38 |
40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
142 |
143 |
144 |
145 |
154 |
155 |
156 |
--------------------------------------------------------------------------------
/header.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/特征工程/特征降维/README.md:
--------------------------------------------------------------------------------
1 | # 特征降纬
2 |
3 | 维度变换是将现有数据降低到更小的维度,尽量保证数据信息的完整性。楼主将介绍常用的几种有损失的维度变换方法,将大大地提高实践中建模的效率:
4 |
5 | - 主成分分析(PCA)和因子分析(FA):PCA 通过空间映射的方式,将当前维度映射到更低的维度,使得每个变量在新空间的方差最大。FA 则是找到当前特征向量的公因子(维度更小),用公因子的线性组合来描述当前的特征向量。
6 |
7 | - 奇异值分解(SVD):SVD 的降维可解释性较低,且计算量比 PCA 大,一般用在稀疏矩阵上降维,例如图片压缩,推荐系统。
8 |
9 | - 聚类:将某一类具有相似性的特征聚到单个变量,从而大大降低维度。
10 |
11 | - 线性组合:将多个变量做线性回归,根据每个变量的表决系数,赋予变量权重,可将该类变量根据权重组合成一个变量。
12 |
13 | - 流行学习:流行学习中一些复杂的非线性方法,可参考 skearn:LLE Example
14 |
15 | - [维度打击,机器学习中的降维算法:ISOMAP & MDS ](http://blog.csdn.net/dark_scope/article/details/53229427)
16 |
17 | # Dimensionality Reduction(降维)
18 |
19 | 
20 |
21 | Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarise or describe data using less information.
22 |
23 | This can be useful to visualize dimensional data or to simplify data which can then be used in a supervized learning method. Many of these methods can be adapted for use in classification and regression.
24 |
25 | - Principal Component Analysis (PCA)
26 | - Principal Component Regression (PCR)
27 | - Partial Least Squares Regression (PLSR)
28 | - Sammon Mapping
29 | - Multidimensional Scaling (MDS)
30 | - Projection Pursuit
31 | - Linear Discriminant Analysis (LDA)
32 | - Mixture Discriminant Analysis (MDA)
33 | - Quadratic Discriminant Analysis (QDA)
34 | - Flexible Discriminant Analysis (FDA)
35 |
36 | 降维的必要性:
37 |
38 | 1.多重共线性--预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。2.高维空间本身具有稀疏性。一维正态分布有 68%的值落于正负标准差之间,而在十维空间上只有 0.02%。3.过多的变量会妨碍查找规律的建立。4.仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
39 | 降维的目的:1.减少预测变量的个数 2.确保这些变量是相互独立的 3.提供一个框架来解释结果
40 | 降维的方法有:主成分分析、因子分析、用户自定义复合等。
41 |
42 | # 数据的向量表示
43 |
44 | 一般情况下,在数据挖掘和机器学习中,数据被表示为向量。例如某个淘宝店 2012 年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
45 | (日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)
46 | 其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条看起来大约是这个样子:
47 | $
48 | (500,240,25,13,2312.15)^T
49 | $
50 | 注意这里我用了转置,因为习惯上使用列向量表示一条记录(后面会看到原因),本文后面也会遵循这个准则。不过为了方便有时我会省略转置符号,但我们说到向量默认都是指列向量。
51 | 我们当然可以对这一组五维向量进行分析和挖掘,不过我们知道,很多机器学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈 指数级关联。当然,这里区区五维的数据,也许还无所谓,但是实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗 是不可接受的,因此我们必须对数据进行降维。
52 | 降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低。
53 | 举个例子,假如某学籍数据有两列 M 和 F,其中 M 列的取值是如何此学生为男性取值 1,为女性取值 0;而 F 列是学生为女性取值 1,男 性取值 0。此时如果我们统计全部学籍数据,会发现对于任何一条记录来说,当 M 为 1 时 F 必定为 0,反之当 M 为 0 时 F 必定为 1。在这种情况下,我们将 M 或 F 去 掉实际上没有任何信息的损失,因为只要保留一列就可以完全还原另一列。
54 | 当然上面是一个极端的情况,在现实中也许不会出现,不过类似的情况还是很常见的。例如上面淘宝店铺的数据,从经验我们可以知道,“浏览量”和“访客数”往往具有较强的相关关系,而“下单数”和“成交数”也具有较强的相关关系。这里我们非正式的使用“相关关系”这个词,可以直观理解 为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。后面的章节中我们会给出相关性的严格数学定义。
55 | 这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。
56 | 上面给出的是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。例如,我们到底删除哪一列损 失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始 数据决定具体的降维操作步骤?
57 | 要回答上面的问题,就要对降维问题进行数学化和形式化的讨论。而 PCA 是一种具有严格数学基础并且已被广泛采用的降维方法。下面我不会直接描述 PCA,而是通过逐步分析问题,让我们一起重新“发明”一遍 PCA。
58 |
59 | ## 向量的表示及基变换
60 |
61 | ## 内积与投影
62 |
63 | 两个维数相同的向量的内积被定义为:
64 |
65 | $$
66 | (a_1,a_2,\cdots,a_n)^{T}\cdot (b_1,b_2,\cdots,b_n)^{T}=a_1b_1+a_2b_2+\cdots+a_nb_n
67 | $$
68 |
69 | 内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。下面我们分析内积的几何意义。假设 A 和 B 是两个 n 维向量,我们知道 n 维向量可以等价表示为 n 维空间中的一条从原点发射的有向线段,为了简单起见我们假设 A 和 B 均为二维向量,则 A=(x_1,y_1),B=(x_2,y_2)。则在二维平面上 A 和 B 可以用两条发自原点的有向线段表示,见下图:
70 | 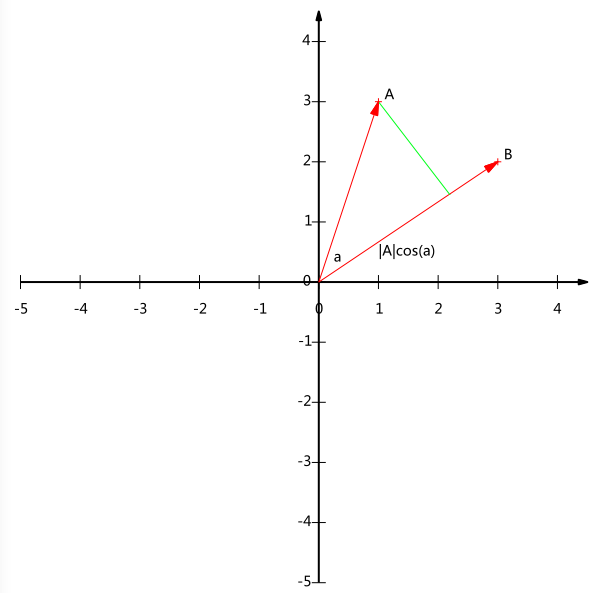
71 | 好,现在我们从 A 点向 B 所在直线引一条垂线。我们知道垂线与 B 的交点叫做 A 在 B 上的投影,再设 A 与 B 的夹角是 a,则投影的矢量长度为$|A|cos(a)$,其中$|A|=\sqrt{x_1^2+y_1^2}$是向量 A 的模,也就是 A 线段的标量长度。
72 | 注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于 0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
73 | 到这里还是看不出内积和这东西有什么关系,不过如果我们将内积表示为另一种我们熟悉的形式:
74 | $A\cdot B=|A||B|cos(a)$
75 | x(1,0)T+y(0,1)T
76 |
77 | 现在事情似乎是有点眉目了:A 与 B 的内积等于 A 到 B 的投影长度乘以 B 的模。再进一步,如果我们假设 B 的模为 1,即让|B|=1,那么就变成了:
78 | $A\cdot B=|A|cos(a)$
79 | 也就是说,设向量 B 的模为 1,则 A 与 B 的内积值等于 A 向 B 所在直线投影的矢量长度!这就是内积的一种几何解释,也是我们得到的第一个重要结论。在后面的推导中,将反复使用这个结论。
80 |
81 | ## 基
82 |
83 | 一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。例如下面这个向量:
84 | 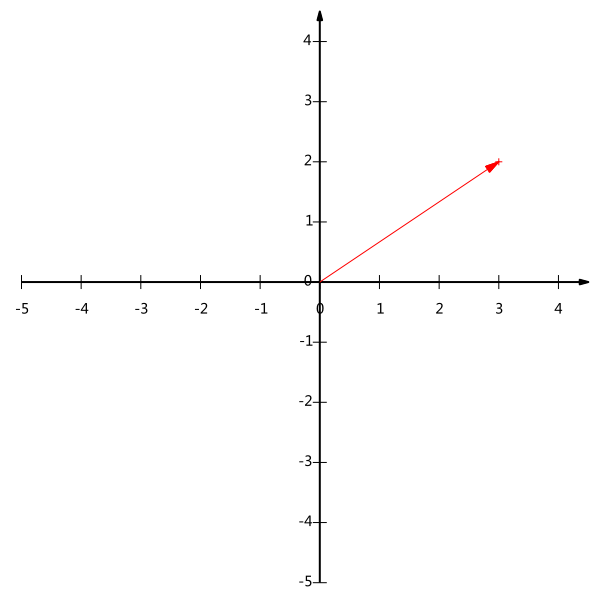
85 | 在代数表示方面,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2),这是我们再熟悉不过的向量表示。
86 | 不过我们常常忽略,只有一个(3,2)本身是不能够精确表示一个向量的。我们仔细看一下,这里的 3 实际表示的是向量在 x 轴上的投影值是 3,在 y 轴上的投影值是 2。也就是说我们其实隐式引入了一个定义:以 x 轴和 y 轴上正方向长度 为 1 的向量为标准。那么一个向量(3,2)实际是说在 x 轴投影为 3 而 y 轴的投影为 2。注意投影是一个矢量,所以可以为负。
87 | 更正式的说,向量(x,y)实际上表示线性组合:
88 | $x(1,0)^{T}+y(0,1)^{T}$
89 | (52,−12)
90 |
91 | 不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
92 | 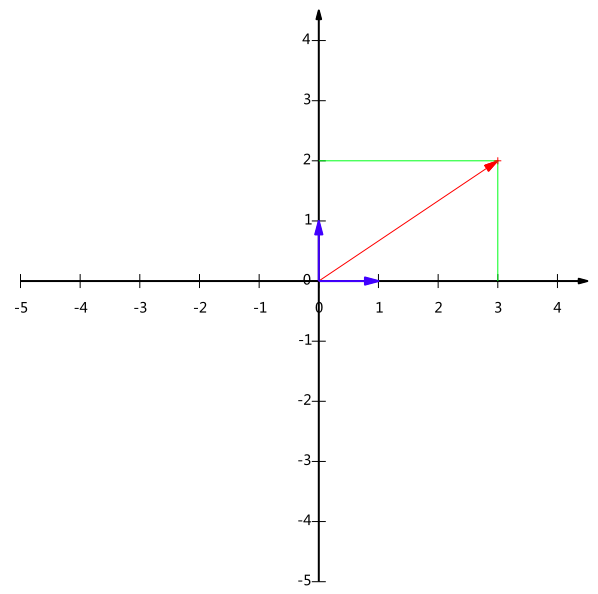
93 | 所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。只不过我们经常省略第一步,而默认以(1,0)和(0,1)为基。
94 | 我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为它们分别是 x 和 y 轴正方向上的单位向量,因此就使得二维平 面上点坐标和向量一一对应,非常方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上 的向量。
95 | 例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是 1,因为从内积的意义可以看到,如果基的模是 1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为 1 的向量,只要让两个分量分别除以模 就好了。例如,上面的基可以变为$(\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
96 | $和$(-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
97 | $。
98 | 现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为$(\frac{5}{\sqrt{2}},-\frac{1}{\sqrt{2}})
99 | $。下图给出了新的基以及(3,2)在新基上坐标值的示意图:
100 | 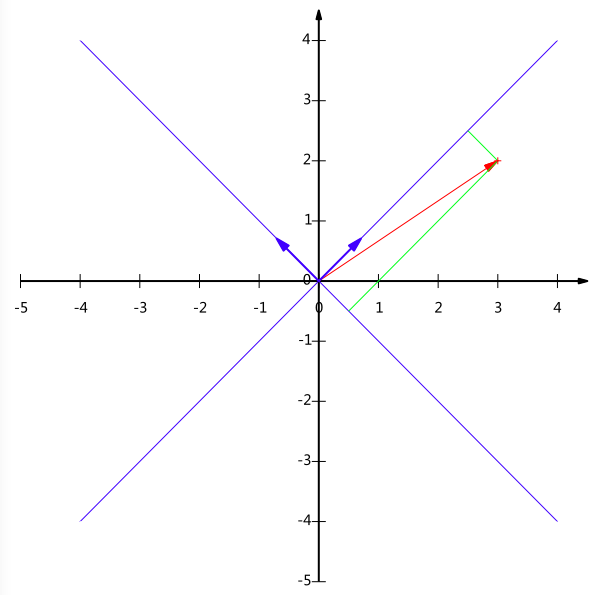
101 | 另外这里要注意的是,我们列举的例子中基是正交的(即内积为 0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
102 |
103 | ## 基变换的矩阵表示
104 |
105 | 下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个 新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
106 |
107 | $$
108 | \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 3 \\ 2 \end{pmatrix} = \begin{pmatrix} 5/\sqrt{2} \\ -1/\sqrt{2} \end{pmatrix}
109 | $$
110 |
111 | 太漂亮了!其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。可以稍微推广一下,如果我们有 m 个二维向量,只要 将二维向量按列排成一个两行 m 列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变 换到刚才那组基上,则可以这样表示:
112 |
113 | $$
114 | \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3 \end{pmatrix} = \begin{pmatrix} 2/\sqrt{2} & 4/\sqrt{2} & 6/\sqrt{2} \\ 0 & 0 & 0 \end{pmatrix}
115 | $$
116 |
117 | aj
118 | 于是一组向量的基变换被干净的表示为矩阵的相乘。
119 | 一般的,如果我们有 M 个 N 维向量,想将其变换为由 R 个 N 维向量表示的新空间中,那么首先将 R 个基按行组成矩阵 A,然后将向量按列组成矩阵 B,那么两矩阵的乘积 AB 就是变换结果,其中 AB 的第 m 列为 A 中第 m 列变换后的结果。
120 | 数学表示为:
121 |
122 | $$
123 | \begin{pmatrix} p_1 \\ p_2 \\ \vdots \\ p_R \end{pmatrix} \begin{pmatrix} a_1 & a_2 & \cdots & a_M \end{pmatrix} = \begin{pmatrix} p_1a_1 & p_1a_2 & \cdots & p_1a_M \\ p_2a_1 & p_2a_2 & \cdots & p_2a_M \\ \vdots & \vdots & \ddots & \vdots \\ p_Ra_1 & p_Ra_2 & \cdots & p_Ra_M \end{pmatrix}
124 | $$
125 |
126 | (1124213344)
127 | 其中$p_i
128 | $是一个行向量,表示第 i 个基,$a_j$是一个列向量,表示第 j 个原始数据记录。
129 | 特别要注意的是,这里 R 可以小于 N,而 R 决定了变换后数据的维数。也就是说,我们可以将一 N 维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
130 | 最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
131 |
132 | ## 协方差矩阵及优化目标
133 |
134 | 上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但 是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组 N 维向量,现在要将其降到 K 维(K 小于 N),那么我们应该如何选择 K 个基才能最大程度保留原有的信息?
135 | 要完全数学化这个问题非常繁杂,这里我们用一种非形式化的直观方法来看这个问题。
136 | 为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
137 |
138 | $$
139 | \begin{pmatrix} 1 & 1 & 2 & 4 & 2 \\ 1 & 3 & 3 & 4 & 4 \end{pmatrix}
140 | $$
141 |
142 | 其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为 0(这样做的道理和好处后面会看到)。
143 | 我们看上面的数据,第一个字段均值为 2,第二个字段均值为 3,所以变换后:
144 |
145 | $$
146 | \begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}
147 | $$
148 |
149 | 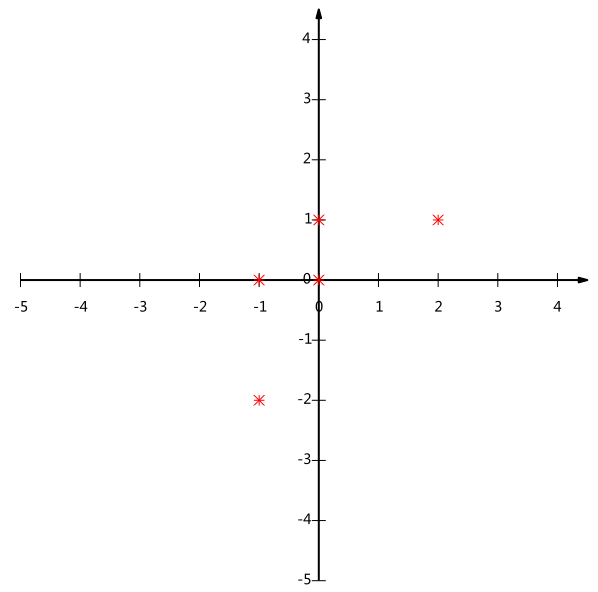
150 | 现在问题来了:如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
151 | 通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
152 | 那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
153 | 以上图为例,可以看出如果向 x 轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二 维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向 y 轴投影最上面的两个点和分布在 x 轴上的两个点也会重叠。所以看来 x 和 y 轴都不是 最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
154 | 下面,我们用数学方法表述这个问题。
155 |
156 | ### 方差
157 |
158 | 上文说到,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
159 | $Var(a)=\frac{1}{m}\sum_{i=1}^m{(a_i-\mu)^2}$
160 | X=(a1a2⋯amb1b2⋯bm)
161 | 由于上面我们已经将每个字段的均值都化为 0 了,因此方差可以直接用每个元素的平方和除以元素个数表示:
162 | $Var(a)=\frac{1}{m}\sum_{i=1}^m{a_i^2}$
163 | 1mXXT=(1m∑i=1mai21m∑i=1maibi1m∑i=1maibi1m∑i=1mbi2)
164 | 于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
165 |
166 | ### 协方差
167 |
168 | 对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
169 | 如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因 此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完 全独立,必然存在重复表示的信息。
170 | 数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为 0,则:
171 | $Cov(a,b)=\frac{1}{m}\sum_{i=1}^m{a_ib_i}$
172 | D=1mYYT=1m(PX)(PX)T=1mPXXTPT=P(1mXXT)PT=PCPT
173 | 可以看到,在字段均值为 0 的情况下,两个字段的协方差简洁的表示为其内积除以元素数 m。
174 | 当协方差为 0 时,表示两个字段完全独立。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
175 | 至此,我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维(K 大于 0,小于 N),其目标是选择 K 个单位(模为 1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为 0,而字段的方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
176 |
177 | ### 协方差矩阵
178 |
179 | 上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
180 | 我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感:
181 | 假设我们只有 a 和 b 两个字段,那么我们将它们按行组成矩阵 X:
182 | $X=\begin{pmatrix} a_1 & a_2 & \cdots & a_m \\ b_1 & b_2 & \cdots & b_m \end{pmatrix}$
183 | (e1e2⋯en)
184 | 然后我们用 X 乘以 X 的转置,并乘上系数 1/m:
185 | $\frac{1}{m}XX^\mathsf{T}=\begin{pmatrix} \frac{1}{m}\sum_{i=1}^m{a_i^2} & \frac{1}{m}\sum_{i=1}^m{a_ib_i} \\ \frac{1}{m}\sum_{i=1}^m{a_ib_i} & \frac{1}{m}\sum_{i=1}^m{b_i^2} \end{pmatrix}$
186 | (λ1λ2⋱λn)
187 | 奇迹出现了!这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵的。
188 | 根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
189 | 设我们有 m 个 n 维数据记录,将其按列排成 n 乘 m 的矩阵 X,设 C=\frac{1}{m}XX^\mathsf{T},则 C 是一个对称矩阵,其对角线分别个各个字段的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个字段的协方差。
190 |
191 | ## 协方差矩阵对角化
192 |
193 | 根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
194 | 设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:
195 | \begin{array}{l l l} D & = & \frac{1}{m}YY^\mathsf{T} \\ & = & \frac{1}{m}(PX)(PX)^\mathsf{T} \\ & = & \frac{1}{m}PXX^\mathsf{T}P^\mathsf{T} \\ & = & P(\frac{1}{m}XX^\mathsf{T})P^\mathsf{T} \\ & = & PCP^\mathsf{T} \end{array}
196 | 现在事情很明白了!我们要找的 P 不是别的,而是能让原始协方差矩阵对角化的 P。换句话说,优化目标变成了寻找一个矩阵 P,满足 PCP^\mathsf{T}是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
197 | 至此,我们离“发明”PCA 还有仅一步之遥!
198 | 现在所有焦点都聚焦在了协方差矩阵对角化问题上,有时,我们真应该感谢数学家的先行,因为矩阵对角化在线性代数领域已经属于被玩烂了的东西,所以这在数学上根本不是问题。
199 | 由上文知道,协方差矩阵 C 是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:1)实对称矩阵不同特征值对应的特征向量必然正交。2)设特征向量\lambda 重数为 r,则必然存在 r 个线性无关的特征向量对应于\lambda,因此可以将这 r 个特征向量单位正交化。
200 | 由上面两条可知,一个 n 行 n 列的实对称矩阵一定可以找到 n 个单位正交特征向量,设这 n 个特征向量为 e_1,e_2,\cdots,e_n,我们将其按列组成矩阵:
201 | E=\begin{pmatrix} e_1 & e_2 & \cdots & e_n \end{pmatrix}
202 | 则对协方差矩阵 C 有如下结论:
203 | E^\mathsf{T}CE=\Lambda=\begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix}
204 | 其中\Lambda 为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
205 | 以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。
206 | 到这里,我们发现我们已经找到了需要的矩阵 P:
207 | P=E^\mathsf{T}
208 | P 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 C 的一个特征向量。如果设 P 按照\Lambda 中特征值的从大到小,将特征向量从上到下排列,则用 P 的前 K 行组成的矩阵乘以原始数据矩阵 X,就得到了我们需要的降维后的数据矩阵 Y。
209 | 至此我们完成了整个 PCA 的数学原理讨论。在下面的一节,我们将给出 PCA 的一个实例。
210 |
--------------------------------------------------------------------------------
/特征工程/数据集/文本/常用数据集介绍.md:
--------------------------------------------------------------------------------
1 | # 搜狗实验室数据
2 |
3 | 
4 |
5 | 搜狗实验室(Sogo Labs)是搜狗搜索核心研发团队对外交流的窗口,包含数据资源、数据挖掘云、研究合作等几个栏目。数据资源包括评测集合、语料数据、新闻数据、图片数据和自然语言处理相关数据,网址为[这里](http://www.sogou.com/labs/resource/list_pingce.php)
6 |
7 | ## 互联网语料库(SogouT)
8 |
9 | SogouT 来自互联网各种类型的 1.3 亿个原始网页, 压缩前的大小超过了 5TB,格式如下:
10 |
11 | ```xml
12 |
13 | 页面 ID
14 | 页面 URL
15 | 页面原始内容
16 |
17 | ```
18 |
19 | 为了满足不同需求,SogouT 分为了不同的版本,差别体现在数据量上:
20 |
21 | - 迷你版(样例数据, 61KB):tar.gz 格式,zip 格式
22 | - 完整版(1TB):(硬盘拷贝)
23 | - 历史版本(130GB):V2.0(硬盘拷贝)
24 |
25 | ## 全网新闻数据(SogouCA)
26 |
27 | SogouCA 来自若干新闻站点 2012 年 6 月—7 月期间国内,国际,体育,社会,娱乐等 18 个频道的新闻数据,提供 URL 和正文信息,格式如下:
28 |
29 | ```html
30 |
31 | 页面URL
32 |
33 | 页面ID
34 |
35 | 页面标题
36 |
37 | 页面内容
38 |
39 | ```
40 |
41 | 为了满足不同需求,SogouCA 分为了不同的版本,差别体现在数据量上:
42 |
43 | - 迷你版(样例数据, 101KB):tar.gz 格式,zip 格式
44 | - 完整版(711MB):tar.gz 格式,zip 格式
45 | - 历史版本:- 完整版(同时提供硬盘拷贝,1.02GB):tar.gz 格式 - 迷你版(样例数据, 3KB):tar.gz 格式 - 精简版(一个月数据, 437MB):tar.gz 格式
46 |
47 | ## 搜狐新闻数据(SogouCS)
48 |
49 | SogouCS 来自搜狐新闻 2012 年 6 月—7 月期间国内,国际,体育,社会,娱乐等 18 个频道的新闻数据,提供 URL 和正文信息,格式如下:
50 |
51 | ```html
52 |
53 | 页面URL
54 |
55 | 页面ID
56 |
57 | 页面标题
58 |
59 | 页面内容
60 |
61 | ```
62 |
63 | 为了满足不同需求,SogouCS 分为了不同的版本,差别体现在数据量上:
64 |
65 | - 迷你版(样例数据, 110KB):tar.gz 格式,zip 格式
66 | - 完整版(648MB):tar.gz 格式,zip 格式
67 | - 历史版本:- 完整版(同时提供硬盘拷贝,65GB):tar.gz 格式 - 迷你版(样例数据, 1KB):tar.gz 格式 - 精简版(一个月数据, 347MB):tar.gz 格式 - 特别版(王灿辉 WWW08 论文数据, 647KB):tar.gz 格式
68 |
69 | ## 文本分类评价(SogouTCE)
70 |
71 | SogouTCE 用以评估文本分类结果的正确性,语料来自搜狐等多个新闻网站近 20 个频道,格式如下:
72 |
73 | ```sh
74 | URL前缀\t对应类别标记
75 | ```
76 |
77 | SogouTCE 只包含 URL 前缀和对应类别标记的数据,原始的文本数据可以使用 SogouCA 和 SogouCS。
78 |
79 | ## 互联网词库(SogouW)
80 |
81 | SogouW 来自于对 SOGOU 搜索引擎所索引到的中文互联网语料的统计分析,统计所进行的时间是 2006 年 10 月,涉及到的互联网语料规模在 1 亿页面以上。统计出的词条数约为 15 万条高频词,除标出这部分词条的词频信息之外,还标出了常用的词性信息,格式如下:
82 |
83 | ```
84 | 词A 词频 词性1 词性2 … 词性N
85 |
86 | 词B 词频 词性1 词性2 … 词性N
87 |
88 | 词C 词频 词性1 词性2 … 词性N
89 | ```
90 |
91 | # IMDB Reviews
92 |
93 | 互联网电影资料库(Internet Movie Database,简称 IMDB)是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库。IMDB Reviews 是记录了观众对 IMDB 中作品的评价。除了训练和测试评估示例之外,还有更多未标记的数据可供使用,包括文本和预处理的词袋格式。IMDB Reviews 包含 25,000 个高度差异化的电影评论用于训练,25,000 个测试,通常用于英文的情感理解。
94 |
95 | # Sentiment140
96 |
97 | Sentiment140 是一个可用于情感分析的数据集,包含 160,000 条推文。一个流行的数据集,非常适合开始你的 NLP 旅程。情绪已经从数据中预先移除。最终的数据集具有以下 6 个特征:
98 |
99 | - 推文的极性
100 | - 推文的 ID
101 | - 推文的日期
102 | - 问题
103 | - 推文的用户名
104 | - 推文的文本
105 |
106 | # Yelp Reviews
107 |
108 | Yelp Reviews 是 Yelp 为了学习目的而发布的一个开源数据集。它包含了由数百万用户评论,商业属性和来自多个大都市地区的超过 20 万张照片。这是一个常用的全球 NLP 挑战数据集,包含 5,200,000 条评论,174,000 条商业属性。
109 | 数据集下载地址为:
110 |
111 | > https://www.yelp.com/dataset/download
112 |
113 | 
114 |
115 | 数据集格式分为 JSON 和 SQL 两种,以 JSON 格式为例,其中最重要的 review.json,包含评论数据,格式如下:
116 |
117 | ```json
118 | {
119 | // string, 22 character unique review id
120 | "review_id": "zdSx_SD6obEhz9VrW9uAWA",
121 |
122 | // string, 22 character unique user id, maps to the user in user.json
123 | "user_id": "Ha3iJu77CxlrFm-vQRs_8g",
124 |
125 | // string, 22 character business id, maps to business in business.json
126 | "business_id": "tnhfDv5Il8EaGSXZGiuQGg",
127 |
128 | // integer, star rating
129 | "stars": 4,
130 |
131 | // string, date formatted YYYY-MM-DD
132 | "date": "2016-03-09",
133 |
134 | // string, the review itself
135 | "text": "Great place to hang out after work: the prices are decent, and the ambience is fun. It's a bit loud, but very lively. The staff is friendly, and the food is good. They have a good selection of drinks.",
136 |
137 | // integer, number of useful votes received
138 | "useful": 0,
139 |
140 | // integer, number of funny votes received
141 | "funny": 0,
142 |
143 | // integer, number of cool votes received
144 | "cool": 0
145 | }
146 | ```
147 |
148 | 另外 tip.json 文件记录了短评数据,格式如下:
149 |
150 | ```json
151 | {
152 | // string, text of the tip
153 | "text": "Secret menu - fried chicken sando is da bombbbbbb Their zapatos are good too.",
154 |
155 | // string, when the tip was written, formatted like YYYY-MM-DD
156 | "date": "2013-09-20",
157 |
158 | // integer, how many likes it has
159 | "likes": 172,
160 |
161 | // string, 22 character business id, maps to business in business.json
162 | "business_id": "tnhfDv5Il8EaGSXZGiuQGg",
163 |
164 | // string, 22 character unique user id, maps to the user in user.json
165 | "user_id": "49JhAJh8vSQ-vM4Aourl0g"
166 | }
167 | ```
168 |
169 | 专门有个开源项目用于解析该 JSON 文件:
170 |
171 | > https://github.com/Yelp/dataset-examples
172 |
173 | # Enron-Spam
174 |
175 | Enron-Spam 数据集是目前在电子邮件相关研究中使用最多的公开数据集,其邮件数据是安然公司(Enron Corporation, 原是世界上最大的综合性天然气和电力公司之一,在北美地区是头号天然气和电力批发销售商)150 位高级管理人员的往来邮件。这些邮件在安然公司接受美国联邦能源监管委员会调查时被其公布到网上。机器学习领域使用 Enron-Spam 数据集来研究文档分类、词性标注、垃圾邮件识别等,由于 Enron-Spam 数据集都是真实环境下的真实邮件,非常具有实际意义。
176 | Enron-Spam 数据集合如下图所示,使用不同文件夹区分正常邮件和垃圾邮件。
177 |
178 | 
179 |
180 | 正常邮件内容举例如下:
181 |
182 | > Subject: christmas baskets
183 | > the christmas baskets have been ordered .
