93 | - 网易吴彦祖 👍(9) 💬(1)
KNN 核心原理你可以理解为“近朱者赤近墨者黑”,老师解释的很形象啊!我目前不打算深入了解具体算法原理,就是想大致了解一下,以后和模型工程师可以聊聊。您这个解释让我一下子能知道这个算法是什么,很赞!
2021-01-11
- 徐榕泽 👍(7) 💬(6)
老师,这个K值到底是如何计算出来的呢?文章里说一个一个试试,那试的标准是什么?
2021-02-08
- April王燕 👍(2) 💬(0)
老师的讲解让我一下子对算法的理解有了思路,核心原理,应用场景,优缺点,而且通过场景代入,容易理解,但是有一点,对于成熟的主流电商系统,其推荐算法应该比这个要复杂很多吧,如果有类似拆解的课程就更完美啦
2023-02-27
- 我是大幂幂 👍(2) 💬(0)
对K的取值说的不清不楚。如果是二分类问题,恐怕这个k只能取奇数吧,不然出现两个分类各占半的情况如何进行分类?
2022-12-30
- 有机体 👍(2) 💬(1)
数据量 大 怎么界定
2022-01-11
- AsyDong 👍(2) 💬(2)
电商平台里那种看过此商品的人还喜欢XXX这种场景是通过KNN算法推荐
2021-02-02
- Geek_531536 👍(1) 💬(0)
老师你好,“所以,对于 K 的取值,一种有效的办法就是从 1 开始不断地尝试,并对比准确率,然后选取效果最好的那个 K 值。”
94 | 请问这句是不是这样理解:这是个调参过程,是不是用已知的样本来计算,从而选取效果最好的那个K值,然后用这个K值预测未知样本的分类?
95 | 毕竟不知道未知样本是哪个分类,因而也不清楚它的分类是否正确。
2022-05-18
- 俯瞰风景. 👍(1) 💬(0)
KNN算法可以用于寻找认知边界,兴趣边界。通过研究学习兴趣相似的同学的学习内容,可以实现个性化的学习内容推荐。
2021-08-26
- Rosa rugosa 👍(1) 💬(0)
各种推荐场景如视频推荐,音乐推荐,商品推荐。
2021-03-12
- 宋秀娟 👍(0) 💬(0)
如何确定这个关键的K值
2024-08-14
- Geek_7814c7 👍(0) 💬(0)
KNN可以应用于预测早高峰地铁某个热门站点乘客是否下车
96 | 样本数据不需要太多
97 | 特征可以是乘客上车站、年龄段和乘车目的,也满足特征单一的要求
2024-03-26
- cesc 👍(0) 💬(0)
房产的推荐可以使用K近邻算法
2024-02-19
- Doria 👍(0) 💬(0)
欠拟合是在训练集上误差较大 过拟合是测试集上误差较大泛化能力差 k值越大不应该过拟合吗?
2023-11-04
- escray 👍(0) 💬(0)
K 近邻算法,如何定义“最近”,或者说是距离,可能是算法准确与否的关键。
98 |
99 | 虽然 KNN 相对比较简单,不过只要有效果,也没什么不可以。可能最终还是要看数据的情况,以及模型的检验结果。
100 |
101 | 对于 Kd-tree,二维或者三维的分割比较容易理解,但是更高维度的,就想象不出来了。
102 |
103 | 如果在高德地图上找最近的 ATM 机,使用的是 Kd-tree 或者 KNN 么?
2022-04-13
- 👍(0) 💬(0)
网易云音乐的歌单推荐
2021-07-09
104 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/17 - 模型评估:从一个失控的项目看优秀的产品经理如何评估AI模型?.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。今天,我们正式进入模型评估能力篇的学习。
2 |
3 | 在开始今天的课程之前,我想请你先想一想,你在工作中推进AI相关产品需求的时候,是不是经常会遇到这样的问题。
4 |
5 | 在算法模型上线阶段,你拿不准到底要不要验收算法同学交付的模型,就算你想要验收,你也不知道该怎么去评估模型的好坏,只能算法同学说什么就是什么,甚至对算法同学说的名词都没有概念,非常被动。
6 |
7 | 针对这个问题,这节课,我想和你分享一个我曾经踩过的坑。我会通过我处理这个事故的过程来和你详细讲讲,在推进AI相关项目的时候,我们该如何去评估一个模型,怎么化被动为主动。
8 |
9 | ## 问题复现:一个没有经过验收的金融大数据风控AI产品
10 |
11 | 我先来讲讲整个事情的背景。因为AI在金融领域的发展一直处于引领的地位,所以基于大数据的AI风控产品也层出不穷。我的团队主营业务就是给金融机构做AI大数据风控,开发一个**信用评估模型**,这个产品的功能就是基于借款人的留存信息,预测他未来是否可能会逾期还款。
12 |
13 | 金融机构在给借款人放款之前会通过系统调用我们这个模型,如果模型返回“逾期”,金融机构就会拒绝借款人的贷款申请,反之就通过这个借款人的申请。下面是一个最为简单的信贷申请流程样例:
14 |
15 | 
16 |
17 | 本来,上线后模型表现一直还不错。但是突然有一天,我们的客户反馈,模型对所有借款人预测的结果都是“逾期还款”,当天所有借款人向这个客户提交的贷款申请全部被拒绝了,影响的金额巨大。这样的线上事故简直就是灾难,直接导致我们客户的线上业务全部停滞。
18 |
19 | 于是,我和几个核心人员紧急开会讨论。最后发现,模型全部返回“逾期”是因为,算法工程师在模型中引用的一个重要特征突然全部返回空值。后来,算法同学紧急调整了模型代码并重新上线才解决了问题。问题虽然解决了,模型的预测效果却下降很多,也给金融机构造成了极大的损失。
20 |
21 | ## 事故复盘:我们犯的三个错误
22 |
23 | 事后,我和我的团队按照模型的上线时间线,组织了事故复盘,找到了造成这次事故的问题,主要有三个,我一个一个来说。
24 |
25 | **第一:模型上线前无评估。**当模型构建完成后,没有经过产品经理验收,导致这个问题没有被提前发现。
26 |
27 | **第二:模型上线后无监控。**当模型在上线之后,大家都没有对模型进行监控,所以模型出现问题我们没有及时发现。直到模型结果影响到客户,被客户发现了。最终,不但给客户造成了极大的损失,也让客户对我们的技术能力产生了怀疑。
28 |
29 | **第三:特征无评估、无监控。**我们说过,**一个模型的训练包含了很多特征,这些特征加上算法组合成了最终的模型,所以对于模型特征的评估就很重要了**。
30 |
31 | 在此次事故中,算法同学没有评估这个特征稳定性就贸然引入了它,而且,它在模型中还占有很高的比重,这就导致模型对该特征依赖性过强。再加上模型上线后,算法同学没有对模型的特征数据进行监控,所以这些特征数据出现问题以后,整个模型都失效了。
32 |
33 | ## 流程优化:增加模型宣讲和模型评估节点
34 |
35 | 通过刚才的复盘,我想你可以看到,整个过程中产品经理是缺位的。产品经理对于算法同学训练的模型没有能力评估,算法同学说什么就是什么,根本无法把控产品的质量。最后的结果就是产品经理变成了传话筒,交付的产品也不可控,最终就给这次事故埋下了隐患。
36 |
37 | 因此,模型的评估是我们必须要做的事情,但是该怎么做呢?接下来,我带你看看我当时是怎么做的,然后帮助你梳理出一个完整的流程,希望你能把这些经验好好利用起来。
38 |
39 | ### 第一步:改流程,增加单独的模型宣讲和评估节点
40 |
41 | 我先修改了原有流程,增加了模型宣讲和评估的节点。原来的流程是,算法同学完成模型训练之后,由工程同学进行模型的上线,之后测试同学介入测试,产品经理再做最后的验收,整个流程都和传统互联网产品的上线流程一致。
42 |
43 | 这样做看似没有问题,但是会存在两个弊端。
44 |
45 | **第一,模型问题发现时间太晚。**如果模型构建完成之后不进行评估,而是等工程上线之后,测试或者验收阶段才发现模型有问题就太晚了。这个时候,我们再去调整模型大概率会影响产品上线时间。毕竟大多数时候,模型的调整比研发修复Bug要麻烦得多。
46 |
47 | **第二,容易导致评估范围不完整。**产品上线之后验收,大家很自然就会更加关注业务指标,容易忽略模型本身的指标,比如在上面的例子中,我们只关注模型性能表现但没有去评估模型特征的稳定性,特征一旦失效就让整个产品出现了问题。
48 |
49 | 针对这两个问题,我的解决办法是:**制定新的流程,在模型构建完成之后,必须要经过模型宣讲和模型验收两个环节,只有模型验收通过之后,才可以进行后续的工程上线工作。**
50 |
51 | 下面,我再具体说一说这样改造流程的目的。
52 |
53 | 首先,我为什么要增加模型宣讲环节?这是因为,模型本身是一个偏黑盒的产物,它不像一般的互联网产品,有页面、有结果,产品经理可以通过页面功能去评估工程师的产出是否满足需求。所以,要由算法同学先给产品经理讲解清楚模型的加工逻辑,这样产品经理才可以进行后续的验收评估工作。
54 |
55 | 其次,为什么单独增加模型验收环节?这是因为,在模型构建完成之后立刻进行验收,有助于提早发现问题,以免影响最后的产品上线。
56 |
57 | ### 第二步:定标准,定义评估节点内容和交付物
58 |
59 | 流程调整之后,我又和算法同学一起讨论了模型宣讲和模型评估两个环节的人员分工和交付物,确定了我们在这两个节点上的工作标准。
60 |
61 | **1.模型宣讲环节的工作内容和交付物**
62 |
63 | 首先,在模型宣讲前,算法同学需要给产品经理提供一份模型报告。报告中需要包括模型设计、算法选型、特征筛选,验证结果等内容。产品经理看过模型报告之后,再组织算法同学进行模型宣讲。
64 |
65 | 其次,在模型宣讲中,产品经理要有目的地去了解算法逻辑。在这个过程中,我会要求算法同学帮忙说明,这个模型使用了什么算法和选择这个算法的原因,这个模型选择了哪些重要特征,训练的样本,以及算法同学的测试方案与结果。
66 |
67 | 具体来说就是,产品经理需要根据算法同学提供的模型报告,对AI产品影响比较大或者是模型同学容易忽略的三个点进行评估,它们分别是重要特征的来源、训练样本的合理性,以及测试结果是否符合业务预期、是否合理。
68 |
69 | 那为什么要对这三点进行评估呢?我在下面总结了一张表格,你可以先去看看。至于评估的具体方法我会在模型评估环节来讲。
70 |
71 | 
72 |
73 | **总的来说,模型宣讲环节相当于是产品经理给模型上线设立的第一道门槛。针对算法同学给到的模型报告,我们要弄清楚它的算法方案,同时,借助对上面这三点的粗略评估,判断模型的特征、样本、测试方案和结果是否合理。**通过这次评估之后,我们就可以把模型报告归档,进入到模型评估环节了。
74 |
75 | **2.模型评估环节的工作内容和交付物**
76 |
77 | 在模型评估环节,产品经理需要做的是,根据业务需求挑选合适的测试样本,请算法同学进行测试,并且提交测试结果。最后,再根据模型宣讲和测试的内容编写模型验收报告。
78 |
79 | 我在下面给出了一个模型验收报告的例子,虽然,不同业务场景下的评估内容可能不同,但你完全可以进行参考。
80 |
81 | **我们的模型验收报告主要有三个部分,分别是重要特征,选择的测试样本,具体的模型性能和稳定性的测试结果。选择体现这三个部分是因为,它们对我们模型稳定性的影响比较大,有时候会直接影响我们的业务指标。**
82 |
83 | 这个时候,有的同学可能会问,“老师,这三个部分是不是已经包含了模型宣讲环节的评估呀?既然已经评估过了,为什么又要重新评估呢?”这是因为,宣讲环节的评估只是初步评估,让产品经理粗略地了解模型的结果能不能满足业务的诉求。到了这个环节,产品经理要站在业务的角度,更详细地对模型进行评估。
84 |
85 | 我们先来看重要特征部分。模型是由特征组成的,所以评估特征是必不可少的环节。在这个部分,我们需要列出重要特征,评估这些特征的选择是否合理。然后,我们要对每个特征的来源和特征意义进行合理性的评估。
86 |
87 | 针对特征来源,我们要考虑这个特征是外部接入的数据产生的特征,还是我们内部业务数据产生的特征,对于外部数据我们更需要关注数据的稳定性和可持续性。
88 |
89 | 针对特征意义,我们要考虑的是,这个特征的含义是否符合业务或者常理。比如,我们要用到夜间购物特征,但是这个特征时间点设置为23点到2点就不合理,一般应该设置成是0点到5点。
90 |
91 | 接下来是测试样本部分。因为同样的模型选择不同的测试样本,得到的结果就会完全不同,所以我们应该选择和实际业务场景相近的样本进行测试。
92 |
93 | 同时,在模型验收报告中,我们必须把选择的测试样本是哪些,以及为什么选择这些样本都一一说明。比如,在测试用户信用评分模型时候,我选择的样本是2019年10月到2020年4月的消费金融用户。原因是,本模型主要面向消费金融客群,产品为按月分期。这个时间段,这个客群已经有了信贷表现,所以我选择它们作为测试样本。
94 |
95 | 最后,也是最关键的,我们要去评估模型的性能和稳定性。模型性能直接和业务目标相关,如果模型性能达不到业务需要的标准,那么模型根本不具备上线条件。同时,模型稳定性也和业务需求直接相关,我们的业务场景就要求模型必须稳定的(PSI<0.2)。
96 |
97 | 具体来说,我们会分为四步去评估:
98 |
99 | - 评估重要特征的性能测试结果是否符合预期,包括特征 IV、KS 等等;
100 | - 评估重要特征的稳定性,一般是PSI值;
101 | - 评估模型性能测试结果是否符合预期,包括模型 KS、AUC、MSE 等等;
102 | - 评估模型稳定性测试结果,一般也是PSI值。
103 |
104 | 以上,就是我们模型验收报告中需要包括的内容了。不过,这些内容需要根据实际业务情况进行调整,如果算法模型是一个回归模型,那么性能测试报告中就不需要包括KS、AUC这些指标。
105 |
106 | 说了这么多,我再带你总结一下,模型评估环节的验收报告中必须要体现的内容,如下表所示:
107 |
108 | 
109 |
110 | 模型验收通过之后,就可以进入工程联调、上线和测试环节了。这和之前的流程一致,我就不再多说了。
111 |
112 | ## 总结
113 |
114 | 今天,我通过一个因为产品没有验收就匆忙上线而出现的事故,为你讲解了产品经理在模型评估上面的重要性以及我们的模型验收流程是怎么样的。希望你能根据我总结出来的验收流程,结合你的业务情况,形成你自己的验收方案。
115 |
116 | 为了帮助你形象地理解,我梳理了一张验收流程图,放在了下面。
117 |
118 | 
119 |
120 | 了解了验收的流程,只是我们模型评估的第一步,但是具体到模型验收环节,产品经理要根据什么指标进行验收,你肯定还充满了疑问,这些内容我会在下节课和你详细讲解。
121 |
122 | 另外,在这次事故之后,我除了调整产品的上线流程之外,还组织搭建了模型监控系统。具体该如何搭建这个监控系统,监控系统需要观测哪些指标,我也会在后面和你分享。
123 |
124 | ## 课后讨论
125 |
126 | 我想听听你在做产品经理时候,遇到过哪些坑,你是怎么解决的。现在回过头再看,你会不会有更好的解决方式呢?
127 |
128 | 期待在留言区看到你的分享,我们下节课再见!
129 |
102 | - 橙gě狸 👍(7) 💬(2)
有2个小疑问,
103 | 1、核函数和激活函数本质作用是否是相同的?区别是否仅仅是服务的算法不同?
104 | 2、如果算力不断增长,是否svm就会成为一种极其通用的分类算法?
2021-01-14
- Rosa rugosa 👍(2) 💬(1)
LR(逻辑回归)适合推荐项目如CTR预估,商品排序等;SVM适合小样本数据量的多分类,如文本分析中的情感分析,短文本分类。以及对预测值要求比较精确的项目,如金融领域。(上一个答案把LR当成线性回归了,写错了)
2021-03-12
- Yesss! 👍(2) 💬(0)
LR的优点
105 |
106 | 算法简单、运算效率高、可解释性强(svn的算法比较复杂)
107 |
108 | LR的缺点
109 |
110 | 不具备求解一个非线性分布的问题(这是svn算法所具备的)、精确度低
111 |
112 | SVN的优点
113 | 1、具备非线性和线性的解决方式。对于文本问题分析、情感问题分析尤为卓越(LR只能解决线性问题)
114 |
115 | SVN的缺点
116 | 1、需要的资源开销较大、对于样本数量比较多的情景下,要考虑消耗的资源和内存。
2021-01-28
- Geek_d54869 👍(1) 💬(0)
线性问题,样本比较大,特征较少的情况下用LR;
117 | 特征较多,样本数量几千条,又是非线性问题就用SVM;
2023-05-24
- 潘平 👍(0) 💬(0)
老师,“首当其冲的优点”用的不对,首当其冲指的是不好的事情发生
2023-08-17
- weiwei 👍(0) 💬(0)
LR还是适合特征和目标有线性关系;SVM可以处理非线性
2022-01-01
- 俯瞰风景. 👍(0) 💬(0)
LR的优点:运算效率高;可解释强;不受极端值影响
118 | 相比来说SVM的缺点:运算效率低,开销大;可解释性不强;受极端值影响。
119 |
120 | SVM的优点:即可以处理线性可分,又可以处理线性不可分;
121 | 相比来说LR的缺点:对于非线性可分数据预测不理想。
2021-08-27
- Shirley 👍(0) 💬(0)
SVM相较于LR所需样本量更小,能应对非线性的情况。LR相较于SVM所需运算资源更小,逻辑解释性更强。
2021-07-01
- hcm🙈 👍(0) 💬(0)
非常棒,讲的很清晰~ 算法之美~
2021-04-29
- Rosa rugosa 👍(0) 💬(0)
LR适合用来预测达成目标的参数值,如预测身高,房价,库存等;SVM适合应在小样本数量的分类,如文本分析中的情感分析和短文本分类。
2021-03-12
- Yesss! 👍(0) 💬(0)
首先我们需要知道LR(线性回归)的优缺点和 SVN(支持向量机)的优缺点:
2021-01-28
122 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/28 - 预测类产品(三):从0打造一款“大白信用评分产品”.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。今天,我们接着来讲预测类产品的打造。我会以小白信用评分产品为例,来教你模拟构建一个大白信用评分产品,从而学习到机器学习在互联网金融行业的产品落地方法。
2 |
3 | 什么是小白信用评分产品呢?你可以看我下面给出的解释:
4 |
5 | > 小白信用评分:指根据用户在京东的浏览、购物、投资理财、信用产品使用和履约情况、个人信息完整度等多个维度的数据,通过大数据算法,对用户的信用水平给出的综合评估的产品。评分越高表明用户的信用越好,受评用户就可以在京东及京东合作商户享受优惠商业政策。
6 |
7 | 需要提前声明的是,构建“大白信用产品”的过程中,我们不会涉及任何与小白信用产品相关的内容,你只要学会构建的通用流程就可以了。整个构建流程可以分为四部分,分别是案例背景、特征构建、模型训练和模型评估。下面,我们就详细来说说。
8 |
9 | ## 案例背景
10 |
11 | 开头说了,我们要设计一个大白信用评分模型,那这个模型具体长什么样呢?一个标准的“大白信用模型”由五大维度构成,如下图所示。
12 |
13 | 
14 |
15 | **第一是身份特质**,包括你的实名情况、社会属性、居住环境、教育情况,它们代表了你的出身、社会层次和稳定性,是一个人短时间内不会被改变的特质。
16 |
17 | **第二是资产评估**:通过你提交的收入和资产信息来综合判断你的履约能力,包括社保、公积金、动产和不动产等。
18 |
19 | **第三是行为偏好**:就是通过你的消费、缴费还款、公益活动等行为,判断你的行为特点,比如从消费偏好上看出你消费的高低。这部分数据对产品后续决策有很大的参考价值。
20 |
21 | **第四是履约信用**:评估你在金融产品、电商平台和社会行为表现出来的履约和违约情况,比如看你历史的信用,来判断你的诚信度。
22 |
23 | **第五是人脉关系**:这一步主要是对你的社交关系,人脉丰富程度进行评估。
24 |
25 | 通过这五个维度,我们除了能够判断一个人的信用到底好不好,还可以结合人的行为偏好来做更精准的个性化推荐。
26 |
27 | 在建模之前,我们先假设一个信用场景,比如通过“大白信用分”来决定用户是否可以免押金租相机。这个场景就是一个二分类问题。它的核心思路是,计算出用户在“大白信用”5 个维度上的违约概率,然后把它们综合起来计算出一个最终概率,再把它转化成一个实际的得分,也就是这个用户最终的“大白信用分”。
28 |
29 | ## 特征构建
30 |
31 | 接下来,我们就可以从刚才说的五大维度入手,来做“大白信用”评分模型的数据准备了。在做数据准备的时候,这 5 大维度还可以继续拆分成更多详细的分类和数据字段。比如“资产评估”就可以拆分成“固定资产”和“流动资产”等等,示例如下:
32 |
33 | 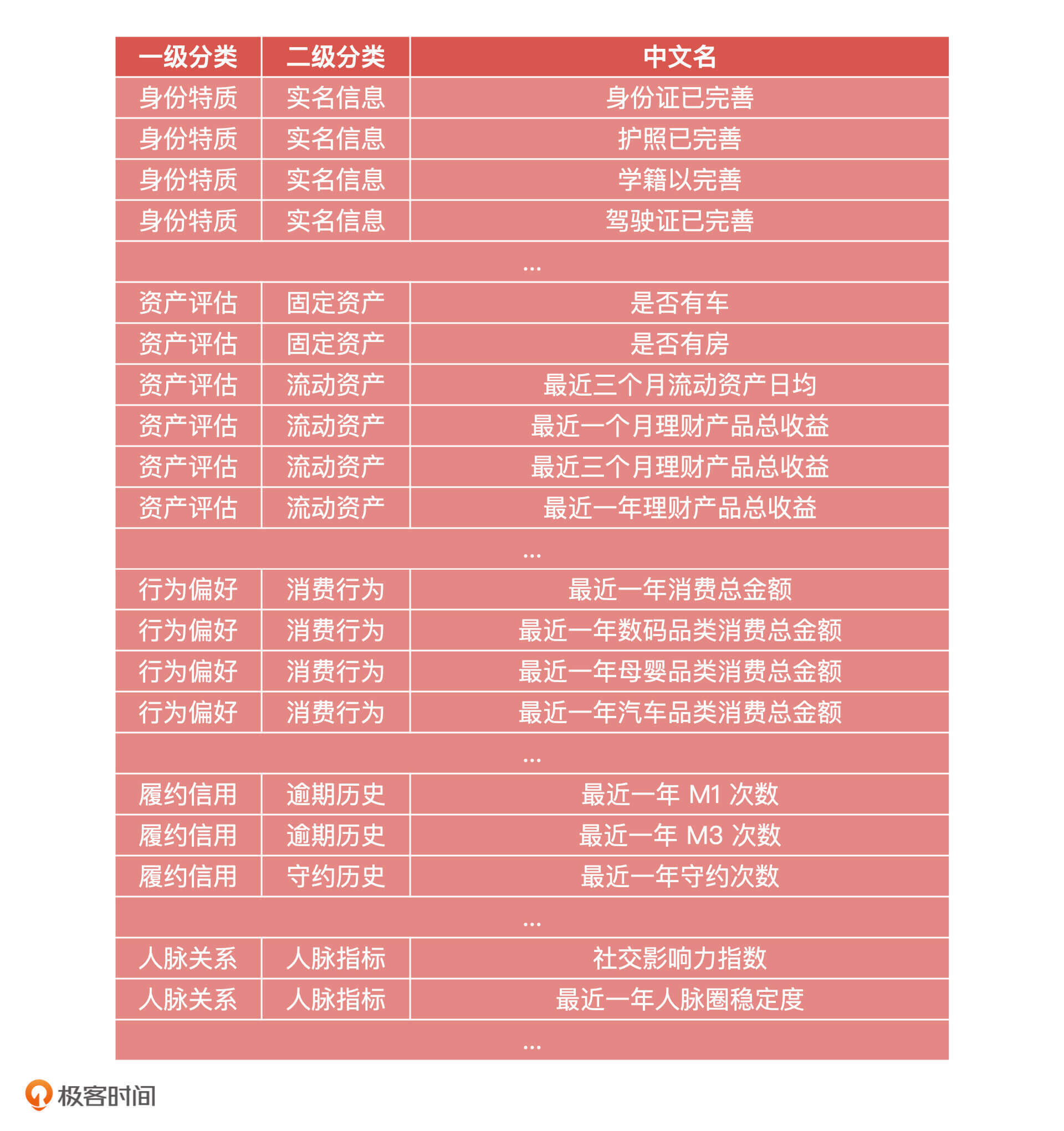
34 |
35 | 当然,在实际工作中,对于产品级数据模型构建来说,上面的数据信息还远远不够,我们还需要增加更多的**原始数据和扩展数据**。
36 |
37 | 原始数据就是存储在业务系统中的基础字段,比如日交易额、下单量、点击或搜索次数等原始字段信息。扩展数据是原始数据加工转化后的数据,一般有三种生成方式:按照时间维度衍生,如最近 1 个月或者 3 个月交易额;通过函数衍生,如最大或最小交易额,以及交易额方差;通过比率衍生,如“最近 1 个月交易额/最近 3 个月交易额”。
38 |
39 | 下一步就是对这些特征数据进行处理了。
40 |
41 | 在真实工作中,特征处理和选择是一个循环迭代、优化的过程,所以在业务前期,我们要尽可能多地抽取数据特征。特征处理的方法可以分为三种,分别是**特征的通用处理,数值型特征处理和字符串特征处理**。
42 |
43 | ### 特征的通用处理
44 |
45 | 特征的通用处理是我们在拿到特征数据之后都需要做的,包括**数据分布分析、缺失值处理与异常值校验。**
46 |
47 | 首先是特征数据的分布分析,我们要先通过数据可视化的方式查看数据的分布情况,然后对分布不均衡的数据采用“随机欠采样”、“随机过采样”或 “SMOTE 算法”进行处理。这和我们上节课讲的一样,我就不再重复了。
48 |
49 | 其次,对“大白信用评分产品”中的数值型和字符串型字段进行缺失值和异常值检验,我们可以采用补充缺失值、或者直接剔除掉无效字段的方式进行处理。
50 |
51 | ### 数值型特征处理
52 |
53 | 对于数值型特征的处理,我们主要是看特征的 IV 值,因为 IV 值衡量了各特征对$y$值的预测能力。例如,下面是我们对员工工作信息模型的特征相关性排序。
54 |
55 | 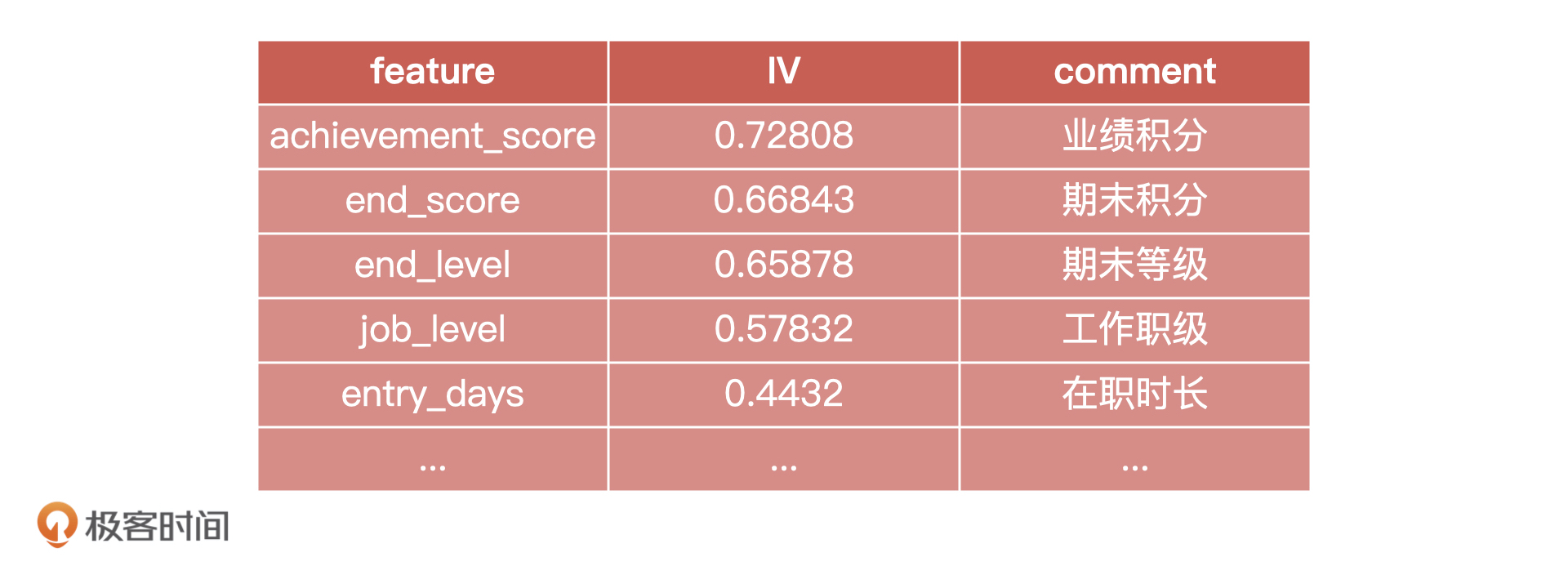
56 |
57 | 需要注意的是,IV 值并不是越大越好。根据不同场景 IV 值的取值有所不同,实际的场景中,我们可以选择 IV 值大于 0.1 的指标。
58 |
59 | 除此之外,我们还要对特征进行归一化处理,来消除数据特征之间的量纲影响,让不同指标之间具有可比性。比如交易额和交易次数,这两个指标就没有可比性。我们通常使用的**归一化方法有线性函数归一化和零均值归一化**。
60 |
61 | 线性函数归一化也称为最大值 - 最小值归一化,原理是将数据映射到 \[0, 1] 的范围内,公式为:$x' = \\frac{X - X\_{min}}{X\_{max} - X\_{min}}$。
62 |
63 | 零均值归一化的原理是将数据映射到均值为 0,标准差为 1 的分布上,公式为:$x' = \\frac{x - \\bar{X}}{S}$。
64 |
65 | ### 字符串特征处理
66 |
67 | **对于字符串特征的处理主要就是对字符串做离散化,也就是将字符串映射到一个个离散的区间中**。字符串离散化的目的是将变量数值化,因为数值化后的变量才能应用到数学模型中。
68 |
69 | 以“身份特质”为例,如果你的学历是硕士,那么我们该如何处理这个字段呢?
70 |
71 | 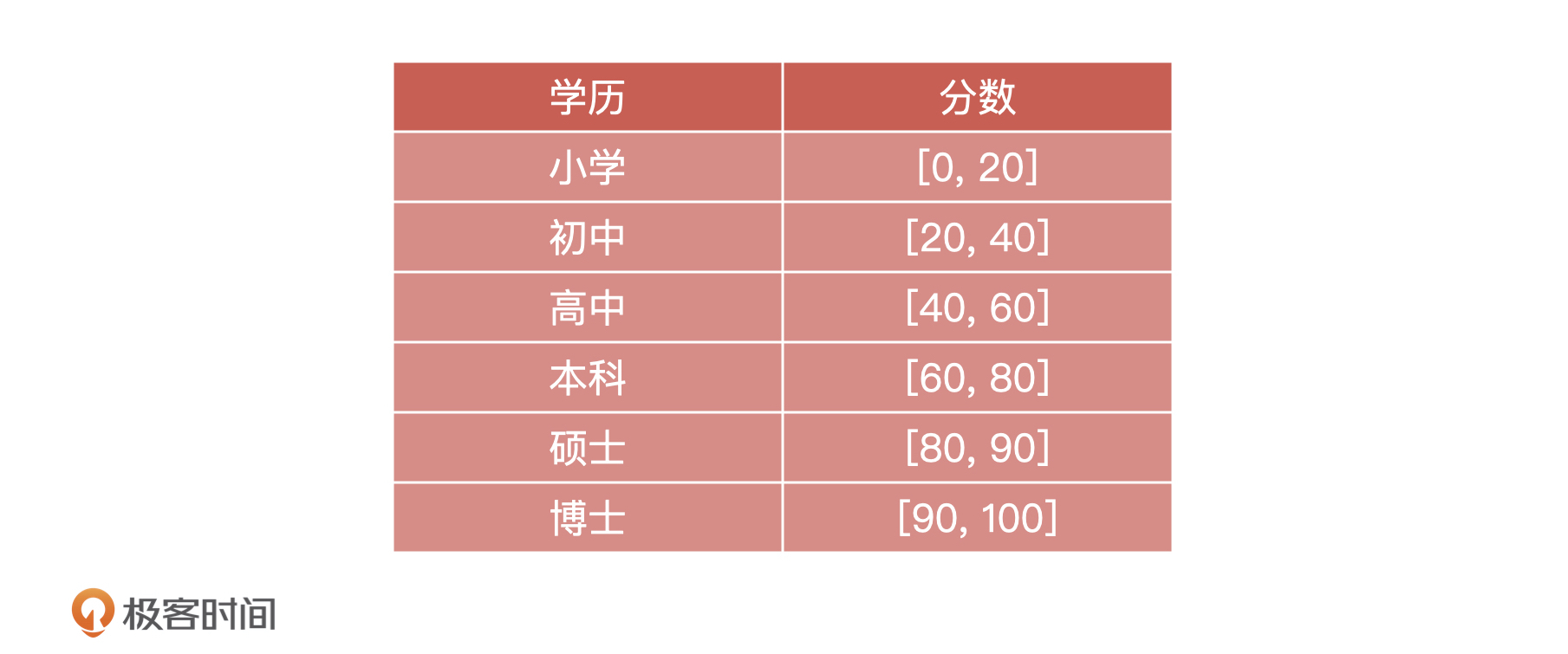
72 |
73 | 如表格所示,我们把100分分成6段,小学是 0~20,初中是 20~40,高中是 40~60,以此类推,我们直接把字符串映射到一个个的分段区间中就可以了。这里的具体取值按照业务常识设置的,我们只要做到逻辑上没有问题就行了。
74 |
75 | ## 模型训练
76 |
77 | 处理完数据,我们就要开始训练模型了。不过在那之前,我们要先选择算法。因为这是一个二分类问题,所以我们要选择二分类算法,又因为现在是项目前期,所以我们可以选择相对简单的算法模型进行实验,比如逻辑回归模型。接下来,我们就可以按照如下步骤进行操作了 。
78 |
79 | 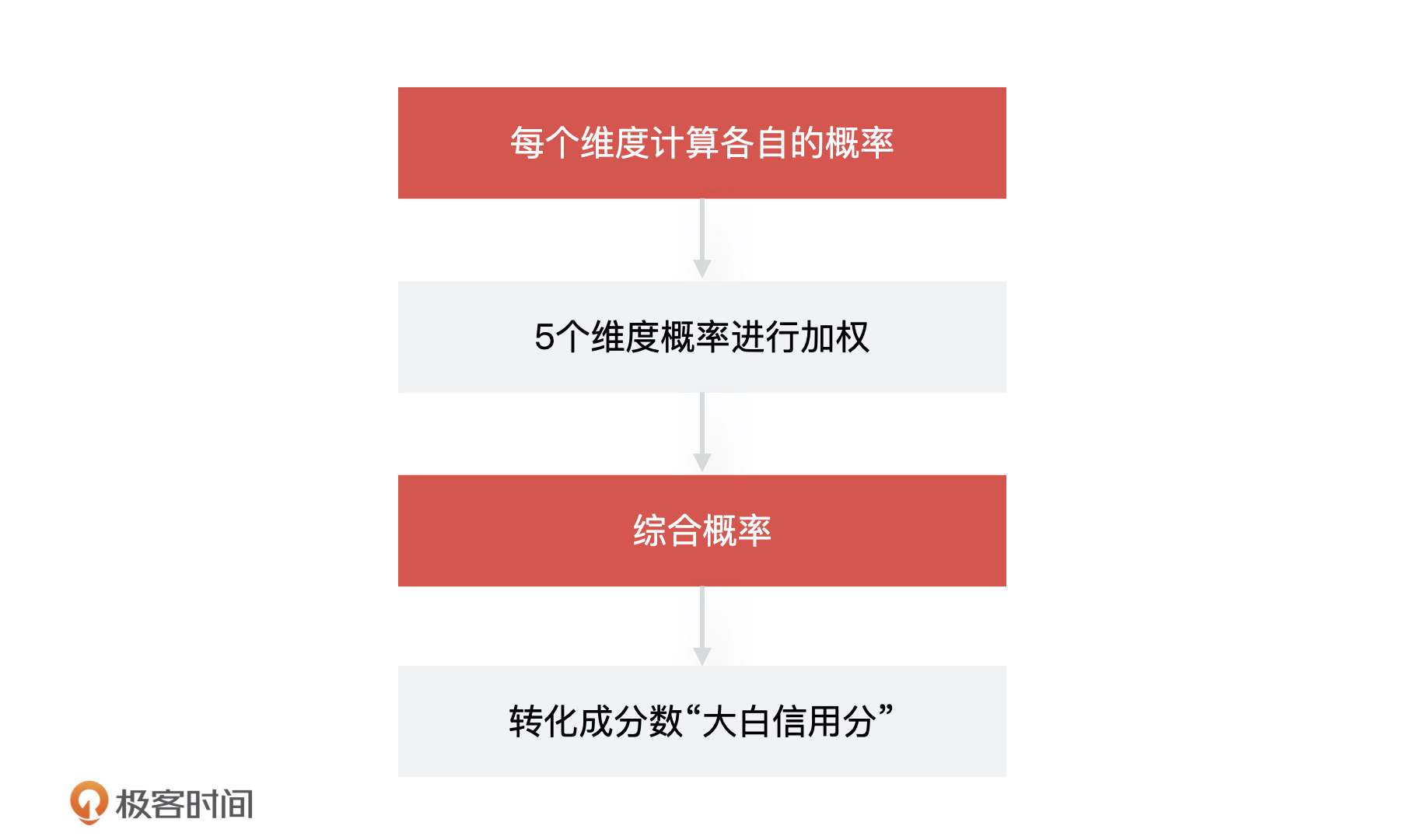
80 |
81 | 我们以“履约信用”维度为例,假设“履约信用”包含的字段有最近一个月需还款金额 $x\_{1}$,最近一个月逾期金额$x\_{2}$,最近一个月消费金额 $x\_{3}$。根据 LR 公式,我们可以计算得到你违约的概率:$P = sigmod(y) = \\frac{1}{1 + e^{-y}} = \\frac{1}{1 + e^{-(ax\_{1} + bx\_{2} + cx\_{3}))}}$。
82 |
83 | 其中,$P$为用户违约的概率,$a$、$b$、$c$为逻辑回归模型的拟合系数。
84 |
85 | 通过这个方法,我们依次计算出 5 个维度(身份特质、资产评估、行为偏好、履约信用、关系人脉)的概率,分别为 0.1、0.2、0.3、0.4、0.5。然后,我们再假设每个维度的权重都为 0.2,具体如下表所示:
86 |
87 | 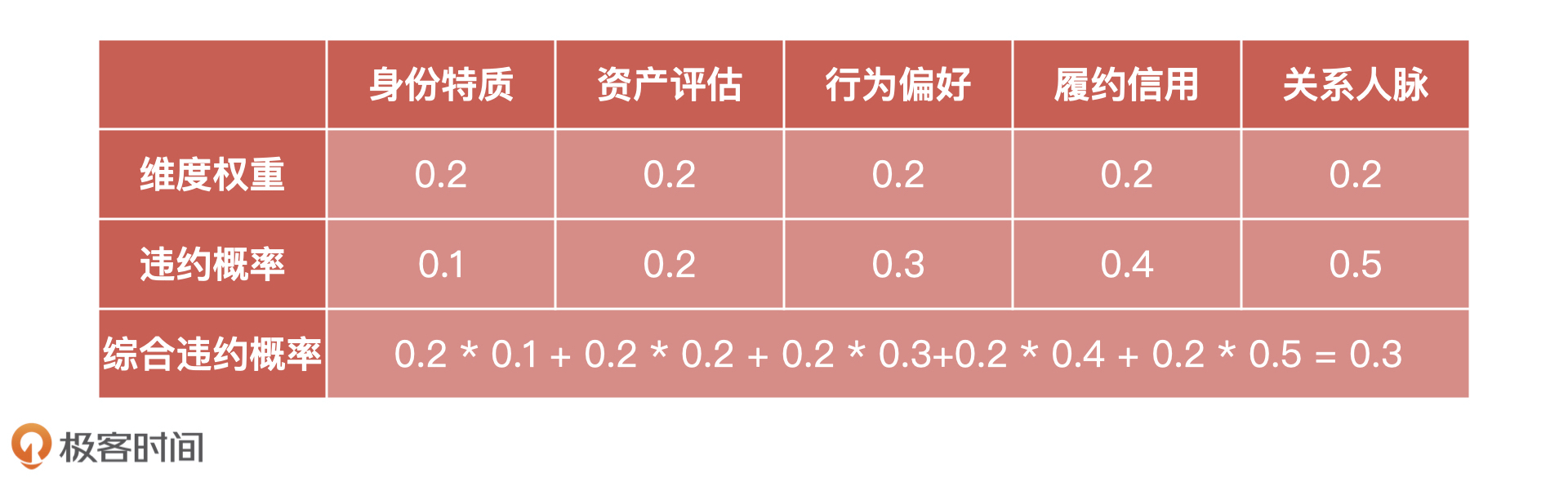
88 |
89 | 最后,我们还需要将综合概率$P$转化为实际的数值,转化公式为:$score=(1-P) \\times A+B$
90 |
91 | 其中,分数区间为 \[200, 1000],所以 A=800,B=200,然后我们再将上面的综合违约概率带入公式,就能得到你最后的大白信用分了,它等于760。
92 |
93 | 当然,真实产品的模型构建过程肯定更为复杂,但它们的核心思想是一致的,**都是先划分维度,然后准备每一个维度的数据特征,对它们进行特征处理,构建好训练集和测试集,通过分类算法计算每一个维度的概率分,再通过加权的方式得出综合概率分,最终转化成具体的分数,这就是最终的信用得分了**。
94 |
95 | ## 模型评估
96 |
97 | 得到预测结果之后,我们要对模型进行抽样评估。**对于信用评分模型,我们只需关注两个重要的指标:混淆矩阵和 KS 值。**
98 |
99 | 比如说,在得到的预测结果中,60分为切分点,60以下我们认为会违约,60分以上我们认为不会违约,我们预测可能会违约的是180人,不会违约的是220。但在实际表现上,违约有 120 人,未违约有 280 人,相应的混淆矩阵如下:
100 |
101 | 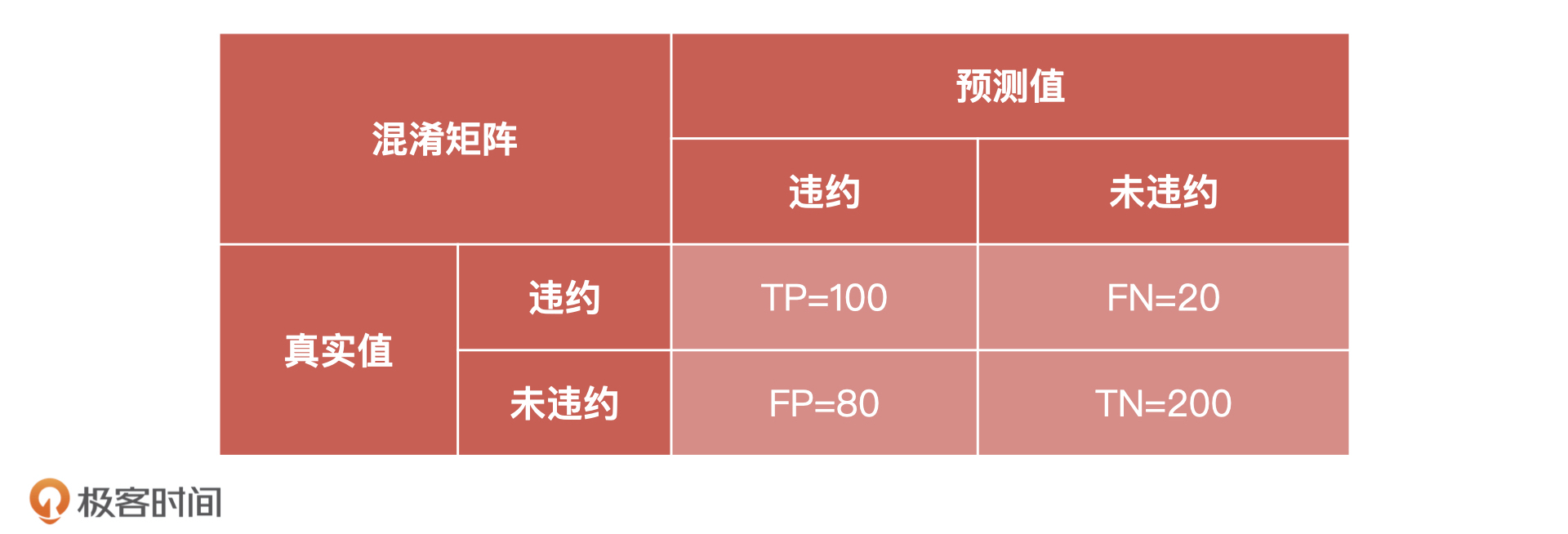
102 |
103 | 这样我们就能计算出模型的准确率和召回率了:
104 |
105 | - 模型的准确率的计算是:$\\frac{TP+TN}{TP+TN+FP+FN}=\\frac{100 + 200}{100 + 20 + 80 + 200} =0. 75$
106 | - 模型的召回率的计算是:$\\frac{TP}{TP+FN} = \\frac{100}{100 + 20} = 0.83$
107 |
108 | 从结果上来看,模型的效果还是不错的。
109 |
110 | 相应的,我们还可以将10分、20分、30分这些分数分别作为切分点,得到一系列的混淆矩阵和对应的准确率和召回率,以及TPR和FPR。我们把每一个切分点所对应的TPR和FPR相减,得到的最大值就是这个模型的KS值。
111 |
112 | KS的具体计算过程,你可以参考[第20讲](https://time.geekbang.org/column/article/339604),这里我就不多说了。不过,最终KS值可以直接通过算法工程师的代码跑出来,不需要我们手工计算。
113 |
114 | ## 小结
115 |
116 | 这节课,我们一起打造了一个“大白信用评分产品”。还是和前几节课一样,想要成为金融风控方面的产品经理,你要从能力、技术和岗位这三方面进行准备。
117 |
118 | **在能力方面**,金融行业的数据比较成熟,所以数据来源很多,这就要求产品经理对于数据源的成熟度和稳定性有**把控能力**。并且,如果我们想在项目前期尽快赢得客户认可,还要具备良好的**沟通能力和快速的反馈能力**。因此,相比于数据分析师这样的岗位,我们要注意锻炼自己能够站在产品、公司以及客户这三方角度来分析问题,提出自己的想法。
119 |
120 | **在技术方面**,我们要理解机器学习算法模型。更具体点来说,你要理解逻辑回归、决策树、GBDT、随机森林、神经网络这些常用算法的原理、应用场景和优缺点,具体的内容你可以回顾算法技术能力篇。
121 |
122 | **在岗位方面,**因为互联网金融的核心是风控,而风控领域的产品经理岗位,又可以细分为风控策略产品、系统产品,随着 AI 能力的普及,又有了风控 AI 产品经理等等岗位。如下是一张风控AI产品经理的JD,你可以看一看。
123 |
124 | 
125 |
126 | 并且,我也把这节课和上节课产品经理岗位之间的区别总结在下表中,希望你能更直观地理解。
127 |
128 | 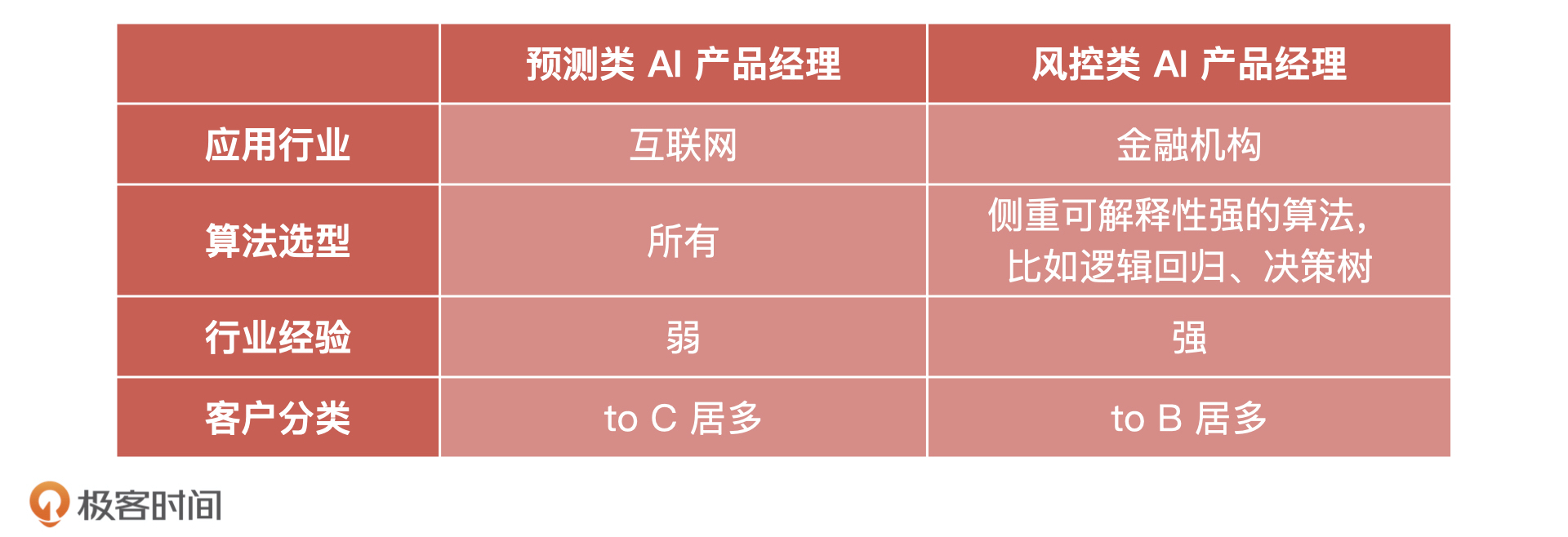
129 |
130 | ## 课后讨论
131 |
132 | 在这里,我想请你谈一谈你对“芝麻信用分”和“小白信用分”的理解,他们的分数的取值范围分别是多少,为什么这样设定?
