├── .github
├── FUNDING.yml
└── workflows
│ ├── release-pypi.yml
│ └── release-win.yml
├── .gitignore
├── LICENSE
├── Makefile
├── README.md
├── epr.py
├── poetry.lock
├── poetry.toml
├── pyproject.toml
└── screenshot.png
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | custom: "https://paypal.me/wustho"
2 |
--------------------------------------------------------------------------------
/.github/workflows/release-pypi.yml:
--------------------------------------------------------------------------------
1 | name: Upload Tags to PyPI
2 |
3 | on:
4 | workflow_dispatch:
5 | push:
6 | tags:
7 | - v**
8 |
9 | jobs:
10 | deploy:
11 | runs-on: ubuntu-latest
12 | steps:
13 | - uses: actions/checkout@v2
14 | - uses: actions/setup-python@v2
15 | - name: Install dependencies
16 | run: |
17 | python -m pip install --upgrade pip
18 | pip install build twine
19 | - name: Build and publish
20 | env:
21 | TWINE_USERNAME: __token__
22 | TWINE_PASSWORD: ${{ secrets.PYPI_API_TOKEN }}
23 | run: |
24 | python -m build
25 | twine upload --skip-existing dist/*
26 |
27 |
--------------------------------------------------------------------------------
/.github/workflows/release-win.yml:
--------------------------------------------------------------------------------
1 | name: Build and Release Windows Binary
2 |
3 | on:
4 | workflow_dispatch:
5 | push:
6 | tags:
7 | - v**
8 |
9 | jobs:
10 | deploy:
11 | runs-on: windows-latest
12 | steps:
13 | - uses: actions/checkout@v2
14 | - uses: actions/setup-python@v2
15 | - name: Install dependencies
16 | run: |
17 | python -m pip install --upgrade pip
18 | pip install windows-curses pyinstaller
19 | - name: Build binary
20 | run: |
21 | pyinstaller --onefile --name epr-win epr.py
22 | - name: Release Windows Binary
23 | uses: softprops/action-gh-release@v1
24 | with:
25 | files: ./dist/epr-win.exe
26 | token: ${{ secrets.GITHUB_TOKEN }}
27 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | __pycache__/
2 | *.pyc
3 | epr_reader.egg-info/*
4 | .venv
5 | .idea
6 | build
7 | dist
8 | tmp/
9 | .coverage
10 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Benawi Adha
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | dev:
2 | poetry install
3 |
4 | release:
5 | python -m build
6 | twine upload --skip-existing dist/*
7 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # `$ epr`
2 |
3 | 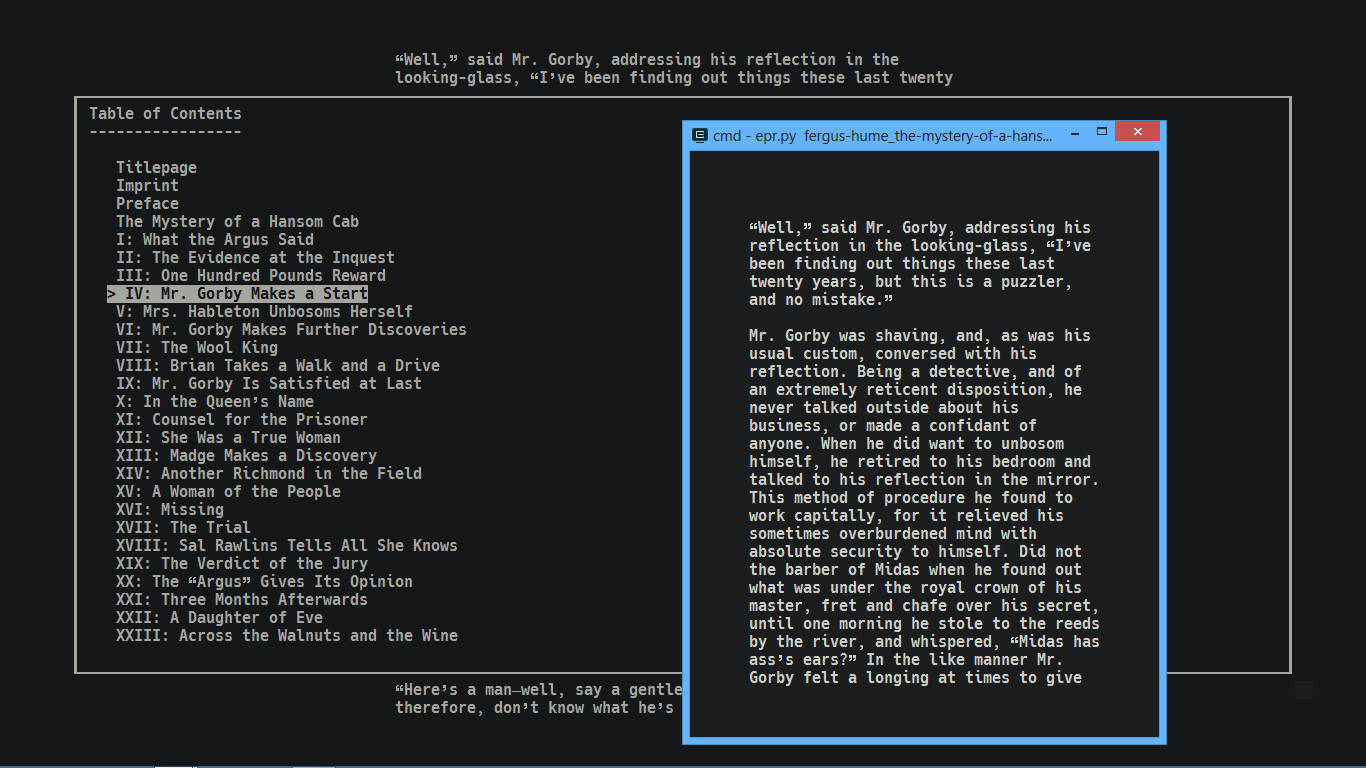
4 |
5 | Terminal/CLI Epub reader written in Python 3.6 with features:
6 |
7 | - Remembers last read file (just run `epr` without any argument)
8 | - Remembers last reading state for each file (per file saved state written to `$HOME/.config/epr/config` or `$HOME/.epr` respectively depending on availability)
9 | - Adjustable text area width
10 | - Adaptive to terminal resize
11 | - Supports EPUB3 (no audio support)
12 | - Secondary vim-like bindings
13 | - Supports opening images
14 | - Dark/Light colorscheme (depends on terminal color capability)
15 |
16 | ## Limitations
17 |
18 | - Minimum width: 22 cols
19 | - Supports regex search only
20 | - Supports only horizontal left-to-right text
21 | - Currently, only supports language with latin alphabet (see [issue30](https://github.com/wustho/epr/issues/30))
22 | - Doesn't support hyperlinks
23 | - Superscript and subscript displayed as `^{Superscript}` and `_{subscript}`.
24 | - Some known issues mentioned below
25 |
26 | ## Dependencies
27 |
28 | - Windows: `windows-curses`
29 |
30 | ## Installation
31 |
32 | - Via PyPI
33 |
34 | ```shell
35 | $ pip3 install epr-reader
36 | ```
37 |
38 | - Via Pip+Git
39 |
40 | ```shell
41 | $ pip3 install git+https://github.com/wustho/epr.git
42 | ```
43 |
44 | - Via [Homebrew](https://formulae.brew.sh/formula/epr) for macOS or Linux
45 |
46 | ```shell
47 | $ brew install epr
48 | ```
49 |
50 | - Via Chocolatey
51 |
52 | Maintained by [cybercatgurrl](https://github.com/cybercatgurrl/chocolatey-pkgs/tree/master/epr)
53 |
54 | ```shell
55 | $ choco install epr
56 | ```
57 |
58 | - Via AUR
59 |
60 | Maintained by [jneidel](https://aur.archlinux.org/packages/epr-git/)
61 |
62 | ```shell
63 | $ yay -S epr-git
64 | ```
65 |
66 | - Manually
67 |
68 | Clone this repo, tweak `epr.py` as much as you see fit, rename it to `epr`, make it executable and put it somewhere in `PATH`.
69 |
70 | ## Checkout [`epy`](https://github.com/wustho/epy)!
71 |
72 | It's just a fork of this `epr` with little more features:
73 |
74 | - Formats supported: epub, epub3, fb2, mobi, azw3, url.
75 | - Reading progress percentage
76 | - Bookmarks
77 | - External dictionary integration
78 | - Table of contents scheme like regular ebook reader
79 | - Inline formats: **bold** and _italic_ (depend on terminal and font capability. Italic only supported in python>=3.7)
80 | - Text-to-Speech (with additional setup)
81 | - Page flip animation
82 | - Seamless between chapter
83 |
84 | Install it with:
85 |
86 | ```shell
87 | $ pip3 install git+https://github.com/wustho/epy
88 | ```
89 |
90 | ## Quickly Read from History
91 |
92 | Rather than invoking `epr /path/to/file` each time you are going to read, you might find it easier to do just `epr STRINGS.`
93 |
94 | Example:
95 |
96 | ``` shell
97 | $ epr dumas count mont
98 | ```
99 |
100 | If `STRINGS` is not any file, `epr` will choose from reading history, best matched `path/to/file` with those `STRINGS.` So, the more `STRINGS` given the more accurate it will find.
101 |
102 | Run `epr -r` to show list of all reading history.
103 |
104 | ## Opening an Image
105 |
106 | Just hit `o` when `[IMG:n]` (_n_ is any number) comes up on a page. If there's only one of those, it will automatically open the image using viewer, but if there are more than one, cursor will appear to help you choose which image then press `RET` to open it and `q` to cancel.
107 |
108 | ## Colorscheme
109 |
110 | This is just a simple colorscheme involving foreground dan background color only, no syntax highlighting.
111 | You can cycle color between default terminal color, dark or light respectively by pressing `c`.
112 | You can also switch color to default, dark or light by pressing `0c`, `1c` or `2c` respectively.
113 |
114 | Customizing dark/light colorscheme needs to be done inside the source code by editing these lines:
115 |
116 | ```python
117 | # colorscheme
118 | # DARK/LIGHT = (fg, bg)
119 | # -1 is default terminal fg/bg
120 | DARK = (252, 235)
121 | LIGHT = (239, 223)
122 | ```
123 |
124 | To see available values assigned to colors, you can run this one-liner on bash:
125 |
126 | ```shell
127 | $ i=0; for j in {1..16}; do for k in {1..16}; do printf "\e[1;48;05;${i}m %03d \e[0m" $i; i=$((i+1)); done; echo; done
128 | ```
129 |
130 | ## Known Issues
131 |
132 | 1. Search function can't find occurrences that span across multiple lines
133 |
134 | Only capable of finding pattern that span inside a single line, not sentence.
135 | So works more effectively for finding word or letter rather than long phrase or sentence.
136 |
137 | As workarounds, You can increase text area width to increase its reach or dump
138 | the content of epub using `-d` option, which will dump each paragraph into a single line separated by empty line
139 | (or lines depending on the epub), to be later piped into `grep`, `rg` etc. Pretty useful to find book quotes.
140 |
141 | Example:
142 |
143 | ```shell
144 | # to get 1 paragraph before and after a paragraph containing "Overdue"
145 | $ epr -d the_girl_next_door.epub | grep Overdue -C 2
146 | ```
147 |
148 | 2. Some TOC issues (Checkout [`epy`](https://github.com/wustho/epy) if you're bothered with these issues):
149 |
150 | - "-" chapters in TOC
151 |
152 | This happens because not every chapter file (inside some epubs) is given navigation points.
153 | Some epubs even won't let you navigate between chapter, thus you'll find all chapters named as
154 | "-" using `epr` for these kind of epubs.
