8 |
9 |
10 |
11 |  12 |
13 |
14 |
12 |
13 |
14 |
15 | 在线阅读 >>
16 |
17 |
18 | 代码案例
19 | ·
20 | 参考资料
21 |
22 |
23 |
24 |
25 | # Distributed System Series(分布式系统·实践笔记)
26 |
27 | 深入浅出分布式基础架构是笔者归档自己,在学习与实践软件分布式架构过程中的,笔记与代码的仓库;主要包含分布式计算、分布式系统、数据存储、虚拟化、网络、操作系统等几个部分。所谓的分布式系统,其主要由网络、分布式存储与分布式计算等部分构成,分布式存储侧重于数据的读写存取及一致性等方面,而分布式计算则侧重于资源、任务的编排调度。
28 |
29 | 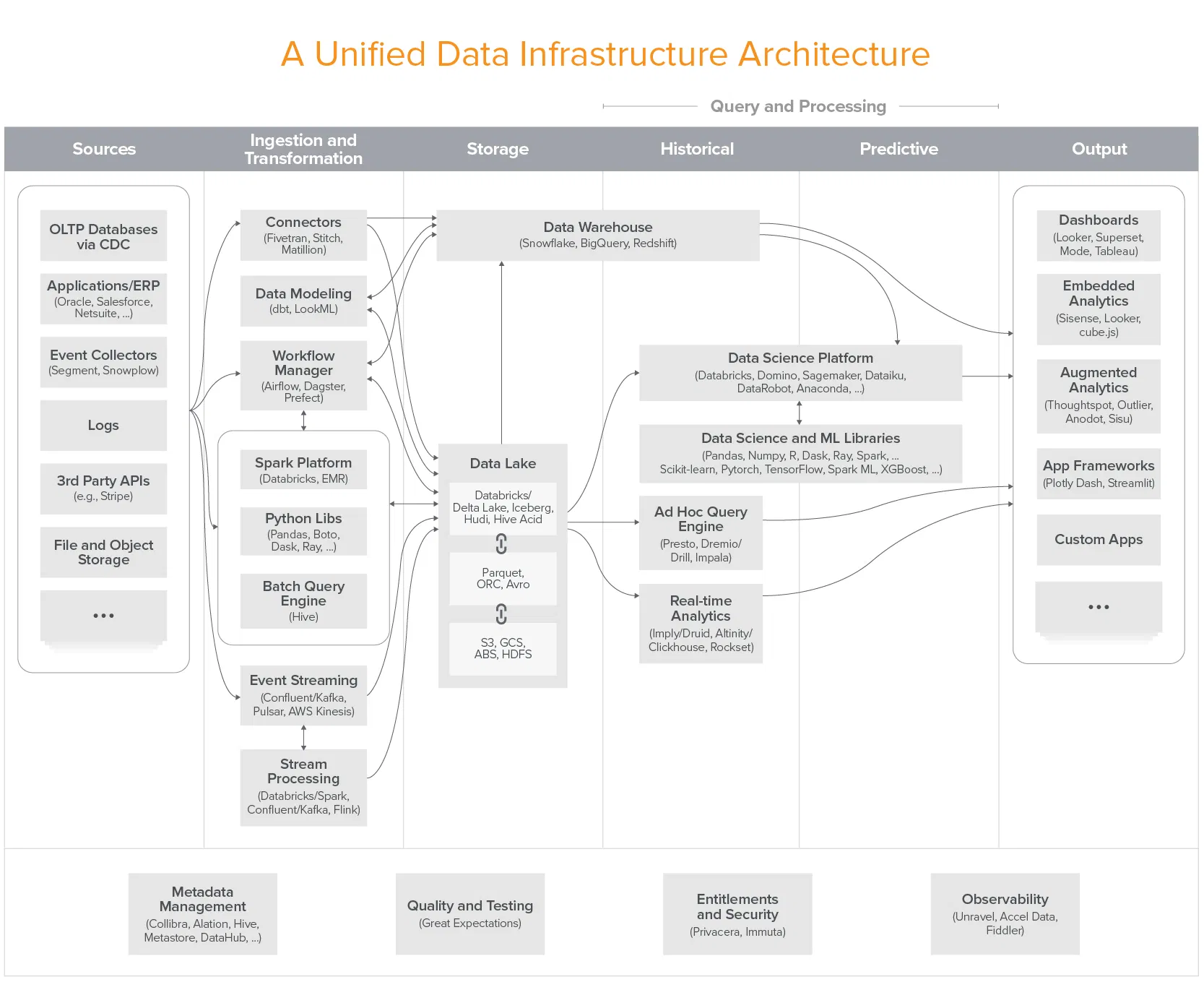
30 |
31 | ## Nav | 关联导航
32 |
33 | > 如果你想了解微服务/云原生等分布式系统的应用实践,可以参阅;如果你想了解数据库相关,可以参阅 [Database-Notes](https://github.com/wx-chevalier/Database-Notes);如果你想了解虚拟化与云计算相关,可以参阅 [Cloud-Notes](https://github.com/wx-chevalier/Cloud-Notes);如果你想了解 Linux 与操作系统相关,可以参阅 [Linux-Notes](https://github.com/wx-chevalier/Linux-Notes)。
34 |
35 | # About
36 |
37 | ## Copyright & More | 延伸阅读
38 |
39 | 笔者所有文章遵循 [知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.zh),欢迎转载,尊重版权。您还可以前往 [NGTE Books](https://ng-tech.icu/books-gallery/) 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
40 |
41 | [](https://ng-tech.icu/books-gallery/)
42 |
43 |
44 |
45 |
46 | [contributors-shield]: https://img.shields.io/github/contributors/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
47 | [contributors-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/graphs/contributors
48 | [forks-shield]: https://img.shields.io/github/forks/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
49 | [forks-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/network/members
50 | [stars-shield]: https://img.shields.io/github/stars/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
51 | [stars-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/stargazers
52 | [issues-shield]: https://img.shields.io/github/issues/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
53 | [issues-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/issues
54 | [license-shield]: https://img.shields.io/github/license/wx-chevalier/DistributedSystem-Notes.svg?style=flat-square
55 | [license-url]: https://github.com/wx-chevalier/DistributedSystem-Notes/blob/master/LICENSE.txt
56 |
--------------------------------------------------------------------------------
/_sidebar.md:
--------------------------------------------------------------------------------
1 | - [1 INTRODUCTION](/INTRODUCTION.md)
2 | - [2 一致性与共识 [4]](/一致性与共识/README.md)
3 | - [2.1 一致性模型 [5]](/一致性与共识/一致性模型/README.md)
4 | - [2.1.1 其他一致性模型](/一致性与共识/一致性模型/其他一致性模型.md)
5 | - [2.1.2 因果一致性](/一致性与共识/一致性模型/因果一致性.md)
6 | - [2.1.3 最终一致性](/一致性与共识/一致性模型/最终一致性.md)
7 | - [2.1.4 线性一致性](/一致性与共识/一致性模型/线性一致性.md)
8 | - [2.1.5 顺序一致性](/一致性与共识/一致性模型/顺序一致性.md)