133 |
134 | 期待在留言区看到你的思考,我们下节课见!
135 |
96 | - 云师兄 👍(7) 💬(1)
通俗易懂,这是讲算法最好课程
2021-01-06
- Geek_b04564 👍(29) 💬(1)
y=ax+b 一元一次方程 名字改成 线性回归 瞬间牛气
2021-03-26
- AsyDong 👍(7) 💬(0)
可以根据公司(或竞争对手)历史同类产品的价格和销量来找规律
2021-02-02
- 悠悠 👍(6) 💬(2)
1、问卷调研,根据产品的目标,成本、供需、竞争对手等因素,得出一个定价区间,分成等距的多个价格共用户选择;
97 | 2、横轴价格,纵轴选择该价格的人数,拟合直线;
98 | 3、输入价格,就能输出购买人数;
99 | 4、落地的时候要考虑这个产品的目标,成本、供需、竞争对手,调研样本不均等;
2021-01-06
- 俯瞰风景. 👍(4) 💬(1)
老师能不能形象地解释一下“拟合”这个概念?
2021-08-26
- 俯瞰风景. 👍(3) 💬(0)
1、先分析出市场中的类似产品。然后分析其销量和之间的关系,绘制线性回归曲线,然后结合曲线对新品进行定价;
100 | 2、也可以通过问卷调查,根据价格和购买意愿,绘制出线性回归曲线,然后结合曲线对新品进行定价;
2021-08-26
- 邢瑞豪 👍(3) 💬(2)
还有点疑问,如何根据已有的数据 得到最优化的 A 和 B 的值?
2021-01-08
- 炯 👍(2) 💬(2)
还是对欠拟合和过拟合的概念有点不理解,本文提到算法过于简单,在样本量过小的情况下,不是应该是欠拟合吗?为什么文中提到的是过拟合呢?
2021-08-12
- weiwei 👍(1) 💬(0)
实践方案设计好后,你觉得在具体的落地实践上还有什么需要考虑的吗?
101 | 销量和客单价格会呈现一条斜率向下的直线,意思就是单价越高,销量越小。要找到 单价*销量 最大的点,作为最后实际销售单价的点。
2021-12-31
- Rosa rugosa 👍(1) 💬(0)
需要注意利润目标的达成,所以要有成本控制,包括广告费用,运营费用等。还要注意产品发布时间,竞品动态等。
2021-03-12
- 小太白 👍(1) 💬(0)
具体落地,要考虑除了价格的其他影响销售额的各类因素,如销售渠道、客户细分、同类竞品等。也许要多元回归,可能还要考虑各影响因素间的联系或者隐藏因素。
2021-03-04
- 星米 👍(0) 💬(0)
新产品,首先要进行同类竞品的调研,最好的情况是获得2到3个竞品的售价及销售数据,以此来获得初步的函数公式。
2024-02-28
- Geek_d54869 👍(0) 💬(0)
1.根据成本定价法,制定不同利润率的几个定价;根据客户沟通获取用户预算和竞品厂家的定价区间。
102 | 2.根据同类竞品的定价和销售额关系,建立线性回归模型,来确定最合适的价格点。这里需要考虑产品定位,销售周期,数据样本,上面提到的客户预期和竞品定价区间。
2023-05-23
- Geek_d54869 👍(0) 💬(0)
1.根据成本定价法给产品定价,得到不同利润率的价格点;根据与客户前期沟通获得客户对价格的倾向;实际参考同类竞品定价。
2023-05-23
- Macavity 👍(0) 💬(0)
怎样正确理解“回归”这个词在这里的概念呢?恳求各位同学老师指教
2023-03-23
103 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/19~模型性能评估(一):从信用评分产品看什么是混淆矩阵?.md:
--------------------------------------------------------------------------------
1 | # 19~模型性能评估(一):从信用评分产品看什么是混淆矩阵?
2 |
3 | 你好,我是海丰。
4 |
5 | 这节课,我们来学习分类模型的评估指标。上节课我们说了,分类模型的性能评估指标有混淆矩阵、$KS、AUC$等等。混淆矩阵是其中最基础的性能评估指标,通过它,我们可以直观地看出二分类模型预测准确和不准确的结果具体有多少,而且像是$KS、AUC$这些高阶的评估指标也都来自于混淆矩阵。
6 |
7 | 比如说,对信用评分这样典型的分类问题进行评估,其实就是要知道一个人信用的好坏。通过混淆矩阵,我们就能知道这个信用评分能够找到多少坏人(召回率),以及找到的坏人中有多少是真的坏人(精确率)。
8 |
9 | 因此,要对分类模型的性能进行评估,我们一定要掌握混淆矩阵。接下来,我们就通过一个信用评分产品的例子来详细说一说,混淆矩阵是什么,以及相关指标的计算方法。
10 |
11 | ## 什么是混淆矩阵?
12 |
13 | 信用评分的产品指的是利用客户提交的资料和系统中留存的客户信息,通过模型来评估用户信用情况的模型。信用评分主要应用于信贷场景中,对用户和中小企业进行信用风险评估。
14 |
15 | 假设,你的算法团队做了一个信用评分产品,分数范围是 \[0, 100]。同时,算法团队给出一个参考阈值,60 分以下的人逾期概率远高于 60 分以上的人群。
16 |
17 | 这个时候,你可以抽取一部分用户用于验证模型的效果。但是,这些用户必须是已经具有信贷表现的,否则我们无法通过它们确定模型有效性。我们把从来没有逾期的用户定义为“好人”,逾期用户定义为“坏人”。
18 |
19 | 假设我们抽取了 100 个测试用户,向信用评分模型中输入这一百个测试用户的信贷信息(用户身份证号/手机号码)以后,我们能得到 100 个模型的预测结果,以及每个用户的评分。结合算法团队给出的参考阈值,我们把信用分小于等于 60 的人定义为“坏人”,大于 60 的人定义为“好人”。
20 |
21 | 这之后,我们就可以通过混淆矩阵,知道模型预测结果和实际结果的差距,从而判断模型性能的好坏了。
22 |
23 | 混淆矩阵有两个定义,分别是 Positive 和 Negative,它们分别代表模型结果的好和坏。下表就是一个标准的混淆矩阵。其中,行表示真实值,列表示预测值。$T$代表模型预测对了,也就是预测值和实际值一样,$F$则相反。$P$就是 Positive 的缩写,我们可以理解为“坏人”,$N$就是 Negative 的缩写,我们可以理解为好人。这里要特殊说明一下,好人坏人的定义是为了方便我们理解的,一般教材上会说明 Positive 为正例,Negative 为负例。
24 |
25 | 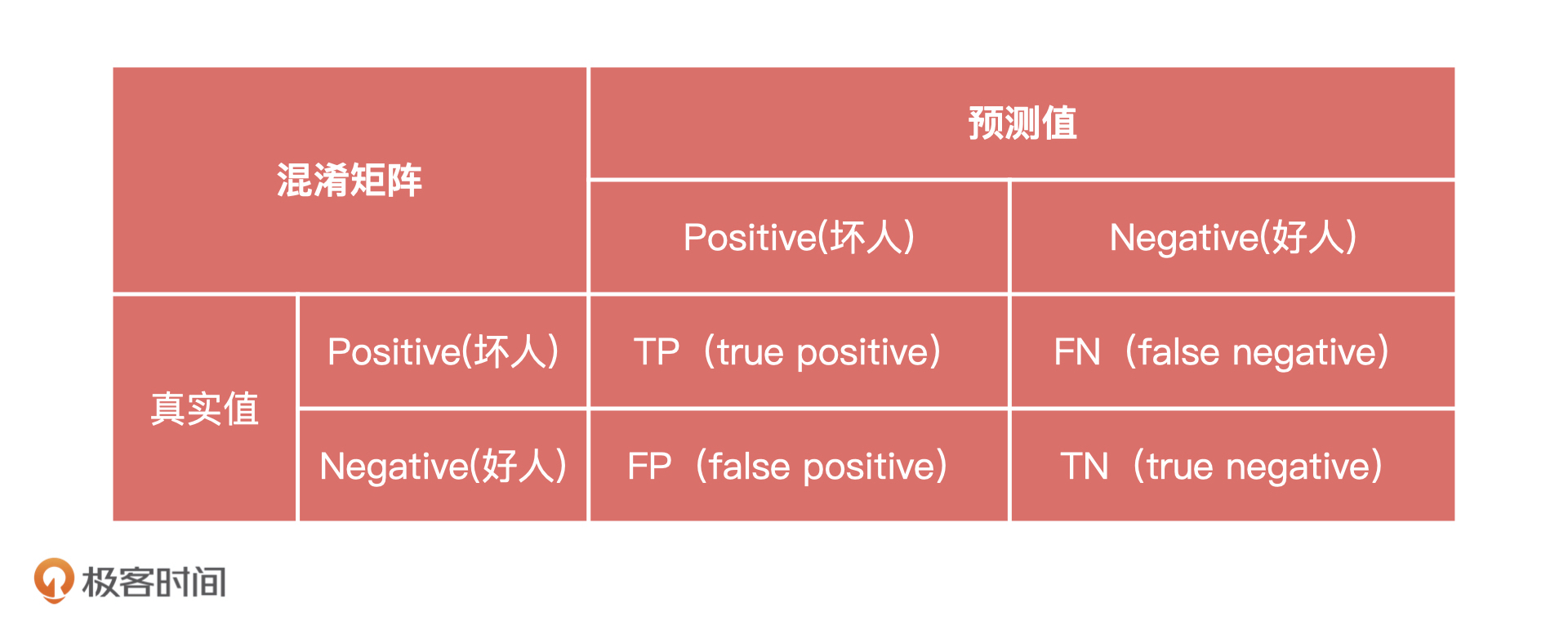
26 |
27 | 由此,我们可以总结出 4 种情况:
28 |
29 | - $TP$是指模型预测这个人是坏人,实际上这个人是坏人,模型预测正确;
30 | - $FP$是指模型预测这个人是坏人,实际上这个人是好人,模型预测错误;
31 | - $FN$是指模型预测这个人是好人,实际上这个人是坏人,模型预测错误;
32 | - $TN$是指模型预测这个人是好人,实际上这个人是好人,模型预测正确。
33 |
34 | 刚刚接触混淆矩阵的同学,可能还不能完全理解$TP、FP$代表什么。其实,我们也不需要对这 4 种情况死记硬背,只需要记住:$T$和$F$代表模型判断的对和错,$P$和$N$代表模型预测结果的好和坏。
35 |
36 | 我们每预测一个人,都可以得到这样一个混淆矩阵。
37 |
38 | 比如,用户张三实际是一个逾期用户,也就是“坏人”,但模型给出的评分是 80 分。这个时候,张三的混淆矩阵中$FN=1$,就代表模型预测错误。
39 |
40 | 
41 |
42 | 再比如,用户李四也是一个逾期用户,但模型给出的评分是 40 分。这个时候,李四的混淆矩阵中$TP=1$,模型预测正确。
43 |
44 | 
45 |
46 | 假设,这 100 个人里面实际有 40 个坏人,60 个好人。模型一共预测出 50 个坏人,在这 50 个坏人中,有 30 个预测对了,20 个预测错了。
47 |
48 | 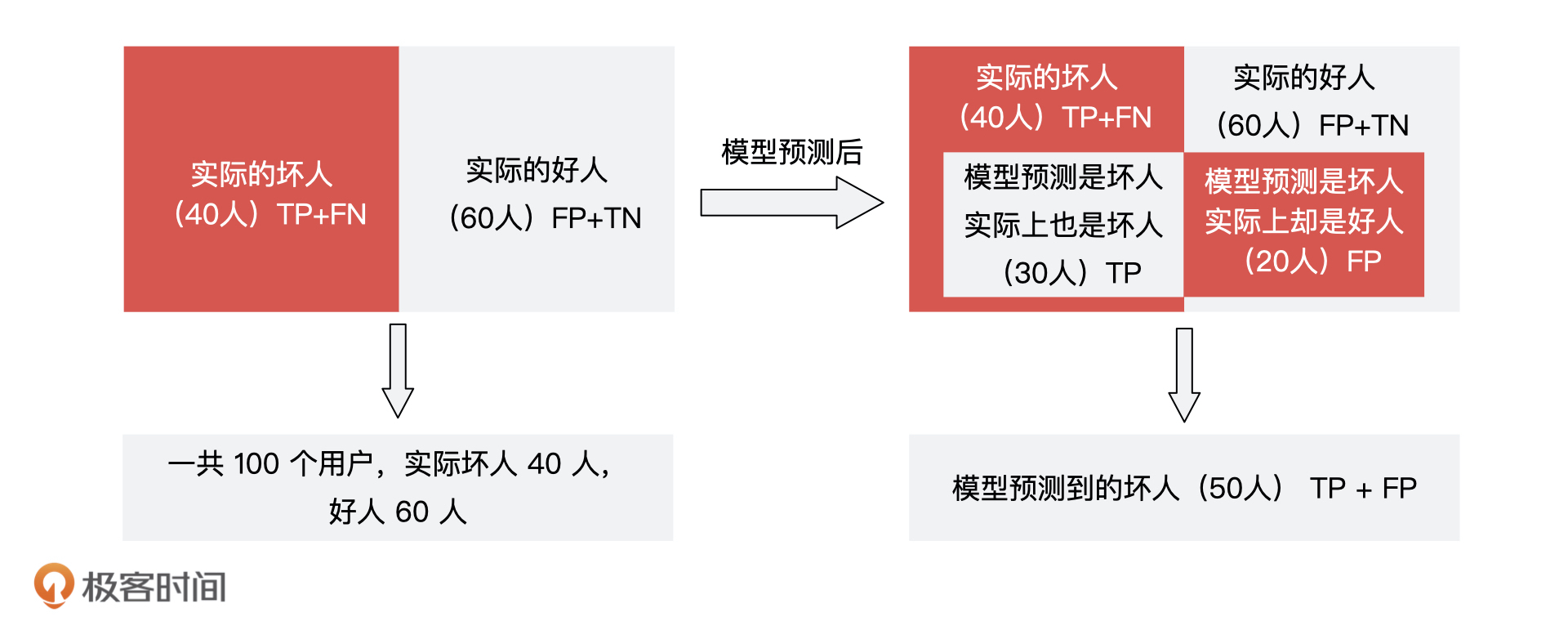
49 |
50 | 综合了这 100 个人的模型结果和实际的结果,我们就能得到一个如下的混淆矩阵:
51 |
52 | 
53 |
54 | 我们当然希望所有测试的结果都是 $TP$ 或者 $TN$,也就是模型预测每个人的结果都和实际结果是一致的。
55 |
56 | 但是,现实中不太可能存在这样的情况,而且单独看混淆矩阵,我们只能知道模型预测结果中有多少个$TP$和$FP$,没办法直接告诉业务方这个模型到底好不好。因此,为了能够更全面地评估模型,我们又在混淆矩阵的结果上,延伸出另外 3 个指标,分别是准确率、精确率和召回率。
57 |
58 | ## 混淆矩阵的指标:准确率、精确率、召回率
59 |
60 | **准确率(Accuracy)这个指标是从全局的角度判断模型正确分类的能力。对应到信用评分的产品上,就是评价模型预测对的人$TP+TN$,占全部人员$TP+TN+FP+FN$的比例。** 极端情况下,模型所有人都预测对了,这个准确率就是 100%。
61 |
62 | 准确率的计算公式是:$accuracy = \frac{TP+TN}{TP+TN+FP+FN}$。
63 |
64 | 虽然通过准确率这个指标,我们可以直观评价模型正确分类的能力。但是,在样本不均衡的情况下,占比大的类别对评价结果的影响太大。比如说,100 个用户里有 90 个坏用户,当我们模型预测到 99 个坏用户的时候,它还能有 90% 的准确率。这肯定是不对的。
65 |
66 | 在这种情况下,我们还要借助精确率(Precision)。**精确率是判断模型识别出来的结果有多精确的指标。对应到信用评分的产品上,就是模型找到的真的坏人(对应混淆矩阵中的$TP$)的比率占模型找到的所有坏人(对应混淆矩阵中的$TP+FP$)的比率。**
67 |
68 | 精确率的计算公式是:$precision =\frac{TP}{TP+FP}$。
69 |
70 | 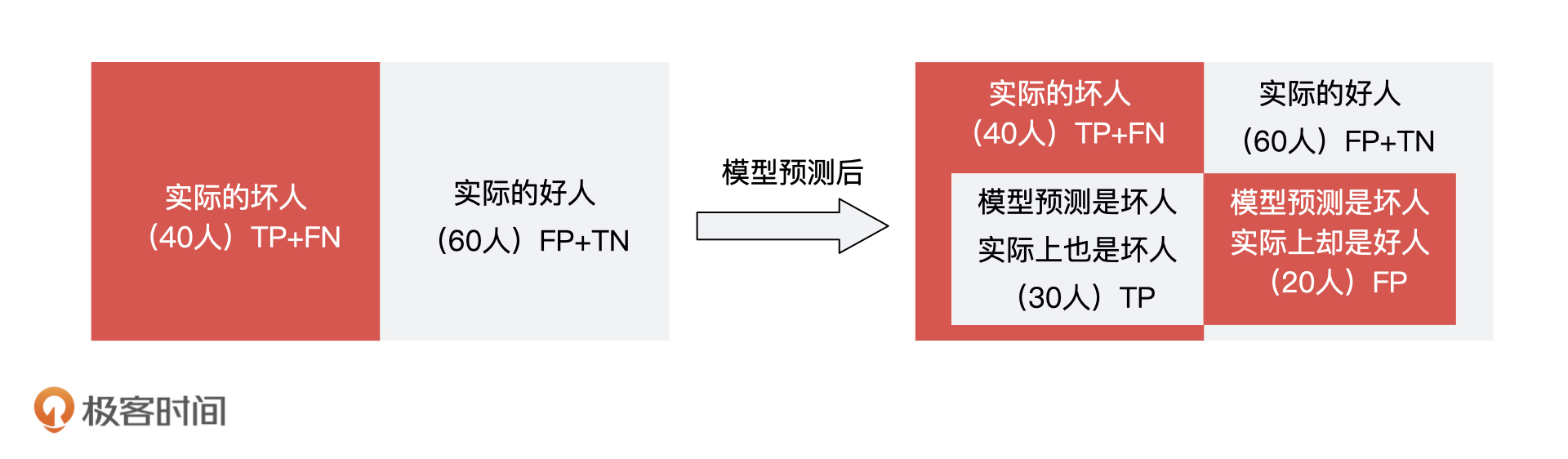
71 |
72 | **除此之外,我们也要看召回率。召回率(Recall)也叫做查全率,是判断模型识别广度的指标。对应到信用评分的产品上,就是模型找到的真的坏人(对应混淆矩阵中的$TP$)占实际坏人$(TP+FN)$的比例**。也就是看模型能识别出多少真正的坏人,模型认为的坏人占实际坏人的比率是多少,公式是:$recall=\frac{TP}{TP+FN}$。
73 |
74 | 知道了模型的准确率、精确率、召回率的计算公式,我们通过刚才的混淆矩阵,就可以把它们分别计算出来了:
75 |
76 | - 准确率 =$\frac{TP+TN}{TP+TN+FP+FN}=\frac{30+40}{30+40+20+10}=70%$
77 | - 精确率 = $\frac{TP}{TP+FP}= \frac{30}{30+20}= 60%$
78 | - 召回率 = $\frac{TP}{TP+FN}=\frac{30}{30+10}= 75%$
79 |
80 | 总的来说,准确率、精确率和召回率是混淆矩阵的三个基本指标。准确率可以从全局的角度描述模型预测正确的能力,精确率和召回率可以分别描述模型识别的精确度和广度。
81 |
82 | 在实际工作中,我们一般通过精确率、召回率就可以判断模型预测的好坏,因为召回率可以知道我们找到了多少想找到人,精确率可以知道,我们找到的人有多准。
83 |
84 | 不过,精确率和召回率实际上是一对矛盾的指标,精确率提升,召回率可能会随之降低。比如说,如果想要识别出来的坏人都是真的坏人,模型就很可能会因为保守而缩小自己识别的范围,这就会导致召回率的下降。
85 |
86 | 因此,我们不仅会一起来看这两个指标,也会把它们放到一起来提需求。比如说,我们会要求算法同学,在 30% 召回率下把模型的精确率提升 5 倍。
87 |
88 | 除此之外,还有一个指标可以综合反映精确率和召回率,它就是 $F1$ 值,$F1$ 值越高,代表模型在精确率和召回率的综合表现越好。
89 |
90 | F1 的计算公式:$F1 = \frac{2 \\times precision \\times recall}{precision + recall}$。
91 |
92 | 不过,在实际对模型评估的时候,我们还是习惯看召回率和精确率,这两个指标给业务方去讲,也比较容易理解(不使用准确率是因为在样本偏差情况下,准确率反而不准确)。
93 |
94 | 最后,在使用这三个指标的时候,我还有几点建议:
95 |
96 | - **准确率:理解成本最低,但不要滥用。在样本不均衡情况下,指标结果容易出现较大偏差;**
97 | - **精确率:用于关注筛选结果是不是正确的场景,宁可没有预测出来,也不能预测错了。** 比如,在刷脸支付的场景下,我们宁可告诉用户检测不通过,也不能让另外一个人的人脸通过检测;
98 | - **召回率:用于关注筛选结果是不是全面的场景,“宁可错杀一千,绝不放过一个”。** 比如,在信贷场景下,我要控制逾期率,所以宁可把好用户拦在外面,不让他们贷款,也不能放进来一个可能逾期的用户。毕竟,用户一旦逾期,无法收回的本金产生的损失,比我多放过几个好用户带来的收益要多很多。
99 |
100 | ## 小结
101 |
102 | 混淆矩阵是分类模型评估的基础,准确率、精确率和召回率是从混淆矩阵衍生出来的评估指标。为了帮助你记忆,我把这些指标的公式、解释和注意事项都总结在了下面的表格里,方便你对比和回顾。
103 |
104 | 
105 |
106 | 最后,我们要记住一点:在实际对分类模型性能进行评估的时候,我们一般会用精确率和召回率一起使用,比如,在召回率 20%的基础上,达到精确率 5%。但是,对于信用评分的模型,我们很少只用召回率和精确率这样的指标去做判断,而是用$KS、AUC$这样的指标进行判断。这些指标我们下节课会详细来讲。
107 |
108 | ## 课后讨论
109 |
110 | 刚才我们说,对于信用评分模型一般用$KS、AUC$这样的指标进行评估。你觉得,我们为什么不用准确率呢?
111 |
112 | 期待在留言区看到你的思考,我们下节课见!
113 |
114 |
111 | - 悠悠 👍(26) 💬(1)
我觉得可能可以从该员工最近的请假情况等来判断(可能还有其他元素,暂时先理清这一个因素),暂定两周内请假3天及以上(事件B)。比较事件B下离职和不离职的概率,
112 | P(A):离职的概率;
113 | P(B):近两周内请假3天及以上的概率;
114 | P(A|B):近两周内请假3天及以上,离职的概率;
115 | P(B|A):离职的人中,近两周内请假3天及以上的概率;
116 | P(C):不离职的概率
117 | P(C|B):近两周内请假3天及以上,不离职的概率;
118 | P(B|C):不离职的人中,近两周内请假3天及以上的概率;
119 |
120 | P(A|B)=P(B|A)P(A)/P(B)
121 | P(C|B)=P(B|C)P(C)/P(B)
122 |
123 | 若P(A|B)>P(C|B),则离职概率大
124 | 若P(A|B)<P(C|B),则不离职概率大
2021-01-08
- 网易吴彦祖 👍(16) 💬(2)
离职率是一个非常复杂的模型,朴素贝叶斯算法过于简单了,我认为不太合适
2021-01-08
- 我不过是善良 👍(8) 💬(4)
离职看似简单,主要原因其实就那么2条:钱给少了、领导不对付;前者可以用同等条件招聘网站薪资平均计算,后者可以用问卷计算。
2021-01-13
- 刘启宇 👍(4) 💬(2)
工作年限 性别 岗位 薪资数据 部门 等
125 | 可以选几个相对独立的数据进行分析,所以是合适的。
2021-01-08
- weiwei 👍(4) 💬(0)
我觉得离职预测案例中,难点就是特征之间的独立性。
2021-12-31
- 小亮 👍(1) 💬(1)
20% * 40% * 30% = 24%?
2023-04-04
- 热寂 👍(0) 💬(1)
能否解答一下:飞机延误和不延误的那张表格,4个概率加起来是0.8,为什么不是1?这4个事件不应该是组成一个全集吗?
2022-05-28
- escray 👍(0) 💬(0)
贝叶斯就是根据 先验概率 P(A)、P(B) 和 条件概率 P(B|A) 估算 后验概率 P(A|B)
126 |
127 | 朴素贝叶斯假设所有条件对结果都是独立发生作用的,那么不朴素的呢?如果条件对结果的作用不独立,是不是就没有办法预测了?
128 |
129 | 飞机延误的例子稍微有一点复杂,看了一会儿才明白,其中 P(A1A2) = P(A1)*P(A2),这也就是说 A1 和 A2 之间是独立的。比如深圳和北京的天气,如果是深圳和广州的话,估计就不独立了。
130 |
131 | 对于离职概率的计算,个人感觉朴素贝叶斯可能过于简化了。或者说,我感觉对于人的预测,一般很难准确,悠悠的答案可能是比较接近实际情况的,但是如果行业处于风口,跳槽的收益很高,那么就没法预测了。
2022-04-13
- 产品部1 👍(0) 💬(0)
朴素贝叶斯算法适合分析条件相对独立的场景,而员工多种离职因素不具备独立性,因此比较适合用线性回归算法来预测。
2022-04-05
- 澄镜之水 👍(0) 💬(4)
从上面飞机延误的公式到下面飞机延误概率值的计算,中间是怎么转换的呀?
132 |
2022-02-09
- 俯瞰风景. 👍(0) 💬(0)
首先分析出离职原因可能有哪些,确定特征标签,然后根据以往员工离职的数据进行进行KNN分类,找出来和离职相关度高的特征标签,并且根据样本总量计算出每个特征导致离职的大概概率。
133 |
134 | 用这些特征标签结合朴素贝叶斯进行预测。
2021-08-26
- AnMin 👍(0) 💬(0)
离职的条件有很多种,里面有很多条件都不是相互独立的,所以从这点上来看,不太适用于预测离职概率的条件,但是如果可以从很多条件中筛选出相对对立而且对离职影响比较大的条件的话,还是可以尝试使用朴素贝叶斯的。
2021-07-06
- 发条 👍(0) 💬(0)
从文章角度强调的原则来说,朴素贝叶斯适用于独立条件的先后验概率分析。 一个员工的离职原因可以有很多,这些原因之间往往不是完全独立的,网友提到的收入高低、晋升快慢、职级高低、绩效好坏、与领导关系等等往往都是环环相扣的。如果基于成本的考虑不得不先用朴素贝叶斯,难点在于原因的挖掘,原因的独立性评估和合并,经验数据的测算。 比如年终奖的绝对数值往往绩效好坏、所属部门、岗位种类、社会工龄长短有密切关系,尽可能把这些相关因素找出来,设置算法把这些特征合并成一个影响因子,比如上述这些因素是否可以合成一个名为【收入等级】的独立因素,依据各因素权重测算每个员工的【收入等级】,最后把这个因子作为独立因子之一代入朴素贝叶斯。
2021-06-27
- 小太白 👍(0) 💬(2)
离职预测的关键指标如绩效考核/工资将近,职业发展和晋升通道,公司文化和团队氛围。而这些指标间相辅相成,比较复杂,不适合用朴素贝叶斯这类简单且假设影响因素条件相互独立的模型。可能还是逻辑回归比较好?
2021-03-08
135 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/16 - 深度学习:当今最火的机器学习技术,你一定要知道.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 深度学习(Deep Learning)是一种特殊的机器学习,是借鉴了人脑由很多神经元组成的特性而形成的一个框架。相对于普通的机器学习,深度学习在海量数据情况下的效果要比机器学习更为出色。
4 |
5 | 并且,自从 2016 年 Alpha Go 打败了李世石之后,深度学习就正式确立了在机器学习领域中的霸主地位。可以说,目前所有应用了人工智能的行业,基本都用到了深度学习模型。因此,产品经理也必须要了解深度学习的基础知识。
6 |
7 | 这节课,我们就来学习这个当今最火的机器学习技术,以及它的应用场景和算法效果。
8 |
9 | ## 如何理解深度学习?
10 |
11 | 因为深度学习可以简单理解为多层的神经网络模型,所以想要理解**深度学习**,我们就要先理解**神经网络。**接下来,我就通过一个例子来讲讲什么是神经网络。
12 |
13 | ### 什么是神经网络?