155 |
156 | - Skipped chapters in TOC
157 |
158 | Example:
159 |
160 | ```
161 | Table of Contents
162 | -----------------
163 |
164 | 1. Title Page
165 | 2. Chapter I
166 | 3. Chapter V
167 | ```
168 |
169 | This happens because Chapter II to Chapter IV is probably in the same file with Chapter I,
170 | but in different sections, e. g. `ch000.html#section1` and `ch000.html#section2.`
171 |
172 | But don't worry, you should not miss any part to read. This just won't let you navigate
173 | to some points using TOC.
174 |
175 | - Sometimes page flipping itself to new chapter when scrolling
176 |
177 | This might be disorienting. To avoid this issue, you can use [`epy`](https://github.com/wustho/epy) instead
178 | which fixed this issue by setting its config `SeamlessBetweenChapters`.
179 |
180 | ## Inspirations
181 |
182 | - https://github.com/aerkalov/ebooklib
183 | - https://github.com/rupa/epub
184 |
--------------------------------------------------------------------------------
/epr.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | """\
3 | Usages:
4 | epr read last epub
5 | epr EPUBFILE read EPUBFILE
6 | epr STRINGS read matched STRINGS from history
7 | epr NUMBER read file from history
8 | with associated NUMBER
9 |
10 | Options:
11 | -r print reading history
12 | -d dump epub
13 | -h, --help print short, long help
14 |
15 | Key Binding:
16 | Help : ?
17 | Quit : q
18 | Scroll down : DOWN j
19 | Scroll up : UP k
20 | Half screen up : C-u
21 | Half screen dn : C-d
22 | Page down : PGDN RIGHT SPC
23 | Page up : PGUP LEFT
24 | Next chapter : n
25 | Prev chapter : p
26 | Beginning of ch : HOME g
27 | End of ch : END G
28 | Open image : o
29 | Search : /
30 | Next Occurrence : n
31 | Prev Occurrence : N
32 | Toggle width : =
33 | Set width : [count]=
34 | Shrink : -
35 | Enlarge : +
36 | ToC : TAB t
37 | Metadata : m
38 | Mark pos to n : b[n]
39 | Jump to pos n : `[n]
40 | Switch colorsch : [default=0, dark=1, light=2]c
41 | """
42 |
43 |
44 | __version__ = "2.4.15"
45 | __license__ = "MIT"
46 | __author__ = "Benawi Adha"
47 | __email__ = "benawiadha@gmail.com"
48 | __url__ = "https://github.com/wustho/epr"
49 |
50 |
51 | import curses
52 | import zipfile
53 | import sys
54 | import re
55 | import os
56 | import textwrap
57 | import json
58 | import tempfile
59 | import shutil
60 | import subprocess
61 | import xml.etree.ElementTree as ET
62 | from urllib.parse import unquote
63 | from html import unescape
64 | from html.parser import HTMLParser
65 | from difflib import SequenceMatcher as SM
66 |
67 |
68 | # key bindings
69 | SCROLL_DOWN = {curses.KEY_DOWN}
70 | SCROLL_DOWN_J = {ord("j")}
71 | SCROLL_UP = {curses.KEY_UP}
72 | SCROLL_UP_K = {ord("k")}
73 | HALF_DOWN = {4}
74 | HALF_UP = {21}
75 | PAGE_DOWN = {curses.KEY_NPAGE, ord("l"), ord(" "), curses.KEY_RIGHT}
76 | PAGE_UP = {curses.KEY_PPAGE, ord("h"), curses.KEY_LEFT}
77 | CH_NEXT = {ord("n")}
78 | CH_PREV = {ord("p")}
79 | CH_HOME = {curses.KEY_HOME, ord("g")}
80 | CH_END = {curses.KEY_END, ord("G")}
81 | SHRINK = ord("-")
82 | WIDEN = ord("+")
83 | WIDTH = ord("=")
84 | META = {ord("m")}
85 | TOC = {9, ord("\t"), ord("t")}
86 | FOLLOW = {10}
87 | QUIT = {ord("q"), 3, 27, 304}
88 | HELP = {ord("?")}
89 | MARKPOS = ord("b")
90 | JUMPTOPOS = ord("`")
91 | COLORSWITCH = ord("c")
92 |
93 |
94 | # colorscheme
95 | # DARK/LIGHT = (fg, bg)
96 | # -1 is default terminal fg/bg
97 | DARK = (252, 235)
98 | LIGHT = (239, 223)
99 |
100 |
101 | # some global envs, better leave these alone
102 | STATEFILE = ""
103 | STATE = {}
104 | LINEPRSRV = 0 # default = 2
105 | COLORSUPPORT = False
106 | SEARCHPATTERN = None
107 | VWR = None
108 | JUMPLIST = {}
109 |
110 |
111 | class Epub:
112 | NS = {
113 | "DAISY": "http://www.daisy.org/z3986/2005/ncx/",
114 | "OPF": "http://www.idpf.org/2007/opf",
115 | "CONT": "urn:oasis:names:tc:opendocument:xmlns:container",
116 | "XHTML": "http://www.w3.org/1999/xhtml",
117 | "EPUB": "http://www.idpf.org/2007/ops"
118 | }
119 |
120 | def __init__(self, fileepub):
121 | self.path = os.path.abspath(fileepub)
122 | self.file = zipfile.ZipFile(fileepub, "r")
123 | cont = ET.parse(self.file.open("META-INF/container.xml"))
124 | self.rootfile = cont.find(
125 | "CONT:rootfiles/CONT:rootfile",
126 | self.NS
127 | ).attrib["full-path"]
128 | self.rootdir = os.path.dirname(self.rootfile)\
129 | + "/" if os.path.dirname(self.rootfile) != "" else ""
130 | cont = ET.parse(self.file.open(self.rootfile))
131 | # EPUB3
132 | self.version = cont.getroot().get("version")
133 | if self.version == "2.0":
134 | # self.toc = self.rootdir + cont.find("OPF:manifest/*[@id='ncx']", self.NS).get("href")
135 | self.toc = self.rootdir\
136 | + cont.find(
137 | "OPF:manifest/*[@media-type='application/x-dtbncx+xml']",
138 | self.NS
139 | ).get("href")
140 | elif self.version == "3.0":
141 | self.toc = self.rootdir\
142 | + cont.find(
143 | "OPF:manifest/*[@properties='nav']",
144 | self.NS
145 | ).get("href")
146 |
147 | self.contents = []
148 | self.toc_entries = []
149 |
150 | def get_meta(self):
151 | meta = []
152 | # why self.file.read(self.rootfile) problematic
153 | cont = ET.fromstring(self.file.open(self.rootfile).read())
154 | for i in cont.findall("OPF:metadata/*", self.NS):
155 | if i.text is not None:
156 | meta.append([re.sub("{.*?}", "", i.tag), i.text])
157 | return meta
158 |
159 | def initialize(self):
160 | cont = ET.parse(self.file.open(self.rootfile)).getroot()
161 | manifest = []
162 | for i in cont.findall("OPF:manifest/*", self.NS):
163 | # EPUB3
164 | # if i.get("id") != "ncx" and i.get("properties") != "nav":
165 | if i.get("media-type") != "application/x-dtbncx+xml"\
166 | and i.get("properties") != "nav":
167 | manifest.append([
168 | i.get("id"),
169 | i.get("href")
170 | ])
171 |
172 | spine, contents = [], []
173 | for i in cont.findall("OPF:spine/*", self.NS):
174 | spine.append(i.get("idref"))
175 | for i in spine:
176 | for j in manifest:
177 | if i == j[0]:
178 | self.contents.append(self.rootdir+unquote(j[1]))
179 | contents.append(unquote(j[1]))
180 | manifest.remove(j)
181 | # TODO: test is break necessary
182 | break
183 |
184 | toc = ET.parse(self.file.open(self.toc)).getroot()
185 | # EPUB3
186 | if self.version == "2.0":
187 | navPoints = toc.findall("DAISY:navMap//DAISY:navPoint", self.NS)
188 | elif self.version == "3.0":
189 | navPoints = toc.findall(
190 | "XHTML:body//XHTML:nav[@EPUB:type='toc']//XHTML:a",
191 | self.NS
192 | )
193 | for i in contents:
194 | name = "-"
195 | for j in navPoints:
196 | # EPUB3
197 | if self.version == "2.0":
198 | # if i == unquote(j.find("DAISY:content", self.NS).get("src")):
199 | if re.search(i, unquote(j.find("DAISY:content", self.NS).get("src"))) is not None:
200 | name = j.find("DAISY:navLabel/DAISY:text", self.NS).text
201 | break
202 | elif self.version == "3.0":
203 | # if i == unquote(j.get("href")):
204 | if re.search(i, unquote(j.get("href"))) is not None:
205 | name = "".join(list(j.itertext()))
206 | break
207 | self.toc_entries.append(name)
208 |
209 |
210 | class HTMLtoLines(HTMLParser):
211 | para = {"p", "div"}
212 | inde = {"q", "dt", "dd", "blockquote"}
213 | pref = {"pre"}
214 | bull = {"li"}
215 | hide = {"script", "style", "head"}
216 | # hide = {"script", "style", "head", ", "sub}
217 |
218 | def __init__(self):
219 | HTMLParser.__init__(self)
220 | self.text = [""]
221 | self.imgs = []
222 | self.ishead = False
223 | self.isinde = False
224 | self.isbull = False
225 | self.ispref = False
226 | self.ishidden = False
227 | self.idhead = set()
228 | self.idinde = set()
229 | self.idbull = set()
230 | self.idpref = set()
231 |
232 | def handle_starttag(self, tag, attrs):
233 | if re.match("h[1-6]", tag) is not None:
234 | self.ishead = True
235 | elif tag in self.inde:
236 | self.isinde = True
237 | elif tag in self.pref:
238 | self.ispref = True
239 | elif tag in self.bull:
240 | self.isbull = True
241 | elif tag in self.hide:
242 | self.ishidden = True
243 | elif tag == "sup":
244 | self.text[-1] += "^{"
245 | elif tag == "sub":
246 | self.text[-1] += "_{"
247 | # NOTE: "img" and "image"
248 | # In HTML, both are startendtag (no need endtag)
249 | # but in XHTML both need endtag
250 | elif tag in {"img", "image"}:
251 | for i in attrs:
252 | if (tag == "img" and i[0] == "src")\
253 | or (tag == "image" and i[0].endswith("href")):
254 | self.text.append("[IMG:{}]".format(len(self.imgs)))
255 | self.imgs.append(unquote(i[1]))
256 |
257 | def handle_startendtag(self, tag, attrs):
258 | if tag == "br":
259 | self.text += [""]
260 | elif tag in {"img", "image"}:
261 | for i in attrs:
262 | if (tag == "img" and i[0] == "src")\
263 | or (tag == "image" and i[0].endswith("href")):
264 | self.text.append("[IMG:{}]".format(len(self.imgs)))
265 | self.imgs.append(unquote(i[1]))
266 | self.text.append("")
267 |
268 | def handle_endtag(self, tag):
269 | if re.match("h[1-6]", tag) is not None:
270 | self.text.append("")
271 | self.text.append("")
272 | self.ishead = False
273 | elif tag in self.para:
274 | self.text.append("")
275 | elif tag in self.hide:
276 | self.ishidden = False
277 | elif tag in self.inde:
278 | if self.text[-1] != "":
