input_final.ftr")
16 |
17 |
18 | # In[3]:
19 |
20 |
21 | paper['abst'] = paper['abst'].apply(lambda s: s.replace('no_content', ''))
22 | paper['corp'] = paper['titl']+' '+paper['keywords'].fillna('').replace(';', ' ')+paper['abst']
23 |
24 |
25 | # In[4]:
26 |
27 |
28 | df_train = pd.read_feather("../../../input/tr_input_final.ftr")
29 |
30 |
31 | # In[5]:
32 |
33 |
34 | df_train.head()
35 |
36 |
37 | # In[6]:
38 |
39 |
40 | df_test = pd.read_feather("../../../input/te_input_final.ftr")
41 |
42 |
43 | # In[7]:
44 |
45 |
46 | df_test.head()
47 |
48 |
49 | # In[8]:
50 |
51 |
52 | #####reduce mem
53 | import datetime
54 | def pandas_reduce_mem_usage(df):
55 | start_mem=df.memory_usage().sum() / 1024**2
56 | print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
57 | starttime = datetime.datetime.now()
58 | for col in df.columns:
59 | col_type=df[col].dtype #每一列的类型
60 | if col_type !=object: #不是object类型
61 | c_min=df[col].min()
62 | c_max=df[col].max()
63 | # print('{} column dtype is {} and begin convert to others'.format(col,col_type))
64 | if str(col_type)[:3]=='int':
65 | #是有符号整数
66 | if c_min<0:
67 | if c_min >= np.iinfo(np.int8).min and c_max <= np.iinfo(np.int8).max:
68 | df[col] = df[col].astype(np.int8)
69 | elif c_min >= np.iinfo(np.int16).min and c_max <= np.iinfo(np.int16).max:
70 | df[col] = df[col].astype(np.int16)
71 | elif c_min >= np.iinfo(np.int32).min and c_max <= np.iinfo(np.int32).max:
72 | df[col] = df[col].astype(np.int32)
73 | else:
74 | df[col] = df[col].astype(np.int64)
75 | else:
76 | if c_min >= np.iinfo(np.uint8).min and c_max<=np.iinfo(np.uint8).max:
77 | df[col]=df[col].astype(np.uint8)
78 | elif c_min >= np.iinfo(np.uint16).min and c_max <= np.iinfo(np.uint16).max:
79 | df[col] = df[col].astype(np.uint16)
80 | elif c_min >= np.iinfo(np.uint32).min and c_max <= np.iinfo(np.uint32).max:
81 | df[col] = df[col].astype(np.uint32)
82 | else:
83 | df[col] = df[col].astype(np.uint64)
84 | #浮点数
85 | else:
86 | if c_min >= np.finfo(np.float16).min and c_max <= np.finfo(np.float32).max:
87 | df[col] = df[col].astype(np.float32)
88 | else:
89 | df[col] = df[col].astype(np.float64)
90 | # print('\t\tcolumn dtype is {}'.format(df[col].dtype))
91 |
92 | #是object类型,比如str
93 | else:
94 | # print('\t\tcolumns dtype is object and will convert to category')
95 | df[col] = df[col].astype('category')
96 | end_mem = df.memory_usage().sum() / 1024 ** 2
97 | endtime = datetime.datetime.now()
98 | print('consume times: {:.4f}'.format((endtime - starttime).seconds))
99 | print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
100 | print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
101 | return df
102 |
103 |
104 | # In[9]:
105 |
106 |
107 | recall_train = pd.read_feather('../../../input/tr_s0_32-50.ftr')
108 | recall_test = pd.read_feather('../../../input/te_s0_32-50.ftr')
109 |
110 |
111 | # In[10]:
112 |
113 |
114 | recall_train = pandas_reduce_mem_usage(recall_train)
115 |
116 |
117 | # In[11]:
118 |
119 |
120 | recall_test = pandas_reduce_mem_usage(recall_test)
121 |
122 |
123 | # In[12]:
124 |
125 |
126 | recall_train.shape
127 |
128 |
129 | # In[13]:
130 |
131 |
132 | cv_id = pd.read_csv("../../../input/cv_ids_0109.csv")
133 | recall_train.drop(columns=['cv'],axis=1,inplace=True)
134 | recall_train = recall_train.merge(cv_id,on=['description_id'],how='left')
135 |
136 |
137 | # In[14]:
138 |
139 |
140 | recall_train = recall_train.dropna(subset=['cv']).reset_index(drop=True)
141 |
142 |
143 | # In[15]:
144 |
145 |
146 | recall_train.shape,recall_test.shape
147 |
148 |
149 | # In[16]:
150 |
151 |
152 | recall_train = recall_train.merge(paper[['paper_id','corp']],on=['paper_id'],how='left')
153 | recall_test = recall_test.merge(paper[['paper_id','corp']],on=['paper_id'],how='left')
154 |
155 |
156 | # In[17]:
157 |
158 |
159 | recall_train = recall_train.merge(df_train[['description_id','quer_key','quer_all']],on=['description_id'],how='left')
160 | recall_test = recall_test.merge(df_test[['description_id','quer_key','quer_all']],on=['description_id'],how='left')
161 |
162 |
163 | # In[18]:
164 |
165 |
166 | recall_train = recall_train.sort_values(['description_id', 'corp_sim_score'], ascending=False)
167 | recall_train['rank'] = recall_train.groupby('description_id').cumcount().values
168 | recall_test = recall_test.sort_values(['description_id', 'corp_sim_score'], ascending=False)
169 | recall_test['rank'] = recall_test.groupby('description_id').cumcount().values
170 |
171 |
172 | # In[19]:
173 |
174 |
175 | keep_columns = ['description_id','paper_id','corp','quer_key','quer_all','corp_sim_score','cv','rank','target']
176 | recall_train = recall_train[keep_columns].reset_index(drop=True)
177 | recall_test = recall_test[keep_columns].reset_index(drop=True)
178 |
179 |
180 | # In[20]:
181 |
182 |
183 | recall_train.head()
184 |
185 |
186 | # In[22]:
187 |
188 |
189 | recall_train.to_csv('recall_train.csv',index=False)
190 |
191 |
192 | # In[23]:
193 |
194 |
195 | recall_test.to_csv('recall_test.csv',index=False)
196 |
197 |
198 | # In[ ]:
199 |
200 |
201 | # recall_train.shape
202 |
203 |
--------------------------------------------------------------------------------
/src/rank/m1/run.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | ####依赖paper_input_1.ftr、te_input_1.ftr
4 | ####写入语料,并训练word2vector词向量
5 | python3 w2v_training.py ###暂时用jupyter notebook占位
6 |
7 | ###训练glove词向量
8 | cd glove && make
9 | bash demo.sh
10 | ####回到目录
11 | cd ..
12 |
13 | ###词向量序列化
14 |
15 |
16 |
17 | ###准备训练数据
18 | python3 prepare_rank_train.py ###暂时用jupyter notebook占位
19 |
20 | ###inferSent-simple-5-fold训练
21 | python3 inferSent1-5-fold_train.py ###暂时用jupyter notebook 占位
22 |
23 | ###inferSent-simple-5-fold预测
24 | python3 inferSent1-5-fold_predict.py ###暂时用jupyter notebook 占位
25 |
26 | ###catboost模型训练&预测
27 | python3 catboost3.py ###暂时用jupyter notebook 占位
28 |
29 | ###nn02模型训练
30 | python3 nn02_train.py ###暂时用jupyter notebook 占位
31 | python3 nn02_predict.py ###暂时用jupyter notebook 占位
32 |
--------------------------------------------------------------------------------
/src/rank/m1/w2v_training.py:
--------------------------------------------------------------------------------
1 |
2 | # coding: utf-8
3 |
4 | # In[1]:
5 |
6 |
7 | # external vec
8 | import warnings
9 | warnings.filterwarnings('always')
10 | warnings.filterwarnings('ignore')
11 |
12 | import os
13 | import sys
14 | import numpy as np
15 | import pandas as pd
16 | from tqdm import tqdm
17 |
18 | import time
19 | from datetime import datetime
20 | from gensim.models import Word2Vec
21 | from gensim.models.word2vec import LineSentence
22 | from gensim import corpora, models, similarities
23 | from gensim.similarities import SparseMatrixSimilarity
24 | from gensim.similarities import MatrixSimilarity
25 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
26 |
27 |
28 | # In[3]:
29 |
30 |
31 | paper = pd.read_feather("../../../input/paper_input_final.ftr")
32 |
33 |
34 | # In[4]:
35 |
36 |
37 | paper['abst'] = paper['abst'].apply(lambda s: s.replace('no_content', ''))
38 | paper['corp'] = paper['titl']+' '+paper['keywords'].fillna('').replace(';', ' ')+paper['abst']
39 |
40 |
41 | # In[5]:
42 |
43 |
44 | paper.head()
45 |
46 |
47 | # In[6]:
48 |
49 |
50 | paper['len'] = paper['corp'].apply(len)
51 |
52 |
53 | # In[7]:
54 |
55 |
56 | paper['len'].describe()
57 |
58 |
59 | # In[8]:
60 |
61 |
62 | df_train = pd.read_feather("../../../input/tr_input_final.ftr")
63 |
64 |
65 | # In[9]:
66 |
67 |
68 | df_train.head()
69 |
70 |
71 | # In[10]:
72 |
73 |
74 | df_train['len'] = df_train['quer_key'].apply(len)
75 | df_train['len'].describe()
76 |
77 |
78 | # In[16]:
79 |
80 |
81 | df_test = pd.read_feather("../../../input/te_input_final.ftr")
82 |
83 |
84 | # In[17]:
85 |
86 |
87 | df_test.head()
88 |
89 |
90 | # In[18]:
91 |
92 |
93 | # df_train[df_train['quer_all'].str.contains("[##]")]
94 |
95 |
96 | # In[19]:
97 |
98 |
99 | from tqdm import tqdm
100 | ###训练语料准备
101 | with open("corpus.txt","w+") as f:
102 | for i in tqdm(range(len(paper))):
103 | abst = paper.iloc[i]['abst']
104 | if abst!='no_content' and abst!="none":
105 | f.write(abst+"\n")
106 | title = paper.iloc[i]['titl']
107 | if title!='no_content' and title!="none":
108 | f.write(title+"\n")
109 | for i in tqdm(range(len(df_train))):
110 | quer_all = df_train.iloc[i]['quer_all']
111 | f.write(quer_all+"\n")
112 | for i in tqdm(range(len(df_test))):
113 | quer_all = df_test.iloc[i]['quer_all']
114 | f.write(quer_all+"\n")
115 |
116 |
117 | # In[23]:
118 |
119 |
120 | ####word2vector
121 | from gensim.models import word2vec
122 | sentences = word2vec.LineSentence('./corpus.txt')
123 | model = word2vec.Word2Vec(sentences, sg=1,min_count=2,window=8,size=300,iter=6,sample=1e-4, hs=1, workers=12)
124 |
125 |
126 | # In[24]:
127 |
128 |
129 | model.save("word2vec.model")
130 |
131 |
132 | # In[34]:
133 |
134 |
135 | model.wv.save_word2vec_format("word2vec.txt",binary=False)
136 |
137 |
138 | # In[26]:
139 |
140 |
141 | #glove的已有
142 | from gensim.test.utils import datapath, get_tmpfile
143 | from gensim.models import KeyedVectors
144 |
145 |
146 | # In[31]:
147 |
148 |
149 | # 输入文件
150 | glove_file = datapath('glove/vectors.txt')
151 | # 输出文件
152 | tmp_file = get_tmpfile("glove_vec.txt")
153 |
154 |
--------------------------------------------------------------------------------
/src/rank/m2/bert_5_fold_predict.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gc
3 | from tqdm import tqdm
4 | import numpy as np
5 | import pandas as pd
6 |
7 | import torch
8 | from pytorch_transformers import AdamW, WarmupLinearSchedule
9 | import matchzoo as mz
10 | from matchzoo.preprocessors.units.truncated_length import TruncatedLength
11 | from utils import MAP, build_matrix, topk_lines, predict, Logger
12 |
13 | os.environ["CUDA_VISIBLE_DEVICES"] = "1"
14 |
15 | import argparse
16 |
17 | parser = argparse.ArgumentParser()
18 | parser.add_argument('--model_id', type=str, default='bert_002')
19 | args = parser.parse_args()
20 |
21 | model_id = args.model_id
22 |
23 | if model_id=="bert_002":
24 | test_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_final_test_processed_query_key.dp")
25 | bst_epochs = {1:1, 2:1, 3:2, 4:1, 5:1}
26 | if model_id=="bert_003":
27 | test_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_test_processed_query_all.dp")
28 | bst_epochs = {1:2, 2:1, 3:1, 4:2, 5:1}
29 | if model_id=="bert_004":
30 | test_processed = mz.data_pack.data_pack.load_data_pack(
31 | "bert_data/bert_final_test_processed_query_all_nopreprocessing.dp/")
32 | bst_epochs = {1:2, 2:2, 3:1, 4:1, 5:1}
33 |
34 | padding_callback = mz.models.Bert.get_default_padding_callback()
35 | testset = mz.dataloader.Dataset(
36 | data_pack=test_processed,
37 | batch_size=128,
38 | sort=False,
39 | shuffle=False
40 | )
41 | testloader = mz.dataloader.DataLoader(
42 | dataset=testset,
43 | stage='dev',
44 | callback=padding_callback
45 | )
46 |
47 |
48 | num_dup = 1
49 | num_neg = 7
50 |
51 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
52 | padding_callback = mz.models.Bert.get_default_padding_callback()
53 | task = mz.tasks.Ranking(losses=losses)
54 | task.metrics = [
55 | mz.metrics.MeanAveragePrecision(),
56 | MAP()
57 | ]
58 |
59 | model = mz.models.Bert()
60 |
61 | model.params['task'] = task
62 | model.params['mode'] = 'bert-base-uncased'
63 | model.params['dropout_rate'] = 0.2
64 |
65 | model.build()
66 |
67 | print('Trainable params: ', sum(p.numel() for p in model.parameters() if p.requires_grad))
68 |
69 | no_decay = ['bias', 'LayerNorm.weight']
70 | optimizer_grouped_parameters = [
71 | {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 5e-5},
72 | {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
73 | ]
74 |
75 |
76 | optimizer = AdamW(optimizer_grouped_parameters, lr=5e-5, betas=(0.9, 0.98), eps=1e-8)
77 | scheduler = WarmupLinearSchedule(optimizer, warmup_steps=6, t_total=-1)
78 |
79 | trainer = mz.trainers.Trainer(
80 | model=model,
81 | optimizer=optimizer,
82 | scheduler=scheduler,
83 | trainloader=testloader,
84 | validloader=testloader,
85 | validate_interval=None,
86 | epochs=1
87 | )
88 |
89 |
90 | for fold in range(1,6):
91 | i = bst_epochs[fold]
92 | trainer.restore_model("save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
93 |
94 | score = predict(trainer, testloader)
95 | X, y = test_processed.unpack()
96 | result = pd.DataFrame(data={
97 | 'description_id': X['id_left'],
98 | 'paper_id': X['id_right'],
99 | 'score': score[:,0]})
100 | # result.to_csv("result/{}/{}_fold_{}_test.csv".format(model_id, model_id, fold), index=False)
101 | result.to_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold), index=False)
102 |
103 |
104 |
--------------------------------------------------------------------------------
/src/rank/m2/bert_5_fold_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | os.environ["CUDA_VISIBLE_DEVICES"] = "1"
3 |
4 | import gc
5 | from tqdm import tqdm
6 | import numpy as np
7 | import pandas as pd
8 |
9 | import torch
10 | from pytorch_transformers import AdamW, WarmupLinearSchedule
11 | import matchzoo as mz
12 | from matchzoo.preprocessors.units.truncated_length import TruncatedLength
13 | from utils import MAP, build_matrix, topk_lines, predict, Logger
14 |
15 | from matchzoo.data_pack import DataPack
16 |
17 | import argparse
18 |
19 | parser = argparse.ArgumentParser()
20 | parser.add_argument('--model_id', type=str, default='bert_002')
21 | args = parser.parse_args()
22 |
23 | model_id = args.model_id
24 |
25 | num_dup = 1
26 | num_neg = 7
27 |
28 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
29 | padding_callback = mz.models.Bert.get_default_padding_callback()
30 | task = mz.tasks.Ranking(losses=losses)
31 | task.metrics = [
32 | mz.metrics.MeanAveragePrecision(),
33 | MAP()
34 | ]
35 |
36 | with Logger(log_filename = '{}.log'.format(model_id)):
37 | for fold in range(1,6):
38 | if model_id=='bert_002':
39 | train_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_train_processed_{}.dp".format(fold))
40 | val_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_val_processed_{}.dp".format(fold))
41 | if model_id=='bert_003':
42 | train_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_train_processed_query_all_{}.dp".format(fold))
43 | val_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_val_processed_query_all_{}.dp".format(fold))
44 | if model_id=='bert_004':
45 | train_processed = mz.data_pack.data_pack.load_data_pack(
46 | "bert_data/bert_train_processed_query_all_nopreprocessing_{}.dp".format(fold))
47 | val_processed = mz.data_pack.data_pack.load_data_pack(
48 | "bert_data/bert_val_processed_query_all_nopreprocessing_{}.dp".format(fold))
49 |
50 | model = mz.models.Bert()
51 |
52 | model.params['task'] = task
53 | model.params['mode'] = 'bert-base-uncased'
54 | model.params['dropout_rate'] = 0.2
55 |
56 | model.build()
57 |
58 | print('Trainable params: ', sum(p.numel() for p in model.parameters() if p.requires_grad))
59 |
60 |
61 | trainset = mz.dataloader.Dataset(
62 | data_pack=train_processed,
63 | mode='pair',
64 | num_dup=num_dup,
65 | num_neg=num_neg,
66 | batch_size=1,
67 | resample=True,
68 | sort=False,
69 | shuffle=True
70 | )
71 | trainloader = mz.dataloader.DataLoader(
72 | dataset=trainset,
73 | stage='train',
74 | callback=padding_callback
75 | )
76 |
77 | valset = mz.dataloader.Dataset(
78 | data_pack=val_processed,
79 | batch_size=32,
80 | sort=False,
81 | shuffle=False
82 | )
83 | valloader = mz.dataloader.DataLoader(
84 | dataset=valset,
85 | stage='dev',
86 | callback=padding_callback
87 | )
88 |
89 |
90 | no_decay = ['bias', 'LayerNorm.weight']
91 | optimizer_grouped_parameters = [
92 | {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 5e-5},
93 | {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
94 | ]
95 |
96 | optimizer = AdamW(optimizer_grouped_parameters, lr=5e-5, betas=(0.9, 0.98), eps=1e-8)
97 | scheduler = WarmupLinearSchedule(optimizer, warmup_steps=6, t_total=-1)
98 |
99 | trainer = mz.trainers.Trainer(
100 | model=model,
101 | optimizer=optimizer,
102 | scheduler=scheduler,
103 | trainloader=trainloader,
104 | validloader=valloader,
105 | validate_interval=None,
106 | epochs=1
107 | )
108 |
109 | for i in range(0,8):
110 | print("="*10+" epoch: "+str(i)+" "+"="*10)
111 | trainer.run()
112 | trainer.save_model()
113 | os.rename("save/model.pt", "save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
114 |
115 |
116 |
--------------------------------------------------------------------------------
/src/rank/m2/bert_preprocessing.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gc
3 | from tqdm import tqdm
4 | import numpy as np
5 | import pandas as pd
6 |
7 | import torch
8 | import matchzoo as mz
9 | from matchzoo.preprocessors.units.truncated_length import TruncatedLength
10 | from utils import MAP, build_matrix, topk_lines, predict
11 |
12 | import argparse
13 |
14 | parser = argparse.ArgumentParser()
15 | parser.add_argument('--preprocessing_type', type=str, default='fine')
16 | parser.add_argument('--left_truncated_length', type=int, default=64)
17 | parser.add_argument('--query_type', type=str, default='query_key')
18 | args = parser.parse_args()
19 |
20 | preprocessing_type = args.preprocessing_type
21 | left_truncated_length = args.left_truncated_length
22 | dp_type = args.query_type
23 |
24 | num_neg = 7
25 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
26 | task = mz.tasks.Ranking(losses=losses)
27 | task.metrics = [
28 | mz.metrics.MeanAveragePrecision(),
29 | MAP()
30 | ]
31 |
32 | preprocessor = mz.models.Bert.get_default_preprocessor(mode='bert-base-uncased')
33 |
34 |
35 | if preprocessing_type == 'fine':
36 | candidate_dic = pd.read_feather('data/candidate_dic.ftr')
37 | train_description = pd.read_feather('data/train_description_{}.ftr'.format(dp_type))
38 | else:
39 | candidate_dic = pd.read_csv('../../../input/candidate_paper_for_wsdm2020.csv')
40 | candidate_dic.loc[candidate_dic['keywords'].isna(),'keywords'] = ''
41 | candidate_dic.loc[candidate_dic['title'].isna(),'title'] = ''
42 | candidate_dic.loc[candidate_dic['abstract'].isna(),'abstract'] = ''
43 | candidate_dic['text_right'] = candidate_dic['abstract'].str.cat(
44 | candidate_dic['keywords'], sep=' ').str.cat(
45 | candidate_dic['title'], sep=' ')
46 | candidate_dic = candidate_dic.rename(columns={'paper_id': 'id_right'})[['id_right', 'text_right']]
47 |
48 | train_description = pd.read_csv('../../../input/train_release.csv')
49 | train_description = train_description.rename(
50 | columns={'description_id': 'id_left',
51 | 'description_text': 'text_left'})[['id_left', 'text_left']]
52 | dp_type = 'query_all_nopreprocessing'
53 |
54 | train_recall = pd.read_feather('data/train_recall.ftr')[['id_left', 'id_right', 'label', 'cv']]
55 | train_recall = pd.merge(train_recall, train_description, how='left', on='id_left')
56 | train_recall = pd.merge(train_recall, candidate_dic, how='left', on='id_right')
57 | train_recall = train_recall.drop_duplicates().reset_index(drop=True)
58 | train_recall = train_recall[['id_left', 'text_left', 'id_right', 'text_right', 'label', 'cv']]
59 | del train_description
60 | gc.collect()
61 |
62 |
63 |
64 | for i in range(1,6):
65 | print("="*20, i, "="*20)
66 | train_df = train_recall[train_recall.cv!=i][
67 | ['id_left', 'text_left', 'id_right', 'text_right', 'label']].reset_index(drop=True)
68 | val_df = train_recall[train_recall.cv==i][
69 | ['id_left', 'text_left', 'id_right', 'text_right', 'label']].reset_index(drop=True)
70 |
71 | train_raw = mz.pack(train_df, task)
72 | train_processed = preprocessor.transform(train_raw)
73 | train_processed.apply_on_text(TruncatedLength(left_truncated_length, 'pre').transform,
74 | mode='left', inplace=True, verbose=1)
75 | train_processed.apply_on_text(TruncatedLength(256, 'pre').transform, mode='right', inplace=True, verbose=1)
76 | train_processed.append_text_length(inplace=True, verbose=1)
77 | train_processed.save("bert_data/bert_train_processed_{}_{}.dp".format(dp_type, i))
78 |
79 | val_raw = mz.pack(val_df, task)
80 | val_processed = preprocessor.transform(val_raw)
81 | val_processed.apply_on_text(TruncatedLength(left_truncated_length, 'pre').transform,
82 | mode='left', inplace=True, verbose=1)
83 | val_processed.apply_on_text(TruncatedLength(256, 'pre').transform, mode='right', inplace=True, verbose=1)
84 | val_processed.append_text_length(inplace=True, verbose=1)
85 | val_processed.save("bert_data/bert_val_processed_{}_{}.dp".format(dp_type, i))
86 |
87 |
88 | if preprocessing_type == 'fine':
89 | test_description = pd.read_feather('data/test_description_quer_all.ftr')
90 | else:
91 | test_description = pd.read_csv('../../input/test.csv')
92 | test_description = test_description.rename(
93 | columns={'description_id': 'id_left',
94 | 'description_text': 'text_left'})[['id_left', 'text_left']]
95 |
96 |
97 | test_recall = pd.read_feather('data/test_recall.ftr')[['id_left', 'id_right', 'label']]
98 | test_recall = pd.merge(test_recall, test_description, how='left', on='id_left')
99 | test_recall = pd.merge(test_recall, candidate_dic, how='left', on='id_right')
100 | del test_description, candidate_dic
101 | gc.collect()
102 |
103 | test_raw = mz.pack(test_recall, task)
104 | test_processed = preprocessor.transform(test_raw)
105 | test_processed.apply_on_text(TruncatedLength(left_truncated_length, 'pre').transform,
106 | mode='left', inplace=True, verbose=1)
107 | test_processed.apply_on_text(TruncatedLength(256, 'pre').transform, mode='right', inplace=True, verbose=1)
108 | test_processed.append_text_length(inplace=True, verbose=1)
109 | test_processed.save("bert_data/bert_test_processed_{}.dp".format(dp_type))
110 |
111 |
112 |
113 |
--------------------------------------------------------------------------------
/src/rank/m2/change_formatting4stk.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 |
4 |
5 | import argparse
6 |
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
9 | args = parser.parse_args()
10 |
11 | model_id = args.model_id
12 |
13 | stk_path = "../../../stk_feat"
14 |
15 | df = pd.read_csv("oof_m2_{}_5cv.csv".format(model_id))
16 | df = df.rename(columns={"target": "pred"})
17 | df.to_feather("{}/m2_{}_tr.ftr".format(stk_path, model_name))
18 |
19 | df = pd.read_csv("result_m2_{}_5cv.csv".format(model_id))
20 | df = df.rename(columns={"target": "pred"})
21 | df.to_feather("{}/final_m2_{}_te.ftr".format(stk_path, model_name))
22 |
23 |
--------------------------------------------------------------------------------
/src/rank/m2/final_blend.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 | from tqdm import tqdm
4 |
5 | np.set_printoptions(precision=4)
6 |
7 | def map3_func(df, topk = 50, verbose=0):
8 | ids = df[df.label==1].description_id.values
9 | df_recalled = df[df.description_id.isin(ids)].reset_index(drop=True)
10 | df_recalled = df_recalled.sort_values(
11 | by=['description_id', 'label'], ascending=False).reset_index(drop=True)
12 | result = df_recalled.score.values.reshape([-1,topk])
13 | ranks = topk-result.argsort(axis=1).argsort(axis=1)
14 | map3_sum = sum(((1/ranks[:,0])*(ranks[:,0]<4)))
15 | if verbose>0:
16 | print("recall rate: "+str((df_recalled.shape[0]/topk)/(df.shape[0]/topk)))
17 | print("map@3 in recall: "+str(map3_sum/(df_recalled.shape[0]/topk)))
18 | print("map@3 in all: "+str(map3_sum/(df.shape[0]/topk)))
19 |
20 |
21 | m2_path = "../../model/"
22 |
23 | res = pd.read_feather('{}/lgb_s0_m2_33-0/lgb_s0_m3_33.ftr'.format(m2_path))
24 | res['score'] = res['target'].apply(lambda x:np.log(x/(1-x)))
25 | res.loc[res['score']<-12, 'score'] = -12
26 | res = res[['description_id', 'paper_id', 'score']]
27 | res.head()
28 |
29 | res1 = pd.read_feather('{}/lgb_s0_m2_33-1/lgb_s0_m3_33.ftr'.format(m2_path))
30 | res1['score'] = res1['target'].apply(lambda x:np.log(x/(1-x)))
31 | res1.loc[res1['score']<-12, 'score'] = -12
32 | res1 = res1[['description_id', 'paper_id', 'score']]
33 | res1.head()
34 |
35 |
36 | res2 = pd.read_feather('{}/lgb_s0_m3_34-0/lgb_s0_m3_34.ftr'.format(m2_path))
37 | res2['score'] = res2['target'].apply(lambda x:np.log(x/(1-x)))
38 | res2.loc[res2['score']<-12, 'score'] = -12
39 | res2 = res2[['description_id', 'paper_id', 'score']]
40 | res2.head()
41 |
42 |
43 | res3 = pd.read_feather('{}/lgb_s0_m3_34-1/lgb_s0_m3_34.ftr'.format(m2_path))
44 | res3['score'] = res3['target'].apply(lambda x:np.log(x/(1-x)))
45 | res3.loc[res3['score']<-12, 'score'] = -12
46 | res3 = res3[['description_id', 'paper_id', 'score']]
47 | res3.head()
48 |
49 |
50 | res4 = pd.read_feather('{}/lgb_s0_m3_35-0/lgb_s0_m3_35.ftr'.format(m2_path))
51 | res4['score'] = res4['target'].apply(lambda x:np.log(x/(1-x)))
52 | res4.loc[res4['score']<-12, 'score'] = -12
53 | res4 = res4[['description_id', 'paper_id', 'score']]
54 | res4.head()
55 |
56 |
57 | res5 = pd.read_feather('{}/lgb_s0_m3_35-1/lgb_s0_m3_35.ftr'.format(m2_path))
58 | res5['score'] = res5['target'].apply(lambda x:np.log(x/(1-x)))
59 | res5.loc[res5['score']<-12, 'score'] = -12
60 | res5 = res5[['description_id', 'paper_id', 'score']]
61 | res5.head()
62 |
63 |
64 | res6 = pd.read_feather('{}/lgb_s0_m3_38-0lgb_s0_m3_38.ftr'.format(m2_path))
65 | res6['score'] = res6['target'].apply(lambda x:np.log(x/(1-x)))
66 | res6.loc[res6['score']<-12, 'score'] = -12
67 | res6 = res6[['description_id', 'paper_id', 'score']]
68 | res6.head()
69 |
70 |
71 | res7 = pd.read_feather('{}/lgb_s0_m3_38-1/lgb_s0_m3_38.ftr'.format(m2_path))
72 | res7['score'] = res7['target'].apply(lambda x:np.log(x/(1-x)))
73 | res7.loc[res7['score']<-12, 'score'] = -12
74 | res7 = res7[['description_id', 'paper_id', 'score']]
75 | res7.head()
76 |
77 |
78 | res8 = pd.read_feather('{}/lgb_s0_m3_40-0/lgb_s0_m3_40.ftr'.format(m2_path))
79 | res8['score'] = res8['target'].apply(lambda x:np.log(x/(1-x)))
80 | res8.loc[res8['score']<-12, 'score'] = -12
81 | res8 = res8[['description_id', 'paper_id', 'score']]
82 | res8.head()
83 |
84 |
85 | res9 = pd.read_feather('{}/model/m1/m1_catboost13.ftr'.format(m2_path))
86 | res9['score'] = res9['pred'].apply(lambda x:np.log(x/(1-x)))
87 | res9.loc[res9['score']<-12, 'score'] = -12
88 | res9 = res9[['description_id', 'paper_id', 'score']]
89 | res9.head()
90 |
91 |
92 | model_id = 'bert_002'
93 | res_b1 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
94 | res_b1['score'] = res_b1['target'].apply(lambda x:np.log(x/(1-x)))
95 | res_b1.loc[res_b1['score']<-12, 'score'] = -12
96 | res_b1 = res_b1[['description_id', 'paper_id', 'score']]
97 | res_b1.head()
98 |
99 |
100 | model_id = 'bert_003'
101 | res_b2 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
102 | res_b2['score'] = res_b2['target'].apply(lambda x:np.log(x/(1-x)))
103 | res_b2.loc[res_b2['score']<-12, 'score'] = -12
104 | res_b2 = res_b2[['description_id', 'paper_id', 'score']]
105 | res_b2.head()
106 |
107 |
108 | model_id = 'bert_004'
109 | res_b3 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
110 | res_b3['score'] = res_b3['target'].apply(lambda x:np.log(x/(1-x)))
111 | res_b3.loc[res_b3['score']<-12, 'score'] = -12
112 | res_b3 = res_b3[['description_id', 'paper_id', 'score']]
113 | res_b3.head()
114 |
115 | model_id = 'bert_year_test'
116 | res_b4 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
117 | res_b4['score'] = res_b4['target'].apply(lambda x:np.log(x/(1-x)))
118 | res_b4.loc[res_b4['score']<-12, 'score'] = -12
119 | res_b4 = res_b4[['description_id', 'paper_id', 'score']]
120 | res_b4.head()
121 |
122 |
123 | res_all = res.rename(columns={'score': 'score_0'}).merge(
124 | res1.rename(columns={'score': 'score_1'}), how='outer', on=['description_id', 'paper_id']).merge(
125 | res2.rename(columns={'score': 'score_2'}), how='outer', on=['description_id', 'paper_id']).merge(
126 | res3.rename(columns={'score': 'score_3'}), how='outer', on=['description_id', 'paper_id']).merge(
127 | res4.rename(columns={'score': 'score_4'}), how='outer', on=['description_id', 'paper_id']).merge(
128 | res5.rename(columns={'score': 'score_5'}), how='outer', on=['description_id', 'paper_id']).merge(
129 | res6.rename(columns={'score': 'score_6'}), how='outer', on=['description_id', 'paper_id']).merge(
130 | res7.rename(columns={'score': 'score_7'}), how='outer', on=['description_id', 'paper_id']).merge(
131 | res8.rename(columns={'score': 'score_8'}), how='outer', on=['description_id', 'paper_id']).merge(
132 | res9.rename(columns={'score': 'score_9'}), how='outer', on=['description_id', 'paper_id']).merge(
133 | res_b1.rename(columns={'score': 'score_b1'}), how='outer', on=['description_id', 'paper_id']).merge(
134 | res_b2.rename(columns={'score': 'score_b2'}), how='outer', on=['description_id', 'paper_id']).merge(
135 | res_b3.rename(columns={'score': 'score_b3'}), how='outer', on=['description_id', 'paper_id']).merge(
136 | res_b4.rename(columns={'score': 'score_b4'}), how='outer', on=['description_id', 'paper_id'])
137 | res_all = res_all.fillna(0.0)
138 | res_all.head()
139 |
140 |
141 | cols = ['score_0', 'score_1', 'score_2', 'score_3', 'score_4', 'score_5',
142 | 'score_6', 'score_7', 'score_8', 'score_9',
143 | 'score_b1', 'score_b2', 'score_b3']
144 |
145 | corr_matrix = []
146 | for description_id, df_tmp in tqdm(res_all.groupby('description_id')):
147 | corr_matrix.append(
148 | df_tmp[cols].corr().values[:,:,np.newaxis])
149 | corr_matrix = np.concatenate(corr_matrix, axis=2)
150 | corr_matrix[np.isnan(corr_matrix)] = 0
151 | pd.DataFrame(data=corr_matrix.mean(axis=2), columns=cols, index=cols)
152 |
153 | res_all['score'] = (
154 | (
155 | res_all['score_0'] + res_all['score_1'] + res_all['score_2'] + res_all['score_3'] +
156 | res_all['score_4'] + res_all['score_5'] + res_all['score_6'] + res_all['score_7']
157 | )/8 +
158 | (
159 | res_all['score_8'] + res_all['score_9']
160 | )/2 +
161 | (
162 | res_all['score_b1'] + 1.5*res_all['score_b2']
163 | )/2.5*5 +
164 | (
165 | res_all['score_b2'] + 3*res_all['score_b3']
166 | )/4
167 | )
168 |
169 |
170 | result = res_all.sort_values(by=['description_id', 'score'], na_position='first').groupby(
171 | 'description_id').tail(3)
172 |
173 |
174 | model_id = 'all_model'
175 |
176 | description_id_list = []
177 | paper_id_list_1 = []
178 | paper_id_list_2 = []
179 | paper_id_list_3 = []
180 | for description_id, df_tmp in tqdm(result.groupby('description_id')):
181 | description_id_list.append(description_id)
182 | paper_id_list_1.append(df_tmp.iloc[2,1])
183 | paper_id_list_2.append(df_tmp.iloc[1,1])
184 | paper_id_list_3.append(df_tmp.iloc[0,1])
185 |
186 | sub = pd.DataFrame(data={'description_id':description_id_list,
187 | 'paper_id_1': paper_id_list_1,
188 | 'paper_id_2': paper_id_list_2,
189 | 'paper_id_3': paper_id_list_3})
190 | sub.to_csv("blend_{}.csv".format(model_id), header=False, index=False)
191 | print("blend_{}.csv".format(model_id))
192 |
193 |
--------------------------------------------------------------------------------
/src/rank/m2/fold_result_integration.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 | from tqdm import tqdm
4 |
5 |
6 | import argparse
7 |
8 | parser = argparse.ArgumentParser()
9 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
10 | args = parser.parse_args()
11 | model_id = args.model_id
12 |
13 |
14 | def map3_func(df, topk = 50, verbose=0):
15 | ids = df[df.label==1].description_id.values
16 | df_recalled = df[df.description_id.isin(ids)].reset_index(drop=True)
17 | df_recalled = df_recalled.sort_values(
18 | by=['description_id', 'label'], ascending=False).reset_index(drop=True)
19 | result = df_recalled.score.values.reshape([-1,topk])
20 | ranks = topk-result.argsort(axis=1).argsort(axis=1)
21 | map3_sum = sum(((1/ranks[:,0])*(ranks[:,0]<4)))
22 | if verbose>1:
23 | print("recall rate: "+str((df_recalled.shape[0]/topk)/(df.shape[0]/topk)))
24 | print("map@3 in recall: "+str(map3_sum/(df_recalled.shape[0]/topk)))
25 | if verbose>0:
26 | print("map@3 in all: "+str(map3_sum/(df.shape[0]/topk)))
27 | return map3_sum/(df.shape[0]/topk)
28 |
29 |
30 | fold = 1
31 | val_df = pd.read_csv("result/{}/{}_fold_{}_cv.csv".format(model_id, model_id, fold))
32 | test_df = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
33 | columns={'score':'score_1'})
34 |
35 | for fold in tqdm(range(2,6)):
36 | val_df_cv = pd.read_csv("result/{}/{}_fold_{}_cv.csv".format(model_id, model_id, fold))
37 | val_df = pd.concat([val_df, val_df_cv], ignore_index=True, sort=True)
38 |
39 | test_df_cv = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
40 | columns={'score':'score_{}'.format(fold)})
41 | test_df = test_df.merge(test_df_cv)
42 |
43 | val_df = val_df.merge(train_recall, how='left')
44 | val_df = val_df[val_df.description_id!='6.45E+04'].reset_index(drop=True)
45 | # assert val_df.description_id.nunique()==49945
46 | map3_func(val_df)
47 | val_df['target'] = val_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
48 | val_df.to_csv("oof_m2_{}_5cv.csv".format(model_id), index=False)
49 |
50 | score_cols = ['score_1', 'score_2', 'score_3', 'score_4', 'score_5']
51 | test_df['score'] = test_df[score_cols].mean(axis=1)
52 | print(test_df[score_cols+['score']].corr(method='spearman'))
53 |
54 | test_df['target'] = test_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
55 | val_df['target'] = val_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
56 |
57 | test_df = test_recall.merge(
58 | test_df[['description_id', 'paper_id', 'score']], how='left', on=['description_id', 'paper_id'])
59 | test_df['target'] = test_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
60 | test_df['target'] = test_df['target'].fillna(0)
61 | test_df[['description_id', 'paper_id', 'target']].to_csv("result_m2_{}_5cv.csv".format(model_id), index=False)
62 |
63 |
64 |
--------------------------------------------------------------------------------
/src/rank/m2/gen_w2v.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # set -e
3 |
4 | BUILDDIR=build
5 | CORPUS=corpus.txt
6 | VOCAB_FILE=vocab.txt
7 | SAVE_FILE=glove.w2v
8 |
9 | VERBOSE=2
10 | MEMORY=4.0
11 |
12 | VOCAB_MIN_COUNT=5
13 |
14 | WINDOW_SIZE=5
15 | COOCCURRENCE_FILE=cooccurrence.bin
16 | WEIGHT=1
17 |
18 | COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
19 |
20 | VECTOR_SIZE=256
21 | MAX_ITER=25
22 | WINDOW_SIZE=2
23 | BINARY=0
24 | NUM_THREADS=8
25 | X_MAX=10
26 | HEADLINE=1
27 |
28 | echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
29 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
30 |
31 | echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE -distance-weighting $WEIGHT < $CORPUS > $COOCCURRENCE_FILE"
32 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE -distance-weighting $WEIGHT < $CORPUS > $COOCCURRENCE_FILE
33 |
34 | echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
35 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
36 |
37 | echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE -write-header $HEADLINE"
38 | $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE -write-header $HEADLINE
39 |
40 |
41 |
--------------------------------------------------------------------------------
/src/rank/m2/mk_submission.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 | from tqdm import tqdm
4 |
5 | test_recall = pd.read_feather('../../feat/te_s0_32-50.ftr')[['description_id', 'paper_id', 'corp_sim_score']]
6 |
7 | import argparse
8 |
9 | parser = argparse.ArgumentParser()
10 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
11 | args = parser.parse_args()
12 | model_id = args.model_id
13 |
14 | if '_pointwise' in model_id:
15 | fold = 1
16 | test_df = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
17 | columns={'target':'target_1'})
18 |
19 | for fold in tqdm(range(2,6)):
20 | test_df_cv = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
21 | columns={'target':'target_{}'.format(fold)})
22 | test_df = test_df.merge(test_df_cv)
23 |
24 | score_cols = ['target_1', 'target_2', 'target_3', 'target_4', 'target_5']
25 | test_df['target'] = test_df[score_cols].mean(axis=1)
26 | print(test_df[score_cols+['target']].corr(method='spearman'))
27 | else:
28 | fold = 1
29 | test_df = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
30 | columns={'score':'score_1'})
31 |
32 | for fold in tqdm(range(2,6)):
33 | test_df_cv = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
34 | columns={'score':'score_{}'.format(fold)})
35 | test_df = test_df.merge(test_df_cv)
36 |
37 | score_cols = ['score_1', 'score_2', 'score_3', 'score_4', 'score_5']
38 | test_df['score'] = test_df[score_cols].mean(axis=1)
39 | print(test_df[score_cols+['score']].corr(method='spearman'))
40 |
41 |
42 | if 'target' not in test_df.columns:
43 | test_df['target'] = test_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
44 |
45 | test_df = test_recall.merge(
46 | test_df[['description_id', 'paper_id', 'target']], how='left', on=['description_id', 'paper_id'])
47 | test_df[['description_id', 'paper_id', 'target']].to_csv("final_result_m2_{}_5cv.csv".format(model_id), index=False)
48 |
49 | result = test_df.sort_values(by=['description_id', 'target', 'corp_sim_score'], na_position='first').groupby(
50 | 'description_id').tail(3)
51 |
52 | description_id_list = []
53 | paper_id_list_1 = []
54 | paper_id_list_2 = []
55 | paper_id_list_3 = []
56 | for description_id, df_tmp in tqdm(result.groupby('description_id')):
57 | description_id_list.append(description_id)
58 | paper_id_list_1.append(df_tmp.iloc[2,1])
59 | paper_id_list_2.append(df_tmp.iloc[1,1])
60 | paper_id_list_3.append(df_tmp.iloc[0,1])
61 |
62 | sub = pd.DataFrame(data={'description_id':description_id_list,
63 | 'paper_id_1': paper_id_list_1,
64 | 'paper_id_2': paper_id_list_2,
65 | 'paper_id_3': paper_id_list_3})
66 | sub.to_csv("final_{}_sub_5cv.csv".format(model_id), header=False, index=False)
67 | print("final_{}_sub_5cv.csv".format(model_id))
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
--------------------------------------------------------------------------------
/src/rank/m2/model.py:
--------------------------------------------------------------------------------
1 | import typing
2 |
3 | import torch
4 | import torch.nn as nn
5 | from torch.nn import functional as F
6 |
7 | import matchzoo as mz
8 | from matchzoo.engine.param_table import ParamTable
9 | from matchzoo.engine.param import Param
10 | from matchzoo.engine.base_model import BaseModel
11 | from matchzoo.modules import RNNDropout
12 | from matchzoo.modules import BidirectionalAttention
13 | from matchzoo.modules import StackedBRNN
14 |
15 |
16 | class ESIMplus(mz.models.ESIM):
17 | def set_feature_dim(self, feature_dim):
18 | self.feature_dim = feature_dim
19 |
20 | def build(self):
21 | """Instantiating layers."""