14 |
15 | 假如,你现在就职于一家很“民主”的公司,每年年终总结的时候,公司会让每一名员工写下自己对公司的意见,并且收集起来。为了节约行政成本,这些意见都会由当前层级的领导整合后,提交给他的上一级领导。
16 |
17 | 比如说,每个“部门组长”收集所有“部门员工”的意见,整合后统一提交给所有“部门经理”。每个“部门经理”收集所有“部门组长”的意见,整合后统一提交给所有“事业群经理”。就这样层层汇总传递,最后由事业群经理汇总提交给总经理,下图就是这个公司收集员工意见的流程图。
18 |
19 | 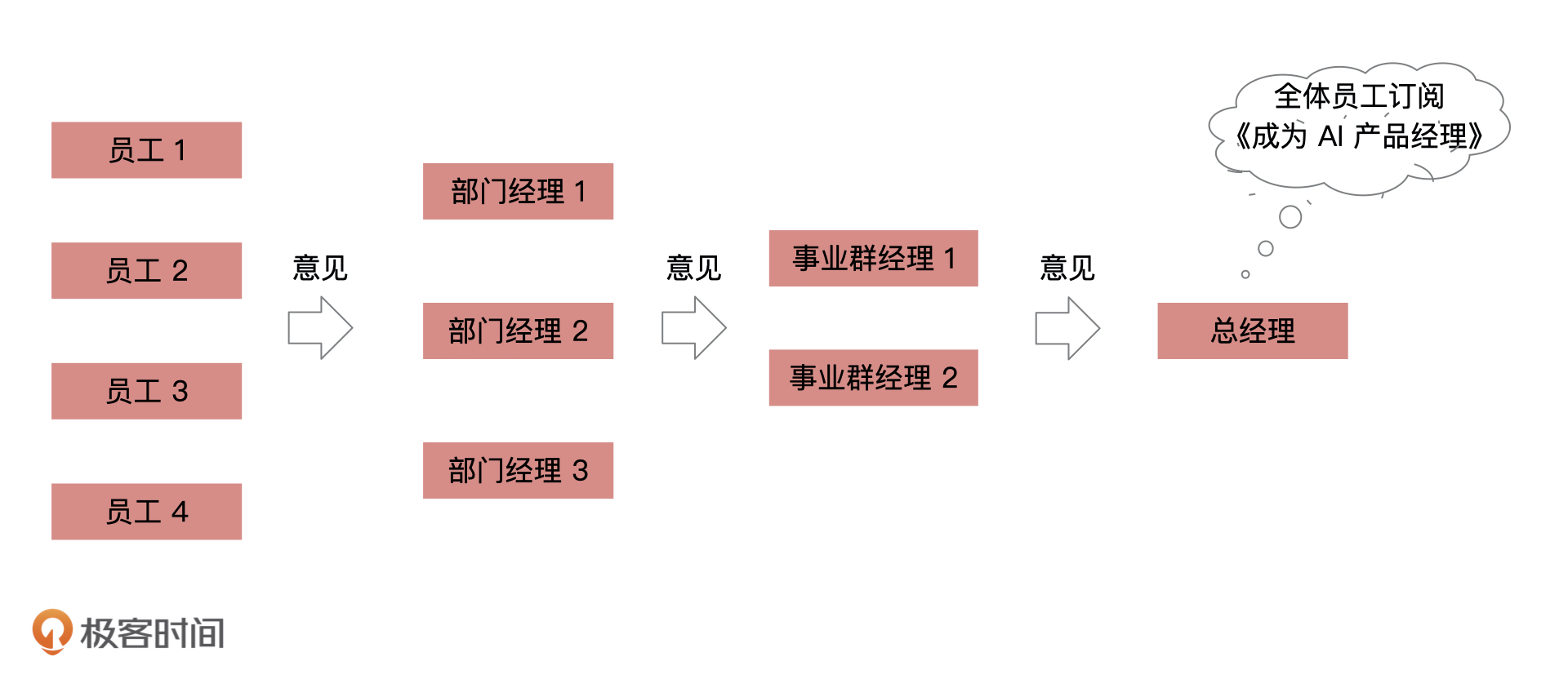
20 |
21 | 这个例子其实完全可以通过机器学习模型来描述。我们可以把每个“员工”的意见,想象成机器学习中的“**特征**”,把每一层“领导”对收集上来的意见的整合,想象成当前层级的“**输出**”,最后把“总经理”收到的结果想象成模型的“**最终输出**”。这样一来,就形成了一个多层级的机器学习模型,也就是我们说的**神经网络**。
22 |
23 | 具体来说,我们可以把这个神经网络用三层结构来表示,分别为**输入层**、**隐藏层**,以及**输出层**。其中,隐藏层对我们来说是黑盒,隐藏层中的每上一个隐藏层的输出都是下一个隐藏层的输入,每一层都是在表达一种中间特征,**目的是将特征做非线性高阶变换**。
24 |
25 | 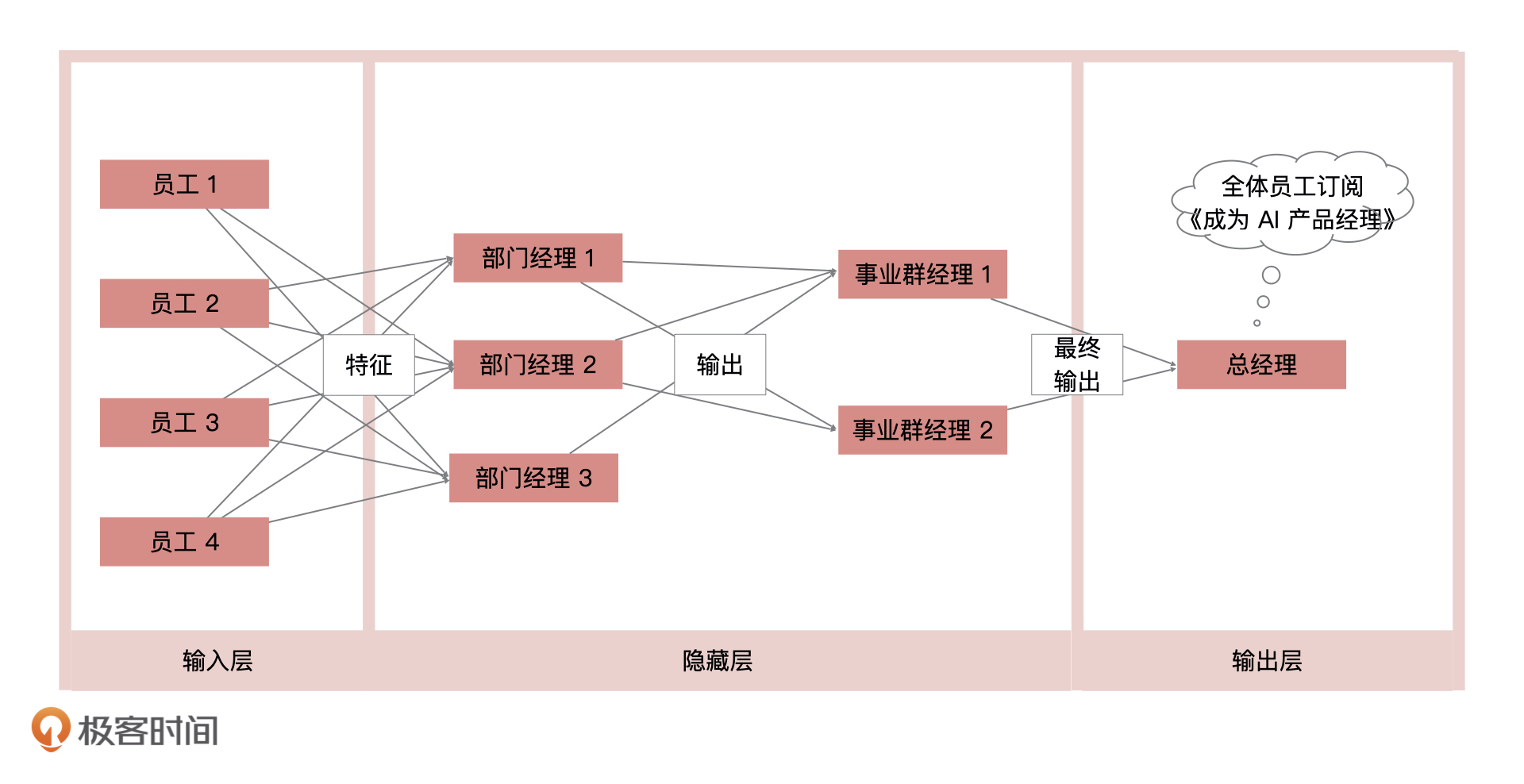
26 |
27 | 在这个神经网络的结构中,不同层级之间的联系是非常紧密的,因为每个连接层之间的节点(领导),都会和上下两个层级中的所有节点(领导)进行沟通。我们也把这种结构叫做**全连接神经网络模型**。
28 |
29 | ### 神经网络模型的组成
30 |
31 | 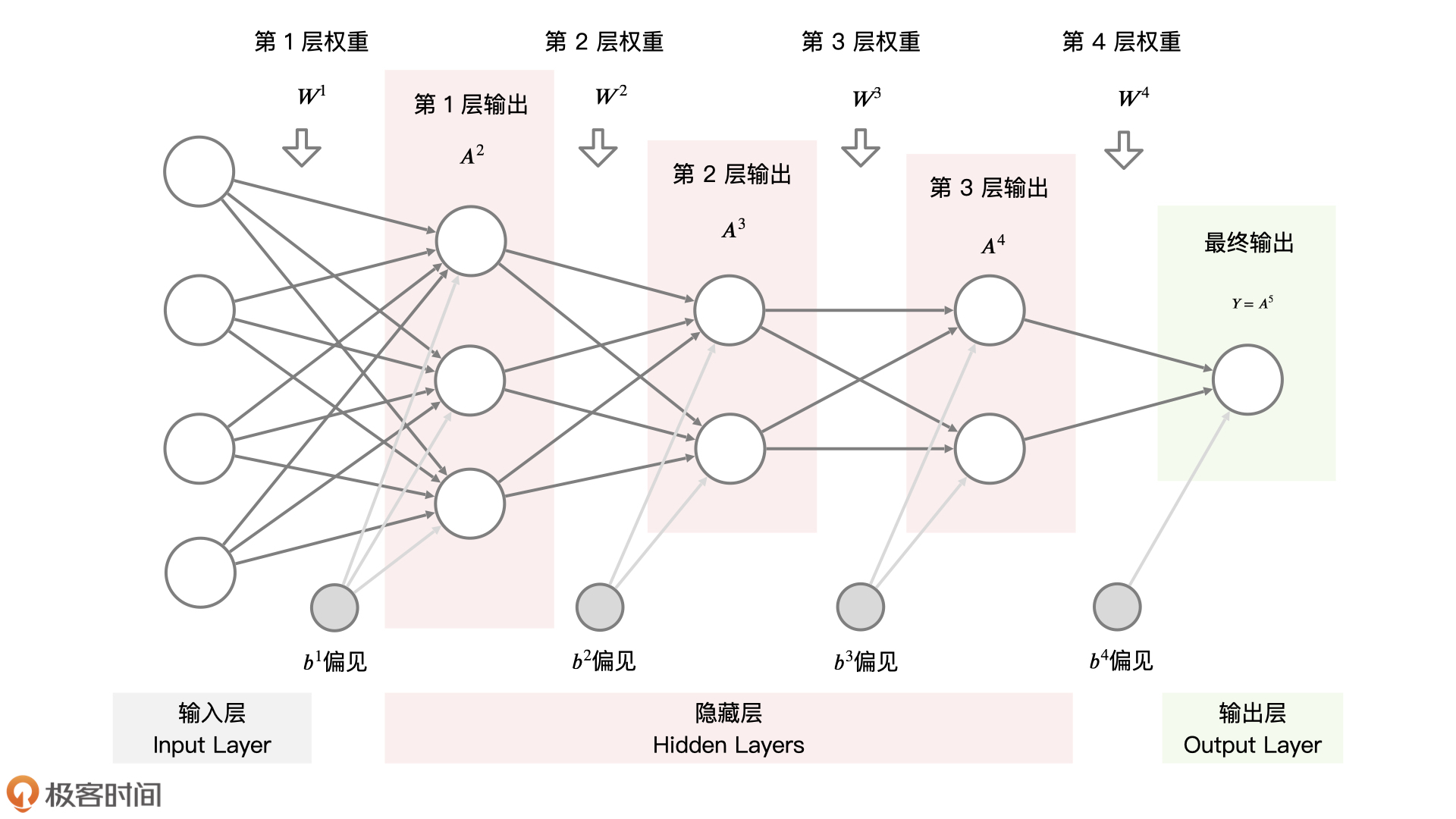
32 |
33 | 上图这样由“圆圈”和“连接线”组成的图就是神经网络结构图,我们可以通过一个数学公式来表达:$A^{(n+1)}=\\delta^{n}(W^{n}A^{n}+b^{n})$。
34 |
35 | 理解公式是理解神经网络组成的关键,接下来我就给你详细讲讲这些参数都是什么。
36 |
37 | 首先,图中的一个个“圆圈”就是 **Neuron**(神经元),表示当前层级下计算节点的输出,也就是$A^{(n+1)}$,我们可以把它想象成某个层级的领导对收集上来的意见整合后的结果。
38 |
39 | 而“连接线”就是 **Weights**(网络权重),表示不同层级之间的连接,用$W^{n}$表示。我们可以把它想象成不同员工意见的权重,比如核心员工的意见份量就重一些,绩效差的员工份量就轻一些。
40 |
41 | 同时,因为每个人所在公司位置不同,所以对于意见的反馈结果也会不同。比如,有些“部门经理”在收到员工的意见后,决定直接放大负面反馈的意见,而有些“部门经理”则决定谨慎处理,减少负面意见反馈的声音。在机器学习中,我们会把这些带有主观偏见的处理,叫做神经网络模型中的 **bias 偏移**,用$b^{n}$表示。
42 |
43 | 说到这,不知道你意识到一个问题没有,如果只是把“员工”意见反馈给“总经理”,那中间几层的“领导”就没有存在意义了,因为“员工”完全可以直接跳过所有“领导”把意见传递给最终的“总经理”。
44 |
45 | 因此,神经网络模型还设计了一个对下层意见解读和调整的操作。一般来说,我们会采用增加激活函数对每一层整体的输出做改进,把每层的结果做非线性的变化,去更好地拟合数据分布,或者说来更好地展示给上层的“领导”。常见的激活函数有 $ReLU$、$tanh$、$Sigmoid$等等,我们用$\\delta^{n}()$表示。
46 |
47 | ### 深度学习模型训练目标
48 |
49 | 理解了神经网络的基本知识之后,深度学习模型的训练目标就很好理解了。
50 |
51 | 前面的学习让我们知道,**监督类机器学习模型的目标就是在给定一个任务的情况下,找到最优化的参数,使得 Loss 损失值最小,其中 Loss 损失值就是预测结果和真实结果之间的误差。**
52 |
53 | 神经网络作为一个有监督机器学习模型,自然也不会例外,它的**目标就是在给定一个任务的情况下,找到最优的Weights 和 bias,使得 Loss 最低**。
54 |
55 | 由于最开始的参数都是随机设置的,因此获得的结果肯定与真实的结果差距比较大。那么,为了训练神经网络中的参数,神经网络模型会采用反向传播,把 Loss 误差从最后逐层向前传递,使当前层知道自己在哪里,然后再更新当前层的 Weights 权重和 bias 偏移,进而减小最后的误差。这部分数学推导比较复杂,产品经理只要了解就可以了。
56 |
57 | ## 深度学习的应用案例:图像识别是如何实现的?
58 |
59 | 近几年,神经网络在图像处理和自然语言处理方面都有非常大的成果。所以,我们也借助一个图像识别的案例,来讲讲深度学习的应用。
60 |
61 | 如今,图像识别这项技术已经发展得很成熟,**卷积神经网络(Convolutional Neural Networks,CNN)**又是其中的主流技术,像Facebook、Google、Amazon等公司都在利用 CNN 进行图像识别的工作。
62 |
63 | [](http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/)
64 |
65 | ### CNN是如何实现图像识别的?
66 |
67 | 下面,我们就来学习一下,CNN 实现图像识别的具体过程。
68 |
69 | 因为 CNN 是深度学习的算法之一,所以它同样包含输入层、隐藏层,以及输出层这三大部分,更具体点来说,CNN 的整个组成部分可以分为,数据输入、特征提取、全连接以及输出层四个部分。其中,特征提取、全连接对应神经网络的隐藏层,数据输入和输出层对应神经网络的输入层和输出层。同样的,我也把它和神经网络的对应关系梳理出来了,如下图所示。
70 |
71 | 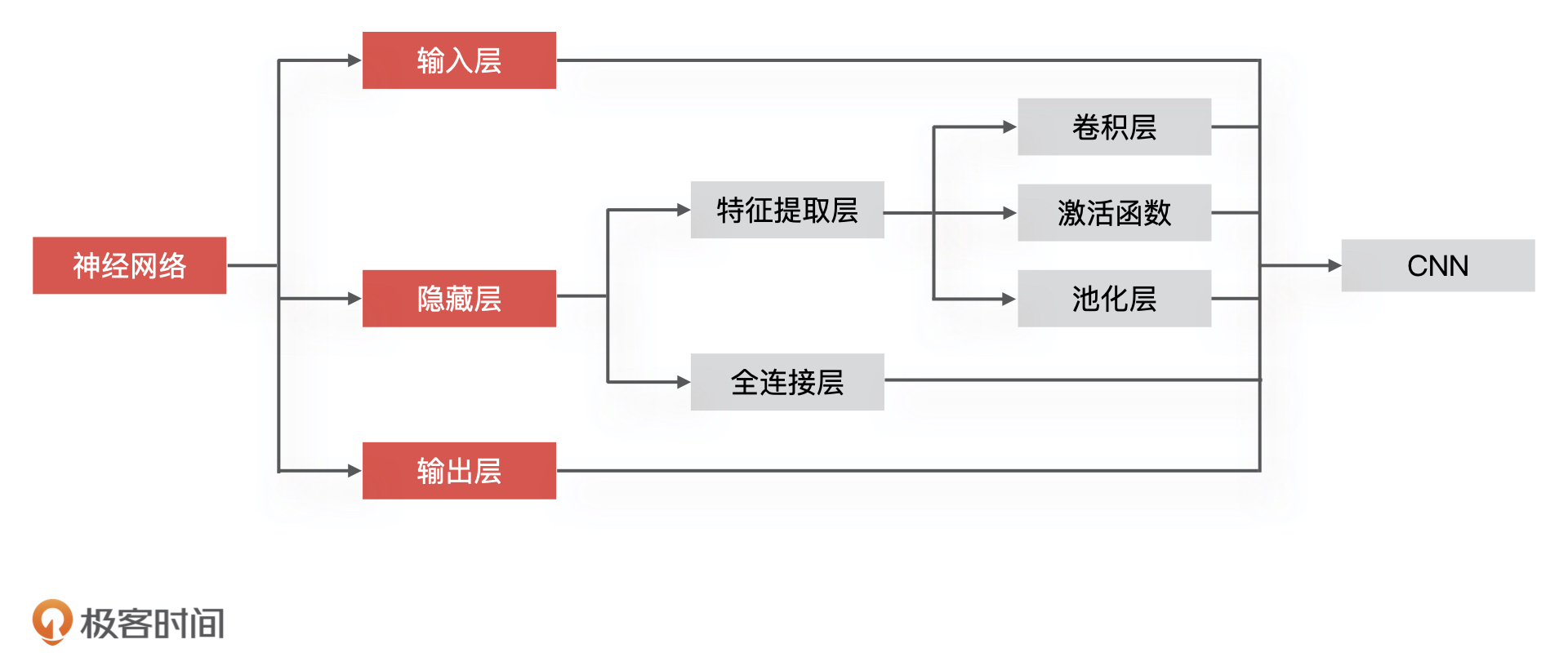
72 |
73 | 接下来,我就结合下面的示意图,给你详细讲讲它对图像的处理过程。
74 |
75 | 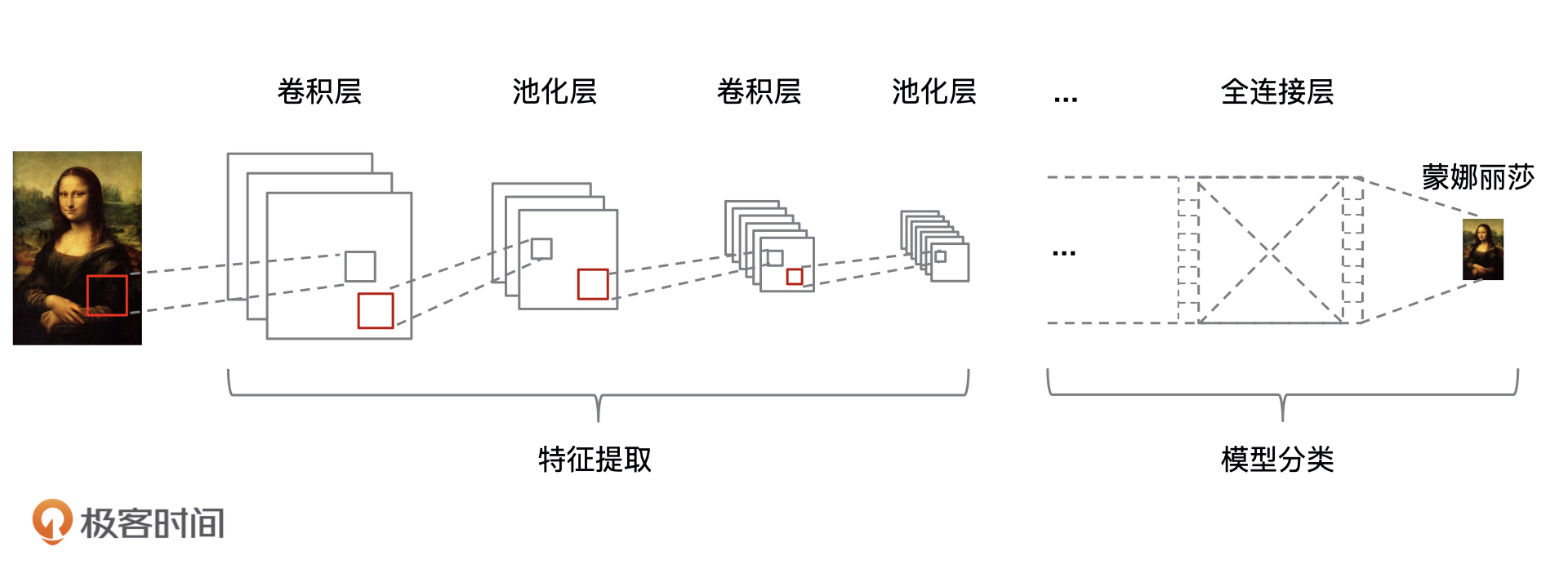
76 |
77 | CNN 实现图像处理的第一步,就是把图像数据输入到 CNN 网络模型中。我们在[第3讲](https://time.geekbang.org/column/article/322393)中讲到,任意一张彩色图片都可以表示成一个三阶张量,即三维数组。
78 |
79 | 其实所有彩色图像都是由红、绿、蓝(RGB)叠加而成的,比如一个 12px * 12px 的图像可以用 3 个 12 * 12 的矩阵来表示,如果是白色的图像就可以表示成 GRB(255, 255, 255)。 **那么, CNN 网络模型的数据输入就是将彩色图像分解为 R、G、B 这 3 个通道,其中每个通道的值都在 0 到 255 之间。**
80 |
81 | 数据输入之后,就到了特征提取的阶段了。在讲具体操作之前,我想你肯定会有一个疑问:**为什么CNN就适合于图像类的任务,全连接神经网络为什么不可以呢?**
82 |
83 | 这是因为,CNN 能够在众多深度学习算法中,以最短时间提取图像的特征。普通的神经网络对输入层与隐藏层会采用全连接的方式进行特征提取,所以在处理较大图像的时候,处理速度就会因为计算量巨大而变得十分缓慢。这个时候,计算能力就会成为最大的瓶颈。如果换成现在互联网上动不动就出现的高清大图,全连接神经网络就更行不通了。
84 |
85 | 举个例子,人在识别图像的时候,图像越清晰越好,但是这一点对于机器来说却很难,因为机器在识别图像的时候,往往需要将图像转换成像素值,再输入到模型中进行学习,而越清晰的图片意味着需要处理的像素越多,会带来更多的计算压力。
86 |
87 | 为了解决这个问题,CNN 就通过过滤无关信息,来提高识别效率。比如下面的这张图片,背景对于图像识别来说其实没有帮助的,反而増加了很多干扰信息。
88 |
89 | 
90 |
91 | 那么,如何有效地过滤掉干扰信息,并且识别图像中的主体信息呢?做法就是不断模糊化一张图片,最后只剩下狗的轮廓,而背景信息这类无关项就会越来越不可见。
92 |
93 | 
94 |
95 | 对于 CNN 网络模型来说,“模糊化图像”的这个操作就是通过 CNN 的**卷积和池化**来实现的。
96 |
97 | 我们先来看卷积运算。CNN 的每一个隐含单元(即,前文中的各中间层“领导”)只连接输入单元(即上一层输入)的一部分,这样就能让模型中不同输出对应不同的局部特征。对应到图像中,就是可以提取图像的不同局部特征,从而实现既减少了输入值,又提取到了图像的最主要的内容。
98 |
99 | 在完成各层的卷积运算后,深度学习模型还需要进行非线性的变换,非线性的变换是通过增加**激活函数**来实现的,通过激活函数将“线性回归”拟合的直线编程曲线,这样可以拟合各种复杂的问题,这里激活函数选型的是 $ReLU$函数。非线性变换的内容我们在“[逻辑回归](https://time.geekbang.org/column/article/329236)”那节课也讲过,你也可以去回顾一下。
100 |
101 | **池化**的目的也是提取特征,减少向下一阶段传递的数据量,池化过程的本质是“丢弃”,即只保留图像主体特征,过滤掉无关信息的数据特征。
102 |
103 | CNN 的所有卷积和池化操作都是在提取特征,直到**全连接**层才进入真正的训练学习阶段,做最后的分类计算。在 CNN 中,**全连接**层一般是用的是 Softmax 函数来进行分类,这部分我们简单了解就行了。
104 |
105 | ## 深度学习的优缺点
106 |
107 | 接下来,我再结合深度学习的优缺点,来说说它的适用场景。
108 |
109 | 首先,深度学习的可解释性非常差,因为它的内部计算复杂,对我们来说是一个黑盒,我们只需要输入数据,由它来告诉我们结果,至于为什么会这样,它不做任何解释。所以在很多对解释性要求比较高的场景,比如信用评级、金融风控等情况下,深度学习没办法使用。
110 |
111 | 其次是训练深度学习模型非常消耗资源,所以想利用深度学习网络进行实际工作,我们就必须要提前准备好相应的计算资源,如硬件设备。
112 |
113 | 最后,因为深度学习模型复杂,对数据依赖很强,所以它比我们之前讲的传统机器学习网络更难理解和学习。因此,在实际工作中,训练深度学习模型也需要配置专业的人才。
114 |
115 | 总之,深度学习具有**可解释性弱,模型训练慢,对数据依赖很强,模型复杂这四个缺点。**尽管深度学习的应用有着非常苛刻的条件,但是相对于它的模型性能来说,这些成本的付出还是值得的。深度学习自身的神经网络结构,让它每层的 Activation 激活函数都可以做非常复杂的非线性变化,这也意味着你的模型可以拟合任意复杂的数据分布,所以,它比我们之前讲过的所有算法的性能都要好。
116 |
117 | ## 总结
118 |
119 | 今天,我们围绕深度学习,讲解了它的原理结构、优缺点和应用场景。
120 |
121 | 深度学习是机器学习的一种,它源于神经网络模型的研究,由输入层、隐藏层,以及输出层组成,在计算机视觉、语音识别、自然语言处理等领域应用最为广泛。
122 |
123 | 在目前的机器学习领域中,它可以说是性能最好的网络模型了。但同时,它也具有可解释弱,模型训练慢,对大数据有依赖,模型复杂度高的缺点,这让它的应用场景受到了局限。
124 |
125 | 因此,在目前工业中,深度学习常用来处理计算机视觉、人脸识别、语音识别、机器翻译、自然语言处理、推荐系统等等。
126 |
127 | 最后,我还想补充一点,除了我们今天讲的CNN,深度学习还有很多其他的模型,比如 LSTM、RNN、Seq2Seq、Gen,以及很多开源的深度学习框架,比如 TensorFlow、PyTorch 等等。这些都为算法工程师构建和使用神经网络创造了极大的便利,并且在实际的工作中,他们通常也会选择这些框架来进行模型的构建和训练。作为产品经理,如果你掌握了我们今天讲的内容,你也可以结合自己的业务,多去了解一下这些内容。
128 |
129 | ## 课后讨论
130 |
131 | 最后,我还想请你介绍一下,你曾经在工作中遇到过的深度学习模型案例,以及当时为什么要基于深度学习来做?
132 |
133 | 欢迎在留言区给分享你的故事,也欢迎你把这节课分享给你的朋友,我们下节课见!
134 |
122 | - 珊羽 👍(31) 💬(0)
看了一眼评论,我觉得大部分人都陷入了技术思维,我个人认为这个问题应该要从产品经理的视角来思考,从整个产品设计流程来看,模型选择只是其中的一部分,而不是产品经理关注的全部。
123 | 1、产品目标:过滤垃圾评论
124 | 2、具体需求:通过算法模型来找出垃圾评论,并过滤掉
125 | 3、算法(这部分可以与算法同学沟通)
126 | (1)定义目标变量:即是否垃圾评论
127 | (2)定义垃圾评论:即什么是垃圾评论,如广告?
128 | (3)算法选型:这个问题本质上是个分类问题,可以通过聚类算法对评论进行分类,找出垃圾评论
129 | (4)确定样本:选定一部分数据,如果是有监督的学习需进行标注,如果是无监督学习则不需要标注,这里要根据算法同学最终选定的模型来定
130 | (5)训练模型
131 | (6)验证模型
132 | 4、系统工程侧的开发任务:即模型的运用,模型上线后,工程侧的同学如何通过模型过滤垃圾评论
133 | 5、核心指标:即算法最终要达成的目标
134 |
2021-03-17
- 悠悠 👍(8) 💬(0)
1、用聚类算法将海量的评论进行分类;
135 | 2、对分类的评论进行标注,是否为垃圾评论;
136 | 3、用朴素贝叶斯训练模型。
2021-01-18
- 悠悠 👍(3) 💬(1)
期待后面的项目,希望能转成功
2021-01-18
- 王小玥 👍(2) 💬(0)
“产品经理决定做一个事情的出发点,是通过技术来实现业务价值,有时候技术如何做反而不重要”
137 | “产品经理需要的是知识的广度,需要打通上下游与横向部门”
138 | 这两句话说的深有感触。
2023-03-20
- 阿小 👍(1) 💬(0)
首先,业务需求沟通,1)明确垃圾评论的定义、是否有初步的分类想法,是否有关键词规则等;是否有数据标注?判定可容忍的误差范围等。2)过滤后是否需要处置?3)周期有多长?
139 | 其次,明确业务的分类目标和项目周期后,和算法同学进行沟通,就实际数据情况、业务效果预期进行算法设计讨论、例如如果是有标注的二分类问题可以用TextCNN、无标注则考虑用K- Means等,当然文本类数据需要做命名实体识别等处理。同工程化产品研发的同学讨论实际分类后的处置实现,例如如果期望基于某个分类自动回复等。
140 | 接着,在算法同学出来算法预研方案后制定产品计划,跟进产品、算法研发进度。
141 | 最后,验收模型、产品,发版。
2021-04-07
- BAYBREEZE 👍(1) 💬(0)
我看到这些算法,和数据挖掘的算法是一样的,让我差点把AI与数据挖掘搞混了。
142 | 请问老师,机器学习和数据挖掘的区别是什么呢,都是一样的算法情况下,还有哪些区别?
143 | 望回复
2021-01-21
- Geek_27fa97 👍(0) 💬(0)
可以加您微信吗
2025-02-10
- 哈雷 👍(0) 💬(0)
1、核心需求:过滤垃圾评论
144 | 2、业务沟通(与业务小伙伴具体沟通):哪些评论属于垃圾评论,确定需求边界
145 | 3、算法预研(与算法小伙伴具体沟通):说清需求,需求边界,界定预期结果,算法选型。
146 | 4、数据清洗和样本选择(与算法小伙伴具体沟通,需业务部门配合):根据需求,确定特征工程,并建立样本。
147 | 5、训练模型
148 | 6、验证模型
149 | 7、场景回归测试(a/b测试或人工测试)
150 | 8、发布上线
151 | 9、跟踪效果并迭代
2024-04-02
- Pale Blue 👍(0) 💬(0)
假如,你现在是一家电商平台的产品经理,负责点评系统的产品设计,现在有一个需求是要通过计算将海量评论中的垃圾评论(如,打广告的情况)过滤出来,你会怎么思考和设计产品呢?
152 | 1. 目标:过滤垃圾评论
153 | 2. 用算法模型过滤掉垃圾评论
154 | 3.实现步骤:
155 | (1)定义垃圾评论
156 | (2)数据处理阶段:针对评论文本数据进行处理,进行分词->计算词权重->去掉停用词(https://baike.baidu.com/item/tf-idf/8816134?fr=aladdin)
157 | (3)使用朴素贝叶斯分类器,并且进行训练
158 | (4)验证分类模型
2021-09-21
- Yesss! 👍(0) 💬(0)
首先考虑的是:项目周期是否紧张、相关算法资源是否充足。我假设这里是以节省成本以最优法进行解释:
159 | 1、这是一个分类问题
160 | 2、可以用我学过的 k-means 算法 进行分类。随意采取几个质心 - 计算每个数据点与质心的距离 -均值作为下一个质心的位置 - 新质心与老质心距离不再变化或小于某一个阈值。结束算法。筛选出文本聚类
161 | 选择k-means原因:运算效率高、可解释性强、容易实现、大部分聚类都能解决
162 | 3、使用朴素贝叶斯算法(适合垃圾评论分类)-查看了悠悠的评论
163 | 选择朴素贝叶碎算法原因:算法资源占用不高、构建模型快。评论属于互相独立性比较高的数据
2021-01-31
164 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/25 - 推荐类产品(二):从0打造电商个性化推荐系统产品.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 假设,你是一家电商平台公司的产品经理,公司经过一年多的供应链打造和用户运营的投入,业务已经发展到了一个高速增长的阶段。
4 |
5 | 但问题也随之暴露了出来:之前产品首页是人工配置选品的,每个用户在浏览 App 的时候,看到的都是千篇一律的商品。这种无法体现用户对于商品兴趣的偏好情况,不但削减了用户的体验,也没法让供应商满意,因为随着接入的供应链多了起来,供应商也希望自己的商品能有更多的曝光。
6 |
7 | 为了尽快解决这个问题,老板决定让你牵头打造一个个性化电商MVP推荐系统 (Minimum Viable Product,最小可行性产品)。已知,推荐系统的建设可以分为 4 个重要的阶段,分别是需求定义、数据准备、技术实现和评价标准。
8 |
9 | 那么,每个阶段产品经理都要做些什么呢?接下来,我就和你详细说说。
10 |
11 | ## 需求定义
12 |
13 | 在需求定义环节,我们最重要的工作就是产出需求文档。具体来说,产品经理需要做的有3件事,分别是交代需求背景、描述交互逻辑,以及明确预期目标。下面,我们一一来说。
14 |
15 | ### 1. 构建需求背景
16 |
17 | 在需求背景部分,**我们要重点交代清楚为什么要建设推荐系统,让协同部门能够理解背景,和我们对齐这个项目的价值**。一般来说,我们会和业务方进行频繁沟通,发掘他们最核心的诉求。那么,今天这个例子中的核心诉求其实就是要展现所有用户对商品的偏好,避免“千人一面”。
18 |
19 | ### 2. 描述交互逻辑
20 |
21 | 接下来,我们要**对推荐系统的交互逻辑进行描述,主要包括描述用户的动线流程、模型诉求和产品功能上的逻辑**。
22 |
23 | 因为我们这次构建的是MVP推荐系统,所以不需要通过算法模型来实现所有的推荐逻辑,而是分成两部分,一部分通过算法进行推荐,另一部分通过运营系统配置进行推荐。
24 |
25 | 那再说回到这个推荐系统产品的交互逻辑上。
26 |
27 | 首先,当用户进入商品主页的时候,推荐系统会检查是否已存在当前用户的画像信息。如果存在就获取用户的商品偏好标签,执行商品召回的算法逻辑,如果不存在就把运营系统配置的商品数据展示给用户。
28 |
29 | 然后进入商品召回模块,由于只需要打造一个 MVP 的推荐系统,因此我们只设计一种召回策略就可以了,如“基于协同过滤的召回策略”。这样,推荐系统就不涉及多路召回融合的问题,在产品需求中也就不用涉及“排序阶段”的需求了。
30 |
31 | 所以我们直接进入“调整阶段”。这一阶段,推荐系统需要通过规则,将算法召回的商品列表和运营系统配置的商品列表进行融合。常见的运营配置有,商品在第一周上新期内需要在展示列表中置顶等等。
32 |
33 | 最终,推荐系统会将融合后的商品列表展示给用户。完整的交互逻辑如下,你可以看看。
34 |
35 | 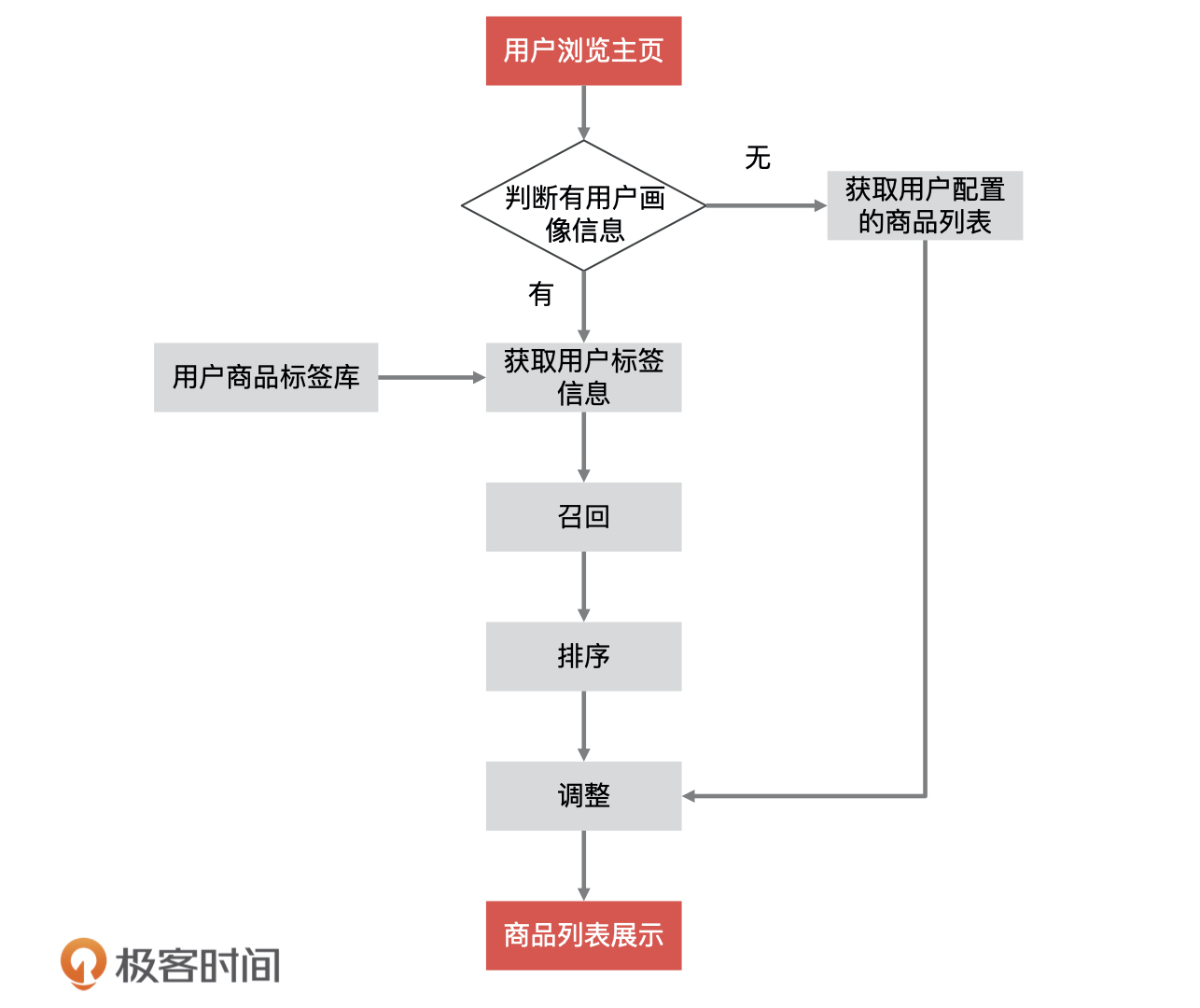
36 |
37 | ### 3. 制定预期目标
38 |
39 | **最后就是制定电商推荐系统的预期目标了,这个目标是根据业务的实际情况而设定的。有了目标就要有衡量目标的指标,** 虽然大多数推荐系统的衡量指标都是 CTR,但我建议你从业务的建设阶段来设定衡量指标,就像我上节课讲的那样。这里,因为我们的业务发展属于成熟阶段,所以设定的衡量指标为 CVR。
40 |
41 | 
42 |
43 | 总的来说,产品经理要能够清晰地设计需求,需求定义要明确需求背景、描述交互逻辑,以及制定预期目标,那么如何做才是清晰的设计需求呢?我为你准备了一份推荐系统需求模板,你可以作为参考。
44 |
45 | 
46 |
47 | ## 数据准备
48 |
49 | 接下来是数据准备阶段。在推荐系统中,如果用户在某个环境下对某个商品做了某种操作,我们就认为这个操作表达了用户对这个商品的兴趣偏好。推荐系统要做的就是挖掘这个偏好,然后给这个用户推荐相同偏好的其他商品。因此,数据对于推荐系统是非常重要性。我们要做到的就是在搭建推荐系统之前,完成大量数据的收集和整理工作。
50 |
51 | **这些数据的来源一般包含三类:业务数据、埋点日志和外部数据。**并且每个来源的数据都有着详细的数据分类,这些数据会应用于机器学习的离线预估模型训练和实时模型预估计算。具体内容我都总结在了下面的表格中,你可以看一看。
52 |
53 | 
54 |
55 | 像是“用户数据”、“商品数据”和“上下文环境数据”本来就是存在于数据库中的,产品经理只需告诉算法同学数据源在哪里即可,后续算法同学会自行抽数。我们唯一提前要进行收集的就是用户的前端埋点日志,如果系统之前没有做过埋点,那么势必会影响推荐系统的准确性。
56 |
57 | **因此,在搭建推荐系统之前,我们要通过埋点尽可能地收集用户的前端行为日志。**
58 |
59 | 那么问题来了,我们都需要埋哪些数据,把它们埋在哪些页面呢?这需要产品经理根据自己对业务的理解,整理出一套页面埋点文档,为算法同学提供数据支持。虽然根据业务的不同,具体的埋点策略会有差别,但我还是根据经验梳理出了一些用户行为与商品信息的数据埋点字段,供你参考。
60 |
61 | 首先是用户行为数据埋点字段:
62 |
63 | 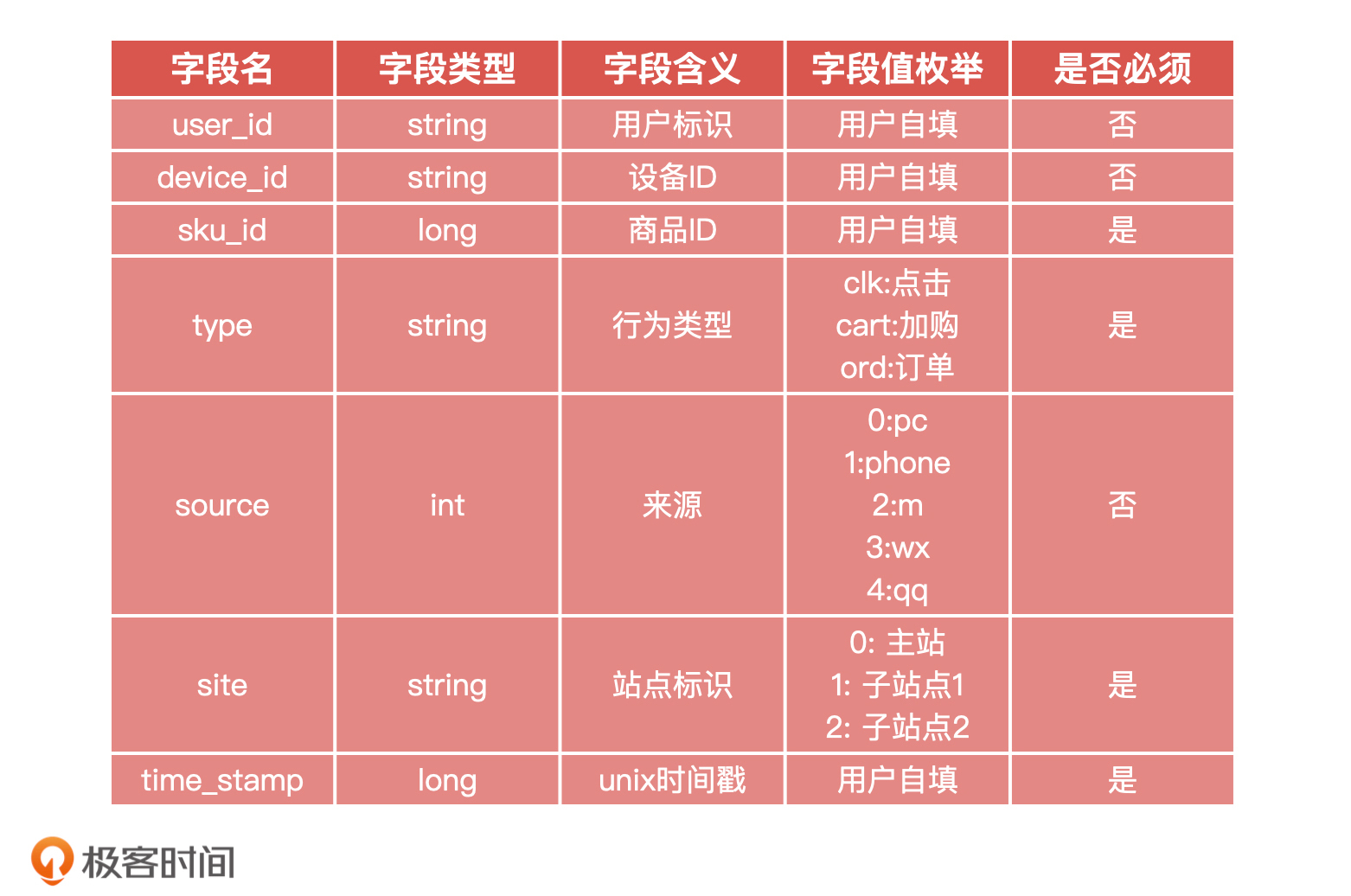
64 |
65 | 然后是商品信息数据埋点字段:
66 |
67 | 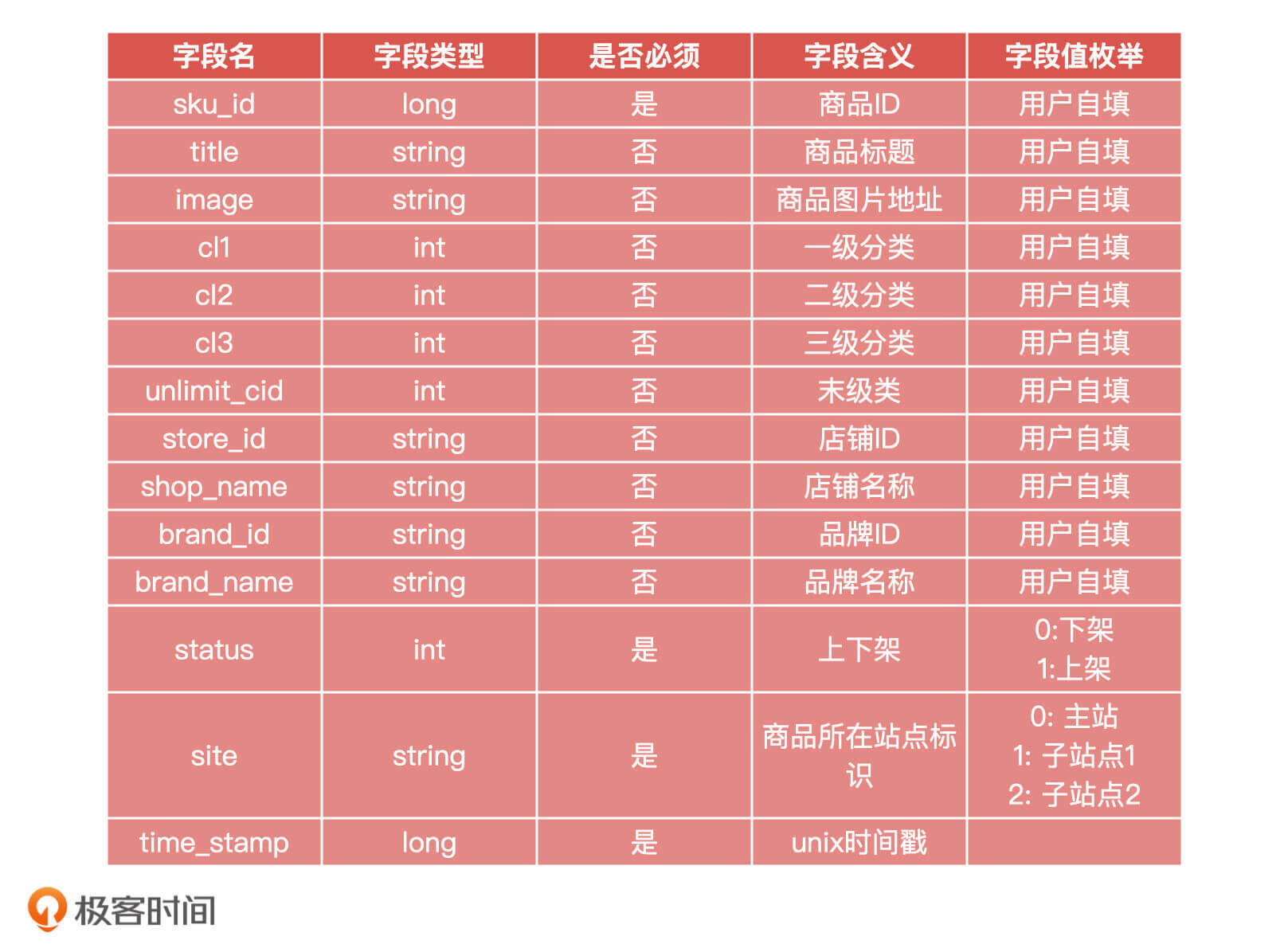
68 |
69 | 有了数据之后,算法同学就可以根据数据建立特征工程,然后我们就可以进入到模型构建的环节了。
70 |
71 | ## 技术实现
72 |
73 | 从项目管控上来看,在推荐系统的项目建设过程中会涉及两波技术团队,分别是算法团队和工程团队,他们是并行进行的。 算法工程师在构建模型的同时,研发工程师也在进行系统功能的开发,最终系统工程与算法模型会通过 API 接口进行通信,这需要双方提前约定好接口协议。**因此作为产品经理,我们除了要关注算法同学的模型构建,同时也要关注推荐系统工程的整体设计。**
74 |
75 | 具体来说,对于系统工程的整体设计,产品经理要关注推荐系统进行一次完整推荐会涉及哪些系统模块,它们和算法模型是怎么交互的,数据流向什么样,产品的关键逻辑是在哪个模块中实现的。
76 |
77 | 下面,我们就来看下工程系统和算法模型的数据架构图,图中的箭头都是数据流向,方向是从左往右。
78 |
79 | 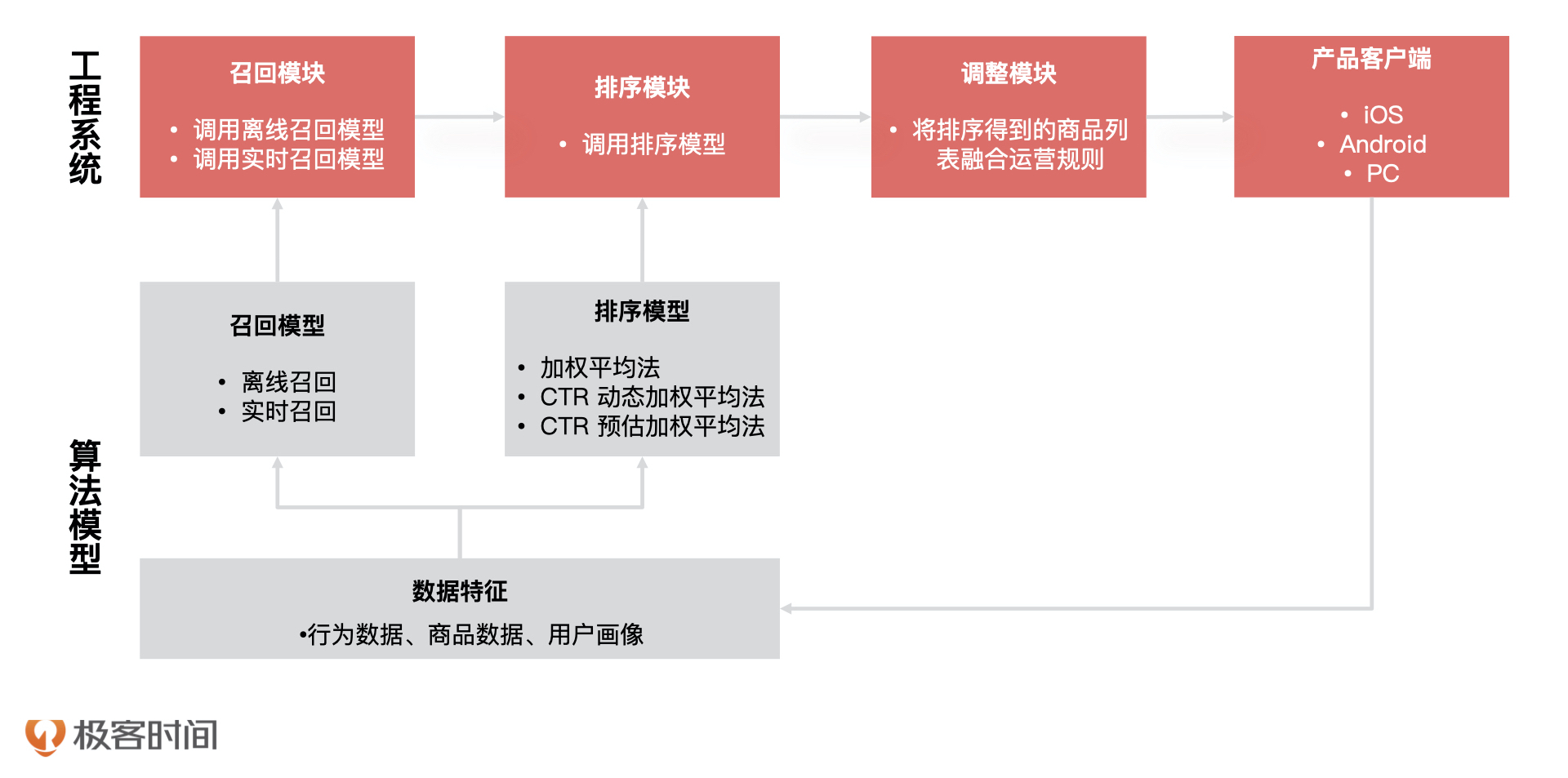
80 |
81 | 从架构图中,我们可以看到**工程系统在进行推荐的时候,先后经过3个模块分别是召回模块、排序模块和调整模块,每个模块都调用了算法模型对应训练好的机器模型提供的服务。**
82 |
83 | 在召回模块中,系统调用了算法模型的“离线召回模型”和“实时召回模型”,它们都做了哪些事儿呢?
