├── .nojekyll
├── 02~数据集成
├── Canal
│ ├── 架构机制.md
│ ├── README.md
│ └── 部署与配置.md
├── Debezium.md
├── README.md
├── DataPipeline
│ ├── 数据转换与检索.md
│ ├── 一致性语义.md
│ ├── 运行环境与引擎.md
│ ├── 数据汇集层.md
│ ├── README.md
│ └── 数据源监听.md
└── ETL
│ └── README.md
├── 04~数据可视化
├── 可视化开发库
│ └── D3
│ │ ├── 交互反馈
│ │ └── README.md
│ │ ├── 图表示例
│ │ └── README.md
│ │ ├── 数据操作
│ │ └── README.md
│ │ └── README.md
├── 数据与图表类别
│ ├── 关联类.md
│ ├── 平面比较类.md
│ ├── 韦恩图.md
│ ├── README.md
│ ├── 柱状比较类.md
│ └── 数据类别.md
├── 图形语法
│ └── README.md
├── 探索分析
│ ├── 数据透视表.md
│ └── README.md
├── 多维数据可视化
│ ├── 可视化过程.md
│ └── README.md
├── BI 工具
│ └── 99~参考资料
│ │ └── 2022-吐血测评九款 BI 工具,BI 选型就看这篇.md
├── 可视化基础
│ └── README.md
└── README.md
├── 10~OLAP
├── 02.MOLAP
│ ├── Kylin
│ │ └── README.md
│ ├── Druid
│ │ └── README.md
│ └── HBase
│ │ ├── 架构分析.md
│ │ ├── CRUD.md
│ │ └── 部署与使用.md
├── 03.ROLAP
│ ├── Hive
│ │ ├── README.md
│ │ ├── 文件类型与存储格式.md
│ │ ├── 数据类型.md
│ │ └── 表操作.md
│ ├── Presto
│ │ ├── README.md
│ │ └── 部署与控制.md
│ ├── StarRocks
│ │ ├── README.md
│ │ └── 99~参考资料
│ │ │ └── 2022-10 分钟带你全面了解 StarRocks!.md
│ ├── ClickHouse
│ │ ├── 99~参考资料
│ │ │ ├── 2022-陈峰-ClickHouse 架构及源码解析
│ │ │ │ └── README.md
│ │ │ └── 2023-ClickHouse 从入门到放弃
│ │ │ │ └── README.md
│ │ └── README.md
│ ├── QuickSQL
│ │ └── README.md
│ └── Sqoop
│ │ └── 介绍与部署.md
├── 01.引擎架构
│ ├── 99~参考资料
│ │ ├── 2020-Kylin、Druid、ClickHouse核心技术对比.md
│ │ └── 2021-常用引擎对比与概述.md
│ ├── 03.引擎操作
│ │ └── README.md
│ ├── 01.MPP
│ │ ├── README.md
│ │ └── 99~参考资料
│ │ │ └── 2022-MPP 架构、常见 OLAP 引擎分析.md
│ └── 02.建模类型划分
│ │ ├── README.md
│ │ ├── 01.MOLAP.md
│ │ └── 02.ROLAP.md
├── README.md
└── 10.实践案例
│ └── 2021-贝壳 OLAP 平台架构演进.md
├── 03~数仓建模
├── 05~元数据管理
│ ├── README.md
│ └── Amundsen.md
├── 02~多维数据模型
│ ├── 01~事实表、维度表、聚合表
│ │ ├── README.md
│ │ ├── 03~聚合表.md
│ │ ├── 01~事实表.md
│ │ └── 02~维度表.md
│ ├── README.md
│ ├── 03~数据立方体
│ │ └── README.md
│ └── 02~星型与雪花模型
│ │ ├── 99~参考资料
│ │ └── 2021-数据仓库系列:星型模型和雪花型模型.md
│ │ └── README.md
├── 03~数仓搭建流程
│ ├── README.md
│ ├── 01~数仓分层架构
│ │ └── 数仓分层.md
│ ├── 02~事实表设计
│ │ └── README.md
│ ├── 03~维度表设计
│ │ └── README.md
│ └── 99~参考资料
│ │ ├── 2022-园陌-做数仓必须搞明白的各种名词及关系,吐血整理.md
│ │ └── 2021-数据产品小 Lee-数据仓库基础.md
├── 04~指标体系
│ └── README.md
├── 01~Kimball 与 Inmon
│ ├── Kimball.md
│ └── README.md
└── README.md
├── 01~大数据体系
├── 03~数据组织方式
│ ├── 02~数据仓库
│ │ └── README.md
│ ├── README.md
│ ├── 05~数据网格
│ │ └── README.md
│ ├── 04~数据中台
│ │ ├── README.md
│ │ ├── 数据栈.md
│ │ └── 评价维度.md
│ └── 03~数据湖
│ │ └── README.md
├── 01~大数据生态
│ ├── 99~参考资料
│ │ └── 2021-数据库领域投资总结.md
│ ├── 大数据生态圈.md
│ ├── README.md
│ ├── 大数据的未来.md
│ ├── 大数据平台.md
│ ├── 数据的特性.md
│ └── 不作恶.md
├── README.md
├── 02~数据治理原则
│ ├── 数据零散化.md
│ └── 原则与要素.md
├── 04~数据中心
│ ├── README.md
│ └── 云数据中心.md
└── 99~参考资料
│ └── 2022-一文读懂数据仓库、数据平台、数据中台、数据湖的概念和区别.md
├── 99~参考资料
└── 《Designing Data-Intensive Application》
│ ├── 《DDIA 逐章精读》
│ └── README.md
│ └── 原书翻译
│ ├── 01~数据系统基础
│ └── README.md
│ └── README.md
├── .gitignore
├── README.md
├── index.html
└── _sidebar.md
/.nojekyll:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/02~数据集成/Canal/架构机制.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/04~数据可视化/可视化开发库/D3/交互反馈/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/04~数据可视化/可视化开发库/D3/图表示例/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/04~数据可视化/可视化开发库/D3/数据操作/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/04~数据可视化/数据与图表类别/关联类.md:
--------------------------------------------------------------------------------
1 | # 关联类
2 |
--------------------------------------------------------------------------------
/10~OLAP/02.MOLAP/Kylin/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/Hive/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/Presto/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/03~数仓建模/05~元数据管理/README.md:
--------------------------------------------------------------------------------
1 | # 元数据管理
2 |
--------------------------------------------------------------------------------
/04~数据可视化/图形语法/README.md:
--------------------------------------------------------------------------------
1 | # 图形语法
2 |
--------------------------------------------------------------------------------
/04~数据可视化/探索分析/数据透视表.md:
--------------------------------------------------------------------------------
1 | # 数据透视表
2 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/01~事实表、维度表、聚合表/README.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/04~数据可视化/数据与图表类别/平面比较类.md:
--------------------------------------------------------------------------------
1 | # 平面比较类图表
2 |
--------------------------------------------------------------------------------
/01~大数据体系/03~数据组织方式/02~数据仓库/README.md:
--------------------------------------------------------------------------------
1 | # 数据仓库
2 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/StarRocks/README.md:
--------------------------------------------------------------------------------
1 | # StarRocks
2 |
--------------------------------------------------------------------------------
/01~大数据体系/01~大数据生态/99~参考资料/2021-数据库领域投资总结.md:
--------------------------------------------------------------------------------
1 | # Todos
2 |
3 | - https://zhuanlan.zhihu.com/p/452628664
--------------------------------------------------------------------------------
/01~大数据体系/README.md:
--------------------------------------------------------------------------------
1 | # 大数据体系
2 |
3 | # Links
4 |
5 | - https://mp.weixin.qq.com/s/gaYCcBOycQTlTq8zeIrYQg
6 |
--------------------------------------------------------------------------------
/04~数据可视化/数据与图表类别/韦恩图.md:
--------------------------------------------------------------------------------
1 | # 韦恩图
2 |
3 | # Links
4 |
5 | - https://zhuanlan.zhihu.com/p/83759111 圆形韦恩图的 3 种布局算法
6 |
--------------------------------------------------------------------------------
/03~数仓建模/03~数仓搭建流程/README.md:
--------------------------------------------------------------------------------
1 | # 数据仓库搭建流程
2 |
3 | # Links
4 |
5 | - https://mp.weixin.qq.com/s/TuT0Ob9fFqTOHEFMSDJ3Hg 一文教你如何搭建数据仓库
--------------------------------------------------------------------------------
/03~数仓建模/03~数仓搭建流程/01~数仓分层架构/数仓分层.md:
--------------------------------------------------------------------------------
1 | # Links
2 |
3 | - https://juejin.cn/post/6969874734355841031 详解数仓中的数据分层:ODS、DWD、DWM、DWS、ADS
4 |
--------------------------------------------------------------------------------
/03~数仓建模/04~指标体系/README.md:
--------------------------------------------------------------------------------
1 | # 指标体系
2 |
3 | # Links
4 |
5 | - https://mp.weixin.qq.com/s/byRl62YmmbEAnauM6ht7CQ 网易传媒数据指标体系建设实践
6 |
--------------------------------------------------------------------------------
/01~大数据体系/03~数据组织方式/README.md:
--------------------------------------------------------------------------------
1 | # 数据组织方式
2 |
3 | 
4 |
--------------------------------------------------------------------------------
/04~数据可视化/多维数据可视化/可视化过程.md:
--------------------------------------------------------------------------------
1 | # 多维数据可视化过程
2 |
3 | 多维数据可视化依托于[多维数据模型](https://github.com/wx-chevalier/Database-Notes/search?unscoped_q=多维数据模型)。
4 |
--------------------------------------------------------------------------------
/99~参考资料/《Designing Data-Intensive Application》/《DDIA 逐章精读》/README.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://github.com/DistSysCorp/ddia/tree/main)
2 |
3 | # 精读
4 |
--------------------------------------------------------------------------------
/03~数仓建模/01~Kimball 与 Inmon/Kimball.md:
--------------------------------------------------------------------------------
1 | # Kimball
2 |
3 | # Links
4 |
5 | - https://zhuanlan.zhihu.com/p/265954615 基于 Flink+ClickHouse 打造轻量级点击流实时数仓 作为案例提取
6 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/ClickHouse/99~参考资料/2022-陈峰-ClickHouse 架构及源码解析/README.md:
--------------------------------------------------------------------------------
1 | # ClickHouse 架构及源码解析
2 |
3 | # Links
4 |
5 | - https://www.zhihu.com/column/c_1384650064271351808
6 |
--------------------------------------------------------------------------------
/10~OLAP/01.引擎架构/99~参考资料/2020-Kylin、Druid、ClickHouse核心技术对比.md:
--------------------------------------------------------------------------------
1 | # Kylin、Druid、ClickHouse 核心技术对比
2 |
3 | # Links
4 |
5 | - https://blog.csdn.net/u013256816/article/details/108271371
6 |
--------------------------------------------------------------------------------
/03~数仓建模/05~元数据管理/Amundsen.md:
--------------------------------------------------------------------------------
1 | # Amundsen
2 |
3 | 数据科学家将大量时间花在数据发现上,这意味着在这一领域能够提供帮助的工具势必会令人兴奋。尽管 Apache Atlas 项目已经成为了元数据管理的实际工具,但数据发现仍然不是那么容易完成的。Amundsen 可以与 Apache Atlas 协同部署,为数据发现提供更好的搜索界面。
4 |
--------------------------------------------------------------------------------
/04~数据可视化/BI 工具/99~参考资料/2022-吐血测评九款 BI 工具,BI 选型就看这篇.md:
--------------------------------------------------------------------------------
1 | # Links
2 |
3 | - 吐血测评九款 BI 工具,BI 选型就看这篇(Tableau vs PowerBI vs superset vs DataEase vs ……) https://zhuanlan.zhihu.com/p/543473848?utm_id=0
4 |
--------------------------------------------------------------------------------
/04~数据可视化/数据与图表类别/README.md:
--------------------------------------------------------------------------------
1 | # 图表
2 |
3 | 
4 |
5 | # Links
6 |
7 | - https://antv.alipay.com/zh-cn/vis/chart/index.html
8 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/ClickHouse/99~参考资料/2023-ClickHouse 从入门到放弃/README.md:
--------------------------------------------------------------------------------
1 | # ClickHouse 从入门到放弃
2 |
3 | # Links
4 |
5 | - https://developer.aliyun.com/article/1129023?spm=a2c6h.12873639.article-detail.142.63dbdfaaKSJHfD
6 |
--------------------------------------------------------------------------------
/04~数据可视化/探索分析/README.md:
--------------------------------------------------------------------------------
1 | # 探索分析
2 |
3 | 探索分析是 BI 领域重要的研究方向之一,随着信息量的激增,业务数据的维度,大小,关联关系逐渐变得愈加复杂,使得即便是拥有多年经验的业务人员,也无法探知数据中蕴藏的全部规律、模式与领域知识。由此带来设计开发对应的探索分析系统,使得用户能够快速的从庞大的数据集中筛选自己关心的数据、选择关心的维度与度量来研究验证某一猜想假设,得出可以指导决策的有效结论。
4 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/01~事实表、维度表、聚合表/03~聚合表.md:
--------------------------------------------------------------------------------
1 | # 聚合表
2 |
3 | 数据是按照最详细的格式存储在事实表中,各种报表可以充分利用这些数据。一般的查询语句在查询事实表时,一次操作经常涉及成千上万条记录,但是通过使用汇总、平均、极值等聚合技术可以大大降低数据的查询数量。因此,来自事实表中的底层数据应该事先经过聚合存储在中间表中。中间表存储了聚合信息,所以被称为聚合表,这种处理过程被称为聚合过程。
4 |
--------------------------------------------------------------------------------
/02~数据集成/Debezium.md:
--------------------------------------------------------------------------------
1 | # Debezium
2 |
3 | Debezium 是一个变更数据捕获(Change Data Capture, CDC)平台,可以将数据库变更流式传输到 Kafka 的 topics。CDC 是一种流行的技术,具有多种应用场景,例如:将数据复制到其他数据库、输送数据给分析系统、从单体中提取数据至微服务以及废除缓存。Debezium 对数据库日志文件中的变更做出反应,并具有多个 CDC 连接器,适用于多种数据库,其中包括 Postgres、MySQL、Oracle 和 MongoDB。
4 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/QuickSQL/README.md:
--------------------------------------------------------------------------------
1 | # QuickSQL
2 |
3 | 随着业务的不断增多,为满足不同场景下对计算时延和吞吐的需求,各式各样的数据源大显身手。然而,由于不同数据源的发展历程不同,迭代速度不一,无法向用户提供统一的数据处理范式。且数据源所处介质天然隔离,交叉关联分析阻碍重重,导致数据人员要为此承担高额的学习和分析成本。
4 |
5 | # Links
6 |
7 | - https://mp.weixin.qq.com/s/DBcGC1ViNlIda0u9pr7djQ
8 |
--------------------------------------------------------------------------------
/01~大数据体系/03~数据组织方式/05~数据网格/README.md:
--------------------------------------------------------------------------------
1 | # 数据网格
2 |
3 | 在管理大量分析数据方面,[Data Mesh](https://martinfowler.com/articles/data-monolith-to-mesh.html) 标志着架构和组织范式的一种可喜转变。该范式建立在四个原则之上:
4 |
5 | (1) 数据所有权和架构的面向领域去中心化;
6 | (2) 将面向领域的数 据视为产品;
7 | (3) 将自助数据基础设施作为平台,支持自治且面向领域的数据团队;
8 | (4) 联合控制以实现生态系统和互操作性。
9 |
10 | 尽管这些原则很直观,并且只是试图解决以前集中分析数据管理的许多已知挑战,它们仍胜过了现有的分析数据技术。
11 |
--------------------------------------------------------------------------------
/04~数据可视化/可视化基础/README.md:
--------------------------------------------------------------------------------
1 | # 可视化基础
2 |
3 | # Links
4 |
5 | - https://mp.weixin.qq.com/s?__biz=MzIzMTc4NzIyNw==&mid=2247489265&idx=1&sn=690c1bb677ed107e75d51841d22af5d5&chksm=e89f8945dfe80053270c1b0b9e4ec560de35353a7c05d4975ce57d0eba93ecb42d7280523c7d&mpshare=1&scene=1&srcid=0817pEMgQlcpvg4rRFT0GYuH&sharer_sharetime=1629203025146&sharer_shareid=ab27ca96b5bf5b0b51edd5a0f67fd6c7#rd vivo官网 Web 3D 实战
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/ClickHouse/README.md:
--------------------------------------------------------------------------------
1 | # ClickHouse
2 |
3 | 数据处理现在还是分为 OLTP 和 OLAP。OLTP(在线事务处理)优化的方向是高并发、高可用,是精确,是各种增删改查。所以面临和解决的问题都是怎么解决高并发下的增删改查,怎么解决脏读、脏写,保证数据一致性等问题。
4 |
5 | OLAP(在线分析处理)的优化方向则是高速数据处理能力、高速读取能力。一般又分为两个优化方向,一个是预先计算好各个维度的数据,存成 CUBE,分析的时候直接查询结果就行,这是 MOLAP(Multidimensional OLAP,多维在线分析处理),典型代表的是 Kylin。一个是结构化存好,然后用尽各种方法优化,分析的时候拼命计算,这是 ROLAP(Relational OLAP,关系型在线分析处理),典型代表就是 ClickHouse 了。
6 |
--------------------------------------------------------------------------------
/02~数据集成/README.md:
--------------------------------------------------------------------------------
1 | # 数据集成
2 |
3 | 多个不同数据系统(可能有着不同数据模型,并针对不同的访问模式进行优化)集成为一个协调一致的应用架构时,集成不同的系统是实际应用中最重要的事情之一。例如,为了处理任意关键词的搜索查询,将 OLTP 数据库与全文搜索索引集成在一起是很常见的的需求。尽管一些数据库(例如 PostgreSQL)包含了全文索引功能,对于简单的应用完全够了,但更复杂的搜索能力就需要专业的信息检索工具了。相反的是,搜索索引通常不适合作为持久的记录系统,因此许多应用需要组合这两种不同的工具以满足所有需求。随着数据不同表示形式的增加,集成问题变得越来越困难。除了数据库和搜索索引之外,也许你需要在分析系统(数据仓库,或批处理和流处理系统)中维护数据副本;维护从原始数据中衍生的缓存,或反规范化的数据版本;将数据灌入机器学习,分类,排名,或推荐系统中;或者基于数据变更发送通知。
4 |
--------------------------------------------------------------------------------
/10~OLAP/README.md:
--------------------------------------------------------------------------------
1 | # OLAP
2 |
3 | 
4 |
5 | OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合。可以比较下其与传统的 OLTP(On-line Transaction Processing,联机事务处理)的区别来看一下它的特点:
6 |
7 | 
8 |
9 | OLAP 的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离的这两点,OLAP 将不复存在,也就没有优势可言。
10 |
--------------------------------------------------------------------------------
/02~数据集成/DataPipeline/数据转换与检索.md:
--------------------------------------------------------------------------------
1 | # 数据转换与检索
2 |
3 | 数据转换是一个业务性很强的处理步骤。当数据进入汇集层后,一般会用于两个典型的后继处理场景:数仓构建和数据流服务。数仓构建包括模型定义和预计算两部分。数据工程师根据业务分析需要,使用星型或雪花模型设计数据仓库结构,利用数据仓库中间件完成模型构建和更新。
4 |
5 | 如前文所述,源端采集的数据建议放入一个汇集层,优选是类似 Kafka 这样的消息队列。包括 Kylin 和 Druid 在内的数据仓库可以直接以流式的方式消费数据进行更新。一种常见的情形为:原始采集的数据格式、粒度不一定满足数据仓库中表结构的需要,而数仓提供的配置灵活度可能又不足够。这种情况下需要在进入数仓前对数据做额外的处理。
6 |
7 | 常见的处理包括过滤、字段替换、嵌套结构一拆多、维度填充等,以上皆为无状态的转换。有状态的转换,例如 SUM、COUNT 等,在此过程中较少被使用,因为数仓本身就提供了这些聚合能力。数据流服务的构建则是基于流式计算引擎,对汇集层的数据进一步加工计算,并将结果实时输出给下游应用系统。
8 |
--------------------------------------------------------------------------------
/02~数据集成/Canal/README.md:
--------------------------------------------------------------------------------
1 | # Canal
2 |
3 | 数据抽取是 ETL 流程的第一步。我们会将数据从 RDBMS 或日志服务器等外部系统抽取至数据仓库,进行清洗、转换、聚合等操作。在现代网站技术栈中,MySQL 是最常见的数据库管理系统,我们会从多个不同的 MySQL 实例中抽取数据,存入一个中心节点,或直接进入 Hive。市面上已有多种成熟的、基于 SQL 查询的抽取软件,如著名的开源项目 Apache Sqoop,然而这些工具并不支持实时的数据抽取。MySQL Binlog 则是一种实时的数据流,用于主从节点之间的数据复制,我们可以利用它来进行数据抽取。借助阿里巴巴开源的 Canal 项目,我们能够非常便捷地将 MySQL 中的数据抽取到任意目标存储中。
4 |
5 | 简单来说,Canal 会将自己伪装成 MySQL 从节点(Slave),并从主节点(Master)获取 Binlog,解析和贮存后供下游消费端使用。Canal 包含两个组成部分:服务端和客户端。服务端负责连接至不同的 MySQL 实例,并为每个实例维护一个事件消息队列;客户端则可以订阅这些队列中的数据变更事件,处理并存储到数据仓库中。
6 |
--------------------------------------------------------------------------------
/02~数据集成/Canal/部署与配置.md:
--------------------------------------------------------------------------------
1 | # Canal 部署与配置
2 |
3 | # 单机部署
4 |
5 | MySQL 默认没有开启 Binlog,因此我们需要对 my.cnf 文件做以下修改:
6 |
7 | ```cnf
8 | server-id = 1
9 | log_bin = /path/to/mysql-bin.log
10 | binlog_format = ROW
11 | ```
12 |
13 | 注意 binlog_format 必须设置为 ROW, 因为在 STATEMENT 或 MIXED 模式下, Binlog 只会记录和传输 SQL 语句(以减少日志大小),而不包含具体数据,我们也就无法保存了。从节点通过一个专门的账号连接主节点,这个账号需要拥有全局的 REPLICATION 权限。我们可以使用 GRANT 命令创建这样的账号:
14 |
15 | ```sql
16 | GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON _._ TO 'canal'@'%' IDENTIFIED BY 'canal';
17 | ```
18 |
--------------------------------------------------------------------------------
/04~数据可视化/多维数据可视化/README.md:
--------------------------------------------------------------------------------
1 | # 多维数据可视化
2 |
3 | 多维关系型数据库的可视化研究一直是 BI 开发中的基础领域,该领域的主要挑战是如何将数据库中的知识呈现出来,发现规律、异常并理解数据间的关系。由此,诞生了基于假设、猜想对数据库进行探索分析的需求。这种探索分析的特性是对于结果、方法与步骤的不确定性,同时要求快速改变用户研究的数据视图以及观察这些视图的方式的能力[2]。
4 |
5 | 常见的方式是将这样的一个多维的关系型数据库视为一个多维的数据立方体(cube),这种方式最知名的实践之一便是数据透视表,但数据透视表在数据的直观展示能力上非常欠缺。
6 |
7 | 
8 |
9 | # Links
10 |
11 | - http://lobay.moe/2019/06/17/GoG/canary-base-theory/#%E5%8F%AF%E8%A7%86%E5%8C%96%E8%BF%87%E7%A8%8B
12 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/StarRocks/99~参考资料/2022-10 分钟带你全面了解 StarRocks!.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://zhuanlan.zhihu.com/p/532302941)
2 |
3 | # 10 分钟带你全面了解 StarRocks!
4 |
5 | StarRocks 是一款极速全场景 MPP 企业级数据库产品,具备水平在线扩缩容,金融级高可用,兼容 MySQL 5.7 协议和 MySQL 生态,提供全面向量化引擎与多种数据源联邦查询等重要特性。StarRocks 致力于在全场景 OLAP 业务上为用户提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。接下来会从三个方面来剖析 StarRocks 的能力与特点:
6 |
7 | - 首先我们先来看一下 StarRocks 是一款什么样的数据库,他的产品定位是什么样的,他处于大数据生态什么位置上
8 | - 接下来我们详细的看一下 StarRocks 的功能与特性,了解一下为什么说 StarRocks 是一款全场景的 MPP 数据库
9 | - 最后我们通过解读一些基准测试的性能报测试告,看一下 StarRocks 的性能优势如何
10 |
11 | # OLAP 数仓挑战
12 |
--------------------------------------------------------------------------------
/10~OLAP/01.引擎架构/03.引擎操作/README.md:
--------------------------------------------------------------------------------
1 | # OLAP 引擎的常见操作
2 |
3 | 
4 |
5 | 下面所述几种 OLAP 操作,是针对 Kimball 的星型模型(Star Schema)和雪花模型(Snowflake Schema)来说的。在 Kimball 模型中,定义了事实和维度。
6 |
7 | - 上卷(Roll Up)/聚合:选定某些维度,根据这些维度来聚合事实,如果用 SQL 来表达就是 select dim_a, aggs_func(fact_b) from fact_table group by dim_a.