279 | self.text.append("")
280 | self.isinde = False
281 | elif tag in self.pref:
282 | if self.text[-1] != "":
283 | self.text.append("")
284 | self.ispref = False
285 | elif tag in self.bull:
286 | if self.text[-1] != "":
287 | self.text.append("")
288 | self.isbull = False
289 | elif tag in {"sub", "sup"}:
290 | self.text[-1] += "}"
291 | elif tag in {"img", "image"}:
292 | self.text.append("")
293 |
294 | def handle_data(self, raw):
295 | if raw and not self.ishidden:
296 | if self.text[-1] == "":
297 | tmp = raw.lstrip()
298 | else:
299 | tmp = raw
300 | if self.ispref:
301 | line = unescape(tmp)
302 | else:
303 | line = unescape(re.sub(r"\s+", " ", tmp))
304 | self.text[-1] += line
305 | if self.ishead:
306 | self.idhead.add(len(self.text)-1)
307 | elif self.isbull:
308 | self.idbull.add(len(self.text)-1)
309 | elif self.isinde:
310 | self.idinde.add(len(self.text)-1)
311 | elif self.ispref:
312 | self.idpref.add(len(self.text)-1)
313 |
314 | def get_lines(self, width=0):
315 | text = []
316 | if width == 0:
317 | return self.text
318 | for n, i in enumerate(self.text):
319 | if n in self.idhead:
320 | text += [i.rjust(width//2 + len(i)//2)] + [""]
321 | elif n in self.idinde:
322 | text += [" "+j for j in textwrap.wrap(i, width - 3)] + [""]
323 | elif n in self.idbull:
324 | tmp = textwrap.wrap(i, width - 3)
325 | text += [" - "+j if j == tmp[0] else " "+j for j in tmp] + [""]
326 | elif n in self.idpref:
327 | tmp = i.splitlines()
328 | wraptmp = []
329 | for line in tmp:
330 | wraptmp += [j for j in textwrap.wrap(line, width - 6)]
331 | text += [" "+j for j in wraptmp] + [""]
332 | else:
333 | text += textwrap.wrap(i, width) + [""]
334 | return text, self.imgs
335 |
336 |
337 | def loadstate():
338 | global STATE, STATEFILE
339 | if os.getenv("HOME") is not None:
340 | STATEFILE = os.path.join(os.getenv("HOME"), ".epr")
341 | if os.path.isdir(os.path.join(os.getenv("HOME"), ".config")):
342 | configdir = os.path.join(os.getenv("HOME"), ".config", "epr")
343 | os.makedirs(configdir, exist_ok=True)
344 | if os.path.isfile(STATEFILE):
345 | if os.path.isfile(os.path.join(configdir, "config")):
346 | os.remove(os.path.join(configdir, "config"))
347 | shutil.move(STATEFILE, os.path.join(configdir, "config"))
348 | STATEFILE = os.path.join(configdir, "config")
349 | elif os.getenv("USERPROFILE") is not None:
350 | STATEFILE = os.path.join(os.getenv("USERPROFILE"), ".epr")
351 | else:
352 | STATEFILE = os.devnull
353 |
354 | if os.path.exists(STATEFILE):
355 | with open(STATEFILE, "r") as f:
356 | STATE = json.load(f)
357 |
358 |
359 | def savestate(file, index, width, pos, pctg ):
360 | for i in STATE:
361 | STATE[i]["lastread"] = str(0)
362 | STATE[file]["lastread"] = str(1)
363 | STATE[file]["index"] = str(index)
364 | STATE[file]["width"] = str(width)
365 | STATE[file]["pos"] = str(pos)
366 | STATE[file]["pctg"] = str(pctg)
367 | with open(STATEFILE, "w") as f:
368 | json.dump(STATE, f, indent=4)
369 |
370 |
371 | def pgup(pos, winhi, preservedline=0, c=1):
372 | if pos >= (winhi - preservedline) * c:
373 | return pos - (winhi - preservedline) * c
374 | else:
375 | return 0
376 |
377 |
378 | def pgdn(pos, tot, winhi, preservedline=0,c=1):
379 | if pos + (winhi * c) <= tot - winhi:
380 | return pos + (winhi * c)
381 | else:
382 | pos = tot - winhi
383 | if pos < 0:
384 | return 0
385 | return pos
386 |
387 |
388 | def pgend(tot, winhi):
389 | if tot - winhi >= 0:
390 | return tot - winhi
391 | else:
392 | return 0
393 |
394 |
395 | def toc(stdscr, src, index):
396 | rows, cols = stdscr.getmaxyx()
397 | hi, wi = rows - 4, cols - 4
398 | Y, X = 2, 2
399 | oldindex = index
400 | toc = curses.newwin(hi, wi, Y, X)
401 | if COLORSUPPORT:
402 | toc.bkgd(stdscr.getbkgd())
403 |
404 | toc.box()
405 | toc.keypad(True)
406 | toc.addstr(1,2, "Table of Contents")
407 | toc.addstr(2,2, "-----------------")
408 | key_toc = 0
409 |
410 | totlines = len(src)
411 | toc.refresh()
412 | pad = curses.newpad(totlines, wi - 2 )
413 | if COLORSUPPORT:
414 | pad.bkgd(stdscr.getbkgd())
415 |
416 | pad.keypad(True)
417 |
418 | padhi = rows - 5 - Y - 4 + 1
419 | y = 0
420 | if index in range(padhi//2, totlines - padhi//2):
421 | y = index - padhi//2 + 1
422 | d = len(str(totlines))
423 | span = []
424 |
425 | for n, i in enumerate(src):
426 | # strs = " " + str(n+1).rjust(d) + " " + i[0]
427 | strs = " " + i
428 | strs = strs[0:wi-3]
429 | pad.addstr(n, 0, strs)
430 | span.append(len(strs))
431 |
432 | countstring = ""
433 | while key_toc not in TOC|QUIT:
434 | if countstring == "":
435 | count = 1
436 | else:
437 | count = int(countstring)
438 | if key_toc in range(48, 58): # i.e., k is a numeral
439 | countstring = countstring + chr(key_toc)
440 | else:
441 | if key_toc in SCROLL_UP|SCROLL_UP_K or key_toc in PAGE_UP:
442 | index -= count
443 | if index < 0:
444 | index = 0
445 | elif key_toc in SCROLL_DOWN|SCROLL_DOWN_J or key_toc in PAGE_DOWN:
446 | index += count
447 | if index + 1 >= totlines:
448 | index = totlines - 1
449 | elif key_toc in FOLLOW:
450 | # if index == oldindex:
451 | # break
452 | return index
453 | # elif key_toc in PAGE_UP:
454 | # index -= 3
455 | # if index < 0:
456 | # index = 0
457 | # elif key_toc in PAGE_DOWN:
458 | # index += 3
459 | # if index >= totlines:
460 | # index = totlines - 1
461 | elif key_toc in CH_HOME:
462 | index = 0
463 | elif key_toc in CH_END:
464 | index = totlines - 1
465 | elif key_toc in {curses.KEY_RESIZE}|HELP|META:
466 | return key_toc
467 | countstring = ""
468 |
469 | while index not in range(y, y+padhi):
470 | if index < y:
471 | y -= 1
472 | else:
473 | y += 1
474 |
475 | for n in range(totlines):
476 | att = curses.A_REVERSE if index == n else curses.A_NORMAL
477 | pre = ">>" if index == n else " "
478 | pad.addstr(n, 0, pre)
479 | pad.chgat(n, 0, span[n], pad.getbkgd() | att)
480 |
481 | pad.refresh(y, 0, Y+4,X+4, rows - 5, cols - 6)
482 | key_toc = toc.getch()
483 |
484 | toc.clear()
485 | toc.refresh()
486 | return
487 |
488 |
489 | def meta(stdscr, ebook):
490 | rows, cols = stdscr.getmaxyx()
491 | hi, wi = rows - 4, cols - 4
492 | Y, X = 2, 2
493 | meta = curses.newwin(hi, wi, Y, X)
494 | if COLORSUPPORT:
495 | meta.bkgd(stdscr.getbkgd())
496 |
497 | meta.box()
498 | meta.keypad(True)
499 | meta.addstr(1,2, "Metadata")
500 | meta.addstr(2,2, "--------")
501 | key_meta = 0
502 |
503 | mdata = []
504 | for i in ebook.get_meta():
505 | data = re.sub("<[^>]*>", "", i[1])
506 | data = re.sub("\t", "", data)
507 | mdata += textwrap.wrap(i[0].upper() + ": " + data, wi - 6)
508 | src_lines = mdata
509 | totlines = len(src_lines)
510 |
511 | pad = curses.newpad(totlines, wi - 2 )
512 | if COLORSUPPORT:
513 | pad.bkgd(stdscr.getbkgd())
514 |
515 | pad.keypad(True)
516 | for n, i in enumerate(src_lines):
517 | pad.addstr(n, 0, i)
518 | y = 0
519 | meta.refresh()
520 | pad.refresh(y,0, Y+4,X+4, rows - 5, cols - 6)
521 |
522 | padhi = rows - 5 - Y - 4 + 1
523 |
524 | while key_meta not in META|QUIT:
525 | if key_meta in SCROLL_UP|SCROLL_UP_K and y > 0:
526 | y -= 1
527 | elif key_meta in SCROLL_DOWN|SCROLL_DOWN_J and y < totlines - hi + 6:
528 | y += 1
529 | elif key_meta in PAGE_UP:
530 | y = pgup(y, padhi)
531 | elif key_meta in PAGE_DOWN:
532 | y = pgdn(y, totlines, padhi)
533 | elif key_meta in CH_HOME:
534 | y = 0
535 | elif key_meta in CH_END:
536 | y = pgend(totlines, padhi)
537 | elif key_meta in {curses.KEY_RESIZE}|HELP|TOC:
538 | return key_meta
539 | pad.refresh(y,0, 6,5, rows - 5, cols - 5)
540 | key_meta = meta.getch()
541 |
542 | meta.clear()
543 | meta.refresh()
544 | return
545 |
546 |
547 | def help(stdscr):
548 | rows, cols = stdscr.getmaxyx()
549 | hi, wi = rows - 4, cols - 4
550 | Y, X = 2, 2
551 | help = curses.newwin(hi, wi, Y, X)
552 | if COLORSUPPORT:
553 | help.bkgd(stdscr.getbkgd())
554 |
555 | help.box()
556 | help.keypad(True)
557 | help.addstr(1,2, "Help")
558 | help.addstr(2,2, "----")
559 | key_help = 0
560 |
561 | src = re.search("Key Bind(\n|.)*", __doc__).group()
562 | src_lines = src.splitlines()
563 | totlines = len(src_lines)
564 |
565 | pad = curses.newpad(totlines, wi - 2 )
566 | if COLORSUPPORT:
567 | pad.bkgd(stdscr.getbkgd())
568 |
569 | pad.keypad(True)
570 | for n, i in enumerate(src_lines):
571 | pad.addstr(n, 0, i)
572 | y = 0
573 | help.refresh()
574 | pad.refresh(y,0, Y+4,X+4, rows - 5, cols - 6)
575 |
576 | padhi = rows - 5 - Y - 4 + 1
577 |
578 | while key_help not in HELP|QUIT:
579 | if key_help in SCROLL_UP|SCROLL_UP_K and y > 0:
580 | y -= 1
581 | elif key_help in SCROLL_DOWN|SCROLL_DOWN_J and y < totlines - hi + 6:
582 | y += 1
583 | elif key_help in PAGE_UP:
584 | y = pgup(y, padhi)
585 | elif key_help in PAGE_DOWN:
586 | y = pgdn(y, totlines, padhi)
587 | elif key_help in CH_HOME:
588 | y = 0
589 | elif key_help in CH_END:
590 | y = pgend(totlines, padhi)
591 | elif key_help in {curses.KEY_RESIZE}|META|TOC:
592 | return key_help
593 | pad.refresh(y,0, 6,5, rows - 5, cols - 5)
594 | key_help = help.getch()
595 |
596 | help.clear()
597 | help.refresh()
598 | return
599 |
600 |
601 | def dots_path(curr, tofi):
602 | candir = curr.split("/")
603 | tofi = tofi.split("/")
604 | alld = tofi.count("..")