9 | - [2.2 共识算法 [4]](/一致性与共识/共识算法/README.md)
10 | - [2.2.1 Paxos [1]](/一致性与共识/共识算法/Paxos/README.md)
11 | - [2.2.1.1 Multiple Paxos](/一致性与共识/共识算法/Paxos/Multiple-Paxos.md)
12 | - [2.2.2 Raft [4]](/一致性与共识/共识算法/Raft/README.md)
13 | - 2.2.2.1 99~参考资料 [2]
14 | - [2.2.2.1.1 Raft 原论文 寻找一种易于理解的一致性算法](/一致性与共识/共识算法/Raft/99~参考资料/2016-Raft%20原论文-寻找一种易于理解的一致性算法.md)
15 | - [2.2.2.1.2 多颗糖 条分缕析 Raft](/一致性与共识/共识算法/Raft/99~参考资料/2021-多颗糖-条分缕析%20Raft.md)
16 | - [2.2.2.2 安全性](/一致性与共识/共识算法/Raft/安全性.md)
17 | - [2.2.2.3 日志复制](/一致性与共识/共识算法/Raft/日志复制.md)
18 | - [2.2.2.4 选举与成员变更](/一致性与共识/共识算法/Raft/选举与成员变更.md)
19 | - [2.2.3 ZAB](/一致性与共识/共识算法/ZAB/README.md)
20 |
21 | - [2.2.4 算法设计 [1]](/一致性与共识/共识算法/算法设计/README.md)
22 | - [2.2.4.1 算法对比](/一致性与共识/共识算法/算法设计/算法对比.md)
23 | - [2.3 分布式时钟 [1]](/一致性与共识/分布式时钟/README.md)
24 | - 2.3.1 序列号 [2]
25 | - [2.3.1.1 全序广播](/一致性与共识/分布式时钟/序列号/全序广播.md)
26 | - [2.3.1.2 序列号顺序](/一致性与共识/分布式时钟/序列号/序列号顺序.md)
27 | - [2.4 拜占庭问题 [2]](/一致性与共识/拜占庭问题/README.md)
28 | - [2.4.1 拜占庭故障](/一致性与共识/拜占庭问题/拜占庭故障.md)
29 | - [2.4.2 系统模型](/一致性与共识/拜占庭问题/系统模型.md)
30 | - [3 分布式事务 [5]](/分布式事务/README.md)
31 | - [3.1 事务方案 [3]](/分布式事务/事务方案/README.md)
32 | - [3.1.1 事务分类 [2]](/分布式事务/事务方案/事务分类/README.md)
33 | - [3.1.1.1 NewSQL 的分布式事务](/分布式事务/事务方案/事务分类/NewSQL%20的分布式事务.md)
34 | - [3.1.1.2 跨服务跨库的分布式事务](/分布式事务/事务方案/事务分类/跨服务跨库的分布式事务.md)
35 | - 3.1.2 事务方案对比 [1]
36 | - [3.1.2.1 事务方案对比](/分布式事务/事务方案/事务方案对比/事务方案对比.md)
37 | - [3.1.3 分布式事务案例](/分布式事务/事务方案/分布式事务案例/README.md)
38 |
39 | - 3.2 事务框架 [3]
40 | - [3.2.1 JDTX](/分布式事务/事务框架/JDTX/README.md)
41 |
42 | - [3.2.2 Seata](/分布式事务/事务框架/Seata/README.md)
43 |
44 | - [3.2.3 dtm](/分布式事务/事务框架/dtm/README.md)
45 |
46 | - [3.3 事务消息 [3]](/分布式事务/事务消息/README.md)
47 | - 3.3.1 实践案例 [1]
48 | - [3.3.1.1 事务消息保障抢购业务的分布式一致性](/分布式事务/事务消息/实践案例/事务消息保障抢购业务的分布式一致性.md)
49 | - [3.3.2 流处理方案](/分布式事务/事务消息/流处理方案.md)
50 | - [3.3.3 消息队列方案](/分布式事务/事务消息/消息队列方案.md)
51 | - [3.4 多阶段提交 [3]](/分布式事务/多阶段提交/README.md)
52 | - [3.4.1 XA 事务](/分布式事务/多阶段提交/XA%20事务.md)
53 | - [3.4.2 三阶段提交](/分布式事务/多阶段提交/三阶段提交.md)
54 | - [3.4.3 二阶段提交](/分布式事务/多阶段提交/二阶段提交.md)
55 | - [3.5 柔性事务 [2]](/分布式事务/柔性事务/README.md)
56 | - 3.5.1 Saga [1]
57 | - [3.5.1.1 Saga](/分布式事务/柔性事务/Saga/Saga.md)
58 | - [3.5.2 TCC](/分布式事务/柔性事务/TCC/README.md)
59 |
60 | - [4 分布式基础 [5]](/分布式基础/README.md)
61 | - [4.1 01~不可靠的分布式系统 [3]](/分布式基础/01~不可靠的分布式系统/README.md)
62 | - [4.1.1 不可靠时钟](/分布式基础/01~不可靠的分布式系统/不可靠时钟.md)
63 | - [4.1.2 不可靠网络](/分布式基础/01~不可靠的分布式系统/不可靠网络.md)
64 | - [4.1.3 不可靠进程](/分布式基础/01~不可靠的分布式系统/不可靠进程.md)
65 | - 4.2 02.节点与集群 [2]
66 | - [4.2.1 主从节点 [1]](/分布式基础/02.节点与集群/主从节点/README.md)