184 | > we have ordered several baskets .
185 | > individual earth - sat freeze - notis
186 | > smith barney group baskets
187 | > rodney keys matt rodgers charlie
188 | > notis jon davis move
189 | > team
190 | > phillip randle chris hyde
191 | > harvey
192 | > freese
193 | > faclities
194 |
195 | 垃圾邮件内容举例如下:
196 |
197 | > Subject: fw : this is the solution i mentioned lscoo
198 | > thank you ,
199 | > your email address was obtained from a purchased list ,reference # 2020 mid = 3300 . if you wish to unsubscribe
200 | > from this list, please click here and enter
201 | > your name into the remove box . if you have previously unsubscribed
202 | > and are still receiving this message, you may email our abuse
203 | > control center, or call 1 - 888 - 763 - 2497, or write us at : nospam ,
204 | > 6484 coral way, miami, fl, 33155 " . 2002
205 | > web credit inc . all rights reserved .
206 |
207 | Enron-Spam 数据集对应的网址为:
208 |
209 | > http://www2.aueb.gr/users/ion/data/enron-spam/
210 |
211 | # babi 阅读理解数据集
212 |
213 | babi 是来自 FAIR(Facebook AI Research)的合成式阅读理解与问答数据集,是个入门级的阅读理解数据集,其训练集以对话集合[2] + 问题[1] + 回答[1]的形式组成:
214 |
215 | 1 Mary moved to the bathroom.
216 | 2 John went to the hallway.
217 | 3 Where is Mary? bathroom 1
218 | 4 Daniel went back to the hallway.
219 | 5 Sandra moved to the garden.
220 | 6 Where is Daniel? hallway 4
221 | 7 John moved to the office.
222 | 8 Sandra journeyed to the bathroom.
223 | 9 Where is Daniel? hallway 4
224 | 10 Mary moved to the hallway.
225 | 11 Daniel travelled to the office.
226 | 12 Where is Daniel? office 11
227 | 13 John went back to the garden.
228 | 14 John moved to the bedroom.
229 | 15 Where is Sandra? bathroom 8
230 | 1 Sandra travelled to the office.
231 | 2 Sandra went to the bathroom.
232 | 3 Where is Sandra? bathroom 2
233 | 4 Mary went to the bedroom.
234 | 5 Daniel moved to the hallway.
235 | 6 Where is Sandra? bathroom 2
236 | 7 John went to the garden.
237 | 8 John travelled to the office.
238 | 9 Where is Sandra? bathroom 2
239 | 10 Daniel journeyed to the bedroom.
240 | 11 Daniel travelled to the hallway.
241 | 12 Where is John? office 8
242 |
243 | 抽象表示格式为:
244 |
245 | ID text
246 | ID text
247 | ID text
248 | ID question[tab]answer[tab]supporting fact IDS.
249 |
250 | 项目主页地址为:
251 |
252 | > https://research.fb.com/downloads/babi/
253 |
254 | 数据下载地址为:
255 |
256 | > http://www.thespermwhale.com/jaseweston/babi/tasks_1-20_v1.tar.gz
257 |
258 | 下载压缩包,解压后,全部文件保存在 en 文件下,文件夹下包含以下文件:
259 |
260 | qa10_indefinite-knowledge_test.txt
261 | qa1_single-supporting-fact_test.txt
262 | qa10_indefinite-knowledge_train.txt
263 | qa1_single-supporting-fact_train.txt
264 | qa11_basic-coreference_test.txt
265 | qa20_agents-motivations_test.txt
266 | qa11_basic-coreference_train.txt
267 | qa20_agents-motivations_train.txt
268 | qa12_conjunction_test.txt
269 | qa2_two-supporting-facts_test.txt
270 | qa12_conjunction_train.txt
271 | qa2_two-supporting-facts_train.txt
272 | qa13_compound-coreference_test.txt
273 | qa3_three-supporting-facts_test.txt
274 | qa13_compound-coreference_train.txt
275 | qa3_three-supporting-facts_train.txt
276 | qa14_time-reasoning_test.txt
277 | qa4_two-arg-relations_test.txt
278 | qa14_time-reasoning_train.txt
279 | qa4_two-arg-relations_train.txt
280 | qa15_basic-deduction_test.txt
281 | qa5_three-arg-relations_test.txt
282 | qa15_basic-deduction_train.txt
283 | qa5_three-arg-relations_train.txt
284 | qa16_basic-induction_test.txt
285 | qa6_yes-no-questions_test.txt
286 | qa16_basic-induction_train.txt
287 | qa6_yes-no-questions_train.txt
288 | qa17_positional-reasoning_test.txt
289 | qa7_counting_test.txt
290 | qa17_positional-reasoning_train.txt
291 | qa7_counting_train.txt
292 | qa18_size-reasoning_test.txt
293 | qa8_lists-sets_test.txt
294 | qa18_size-reasoning_train.txt
295 | qa8_lists-sets_train.txt
296 | qa19_path-finding_test.txt
297 | qa9_simple-negation_test.txt
298 | qa19_path-finding_train.txt
299 | qa9_simple-negation_train.txt
300 |
301 | # SMS Spam Collection
302 |
303 | SMS Spam Collection 是用于骚扰短信识别的经典数据集,完全来自真实短信内容,包括 4831 条正常短信和 747 条骚扰短信。从官网下载数据集压缩包,解压,正常短信和骚扰短信保存在一个文本文件中。
304 | 每行完整记录一条短信内容,每行开头通过 ham 和 spam 标识正常短信和骚扰短信,数据集文件内容举例如下:
305 |
306 | > ham What you doing?how are you?
307 | > ham Ok lar... Joking wif u oni...
308 | > ham dun say so early hor... U c already then say...
309 | > ham MY NO. IN LUTON 0125698789 RING ME IF UR AROUND! H\*
310 | > ham Siva is in hostel aha:-.
311 | > ham Cos i was out shopping wif darren jus now n i called him 2 ask wat present he wan lor. Then he started guessing who i was wif n he finally guessed darren lor.
312 | > spam FreeMsg: Txt: CALL to No: 86888 & claim your reward of 3 hours talk time to use from your phone now! ubscribe6GBP/ mnth inc 3hrs 16 stop?txtStop
313 | > spam Sunshine Quiz! Win a super Sony DVD recorder if you canname the capital of Australia? Text MQUIZ to 82277. B
314 | > spam URGENT! Your Mobile No 07808726822 was awarded a L2,000 Bonus Caller Prize on 02/09/03! This is our 2nd attempt to contact YOU! Call 0871-872-9758 BOX95QU
315 |
316 | SMS Spam Collection 数据集主页地址为:
317 |
318 | > http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
319 |
320 | 
321 |
322 | # UBUNTU DIALOG CORPUS
323 |
324 | UBUNTU DIALOG CORPUS(UDC)是可用的最大的公共对话数据集之一,下载地址为:
325 |
326 | > cs.mcgill.ca/~jpineau/datasets/ubuntu-corpus-1.0/ubuntu_dialogs.tgz
327 |
328 | 它基于公共 IRC 网络上的 Ubuntu 频道的聊天记录。训练数据包括 100 万个样例,50%的正样例(标签 1)和 50%的负样例(标签 0)。每个样例都包含一个上下文,即直到这一点的谈话记录,以及一个话语,即对上下文的回应。一个正标签意味着话语是对当前语境上下文的实际响应,一个负标签意味着这个话语不是真实的响应 ,它是从语料库的某个地方随机挑选出来的。这是一些示例数据:
329 |
330 | 
331 |
332 | UDC 相关的经典论文地址为:
333 |
334 | > https://arxiv.org/abs/1506.08909
335 |
336 | UDC 相关的 Github 地址为:
337 |
338 | > https://github.com/rkadlec/ubuntu-ranking-dataset-creator
339 |
340 | # Hate speech identification
341 |
342 | Hate speech identification 由 ICWSM 2017 论文“自动仇恨语音检测和无礼语言问题”的作者提供。包含 3 类短文本:
343 |
344 | - 包含仇恨言论;
345 | - 是冒犯性的,但没有仇恨言论;
346 | - 根本没有冒犯性。
347 |
348 | 由 15,000 行文本构成,每个字符串都经过 3 人判断。
349 |
350 | 下载链接为:
351 |
352 | > https://github.com/t-davidson/hate-speech-and-offensive-language
353 |
354 | # Twitter Progressive issues sentiment analysis
355 |
356 | Twitter Progressive issues sentiment analysis 是关于诸如堕胎合法化、女权主义、希拉里·克林顿等各种左倾问题的推文,分为赞成、反对或保持中立的三种类别。
357 |
358 | 下载链接为:
359 |
360 | > https://www.figure-eight.com/data-for-everyone/
361 |
362 | # 今日头条新闻文本分类数据集
363 |
364 | 今日头条新闻文本分类数据集共 382688 条,分布于 15 个分类中,分类 code 与名称:
365 |
366 | - 100 民生 故事 news_story
367 | - 101 文化 文化 news_culture
368 | - 102 娱乐 娱乐 news_entertainment
369 | - 103 体育 体育 news_sports
370 | - 104 财经 财经 news_finance
371 | - 106 房产 房产 news_house
372 | - 107 汽车 汽车 news_car
373 | - 108 教育 教育 news_edu
374 | - 109 科技 科技 news_tech
375 | - 110 军事 军事 news_military
376 | - 112 旅游 旅游 news_travel
377 | - 113 国际 国际 news_world
378 | - 114 证券 股票 stock
379 | - 115 农业 三农 news_agriculture
380 | - 116 电竞 游戏 news_game
381 |
382 | 数据格式为:
383 |
384 | ```sh
385 | 6552431613437805063_!_102_!_news_entertainment_!_谢娜为李浩菲澄清网络谣言,
386 | 之后她的两个行为给自己加分_!_佟丽娅,网络谣言,快乐大本营,李浩菲,谢娜,观众们
387 | ```
388 |
389 | 每行为一条数据,以 `_!_` 分割的个字段,从前往后分别是 新闻 ID,分类 code,分类名称,新闻字符串(仅含标题),新闻关键词.
390 |
391 | 项目主页在 github 上,运行 get_data.py 即可获取实时获取对应的数据:https://github.com/fateleak/toutiao-text-classfication-dataset
392 |
393 | 也可以直接使用 github 上的历史数据进行分析:https://github.com/fateleak/toutiao-text-classfication-dataset/raw/master/toutiao_cat_data.txt.zip
394 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
2 | Public License
3 |
4 | By exercising the Licensed Rights (defined below), You accept and agree
5 | to be bound by the terms and conditions of this Creative Commons
6 | Attribution-NonCommercial-ShareAlike 4.0 International Public License
7 | ("Public License"). To the extent this Public License may be
8 | interpreted as a contract, You are granted the Licensed Rights in
9 | consideration of Your acceptance of these terms and conditions, and the
10 | Licensor grants You such rights in consideration of benefits the
11 | Licensor receives from making the Licensed Material available under
12 | these terms and conditions.
13 |
14 |
15 | Section 1 -- Definitions.
16 |
17 | a. Adapted Material means material subject to Copyright and Similar
18 | Rights that is derived from or based upon the Licensed Material
19 | and in which the Licensed Material is translated, altered,
20 | arranged, transformed, or otherwise modified in a manner requiring
21 | permission under the Copyright and Similar Rights held by the
22 | Licensor. For purposes of this Public License, where the Licensed
23 | Material is a musical work, performance, or sound recording,
24 | Adapted Material is always produced where the Licensed Material is
25 | synched in timed relation with a moving image.
26 |
27 | b. Adapter's License means the license You apply to Your Copyright
28 | and Similar Rights in Your contributions to Adapted Material in
29 | accordance with the terms and conditions of this Public License.
30 |
31 | c. BY-NC-SA Compatible License means a license listed at
32 | creativecommons.org/compatiblelicenses, approved by Creative
33 | Commons as essentially the equivalent of this Public License.
34 |
35 | d. Copyright and Similar Rights means copyright and/or similar rights
36 | closely related to copyright including, without limitation,
37 | performance, broadcast, sound recording, and Sui Generis Database
38 | Rights, without regard to how the rights are labeled or
39 | categorized. For purposes of this Public License, the rights
40 | specified in Section 2(b)(1)-(2) are not Copyright and Similar
41 | Rights.
42 |
43 | e. Effective Technological Measures means those measures that, in the
44 | absence of proper authority, may not be circumvented under laws
45 | fulfilling obligations under Article 11 of the WIPO Copyright
46 | Treaty adopted on December 20, 1996, and/or similar international
47 | agreements.
48 |
49 | f. Exceptions and Limitations means fair use, fair dealing, and/or
50 | any other exception or limitation to Copyright and Similar Rights
51 | that applies to Your use of the Licensed Material.
52 |
53 | g. License Elements means the license attributes listed in the name
54 | of a Creative Commons Public License. The License Elements of this
55 | Public License are Attribution, NonCommercial, and ShareAlike.
56 |
57 | h. Licensed Material means the artistic or literary work, database,
58 | or other material to which the Licensor applied this Public
59 | License.
60 |
61 | i. Licensed Rights means the rights granted to You subject to the
62 | terms and conditions of this Public License, which are limited to
63 | all Copyright and Similar Rights that apply to Your use of the
64 | Licensed Material and that the Licensor has authority to license.
65 |
66 | j. Licensor means the individual(s) or entity(ies) granting rights
67 | under this Public License.
68 |
69 | k. NonCommercial means not primarily intended for or directed towards
70 | commercial advantage or monetary compensation. For purposes of
71 | this Public License, the exchange of the Licensed Material for
72 | other material subject to Copyright and Similar Rights by digital
73 | file-sharing or similar means is NonCommercial provided there is
74 | no payment of monetary compensation in connection with the
75 | exchange.
76 |
77 | l. Share means to provide material to the public by any means or
78 | process that requires permission under the Licensed Rights, such
79 | as reproduction, public display, public performance, distribution,
80 | dissemination, communication, or importation, and to make material
81 | available to the public including in ways that members of the
82 | public may access the material from a place and at a time
83 | individually chosen by them.
84 |
85 | m. Sui Generis Database Rights means rights other than copyright
86 | resulting from Directive 96/9/EC of the European Parliament and of
87 | the Council of 11 March 1996 on the legal protection of databases,
88 | as amended and/or succeeded, as well as other essentially
89 | equivalent rights anywhere in the world.
90 |
91 | n. You means the individual or entity exercising the Licensed Rights
92 | under this Public License. Your has a corresponding meaning.
93 |
94 |
95 | Section 2 -- Scope.
96 |
97 | a. License grant.
98 |
99 | 1. Subject to the terms and conditions of this Public License,
100 | the Licensor hereby grants You a worldwide, royalty-free,
101 | non-sublicensable, non-exclusive, irrevocable license to
102 | exercise the Licensed Rights in the Licensed Material to:
103 |
104 | a. reproduce and Share the Licensed Material, in whole or
105 | in part, for NonCommercial purposes only; and
106 |
107 | b. produce, reproduce, and Share Adapted Material for
108 | NonCommercial purposes only.
109 |
110 | 2. Exceptions and Limitations. For the avoidance of doubt, where
111 | Exceptions and Limitations apply to Your use, this Public
112 | License does not apply, and You do not need to comply with
113 | its terms and conditions.
114 |
115 | 3. Term. The term of this Public License is specified in Section
116 | 6(a).
117 |
118 | 4. Media and formats; technical modifications allowed. The
119 | Licensor authorizes You to exercise the Licensed Rights in
120 | all media and formats whether now known or hereafter created,
121 | and to make technical modifications necessary to do so. The
122 | Licensor waives and/or agrees not to assert any right or
123 | authority to forbid You from making technical modifications
124 | necessary to exercise the Licensed Rights, including
125 | technical modifications necessary to circumvent Effective
126 | Technological Measures. For purposes of this Public License,
127 | simply making modifications authorized by this Section 2(a)
128 | (4) never produces Adapted Material.
129 |
130 | 5. Downstream recipients.
131 |
132 | a. Offer from the Licensor -- Licensed Material. Every
133 | recipient of the Licensed Material automatically
134 | receives an offer from the Licensor to exercise the
135 | Licensed Rights under the terms and conditions of this
136 | Public License.
137 |
138 | b. Additional offer from the Licensor -- Adapted Material.
139 | Every recipient of Adapted Material from You
140 | automatically receives an offer from the Licensor to
141 | exercise the Licensed Rights in the Adapted Material
142 | under the conditions of the Adapter's License You apply.
143 |
144 | c. No downstream restrictions. You may not offer or impose
145 | any additional or different terms or conditions on, or
146 | apply any Effective Technological Measures to, the
147 | Licensed Material if doing so restricts exercise of the
148 | Licensed Rights by any recipient of the Licensed
149 | Material.
150 |
151 | 6. No endorsement. Nothing in this Public License constitutes or
152 | may be construed as permission to assert or imply that You
153 | are, or that Your use of the Licensed Material is, connected
154 | with, or sponsored, endorsed, or granted official status by,
155 | the Licensor or others designated to receive attribution as
156 | provided in Section 3(a)(1)(A)(i).
157 |
158 | b. Other rights.
159 |
160 | 1. Moral rights, such as the right of integrity, are not
161 | licensed under this Public License, nor are publicity,
162 | privacy, and/or other similar personality rights; however, to
163 | the extent possible, the Licensor waives and/or agrees not to
164 | assert any such rights held by the Licensor to the limited
165 | extent necessary to allow You to exercise the Licensed
166 | Rights, but not otherwise.
167 |
168 | 2. Patent and trademark rights are not licensed under this
169 | Public License.
170 |
171 | 3. To the extent possible, the Licensor waives any right to
172 | collect royalties from You for the exercise of the Licensed
173 | Rights, whether directly or through a collecting society
174 | under any voluntary or waivable statutory or compulsory
175 | licensing scheme. In all other cases the Licensor expressly
176 | reserves any right to collect such royalties, including when
177 | the Licensed Material is used other than for NonCommercial
178 | purposes.
179 |
180 |
181 | Section 3 -- License Conditions.
182 |
183 | Your exercise of the Licensed Rights is expressly made subject to the
184 | following conditions.
185 |
186 | a. Attribution.
187 |
188 | 1. If You Share the Licensed Material (including in modified
189 | form), You must:
190 |
191 | a. retain the following if it is supplied by the Licensor
192 | with the Licensed Material:
193 |
194 | i. identification of the creator(s) of the Licensed
195 | Material and any others designated to receive
196 | attribution, in any reasonable manner requested by
197 | the Licensor (including by pseudonym if
198 | designated);
199 |
200 | ii. a copyright notice;
201 |
202 | iii. a notice that refers to this Public License;
203 |
204 | iv. a notice that refers to the disclaimer of
205 | warranties;
206 |
207 | v. a URI or hyperlink to the Licensed Material to the
208 | extent reasonably practicable;
209 |
210 | b. indicate if You modified the Licensed Material and
211 | retain an indication of any previous modifications; and
212 |
213 | c. indicate the Licensed Material is licensed under this
214 | Public License, and include the text of, or the URI or
215 | hyperlink to, this Public License.
216 |
217 | 2. You may satisfy the conditions in Section 3(a)(1) in any
218 | reasonable manner based on the medium, means, and context in
219 | which You Share the Licensed Material. For example, it may be
220 | reasonable to satisfy the conditions by providing a URI or
221 | hyperlink to a resource that includes the required
222 | information.
223 | 3. If requested by the Licensor, You must remove any of the
224 | information required by Section 3(a)(1)(A) to the extent
225 | reasonably practicable.
226 |
227 | b. ShareAlike.
228 |
229 | In addition to the conditions in Section 3(a), if You Share
230 | Adapted Material You produce, the following conditions also apply.
231 |
232 | 1. The Adapter's License You apply must be a Creative Commons
233 | license with the same License Elements, this version or
234 | later, or a BY-NC-SA Compatible License.
235 |
236 | 2. You must include the text of, or the URI or hyperlink to, the
237 | Adapter's License You apply. You may satisfy this condition
238 | in any reasonable manner based on the medium, means, and
239 | context in which You Share Adapted Material.
240 |
241 | 3. You may not offer or impose any additional or different terms
242 | or conditions on, or apply any Effective Technological
243 | Measures to, Adapted Material that restrict exercise of the
244 | rights granted under the Adapter's License You apply.
245 |
246 |
247 | Section 4 -- Sui Generis Database Rights.
248 |
249 | Where the Licensed Rights include Sui Generis Database Rights that
250 | apply to Your use of the Licensed Material:
251 |
252 | a. for the avoidance of doubt, Section 2(a)(1) grants You the right
253 | to extract, reuse, reproduce, and Share all or a substantial
254 | portion of the contents of the database for NonCommercial purposes
255 | only;
256 |
257 | b. if You include all or a substantial portion of the database
258 | contents in a database in which You have Sui Generis Database
259 | Rights, then the database in which You have Sui Generis Database
260 | Rights (but not its individual contents) is Adapted Material,
261 | including for purposes of Section 3(b); and
262 |
263 | c. You must comply with the conditions in Section 3(a) if You Share
264 | all or a substantial portion of the contents of the database.
265 |
266 | For the avoidance of doubt, this Section 4 supplements and does not
267 | replace Your obligations under this Public License where the Licensed
268 | Rights include other Copyright and Similar Rights.
269 |
270 |
271 | Section 5 -- Disclaimer of Warranties and Limitation of Liability.
272 |
273 | a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
274 | EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
275 | AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
276 | ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
277 | IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
278 | WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
279 | PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
280 | ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
281 | KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
282 | ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
283 |
284 | b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
285 | TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
286 | NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
287 | INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
288 | COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
289 | USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
290 | ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
291 | DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
292 | IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
293 |
294 | c. The disclaimer of warranties and limitation of liability provided
295 | above shall be interpreted in a manner that, to the extent
296 | possible, most closely approximates an absolute disclaimer and
297 | waiver of all liability.
298 |
299 |
300 | Section 6 -- Term and Termination.
301 |
302 | a. This Public License applies for the term of the Copyright and
303 | Similar Rights licensed here. However, if You fail to comply with
304 | this Public License, then Your rights under this Public License
305 | terminate automatically.
306 |
307 | b. Where Your right to use the Licensed Material has terminated under
308 | Section 6(a), it reinstates:
309 |
310 | 1. automatically as of the date the violation is cured, provided
311 | it is cured within 30 days of Your discovery of the
312 | violation; or
313 |
314 | 2. upon express reinstatement by the Licensor.
315 |
316 | For the avoidance of doubt, this Section 6(b) does not affect any
317 | right the Licensor may have to seek remedies for Your violations
318 | of this Public License.
319 |
320 | c. For the avoidance of doubt, the Licensor may also offer the
321 | Licensed Material under separate terms or conditions or stop
322 | distributing the Licensed Material at any time; however, doing so
323 | will not terminate this Public License.
324 |
325 | d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
326 | License.
327 |
328 |
329 | Section 7 -- Other Terms and Conditions.
330 |
331 | a. The Licensor shall not be bound by any additional or different
332 | terms or conditions communicated by You unless expressly agreed.
333 |
334 | b. Any arrangements, understandings, or agreements regarding the
335 | Licensed Material not stated herein are separate from and
336 | independent of the terms and conditions of this Public License.
337 |
338 |
339 | Section 8 -- Interpretation.
340 |
341 | a. For the avoidance of doubt, this Public License does not, and
342 | shall not be interpreted to, reduce, limit, restrict, or impose
343 | conditions on any use of the Licensed Material that could lawfully
344 | be made without permission under this Public License.