22 | rnn_mapping = {'lstm': nn.LSTM, 'gru': nn.GRU}
23 | self.embedding = self._make_default_embedding_layer()
24 | self.rnn_dropout = RNNDropout(p=self._params['dropout'])
25 | lstm_size = self._params['hidden_size']
26 | if self._params['concat_lstm']:
27 | lstm_size /= self._params['lstm_layer']
28 | self.input_encoding = StackedBRNN(
29 | self._params['embedding_output_dim'],
30 | int(lstm_size / 2),
31 | self._params['lstm_layer'],
32 | dropout_rate=self._params['dropout'],
33 | dropout_output=self._params['drop_lstm'],
34 | rnn_type=rnn_mapping[self._params['rnn_type'].lower()],
35 | concat_layers=self._params['concat_lstm'])
36 | self.attention = BidirectionalAttention()
37 | self.projection = nn.Sequential(
38 | nn.Linear(
39 | 4 * self._params['hidden_size'],
40 | self._params['hidden_size']),
41 | nn.ReLU())
42 | self.composition = StackedBRNN(
43 | self._params['hidden_size'],
44 | int(lstm_size / 2),
45 | self._params['lstm_layer'],
46 | dropout_rate=self._params['dropout'],
47 | dropout_output=self._params['drop_lstm'],
48 | rnn_type=rnn_mapping[self._params['rnn_type'].lower()],
49 | concat_layers=self._params['concat_lstm'])
50 | self.wide_net = nn.Sequential(
51 | nn.Linear(self.feature_dim, self._params['hidden_size']),
52 | nn.ReLU(),
53 | nn.Linear(self._params['hidden_size'], self._params['hidden_size']),
54 | nn.ReLU())
55 | self.classification = nn.Sequential(
56 | nn.Dropout(
57 | p=self._params['dropout']),
58 | nn.Linear(
59 | 4 * self._params['hidden_size']+self._params['hidden_size'],
60 | self._params['hidden_size']),
61 | nn.Tanh(),
62 | nn.Dropout(
63 | p=self._params['dropout']))
64 | self.out = self._make_output_layer(self._params['hidden_size'])
65 |
66 |
67 | def forward(self, inputs):
68 | """Forward."""
69 | # Scalar dimensions referenced here:
70 | # B = batch size (number of sequences)
71 | # D = embedding size
72 | # L = `input_left` sequence length
73 | # R = `input_right` sequence length
74 | # F = `feature` dim
75 | # H = hidden size
76 |
77 | # [B, L], [B, R]
78 |
79 | query, doc = inputs['text_left'].long(), inputs['text_right'].long()
80 |
81 | # [B, L]
82 | # [B, R]
83 | query_mask = (query == self._params['mask_value'])
84 | doc_mask = (doc == self._params['mask_value'])
85 |
86 | # [B, L, D]
87 | # [B, R, D]
88 | query = self.embedding(query)
89 | doc = self.embedding(doc)
90 |
91 | # [B, L, D]
92 | # [B, R, D]
93 | query = self.rnn_dropout(query)
94 | doc = self.rnn_dropout(doc)
95 |
96 | # [B, L, H]
97 | # [B, R, H]
98 | query = self.input_encoding(query, query_mask)
99 | doc = self.input_encoding(doc, doc_mask)
100 |
101 | # [B, L, H], [B, L, H]
102 | attended_query, attended_doc = self.attention(
103 | query, query_mask, doc, doc_mask)
104 |
105 | # [B, L, 4 * H]
106 | # [B, L, 4 * H]
107 | enhanced_query = torch.cat([query,
108 | attended_query,
109 | query - attended_query,
110 | query * attended_query],
111 | dim=-1)
112 | enhanced_doc = torch.cat([doc,
113 | attended_doc,
114 | doc - attended_doc,
115 | doc * attended_doc],
116 | dim=-1)
117 | # [B, L, H]
118 | # [B, L, H]
119 | projected_query = self.projection(enhanced_query)
120 | projected_doc = self.projection(enhanced_doc)
121 |
122 | # [B, L, H]
123 | # [B, L, H]
124 | query = self.composition(projected_query, query_mask)
125 | doc = self.composition(projected_doc, doc_mask)
126 |
127 | # [B, L]
128 | # [B, R]
129 | reverse_query_mask = 1. - query_mask.float()
130 | reverse_doc_mask = 1. - doc_mask.float()
131 |
132 | # [B, H]
133 | # [B, H]
134 | query_avg = torch.sum(query * reverse_query_mask.unsqueeze(2), dim=1)\
135 | / (torch.sum(reverse_query_mask, dim=1, keepdim=True) + 1e-8)
136 | doc_avg = torch.sum(doc * reverse_doc_mask.unsqueeze(2), dim=1)\
137 | / (torch.sum(reverse_doc_mask, dim=1, keepdim=True) + 1e-8)
138 |
139 | # [B, L, H]
140 | # [B, L, H]
141 | query = query.masked_fill(query_mask.unsqueeze(2), -1e7)
142 | doc = doc.masked_fill(doc_mask.unsqueeze(2), -1e7)
143 |
144 | # [B, H]
145 | # [B, H]
146 | query_max, _ = query.max(dim=1)
147 | doc_max, _ = doc.max(dim=1)
148 |
149 | feature = inputs['feature'].float()
150 | feat_emb = self.wide_net(feature)
151 |
152 | # [B, 4 * H + H]
153 | v = torch.cat([query_avg, query_max, doc_avg, doc_max, feat_emb], dim=-1)
154 |
155 | # [B, H]
156 | hidden = self.classification(v)
157 |
158 | # [B, num_classes]
159 | out = self.out(hidden)
160 |
161 | return out
162 |
163 |
164 |
--------------------------------------------------------------------------------
/src/rank/m2/nn_5_fold_predict.py:
--------------------------------------------------------------------------------
1 | import os
2 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
3 |
4 | import gc
5 | from tqdm import tqdm
6 | import numpy as np
7 | import pandas as pd
8 |
9 | import torch
10 | import matchzoo as mz
11 | from model import ESIMplus
12 |
13 | from utils import MAP, build_matrix, topk_lines, predict, Logger
14 |
15 |
16 | import argparse
17 |
18 | parser = argparse.ArgumentParser()
19 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
20 | args = parser.parse_args()
21 |
22 | model_id = args.model_id
23 |
24 | num_dup = 6
25 | num_neg = 10
26 | batch_size = 128
27 | add_lgb_feat = False
28 | debug = False
29 |
30 | if model_id == 'ESIMplus_001':
31 | bst_epochs = {1:0, 2:2, 3:4, 4:2, 5:1}
32 | Model = ESIMplus
33 | lr = 0.001
34 | add_lgb_feat = True
35 | params = {'embedding_freeze': True,
36 | 'mask_value': 0,
37 | 'lstm_layer': 2,
38 | 'hidden_size': 200,
39 | 'dropout': 0.2}
40 |
41 |
42 | if model_id == 'aNMM_001':
43 | bst_epochs = {1:4, 2:4, 3:3, 4:4, 5:9}
44 | Model = mz.models.aNMM
45 | lr = 0.001
46 | params = {'embedding_freeze': True,
47 | 'mask_value': 0,
48 | 'dropout_rate': 0.1}
49 |
50 | if model_id == 'ESIM_001':
51 | bst_epochs = {1:4, 2:4, 3:2, 4:2, 5:6}
52 | Model = mz.models.ESIM
53 | lr = 0.001
54 | params = {'embedding_freeze': True,
55 | 'mask_value': 0,
56 | 'lstm_layer': 2,
57 | 'hidden_size': 200,
58 | 'dropout': 0.2}
59 |
60 | if model_id == 'MatchLSTM_001':
61 | bst_epochs = {1:4, 2:2, 3:2, 4:4, 5:3}
62 | Model = mz.models.MatchLSTM
63 | lr = 0.001
64 | params = {'embedding_freeze': True,
65 | 'mask_value': 0}
66 |
67 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
68 | task = mz.tasks.Ranking(losses=losses)
69 | task.metrics = [
70 | mz.metrics.MeanAveragePrecision(),
71 | MAP()
72 | ]
73 |
74 | if model_id == 'ESIM_001_pointwise':
75 | bst_epochs = {1:4, 2:3, 3:7, 4:12, 5:5}
76 | Model = mz.models.ESIM
77 | lr = 0.001
78 | params = {'embedding_freeze': True,
79 | 'mask_value': 0,
80 | 'lstm_layer': 2,
81 | 'hidden_size': 200,
82 | 'dropout': 0.2}
83 |
84 | task = mz.tasks.Classification(num_classes=2)
85 | task.metrics = ['acc']
86 |
87 |
88 | padding_callback = Model.get_default_padding_callback()
89 | embedding_matrix = np.load("data/embedding_matrix.npy")
90 | # l2_norm = np.sqrt((embedding_matrix * embedding_matrix).sum(axis=1))
91 | # embedding_matrix = embedding_matrix / l2_norm[:, np.newaxis]
92 |
93 | test_processed = mz.data_pack.data_pack.load_data_pack("test_processed.dp")
94 | testset = mz.dataloader.Dataset(
95 | data_pack=test_processed,
96 | batch_size=batch_size,
97 | sort=False,
98 | shuffle=False
99 | )
100 |
101 | testloader = mz.dataloader.DataLoader(
102 | dataset=testset,
103 | stage='dev',
104 | callback=padding_callback
105 | )
106 |
107 |
108 |
109 | model = Model()
110 | if add_lgb_feat: model.set_feature_dim(30)
111 |
112 | model.params['task'] = task
113 | model.params['embedding'] = embedding_matrix
114 |
115 | for param in params:
116 | model.params[param] = params[param]
117 |
118 | model.build()
119 |
120 | optimizer = torch.optim.Adam(model.parameters(), lr=lr)
121 | trainer = mz.trainers.Trainer(
122 | model=model,
123 | optimizer=optimizer,
124 | trainloader=testloader,
125 | validloader=testloader,
126 | validate_interval=None,
127 | epochs=1
128 | )
129 |
130 |
131 | for fold in range(1,6):
132 | i = bst_epochs[fold]
133 | val_processed = mz.data_pack.data_pack.load_data_pack("5fold/val_processed_{}.dp".format(fold))
134 | valset = mz.dataloader.Dataset(
135 | data_pack=val_processed,
136 | batch_size=batch_size,
137 | sort=False,
138 | shuffle=False
139 | )
140 |
141 | valloader = mz.dataloader.DataLoader(
142 | dataset=valset,
143 | stage='dev',
144 | callback=padding_callback
145 | )
146 |
147 | trainer.restore_model("save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
148 |
149 | score = predict(trainer, valloader)
150 | X, y = val_processed.unpack()
151 | result = pd.DataFrame(data={
152 | 'description_id': X['id_left'],
153 | 'paper_id': X['id_right'],
154 | 'score': score[:,0]})
155 | result.to_csv("result/{}/{}_fold_{}_cv.csv".format(model_id, model_id, fold), index=False)
156 |
157 | score = predict(trainer, testloader)
158 | X, y = test_processed.unpack()
159 | result = pd.DataFrame(data={
160 | 'description_id': X['id_left'],
161 | 'paper_id': X['id_right'],
162 | 'score': score[:,0]})
163 | result.to_csv("result/{}/{}_fold_{}_test.csv".format(model_id, model_id, fold), index=False)
164 |
165 |
166 |
--------------------------------------------------------------------------------
/src/rank/m2/nn_5_fold_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
3 |
4 | import gc
5 | from tqdm import tqdm
6 | import numpy as np
7 | import pandas as pd
8 |
9 | import torch
10 | import matchzoo as mz
11 | from model import ESIMplus
12 |
13 | from utils import MAP, build_matrix, topk_lines, predict, Logger
14 |
15 | import argparse
16 |
17 | parser = argparse.ArgumentParser()
18 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
19 | args = parser.parse_args()
20 |
21 | num_dup = 6
22 | num_neg = 10
23 | batch_size = 128
24 | add_lgb_feat = False
25 | debug = False
26 |
27 | if model_id == 'ESIMplus_001':
28 | Model = ESIMplus
29 | lr = 0.001
30 | add_lgb_feat = True
31 | params = {'embedding_freeze': True,
32 | 'mask_value': 0,
33 | 'lstm_layer': 2,
34 | 'hidden_size': 200,
35 | 'dropout': 0.2}
36 |
37 |
38 | if model_id == 'aNMM_001':
39 | Model = mz.models.aNMM
40 | lr = 0.001
41 | params = {'embedding_freeze': True,
42 | 'mask_value': 0,
43 | 'dropout_rate': 0.1}
44 |
45 | if model_id == 'ESIM_001':
46 | Model = mz.models.ESIM
47 | lr = 0.001
48 | params = {'embedding_freeze': True,
49 | 'mask_value': 0,
50 | 'lstm_layer': 2,
51 | 'hidden_size': 200,
52 | 'dropout': 0.2}
53 |
54 | if model_id == 'MatchLSTM':
55 | model_id = 'MatchLSTM_001'
56 | Model = mz.models.MatchLSTM
57 | lr = 0.001
58 | params = {'embedding_freeze': True,
59 | 'mask_value': 0}
60 |
61 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
62 | padding_callback = Model.get_default_padding_callback()
63 | task = mz.tasks.Ranking(losses=losses)
64 | task.metrics = [
65 | mz.metrics.MeanAveragePrecision(),
66 | MAP()
67 | ]
68 |
69 | if model_id == 'ESIM_001_pointwise':
70 | Model = mz.models.ESIM
71 | lr = 0.001
72 | params = {'embedding_freeze': True,
73 | 'mask_value': 0,
74 | 'lstm_layer': 2,
75 | 'hidden_size': 200,
76 | 'dropout': 0.2}
77 |
78 | task = mz.tasks.Classification(num_classes=2)
79 | task.metrics = ['acc']
80 |
81 | embedding_matrix = np.load("data/embedding_matrix.npy")
82 |
83 |
84 | if not os.path.exists('result/{}'.format(model_id)):
85 | os.makedirs('result/{}'.format(model_id))
86 |
87 | with Logger(log_filename = '{}.log'.format(model_id)):
88 | for fold in range(1,5):
89 | print("="*10+" fold: "+str(fold)+" data_processed prepare "+"="*10)
90 | train_processed = mz.data_pack.data_pack.load_data_pack("5fold/train_processed_{}.dp".format(fold))
91 | val_processed = mz.data_pack.data_pack.load_data_pack("5fold/val_processed_{}.dp".format(fold))
92 |
93 | if model_id == 'ESIM_001_pointwise':
94 | train_processed.relation.label = train_processed.relation.label.astype(np.long)
95 | val_processed.relation.label = val_processed.relation.label.astype(np.long)
96 |
97 |
98 | print("="*10+" fold: "+str(fold)+" dataset prepare "+"="*10)
99 | trainset = mz.dataloader.Dataset(
100 | data_pack=train_processed,
101 | mode='pair',
102 | num_dup=num_dup,
103 | num_neg=num_neg,
104 | batch_size=batch_size,
105 | resample=True,
106 | sort=False,
107 | shuffle=True
108 | )
109 | valset = mz.dataloader.Dataset(
110 | data_pack=val_processed,
111 | batch_size=batch_size,
112 | sort=False,
113 | shuffle=False
114 | )
115 |
116 | print("="*10+" fold: "+str(fold)+" dataloader prepare "+"="*10)
117 | trainloader = mz.dataloader.DataLoader(
118 | dataset=trainset,
119 | stage='train',
120 | callback=padding_callback
121 | )
122 | valloader = mz.dataloader.DataLoader(
123 | dataset=valset,
124 | stage='dev',
125 | callback=padding_callback
126 | )
127 |
128 | print("="*10+" fold: "+str(fold)+" model build "+"="*10)
129 | model = Model()
130 | if add_lgb_feat: model.set_feature_dim(30)
131 |
132 | model.params['task'] = task
133 | model.params['embedding'] = embedding_matrix
134 |
135 | for param in params:
136 | model.params[param] = params[param]
137 |
138 | model.build()
139 | if debug: print(model)
140 |
141 | print("="*10+" fold: "+str(fold)+" trainers build "+"="*10)
142 | optimizer = torch.optim.Adam(model.parameters(), lr=lr)
143 |
144 | trainer = mz.trainers.Trainer(
145 | model=model,
146 | optimizer=optimizer,
147 | trainloader=trainloader,
148 | validloader=valloader,
149 | validate_interval=None,
150 | epochs=1
151 | )
152 |
153 | print("="*10+" fold: "+str(fold)+" training "+"="*10)
154 | trainer.restore_model("save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, 1))
155 | for i in range(2,6):
156 | trainer._model.embedding.requires_grad_(requires_grad=False)
157 | print("="*10+" fold: "+str(fold)+" epoch: "+str(i)+" "+"="*10)
158 | trainer.run()
159 | trainer.save_model()
160 | os.rename("save/model.pt", "save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
161 |
162 |
163 |
--------------------------------------------------------------------------------
/src/rank/m2/nn_preprocessing.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gc
3 | from tqdm import tqdm
4 | import numpy as np
5 | import pandas as pd
6 |
7 | import torch
8 | import matchzoo as mz
9 | from model import ESIMplus
10 |
11 | from gensim.models import KeyedVectors
12 | from utils import MAP, build_matrix, topk_lines, predict
13 |
14 | pd.set_option('display.max_columns', None)
15 | pd.set_option('display.max_rows', 200)
16 | pd.set_option('max_colwidth',400)
17 |
18 |
19 | num_neg = 10
20 | fit_preprocessor = True
21 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
22 | feature = [
23 | 'quer_key_tfidf_corp_cos_dis',
24 | 'quer_key_tfidf_corp_eucl_dis',
25 | 'quer_key_corp_bm25_score',
26 | 'corp_sim_score',
27 | 'quer_all_tfidf_corp_eucl_dis',
28 | 'quer_all_corp_bm25_score',
29 | 'quer_key_tfidf_titl_manh_dis',
30 | 'quer_all_titl_bm25_score',
31 | 'quer_all_tfidf_corp_cos_dis',
32 | 'jaccard_coef_of_unigram_between_corp_quer_key',
33 | 'ratio_of_unique_corp_unigram',
34 | 'jaccard_coef_of_unigram_between_corp_quer_all',
35 | 'jaccard_coef_of_unigram_between_titl_quer_key',
36 | 'quer_key_tfidf_titl_cos_dis',
37 | 'jaccard_coef_of_unigram_between_abst_quer_key',
38 | 'quer_key_abst_bm25_score',
39 | 'quer_all_tfidf_titl_cos_dis',
40 | 'quer_key_tfidf_titl_eucl_dis',
41 | 'count_of_quer_key_unigram',
42 | 'quer_all_tfidf_titl_eucl_dis',
43 | 'ratio_of_unique_quer_all_unigram',
44 | 'quer_key_tfidf_abst_cos_dis',
45 | 'count_of_unique_corp_unigram',
46 | 'ratio_of_unique_abst_unigram',
47 | 'normalized_pos_of_corp_unigram_in_quer_all_max',
48 | 'quer_all_abst_bm25_score',
49 | 'normalized_pos_of_titl_unigram_in_quer_all_std',
50 | 'quer_all_tfidf_titl_manh_dis',
51 | 'jaccard_coef_of_unigram_between_abst_quer_all',
52 | 'dice_dist_of_unigram_between_corp_quer_key']
53 |
54 | task = mz.tasks.Ranking(losses=losses)
55 | task.metrics = [
56 | mz.metrics.MeanAveragePrecision(),
57 | MAP()
58 | ]
59 | print("task is", task)
60 | print("`task` initialized with metrics", task.metrics)
61 |
62 | if fit_preprocessor:
63 |
64 | preprocessor = mz.models.ESIM.get_default_preprocessor(
65 | truncated_mode='pre',
66 | truncated_length_left=64,
67 | truncated_length_right=256,
68 | filter_mode='df',
69 | filter_low_freq=2)
70 |
71 | preprocessor = preprocessor.fit(all_data_raw)
72 | preprocessor.save("preprocessor.prep")
73 | else:
74 | preprocessor = mz.load_preprocessor("preprocessor.prep")
75 |
76 |
77 | candidate_dic = pd.read_feather('data/candidate_dic.ftr')
78 |
79 | train_recall = pd.read_feather('data/train_recall.ftr')
80 | train_description = pd.read_feather('data/train_description.ftr')
81 | train_recall = pd.merge(train_recall, train_description, how='left', on='id_left')
82 | train_recall = pd.merge(train_recall, candidate_dic, how='left', on='id_right')
83 | train_recall = train_recall.drop_duplicates().reset_index(drop=True)
84 | del train_description
85 | gc.collect()
86 |
87 |
88 | test_recall = pd.read_feather('data/test_recall.ftr')
89 | test_description = pd.read_feather('data/test_description.ftr')
90 | test_recall = pd.merge(test_recall, test_description, how='left', on='id_left')
91 | test_recall = pd.merge(test_recall, candidate_dic, how='left', on='id_right')
92 | del test_description, candidate_dic
93 | gc.collect()
94 |
95 | all_data_df = train_recall.copy()
96 | all_data_df.id_left = all_data_df.id_left+'_tr'
97 | all_data_df = pd.concat([all_data_df, test_recall]).reset_index(drop=True)
98 | norm_df = all_data_df[feature].quantile(q=0.99)
99 |
100 | del all_data_df, train_recall, test_recall
101 | gc.collect()
102 |
103 | train_recall[feature] = train_recall[feature]/norm_df
104 | train_recall['feature'] = list(train_recall[feature].values)
105 | train_recall = train_recall[['id_left', 'text_left', 'id_right', 'text_right', 'label', 'feature']]
106 | cv_ids = pd.read_csv("../../input/cv_ids_0109.csv")
107 | train_recall = train_recall.merge(
108 | cv_ids.rename(columns={'description_id': 'id_left'}),
109 | how='left',
110 | on='id_left').fillna(5.0)
111 |
112 |
113 | for i in range(1,6):
114 | print("="*20, i, "="*20)
115 | train_df = train_recall[train_recall.cv!=i][
116 | ['id_left', 'text_left', 'id_right', 'text_right', 'label', 'feature']].reset_index(drop=True)
117 | val_df = train_recall[train_recall.cv==i][
118 | ['id_left', 'text_left', 'id_right', 'text_right', 'label', 'feature']].reset_index(drop=True)
119 |
120 | train_raw = mz.pack(train_df, task)
121 | val_raw = mz.pack(val_df, task)
122 |
123 | train_processed = preprocessor.transform(train_raw)
124 | val_processed = preprocessor.transform(val_raw)
125 |
126 | train_processed.save("5fold/train_processed_{}.dp".format(i))
127 | val_processed.save("5fold/val_processed_{}.dp".format(i))
128 |
129 |
130 | test_recall[feature] = test_recall[feature]/norm_df
131 | test_recall['feature'] = list(test_recall[feature].values)
132 | test_recall = test_recall[['id_left', 'text_left', 'id_right', 'text_right', 'feature']]
133 |
134 | test_raw = mz.pack(test_recall, task)
135 | test_processed = preprocessor.transform(test_raw)
136 | # test_processed.save("test_processed.dp")
137 | test_processed.save("final_test_processed.dp")
138 |
139 |
140 | from gensim.models import KeyedVectors
141 | w2v_path = "data/glove.w2v"
142 | w2v_model = KeyedVectors.load_word2vec_format(w2v_path, binary=False)
143 | term_index = preprocessor.context['vocab_unit'].state['term_index']
144 | embedding_matrix = build_matrix(term_index, w2v_model)
145 | del w2v_model, term_index
146 | gc.collect()
147 | np.save("data/embedding_matrix.npy", embedding_matrix)
148 |
149 |
150 |
--------------------------------------------------------------------------------
/src/rank/m2/preprocessing.py:
--------------------------------------------------------------------------------
1 | from tqdm import tqdm
2 | import numpy as np
3 | import pandas as pd
4 | import feather
5 |
6 | import argparse
7 |
8 | parser = argparse.ArgumentParser()
9 | parser.add_argument('--query_type', type=str, default='query_key')
10 | args = parser.parse_args()
11 |
12 | query_type = args.query_type
13 |
14 | def topk_lines(df, k):
15 | print(df.shape)
16 | df.loc[:, 'rank'] = df.groupby(['description_id', 'type']).cumcount().values
17 | df = df[df['rank'] < k]
18 | df.drop(['rank'], axis=1, inplace=True)
19 | print(df.shape)
20 | return df
21 |
22 |
23 | ## preprocess
24 | candidate_dic = feather.read_dataframe('../../../input/paper_input_final.ftr')
25 |
26 | candidate_dic.loc[candidate_dic['keywords'].isna(),'keywords'] = ''
27 | candidate_dic.loc[candidate_dic['titl'].isna(),'titl'] = ''
28 | candidate_dic.loc[candidate_dic['abst'].isna(),'abst'] = ''
29 |
30 | candidate_dic['text_right'] = candidate_dic['abst'].str.cat(
31 | candidate_dic['keywords'], sep=' ').str.cat(
32 | candidate_dic['titl'], sep=' ')
33 |
34 | candidate_dic = candidate_dic.rename(columns={'paper_id': 'id_right'})[['id_right', 'text_right']]
35 | candidate_dic.to_feather('data/candidate_dic.ftr')
36 |
37 | train_description = feather.read_dataframe('../../../input/tr_input_final.ftr')
38 |
39 | train_description = train_description.rename(
40 | columns={'description_id': 'id_left', query_type: 'text_left'})
41 | train_description[['id_left', 'text_left']].to_feather('data/train_description_{}.ftr'.format(query_type))
42 |
43 |
44 | test_description = feather.read_dataframe('../../../input/te_input_final.ftr')
45 |
46 | test_description = test_description.rename(
47 | columns={'description_id': 'id_left', query_type: 'text_left'})
48 |
49 | test_description[['id_left', 'text_left']].to_feather('data/test_description_{}.ftr'.format(query_type))
50 |
51 | train_recall = feather.read_dataframe('../../../feat/tr_s0_32-50.ftr')
52 |
53 | ## recall
54 | train_recall = train_recall.rename(
55 | columns={'description_id': 'id_left', 'paper_id': 'id_right', 'target': 'label'})
56 |
57 | train_recall = train_recall[train_recall.id_left.isin(train_description.id_left.values)].reset_index(drop=True)
58 | train_recall = train_recall.drop_duplicates()
59 | train_recall = train_recall.fillna(0)
60 | train_recall.to_feather('data/train_recall.ftr')
61 |
62 | test_recall = feather.read_dataframe('../../../feat/te_s0_32-50.ftr')
63 | test_recall = test_recall.reset_index(drop=True)
64 |
65 | test_recall = test_recall.rename(
66 | columns={'description_id': 'id_left',
67 | 'paper_id': 'id_right',
68 | 'target': 'label'})
69 |
70 | # test_recall[['id_left', 'id_right', 'label']].to_feather('data/test_recall.ftr')
71 | test_recall[['id_left', 'id_right', 'label']].to_feather('data/final_test_recall.ftr')
72 |
73 |
74 | ## corpus
75 | if query_type== 'query_key':
76 | candidate_dic = feather.read_dataframe('data/candidate_dic.ftr')
77 | train_description = feather.read_dataframe('data/train_description.ftr')
78 | test_description = feather.read_dataframe('data/test_description.ftr')
79 |
80 | with open('data/corpus.txt','a') as fid:
81 | for sent in tqdm(candidate_dic['text_right']):
82 | if type(sent)==str:
83 | fid.write(sent+'\n')
84 | for sent in tqdm(train_description['text_left']):
85 | if type(sent)==str:
86 | fid.write(sent+'\n')
87 | for sent in tqdm(test_description['text_left']):
88 | if type(sent)==str:
89 | fid.write(sent+'\n')
90 |
91 |
--------------------------------------------------------------------------------
/src/rank/m2/run.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | python3 preprocessing.py --query_type quer_key
4 | python3 preprocessing.py --query_type quer_all
5 |
6 | git clone http://github.com/stanfordnlp/glove
7 | cp gen_w2v.sh glove/
8 | cp data/corpus.txt glove/
9 | cd glove && make
10 | . gen_w2v.sh
11 | cd ..