8 | - 下钻(Drill Down):上卷和下钻是相反的操作。它是选定某些维度,将这些维度拆解出小的维度(如年拆解为月,省份拆解为城市),之后聚合事实。
9 | - 切片(Slicing、Dicing):选定某些维度,并根据特定值过滤这些维度的值,将原来的大 Cube 切成小 cube。如 dim_a in ('CN', 'USA')
10 | - 旋转(Pivot/Rotate):维度位置的互换。
11 |
12 | 
13 |
--------------------------------------------------------------------------------
/99~参考资料/《Designing Data-Intensive Application》/原书翻译/01~数据系统基础/README.md:
--------------------------------------------------------------------------------
1 | # [第一部分:数据系统基础](https://vonng.github.io/ddia/#/part-i?id=第一部分:数据系统基础)
2 |
3 | 本书前四章介绍了数据系统底层的基础概念,无论是在单台机器上运行的单点数据系统,还是分布在多台机器上的分布式数据系统都适用。
4 |
5 | 1. [第一章](https://vonng.github.io/ddia/#/ch1) 将介绍本书使用的术语和方法。**可靠性,可伸缩性和可维护性** ,这些词汇到底意味着什么?如何实现这些目标?
6 | 2. [第二章](https://vonng.github.io/ddia/#/ch2) 将对几种不同的 **数据模型和查询语言** 进行比较。从程序员的角度看,这是数据库之间最明显的区别。不同的数据模型适用于不同的应用场景。
7 | 3. [第三章](https://vonng.github.io/ddia/#/ch3) 将深入 **存储引擎** 内部,研究数据库如何在磁盘上摆放数据。不同的存储引擎针对不同的负载进行优化,选择合适的存储引擎对系统性能有巨大影响。
8 | 4. [第四章](https://vonng.github.io/ddia/#/ch4) 将对几种不同的 **数据编码** 进行比较。特别研究了这些格式在应用需求经常变化、模式需要随时间演变的环境中表现如何。
9 |
10 | 第二部分将专门讨论在 **分布式数据系统** 中特有的问题。
11 |
--------------------------------------------------------------------------------
/03~数仓建模/03~数仓搭建流程/02~事实表设计/README.md:
--------------------------------------------------------------------------------
1 | ## 事实表
2 |
3 | 事实表产生于业务过程,存储了业务活动或事件提炼出来的性能度量。从最低的粒度级别来看,事实表的一个行对应一个度量事件。
4 |
5 | 事实表根据粒度的角色划分,可分为 事务事实表、周期快照事实表、累计快照事实表。
6 |
7 | > 需要注意的是,同一张表里的粒度必须相同,以上三种表不能混用。
8 |
9 | 1. **事务事实表**
10 |
11 | 用于承载事务数据,通常粒度比较低。它是面向事务的,其粒度是每一行对应一个事务,它是最细粒度的事实表。例如商品交易事实表、用户充值事实表。
12 |
13 | 2. **周期快照事实表**
14 |
15 | 按照一定的时间周期间隔来捕捉业务活动的执行情况。两个关键字:`周期`、`快照`,简单说就是粒度比较粗事务事实表的定期快照。一旦装入事实表就不会再更新,它是事务事实表的补充。用来记录有规律、固定时间间隔的业务累计数据,通常粒度比较高。例如账户的月平均余额事实表、年商品销售额。
16 |
17 | 3. **累计快照事实表**
18 |
19 | 累积快照事实表和周期快照事实表有些相似之处,它们存储的都是事务数据的快照信息。但是它们之间也有着很大的不同,周期快照事实表记录的确定的周期的数据,而累积快照事实表记录的不确定的周期的数据。
20 |
21 | 累积快照事实表记录的是完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点,一个生命周期对应一行。另外,它还会有一个用于指示最后更新日期的附加日期字段。由于事实表中许多日期在首次加载时是不知道的,所以必须使用代理关键字来处理未定义的日期,而且这类事实表在数据加载完后,是可以对它进行更新的,来补充随后知道的日期信息。
22 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/README.md:
--------------------------------------------------------------------------------
1 | # 多维数据模型
2 |
3 | 在 OLAP 中,我们通常会通过 Schema 来定义一个多维数据库,它是一个逻辑概念上的模型,其中包含 Cube(立方体)、Dimension(维度)、Hierarchy(层次)、Level(级别)、Measure(度量),这些被映射到数据库物理模型。
4 |
5 | - Cube(立方体)是一系列 Dimension 和 Measure 的集合区域,它们共用一个事实表。
6 |
7 | - Dimension(维度)是一个 Hierarchy 的集合,维度一般有其相对应的维度表,它由 Hierarchy(层次)组成,而 Hierarchy(层次)又是由组成 Level(级别)的。
8 |
9 | - Hierarchy(层次)是指定维度的层级关系的,如果没有指定,默认 Hierarchy 里面装的是来自立方体中的真实表。
10 |
11 | - Level(级别)是 Hierarchy 的组成部分,使用它可以构成一个结构树,Level 的先后顺序决定了 Level 在结构树上的位置,最顶层的 Level 位于树的第一级,依次类推。
12 |
13 | - Measure(度量)是我们要进行度量计算的数值,支持的操作有 sum、count、avg、distinct-count、max、min 等。
14 |
15 | 概括总结一下:在多维分析中,关注的内容通常被称为度量(Measure),而把限制条件称为维度(Dimension)。多维分析就是对同时满足多种限制条件的所有度量值做汇总统计。包含度量值的表被称为事实表(Fact Table),描述维度具体信息的表被称为维表(Dimension Table),同时有一点需要注意:并不是所有的维度都要有维表,对于取值简单的维度,可以直接使用事实表中的一列作为维度展示。
16 |
--------------------------------------------------------------------------------
/10~OLAP/10.实践案例/2021-贝壳 OLAP 平台架构演进.md:
--------------------------------------------------------------------------------
1 | # Links
2 |
3 | - https://sctrack.sendcloud.net/track/click/eyJuZXRlYXNlIjogImZhbHNlIiwgIm1haWxsaXN0X2lkIjogMCwgInRhc2tfaWQiOiAiIiwgImVtYWlsX2lkIjogIjE2MTkxNzY0NzU4NDJfMTg3XzYwNDA0XzY2MDAuc2MtMTBfOV82XzE4MS1pbmJvdW5kMCQzODQ5MjQ1NTJAcXEuY29tIiwgInNpZ24iOiAiZjhkNjJjZTU3NDI0ZjhhMGRkYzE0MDBkNTBkNTFjNmMiLCAidXNlcl9oZWFkZXJzIjoge30sICJsYWJlbCI6ICI2MTkyMDMwIiwgInRyYWNrX2RvbWFpbiI6ICJzY3RyYWNrLnNlbmRjbG91ZC5uZXQiLCAicmVhbF90eXBlIjogIiIsICJsaW5rIjogImh0dHBzJTNBLy92aXAubWFub25nLmlvL2JvdW5jZSUzRm5pZCUzRDUwJTI2YWlkJTNEMjA3MSUyNnVybCUzRGh0dHBzJTI1M0ElMjUyRiUyNTJGdG91dGlhby5pbyUyNTJGayUyNTJGaTJsNm1tMCUyNm4lM0RNVE15Ljcwa3lyQmNnSXU4c0lkeWdYMThFWFFkUkVhSSIsICJvdXRfaXAiOiAiMTA2Ljc1LjguODkiLCAiY29udGVudF90eXBlIjogIjAiLCAidXNlcl9pZCI6IDE4NywgIm92ZXJzZWFzIjogImZhbHNlIiwgImNhdGVnb3J5X2lkIjogNjAzNDl9.html 贝壳 OLAP 平台架构演进
--------------------------------------------------------------------------------
/03~数仓建模/03~数仓搭建流程/03~维度表设计/README.md:
--------------------------------------------------------------------------------
1 | ## 维度表
2 |
3 | 维度表可以看成是用户用来分析一个事实的窗口,它里面的数据应该是对事实的各个方面描述,比如时间维度表,它里面的数据就是一些日,周,月,季,年,日期等数据,维度表只能是事实表的一个分析角度。
4 |
5 | #### 维度表的设计步骤
6 |
7 | 1. 完成维度的初步定义,并保证维度的一致性。
8 | 2. 确定主维表(中心事实表)。此处的主维表通常是数据引入层(ODS)表,直接与业务系统同步。例如,s_auction 是与前台商品中心系统同步的商品表,此表即是主维表。
9 | 3. 确定相关维表。数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。根据对业务的梳理,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以商品维度为例,根据对业务逻辑的梳理,可以得到商品与类目、卖家、店铺等维度存在关联关系。
10 | 4. 确定维度属性,主要包括两个阶段。第一个阶段是从主维表中选择维度属性或生成新的维度属性;第二个阶段是从相关维表中选择维度属性或生成新的维度属性。以商品维度为例,从主维表(s_auction)和类目、卖家、店铺等相关维表中选择维度属性或生成新的维度属性。
11 |
12 | 维度表常涉及到两种概念:`退化维度`和`缓慢变化维度`
13 |
14 | 1. **退化维度**
15 |
16 | 退化维度不是维度,它表示一种针对维度展现的方法。在实际开发中,经常遇到在一些事实表频繁使用的维度,比如订单表中的用户信息、商品信息。为了使用方便,这些维度信息便可以直接放到事实表中,毕竟对于目前大数据来讲,存储成本还是很低的,这种设计就称为退化维度。
17 |
18 | 2. **缓慢变化维**
19 |
20 | 维度并不是保持不变,它会随着业务的发展而发生改动。这种随着时间发生变化的维度称为缓慢变化维。
21 |
--------------------------------------------------------------------------------
/01~大数据体系/01~大数据生态/大数据生态圈.md:
--------------------------------------------------------------------------------
1 | # 大数据与其他技术
2 |
3 | # 云计算
4 |
5 | 说到这里,我们要回答一个很多人心里都存在的疑惑——大数据和云计算之间,到底有什么关系?
6 | 可以这么解释:数据本身是一种资产,而云计算,则是为挖掘资产价值提供合适的工具。
7 |
8 | 从技术上,大数据是依赖于云计算的。云计算里面的海量数据存储技术、海量数据管理技术、分布式计算模型等,都是大数据技术的基础。
9 |
10 | 云计算就像是挖掘机,大数据就是矿山。如果没有云计算,大数据的价值就发挥不出来。
11 |
12 | 相反的,大数据的处理需求,也刺激了云计算相关技术的发展和落地。
13 |
14 | 也就是说,如果没有大数据这座矿山,云计算这个挖掘机,很多强悍的功能都发展不起来。
15 |
16 | 套用一句老话——云计算和大数据,两者是相辅相成的。
17 |
18 | # 大数据与物联网
19 |
20 | 第二个问题,大数据和物联网有什么关系?
21 |
22 | 这个问题我觉得大家应该能够很快想明白,前面其实也提到了。
23 |
24 | 物联网就是“物与物互相连接的互联网”。物联网的感知层,产生了海量的数据,将会极大地促进大数据的发展。
25 |
26 | 同样,大数据应用也发挥了物联网的价值,反向刺激了物联网的使用需求。越来越多的企业,发觉能够通过物联网大数据获得价值,就会愿意投资建设物联网。
27 |
28 | 其实这个问题也可以进一步延伸为“大数据和 5G 之间的关系”。
29 |
30 | 即将到来的 5G,通过提升连接速率,提升了“人联网”的感知,也促进了人类主动创造数据。
31 |
32 | 另一方面,它更多是为“物联网”服务的。包括低延时、海量终端连接等,都是物联网场景的需求。
33 |
34 | 5G 刺激物联网的发展,而物联网刺激大数据的发展。所有通信基础设施的强大,都是为大数据崛起铺平道路。
35 |
--------------------------------------------------------------------------------
/01~大数据体系/02~数据治理原则/数据零散化.md:
--------------------------------------------------------------------------------
1 | # 数据离散化
2 |
3 | 数据资源平台(数据中台)作为城市大脑一部分,起着业务数据底座的重要作用,在整个城市大脑中,数据资源平台处于一个相对较底层的位置,需要为上层业务提供了有力的数据、算法、数据服务等支撑。数据资源平台包含工具平台、内容平台两大部分,其中最核心的部分是数据内容了数据资源平台(数据中台)作为城市大脑一部分,起着业务数据底座的重要作用,在整个城市大脑中,数据资源平台处于一个相对较底层的位置,需要为上层业务提供了有力的数据、算法、数据服务等支撑。数据资源平台包含工具平台、内容平台两大部分,其中最核心的部分是数据内容。在梳理数据层过程中,我们可能的困难是:
4 |
5 | 1、数据多而广,数据散落,城市底数不清晰。
6 |
7 | 政府数据涉及的面很广,量很大,但是无法直观的讲清楚到底有哪些数据,条目情况,数据更新情况。没有一个清晰的数据资产盘点,就无法有效的使用数据。市里面没用数据清单,数据散落在各个业务系统,也没有人清楚业务系统的数据,业务人员只管用系统,数据摸底十分困难。
8 |
9 | 2、数据共享错综复杂,未融合。
10 |
11 | 政务领域的数据共享情况,一般有两类,一是基于政务畅通工程的共享,将部分重要的数据表项在畅通工程中进行编目,并提供基于库表交换的共享,本质上按需分发式的共享。二是委办局间的点对点共享,由需求方和供给方自行协商数据的交换共享。这两种方式共同的问题是数据共享的广度和深度都不够,数据也未经过整理融合,是浅层次的数据共享。
12 |
13 | 3、多部门数据有冲突的情况。
14 |
15 | 不同的委办局间,因为业务侧重点、数据采集时效、数据口径不同等种种原因,存在着数据相互打架的情况,如个人的家庭住址的信息,在公安、人社、民政等口子的数据存在登记地址不一致的情况。
16 |
17 | # Links
18 |
19 | - https://parg.co/hPH
20 |
--------------------------------------------------------------------------------
/02~数据集成/ETL/README.md:
--------------------------------------------------------------------------------
1 | # ETL
2 |
3 | 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心。服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数据库集群来支撑不断增长的业务需要。以应用为中心的数据持久化架构,在带来可伸缩性好处的同时,也给数据的融合计算带来了障碍。
4 |
5 | 由于数据散落在不同的数据库、消息队列、文件系统中,计算平台如果直接访问这些数据,会遇到可访问性和数据传输延迟等问题。在一些场景下,计算平台直接访问应用系统数据库会对系统吞吐造成显著影响,通常也是不被允许的。因此,在进行跨应用的数据融合计算时,首先需要将数据从孤立的数据源中采集出来,汇集到可被计算平台高效访问的目的地,此过程被称为 ETL,即数据的抽取(Extract)、转换(Transform)和加载(Load)。
6 |
7 | # 离线 ETL 与实时 ETL
8 |
9 | 该领域的传统公司,例如 Informatica,早在 1993 年就已经成立,并且提供了成熟的商业化解决方案。开源工具,例如 Kettle、DataX 等,在很多企业中也得到了广泛的应用。传统上,ETL 是通过批量作业完成的。即定期从数据源加载(增量)数据,按照转换逻辑进行处理,并写入目的地。根据业务需要和计算能力的不同,批量处理的延时通常从天到分钟级不等。在一些应用场景下,例如电子商务网站的商品索引更新,ETL 需要尽可能短的延迟,这就出现了实时 ETL 的需求。
10 |
11 | 在实时 ETL 中,数据源和数据目的地之间仿佛由管道连接在一起。数据从源端产生后,以极低的延迟被采集、加工,并写入目的地,整个过程没有明显的处理批次边界,因此实时 ETL 又被称为 Data Pipeline 模式。
12 |
13 | 
14 |
--------------------------------------------------------------------------------
/04~数据可视化/数据与图表类别/柱状比较类.md:
--------------------------------------------------------------------------------
1 | # 柱状比较类图表
2 |
3 | # Bullet Graph | 子弹图
4 |
5 | 
6 |
7 | 子弹图的样子很像子弹射出后带出的轨道,所以称为子弹图。子弹图的发明是为了取代仪表盘上常见的那种里程表,时速表等基于圆形的信息表达方式。子弹图的特点如下:
8 |
9 | - 每一个单元的子弹图只能显示单一的数据信息源
10 | - 通过添加合理的度量标尺可以显示更精确的阶段性数据信息
11 | - 通过优化设计还能够用于表达多项同类数据的对比
12 | - 可以表达一项数据与不同目标的校对结果
13 |
14 | 子弹图无修饰的线性表达方式使我们能够在狭小的空间中表达丰富的数据信息,线性的信息表达方式与我们习以为常的文字阅读相似,相对于圆形构图的信息表达,在信息传递上有更大的效能优势。
15 |
16 | 
17 |
18 | 下图是一个模拟商铺一段时间内的经营情况的数据,一共 5 条数据,分别代表收入(单位:千美元)、利率(单位:%)、平均成交额(单位:美元)、新客户(单位:个)和满意度(1-5)五个方面,每个方面都有代表好、中、差的 3 个范围和预先设定的目标。
19 |
20 | | title | ranges | actual | target | subtitle |
21 | | ------- | ------------- | ------ | ------ | ------------------ |
22 | | Revenue | [150,225,300] | 270 | 250 | US\$, in thousands |
23 | | ... | ... | ... | ... | ... |
24 |
25 | 
26 |
--------------------------------------------------------------------------------
/02~数据集成/DataPipeline/一致性语义.md:
--------------------------------------------------------------------------------
1 | # 一致性语义
2 |
3 | 批量同步需要以一种事务性的方式完成同步,无论是同步一整块的历史数据,还是同步某一天的增量,该部分数据到目的地,必须是以事务性的方式出现的。而不是在同步一半时,数据就已经在目的地出现了,这可能会影响下游的一些计算逻辑。并且作为一个数据融合产品,当用户在使用 DataPipeline 时,通常需要将存量数据同步完,后面紧接着去接增量。然后存量与增量之间需要进行一个无缝切换,中间的数据不要丢、也不要多。
4 |
5 | DataPipeline 作为一个产品,在客户的环境中,我们无法对客户数据本身的特性提出强制要求。我们不能要求客户数据一定要有主键或者有唯一性的索引。所以在不同场景下,对于一致性语义保证,用户的要求也不一样的:比如在有主键的场景下,一般我们做到至少有一次就够了,因为在下游如果对方也是一个类似于关系型数据库这样的目的地,其本身就有去重能力,不需要在过程中间做一个强一致的保证。但是,如果其本身没有主键,或者其下游是一个文件系统,如果不在过程中间做额外的一致性保证,就有可能在目的地产生多余的数据,这部分数据对于下游可能会造成非常严重的影响。
6 |
7 | # 数据一致性的链路视角
8 |
9 | - 在源端做一个一致性抽取,即当数据从通过数据连接器写入到 MQ 时,和与其对应的 offset 必须是以事务方式进入 MQ 的。
10 |
11 | - 一致性处理,譬如 Flink 提供了一个端到端一致性处理的能力,它是内部通过 checkpoint 机制,并结合 Sink 端的二阶段提交协议,实现从数据读取处理到写入的一个端到端事务一致性。其它框架,例如 Spark Streaming 和 Kafka Streams 也有各自的机制来实现一致性处理。
12 |
13 | - 一致性写入,在 MQ 模式下,一致性写入,即 consumer offset 跟实际的数据写入目的时,必须是同时持久化的,要么全都成功,要么全部失败。
14 |
15 | - 一致性衔接,在 DataPipeline 的产品应用中,历史数据与实时数据的传输有时需要在一个任务中共同完成。所以产品本身需要有这种一致性衔接的能力,即历史数据和流式数据,必须能够在一个任务中,由程序自动完成它们之间的切换。
16 |
17 | # Links
18 |
19 | - https://mp.weixin.qq.com/s/Ws0hy3XY6Bry4AmsMBjOiw
20 |
--------------------------------------------------------------------------------
/03~数仓建模/01~Kimball 与 Inmon/README.md:
--------------------------------------------------------------------------------
1 | # Kimball 与 Inmon
2 |
3 | Kimball 和 Inmon 是两种主流的数据仓库方法论,分别由 Ralph Kimbal 大神 和 Bill Inmon 大神提出,在实际数据仓库建设中,业界往往会相互借鉴使用两种开发模式。本文将详细介绍 Kimball 和 Inmon 理论在实际数据仓库建设中的应用与对比,通过数据仓库理论武装数据仓库实践。
4 |
5 | # Kimball
6 |
7 | Kimball 模式从流程上看是是自底向上的,即从数据集市到数据仓库再到数据源(先有数据集市再有数据仓库)的一种敏捷开发方法。对于 Kimball 模式,数据源往往是给定的若干个数据库表,数据较为稳定但是数据之间的关联关系比较复杂,需要从这些 OLTP 中产生的事务型数据结构抽取出分析型数据结构,再放入数据集市中方便下一步的 BI 与决策支持。
8 |
9 | 通常,Kimball 都是以最终任务为导向。首先,在得到数据后需要先做数据的探索,尝试将数据按照目标先拆分出不同的表需求。其次,在明确数据依赖后将各个任务再通过 ETL 由 Stage 层转化到 DM 层。这里 DM 层数据则由若干个事实表和维度表组成。接着,在完成 DM 层的事实表维度表拆分后,数据集市一方面可以直接向 BI 环节输出数据了,另一方面可以先 DW 层输出数据,方便后续的多维分析。
10 |
11 | Kimball 往往意味着快速交付、敏捷迭代,不会对数据仓库架构做过多复杂的设计,在变换莫测的互联网行业,这种架构方式逐渐成为一种主流范式。
12 |
13 | # Inmon
14 |
15 | Inmon 模式从流程上看是自顶向下的,即从数据源到数据仓库再到数据集市的(先有数据仓库再有数据市场)一种瀑布流开发方法。对于 Inmon 模式,数据源往往是异构的,比如从自行定义的爬虫数据就是较为典型的一种,数据源是根据最终目标自行定制的。这里主要的数据处理工作集中在对异构数据的清洗,包括数据类型检验,数据值范围检验以及其他一些复杂规则。在这种场景下,数据无法从 stage 层直接输出到 dm 层,必须先通过 ETL 将数据的格式清洗后放入 dw 层,再从 dw 层选择需要的数据组合输出到 dm 层。在 Inmon 模式中,并不强调事实表和维度表的概念,因为数据源变化的可能性较大,需要更加强调数据的清洗工作,从中抽取实体-关系。
16 |
17 | 通常,Inmon 都是以数据源头为导向。首先,需要探索性地去获取尽量符合预期的数据,尝试将数据按照预期划分为不同的表需求。其次,明确数据的清洗规则后将各个任务通过 ETL 由 Stage 层转化到 DW 层,这里 DW 层通常涉及到较多的 UDF 开发,将数据抽象为实体-关系模型。接着,在完成 DW 的数据治理之后,可以将数据输出到数据集市中做基本的数据组合。最后,将数据集市中的数据输出到 BI 系统中去辅助具体业务。
18 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/03~数据立方体/README.md:
--------------------------------------------------------------------------------
1 | # Data Cube
2 |
3 | 数据仓库的另一个值得一提的是物化汇总。如前所述,数据仓库查询通常涉及一个聚合函数,如 SQL 中的 COUNT,SUM,AVG,MIN 或 MAX。如果相同的聚合被许多不同的查询使用,那么每次都可以通过原始数据来处理。为什么不缓存一些查询使用最频繁的计数或总和?创建这种缓存的一种方式是物化视图。在关系数据模型中,它通常被定义为一个标准(虚拟)视图:一个类似于表的对象,其内容是一些查询的结果。不同的是,物化视图是查询结果的实际副本,写入磁盘,而虚拟视图只是写入查询的捷径。从虚拟视图读取时,SQL 引擎会将其展开到视图的底层查询中,然后处理展开的查询。
4 |
5 | 当底层数据发生变化时,物化视图需要更新,因为它是数据的非规范化副本。数据库可以自动完成,但是这样的更新使得写入成本更高,这就是在 OLTP 数据库中不经常使用物化视图的原因。在读取繁重的数据仓库中,它们可能更有意义(不管它们是否实际上改善了读取性能取决于个别情况)。
6 |
7 | 物化视图的常见特例称为数据立方体或 OLAP 立方。它是按不同维度分组的聚合网格。Data Cube 的直观理解,即是对于数据不同维度组合而成的某个指标。
8 |
9 | 
10 |
11 | 想象一下,现在每个事实都只有两个维度表的外键:在图中,这些是日期和产品。您现在可以绘制一个二维表格,一个轴线上的日期和另一个轴上的产品。每个单元包含具有该日期 - 产品组合的所有事实的属性(例如,net_price)的聚集(例如,SUM)。然后,您可以沿着每行或每列应用相同的汇总,并获得一个维度减少的汇总(按产品的销售额,无论日期,还是按日期销售,无论产品如何)。
12 |
13 | 一般来说,事实往往有两个以上的维度,譬如:日期,产品,商店,促销和客户。要想象一个五维超立方体是什么样子是很困难的,但是原理是一样的:每个单元格都包含特定日期(产品-商店-促销-客户)组合的销售。这些值可以在每个维度上重复概括。
14 |
15 | 物化数据立方体的优点是某些查询变得非常快,因为它们已经被有效地预先计算了。例如,如果您想知道每个商店的总销售额,则只需查看合适维度的总计,无需扫描数百万行。
16 |
17 | 缺点是数据立方体不具有查询原始数据的灵活性。例如,没有办法计算哪个销售比例来自成本超过 100 美元的项目,因为价格不是其中的一个维度。因此,大多数数据仓库试图保留尽可能多的原始数据,并将聚合数据(如数据立方体)仅用作某些查询的性能提升。
18 |
19 | # 指标
20 |
21 | 某个指标包含三个部分:时间修饰、维度(Dimension)以及原子词/度量(Measure)。
22 |
23 | 
24 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Ignore all
2 | *
3 |
4 | # Unignore all with extensions
5 | !*.*
6 |
7 | # Unignore all dirs
8 | !*/
9 |
10 | .DS_Store
11 |
12 | # Logs
13 | logs
14 | *.log
15 | npm-debug.log*
16 | yarn-debug.log*
17 | yarn-error.log*
18 |
19 | # Runtime data
20 | pids
21 | *.pid
22 | *.seed
23 | *.pid.lock
24 |
25 | # Directory for instrumented libs generated by jscoverage/JSCover
26 | lib-cov
27 |
28 | # Coverage directory used by tools like istanbul
