├── .gitignore
├── .nojekyll
├── INTRODUCTION.md
├── LICENSE
├── README.md
├── _sidebar.md
├── header.svg
├── index.html
├── 分布式调度
├── README.md
├── 延时任务
│ └── README.md
├── 开源框架
│ └── xxl-job
│ │ └── README.md
├── 流程引擎
│ ├── Activiti
│ │ └── README.md
│ ├── BPMN
│ │ ├── BPMN 规范.md
│ │ └── README.md
│ └── README.md
└── 调度系统架构
│ ├── README.md
│ ├── 两层调度.md
│ ├── 体系结构
│ └── 集中式架构.md
│ ├── 共享状态调度.md
│ └── 单体调度.md
├── 批处理
├── Hadoop
│ ├── Hadoop 与数据库对比.md
│ ├── MapReduce
│ │ ├── CRUD.md
│ │ ├── README.md
│ │ ├── WordCount.md
│ │ └── 聚合计算.md
│ └── README.md
├── MapReduce
│ ├── README.md
│ ├── 作业执行.md
│ ├── 作业输出.md
│ └── 连接与分组.md
├── README.md
├── Waltz
│ └── README.md
├── 使用 Unix 工具的批处理.md
├── 执行框架
│ ├── README.md
│ ├── 图与迭代处理.md
│ ├── 物化中间状态.md
│ └── 高级 API 和语言.md
└── 编程模型
│ ├── Data Parallelism.md
│ ├── README.md
│ ├── 图的大规模并行.md
│ └── 查询与声明式接口.md
├── 流处理
├── 01~流处理系统设计
│ ├── DAG
│ │ ├── Dryad.md
│ │ └── README.md
│ ├── 执行框架
│ │ ├── 分布式快照.md
│ │ ├── 反压.md
│ │ ├── 容错.md
│ │ └── 流式连接.md
│ ├── 状态存储
│ │ └── 99~参考资料
│ │ │ └── 2022-流处理系统中状态的表示和存储.md
│ └── 编程模型
│ │ └── 时间窗口.md
├── 08~开源框架
│ ├── Beam
│ │ ├── Dataflow 模型.md
│ │ ├── README.md
│ │ ├── 快速开始.md
│ │ └── 部署与配置.md
│ ├── Spark
│ │ ├── README.md
│ │ ├── 代码开发.md
│ │ └── 环境配置.md
│ └── 流计算框架对比.md
├── 09~流处理数据库
│ └── README.md
├── 10~Flink
│ ├── Blink
│ │ └── README.md
│ ├── README.md
│ ├── Table API.md
│ ├── 代码开发.md
│ └── 快速开始.md
├── 99~参考资料
│ └── 2023-吴英俊-重新思考流处理与流数据库.md
└── README.md
└── 计算处理模式
├── Lambda 架构.md
├── README.md
├── 事务处理.md
├── 批处理与流处理.md
└── 量子计算
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | # Ignore all
2 | *
3 |
4 | # Unignore all with extensions
5 | !*.*
6 |
7 | # Unignore all dirs
8 | !*/
9 |
10 | .DS_Store
11 |
12 | # Logs
13 | logs
14 | *.log
15 | npm-debug.log*
16 | yarn-debug.log*
17 | yarn-error.log*
18 |
19 | # Runtime data
20 | pids
21 | *.pid
22 | *.seed
23 | *.pid.lock
24 |
25 | # Directory for instrumented libs generated by jscoverage/JSCover
26 | lib-cov
27 |
28 | # Coverage directory used by tools like istanbul
29 | coverage
30 |
31 | # nyc test coverage
32 | .nyc_output
33 |
34 | # Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
35 | .grunt
36 |
37 | # Bower dependency directory (https://bower.io/)
38 | bower_components
39 |
40 | # node-waf configuration
41 | .lock-wscript
42 |
43 | # Compiled binary addons (https://nodejs.org/api/addons.html)
44 | build/Release
45 |
46 | # Dependency directories
47 | node_modules/
48 | jspm_packages/
49 |
50 | # TypeScript v1 declaration files
51 | typings/
52 |
53 | # Optional npm cache directory
54 | .npm
55 |
56 | # Optional eslint cache
57 | .eslintcache
58 |
59 | # Optional REPL history
60 | .node_repl_history
61 |
62 | # Output of 'npm pack'
63 | *.tgz
64 |
65 | # Yarn Integrity file
66 | .yarn-integrity
67 |
68 | # dotenv environment variables file
69 | .env
70 |
71 | # next.js build output
72 | .next
73 |
--------------------------------------------------------------------------------
/.nojekyll:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/.nojekyll
--------------------------------------------------------------------------------
/INTRODUCTION.md:
--------------------------------------------------------------------------------
1 | # 本篇导读
2 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
2 | Public License
3 |
4 | By exercising the Licensed Rights (defined below), You accept and agree
5 | to be bound by the terms and conditions of this Creative Commons
6 | Attribution-NonCommercial-ShareAlike 4.0 International Public License
7 | ("Public License"). To the extent this Public License may be
8 | interpreted as a contract, You are granted the Licensed Rights in
9 | consideration of Your acceptance of these terms and conditions, and the
10 | Licensor grants You such rights in consideration of benefits the
11 | Licensor receives from making the Licensed Material available under
12 | these terms and conditions.
13 |
14 |
15 | Section 1 -- Definitions.
16 |
17 | a. Adapted Material means material subject to Copyright and Similar
18 | Rights that is derived from or based upon the Licensed Material
19 | and in which the Licensed Material is translated, altered,
20 | arranged, transformed, or otherwise modified in a manner requiring
21 | permission under the Copyright and Similar Rights held by the
22 | Licensor. For purposes of this Public License, where the Licensed
23 | Material is a musical work, performance, or sound recording,
24 | Adapted Material is always produced where the Licensed Material is
25 | synched in timed relation with a moving image.
26 |
27 | b. Adapter's License means the license You apply to Your Copyright
28 | and Similar Rights in Your contributions to Adapted Material in
29 | accordance with the terms and conditions of this Public License.
30 |
31 | c. BY-NC-SA Compatible License means a license listed at
32 | creativecommons.org/compatiblelicenses, approved by Creative
33 | Commons as essentially the equivalent of this Public License.
34 |
35 | d. Copyright and Similar Rights means copyright and/or similar rights
36 | closely related to copyright including, without limitation,
37 | performance, broadcast, sound recording, and Sui Generis Database
38 | Rights, without regard to how the rights are labeled or
39 | categorized. For purposes of this Public License, the rights
40 | specified in Section 2(b)(1)-(2) are not Copyright and Similar
41 | Rights.
42 |
43 | e. Effective Technological Measures means those measures that, in the
44 | absence of proper authority, may not be circumvented under laws
45 | fulfilling obligations under Article 11 of the WIPO Copyright
46 | Treaty adopted on December 20, 1996, and/or similar international
47 | agreements.
48 |
49 | f. Exceptions and Limitations means fair use, fair dealing, and/or
50 | any other exception or limitation to Copyright and Similar Rights
51 | that applies to Your use of the Licensed Material.
52 |
53 | g. License Elements means the license attributes listed in the name
54 | of a Creative Commons Public License. The License Elements of this
55 | Public License are Attribution, NonCommercial, and ShareAlike.
56 |
57 | h. Licensed Material means the artistic or literary work, database,
58 | or other material to which the Licensor applied this Public
59 | License.
60 |
61 | i. Licensed Rights means the rights granted to You subject to the
62 | terms and conditions of this Public License, which are limited to
63 | all Copyright and Similar Rights that apply to Your use of the
64 | Licensed Material and that the Licensor has authority to license.
65 |
66 | j. Licensor means the individual(s) or entity(ies) granting rights
67 | under this Public License.
68 |
69 | k. NonCommercial means not primarily intended for or directed towards
70 | commercial advantage or monetary compensation. For purposes of
71 | this Public License, the exchange of the Licensed Material for
72 | other material subject to Copyright and Similar Rights by digital
73 | file-sharing or similar means is NonCommercial provided there is
74 | no payment of monetary compensation in connection with the
75 | exchange.
76 |
77 | l. Share means to provide material to the public by any means or
78 | process that requires permission under the Licensed Rights, such
79 | as reproduction, public display, public performance, distribution,
80 | dissemination, communication, or importation, and to make material
81 | available to the public including in ways that members of the
82 | public may access the material from a place and at a time
83 | individually chosen by them.
84 |
85 | m. Sui Generis Database Rights means rights other than copyright
86 | resulting from Directive 96/9/EC of the European Parliament and of
87 | the Council of 11 March 1996 on the legal protection of databases,
88 | as amended and/or succeeded, as well as other essentially
89 | equivalent rights anywhere in the world.
90 |
91 | n. You means the individual or entity exercising the Licensed Rights
92 | under this Public License. Your has a corresponding meaning.
93 |
94 |
95 | Section 2 -- Scope.
96 |
97 | a. License grant.
98 |
99 | 1. Subject to the terms and conditions of this Public License,
100 | the Licensor hereby grants You a worldwide, royalty-free,
101 | non-sublicensable, non-exclusive, irrevocable license to
102 | exercise the Licensed Rights in the Licensed Material to:
103 |
104 | a. reproduce and Share the Licensed Material, in whole or
105 | in part, for NonCommercial purposes only; and
106 |
107 | b. produce, reproduce, and Share Adapted Material for
108 | NonCommercial purposes only.
109 |
110 | 2. Exceptions and Limitations. For the avoidance of doubt, where
111 | Exceptions and Limitations apply to Your use, this Public
112 | License does not apply, and You do not need to comply with
113 | its terms and conditions.
114 |
115 | 3. Term. The term of this Public License is specified in Section
116 | 6(a).
117 |
118 | 4. Media and formats; technical modifications allowed. The
119 | Licensor authorizes You to exercise the Licensed Rights in
120 | all media and formats whether now known or hereafter created,
121 | and to make technical modifications necessary to do so. The
122 | Licensor waives and/or agrees not to assert any right or
123 | authority to forbid You from making technical modifications
124 | necessary to exercise the Licensed Rights, including
125 | technical modifications necessary to circumvent Effective
126 | Technological Measures. For purposes of this Public License,
127 | simply making modifications authorized by this Section 2(a)
128 | (4) never produces Adapted Material.
129 |
130 | 5. Downstream recipients.
131 |
132 | a. Offer from the Licensor -- Licensed Material. Every
133 | recipient of the Licensed Material automatically
134 | receives an offer from the Licensor to exercise the
135 | Licensed Rights under the terms and conditions of this
136 | Public License.
137 |
138 | b. Additional offer from the Licensor -- Adapted Material.
139 | Every recipient of Adapted Material from You
140 | automatically receives an offer from the Licensor to
141 | exercise the Licensed Rights in the Adapted Material
142 | under the conditions of the Adapter's License You apply.
143 |
144 | c. No downstream restrictions. You may not offer or impose
145 | any additional or different terms or conditions on, or
146 | apply any Effective Technological Measures to, the
147 | Licensed Material if doing so restricts exercise of the
148 | Licensed Rights by any recipient of the Licensed
149 | Material.
150 |
151 | 6. No endorsement. Nothing in this Public License constitutes or
152 | may be construed as permission to assert or imply that You
153 | are, or that Your use of the Licensed Material is, connected
154 | with, or sponsored, endorsed, or granted official status by,
155 | the Licensor or others designated to receive attribution as
156 | provided in Section 3(a)(1)(A)(i).
157 |
158 | b. Other rights.
159 |
160 | 1. Moral rights, such as the right of integrity, are not
161 | licensed under this Public License, nor are publicity,
162 | privacy, and/or other similar personality rights; however, to
163 | the extent possible, the Licensor waives and/or agrees not to
164 | assert any such rights held by the Licensor to the limited
165 | extent necessary to allow You to exercise the Licensed
166 | Rights, but not otherwise.
167 |
168 | 2. Patent and trademark rights are not licensed under this
169 | Public License.
170 |
171 | 3. To the extent possible, the Licensor waives any right to
172 | collect royalties from You for the exercise of the Licensed
173 | Rights, whether directly or through a collecting society
174 | under any voluntary or waivable statutory or compulsory
175 | licensing scheme. In all other cases the Licensor expressly
176 | reserves any right to collect such royalties, including when
177 | the Licensed Material is used other than for NonCommercial
178 | purposes.
179 |
180 |
181 | Section 3 -- License Conditions.
182 |
183 | Your exercise of the Licensed Rights is expressly made subject to the
184 | following conditions.
185 |
186 | a. Attribution.
187 |
188 | 1. If You Share the Licensed Material (including in modified
189 | form), You must:
190 |
191 | a. retain the following if it is supplied by the Licensor
192 | with the Licensed Material:
193 |
194 | i. identification of the creator(s) of the Licensed
195 | Material and any others designated to receive
196 | attribution, in any reasonable manner requested by
197 | the Licensor (including by pseudonym if
198 | designated);
199 |
200 | ii. a copyright notice;
201 |
202 | iii. a notice that refers to this Public License;
203 |
204 | iv. a notice that refers to the disclaimer of
205 | warranties;
206 |
207 | v. a URI or hyperlink to the Licensed Material to the
208 | extent reasonably practicable;
209 |
210 | b. indicate if You modified the Licensed Material and
211 | retain an indication of any previous modifications; and
212 |
213 | c. indicate the Licensed Material is licensed under this
214 | Public License, and include the text of, or the URI or
215 | hyperlink to, this Public License.
216 |
217 | 2. You may satisfy the conditions in Section 3(a)(1) in any
218 | reasonable manner based on the medium, means, and context in
219 | which You Share the Licensed Material. For example, it may be
220 | reasonable to satisfy the conditions by providing a URI or
221 | hyperlink to a resource that includes the required
222 | information.
223 | 3. If requested by the Licensor, You must remove any of the
224 | information required by Section 3(a)(1)(A) to the extent
225 | reasonably practicable.
226 |
227 | b. ShareAlike.
228 |
229 | In addition to the conditions in Section 3(a), if You Share
230 | Adapted Material You produce, the following conditions also apply.
231 |
232 | 1. The Adapter's License You apply must be a Creative Commons
233 | license with the same License Elements, this version or
234 | later, or a BY-NC-SA Compatible License.
235 |
236 | 2. You must include the text of, or the URI or hyperlink to, the
237 | Adapter's License You apply. You may satisfy this condition
238 | in any reasonable manner based on the medium, means, and
239 | context in which You Share Adapted Material.
240 |
241 | 3. You may not offer or impose any additional or different terms
242 | or conditions on, or apply any Effective Technological
243 | Measures to, Adapted Material that restrict exercise of the
244 | rights granted under the Adapter's License You apply.
245 |
246 |
247 | Section 4 -- Sui Generis Database Rights.
248 |
249 | Where the Licensed Rights include Sui Generis Database Rights that
250 | apply to Your use of the Licensed Material:
251 |
252 | a. for the avoidance of doubt, Section 2(a)(1) grants You the right
253 | to extract, reuse, reproduce, and Share all or a substantial
254 | portion of the contents of the database for NonCommercial purposes
255 | only;
256 |
257 | b. if You include all or a substantial portion of the database
258 | contents in a database in which You have Sui Generis Database
259 | Rights, then the database in which You have Sui Generis Database
260 | Rights (but not its individual contents) is Adapted Material,
261 | including for purposes of Section 3(b); and
262 |
263 | c. You must comply with the conditions in Section 3(a) if You Share
264 | all or a substantial portion of the contents of the database.
265 |
266 | For the avoidance of doubt, this Section 4 supplements and does not
267 | replace Your obligations under this Public License where the Licensed
268 | Rights include other Copyright and Similar Rights.
269 |
270 |
271 | Section 5 -- Disclaimer of Warranties and Limitation of Liability.
272 |
273 | a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
274 | EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
275 | AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
276 | ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
277 | IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
278 | WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
279 | PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
280 | ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
281 | KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
282 | ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
283 |
284 | b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
285 | TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
286 | NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
287 | INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
288 | COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
289 | USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
290 | ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
291 | DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
292 | IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
293 |
294 | c. The disclaimer of warranties and limitation of liability provided
295 | above shall be interpreted in a manner that, to the extent
296 | possible, most closely approximates an absolute disclaimer and
297 | waiver of all liability.
298 |
299 |
300 | Section 6 -- Term and Termination.
301 |
302 | a. This Public License applies for the term of the Copyright and
303 | Similar Rights licensed here. However, if You fail to comply with
304 | this Public License, then Your rights under this Public License
305 | terminate automatically.
306 |
307 | b. Where Your right to use the Licensed Material has terminated under
308 | Section 6(a), it reinstates:
309 |
310 | 1. automatically as of the date the violation is cured, provided
311 | it is cured within 30 days of Your discovery of the
312 | violation; or
313 |
314 | 2. upon express reinstatement by the Licensor.
315 |
316 | For the avoidance of doubt, this Section 6(b) does not affect any
317 | right the Licensor may have to seek remedies for Your violations
318 | of this Public License.
319 |
320 | c. For the avoidance of doubt, the Licensor may also offer the
321 | Licensed Material under separate terms or conditions or stop
322 | distributing the Licensed Material at any time; however, doing so
323 | will not terminate this Public License.
324 |
325 | d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
326 | License.
327 |
328 |
329 | Section 7 -- Other Terms and Conditions.
330 |
331 | a. The Licensor shall not be bound by any additional or different
332 | terms or conditions communicated by You unless expressly agreed.
333 |
334 | b. Any arrangements, understandings, or agreements regarding the
335 | Licensed Material not stated herein are separate from and
336 | independent of the terms and conditions of this Public License.
337 |
338 |
339 | Section 8 -- Interpretation.
340 |
341 | a. For the avoidance of doubt, this Public License does not, and
342 | shall not be interpreted to, reduce, limit, restrict, or impose
343 | conditions on any use of the Licensed Material that could lawfully
344 | be made without permission under this Public License.
345 |
346 | b. To the extent possible, if any provision of this Public License is
347 | deemed unenforceable, it shall be automatically reformed to the
348 | minimum extent necessary to make it enforceable. If the provision
349 | cannot be reformed, it shall be severed from this Public License
350 | without affecting the enforceability of the remaining terms and
351 | conditions.
352 |
353 | c. No term or condition of this Public License will be waived and no
354 | failure to comply consented to unless expressly agreed to by the
355 | Licensor.
356 |
357 | d. Nothing in this Public License constitutes or may be interpreted
358 | as a limitation upon, or waiver of, any privileges and immunities
359 | that apply to the Licensor or You, including from the legal
360 | processes of any jurisdiction or authority.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [![Contributors][contributors-shield]][contributors-url]
2 | [![Forks][forks-shield]][forks-url]
3 | [![Stargazers][stars-shield]][stars-url]
4 | [![Issues][issues-shield]][issues-url]
5 | [][license-url]
6 |
7 |
8 |
10 |
11 |
13 |
14 |
15 | 在线阅读 >> 代码案例
19 | ·
20 | 参考资料
21 |
22 |
23 |
24 |
25 | # Distributed System Series(分布式系统·实践笔记)
26 |
27 | 现实世界中的数据系统往往颇为复杂。大型应用程序经常需要以多种方式访问和处理数据,没有一个数据库可以同时满足所有这些不同的需求。因此应用程序通常组合使用多种组件:数据存储,索引,缓存,分析系统,等等,并实现在这些组件中移动数据的机制。许多现有数据系统中都采用这种数据处理方式:你发送请求指令,一段时间后(我们期望)系统会给出一个结果。数据库,缓存,搜索索引,Web 服务器以及其他一些系统都以这种方式工作。
28 |
29 | 像这样的在线(online)系统,无论是浏览器请求页面还是调用远程 API 的服务,我们通常认为请求是由人类用户触发的,并且正在等待响应。他们不应该等太久,所以我们非常关注系统的响应时间。值得说明的是,这不是构建系统的唯一方式,其他方法也有其优点。我们来看看三种不同类型的系统:
30 |
31 | - 服务(在线系统):服务等待客户的请求或指令到达。每收到一个,服务会试图尽快处理它,并发回一个响应。响应时间通常是服务性能的主要衡量指标,可用性通常非常重要(如果客户端无法访问服务,用户可能会收到错误消息)。
32 |
33 | - 批处理系统(离线系统):一个批处理系统有大量的输入数据,跑一个作业(job)来处理它,并生成一些输出数据,这往往需要一段时间(从几分钟到几天),所以通常不会有用户等待作业完成。相反,批量作业通常会定期运行(例如,每天一次)。批处理作业的主要性能衡量标准通常是吞吐量(处理特定大小的输入所需的时间)。
34 |
35 | - 流处理系统(准实时系统):流处理介于在线和离线(批处理)之间,所以有时候被称为准实时(near-real-time)或准在线(nearline)处理。像批处理系统一样,流处理消费输入并产生输出(并不需要响应请求)。但是,流式作业在事件发生后不久就会对事件进行操作,而批处理作业则需等待固定的一组输入数据。这种差异使流处理系统比起批处理系统具有更低的延迟。
36 |
37 | 
38 |
39 | ## Nav | 关联导航
40 |
41 | - 如果你想了解微服务/云原生等分布式系统的应用实践,可以参阅;如果你想了解数据库相关,可以参阅 [Database-Notes](https://github.com/wx-chevalier/Database-Notes);如果你想了解虚拟化与云计算相关,可以参阅 [Cloud-Notes](https://github.com/wx-chevalier/Cloud-Notes);如果你想了解 Linux 与操作系统相关,可以参阅 [Linux-Notes](https://github.com/wx-chevalier/Linux-Notes)。
42 |
43 | # About
44 |
45 | ## Copyright & More | 延伸阅读
46 |
47 | 笔者所有文章遵循 [知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.zh),欢迎转载,尊重版权。您还可以前往 [NGTE Books](https://ng-tech.icu/books-gallery/) 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
48 |
49 | [](https://ng-tech.icu/books-gallery/)
50 |
51 |
52 |
53 |
54 | [contributors-shield]: https://img.shields.io/github/contributors/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
55 | [contributors-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/graphs/contributors
56 | [forks-shield]: https://img.shields.io/github/forks/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
57 | [forks-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/network/members
58 | [stars-shield]: https://img.shields.io/github/stars/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
59 | [stars-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/stargazers
60 | [issues-shield]: https://img.shields.io/github/issues/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
61 | [issues-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/issues
62 | [license-shield]: https://img.shields.io/github/license/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
63 | [license-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/blob/master/LICENSE.txt
64 |
--------------------------------------------------------------------------------
/_sidebar.md:
--------------------------------------------------------------------------------
1 | - [1 INTRODUCTION](/INTRODUCTION.md)
2 | - [2 分布式调度 [4]](/分布式调度/README.md)
3 | - [2.1 延时任务](/分布式调度/延时任务/README.md)
4 |
5 | - 2.2 开源框架 [1]
6 | - [2.2.1 xxl job](/分布式调度/开源框架/xxl-job/README.md)
7 |
8 | - [2.3 流程引擎 [2]](/分布式调度/流程引擎/README.md)
9 | - [2.3.1 Activiti](/分布式调度/流程引擎/Activiti/README.md)
10 |
11 | - [2.3.2 BPMN [1]](/分布式调度/流程引擎/BPMN/README.md)
12 | - [2.3.2.1 BPMN 规范](/分布式调度/流程引擎/BPMN/BPMN%20规范.md)
13 | - [2.4 调度系统架构 [4]](/分布式调度/调度系统架构/README.md)
14 | - [2.4.1 两层调度](/分布式调度/调度系统架构/两层调度.md)
15 | - 2.4.2 体系结构 [1]
16 | - [2.4.2.1 集中式架构](/分布式调度/调度系统架构/体系结构/集中式架构.md)
17 | - [2.4.3 共享状态调度](/分布式调度/调度系统架构/共享状态调度.md)
18 | - [2.4.4 单体调度](/分布式调度/调度系统架构/单体调度.md)
19 | - [3 批处理 [6]](/批处理/README.md)
20 | - [3.1 Hadoop [2]](/批处理/Hadoop/README.md)
21 | - [3.1.1 Hadoop 与数据库对比](/批处理/Hadoop/Hadoop%20与数据库对比.md)
22 | - [3.1.2 MapReduce [3]](/批处理/Hadoop/MapReduce/README.md)
23 | - [3.1.2.1 CRUD](/批处理/Hadoop/MapReduce/CRUD.md)
24 | - [3.1.2.2 WordCount](/批处理/Hadoop/MapReduce/WordCount.md)
25 | - [3.1.2.3 聚合计算](/批处理/Hadoop/MapReduce/聚合计算.md)
26 | - [3.2 MapReduce [3]](/批处理/MapReduce/README.md)
27 | - [3.2.1 作业执行](/批处理/MapReduce/作业执行.md)
28 | - [3.2.2 作业输出](/批处理/MapReduce/作业输出.md)
29 | - [3.2.3 连接与分组](/批处理/MapReduce/连接与分组.md)
30 | - [3.3 Waltz](/批处理/Waltz/README.md)
31 |
32 | - [3.4 使用 Unix 工具的批处理](/批处理/使用%20Unix%20工具的批处理.md)
33 | - [3.5 执行框架 [3]](/批处理/执行框架/README.md)
34 | - [3.5.1 图与迭代处理](/批处理/执行框架/图与迭代处理.md)
35 | - [3.5.2 物化中间状态](/批处理/执行框架/物化中间状态.md)
36 | - [3.5.3 高级 API 和语言](/批处理/执行框架/高级%20API%20和语言.md)
37 | - [3.6 编程模型 [3]](/批处理/编程模型/README.md)
38 | - [3.6.1 Data Parallelism](/批处理/编程模型/Data%20Parallelism.md)
39 | - [3.6.2 图的大规模并行](/批处理/编程模型/图的大规模并行.md)
40 | - [3.6.3 查询与声明式接口](/批处理/编程模型/查询与声明式接口.md)
41 | - [4 流处理 [5]](/流处理/README.md)
42 | - 4.1 01~流处理系统设计 [4]
43 | - [4.1.1 DAG [1]](/流处理/01~流处理系统设计/DAG/README.md)
44 | - [4.1.1.1 Dryad](/流处理/01~流处理系统设计/DAG/Dryad.md)
45 | - 4.1.2 执行框架 [4]
46 | - [4.1.2.1 分布式快照](/流处理/01~流处理系统设计/执行框架/分布式快照.md)
47 | - [4.1.2.2 反压](/流处理/01~流处理系统设计/执行框架/反压.md)
48 | - [4.1.2.3 容错](/流处理/01~流处理系统设计/执行框架/容错.md)
49 | - [4.1.2.4 流式连接](/流处理/01~流处理系统设计/执行框架/流式连接.md)
50 | - 4.1.3 状态存储 [1]
51 | - 4.1.3.1 99~参考资料 [1]
52 | - [4.1.3.1.1 流处理系统中状态的表示和存储](/流处理/01~流处理系统设计/状态存储/99~参考资料/2022-流处理系统中状态的表示和存储.md)
53 | - 4.1.4 编程模型 [1]
54 | - [4.1.4.1 时间窗口](/流处理/01~流处理系统设计/编程模型/时间窗口.md)
55 | - 4.2 08.开源框架 [3]
56 | - [4.2.1 Beam [3]](/流处理/08.开源框架/Beam/README.md)
57 | - [4.2.1.1 Dataflow 模型](/流处理/08.开源框架/Beam/Dataflow%20模型.md)
58 | - [4.2.1.2 快速开始](/流处理/08.开源框架/Beam/快速开始.md)
59 | - [4.2.1.3 部署与配置](/流处理/08.开源框架/Beam/部署与配置.md)
60 | - [4.2.2 Spark [2]](/流处理/08.开源框架/Spark/README.md)
61 | - [4.2.2.1 代码开发](/流处理/08.开源框架/Spark/代码开发.md)
62 | - [4.2.2.2 环境配置](/流处理/08.开源框架/Spark/环境配置.md)
63 | - [4.2.3 流计算框架对比](/流处理/08.开源框架/流计算框架对比.md)
64 | - [4.3 09.流处理数据库](/流处理/09.流处理数据库/README.md)
65 |
66 | - [4.4 10.Flink [4]](/流处理/10.Flink/README.md)
67 | - [4.4.1 Blink](/流处理/10.Flink/Blink/README.md)
68 |
69 | - [4.4.2 Table API](/流处理/10.Flink/Table%20API.md)
70 | - [4.4.3 代码开发](/流处理/10.Flink/代码开发.md)
71 | - [4.4.4 快速开始](/流处理/10.Flink/快速开始.md)
72 | - 4.5 99~参考资料 [1]
73 | - [4.5.1 吴英俊 重新思考流处理与流数据库](/流处理/99~参考资料/2023-吴英俊-重新思考流处理与流数据库.md)
74 | - [5 计算处理模式 [4]](/计算处理模式/README.md)
75 | - [5.1 Lambda 架构](/计算处理模式/Lambda%20架构.md)
76 | - [5.2 事务处理](/计算处理模式/事务处理.md)
77 | - [5.3 批处理与流处理](/计算处理模式/批处理与流处理.md)
78 | - [5.4 量子计算](/计算处理模式/量子计算/README.md)
79 |
--------------------------------------------------------------------------------
/header.svg:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
101 |
366 |
367 |
368 | Distributed System Series by 王下邀月熊
369 |
370 |
371 | 分布式系统实战
372 |
373 |
374 |
375 |
390 |
391 |
392 |
394 |
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | DistributedSystem-Series
7 |
47 |
56 | {
21 |
22 | private final static IntWritable one = new IntWritable(1);
23 | private Text word = new Text();
24 |
25 | public void map(Object key, Text value, Context context
26 | ) throws IOException, InterruptedException {
27 | StringTokenizer itr = new StringTokenizer(value.toString());
28 | while (itr.hasMoreTokens()) {
29 | word.set(itr.nextToken());
30 | context.write(word, one);
31 | }
32 | }
33 | }
34 |
35 | public static class IntSumReducer
36 | extends Reducer {
37 | private IntWritable result = new IntWritable();
38 |
39 | public void reduce(Text key, Iterable values,
40 | Context context
41 | ) throws IOException, InterruptedException {
42 | int sum = 0;
43 | for (IntWritable val : values) {
44 | sum += val.get();
45 | }
46 | result.set(sum);
47 | context.write(key, result);
48 | }
49 | }
50 |
51 | public static void main(String[] args) throws Exception {
52 | Configuration conf = new Configuration();
53 | Job job = Job.getInstance(conf, "word count");
54 | job.setJarByClass(WordCount.class);
55 | job.setMapperClass(TokenizerMapper.class);
56 | job.setCombinerClass(IntSumReducer.class);
57 | job.setReducerClass(IntSumReducer.class);
58 | job.setOutputKeyClass(Text.class);
59 | job.setOutputValueClass(IntWritable.class);
60 | FileInputFormat.addInputPath(job, new Path(args[0]));
61 | FileOutputFormat.setOutputPath(job, new Path(args[1]));
62 | System.exit(job.waitForCompletion(true) ? 0 : 1);
63 | }
64 | }
65 | ```
66 |
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/聚合计算.md:
--------------------------------------------------------------------------------
1 | # Sort
2 |
3 | ## 简单排序
4 |
5 | 对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。样例输入:
6 |
7 | ```
8 | 1)file1:
9 |
10 | 2
11 |
12 | 32
13 |
14 | 654
15 |
16 | 32
17 |
18 | 15
19 |
20 | 756
21 |
22 | 65223
23 |
24 |
25 | 2)file2:
26 |
27 | 5956
28 |
29 | 22
30 |
31 | 650
32 |
33 | 92
34 |
35 |
36 | 3)file3:
37 |
38 | 26
39 |
40 | 54
41 |
42 | 6
43 |
44 |
45 | 样例输出:
46 |
47 | 1 2
48 |
49 | 2 6
50 |
51 | 3 15
52 |
53 | 4 22
54 |
55 | 5 26
56 |
57 | 6 32
58 |
59 | 7 32
60 |
61 | 8 54
62 |
63 | 9 92
64 |
65 | 10 650
66 |
67 | 11 654
68 |
69 | 12 756
70 |
71 | 13 5956
72 |
73 | 14 65223
74 | ```
75 |
76 | 这个实例仅仅要求对输入数据进行排序,熟悉 MapReduce 过程的读者会很快想到在 MapReduce 过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。
77 |
78 | 但是在使用之前首先需要了解它的默认排序规则。它是按照 key 值进行排序的,如果 key 为封装 int 的 IntWritable 类型,那么 MapReduce 按照数字大小对 key 排序,如果 key 为封装为 String 的 Text 类型,那么 MapReduce 按照字典顺序对字符串排序。
79 |
80 | 了解了这个细节,我们就知道应该使用封装 int 的 IntWritable 型数据结构了。也就是在 map 中将读入的数据转化成 IntWritable 型,然 后作为 key 值输出(value 任意)。reduce 拿到之后,将输入的 key 作为 value 输出,并根据 value-list 中元素的个数决定输出的次数。输出的 key(即代码中的 linenum)是一个全局变量,它统计当前 key 的位次。需要注意的是这个 程序中没有配置 Combiner,也就是在 MapReduce 过程中不使用 Combiner。这主要是因为使用 map 和 reduce 就已经能够完成任务 了。
81 |
82 | ```java
83 | public class Sort {
84 |
85 |
86 | //map将输入中的value化成IntWritable类型,作为输出的key
87 |
88 | public static class Map extends
89 |
90 | Mapper
91 |
92 | {
93 |
94 | private static IntWritable data = new IntWritable();
95 |
96 | //实现map函数
97 |
98 | public void map(Object key, Text value, Context context)
99 |
100 | throws IOException, InterruptedException {
101 |
102 | String line = value.toString();
103 |
104 | data.set(Integer.parseInt(line));
105 |
106 | context.write(data, new IntWritable(1));
107 |
108 | }
109 |
110 | }
111 |
112 |
113 | //reduce将输入中的key复制到输出数据的key上,
114 |
115 | //然后根据输入的value-list中元素的个数决定key的输出次数
116 |
117 | //用全局linenum来代表key的位次
118 |
119 | public static class Reduce extends
120 |
121 | Reducer {
122 |
123 |
124 | private static IntWritable linenum = new IntWritable(1);
125 |
126 |
127 | //实现reduce函数
128 |
129 | public void reduce(IntWritable key, Iterable values, Context context)
130 |
131 | throws IOException, InterruptedException {
132 |
133 | for (IntWritable val : values) {
134 |
135 | context.write(linenum, key);
136 |
137 | linenum = new IntWritable(linenum.get() + 1);
138 |
139 | }
140 |
141 |
142 | }
143 |
144 |
145 | }
146 |
147 |
148 | public static void main(String[] args) throws Exception {
149 |
150 | Configuration conf = new Configuration();
151 |
152 | //这句话很关键
153 |
154 | conf.set("mapred.job.tracker", "192.168.1.2:9001");
155 |
156 |
157 | String[] ioArgs = new String[]{"sort_in", "sort_out"};
158 |
159 | String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
160 |
161 | if (otherArgs.length != 2) {
162 |
163 | System.err.println("Usage: Data Sort ");
164 |
165 | System.exit(2);
166 |
167 | }
168 |
169 |
170 | Job job = new Job(conf, "Data Sort");
171 |
172 | job.setJarByClass(Sort.class);
173 |
174 |
175 | //设置Map和Reduce处理类
176 |
177 | job.setMapperClass(Map.class);
178 |
179 | job.setReducerClass(Reduce.class);
180 |
181 |
182 | //设置输出类型
183 |
184 | job.setOutputKeyClass(IntWritable.class);
185 |
186 | job.setOutputValueClass(IntWritable.class);
187 |
188 |
189 | //设置输入和输出目录
190 |
191 | FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
192 |
193 | FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
194 |
195 | System.exit(job.waitForCompletion(true) ? 0 : 1);
196 | }
197 | }
198 | ```
199 |
--------------------------------------------------------------------------------
/批处理/Hadoop/README.md:
--------------------------------------------------------------------------------
1 | # Introduction
2 |
3 | 
4 |
5 | # Quick Start
6 |
7 | | 组件 | 节点 | 默认端口 | 配置 | 用途说明 |
8 | | --------- | ----------------- | -------- | ---------------------------------------------------------------------------------- | ---------------------------------------------------------------- |
9 | | HDFS | DataNode | 50010 | dfs.datanode.address | datanode 服务端口,用于数据传输 |
10 | | HDFS | DataNode | 50075 | dfs.datanode.http.address | http 服务的端口 |
11 | | HDFS | DataNode | 50475 | dfs.datanode.https.address | https 服务的端口 |
12 | | HDFS | DataNode | 50020 | dfs.datanode.ipc.address | ipc 服务的端口 |
13 | | HDFS | NameNode | 50070 | dfs.namenode.http-address | http 服务的端口 |
14 | | HDFS | NameNode | 50470 | dfs.namenode.https-address | https 服务的端口 |
15 | | HDFS | NameNode | 8020 | fs.defaultFS | 接收 Client 连接的 RPC 端口,用于获取文件系统 metadata 信息 |
16 | | HDFS | journalnode | 8485 | dfs.journalnode.rpc-address | RPC 服务 |
17 | | HDFS | journalnode | 8480 | dfs.journalnode.http-address | HTTP 服务 |
18 | | HDFS | ZKFC | 8019 | dfs.ha.zkfc.port | ZooKeeper FailoverController,用于 NN HA |
19 | | YARN | ResourceManager | 8032 | yarn.resourcemanager.address | RM 的 applications manager(ASM)端口 |
20 | | YARN | ResourceManager | 8030 | yarn.resourcemanager.scheduler.address | scheduler 组件的 IPC 端口 |
21 | | YARN | ResourceManager | 8031 | yarn.resourcemanager.resource-tracker.address | IPC |
22 | | YARN | ResourceManager | 8033 | yarn.resourcemanager.admin.address | IPC |
23 | | YARN | ResourceManager | 8088 | yarn.resourcemanager.webapp.address | http 服务端口 |
24 | | YARN | NodeManager | 8040 | yarn.nodemanager.localizer.address | localizer IPC |
25 | | YARN | NodeManager | 8042 | yarn.nodemanager.webapp.address | http 服务端口 |
26 | | YARN | NodeManager | 8041 | yarn.nodemanager.address | NM 中 container manager 的端口 |
27 | | YARN | JobHistory Server | 10020 | mapreduce.jobhistory.address | IPC |
28 | | YARN | JobHistory Server | 19888 | mapreduce.jobhistory.webapp.address | http 服务端口 |
29 | | HBase | Master | 60000 | hbase.master.port | IPC |
30 | | HBase | Master | 60010 | hbase.master.info.port | http 服务端口 |
31 | | HBase | RegionServer | 60020 | hbase.regionserver.port | IPC |
32 | | HBase | RegionServer | 60030 | hbase.regionserver.info.port | http 服务端口 |
33 | | HBase | HQuorumPeer | 2181 | hbase.zookeeper.property.clientPort | HBase-managed ZK mode,使用独立的 ZooKeeper 集群则不会启用该端口 |
34 | | HBase | HQuorumPeer | 2888 | hbase.zookeeper.peerport | HBase-managed ZK mode,使用独立的 ZooKeeper 集群则不会启用该端口 |
35 | | HBase | HQuorumPeer | 3888 | hbase.zookeeper.leaderport | HBase-managed ZK mode,使用独立的 ZooKeeper 集群则不会启用该端口 |
36 | | Hive | Metastore | 9083 | /etc/default/hive-metastore 中 export PORT=来更新默认端口 | |
37 | | Hive | HiveServer | 10000 | /etc/hive/conf/hive-env.sh 中 export HIVE_SERVER2_THRIFT_PORT=来更新默认端口 | |
38 | | ZooKeeper | Server | 2181 | /etc/zookeeper/conf/zoo.cfg 中 clientPort= | 对客户端提供服务的端口 |
39 | | ZooKeeper | Server | 2888 | /etc/zookeeper/conf/zoo.cfg 中 server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | follower 用来连接到 leader,只在 leader 上监听该端口, |
40 | | ZooKeeper | Server | 3888 | /etc/zookeeper/conf/zoo.cfg 中 server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | 用于 leader 选举的。只在 electionAlg 是 1,2 或 3(默认)时需要, |
41 |
42 | # EcoSystem
43 |
44 | 云计算由位于网络上的一组服务器把其计算、存储、数据等资源以服务的形式提供给请求者以完成信息处理任务的方法和过程。针对海量文本数据处理,为实现快速 文本处理响应,缩短海量数据为辅助决策提供服务的时间,基于 Hadoop 云计算平台,建立 HDFS 分布式文件系统存储海量文本数据集,通过文本词频利用 MapReduce 原理建立分布式索引,以分布式数据库 HBase 存储关键词索引,并提供实时检索,实现对海量文本数据的分布式并行处理。所 以,Hadoop 是云计算的部分构建。
45 | Hadoop 的生态系统核心组成部分如下图所示:
46 | 
47 |
48 | ## Docker
49 |