67 | - [4.2.1.1 节点选举](/分布式基础/02.节点与集群/主从节点/节点选举.md)
68 | - [4.2.2 分布式互斥](/分布式基础/02.节点与集群/分布式互斥.md)
69 | - [4.3 03.CAP [3]](/分布式基础/03.CAP/README.md)
70 | - [4.3.1 BASE](/分布式基础/03.CAP/BASE.md)
71 | - [4.3.2 DLS](/分布式基础/03.CAP/DLS.md)
72 | - [4.3.3 特性与模型](/分布式基础/03.CAP/特性与模型.md)
73 | - 4.4 04.日志模型 [2]
74 | - [4.4.1 WAL](/分布式基础/04.日志模型/WAL/README.md)
75 |
76 | - [4.4.2 分割日志](/分布式基础/04.日志模型/分割日志/README.md)
77 |
78 | - 4.5 99~参考资料 [3]
79 | - [4.5.1 Distributed Systems for Fun and Profit [1]](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/README.md)
80 | - 4.5.1.1 中文翻译 [7]
81 | - [4.5.1.1.1 00.引言](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/00.引言.md)
82 | - [4.5.1.1.2 01.Basics](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/01.Basics.md)
83 | - [4.5.1.1.3 02.Abstraction](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/02.Abstraction.md)
84 | - [4.5.1.1.4 03.TimeAndOrder](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/03.TimeAndOrder.md)
85 | - [4.5.1.1.5 04.PreventingDivergence](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/04.PreventingDivergence.md)
86 | - [4.5.1.1.6 05.AcceptingDivergence](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/05.AcceptingDivergence.md)
87 | - [4.5.1.1.7 10.Appendix](/分布式基础/99~参考资料/Distributed%20Systems%20for%20Fun%20and%20Profit/中文翻译/10.Appendix.md)
88 | - [4.5.2 Patterns of Distributed Systems [25]](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/README.md)
89 | - [4.5.2.1 consistent core](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/consistent-core.md)
90 | - [4.5.2.2 follower reads](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/follower-reads.md)
91 | - [4.5.2.3 generation clock](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/generation-clock.md)
92 | - [4.5.2.4 gossip dissemination](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/gossip-dissemination.md)
93 | - [4.5.2.5 heartbeat](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/heartbeat.md)
94 | - [4.5.2.6 high water mark](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/high-water-mark.md)
95 | - [4.5.2.7 hybrid clock](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/hybrid-clock.md)
96 | - [4.5.2.8 idempotent receiver](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/idempotent-receiver.md)
97 | - [4.5.2.9 lamport clock](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/lamport-clock.md)
98 | - [4.5.2.10 leader and followers](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/leader-and-followers.md)