29 | coverage
30 |
31 | # nyc test coverage
32 | .nyc_output
33 |
34 | # Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
35 | .grunt
36 |
37 | # Bower dependency directory (https://bower.io/)
38 | bower_components
39 |
40 | # node-waf configuration
41 | .lock-wscript
42 |
43 | # Compiled binary addons (https://nodejs.org/api/addons.html)
44 | build/Release
45 |
46 | # Dependency directories
47 | node_modules/
48 | jspm_packages/
49 |
50 | # TypeScript v1 declaration files
51 | typings/
52 |
53 | # Optional npm cache directory
54 | .npm
55 |
56 | # Optional eslint cache
57 | .eslintcache
58 |
59 | # Optional REPL history
60 | .node_repl_history
61 |
62 | # Output of 'npm pack'
63 | *.tgz
64 |
65 | # Yarn Integrity file
66 | .yarn-integrity
67 |
68 | # dotenv environment variables file
69 | .env
70 |
71 | # next.js build output
72 | .next
73 |
--------------------------------------------------------------------------------
/10~OLAP/01.引擎架构/01.MPP/README.md:
--------------------------------------------------------------------------------
1 | # MPP
2 |
3 | 数仓构建包括模型定义和预计算两部分,数据工程师根据业务分析需要,使用星型或雪花模型设计数据仓库结构,利用数据仓库中间件完成模型构建和更新。一个普遍的共识是,没有一个 OLAP 引擎能同时在数据量,灵活性和性能这三个方面做到完美,用户需要基于自己的需求进行取舍和选型。预计算模式的 OLAP 引擎在查询响应时间上相较于 MPP 引擎(Impala、SparkSQL、Presto 等)有一定优势,但相对限制了灵活性。
4 |
5 | MPP 即大规模并行处理(Massively Parallel Processor)。在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据 库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
6 |
7 | 
8 |
9 | ## 案例
10 |
11 | - Greenplum 是一种基于 PostgreSQL 的分布式数据库。其采用 shared nothing 架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享。也就是每个节点都是一个单独的数据库。节点之间的信息交互是通过节点互联网络实现。通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。这个就像是把小数据库组织起来,联合成一个大型数据库。将数据分片,存储在每个节点上。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
12 |
13 | - ElasticSearch 也是一种 MPP 架构的数据库,Presto、Impala 等都是 MPP engine,各节点不共享资源,每个 executor 可以独自完成数据的读取和计算,缺点在于怕 stragglers,遇到后整个 engine 的性能下降到该 straggler 的能力,所谓木桶的短板,这也是为什么 MPP 架构不适合异构的机器,要求各节点配置一样。Spark SQL 应该还是算做 Batching Processing, 中间计算结果需要落地到磁盘,所以查询效率没有 MPP 架构的引擎(如 Impala)高。
14 |
15 | ## 预计算/预聚合
16 |
17 | 开源领域,Apache Kylin 是预聚合模式 OLAP 代表,支持从 HIVE、Kafka、HDFS 等数据源加载原始表数据,并通过 Spark/MR 来完成 CUBE 构建和更新。
18 |
19 | Druid 则是另一类预聚合 OLAP 的代表。在 Druid 的表结构模型中,分为时间列、维度列和指标列,允许对任意指标列进行聚合计算而无需定义维度数量。Druid 在数据存储时便可对数据进行聚合操作,这使得其更新延迟可以做到很低。在这些方面,Baidu 开源的 Palo 和 Druid 有类似之处。
20 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/01~事实表、维度表、聚合表/01~事实表.md:
--------------------------------------------------------------------------------
1 | # 事实表
2 |
3 | 每个数据仓库都包含一个或者多个事实数据表。事实数据表可能包含业务销售数据,如现金登记事务。所产生的数据,事实数据表通常包含大量的行。事实数据表的主要特点是包含数字数据(事实),并且这些数字信息可以汇总,以提供有关单位作为历史的数据,每个事实数据表包含一个由多个部分组成的索引,该索引包含作为外键的相关性纬度表的主键,而维度表包含事实记录的特性。事实数据表不应该包含描述性的信息,也不应该包含除数字度量字段及使事实与纬度表中对应项的相关索引字段之外的任何数据。
4 |
5 | 包含在事实数据表中的“度量值”有两中:一种是可以累计的度量值,另一种是非累计的度量值。最有用的度量值是可累计的度量值,其累计起来的数字是非常有意义的。用户可以通过累计度量值获得汇总信息,例如。可以汇总具体时间段内一组商店的特定商品的销售情况。非累计的度量值也可以用于事实数据表,单汇总结果一般是没有意义的,例如,在一座大厦的不同位置测量温度时,如果将大厦中所有不同位置的温度累加是没有意义的,但是求平均值是有意义的。一般来说,一个事实数据表都要和一个或多个纬度表相关联,用户在利用事实数据表创建多维数据集时,可以使用一个或多个维度表。
6 |
7 | 一个按照州、产品和月份划分的销售量和销售额存储的事实表有 5 个列,概念上与下面的示例类似。
8 |
9 | | Sate | Product | Mouth | Units | Dollars |
10 | | ---- | ------------ | -------- | ----- | ------- |
11 | | WA | Mountain-100 | January | 3 | 7.95 |
12 | | WA | Cable Lock | January | 4 | 7.32 |
13 | | OR | Mountain-100 | January | 3 | 7.95 |
14 | | OR | Cable Lock | January | 4 | 7.32 |
15 | | WA | Mountain-100 | February | 16 | 42.40 |
16 |
17 | 在这些事实表的示例数据行中,前 3 个列——州、产品和月份——为键值列。剩下的两个列——销售额和销售量——为度量值。事实表中的每个列通常要么是键值列,要么是度量值列,但也可能包含其他参考目的的列——例如采购订单号或者发票号。事实表中,每个度量值都有一个列。不同事实表将有不同的度量值。一个销售数据仓库可能含有这两个度量值列:销售额和销售量。一个现场信息数据仓库可能包含 3 个度量值列:总量、分钟数和瑕疵数。创建报表时,可以认为度量值形成了一个额外的维度。即可以把销售额和销售量作为并列的列标题,或者也可以把它们作为行标题。然而在事实表中,每个度量值都作为一个单独的列显示。
18 |
19 | 事实表数据行中包含了您想从中获取度量值信息的最底层级别的明细。换句话说,事实表中对每个维度的最详细的项目成员都有数据行。如果有使用其他维度的度量,只要为那些度量和维度创建另一个事实表即可。数据仓库中可能包含拥有不同度量值和维度的不同事实表。
20 |
21 | 事实表前缀为 Fact。
22 |
--------------------------------------------------------------------------------
/01~大数据体系/04~数据中心/README.md:
--------------------------------------------------------------------------------
1 | # 数据中心
2 |
3 | 数据中心是一个数据聚合应用,数据聚合的意思就是聚合来自各个来源的数据对外提供统一的服务,而且需要什么数据由你决定,不多不少,只要把 HSF 服务或者 HTTP 服务接入数据中心,你的服务就可以作为数据中心的一个数据源通过数据聚合的方式对方提供服务,如下图所示:
4 |
5 | 
6 |
7 | 数据中心的定位是面向后端开发,当然也可以对前端提供 HTTP 服务,数据中心也有一些产品和运营在使用,他们经常通过数据中心查询一些基础数据,然后把字段告诉开发完成对接。
8 |
9 | 数据中心的优势是可以让一个不了解各个数据源开发细节的开发,产品甚至运营,直接通过可视化界面,采用勾选配置的方式,自动化直接聚合出灵活多变的业务数据,并支持异构数据源的装配。在业务多变,组织架构多变,数据来源多元的当下,数据中心可以说是一个强刚需的应用,它可以通过实时配置的方式,自动完成不同数据源的数据路由和装配,帮助技术快速响应需求变化,按需获取自己需要的数据,解放开发资源,并且通过数据的智能并行获取和流量控制,多级缓存优化,达到资源和性能的综合优化与利用。
10 |
11 | # 场景分析
12 |
13 | ## 适用场景
14 |
15 | - 数据多样。数据来源多样,你需要的数据来自多个 HSF 或者 Http 服务,这是数据中心的本源,优势就是数据聚合能力,比如会场数据展示就非常建议使用数据中心。
16 |
17 | - 数据拆分。有的数据源考虑到性能问题,会对调用的数据个数进行限制,比如 MKC 的营销接口,一次性最多只能传入 10 个商品 ID,如果数据量比较多的场景直接调用这种接口的话,你需要写数据拆分和多线程并发调用的代码,写起来费时费力,而且不一定有数据中心的写的好,数据中心对这种数据拆分做了很好的支持。
18 |
19 | - DT 数据。DT 都会将数据灌进 oneservice,然后对外提供服务,数据中心底层整合了 oneservice 常用的调用模型,对 oneservice 做了很好的支持,如果有新接入的指标,数据中心只需要增加配置字段,零开发即可直接使用。
20 |
21 | - 流量缓冲。如果你的服务扛不住流量,那么也可以考虑使用数据中心的缓存功能,一个配置即可搞定,有非常多的服务接入数据中心的目的就是用来做流量缓冲的,典型的就是 MKC 的营销活动服务,这个服务本身的流量就很大,面临大促这种场景的突发流量,需要上层进行一个缓冲。
22 |
23 | - 服务降级。这个跟上面的流量缓冲有点类似,但不一样的是,把入口步在数据中心之后,如果服务出现问题,不降级就可能挂掉,那么数据中心可以快速的进行降级,可以从调用方,单机并发量等维度进行快速降级,避免出现雪崩。
24 |
25 | ## 不适用场景
26 |
27 | 数据中心有比较完善的自我保护功能,如果数据源出现问题,会对其进行降级,所以下面几种场景不太适合使用数据中心。
28 |
29 | - RT 敏感。如果不需要数据聚合场景,而且对 RT 要求很高,建议直接调用数据服务,不建议通过数据中心进行一次中转。
30 |
31 | - 不接受降级。数据中心会对慢数据源进行降级,如果数据源不接受降级,或者降级会导致故障,不建议接入数据中心。
32 |
33 | - 交易系统。交易系统不建议使用数据中心,底层数据源出现问题,数据中心的降级很可能导致资损,引发故障。
34 |
35 | - RT 高。RT 高(100ms 以上)的系统接入数据中心,如果长期 RT 很高,一方面数据中心会对其降级,另外也会影响到数据中心的整体性能,所以 RT 比较高的数据源建议进行优化之后再接入。
36 |
--------------------------------------------------------------------------------
/10~OLAP/01.引擎架构/02.建模类型划分/README.md:
--------------------------------------------------------------------------------
1 | # OLAP 分类
2 |
3 | 
4 |
5 | OLAP 是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。主流的 OLAP 可以分为 3 类:多维 OLAP (Multi-dimensional OLAP)、关系型 OLAP(Relational OLAP) 和混合 OLAP(Hybrid OLAP) 三大类。
6 |
7 | ## MOLAP 的优点和缺点
8 |
9 | MOLAP 的典型代表是:Druid,Kylin,Doris,MOLAP 一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query 查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
10 |
11 | MOLAP 的优点和缺点都来自于其数据预处理(pre-processing)环节。数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的即使计算,提升了查询性能。但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)。
12 |
13 | 因此,MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析。
14 |
15 | ## ROLAP 的优点和缺点
16 |
17 | ROLAP 的典型代表是:Presto,Impala,GreenPlum,ClickHouse,Elasticsearch,Hive,Spark SQL,Flink SQL
18 |
19 | 数据写入时,ROLAP 并未使用像 MOLAP 那样的预聚合技术;ROLAP 收到 Query 请求时,会先解析 Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
20 |
21 | ROLAP 不需要进行数据预处理(pre-processing),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构(与 Hadoop 相似的大型并行处理架构,可以通过扩大并发来增加计算资源),可以高效处理大量数据。
22 |
23 | 但是当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发(没有预处理),因此会耗费更多的计算资源,带来潜在的重复计算。
24 |
25 | 因此,ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
26 |
27 | ## HOLAP
28 |
29 | 混合 OLAP,是 MOLAP 和 ROLAP 的一种融合。当查询聚合性数据的时候,使用 MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。
30 |
31 | 顺便提一下,国内外有一些闭源的商业 OLAP 引擎,没有在这里归类和介绍,主要是因为使用的公司不多并且源码不可见、资料少,很难分析学习其中的源码和技术点。在一二线的互联网公司中,应用较为广泛的还是上面提到的各种 OLAP 引擎,如果你希望能够通过掌握一种 OLAP 技术,学习这些就够了。
32 |
--------------------------------------------------------------------------------
/10~OLAP/01.引擎架构/02.建模类型划分/01.MOLAP.md:
--------------------------------------------------------------------------------
1 | # MOLAP
2 |
3 | 这应该算最传统的数仓了,1993 年 olap 概念提出来时,指的就是 MOLAP 数仓,M 即表示多维。大多数 MOLAP 产品均对原始数据进行预计算得到用户可能需要的所有结果,将其存储到优化过的多维数组中,也就是常听到的 数据立方体。
4 |
5 | 由于所有可能结果均已计算出来并持久化存储,查询时无需进行复杂计算,且以数组形式可以进行高效的免索引数据访问,因此用户发起的查询均能够稳定地快速响应。这些结果集是高度结构化的,可以进行压缩/编码来减少存储占用空间。
6 |
7 | 但高性能并不是没有代价的。首先,MOLAP 需要进行预计算,这会花去很多时间。如果每次写入增量数据后均要进行全量预计算,显然是低效率的,因此支持仅对增量数据进行迭代计算非常重要。其次,如果业务发生需求变更,需要进行预定模型之外新的查询操作,现有的 MOLAP 实例就无能为力了,只能重新进行建模和预计算。
8 |
9 | 在开源软件中,由 eBay 开发并贡献给 Apache 基金会的 Kylin 即属于这类 OLAP 引擎,支持在百亿规模的数据集上进行亚秒级查询。
10 |
11 | 下图是官方对 Kylin 的描述。
12 |
13 | 
14 |
15 | #### 代表
16 |
17 | - **Kylin**是完全的预计算引擎,通过枚举所有维度的组合,建立各种 Cube 进行提前聚合,以 HBase 为基础的 OLAP 引擎。
18 | - **Druid**则是轻量级的提前聚合(roll-up),同时根据倒排索引以及 bitmap 提高查询效率的时间序列数据和存储引擎。
19 |
20 | #### 优点
21 |
22 | - **Kylin**
23 |
24 | 1. 支持数据规模超大(HBase)
25 | 2. 易用性强,支持标准 SQL
26 | 3. 性能很高,查询速度很快
27 |
28 | - **Druid**
29 |
30 | 1. 支持的数据规模大(本地存储+DeepStorage–HDFS)
31 | 2. 性能高,列存压缩,预聚合加上倒排索引以及位图索引,秒级查询
32 | 3. 实时性高,可以通过 kafka 实时导入数据
33 |
34 | #### 缺点
35 |
36 | - **Kylin**
37 |
38 | 1. 灵活性较弱,不支持 adhoc 查询;且没有二级索引,过滤时性能一般;不支持 join 以及对数据的更新。
39 | 2. 处理方式复杂,需要定义 Cube 预计算;当维度超过 20 个时,存储可能会爆炸式增长;且无法查询明细数据了;维护复杂。
40 | 3. 实时性很差,很多时候只能查询前一天或几个小时前的数据。
41 |
42 | - **Druid**
43 |
44 | 1. 灵活性适中,虽然维度之间随意组合,但不支持 adhoc 查询,不能自由组合查询,且丢失了明细数据。
45 | 2. 易用性较差,不支持 join,不支持更新,sql 支持很弱(有些插件类似于 pinot 的 PQL 语言),只能 JSON 格式查询;对于去重操作不能精准去重。
46 | 3. 处理方式复杂,需要流处理引擎将数据 join 成宽表,维护相对复杂;对内存要求较高。
47 |
48 | #### 场景
49 |
50 | - **Kylin**:适合对实时数据需求不高,但响应时间较高的查询,且维度较多,需求较为固定的特定查询;而不适合实时性要求高的 adhoc 类查询。
51 | - **Druid**:数据量大,对实时性要求高且响应时间短,以及维度较少且需求固定的简单聚合类查询(sum,count,TopN),多以 Storm 和 Flink 组合进行预处理;而不适合需要 join、update 和支持 SQL 和窗口函数等复杂的 adhoc 查询;不适合用于 SQL 复杂数据分析的场景。
52 |
--------------------------------------------------------------------------------
/10~OLAP/02.MOLAP/Druid/README.md:
--------------------------------------------------------------------------------
1 | # Druid
2 |
3 | Druid 单词来源于西方古罗马的神话人物,中文常常翻译成德鲁伊。Druid 是一个分布式的支持实时分析的数据存储系统(Data Store)。美国广告技术公司 MetaMarkets 于 2011 年创建了 Druid 项目,并且于 2012 年晚期开源了 Druid 项目。Druid 设计之初的想法就是为分析而生,它在处理数据的规模、数据处理的实时性方面,比传统的 OLAP 系统有了显著的性能改进,而且拥抱主流的开源生态,包括 Hadoop 等。多年以来,Druid 一直是非常活跃的开源项目。
4 |
5 | # 背景分析
6 |
7 | ## 设计原则
8 |
9 | 在设计之初,开发人员确定了三个设计原则(Design Principle)。
10 |
11 | - 快速查询(Fast Query):部分数据的聚合(Partial Aggregate)+内存化(In-emory)+索引(Index)。
12 |
13 | - 水平扩展能力(Horizontal Scalability):分布式数据(Distributed Data)+ 并行化查询(Parallelizable Query)。
14 |
15 | - 实时分析(Realtime Analytics):不可变的过去,只追加的未来(Immutable Past,Append-Only Future)。
16 |
17 | ### 快速查询(Fast Query)
18 |
19 | 对于数据分析场景,大部分情况下,我们只关心一定粒度聚合的数据,而非每一行原始数据的细节情况。因此,数据聚合粒度可以是 1 分钟、5 分钟、1 小时或 1 天等。部分数据聚合(Partial Aggregate)给 Druid 争取了很大的性能优化空间。
20 |
21 | 数据内存化也是提高查询速度的杀手锏。内存和硬盘的访问速度相差近百倍,但内存的大小是非常有限的,因此在内存使用方面要精细设计,比如 Druid 里面使用了 Bitmap 和各种压缩技术。
22 |
23 | 另外,为了支持 Drill-Down 某些维度,Druid 维护了一些倒排索引。这种方式可以加快 AND 和 OR 等计算操作。
24 |
25 | ### 水平扩展能力(Horizontal Scalability)
26 |
27 | Druid 查询性能在很大程度上依赖于内存的优化使用。数据可以分布在多个节点的内存中,因此当数据增长的时候,可以通过简单增加机器的方式进行扩容。为了保持平衡,Druid 按照时间范围把聚合数据进行分区处理。对于高基数的维度,只按照时间切分有时候是不够的(Druid 的每个 Segment 不超过 2000 万行),故 Druid 还支持对 Segment 进一步分区。
28 |
29 | 历史 Segment 数据可以保存在深度存储系统中,存储系统可以是本地磁盘、HDFS 或远程的云服务。如果某些节点出现故障,则可借助 Zookeeper 协调其他节点重新构造数据。
30 |
31 | Druid 的查询模块能够感知和处理集群的状态变化,查询总是在有效的集群架构中进行。集群上的查询可以进行灵活的水平扩展。Druid 内置提供了一些容易并行化的聚合操作,例如 Count、Mean、Variance 和其他查询统计。对于一些无法并行化的操作,例如 Median,Druid 暂时不提供支持。在支持直方图(Histogram)方面,Druid 也是通过一些近似计算的方法进行支持,以保证 Druid 整体的查询性能,这些近似计算方法还包括 HyperLoglog、DataSketches 的一些基数计算。
32 |
33 | ### 实时分析(Realtime Analytics)
34 |
35 | Druid 提供了包含基于时间维度数据的存储服务,并且任何一行数据都是历史真实发生的事件,因此在设计之初就约定事件一但进入系统,就不能再改变。
36 |
37 | 对于历史数据 Druid 以 Segment 数据文件的方式组织,并且将它们存储到深度存储系统中,例如文件系统或亚马逊的 S3 等。当需要查询这些数据的时候,Druid 再从深度存储系统中将它们装载到内存供查询使用。
38 |
--------------------------------------------------------------------------------
/01~大数据体系/03~数据组织方式/04~数据中台/README.md:
--------------------------------------------------------------------------------
1 | # 数据中台
2 |
3 | 阿里在 2018 年提出了所谓“数据中台”的概念:即数据被统一采集,规范数据语义和业务口径形成企业基础数据模型,提供统一的分析查询和新业务的数据对接能力。数据中台,是通过获取各类数据,对数据进行分析和挖掘,产出结果和洞察,提供给业务和决策者使用,进而打造创新产品和服务,优化管理推动组织数字化转型。“让数据用起来”,是数据中台终极目标,也是数据中台要为处于不同数据认知成熟度阶段的企业实现一个个具体的目标。企业在业务的快速发展、信息化越来越高前提下追求自身的价值,业务部门不停的提出新的需求和挑战,给普惠数据服务提出了数据服务的按需提供、业务流程化、数据自我治理、统一数据服务、智能化数据运营等特点。
4 |
5 | 数据中台并不是新的颠覆式技术,而是一种企业数据资产管理和应用方法学,涵盖了数据集成、数据质量管理、元数据与主数据管理、数仓建模、支持高并发访问的数据服务接口层开发等内容。
6 |
7 | 在数据中台建设中,结合企业自身的业务需求特点,架构和功能可能各不相同,但其中一个最基本的需求是数据采集的实时性和完整性。数据从源端产生,到被采集到数据汇集层的时间要尽可能短,至少应做到秒级延迟,这样中台的数据模型更新才可能做到近实时,构建在中台之上依赖实时数据流驱动的应用(例如商品推荐、欺诈检测等)才能够满足业务的需求。
8 |
9 | 以阿里双十一为例,在极高的并发情况下,订单产生到大屏统计数据更新延迟不能超过 5s,一般在 2s 内。中台对外提供的数据应该是完整的,源端数据的 Create、Update 和 Delete 都要能够被捕获,不能少也不能多,即数据需要有端到端一致性的能力(Exactly Once Semantic,EOS)。当然,EOS 并非在任何业务场景下都需要,但从平台角度必须具备这种能力,并且允许用户根据业务需求灵活开启和关闭。
10 |
11 | # 数据中台的产生背景
12 |
13 | 起初,企业只有一个主营业务,比如电商,但随着公司战略和发展需要,会新增多支业务线,由于存在负责业务线开发的团队不一致,随之而来的就是风格迥异的代码风格和数据烟囱问题。
14 |
15 | 数据中台的产生就是为了解决数据烟囱的问题,打通数据孤岛,让数据活起来,让数据产生价值,结合前台能力,达到快速响应用户的目标。
16 |
17 | 中台只会同步能服务于超过两个业务线的数据,如果仅仅带有自身业务属性(不存在共性)的数据,不在中台的考虑范围内。例如:电商的产品产地信息,对于金融业务来说,其实是没有价值的,但电商的用户收货地址对金融业务来说是有价值的。所以不要简单的认为数据中台会汇集企业的所有数据,还是有侧重点的。导致这个结果的原因还包括数据中台建设本身是一个长周期的事,如果数据仅仅作用于一方,由业务方(前台)自行开发,更符合敏捷开发的特性。
18 |
19 | 关于何时应该建立数据中台这个问题,我的思考是这样的。复杂的业务线、丰富的数据维度和公司上层领导主推。三者缺一,都没有实行的必要。
20 | 一只手都能数的过来的业务线量,跨多个项目的需求相对还是比较少的,取数也比较方便,直接走接口方式基本就能满足。反而,通过数据中台流转,将问题复杂化了。
21 |
22 | 数据的维度越丰富,数据的价值越大。只知道性别数据,与知道性别和年龄,所得到的用户画像,肯定是维度丰富的准确性高。维度不丰富的情况下,没有计算的价值。
23 |
24 | 可能会很奇怪为什么一定需要公司上层的同意。这里就可能涉及到动了谁的奶酪的问题,数据是每个业务线最重要的资源,在推行中台过程中,势必会遇到阻力,只有成为全公司的战略任务,才有可能把事情做好。
25 |
26 | 中台如果没有考虑通用的业务能力,也会导致无法更专注于对中台技术的深入研究。中台如果不从抽象度、共性等角度出发,很有可能局限于某单一业务,导致中台无法很好地适应其他相关业务的要求,从而不能很好地应对业务的变化。如果中台的抽象程度低、扩展性差,则会导致中台无法满足前台业务需求。这时前台应用又因为业务本身的发展目标和压力不得不自行组织团队完成这部分功能,由此可能发生本应由中台提供的能力却最终实现在业务应用中,失去了中台存在的价值。
27 |
28 | 
29 |
30 | # Links
31 |
32 | - https://www.infoq.cn/article/zCf76o7YlsAN6AbOeQL0
33 |
--------------------------------------------------------------------------------
/01~大数据体系/03~数据组织方式/03~数据湖/README.md:
--------------------------------------------------------------------------------
1 | # 数据湖
2 |
3 | # 为什么需要数据湖?