50 | 如果你本机已经安装好了 Docker 环境,那么可以直接使用如下命令启动某个 Hadoop 实例:
51 |
52 | ```
53 | docker run -it sequenceiq/hadoop-docker:2.7.1 -p 127.0.0.1:50070:50070 -p 127.0.0.1:18042:8042 -p 127.0.0.1:18088:8088 /etc/bootstrap.sh -bash
54 | ```
55 |
--------------------------------------------------------------------------------
/批处理/MapReduce/README.md:
--------------------------------------------------------------------------------
1 | # MapReduce
2 |
3 | MapReduce 有点像 Unix 工具,但分布在数千台机器上。像 Unix 工具一样,它相当简单粗暴,但令人惊异地管用。一个 MapReduce 作业可以和一个 Unix 进程相类比:它接受一个或多个输入,并产生一个或多个输出。和大多数 Unix 工具一样,运行 MapReduce 作业通常不会修改输入,除了生成输出外没有任何副作用。输出文件以连续的方式一次性写入(一旦写入文件,不会修改任何现有的文件部分)。
4 |
5 | 虽然 Unix 工具使用 stdin 和 stdout 作为输入和输出,但 MapReduce 作业在分布式文件系统上读写文件。在 Hadoop 的 Map-Reduce 实现中,该文件系统被称为 HDFS(Hadoop 分布式文件系统),一个 Google 文件系统(GFS)的开源实现。除 HDFS 外,还有各种其他分布式文件系统,如 GlusterFS 和 Quantcast File System(QFS)。诸如 Amazon S3,Azure Blob 存储和 OpenStack Swift 等对象存储服务在很多方面都是相似的。这里我们将主要使用 HDFS 作为示例,但是这些原则适用于任何分布式文件系统。
6 |
7 | 与网络连接存储(NAS)和存储区域网络(SAN)架构的共享磁盘方法相比,HDFS 基于无共享原则。共享磁盘存储由集中式存储设备实现,通常使用定制硬件和专用网络基础设施(如光纤通道)。而另一方面,无共享方法不需要特殊的硬件,只需要通过传统数据中心网络连接的计算机。
8 |
9 | HDFS 包含在每台机器上运行的守护进程,对外暴露网络服务,允许其他节点访问存储在该机器上的文件(假设数据中心中的每台通用计算机都挂载着一些磁盘)。名为 NameNode 的中央服务器会跟踪哪个文件块存储在哪台机器上。因此,HDFS 在概念上创建了一个大型文件系统,可以使用所有运行有守护进程的机器的磁盘。为了容忍机器和磁盘故障,文件块被复制到多台机器上。复制可能意味着多个机器上的相同数据的多个副本,或者诸如 Reed-Solomon 码这样的纠删码方案,它允许以比完全复制更低的存储开销以恢复丢失的数据。这些技术与 RAID 相似,可以在连接到同一台机器的多个磁盘上提供冗余;区别在于在分布式文件系统中,文件访问和复制是在传统的数据中心网络上完成的,没有特殊的硬件。
10 |
--------------------------------------------------------------------------------
/批处理/MapReduce/作业执行.md:
--------------------------------------------------------------------------------
1 | # MapReduce 作业执行
2 |
3 | MapReduce 是一个编程框架,你可以使用它编写代码来处理 HDFS 等分布式文件系统中的大型数据集。MapReduce 中的数据处理模式与 Unix 中的文件分析非常相似:
4 |
5 | 1. 读取一组输入文件,并将其分解成记录(records)。在 Web 服务器日志示例中,每条记录都是日志中的一行(即`\n`是记录分隔符)。
6 | 2. 调用 Mapper 函数,从每条输入记录中提取一对键值。在前面的例子中,Mapper 函数是`awk '{print $7}'`:它提取 URL(`$7`)作为关键字,并将值留空。
7 | 3. 按键排序所有的键值对。在日志的例子中,这由第一个`sort`命令完成。
8 | 4. 调用 Reducer 函数遍历排序后的键值对。如果同一个键出现多次,排序使它们在列表中相邻,所以很容易组合这些值而不必在内存中保留很多状态。在前面的例子中,Reducer 是由`uniq -c`命令实现的,该命令使用相同的键来统计相邻记录的数量。
9 |
10 | 这四个步骤可以作为一个 MapReduce 作业执行。步骤 2(Map)和 4(Reduce)是你编写自定义数据处理代码的地方。步骤 1(将文件分解成记录)由输入格式解析器处理。步骤 3 中的排序步骤隐含在 MapReduce 中,你不必编写它,因为 Mapper 的输出始终在送往 Reducer 之前进行排序。
11 |
12 | # Mapper 与 Reducer
13 |
14 | 要创建 MapReduce 作业,你需要实现两个回调函数,Mapper 和 Reducer,其行为如下
15 |
16 | - Mapper:Mapper 会在每条输入记录上调用一次,其工作是从输入记录中提取键值。对于每个输入,它可以生成任意数量的键值对(包括 None)。它不会保留从一个输入记录到下一个记录的任何状态,因此每个记录都是独立处理的。
17 |
18 | - Reducer:MapReduce 框架拉取由 Mapper 生成的键值对,收集属于同一个键的所有值,并使用在这组值列表上迭代调用 Reducer。Reducer 可以产生输出记录(例如相同 URL 的出现次数)。
19 |
20 | 在 Web 服务器日志的例子中,我们在第 5 步中有第二个 sort 命令,它按请求数对 URL 进行排序。在 MapReduce 中,如果你需要第二个排序阶段,则可以通过编写第二个 MapReduce 作业并将第一个作业的输出用作第二个作业的输入来实现它。这样看来,Mapper 的作用是将数据放入一个适合排序的表单中,并且 Reducer 的作用是处理已排序的数据。
21 |
22 | # 分布式执行 MapReduce
23 |
24 | MapReduce 与 Unix 命令管道的主要区别在于,MapReduce 可以在多台机器上并行执行计算,而无需编写代码来显式处理并行问题。Mapper 和 Reducer 一次只能处理一条记录;它们不需要知道它们的输入来自哪里,或者输出去往什么地方,所以框架可以处理在机器之间移动数据的复杂性。在分布式计算中可以使用标准的 Unix 工具作为 Mapper 和 Reducer,但更常见的是,它们被实现为传统编程语言的函数。在 Hadoop MapReduce 中,Mapper 和 Reducer 都是实现特定接口的 Java 类。在 MongoDB 和 CouchDB 中,Mapper 和 Reducer 都是 JavaScript 函数。
25 |
26 | 下图显示了 Hadoop MapReduce 作业中的数据流。其并行化基于分区:作业的输入通常是 HDFS 中的一个目录,输入目录中的每个文件或文件块都被认为是一个单独的分区,可以单独处理 map 任务。每个输入文件的大小通常是数百兆字节。MapReduce 调度器(图中未显示)试图在其中一台存储输入文件副本的机器上运行每个 Mapper,只要该机器有足够的备用 RAM 和 CPU 资源来运行 Mapper 任务。这个原则被称为将计算放在数据附近:它节省了通过网络复制输入文件的开销,减少网络负载并增加局部性。
27 |
28 | 
29 |
30 | 在大多数情况下,应该在 Mapper 任务中运行的应用代码在将要运行它的机器上还不存在,所以 MapReduce 框架首先将代码(例如 Java 程序中的 JAR 文件)复制到适当的机器。然后启动 Map 任务并开始读取输入文件,一次将一条记录传入 Mapper 回调函数。Mapper 的输出由键值对组成。计算的 Reduce 端也被分区。虽然 Map 任务的数量由输入文件块的数量决定,但 Reducer 的任务的数量是由作业作者配置的(它可以不同于 Map 任务的数量)。为了确保具有相同键的所有键值对最终落在相同的 Reducer 处,框架使用键的哈希值来确定哪个 Reduce 任务应该接收到特定的键值对。
31 |
32 | 键值对必须进行排序,但数据集可能太大,无法在单台机器上使用常规排序算法进行排序。相反,分类是分阶段进行的。首先每个 Map 任务都按照 Reducer 对输出进行分区。每个分区都被写入 Mapper 程序的本地磁盘。只要当 Mapper 读取完输入文件,并写完排序后的输出文件,MapReduce 调度器就会通知 Reducer 可以从该 Mapper 开始获取输出文件。Reducer 连接到每个 Mapper,并下载自己相应分区的有序键值对文件。按 Reducer 分区,排序,从 Mapper 向 Reducer 复制分区数据,这一整个过程被称为混洗(shuffle)(一个容易混淆的术语:不像洗牌,在 MapReduce 中的混洗没有随机性)。
33 |
34 | Reduce 任务从 Mapper 获取文件,并将它们合并在一起,并保留有序特性。因此,如果不同的 Mapper 生成了键相同的记录,则在 Reducer 的输入中,这些记录将会相邻。Reducer 调用时会收到一个键,和一个迭代器作为参数,迭代器会顺序地扫过所有具有该键的记录(因为在某些情况可能无法完全放入内存中)。Reducer 可以使用任意逻辑来处理这些记录,并且可以生成任意数量的输出记录。这些输出记录会写入分布式文件系统上的文件中(通常是在跑 Reducer 的机器本地磁盘上留一份,并在其他机器上留几份副本)。
35 |
36 | # MapReduce 工作流
37 |
38 | 单个 MapReduce 作业可以解决的问题范围很有限。以日志分析为例,单个 MapReduce 作业可以确定每个 URL 的页面浏览次数,但无法确定最常见的 URL,因为这需要第二轮排序。因此将 MapReduce 作业链接成为工作流(workflow)中是极为常见的,例如,一个作业的输出成为下一个作业的输入。Hadoop Map-Reduce 框架对工作流没有特殊支持,所以这个链是通过目录名隐式实现的:第一个作业必须将其输出配置为 HDFS 中的指定目录,第二个作业必须将其输入配置为从同一个目录。从 MapReduce 框架的角度来看,这是是两个独立的作业。
39 |
40 | 因此,被链接的 MapReduce 作业并没有那么像 Unix 命令管道(它直接将一个进程的输出作为另一个进程的输入,仅用一个很小的内存缓冲区)。它更像是一系列命令,其中每个命令的输出写入临时文件,下一个命令从临时文件中读取。这种设计有利也有弊。
41 |
42 | 只有当作业成功完成后,批处理作业的输出才会被视为有效的(MapReduce 会丢弃失败作业的部分输出)。因此,工作流中的一项作业只有在先前的作业:即生产其输入的作业:成功完成后才能开始。为了处理这些作业之间的依赖,有很多针对 Hadoop 的工作流调度器被开发出来,包括 Oozie,Azkaban,Luigi,Airflow 和 Pinball 。
43 |
44 | 这些调度程序还具有管理功能,在维护大量批处理作业时非常有用。在构建推荐系统时,由 50 到 100 个 MapReduce 作业组成的工作流是常见的。而在大型组织中,许多不同的团队可能运行不同的作业来读取彼此的输出。工具支持对于管理这样复杂的数据流而言非常重要。Hadoop 的各种高级工具(如 Pig,Hive,Cascading,Crunch 和 FlumeJava)也能自动布线组装多个 MapReduce 阶段,生成合适的工作流。
45 |
--------------------------------------------------------------------------------
/批处理/MapReduce/作业输出.md:
--------------------------------------------------------------------------------
1 | # 批处理工作流的输出
2 |
3 | 我们已经说了很多用于实现 MapReduce 工作流的算法,但却忽略了一个重要的问题:这些处理完成之后的最终结果是什么?我们最开始为什么要跑这些作业?在数据库查询的场景中,我们将事务处理(OLTP)与分析两种目的区分开来,OLTP 查询通常根据键查找少量记录,使用索引,并将其呈现给用户(比如在网页上)。另一方面,分析查询通常会扫描大量记录,执行分组与聚合,输出通常有着报告的形式:显示某个指标随时间变化的图表,或按照某种排位取前 10 项,或一些数字细化为子类。这种报告的消费者通常是需要做出商业决策的分析师或经理。
4 |
5 | 批处理放哪里合适?它不属于事务处理,也不是分析。它和分析比较接近,因为批处理通常会扫过输入数据集的绝大部分。然而 MapReduce 作业工作流与用于分析目的的 SQL 查询是不同的。批处理过程的输出通常不是报表,而是一些其他类型的结构。
6 |
7 | # 建立搜索索引
8 |
9 | Google 最初使用 MapReduce 是为其搜索引擎建立索引,用了由 5 到 10 个 MapReduce 作业组成的工作流实现。虽然 Google 后来也不仅仅是为这个目的而使用 MapReduce,但如果从构建搜索索引的角度来看,更能帮助理解 MapReduce。(直至今日,Hadoop MapReduce 仍然是为 Lucene/Solr 构建索引的好方法)。Lucene 这样的全文搜索索引是如何工作的:它是一个文件(关键词字典),你可以在其中高效地查找特定关键字,并找到包含该关键字的所有文档 ID 列表(文章列表)。这是一种非常简化的看法,实际上,搜索索引需要各种额外数据,以便根据相关性对搜索结果进行排名,纠正拼写错误,解析同义词等等,但这个原则是成立的。
10 |
11 | 如果需要对一组固定文档执行全文搜索,则批处理是一种构建索引的高效方法:Mapper 根据需要对文档集合进行分区,每个 Reducer 构建该分区的索引,并将索引文件写入分布式文件系统。构建这样的文档分区索引并行处理效果拔群。由于按关键字查询搜索索引是只读操作,因而这些索引文件一旦创建就是不可变的。如果索引的文档集合发生更改,一种选择是定期重跑整个索引工作流,并在完成后用新的索引文件批量替换以前的索引文件。如果只有少量的文档发生了变化,这种方法的计算成本可能会很高。但它的优点是索引过程很容易理解:文档进,索引出。另一个选择是,可以增量建立索引,如果要在索引中添加,删除或更新文档,Lucene 会写新的段文件,并在后台异步合并压缩段文件。
12 |
13 | # 键值存储作为批处理输出
14 |
15 | 搜索索引只是批处理工作流可能输出的一个例子。批处理的另一个常见用途是构建机器学习系统,例如分类器(比如垃圾邮件过滤器,异常检测,图像识别)与推荐系统(例如,你可能认识的人,你可能感兴趣的产品或相关的搜索)。这些批处理作业的输出通常是某种数据库:例如,可以通过给定用户 ID 查询该用户推荐好友的数据库,或者可以通过产品 ID 查询相关产品的数据库。
16 |
17 | 这些数据库需要被处理用户请求的 Web 应用所查询,而它们通常是独立于 Hadoop 基础设施的。那么批处理过程的输出如何回到 Web 应用可以查询的数据库中呢?最直接的选择可能是,直接在 Mapper 或 Reducer 中使用你最爱数据库的客户端库,并从批处理作业直接写入数据库服务器,一次写入一条记录。它能工作(假设你的防火墙规则允许从你的 Hadoop 环境直接访问你的生产数据库),但这并不是一个好主意,出于以下几个原因:
18 |
19 | - 正如前面在连接的上下文中讨论的那样,为每条记录发起一个网络请求,要比批处理任务的正常吞吐量慢几个数量级。即使客户端库支持批处理,性能也可能很差。
20 |
21 | - MapReduce 作业经常并行运行许多任务。如果所有 Mapper 或 Reducer 都同时写入相同的输出数据库,并以批处理的预期速率工作,那么该数据库很可能被轻易压垮,其查询性能可能变差。这可能会导致系统其他部分的运行问题。
22 |
23 | - 通常情况下,MapReduce 为作业输出提供了一个干净利落的“全有或全无”保证:如果作业成功,则结果就是每个任务恰好执行一次所产生的输出,即使某些任务失败且必须一路重试。如果整个作业失败,则不会生成输出。然而从作业内部写入外部系统,会产生外部可见的副作用,这种副作用是不能以这种方式被隐藏的。因此,你不得不去操心部分完成的作业对其他系统可见的结果,并需要理解 Hadoop 任务尝试与预测执行的复杂性。
24 |
25 | 更好的解决方案是在批处理作业内创建一个全新的数据库,并将其作为文件写入分布式文件系统中作业的输出目录,就像上节中的搜索索引一样。这些数据文件一旦写入就是不可变的,可以批量加载到处理只读查询的服务器中。不少键值存储都支持在 MapReduce 作业中构建数据库文件,包括 Voldemort,Terrapin,ElephantDB 和 HBase 批量加载。构建这些数据库文件是 MapReduce 的一种很好用法的使用方法:使用 Mapper 提取出键并按该键排序,现在已经是构建索引所必需的大量工作。由于这些键值存储大多都是只读的(文件只能由批处理作业一次性写入,然后就不可变),所以数据结构非常简单。比如它们就不需要 WAL。
26 |
27 | 将数据加载到 Voldemort 时,服务器将继续用旧数据文件服务请求,同时将新数据文件从分布式文件系统复制到服务器的本地磁盘。一旦复制完成,服务器会自动将查询切换到新文件。如果在这个过程中出现任何问题,它可以轻易回滚至旧文件,因为它们仍然存在而且不可变。
28 |
29 | # 批处理输出的哲学
30 |
31 | Unix 的设计哲学中鼓励以显式指明数据流的方式进行实验:程序读取输入并写入输出。在这一过程中,输入保持不变,任何先前的输出都被新输出完全替换,且没有其他副作用。这意味着你可以随心所欲地重新运行一个命令,略做改动或进行调试,而不会搅乱系统的状态。MapReduce 作业的输出处理遵循同样的原理。通过将输入视为不可变且避免副作用(如写入外部数据库),批处理作业不仅实现了良好的性能,而且更容易维护:
32 |
33 | - 如果在代码中引入了一个错误,而输出错误或损坏了,则可以简单地回滚到代码的先前版本,然后重新运行该作业,输出将重新被纠正。或者,甚至更简单,你可以将旧的输出保存在不同的目录中,然后切换回原来的目录。具有读写事务的数据库没有这个属性:如果你部署了错误的代码,将错误的数据写入数据库,那么回滚代码将无法修复数据库中的数据。(能够从错误代码中恢复的概念被称为**人类容错(human fault tolerance)**)
34 | - 由于回滚很容易,比起在错误意味着不可挽回的伤害的环境,功能开发进展能快很多。这种**最小化不可逆性(minimizing irreversibility)**的原则有利于敏捷软件开发。
35 | - 如果 Map 或 Reduce 任务失败,MapReduce 框架将自动重新调度,并在同样的输入上再次运行它。如果失败是由代码中的错误造成的,那么它会不断崩溃,并最终导致作业在几次尝试之后失败。但是如果故障是由于临时问题导致的,那么故障就会被容忍。因为输入不可变,这种自动重试是安全的,而失败任务的输出会被 MapReduce 框架丢弃。
36 | - 同一组文件可用作各种不同作业的输入,包括计算指标的监控作业可以评估作业的输出是否具有预期的性质(例如,将其与前一次运行的输出进行比较并测量差异)。
37 | - 与 Unix 工具类似,MapReduce 作业将逻辑与布线(配置输入和输出目录)分离,这使得关注点分离,可以重用代码:一个团队可以实现一个专注做好一件事的作业;而其他团队可以决定何时何地运行这项作业。
38 |
39 | 在这些领域,在 Unix 上表现良好的设计原则似乎也适用于 Hadoop,但 Unix 和 Hadoop 在某些方面也有所不同。例如,因为大多数 Unix 工具都假设输入输出是无类型文本文件,所以它们必须做大量的输入解析工作(本章开头的日志分析示例使用 `{print $7}` 来提取 URL)。在 Hadoop 上可以通过使用更结构化的文件格式消除一些低价值的语法转换:比如 Avro 和 Parquet 经常使用,因为它们提供了基于模式的高效编码,并允许模式随时间推移而演进。
40 |
--------------------------------------------------------------------------------
/批处理/MapReduce/连接与分组.md:
--------------------------------------------------------------------------------
1 | # Reduce 端连接与分组
2 |
3 | 在许多数据集中,一条记录与另一条记录存在关联是很常见的:关系模型中的外键,文档模型中的文档引用或图模型中的边。当你需要同时访问这一关联的两侧(持有引用的记录与被引用的记录)时,连接就是必须的。(包含引用的记录和被引用的记录),连接就是必需的。在数据库中,如果执行只涉及少量记录的查询,数据库通常会使用索引来快速定位感兴趣的记录,如果查询涉及到连接,则可能涉及到查找多个索引。然而 MapReduce 没有索引的概念,至少在通常意义上没有。
4 |
5 | 当 MapReduce 作业被赋予一组文件作为输入时,它读取所有这些文件的全部内容;数据库会将这种操作称为全表扫描。如果你只想读取少量的记录,则全表扫描与索引查询相比,代价非常高昂。但是在分析查询中,通常需要计算大量记录的聚合。在这种情况下,特别是如果能在多台机器上并行处理时,扫描整个输入可能是相当合理的事情。当我们在批处理的语境中讨论连接时,我们指的是在数据集中解析某种关联的全量存在。例如我们假设一个作业是同时处理所有用户的数据,而非仅仅是为某个特定用户查找数据(而这能通过索引更高效地完成)。
6 |
7 | # 案例:分析用户活动事件
8 |
9 | 下图给出了一个批处理作业中连接的典型例子。左侧是事件日志,描述登录用户在网站上做的事情(称为活动事件(activity events)或点击流数据(clickstream data)),右侧是用户数据库。你可以将此示例看作是星型模式的一部分:事件日志是事实表,用户数据库是其中的一个维度。
10 |
11 | 
12 |
13 | 分析任务可能需要将用户活动与用户简档相关联:例如,如果档案包含用户的年龄或出生日期,系统就可以确定哪些页面更受哪些年龄段的用户欢迎。然而活动事件仅包含用户 ID,而没有包含完整的用户档案信息。在每个活动事件中嵌入这些档案信息很可能会非常浪费。因此,活动事件需要与用户档案数据库相连接。
14 |
15 | 实现这一连接的最简单方法是,逐个遍历活动事件,并为每个遇到的用户 ID 查询用户数据库(在远程服务器上)。这是可能的,但是它的性能可能会非常差:处理吞吐量将受限于受数据库服务器的往返时间,本地缓存的有效性很大程度上取决于数据的分布,并行运行大量查询可能会轻易压垮数据库。为了在批处理过程中实现良好的吞吐量,计算必须(尽可能)限于单台机器上进行。为待处理的每条记录发起随机访问的网络请求实在是太慢了。而且,查询远程数据库意味着批处理作业变为非确定的(nondeterministic),因为远程数据库中的数据可能会改变。因此,更好的方法是获取用户数据库的副本(例如,使用 ETL 进程从数据库备份中提取数据,参阅“数据仓库”),并将它和用户行为日志放入同一个分布式文件系统中。然后你可以将用户数据库存储在 HDFS 中的一组文件中,而用户活动记录存储在另一组文件中,并能用 MapReduce 将所有相关记录集中到同一个地方进行高效处理。
16 |
17 | ## 排序合并连接
18 |
19 | Mapper 的目的是从每个输入记录中提取一对键值,这个键就是用户 ID:一组 Mapper 会扫过活动事件(提取用户 ID 作为键,活动事件作为值),而另一组 Mapper 将会扫过用户数据库(提取用户 ID 作为键,用户的出生日期作为值)。这个过程如下图所示。
20 |
21 | 
22 |
23 | 当 MapReduce 框架通过键对 Mapper 输出进行分区,然后对键值对进行排序时,效果是具有相同 ID 的所有活动事件和用户记录在 Reducer 输入中彼此相邻。Map-Reduce 作业甚至可以也让这些记录排序,使 Reducer 总能先看到来自用户数据库的记录,紧接着是按时间戳顺序排序的活动事件,这种技术被称为二次排序(secondary sort)。然后 Reducer 可以容易地执行实际的连接逻辑:每个用户 ID 都会被调用一次 Reducer 函数,且因为二次排序,第一个值应该是来自用户数据库的出生日期记录。Reducer 将出生日期存储在局部变量中,然后使用相同的用户 ID 遍历活动事件,输出已观看网址和观看者年龄的结果对。随后的 Map-Reduce 作业可以计算每个 URL 的查看者年龄分布,并按年龄段进行聚集。
24 |
25 | 由于 Reducer 一次处理一个特定用户 ID 的所有记录,因此一次只需要将一条用户记录保存在内存中,而不需要通过网络发出任何请求。这个算法被称为排序合并连接(sort-merge join),因为 Mapper 的输出是按键排序的,然后 Reducer 将来自连接两侧的有序记录列表合并在一起。
26 |
27 | ## 把相关数据放在一起
28 |
29 | 在排序合并连接中,Mapper 和排序过程确保了所有对特定用户 ID 执行连接操作的必须数据都被放在同一个地方:单次调用 Reducer 的地方。预先排好了所有需要的数据,Reducer 可以是相当简单的单线程代码,能够以高吞吐量和与低内存开销扫过这些记录。
30 |
31 | 这种架构可以看做,Mapper 将“消息”发送给 Reducer。当一个 Mapper 发出一个键值对时,这个键的作用就像值应该传递到的目标地址。即使键只是一个任意的字符串(不是像 IP 地址和端口号那样的实际的网络地址),它表现的就像一个地址:所有具有相同键的键值对将被传递到相同的目标(一次 Reduce 的调用)。
32 |
33 | 使用 MapReduce 编程模型,能将计算的物理网络通信层面(从正确的机器获取数据)从应用逻辑中剥离出来(获取数据后执行处理)。这种分离与数据库的典型用法形成了鲜明对比,从数据库中获取数据的请求经常出现在应用代码内部。由于 MapReduce 能够处理所有的网络通信,因此它也避免了应用代码去担心部分故障,例如另一个节点的崩溃:MapReduce 在不影响应用逻辑的情况下能透明地重试失败的任务。
34 |
35 | # GROUP BY
36 |
37 | 除了连接之外,“把相关数据放在一起”的另一种常见模式是,按某个键对记录分组(如 SQL 中的 GROUP BY 子句)。所有带有相同键的记录构成一个组,而下一步往往是在每个组内进行某种聚合操作,例如:
38 |
39 | - 统计每个组中记录的数量(例如在统计 PV 的例子中,在 SQL 中表示为 `COUNT(*)` 聚合)
40 | - 对某个特定字段求和(SQL 中的 SUM(fieldname))
41 | - 按某种分级函数取出排名前 k 条记录。
42 |
43 | 使用 MapReduce 实现这种分组操作的最简单方法是设置 Mapper,以便它们生成的键值对使用所需的分组键。然后分区和排序过程将所有具有相同分区键的记录导向同一个 Reducer。因此在 MapReduce 之上实现分组和连接看上去非常相似。分组的另一个常见用途是整理特定用户会话的所有活动事件,以找出用户进行的一系列操作(称为会话化(sessionization))。例如,可以使用这种分析来确定显示新版网站的用户是否比那些显示旧版本(A/B 测试)的用户更有购买欲,或者计算某个营销活动是否值得。如果你有多个 Web 服务器处理用户请求,则特定用户的活动事件很可能分散在各个不同的服务器的日志文件中。你可以通过使用会话 cookie,用户 ID 或类似的标识符作为分组键,以将特定用户的所有活动事件放在一起来实现会话化,与此同时,不同用户的事件仍然散步在不同的分区中。
44 |
45 | ## 处理倾斜
46 |
47 | 如果存在与单个键关联的大量数据,则“将具有相同键的所有记录放到相同的位置”这种模式就被破坏了。例如在社交网络中,大多数用户可能会与几百人有连接,但少数名人可能有数百万的追随者。这种不成比例的活动数据库记录被称为关键对象(linchpin object)或热键(hot key)。在单个 Reducer 中收集与某个名流相关的所有活动(例如他们发布内容的回复)可能导致严重的倾斜(也称为热点(hot spot)),也就是说,一个 Reducer 必须比其他 Reducer 处理更多的记录。由于 MapReduce 作业只有在所有 Mapper 和 Reducer 都完成时才完成,所有后续作业必须等待最慢的 Reducer 才能启动。
48 |
49 | 如果连接的输入存在热点键,可以使用一些算法进行补偿。例如,Pig 中的倾斜连接(skewed join)方法首先运行一个抽样作业来确定哪些键是热键。连接实际执行时,Mapper 会将热键的关联记录随机(相对于传统 MapReduce 基于键哈希的确定性方法)发送到几个 Reducer 之一。对于另外一侧的连接输入,与热键相关的记录需要被复制到所有处理该键的 Reducer 上。这种技术将处理热键的工作分散到多个 Reducer 上,这样可以使其更好地并行化,代价是需要将连接另一侧的输入记录复制到多个 Reducer 上。Crunch 中的分片连接(sharded join)方法与之类似,但需要显式指定热键而不是使用采样作业。
50 |
51 | Hive 的偏斜连接优化采取了另一种方法。它需要在表格元数据中显式指定热键,并将与这些键相关的记录单独存放,与其它文件分开。当在该表上执行连接时,对于热键,它会使用 Map 端连接。当按照热键进行分组并聚合时,可以将分组分两个阶段进行。第一个 MapReduce 阶段将记录发送到随机 Reducer,以便每个 Reducer 只对热键的子集执行分组,为每个键输出一个更紧凑的中间聚合结果。然后第二个 MapReduce 作业将所有来自第一阶段 Reducer 的中间聚合结果合并为每个键一个值。
52 |
53 | # Map 端连接
54 |
55 | 上一节描述的连接算法在 Reducer 中执行实际的连接逻辑,因此被称为 Reduce 端连接。Mapper 扮演着预处理输入数据的角色:从每个输入记录中提取键值,将键值对分配给 Reducer 分区,并按键排序。Reduce 端方法的优点是不需要对输入数据做任何假设:无论其属性和结构如何,Mapper 都可以对其预处理以备连接。然而不利的一面是,排序,复制至 Reducer,以及合并 Reducer 输入,所有这些操作可能开销巨大。当数据通过 MapReduce 阶段时,数据可能需要落盘好几次,取决于可用的内存缓冲区。
56 |
57 | 另一方面,如果你能对输入数据作出某些假设,则通过使用所谓的 Map 端连接来加快连接速度是可行的。这种方法使用了一个阉掉 Reduce 与排序的 MapReduce 作业,每个 Mapper 只是简单地从分布式文件系统中读取一个输入文件块,然后将输出文件写入文件系统,仅此而已。
58 |
59 | # 广播哈希连接
60 |
61 | 适用于执行 Map 端连接的最简单场景是大数据集与小数据集连接的情况。要点在于小数据集需要足够小,以便可以将其全部加载到每个 Mapper 的内存中。用户数据库小到足以放进内存中。在这种情况下,当 Mapper 启动时,它可以首先将用户数据库从分布式文件系统读取到内存中的哈希中。完成此操作后,Map 程序可以扫描用户活动事件,并简单地在哈希表中查找每个事件的用户 ID。
62 |
63 | 参与连接的较大输入的每个文件块各有一个 Mapper,每个 Mapper 都会将较小输入整个加载到内存中。这种简单有效的算法被称为广播哈希连接(broadcast hash join):广播一词反映了这样一个事实,每个连接较大输入端分区的 Mapper 都会将较小输入端数据集整个读入内存中(所以较小输入实际上“广播”到较大数据的所有分区上),哈希一词反映了它使用一个哈希表。Pig(名为“复制链接(replicated join)”),Hive(“MapJoin”),Cascading 和 Crunch 支持这种连接。它也被诸如 Impala 的数据仓库查询引擎使用。
64 |
65 | 除了将连接较小输入加载到内存哈希表中,另一种方法是将较小输入存储在本地磁盘上的只读索引中。索引中经常使用的部分将保留在操作系统的页面缓存中,因而这种方法可以提供与内存哈希表几乎一样快的随机查找性能,但实际上并不需要数据集能放入内存中。
66 |
67 | # 分区哈希连接
68 |
69 | 如果 Map 端连接的输入以相同的方式进行分区,则哈希连接方法可以独立应用于每个分区。譬如你可以根据用户 ID 的最后一位十进制数字来对活动事件和用户数据库进行分区(因此连接两侧各有 10 个分区)。例如,Mapper3 首先将所有具有以 3 结尾的 ID 的用户加载到哈希表中,然后扫描 ID 为 3 的每个用户的所有活动事件。
70 |
71 | 如果分区正确无误,可以确定的是,所有你可能需要连接的记录都落在同一个编号的分区中。因此每个 Mapper 只需要从输入两端各读取一个分区就足够了。好处是每个 Mapper 都可以在内存哈希表中少放点数据。这种方法只有当连接两端输入有相同的分区数,且两侧的记录都是使用相同的键与相同的哈希函数做分区时才适用。如果输入是由之前执行过这种分组的 MapReduce 作业生成的,那么这可能是一个合理的假设。
72 |
73 | 分区哈希连接在 Hive 中称为 Map 端桶连接(bucketed map joins)。
74 |
75 | # Map 端合并连接
76 |
77 | 如果输入数据集不仅以相同的方式进行分区,而且还基于相同的键进行排序,则可适用另一种 Map 端联接的变体。在这种情况下,输入是否小到能放入内存并不重要,因为这时候 Mapper 同样可以执行归并操作(通常由 Reducer 执行)的归并操作:按键递增的顺序依次读取两个输入文件,将具有相同键的记录配对。
78 |
79 | 如果能进行 Map 端合并连接,这通常意味着前一个 MapReduce 作业可能一开始就已经把输入数据做了分区并进行了排序。原则上这个连接就可以在前一个作业的 Reduce 阶段进行。但使用独立的仅 Map 作业有时也是合适的,例如,分好区且排好序的中间数据集可能还会用于其他目的。
80 |
81 | # MapReduce 工作流与 Map 端连接
82 |
83 | 当下游作业使用 MapReduce 连接的输出时,选择 Map 端连接或 Reduce 端连接会影响输出的结构。Reduce 端连接的输出是按照连接键进行分区和排序的,而 Map 端连接的输出则按照与较大输入相同的方式进行分区和排序(因为无论是使用分区连接还是广播连接,连接较大输入端的每个文件块都会启动一个 Map 任务)。
84 |
85 | 如前所述,Map 端连接也对输入数据集的大小,有序性和分区方式做出了更多假设。在优化连接策略时,了解分布式文件系统中数据集的物理布局变得非常重要:仅仅知道编码格式和数据存储目录的名称是不够的;你还必须知道数据是按哪些键做的分区和排序,以及分区的数量。
86 |
87 | 在 Hadoop 生态系统中,这种关于数据集分区的元数据通常在 HCatalog 和 Hive Metastore 中维护。
88 |
--------------------------------------------------------------------------------
/批处理/README.md:
--------------------------------------------------------------------------------
1 | # 批处理
2 |
3 | 互联网的发展产生了所谓的大数据(TB 或 PB),不可能在一个有限的时间范围内将数据拟合到一台机器上或用一个程序处理它。在批处理中,新到达的数据元素被收集到一个组中。整个组在未来的时间进行处理(作为批处理,因此称为“批处理”)。确切地说,何时处理每个组可以用多种方式来确定,它可以基于预定的时间间隔(例如,每五分钟,处理任何新的数据已被收集)或在某些触发的条件下(例如,处理只要它包含五个数据元素或一旦它拥有超过 1MB 的数据)。
4 |
5 | 
6 |
7 | 通过类比的方式,批处理就像你的朋友(你当然知道这样的人)从干衣机中取出一大堆衣物,并简单地把所有东西都扔进一个抽屉里,只有当它很难找到东西时才分类和组织它。这个人避免每次洗衣时都要进行分拣工作,但是他们需要花费大量时间在抽屉里搜索抽屉,并最终需要花费大量时间分离衣服,匹配袜子等。当它变得很难找到东西的时候。历史上,绝大多数数据处理技术都是为批处理而设计的。传统的数据仓库和 Hadoop 是专注于批处理的系统的两个常见示例。
8 |
9 | 术语 MicroBatch 经常用于描述批次小和/或以小间隔处理的情况。即使处理可能每隔几分钟发生一次,数据仍然一次处理一批。Spark Streaming 是设计用于支持微批处理的系统的一个例子。
10 |
11 | # Links
12 |
13 | - http://dist-prog-book.com/chapter/8/big-data.html
14 |
--------------------------------------------------------------------------------
/批处理/Waltz/README.md:
--------------------------------------------------------------------------------
1 | # Waltz
2 |
3 | Waltz 类似于 Kafka 等现有日志系统,同样能够接收 / 持久化 / 传播由大量服务生成 / 消费的交易数据。但与其它系统的区别在于,Wlatz 在分布式应用程序之内提供一套更加便捷的序列化一致性实现机制。它能够在将交易提交至日志之前,首先对其中的冲突进行检测。Waltz 可以充当唯一事实来源,而非普通的数据库,并由此建立极为可靠的、以日志为中心的系统架构。
4 |
5 | # Links
6 |
7 | - https://mp.weixin.qq.com/s/1LWTuNcPFGRPDXsxlVgWYA
8 |
--------------------------------------------------------------------------------
/批处理/使用 Unix 工具的批处理.md:
--------------------------------------------------------------------------------
1 | # 使用 Unix 工具的批处理
2 |
3 | 我们从一个简单的例子开始。假设您有一台 Web 服务器,每次处理请求时都会在日志文件中附加一行。例如,使用 nginx 默认访问日志格式,日志的一行可能如下所示:
4 |
5 | ```sh
6 | 216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
7 | 200 3377 "http://test.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)
8 | AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36"
9 | ```
10 |
11 | 日志的格式定义如下:
12 |
13 | ```sh
14 | $remote_addr - $remote_user [$time_local] "$request"
15 | $status $body_bytes_sent "$http_referer" "$http_user_agent"
16 | ```
17 |
18 | 日志的这一行表明在 2015 年 2 月 27 日 17:55:11 UTC,服务器从客户端 IP 地址 216.58.210.78 接收到对文件/css/typography.css 的请求。用户没有被认证,所以\$remote_user 被设置为连字符(-)。响应状态是 200(即请求成功),响应的大小是 3377 字节。网页浏览器是 Chrome 40,URL http://test.com/ 的页面中的引用导致该文件被加载。
19 |
20 | ## 分析简单日志
21 |
22 | 很多工具可以从这些日志文件生成关于网站流量的漂亮的报告,但为了练手,让我们使用基本的 Unix 功能创建自己的工具。例如,假设你想在你的网站上找到五个最受欢迎的网页。则可以在 Unix shell 中这样做:
23 |
24 | ```sh
25 | cat /var/log/nginx/access.log | #1 读取日志文件
26 | awk '{print $7}' | #2 将每一行按空格分割成不同的字段,每行只输出第七个字段,恰好是请求的URL。在我们的例子中是/css/typography.css
27 | sort | #3 按字母顺序排列请求的URL列表。如果某个URL被请求过n次,那么排序后,文件将包含连续重复出现n次的该URL
28 | uniq -c | #4 uniq命令通过检查两个相邻的行是否相同来过滤掉输入中的重复行。-c则表示还要输出一个计数器:对于每个不同的URL,它会报告输入中出现该URL的次数
29 | sort -r -n | #5 第二种排序按每行起始处的数字(-n)排序,这是URL的请求次数。然后逆序(-r)返回结果,大的数字在前
30 | head -n 5 #6 最后,只输出前五行(-n 5),并丢弃其余的
31 | ```
32 |
33 | 最后输出的结果如下:
34 |
35 | ```sh
36 | 4189 /favicon.ico
37 | 3631 /2013/05/24/improving-security-of-ssh-private-keys.html
38 | 2124 /2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
39 | 1369 /
40 | 915 /css/typography.css
41 | ```
42 |
43 | Unix 工具非常强大,能在几秒钟内处理几 GB 的日志文件,并且您可以根据需要轻松修改命令。例如,如果要从报告中省略 CSS 文件,可以将 awk 参数更改为 `'$7 !~ /\.css$/ {print \$7}'`,如果想统计最多的客户端 IP 地址,可以把 awk 参数改为 `'{print $1}'` 等等。
44 |
45 | ## 命令链与自定义程序
46 |
47 | 除了 Unix 命令链,你还可以写一个简单的程序来做同样的事情。例如在 Ruby 中,它可能看起来像这样:
48 |
49 | ```sh
50 | counts = Hash.new(0) # 1 counts是一个存储计数器的哈希表,保存了每个URL被浏览的次数,默认为0。
51 |
52 | File.open('/var/log/nginx/access.log') do |file|
53 | file.each do |line|
54 | url = line.split[6] # 2 逐行读取日志,抽取每行第七个被空格分隔的字段为URL(这里的数组索引是6,因为Ruby的数组索引从0开始计数)
55 | counts[url] += 1 # 3 将日志当前行中URL对应的计数器值加一。
56 | end
57 | end
58 |
59 | top5 = counts.map{|url, count| [count, url] }.sort.reverse[0...5] # 4 按计数器值(降序)对哈希表内容进行排序,并取前五位。
60 | top5.each{|count, url| puts "#{count} #{url}" } # 5 打印出前五个条目。
61 |
62 | ```
63 |
64 | ## 排序 VS 内存中的聚合
65 |
66 | Ruby 脚本在内存中保存了一个 URL 的哈希表,将每个 URL 映射到它出现的次数。Unix 管道没有这样的哈希表,而是依赖于对 URL 列表的排序,在这个 URL 列表中,同一个 URL 的只是简单地重复出现。
67 |
68 | 哪种方法更好?这取决于你有多少个不同的 URL。对于大多数中小型网站,你可能可以为所有不同网址提供一个计数器(假设我们使用 1GB 内存)。在此例中,作业的工作集(working set)(作业需要随机访问的内存大小)仅取决于不同 URL 的数量:如果日志中只有单个 URL,重复出现一百万次,则哈希表所需的空间表就只有一个 URL 加上一个计数器的大小。当工作集足够小时,内存哈希表表现良好,甚至在性能较差的笔记本电脑上也可以正常工作。
69 |
70 | 另一方面,如果作业的工作集大于可用内存,则排序方法的优点是可以高效地使用磁盘。这与我们在“SSTables 和 LSM 树”中讨论过的原理是一样的:数据块可以在内存中排序并作为段文件写入磁盘,然后多个排序好的段可以合并为一个更大的排序文件。归并排序具有在磁盘上运行良好的顺序访问模式。(请记住,针对顺序 I/O 进行优化是第 3 章中反复出现的主题,相同的模式在此重现)
71 |
72 | GNU Coreutils(Linux)中的 sort 程序通过溢出至磁盘的方式来自动应对大于内存的数据集,并能同时使用多个 CPU 核进行并行排序。这意味着我们之前看到的简单的 Unix 命令链很容易扩展到大数据集,且不会耗尽内存。瓶颈可能是从磁盘读取输入文件的速度。
73 |
--------------------------------------------------------------------------------
/批处理/执行框架/README.md:
--------------------------------------------------------------------------------
1 | # 批处理引擎
2 |
3 | 虽然 MapReduce 在二十世纪二十年代后期变得非常流行,并受到大量的炒作,但它只是分布式系统的许多可能的编程模型之一。对于不同的数据量,数据结构和处理类型,其他工具可能更适合表示计算。不管如何,我们在这一章花了大把时间来讨论 MapReduce,因为它是一种有用的学习工具,它是分布式文件系统的一种相当简单明晰的抽象。在这里,简单意味着我们能理解它在做什么,而不是意味着使用它很简单。恰恰相反:使用原始的 MapReduce API 来实现复杂的处理工作实际上是非常困难和费力的,例如,任意一种连接算法都需要你从头开始实现。
4 |
5 | 针对直接使用 MapReduce 的困难,在 MapReduce 上有很多高级编程模型(Pig,Hive,Cascading,Crunch)被创造出来,作为建立在 MapReduce 之上的抽象。如果你了解 MapReduce 的原理,那么它们学起来相当简单。而且它们的高级结构能显著简化许多常见批处理任务的实现。但是,MapReduce 执行模型本身也存在一些问题,这些问题并没有通过增加另一个抽象层次而解决,而对于某些类型的处理,它表现得非常差劲。一方面,MapReduce 非常稳健:你可以使用它在任务会频繁终止的多租户系统上处理几乎任意大量级的数据,并且仍然可以完成工作(虽然速度很慢)。另一方面,对于某些类型的处理而言,其他工具有时会快上几个数量级。
6 |
7 | # 分布式批处理框架的挑战
8 |
9 | 批处理作业的显著特点是,它读取一些输入数据并产生一些输出数据,但不修改输入—— 换句话说,输出是从输入衍生出的。最关键的是,输入数据是有界的(bounded):它有一个已知的,固定的大小(例如,它包含一些时间点的日志文件或数据库内容的快照)。因为它是有界的,一个作业知道自己什么时候完成了整个输入的读取,所以一个工作在做完后,最终总是会完成的。分布式批处理框架需要解决的两个主要问题是:
10 |
11 | - 分区:在 MapReduce 中,Mapper 根据输入文件块进行分区。Mapper 的输出被重新分区,排序,并合并到可配置数量的 Reducer 分区中。这一过程的目的是把所有的相关数据(例如带有相同键的所有记录)都放在同一个地方。后 MapReduce 时代的数据流引擎若非必要会尽量避免排序,但它们也采取了大致类似的分区方法。
12 |
13 | - 容错:MapReduce 经常写入磁盘,这使得从单个失败的任务恢复很轻松,无需重新启动整个作业,但在无故障的情况下减慢了执行速度。数据流引擎更多地将中间状态保存在内存中,更少地物化中间状态,这意味着如果节点发生故障,则需要重算更多的数据。确定性算子减少了需要重算的数据量。
14 |
15 | 我们讨论了几种 MapReduce 的连接算法,其中大多数也在 MPP 数据库和数据流引擎内部使用。它们也很好地演示了分区算法是如何工作的:
16 |
17 | - 排序合并连接:每个参与连接的输入都通过一个提取连接键的 Mapper。通过分区,排序和合并,具有相同键的所有记录最终都会进入相同的 Reducer 调用。这个函数能输出连接好的记录。
18 |
19 | - 广播哈希连接:两个连接输入之一很小,所以它并没有分区,而且能被完全加载进一个哈希表中。因此,你可以为连接输入大端的每个分区启动一个 Mapper,将输入小端的哈希表加载到每个 Mapper 中,然后扫描大端,一次一条记录,并为每条记录查询哈希表。
20 |
21 | - 分区哈希连接:如果两个连接输入以相同的方式分区(使用相同的键,相同的哈希函数和相同数量的分区),则可以独立地对每个分区应用哈希表方法。
22 |
23 | 分布式批处理引擎有一个刻意限制的编程模型:回调函数(比如 Mapper 和 Reducer)被假定是无状态的,而且除了指定的输出外,必须没有任何外部可见的副作用。这一限制允许框架在其抽象下隐藏一些困难的分布式系统问题:当遇到崩溃和网络问题时,任务可以安全地重试,任何失败任务的输出都被丢弃。如果某个分区的多个任务成功,则其中只有一个能使其输出实际可见。得益于这个框架,你在批处理作业中的代码无需操心实现容错机制:框架可以保证作业的最终输出与没有发生错误的情况相同,也许不得不重试各种任务。在线服务处理用户请求,并将写入数据库作为处理请求的副作用,比起在线服务,批处理提供的这种可靠性语义要强得多。
24 |
--------------------------------------------------------------------------------
/批处理/执行框架/图与迭代处理.md:
--------------------------------------------------------------------------------
1 | # 图与迭代处理
2 |
3 | 在《图数据模型》中,我们讨论了使用图来建模数据,并使用图查询语言来遍历图中的边与点。批处理上下文中的图也很有趣,其目标是在整个图上执行某种离线处理或分析。这种需求经常出现在机器学习应用(如推荐引擎)或排序系统中。例如,最着名的图形分析算法之一是 PageRank,它试图根据链接到某个网页的其他网页来估计该网页的流行度。它作为配方的一部分,用于确定网络搜索引擎呈现结果的顺序。
4 |
5 | 注意,像 Spark,Flink 和 Tez 这样的数据流引擎通常将算子作为**有向无环图(DAG)**的一部分安排在作业中。但是这与图处理不一样:在数据流引擎中,从一个算子到另一个算子的数据流被构造成一个图,而数据本身通常由关系型元组构成。在图处理中,数据本身具有图的形式。又一个不幸的命名混乱。
6 |
7 | 许多图算法是通过一次遍历一条边来表示的,将一个顶点与近邻的顶点连接起来,以传播一些信息,并不断重复,直到满足一些条件为止。例如,直到没有更多的边要跟进,或直到一些指标收敛;通过重复跟进标明地点归属关系的边,生成了数据库中北美包含的所有地点列表(这种算法被称为闭包传递(transitive closure))。
8 |
9 | 可以在分布式文件系统中存储图(包含顶点和边的列表的文件),但是这种“重复至完成”的想法不能用普通的 MapReduce 来表示,因为它只扫过一趟数据。这种算法因此经常以迭代的风格实现:
10 |
11 | - 外部调度程序运行批处理来计算算法的一个步骤。
12 | - 当批处理过程完成时,调度器检查它是否完成(基于完成条件:例如,没有更多的边要跟进,或者与上次迭代相比的变化低于某个阈值)。
13 | - 如果尚未完成,则调度程序返回到步骤 1 并运行另一轮批处理。
14 |
15 | 这种方法是有效的,但是用 MapReduce 实现它往往非常低效,因为 MapReduce 没有考虑算法的迭代性质:它总是读取整个输入数据集并产生一个全新的输出数据集,即使与上次迭代相比,改变的仅仅是图中的一小部分。
16 |
17 | # Pregel 处理模型
18 |
19 | 针对图批处理的优化,批量同步并行(BSP)计算模型已经开始流行起来。其中,Apache Giraph,Spark 的 GraphX API 和 Flink 的 Gelly API 实现了它。它也被称为 Pregel 模型,因为 Google 的 Pregel 论文推广了这种处理图的方法。回想一下在 MapReduce 中,Mapper 在概念上向 Reducer 的特定调用“发送消息”,因为框架将所有具有相同键的 Mapper 输出集中在一起。Pregel 背后有一个类似的想法:一个顶点可以向另一个顶点“发送消息”,通常这些消息是沿着图的边发送的。
20 |
21 | 在每次迭代中,为每个顶点调用一个函数,将所有发送给它的消息传递给它,就像调用 Reducer 一样。与 MapReduce 的不同之处在于,在 Pregel 模型中,顶点在一次迭代到下一次迭代的过程中会记住它的状态,所以这个函数只需要处理新的传入消息。如果图的某个部分没有被发送消息,那里就不需要做任何工作。
22 |
23 | 这与 Actor 模型有些相似,除了顶点状态和顶点之间的消息具有容错性和耐久性,且通信以固定的方式进行:在每次迭代中,框架递送上次迭代中发送的所有消息。Actor 通常没有这样的时间保证。
24 |
25 | # 容错
26 |
27 | 顶点只能通过消息传递进行通信(而不是直接相互查询)的事实有助于提高 Pregel 作业的性能,因为消息可以成批处理,且等待通信的次数也减少了。唯一的等待是在迭代之间:由于 Pregel 模型保证所有在一轮迭代中发送的消息都在下轮迭代中送达,所以在下一轮迭代开始前,先前的迭代必须完全完成,而所有的消息必须在网络上完成复制。
28 |
29 | 即使底层网络可能丢失,重复或任意延迟消息,Pregel 的实现能保证在后续迭代中消息在其目标顶点恰好处理一次。像 MapReduce 一样,框架能从故障中透明地恢复,以简化在 Pregel 上实现算法的编程模型。这种容错是通过在迭代结束时,定期存档所有顶点的状态来实现的,即将其全部状态写入持久化存储。如果某个节点发生故障并且其内存中的状态丢失,则最简单的解决方法是将整个图计算回滚到上一个存档点,然后重启计算。如果算法是确定性的,且消息记录在日志中,那么也可以选择性地只恢复丢失的分区(就像之前讨论过的数据流引擎)。
30 |
31 | # 并行执行
32 |
33 | 顶点不需要知道它在哪台物理机器上执行;当它向其他顶点发送消息时,它只是简单地将消息发往某个顶点 ID。图的分区取决于框架。即,确定哪个顶点运行在哪台机器上,以及如何通过网络路由消息,以便它们到达正确的地方。由于编程模型一次仅处理一个顶点(有时称为“像顶点一样思考”),所以框架可以以任意方式对图分区。理想情况下如果顶点需要进行大量的通信,那么它们最好能被分区到同一台机器上。然而找到这样一种优化的分区方法是很困难的,在实践中,图经常按照任意分配的顶点 ID 分区,而不会尝试将相关的顶点分组在一起。
34 |
35 | 因此,图算法通常会有很多跨机器通信的额外开销,而中间状态(节点之间发送的消息)往往比原始图大。通过网络发送消息的开销会显著拖慢分布式图算法的速度。出于这个原因,如果你的图可以放入一台计算机的内存中,那么单机(甚至可能是单线程)算法很可能会超越分布式批处理。图比内存大也没关系,只要能放入单台计算机的磁盘,使用 GraphChi 等框架进行单机处理是就一个可行的选择。如果图太大,不适合单机处理,那么像 Pregel 这样的分布式方法是不可避免的。高效的并行图算法是一个进行中的研究领域。
36 |
--------------------------------------------------------------------------------
/批处理/执行框架/物化中间状态.md:
--------------------------------------------------------------------------------
1 | # 物化中间状态
2 |
3 | 如前所述,每个 MapReduce 作业都独立于其他任何作业。作业与世界其他地方的主要连接点是分布式文件系统上的输入和输出目录。如果希望一个作业的输出成为第二个作业的输入,则需要将第二个作业的输入目录配置为第一个作业输出目录,且外部工作流调度程序必须在第一个作业完成后再启动第二个。如果第一个作业的输出是要在组织内广泛发布的数据集,则这种配置是合理的。在这种情况下,你需要通过名称引用它,并将其重用为多个不同作业的输入(包括由其他团队开发的作业)。将数据发布到分布式文件系统中众所周知的位置能够带来松耦合,这样作业就不需要知道是谁在提供输入或谁在消费输出。
4 |
5 | 但在很多情况下,你知道一个作业的输出只能用作另一个作业的输入,这些作业由同一个团队维护。在这种情况下,分布式文件系统上的文件只是简单的中间状态(intermediate state):一种将数据从一个作业传递到下一个作业的方式。在一个用于构建推荐系统的,由 50 或 100 个 MapReduce 作业组成的复杂工作流中,存在着很多这样的中间状态。
6 |
7 | 将这个中间状态写入文件的过程称为物化(materialization),它意味着对某个操作的结果立即求值并写出来,而不是在请求时按需计算。与 Unix 管道相比,MapReduce 完全物化中间状态的方法存在不足之处:
8 |
9 | - MapReduce 作业只有在前驱作业(生成其输入)中的所有任务都完成时才能启动,而由 Unix 管道连接的进程会同时启动,输出一旦生成就会被消费。不同机器上的数据倾斜或负载不均意味着一个作业往往会有一些掉队的任务,比其他任务要慢得多才能完成。必须等待至前驱作业的所有任务完成,拖慢了整个工作流程的执行。
10 |
11 | - Mapper 通常是多余的:它们仅仅是读取刚刚由 Reducer 写入的同样文件,为下一个阶段的分区和排序做准备。在许多情况下,Mapper 代码可能是前驱 Reducer 的一部分:如果 Reducer 和 Mapper 的输出有着相同的分区与排序方式,那么 Reducer 就可以直接串在一起,而不用与 Mapper 相互交织。
12 |
13 | - 将中间状态存储在分布式文件系统中意味着这些文件被复制到多个节点,这些临时数据这么搞就比较过分了。
14 |
15 | # 数据流引擎
16 |
17 | 了解决 MapReduce 的这些问题,几种用于分布式批处理的新执行引擎被开发出来,其中最著名的是 Spark,Tez 和 Flink 。它们的设计方式有很多区别,但有一个共同点:把整个工作流作为单个作业来处理,而不是把它分解为独立的子作业。由于它们将工作流显式建模为 数据从几个处理阶段穿过,所以这些系统被称为数据流引擎(dataflow engines)。像 MapReduce 一样,它们在一条线上通过反复调用用户定义的函数来一次处理一条记录,它们通过输入分区来并行化载荷,它们通过网络将一个函数的输出复制到另一个函数的输入。
18 |
19 | 与 MapReduce 不同,这些功能不需要严格扮演交织的 Map 与 Reduce 的角色,而是可以以更灵活的方式进行组合。我们称这些函数为算子(operators),数据流引擎提供了几种不同的选项来将一个算子的输出连接到另一个算子的输入:
20 |
21 | - 一种选项是对记录按键重新分区并排序,就像在 MapReduce 的混洗阶段一样。这种功能可以用于实现排序合并连接和分组,就像在 MapReduce 中一样。
22 |
23 | - 另一种可能是接受多个输入,并以相同的方式进行分区,但跳过排序。当记录的分区重要但顺序无关紧要时,这省去了分区哈希连接的工作,因为构建哈希表还是会把顺序随机打乱。
24 |
25 | - 对于广播哈希连接,可以将一个算子的输出,发送到连接算子的所有分区。
26 |
27 | 这种类型的处理引擎是基于像 Dryad 和 Nephele 这样的研究系统,与 MapReduce 模型相比,它有几个优点:
28 |
29 | - 排序等昂贵的工作只需要在实际需要的地方执行,而不是默认地在每个 Map 和 Reduce 阶段之间出现。
30 |
31 | - 没有不必要的 Map 任务,因为 Mapper 所做的工作通常可以合并到前面的 Reduce 算子中(因为 Mapper 不会更改数据集的分区)。
32 |
33 | - 由于工作流中的所有连接和数据依赖都是显式声明的,因此调度程序能够总览全局,知道哪里需要哪些数据,因而能够利用局部性进行优化。例如,它可以尝试将消费某些数据的任务放在与生成这些数据的任务相同的机器上,从而数据可以通过共享内存缓冲区传输,而不必通过网络复制。
34 |
35 | 通常,算子间的中间状态足以保存在内存中或写入本地磁盘,这比写入 HDFS 需要更少的 I/O(必须将其复制到多台机器,并将每个副本写入磁盘)。MapReduce 已经对 Mapper 的输出做了这种优化,但数据流引擎将这种思想推广至所有的中间状态。算子可以在输入就绪后立即开始执行;后续阶段无需等待前驱阶段整个完成后再开始。与 MapReduce(为每个任务启动一个新的 JVM)相比,现有 Java 虚拟机(JVM)进程可以重用来运行新算子,从而减少启动开销。
36 |
37 | 你可以使用数据流引擎执行与 MapReduce 工作流同样的计算,而且由于此处所述的优化,通常执行速度要明显快得多。既然算子是 Map 和 Reduce 的泛化,那么相同的处理代码就可以在任一执行引擎上运行:Pig,Hive 或 Cascading 中实现的工作流可以无需修改代码,可以通过修改配置,简单地从 MapReduce 切换到 Tez 或 Spark。Tez 是一个相当薄的库,它依赖于 YARN shuffle 服务来实现节点间数据的实际复制,而 Spark 和 Flink 则是包含了独立网络通信层,调度器,及用户向 API 的大型框架。我们将简要讨论这些高级 API。
38 |
39 | # 容错
40 |
41 | 完全物化中间状态至分布式文件系统的一个优点是,它具有持久性,这使得 MapReduce 中的容错相当容易:如果一个任务失败,它可以在另一台机器上重新启动,并从文件系统重新读取相同的输入。Spark,Flink 和 Tez 避免将中间状态写入 HDFS,因此它们采取了不同的方法来容错:如果一台机器发生故障,并且该机器上的中间状态丢失,则它会从其他仍然可用的数据重新计算(在可行的情况下是先前的中间状态,要么就只能是原始输入数据,通常在 HDFS 上)。
42 |
43 | 为了实现这种重新计算,框架必须跟踪一个给定的数据是如何计算的,使用了哪些输入分区?应用了哪些算子?Spark 使用**弹性分布式数据集(RDD)**的抽象来跟踪数据的谱系,而 Flink 对算子状态存档,允许恢复运行在执行过程中遇到错误的算子。在重新计算数据时,重要的是要知道计算是否是确定性的:也就是说,给定相同的输入数据,算子是否始终产生相同的输出?如果一些丢失的数据已经发送给下游算子,这个问题就很重要。如果算子重新启动,重新计算的数据与原有的丢失数据不一致,下游算子很难解决新旧数据之间的矛盾。对于不确定性算子来说,解决方案通常是杀死下游算子,然后再重跑新数据。
44 |
45 | 为了避免这种级联故障,最好让算子具有确定性。但需要注意的是,非确定性行为很容易悄悄溜进来:例如,许多编程语言在迭代哈希表的元素时不能对顺序作出保证,许多概率和统计算法显式依赖于使用随机数,以及用到系统时钟或外部数据源,这些都是都不确定性的行为。为了能可靠地从故障中恢复,需要消除这种不确定性因素,例如使用固定的种子生成伪随机数。通过重算数据来从故障中恢复并不总是正确的答案:如果中间状态数据要比源数据小得多,或者如果计算量非常大,那么将中间数据物化为文件可能要比重新计算廉价的多。
46 |
47 | # 关于物化的讨论
48 |
49 | 回到 Unix 的类比,我们看到,MapReduce 就像是将每个命令的输出写入临时文件,而数据流引擎看起来更像是 Unix 管道。尤其是 Flink 是基于管道执行的思想而建立的:也就是说,将算子的输出增量地传递给其他算子,不待输入完成便开始处理。排序算子不可避免地需要消费全部的输入后才能生成任何输出,因为输入中最后一条输入记录可能具有最小的键,因此需要作为第一条记录输出。因此,任何需要排序的算子都需要至少暂时地累积状态。但是工作流的许多其他部分可以以流水线方式执行。
50 |
51 | 当作业完成时,它的输出需要持续到某个地方,以便用户可以找到并使用它—— 很可能它会再次写入分布式文件系统。因此,在使用数据流引擎时,HDFS 上的物化数据集通常仍是作业的输入和最终输出。和 MapReduce 一样,输入是不可变的,输出被完全替换。比起 MapReduce 的改进是,你不用再自己去将中间状态写入文件系统了。
52 |
--------------------------------------------------------------------------------
/批处理/执行框架/高级 API 和语言.md:
--------------------------------------------------------------------------------
1 | # 高级 API 和语言
2 |
3 | 自 MapReduce 开始流行的这几年以来,分布式批处理的执行引擎已经很成熟了。到目前为止,基础设施已经足够强大,能够存储和处理超过 10,000 台机器群集上的数 PB 的数据。由于在这种规模下物理执行批处理的问题已经被认为或多或少解决了,所以关注点已经转向其他领域:改进编程模型,提高处理效率,扩大这些技术可以解决的问题集。如前所述,Hive,Pig,Cascading 和 Crunch 等高级语言和 API 变得越来越流行,因为手写 MapReduce 作业实在是个苦力活。随着 Tez 的出现,这些高级语言还有一个额外好处,可以迁移到新的数据流执行引擎,而无需重写作业代码。Spark 和 Flink 也有它们自己的高级数据流 API,通常是从 FlumeJava 中获取的灵感。
4 |
5 | 这些数据流 API 通常使用关系型构建块来表达一个计算:按某个字段连接数据集;按键对元组做分组;按某些条件过滤;并通过计数求和或其他函数来聚合元组。在内部,这些操作是使用本章前面讨论过的各种连接和分组算法来实现的。除了少写代码的明显优势之外,这些高级接口还支持交互式用法,在这种交互式使用中,你可以在 Shell 中增量式编写分析代码,频繁运行来观察它做了什么。这种开发风格在探索数据集和试验处理方法时非常有用。
6 |
7 | 此外,这些高级接口不仅提高了人类的工作效率,也提高了机器层面的作业执行效率。
8 |
9 | # 向声明式查询语言的转变
10 |
11 | 与硬写执行连接的代码相比,指定连接关系算子的优点是,框架可以分析连接输入的属性,并自动决定哪种上述连接算法最适合当前任务。Hive,Spark 和 Flink 都有基于代价的查询优化器可以做到这一点,甚至可以改变连接顺序,最小化中间状态的数量。连接算法的选择可以对批处理作业的性能产生巨大影响,而无需理解和记住本章中讨论的各种连接算法。如果连接是以**声明式(declarative)**的方式指定的,那这就这是可行的:应用只是简单地说明哪些连接是必需的,查询优化器决定如何最好地执行连接。
12 |
13 | 但 MapReduce 及其后继者数据流在其他方面,与 SQL 的完全声明式查询模型有很大区别。MapReduce 是围绕着回调函数的概念建立的:对于每条记录或者一组记录,调用一个用户定义的函数(Mapper 或 Reducer),并且该函数可以自由地调用任意代码来决定输出什么。这种方法的优点是可以基于大量已有库的生态系统创作:解析,自然语言分析,图像分析以及运行数值算法或统计算法等。自由运行任意代码,长期以来都是传统 MapReduce 批处理系统与 MPP 数据库的区别所在。虽然数据库具有编写用户定义函数的功能,但是它们通常使用起来很麻烦,而且与大多数编程语言中广泛使用的程序包管理器和依赖管理系统兼容不佳(例如 Java 的 Maven,Javascript 的 npm,以及 Ruby 的 gems)。
14 |
15 | 然而数据流引擎已经发现,支持除连接之外的更多声明式特性还有其他的优势。例如,如果一个回调函数只包含一个简单的过滤条件,或者只是从一条记录中选择了一些字段,那么在为每条记录调用函数时会有相当大的额外 CPU 开销。如果以声明方式表示这些简单的过滤和映射操作,那么查询优化器可以利用面向列的存储布局,只从磁盘读取所需的列。Hive,Spark DataFrames 和 Impala 还使用了向量化执行:在对 CPU 缓存友好的内部循环中迭代数据,避免函数调用。Spark 生成 JVM 字节码,Impala 使用 LLVM 为这些内部循环生成本机代码。
16 |
17 | 通过在高级 API 中引入声明式的部分,并使查询优化器可以在执行期间利用这些来做优化,批处理框架看起来越来越像 MPP 数据库了(并且能实现可与之媲美的性能)。同时,通过拥有运行任意代码和以任意格式读取数据的可扩展性,它们保持了灵活性的优势。
18 |
19 | # 专业化的不同领域
20 |
21 | 尽管能够运行任意代码的可扩展性是很有用的,但是也有很多常见的例子,不断重复着标准的处理模式。因而这些模式值得拥有自己的可重用通用构建模块实现,传统上,MPP 数据库满足了商业智能分析和业务报表的需求,但这只是许多使用批处理的领域之一。
22 |
23 | 另一个越来越重要的领域是统计和数值算法,它们是机器学习应用所需要的(例如分类器和推荐系统)。可重用的实现正在出现:例如,Mahout 在 MapReduce,Spark 和 Flink 之上实现了用于机器学习的各种算法,而 MADlib 在关系型 MPP 数据库(Apache HAWQ)中实现了类似的功能。
24 |
25 | 空间算法也是有用的,例如最近邻搜索(k-nearest neghbors, kNN),它在一些多维空间中搜索与给定项最近的项目:这是一种相似性搜索。近似搜索对于基因组分析算法也很重要,它们需要找到相似但不相同的字符串。批处理引擎正被用于分布式执行日益广泛的各领域算法。随着批处理系统获得各种内置功能以及高级声明式算子,且随着 MPP 数据库变得更加灵活和易于编程,两者开始看起来相似了:最终,它们都只是存储和处理数据的系统。
26 |
--------------------------------------------------------------------------------
/批处理/编程模型/Data Parallelism.md:
--------------------------------------------------------------------------------
1 | # Data Parallelism
2 |
3 | 在给定数据集的情况下,数据并行性是指跨数据集的元素组在同一功能的多台机器或线程上同时执行。数据并行性也可以视为 SIMD(“单指令,多个数据”)执行的子集,这是 Flynn 分类法中的一类并行执行。相比之下,人们可以将顺序计算视为“对数据集中的所有元素都执行操作 A”,该数据集的大小可以达到 TB 或 PB。以并行方式进行此顺序计算的挑战包括如何以一种简单且正确的方式抽象不同类型的计算,如何将数据分发到成千上万的计算机或群集以及如何安排任务和处理故障。
4 |
5 | MapReduce(Dean&Ghemawat,2008)是 Google 提出的一种编程模型,最初可以满足他们对网络搜索服务的大规模索引的需求。它提供了一个简单的用户程序界面:Map 和 Reduce 功能,并自动处理并行化和分发;底层的执行系统可以提供容错能力和调度功能。
6 |
7 | MapReduce 模型简单而强大,并且很快在开发人员中变得非常流行。但是,当开发人员开始编写实际应用程序时,他们通常最终会编写许多样板代码并将这些阶段链接在一起。而且,MapReduce 的流水线迫使他们编写附加的协调代码,即开发风格从简单的逻辑计算抽象向低级的协调管理倒退。
8 |
9 | MapReduce 在每个阶段之后将所有数据写入磁盘,这会导致严重的延迟。程序员需要针对目标性能进行手动优化,这又需要他们了解底层的执行模型。整个过程很快变得麻烦。FlumeJava 库旨在通过抽象化数据表示所涉及的复杂性并隐式地处理优化来为开发数据并行管道提供支持。它推迟 Evaluation,从并行集合构造执行计划,优化计划,然后执行基础的 MR 原语。优化的执行与手工优化的流水线相当,因此,不需要直接编写原始 MR 程序。
10 |
11 | 在 MapReduce 之后,Microsoft 提出了其对应的数据并行性模型 Dryad。程序员需要做的是描述这个 DAG,并让 Dryad 执行引擎构造执行计划并管理调度和优化。Dryad 相对于 MapReduce 的优点之一是 Dryad 顶点可以处理任意数量的输入和输出,而 MR 仅支持每个顶点一个输入和一个输出。除了计算的灵活性外,Dryad 还支持不同类型的通信通道:文件,TCP 管道和共享内存 FIFO。编程模型不如 MapReduce 优雅,因为程序员并不打算直接与之交互。而是希望他们使用高级编程接口 DryadLinq,该接口更具表现力,并且更好地嵌入 .NET 框架中。我们稍后将在专门讨论 Dryad 的部分中看到一些示例。
12 |
13 | Dryad 将计算表示为非循环数据流,这对于某些复杂的应用(例如,迭代机器学习算法。Spark 是一个使用函数式编程和流水线提供此类支持的框架。Spark 在很大程度上受到 MapReduce 模型的启发,并建立在使用 DAG 和 DryadLinq 中的惰性评估背后的思想的基础上。无需像 MapReduce 那样为每个作业将数据写入磁盘,Spark 可以跨作业缓存结果。Spark 通过称为弹性分布集(RDD)的专用不变数据结构将计算数据显式缓存在内存中,并在多个并行操作中重用同一数据集。Spark 通过重新使用丢失的 RDD 的沿袭信息,在 RDD 的基础上实现容错。与使用分布式共享内存系统中的检查点实现的容错能力相比,这导致了更少的开销。此外,Spark 是构建许多非常不同的系统的基础框架,例如 Spark SQL 和 DataFrames,GraphX,Streaming Spark,这使得在同一应用程序中轻松混合和匹配这些系统的使用变得容易。这些功能使 Spark 最适合迭代作业和交互式分析,还有助于提供更好的性能。
14 |
15 | # MapReduce
16 |
17 | 在此模型中,可并行化的计算被抽象为 map 和 reduce 函数。该计算接受一组键/值对作为输入,并生成一组键/值对作为输出。该过程涉及两个阶段:
18 |
19 | - Map:用户编写的 Map 接受一组键/值对(“记录”)作为输入,对每个记录应用 map 操作,并计算一组中间键/值对作为输出。
20 |
21 | - Reduce:还由用户编写的 Reduce 接受中间键和与该键关联的一组值,对其进行操作,并产生零个或一个输出值。
22 |
23 | MapReduce 库提供的 Map 和 Reduce 之间还有一个 Shuffle 阶段,该阶段将同一键的所有中间值组合在一起,并将它们传递给 Reduce 函数。关于执行模型的部分将对此进行更多讨论。从概念上讲,map 和 reduce 函数具有关联的类型:
24 |
25 | $$
26 | \begin{array}{c}\operatorname{map}(k 1, v 1) \rightarrow \operatorname{list}(k 2, v 2) \\ \text {reduce}(k 2, \text {list}(v 2)) \rightarrow \operatorname{list}(v 2)\end{array}
27 | $$
28 |
29 | 输入键和值是从与输出键和值不同的域中提取的。中间键和值与输出键和值来自同一域。例如,我们可以考虑对大量文档中每个单词出现的次数进行计数的问题。可以将其建模为一个 Map 函数,该 Map 函数发出一个单词加上其计数 1 和一个 reduce 函数,该函数将针对同一单词发出的所有计数加在一起。
30 |
31 | ```ts
32 | map(String key, String value):
33 | // key: document name
34 | // value: document contents
35 | for each word in value:
36 | EmitIntermediate(word, "1");
37 |
38 | reduce(String key, Iterator values):
39 | // key: a word
40 | // values: a list of counts
41 | int result = 0;
42 | for each value in values:
43 | result += ParseInt(value);
44 | Emit(AsString(result));
45 | ```
46 |
47 | 在执行期间,MapReduce 库分配一个主节点来管理数据分区和调度。其他节点可以充当工作节点来按需运行 Map 或者 Reduce 操作。稍后将讨论执行模型的更多细节。在这里,值得一提的是,将映射阶段输出的中间结果写入磁盘,然后 reduce 操作从磁盘读取其输入。这对于容错至关重要。
48 |
49 | ## Fault Tolerance
50 |
51 | MapReduce 可在成百上千个不可靠的商用机器上运行,因此该库必须提供容错能力。该库假定主节点不会发生故障,并且它监视工作程序故障。如果在超时时未收到任何来自工人的状态更新,则主服务器会将其标记为失败。然后,主机可以根据任务类型和状态将关联的任务安排给其他工作节点。map 和 reduce 任务输出的提交是原子的,正在进行的任务将数据写入私有临时文件,然后一旦任务成功,它将与主服务器协商并重命名文件以完成任务。如果发生故障,工作节点将丢弃这些临时文件。这保证了,如果计算是确定性的,则分布式实现应产生与无故障顺序执行相同的输出。
52 |
53 | ## Limitations
54 |
55 | 许多分析工作负载(例如 K 均值,逻辑回归,PageRank 之类的图形处理应用程序以及使用并行广度优先搜索的最短路径)需要多个阶段的 MapReduce 作业。在像 Hadoop 这样的常规 MapReduce 框架中,这要求开发人员手动处理驱动程序代码中的迭代。在每次迭代时,每个阶段 T 的结果都会写入 HDFS,并在阶段 T + 1 再次加载回去,从而导致性能瓶颈。这样做的原因是浪费网络带宽,CPU 资源,并且本质上是固有的磁盘 I/O 操作缓慢。为了解决 MapReduce 上的迭代工作负载中的此类挑战,诸如 Haloop,Twister 和 iMapReduce 之类的框架采用了特殊的技术,例如在迭代之间缓存数据并在迭代期间使映射器和化简器保持活动状态。
56 |
57 | # FlumeJava
58 |
59 | 引入 FlumeJava 是为了使其易于开发,测试和运行有效的数据并行管道。FlumeJava 将每个数据集表示为一个对象,并通过在这些对象上应用方法来调用转换。它从 MapReduce 作业流水线构造了一个有效的内部执行计划,使用了延迟评估并根据计划结构进行了优化。调试功能使程序员可以先在本地计算机上运行,然后再将其作业部署到大型群集中。FlumeJava 的核心抽象包含了以下部分:
60 |
61 | - `PCollection`, a immutable bag of elements of type `T`, which can be created from an in-memory Java `Collection` or from reading a file with encoding specified by `recordOf`.