345 |
346 | b. To the extent possible, if any provision of this Public License is
347 | deemed unenforceable, it shall be automatically reformed to the
348 | minimum extent necessary to make it enforceable. If the provision
349 | cannot be reformed, it shall be severed from this Public License
350 | without affecting the enforceability of the remaining terms and
351 | conditions.
352 |
353 | c. No term or condition of this Public License will be waived and no
354 | failure to comply consented to unless expressly agreed to by the
355 | Licensor.
356 |
357 | d. Nothing in this Public License constitutes or may be interpreted
358 | as a limitation upon, or waiver of, any privileges and immunities
359 | that apply to the Licensor or You, including from the legal
360 | processes of any jurisdiction or authority.
361 |
--------------------------------------------------------------------------------
/00~导论/MachineLearning-Is-Fun-For-Anyone-Curious-About-ML.md:
--------------------------------------------------------------------------------
1 | > 系列翻译自 [machine-learning-is-fun-part-1](https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471#.dniejuowp),原文共分三个部分,笔者在这里合并到一篇文章中,并且对内容进行了重新排版以方便阅读,归档到了 [人工智能与深度学习实战--机器学习篇中](https://github.com/wx-chevalier/AIDL-Notes) 中。
2 |
3 | # What is Machine Learning:Machine Learning 的概念与算法介绍
4 |
5 | 估计你已经厌烦了听身边人高谈阔论什么机器学习、深度学习但是自己摸不着头脑,这篇文章就由浅入深高屋建瓴地给你介绍一下机器学习的方方面面。本文的主旨即是让每个对机器学习的人都有所得,因此你也不能指望在这篇文章中学到太多高深的东西。言归正传,我们先来看看到底什么是机器学习:
6 |
7 | > Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
8 |
9 | 笔者在这里放了原作者的英文描述,以帮助更好地理解。Machine Learning 即是指能够帮你从数据中寻找到感兴趣的部分而不需要编写特定的问题解决方案的通用算法的集合。通用的算法可以根据你不同的输入数据来自动地构建面向数据集合最优的处理逻辑。举例而言,算法中一个大的分类即分类算法,它可以将数据分类到不同的组合中。而可以用来识别手写数字的算法自然也能用来识别垃圾邮件,只不过对于数据特征的提取方法不同。相同的算法输入不同的数据就能够用来处理不同的分类逻辑。
10 |
11 | 
12 |
13 | > “Machine learning” is an umbrella term covering lots of these kinds of generic algorithms.
14 |
15 | ## Two kinds of Machine Learning Algorithms: 两类机器学习算法
16 |
17 | 粗浅的划分,可以认为机器学习攘括的算法主要分为有监督学习与无监督学习,概念不难,但是很重要。
18 |
19 | ### Supervised Learning: 有监督学习
20 |
21 | 假设你是一位成功的房地产中介,你的事业正在蒸蒸日上,现在打算雇佣更多的中介来帮你一起工作。不过问题来了,你可以一眼看出某个房子到底估值集合,而你的实习生们可没你这个本事。为了帮你的实习生尽快适应这份工作,你打算写个小的 APP 来帮他们根据房子的尺寸、邻居以及之前卖的类似的屋子的价格来评估这个屋子值多少钱。因此你翻阅了之前的资料,总结成了下表:
22 |
23 | 
24 |
25 | 利用这些数据,我们希望最后的程序能够帮我们自动预测一个新的屋子大概能卖到多少钱:
26 |
27 | 
28 |
29 | 解决这个问题的算法呢就是叫做监督学习,你已知一些历史数据,可以在这些历史数据的基础上构造出大概的处理逻辑。在将这些训练数据用于算法训练之后,通用的算法可以根据这个具体的场景得出最优的参数,有点像下面这张图里描述的一个简单的智力题:
30 |
31 | 
32 |
33 | 这个例子里,你能够知道根据左边的数字的不同推导出不同的右边的数字,那么你脑子里就自然而然生成了一个处理该问题的具体的逻辑。在监督学习里,你则是让机器帮你推导出这种关系,一旦知道了处理特定系列问题的数学方法,其他类似的问题也就都能迎刃而解。
34 |
35 | ### Unsupervised Learning: 无监督学习
36 |
37 | 我们再回到最初的那个问题,如果你现在不知道每个房间的售价,而只知道房间大小、尺寸以及临近的地方,那咋办呢?这个时候,就是无监督学习派上用场的时候了。
38 |
39 | 
40 |
41 | 这种问题有点类似于某人给了你一长串的数字然后跟你说,我不知道每个数字到底啥意思,不过你看看能不能通过某种模式或者分类或者啥玩意找出它们之间是不是有啥关系。那么对于你的实习生来说,这种类型的数据有啥意义呢?你虽然不能知道每个屋子的价格,但是你可以把这些屋子划分到不同的市场区间里,然后你大概能发现购买靠近大学城旁边的屋子的人们更喜欢更多的小卧室户型,而靠近城郊的更喜欢三个左右的卧室。知道不同地方的购买者的喜好可以帮助你进行更精确的市场定位。另外你也可以利用无监督学习发现些特殊的房产,譬如一栋大厦,和其他你售卖的屋子差别很大,销售策略也不同,不过呢却能让你收获更多的佣金。本文下面会更多的关注于有监督学习,不过千万不能觉得无监督学习就无关紧要了。实际上,在大数据时代,无监督学习反而越来越重要,因为它不需要标注很多的测试数据。
42 |
43 | > 这里的算法分类还是很粗浅的,如果要了解更多的细致的分类可以参考:
44 |
45 | - [维基百科](https://en.wikipedia.org/wiki/Machine_learning#Algorithm_types)
46 | >
47 | - [笔者的数据科学与机器学习算法分类](https://github.com/wx-chevalier/datascience-practice-handbook/blob/master/datascience-machinelearning-algorithms.md)
48 |
49 | # House Price Estimation With Supervised Learning: 利用监督学习进行房屋价格估计
50 |
51 | 作为高等智慧生物,人类可以自动地从环境与经历中进行学习,所谓熟读唐诗三百首,不会做诗也会吟,你房子卖多了那自然而然看到了某个屋子也就能知道价格以及该卖给啥样的人了。这个 [Strong_AI](https://en.wikipedia.org/wiki/Strong_AI) 项目也就是希望能够将人类的这种能力复制到计算机上。不过目前的机器学习算法还没这么智能,它们只能面向一些特定的有一定限制的问题。因此,`Learning`这个概念,在这里更应该描述为 : 基于某些测试数据找出解决某个问题的等式,笔者也喜欢描述为对于数据的非线性拟合。希望五十年后看到这篇文章的人,能够推翻这个论述。
52 |
53 | ## Let's Write the Program
54 |
55 | 基本的思想很好理解,下面就开始简单的实战咯。这里假设你还没写过任何机器学习的算法,那么直观的来说,我们可以编写一些简单的条件判断语句来进行房屋价格预测,譬如:
56 |
57 | ```py
58 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
59 | price = 0
60 | # 俺们这嘎达,房子基本上每平方200
61 | price_per_sqft = 200
62 | if neighborhood == "hipsterton":
63 | # 市中心会贵一点
64 | price_per_sqft = 400
65 | elif neighborhood == "skid row":
66 | # 郊区便宜点
67 | price_per_sqft = 100
68 | # 可以根据单价*房子大小得出一个基本价格
69 | price = price_per_sqft * sqft
70 | # 基于房间数做点调整
71 | if num_of_bedrooms == 0:
72 | # 没房间的便宜点
73 | price = price — 20000
74 | else:
75 | # 房间越多一般越值钱
76 | price = price + (num_of_bedrooms * 1000)
77 | return price
78 | ```
79 |
80 | 这就是典型的简答的基于经验的条件式判断,你也能通过这种方法得出一个较好地模型。不过如果数据多了或者价格发生较大波动的时候,你就有心无力了。而应用机器学习算法则是让计算机去帮你总结出这个规律,大概如下所示:
81 |
82 | ```py
83 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
84 | price =
85 | return price
86 | ```
87 |
88 | 通俗的理解,价格好比一锅炖汤,而卧室的数量、客厅面积以及邻近的街区就是食材,计算机帮你自动地根据不同的食材炖出不同的汤来。如果你是喜欢数学的,那就好比有三个自变量的方程,代码表述的话大概是下面这个样子:
89 |
90 | ```py
91 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
92 | price = 0
93 | # a little pinch of this
94 | price += num_of_bedrooms * .841231951398213
95 | # and a big pinch of that
96 | price += sqft * 1231.1231231
97 | # maybe a handful of this
98 | price += neighborhood * 2.3242341421
99 | # and finally, just a little extra salt for good measure
100 | price += 201.23432095
101 | return price
102 | ```
103 |
104 | 注意,上面那些譬如 `.841...` 这样奇怪的数据,它们就是被称为 `权重`,只要我们能根据数据寻找出最合适的权重,那我们的函数就能较好地预测出房屋的价格。
105 |
106 | ## Weights
107 |
108 | 首先,我们用一个比较机械式的方法来寻找最佳的权重。
109 |
110 | ### Step 1
111 |
112 | 首先将所有的权重设置为 1:
113 |
114 | ```py
115 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
116 | price = 0
117 | # a little pinch of this
118 | price += num_of_bedrooms * 1.0
119 | # and a big pinch of that
120 | price += sqft * 1.0
121 | # maybe a handful of this
122 | price += neighborhood * 1.0
123 | # and finally, just a little extra salt for good measure
124 | price += 1.0
125 | return price
126 | ```
127 |
128 | ### Step 2
129 |
130 | 拿已知的数据来跑一波,看看预测出来的值和真实值之间有多少差距,大概效果如下所示:
131 |
132 | 
133 |
134 | 咳咳,可以看出这个差距还是很大的啊,不过不要担心,获取正确的权重参数的过程漫漫,我们慢慢来。我们将每一行的真实价格与预测价格的差价相加再除以总的屋子的数量得到一个差价的平均值,即将这个平均值称为 `cost`,即所谓的代价函数。最理想的状态就是将这个代价值归零,不过基本上不太可能。因此,我们的目标就是通过不断的迭代使得代价值不断地逼近零。
135 |
136 | ### Step 3
137 |
138 | 不断测试不同的权重的组合,从而找出其中最靠近零的一组。## Mind Blowage Time 很简单,不是吗?让我们再回顾下你刚才做了啥,拿了一些数据,通过三个泛化的简单的步骤获取一个预测值,不过在进一步优化之前,我们先来讨论一些小小的思考:
139 |
140 | - 过去 40 年来,包括语言学、翻译等等在内的很多领域都证明了通用的学习算法也能表现出色,尽管这些算法本身看上去毫无意义。
141 | - 刚才咱写的那个函数也是所谓的无声的,即函数中,并不知道卧室数目 bedrooms、客厅大小 square_feet 这些变量到底是啥意思,它只知道输入某些数字然后得出一个值。这一点就很明显地和那些面向特定的业务逻辑的处理程序有很大区别。
142 | - 估计你是猜不到哪些权重才是最合适的,或许你连自己为啥要这么写函数都不能理解,虽然你能证明这么写就是有用的。
143 | - 如果我们把参数`sqft`改成了图片中的像素的敏感度,那么原来输出的值是所谓的价格,而现在的值就是所谓的图片的类型,输入的不同,输出值的意义也就可以不一样。
144 |
145 | ## Try every number?
146 |
147 | 言归正传,我们还是回到寻找最优的权重组合上来。你可以选择去带入所有的可能的权重组合,很明显是无穷大的一个组合,这条路肯定是行不通的。是时候展示一波数学的魅力了,这里我们介绍一个数学中常见的优化求值的方法:首先,我们将 Step 2 中提出的代价方程公式化为如下形式:
148 |
149 | 
150 |
151 | 然后,我们将这个代价方程变得更加通用一点:  这个方程就代表了我们目前的权重组合离真实的权重组合的差距,如果我们测试多组数据,那么大概可以得出如下的数据图:
152 |
153 | 
154 |
155 | 图中的蓝色低点即意味着代价最小,也就是权重组合最接近完美值的时候。
156 |
157 | 
158 |
159 | 有了图之后是不是感觉形象多了?我们寻找最优权重的过程就是一步一步走到谷底的过程,如果我们每次小小地修改权重而使得其不断向谷底靠近,我们也就在向结果靠近。如果你还记得微积分的一些知识,应该知道函数的导数代表着函数的切线方向,换言之,在图中的任何一点我们通过计算函数的导数就知道变化的方向,即梯度下降的方向。我们可以计算出代价函数中每个变量的偏导数然后将每个当前变量值减去该偏导数,即按照梯度相反的方向前进,那就可以逐步解决谷底咯。如果你感兴趣的话,可以深入看看[批量梯度下降](https://hbfs.wordpress.com/2012/04/24/introduction-to-gradient-descent/)相关的知识。如果你是打算找个机器学习的工具库来辅助工具,那么到这里你的知识储备已经差不多咯,下面我们再扯扯其他的东西。
160 |
161 | ## Something Skip Over: 刚才没提到的一些东西
162 |
163 | 上文提到的所谓三步的算法,用专业的名词表述应该是多元线性回归。即通过输入含有多个自变量的训练数据获得一个有效的计算表达式用于预测未来的部分房屋的价格。但是上面所讲的还是一个非常简单的例子,可能并不能在真实的环境中完美地工作,这时候就会需要下文即将介绍的包括神经网络、SVM 等等更复杂一点的算法了。另外,我还没提到一个概念:overfitting(过拟合)。在很多情况下,只要有充足的时间我们都能得到一组在训练数据集上工作完美的权重组合,但是一旦它们用于预测,就会跌破眼镜,这就是所谓的过拟合问题。同样的,关于这方面也有很多的方法可以解决,譬如[正则化](http://en.wikipedia.org/wiki/Regularization_%28mathematics%29#Regularization_in_statistics_and_machine_learning) 或者使用 [交叉验证](http://en.wikipedia.org/wiki/Cross-validation_%28statistics%29)。一言以蔽之,尽管基础的概念非常简单,仍然会需要一些技巧或者经验来让整个模型更好地工作,就好像一个才学完 Java 基础的菜鸟和一个十年的老司机一样。
164 |
165 | ## Further Reading | 深入阅读
166 |
167 | 可能看完了这些,觉着 ML 好简单啊,那这么简单的东西又是如何应用到图片识别等等复杂的领域的呢?你可能会觉得可以用机器学习来解决任何问题,只要你有足够多的数据。不过还是要泼点冷水,千万记住,机器学习的算法只在你有足够的解决某个特定的问题的数据的时候才能真正起作用。譬如,如果你想依靠某个屋子内盆栽的数目来预测某个屋子的价格,呵呵。这是因为房屋的价格和里面的盆栽数目没啥必然联系,不管你怎么尝试,输入怎么多的数据,可能都不能如你所愿。
168 |
169 | 
170 |
171 | 所以,总结而言,如果是能够手动解决的问题,那计算机可能解决的更快,但是它也无法解决压根解决不了的问题。在原作者看来,目前机器学习存在的一个很大的问题就是依然如阳春白雪般,只是部分科研人员或者商业分析人员的关注对象,其他人并不能简单地理解或者使用,在本节的最后也推荐一些公开的课程给对机器学习有兴趣的朋友:
172 |
173 | - [Machine Learning class on Coursera](https://www.coursera.org/course/ml)
174 |
175 | - [scikit-learn](http://scikit-learn.org/stable/)
176 |
177 | # Neural Network: 神经网络
178 |
179 | 上文中,我们通过一个简单的房价预测的例子了解了机器学习的基本含义,在本节,我们将会继续用一些泛化的算法搭配上一些特定的数据做些有趣的事情。本节的例子大概如下图所示,一个很多人的童年必备的游戏:马里奥,让我们用神经网络帮你设计一些新奇的关卡吧。
180 |
181 | 在正文之前,还是要强调下,本文是面向所有对机器学习有兴趣的朋友,所以大牛们看到了勿笑。
182 |
183 | ## Introduction To Neural Networks: 神经网络模型初探
184 |
185 | 上文中我们是使用了多元线性回归来进行房屋价格预测,数据格式大概这个样子:
186 |
187 | 
188 |
189 | 最后得到的函数是:
190 |
191 | ```py
192 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
193 | price = 0
194 | # a little pinch of this
195 | price += num_of_bedrooms * 0.123
196 | # and a big pinch of that
197 | price += sqft * 0.41
198 | # maybe a handful of this
199 | price += neighborhood * 0.57
200 | return price
201 | ```
202 |
203 | 如果用图来表示的话,大概是这个样子
204 |
205 | 
206 |
207 | 不过正如上文中提到的,这个算法只能处理一些较为简单的问题,即结果与输入的变量之间存在着某些线性关系。Too young,Too Simple, 真实的房价和这些可不仅仅只有简单的线性关系,譬如邻近的街区这个因子可能对面积较大和面积特别小的房子有影响,但是对于那些中等大小的毫无关系,换言之,price 与 neighborhood 之间并不是线性关联,而是类似于二次函数或者抛物线函数图之间的非线性关联。这种情况下,我们可能得到不同的权重值(形象来理解,可能部分权重值是收敛到某个局部最优):
208 |
209 | 
210 |
211 | 现在等于每次预测我们有了四个独立的预测值,下一步就是需要将四个值合并为一个最终的输出值:
212 |
213 | 
214 |
215 | ### What is Neural Network?: 神经网络初识
216 |
217 | 我们将上文提到的两个步骤合并起来,大概如下图所示:
218 |
219 | 
220 |
221 | 咳咳,没错,这就是一个典型的神经网络,每个节点接收一系列的输入,为每个输入分配权重,然后计算输出值。通过连接这一系列的节点,我们就能够为复杂的函数建模。同样为了简单起见,我在这里也跳过了很多概念,譬如 [feature scaling](https://en.wikipedia.org/wiki/Feature_scaling) 以及 [activation function](https://en.wikipedia.org/wiki/Activation_function),不过核心的概念是:
222 |
223 | - 每个能够接收一系列的输入并且能够按权重求和的估值函数被称为 Neuron( 神经元 )
224 | - 多个简单的神经元的连接可以用来构造处理复杂问题的模型
225 |
226 | 有点像乐高方块,单个的乐高方块非常简单,而大量的乐高方块却可以构建出任何形状的物体:
227 |
228 | 
229 |
230 | ### Giving Our Neural Network a Memory: 给神经网络加点上下文
231 |
232 | 目前,整个神经网络是无状态的,即对于任何相同的输入都返回相同的输出。这个特性在很多情况下,譬如房屋价格估计中是不错的,不过这种模式并不能处理时间序列的数据。举个栗子,我们常用的输入法中有个智能联想的功能,可以根据用户输入的前几个字符预测下一个可能的输入字符。最简单的,可以根据常见的语法来推测下一个出现的字符,而我们也可以根据用户历史输入的记录来推测下一个出现的字符。基于这些考虑,我们的神经网络模型即如下所示:
233 |
234 | 
235 |
236 | 譬如用户已经输入了如下的语句:
237 |
238 | ```
239 | Robert Cohn was once middleweight boxi
240 | ```
241 |
242 | 你可能会猜想是`n`,这样整个词汇就是`boxing`,这是基于你看过了前面的语句以及基本的英文语法得出的推论,另外,`middleweight`这个单词也给了我们额外的提示,跟在它后面的是`boxing`。换言之,在文本预测中,如果你能将句子的上下文也考虑进来,再加上基本的语法知识就能较为准确地预测出下一个可能的字符。因此,我们需要给上面描述的神经网络模型添加一些状态信息,也就是所谓的上下文的信息:
243 |
244 | 
245 |
246 | 在神经网络模型中也保持了对于上下文的追踪,从而使得该模型不仅仅能预测第一个词是啥,也能预测最有可能出现的下一个词汇。该模型就是所谓的 Recurrent Neural Network: 循环神经网络的基本概念。每次使用神经网络的同时也在更新其参数,也就保证了能够根据最新的输入内容预测下一个可能的字符,只要有足够的内存情况下,它可以将完整的时序上下文全部考虑进去。
247 |
248 | ### Generating a story: 生成一个完整的故事
249 |
250 | 正如上文所说,文本预测在实际应用中一个典型的例子就是输入法,譬如 iPhone 里面会根据你之前输入的字符自动帮你补全:
251 |
252 | 
253 |
254 | 不过我们做的更疯狂一点,既然模型可以根据上一个字符自动预测下一个字符,那我们何不让模型来自动构建一个完整的故事?我们在这里使用[Andrej Karpathy](http://karpathy.github.io/about/)创建的[Recurrent Neural Network implementation](https://github.com/karpathy/char-rnn)框架来进行实验,他也发表了一系列[关于如何使用 RNN 进行文档生成的博客](http://karpathy.github.io/2015/05/21/rnn-effectiveness/)。我们还是使用 `The Sun Also Rises` 这篇文章,该文章包括大小写、标点符号等在内一共有 84 个不同的字符以及 362239 个词汇。这个数据集合的大小和真实环境中的应用文本相比还是很小的,为了尽可能模仿原作者的风格,最好的是能有数倍的文本进行训练,不过作为例子这边还是足够的。经过大概 100 次迭代之后,得到的结果是:
255 |
256 | ```
257 | hjCTCnhoofeoxelif edElobe negnk e iohehasenoldndAmdaI ayio pe e h’e btentmuhgehi bcgdltt. gey heho grpiahe.
258 | Ddelnss.eelaishaner” cot AAfhB ht ltny
259 | ehbih a”on bhnte ectrsnae abeahngy
260 | amo k ns aeo?cdse nh a taei.rairrhelardr er deffijha
261 | ```
262 |
263 | 惨不忍睹啊,继续进行训练,大概 1000 次迭代之后,内容看起来好一点了:
264 |
265 | ```
266 | hing soor ither. And the caraos, and the crowebel for figttier and ale the room of me? Streat was not to him Bill-stook of the momansbed mig out ust on the bull, out here. I been soms
267 | inick stalling that aid.
268 | “Hon’t me and acrained on .Hw’s don’t you for the roed,” In’s pair.”
269 | “Alough marith him.”
270 | ```
271 |
272 | 已经能够识别基本的句型结构与语法规则咯,甚至能够较好地为上下文添加标点符号了,不过还是存在着大量的无意义词汇,我们继续增加训练的次数:
273 |
274 | ```
275 | He went over to the gate of the café. It was like a country bed.
276 | “Do you know it’s been me.”
277 | “Damned us,” Bill said.
278 | “I was dangerous,” I said. “You were she did it and think I would a fine cape you,” I said.
279 | “I can’t look strange in the cab.”
280 | “You know I was this is though,” Brett said.
281 | “It’s a fights no matter?”
282 | “It makes to do it.”
283 | “You make it?”
284 | “Sit down,” I said. “I wish I wasn’t do a little with the man.”
285 | “You found it.”
286 | “I don’t know.”
287 | “You see, I’m sorry of chatches,” Bill said. “You think it’s a friend off back and make you really drunk.”
288 | ```
289 |
290 | 现在差不多能看了,有些句式还是很模仿 Hemingway’s 的风格的,而原作者的内容是:
291 |
292 | ```
293 | There were a few people inside at the bar, and outside, alone, sat Harvey Stone. He had a pile of saucers in front of him, and he needed a shave.
294 | “Sit down,” said Harvey, “I’ve been looking for you.”
295 | “What’s the matter?”
296 | “Nothing. Just looking for you.”
297 | “Been out to the races?”
298 | “No. Not since Sunday.”
299 | “What do you hear from the States?”
300 | “Nothing. Absolutely nothing.”
301 | “What’s the matter?”
302 | ```
303 |
304 | ## Super Mario: 利用神经网络进行 Mario 过关训练
305 |
306 | In 2015, Nintendo 宣布了 [Super Mario Maker™](http://supermariomaker.nintendo.com/) 用于 Wii U 游戏系统上。
307 |
308 | 
309 |
310 | 这个制作器能够让你去手动制作马里奥的一些关卡,很不错的和朋友之间进行互动的小工具。你可以添加常见的障碍物或者敌人到你自己设计的关卡中,有点像可视化的乐高工作台。我们可以使用刚才创建的用于预测 Hemingway 文本的模型来自动地创建一个超级马里奥的关卡。首先呢,我们还是需要去找一些训练数据,最早的 1985 年推出的经典的超级马里奥的游戏不错:
311 |
312 | 这个游戏有大概 32 个关卡,其中 70% 的场景都有相似的外观,很适合用来做训练数据啊。我找来了每一关的设计方案,网上有很多类似的教程教你怎么从内存中读取游戏的设计方案,有兴趣的话你也可以试试。下面呢就是一个经典的全景视图:
313 |
314 | 
315 |
316 | 用放大镜观察的话,可以看出每一关都是由一系列的网格状对象组成的:
317 |
318 | 
319 |
320 | 这样的话,我们可以将每个网格中的对象用一个字符代替,而整个关卡的字符化表述就是:
321 |
322 | ```
323 | --------------------------
324 | --------------------------
325 | --------------------------
326 | #??#----------------------
327 | --------------------------
328 | --------------------------
329 | --------------------------
330 | -##------=--=----------==-
331 | --------==--==--------===-
332 | -------===--===------====-
333 | ------====--====----=====-
334 | =========================-
335 | ```
336 |
337 | 其中:
338 |
339 | - `-` 代表空白
340 | - `=` 代表坚固的方块
341 | - `#` 代表那些可以被撞破的块
342 | - `?` 代表钱币块
343 |
344 | 
345 |
346 | 仔细瞅瞅这个文件,你会发现如果按照一行一行从左到右读的话,好像是毫无头绪:
347 |
348 | 
349 |
350 | 不过如果按照列的次序从上往下读的话,你会发现还是有点套路的:
351 |
352 | 
353 |
354 | 为了更好地训练数据,我们打算按列来分割数据,这里我们会使用[特征选择](https://en.wikipedia.org/wiki/Feature_selection)的技术来将数据转化为最合适的表示。首先,我们将整个文本旋转 90 度:
355 |
356 | ```-----------=
357 | -------#---=
358 | -------#---=
359 | -------?---=
360 | -------#---=
361 | -----------=
362 | -----------=
363 | ----------@=
364 | ----------@=
365 | -----------=
366 | -----------=
367 | -----------=
368 | ---------PP=
369 | ---------PP=
370 | ----------==
371 | ---------===
372 | --------====
373 | -------=====
374 | ------======
375 | -----=======
376 | ---=========
377 | ---=========
378 | ```
379 |
380 | 然后就可以使用上面创建好的模型进行训练咯,经过几轮训练之后大概可以得出这个样子:
381 |
382 | ```--------------------------
383 | LL+<&=------P-------------
384 | --------
385 | ---------------------T--#--
386 | -----
387 | -=--=-=------------=-&--T--------------
388 | --------------------
389 | --=------$-=#-=-_
390 | --------------=----=<----
391 | -------b
392 | -
393 | ```
394 |
395 | 最初的训练里模型认知到应该大量的出现`-`与`=`字符,不过还是很粗糙,再经过几千次的训练,得出的内容是:
396 |
397 | ```--
398 | -----------=
399 | ----------=
400 | --------PP=
401 | --------PP=
402 | -----------=
403 | -----------=
404 | -----------=
405 | -------?---=
406 | -----------=
407 | -----------=
408 | ```
409 |
410 | 此时模型已经能够认知到需要将每行保证相同的长度,甚至开始寻找出 Mario 内在的规律:管道呢一般都是两个块这么宽,所以它将所有的`P`都放到了 2\*2 的矩阵中,聪明了一点啊。继续学习:
411 |
412 | ```
413 | --------PP=
414 | --------PP=
415 | ----------=
416 | ----------=
417 | ----------=
418 | ---PPP=---=
419 | ---PPP=---=
420 | ----------=
421 | ```
422 |
423 | 
424 |
425 | 看上去像模像样了,其中有几个需要特别注意的地方:
426 |
427 | - Lakitu,就是那个小怪兽被放到了半空中,跟 Mario 关卡一样一样的。
428 | - 它认知到了应该把管道插入大地
429 | - 并没有让玩家无路可走
430 | - 看起来风格非常像最传统的马里奥的版本
431 |
432 | 最后生成出来的游戏截图大概是这样的:
433 |
434 | 
435 |
436 | 你可以在[这里](https://youtu.be/_-Gc6diodcY)观看完整的游戏视频。
437 |
438 | ## Toys VS Real World Applications
439 |
440 | 这里用于训练模型的循环神经网络算法与真实环境下大公司用于解决语音识别以及文本翻译等常见问题的算法一本同源,而让我们的模型看上去好像个玩具一样的原因在于我们的训练数据。仅仅取自最早期的超级马里奥的一些关卡数据远远不足以让我们的模型出类拔萃。如果我们能够获取由其他玩家创建的成百上千的关卡信息,我们可以让模型变得更加完善。不过可惜的是我们压根获取不到这些数据。随着机器学习在不同的产业中变得日渐重要,好的程序与坏的程序之间的差异越发体现在输入数据的多少。这也就是为啥像 Google 或者 Facebook 这样的大公司千方百计地想获取你的数据。譬如 Google 最近开源的[TensorFlow](https://www.tensorflow.org/),一个用于大规模可扩展的机器学习的集群搭建应用,它本身就是 Google 内部集群的重要组成部分。不过没有 Google 的海量数据作为辅助,你压根创建不了媲美于 Google 翻译那样的牛逼程序。下次你再打开 [Google Maps Location History](https://maps.google.com/locationhistory/b/0) 或者 [Facebook Location History](https://www.facebook.com/help/1026190460827516),想想它们是不是记录下你日常的东西。
441 |
442 | ## Further Reading
443 |
444 | 条条大道通罗马,在机器学习中解决问题的办法也永远不止一个。你可以有很多的选项来决定如何进行数据预处理以及应该用啥算法。[增强学习](https://en.wikipedia.org/wiki/Ensemble_learning)正是可以帮你将多个单一的方法组合起来的好途径。如果你想更深入的了解,你可以参考下面几篇较为专业的论文:
445 |
446 | - [Amy K. Hoover](http://amykhoover.com/)’s team used an approach that [represents each type of level object (pipes, ground, platforms, etc) as if it were single voice in an overall symphony](http://julian.togelius.com/Hoover2015Composing.pdf). Using a process called functional scaffolding, the system can augment levels with blocks of any given object type. For example, you could sketch out the basic shape of a level and it could add in pipes and question blocks to complete your design.