4 |
5 | 以 Databricks 推出的 delta 为例,它要解决的核心问题基本上集中在下图:
6 |
7 | 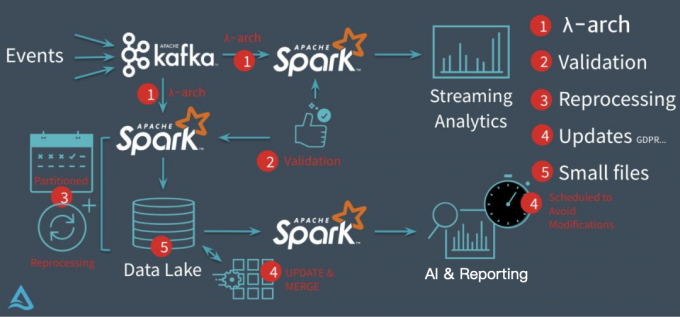
8 |
9 | 在没有 delta 数据湖之前,Databricks 的客户一般会采用经典的 lambda 架构来构建他们的流批处理场景。以用户点击行为分析为例,点击事件经 Kafka 被下游的 Spark Streaming 作业消费,分析处理(业务层面聚合等)后得到一个实时的分析结果,这个实时结果只是当前时间所看到的一个状态,无法反应时间轴上的所有点击事件。所以为了保存全量点击行为,Kafka 还会被另外一个 Spark Batch 作业分析处理,导入到文件系统上(一般就是 parquet 格式写 HDFS 或者 S3,可以认为这个文件系统是一个简配版的数据湖),供下游的 Batch 作业做全量的数据分析以及 AI 处理等。
10 |
11 | 这套方案其实存在很多问题
12 |
13 | 第一、批量导入到文件系统的数据一般都缺乏全局的严格 schema 规范,下游的 Spark 作业做分析时碰到格式混乱的数据会很麻烦,每一个分析作业都要过滤处理错乱缺失的数据,成本较大;
14 |
15 | 第二、数据写入文件系统这个过程没有 ACID 保证,用户可能读到导入中间状态的数据。所以上层的批处理作业为了躲开这个坑,只能调度避开数据导入时间段,可以想象这对业务方是多么不友好;同时也无法保证多次导入的快照版本,例如业务方想读最近 5 次导入的数据版本,其实是做不到的。
16 |
17 | 第三、用户无法高效 upsert/delete 历史数据,parquet 文件一旦写入 HDFS 文件,要想改数据,就只能全量重新写一份的数据,成本很高。事实上,这种需求是广泛存在的,例如由于程序问题,导致错误地写入一些数据到文件系统,现在业务方想要把这些数据纠正过来;线上的 MySQL Binlog 不断地导入 update/delete 增量更新到下游数据湖中;某些数据审查规范要求做强制数据删除,例如欧洲出台的 GDPR 隐私保护等等。
18 |
19 | 第四、频繁地数据导入会在文件系统上产生大量的小文件,导致文件系统不堪重负,尤其是 HDFS 这种对文件数有限制的文件系统。
20 |
21 | ## 数据湖对比
22 |
23 | | 特性 | Table Schema | 抽象程度高,不绑定 Engine | ACID 语义保证,多版本保证 | 廉价存储 | Python 接口支持 | 流批读写 | 快速 CUDR 和 Pull 增量 | 企业级性能优化 |
24 | | ------- | ------------ | ------------------------- | ------------------------- | -------- | --------------- | -------- | ---------------------- | -------------- |
25 | | Delta | 有 | 无 | 有 | 有 | 有 | 有 | 无 | 无 |
26 | | Hudi | 无 | 无 | 有 | 有 | 无 | 有 | 有 | 无 |
27 | | Iceberg | 有 | 有 | 有 | 有 | 有 | 有 | 无 | 有 |
28 |
29 | # Links
30 |
31 | - https://mp.weixin.qq.com/s/Io6fPomYgBb9E3g8ZzDt1Q
32 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/02~星型与雪花模型/99~参考资料/2021-数据仓库系列:星型模型和雪花型模型.md:
--------------------------------------------------------------------------------
1 | # 数据仓库系列:星型模型和雪花型模型
2 |
3 | 数据仓库建模包含了几种数据建模技术,最常用的是:维度建模技术。维度建模的基本概念: 维度建模(dimensional modeling)是专门用于分析型数据库、数据仓库、数据集市建模的方法。它本身属于一种关系建模方法
4 |
5 | - 维度表(dimension):表示对分析主题所属类型的描述。
6 | - 事实表(fact table):表示对分析主题的度量。事实表包含了与各维度表相关联的外键,并通过 JOIN 方式与维度表关联。事实表的度量通常是数值类型,且记录数会不断增加,表规模迅速增长。
7 |
8 | # 1. 星型模型
9 |
10 | ## 1.1 概念
11 |
12 | 星型模型:是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据;如下图:
13 |
14 | 
15 |
16 | 星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,所以数据有一定的冗余
17 |
18 | ## 1.2 示例
19 |
20 | 
21 |
22 | # 2. 雪花型模型
23 |
24 | ## 2.1 概念
25 |
26 | 雪花型模型:是星型模式的变种,其中某些维表是规范化(将冗余字段用新的表来表示)的,因而把数据进一步分解到附加表中,结果,模式图形成类似于雪花的形状。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。
27 |
28 | 
29 |
30 | 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
31 |
32 | ## 2.2 示例
33 |
34 | 
35 |
36 | # 3. 维度模型
37 |
38 | ## 3.1 概念
39 |
40 | - 为了分析方便,将同一维度的不同层次的维度(如地市 ID,区县 ID)都融合到事实表中
41 | - 维度模型也是星型模型
42 | - 强调的是先对维度进行预处理,将多个维度集合到一个事实表(包含了多个维度,这样可以组合各维度,形成灵活的报表查询)
43 |
44 | ## 3.2 示例
45 |
46 | 
47 |
48 | # 4. 星型模型 VS 雪花型模型
49 |
50 | 星型模型和雪花模型的对比,可以从以下四个角度来对比。
51 |
52 | ## 4.1 查询性能角度来看
53 |
54 | 在 OLTP-DW 环节,由于雪花型要做多个表联接,性能会低于星型架构;但从 DW-OLAP 环节,由于雪花型架构更有利于度量值的聚合,因此性能要高于星型架构。
55 |
56 | ## 4.2 模型复杂度角度
57 |
58 | 星型架构更简单方便处理
59 |
60 | ## 4.3 层次结构角度
61 |
62 | 雪花型架构更加贴近 OLTP 系统的结构,比较符合业务逻辑,层次比较清晰。
63 |
64 | ## 4.4 存储角度
65 |
66 | 雪花型架构具有关系数据模型的所有优点,不会产生冗余数据,而相比之下星型架构会产生数据冗余。
67 |
68 | # 5 总结
69 |
70 | 根据项目经验,一般建议使用星型模型。因为在实际项目中,往往最关注的是查询性能问题,至于磁盘空间一般都不是问题。当然,在维度表数据量极大,需要节省存储空间的情况下,或者是业务逻辑比较复杂、必须要体现清晰的层次概念情况下,可以使用雪花型模型。
71 |
--------------------------------------------------------------------------------
/10~OLAP/03.ROLAP/Presto/部署与控制.md:
--------------------------------------------------------------------------------
1 | # Presto
2 |
3 | Facebook 拥有世界上最大的数据仓库之一,这些数据被一系列不同种类的程序所使用,包括传统的数据批处理程序、基于图论的数据分析、机器学习、和实时性的数据分析。在以前,Facebook 的科学家和分析师一直依靠 Hive 来做数据分析。但 Hive 使用 MapReduce 作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用 Hive 进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。Facebook 也调研了其他比 Hive 更快的工具,但它们要么在功能有所限制要么就太简单,以至于无法操作 Facebook 庞大的数据仓库。2012 年开始试用的一些外部项目都不合适,他们决定自己开发,这就是 Presto,2013 年 Facebook 正式宣布开源 Presto。
4 |
5 | 
6 |
7 | Presto 主要以 Java 开发,被设计为用来专门进行高速、实时的数据分析。它支持标准的 ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。在支持基础的对于 HDFS 的查询之外,Presto 还支持对于异构数据库的查询,建立统一的抽象屏蔽层,保证了用户以通用的 SQL 语法能够忽略底层数据库差异进行统一查询。
8 |
9 | 
10 |
11 | ## 架构
12 |
13 | 
14 | Presto 查询引擎是一个 Master-Slave 的架构,由一个 Coordinator 节点,一个 Discovery Server 节点,多个 Worker 节点组成,Discovery Server 通常内嵌于 Coordinator 节点中。Coordinator 负责解析 SQL 语句,生成执行计划,分发执行任务给 Worker 节点执行。Worker 节点负责实际执行查询任务。Worker 节点启动后向 Discovery Server 服务注册,Coordinator 从 Discovery Server 获得可以正常工作的 Worker 节点。如果配置了 Hive Connector,需要配置一个 Hive MetaStore 服务为 Presto 提供 Hive 元信息,Worker 节点与 HDFS 交互读取数据。
15 |
16 | 
17 |
18 | Presto 的运行模型和 Hive 或 MapReduce 有着本质的区别。Hive 将查询翻译成多阶段的 MapReduce 任务,一个接着一个地运行。每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然而 Presto 引擎没有使用 MapReduce。为支持 SQL 语法,它实现了一个定制的查询、执行引擎和操作符。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的时候就会将数据从一个处理段传入到下一个处理段。这样的方式会大大的减少各种查询的端到端延迟。Presto 动态编译部分查询计划为字节码,使得 JVM 能够优化并生成本地机器码。在扩展性方面,Presto 只设计了一种简单的存储抽象,使得能够在多种数据源上进行 SQL 查询。连接器只需要提供获取元数据的接口,获得数据地址后自动访问数据。
19 |
20 | 
21 |
22 | # 部署
23 |
24 | ## 安装
25 |
26 | ## 环境配置
27 |
28 | ### 节点属性
29 |
30 | ### JVM
31 |
32 | ### 日志
33 |
34 | ## 连接配置
35 |
36 | ## 运行
37 |
38 | # 交互
39 |
40 | ## 命令行
41 |
42 | ## JDBC Driver
43 |
44 | # WebUI
45 |
--------------------------------------------------------------------------------
/01~大数据体系/01~大数据生态/README.md:
--------------------------------------------------------------------------------
1 | # 大数据
2 |
3 | 大数据时代始于 ApacheHadoop 在 2006 年的亮相,开发人员和架构师将此工具视为有助于处理和存储多结构化数据和半结构化数据。企业在数据方面的理念发生了根本性转变,并不仅限于传统企业数据库的 ACID(原子性、一致性、隔离性和持久性),导致数据使用场合发生了变化,许多公司意识到以前丢弃或保存在静态归档中的数据实际上有助于了解客户行为、采取行动的倾向、风险因素以及复杂的组织、环境和商业行为。Cloudera 这款商业发行版推出后,Hadoop 的商业价值在 2009 年开始得到确立,MapR、Hortonworks 和 EMC Greenplum(现在的 Pivotal HD)紧随其后。
4 |
5 | # 大数据的定义
6 |
7 | 行业里对大数据的定义有很多,有广义的定义,也有狭义的定义。广义的定义,有点哲学味道——大数据,是指物理世界到数字世界的映射和提炼。通过发现其中的数据特征,从而做出提升效率的决策行为。狭义的定义,是技术工程师给的——大数据,是通过获取、存储、分析,从大容量数据中挖掘价值的一种全新的技术架构。
8 |
9 | 大数据往往是一种手段,而不是一个目标。最早提出“大数据”时代到来的是全球知名咨询公司麦肯锡,麦肯锡称:“数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来。”数据,让一切有迹可循,让一切有源可溯。我们每天都在产生数据,创造大数据和使用大数据,只是,你,仍然浑然不知。企业组织利用相关数据和分析可以帮助它们降低成本、提高效率、开发新产品、做出更明智的业务决策等等。大数据的价值,远远不止于此,大数据对各行各业的渗透,大大推动了社会生产和生活,未来必将产生重大而深远的影响。对海量数据进行存储、计算、分析、挖掘处理需要依赖一系列的大数据技术。然而大数据技术其涉及的技术有分布式计算、高并发处理、高可用处理、集群、实时性计算等,汇集了当前 IT 领域热门流行的技术。
10 |
11 | # 大数据的价值
12 |
13 | 刚才说到价值密度,也就说到了大数据的核心本质,那就是价值。
14 |
15 | 人类提出大数据、研究大数据的主要目的,就是为了挖掘大数据里面的价值。
16 |
17 | 大数据,究竟有什么价值?
18 |
19 | 早在 1980 年,著名未来学家阿尔文·托夫勒在他的著作《第三次浪潮》中,就明确提出:“数据就是财富”,并且,将大数据称为“第三次浪潮的华彩乐章”。
20 |
21 | 第一次浪潮:农业阶段,约 1 万年前开始
22 |
23 | 第二次浪潮:工业阶段,17 世纪末开始
24 |
25 | 第三次浪潮:信息化阶段,20 世纪 50 年代后期开始
26 |
27 | 进入 21 世纪之后,随着前面所说的第二第三阶段的发展,移动互联网崛起,存储能力和云计算能力飞跃,大数据开始落地,也引起了越来越多的重视。
28 |
29 | 2012 年的世界经济论坛指出:“数据已经成为一种新的经济资产类别,就像货币和黄金一样”。这无疑将大数据的价值推到了前所未有的高度层面上。
30 |
31 | 如今,大数据应用开始走进我们的生活,影响我们的衣食住行。
32 |
33 | 之所以大数据会有这么快的发展,就是因为越来越多的行业和企业,开始认识到大数据的价值,开始试图参与挖掘大数据的价值。
34 |
35 | 归纳来说,大数据的价值主要来自于两个方面:
36 |
37 | 1 帮助企业了解用户
38 |
39 | 大数据通过相关性分析,将客户和产品、服务进行关系串联,对用户的偏好进行定位,从而提供更精准、更有导向性的产品和服务,提升销售业绩。
40 |
41 | 典型的例子就是电商。
42 |
43 | 像阿里淘宝这样的电子商务平台,积累了大量的用户购买数据。在早期的时候,这些数据都是累赘和负担,存储它们需要大量的硬件成本。但是,现在这些数据都是阿里最宝贵的财富。
44 |
45 | 通过这些数据,可以分析用户行为,精准定位目标客群的消费特点、品牌偏好、地域分布,从而引导商家的运营管理、品牌定位、推广营销等。
46 |
47 | 大数据可以对业绩产生直接影响。它的效率和准确性,远远超过传统的用户调研。
48 |
49 | 除了电商,包括能源、影视、证券、金融、农业、工业、交通运输、公共事业等,都是大数据的用武之地。
50 |
51 | 2 帮助企业了解自己
52 |
53 | 除了帮助了解用户之外,大数据还能帮助了解自己。
54 |
55 | 企业生产经营需要大量的资源,大数据可以分析和锁定资源的具体情况,例如储量分布和需求趋势。这些资源的可视化,可以帮助企业管理者更直观地了解企业的运作状态,更快地发现问题,及时调整运营策略,降低经营风险。
56 |
57 | 总而言之,“知己知彼,百战百胜”。大数据,就是为决策服务的。
58 |
59 | # Links
60 |
61 | - https://cubox.pro/c/r3NNli 关于大数据的完整讲解
--------------------------------------------------------------------------------
/01~大数据体系/01~大数据生态/大数据的未来.md:
--------------------------------------------------------------------------------
1 | # 大数据的未来
2 |
3 | 随着大数据的消逝,我们进入到了后大数据时代,包括多云时代、机器学习时代以及实时和无处不在的上下文时代。
4 |
5 | - 多云时代恰恰表明日益需要基于现有的各种应用系统跨多云支持应用软件和平台,也日益需要支持持续交付和业务连续性。“某项任务有一个应用软件”这种观念导致了企业中每个员工平均有一个 SaaS 应用软件的业务环境,这意味着每家大企业在为数千个 SaaS 应用软件支持数据和流量。后端容器化这个趋势导致支持按需和峰值使用环境的存储和工作负载环境日益分散化和专业化。
6 |
7 | - 机器学习时代专注于分析模型、算法、模型训练、深度学习以及算法和深度学习技术的伦理。机器学习需要处理创建干净数据供分析所用所需的大量相同工作,但还需要另外的数学、业务和伦理上下文以创建持久的长期价值。
8 |
9 | - 实时和无处不在的上下文恰恰表明,从分析的角度和交互的角度来看,日益需要及时的更新。从分析的角度来看,公司分析处理仅仅每周更新一次或每天更新一次已不够。员工现在需要近乎实时的更新,否则有可能做出糟糕的公司决策,这些决策在制定的那一刻就已过时或落伍了。有效使用实时分析需要广泛的业务数据,以提供适当的整体上下文以及供针对数据按需执行的分析所用。无处不在还表明了交互的兴起,包括物联网提供表明环境和机械活动的更多边缘观察信息,以及仍在发展中的扩展现实(Extended Reality,包括增强现实和虚拟现实)提供身临其境的体验。为了提供这种级别的交互,必须以交互的速度分析数据,可能短至 300-500 毫秒,以提供有效的行为反馈。
10 |
11 | 随着大数据时代走到尽头,我们现在可以少关注收集大量数据的机制,多关注处理、分析海量数据并与之实时交互方面的无数挑战。我们迈入大数据驱动的新时代时,请牢记以下几个概念。
12 |
13 | - 首先,Hadoop 在企业数据界仍占有一席之地。Amalgam Insights 预计,MapR 最终会被一家以管理 IT 软件出名的公司收购,比如 BMC、冠群或 MicroFocus;并认为 Cloudera 已采取了措施,不仅限于企业 Hadoop,以支持数据的下几个时代。但技术的步伐不可阻挡,Cloudera 的问题在于它的行动是否够快、随势而变。Cloudera 在将其企业数据平台完善成下一代洞察力和机器学习平台方面面临数字化转型挑战。过去几十年,公司能够为转型敲定时间表。现在正如我们从亚马逊、Facebook 和微软等公司看到的那样,仅仅为了活命,成功的科技公司必须准备好每十年就要转型,可能甚至牺牲掉自己的部分业务。
14 |
15 | - 其次,对多云分析和数据可视化的需求比以往任何时候都要大。谷歌和 Salesforce 刚斥资 180 亿美元收购了 Looker 和 Tableau,那些收购基本上是针对颇具规模和收入增长的公司的市场价值收购。会投入更多的巨额资金,以克服这一挑战:针对众多数据源提供分析技术,并支持与多云有关的日益分散且多样的存储、计算和集成需求。这意味着企业需要慎重地搞清楚数据集成、数据建模、分析及/或机器学习/数据科学团队可以在多大程度上应对这个挑战,因为处理和分析异构数据变得越来越困难、复杂,但要支持战略业务需求并将数据用作真正的战略优势又势必需要这么做。而仅看国内发展,企业对多云分析和数据可视化的需求也是一样剧增。2006 年成立的国产 BI 软件厂商帆软软件自 2016 年 300 人左右的团队短短三年内成长到现在的 1100 余人,据知为了应对更多的市场需求其团队还在不断扩大。这样的成长速度源自市场需求的增多和帆软对于市场需求走势的判断。
16 |
17 | - 第三,机器学习和数据科学是下一代分析技术,需要各自做好新的数据管理工作。大规模创建测试数据、合成数据和掩蔽数据,以及数据沿袭、治理、参数和超参数定义以及算法假设,这些都超出了传统大数据假设的范畴。这里最重要的考量因素是,使用由于种种原因未能很好地服务于企业的数据:样本量小、缺乏数据源、数据定义不清晰、数据上下文不明确,或者算法和分类假设不准确。换句话说,不使用失实的数据。失实的数据会导致有偏见、不合规、不准确的结果,还可能导致诸多问题:比如 Nick Leeson 在 1995 年导致巴林银行(BaringsBank)垮台,或法国兴业银行因 Jerome Kerviel 精心操纵交易而蒙受 70 亿美元的交易损失。AI 现在是新的潜在“流氓交易者”,需要得到适当的治理、管理和支持。
18 |
19 | - 第四,需要将实时和无处不在的上下文既视为协作和技术上的挑战,又视为数据挑战。我们正进入这样一个世界:每个对象、流程和对话都可以用附加的上下文加以标记、标注或增强,可以实时处理数 GB 的数据,以生成简单的两个单词警报,可能就像“减慢速度”或“立即购买”这么简单。我们看到“数字孪生”(digital twin)这个概念方兴未艾:在工业界,PTC、GE 及其他产品生命周期和制造公司为设备创建数字孪生;而在销售界,Gong、Tact 和 Voicera 等公司借助额外的上下文以数字方式记录、分析和增强模拟对话。
20 |
--------------------------------------------------------------------------------
/01~大数据体系/03~数据组织方式/04~数据中台/数据栈.md:
--------------------------------------------------------------------------------
1 | # 数据栈
2 |
3 | 我们发现,公司处理数据的过程主要分为四个主要阶段,这些阶段与每个阶段数据的外化使用密切相关。
4 |
5 | 
6 |
7 | 上图中的每个垂直阶段都是一个相对的平衡点,可根据您的资源,规模和组织中数据的重要性来进行操作。例如,一个有 20 个人的具有典型数据需求的团队可能会直接在 Source 级别上很好地工作,并且在他们开始感觉到增长的痛苦之前,不希望进入 Lake 阶段。但是,随着该公司的规模超过 200 名员工,并且他们的数据需求不断增长,将其推进到 Mart 的整个过程将具有不可估量的价值,甚至可能是至关重要的。
8 |
9 | ## Sources
10 |
11 | 当您开始使用数据时,可能只有几个感兴趣的来源。早期的两个常见来源是 Google Analytics(分析)和产品所使用的 PostgreSQL 或 MySQL 数据库中的应用程序数据。如果您公司中只有少数几个人需要使用这些资源,则可以将其设置为具有直接访问权限;他们直接直接处理数据会更简单,更灵活。
12 |
13 | 在此早期阶段,您将受益于使用 BI 产品,该产品可让您在需要时编写 SQL,因为您的数据很可能是出于交易目的而构造的,并且通常需要某些复杂查询的全部功能。
14 |
15 | ## Lake
16 |
17 | 当您开始依赖更多的数据源,并且更频繁地需要合并数据时,您将需要构建一个 Data Lake,这是所有数据以统一格式一起存在的地方。尤其是当您需要使用 Salesforce,HubSpot,Jira 和 Zendesk 等应用程序中的数据时,您将需要为这些数据创建一个主目录,以便可以使用单个 SQL 语法一起访问所有数据,而不是许多不同的 API。
18 |
19 | 如果这是大量数据(每天> 100GB),则需要将其存储在 S3 中。但是对于大多数使用情况,您将需要将其存储在数据仓库引擎中,例如 Redshift,Panoply,Snowflake 或 Big Query。在这里,您的数据仍处于其原始事务或事件结构中,并且有时会需要一些凌乱的 SQL,这仍然会限制谁可以实际使用数据。但是,Data Lake 将具有更高的性能,可以使用一种 SQL 语法在一个地方使用,并且可以为下一个重要阶段做好准备。
20 |
21 | ## Warehouse (single source of truth)
22 |
23 | 在 Lake 阶段,当您吸引更多人使用数据时,您必须向他们解释每种模式的奇特之处,哪些数据在哪里以及需要在每个表中进行过滤的特殊条件。这变得很繁重,并且会导致您经常遇到数据的完整性问题。最终,您将需要开始将数据整理到一个单一的真实来源中。从历史上看,这个阶段(创建数据仓库)一直是一场噩梦,并且有许多著作着眼于如何最好地建模数据以进行分析处理。但是,如今这并不困难了,它不仅使您不必向新团队成员解释所有架构的怪异,而且还可以节省您重复,编辑和维护自己的混乱查询的时间。
24 |
25 | - 使用您自己的文件或使用 dbt 之类的出色框架,以 SQL 中新的视图模式进行建模。不要使用专有的第三方建模语言;最好用 SQL 完成。它功能强大,性能卓越,与供应商无关,并且您的团队已经知道这一点。
26 |
27 | - 不要阅读过多的有关 Inman 或 Kimball 等传奇人物关于尺寸建模的书籍,以免过分思考您的建模。那里的大多数书籍都有几十年的历史了,正如我上文所述,最佳实践是基于完全不同的技术考量。
28 |
29 | - 您的分析模型现在应该仅是原始事务模式的简化,过滤,最小化,描述性命名的纯净版本。就像您的公司没有在许多不同的详细 SaaS 应用程序和具有奇特情况和复杂集成的事务性数据库上运行一样,创建它们。而是在单个理想的,完美清洁的整体应用程序上运行。这个理想的应用程序具有干净的操作架构,随着它成为您公司的真理之源,它会慢慢发展。
30 |
31 | ## Marts
32 |
33 | 当您拥有干净的数据并在其上拥有良好的 BI 产品时,您应该开始注意到公司中的许多人都能够回答他们自己的问题,并且越来越多的人参与其中。这是个好消息:您的公司越来越了解信息,业务和生产力结果也应显示出来。您也不必担心完整性问题,因为您已经对数据进行了建模,并且不断将其维护为干净,清晰的事实来源。
34 |
35 | 最终,您将在该事实来源中拥有数百张表,并且当用户尝试查找与其相关的数据时,他们将不知所措。您可能还会发现,根据团队,部门或用例的不同,不同的人希望使用以不同方式构造的同一数据。由于这些原因,您将要开始推出 Data Marts。
36 |