62 | - `recordOf(...)`, specifies the encoding of the instance
63 | - `PTable`, a subclass of `PCollection>`, an immutable multi-map with keys of type `K` and values of type `V`
64 | - `parallelDo()`, can express both the map and reduce parts of MapReduce
65 | - `groupByKey()`, same as shuffle step of MapReduce
66 | - `combineValues()`, semantically a special case of `parallelDo()`, a combination of a MapReduce combiner and a MapReduce reducer, which is more efficient than doing all the combining in the reducer.
67 | - `flatten`, takes a list of `PCollection`s and returns a single `PCollection`.
68 |
69 | FlumeJava 的典型代码实现如下:
70 |
71 | ```java
72 | PTable wordsWithOnes =
73 | words.parallelDo(
74 | new DoFn> () {
75 | void process(String word,
76 | EmitFn> emitFn) {
77 | emitFn.emit(Pair.of(word, 1));
78 | }
79 | }, tableOf(strings(), ints()));
80 | PTable>
81 | groupedWordsWithOnes = wordsWithOnes.groupByKey();
82 | PTable wordCounts =
83 | groupedWordsWithOnes.combineValues(SUM_INTS);
84 | ```
85 |
86 | 使用 FlumeJava 传递 MapReduce 作业的优点之一是,它通过使用延迟评估延迟执行并行操作来自动启用优化。每个 PCollection 对象的状态都可以推迟(尚未计算)并具体化(计算)。程序调用 parallelDo() 时,它将创建一个指向实际延迟操作对象的操作指针。这些操作形成一个称为执行计划的有向无环图。在调用 run() 之前,不会对执行计划进行评估。这将导致执行计划的优化和前向拓扑顺序的评估。这些将模块化执行计划转变为有效计划的优化策略包括:
87 |
88 | - Fusion: $f(g(x))=>g \circ f(x)$,本质上是功能组成。通过将多个可组合步骤组合为一个步骤,通常可以帮助减少给定工作所需的步骤数量。
89 |
90 | - MapShuffleCombineReduce (MSCR) Operation: 将 ParallelDo,GroupByKey,CombineValues 和 Flatten 组合到一个 MapReduce 作业中。这将 MapReduce 扩展为接受多个输入和多个输出。下图说明了具有 3 个输入通道,2 个分组(“ GroupByKey”)输出通道和 1 个直通输出通道的 MSCR 操作的情况。
91 |
92 | 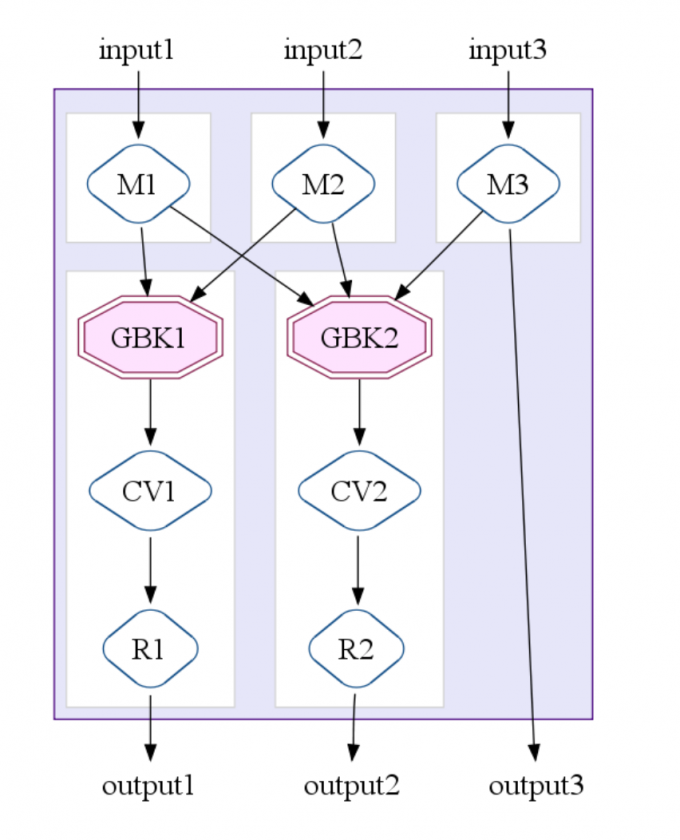
93 |
94 | 总体优化器策略涉及一系列优化操作,其最终目标是产生最少,最有效的 MSCR 操作:
95 |
96 | - Sink Flatten: $h(f(a)+g(b)) \rightarrow h(f(a))+h(g(b))$
97 | - Lift combineValues operations: If a `CombineValues` operation immediately follows a `GroupByKey` operation, the `GroupByKey` records the fact and original `CombineValues` is left in place, which can be treated as normal `ParallelDo` operation and subject to ParallelDo fusions.
98 | - Insert fusion blocks:
99 | - Fuse `ParallelDo`s
100 | - Fuse MSCRs: create MSCR operations, and convert any remaining unfused ParallelDo operations into trivial MSCRs.
101 |
102 | SiteData 示例显示,在最终执行计划中,可以将 16 个并行数据操作优化为两个 MSCR 操作。优化器的局限性在于所有这些优化都是基于执行计划的结构,FlumeJava 不会分析用户定义函数的内容。
103 |
104 | # Dryad
105 |
106 | Dryad 是一种通用的数据并行执行引擎,可让开发人员为计算明确地指定任意有向无环图(DAG),其中每个顶点都是计算任务,边代表通信通道(文件,TCP 管道或 Shared-Memory FIFI)。Dryad 作业是一种逻辑计算图,在运行时会自动映射到物理资源。从程序员的角度来看,通道产生或消耗堆对象,而数据通道的类型在读取或写入这些对象时没有区别。在 Dryad 系统中,一个名为“作业管理器”的进程连接到集群网络,并通过咨询名称服务器(NS)并将命令委派给在集群中每台计算机上运行的守护程序(D)来调度作业。
107 |
--------------------------------------------------------------------------------
/批处理/编程模型/README.md:
--------------------------------------------------------------------------------
1 | # Programming Models
2 |
3 | # 编程模型
4 |
--------------------------------------------------------------------------------
/批处理/编程模型/图的大规模并行.md:
--------------------------------------------------------------------------------
1 | # 图的大规模并行
2 |
--------------------------------------------------------------------------------
/批处理/编程模型/查询与声明式接口.md:
--------------------------------------------------------------------------------
1 | # 查询与声明式接口
2 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/DAG/Dryad.md:
--------------------------------------------------------------------------------
1 | # Dyrad
2 |
3 | 微软于 2010 年 12 月 21 日发布了分布式并行计算基础平台 Dryad 测试版,成为谷歌 MapReduce 分布式数据计算平台的竞争对手。它可以使开发人员能够在 Windows 或者 .Net 平台上编写大规模的并行应用程序模型,并能够在单机上所编写的程序很轻易的运行在分布式并行计算平台上,程序员可以利用数据中心的服务器集群对数据进行并行处理,当程序开发人员在操作数千台机器时,而无需关心分布式并行处理系统方面的细节。
4 |
5 | 
6 |
7 | Dryad 将具体计算组织成有向无环图,其中图节点代表用户写的表达式应用逻辑,图节点之间的边代表了数据流动通道。Dryad 在实时以共享内存,TCP 连接以及临时文件的方式来进行数据传递,绝大多数情况下采用临时文件的方式。
8 |
9 | # Dryad 系统架构(Dryad Architecture)
10 |
11 | Dryad 系统的总体的构建用来支持有向无环图(Directed Acycline Graph,DAG)类型数据流的并行程序。Dryad 的整体框架根据程序的要求完成调度工作,自动完成任务在各个节点上的运行。在 Dryad 平台上,每个 Dryad 工作或并行计算过程被表示为一个有向无环图。图中的每个节点表示一个要执行的程序,节点之间的边表示数据通道中数据的传输方式,其可能是文件、TCP Pipe、共享内存等,为了支持数据类型需要针对每个类型有序列化代码。
12 |
13 | 
14 |
15 | Dryad 的作业管理模块(Job Manager)JM 在应用程序内部维护了一个基于 DAG 图模型的计算节点依赖关系图,作业管理模块通过命名服务器(Name Server)NS 来获取可用的服务器列表,而后通过在这些服务器上运行的守护进程 Daemon(图中 D)来调度和执行计算节点 Vertex(执行和监控)。各个计算节点之间通过例如文件,管道,网络等形式的数据通道交换数据。为了能方便地描述复杂任务,Dryad 采用了若干简单和 DAG 结构及其描述符的不断组合来构建复杂结构和方式。
16 |
17 | 
18 |
19 | 从总体来看,传统的 Linux/Unix 管道是一维管道,每个节点在管道中是单个的程序。而 Dryad 的执行过程就可以看做是一个二维的管道流的处理过程。在每个节点进程(Vertices Processes)上都有一个处理程序在运行,并且通过数据管道(Channels)的方式在它们之间传送数据。二维的 Dryad 管道模型定义了一系列的操作,可以用来动态的建立并且改变这个有向无环图。这些操作包括建立新的节点,在节点之间加入边,合并两个图以及对任务的输入和输出进行处理等。
20 |
21 | 其中,每个节点可以具有多个程序的执行,通过这种算法可以同时处理大规模数据。Dryad 将图节点的可执行代码分发到可用机器节点上,同时将该图节点涉及的输入和输出数据路径地址发送给相应和工作机,这样该工作机就可执行计算任务。调度程序跟踪 DAG 图中节点和执行状态和执行历史,如果 JM 调度程序崩溃,则整个任务失败。如果工作节点发生故障,调度程序会将图中节点对应代码发送到其他可用节点重新执行图节点程序,以此来达到容错目的。
22 |
23 | # Dryad 模型算法应用(Computational Model)
24 |
25 | DryadLINQ 可以根据程序员给出的 LINQ 查询生成可以在 Dryad 引擎上执行的分布式策略算法建模(运算规则),并负责任务的自动并行处理及数据传递时所需要的序列化等操作。此外,它还提供了一系列易于使用的高级特性,如强类型数据,Visual Studio 集成调试,以及丰富的任务优化策略(规则)算法等等。这种模型策略开发框架也比较适合采用领域驱动开发设计(DDD)来构建“云”平台应用,并能够较容易的做到自动化分布式计算。
26 |
27 | ## 并行算法分治策略
28 |
29 | Y=(A+B(C+DEF))+G,串行计算需要 6 步。利用结合律和交换律,该式变为 Y1=Y2+(分裂为两个问题),其中 Y1=A+G,Y2=B(C+DEF),在两台处理机的系统上只需 5 步并行计算。在用分配率,Y=(A+B(C+DEF))+G 可变为 Y=Y3+Y4,其中 Y3=A+G+BC,Y4=BDEF,在两台处理机的系统上并行计算只需 4 步。如四台处理机的系统,并行计算可进一步减少为 3 步。两台处理机下的运算分解树和四台处理机下的运算分解树,如下图所示。
30 |
31 | 
32 |
33 | 从上面分析我们可以看到,通过并行算法策略建模,可以有效的控制数据的颗粒度,当程序运行在 Dryad 分布式并行平台时候,可最大化的提高分布式并行运算效率。
34 |
35 | ## 分布式并行策略
36 |
37 | 我们经常会遇到所开发的网站/系统,无法承载大规模用户并发访问的问题。解决该问题的传统方法是使用数据库,通过数据库所提供的访问操作接口来保证处理复杂的查询能力。当访问量增大,单数据库处理不过来时便增加数据库服务器。如果增加了 3 台服务器,再把用户分成了三类(关注:策略建模、颗粒度和映射):A(学生),B(老师),C(程序员)。每次访问的时候,Dryad 会先查看用户属于哪一类,然后直接访问存储那类用户数据的数据库,可能处理能力增加了三倍。这时我们已经实现了一个分布式的存储引擎过程,而 Dryad 与 Dynamo 具有相似的功能。
38 |
39 | 我们可以通过 Dryad 分布式平台来解决云存储扩容困难问题。如果这 3 台服务器也承载不了更大的数据要求时,需要增加到 5 台服务器,那必须更改分类方法把用户分成 5 类,然后重新迁移已经存在的数据,这时候就需要非常大的迁移工作,这种方法显然不可取。另外,当群集服务器进行分布式计算运行的时候,每个资源节点处理能力可能有所不同(例如不同硬件配置的服务器等等),如果只是简单的把机器直接分布上去,性能高的机器得不到充分利用,性能低的机器处理不过来。
40 |
41 | 
42 |
43 | - P parses lines(解析线)
44 | - D hash distribute(哈希分布)
45 | - S quicksort(快速排序)
46 | - C count occurrences(事件计算)
47 | - MS merge sort(合并分类)
48 | - M non-deterministic merge(未确定合并)
49 |
50 | Dryad 解决此问题的方法是采用虚节点。把上面的 A B C 三类等用户都想象成一个逻辑上的节点。一台真实的物理节点可能会包含一个或者几个虚节点(逻辑节点),看机器的性能而定。我们可以把那任务程序分成 Q 等份(每一个等份就是一个虚节点),这个 Q 要远大于我们的资源数。现在假设我们有 S 个资源,那么每个资源就承担 Q/S 个等份。当一个资源节点离开系统的时候,它所负责的等份要重新均分到其他资源节点上,一个新节点加入的时候,要从其他的节点“偷取”到一定数额的等份。
51 |
52 | 在这个策略建模算法下,当一个节点离开系统的时候,虽然需要影响到很多节点,但是迁移的数据总量只是离开那个节点的数据量。同样,一个新节点的加入,迁移的数据总量也只是一个新节点的数据量。之所以有这个效果是因为 Q 的存在,使得增加和减少机器的时候不需要对已有的数据做重新哈希(D)。这个策略的要求是 Q>>S(存储备份上,假设每个数据存储 N 个备份则要满足 Q>>S\*N)。如果业务快速发展,使得不断的增加主机,从而导致 Q 不再满足 Q>>S,那么这个策略将重新变化。
53 |
54 | 通过上述的论述,我们可以看到 Dryad 通过一个有向无环图的策略建模算法,提供给用户一个比较清晰的编程框架。在这个编程框架下,用户需要将自己的应用程序表达为有向无环图的形式,节点程序则编写为串行程序的形式,而后用 Dryad 方法将程序组织起来。用户不需要考虑分布式系统中关于节点的选择,节点与通信的出错处理手段都简单明确,内建在 Dryad 框架内部,满足了分布式程序的可扩展性、可靠性和性能的要求。
55 |
56 | # DryadLINQ
57 |
58 | 通过使用 DryadLINQ 编程,使普通的程序员编写大型数据并行程序能够轻易的运行在大型计算机集群里。DryadLINQ 开发的程序是一组顺序的 LINQ 代码,它们可以针对数据集做任何无副作用的操作,编译器会自动将其中数据并行的部分翻译成并行执行的计划,并交由底层的 Dryad 平台完成计算,从而生成每个节点要执行的代码和静态数据,并为所需要传输的数据类型生成序列化代码。
59 |
60 | DryadLINQ 使用和 LINQ 相同的编程模型,并扩展了少量操作符和数据类型以适用于数据并行的分布式计算。并从两方面扩展了以前的计算模型(SQL、MapReduce、Dryad 等):它是基于 .NET 强类型对象的、表达力更强的数据模型和支持通用的命令式和声明式编程(混合编程),从而延续了 LINQ 代码即数据(treat code as data)的特性。
61 |
62 | 
63 |
64 | LINQ 本身是 .NET 引入的一组编程结构,它用于像操作数据库中的表一样来操作内存中的数据集合。DryadLINQ 提供的是一种通用的开发/运行支持,而不包含任何与实际业务、算法相关的逻辑,Dryad 和 DryadLINQ 都提供有 API。DryadLINQ 使用动态的代码生成器,将 DryadLINQ 表达式编译成.NET 字节码。这些编译后的字节码会根据调度执行的需要,被传输到执行它的机器上去。字节码中包含两类代码:完成某个子表达式计算的代码和完成输入输出序列化的代码。DryadLINQ 表达式代码示例片段如下:
65 |
66 | ```c#
67 | Collection collection;
68 |
69 | bool IsLegal(Key k);
70 |
71 | string Hash(Key);
72 |
73 | var results = from c in collection
74 | where IsLegal(c.key)
75 | select new { Hash(c.key), c.value};
76 | ```
77 |
78 | 这种表达式并不会被立刻计算,而是等到需要其结果的时候才进行计算。DryadLINQ 设计的核心是在分布式执行层采用了一种完全函数式的、声明式的表述,用于表达数据并行计算中的计算。这种设计使得我们可以对计算进行复杂的重写和优化,类似于传统的并行数据库。从而解决了传统分布式数据库 SQL 语句功能受限与类型系统受限问题,以及 MapReduce 模型中的计算模型受限和没有系统级的自动优化等问题。另外,在 MapReduce 编程方式下,应用程序编写人员需要关注与自己的应用逻辑如何使用 Map 函数以及 Reduce 函数进行表达。在 Dryad 编程模式中,应用程序的大规模数据处理被分解为多个步骤,并构成有向无环图形式的任务组织,由执行引擎去执行。这两种模式都提供了简单明了的编程方式,使得应用程序开发人员能够很好的驾驭云计算处理平台,对大规模数据进行处理。Dryad 的编程方式可适应的应用也更加广泛,通过 DryadLinq 所提供的高级语言接口,使应用程序员可以快速进行大规模的分布式计算应用程序的编写。
79 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/DAG/README.md:
--------------------------------------------------------------------------------
1 | # DAG
2 |
3 | DAG 是有向无环图(Directed Acyclic Graph)的简称。在大数据处理中,DAG 计算常常指的是将计算任务在内部分解成为若干个子任务,将这些子任务之间的逻辑关系或顺序构建成 DAG(有向无环图)结构。
4 | DAG 在分布式计算中是非常常见的一种结构,在各个细分领域都可以看见它,比如 Dryad,FlumeJava 和 Tez,都是明确构建 DAG 计算模型的典型,再如流式计算的 Storm 等系统或机器学习框架 Spark 等,其计算任务大多也是 DAG 形式出现的,除此外还有很多场景都能见到。
5 |
6 | DAG 计算的三层结构:
7 |
8 | - 最上层是应用表达层,即是通过一定手段将计算任务分解成由若干子任务形成的 DAG 结构,其核心是表达的便捷性,主要是方便应用开发者快速描述或构建应用。
9 |
10 | - 中间层是 DAG 执行引擎层,主要目的是将上层以特殊方式表达的 DAG 计算任务通过转换和映射,将其部署到下层的物理机集群中运行,这层是 DAG 计算的核心部件,计算任务的调度,底层硬件的容错,数据与管理信息的传递,整个系统的管理与正常运转等都需要由这层来完成。
11 |
12 | - 最下层是物理机集群,即由大量物理机器搭建的分布式计算环境,这是计算任务最终执行的场所。
13 |
14 | 常见框架包括了:
15 |
16 | - Dryad 是微软的批处理 DAG 计算系统,其主要目的是为了便于开发者便携地进行分布式任务处理。Dryad 将具体计算组织成有向无环图,其中图节点代表用户写的表达式应用逻辑,图节点之间的边代表了数据流动通道。Dryad 在实时以共享内存,TCP 连接以及临时文件的方式来进行数据传递,绝大多数情况下采用临时文件的方式。
17 |
18 | - FlumeJava 是 Google 内部开发的 DAG 系统,考虑到很多任务是需要多个 MR 任务连接起来共同完成的,而如果直接使用 MR 来完成会非常烦琐,因为除了完成 MR 任务本身外,还需要考虑如何衔接 MR 及清理各种中部结果等琐碎工作。
19 |
20 | - Tez 是 Apache 孵化项目,其本身也是一个相对通用的 DAG 计算系统,最初提出 Tez 是为了改善交互数据分析系统 Stinger 的底层执行引擎,Stinger 是 Hive 的改进版本,最初底层的执行引擎是 Hadoop 和 MR 任务形成的 DAG 任务图,Tez 是它的升级版,效率更高。Tez 通过消除 Map 阶段中间文件输出到磁盘过程以及引入 Reduce-Reduce 结构等改进措施极大提升了底层执行引擎和效率。
21 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/执行框架/分布式快照.md:
--------------------------------------------------------------------------------
1 | # 分布式快照
2 |
3 | # Links
4 |
5 | - [简单解释: 分布式快照(Chandy-Lamport 算法)](https://zhuanlan.zhihu.com/p/44454670)
6 |
7 | - [(十)简单解释: 分布式数据流的异步快照(Flink 的核心)](https://zhuanlan.zhihu.com/p/43536305)
8 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/执行框架/反压.md:
--------------------------------------------------------------------------------
1 | # 反压
2 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/执行框架/容错.md:
--------------------------------------------------------------------------------
1 | # 容错
2 |
3 | 批处理框架可以很容易地容错:如果 MapReduce 作业中的任务失败,可以简单地在另一台机器上再次启动,并且丢弃失败任务的输出。这种透明的重试是可能的,因为输入文件是不可变的,每个任务都将其输出写入到 HDFS 上的独立文件中,而输出仅当任务成功完成后可见。特别是,批处理容错方法可确保批处理作业的输出与没有出错的情况相同,即使实际上某些任务失败了。看起来好像每条输入记录都被处理了恰好一次,没有记录被跳过,而且没有记录被处理两次。尽管重启任务意味着实际上可能会多次处理记录,但输出中的可见效果看上去就像只处理过一次。这个原则被称为恰好一次语义(exactly-once semantics),尽管有效一次(effectively-once)可能会是一个更写实的术语。
4 |
5 | 在流处理中也出现了同样的容错问题,但是处理起来没有那么直观:等待某个任务完成之后再使其输出可见并不是一个可行选项,因为你永远无法处理完一个无限的流。
6 |
7 | # 微批量与存档点
8 |
9 | 一个解决方案是将流分解成小块,并像微型批处理一样处理每个块。这种方法被称为微批次(microbatching),它被用于 Spark Streaming。批次的大小通常约为 1 秒,这是对性能妥协的结果:较小的批次会导致更大的调度与协调开销,而较大的批次意味着流处理器结果可见之前的延迟要更长。微批次也隐式提供了一个与批次大小相等的滚动窗口(按处理时间而不是事件时间戳分窗)。任何需要更大窗口的作业都需要显式地将状态从一个微批次转移到下一个微批次。
10 |
11 | Apache Flink 则使用不同的方法,它会定期生成状态的滚动存档点并将其写入持久存储。如果流算子崩溃,它可以从最近的存档点重启,并丢弃从最近检查点到崩溃之间的所有输出。存档点会由消息流中的 壁障(barrier)触发,类似于微批次之间的边界,但不会强制一个特定的窗口大小。在流处理框架的范围内,微批次与存档点方法提供了与批处理一样的恰好一次语义。但是,只要输出离开流处理器(例如,写入数据库,向外部消息代理发送消息,或发送电子邮件),框架就无法抛弃失败批次的输出了。在这种情况下,重启失败任务会导致外部副作用发生两次,只有微批次或存档点不足以阻止这一问题。
12 |
13 | # 原子提交再现
14 |
15 | 为了在出现故障时表现出恰好处理一次的样子,我们需要确保事件处理的所有输出和副作用当且仅当处理成功时才会生效。这些影响包括发送给下游算子或外部消息传递系统(包括电子邮件或推送通知)的任何消息,任何数据库写入,对算子状态的任何变更,以及对输入消息的任何确认(包括在基于日志的消息代理中将消费者偏移量前移)。
16 |
17 | 这些事情要么都原子地发生,要么都不发生,但是它们不应当失去同步,该方法很类似于分布式事务与两阶段提交。
18 |
19 | # 幂等性
20 |
21 | 我们的目标是丢弃任何失败任务的部分输出,以便能安全地重试,而不会生效两次。分布式事务是实现这个目标的一种方式,而另一种方式是依赖幂等性(idempotence)。幂等操作是多次重复执行与单次执行效果相同的操作。例如,将键值存储中的某个键设置为某个特定值是幂等的(再次写入该值,只是用同样的值替代),而递增一个计数器不是幂等的(再次执行递增意味着该值递增两次)。
22 |
23 | 即使一个操作不是天生幂等的,往往可以通过一些额外的元数据做成幂等的。例如,在使用来自 Kafka 的消息时,每条消息都有一个持久的,单调递增的偏移量。将值写入外部数据库时可以将这个偏移量带上,这样你就可以判断一条更新是不是已经执行过了,因而避免重复执行。Storm 的 Trident 基于类似的想法来处理状态。依赖幂等性意味着隐含了一些假设:重启一个失败的任务必须以相同的顺序重放相同的消息(基于日志的消息代理能做这些事),处理必须是确定性的,没有其他节点能同时更新相同的值。
24 |
25 | 当从一个处理节点故障切换到另一个节点时,可能需要进行防护(fencing),以防止被假死节点干扰。尽管有这么多注意事项,幂等操作是一种实现恰好一次语义的有效方式,仅需很小的额外开销。
26 |
27 | # 失败后重建状态
28 |
29 | 任何需要状态的流处理,例如,任何窗口聚合(例如计数器,平均值和直方图)以及任何用于连接的表和索引,都必须确保在失败之后能恢复其状态。一种选择是将状态保存在远程数据存储中,并进行复制,然而正如在“流表连接”中所述,每个消息都要查询远程数据库可能会很慢。另一种方法是在流处理器本地保存状态,并定期复制。然后当流处理器从故障中恢复时,新任务可以读取状态副本,恢复处理而不丢失数据。例如,Flink 定期捕获算子状态的快照,并将它们写入 HDFS 等持久存储中。Samza 和 Kafka Streams 通过将状态变更发送到具有日志压缩功能的专用 Kafka 主题来复制状态变更,这与变更数据捕获类似。VoltDB 通过在多个节点上对每个输入消息进行冗余处理来复制状态。
30 |
31 | 在某些情况下,甚至可能都不需要复制状态,因为它可以从输入流重建。例如,如果状态是从相当短的窗口中聚合而成,则简单地重放该窗口中的输入事件可能是足够快的。如果状态是通过变更数据捕获来维护的数据库的本地副本,那么也可以从日志压缩的变更流中重建数据库。然而,所有这些权衡取决于底层基础架构的性能特征:在某些系统中,网络延迟可能低于磁盘访问延迟,网络带宽可能与磁盘带宽相当。没有针对所有情况的普世理想权衡,随着存储和网络技术的发展,本地状态与远程状态的优点也可能会互换。
32 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/执行框架/流式连接.md:
--------------------------------------------------------------------------------
1 | # 流式连接
2 |
3 | 我们讨论了批处理作业如何通过键来连接数据集,以及这种连接是如何成为数据管道的重要组成部分的。由于流处理将数据管道泛化为对无限数据集进行增量处理,因此对流进行连接的需求也是完全相同的。然而,新事件随时可能出现在一个流中,这使得流连接要比批处理连接更具挑战性。为了更好地理解情况,让我们先来区分三种不同类型的连接:流-流连接,流-表连接,与表-表连接。
4 |
5 | - 流流连接:两个输入流都由活动事件组成,而连接算子在某个时间窗口内搜索相关的事件。例如,它可能会将同一个用户 30 分钟内进行的两个活动联系在一起。如果你想要找出一个流内的相关事件,连接的两侧输入可能实际上都是同一个流(自连接(self-join))。
6 |
7 | - 流表连接:一个输入流由活动事件组成,另一个输入流是数据库变更日志。变更日志保证了数据库的本地副本是最新的。对于每个活动事件,连接算子将查询数据库,并输出一个扩展的活动事件。
8 |
9 | - 表表连接:两个输入流都是数据库变更日志。在这种情况下,一侧的每一个变化都与另一侧的最新状态相连接。结果是两表连接所得物化视图的变更流。
10 |
11 | # 流流连接(窗口连接)
12 |
13 | 假设你的网站上有搜索功能,而你想要找出搜索 URL 的近期趋势。每当有人键入搜索查询时,都会记录下一个包含查询与其返回结果的事件。每当有人点击其中一个搜索结果时,就会记录另一个记录点击事件。为了计算搜索结果中每个 URL 的点击率,你需要将搜索动作与点击动作的事件连在一起,这些事件通过相同的会话 ID 进行连接。广告系统中需要类似的分析。
14 |
15 | 如果用户丢弃了搜索结果,点击可能永远不会发生,即使它出现了,搜索与点击之间的时间可能是高度可变的:在很多情况下,它可能是几秒钟,但也可能长达几天或几周(如果用户执行搜索,忘掉了这个浏览器页面,过了一段时间后重新回到这个浏览器页面上,并点击了一个结果)。由于可变的网络延迟,点击事件甚至可能先于搜索事件到达。你可以选择合适的连接窗口,例如,如果点击与搜索之间的时间间隔在一小时内,你可能会选择连接两者。
16 |
17 | 请注意,在点击事件中嵌入搜索详情与事件连接并不一样:这样做的话,只有当用户点击了一个搜索结果时你才能知道,而那些没有点击的搜索就无能为力了。为了衡量搜索质量,你需要准确的点击率,为此搜索事件和点击事件两者都是必要的。为了实现这种类型的连接,流处理器需要维护状态:例如,按会话 ID 索引最近一小时内发生的所有事件。无论何时发生搜索事件或点击事件,都会被添加到合适的索引中,而流处理器也会检查另一个索引是否有具有相同会话 ID 的事件到达。如果有匹配事件就会发出一个表示搜索结果被点击的事件;如果搜索事件直到过期都没看见有匹配的点击事件,就会发出一个表示搜索结果未被点击的事件。
18 |
19 | # 流表连接(流扩展)
20 |
21 | 一般的用户活动事件分析中,我们看到了连接两个数据集的批处理作业示例:一组用户活动事件和一个用户档案数据库。将用户活动事件视为流,并在流处理器中连续执行相同的连接是很自然的想法:输入是包含用户 ID 的活动事件流,而输出还是活动事件流,但其中用户 ID 已经被扩展为用户的档案信息。这个过程有时被称为 使用数据库的信息来扩充(enriching)活动事件。要执行此联接,流处理器需要一次处理一个活动事件,在数据库中查找事件的用户 ID,并将档案信息添加到活动事件中。数据库查询可以通过查询远程数据库来实现。不过,此类远程查询可能会很慢,并且有可能导致数据库过载。
22 |
23 | 另一种方法是将数据库副本加载到流处理器中,以便在本地进行查询而无需网络往返。这种技术与我们在“Map 端连接”中讨论的哈希连接非常相似:如果数据库的本地副本足够小,则可以是内存中的哈希表,比较大的话也可以是本地磁盘上的索引。与批处理作业的区别在于,批处理作业使用数据库的时间点快照作为输入,而流处理器是长时间运行的,且数据库的内容可能随时间而改变,所以流处理器数据库的本地副本需要保持更新。这个问题可以通过变更数据捕获来解决:流处理器可以订阅用户档案数据库的更新日志,如同活跃事件流一样。当增添或修改档案时,流处理器会更新其本地副本。因此,我们有了两个流之间的连接:活动事件和档案更新。
24 |
25 | 流表连接实际上非常类似于流流连接;最大的区别在于对于表的变更日志流,连接使用了一个可以回溯到“时间起点”的窗口(概念上是无限的窗口),新版本的记录会覆盖更早的版本。对于输入的流,连接可能压根儿就没有维护窗口。