605 | t = len(candir)
606 | candir = candir[0:t-alld-1]
607 | try:
608 | while True:
609 | tofi.remove("..")
610 | except ValueError:
611 | pass
612 | return "/".join(candir+tofi)
613 |
614 |
615 | def find_media_viewer():
616 | global VWR
617 | VWR_LIST = [
618 | "feh",
619 | "gio",
620 | "sxiv",
621 | "gnome-open",
622 | "gvfs-open",
623 | "xdg-open",
624 | "kde-open",
625 | "firefox"
626 | ]
627 | if sys.platform == "win32":
628 | VWR = ["start"]
629 | elif sys.platform == "darwin":
630 | VWR = ["open"]
631 | else:
632 | for i in VWR_LIST:
633 | if shutil.which(i) is not None:
634 | VWR = [i]
635 | break
636 |
637 | if VWR[0] in {"gio"}:
638 | VWR.append("open")
639 |
640 |
641 | def open_media(scr, epub, src):
642 | sfx = os.path.splitext(src)[1]
643 | fd, path = tempfile.mkstemp(suffix=sfx)
644 | try:
645 | with os.fdopen(fd, "wb") as tmp:
646 | tmp.write(epub.file.read(src))
647 | # run(VWR +" "+ path, shell=True)
648 | subprocess.call(
649 | VWR + [path],
650 | # shell=True,
651 | stdout=subprocess.DEVNULL,
652 | stderr=subprocess.DEVNULL
653 | )
654 | k = scr.getch()
655 | finally:
656 | os.remove(path)
657 | return k
658 |
659 |
660 | def searching(stdscr, pad, src, width, y, ch, tot):
661 | global SEARCHPATTERN
662 | rows, cols = stdscr.getmaxyx()
663 | x = (cols - width) // 2
664 |
665 | if SEARCHPATTERN is None:
666 | stat = curses.newwin(1, cols, rows-1, 0)
667 | if COLORSUPPORT:
668 | stat.bkgd(stdscr.getbkgd())
669 | stat.keypad(True)
670 | curses.echo(1)
671 | curses.curs_set(1)
672 | SEARCHPATTERN = ""
673 | stat.addstr(0, 0, " Regex:", curses.A_REVERSE)
674 | stat.addstr(0, 7, SEARCHPATTERN)
675 | stat.refresh()
676 | while True:
677 | ipt = stat.get_wch()
678 | if type(ipt) == str:
679 | ipt = ord(ipt)
680 |
681 | if ipt == 27:
682 | stat.clear()
683 | stat.refresh()
684 | curses.echo(0)
685 | curses.curs_set(0)
686 | SEARCHPATTERN = None
687 | return None, y
688 | elif ipt == 10:
689 | SEARCHPATTERN = "/"+SEARCHPATTERN
690 | stat.clear()
691 | stat.refresh()
692 | curses.echo(0)
693 | curses.curs_set(0)
694 | break
695 | # TODO: why different behaviour unix dos or win lin
696 | elif ipt in {8, 127, curses.KEY_BACKSPACE}:
697 | SEARCHPATTERN = SEARCHPATTERN[:-1]
698 | elif ipt == curses.KEY_RESIZE:
699 | stat.clear()
700 | stat.refresh()
701 | curses.echo(0)
702 | curses.curs_set(0)
703 | SEARCHPATTERN = None
704 | return curses.KEY_RESIZE, None
705 | else:
706 | SEARCHPATTERN += chr(ipt)
707 |
708 | stat.clear()
709 | stat.addstr(0, 0, " Regex:", curses.A_REVERSE)
710 | # stat.addstr(0, 7, SEARCHPATTERN)
711 | stat.addstr(
712 | 0, 7,
713 | SEARCHPATTERN if 7+len(SEARCHPATTERN) < cols else "..."+SEARCHPATTERN[7-cols+4:]
714 | )
715 | stat.refresh()
716 |
717 | if SEARCHPATTERN in {"?", "/"}:
718 | SEARCHPATTERN = None
719 | return None, y
720 |
721 | found = []
722 | try:
723 | pattern = re.compile(SEARCHPATTERN[1:], re.IGNORECASE)
724 | except re.error:
725 | stdscr.addstr(rows-1, 0, "Invalid Regex!", curses.A_REVERSE)
726 | SEARCHPATTERN = None
727 | s = stdscr.getch()
728 | if s in QUIT:
729 | return None, y
730 | else:
731 | return s, None
732 |
733 | for n, i in enumerate(src):
734 | for j in pattern.finditer(i):
735 | found.append([n, j.span()[0], j.span()[1] - j.span()[0]])
736 |
737 | if found == []:
738 | if SEARCHPATTERN[0] == "/" and ch + 1 < tot:
739 | return None, 1
740 | elif SEARCHPATTERN[0] == "?" and ch > 0:
741 | return None, -1
742 | else:
743 | s = 0
744 | while True:
745 | if s in QUIT:
746 | SEARCHPATTERN = None
747 | stdscr.clear()
748 | stdscr.refresh()
749 | return None, y
750 | elif s == ord("n") and ch == 0:
751 | SEARCHPATTERN = "/"+SEARCHPATTERN[1:]
752 | return None, 1
753 | elif s == ord("N") and ch +1 == tot:
754 | SEARCHPATTERN = "?"+SEARCHPATTERN[1:]
755 | return None, -1
756 |
757 | stdscr.clear()
758 | stdscr.addstr(rows-1, 0, " Finished searching: " + SEARCHPATTERN[1:cols-22] + " ", curses.A_REVERSE)
759 | stdscr.refresh()
760 | pad.refresh(y,0, 0,x, rows-2,x+width)
761 | s = pad.getch()
762 |
763 | sidx = len(found) - 1
764 | if SEARCHPATTERN[0] == "/":
765 | if y > found[-1][0]:
766 | return None, 1
767 | for n, i in enumerate(found):
768 | if i[0] >= y:
769 | sidx = n
770 | break
771 |
772 | s = 0
773 | msg = " Searching: " + SEARCHPATTERN[1:] + " --- Res {}/{} Ch {}/{} ".format(
774 | sidx + 1,
775 | len(found),
776 | ch+1, tot)
777 | while True:
778 | if s in QUIT:
779 | SEARCHPATTERN = None
780 | for i in found:
781 | pad.chgat(i[0], i[1], i[2], pad.getbkgd())
782 | stdscr.clear()
783 | stdscr.refresh()
784 | return None, y
785 | elif s == ord("n"):
786 | SEARCHPATTERN = "/"+SEARCHPATTERN[1:]
787 | if sidx == len(found) - 1:
788 | if ch + 1 < tot:
789 | return None, 1
790 | else:
791 | s = 0
792 | msg = " Finished searching: " + SEARCHPATTERN[1:] + " "
793 | continue
794 | else:
795 | sidx += 1
796 | msg = " Searching: " + SEARCHPATTERN[1:] + " --- Res {}/{} Ch {}/{} ".format(
797 | sidx + 1,
798 | len(found),
799 | ch+1, tot)
800 | elif s == ord("N"):
801 | SEARCHPATTERN = "?"+SEARCHPATTERN[1:]
802 | if sidx == 0:
803 | if ch > 0:
804 | return None, -1
805 | else:
806 | s = 0
807 | msg = " Finished searching: " + SEARCHPATTERN[1:] + " "
808 | continue
809 | else:
810 | sidx -= 1
811 | msg = " Searching: " + SEARCHPATTERN[1:] + " --- Res {}/{} Ch {}/{} ".format(
812 | sidx + 1,
813 | len(found),
814 | ch+1, tot)
815 | elif s == curses.KEY_RESIZE:
816 | return s, None
817 |
818 | while found[sidx][0] not in list(range(y, y+rows-1)):
819 | if found[sidx][0] > y:
820 | y += rows - 1
821 | else:
822 | y -= rows - 1
823 | if y < 0:
824 | y = 0
825 |
826 | for n, i in enumerate(found):
827 | # attr = (pad.getbkgd() | curses.A_REVERSE) if n == sidx else pad.getbkgd()
828 | attr = curses.A_REVERSE if n == sidx else curses.A_NORMAL
829 | pad.chgat(i[0], i[1], i[2], pad.getbkgd() | attr)
830 |
831 | stdscr.clear()
832 | stdscr.addstr(rows-1, 0, msg, curses.A_REVERSE)
833 | stdscr.refresh()
834 | pad.refresh(y,0, 0,x, rows-2,x+width)
835 | s = pad.getch()
836 |
837 |
838 | def reader(stdscr, ebook, index, width, y, pctg):
839 | k = 0 if SEARCHPATTERN is None else ord("/")
840 | rows, cols = stdscr.getmaxyx()
841 | x = (cols - width) // 2
842 |
843 | contents = ebook.contents
844 | toc_src = ebook.toc_entries
845 | chpath = contents[index]
846 | content = ebook.file.open(chpath).read()
847 | content = content.decode("utf-8")
848 |
849 | parser = HTMLtoLines()
850 | try:
851 | parser.feed(content)
852 | parser.close()
853 | except:
854 | pass
855 |
856 | src_lines, imgs = parser.get_lines(width)
857 | totlines = len(src_lines)
858 |
859 | if y < 0 and totlines <= rows:
860 | y = 0
861 | elif pctg is not None:
862 | y = round(pctg*totlines)
863 | else:
864 | y = y % totlines
865 |
866 | pad = curses.newpad(totlines, width + 2) # + 2 unnecessary
867 |
868 | if COLORSUPPORT:
869 | pad.bkgd(stdscr.getbkgd())
870 |
871 | pad.keypad(True)
872 | for n, i in enumerate(src_lines):
873 | if re.search("\[IMG:[0-9]+\]", i):
874 | pad.addstr(n, width//2 - len(i)//2, i, curses.A_REVERSE)
875 | else:
876 | pad.addstr(n, 0, i)
877 | if index == 0:
878 | suff = " End --> "
879 | elif index == len(contents) - 1:
880 | suff = " <-- End "
881 | else:
882 | suff = " <-- End --> "
883 | # try except to be more flexible on terminal resize
884 | try:
885 | pad.addstr(n, width//2 - 7, suff, curses.A_REVERSE)
886 | except curses.error:
887 | pass
888 |
889 | stdscr.clear()
890 | stdscr.refresh()
891 | # try except to be more flexible on terminal resize
892 | try:
893 | pad.refresh(y,0, 0,x, rows-1,x+width)
894 | except curses.error:
895 | pass
896 |
897 | countstring = ""
898 | svline = "dontsave"
899 | while True:
900 | if countstring == "":
901 | count = 1
902 | else:
903 | count = int(countstring)
904 | if k in range(48, 58): # i.e., k is a numeral
905 | countstring = countstring + chr(k)
906 | else:
907 | if k in QUIT:
908 | if k == 27 and countstring != "":
909 | countstring = ""
910 | else:
911 | savestate(ebook.path, index, width, y, y/totlines)
912 | sys.exit()
913 | elif k in SCROLL_UP:
914 | if count > 1:
915 | svline = y - 1
916 | if y >= count:
917 | y -= count
918 | elif y == 0 and index != 0:
919 | return -1, width, -rows, None
920 | else:
921 | y = 0
922 | elif k in SCROLL_UP_K:
923 | if count > 1:
924 | svline = y - 1
925 | if y >= count:
926 | y -= count
927 | elif k in PAGE_UP:
928 | if y == 0 and index != 0:
929 | return -1, width, -rows, None
930 | else:
931 | y = pgup(y, rows, LINEPRSRV, count)
932 | elif k in SCROLL_DOWN:
933 | if count > 1:
934 | svline = y + rows - 1
935 | if y + count <= totlines - rows:
936 | y += count
937 | elif y == totlines - rows and index != len(contents)-1:
938 | return 1, width, 0, None
939 | else:
940 | y = totlines - rows
941 | elif k in SCROLL_DOWN_J:
942 | if count > 1:
943 | svline = y + rows - 1
944 | if y + count <= totlines - rows:
945 | y += count
946 | elif k in PAGE_DOWN:
947 | if totlines - y - LINEPRSRV > rows:
948 | # y = pgdn(y, totlines, rows, LINEPRSRV, count)
949 | y += rows - LINEPRSRV
950 | elif index != len(contents)-1:
951 | return 1, width, 0, None
952 | elif k in HALF_UP:
953 | countstring = str(rows//2)
954 | k = list(SCROLL_UP)[0]
955 | continue
956 | elif k in HALF_DOWN:
957 | countstring = str(rows//2)
958 | k = list(SCROLL_DOWN)[0]
959 | continue
960 | elif k in CH_NEXT:
961 | if index + count < len(contents) - 1:
962 | return count, width, 0, None
963 | if index + count >= len(contents) - 1:
964 | return len(contents) - index - 1, width, 0, None
965 | elif k in CH_PREV:
966 | if index - count > 0:
967 | return -count, width, 0, None
968 | elif index - count <= 0:
969 | return -index, width, 0, None
970 | elif k in CH_HOME:
971 | y = 0
972 | elif k in CH_END:
973 | y = pgend(totlines, rows)
974 | elif k in TOC:
975 | fllwd = toc(stdscr, toc_src, index)
976 | if fllwd is not None:
977 | if fllwd in {curses.KEY_RESIZE}|HELP|META:
978 | k = fllwd
979 | continue
980 | return fllwd - index, width, 0, None
981 | elif k in META:
982 | k = meta(stdscr, ebook)
983 | if k in {curses.KEY_RESIZE}|HELP|TOC:
984 | continue
985 | elif k in HELP:
986 | k = help(stdscr)
987 | if k in {curses.KEY_RESIZE}|META|TOC:
988 | continue
989 | elif k == WIDEN and (width + count) < cols - 4:
990 | width += count
991 | return 0, width, 0, y/totlines
992 | elif k == SHRINK:
993 | width -= count
994 | if width < 20:
995 | width = 20
996 | return 0, width, 0, y/totlines
997 | elif k == WIDTH:
998 | if countstring == "":
999 | # if called without a count, toggle between 80 cols and full width
1000 | if width != 80 and cols - 4 >= 80:
1001 | return 0, 80, 0, y/totlines
1002 | else:
1003 | return 0, cols - 4, 0, y/totlines
1004 | else:
1005 | width = count
1006 | if width < 20:
1007 | width = 20
1008 | elif width >= cols - 4:
1009 | width = cols - 4
1010 | return 0, width, 0, y/totlines
1011 | # elif k == ord("0"):
1012 | # if width != 80 and cols - 2 >= 80:
1013 | # return 0, 80, 0, y/totlines
1014 | # else:
1015 | # return 0, cols - 2, 0, y/totlines
1016 | elif k == ord("/"):
1017 | ks, idxs = searching(stdscr, pad, src_lines, width, y, index, len(contents))
1018 | if ks in {curses.KEY_RESIZE, ord("/")}:
1019 | k = ks
1020 | continue
1021 | elif SEARCHPATTERN is not None:
1022 | return idxs, width, 0, None
1023 | elif idxs is not None:
1024 | y = idxs
1025 | elif k == ord("o") and VWR is not None:
1026 | gambar, idx = [], []
1027 | for n, i in enumerate(src_lines[y:y+rows]):
1028 | img = re.search("(?<=\[IMG:)[0-9]+(?=\])", i)
1029 | if img is not None:
1030 | gambar.append(img.group())
1031 | idx.append(n)
1032 |
1033 | impath = ""
1034 | if len(gambar) == 1:
1035 | impath = imgs[int(gambar[0])]
1036 | elif len(gambar) > 1:
1037 | p, i = 0, 0
1038 | while p not in QUIT and p not in FOLLOW:
1039 | stdscr.move(idx[i], x + width//2 + len(gambar[i]) + 1)
1040 | stdscr.refresh()
1041 | curses.curs_set(1)
1042 | p = pad.getch()
1043 | if p in SCROLL_DOWN:
1044 | i += 1
1045 | elif p in SCROLL_UP:
1046 | i -= 1
1047 | i = i % len(gambar)
1048 |
1049 | curses.curs_set(0)
1050 | if p in FOLLOW:
1051 | impath = imgs[int(gambar[i])]
1052 |
1053 | if impath != "":
1054 | imgsrc = dots_path(chpath, impath)
1055 | k = open_media(pad, ebook, imgsrc)
1056 | continue
1057 | elif k == MARKPOS:
1058 | jumnum = pad.getch()
1059 | if jumnum in range(49, 58):
1060 | JUMPLIST[chr(jumnum)] = [index, width, y, y/totlines]
1061 | else:
1062 | k = jumnum
1063 | continue
1064 | elif k == JUMPTOPOS:
1065 | jumnum = pad.getch()
1066 | if jumnum in range(49, 58) and chr(jumnum) in JUMPLIST.keys():
1067 | tojumpidxdiff = JUMPLIST[chr(jumnum)][0]-index
1068 | tojumpy = JUMPLIST[chr(jumnum)][2]
1069 | tojumpctg = None if JUMPLIST[chr(jumnum)][1] == width else JUMPLIST[chr(jumnum)][3]
1070 | return tojumpidxdiff, width, tojumpy, tojumpctg
1071 | else:
1072 | k = jumnum
1073 | continue
1074 | elif k == COLORSWITCH and COLORSUPPORT and countstring in {"", "0", "1", "2"}:
1075 | if countstring == "":
1076 | count_color = curses.pair_number(stdscr.getbkgd())
1077 | if count_color not in {2, 3}: count_color = 1
1078 | count_color = count_color % 3
1079 | else:
1080 | count_color = count
1081 | stdscr.bkgd(curses.color_pair(count_color+1))
1082 | return 0, width, y, None
1083 | elif k == curses.KEY_RESIZE:
1084 | savestate(ebook.path, index, width, y, y/totlines)
1085 | # stated in pypi windows-curses page:
1086 | # to call resize_term right after KEY_RESIZE
1087 | if sys.platform == "win32":
1088 | curses.resize_term(rows, cols)
1089 | rows, cols = stdscr.getmaxyx()
1090 | else:
1091 | rows, cols = stdscr.getmaxyx()
1092 | curses.resize_term(rows, cols)
1093 | if cols < 22 or rows < 12:
1094 | sys.exit("ERR: Screen was too small (min 22cols x 12rows).")
1095 | if cols <= width + 4:
1096 | return 0, cols - 4, 0, y/totlines
1097 | else:
1098 | return 0, width, y, None
1099 | countstring = ""
1100 |
1101 | if svline != "dontsave":
1102 | pad.chgat(svline, 0, width, curses.A_UNDERLINE)
1103 | try:
1104 | stdscr.clear()
1105 | stdscr.addstr(0, 0, countstring)
1106 | stdscr.refresh()
1107 | if totlines - y < rows:
1108 | pad.refresh(y,0, 0,x, totlines-y,x+width)
1109 | else:
1110 | pad.refresh(y,0, 0,x, rows-1,x+width)
1111 | except curses.error:
1112 | pass
1113 | k = pad.getch()
1114 |
1115 | if svline != "dontsave":
1116 | pad.chgat(svline, 0, width, curses.A_NORMAL)
1117 | svline = "dontsave"
1118 |
1119 |
1120 | def preread(stdscr, file):
1121 | global COLORSUPPORT
1122 |
1123 | curses.use_default_colors()
1124 | try:
1125 | curses.init_pair(1, -1, -1)
1126 | curses.init_pair(2, DARK[0], DARK[1])
1127 | curses.init_pair(3, LIGHT[0], LIGHT[1])
1128 | COLORSUPPORT = True
1129 | except:
1130 | COLORSUPPORT = False
1131 |
1132 | stdscr.keypad(True)
1133 | curses.curs_set(0)
1134 | stdscr.clear()
1135 | rows, cols = stdscr.getmaxyx()
1136 | stdscr.addstr(rows-1,0, "Loading...")
1137 | stdscr.refresh()
1138 |
1139 | epub = Epub(file)
1140 |
1141 | if epub.path in STATE:
1142 | idx = int(STATE[epub.path]["index"])
1143 | width = int(STATE[epub.path]["width"])
1144 | y = int(STATE[epub.path]["pos"])
1145 | pctg = None
1146 | else:
1147 | STATE[epub.path] = {}
1148 | idx = 0
1149 | y = 0
1150 | width = 80
1151 | pctg = None
1152 |
1153 | if cols <= width + 4:
1154 | width = cols - 4
1155 | if "pctg" in STATE[epub.path]:
1156 | pctg = float(STATE[epub.path]["pctg"])
1157 |
1158 | epub.initialize()
1159 | find_media_viewer()
1160 |
1161 | while True:
1162 | incr, width, y, pctg = reader(stdscr, epub, idx, width, y, pctg)
1163 | idx += incr
1164 |
1165 |
1166 | def main():
1167 | termc, termr = shutil.get_terminal_size()
1168 |
1169 | args = []
1170 | if sys.argv[1:] != []:
1171 | args += sys.argv[1:]
1172 |
1173 | if len({"-h", "--help"} & set(args)) != 0:
1174 | hlp = __doc__.rstrip()
1175 | if "-h" in args:
1176 | hlp = re.search("(\n|.)*(?=\n\nKey)", hlp).group()
1177 | print(hlp)
1178 | sys.exit()
1179 |
1180 | if len({"-v", "--version", "-V"} & set(args)) != 0:
1181 | print(__version__)
1182 | print(__license__, "License")
1183 | print("Copyright (c) 2019", __author__)
1184 | print(__url__)
1185 | sys.exit()
1186 |
1187 | if len({"-d"} & set(args)) != 0:
1188 | args.remove("-d")
1189 | dump = True
1190 | else:
1191 | dump = False
1192 |
1193 | loadstate()
1194 |
1195 | if args == []:
1196 | file, todel = False, []
1197 | for i in STATE:
1198 | if not os.path.exists(i):
1199 | todel.append(i)
1200 | elif STATE[i]["lastread"] == str(1):
1201 | file = i
1202 |
1203 | for i in todel:
1204 | del STATE[i]
1205 |
1206 | if not file:
1207 | print(__doc__)
1208 | sys.exit("ERROR: Found no last read file.")
1209 |
1210 | elif os.path.isfile(args[0]):
1211 | file = args[0]
1212 |
1213 | else:
1214 | val = cand = 0
1215 | todel = []
1216 | for i in STATE.keys():
1217 | if not os.path.exists(i):
1218 | todel.append(i)
1219 | else:
1220 | match_val = sum([j.size for j in SM(None, i.lower(), " ".join(args).lower()).get_matching_blocks()])
1221 | if match_val >= val:
1222 | val = match_val
1223 | cand = i
1224 | for i in todel:
1225 | del STATE[i]
1226 | with open(STATEFILE, "w") as f:
1227 | json.dump(STATE, f, indent=4)
1228 | if len(args) == 1 and re.match(r"[0-9]+", args[0]) is not None:
1229 | try:
1230 | cand = list(STATE.keys())[int(args[0])-1]
1231 | val = 1
1232 | except IndexError:
1233 | val = 0
1234 | if val != 0 and len({"-r"} & set(args)) == 0:
1235 | file = cand
1236 | else:
1237 | print("Reading history:")
1238 | dig = len(str(len(STATE.keys())+1))
1239 | for n, i in enumerate(STATE.keys()):
1240 | print(str(n+1).rjust(dig) + ("* " if STATE[i]["lastread"] == "1" else " ") + i)
1241 | if len({"-r"} & set(args)) != 0:
1242 | sys.exit()
1243 | else:
1244 | print()
1245 | sys.exit("ERROR: Found no matching history.")