37 | 数据集市是团队或调查主题的更小更具体的真理来源。例如,销售团队可能只需要主仓库中的 12 个左右的表,而营销团队可能需要 20 个表。其中一些是相同的,但有些不同。创建这些数据集市的方法与仓库相同。只需使用视图的 SQL(无论是否实现)指向真相的源来创建新的架构。
38 |
--------------------------------------------------------------------------------
/02~数据集成/DataPipeline/运行环境与引擎.md:
--------------------------------------------------------------------------------
1 | # 运行环境
2 |
3 | 无论采用何种数据变化捕获技术,程序必须在一个可靠的平台运行。该平台需要解决分布式系统的一些共性问题,主要包括:水平扩展、容错、进度管理等。
4 |
5 | ## 水平扩展
6 |
7 | 程序必须能够以分布式 job 的形式在集群中运行,从而允许在业务增长时通过增加运行时节点的方式实现扩展。
8 |
9 | 因为在一个规模化的企业中,通常要同时运行成百上千的 job。随着业务的增长,job 的数量以及 job 的负载还有可能持续增长。
10 |
11 | ## 容错
12 |
13 | 分布式运行环境的执行节点可能因为过载、网络连通性等原因无法正常工作。
14 |
15 | 当节点出现问题时,运行环境需要能够及时监测到,并将问题节点上的 job 分配给健康的节点继续运行。
16 |
17 | ## 进度管理
18 |
19 | job 需要记录自身处理的进度,避免重复处理数据。另外,job 会因为上下游系统的问题、网络连通性、程序 bug 等各种原因异常中止,当 job 重启后,必须能够从上次记录的正常进度位置开始处理后继的数据。
20 |
21 | 有许多优秀的开源框架都可以满足上述要求,包括 Kafka Connect、Spark、Flink 等。
22 |
23 | Kafka Connect 是一个专注数据进出 Kafka 的数据集成框架。Spark 和 Flink 则更为通用,既可以用于数据集成,也适用于更加复杂的应用场景,例如机器学习的模型训练和流式计算。
24 |
25 | 就数据集成这一应用场景而言,不同框架的概念是非常类似的。
26 |
27 | 首先,框架提供 Source Connector 接口封装对数据源的访问。应用开发者基于这一接口开发适配特定数据源的 Connector,实现数据抽取逻辑和进度(offset)更新逻辑。
28 |
29 | 其次,框架提供一个分布式的 Connector 运行环境,处理任务的分发、容错和进度更新等问题。
30 |
31 | 不同之处在于,Kafka Connect 总是将数据抽取到 Kafka,而对于 Spark 和 Flink,Source Connector 是将数据抽取到内存中构建对象,写入目的地是由程序逻辑定义的,包括但不限于消息队列。
32 |
33 | 但无论采用何种框架,都建议首先将数据写入一个汇集层,通常是 Kafka 这样的消息队列。单就数据源采集而言,Kafka Connect 这样专注于数据集成的框架是有一定优势的,这主要体现在两方面:
34 |
35 | - 首先是 Connector 的丰富程度,几乎所有较为流行的数据库、对象存储、文件系统都有开源的 Connector 实现。尤其在数据库的 CDC 方面,有 Debezium 这样优秀的开源项目存在,降低了应用的成本。
36 |
37 | - 其次是开发的便捷性,专有框架的设计相较于通用框架更为简洁,开发新的 Connector 门槛较低。Kafka Connect 的 runtime 实现也较为轻量,出现框架级别问题时 debug 也比较便捷。
38 |
39 | # 引擎对比
40 |
41 | 数据流服务的构建则是基于流式计算引擎,对汇集层的数据进一步加工计算,并将结果实时输出给下游应用系统。这涉及到流式计算引擎的选择:Spark Streaming、Flink、还是 Kafka Streams
42 |
43 | ## 延迟性
44 |
45 | Spark 对流的支持是 MicroBatch,提供的是亚秒级的延迟,相较于 Flink 和 Kafka Streams 在实时性上要差一些。
46 |
47 | ## 应用模式
48 |
49 | Spark 和 Flink 都是将作业提交到计算集群上运行,需要搭建专属的运行环境。Kafka Streams 的作业是以普通 Java 程序方式运行,本质上是一个调用 Kafka Streaming API 的 Kafka Consumer,可以方便地嵌入各种应用。
50 |
51 | 但相应的,用户需要自己解决作业程序在不同服务器上的分发问题,例如通过 K8s 集群方案进行应用的容器化部署。如果使用 KSQL,还需要部署 KSQL 的集群。
52 |
53 | ## SQL 支持
54 |
55 | 三者都提供 Streaming SQL,但 Flink 的 SQL 支持要更为强大些,可以运行更加复杂的分组聚合操作。
56 |
57 | ## EOS
58 |
59 | Flink 对于数据进出计算集群提供了框架级别的支持,这是通过结合 CheckPoint 机制和 Sink Connector 接口封装的二阶段提交协议实现的。
60 |
61 | Kafka Streams 利用 Kafka 事务性消息,可以实现“消费 - 计算 - 写入 Kafka“的 EOS,但当结果需要输出到 Kafka 以外的目的地时,还需要利用 Kafka Connect 的 Sink Connector。遗憾的是,Kafka Connect 不提供 Kafka 到其它类型 Sink 的 EOS 保证,需要用户自己实现。
62 |
63 | Spark Streaming 与 Kafka Streams 类似,在读取和计算过程中可以保证 EOS,但将结果输出到外部时,依然需要额外做一些工作来确保数据一致性。常见的方式包括:利用数据库的事务写入机制将 Offset 持久化到外部、利用主键保证幂等写入、参考二阶段提交协议做分布式事务等。
64 |
--------------------------------------------------------------------------------
/10~OLAP/01.引擎架构/02.建模类型划分/02.ROLAP.md:
--------------------------------------------------------------------------------
1 | # ROLAP
2 |
3 | 与 MOLAP 相反,ROLAP 无需预计算,直接在构成多维数据模型的事实表和维度表上进行计算。R 即表示关系型(Relational)。显然,这种方式相比 MOLAP 更具可扩展性,增量数据导入后,无需进行重新计算,用户有新的查询需求时只需写好正确的 SQL 语句既能完成获取所需的结果。
4 |
5 | 但 ROLAP 的不足也很明显,尤其是在数据体量巨大的场景下,用户提交 SQL 后,获取查询结果所需的时间无法准确预知,可能秒回,也可能需要花费数十分钟甚至数小时。本质上,ROLAP 是把 MOLAP 预计算所需的时间分摊到了用户的每次查询上,肯定会影响用户的查询体验。
6 |
7 | 当然 ROLAP 的性能是否能够接受,取决于用户查询的 SQL 类型,数据规模以及用户对性能的预期。对于相对简单的 SQL,比如 TPCH 中的 Query 响应时间较快。但如果是复杂 SQL,比如 TPC-DS 中的数据分析和挖掘类的 Query,可能需要数分钟。
8 |
9 | 相比 MOLAP,ROLAP 的使用门槛更低,在完成星型或雪花型模型的构建,创建对应 schema 的事实表和维度表并导入数据后,用户只需会写出符合需求的 SQL,就可以得到想要的结果。相比创建 `数据立方体`,显然更加方便。
10 |
11 | 目前生产环境使用较多的开源 ROLAP 主要可以分为 2 大类,一个是**宽表模型**,另一个是**多表组合模型**(就是前述的星型或雪花型)。
12 |
13 | ### 宽表类型
14 |
15 | 宽表模型能够提供比多表组合模型更好的查询性能,不足的是支持的 SQL 操作类型比较有限,比如对 Join 等复杂操作支持较弱或不支持。
16 |
17 | 目前该类 OLAP 系统包括`Druid`和`ClickHouse`等,两者各有优势,Druid 支持更大的数据规模,具备一定的预聚合能力,通过倒排索引和位图索引进一步优化查询性能,在广告分析场景、监控报警等时序类应用均有广泛使用;ClickHouse 部署架构简单,易用,保存明细数据,依托其向量化查询、减枝等优化能力,具备强劲的查询性能。两者均具备较高的数据实时性,在互联网企业均有广泛使用。
18 |
19 | 除了上面介绍的 Druid 和 ClickHouse 外,ElasticSearch 和 Solar 也可以归为宽表模型。但其系统设计架构有较大不同,这两个一般称为搜索引擎,通过倒排索引,应用 Scatter-Gather 计算模型提高查询性能。对于搜索类的查询效果较好,但当数据量较大或进行扫描聚合类查询时,查询性能会有较大影响。
20 |
21 | #### 代表
22 |
23 | - **ClickHouse**是个列存数据库,保存原始明细数据,通过`MergeTree`使得数据存储本地化来提高性能。是个单机版超高性能的数据库
24 |
25 | #### 优点
26 |
27 | 1. 性能高,列存压缩比高,通过索引实现秒级响应
28 | 2. 实时性强,支持 kafka 导入
29 | 3. 处理方式简单,无需预处理,保存明细数据
30 |
31 | #### 缺点
32 |
33 | 1. 数据规模一般
34 | 2. 灵活性差,不支持任意的 adhoc 查询,join 的支持不好。
35 | 3. 易用性较弱,SQL 语法不标准,不支持窗口函数等;维护成本高
36 |
37 | ### 多表组合模型
38 |
39 | 采用星型或雪花型建模是最通用的一种 ROLAP 系统,常见的包括`GreenPlum`、`Presto`和`Impala`等,他们均基于 MPP 架构,采用该模型和架构的系统具有支持的数据量大、扩展性较好、灵活易用和支持的 SQL 类型多样等优点。
40 |
41 | 相比其他类型 ROLAP 和 MOLAP,该类系统性能不具有优势,实时性较一般。通用系统往往比专用系统更难实现和进行优化,这是因为通用系统需要考虑的场景更多,支持的查询类型更丰富。而专用系统只需要针对所服务的某个特定场景进行优化即可,相对复杂度会有所降低。
42 |
43 | 对于 ROLAP 系统,尤其是星型或雪花型的系统,如果能够尽可能得缩短响应时间非常重要,这将是该系统的核心竞争力。
44 |
45 | #### 代表
46 |
47 | - **Presto**、**Impala**以及**Spark SQL**等利用关系模型来处理 OLAP 查询,通过并发来提高查询性能。同时三者是有很多相似点。我日常工作中,接触最多也就是这三兄弟和一个大哥(Hive)。Hive 就不多谈了,是基于 MR 最基础的 OLAP 引擎,也是对于大数据量的分析支持最好得。
48 |
49 | #### 优点
50 |
51 | 1. 支持的计算数据规模大(非存储引擎)
52 | 2. 灵活性高,随意查询数据
53 | 3. 易用性强,支持标准 SQL 以及多表 join 和窗口函数
54 | 4. 处理方式简单,无需预处理,全部后处理,没有冗余数据
55 |
56 | #### 缺点
57 |
58 | 1. 性能较差,当查询复杂度高且数据量大时,可能分钟级别的响应。同时其不是存储引擎,因此没有本地存储,当 join 时 shuffle 开销大,性能差 举例:SparkSql 为例子,其只是计算引擎,导致需要从外部加载数据,从而数据的实时性得不到保证;多表 join 的时候性能也很难得到秒级的响应。
59 | 2. 实时性较差,不支持数据的实时导入,偏离线处理。如果需要实时数据,经常的做法是 Presto 或者 Impala 和 Kudu 的结合,解决了 Kudu 的磁盘存储问题,实时性能也不会太差。
60 |
--------------------------------------------------------------------------------
/04~数据可视化/数据与图表类别/数据类别.md:
--------------------------------------------------------------------------------
1 | # 数据类别
2 |
3 | # 序数数据
4 |
5 | 可明确每项数据的定义或者边界,数据可被枚举。例:部门;性别;花名;商家常用序数比例尺将数据映射为图形,比例尺为等比例等比例尺,对应图表的序数类型的展示。可使用的图形元素包括不仅限于:序数的 XY 轴,形状或图标,枚举的颜色,区域位置,表格行列···
6 |
7 | 常见的数据问题:
8 |
9 | - 问题:枚举数目可能过多;解决:取 TOP N,剩余的归纳为“其他”。N 不宜过大
10 |
11 | - 问题:数据项的定义可能不清晰;解决:tooltip,或者说明文案;
12 |
13 | 展示建议:1.采用用户关注的指标进行排序。2.如果数据项固定,则固定展示位置以及固定使用某种图形元素,培养用户习惯。一旦用户养成习惯,即可减少很多繁琐的文字说明,用户认知更能统一。
14 |
15 | # 线性数据
16 |
17 | 连续的不能明确每项的边界。这里容易与上诉等序数数据混淆的类型,例:[1,2) ; [2,3) ; [3,4)······。此类数据可明确每项数据的边界,所以应该归类为序数数据而不是连续数据。例如,SDR 评分,在客户端打分,用户只能打整数分,计算商家平均评分为 1.1 与得分 1.25 的商家数从分析上来说区别不大,我们可以合并为区间数据,假设使用散点图展示,便可解决散点互相覆盖而不清晰的问题。
18 |
19 | 在展示中若用户关注数据变化,可按大小递增递减排序。若用户关注其所携带的值 value 大小,可不用考虑其自身顺序甚至打乱顺序。例:营销额
20 |
21 | 常见的数据问题:
22 |
23 | - 数据区间分布不均,通常表现为,多个指标在一个图表中。例如多条折线图,其中一个折线数据区间值范围分布在[10000,2000],而其他指标分布在[100,1000],这样会把其他折线压平而看不到变化趋势。从视觉上就是一条横线。
24 |
25 | - 峰值过大压低其他变化趋势。解决方案:将指标按照数据分布区间拆分成同 X 轴或者同 Y 轴的多图展示方式。
26 |
27 | # 时序数据
28 |
29 | 按照时间顺序,以特定时间粒度为步长增长,例:股票,网站日志,周 PV/UV。此类数据展示通常建议采用时间轴的展示方式,通常有横向时间轴,与纵向时间轴。横向时间轴,常用于统计数据折线图,柱状图等。如果时间跨度较大:
30 |
31 | - 可采用拉伸 slider 控制展示的时间范围;
32 | - 通过切换时间粒度控制展示。
33 |
34 | 纵向时间轴,纵向图表的一大特性就是可以展示坐标轴刻度较大的数据。也就是说可展示的内容更多。但纵向时间轴不如横向图表一目了然,所以更适合具有故事发展性但数据展示(例如:大事记;版本修订记录)。
35 |
36 | 常见的数据问题:
37 |
38 | - 数据缺失。时序不像序数数据,类别。缺少某段时间但数据,会使数据视觉上出现跳跃,或者出现空白。非常影响可视化但美观,简而言之,容易误以为有 bug。解决方案建议:1.补全时序,数据值补 0。优点:简单,符合数据情况。缺点:展示 0,不能判断出是真实数据 0,还是缺失数据。2.线性过度。注意,线性过度后的展示一定要区别与正常数据的。例如,鼠标经过无效果,或者用虚线或灰线展示。
39 |
40 | # 地理数据
41 |
42 | 含有单个地理位置的信息,
43 | 例:手机机站位置,商场 wifi 位置 {x:000,y:0001}
44 | 地理信息通常会伴随其他指标,例如人数,城市类型,迁徙。这些即地理信息与其他数据类型的组合。单纯从地理信息的数据考虑,常见问题:1.数据量大,检索、渲染效率低。
45 | 建议优化方案:通过四叉树优化二维空间检索(八叉树优化三维空间);渲染可以分批次渲染;减少渲染过度效果,等。2.商场园区平面图位置等非经纬度数据,与背景图契合。可采用 0 到 1 的坐标系,按比例尺映射于平面图。
46 |
47 | # 关系数据
48 |
49 | 包含节点信息,关系信息的数据,可能带有方向性,例:微博数据
50 | 关系数据可能包含:节点类别,节点值大小,关系类型,关系数量,关系权重,关系方向,路径等属性,属性可选。
51 | 按照关系类型又可分为:1.树型关系 tree 2.簇群关系 cluster 3.图(包含树和簇群)允许出现关系回路,也称网状关系。4.链路/流程关系,具有明显方向性,通常会结合时序数据。
52 |
53 | 除开算法分析外,在可视化过程中,我们可以做哪些?1.聚类,社群分析。2.关联关系,发现大 V。即关联关系中关键连接点。3.最短路径。从 A 点到 B 节点最短发生关联关系的路径,通常用于线索发现,分析本不存在直接关联的 AB 两个实体之间的关联,从而发现关系线索节点(关系桥接点)。4.边捆绑算法展示与路径热力,用于航线等路径规划等。5.流程/路径/轨迹播放 6.知识图谱与思维导图分析,要求典型树型数据结构。
54 |
55 | 问题:1.布局切换。通常根据数据类型,会选择不同的布局方式。然而在有些场景下,我们需要这样的操作。例如,将网状结构的关系数据,希望通过树形机构进行展示。通常树结构只有一个根节点,并且无回路,所以,
56 | 解决方案:则取最核心(关联关系最多的)的节点为根节点。如果数据是多个集群,即由多个图组成,相当于多个树;可虚拟一个根节点,这样绘制的时候可以作为树结构处理,大大减少计算难度。回路,可以在树的机构上,增加线条。严格意义上,这个可视化只是树布局,并非树。2.强交互的关系图谱 请为每个节点配置唯一 ID,次 id 作为关系链接的标志。尽量不要使用节点数组下标作为关系链接标志。3.两个节点间关系繁杂的情况下,可以先进行统计规整。
57 |
58 | # 组合数据
59 |
60 | 通常我们的数据较少是一维数据,通常都是二维以上数据。在数据可视化中,两个和三个维度的数据展示是最清晰的。四个维度的数据基本是一张图表可视化能理解的上限了。再多就使得图表理解困难。最好对图表进行拆分,进行联动等其他展示方案。
61 |
--------------------------------------------------------------------------------
/01~大数据体系/04~数据中心/云数据中心.md:
--------------------------------------------------------------------------------
1 | # 云数据中心
2 |
3 | 所谓的 IT 架构广泛理解即是 Informatica and Communications Technology Infrastructure,其由硬件设备、数据中心系统、企业级软件、电信服务、信息技术服务等几方面构成。而其中的数据中心系统则是现代 IT 核心基础架构,它是云计算的物理载体,为云计算提供底层的数据处理、存储和高性能计算的一体化支撑;数据中心包含了冷却、网络、机房空间、服务器、能耗管理、存储等多个方面。超大规模的云计算数据中心中 PUE(Power Usage Efficiency)则显得尤为重要;现代化的数据中心也采用了虚拟化、软件定义实现按需分配 IT 资源,最大化资源利用率。
4 |
5 | IT 产业始于 1964 年,第一代平台以大型机与终端机为典型代表,服务于百万级用户;第二代平台始于 1981 年,以局域网、服务器、因特网为典型代表,服务于亿级用户,万级应用;第三代平台始于 2012 年,以云计算、大数据、移动与社交为典型代表,服务于数十亿用户。云计算从运营模式分为了公有云、私有云与混合云三种。
6 |
7 | 公有云按照交付模式,又分为 IaaS、PaaS、SaaS 这三种,越来越多的企业也选择了从自建 IT 架构到租借公有云服务商提供的云服务。公有云能够帮助企业实现均衡优化的 IT 资源管理,降低整体成本,并且将企业固定成本转化为可变运营成本;从而能够让企业聚焦其核心业务。云计算将传统的烟囱模式:网络->存储->计算->虚拟化->系统->中间件->运行环境->数据,改造为了硬件资源层->虚拟化层->云管理层->应用平台层->应用层架构。
8 |
9 | 云计算融合了虚拟化技术、分布式数据存储技术、大规模数据管理技术、编程模型、分布式的资源管理、云计算平台管理技术、信息安全等多个领域,其中虚拟化技术是云计算技术的核心之一,为云计算技术提供了基础架构的支撑;不过需要注意的是,云计算不仅仅是虚拟化,而是从单一虚拟化走向了以资源为核心,以应用为核心的阶段。在以应用为核心阶段,云计算的核心技术包括了 PaaS、容器引擎、应用管理框架、容器集群资源管理等方面。
10 |
11 | 大数据指的是所涉及的资料量的规模巨大到无法通过人工在合理时间内获取、管理和处理的数据集合。一般来说,数据类型分为传统企业数据,即企业的 ERP 数据、库存数据、账目数据等;机器产生和传感器数据,包括呼叫记录、智能仪表、工业设备传感器、设备日志、交易数据等等;还有就是社交数据,譬如用户行为记录、反馈数据等。而我们所谓的大数据处理平台包含了数据的采集、传输、存储、分析、挖掘、可视化、价值体现等完整的大数据处理过程。
12 |
13 | 传统企业应用的特征是成熟的架构设计、标准的套装软件与良好的纵向扩展能力,而云计算应用的特征是基于开源平台开发、良好的横向扩展能力与很强的自愈能力。现代互联网用户的应用需求包括了实时-RealTime,按需定制-OnDemand,全在线-All on-line,自助服务-DIY,社交分享-Social 这几个部分。
14 |
15 | AWS 的举措:从 IaaS 向 PaaS 扩展、向传统企业级市场进军。2013 年,CIA 情报社区云项目的竞标中 AWS 以高价但优质的云数据中心服务战胜了 IBM 的传统数据中心,云数据中心已然成为了未来 IT 发展的方向与必然选择。传统数据中心装上云操作系统,变成水平扩展的云数据中心。云操作系统把服务器、网络、安全等 IT 设备能力变为 IT 服务,提供给平台软件和应用软件使用。云数据中心提供 IT 服务,实现了资源共享、资源的水平扩展,提高了资源利用率,并且使能低成本线性扩容,扩容不需要暂停业务。
16 |
17 | NFV 表示网络功能虚拟化,SDN 表示软件定义网络,两种技术的核心即是用 IT 技术改造 CT 网络,重构电信网络的核心。
18 |
19 | 数据中心机房配套层标准与数据中心基础设施层标准,其中机房配套层常见的是 Uptime 标准和 ISO17001 标准,Tier 4 指全年只能有不超过 24 分钟的服务不可用,而 Tier 3 指全年可以有不超过 1.6 小时的不可用;PUE 指机房用电总量是 IT 设备用电量。基础设施层则是 SHARE 78 国际标准,其定义了 1 到 7 级标准,容灾级别越高,RTO 恢复时间就越短,成本越高。而目前云服务的事实标准则是 OpenStack
20 |
21 | 我们还需要强调企业级云数据中心的统一架构,资源池是云数据中心的基本单元,包括了计算资源池、存储资源池、网络资源池等等。统一架构的核心就是物理分散、逻辑集中、异构共存、资源共享、按需服务。
22 |
23 | 大型企业的演进策略是,通过 DC 整合进行全局规划、分布实施:包括建立云 DC 核心样板点,确立云服务标准;建立云 DC 企业级统一调度平台;向周边复制云 DC,强化网络自动化,实现多 DC 互连互通;将业务云化搬迁到云 DC 上;持续优化经营。而小公司的演进策略往往是通过融合资源池,以点带面,逐步渗透。
24 |
25 | 为了更好地实践统一的云管理平台和主动运维模式,Google 建立了全局资源集中管控面与大数据平台。主动运维的核心是企业级 DC 的运行可视化,健康可视化帮助推动运维转型,从被动运维到主动运维;还需要通过脚本编程将运维经验固化下来。还需要辅助以良好的云服务流程机制和资源调度管理,企业级 DC 资源调度往往分为两种方式:IT 系统设置规则或者大的业务部门之间,要考资源的配额调度去管控;企业应该构建具有自我约束、自我修复的云服务流程,并且建立专门的组织保障企业级的资源可调度。
26 |
27 | 传统的数据中心是面向应用软件提供设备,属于典型的烟囱式架构;而云数据中心致力于提供 IT 服务,属于共享服务式架构。
28 |
29 | 传统数据中心的 IT 资源是各个业务应用独占,即使某个业务处于波谷阶段也无法将资源分配给其他波峰阶段的业务使用;并且传统数据中心只能采用垂直扩容方式,扩容时业务需要中断,并且基础设施的建设时间也过长。云数据中心则能有效实现企业级资源共享,能够在分钟级完成资源获取。
30 |
--------------------------------------------------------------------------------
/02~数据集成/DataPipeline/数据汇集层.md:
--------------------------------------------------------------------------------
1 | # 数据汇集层
2 |
3 | 数据汇集层在部分场景下又称为变更分发平台。当各类数据从源端抽取后,首先应当被写入一个数据汇集层,然后再进行后继的转换处理,直至将最终结果写入目的地。数据汇集层的作用主要有两点:
4 |
5 | - 数据汇集层将异构的数据源数据存储为统一的格式,并且为后继的处理提供一致的访问接口。这就将处理逻辑和数据源解耦开来,同时屏蔽了数据抽取过程中可能发生的异常对后继作业的影响。
6 |
7 | - 数据汇集层独立于数据源,可被多次访问,亦可根据业务需要缓存全部或一定期限的原始数据,这为转换分析提供了更高的灵活度。当业务需求发生变化时,无需重复读取源端数据,直接基于数据汇集层就可以开发新的模型和应用。数据汇集层可基于任意支持海量 / 高可用的文件系统、数据仓库或者消息队列构建,常见的方案包括 HDFS、HBase、Kafka 等。
8 |
9 | # 数据汇集层的技术考量
10 |
11 | 变更分发平台可以有很多种形式,本质上它只是一个存储变更的中间件,那么如何进行选型呢?首先由于变更数据数据量级大,且操作时没有事务需求,所以先排除了关系型数据库,剩下的 NoSQL 如 Cassandra,mq 如 Kafka、RabbitMQ 都可以胜任。其区别在于,消费端到分发平台拉取变更时,假如是 NoSQL 的实现,那么就能很容易地实现条件过滤等操作(比如某个客户端只对特定字段为 true 的消息感兴趣); 但 NoSQL 的实现往往会在吞吐量和一致性上输给 mq。这里就是一个设计抉择的问题,最终我们选择了 mq,主要考虑的点是:消费端往往是无状态应用,很容易进行水平扩展,因此假如有条件过滤这样的需求,我们更希望把这样的计算压力放在消费端上。
12 |
13 | 而在 mq 里,Kafka 则显得具有压倒性优势。Kafka 本身就有大数据的基因,通常被认为是目前吞吐量最大的消息队列,同时,使用 Kafka 有一项很适合该场景的特性:Log Compaction。Kafka 默认的过期清理策略(log.cleanup.policy)是 delete,也就是删除过期消息,配置为 compact 则可以启用 Log Compaction 特性,这时 Kafka 不再删除过期消息,而是对所有过期消息进行”折叠”:对于 key 相同的所有消息会,保留最新的一条。
14 |