26 |
27 | # 表表连接(维护物化视图)
28 |
29 | 譬如在推特时间线中,当用户想要查看他们的主页时间线时,迭代用户所关注人群的推文并合并它们是一个开销巨大的操作。相反,我们需要一个时间线缓存:一种每个用户的“收件箱”,在发送推文的时候写入这些信息,因而读取时间线时只需要简单地查询即可。物化与维护这个缓存需要处理以下事件:
30 |
31 | - 当用户 u 发送新的推文时,它将被添加到每个关注用户 u 的时间线上。
32 | - 用户删除推文时,推文将从所有用户的时间表中删除。
33 | - 当用户$u_1$开始关注用户$u_2$时,$u_2$最近的推文将被添加到$u_1$的时间线上。
34 | - 当用户$u_1$取消关注用户$u_2$时,$u_2$的推文将从$u_1$的时间线中移除。
35 |
36 | 要在流处理器中实现这种缓存维护,你需要推文事件流(发送与删除)和关注关系事件流(关注与取消关注)。流处理需要为维护一个数据库,包含每个用户的粉丝集合。以便知道当一条新推文到达时,需要更新哪些时间线。观察这个流处理过程的另一种视角是:它维护了一个连接了两个表(推文与关注)的物化视图,如下所示:
37 |
38 | ```sql
39 | SELECT follows.follower_id AS timeline_id,
40 | array_agg(tweets.* ORDER BY tweets.timestamp DESC)
41 | FROM tweets
42 | JOIN follows ON follows.followee_id = tweets.sender_id
43 | GROUP BY follows.follower_id
44 | ```
45 |
46 | 流连接直接对应于这个查询中的表连接。时间线实际上是这个查询结果的缓存,每当基础表发生变化时都会更新。
47 |
48 | # 连接的时间依赖性
49 |
50 | 这里描述的三种连接(流流,流表,表表)有很多共通之处:它们都需要流处理器维护连接一侧的一些状态(搜索与点击事件,用户档案,关注列表),然后当连接另一侧的消息到达时查询该状态。用于维护状态的事件顺序是很重要的(先关注然后取消关注,或者其他类似操作)。在分区日志中,单个分区内的事件顺序是保留下来的。但典型情况下是没有跨流或跨分区的顺序保证的。
51 |
52 | 这就产生了一个问题:如果不同流中的事件发生在近似的时间范围内,则应该按照什么样的顺序进行处理?在流表连接的例子中,如果用户更新了它们的档案,哪些活动事件与旧档案连接(在档案更新前处理),哪些又与新档案连接(在档案更新之后处理)?换句话说:你需要对一些状态做连接,如果状态会随着时间推移而变化,那应当使用什么时间点来连接呢?
53 |
54 | 这种时序依赖可能出现在很多地方。例如销售东西需要对发票应用适当的税率,这取决于所处的国家/州,产品类型,销售日期(因为税率会随时变化)。当连接销售额与税率表时,你可能期望的是使用销售时的税率参与连接。如果你正在重新处理历史数据,销售时的税率可能和现在的税率有所不同。如果跨越流的事件顺序是未定的,则连接会变为不确定性的,这意味着你在同样输入上重跑相同的作业未必会得到相同的结果:当你重跑任务时,输入流上的事件可能会以不同的方式交织。
55 |
56 | 在数据仓库中,这个问题被称为缓慢变化的维度(slowly changing dimension, SCD),通常通过对特定版本的记录使用唯一的标识符来解决:例如,每当税率改变时都会获得一个新的标识符,而发票在销售时会带有税率的标识符。这种变化使连接变为确定性的,但也会导致日志压缩无法进行:表中所有的记录版本都需要保留。
57 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/状态存储/99~参考资料/2022-流处理系统中状态的表示和存储.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://www.skyzh.dev/posts/articles/2022-01-15-store-of-streaming-states/)
2 |
3 | # 流处理系统中状态的表示和存储
4 |
5 | 流处理系统处理的数据往往是没有边界的:数据会一直从数据源输入,用户需要看到 SQL 查询的实时结果。与此同时,流处理系统中的计算节点可能出错、失败,可能根据用户的需求实时扩容、缩容。在这一过程中,系统需要能够高效地将计算的中间状态在节点之间转移,并持久化到外部系统上,从而保证计算的不间断进行。
6 |
7 | 本文介绍了工业界学术界中流处理系统状态存储的三种方案:存储完整状态 ([Flink](https://flink.apache.org/) 等系统),存储共享状态 (以 [Materialize](https://github.com/MaterializeInc/materialize) / [Differential Dataflow](https://github.com/TimelyDataflow/differential-dataflow) 为例),存储部分状态 (以 [Noria (OSDI ‘18)](https://github.com/mit-pdos/noria) 为例)。这些存储方案各有优势,可以为未来的流处理引擎开发提供一些借鉴意义。
8 |
9 | ## 引入
10 |
11 | 假设某个购物系统中有两个表:
12 |
13 | - `visit(product, user, length)` 表示用户查看某产品多少秒。
14 | - `info(product, category)` 表示某个产品属于某个分类。
15 |
16 | 现在我们要查询:某个分类下用户查看产品最长的时间是多少。
17 |
18 | ```sql
19 | CREATE VIEW result AS
20 | SELECT category,
21 | MAX(length) as max_length FROM
22 | info INNER JOIN visit ON product
23 | GROUP BY category
24 | ```
25 |
26 | 这个查询中包含两表 Join 和一个聚合操作。后文的讨论都将基于这个查询进行。
27 |
28 | 假设系统现在的状态是:
29 |
30 | ```plain
31 | info(product, category)
32 | Apple, Fruit
33 | Banana, Fruit
34 | Carrot, Vegetable
35 | Potato, Vegetable
36 |
37 | visit(product, user, length)
38 | Apple, Alice, 10
39 | Apple, Bob, 20
40 | Carrot, Bob, 50
41 | Banana, Alice, 40
42 | Potato, Eve, 60
43 | ```
44 |
45 | 此时,查询的结果应该是
46 |
47 | ```plain
48 | category, max_length
49 | Fruit, 40
50 | Vegetable, 60
51 | ```
52 |
53 | 代表 Fruit 分类被用户查看最长的时间为 40 秒(对应 Alice 访问 Banana 的时间);Vegetable 分类被用户查看的最长时间为 60 秒(对应 Eve 访问 Potato 的时间)。
54 |
55 | 在常见的数据库产品中,系统通常来说会为这个查询生成如下的执行计划(不考虑 optimizer):
56 |
57 | 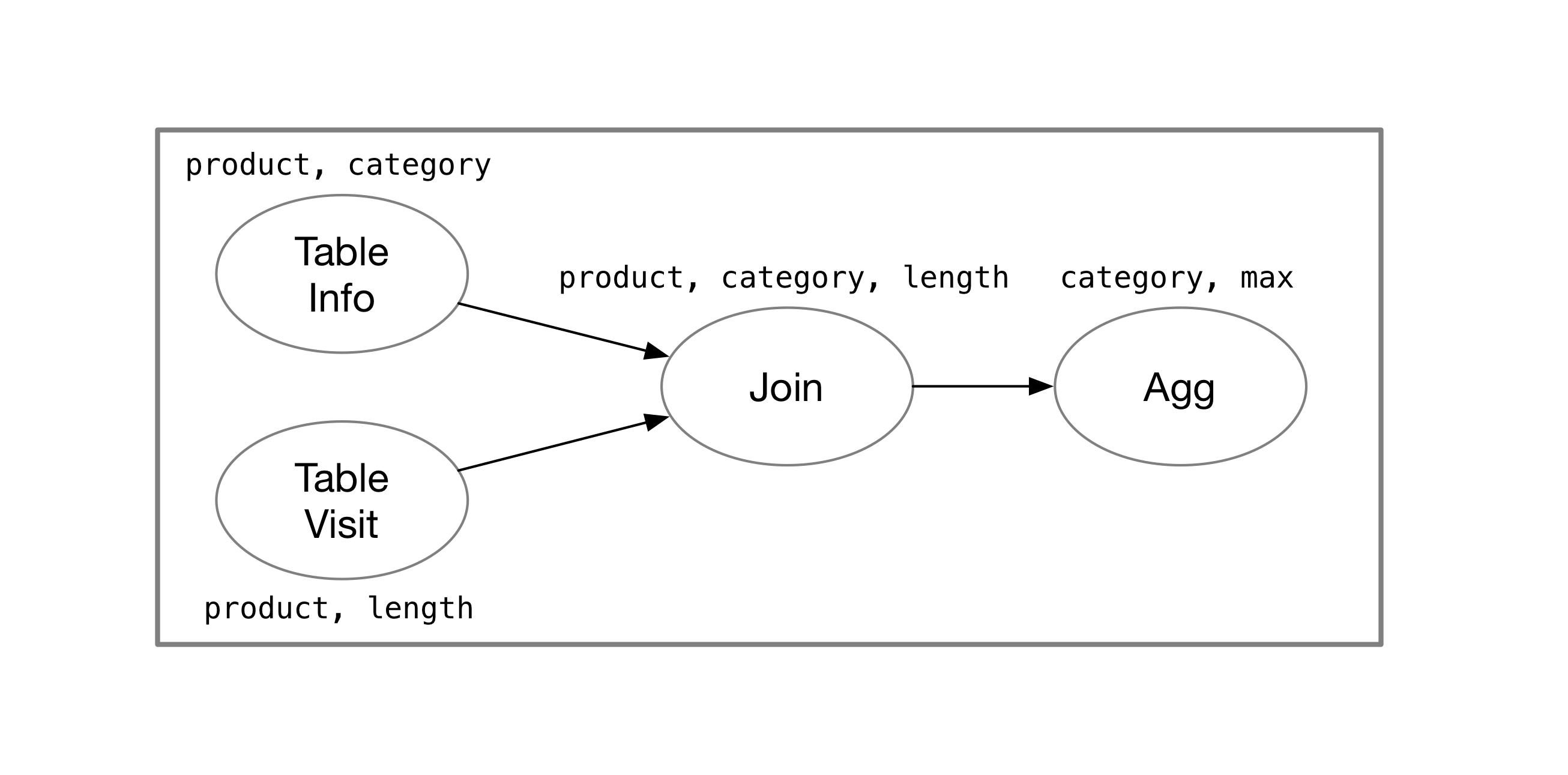
58 |
59 | 流处理系统的执行计划和常见数据库系统的计划没有太多区别。下面将具体介绍各种流处理系统会如何表示和存储计算的中间状态。
60 |
61 | ## Full State - 算子维护自己的完整状态
62 |
63 | 诸如 [Flink](https://flink.apache.org/) 的流处理系统持久化每个算子的完整状态;与此同时,流计算图上,算子之间传递数据的更新信息。这种存储状态的方法非常符合直觉。前文所述的 SQL,在 Flink 等系统中大致会创建出这个计算图:
64 |
65 | 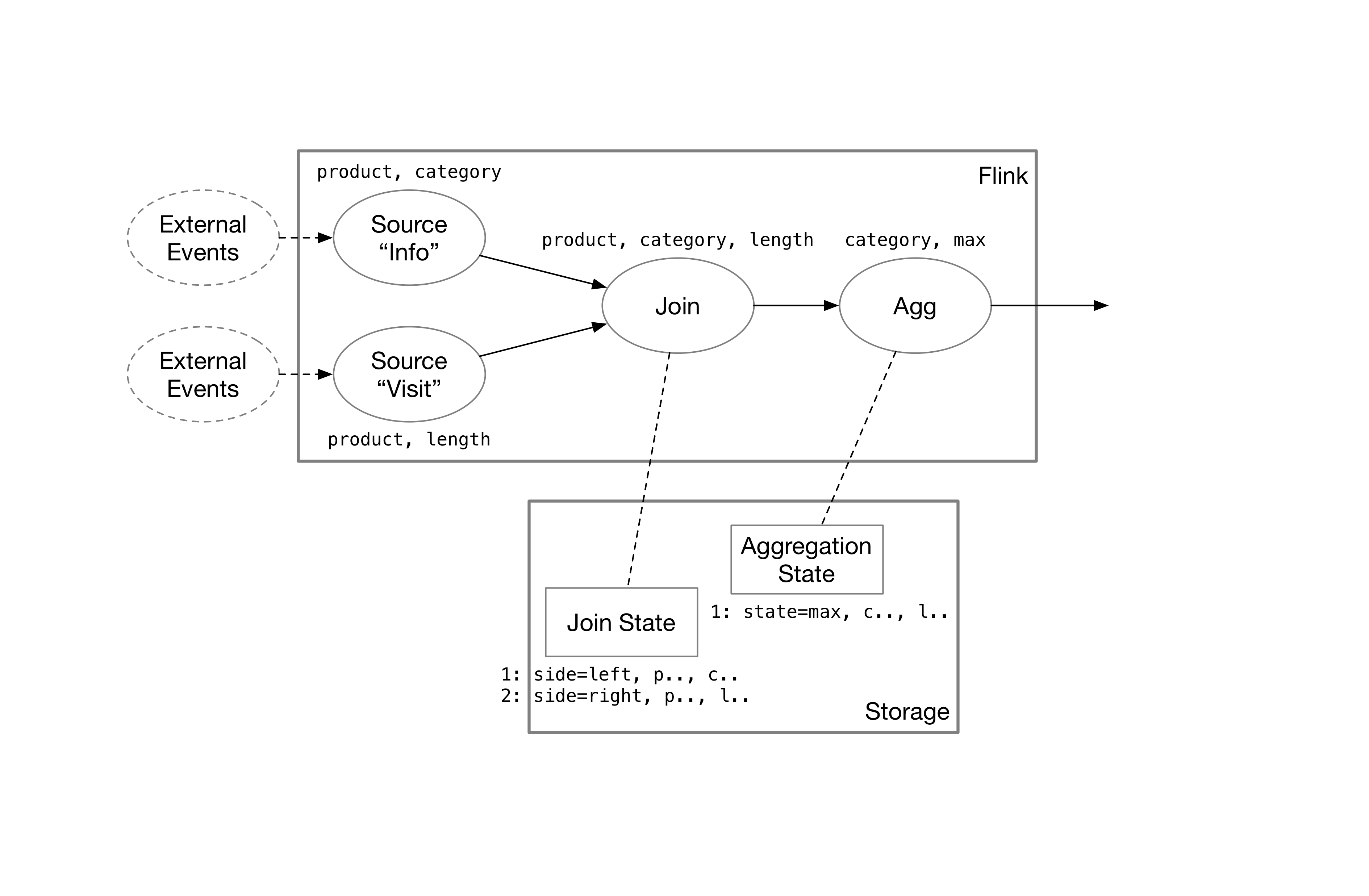
66 |
67 | 数据源会发出增加一行或是减少一行的消息。经过流算子的处理,这些消息会转变为用户需要的结果。
68 |
69 | ### Join State 的存储
70 |
71 | 数据源的消息进入系统后,碰到的第一个算子就是 Join。回顾 SQL 查询的 Join 条件: `info INNER JOIN visit ON product`。Join 算子在收到左侧 `info` 的消息后,会先将 `visit` 一侧的 `product` 相同的行查出来,然后发给下游。之后,将 `info` 一侧的消息记录在自己的状态中。对于右侧消息的处理也如出一辙。
72 |
73 | 比如,现在 `visit` 一侧收到 Eve 对着 Potato 看了 60 秒 `+ Potato Eve 60` 的消息。假设此时 `info` 一侧的状态已经有了四条记录。
74 |
75 | 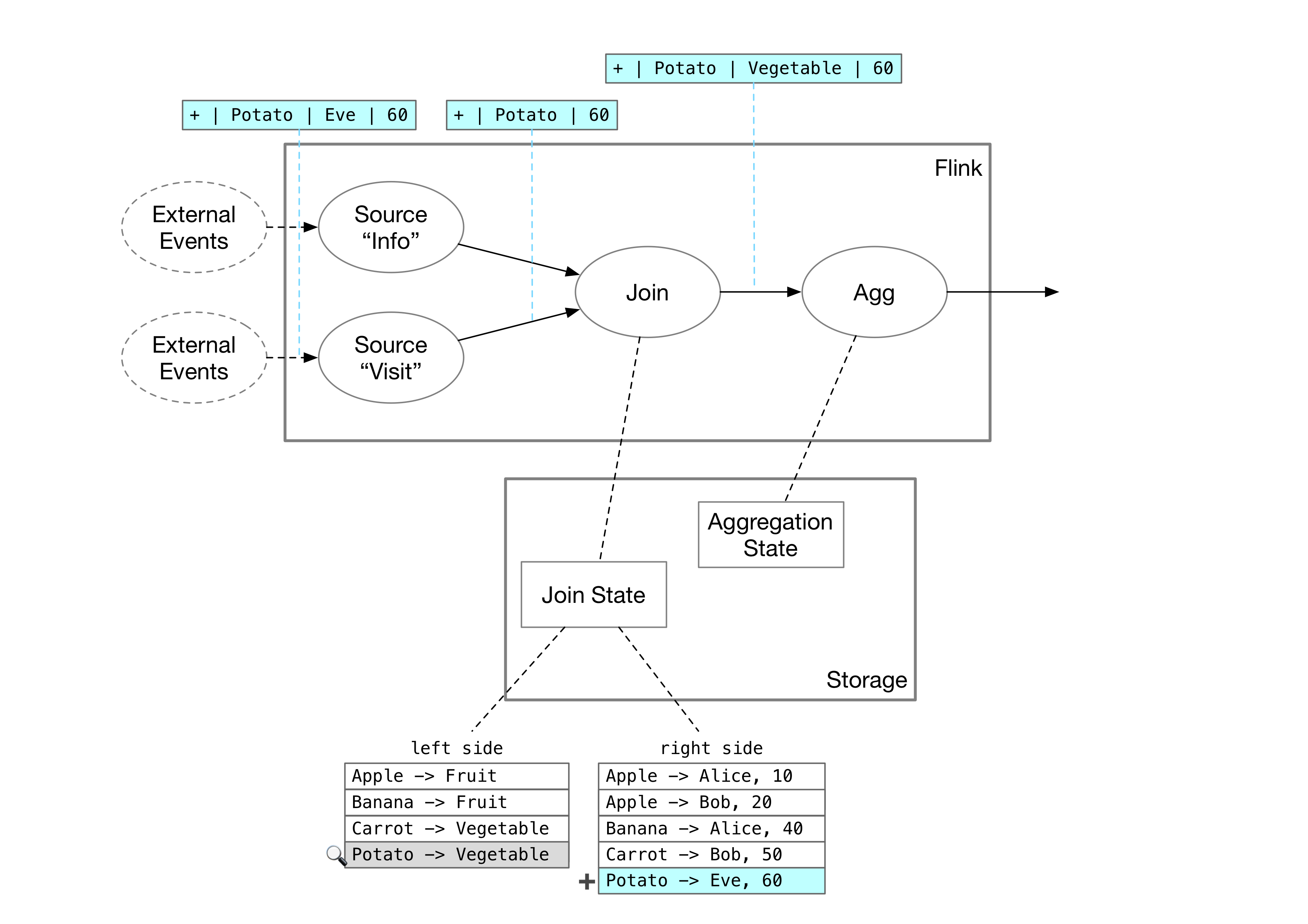
76 |
77 | Join 算子会查询 `info` 一侧 `product = Potato` 的记录,得到 Potato 是 Vegetable 的结果,之后将 `Potato, Vegetable, 60` 发给下游。
78 |
79 | 而后,`visit` 一侧的状态会加入 `Potato -> Eve, 60` 的记录,这样一来,如果 `info` 发生变化,Join 算子也能对应 `visit` 给下游发送 Join 算子的更新。
80 |
81 | ### Aggregation State 的存储
82 |
83 | 消息接下来被传递到了 Agg 算子上,Agg 算子需要根据 category 分组,计算每个 category 中 length 的最大值。
84 |
85 | 一些简单的 Agg 状态 (比如 sum) 只需要记录每一个 group 当前的值就行了。上游发来 insert,就将 sum 加上对应的值;上游发来 delete,就将 sum 减去对应的值。所以,诸如 sum、不带 distinct 的 count 等聚合表达式需要记录的状态非常小。
86 |
87 | 但对于 max 状态来说,我们就不能只记录最大的那个值了。如果上游发来了一条 delete 消息,max 状态需要把第二大的值作为新的最大值发给下游。如果只记录最大值,删掉最大值以后就没法知道第二大的值是多少。因此,Agg 算子需要存储一个 group 对应的完整数据。比如在我们的例子里,AggMaxState 现在存的数据有:
88 |
89 | ```fallback
90 | Fruit -> { 10, 20, 30, 40 }
91 | Vegetable -> { 50 }
92 | ```
93 |
94 | 上游 Join 算子发来一条插入 `Potato, Vegetable, 60` 的消息,Agg 算子会更新自己的状态:
95 |
96 | ```fallback
97 | Fruit -> { 10, 20, 30, 40 }
98 | Vegetable -> { 50, [60] }
99 | ```
100 |
101 | 并把 Vegetable 这一组的更新发给下游。
102 |
103 | ```fallback
104 | DELETE Vegetable, 50
105 | INSERT Vegetable, 60
106 | ```
107 |
108 | 整个过程如下图所示:
109 |
110 | 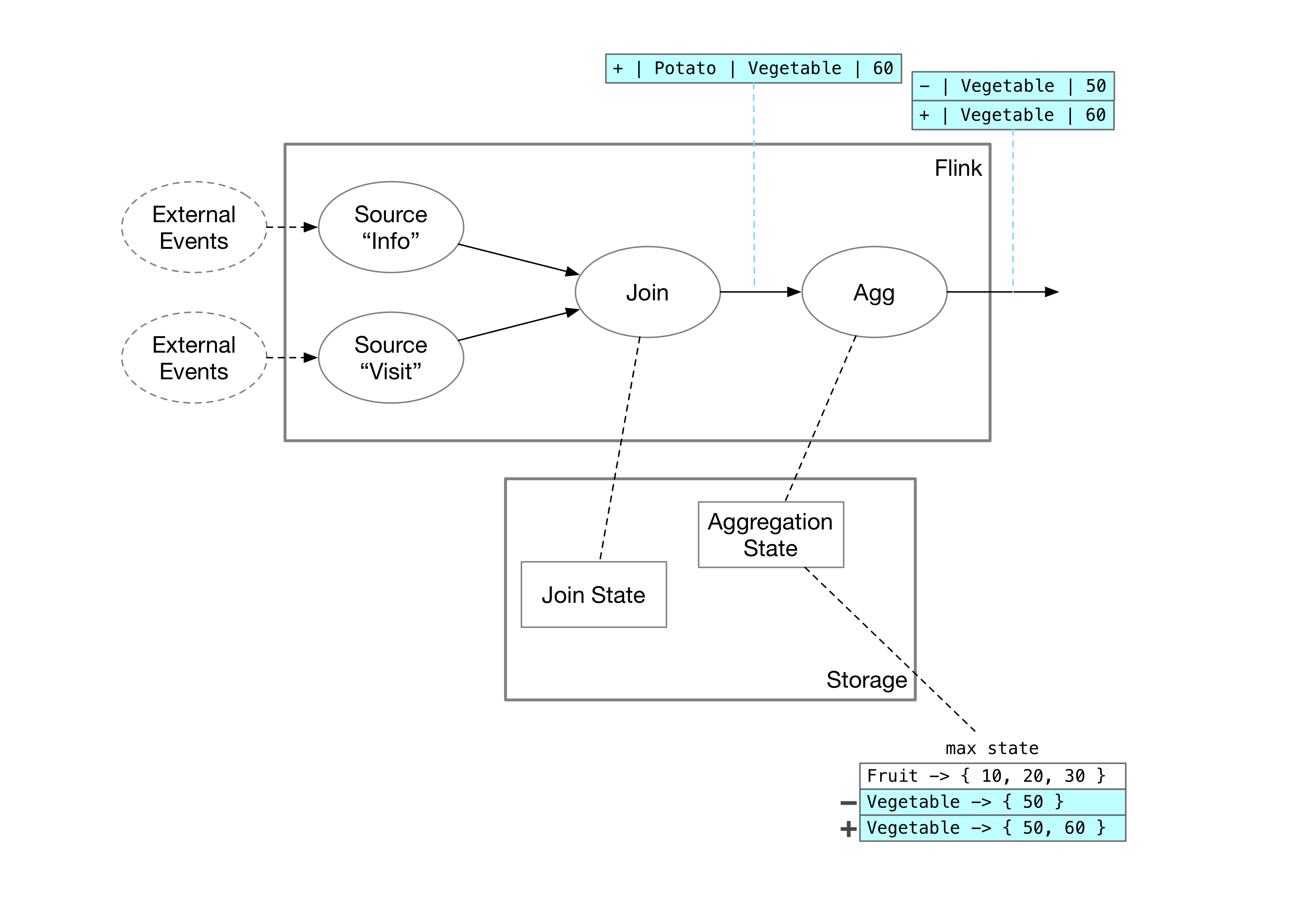
111 |
112 | ### 总结
113 |
114 | 存储完整状态的流系统通常来说有这么几个特点:
115 |
116 | - 流计算图上单向传递数据变更的消息 (添加/删除)。
117 | - 流算子维护、访问自己的状态;与此同时,在多路 Join 的时候,存储的状态可能重复。后文在介绍共享状态时也会详细介绍这一点。
118 |
119 | ## Shared State - 算子之间共享状态
120 |
121 | 我们以 [Differential Dataflow](https://github.com/TimelyDataflow/differential-dataflow) ([Materialize](https://github.com/MaterializeInc/materialize) 下面的计算引擎) 的 Shared Arrangement 为例介绍这种共享状态的实现。下文将使用 DD 简称 Differential Dataflow。
122 |
123 | ### DD 的 Arrange 算子与 Arrangement
124 |
125 | 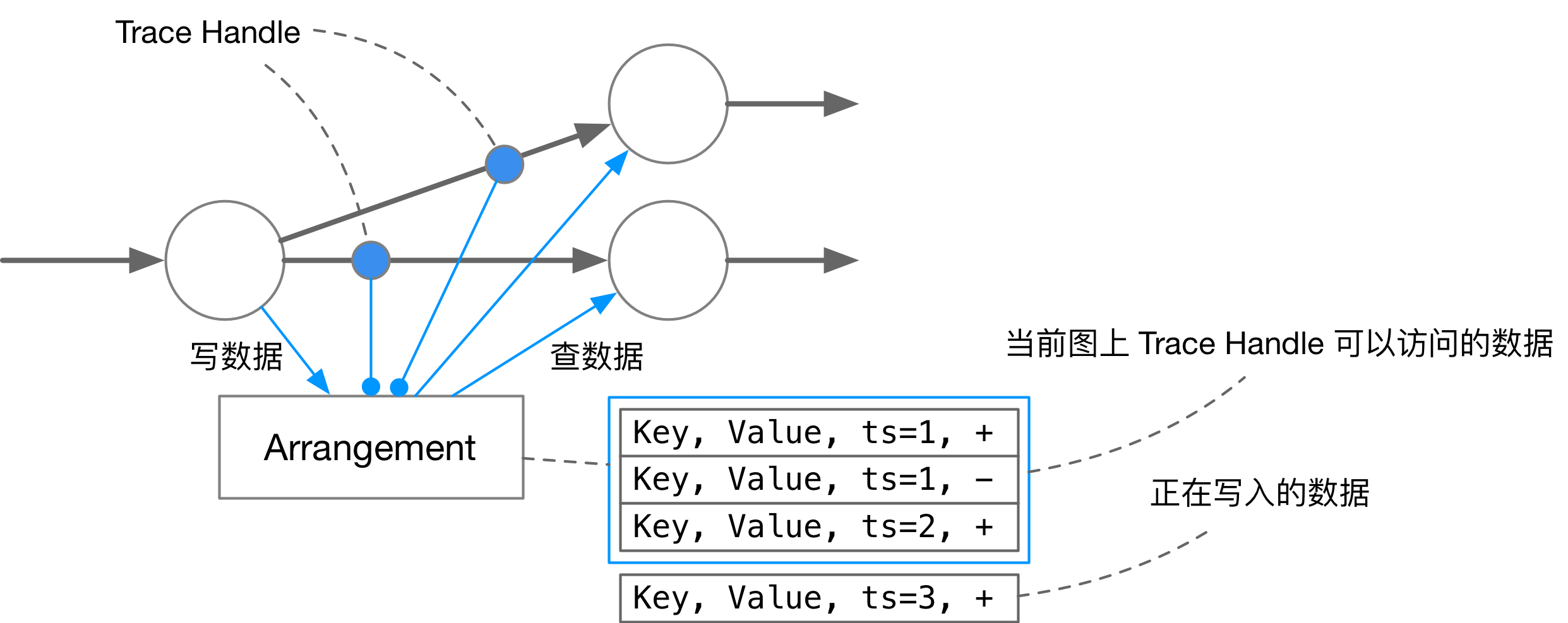
126 |
127 | DD 使用 Arrangement 来维护状态。简单来说,Arrangement 是一个支持 MVCC 的 key-value map 数据结构,存储 key 到 (value, time, diff) 的映射。在 Arrangement 上可以:
128 |
129 | - 通过 handler 任意查询某个时间点 key-value 的映射关系。
130 | - 查询某一个 key 在一段时间内的变更情况。
131 | - 指定查询的水位,后台合并或删除不再使用的历史数据。
132 |
133 | DD 中大部分算子都是没有状态的,所有的状态都存储在 Arrangement 里。Arrangement 可以使用 Arrange 算子生成,也可以由算子 (比如 Reduce 算子) 自己维护。在 DD 的计算图上,有两种消息传递:
134 |
135 | - 数据在某一时刻的变更 `(data, time, diff)`。这种数据流叫做 Collection。
136 | - 数据的快照,也就是 Arrangement 的 handler。这种数据流叫做 Arranged。
137 |
138 | DD 中每个算子的对自己的输入输出也有一定的要求,比如下面几个例子:
139 |
140 | - Map 算子(对应 SQL 的 Projection)输入 Collection 输出 Collection。
141 | - JoinCore 算子 (Join 的一个阶段) 输入 Arranged 输出 Collection。
142 | - ReduceCore 算子 (Agg 的一个阶段) 输入 Arranged 输出 Arranged。
143 |
144 | 之后我们会详细介绍 DD 中的 JoinCore 和 ReduceCore 算子。
145 |
146 | ### 从 Differential Dataflow 到 Materialize
147 |
148 | Materialize 会将用户输入的 SQL 查询转换为 DD 的计算图。值得一提的是,`join`, `group by` 等 SQL 操作在 DD 中往往不会只对应一个算子。我们顺着消息的流动,看看 Materialize 是如何存储状态的。
149 |
150 | 
151 |
152 | ### Join State 的存储
153 |
154 | SQL 的 A Join B 操作在 DD 中对应三个算子:两个 `Arrange` 和一个 `JoinCore`。Arrange 算子根据 join key 分别持久化状态两个 source 的状态,以 KV 的形式存储在 Arrangement 中。Arrange 算子对输入攒批后,将 TraceHandle 发给下游的 `JoinCore` 算子。实际的 Join 逻辑在 `JoinCore` 算子中发生,`JoinCore` 不存储任何状态。
155 |
156 | 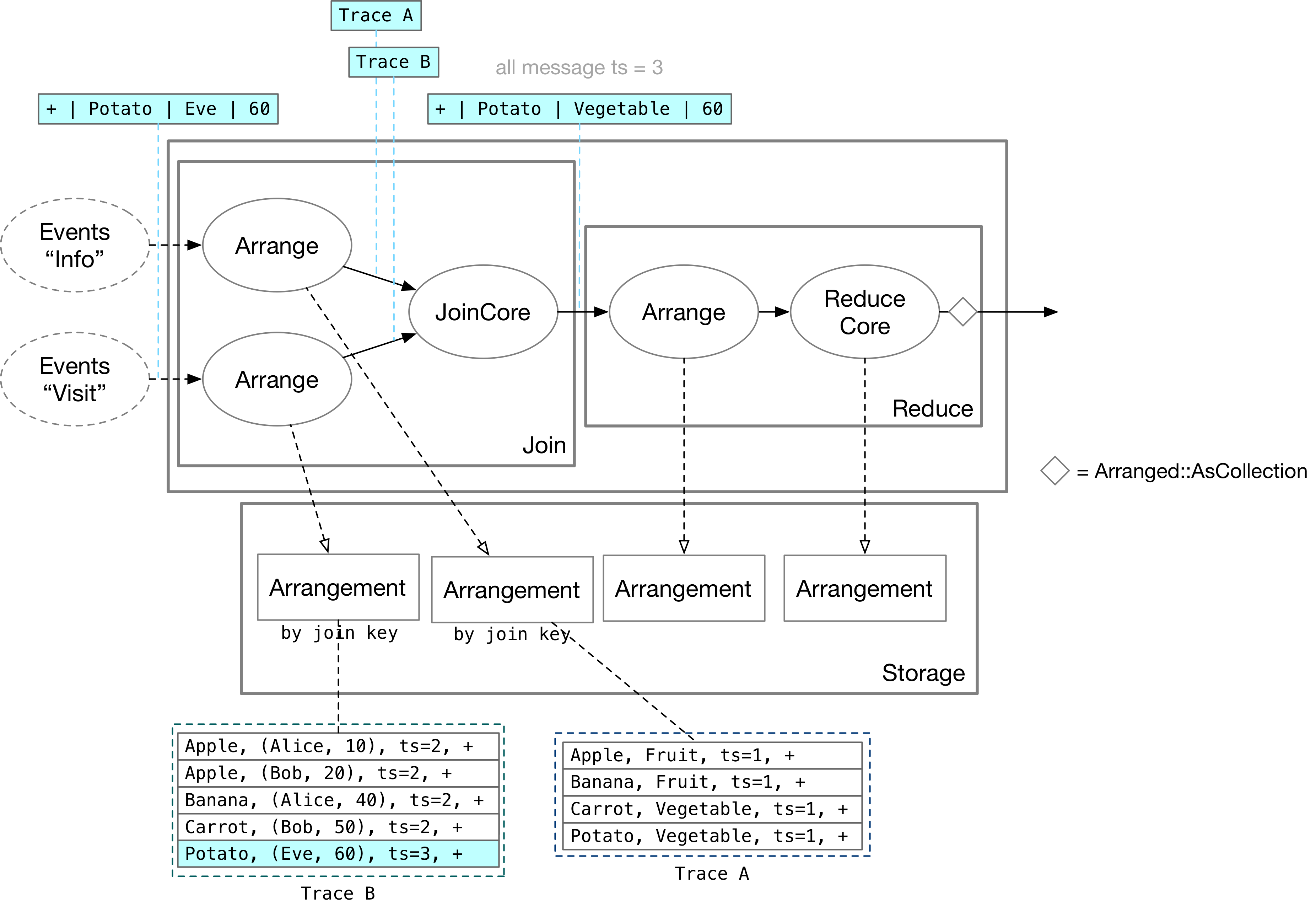
157 |
158 | 如上图所示,现在 Visit 侧来了一条更新:Eve 对着 Potato 看了 60 秒。`JoinCore` 算子通过 Trace B 访问到这条更新,并向另一侧的 Trace A 查询 `product = Potato` 的行,匹配到 `Potato` 是一种蔬菜,往下游输出 `Potato, Vegetable, 60` 的更改。
159 |
160 | ### Reduce 状态的存储
161 |
162 | DD 中 SQL Agg 算子对应 Reduce 操作。Reduce 中又包含两个算子:`Arrange` 和 `ReduceCore`。`Arrange` 算子根据 group key 存储输入数据,`ReduceCore` 算子自己维护一个存储聚合结果的 Arrangement,而后通过 `as_collection` 操作将聚合结果输出成一个 collection。
163 |
164 | 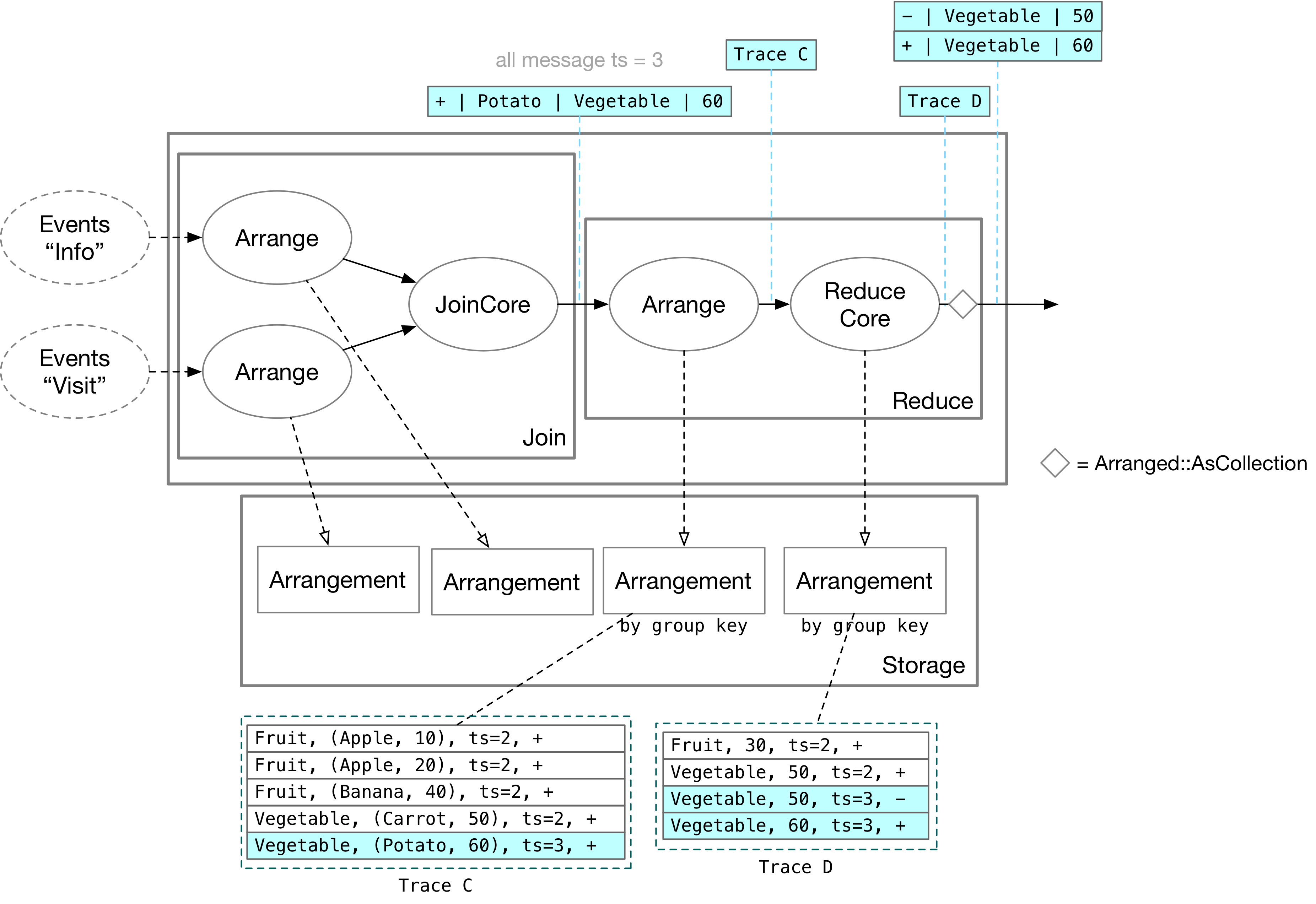
165 |
166 | Join 的更新来到 Reduce 算子后,先被 Arrange 算子根据 group key 存储在 Arrangement 中。ReduceCore 收到 Trace C 后,将 `key = Vegetable` 的行全部扫描出来,并求最大值,最后将最大值更新到自己的 Arrangement 中。Trace D 经过 `as_collection` 操作后,即可输出为数据更新的形式,变成其他算子可以处理的信息。
167 |
168 | ### 更方便的算子状态复用
169 |
170 | 由于 DD 中存储状态的算子和实际计算的算子是分开的,我们可以利用这个性质做算子状态的复用。
171 |
172 | 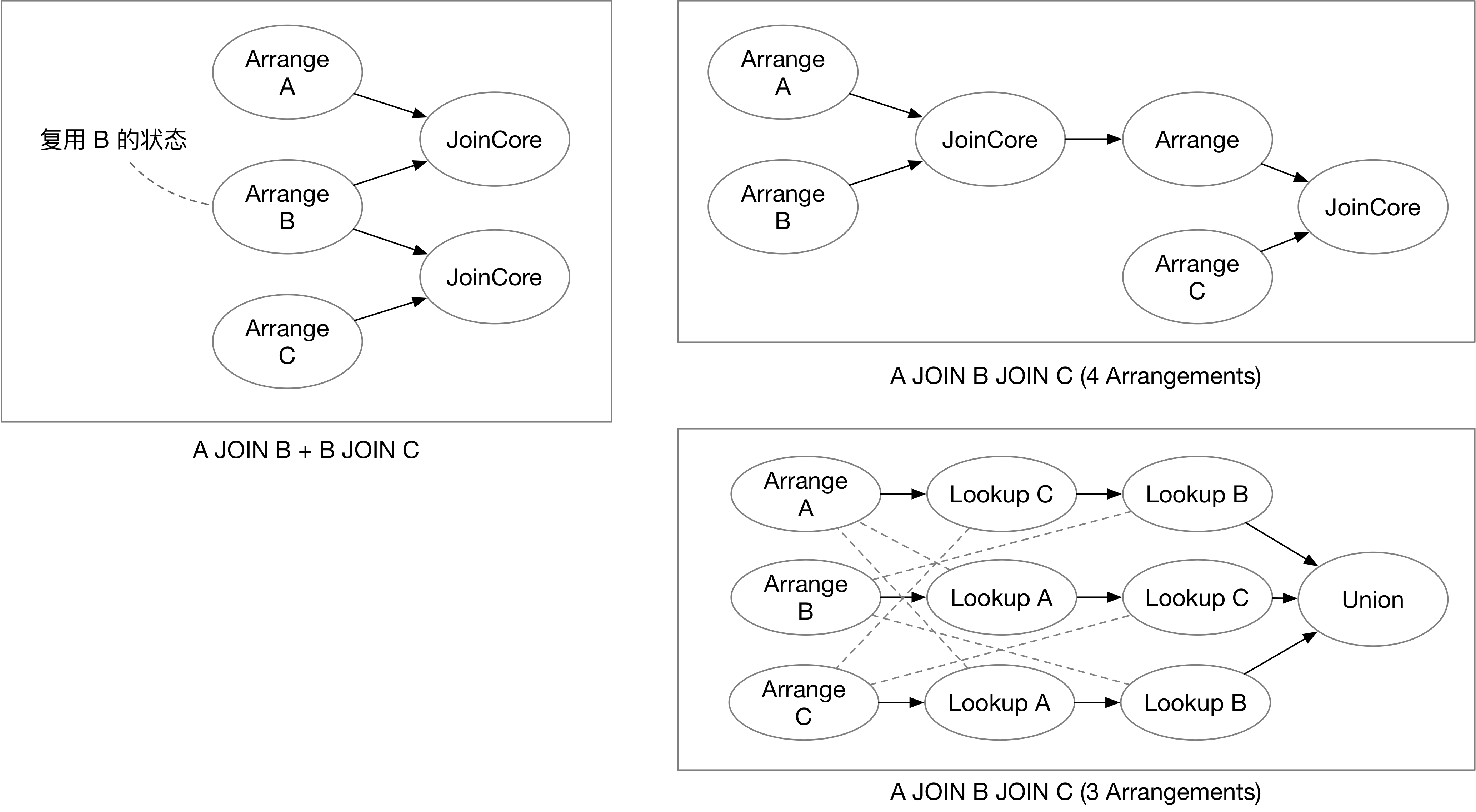
173 |
174 | 比如用户想要同时查询 `A JOIN B` 和 `B JOIN C`,在 DD 中,一种可能的计算图就是生成三个 Arrange 算子和两个 JoinCore 算子。相比于存储完整状态的流处理系统,我们可以避免 B 的状态被存两遍
175 |
176 | 另一个例子是多路 Join,比如 `SELECT * FROM A, B, C WHERE A.x = B.x and A.x = C.x`。在这个例子中,如果使用 JoinCore 算子来生成计算图,状态还是有可能重复,一共需要生成 4 个 Arrangement。
177 |
178 | Materialize 的 SQL Join 除了被转换为上文所述 DD 的 JoinCore 算子之外,也有可能转换为 Delta Join。如图所示,我们只需要分别生成 A, B, C 的 3 个 Arrangement,然后使用 lookup 算子查询 A 的修改在 B C 中对应的行(其他两个表的修改亦然),最后做一个 union,即可得到 Join 的结果。Delta Join 可以充分利用已有的 Arrangement 进行计算,大大减小 Join 所需的状态存储数。
179 |
180 | ### 远程访问状态的开销
181 |
182 | 在流系统中,计算中间产生的数据往往无法全部放在一个结点上;与此同时,同一个执行计划中的节点,也会有很多并行度。比如下面这个两表 Join 的例子。两个表 A、B 的 Arrangement 可能分别在两个结点上产生 (Node 1, 2),然后同时用两个结点分别对其中一部分数据做 Join。
183 |
184 | 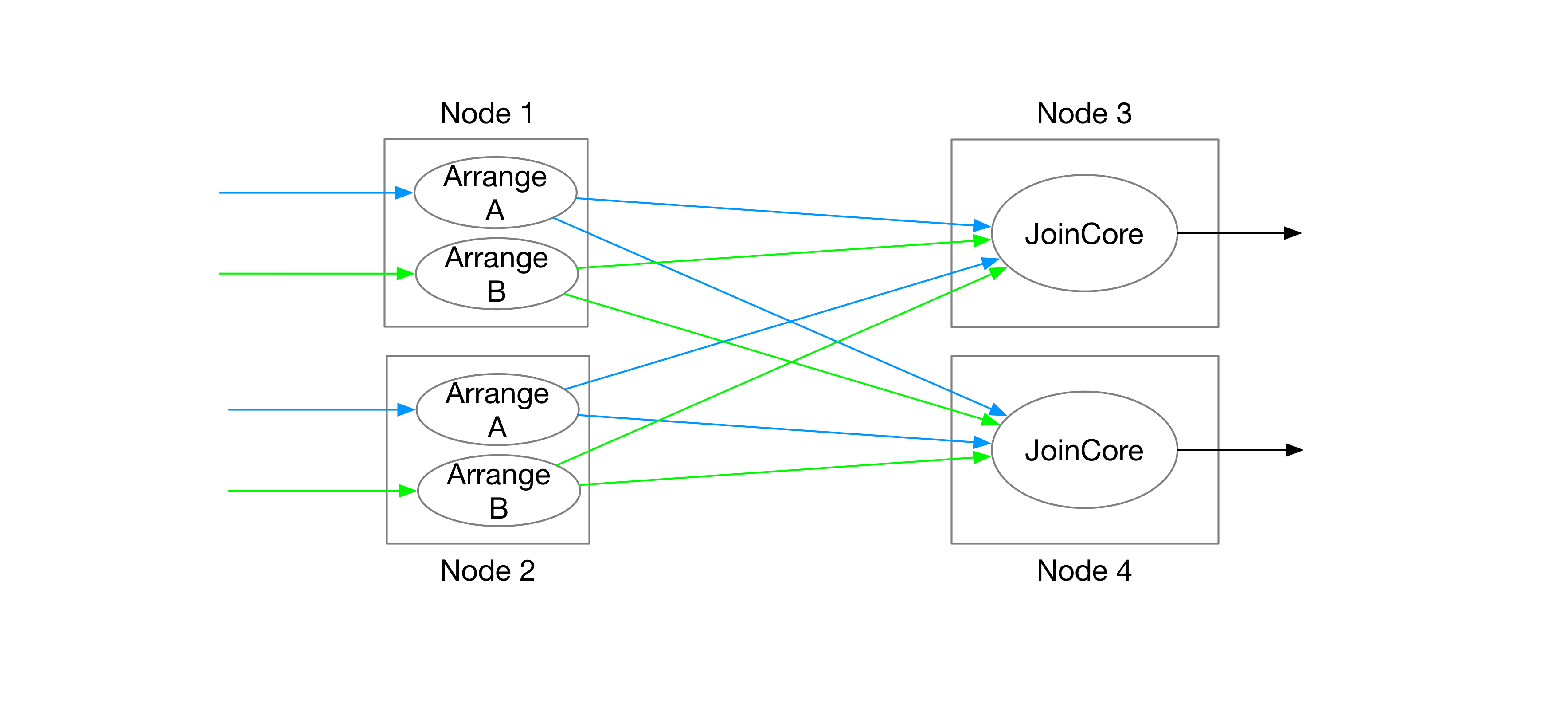
185 |
186 | 在这个情况下,DD 中势必会发生远程访问 Arrangement 的问题。由于算子完全没有内部状态,JoinCore 每处理一行都需要一次远程访问,查找 join key 对应的数据。总的来说,Arrange 和计算放在两个结点上会大大增加计算的延迟,放在一个结点上又无法充分利用分布式系统的资源,这是一个比较矛盾的地方。
187 |
188 | ### 总结
189 |
190 | 在共享状态的流处理系统中,算子的计算逻辑和存储逻辑被拆分到多个算子中。因此,不同的计算任务可以共享同一个存储,从而减少存储状态的数量。如果要实现共享状态的流处理系统,一般会有这样的特点:
191 |
192 | - 流计算图上传递的不仅仅是数据的变更,可能还会包括状态的共享信息(比如 DD 的 Trace Handle)。
193 | - 流算子访问状态会有一定的开销;但相对而言存储完整状态的流计算系统而言,整个流计算过程中由于状态复用,存储的状态数量更小。
194 |
195 | ## Partial State - 算子只存储部分信息
196 |
197 | 在 [Noria (OSDI ‘18)](https://github.com/mit-pdos/noria) 这一系统中,计算不会在数据源更新信息时触发,流处理算子并不会保存完整的信息。
198 |
199 | 比如,如果用户在之前创建的视图上执行:
200 |
201 | ```fallback
202 | SELECT * FROM result WHERE category = "Vegetable"
203 | ```
204 |
205 | 执行这条 SQL 的时候,才会触发流系统的计算。计算过程中,也只计算 `category = "Vegetable"` 相关的数据,保存相关的状态。下面将以这条查询为例,说明 Noria 的计算方式与状态存储。
206 |
207 | ### Upquery
208 |
209 | Noria 的各个算子仅存储部分数据。用户的查询可能直接击中这个部分状态的缓存,也有可能需要回溯到上游查询。假设现在所有算子的状态都为空,Noria 需要通过 upquery 来递归查询上游算子的状态,从而得到正确的结果。
210 |
211 | 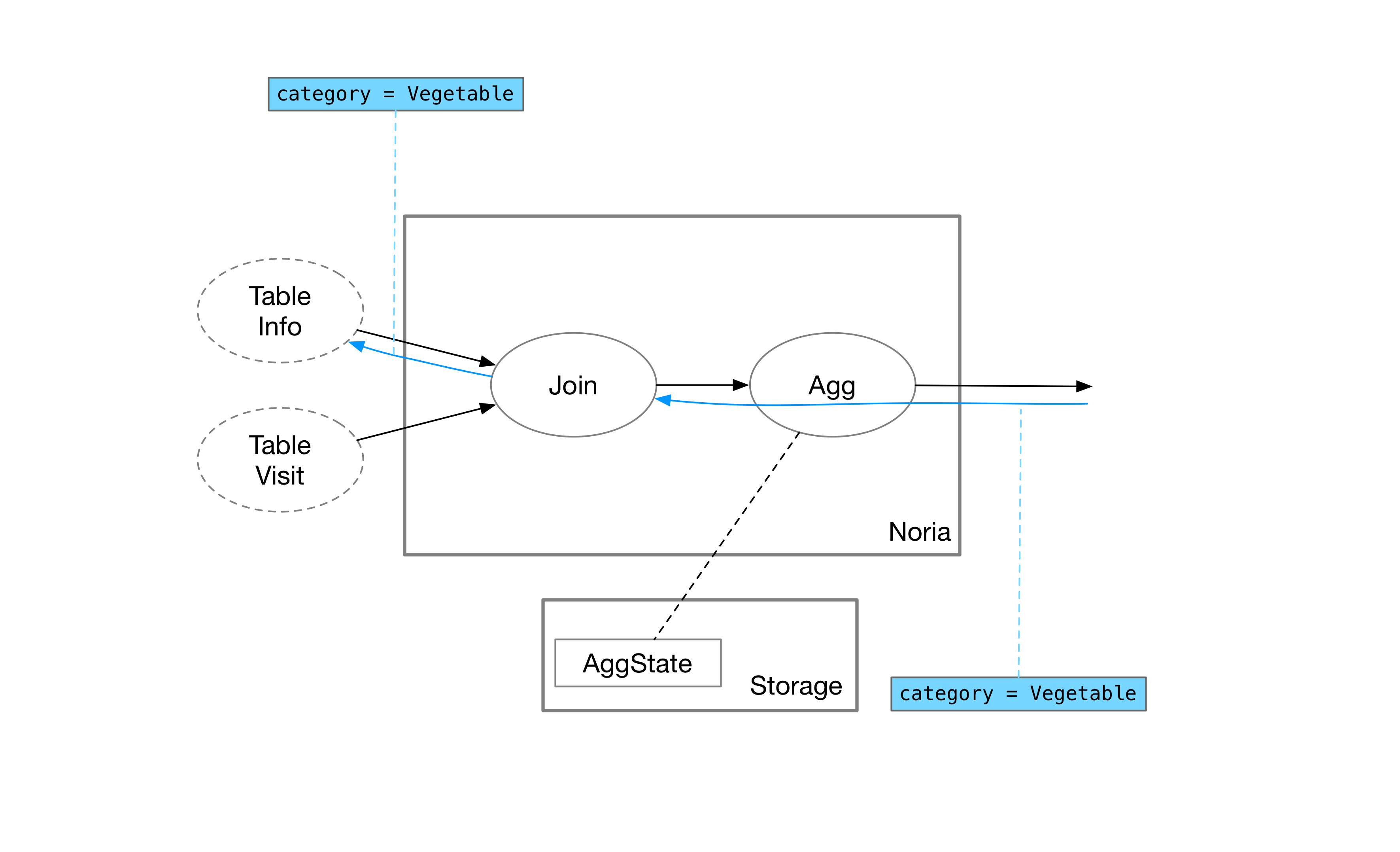
212 |
213 | 用户向流计算引擎查询 `category = "Vegetable"` 的最大值。Agg 算子为了计算出它的结果,需要知道所有 category 为蔬菜的记录。于是,Agg 算子将这个 upquery 转发到上游 Join 算子。
214 |
215 | Join 算子要得到蔬菜对应的所有信息,需要向两个上游表分别查询情况。category 属于 Info 表的列,因此,Join 算子将这条 upquery 转发给 Info 表。
216 |
217 | ### Join 算子的实现
218 |
219 | 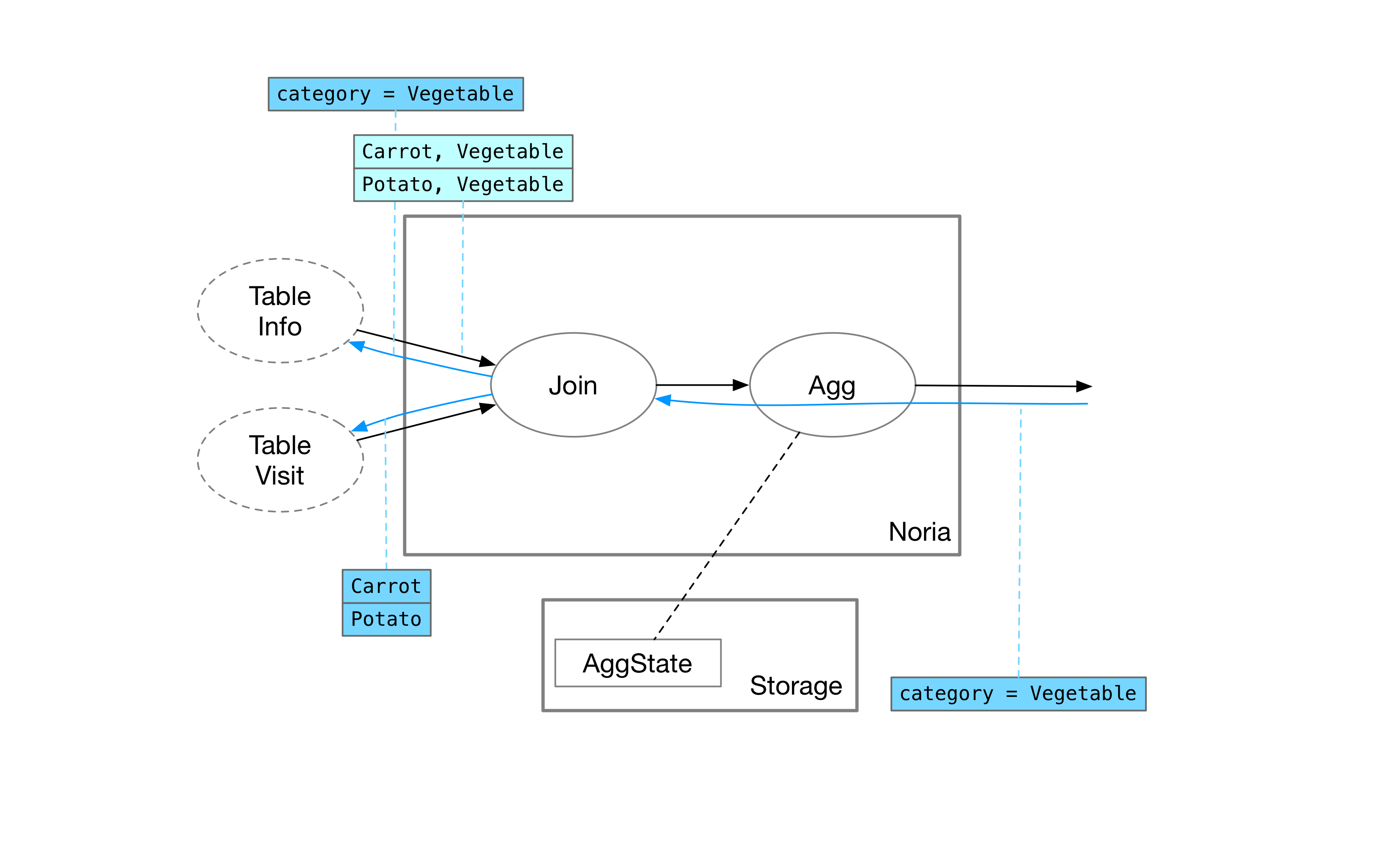
220 |
221 | Info table 返回蔬菜分类下的所有产品后,Join 算子会再发一个 upquery 给另一边 Visit table,查询胡萝卜、土豆对应的浏览记录。
222 |
223 | 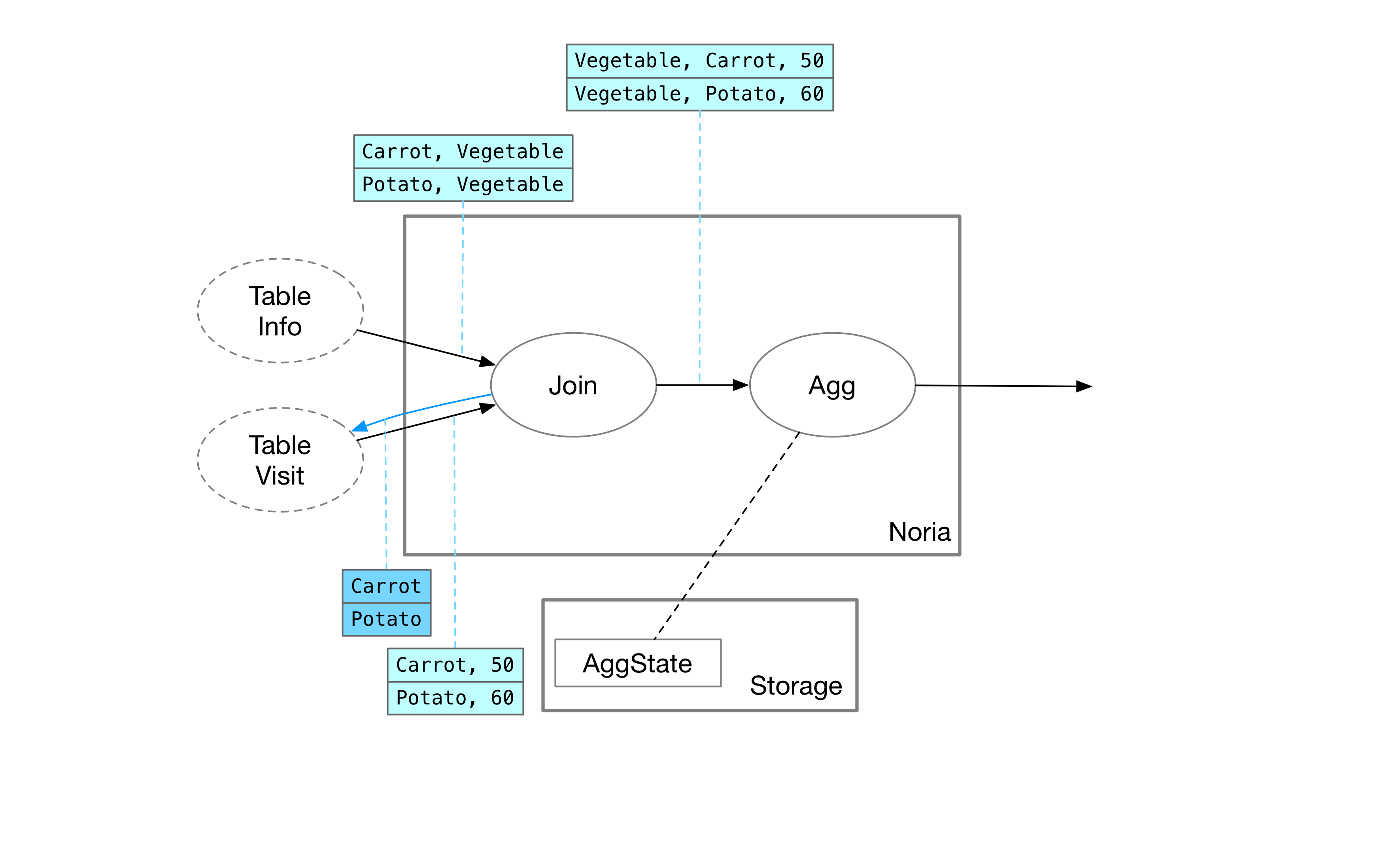
224 |
225 | Visit table 返回对应记录后,Join 算子就可以根据两次 Upquery 的输出计算出 Join 结果了。
226 |
227 | 在 Noria 中,Join 算子无需保存任何实际状态,仅需要记录正在进行的 upquery 即可。
228 |
229 | ### Agg 算子的实现
230 |
231 | 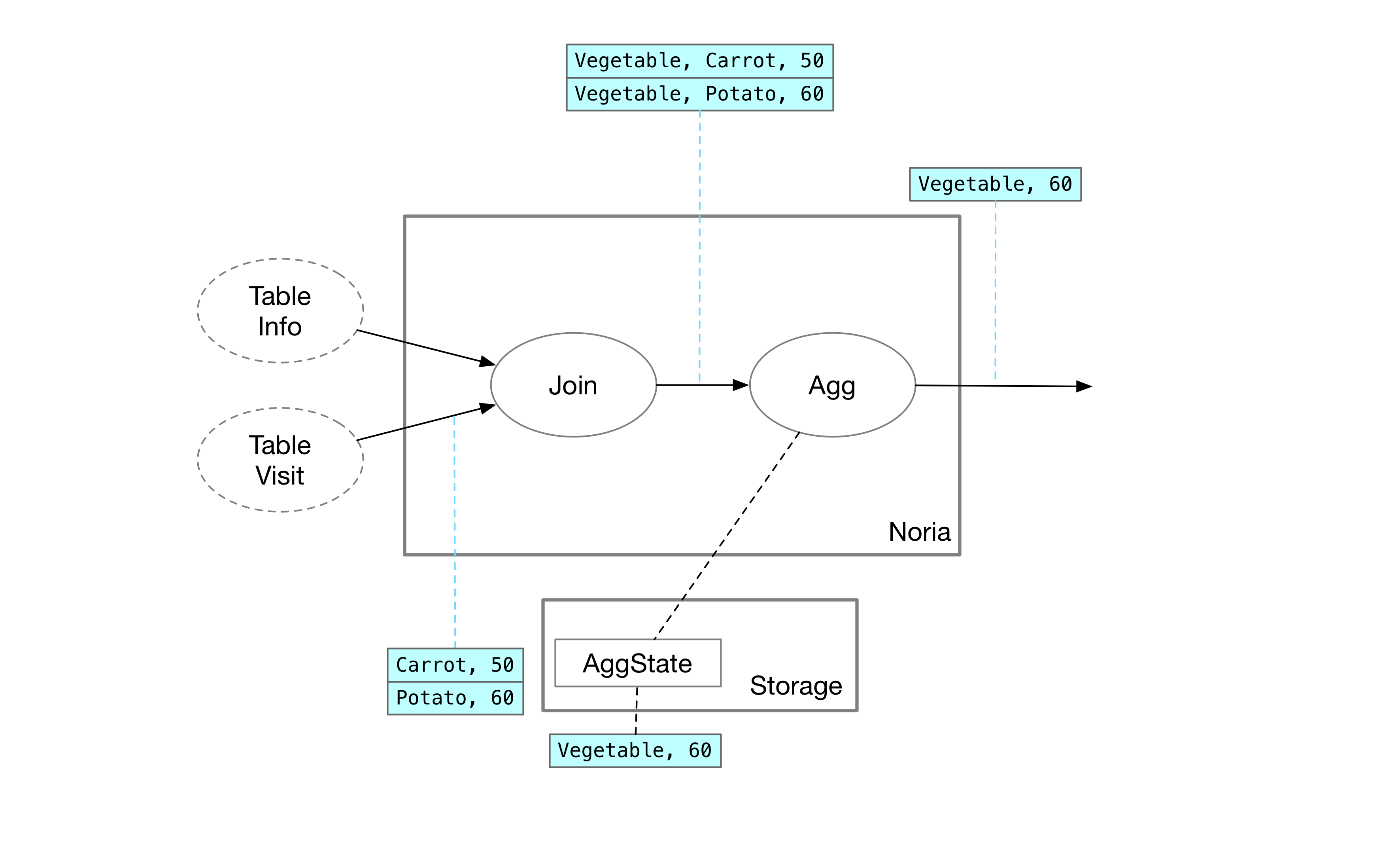
232 |
233 | 数据来到 Agg 算子后,Noria 将直接计算出最大值,并将最大值存储在算子的状态中。在前文所述的系统里,Agg 算子的状态需要保存完整的数据(水果的所有浏览记录、蔬菜的所有浏览记录)。Noria 只需要缓存用户请求的状态,因此在这个请求中只要记录蔬菜的记录。与此同时,如果上游发生了删除操作,Noria 可以直接将蔬菜对应的行删除,以便之后重新计算最大值。因此,在存储部分状态的系统中,也无需通过记录所有值的方法回推第二大的值——直接清空缓存就行了。
234 |
235 | ### 总结
236 |
237 | 存储部分状态的流处理系统通过 upquery 的方式实时响应用户的请求,在本文所述的实现中,所需要存储的状态数最少。它一般有以下特点:
238 |
239 | - 计算图的数据流向是双向的——既可以从上游到下游输出数据,也可以从下游到上游发 upquery。
240 | - 由于需要递归 upquery,计算的延迟可能比其他状态存储方式略微大一点。
241 | - 数据一致性比较难实现。本文所述的其他存储方法都可以比较简单地实现最终一致;但对于存储部分状态的系统来说,需要比较小心地处理更新和 upquery 返回结果同时在流上传递的问题,对于每个算子都要仔细证明实现的正确性。
242 | - DDL / Recovery 非常快。由于算子里面的信息都是按需计算的,如果用户对 View 进行增删列的操作,或是做迁移,都可以直接清空缓存分配新节点,无需代价较高的状态恢复。
243 |
244 | 最后对比一下所有的状态存储方式所对应的流处理系统特征:
245 |
246 | 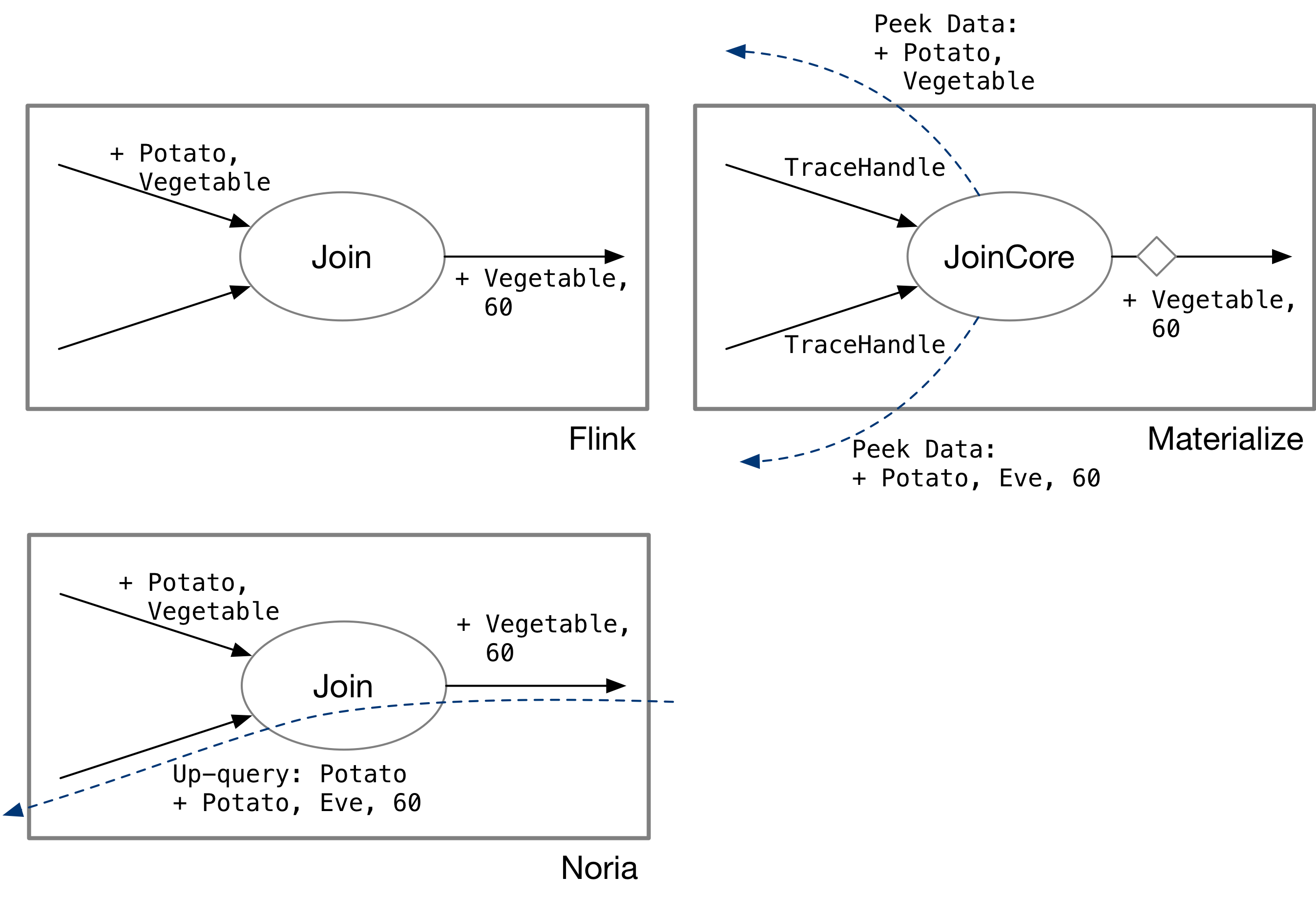
247 |
248 | - 存储完整状态 (以 Flink 为例):流上传递数据。
249 | - 共享状态存储 (以 Materialize / DD 为例):流上传递数据和 snapshot。
250 | - 存储部分状态 (以 Noria 为例):流上传递数据,流上双向都有消息。
251 |
252 | ## Reference
253 |
254 | - [Apache Flink](https://flink.apache.org/)
255 | - [Flink SQL](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/sql/gettingstarted/)
256 | - [Materialize](https://github.com/MaterializeInc/materialize)
257 | - [Joins in Materialize](https://materialize.com/joins-in-materialize/)
258 | - [Maintaining Joins using Few Resources](https://materialize.com/maintaining-joins-using-few-resources/)
259 | - [differential-dataflow](https://github.com/TimelyDataflow/differential-dataflow)
260 | - [Noria](https://github.com/mit-pdos/noria)
261 |
--------------------------------------------------------------------------------
/流处理/01~流处理系统设计/编程模型/时间窗口.md:
--------------------------------------------------------------------------------
1 | # 时间推理
2 |
3 | 流处理通常需要与时间打交道,尤其是用于分析目的时候,会频繁使用时间窗口,例如“过去五分钟的平均值”。“最后五分钟”的含义看上去似乎是清晰而无歧义的,但不幸的是,这个概念非常棘手。在批处理中过程中,大量的历史事件迅速收缩。如果需要按时间来分析,批处理器需要检查每个事件中嵌入的时间戳。读取运行批处理机器的系统时钟没有任何意义,因为处理运行的时间与事件实际发生的时间无关。
4 |
5 | 批处理可以在几分钟内读取一年的历史事件;在大多数情况下,感兴趣的时间线是历史中的一年,而不是处理中的几分钟。而且使用事件中的时间戳,使得处理是确定性的:在相同的输入上再次运行相同的处理过程会得到相同的结果。另一方面,许多流处理框架使用处理机器上的本地系统时钟(处理时间(processing time))来确定窗口。这种方法的优点是简单,事件创建与事件处理之间的延迟可以忽略不计。然而,如果存在任何显著的处理延迟,即,事件处理显著地晚于事件实际发生的时间,处理就失效了。
6 |
7 | # 事件时间与处理时间
8 |
9 | 很多原因都可能导致处理延迟:排队,网络故障,性能问题导致消息代理/消息处理器出现争用,流消费者重启,重新处理过去的事件,或者在修复代码 BUG 之后从故障中恢复。而且,消息延迟还可能导致无法预测消息顺序。例如,假设用户首先发出一个 Web 请求(由 Web 服务器 A 处理),然后发出第二个请求(由服务器 B 处理)。A 和 B 发出描述它们所处理请求的事件,但是 B 的事件在 A 的事件发生之前到达消息代理。现在,流处理器将首先看到 B 事件,然后看到 A 事件,即使它们实际上是以相反的顺序发生的。
10 |
11 | 有一个类比也许能帮助理解,“星球大战”电影:第四集于 1977 年发行,第五集于 1980 年,第六集于 1983 年,紧随其后的是 1999 年的第一集,2002 年的第二集,和 2005 年的三集,以及 2015 年的第七集。如果你按照按照它们上映的顺序观看电影,你处理电影的顺序与它们叙事的顺序就是不一致的。(集数编号就像事件时间戳,而你观看电影的日期就是处理时间)作为人类,我们能够应对这种不连续性,但是流处理算法需要专门编写,以适应这种时机与顺序的问题。
12 |
13 | 将事件时间和处理时间搞混会导致错误的数据。例如,假设你有一个流处理器用于测量请求速率(计算每秒请求数)。如果你重新部署流处理器,它可能会停止一分钟,并在恢复之后处理积压的事件。如果你按处理时间来衡量速率,那么在处理积压日志时,请求速率看上去就像有一个异常的突发尖峰,而实际上请求速率是稳定的。
14 |
15 | 
16 |
17 | ## 事件完结
18 |
19 | 用事件时间来定义窗口的一个棘手的问题是,你永远也无法确定是不是已经收到了特定窗口的所有事件,还是说还有一些事件正在来的路上。例如,假设你将事件分组为一分钟的窗口,以便统计每分钟的请求数。你已经计数了一些带有本小时内第 37 分钟时间戳的事件,时间流逝,现在进入的主要都是本小时内第 38 和第 39 分钟的事件。什么时候才能宣布你已经完成了第 37 分钟的窗口计数,并输出其计数器值?
20 |
21 | 在一段时间没有看到任何新的事件之后,你可以超时并宣布一个窗口已经就绪,但仍然可能发生这种情况:某些事件被缓冲在另一台机器上,由于网络中断而延迟。你需要能够处理这种在窗口宣告完成之后到达的 滞留(straggler)事件。大体上,你有两种选择:
22 |
23 | - 忽略这些滞留事件,因为在正常情况下它们可能只是事件中的一小部分。你可以将丢弃事件的数量作为一个监控指标,并在出现大量丢消息的情况时报警。
24 |
25 | - 发布一个更正(correction),一个包括滞留事件的更新窗口值。更新的窗口与包含散兵队员的价值。你可能还需要收回以前的输出。
26 |
27 | 在某些情况下,可以使用特殊的消息来指示“从现在开始,不会有比 t 更早时间戳的消息了”,消费者可以使用它来触发窗口。但是,如果不同机器上的多个生产者都在生成事件,每个生产者都有自己的最小时间戳阈值,则消费者需要分别跟踪每个生产者。在这种情况下,添加和删除生产者都是比较棘手的。
28 |
29 | ## 时钟选择
30 |
31 | 当事件可能在系统内多个地方进行缓冲时,为事件分配时间戳更加困难了。例如,考虑一个移动应用向服务器上报关于用量的事件。该应用可能会在设备处于脱机状态时被使用,在这种情况下,它将在设备本地缓冲事件,并在下一次互联网连接可用时向服务器上报这些事件(可能是几小时甚至几天)。对于这个流的任意消费者而言,它们就如延迟极大的滞留事件一样。
32 |
33 | 在这种情况下,事件上的事件戳实际上应当是用户交互发生的时间,取决于移动设备的本地时钟。然而用户控制的设备上的时钟通常是不可信的,因为它可能会被无意或故意设置成错误的时间。服务器收到事件的时间(取决于服务器的时钟)可能是更准确的,因为服务器在你的控制之下,但在描述用户交互方面意义不大。
34 |
35 | 要校正不正确的设备时钟,一种方法是记录三个时间戳:
36 |
37 | - 事件发生的时间,取决于设备时钟
38 |
39 | - 事件发送往服务器的时间,取决于设备时钟
40 |
41 | - 事件被服务器接收的时间,取决于服务器时钟
42 |
43 | 通过从第三个时间戳中减去第二个时间戳,可以估算设备时钟和服务器时钟之间的偏移(假设网络延迟与所需的时间戳精度相比可忽略不计)。然后可以将该偏移应用于事件时间戳,从而估计事件实际发生的真实时间(假设设备时钟偏移在事件发生时与送往服务器之间没有变化)。这并不是流处理独有的问题,批处理有着完全一样的时间推理问题。只是在流处理的上下文中,我们更容易意识到时间的流逝。
44 |
45 | # 窗口的类型
46 |
47 | 当你知道如何确定一个事件的时间戳后,下一步就是如何定义时间段的窗口。然后窗口就可以用于聚合,例如事件计数,或计算窗口内值的平均值。有几种窗口很常用.