12 | cp glove/glove.w2v data/
13 |
14 | python3 nn_preprocessing.py
15 | python3 bert_preprocessing.py --preprocessing_type fine --left_truncated_length 64 --query_type query_key
16 | python3 bert_preprocessing.py --preprocessing_type fine --left_truncated_length 200 --query_type query_all
17 | python3 bert_preprocessing.py --preprocessing_type coarse --left_truncated_length 200 --query_type query_all
18 |
19 | python3 nn_5_fold_train.py --model_id ESIM_001
20 | python3 nn_5_fold_train.py --model_id ESIMplus_001
21 | python3 nn_5_fold_train.py --model_id aNMM_001
22 | python3 nn_5_fold_train.py --model_id MatchLSTM_001
23 | python3 nn_5_fold_train.py --model_id ESIM_001_pointwise
24 |
25 | python3 bert_5_fold_train.py --model_id bert_002
26 | python3 bert_5_fold_train.py --model_id bert_003
27 | python3 bert_5_fold_train.py --model_id bert_004
28 |
29 | python3 nn_5_fold_predict.py --model_id ESIM_001
30 | python3 nn_5_fold_predict.py --model_id ESIMplus_001
31 | python3 nn_5_fold_predict.py --model_id aNMM_001
32 | python3 nn_5_fold_predict.py --model_id MatchLSTM_001
33 | python3 nn_5_fold_predict.py --model_id ESIM_001_pointwise
34 |
35 | python3 bert_5_fold_predict.py --model_id bert_002
36 | python3 bert_5_fold_predict.py --model_id bert_003
37 | python3 bert_5_fold_predict.py --model_id bert_004
38 |
39 | python3 fold_result_integration.py --model_id ESIM_001
40 | python3 fold_result_integration.py --model_id ESIMplus_001
41 | python3 fold_result_integration.py --model_id aNMM_001
42 | python3 fold_result_integration.py --model_id MatchLSTM_001
43 | python3 fold_result_integration.py --model_id ESIM_001_pointwise
44 | python3 fold_result_integration.py --model_id bert_002
45 | python3 fold_result_integration.py --model_id bert_003
46 | python3 fold_result_integration.py --model_id bert_004
47 |
48 | python3 mk_submission.py --model_id ESIM_001
49 | python3 mk_submission.py --model_id ESIMplus_001
50 | python3 mk_submission.py --model_id aNMM_001
51 | python3 mk_submission.py --model_id MatchLSTM_001
52 | python3 mk_submission.py --model_id ESIM_001_pointwise
53 | python3 mk_submission.py --model_id bert_002
54 | python3 mk_submission.py --model_id bert_003
55 | python3 mk_submission.py --model_id bert_004
56 |
57 | python3 change_formatting4stk.py --model_id ESIM_001
58 | python3 change_formatting4stk.py --model_id ESIMplus_001
59 | python3 change_formatting4stk.py --model_id aNMM_001
60 | python3 change_formatting4stk.py --model_id MatchLSTM_001
61 | python3 change_formatting4stk.py --model_id ESIM_001_pointwise
62 | python3 change_formatting4stk.py --model_id bert_002
63 | python3 change_formatting4stk.py --model_id bert_003
64 | python3 change_formatting4stk.py --model_id bert_004
65 |
66 | ###### finally #####
67 | python3 final_blend.py
68 |
69 |
--------------------------------------------------------------------------------
/src/rank/m2/utils.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import time
3 | import numpy as np
4 | from tqdm import tqdm
5 | import torch
6 | from matchzoo.engine.base_metric import sort_and_couple, RankingMetric
7 |
8 |
9 | def build_matrix(term_index, gv_model, dim=256):
10 |
11 | input_dim = len(term_index)
12 | matrix = np.empty((input_dim, dim))
13 |
14 | valid_keys = gv_model.vocab.keys()
15 | for term, index in term_index.items():
16 | if term in valid_keys:
17 | matrix[index] = gv_model.word_vec(term)
18 | else:
19 | if '' in gv_model.vocab.keys():
20 | matrix[index] = gv_model.word_vec("")
21 | else:
22 | matrix[index] = np.random.randn(dim).astype(dtype=np.float32)
23 | return matrix
24 |
25 | def topk_lines(df, k):
26 | print(df.shape)
27 | df.loc[:, 'rank'] = df.groupby(['description_id', 'type']).cumcount().values
28 | df = df[df['rank'] < k]
29 | df.drop(['rank'], axis=1, inplace=True)
30 | print(df.shape)
31 | return df
32 |
33 |
34 | class MAP(RankingMetric):
35 |
36 | def __init__(self, k = 3):
37 | self._k = k
38 |
39 | def __repr__(self) -> str:
40 | return 'mean_average_precision@{}'.format(self._k)
41 |
42 | def __call__(self, y_true, y_pred):
43 | coupled_pair = sort_and_couple(y_true, y_pred)
44 | for idx, (label, pred) in enumerate(coupled_pair):
45 | if idx+1>self._k:
46 | return 0
47 | if label > 0:
48 | return 1. / (idx + 1)
49 | return 0.
50 |
51 |
52 | def predict(trainer, testloader):
53 | with torch.no_grad():
54 | trainer._model.eval()
55 | predictions = []
56 | for batch in tqdm(testloader):
57 | inputs = batch[0]
58 | outputs = trainer._model(inputs).detach().cpu()
59 | predictions.append(outputs)
60 | trainer._model.train()
61 |
62 | return torch.cat(predictions, dim=0).numpy()
63 |
64 |
65 | class Logger:
66 | def __init__(self, log_filename="log.txt"):
67 | self.terminal = sys.stdout
68 | self.log = open(log_filename, "a")
69 | self.log.write("="*10+" Start Time:"+time.ctime()+" "+"="*10+"\n")
70 |
71 | def __enter__(self):
72 | sys.stdout = self
73 |
74 | def __exit__(self, e_t, e_v, t_b):
75 | sys.stdout = self.close()
76 |
77 | def stop_log(self):
78 | sys.stdout = self.close()
79 |
80 | def write(self, message):
81 | self.terminal.write(message)
82 | if message=="\n":
83 | self.log.write(message)
84 | else:
85 | self.log.write("["+time.ctime()+"]: "+message)
86 |
87 | def flush(self):
88 | self.terminal.flush()
89 | self.log.flush()
90 |
91 | def close(self):
92 | self.log.write("="*10+" End Time"+time.ctime()+" "+"="*10+"\n")
93 | self.log.close()
94 | return self.terminal
95 |
96 |
--------------------------------------------------------------------------------
/src/rank/m3/convert.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 |
17 | # 自定义工具包
18 | sys.path.append('../../../tools/')
19 | import loader
20 |
21 | # 设置随机种子
22 | SEED = 2020
23 | np.random.seed (SEED)
24 |
25 | def val_convert(df_path, pred_path, out_path):
26 | tr_data = loader.load_df(df_path)
27 | df_pred = loader.load_df(pred_path)
28 |
29 | sort_df_pred = df_pred.sort_values(['description_id', 'target'], ascending=False)
30 | df_pred = df_pred[['description_id']].drop_duplicates() \
31 | .merge(sort_df_pred, on=['description_id'], how='left')
32 | df_pred['rank'] = df_pred.groupby('description_id').cumcount().values
33 | df_pred = df_pred[df_pred['rank'] < 3]
34 | df_pred = df_pred.groupby(['description_id'])['paper_id'] \
35 | .apply(lambda s : ','.join((s))).reset_index()
36 |
37 | tr_data = tr_data[['description_id', 'paper_id']].rename(columns={'paper_id': 'target_id'})
38 | df_pred = df_pred.merge(tr_data, on=['description_id'], how='left')
39 | loader.save_df(df_pred, out_path)
40 |
41 | def output(df, out_path):
42 | fo = open(out_path, 'w')
43 | for i in range(df.shape[0]):
44 | desc_id = df.iloc[i]['description_id']
45 | paper_ids = df.iloc[i]['paper_id']
46 | print (desc_id + ',' + paper_ids, file=fo)
47 | fo.close()
48 |
49 | def sub_convert(df_path, pred_path, out_path1, out_path2):
50 | te_data = loader.load_df(df_path)
51 | df_pred = loader.load_df(pred_path)
52 |
53 | sort_df_pred = df_pred.sort_values(['description_id', 'target'], ascending=False)
54 | df_pred = df_pred[['description_id']].drop_duplicates() \
55 | .merge(sort_df_pred, on=['description_id'], how='left')
56 | df_pred['rank'] = df_pred.groupby('description_id').cumcount().values
57 | df_pred = df_pred[df_pred['rank'] < 3]
58 | df_pred = df_pred.groupby(['description_id'])['paper_id'] \
59 | .apply(lambda s : ','.join((s))).reset_index()
60 |
61 | df_pred = te_data[['description_id']].merge(df_pred, on=['description_id'], how='left')
62 | loader.save_df(df_pred, out_path1)
63 | #output(df_pred, out_path2)
64 |
65 | if __name__ == "__main__":
66 |
67 | print('start time: %s' % datetime.now())
68 | root_path = '../../../feat/'
69 | base_tr_path = '../../../input/train_release.csv'
70 | base_te_path = '../../../input/test.csv'
71 |
72 | sub_file_path = sys.argv[1]
73 | sub_name = sys.argv[2]
74 |
75 | val_path = '{}/{}_cv.ftr'.format(sub_file_path, sub_name)
76 | val_out_path = '{}/r_{}_cv.csv'.format(sub_file_path, sub_name)
77 | val_convert(base_tr_path, val_path, val_out_path)
78 |
79 | sub_path = '{}/{}.ftr'.format(sub_file_path, sub_name)
80 | sub_out_pathA = '{}/r_{}.csv'.format(sub_file_path, sub_name)
81 | sub_out_pathB = '{}/s_{}.csv'.format(sub_file_path, sub_name)
82 | sub_out_pathA2 = '{}/r2_{}.csv'.format(sub_file_path, sub_name)
83 | sub_out_pathB2 = '{}/s2_{}.csv'.format(sub_file_path, sub_name)
84 | sub_convert(base_te_path, sub_path, sub_out_pathA, sub_out_pathB)
85 |
86 | print('all completed: %s' % datetime.now())
87 |
88 |
89 |
--------------------------------------------------------------------------------
/src/rank/m3/eval.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 |
17 | # 自定义工具包
18 | sys.path.append('../../../tools/')
19 | import loader
20 |
21 | # 开源工具包
22 | import ml_metrics as metrics
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | def calc_map(df, k):
29 | df.rename(columns={'paper_id': 'paper_ids'}, inplace=True)
30 | df['paper_ids'] = df['paper_ids'].apply(lambda s: s.split(','))
31 | df['target_id'] = df['target_id'].apply(lambda s: [s])
32 | return metrics.mapk(df['target_id'].tolist(), df['paper_ids'].tolist(), k)
33 |
34 | if __name__ == "__main__":
35 |
36 | print('start time: %s' % datetime.now())
37 | in_path = sys.argv[1]
38 | df = loader.load_df(in_path)
39 | mapk = calc_map(df, k=3)
40 | print ('{} {}'.format(df.shape, round(mapk, 5)))
41 | print('all completed: %s' % datetime.now())
42 |
43 |
--------------------------------------------------------------------------------
/src/rank/m3/flow.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import time
8 |
9 | ts = time.time()
10 |
11 | num = sys.argv[1]
12 |
13 | sub_file_path = '../../../output/m3/lgb_m3_{}'.format(num)
14 | sub_name = 'lgb_m3_{}'.format(num)
15 |
16 | # lgb train
17 | print ('lgb_train-%s.py %s' % (num, num))
18 | os.system('python3 -u lgb_train_%s.py %s' % (num, num))
19 |
20 | # merge cv & sub
21 | print('\nkfold_merge')
22 | os.system('python3 -u kfold_merge.py %s %s' % (sub_file_path, sub_name))
23 |
24 | # convert cv & sub to list format
25 | print ('\nconvert')
26 | os.system('python3 -u convert.py %s %s' % (sub_file_path, sub_name))
27 |
28 | # calculate mrr & auc
29 | print ('\neval')
30 | os.system('python3 -u eval.py %s' % ('{}/r_{}_cv.csv'.format(sub_file_path, sub_name)))
31 |
32 | print ('all completed, cost {}s'.format(time.time() - ts))
33 |
--------------------------------------------------------------------------------
/src/rank/m3/kfold_merge.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 |
23 | # 设置随机种子
24 | SEED = 2020
25 | np.random.seed (SEED)
26 |
27 | TARGET_NAME = 'target'
28 | FOLD_NUM = 5
29 |
30 | def merge_val(file_path, sub_name, fold_num):
31 | file_list = os.listdir(file_path)
32 |
33 | paths = ['{}_cv_{}.csv'.format(sub_name, i) for i in range(1, fold_num + 1)]
34 | print (paths)
35 |
36 | dfs = []
37 | for path in paths:
38 | assert path in file_list, '{} not exist'.format(path)
39 | path = '{}/{}'.format(file_path, path)
40 | dfs.append(loader.load_df(path))
41 |
42 | df = pd.concat(dfs)
43 | print (df.head())
44 | print (df.describe())
45 | out_path = '{}/{}_cv.ftr'.format(file_path, sub_name)
46 | loader.save_df(df, out_path)
47 |
48 | def merge_sub(file_path, sub_name, fold_num):
49 | file_list = os.listdir(file_path)
50 |
51 | paths = ['{}_{}.csv'.format(sub_name, i) for i in range(1, fold_num + 1)]
52 | print (paths)
53 |
54 | df = pd.DataFrame()
55 | for i, path in enumerate(paths):
56 | assert path in file_list, '{} not exist'.format(path)
57 | path = '{}/{}'.format(file_path, path)
58 | if i == 0:
59 | df = loader.load_df(path)
60 | else:
61 | df[TARGET_NAME] += loader.load_df(path)[TARGET_NAME]
62 |
63 | df[TARGET_NAME] /= fold_num
64 | print (df.head())
65 | print (df.describe())
66 | out_path = '{}/{}.ftr'.format(file_path, sub_name)
67 | loader.save_df(df, out_path)
68 |
69 |
70 | if __name__ == '__main__':
71 |
72 | sub_file_path = sys.argv[1]
73 | sub_name = sys.argv[2]
74 |
75 | merge_val(sub_file_path, sub_name, FOLD_NUM)
76 | merge_sub(sub_file_path, sub_name, FOLD_NUM)
77 |
78 |
79 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_32-50-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '32-50'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | #train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_37-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '37'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | #train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_38-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '38'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | #train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_38-1.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '38'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | if sub_col in col and col != 'year':
57 | #if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_40-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '40'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/recall/tfidf_recall_30.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # bm25 recall
5 |
6 | # 基础模块
7 | import os
8 | import gc
9 | import sys
10 | import time
11 | import functools
12 | from tqdm import tqdm
13 | from six import iteritems
14 | from datetime import datetime
15 |
16 | # 数据处理
17 | import re
18 | import math
19 | import pickle
20 | import numpy as np
21 | import pandas as pd
22 | from multiprocessing import Pool
23 |
24 | # 自定义工具包
25 | sys.path.append('../../tools/')
26 | import loader
27 | import pandas_util
28 | import custom_bm25 as bm25
29 |
30 | # 开源工具包
31 | from gensim.models import Word2Vec
32 | from gensim.models.word2vec import LineSentence
33 | from gensim import corpora, models, similarities
34 | from gensim.similarities import SparseMatrixSimilarity
35 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
36 |
37 | # 设置随机种子
38 | SEED = 2020
39 | PROCESS_NUM, PARTITION_NUM = 18, 18
40 |
41 | input_root_path = '../../input/'
42 | output_root_path = '../../feat/'
43 |
44 | postfix = '30'
45 | file_type = 'ftr'
46 |
47 | train_out_path = output_root_path + 'tr_tfidf_{}.{}'.format(postfix, file_type)
48 | test_out_path = output_root_path + 'te_tfidf_{}.{}'.format(postfix, file_type)
49 |
50 | def topk_sim_samples(desc, desc_ids, paper_ids, bm25_model, k=10):
51 | desc_id2papers = {}
52 | for desc_i in tqdm(range(len(desc))):
53 | query_vec, query_desc_id = desc[desc_i], desc_ids[desc_i]
54 | sims = bm25_model.get_scores(query_vec)
55 | sort_sims = sorted(enumerate(sims), key=lambda item: -item[1])
56 | sim_papers = [paper_ids[val[0]] for val in sort_sims[:k]]
57 | sim_scores = [str(val[1]) for val in sort_sims[:k]]
58 | desc_id2papers[query_desc_id] = ['|'.join(sim_papers), '|'.join(sim_scores)]
59 | sim_df = pd.DataFrame.from_dict(desc_id2papers, orient='index', columns=['paper_id', 'sim_score'])
60 | sim_df = sim_df.reset_index().rename(columns={'index':'description_id'})
61 | return sim_df
62 |
63 | def partition(queries, num):
64 | queries_partitions, step = [], int(np.ceil(len(queries)/num))
65 | for i in range(0, len(queries), step):
66 | queries_partitions.append(queries[i:i+step])
67 | return queries_partitions
68 |
69 | def single_process_search(params=None):
70 | (query_vecs, desc_ids, paper_ids, bm25_model, k, i) = params
71 | print (i, 'start', datetime.now())
72 | gc.collect()
73 | sim_df = topk_sim_samples(query_vecs, desc_ids, paper_ids, bm25_model, k)
74 | print (i, 'completed', datetime.now())
75 | return sim_df
76 |
77 | def multi_process_search(query_vecs, desc_ids, paper_ids, bm25_model, k):
78 | pool = Pool(PROCESS_NUM)
79 | queries_parts = partition(query_vecs, PARTITION_NUM)
80 | desc_ids_parts = partition(desc_ids, PARTITION_NUM)
81 | print ('{} processes init and partition to {} parts' \
82 | .format(PROCESS_NUM, PARTITION_NUM))
83 |
84 | param_list = [(queries_parts[i], desc_ids_parts[i], \
85 | paper_ids, bm25_model, k, i) for i in range(PARTITION_NUM)]
86 | sim_dfs = pool.map(single_process_search, param_list)
87 | sim_df = pd.concat(sim_dfs, axis=0)
88 | return sim_df
89 |
90 | def gen_samples(df, desc, desc_ids, corpus_list, paper_ids_list, k):
91 | df_samples_list = []
92 | for i, corpus in enumerate(corpus_list):
93 | bm25_model = bm25.BM25(corpus[0])
94 | cur_df_sample = multi_process_search(desc, desc_ids, \
95 | paper_ids_list[i], bm25_model, k)
96 | cur_df_sample_out = pandas_util.explode(cur_df_sample, ['paper_id', 'sim_score'])
97 | cur_df_sample_out['type'] = corpus[1] # recall_name
98 | df_samples_list.append(cur_df_sample_out)
99 | df_samples = pd.concat(df_samples_list, axis=0)
100 | df_samples.drop_duplicates(subset=['description_id', 'paper_id'], inplace=True)
101 | df_samples['target'] = 0
102 | return df_samples
103 |
104 | if __name__ == "__main__":
105 |
106 | ts = time.time()
107 | tqdm.pandas()
108 | print('start time: %s' % datetime.now())
109 | # load data
110 | df = loader.load_df(input_root_path + 'paper_input_final.ftr')
111 | df = df[~pd.isnull(df['paper_id'])]
112 |
113 | # gen tfidf vecs
114 | dictionary = pickle.load(open('../../feat/corpus.dict', 'rb'))
115 | print ('dic len', len(dictionary))
116 |
117 | df['corp'] = df['abst'] + ' ' + df['titl'] + ' ' + df['keywords'].fillna('').replace(';', ' ')
118 | df_corp, corp_paper_ids = [dictionary.doc2bow(line.split(' ')) for line in df['corp'].tolist()], \
119 | df['paper_id'].tolist()
120 |
121 | # gen topk sim samples
122 | paper_ids_list = [corp_paper_ids]
123 | corpus_list = [(df_corp, 'corp_bm25')]
124 | out_cols = ['description_id', 'paper_id', 'sim_score', 'target', 'type']
125 |
126 | if sys.argv[1] in ['tr']:
127 | # for tr ins
128 | tr = loader.load_df(input_root_path + 'tr_input_final.ftr')
129 | tr = tr[~pd.isnull(tr['description_id'])]
130 |
131 | # tr = tr.head(1000)
132 | tr_desc, tr_desc_ids = [dictionary.doc2bow(line.split(' ')) for line in tr['quer_all'].tolist()], \
133 | tr['description_id'].tolist()
134 | print ('gen tf completed, cost {}s'.format(np.round(time.time() - ts, 2)))
135 |
136 | tr_samples = gen_samples(tr, tr_desc, tr_desc_ids, \
137 | corpus_list, paper_ids_list, k=50)
138 | tr_samples = tr.rename(columns={'paper_id': 'target_paper_id'}) \
139 | .merge(tr_samples, on='description_id', how='left')
140 | tr_samples.loc[tr_samples['target_paper_id'] == tr_samples['paper_id'], 'target'] = 1
141 | loader.save_df(tr_samples[out_cols], train_out_path)
142 | print ('recall succ {} from {}'.format(tr_samples['target'].sum(), tr.shape[0]))
143 | print (tr.shape, tr_samples.shape)
144 |
145 | if sys.argv[1] in ['te']:
146 | # for te ins
147 | te = loader.load_df(input_root_path + 'te_input_final.ftr')
148 | te = te[~pd.isnull(te['description_id'])]
149 |
150 | # te = te.head(1000)
151 | te_desc, te_desc_ids = [dictionary.doc2bow(line.split(' ')) for line in te['quer_all'].tolist()], \
152 | te['description_id'].tolist()
153 | print ('gen tf completed, cost {}s'.format(np.round(time.time() - ts, 2)))
154 |
155 | te_samples = gen_samples(te, te_desc, te_desc_ids, \
156 | corpus_list, paper_ids_list, k=50)
157 | te_samples = te.merge(te_samples, on='description_id', how='left')
158 | loader.save_df(te_samples[out_cols], test_out_path)
159 | print (te.shape, te_samples.shape)
160 |
161 | print('all completed: {}, cost {}s'.format(datetime.now(), np.round(time.time() - ts, 2)))
162 |
163 |
164 |
165 |
--------------------------------------------------------------------------------
/src/utils/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/src/utils/.gitkeep
--------------------------------------------------------------------------------
/stk_feat/README.md:
--------------------------------------------------------------------------------
1 | ## Dir of generated stacking features
2 |
--------------------------------------------------------------------------------
/tools/__pycache__/basic_learner.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/basic_learner.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/custom_bm25.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/custom_bm25.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/custom_metrics.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/custom_metrics.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/feat_utils.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/feat_utils.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/lgb_learner.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/lgb_learner.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/loader.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/loader.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/nlp_preprocess.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/nlp_preprocess.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/pandas_util.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/pandas_util.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/basic_learner.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | import loader
21 | import custom_metrics
22 |
23 | # 设置随机种子
24 | SEED = 2018
25 | np.random.seed (SEED)
26 |
27 | class BaseLearner(object):
28 |
29 | def __init__(self, train_data, test_data,
30 | fea_names, id_names, target_name, \
31 | params, fold_num, out_name, metric_names=['auc'], \
32 | model_postfix=''):
33 | # 深度拷贝原始数据,防止外部主函数修改导致的数据异常
34 | self.train_data = train_data.copy(deep=True)
35 | self.test_data = test_data.copy(deep=True)
36 |
37 | # 基础数据信息
38 | self.fea_names = fea_names
39 | self.id_names = id_names
40 | self.target_name = target_name
41 |
42 | self.params = params
43 | self.fold_num = fold_num
44 | self.out_name = out_name
45 | self.root_path = '../../../output/m3/' + out_name + '/'
46 | self.metric_names = metric_names
47 | self.model_postfix = model_postfix
48 |
49 | # 获取模型存储路径
50 | def get_model_path(self, predicted_fold_index):
51 | model_path = self.root_path + 'model_' + str(predicted_fold_index)
52 | if self.model_postfix != '':
53 | model_path += '_' + self.model_postfix
54 | return model_path
55 |
56 | # 获取预测结果输出路径
57 | def get_preds_outpath(self, predicted_fold_index):
58 | out_path = self.root_path + self.out_name
59 | if self.model_postfix != '':
60 | out_path += '_' + self.model_postfix
61 | if predicted_fold_index != 0:
62 | out_path += '_cv_' + str(predicted_fold_index)
63 | return out_path
64 |
65 | # 训练、验证集划分接口,需要被重载
66 | def extract_train_data(self, data, predicted_fold_index):
67 | pass
68 |
69 | # 单 fold 训练接口,需要被重载
70 | def train(self, data, predicted_fold_index, model_dump_path=None):
71 | pass
72 |
73 | # 单 fold 预测接口,需要被重载
74 | def predict(self, data, predicted_fold_index, model_load_path=None):
75 | pass
76 |
77 | # 多 fold 训练
78 | def multi_fold_train(self, data, predicted_folds=[1,2,3,4,5], \
79 | need_predict_test=False):
80 | print ("multi_fold train start {}".format(datetime.now()))
81 | ts = time.time()
82 | for fold_index in predicted_folds:
83 | print ('training fold {}'.format(fold_index))
84 | self.train(data, fold_index)
85 | print ('fold {} completed, cost {}s'.format( \
86 | fold_index, time.time() - ts))
87 | self.multi_fold_predict(data, predicted_folds, need_predict_test)
88 |
89 | # 多 fold 预测
90 | def multi_fold_predict(self, data, predicted_folds, \
91 | need_predict_test=False):
92 | print ("multi_fold predict start {}".format(datetime.now()))
93 |
94 | multi_fold_eval_lis = []
95 |
96 | for fold_index in predicted_folds:
97 | dtrain, dvalid, Xvalid = self.extract_train_data( \
98 | self.train_data, fold_index)
99 |
100 | ypreds = self.predict(Xvalid, fold_index)
101 | labels = Xvalid[self.target_name]
102 |
103 | eval_lis = custom_metrics.calc_metrics(labels, ypreds, \
104 | self.metric_names)
105 |
106 | multi_fold_eval_lis.append(eval_lis)
107 | print ('{} eval: {}'.format(fold_index, eval_lis))
108 | loader.out_preds(self.target_name, \
109 | Xvalid[self.id_names], ypreds, \
110 | '{}.csv'.format(self.get_preds_outpath(fold_index)), \
111 | labels.tolist())
112 |
113 | if need_predict_test:
114 | print ('predict test data')
115 | ypreds = self.predict(self.test_data, 0,
116 | model_load_path=self.get_model_path(fold_index))
117 | # output preds
118 | loader.out_preds(self.target_name, \
119 | self.test_data[self.id_names], ypreds, \
120 | '{}_{}.csv'.format(self.get_preds_outpath(0), fold_index))
121 |
122 | multi_fold_eval_avgs = []
123 | for i in range(len(self.metric_names)):
124 | eval_avg = np.array([val[i] for val in multi_fold_eval_lis]).mean()
125 | eval_avg = round(eval_avg, 5)
126 | multi_fold_eval_avgs.append(eval_avg)
127 | print ('multi fold eval mean: ', multi_fold_eval_avgs)
128 |
129 | return multi_fold_eval_avgs
130 |
131 |
132 |
--------------------------------------------------------------------------------
/tools/basic_learner.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/basic_learner.pyc
--------------------------------------------------------------------------------
/tools/custom_bm25.py:
--------------------------------------------------------------------------------
1 | import math
2 | from six import iteritems
3 | from six.moves import range
4 |
5 | PARAM_K1 = 1.5
6 | PARAM_B = 0.75
7 | EPSILON = 0.25
8 |
9 | class BM25(object):
10 | def __init__(self, corpus):
11 | """
12 | Parameters
13 | ----------
14 | corpus : list of list of str
15 | Given corpus.
16 | """
17 | self.corpus_size = 0
18 | self.avgdl = 0
19 | self.doc_freqs = []
20 | self.idf = {}
21 | self.doc_len = []
22 | self._initialize(corpus)
23 |
24 | def _initialize(self, corpus):
25 | """Calculates frequencies of terms in documents and in corpus. Also computes inverse document frequencies."""
26 | nd = {} # word -> number of documents with word
27 | num_doc = 0
28 |
29 | for document in corpus:
30 | self.corpus_size += 1
31 | cur_doc_len = 0
32 | frequencies = {}
33 |
34 | for word_tuple in document:
35 | word, word_cnt = word_tuple[0], word_tuple[1]
36 | if word not in frequencies:
37 | frequencies[word] = 0
38 | frequencies[word] += word_cnt
39 | cur_doc_len += word_cnt
40 | self.doc_freqs.append(frequencies)
41 | self.doc_len.append(cur_doc_len)
42 | num_doc += cur_doc_len
43 |
44 | for word, freq in iteritems(frequencies):
45 | if word not in nd:
46 | nd[word] = 0
47 | nd[word] += 1
48 |
49 | self.avgdl = float(num_doc) / self.corpus_size
50 | # collect idf sum to calculate an average idf for epsilon value
51 | idf_sum = 0
52 | # collect words with negative idf to set them a special epsilon value.
53 | # idf can be negative if word is contained in more than half of documents
54 | negative_idfs = []
55 | for word, freq in iteritems(nd):
56 | idf = math.log(self.corpus_size - freq + 0.5) - math.log(freq + 0.5)
57 | self.idf[word] = idf
58 | idf_sum += idf
59 | if idf < 0:
60 | negative_idfs.append(word)
61 | self.average_idf = float(idf_sum) / len(self.idf)
62 |
63 | eps = EPSILON * self.average_idf
64 | for word in negative_idfs:
65 | self.idf[word] = eps
66 |
67 | def get_score(self, document, index):
68 | """Computes BM25 score of given `document` in relation to item of corpus selected by `index`.
69 | Parameters
70 | ----------
71 | document : list of str
72 | Document to be scored.
73 | index : int
74 | Index of document in corpus selected to score with `document`.
75 | Returns
76 | -------
77 | float
78 | BM25 score.
79 | """
80 | score = 0
81 | doc_freqs = self.doc_freqs[index]
82 | for word_tuple in document:
83 | word = word_tuple[0]
84 | if word not in doc_freqs:
85 | continue
86 | score += (self.idf[word] * doc_freqs[word] * (PARAM_K1 + 1)
87 | / (doc_freqs[word] + PARAM_K1 * (1 - PARAM_B + PARAM_B * self.doc_len[index] / self.avgdl)))
88 | return score
89 |
90 | def get_scores(self, document):
91 | """Computes and returns BM25 scores of given `document` in relation to
92 | every item in corpus.