447 |
448 | - [Steve Dahlskog](http://forskning.mah.se/en/id/tsstda)’s team showed that modeling each column of level data as a series of n-gram “words” [makes it possible to generate levels with a much simpler algorithm](http://julian.togelius.com/Dahlskog2014Linear.pdf) than a large RNN.
449 |
450 | # Object Recognition In Images With Deep Learning: 利用深度学习对于图片中对象进行识别
451 |
452 | 近年来关于深度学习的讨论非常火爆,特别是之前阿尔法狗大战李世乭之后,更是引发了人们广泛地兴趣。南大的周志华教授在《机器学习》这本书的引言里,提到了他对于深度学习的看法:深度学习掀起的热潮也许大过它本身真正的贡献,在理论和技术上并没有太大的创新,只不过是由于硬件技术的革命,从而得到比过去更精细的结果。相信读者看完了第三部分也会有所感。仁者见仁智者见智,这一章节就让我们一起揭开深度学习的神秘面纱。在本章中,我们还是基于一个实际的例子来介绍下深度学习的大概原理,这里我们会使用简单的卷积神经网络来进行图片中的对象识别。换言之,就类似于 Google Photos 的以图搜图的简单实现,大概最终的产品功能是这个样子的:
453 |
454 | 
455 |
456 | 就像前两章一样,本节的内容尽量做到即不云山雾罩,不知所云,也不阳春白雪,曲高和寡,希望每个队机器学习感兴趣的人都能有所收获。这里我们不会提到太多的数学原理与实现细节,所以也不能眼高手低,觉得深度学习不过尔尔呦。
457 |
458 | ## Recognizing Objects: 对象识别
459 |
460 | 先来看一个有趣的漫画:
461 |
462 | 
463 |
464 | 这个漫画可能有点夸张了,不过它的灵感还是来自于一个现实的问题:一个三岁的小孩能够轻易的辨别出照片中的鸟儿,而最优秀的计算机科学家需要用 50 年的时间来教会机器去识别鸟儿。在过去的数年中,我们发现了一个对象识别的好办法,即是利用深度卷积神经网络。有点像 William Gibson 的科幻小说哈,不过只要跟着本文一步一步来,你就会发现这事一点也不神秘。Talk is cheap, Show you the word~
465 |
466 | ## Starting Simple: 先来点简单的
467 |
468 | 在尝试怎么识别照片中的鸟儿之前,我们先从一些简单的识别开始:怎么识别手写的数字 8。在上一章节,我们了解了神经网络是如何通过链式连接组合大量的简单的 neurons(神经元) 来解决一些复杂的问题。我们创建了一个简单的神经网络来基于床铺数目、房间大小以及邻居的类型来预测某个屋子的可能的价格。
469 |
470 | 
471 |
472 | 再重述下机器学习的理念,即是一些通用的,可以根据不同的数据来处理不同的问题的算法。因此我们可以简单地修改一些神经网络就可以识别手写文字,在这里简单起见,我们只考虑一个字符:手写的数字 8。大量的数据是机器学习不可代替的前提条件与基石,首先我们需要去寻找很多的训练数据。索性对于这个问题的研究已持续了很久,也有很多的开源数据集合,譬如[MNIST 关于手写数字的数据集](http://yann.lecun.com/exdb/mnist/)。MNIST 提供了 60000 张不同的关于手写数字的图片,每个都是 `18*18` 的大小,其中部分关于 8 的大概是这个样子:
473 |
474 | 
475 |
476 | 上章节中构造的神经网络有三个输入,在这里我们希望用神经网络来处理图片,第二步就是需要将一张图片转化为数字的组合,即是计算机可以处理的样子。表担心,这一步还是很简单的。对于电脑而言,一张图片就是一个多维的整型数组,每个元素代表了每个像素的模糊度,大概是这样子:  为了能够将图片应用到我们的神经网络模型中,我们需要将 `18*18` 像素的图片转化为 324 个数字:
477 |
478 | 
479 |
480 | 这次的共有 324 个输入,我们需要将神经网络扩大化转化为 324 个输入的模型:
481 |
482 | 
483 |
484 | 注意,我们的神经网络模型中有两个输出,第一个输出预测该图片是 8 的概率,第二个输出是预测图片不是 8 的概率。对于要辨别的图片,我们可以使用神经网络将对象划分到不同的群组中。虽然这次我们的神经网络比上次大那么多,但是现代的电脑仍然可以在眨眼间处理上百个节点,甚至于能够在你的手机上工作。( PS: TensorFlow 最近支持 iOS 了)在训练的时候,当我们输入一张确定是 8 的图片的时候,会告诉它概率是 100%,不是 8 的时候输入的概率就是 0%。我们部分的训练数据如下所示:
485 |
486 | 
487 |
488 | ### Tunnel Vision
489 |
490 | 虽然我们上面一直说这个任务不难,不过也没那么简单。首先,我们的识别器能够对于标准的图片,就是那些数字端端正正坐在中间,不歪不扭的图片,可以非常高效准确地识别,譬如:
491 |
492 | 
493 |
494 | 不过实际情况总不会如我们所愿,当那些熊孩子一般的 8 也混进来的时候,我们的识别器就懵逼了。
495 |
496 | 
497 |
498 | #### Searching with a Sliding Window: 基于滑动窗口的搜索
499 |
500 | 虽然道路很曲折,但是问题还是要解决的,我们先来试试暴力搜索法。我们已经创建了一个可以识别端端正正的 8 的识别器,我们的第一个思路就是把图片分为一块块地小区域,然后对每个区域进行识别,判断是否属于 8,大概思路如下所示:
501 |
502 | 
503 |
504 | 这方法叫滑动窗口法,典型的暴力搜索解决方法。在部分特定的情况下能起到较好地作用,不过效率非常低下。譬如对于同一类型但是大小不同的图片,你可能就需要一遍遍地搜索。
505 |
506 | #### More data and a Deep Neural Net
507 |
508 | 刚才那个识别器训练的时候,我们只是把部分规规矩矩的图片作为输入的训练数据。不过如果我们选择更多的训练数据时,自然也包含那些七歪八斜的 8 的图片,会不会起到什么神奇的效果呢?我们甚至不需要去搜集更多的测试数据,只要写个脚本然后把 8 放到图片不同的位置上即可:
509 |
510 | 
511 |
512 | 用这种方法,我们可以方便地创建无限的训练数据。数据有了,我们也需要来扩展下我们的神经网络,从而使它能够学习些更复杂的模式。具体而言,我们需要添加更多的中间层:
513 |
514 | 
515 |
516 | 这个呢,就是我们所谓的`深度神经网络`,因为它比传统的神经网络有更多的中间层。这个概念从十九世纪六十年代以来就有了,不过训练大型的神经网络一直很缓慢而无法达到真实的应用预期。不过近年来随着我们认识到使用 3D 图卡来代替传统的 CPU 处理器来进行神经网络的训练,使用大型的神经网络突然之间就变得不再那么遥不可及。
517 |
518 | 
519 |
520 | 不过尽管我们可以依靠 3D 图卡解决计算问题,仍然需要寻找合适的解决方案。我们需要寻找合适的将图片处理能够输入神经网络的方法。好好考虑下,我们训练一个网络用来专门识别图片顶部的 8 与训练一个网络专门用来识别图片底部的 8,把这两个网络分割开来,好像压根没啥意义。因此,我们最终要得到的神经网络是要能智能识别无论在图片中哪个位置的 8。
521 |
522 | ## The Solution is Convolution: 卷积神经网络
523 |
524 | 人们在看图片的时候一般都会自带层次分割的眼光,譬如下面这张图:
525 |
526 | 
527 |
528 | 你可以一眼看出图片中的不同的层次:
529 |
530 | - 地上覆盖着草皮与水泥
531 | - 有个宝宝
532 | - 宝宝坐在个木马上
533 | - 木马在草地上
534 |
535 | 更重要的是,不管宝宝坐在啥上面,我们都能一眼看到那嘎达有个宝宝。即使宝宝坐在汽车、飞机上,我们不经过重新的学习也可以一眼分辨出来。可惜现在我们的神经网络还做不到这一点,它会把不同图片里面的 8 当成不同的东西对待,并不能理解如果在图片中移动 8,对于 8 而言是没有任何改变的。也就意味着对于不同位置的图片仍然需要进行重新学习。我们需要赋予我们的神经网络能够理解平移不变性:不管 8 出现在图片的哪个地方,它还是那个 8。我们打算用所谓的卷积的方法来进行处理,这个概念部分来自于计算机科学,部分来自生物学,譬如神经学家教会猫如何去辨别图片。
536 |
537 | ### How Convolution Works
538 |
539 | 上面我们提到一个暴力破解的办法是将图片分割到一个又一个的小网格中,我们需要稍微改进下这个办法。
540 |
541 | #### 将图片分割为重叠的砖块
542 |
543 | 譬如上面提到的滑动窗口搜索,我们将原图片分割为独立的小块,大概如下图所示:
544 |
545 | 通过这一步操作,我们将原始图片分割为了 77 张大小相同的小图片。
546 |
547 | #### 将每个图片瓷砖输入到小的神经网络中
548 |
549 | 之前我们就训练一个小的神经网络可以来判断单个图片是否属于 8,不过在这里我们的输出并不是直接判断是不是 8,而是处理输出一个特征数组:
550 |
551 | 
552 |
553 | 对于不同的图片的瓷砖块,我们都会使用`具有相同权重的神经网络`来进行处理。换言之,我们将不同的图片小块都同等对待,如果在图片里发现了啥好玩的东西,我们会将该图片标识为待进一步观察的。
554 |
555 | #### 将每个小块的处理结果存入一个新的数组
556 |
557 | 对于每个小块输出的数组,我们希望依然保持图片块之间的相对位置关联,因此我们将每个输出的数组仍然按照之前的图片块的次序排布:
558 |
559 | 
560 |
561 | 到这里,我们输入一个大图片,输出一个相对而言紧密一点的数组,包含了我们可能刚兴趣的块的记录。#### 缩减像素采样上一步的结果是输出一个数组,会映射出原始图片中的哪些部分是我们感兴趣的。不过整个数组还是太大了:
562 |
563 | 
564 |
565 | 为了缩减该特征数组的大小,我们打算使用所谓的[max pooling](https://en.wikipedia.org/wiki/Convolutional_neural_network#Pooling_layer)算法来缩减像素采样数组的大小,这算法听起来高大上,不过还是挺简单的:
566 |
567 | 
568 |
569 | Max pooling 处理过程上呢就是将原特征矩阵按照 2\*2 分割为不同的块,然后从每个方块中找出最有兴趣的位保留,然后丢弃其他三个数组。
570 |
571 | #### 进行预测
572 |
573 | 截至目前,一个大图片已经转化为了一个相对较小地数组。该数组中只是一系列的数字,因此我们可以将该小数组作为输入传入另一个神经网络,该神经网络会判断该图片是否符合我们的预期判断。为了区别于上面的卷积步骤,我们将此称为`fully connected`网络,整个步骤呢,如下所示: 
574 |
575 | #### 添加更多的步骤
576 |
577 | 上面的图片处理过程可以总结为以下步骤:
578 |
579 | - Convolution: 卷积
580 | - Max-pooling: 特征各维最大汇总
581 | - Full-connected: 全连接网络
582 |
583 | 在真实的应用中,这几个步骤可以组合排列使用多次,你可以选择使用两个、三个甚至十个卷积层,也可以在任何时候使用 Max-pooling 来减少数据的大小。基本的思想就是将一个大图片不断地浓缩直到输出一个单一值。使用更多地卷积步骤,你的网络就可以处理学习更多地特征。举例而言,第一个卷积层可以用于识别锐边,第二个卷积层能够识别尖锐物体中的鸟嘴,而第三个卷积层可以基于其对于鸟嘴的知识识别整个鸟。下图就展示一个更现实点地深度卷积网络:
584 |
585 | 
586 |
587 | 在这个例子中,最早地是输入一个 224\*224 像素的图片,然后分别使用两次卷积与 Max-pooling,然后再依次使用卷积与 Max-pooling,最后使用两个全连接层。最后的结果就是图片被分到哪一类。
588 |
589 | ## Building our Bird Classifier: 构建一个真实的鸟儿分类器
590 |
591 | 概念了解了,下面我们就动手写一个真正的鸟类分类器。同样地,我们需要先收集一些数据。免费的 [CIFAR10 data set](https://www.cs.toronto.edu/~kriz/cifar.html)包含了关于鸟儿的 6000 多张图片以及 52000 张不是鸟类的图片。如果不够,[Caltech-UCSD Birds-200–2011 data set](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html) 中还有 12000 张鸟类的图片。其中关于鸟类的图片大概如下所示:
592 |
593 | 非鸟类的图片大概这样:
594 |
595 | 这边我们会使用[TFLearn](http://tflearn.org/)来构建我们的程序,TFLearn 是对于 Google 的 [TensorFlow](https://www.tensorflow.org/) 深度学习库的一个包裹,提供了更易用的 API,可以让编写卷积神经网络就好像编译我们其他的网络层一样简单:
596 |
597 | ```py
598 | # -*- coding: utf-8 -*-
599 |
600 | """
601 | Based on the tflearn example located here:
602 | https://github.com/tflearn/tflearn/blob/master/examples/images/convnet_cifar10.py
603 | """
604 | from __future__ import division, print_function, absolute_import
605 |
606 |
607 | # Import tflearn and some helpers
608 | import tflearn
609 | from tflearn.data_utils import shuffle
610 | from tflearn.layers.core import input_data, dropout, fully_connected
611 | from tflearn.layers.conv import conv_2d, max_pool_2d
612 | from tflearn.layers.estimator import regression
613 | from tflearn.data_preprocessing import ImagePreprocessing
614 | from tflearn.data_augmentation import ImageAugmentation
615 | import pickle
616 |
617 |
618 | # Load the data set
619 | X, Y, X_test, Y_test = pickle.load(open("full_dataset.pkl", "rb"))
620 |
621 |
622 | # Shuffle the data
623 | X, Y = shuffle(X, Y)
624 |
625 |
626 | # Make sure the data is normalized
627 | img_prep = ImagePreprocessing()
628 | img_prep.add_featurewise_zero_center()
629 | img_prep.add_featurewise_stdnorm()
630 |
631 |
632 | # Create extra synthetic training data by flipping, rotating and blurring the
633 | # images on our data set.
634 | img_aug = ImageAugmentation()
635 | img_aug.add_random_flip_leftright()
636 | img_aug.add_random_rotation(max_angle=25.)
637 | img_aug.add_random_blur(sigma_max=3.)
638 |
639 |
640 | # Define our network architecture:
641 |
642 |
643 | # Input is a 32x32 image with 3 color channels (red, green and blue)
644 | network = input_data(shape=[None, 32, 32, 3],
645 | data_preprocessing=img_prep,
646 | data_augmentation=img_aug)
647 |
648 |
649 | # Step 1: Convolution
650 | network = conv_2d(network, 32, 3, activation='relu')
651 |
652 |
653 | # Step 2: Max pooling
654 | network = max_pool_2d(network, 2)
655 |
656 |
657 | # Step 3: Convolution again
658 | network = conv_2d(network, 64, 3, activation='relu')
659 |
660 |
661 | # Step 4: Convolution yet again
662 | network = conv_2d(network, 64, 3, activation='relu')
663 |
664 |
665 | # Step 5: Max pooling again
666 | network = max_pool_2d(network, 2)
667 |
668 |
669 | # Step 6: Fully-connected 512 node neural network
670 | network = fully_connected(network, 512, activation='relu')
671 |
672 |
673 | # Step 7: Dropout - throw away some data randomly during training to prevent over-fitting
674 | network = dropout(network, 0.5)
675 |
676 |
677 | # Step 8: Fully-connected neural network with two outputs (0=isn't a bird, 1=is a bird) to make the final prediction
678 | network = fully_connected(network, 2, activation='softmax')
679 |
680 |
681 | # Tell tflearn how we want to train the network
682 | network = regression(network, optimizer='adam',
683 | loss='categorical_crossentropy',
684 | learning_rate=0.001)
685 |
686 |
687 | # Wrap the network in a model object
688 | model = tflearn.DNN(network, tensorboard_verbose=0, checkpoint_path='bird-classifier.tfl.ckpt')
689 |
690 |
691 | # Train it! We'll do 100 training passes and monitor it as it goes.
692 | model.fit(X, Y, n_epoch=100, shuffle=True, validation_set=(X_test, Y_test),
693 | show_metric=True, batch_size=96,
694 | snapshot_epoch=True,
695 | run_id='bird-classifier')
696 |
697 |
698 | # Save model when training is complete to a file
699 | model.save("bird-classifier.tfl")
700 | print("Network trained and saved as bird-classifier.tfl!")
701 | ```
702 |
703 | 如果你有足够的 RAM,譬如 Nvidia GeForce GTX 980 Ti 或者更好地硬件设备,大概能在 1 小时内训练结束,如果是普通的电脑,时间要耗费地更久一点。随着一轮一轮地训练,准确度也在不断提高,第一轮中准确率只有 75.4%,十轮之后准确率到 91.7%,在 50 轮之后,可以达到 95.5% 的准确率。
704 |
705 | ### Testing out Network
706 |
707 | 我们可以使用如下脚本进行图片的分类预测:
708 |
709 | ```py
710 | # -*- coding: utf-8 -*-
711 | from __future__ import division, print_function, absolute_import
712 |
713 | import tflearn
714 | from tflearn.layers.core import input_data, dropout, fully_connected
715 | from tflearn.layers.conv import conv_2d, max_pool_2d
716 | from tflearn.layers.estimator import regression
717 | from tflearn.data_preprocessing import ImagePreprocessing
718 | from tflearn.data_augmentation import ImageAugmentation
719 | import scipy
720 | import numpy as np
721 | import argparse
722 |
723 |
724 | parser = argparse.ArgumentParser(description='Decide if an image is a picture of a bird')
725 | parser.add_argument('image', type=str, help='The image image file to check')
726 | args = parser.parse_args()
727 |
728 | # Same network definition as before
729 | img_prep = ImagePreprocessing()
730 | img_prep.add_featurewise_zero_center()
731 | img_prep.add_featurewise_stdnorm()
732 | img_aug = ImageAugmentation()
733 | img_aug.add_random_flip_leftright()
734 | img_aug.add_random_rotation(max_angle=25.)
735 | img_aug.add_random_blur(sigma_max=3.)
736 |
737 |
738 | network = input_data(shape=[None, 32, 32, 3],
739 | data_preprocessing=img_prep,
740 | data_augmentation=img_aug)
741 | network = conv_2d(network, 32, 3, activation='relu')
742 | network = max_pool_2d(network, 2)
743 | network = conv_2d(network, 64, 3, activation='relu')
744 | network = conv_2d(network, 64, 3, activation='relu')
745 | network = max_pool_2d(network, 2)
746 | network = fully_connected(network, 512, activation='relu')
747 | network = dropout(network, 0.5)
748 | network = fully_connected(network, 2, activation='softmax')
749 | network = regression(network, optimizer='adam',
750 | loss='categorical_crossentropy',
751 | learning_rate=0.001)
752 |
753 |
754 | model = tflearn.DNN(network, tensorboard_verbose=0, checkpoint_path='bird-classifier.tfl.ckpt')
755 | model.load("bird-classifier.tfl.ckpt-50912")
756 |
757 |
758 | # Load the image file
759 | img = scipy.ndimage.imread(args.image, mode="RGB")
760 |
761 |
762 | # Scale it to 32x32
763 | img = scipy.misc.imresize(img, (32, 32), interp="bicubic").astype(np.float32, casting='unsafe')
764 |
765 |
766 | # Predict
767 | prediction = model.predict([img])
768 |
769 |
770 | # Check the result.
771 | is_bird = np.argmax(prediction[0]) == 1
772 |
773 |
774 | if is_bird:
775 | print("That's a bird!")
776 | else:
777 | print("That's not a bird!")
778 | ```
779 |
780 | ## How accurate is 95% accurate?: 怎么理解这 95% 的准确率
781 |
782 | 刚才有提到,我们的程序有 95% 的准确度,不过这并不意味着你拿张图片来,就肯定有 95% 的概率进行准确分类。举个栗子,如果我们的训练数据中有 5% 的图片是鸟类而其他 95% 的都不是鸟类,那么就意味着每次预测其实不是鸟类的准确度达到 95%。因此,我们不仅要关注整体的分类的准确度,还需要关注分类正确的数目,以及哪些图片分类失败,为啥失败的。这里我们假设预测结果并不是简单的正确或者错误,而是分到不同的类别中:
783 |
784 | - 首先,我们将正确被标识为鸟类的鸟类图片称为:True Positives
785 |
786 | 
787 |
788 | - 其次,对于标识为鸟类的非鸟类图片称为:True Negatives
789 |
790 | 
791 |
792 | - 对于划分为鸟类的非鸟类图片称为:False Positives
793 |
794 | 
795 |
796 | - 对于划分为非鸟类的鸟类图片称为:False Negatives
797 |
798 | 
799 |
800 | 最后的值可以用如下矩阵表示:
801 |
802 | 
803 |
804 | 这种分法的一个现实的意义譬如我们编写一个程序在 MRI 图片中检测癌症,false positives 的结果很明显好于 false negatives。False negatives 意味着那些你告诉他没得癌症但是人家就是癌症的人。这种错误的比例应该着重降低。除此之外,我们还计算[Precision_and_recall](https://en.wikipedia.org/wiki/Precision_and_recall)来衡量整体的准确度: 
805 |
806 | ## Further Reading
807 |
808 | - [https://segmentfault.com/a/1190000003984727](https://segmentfault.com/a/1190000003984727)
809 |
810 | - [TensorFlow 实战之 K-Means 聚类算法实践](https://segmentfault.com/a/1190000004006924)
811 |
812 | - [TensorFlow 实战之 Scikit Flow 系列指导:Part 2 ](https://segmentfault.com/a/1190000004045926)
813 |
814 | - [TFLearn 的示例](https://github.com/tflearn/tflearn/tree/master/examples#tflearn-examples)
815 |
816 | - [how to use algorithms to train computers how to play Atari games](http://karpathy.github.io/2016/05/31/rl/) next?