84 |
85 | 首先是实时召回,实时召回模型根据历史的用户行为数据,集合当前用户实时的浏览行为,计算并更新用户召回商品的列表信息。实时召回的计算是秒级运算,比如你在京东 App 上搜索华为手机后,Feed 流就会推荐给你很多其他品牌手机。
86 |
87 | 离线召回则是每天通过定时脚本触发模型的计算,如全量更新用户的偏好信息,计算热度榜单等等不要求实时性的数据,这些数据会被存储到数据库中。这样,当工程系统调用某个用户的召回商品列表的时候,推荐系统直接查询数据库就能得到,不需要再计算一遍,从而提高了系统性能。
88 |
89 | 说完了召回模块,下一个是排序模块。 排序模块就比较好理解了,推荐系统会直接调用模型提供的排序服务。这里我们需要注意的是,在系统工程中排序服务可以通过规则(如加权平均、CTR 动态加权平均)的方式实现,也可以基于机器学习模型的 CTR 预估方式实现。至于,具体选择哪种技术策略,我们根据业务现状和技术驾驭能力来决策就可以。
90 |
91 | 然后是调整模块,调整模块是对排好序的商品列表进行运营策略上的调整,它和业务规则强相关,我们就不做过多介绍了。最后,推荐系统会把最终的商品列表返回给产品客户端。
92 |
93 | 这样,整个工程上的数据流向我们就讲完了,但这只是一个最为简单的 MVP 推荐系统的构建。在实际情况下,技术同学还需要考虑很多非功能性的需求,比如系统响应时长、系统稳定性等等,但产品经理的重点还是要放在“召回”、“排序”和“调整”上面。
94 |
95 | ## 评价标准
96 |
97 | 最后,也是业务方最为关注的,那就是如何评估推荐系统给业务提升了多少效果。评估方法并不难,产品经理可以通过 AB 测试的方式进行评估,推荐系统要想做 AB 测试,有三点我们必须要注意:
98 |
99 | 第一,**推荐系统的工程代码要提前准备两套实现方案**,一套千人一面,一套千人千面;
100 |
101 | 第二,**推荐系统要能进行 AB 测试的切量配置**,也就是多少流量流向改造前的系统,多少流量流向改造后的系统,当然这个功能要让系统工程研发同学给予支持;
102 |
103 | 第三,为了查看 AB 测试的效果,对比 CTR、UCTR、转化率等指标,我们要生成最终的效果统计报表。**但在 AB 测试切量的时候,我们要注意打上流量标志位,标识是哪种方案。**这样在统计报表的时候,我们才能分别计算指标,进而比较推荐系统在原有系统之上做到了多少提升。
104 |
105 | 除了这三点,我也把做 AB 测试时常见的几个错误总结在了下面,你在做AB测试的时候要尽量避免。
106 |
107 | 
108 |
109 | 这些其实还不是我们做AB测试的难点,实际的难点在于产品经理对指标的分析过程,以及最终给出的迭代计划,下面我们就来详细讲讲。
110 |
111 | 因为我们的业务比较成熟,并且业务方的 PKI 是 GMV(Gross Merchandise Volume,成交总额),所以我们选用了 CVR 作为推荐系统的衡量标准。CVR的计算方式是转化数/点击数,也就是最终点击商品并且购买的转化率,它通常在广告领域用的比较多。这个指标和最终的 GMV 直接相关,所以也受到业务方的重点关注。那么,对于得到的指标,我们该怎么分析呢?
112 |
113 | 下表就是推荐指标的汇总,我们按照 0~3、3~6、6~9 对商品进行了分段。
114 |
115 | 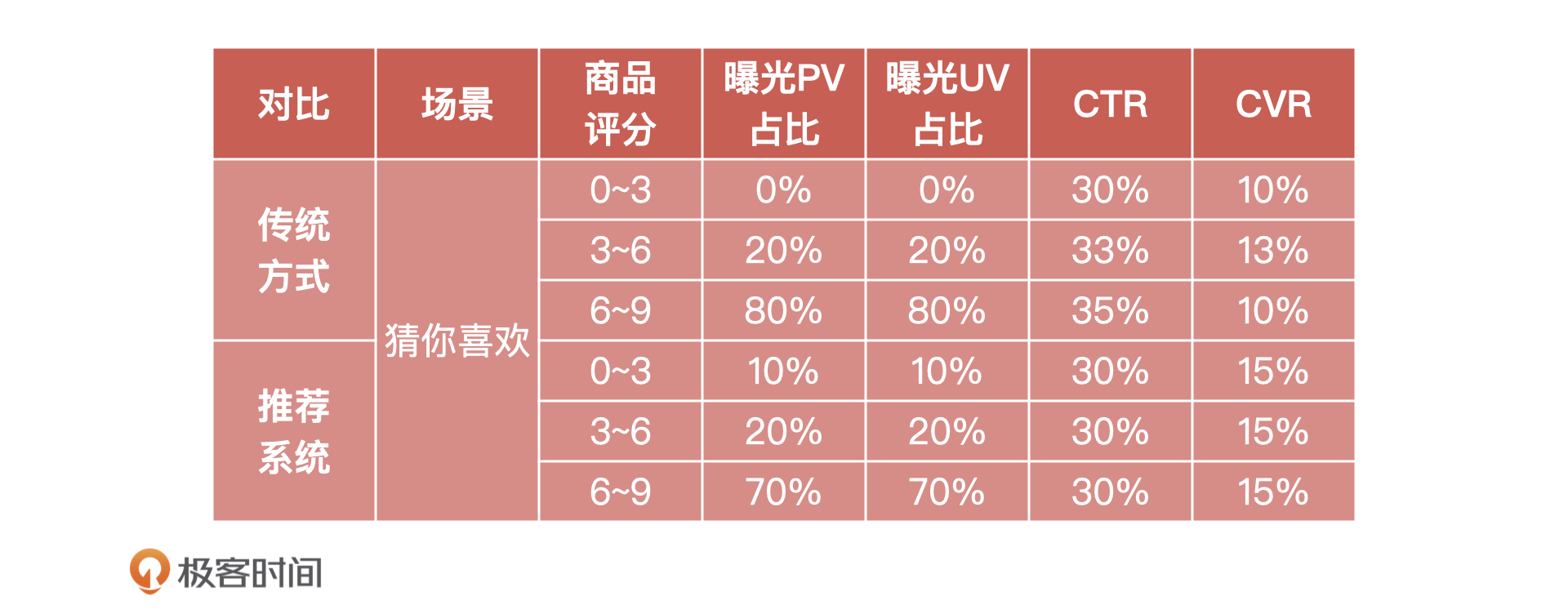
116 |
117 | 对比之下,我们可以看到,“传统方式”的 0~3 分的长尾商品没有曝光,这是因为我们之前一味地追求 GMV,所以运营同学对于低评分的长尾商品不做展示,把所有资源都倾向于头部品牌商的商品,让中小商家在平台上无法生存。**因此,从长远的角度来看,一味的追求GMV并不健康。**
118 |
119 | 除此之外,在对于推荐系统的迭代计划中,产品经理至少还要对不同人群、不同位置设置不同的评价指标,最后再综合所有的评估指标来优化整体数据指标。具体操作时的注意事项,我都总结在了下面的表格中,你可以看看。
120 |
121 | 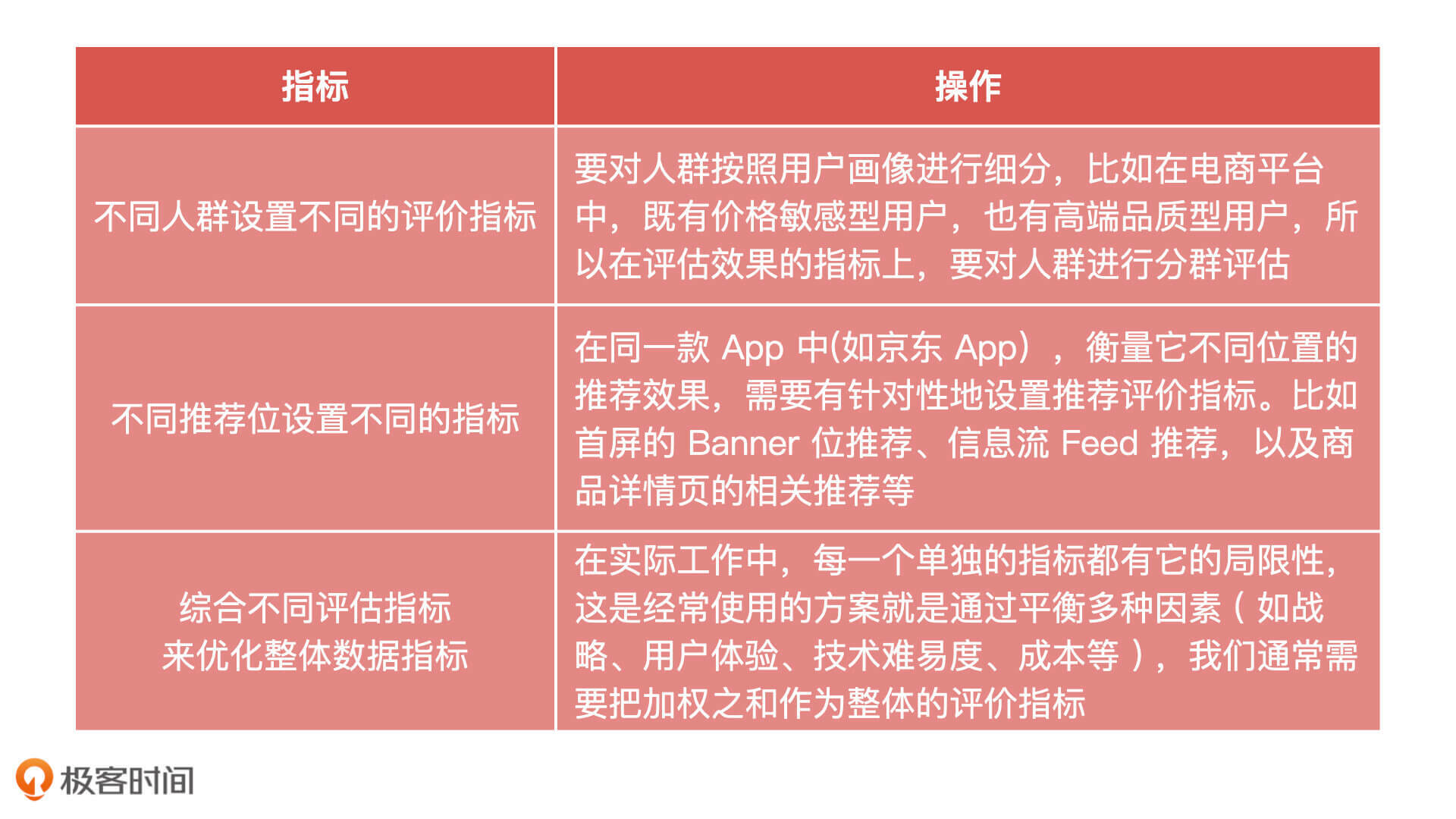
122 |
123 | ## 小结
124 |
125 | 今天,我带你一起走完了一个个性化MVP推荐系统构建的全流程。这其中,产品经理需要关注的内容可以从三方面概括,分别是能力、技术和岗位。
126 |
127 | **能力可以总结为三点:**
128 |
129 | 第一,我们要能够清晰地设计需求:需求定义要明确需求背景、功能描述,以及预期的收益。
130 | 第二,我们要能够理解数据:在推荐系统的数据准备阶段,产品经理要关注用户前端的埋点日志,提前设计埋点,以及给研发工程师提需求收集行为日志。
131 | 第三,我们要能够对通过 AB 测试来评估推荐系统的效果,然后做出分析再给予持续的迭代计划。
132 |
133 | **关于技术,我们要重点掌握推荐系统中召回和排序模块的策略。** 这不仅包括我们这节课说的,工程系统进行一次完整推荐的时候各个系统模块的工作原理、交互逻辑,还有我们上节课讲的常用协同过滤算法和相似度算法的原理。
134 |
135 | **关于岗位,无论你要转型成为哪类产品经理,都要时刻关注目前互联网公司中的招聘。**对于推荐产品岗位,除了要知道我们今天讲的内容,你还要注重积累推荐策略、推荐效果数据分析,以及产品的优化升级方面的经验。我在下面列举了一个市场上推荐产品经理的 JD,你可以参考下。
136 |
137 | 
138 |
139 | 最后,今天的内容比较多,为了帮助你理解,我梳理了一个知识脑图,你可以利用它查缺补漏。
140 |
141 | 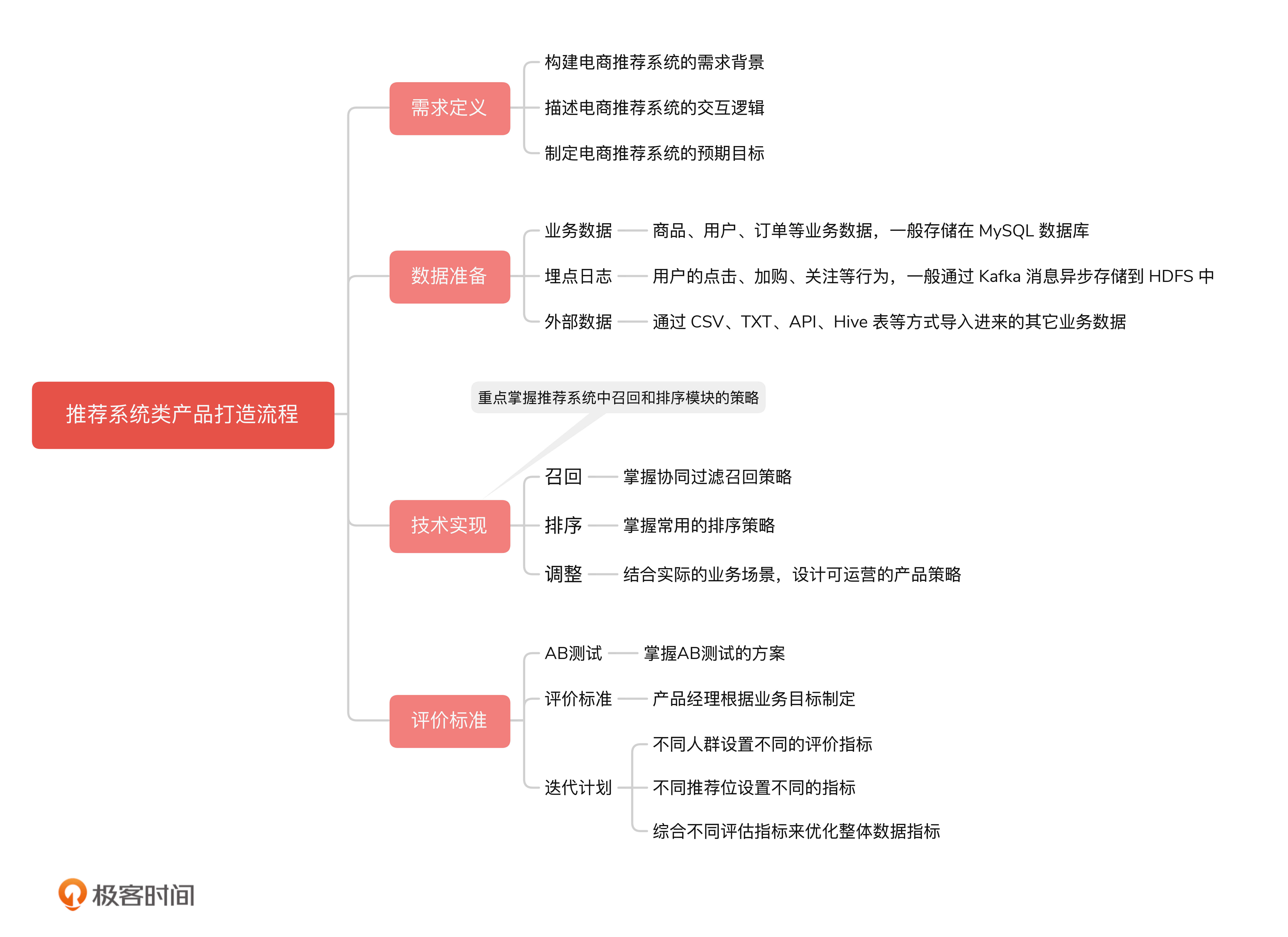
142 |
143 | 总的来说,推荐系统是一个需要长期根据效果进行迭代的产品,产品经理要能做到以“Zoom Out”的眼光看待系统的长远发展。因为极有可能,系统在上线初期的效果,反而不如传统运营的手动配置策略,但是作为产品经理,我们要有信心,并且要能通过持续的 AB 测试分析和迭代来逐步优化它的最终效果。
144 |
145 | ## 课后讨论
146 |
147 | 结合你所处的业务场景,对于推荐系统的评价标准,你觉得哪些评价方法更为适合?
148 |
149 | 欢迎把你的答案写到留言区和我一起讨论,我们下节课见!
150 |
109 | - 悠悠 👍(9) 💬(2)
协同过滤是什么
110 |
111 | 利用集体智慧,基于以下两个出发点:(1)兴趣相近的用户可能会对同样的东西感兴趣;(2)用户可能较偏爱与其已购买的东西相类似的商品。
2020-12-24
- 晨 👍(4) 💬(1)
传统产品经理与AI产品经理,C端B端G端都有吧,不能一棍子就敲定边界。
2020-12-20
- 悠悠 👍(8) 💬(3)
“模型”是什么样的存在
112 |
113 | 妈妈教孩子认字,那一个个的汉字就是数据,妈妈教孩子的过程就是训练的过程,妈妈用的方法就是算法,孩子最后就成了一个能够认识不同字的模型。
2020-12-24
- Jenny 👍(6) 💬(3)
那这些知识有推荐的学习渠道嘛?
2020-12-16
- 悠悠 👍(5) 💬(3)
归一化是什么
114 |
115 | 机器学习中,数据预处理的一个步骤,大概意思感觉就是把数据整理一下,方便后面处理吧
2020-12-24
- 悠悠 👍(4) 💬(1)
不知道是否可以这么理解:协同过滤输出推荐内容,逻辑回归输出推荐这个内容的概率值,概率高才推荐
2020-12-24
- yiwu 👍(2) 💬(1)
公司在转型,刚好推荐了这个AI课程,想都不想就报名了。AI这块从大学开始一直想搞懂,奈何数学功底太差,现在才来狂补。
2020-12-17
- Geek_d7623f 👍(1) 💬(1)
老师对AI产品经理主导的四个环节总结得很到位。个人对算法原理,模型评估存在短板,尤其是模型评估是系统集成前的重要环节。先按照课程节奏,逐渐深入。
2020-12-19
- 悠悠 👍(0) 💬(1)
数据结构化是什么
116 | 让数据之间产生联系
2020-12-24
- 悠悠 👍(0) 💬(1)
XGboost,基于决策树的机器学习算法,大概就是,训练很多树,把每棵树的叶子分数加起来,就是预测结果🙄
2020-12-24
- 孙洪伟 👍(0) 💬(1)
没看出来和普通的智能上有什么区别,为啥ai产品经理就得面向B端?
2020-12-19
- Shell谈 👍(0) 💬(1)
推荐系统的例子特别好,各种算计/技术的能力边界一定要有概念
2020-12-17
- 影子 👍(5) 💬(1)
作为AI四小龙之一的产品经理,看了老师的文章发现自己还差很远。
117 | 日常工作中偏应用层设计,算法相关的评估由专门的算法产品经理负责。责任范围的划分导致我们都有点“偏科”,现在想换工作,发现距离市面上大厂AI产品经理的JD要求还有距离。
118 | 赶紧跟着老师的课程学起来。
2021-03-17
- 夏天的芭蕉 👍(3) 💬(0)
ai从业产品有一个困惑:搜索推荐是现在ai技术落地比较好的方向了,但是技术成熟导致产品经理更多的变成做模版的,对算法其实不需要干预,算法工程师可以自己ab验证上线,那搜推还是ai产品的好选择么?
2021-09-27
- 俯瞰风景. 👍(2) 💬(1)
技术转型的同学,拥有编程能力,可以从代码层面理解算法模型,更好地理解AI技术的边界。
119 | 业务转型的同学,对用户模型和交易模型理解比较深刻,更容易结合用户需求设计出有市场前景的AI产品。
2021-08-25
120 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/07-AI模型的构建过程是怎样的?(下).md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 上节课,我们讲了一个模型构建的前 2 个环节,模型设计和特征工程。今天,我们继续来讲模型构建的其他 3 个环节,说说模型训练、模型验证和模型融合中,算法工程师的具体工作内容,以及AI 产品经理需要掌握的重点。
4 |
5 | 
6 |
7 | ## 模型训练
8 |
9 | 模型训练是通过不断训练、验证和调优,让模型达到最优的一个过程。**那怎么理解这个模型最优呢?**下面,我拿用户流失预测模型这个例子来给你讲讲。
10 |
11 | 这里,我想先给你讲一个概念,它叫做**决策边界**,你可以把它简单理解为我们每天生活当中的各种决策。比如,当华为 Mate 降价到 5000 元的时候我就打算购买,那这种情况下我的决策边界就是 5000 元,因为大于 5000 元的时候我不会购买,只有小于 5000 元时我会选择购买。
12 |
13 | 那放到预测用户流失这个案例中,我们模型训练的目标就是,在已知的用户中用分类算法找到一个决策边界,然后再用决策边界把未知新用户快速划分成流失用户或者是非流失用户。
14 |
15 | 不同算法的决策边界也不一样,比如线性回归和逻辑回归这样的线性算法,它们的决策边界也是线性的,长得像线条或者平面,而对于决策树和随机森林这样的非线性算法,它们的决策边界也是非线性是一条曲线。因此,**决策边界是判断一个算法是线性还是非线性最重要的标准**。
16 |
17 | 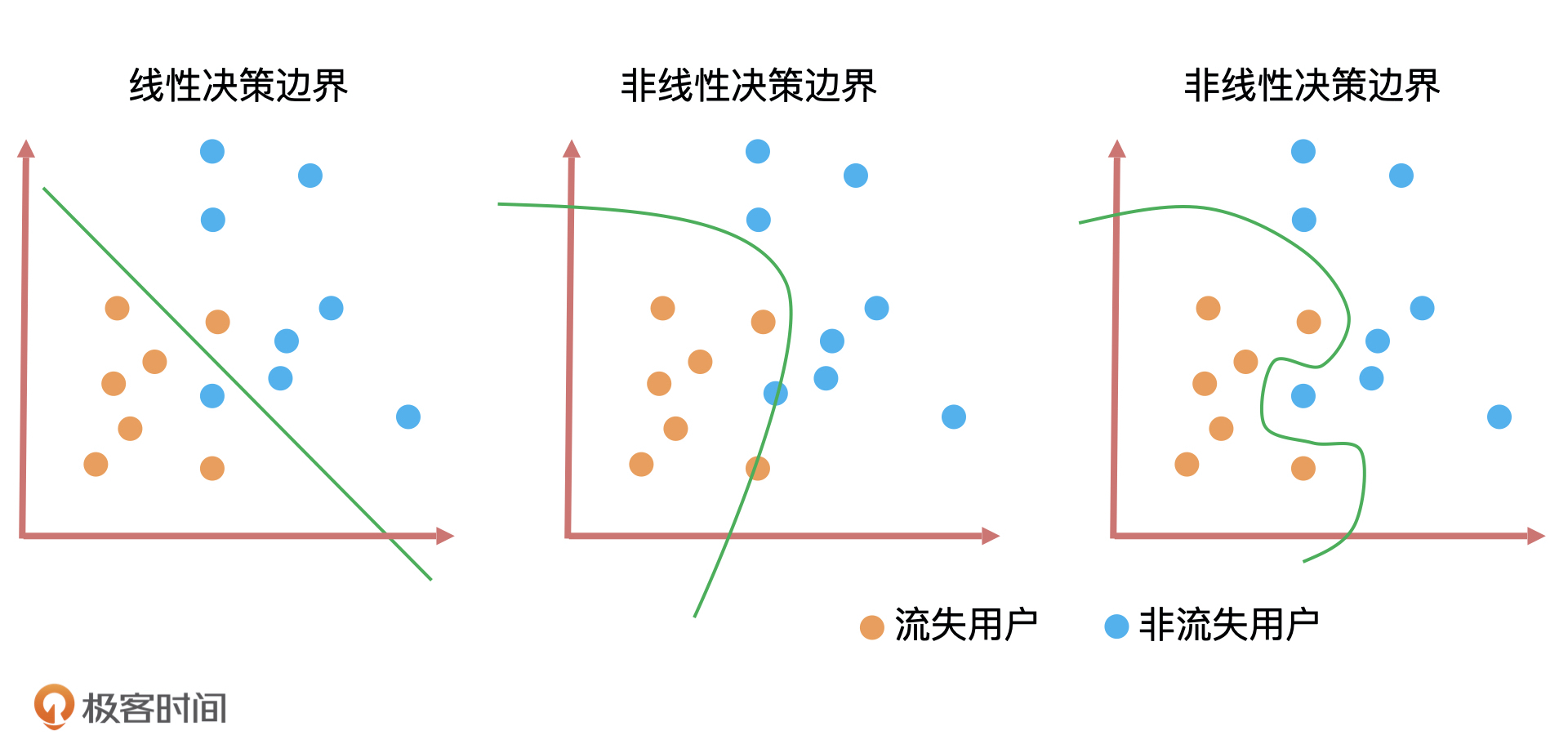
18 |
19 | 上图就是三种算法的决策边界。决策边界的形式无非就是直线和曲线两种,并且这些曲线的复杂度(曲线的平滑程度)和算法训练出来的模型能力息息相关。**一般来说决策边界曲线越陡峭,模型在训练集上的准确率越高,但陡峭的决策边界可能会让模型对未知数据的预测结果不稳定。**
20 |
21 | 这就类似于我们投资股票,低收益低风险,高收益高风险,所以我们一般都会平衡风险和收益,选择出最合适的平衡点。
22 |
23 | 对于模型训练来说,这个风险和收益的平衡点,就是拟合能力与泛化能力的平衡点。拟合能力代表模型在已知数据上表现得好坏,泛化能力代表模型在未知数据上表现得好坏。它们之间的平衡点,就是我们通过**不断地训练和验证找到的模型参数的最优解,因此,这个最优解绘制出来的决策边界就具有最好的拟合和泛化能力**。这是模型训练中“最优”的意思,也是模型训练的核心目标,我们一定要记住。
24 |
25 | 具体到我们这个流失用户预测的例子上,模型训练的目的就是找到一个平衡点,让模型绘制出的决策边界,能够最大地区分流失用户和非流失用户,也就是预测流失用户的准确率最高,并且还兼顾了模型的稳定性。
26 |
27 | 一般情况下,算法工程师会通过**交叉验证**(Cross Validation)的方式,找到模型参数的最优解。
28 |
29 | ## 模型验证
30 |
31 | 刚才我们说了,模型训练的目标是找到拟合能力和泛化能力的平衡点,让拟合和泛化能力同时达到最优。那这该怎么做呢?
32 |
33 | 如果算法工程师想让拟合能力足够好,就需要构建一个复杂的模型对训练集进行训练,可越复杂的模型就会越依赖训练集的信息,就很可能让模型在训练集上的效果足够好,在测试集上表现比较差,产生**过拟合**的情况,最终导致模型泛化能力差。
34 |
35 | 这个时候,如果算法工程师想要提高模型的泛化能力,就要降低模型复杂度,减少对现有样本的依赖,但如果过分地减少对训练样本的依赖,最终也可能导致模型出现**欠拟合**的情况。
36 |
37 | 因此,算法工程师需要花费大量的时间去寻找这个平衡点,而且很多时候我们认为的最优,未必是真正的最优。**这个时候,模型验证就起到了关键性的作用。**
38 |
39 | 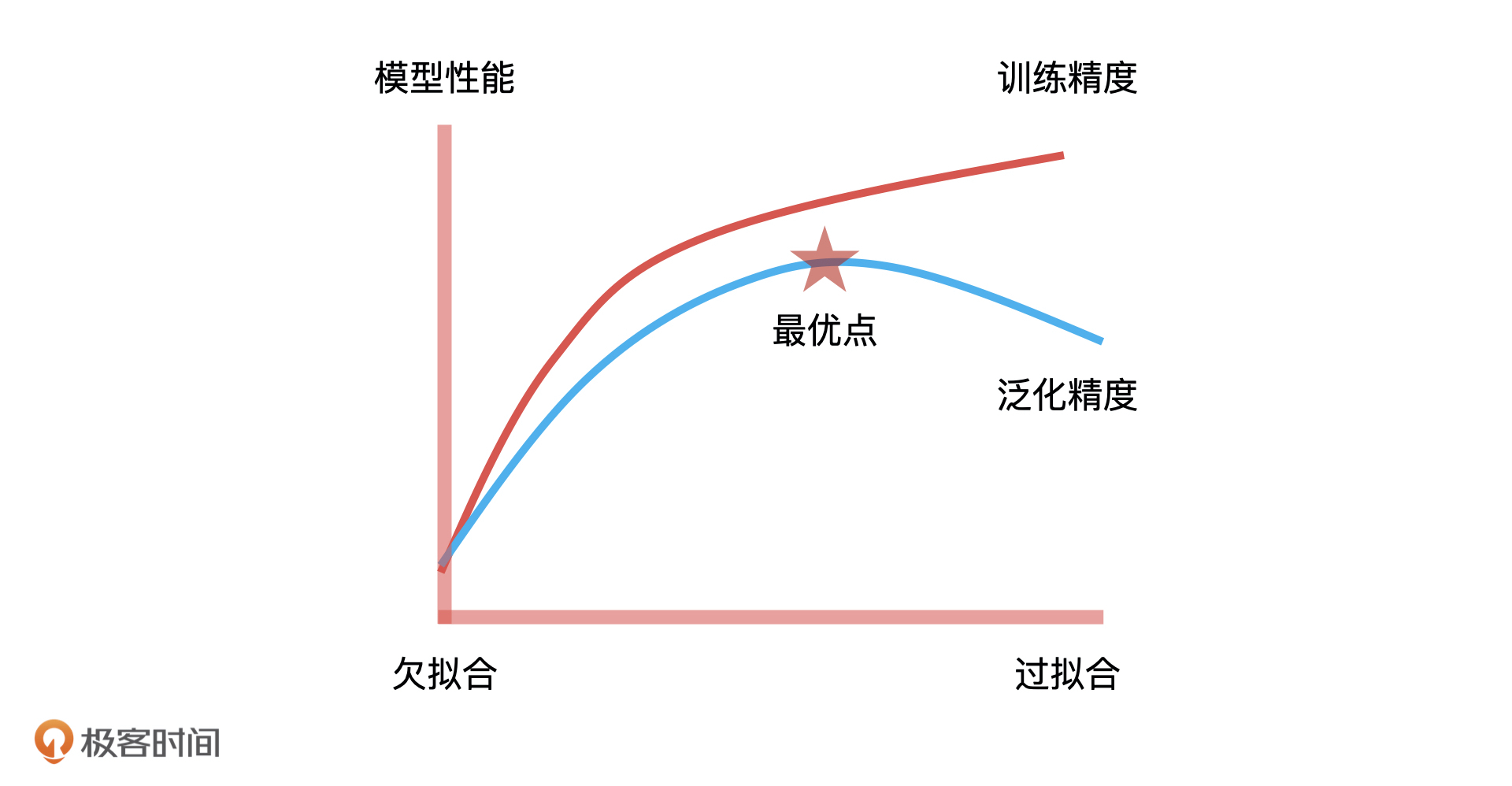
40 |
41 | 模型验证主要是对待验证数据上的表现效果进行验证,一般是通过模型的性能指标和稳定性指标来评估。下面,我一一来解释一下。
42 |
43 | **首先是模型性能。模型性能可以理解为模型预测的效果,你可以简单理解为“预测结果准不准”**,它的评估方式可以分为两大类:分类模型评估和回归模型评估 。
44 |
45 | 分类模型解决的是将一个人或者物体进行分类,例如在风控场景下,区分用户是不是“好人”,或者在图像识别场景下,识别某张图片是不是包含人脸。对于分类模型的性能评估,我们会用到包括召回率、F1、KS、AUC 这些评估指标。而回归模型解决的是预测连续值的问题,如预测房产或者股票的价格,所以我们会用到方差和 MSE 这些指标对回归模型评估。
46 |
47 | 对于产品经理来说,我们除了要知道可以对模型性能进行评估的指标都有什么,还要知道这些指标值到底在什么范围是合理的。虽然,不同业务的合理值范围不一样,我们要根据自己的业务场景来确定指标预期,但我们至少要知道什么情况是不合理的。
48 |
49 | 比如说,如果算法同学跟我说,AUC 是 0.5,我想都不想就知道,这个模型可能上不了线了,因为 AUC = 0.5 说明这个模型预测的结果没有分辨能力,准确率太差,这和瞎猜得到的结果几乎没啥区别,那这样的指标值就是不合理的。
50 |
51 | **其次是模型的稳定性,你可以简单理解为模型性能(也就是模型的效果)可以持续多久。**我们可以使用 PSI 指标来判断模型的稳定性,如果一个模型的 PSI > 0.2,那它的稳定性就太差了,这就说明算法同学的工作交付不达标。
52 |
53 | 总的来说,模型的验证除了是算法工程师必须要做的事情之外,也是产品经理要重点关注的。就好像研发同学需要单元测试,测试同学需要冒烟测试,产品经理需要产品验收一样。这节课,我们先熟悉它在整个模型构建中所扮演的角色,之后,我也会单独拿出一模块的时间来和你详细讲一讲,模型评估的核心指标都有什么,以及它们的计算逻辑、合理的值都是什么。掌握了这些,你就可以清楚知道算法同学交付的模型到底是好是坏,模型到底能不能上线,上线后算法同学是不是该对模型进行迭代了。
54 |
55 | ## 模型融合
56 |
57 | 前面我们讲的 4 个环节都是针对一个模型来说的,但在实际工作中,为了解决很多具体的细节问题,算法工程师经常需要构建多个模型才获得最佳效果。这个时候,就要涉及多个模型集成的问题了。那模型集成或者说集成学习究竟是怎么一回事儿呢?听我慢慢给你讲。
58 |
59 | 我们先来看一个生活中的例子,如果你打算买一辆车,你会直接找一家 4S 店,然后让汽车销售员推销一下,就直接决定购买了吗?大概率不会,你会先去各头部汽车咨询网站看看其他车主的评价,或者咨询一下同事或朋友的意见,甚至会自己整理一堆汽车各维度的专业对比资料,再经过几次讨价还价,才会最终做出购买的决定。
60 |
61 | 模型融合就是采用的这个思路,同时训练多个模型,再通过模型集成的方式把这些模型合并在一起,从而提升模型的准确率。简单来说,就是用多个模型的组合来改善整体的表现。
62 |
63 | 模型融合有许多方法,我们知道一些常用的就可以了,比如对于回归模型的融合,最简单的方式是采用算数平均或加权平均的方法来融合;对于分类模型来说,利用投票的方法来融合最简单,就是把票数最多的模型预测的类别作为结果。另外,还有 Blending 和 Stacking,以及 Bagging 和 Boosting这些比较复杂的模型融合方法。
64 |
65 | 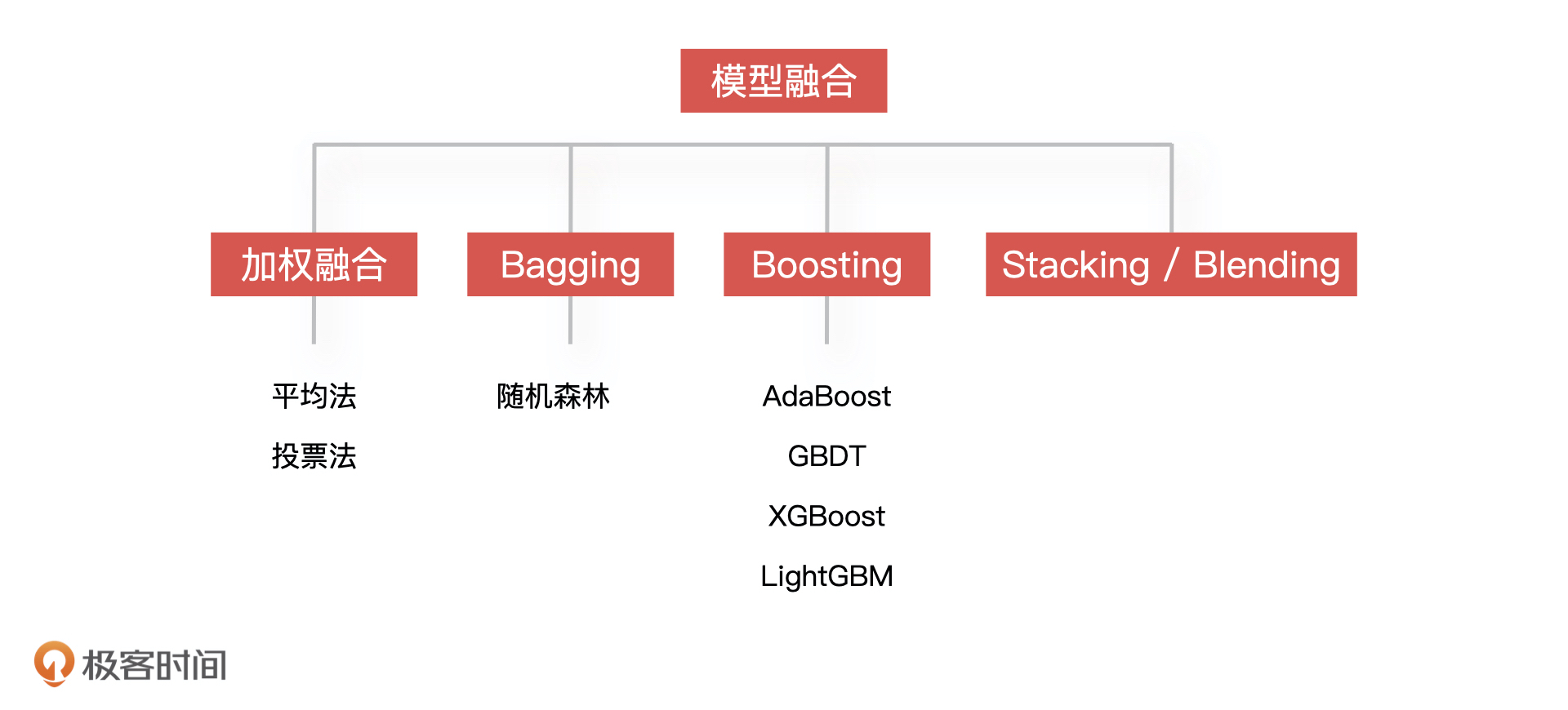
66 |
67 | 除了要注意模型融合的方法,我们还要注意算法模型的选择,不同行业选择的算法模型一定不一样。比如,互联网数据和银行金融机构数据就不一样,因为银行数据大部分都是强相关性的金融性数据,所以它可能会更多考虑机器学习算法,而互联网的数据特征基本都是高维稀疏,会较多考虑深度学习算法。
68 |
69 | 并且,由于不同行业对于算法模型的风险状况也有不同的考虑,所以对模型的选择也会有不同的限制标准,比如银行、金融行业会监管模型的特征和解释性,因此,会选择可解释性很强的算法模型,如逻辑回归。
70 |
71 | 除此之外,我们还要考虑算法模型选择的成本。比如说,产品经理可能认为通过 Boosting 或 Bagging 的方式集成模型的效果,一定比单一的算法模型效果要好。
72 |
73 | 但是在实际中,算法工程师常常会为了提成模型 AUC 的一个点,让特征的规模增大很多,导致模型部署上线的成本翻倍,这就非常不划算了。因此,成本是算法工程师在选择算法模型时会去考虑的事情,也是需要产品经理去理解算法同学工作的地方。
74 |
75 | ## 模型部署
76 |
77 | 一个模型训练完成并通过评估后,算法工程师就要考虑怎么把它部署到线上,并应用到业务场景中。虽然模型部署不属于模型构建中的环节,但它却是 AI 产品上线中必不可少的一环,所以我也要在这里和你讲一下。
78 |
79 | 一般情况下,因为算法团队和工程团队是分开的两个组织架构,所以算法模型基本也是部署成独立的服务,然后暴露一个 HTTP API 给工程团队进行调用,这样可以解耦相互之间的工作依赖,简单的机器学习模型一般通过 Flask 来实现模型的部署,深度学习模型一般会选 TensorFlow Serving 来实现模型部署。
80 |
81 | 但是,具体的交互方式也还要看模型应用的业务场景,比如业务需求就是要对 UGC 内容进行分类,如果业务场景是要实时预测用户 UGC 的类别,那我们的分类模型就需要部署成在线的 Web 服务并提供实时响应的 API 接口;如果我们只是需要对一批已有的 UGC 数据进行分类,然后使用分类后的结果,那我们的模型通过离线任务的方式运行,每日定时处理增量的 UGC 数据就可以了 。
82 |
83 | ## 小结
84 |
85 | 通过第 6 和第 7 课的学习,我们一起梳理了整个模型构建的流程。
86 |
87 | **模型设计**是模型构建的第一个环节,这个环节需要做模型样本的选取和模型目标变量的设置,模型样本和目标变量的选择决定了模型应用的场景。
88 |
89 | **特征工程**是所有环节中最乏味和耗时的。因为,实际生产中的数据会存在各种各样的问题,如数据缺失、异常、分布不均、量纲不统一等等,这些问题都需要在特征工程中解决的。 但是这种耗时绝对值得,一个好的特征工程直接影响算法模型最终的效果。
90 |
91 | **模型训练**就是一个通过不断训练数据,验证效果和调优参数的一个过程,而**模型验证**和它是一个不断循环迭代的过程,目标都是寻找模型泛化能力和模型效果的平衡点。所以模型训练我们要和模型验证一块来看。
92 |
93 | 更具体点,在我们的例子中,模型训练的目标就是为了预测用户是否为流失用户,模型训练就是在已知用户数据中通过算法找到一个决策边界,然后在这条决策边界上,模型的拟合和泛化能力都能达到最好,也就是说,在训练集和测试集上对流失用户预测准确率都很高。
94 |
95 | 而**模型验证**主要是对待测数据上的表现效果进行验证,一般是通过模型的性能指标和稳定性指标来进行评估。
96 |
97 | **模型融合**环节主要是通过多个模型的组合来改善整体的表现。模型融合有许多方法,简单的有加权平均和投票法,复杂的有 Bagging 和 Bosting。作为产品经理,我们要知道,模型融合虽然可以提升模型的准确率,但也需要均衡开发成本来综合考虑。
98 |
99 | **模型部署**关注的是模型的部署上线和提供服务的方式,这里一般只需要事先约定好算法与工程的交互方式即可。
100 |
101 | 最后,我还想给你一个小建议,如果你是**偏基础层或者技术层的产品经理**,需要对模型构建的过程了解得更加清楚,你可以在一些开放的机器学习平台(比如阿里的机器学习平台 PAI)上,尝试自己搭建一个简单的模型。**对于应用层的产品经理**,你只需要了解大概流程就可以了,把学习的重点放到如何去评估模型效果上。
102 |
103 | ## 课后讨论
104 |
105 | 在整个模型构建的过程中,你认为最重要的阶段是哪个?为什么?