93 | Parameters
94 | ----------
95 | document : list of str
96 | Document to be scored.
97 | Returns
98 | -------
99 | list of float
100 | BM25 scores.
101 | """
102 | scores = [self.get_score(document, index) for index in range(self.corpus_size)]
103 | return scores
104 |
105 | def get_scores_bow(self, document):
106 | """Computes and returns BM25 scores of given `document` in relation to
107 | every item in corpus.
108 | Parameters
109 | ----------
110 | document : list of str
111 | Document to be scored.
112 | Returns
113 | -------
114 | list of float
115 | BM25 scores.
116 | """
117 | scores = []
118 | for index in range(self.corpus_size):
119 | score = self.get_score(document, index)
120 | if score > 0:
121 | scores.append((index, score))
122 | return scores
123 |
--------------------------------------------------------------------------------
/tools/custom_bm25.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/custom_bm25.pyc
--------------------------------------------------------------------------------
/tools/custom_metrics.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | import os
5 | import sys
6 | import gc
7 | import json
8 | import time
9 | import functools
10 | from datetime import datetime
11 |
12 | # 数据处理
13 | import numpy as np
14 | import pandas as pd
15 | from math import sqrt
16 |
17 | # 评价指标
18 | from sklearn.metrics import log_loss
19 | from sklearn.metrics import roc_auc_score
20 | from sklearn.metrics import accuracy_score
21 | from sklearn.metrics import mean_absolute_error
22 | from sklearn.metrics import mean_squared_error
23 |
24 | def _calc_auc(labels, ypreds):
25 | return roc_auc_score(labels, ypreds)
26 |
27 | def _calc_logloss(labels, ypreds):
28 | return log_loss(labels, ypreds)
29 |
30 | def _calc_mae(labels, ypreds):
31 | return mean_absolute_error(labels, ypreds)
32 |
33 | def _calc_rmse(labels, ypreds):
34 | return sqrt(mean_squared_error(labels, ypreds))
35 |
36 | # kappa
37 |
38 | # multi-logloss
39 |
40 | def _calc_metric(labels, ypreds, metric_name='auc'):
41 | if metric_name == 'auc':
42 | return _calc_auc(labels, ypreds)
43 | elif metric_name == 'logloss':
44 | return _calc_logloss(labels, ypreds)
45 | elif metric_name == 'mae':
46 | return _calc_mae(labels, ypreds)
47 | elif metric_name == 'rmse':
48 | return _calc_rmse(labels, ypreds)
49 |
50 | def calc_metrics(labels, ypreds, metric_names=['auc']):
51 | eval_lis = []
52 | for metric_name in metric_names:
53 | eval_val = _calc_metric(labels, ypreds, metric_name=metric_name)
54 | eval_val = round(eval_val, 5)
55 | eval_lis.append(eval_val)
56 | return eval_lis
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/tools/custom_metrics.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/custom_metrics.pyc
--------------------------------------------------------------------------------
/tools/feat_utils.py:
--------------------------------------------------------------------------------
1 | def try_divide(x, y, val=0.0):
2 | """
3 | Try to divide two numbers
4 | """
5 | if y != 0.0:
6 | val = float(x) / y
7 | return val
8 |
9 |
10 | def get_sample_indices_by_relevance(dfTrain, additional_key=None):
11 | """
12 | return a dict with
13 | key: (additional_key, median_relevance)
14 | val: list of sample indices
15 | """
16 | dfTrain["sample_index"] = range(dfTrain.shape[0])
17 | group_key = ["median_relevance"]
18 | if additional_key != None:
19 | group_key.insert(0, additional_key)
20 | agg = dfTrain.groupby(group_key, as_index=False).apply(lambda x: list(x["sample_index"]))
21 | d = dict(agg)
22 | dfTrain = dfTrain.drop("sample_index", axis=1)
23 | return d
24 |
25 |
26 | def dump_feat_name(feat_names, feat_name_file):
27 | """
28 | save feat_names to feat_name_file
29 | """
30 | with open(feat_name_file, "wb") as f:
31 | for i,feat_name in enumerate(feat_names):
32 | if feat_name.startswith("count") or feat_name.startswith("pos_of"):
33 | f.write("('%s', SimpleTransform(config.count_feat_transform)),\n" % feat_name)
34 | else:
35 | f.write("('%s', SimpleTransform()),\n" % feat_name)
36 |
--------------------------------------------------------------------------------
/tools/lgb_learner.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | import os
5 | import sys
6 | import gc
7 | import json
8 | import time
9 | import functools
10 | from datetime import datetime
11 |
12 | # 数据处理
13 | import numpy as np
14 | import pandas as pd
15 |
16 | # 模型相关
17 | import lightgbm as lgb
18 | from basic_learner import BaseLearner
19 |
20 | # 设置随机种子
21 | SEED = 2018
22 | np.random.seed (SEED)
23 |
24 | # 设置模型通用参数
25 | EVAL_ROUND = 100
26 | PRINT_TRAIN_METRICS = False
27 |
28 |
29 | class lgbLearner(BaseLearner):
30 |
31 | def __init__(self, train_data, test_data, \
32 | fea_names, id_names, target_name, \
33 | params, num_trees, fold_num, out_name, \
34 | cv_name='cv', metric_names=['auc'], model_postfix=''):
35 | super(lgbLearner, self).__init__(train_data, test_data, fea_names, \
36 | id_names, target_name, params, fold_num, \
37 | out_name, metric_names, model_postfix)
38 | self.num_trees = num_trees
39 | self.cv_name = cv_name
40 |
41 | self.eval_round = EVAL_ROUND
42 | self.print_train_metrics = PRINT_TRAIN_METRICS
43 |
44 | def extract_train_data(self, data, predicted_fold_index):
45 |
46 | Xtrain = data[data[self.cv_name] != predicted_fold_index]
47 | Xvalid = data[data[self.cv_name] == predicted_fold_index]
48 |
49 | dtrain = lgb.Dataset(Xtrain[self.fea_names].values, \
50 | Xtrain[self.target_name])
51 | dvalid = lgb.Dataset(Xvalid[self.fea_names].values, \
52 | Xvalid[self.target_name])
53 |
54 | print ('train, valid', Xtrain.shape, Xvalid.shape)
55 | return dtrain, dvalid, Xvalid
56 |
57 | def train(self, data, predicted_fold_index, model_dump_path=None):
58 | if model_dump_path == None:
59 | model_dump_path = self.get_model_path(predicted_fold_index)
60 |
61 | dtrain, dvalid, Xvalid = self.extract_train_data(self.train_data,
62 | predicted_fold_index)
63 |
64 | if self.print_train_metrics:
65 | valid_sets = [dtrain, dvalid] \
66 | if predicted_fold_index != 0 else [dtrain]
67 | valid_names = ['train', 'valid'] \
68 | if predicted_fold_index != 0 else ['train']
69 | else:
70 | valid_sets = [dvalid] if predicted_fold_index != 0 else [dtrain]
71 | valid_names = ['valid'] if predicted_fold_index != 0 else ['train']
72 |
73 | params = self.params
74 |
75 | bst = lgb.train(params, dtrain, self.num_trees,
76 | valid_sets=valid_sets,
77 | valid_names=valid_names,
78 | verbose_eval=self.eval_round)
79 | bst.save_model(model_dump_path)
80 |
81 | def predict(self, data, predicted_fold_index, \
82 | model_load_path=None):
83 | if model_load_path is None:
84 | model_load_path = self.get_model_path(predicted_fold_index)
85 |
86 | bst = lgb.Booster(model_file=model_load_path)
87 | ypreds = bst.predict(data[self.fea_names], num_iteration=self.num_trees)
88 |
89 | if predicted_fold_index != 0:
90 | # output fea importance
91 | df = pd.DataFrame(self.fea_names, columns=['feature'])
92 | df['importance'] = list(bst.feature_importance('gain'))
93 | df['precent'] = np.round(df.importance * 100 / sum(df.importance), 2)
94 | df['precent'] = df.precent.apply(lambda x : str(x) + '%')
95 |
96 | df = df.sort_values(by='importance', ascending=False)
97 | imp_path = 'imp'
98 | if self.model_postfix != '':
99 | imp_path = 'imp-{}'.format(self.model_postfix)
100 | df.to_csv(self.root_path + imp_path, sep='\t')
101 | return ypreds
102 |
103 |
--------------------------------------------------------------------------------
/tools/lgb_learner.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/lgb_learner.pyc
--------------------------------------------------------------------------------
/tools/loader.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python$
2 | # -*- coding: utf-8 -*-$
3 |
4 | # 数据处理
5 | import numpy as np
6 | import pandas as pd
7 | import feather
8 |
9 | # 基础文件读写
10 | def load_df(filename, nrows=None):
11 | if filename.endswith('csv'):
12 | return pd.read_csv(filename, nrows = nrows)
13 | elif filename.endswith('ftr'):
14 | return feather.read_dataframe(filename)
15 |
16 | def save_df(df, filename, index=False):
17 | if filename.endswith('csv'):
18 | df.to_csv(filename, index=index)
19 | elif filename.endswith('ftr'):
20 | df = df.reset_index(drop=True)
21 | df.columns = [str(col) for col in df.columns]
22 | df.to_feather(filename)
23 |
24 | # merge 特征文件
25 | def merge_fea(df_list, primary_keys=[]):
26 | assert len(primary_keys) >= 0, 'empty primary keys'
27 | print (df_list)
28 |
29 | df_base = load_df(df_list[0])
30 | for i in range(1, len(df_list)):
31 | print (df_list[i])
32 | cur_df = load_df(df_list[i])
33 | df_base = pd.concat([df_base, \
34 | cur_df.drop(primary_keys, axis=1)], axis=1)
35 | print ('merge completed, df shape', df_base.shape)
36 | return df_base
37 |
38 | # 模型预测结果输出
39 | def out_preds(target_name, df_ids, ypreds, out_path, labels=[]):
40 | preds_df = pd.DataFrame(df_ids)
41 | preds_df[target_name] = ypreds
42 | if len(labels) == preds_df.shape[0]:
43 | preds_df['label'] = np.array(labels)
44 | elif len(labels) > 0:
45 | print ('labels length not match')
46 | preds_df.to_csv(out_path, float_format = '%.4f', index=False)
47 |
48 | #def out_preds(id_name, target_name, ids, ypreds, out_path, labels=[]):
49 | # preds_df = pd.DataFrame({id_name: np.array(ids)})
50 | # preds_df[target_name] = ypreds
51 | # if len(labels) == preds_df.shape[0]:
52 | # preds_df['label'] = np.array(labels)
53 | # elif len(labels) > 0:
54 | # print ('labels length not match')
55 | # preds_df.to_csv(out_path, float_format = '%.4f', index=False)
56 |
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/tools/loader.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/loader.pyc
--------------------------------------------------------------------------------
/tools/nlp_preprocess.py:
--------------------------------------------------------------------------------
1 | import re
2 | import time
3 | import numpy as np
4 | import nltk
5 | # nltk.download('punkt')
6 | from nltk.corpus import stopwords
7 | from nltk import word_tokenize, pos_tag
8 | from nltk.stem import WordNetLemmatizer
9 |
10 | def tokenize(sentence):
11 | '''
12 | 去除多余空白、分词、词性标注
13 | '''
14 | sentence = re.sub(r'\s+', ' ', sentence)
15 | token_words = word_tokenize(sentence) # 输入的是列表
16 | token_words = pos_tag(token_words)
17 | return token_words
18 |
19 | def stem(token_words):
20 | '''
21 | 词形归一化
22 | '''
23 | wordnet_lematizer = WordNetLemmatizer() # 单词转换原型
24 | words_lematizer = []
25 | for word, tag in token_words:
26 | if tag.startswith('NN'):
27 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='n') # n代表名词
28 | elif tag.startswith('VB'):
29 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='v') # v代表动词
30 | elif tag.startswith('JJ'):
31 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='a') # a代表形容词
32 | elif tag.startswith('R'):
33 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='r') # r代表代词
34 | else:
35 | word_lematizer = wordnet_lematizer.lemmatize(word)
36 | words_lematizer.append(word_lematizer)
37 | return words_lematizer
38 |
39 |
40 | sr = stopwords.words('english')
41 |
42 |
43 | def delete_stopwords(token_words):
44 | '''
45 | 去停用词
46 | '''
47 | cleaned_words = [word for word in token_words if word not in sr]
48 | return cleaned_words
49 |
50 |
51 | def is_number(s):
52 | '''
53 | 判断字符串是否为数字
54 | '''
55 | try:
56 | float(s)
57 | return True
58 | except ValueError:
59 | pass
60 |
61 | try:
62 | import unicodedata
63 | unicodedata.numeric(s)
64 | return True
65 | except (TypeError, ValueError):
66 | pass
67 |
68 | return False
69 |
70 |
71 | characters = [' ', ',', '.', 'DBSCAN', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%', '-', '...',
72 | '^', '{', '}']
73 |
74 |
75 | def delete_characters(token_words):
76 | '''
77 | 去除特殊字符、数字
78 | '''
79 | words_list = [word for word in token_words if word not in characters and not is_number(word)]
80 | return words_list
81 |
82 |
83 | def to_lower(token_words):
84 | '''
85 | 统一为小写
86 | '''
87 | words_lists = [x.lower() for x in token_words]
88 | return words_lists
89 |
90 | def replace_process(line):
91 | m = replace = {
92 | 'α': 'alpha',
93 | 'β': 'beta',
94 | 'γ': 'gamma',
95 | 'δ': 'delta',
96 | 'ε': 'epsilon',
97 | 'ζ': 'zeta',
98 | 'η': 'eta',
99 | 'θ': 'theta',
100 | 'ι': 'iota',
101 | 'κ': 'kappa',
102 | 'λ': 'lambda',
103 | 'μ': 'mu',
104 | 'ν': 'nu',
105 | 'ξ': 'xi',
106 | 'ο': 'omicron',
107 | 'π': 'pi',
108 | 'ρ': 'rho',
109 | 'ς': 'sigma',
110 | 'σ': 'sigma',
111 | 'τ': 'tau',
112 | 'υ': 'upsilon',
113 | 'φ': 'phi',
114 | 'χ': 'chi',
115 | 'ψ': 'psi',
116 | 'ω': 'omega',
117 | 'ϑ': 'theta',
118 | 'ϒ': 'gamma',
119 | 'ϕ': 'phi',
120 | 'ϱ': 'rho',
121 | 'ϵ': 'epsilon',
122 | '𝛼': 'alpha',
123 | '𝛽': 'beta',
124 | '𝜀': 'epsilon',
125 | '𝜃': 'theta',
126 | '𝜏': 'tau',
127 | '𝜖': 'epsilon',
128 | '𝜷': 'beta',
129 | }
130 | empty_str = ['etc.','et al.','fig.','figure.','e.g.','(', ')','[', ']',';',':','!',',','.','?','"','\'', \
131 | '%','>','<','+','&']
132 | m.update({s: ' ' for s in empty_str})
133 |
134 | for k, v in m.items():
135 | line = line.replace(k, v)
136 | line = ' '.join([s.strip() for s in line.split(' ') if s != ''])
137 | return line
138 |
139 | def preprocess(line):
140 | '''
141 | 文本预处理
142 | '''
143 | line = line.lower()
144 | line = replace_process(line)
145 | token_words = tokenize(line)
146 | token_words = stem(token_words)
147 | token_words = delete_stopwords(token_words)
148 | token_words = delete_characters(token_words)
149 | token_words = to_lower(token_words)
150 | return ' '.join(token_words)
151 |
152 | if __name__ == '__main__':
153 | text = 'This experiment was conducted to determine whether feeding meal and hulls derived from genetically modified soybeans to dairy cows affected production measures and sensory qualities of milk. The soybeans were genetically modified (Event DAS-444Ø6-6) to be resistant to multiple herbicides. Twenty-six Holstein cows (13/treatment) were fed a diet that contained meal and hulls derived from transgenic soybeans or a diet that contained meal and hulls from a nontransgenic near-isoline variety. Soybean products comprised approximately 21% of the diet dry matter, and diets were formulated to be nearly identical in crude protein, neutral detergent fiber, energy, and minerals and vitamins. The experimental design was a replicated 2×2 Latin square with a 28-d feeding period. Dry matter intake (21.3 vs. 21.4kg/d), milk yield (29.3 vs. 29.4kg/d), milk fat (3.70 vs. 3.68%), and milk protein (3.10 vs. 3.12%) did not differ between cows fed control or transgenic soybean products, respectively. Milk fatty acid profile was virtually identical between treatments. Somatic cell count was significantly lower for cows fed transgenic soybean products, but the difference was biologically trivial. Milk was collected from all cows in period 1 on d 0 (before treatment), 14, and 28 for sensory evaluation. On samples from all days (including d 0) judges could discriminate between treatments for perceived appearance of the milk. The presence of this difference at d 0 indicated that it was likely not a treatment effect but rather an initial bias in the cow population. No treatment differences were found for preference or acceptance of the milk. Overall, feeding soybean meal and hulls derived from this genetically modified soybean had essentially no effects on production or milk acceptance when fed to dairy cows. '
154 | text = 'Pyrvinium is a drug approved by the FDA and identified as a Wnt inhibitor by inhibiting Axin degradation and stabilizing 尾-catenin, which can increase Ki67+ cardiomyocytes in the peri-infarct area and alleviate cardiac remodeling in a mouse model of MI . UM206 is a peptide with a high homology to Wnt-3a/5a, and acts as an antagonist for Frizzled proteins to inhibit Wnt signaling pathway transduction. UM206 could reduce infarct size, increase the numbers of capillaries, decrease myofibroblasts in infarct area of post-MI heart, and ultimately suppress the development of heart failure . ICG-001, which specifically inhibits the interaction between 尾-catenin and CBP in the Wnt canonical signaling pathway, can promote the differentiation of epicardial progenitors, thereby contributing to myocardial regeneration and improving cardiac function in a rat model of MI . Small molecules invaliding Porcupine have been further studied, such as WNT-974, GNF-6231 and CGX-1321. WNT-974 decreases fibrosis in post-MI heart, with a mechanism of preventing collagen production in cardiomyocytes by blocking secretion of Wnt-3, a pro-fibrotic agonist, from cardiac fibroblasts and its signaling to cardiomyocytes . The phosphorylation of DVL protein is decreased in both the canonical and non-canonical Wnt signaling pathways by WNT-974 administration . GNF-6231 prevents adverse cardiac remodeling in a mouse model of MI by inhibiting the proliferation of interstitial cells, increasing the proliferation of Sca1+ cardiac progenitors and reducing the apoptosis of cardiomyocytes [[**##**]]. Similarly, we demonstrate that CGX-1321, which has also been applied in a phase I clinical trial to treat solid tumors ({"type":"clinical-trial","attrs":{"text":"NCT02675946","term_id":"NCT02675946"}}NCT02675946), inhibits both canonical and non-canonical Wnt signaling pathways in post-MI heart. CGX-1321 promotes cardiac function by reducing fibrosis and stimulating cardiomyocyte proliferation-mediated cardiac regeneration in a Hippo/YAP-independent manner . These reports implicate that Wnt pathway inhibitors are a class of potential drugs for treating MI through complex mechanisms, including reducing cardiomyocyte death, increasing angiogenesis, suppressing fibrosis and stimulating cardiac regeneration.'
155 | token_words = tokenize(text)
156 | print(token_words)
157 | token_words = stem(token_words) # 单词原型
158 | token_words = delete_stopwords(token_words) # 去停
159 | token_words = delete_characters(token_words)
160 | token_words = to_lower(token_words)
161 | print(token_words)
162 |
--------------------------------------------------------------------------------
/tools/pandas_util.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # 基础模块
5 | import math
6 | import os
7 | import sys
8 | import time
9 | from datetime import datetime
10 | from tqdm import tqdm
11 |
12 | # 数据处理
13 | import numpy as np
14 | import pandas as pd
15 |
16 | def string_to_array(s):
17 | """Convert pipe separated string to array."""
18 |
19 | if isinstance(s, str):
20 | out = s.split("|")
21 | elif math.isnan(s):
22 | out = []
23 | else:
24 | raise ValueError("Value must be either string of nan")
25 | return out
26 |
27 |
28 | def explode(df_in, col_expls):
29 | """Explode column col_expl of array type into multiple rows."""
30 |
31 | df = df_in.copy()
32 | for col_expl in col_expls:
33 | df.loc[:, col_expl] = df[col_expl].apply(string_to_array)
34 |
35 | base_cols = list(set(df.columns) - set(col_expls))
36 | df_out = pd.DataFrame(
37 | {col: np.repeat(df[col].values,
38 | df[col_expls[0]].str.len())
39 | for col in base_cols}
40 | )
41 |
42 | for col_expl in col_expls:
43 | df_out.loc[:, col_expl] = np.concatenate(df[col_expl].values)
44 | df_out.loc[:, col_expl] = df_out[col_expl]
45 | return df_out
46 |
--------------------------------------------------------------------------------
/tools/pandas_util.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/pandas_util.pyc
--------------------------------------------------------------------------------
28 |
29 | If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
30 |
31 | $ git clone http://github.com/stanfordnlp/glove
32 | $ cd glove && make
33 | $ ./demo.sh
34 |
35 | The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading [demo.sh](https://github.com/stanfordnlp/GloVe/blob/master/demo.sh) or the [src/README.md](https://github.com/stanfordnlp/GloVe/tree/master/src)
36 |
37 | ### License
38 | All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.
39 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/demo.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | # Makes programs, downloads sample data, trains a GloVe model, and then evaluates it.
5 | # One optional argument can specify the language used for eval script: matlab, octave or [default] python
6 |
7 | make
8 | if [ ! -e text8 ]; then
9 | if hash wget 2>/dev/null; then
10 | wget http://mattmahoney.net/dc/text8.zip
11 | else
12 | curl -O http://mattmahoney.net/dc/text8.zip
13 | fi
14 | unzip text8.zip
15 | rm text8.zip
16 | fi
17 |
18 | CORPUS=../corpus.txt
19 | VOCAB_FILE=vocab.txt
20 | COOCCURRENCE_FILE=cooccurrence.bin
21 | COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
22 | BUILDDIR=build
23 | SAVE_FILE=vectors
24 | VERBOSE=2
25 | MEMORY=4.0
26 | VOCAB_MIN_COUNT=2
27 | VECTOR_SIZE=300
28 | MAX_ITER=15
29 | WINDOW_SIZE=15
30 | BINARY=2
31 | NUM_THREADS=8
32 | X_MAX=10
33 |
34 | echo
35 | echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
36 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
37 | echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE"
38 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE
39 | echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
40 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
41 | echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE"
42 | $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE
43 | if [ "$CORPUS" = 'text8' ]; then
44 | if [ "$1" = 'matlab' ]; then
45 | matlab -nodisplay -nodesktop -nojvm -nosplash < ./eval/matlab/read_and_evaluate.m 1>&2
46 | elif [ "$1" = 'octave' ]; then
47 | octave < ./eval/octave/read_and_evaluate_octave.m 1>&2
48 | else
49 | echo "$ python eval/python/evaluate.py"
50 | python eval/python/evaluate.py
51 | fi
52 | fi
53 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/matlab/WordLookup.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup(InputString)
2 | global wordMap
3 | if wordMap.isKey(InputString)
4 | index = wordMap(InputString);
5 | elseif wordMap.isKey('')
6 | index = wordMap('');
7 | else
8 | index = 0;
9 | end
10 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/matlab/evaluate_vectors.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 | if wordMap.isKey('')
21 | unkkey = wordMap('');
22 | else
23 | unkkey = 0;
24 | end
25 |
26 | for j=1:length(filenames);
27 |
28 | clear dist;
29 |
30 | fid=fopen([path filenames{j} '.txt']);
31 | temp=textscan(fid,'%s%s%s%s');
32 | fclose(fid);
33 | ind1 = cellfun(@WordLookup,temp{1}); %indices of first word in analogy
34 | ind2 = cellfun(@WordLookup,temp{2}); %indices of second word in analogy
35 | ind3 = cellfun(@WordLookup,temp{3}); %indices of third word in analogy
36 | ind4 = cellfun(@WordLookup,temp{4}); %indices of answer word in analogy
37 | full_count = full_count + length(ind1);
38 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
39 | ind1 = ind1(ind);
40 | ind2 = ind2(ind);
41 | ind3 = ind3(ind);
42 | ind4 = ind4(ind);
43 | disp([filenames{j} ':']);
44 | mx = zeros(1,length(ind1));
45 | num_iter = ceil(length(ind1)/split_size);
46 | for jj=1:num_iter
47 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
48 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
49 | for i=1:length(range)
50 | dist(ind1(range(i)),i) = -Inf;
51 | dist(ind2(range(i)),i) = -Inf;
52 | dist(ind3(range(i)),i) = -Inf;
53 | end
54 | [~, mx(range)] = max(dist); %predicted word index
55 | end
56 |
57 | val = (ind4 == mx'); %correct predictions
58 | count_tot = count_tot + length(ind1);
59 | correct_tot = correct_tot + sum(val);
60 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
61 | if j < 6
62 | count_sem = count_sem + length(ind1);
63 | correct_sem = correct_sem + sum(val);
64 | else
65 | count_syn = count_syn + length(ind1);
66 | correct_syn = correct_syn + sum(val);
67 | end
68 |
69 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
70 |
71 | end
72 | disp('________________________________________________________________________________');
73 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
74 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
75 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
76 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
77 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
78 |
79 | end
80 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/matlab/read_and_evaluate.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/matlab');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 | wordMap = containers.Map(words(1:vocab_size),1:vocab_size);
16 |
17 | fid = fopen(vectors_file,'r');
18 | fseek(fid,0,'eof');
19 | vector_size = ftell(fid)/16/vocab_size - 1;
20 | frewind(fid);
21 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
22 | fclose(fid);
23 |
24 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
25 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
26 |
27 | W = W1 + W2; %Evaluate on sum of word vectors
28 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
29 | evaluate_vectors(W);
30 | exit
31 |
32 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/octave/WordLookup_octave.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup_octave(InputString)
2 | global wordMap
3 |
4 | if isfield(wordMap, InputString)
5 | index = wordMap.(InputString);
6 | elseif isfield(wordMap, '')
7 | index = wordMap.('');
8 | else
9 | index = 0;
10 | end
11 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/octave/evaluate_vectors_octave.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors_octave(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 |
21 | if isfield(wordMap, '')
22 | unkkey = wordMap.('');
23 | else
24 | unkkey = 0;
25 | end
26 |
27 | for j=1:length(filenames);
28 |
29 | clear dist;
30 |
31 | fid=fopen([path filenames{j} '.txt']);
32 | temp=textscan(fid,'%s%s%s%s');
33 | fclose(fid);
34 | ind1 = cellfun(@WordLookup_octave,temp{1}); %indices of first word in analogy
35 | ind2 = cellfun(@WordLookup_octave,temp{2}); %indices of second word in analogy
36 | ind3 = cellfun(@WordLookup_octave,temp{3}); %indices of third word in analogy
37 | ind4 = cellfun(@WordLookup_octave,temp{4}); %indices of answer word in analogy
38 | full_count = full_count + length(ind1);
39 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
40 | ind1 = ind1(ind);
41 | ind2 = ind2(ind);
42 | ind3 = ind3(ind);
43 | ind4 = ind4(ind);
44 | disp([filenames{j} ':']);
45 | mx = zeros(1,length(ind1));
46 | num_iter = ceil(length(ind1)/split_size);
47 | for jj=1:num_iter
48 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
49 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
50 | for i=1:length(range)
51 | dist(ind1(range(i)),i) = -Inf;
52 | dist(ind2(range(i)),i) = -Inf;
53 | dist(ind3(range(i)),i) = -Inf;
54 | end
55 | [~, mx(range)] = max(dist); %predicted word index
56 | end
57 |
58 | val = (ind4 == mx'); %correct predictions
59 | count_tot = count_tot + length(ind1);
60 | correct_tot = correct_tot + sum(val);
61 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
62 | if j < 6
63 | count_sem = count_sem + length(ind1);
64 | correct_sem = correct_sem + sum(val);
65 | else
66 | count_syn = count_syn + length(ind1);
67 | correct_syn = correct_syn + sum(val);
68 | end
69 |
70 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
71 |
72 | end
73 | disp('________________________________________________________________________________');
74 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
75 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
76 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
77 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
78 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
79 |
80 | end
81 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/octave/read_and_evaluate_octave.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/octave');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 |
16 | wordMap = struct();
17 | for i=1:numel(words)
18 | wordMap.(words{i}) = i;
19 | end
20 |
21 | fid = fopen(vectors_file,'r');
22 | fseek(fid,0,'eof');
23 | vector_size = ftell(fid)/16/vocab_size - 1;
24 | frewind(fid);
25 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
26 | fclose(fid);
27 |
28 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
29 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
30 |
31 | W = W1 + W2; %Evaluate on sum of word vectors
32 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
33 | evaluate_vectors_octave(W);
34 | exit
35 |
36 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/python/distance.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import sys
4 |
5 | def generate():
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
8 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
9 | args = parser.parse_args()
10 |
11 | with open(args.vocab_file, 'r') as f:
12 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
13 | with open(args.vectors_file, 'r') as f:
14 | vectors = {}
15 | for line in f:
16 | vals = line.rstrip().split(' ')
17 | vectors[vals[0]] = [float(x) for x in vals[1:]]
18 |
19 | vocab_size = len(words)
20 | vocab = {w: idx for idx, w in enumerate(words)}
21 | ivocab = {idx: w for idx, w in enumerate(words)}
22 |
23 | vector_dim = len(vectors[ivocab[0]])
24 | W = np.zeros((vocab_size, vector_dim))
25 | for word, v in vectors.items():
26 | if word == '':
27 | continue
28 | W[vocab[word], :] = v
29 |
30 | # normalize each word vector to unit variance
31 | W_norm = np.zeros(W.shape)
32 | d = (np.sum(W ** 2, 1) ** (0.5))
33 | W_norm = (W.T / d).T
34 | return (W_norm, vocab, ivocab)
35 |
36 |
37 | def distance(W, vocab, ivocab, input_term):
38 | for idx, term in enumerate(input_term.split(' ')):
39 | if term in vocab:
40 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
41 | if idx == 0:
42 | vec_result = np.copy(W[vocab[term], :])
43 | else:
44 | vec_result += W[vocab[term], :]
45 | else:
46 | print('Word: %s Out of dictionary!\n' % term)
47 | return
48 |
49 | vec_norm = np.zeros(vec_result.shape)
50 | d = (np.sum(vec_result ** 2,) ** (0.5))
51 | vec_norm = (vec_result.T / d).T
52 |
53 | dist = np.dot(W, vec_norm.T)
54 |
55 | for term in input_term.split(' '):
56 | index = vocab[term]
57 | dist[index] = -np.Inf
58 |
59 | a = np.argsort(-dist)[:N]
60 |
61 | print("\n Word Cosine distance\n")
62 | print("---------------------------------------------------------\n")
63 | for x in a:
64 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
65 |
66 |
67 | if __name__ == "__main__":
68 | N = 100; # number of closest words that will be shown
69 | W, vocab, ivocab = generate()
70 | while True:
71 | input_term = raw_input("\nEnter word or sentence (EXIT to break): ")
72 | if input_term == 'EXIT':
73 | break
74 | else:
75 | distance(W, vocab, ivocab, input_term)
76 |
77 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/python/evaluate.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 |
4 | def main():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
7 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
8 | args = parser.parse_args()
9 |
10 | with open(args.vocab_file, 'r') as f:
11 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
12 | with open(args.vectors_file, 'r') as f:
13 | vectors = {}
14 | for line in f:
15 | vals = line.rstrip().split(' ')
16 | vectors[vals[0]] = [float(x) for x in vals[1:]]
17 |
18 | vocab_size = len(words)
19 | vocab = {w: idx for idx, w in enumerate(words)}
20 | ivocab = {idx: w for idx, w in enumerate(words)}
21 |
22 | vector_dim = len(vectors[ivocab[0]])
23 | W = np.zeros((vocab_size, vector_dim))
24 | for word, v in vectors.items():
25 | if word == '':
26 | continue
27 | W[vocab[word], :] = v
28 |
29 | # normalize each word vector to unit length
30 | W_norm = np.zeros(W.shape)
31 | d = (np.sum(W ** 2, 1) ** (0.5))
32 | W_norm = (W.T / d).T
33 | evaluate_vectors(W_norm, vocab, ivocab)
34 |
35 | def evaluate_vectors(W, vocab, ivocab):
36 | """Evaluate the trained word vectors on a variety of tasks"""
37 |
38 | filenames = [
39 | 'capital-common-countries.txt', 'capital-world.txt', 'currency.txt',
40 | 'city-in-state.txt', 'family.txt', 'gram1-adjective-to-adverb.txt',
41 | 'gram2-opposite.txt', 'gram3-comparative.txt', 'gram4-superlative.txt',
42 | 'gram5-present-participle.txt', 'gram6-nationality-adjective.txt',
43 | 'gram7-past-tense.txt', 'gram8-plural.txt', 'gram9-plural-verbs.txt',
44 | ]
45 | prefix = './eval/question-data/'
46 |
47 | # to avoid memory overflow, could be increased/decreased
48 | # depending on system and vocab size
49 | split_size = 100
50 |
51 | correct_sem = 0; # count correct semantic questions
52 | correct_syn = 0; # count correct syntactic questions
53 | correct_tot = 0 # count correct questions
54 | count_sem = 0; # count all semantic questions
55 | count_syn = 0; # count all syntactic questions
56 | count_tot = 0 # count all questions
57 | full_count = 0 # count all questions, including those with unknown words
58 |
59 | for i in range(len(filenames)):
60 | with open('%s/%s' % (prefix, filenames[i]), 'r') as f:
61 | full_data = [line.rstrip().split(' ') for line in f]
62 | full_count += len(full_data)
63 | data = [x for x in full_data if all(word in vocab for word in x)]
64 |
65 | indices = np.array([[vocab[word] for word in row] for row in data])
66 | ind1, ind2, ind3, ind4 = indices.T
67 |
68 | predictions = np.zeros((len(indices),))
69 | num_iter = int(np.ceil(len(indices) / float(split_size)))
70 | for j in range(num_iter):
71 | subset = np.arange(j*split_size, min((j + 1)*split_size, len(ind1)))
72 |
73 | pred_vec = (W[ind2[subset], :] - W[ind1[subset], :]
74 | + W[ind3[subset], :])
75 | #cosine similarity if input W has been normalized
76 | dist = np.dot(W, pred_vec.T)
77 |
78 | for k in range(len(subset)):
79 | dist[ind1[subset[k]], k] = -np.Inf
80 | dist[ind2[subset[k]], k] = -np.Inf
81 | dist[ind3[subset[k]], k] = -np.Inf
82 |
83 | # predicted word index
84 | predictions[subset] = np.argmax(dist, 0).flatten()
85 |
86 | val = (ind4 == predictions) # correct predictions
87 | count_tot = count_tot + len(ind1)
88 | correct_tot = correct_tot + sum(val)
89 | if i < 5:
90 | count_sem = count_sem + len(ind1)
91 | correct_sem = correct_sem + sum(val)
92 | else:
93 | count_syn = count_syn + len(ind1)
94 | correct_syn = correct_syn + sum(val)
95 |
96 | print("%s:" % filenames[i])
97 | print('ACCURACY TOP1: %.2f%% (%d/%d)' %
98 | (np.mean(val) * 100, np.sum(val), len(val)))
99 |
100 | print('Questions seen/total: %.2f%% (%d/%d)' %
101 | (100 * count_tot / float(full_count), count_tot, full_count))
102 | print('Semantic accuracy: %.2f%% (%i/%i)' %
103 | (100 * correct_sem / float(count_sem), correct_sem, count_sem))
104 | print('Syntactic accuracy: %.2f%% (%i/%i)' %
105 | (100 * correct_syn / float(count_syn), correct_syn, count_syn))
106 | print('Total accuracy: %.2f%% (%i/%i)' % (100 * correct_tot / float(count_tot), correct_tot, count_tot))
107 |
108 |
109 | if __name__ == "__main__":
110 | main()
111 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/eval/python/word_analogy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import sys
4 |
5 | def generate():
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
8 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
9 | args = parser.parse_args()
10 |
11 | with open(args.vocab_file, 'r') as f:
12 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
13 | with open(args.vectors_file, 'r') as f:
14 | vectors = {}
15 | for line in f:
16 | vals = line.rstrip().split(' ')
17 | vectors[vals[0]] = [float(x) for x in vals[1:]]
18 |
19 | vocab_size = len(words)
20 | vocab = {w: idx for idx, w in enumerate(words)}
21 | ivocab = {idx: w for idx, w in enumerate(words)}
22 |
23 | vector_dim = len(vectors[ivocab[0]])
24 | W = np.zeros((vocab_size, vector_dim))
25 | for word, v in vectors.items():
26 | if word == '':
27 | continue
28 | W[vocab[word], :] = v
29 |
30 | # normalize each word vector to unit variance
31 | W_norm = np.zeros(W.shape)
32 | d = (np.sum(W ** 2, 1) ** (0.5))
33 | W_norm = (W.T / d).T
34 | return (W_norm, vocab, ivocab)
35 |
36 |
37 | def distance(W, vocab, ivocab, input_term):
38 | vecs = {}
39 | if len(input_term.split(' ')) < 3:
40 | print("Only %i words were entered.. three words are needed at the input to perform the calculation\n" % len(input_term.split(' ')))
41 | return
42 | else:
43 | for idx, term in enumerate(input_term.split(' ')):
44 | if term in vocab:
45 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
46 | vecs[idx] = W[vocab[term], :]
47 | else:
48 | print('Word: %s Out of dictionary!\n' % term)
49 | return
50 |
51 | vec_result = vecs[1] - vecs[0] + vecs[2]
52 |
53 | vec_norm = np.zeros(vec_result.shape)
54 | d = (np.sum(vec_result ** 2,) ** (0.5))
55 | vec_norm = (vec_result.T / d).T
56 |
57 | dist = np.dot(W, vec_norm.T)
58 |
59 | for term in input_term.split(' '):
60 | index = vocab[term]
61 | dist[index] = -np.Inf
62 |
63 | a = np.argsort(-dist)[:N]
64 |
65 | print("\n Word Cosine distance\n")
66 | print("---------------------------------------------------------\n")
67 | for x in a:
68 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
69 |
70 |
71 | if __name__ == "__main__":
72 | N = 100; # number of closest words that will be shown
73 | W, vocab, ivocab = generate()
74 | while True:
75 | input_term = raw_input("\nEnter three words (EXIT to break): ")
76 | if input_term == 'EXIT':
77 | break
78 | else:
79 | distance(W, vocab, ivocab, input_term)
80 |
81 |
--------------------------------------------------------------------------------
/src/rank/m1/glove/src/README.md:
--------------------------------------------------------------------------------
1 | ### Package Contents
2 |
3 | To train your own GloVe vectors, first you'll need to prepare your corpus as a single text file with all words separated by one or more spaces or tabs. If your corpus has multiple documents, the documents (only) should be separated by new line characters. Cooccurrence contexts for words do not extend past newline characters. Once you create your corpus, you can train GloVe vectors using the following 4 tools. An example is included in `demo.sh`, which you can modify as necessary.