15 | 对应的在 mq 中的流总共会产生 4 条变更消息,而最下面两条分别是 id:1 id:2 下的最新记录,在它们之前的两条 INSERT 引起的变更就会被 Kafka 删除,最终我们在 Kafka 中看到的就是两行记录的最新状态,而一个持续订阅该流的消费者则能收到全部 4 条记录。这种行为有一个有趣的名字,流表二相性(Stream Table Durability):Topic 中有无尽的变更消息不断被写入,这是流的特质;而 Topic 某一时刻的状态,恰恰是该时刻对应的数据表的一个快照(参见上面的例子),每条新消息的到来相当于一次 Upsert,这又是表的特性。落到实践中来讲,Log Compaction 对于我们的场景有一个重要应用:全量数据迁移与数据补偿,我们可以直接编写针对每条变更数据的处理程序,就能兼顾全量迁移与之后的增量同步两个过程;而在数据异常时,我们可以重新回放整个 Kafka Topic:该 Topic 就是对应表的快照,针对上面的例子,我们回放时只会读到最新的两条消息,不需要读全部四条消息也能保证数据正确。
16 |
17 | 关于 Kafka 作为变更分发平台,最后要说的就是消费顺序的问题。大家都知道 Kafka 只能保证单个 Partition 内消息有序,而对于整个 Topic,消息是无序的。一般的认知是,数据变更的消费为了逻辑的正确性,必须按序消费。按着这个逻辑,我们的 Topic 只能有单个 Partition,这就大大牺牲了 Kafka 的扩展性与吞吐量。其实这里有一个误区,对于数据库变更抓取,我们只要保证 同一行记录的变更有序 就足够了。还是上面的例子,我们只需要保证对 id:2 这行的 insert 消息先于 update 消息,该行数据最后就是正确的。而实现”同一行记录变更有序”就简单多了,Kafka Producer 对带 key 的消息默认使用 key 的 hash 决定分片,因此只要用数据行的主键作为消息的 key,所有该行的变更都会落到同一个 Parition 上,自然也就有序了。这有一个要求就是 CDC 模块必须解析出变更数据的主键:而这点 Debezium 已经帮助我们解决了。
18 |
19 | # 统一数据格式
20 |
21 | 数据格式的选择同样十分重要。首先想到的当然是 json, 目前最常见的消息格式,不仅易读,开发也都对它十分熟悉。但 json 本身有一个很大的不足,那就是契约性太弱,它的结构可以随意更改:试想假如有一个接口返回 String,注释上说这是个 json,那我们该怎么编写对应的调用代码呢?是不是需要翻接口文档,提前获知这段 json 的 schema,然后才能开始编写代码,并且这段代码随时可能会因为这段 json 的格式改变而 break。
22 |
23 | 在规模不大的系统中,这个问题并不显著。但假如在一个拥有上千种数据格式的数据管道上工作,这个问题就会很麻烦,首先当你订阅一个变更 topic 时,你完全处于懵逼状态——不知道这个 topic 会给你什么,当你经过文档的洗礼与不断地调试终于写完了客户端代码,它又随时会因为 topic 中的消息格式变更而挂掉。参考 Yelp 和 Linkedin 的选择,我们决定使用 Apache Avro 作为统一的数据格式。Avro 依赖模式 Schema 来实现数据结构定义,而 Schema 通常使用 json 格式进行定义,一个典型的 Schema 如下:这里要介绍一点背景知识,Avro 的一个重要特性就是支持 Schema 演化,它定义了一系列的演化规则,只要符合该规则,使用不同的 Schema 也能够正常通信。也就是说,使用 Avro 作为数据格式进行通信的双方是有自由更迭 Schema 的空间的。
24 |
25 | 在我们的场景中,数据库表的 Schema 变更会引起对应的变更数据 Schema 变更,而每次进行数据库表 Schema 变更就更新下游消费端显然是不可能的。所以这时候 Avro 的 Schema 演化机制就很重要了。我们做出约定,同一个 Topic 上传输的消息,其 Avro Schema 的变化必须符合演化规则,这么一来,消费者一旦开始正常消费之后就不会因为消息的 Schema 变化而挂掉。
26 |
--------------------------------------------------------------------------------
/99~参考资料/《Designing Data-Intensive Application》/原书翻译/README.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://vonng.github.io/ddia/#/preface)
2 |
3 | # [DDIA](https://vonng.github.io/ddia/#/preface)
4 |
5 | 如果近几年从业于软件工程,特别是服务器端和后端系统开发,那么你很有可能已经被大量关于数据存储和处理的时髦词汇轰炸过了: NoSQL!大数据!Web-Scale!分片!最终一致性!ACID! CAP 定理!云服务!MapReduce!实时!
6 |
7 | 在最近十年中,我们看到了很多有趣的进展,关于数据库,分布式系统,以及在此基础上构建应用程序的方式。这些进展有着各种各样的驱动力:
8 |
9 | - 谷歌、雅虎、亚马逊、脸书、领英、微软和推特等互联网公司正在和巨大的流量 / 数据打交道,这迫使他们去创造能有效应对如此规模的新工具。
10 | - 企业需要变得敏捷,需要低成本地检验假设,需要通过缩短开发周期和保持数据模型的灵活性,快速地响应新的市场洞察。
11 | - 免费和开源软件变得非常成功,在许多环境中比商业软件和定制软件更受欢迎。
12 | - 处理器主频几乎没有增长,但是多核处理器已经成为标配,网络也越来越快。这意味着并行化程度只增不减。
13 | - 即使你在一个小团队中工作,现在也可以构建分布在多台计算机甚至多个地理区域的系统,这要归功于譬如亚马逊网络服务(AWS)等基础设施即服务(IaaS)概念的践行者。
14 | - 许多服务都要求高可用,因停电或维护导致的服务不可用,变得越来越难以接受。
15 |
16 | **数据密集型应用(data-intensive applications)** 正在通过使用这些技术进步来推动可能性的边界。一个应用被称为 **数据密集型** 的,如果 **数据是其主要挑战**(数据量,数据复杂度或数据变化速度)—— 与之相对的是 **计算密集型**,即处理器速度是其瓶颈。
17 |
18 | 帮助数据密集型应用存储和处理数据的工具与技术,正迅速地适应这些变化。新型数据库系统(“NoSQL”)已经备受关注,而消息队列,缓存,搜索索引,批处理和流处理框架以及相关技术也非常重要。很多应用组合使用这些工具与技术。
19 |
20 | 这些生意盎然的时髦词汇体现出人们对新的可能性的热情,这是一件好事。但是作为软件工程师和架构师,如果要开发优秀的应用,我们还需要对各种层出不穷的技术及其利弊权衡有精准的技术理解。为了获得这种洞察,我们需要深挖时髦词汇背后的内容。
21 |
22 | 幸运的是,在技术迅速变化的背后总是存在一些持续成立的原则,无论你使用了特定工具的哪个版本。如果你理解了这些原则,就可以领会这些工具的适用场景,如何充分利用它们,以及如何避免其中的陷阱。这正是本书的初衷。
23 |
24 | 本书的目标是帮助你在飞速变化的数据处理和数据存储技术大观园中找到方向。本书并不是某个特定工具的教程,也不是一本充满枯燥理论的教科书。相反,我们将看到一些成功数据系统的样例:许多流行应用每天都要在生产中满足可伸缩性、性能、以及可靠性的要求,而这些技术构成了这些应用的基础。
25 |
26 | 我们将深入这些系统的内部,理清它们的关键算法,讨论背后的原则和它们必须做出的权衡。在这个过程中,我们将尝试寻找 **思考** 数据系统的有效方式 —— 不仅关于它们 **如何** 工作,还包括它们 **为什么** 以这种方式工作,以及哪些问题是我们需要问的。
27 |
28 | 阅读本书后,你能很好地决定哪种技术适合哪种用途,并了解如何将工具组合起来,为一个良好应用架构奠定基础。本书并不足以使你从头开始构建自己的数据库存储引擎,不过幸运的是这基本上很少有必要。你将获得对系统底层发生事情的敏锐直觉,这样你就有能力推理它们的行为,做出优秀的设计决策,并追踪任何可能出现的问题。
29 |
30 | ## [本书纲要](https://vonng.github.io/ddia/#/preface?id=本书纲要)
31 |
32 | 本书分为三部分:
33 |
34 | 1. 在 [第一部分](https://vonng.github.io/ddia/#/part-i) 中,我们会讨论设计数据密集型应用所赖的基本思想。我们从 [第一章](https://vonng.github.io/ddia/#/ch1) 开始,讨论我们实际要达到的目标:可靠性、可伸缩性和可维护性;我们该如何思考这些概念;以及如何实现它们。在 [第二章](https://vonng.github.io/ddia/#/ch2) 中,我们比较了几种不同的数据模型和查询语言,看看它们如何适用于不同的场景。在 [第三章](https://vonng.github.io/ddia/#/ch3) 中将讨论存储引擎:数据库如何在磁盘上摆放数据,以便能高效地再次找到它。[第四章](https://vonng.github.io/ddia/#/ch4) 转向数据编码(序列化),以及随时间演化的模式。
35 | 2. 在 [第二部分](https://vonng.github.io/ddia/#/part-ii) 中,我们从讨论存储在一台机器上的数据转向讨论分布在多台机器上的数据。这对于可伸缩性通常是必需的,但带来了各种独特的挑战。我们首先讨论复制([第五章](https://vonng.github.io/ddia/#/ch5))、分区 / 分片([第六章](https://vonng.github.io/ddia/#/ch6))和事务([第七章](https://vonng.github.io/ddia/#/ch7))。然后我们将探索关于分布式系统问题的更多细节([第八章](https://vonng.github.io/ddia/#/ch8)),以及在分布式系统中实现一致性与共识意味着什么([第九章](https://vonng.github.io/ddia/#/ch9))。
36 | 3. 在 [第三部分](https://vonng.github.io/ddia/#/part-iii) 中,我们讨论那些从其他数据集衍生出一些数据集的系统。衍生数据经常出现在异构系统中:当没有单个数据库可以把所有事情都做的很好时,应用需要集成几种不同的数据库、缓存、索引等。在 [第十章](https://vonng.github.io/ddia/#/ch10) 中我们将从一种衍生数据的批处理方法开始,然后在此基础上建立在 [第十一章](https://vonng.github.io/ddia/#/ch11) 中讨论的流处理。最后,在 [第十二章](https://vonng.github.io/ddia/#/ch12) 中,我们将所有内容汇总,讨论在将来构建可靠、可伸缩和可维护的应用程序的方法。
37 |
--------------------------------------------------------------------------------
/03~数仓建模/README.md:
--------------------------------------------------------------------------------
1 | # 数据仓库
2 |
3 | 数据仓库(Data Warehouse),可简写为 DW 或 DWH;数据仓库,是为了企业所有级别的决策制定计划过程,提供所有类型数据类型的战略集合。它出于分析性报告和决策支持的目的而创建。为需要业务智能的企业,为需要指导业务流程改进、监视时间,成本,质量以及控制等支持。
4 |
5 | 一个企业可能有几十个不同的交易处理系统:面向终端客户的网站,控制实体商店的收银系统,跟踪仓库库存,规划车辆路线,供应链管理,员工管理等。这些系统中每一个都很复杂,需要专人维护,所以系统最终都是自动运行的。这些 OLTP 系统往往对业务运作至关重要,因而通常会要求 高可用 与 低延迟。所以 DBA 会密切关注他们的 OLTP 数据库,他们通常不愿意让业务分析人员在 OLTP 数据库上运行临时分析查询,因为这些查询通常开销巨大,会扫描大部分数据集,这会损害同时执行的事务的性能。
6 |
7 | 相比之下,数据仓库是一个独立的数据库,分析人员可以查询他们想要的内容而不影响 OLTP 操作。数据仓库包含公司各种 OLTP 系统中所有的只读数据副本。从 OLTP 数据库中提取数据(使用定期的数据转储或连续的更新流),转换成适合分析的模式,清理并加载到数据仓库中。将数据存入仓库的过程称为“抽取-转换-加载(ETL)”。
8 |
9 | 
10 |
11 | > 数据仓库中很多的内容都涉及到[《分布式数据处理》](https://github.com/wx-chevalier/DistributedSystem-Notes),请自行参阅。
12 |
13 | # 数仓特性
14 |
15 | 数据仓库能够极大地辅助商业智能决策,譬如年度销售目标的制定,需要根据以往的历史报表进行决策,不能随便制定。某电商平台某品牌的手机,在过去 5 年主要的的购买人群的年龄在什么年龄段,在那个季节购买量人多,这样就可以根据这个特点为目标人群设定他们主要的需求和动态分配产生的生产量,和仓库的库存。
16 |
17 | ## 面向主题
18 |
19 | 与传统的数据库不一样,数据仓库是面向主题的,那什么是主题呢?首页主题是一个较高乘次的概念,是较高层次上企业信息系统中的数据综合,归类并进行分析的对象。在逻辑意义上,他是对企业中某一个宏观分析领域所涉及的分析对象。
20 |
21 | 就是用户用数据仓库进行决策所关心的重点方面,一个主题通常与多个操作信息型系统有关,而操作型数据库的数据组织面向事务处理任务,各个任务之间是相互隔离的。
22 |
23 | ## 数据集成
24 |
25 | 数据仓库的数据是从原来的分散的数据库数据(mysql 等关系型数据库)抽取出来的。操作型数据库与 DSS(决策支持系统)分析型数据库差别甚大。第一,数据仓库的每一个主题所对应的源数据在所有的各个分散的数据库中,有许多重复和不一样的地方,且来源于不同的联机系统的数据都和不同的应用逻辑捆绑在一起;第二,数据仓库中的综合数据不能从原来有的数据库系统直接得到。因此子在数据进入数据仓库之前,必然要经过统一与综合,这一步是数据仓库建设中最关键,最复杂的一步,所要完成的工作有:
26 |
27 | - 要统计源数据中所有矛盾之处,如字段的同名异议、异名同义、单位不统一,字长不统一等。
28 | - 进行数据的综合和计算。数据仓库中的数据综合工作可以在原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
29 |
30 | ## 时序数据
31 |
32 | 数据仓库的数据是随着时间的变化而变化的,数据仓库中的数据不可更新是针对应用来说的,也就是说,数据仓库的用户进行分析处理是不进行数据更新操作的。但并不是说,在从数据集成输入数据仓库开始到最后被删除的整个生存周期中,所有的数据仓库数据都是永远不变的。
33 |
34 | 数据仓库的数据是随着时间变化而变化的,这是数据仓库的特征之一。这一特征主要有以下三个表现:
35 |
36 | - 数据仓库随着时间变化不断增加新的数据内容。数据仓库系统必须不断捕捉 OLTP 数据库中变化的数据,追加到数据仓库当中去,也就是要不断的生成 OLTP 数据库的快照,经统一集成增加到数据仓库中去;但对于确实不在变化的数据库快照,如果捕捉到新的变化数据,则只生成一个新的数据库快照增加进去,而不会对原有的数据库快照进行修改。
37 |
38 | - 数据库随着时间变化不断删去旧的数据内容。数据仓库内的数据也有存储期限,一旦过了这一期限,过期数据就要被删除。只是数据库内的数据时限要远远的长于操作型环境中的数据时限。在操作型环境中一般只保存有 60~90 天的数据,而在数据仓库中则要需要保存较长时限的数据(例如:5~10 年),以适应 DSS 进行趋势分析的要求。
39 |
40 | - 数据仓库中包含有大量的综合数据,这些综合数据中很多跟时间有关,如数据经常按照时间段进行综合,或隔一定的时间片进行抽样等等。这些数据要随着时间的变化不断地进行从新综合。因此数据仓库的数据特征都包含时间项,以标明数据的历史时期。
41 |
42 | ## 不可变性
43 |
44 | 数据仓库的数据主要提供企业决策分析之用,所涉及的数据操作主要是数据查询,一般情况下并不进行修改操作。数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据,而不是联机处理的数据。数据库中进行联机处理的书库进过集成输入到数据仓库中,一旦数据仓库存放的数据已经超过数据仓库的数据存储期限,这些数据将从当前的数据仓库中删去。
45 |
46 | 因为数据仓库只进行数据查询操作,所以数据仓库当中的系统要比数据库中的系统要简单的多。数据库管理系统中许多技术难点,如完整性保护、并发控制等等,在数据仓库的管理中几乎可以省去。但是由于数据仓库的查询数据量往往很大,所以就对数据查询提出了更高的要求,他要求采用各种复杂的索引技术;同时数据仓库面向的是商业企业的高层管理层,他们会对数据查询的界面友好性和数据表示提出更高的要求。
47 |
48 | # 建设难点
49 |
50 | 数据仓库建设难点:
51 |
52 | - 数据孤岛、烟囱式重复建设 缺少公共数据的提炼和汇总,出现烟囱式重复建设,同时也加剧了数据孤岛的问题。
53 | - 数据不一致 孤岛式的建设,缺少统一的组织及方法论,指标口径不统一、数据表级字段名不一致,数据有二义性
54 | - 缺少统一模型规范 当不同业务之间有数据交叉的场景时,为了尽快响应业务需求,直接从其他业务明细层甚至原始数据层获取数据,不同的研发团队不同规范,造成模型设计不统一,复用性差。
55 | - 效率差、响应慢 缺少公共聚合数据的沉淀和积累,每次新的需求都需要 5-7 天以上的研发,无法服用,产出时效差,数据质量低,资源消耗成本高居不下
56 |
57 | # Links
58 |
59 | - http://webdataanalysis.net/web-data-warehouse/ 网站数据仓库
60 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [![Contributors][contributors-shield]][contributors-url]
2 | [![Forks][forks-shield]][forks-url]
3 | [![Stargazers][stars-shield]][stars-url]
4 | [![Issues][issues-shield]][issues-url]
5 | [][license-url]
6 |
7 |
8 |
9 |
10 |
11 |  12 |
13 |
14 |
12 |
13 |
14 |
15 | 在线阅读 >>
16 |
17 |
18 | 代码案例
19 | ·
20 | 参考资料
21 |
22 |
23 |
24 |
25 | # 数据仓库
26 |
27 | 在《[Database-Notes/数据库基础](https://github.com/wx-chevalier/Database-Notes?q=)》中我们讨论了数据仓库的基础理论知识,本章则着眼于如何实践数据仓库的相关应用。
28 |
29 | ## Nav | 关联导航
30 |
31 | - 如果你想了解微服务/云原生等分布式系统的应用实践,可以参阅;如果你想了解数据库相关,可以参阅 [Database-Notes](https://github.com/wx-chevalier/Database-Notes);如果你想了解虚拟化与云计算相关,可以参阅 [Cloud-Notes](https://github.com/wx-chevalier/Cloud-Notes);如果你想了解 Linux 与操作系统相关,可以参阅 [Linux-Notes](https://github.com/wx-chevalier/Linux-Notes)。
32 |
33 | # Links
34 |
35 | - 万字详解整个数据仓库建设体系 https://cubox.pro/c/CHuVAT 提取关键内容
36 |
37 | # About
38 |
39 | ## Copyright & More | 延伸阅读
40 |
41 | 笔者所有文章遵循 [知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.zh),欢迎转载,尊重版权。您还可以前往 [NGTE Books](https://ng-tech.icu/books-gallery/) 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
42 |
43 | [](https://ng-tech.icu/books-gallery/)
44 |
45 |
46 |
47 |
48 | [contributors-shield]: https://img.shields.io/github/contributors/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
49 | [contributors-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/graphs/contributors
50 | [forks-shield]: https://img.shields.io/github/forks/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
51 | [forks-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/network/members
52 | [stars-shield]: https://img.shields.io/github/stars/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
53 | [stars-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/stargazers
54 | [issues-shield]: https://img.shields.io/github/issues/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
55 | [issues-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/issues
56 | [license-shield]: https://img.shields.io/github/license/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
57 | [license-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/blob/master/LICENSE.txt
58 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/02~星型与雪花模型/README.md:
--------------------------------------------------------------------------------
1 | # 星型与雪花模型
2 |
3 | 在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
4 |
5 | # 星型模型
6 |
7 | “星型模式”这个名字来源于这样一个事实,即当表关系可视化时,事实表在中间,由维表包围;与这些表的连接就像星星的光芒。
8 |
9 | 当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型。星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
10 |
11 | 
12 |
13 | 下例模式显示了可能在食品零售商处找到的数据仓库。在模式的中心是一个所谓的事实表(在这个例子中,它被称为 fact_sales)。事实表的每一行代表在特定时间发生的事件(这里,每一行代表客户购买的产品)。如果我们分析的是网站流量而不是零售量,则每行可能代表一个用户的页面浏览量或点击量。
14 |
15 | 
16 |
17 | 通常情况下,事实被视为单独的事件,因为这样可以在以后分析中获得最大的灵活性。但是,这意味着事实表可以变得非常大。像苹果,沃尔玛或 eBay 这样的大企业在其数据仓库中可能有几十 PB 的交易历史,其中大部分实际上是表。
18 |
19 | 事实表中的一些列是属性,例如产品销售的价格和从供应商那里购买的成本(允许计算利润余额)。事实表中的其他列是对其他表(称为维表)的外键引用。由于事实表中的每一行都表示一个事件,因此这些维度代表事件的发生地点,时间,方式和原因。
20 |
21 | 例如上图中其中一个维度是已售出的产品 dim_product 表中的每一行代表一种待售产品,包括库存单位(SKU),说明,品牌名称,类别,脂肪含量,包装尺寸等。fact_sales 表中的每一行都使用外部表明在特定交易中销售了哪些产品。为了简单起见,如果客户一次购买几种不同的产品,则它们在事实表中被表示为单独的行
22 |
23 | 即使日期和时间通常使用维度表来表示,因为这允许对日期(诸如公共假期)的附加信息进行编码,从而允许查询区分假期和非假期的销售。
24 |
25 | # 雪花模型
26 |
27 | 星型模型的变体被称为雪花模式,其中尺寸被进一步分解为子尺寸。例如,品牌和产品类别可能有单独的表格,并且 dim_product 表格中的每一行都可以将品牌和类别作为外键引用,而不是将它们作为字符串存储在 dim_product 表格中。雪花模式比星形模式更规范化,但是星形模式通常是首选,因为分析师使用它更简单。
28 |
29 | 在典型的数据仓库中,表格通常非常宽泛:事实表格通常有 100 列以上,有时甚至有数百列。维度表也可以是非常宽的,因为它们包括可能与分析相关的所有元数据——例如,dim_store 表可以包括在每个商店提供哪些服务的细节,它是否具有店内面包房,方形镜头,商店第一次开幕的日期,最后一次改造的时间,离最近的高速公路的距离等等。
30 |
31 | 当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如下图,将地域维表又分解为国家,省份,城市等维表。它的优点是: 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
32 |
33 | 
34 |
35 | 星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
36 |
37 | # 模型选择分析
38 |
39 | 雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”星形模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?”