1246 |
1247 | if dump:
1248 | epub = Epub(file)
1249 | epub.initialize()
1250 | for i in epub.contents:
1251 | content = epub.file.open(i).read()
1252 | content = content.decode("utf-8")
1253 | parser = HTMLtoLines()
1254 | try:
1255 | parser.feed(content)
1256 | parser.close()
1257 | except:
1258 | pass
1259 | src_lines = parser.get_lines()
1260 | # sys.stdout.reconfigure(encoding="utf-8") # Python>=3.7
1261 | for j in src_lines:
1262 | sys.stdout.buffer.write((j+"\n\n").encode("utf-8"))
1263 | sys.exit()
1264 |
1265 | else:
1266 | if termc < 22 or termr < 12:
1267 | sys.exit("ERR: Screen was too small (min 22cols x 12rows).")
1268 | curses.wrapper(preread, file)
1269 |
1270 |
1271 | if __name__ == "__main__":
1272 | main()
1273 |
--------------------------------------------------------------------------------
/poetry.lock:
--------------------------------------------------------------------------------
1 | [[package]]
2 | name = "bleach"
3 | version = "5.0.1"
4 | description = "An easy safelist-based HTML-sanitizing tool."
5 | category = "dev"
6 | optional = false
7 | python-versions = ">=3.7"
8 |
9 | [package.dependencies]
10 | six = ">=1.9.0"
11 | webencodings = "*"
12 |
13 | [package.extras]
14 | css = ["tinycss2 (>=1.1.0,<1.2)"]
15 | dev = ["build (==0.8.0)", "flake8 (==4.0.1)", "hashin (==0.17.0)", "pip-tools (==6.6.2)", "pytest (==7.1.2)", "Sphinx (==4.3.2)", "tox (==3.25.0)", "twine (==4.0.1)", "wheel (==0.37.1)", "black (==22.3.0)", "mypy (==0.961)"]
16 |
17 | [[package]]
18 | name = "build"
19 | version = "0.8.0"
20 | description = "A simple, correct PEP 517 build frontend"
21 | category = "dev"
22 | optional = false
23 | python-versions = ">=3.6"
24 |
25 | [package.dependencies]
26 | colorama = {version = "*", markers = "os_name == \"nt\""}
27 | importlib-metadata = {version = ">=0.22", markers = "python_version < \"3.8\""}
28 | packaging = ">=19.0"
29 | pep517 = ">=0.9.1"
30 | tomli = {version = ">=1.0.0", markers = "python_version < \"3.11\""}
31 |
32 | [package.extras]
33 | virtualenv = ["virtualenv (>=20.0.35)"]
34 | typing = ["typing-extensions (>=3.7.4.3)", "mypy (==0.950)", "importlib-metadata (>=4.6.4)"]
35 | test = ["setuptools (>=56.0.0)", "setuptools (>=42.0.0)", "wheel (>=0.36.0)", "toml (>=0.10.0)", "pytest-xdist (>=1.34)", "pytest-rerunfailures (>=9.1)", "pytest-mock (>=2)", "pytest-cov (>=2.12)", "pytest (>=6.2.4)", "filelock (>=3)"]
36 | docs = ["sphinx-autodoc-typehints (>=1.10)", "sphinx-argparse-cli (>=1.5)", "sphinx (>=4.0,<5.0)", "furo (>=2021.08.31)"]
37 |
38 | [[package]]
39 | name = "certifi"
40 | version = "2022.9.24"
41 | description = "Python package for providing Mozilla's CA Bundle."
42 | category = "dev"
43 | optional = false
44 | python-versions = ">=3.6"
45 |
46 | [[package]]
47 | name = "cffi"
48 | version = "1.15.1"
49 | description = "Foreign Function Interface for Python calling C code."
50 | category = "dev"
51 | optional = false
52 | python-versions = "*"
53 |
54 | [package.dependencies]
55 | pycparser = "*"
56 |
57 | [[package]]
58 | name = "charset-normalizer"
59 | version = "2.1.1"
60 | description = "The Real First Universal Charset Detector. Open, modern and actively maintained alternative to Chardet."
61 | category = "dev"
62 | optional = false
63 | python-versions = ">=3.6.0"
64 |
65 | [package.extras]
66 | unicode_backport = ["unicodedata2"]
67 |
68 | [[package]]
69 | name = "colorama"
70 | version = "0.4.5"
71 | description = "Cross-platform colored terminal text."
72 | category = "dev"
73 | optional = false
74 | python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*"
75 |
76 | [[package]]
77 | name = "commonmark"
78 | version = "0.9.1"
79 | description = "Python parser for the CommonMark Markdown spec"
80 | category = "dev"
81 | optional = false
82 | python-versions = "*"
83 |
84 | [package.extras]
85 | test = ["flake8 (==3.7.8)", "hypothesis (==3.55.3)"]
86 |
87 | [[package]]
88 | name = "cryptography"
89 | version = "38.0.1"
90 | description = "cryptography is a package which provides cryptographic recipes and primitives to Python developers."
91 | category = "dev"
92 | optional = false
93 | python-versions = ">=3.6"
94 |
95 | [package.dependencies]
96 | cffi = ">=1.12"
97 |
98 | [package.extras]
99 | docs = ["sphinx (>=1.6.5,!=1.8.0,!=3.1.0,!=3.1.1)", "sphinx-rtd-theme"]
100 | docstest = ["pyenchant (>=1.6.11)", "twine (>=1.12.0)", "sphinxcontrib-spelling (>=4.0.1)"]
101 | pep8test = ["black", "flake8", "flake8-import-order", "pep8-naming"]
102 | sdist = ["setuptools-rust (>=0.11.4)"]
103 | ssh = ["bcrypt (>=3.1.5)"]
104 | test = ["pytest (>=6.2.0)", "pytest-benchmark", "pytest-cov", "pytest-subtests", "pytest-xdist", "pretend", "iso8601", "pytz", "hypothesis (>=1.11.4,!=3.79.2)"]
105 |
106 | [[package]]
107 | name = "debugpy"
108 | version = "1.6.3"
109 | description = "An implementation of the Debug Adapter Protocol for Python"
110 | category = "dev"
111 | optional = false
112 | python-versions = ">=3.7"
113 |
114 | [[package]]
115 | name = "docutils"
116 | version = "0.19"
117 | description = "Docutils -- Python Documentation Utilities"
118 | category = "dev"
119 | optional = false
120 | python-versions = ">=3.7"
121 |
122 | [[package]]
123 | name = "greenlet"
124 | version = "0.4.17"
125 | description = "Lightweight in-process concurrent programming"
126 | category = "dev"
127 | optional = false
128 | python-versions = "*"
129 |
130 | [[package]]
131 | name = "idna"
132 | version = "3.4"
133 | description = "Internationalized Domain Names in Applications (IDNA)"
134 | category = "dev"
135 | optional = false
136 | python-versions = ">=3.5"
137 |
138 | [[package]]
139 | name = "importlib-metadata"
140 | version = "4.12.0"
141 | description = "Read metadata from Python packages"
142 | category = "dev"
143 | optional = false
144 | python-versions = ">=3.7"
145 |
146 | [package.dependencies]
147 | typing-extensions = {version = ">=3.6.4", markers = "python_version < \"3.8\""}
148 | zipp = ">=0.5"
149 |
150 | [package.extras]
151 | docs = ["sphinx", "jaraco.packaging (>=9)", "rst.linker (>=1.9)"]
152 | perf = ["ipython"]
153 | testing = ["pytest (>=6)", "pytest-checkdocs (>=2.4)", "pytest-flake8", "pytest-cov", "pytest-enabler (>=1.3)", "packaging", "pyfakefs", "flufl.flake8", "pytest-perf (>=0.9.2)", "pytest-black (>=0.3.7)", "pytest-mypy (>=0.9.1)", "importlib-resources (>=1.3)"]
154 |
155 | [[package]]
156 | name = "jaraco.classes"
157 | version = "3.2.3"
158 | description = "Utility functions for Python class constructs"
159 | category = "dev"
160 | optional = false
161 | python-versions = ">=3.7"
162 |
163 | [package.dependencies]
164 | more-itertools = "*"
165 |
166 | [package.extras]
167 | docs = ["sphinx (>=3.5)", "jaraco.packaging (>=9)", "rst.linker (>=1.9)", "jaraco.tidelift (>=1.4)"]
168 | testing = ["pytest (>=6)", "pytest-checkdocs (>=2.4)", "pytest-flake8", "flake8 (<5)", "pytest-cov", "pytest-enabler (>=1.3)", "pytest-black (>=0.3.7)", "pytest-mypy (>=0.9.1)"]
169 |
170 | [[package]]
171 | name = "jeepney"
172 | version = "0.8.0"
173 | description = "Low-level, pure Python DBus protocol wrapper."
174 | category = "dev"
175 | optional = false
176 | python-versions = ">=3.7"
177 |
178 | [package.extras]
179 | trio = ["async-generator", "trio"]
180 | test = ["async-timeout", "trio", "testpath", "pytest-asyncio (>=0.17)", "pytest-trio", "pytest"]
181 |
182 | [[package]]
183 | name = "keyring"
184 | version = "23.9.3"
185 | description = "Store and access your passwords safely."
186 | category = "dev"
187 | optional = false
188 | python-versions = ">=3.7"
189 |
190 | [package.dependencies]
191 | importlib-metadata = {version = ">=3.6", markers = "python_version < \"3.10\""}
192 | "jaraco.classes" = "*"
193 | jeepney = {version = ">=0.4.2", markers = "sys_platform == \"linux\""}
194 | pywin32-ctypes = {version = "<0.1.0 || >0.1.0,<0.1.1 || >0.1.1", markers = "sys_platform == \"win32\""}
195 | SecretStorage = {version = ">=3.2", markers = "sys_platform == \"linux\""}
196 |
197 | [package.extras]
198 | docs = ["sphinx", "jaraco.packaging (>=9)", "rst.linker (>=1.9)", "jaraco.tidelift (>=1.4)"]
199 | testing = ["pytest (>=6)", "pytest-checkdocs (>=2.4)", "pytest-flake8", "flake8 (<5)", "pytest-cov", "pytest-enabler (>=1.3)", "pytest-black (>=0.3.7)", "pytest-mypy (>=0.9.1)"]
200 |
201 | [[package]]
202 | name = "more-itertools"
203 | version = "8.14.0"
204 | description = "More routines for operating on iterables, beyond itertools"
205 | category = "dev"
206 | optional = false
207 | python-versions = ">=3.5"
208 |
209 | [[package]]
210 | name = "msgpack"
211 | version = "1.0.3"
212 | description = "MessagePack (de)serializer."