817 |
--------------------------------------------------------------------------------
/聚类算法/DBSCAN/DBSCAN_Scratch.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "DBSCAN Scratch.ipynb",
7 | "provenance": []
8 | },
9 | "kernelspec": {
10 | "name": "python3",
11 | "display_name": "Python 3"
12 | }
13 | },
14 | "cells": [
15 | {
16 | "cell_type": "code",
17 | "metadata": {
18 | "id": "cG7P-KKZCxsM"
19 | },
20 | "source": [
21 | "!git clone https://github.com/eriklindernoren/ML-From-Scratch\n",
22 | "!mv ./ML-From-Scratch/* ./\n",
23 | "!(python setup.py install)"
24 | ],
25 | "execution_count": null,
26 | "outputs": []
27 | },
28 | {
29 | "cell_type": "code",
30 | "metadata": {
31 | "id": "ZYPtymW2Dvlp"
32 | },
33 | "source": [
34 | "from __future__ import print_function, division\n",
35 | "import numpy as np\n",
36 | "from mlfromscratch.utils import Plot, euclidean_distance, normalize\n",
37 | "\n",
38 | "class DBSCAN():\n",
39 | " \"\"\"A density based clustering method that expands clusters from \n",
40 | " samples that have more neighbors within a radius specified by eps\n",
41 | " than the value min_samples.\n",
42 | "\n",
43 | " Parameters:\n",
44 | " -----------\n",
45 | " eps: float\n",
46 | " The radius within which samples are considered neighbors\n",
47 | " min_samples: int\n",
48 | " The number of neighbors required for the sample to be a core point. \n",
49 | " \"\"\"\n",
50 | " def __init__(self, eps=1, min_samples=5):\n",
51 | " self.eps = eps\n",
52 | " self.min_samples = min_samples\n",
53 | "\n",
54 | " def _get_neighbors(self, sample_i):\n",
55 | " \"\"\" Return a list of indexes of neighboring samples\n",
56 | " A sample_2 is considered a neighbor of sample_1 if the distance between\n",
57 | " them is smaller than epsilon \"\"\"\n",
58 | " neighbors = []\n",
59 | " idxs = np.arange(len(self.X))\n",
60 | " for i, _sample in enumerate(self.X[idxs != sample_i]):\n",
61 | " distance = euclidean_distance(self.X[sample_i], _sample)\n",
62 | " if distance < self.eps:\n",
63 | " neighbors.append(i)\n",
64 | " return np.array(neighbors)\n",
65 | "\n",
66 | " def _expand_cluster(self, sample_i, neighbors):\n",
67 | " \"\"\" Recursive method which expands the cluster until we have reached the border\n",
68 | " of the dense area (density determined by eps and min_samples) \"\"\"\n",
69 | " cluster = [sample_i]\n",
70 | " # Iterate through neighbors\n",
71 | " for neighbor_i in neighbors:\n",
72 | " if not neighbor_i in self.visited_samples:\n",
73 | " self.visited_samples.append(neighbor_i)\n",
74 | " # Fetch the sample's distant neighbors (neighbors of neighbor)\n",
75 | " self.neighbors[neighbor_i] = self._get_neighbors(neighbor_i)\n",
76 | " # Make sure the neighbor's neighbors are more than min_samples\n",
77 | " # (If this is true the neighbor is a core point)\n",
78 | " if len(self.neighbors[neighbor_i]) >= self.min_samples:\n",
79 | " # Expand the cluster from the neighbor\n",
80 | " expanded_cluster = self._expand_cluster(\n",
81 | " neighbor_i, self.neighbors[neighbor_i])\n",
82 | " # Add expanded cluster to this cluster\n",
83 | " cluster = cluster + expanded_cluster\n",
84 | " else:\n",
85 | " # If the neighbor is not a core point we only add the neighbor point\n",
86 | " cluster.append(neighbor_i)\n",
87 | " return cluster\n",
88 | "\n",
89 | " def _get_cluster_labels(self):\n",
90 | " \"\"\" Return the samples labels as the index of the cluster in which they are\n",
91 | " contained \"\"\"\n",
92 | " # Set default value to number of clusters\n",
93 | " # Will make sure all outliers have same cluster label\n",
94 | " labels = np.full(shape=self.X.shape[0], fill_value=len(self.clusters))\n",
95 | " for cluster_i, cluster in enumerate(self.clusters):\n",
96 | " for sample_i in cluster:\n",
97 | " labels[sample_i] = cluster_i\n",
98 | " return labels\n",
99 | "\n",
100 | " # DBSCAN\n",
101 | " def predict(self, X):\n",
102 | " self.X = X\n",
103 | " self.clusters = []\n",
104 | " self.visited_samples = []\n",
105 | " self.neighbors = {}\n",
106 | " n_samples = np.shape(self.X)[0]\n",
107 | " # Iterate through samples and expand clusters from them\n",
108 | " # if they have more neighbors than self.min_samples\n",
109 | " for sample_i in range(n_samples):\n",
110 | " if sample_i in self.visited_samples:\n",
111 | " continue\n",
112 | " self.neighbors[sample_i] = self._get_neighbors(sample_i)\n",
113 | " if len(self.neighbors[sample_i]) >= self.min_samples:\n",
114 | " # If core point => mark as visited\n",
115 | " self.visited_samples.append(sample_i)\n",
116 | " # Sample has more neighbors than self.min_samples => expand\n",
117 | " # cluster from sample\n",
118 | " new_cluster = self._expand_cluster(\n",
119 | " sample_i, self.neighbors[sample_i])\n",
120 | " # Add cluster to list of clusters\n",
121 | " self.clusters.append(new_cluster)\n",
122 | "\n",
123 | " # Get the resulting cluster labels\n",
124 | " cluster_labels = self._get_cluster_labels()\n",
125 | " return cluster_labels\n"
126 | ],
127 | "execution_count": 44,
128 | "outputs": []
129 | },
130 | {
131 | "cell_type": "code",
132 | "metadata": {
133 | "id": "WUt0ts7PGuBl",
134 | "outputId": "a02e20c9-d308-485a-88eb-0a6361d2b278",
135 | "colab": {
136 | "base_uri": "https://localhost:8080/",
137 | "height": 573
138 | }
139 | },
140 | "source": [
141 | "import sys\n",
142 | "import os\n",
143 | "import math\n",
144 | "import random\n",
145 | "from sklearn import datasets\n",
146 | "import numpy as np\n",
147 | "\n",
148 | "from mlfromscratch.utils import Plot\n",
149 | "\n",
150 | "# Load the dataset\n",
151 | "X, y = datasets.make_moons(n_samples=300, noise=0.08, shuffle=False)\n",
152 | "\n",
153 | "# Cluster the data using DBSCAN\n",
154 | "clf = DBSCAN(eps=0.17, min_samples=5)\n",
155 | "y_pred = clf.predict(X)\n",
156 | "\n",
157 | "# Project the data onto the 2 primary principal components\n",
158 | "p = Plot()\n",
159 | "p.plot_in_2d(X, y_pred, title=\"DBSCAN\")\n",
160 | "p.plot_in_2d(X, y, title=\"Actual Clustering\")\n"
161 | ],
162 | "execution_count": 45,
163 | "outputs": [
164 | {
165 | "output_type": "display_data",
166 | "data": {
167 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEWCAYAAABIVsEJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO2de5xVZbn4v8/MwAzIVcDEC6LmQbSLCWlHJSUUbynndFHDCiF/pFmYlnY9WtbxmGYmeYtjmscks44FHjVQREPNC3hHIpXICygIgoPAMMw8vz/W2sOaPeu+174/389nPjP7Xbdn71n7fdb7XEVVMQzDMIykNJRbAMMwDKM6MQViGIZhpMIUiGEYhpEKUyCGYRhGKkyBGIZhGKkwBWIYhmGkwhSIYRiGkQpTIIYRAxFZKSJbRKRVRDaIyKMicpaINLjbfy0i20Rkk7vPEhE50nP8HiLyvyLytohsFJEXROQMz/beIvIDEXlJRN5zr3eTiIzMk+PXIrJdRIbnjf9ARFRETvGMNblj3c5hGFlhCsQw4nOSqvYH9gIuA74F/Mqz/XJV7QcMAK4H7hSRRnfbrcBr7rFDgC8Ab3mO/QNwMjAZGAh8GFgCTMjtICI7AZ8GNgKf95FvPfBDzzUNo6iYAjGMhKjqRlWdC5wKTBGRD+RtV2A2sDPwPnf4o8CvVfU9Vd2uqk+r6r0AInI0cAwwSVWfdLdvVNVrVdWroD4NbAAuAab4iPZnYBv+ysUwMscUiGGkRFWfAF4HxnnH3RXAF4F/sGOV8RhwrYicJiIj8k51NPCEqr4WcckpwG+B24H9RWRMvkjAfwAXi0ivpO/HMJJiCsQwCmMVzkoD4JsisgHYBPwc+A9V7XC3fRZYhDPB/0NEnhGRj7rbhgCrwy7iKp3xwGxVfQtYgKOkuuGujNYCZxb0rgwjBqZADKMwdsfxPQD8VFUHAX2BscAVInI8gKq+o6rfVtUDccxazwB/EhEB1gHDe566G18AlqnqM+7r24DJASuN7wPfA1oKeF+GEYkpEMNIibuC2B142DuuDi8AjwAn5h+nqm8DPwV2w1m93A8cIiJ7hFzui8A+IvKmiLwJ/AwYCpzgc/77gJeBr6R5X4YRF1MghpEQERkgIp/E8UX8RlWf99lnf+AIYKn7+ici8gE3tLY/cDbwsqquU9X7gfuAP4rImNw+bpjwNBH5V2Bf4BDgIPfnAziO+h5mLJfvARdm+sYNIw9TIIYRn7tEpBUnHPd7OKuAqZ7tF7p5IO8B84GbgV+62/oCf8SJolqBE857sufYzwD3AL/DCdN9AccMdj+O83yOqj6vqm/mfoCrgU+KyM7koaqPAE9k87YNwx+xhlKGYRhGGmwFYhiGYaTCFIhhGIaRClMghmEYRipMgRiGYRipaCq3AKVk6NChOnLkyHKLYRiGUVUsWbLkbVUdlj9eVwpk5MiRLF68uNxiGIZhVBUi8k+/cTNhGYZhGKkoqwJxG+asEZEXArafLiLPicjzbgOfD3u2rXTHnxERW1YYhmGUmHKvQH4NHBey/R/Akar6QeBHwKy87eNV9SBVHVsk+QzDMIwAyuoDUdW/hLXbVNVHPS8fA8KKzRmGYRglpNwrkCR8CbjX81qB+W7v6elBB4nIdBFZLCKL165dW3QhDcMw6oWqUCAiMh5HgXzLM3yEqh4MHA+cIyIf9ztWVWep6lhVHTtsWI8oNKPCWTB7EaePPJuJjadw+sizWTB7UblFMgzDpeIViIh8CLgRp1/0uty4qr7h/l6DU+X0kPJIaBSLBbMXcdX0G1jz6tuoKmtefZurpt9gSsQwKoSKViBuG887gS+o6t894zu5PRUQkZ2AiTjlr40a4qbvzqZt87ZuY22bt3HTd2eXSSLDMLyU1YkuIr8FjgKGisjrwMVALwBVvQG4CKdf9HVO50+2uxFX78NpvgPOe5itqn8u+Rswisra19YlGjcMo7SUOwrrcxHbzwTO9BlfAXy45xFGLTFszyGsefVt33HDMMpPRZuwjPpm2qWTae7bu9tYc9/eTLt0cpkkMgzDiykQo2KZMHkc5806i11GDEVEGDCkP71bevOTL/zCIrIMowIwBWJUNBMmj+O2ldfzrVu/RtuWNlrXb0ockWWhwEatMWf5Mo64eRb7zrySI26exZzly8oihykQoypIG5FlocBGrTFn+TK+u2A+q1pbUWBVayvfXTC/LErEFIhRFaSNyMoqFNhWMUalcMWji9iyfXu3sS3bt3PFo6W/J02BGFVBUORVVERWFqHAtooxKonVra2JxouJKRCjKkgbkZVW8XixhEajkhjev3+i8WJiCsSoCvIjsnYZMZTzZp3FhMnjQo/LIhTYEhqNSuKCw8bRp6l7Cl+fpiYuOCz8u1AM6qqlrVHdTJg8rofCWDB7ETd9dzZrX1vHsD2HMO3Syd32yf0dtk8UxU5ojHoPRu3zaus9LF1/DVu2v0mfpl05cOevMqL/Cb77Tho1GnB8IatbWxnevz8XHDaua7yUiKqW/KLlYuzYsWo90WuHnG/Ca15q7ts71sqkUq5TqvdgVC6vtt7D02t/RIdu7RprlBY+Muw/ApVIqRGRJX6N+8yEZVQtpfJNpDWfxcH8K8bS9dd0Ux4AHbqVpeuvKZNE8TEFYpSdtCGypfRN5BIa53fcwbRLJ3PTd2dnEtJr/hVjy/Y3E41XEqZAjLJSSIhskA9CGqRo+RpZh/RmESVmVDd9mnZNNF5JmAIxykohJhy/CCuAzo7OouVrZG1ysoKRxoE7fxU07z7W3s54hWMKxCgrhZhw8n0TDY09b+es/QlZm5yK6V8xqoOnV+3N7587lPWbd0IV1m/eid8/dyhPr9q73KJFYmG8RlkpNETWG9o7sfEU332y9CcUI6TXLzzZqB+ueHQRq1r34vHX9+o2/trGRWUJzU2CrUCMsuJrhhI49MQxgccEOd1L4U8wk5ORJXOWL2NVgaVJylmZ1xSIUVYmTB7HxCnjQTyDCvNvWejruwhzYvtN7k29m9iyaWtmTvUsTE5WmNGAHVV1gxjY3Bz7HOWqzGuJhEYiipE1ffrIs33NQruMGMptK69PtK9Xvv479+O9dzfT0d7RtV+5k/QscdDIccTNswJXHwC9Ghq4/JjjQs1YQefYrX9/Hp46PRM5wRIJjQwoVlXaJI7pqH29+RotOzV3Ux7gONWvO/fmrtelXg1Y4qCRI8pE1d7ZGVmivdyVecuqQETkJhFZIyIvBGwXEZkpIi+LyHMicrBn2xQRecn9mVI6qeuXNJNfnAk6ie8iyb5Byubdda0smL2oLGXag2TyW1UZtU2c6rlRiqDclXnLvQL5NXBcyPbjgf3cn+nA9QAisjNwMXAocAhwsYgMLqqkRuIQ1rgTdBLHdJBz3W+83+CdfPcFRxmWYzUQ6NAXzBdSZ/hV1c0nShGUuzJvWRWIqv4FWB+yyyTgf9ThMWCQiAwHjgXuU9X1qvoOcB/hisjIgKRRTtede3OsCdrrmAZoaGzo2i9/Un387iW+1/IbFxGfPR3WvrYudDVwbK9TmXnOjb7bo1ZVYdunXTq5e8BADsXMWHXGpFGjuXTCRHZzlUT+bRFHEXjPITi+j0snTCxZ+G+l54HsDrzmef26OxY0bhSRaZdO9nUA+60UFsxexLvr/JfffhN3zoHsPX9uxeLdnmQV1Lp+U+B7ySm9INNRZ0cnd10/D4AZ157ZNZ7vBM+XMWj70keW8/jdSxw5A+JWrP5V/TFp1OiuyX7O8mWpSrR7z1FqKl2BFIyITMcxfzFixIgyS1PdJOmtEfY0HbRiCTMp5a6RJJEvaF+ELqWXrxDzuXvWfd0USJCMl0+5hp984RdIg9DZ0dlj+103zAtUHGHvAaxfSL1QTkWQlkpXIG8Ae3pe7+GOvQEclTf+oN8JVHUWMAucMN5iCFlPxM2aDnuaDkq6i7O6SLIK8tsXgZPOOrbbe7jpu7NDVyJxZMztpx0Bt1jEnRe2kotalRlGuSi3Ez2KucAX3WisjwEbVXU1MA+YKCKDXef5RHfMKAGFRFb137lf4MQXx8eSJJHPb99v3zqj24piwuRxoVnk+fW1sq6SG/UeLOy3vilnlnkcyroCEZHf4qwkhorI6ziRVb0AVPUG4B7gBOBlYDMw1d22XkR+BDzpnuoSVQ1zxhsZEfeJOGilcM7MaYHnPvTEMV1+h/xxL0lqR4Xtu2D2Iq6dcVOor+TE6cd0e+27qolC8F2B+CVK5mP9QuqXXJb5lu3bgR1Z5otXvcHClSvK3s4WLBPdiCDf/r5l01bfCddvMvQe22/wTogIres3Bdrxk2SkZ/G+ohTBSWcf22214j02977Cvj8iwrA9h3DoiWOYf8vCVNnnQZ/JgCH9admp2fwiNUxUpnqOPk1NRY+8CspENwViBBJnks0hIszvuCP2efwm0ImNp/hOyGHnTkvQxJz0msc0fDZw232dv+/6O60j3O+za+rdhKpWVIkWI3v2nXlllOusi6xLl+RjpUyMxPjZ34MI8w3EteMXWk03SVmSKBNQ3GvmclfyaWhs6HZ9b4mV21Zen8gEl+/H6dOvxbdEi/fztIKN1U+SbPJVra1l8ZWYAjECiWtnjypnHteOX0ip9KRlScIURHPf3hx64piuCfhTQ6fy6WHTAhMDg7oiZlEWxW/lsumd93z3zX2e5SjRYmRPkmxygbJU5DUFYgQSNMkOGNI/UTnzuCuLQkqlJ41WCpr4Bwzpz8Qp45l/y8KuCbh1/SbeXdfqOxnnZM66G+KC2Yv49LBpXPb5mT0UQVCJltznaZFblUuSqKpJo0YzKEZJd78YjS3bt0cWYswCUyBGIEErgq9cPTWROSZsZZFvagFSmXqSRiv5hvj+Zgb/u/YmHr97SajpLn8ynjB5HNrpb61OEy2VW0H4ZfK3bd6GiISu1CxyqzJJ07vj4qMm9Kh11cCOsieNIoF+klJU5K30REKjTORMJ22bt9HQ2EBnRye7jBiaKtonKIMdokuXxCVNq9mgEN84E23+Plm2uo3yPbWu38S3bv1aoFO+GG13jcK54tFFXSG5OXIrhaAIqtx4rsTJwOZm3mtvp73TSVztUA2KEi9JRV5TIHVA0gig/Mifzo7OrifctFE+fpP16SPPjixdEvf9JMlQj6L/zv0C63jlyJ+Ms7x+HAd/WH5LlrIY2ZG2d4e3xMkRN89iQ1tbt+1KTzNWqSrymgmrCkkSYZPGoVqIDT2LSKiwCTTo/QAFt5rNERXaHjQZN/fZYa/uv3O/1NePcvBHKYIs2u4a2ZNF744gZaNQloq8tgKpMpLWRopToDCftDb0pLKlMbWEvZ8kPpMwgqKcAF8znl+uxratCTLV8wjKdu+/cz/OmTmtpIrACjlmxwWHjeuWWQ7dVwpxqvEO79+/JC1s42IrkCojzurAuwoISpYLUwZp8zGyiITKKiS4EILeZy4jPn8CzTrqacLkcUycMr4rsquhsYGTzj6WO9++OXLyDoveShrGa+HA2RLWuyOug73cDaTyMQVSZURNoPlf+iDClEHafIwsIqGyCgkuhKTvP2ultmD2IubfsrCrwm9nRyfzb1kYOXFHRW8lVWgWDpw9k0aN5uGp03llxjd4eOr0bk7yIAd7/vHlbCCVj5mwqowos0+c7PEoZZCk70cS2YKulcQkUgoHcdL3n3XUUxqzY9BxXpIqNAsHLh1JHOyV1DfEFEiVETWBhn25c8X94iiDpBN7HNmyIK1yS3OduOfM+n2nnbizKs/i3d/CgUtDkG+jFKG4hWAKpMqImkCDvvRZVLSNcqhW4uSeFWHvPev3nXbiDuzASDqFZuHApSPKwZ6UtO1xkxJYjVdEPgj8N06v8XuBb6nqO+62J1T1kMylKTL1UI03buXbSjlvNVDq9572ekHVkwuJ3spXnIeeOKart7tFZWVLVpN+fh8RKLzke+Jy7iLyMPBj4DHgTJxmTier6isi8rSqfiSVJGWkHhQIFCf0Mqj8ef+d+3Hn2zcXdO5Kp5R9SnIUUv7dL+M/7Fxxr1XPDxHVRFAfkUJCfdMokGdV9cOe1+Nxeot/AbhOVQ9OJUkZqRcFUgyCenUAfPs3M2p6AillnxIvWTwIRE36SZRCORSp0ZOolUpYH5Grjj0h1SokVT8QERmY+1tVFwKfBm4F9kosgVHVRCX31TKlCB3OJ6scjKCIrsunXMPExlO4fMo1sUN1LSqr/MTJFwlzvGdd5j1MgfwE6KaqVPU5YAJwZ2YSGIkpR7OgNMl9tdLUqJA+JWnJKgcj6H/T2dGJqnblmsQ5rhyK1OhOnHwRv2TDoH0LJVCBqOpsVX3MZ/xVVf1/mUlgJKJc2cETJo9jwBD/Jxu/CaSWspjLUVsqq6f9tJO733HlUKRGd+Lki+SSDZOeIw2WiV5llDM7+CtXT409gdRaFnPalrRpyeppP6hxVhhB/1Mr0lg84jaailuQcdKo0eyWQfHGKMqqQETkOBFZLiIvi8i3fbZfJSLPuD9/F5ENnm0dnm1zSyt5+SiGHTquqSnJBGL28sLI6mk//3/m1zkRnHpbcZRCqRVpPZCk0VSSWlilqJsVmUgoIoer6iNRY0kRkUbgWuAY4HXgSRGZq6ov5vZR1fM8+38N8IYOb1HVgwqRoRrJOjs4aQXduEl8lsVcGFkmJ3r/ZxaKW3kkaTSV32AqLF8kyb5piZOJ/gsgP2TXbywphwAvq+oKABG5HZgEvBiw/+eAiwu8ZtXjW+pb4NATx6Q6X