40 |
41 | ## 数据优化
42 |
43 | 雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。相比较而言,星形模型实用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。
44 |
45 | 
46 |
47 | ## 业务模型
48 |
49 | 主键是一个单独的唯一键(数据属性),为特殊数据所选择。在上面的例子中,Advertiser_ID 就将是一个主键。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。在我们所引用的例子中,Advertiser_ID 将是 Account_dimension 的一个外键。
50 |
51 | 在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
52 |
53 | ## 性能
54 |
55 | 第三个区别在于性能的不同。雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道 Advertiser 的详细信息,雪花模型就会请求许多信息,比如 Advertiser Name、ID 以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。
56 |
57 | 而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将 Advertiser 的维度表和事实表连接即可。
58 |
59 | ## ETL
60 |
61 | 雪花模型加载数据集市,因此 ETL 操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。星形模型加载维度表,不需要再维度之间添加附属模型,因此 ETL 就相对简单,而且可以实现高度的并行化。
62 |
--------------------------------------------------------------------------------
/01~大数据体系/02~数据治理原则/原则与要素.md:
--------------------------------------------------------------------------------
1 | # 零散化存放
2 |
3 | 当今的大型企业,内部分工日趋细化,采购、服务、市场、销售、开发、支持、物流、财务、人力等各个环节,无不每时每刻产生着大量的数据。数据的格式也越来越多样化,包括 IT 系统里存储的结构化、非结构化数据,各样电子文档数据等。与此同时,企业管理者对数据的困惑也与日俱增,这些数据从哪里来?我们能相信这些数据吗?数据之间有什么样的关系?谁能理解这些数据?
4 |
5 | 零散化存放是数据问题根源,造成上述情况最根本的原因是:数据零散化存放。大型企业在不同发展阶段,会根据业务需求建设很多内部 IT 支撑系统,比如 ERP(企业资源计划)系统、CRM(客户服务管理)系统、财务管理系统等,这些系统的分散建设,数据割裂,造成了数据零散化存放的现状。基于数据作分析,首先需要数据的聚合,但由于生产系统和数据的离散化,造成了数据标准、数据模型不统一,因而企业最需要做的就是对数据整合和标准化。
6 |
7 | 根据 DAMA(国际数据管理协会)的定义,数据治理(DG,Data Governance)是指对数据资产的管理活动行使权力和控制的活动集合(规划、监控和执行)。大数据治理,即基于大数据的数据治理。大数据,一般指符合 4V 特征的数据,包括社交数据、机器数据等,大数据对传统数据治理工作带来很多的扩展,在政策/流程上,大数据治理应覆盖大数据的获取、处理、存储、安全等环节,需要为大数据设置数据管理专员制度;需考虑大数据与主数据管理能力的集成,需要对大数据做定义,统一主数据标准;在数据生命周期管理各阶段,如数据存储、保留、归档、处置时,要考虑大数据保存时间与存储空间的平衡,大数据量大,因此应识别对业务有关键影响的数据元素,检查和保证数据质量。此外,在隐私方面,应考虑社交数据的隐私保护需求,制定相应政策,还要将大数据治理与企业内外部风险管控需求建立联系。
8 |
9 | # 大数据治理的商业价值
10 |
11 | 企业只有建立了完整的大数据治理体系,保证数据的质量,才能够真正有效地挖掘企业内部的数据价值,对外提高竞争力。
12 |
13 | 首先,高质量数据是企业业务创新、管理决策的基础。随着互联网企业对其他各行业的冲击,加剧了市场的竞争,许多企业面临收入增速放缓、利润空间逐步缩小的局面,过去单纯的外延式增长已经难以为继。因此,必须向外延与内涵相结合的增长方式转变,未来效益的提升很大程度上要依靠企业的内部挖潜实现,这从客观上对企业的创新能力提出了更高的要求,而提升企业内部数据管理的精细化水平,是企业开展业务创新和管理决策的重要基础,能够为企业创造巨大效益。
14 |
15 | 其次,标准化的数据是优化商业模式、指导生产经营的前提。许多企业的 IT 系统经历了数据量高速膨胀的时期,这些海量的、分散在不同角落的数据导致了数据资源利用的复杂性和管理的高难度,形成了一个个系统竖井。系统之间的关系、标准化数据从哪里获取都无从知晓,通过数据治理工作,可以对分散在各系统中的数据提供一套统一的数据命名、数据定义、数据类型、赋值规则等的定义基准,通过数据标准化可以防止数据的混乱使用,确保数据的正确性及质量,并可以优化商业模式,指导企业生产经营工作。
16 |
17 | 最后,多角度、全方位的数据是企业开展市场营销、争夺客户资源的关键。数据已成为企业最核心的隐形财富,谁掌握了准确的数据谁就能获得先机,在当前竞争日益激烈的市场上,企业如何在不同的细分市场构建客户画像、开展精准营销,如何选择竞争策略、进行经营管理决策,都必须基于 360 度全方位、准确的客户数据加以分析判断才能得出。
18 |
19 | # 核心要素
20 |
21 | - 明确数据治理责任,建立数据治理组织
22 |
23 | 数据出了问题,到底是谁的责任?因为数据主要是 IT 系统产生的,所以一直以来,解决数据问题都被认为是 IT 部门的职责。而 IT 部门也饱受其苦,数据定义和业务规则,业务部门最清楚;数据录入,业务人员负责;数据使用,业务人员是用户;数据考核,业务部门有权力……但实际上,要切实解决数据问题,开展数据治理工作,就必须先清楚一点:数据治理,是业务部门和 IT 部门共同的职责。值得一提的是,越来越多的企业开始重视数据治理工作,一些企业高管团队中也产生了一个全新的职位——首席数据官(CDO),是组织内大数据战略的制定者和推动者,负责组织内数据资产的开发和利用,通过数据推动组织业务的创新和发展,通常直接汇报给 CEO 或 CIO。
24 |
25 | - 管理出成效,制度是保障
26 |
27 | 大数据治理需要管理和制度的有力支撑,可结合企业的现状,制定相应的管理办法、管理流程、认责体系、人员角色和岗位职责等,颁布相关的数据治理的企业规章制度等。
28 |
29 | - 数据规范:没有规矩,不成方圆
30 |
31 | 数据规范是指对企业核心数据进行有关存在性、完整性、质量及归档的测量标准,为评估企业数据质量,并且为手动录入、设计数据加载程序、更新信息以及开发应用软件提供的约束性规则,数据规范一般包括数据标准、数据模型、业务规则、元数据、主数据和参考数据。
32 |
33 | 制定数据标准的目的是为了使业务人员、技术人员在提到同一个指标、名词、术语的时候有一致的含义。数据模型对企业运营过程中涉及的业务概念和逻辑规则进行统一定义。业务规则是一种权威性原则或指导方针,用来描述业务交互,并建立行动和数据行为结果及完整性的规则。元数据能够帮助增强数据理解,可以架起企业内业务与 IT 部门之间的桥梁。主数据用来描述参与组织业务的人员、地点和事物。参考数据是系统、应用软件、数据库、流程、报告中及交易记录中用来参考的数值集合或分类表。
34 |
35 | - 数据治理活动,理论结合实践
36 |
37 | 数据治理活动是指为实现数据资产价值的获取、控制、保护、交付以及提升,对数据规范所做的计划、执行和监督工作,一般包括以下活动。
38 |
39 | 数据架构管理,用于定义企业数据需求,设计实现数据需求的主要蓝图,通常包括数据标准管理、数据模型管理、数据集成架构等;数据质量管理,指通过计划、实施和控制活动,运用质量管理技术度量、评估、改进和保证数据的恰当使用;元数据管理,指通过计划、实施和控制活动,以实现轻松访问高质量和整合的元数据;数据安全管理,指通过计划、制定并执行数据安全政策和措施,为数据和信息提供适当的认证、授权、访问和审计;参考数据和主数据管理,指通过计划、实施和控制活动,达到保证参考数据与主数据的一致性。
40 |
41 | - 数据治理软件:工欲善其事,必先利其器
42 |
43 | 目前业界流行的数据治理软件,一般也称为数据资产管理产品、数据治理产品,主要包括的功能组件有元数据管理工具、数据标准管理工具、数据模型管理工具、数据质量管理工具、主数据管理工具、数据安全管理工具等。
44 |
45 | 利用数据治理软件主要解决企业不同来源数据集成过程中遇到的问题,需要数据治理软件能够为企业提供统一的元数据集成、数据标准管理、数据模型设计、数据质量稽核、数据资产目录、数据分析服务等能力。
46 |
47 | 基于大数据的人工智能时代的到来,为各行业带来基于数据资产进行业务创新、管理创新的契机,伴随着企业数字化转型过程,越来越多的数据被收集,大数据治理将为企业提供更全面更准确的数据,届时人类的大部分行为将可以被计算和预测,这种对社会成员的行为逻辑、社会事件的发展态势提前作出判断、预测和模拟,将使社会治理模式得到极大变革,从而极可能推动社会治理也由传统的人类精英经验治理向基于大数据的智能化治理转型。
48 |
--------------------------------------------------------------------------------
/04~数据可视化/README.md:
--------------------------------------------------------------------------------
1 | # 数据可视化与 BI
2 |
3 | [大数据汇聚](https://ng-tech.icu/books/DistributedSystem-Notes/#/?q=大数据)、[数据处理与分析](https://ngte-aidl.gitbook.io/?q=数据处理)、《[CG-Notes](https://github.com/wx-chevalier/CG-Notes?q=)》这三者构成了数据科学的主要流程,本篇数据可视化更多地关注于数据展示相关的技术知识。
4 |
5 | # 可视化定义
6 |
7 | 数据可视化研究的是,如何将数据转化成为交互的图形或图像等,以视觉可以感受的方式表达,增强人的认知能力,达到发现、解释、分析、探索、决策和学习的目的。《数据可视化之美》一书中阐述道:数据可视化(Data Visualization)和信息可视化(Infographics)是两个相近的专业领域名词。狭义上的数据可视化指的是数据用统计图表方式呈现,而信息可视化则是将非数字的信息进行可视化。前者用于传递信息,后者用于表现抽象或复杂的概念、技术和信息。而广义上的数据可视化则是数据可视化、信息可视化以及科学可视化等等多个领域的统称。
8 |
9 | 
10 |
11 | 科学可视化(Scientific Visualization)、信息可视化(Information Visualization)和可视分析学(Visual Analytics)三个学科方向通常被看成可视化的三个主要分支。这三个分支整合在一起形成的新学科“数据可视化”,是可视化研究领域的新起点。
12 |
13 | ## 科学可视化
14 |
15 | 科学可视化(Scientific Visualization)是可视化领域最早、最成熟的一个跨学科研究与应用领域[石教英 1996]。面向的领域主要是自然科学,如物理、化学、气象气候、航空航天、医学、生物学等各个学科,这些学科通常需要对数据和模型进行解释、操作与处理,旨在寻找其中的模式、特点、关系以及异常情况[Schroeder2004]。
16 |
17 | 
18 |
19 | ## 信息可视化
20 |
21 | 信息可视化(Information Visualization)处理的对象是抽象数据集合,起源于统计图形学,又与信息图形、视觉设计等现代技术相关。其表现形式通常在二维空间,因此关键问题是在有限的展现空间中以直观的方式传达大量的抽象信息。与科学可视化相比,科学可视化处理的数据具有天然几何结构(如磁感线、流体分布等),信息可视化更关注抽象、高维数据。柱状图、趋势图、流程图、树状图等,都属于信息可视化最常用的可视表达,这些图形的设计都将抽象的数据概念转化成为可视化信息。
22 |
23 | 
24 |
25 | ## 可视分析学
26 |
27 | 可视分析学(Visual Analytics)被定义为一门以可视交互为基础的分析推理科学[Thomas2005]。它综合了图形学、数据挖掘和人机交互等技术,以可视交互界面为通道,将人感知和认知能力以可视的方式融入数据处理过程,形成人脑智能和机器智能优势互补和相互提升,建立螺旋式信息交流与知识提炼途径,完成有效的分析推理和决策。
28 |
29 | 
30 |
31 | # 可视化流程
32 |
33 | 数据可视化的本质是将数据通过各种视觉通道映射成图形,可以使得用户更快、更准确的理解数据。因此数据可视化要解决的问题是如何将数据通过视觉可观测的方式表达出来,同时需要考虑美观、可理解性,需要解决在展示的空间(画布)有限的情况下覆盖、杂乱、冲突等问题,再以交互的形式查看数据的细节。
34 |
35 | 
36 |
37 | 整个可视化流程,可以抽象地分为视觉编码与视觉通道两部分:
38 |
39 | - 视觉编码描述的是将数据映射到最终可视化结果上的过程。这里的可视化结果可能是图标,图片,也可能是一张网页等等;数据映射指把我们要分析的数据转换成可视化结果可以展示的数据,比如在把业务数据转换成 ECharts 或者 G2 Chart,为展示的数据封装了一些组件。
40 |
41 | - 视觉通道是利用几何图形的尺寸、数值、纹理、颜色、方向和形状来表示数据的图形,后来人们又补充了长度、面积、体积、透明度、模糊/聚焦、动画等特征;通过这些特征最终呈现的图形主要有散点图、条形图、直方图、饼形图、线形图和累计图等。
42 |
43 | 数据可视化过程可以分为下面几个步骤:
44 |
45 | - 定义要解决问题
46 | - 确定要展示的数据和数据结构
47 | - 确定要展示的数据的维度(字段)
48 | - 确定使用的图表类型
49 | - 确定图表的交互
50 |
51 | ## 问题定义
52 |
53 | 首先明确数据可视化是要让用户看懂数据,理解数据。所以开始数据可视化前一定要定义通要解决的问题。例如:我想看过去两周销售额的变化,是增长了还是下跌了,什么原因导致的?你可以从 趋势、对比、分布、流程、时序、空间、关联性等角度来定义自己要解决的问题。
54 |
55 | ## 数据选择
56 |
57 | 进行数据可视化首先要有数据,由于画布大小的限制,过量的数据不能够在直接显示出来,所以要确定展示的数据:
58 |
59 | - 我要展示的数据是否已经加工好,是否存在空值?
60 | - 是列表数据还是树形数据?
61 | - 数据的规模有多大?
62 | - 是否要对数据进行聚合,是否要分层展示数据?
63 | - 如何加载到页面,是否需要在前端对数据处理?
64 |
65 | ## 维度选择
66 |
67 | 进行可视化时要对字段进行选择,选择不同的字段在后面环节中选择适合的图表类型也不同。
68 |
69 | ## 图表选择
70 |
71 | 视觉编码设计的原则:
72 |
73 | - 表达性、一致性:可视化的结果应该充分表达了数据想要表达的信息,且没有多余。
74 | - 有效性、理解性:可视化之后比前一种数据表达方案更加有效,更加容易让人理解。
75 |
76 | 
77 |
78 | # 数据可视化场景
79 |
80 | - 通用报表
81 | - 移动端图表
82 | - 大屏可视化
83 | - 图编辑与图分析
84 | - 地理可视化
85 |
86 | # Links
87 |
88 | - https://zhuanlan.zhihu.com/p/24835341
89 |
--------------------------------------------------------------------------------
/02~数据集成/DataPipeline/README.md:
--------------------------------------------------------------------------------
1 | # Data Pipeline | 实时数据集成平台
2 |
3 | 传统的数据融合通常基于批模式。在批的模式下,我们会通过一些周期性运行的 ETL JOB,将数据从关系型数据库、文件存储向下游的目标数据库进行同步,中间可能有各种类型的转换。
4 |
5 | 
6 |
7 | 另一种是 Data Pipeline 模式。与批模式相比相比,其最核心的区别是将批量变为实时:输入的数据不再是周期性的去获取,而是源源不断的来自于数据库的日志、消息队列的消息。进而通过一个实时计算引擎,进行各种聚合运算,产生输出结果,并且写入下游。现代的一些处理框架,包括 Flink、Kafka Streams、Spark,或多或少都能够支持批和流两种概念。换言之,流式处理能力是实时数据集成平台必要的组件;结合企业技术栈特点,选用包括 Flink、Spark Streaming、Kafka Streams 等流行的引擎在多数情况下都能够满足要求。端到端数据的 EOS 是数据集成中的一个难题,需要用户根据业务实际需求、数据本身的特性、目的地特点 case by case 去解决。
8 |
9 | ## 系统挑战
10 |
11 | 如果问题简化到一张 MySQL 的表,里面只有几百万行数据,你可能想将其同步到一张 Hive 表中。基于这种情况,大部分问题都不会遇到。因为结构是确定的,数据量很小,且没有所谓的并行化问题。但在一个实际的企业场景下,如果做一个数据融合系统,就不可避免要面临几方面的挑战:
12 |
13 | - 动态性: 数据源会不断地发生变化,主要归因于:表结构的变化,表的增减。针对这些情况,你需要有一些相应的策略进行处理。
14 |
15 | - 可伸缩性: 任何一个分布式系统,必须要提供可伸缩性。因为你不是只同步一张表,通常会有大量数据同步任务在进行着。如何在一个集群或多个集群中进行统一的调度,保证任务并行执行的效率,这是一个要解决的基本问题。
16 |
17 | - 容错性: 在任何环境里你都不能假定服务器是永远在正常运行的,网络、磁盘、内存都有可能发生故障。这种情况下一个 Job 可能会失败,之后如何进行恢复?状态能否延续?是否会产生数据的丢失和重复?这都是要考虑的问题。
18 |
19 | - 异构性: 当我们做一个数据融合项目时,由于源和目的地是不一样的,比如,源是 MySQL,目的地是 Oracle,可能它们对于一个字段类型定义的标准是有差别的。在同步时,如果忽略这些差异,就会造成一系列的问题。
20 |
21 | - 一致性: 一致性是数据融合中最基本的问题,即使不考虑数据同步的速度,也要保证数据一致。数据一致性的底线为:数据先不丢,如果丢了一部分,通常会导致业务无法使用;在此基础上更好的情况是:源和目的地的数据要完全一致,即所谓的端到端一致性,如何做到呢?