4 |
5 | The four main tools in this package are:
6 |
7 | #### 1) vocab_count
8 | This tool requires an input corpus that should already consist of whitespace-separated tokens. Use something like the [Stanford Tokenizer](https://nlp.stanford.edu/software/tokenizer.html) first on raw text. From the corpus, it constructs unigram counts from a corpus, and optionally thresholds the resulting vocabulary based on total vocabulary size or minimum frequency count.
9 |
10 | #### 2) cooccur
11 | Constructs word-word cooccurrence statistics from a corpus. The user should supply a vocabulary file, as produced by `vocab_count`, and may specify a variety of parameters, as described by running `./build/cooccur`.
12 |
13 | #### 3) shuffle
14 | Shuffles the binary file of cooccurrence statistics produced by `cooccur`. For large files, the file is automatically split into chunks, each of which is shuffled and stored on disk before being merged and shuffled together. The user may specify a number of parameters, as described by running `./build/shuffle`.
15 |
16 | #### 4) glove
17 | Train the GloVe model on the specified cooccurrence data, which typically will be the output of the `shuffle` tool. The user should supply a vocabulary file, as given by `vocab_count`, and may specify a number of other parameters, which are described by running `./build/glove`.
18 |
--------------------------------------------------------------------------------
/src/rank/m1/prepare_rank_train.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | # In[1]:
5 |
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from tqdm import tqdm
10 |
11 |
12 | # In[2]:
13 |
14 |
15 | paper = pd.read_feather("../../../input/paper_input_final.ftr")
16 |
17 |
18 | # In[3]:
19 |
20 |
21 | paper['abst'] = paper['abst'].apply(lambda s: s.replace('no_content', ''))
22 | paper['corp'] = paper['titl']+' '+paper['keywords'].fillna('').replace(';', ' ')+paper['abst']
23 |
24 |
25 | # In[4]:
26 |
27 |
28 | df_train = pd.read_feather("../../../input/tr_input_final.ftr")
29 |
30 |
31 | # In[5]:
32 |
33 |
34 | df_train.head()
35 |
36 |
37 | # In[6]:
38 |
39 |
40 | df_test = pd.read_feather("../../../input/te_input_final.ftr")
41 |
42 |
43 | # In[7]:
44 |
45 |
46 | df_test.head()
47 |
48 |
49 | # In[8]:
50 |
51 |
52 | #####reduce mem
53 | import datetime
54 | def pandas_reduce_mem_usage(df):
55 | start_mem=df.memory_usage().sum() / 1024**2
56 | print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
57 | starttime = datetime.datetime.now()
58 | for col in df.columns:
59 | col_type=df[col].dtype #每一列的类型
60 | if col_type !=object: #不是object类型
61 | c_min=df[col].min()
62 | c_max=df[col].max()
63 | # print('{} column dtype is {} and begin convert to others'.format(col,col_type))
64 | if str(col_type)[:3]=='int':
65 | #是有符号整数
66 | if c_min<0:
67 | if c_min >= np.iinfo(np.int8).min and c_max <= np.iinfo(np.int8).max:
68 | df[col] = df[col].astype(np.int8)
69 | elif c_min >= np.iinfo(np.int16).min and c_max <= np.iinfo(np.int16).max:
70 | df[col] = df[col].astype(np.int16)
71 | elif c_min >= np.iinfo(np.int32).min and c_max <= np.iinfo(np.int32).max:
72 | df[col] = df[col].astype(np.int32)
73 | else:
74 | df[col] = df[col].astype(np.int64)
75 | else:
76 | if c_min >= np.iinfo(np.uint8).min and c_max<=np.iinfo(np.uint8).max:
77 | df[col]=df[col].astype(np.uint8)
78 | elif c_min >= np.iinfo(np.uint16).min and c_max <= np.iinfo(np.uint16).max:
79 | df[col] = df[col].astype(np.uint16)
80 | elif c_min >= np.iinfo(np.uint32).min and c_max <= np.iinfo(np.uint32).max:
81 | df[col] = df[col].astype(np.uint32)
82 | else:
83 | df[col] = df[col].astype(np.uint64)
84 | #浮点数
85 | else:
86 | if c_min >= np.finfo(np.float16).min and c_max <= np.finfo(np.float32).max:
87 | df[col] = df[col].astype(np.float32)
88 | else:
89 | df[col] = df[col].astype(np.float64)
90 | # print('\t\tcolumn dtype is {}'.format(df[col].dtype))
91 |
92 | #是object类型,比如str
93 | else:
94 | # print('\t\tcolumns dtype is object and will convert to category')
95 | df[col] = df[col].astype('category')
96 | end_mem = df.memory_usage().sum() / 1024 ** 2
97 | endtime = datetime.datetime.now()
98 | print('consume times: {:.4f}'.format((endtime - starttime).seconds))
99 | print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
100 | print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
101 | return df
102 |
103 |
104 | # In[9]:
105 |
106 |
107 | recall_train = pd.read_feather('../../../input/tr_s0_32-50.ftr')
108 | recall_test = pd.read_feather('../../../input/te_s0_32-50.ftr')
109 |
110 |
111 | # In[10]:
112 |
113 |
114 | recall_train = pandas_reduce_mem_usage(recall_train)
115 |
116 |
117 | # In[11]:
118 |
119 |
120 | recall_test = pandas_reduce_mem_usage(recall_test)
121 |
122 |
123 | # In[12]:
124 |
125 |
126 | recall_train.shape
127 |
128 |
129 | # In[13]:
130 |
131 |
132 | cv_id = pd.read_csv("../../../input/cv_ids_0109.csv")
133 | recall_train.drop(columns=['cv'],axis=1,inplace=True)
134 | recall_train = recall_train.merge(cv_id,on=['description_id'],how='left')
135 |
136 |
137 | # In[14]:
138 |
139 |
140 | recall_train = recall_train.dropna(subset=['cv']).reset_index(drop=True)
141 |
142 |
143 | # In[15]:
144 |
145 |
146 | recall_train.shape,recall_test.shape
147 |
148 |
149 | # In[16]:
150 |
151 |
152 | recall_train = recall_train.merge(paper[['paper_id','corp']],on=['paper_id'],how='left')
153 | recall_test = recall_test.merge(paper[['paper_id','corp']],on=['paper_id'],how='left')
154 |
155 |
156 | # In[17]:
157 |
158 |
159 | recall_train = recall_train.merge(df_train[['description_id','quer_key','quer_all']],on=['description_id'],how='left')
160 | recall_test = recall_test.merge(df_test[['description_id','quer_key','quer_all']],on=['description_id'],how='left')
161 |
162 |
163 | # In[18]:
164 |
165 |
166 | recall_train = recall_train.sort_values(['description_id', 'corp_sim_score'], ascending=False)
167 | recall_train['rank'] = recall_train.groupby('description_id').cumcount().values
168 | recall_test = recall_test.sort_values(['description_id', 'corp_sim_score'], ascending=False)
169 | recall_test['rank'] = recall_test.groupby('description_id').cumcount().values
170 |
171 |
172 | # In[19]:
173 |
174 |
175 | keep_columns = ['description_id','paper_id','corp','quer_key','quer_all','corp_sim_score','cv','rank','target']
176 | recall_train = recall_train[keep_columns].reset_index(drop=True)
177 | recall_test = recall_test[keep_columns].reset_index(drop=True)
178 |
179 |
180 | # In[20]:
181 |
182 |
183 | recall_train.head()
184 |
185 |
186 | # In[22]:
187 |
188 |
189 | recall_train.to_csv('recall_train.csv',index=False)
190 |
191 |
192 | # In[23]:
193 |
194 |
195 | recall_test.to_csv('recall_test.csv',index=False)
196 |
197 |
198 | # In[ ]:
199 |
200 |
201 | # recall_train.shape
202 |
203 |
--------------------------------------------------------------------------------
/src/rank/m1/run.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | ####依赖paper_input_1.ftr、te_input_1.ftr
4 | ####写入语料,并训练word2vector词向量
5 | python3 w2v_training.py ###暂时用jupyter notebook占位
6 |
7 | ###训练glove词向量
8 | cd glove && make
9 | bash demo.sh
10 | ####回到目录
11 | cd ..
12 |
13 | ###词向量序列化
14 |
15 |
16 |
17 | ###准备训练数据
18 | python3 prepare_rank_train.py ###暂时用jupyter notebook占位
19 |
20 | ###inferSent-simple-5-fold训练
21 | python3 inferSent1-5-fold_train.py ###暂时用jupyter notebook 占位
22 |
23 | ###inferSent-simple-5-fold预测
24 | python3 inferSent1-5-fold_predict.py ###暂时用jupyter notebook 占位
25 |
26 | ###catboost模型训练&预测
27 | python3 catboost3.py ###暂时用jupyter notebook 占位
28 |
29 | ###nn02模型训练
30 | python3 nn02_train.py ###暂时用jupyter notebook 占位
31 | python3 nn02_predict.py ###暂时用jupyter notebook 占位
32 |
--------------------------------------------------------------------------------
/src/rank/m1/w2v_training.py:
--------------------------------------------------------------------------------
1 |
2 | # coding: utf-8
3 |
4 | # In[1]:
5 |
6 |
7 | # external vec
8 | import warnings
9 | warnings.filterwarnings('always')
10 | warnings.filterwarnings('ignore')
11 |
12 | import os
13 | import sys
14 | import numpy as np
15 | import pandas as pd
16 | from tqdm import tqdm
17 |
18 | import time
19 | from datetime import datetime
20 | from gensim.models import Word2Vec
21 | from gensim.models.word2vec import LineSentence
22 | from gensim import corpora, models, similarities
23 | from gensim.similarities import SparseMatrixSimilarity
24 | from gensim.similarities import MatrixSimilarity
25 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
26 |
27 |
28 | # In[3]:
29 |
30 |
31 | paper = pd.read_feather("../../../input/paper_input_final.ftr")
32 |
33 |
34 | # In[4]:
35 |
36 |
37 | paper['abst'] = paper['abst'].apply(lambda s: s.replace('no_content', ''))
38 | paper['corp'] = paper['titl']+' '+paper['keywords'].fillna('').replace(';', ' ')+paper['abst']
39 |
40 |
41 | # In[5]:
42 |
43 |
44 | paper.head()
45 |
46 |
47 | # In[6]:
48 |
49 |
50 | paper['len'] = paper['corp'].apply(len)
51 |
52 |
53 | # In[7]:
54 |
55 |
56 | paper['len'].describe()
57 |
58 |
59 | # In[8]:
60 |
61 |
62 | df_train = pd.read_feather("../../../input/tr_input_final.ftr")
63 |
64 |
65 | # In[9]:
66 |
67 |
68 | df_train.head()
69 |
70 |
71 | # In[10]:
72 |
73 |
74 | df_train['len'] = df_train['quer_key'].apply(len)
75 | df_train['len'].describe()
76 |
77 |
78 | # In[16]:
79 |
80 |
81 | df_test = pd.read_feather("../../../input/te_input_final.ftr")
82 |
83 |
84 | # In[17]:
85 |
86 |
87 | df_test.head()
88 |
89 |
90 | # In[18]:
91 |
92 |
93 | # df_train[df_train['quer_all'].str.contains("[##]")]
94 |
95 |
96 | # In[19]:
97 |
98 |
99 | from tqdm import tqdm
100 | ###训练语料准备
101 | with open("corpus.txt","w+") as f:
102 | for i in tqdm(range(len(paper))):
103 | abst = paper.iloc[i]['abst']
104 | if abst!='no_content' and abst!="none":
105 | f.write(abst+"\n")
106 | title = paper.iloc[i]['titl']
107 | if title!='no_content' and title!="none":
108 | f.write(title+"\n")
109 | for i in tqdm(range(len(df_train))):
110 | quer_all = df_train.iloc[i]['quer_all']
111 | f.write(quer_all+"\n")
112 | for i in tqdm(range(len(df_test))):
113 | quer_all = df_test.iloc[i]['quer_all']
114 | f.write(quer_all+"\n")
115 |
116 |
117 | # In[23]:
118 |
119 |
120 | ####word2vector
121 | from gensim.models import word2vec
122 | sentences = word2vec.LineSentence('./corpus.txt')
123 | model = word2vec.Word2Vec(sentences, sg=1,min_count=2,window=8,size=300,iter=6,sample=1e-4, hs=1, workers=12)
124 |
125 |
126 | # In[24]:
127 |
128 |
129 | model.save("word2vec.model")
130 |
131 |
132 | # In[34]:
133 |
134 |
135 | model.wv.save_word2vec_format("word2vec.txt",binary=False)
136 |
137 |
138 | # In[26]:
139 |
140 |
141 | #glove的已有
142 | from gensim.test.utils import datapath, get_tmpfile
143 | from gensim.models import KeyedVectors
144 |
145 |
146 | # In[31]:
147 |
148 |
149 | # 输入文件
150 | glove_file = datapath('glove/vectors.txt')
151 | # 输出文件
152 | tmp_file = get_tmpfile("glove_vec.txt")
153 |
154 |
--------------------------------------------------------------------------------
/src/rank/m2/bert_5_fold_predict.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gc
3 | from tqdm import tqdm
4 | import numpy as np
5 | import pandas as pd
6 |
7 | import torch
8 | from pytorch_transformers import AdamW, WarmupLinearSchedule
9 | import matchzoo as mz
10 | from matchzoo.preprocessors.units.truncated_length import TruncatedLength
11 | from utils import MAP, build_matrix, topk_lines, predict, Logger
12 |
13 | os.environ["CUDA_VISIBLE_DEVICES"] = "1"
14 |
15 | import argparse
16 |
17 | parser = argparse.ArgumentParser()
18 | parser.add_argument('--model_id', type=str, default='bert_002')
19 | args = parser.parse_args()
20 |
21 | model_id = args.model_id
22 |
23 | if model_id=="bert_002":
24 | test_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_final_test_processed_query_key.dp")
25 | bst_epochs = {1:1, 2:1, 3:2, 4:1, 5:1}
26 | if model_id=="bert_003":
27 | test_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_test_processed_query_all.dp")
28 | bst_epochs = {1:2, 2:1, 3:1, 4:2, 5:1}
29 | if model_id=="bert_004":
30 | test_processed = mz.data_pack.data_pack.load_data_pack(
31 | "bert_data/bert_final_test_processed_query_all_nopreprocessing.dp/")
32 | bst_epochs = {1:2, 2:2, 3:1, 4:1, 5:1}
33 |
34 | padding_callback = mz.models.Bert.get_default_padding_callback()
35 | testset = mz.dataloader.Dataset(
36 | data_pack=test_processed,
37 | batch_size=128,
38 | sort=False,
39 | shuffle=False
40 | )
41 | testloader = mz.dataloader.DataLoader(
42 | dataset=testset,
43 | stage='dev',
44 | callback=padding_callback
45 | )
46 |
47 |
48 | num_dup = 1
49 | num_neg = 7
50 |
51 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
52 | padding_callback = mz.models.Bert.get_default_padding_callback()
53 | task = mz.tasks.Ranking(losses=losses)
54 | task.metrics = [
55 | mz.metrics.MeanAveragePrecision(),
56 | MAP()
57 | ]
58 |
59 | model = mz.models.Bert()
60 |
61 | model.params['task'] = task
62 | model.params['mode'] = 'bert-base-uncased'
63 | model.params['dropout_rate'] = 0.2
64 |
65 | model.build()
66 |
67 | print('Trainable params: ', sum(p.numel() for p in model.parameters() if p.requires_grad))
68 |
69 | no_decay = ['bias', 'LayerNorm.weight']
70 | optimizer_grouped_parameters = [
71 | {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 5e-5},
72 | {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
73 | ]
74 |
75 |
76 | optimizer = AdamW(optimizer_grouped_parameters, lr=5e-5, betas=(0.9, 0.98), eps=1e-8)
77 | scheduler = WarmupLinearSchedule(optimizer, warmup_steps=6, t_total=-1)
78 |
79 | trainer = mz.trainers.Trainer(
80 | model=model,
81 | optimizer=optimizer,
82 | scheduler=scheduler,
83 | trainloader=testloader,
84 | validloader=testloader,
85 | validate_interval=None,
86 | epochs=1
87 | )
88 |
89 |
90 | for fold in range(1,6):
91 | i = bst_epochs[fold]
92 | trainer.restore_model("save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
93 |
94 | score = predict(trainer, testloader)
95 | X, y = test_processed.unpack()
96 | result = pd.DataFrame(data={
97 | 'description_id': X['id_left'],
98 | 'paper_id': X['id_right'],
99 | 'score': score[:,0]})
100 | # result.to_csv("result/{}/{}_fold_{}_test.csv".format(model_id, model_id, fold), index=False)
101 | result.to_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold), index=False)
102 |
103 |
104 |
--------------------------------------------------------------------------------
/src/rank/m2/bert_5_fold_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | os.environ["CUDA_VISIBLE_DEVICES"] = "1"
3 |
4 | import gc
5 | from tqdm import tqdm
6 | import numpy as np
7 | import pandas as pd
8 |
9 | import torch
10 | from pytorch_transformers import AdamW, WarmupLinearSchedule
11 | import matchzoo as mz
12 | from matchzoo.preprocessors.units.truncated_length import TruncatedLength
13 | from utils import MAP, build_matrix, topk_lines, predict, Logger
14 |
15 | from matchzoo.data_pack import DataPack
16 |
17 | import argparse
18 |
19 | parser = argparse.ArgumentParser()
20 | parser.add_argument('--model_id', type=str, default='bert_002')
21 | args = parser.parse_args()
22 |
23 | model_id = args.model_id
24 |
25 | num_dup = 1
26 | num_neg = 7
27 |
28 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
29 | padding_callback = mz.models.Bert.get_default_padding_callback()
30 | task = mz.tasks.Ranking(losses=losses)
31 | task.metrics = [
32 | mz.metrics.MeanAveragePrecision(),
33 | MAP()
34 | ]
35 |
36 | with Logger(log_filename = '{}.log'.format(model_id)):
37 | for fold in range(1,6):
38 | if model_id=='bert_002':
39 | train_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_train_processed_{}.dp".format(fold))
40 | val_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_val_processed_{}.dp".format(fold))
41 | if model_id=='bert_003':
42 | train_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_train_processed_query_all_{}.dp".format(fold))
43 | val_processed = mz.data_pack.data_pack.load_data_pack("bert_data/bert_val_processed_query_all_{}.dp".format(fold))
44 | if model_id=='bert_004':
45 | train_processed = mz.data_pack.data_pack.load_data_pack(
46 | "bert_data/bert_train_processed_query_all_nopreprocessing_{}.dp".format(fold))
47 | val_processed = mz.data_pack.data_pack.load_data_pack(
48 | "bert_data/bert_val_processed_query_all_nopreprocessing_{}.dp".format(fold))
49 |
50 | model = mz.models.Bert()
51 |
52 | model.params['task'] = task
53 | model.params['mode'] = 'bert-base-uncased'
54 | model.params['dropout_rate'] = 0.2
55 |
56 | model.build()
57 |
58 | print('Trainable params: ', sum(p.numel() for p in model.parameters() if p.requires_grad))
59 |
60 |
61 | trainset = mz.dataloader.Dataset(
62 | data_pack=train_processed,
63 | mode='pair',
64 | num_dup=num_dup,
65 | num_neg=num_neg,
66 | batch_size=1,
67 | resample=True,
68 | sort=False,
69 | shuffle=True
70 | )
71 | trainloader = mz.dataloader.DataLoader(
72 | dataset=trainset,
73 | stage='train',
74 | callback=padding_callback
75 | )
76 |
77 | valset = mz.dataloader.Dataset(
78 | data_pack=val_processed,
79 | batch_size=32,
80 | sort=False,
81 | shuffle=False
82 | )
83 | valloader = mz.dataloader.DataLoader(
84 | dataset=valset,
85 | stage='dev',
86 | callback=padding_callback
87 | )
88 |
89 |
90 | no_decay = ['bias', 'LayerNorm.weight']
91 | optimizer_grouped_parameters = [
92 | {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 5e-5},
93 | {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
94 | ]
95 |
96 | optimizer = AdamW(optimizer_grouped_parameters, lr=5e-5, betas=(0.9, 0.98), eps=1e-8)
97 | scheduler = WarmupLinearSchedule(optimizer, warmup_steps=6, t_total=-1)
98 |
99 | trainer = mz.trainers.Trainer(
100 | model=model,
101 | optimizer=optimizer,
102 | scheduler=scheduler,
103 | trainloader=trainloader,
104 | validloader=valloader,
105 | validate_interval=None,
106 | epochs=1
107 | )
108 |
109 | for i in range(0,8):
110 | print("="*10+" epoch: "+str(i)+" "+"="*10)
111 | trainer.run()
112 | trainer.save_model()
113 | os.rename("save/model.pt", "save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
114 |
115 |
116 |
--------------------------------------------------------------------------------
/src/rank/m2/bert_preprocessing.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gc
3 | from tqdm import tqdm
4 | import numpy as np
5 | import pandas as pd
6 |
7 | import torch
8 | import matchzoo as mz
9 | from matchzoo.preprocessors.units.truncated_length import TruncatedLength
10 | from utils import MAP, build_matrix, topk_lines, predict
11 |
12 | import argparse
13 |
14 | parser = argparse.ArgumentParser()
15 | parser.add_argument('--preprocessing_type', type=str, default='fine')
16 | parser.add_argument('--left_truncated_length', type=int, default=64)
17 | parser.add_argument('--query_type', type=str, default='query_key')
18 | args = parser.parse_args()
19 |
20 | preprocessing_type = args.preprocessing_type
21 | left_truncated_length = args.left_truncated_length
22 | dp_type = args.query_type
23 |
24 | num_neg = 7
25 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
26 | task = mz.tasks.Ranking(losses=losses)
27 | task.metrics = [
28 | mz.metrics.MeanAveragePrecision(),
29 | MAP()
30 | ]
31 |
32 | preprocessor = mz.models.Bert.get_default_preprocessor(mode='bert-base-uncased')
33 |
34 |
35 | if preprocessing_type == 'fine':
36 | candidate_dic = pd.read_feather('data/candidate_dic.ftr')
37 | train_description = pd.read_feather('data/train_description_{}.ftr'.format(dp_type))
38 | else:
39 | candidate_dic = pd.read_csv('../../../input/candidate_paper_for_wsdm2020.csv')
40 | candidate_dic.loc[candidate_dic['keywords'].isna(),'keywords'] = ''
41 | candidate_dic.loc[candidate_dic['title'].isna(),'title'] = ''
42 | candidate_dic.loc[candidate_dic['abstract'].isna(),'abstract'] = ''
43 | candidate_dic['text_right'] = candidate_dic['abstract'].str.cat(
44 | candidate_dic['keywords'], sep=' ').str.cat(
45 | candidate_dic['title'], sep=' ')
46 | candidate_dic = candidate_dic.rename(columns={'paper_id': 'id_right'})[['id_right', 'text_right']]
47 |
48 | train_description = pd.read_csv('../../../input/train_release.csv')
49 | train_description = train_description.rename(
50 | columns={'description_id': 'id_left',
51 | 'description_text': 'text_left'})[['id_left', 'text_left']]
52 | dp_type = 'query_all_nopreprocessing'
53 |
54 | train_recall = pd.read_feather('data/train_recall.ftr')[['id_left', 'id_right', 'label', 'cv']]
55 | train_recall = pd.merge(train_recall, train_description, how='left', on='id_left')
56 | train_recall = pd.merge(train_recall, candidate_dic, how='left', on='id_right')
57 | train_recall = train_recall.drop_duplicates().reset_index(drop=True)
58 | train_recall = train_recall[['id_left', 'text_left', 'id_right', 'text_right', 'label', 'cv']]
59 | del train_description
60 | gc.collect()
61 |
62 |
63 |
64 | for i in range(1,6):
65 | print("="*20, i, "="*20)
66 | train_df = train_recall[train_recall.cv!=i][
67 | ['id_left', 'text_left', 'id_right', 'text_right', 'label']].reset_index(drop=True)
68 | val_df = train_recall[train_recall.cv==i][
69 | ['id_left', 'text_left', 'id_right', 'text_right', 'label']].reset_index(drop=True)
70 |
71 | train_raw = mz.pack(train_df, task)
72 | train_processed = preprocessor.transform(train_raw)
73 | train_processed.apply_on_text(TruncatedLength(left_truncated_length, 'pre').transform,
74 | mode='left', inplace=True, verbose=1)
75 | train_processed.apply_on_text(TruncatedLength(256, 'pre').transform, mode='right', inplace=True, verbose=1)
76 | train_processed.append_text_length(inplace=True, verbose=1)
77 | train_processed.save("bert_data/bert_train_processed_{}_{}.dp".format(dp_type, i))
78 |
79 | val_raw = mz.pack(val_df, task)
80 | val_processed = preprocessor.transform(val_raw)
81 | val_processed.apply_on_text(TruncatedLength(left_truncated_length, 'pre').transform,
82 | mode='left', inplace=True, verbose=1)
83 | val_processed.apply_on_text(TruncatedLength(256, 'pre').transform, mode='right', inplace=True, verbose=1)
84 | val_processed.append_text_length(inplace=True, verbose=1)
85 | val_processed.save("bert_data/bert_val_processed_{}_{}.dp".format(dp_type, i))
86 |
87 |
88 | if preprocessing_type == 'fine':
89 | test_description = pd.read_feather('data/test_description_quer_all.ftr')
90 | else:
91 | test_description = pd.read_csv('../../input/test.csv')
92 | test_description = test_description.rename(
93 | columns={'description_id': 'id_left',
94 | 'description_text': 'text_left'})[['id_left', 'text_left']]
95 |
96 |
97 | test_recall = pd.read_feather('data/test_recall.ftr')[['id_left', 'id_right', 'label']]
98 | test_recall = pd.merge(test_recall, test_description, how='left', on='id_left')
99 | test_recall = pd.merge(test_recall, candidate_dic, how='left', on='id_right')
100 | del test_description, candidate_dic
101 | gc.collect()
102 |
103 | test_raw = mz.pack(test_recall, task)
104 | test_processed = preprocessor.transform(test_raw)
105 | test_processed.apply_on_text(TruncatedLength(left_truncated_length, 'pre').transform,
106 | mode='left', inplace=True, verbose=1)
107 | test_processed.apply_on_text(TruncatedLength(256, 'pre').transform, mode='right', inplace=True, verbose=1)
108 | test_processed.append_text_length(inplace=True, verbose=1)
109 | test_processed.save("bert_data/bert_test_processed_{}.dp".format(dp_type))
110 |
111 |
112 |
113 |
--------------------------------------------------------------------------------
/src/rank/m2/change_formatting4stk.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 |
4 |
5 | import argparse
6 |
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
9 | args = parser.parse_args()
10 |
11 | model_id = args.model_id
12 |
13 | stk_path = "../../../stk_feat"
14 |
15 | df = pd.read_csv("oof_m2_{}_5cv.csv".format(model_id))
16 | df = df.rename(columns={"target": "pred"})
17 | df.to_feather("{}/m2_{}_tr.ftr".format(stk_path, model_name))
18 |
19 | df = pd.read_csv("result_m2_{}_5cv.csv".format(model_id))
20 | df = df.rename(columns={"target": "pred"})
21 | df.to_feather("{}/final_m2_{}_te.ftr".format(stk_path, model_name))
22 |
23 |
--------------------------------------------------------------------------------
/src/rank/m2/final_blend.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 | from tqdm import tqdm
4 |
5 | np.set_printoptions(precision=4)
6 |
7 | def map3_func(df, topk = 50, verbose=0):
8 | ids = df[df.label==1].description_id.values
9 | df_recalled = df[df.description_id.isin(ids)].reset_index(drop=True)
10 | df_recalled = df_recalled.sort_values(
11 | by=['description_id', 'label'], ascending=False).reset_index(drop=True)
12 | result = df_recalled.score.values.reshape([-1,topk])
13 | ranks = topk-result.argsort(axis=1).argsort(axis=1)
14 | map3_sum = sum(((1/ranks[:,0])*(ranks[:,0]<4)))
15 | if verbose>0:
16 | print("recall rate: "+str((df_recalled.shape[0]/topk)/(df.shape[0]/topk)))
17 | print("map@3 in recall: "+str(map3_sum/(df_recalled.shape[0]/topk)))
18 | print("map@3 in all: "+str(map3_sum/(df.shape[0]/topk)))
19 |
20 |
21 | m2_path = "../../model/"
22 |
23 | res = pd.read_feather('{}/lgb_s0_m2_33-0/lgb_s0_m3_33.ftr'.format(m2_path))
24 | res['score'] = res['target'].apply(lambda x:np.log(x/(1-x)))
25 | res.loc[res['score']<-12, 'score'] = -12
26 | res = res[['description_id', 'paper_id', 'score']]
27 | res.head()
28 |
29 | res1 = pd.read_feather('{}/lgb_s0_m2_33-1/lgb_s0_m3_33.ftr'.format(m2_path))
30 | res1['score'] = res1['target'].apply(lambda x:np.log(x/(1-x)))
31 | res1.loc[res1['score']<-12, 'score'] = -12
32 | res1 = res1[['description_id', 'paper_id', 'score']]
33 | res1.head()
34 |
35 |
36 | res2 = pd.read_feather('{}/lgb_s0_m3_34-0/lgb_s0_m3_34.ftr'.format(m2_path))
37 | res2['score'] = res2['target'].apply(lambda x:np.log(x/(1-x)))
38 | res2.loc[res2['score']<-12, 'score'] = -12
39 | res2 = res2[['description_id', 'paper_id', 'score']]
40 | res2.head()
41 |
42 |
43 | res3 = pd.read_feather('{}/lgb_s0_m3_34-1/lgb_s0_m3_34.ftr'.format(m2_path))
44 | res3['score'] = res3['target'].apply(lambda x:np.log(x/(1-x)))
45 | res3.loc[res3['score']<-12, 'score'] = -12
46 | res3 = res3[['description_id', 'paper_id', 'score']]
47 | res3.head()
48 |
49 |
50 | res4 = pd.read_feather('{}/lgb_s0_m3_35-0/lgb_s0_m3_35.ftr'.format(m2_path))
51 | res4['score'] = res4['target'].apply(lambda x:np.log(x/(1-x)))
52 | res4.loc[res4['score']<-12, 'score'] = -12
53 | res4 = res4[['description_id', 'paper_id', 'score']]
54 | res4.head()
55 |
56 |
57 | res5 = pd.read_feather('{}/lgb_s0_m3_35-1/lgb_s0_m3_35.ftr'.format(m2_path))
58 | res5['score'] = res5['target'].apply(lambda x:np.log(x/(1-x)))
59 | res5.loc[res5['score']<-12, 'score'] = -12
60 | res5 = res5[['description_id', 'paper_id', 'score']]
61 | res5.head()
62 |
63 |
64 | res6 = pd.read_feather('{}/lgb_s0_m3_38-0lgb_s0_m3_38.ftr'.format(m2_path))
65 | res6['score'] = res6['target'].apply(lambda x:np.log(x/(1-x)))
66 | res6.loc[res6['score']<-12, 'score'] = -12
67 | res6 = res6[['description_id', 'paper_id', 'score']]
68 | res6.head()
69 |
70 |
71 | res7 = pd.read_feather('{}/lgb_s0_m3_38-1/lgb_s0_m3_38.ftr'.format(m2_path))
72 | res7['score'] = res7['target'].apply(lambda x:np.log(x/(1-x)))
73 | res7.loc[res7['score']<-12, 'score'] = -12
74 | res7 = res7[['description_id', 'paper_id', 'score']]
75 | res7.head()
76 |
77 |
78 | res8 = pd.read_feather('{}/lgb_s0_m3_40-0/lgb_s0_m3_40.ftr'.format(m2_path))
79 | res8['score'] = res8['target'].apply(lambda x:np.log(x/(1-x)))
80 | res8.loc[res8['score']<-12, 'score'] = -12
81 | res8 = res8[['description_id', 'paper_id', 'score']]
82 | res8.head()
83 |
84 |
85 | res9 = pd.read_feather('{}/model/m1/m1_catboost13.ftr'.format(m2_path))
86 | res9['score'] = res9['pred'].apply(lambda x:np.log(x/(1-x)))
87 | res9.loc[res9['score']<-12, 'score'] = -12
88 | res9 = res9[['description_id', 'paper_id', 'score']]
89 | res9.head()
90 |
91 |
92 | model_id = 'bert_002'
93 | res_b1 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
94 | res_b1['score'] = res_b1['target'].apply(lambda x:np.log(x/(1-x)))
95 | res_b1.loc[res_b1['score']<-12, 'score'] = -12
96 | res_b1 = res_b1[['description_id', 'paper_id', 'score']]
97 | res_b1.head()
98 |
99 |
100 | model_id = 'bert_003'
101 | res_b2 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
102 | res_b2['score'] = res_b2['target'].apply(lambda x:np.log(x/(1-x)))
103 | res_b2.loc[res_b2['score']<-12, 'score'] = -12
104 | res_b2 = res_b2[['description_id', 'paper_id', 'score']]
105 | res_b2.head()
106 |
107 |
108 | model_id = 'bert_004'
109 | res_b3 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
110 | res_b3['score'] = res_b3['target'].apply(lambda x:np.log(x/(1-x)))
111 | res_b3.loc[res_b3['score']<-12, 'score'] = -12
112 | res_b3 = res_b3[['description_id', 'paper_id', 'score']]
113 | res_b3.head()
114 |
115 | model_id = 'bert_year_test'
116 | res_b4 = pd.read_csv("final_result_m2_{}_5cv.csv".format(model_id))
117 | res_b4['score'] = res_b4['target'].apply(lambda x:np.log(x/(1-x)))