106 |
107 | 欢迎在留言区写下你的思考和疑惑,我们下节课见!
108 |
109 | - Yesss! 👍(3) 💬(1)
数据准备最重要,这决定了整个模型的上限
2021-01-13
- Rosa rugosa 👍(18) 💬(0)
数据和特征工程决定了机器学习的上限,模型和算法只是逼近这个上限。
2021-03-11
- 刘科-悟方 👍(11) 💬(1)
深度学习数据准备最重要,数据样本越多模型会自寻到特征工程;机器学习特征工程最重要,依靠人工归纳的特征来提高模型预测准确度。
2020-12-28
- Pale Blue 👍(4) 💬(0)
最重要的是特征工程。
110 | 因为特征工程考验了产品经理对自己业务以及业务目标的理解程度,比方说根据自身对业务的理解创建出超级特征值,可以对模型的性能有极大的提升,减少很多工作内容。
2021-09-06
- escray 👍(3) 💬(0)
模型训练一般是算法工程师为主,如何找到拟合能力和泛化能力的平衡点,这个有点“玄学”。对于交叉验证,文中并没有给出进一步的解释,我猜大概就是不断的调整参数,然后看验证结果吧。
111 |
112 | 召回率、F1、KS、AUC
113 | 方差、MSE
114 | PSI
115 | Blending、Staking、Bagging、Boosting、AdaBoost、GBDT、XGBoost、LightGBM
116 |
117 | 又多了一些不明觉厉的“黑话”,希望课程后面有解释,作为产品经理,能够明白这些“行话”是什么意思,能够判断数字大小代表模型的优劣,估计也就足够了。
2022-04-13
- 产品部1 👍(3) 💬(0)
对于产品经理来说,特征工程(尤其是特征)选择是整个模型构建的最重要阶段,其他的事情可以交给算法同学。
2022-03-20
- 伟鸿 👍(3) 💬(0)
模型验证部分的配图没太看懂,「训练精度」和「泛化精度」两条曲线是否可以这样理解:训练精度——模型越复杂,对「样本数据」的预测越准(模型性能不断递增);「泛化精度」——但是在对「未知数据」的预测上,训练精度过高的模型,预测准确性反而会回落,称之为「过拟合」或者「泛化能力弱」。
2020-12-28
- 俯瞰风景. 👍(1) 💬(0)
建立特征最重要。
118 | 就算是样本量小,如果能够提取具有洞察的特征标签,也能得到不错的模型。
2021-08-25
- Geek_52525e 👍(1) 💬(0)
特征构建最重要,也是我最喜欢的部分。
2021-04-17
- BAYBREEZE 👍(1) 💬(0)
标准答案:最重要的是样本选择与特征工程。这个决定了机器学习的上限。
2021-01-21
- 宋秀娟 👍(0) 💬(0)
选取正确的样本进行特征工程是最重要的了
2024-08-14
- 哈哈猪婉·梁 👍(0) 💬(0)
模型的性能和稳定性可以理解为统计里的效度和信度吗
2024-01-20
- Geek_1cb9db 👍(0) 💬(0)
老师,能不能再讲一下怎么进行模型验证的? 怎么知道已经达到了最优解?用测试集算出来的量化指标结果,也受限于构建测试集的人的认知能力?在他认知之外是否能覆盖到是否就无法验证了?
2023-11-16
- 潘平 👍(0) 💬(0)
老师问一个问题,为什么模型融合不要放到模型验证后面去做呢?
2023-08-21
- From-v 👍(0) 💬(0)
海丰老师,这种模型遇到不可预测,怎么建立呢。
2022-12-26
119 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/04 - 过来人讲:成为AI产品经理的两条路径.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 通过前面几节课,你已经知道了 AI 领域的发展现状,AI 产品落地的工作全流程,以及 AI 产品经理的能力模型。这些都是你成为或者说是转型成为一个AI产品经理之前,必须要储备的知识。
4 |
5 | 掌握了这些之后,想要真正成为AI产品经理,你还需要一些切实可行的落地路径。我觉得,我们在做出每一个职业转变的决定之后,都必须要制定好相应的实现路径,这不仅能帮助我们明晰每个阶段的目标,还能让我们坚定不移地走向终点。
6 |
7 | 今天,我就结合自己的转型经验,给你梳理出两条切实可行的转型路径。而且,我会把我踩过的“坑”都总结出来,当你真正去走的时候,就能少走很多弯路啦。
8 |
9 | ## 内部转岗:从下到上,由点及面
10 |
11 | 首先,我们来看这样一种情况。公司突然要上线一个AI项目,领导希望你能从产品经理转变成一个AI产品经理去推动这个项目。当然,目前这种情况并不多见,但随着越来越多的公司认识到AI的重要性,并且建立了算法团队,这种情况就会变得很普遍。我就是在这样的情况下转型成功的,如果你也正面临这种情况,我建议你参考我当时的经历。
12 |
13 | 我最初是产品和研发的总负责人,做的是传统的互联网业务。当时机缘巧合,我们服务的客户让我们帮他们做一个用于金融风控场景的用户信用评分产品。这种产品,其实底层就是基于大数据和机器学习算法,来对贷款人的还款能力和还款意愿进行预测。我就通过这样一个契机主导了这个 AI 产品,走上了 AI 产品经理之路。
14 |
15 | 但是由于之前完全没有接触过算法,我在最初接触这个产品的时候,一直都是“懵”的。还好,当时有一个算法团队的负责人协助我来完成相关工作。但是这样一来,我就从一个产研负责人变成了算法配合人。整个产品的交付形式、节奏、上线标准,基本都是由算法负责人决定,我只能做一些执行层面的事情。
16 |
17 | 当然,为了项目能够顺利上线,短暂去协助算法做支持是可以的,但我不可能一直处于被动的局面中,所以我当时的做法是 “**从下到上,由点及面**”。那我具体是怎么做的呢?我其实就是从底层知识和细节问题入手,去拓展学习整个知识体系和相关知识点。这里,我就和你分享两个例子。
18 |
19 | 比如,在项目周会上,大家介绍项目进展的时候,算法同学经常会提到,我们本周做了洗数工作,或者我们在筛选特征。那我就会带着具体的问题去进行补课,像是 “洗数怎么做的, 筛选特征怎么做的,等到有拿不准的问题再去请教算法同学,基本上他们都会倾囊相授。这样一来,我再把这些碎片化的知识梳理出来,慢慢地就形成了一个相对完整的知识体系。
20 |
21 | 再比如,我知道有个算法叫做 GBDT,也知道有个算法叫做 LR。但我根本不知道它们代表什么意思,都是做什么的,对我来说算法就是个黑盒子,可为了能带领整个AI项目团队,我又一定要弄懂这些知识。
22 |
23 | 所以,我先是向算法同学学习,再加上自己上网查询资料,去了解机器学习算法的几种分类,以及每种分类下的常用算法。其中 LR 是逻辑回归,GBDT 是优化后的决策树,它们都是用于解决分类问题的算法。就这样,我慢慢梳理出来了一棵和**算法相关的知识树**。
24 |
25 | 除了学习和算法相关的知识之外,数学、统计学,概率论这些和AI相关的名词,我也进行了解和学习。因为在和算法同学沟通需求的时候,他们经常会提到这类名词概念,所以我就将这些名词概念组织整理出来,慢慢向上汇总,形成了一棵和**数学相关的知识树**。
26 |
27 | 另外,既然涉足了 AI 领域,我觉得有必要对整个行业有所了解,比如算法同学都关注了哪些行业会议和业界大牛。根据我的经验,这些 AI 技术视野相关的东西,不需要集中学习,随着我们的关注慢慢补充就可以了。
28 |
29 | 以上,就是我当时如何一点点弥补我在 AI 技术知识上的不足的,并最终转型 AI 产品经理的全部过程。**如果你与我类似,都是在工作中遇到了做 AI 产品的机会,我建议你可以参考我的路径,暂时让算法同学去主导项目,同时由点及面地去学习,补充知识和积累经验**。
30 |
31 | ## 外部求职:从上到下,从面到点
32 |
33 | 但如果你就是一个刚毕业的学生,想要踏足AI行业,或者是一个技术同学,希望成为一个AI产品经理,那我建议你采用 “**从上到下,从面到点**”的学习路径。这句话的意思是,你要先了解全局,从全局中挑出一条线,再抓住这条线的一端,一点点地深入到具体细节的知识点。
34 |
35 | 这么说还是太抽象了,我给这个路径总结了4个步骤,下面我再详细说说。
36 |
37 | **第一步,对 AI 行业有全局的认识,持续了解 AI 发展。**
38 |
39 | 作为产品经理,我们要站在一定的高度上去看整个行业,了解整个行业的全景,产业链条,商业模式,人才结构,甚至是每个方向的头部公司情况。除了对全局的把控之外,还需要实时去关注行业的变化,技术的更迭,只有站在行业的前沿,我们才有可能抓到新的机会点。
40 |
41 | 我建议你可以参加一些 AI 产业相关的会议,你可以从类似于 “活动行” 等App上面搜索这些会议的信息再报名,也可以找一些 AI 产业相关的公众号,看看能不能从上面发现这些会议信息,再积极报名。
42 |
43 | 说到公众号,我认为在刚开始决定转型的时候,你可以不用关注那种技术导向非常强的公众号,上来就看非常深的技术文章。因为可能还没有了解到行业新闻,你就已经被一些数学公式或算法模型给打败了。
44 |
45 | 我推荐你关注类似《AI前线》这样的公众号,它是面向 AI 爱好者、开发者和产品经理的,它关注的领域比较广泛,涉及国内外的 AI 相关公司、技术的资讯,内容也不算太过于技术化,作为入门AI产品经理的信息来源足够了。
46 |
47 | 除了公众号,我建议你去知乎上看看和 AI 相关的专栏和问题,再买一些入门的书籍。只要你善于发现,好的学习资源是非常多的。
48 |
49 | 查看这些资料只是我们了解行业的第一步,最重要的是,你一定要对这些信息进行**归纳总结,提炼出自己的思考**。你可以尝试自己去搭建一个行业的框架,框架中可以包括很多方面,我把它们进行了总结:
50 |
51 | - 行业专有名词、基本术语
52 | - 行业的整体规模,未来的发展空间
53 | - 整个行业的生命周期,当前处于哪个阶段
54 | - 行业的产业链,上下游供应商情况
55 | - 行业中不同企业的商业模式
56 | - 行业整体的人才结构分布情况
57 | - 当前行业中头尾部企业
58 |
59 | 这样的话,当你去面试AI产品这个岗位的时候,因为你之前对整个行业做过充分的总结,就可以很有结构地表达出你对这个行业的看法,你的答案也会比其他竞争者更有高度。这对你提高面试通过率,甚至是面试定级都非常有帮助。
60 |
61 | **第二步,给自己定方向。**
62 |
63 | 对于整个行业的全景有了基础的认识之后,你除了要持续去跟进这些信息,接下来就需要开始评估自己的兴趣偏好和能力优势,为自己确定方向了。
64 |
65 | 首先,你要分析自己的兴趣偏好,更倾向于商业化去做 ToB 服务,还是更倾向于底层的技术或技术上层的应用,通过自己的兴趣偏好选出自己心仪的行业和公司。
66 |
67 | 其次,你也要考虑自身的能力优势,对于自己心仪的公司,你有多大的差距。
68 |
69 | 如果差距实在太大,比如你喜欢寒武纪这样做 AI 芯片服务的公司,可是自己对 AI 技术完全不懂,也从来没有做过硬件相关的产品。那你就可以考虑曲线救国,尝试先去对技术要求没有那么高的公司试试,让自己踏入这个行业再说,或者,你也可以考虑这家公司对技术要求没有那么高的岗位,之后再寻求技术转岗。
70 |
71 | 当然,如果你非要一步到位,可能难度比较高,但也不是不可能,你要做好充足的技能储备,有着坚定的信心。
72 |
73 | 最后,在确定了自己的方向之后,你可以定向分析一下这个细分方向上的几个头部企业,它们的商业模式、上下游企业、可提供的岗位,以及每个岗位的职责要求,再去定向地补足自己的差距。
74 |
75 | 另外,除了分析头部企业之外,我建议你再看看这个行业中尾部的一两个企业,分析它们为什么会处于行业尾部,是入场时间太晚,还是商业方向不确定,又或者是相关资源不足。这也能够让你对这个细分领域有整体的了解。
76 |
77 | **第三步,补足技术。**
78 |
79 | 在确定了自己的未来方向之后,你就可以有针对性地去补足技术上的短板了。
80 |
81 | 如果你倾向于去做机器学习平台的产品经理,就去重点学习模型建模的过程,甚至要自己尝试去使用一些公共的机器学习平台,去创建一个算法模型。比如阿里云的 PAI、百度的 EasyDL,它们都是很优秀的建模平台。
82 |
83 | 如果你想做大数据风控方向的 AI 产品经理,就需要知道机器学习模型内部逻辑,甚至要了解一下算法的逻辑是怎么样的。
84 |
85 | 在学习技术知识方面,我建议你可以购买一些入门的课程,可以先从简单的内容学起,再慢慢深入。在选择课程的时候,我建议你避开一些包含大量数学公式的课程,不是因为这些课不好,而是因为它们主要面向数据工程师或者算法工程师,对产品经理来说学起来太困难。
86 |
87 | **第四步,总结、输出、实践。**
88 |
89 | 总结、输出、实践,这几个词你肯定听过很多遍,但我还是要说,你可别嫌我啰嗦。
90 |
91 | **学习这件事,去学习只是第一步,更重要的是做总结。但只是总结还不够,我希望你还能借着这些总结去做输出,强迫自己整理出一篇文章,或者给其他人分享。当你可以用浅显的语言把复杂的知识讲解清楚的时候,就说明你对这个知识真正掌握了。**
92 |
93 | 基础知识掌握之后,你就可以开始实践了。我建议你先尝试去面试一些 AI 公司,感受一下具体 AI 企业关注求职者哪些技能,他们都会提出哪些问题,再去迭代自己的技能。这样,去心仪的公司面试成功的几率就会更高。
94 |
95 | ## 总结
96 |
97 | 今天,我和你分享了两条转型AI产品经理的路径,这里我们再一起对里面涉及的方法做个总结。
98 |
99 | 如果你是内部转岗,我建议你采用从下到上,由点及面的学习方式,可以暂时先让算法同学主导整个项目,但是对于工作中任何一个细节问题你都不要放过,想办法去补充相关知识,建立自己的知识体系。
100 |
101 | 如果你是外部求职,我建议你采用从上到下,从面到点的学习方式。总的来说,就是先了解AI行业,再给自己定好方向,然后补足技术,最后做总结多输出,多实践。
102 |
103 | 这两条路径总结起来很简单,但是里面涉及的每一点,实现起来都不容易。总的来说,我希望你能记住一句话,多总结、多输出,然后用以教促学的方式来迭代自己对 AI 知识的领悟。
104 |
105 | ## 课后讨论
106 |
107 | 目前,对于行业的知识,产品经理的岗位职责以及转型准备上,你还有什么疑问吗?你能根据自己的理解再加上收集的一些信息,去搭建一个行业框架呢?当然,如果你能整理出一个脑图出来,那就再好不过了。
108 |
109 | 如果你的朋友也正在为不知道怎么转型AI产品经理而苦恼,那就快把这节课分享给他吧!如果你不想自己去找学习资源的话,课程的最后,我还整理出了一些我认为值得关注和学习的公众号、图书和视频课程,如果你有兴趣可以参考一下。我们下节课见!
110 |
111 | * * *
112 |
113 | 拓展阅读
114 |
115 | 我把我在转型时关注的一些网站和资料梳理出来了,你可以根据你的情况进行选择。
116 |
117 | 1\. 行业知识
118 |
119 | 你可以关注《爱分析》这个公众号,它会发布一些类似《智慧医院厂商全景报告》、《2020爱分析中国人工智能厂商全景报告》、《中国知识图谱应用趋势报告》的行业报告,也会组织一些类似《2020爱分析金融机构数字化论坛》的线下论坛。
120 |
121 | 另外,你也可以关注艾瑞咨询这样的网站,上面有一些类似《2020年中国AI+零售行业发展研究报告》的行业报告。这些信息相对体系化,可以帮你梳理整个行业框架的思路。
122 |
123 | 除此之外,你也可以关注 《36 氪》这样的新闻网站,用一些及时的碎片化新闻,来实时了解当前行业动态。
124 |
125 | 2\. 技术基础
126 |
127 | 你可以关注一些技术类的公众号,比如《大数据文摘》、《大数据分析与人工智能》、《机器之心》、《AI启蒙者》等等。另外,你也可以关注我自己的公众号《成为AI产品经理》,我在上面分享了很多关于转型 AI 产品经理的心得。
128 |
129 | 3\. 技术进阶
130 |
131 | 如果想提高技术能力,我建议你可以学习这两个视频课程:李宏毅的《Machine Learning》和吴恩达的《机器学习》课程。这两门课程的老师讲解细致,内容通俗易懂,也是机器学习的经典课程,非常推荐你学习。
132 |
133 | 除了一些视频教程之外,你还需要阅读一些技术书籍。我首先推荐的是李航的《统计学习方法》,这是我在最开始接触 AI 时候,我们算法团队负责人推荐给我的,可以作为算法学习的基础。不过,因为它的专业性比较强,非技术出身的产品经理看起来可能有些难度,你可以选择性地学习。
134 |
135 | 另外一个就是周志华的《机器学习》,也就是我们俗称的西瓜书。这本书覆盖面广,有大量的实例可供参考,对于非技术人员来说比较友好。
136 |
137 | - 奔跑的三石 👍(15) 💬(2)
海丰老师好,目前正在计划转行AI产品经理,遇到一个困境:作为一个没有任何AI方向项目经验的产品经理,如何能打造自己的“敲门砖”呢?您有提到输出文章的方式,我自己还参加过一些AI领域的比赛,想知道还有别的方式吗?
2020-12-22
- 一切都好 👍(2) 💬(1)
海丰老师好,做为传统行业的算法工程师,明年要和互联网厂商合作做业务场景了。也就是说我要转型产品经理方向,想问问有什么要注意的吗。
2021-01-06
- Fan 👍(1) 💬(2)
一三五必读专栏
2020-12-22
- 小饼子 👍(0) 💬(1)
打卡学习➕1
2021-04-26
- Miss斑马 👍(0) 💬(1)
打卡学习
2020-12-23
- 加菲猫 👍(6) 💬(0)
老师推荐的有几个公众号也一直在关注,发现自己的一个缺点:收集资料很勤快,但梳理归纳总结很少。语言精炼能力需要提升,很多内容觉得看懂了,准备输出时还是词穷,总是觉得表达不够简洁明了,输出都变成了笔记复述,没有转化到自己的知识架构里,最常用的方法是用脑图来填关键字,不知道是不是思维太发散,脑图上满屏的零碎知识点,没有一条线去梳理思路,记的笔记很少去看第二遍,老师在知识架构梳理上有什么经验可以分享下么,怎么能高效输出?
2021-04-24
- 想做产品的一帆 👍(4) 💬(2)
《统计学习方法》看过一些,公式太多,被劝退了,没有强大的统计学、数学基础最好先别看,先补高数、线代、概率论、数理统计这些课。深度学习的有一本鱼书挺不错的,很薄,学算法的同学推荐的。
2021-02-09
- LLM流浪猫 👍(1) 💬(0)
根据评论区留言,补充几本书《深度学习入门_基于Python的理论与实现》《Python神经网络编程》,建议先到豆瓣网搜搜书评,再作阅读决定。
2023-06-13
- Geek_27fa97 👍(0) 💬(0)
老师,可以加您微信吗
2025-02-17
- St.Peter 👍(0) 💬(0)
关注了《成为AI产品经理》的公众号。里面只有一篇公众号啊
2024-10-20
- Geek_fea0e3 👍(0) 💬(0)
加油,刚开始学习,期待有好的结果
2024-10-16
- 知更 👍(0) 💬(0)
老师讲的太好了,每个步骤又清晰又可执行,给迷茫的我指明了方向,要不是看了老师的课程,我肯定一股脑扎进技术去了
2024-10-14
- coderlee 👍(0) 💬(0)
感谢老师提供的公众号、网站、课程推荐,对于0基础学习AI的我来讲,确实是一个多方面了解AI的途径
2024-03-25
- TinaJin 👍(0) 💬(0)
分析企业处于尾部的原因有点难,你是怎么进行分析的呢
2023-11-08
- escray 👍(0) 💬(0)
我不是岗位明确的 AI 产品经理,但是可以做一些这方面的工作,可能比较类似于内部转岗的情况。
138 |
139 | 手头的项目应该主要是在自然语言处理和知识图谱方面做一些人工智能应用的探索。
140 |
141 | 拓展阅读里面提到的课程和书籍都很不错,不过还是学完本专栏的内容再说。
2022-04-12
142 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/15 - K-means 聚类算法:如何挖掘高价值用户?.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 在前面的课程中,我们学习了分类算法:K 近邻、逻辑回归、朴素贝叶斯、决策树,以及支持向量机,也学习了回归算法:线性回归。它们有一个共同点,都是有监督学习算法,也就是都需要提前准备样本数据(包含特征和标签,即特征和分类)。
4 |
5 | 但有的情况下,我们事先并不能知道数据的类别标签,比如在[第8讲](https://time.geekbang.org/column/article/326965)智能客服的例子中,因为事先并不知道用户的咨询问题属于什么类别,所以我们通过层次聚类算法把相似度比较高的用户咨询问题进行了聚类分组,然后把分析出的常见高频问题交由机器人回复,从而减轻人工客服的压力。
6 |
7 | 聚类算法是无监督学习算法中最常用的一种,无监督就是事先并不需要知道数据的类别标签,而只是根据数据特征去学习,找到相似数据的特征,然后把已知的数据集划分成不同的类别。
8 |
9 | 不过,因为第 8 讲中的层次聚类算法在实际工业中的应用并不多。所以今天,我们就来讲一种应用最广泛的聚类算法,它就是 K 均值( K-means )算法。
10 |
11 | ## 如何理解 K-means 算法?
12 |
13 | 每次大学开学的时候都会迎来一批新生,他们总会根据自己的兴趣爱好,自发地加入校园一个个小社团中。比如,喜欢音乐的同学会加入音乐社,喜欢动漫的同学会加入动漫社,而喜欢健身的同学会加入健身社等等。
14 |
15 | 于是,这些来自天南地北从来不认识的人,追随着同样的兴趣爱好走到了一起,相互认识。这就是我们常说的,人以群分,物以类聚。
16 |
17 | ### K-means算法的原理
18 |
19 | 如果把这个故事的主角换成机器学习中的数据样本,我们是不是就可以快速给它们进行分类了呢?比如,当几个样本非常相似的时候,我们就把它们归为一类,再用这几个样本的中心位置表示这个类别,以方便其他相似样本的加入。
20 |
21 | 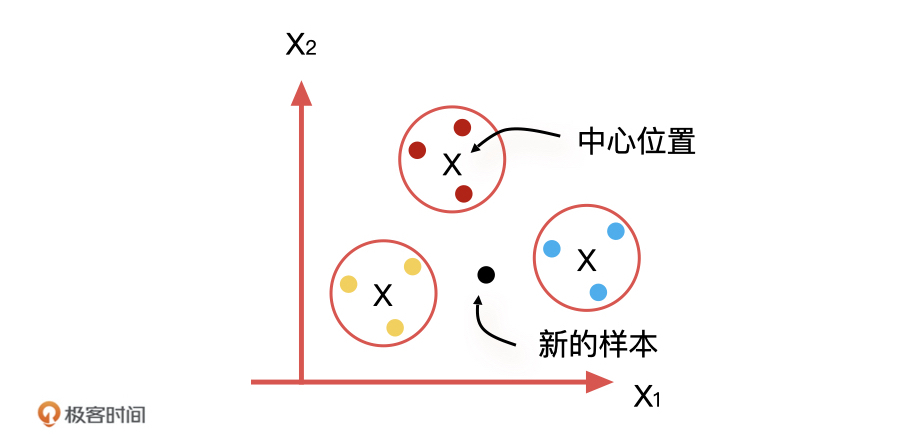
22 |
23 | 每当这个类别中有了新的相似样本加入的时候,我们要做的就是更新这个类别的中心位置,以方便这个新样本去适应这个类别。
24 |
25 | 这其实就是K-means算法的思路:**对于n个样本点来说,根据距离公式(如欧式距离)去计算它们的远近,距离越近越相似。按照这样的规则,我们把它们划分到 K 个类别中,让每个类别中的样本点都是最相似的**。
26 |
27 | 为了方便理解,我们引入了聚类的概念,聚类就是相似度很高的样本点的集合,我们刚才说的K个类别就等于K个聚类。同时,为了准确描述聚类的位置信息,我们还需要定义这个聚类的坐标位置,就是聚类中心,也就是质心(Centroid),来方便其他待测样本点去评估它距离哪个聚类更近,每个质心的坐标就是这个聚类的所有样本点的中心点,也就是均值。
28 |
29 | ### K-means算法解决聚类问题的过程
30 |
31 | K-means算法是怎么解决聚类问题的呢?为了帮助你理解,我们来举个具体点的例子。假设我们现在要给 9 个样本进行聚类,它们有两个特征维度,分布在一个二维平面上,如下图所示。
32 |
33 | 第一步,我们先随机在这个空间中选取三个点,也就是质心。
34 |
35 | 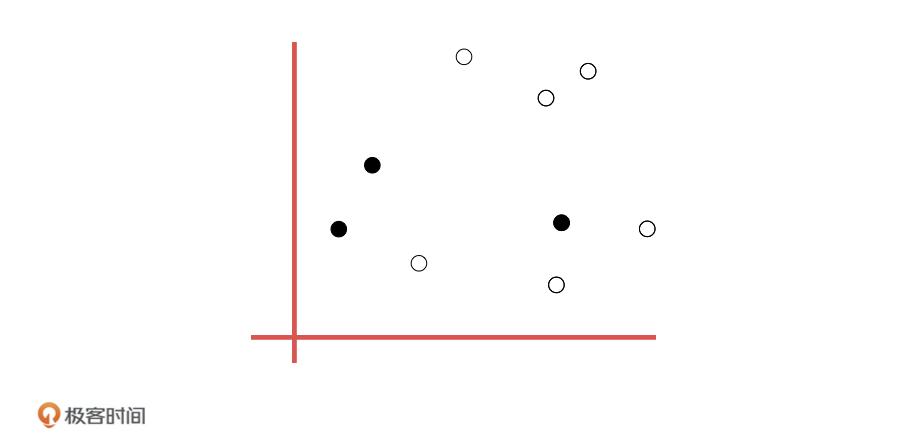
36 |
37 | 第二步,我们用欧式距离计算所有点到这三个点的距离,每个点都选择距离最近的质心作为的中心点。这样一来,我们就可以把数据分成三个组。
38 |
39 | 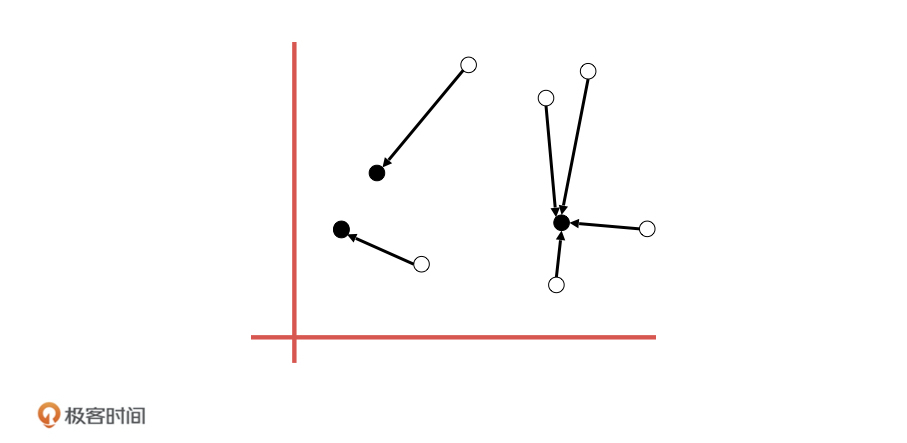
40 |
41 | 第三步,在划分好的每一个组内,我们计算每一个数据到质心的距离,取均值,用这个均值作为下一轮迭代的中心点。
42 |
43 | 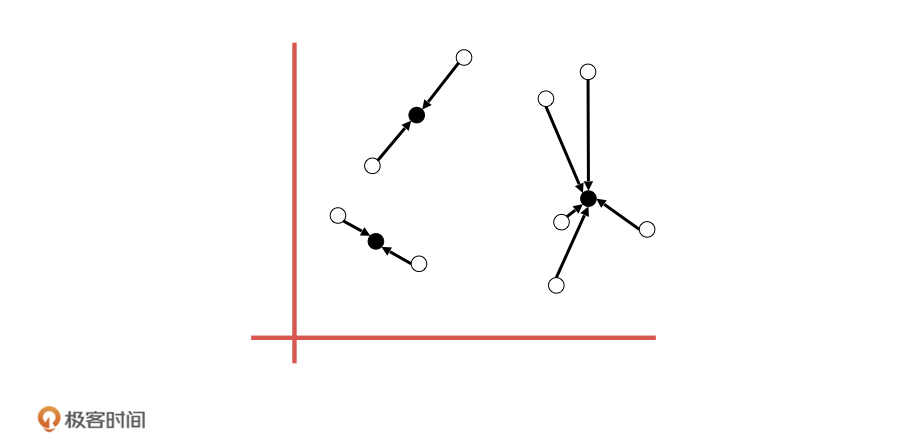
44 |
45 | 最后,我们不断重复第二步和第三步进行迭代,直到所有的点已经无法再更新到其他分类,也就是聚类中心不会再改变的时候,算法结束。
46 |
47 | 
48 |
49 | ### K 值如何确定
50 |
51 | K-means 的算法原理我们就解释完了,但还有一个问题没有解决,那就是**我们怎么知道数据需要分成几个类别,也就是怎么确定K 值呢?**
52 |
53 | K 值的确定,一般来说要取决于个人的经验和感觉,没有一个统一的标准。所以,要确定 K 值是一项比较费时费力的事情,最差的办法是去循环尝试每一个 K 值。然后,在不同的 K 值情况下,通过每一个待测样本点到质心的距离之和,来计算平均距离。
54 |
55 | 比如,在刚才这个例子中,当 K=1 的时候,这个距离和肯定最大,平均距离也最大;当 K=9 的时候,每个点也是自己的质心,这个时候距离和是 0,平均距离也是 0。随着 K 值的变化,我们最终会找到一个点,让平均距离变化放缓,这个时候我们就基本可以确定 K 值了。
56 |
57 | ## 应用案例:K-means算法对用户分层
58 |
59 | 接下来,我们再借助电商平台分类用户的例子,说说K-means算法的应用。电商平台的运营工作经常需要对用户进行分层,针对不同层次的用户采取不同的运营策略,这个过程也叫做精细化运营。
60 |
61 | 就我知道的情况来说,运营同学经常会按照自己的经验,比如按照用户的下单次数,或者按照用户的消费金额,通过制定的一些分类规则给用户进行分层,如下表格,我们就可以得到三种不同价值的用户。
62 |
63 | 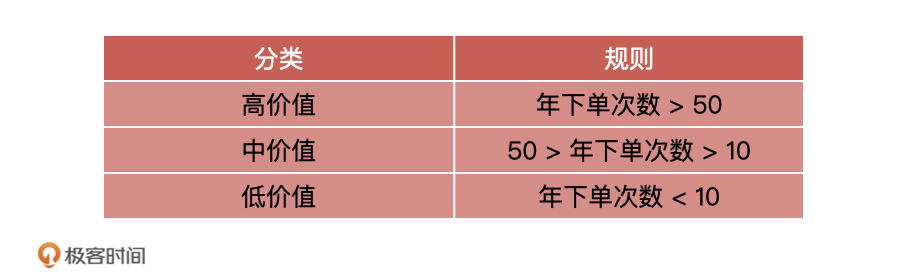
64 |
65 | 这种划分的方法简单来看是没有大问题的,但是并不科学。为什么这么说呢?这主要有两方面原因。
66 |
67 | 一方面,只用单一的“下单次数”来衡量用户的价值度并不合理,因为用户下单的品类价格不同,很可能会出现的情况是,用户 A 多次下单的金额给平台带来的累计 GMV(网站的成交金额) ,还不如用户 B 的一次下单带来的多。因此,只通过“下单次数”来衡量用户价值就不合理。因为一般来说,我们会结合下单次数、消费金额、活跃程度等等很多的指标进行综合分析。
68 |
69 | 另一方面,就算我们可以用单一的“下单次数”进行划分用户,但是不同人划分的标准不一样,“下单次数”的阈值需要根据数据分析求出来,直接用 10 和 50 就不合理。
70 |
71 | 这两方面原因,就会导致我们分析出来的用户对平台的贡献度差别特别大。因此,我们需要用一种科学的、通用的划分方法去做用户分群。
72 |
73 | RFM 作为用户价值划分的经典模型,就可以解决这种分群的问题,RFM 是客户分析及衡量客户价值的重要模型之一。其中 ,R 表示最近一次消费(Recency),F 表示消费频率(Frequency),M 表示消费金额(Monetary)。
74 |
75 | 
76 |
77 | 我们可以将每个维度分为高低两种情况,如 R 的高低、F 的高低,以及 M 的高低,构建出一个三维的坐标系。
78 |
79 | 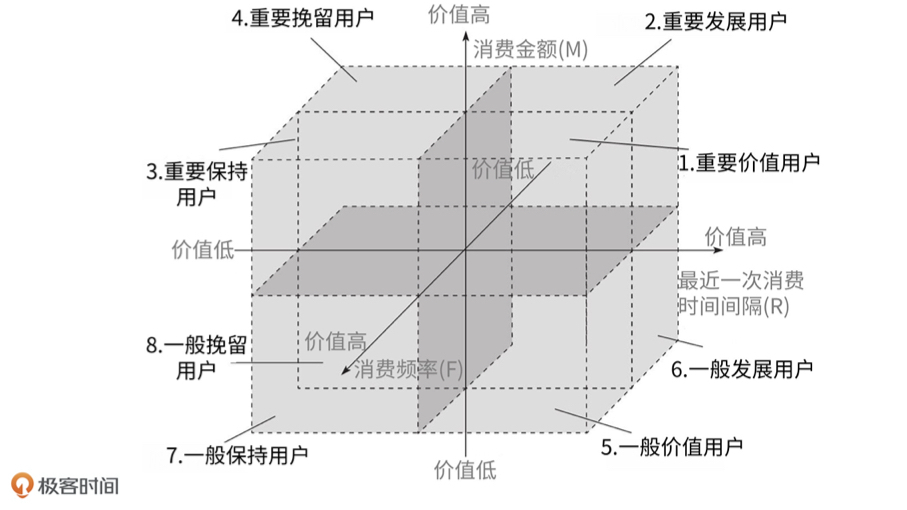
80 |
81 | 这样一来,我们就把客户分为了$2^{3}$,也就是 8 个群体,具体的分类如下:
82 |
83 | 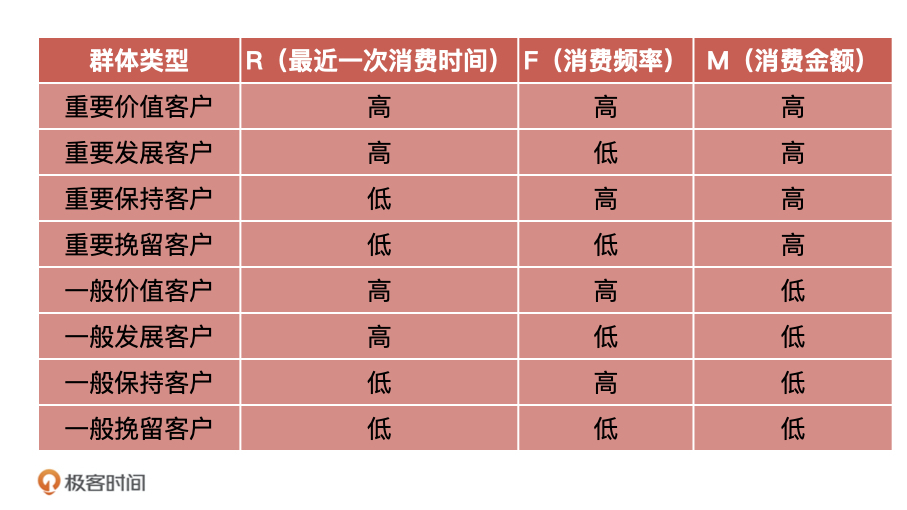
84 |
85 | 然后,我们通过用户历史数据(如订单数据、浏览日志),统计出每个用户的 RFM 数据:
86 |
87 | - USERPIN:用户唯一ID;
88 | - R:最后一次消费日期距现在的时间,例如最后消费时间到现在距离 5 天,则 R 就是 5;
89 | - F:消费频率,例如待统计的一段时间内用户消费了 20 次,则 F 就是 20;
90 | - M:消费金额,例如待统计的一段时间内用户累计消费了 1000 元钱,则 M 就是 1000;
91 |
92 | 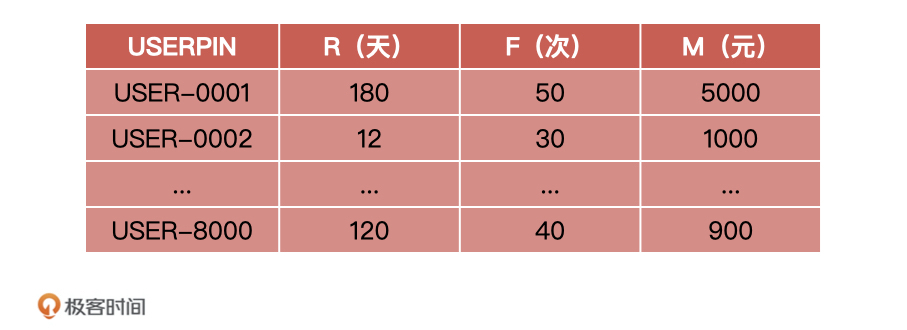
93 |
94 | 这样,我们就有了 8000 个样本数据,每个样本数据包含三个特征,分别为 R、F,M,然后根据前面 RFM 分为 8 个用户群体,则意味着 K 值为 8。
95 |
96 | 最后,我们将数据代入到 K-means 算法,K-means 将按照本节课讲解的计算逻辑进行计算,最终将 8000 个样本数据聚类成 8 个用户群体。这个时候,运营同学就可以根据新生成的 RFM 用户分群进行针对性的营销策略了。
97 |
98 | 好了,这就是K-means 算法对用户进行聚类的全部过程了。除了对用户聚类,K-means 算法可以应用场景还有很多,常见的有**文本聚类、售前辅助、风险监测等等**。下面,我们一一来说。
99 |
100 | **文本聚类**:根据文档内容或主题对文档进行聚类。有些 APP 或小程序做的事儿,就是从网络中爬取文章,然后通过 K-means 算法对文本进行聚类,结构化后最终展示给自己的用户。
101 |
102 | **售前辅助**:根据用户的通话、短信和在线留言等信息,结合用户个人资料,帮助公司在售前对客户做更多的预测。
103 |
104 | **风险监测**:在金融风控场景中,在没有先验知识的情况下,通过无监督方法对用户行为做异常检测。
105 |
106 | ## K-means 聚类算法的优缺点
107 |
108 | 在优点方面,K-means 算法原理简单,程序容易实现,运算效率高,并且可解释性强,能够处理绝大多数聚类问题。而且,因为它属于无监督算法,所以不需要利用样本的标注信息就可以训练,这意味着它不需要像监督学习一样过分追溯样本的标注质量。
109 |
110 | 在缺点方面,K-means 由于不能利用样本的标注信息,所以这类模型的准确度比不上监督类算法。而且,K-means 算法受噪声影响较大,如果存在一些噪声数据,会影响均值的计算,进而引起聚类的效果偏差。
111 |
112 | ## 总结
113 |
114 | K-means 算法是机器学习领域中处理无监督学习最流行、经典的聚类分析方法之一。它是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,待测样本点距离聚类中心的距离越近,它的相似度就越大。
115 |
116 | 今天,我先讲了 K-means 算法的原理。我们要重点理解它的应用思路,我把它们总结成四步:
117 |
118 | 第一步,随机选取任意 K 个数据点作为初始质心;
119 | 第二步,分别计算数据集中每一个数据点与每一个质心的距离,数据点距离哪个质心最近,就属于哪个聚类;
120 | 第三步,在每一个聚类内,分别计算每个数据点到质心的距离,取均值作为下一轮迭代的质心;
121 | 第四步,如果新质心和老质心之间的距离不再变化或小于某一个阈值,计算结束。
122 |
123 | K-means 最经典的应用场景就是文本聚类,也就是根据文档内容或主题对文档进行聚类,再有就是对用户进行分类,它们是 K-means 最常用的两个场景。
124 |
125 | 然后,我还给你讲了K-means 算法的优缺点。关于优点你记住3点就够了,分别是简单易实现,运算效率高,可解释性很强。缺点也是3点,分别是不稳定,容易受到噪声影响,并且不如有监督学习算法准确。
126 |
127 | 那重要知识总结完之后,我还想带你对K-means算法和KNN 做一个区分。很多同学容易把它们弄混,因为它们的类别信息都会受到当前样本周围的环境的影响,但 K-means和KNN 有着本质的区别,我在下面对它们进行了对比,你可以去看看,希望能帮助你加深理解。
128 |
129 | 
130 |
131 | ## 课后讨论
132 |
133 | 我想请你想一想,在你的业务场景中,有哪些需求可以通过聚类分析的方式来实现。为什么?