48 |
49 | ## 滚动窗口(Tumbling Window)
50 |
51 | 滚动窗口有着固定的长度,每个事件都仅能属于一个窗口。例如,假设你有一个 1 分钟的滚动窗口,则所有时间戳在 10:03:00 和 10:03:59 之间的事件会被分组到一个窗口中,10:04:00 和 10:04:59 之间的事件被分组到下一个窗口,依此类推。通过将每个事件时间戳四舍五入至最近的分钟来确定它所属的窗口,可以实现 1 分钟的滚动窗口。
52 |
53 | ## 跳动窗口(Hopping Window)
54 |
55 | 跳动窗口也有着固定的长度,但允许窗口重叠以提供一些平滑。例如,一个带有 1 分钟跳跃步长的 5 分钟窗口将包含 10:03:00 至 10:07:59 之间的事件,而下一个窗口将覆盖 10:04:00 至 10:08:59 之间的事件,等等。通过首先计算 1 分钟的滚动窗口,然后在几个相邻窗口上进行聚合,可以实现这种跳动窗口。
56 |
57 | ## 滑动窗口(Sliding Window)
58 |
59 | 滑动窗口包含了彼此间距在特定时长内的所有事件。例如,一个 5 分钟的滑动窗口应当覆盖 10:03:39 和 10:08:12 的事件,因为它们相距不超过 5 分钟(注意滚动窗口与步长 5 分钟的跳动窗口可能不会把这两个事件分组到同一个窗口中,因为它们使用固定的边界)。通过维护一个按时间排序的事件缓冲区,并不断从窗口中移除过期的旧事件,可以实现滑动窗口。
60 |
61 | ## 会话窗口(Session window)
62 |
63 | 与其他窗口类型不同,会话窗口没有固定的持续时间,而定义为:将同一用户出现时间相近的所有事件分组在一起,而当用户一段时间没有活动时(例如,如果 30 分钟内没有事件)窗口结束。会话切分是网站分析的常见需求。
64 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/Beam/Dataflow 模型.md:
--------------------------------------------------------------------------------
1 | # 流处理模型
2 |
3 | Dataflow 模型(或者说 Beam 模型)旨在建立一套准确可靠的关于流处理的解决方案。在 Dataflow 模型提出以前,流处理常被认为是一种不可靠但低延迟的处理方式,需要配合类似于 MapReduce 的准确但高延迟的批处理框架才能得到一个可靠的结果,这就是著名的 Lambda 架构。这种架构给应用带来了很多的麻烦,例如引入多套组件导致系统的复杂性、可维护性难度提高。因此 Lambda 架构遭到很多开发者的炮轰,并试图设计一套统一批流的架构减少这种复杂性。Spark 1.X 的 Mirco-Batch 模型就尝试从批处理的角度处理流数据,将不间断的流数据切分为一个个微小的批处理块,从而可以使用批处理的 transform 操作处理数据。还有 Jay 提出的 Kappa 架构,使用类似于 Kafka 的日志型消息存储作为中间件,从流处理的角度处理批处理。在工程师的不断努力和尝试下,Dataflow 模型孕育而生。
4 |
5 | 起初,Dataflow 模型是为了解决 Google 的广告变现问题而设计的。因为广告主需要实时的知道自己投放的广告播放、观看情况等指标从而更好的进行决策,但是批处理框架 Mapreduce、Spark 等无法满足时延的要求(因为它们需要等待所有的数据成为一个批次后才会开始处理),(当时)新生的流处理框架 Aurora、Niagara 等还没经受大规模生产环境的考验,饱经考验的流处理框架 Storm、Samza 却没有“恰好一次”的准确性保障(在广告投放时,如果播放量算多一次,意味广告主的亏损,导致对平台的不信任,而少算一次则是平台的亏损,平台方很难接受),DStreaming(Spark1.X)无法处理事件时间,只有基于记录数或基于数据处理时间的窗口,Lambda 架构过于复杂且可维护性低,最契合的 Flink 在当时并未成熟。最后 Google 只能基于 MillWheel 重新审视流的概念设计出 Dataflow 模型和 Google Cloud Dataflow 框架,并最终影响了 Spark 2.x 和 Flink 的发展,也促使了 Apache Beam 项目的开源。
6 |
7 | # 核心概念
8 |
9 | Dataflow 模型从流处理的角度重新审视数据处理过程,将批和流处理的数据抽象成数据集的概念,并将数据集划分为无界数据集和有界数据集,认为流处理是批处理的超集。模型定义了时间域(time domain)的概念,将时间明确的区分为事件时间(event-time)和处理时间(process-time),给出构建一个正确、稳定、低时延的流处理系统所会面临的四个问题及其解决办法:
10 |
11 | - 计算的结果是什么(What results are calculated)?通过 transformations 操作
12 |
13 | - 在事件时间中的哪个位置计算结果(Where in event time are results calculated)?使用窗口(windowing)的概念
14 |
15 | - 在处理时间中的哪个时刻触发计算结果(When in processing time are results materialized)?使用 triggers + watermarks 进行触发计算
16 |
17 | - 如何修正结果(How do refinements of results relate)?通过 accumulation 的类型修正结果数据
18 |
19 | 基于这些考虑,模型的核心概念包括了:
20 |
21 | - 事件时间(Event time)和处理时间(processing time)流处理中最重要的问题是事件发生的时间(事件时间)和处理系统观测到的时间(处理时间)存在延迟。
22 |
23 | - 窗口(Windowing)为了合理地计算无界数据集地结果,所以需要沿时间边界切分数据集(也就是窗口)。
24 |
25 | - 触发器(Triggers)触发器是一种表示处理过程中遇上某种特殊情况时,此刻的输出结果可以是精确的,有意义的机制。
26 |
27 | - 水印(Watermarks)水印是针对事件时间的概念,提供了一种事件时间相对于处理时间是乱序的系统中合理推测无界数据集里数据完整性的工具。
28 |
29 | 累计类型(Accumulation)累计类型是处理单个窗口的输出数据是如何随着流处理的进程而发生变化的。
30 |
31 | # Links
32 |
33 | - https://www.zhihu.com/question/30151872/answer/640568211
34 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/Beam/README.md:
--------------------------------------------------------------------------------
1 | # Apache Beam
2 |
3 | 在大数据的浪潮之下,技术的更新迭代十分频繁。受技术开源的影响,大数据开发者提供了十分丰富的工具。但也因为如此,增加了开发者选择合适工具的难度。在大数据处理一些问题的时候,往往使用的技术是多样化的。这完全取决于业务需求,比如进行批处理的 MapReduce,实时流处理的 Flink,以及 SQL 交互的 Spark SQL 等等。而把这些开源框架,工具,类库,平台整合到一起,所需要的工作量以及复杂度,可想而知。这也是大数据开发者比较头疼的问题。
4 |
5 | 
6 |
7 | Apache Beam 最初叫 Apache Dataflow,由谷歌和其合作伙伴向 Apache 捐赠了大量的核心代码,并创立孵化了该项目。该项目的大部分大码来自于 Cloud Dataflow SDK,其特点有以下几点:
8 |
9 | - 统一数据批处理(Batch)和流处理(Stream)编程的范式
10 | - 能运行在任何可执行的引擎之上
11 |
12 | 整个技术的发展流向;一部分是谷歌派系,另一部分则是 Apache 派系。在开发大数据应用时,我们有时候使用谷歌的框架,API,类库,平台等,而有时候我们则使用 Apache 的,比如:HBase,Flink,Spark 等。而我们要整合这些资源则是一个比较头疼的问题,Apache Beam 的问世,整合这些资源提供了很方便的解决方案。
13 |
14 | 
15 |
16 | Beam SDK 提供了一个统一的编程模型,来处理任意规模的数据集,其中包括有限的数据集,无限的流数据。Apache Beam SDK 使用相同的类来表达有限和无限的数据,同样使用相同的转换方法对数据进行操作。Beam 提供了多种 SDK,你可以选择一种你熟悉的来建立数据处理管道,如上述的图,我们可以知道,目前 Beam 支持 Java,Python 以及其他待开发的语言。
17 |
18 | 在 Beam 管道上运行引擎会根据你选择的分布式处理引擎,其中兼容的 API 转换你的 Beam 程序应用,让你的 Beam 应用程序可以有效的运行在指定的分布式处理引擎上。因而,当运行 Beam 程序的时候,你可以按照自己的需求选择一种分布式处理引擎。当前 Beam 支持的管道运行引擎有以下几种:Apache Apex,Apache Flink,Apache Spark,Google Cloud Dataflow。
19 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/Beam/快速开始.md:
--------------------------------------------------------------------------------
1 | # Apache Beam 快速开始
2 |
3 | # Simple Word Count
4 |
5 | 可以通过 Beam 提供的 Maven 模板来快速创建项目:
6 |
7 | ```s
8 | $ mvn archetype:generate \
9 | -DarchetypeRepository=https://repository.apache.org/content/groups/snapshots \
10 | -DarchetypeGroupId=org.apache.beam \
11 | -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
12 | -DarchetypeVersion=LATEST \
13 | -DgroupId=org.example \
14 | -DartifactId=word-count-beam \
15 | -Dversion="0.1" \
16 | -Dpackage=org.apache.beam.examples \
17 | -DinteractiveMode=false
18 | ```
19 |
20 | 一个 Beam 程序可以运行在多个 Beam 的可执行引擎上,包括 ApexRunner,FlinkRunner,SparkRunner 或者 DataflowRunner。另外还有 DirectRunner。不需要特殊的配置就可以在本地执行,方便测试使用。使用不同的命令:通过 `--runner=` 参数指明引擎类型,默认是 DirectRunner;添加引擎相关的参数;指定输出文件和输出目录,当然这里需要保证文件目录是执行引擎可以访问到的,比如本地文件目录是不能被外部集群访问的。
21 |
22 | ```sh
23 | # Direct
24 | $ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
25 | -Dexec.args="--inputFile=pom.xml --output=counts" -Pdirect-runner
26 |
27 | # Apex
28 | $ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
29 | -Dexec.args="--inputFile=pom.xml --output=counts --runner=ApexRunner" -Papex-runner
30 |
31 | # Flink-Local
32 | $ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
33 | -Dexec.args="--runner=FlinkRunner --inputFile=pom.xml --output=counts" -Pflink-runner
34 |
35 | # Flink-Cluster
36 | $ mvn package exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
37 | -Dexec.args="--runner=FlinkRunner --flinkMaster= --filesToStage=target/word-count-beam-bundled-0.1.jar \
38 | --inputFile=/path/to/quickstart/pom.xml --output=/tmp/counts" -Pflink-runner
39 |
40 | # Spark
41 | $ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
42 | -Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
43 |
44 | # Dataflow
45 | $ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
46 | -Dexec.args="--runner=DataflowRunner --gcpTempLocation=gs:///tmp \
47 | --inputFile=gs://apache-beam-samples/shakespeare/* --output=gs:///counts" \
48 | -Pdataflow-runner
49 | ```
50 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/Beam/部署与配置.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/流处理/08~开源框架/Beam/部署与配置.md
--------------------------------------------------------------------------------
/流处理/08~开源框架/Spark/README.md:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/Spark/代码开发.md:
--------------------------------------------------------------------------------
1 | # DebugTest
2 |
3 | ## UnitTest
4 |
5 | Spark 的任务需要允许在 Spark 的上下文中,可以用一个叫做 FindSpark 的包来辅助:
6 |
7 | ```
8 | pip install findspark
9 | ```
10 |
11 | 在初始化上下文之前,需要调用`findspark.init()`方法,它会自动地根据本地的`SPARK_HOME`环境变量来定位到 Spark 的 Python 依赖包。
12 |
13 | ```python
14 | import unittest2
15 | import logging
16 |
17 | import findspark
18 | findspark.init()
19 | from pyspark.context import SparkContext
20 |
21 | class ExampleTest(unittest2.TestCase):
22 |
23 | def setUp(self):
24 | self.sc = SparkContext('local[4]')
25 | quiet_logs(self.sc)
26 |
27 | def tearDown(self):
28 | self.sc.stop()
29 |
30 | def test_something(self):
31 | # start by creating a mockup dataset
32 | l = [(1, 'hello'), (2, 'world'), (3, 'world')]
33 | # and create a RDD out of it
34 | rdd = self.sc.parallelize(l)
35 | # pass it to the transformation you're unit testing
36 | result = non_trivial_transform(rdd)
37 | # collect the results
38 | output = result.collect()
39 | # since it's unit test let's make an assertion
40 | self.assertEqual(output[0][1], 2)
41 |
42 |
43 | def non_trivial_transform(rdd):
44 | """ a transformation to unit test (word count) - defined here for convenience only"""
45 | return rdd.map(lambda x: (x[1], 1)).reduceByKey(lambda a, b: a + b)
46 |
47 | if __name__ == "__main__":
48 | unittest2.main()
49 | ```
50 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/Spark/环境配置.md:
--------------------------------------------------------------------------------
1 | # Introduction
2 |
3 | ## Tutorial & Docs
4 |
5 | # Quick Start
6 |
7 | ## Deploy
8 |
9 | Spark 的部署方式可以独立部署,也可以基于 Yarn 或者 Mesos 这样的资源调度框架进行部署。
10 |
11 | - [Spark 下载地址][1]
12 |
13 | ### StandAlone
14 |
15 | 将 Spark 的程序文件解压之后可以通过如下命令直接启动一个独立的主机:
16 |
17 | ```
18 | ./sbin/start-master.sh
19 | ```
20 |
21 | 执行该命令之后 Spark 会自动执行 jetty 命令启动服务器,同时在命令行或者 log 日志文件中打印出系统地址,譬如:
22 |
23 | ```
24 | 15/05/28 13:20:57 INFO Master: Starting Spark master at spark://localhost.localdomain:7077
25 | 15/05/28 13:21:07 INFO MasterWebUI: Started MasterWebUI at http://192.168.199.166:8080
26 | ```
27 |
28 | 给出的这个 spark://HOST:PORT 地址可以供 Spark work 节点连接或者作为 master 的参数传入到 SparkContext 中。
29 |
30 | 需要启动 work 进程并在 master 中完成注册,可以使用如下命令:
31 |
32 | ```
33 | ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://IP:PORT
34 | ```
35 |
36 | > 注意,这边的 IP 地址实际上指的是启动 master 时候他监听的域名而来的 IP 地址。
37 |
38 | ![enter description here][2]
39 |
40 | 执行上述命令时可以传入的参数为:
41 |
42 | | Argument | Meaning |
43 | | ----------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
44 | | -h HOST, --host HOST | Hostname to listen on |
45 | | -i HOST, --ip HOST | Hostname to listen on (deprecated, use -h or --host) |
46 | | -p PORT, --port PORT | Port for service to listen on (default: 7077 for master, random for worker) |
47 | | --webui-port PORT | Port for web UI (default: 8080 for master, 8081 for worker) |
48 | | -c CORES, --cores CORES | Total CPU cores to allow Spark applications to use on the machine (default: all available); only on worker |
49 | | -m MEM, --memory MEM | Total amount of memory to allow Spark applications to use on the machine, in a format like 1000M or 2G (default: your machine's total RAM minus 1 GB); only on worker |
50 | | -d DIR, --work-dir DIR | Directory to use for scratch space and job output logs (default: SPARK_HOME/work); only on worker |
51 | | --properties-file FILE | Path to a custom Spark properties file to load (default: conf/spark-defaults.conf) |
52 |
53 | #### Cluster Launch
54 |
55 | - sbin/start-master.sh - Starts a master instance on the machine the script is executed on.
56 | - sbin/start-slaves.sh - Starts a slave instance on each machine specified in the conf/slaves file.
57 | - sbin/start-all.sh - Starts both a master and a number of slaves as described above.
58 | - sbin/stop-master.sh - Stops the master that was started via the bin/start-master.sh script.
59 | - sbin/stop-slaves.sh - Stops all slave instances on the machines specified in the conf/slaves file.
60 | - sbin/stop-all.sh - Stops both the master and the slaves as described above.
61 |
62 | ## Docker
63 |
64 | - [基于 Docker 的 Spark 集群搭建](http://blog.csdn.net/yeasy/article/details/48654965)
65 |
66 | ## Application Submit
67 |
68 | ```
69 | ./bin/spark-submit \
70 | --class
71 | --master \
72 | --deploy-mode \
73 | --conf = \
74 | ... # other options
75 | \
76 | [application-arguments]
77 | ```
78 |
79 | > 参数如下:
80 |
81 | - --class: The entry point for your application (e.g. org.apache.spark.examples.SparkPi)
82 | - --master: The master URL for the cluster (e.g. spark://23.195.26.187:7077)
83 | - --deploy-mode: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client)
84 | - --conf: Arbitrary Spark configuration property in key=value format. For values that contain spaces wrap “key=value” in quotes (as shown).
85 | - application-jar: Path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, an hdfs:// path or a file:// path that is present on all nodes.
86 | - application-arguments: Arguments passed to the main method of your main class, if any
87 |
88 | ### StandAlone
89 |
90 | ```
91 | # Run application locally on 8 cores
92 | ./bin/spark-submit \
93 | --class org.apache.spark.examples.SparkPi \
94 | --master local[8] \
95 | /path/to/examples.jar \
96 | 100
97 |
98 | # Run on a Spark Standalone cluster in client deploy mode
99 | ./bin/spark-submit \
100 | --class org.apache.spark.examples.SparkPi \
101 | --master spark://207.184.161.138:7077 \
102 | --executor-memory 20G \
103 | --total-executor-cores 100 \
104 | /path/to/examples.jar \
105 | 1000
106 |
107 | # Run on a Spark Standalone cluster in cluster deploy mode with supervise
108 | ./bin/spark-submit \
109 | --class org.apache.spark.examples.SparkPi \
110 | --master spark://207.184.161.138:7077 \
111 | --deploy-mode cluster
112 | --supervise
113 | --executor-memory 20G \
114 | --total-executor-cores 100 \
115 | /path/to/examples.jar \
116 | 1000
117 | ```
118 |
119 | 在任务提交之后,在管理界面会显示:
120 |
121 | ![enter description here][3]
122 |
123 | # Program
124 |
125 | ## Initializing Spark
126 |
127 | 编写 Spark 程序的首先是需要创建一个 JavaSparkContext 对象,用于确定如何去连接到一个集群中。而如果需要创建一个 SparkContext 对象则需要新创建一个包含应用的基本信息 SparkConf 对象。
128 |
129 | ```
130 | SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
131 | JavaSparkContext sc = new JavaSparkContext(conf);
132 | ```
133 |
134 | 上述代码中的 appName 是该应用的名称,而 master 指 Spark 进程的 URL,如果对于 StandAlone 进程既是类似于 spark://Host:Port
135 |
136 | ## Resilient Distributed Datasets (RDDs)
137 |
138 | ### Parallelized Collections
139 |
140 | ```
141 | List data = Arrays.asList(1, 2, 3, 4, 5);
142 | JavaRDD distData = sc.parallelize(data);
143 | ```
144 |
145 | ### External Datasets
146 |
147 | ### RDD Operations
148 |
149 | 注意,由于 Spark 中采用了大量的异步操作,并不能像普通的 Java 程序中一样去同步进行遍历,大量的遍历等操作是利用类似于回调的方式构造的。
150 |
--------------------------------------------------------------------------------
/流处理/08~开源框架/流计算框架对比.md:
--------------------------------------------------------------------------------
1 | # 流计算框架对比
2 |
3 | 几个月之前我们在这里讨论过目前对于这种日渐增加的分布式流处理的需求的原因。当然,目前也有很多的各式各样的框架被用于处理这一些问题。现在我们会在这篇文章中进行回顾,来讨论下各种框架之间的相似点以及区别在哪里,还有就是从我的角度分析的,推荐的适用的用户场景。
4 |
5 | DAG 主要功能即是用图来表示链式的任务组合,而在流处理系统中,我们便常常用 DAG 来描述一个流工作的拓扑。笔者自己是从 Akka 的 Stream 中的术语得到了启发。如下图所示,数据流经过一系列的处理器从源点流动到了终点,也就是用来描述这流工作。谈到 Akka 的 Streams,我觉得要着重强调下分布式这个概念,因为即使也有一些单机的解决方案可以创建并且运行 DAG,但是我们仍然着眼于那些可以运行在多机上的解决方案。
6 |
7 | 
8 |
9 | # 核心关注点
10 |
11 | 在不同的系统之间进行选择的时候,我们主要关注到以下几点。
12 |
13 | - Runtime and Programming model(运行与编程模型):一个平台提供的编程模型往往会决定很多它的特性,并且这个编程模型应该足够处理所有可能的用户案例。这是一个决定性的因素,我也会在下文中多次讨论。
14 |
15 | - Functional Primitives(函数式单元): 一个合格的处理平台应该能够提供丰富的能够在独立信息级别进行处理的函数,像 map、filter 这样易于实现与扩展的一些函数。同样也应提供像 aggregation 这样的跨信息处理函数以及像 join 这样的跨流进行操作的函数,虽然这样的操作会难以扩展。
16 |
17 | - State Management(状态管理): 大部分这些应用都有状态性的逻辑处理过程,因此,框架本身应该允许开发者去维护、访问以及更新这些状态信息。
18 |
19 | - Message Delivery Guarantees(消息投递的可达性保证): 一般来说,对于消息投递而言,我们有至多一次(at most once)、至少一次(at least once)以及恰好一次(exactly once)这三种方案。
20 |
21 | - At most once 投递保证每个消息会被投递 0 次或者 1 次,在这种机制下消息很有可能会丢失。
22 | - At least once 投递保证了每个消息会被默认投递多次,至少保证有一次被成功接收,信息可能有重复,但是不会丢失。- Exactly once 意味着每个消息对于接收者而言正好被接收一次,保证即不会丢失也不会重复。
23 |
24 | - Failures Handling
25 | 在一个流处理系统中,错误可能经常在不同的层级发生,譬如网络分割、磁盘错误或者某个节点莫名其妙挂掉了。平台要能够从这些故障中顺利恢复,并且能够从最后一个正常的状态继续处理而不会损害结果。
26 |
27 | 除此之外,我们也应该考虑到平台的生态系统、社区的完备程度,以及是否易于开发或者是否易于运维等等。
28 |
29 | # RunTime and Programming Model
30 |
31 | 运行环境与编程模型可能是某个系统的最重要的特性,因为它定义了整个系统的呈现特性、可能支持的操作以及未来的一些限制等等。因此,运行环境与编程模型就确定了系统的能力与适用的用户案例。目前,主要有两种不同的方法来构建流处理系统,其中一个叫 Native Streaming,意味着所有输入的记录或者事件都会根据它们进入的顺序一个接着一个的处理。
32 |
33 | 
34 |
35 | 另一种方法叫做 Micro-Batching。大量短的 Batches 会从输入的记录中创建出然后经过整个系统的处理,这些 Batches 会根据预设好的时间常量进行创建,通常是每隔几秒创建一批。
36 |
37 | 
38 |
39 | 两种方法都有一些内在的优势与不足,首先来谈谈 Native Streaming。好的一方面呢是 Native Streaming 的表现性会更好一点,因为它是直接处理输入的流本身的,并没有被一些不自然的抽象方法所限制住。同时,因为所有的记录都是在输入之后立马被处理,这样对于请求方而言响应的延迟就会优于那种 Micro Batching 系统。处理这些,有状态的操作符也会更容易被实现,我们在下文中也会描述这个特点。不过 Native Streaming 系统往往吞吐量会比较低,并且因为它需要去持久化或者重放几乎每一条请求,它的容错的代价也会更高一些。并且负载均衡也是一个不可忽视的问题,举例而言,我们根据键对数据进行了分割并且想做进一步地处理。如果某些键对应的分区因为某些原因需要更多地资源去处理,那么这个分区往往就会变成整个系统的瓶颈。
40 |
41 | 而对于 Micro Batching 而言,将流切分为小的 Batches 不可避免地会降低整个系统的变现性,也就是可读性。而一些类似于状态管理的或者 joins、splits 这些操作也会更加难以实现,因为系统必须去处理整个 Batch。另外,每个 Batch 本身也将架构属性与逻辑这两个本来不应该被糅合在一起的部分相连接了起来。而 Micro Batching 的优势在于它的容错与负载均衡会更加易于实现,它只要简单地在某个节点上处理失败之后转发给另一个节点即可。最后,值得一提的是,我们可以在 Native Streaming 的基础上快速地构建 Micro Batching 的系统。
42 |
43 | 而对于编程模型而言,又可以分为 Compositional(组合式)与 Declarative(声明式)。组合式会提供一系列的基础构件,类似于源读取与操作符等等,开发人员需要将这些基础构件组合在一起然后形成一个期望的拓扑结构。新的构件往往可以通过继承与实现某个接口来创建。另一方面,声明式 API 中的操作符往往会被定义为高阶函数。声明式编程模型允许我们利用抽象类型和所有其他的精选的材料来编写函数式的代码以及优化整个拓扑图。同时,声明式 API 也提供了一些开箱即用的高等级的类似于窗口管理、状态管理这样的操作符。下文中我们也会提供一些代码示例。
44 |
45 | # Fault Tolerance
46 |
47 | 与批处理系统相比,流处理系统中的容错机制固然的会比批处理中的要难一点。在批处理系统中,如果碰到了什么错误,只要将计算中与该部分错误关联的重新启动就好了。不过在流处理的场景下,容错处理会更加困难,因为会不断地有数据进来,并且有些任务可能需要 `7*24` 地运行着。另一个我们碰到的挑战就是如何保证状态的一致性,在每天结束的时候我们会开始事件重放,当然不可能所有的状态操作都会保证幂等性。
48 |
49 | ## 反压
50 |
51 | 流处理系统需要能优雅地处理反压(backpressure)问题。反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。反压如果不能得到正确的处理,可能会导致资源耗尽甚至系统崩溃。目前主流的流处理系统 Storm/JStorm/Spark Streaming/Flink 都已经提供了反压机制,不过其实现各不相同。
52 |
53 | - Storm 是通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。具体实现可以看这个 JIRA STORM-886。
54 |
55 | - JStorm 认为直接停止 Spout 的发送太过暴力,存在大量问题。当下游出现阻塞时,上游停止发送,下游消除阻塞后,上游又开闸放水,过了一会儿,下游又阻塞,上游又限流,如此反复,整个数据流会一直处在一个颠簸状态。所以 JStorm 是通过逐级降速来进行反压的,效果会较 Storm 更为稳定,但算法也更复杂。另外 JStorm 没有引入 Zookeeper 而是通过 TopologyMaster 来协调拓扑进入反压状态,这降低了 Zookeeper 的负载。
56 |
57 | - Flink 没有使用任何复杂的机制来解决反压问题,因为根本不需要那样的方案!它利用自身作为纯数据流引擎的优势来优雅地响应反压问题。
58 |
59 | 下面我们就看看其他的系统是怎么处理的:
60 |
61 | ## Storm
62 |
63 | Storm 使用了所谓的逆流备份与记录确认的机制来保证消息会在某个错误之后被重新处理。记录确认这一个操作工作如下:一个操作器会在处理完成一个记录之后向它的上游发送一个确认消息。而一个拓扑的源会保存有所有其创建好的记录的备份。一旦受到了从 Sinks 发来的包含有所有记录的确认消息,就会把这些确认消息安全地删除掉。当发生错误时,如果还没有接收到全部的确认消息,就会从拓扑的源开始重放这些记录。这就确保了没有数据丢失,不过会导致重复的 Records 处理过程,这就属于 At-Least 投送原则。
64 |
65 | Storm 用一套非常巧妙的机制来保证了只用很少的字节就能保存并且追踪确认消息,但是并没有太多关注于这套机制的性能,从而使得 Storm 有较低地吞吐量,并且在流控制上存在一些问题,譬如这种确认机制往往在存在背压的时候错误地认为发生了故障。
66 |
67 | 
68 |
69 | ## Spark Streaming
70 |
71 | 
72 | Spark Streaming 以及它的 Micro Batching 机制则使用了另一套方案,道理很简单,Spark 将 Micro-Batches 分配到多个节点运行,每个 Micro-Batch 可以成功运行或者发生故障,当发生故障时,那个对应的 Micro-Batch 只要简单地重新计算即可,因为它是持久化并且无状态的,所以要保证 Exactly-Once 这种投递方式也是很简单的。
73 |
74 | ## Samza
75 |
76 | Samza 的实现手段又不一样了,它利用了一套可靠地、基于 Offset 的消息系统,在很多情况下指的就是 Kafka。Samza 会监控每个任务的偏移量,然后在接收到消息的时候修正这些偏移量。Offset 可以是存储在持久化介质中的一个检查点,然后在发生故障时可以进行恢复。不过问题在于你并不知道恢复到上一个 CheckPoint 之后到底哪个消息是处理过的,有时候会导致某些消息多次处理,这也是 At-Least 的投递原则。
77 | 
78 |
79 | ## Flink
80 |
81 | Flink 主要是基于分布式快照,每个快照会保存流任务的状态。链路中运送着大量的 CheckPoint Barrier(检查点障碍,就是分隔符、标识器之类的),当这些 Barrier 到达某个 Operator 的时候,Operator 将自身的检查点与流相关联。与 Storm 相比,这种方式会更加高效,毕竟不用对每个 Record 进行确认操作。不过要注意的是,Flink 还是 Native Streaming,概念上和 Spark 还是相去甚远的。Flink 也是达成了 Exactly-Once 投递原则。
82 |
83 | 
84 |
85 | # Managing State(状态管理)
86 |
87 | 大部分重要的流处理应用都会保有状态,与无状态的操作符相比,这些应用中需要一个输入和一个状态变量,然后进行处理最终输出一个改变了的状态。我们需要去管理、存储这些状态,要保证在发生故障的时候能够重现这些状态。状态的重造可能会比较困难,毕竟上面提到的不少框架都不能保证 Exactly-Once,有些 Record 可能被重放多次。
88 |
89 | ## Storm
90 |
91 | Storm 是实践了 At-Least 投递原则,而怎么利用 Trident 来保证 Exactly-Once 呢?概念上还是很简单的,只需要使用事务进行提交 Records,不过很明显这种方式及其低效。所以呢,还是可以构建一些小的 Batches,并且进行一些优化。Trident 是提供了一些抽象的接口来保证实现 Exactly-Once,如下图所示,还有很多东西等着你去挖掘。
92 | 
93 |
94 | ## Spark Streaming
95 |
96 | 当想要在流处理系统中实现有状态的操作时,我们往往想到的是一个长时间运行的 Operator,然后输入一个状态以及一系列的 Records。不过 Spark Streaming 是以另外一种方式进行处理的,Spark Streaming 将状态作为一个单独地 Micro Batching 流进行处理,所以在对每个小的 Micro-Spark 任务进行处理时会输入一个当前的状态和一个代表当前操作的函数,最后输出一个经过处理的 Micro-Batch 以及一个更新好的状态。
97 |
98 | 
99 |
100 | ## Samza
101 |
102 | Samza 的处理方式更加简单明了,就是把它们放到 Kafka 中,然后问题就解决了。Samza 提供了真正意义上的有状态的 Operators,这样每个任务都能保有状态,然后所有状态的变化都会被提交到 Kafka 中。在有需要的情况下某个状态可以很方便地从 Kafka 的 Topic 中完成重造。为了提高效率,Samza 允许使用插件化的键值本地存储来避免所有的消息全部提交到 Kafka。这种思路如下图所示,不过 Samza 只是提高了 At-Least 这种机制,未来可能会提供 Exactly-Once。
103 |
104 | 
105 |
106 | ## Flink
107 |
108 | Flink 提供了类似于 Samza 的有状态的 Operator 的概念,在 Flink 中,我们可以使用两种不同的状态。第一种是本地的或者叫做任务状态,它是某个特定的 Operator 实例的当前状态,并且这种状态不会与其他进行交互。另一种呢就是维护了整个分区的状态。
109 |
110 | 
111 |
112 | # Counting Words with State
113 |
114 | ## Trident
115 |
116 | ```java
117 | public static StormTopology buildTopology(LocalDRPC drpc) {
118 | FixedBatchSpout spout = ...
119 |
120 | TridentTopology topology = new TridentTopology();
121 |
122 | TridentState wordCounts = topology.newStream("spout1", spout)
123 | .each(new Fields("sentence"),new Split(), new Fields("word"))
124 | .groupBy(new Fields("word"))
125 | .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
126 | ...
127 | }
128 | ```
129 |
130 | 在第 9 行中,我们可以通过调用一个持久化的聚合函数来创建一个状态。
131 |
132 | ## Spark Streaming
133 |
134 | ```java
135 | // Initial RDD input to updateStateByKey
136 | val initialRDD = ssc.sparkContext.parallelize(List.empty[(String, Int)])
137 |
138 | val lines = ...
139 | val words = lines.flatMap(_.split(" "))
140 | val wordDstream = words.map(x => (x, 1))
141 |
142 | val trackStateFunc = (batchTime: Time, word: String, one: Option[Int],
143 | state: State[Int]) => {
144 | val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
145 | val output = (word, sum)
146 | state.update(sum)
147 | Some(output)
148 | }
149 |
150 | val stateDstream = wordDstream.trackStateByKey(
151 | StateSpec.function(trackStateFunc).initialState(initialRDD))
152 | ```
153 |
154 | 在第 2 行中,我们创建了一个 RDD 用来保存初始状态。然后在 5,6 行中进行一些转换,接下来可以看出,在 8-14 行中,我们定义了具体的转换方程,即输入时一个单词、它的统计数量和它的当前状态。函数用来计算、更新状态以及返回结果,最后我们将所有的 Bits 一起聚合。
155 |
156 | ## Samza
157 |
158 | ```java
159 | class WordCountTask extends StreamTask with InitableTask {
160 |
161 | private var store: CountStore = _
162 |
163 | def init(config: Config, context: TaskContext) {
164 | this.store = context.getStore("wordcount-store")
165 | .asInstanceOf[KeyValueStore[String, Integer]]
166 | }
167 |
168 | override def process(envelope: IncomingMessageEnvelope,
169 | collector: MessageCollector, coordinator: TaskCoordinator) {
170 |
171 | val words = envelope.getMessage.asInstanceOf[String].split(" ")
172 |
173 | words.foreach { key =>
174 | val count: Integer = Option(store.get(key)).getOrElse(0)
175 | store.put(key, count + 1)
176 | collector.send(new OutgoingMessageEnvelope(new SystemStream("kafka", "wordcount"),
177 | (key, count)))
178 | }
179 | }
180 | ```
181 |
182 | 在上述代码中第 3 行定义了全局的状态,这里是使用了键值存储方式,并且在 5~6 行中定义了如何初始化。然后,在整个计算过程中我们都使用了该状态。
183 |
184 | ## Flink
185 |
186 | ```java
187 | val env = ExecutionEnvironment.getExecutionEnvironment
188 |
189 | val text = env.fromElements(...)
190 | val words = text.flatMap ( _.split(" ") )
191 |
192 | words.keyBy(x => x).mapWithState {
193 | (word, count: Option[Int]) =>
194 | {
195 | val newCount = count.getOrElse(0) + 1
196 | val output = (word, newCount)
197 | (output, Some(newCount))
198 | }
199 | }
200 | ```
201 |
202 | 在第 6 行中使用了 `mapWithState` 函数,第一个参数是即将需要处理的单次,第二个参数是一个全局的状态。
203 |
204 | # Performance
205 |
206 | 合理的性能比较也是本文的一个重要主题之一。不同的系统的解决方案差异很大,因此也是很难设置一个无偏的测试。通常而言,在一个流处理系统中,我们常说的性能就是指延迟与吞吐量。这取决于很多的变量,但是总体而言标准为如果单节点每秒能处理 500K 的 Records 就是个合格的,如果能达到 100 万次以上就已经不错了。每个节点一般就是指 24 核附带上 24 或者 48GB 的内存。对于延迟而言,如果是 Micro-Batch 的话往往希望能在秒级别处理。如果是 Native Streaming 的话,希望能有百倍的减少,调优之后的 Storm 可以很轻易达到几十毫秒。
207 |
208 | 另一方面,消息的可达性保证、容错以及状态管理都是需要考虑进去的。譬如如果你开启了容错机制,那么会增加 10%到 15%的额外消耗。除此之外,以文章中两个 WordCount 为例,第一个是无状态的 WordCount,第二个是有状态的 WordCount,后者在 Flink 中可能会有 25%额外的消耗,而在 Spark 中可能有 50% 的额外消耗。当然,我们肯定可以通过调优来减少这种损耗,并且不同的系统都提供了很多的可调优的选项。
209 |
210 | 还有就是一定要记住,在分布式环境下进行大数据传输也是一件非常昂贵的消耗,因此我们要利用好数据本地化以及整个应用的序列化的调优。
211 |
212 | # Project Maturity(项目成熟度)
213 |
214 | 在为你的应用选择一个合适的框架的时候,框架本身的成熟度与社区的完备度也是一个不可忽略的部分。Storm 是第一个正式提出的流处理框架,它已经成为了业界的标准并且被应用到了像 Twitter、Yahoo、Spotify 等等很多公司的生产环境下。Spark 则是目前最流行的 Scala 的库之一,并且 Spark 正逐步被更多的人采纳,它已经成功应用在了像 Netflix、Cisco、DataStax、Indel、IBM 等等很多公司内。而 Samza 最早由 LinkedIn 提出,并且正在运行在几十个公司内。Flink 则是一个正在开发中的项目,不过我相信它发展的会非常迅速。
215 |
216 | # Summary
217 |
218 | 在我们进最后的框架推荐之前,我们再看一下上面那张图:
219 |
220 | 
221 |
222 | ## Framework Recommendations
223 |
224 | 这个问题的回答呢,也很俗套,具体情况具体分析。总的来说,你首先呢要仔细评估下你应用的需求并且完全理解各个框架之间的优劣比较。同时我建议是使用一个提供了上层接口的框架,这样会更加的开发友好,并且能够更快地投入生产环境。不过别忘了,绝大部分流应用都是有状态的,因此状态管理也是不可忽略地一个部分。同时,我也是推荐那些遵循 Exactly-Once 原则的框架,这样也会让开发和维护更加简单。不过不能教条主义,毕竟还是有很多应用会需要 At-Least-Once 与 At-Most-Once 这些投递模式的。最后,一定要保证你的系统可以在故障情况下很快恢复,可以使用 Chaos Monkey 或者其他类似的工具进行测试。在我们之前的讨论中也发现这个快速恢复的能力至关重要。
225 |
226 | - 对于小型与需要快速响应地项目,Storm 依旧是一个非常好的选择,特别是在你非常关注延迟度的情况下。不过还是要谨记容错机制和 Trident 的状态管理会严重影响性能。Twitter 目前正在设计新的流处理系统 Heron 用来替代 Storm,它可以在单个项目中有很好地表现。不过 Twitter 可不一定会开源它。
227 |
228 | - 对于 Spark Streaming 而言,如果你的系统的基础架构中已经使用了 Spark,那还是很推荐你试试的。另一方面,如果你想使用 Lambda 架构,那 Spark 也是个不错的选择。不过你一定要记住,Micro-Batching 本身的限制和延迟对于你而言不是一个关键因素。
229 |
230 | - 如果你想用 Samza 的话,那最好 Kafka 已经是你的基础设施的一员了。虽然在 Samza 中 Kafka 只是个可插拔的组件,不过基本上所有人都会使用 Kafka。正如上文所说,Samza 提供了强大的本地存储功能,能够轻松管理数十 G 的状态数据。不过它的 At-Least-Once 的投递限制也是很大一个瓶颈。
231 |
232 | - Flink 目前在概念上是一个非常优秀的流处理系统,它能够满足大部分的用户场景并且提供了很多先进的功能,譬如窗口管理或者时间控制。所以当你发现你需要的功能在 Spark 当中无法很好地实现的时候,你可以考虑下 Flink。另外,Flink 也提供了很好地通用的批处理的接口,只不过你需要很大的勇气来将你的项目结合到 Flink 中,并且别忘了多关注关注它的路线图。
233 |
234 | ## Dataflow 与开源
235 |
236 | 我最后一个要提到的就是 Dataflow 和它的开源计划。Dataflow 是 Google 云平台的一个组成部分,是目前在 Google 内部提供了统一的用于批处理与流处理的服务接口。譬如用于批处理的 MapReduce,用于编程模型定义的 FlumeJava 以及用于流处理的 MillWheel。Google 最近打算开源这货的 SDK 了,Spark 与 Flink 都可以成为它的一个运行驱动。
237 |
238 | 
239 |
--------------------------------------------------------------------------------
/流处理/09~流处理数据库/README.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/流处理/09~流处理数据库/README.md
--------------------------------------------------------------------------------
/流处理/10~Flink/Blink/README.md:
--------------------------------------------------------------------------------
1 | # Blink
2 |
3 | Blink 是 Flink 的一个分支,最初在阿里巴巴内部创建的,针对内部用例对 Flink 进行改进。Blink 添加了一系列改进和集成(https://github.com/apache/flink/blob/blink/README.md),其中有很多与有界数据 / 批处理和 SQL 有关。实际上,在上面的功能列表中,除了第 4 项外,Blink 在其他方面都迈出了重要的一步:
4 |
5 | - 统一的流式操作符:Blink 扩展了 Flink 的流式运行时操作符模型,支持选择性读取不同的输入源,同时保持推送模型的低延迟特性。这种对输入源的选择性读取可以更好地支持一些算法(例如相同操作符的混合哈希连接)和线程模型(通过 RocksDB 的连续对称连接)。这些操作符为“侧边输入”(https://cwiki.apache.org/confluence/display/FLINK/FLIP-17+Side+Inputs+for+DataStream+API)等新功能打下了基础。
6 |
7 | - Table API 和 SQL 查询处理器:与最新的 Flink 主分支相比,SQL 查询处理器是演变得最多的一个组件:
8 |
9 | - Flink 目前将查询转换为 DataSet 或 DataStream 程序(取决于输入的特性),而 Blink 会将查询转换为上述流式操作符的数据流。
10 | Blink 为常见的 SQL 操作添加了更多的运行时操作符,如半连接(semi-join)、反连接(anti-join)等。
11 |
12 | - 查询规划器(优化器)仍然是基于 Apache Calcite,但提供了更多的优化规则(包括连接重排序),并且使用了适当的成本模型。
13 | 更加积极的流式操作符链接。
14 |
15 | - 扩展通用数据结构(分类器、哈希表)和序列化器,在操作二进制数据上更进一步,并减小了序列化开销。代码生成被用于行序列化器。
16 |
17 | - 改进的调度和故障恢复:最后,Blink 实现了对任务调度和容错的若干改进。调度策略通过利用操作符处理输入数据的方式来更好地使用资源。故障转移策略沿着持久 shuffle 的边界进行更细粒度的恢复。不需重新启动正在运行的应用程序就可以替换发生故障的 JobManager。
18 |
--------------------------------------------------------------------------------
/流处理/10~Flink/README.md:
--------------------------------------------------------------------------------
1 | # Flink
2 |
3 | 从早期开始,Flink 就有意采用统一的批处理和流式处理方法。其核心构建块是“持续处理无界的数据流”:如果可以做到这一点,还可以离线处理有界数据集(批处理),因为有界数据集就是在某个时刻结束的数据流。
4 |
5 | Flink 包含了一个网络栈,支持低延迟 / 高吞吐的流式数据交换和高吞吐的批次 shuffle。它还提供了很多流式运行时操作符,也为有界输入提供了专门的操作符,如果你选择了 DataSet API 或 Table API,就可以使用这些操作符。
6 |
7 | 
8 |
9 | Apache Flink 已经被业界公认是最好的流处理引擎。然而 Flink 的计算能力不仅仅局限于做流处理。Apache Flink 的定位是一套兼具流、批、机器学习等多种计算功能的大数据引擎。在最近的一段时间,Flink 在批处理以及机器学习等诸多大数据场景都有长足的突破。
10 |
11 | # API
12 |
13 | 
14 |
15 | ## 关系型 API
16 |
17 | 关系型 API 其实是 Table API 和 SQL API 的统称:
18 |
19 | - Table API:为 Java&Scala SDK 提供类似于 LINQ(语言集成查询)模式的 API(自 0.9.0 版本开始)
20 |
21 | - SQL API:支持标准 SQL(自 1.1.0 版本开始)
22 |
23 | 关系型 API 作为一个统一的 API 层,既能够做到在 Batch 模式的表上进行可终止地查询并生成有限的结果集,同时也能做到在 Streaming 模式的表上持续地运行并生产结果流,并且在两种模式的表上的查询具有相同的语法跟语义。这其中最重要的概念是 Table,Table 与 DataSet、DataStream 紧密结合,DataSet 和 DataStream 都可以很容易地转换成 Table,同样转换回来也很方便。下面的代码段展示了采用关系型 API 编写 Flink 程序的示例:
24 |
25 | ```scala
26 | val tEnv = TableEnvironment.getTableEnvironment(env)
27 | //配置数据源
28 | val customerSource = CsvTableSource.builder()
29 | .path("/path/to/customer_data.csv")
30 | .field("name", Types.STRING).field("prefs", Types.STRING)
31 | .build()
32 |
33 | //将数据源注册为一个Table
34 | tEnv.registerTableSource(”cust", customerSource)
35 |
36 | //定义你的table程序(在一个Flink程序中Table API和SQL API可以混用)
37 | val table = tEnv.scan("cust").select('name.lowerCase(), myParser('prefs))
38 | val table = tEnv.sql("SELECT LOWER(name), myParser(prefs) FROM cust")
39 |
40 | //转换为DataStraem
41 | val ds: DataStream[Customer] = table.toDataStream[Customer]
42 | ```
43 |
44 | Flink 并没有自己去实现转换、SQL 的解析、执行计划的生成、优化等操作,它将一些“不擅长”的任务转交给了 Apache Calcite。整体架构如下图:
45 |
46 | 
47 |
48 | Apache Calcite 是一个 SQL 解析与查询优化框架(这个定义是从 Flink 关注的视角来看,Calcite 官方的定义为动态的数据管理框架),目前已被许多项目选择用来解析并优化 SQL 查询,比如:Drill、Hive、Kylin 等。可以从 DataSet、DataStream 以及 Table Source 等多种渠道来创建 Table,Table 相关的一些信息比如 schema、数据字段及类型等信息统一被注册并存放到 Calcite Catalog 中。这些信息将为 Table & SQL API 提供元数据。接着往下看,Table API 跟 SQL 构建的查询将被翻译成共同的逻辑计划表示,逻辑计划将作为 Calcite 优化器的输入。优化器结合逻辑计划以及特定的后端(DataSet、DataStream)规则进行翻译和优化,随之产生不同的计划。计划将通过代码生成器,生成特定的后端程序。后端程序的执行将返回 DataSet 或 DataStream。
49 |
50 | # 事务支持
51 |
52 | 扩展了 Apache Flink,提供了跨表、键和事件流执行可序列化 ACID 事务的功能。在发布 Streaming Ledger 之前,流式处理框架(如 Flink 和 Spark)只提供一次性语义,只能在单个键上实现一致性。
53 |
54 | 根据 ACID 原则实现的事务作为单个操作执行,要么全部完成要么全部失败。这确保了数据一致性,即使是发生了中断或应用程序错误。ACID 事务的一个常用例子是将资金从一个银行账户转移到另一个银行账户。虽然 Streaming Ledger 是流式处理框架中第一个实现 ACID 事务的,但 ACID 事务已经在 SQL Server 和 Oracle 等关系数据库系统中存在了很长时间。
55 |
56 | 该架构由四个基本构建块组成。用于维护应用程序状态的表、用于更新表的事务函数、驱动事务的事务事件流和根据流处理成功或失败发出事件的可选结果流。此外,在事务中修改表时,表与并发更改是相互隔离的。因此,即使是跨多个流,也可以确保数据一致性。
57 |
58 | # Links
59 |
60 | - https://read.douban.com/reader/ebook/114289022/?from=book
61 |
--------------------------------------------------------------------------------
/流处理/10~Flink/Table API.md:
--------------------------------------------------------------------------------
1 | 近年来,开源的分布式流处理系统层出不穷,引起了广泛的关注与讨论。其中的先行者,譬如 [Apache Storm](https://storm.apache.org/)提供了低延迟的流式处理功能,但是受限于 at-least-once 的投递保证,背压等不太良好的处理以及相对而言的开放 API 的底层化。不过 Storm 也起到了抛砖引玉的作用,自此之后,很多新的流处理系统在不同的维度上大放光彩。今日,Apache Flink 或者 [Apache Beam](https://beam.incubator.apache.org/)的使用者能够使用流式的 Scala 或者 Java APIs 来进行流处理任务,同时保证了 exactly-once 的投递机制以及高吞吐情况下的的低延迟响应。与此同时,流处理也在产界得到了应用,从 Apache Kafka 与 Apache Flink 在流处理的基础设施领域的大规模部署也折射除了流处理在产界的快速发展。与日俱增的实时数据流催生了开发人员或者分析人员对流数据进行分析以及实时展现的需求。不过,流数据分析也需要一些必备的技能与知识储备,譬如无限流的基本特性、窗口、时间以及状态等等,这些概念都会在利用 Java 或者 Scala API 来完成一个流分析的任务时候起到很大的作用。
2 | 大概六个月之前,Apache Flink 社区着手为流数据分析系统引入一个 SQL 交互功能。众所周知,SQL 是访问与处理数据的标准语言,基本上每个用过数据库的或者进行或数据分析的都对 SQL 不陌生。鉴于此,为流处理系统添加一个 SQL 交互接口能够有效地扩大该技术的受用面,让更多的人可以熟悉并且使用。除此之外,引入 SQL 的支持还能满足于一些需要实时交互地用户场景,大大简化一些需要进行流操作或者转化的应用代码。这篇文章中,我们会从现有的状态、架构的设计以及未来 Apache Flink 社区准备添加 SQL 支持的计划这几个方面进行讨论。
3 |
4 | ## 从何开始,先来回顾下已有的 Table API
5 |
6 | 在 [0.9.0-milestone1](http://flink.apache.org/news/2015/04/13/release-0.9.0-milestone1.html) 发布之后,Apache Flink 添加了所谓的 Table API 来提供类似于 SQL 的表达式用于对关系型数据进行处理。这系列 API 的操作对象就是抽象而言的能够进行关系型操作的结构化数据或者流。Table API 一般与 DataSet 或者 DataStream 紧密关联,可以从 DataSet 或者 DataStream 来方便地创建一个 Table 对象,也可以用如下的操作将一个 Table 转化回一个 DataSet 或者 DataStream 对象:
7 |
8 | ```scala
9 | val execEnv = ExecutionEnvironment.getExecutionEnvironment
10 | val tableEnv = TableEnvironment.getTableEnvironment(execEnv)
11 |
12 | // obtain a DataSet from somewhere
13 | val tempData: DataSet[(String, Long, Double)] =
14 |
15 | // convert the DataSet to a Table
16 | val tempTable: Table = tempData.toTable(tableEnv, 'location, 'time, 'tempF)
17 | // compute your result
18 | val avgTempCTable: Table = tempTable
19 | .where('location.like("room%"))
20 | .select(
21 | ('time / (3600 * 24)) as 'day,
22 | 'Location as 'room,
23 | (('tempF - 32) * 0.556) as 'tempC
24 | )
25 | .groupBy('day, 'room)
26 | .select('day, 'room, 'tempC.avg as 'avgTempC)
27 | // convert result Table back into a DataSet and print it
28 | avgTempCTable.toDataSet[Row].print()
29 | ```
30 |
31 | 上面这坨代码是 Scala 的,不过你可以简单地用 Java 版本的 Table API 进行实现,下面这张图就展示了 Table API 的原始的结构:
32 | 
33 | 在我们从 DataSet 或者 DataStream 创建了 Table 之后,可以利用类似于`filter`, `join`, 或者 `select`关系型转化操作来转化为一个新的 Table 对象。而从内部实现上来说,所有应用于 Table 的转化操作都会变成一棵逻辑表操作树,在 Table 对象被转化回 DataSet 或者 DataStream 之后,专门的转化器会将这棵逻辑操作符树转化为对等的 DataSet 或者 DataStream 操作符。譬如`'location.like("room%")`这样的表达式会经由代码生成编译为 Flink 中的函数。
34 | 不过,老版本的 Table API 还是有很多的限制的。首先,Table API 并不能单独使用,而必须嵌入到 DataSet 或者 DataStream 的程序中,对于批处理表的查询并不支持外连接、排序以及其他很多在 SQL 中经常使用的扩展操作。而流处理表中只支持譬如 filters、union 以及 projections,不能支持 aggregations 以及 joins。并且,这个转化处理过程并不能有查询优化,你要优化的话还是要去参考那些对于 DataSet 操作的优化。
35 |
36 | ## Table API joining forces with SQL
37 |
38 | 关于是否需要添加 SQL 支持的讨论之前就在 Flink 社区中发生过几次,Flink 0.9 发布之后,Table API、关系表达式的代码生成工具以及运行时的操作符等都预示着添加 SQL 支持的很多基础已经具备,可以考虑进行添加了。不过另一方面,在整个 Hadoop 生态链里已经存在了大量的所谓“SQL-on-Hadoop”的解决方案,譬如[Apache Hive](https://hive.apache.org/), [Apache Drill](https://drill.apache.org/), [Apache Impala](http://impala.io/), [Apache Tajo](https://tajo.apache.org/),在已经有了这么多的可选方案的情况下,我们觉得应该优先提升 Flink 其他方面的特性,于是就暂时搁置了 SQL-on-Hadoop 的开发。
39 | 不过,随着流处理系统的日渐火热以及 Flink 受到的越来越广泛地应用,我们发现有必要为用户提供一个更简单的可以用于数据分析的接口。大概半年前,我们决定要改造下 Table API,扩展其对于流处理的能力并且最终完成在流处理上的 SQL 支持。不过我们也不打算重复造轮子,因此打算基于[Apache Calcite](https://calcite.apache.org/)这个非常流行的 SQL 解析器进行重构操作。Calcite 在其他很多开源项目里也都应用到了,譬如 Apache Hive, Apache Drill, Cascading, and many [more](https://calcite.apache.org/docs/powered_by.html)。此外,Calcite 社区本身也有将[SQL on streams](https://calcite.apache.org/docs/stream.html)列入到它们的路线图中,因此我们一拍即合。Calcite 在新的架构设计中的地位大概如下所示:
40 | 
41 | 新的架构主要是将 Table API 与 SQL 集成起来,用这两货的 API 构建的查询最终都会转化到 Calcite 的所谓的 logicl plans 表述。转化之后的流查询与批查询基本上差不多,然后 Calcite 的优化器会基于转化和优化规则来优化这些 logical plans,针对数据源(流还是静态数据)的不同我们会应用不同的规则。最后,经过优化的 logical plan 会转化为一个普通的 Flink DataStream 或者 DataSet 对象,即还是利用代码生成来将关系型表达式编译为 Flink 的函数。
42 | 新的架构继续提供了 Table API 并且在此基础上进行了很大的提升,它为流数据与关系型数据提供了统一的查询接口。另外,我们利用了 Calcite 的查询优化框架与 SQL 解释器来进行了查询优化。不过,因为这些设计都还是基于 Flink 的已有的 API,譬如 DataStream API 提供的低延迟、高吞吐以及 exactly-once 投递的功能,以及 DataSet API 通过的健壮与高效的内存级别的操作器与管道式的数据交换,任何对于 Flink 核心 API 的提升都能够自动地提升 Table API 或者 SQL 查询的效率。
43 | 在这些工作之后,Flink 就已经具备了同时对于流数据与静态数据的 SQL 支持。不过,我们并不想把这个当成一个高效的 SQL-on-Hadoop 的解决方案,就像 Impala, Drill, 以及 Hive 那样的角色,我们更愿意把它当成为流处理提供便捷的交互接口的方案。另外,这套机制还能促进同时用了 Flink API 与 SQL 的应用的性能。
44 |
45 | ## How will Flink’s SQL on streams look like?
46 |
47 | 我们讨论了为啥要重构 Flink 的流 SQL 接口的原因以及大概怎么去完成这个任务,现在我们讨论下最终的 API 或者使用方式会是啥样的。新的 SQL 接口会集成到 Table API 中。DataStreams、DataSet 以及额外的数据源都会先在 TableEnvironment 中注册成一个 Table 然后再进行 SQL 操作。`TableEnvironment.sql()`方法会允许你输入 SQL 查询语句然后执行返回一个新的 Table,下面这个例子就展示了一个完整的从 JSON 编码的 Kafka 主题中读取数据然后利用 SQL 查询进行处理最终写入另一个 Kafka 主题的模型。注意,这下面提到的 KafkaJsonSource 与 KafkaJsonSink 都还未发布,未来的话 TableSource 与 TableSinks 都会固定提供,这样可以减少很多的模板代码。
48 |
49 | ```
50 | // get environments
51 | val execEnv = StreamExecutionEnvironment.getExecutionEnvironment
52 | val tableEnv = TableEnvironment.getTableEnvironment(execEnv)
53 |
54 | // configure Kafka connection
55 | val kafkaProps = ...
56 | // define a JSON encoded Kafka topic as external table
57 | val sensorSource = new KafkaJsonSource[(String, Long, Double)](
58 | "sensorTopic",
59 | kafkaProps,
60 | ("location", "time", "tempF"))
61 |
62 | // register external table
63 | tableEnv.registerTableSource("sensorData", sensorSource)
64 |
65 | // define query in external table
66 | val roomSensors: Table = tableEnv.sql(
67 | "SELECT STREAM time, location AS room, (tempF - 32) * 0.556 AS tempC " +
68 | "FROM sensorData " +
69 | "WHERE location LIKE 'room%'"
70 | )
71 |
72 | // define a JSON encoded Kafka topic as external sink
73 | val roomSensorSink = new KafkaJsonSink(...)
74 |
75 | // define sink for room sensor data and execute query
76 | roomSensors.toSink(roomSensorSink)
77 | execEnv.execute()
78 | ```
79 |
80 | 你可能会发现上面这个例子中没有体现流处理中两个重要的方面:基于窗口的聚合与关联。下面我就会解释下怎么在 SQL 中表达关于窗口的操作。Apache Calcite 社区关于这方面已经有所讨论:[SQL on streams](https://calcite.apache.org/docs/stream.html)。Calcite 的流 SQL 被认为是一个标准 SQL 的扩展,而不是另一个类似于 SQL 的语言。这会有几个方面的好处,首先,已经熟悉了标准 SQL 语法的同学就没必要花时间再学一波新的语法了,皆大欢喜。现在对于静态表与流数据的查询已经基本一致了,可以很方便地进行转换。Flink 一直主张的是批处理只是流处理的一个特殊情况,因此用户也可以同时在静态表与流上进行查询,譬如处理有限的流。最后,未来也会有很多工具支持进行标准的 SQL 进行数据分析。
81 | 尽管我们还没有完全地定义好在 Flink SQL 表达式与 Table API 中如何进行窗口等设置,下面这个简单的例子会指明如何在 SQL 与 Table API 中进行滚动窗口式查询:
82 |
83 | ### SQL (following the syntax proposal of Calcite’s streaming SQL document)
84 |
85 | ```
86 | SELECT STREAM
87 | TUMBLE_END(time, INTERVAL '1' DAY) AS day,
88 | location AS room,
89 | AVG((tempF - 32) * 0.556) AS avgTempC
90 | FROM sensorData
91 | WHERE location LIKE 'room%'
92 | GROUP BY TUMBLE(time, INTERVAL '1' DAY), location
93 | ```
94 |
95 | ### Table API
96 |
97 | ```
98 | val avgRoomTemp: Table = tableEnv.ingest("sensorData")
99 | .where('location.like("room%"))
100 | .partitionBy('location)
101 | .window(Tumbling every Days(1) on 'time as 'w)
102 | .select('w.end, 'location,, (('tempF - 32) * 0.556).avg as 'avgTempCs)
103 | ```
104 |
--------------------------------------------------------------------------------
/流处理/10~Flink/代码开发.md:
--------------------------------------------------------------------------------
1 | # Quick Start
2 |
3 | ## Installation
4 |
5 | 最简单的引入 Flink 依赖项的方式就是利用 Maven 或者 Gradle:
6 |
7 | ```xml
8 |
9 |
10 | org.apache.flink
11 | flink-streaming-java_2.10
12 | 1.1-SNAPSHOT
13 |
14 |
15 |
16 | org.apache.flink
17 | flink-java
18 | 1.1-SNAPSHOT
19 |
20 |
21 | org.apache.flink
22 | flink-clients_2.10
23 | 1.1-SNAPSHOT
24 |
25 | ```
26 |
27 | 不过需要注意的是,由于 Scala 2.11 编译版本与 2.10 版本无法兼容,因此在 Flink 的依赖项后面也加了个后缀来表示使用的 Scala 版本,你可以选择需要的 Scala 版本进行操作。
28 |
29 | ## WordCount
30 |
31 | Flink 有个方便的地方就是能够直接在本地运行而不需要提交到集群上,下面的测试程序直接右键点击 Run 即可。
32 |
33 | ### Stream
34 |
35 | 这里展示的是经典的 WordCount 程序:
36 |
37 | ```java
38 | public class WordCount {
39 |
40 | public static void main(String[] args) throws Exception {
41 |
42 | // set up the execution environment
43 | final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
44 |
45 | // get input data
46 | DataSet text = env.fromElements(
47 | "To be, or not to be,--that is the question:--",
48 | "Whether 'tis nobler in the mind to suffer",
49 | "The slings and arrows of outrageous fortune",
50 | "Or to take arms against a sea of troubles,"
51 | );
52 |
53 | DataSet> counts =
54 | // split up the lines in pairs (2-tuples) containing: (word,1)
55 | text.flatMap(new LineSplitter())
56 | // group by the tuple field "0" and sum up tuple field "1"
57 | .groupBy(0)
58 | .sum(1);
59 |
60 | // execute and print result
61 | counts.print();
62 |
63 | }
64 |
65 | public static final class LineSplitter implements FlatMapFunction> {
66 |
67 | @Override
68 | public void flatMap(String value, Collector> out) {
69 | // normalize and split the line
70 | String[] tokens = value.toLowerCase().split("\\W+");
71 |
72 | // emit the pairs
73 | for (String token : tokens) {
74 | if (token.length() > 0) {
75 | out.collect(new Tuple2(token, 1));
76 | }
77 | }
78 | }
79 | }
80 | }
81 | ```
82 |
83 | ### Window Word Count
84 |
85 | ```java
86 | public class WindowWordCount {
87 |
88 | public static void main(String[] args) throws Exception {
89 |
90 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
91 |
92 | DataStream> dataStream = env
93 | .socketTextStream("localhost", 9999)
94 | .flatMap(new Splitter()) //将Sentence转化为Collector流
95 | .keyBy(0) //将Collector中的Tuple2按照word排序
96 | .timeWindow(Time.seconds(5))
97 | .sum(1); //进行求和操作
98 |
99 | dataStream.print();
100 |
101 | env.execute("Window WordCount");
102 | }
103 |
104 | public static class Splitter implements FlatMapFunction> {
105 | @Override
106 | public void flatMap(String sentence, Collector> out) throws Exception {
107 | for (String word : sentence.split(" ")) {
108 | //每遇到1个词,将它设置加1
109 | out.collect(new Tuple2(word, 1));
110 | }
111 | }
112 | }
113 |
114 | }
115 | ```
116 |
117 | ## Submit Jobs
118 |
119 | ### Command-Line Interface
120 |
121 | 笔者建议可以将 Flink 的命令添加到全局:
122 |
123 | ```
124 | export FLINK_HOME=/Users/apple/Desktop/Tools/SDK/Flink/flink-1.0.3
125 | export PATH=$PATH:$FLINK_HOME/bin
126 | ```
127 |
128 | 完整的参数列表列举如下:
129 |
130 | - Run example program with no arguments.