118 | res_b4.loc[res_b4['score']<-12, 'score'] = -12
119 | res_b4 = res_b4[['description_id', 'paper_id', 'score']]
120 | res_b4.head()
121 |
122 |
123 | res_all = res.rename(columns={'score': 'score_0'}).merge(
124 | res1.rename(columns={'score': 'score_1'}), how='outer', on=['description_id', 'paper_id']).merge(
125 | res2.rename(columns={'score': 'score_2'}), how='outer', on=['description_id', 'paper_id']).merge(
126 | res3.rename(columns={'score': 'score_3'}), how='outer', on=['description_id', 'paper_id']).merge(
127 | res4.rename(columns={'score': 'score_4'}), how='outer', on=['description_id', 'paper_id']).merge(
128 | res5.rename(columns={'score': 'score_5'}), how='outer', on=['description_id', 'paper_id']).merge(
129 | res6.rename(columns={'score': 'score_6'}), how='outer', on=['description_id', 'paper_id']).merge(
130 | res7.rename(columns={'score': 'score_7'}), how='outer', on=['description_id', 'paper_id']).merge(
131 | res8.rename(columns={'score': 'score_8'}), how='outer', on=['description_id', 'paper_id']).merge(
132 | res9.rename(columns={'score': 'score_9'}), how='outer', on=['description_id', 'paper_id']).merge(
133 | res_b1.rename(columns={'score': 'score_b1'}), how='outer', on=['description_id', 'paper_id']).merge(
134 | res_b2.rename(columns={'score': 'score_b2'}), how='outer', on=['description_id', 'paper_id']).merge(
135 | res_b3.rename(columns={'score': 'score_b3'}), how='outer', on=['description_id', 'paper_id']).merge(
136 | res_b4.rename(columns={'score': 'score_b4'}), how='outer', on=['description_id', 'paper_id'])
137 | res_all = res_all.fillna(0.0)
138 | res_all.head()
139 |
140 |
141 | cols = ['score_0', 'score_1', 'score_2', 'score_3', 'score_4', 'score_5',
142 | 'score_6', 'score_7', 'score_8', 'score_9',
143 | 'score_b1', 'score_b2', 'score_b3']
144 |
145 | corr_matrix = []
146 | for description_id, df_tmp in tqdm(res_all.groupby('description_id')):
147 | corr_matrix.append(
148 | df_tmp[cols].corr().values[:,:,np.newaxis])
149 | corr_matrix = np.concatenate(corr_matrix, axis=2)
150 | corr_matrix[np.isnan(corr_matrix)] = 0
151 | pd.DataFrame(data=corr_matrix.mean(axis=2), columns=cols, index=cols)
152 |
153 | res_all['score'] = (
154 | (
155 | res_all['score_0'] + res_all['score_1'] + res_all['score_2'] + res_all['score_3'] +
156 | res_all['score_4'] + res_all['score_5'] + res_all['score_6'] + res_all['score_7']
157 | )/8 +
158 | (
159 | res_all['score_8'] + res_all['score_9']
160 | )/2 +
161 | (
162 | res_all['score_b1'] + 1.5*res_all['score_b2']
163 | )/2.5*5 +
164 | (
165 | res_all['score_b2'] + 3*res_all['score_b3']
166 | )/4
167 | )
168 |
169 |
170 | result = res_all.sort_values(by=['description_id', 'score'], na_position='first').groupby(
171 | 'description_id').tail(3)
172 |
173 |
174 | model_id = 'all_model'
175 |
176 | description_id_list = []
177 | paper_id_list_1 = []
178 | paper_id_list_2 = []
179 | paper_id_list_3 = []
180 | for description_id, df_tmp in tqdm(result.groupby('description_id')):
181 | description_id_list.append(description_id)
182 | paper_id_list_1.append(df_tmp.iloc[2,1])
183 | paper_id_list_2.append(df_tmp.iloc[1,1])
184 | paper_id_list_3.append(df_tmp.iloc[0,1])
185 |
186 | sub = pd.DataFrame(data={'description_id':description_id_list,
187 | 'paper_id_1': paper_id_list_1,
188 | 'paper_id_2': paper_id_list_2,
189 | 'paper_id_3': paper_id_list_3})
190 | sub.to_csv("blend_{}.csv".format(model_id), header=False, index=False)
191 | print("blend_{}.csv".format(model_id))
192 |
193 |
--------------------------------------------------------------------------------
/src/rank/m2/fold_result_integration.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 | from tqdm import tqdm
4 |
5 |
6 | import argparse
7 |
8 | parser = argparse.ArgumentParser()
9 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
10 | args = parser.parse_args()
11 | model_id = args.model_id
12 |
13 |
14 | def map3_func(df, topk = 50, verbose=0):
15 | ids = df[df.label==1].description_id.values
16 | df_recalled = df[df.description_id.isin(ids)].reset_index(drop=True)
17 | df_recalled = df_recalled.sort_values(
18 | by=['description_id', 'label'], ascending=False).reset_index(drop=True)
19 | result = df_recalled.score.values.reshape([-1,topk])
20 | ranks = topk-result.argsort(axis=1).argsort(axis=1)
21 | map3_sum = sum(((1/ranks[:,0])*(ranks[:,0]<4)))
22 | if verbose>1:
23 | print("recall rate: "+str((df_recalled.shape[0]/topk)/(df.shape[0]/topk)))
24 | print("map@3 in recall: "+str(map3_sum/(df_recalled.shape[0]/topk)))
25 | if verbose>0:
26 | print("map@3 in all: "+str(map3_sum/(df.shape[0]/topk)))
27 | return map3_sum/(df.shape[0]/topk)
28 |
29 |
30 | fold = 1
31 | val_df = pd.read_csv("result/{}/{}_fold_{}_cv.csv".format(model_id, model_id, fold))
32 | test_df = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
33 | columns={'score':'score_1'})
34 |
35 | for fold in tqdm(range(2,6)):
36 | val_df_cv = pd.read_csv("result/{}/{}_fold_{}_cv.csv".format(model_id, model_id, fold))
37 | val_df = pd.concat([val_df, val_df_cv], ignore_index=True, sort=True)
38 |
39 | test_df_cv = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
40 | columns={'score':'score_{}'.format(fold)})
41 | test_df = test_df.merge(test_df_cv)
42 |
43 | val_df = val_df.merge(train_recall, how='left')
44 | val_df = val_df[val_df.description_id!='6.45E+04'].reset_index(drop=True)
45 | # assert val_df.description_id.nunique()==49945
46 | map3_func(val_df)
47 | val_df['target'] = val_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
48 | val_df.to_csv("oof_m2_{}_5cv.csv".format(model_id), index=False)
49 |
50 | score_cols = ['score_1', 'score_2', 'score_3', 'score_4', 'score_5']
51 | test_df['score'] = test_df[score_cols].mean(axis=1)
52 | print(test_df[score_cols+['score']].corr(method='spearman'))
53 |
54 | test_df['target'] = test_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
55 | val_df['target'] = val_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
56 |
57 | test_df = test_recall.merge(
58 | test_df[['description_id', 'paper_id', 'score']], how='left', on=['description_id', 'paper_id'])
59 | test_df['target'] = test_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
60 | test_df['target'] = test_df['target'].fillna(0)
61 | test_df[['description_id', 'paper_id', 'target']].to_csv("result_m2_{}_5cv.csv".format(model_id), index=False)
62 |
63 |
64 |
--------------------------------------------------------------------------------
/src/rank/m2/gen_w2v.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # set -e
3 |
4 | BUILDDIR=build
5 | CORPUS=corpus.txt
6 | VOCAB_FILE=vocab.txt
7 | SAVE_FILE=glove.w2v
8 |
9 | VERBOSE=2
10 | MEMORY=4.0
11 |
12 | VOCAB_MIN_COUNT=5
13 |
14 | WINDOW_SIZE=5
15 | COOCCURRENCE_FILE=cooccurrence.bin
16 | WEIGHT=1
17 |
18 | COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
19 |
20 | VECTOR_SIZE=256
21 | MAX_ITER=25
22 | WINDOW_SIZE=2
23 | BINARY=0
24 | NUM_THREADS=8
25 | X_MAX=10
26 | HEADLINE=1
27 |
28 | echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
29 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
30 |
31 | echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE -distance-weighting $WEIGHT < $CORPUS > $COOCCURRENCE_FILE"
32 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE -distance-weighting $WEIGHT < $CORPUS > $COOCCURRENCE_FILE
33 |
34 | echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
35 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
36 |
37 | echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE -write-header $HEADLINE"
38 | $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE -write-header $HEADLINE
39 |
40 |
41 |
--------------------------------------------------------------------------------
/src/rank/m2/mk_submission.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pandas as pd
3 | from tqdm import tqdm
4 |
5 | test_recall = pd.read_feather('../../feat/te_s0_32-50.ftr')[['description_id', 'paper_id', 'corp_sim_score']]
6 |
7 | import argparse
8 |
9 | parser = argparse.ArgumentParser()
10 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
11 | args = parser.parse_args()
12 | model_id = args.model_id
13 |
14 | if '_pointwise' in model_id:
15 | fold = 1
16 | test_df = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
17 | columns={'target':'target_1'})
18 |
19 | for fold in tqdm(range(2,6)):
20 | test_df_cv = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
21 | columns={'target':'target_{}'.format(fold)})
22 | test_df = test_df.merge(test_df_cv)
23 |
24 | score_cols = ['target_1', 'target_2', 'target_3', 'target_4', 'target_5']
25 | test_df['target'] = test_df[score_cols].mean(axis=1)
26 | print(test_df[score_cols+['target']].corr(method='spearman'))
27 | else:
28 | fold = 1
29 | test_df = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
30 | columns={'score':'score_1'})
31 |
32 | for fold in tqdm(range(2,6)):
33 | test_df_cv = pd.read_csv("result/{}/final_{}_fold_{}_test.csv".format(model_id, model_id, fold)).rename(
34 | columns={'score':'score_{}'.format(fold)})
35 | test_df = test_df.merge(test_df_cv)
36 |
37 | score_cols = ['score_1', 'score_2', 'score_3', 'score_4', 'score_5']
38 | test_df['score'] = test_df[score_cols].mean(axis=1)
39 | print(test_df[score_cols+['score']].corr(method='spearman'))
40 |
41 |
42 | if 'target' not in test_df.columns:
43 | test_df['target'] = test_df['score'].apply(lambda x: np.exp(x)/(1+np.exp(x)))
44 |
45 | test_df = test_recall.merge(
46 | test_df[['description_id', 'paper_id', 'target']], how='left', on=['description_id', 'paper_id'])
47 | test_df[['description_id', 'paper_id', 'target']].to_csv("final_result_m2_{}_5cv.csv".format(model_id), index=False)
48 |
49 | result = test_df.sort_values(by=['description_id', 'target', 'corp_sim_score'], na_position='first').groupby(
50 | 'description_id').tail(3)
51 |
52 | description_id_list = []
53 | paper_id_list_1 = []
54 | paper_id_list_2 = []
55 | paper_id_list_3 = []
56 | for description_id, df_tmp in tqdm(result.groupby('description_id')):
57 | description_id_list.append(description_id)
58 | paper_id_list_1.append(df_tmp.iloc[2,1])
59 | paper_id_list_2.append(df_tmp.iloc[1,1])
60 | paper_id_list_3.append(df_tmp.iloc[0,1])
61 |
62 | sub = pd.DataFrame(data={'description_id':description_id_list,
63 | 'paper_id_1': paper_id_list_1,
64 | 'paper_id_2': paper_id_list_2,
65 | 'paper_id_3': paper_id_list_3})
66 | sub.to_csv("final_{}_sub_5cv.csv".format(model_id), header=False, index=False)
67 | print("final_{}_sub_5cv.csv".format(model_id))
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
--------------------------------------------------------------------------------
/src/rank/m2/model.py:
--------------------------------------------------------------------------------
1 | import typing
2 |
3 | import torch
4 | import torch.nn as nn
5 | from torch.nn import functional as F
6 |
7 | import matchzoo as mz
8 | from matchzoo.engine.param_table import ParamTable
9 | from matchzoo.engine.param import Param
10 | from matchzoo.engine.base_model import BaseModel
11 | from matchzoo.modules import RNNDropout
12 | from matchzoo.modules import BidirectionalAttention
13 | from matchzoo.modules import StackedBRNN
14 |
15 |
16 | class ESIMplus(mz.models.ESIM):
17 | def set_feature_dim(self, feature_dim):
18 | self.feature_dim = feature_dim
19 |
20 | def build(self):
21 | """Instantiating layers."""
22 | rnn_mapping = {'lstm': nn.LSTM, 'gru': nn.GRU}
23 | self.embedding = self._make_default_embedding_layer()
24 | self.rnn_dropout = RNNDropout(p=self._params['dropout'])
25 | lstm_size = self._params['hidden_size']
26 | if self._params['concat_lstm']:
27 | lstm_size /= self._params['lstm_layer']
28 | self.input_encoding = StackedBRNN(
29 | self._params['embedding_output_dim'],
30 | int(lstm_size / 2),
31 | self._params['lstm_layer'],
32 | dropout_rate=self._params['dropout'],
33 | dropout_output=self._params['drop_lstm'],
34 | rnn_type=rnn_mapping[self._params['rnn_type'].lower()],
35 | concat_layers=self._params['concat_lstm'])
36 | self.attention = BidirectionalAttention()
37 | self.projection = nn.Sequential(
38 | nn.Linear(
39 | 4 * self._params['hidden_size'],
40 | self._params['hidden_size']),
41 | nn.ReLU())
42 | self.composition = StackedBRNN(
43 | self._params['hidden_size'],
44 | int(lstm_size / 2),
45 | self._params['lstm_layer'],
46 | dropout_rate=self._params['dropout'],
47 | dropout_output=self._params['drop_lstm'],
48 | rnn_type=rnn_mapping[self._params['rnn_type'].lower()],
49 | concat_layers=self._params['concat_lstm'])
50 | self.wide_net = nn.Sequential(
51 | nn.Linear(self.feature_dim, self._params['hidden_size']),
52 | nn.ReLU(),
53 | nn.Linear(self._params['hidden_size'], self._params['hidden_size']),
54 | nn.ReLU())
55 | self.classification = nn.Sequential(
56 | nn.Dropout(
57 | p=self._params['dropout']),
58 | nn.Linear(
59 | 4 * self._params['hidden_size']+self._params['hidden_size'],
60 | self._params['hidden_size']),
61 | nn.Tanh(),
62 | nn.Dropout(
63 | p=self._params['dropout']))
64 | self.out = self._make_output_layer(self._params['hidden_size'])
65 |
66 |
67 | def forward(self, inputs):
68 | """Forward."""
69 | # Scalar dimensions referenced here:
70 | # B = batch size (number of sequences)
71 | # D = embedding size
72 | # L = `input_left` sequence length
73 | # R = `input_right` sequence length
74 | # F = `feature` dim
75 | # H = hidden size
76 |
77 | # [B, L], [B, R]
78 |
79 | query, doc = inputs['text_left'].long(), inputs['text_right'].long()
80 |
81 | # [B, L]
82 | # [B, R]
83 | query_mask = (query == self._params['mask_value'])
84 | doc_mask = (doc == self._params['mask_value'])
85 |
86 | # [B, L, D]
87 | # [B, R, D]
88 | query = self.embedding(query)
89 | doc = self.embedding(doc)
90 |
91 | # [B, L, D]
92 | # [B, R, D]
93 | query = self.rnn_dropout(query)
94 | doc = self.rnn_dropout(doc)
95 |
96 | # [B, L, H]
97 | # [B, R, H]
98 | query = self.input_encoding(query, query_mask)
99 | doc = self.input_encoding(doc, doc_mask)
100 |
101 | # [B, L, H], [B, L, H]
102 | attended_query, attended_doc = self.attention(
103 | query, query_mask, doc, doc_mask)
104 |
105 | # [B, L, 4 * H]
106 | # [B, L, 4 * H]
107 | enhanced_query = torch.cat([query,
108 | attended_query,
109 | query - attended_query,
110 | query * attended_query],
111 | dim=-1)
112 | enhanced_doc = torch.cat([doc,
113 | attended_doc,
114 | doc - attended_doc,
115 | doc * attended_doc],
116 | dim=-1)
117 | # [B, L, H]
118 | # [B, L, H]
119 | projected_query = self.projection(enhanced_query)
120 | projected_doc = self.projection(enhanced_doc)
121 |
122 | # [B, L, H]
123 | # [B, L, H]
124 | query = self.composition(projected_query, query_mask)
125 | doc = self.composition(projected_doc, doc_mask)
126 |
127 | # [B, L]
128 | # [B, R]
129 | reverse_query_mask = 1. - query_mask.float()
130 | reverse_doc_mask = 1. - doc_mask.float()
131 |
132 | # [B, H]
133 | # [B, H]
134 | query_avg = torch.sum(query * reverse_query_mask.unsqueeze(2), dim=1)\
135 | / (torch.sum(reverse_query_mask, dim=1, keepdim=True) + 1e-8)
136 | doc_avg = torch.sum(doc * reverse_doc_mask.unsqueeze(2), dim=1)\
137 | / (torch.sum(reverse_doc_mask, dim=1, keepdim=True) + 1e-8)
138 |
139 | # [B, L, H]
140 | # [B, L, H]
141 | query = query.masked_fill(query_mask.unsqueeze(2), -1e7)
142 | doc = doc.masked_fill(doc_mask.unsqueeze(2), -1e7)
143 |
144 | # [B, H]
145 | # [B, H]
146 | query_max, _ = query.max(dim=1)
147 | doc_max, _ = doc.max(dim=1)
148 |
149 | feature = inputs['feature'].float()
150 | feat_emb = self.wide_net(feature)
151 |
152 | # [B, 4 * H + H]
153 | v = torch.cat([query_avg, query_max, doc_avg, doc_max, feat_emb], dim=-1)
154 |
155 | # [B, H]
156 | hidden = self.classification(v)
157 |
158 | # [B, num_classes]
159 | out = self.out(hidden)
160 |
161 | return out
162 |
163 |
164 |
--------------------------------------------------------------------------------
/src/rank/m2/nn_5_fold_predict.py:
--------------------------------------------------------------------------------
1 | import os
2 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
3 |
4 | import gc
5 | from tqdm import tqdm
6 | import numpy as np
7 | import pandas as pd
8 |
9 | import torch
10 | import matchzoo as mz
11 | from model import ESIMplus
12 |
13 | from utils import MAP, build_matrix, topk_lines, predict, Logger
14 |
15 |
16 | import argparse
17 |
18 | parser = argparse.ArgumentParser()
19 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
20 | args = parser.parse_args()
21 |
22 | model_id = args.model_id
23 |
24 | num_dup = 6
25 | num_neg = 10
26 | batch_size = 128
27 | add_lgb_feat = False
28 | debug = False
29 |
30 | if model_id == 'ESIMplus_001':
31 | bst_epochs = {1:0, 2:2, 3:4, 4:2, 5:1}
32 | Model = ESIMplus
33 | lr = 0.001
34 | add_lgb_feat = True
35 | params = {'embedding_freeze': True,
36 | 'mask_value': 0,
37 | 'lstm_layer': 2,
38 | 'hidden_size': 200,
39 | 'dropout': 0.2}
40 |
41 |
42 | if model_id == 'aNMM_001':
43 | bst_epochs = {1:4, 2:4, 3:3, 4:4, 5:9}
44 | Model = mz.models.aNMM
45 | lr = 0.001
46 | params = {'embedding_freeze': True,
47 | 'mask_value': 0,
48 | 'dropout_rate': 0.1}
49 |
50 | if model_id == 'ESIM_001':
51 | bst_epochs = {1:4, 2:4, 3:2, 4:2, 5:6}
52 | Model = mz.models.ESIM
53 | lr = 0.001
54 | params = {'embedding_freeze': True,
55 | 'mask_value': 0,
56 | 'lstm_layer': 2,
57 | 'hidden_size': 200,
58 | 'dropout': 0.2}
59 |
60 | if model_id == 'MatchLSTM_001':
61 | bst_epochs = {1:4, 2:2, 3:2, 4:4, 5:3}
62 | Model = mz.models.MatchLSTM
63 | lr = 0.001
64 | params = {'embedding_freeze': True,
65 | 'mask_value': 0}
66 |
67 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
68 | task = mz.tasks.Ranking(losses=losses)
69 | task.metrics = [
70 | mz.metrics.MeanAveragePrecision(),
71 | MAP()
72 | ]
73 |
74 | if model_id == 'ESIM_001_pointwise':
75 | bst_epochs = {1:4, 2:3, 3:7, 4:12, 5:5}
76 | Model = mz.models.ESIM
77 | lr = 0.001
78 | params = {'embedding_freeze': True,
79 | 'mask_value': 0,
80 | 'lstm_layer': 2,
81 | 'hidden_size': 200,
82 | 'dropout': 0.2}
83 |
84 | task = mz.tasks.Classification(num_classes=2)
85 | task.metrics = ['acc']
86 |
87 |
88 | padding_callback = Model.get_default_padding_callback()
89 | embedding_matrix = np.load("data/embedding_matrix.npy")
90 | # l2_norm = np.sqrt((embedding_matrix * embedding_matrix).sum(axis=1))
91 | # embedding_matrix = embedding_matrix / l2_norm[:, np.newaxis]
92 |
93 | test_processed = mz.data_pack.data_pack.load_data_pack("test_processed.dp")
94 | testset = mz.dataloader.Dataset(
95 | data_pack=test_processed,
96 | batch_size=batch_size,
97 | sort=False,
98 | shuffle=False
99 | )
100 |
101 | testloader = mz.dataloader.DataLoader(
102 | dataset=testset,
103 | stage='dev',
104 | callback=padding_callback
105 | )
106 |
107 |
108 |
109 | model = Model()
110 | if add_lgb_feat: model.set_feature_dim(30)
111 |
112 | model.params['task'] = task
113 | model.params['embedding'] = embedding_matrix
114 |
115 | for param in params:
116 | model.params[param] = params[param]
117 |
118 | model.build()
119 |
120 | optimizer = torch.optim.Adam(model.parameters(), lr=lr)
121 | trainer = mz.trainers.Trainer(
122 | model=model,
123 | optimizer=optimizer,
124 | trainloader=testloader,
125 | validloader=testloader,
126 | validate_interval=None,
127 | epochs=1
128 | )
129 |
130 |
131 | for fold in range(1,6):
132 | i = bst_epochs[fold]
133 | val_processed = mz.data_pack.data_pack.load_data_pack("5fold/val_processed_{}.dp".format(fold))
134 | valset = mz.dataloader.Dataset(
135 | data_pack=val_processed,
136 | batch_size=batch_size,
137 | sort=False,
138 | shuffle=False
139 | )
140 |
141 | valloader = mz.dataloader.DataLoader(
142 | dataset=valset,
143 | stage='dev',
144 | callback=padding_callback
145 | )
146 |
147 | trainer.restore_model("save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
148 |
149 | score = predict(trainer, valloader)
150 | X, y = val_processed.unpack()
151 | result = pd.DataFrame(data={
152 | 'description_id': X['id_left'],
153 | 'paper_id': X['id_right'],
154 | 'score': score[:,0]})
155 | result.to_csv("result/{}/{}_fold_{}_cv.csv".format(model_id, model_id, fold), index=False)
156 |
157 | score = predict(trainer, testloader)
158 | X, y = test_processed.unpack()
159 | result = pd.DataFrame(data={
160 | 'description_id': X['id_left'],
161 | 'paper_id': X['id_right'],
162 | 'score': score[:,0]})
163 | result.to_csv("result/{}/{}_fold_{}_test.csv".format(model_id, model_id, fold), index=False)
164 |
165 |
166 |
--------------------------------------------------------------------------------
/src/rank/m2/nn_5_fold_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
3 |
4 | import gc
5 | from tqdm import tqdm
6 | import numpy as np
7 | import pandas as pd
8 |
9 | import torch
10 | import matchzoo as mz
11 | from model import ESIMplus
12 |
13 | from utils import MAP, build_matrix, topk_lines, predict, Logger
14 |
15 | import argparse
16 |
17 | parser = argparse.ArgumentParser()
18 | parser.add_argument('--model_id', type=str, default='ESIMplus_001')
19 | args = parser.parse_args()
20 |
21 | num_dup = 6
22 | num_neg = 10
23 | batch_size = 128
24 | add_lgb_feat = False
25 | debug = False
26 |
27 | if model_id == 'ESIMplus_001':
28 | Model = ESIMplus
29 | lr = 0.001
30 | add_lgb_feat = True
31 | params = {'embedding_freeze': True,
32 | 'mask_value': 0,
33 | 'lstm_layer': 2,
34 | 'hidden_size': 200,
35 | 'dropout': 0.2}
36 |
37 |
38 | if model_id == 'aNMM_001':
39 | Model = mz.models.aNMM
40 | lr = 0.001
41 | params = {'embedding_freeze': True,
42 | 'mask_value': 0,
43 | 'dropout_rate': 0.1}
44 |
45 | if model_id == 'ESIM_001':
46 | Model = mz.models.ESIM
47 | lr = 0.001
48 | params = {'embedding_freeze': True,
49 | 'mask_value': 0,
50 | 'lstm_layer': 2,
51 | 'hidden_size': 200,
52 | 'dropout': 0.2}
53 |
54 | if model_id == 'MatchLSTM':
55 | model_id = 'MatchLSTM_001'
56 | Model = mz.models.MatchLSTM
57 | lr = 0.001
58 | params = {'embedding_freeze': True,
59 | 'mask_value': 0}
60 |
61 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
62 | padding_callback = Model.get_default_padding_callback()
63 | task = mz.tasks.Ranking(losses=losses)
64 | task.metrics = [
65 | mz.metrics.MeanAveragePrecision(),
66 | MAP()
67 | ]
68 |
69 | if model_id == 'ESIM_001_pointwise':
70 | Model = mz.models.ESIM
71 | lr = 0.001
72 | params = {'embedding_freeze': True,
73 | 'mask_value': 0,
74 | 'lstm_layer': 2,
75 | 'hidden_size': 200,
76 | 'dropout': 0.2}
77 |
78 | task = mz.tasks.Classification(num_classes=2)
79 | task.metrics = ['acc']
80 |
81 | embedding_matrix = np.load("data/embedding_matrix.npy")
82 |
83 |
84 | if not os.path.exists('result/{}'.format(model_id)):
85 | os.makedirs('result/{}'.format(model_id))
86 |
87 | with Logger(log_filename = '{}.log'.format(model_id)):
88 | for fold in range(1,5):
89 | print("="*10+" fold: "+str(fold)+" data_processed prepare "+"="*10)
90 | train_processed = mz.data_pack.data_pack.load_data_pack("5fold/train_processed_{}.dp".format(fold))
91 | val_processed = mz.data_pack.data_pack.load_data_pack("5fold/val_processed_{}.dp".format(fold))
92 |
93 | if model_id == 'ESIM_001_pointwise':
94 | train_processed.relation.label = train_processed.relation.label.astype(np.long)
95 | val_processed.relation.label = val_processed.relation.label.astype(np.long)
96 |
97 |
98 | print("="*10+" fold: "+str(fold)+" dataset prepare "+"="*10)
99 | trainset = mz.dataloader.Dataset(
100 | data_pack=train_processed,
101 | mode='pair',
102 | num_dup=num_dup,
103 | num_neg=num_neg,
104 | batch_size=batch_size,
105 | resample=True,
106 | sort=False,
107 | shuffle=True
108 | )
109 | valset = mz.dataloader.Dataset(
110 | data_pack=val_processed,
111 | batch_size=batch_size,
112 | sort=False,
113 | shuffle=False
114 | )
115 |
116 | print("="*10+" fold: "+str(fold)+" dataloader prepare "+"="*10)
117 | trainloader = mz.dataloader.DataLoader(
118 | dataset=trainset,
119 | stage='train',
120 | callback=padding_callback
121 | )
122 | valloader = mz.dataloader.DataLoader(
123 | dataset=valset,
124 | stage='dev',
125 | callback=padding_callback
126 | )
127 |
128 | print("="*10+" fold: "+str(fold)+" model build "+"="*10)
129 | model = Model()
130 | if add_lgb_feat: model.set_feature_dim(30)
131 |
132 | model.params['task'] = task
133 | model.params['embedding'] = embedding_matrix
134 |
135 | for param in params:
136 | model.params[param] = params[param]
137 |
138 | model.build()
139 | if debug: print(model)
140 |
141 | print("="*10+" fold: "+str(fold)+" trainers build "+"="*10)
142 | optimizer = torch.optim.Adam(model.parameters(), lr=lr)
143 |
144 | trainer = mz.trainers.Trainer(
145 | model=model,
146 | optimizer=optimizer,
147 | trainloader=trainloader,
148 | validloader=valloader,
149 | validate_interval=None,
150 | epochs=1
151 | )
152 |
153 | print("="*10+" fold: "+str(fold)+" training "+"="*10)
154 | trainer.restore_model("save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, 1))
155 | for i in range(2,6):
156 | trainer._model.embedding.requires_grad_(requires_grad=False)
157 | print("="*10+" fold: "+str(fold)+" epoch: "+str(i)+" "+"="*10)
158 | trainer.run()
159 | trainer.save_model()
160 | os.rename("save/model.pt", "save/{}_fold_{}_epoch_{}.pt".format(model_id, fold, i))
161 |
162 |
163 |
--------------------------------------------------------------------------------
/src/rank/m2/nn_preprocessing.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gc
3 | from tqdm import tqdm
4 | import numpy as np
5 | import pandas as pd
6 |
7 | import torch
8 | import matchzoo as mz
9 | from model import ESIMplus
10 |
11 | from gensim.models import KeyedVectors
12 | from utils import MAP, build_matrix, topk_lines, predict
13 |
14 | pd.set_option('display.max_columns', None)
15 | pd.set_option('display.max_rows', 200)
16 | pd.set_option('max_colwidth',400)
17 |
18 |
19 | num_neg = 10
20 | fit_preprocessor = True
21 | losses = mz.losses.RankCrossEntropyLoss(num_neg=num_neg)
22 | feature = [
23 | 'quer_key_tfidf_corp_cos_dis',
24 | 'quer_key_tfidf_corp_eucl_dis',
25 | 'quer_key_corp_bm25_score',
26 | 'corp_sim_score',
27 | 'quer_all_tfidf_corp_eucl_dis',
28 | 'quer_all_corp_bm25_score',
29 | 'quer_key_tfidf_titl_manh_dis',
30 | 'quer_all_titl_bm25_score',
31 | 'quer_all_tfidf_corp_cos_dis',
32 | 'jaccard_coef_of_unigram_between_corp_quer_key',
33 | 'ratio_of_unique_corp_unigram',
34 | 'jaccard_coef_of_unigram_between_corp_quer_all',
35 | 'jaccard_coef_of_unigram_between_titl_quer_key',
36 | 'quer_key_tfidf_titl_cos_dis',
37 | 'jaccard_coef_of_unigram_between_abst_quer_key',
38 | 'quer_key_abst_bm25_score',
39 | 'quer_all_tfidf_titl_cos_dis',
40 | 'quer_key_tfidf_titl_eucl_dis',
41 | 'count_of_quer_key_unigram',
42 | 'quer_all_tfidf_titl_eucl_dis',
43 | 'ratio_of_unique_quer_all_unigram',
44 | 'quer_key_tfidf_abst_cos_dis',
45 | 'count_of_unique_corp_unigram',
46 | 'ratio_of_unique_abst_unigram',
47 | 'normalized_pos_of_corp_unigram_in_quer_all_max',
48 | 'quer_all_abst_bm25_score',
49 | 'normalized_pos_of_titl_unigram_in_quer_all_std',
50 | 'quer_all_tfidf_titl_manh_dis',
51 | 'jaccard_coef_of_unigram_between_abst_quer_all',
52 | 'dice_dist_of_unigram_between_corp_quer_key']
53 |
54 | task = mz.tasks.Ranking(losses=losses)
55 | task.metrics = [
56 | mz.metrics.MeanAveragePrecision(),
57 | MAP()
58 | ]
59 | print("task is", task)
60 | print("`task` initialized with metrics", task.metrics)
61 |
62 | if fit_preprocessor:
63 |
64 | preprocessor = mz.models.ESIM.get_default_preprocessor(
65 | truncated_mode='pre',
66 | truncated_length_left=64,
67 | truncated_length_right=256,
68 | filter_mode='df',
69 | filter_low_freq=2)
70 |
71 | preprocessor = preprocessor.fit(all_data_raw)
72 | preprocessor.save("preprocessor.prep")
73 | else:
74 | preprocessor = mz.load_preprocessor("preprocessor.prep")
75 |
76 |
77 | candidate_dic = pd.read_feather('data/candidate_dic.ftr')
78 |
79 | train_recall = pd.read_feather('data/train_recall.ftr')
80 | train_description = pd.read_feather('data/train_description.ftr')
81 | train_recall = pd.merge(train_recall, train_description, how='left', on='id_left')
82 | train_recall = pd.merge(train_recall, candidate_dic, how='left', on='id_right')
83 | train_recall = train_recall.drop_duplicates().reset_index(drop=True)
84 | del train_description
85 | gc.collect()
86 |
87 |
88 | test_recall = pd.read_feather('data/test_recall.ftr')
89 | test_description = pd.read_feather('data/test_description.ftr')
90 | test_recall = pd.merge(test_recall, test_description, how='left', on='id_left')
91 | test_recall = pd.merge(test_recall, candidate_dic, how='left', on='id_right')
92 | del test_description, candidate_dic
93 | gc.collect()
94 |
95 | all_data_df = train_recall.copy()
96 | all_data_df.id_left = all_data_df.id_left+'_tr'
97 | all_data_df = pd.concat([all_data_df, test_recall]).reset_index(drop=True)
98 | norm_df = all_data_df[feature].quantile(q=0.99)
99 |
100 | del all_data_df, train_recall, test_recall
101 | gc.collect()
102 |
103 | train_recall[feature] = train_recall[feature]/norm_df
104 | train_recall['feature'] = list(train_recall[feature].values)