22 |
23 | # Lambda 架构
24 |
25 | Lambda 架构的核心是按需使用批量和流式的处理框架,分别针对批式和流式数据提供相应的处理逻辑。最终通过一个服务层进行对外服务的输出。与之相对,还有一种架构叫 Kappa 架构,即用一个流式处理引擎解决所有问题。我们认为 Lambda 架构是批流一体化的必然要求。
26 |
27 | 实际上,这在很大程度来自于现实中用户的需求。DataPipeline 在刚刚成立时只有一种模式,只支持实时流同步,在我们看来这是未来的一种趋势。但后来发现,很多客户实际上有批量同步的需求。比如,银行在每天晚上可能会有一些月结、日结,证券公司也有类似的结算服务。基于一些历史原因,或出于对性能、数据库配置的考虑,可能有的数据库本身不能开 change log。所以实际上并不是所有情况下都能从源端获取实时的流数据。考虑到上述问题,我们认为一个产品在支撑数据融合过程中,必须能同时支撑批量和流式两种处理模式,且在产品里面出于性能和稳定性考虑提供不同的处理策略,这才是一个相对来说比较合理的基础架构。
28 |
29 | ## 数据融合
30 |
31 | 数据源变化捕获是数据集成的起点,结合日志的解析、增量条件查询模式和数据源主动 Push 模式,最终构建出一个数据汇集层。在这个阶段,推荐考虑 Kafka Connect 这类面向数据集成的专有框架,可以有效缩短研发周期和成本。数据汇集层建议构建在消息队列之上,为后继的加工处理提供便利。如果需要全量持久化长期保存,建议结合使用消息队列和分布式文件系统分别做实时数据和全量数据的存储。
32 |
33 | ### Ad-Hoc 模式
34 |
35 | 假如我需要将数据从 MySQL 同步到 Hive,可以直接建立一个 ETL 的 JOB(例如基于 Flink),其中封装所有的处理逻辑,包括从源端读取数据,然后进行变换写入目的地。在将代码编译好以后,就可以放到 Flink 集群上运行,得到想要的结果。这个集群环境可以提供所需要的基础能力,刚才提到的包括分布式,容错等。
36 |
37 | ETL Job 封装所有的处理逻辑,从源端读取,注入数据,将结果写入到目的地,并且完成有状态,无状态的转换。批流处理框架提供了可重用的源与目的地连接器,Operator 与 DAG,以及分布式的环境与容错。
38 |
39 | ### MQ 模式
40 |
41 | 另一种模式是 ETL JOB 本身输入输出实际上都是面对消息队列的,实际上这是现在最常使用的一种模式。在这种模式下,需要通过一些独立的数据源和目的地连接器,来完成数据到消息队列的输入和输出。ETL JOB 可以用多种框架实现,包括 Flink、Kafka Streams 等,ETL JOB 只和消息队列发生数据交换。。DataPipeline 选择 MQ 模式,主要有几点考虑:
42 |
43 | - 要做数据的一对多分发。数据要进行一次读取,然后分发到各种不同的目的地,这是一个非常适合消息队列使用的分发模型。详情见:数据融合重磅功能丨一对多实时分发、批量读取模式
44 | - 有时会对一次读取的数据加不同的处理逻辑,我们希望这种处理不要重新对源端产生一次读取。所以在多数情况下,都需将数据先读到消息队列,然后再配置相应的处理逻辑。
45 | - Kafka Connect 就是基于 MQ 模式的,它有大量的开源连接器。基于 Kafka Connect 框架,我们可以重用这些连接器,节省研发的投入。
46 | - 当你把数据抽取跟写入目的地,从处理逻辑中独立出来之后,便可以提供更强大的集成能力。因为你可以在消息队列上集成更多的处理逻辑,而无需考虑重新写整个 Job。
47 |
48 | 相应而言,如果你选择将 MQ 作为所有 JOB 的传输通道,就必须要克服几个缺点:
49 |
50 | - 所有数据的吞吐都经过 MQ,所以 MQ 会成为一个吞吐瓶颈。
51 | - 因为是一个完全的流式架构,所以针对批量同步,你需要引入一些边界消息来实现一些批量控制。
52 | - Kafka 是一个有持久化能力的消息队列,这意味着数据留存是有极限的。比如,你将源端的读到 Kafka Topic 里面,Topic 不会无限的大,有可能会造成数据容量超限,导致一些数据丢失。
53 | - 当批量同步在中间因为某种原因被打断,无法做续传时,你需要进行重传。在重传过程中,首先要将数据进行清理,如果基于消息队列模式,清理过程就会带来额外的工作。你会面临两个困境:要么清空原有的消息队列,要么你创造新的消息队列。这肯定不如像直接使用一些批量同步框架那样来的直接。
54 |
--------------------------------------------------------------------------------
/03~数仓建模/02~多维数据模型/01~事实表、维度表、聚合表/02~维度表.md:
--------------------------------------------------------------------------------
1 | # 维度表
2 |
3 | 维度表可以看作是用户来分析数据的窗口,纬度表中包含事实数据表中事实记录的特性,有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息,维度表包含帮助汇总数据的特性的层次结构。例如,包含产品信息的维度表通常包含将产品分为食品、饮料、非消费品等若干类的层次结构,这些产品中的每一类进一步多次细分,直到各产品达到最低级别。
4 |
5 | 在维度表中,每个表都包含独立于其他维度表的事实 特性,例如,客户维度表包含有关客户的数据。维度表中的列字段可以将信息分为不同层次的结构级。维度表包含了维度的每个成员的特定名称。维度成员的名称称为“属性”(Attribute)。假设 Product 维度中有 3 种产品,那么维度表将如下所示。
6 |
7 | | PROD_ID | Product_Name |
8 | | ------- | ------------ |
9 | | 347 | Mountain-100 |
10 | | 339 | Road-650 |
11 | | 447 | Cable Lock |
12 |
13 | 产品名称是产品成员的一个属性。因为维度表中的 Product ID 与事实表中的 Product ID 相匹配,称为“键属性”。因为每个 Product ID 只有一个 Product Name,显示时用名称来替代整数值,所以它仍然被认为是键属性的一部分。
14 |
15 | 在数据仓库中,维度表中的键属性必须为维度的每个成员包含一个对应的唯一值。用关系型数据库术语描述就是,键属性称为主键列。每个维度表中的主键值都与任何相关的事实表中的键值相关。在维度表中出现一次的每个键值都会在事实表中出现多次。例如 Mountain-100 的 Product ID 347 只在一个维度表数据行中出现,但它会出现在多个事实表数据行中。这称为一对多关系。在事实表中,键值列(它是一对多关系的“多”的一方)称为外键列。关系型数据库使用匹配的主键列(在维度表中)和外键列(在事实表中)值来联接维度表到事实表。
16 |
17 | 把维度信息移动到一个单独的表中,除了使得事实表更小外,还有额外的优点——可以为每个维度成员添加额外的信息。例如,维度表可能为每个产品添加种类(Category)信息,如下所示。
18 |
19 | | PROD_ID | Product_Name | Category |
20 | | ------- | ------------ | ----------- |
21 | | 347 | Mountain-100 | Bikes |
22 | | 339 | Road-650 | Bikes |
23 | | 447 | Cable Lock | Accessories |
24 |
25 | 现在种类是产品的另一个属性。如果知道 Product ID,不但可以推断出 Product Name,而且可以推断出 Category。键属性的名称可能是唯一的——因为每个键只有一个名称,但其他属性不需要是唯一的,例如 Category 属性可能会出现好几次。这样一来,便可以创建按照产品和类别对事实表信息进行分组的报表。除了名称外,维度表可以包含许多其他的属性。本质上,每个属性都对应于维度表中的一个列。下面是带有其他额外属性的只有 3 个成员的 Product 维度表的示例。
26 |
27 | | PROD_ID | Product_Name | Category | Color | Size | Price |
28 | | ------- | ------------ | ----------- | ------ | ---- | ------- |
29 | | 347 | Mountain-100 | Bikes | Black | 44 | 782.99 |
30 | | 339 | Road-650 | Bikes | Silver | 48 | 3399.99 |
31 | | 447 | Cable Lock | Accessories | NA | NA | 25.00 |
32 |
33 | 维度属性可以是可分组的,也可以是不可分组的。换句话就是,您是否见过按照哪个属性来分组度量值的报表?在我们的示例中,Category、Size 和 Color 全都是可分组的属性。由此自然会联想到可能在某个报表中按照颜色、大小或种类来分组销售额。但 Price 看起来不像是可分组的属性——至少它本身不是。在报表中可能会有一个更有意义的其他属性——例如 Price Group,但价格本身变化太大,导致在报表上分组意义不大。同样地,按照 Product Description 属性在报表上进行分组意义也不大。在一个 Customer 维度中,City、Country、Gender 和 Marital Status 都是可以在报表上按照它们进行有意义分组的属性,但 Street Address 或 Nickname 都应当是不可分组的。不可分组的属性通常称为成员属性(member property)。
34 |
35 | ## Hierarchy 与 Level
36 |
37 | 某些可分组的属性可以组合起来创建一个自然层次结构(natural hierarchy)。例如假设 Product 有 Category 和 Subcategory 属性,在多数情况下,单个产品只会属于单个 Subcategory,并且单个 Subcategory 只会属于单个 Category。这将形成一个自然层次结构。在报表中,可能会显示 Categories,然后允许用户从某个 Category 钻取到 Subcategories,以及最终钻取到 Products。
38 |
39 | 层次结构——或者说钻取路径——不一定要是自然的(例如,每个低层次的成员会决定下一个高层次的成员)。例如,您可能会创建一个按照 Color 分组产品的报表,但允许用户根据每个 Color 钻取到每个不同的 Size。因为报表的钻取能力,Color 和 Size 形成了一个层次结构,但是根据 Size 却没有任何信息可以用来断定产品的 Color 将是什么。这是一个层次结构,但不是一个自然层次结构——但也不是说它是个非自然层次结构。Color 和 Size 形成一个层次结构并没有什么不对,它只是这样一个简单的事实:相同的 Size 可以出现在多个 Color 中。
40 |
41 | 在 OLAP 中定义维度时,层(Hierarchy)与级(Level)是比较让人迷惑的两个概念。简单的说,层就是一种维度成员的分类方式,级就是维度成员之间或维度成员属性之间的包含关系。一个维度至少要包含一个层。以【产品】维度为例,可以创建一个【产地】层,可以创建一个【厂商】层,也可以创建一个【分类】层。在 SSAS 中,可以不定义层,此时维度的默认层为 AllMembers 层。在 Mondrian 的 Schema 定义工具中,则要求全部手工定义。
42 |
43 | 一个层至少要包含一个级,以【产品】维度为例,【产地】层可以包含省-市-县三个级别,【分类】层可以包含日用品-洗涤用品-洗衣粉三个级别。级别的定义有 2 种方式,一种是在一个维度成员的属性之间定义,例如【产品】维度的每个成员都有产品系列、大类、小类三个属性,这样定义【分类】层的级别时,直接利用这三个属性即可,即:每个级别都是一个成员的一个属性。另一种是在维度成员之间进行,例如 HR 中的上下级关系,每个级别都是一个具体的维度成员,即:每个级别都是一个或多个维度成员,每个级都包含多个属性。后一种级别在数据库中往往是以递归的方式进行保存的。
44 |
--------------------------------------------------------------------------------
/01~大数据体系/01~大数据生态/大数据平台.md:
--------------------------------------------------------------------------------
1 | # 大数据平台
2 |
3 | 大数据平台是将互联网产品和后台的大数据系统整合起来,将应用系统产生的数据导入大数据平台,经过计算后导出给应用系统使用。大数据平台将互联网应用和大数据产品整合起来,将实时数据和离线数据打通,使数据可以实现更大规模的关联计算,挖掘出数据更大的价值,从而实现数据驱动业务。大数据平台使得大数据技术产品可以落地应用,实现了自身价值。
4 |
5 | 总体来说:大数据平台可以分为四个部分:数据采集、数据处理、数据输出和任务调度管理。
6 |
7 | 
8 |
9 | # 数据采集
10 |
11 | ## 数据库数据
12 |
13 | 目前比较常用的数据库导入工具有 Sqoop 和 Canal。
14 |
15 | Sqoop 是一个数据库批量导入导出工具,可以将关系数据库的数据批量导入到 Hadoop,也可以将 Hadoop 的数据导出到关系数据库。
16 |
17 | Sqoop 适合关系数据库数据的批量导入,如果想实时导入关系数据库的数据,可以选择 Canal。Canal 是阿里巴巴开源的一个 MySQLbinlog 获取工具,Binlog 是 MySQL 的事务日志,可用于 MySQL 数据库主从复制,Canal 将自己伪装成 MySQL 从库,从 MySQL 获取 Binlog。
18 |
19 | ## 日志数据
20 |
21 | 日志是大数据平台重要数据来源之一,应用程序日志一方面记录各种程序执行状况,一方面记录用户的操作轨迹。Flume 是大数据日志收集常用的工具。Flume 最早由 Cloudera 开发,后来捐赠给 Apache 基金会作为开源项目运营。
22 |
23 | ## 前端程序埋点
24 |
25 | 所谓前端埋点,是应用前端为了进行数据统计和分析采集数据。
26 |
27 | 用户的某些前端行为并不会产生后端请求,比如用户页面停留时间、用户浏览速度、用户点选又取消等等。这些信息对于分析用户行为等都很有价值。但是这些数据必须通过前端埋点获得,有些互联网公司会将前端埋点数据当作最主要的大数据来源,用户所有前端行为,都会埋点采集,再辅助结合其他的数据源,构建自己的大数据仓库,进而进行数据分析和挖掘。
28 |
29 | 对于一个互联网应用,当我们提到前端的时候,可能指的是如下几类:
30 |
31 | - App 程序,比如一个 iOS 应用或者 Android 应用,安装在用户的手机或者平板上;
32 |
33 | - PC Web 前端,使用 PC 浏览器打开;
34 |
35 | - H5 前端,由移动设备浏览器打开;
36 |
37 | - 微信小程序,在微信内打开。
38 |
39 | 这些不同的前端使用不同的开发语言开发,运行在不同的设备上,每一类前端都需要解决自己的埋点问题。埋点的方式主要有手工埋点、自动化埋点和可视化埋点。
40 |
41 | - 手工埋点就是前端开发者手动编程将需要采集的前端数据发送到后端的数据采集系统。通常公司会开发一些前端数据上报的 SDK,前端工程师在需要埋点的地方,调用 SDK,按照接口规范传入相关参数,比如 ID、名称、页面、控件等通用参数,还有业务逻辑数据等,SDK 将这些数据通过 HTTP 的方式发送到后端服务器。
42 |
43 | - 自动化埋点则是通过一个前端程序 SDK,自动收集全部用户操作事件,然后全量上传到后端服器。自动化埋点有时候也被称作无埋点,意思是无需埋点,实际上是全埋点,即全部用户操作都埋点采集。自动化埋点的好处是开发工作量小,数据规范统一。缺点是采集的数据量大,很多数据采集来也不知道有什么用,白白浪费了计算资源,特别是对于流量敏感的移动端用户而言,因为自动化埋点采集上传花费了大量的流量,可能因此成为卸载应用的理由,这样就得不偿失了。在实践中,有时候只是针对部分用户做自动埋点,抽样一部分数据做统计分析。
44 |
45 | - 介于手工埋点和自动化埋点之间的,还有一种方案是可视化埋点。通过可视化的方式配置哪些前端操作需要埋点,根据配置采集数据。可视化埋点实际上是可以人工干预的自动化埋点。
46 |
47 | ## 爬虫系统
48 |
49 | 通过网络爬虫获取外部数据用于行业数据支撑,管理决策等。由于涉及到敏感内容,不做更多的展开。
50 |
51 | # 数据处理
52 |
53 | 大数据平台的核心,分为离线计算和实时计算两类。
54 |
55 | - 离线计算:由 MapReduce、Hive、Spark 等进行的计算处理。
56 |
57 | - 实时计算:由 Storm、SparkSteaming 等流式大数据引擎完成,可以在秒级甚至毫秒级时间内完成计算。
58 |
59 | ## 数据输出
60 |
61 | 大数据处理与计算产生的数据写入到 HDFS 中,但应用程序不会到 HDFS 中读取数据,所以必须要将 HDFS 中的数据导出到数据库中。除了给用户提供数据,大数据平台还需要在一些后台系统中给运营和决策层提供各种统计数据,这些数据也写入数据库,被相应的后台系统访问。
62 |
63 | ## 任务调度
64 |
65 | 将上面三个部分有效整合和运转起来的是任务调度管理系统,它的主要作用是:
66 |
67 | - 合理调度各种 MapReduce、Spark 任务使资源利用最合理
68 |
69 | - 尽快执行临时的重要任务
70 |
71 | - 对作业提交、进度跟踪、数据查看等功能
72 |
73 | 简单的大数据平台任务调度管理系统其实就是一个类似 Crontab 的定时任务系统,按预设时间启动不同的大数据作业脚本。复杂的大数据平台任务调度还要考虑不同作业之间的依赖关系。开源的大数据调度系统有 Oozie,也可以在此基础进行扩展。
74 |
75 | # Hadoop 不足
76 |
77 | 虽然 Hadoop 在通过批处理支持大型存储和 ETL(提取、转换和加载)作业以及支持机器学习任务方面大有价值,但它在支持公司和大型组织用来管理日常运营的较为传统的分析工作方面并非最佳选择。Hive、Dremel 和 Spark 等工具在 Hadoop 上面使用以支持分析,但 Hadoop 从未变得足够快,无法真正取代数据仓库。
78 |
79 | Hadoop 还面临这样的挑战:NoSQL 数据库和对象存储提供商在解决 Hadoop 最初旨在帮助解决的部分存储和管理难题方面取得了进展。随着时间的推移,在 Hadoop 上支持业务连续性面临挑战,加上支持实时、地理空间及其他新兴的分析使用场合方面缺乏灵活性,这使得 Hadoop 面对海量数据时很难在批处理之外大有作为。
80 |
81 | 此外,久而久之,许多公司开始发现大数据难题越来越与此有关:支持一系列广泛的数据源,并迅速调整数据模式、查询、定义和上下文,新的应用程序、平台和云基础设施供应商就体现了这一点。为了克服这个挑战,分析、集成和复制就必须变得更敏捷更快速。许多供应商纷纷创办就体现了这个挑战,包括:
82 |
83 | - 分析解决方案:比如 ClearStory Data、Domo、Incorta、Looker、FineBI、Microsoft Power BI、Qlik、Sisense、Tableau 和 ThoughtSpot
84 |
85 | - 数据管道供应商:比如 Alooma、Attunity、Alteryx、Fivetran 和 Matillion
86 |
87 | - 数据集成供应商:包括 Informatica、MuleSoft、SnapLogic、Talend 和 TIBCO(后者还凭借其 Spotfire 产品组合角逐分析领域)。
88 |
89 | # Links
90 |
91 | - https://www.freebuf.com/articles/database/221147.html?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
92 |
--------------------------------------------------------------------------------
/10~OLAP/02.MOLAP/HBase/架构分析.md:
--------------------------------------------------------------------------------
1 | # HBase Architecture
2 |
3 | HBase 采用 Master/Slave 架构搭建集群,它隶属于 Hadoop 生态系统,由一下类型节点组成:HMaster 节点、HRegionServer 节点、ZooKeeper 集群,而在底层,它将数据存储于 HDFS 中,因而涉及到 HDFS 的 NameNode、DataNode 等,总体结构如下:  其中**HMaster 节点**用于:
4 |
5 | 管理HRegionServer,实现其负载均衡。
6 | 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。
7 | 实现DDL操作(Data Definition
8 | Language,namespace和table的增删改,column
9 | familiy的增删改等)。
10 | 管理namespace和table的元数据(实际存储在HDFS上)。
11 | 权限控制(ACL)。
12 |
13 | **HRegionServer 节点**用于:
14 |
15 | 存放和管理本地HRegion。
16 | 读写HDFS,管理Table中的数据。
17 | Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
18 |
19 | **ZooKeeper 集群是协调系统**,用于:
20 |
21 | 存放整个
22 | HBase集群的元数据以及集群的状态信息。
23 | 实现HMaster主从节点的failover。
24 |
25 | HBase Client 通过 RPC 方式和 HMaster、HRegionServer 通信;一个 HRegionServer 可以存放 1000 个 HRegion;底层 Table 数据存储于 HDFS 中,而 HRegion 所处理的数据尽量和数据所在的 DataNode 在一起,实现数据的本地化;数据本地化并不是总能实现,比如在 HRegion 移动 ( 如因 Split) 时,需要等下一次 Compact 才能继续回到本地化。
26 |
27 | # HFile
28 |
29 | HFile 数据格式中的 Data 字段用于存储实际的 KeyValue 数据,MetaIndex 字段用于 Meta 块的起始点,Magic 字段用于存储随机数,防止数据被破坏。而 HFile 中的 KeyValue 数据格式中的 Key 应该是 byte[] 数组,Value 部分是二进制数据。
30 |
31 | # 预分区
32 |
33 | HBase中,表会被划分为1...n个Region,被托管在RegionServer中。Region二个重要的属性:StartKey与 EndKey表示这个Region维护的rowKey范围,当我们要读/写数据时,如果rowKey落在某个start-end key范围内,那么就会定位到目标region并且读/写到相关的数据。简单地说,有那么一点点类似人群划分,1-15岁为小朋友,16-39岁为年轻 人,40-64为中年人,65岁以上为老年人。(这些数值都是拍脑袋出来的,只是举例,非真实),然后某人找队伍,然后根据年龄,处于哪个范围,就找到它 所属的队伍。: ( 有点废话了。。。。
34 | 然后,默认地,当我们只是通过HBaseAdmin指定TableDescriptor来创建一张表时,只有一个region,正处于混沌时 期,start-end key无边界,可谓海纳百川。啥样的rowKey都可以接受,都往这个region里装,然而,当数据越来越多,region的size越来越大时,大到 一定的阀值,hbase认为再往这个region里塞数据已经不合适了,就会找到一个midKey将region一分为二,成为2个region,这个过 程称为分裂(region-split).而midKey则为这二个region的临界,左为N无下界,右为M无上界。< midKey则为阴被塞到N区,> midKey则会被塞到M区。
35 | 如何找到midKey?涉及的内容比较多,暂且不去讨论,最简单的可以认为是region的总行数 / 2 的那一行数据的rowKey.虽然实际上比它会稍复杂点。
36 | 如果我们就这样默认地,建表,表里不断地Put数据,更严重的是我们的rowkey还是顺序增大的,是比较可怕的。存在的缺点比较明显。
37 | 首先是热点写,我们总是会往最大的start-key所在的region写东西,因为我们的rowkey总是会比之前的大,并且hbase的是按升序方式排序的。所以写操作总是被定位到无上界的那个region中。
38 | 其次,由于写热点,我们总是往最大start-key的region写记录,之前分裂出来的region不会再被写数据,有点被打进冷宫的赶脚,它们都处于半满状态,这样的分布也是不利的。
39 | 如果在写比较频率的场景下,数据增长快,split的次数也会增多,由于split是比较耗时耗资源的,所以我们并不希望这种事情经常发生。
40 | ............
41 | 看到这些缺点,我们知道,在集群的环境中,为了得到更好的并行性,我们希望有好的load blance,让每个节点提供的请求处理都是均等的。我们也希望,region不要经常split,因为split会使server有一段时间的停顿,如何能做到呢?
42 |
43 | 随机哈希与预分区。二者结合起来,是比较完美的,预分区一开始就预建好了一部分 region, 这些 region 都维护着自已的 start-end keys,再配合上随机哈希,写数据能均等地命中这些预建的 region,就能解决上面的那些缺点,大大地提高了性能。提供 2 种思路 : hash 与 partition. 一、hash 就是 rowkey 前面由一串随机字符串组成, 随机字符串生成方式可以由 SHA 或者 MD5 等方式生成,只要 region 所管理的 start-end keys 范围比较随机,那么就可以解决写热点问题。long currentId = 1L; byte [] rowkey = Bytes.add(MD5Hash.getMD5AsHex(Bytes.toBytes(currentId)).substring(0, 8).getBytes(), Bytes.toBytes(currentId));
44 |
45 | 假设 rowKey 原本是自增长的 long 型,可以将 rowkey 转为 hash 再转为 bytes,加上本身 id 转为 bytes, 组成 rowkey,这样就生成随便的 rowkey。那么对于这种方式的 rowkey 设计,如何去进行预分区呢?1. 取样,先随机生成一定数量的 rowkey, 将取样数据按升序排序放到一个集合里 2. 根据预分区的 region 个数,对整个集合平均分割,即是相关的 splitKeys. 3.HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][] splitkeys) 可以指定预分区的 splitKey,即是指定 region 间的 rowkey 临界值 .
46 |
47 | 以上,就已经按hash方式,预建好了分区,以后在插入数据的时候,也要按照此rowkeyGenerator的方式生成rowkey,有兴趣的话,也可以做些试验,插入些数据,看看数据的分布。
48 |
49 | 二、partition故名思义,就是分区式,这种分区有点类似于mapreduce中的partitioner,将区域用长整数(Long)作为分区号,每个region管理着相应的区域数据,在rowKey生成时,将id取模后,然后拼上id整体作为rowKey.这个比较简单,不需要取 样,splitKeys也非常简单,直接是分区号即可。直接上代码吧:
50 |
51 | calcSplitKeys 方法比较单纯,splitKey 就是 partition 的编号, 我们看看测试类 : Java 代码 收藏代码
52 |
53 | 通过partition实现的loadblance写的话,当然生成rowkey方式也要结合当前的region数目取模而求得,大家同样也可以做些实验,看看数据插入后的分布。
54 |
55 | 在这里也顺提一下,如果是顺序的增长型原 id, 可以将 id 保存到一个数据库,传统的也好 ,redis 的也好,每次取的时候,将数值设大 1000 左右,以后 id 可以在内存内增长,当内存数量已经超过 1000 的话,再去 load 下一个,有点类似于 oracle 中的 sqeuence.
56 |
57 | 随机分布加预分区也不是一劳永逸的。因为数据是不断地增长的,随着时间不断地推移,已经分好的区域,或许已经装不住更多的数据,当然就要进一步进行 split了,同样也会出现性能损耗问题,所以我们还是要规划好数据增长速率,观察好数据定期维护,按需分析是否要进一步分行手工将分区再分好,也或者是 更严重的是新建表,做好更大的预分区然后进行数据迁移。
58 |
--------------------------------------------------------------------------------
/04~数据可视化/可视化开发库/D3/README.md:
--------------------------------------------------------------------------------
1 | # D3
2 |
3 | D3 是一个 JavaScript 库,用于在网络上创建定制的交互式图表和地图。虽然大多数图表库(如 Chart.js 和 Highcharts)都提供了现成的图表,但 D3 由大量的构件组成,可以从这些构件中构建自定义的图表或地图。D3 的方法比其他图表库的层次要低得多。用 Chart.js 创建一个条形图只需要几行代码。
4 |
5 | 用 D3 创建同样的图表,你需要:创建 SVG 矩形元素并将它们连接到数据上;矩形元素定位;根据数据确定矩形元素的大小;最后添加坐标轴。您可能还想当图表首次加载时,对条形图进行动画处理;容器自适应处理;添加工具提示等。这都是额外的工作,但它能让你完全控制图表的外观和行为。
6 |
7 | 如果一个标准的条形图、线形图或饼形图就足够了,你应该考虑使用 Chart.js 这样的库。然而,如果你希望按照精确的规格创建一个定制的图表,那么 D3 是值得考虑的。D3 的功能包括:
8 |
9 | - 数据驱动的 HTML/SVG 元素的修改
10 | - 加载和转换数据(如 CSV 数据)。
11 | - 生成复杂的图表,如树状图、包装圆和网络。
12 | - 一个强大的过渡系统,用于在不同的视图之间制作动画
13 | - 强大的用户交互支持,包括平移、缩放和拖动。
14 |
15 | # Hello World
16 |
17 | 
18 |
19 | ```html
20 |
21 |
22 |
23 | DOM Manipulation
24 |
25 |
26 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
70 |
71 |
72 |
73 |
74 |
184 |
185 |