131 | ```
132 | ./bin/flink run ./examples/batch/WordCount.jar
133 | ```
134 | - Run example program with arguments for input and result files
135 | ```
136 | ./bin/flink run ./examples/batch/WordCount.jar \
137 | file:///home/user/hamlet.txt file:///home/user/wordcount_out
138 | ```
139 | - Run example program with parallelism 16 and arguments for input and result files
140 |
141 | ```
142 | ./bin/flink run -p 16 ./examples/batch/WordCount.jar \
143 | file:///home/user/hamlet.txt file:///home/user/wordcount_out
144 | ```
145 |
146 | - Run example program with flink log output disabled
147 | ```
148 | ./bin/flink run -q ./examples/batch/WordCount.jar
149 | ```
150 | - Run example program in detached mode
151 | ```
152 | ./bin/flink run -d ./examples/batch/WordCount.jar
153 | ```
154 | - Run example program on a specific JobManager:
155 | ```
156 | ./bin/flink run -m myJMHost:6123 \
157 | ./examples/batch/WordCount.jar \
158 | file:///home/user/hamlet.txt file:///home/user/wordcount_out
159 | ```
160 | - Run example program with a specific class as an entry point:
161 | ```
162 | ./bin/flink run -c org.apache.flink.examples.java.wordcount.WordCount \
163 | ./examples/batch/WordCount.jar \
164 | file:///home/user/hamlet.txt file:///home/user/wordcount_out
165 | ```
166 | - Run example program using a [per-job YARN cluster](https://ci.apache.org/projects/flink/flink-docs-master/setup/yarn_setup.html#run-a-single-flink-job-on-hadoop-yarn) with 2 TaskManagers:
167 | ```
168 | ./bin/flink run -m yarn-cluster -yn 2 \
169 | ./examples/batch/WordCount.jar \
170 | hdfs:///user/hamlet.txt hdfs:///user/wordcount_out
171 | ```
172 | - Display the optimized execution plan for the WordCount example program as JSON:
173 | ```
174 | ./bin/flink info ./examples/batch/WordCount.jar \
175 | file:///home/user/hamlet.txt file:///home/user/wordcount_out
176 | ```
177 | - List scheduled and running jobs (including their JobIDs):
178 | ```
179 | ./bin/flink list
180 | ```
181 | - List scheduled jobs (including their JobIDs):
182 | ```
183 | ./bin/flink list -s
184 | ```
185 | - List running jobs (including their JobIDs):
186 |
187 | ```
188 | ./bin/flink list -r
189 | ```
190 |
191 | - Cancel a job:
192 | ```
193 | ./bin/flink cancel
194 | ```
195 | - Stop a job (streaming jobs only):
196 | ```
197 | ./bin/flink stop
198 | ```
199 |
200 | ### Program:貌似不可用,API 变化了
201 |
202 | ```java
203 | try {
204 | PackagedProgram program = new PackagedProgram(file, args);
205 | InetSocketAddress jobManagerAddress = RemoteExecutor.getInetFromHostport("localhost:6123");
206 | Configuration config = new Configuration();
207 |
208 | Client client = new Client(jobManagerAddress, config, program.getUserCodeClassLoader());
209 |
210 | // set the parallelism to 10 here
211 | client.run(program, 10, true);
212 |
213 | } catch (ProgramInvocationException e) {
214 | e.printStackTrace();
215 | }
216 | ```
217 |
--------------------------------------------------------------------------------
/流处理/10~Flink/快速开始.md:
--------------------------------------------------------------------------------
1 | # 快速开始
2 |
3 | # 环境配置
4 |
5 | ## 搭建本地实例
6 |
7 | Flink 本身可以单独部署,如果你需要读写 HDFS 中的数据,则需要选择对应的 Hadoop 版本了,在初学阶段笔者还是建议单独部署即可,到[这里](http://flink.apache.org/downloads.html)下载一个编译好的版本,然后直接解压缩即可:
8 |
9 | ```
10 | $ cd ~/Downloads # Go to download directory
11 | $ tar xzf flink-*.tgz # Unpack the downloaded archive
12 | $ cd flink-1.0.3
13 | $ bin/start-local.sh # Start Flink
14 | ```
15 |
16 | 然后转到 [http://localhost:8081](http://localhost:8081/) 就可以看到一个运行的 JobManager 实例,注意,这里也会提示你存在一个 TaskManager 实例,如下图所示:
17 |
18 | 
19 |
20 | ## 运行示例
21 |
22 | 在搭建好了基本的运行环境之后,我们开始测试 [SocketTextStreamWordCount example](https://github.com/apache/flink/blob/release-1.0.0/flink-quickstart/flink-quickstart-java/src/main/resources/archetype-resources/src/main/java/SocketTextStreamWordCount.java),即从 Socket 中读取数据然后统计出独立的单词数目,典型的 WordCounts。
23 |
24 | 首先,使用 nc 来启动一个本地的 Server
25 |
26 | ```
27 | $ nc -l -p 9000
28 | // mac 下是 nc -l 9000
29 | ```
30 |
31 | 将任务的 Jar 包提交到 Flink:
32 |
33 | ```
34 | $ bin/flink run examples/streaming/SocketTextStreamWordCount.jar \
35 | --hostname localhost \
36 | --port 9000
37 | Printing result to stdout. Use --output to specify output path.
38 | 03/08/2016 17:21:56 Job execution switched to status RUNNING.
39 | 03/08/2016 17:21:56 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED
40 | 03/08/2016 17:21:56 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING
41 | 03/08/2016 17:21:56 Keyed Aggregation -> Sink: Unnamed(1/1) switched to SCHEDULED
42 | 03/08/2016 17:21:56 Keyed Aggregation -> Sink: Unnamed(1/1) switched to DEPLOYING
43 | 03/08/2016 17:21:56 Source: Socket Stream -> Flat Map(1/1) switched to RUNNING
44 | 03/08/2016 17:21:56 Keyed Aggregation -> Sink: Unnamed(1/1) switched to RUNNING
45 | ```
46 |
47 | 该任务会连接到 Socket 然后等待输入,你可以在 Web 界面中判断任务是否正常运行:
48 |
49 | 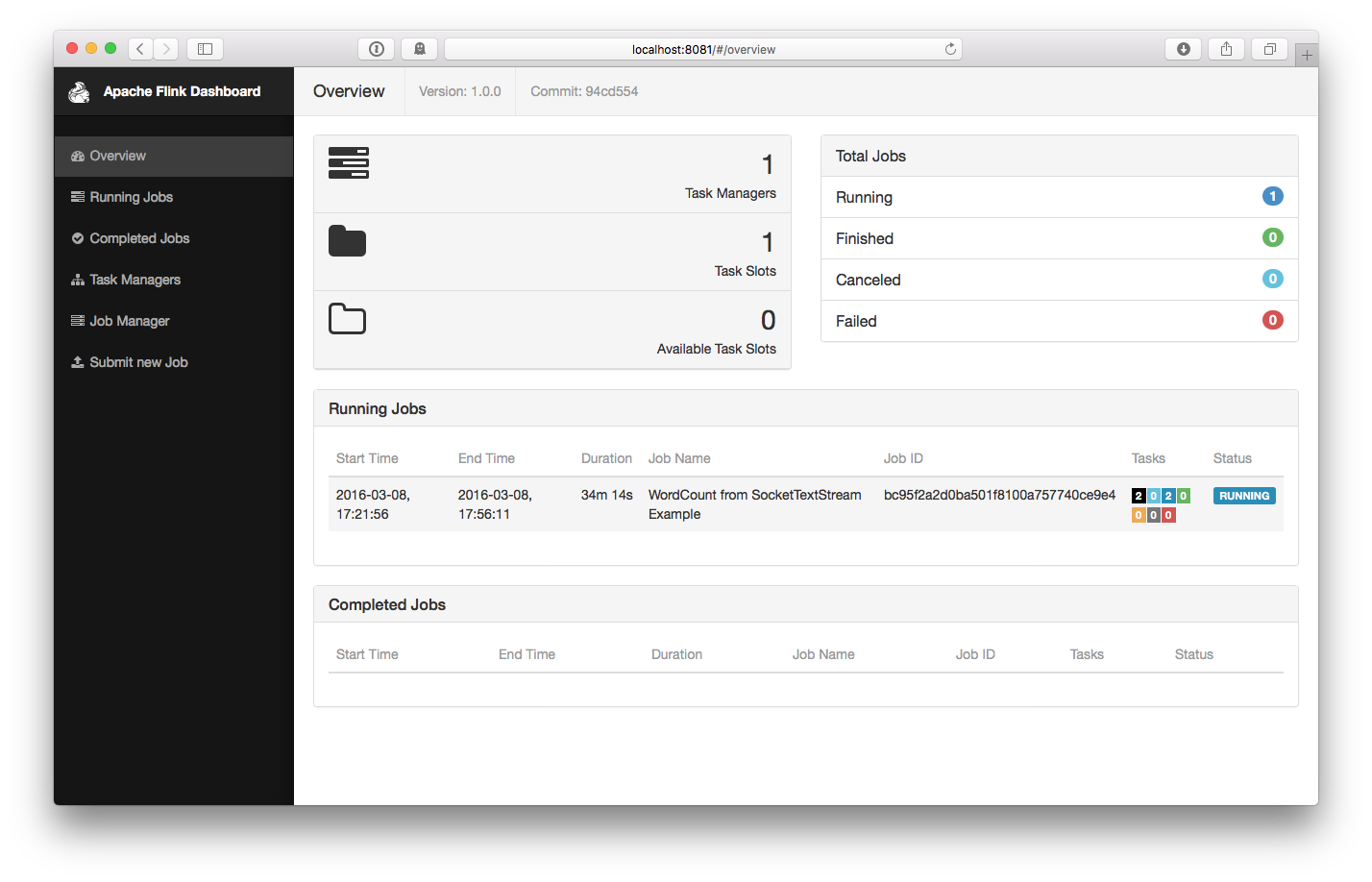
50 |
51 | 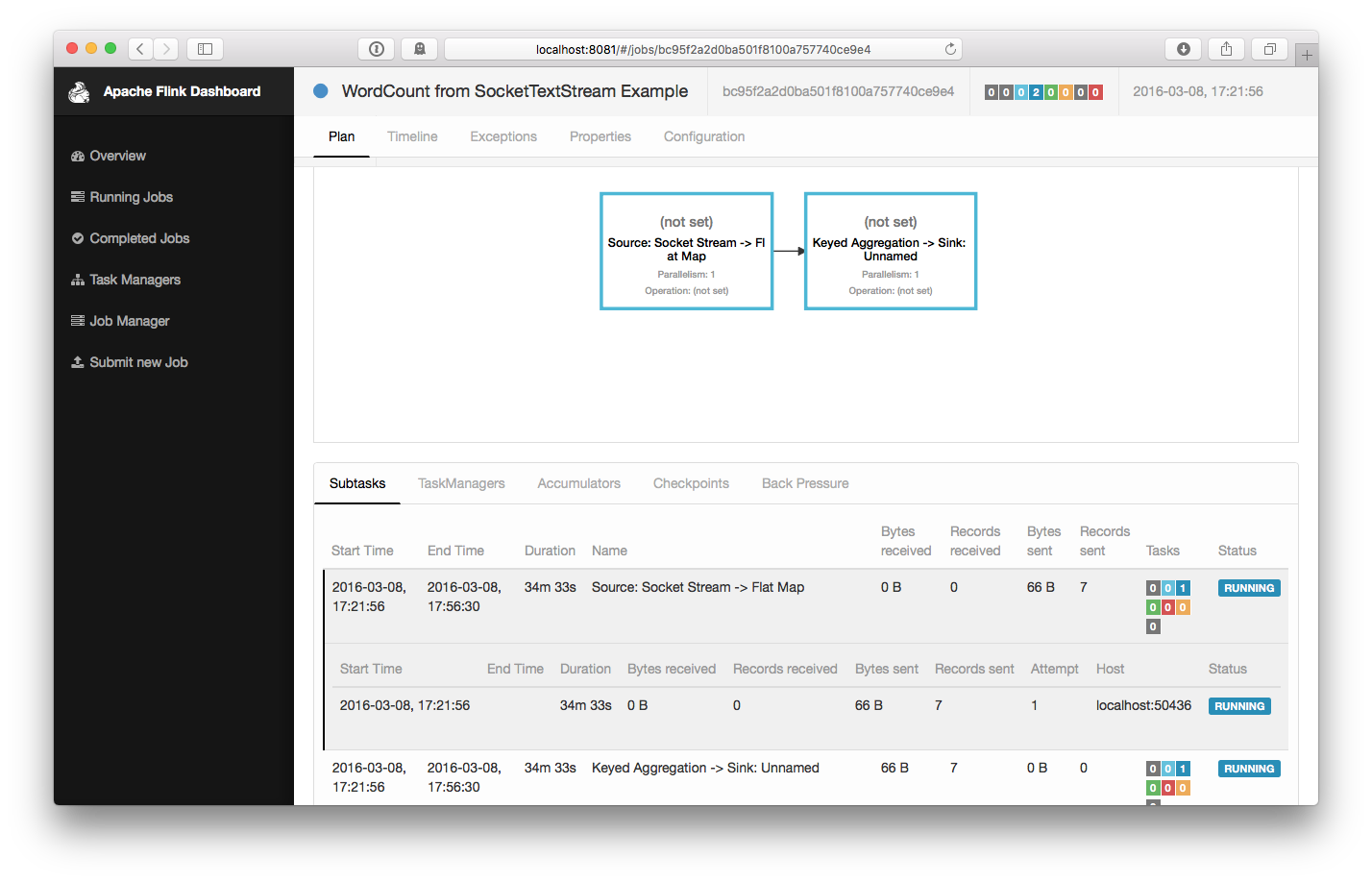
52 |
53 | 在刚才的 nc 终端里输入一些数据
54 |
55 | ```
56 | $ nc -l -p 9000
57 | lorem ipsum
58 | ipsum ipsum ipsum
59 | bye
60 | ```
61 |
62 | 结果会被直接统计出来
63 |
64 | ```
65 | $ tail -f log/flink-*-jobmanager-*.out
66 | (lorem,1)
67 | (ipsum,1)
68 | (ipsum,2)
69 | (ipsum,3)
70 | (ipsum,4)
71 | (bye,1)
72 | ```
73 |
74 | 如果你要停止 Flink 集群
75 |
76 | ```
77 | $ bin/stop-local.sh
78 | ```
79 |
80 | 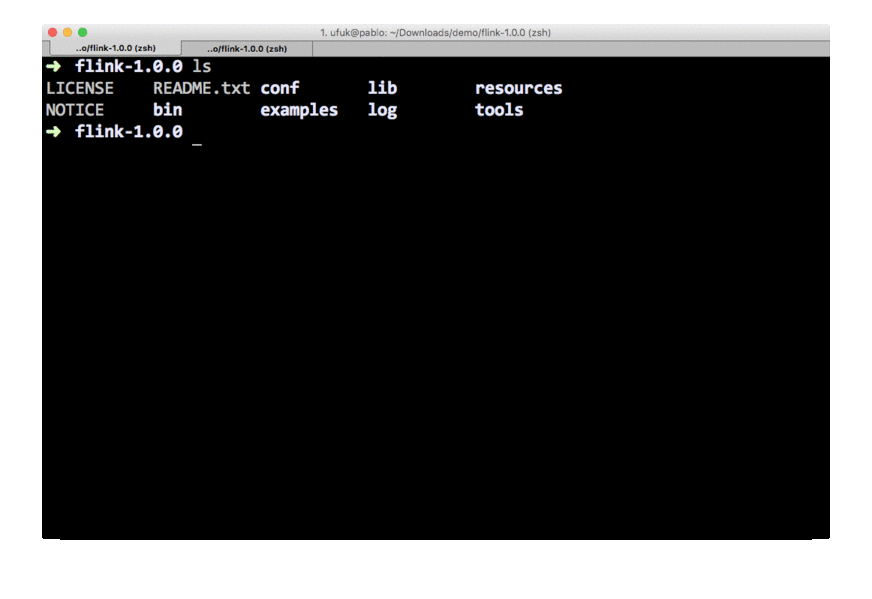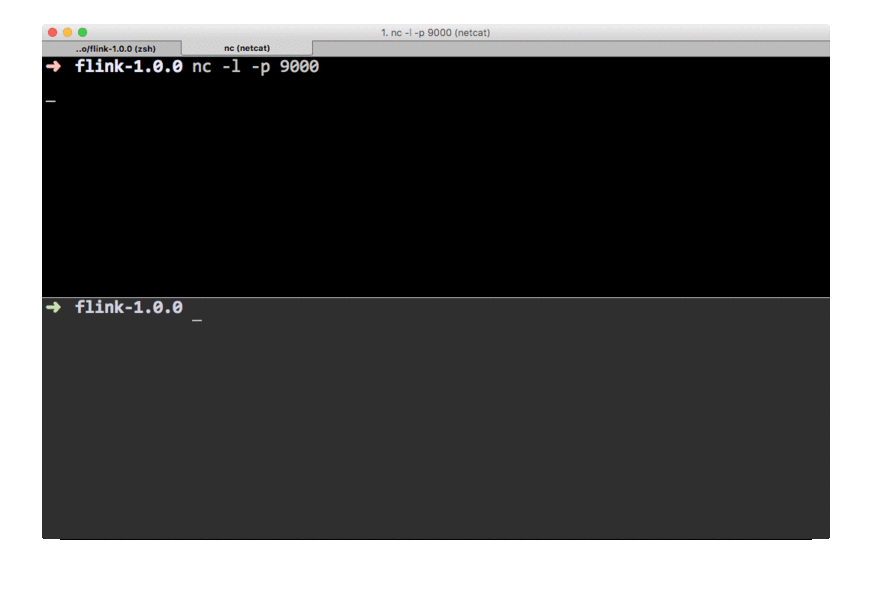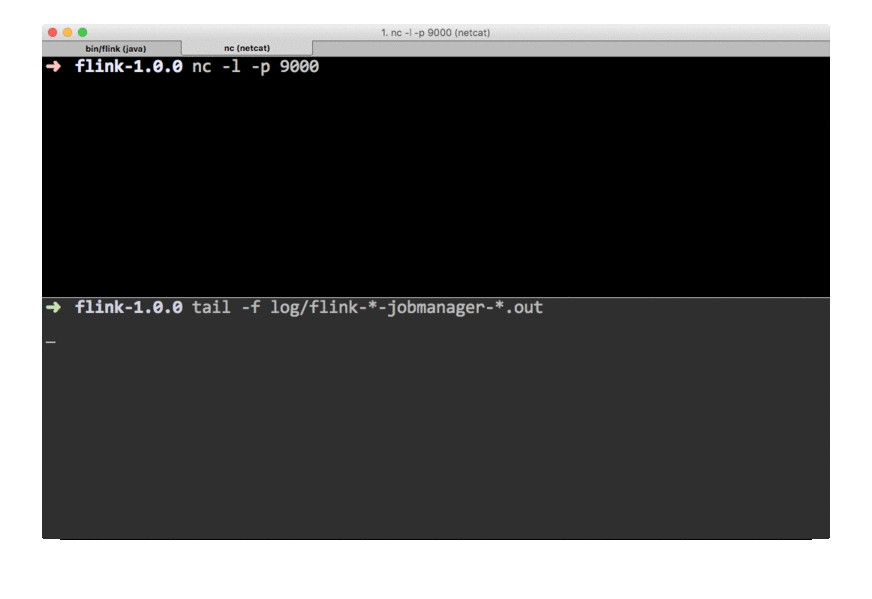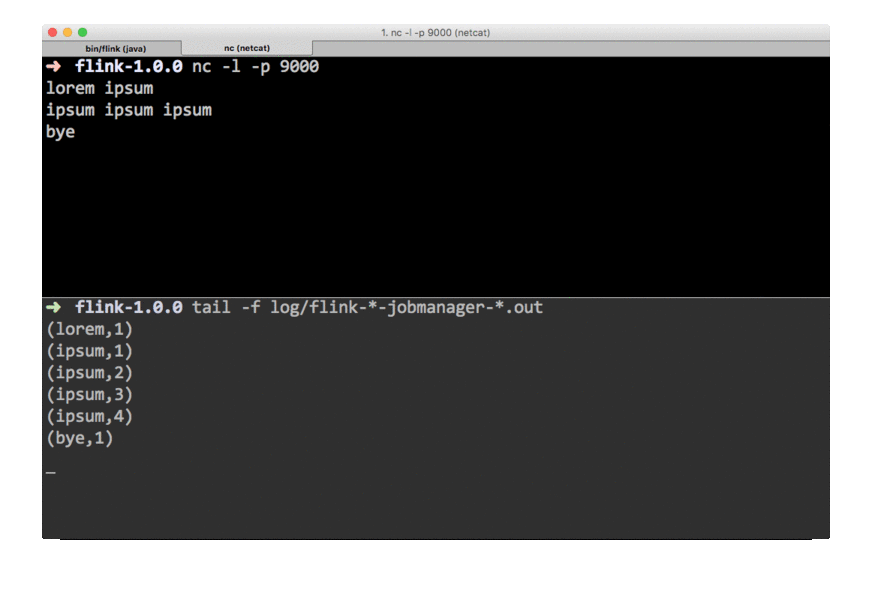
81 |
--------------------------------------------------------------------------------
/流处理/99~参考资料/2023-吴英俊-重新思考流处理与流数据库.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://xie.infoq.cn/article/aa368384d07d286682990be64)
2 |
3 | # 重新思考流处理与流数据库
4 |
5 | 
6 |
7 | 在过去的数年里,我们见证了流处理技术的飞速进步与普及。我第一次接触流处理是在 2012 年。那时候的我有幸在微软亚洲研究院实习,在系统组里做分布式流处理系统。之后我分别在新加坡国立大学、卡耐基梅隆大学、IBM Almaden 研究院、AWS Redshift 从事流处理与数据库系统的研究与开发。如今,我正在 RisingWave Labs([RisingWave: A Cloud-Native Streaming Database](https://xie.infoq.cn/link?target=https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%3A%2F%2Fwww.risingwave-labs.com%2F))搭建下一代流数据库系统。
8 |
9 | 一晃 11 年过去,当时在微软亚研院实习的我万万没想到,我在这个领域持续做了十多年,并不断突破边界,从纯技术开发逐步转向探索该领域商业化的道路。在创业公司里,最令人兴奋也最具有挑战的事情便是预测未来 — 根据历史的轨迹思考与判断行业的发展方向。在过去的数月中,我一直在思考几个问题:**为什么需要流处理?为什么需要流数据库?流处理系统真的能够颠覆批处理系统吗?**在这篇文章中,我将结合自己的软件开发与客户沟通经验,从实践角度探讨流处理与流数据库的过去、现在与未来。
10 |
11 | ## 流处理系统的正确使用姿势
12 |
13 | 说到流处理系统,大家自然而然的会想到一些低延迟用例:股票交易、异常监控、广告计算等等。然而,在这些用例中,流处理系统到底如何被使用的呢?使用流处理系统时,用户期望的延迟到底有多低?为什么不用一些批处理系统来解决问题?在这里,我来结合自己的经验回答这些问题。
14 |
15 | ### 典型流处理场景
16 |
17 | 无论什么具体的用例,流处理系统通常被应用在以下两个场景中:**数据接入**与**数据分析**。
18 |
19 | 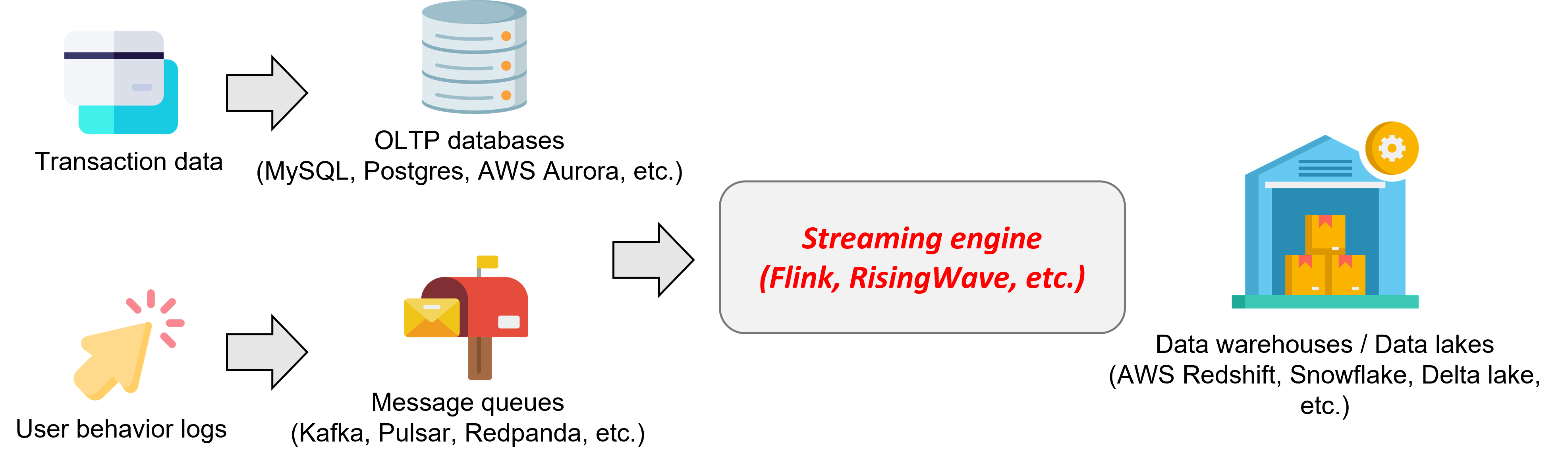
20 |
21 | 数据接入:将 OLTP 数据库与消息队列中的数据做 join 操作之后插入到数据仓库与数据湖中。
22 |
23 | - **数据接入(data ingestion)。**所谓数据接入,就是将数据从一个(或多个)数据系统经过一定计算之后插入到另一个(或多个)数据系统中。另一种常见的说法便是 ETL。用户为什么要做数据接入?我举几个简单例子大家就明白了。我们可以考虑有个电商网站,使用一个 OLTP 数据库(比如 AWS Aurora、CockroachDB、TiDB 等)支撑线上交易。同时,为了更好的分析用户的行为,网站也可能使用了一个程序采集用户行为(比如点击广告等),并将用户行为日志插入了消息队列(如 Kafka、Pulsar、Redpanda 等)中。为了更好的提升销量,电商网站通常会将交易数据与用户行为日志导入到同一个数据系统,如 Snowflake 或是 Redshift 这样的数据仓库中,以便进行分析。在这里,电商网站的工程师们便可以使用流处理系统将数据从 OLTP 数据库与消息队列实时的搬到数据仓库里。在数据搬运的过程中,流处理系统会做各类计算,来进行脏数据清理、多个数据源 join 等操作。在我们接触过的场景中,数据的源头往往是 OLTP 数据库、消息队列、存储系统等,而数据的终点除了 OLTP 数据库、消息队列、存储系统外,更常见的便是数据仓库与数据湖。值得一提的是,我们目前没有见过从数据仓库与数据湖导出数据到其他系统的案例,主要原因还是用户通常将数据仓库与数据湖看作是数据的终点,同时由于数据仓库与数据湖一般不提供数据变更日志,这使得数据实时导出更加困难。
24 | - **数据分析(data analytics)。**数据分析很容易理解,就是对一个(或多个)数据系统中的数据进行计算得到分析结果,并将结果推送给用户。当使用流处理系统做数据分析时,往往意味着用户希望是对最近(比如 30 分钟、1 小时、7 天等)的数据更加感兴趣,而不是去到数仓中批量处理数月甚至数年的数据。在数据分析场景中,流数据系统的上游往往还是 OLTP 数据库、消息队列、存储系统等,而下游通常是个 key-value store(如 Cassandra、DynamoDB 等)或者是个缓存系统(如 Redis 等)。当然,也有些用户会直接将流处理的结果发送给应用层,这种使用方式一般在告警系统中比较普遍。
25 |
26 | 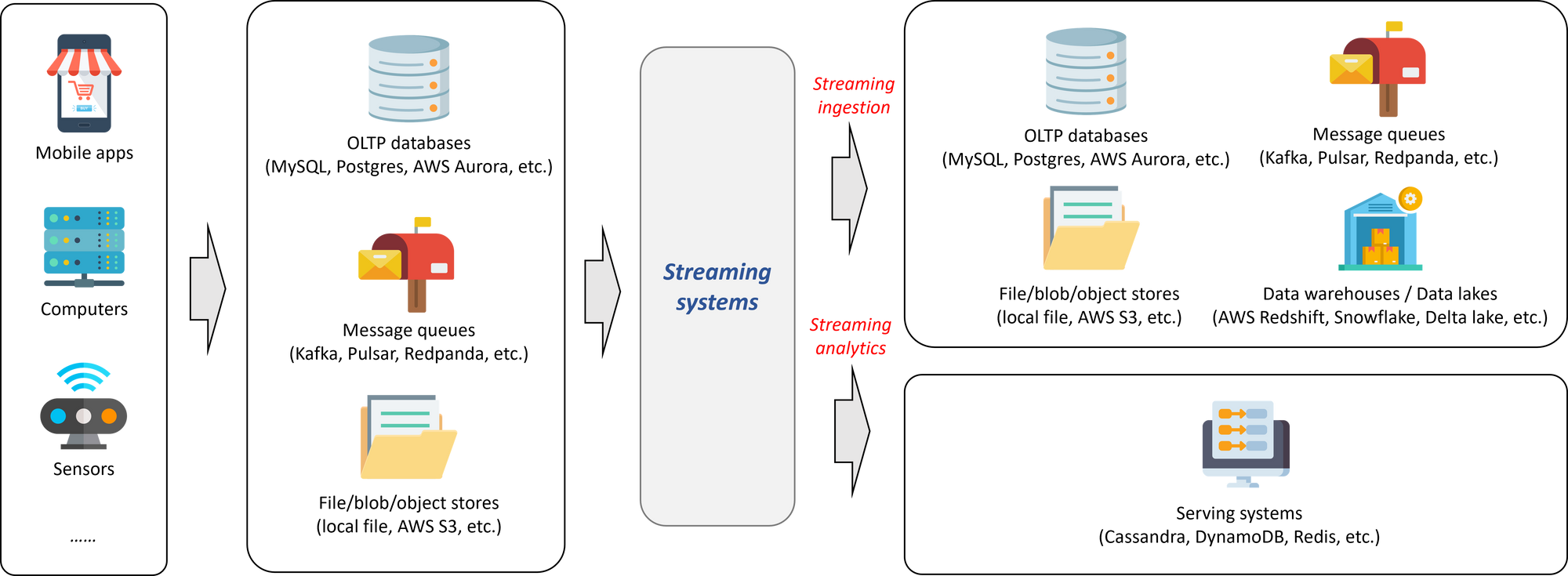
27 |
28 | 流处理的两个典型场景:数据接入与数据分析。
29 |
30 | 尽管批处理系统同样能做数据接入与数据分析,但是流处理系统相比于批处理系统,能够将延迟从小时或者天级别降低到秒级或者分钟级。这在一些业务中将带来巨大好处。对于数据接入这个场景中,降低延迟可以让下游系统(比如数据仓库)用户更及时的得到最新的数据,并对最新的数据进行处理。而在数据分析这个场景中,下游系统可以实时看到最新的数据处理结果,从而能够将结果及时呈现给用户。
31 |
32 | 有朋友一定会问:
33 |
34 | - _对于数据接入(或者 ETL)这个场景,我们拿个编排工具(比如 Apache Airflow)定时触发批处理系统(比如 Apache Spark)做计算不就可以了吗?_
35 | - _对于数据分析场景,许多实时分析系统(比如 Clickhouse、Apache Pinot、Apache Doris 等)都能对数据进行在线分析,为什么还要用流处理系统?_
36 |
37 | 这两个问题非常值得深入探讨,我们将会在文章最后一节进行讨论。
38 |
39 | ### 用户的期望:延迟到底需要有多低?
40 |
41 | 对于流处理系统的用户来说,他们期望的延迟到底是多少呢?秒?毫秒?微秒?越低越好?根据我们的客户访谈结果,多数流处理系统用户的用例所需要的延迟在百毫秒到数十分钟不等。在我们的用户访谈中,不少科技企业的在线数据系统工程师对我们说:“使用了流处理系统之后,我们的计算延迟从天级别降到了分钟级,这样的转变已经让我们非常满意了,并没有特别的需求进一步降低延迟。”所谓”延迟越低越好“,在我们看来,听上去很美好,但实际上并没有太多实际用例做支撑。事实上,在一些超低延迟场景中,通用的流处理系统也达不到其所需的延迟需求。
42 |
43 | 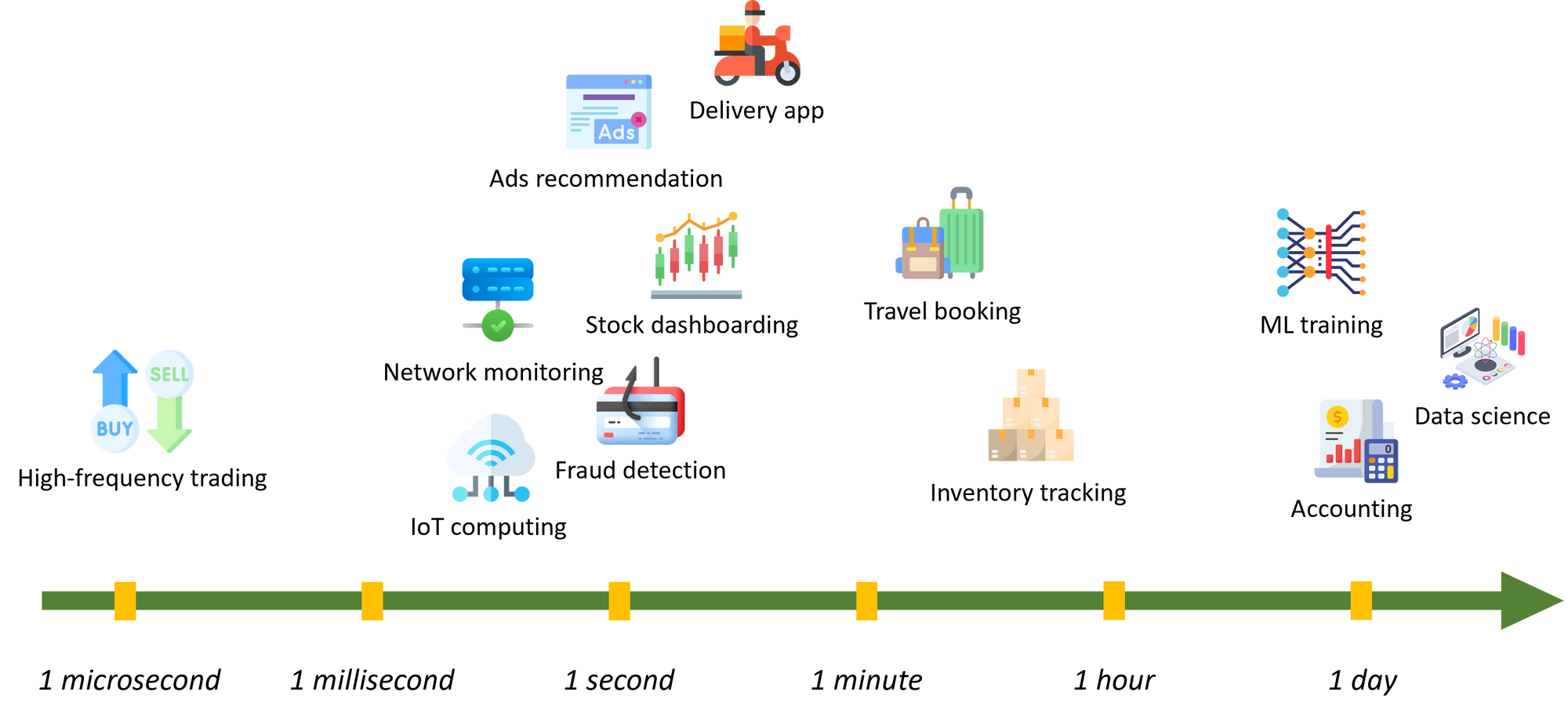
44 |
45 | 各类真实场景对延迟的需求。
46 |
47 | 一个很典型的超低延迟场景便是高频量化交易场景。量化公司都期望自己的系统能够在极短时间内响应市场的波动,从而对股票或者期货进行买入卖出。量化公司需要的延迟通常在微秒级别。为了达到这种级别的延迟,许多量化公司都会将自己的机房搬去离交易所物理位置更近的大楼,并精心挑选网络运营商来减少由于网络通信造成的延迟。在这种场景中,量化公司几乎都会选择自己自建系统,而非采用市面上的通用流处理系统(如 Flink、RisingWave 等)。这不仅是因为通用流处理系统往往由于封装达不到延迟的需求,也是因为量化交易通常需要一些特殊的自定义算子,而这些算子一般都不会被通用流处理系统所支持。
48 |
49 | 还有一些低延迟场景是 IoT(物联网)与网络监控。这类场景的延迟通常在毫秒级,可能是几毫秒,也可能是几百毫秒。在这类场景中,通用流处理系统(如 Flink、RisingWave 等)可能可以做到很好的支撑。但在一些用例中,还是需要使用特化的系统。一个很好的例子就是车载传感器。车载传感器可能会监控车辆的行驶速度、车辆坐标、踩油门与刹车的频率等等信息。这类信息可能由于隐私、网络带宽等原因,一般不会回传给数据中心。因此,常见的解决方案就是在车辆上直接装处理器(或者说是嵌入式设备)来进行数据处理。在这类设备上安装通用流处理系统还是不太合适的。
50 |
51 | 接下来要谈的便是一些大家耳熟能详的低延迟场景了:广告推荐、欺诈检测、股市大盘报表、订餐 APP 等。这类场景的延迟通常来说都是在百毫秒或者数分钟之间。更低的延迟听起来可能更好,但不一定有必要。就拿股票大盘报表来举例。普通散户通常通过盯着网站或者手机看股票波动来进行交易决策。这些散户真的有需求知道 10 毫秒之前的股票交易信息吗?其实是没有必要的。人眼看到的极限频率是 60Hz,也就是人眼根本分辨不出 16 毫秒以下的刷新。同时,人做决策的反应速度都是在秒级,哪怕是训练有素的运动员听到枪声的反应速度也只能在 100-200 毫秒左右。因此,对于股票大盘这种给人提供决策信息的场景,低于百毫秒的延迟都是没有必要的。而这类需求百毫秒到分钟级的场景,便是通用流处理系统(如 Flink、RisingWave 等)最擅长的场景了。
52 |
53 | 然后就到了一些对延迟没有很高要求的场景了:酒店预订、库存管理等。对于这类延迟不敏感场景来说,流处理系统与批处理系统其实都能做比较好的支持,因此在用户选择系统的时候,考虑的点往往不是性能,而是成本、灵活性等方面了。
54 |
55 | 对于机器学习模型训练、数据科学、财务报表等这些对延迟完全没有要求的场景,很显然批处理系统更加适用。当然了,随着技术的不断进步,我们也看到了在线机器学习、在线数据科学等方向的兴起,而不少公司也的确开始使用流处理系统来将这些应用实时化。在本文,我们就不对这类场景进行过多讨论了。
56 |
57 | ## 回顾(被遗忘的)历史
58 |
59 | 上一节讲了流处理系统的使用场景。在这一节里,我们来谈谈流处理系统的历史。
60 |
61 | ### Apache Storm 与其之后的系统
62 |
63 | 对于许多资深工程师来说,Apache Storm 也许是他们接触过的第一个流处理的系统。Storm 是使用一门称为 Clojure 的小众 JVM 编程语言编写的分布式流计算引擎。相信很多新一代的程序员可能都没听说过 Clojure 这种语言。Storm 在 2011 年被 Twitter 公司开源。在那个被 Apache Hadoop 统治的年代,Storm 的出现改变了许多人对数据处理的认知。传统来讲,用户处理数据的方式都是将大量数据首先导入到 HDFS,再用 Hadoop 等批计算引擎对数据进行分析。而有了 Storm,用户可以在数据刚流入系统的时候就被处理。用户也能够在几秒钟或者几分钟内获得结果,而不是要等待数小时或者数天。
64 |
65 | 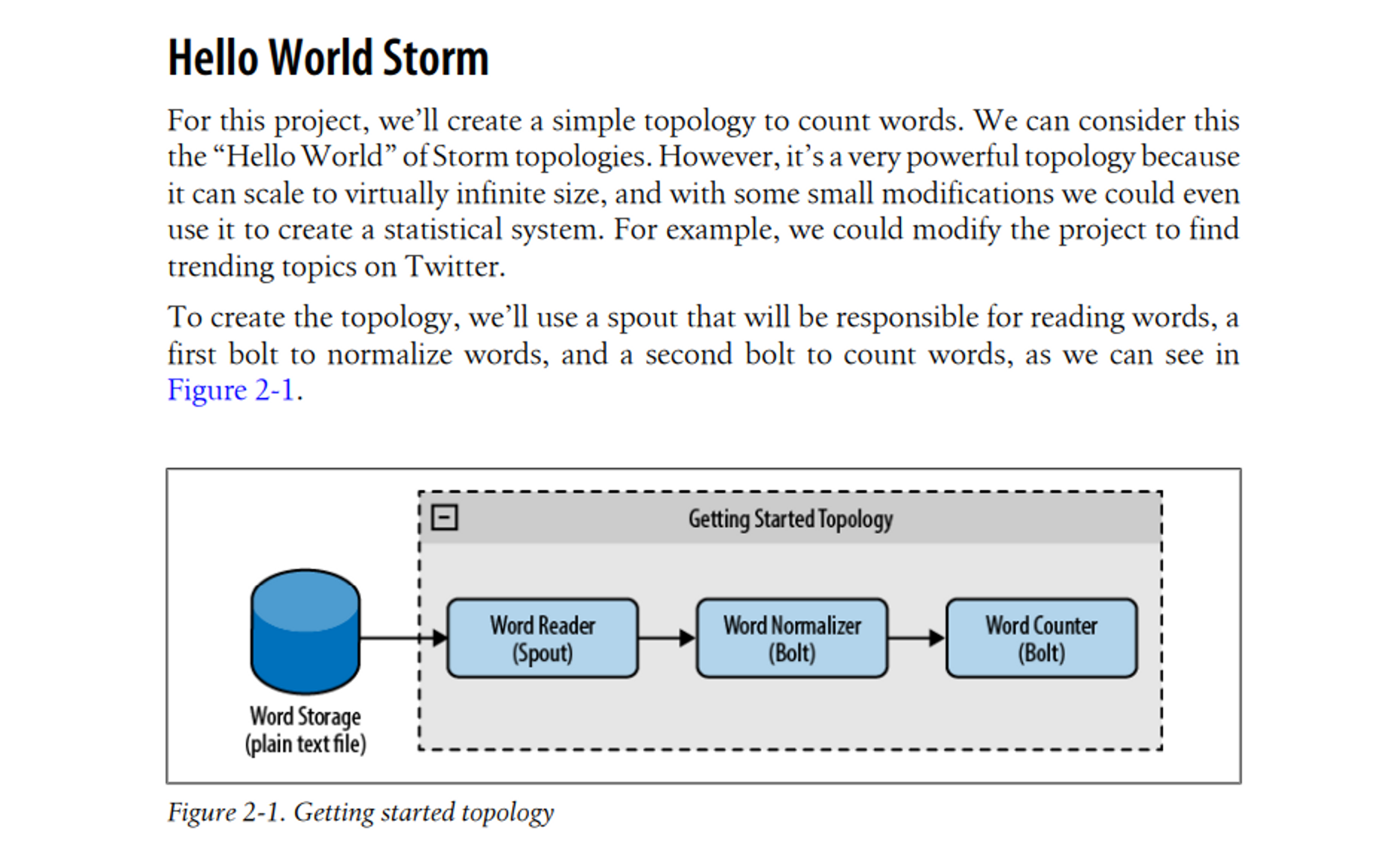
66 |
67 | 想要使用 Storm 做最简单的 work count 操作,用户也必须学许多 Storm 特有的概念。图片来源:书籍 “Getting started with Storm”
68 |
69 | Storm 在当时是相当有突破性的。然而,早期 Storm 的设计远远没有达到用户预期的完美:它所要求的编程方式过于复杂,并缺少很多现代流处理系统中默认提供的基本功能,例如状态管理、exactly-once 语义、动态扩缩容等等。当然也正是因为这些设计的不完美,才使得诸多才华横溢的工程师去搭建下一代流计算引擎。在 Storm 开源之后两三年内,我们鉴证了一批流计算引擎的诞生:Apache Spark Streaming,Apache Flink,Apache Samza,Apache Heron,Apache S4 等等。而如今,Spark Streaming 与 Flink 成了非常成功的两个流计算引擎。
70 |
71 | ### Apache Storm 之前的历史
72 |
73 | 如果你认为流处理系统的历史起源于 Storm 的诞生,那就错了。事实上,流处理系统的历史远比很多人想象的精彩。不算特别意外的是,流处理这一概念来自于数据库圈。在 2002 年的数据库领域顶级会议 VLDB 上,布朗大学与 MIT 的学者发表了“Monitoring Streams – A New Class of Data Management Applications”论文,指出了流处理这一新的需求。在这篇文章中,作者提出,为了处理流数据,我们应该抛弃传统的“Human-Active, DBMS-Passive”传统数据库处理模式,而转向“DBMS-Active, Human-Passive”这一新型处理模式。也就是说,在新型的流处理系统中,数据库应该主动接收数据并触发查询,而人只需要被动接受结果即可。在学术界,最早的流处理系统叫做 Aurora,随后又有 Borealis、STREAM 等系统在同时代诞生。
74 |
75 | 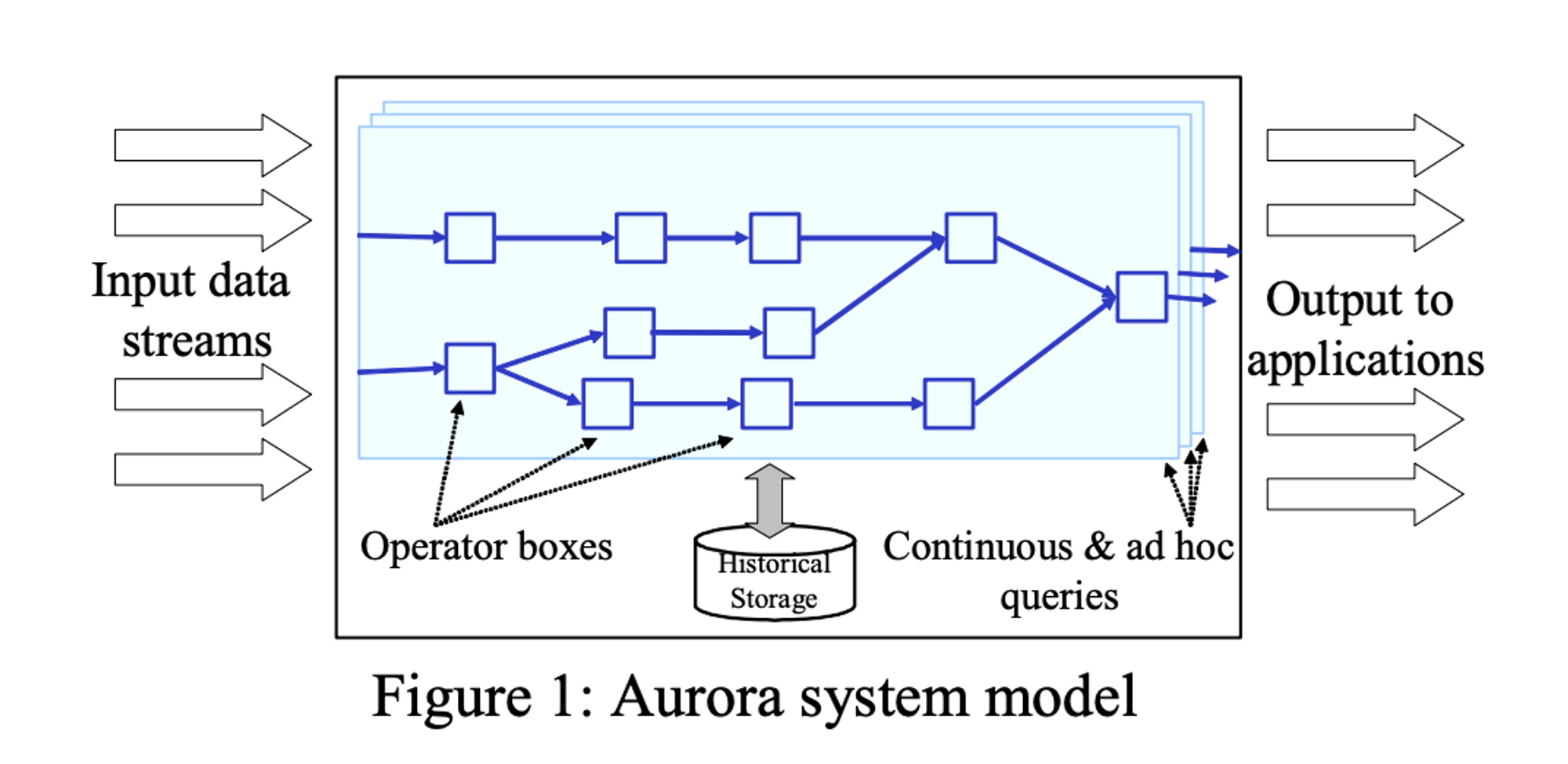
76 |
77 | Aurora: 学术界的第一个流数据处理系统。
78 |
79 | 在被学术界提出的几年后,流处理技术便在大型数据库厂商中得到了应用。数据库领域的三大老牌厂商 Oracle、IBM、Microsoft 分别推出了他们自己的流处理解决方案,分别称为 Oracle CQL、IBM System S、Microsoft SQL Sever StreamInsight。非常一致的是,三个厂商都选择了在自己现有系统中集成流处理功能,而非将流处理功能单独拿出来开发成独立系统。
80 |
81 | ### 2002 年至今:到底什么被改变了?
82 |
83 | 
84 |
85 | 流处理系统的变革:从商业化数据库系统的一个功能组件转变成独立的开源大数据系统。
86 |
87 | 通过以上的讨论,大家可以看到,在 2002 年第一个流处理系统 Aurora 在学术界诞生之后,很快被数据库巨头吸收进自身产品中。但在 2010 年前后,该领域出现了一个重大转变,那便是流处理模块被从数据库系统中独立出来,并单独发展成了完整的、可扩展的分布式流计算引擎。是什么造成了这一变革?我认为是与 Hadoop(或者说 MapReduce)的诞生与发展息息相关。在传统单机数据库世界中,计算与存储都被封装在同一个系统中。尽管这样可以大大简化系统架构,给用户单一接口进行操作,但这种架构无法很好的扩展到集群环境中。Hadoop 所统治的大数据时代的理念便是将计算与持久化存储分割成独立的系统(注意这里所说的“分割成独立的系统”跟人们时常讨论的“存算分离”还是有不少区别),并暴露底层接口给用户,依赖用户提供足够多的信息(例如并行度、partition key 等)来去做水平扩展。这样的模式完美的满足了工程师驱动的新一批互联网公司(如 Twitter、LinkedIn、Uber 等)的需求。我们现在看到的 Storm 及其之后的大数据流计算引擎,无一不是这种设计思路:只负责计算层、暴露底层接口、通过 partition 方式暴力使用资源进行无限扩展。很显然,Storm、Flink 所代表的大数据时代流计算引擎的发展规律,与 Hadoop、Spark 所代表的同一时代的批计算引擎的发展规律完全吻合。
88 |
89 | ## 流数据库的复兴
90 |
91 | 回望历史我们发现,流数据库这一概念在 20 多年前便已被提出并实现。然而,大数据时代所带来的巨大技术变革推动了 Storm、Flink、Spark Streaming 等一批流计算引擎的诞生与发展,并推翻了 Oracle、IBM、Microsoft 这三巨头在流处理技术上的垄断。历史总是螺旋形上升的。在批处理系统领域,我们看到了 Redshift、Snowflake、Clickhouse 等系统重新将人们从“计算引擎”拉回到“数据库“这一理念中来。同样,在流处理领域,我们也看到了如 RisingWave、Materialize 等流数据库的诞生。为什么会这样?我们在这一节详细分析。
92 |
93 | ### PipelineDB 与 ksqlDB 的故事
94 |
95 | 随着 2011 年 Storm 开源之后,流计算引擎便进入了发展的快车道。但流数据库并没有就此销声匿迹。有两个知名流数据库系统就诞生在大数据时代中。一个名叫 PipelineDB,另一个名叫 ksqlDB。先不说技术,这两个系统在商业上有着不小的联系。PipelineDB 是于 2013 年创立,2014 年 PipelineDB 团队加入了硅谷知名孵化器 Y Combinator 孵化,2019 年 PipelineDB 被 Apache Kafka 原创团队所成立的商业化公司 Confluent 收购。而 ksqlDB 正是由 Confluent 公司于 2016 年创立(其实最早是先做了 Kafka Stream)。PipelineDB 与 ksqlDB 尽管都是流数据库,但它们在技术路线上的选择截然不同。PipelineDB 是完全基于 PostgreSQL 的。更准确的说,PipelineDB 使用了 PostgreSQL 的扩展接口。也就是说,只要用户安装了 PostgreSQL,就可以像安装插件一样安装 PipelineDB。这一理念对用户非常友好:用户无需迁移自己的数据库,便可以使用 PipelineDB。PipelineDB 非常核心的卖点就是实时更新的物化视图。当用户将数据插入 PipelineDB 之后,用户所创建的物化视图上便会实时显示最新结果。KsqlDB 选择了与 Kafka 强耦合的策略:在 ksqlDB 中,计算的中间结果存储在 Kafka 中;节点之间的通信使用 Kafka。这种技术路线的优势与缺陷非常鲜明:其优势是高度复用成熟组件,大大降低开发成本,缺陷是强绑 Kafka,严重缺乏灵活性,使得系统的性能与可扩展性大打折扣。
96 |
97 | PipelineDB 与 ksqlDB 从用户认可度来讲还是逊色于 Spark Streaming 与 Flink:PipelineDB 已于 2019 年被收购之后停止了更新,而 ksqlDB 由于强绑 Kafka 以及技术成熟度等原因,在 Kafka 生态以外并没有得到足够多的关注。而在最近(2023 年 1 月),Confluent 公司又收购了由 Flink 核心成员创立的 Flink 商业化公司 Immerok,并高调宣布会推出基于 Flink SQL 的计算平台。这使得 ksqlDB 未来在 Confluent 内部的地位变得更加扑朔迷离。
98 |
99 | ### 云原生流数据库的兴起
100 |
101 | 经历了 Hadoop、Spark 领导的大数据时代,我们便来到了云时代。近年来,诸多云原生系统逐步超越并颠覆了其所对标的大数据系统。一个最为人所知的例子便是 Snowflake 的崛起。Snowflake 基于云构建出的存算分离的新一代云数据仓库形成了对 Impala 等上一代大数据系统的降维打击,在市场上实现了称霸。在流数据库领域,类似的事情可能会再次发生。RisingWave、Materialize、DeltaStream、TimePlus 等就是近几年涌现出来的云上流数据库。尽管商业化路线、技术路线等方面的选择有着各种差异,但它们的大方向都是希望为用户在云上提供流数据库服务。在云上构建流数据库,重点就在于如何使用云的架构来实现无限水平扩展与成本降低。如果能够很好的选择技术路线与产品方向,相信会逐步挑战上一代流处理系统(如 Flink 与 Spark Streaming)的地位。
102 |
103 | ### 流计算引擎与流数据库
104 |
105 | 上面两段简述了流数据库在最近几年的兴起。相信大家都能够看出云原生是个趋势,但为什么大家在云上构建的是“云原生流数据库”,而不是“云原生流计算引擎”?