213 | category = "dev"
214 | optional = false
215 | python-versions = "*"
216 |
217 | [[package]]
218 | name = "packaging"
219 | version = "21.3"
220 | description = "Core utilities for Python packages"
221 | category = "dev"
222 | optional = false
223 | python-versions = ">=3.6"
224 |
225 | [package.dependencies]
226 | pyparsing = ">=2.0.2,<3.0.5 || >3.0.5"
227 |
228 | [[package]]
229 | name = "pep517"
230 | version = "0.13.0"
231 | description = "Wrappers to build Python packages using PEP 517 hooks"
232 | category = "dev"
233 | optional = false
234 | python-versions = ">=3.6"
235 |
236 | [package.dependencies]
237 | importlib_metadata = {version = "*", markers = "python_version < \"3.8\""}
238 | tomli = {version = ">=1.1.0", markers = "python_version < \"3.11\""}
239 | zipp = {version = "*", markers = "python_version < \"3.8\""}
240 |
241 | [[package]]
242 | name = "pkginfo"
243 | version = "1.8.3"
244 | description = "Query metadatdata from sdists / bdists / installed packages."
245 | category = "dev"
246 | optional = false
247 | python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*"
248 |
249 | [package.extras]
250 | testing = ["nose", "coverage"]
251 |
252 | [[package]]
253 | name = "pycparser"
254 | version = "2.21"
255 | description = "C parser in Python"
256 | category = "dev"
257 | optional = false
258 | python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*"
259 |
260 | [[package]]
261 | name = "pygments"
262 | version = "2.13.0"
263 | description = "Pygments is a syntax highlighting package written in Python."
264 | category = "dev"
265 | optional = false
266 | python-versions = ">=3.6"
267 |
268 | [package.extras]
269 | plugins = ["importlib-metadata"]
270 |
271 | [[package]]
272 | name = "pynvim"
273 | version = "0.4.3"
274 | description = "Python client to neovim"
275 | category = "dev"
276 | optional = false
277 | python-versions = "*"
278 |
279 | [package.dependencies]
280 | greenlet = "*"
281 | msgpack = ">=0.5.0"
282 |
283 | [package.extras]
284 | pyuv = ["pyuv (>=1.0.0)"]
285 | test = ["pytest (>=3.4.0)"]
286 |
287 | [[package]]
288 | name = "pyparsing"
289 | version = "3.0.9"
290 | description = "pyparsing module - Classes and methods to define and execute parsing grammars"
291 | category = "dev"
292 | optional = false
293 | python-versions = ">=3.6.8"
294 |
295 | [package.extras]
296 | diagrams = ["railroad-diagrams", "jinja2"]
297 |
298 | [[package]]
299 | name = "pywin32-ctypes"
300 | version = "0.2.0"
301 | description = ""
302 | category = "dev"
303 | optional = false
304 | python-versions = "*"
305 |
306 | [[package]]
307 | name = "readme-renderer"
308 | version = "37.2"
309 | description = "readme_renderer is a library for rendering \"readme\" descriptions for Warehouse"
310 | category = "dev"
311 | optional = false
312 | python-versions = ">=3.7"
313 |
314 | [package.dependencies]
315 | bleach = ">=2.1.0"
316 | docutils = ">=0.13.1"
317 | Pygments = ">=2.5.1"
318 |
319 | [package.extras]
320 | md = ["cmarkgfm (>=0.8.0)"]
321 |
322 | [[package]]
323 | name = "requests"
324 | version = "2.28.1"
325 | description = "Python HTTP for Humans."
326 | category = "dev"
327 | optional = false
328 | python-versions = ">=3.7, <4"
329 |
330 | [package.dependencies]
331 | certifi = ">=2017.4.17"
332 | charset-normalizer = ">=2,<3"
333 | idna = ">=2.5,<4"
334 | urllib3 = ">=1.21.1,<1.27"
335 |
336 | [package.extras]
337 | socks = ["PySocks (>=1.5.6,!=1.5.7)"]
338 | use_chardet_on_py3 = ["chardet (>=3.0.2,<6)"]
339 |
340 | [[package]]
341 | name = "requests-toolbelt"
342 | version = "0.9.1"
343 | description = "A utility belt for advanced users of python-requests"
344 | category = "dev"
345 | optional = false
346 | python-versions = "*"
347 |
348 | [package.dependencies]
349 | requests = ">=2.0.1,<3.0.0"
350 |
351 | [[package]]
352 | name = "rfc3986"
353 | version = "2.0.0"
354 | description = "Validating URI References per RFC 3986"
355 | category = "dev"
356 | optional = false
357 | python-versions = ">=3.7"
358 |
359 | [package.extras]
360 | idna2008 = ["idna"]
361 |
362 | [[package]]
363 | name = "rich"
364 | version = "12.5.1"
365 | description = "Render rich text, tables, progress bars, syntax highlighting, markdown and more to the terminal"
366 | category = "dev"
367 | optional = false
368 | python-versions = ">=3.6.3,<4.0.0"
369 |
370 | [package.dependencies]
371 | commonmark = ">=0.9.0,<0.10.0"
372 | pygments = ">=2.6.0,<3.0.0"
373 | typing-extensions = {version = ">=4.0.0,<5.0", markers = "python_version < \"3.9\""}
374 |
375 | [package.extras]
376 | jupyter = ["ipywidgets (>=7.5.1,<8.0.0)"]
377 |
378 | [[package]]
379 | name = "secretstorage"
380 | version = "3.3.3"
381 | description = "Python bindings to FreeDesktop.org Secret Service API"
382 | category = "dev"
383 | optional = false
384 | python-versions = ">=3.6"
385 |
386 | [package.dependencies]
387 | cryptography = ">=2.0"
388 | jeepney = ">=0.6"
389 |
390 | [[package]]
391 | name = "six"
392 | version = "1.16.0"
393 | description = "Python 2 and 3 compatibility utilities"
394 | category = "dev"
395 | optional = false
396 | python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*"
397 |
398 | [[package]]
399 | name = "tomli"
400 | version = "2.0.1"
401 | description = "A lil' TOML parser"
402 | category = "dev"
403 | optional = false
404 | python-versions = ">=3.7"
405 |
406 | [[package]]
407 | name = "twine"
408 | version = "4.0.1"
409 | description = "Collection of utilities for publishing packages on PyPI"
410 | category = "dev"
411 | optional = false
412 | python-versions = ">=3.7"
413 |
414 | [package.dependencies]
415 | importlib-metadata = ">=3.6"
416 | keyring = ">=15.1"
417 | pkginfo = ">=1.8.1"
418 | readme-renderer = ">=35.0"
419 | requests = ">=2.20"
420 | requests-toolbelt = ">=0.8.0,<0.9.0 || >0.9.0"
421 | rfc3986 = ">=1.4.0"
422 | rich = ">=12.0.0"
423 | urllib3 = ">=1.26.0"
424 |
425 | [[package]]
426 | name = "typing-extensions"
427 | version = "4.3.0"
428 | description = "Backported and Experimental Type Hints for Python 3.7+"
429 | category = "dev"
430 | optional = false
431 | python-versions = ">=3.7"
432 |
433 | [[package]]
434 | name = "urllib3"
435 | version = "1.26.12"
436 | description = "HTTP library with thread-safe connection pooling, file post, and more."
437 | category = "dev"
438 | optional = false
439 | python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*, <4"
440 |
441 | [package.extras]
442 | brotli = ["brotlicffi (>=0.8.0)", "brotli (>=1.0.9)", "brotlipy (>=0.6.0)"]
443 | secure = ["pyOpenSSL (>=0.14)", "cryptography (>=1.3.4)", "idna (>=2.0.0)", "certifi", "urllib3-secure-extra", "ipaddress"]
444 | socks = ["PySocks (>=1.5.6,!=1.5.7,<2.0)"]
445 |
446 | [[package]]
447 | name = "webencodings"
448 | version = "0.5.1"
449 | description = "Character encoding aliases for legacy web content"
450 | category = "dev"
451 | optional = false
452 | python-versions = "*"
453 |
454 | [[package]]
455 | name = "windows-curses"
456 | version = "2.3.0"
457 | description = "Support for the standard curses module on Windows"
458 | category = "main"
459 | optional = false
460 | python-versions = "*"
461 |
462 | [[package]]
463 | name = "zipp"
464 | version = "3.8.1"
465 | description = "Backport of pathlib-compatible object wrapper for zip files"
466 | category = "dev"
467 | optional = false
468 | python-versions = ">=3.7"
469 |
470 | [package.extras]
471 | docs = ["sphinx", "jaraco.packaging (>=9)", "rst.linker (>=1.9)", "jaraco.tidelift (>=1.4)"]
472 | testing = ["pytest (>=6)", "pytest-checkdocs (>=2.4)", "pytest-flake8", "pytest-cov", "pytest-enabler (>=1.3)", "jaraco.itertools", "func-timeout", "pytest-black (>=0.3.7)", "pytest-mypy (>=0.9.1)"]
473 |
474 | [metadata]
475 | lock-version = "1.1"
476 | python-versions = "^3.7"
477 | content-hash = "3651553b63ddfc756cb97fa046008e837e23e023dfeecc6de7b67d8d1cdf1f50"
478 |
479 | [metadata.files]
480 | bleach = []
481 | build = []
482 | certifi = []
483 | cffi = []
484 | charset-normalizer = []
485 | colorama = []
486 | commonmark = [
487 | {file = "commonmark-0.9.1-py2.py3-none-any.whl", hash = "sha256:da2f38c92590f83de410ba1a3cbceafbc74fee9def35f9251ba9a971d6d66fd9"},
488 | {file = "commonmark-0.9.1.tar.gz", hash = "sha256:452f9dc859be7f06631ddcb328b6919c67984aca654e5fefb3914d54691aed60"},
489 | ]
490 | cryptography = []
491 | debugpy = []
492 | docutils = []
493 | greenlet = []
494 | idna = []
495 | importlib-metadata = []
496 | "jaraco.classes" = []
497 | jeepney = []
498 | keyring = []
499 | more-itertools = []
500 | msgpack = [
501 | {file = "msgpack-1.0.3-cp310-cp310-macosx_10_9_universal2.whl", hash = "sha256:96acc674bb9c9be63fa8b6dabc3248fdc575c4adc005c440ad02f87ca7edd079"},
502 | {file = "msgpack-1.0.3-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:2c3ca57c96c8e69c1a0d2926a6acf2d9a522b41dc4253a8945c4c6cd4981a4e3"},
503 | {file = "msgpack-1.0.3-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:b0a792c091bac433dfe0a70ac17fc2087d4595ab835b47b89defc8bbabcf5c73"},
504 | {file = "msgpack-1.0.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:1c58cdec1cb5fcea8c2f1771d7b5fec79307d056874f746690bd2bdd609ab147"},
505 | {file = "msgpack-1.0.3-cp310-cp310-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:2f97c0f35b3b096a330bb4a1a9247d0bd7e1f3a2eba7ab69795501504b1c2c39"},
506 | {file = "msgpack-1.0.3-cp310-cp310-win32.whl", hash = "sha256:36a64a10b16c2ab31dcd5f32d9787ed41fe68ab23dd66957ca2826c7f10d0b85"},