99 | - [4.5.2.11 lease](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/lease.md)
100 | - [4.5.2.12 low water mark](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/low-water-mark.md)
101 | - [4.5.2.13 overview](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/overview.md)
102 | - [4.5.2.14 paxos](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/paxos.md)
103 | - [4.5.2.15 quorum](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/quorum.md)
104 | - [4.5.2.16 replicated log](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/replicated-log.md)
105 | - [4.5.2.17 request pipeline](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/request-pipeline.md)
106 | - [4.5.2.18 segmented log](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/segmented-log.md)
107 | - [4.5.2.19 single socket channel](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/single-socket-channel.md)
108 | - [4.5.2.20 singular update queue](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/singular-update-queue.md)
109 | - [4.5.2.21 state watch](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/state-watch.md)
110 | - [4.5.2.22 two phase commit](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/two-phase-commit.md)
111 | - [4.5.2.23 version vector](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/version-vector.md)
112 | - [4.5.2.24 versioned value](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/versioned-value.md)
113 | - [4.5.2.25 write ahead log](/分布式基础/99~参考资料/Patterns%20of%20Distributed%20Systems/write-ahead-log.md)
114 | - [4.5.3 分布式系统的八大谬误](/分布式基础/99~参考资料/分布式系统的八大谬误.md)
115 | - [5 分布式存储](/分布式存储/README.md)
116 |
117 | - [6 分布式计算](/分布式计算/README.md)
118 |
119 | - [7 分布式锁 [5]](/分布式锁/README.md)
120 | - [7.1 分布式锁方案对比](/分布式锁/分布式锁方案对比.md)
121 | - [7.2 基于 Redis 的分布式锁 [2]](/分布式锁/基于%20Redis%20的分布式锁/README.md)
122 | - [7.2.1 Redis 分布式锁](/分布式锁/基于%20Redis%20的分布式锁/Redis%20分布式锁.md)
123 | - [7.2.2 Redisson 锁实现](/分布式锁/基于%20Redis%20的分布式锁/Redisson%20锁实现.md)
124 | - [7.3 基于 ZooKeeper 的分布式锁 [2]](/分布式锁/基于%20ZooKeeper%20的分布式锁/README.md)
125 | - [7.3.1 基于 Apache Curator 的使用](/分布式锁/基于%20ZooKeeper%20的分布式锁/基于%20Apache%20Curator%20的使用.md)
126 | - [7.3.2 实现原理](/分布式锁/基于%20ZooKeeper%20的分布式锁/实现原理.md)
127 | - [7.4 数据库锁](/分布式锁/数据库锁/README.md)
128 |
129 | - 7.5 服务锁 [1]
130 | - [7.5.1 RESTful 分布式锁](/分布式锁/服务锁/RESTful%20分布式锁.md)
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | DistributedSystem-Series
7 |
8 |
9 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
34 |
38 |  40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------