106 |
107 | 也许有人会认为是 SQL 的影响。云服务带来的一大变革便是普及数据系统的使用。在大数据时代,系统用户基本都是工程师,他们熟悉 Java 等编程语言进行应用开发。而云服务的兴起急需系统提供一种简单易懂的语言使广大没有编程基础的工作者受益。SQL 这种标准化的数据库语言很显然满足了这个需求。看起来,SQL 的广泛应用推动了“数据库”这个概念在流处理领域的普及。然而,**SQL 只是间接因素,而非直接因素**。证据很清晰:诸多流计算引擎(如 Flink 与 Spark Streaming)已经提供了 SQL 接口。尽管这些系统的 SQL 接口与 MySQL、PostgreSQL 等传统数据库的 SQL 使用体验有极大区别,但至少证明了有 SQL 不一定代表要有数据库。
108 |
109 | 我们回看“流数据库”与“流计算引擎”的区别,会发现流数据库拥有自的存储,而流计算引擎并没有。在这一表象底下更加深层的理念是:**流数据库将存储视为一等公民(first-class citizen)**。这一理念使得流数据库很好的满足了用户的两个最根本需求:简单、好用。这是如何做到呢?我们列举以下几个方面。
110 |
111 | - **统一数据操作对象。**在流计算引擎中,流(stream)是基本的数据操作对象;在数据库中,表(table)是基本的数据操作对象。在流数据库中,流与表的概念得到了完美的统一:用户不再需要考虑流与表的区别,而是可以把流看做是无限大小的表,并使用操作传统数据库的方式对表这个概念进行处理。
112 | - **简化用户数据栈。**相比于流计算引擎,流数据库拥有了对数据的**所有权**:用户可以直接将数据存储在表中。当用户通过流数据库处理完数据之后,可以直接将处理后的结果存储在同一系统中,供用户进行并发访问。而由于流计算引擎无法存储数据,这就意味着其进行计算之后,必须将结果导出到 key-value store 或缓存系统中,才能供用户访问。这也就是说,用户可以使用单一的流数据库系统替换掉之前 Flink+Cassandra/DynamoDB 等服务组合。简化用户的数据栈,削减运维成本,这很显然是很多公司期待的。
113 |
114 | 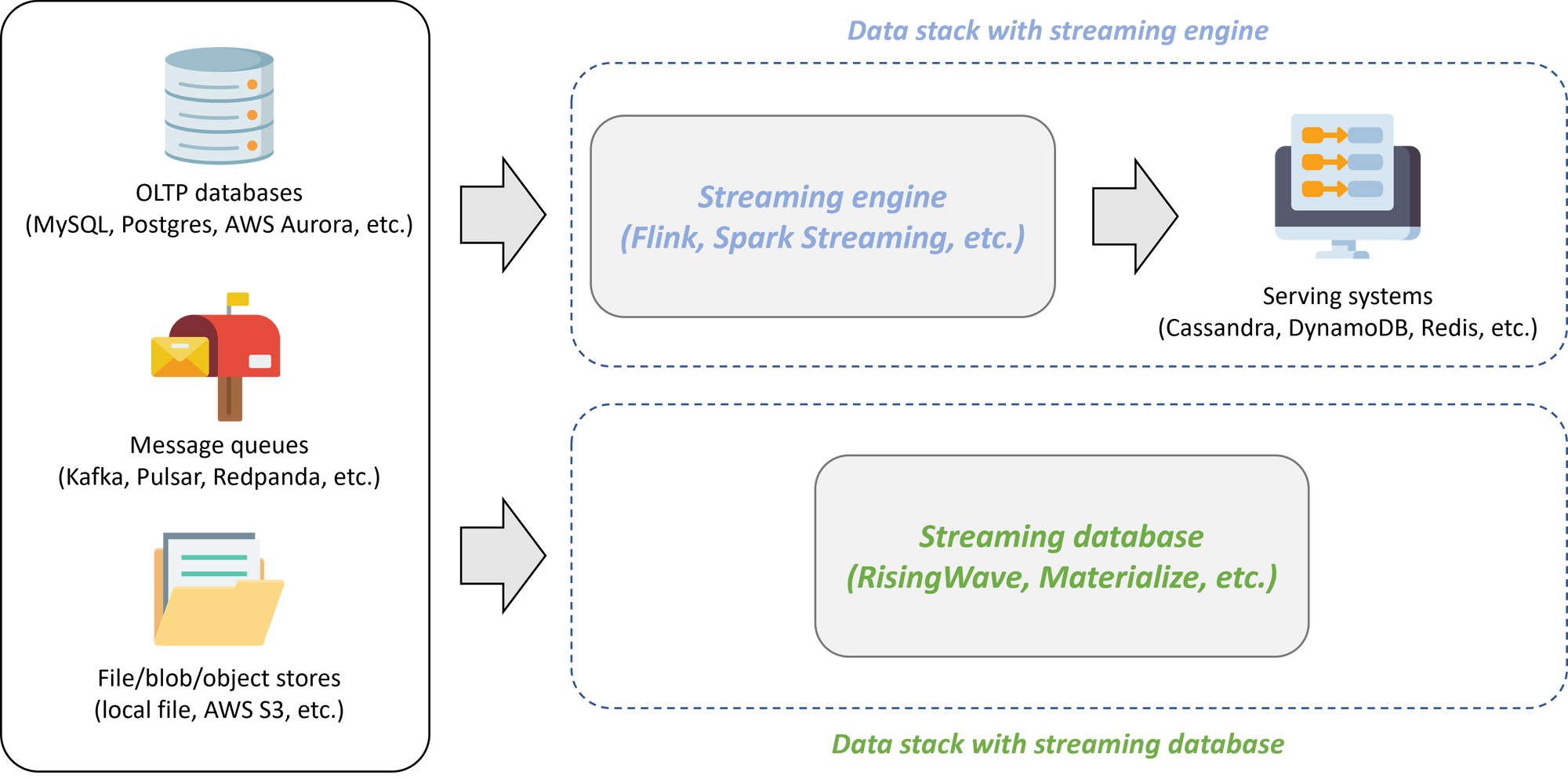
115 |
116 | 流数据库这一系统可以替代流计算引擎+服务系统这一系统组合。
117 |
118 | - **减少外部访问开销。**现代企业的数据源是多样的。当使用流处理系统的时候,用户往往需要访问外部系统数据(考虑要将 Kafka 导出的数据流与 MySQL 中的一个表做 join)。对于流计算引擎来说,要想访问 MySQL 中的数据,必须进行一次跨系统外部调用。这种调用造成的性能代价是巨大的。当流数据库拥有存储数据的能力之后,很显然能将外部系统中的数据保存(或缓存)在流数据库内部,从而大幅提升数据访问性能。
119 |
120 | 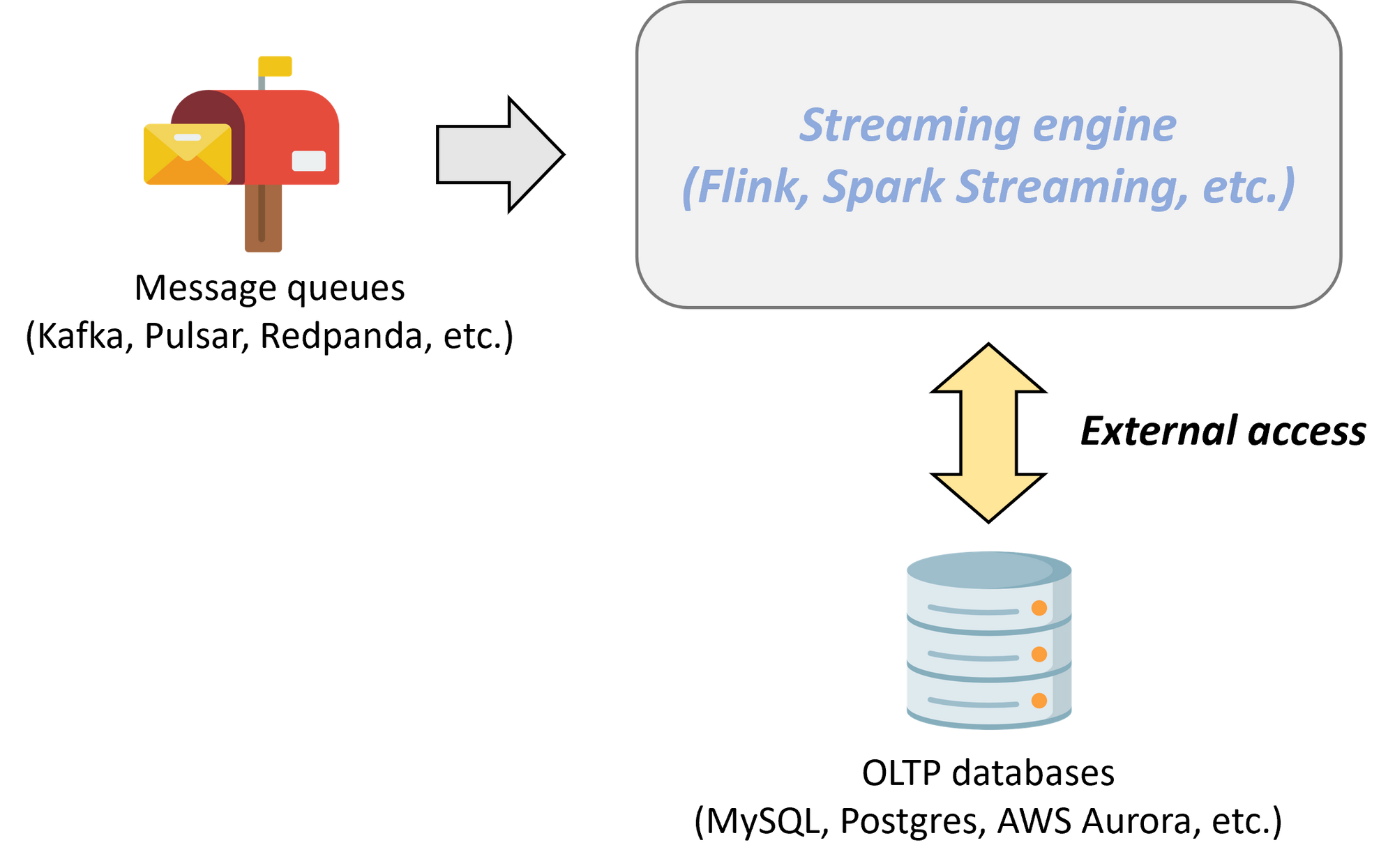
121 |
122 | 在流计算引擎中,跨系统外部调用会造成巨大性能代价。
123 |
124 | - **提供结果可解释性与一致性保证。**流计算引擎的一大痛点在于计算结果缺乏**可解释性**与**一致性保证**。我们考虑一个非常简单的例子:用户使用 Flink 提交了两个 job,一个是求过去十分钟内 Tesla 股票的被买入次数,另一个是求过去十分钟内 Tesla 股票的被卖出次数。在 Flink 中,不同 job 独立运行,两个 job 不断向下游系统输出结果。由于流计算引擎的计算进度不同、输入输出不被系统管理,导致下游系统接收到的两个结果缺乏一致性(比如一个可能是 8 点 10 分的结果,另一个可能是 8 点 11 分的结果),也无法被溯源。看到这样的结果,用户是非常困惑的:他们无法判断结果是否正确、如何得出、如何演变。而当流数据库可以拥有对输入、输出数据的所有权之后,系统的计算行为从理论来说都变得可观测、可解释、强一致了。毕竟,在流数据库中,一切计算的输入数据都可以被存储到表中并打上时间戳,一切计算产生的结果都可以保存在物化视图中并通过时间戳溯源。这样,用户就可以很好的理解计算结果了。当然理论归理论,实际还得看系统是否实现。RisingWave 就是实现了这种强一致性并提供可解释性的系统之一。
125 |
126 | - **深度优化计算执行。**将“存储被视为一等公民”,意味着流数据库的计算层可以感知存储,而这种感知能力使得系统能够在查询优化层以及计算执行层进行大幅优化。一个简单的例子就是可以更好的共享计算状态节省资源开销。由于涉及大量技术细节,我们不在这里进行过多讨论,有兴趣的朋友可以参考其他一些文章:[https://zhuanlan.zhihu.com/p/521759464](https://xie.infoq.cn/link?target=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F521759464)。
127 |
128 | ### 云原生流数据库的设计准则
129 |
130 | _(这一节的讨论可能会显得无趣,因为已经有太多文章讨论过云原生系统的设计与实现了。大家可以选择跳过。)_
131 |
132 | 云与集群的最大区别在于,云可以被认为是资源无限,且资源解耦;而集群是资源有限,且资源耦合。什么意思呢?第一,云上用户已经不再需要感知物理机器的数量:他们只需要付钱就可以获得他们想要的资源;而大数据时代的集群用户往往只拥有有限的物理机器;第二,云对用户暴露出来的是分类资源:用户可以根据需求单独购买计算、存储、缓存等资源。而大数据集群暴露出来的就是一台一台物理机器,用户只能是按机器数量来请求资源。第一点区别使得数据系统的设计目标发生了本质转变:大数据系统的目标是在有限资源内最大化系统性能,而云系统的目标是在无限资源内最小化成本开销;第二点区别则使得数据系统的实现方式发生了本质转变:大数据系统通过存算耦合的 shared-nothing 架构实现暴力并行,而云系统则通过存算分离的 shared-storage 架构实现按需伸缩。在流处理系统中,所谓中间计算结果即是存储。当中间计算结果需要从计算节点剥离出来放到 S3 等持久化云存储服务上时,大家会很自然的想到,S3 带来的数据访问延迟可能大幅影响流处理系统这种低延迟系统的性能。因此,云原生流处理系统不得不去考虑使用计算节点的本地存储以及外挂存储(如 EBS 等)去缓存数据,从而最大化减小 S3 访问带来的性能下降问题。
133 |
134 | 
135 |
136 | 大数据系统与云系统的优化目标不同。
137 |
138 | ## 流处理还是批处理:替代还是共存?
139 |
140 | 流处理技术因其能够极大降低数据处理延迟,被很多人视为一种可以颠覆批处理的技术。当然也有另一种观点认为,大多数批处理系统都已经“升级”成实时分析系统,流处理系统的价值将非常有限。我自己投身于流处理技术的研发与商业化,自然对流处理的前景极度乐观。而我并不认同流处理与批处理会互相取代。在本章,我们详细探究流处理与批处理各自的独特之处。
141 |
142 | ### 流处理与实时分析
143 |
144 | 目前多数的批处理系统,包括 Snowflake、Redshift、Clickhouse 等,都宣称自己是实时分析系统,能够对数据进行实时大规模分析。我们在第一章也提到一个问题:对于数据分析场景,在已有许多实时分析系统的情况下,为什么还要用流处理系统?”我认为这完全是对所谓”实时“定义的不同。在流处理系统中,查询被用户事先定义,而查询处理由数据驱动;在实时分析系统中,查询由用户随时定义,而查询处理由用户驱动。流处理系统所说的“实时”是指系统对用户预定义的查询实时给出最新的结果,而实时分析系统所说的”实时“是指用户随时给出的查询实时给出结果。没看出来区别?那更简化一下,就是**流处理系统强调计算结果的实时性,而实时分析系统强调用户交互的实时性**。对于股票交易、广告计算、网络异常监控等对数据结果新鲜度要求很高的场景,流处理系统也许是最佳选择;而对于交互式自定义报表、用户行为日志查询等对用户交互式体验要求很高的场景,实时分析系统可能会更胜一筹。
145 |
146 | 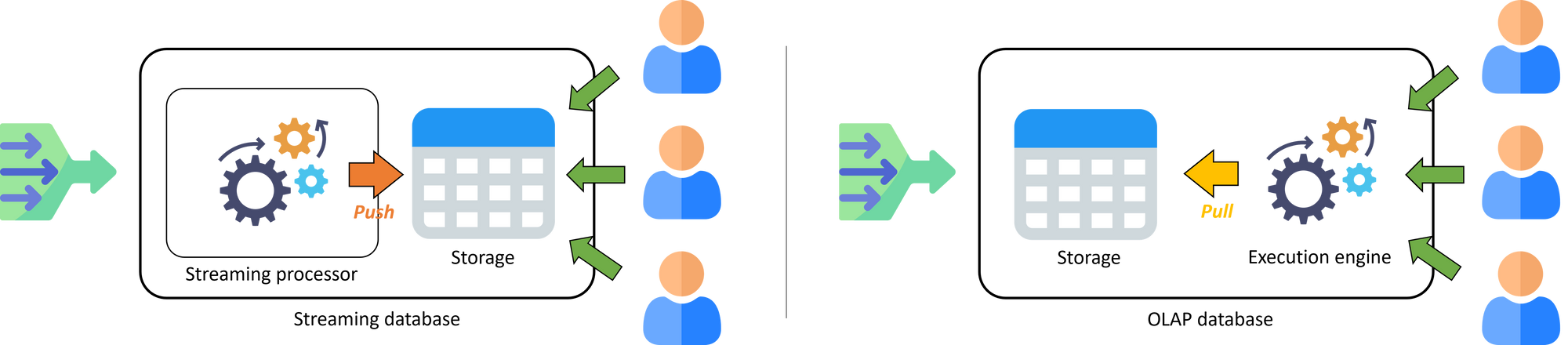
147 |
148 | 流数据库与实时分析数据库的区别。流数据库先计算后存储,计算由数据驱动,注重结果的实时性;实时分析数据库先存储后计算,计算由用户驱动,注重用户交互的实时性。
149 |
150 | 也许有人会说,既然实时分析系统能够对用户发送的查询实时给出结果,那么只要用户一直向实时分析系统中发送相同的查询,岂不是就能时刻保证结果的新鲜度,实现流处理系统的效果?这种想法有两个问题。第一个问题是实现复杂。用户毕竟不是机器,无法一直守在电脑前不间断的发送查询。想要实现这一效果无非只有两条路:要么是自己写程序定时发送查询,要么是自己运维编排工具(如 Airflow 等)循环发送查询。无论是哪条路,都意味着用户需要付出额外的代价运维外部系统(或程序)。第二个问题(也是最根本的问题)是成本过高。原因很简单:实时分析系统进行的是全量计算,而流处理系统进行的是增量计算。当所需处理的数据量较大时,实时分析系统不得不进行大量冗余的计算,带来巨量资源浪费。说到这里,相信大家应该也对之前本文第一章“为什么不拿个编排工具定时触发批处理系统做计算”这个问题有了答案。
151 |
152 | 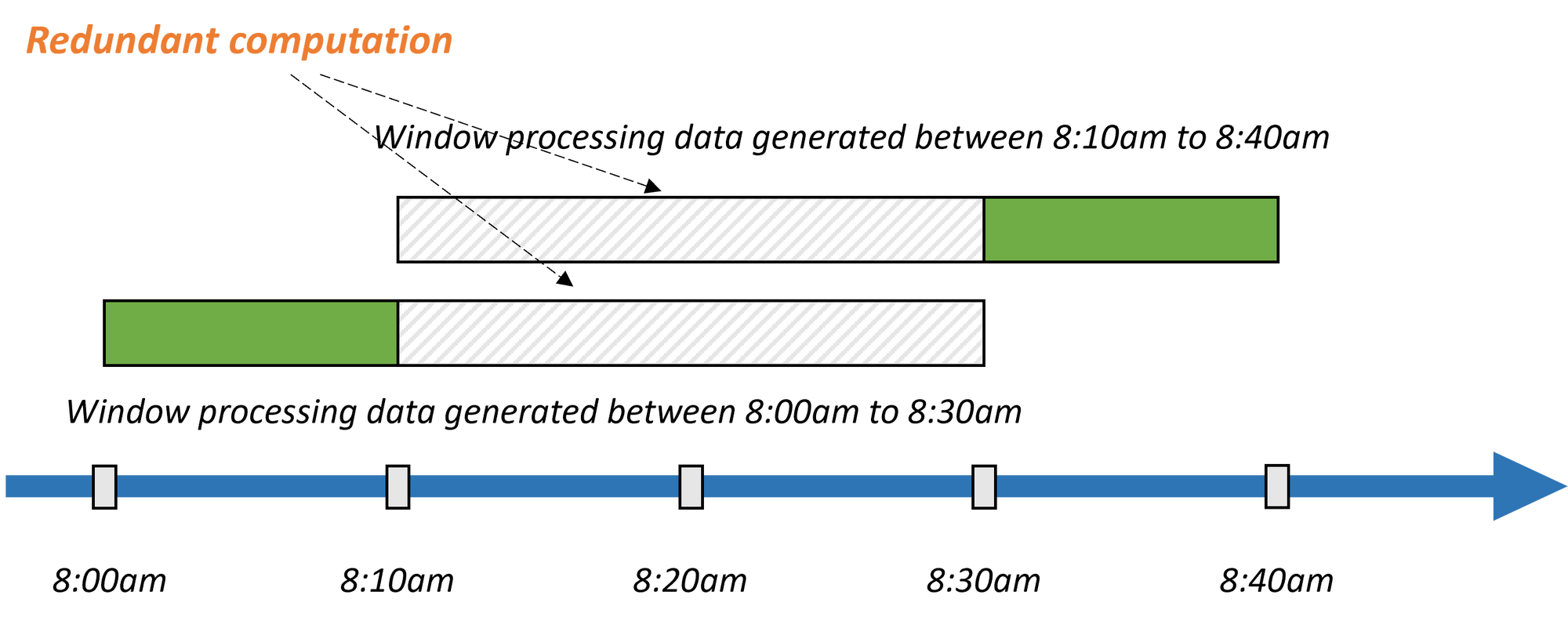
153 |
154 | 流处理系统采用增量计算方式避免不必要的重复计算。
155 |
156 | ### 流处理与实时物化视图
157 |
158 | 如今诸多实时分析系统都已经提供了实时物化视图功能,而实时物化视图就是流处理在数据库内的表达形式。有种观点认为,有了带有实时物化视图的分析系统,我们就不再需要需要单独的流处理系统。我认为这个观点并不成立。我们可以从以下几个方面考虑。
159 |
160 | - **资源竞争。**分析型数据库要解决的核心问题是在大规模数据集上高效的对复杂查询进行处理。在这类系统中,物化视图的定位本质上与数据库索引无异:都是计算的缓存。创建这样的缓存有两个好处:一方面,为经常处理的查询创建物化视图可以有效避免重复计算;另一方面,为不同查询的共享子查询创建物化视图可以加速查询执行。这样的定位实质上使得物化视图几乎不可能得到及时更新:积极主动的更新物化视图势必会持续抢占计算与内存资源,导致用户发送的查询得不到及时响应。为了防止这种“本末倒置”的事情发生,几乎所有分析性数据库采用的都是被动更新(也就是需要用户主动驱动)或是延迟更新(等到系统空闲时再更新)的方式。
161 | - **正确性保证。**如果说资源竞争问题可以通过多加计算节点来解决,那么正确性问题就不是实时分析系统的物化视图能够解决的问题了。批处理系统处理的是有限有边界数据,而流处理系统处理的是无限无边界数据。在处理无边界数据时,由于网络通信等各种原因可能产生数据乱序问题。而流处理系统特别设计了水位线等概念来解决这一问题。当乱序数据只有当按照某一特定顺序至行之后,输出的结果才被认为是完全正确的。然而,实时分析系统缺少水位线等基础设计,这使得无法达到流处理系统所能达到的正确性。而这种正确性保证在各种流处理场景(比如风险控制、广告计算等)中至关重要。缺少了正确性保证的系统,自然无法替代流处理系统。
162 |
163 | ### 流处理的软肋
164 |
165 | 流处理并不是万能的,流处理也不无法彻底替代批处理。有几方面的原因。
166 |
167 | - **灵活性。**流处理要求用户事先预定义好查询,从而来实现不间断的对最新数据进行实时计算。这一要求使得流处理在灵活性方面弱于批处理。正如本文之前所提到的,尽管流处理对查询相对固定的场景有很好的支持,但是当面对需要与用户频繁交互的场景时,批处理系统会更加适合。
168 | - **表达性。**我们在上文提到,流处理使用增量计算的方式通过避免冗余计算来减小资源开销。但增量计算也带来了一大问题,就是系统的表达性受限。主要原因就是并非所有计算都能够被增量的处理。一个很简单的例子就是求中位数:并没有增量算法保证精确求出中位数值。因此,当面对一些及其复杂的场景时,流处理系统难以胜任。
169 | - **计算成本。**流处理可以大幅降低实时计算的成本。但这并不意味着,流处理在任何场景下都能够比批处理更具成本优势。事实上,在对计算结果新鲜度不敏感的场景中(比如财务报表统计等),批处理才能更加节约成本。这是因为,为了在数据进入系统时便进行增量计算,流处理系统不得不持续维护计算状态,消耗资源。相比之下,批处理在只有用户请求到达时才进行计算,自然在无需实时结果的场景下节省成本。
170 |
171 | ### 流处理与批处理的融合
172 |
173 | 讨论了这么多,相信大家也看出来,流处理与批处理各具特点,很难在全场景中实现完全替代。既然这两种处理模式会共存,那很自然有些人会想到在同一套系统中同时支持流处理与批处理。不少系统已经进行了一些探索,这里就包括了 Flink、Spark 等这类老牌大数据系统。尽管这些系统的流批一体方案已经在一些场景落地,但是从实际的市场接受度来看,至少目前来讲,大多数用户仍然选择分别部署流处理、批处理两套系统。这其中不仅包含性能、稳定性的考量,同时也能在功能上各取所长:既保证了实时性,又同时能对归档数据运行复杂的 AI 算法、ad-hoc 分析等等。
174 |
175 | 目前阶段,RisingWave 还是更加专注于流处理本身,但也会通过 Sink、开放格式以及第三方 connector 等方式,方便用户使用第三方实时分析系统进行数据分析。事实上,在现在的 RisingWave 版本中,用户可以很轻松的将数据导出到 Snowflake、Redshift、Spark、ClickHouse 等系统中。我认可流批一体方案的意义,从长期来讲,RisingWave 也会进行这方面的探索。实际上,流数据库就是在做流处理与批处理的统一:当有新的数据流入流数据库时,流数据库就进行流计算;当有用户发起随机查询请求时,流数据库就进行批计算。至于内部实现如何,本文就不再展开赘述了,我们可以开一篇新文章详细探讨流批一体的设计。
176 |
177 | ## 后记
178 |
179 | 在文章最开始的时候,我提到自己已经在流处理领域做了 11 年的时间。然而,在 2015 到 2016 年的时候,我一度认为流处理的这座大厦已经建成,剩下的工作仅是小修小补。那时的我并没有想到,云计算的快速发展与普及让流处理系统在 2020 年之后重新回到了舞台的正中央,越来越多的人正在研究、开发、使用这一技术。本文是我最近几个月结合技术与商业化对流处理进行的思考。希望能够抛砖引玉,欢迎大家一起讨论!
180 |
--------------------------------------------------------------------------------
/流处理/README.md:
--------------------------------------------------------------------------------
1 | # 流处理
2 |
3 | 在批处理中,我们假设输入是有界的,即已知和有限的大小,所以批处理知道它何时完成输入的读取。例如,MapReduce 核心的排序操作必须读取其全部输入,然后才能开始生成输出:可能发生这种情况:最后一条输入记录具有最小的键,因此需要第一个被输出,所以提早开始输出是不可行的。实际上,很多数据是无界限的,因为它随着时间的推移而逐渐到达:你的用户在昨天和今天产生了数据,明天他们将继续产生更多的数据。除非你停业,否则这个过程永远都不会结束,所以数据集从来就不会以任何有意义的方式“完成”。因此,批处理程序必须将数据人为地分成固定时间段的数据块,例如,在每天结束时处理一天的数据,或者在每小时结束时处理一小时的数据。
4 |
5 | 日常批处理中的问题是,输入的变更只会在一天之后的输出中反映出来,这对于许多急躁的用户来说太慢了。为了减少延迟,我们可以更频繁地运行处理:比如说,在每秒钟的末尾:或者甚至更连续一些,完全抛开固定的时间切片,当事件发生时就立即进行处理,这就是**流处理(stream processing)**背后的想法。
6 |
7 | 流处理系统的设计是为了在数据到达时对其进行响应。这就要求它们实现一个由事件驱动的体系结构, 即系统的内部工作流设计为在接收到数据后立即连续监视新数据和调度处理。分布式的流处理也就是通常意义上的持续处理、数据富集以及对于无界数据的分析过程的组合。它是一个类似于 MapReduce 这样的通用计算模型,但是我们希望它能够在毫秒级别或者秒级别完成响应。这些系统经常被有向非循环图(Directed ACyclic Graphs,DAGs)来表示。
8 |
9 | 流处理的事件来源譬如有用户活动事件、传感器和写入数据库,流传输的方式有直接通过消息传送、通过消息代理、通过 DataPipeline 事件日志等。它们都是在无限的(永无止境的)流而不是固定大小的输入上持续进行;从这个角度来看,消息代理和事件日志可以视作文件系统的流式等价物。
10 |
11 | # 流处理的应用
12 |
13 | 我们常见处理流的方式有以下三种:
14 |
15 | - 我们可以将事件中的数据写入数据库,缓存,搜索索引或类似的存储系统,然后能被其他客户端查询。这是数据库与系统其他部分发生变更保持同步的好方法,特别是当流消费者是写入数据库的唯一客户端时。
16 |
17 | - 你能以某种方式将事件推送给用户,例如发送报警邮件或推送通知,或将事件流式传输到可实时显示的仪表板上。在这种情况下,人是流的最终消费者。
18 |
19 | - 你可以处理一个或多个输入流,并产生一个或多个输出流。流可能会经过由几个这样的处理阶段组成的流水线,最后再输出。
20 |
21 | 处理流以产生其他衍生流的操作中处理这样的流的代码片段,被称为算子(operator)或作业(job),这与我们讨论过的 Unix 进程和 MapReduce 作业密切相关,数据流的模式是相似的:一个流处理器以只读的方式使用输入流,并将其输出以仅追加的方式写入一个不同的位置。与批量作业相比的一个关键区别是,流不会结束。这种差异会带来很多隐含的结果,排序对无界数据集没有意义,因此无法使用排序合并联接。容错机制也必须改变:对于已经运行了几分钟的批处理作业,可以简单地从头开始重启失败任务,但是对于已经运行数年的流作业,重启后从头开始跑可能并不是一个可行的选项。
22 |
23 | 长期以来,流处理一直用于监控目的,如果某个事件发生,单位希望能得到警报。例如:
24 |
25 | - 欺诈检测系统需要确定信用卡的使用模式是否有意外地变化,如果信用卡可能已被盗刷,则锁卡。
26 | - 交易系统需要检查金融市场的价格变化,并根据指定的规则进行交易。
27 | - 制造系统需要监控工厂中机器的状态,如果出现故障,可以快速定位问题。
28 | - 军事和情报系统需要跟踪潜在侵略者的活动,并在出现袭击征兆时发出警报。
29 |
30 | ## 复合事件处理
31 |
32 | 复合事件处理(complex, event processing, CEP)是 20 世纪 90 年代为分析事件流而开发出的一种方法,尤其适用于需要搜索某些事件模式的应用。与正则表达式允许你在字符串中搜索特定字符模式的方式类似,CEP 允许你指定规则以在流中搜索某些事件模式。CEP 系统通常使用高层次的声明式查询语言,比如 SQL,或者图形用户界面,来描述应该检测到的事件模式。这些查询被提交给处理引擎,该引擎消费输入流,并在内部维护一个执行所需匹配的状态机。当发现匹配时,引擎发出一个复合事件(complex event)(因此得名),并附有检测到的事件模式详情。
33 |
34 | 在这些系统中,查询和数据之间的关系与普通数据库相比是颠倒的。通常情况下,数据库会持久存储数据,并将查询视为临时的:当查询进入时,数据库搜索与查询匹配的数据,然后在查询完成时丢掉查询。CEP 引擎反转了角色:查询是长期存储的,来自输入流的事件不断流过它们,搜索匹配事件模式的查询。CEP 的实现包括 Esper,IBM InfoSphere Streams,Apama,TIBCO StreamBase 和 SQLstream。像 Samza 这样的分布式流处理组件,支持使用 SQL 在流上进行声明式查询。
35 |
36 | ## 流分析
37 |
38 | 使用流处理的另一个领域是对流进行分析。CEP 与流分析之间的边界是模糊的,但一般来说,分析往往对找出特定事件序列并不关心,而更关注大量事件上的聚合与统计指标,例如:
39 |
40 | - 测量某种类型事件的速率(每个时间间隔内发生的频率)
41 | - 滚动计算一段时间窗口内某个值的平均值
42 | - 将当前的统计值与先前的时间区间的值对比(例如,检测趋势,当指标与上周同比异常偏高或偏低时报警)
43 |
44 | 这些统计值通常是在固定时间区间内进行计算的,例如,你可能想知道在过去 5 分钟内服务每秒查询次数的均值,以及此时间段内响应时间的第 99 百分位点。在几分钟内取平均,能抹平秒和秒之间的无关波动,且仍然能向你展示流量模式的时间图景。聚合的时间间隔称为窗口(window)。
45 |
46 | 流分析系统有时会使用概率算法,例如 Bloom filter 来管理成员资格,HyperLogLog,用于基数估计以及各种百分比估计算法。概率算法产出近似的结果,但比起精确算法的优点是内存使用要少得多。使用近似算法有时让人们觉得流处理系统总是有损的和不精确的,但这是错误看法:流处理并没有任何内在的近似性,而概率算法只是一种优化。许多开源分布式流处理框架的设计都是针对分析设计的:例如 Apache Storm,Spark Streaming,Flink,Concord,Samza 和 Kafka Streams 。托管服务包括 Google Cloud Dataflow 和 Azure Stream Analytics。
47 |
48 | ## 维护物化视图
49 |
50 | 数据库的变更流可以用于维护衍生数据系统(如缓存,搜索索引和数据仓库),使其与源数据库保持最新;我们可以将这些示例视作维护物化视图(Materialized View)的一种具体场景:在某个数据集上衍生出一个替代视图以便高效查询,并在底层数据变更时更新视图。同样,在事件溯源中,应用程序的状态是通过应用(apply)事件日志来维护的;这里的应用状态也是一种物化视图。与流分析场景不同的是,仅考虑某个时间窗口内的事件通常是不够的:构建物化视图可能需要任意时间段内的所有事件,除了那些可能由日志压缩丢弃的过时事件。实际上,你需要一个可以一直延伸到时间开端的窗口。
51 |
52 | 原则上讲,任何流处理组件都可以用于维护物化视图,尽管“永远运行”与一些面向分析的框架假设的“主要在有限时间段窗口上运行”背道而驰,Samza 和 Kafka Streams 支持这种用法,建立在 Kafka 对日志压缩 comp 的支持上。
53 |
54 | ## 在流上搜索
55 |
56 | 除了允许搜索由多个事件构成模式的 CEP 外,有时也存在基于复杂标准(例如全文搜索查询)来搜索单个事件的需求。例如,媒体监测服务可以订阅新闻文章 Feed 与来自媒体的播客,搜索任何关于公司,产品或感兴趣的话题的新闻。这是通过预先构建一个搜索查询来完成的,然后不断地将新闻项的流与该查询进行匹配。在一些网站上也有类似的功能:例如,当市场上出现符合其搜索条件的新房产时,房地产网站的用户可以要求网站通知他们。Elasticsearch 的这种过滤器功能,是实现这种流搜索的一种选择。
57 |
58 | 传统的搜索引擎首先索引文件,然后在索引上跑查询。相比之下,搜索一个数据流则反了过来:查询被存储下来,文档从查询中流过,就像在 CEP 中一样。在简单的情况就是,你可以为每个文档测试每个查询。但是如果你有大量查询,这可能会变慢。为了优化这个过程,可以像对文档一样,为查询建立索引。因而收窄可能匹配的查询集合。
59 |
60 | ## 消息传递和 RPC
61 |
62 | 消息传递系统可以作为 RPC 的替代方案,即作为一种服务间通信的机制,比如在 Actor 模型中所使用的那样。尽管这些系统也是基于消息和事件,但我们通常不会将其视作流处理组件:
63 |
64 | - Actor 框架主要是管理模块通信的并发和分布式执行的一种机制,而流处理主要是一种数据管理技术。
65 |
66 | - Actor 之间的交流往往是短暂的,一对一的;而事件日志则是持久的,多订阅者的。
67 |
68 | - Actor 可以以任意方式进行通信(允许包括循环的请求/响应),但流处理通常配置在无环流水线中,其中每个流都是一个特定作业的输出,由良好定义的输入流中派生而来。
69 |
70 | 也就是说,RPC 类系统与流处理之间有一些交叉领域。例如,Apache Storm 有一个称为分布式 RPC 的功能,它允许将用户查询分散到一系列也处理事件流的节点上;然后这些查询与来自输入流的事件交织,而结果可以被汇总并发回给用户。也可以使用 Actor 框架来处理流。但是,很多这样的框架在崩溃时不能保证消息的传递,除非你实现了额外的重试逻辑,否则这种处理不是容错的。
71 |
72 | # 消息代理的类别
73 |
74 | 目前的消息代理可以分为两种风格:
75 |
76 | - AMQP/JMS 风格的消息代理:代理将单条消息分配给消费者,消费者在成功处理单条消息后确认消息。消息被确认后从代理中删除。这种方法适合作为一种异步形式的 RPC,例如在任务队列中,消息处理的确切顺序并不重要,而且消息在处理完之后,不需要回头重新读取旧消息。
77 |
78 | - 基于日志的消息代理:代理将一个分区中的所有消息分配给同一个消费者节点,并始终以相同的顺序传递消息。并行是通过分区实现的,消费者通过存档最近处理消息的偏移量来跟踪工作进度。消息代理将消息保留在磁盘上,因此如有必要的话,可以回跳并重新读取旧消息。
79 |
80 | # Streaming Computing CheatSheet | 流处理原理与机制概述
81 |
82 | 自从数据处理需求超过了传统数据库能有效处理的数据量之后,Hadoop 等各种基于 MapReduce 的海量数据处理系统应运而生。从 2004 年 Google 发表 MapReduce 论文开始,经过近 10 年的发展,基于 Hadoop 开源生态或者其它相应系统的海量数据处理已经成为业界的基本需求。
83 |
84 | Spark 在当时除了在某些场景比 Hadoop MapReduce 带来几十到上百倍的性能提升外,还提出了用一个统一的引擎支持批处理、流处理、交互式查询、机器学习等常见的数据处理场景。看过在一个 Notebook 里完成上述所有场景的 Spark 演示,对比之前的数据流程开发,对很多开发者来说不难做出选择。经过几年的发展,Spark 已经被视为可以完全取代 Hadoop 中的 MapReduce 引擎。
85 |
86 | 正在 Spark 如日中天高速发展的时候,2016 年左右 Flink 开始进入大众的视野并逐渐广为人知。为什么呢?原来在人们开始使用 Spark 之后,发现 Spark 虽然支持各种常见场景,但并不是每一种都同样好用。数据流的实时处理就是其中相对较弱的一环。Flink 凭借更优的流处理引擎,同时也支持各种处理场景,成为 Spark 的有力挑战者。
87 |
88 | 分布式的流处理也就是通常意义上的持续处理、数据富集以及对于无界数据的分析过程的组合。它是一个类似于 MapReduce 这样的通用计算模型,但是我们希望它能够在毫秒级别或者秒级别完成响应。这些系统经常被有向非循环图(Directed ACyclic Graphs,DAGs)来表示。
89 |
90 | 
91 |
92 | DAG 主要功能即是用图来表示链式的任务组合,而在流处理系统中,我们便常常用 DAG 来描述一个流工作的拓扑。笔者自己是从 Akka 的 Stream 中的术语得到了启发。如下图所示,数据流经过一系列的处理器从源点流动到了终点,也就是用来描述这流工作。谈到 Akka 的 Streams,我觉得要着重强调下分布式这个概念,因为即使也有一些单机的解决方案可以创建并且运行 DAG,但是我们仍然着眼于那些可以运行在多机上的解决方案。
93 |
94 | 流式数据平台的在线可进化性(online-evolvable)。就像是一个流数据平台本身,因为不会有一个零流量的时刻,所以所有的维护和升级都需要保证同步在线完成,而且期间最好没有任何用户可感知到的性能弱化或者服务差别。
95 |
96 | # 机制与考量
97 |
98 | ## Runtime Model | 运行模型
99 |
100 | 运行模型就是包含了数据模型与处理模型,
101 |
102 | Spark 的数据模型是弹性分布式数据集 RDD(Resilient Distributed Datasets)。比起 MapReduce 的文件模型,RDD 是一个更抽象的模型,RDD 靠血缘(lineage)等方式来保证可恢复性。Flink 的基本数据模型是数据流,及事件(Event)的序列。数据流作为数据的基本模型可能没有表或者数据块直观熟悉,但是可以证明是完全等效的。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。
103 |
104 | 主要有两种不同的方法来构建流处理系统: Native Streaming 与 Micro-Batching。
105 |
106 | ### Micro-Batching
107 |
108 | Micro-Batching,大量短的 Batches 会从输入的记录中创建出然后经过整个系统的处理,这些 Batches 会根据预设好的时间常量进行创建,通常是每隔几秒创建一批。
109 |
110 | 
111 |
112 | 对于 Micro-Batching 而言,将流切分为小的 Batches 不可避免地会降低整个系统的变现性,也就是可读性。而一些类似于状态管理的或者 joins、splits 这些操作也会更加难以实现,因为系统必须去处理整个 Batch。另外,每个 Batch 本身也将架构属性与逻辑这两个本来不应该被糅合在一起的部分相连接了起来。而 Micro-Batching 的优势在于它的容错与负载均衡会更加易于实现,它只要简单地在某个节点上处理失败之后转发给另一个节点即可。最后,值得一提的是,我们可以在 Native Streaming 的基础上快速地构建 Micro-Batching 的系统。
113 |
114 | 从 Spark 2.0 开始引入的 Structured Streaming 重新整理了流处理的语义,支持按事件时间处理和端到端的一致性。虽然在功能上还有不少限制,比之前已经有了长足的进步。不过 micro batch 执行方式带来的问题还是存在,特别在规模上去以后性能问题会比较突出。最近 Spark 受一些应用场景的推动,也开始开发持续执行模式。
115 |
116 | ### Native Streaming
117 |
118 | Native Streaming 意味着所有输入的记录或者事件都会根据它们进入的顺序一个接着一个的处理。
119 |
120 | 
121 |
122 | Native Streaming 的表现性会更好一点,因为它是直接处理输入的流本身的,并没有被一些不自然的抽象方法所限制住。同时,因为所有的记录都是在输入之后立马被处理,这样对于请求方而言响应的延迟就会优于那种 Micro-Batching 系统。处理这些,有状态的操作符也会更容易被实现,我们在下文中也会描述这个特点。不过 Native Streaming 系统往往吞吐量会比较低,并且因为它需要去持久化或者重放几乎每一条请求,它的容错的代价也会更高一些。并且负载均衡也是一个不可忽视的问题,举例而言,我们根据键对数据进行了分割并且想做进一步地处理。如果某些键对应的分区因为某些原因需要更多地资源去处理,那么这个分区往往就会变成整个系统的瓶颈。
123 |
124 | Flink 用数据流上的变换(算子)来描述数据处理。每个算子生成一个新的数据流。
125 |
126 | 
127 |
128 | ## State Management | 状态管理
129 |
130 | AI 的瓶颈在计算,计算的瓶颈在存储。
131 |
132 | 大部分这些应用都有状态性的逻辑处理过程,因此,框架本身应该允许开发者去维护、访问以及更新这些状态信息。
133 |
134 | 比如常见的窗口聚合,如果批处理的数据时间段比窗口大,是可以不考虑状态的,用户逻辑经常会忽略这个问题。但是当批处理时间段变得比窗口小的时候,一个批的结果实际上依赖于以前处理过的批。这时,因为批处理引擎一般没有这个需求不会有很好的内置支持,维护状态就成为了用户需要解决的事情。比如窗口聚合的情况用户就要加一个中间结果表记住还没有完成的窗口的结果。这样当用户把批处理时间段变短的时候就会发现逻辑变复杂了。这是早期 Spark Streaming 用户 经常碰到的问题,直到 Structured Streaming 出来才得到缓解。
135 |
136 | Flink 还有一个非常独特的地方是在引擎中引入了托管状态(managed state)。要理解托管状态,首先要从有状态处理说起。如果处理一个事件(或一条数据)的结果只跟事件本身的内容有关,称为无状态处理;反之结果还和之前处理过的事件有关,称为有状态处理。稍微复杂一点的数据处理,比如说基本的聚合,都是有状态处理。Flink 很早就认为没有好的状态支持是做不好流处理的,因此引入了 managed state 并提供了 API 接口。
137 |
138 | 
139 |
140 | ## Message Delivery Guarantees | 消息的可达性
141 |
142 | 一般来说,对于消息投递而言,我们有至多一次(at most once)、至少一次(at least once)以及恰好一次(exactly once)这三种方案。
143 |
144 | - At most once 投递保证每个消息会被投递 0 次或者 1 次,在这种机制下消息很有可能会丢失。
145 |
146 | - At least once 投递保证了每个消息会被默认投递多次,至少保证有一次被成功接收,信息可能有重复,但是不会丢失。
147 |
148 | - Exactly once 意味着每个消息对于接收者而言正好被接收一次,保证即不会丢失也不会重复。
149 |
150 | ## Back Pressure | 背压
151 |
152 | 流处理系统需要能优雅地处理反压(Back Pressure)问题。反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。反压如果不能得到正确的处理,可能会导致资源耗尽甚至系统崩溃。目前主流的流处理系统 Storm/JStorm/Spark Streaming/Flink 都已经提供了反压机制,不过其实现各不相同。
153 |
154 | - Storm 是通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。具体实现可以看这个 JIRA STORM-886。
155 |
156 | - JStorm 认为直接停止 Spout 的发送太过暴力,存在大量问题。当下游出现阻塞时,上游停止发送,下游消除阻塞后,上游又开闸放水,过了一会儿,下游又阻塞,上游又限流,如此反复,整个数据流会一直处在一个颠簸状态。所以 JStorm 是通过逐级降速来进行反压的,效果会较 Storm 更为稳定,但算法也更复杂。另外 JStorm 没有引入 Zookeeper 而是通过 TopologyMaster 来协调拓扑进入反压状态,这降低了 Zookeeper 的负载。
157 |
158 | - Flink 没有使用任何复杂的机制来解决反压问题,因为根本不需要那样的方案!它利用自身作为纯数据流引擎的优势来优雅地响应反压问题。
159 |
160 | ## Failures Handling | 异常处理
161 |
162 | 在一个流处理系统中,错误可能经常在不同的层级发生,譬如网络分割、磁盘错误或者某个节点莫名其妙挂掉了。平台要能够从这些故障中顺利恢复,并且能够从最后一个正常的状态继续处理而不会损害结果。
163 |
164 | ## User Interface | 通用用户接口
165 |
166 | SQL(dynamic tables)
167 |
168 | DStream / Dset API(iteration)
169 |
170 | ```
171 | val stats = stream.keyBy().timeWindow().sum(...)