134 |
135 | 欢迎在留言区分享你的故事,我们下节课见!
136 |
137 | - 橙gě狸 👍(8) 💬(0)
在给销售人员提供个性化培训的这个场景上,使用聚类算法。
138 | 可以先根据销售人员能力模型内的几大标签作为聚类算法的特征,通过算法将销售人员划分为2的n次方个群体,并根据最终聚类结果推送不同的培训课程。
2021-01-15
- 汉堡吃不饱 👍(5) 💬(4)
老师,不明白的一点:
139 | 既然都已经分成8类了,且知道每一类的特征与类别了,那这不是有监督学习吗?
140 | 聚类按照8类出结果后,如果这8类不符合之前定义的8类的标准,怎么办?
2021-01-18
- 小太白 👍(2) 💬(0)
应用场景:差异化教学。通过对学生多维数据进行标签,分组,聚类,对学生进行愈发精细的画像,给老师教学决策和差异化教学提供依据和抓手。
2021-03-25
- Rosa rugosa 👍(2) 💬(0)
在股票软件中,判断资讯发布在那个类别下适合用K-means聚类。K-means聚类适合用在文本分类和精细化运行中的用户分层中。
2021-03-12
- Yesss! 👍(2) 💬(0)
我暂时接触过环保业务,R:最近一次扔垃圾的频率 F:扔垃圾的频率 M:扔垃圾的重量。在后台得到样本数据,并用K-means。分析出哪一些人员是相似性最大的。从而决定人员相似性最高的楼栋作为标准(实行奖惩等制度)。
141 | 银行借贷业务也是相似的:R:最近一次借贷频率,F:借贷的频率次数 M:借贷的金额。分析出哪一些人员是最接近老赖的
142 | 保险业务、电商、社交同理
2021-01-31
- 加菲猫 👍(1) 💬(0)
聚类算法可以用在社区运营和内容推荐上,例如B站、视频网站的内容推荐,电商社区不同用户群的内容、商品推荐;腾讯视频号的内容推荐。
2021-05-06
- 文杰 👍(1) 💬(3)
客户分层,通过聚类后怎么对应到那8个分类去?用户数据是每天变的,每天都要全量数据跑下聚类?还有一个用户今天被分到类1,明天分到类2,前端营销怎么搞?
2021-02-24
- 熊猫要吃酒 👍(1) 💬(1)
RFM模型中,R的值越低越好,但是F和M越高越好,怎么看权重呢?
2021-01-15
- Geek_ac620e 👍(0) 💬(0)
hhh
143 |
2023-11-03
- Juha 👍(0) 💬(0)
老师,“第三步,在划分好的每一个组内,我们计算每一个数据到质心的距离,取均值,用这个均值作为下一轮迭代的中心点。”这里没看明白,是不是应该是取每个组的所有点的坐标的平均值作为新的质点呀
2022-02-18
- AsyDong 👍(0) 💬(0)
质心位置的选择是随机的话,对结果会有影响吧。比如数据在第一象限,然后2个质心,一个随机放在第三象限,一个随机放在第一象限,那第三象限的质心岂不是成了摆设,这样分出来的类不精准吧。
2021-05-07
- 云师兄 👍(0) 💬(0)
这些算法在落地时是用啥技术实现的啊
2021-01-15
144 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/13 - 决策树与随机森林:如何预测用户会不会违约?.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 今天,我们要讲决策树与随机森林。决策树是一种基础的分类和回归算法,随机森林是由多棵决策树集成在一起的集成学习算法,它们都非常常用。
4 |
5 | 这节课,我就通过决策树预测用户会不会违约的例子,来给你讲讲决策树和随机森林的原理和应用。
6 |
7 | ## 如何理解决策树?
8 |
9 | 很多人都有过租房子的经历,那你是怎么决定要不要租一个房子的呢?你可以先想一想,我先把我的做法说一下,我会先判断房子的位置,再看价格,最后看装修。
10 |
11 | 更具体点来说,我只会选择离公司近的房子,比如说 5 公里以内的或者通勤时间在 40 分钟以内的。其次,如果价格便宜,不管装修得好不好我都租,如果价格贵那我就要看装修情况,装修好就租,装修不好就不租。
12 |
13 | 这就是一棵典型的决策树:对于租房子这个问题,我根据距离、价格、装修这几个条件 ,对一个房子进行了判断,最后得到一个解决结果,就是这个房子我是租或者不租。下图就是这棵决策树的示意图。
14 |
15 | 
16 |
17 | 我们可以看到,决策树(Decision Tree)就是一种树形结构的算法,上面的节点代表算法的某一个**特征(如距离、价格),节点上可能存在多个分支,每一个分支代表的是这个特征的不同种类(如距离远、距离近),最后的叶子节点代表最终的决策结果(如租、不租)**。
18 |
19 | ### 决策树的生成
20 |
21 | 知道了决策树的形式和原理,我们再来看看决策树的生成过程,它是决策树的核心。不过,对于产品经理来说,更重要的还是掌握决策树的原理、形式、优缺点。那我把它的详细过程写在下面,就是让你在工作中遇到类似问题的时候,能直接回来补充必要的知识,所以今天我们先对整体过程有个大致了解就可以了。
22 |
23 | **决策树生成的过程包括三个部分,分别是特征选择、决策树生成、决策树剪枝。**下面,我们还是拿上面租房子的例子,来说一说这个决策树生成的过程。假设现在有如下条件的一个房子,根据我上面定下的规则,你觉得这个房子我会不会租呢?
24 |
25 | 
26 |
27 | 我们先看距离,因为这个房子距离公司远,所以根据上面的决策树,我们就能直接得出结论:不租。但是,假设我们的决策树不是用距离作为根节点,而是用价格作为根节点的话,结果会不会不一样呢?
28 |
29 | 这个时候,决策棵树可能会变成下面的样子:
30 |
31 | 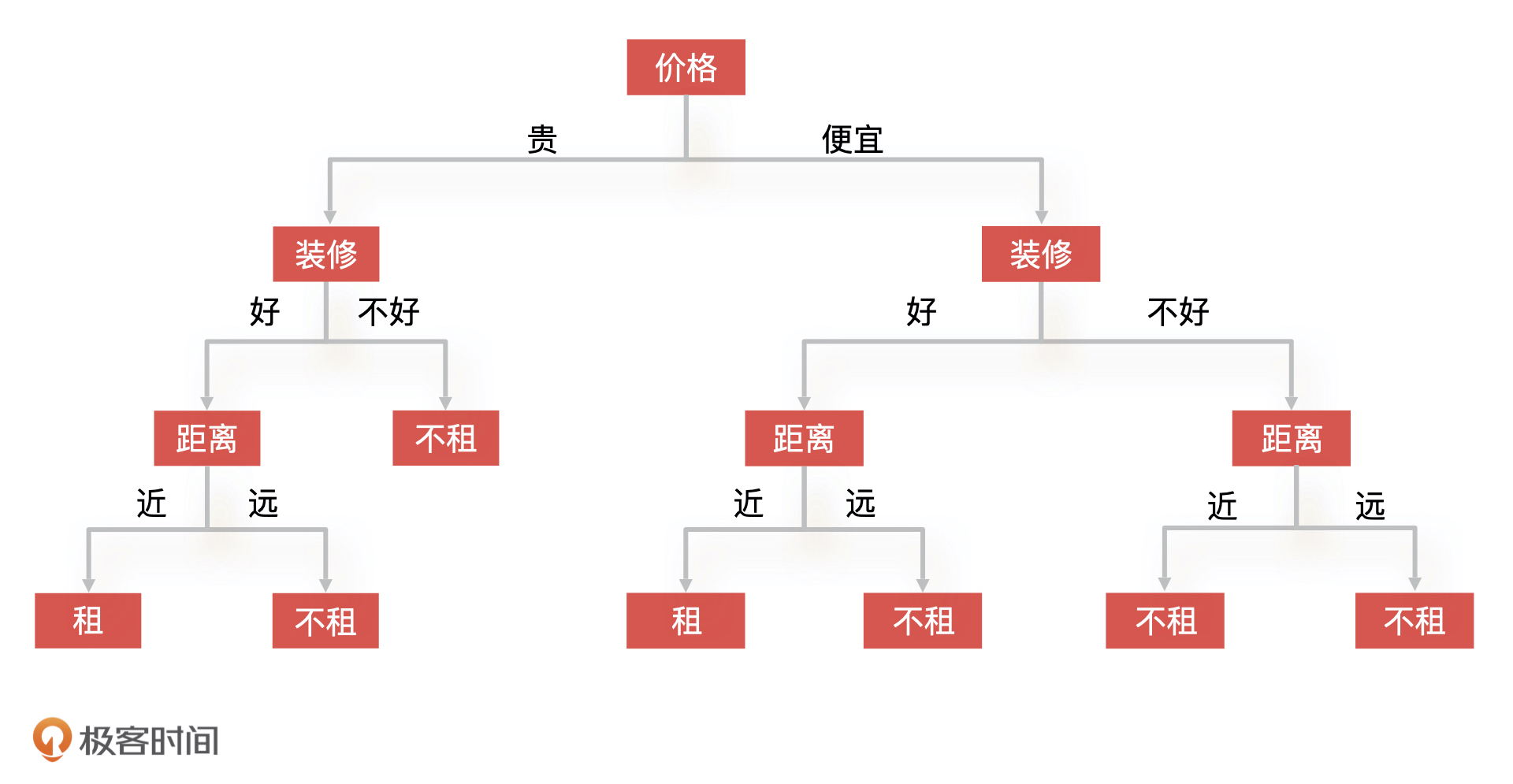
32 |
33 | 你会发现,我们的决策树一下子变“大”了,判断这个房子的过程就变成了,先看价格,再看装修,最后看距离。我们发现,即使决策树的结构发生了变化,可我们还是会得到之前的结论:不租,所以,决策树的构造只会影响到算法的复杂度和计算的时间,而不会影响决策的结果。
34 |
35 | 因此,在实际工作中,我们就需要优化决策树的结构,让它的效率更高,但这具体该怎么做呢?
36 |
37 | ### 信息熵
38 |
39 | 我们一般会在特征选择和决策树的生成阶段,通过**信息熵**来决定哪些特征重要以及它们应该放到哪个节点上,因为信息熵是用来衡量**一个节点内信息的不确定性的**。一个系统中信息熵越大,这个系统的不确定性就越大,样本就越多样,你也可以理解成是样本的**纯度越低**,信息熵越小,系统的不确定性就越小,样本越趋于一致,那样本的**纯度就越高**。
40 |
41 | 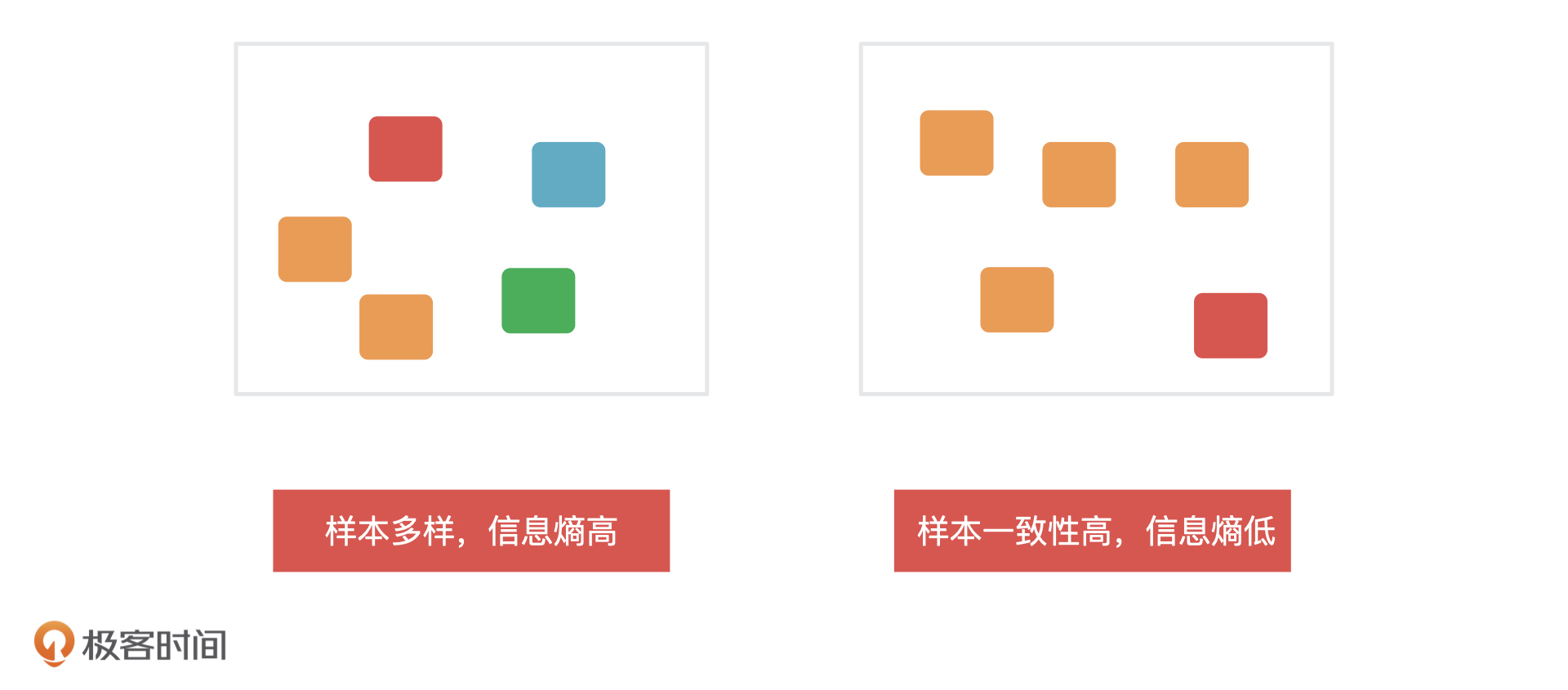
42 |
43 | 我们肯定是希望决策树在每次划分的时候,每个条件分支都能够最大化地去划分这些样本,让每个节点的信息熵更低,样本一致性更高。所以,决策树会计算每一个特征划分后样本的“**纯度**”,纯度越高的特征越接近根节点。这样一来,决策树的复杂度和计算时间肯定就会越少,也就不会出现我们刚才说的那种“很大”的决策树。这就是实际工作中我们构造决策树的思路了。
44 |
45 | 实际上,决策树的算法有很多,最典型的三种分别是 ID3(Iterative Dichotomiser 3,迭代二叉树3代)、C4.5 和 CART(Classification and Regression Trees,分类与回归树)。ID3 是最初代的决策树算法,它使用的计算指标是信息增益;C4.5 是在 ID3 基础上改进后的算法,它使用的计算指标是信息增益率;CART 分类与回归树,做分类问题时使用的是 [Gini 系数(Gini Coefficient,基尼系数)](https://zh.wikipedia.org/wiki/%E5%9F%BA%E5%B0%BC%E7%B3%BB%E6%95%B0),做回归问题的时候使用的是偏差值。
46 |
47 | 作为产品经理,我们简单了解这三种算法的特点就可以了,我在下面对它们进行了总结,你可以参考一下。
48 |
49 | 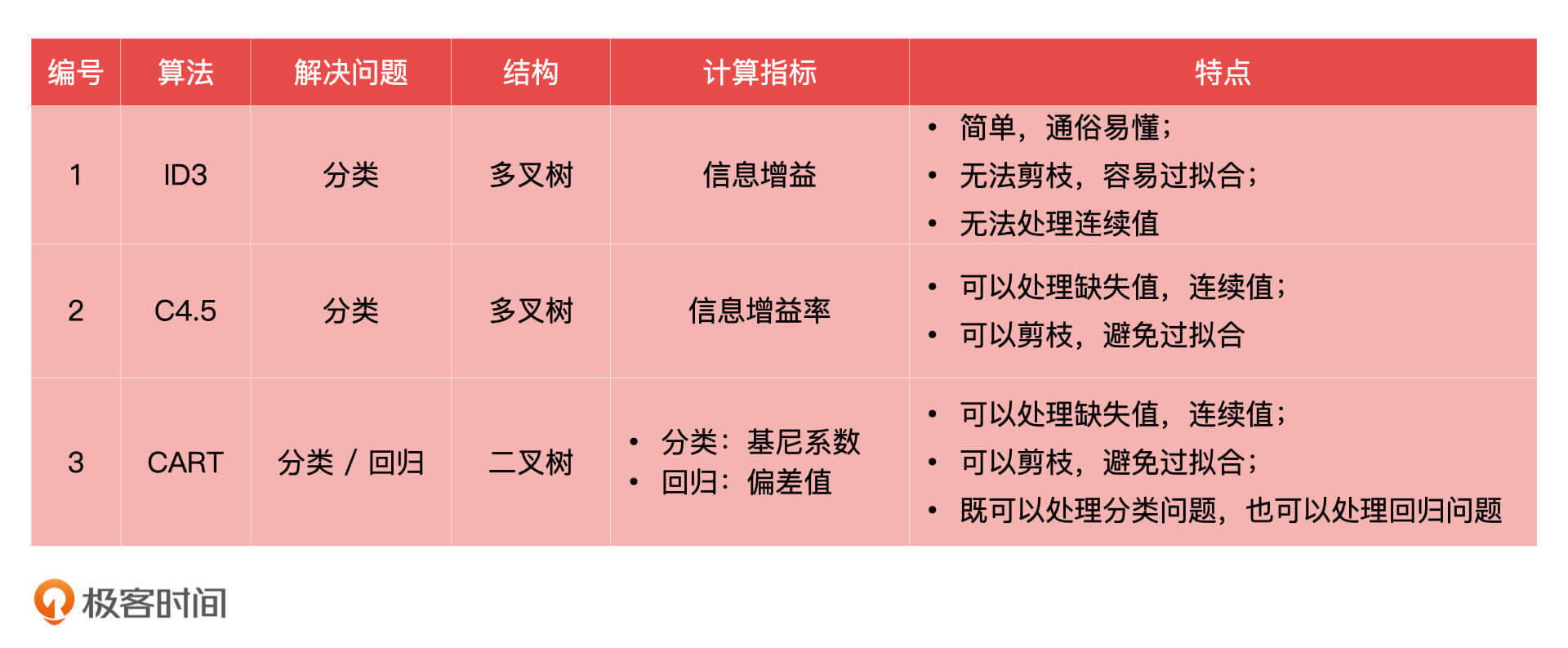
50 |
51 | ### 剪枝操作
52 |
53 | 最后,因为决策树很容易出现过拟合情况,所以我们还会引入剪枝操作这个环节。剪枝就是我们对一棵树进行简化,减少它的复杂程度,提高模型的泛化能力。剪枝的原理很好理解,主要就是判断把某个节点去掉之后,模型的准确度会不会降低了,如果没有降低,就可以减掉这个节点。
54 |
55 | 剪枝的操作还分为预剪枝和后剪枝,它们的区别是剪枝发生的阶段不同。预剪枝在决策树生成时候同步进行。而后剪枝是决策树生成之后,再对决策树的叶子节点开始一步一步地向根方向剪枝。
56 |
57 | ## 决策树的应用案例:预测用户违约
58 |
59 | 决策树的生成讲完了,我们重点来看看决策树的应用。在金融风控场景下,我们经常需要判断用户的违约风险。
60 |
61 | 最早的风控模型都是使用逻辑回归来做的,因为它相对简单而且可解释性强。但逻辑回归属于线性模型,不能很好处理非线性特征,所以决策树算法也慢慢用于违约风险的预测。接下来,我们就来看看决策树是怎么预测违约风险的。
62 |
63 | 决策树预测用户违约的核心思想是:**先获取部分用户的历史数据,历史数据中包括过去的信贷数据和还款结果;然后将贷款客户不断进行分类,直到某个节点的样本用户都是同一个类型为止;最后,再对决策树进行剪枝,简化树的复杂度。**
64 |
65 | 假设我们得到的用户历史数据如下所示。对于这个表格,我再补充解释一下,过去的信贷数据应该包括申请数据、金融产品相关数据等等。年龄,是否有房这些都属于申请数据,是包括在信贷数据里的。
66 |
67 | 还款结果指的是什么时候还款,还了多少,但是做模型设计,定义模型目标变量的时候,我们不可能直接用还款数据,所以我们定义是否逾期作为目标值,也就是 Y 值。1 代表逾期,0 代表不逾期。
68 |
69 | 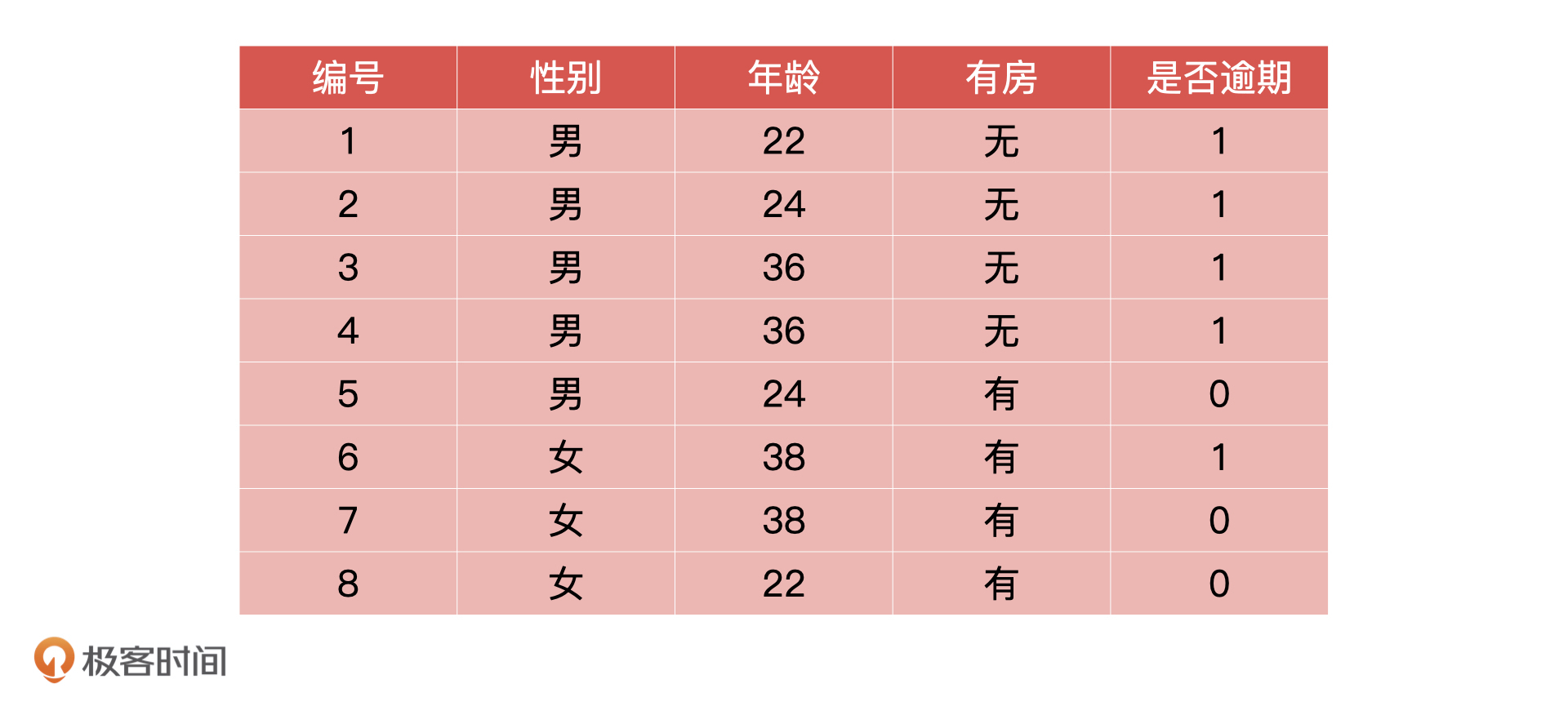
70 |
71 | 因为目前决策树算法中,使用比较多的是 CART 算法,所以我们也选择它进行模型构建,而特征选择阶段会使用 Gini 系数。 CART 算法选择 Gini 系数,是因为信息熵模型使用了大量的对数计算导致效率很低,而 Gini 系统可以避免这个问题,从而提升计算效率。
72 |
73 | 从上面的历史数据中,我们可以提取出三个特征,分别是性别、年龄和是否有房。接下来,我们就分别计算一下这三个特征的 Gini 系数。
74 |
75 | 首先,性别特征的 Gini 系数直接根据公式计算就可以了,我们假设它就是 0.412。
76 |
77 | 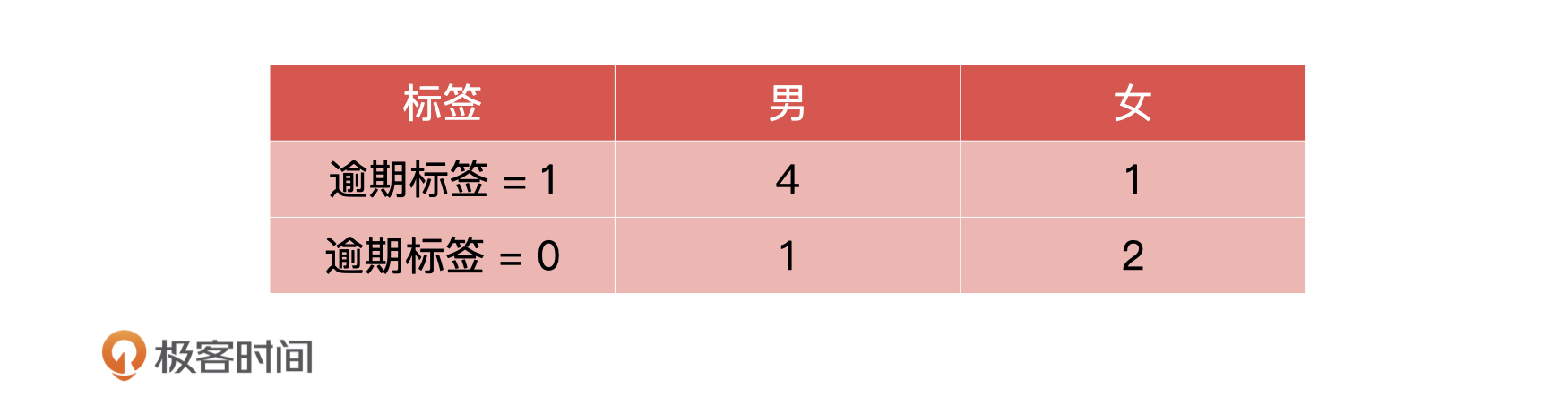
78 |
79 | 我们重点来看第二个特征:年龄。年龄是一个连续的值,我们的历史数据中一共有 4 种数值,每两个相邻值之间都可以是一个特征分类的点(比如说,年龄 22 和年龄 24 的分类点就是23),所以对于年龄这个特征,我们一共有3种不同的分类方式。因为分类方式比较多,相对应的,Gini 的计算方式就会比较复杂,我们需要分别计算3种不同分类方式时的 Gini 系数,选出 Gini 最小的分类方式,把它作为年龄的分类。
80 |
81 | 假设年龄在 37 的时候 Gini 系数最小,等于 0.511,那么年龄这个特征的条件分支就是小于 37 和大于 37。
82 |
83 | 相同的,我们可以再计算是否有房的 Gini 系数。假设这个特征的 Gini 系数为 0.113,最后,根据 Gini 排序我们就能得到如下的决策树结构。
84 |
85 | 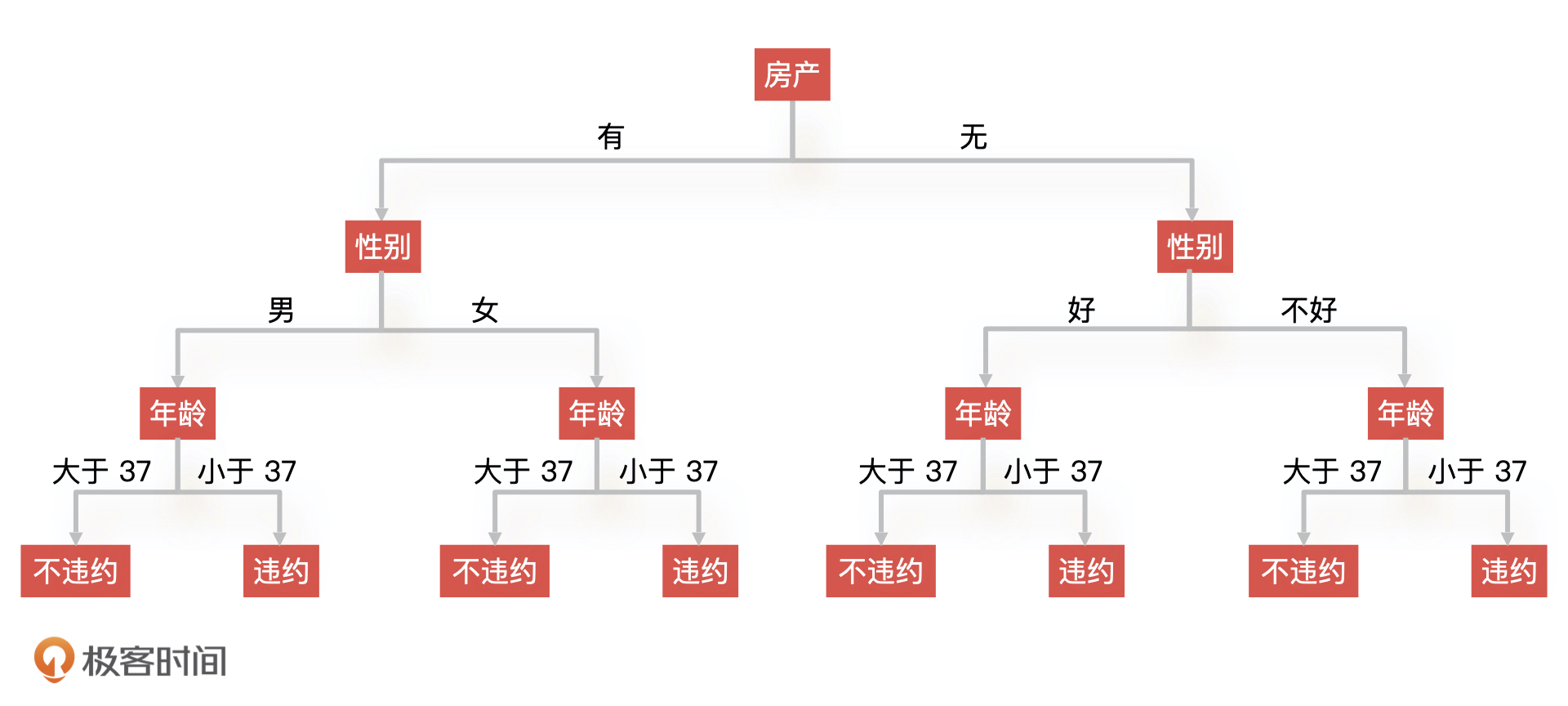
86 |
87 | 但是,这个决策树还不是最终的结构,因为有些节点我们是可以去掉的。比如说,我们发现有房产这个条件下面的所有节点,去掉和不去掉的时候模型准确性没有变化,那我们就可以把有房产下面的所有节点裁剪掉,从而得到新的决策树。
88 |
89 | 这就是剪枝操作,在我们实际工作中通常采取后剪枝的操作,从叶子节点逐步向上判断哪些节点是可以去掉的,剪枝后的决策树如下所示。
90 |
91 | 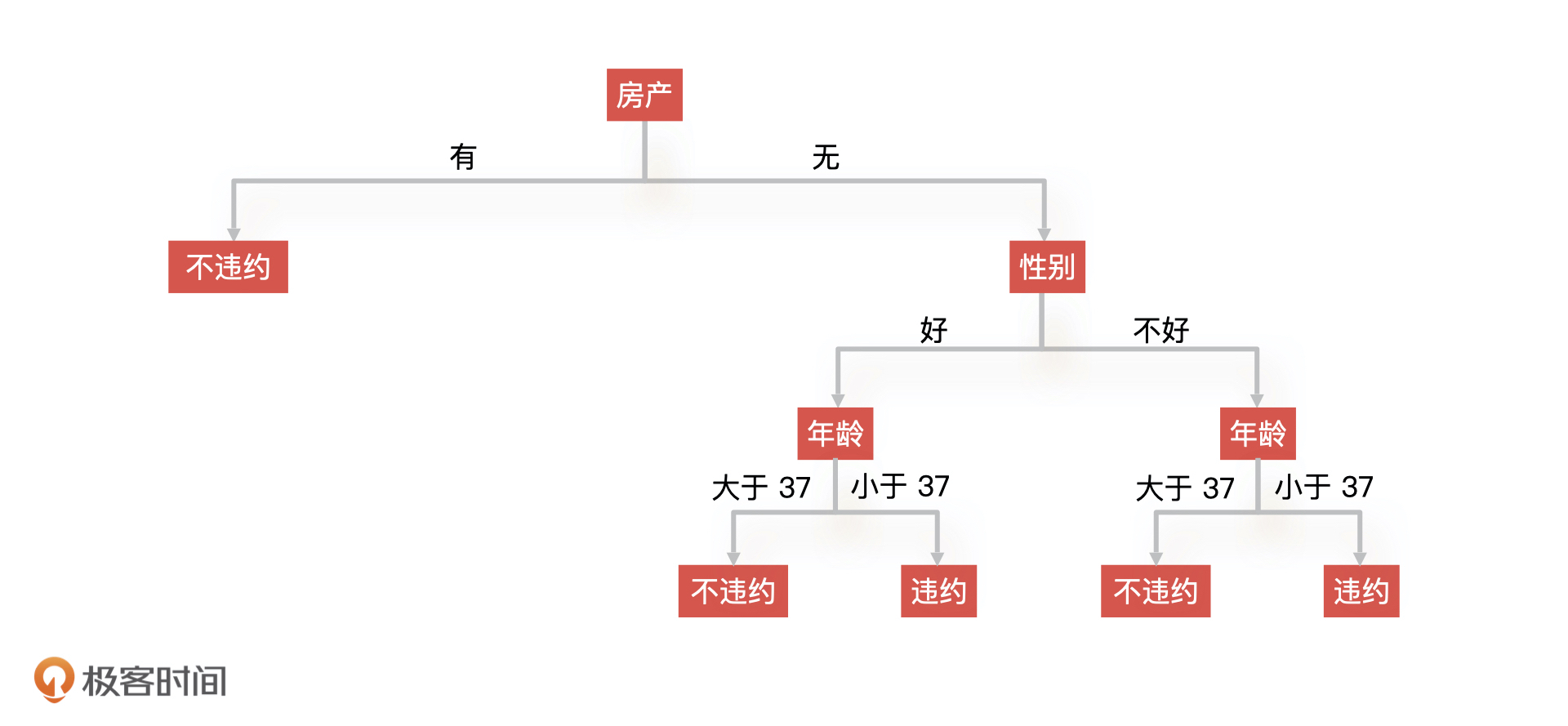
92 |
93 | 以上就是决策树创建的过程,因为没有进行实际计算,实际结果可能有偏差,你只要理解这个过程就可以了。
94 |
95 | ## 决策树的优缺点
96 |
97 | 通过上面的学习我们可以发现,决策树的优点和缺点都很明显。由于具有树形结构所以决策树的可解释性强,直观好理解,而且我们还可以从结果向上去追溯原因。采用决策树,我们可以很方便地和领导、业务方、甲方去解释我们的模型是什么,以及有哪些因素影响了模型的结果。
98 |
99 | 不过,决策树的缺点也非常明显。当数据量大,数据维度(样本具有的特征或者属性,如价格、位置)很多的时候,决策树会变得非常复杂,训练时间会很久。
100 |
101 | 另外,决策树还有一个很明显的缺点就是,需要算法同学手工设置决策树的深度(决策树要分多少层),如果设置了不合适的参数,就很可能造成欠拟合或者过拟合的情况。比如说,深度太浅就意味着你的叶子节点分得不干净,很容易造成欠拟合的情况,深度太深也会导致决策树训练时间太久,复杂度太高,很容易造成过拟合的情况。
102 |
103 | ## 随机森林:集体的力量
104 |
105 | 在实际工作中,我们既可以只使用一棵决策树来解决问题,也可以使用多棵决策树来共同解决问题,也就是随机森林。
106 |
107 | 随机森林(Random Forest)指的是由多棵决策树组成,随机指的是每一个决策树的样本是随机从数据集中采样得到的。假设, 模型由三个决策树A、B、C组成,我们给每棵决策树都随机抽取样本进行训练,由于这三棵树的训练样本不一样,因此它们最后得到的决策结果有可能不同。最后,我们再把这三棵树得到的结果做一个综合,就能得到最终的决策结果了。
108 |
109 | 随机森林的原理很好理解,那我们再来说说它的优缺点。因为这个算法是随机从数据集中进行采样的,所以模型的随机性很强,不容易产生过拟合的情况,但正因为样本是随机的,所以模型对于样本数据的异常值也不太敏感。
110 |
111 | 其次,因为算法采样的时候,是从整个数据集中抽取其中一部分进行采样,而且随机森林是由多棵树组合而成的,所以模型中的每一棵决策树都可以并行训练和计算,这样一来,在面向大数据量的情况下,随机森林的运行效率更高。
112 |
113 | 也正是因为这样,随机森林在训练时候需要的计算成本会更高,而且,就算它们整合之后会比之前单一模型表现好,但在面对复杂样本的时候,它们仍然没有办法很好区分,所以模型上限很低。
114 |
115 | 随机森林属于集成学习中的一种。集成学习(Ensemble Learning)可以理解为,不是通过某一个单独的机器学习算法解决问题,而是通过多个机器学习算法结合使用来完成最终的算法,最终达到 1+1>2 的效果。核心原理你可以记成是我们常说的“三个臭皮匠赛过一个诸葛亮”。
116 |
117 | 集成学习的内部由很多[弱监督模型](https://www.cnblogs.com/yumoye/p/11025504.html)组成, 某一个弱监督模型只在某一个方向上表现比较好,当我们把这些算法合而为一的时候,就会得到一个各方面都会表现较好的模型。集成学习的算法有很多,随机森林是其中比较有代表性的一种。我在下面整理了一个集成学习的思维导图,你可以了解一下。
118 |
119 | 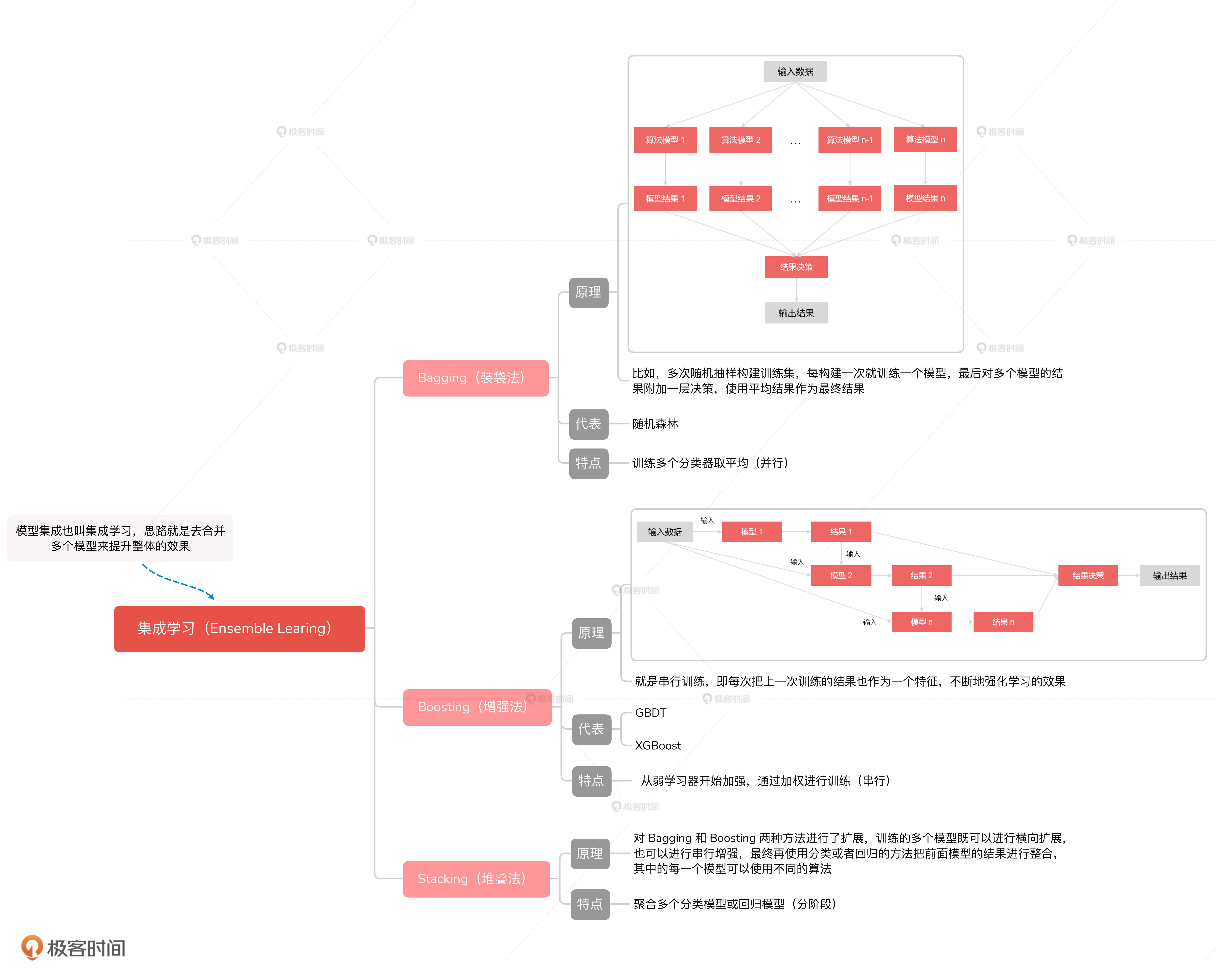
120 |
121 | ## 总结
122 |
123 | 今天,我们讲了决策树、随机森林的原理、应用和优缺点。理解决策树是理解随机森林和集成学习的基础,不过,作为产品经理,我们的重点不在于理解决策树的生成过程,只是借着它的生成加深对决策树原理和应用的理解。
124 |
125 | 总的来说,关于决策树和随机森林,我希望你重点记住这 5 点:
126 |
127 | 1. 决策树就是一种树形结构的算法,它很直观,可视化很强,但也容易过拟合;
128 | 2. 决策树特征选择是生成决策树的基础,不同的算法对应了不同的特征选择方式;
129 | 3. 集成学习是多个机器学习算法的结合;
130 | 4. 随机森林是集成学习中的一种,由多棵决策树组成;
131 | 5. 随机森林的原理你可以记成:三个臭皮匠赛过一个诸葛亮,它的特点你可以记成:模型起点高、天花板低。
132 |
133 | 除此之外,关于决策树和随机森林的应用场景我还想再强调一下。决策树和随机森林模型的可解释度都很高,这就意味着我们可以轻松地把模型的计算逻辑介绍清楚。
134 |
135 | 实际上,这一点对于咨询、金融、医疗领域的公司来说非常重要,因为你的客户往往不懂你的模型内部在做什么,但如果你的模型结构清晰,你就能在最短的时间内介绍出模型的优势。而且,因为随机森林这样的集成学习算法融合了多个模型的优点,所以对于解决分类问题来说,决策树和随机森林是当今的机器学习算法的首选,就比如你可能听过的 GBDT、XGBoost 就是决策树的升级版。
136 |
137 | ## 课后讨论
138 |
139 | 因为产品经理不需要实际进行模型的构建,所以我不会让你去构建一棵决策树,我想请你来梳理一下,你所在的团队中有哪些项目是基于决策树、随机森林或者是升级算法解决的呢?