105 | train_recall = train_recall[['id_left', 'text_left', 'id_right', 'text_right', 'label', 'feature']]
106 | cv_ids = pd.read_csv("../../input/cv_ids_0109.csv")
107 | train_recall = train_recall.merge(
108 | cv_ids.rename(columns={'description_id': 'id_left'}),
109 | how='left',
110 | on='id_left').fillna(5.0)
111 |
112 |
113 | for i in range(1,6):
114 | print("="*20, i, "="*20)
115 | train_df = train_recall[train_recall.cv!=i][
116 | ['id_left', 'text_left', 'id_right', 'text_right', 'label', 'feature']].reset_index(drop=True)
117 | val_df = train_recall[train_recall.cv==i][
118 | ['id_left', 'text_left', 'id_right', 'text_right', 'label', 'feature']].reset_index(drop=True)
119 |
120 | train_raw = mz.pack(train_df, task)
121 | val_raw = mz.pack(val_df, task)
122 |
123 | train_processed = preprocessor.transform(train_raw)
124 | val_processed = preprocessor.transform(val_raw)
125 |
126 | train_processed.save("5fold/train_processed_{}.dp".format(i))
127 | val_processed.save("5fold/val_processed_{}.dp".format(i))
128 |
129 |
130 | test_recall[feature] = test_recall[feature]/norm_df
131 | test_recall['feature'] = list(test_recall[feature].values)
132 | test_recall = test_recall[['id_left', 'text_left', 'id_right', 'text_right', 'feature']]
133 |
134 | test_raw = mz.pack(test_recall, task)
135 | test_processed = preprocessor.transform(test_raw)
136 | # test_processed.save("test_processed.dp")
137 | test_processed.save("final_test_processed.dp")
138 |
139 |
140 | from gensim.models import KeyedVectors
141 | w2v_path = "data/glove.w2v"
142 | w2v_model = KeyedVectors.load_word2vec_format(w2v_path, binary=False)
143 | term_index = preprocessor.context['vocab_unit'].state['term_index']
144 | embedding_matrix = build_matrix(term_index, w2v_model)
145 | del w2v_model, term_index
146 | gc.collect()
147 | np.save("data/embedding_matrix.npy", embedding_matrix)
148 |
149 |
150 |
--------------------------------------------------------------------------------
/src/rank/m2/preprocessing.py:
--------------------------------------------------------------------------------
1 | from tqdm import tqdm
2 | import numpy as np
3 | import pandas as pd
4 | import feather
5 |
6 | import argparse
7 |
8 | parser = argparse.ArgumentParser()
9 | parser.add_argument('--query_type', type=str, default='query_key')
10 | args = parser.parse_args()
11 |
12 | query_type = args.query_type
13 |
14 | def topk_lines(df, k):
15 | print(df.shape)
16 | df.loc[:, 'rank'] = df.groupby(['description_id', 'type']).cumcount().values
17 | df = df[df['rank'] < k]
18 | df.drop(['rank'], axis=1, inplace=True)
19 | print(df.shape)
20 | return df
21 |
22 |
23 | ## preprocess
24 | candidate_dic = feather.read_dataframe('../../../input/paper_input_final.ftr')
25 |
26 | candidate_dic.loc[candidate_dic['keywords'].isna(),'keywords'] = ''
27 | candidate_dic.loc[candidate_dic['titl'].isna(),'titl'] = ''
28 | candidate_dic.loc[candidate_dic['abst'].isna(),'abst'] = ''
29 |
30 | candidate_dic['text_right'] = candidate_dic['abst'].str.cat(
31 | candidate_dic['keywords'], sep=' ').str.cat(
32 | candidate_dic['titl'], sep=' ')
33 |
34 | candidate_dic = candidate_dic.rename(columns={'paper_id': 'id_right'})[['id_right', 'text_right']]
35 | candidate_dic.to_feather('data/candidate_dic.ftr')
36 |
37 | train_description = feather.read_dataframe('../../../input/tr_input_final.ftr')
38 |
39 | train_description = train_description.rename(
40 | columns={'description_id': 'id_left', query_type: 'text_left'})
41 | train_description[['id_left', 'text_left']].to_feather('data/train_description_{}.ftr'.format(query_type))
42 |
43 |
44 | test_description = feather.read_dataframe('../../../input/te_input_final.ftr')
45 |
46 | test_description = test_description.rename(
47 | columns={'description_id': 'id_left', query_type: 'text_left'})
48 |
49 | test_description[['id_left', 'text_left']].to_feather('data/test_description_{}.ftr'.format(query_type))
50 |
51 | train_recall = feather.read_dataframe('../../../feat/tr_s0_32-50.ftr')
52 |
53 | ## recall
54 | train_recall = train_recall.rename(
55 | columns={'description_id': 'id_left', 'paper_id': 'id_right', 'target': 'label'})
56 |
57 | train_recall = train_recall[train_recall.id_left.isin(train_description.id_left.values)].reset_index(drop=True)
58 | train_recall = train_recall.drop_duplicates()
59 | train_recall = train_recall.fillna(0)
60 | train_recall.to_feather('data/train_recall.ftr')
61 |
62 | test_recall = feather.read_dataframe('../../../feat/te_s0_32-50.ftr')
63 | test_recall = test_recall.reset_index(drop=True)
64 |
65 | test_recall = test_recall.rename(
66 | columns={'description_id': 'id_left',
67 | 'paper_id': 'id_right',
68 | 'target': 'label'})
69 |
70 | # test_recall[['id_left', 'id_right', 'label']].to_feather('data/test_recall.ftr')
71 | test_recall[['id_left', 'id_right', 'label']].to_feather('data/final_test_recall.ftr')
72 |
73 |
74 | ## corpus
75 | if query_type== 'query_key':
76 | candidate_dic = feather.read_dataframe('data/candidate_dic.ftr')
77 | train_description = feather.read_dataframe('data/train_description.ftr')
78 | test_description = feather.read_dataframe('data/test_description.ftr')
79 |
80 | with open('data/corpus.txt','a') as fid:
81 | for sent in tqdm(candidate_dic['text_right']):
82 | if type(sent)==str:
83 | fid.write(sent+'\n')
84 | for sent in tqdm(train_description['text_left']):
85 | if type(sent)==str:
86 | fid.write(sent+'\n')
87 | for sent in tqdm(test_description['text_left']):
88 | if type(sent)==str:
89 | fid.write(sent+'\n')
90 |
91 |
--------------------------------------------------------------------------------
/src/rank/m2/run.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | python3 preprocessing.py --query_type quer_key
4 | python3 preprocessing.py --query_type quer_all
5 |
6 | git clone http://github.com/stanfordnlp/glove
7 | cp gen_w2v.sh glove/
8 | cp data/corpus.txt glove/
9 | cd glove && make
10 | . gen_w2v.sh
11 | cd ..
12 | cp glove/glove.w2v data/
13 |
14 | python3 nn_preprocessing.py
15 | python3 bert_preprocessing.py --preprocessing_type fine --left_truncated_length 64 --query_type query_key
16 | python3 bert_preprocessing.py --preprocessing_type fine --left_truncated_length 200 --query_type query_all
17 | python3 bert_preprocessing.py --preprocessing_type coarse --left_truncated_length 200 --query_type query_all
18 |
19 | python3 nn_5_fold_train.py --model_id ESIM_001
20 | python3 nn_5_fold_train.py --model_id ESIMplus_001
21 | python3 nn_5_fold_train.py --model_id aNMM_001
22 | python3 nn_5_fold_train.py --model_id MatchLSTM_001
23 | python3 nn_5_fold_train.py --model_id ESIM_001_pointwise
24 |
25 | python3 bert_5_fold_train.py --model_id bert_002
26 | python3 bert_5_fold_train.py --model_id bert_003
27 | python3 bert_5_fold_train.py --model_id bert_004
28 |
29 | python3 nn_5_fold_predict.py --model_id ESIM_001
30 | python3 nn_5_fold_predict.py --model_id ESIMplus_001
31 | python3 nn_5_fold_predict.py --model_id aNMM_001
32 | python3 nn_5_fold_predict.py --model_id MatchLSTM_001
33 | python3 nn_5_fold_predict.py --model_id ESIM_001_pointwise
34 |
35 | python3 bert_5_fold_predict.py --model_id bert_002
36 | python3 bert_5_fold_predict.py --model_id bert_003
37 | python3 bert_5_fold_predict.py --model_id bert_004
38 |
39 | python3 fold_result_integration.py --model_id ESIM_001
40 | python3 fold_result_integration.py --model_id ESIMplus_001
41 | python3 fold_result_integration.py --model_id aNMM_001
42 | python3 fold_result_integration.py --model_id MatchLSTM_001
43 | python3 fold_result_integration.py --model_id ESIM_001_pointwise
44 | python3 fold_result_integration.py --model_id bert_002
45 | python3 fold_result_integration.py --model_id bert_003
46 | python3 fold_result_integration.py --model_id bert_004
47 |
48 | python3 mk_submission.py --model_id ESIM_001
49 | python3 mk_submission.py --model_id ESIMplus_001
50 | python3 mk_submission.py --model_id aNMM_001
51 | python3 mk_submission.py --model_id MatchLSTM_001
52 | python3 mk_submission.py --model_id ESIM_001_pointwise
53 | python3 mk_submission.py --model_id bert_002
54 | python3 mk_submission.py --model_id bert_003
55 | python3 mk_submission.py --model_id bert_004
56 |
57 | python3 change_formatting4stk.py --model_id ESIM_001
58 | python3 change_formatting4stk.py --model_id ESIMplus_001
59 | python3 change_formatting4stk.py --model_id aNMM_001
60 | python3 change_formatting4stk.py --model_id MatchLSTM_001
61 | python3 change_formatting4stk.py --model_id ESIM_001_pointwise
62 | python3 change_formatting4stk.py --model_id bert_002
63 | python3 change_formatting4stk.py --model_id bert_003
64 | python3 change_formatting4stk.py --model_id bert_004
65 |
66 | ###### finally #####
67 | python3 final_blend.py
68 |
69 |
--------------------------------------------------------------------------------
/src/rank/m2/utils.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import time
3 | import numpy as np
4 | from tqdm import tqdm
5 | import torch
6 | from matchzoo.engine.base_metric import sort_and_couple, RankingMetric
7 |
8 |
9 | def build_matrix(term_index, gv_model, dim=256):
10 |
11 | input_dim = len(term_index)
12 | matrix = np.empty((input_dim, dim))
13 |
14 | valid_keys = gv_model.vocab.keys()
15 | for term, index in term_index.items():
16 | if term in valid_keys:
17 | matrix[index] = gv_model.word_vec(term)
18 | else:
19 | if '' in gv_model.vocab.keys():
20 | matrix[index] = gv_model.word_vec("")
21 | else:
22 | matrix[index] = np.random.randn(dim).astype(dtype=np.float32)
23 | return matrix
24 |
25 | def topk_lines(df, k):
26 | print(df.shape)
27 | df.loc[:, 'rank'] = df.groupby(['description_id', 'type']).cumcount().values
28 | df = df[df['rank'] < k]
29 | df.drop(['rank'], axis=1, inplace=True)
30 | print(df.shape)
31 | return df
32 |
33 |
34 | class MAP(RankingMetric):
35 |
36 | def __init__(self, k = 3):
37 | self._k = k
38 |
39 | def __repr__(self) -> str:
40 | return 'mean_average_precision@{}'.format(self._k)
41 |
42 | def __call__(self, y_true, y_pred):
43 | coupled_pair = sort_and_couple(y_true, y_pred)
44 | for idx, (label, pred) in enumerate(coupled_pair):
45 | if idx+1>self._k:
46 | return 0
47 | if label > 0:
48 | return 1. / (idx + 1)
49 | return 0.
50 |
51 |
52 | def predict(trainer, testloader):
53 | with torch.no_grad():
54 | trainer._model.eval()
55 | predictions = []
56 | for batch in tqdm(testloader):
57 | inputs = batch[0]
58 | outputs = trainer._model(inputs).detach().cpu()
59 | predictions.append(outputs)
60 | trainer._model.train()
61 |
62 | return torch.cat(predictions, dim=0).numpy()
63 |
64 |
65 | class Logger:
66 | def __init__(self, log_filename="log.txt"):
67 | self.terminal = sys.stdout
68 | self.log = open(log_filename, "a")
69 | self.log.write("="*10+" Start Time:"+time.ctime()+" "+"="*10+"\n")
70 |
71 | def __enter__(self):
72 | sys.stdout = self
73 |
74 | def __exit__(self, e_t, e_v, t_b):
75 | sys.stdout = self.close()
76 |
77 | def stop_log(self):
78 | sys.stdout = self.close()
79 |
80 | def write(self, message):
81 | self.terminal.write(message)
82 | if message=="\n":
83 | self.log.write(message)
84 | else:
85 | self.log.write("["+time.ctime()+"]: "+message)
86 |
87 | def flush(self):
88 | self.terminal.flush()
89 | self.log.flush()
90 |
91 | def close(self):
92 | self.log.write("="*10+" End Time"+time.ctime()+" "+"="*10+"\n")
93 | self.log.close()
94 | return self.terminal
95 |
96 |
--------------------------------------------------------------------------------
/src/rank/m3/convert.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 |
17 | # 自定义工具包
18 | sys.path.append('../../../tools/')
19 | import loader
20 |
21 | # 设置随机种子
22 | SEED = 2020
23 | np.random.seed (SEED)
24 |
25 | def val_convert(df_path, pred_path, out_path):
26 | tr_data = loader.load_df(df_path)
27 | df_pred = loader.load_df(pred_path)
28 |
29 | sort_df_pred = df_pred.sort_values(['description_id', 'target'], ascending=False)
30 | df_pred = df_pred[['description_id']].drop_duplicates() \
31 | .merge(sort_df_pred, on=['description_id'], how='left')
32 | df_pred['rank'] = df_pred.groupby('description_id').cumcount().values
33 | df_pred = df_pred[df_pred['rank'] < 3]
34 | df_pred = df_pred.groupby(['description_id'])['paper_id'] \
35 | .apply(lambda s : ','.join((s))).reset_index()
36 |
37 | tr_data = tr_data[['description_id', 'paper_id']].rename(columns={'paper_id': 'target_id'})
38 | df_pred = df_pred.merge(tr_data, on=['description_id'], how='left')
39 | loader.save_df(df_pred, out_path)
40 |
41 | def output(df, out_path):
42 | fo = open(out_path, 'w')
43 | for i in range(df.shape[0]):
44 | desc_id = df.iloc[i]['description_id']
45 | paper_ids = df.iloc[i]['paper_id']
46 | print (desc_id + ',' + paper_ids, file=fo)
47 | fo.close()
48 |
49 | def sub_convert(df_path, pred_path, out_path1, out_path2):
50 | te_data = loader.load_df(df_path)
51 | df_pred = loader.load_df(pred_path)
52 |
53 | sort_df_pred = df_pred.sort_values(['description_id', 'target'], ascending=False)
54 | df_pred = df_pred[['description_id']].drop_duplicates() \
55 | .merge(sort_df_pred, on=['description_id'], how='left')
56 | df_pred['rank'] = df_pred.groupby('description_id').cumcount().values
57 | df_pred = df_pred[df_pred['rank'] < 3]
58 | df_pred = df_pred.groupby(['description_id'])['paper_id'] \
59 | .apply(lambda s : ','.join((s))).reset_index()
60 |
61 | df_pred = te_data[['description_id']].merge(df_pred, on=['description_id'], how='left')
62 | loader.save_df(df_pred, out_path1)
63 | #output(df_pred, out_path2)
64 |
65 | if __name__ == "__main__":
66 |
67 | print('start time: %s' % datetime.now())
68 | root_path = '../../../feat/'
69 | base_tr_path = '../../../input/train_release.csv'
70 | base_te_path = '../../../input/test.csv'
71 |
72 | sub_file_path = sys.argv[1]
73 | sub_name = sys.argv[2]
74 |
75 | val_path = '{}/{}_cv.ftr'.format(sub_file_path, sub_name)
76 | val_out_path = '{}/r_{}_cv.csv'.format(sub_file_path, sub_name)
77 | val_convert(base_tr_path, val_path, val_out_path)
78 |
79 | sub_path = '{}/{}.ftr'.format(sub_file_path, sub_name)
80 | sub_out_pathA = '{}/r_{}.csv'.format(sub_file_path, sub_name)
81 | sub_out_pathB = '{}/s_{}.csv'.format(sub_file_path, sub_name)
82 | sub_out_pathA2 = '{}/r2_{}.csv'.format(sub_file_path, sub_name)
83 | sub_out_pathB2 = '{}/s2_{}.csv'.format(sub_file_path, sub_name)
84 | sub_convert(base_te_path, sub_path, sub_out_pathA, sub_out_pathB)
85 |
86 | print('all completed: %s' % datetime.now())
87 |
88 |
89 |
--------------------------------------------------------------------------------
/src/rank/m3/eval.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 |
17 | # 自定义工具包
18 | sys.path.append('../../../tools/')
19 | import loader
20 |
21 | # 开源工具包
22 | import ml_metrics as metrics
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | def calc_map(df, k):
29 | df.rename(columns={'paper_id': 'paper_ids'}, inplace=True)
30 | df['paper_ids'] = df['paper_ids'].apply(lambda s: s.split(','))
31 | df['target_id'] = df['target_id'].apply(lambda s: [s])
32 | return metrics.mapk(df['target_id'].tolist(), df['paper_ids'].tolist(), k)
33 |
34 | if __name__ == "__main__":
35 |
36 | print('start time: %s' % datetime.now())
37 | in_path = sys.argv[1]
38 | df = loader.load_df(in_path)
39 | mapk = calc_map(df, k=3)
40 | print ('{} {}'.format(df.shape, round(mapk, 5)))
41 | print('all completed: %s' % datetime.now())
42 |
43 |
--------------------------------------------------------------------------------
/src/rank/m3/flow.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import time
8 |
9 | ts = time.time()
10 |
11 | num = sys.argv[1]
12 |
13 | sub_file_path = '../../../output/m3/lgb_m3_{}'.format(num)
14 | sub_name = 'lgb_m3_{}'.format(num)
15 |
16 | # lgb train
17 | print ('lgb_train-%s.py %s' % (num, num))
18 | os.system('python3 -u lgb_train_%s.py %s' % (num, num))
19 |
20 | # merge cv & sub
21 | print('\nkfold_merge')
22 | os.system('python3 -u kfold_merge.py %s %s' % (sub_file_path, sub_name))
23 |
24 | # convert cv & sub to list format
25 | print ('\nconvert')
26 | os.system('python3 -u convert.py %s %s' % (sub_file_path, sub_name))
27 |
28 | # calculate mrr & auc
29 | print ('\neval')
30 | os.system('python3 -u eval.py %s' % ('{}/r_{}_cv.csv'.format(sub_file_path, sub_name)))
31 |
32 | print ('all completed, cost {}s'.format(time.time() - ts))
33 |
--------------------------------------------------------------------------------
/src/rank/m3/kfold_merge.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 |
23 | # 设置随机种子
24 | SEED = 2020
25 | np.random.seed (SEED)
26 |
27 | TARGET_NAME = 'target'
28 | FOLD_NUM = 5
29 |
30 | def merge_val(file_path, sub_name, fold_num):
31 | file_list = os.listdir(file_path)
32 |
33 | paths = ['{}_cv_{}.csv'.format(sub_name, i) for i in range(1, fold_num + 1)]
34 | print (paths)
35 |
36 | dfs = []
37 | for path in paths:
38 | assert path in file_list, '{} not exist'.format(path)
39 | path = '{}/{}'.format(file_path, path)
40 | dfs.append(loader.load_df(path))
41 |
42 | df = pd.concat(dfs)
43 | print (df.head())
44 | print (df.describe())
45 | out_path = '{}/{}_cv.ftr'.format(file_path, sub_name)
46 | loader.save_df(df, out_path)
47 |
48 | def merge_sub(file_path, sub_name, fold_num):
49 | file_list = os.listdir(file_path)
50 |
51 | paths = ['{}_{}.csv'.format(sub_name, i) for i in range(1, fold_num + 1)]
52 | print (paths)
53 |
54 | df = pd.DataFrame()
55 | for i, path in enumerate(paths):
56 | assert path in file_list, '{} not exist'.format(path)
57 | path = '{}/{}'.format(file_path, path)
58 | if i == 0:
59 | df = loader.load_df(path)
60 | else:
61 | df[TARGET_NAME] += loader.load_df(path)[TARGET_NAME]
62 |
63 | df[TARGET_NAME] /= fold_num
64 | print (df.head())
65 | print (df.describe())
66 | out_path = '{}/{}.ftr'.format(file_path, sub_name)
67 | loader.save_df(df, out_path)
68 |
69 |
70 | if __name__ == '__main__':
71 |
72 | sub_file_path = sys.argv[1]
73 | sub_name = sys.argv[2]
74 |
75 | merge_val(sub_file_path, sub_name, FOLD_NUM)
76 | merge_sub(sub_file_path, sub_name, FOLD_NUM)
77 |
78 |
79 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_32-50-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '32-50'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | #train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_37-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '37'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | #train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_38-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '38'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | #train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_38-1.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '38'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | if sub_col in col and col != 'year':
57 | #if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/rank/m3/lgb_train_40-0.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | sys.path.append('../../../tools/')
21 | import loader
22 | from lgb_learner import lgbLearner
23 |
24 | # 设置随机种子
25 | SEED = 2020
26 | np.random.seed (SEED)
27 |
28 | FEA_NUM = sys.argv[1]
29 | FEA_NUM = '40'
30 |
31 | fold_num = 5
32 | out_name = 'lgb_m3_{}-0'.format(FEA_NUM)
33 | root_path = '../../../output/m3/' + out_name + '/'
34 |
35 | ID_NAMES = ['description_id', 'paper_id']
36 | TARGET_NAME = 'target'
37 |
38 | TASK_TYPE = 'te'
39 | #TASK_TYPE = 'tr'
40 | #TASK_TYPE = 'pe'
41 |
42 | if not os.path.exists(root_path):
43 | os.mkdir(root_path)
44 | print ('create dir succ {}'.format(root_path))
45 |
46 | def sum_score(x, y):
47 | return max(x, 0) + max(y, 0)
48 |
49 | def get_feas(data):
50 |
51 | cols = data.columns.tolist()
52 | del_cols = ID_NAMES + ['target', 'cv']
53 | sub_cols = ['year']
54 | for col in data.columns:
55 | for sub_col in sub_cols:
56 | #if sub_col in col and col != 'year':
57 | if sub_col in col:
58 | del_cols.append(col)
59 |
60 | cols = [val for val in cols if val not in del_cols]
61 | print ('del_cols', del_cols)
62 | return cols
63 |
64 | def lgb_train(train_data, test_data, fea_col_names, seed=SEED, cv_index=0):
65 | params = {
66 | "objective": "binary",
67 | "boosting_type": "gbdt",
68 | #"metric": ['binary_logloss'],
69 | "metric": ['auc'],
70 | "boost_from_average": False,
71 | "learning_rate": 0.03,
72 | "num_leaves": 32,
73 | "max_depth": -1,
74 | "feature_fraction": 0.7,
75 | "bagging_fraction": 0.7,
76 | "bagging_freq": 2,
77 | "lambda_l1": 0,
78 | "lambda_l2": 0,
79 | "seed": seed,
80 | 'min_child_weight': 0.005,
81 | 'min_data_in_leaf': 50,
82 | 'max_bin': 255,
83 | "num_threads": 16,
84 | "verbose": -1,
85 | "early_stopping_round": 50
86 | }
87 | params['learning_rate'] = 0.03
88 | num_trees = 2000
89 | print ('training params:', num_trees, params)
90 |
91 | lgb_learner = lgbLearner(train_data, test_data, \
92 | fea_col_names, ID_NAMES, TARGET_NAME, \
93 | params, num_trees, fold_num, out_name, \
94 | metric_names=['auc', 'logloss'], \
95 | model_postfix='')
96 | predicted_folds = [1,2,3,4,5]
97 |
98 | if TASK_TYPE == 'te':
99 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
100 | predicted_folds=predicted_folds, need_predict_test=True)
101 | elif TASK_TYPE == 'tr':
102 | lgb_learner.multi_fold_train(lgb_learner.train_data, \
103 | predicted_folds=predicted_folds, need_predict_test=False)
104 | elif TASK_TYPE == 'pe':
105 | lgb_learner.multi_fold_predict(lgb_learner.train_data, \
106 | predicted_folds=predicted_folds, need_predict_test=False)
107 |
108 | if __name__ == '__main__':
109 |
110 | ################## params ####################
111 | print("Load the training, test and store data using pandas")
112 | ts = time.time()
113 | root_path = '../../../feat/'
114 | postfix = 's0_{}'.format(FEA_NUM)
115 | file_type = 'ftr'
116 |
117 | train_path = root_path + 'tr_{}.{}'.format(postfix, file_type)
118 | test_path = root_path + 'te_{}.{}'.format('s0_4', file_type)
119 | if TASK_TYPE in ['te', 'pe']:
120 | test_path = root_path + 'te_{}.{}'.format(postfix, file_type)
121 |
122 | print ('tr path', train_path)
123 | print ('te path', test_path)
124 | train_data = loader.load_df(train_path)
125 | test_data = loader.load_df(test_path)
126 |
127 | paper = loader.load_df('../../../input/candidate_paper_for_wsdm2020.ftr')
128 | tr = loader.load_df('../../../input/tr_input_final.ftr')
129 | tr = tr.merge(paper[['paper_id', 'journal', 'year']], on=['paper_id'], how='left')
130 | desc_list = tr[tr['journal'] != 'no-content'][~pd.isnull(tr['year'])]['description_id'].tolist()
131 | train_data = train_data[train_data['description_id'].isin(desc_list)]
132 |
133 | print (train_data.columns)
134 | print (train_data.shape, test_data.shape)
135 |
136 | fea_col_names = get_feas(train_data)
137 | print (len(fea_col_names), fea_col_names)
138 |
139 | required_cols = ID_NAMES + ['cv', 'target']
140 | drop_cols = [col for col in train_data.columns \
141 | if col not in fea_col_names and col not in required_cols]
142 |
143 | train_data = train_data.drop(drop_cols, axis=1)
144 | test_data = test_data.drop([col for col in drop_cols if col in test_data.columns], axis=1)
145 |
146 | lgb_train(train_data, test_data, fea_col_names)
147 | print('all completed: %s, cost %s' % (datetime.now(), time.time() - ts))
148 |
149 |
150 |
151 |
152 |
--------------------------------------------------------------------------------
/src/recall/tfidf_recall_30.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # bm25 recall
5 |
6 | # 基础模块
7 | import os
8 | import gc
9 | import sys
10 | import time
11 | import functools
12 | from tqdm import tqdm
13 | from six import iteritems
14 | from datetime import datetime
15 |
16 | # 数据处理
17 | import re
18 | import math
19 | import pickle
20 | import numpy as np
21 | import pandas as pd
22 | from multiprocessing import Pool
23 |
24 | # 自定义工具包
25 | sys.path.append('../../tools/')
26 | import loader
27 | import pandas_util
28 | import custom_bm25 as bm25
29 |
30 | # 开源工具包
31 | from gensim.models import Word2Vec
32 | from gensim.models.word2vec import LineSentence
33 | from gensim import corpora, models, similarities
34 | from gensim.similarities import SparseMatrixSimilarity
35 | from sklearn.metrics.pairwise import cosine_similarity as cos_sim
36 |
37 | # 设置随机种子
38 | SEED = 2020
39 | PROCESS_NUM, PARTITION_NUM = 18, 18
40 |
41 | input_root_path = '../../input/'
42 | output_root_path = '../../feat/'
43 |
44 | postfix = '30'
45 | file_type = 'ftr'
46 |
47 | train_out_path = output_root_path + 'tr_tfidf_{}.{}'.format(postfix, file_type)
48 | test_out_path = output_root_path + 'te_tfidf_{}.{}'.format(postfix, file_type)
49 |
50 | def topk_sim_samples(desc, desc_ids, paper_ids, bm25_model, k=10):
51 | desc_id2papers = {}
52 | for desc_i in tqdm(range(len(desc))):
53 | query_vec, query_desc_id = desc[desc_i], desc_ids[desc_i]
54 | sims = bm25_model.get_scores(query_vec)
55 | sort_sims = sorted(enumerate(sims), key=lambda item: -item[1])
56 | sim_papers = [paper_ids[val[0]] for val in sort_sims[:k]]
57 | sim_scores = [str(val[1]) for val in sort_sims[:k]]
58 | desc_id2papers[query_desc_id] = ['|'.join(sim_papers), '|'.join(sim_scores)]
59 | sim_df = pd.DataFrame.from_dict(desc_id2papers, orient='index', columns=['paper_id', 'sim_score'])
60 | sim_df = sim_df.reset_index().rename(columns={'index':'description_id'})
61 | return sim_df
62 |
63 | def partition(queries, num):
64 | queries_partitions, step = [], int(np.ceil(len(queries)/num))
65 | for i in range(0, len(queries), step):
66 | queries_partitions.append(queries[i:i+step])
67 | return queries_partitions
68 |
69 | def single_process_search(params=None):
70 | (query_vecs, desc_ids, paper_ids, bm25_model, k, i) = params
71 | print (i, 'start', datetime.now())
72 | gc.collect()
73 | sim_df = topk_sim_samples(query_vecs, desc_ids, paper_ids, bm25_model, k)
74 | print (i, 'completed', datetime.now())
75 | return sim_df
76 |
77 | def multi_process_search(query_vecs, desc_ids, paper_ids, bm25_model, k):
78 | pool = Pool(PROCESS_NUM)
79 | queries_parts = partition(query_vecs, PARTITION_NUM)
80 | desc_ids_parts = partition(desc_ids, PARTITION_NUM)
81 | print ('{} processes init and partition to {} parts' \
82 | .format(PROCESS_NUM, PARTITION_NUM))
83 |
84 | param_list = [(queries_parts[i], desc_ids_parts[i], \
85 | paper_ids, bm25_model, k, i) for i in range(PARTITION_NUM)]
86 | sim_dfs = pool.map(single_process_search, param_list)
87 | sim_df = pd.concat(sim_dfs, axis=0)
88 | return sim_df
89 |
90 | def gen_samples(df, desc, desc_ids, corpus_list, paper_ids_list, k):
91 | df_samples_list = []
92 | for i, corpus in enumerate(corpus_list):
93 | bm25_model = bm25.BM25(corpus[0])
94 | cur_df_sample = multi_process_search(desc, desc_ids, \
95 | paper_ids_list[i], bm25_model, k)
96 | cur_df_sample_out = pandas_util.explode(cur_df_sample, ['paper_id', 'sim_score'])
97 | cur_df_sample_out['type'] = corpus[1] # recall_name
98 | df_samples_list.append(cur_df_sample_out)
99 | df_samples = pd.concat(df_samples_list, axis=0)
100 | df_samples.drop_duplicates(subset=['description_id', 'paper_id'], inplace=True)
101 | df_samples['target'] = 0
102 | return df_samples
103 |
104 | if __name__ == "__main__":
105 |
106 | ts = time.time()
107 | tqdm.pandas()
108 | print('start time: %s' % datetime.now())
109 | # load data
110 | df = loader.load_df(input_root_path + 'paper_input_final.ftr')
111 | df = df[~pd.isnull(df['paper_id'])]
112 |
113 | # gen tfidf vecs
114 | dictionary = pickle.load(open('../../feat/corpus.dict', 'rb'))
115 | print ('dic len', len(dictionary))
116 |
117 | df['corp'] = df['abst'] + ' ' + df['titl'] + ' ' + df['keywords'].fillna('').replace(';', ' ')
118 | df_corp, corp_paper_ids = [dictionary.doc2bow(line.split(' ')) for line in df['corp'].tolist()], \
119 | df['paper_id'].tolist()
120 |
121 | # gen topk sim samples
122 | paper_ids_list = [corp_paper_ids]
123 | corpus_list = [(df_corp, 'corp_bm25')]
124 | out_cols = ['description_id', 'paper_id', 'sim_score', 'target', 'type']
125 |
126 | if sys.argv[1] in ['tr']:
127 | # for tr ins
128 | tr = loader.load_df(input_root_path + 'tr_input_final.ftr')
129 | tr = tr[~pd.isnull(tr['description_id'])]
130 |
131 | # tr = tr.head(1000)
132 | tr_desc, tr_desc_ids = [dictionary.doc2bow(line.split(' ')) for line in tr['quer_all'].tolist()], \
133 | tr['description_id'].tolist()
134 | print ('gen tf completed, cost {}s'.format(np.round(time.time() - ts, 2)))
135 |
136 | tr_samples = gen_samples(tr, tr_desc, tr_desc_ids, \
137 | corpus_list, paper_ids_list, k=50)
138 | tr_samples = tr.rename(columns={'paper_id': 'target_paper_id'}) \
139 | .merge(tr_samples, on='description_id', how='left')
140 | tr_samples.loc[tr_samples['target_paper_id'] == tr_samples['paper_id'], 'target'] = 1
141 | loader.save_df(tr_samples[out_cols], train_out_path)
142 | print ('recall succ {} from {}'.format(tr_samples['target'].sum(), tr.shape[0]))
143 | print (tr.shape, tr_samples.shape)
144 |
145 | if sys.argv[1] in ['te']:
146 | # for te ins
147 | te = loader.load_df(input_root_path + 'te_input_final.ftr')
148 | te = te[~pd.isnull(te['description_id'])]