172 | ```
173 |
174 | Function API(events, state, time)
175 |
176 | ```
177 | (event, state, time).match{...}
178 |
179 | processEvent();
180 |
181 | storeState();
182 | ```
183 |
184 | 编程模型往往会决定很多它的特性,并且应该足够处理所有可能的用户案例。很多的流处理系统都会提供 Functional Primitives(函数式单元),即能够在独立信息级别进行处理的函数,像 map、filter 这样易于实现与扩展的一些函数;同样也应提供像 aggregation 这样的跨信息处理函数以及像 join 这样的跨流进行操作的函数,虽然这样的操作会难以扩展。
185 |
186 | 对于编程模型而言,又可以分为 Compositional(组合式)与 Declarative(声明式)。组合式会提供一系列的基础构件,类似于源读取与操作符等等,开发人员需要将这些基础构件组合在一起然后形成一个期望的拓扑结构。新的构件往往可以通过继承与实现某个接口来创建。另一方面,声明式 API 中的操作符往往会被定义为高阶函数。声明式编程模型允许我们利用抽象类型和所有其他的精选的材料来编写函数式的代码以及优化整个拓扑图。同时,声明式 API 也提供了一些开箱即用的高等级的类似于窗口管理、状态管理这样的操作符。
187 |
188 | Spark 的初衷之一就是用统一的编程模型来解决用户的各种需求,在这方面一直很下功夫。最初基于 RDD 的 API 就可以做各种类型的数据处理。后来为了简化用户开发,逐渐推出了更高层的 DataFrame(在 RDD 中加了列变成结构化数据)和 Datasets(在 DataFrame 的列上加了类型),并在 Spark 2.0 中做了整合(DataFrame = DataSet[Row])。Spark SQL 的支持也比较早就引入了。在加上各个处理类型 API 的不断改进,比如 Structured Streaming 以及和机器学习深度学习的交互,到了今天 Spark 的 API 可以说是非常好用的,也是 Spark 最强的方面之一。
189 |
190 | # 生态圈
191 |
192 | 目前已经有了各种各样的流处理框架,自然也无法在本文中全部攘括。所以我必须将讨论限定在某些范围内,本文中是选择了所有 Apache 旗下的流处理的框架进行讨论,并且这些框架都已经提供了 Scala 的语法接口。主要的话就是 Storm 以及它的一个改进 Trident Storm,还有就是当下正火的 Spark。最后还会讨论下来自 LinkedIn 的 Samza 以及比较有希望的 Apache Flink。笔者个人觉得这是一个非常不错的选择,因为虽然这些框架都是出于流处理的范畴,但是他们的实现手段千差万别。
193 |
194 | 
195 |
196 | - Apache Storm 最初由 Nathan Marz 以及他的 BackType 的团队在 2010 年创建。后来它被 Twitter 收购并且开源出来,并且在 2014 年变成了 Apache 的顶层项目。毫无疑问,Storm 是大规模流处理中的先行者并且逐渐成为了行业标准。Storm 是一个典型的 Native Streaming 系统并且提供了大量底层的操作接口。另外,Storm 使用了 Thrift 来进行拓扑的定义,并且提供了大量其他语言的接口。
197 |
198 | - Trident 是一个基于 Storm 构建的上层的 Micro-Batching 系统,它简化了 Storm 的拓扑构建过程并且提供了类似于窗口、聚合以及状态管理等等没有被 Storm 原生支持的功能。另外,Storm 是实现了至多一次的投递原则,而 Trident 实现了恰巧一次的投递原则。Trident 提供了 Java, Clojure 以及 Scala 接口。
199 |
200 | - 众所周知,Spark 是一个非常流行的提供了类似于 SparkSQL、Mlib 这样内建的批处理框架的库,并且它也提供了 Spark Streaming 这样优秀地流处理框架。Spark 的运行环境提供了批处理功能,因此,Spark Streaming 毫无疑问是实现了 Micro-Batching 机制。输入的数据流会被接收者分割创建为 Micro-Batches,然后像其他 Spark 任务一样进行处理。Spark 提供了 Java, Python 以及 Scala 接口。
201 |
202 | - Samza 最早是由 LinkedIn 提出的与 Kafka 协同工作的优秀地流解决方案,Samza 已经是 LinkedIn 内部关键的基础设施之一。Samza 重负依赖于 Kafaka 的基于日志的机制,二者结合地非常好。Samza 提供了 Compositional 接口,并且也支持 Scala。
203 |
204 | * 最后聊聊 Flink. Flink 可谓一个非常老的项目了,最早在 2008 年就启动了,不过目前正在吸引越来越多的关注。Flink 也是一个 Native Streaming 的系统,并且提供了大量高级别的 API。Flink 也像 Spark 一样提供了批处理的功能,可以作为流处理的一个特殊案例来看。Flink 强调万物皆流,这是一个绝对的更好地抽象,毕竟确实是这样。
205 |
206 | 下表就简单列举了上述几个框架之间的特性:
207 | 
208 |
209 | # Links
210 |
211 | - http://dist-prog-book.com/chapter/3/message-passing.html#akka
212 |
--------------------------------------------------------------------------------
/计算处理模式/Lambda 架构.md:
--------------------------------------------------------------------------------
1 | # Lambda 架构
2 |
3 | 如果批处理用于重新处理历史数据,并且流处理用于处理最近的更新,那么如何将这两者结合起来?Lambda 架构是这方面的一个建议,引起了很多关注。Lambda 架构的核心思想是通过将不可变事件附加到不断增长的数据集来记录传入数据,这类似于事件溯源,为了从这些事件中衍生出读取优化的视图,Lambda 架构建议并行运行两个不同的系统:批处理系统(如 Hadoop MapReduce)和独立的流处理系统(如 Storm)。
4 |
5 | 在 Lambda 方法中,流处理器消耗事件并快速生成对视图的近似更新;批处理器稍后将使用同一组事件并生成衍生视图的更正版本。这个设计背后的原因是批处理更简单,因此不易出错,而流处理器被认为是不太可靠和难以容错的,流处理可以使用快速近似算法,而批处理使用较慢的精确算法。
6 |
7 | Lambda 架构是一种有影响力的想法,它将数据系统的设计变得更好,尤其是通过推广这样的原则:在不可变事件流上建立衍生视图,并在需要时重新处理事件。但是我也认为它有一些实际问题:
8 |
9 | - 在批处理和流处理框架中维护相同的逻辑是很显著的额外工作。虽然像 Summingbird 这样的库提供了一种可以在批处理和流处理的上下文中运行的计算抽象。调试,调整和维护两个不同系统的操作复杂性依然存在。
10 |
11 | - 由于流管道和批处理管道产生独立的输出,因此需要合并它们以响应用户请求。如果计算是基于滚动窗口的简单聚合,则合并相当容易,但如果视图基于更复杂的操作(例如连接和会话化)而导出,或者输出不是时间序列,则会变得非常困难。
12 |
13 | - 尽管有能力重新处理整个历史数据集是很好的,但在大型数据集上这样做经常会开销巨大。因此,批处理流水线通常需要设置为处理增量批处理(例如,在每小时结束时处理一小时的数据),而不是重新处理所有内容。这引发了“关于时间的推理”中讨论的问题,例如处理分段器和处理跨批次边界的窗口。增加批量计算会增加复杂性,使其更类似于流式传输层,这与保持批处理层尽可能简单的目标背道而驰。
14 |
15 | ## 统一批处理和流处理
16 |
17 | 最近的工作使得 Lambda 架构的优点在没有其缺点的情况下得以实现,允许批处理计算(重新处理历史数据)和流计算(处理事件到达时)在同一个系统中实现。在一个系统中统一批处理和流处理需要以下功能,这些功能越来越广泛:
18 |
19 | - 通过处理最近事件流的相同处理引擎来重放历史事件的能力。例如,基于日志的消息代理可以重放消息,某些流处理器可以从 HDFS 等分布式文件系统读取输入。
20 |
21 | - 对于流处理器来说,恰好一次语义,即确保输出与未发生故障的输出相同,即使事实上发生故障。与批处理一样,这需要丢弃任何失败任务的部分输出。
22 |
23 | - 按事件时间进行窗口化的工具,而不是按处理时间进行窗口化,因为处理历史事件时,处理时间毫无意义。例如,Apache Beam 提供了用于表达这种计算的 API,然后可以使用 Apache Flink 或 Google Cloud Dataflow 运行。
24 |
--------------------------------------------------------------------------------
/计算处理模式/README.md:
--------------------------------------------------------------------------------
1 | # 数据处理架构
2 |
3 | # OLTP 与 OLAP
4 |
5 | 数十年来,数据和数据处理在企业中无处不在。多年来,数据的收集和使用一直在增长,公司已经设计并构建了基础架构来管理数据。大多数企业实施的传统架构区分了两种类型的数据处理:事务处理(OLTP, Online Transactional Processing)和分析处理(OLAP, Online Analytical Processing)。在互联网浪潮出现之前,企业的数据量普遍不大,特别是核心的业务数据,通常一个单机的数据库就可以保存。在业务数据处理的早期,对数据库的写入通常对应于正在进行的商业交易:进行销售,向供应商下订单,支付员工工资等等。随着数据库扩展到那些没有不涉及钱易手的业务,我们仍然使用术语交易(transaction)来代指形成一个逻辑单元的一组读写。事务不一定具有 ACID(原子性,一致性,隔离性和持久性)属性。事务处理只是意味着允许客户端进行低延迟读取和写入,而不是只能定期运行(例如每天一次)的批量处理作业。
6 |
7 | 同时,数据库也开始越来越多地用于数据分析,这些数据分析具有非常不同的访问模式。通常,分析查询需要扫描大量记录,每个记录只读取几列,并计算汇总统计信息(如计数,总和或平均值),而不是将原始数据返回给用户。早期所有的线上请求(OLTP) 和后台分析 (OLAP) 都跑在同一个数据库实例上。后来随着数据量不断增大,在二十世纪八十年代末和九十年代初期,公司倾向于在单独的数据库上运行分析,这个单独的数据库被称为数据仓库(data warehouse)。在这样的背景下,以 Hadoop 为代表的大数据技术开始蓬勃发展,它用许多相对廉价的 x86 机器构建了一个数据分析平台,用并行的能力破解大数据集的计算问题。由此,架构师把存储划分成线上业务和数据分析两个模块。如下图所示,业务库的数据通过 ETL 工具抽取出来,导入专用的分析平台。业务数据库专注提供 TP 能力,分析平台提供 AP 能力,各施其职,看起来已经很完美了。但其实这个架构也有自己的不足。
8 |
9 | 
10 |
11 | | 属性 | 事务处理 OLTP | 分析系统 OLAP |
12 | | ------------ | ---------------------------- | ------------------------ |
13 | | 主要读取模式 | 查询少量记录,按键读取 | 在大批量记录上聚合 |
14 | | 主要写入模式 | 随机访问,写入要求低延时 | 批量导入(ETL),事件流 |
15 | | 主要用户 | 终端用户,通过 Web 应用 | 内部数据分析师,决策支持 |
16 | | 处理的数据 | 数据的最新状态(当前时间点) | 随时间推移的历史事件 |
17 | | 数据集尺寸 | GB ~ TB | TB ~ PB |
18 |
--------------------------------------------------------------------------------
/计算处理模式/事务处理.md:
--------------------------------------------------------------------------------
1 | # 事务处理
2 |
3 | 公司将各种应用程序用于日常业务活动,例如企业资源规划(ERP)系统,客户关系管理(CRM)软件和基于 Web 的应用程序。这些系统通常设计有单独的层,用于数据处理(应用程序本身)和数据存储(事务数据库系统):
4 |
5 | 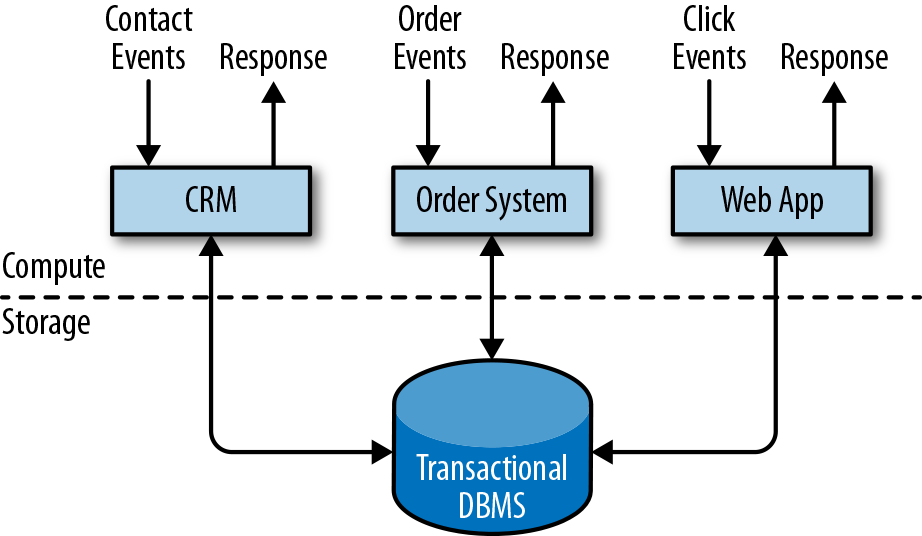
6 |
7 | 应用程序通常连接到外部服务或直接面向用户,并持续处理传入的事件,如网站上的订单,电子邮件或点击。处理事件时,应用程序将会读取远程数据库的状态,或者通过运行事务来更新它。通常,一个数据库系统可以服务于多个应用程序,它们有时会访问相同的数据库或表。
8 |
--------------------------------------------------------------------------------
/计算处理模式/批处理与流处理.md:
--------------------------------------------------------------------------------
1 | # 批处理与流处理
2 |
3 | 数据集成的目标是,确保数据最终能在所有正确的地方表现出正确的形式。这样做需要消费输入,转换,连接,过滤,聚合,训练模型,评估,以及最终写出适当的输出。批处理和流处理是实现这一目标的工具。批处理和流处理的输出是衍生数据集,例如搜索索引,物化视图,向用户显示的建议,聚合指标等;流处理允许将输入中的变化以低延迟反映在衍生视图中,而批处理允许重新处理大量累积的历史数据以便将新视图导出到现有数据集上。批处理和流处理有许多共同的原则,主要的根本区别在于流处理器在无限数据集上运行,而批处理输入是已知的有限大小。处理引擎的实现方式也有很多细节上的差异,但是这些区别已经开始模糊。
4 |
5 | Spark 在批处理引擎上执行流处理,将流分解为微批次(Micro Batches),而 Apache Flink 则在流处理引擎上执行批处理。原则上,一种类型的处理可以用另一种类型来模拟,但是性能特征会有所不同:例如,在跳跃或滑动窗口上,微批次可能表现不佳。批处理有着很强的函数式风格(即使其代码不是用函数式语言编写的):它鼓励确定性的纯函数,其输出仅依赖于输入,除了显式输出外没有副作用,将输入视作不可变的,且输出是仅追加的。流处理与之类似,但它扩展了算子以允许受管理的,容错的状态。具有良好定义的输入和输出的确定性函数的原理不仅有利于容错,也简化了有关组织中数据流的推理。无论衍生数据是搜索索引,统计模型还是缓存,采用这种观点思考都是很有帮助的:将其视为从一个东西衍生出另一个的数据管道,将一个系统的状态变更推送至函数式应用代码中,并将其效果应用至衍生系统中。
6 |
7 | 原则上,衍生数据系统可以同步地维护,就像关系数据库在与被索引表写入操作相同的事务中同步更新辅助索引一样。然而,异步是基于事件日志的系统稳健的原因:它允许系统的一部分故障被抑制在本地,而如果任何一个参与者失败,分布式事务将中止,因此它们倾向于通过将故障传播到系统的其余部分来放大故障。我们在“分区与次级索引”中看到,二级索引经常跨越分区边界。具有二级索引的分区系统需要将写入发送到多个分区(如果索引按关键词分区的话)或将读取发送到所有分区。如果索引是异步维护的,这种交叉分区通信也是最可靠和最可扩展的。
8 |
9 | ## 批处理与流处理
10 |
11 | 流处理和批处理之间的差异对于应用程序来说也是非常重要的。为批处理而构建的应用程序,通过定义处理数据,具有延迟性。在具有多个步骤的数据管道中,这些延迟会累积。此外,新数据的到达与该数据的处理之间的延迟将取决于直到下一批处理窗口的时间--从在某些情况下完全没有时间到批处理窗口之间的全部时间不等,这些数据是在批处理开始后到达的。因此,批处理应用程序(及其用户)不能依赖一致的响应时间,需要相应地调整以适应这种不一致性和更大的延迟。
12 |
13 | Flink、Beam 等都支持流式处理优先,将批处理视为流式处理的特殊情况的理念,这个理念也经常被认为是构建跨实时和离线数据应用程序的强大方式,可以大大降低数据基础设施的复杂性。“批处理只是流式处理的一个特例”并不意味着所有的流式处理器都能用于批处理——流式处理器的出现并没有让批处理器变得过时:
14 |
15 | - 纯流式处理系统在批处理工作负载时其实是很慢的。没有人会认为使用流式处理器来分析海量数据是个好主意。
16 |
17 | - 像 Apache Beam 这样的统一 API 通常会根据数据是持续的(无界)还是固定的(有界)将工作负载委托给不同的运行时。
18 |
19 | - Flink 提供了一个流式 API,可以处理有界和无界的场景,同时仍然提供了单独的 DataSet API 和运行时用于批处理,因为速度会更快。
20 |
--------------------------------------------------------------------------------
/计算处理模式/量子计算/README.md:
--------------------------------------------------------------------------------
1 | # 量子计算
2 |
3 | 量子计算是一种遵循量子力学规律调控量子信息单元进行计算的新型计算模式,即利用量子叠加和纠缠等物理特性,以微观粒子构成的量子比特为基本单元,通过量子态的受控演化实现计算处理。
4 |
5 | 与传统计算机相比,量子计算机能够实现算力呈指数级规模拓展和爆发式增长,形成“量子优越性”。传统计算机的基础原理是二极管和逻辑门,每一个信息单元叫做比特,只能代表 0 或者 1 中的任意一个数字,对二进制数字或字节组成的信息进行存储和处理;而量子态叠加原理使得每个量子比特同时处于比特 0 和比特 1 的状态,通过两种状态的叠加实现并行存储和计算。这样操纵 1 个量子比特的量子计算机可以同时操纵 2 个状态,当一个量子计算机同时操控 n 个量子比特的时候,它实际上能够同时操控 2n 个状态。
6 |
7 | # 量子计算优势
8 |
9 | 量子计算最主要的价值可以归纳为两点:开源(提高算力)+节流(降低能耗)。
10 |
11 | 首先是对算力的提升:量子计算的核心优势是可以实现高速并行计算。在计算机科学中,无论经典计算还是量子计算,他们的计算功能的实现都可以分解为简单的逻辑门的运算,包括:“与”门,“或”门,“非”门,“异或”门等。简单来讲,每一次逻辑门的运算(简称操作)都是都要消耗一个单位时间来完成。经典计算机的运算模式通常是一步一步进行的。它的每一个数字都是单独存储的,而且是逐个运算。所以对于 4 个数字进行同一个操作时,要消耗 4 单位时间。量子的并行性决定了其可以同时对 2n 个数进行数学运算,相当于经典计算机重复实施 2n 次操作。可以看到,当量子比特数量越大时,这种运算速度的优势将越明显。它可以达到经典计算机不可比拟的运算速度和信息处理功能。
12 |
13 | 其次是降低能耗:量子计算另一核心优势是低能耗。众所周知,在经典计算机中,能耗是一大技术难题。处理器对输入两串数据的异或操作,而输出结果只有一组数据,计算之后数据量减少了,根据能量守恒定律,消失的数据信号必然会产生热量。但量子计算中,输入多少组数据输出依旧是多少组数据,计算过程中数据量没有改变,因此计算过程没有能耗。这也就意味着,只有在最后测量的时候产生了能耗。而经典计算在每一个比特的计算过程中都将产生能耗。因而经典计算的集成度越高,散热越困难。随着摩尔定律渐近极限,以后的计算能力的提高只能依靠堆积更多的计算芯片,这将导致更大的能耗。这方面的突破只能依靠量子计算的发展。[1]
14 |
15 | 受滞于摩尔定律的上限、芯片大小的极限、芯片散热等问题,传统计算机在执行某些任务时遇到瓶颈,例如:1)大数因数分解;2)数据库随机搜索。而量子计算中提出的大数质因子(Shor 算法)、随机数据库搜索(Grover 算法)就很好的解决了这两个问题,能够应用于复杂的大规模数据处理与计算难题。
16 |
--------------------------------------------------------------------------------
 12 |
13 |
14 |
12 |
13 |
14 |  40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/分布式调度/README.md:
--------------------------------------------------------------------------------
1 | # 分布式调度
2 |
--------------------------------------------------------------------------------
/分布式调度/延时任务/README.md:
--------------------------------------------------------------------------------
1 | # 延时任务
--------------------------------------------------------------------------------
/分布式调度/开源框架/xxl-job/README.md:
--------------------------------------------------------------------------------
1 | # xxl-job
2 |
3 | # Links
4 |
5 | - https://blog.csdn.net/shu616048151/article/details/108033087 xxl-job 架构源码解析
6 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/Activiti/README.md:
--------------------------------------------------------------------------------
1 | # Activiti
2 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/BPMN/BPMN 规范.md:
--------------------------------------------------------------------------------
1 | # BPMN 规范
2 |
3 | # Task | 任务
4 |
5 | Task 是一个极具威力的元素,它能描述业务过程中所有能发生工时的行为,它包括 User Task、Manual Task、Service Task、Script Task 等,可以被用来描述人机交互任务、线下操作任务、服务调用、脚本计算任务等常规功能。
6 |
7 | - User Task: 生成人机交互任务,主要被用来描述需要人为在软件系统中进行诸如任务明细查阅、填写审批意见等业务行为的操作,流程引擎流转到此类节点时,系统会自动生成被动触发任务,须人工响应后才能继续向下流转。常用于审批任务的定义。
8 |
9 | - Manual Task: 线下人为操作任务,常用于为了满足流程图对实际业务定义的完整性而进行的与流程驱动无关的线下任务,即此类任务不参与实际工作流流转。常用于诸如物流系统中的装货、运输等任务的描述。
10 |
11 | - Service Task: 服务任务,通常工作流流转过程中会涉及到与自身系统服务 API 调用或与外部服务相互调用的情况,此类任务往往由一个具有特定业务服务功能的 Java 类承担,与 User Task 不同,流程引擎流经此节点会自动调用 Java 类中定义的方法,方法执行完毕自动向下一流程节点流转。另外,此类任务还可充当“条件路由”的功能对流程流转可选分支进行自动判断。常用于业务逻辑 API 的调用。
12 |
13 | - Script Task: 脚本任务,在流程流转期间以“脚本”的声明或语法参与流程变量的计算,目前支持的脚本类型有三种:juel(即 JSP EL)、groovy 和 JavaScript。在 Activiti5.9 中新增了 Shell Task,可以处理系统外部定义的 Shell 脚本文件,也与 Script Task 有类似的功能。常用于流程变量的处理。
14 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/BPMN/README.md:
--------------------------------------------------------------------------------
1 | # BPMN
2 |
3 | 遵循 BPMN2.0 新规范的工作流产品能很大程度上解决此类问题。BPMN2.0 相对于旧的 1.0 规范以及 XPDL、BPML 及 BPEL 等最大的区 别是定义了规范的执行语义和格式,利用标准的图元去描述真实的业务发生过程,保证相同的流程在不同的流程引擎得到的执行结果一致。BPMN2.0 对流程执行语义定义了三类基本要素:
4 |
5 | - Activities(活动)——在工作流中所有具备生命周期状态的都可以称之为“活动”,如原子级的任务(Task)、流向(Sequence Flow),以及子流程(Sub-Process)等
6 | - Gateways(网关)——顾名思义,所谓“网关”就是用来决定流程流转指向的,可能会被用作条件分支或聚合,也可以被用作并行执行或基于事件的排它性条件判断
7 | - Events(事件)——在 BPMN2.0 执行语义中也是一个非常重要的概念,像启动、结束、边界条件以及每个活动的创建、开始、流转等都是流程事件,利用事件机制,可以通过事件控制器为系统增加辅助功能,如其它业务系统集成、活动预警等。
8 |
9 | 这三类执行语义的定义涵盖了业务流程常用的 Sequence Flow(流程转向)、Task(任务)、Sub-Process(子流程)、Parallel Gateway(并行执行网关)、ExclusiveGateway(排它型网关)、InclusiveGateway(包容型网关)等常用图元。
10 |
11 | 
12 |
13 | BPMN2.0 为所有业务元素定义了标准的符号,不同的符号代表不同的含义,以 OA 应用中请假流程为例,使用标准的 BPMN2.0 图元定义:
14 |
15 | 
16 |
17 | 现实业务所有的业务环节都离不开 Activities、Gateways 和 Events,无论是简单的条件审批还是复杂的父子流程循环处理,在一个 流程定义描述中,所有的业务环节都离不开 Task、Sequence Flow、Exclusive Gateway、Inclusive Gateway。
18 |
19 | 应用 BPMN2.0 标准的一个最显著的特色是,不同阶段的人员,无论是需求分析、概要设计、详细设计或是具体的业务实现,都可在一个流程图上开展工作,避免业务理解存在偏差。一个系统的实现,需求分析人员可以利用 BPMN2.0 标准图元草绘一下搜集到的需求;然后可以拿给设计人员,讨论出具体的业务需求进行功能设计,由设计人员在草图的基础上逐步细化,并得到需求人员的认同;设计人员又将细化后的流程图交给开发人员,罗列要实现的功能点,指出流程图上各活动节点所具备的行为,设计人员与开发人员依据此图达成共识,进入具体的开发阶段;如果后期请假流程发生更改,仍然是在现有流程图上更改,随着项目的推进,流程图也在不断的演进,但至始至终,项目受众都使用同一个流程图交流,保障需求理解的一致性,一定程度上推动了项目的敏捷性。
20 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/README.md:
--------------------------------------------------------------------------------
1 | # 流程引擎
2 |
3 | 工作流管理联盟 WfMC 组织对工作流 Workflow 概念的经典定义是全部或者部分由计算机支持或自动处理的业务过程。BPM(Business Process Management)的定义则是通过建模、自动化、管理和优化流程,打破跨部门跨系统业务过程依赖,提高业务效率和效果。
4 |
5 | BPM 基本内容是管理既定工作的流程,通过服务编排,统一调控各个业务流程,以确保工作在正确的时间被正确的人执行,达到优化整体业务过程的目的。BPM 概念的贯彻执行,需要有标准化的流程定义语言来支撑,使用统一的语言遵循一致的标准描述具体业务过程,这些流程定义描述由专有引擎去驱动执行。这个 引擎就是工作流引擎,它作为 BPM 的核心发动机,为各个业务流程定义提供解释、执行和编排,驱动流程“动“起来,让大家的工作“流”起来,为 BPM 的应用 提供基本、核心的动力来源。
6 |
7 | 现实工作中,不可避免的存在跨系统跨业务的情况,而大部分企业在信息化建设过程中是分阶段或分部门(子系统)按步实施的,后期实施的基础可能是前期 实施成果的输出,在耦合业务实施阶段,相同的业务过程可能会在不同的实施阶段重用,在进行流程梳理过程中,不同的实施阶段所使用的流程描述语言或遵循的标 准会有所不同(服务厂商不同),有的使用 WfMC 的 XPDL,还有些使用 BPML、BPEL、WSCI 等,这就造成流程管理、业务集成上存在很大的一致 性、局限性,提高了企业应用集成的成本。
8 |
9 | # 优劣对比
10 |
11 | 这里要分清楚两个概念,业务逻辑流和工作流,很多同学混淆了这两个概念。业务逻辑流是响应一次用户请求的业务处理过程,其本身就是业务逻辑,对其编排和可视化的意义并不是很大,无外乎只是把代码逻辑可视化了。而工作流是指完成一项任务所需要不同节点的连接,节点主要分为自动节点和人工节点,其中每个人工节点都需要用户的参与,也就是响应一次用户的请求,比如审批流程中的经理审批节点,CRM 销售过程的业务员的处理节点等等。此时可以考虑使用工作流引擎,特别是当你的系统需要让用户自定义流程的时候,那就不得不使用可视化和可配置的工作流引擎了,除此之外,最好不要自找麻烦。
12 |
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/README.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/分布式调度/调度系统架构/README.md
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/两层调度.md:
--------------------------------------------------------------------------------
1 | # 两层调度
2 |
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/体系结构/集中式架构.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/分布式调度/调度系统架构/体系结构/集中式架构.md
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/共享状态调度.md:
--------------------------------------------------------------------------------
1 | # 共享状态调度
2 |
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/单体调度.md:
--------------------------------------------------------------------------------
1 | # 单体调度
2 |
--------------------------------------------------------------------------------
/批处理/Hadoop/Hadoop 与数据库对比.md:
--------------------------------------------------------------------------------
1 | # Hadoop 与分布式数据库对比
2 |
3 | 正如我们所看到的,Hadoop 有点像 Unix 的分布式版本,其中 HDFS 是文件系统,而 MapReduce 是 Unix 进程的怪异实现(总是在 Map 阶段和 Reduce 阶段运行 sort 工具)。我们了解了如何在这些原语的基础上实现各种连接和分组操作。当 MapReduce 论文发表时,它从某种意义上来说:并不新鲜。我们在前几节中讨论的所有处理和并行连接算法已经在十多年前所谓的**大规模并行处理(MPP,massively parallel processing)**数据库中实现了。比如 Gamma database machine,Teradata 和 Tandem NonStop SQL 就是这方面的先驱。
4 |
5 | 最大的区别是,MPP 数据库专注于在一组机器上并行执行分析 SQL 查询,而 MapReduce 和分布式文件系统的组合则更像是一个可以运行任意程序的通用操作系统。
6 |
7 | # 存储多样性
8 |
9 | 数据库要求你根据特定的模型(例如关系或文档)来构造数据,而分布式文件系统中的文件只是字节序列,可以使用任何数据模型和编码来编写。它们可能是数据库记录的集合,但同样可以是文本,图像,视频,传感器读数,稀疏矩阵,特征向量,基因组序列或任何其他类型的数据。说白了,Hadoop 开放了将数据不加区分地转储到 HDFS 的可能性,允许后续再研究如何进一步处理。相比之下,在将数据导入数据库专有存储格式之前,MPP 数据库通常需要对数据和查询模式进行仔细的前期建模。在纯粹主义者看来,这种仔细的建模和导入似乎是可取的,因为这意味着数据库的用户有更高质量的数据来处理。然而实践经验表明,简单地使数据快速可用:即使它很古怪,难以使用,使用原始格式:也通常要比事先决定理想数据模型要更有价值。
10 |
11 | 这个想法与数据仓库类似:将大型组织的各个部分的数据集中在一起是很有价值的,因为它可以跨越以前相分离的数据集进行连接。MPP 数据库所要求的谨慎模式设计拖慢了集中式数据收集速度;以原始形式收集数据,稍后再操心模式的设计,能使数据收集速度加快(有时被称为“数据湖(data lake)”或“企业数据中心(enterprise data hub)”)。
12 |
13 | 不加区分的数据转储转移了解释数据的负担:数据集的生产者不再需要强制将其转化为标准格式,数据的解释成为消费者的问题(读时模式方法;参阅“文档模型中的架构灵活性”)。如果生产者和消费者是不同优先级的不同团队,这可能是一种优势。甚至可能不存在一个理想的数据模型,对于不同目的有不同的合适视角。以原始形式简单地转储数据,可以允许多种这样的转换。这种方法被称为寿司原则(sushi principle):“原始数据更好”。
14 |
15 | 因此,Hadoop 经常被用于实现 ETL 过程:事务处理系统中的数据以某种原始形式转储到分布式文件系统中,然后编写 MapReduce 作业来清理数据,将其转换为关系形式,并将其导入 MPP 数据仓库以进行分析。数据建模仍然在进行,但它在一个单独的步骤中进行,与数据收集相解耦。这种解耦是可行的,因为分布式文件系统支持以任何格式编码的数据。
16 |
17 | # 处理模型多样性
18 |
19 | MPP 数据库是单体的,紧密集成的软件,负责磁盘上的存储布局,查询计划,调度和执行。由于这些组件都可以针对数据库的特定需求进行调整和优化,因此整个系统可以在其设计针对的查询类型上取得非常好的性能。而且,SQL 查询语言允许以优雅的语法表达查询,而无需编写代码,使业务分析师用来做商业分析的可视化工具(例如 Tableau)能够访问。另一方面,并非所有类型的处理都可以合理地表达为 SQL 查询。例如,如果要构建机器学习和推荐系统,或者使用相关性排名模型的全文搜索索引,或者执行图像分析,则很可能需要更一般的数据处理模型。这些类型的处理通常是特别针对特定应用的(例如机器学习的特征工程,机器翻译的自然语言模型,欺诈预测的风险评估函数),因此它们不可避免地需要编写代码,而不仅仅是查询。
20 |
21 | MapReduce 使工程师能够轻松地在大型数据集上运行自己的代码。如果你有 HDFS 和 MapReduce,那么你可以在它之上建立一个 SQL 查询执行引擎,事实上这正是 Hive 项目所做的。但是,你也可以编写许多其他形式的批处理,这些批处理不必非要用 SQL 查询表示。随后,人们发现 MapReduce 对于某些类型的处理而言局限性很大,表现很差,因此在 Hadoop 之上其他各种处理模型也被开发出来。有两种处理模型,SQL 和 MapReduce,还不够,需要更多不同的模型!而且由于 Hadoop 平台的开放性,实施一整套方法是可行的,而这在单体 MPP 数据库的范畴内是不可能的。
22 |
23 | 至关重要的是,这些不同的处理模型都可以在共享的单个机器集群上运行,所有这些机器都可以访问分布式文件系统上的相同文件。在 Hadoop 方法中,不需要将数据导入到几个不同的专用系统中进行不同类型的处理:系统足够灵活,可以支持同一个群集内不同的工作负载。不需要移动数据,使得从数据中挖掘价值变得容易得多,也使采用新的处理模型容易的多。Hadoop 生态系统包括随机访问的 OLTP 数据库,如 HBase 和 MPP 风格的分析型数据库,如 Impala 。HBase 与 Impala 都不使用 MapReduce,但都使用 HDFS 进行存储。它们是迥异的数据访问与处理方法,但是它们可以共存,并被集成到同一个系统中。
24 |
25 | # 针对频繁故障设计
26 |
27 | 当比较 MapReduce 和 MPP 数据库时,两种不同的设计思路出现了:处理故障和使用内存与磁盘的方式。与在线系统相比,批处理对故障不太敏感,因为就算失败也不会立即影响到用户,而且它们总是能再次运行。如果一个节点在执行查询时崩溃,大多数 MPP 数据库会中止整个查询,并让用户重新提交查询或自动重新运行它。由于查询通常最多运行几秒钟或几分钟,所以这种错误处理的方法是可以接受的,因为重试的代价不是太大。MPP 数据库还倾向于在内存中保留尽可能多的数据(例如,使用哈希连接)以避免从磁盘读取的开销。
28 |
29 | 另一方面,MapReduce 可以容忍单个 Map 或 Reduce 任务的失败,而不会影响作业的整体,通过以单个任务的粒度重试工作。它也会非常急切地将数据写入磁盘,一方面是为了容错,另一部分是因为假设数据集太大而不能适应内存。
30 |
31 | MapReduce 方式更适用于较大的作业:要处理如此之多的数据并运行很长时间的作业,以至于在此过程中很可能至少遇到一个任务故障。在这种情况下,由于单个任务失败而重新运行整个作业将是非常浪费的。即使以单个任务的粒度进行恢复引入了使得无故障处理更慢的开销,但如果任务失败率足够高,这仍然是一种合理的权衡。但是这些假设有多么现实呢?在大多数集群中,机器故障确实会发生,但是它们不是很频繁:可能少到绝大多数作业都不会经历机器故障。为了容错,真的值得带来这么大的额外开销吗?
32 |
33 | 要了解 MapReduce 节约使用内存和在任务的层次进行恢复的原因,了解最初设计 MapReduce 的环境是很有帮助的。Google 有着混用的数据中心,在线生产服务和离线批处理作业在同样机器上运行。每个任务都有一个通过容器强制执行的资源配给(CPU 核心,RAM,磁盘空间等)。每个任务也具有优先级,如果优先级较高的任务需要更多的资源,则可以终止(抢占)同一台机器上较低优先级的任务以释放资源。优先级还决定了计算资源的定价:团队必须为他们使用的资源付费,而优先级更高的进程花费更多。
34 |
35 | 这种架构允许非生产(低优先级)计算资源被过量使用(overcommitted),因为系统知道必要时它可以回收资源。与分离生产和非生产任务的系统相比,过量使用资源可以更好地利用机器并提高效率。但由于 MapReduce 作业以低优先级运行,它们随时都有被抢占的风险,因为优先级较高的进程可能需要其资源。在高优先级进程拿走所需资源后,批量作业能有效地“捡面包屑”,利用剩下的任何计算资源。在谷歌,运行一个小时的 MapReduce 任务有大约有 5%的风险被终止,为了给更高优先级的进程挪地方。这一概率比硬件问题,机器重启或其他原因的概率高了一个数量级。按照这种抢占率,如果一个作业有 100 个任务,每个任务运行 10 分钟,那么至少有一个任务在完成之前被终止的风险大于 50%。
36 |
37 | 这就是 MapReduce 被设计为容忍频繁意外任务终止的原因:不是因为硬件很不可靠,而是因为任意终止进程的自由有利于提高计算集群中的资源利用率。在开源的集群调度器中,抢占的使用较少。YARN 的 CapacityScheduler 支持抢占,以平衡不同队列的资源分配,但在编写本文时,YARN,Mesos 或 Kubernetes 不支持通用优先级抢占。在任务不经常被终止的环境中,MapReduce 的这一设计决策就没有多少意义了。在下一节中,我们将研究一些与 MapReduce 设计决策相异的替代方案。
38 |
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/CRUD.md:
--------------------------------------------------------------------------------
1 | # Join
2 |
3 | 在传统数据库(如:MYSQL)中,JOIN 操作是非常常见且非常耗时的。而在 HADOOP 中进行 JOIN 操作,同样常见且耗时,由于 Hadoop 的独特设计思想,当进行 JOIN 操作时,有一些特殊的技巧。
4 |
5 | ## Reduce Side Join
6 |
7 | reduce side join 是一种最简单的 join 方式,其主要思想如下:
8 | 在 map 阶段,map 函数同时读取两个文件 File1 和 File2,为了区分两种来源的 key/value 数据对,对每条数据打一个标签(tag),比如:tag=0 表示来自文件 File1,tag=2 表示来自文件 File2。即:map 阶段的主要任务是对不同文件中的数据打标签。
9 | 在 reduce 阶段,reduce 函数获取 key 相同的来自 File1 和 File2 文件的 value list,然后对于同一个 key,对 File1 和 File2 中的数据进行 join(笛卡尔乘积)。即:reduce 阶段进行实际的连接操作。
10 | REF:hadoop join 之 reduce side join
11 | http://blog.csdn.net/huashetianzu/article/details/7819244
12 |
13 | ### BloomFilter
14 |
15 | 在某些情况下,SemiJoin 抽取出来的小表的 key 集合在内存中仍然存放不下,这时候可以使用 BloomFiler 以节省空间。
16 | BloomFilter 最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和 contains()。最大的特点是不会存在 false negative,即:如果 contains()返回 false,则该元素一定不在集合中,但会存在一定的 false positive,即:如果 contains()返回 true,则该元素一定可能在集合中。
17 | 因而可将小表中的 key 保存到 BloomFilter 中,在 map 阶段过滤大表,可能有一些不在小表中的记录没有过滤掉(但是在小表中的记录一定不会过滤掉),这没关系,只不过增加了少量的网络 IO 而已。
18 | 更多关于 BloomFilter 的介绍,可参考:http://blog.csdn.net/jiaomeng/article/details/1495500
19 |
20 | ### Map Side Join
21 |
22 | 之所以存在 reduce side join,是因为在 map 阶段不能获取所有需要的 join 字段,即:同一个 key 对应的字段可能位于不同 map 中。Reduce side join 是非常低效的,因为 shuffle 阶段要进行大量的数据传输。
23 | Map side join 是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个 map task 内存中存在一份(比如存放到 hash table 中),然后只扫描大表:对于大表中的每一条记录 key/value,在 hash table 中查找是否有相同的 key 的记录,如果有,则连接后输出即可。
24 | 为了支持文件的复制,Hadoop 提供了一个类 DistributedCache,使用该类的方法如下:
25 | (1)用户使用静态方法 DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的 URI(如果是 HDFS 上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中 9000 是自己配置的 NameNode 端口号)。JobTracker 在作业启动之前会获取这个 URI 列表,并将相应的文件拷贝到各个 TaskTracker 的本地磁盘上。(2)用户使用 DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写 API 读取相应的文件。
26 | REF:hadoop join 之 map side join
27 | http://blog.csdn.net/huashetianzu/article/details/7821674
28 |
29 | ### Semi Join
30 |
31 | Semi Join,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于 reduce side join,跨机器的数据传输量非常大,这成了 join 操作的一个瓶颈,如果能够在 map 端过滤掉不会参加 join 操作的数据,则可以大大节省网络 IO。
32 | 实现方法很简单:选取一个小表,假设是 File1,将其参与 join 的 key 抽取出来,保存到文件 File3 中,File3 文件一般很小,可以放到内存中。在 map 阶段,使用 DistributedCache 将 File3 复制到各个 TaskTracker 上,然后将 File2 中不在 File3 中的 key 对应的记录过滤掉,剩下的 reduce 阶段的工作与 reduce side join 相同。
33 | 更多关于半连接的介绍,可参考:半连接介绍:http://wenku.baidu.com/view/ae7442db7f1922791688e877.html
34 | REF:hadoop join 之 semi join
35 | http://blog.csdn.net/huashetianzu/article/details/7823326
36 |
37 | # 二次排序
38 |
39 | 在 Hadoop 中,默认情况下是按照 key 进行排序,如果要按照 value 进行排序怎么办?即:对于同一个 key,reduce 函数接收到的 value list 是按照 value 排序的。这种应用需求在 join 操作中很常见,比如,希望相同的 key 中,小表对应的 value 排在前面。
40 | 有两种方法进行二次排序,分别为:buffer and in memory sort 和 value-to-key conversion。
41 | 对于 buffer and in memory sort,主要思想是:在 reduce()函数中,将某个 key 对应的所有 value 保存下来,然后进行排序。这种方法最大的缺点是:可能会造成 out of memory。
42 | 对于 value-to-key conversion,主要思想是:将 key 和部分 value 拼接成一个组合 key(实现 WritableComparable 接口或者调用 setSortComparatorClass 函数),这样 reduce 获取的结果便是先按 key 排序,后按 value 排序的结果,需要注意的是,用户需要自己实现 Paritioner,以便只按照 key 进行数据划分。Hadoop 显式的支持二次排序,在 Configuration 类中有个 setGroupingComparatorClass()方法,可用于设置排序 group 的 key 值,具体参考:http://www.cnblogs.com/xuxm2007/archive/2011/09/03/2165805.html
43 |
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/README.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/批处理/Hadoop/MapReduce/README.md
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/WordCount.md:
--------------------------------------------------------------------------------
1 | # Word Count
2 |
3 | ```java
4 | import java.io.IOException;
5 | import java.util.StringTokenizer;
6 |
7 | import org.apache.hadoop.conf.Configuration;
8 | import org.apache.hadoop.fs.Path;
9 | import org.apache.hadoop.io.IntWritable;
10 | import org.apache.hadoop.io.Text;
11 | import org.apache.hadoop.mapreduce.Job;
12 | import org.apache.hadoop.mapreduce.Mapper;
13 | import org.apache.hadoop.mapreduce.Reducer;
14 | import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
15 | import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
16 |
17 | public class WordCount {
18 |
19 | public static class TokenizerMapper
20 | extends Mapper
40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/分布式调度/README.md:
--------------------------------------------------------------------------------
1 | # 分布式调度
2 |
--------------------------------------------------------------------------------
/分布式调度/延时任务/README.md:
--------------------------------------------------------------------------------
1 | # 延时任务
--------------------------------------------------------------------------------
/分布式调度/开源框架/xxl-job/README.md:
--------------------------------------------------------------------------------
1 | # xxl-job
2 |
3 | # Links
4 |
5 | - https://blog.csdn.net/shu616048151/article/details/108033087 xxl-job 架构源码解析
6 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/Activiti/README.md:
--------------------------------------------------------------------------------
1 | # Activiti
2 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/BPMN/BPMN 规范.md:
--------------------------------------------------------------------------------
1 | # BPMN 规范
2 |
3 | # Task | 任务
4 |
5 | Task 是一个极具威力的元素,它能描述业务过程中所有能发生工时的行为,它包括 User Task、Manual Task、Service Task、Script Task 等,可以被用来描述人机交互任务、线下操作任务、服务调用、脚本计算任务等常规功能。
6 |
7 | - User Task: 生成人机交互任务,主要被用来描述需要人为在软件系统中进行诸如任务明细查阅、填写审批意见等业务行为的操作,流程引擎流转到此类节点时,系统会自动生成被动触发任务,须人工响应后才能继续向下流转。常用于审批任务的定义。
8 |
9 | - Manual Task: 线下人为操作任务,常用于为了满足流程图对实际业务定义的完整性而进行的与流程驱动无关的线下任务,即此类任务不参与实际工作流流转。常用于诸如物流系统中的装货、运输等任务的描述。
10 |
11 | - Service Task: 服务任务,通常工作流流转过程中会涉及到与自身系统服务 API 调用或与外部服务相互调用的情况,此类任务往往由一个具有特定业务服务功能的 Java 类承担,与 User Task 不同,流程引擎流经此节点会自动调用 Java 类中定义的方法,方法执行完毕自动向下一流程节点流转。另外,此类任务还可充当“条件路由”的功能对流程流转可选分支进行自动判断。常用于业务逻辑 API 的调用。
12 |
13 | - Script Task: 脚本任务,在流程流转期间以“脚本”的声明或语法参与流程变量的计算,目前支持的脚本类型有三种:juel(即 JSP EL)、groovy 和 JavaScript。在 Activiti5.9 中新增了 Shell Task,可以处理系统外部定义的 Shell 脚本文件,也与 Script Task 有类似的功能。常用于流程变量的处理。
14 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/BPMN/README.md:
--------------------------------------------------------------------------------
1 | # BPMN
2 |
3 | 遵循 BPMN2.0 新规范的工作流产品能很大程度上解决此类问题。BPMN2.0 相对于旧的 1.0 规范以及 XPDL、BPML 及 BPEL 等最大的区 别是定义了规范的执行语义和格式,利用标准的图元去描述真实的业务发生过程,保证相同的流程在不同的流程引擎得到的执行结果一致。BPMN2.0 对流程执行语义定义了三类基本要素:
4 |
5 | - Activities(活动)——在工作流中所有具备生命周期状态的都可以称之为“活动”,如原子级的任务(Task)、流向(Sequence Flow),以及子流程(Sub-Process)等
6 | - Gateways(网关)——顾名思义,所谓“网关”就是用来决定流程流转指向的,可能会被用作条件分支或聚合,也可以被用作并行执行或基于事件的排它性条件判断
7 | - Events(事件)——在 BPMN2.0 执行语义中也是一个非常重要的概念,像启动、结束、边界条件以及每个活动的创建、开始、流转等都是流程事件,利用事件机制,可以通过事件控制器为系统增加辅助功能,如其它业务系统集成、活动预警等。
8 |
9 | 这三类执行语义的定义涵盖了业务流程常用的 Sequence Flow(流程转向)、Task(任务)、Sub-Process(子流程)、Parallel Gateway(并行执行网关)、ExclusiveGateway(排它型网关)、InclusiveGateway(包容型网关)等常用图元。
10 |
11 | 
12 |
13 | BPMN2.0 为所有业务元素定义了标准的符号,不同的符号代表不同的含义,以 OA 应用中请假流程为例,使用标准的 BPMN2.0 图元定义:
14 |
15 | 
16 |
17 | 现实业务所有的业务环节都离不开 Activities、Gateways 和 Events,无论是简单的条件审批还是复杂的父子流程循环处理,在一个 流程定义描述中,所有的业务环节都离不开 Task、Sequence Flow、Exclusive Gateway、Inclusive Gateway。
18 |
19 | 应用 BPMN2.0 标准的一个最显著的特色是,不同阶段的人员,无论是需求分析、概要设计、详细设计或是具体的业务实现,都可在一个流程图上开展工作,避免业务理解存在偏差。一个系统的实现,需求分析人员可以利用 BPMN2.0 标准图元草绘一下搜集到的需求;然后可以拿给设计人员,讨论出具体的业务需求进行功能设计,由设计人员在草图的基础上逐步细化,并得到需求人员的认同;设计人员又将细化后的流程图交给开发人员,罗列要实现的功能点,指出流程图上各活动节点所具备的行为,设计人员与开发人员依据此图达成共识,进入具体的开发阶段;如果后期请假流程发生更改,仍然是在现有流程图上更改,随着项目的推进,流程图也在不断的演进,但至始至终,项目受众都使用同一个流程图交流,保障需求理解的一致性,一定程度上推动了项目的敏捷性。
20 |
--------------------------------------------------------------------------------
/分布式调度/流程引擎/README.md:
--------------------------------------------------------------------------------
1 | # 流程引擎
2 |
3 | 工作流管理联盟 WfMC 组织对工作流 Workflow 概念的经典定义是全部或者部分由计算机支持或自动处理的业务过程。BPM(Business Process Management)的定义则是通过建模、自动化、管理和优化流程,打破跨部门跨系统业务过程依赖,提高业务效率和效果。
4 |
5 | BPM 基本内容是管理既定工作的流程,通过服务编排,统一调控各个业务流程,以确保工作在正确的时间被正确的人执行,达到优化整体业务过程的目的。BPM 概念的贯彻执行,需要有标准化的流程定义语言来支撑,使用统一的语言遵循一致的标准描述具体业务过程,这些流程定义描述由专有引擎去驱动执行。这个 引擎就是工作流引擎,它作为 BPM 的核心发动机,为各个业务流程定义提供解释、执行和编排,驱动流程“动“起来,让大家的工作“流”起来,为 BPM 的应用 提供基本、核心的动力来源。
6 |
7 | 现实工作中,不可避免的存在跨系统跨业务的情况,而大部分企业在信息化建设过程中是分阶段或分部门(子系统)按步实施的,后期实施的基础可能是前期 实施成果的输出,在耦合业务实施阶段,相同的业务过程可能会在不同的实施阶段重用,在进行流程梳理过程中,不同的实施阶段所使用的流程描述语言或遵循的标 准会有所不同(服务厂商不同),有的使用 WfMC 的 XPDL,还有些使用 BPML、BPEL、WSCI 等,这就造成流程管理、业务集成上存在很大的一致 性、局限性,提高了企业应用集成的成本。
8 |
9 | # 优劣对比
10 |
11 | 这里要分清楚两个概念,业务逻辑流和工作流,很多同学混淆了这两个概念。业务逻辑流是响应一次用户请求的业务处理过程,其本身就是业务逻辑,对其编排和可视化的意义并不是很大,无外乎只是把代码逻辑可视化了。而工作流是指完成一项任务所需要不同节点的连接,节点主要分为自动节点和人工节点,其中每个人工节点都需要用户的参与,也就是响应一次用户的请求,比如审批流程中的经理审批节点,CRM 销售过程的业务员的处理节点等等。此时可以考虑使用工作流引擎,特别是当你的系统需要让用户自定义流程的时候,那就不得不使用可视化和可配置的工作流引擎了,除此之外,最好不要自找麻烦。
12 |
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/README.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/分布式调度/调度系统架构/README.md
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/两层调度.md:
--------------------------------------------------------------------------------
1 | # 两层调度
2 |
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/体系结构/集中式架构.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/分布式调度/调度系统架构/体系结构/集中式架构.md
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/共享状态调度.md:
--------------------------------------------------------------------------------
1 | # 共享状态调度
2 |
--------------------------------------------------------------------------------
/分布式调度/调度系统架构/单体调度.md:
--------------------------------------------------------------------------------
1 | # 单体调度
2 |
--------------------------------------------------------------------------------
/批处理/Hadoop/Hadoop 与数据库对比.md:
--------------------------------------------------------------------------------
1 | # Hadoop 与分布式数据库对比
2 |
3 | 正如我们所看到的,Hadoop 有点像 Unix 的分布式版本,其中 HDFS 是文件系统,而 MapReduce 是 Unix 进程的怪异实现(总是在 Map 阶段和 Reduce 阶段运行 sort 工具)。我们了解了如何在这些原语的基础上实现各种连接和分组操作。当 MapReduce 论文发表时,它从某种意义上来说:并不新鲜。我们在前几节中讨论的所有处理和并行连接算法已经在十多年前所谓的**大规模并行处理(MPP,massively parallel processing)**数据库中实现了。比如 Gamma database machine,Teradata 和 Tandem NonStop SQL 就是这方面的先驱。
4 |
5 | 最大的区别是,MPP 数据库专注于在一组机器上并行执行分析 SQL 查询,而 MapReduce 和分布式文件系统的组合则更像是一个可以运行任意程序的通用操作系统。
6 |
7 | # 存储多样性
8 |
9 | 数据库要求你根据特定的模型(例如关系或文档)来构造数据,而分布式文件系统中的文件只是字节序列,可以使用任何数据模型和编码来编写。它们可能是数据库记录的集合,但同样可以是文本,图像,视频,传感器读数,稀疏矩阵,特征向量,基因组序列或任何其他类型的数据。说白了,Hadoop 开放了将数据不加区分地转储到 HDFS 的可能性,允许后续再研究如何进一步处理。相比之下,在将数据导入数据库专有存储格式之前,MPP 数据库通常需要对数据和查询模式进行仔细的前期建模。在纯粹主义者看来,这种仔细的建模和导入似乎是可取的,因为这意味着数据库的用户有更高质量的数据来处理。然而实践经验表明,简单地使数据快速可用:即使它很古怪,难以使用,使用原始格式:也通常要比事先决定理想数据模型要更有价值。
10 |
11 | 这个想法与数据仓库类似:将大型组织的各个部分的数据集中在一起是很有价值的,因为它可以跨越以前相分离的数据集进行连接。MPP 数据库所要求的谨慎模式设计拖慢了集中式数据收集速度;以原始形式收集数据,稍后再操心模式的设计,能使数据收集速度加快(有时被称为“数据湖(data lake)”或“企业数据中心(enterprise data hub)”)。
12 |
13 | 不加区分的数据转储转移了解释数据的负担:数据集的生产者不再需要强制将其转化为标准格式,数据的解释成为消费者的问题(读时模式方法;参阅“文档模型中的架构灵活性”)。如果生产者和消费者是不同优先级的不同团队,这可能是一种优势。甚至可能不存在一个理想的数据模型,对于不同目的有不同的合适视角。以原始形式简单地转储数据,可以允许多种这样的转换。这种方法被称为寿司原则(sushi principle):“原始数据更好”。
14 |
15 | 因此,Hadoop 经常被用于实现 ETL 过程:事务处理系统中的数据以某种原始形式转储到分布式文件系统中,然后编写 MapReduce 作业来清理数据,将其转换为关系形式,并将其导入 MPP 数据仓库以进行分析。数据建模仍然在进行,但它在一个单独的步骤中进行,与数据收集相解耦。这种解耦是可行的,因为分布式文件系统支持以任何格式编码的数据。
16 |
17 | # 处理模型多样性
18 |
19 | MPP 数据库是单体的,紧密集成的软件,负责磁盘上的存储布局,查询计划,调度和执行。由于这些组件都可以针对数据库的特定需求进行调整和优化,因此整个系统可以在其设计针对的查询类型上取得非常好的性能。而且,SQL 查询语言允许以优雅的语法表达查询,而无需编写代码,使业务分析师用来做商业分析的可视化工具(例如 Tableau)能够访问。另一方面,并非所有类型的处理都可以合理地表达为 SQL 查询。例如,如果要构建机器学习和推荐系统,或者使用相关性排名模型的全文搜索索引,或者执行图像分析,则很可能需要更一般的数据处理模型。这些类型的处理通常是特别针对特定应用的(例如机器学习的特征工程,机器翻译的自然语言模型,欺诈预测的风险评估函数),因此它们不可避免地需要编写代码,而不仅仅是查询。
20 |
21 | MapReduce 使工程师能够轻松地在大型数据集上运行自己的代码。如果你有 HDFS 和 MapReduce,那么你可以在它之上建立一个 SQL 查询执行引擎,事实上这正是 Hive 项目所做的。但是,你也可以编写许多其他形式的批处理,这些批处理不必非要用 SQL 查询表示。随后,人们发现 MapReduce 对于某些类型的处理而言局限性很大,表现很差,因此在 Hadoop 之上其他各种处理模型也被开发出来。有两种处理模型,SQL 和 MapReduce,还不够,需要更多不同的模型!而且由于 Hadoop 平台的开放性,实施一整套方法是可行的,而这在单体 MPP 数据库的范畴内是不可能的。
22 |
23 | 至关重要的是,这些不同的处理模型都可以在共享的单个机器集群上运行,所有这些机器都可以访问分布式文件系统上的相同文件。在 Hadoop 方法中,不需要将数据导入到几个不同的专用系统中进行不同类型的处理:系统足够灵活,可以支持同一个群集内不同的工作负载。不需要移动数据,使得从数据中挖掘价值变得容易得多,也使采用新的处理模型容易的多。Hadoop 生态系统包括随机访问的 OLTP 数据库,如 HBase 和 MPP 风格的分析型数据库,如 Impala 。HBase 与 Impala 都不使用 MapReduce,但都使用 HDFS 进行存储。它们是迥异的数据访问与处理方法,但是它们可以共存,并被集成到同一个系统中。
24 |
25 | # 针对频繁故障设计
26 |
27 | 当比较 MapReduce 和 MPP 数据库时,两种不同的设计思路出现了:处理故障和使用内存与磁盘的方式。与在线系统相比,批处理对故障不太敏感,因为就算失败也不会立即影响到用户,而且它们总是能再次运行。如果一个节点在执行查询时崩溃,大多数 MPP 数据库会中止整个查询,并让用户重新提交查询或自动重新运行它。由于查询通常最多运行几秒钟或几分钟,所以这种错误处理的方法是可以接受的,因为重试的代价不是太大。MPP 数据库还倾向于在内存中保留尽可能多的数据(例如,使用哈希连接)以避免从磁盘读取的开销。
28 |
29 | 另一方面,MapReduce 可以容忍单个 Map 或 Reduce 任务的失败,而不会影响作业的整体,通过以单个任务的粒度重试工作。它也会非常急切地将数据写入磁盘,一方面是为了容错,另一部分是因为假设数据集太大而不能适应内存。
30 |
31 | MapReduce 方式更适用于较大的作业:要处理如此之多的数据并运行很长时间的作业,以至于在此过程中很可能至少遇到一个任务故障。在这种情况下,由于单个任务失败而重新运行整个作业将是非常浪费的。即使以单个任务的粒度进行恢复引入了使得无故障处理更慢的开销,但如果任务失败率足够高,这仍然是一种合理的权衡。但是这些假设有多么现实呢?在大多数集群中,机器故障确实会发生,但是它们不是很频繁:可能少到绝大多数作业都不会经历机器故障。为了容错,真的值得带来这么大的额外开销吗?
32 |
33 | 要了解 MapReduce 节约使用内存和在任务的层次进行恢复的原因,了解最初设计 MapReduce 的环境是很有帮助的。Google 有着混用的数据中心,在线生产服务和离线批处理作业在同样机器上运行。每个任务都有一个通过容器强制执行的资源配给(CPU 核心,RAM,磁盘空间等)。每个任务也具有优先级,如果优先级较高的任务需要更多的资源,则可以终止(抢占)同一台机器上较低优先级的任务以释放资源。优先级还决定了计算资源的定价:团队必须为他们使用的资源付费,而优先级更高的进程花费更多。
34 |
35 | 这种架构允许非生产(低优先级)计算资源被过量使用(overcommitted),因为系统知道必要时它可以回收资源。与分离生产和非生产任务的系统相比,过量使用资源可以更好地利用机器并提高效率。但由于 MapReduce 作业以低优先级运行,它们随时都有被抢占的风险,因为优先级较高的进程可能需要其资源。在高优先级进程拿走所需资源后,批量作业能有效地“捡面包屑”,利用剩下的任何计算资源。在谷歌,运行一个小时的 MapReduce 任务有大约有 5%的风险被终止,为了给更高优先级的进程挪地方。这一概率比硬件问题,机器重启或其他原因的概率高了一个数量级。按照这种抢占率,如果一个作业有 100 个任务,每个任务运行 10 分钟,那么至少有一个任务在完成之前被终止的风险大于 50%。
36 |
37 | 这就是 MapReduce 被设计为容忍频繁意外任务终止的原因:不是因为硬件很不可靠,而是因为任意终止进程的自由有利于提高计算集群中的资源利用率。在开源的集群调度器中,抢占的使用较少。YARN 的 CapacityScheduler 支持抢占,以平衡不同队列的资源分配,但在编写本文时,YARN,Mesos 或 Kubernetes 不支持通用优先级抢占。在任务不经常被终止的环境中,MapReduce 的这一设计决策就没有多少意义了。在下一节中,我们将研究一些与 MapReduce 设计决策相异的替代方案。
38 |
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/CRUD.md:
--------------------------------------------------------------------------------
1 | # Join
2 |
3 | 在传统数据库(如:MYSQL)中,JOIN 操作是非常常见且非常耗时的。而在 HADOOP 中进行 JOIN 操作,同样常见且耗时,由于 Hadoop 的独特设计思想,当进行 JOIN 操作时,有一些特殊的技巧。
4 |
5 | ## Reduce Side Join
6 |
7 | reduce side join 是一种最简单的 join 方式,其主要思想如下:
8 | 在 map 阶段,map 函数同时读取两个文件 File1 和 File2,为了区分两种来源的 key/value 数据对,对每条数据打一个标签(tag),比如:tag=0 表示来自文件 File1,tag=2 表示来自文件 File2。即:map 阶段的主要任务是对不同文件中的数据打标签。
9 | 在 reduce 阶段,reduce 函数获取 key 相同的来自 File1 和 File2 文件的 value list,然后对于同一个 key,对 File1 和 File2 中的数据进行 join(笛卡尔乘积)。即:reduce 阶段进行实际的连接操作。
10 | REF:hadoop join 之 reduce side join
11 | http://blog.csdn.net/huashetianzu/article/details/7819244
12 |
13 | ### BloomFilter
14 |
15 | 在某些情况下,SemiJoin 抽取出来的小表的 key 集合在内存中仍然存放不下,这时候可以使用 BloomFiler 以节省空间。
16 | BloomFilter 最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和 contains()。最大的特点是不会存在 false negative,即:如果 contains()返回 false,则该元素一定不在集合中,但会存在一定的 false positive,即:如果 contains()返回 true,则该元素一定可能在集合中。
17 | 因而可将小表中的 key 保存到 BloomFilter 中,在 map 阶段过滤大表,可能有一些不在小表中的记录没有过滤掉(但是在小表中的记录一定不会过滤掉),这没关系,只不过增加了少量的网络 IO 而已。
18 | 更多关于 BloomFilter 的介绍,可参考:http://blog.csdn.net/jiaomeng/article/details/1495500
19 |
20 | ### Map Side Join
21 |
22 | 之所以存在 reduce side join,是因为在 map 阶段不能获取所有需要的 join 字段,即:同一个 key 对应的字段可能位于不同 map 中。Reduce side join 是非常低效的,因为 shuffle 阶段要进行大量的数据传输。
23 | Map side join 是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个 map task 内存中存在一份(比如存放到 hash table 中),然后只扫描大表:对于大表中的每一条记录 key/value,在 hash table 中查找是否有相同的 key 的记录,如果有,则连接后输出即可。
24 | 为了支持文件的复制,Hadoop 提供了一个类 DistributedCache,使用该类的方法如下:
25 | (1)用户使用静态方法 DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的 URI(如果是 HDFS 上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中 9000 是自己配置的 NameNode 端口号)。JobTracker 在作业启动之前会获取这个 URI 列表,并将相应的文件拷贝到各个 TaskTracker 的本地磁盘上。(2)用户使用 DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写 API 读取相应的文件。
26 | REF:hadoop join 之 map side join
27 | http://blog.csdn.net/huashetianzu/article/details/7821674
28 |
29 | ### Semi Join
30 |
31 | Semi Join,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于 reduce side join,跨机器的数据传输量非常大,这成了 join 操作的一个瓶颈,如果能够在 map 端过滤掉不会参加 join 操作的数据,则可以大大节省网络 IO。
32 | 实现方法很简单:选取一个小表,假设是 File1,将其参与 join 的 key 抽取出来,保存到文件 File3 中,File3 文件一般很小,可以放到内存中。在 map 阶段,使用 DistributedCache 将 File3 复制到各个 TaskTracker 上,然后将 File2 中不在 File3 中的 key 对应的记录过滤掉,剩下的 reduce 阶段的工作与 reduce side join 相同。
33 | 更多关于半连接的介绍,可参考:半连接介绍:http://wenku.baidu.com/view/ae7442db7f1922791688e877.html
34 | REF:hadoop join 之 semi join
35 | http://blog.csdn.net/huashetianzu/article/details/7823326
36 |
37 | # 二次排序
38 |
39 | 在 Hadoop 中,默认情况下是按照 key 进行排序,如果要按照 value 进行排序怎么办?即:对于同一个 key,reduce 函数接收到的 value list 是按照 value 排序的。这种应用需求在 join 操作中很常见,比如,希望相同的 key 中,小表对应的 value 排在前面。
40 | 有两种方法进行二次排序,分别为:buffer and in memory sort 和 value-to-key conversion。
41 | 对于 buffer and in memory sort,主要思想是:在 reduce()函数中,将某个 key 对应的所有 value 保存下来,然后进行排序。这种方法最大的缺点是:可能会造成 out of memory。
42 | 对于 value-to-key conversion,主要思想是:将 key 和部分 value 拼接成一个组合 key(实现 WritableComparable 接口或者调用 setSortComparatorClass 函数),这样 reduce 获取的结果便是先按 key 排序,后按 value 排序的结果,需要注意的是,用户需要自己实现 Paritioner,以便只按照 key 进行数据划分。Hadoop 显式的支持二次排序,在 Configuration 类中有个 setGroupingComparatorClass()方法,可用于设置排序 group 的 key 值,具体参考:http://www.cnblogs.com/xuxm2007/archive/2011/09/03/2165805.html
43 |
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/README.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/DistributedCompute-Notes/aaa2252c44940b32672fa70c35747efd84519438/批处理/Hadoop/MapReduce/README.md
--------------------------------------------------------------------------------
/批处理/Hadoop/MapReduce/WordCount.md:
--------------------------------------------------------------------------------
1 | # Word Count
2 |
3 | ```java
4 | import java.io.IOException;
5 | import java.util.StringTokenizer;
6 |
7 | import org.apache.hadoop.conf.Configuration;
8 | import org.apache.hadoop.fs.Path;
9 | import org.apache.hadoop.io.IntWritable;
10 | import org.apache.hadoop.io.Text;
11 | import org.apache.hadoop.mapreduce.Job;
12 | import org.apache.hadoop.mapreduce.Mapper;
13 | import org.apache.hadoop.mapreduce.Reducer;
14 | import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
15 | import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
16 |
17 | public class WordCount {
18 |
19 | public static class TokenizerMapper
20 | extends Mapper