140 |
141 | 欢迎在留言区分享你的经验,我们下节课见!
142 |
109 | - 悠悠 👍(20) 💬(4)
1、目标变量:性别的概率,男标记为0,女标记为1,阈值为0.5;
110 | 2、数据样本1000条,分成训练集900条和测试集50条,验证集50条(不确定总消费额是否要加入模型,男女一样的能花钱);
111 | 3、训练模型,性别=美妆x+零食y+母婴z+服装k,使用平滑函数;
112 | 4、输入新的用户行为数据,输出大于等于0.5为女性,小于0.5为男性。
2021-01-06
- 热寂 👍(17) 💬(0)
step1:模型设计
113 | 目标变量:确定用户性别
114 | 数据样本:1000个
115 | step2:特征工程
116 | 数据清洗:用归一化让量纲一致
117 | 特征提取:已提供的数据都是数值型特征,无需继续处理
118 | 特征选择:选择的特征有美妆PV、服装PV、零食PV、母婴PV、消费额
119 | 训练集500、测试集300、验证集200
120 | step3:模型训练
121 | 选择算法:把选择出来的特征做成散点图,确定特征之间是线性关系,决定采用逻辑回归的算法
122 | 模型训练:公式y=a1x1+a2x2+a3x3+a4x4+a5x5+b,且用平滑函数P处理y,P=f(y),P大于0.5为女性,小于0.5为男性
123 | 将训练集代入模型进行训练,找到让损失函数即交叉熵函数L最小的参数a1、a2、a3、a4、a5、b
124 | step4:模型验证
125 | 将测试集的数据代入确定参数的模型中,找到拟合能力和泛化能力的平衡点,该过程可用的评估指标:判断模型性能的有召回率、F1、KS、AUC;判断模型稳定性的有PSI
126 | step5:模型融合
127 | 利用投票方法进行模型融合
128 | step6:模型部署
129 | 根据模型所服务的业务是实时响应类型的还是可以非实时响应的,确定交付给开发人员的接口类型
2022-05-28
- 无觅 👍(15) 💬(0)
1.本身想用k邻近算法,但考虑到特征比较多,不适合用k邻近算法。
130 | 2.前几个特征单位都是PV,后面一个是消费金额单位元,所以量纲不一致,需要特征归一化,归一化特征值=(原值-最小特征值)/(最大特征值-最小特征值)。
131 | 3.设线性回归函数Y=X+a*PV1+ b*PV2+c*PV3+ d*PV4+ e*Money。
132 | 4.然后用平滑函数处理函数Y,目标变量是性别的概率,可以定义0为男,1为女,如果平滑函数结果大于0.5则是女,小于0.5则是男。
133 | 5.再用交叉熵函数处理平滑函数。
134 | 6.用800条数据训练,100条数据验证,100条数据测试。
2021-10-17
- Justin 👍(4) 💬(0)
1、性别=x美妆+y服装+z零食+k母婴+h总消费额。
135 | 2、给这个线性回归函数加一个sgmod函数
136 | 3、根据后续输入的值预估概率,美妆、零食概率、总消费额加权概率大的为女性;美妆小、零食小、总金额加权概率小的为男性?
2021-01-06
- Rosa rugosa 👍(3) 💬(0)
【借鉴悠悠同学的】
137 | 1、目标变量:性别的概率,男标记为0,女标记为1,阈值为0.5;
138 | 2、数据样本1000条,分成训练集600条和测试集200条,验证集200条;
139 | 3、训练模型,性别=美妆x+零食y+服装k,使用平滑函数;
140 | 4、输入新的用户行为数据,输出大于等于0.5为女性,小于0.5为男性
2021-03-12
- escray 👍(2) 💬(0)
刚才发现自己犯了一个新手错误,LR 代表逻辑回归 Logistic Regression,而不是线性回归 Linear Regression。
141 |
142 | 另外一点,逻辑回归处理的是分类问题,而线性回归属于回归问题。
143 |
144 | 看的有一点迷糊,我怎么感觉逻辑回归就是在线性回归的基础上,增加了一个平滑函数,比如 sigmod?结果从一个数值,变成了从 0 到 1 的一个概率值?
145 |
146 | 比如,线性回归,可以预测房价在 1 年后涨到多少;如果是逻辑回归,那么可能就是预测房价 1 年后是涨是跌(或者上涨是否超过某一个阈值)?
147 |
148 | 查询平滑函数 sigmod 的时候,发现 sigmoid 也是同样的意思,在神经网络中也经常使用,被称为激活函数或者激励函数。
149 |
150 | 除了 Sigmoid 之外,常见的激活函数还有 Tanh、ReLu、leaky relu 等。
2022-04-13
- liqin 👍(1) 💬(1)
道理我都懂,但为什么大家如此自觉认为大于0.5就是女性,小于0.5就是男性?哈哈
2022-10-15
- 我不过是善良 👍(1) 💬(2)
总额消费不应该算在x里吧,它是前面几个的线性和
2021-01-12
- Jove 👍(1) 💬(0)
对数几率函数,Sigmoid
151 | 均方误差,MSE
152 | 交叉熵误差,CEE
2021-01-07
- SPIC_DT 👍(0) 💬(0)
这一节讲的不太明白啊
2023-11-25
- 热寂 👍(0) 💬(0)
平滑函数sigmod 函数减小误差的原理是什么呢?
2022-05-20
- 产品部1 👍(0) 💬(0)
逻辑回归就是通过sigmoid函数将线性函数的预测值转化为概率值,从而实现把连续值问题转化分类问题。
2022-04-03
- 青梅(Meya) 👍(0) 💬(0)
用户是否会点击某个商品的案例能否详细说明
2022-02-24
- 青梅(Meya) 👍(0) 💬(0)
是不是选取美妆品类就可以了,这个品类浏览数据差异最大
2022-02-24
- Geek_4d1bf0 👍(0) 💬(0)
1.将单位进行归一化处理;
153 | 2.目标变量:性别的概率,性别为男标记为0,性别为女标记为1,阈值为0.5;
154 | 3.样本数量:用800数据做训练集,100做训练集,100做验证集;
155 | 4.线性公式:性别=美妆*A1+零食*A2+母婴*A3+服装*A4+消费*A5+B;
156 | 5.损失函数:先用平滑函数,再用交叉熵函数;
157 | 6.输入新的用户行为数据,输出大于等于0.5为女性,小于0.5为男性。
158 |
159 |
2022-02-23
160 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/05 - 通过一个 AI 产品的落地,掌握产品经理工作全流程.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 对于任何一家互联网公司来说,用户流失都是我们必须要关注的一个问题。就拿我们公司的电商平台来说,一个很常见的问题就是,新用户的增长逐年缓慢,同时还伴随着老用户的不断流失。当遇到这种情况的时候,作为产品经理,我们该采取哪些措施,来降低用户的流失率呢?
4 |
5 | 今天,我就通过我曾经主导过的一个预测用户流失的项目,带你了解一个 AI 产品从筹备到上线的全流程。从中,你可以体会到 AI 产品经理的完整工作流程是什么,每一个环节都有什么角色参与,每个角色需要做什么工作,他们的产出又都是什么。这能让你明白自身能力和岗位之间的差距,也是你自己主导一个 AI 产品的时候,可以用来借鉴和参考的。
6 |
7 | 不过,我今天讲的上线流程是基于我们公司的业务场景和经验总结出来的,不能保证和所有公司的流程都一致,但无论如何,我们做事的底层逻辑都是一样的。
8 |
9 | 话不多说,我们正式开始今天的课程吧!
10 |
11 | ## 业务背景
12 |
13 | 我们公司是一个电商平台,有段时间我们发现,每个月老用户流失的数量已经远高于新用户的拉新数量,为了防止这个缺口越来越大,我们决定对可能流失的用户做提前预警,同时采取一些措施来挽留这些用户,实现这个目标的前提就是要开发一套用于预测流失用户的产品。
14 |
15 | 那具体怎么做呢?我先把我们当时开发这个产品的流程放在下面。接下来,我再分步骤给你详细讲讲,每一步我们都是怎么做的,以及要重点注意什么。
16 |
17 | 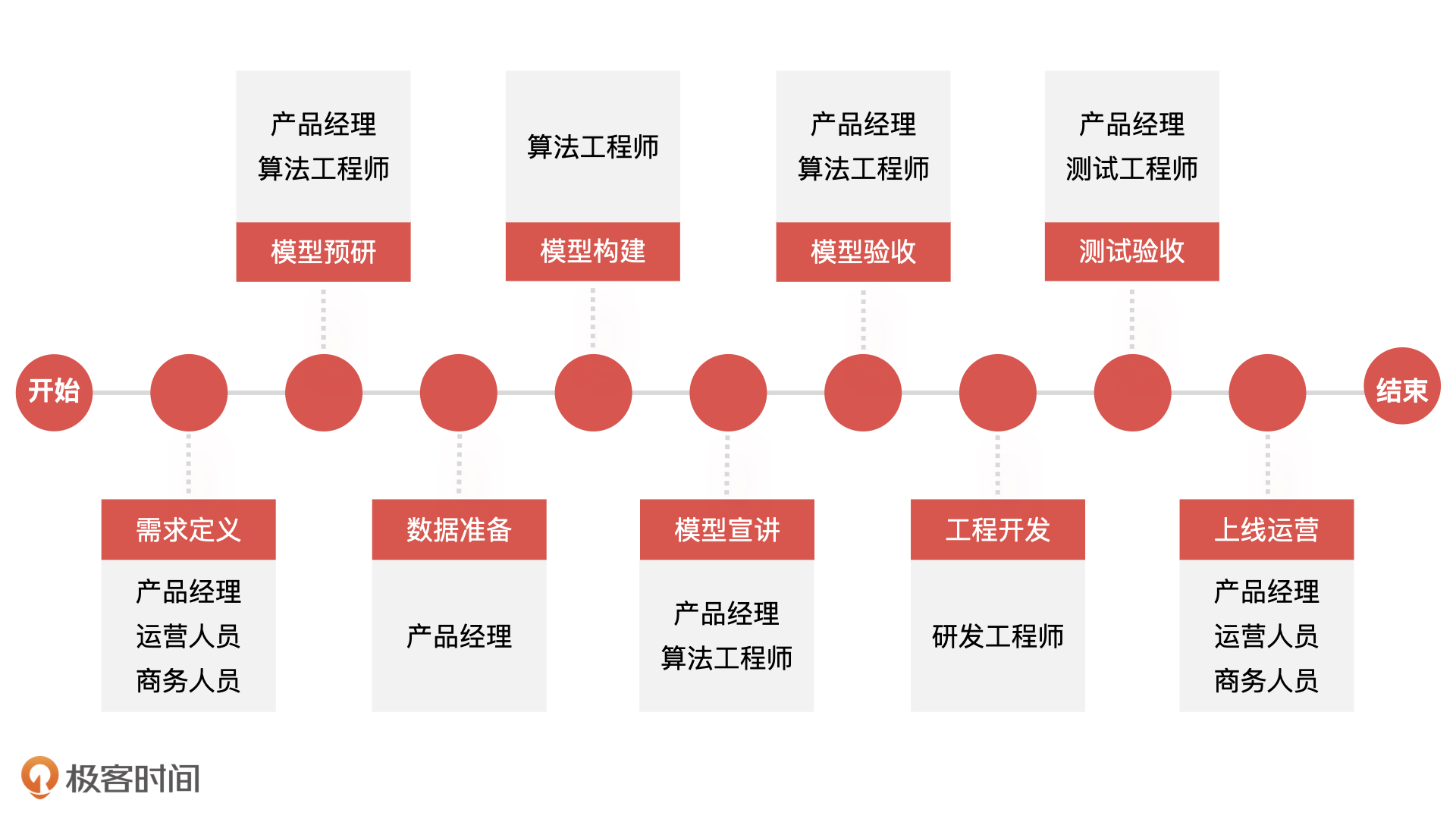
18 |
19 | ## 产品定义
20 |
21 | 当决定实现这个产品之后,首先我们要做的就是定义产品需求,明确做这件事情的背景、价值、以及预期目标都是什么。
22 |
23 | 在这个环节中,我们会和业务方共同沟通,来决定我们的业务预期目标是什么,期望什么时候上线。这里,我提到的业务方可能是运营同学,也可能是商务同学,这和你是一个 ToC 还是 ToB 的产品经理相关。
24 |
25 | 在这个预测用户流失的项目中,我的业务方就是运营,我们的期望是通过算法找出高流失可能性的人群,对这些人进行定向发券召回。这个项目的最终目标是,通过对高流失可能性的人群进行干预,让他们和没被干预过的人群相比,流失率降低 5%。
26 |
27 | 同时,由于我们运营计划是按月为节奏的,所以这个模型可以定义为离线模型,按月更新,每月月初预测一批流失人群。并且,我还期望这个模型的覆盖率能够达到 100%,让它可以对我们业务线所有用户进行预测。这些就是我们对模型的更新周期、离线/实时模式、覆盖率等相关要求了,我们需要把它们都记录到一份需求文档中。
28 |
29 | ## 技术预研
30 |
31 | 需求确定之后,产品经理需要和算法同学进行沟通,请算法同学对需求进行预判。具体来说,就是要判断目前积累的数据和沉淀的算法,是否可以达到我们的业务需求。如果现有数据量和数据维度不能满足算法模型的训练要求,那产品经理还需要协助算法同学进行数据获取,也就是后面我们要说的数据准备工作。
32 |
33 | 当然,**即使数据达到算法的需求,产品经理也还是需要协助算法同学做数据准备,因为垂直业务线的产品经理更了解本领域的数据。**
34 |
35 | 另外,在这个环节中,你可能还需要根据算法的预估,对需求的内容进行调整。比如,我们原定覆盖率为 100%,但是和算法同学沟通后发现,有部分刚刚注册的新用户是没有任何数据的。对于这部分人,算法无法正常打分,而且新用户也不在流失用户干预范围内,所以,我们后面会根据目前新老用户比例得到新的覆盖率指标,再把它放到需求中去。
36 |
37 | ## 数据准备
38 |
39 | 然后,我们就进入数据准备的环节了。这个环节,我们需要根据模型预研的结果以及公司的实际情况,帮助算法同学准备数据。
40 |
41 | 原因我们刚才也说了,就是因为产品经理基于对业务的理解,能判断哪些数据集更具备代表性。而算法同学,只能根据现有的数据去分析这些数据对模型是否有用,因为有些业务数据算法同学是想不到,所以自然不会去申请相关数据权限,也就不会分析这部分数据存在的特征。
42 |
43 | 比如说,我们在过去的用户调研中发现,用户一旦有过客诉并且没有解决,那么大概率会流失。如果出现了客诉,用户问题得到了很好地解决,反而可能成为高粘性的客户。这时候,我们就会把客诉数据提供给算法同学,请他们去申请数据表权限,评估数据是否可用。反之,如果我们没有把这些信息同步给算法同学,那么很可能我们就缺失了一个重要的特征。
44 |
45 | 在数据准备的部分,由于数据的不同,我们的获取方式也会有很大的差别。总的来说,数据可以分为三类,分别是内部业务数据、跨部门集团内数据以及外部采购的数据。接下来,我就分别说说这些数据怎么获取。
46 |
47 | **1. 获取内部业务数据**
48 |
49 | 内部数据是指部门内的业务数据,如我们的订单数据、访问日志,这些都可以直接从数仓中获取。当然还有一些情况是,我们想要的数据目前没有,你可以提需求让工程研发同学留存相关数据,比如,之前有些用户的行为数据没有留存,那我们就需要增加埋点将这些数据留存下来。
50 |
51 | **2. 获取跨部门集团内数据**
52 |
53 | 跨部门集团内数据指的是其他部门的业务数据,或者是统一的中台数据,这些数据需要我们根据公司数据管理规范按流程提取。在提取数据的时候,我们需要注意结合业务情况去判断该提取哪些数据。
54 |
55 | **3. 获取外采数据**
56 |
57 | 最后是外采数据的获取。在公司自己的数据不足以满足建模要求时候,我们可以考虑购买外部公司数据,或者直接去其他拥有数据的公司进行联合建模。
58 |
59 | 这个时候 ,我们就需要知道市场上不同的公司都能够提供什么。比如极光、友盟提供的是开发者服务,所以它们可以提供一些和 App 相关的用户画像等数据服务,再比如运营商可以提供和手机通话、上网流量、话费等相关数据等等。
60 |
61 | 直接采购外部数据非常方便,但我们一定要注意,出于对数据安全和消费者隐私保护的考虑,我们和第三方公司的所有合作都需要经过公司法务的审核,避免采购到不合规的数据产品,对自己的业务和公司造成不好的影响。比如说,在用户流失预测模型这个项目中,我们可以去调研自己的用户近期是否下载了竞品的 App,或者经常使用竞品 App,这都可以作为用户可能流失的一个特征。
62 |
63 | 当然,**在数据准备的环节中,我希望你不仅能根据算法的要求,做一些数据准备的协助工作,还能够根据自己的经验积累,给到算法同学一些帮助,提供一些你认为可能会帮助到模型提升的特征。**
64 |
65 | 具体到预测用户流失的产品上,我们可以根据经验提出用户可能流失的常见情况,比如我们可以参考客诉表,看看有哪些用户在客诉之后,问题没有解决或者解决得还不满意,那这些用户我们大概率就流失了,或者我们也可以分析用户的评价数据 ,如果用户评价中负面信息比较多,那他们也可能会流失等等。
66 |
67 | ## 模型的构建、宣讲及验收
68 |
69 | 完成数据准备之后,就到了模型构建的环节。这个环节会涉及整个模型的构建流程,包括模型设计、特征工程、模型训练、模型验证、模型融合。
70 |
71 | 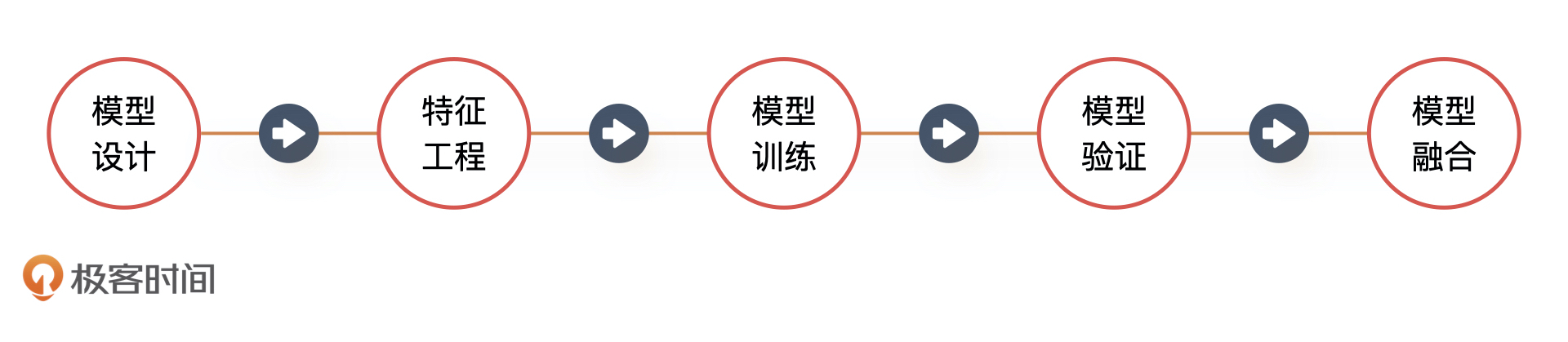
72 |
73 | 即便你不需要进行模型构建的实际工作,你也需要知道这个流程是怎么进行的,这方便你了解算法同学的工作,以便评估整个项目的进度。这就好比互联网产品经理不需要写代码,但也要知道研发的开发流程是怎么样的。
74 |
75 | 不过,今天我们不会重点来讲具体的过程,我先卖个关子,你今天先记住这几个关键节点的名称,下节课我们再详细来讲。
76 |
77 | **模型构建完成之后,你需要组织算法同学对模型进行宣讲**,让他们为你讲明白这个产品选择的算法是什么,为什么选择这个算法,都使用了哪些特征,模型的建模样本、测试样本都是什么,以及这个模型的测试结果是怎么样的。
78 |
79 | 对于流失预测模型来说,我需要知道它的主要特征是什么,选择了哪些样本进行建模,尤其是测试结果是否能够满足业务需求。当看到流失预测模型的测试结果的时候,我们发现模型召回率、KS 值都达到了标准,但是模型覆盖度只有 70%,比预期低了不少。但是,由于我们业务侧也只需要找到一部分流失用户进行挽留操作,所以,暂时不能覆盖全量人群我们也是可以接受的。像这样的问题,都是你在模型宣讲环节需要去注意并且去评估的。
80 |
81 | **在模型宣讲之后,你还需要对模型进行评估验收,从产品经理的角度去评判模型是否满足上线的标准。**那在这个流失用户预测的项目上,我们就需要重点关注模型的准确率,是否模型预测的用户在一定周期后,确实发生了流失。如果模型准确率较低,将一些优惠券错配到了没有流失意愿的用户身上,就会造成营销预算的浪费。
82 |
83 | 模型宣讲环节的具体内容,以及模型宣讲后,我们对模型进行评估验收的具体指标都有哪些,我会在模型验收的章节和你细说,这里你先不用着急,你只要知道有模型宣讲和模型评估验收这两个环节,以及它们的整体流程,让自己对 AI 产品经理的工作流程有一个整体的理解就可以了。
84 |
85 | ## 工程开发及产品上线运营
86 |
87 | 模型通过了验收之后,我们就可以进入工程开发的环节了。其实在实际工作中,工程开发工作通常会和算法模型构建同步进行。毕竟,算法同学和工程同学分属两个团队,只要模型的输入输出确定之后,双方约定好 API 就满足了工程同学开发的条件了。
88 |
89 | 工程开发完成之后,就可以进行工程测试验收了。这和传统的互联网产品上线流程区别不大,也就是测试同学进行测试,发现 BUG 后提交给工程同学进行修复,再当测试同学测试通过之后,产品经理验收,或者叫做产品上线前走查,这里我就不再多说了。
90 |
91 | 另外,在工程上线之后,为了评估 AI 产品整体的效果,我们可以通过对上线后的系统做 AB 测试对比传统方案,进而量化 AI 产品的效果提升。这时候,我们需要关注在产品定义阶段对于产品的指标和目标期望。
92 |
93 | 相比于一般的互联网产品经理,AI 产品经理在产品上线之后,还需要持续观测数据的表现(模型效果)。因为 AI 模型效果表现会随着时间而缓慢衰减,你需要去监控模型表现,出现衰减后需要分析发生衰减的原因,判断是否需要模型进行迭代。
94 |
95 | ## 小结
96 |
97 | 一个 AI 产品构建的整个流程是从产品定义,到技术预研、数据准备、模型构建,再到模型验收和工程开发上线。其中,有三个节点是我们需要重要关注的,因为这三个节点和互联网产品开发流程完全不同,它们分别是产品定义、数据准备和模型构建。
98 |
99 | 在产品定义的阶段,我们需要搞清楚三个问题,这个产品背后的需求是什么,是否需要 AI 技术支持,以及通过AI能力可以达到什么样的业务目标。这需要我们和业务方深入沟通,拆解他们的真实需求。除此之外,我们还要根据自己对 AI 技术的理解,去判断这个项目的可行性,制定相应的目标。
100 |
101 | 因为数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,所以数据特征是否全面,数据量是否足够对于算法同学来说是非常重要的。在数据准备阶段,我们不仅需要帮助算法同学获取更多高质量的数据,来提升模型的整体效果,也可以从业务的角度,给出算法同学一些建议,比如哪些特征可能有帮助等等。
102 |
103 | 数据准备好,就可以进行模型的构建以及评估验收了。模型的构建我们可能没有什么可以介入的地方,但模型的评估验收是一个非常重要的节点,因为模型是一个偏黑盒的工作,它的输出可能只有一个指标值或者分数。
104 |
105 | 但是,很多产品经理会认为:模型好坏是算法工程师的职责范围,反正自己也不太懂算法,只要算法交付了,对方说达到模型指标就可以了。如果你也这么想,那么你可能最后就变成一个协调性或者执行层的产品经理了,最后整个项目就变成算法主导了,所以我们一定要重视模型评估。
106 |
107 | ## 课后讨论
108 |
109 | 你觉得,AI 产品经理的工作流程和你现在的工作流程最大的不同是什么?为什么会产生这些不同呢?
110 |
111 | 期待在留言区看到你对工作流程的思考与复盘,我们下节课见!
112 |
113 | - 橙gě狸 👍(19) 💬(1)
在流程上最大的不同在于AI产品经理在整个项目的过程中,需要围绕数据做很多其他产品经理不那么关心的事情。
114 | 例如
115 | 在准备阶段,基于各种方法论的特征调研,基于特征的数据源调研,数据的质量与可信度分析,制定数据清洗规则等等。
116 | 在研发阶段,基于算法工程师的反馈,调整特征数据,以满足模型需求,并持续理解业务,输出新的特征。
117 | 在验收阶段,充分利用AB测试验收效果,同时还需要重点关注流量本身是否有偏,是否会影响模型的稳定性等等。
118 |
119 | PS:如果AI产品经理能拥有一名专用的数据分析师,就太棒了!
120 |
2021-01-06
- ivan 👍(4) 💬(1)
以实际项目举例,阐述坑点和过程,效果很不错,赞
2020-12-23
- 云师兄 👍(2) 💬(1)
落地有效的流程啊
2020-12-23
- Fan 👍(1) 💬(1)
希望接下来更多的案例解析
2020-12-23
- Yesss! 👍(21) 💬(0)
AI产品的工作流程
121 | 1、产品定义
122 | 2、准备数据
123 | 3、模型构建、宣讲、验收
124 | 4、对上线后的数据持续关注,以及关注模型是否达到产品定义前期预期的指标和期望
125 | 个人的工作流程
126 | 1、需求深入了解、调研
127 | 2、创建原型
128 | 3、原型交付讨论(宣讲)
129 | 4、签订合同
130 | 5、交付开发
131 | 6、产品测试、产品经理上线前走查
132 | 7、交付系统
133 | 8、后续查看是否需要迭代或修复bug。(一年的运维期)
134 | 不同之处:
135 | 1、对于产品,更多的是从需求着眼,没有对整个产品有明确的定义
136 | 2、无需准备数据,更多的是需要对现场进行调研以及对业务进行梳理明确
137 | 3、AI的模型构建与传统产品经理的原型构建不一致。原型构建主要是对功能以及业务的流程进行构建。与AI的模型构建不同。要考虑(算法、召回率,Ks等等等)
138 | 4、与AI产品模型构建不同的是。传统产品经理需要对原型进行明确才能交付开发。无法在构建模型的同时进行工程研发
139 | 5、较少对数据进行关注,更主要的是对功能流程的bug进行关注。
140 |
141 | 个人理解想到的暂时就这么多。有误/需改进/理解不够深刻的。请多多指正教导。
2021-01-10
- 青梅(Meya) 👍(3) 💬(0)
最大的不同:
142 | 1,需求定义阶段需要考虑是否需要使用AI支持,AI能力是否能达到目标
143 | 2,技术预研阶段可能做调整
144 | 3,数据准备阶段提供相关业务指标辅助模型构建
145 | 4,模型评估
146 | 5,上线验收和跟踪,是否需要调整模型
2022-02-23
- 发条 👍(2) 💬(0)
目前做业务系统。工作内容核心是分析和决定:哪些需求不做,定义要做需求的细节如流程和IO。
147 |
148 |
149 | 就这个层面来看:
150 | ① AI产品经理和普通产品一样,都需要分析ROI ,决定哪些需求要做,哪些不做。区别是AI产品更关注技术上可行性;
151 | ② AI产品的资料准备工作,更多是通过业务产品经理筛选出完整、有效的特征集;业务产品更多是定义出IO;
152 | ③ 而建模把关上,可能是两者区别最大的地方。虽然业务PM也适当关注系统设计,但是深度肯定是不如AI PM的; 后在上线前的验证和上线后的评估方面,对数据分析的能力要求,可能AI PM更高一些。
2021-06-05
- Jeo~杨锦汶 👍(1) 💬(0)
有几点体会,
153 | 1、技术预研和数据准备过程中,其实要做的事情非常多,搞数据、模型定义、数据推演,从而才能定义模型对实际场景是否可行,实际操作起来好多琐事,我觉得数据分析师是必须要有的,负责分析数量和质量、数据关系,产品经理分析数据与场景关系,商业化打通
154 | 2、模型构建前最好能把很多问题在之前解决哈
155 | 3、模型评估这个指标定义是关键,在市场预期和实际运营指标要有个平衡…
156 |
2021-12-04
- 神经蛙 👍(1) 💬(0)
老师好,想问下AI项目的可行性该如何评估。个人觉得可行性的不确定因素很多,从数据质量到研发能力,尤其是每个AI产品的需求和场景都不一样,有时候其实没法找到可比的案例。而业务对AI产品要达到的效果都有一个明确的目标,比如某个指标要大于某个数,不然这个产品就是没有价值的。在项目展开前,我们该如何判断一个AI产品最后能否满足需求呢?
2021-06-24
- 宋秀娟 👍(0) 💬(0)
目前做的事情更多的是业务的梳理,需求的定义,原型的设计,跟踪开发,上线前验证。AI产品经理增加了数据的准备,模型的构建,宣讲验收等一些AI核心相关的内容。
2024-08-14
- 三只猫 👍(0) 💬(0)
请教:模型宣讲这个环节,是基于算法工程师拿到数据后,做了少部分数据的测试嘛?还是说模型构建和训练已经完成了,需要和产品侧同步一下选模型的逻辑、以及模型效果呢?
2024-04-24
- coderlee 👍(0) 💬(0)
关于运行在边缘设备上的模型,老师有没有比较推荐的监控模型的方案
2024-03-25
- Geek_76f1b3 👍(0) 💬(0)
请问AI大模型时代,这套流程还管用么
2024-03-25
- Karen.高 👍(0) 💬(0)
针对2024年了,有哪块AI产品课程可以推荐的,现在还没搞清楚全局和怎么入手
2024-03-18
- LII落落 👍(0) 💬(0)
最大的不同是AI产品经理的工作流程需要更多地承上启下,承上要理解业务,启下要根据业务为算法工程师提供一个全局的视角,使模型更加贴合业务。我认为产生这些不同是因为算法本身具有一定的局限性,实际和落地之间存在这鸿沟,需要一点点地理解这些局限性,才能去进行相应的调整
2024-01-22
157 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/08 - 算法全景图:AI产品经理必须要懂的算法有哪些?.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰。
2 |
3 | 从今天开始,我们正式进入算法技术能力篇的学习。在正式开始学习之前,我想先给你讲一个我亲身经历过的小故事。
4 |
5 | 我最开始做 AI 项目的时候,碰到过一个预测员工离职可能性的产品需求。当时,因为我对算法技术不熟悉,所以我只告诉算法工程师,我们要做一个预测员工离职的模型。因此,算法同学按照自己的理解,把它做成了一个预测员工可能离职的排序,而不是离职的概率。
6 |
7 | 很显然,这个模型和业务方的原始诉求是有出入的。但是,当我去说服算法工程师修改模型的时候,却被他说“你自己先搞清楚算法能做什么、不能做什么,再来和我谈”。后来我才知道,他的模型是按照回归的方式做的,得到的结果是未来预计离职的天数,最后自然是按照天数来做排序。
8 |
9 | 这件事也让我下定决定去学习算法技术,不说要学得多么精通,至少要知道常用算法的实现逻辑和应用场景,这也是我在算法技术能力篇要给你讲的。**这样一来,当你和算法同学协作的时候,能够减少很多沟通成本,知道如何给算法工程师提需求,能和他们同频沟通,就算是要对模型结果进行争执,也能更有底气**。
10 |
11 | ## 机器学习分类
12 |
13 | 这节课,我会先带你从宏观上了解目前机器学习的三大类应用场景,分别是分类问题、回归问题、聚类问题,以及怎么用相关算法来处理这些问题,最后帮你梳理一张 AI 产品经理需要掌握的算法技术全景图。这样,我们后面再去学习具体的算法,就能有一个更清晰的学习路径了。
14 |
15 | 这里,我先把分类、聚类和回归问题的定义总结在了下面的表格里,你可以先看看,对它们有个整体印象。
16 |
17 | 
18 |
19 | 有了印象之后,我们再结合具体的例子,来讲讲这些场景问题是怎么用相关算法解决的。
20 |
21 | ## 处理分类问题的算法
22 |
23 | 在实际工作中,我们遇到最多的问题就是分类问题,分类问题经常出现在分类判断、标签预测、行为预测这些场景中。
24 |
25 | 比如说,你现在是一个电商产品经理,有商城全部用户的历史行为数据,以及用户A、B、C、D的性别数据,希望预测商城其他用户的性别,可能是用户E。
26 |
27 | 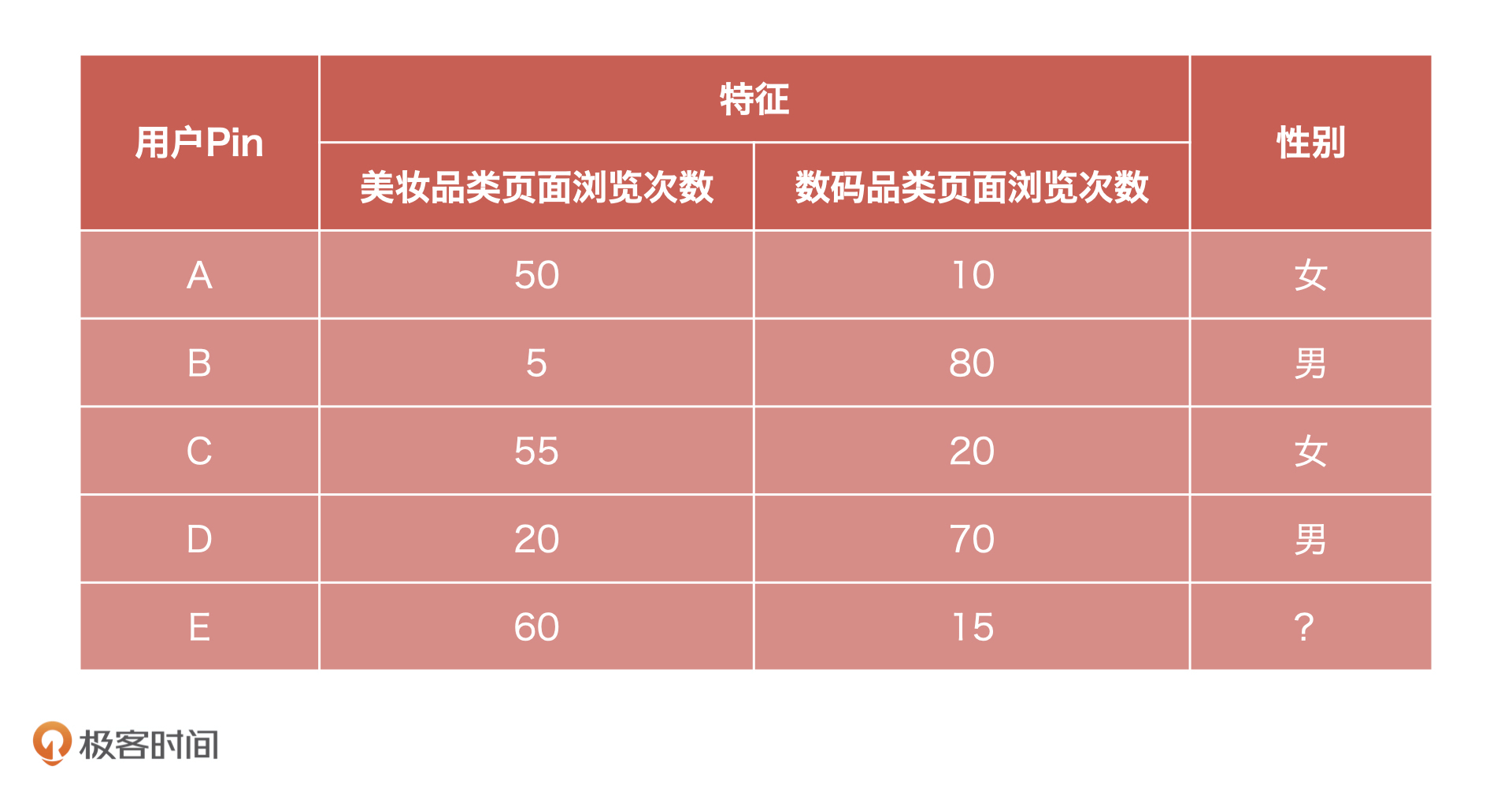
28 |
29 | 这就是一个很经典的分类问题,这个问题的预测结果就是男性或者女性。**像这种判断一个事情的结果是“男/女”、“是/否”、“1/0”的问题就是二分类问题。**
30 |
31 | 不过,如果我把已知条件变换一下:你现在有商城全部用户的历史行为数据,以及用户A、B、C、D的婚姻状况数据,希望预测商城其他用户的婚姻状况。这个时候,预测的结果就是未婚、已婚或者是离异了,**像这种预测结果是多种情况的,就是多分类问题。**
32 |
33 | 那分类问题怎么解决呢?我们再回到刚才这个例子中。结合上面的表格,我们可以看到,已知性别的用户会呈现出来一种规律,就是女性浏览美妆品类次数远高于浏览数码类页面次数,而男性会呈现出相反的趋势。
34 |
35 | 
36 |
37 | 我们可以把性别和浏览页面次数呈现到一个图里,然后将用户浏览美妆品类页面,数码品类页面次数录入。这个时候,你会发现用户 E 和用户 A、C 离得很近,从数学的角度来看,距离越近就越相似,所以我们大概率认为 E 的性别应该和 A、C 一样,是女性。这就是分类问题的解决过程。
38 |
39 | 在机器学习的场景中,分类算法解决分类问题也是利用相似的原理,可用的算法非常多,常见的有逻辑回归、朴素贝叶斯、决策树、随机森林、K 近邻、支持向量机,以及神经网络等等。
40 |
41 | 总的来说,使用分类算法解决问题,我们必须要有已知的训练数据,才能对未知数据进行预测。当已知信息缺失的时候,我们又该怎么办呢?这个时候,我们要么考虑通过人工打标来处理数据,要么考虑使用**聚类算法**。这就是我接下来要讲的聚类问题的处理逻辑了。
42 |
43 | ## 处理聚类问题的算法
44 |
45 | 在机器学习中,我们经常需要给一些数据量很大,用户属性很多的用户数据进行分组,但往往很难下手。
46 |
47 | 我还是代入一个例子来给你讲讲,假设,你现在是一个客服系统负责人,为了减轻人工客服的压力,想把一部分常见的问题交给机器人来回复。解决这件事情的前提,就是我们要对用户咨询的商品问题先进行分组,找到用户最关心的那些问题。
48 |
49 | 这种需要根据用户的特点或行为数据,对用户进行分组,让组内数据尽可能相似的的问题,就属于聚类问题,用一个词概括它的特点就是 “物以类聚”。常见的聚类算法有层次聚类、原型聚类(K-means)、密度聚类(DBSCAN)。
50 |
51 | 那聚类问题该怎么解决呢?我们接着刚才的例子来说,假设我们现在有5条如下的咨询:
52 |
53 | - 小爱同学和小爱音响有什么区别 ?