149 |
150 | # te = te.head(1000)
151 | te_desc, te_desc_ids = [dictionary.doc2bow(line.split(' ')) for line in te['quer_all'].tolist()], \
152 | te['description_id'].tolist()
153 | print ('gen tf completed, cost {}s'.format(np.round(time.time() - ts, 2)))
154 |
155 | te_samples = gen_samples(te, te_desc, te_desc_ids, \
156 | corpus_list, paper_ids_list, k=50)
157 | te_samples = te.merge(te_samples, on='description_id', how='left')
158 | loader.save_df(te_samples[out_cols], test_out_path)
159 | print (te.shape, te_samples.shape)
160 |
161 | print('all completed: {}, cost {}s'.format(datetime.now(), np.round(time.time() - ts, 2)))
162 |
163 |
164 |
165 |
--------------------------------------------------------------------------------
/src/utils/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/src/utils/.gitkeep
--------------------------------------------------------------------------------
/stk_feat/README.md:
--------------------------------------------------------------------------------
1 | ## Dir of generated stacking features
2 |
--------------------------------------------------------------------------------
/tools/__pycache__/basic_learner.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/basic_learner.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/custom_bm25.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/custom_bm25.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/custom_metrics.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/custom_metrics.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/feat_utils.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/feat_utils.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/lgb_learner.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/lgb_learner.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/loader.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/loader.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/nlp_preprocess.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/nlp_preprocess.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/__pycache__/pandas_util.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/__pycache__/pandas_util.cpython-37.pyc
--------------------------------------------------------------------------------
/tools/basic_learner.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # 基础模块
5 | import os
6 | import sys
7 | import gc
8 | import json
9 | import time
10 | import functools
11 | from datetime import datetime
12 |
13 | # 数据处理
14 | import numpy as np
15 | import pandas as pd
16 | from math import sqrt
17 | from collections import Counter
18 |
19 | # 自定义工具包
20 | import loader
21 | import custom_metrics
22 |
23 | # 设置随机种子
24 | SEED = 2018
25 | np.random.seed (SEED)
26 |
27 | class BaseLearner(object):
28 |
29 | def __init__(self, train_data, test_data,
30 | fea_names, id_names, target_name, \
31 | params, fold_num, out_name, metric_names=['auc'], \
32 | model_postfix=''):
33 | # 深度拷贝原始数据,防止外部主函数修改导致的数据异常
34 | self.train_data = train_data.copy(deep=True)
35 | self.test_data = test_data.copy(deep=True)
36 |
37 | # 基础数据信息
38 | self.fea_names = fea_names
39 | self.id_names = id_names
40 | self.target_name = target_name
41 |
42 | self.params = params
43 | self.fold_num = fold_num
44 | self.out_name = out_name
45 | self.root_path = '../../../output/m3/' + out_name + '/'
46 | self.metric_names = metric_names
47 | self.model_postfix = model_postfix
48 |
49 | # 获取模型存储路径
50 | def get_model_path(self, predicted_fold_index):
51 | model_path = self.root_path + 'model_' + str(predicted_fold_index)
52 | if self.model_postfix != '':
53 | model_path += '_' + self.model_postfix
54 | return model_path
55 |
56 | # 获取预测结果输出路径
57 | def get_preds_outpath(self, predicted_fold_index):
58 | out_path = self.root_path + self.out_name
59 | if self.model_postfix != '':
60 | out_path += '_' + self.model_postfix
61 | if predicted_fold_index != 0:
62 | out_path += '_cv_' + str(predicted_fold_index)
63 | return out_path
64 |
65 | # 训练、验证集划分接口,需要被重载
66 | def extract_train_data(self, data, predicted_fold_index):
67 | pass
68 |
69 | # 单 fold 训练接口,需要被重载
70 | def train(self, data, predicted_fold_index, model_dump_path=None):
71 | pass
72 |
73 | # 单 fold 预测接口,需要被重载
74 | def predict(self, data, predicted_fold_index, model_load_path=None):
75 | pass
76 |
77 | # 多 fold 训练
78 | def multi_fold_train(self, data, predicted_folds=[1,2,3,4,5], \
79 | need_predict_test=False):
80 | print ("multi_fold train start {}".format(datetime.now()))
81 | ts = time.time()
82 | for fold_index in predicted_folds:
83 | print ('training fold {}'.format(fold_index))
84 | self.train(data, fold_index)
85 | print ('fold {} completed, cost {}s'.format( \
86 | fold_index, time.time() - ts))
87 | self.multi_fold_predict(data, predicted_folds, need_predict_test)
88 |
89 | # 多 fold 预测
90 | def multi_fold_predict(self, data, predicted_folds, \
91 | need_predict_test=False):
92 | print ("multi_fold predict start {}".format(datetime.now()))
93 |
94 | multi_fold_eval_lis = []
95 |
96 | for fold_index in predicted_folds:
97 | dtrain, dvalid, Xvalid = self.extract_train_data( \
98 | self.train_data, fold_index)
99 |
100 | ypreds = self.predict(Xvalid, fold_index)
101 | labels = Xvalid[self.target_name]
102 |
103 | eval_lis = custom_metrics.calc_metrics(labels, ypreds, \
104 | self.metric_names)
105 |
106 | multi_fold_eval_lis.append(eval_lis)
107 | print ('{} eval: {}'.format(fold_index, eval_lis))
108 | loader.out_preds(self.target_name, \
109 | Xvalid[self.id_names], ypreds, \
110 | '{}.csv'.format(self.get_preds_outpath(fold_index)), \
111 | labels.tolist())
112 |
113 | if need_predict_test:
114 | print ('predict test data')
115 | ypreds = self.predict(self.test_data, 0,
116 | model_load_path=self.get_model_path(fold_index))
117 | # output preds
118 | loader.out_preds(self.target_name, \
119 | self.test_data[self.id_names], ypreds, \
120 | '{}_{}.csv'.format(self.get_preds_outpath(0), fold_index))
121 |
122 | multi_fold_eval_avgs = []
123 | for i in range(len(self.metric_names)):
124 | eval_avg = np.array([val[i] for val in multi_fold_eval_lis]).mean()
125 | eval_avg = round(eval_avg, 5)
126 | multi_fold_eval_avgs.append(eval_avg)
127 | print ('multi fold eval mean: ', multi_fold_eval_avgs)
128 |
129 | return multi_fold_eval_avgs
130 |
131 |
132 |
--------------------------------------------------------------------------------
/tools/basic_learner.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/basic_learner.pyc
--------------------------------------------------------------------------------
/tools/custom_bm25.py:
--------------------------------------------------------------------------------
1 | import math
2 | from six import iteritems
3 | from six.moves import range
4 |
5 | PARAM_K1 = 1.5
6 | PARAM_B = 0.75
7 | EPSILON = 0.25
8 |
9 | class BM25(object):
10 | def __init__(self, corpus):
11 | """
12 | Parameters
13 | ----------
14 | corpus : list of list of str
15 | Given corpus.
16 | """
17 | self.corpus_size = 0
18 | self.avgdl = 0
19 | self.doc_freqs = []
20 | self.idf = {}
21 | self.doc_len = []
22 | self._initialize(corpus)
23 |
24 | def _initialize(self, corpus):
25 | """Calculates frequencies of terms in documents and in corpus. Also computes inverse document frequencies."""
26 | nd = {} # word -> number of documents with word
27 | num_doc = 0
28 |
29 | for document in corpus:
30 | self.corpus_size += 1
31 | cur_doc_len = 0
32 | frequencies = {}
33 |
34 | for word_tuple in document:
35 | word, word_cnt = word_tuple[0], word_tuple[1]
36 | if word not in frequencies:
37 | frequencies[word] = 0
38 | frequencies[word] += word_cnt
39 | cur_doc_len += word_cnt
40 | self.doc_freqs.append(frequencies)
41 | self.doc_len.append(cur_doc_len)
42 | num_doc += cur_doc_len
43 |
44 | for word, freq in iteritems(frequencies):
45 | if word not in nd:
46 | nd[word] = 0
47 | nd[word] += 1
48 |
49 | self.avgdl = float(num_doc) / self.corpus_size
50 | # collect idf sum to calculate an average idf for epsilon value
51 | idf_sum = 0
52 | # collect words with negative idf to set them a special epsilon value.
53 | # idf can be negative if word is contained in more than half of documents
54 | negative_idfs = []
55 | for word, freq in iteritems(nd):
56 | idf = math.log(self.corpus_size - freq + 0.5) - math.log(freq + 0.5)
57 | self.idf[word] = idf
58 | idf_sum += idf
59 | if idf < 0:
60 | negative_idfs.append(word)
61 | self.average_idf = float(idf_sum) / len(self.idf)
62 |
63 | eps = EPSILON * self.average_idf
64 | for word in negative_idfs:
65 | self.idf[word] = eps
66 |
67 | def get_score(self, document, index):
68 | """Computes BM25 score of given `document` in relation to item of corpus selected by `index`.
69 | Parameters
70 | ----------
71 | document : list of str
72 | Document to be scored.
73 | index : int
74 | Index of document in corpus selected to score with `document`.
75 | Returns
76 | -------
77 | float
78 | BM25 score.
79 | """
80 | score = 0
81 | doc_freqs = self.doc_freqs[index]
82 | for word_tuple in document:
83 | word = word_tuple[0]
84 | if word not in doc_freqs:
85 | continue
86 | score += (self.idf[word] * doc_freqs[word] * (PARAM_K1 + 1)
87 | / (doc_freqs[word] + PARAM_K1 * (1 - PARAM_B + PARAM_B * self.doc_len[index] / self.avgdl)))
88 | return score
89 |
90 | def get_scores(self, document):
91 | """Computes and returns BM25 scores of given `document` in relation to
92 | every item in corpus.
93 | Parameters
94 | ----------
95 | document : list of str
96 | Document to be scored.
97 | Returns
98 | -------
99 | list of float
100 | BM25 scores.
101 | """
102 | scores = [self.get_score(document, index) for index in range(self.corpus_size)]
103 | return scores
104 |
105 | def get_scores_bow(self, document):
106 | """Computes and returns BM25 scores of given `document` in relation to
107 | every item in corpus.
108 | Parameters
109 | ----------
110 | document : list of str
111 | Document to be scored.
112 | Returns
113 | -------
114 | list of float
115 | BM25 scores.
116 | """
117 | scores = []
118 | for index in range(self.corpus_size):
119 | score = self.get_score(document, index)
120 | if score > 0:
121 | scores.append((index, score))
122 | return scores
123 |
--------------------------------------------------------------------------------
/tools/custom_bm25.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/custom_bm25.pyc
--------------------------------------------------------------------------------
/tools/custom_metrics.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | import os
5 | import sys
6 | import gc
7 | import json
8 | import time
9 | import functools
10 | from datetime import datetime
11 |
12 | # 数据处理
13 | import numpy as np
14 | import pandas as pd
15 | from math import sqrt
16 |
17 | # 评价指标
18 | from sklearn.metrics import log_loss
19 | from sklearn.metrics import roc_auc_score
20 | from sklearn.metrics import accuracy_score
21 | from sklearn.metrics import mean_absolute_error
22 | from sklearn.metrics import mean_squared_error
23 |
24 | def _calc_auc(labels, ypreds):
25 | return roc_auc_score(labels, ypreds)
26 |
27 | def _calc_logloss(labels, ypreds):
28 | return log_loss(labels, ypreds)
29 |
30 | def _calc_mae(labels, ypreds):
31 | return mean_absolute_error(labels, ypreds)
32 |
33 | def _calc_rmse(labels, ypreds):
34 | return sqrt(mean_squared_error(labels, ypreds))
35 |
36 | # kappa
37 |
38 | # multi-logloss
39 |
40 | def _calc_metric(labels, ypreds, metric_name='auc'):
41 | if metric_name == 'auc':
42 | return _calc_auc(labels, ypreds)
43 | elif metric_name == 'logloss':
44 | return _calc_logloss(labels, ypreds)
45 | elif metric_name == 'mae':
46 | return _calc_mae(labels, ypreds)
47 | elif metric_name == 'rmse':
48 | return _calc_rmse(labels, ypreds)
49 |
50 | def calc_metrics(labels, ypreds, metric_names=['auc']):
51 | eval_lis = []
52 | for metric_name in metric_names:
53 | eval_val = _calc_metric(labels, ypreds, metric_name=metric_name)
54 | eval_val = round(eval_val, 5)
55 | eval_lis.append(eval_val)
56 | return eval_lis
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/tools/custom_metrics.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/custom_metrics.pyc
--------------------------------------------------------------------------------
/tools/feat_utils.py:
--------------------------------------------------------------------------------
1 | def try_divide(x, y, val=0.0):
2 | """
3 | Try to divide two numbers
4 | """
5 | if y != 0.0:
6 | val = float(x) / y
7 | return val
8 |
9 |
10 | def get_sample_indices_by_relevance(dfTrain, additional_key=None):
11 | """
12 | return a dict with
13 | key: (additional_key, median_relevance)
14 | val: list of sample indices
15 | """
16 | dfTrain["sample_index"] = range(dfTrain.shape[0])
17 | group_key = ["median_relevance"]
18 | if additional_key != None:
19 | group_key.insert(0, additional_key)
20 | agg = dfTrain.groupby(group_key, as_index=False).apply(lambda x: list(x["sample_index"]))
21 | d = dict(agg)
22 | dfTrain = dfTrain.drop("sample_index", axis=1)
23 | return d
24 |
25 |
26 | def dump_feat_name(feat_names, feat_name_file):
27 | """
28 | save feat_names to feat_name_file
29 | """
30 | with open(feat_name_file, "wb") as f:
31 | for i,feat_name in enumerate(feat_names):
32 | if feat_name.startswith("count") or feat_name.startswith("pos_of"):
33 | f.write("('%s', SimpleTransform(config.count_feat_transform)),\n" % feat_name)
34 | else:
35 | f.write("('%s', SimpleTransform()),\n" % feat_name)
36 |
--------------------------------------------------------------------------------
/tools/lgb_learner.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | import os
5 | import sys
6 | import gc
7 | import json
8 | import time
9 | import functools
10 | from datetime import datetime
11 |
12 | # 数据处理
13 | import numpy as np
14 | import pandas as pd
15 |
16 | # 模型相关
17 | import lightgbm as lgb
18 | from basic_learner import BaseLearner
19 |
20 | # 设置随机种子
21 | SEED = 2018
22 | np.random.seed (SEED)
23 |
24 | # 设置模型通用参数
25 | EVAL_ROUND = 100
26 | PRINT_TRAIN_METRICS = False
27 |
28 |
29 | class lgbLearner(BaseLearner):
30 |
31 | def __init__(self, train_data, test_data, \
32 | fea_names, id_names, target_name, \
33 | params, num_trees, fold_num, out_name, \
34 | cv_name='cv', metric_names=['auc'], model_postfix=''):
35 | super(lgbLearner, self).__init__(train_data, test_data, fea_names, \
36 | id_names, target_name, params, fold_num, \
37 | out_name, metric_names, model_postfix)
38 | self.num_trees = num_trees
39 | self.cv_name = cv_name
40 |
41 | self.eval_round = EVAL_ROUND
42 | self.print_train_metrics = PRINT_TRAIN_METRICS
43 |
44 | def extract_train_data(self, data, predicted_fold_index):
45 |
46 | Xtrain = data[data[self.cv_name] != predicted_fold_index]
47 | Xvalid = data[data[self.cv_name] == predicted_fold_index]
48 |
49 | dtrain = lgb.Dataset(Xtrain[self.fea_names].values, \
50 | Xtrain[self.target_name])
51 | dvalid = lgb.Dataset(Xvalid[self.fea_names].values, \
52 | Xvalid[self.target_name])
53 |
54 | print ('train, valid', Xtrain.shape, Xvalid.shape)
55 | return dtrain, dvalid, Xvalid
56 |
57 | def train(self, data, predicted_fold_index, model_dump_path=None):
58 | if model_dump_path == None:
59 | model_dump_path = self.get_model_path(predicted_fold_index)
60 |
61 | dtrain, dvalid, Xvalid = self.extract_train_data(self.train_data,
62 | predicted_fold_index)
63 |
64 | if self.print_train_metrics:
65 | valid_sets = [dtrain, dvalid] \
66 | if predicted_fold_index != 0 else [dtrain]
67 | valid_names = ['train', 'valid'] \
68 | if predicted_fold_index != 0 else ['train']
69 | else:
70 | valid_sets = [dvalid] if predicted_fold_index != 0 else [dtrain]
71 | valid_names = ['valid'] if predicted_fold_index != 0 else ['train']
72 |
73 | params = self.params
74 |
75 | bst = lgb.train(params, dtrain, self.num_trees,
76 | valid_sets=valid_sets,
77 | valid_names=valid_names,
78 | verbose_eval=self.eval_round)
79 | bst.save_model(model_dump_path)
80 |
81 | def predict(self, data, predicted_fold_index, \
82 | model_load_path=None):
83 | if model_load_path is None:
84 | model_load_path = self.get_model_path(predicted_fold_index)
85 |
86 | bst = lgb.Booster(model_file=model_load_path)
87 | ypreds = bst.predict(data[self.fea_names], num_iteration=self.num_trees)
88 |
89 | if predicted_fold_index != 0:
90 | # output fea importance
91 | df = pd.DataFrame(self.fea_names, columns=['feature'])
92 | df['importance'] = list(bst.feature_importance('gain'))
93 | df['precent'] = np.round(df.importance * 100 / sum(df.importance), 2)
94 | df['precent'] = df.precent.apply(lambda x : str(x) + '%')
95 |
96 | df = df.sort_values(by='importance', ascending=False)
97 | imp_path = 'imp'
98 | if self.model_postfix != '':
99 | imp_path = 'imp-{}'.format(self.model_postfix)
100 | df.to_csv(self.root_path + imp_path, sep='\t')
101 | return ypreds
102 |
103 |
--------------------------------------------------------------------------------
/tools/lgb_learner.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/lgb_learner.pyc
--------------------------------------------------------------------------------
/tools/loader.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python$
2 | # -*- coding: utf-8 -*-$
3 |
4 | # 数据处理
5 | import numpy as np
6 | import pandas as pd
7 | import feather
8 |
9 | # 基础文件读写
10 | def load_df(filename, nrows=None):
11 | if filename.endswith('csv'):
12 | return pd.read_csv(filename, nrows = nrows)
13 | elif filename.endswith('ftr'):
14 | return feather.read_dataframe(filename)
15 |
16 | def save_df(df, filename, index=False):
17 | if filename.endswith('csv'):
18 | df.to_csv(filename, index=index)
19 | elif filename.endswith('ftr'):
20 | df = df.reset_index(drop=True)
21 | df.columns = [str(col) for col in df.columns]
22 | df.to_feather(filename)
23 |
24 | # merge 特征文件
25 | def merge_fea(df_list, primary_keys=[]):
26 | assert len(primary_keys) >= 0, 'empty primary keys'
27 | print (df_list)
28 |
29 | df_base = load_df(df_list[0])
30 | for i in range(1, len(df_list)):
31 | print (df_list[i])
32 | cur_df = load_df(df_list[i])
33 | df_base = pd.concat([df_base, \
34 | cur_df.drop(primary_keys, axis=1)], axis=1)
35 | print ('merge completed, df shape', df_base.shape)
36 | return df_base
37 |
38 | # 模型预测结果输出
39 | def out_preds(target_name, df_ids, ypreds, out_path, labels=[]):
40 | preds_df = pd.DataFrame(df_ids)
41 | preds_df[target_name] = ypreds
42 | if len(labels) == preds_df.shape[0]:
43 | preds_df['label'] = np.array(labels)
44 | elif len(labels) > 0:
45 | print ('labels length not match')
46 | preds_df.to_csv(out_path, float_format = '%.4f', index=False)
47 |
48 | #def out_preds(id_name, target_name, ids, ypreds, out_path, labels=[]):
49 | # preds_df = pd.DataFrame({id_name: np.array(ids)})
50 | # preds_df[target_name] = ypreds
51 | # if len(labels) == preds_df.shape[0]:
52 | # preds_df['label'] = np.array(labels)
53 | # elif len(labels) > 0:
54 | # print ('labels length not match')
55 | # preds_df.to_csv(out_path, float_format = '%.4f', index=False)
56 |
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/tools/loader.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/loader.pyc
--------------------------------------------------------------------------------
/tools/nlp_preprocess.py:
--------------------------------------------------------------------------------
1 | import re
2 | import time
3 | import numpy as np
4 | import nltk
5 | # nltk.download('punkt')
6 | from nltk.corpus import stopwords
7 | from nltk import word_tokenize, pos_tag
8 | from nltk.stem import WordNetLemmatizer
9 |
10 | def tokenize(sentence):
11 | '''
12 | 去除多余空白、分词、词性标注
13 | '''
14 | sentence = re.sub(r'\s+', ' ', sentence)
15 | token_words = word_tokenize(sentence) # 输入的是列表
16 | token_words = pos_tag(token_words)
17 | return token_words
18 |
19 | def stem(token_words):
20 | '''
21 | 词形归一化
22 | '''
23 | wordnet_lematizer = WordNetLemmatizer() # 单词转换原型
24 | words_lematizer = []
25 | for word, tag in token_words:
26 | if tag.startswith('NN'):
27 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='n') # n代表名词
28 | elif tag.startswith('VB'):
29 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='v') # v代表动词
30 | elif tag.startswith('JJ'):
31 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='a') # a代表形容词
32 | elif tag.startswith('R'):
33 | word_lematizer = wordnet_lematizer.lemmatize(word, pos='r') # r代表代词
34 | else:
35 | word_lematizer = wordnet_lematizer.lemmatize(word)
36 | words_lematizer.append(word_lematizer)
37 | return words_lematizer
38 |
39 |
40 | sr = stopwords.words('english')
41 |
42 |
43 | def delete_stopwords(token_words):
44 | '''
45 | 去停用词
46 | '''
47 | cleaned_words = [word for word in token_words if word not in sr]
48 | return cleaned_words
49 |
50 |
51 | def is_number(s):
52 | '''
53 | 判断字符串是否为数字
54 | '''
55 | try:
56 | float(s)
57 | return True
58 | except ValueError:
59 | pass
60 |
61 | try:
62 | import unicodedata
63 | unicodedata.numeric(s)
64 | return True
65 | except (TypeError, ValueError):
66 | pass
67 |
68 | return False
69 |
70 |
71 | characters = [' ', ',', '.', 'DBSCAN', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%', '-', '...',
72 | '^', '{', '}']
73 |
74 |
75 | def delete_characters(token_words):
76 | '''
77 | 去除特殊字符、数字
78 | '''
79 | words_list = [word for word in token_words if word not in characters and not is_number(word)]
80 | return words_list
81 |
82 |
83 | def to_lower(token_words):
84 | '''
85 | 统一为小写
86 | '''
87 | words_lists = [x.lower() for x in token_words]
88 | return words_lists
89 |
90 | def replace_process(line):
91 | m = replace = {
92 | 'α': 'alpha',
93 | 'β': 'beta',
94 | 'γ': 'gamma',
95 | 'δ': 'delta',
96 | 'ε': 'epsilon',
97 | 'ζ': 'zeta',
98 | 'η': 'eta',
99 | 'θ': 'theta',
100 | 'ι': 'iota',
101 | 'κ': 'kappa',
102 | 'λ': 'lambda',
103 | 'μ': 'mu',
104 | 'ν': 'nu',
105 | 'ξ': 'xi',
106 | 'ο': 'omicron',
107 | 'π': 'pi',
108 | 'ρ': 'rho',
109 | 'ς': 'sigma',
110 | 'σ': 'sigma',
111 | 'τ': 'tau',
112 | 'υ': 'upsilon',
113 | 'φ': 'phi',
114 | 'χ': 'chi',
115 | 'ψ': 'psi',
116 | 'ω': 'omega',
117 | 'ϑ': 'theta',
118 | 'ϒ': 'gamma',
119 | 'ϕ': 'phi',
120 | 'ϱ': 'rho',
121 | 'ϵ': 'epsilon',
122 | '𝛼': 'alpha',
123 | '𝛽': 'beta',
124 | '𝜀': 'epsilon',
125 | '𝜃': 'theta',
126 | '𝜏': 'tau',
127 | '𝜖': 'epsilon',
128 | '𝜷': 'beta',
129 | }
130 | empty_str = ['etc.','et al.','fig.','figure.','e.g.','(', ')','[', ']',';',':','!',',','.','?','"','\'', \
131 | '%','>','<','+','&']
132 | m.update({s: ' ' for s in empty_str})
133 |
134 | for k, v in m.items():
135 | line = line.replace(k, v)
136 | line = ' '.join([s.strip() for s in line.split(' ') if s != ''])
137 | return line
138 |
139 | def preprocess(line):
140 | '''
141 | 文本预处理
142 | '''
143 | line = line.lower()
144 | line = replace_process(line)
145 | token_words = tokenize(line)
146 | token_words = stem(token_words)
147 | token_words = delete_stopwords(token_words)
148 | token_words = delete_characters(token_words)
149 | token_words = to_lower(token_words)
150 | return ' '.join(token_words)
151 |
152 | if __name__ == '__main__':
153 | text = 'This experiment was conducted to determine whether feeding meal and hulls derived from genetically modified soybeans to dairy cows affected production measures and sensory qualities of milk. The soybeans were genetically modified (Event DAS-444Ø6-6) to be resistant to multiple herbicides. Twenty-six Holstein cows (13/treatment) were fed a diet that contained meal and hulls derived from transgenic soybeans or a diet that contained meal and hulls from a nontransgenic near-isoline variety. Soybean products comprised approximately 21% of the diet dry matter, and diets were formulated to be nearly identical in crude protein, neutral detergent fiber, energy, and minerals and vitamins. The experimental design was a replicated 2×2 Latin square with a 28-d feeding period. Dry matter intake (21.3 vs. 21.4kg/d), milk yield (29.3 vs. 29.4kg/d), milk fat (3.70 vs. 3.68%), and milk protein (3.10 vs. 3.12%) did not differ between cows fed control or transgenic soybean products, respectively. Milk fatty acid profile was virtually identical between treatments. Somatic cell count was significantly lower for cows fed transgenic soybean products, but the difference was biologically trivial. Milk was collected from all cows in period 1 on d 0 (before treatment), 14, and 28 for sensory evaluation. On samples from all days (including d 0) judges could discriminate between treatments for perceived appearance of the milk. The presence of this difference at d 0 indicated that it was likely not a treatment effect but rather an initial bias in the cow population. No treatment differences were found for preference or acceptance of the milk. Overall, feeding soybean meal and hulls derived from this genetically modified soybean had essentially no effects on production or milk acceptance when fed to dairy cows. '
154 | text = 'Pyrvinium is a drug approved by the FDA and identified as a Wnt inhibitor by inhibiting Axin degradation and stabilizing 尾-catenin, which can increase Ki67+ cardiomyocytes in the peri-infarct area and alleviate cardiac remodeling in a mouse model of MI . UM206 is a peptide with a high homology to Wnt-3a/5a, and acts as an antagonist for Frizzled proteins to inhibit Wnt signaling pathway transduction. UM206 could reduce infarct size, increase the numbers of capillaries, decrease myofibroblasts in infarct area of post-MI heart, and ultimately suppress the development of heart failure . ICG-001, which specifically inhibits the interaction between 尾-catenin and CBP in the Wnt canonical signaling pathway, can promote the differentiation of epicardial progenitors, thereby contributing to myocardial regeneration and improving cardiac function in a rat model of MI . Small molecules invaliding Porcupine have been further studied, such as WNT-974, GNF-6231 and CGX-1321. WNT-974 decreases fibrosis in post-MI heart, with a mechanism of preventing collagen production in cardiomyocytes by blocking secretion of Wnt-3, a pro-fibrotic agonist, from cardiac fibroblasts and its signaling to cardiomyocytes . The phosphorylation of DVL protein is decreased in both the canonical and non-canonical Wnt signaling pathways by WNT-974 administration . GNF-6231 prevents adverse cardiac remodeling in a mouse model of MI by inhibiting the proliferation of interstitial cells, increasing the proliferation of Sca1+ cardiac progenitors and reducing the apoptosis of cardiomyocytes [[**##**]]. Similarly, we demonstrate that CGX-1321, which has also been applied in a phase I clinical trial to treat solid tumors ({"type":"clinical-trial","attrs":{"text":"NCT02675946","term_id":"NCT02675946"}}NCT02675946), inhibits both canonical and non-canonical Wnt signaling pathways in post-MI heart. CGX-1321 promotes cardiac function by reducing fibrosis and stimulating cardiomyocyte proliferation-mediated cardiac regeneration in a Hippo/YAP-independent manner . These reports implicate that Wnt pathway inhibitors are a class of potential drugs for treating MI through complex mechanisms, including reducing cardiomyocyte death, increasing angiogenesis, suppressing fibrosis and stimulating cardiac regeneration.'
155 | token_words = tokenize(text)
156 | print(token_words)
157 | token_words = stem(token_words) # 单词原型
158 | token_words = delete_stopwords(token_words) # 去停
159 | token_words = delete_characters(token_words)
160 | token_words = to_lower(token_words)
161 | print(token_words)
162 |
--------------------------------------------------------------------------------
/tools/pandas_util.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding=utf-8
3 |
4 | # 基础模块
5 | import math
6 | import os
7 | import sys
8 | import time
9 | from datetime import datetime
10 | from tqdm import tqdm
11 |
12 | # 数据处理
13 | import numpy as np
14 | import pandas as pd
15 |
16 | def string_to_array(s):
17 | """Convert pipe separated string to array."""
18 |
19 | if isinstance(s, str):
20 | out = s.split("|")
21 | elif math.isnan(s):
22 | out = []
23 | else:
24 | raise ValueError("Value must be either string of nan")
25 | return out
26 |
27 |
28 | def explode(df_in, col_expls):
29 | """Explode column col_expl of array type into multiple rows."""
30 |
31 | df = df_in.copy()
32 | for col_expl in col_expls:
33 | df.loc[:, col_expl] = df[col_expl].apply(string_to_array)
34 |
35 | base_cols = list(set(df.columns) - set(col_expls))
36 | df_out = pd.DataFrame(
37 | {col: np.repeat(df[col].values,
38 | df[col_expls[0]].str.len())
39 | for col in base_cols}
40 | )
41 |
42 | for col_expl in col_expls:
43 | df_out.loc[:, col_expl] = np.concatenate(df[col_expl].values)
44 | df_out.loc[:, col_expl] = df_out[col_expl]
45 | return df_out
46 |
--------------------------------------------------------------------------------
/tools/pandas_util.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wsdm-Teamfunny/wsdm2020-solution/dae072da26ccf629d1a96185acedeaf4199b6ec4/tools/pandas_util.pyc
--------------------------------------------------------------------------------