507 | {file = "msgpack-1.0.3-cp310-cp310-win_amd64.whl", hash = "sha256:c1ba333b4024c17c7591f0f372e2daa3c31db495a9b2af3cf664aef3c14354f7"},
508 | {file = "msgpack-1.0.3-cp36-cp36m-macosx_10_9_x86_64.whl", hash = "sha256:c2140cf7a3ec475ef0938edb6eb363fa704159e0bf71dde15d953bacc1cf9d7d"},
509 | {file = "msgpack-1.0.3-cp36-cp36m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:6f4c22717c74d44bcd7af353024ce71c6b55346dad5e2cc1ddc17ce8c4507c6b"},
510 | {file = "msgpack-1.0.3-cp36-cp36m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47d733a15ade190540c703de209ffbc42a3367600421b62ac0c09fde594da6ec"},
511 | {file = "msgpack-1.0.3-cp36-cp36m-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:c7e03b06f2982aa98d4ddd082a210c3db200471da523f9ac197f2828e80e7770"},
512 | {file = "msgpack-1.0.3-cp36-cp36m-win32.whl", hash = "sha256:3d875631ecab42f65f9dce6f55ce6d736696ced240f2634633188de2f5f21af9"},
513 | {file = "msgpack-1.0.3-cp36-cp36m-win_amd64.whl", hash = "sha256:40fb89b4625d12d6027a19f4df18a4de5c64f6f3314325049f219683e07e678a"},
514 | {file = "msgpack-1.0.3-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:6eef0cf8db3857b2b556213d97dd82de76e28a6524853a9beb3264983391dc1a"},
515 | {file = "msgpack-1.0.3-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:0d8c332f53ffff01953ad25131272506500b14750c1d0ce8614b17d098252fbc"},
516 | {file = "msgpack-1.0.3-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9c0903bd93cbd34653dd63bbfcb99d7539c372795201f39d16fdfde4418de43a"},
517 | {file = "msgpack-1.0.3-cp37-cp37m-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:bf1e6bfed4860d72106f4e0a1ab519546982b45689937b40257cfd820650b920"},
518 | {file = "msgpack-1.0.3-cp37-cp37m-win32.whl", hash = "sha256:d02cea2252abc3756b2ac31f781f7a98e89ff9759b2e7450a1c7a0d13302ff50"},
519 | {file = "msgpack-1.0.3-cp37-cp37m-win_amd64.whl", hash = "sha256:2f30dd0dc4dfe6231ad253b6f9f7128ac3202ae49edd3f10d311adc358772dba"},
520 | {file = "msgpack-1.0.3-cp38-cp38-macosx_10_9_universal2.whl", hash = "sha256:f201d34dc89342fabb2a10ed7c9a9aaaed9b7af0f16a5923f1ae562b31258dea"},
521 | {file = "msgpack-1.0.3-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:bb87f23ae7d14b7b3c21009c4b1705ec107cb21ee71975992f6aca571fb4a42a"},
522 | {file = "msgpack-1.0.3-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:8a3a5c4b16e9d0edb823fe54b59b5660cc8d4782d7bf2c214cb4b91a1940a8ef"},
523 | {file = "msgpack-1.0.3-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:f74da1e5fcf20ade12c6bf1baa17a2dc3604958922de8dc83cbe3eff22e8b611"},
524 | {file = "msgpack-1.0.3-cp38-cp38-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:73a80bd6eb6bcb338c1ec0da273f87420829c266379c8c82fa14c23fb586cfa1"},
525 | {file = "msgpack-1.0.3-cp38-cp38-win32.whl", hash = "sha256:9fce00156e79af37bb6db4e7587b30d11e7ac6a02cb5bac387f023808cd7d7f4"},
526 | {file = "msgpack-1.0.3-cp38-cp38-win_amd64.whl", hash = "sha256:9b6f2d714c506e79cbead331de9aae6837c8dd36190d02da74cb409b36162e8a"},
527 | {file = "msgpack-1.0.3-cp39-cp39-macosx_10_9_universal2.whl", hash = "sha256:89908aea5f46ee1474cc37fbc146677f8529ac99201bc2faf4ef8edc023c2bf3"},
528 | {file = "msgpack-1.0.3-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:973ad69fd7e31159eae8f580f3f707b718b61141838321c6fa4d891c4a2cca52"},
529 | {file = "msgpack-1.0.3-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:da24375ab4c50e5b7486c115a3198d207954fe10aaa5708f7b65105df09109b2"},
530 | {file = "msgpack-1.0.3-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:a598d0685e4ae07a0672b59792d2cc767d09d7a7f39fd9bd37ff84e060b1a996"},
531 | {file = "msgpack-1.0.3-cp39-cp39-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:e4c309a68cb5d6bbd0c50d5c71a25ae81f268c2dc675c6f4ea8ab2feec2ac4e2"},
532 | {file = "msgpack-1.0.3-cp39-cp39-win32.whl", hash = "sha256:494471d65b25a8751d19c83f1a482fd411d7ca7a3b9e17d25980a74075ba0e88"},
533 | {file = "msgpack-1.0.3-cp39-cp39-win_amd64.whl", hash = "sha256:f01b26c2290cbd74316990ba84a14ac3d599af9cebefc543d241a66e785cf17d"},
534 | {file = "msgpack-1.0.3.tar.gz", hash = "sha256:51fdc7fb93615286428ee7758cecc2f374d5ff363bdd884c7ea622a7a327a81e"},
535 | ]
536 | packaging = [
537 | {file = "packaging-21.3-py3-none-any.whl", hash = "sha256:ef103e05f519cdc783ae24ea4e2e0f508a9c99b2d4969652eed6a2e1ea5bd522"},
538 | {file = "packaging-21.3.tar.gz", hash = "sha256:dd47c42927d89ab911e606518907cc2d3a1f38bbd026385970643f9c5b8ecfeb"},
539 | ]
540 | pep517 = []
541 | pkginfo = []
542 | pycparser = [
543 | {file = "pycparser-2.21-py2.py3-none-any.whl", hash = "sha256:8ee45429555515e1f6b185e78100aea234072576aa43ab53aefcae078162fca9"},
544 | {file = "pycparser-2.21.tar.gz", hash = "sha256:e644fdec12f7872f86c58ff790da456218b10f863970249516d60a5eaca77206"},
545 | ]
546 | pygments = []
547 | pynvim = [
548 | {file = "pynvim-0.4.3.tar.gz", hash = "sha256:3a795378bde5e8092fbeb3a1a99be9c613d2685542f1db0e5c6fd467eed56dff"},
549 | ]
550 | pyparsing = []
551 | pywin32-ctypes = [
552 | {file = "pywin32-ctypes-0.2.0.tar.gz", hash = "sha256:24ffc3b341d457d48e8922352130cf2644024a4ff09762a2261fd34c36ee5942"},
553 | {file = "pywin32_ctypes-0.2.0-py2.py3-none-any.whl", hash = "sha256:9dc2d991b3479cc2df15930958b674a48a227d5361d413827a4cfd0b5876fc98"},
554 | ]
555 | readme-renderer = []
556 | requests = []
557 | requests-toolbelt = [
558 | {file = "requests-toolbelt-0.9.1.tar.gz", hash = "sha256:968089d4584ad4ad7c171454f0a5c6dac23971e9472521ea3b6d49d610aa6fc0"},
559 | {file = "requests_toolbelt-0.9.1-py2.py3-none-any.whl", hash = "sha256:380606e1d10dc85c3bd47bf5a6095f815ec007be7a8b69c878507068df059e6f"},
560 | ]
561 | rfc3986 = []
562 | rich = []
563 | secretstorage = []
564 | six = [
565 | {file = "six-1.16.0-py2.py3-none-any.whl", hash = "sha256:8abb2f1d86890a2dfb989f9a77cfcfd3e47c2a354b01111771326f8aa26e0254"},
566 | {file = "six-1.16.0.tar.gz", hash = "sha256:1e61c37477a1626458e36f7b1d82aa5c9b094fa4802892072e49de9c60c4c926"},
567 | ]
568 | tomli = [
569 | {file = "tomli-2.0.1-py3-none-any.whl", hash = "sha256:939de3e7a6161af0c887ef91b7d41a53e7c5a1ca976325f429cb46ea9bc30ecc"},
570 | {file = "tomli-2.0.1.tar.gz", hash = "sha256:de526c12914f0c550d15924c62d72abc48d6fe7364aa87328337a31007fe8a4f"},
571 | ]
572 | twine = []
573 | typing-extensions = []
574 | urllib3 = []
575 | webencodings = [
576 | {file = "webencodings-0.5.1-py2.py3-none-any.whl", hash = "sha256:a0af1213f3c2226497a97e2b3aa01a7e4bee4f403f95be16fc9acd2947514a78"},
577 | {file = "webencodings-0.5.1.tar.gz", hash = "sha256:b36a1c245f2d304965eb4e0a82848379241dc04b865afcc4aab16748587e1923"},
578 | ]
579 | windows-curses = [
580 | {file = "windows_curses-2.3.0-cp310-cp310-win32.whl", hash = "sha256:a3a63a0597729e10f923724c2cf972a23ea677b400d2387dee1d668cf7116177"},
581 | {file = "windows_curses-2.3.0-cp310-cp310-win_amd64.whl", hash = "sha256:7a35eda4cb120b9e1a5ae795f3bc06c55b92c9d391baba6be1903285a05f3551"},
582 | {file = "windows_curses-2.3.0-cp36-cp36m-win32.whl", hash = "sha256:4d5fb991d1b90a41c2332f02241a1f84c8a1e6bc8f6e0d26f532d0da7a9f7b51"},
583 | {file = "windows_curses-2.3.0-cp36-cp36m-win_amd64.whl", hash = "sha256:170c0d941c2e0cdf864e7f0441c1bdf0709232bf4aa7ce7f54d90fc76a4c0504"},
584 | {file = "windows_curses-2.3.0-cp37-cp37m-win32.whl", hash = "sha256:d5cde8ec6d582aa77af791eca54f60858339fb3f391945f9cad11b1ab71062e3"},
585 | {file = "windows_curses-2.3.0-cp37-cp37m-win_amd64.whl", hash = "sha256:e913dc121446d92b33fe4f5bcca26d3a34e4ad19f2af160370d57c3d1e93b4e1"},
586 | {file = "windows_curses-2.3.0-cp38-cp38-win32.whl", hash = "sha256:fbc2131cec57e422c6660e6cdb3420aff5be5169b8e45bb7c471f884b0590a2b"},
587 | {file = "windows_curses-2.3.0-cp38-cp38-win_amd64.whl", hash = "sha256:cc5fa913780d60f4a40824d374a4f8ca45b4e205546e83a2d85147315a57457e"},
588 | {file = "windows_curses-2.3.0-cp39-cp39-win32.whl", hash = "sha256:935be95cfdb9213f6f5d3d5bcd489960e3a8fbc9b574e7b2e8a3a3cc46efff49"},
589 | {file = "windows_curses-2.3.0-cp39-cp39-win_amd64.whl", hash = "sha256:c860f596d28377e47f322b7382be4d3573fd76d1292234996bb7f72e0bc0ed0d"},
590 | ]
591 | zipp = []
592 |
--------------------------------------------------------------------------------
/poetry.toml:
--------------------------------------------------------------------------------
1 | [virtualenvs]
2 | in-project = true
3 | create = true
4 | path = ".venv"
5 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "epr-reader"
3 | version = "2.4.15"
4 | description = "CLI Ebook Reader"
5 | readme = "README.md"
6 | authors = ["Benawi Adha "]
7 | license = "MIT"
8 | packages = [
9 | { include = "epr.py" },
10 | ]
11 | keywords = ["EPUB", "EPUB3", "CLI", "TUI", "Terminal", "Reader"]
12 |
13 | [tool.poetry.scripts]
14 | epr = "epr:main"
15 |
16 | [tool.poetry.dependencies]
17 | python = "^3.7"
18 | windows-curses = { version = "*", markers = "platform_system == 'Windows'" }
19 |
20 | [tool.poetry.dev-dependencies]
21 | build = "^0.8.0"
22 | twine = "^4.0.1"
23 | debugpy = "^1.6.3"
24 | pynvim = "^0.4.3"
25 |
26 | [tool.mypy]
27 | strict_optional = true
28 |
29 | [build-system]
30 | requires = ["poetry-core>=1.0.0"]
31 | build-backend = "poetry.core.masonry.api"
32 |
--------------------------------------------------------------------------------
/screenshot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wustho/epr/723c77d34d7f149a2c1bcadd99d288d26f66531d/screenshot.png
--------------------------------------------------------------------------------