54 | - 小爱同学和小爱音响都是小米的吗 ?
55 | - 小米的蓝牙耳机怎么连接 ?
56 | - 华为路由器和小米路由器哪个可以在校园网内使用 ?
57 | - 一定要小米路由器才能用吗 ?
58 |
59 | 如果我们把每句话都看成单独的小组,这一共就是5个小组,那我们的目标就是把相似的问题合并成一个小组。最简单的办法,就是找出每个小组中的名词,把“各句中包含的名词一致的数量”看作“相似度”。这样一来,相同名词数量最多的两个句子就是最相似的。
60 |
61 | 按照这个思路,我把这 5 个句子中含有的名词都整理到了下面的表中,并用 “O” 进行了标记。
62 |
63 | 
64 |
65 | 这样,我们就能算出每一个句子和其他4句之间的相似度了。
66 |
67 | - “句子 1”和“句子 2、3、4、5”的相似度分别是 2、0、0、0。
68 | - “句子 2”和“句子 3、4、5”的相似度是 1、0、0。
69 | - “句子 3”和“句子 4、5”的相似度是 0、0。
70 | - “句子 4”和“句子 5”的相似度是 1。
71 |
72 | 这样,我们也就能得出:最相似的小组是相似度为 2 的“句子 1”和“句子 2”,我们把这两个句子合并之后,5 个小组就变成了 4 个小组:
73 |
74 | - “小组 1”:“句子 1”和“句子 2”
75 | - “小组 2”:“句子 3”
76 | - “小组 3”:“句子 4”
77 | - “小组 4”:“句子 5”
78 |
79 | 然后,我们再按照上面同样的方式把新生成的各小组进行聚类,就又会得到两个相似度为 1 的小组:
80 |
81 | - “小组 5”:“句子 1” 、“句子 2”和“句子 3”
82 | - “小组 6”:“句子 4”和“句子 5”
83 |
84 | 就这样,当我们把所有相似的句子聚类到一起,就完成了聚类的过程。其实,聚类算法的原理很简单,就是根据样本之间的距离把距离相近的聚在一起。刚才,我是通过句子中的名词是否相同来衡量距离的,那在实际应用场景里,衡量样本之间距离关系的方法会更复杂,可能会用语义相似度、情感相似度等等。
85 |
86 | 同时,这个聚类的过程可以表示成带有层次的树形结构图,这就是层次聚类算法的原理也是它名字的由来。这种聚类方式可以是“自底向上”的聚合策略,也可以是“自顶向下”的分拆策略 。
87 |
88 | 
89 |
90 | 总之,聚类算法解决问题的核心思想就是“**物以类聚,人以群分**”,所以,聚类分析较为重要的一个应用就是用户画像。
91 |
92 | 我们刚才说了,分类问题和聚类问题的差异在于分类问题需要根据已知的数据去学习,然后为新的数据进行预测,而聚类分析直接在已有数据中发现联系。但它们还存在着一个共同点,那就是它们都输出的是 “0” 或 “1” 这种**离散型的标签**。
93 |
94 | 离散型的标签指的就是非连续的一个个单独的标签。比如说,一个人的年收入可能是从几万到几千万这样的连续性值,但是如果我们将年收入的具体数值转化成低收入、中等收入、高收入、超高收入这些档,每一个档就是一个离散型的标签。
95 |
96 | 但有时候,我们在项目中确实需要预测一个具体的连续性数值,比如酒店的价格或股票的价格。遇到这类问题我们该怎么办呢?这个时候,我们就可以通过解决回归问题的算法来实现了。
97 |
98 | ## 处理回归问题的算法
99 |
100 | 在实际工作中,我们也经常会遇到回归问题,比如需要预测某个商品未来的销量,预测某只股票未来的价格等等。
101 |
102 | 下面我就通过一个预测销量调整库存的例子,来讲讲回归算法中线性回归的解题过程。
103 |
104 | 有这样的一个场景,你是一个电商产品经理,你们公司每件商品的库存都是通过预测未来产品的销量来动态调整的。这个功能的实现方式是,先根据商城 App 分析出用户的商品搜索次数,然后将每个商品的搜索次数和销量做数据分析,画出一个横轴为搜索次数,纵轴为销量的二维散点图。
105 |
106 | 
107 |
108 | 我们以搜索小米路由器举例,从上图我们可以看到,相对密集的搜索次数都在1000次以下,当搜索次数超过1000次以后,散点变得稀疏起来。这样一来,我们就能根据数据拟合出一条回归直线。
109 |
110 | 这条回归直线上,因为销量和搜索次数成正比,所以它们都可以用**一元回归方程来表示**。如果我们假设影响销量的因素只有搜索次数这一个特征,那么在有了新产品和它的搜索次数之后,我们根据一元回归方程,就可以预测出新产品的销量了。
111 |
112 | 这个时候有的同学可能想说,“用户搜索次数虽然会影响销量,但我认为用户评价和库存也会影响销量啊”。接下来,我们就一起来验证一下这个假设。我们将库存、用户评价作为影响销量的两个因素,去分析它们之间的关系。
113 |
114 | 
115 |
116 | 如上图所示,当库存小于 40% 的时候,用户评价和销量都很低,当库存大于 80% 的时候,用户评价和销量呈线性增长。我们发现,用户评价和库存共同影响了产品销量,只有当库存大于 80% 且用户评价高于 0.6 的时候,产品才有较好的销量。因此,这三者之间的关系可以用**二元回归方程**进行量化。
117 |
118 | 当然,实际情况是像服务态度、物流时间、折扣力度、广告宣传、购物体验这些因素,它们也会或多或少地影响销量。我们可以把**这些因素也就是n个特征,都总结到同一个回归方程中**,用**多元回归方程**表示,具体的公式如下:
119 |
120 | $$
121 | \\text { 销量 }=a\_{0}+a\_{1} * \\text { 搜索次数 }+a\_{2} * \\text { 用户评价 }+a\_{3} * \\text { 库存 }+a\_{4} * \\text { 折扣力度 }+\\cdots a\_{n} * \\text { 广告宣传 }
122 | $$
123 |
124 | 通过这样的方式,我们就可以轻易地预测每种产品的未来销售,进而可以动态地规划库存和物流。当然,回归算法能做的还有很多,比如预测不同促销组合产生的盈利进而确定促销活动,预测广告的投入量进而估算盈利额等等。
125 |
126 | 对于产品经理来说,我们需要清楚的知道线性回归的原理,熟悉回归算法能解决的情况,比如它适合用来预测价格、销量,这类结果是连续值的问题。
127 |
128 | ## 总结
129 |
130 | 今天,我结合三大类问题,给你讲了三大类常见算法和它们的应用场景。为了方便你的记忆,我把重点内容整理成了一张知识脑图,你可以去文稿中看一看,这里我就不重复了。
131 |
132 | 
133 |
134 | 这里,我还想结合这三类算法,再给你举几个常见的应用场景,因为知道什么场景下使用什么算法来解决是我们最需要掌握的。
135 |
136 | 如果你希望知道你的用户会不会购买某个商品,你的用户在你们平台借款之后会不会不还钱,或者你想知道你的用户会不会购买你们平台的会员卡,这些就属于分类问题了,你们的算法工程师可能会选择逻辑回归,决策树来实现你的需求。
137 |
138 | 如果你希望知道你们平台某个商品未来的价格,预测你们小区未来某个时间点的房价,或者预测一下你的用户收入情况是多少,你们的算法工程师可能会选择使用回归算法来解决这些回归问题。
139 |
140 | 如果你想做一个用户画像体系,对用户进行分组打标签,这就属于聚类分析的领域了,你们算法工程师可以选择层次聚类,原型聚类等算法来实现你的需求。
141 |
142 | 当然,算法分类的方式不止一种,我们也可以按照建模时候有没有标签,把它们分成有监督、无监督和半监督算法。我之所以选择根据应用场景来分类,是因为你作为一个产品经理,应该关注的是,如何通过技术(算法)来解决业务场景中遇到的问题。
143 |
144 | ## 课后讨论
145 |
146 | 如果我们要做一个预测用户未来能不能复购的模型,你觉得这属于什么问题,哪种算法可以解决呢?
147 |
148 | 期待在留言区看到你的设计和思考,我们下节课见!
149 |
150 | - 橙gě狸 👍(51) 💬(1)
有两种思考角度:
151 | 1)仅仅分析是否会复购,进而预测与复购率相关的其他指标,那既可以是【分类问题】,也可以是【回归问题】,取决于后续用途。
152 | 2)从业务角度出发,肯定是希望能提高复购率,那基于这个目的,我们更加希望了解到的是,会复购的用户和不会复购的用户各自存在什么特征,这里应该用到【聚类算法】,找到会复购的用户特征是什么,并围绕着这些特征,通过运营手段让不会复购的用户逐步拥有这些特征,以提高整体复购率。
2021-01-11
- 吴洋 👍(8) 💬(1)
课后讨论
153 | 可以用分类问题的算法得出要么复购要么不复购
154 | 也可以用逻辑回归算法得出用户复购的概率
2020-12-30
- 悠悠 👍(5) 💬(0)
课后讨论
155 | 要么能复购,要么不能复购,是二分类问题。
156 | 逻辑回归、朴素贝叶斯,决策树,随机森林,k近邻,支持向量机,神经网络这些分类算法应该都可以用
2020-12-30
- momo 👍(4) 💬(0)
1、判断会不会复购,那么就是分类问题,对应的算法逻辑回归、朴素贝叶斯、决策树、随机森林、支持向量机、神经网络;
157 | 2、复购的前置条件,是发生过一次购买行为,所以如果为了提升复购,还需要将发生过购买行为的用户进行聚类,找出特征用户和关键行为。给运营提供参考。
2022-03-19
- Yesss! 👍(3) 💬(0)
首先,这是分类问题,用户能/不能复购。这是二分类型的问题。算法同学可能会根据逻辑回归、决策树、随机森林、朴素贝叶斯、K近邻算法、支持向量机等算法来实现这个需求
158 |
2021-01-14
- 有机体 👍(2) 💬(0)
预测用户的性别是个多分类问题^_^
159 | 1、男
160 | 2、女
161 | 3、男性化的女性
162 | 4、女性化的男性
163 | 5、深柜男
164 | 6、深柜女
2022-01-07
- 小赖是个憨憨🐛 👍(2) 💬(3)
用户评价和库存影响销量的分析图没看明白
2021-06-14
- 热寂 👍(1) 💬(0)
分类问题可以用的算法里面有一个“逻辑回归”,它跟回归问题这个大类有什么联系和区别?
2022-05-20
- Geek_f1e944 👍(0) 💬(0)
RAG我们不需要了解一下吗?
2024-12-11
- InfoQ_49f2ac5320e3 👍(0) 💬(0)
预测用户未来能不能复购:应该用分类模型
2024-07-15
- 汤肉肉 👍(0) 💬(0)
提问:处理聚类问题的算法中提到的客服系统的咨询问题那个例子没完全看懂,对五个句子进行分组后然后是怎么应用以便把常见问题进行自动回复的?
2024-02-27
- cesc 👍(0) 💬(0)
1. 预测用户未来能不能复购二分类问题
165 | 2. 解决这个问题的算法有:K近邻算法、朴素贝叶斯、决策树、随机森林以及支持向量机
2023-12-10
- Geek_ac620e 👍(0) 💬(0)
留言的按钮不是很好找,而且跟底部播放栏打架建议优化一下
166 | 分析一下用户质量,用于功能ab测试,以及效果评估
167 | 背景:在线教育,是tob项目
168 | 回归问题
169 | 用ks进行分组
170 | 关键特征:由于b强制学习场景,故刷课行为常态,所以活跃和课程学习时长不作为关键特征值,仅从用户学习反馈数据做初步分组。1、课程评论置顶数2、课程评论或提问被回复数3、笔记置顶数4、笔记点赞数5、智能问答问题涉及专业数量7、创建课单数8、课程收藏数
2023-10-23
- Geek_df351f 👍(0) 💬(0)
预测用户未来能不能复购的模型
171 |
172 | 聚类+连续
173 |
174 | 1、先描述用户画像,将该人定位到哪个用户画像上
175 |
176 | 2、连续型预测该用户画像上的复购情况
177 |
178 | 3、得出该用户的复购
2023-02-25
- Nicolas 👍(0) 💬(0)
在实际的一个项目中,发现促销折扣特征的模型相关性不大,排名倒数,枚举值是 【0.6,0.7.....】根据实际折扣力度计算出的,而实际销售中促销折扣应该是影响销量最重要的因素,这种是什么原因?
2023-01-29
179 |
--------------------------------------------------------------------------------
/99~参考资料/2020~成为 AI 产品经理/docs/01 - 行业视角:产品经理眼中的人工智能.md:
--------------------------------------------------------------------------------
1 | 你好,我是海丰,很高兴能在这个专栏和你见面。
2 |
3 | 随着人工智能的火热,越来越多的产品经理开始关注这个领域,希望借着风口转型成为 AI 产品经理,进而可以拓宽自己的职业道路。确实,这是一条很不错的出路,我本人就是一个转型的深度体验者和倡导者。
4 |
5 | 对比传统的产品经理,AI 产品经理更加注重对于人工智能行业、场景算法,以及验收评估标准的理解。这节课,我们就来学习这些内容。不过在学习之前,我准备了 3 个问题,来测试一下你对这个领域的了解程度:
6 |
7 | 1. 你理解人工智能吗?
8 | 2. 它的产业发展现状如何?
9 | 3. 人工智能产品经理的人才结构是怎样的?
10 |
11 | 接下来,我将从人工智能产品经理的角度,带你一起解答以上问题,让你对这个领域有一个整体的认知。这是基础,更是必学!
12 |
13 | ## 理解人工智能
14 |
15 | 对于人工智能的理解,网上的文章早已铺天盖地,如果要我概括一下,**我认为:如果一个系统可以像人类一样思考和行动,同时这些思考和行动都是理性的,那么这个系统我们就可以认为它是人工智能**(Artificial Intelligence,英文缩写为 AI,后面我会直接简称为 AI)。
16 |
17 | 什么意思呢?举个例子。
18 |
19 | 比如说,我们在浏览电商网站的时候,经常会发现自己看到的页面展示的商品和其他人不太一样,这是因为电商平台的推荐系统,会根据我们过去的浏览行为和下单情况,来预测我们可能喜欢的产品,再把它们展示出来。
20 |
21 | 再比如说,我们都使用过类似小爱音箱这样的智能音箱,当我们跟它说:“嘿,小爱同学,明天早上 7 点叫我起床”,它就会为我们设置早上 7 点的闹钟。这是因为在小爱同学背后有一整套的系统,对我们发出的语音进行语义理解,再按照理解到的语义指令执行命令。
22 |
23 | 从这两个例子中,我们能感受到这些产品不仅可以像人类一样去发现我们的喜好,推荐出我们喜欢的商品(精准推荐),还可以理解我们的语言(语义识别)去执行我们的命令(语音识别)。这些就是人工智能赋予它们的能力,也是人工智能应用越来越受欢迎,越来越多的原因。
24 |
25 | 但是作为 AI 产品经理,我们需要注意,**目前 AI 技术可以解决的问题,一定是在某一个明确的特定业务领域内,且有特定目的的问题**,比如是搜索推荐、机器翻译、人脸识别等等。而我们在电影中看到的那些“无所不能”的 AI 机器人,它们属于通用人工智能领域,这离我们还很远。
26 |
27 | ### 关于人工智能,你必须要掌握的概念
28 |
29 | 理解了什么是人工智能和它的边界,我们再来看看人工智能领域的两个重点概念,机器学习和深度学习。这两个关键词时常出现在人工智能相关的新闻中,但还是有很多人不清楚这两者是什么,以及它们和人工智能是什么关系,甚至还有人把它们混为一谈。所以,我希望在正式开始咱们后面的学习之前,先带你扫除这些基础障碍。
30 |
31 | **我们先来看机器学习(Machine Learning)。**机器学习的核心是让机器有能力从数据中发现复杂的规律,并且通过这些规律对未来某些时刻的某些状况进行预测。这怎么理解呢?我们先来看一个简单的例子。
32 |
33 | 假设,我们要通过机器学习预测未来几天内是否下雨,那我们需要筛选出过去一段时间内比较重要的天气特征数据,比如过去的平均气温、湿度、降水量等等,然后通过机器学习算法从这些历史数据中发现规律。
34 |
35 | 这个所谓的规律就是算法工程师常说的模型,而发现这个规律的过程就是训练模型的过程。最终通过这个模型加上相应的气温、湿度等特征数据,我们就可以计算出未来几天内下雨的一个概率。
36 |
37 | 我们可以用一句话来总结机器学习的过程:**机器学习就是让机器从过去已知的大量数据中进行学习,进而得到一个无限接近现实的规律,最后通过这个规律对未知数据进行预测。** 其中,我们使用的过去的数据就是我们说的样本,而气温、湿度这些属性就是特征,过去某一天是否下雨就是我们建模时用到的标签(结果数据)。
38 |
39 | 如果在建模过程中,我们能够获得这些标签并使用它们训练模型,就叫做**有监督学习**(Supervised Learning)。如果没有标签,就叫做**无监督学习**(Unsupervised Learning)。像上面这种预测是否下雨,预测结果是“是/否”这样的问题,就是**分类问题**,如果是预测具体温度是多少,预测的结果是一个连续值的,就是**回归问题**。
40 |
41 | 当然,这只是机器学习中一个很简单的例子,实际分析数据和预测的过程远比我们刚才描述的要复杂,而且实现预测能力的方式也不止一种,我们现阶段只要掌握这些就足够了。
42 |
43 | **接下来我们看第二个概念,深度学习(Deep Learning)。** 深度学习是一种特殊的机器学习,它借鉴了人脑由很多神经元组成的特性,而形成的一个框架或者说是方法论。**相对于普通的机器学习,深度学习在海量数据情况下的效果要比机器学习更为出色。**
44 |
45 | 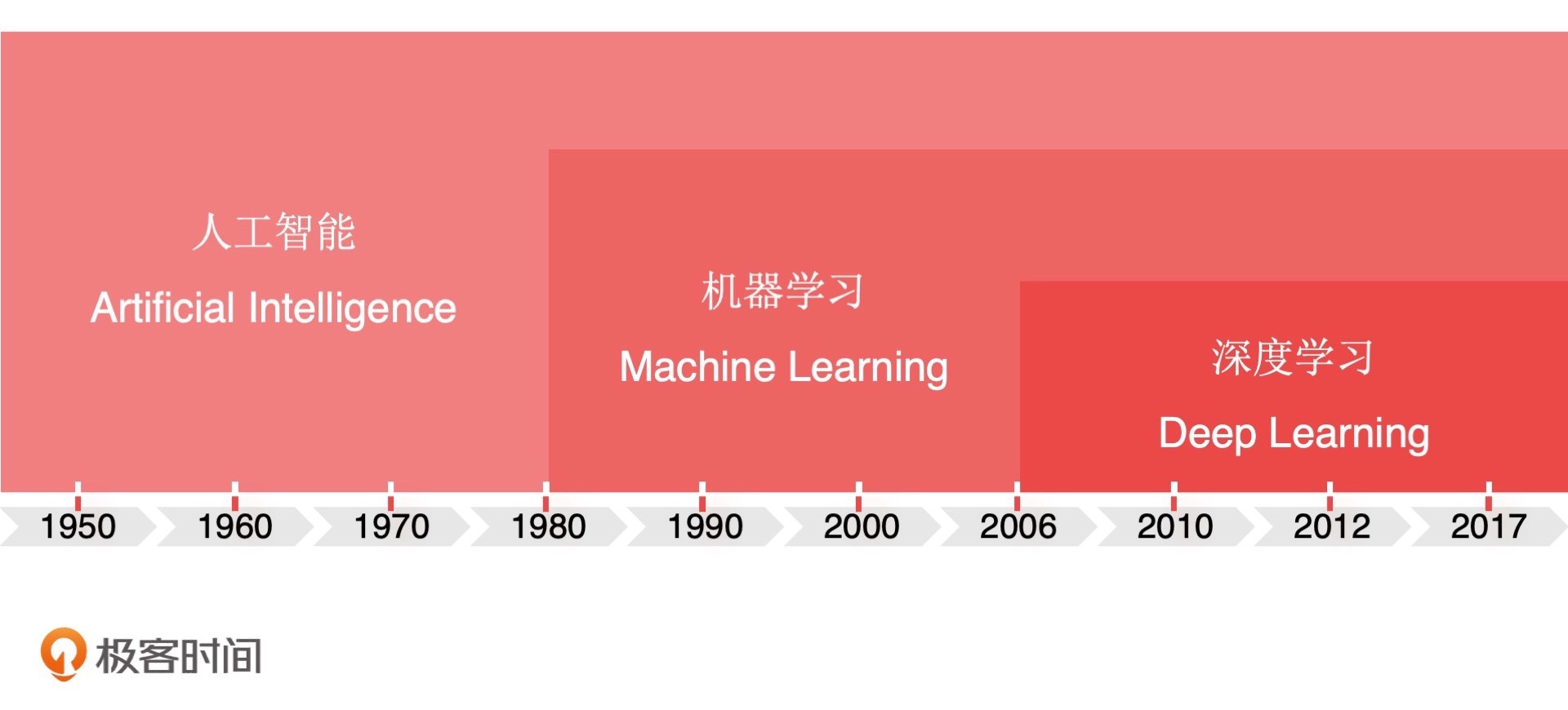
46 |
47 | 我们从上面的“人工智能技术发展时间线”图中也可以分析出来,深度学习是在互联网 DT 时代(数据处理技术时代,Data Technology)到来之后才逐渐火起来的,所以数据量对深度学习的重要性是非常高的。
48 |
49 | 虽然深度学习的效果很好,但它也有局限,比如,深度学习对机器性能的要求会更高,算法模型训练时间相对更长等等。所以,我们需要根据实际业务的场景来选择是否应用深度学习的相关算法。
50 |
51 | ### 人工智能产业现状
52 |
53 | 理解了什么是人工智能之后,接着,我们再来看看人工智能的产业现状怎么样,从全局的视角来了解整个行业,这对我们知识体系的建立是非常有帮助的。对于人工智能的产业,我们可以基于产业链的上下游关系,把它分为基础层、技术层和应用层。
54 |
55 | 我们先来看最下面的基础层,它按照服务的线条被划分成芯片服务、云服务、机器学习平台和数据服务,它们都是我们整个 AI 行业最底层服务提供者。这里面,讯飞的开放平台是我们接触比较多的机器学习平台,阿里云、百度云是做得比较好的云服务提供商。
56 |
57 | 再上一层的技术层是 AI 技术的提供者,我按照技术类别对它进行了划分。这里面,我们比较熟悉的企业有商汤、依图,它们主要是提供计算机视觉服务,最常见的应用场景就是人脸识别了。
58 |
59 | 最上面的应用层是 AI 技术对各行业的应用服务,就拿我们最熟悉的抖音来说,它通过 AI 技术不仅能实现短视频内容的个性化分发,把你感兴趣的内容展示出来,还能在拍摄短视频时候,让你变美变瘦,身体各个部位“收放自如”。
60 |
61 | 除此之外,在整个 AI 产业链中,BAT 提供了全链条的服务,它们既做了最底层的基础服务,如云服务、机器学习平台,也做技术输出,如 BAT 会有自己的计算机视觉、语音识别等能力,同时也有对外的应用场景,所以我把它们放到了一列中。这个产业链上每一层的代表企业非常多,我就不细说了,你可以参考下面的全景图。
62 |
63 | 
64 |
65 | 上面的全景图告诉了我们,整个产业链的分层和每层的典型公司都有哪些。不过如果想要转到 AI 行业,你还需要多了解一些行业内的成熟应用。下面这张典型应用案例图就能帮到你。
66 |
67 | 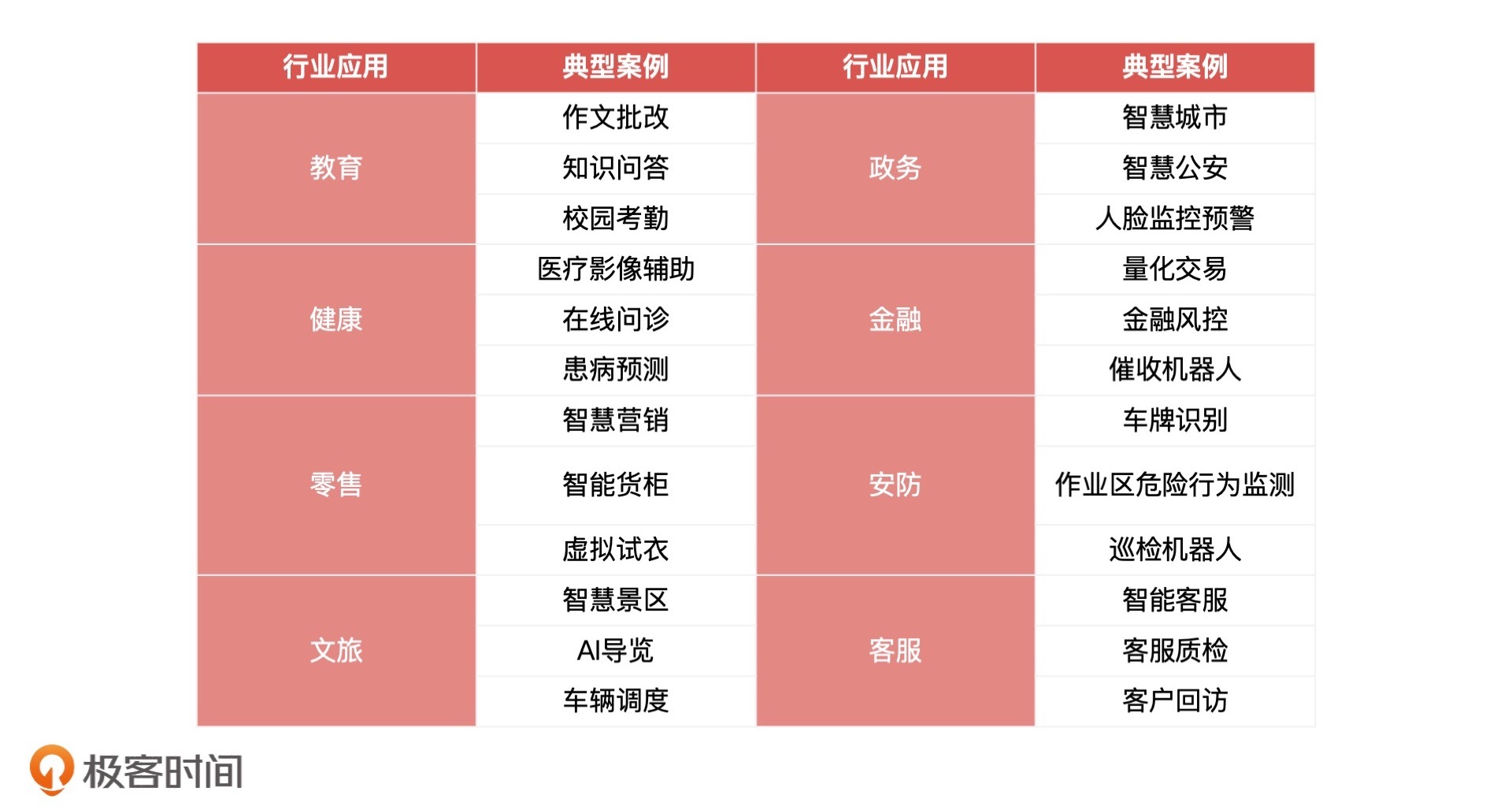
68 |
69 | 这里,我挑出了 4 个应用 AI 技术比较早,发展也相对成熟的行业,它们分别是金融风控,智能支付、智能安防以及智能客服。我会通过它们来给你讲讲,目前一些成熟的 AI 技术都是怎么应用的,应用它们对这些行业有什么帮助,以及这些行业中比较有代表性的企业和产品分别是什么。
70 |
71 | **金融风控行业** 主要是用机器学习技术把原本依赖人工的风险管理变为了依赖机器算法的方式,通过收集借款人的相关数据(收入、年龄、购物偏好、过往平台借贷情况和还款情况等)输入到机器学习模型中,来预测借款人的还款意愿和还款能力,判断是否对他放款。
72 |
73 | AI 技术的应用解决了原有人工信贷审核效率低下、无标准等问题。目前,市场上做金融风控的 AI 企业不只有老牌的百融云创、邦盛科技,还有蚂蚁集团、京东数科、度小满这样的大型互联网公司,还有冰鉴这样新型的创新型公司等等。
74 |
75 | 而**智能支付行业**主要是通过人脸识别、指纹识别、声纹识别、虹膜识别等多种生物识别技术,帮助商户提高支付效率。像蚂蚁、京东数科、商汤和云从科技这些我们比较熟悉的企业,都属于智能支付行业。其中,云从科技、旷视科技、商汤科技和依图科技还一起被誉为 CV 界的四小龙。
76 |
77 | 接着是**智能安防行业** 。互联网产品经理平时接触这个行业可能比较少,因为目前市场上主要做智能安防的企业有海康威视、大华股份、汉邦高科等,它们主要是通过人脸识别、多特征识别、姿态识别、行为分析、图像分析等相关技术融合业务场景的解决方案,来帮助企业、政府解决防控需求的。像我们都听说过,通过 AI 摄像头自动识别犯罪嫌疑人,通过深度学习技术检测车辆,并且识别出车牌号码等特征,用于停车场收费、交通执法等场景。
78 |
79 | 最后是**智能客服行业**。这个行业主要是通过自然语言处理技术、知识图谱,对用户输入的问题进行识别分析,根据知识系统寻找答案,解决原有人工客服效率低下、成本高这样的问题。
80 |
81 | 就像很多银行现在都采用智能客服,对它们的用户进行理财推荐,我就接到过不少这样的电话。但是一般来说,它们和真人的区别还是很明显的。目前市场上比较成熟的智能客服企业主要是环信、云知声、百度等等。
82 |
83 | 好了,现在我们已经知道了什么是人工智能,以及整个产业的现状。**目前人工智能与各个行业还在不断融合,AI 也会继续向各个行业进行渗透。在我看来,AI 最终不会成为一个行业,而是会像移动互联网一样成为一个基础建设,赋能到整个互联网。**
84 |
85 | ## AI 产品经理人才结构
86 |
87 | 了解了人工智能的发展现状,我们就可以有针对性地看一下这些层级的公司对 AI 产品经理都有哪些要求了。
88 |
89 | ### 人工智能商业模式
90 |
91 | 
92 |
93 | 在人工智能产业中,处于不同层级的企业,根据自身能力和方向的不同,都有自己的一套商业模式,充分了解 AI 公司的商业模式,可以成为我们转型 AI 产品经理的重要参考信息,也是我们进一步整理出 AI 产品经理的人才结构图的依据。
94 |
95 | 总的来说,商业模式可以分为:**数据收集和治理、计算资源服务、AI 技术服务以及产品附加 AI 这四种**。下面,我们一一来看。
96 |
97 | 首先,我们来看位于基础层的两类商业模式,数据收集和治理,以及计算资源服务。
98 |
99 | 数据收集和治理类型的公司大多拥有自己的数据流量入口,致力于对于数据的收集和加工。比如数据堂,它主要提供数据采集(包括从特定设备,地点采集,采集范围包括图片、文字、视频等)、数据标注(主要是对图像进行标注,如标注人脸、动作等)服务。
100 |
101 | 而计算资源服务类型的公司,又可以分成两类,一类致力于底层的芯片、传感器的研发服务,就像寒武纪这样的企业,它们作为一个人工智能芯片公司,主要的收入来自云端智能芯片加速卡业务、智能计算集群系统业务、智能处理器 IP 业务。另一类是 AI 计算服务,比如百度的 AI 开放平台,平台除了提供百度自有的 AI 能力之外,也为上下游合作伙伴提供了一个 AI 产品、技术展示与交易平台。
102 |
103 | 接着,我们再来看位于技术层的 AI 技术服务类公司,它们为自己产品或者上游企业提供底层的 AI 技术服务,服务模式更多的是技术接口对接,比如人脸识别服务的服务模式主要就是 API 接口或者 SDK 部署的方式。
104 |
105 | 最后是产品附加 AI,即应用层的大部分产品,它们都是通过 AI 技术叠加产品,赋能某个产业的模式。比如滴滴通过 AI 技术应用于自有的打车业务线,包括营销环节的智能发券、发单环节的订单预测、行车中的实时安全检测等等。
106 |
107 | ### AI 产品经理所需技能
108 |
109 | 通过上面的分析,我们不难发现,不同产业层级和商业模式都需要具有相应能力的 AI 产品经理。那这些产品经理究竟有什么区别呢?接下来,我就结合应用层、技术层和基础层这三个层级企业的特性,来给你讲讲不同层级产品经理所需的技能,同时给你一些具体的转型建议。
110 |
111 | 首先是基础层。处于基础层的企业主要提供算力和数据服务,这些企业的特点是,偏硬件,偏底层技术,技术人员居多。这就要求 AI 产品经理了解如云计算、芯片、CPU/GPU/FPGA/ASIC 等硬件技术,以及行业数据收集处理等底层技术和框架。所以,原来从事底层硬件、技术平台、基础框架的产品经理,就比较适合转型到基础层了。
112 |
113 | 而处于技术层的企业,主要的业务是为自己的业务或者上游企业提供相应的技术接口。这些企业的特点是技术能力强,大部分业务都是 ToB 服务。这个时候,AI 产品经理就必须要具备企业所在领域的技术知识,如语音识别(ASR)、语音合成(TTS)、计算机视觉(CV)、自然语言处理(NLP)等通用技术,最好还能了解 TensorFlow、Caffe、SciKit-learn 这样的机器学习框架。
114 |
115 | 所以,技术层的 AI 产品经理本身必须具备一定的技术基础,最好还能是算法出身的工程师。但不管你属于哪一种,都一定要保有探索的热忱。
116 |
117 | 最后,我们再来看应用层,这类型公司就是我们日常生活中接触最多的互联网公司,只是其中一些公司走的比较靠前,应用了 AI 技术来赋能自己的内部业务。比如滴滴使用 AI 技术做智能分单、智能补贴;京东数科是用 AI 技术做智能反欺诈,大数据风控。这一层是互联网产品经理转型最多,也是成功率最高的一层。
118 |
119 | 处于应用层的企业,大多数直接面向 C 端用户,所以它们关注的是如何结合市场特点,来利用 AI 技术创造性地设计出符合市场需求的产品。所以这类型的产品经理不仅要求对所在行业有深刻的认识,同时也要对 AI 技术有一定的了解。能够与算法和研发工程师顺畅沟通与配合,能够判断算法同学交付的产品是否满足业务需求。
120 |
121 | 总之,这一层的 AI 产品经理岗位,比较适合已经在某个领域具备了行业经验,打算转型做这个领域产品经理的同学。对于这样的同学,这一层的入门门槛比较低,在补充一定的 AI 技术知识后,获得一份 AI 产品经理的 Offer 相对来说会容易很多。
122 |
123 | ## 总结
124 |
125 | 今天,我从一个产品经理的角度,带你从全局了解了人工智能行业。在我看来,虽然人工智能可以让系统像人类一样进行理性的思考和行动,但它目前能够解决的问题还很有限。因此,人工智能未来是有无限潜力的。
126 |
127 | 对于希望进入 AI 领域的产品经理来说,你只有对整个行业有一个全局的认识,才能结合自身的优势,找到最适合自己的领域和岗位。所以,这节课我们要牢牢掌握 AI 产业链的三个层级特点:
128 |
129 | - 基础层偏硬件,技术更底层,对人的技术能力要求最高;
130 | - 技术层多为 ToB 服务,对技术要求相对较高;
131 | - 应用层最接近现在的用户,更多的是利用 AI 技术服务业务,对技术要求相对最低,也是转行最容易的。
132 |
133 | 总的来说,对于想要转型 AI 产品经理的同学,我想给你 3 条建议:
134 |
135 | 1. 如果你对硬件有足够的了解,那么可以尝试进入基础层发展;
136 | 2. 如果你本身就是一个算法工程师,精通一些算法或开发框架,就可以考虑进入技术层,你将有天然的优势;
137 | 3. 如果你和大多数的互联网产品经理一样,在自己所处的行业有足够的经验,但是对于 AI 技术了解还不够,那更适合来应用层发展,发挥自己对于业务的敏感度,发现行业的创新点。
138 |
139 | ## 课后讨论
140 |
141 | 根据你现在的经验和能力,你认为你更适合哪种类型的公司?目前你还需要补充哪些方面的能力?
142 |
143 | 最后,我希望今天的课程能帮助你结合自己的兴趣、能力项,选择出适合自己的赛道。也欢迎把你对人工智能领域和 AI 产品经理的思考写到留言区,我们一起讨论。
144 |
145 |
145 | - 悠悠 👍(63) 💬(1)
模型设计阶段的PRD文档,是什么样子的,老师可以发一个看看吗
2020-12-26
- 大雷子 👍(30) 💬(1)
1、双11、618等促销日,用户会集中下单,促销日前后时间段下单几率较小,这期间30天未下单,不能定义为流失客户;
146 | 2、用户历史购买商品类型,如果大型家电、家居类居多,这一类商品购买频率本身就比较低,如果该用户30天未下单,也不能定义为流失客户;
147 | 3、用户历史订单评价,如果评价较好,30天未下单也不能定义为流失客户
2020-12-30
- 悠悠 👍(7) 💬(2)
课后讨论
148 | 新注册用户、长假期、临近大促消,可能会影响用户下单时间
2020-12-26
- Miss斑马 👍(0) 💬(1)
说了这么多,其实核心就是一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
149 | ---怎么理解这里说的“算法”,是个什么东西?
2021-01-04
- 丸子酱 👍(16) 💬(0)
课后问题答疑:
150 | 1.时间区段:大促、定时抢购前后无下单行为很正常,应该结合活跃程度、浏览产品和加入购物车等行为总和分析;
151 | 2.外界影响:政策、疫情等不可抗力因素导致的不能下单或者快递不可达的情况,不可一刀切为流失用户;
152 | 3.用户层:应对用户画像,历史购物行为中,购买奢侈品、电子产品、大型家具等本身频次比较低的产品,不可判断为流失用户,应综合考虑该类产品的使用寿命、用户行为、购物偏好、季节适配性等条件综合判断
153 | 4.平台和合作平台极端情况:如用户经常性购买的物品,长期属于断货情况、或者合作的快递终止合作,导致无快递送达等因素、或者平台某功能长期不可使用导致用户不可下单等极端情况
2021-01-12
- Geek_c95225 👍(7) 💬(0)
特征值的提取 稳定性 、iv值、覆盖率 是怎么去定义的?
2021-12-23
- AsyDong 👍(6) 💬(0)
平均购物周期;月度购物次数和金额环比:如果上个月大量采购完,这个月不太会再次进行采购;购物品类偏好:日用品消费频次高,大小家电消费频次相对较低
2020-12-25
- Fan 👍(4) 💬(2)
老师问下 如果手头上现在没有AI项目,学习了这些理论的话,有没有更好办法去实践,例如可以进行怎么模拟来部分还原真正的AI项目实践。
2020-12-25
- Geek_d7623f 👍(3) 💬(0)
特征的IV值和稳定性是怎么计算的?如果按照筛选后剩下的特征比较少,是否还要再挖掘之前未想到的特征?
154 |
155 | 课后思考:用户购物车中商品数量,可能用户在等待大促活动一起下单。
2020-12-25
- Geek7419 👍(1) 💬(0)
请问IV值是怎么计算的? 看到结尾了,也没有讲这个指标的计算方式。
2021-12-13
- 冯广 👍(1) 💬(0)
1、临近假期和大促的前后
156 | 2、用户的年龄和其他分群后够买倾向和频率的天然不同
157 | 3、用户是否是会员
158 | 4、用户近期活跃但没有发生够买行为
159 | 5、用户之前的购物行为有没有追加好评
2021-09-15
- Pale Blue 👍(1) 💬(0)
需要考虑的特殊因素:
160 | 1. 上一个30天区间段内用户消费的总额与订单数量。(有可能是之前买了过多商品,目前没有购物的需求);
161 | 2. 所处的时间段,例如在一些购物节之后,用户短期内不会购物;
162 | 3.要参考往期用户购物的习惯,比方说用户一般只会在APP上购买日用品,频率为每2月;
2021-09-06
- 加菲猫 👍(1) 💬(0)
想到的几点因素:
163 | 1.特殊时间节点:大促、春节、两会等
164 | 2.重大事件社会环境:疫情期间、地震、台风等;
165 | 3.地理位置及历史邮寄地址
166 | 4.历史购物信息:购物种类、购物频次、商品评价、客服反馈
167 | 5.平台商品变化信息:购物车中无货或失效商品
2021-04-24
- 马帮 👍(1) 💬(0)
我觉得登录次数和投诉次数的特征就要考虑了。
2021-01-10
- Yue. 👍(1) 💬(0)
用户的信用状况, 付款方式,比如习惯于用白条购物的用户,是不是额度不足等。 还有,用户的地理位置,与收货地址是不是有大的变动。 只想到这些了
2020-12-27
168 |
--------------------------------------------------------------------------------