9q6S2nkNHt5MoqRcV+qagFGfKL8Gn5hu3HzOYpdNytQgYjIvwKHAcNE5HzPpgFAYwbX3h14zfP6deDQAFn2AvYGHvAMt4jIYmA7cJmq/ing2OnAdIARI0ZkIHZ5mTB5HEsfWc5dN8zb0YJMYf4tCznw8FGJJ4JimZpsoqpciqGYrG9IesLqYOVnlefMW0BFFFQM84H0BvrhKJn+np93gc8UX7RunAb8QVU7PGN7uYktk4Gfi8i+fgeq6ixVHauqY4cNG1YKWYvO43cv6dEEuW3zNq47N3lGeDFDM81eXh/UUsRdOQjzVcQt814uwsJ4H1LVHwIfU9Ufen5+pqovZXDtN4A9Pa/3cMf8OA34bZ58b7i/VwAP0t0/UtMErQ7eXdea+Eub1FlbK7kdRnbUWsRdqQnr8ZG2j3qpiOMDaRaRWcBI7/6q+okCr/0ksJ+I7I2jOE7DWU10Q0T2BwYDf/WMDQY2q2qbiAwFDgcuL1CeqiGs6mq+7yLLCrpJHe5G9RPHNGURd4UT5Kuo9DLvccJ4fw88DXwfuMDzUxCquh34KjAPWAbcoapLReQSETnZs+tpwO3avRjRaGCxiDwLLMTxgQQ532uOuFnhUaaF3GriJ1/4BQDfuvVroaYme9KsL+KapixDvXiMH7kPkjcm7nglEFhMsWsHp4hWuhCfCqOWiil+auhUWtdv6jHuLWwXVvwuKEoqLJyzXEUFjWQ8cPcz/Hrmfax9cyPDdh3IGTOO4RMnxot49644pEF8S53kF0+00ODCCCqO6FeWPUeh5dmTElRMMY4J6y4R+QrwR6AtN6iq6zOUz0jIOTOnRYbJhpkW0oTvWm5HZbNg9iKuu+gPbGrZCWlwjAtrVm/k6h/OAYhUIjPPubFbdJ92+D9c5t9XFnGXnrAoq+tf+CMf+OA/ae69nbZtTax8dRfWrhsEBOeJlJo4CmSK+9trtlKgMtZQdUqcL22/wTv5rlL6Dd4pld3acjsql9wqoH2PPbqUR462re38euZ9oQpkwexF3UPDQ/B7YChHl8haICjK6voX/sjQ3VbQ2Oj8Q1qat7PfPqsBupRIJTjSIxWIqu5dCkGM5ER9aUXyrac7xtOsJuxJs3LJrSgbevl/pde+uTHy+DjKA9InrRo9CVICA3f5Z5fyyNHYqIwcsaZLgVSCIz3SiS4ifUXk+24kFiKyn4h8sviiGYXit/rIjaettWS5HZVJ18qxvae9HGDYrgN9x3scH4PH714Se18jnCAl0Nzb//+YG8+6plVa4piwbgaW4GSlgxNy+3vg/4ollBEfr9Oz3+CdEBFa129i2J5DAk1Yw/YcYquJGmLB7EVIg6Adir61FnbftZsZq7mlF2fMOCb0HGGh4flYeG52XHDYON/+5X0bBrBF3+2xf9s2Z8pubsyiGEjhxFEg+6rqqSLyOQBV3SxBthGjJOSUxppX33Zi+tyVrldZrHn1bZp6N9HYq5GO9h0J/N5Vhtmtq5+c7yMXLaUbXZPI+4YhvZoYMLAPZ33nk5EOdN8aawEM23NI6IOLPYjEZ9Ko0Sxe9Qa3v/AcHao0ivCp0Qdy/N6HcN1Lv+pmxuroEFa+ugsAG9raKqKkSZw8kG0i0gd3mnJLhrSFH2IUC29sPhBqt96+bTs7DegbWX7dssurF79oOt3YCq+s5ILvHMcdD38/VgivX6n+k84+1tfMeeiJY7rlh7Su38S761qtjEkK5ixfxp3LltLhhsd3qHLnsqWsXTeIt1ftw9a2JlRha1sTL60Y3uX/gMooaRInD+QYnCTCA4D5OFnfZ6jqg0WXLmNqIQ8kKLcjiKgcDYvhr26KnZvjl4netfoNoaGxAe1UW5FEcMTNs3wzzXdz80GC8kByCPDKjG8UUUL3OmnzQFT1PhF5CvgYjrznqmr8GczIlKT2536DdwrdXqxy7kZpSBJNl6Zirp+ZM1e5IIycSc3K3YQTVuvK28/DT8lA+SOx4nYkbAHewanEe4CIfLx4IhlhJE3a27Jpa6g5weoYVTdxo+myrJib9B60cjfBRLWonTRqNA9Pnc5Vx55Q9O6CaYgTxvsT4BHge+yog/XNIstlBODb49oNaZCGnrEN27dtD/3yWh2j6iZum+Es65il6bNuDyT+xG07G1axt5zEicL6N2CUqprjvAIIC7+d2HiK7zGWXV7bxImmy3KlmX8PeqOwgupn2QOJP3HazubXyvrZsSeUXXHkiKNAVgC9sMiriiFowrDsciOIrOuY5e7BfL/KoSeOYf4tC+2BJAFhbWcrvSNhHAWyGXhGRBbQvZjijKJJZSRmwexFbH2vp46Pm11uCqO2KcZK068/zPxbFjJxyngev3uJPZDEIKgSb46wjoTVokDmuj9GCUgTKeMXigvQf+d+nDNzmn15jUxXmt0SWfNo27yNx+9e0q3cu+FPnNVF1XckVNVbRKQ38C/u0HJVbS+uWPVJ2o5/fg5SgD79Wkx5GF1ksdIMeljxYg7zeMRZXVR9R0IROQp4CbgWuA74u4XxFoe0kTIWimuUiqCHFS/mMI9HnNVF3CitchHHhHUlMFFVlwOIyL8AvwWspnPGpFUE1ujJKBVxHkrMYR6POKuLsCitKP9JKYijQHrllAeAqv5dRHoVUaa6Ja0isFBco1REVe0dMKS/mU1jElSJ1y8HJF8xVEp0VpxM9MUicqOIHOX+/DdQ3QWlKpRCenTESSYzjEIJSyJs7tubr1w9tcQSVS+FJAeG+U9KSZxiis3AOcAR7tAi4LpqTCyshmKKaaKwSnk+w/BGYTU0NtDZ0ckuI4bavVVC9p15pW8h7mIVVwwqphipQNyDewOjgU6cKKzopgHxhDoOuBpoBG5U1cvytp8BXIHTxArgGlW90d02BadKMMCPVfWWqOtVgwLJEqu0axiVTVo/RlgV34enTs9cziAFEicK60TgFZyJ/hrgZRE5PgOBGnEiu47HKRX/ORE5wGfX36nqQe5PTnnsDFwMHAocAlwsIoMLlakaCevlkWX9I8MwsiXnx1jV2oqyw48xZ/myyGMrJTorjg/kSmC8qh6lqkcC44GrMrj2IcDLqrrCXdHcDkyKeeyxwH2qul5V3wHuA47LQKaqIqrCqoX3GkblUogfo1KKK8aJwmpV1Zc9r1cAWaRB7g685nn9Os6KIp9Pu3knfwfOU9XXAo7d3e8iIjIdmA4wYsSIDMSuHKJ6edR6eG8lhDHWO+ZjS0+hWeZhNbRKRRwFslhE7gHuwGmg+lngSRH5FICq3llE+e4CfquqbSLyZeAW4BNJTqCqs4BZ4PhAshexfEStMGo5vDcsjBF6xs37jZX7y1ftpK2cYDgE5YE0iLDvzCur4j6No0BagLeAI93Xa4E+wEk4CiWtAnkD2NPzeg92OMsBUFXvDHkjcLnn2KPyjn0wpRxVS9QKo5Yr7QYt/3/44ALaOjq6KZYL598LIrR3dnaNVVJF02olaAV87YybavKey5qglrW5/ujVcJ/GqYVVrMDuJ4H9RGRvHIVwGtDt0VhEhqvqavflyUDOuzQPuNTjOJ8IfKdIclYscVYYtVppN2iZv6GtZ3R5uyrkRRtWUkXTaiVoBdy6fhOt6zcBtioJIz/LvEGkS3nk8PpEglbQXlPuoJYWVJWNbW0lWcFEKhB3gv8aMNK7v6qeXMiFVXW7iHwVRxk0Ajep6lIRuQRYrKpzgRkicjKwHVgPnOEeu15EfoSjhAAuUdX1hchTjdTyCiOMOcuX+X7ZklIpFU2rlais9Bxev5zRHa8fY9+ZV/ruk1uJBJlrvdve2bq1x3G56xSDOImEzwK/Ap7HyQMBQFUfKopERaRW80DqyZGZ7/vw0qepiZampm5fojCKFTNfL8SpzJtDRJjfcUcJpKpegnI7GgMelhpFGNDcHHm/Z3Gfp84DAbaq6kxVXaiqD+V+CpLGiCQsvyN/v7BQ3lrDz/cBzpfp0gkTuejIT/SIj+8lQq+G7rd6JVU0rVa8JXQAGhqDp5NaifwrJkG5HUEr7Q7VWA9LxVxpx3GiXy0iFwPz6d6R8KmiSVXnJIluiQrlrUbCwnODvgydqj06uVkUVvHJ3WNhK5FaifwrNkGVd694dJHvyiQuxewdEkeBfBD4Ak74bM6EpSQMpzXik0Qp1FqyYFSV0bglsL3lrs+fd48pjYzwM5eG9QixrpjJCMrtuHD+vU4wSEKKvdKOY8L6LLCPqh6pquPdH1MeRSSJUggyDVSrySAqOzduCYdCykQY/gSZS8Mc6du2ZlI2r+aYs3wZR9w8i31nXskRN88KvS8njRpNv+bmwO2Dmpu7MtIHt7QwqLm5ZNnpcVYgLwCDgDVFk8LoRlB0S/+d+/UYqyJEhSEAACAASURBVLVkwajs3LAGO17itAs1khG0Mg6j2s2pxSBNL48NIb6Oi4+aULZ7Oo4CGQT8TUSepLsPpKAwXiOYaZdO5qfTrmP7tu4T4HvvbmbB7EXdvoy1FsqbxEQVRqFlIoyepDWLVqs5tVikebgJ+l4Mbmkp6wNRHAVycdGlMLoxYfI4rp1xU1cyVo6O9g4un3JN1z7e/atVYeQTt0ubFz+nexxFZCQjaGWc6wkSdpyxgzQPN0Hfi4uOLK83IdIH4obs/g3o7/4sszDe4rPpnfd8xzs7Orlq+g1ceMwlHNvrVI5p+CzH9jqVmefcWGIJi0PSKqNBvo7xI/epiHLXtcShJ47xHf/wUQeGdilMa06NG8pebQQ9xIQ93FRK9d184iQSnoLT1OlBnIZX44ALVPUPRZcuY6opkfD0kWfHyvL1ctLZxzLj2jOLJFFlEtZYJxcCaaG72RB0T+a6EWbZpbCWm6H5JcP2aWqqCIUQROqOhG4m+jGqusZ9PQy4X1U/XBRJi0ilKhC/0EiAK6ZeS0d7R+zzNDQ2MK/9d8USsyIpdWvPemZi4yn4zRfFyDIPU1a3rbw+02uVg2prRRCkQOL4QBpyysNlHfHCf40YBCUNHvCvoxIpDyDUDl2rmK+jdJSyv0yt5TflUwm9PLIgjiL4s4jME5Ez3B7ldwP3Fles+iEoNPLpBc8nPldYKYlaZfzIfXzHRw4cFDvO3ojHtEsn9/B1eH0cWfosai2/KS5J8kMqgThO9AuAXwIfcn9mqeqFxRasXkjzRPWRCR/0HT9x+jGFilN1LFy5wnf8r6+/ZkmEGeOtfSUi7DJiaJdPIuuabFHKqhapxuTXQAUiIu8XkcPB6Tqoquer6vnAWhHZt2QSVjFRT2QLZi9CGiTZSQWOnTqek84+tmvF0dDYUJcOdAgOfcy31MftNW2EM2HyOG5beT3zO+7gtpXXd8tDCiq/k/Y6QcqqVimkR3q5CPOB/Bz/Jk0b3W0nFUWiGiGqIGJuu6/fQug5A+ZQ58t628rr61Jh5DOwudm3iZQflkRYPIrhs6jG/KZCnOPVmPwaZsJ6n6r2MMS7YyOLJlGNEPVEFlSArqGxgZPOOjYwrh5qx5GYBSLxV3DmWC8e9eqz8JLWBJXzewQ9M1byfRumQAaFbOuTtSC1RtQTWdB27VRmXHsm5806K9ApXk9fyijCagR5sSTC4jLt0sk09e5u0Gjq3VTTPot80pigvErHj0q/b8MUyGIR+X/5gyJyJrCkeCLVBlFPZFHbJ0wex4W3fLXuHIlJifN0NrilpaKTtGqF/ByRqByzWiONCSqoQRpUTrZ5GGEK5OvAVBF5UESudH8eAr4EnFsa8aqXqCiSOFEm9ehITIpfefd8+vTqVdFfwlrgpu/O7pG31NHekdqJXo2kKVESpFwEeHjq9K6+NpUa2hv4zVPVt4DDRGQ88AF3+G5VfaAkklU5UVVy41bRrUZHYinJKYbz5t0TuE8lOyFrhVpP/ItDmkKgUYmwaUq/l5LIUia1RKWWMjEKJ6gmFjimgIenTi+xRPVFrZceiUvSKKyoulhhtd5KeU8HlTIpa+qyiBwnIstF5GUR+bbP9vNF5EUReU5EFojIXp5tHSLyjPszt7SSZ0etVhwtNRccNo5eDT1v514iFe2ErBWCTLKHnjimru7vSaNG8/DU6bwy4xtdJqio/cOq7FZ6aG+cWlhFQUQagWuBY4DXgSdFZK6qvujZ7WlgrKpuFpGzgcuBU91tW1T1oJIKHRO/4oh+ZqioXJFiXbcWyX3hLnnoAd5xI7MGNTeXtVtbPeFnkj30xDHMv2VhZvd3rRJWF6vSa72VzYQlIv8K/EBVj3VffwdAVf8rYP+PANeo6uHu602q2rPHawilMGElKUMdZ9kfpBTyx/O/rGHXNYxSYGatwqmU0u+Jy7mLSCv++dACqKoOKFCgzwDHqeqZ7usvAIeq6lcD9r8GeFNVf+y+3g48A2wHLlPVPwUcNx2YDjBixIgx//znPwsRO5IkX5qo8thBymjilPE9lEVQ9rp9WYOptpLa1UYpy79XCkH3lN84EOv+q4T7NHE5d1WtjDUSICKfB8YCR3qG91LVN0RkH+ABEXleVV/JP1ZVZwGzwFmBFFvWJNEoUeWxg7LZ77phXk9lEfDO6ikKJgmVHt1SC5Sy/HslEHRPLV71BncuW9pt/ML594II7Z2d3faFnvdfJZd+j+1EF5FdRGRE7ieDa78B7Ol5vYc7ln/do4HvASeralfRI1V9w/29Aqdb4kcykKlgkpR0iMoFCZz8E6jBWv2yFko1Fq6rNuqtom7QPXX7C8/1GG9X7VIe3n2r7f6LVCAicrKIvAT8A3gIWEk2/UCeBPYTkb1FpDdwGtAtmsr1e/wSR3ms8YwPFpFm9++hwOGA1/leNpJ8aaISBRNP/nlloWr5y1oolR7dUgvUYiJsWFJf0L3TkcDP7D1HJScQ5ogThfUj4GM4bWw/4iYWfr7QC6vqdhH5KjAPaARuUtWlInIJsFhV5+L0Yu8H/N4tmveqqp4MjAZ+KSKdOErwsrzorbIRN0HQu3/QtmmXTuayz8+Mdd2cb+Txu5fUZRRWUio9uqVWqOZEWK/vYVBLC1vb29nSsSPbPt/sFHRPJaFaEghzxOmJvlhVx7q90T+iqp0i8qz1RC8Nnx42jXfX9bwpBwzpT8tOzaYsAohyPFZKdItRmfjdH0HkkvqSHNNLpJsPBCozgTBHIT3RN4hIP2ARcJuIrAHey1pAw5+vXD3VNxLrK1dPNYURQJynt9zvcke3GJVJWJHDfHJmpzhldQRiRWFVi4k1jgKZBGzFKa54OjAQuKSYQhk7SGoSqyXShi+GOci9x0dFt1RC+KRRHpJM1F6z56RRo7ni0UWxVw/VmkCYI1KBqOp7IrIrcAiwHpinqhYbWkKq2Y6clkJswFk8vVWLDdooDnH9GX7FEtMUVcwni3OUgjhRWGcCTwCfAj4DPCYi04otmFHfFBJmm6asdn7EyyUPPWBhvnVMnDYBfn1mcqvWLdu30+h2y0zT1yOqRlalEMeEdQGO83wdgIgMAR4FbiqmYEZ9U8gqIunTm99qI4hVra3sO/NKM2nVOPk+skEtLagqG9vaevzvc0pjVWtrt4IQHapd912a+6SSEwhzxFEg6wDvN6rVHTNSUM8FD5NQiA04qYM8icMU6Nbv2ns9o7aIM4HnP3zkx7T6+d5qiTgK5GXgcRGZg/P5TAKeE5HzAVT1Z0WUr6aIqr5rymUHhdqAkzy9pY1sqfXJod6JE0QR5+FjdWtrzQZkxFEgr7g/Oea4vysrHKAKCKptlWv7mWVp92qnmGG2+V/mlsbGbgliOQY1N9O3d29Wt7YGVo+ptLBKIxviBlHE+f8PbG6u2YAM60hYQsKqkwYVnrNqutkSN9mrlwiXTzy+6wteaYldRrbkP1Rs3raNDW1tPfYb1NzMU1/eUTA8rBMmOKvmlqamrh41Xqrp3kmcSCgiP1fVr4vIXfiU73NLihgJCKtOaj2lS0Ncf0e/5uZuT4fVElZpJCdJEMWGtjbmLF/G4lVvcPsLz/nWuco50ndzV83nByQW1sLqNcyEdav7+6elEKQemHbpZN+s8mmXTuam786uq9LXpcT7dBl3vb0h74nRr+Nhc2NjlmIaZSJpEMX3Fsxnc8D+u/mYWoMSCystKTANYf1Alrh/LsZpH9sJXa1om0sgW02Rc5C3bd5GQ2MDnR2d7DJiaDdHeZByMZLhVRgDm5t5r729R+nsKBpE2Hfmld3CNwe1tLDJY9bY0NZWM7bseibpSiBIeTSK+Jqkann1GqcfyAKgr+d1H+D+4ohTm+Sir3IrjM6Ozi7l4HWQ927ZUQZ+wJD+VV/6uhzkzBGr3NXGhra2xMoDnBh+Bd7ZupUNbW1df7fnmSwsubD6CVoJxG6W5BJUtr1akgLTECcKq0VVN+VeqOomEekbdoDRnbDoq1z4bv7qo21LTweeEU0Sc0SusN34kfuwcOUKVre20iCSqH8D1IYtu54JWiF8avSB3ToJ5sa3bt/uawrNZZ77UQ1JgWmIo0DeE5GDVfUpABEZA2wprli1RZSDPErBeLFckXDiTuZBETD7zrwy8TVrwZZdz4SFjI/dbfce2ehBDyinfeBDpRS7IoijQL6O09BpFc5D267AqUWVqsaI6g0dNwIrKhHRiFcEL8z+nLQpUK3YsuudoBVCbjwq/LsBGLvb7kWWsvKINPOp6pPA/sDZwFnAaI+D3YhBVJvbuH3UoxIRDf8ieL1EGNzSEsv+HFcZpLVlV0ObUqMnUabRTnefeiPOCgTgo8BId/+DRQRV/Z+iSVVjRPX0CAvv9WK5ItEUmsE+adRofvjgAt8kMi+vzPhGYtmsRHz1Esc0Wo++sEgFIiK3AvsCzwC5eg8KmAJJQFhPj7hNo6JMYYZDoQ7Li4+aEGquCHOWhhG30VUYtVpTqdKJY9qsR19YnBXIWOAAraeaJ2UgTtOouCsVo3Bampoyd5YW2ujKVjDlwy9Sy0u9+sLiKJAXcBznq4ssixGBtbct/pP3nOXLuHD+vT3yPcBZeZz2gQ/xo/FHpzp3oW1Ks1jBGOnIN40ObG5GRNiwdWtdrwTjKJChwIsi8gTQZRjOohaWiBwHXA00Ajeq6mV525txTGVjcHqQnKqqK91t3wG+hGNWm6Gq8wqVJ0vShttGHWftbYv75P3DBxf4Ko/8InppKDQjOYtWvdVCJZrqajWXoxDiKJAfFOPCbkmUa4FjgNeBJ0Vkrqq+6NntS8A7qvp+ETkN+AlwqogcAJwGHAjsBtwvIv+iqj1rcpeBtOG2FqbrTymfvIOc52FO9biTXaEO/kJXMNWCmeqqh0gFoqoPFenahwAvq+oKABG5HadZlVeBTGKHAvsDcI2IiDt+u6q2Af8QkZfd8/21SLImIkliYBbH1TqV/OSddLIr5Cm2lmsqeSnmA0OQsq/EFU81EFbO/WFVPUJEWulezl0AVdUBBV57d+A1z+vXgUOD9lHV7SKyERjijj+Wd6xvFo+ITAemA4wYMaJAkeMRFFa75tW3WTB7UaAysDBdf0r55D24pcW3d8Pglhbf/Uu5Oipmk61y4TdxF+uBIUjZL171RreSJbbiiU9gIqGqHuH+7q+qAzw//TNQHiVDVWep6lhVHTts2LCSXDMsrPaq6TewYLZ/wlHQcarKMQ2f5fSRZwceW8v4JQcW68n7oiM/Qa+G7l+LXg0NXHTkJ3z3L/XqaNKo0Tw8dTqvzPgGD0+dXtUTXH7hy9zEPShAWRf6wBCk7G9/4bnAhwAjnNBMdBFpFJG/FenabwB7el7v4Y757iMiTcBAHGd6nGPLhl/meY6wzPFpl06mqXewVTHnE6k3JVLKaqaTRo3m8mOO63aty485LvBaQZNa0Lhlou8gaEJX1aI8MAQp9aDimZVgIq10Qn0gqtohIstFZISqvprxtZ8E9hORvXEm/9OA/ISGucAUHN/GZ4AHVFVFZC4wW0R+huNE3w94ImP5UpMzUV32+Zm+28NMUlHpNvXqEyllBEySayXxS5hzuDtBE/TGtjZ+duwJmZvqgkyhjQEVmGstOKEYxInCGgwsdcN438sNFhrG6/o0vgrMwwnjvUlVl4rIJcBiVZ0L/Aq41XWSr8dRMrj73YHjcN8OnFMpEVg5JkweF9llcP5fXuSXtz3MmnXvssuQAWx/4iU62qPfRr37RCqJJH4Jy+PoTphvqxgPDONH7sNtzz/bY/zQ3ffg6TdX13xwQjGIo0D+o1gXV9V7gHvyxi7y/L0V+GzAsf8J/GexZMuCsMzx+X95kZ/cMJ+2Nuemfevtd2HEUHqta6Xp9XAFYaVLKou4k10Wmei15EAvdVTZwpUrfMdXbtzApRMm1tRnWyrCorBacKrvvh94HviVqsZvHFznRLWw/fSXZ3Upjy6aGtl+4J6hCsRKl1QecSf2QqLJatH8VeqosjAF7vcQUGsKuxiErUBuAdqBRcDxwAHAuaUQqtrJTwj0a2G7Zt27vsdqn57Od2kQtFN79FA3yk+Sib2QJ+5aNX+V0reVRIHXosIuBmEK5ABV/SCAiPyKCnJSVzpxEgJ3GTLAMVvlMbBvM4NGDK27WlfVSpKJvZAn7kpOpiwFWawGkijwWlXYWROmQNpzf7gO7xKIUxvESQj88ulH8F/X/Jn2js6usV6NDZw7/Wgm/mZG0WU0siHpxJ72iXtgc7NvOZWBzc2JzwXVZZ7JajWQRIHXu8KOS5gC+bCI5B6RBejjvs4qE71midO3o/H1dTQ9tYLt+w1H+/RGtmyj6aXVNEY40I3KIt8s0tC3naaB25BGZcKff87XD5zASXt+MPF58yf4bZ2dvvulebCrNvNMlquBuAq8XuqOFUpYJnpjXvZ5UzVmopeDqBa24Ji5WPEWLfOeoc+fnqBl3jOw4i1rT1tleLPkG/q20zS4DWlSEFi1ZSMXPX0Xd732fKJz+mVob25v9913g0/ZlSjCJuSsyDJhshyrgVJWP6hmInui1zsLZi/i9JFnM7HxlNilRCZMHsd5s85ilxFDERF2GTGU82ad1c2XkbbuVRp5jOLhzZJvGrgNyftGbe1o5+dLFyQ6Z1T/bS/5T8RxJu5iT8hBJUrSKpGk2f5ZUMrqB9VM3J7odUkh5dWj+nakaU9r5d4rk5xZ5IA//hC/OgKrt2xMdL4kE/n4kfsAzqSd38s9yDRVbPNM1g7o8SP3Yfbzz3b7bEuxGrD+H9GYAgmhmOXV07SntXLvlc3wPgNZ5aMshvcZmOw8Mfpv51i4ckUPn4YXr2kq51MZ1NJCL5FujbOiJuQkTvckK5yo8uqrWlsdp6vnGAE+NfrA0Mm9moIEqhlTICEUs7x6mva0Vu69svn6gRO46Om72Nqxw1/R0tiLrx84IdF5ovpve1nd2hpp8lrV2sqF9/2ZdtcR/87WrTSKMKi5mY1tbZETbFKne9wVTtzy6vmrOqV7Vnm+shg/ch8rz14iTIGEkMbMlISk7WmLLY9RGLloq58vXcDqLRsZ3mdgqigsv3DTzdu2+YbxDu/fP9LkJdClPHJ0qLKts5NXZnwjUp4gk9R58+7hikcX9VA+cfMtwsqrB1XIzZF7z35KKN/clTuv5XBkjymQENKYmepJHqMnJ+35wVRhu/nk29/9zFS5STln6vGjT1NT4Opkc3s7c5Yvi5xUwxSU39N93HyLpOXVveRWM35KKOjoVa2tHPzLaxARNmzdaqatDDAFEkIaM1M9yWOUjqhJ+cL593bzaYDTRfGiIz/BefPu6XG+HHGeyqN8Mn5P93Ec0EHnbQD8s14cvKuZpJFjcYIMjPiYAokgqZmp2FSaPEbpCJ2URcCjQHJdFCeNGt0jOsuL1xQUpJzi+GTShAAHmbpQZUuHf1uD3fJkC1JC+Y73IMy0VRiWB2IYCajEjoJXPLqoh4+jvbOzK/rq4qOCnfjD+/ePzNvI5USEMbC5OfHnEpRrsTVAecCOoIHc+YMS/iZ/8MPsFjMs2cqTpMdWIIYRk0otARIVNjtp1GgWr3ojMJciTt7GpFGjQ30t77W3d61yknwufquqsOt4FZz3/EGrpyNunhUZEm3lSdJjKxDDiEkpSoCkIU6m9o/GH83Pjj3BN7M6bt6G39O+AH179eqxAor7ufit6Pyuk4/3/JNGjebhqdN5ZcY3eHjq9B4RYWHVwqw8SWGYAjGMmMSdaEtt5opbtylooo1bKsTP5PSzY09gS0CdLq9/xe/zCDKdAd2uE0Qc09OkUaNDfSFWnqQwzIRlGDGJkyBXDjNXoZ39/JzZwo4yKfnXimty8vpX/D6PsBWdV8EFmaHimp52C/i/7eb2XjfSYysQw4hJnCf9cpm5wsw4USuiSaNG86nRB3Z72lfgzmVLI1dPc5Yv812BRPlXvjn/3kDfRBzTWRLTk1XWLR5lUSAisrOI3CciL7m/B/vsc5CI/FVElorIcyJyqmfbr0XkHyLyjPtzUGnfgVGPxKnQWmmNiOJWxl24ckVg9nbUud/JKyk/qLk50r8SliwYx3SWxPQUdnwlRtVVE+UyYX0bWKCql4nIt93X38rbZzPwRVV9SUR2A5aIyDxV3eBuv0BV/1BCmRNx95JlXH3vI7z5Tiu7Du7PuccfzoljbLlc7UQlyGVZ6TaLgoBxK+OmUXxBNbj69u4dmacRRNDKoNDKuH7HV2pUXTVRLhPWJOAW9+9bgH/L30FV/66qL7l/rwLWAMNKJmEB3L1kGT/4/f2sfsd56lv9Tis/+P393L3Enm5qnazMJVn11IirGNL03Ag696rW1kQRVTlK3XOjUqPqqolyKZD3qepq9+83gfeF7SwihwC9gVc8w//pmrauEpF0jaGLxNX3PsLW9u435tb27Vx97yNlksgoFVk1Iip0csuZZoIMRfmKIUzxBZl5wpRLUERVY0AL3t369+/huyk2lWZurEaKZsISkfuBXX02fc/7QlVVRAINoiIyHLgVmKKquWDz7+Aont7ALBzz1yUBx08HpgOMGDEi4btIx5vv+N+AQeNGbZFFI6Kop/sk5dfzCQrxhZ6RXECgmSeqxIlfRFVYUchSY33PC6doCkRVjw7aJiJvichwVV3tKog1AfsNAO4Gvqeqj3nOnVu9tInIzcA3Q+SYhaNkGDt2bJzyOAWz6+D+rPZRFrsOthvTiEeY7yDKVh/WHyS/lpQXP8V3xM2zQkNtc9eLG1GVy4rPlWxvFIlsDlUs4padN4IplwlrLjDF/XsKMCd/BxHpDfwR+J98Z7mrdBARwfGfvFBUaRNy7vGH09Kru25u6dXEuccfHvscdy9ZxsQf38iHvnEVE398o/lP6owo30GYOSto9SKQ2EwUtRI63630O7ilxXc/vyZSdy5b2hWF1aHaI1y4VJFR1ve8cMoVhXUZcIeIfAn4J3AKgIiMBc5S1TPdsY8DQ0TkDPe4M1T1GeA2ERmG8514BjirxPKHkou2ShuFlXPC5/woOSe899xGbeM1KcV9us+RpWkmrNptbnxVayu9ROjV0NCtpEmSJlK5qLBSR0ZZ3/PCKIsCUdV1QI8Soaq6GDjT/fs3wG8Cjv9EUQUskKQhvPn7b2lrD3TCmwKpH3KTW9JM7CxNM0FZ6vm24HZVBvXuTd/evVM1kcqNxw07NioDK2WSMUlXD377B2FO+PokqUIotLRJ1LmCVkQb29p46stfDT1f1OrIIqOqC1MgGRMWwuunQPz2D8Kc8PVJGoXg1xL3iJtnpVIo+ecqpDbV+JH7BJaVz53DIqOqB1MgGZM0hDfuqiKpE96oLQqx1WftV0hrIss50L3KQ6BbFJZFRlUXVkwxY4JWCUnHB/ZtZvhgJzpk+OD+/OCzR5v/w0hF1hnXaaOX/ORQnDpchZ7bKA+2AsmYc48/vJtPA8JXD0H7f+ffxpvCMBLjVz+rGH6FNCuiuHJYZFT1YAokY5KG8ObG/+tPC9m42WkJmp9DYhhxCDJVDWpp6VExF0rvVzD/Ru1hM1UROHHM6MSrh7b2jq6/N2zeankfRmKCTFXNjY30aWoqu1/B/Bu1h/lAKgArvlj7dG6eS+eao+h8c5Tze/PczK8RZCLa2NZWEX4F82/UHrYCqQCs+GJt07l5Lrz7fcA1I3Wugne/TyfQ0PfkzK4TZiKqFL9CpchhZIOtQCqApBFaRpWx6Wd0KY8utrrj2WGtW41SYyuQMpIrYeKXfW55HzVE5+pk4ynJMgPdMOJgCqRM5Jcw8TLcWuDWFg3DHbOV33jGmInIKCWmQMpEUAmT4YP7M//7Z5ZBIqNo9Du/uw8EgBZn3DCqGFMgZcIc5/VDQ9+T6QTH59G52ll59Ds/Uwe6YZQDUyBlwroW1hcNfU8GUxhGjWEKpEx4S5gcv//fmfHxx9l1wCbaOobRuXkXezo1DKPiMQVSJnIO8meX/zfnjnuIPr0cf0ifprVFyREwDMPIGlMgZeTEMaM5fs+noDPfme7mCJgCMQyjgrFEwnJTohwBwzCMrDEFUm6CcgGKkCNgGIaRJaZAyk2/84GWvEHLETAMo/IpiwIRkZ1F5D4Recn9PThgvw4Recb9mesZ31tEHheRl0XkdyLSu3TSZ0tD35NhwI+hYTdAnN8DfmwOdMMwKp5yrUC+DSxQ1f2ABe5rP7ao6kHuj3dG/Qlwlaq+H3gH+FJxxS0uDX1PpmGXB2nYdbnz25SHYRhVQLkUyCTgFvfvW4B/i3ugiAjwCeAPaY43DMMwsqFcCuR9qpoLM3oTeF/Afi0islhEHhORnJIYAmxQ1Vzs6+vA7kEXEpHp7jkWr127NhPhDcMwjCLmgYjI/cCuPpu+532hqioiGnCavVT1DRHZB3hARJ4HNiaRQ1VnAbMAxo4dG3QdwzAMIyFFUyCqenTQNhF5S0SGq+pqERkOrAk4xxvu7xUi8iDwEeB/gUEi0uSuQvYA3sj8DRiGYRihlMuENReY4v49BZiTv4OIDBaRZvfvocDhwIuqqsBC4DNhxxuGYRjFRZz5uMQXFRkC3AGMAP4JnKKq60VkLHCWqp4pIocBvwSnLBTwc1X9lXv8PsDtwM7A08DnVbUtxnXXuterFIYCb5dbiAIw+cuLyV9e6kn+vVR1WP5gWRSI4SAii1V1bLnlSIvJX15M/vJi8lsmumEYhpESUyCGYRhGKkyBlJdZ5RagQEz+8mLyl5e6l998IIZhGEYqbAViGIZhpMIUiGEYhpEKUyAlREQ+KyJLRaTTzXkJ2u84EVnulqsPqlRccgotw18uoj5PEWl22wK87LYJGFl6KYOJIf8ZIrLW85mfWQ45/RCRm0RkjYi8ELBdRGSm+96eE5GDSy1jGDHkP0pENno++4tKLWMYIrKniCwUkRfduedcn33S/w9U1X5K9AOMBkYBDwJjA/ZpBF4B9gF6A88CB5Rbdle2y4Fvu39/H9YUzgAABvlJREFUG/hJwH6byi1rks8T+Apwg/v3acDvyi13QvnPAK4pt6wB8n8cOBh4IWD7CcC9gAAfAx4vt8wJ5T8K+L9yyxki/3DgYPfv/sDffe6f1P8DW4GUEFVdpqrLI3Y7BHhZVVeo6jacjPtJxZcuFqnL8JeROJ+n9339AZjgtg2oBCr5fohEVf8CrA/ZZRLwP+rwGE6du4rp5xxD/opGVVer6lPu363AMnpWL0/9PzAFUnnsDrzmeR1arr7EFFKGv1zE+Ty79lGnQOdGnLYBlUDc++HTrvnhDyKyZ2lEy4RKvt/j8q8i8qyI3CsiB5ZbmCBc0+xHgMfzNqX+HxStGm+9ElbGXlUrvuhjscrwq+orWctqdHEX8FtVbRORL+Ospj5RZpnqhadw7vdNInIC8CdgvzLL1AMR6YdTyfzrqvpuVuc1BZIxGlLGPiZvAN4nyJKWqw+Tv8Ay/OVSIHE+z9w+r4tIEzAQWFca8SKJlF9VvbLeiOOrqhbKer8XincyVtV7ROQ6ERmqqhVTZFFEeuEoj9tU9U6fXVL/D8yEVXk8CewnInuLSG8cp27ZI5lcUpfhL5mEPYnzeXrf12eAB9T1LlYAkfLn2atPxrFzVwtzgS+6kUAfAzZ6zKQVj4jsmvOXicghOHNqpTx85FqA/wpYpqo/C9gt/f+g3FEC9fQD/DuOfbENeAuY547vBtzj2e8EnGiJV3BMX2WX3ZVrCLAAeAm4H9jZHR8L3Oj+fRjwPE600PPAlypA7h6fJ3AJcLL7dwvwe+Bl4Algn3LLnFD+/wKWup/5QmD/csvskf23wGqg3b33vwSchdO2AZzIn2vd9/Y8AdGJFSz/Vz2f/WPAYeWWOU/+IwAFngOecX9OyOp/YKVMDMMwjFSYCcswDMNIhSkQwzAMIxWmQAzDMIxUmAIxDMMwUmEKxDAMw0iFKRCjavBU+X1BRH4vIn0D9ns05fnHisjMAuTbFDC+q4jcLiKviMgSEblHRP4l7XUqAbcK7WEB2/YXkb+KSJuIfLPUshmlwxSIUU1sUdWDVPUDwDacWPYu3CxyVNV3YotCVRer6ozCxewmkwB/BB5U1X1VdQzwHYLriFULR+Hk/PixHpgB/LRk0hhlwRSIUa0sAt7vPgkvEqfvyIuwYyXgbnvQLTD4NxG5zZM1/FERedQtgveEiPR39/8/d/sPRORW90n6JRH5f+54PxFZICJPicjzIhJVGXc80K6qN+QGVPVZVV3kZv5e4a6onheRUz1yPyQic0RkhYhcJiKnu3I+LyL7uvv9WkRucAtX/l1EPumOt4jIze6+T4vIeHf8DBG5U0T+7L6nrpInIjLRfa9Puau7fu74ShH5oef97i9OUb6zgPPcFeE47xtW1TWq+iRO8p1Rw1gtLKPqcFcaxwN/docOBj6gqv/w2f0jwIHAKuAR4HAReQL4HXCqqj4pIgOALT7HfginP8JOwNMicjdO/a9/V9V33VItj4nIXA3OyP0AsCRg26eAg4APA0OBJ0XkL+62D+P0j1kPrMDJ9D9EnIZAXwO+7u43Eqfk+77AQhF5P3AOTr3LD4rI/sB8j8nsIPczaQOWi8gv3Pf+feBoVX1PRL4FnI+T7Q7wtqoeLCJfAb6pqmeKyA04fV9slVHHmAIxqok+IvKM+/cinBo/hwFPBCgP3G2vA7jHjsQp177afUpG3YJ40rMFyBxV3QJsEZGFOBP13cClIvJxoBOn7PX7cMrbJ+UInCq6HcBbIvIQ8FHgXeBJdesRicgrwHz3mOdxVjU57lDVTuAlEVkB7O+e9xfue/ubiPwTyCmQBaq60T3vi8BewCDgAOAR9zPoDfzVc41cAb4lOErPMABTIEZ1sUVVD/IOuBPeeyHHtHn+7iDZPZ+/qlDgdGAYMEZV20VkJU4trSCW4hRoTIpX7k7P6066vwc/GeOeN/d5CHCfqn4u4pikn59R45gPxKhHlgPDReSjAK7/w29inOT6E4bgOI2fxCn1vsZVHuNxnuDDeABoFpHpuQER+ZDrN1gEnCoijSIyDKd96hMJ38tnRaTB9Yvs4763RTiKDtd0NcIdD+IxHNPe+91jdpLoKLFWnBapRh1jCsSoO9RpDXsq8AsReRa4D/9VxHM41W0fA36kqquA24CxIvI88EXgbxHXUpwqzEeLE8a7FKd67ps40VnP4VRyfQC4UFWTmsJexVE69+JUV90KXAc0uDL+DjhDVduCTqCqa3H6qv9WRJ7DMV/tH3Hdu4B/93OiixO2/DqOH+X7IvK662cyagyrxmsYPojID6hwJ7GI/Br4P1X9Q7llMeoTW4EYhmEYqbAViGEYhpEKW4EYhmEYqTAFYhiGYaTCFIhhGIaRClMghmEYRipMgRiGYRip+P9sOLtU/rvPuwAAAABJRU5ErkJggg==\n",
168 | "text/plain": [
169 | ""
170 | ]
171 | },
172 | "metadata": {
173 | "tags": [],
174 | "needs_background": "light"
175 | }
176 | },
177 | {
178 | "output_type": "display_data",
179 | "data": {
180 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEWCAYAAABIVsEJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO29ebgcdZX//3rfG5JLSEIgCZsS4jYqjooQg1sEJgIqY3AFDGogMvmxKC6PDujw+7oMg+g4OiAok8EowxARHf1OEBUwLJNxhiVRBEGRRWQ3IQGSEJKQ2+f7R1Xf9O1be1fv5/U8/dzuqk9VnepbXac+Z5WZ4TiO4zh5GWi3AI7jOE534grEcRzHKYQrEMdxHKcQrkAcx3GcQrgCcRzHcQrhCsRxHMcphCsQxykBSZ+X9O8NbP+ApLeUKVNBOY6XdE275XC6A1cgTk8g6QZJT0qakHH8CZL+u9ly1RxviqR/lvSgpE2S7gs/Ty/xGA0pMQAzu8zMjihLJqe3cQXidD2SZgFzAQPmt1WYCCSNB1YArwDeCkwBXg+sA+a0UbRRSBrXbhmc7sIViNMLfAi4CfgusLB2haR9Jf1I0lpJ6yRdIOnlwEXA68PZwFPh2BsknVSz7ahZiqTzJD0kaYOk1ZLm5pBvJvAuM7vLzCpmtsbM/t7Mflo/WNJ3JZ1d8/lQSQ/XfD5D0iOSNkq6W9I8SW8FPgscG57Tb8Kxu0r6tqTHwm3OljRYc36/lPR1SeuAz0ecs0k6WdI9kp6SdKEkhesGJf2TpCck/VHSR8Lxroj6BFcgTi/wIeCy8HWkpD0huMEBPwH+BMwCngdcbma/A04G/tfMJpnZ1IzHuRU4ANgdWAb8QNJQhu3eAvzczDZlP6VoJL0U+AjwWjObDBwJPGBmPwfOAb4fntOrw02+C2wHXgy8BjgCOKlmlwcD9wN7Av8Qc9i/Bl4LvAo4JjwmwN8AbyP4Tg4E3tno+TndhSsQp6uR9CZgP+AKM1sN3AcsCFfPAfYBPm1mz5jZFjMr7Pcws383s3Vmtt3M/gmYALw0w6bTgMeKHreO4fC4+0vaycweMLP7ogaGivTtwMfD818DfB04rmbYo2b2jfCcno055rlm9pSZPQhcT6AwIFAm55nZw2b2JHBuCefndBGuQJxuZyFwjZk9EX5exg4z1r7An8xsexkHkvQpSb+T9HRo9toVyOIEXwfsXYYMZnYv8HHg88AaSZdL2idm+H7ATsBjofnpKeBfgD1qxjyU4bCP17zfDEwK3+9Tt32WfTk9hNsqna5F0s4ET8GDkqo3uQnAVEmvJrihzZQ0LkKJRJWhfgaYWPN5r5pjzQX+FpgH3GlmFUlPAsog6i+AsyXtYmbPZBgfKweAmS0DlkmaQqAQvgx8kLHn9BCwFZieoEQbKcf9GPD8ms/7NrAvpwvxGYjTzbyTwKSzP4FZ5QDg5cBKAr/ILQQ3uXMl7SJpSNIbw23/DDw/jJCqchvwbkkTJb0Y+HDNuskEvoS1wDhJ/4cgmioLlxLczP9D0sskDUiaJumzkt4eMf424O2Sdpe0F8GMAwh8IJL+KgxX3gI8C1RqzmmWpAEAM3sMuAb4pzCMeEDSiyQdklHuNK4APibpeZKmAmeUtF+nS3AF4nQzC4HvmNmDZvZ49QVcABxPMDt4B4ED+UHgYeDYcNvrgDuBxyVVzV9fB7YR3IgvIXDKV7ka+DnwBwKn/BYymmzMbCuBI/33wLXABgLlNh24OWKTS4HfAA8QKIDv16ybQOBreILAtLQH8Jlw3Q/Cv+sk/Sp8/yFgPHAX8CTwQ0oypwH/Gsp3O/Br4KcESna4pP07HY68oZTjOGUg6W3ARWa2X7tlcVqDz0AcxymEpJ0lvV3SOEnPAz4H/Ljdcjmtw2cgjuMUQtJE4EbgZQS+mKuAj5nZhrYK5rQMVyCO4zhOIdyE5TiO4xSir/JApk+fbrNmzWq3GI7jOF3F6tWrnzCzGfXL+0qBzJo1i1WrVrVbDMdxnK5C0p+ilrsJy3EcxylEWxWIpKWS1kj6bcz64yXdLukOSf8TlqeornsgXH6bJJ9WOI7jtJh2z0C+S9BgJ44/AoeY2SuBvweW1K0/zMwOMLPZTZLPcRzHiaGtPhAz+6+wm1zc+v+p+XgTowu3OY7jOG2k3TOQPHwY+FnNZwOuCTvDLY7bSNJiSaskrVq7dm3ThXQcx+kXukKBSDqMQIHUVvt8k5kdSNAR7TRJb47a1syWmNlsM5s9Y8aYKDSnw1mxbCXHzzqFIwaP4fhZp7Bi2cp2i+Q4TkjHKxBJrwIuBo42s3XV5Wb2SPh3DUH9nTntkdBpFiuWreTriy9izYNPYGasefAJvr74IlcijtMhdLQCkTQT+BHwQTP7Q83yXSRNrr4n6PMcGcnldC9LP7uMrZu3jVq2dfM2ln52WZskchynlrY60SV9DzgUmC7pYYJqnjsBmNlFwP8h6Cf9TUkA28OIqz2BH4fLxgHLzOznLT8Bp6msfWhdruWO47SWdkdhvT9l/UnASRHL7wdePXYLp5eYse801jz4RORyx3HaT0ebsJz+ZtE5C5gwcfyoZRMmjmfROQvaJJHjOLW4AnE6lnkL5vKJJSezx8zpSGLKtMmMHxrPlz/4DY/IcpwOwBWI09HMWzCXyx74Fmdc+lG2PruVjes35Y7I8lBgp9eobF5OZc2hVB5/afB38/K2yOEKxOkKikZkeSiw02tUNi+HDWdB5VHAgr8bzmqLEnEF4nQFRSOyygoF9lmM0zFs+hqwpW7hlnB5a3EF4nQFcZFXaRFZZYQC+yzG6Sgqj+Vb3kRcgThdQdGIrKKKpxZPaHQ6ioG98y1vIq5AnK6gPiJrj5nT+cSSk5m3YG7idmWEAntCo9NRTPokMFS3cChc3lr6qqWt093MWzB3jMJYsWwlSz+7jLUPrWPGvtNYdM6CUWOq75PGpNHshMa0c3B6n8rm5YEPo/JYMJOY9EkGJs6PHDswcT4VyDy+mcjMWn7QdjF79mzznui9Q9U3UWtemjBxfKaZSaccp1Xn4HQuI1FVoxzjQzDl7LYohSgkrY5q3OcmLKdraZVvoqj5LAvuX3E6KaoqL65AnLZTNES2lb6JakLjNcNXsOicBSz97LJSQnrdv+J0UlRVXlyBOG2lkRDZOB+EBtS0fI2yQ3rLiBJzupwOiqrKiysQp600YsKJirACqAxXmpavUbbJyQtGOkH01E51C3dqS1RVXlyBOG2lERNOvW9iYHDs5Vy2P6Fsk1Mz/StON1EfzNQdwU0exuu0lUZDZGtDe48YPCZyTJn+hGaE9EaFJzt9xKavAdvrFm4PlndIFFYcPgNx2kqkGUpw8FEHxW4T53RvhT/BTU5OmVQ2Lw+LIkatzOZEb2dlXlcgTluZt2AuRyw8DFSz0OCaS66P9F0kObGjbu7jxo/j2U1bSnOql2Fy8sKMDtTmf8Sxa/Z9tKkyrycSOrloRtb08bNOiTQL7TFzOpc98K1cY2vlm7z7JJ7ZsJnh54ZHxrU7Sc8TB50qlTWHxs8+ANgJpnwpMZkwdh8D+zCwxw0NSrgDTyR0GqZZVWnzOKbTxtbmawztMmGU8oDAqf7Nj31n5HOrZwOeOOiMkGqiei49mbDNOSRtVSCSlkpaI+m3Mesl6XxJ90q6XdKBNesWSronfC1sndT9S5GbX5YbdB7fRZ6xccpmw7qNrFi2si1l2uNkippVOT1OljyPNEXQ5hySds9Avgu8NWH924CXhK/FwLcAJO0OfA44GJgDfE7Sbk2V1Mkdwpr1Bp3HMR3nXI9aPmm3XSLHQqAM2zEbiHXoC/eF9BuRVXXrSFMEba7M21YFYmb/BaxPGHI08G8WcBMwVdLewJHAtWa23syeBK4lWRE5JZA3yumbH/tOpht0rWMaYGBwYGRc/U315qtWRx4rarmkiJEBax9alzgbOHKnYzn/tIsj16fNqpLWLzpnweiAgSqGm7H6jIGJ82HK2TCwT7ik/sJIVwSj96HgbwuLMHZ6HsjzgIdqPj8cLotb7jSRRecsiHQAR80UVixbyYZ1GyP3E3XjrjqQa/dfnbHUrs8zC9q4flPsuVSVXpzpqDJc4cpvXQ3A6ReeNLK83gleL2Pc+jt/eTc3X7U6kDMmbsXrX/UfAxPnj+R65CnpHrePVtNuE1bTkbRY0ipJq9auXdtucbqaPCGsSU/TcTOWLCalMvwlKFCGcaVQarlqybWZZPzKwgs4YvAYvrLwgsj1V1509YgpL444eT3stz8YmDifgT1uYGCvu4O/HZ5ECJ0/A3kE2Lfm8/PDZY8Ah9YtvyFqB2a2BFgCQRhvM4TsJ7JmTSc9Tccl3WWZXeSZBUWNRfCOk48cdQ5LP7sscSaSRcbqOBuOucRSrrykmVzarMxx2kWnz0CWAx8Ko7FeBzxtZo8BVwNHSNotdJ4fES5zWkAjkVWTd58Ue+PLMrvIMwuKGnvmpaePMknNWzA3MYu8vr5W2VVys8zkPOy3f2lnlnkW2joDkfQ9gpnEdEkPE0RW7QRgZhcBPwXeDtwLbAZODNetl/T3wK3hrr5oZknOeKcksj4Rx80UTjt/Uey+Dz7qoBG/Q/3yWvLUjkoau2LZSi48fWmir+SoxYeP+hw5q0lDRM5AohIl6/F+If3LmE6F1Szzbath241tb2cLnonupFCfef7spi2RN9yom2HttpN22wVJbFy/KTaDPU9GehnnlaYI3nHKkaNmK7XbVs8r6fcjiRn7TuPgow7imkuuL5R9HvedTJk2maFdJngf9R4mPVO9SvPb38ZlorsCcWLJcpOtIolrhq/IvJ+oG+gRg8dE3pCT9l2UuBtz3mMePvC+2HXXVn4w8r5oCZio727c+HGYWUeVaHHKp/L4S8lc1r3k0iX1eCkTJzdR9vc4knwDWe34jVbTzROtlGYCynrMau5KPQODA6OOX1ti5bIHvpXLBFfvx9l50lBkiZba79Mjt3qAPNnklUfb4itxBeLEktXOnlbOPKsdv5FS6XnLkiQpiAkTx3PwUQeN3IDfPf1E3jNjUWxiYFxXxDLKokTNXDY9+Uzk2Or32Y4SLU4TyJVNrrZU5HUF4sQSd5OdMm1yrnLmWWcWjZRKzxutFHfjnzJtMkcsPIxrLrl+5Aa8cf0mNqzbGHkzrspcdjfEFctW8p4Zizj3A+ePUQRxJVqq36dHbnUueaKqAp/G1Ix7rjd1bUkvxFgCrkCcWOJmBKeed2Iuc0zSzKLe1AIUMvXkjVaKDPH999P5j7VLufmq1Ymmu/qb8bwFc7FKtK26SLRUdQYRlcm/dfM2JCXO1DxyqzMp1LtjylmMrXU1wI6yJ4MJB2x+Rd5OTyR02kTVdLJ18zYGBgeoDFfYY+b0QtE+1fH1phhIL12SlSKtZuNCfLPcaOvHlNnqNs33tHH9Js649KOxTvlmtN11SmDT1xgJyR1hS2Lr2oGJ86lUt608RtBk6hnguXDEMLFx4i2oyOsKpA/IGwFUH/lTGa6MPOEWjfKJulkfP+uUWFNLmnz155MnQz2NybtPiq3jVaX+Zlzm8bM4+JPyW8qUxSmRgr07RtXLWnMoVJ6qGxE1+21NRV43YXUheSJsijhUG7GhlxEJlXQDjTsfoOFWs1XSQtvjbsYTdp4w8n7y7pMKHz/NwZ+mCMpou+s0gTJ6dyQpmzZU5PUZSJeRtzZSkjKIu6EUtaHnla2IqSXpfPL4TJKIi3ICIs14Ubka27bkyFSvIy7bffLukzjt/EUtVQTNaGHct0z65OjMcqB2ppCpGu/A3i1pYZsVn4F0GVlmB7WzgLhkuSRlUDQfo4xIqLJCghsh7jyrGfH1N9Cyo57mLZjLEQsPG4nsGhgc4B2nHMmPnvhO6s07KXorbxivhwOXS1LvjswO9jY3kKrHFUiXkXYDrf/Rx5GkDIrmY5QRCVVWSHAj5D3/spXaimUrueaS60cq/FaGK1xzyfWpN+606K28Cs3DgcsntmR7koO9bvt2NpCqx01YXUaa2SdL9niaMoiLmkp7+i0zEiqOVjiI855/2VFPRcyOcdvVkleheThwC8nhYG9nA6l6XIF0GWk30KQfd7W4XxZlkPfGnkW2Miiq3IocJ+s+yz7vojfussqz1I73cOAWEevbaH4obiO4Auky0m6gcT/6MirapjlUO/HmXhZJ5172eRe9ccdtB8UUmocDt5AUB3teirbHzUtsNV5JrwT+laDX+M+AM8zsyXDdLWY2p3Rpmkw/VOPNWvm2U/bbDbT63IseL656ciPRW/WK8+CjDhrp7e5RWeVS1k1/TB8RoNGS77nLuUv6b+Bs4CbgJIJmTvPN7D5Jvzaz1xSSpI30gwKB5oRexpU/n7z7JH70xHca2nen08o+JVUaKf8elfGftK+sx+rnh4huIraPSAOhvkUUyG/M7NU1nw8j6C3+QeCbZnZgIUnaSL8okGYQ16sD4Mx/P72nbyCt7FNSSxkPAmk3/TxKoR2K1BlL2kwlsY/IlK8WmoUU6gciadfqezO7HngPcCmwX24JnK4mLbmvl2lF6HA9ZeVgxEV0fWXhBRwxeAxfWXhB5lBdj8pqP5nyRZIc7yWXeU9SIF8GXl67wMxuB+YBPypNAic37WgWVCS5r1eaGjXSp6QoZeVgxP1vKsMVzGwk1yTLdu1QpE4dWfJFIpMNY8Y2SKwCMbNlZnZTxPIHzexvSpPAyUW7soPnLZjLlGmTI9dF3UB6KYu5HbWlynraL3pzj9quHYrUqSNDvshIsmHefRTAM9G7jHZmB5963omZbyC9lsVctCVtUcp62o9rnJVE3P/UizQ2j8yNpjIWZByYOD/MVs+xjwK0VYFIequkuyXdK+nMiPVfl3Rb+PqDpKdq1g3XrGtNA+AOoBl26Kympjw3ELeXN0ZZT/v1/7OozokQ1NvKohRarUj7gVyNpvLUwmpB3azUREJJbzSzX6Yty4ukQeBC4HDgYeBWScvN7K7qGDP7RM34jwK1ocPPmtkBjcjQjZSdHZy3gm7WJD7PYm6MMpMTa/9nHorbgeRoNDWmwVRCvkiesUXJkon+DaA+ZDdqWV7mAPea2f0Aki4Hjgbuihn/fuBzDR6z64ks9S04+KiDCu2vaN2lInK6vTwfzci4b1W1ACcHKX6NyLDdjPkcza6bFatAJL0eeAMwQ1LtnGcKiY14M/M84KGazw8DB8fIsh/wAuC6msVDklYB24Fzzez/xmy7GFgMMHPmzBLEbi/zFszlzl/ezZUXXb0j1Nvgmkuu5xVvfGnuG0GzTE1+o+pcmqGYvG9IAyTUwRqTVV41b0HbKvDWkjQDGQ9MCsfUht9sAN7bTKEiOA74oZkN1yzbz8wekfRC4DpJd5jZffUbmtkSggRIZs+endxqrku4+arVY/KEtm7exjc/lt4vop5mmpraUbPKaT15zaBOHUl1sAr0UW8lSWG8N5rZF4DXmdkXal5fM7N7Sjj2I8C+NZ+fHy6L4jjge3XyPRL+vR+4gdH+kZ4mbnawYd3G3GGyeZ21vZLb4ZRHr0XctZrEHh8F+6i3iixRWBMkLZF0jaTrqq8Sjn0r8BJJL5A0nkBJjAk7kPQyYDfgf2uW7SZpQvh+OvBG4n0nPUeerPC0G36eyKpeyu1wspHlgcEj7honttFUGX3Um0gWJ/oPgIuAi4HhlLGZMbPtkj4CXE3gU1lqZndK+iKwysyqyuQ44HIbXYzo5cC/SKoQKMFza6O3ep1F5yzg3A+cH7mu9kebZlqot1ufcelHczcsKsPh7nQmWU1THnHXRMYfAlsuZ7TNWsHyDiC2mOLIgKCIVrEQnw6jl4opvnv6iWxcv2nM8trCdknF7+KipJLCOdtVVNDJRyMO7dptNaDIUif1xRM9NLgx4oojRpdlr9JYefa8FCqmGHKlpFMl7S1p9+qrCTI6OTjt/EWpvosk00IRu7XXQupsVixbybunn8i5Hzi/kJnx/NMu5twP7tg2a50sz1AvTmIS4YaziVYeUHZNq6JkMWEtDP9+umaZAS8sXxwnK1nCZCfttkvkLGXSbrsUslt7bkfnEtdMCrKZGVcsWzk6NDyBqAcGj7grSFyU1YazgaciNqihAxzpqQrEzF7QCkGc/KT9aCXFLi9it/bcjs4lakZZS5pDe+lnl2VSHlA8adWJIFYJpCgP6AhHepZSJhOBTwIzzWyxpJcALzWznzRdOqchomYf1eWnnndiodmEP2l2JmkKIs3MmCdi6uarVsOFJ2Ue7yQQl0SYSrk1rYqSxYT1HWA1QVY6BLkaPwBcgXQAtU7PSbvtgiQ2rt/EjH2nxZqwZuw7zWcTPcSKZSvRgLDh6ClElgeDuBlpFB6eWyJxSYQaAkuahcT1+2gtWRTIi8zsWEnvBzCzzYqzjTgtoao01jz4BIgR00Otsljz4BOMGz+OwZ0GGX5uR/R17c3EZxPdT9X3EefwnjJtMqeed2Lq/zmyxloMM/adlvjg4g8i2RmYOJ/KttWw5QqCLIlBGHoXjD8INnwqYcunOqKkSZYorG2Sdia8TUl6EbC1qVI5sdQm8wGJduvt27azy5SJqdExnl3evcT5PgYGBzjz30/nP9YuzXQzj4qkescpR0ZG+h181EGjEko3rt/EhnUbPbm0AJXNy2HLj9mRYjccfgaYmrJ1+yOxsuSBHA6cBewPXEOQ9X2Cmd3QdOlKphfyQOJyO+JIy9HwGP7uptm5OVE5JSOz3wQGBgewivmMJIXKmkNjCinuE2PeqkcM7HV3k6SrOUpMHkiWKKxrJf0KeB2BweRjZpb9DuaUSl7786Tddklc79nl3U2eaLoiCYZRZs4vf/AbqXJVTWpeWDGFhFpXo/t5xDja2xyJlbUj4RDwJEEl3v0lvbl5IjlJ5E3ae3bTlkRzgtcx6m6yFsMss45Z3mvQCysmkFLrqlojiylfpdndBYuQqkAkfRn4JfB3BMmEnwaSvDtOE4nscR2GNGhgbGzD9m3bPbu8h8maBV5mxdwifdb9gSSGjG1nEyv2tpEsUVjvJMj7cMd5B5AUfnvE4DGR23h2eW+TJZquzJlm/TVYG4UVVz/LH0iiydJ2dkytrCn/2HbFUSWLArkf2AmPvOoY4m4Ynl3uxFF2xdzqNVjvVzn4qIO45pLr/YEkB0ltZ7u5I2GVzcBtklZQo0TM7PSmSeXkZsWylWx5ZqyO9+xyB5oz04wq937NJddzxMLDuPmq1f5AkoG4SrwjdHhHwiwKZDkRjZ6c5lAkUiaukN7k3Sdx2vmL/MfrlDrTHJXIWsfWzdu4+arVo8q9O9Fkml10eEfC1DwQgLBj4F+EH+82s+eaKlWT6PQ8kKI5GUl9P/yH7JRJUtXfKt4fJhtJOSADe9yQeUwrKNwPRNKhwD3AhcA3gT94GG9zKBop46G4TqtIq/oL7jDPTJbZRcYorXaRJQ/kn4AjzOwQM3szcCTw9eaK1Z8UVQQeiuu0iiwPJe4wz0iGfudJ4buVzcuprDmUyuMvDf5ubr2nIYsC2cnMRnLlzewPBFFZTskUVQRZk8kcp1HSrsUp0ya7zy0rOXJABva4gYG97g7+1ra7jepk2EKyKJBVki6WdGj4+legcx0JXUxRReAtRZ1WkZREOGHieE4978QWS9S9NJQcmBSd1UKyFFOcAJwGvClctBL4ZjcmFna6Ex2KRWG1cn+OUxuFNTA4QGW4wh4zp/u11UIqj7+U6FLczSmuGOdEzxOF9XKgQhCFld40IJtQbwXOAwaBi83s3Lr1JwD/SNDECuACM7s4XLeQoEowwNlmdkna8bpBgZSJV9p1nM4mNQ8kbrsWR2c1EoV1FHAfwY3+AuBeSW8rQaBBgsiutxGUin+/pP0jhn7fzA4IX1XlsTvwOeBgYA7wOUm7NSpTN5LUy6PM+keO45RLQ36MDonOyhqFdZiZHWpmhwCHUU4U1hzgXjO7P5zRXA4cnXHbI4FrzWy9mT0JXAu8tQSZuoq0Cqse3us4HUwDfoxOKa6YRYFsNLN7az7fD2ws4djPAx6q+fxwuKye90i6XdIPJe2bc1skLZa0StKqtWvXliB255A2w+j18N5OCGPsd7ybZQM0mGUeFZ3VarJGYf1U0gmh3+FK4FZJ75b07ibLdyUwy8xeRTDLSPVz1GNmS8xstpnNnjFjRukCtpO0GUYvh/cmTf+jFIsrm/Ips8dIXxLbDGqga67TLApkCPgzcAhwKLAW2Bl4B/DXDRz7EWDfms/PZ4ezHAAzW1cT7XUxcFDWbfuBtBlGT4f3xk3/N5wdoVjOhA2faXvMfK8RNwO+8PSlPivJQqQfA4L+6N1xnWaKwmrKgaVxwB+AeQQ3/1uBBWZ2Z82Yvc3ssfD9u4AzzOx1oRN9NXBgOPRXwEFmtj7pmL0WhdXPUVbxYYw5aHE9oV4jrh97Pf1yTRZhVBQWAwTKo45qf/SYaK1R+9Cu4c/i6VxRXWkU7oku6QXAR4FZtePNrCGpzGy7pI8AVxOE8S41szslfRFYZWbLgdMlzQe2A+uBE8Jt10v6ewKlA/DFNOXRi/RrL4/giSzmx5ZrR51R0bRbiesxUk/VL9fr12URanuBBA9FEYQzkaiqvcDodfbUmO2a2TskSyLhb4BvA3fADpnN7MamSNREem0GUqWfkgXHlMAexRBoaPSPKAmfgTRElsq8VbxCbzqxuR0MEv2wNAianH69l3CdF56BAFvM7PyGju7kJqtSiGrq8/XFFwH0phKJ9H0ADAZhjRChYMYRNI6v7ULQORVNu5XaGXBtVnoUvRL511QmfTLi2h0i+noHGM72sNTEmXYWJ/p5kj4n6fWSDqy+miaRkyu6pReTBRMjpmJ/DJUgrDEyPv5cmPKltsfM9yLzFswdifaLUx69EvnXbOJyO4LPjew4LtqrcbLMQF4JfBD4K3aYsCz87DSBJKVQP6votWTB1C5tA3vHlHCoK4FdrVi66Wuw4dOlOhT7maiZcVKPEO+KmY+o/ugVCCIJ2V5gj82daWeZgbwPeGHYD+Sw8OXKo4nkUQo9lyyYlp2bsYRDp5S77iXiZsZJjvRtW0opm9dz5MlLGpg4HzQpYW9Td8xaNDX43KKZdhYF8ttQIqdFxN38J+8+9iLqufh+6KYAACAASURBVGTBlOzczCUcOqTcdS8RNzNOotvNqc2g0MONPR2/bspZOzLS97yFgb1uaVl2ehYFMhX4vaSrJS2vvpoqVZ+z6JwFjBs/1rr4zIbNY/wgPZcsmLFLW2oJhwbLRDhjKWoW7VZzatMo8nAT97vQ1LaaZbP4QD7XdCmcUcxbMJcLT1/KxvWbRi0ffm6Yryy8YGRM7fiuVRj1xEWiJNhxo0piZ/GVOPmIy/tIir6qbufUUOThJu53MfmsuC1aQuoMJMz3+D0wOXz9rhtzQLqNTU8+E7m8Mlzh64sv4m8P/yJH7nQshw+8jyN3OpbzT7u4xRI2h7xVRuPMAYw/hE4od91LHHzUQZHLX33oKxK7FBY1p/ZsocYMs+wxqzqk+u4YudIGSDoGuIXAmX4McLOk9zZbsH4n6alt6+Zt/HrFHSNPfZXhCld+6+qeUiKZq4zGmQO23diRP7hu5uarVkcuf+Sex0bMqBDMSICGzKk9XaixYC+PTqi+W0/WTPTDzWxN+HkG8Asze3UL5CuVTs1EjwqNBPjHEy9k+Lns5ToGBge4+rnvN0vMjqTVrT37mbjaV83IMj9+1imR5rI9Zk7nsge+Veqx2kHRToTtopFM9IGq8ghZRzbnu5OBuEzy/V//0lzKA0i0Q/cs7utoGXE+kGb4OHotv6meqHyPbiSLIvh5GIF1Qtij/CrgZ80Vq3+IC4389Yo7cu+rajroK8YfEr18YD/v/1EyaSHjZfosei6/KSPd1rcmixP908C/AK8KX0vM7G+bLVi/UOSJ6jXzXhm5/KjFhzcqTvexLSaeY/tNnkRYMkkh42X7LHouvykD3Zj8GusDkfRiYE8z+2Xd8jcBj5nZfS2Qr1Ra7QNJK4i4YtlKvrLwgnymJ8GZl57Onb+8m6uWXEtluMLA4ABHLT6c0y88qQln0dnk6gvi1XebRjN8Fv1UZRoSqvF2wHUb5wNJUiA/AT5jZnfULX8lcI6ZvaMpkjaRViqQtGZPiaWwReI9sVcciWVQeXwOkLF8uzvWm0YrHeydTCPO8U4OCIlTIEkmrD3rlQdAuGxWibL1JGlVcuMK0A0MDvCOk4+MjauH3nEkloJyjHXHetPoV59FLUVNUFW/R+xTYwdft0kKJKn+1c5lC9JrpEWRxK23inH6hSfxiSUnxzrF++lHmUpSjaBReBJhM4kqvzNu/Lie9lmMoUCJktFKJ4rOvm6TFMgqSX9Tv1DSSQT9yJ0E0p7I0tbPWzCXv73kI33nSMxNlqczTfUkwhZQb8LK0i+9pyhSoiS2QRpdkfyapEA+Dpwo6QZJ/xS+bgQ+DHysNeJ1L2lRJFmiTHquUGIziMzqrUMTO/pH2Ass/eyyMXlLw88N91cl3gIlSuKVi0ayzTs5tDc2kdDM/gy8QdJhwF+Gi68ys+taIlmXU9vuMyqKJG197X5cYcQzMHF+2HDnU/GDvAJv0+n1xL9MFCgEmpYIm9pgrc2kljLpJTq1lInTOLEhkNARYZC9Tq+XHslK3iisMQoCgKER01WnhPYWicJqOpLeKuluSfdKOjNi/Scl3SXpdkkrJO1Xs25Y0m3hq3PmdDnp2YqjrWbSJ4GdIlaM62gnZK8QZ5I9+KiD+ur6zlvwMLXKbof3tclSC6spSBoELgQOBx4GbpW03Mzuqhn2a2C2mW2WdArwFeDYcN2zZnZAS4XOSNYEqLg6WEDhCqb9lHhVy4gpa+PZYNW8kKlBt7YOmOr3OlEm2YOPOohrLrm+tOu7V0msi9Xhtd7aZsKS9Hrg82Z2ZPj5MwBm9qWY8a8BLjCzN4afN5lZUqPgMbTChJWWQFhLlml/nFKoX17/Y006ruO0AjdrNU6aiatV5DZhSdooaUPEa6OkDSXI9DzgoZrPD4fL4vgwo4s4DklaJekmSe+M20jS4nDcqrVr1zYmcQbSEghrSXM8xtUXOv+0i8csv/KiqzMf1wno5OiWXqAfHetx11TU8izXX6c2kqqSFIU1uZWCJCHpA8BsoLb06n5m9oikFwLXSbojqj6XmS0BlkAwA2m2rHl+NGnlseOU0ZUXXT02aTXmzHr5x9oInR7d0gu0svx7JxB7TW1bDVt+XLf8TIIyCs+NHsvY66+TS79ndqJL2kPSzOqrhGM/Auxb8/n54bL6474F+DtgvpltrS43s0fCv/cDNwCvKUGmhslT0iEtFyT25p9DDfbqj7VhCmQNO/nou4q6cdfUlisilm9nRHnUju2y6y9LS9v5ku4B/gjcCDxAOf1AbgVeIukFksYDxwGj5nCh3+NfCJTHmprlu0maEL6fDrwRqHW+t408P5q0RMHcN/+6ulA9/WNtlA6PbukFejERNtHsFHvt5GgMV7OPbjCxZm1p+1cEbWxfEyYWfsDMPtzwwaW3A/8MDAJLzewfJH0RWGVmyyX9AnglUP1WHzSz+ZLeQKBYKgRK8J/N7Ntpx2tVHkhZ0VArlq3k3A+cn2nshInjOWLhYdx81eq+jMLKS6fE1zudy6icDu0KthV4tm5UhpyNPITXX6c4z6vkLudes+EqM5sdKpLXmFlF0m+8J3preM+MRWxYt3HM8inTJjO0ywRXFjGkJXR12g/U6Syir48YEm/6cYxjlA8E6MQEwiqN9ER/StIkYCVwmaQ1wDNlC+hEc+p5J0aGBZ963omuMGLI4iAfyRsp2LvB6XGSihzWE5qdMpXVQSPX2shxoq6/LjGxZpmB7ELwTQo4HtgVuMzMui68pxtnINC/CYJFm/OU9fTWSHMgp7tppNNlGddfz8xAzOwZSXsBc4D1wNXdqDy6mX4sqNhQmG0JT28e5tvnxGWAjyGiWGKRoor1lLGPFpAlCusk4Bbg3cB7gZskLWq2YE6f00iYbYGy2vURL2w8u/jxne4nU5uAsX1mRmatbCGIDaJQ8l+nJxBWyeID+TSB83wdgKRpwP8AS5spmNPnNDKLyPn0FjnbiJXr0cC84SatnmaMj0y7hhatp8f873eYOh8lsPRXTV/DVK+7ItdJJycQVsmiQNYBtWFAG8NlTgH61Z+RmwaKyOV2kOdxmAKj+l3jJq1eJcsNfGzkVb3fJJy19ug1kiUT/V7gZkmfl/Q54CbgD2Gp9c4yyHU4cbWtqiWuvbR7DZEmhOw24FxltQtHtrhJq5fJlMiX5eGj8lhXJAUWIcsM5L7wVeU/w78dUyurW0grtFhmafdup5lhtmOiqxhibIIYwFQYmBgqmJiInA4Lq3TKIXMQRab//649G5DhHQlbyBGDxxD1fUuKLTznpa/LJXuy1ziYcu4OO3eHhVU65TLmoaKyGXgqYuRUBva6Zcd2qdnnQ6Chmh41NXTRtZM7jFfSP5vZxyVdScTjl5l1t+psA0nVSfux9HVbyOrv0KTRT4ddElbp5CdXEAVPBeO3rQ6LJCbUuRrYJ7xuPh1z4O6fvSaZsC4N/361FYL0A4vOWRCZVb7onAUs/eyyvip93UpGPV1mTQ6zp0d9jO54mBLm6XQHeYMoNvz/RJs8GVEao0J7RyK06sd2RlfBRkjqB7I6fLuKoH1sBUZa0U5ogWw9RTX6auvmbQwMDlAZrrDHzOmjorDilIuTj9EKY1eCyjv1pbPTGAjCdWvDN7Ur2KaaMU/1jC27r8k9E4hRHgxGm6R6ePaaJQprBTCx5vPOwC+aI05vUht9BVAZrowoh1oH+fihHWXgp0yb3PWlr9vBiDmi8ijBnf8p8isPCEwTFs42nqp5v71unEdidT2xMwHFLI8j2pzVLUmBRciiQIbMdjx2he8nJox36kiLvqoqmI3rdzzdbn12K04Bcpkjwh/z0Pt3/Lir2cN56AFbdl8TFzI+dFz08ljFEn/t5Aor7yKyKJBnJB1Y/SDpIOLncE4EaQ7yPH3UPVckhaw384F9dvyYp35h5McdtJjJSQ/YsvuZ2BnC1C+MXq6pBAokxo82dEzrhO4QsuSBfBz4gaRqnv5ewLFNlarHSOsNnTUCqzpT8VyRBDIVwUuwP2cuopdhX07XEJd1Xl2eHv49AOMPaqqMnUjqDMTMbgVeBpwCnAy8vMbB7mQgrc1t1j7qeWYqfUukOWJc+PSYwf6cWRkUs2X3akZyz5NqGq30pS8sywwE4LXArHD8gZIws39rmlQ9RnV2EFcDKym8txbPFUmn0Qz2gYnzqWw4m+gksppxe92dWzYvEd/FZDGN9qEvLFWBSLoUeBFwGzvCDAxwBZKDpJ4eaQqmSpopzAlouIrplLNSzBUFHO2QXKI+o7ze5KpNZDFt9qEvLMsMZDawv/VTzZM2kKVpVNaZilMCGgKLUSBFnaUNNrryGUwbiczlqKU/fWFZorB+S+A4d9rMvAVz+cSSk9lj5nQkscfM6X2TK9Iq30Fwkz4zunYRgzD0/iA6pwgFGl2NopEmW05DjInUYmp2v1oPk6Un+vXAAQRdCUeSE8qohSXprcB5BDaBi83s3Lr1EwhMZQcR9CA51sweCNd9BvgwgVntdDO7Ou14rSymWLTvh/cLGUt0BMxQU360lcfnkKWIXqF9N3ge8X26Vcgn08m4qa6zKNwTHfh8+eKMlES5EDgceBi4VdJyM7urZtiHgSfN7MWSjgO+DBwraX/gOOAVwD7ALyT9hZklVDZrHUXDbT1MN4YSfAfZiXOexzvVs97sGi5R30CTrW7CTXXdQ5Yw3hujXiUcew5wr5ndb2bbgMuBo+vGHA1cEr7/ITBPksLll5vZVjP7I0HTqzklyFQKRcNtPUw3hgZ9B81kTOmU6s0uxsTWUEZyg022uoYmmuriTKEeXl2MWAUi6b/Dvxslbah5bZS0oYRjPw94qObzw+GyyDFmth14GpiWcdvqeSyWtErSqrVr15YgdjpxYbVrHnwiMXPcw3RjaNR3kAdNzbe8hX6JXqypFHnjbtIDQ6yyf+pzuR4CnB3EKhAze1P4d7KZTal5TTazKa0TsTHMbImZzTaz2TNmzGjJMZPCamtb2Gbdzsw4fOB9/Vu6pJVP3pPPAnaqW7hTuDyCFs+OeqmmUtwNHe0avUGjDwxxyn7LFdHLPTghlUQTlqRBSb9v0rEfAfat+fz8cFnkGEnjCGpzr8u4bduIyjyvkmSSWnTOAsaNj3dL1fdQ7xda+eQdHOtLdcf6Uvyxcs6O3FRSQ9wN3aApDwyxSj3GddoBJtJOJ1GBhE7puyXNbMKxbwVeIukFksYTOMXrf03LgYXh+/cC14X5KMuB4yRNkPQC4CUEUWIdQTXcNo4kk1RaVFy/+kRa+eSd61g5Zkd5/SU9T+wN+unmPDDEzmBiEkN7LDihGWSJwtoNuFPSLQSdeYDGw3jNbLukjwBXE/wHl5rZnZK+CKwys+XAt4FLJd0LrCdQMoTjrgDuImjQcFqnRGBVmbdgbmqXwfqQ3Wc3bWH4ufTT6HufSAeRK7KqpdFkXUBCVFnD1QSiGH8IbPne2OXj5sD2X9OLDZ+aTZY8kEOilpcUidVSWpkHAmPDciHIHK/OTurXZWWPmdO57IFvlSan0xoazePotdyIVub3AFTWHBqjsMLe5T303ZZN7jwQSUME1XdfDNwBfDuMhHIykNbC9vhZpxRSHl66pPPIfGNvII+jF3MjGs6LyUtCwEPUjKfXFHYzSDJhXULQC3Ql8DZgf+BjrRCq26mfeUS1sM1jhtKAsIqN6aHutJ9cN/ZGemP3qPmrKaaq2INlV+C9qLCbQZIC2d/MXgkg6dt0kJO600lKCKze/OMq606ZNpmhXSZ4KZNuIceNvaEn7g5OpmwFpcwG8ijwHlXYZZOkQJ6rvgkd3i0QpzfIkhC46JwFfHXRN9m+bYdVcNz4cZx63omuMLqJnDf24k/cuxJdTiUmZyKFbjLPlDUbyKXA+1xhZyVJgby6JuNcwM7hZwHWTcmErSZr3476AAavmN+FxPaJsMBpW/DGPOYGT4y/rMBzXdeZZ0qcDWRW4H1Sd6xRkjLRB+uyz8d1YyZ6O0hrYQuBmas+ZHf4ueG+zPHoaiLzQEIK5nlE5ouwOXqwPZ1r30BLyq+UmjDZjtlAv9Qda5As/UD6mhXLVnL8rFM4YvCYzKVEsvTtKFr3qog8TvMYnSUfRYEbc2r/7VoBRj8RZ7pxN/mGXHrCZCtroVV33YN1x5pB1p7ofUkj5dXTOgwWaU/r5d47k6pZJDbPI++NOc/48UGaVnDTruvlHmeaarZ5pmwH9PhDYMvljP5umz8baGmEWJfiM5AEmllePYuZq5XyOCVQ1pNynvHbbqzxaUQ52YMbd+3MBNvM2GfH5BtyLpNUjhlOenn1vwizx+sU89C7EmcDXnOsNfgMJIFmllevzhjydB/0cu8dTiN5Hqn7iaHyWLrJq/IobPgMI4GV9hRB9aCpwNOpUVi5ne4ZZzix+922Grb8OPmctu0ohDEm4GD8IaO37/QggS7GFUgCRcxMeUgzc7VaHqcxysqsjtxPZTORM4yBvTOYvERNVH7IMLAtWyvcOJPUhk9R2fS1seeYVZEmlldPqQkXnnOkEoqqd+U5HE3BTVgJFDEz9ZM8zljKqhpcvx+mnEVsVFCiyWuI6PpbAJuzmXaSFFSEgzyzAzpvefVaquecJ+Cg8iiVx+dQ+fMcN22VhCuQBLJEU/WzPE7rSLwpT/okkcYETQ22SSJLhFiqT2ZspFkmRRq737TklprZTO7IsadCE56X0y+D1Gq8vUSrq/E6TisIzDg1Pg4AdhpphFV5fA7RDnaoVgJOykyPrpobvZ/8ckeYuhDwbPRGYeXcEdniKuwG+c7ZBBnYJ5jlObHEVeP1GYjj5KAjo3s2fY2xPo7ndswKpsS04wUY2Ds1b2Nk9pPIrrm/l7hZVXJAwGMjUWVAfMLf0HEJuTkR+3QK4U50x8lIx5YASQmbHZg4P4xsqncuD+3og5GStzEwcX7gMI982gd4BirhLCfH9xJZRj3xODZm/0mBC/EzlFohvDxJUXwG4jhZaUEJkEJkyD8ZmPoFmPLVaB9K1ryN2LItExk7A8r2vUTO6JLKw0TsP9HfkhpC7eVJGsEViONkJeONtuVmrox1m2JvtBkTIKNNTl8l1l9RE2oblywYZToDRh8njgymp9SZoZcnaQg3YTlOVjIkyLXDzNVw/klc4uL4sd2sc5mcav0rEd9H0oxuYI8bRo4T34o2o+lpYJ+Y7fdx5dEgPgNxnKxkedJvk5kryYyTNiMamDgfht7FmKf9LT9OnT1VNi8PS6PUk+Jf2XBGvG8ik+ksh+nJK+s2jbYoEEm7S7pW0j3h390ixhwg6X8l3SnpdknH1qz7rqQ/SrotfB3Q2jNw+pFMCXId1ogoc2XcbTcyNuw1WfGN7NvqQ4SnpvtXkpIFM5nOspuekrbvyKi6LqIteSCSvgKsN7NzJZ0J7GZmZ9SN+QuCxlX3SNoHWA283MyekvRd4Cdm9sM8x21lHsiKZStz1blyeoN4c0v+XIMyugZmlSe2knBCfkeWfWeKghrFUMv8ErF5KO4XGUOn5YEcDVwSvr8EeGf9ADP7g5ndE75/FFgDzGiZhA1QLbu+5sEnMLORsuveu6MPKMlcUlpPjawzoiKVhGP3/WjOiKrqsVrcc6NTo+q6iHYpkD3NrHr1PQ7smTRY0hxgPHBfzeJ/CE1bX5c0oUlyFsLLrvcvpTUiavDmVjXNxGZj1yuGBMUXa+ZJVC5xEVWDMfLs01DtsEJ0mLmxG2laFJakXwB7Raz6u9oPZmaSYu1okvYGLgUWmlklXPwZAsUzHlgCnAF8MWb7xcBigJkzZ+Y8i2J42fX+ppRGRClP97nKr48hOsQ3KpILiI+iSi07HxFRFWc2aodD2/ueN0zTFIiZvSVunaQ/S9rbzB4LFcSamHFTgKuAvzOzm2r2Xf11bZX0HeBTCXIsIVAyzJ49uyUOHy+77jRM3M0N0kODkyrU1tWSGrUqKkR3zaER+9qhGHYonWwRVTuy4qsl2wdTm0M1jbL6t/Qx7TJhLQcWhu8XAv9ZP0DSeODHwL/VO8tDpYMkEfhPfttUaXNSRtl1733e56T6DhLMWbEmGOU3E6XNhDZ8Otz11OhxUU2ktvyYHVFYw2PChVsVGeV9zxunXYmE5wJXSPow8CfgGABJs4GTzeykcNmbgWmSTgi3O8HMbgMukzSDwKh6G3Byi+VPpEi3wVq897kz2qSUMV9iZOMSTTOxMyHtWF55lOBWshOjS5rkaCIV1t1qdSKm9z1vDC/n3gTyhvDWj9/yzFY2rNs4ZtweM6dz2QPfaqboTgeSNzS4zPDUbKXcq0yFgYmJYcdp4cJlhkE75REXxuulTEom7+whanwc7oTvU3La6stqrRu7r9i8jqcZ2OOWlB2mzI48Mqqr8FImJZM3hDdqfBzuhO9Pitjqx7TEhcJ+hTH7iuuzkcVEFlFfa5QyLJKP4rQNVyAlkzeEN+uswnuf9zeN9FovLSmxSsFkyR0O9Fo0OgrL61Z1Fa5ASiZulpB3+eTdJ3nvc6ccSs64Lhy9FCmHhXW4Gty30xbcB1Iyi85ZMMqnAcmzh7jxp52/yBWGk5uo+lnN8CsUil7KKIdHRnUPrkBKJm8Ib3X5hacvZeP6TQBM2LmjKrM4XUJcCCzaNaJiLq33K3jmd8/hCqQJzFswN/fsYduWHTOQDes2et6Hk584U5UNEfgV2pxx7ZnfPYf7QDoAL77Y+7QkuzrWJPV0R/gV3L/Re/gMpAPw4ou9TcuyqxNMRJ3iV+gUOZxy8BlIB5A3QsvpMlrVd8JDYJ0W4wqkjVQLJq558Ikx7ag976OHaFF2tZuInFbjJqw2UV/CBCNQIhbUvPIWuD1EC6OP3ETktBJXIG0isoSJecHEnsSjj5wexRVIm3DHef9QZnFDx+kkXIG0Ce9a2F+4acnpRdyJ3iaiuhYCbHlmq3cfdBynK/AZSJuIKmECnoXuOE734DOQNjJvwVx2njS277VnoTuO0w24Amkz7kx3HKdbcQXSZjwL3XGcbsUVSJuJcqZ7FrrjON1AWxSIpN0lXSvpnvDvbjHjhiXdFr6W1yx/gaSbJd0r6fuSxoYzdQnzFszlE0tO9u6DjuN0HTKz1h9U+gqw3szOlXQmsJuZnRExbpOZTYpYfgXwIzO7XNJFwG/MLDV9e/bs2bZq1aoyTsFxHKdvkLTazGbXL2+XCeto4JLw/SXAO7NuKEnAXwE/LLK94ziOUw7tUiB7mlm1FOnjwJ4x44YkrZJ0k6SqkpgGPGVm28PPDwPPizuQpMXhPlatXbu2FOEdx3GcJiYSSvoFsFfEqr+r/WBmJinOjrafmT0i6YXAdZLuAJ7OI4eZLQGWQGDCyrOt4ziOE0/TFIiZvSVunaQ/S9rbzB6TtDewJmYfj4R/75d0A/Aa4D+AqZLGhbOQ5wOPlH4CjuM4TiLtMmEtBxaG7xcC/1k/QNJukiaE76cDbwTussDrfz3w3qTtHcdxnObSriisacAVwEzgT8AxZrZe0mzgZDM7SdIbgH+BoHU08M9m9u1w+xcClwO7A78GPmBmWzMcd214vE5hOjC2JG/34PK3F5e/vfST/PuZ2Yz6hW1RIE6ApFVRoXHdgsvfXlz+9uLyeya64ziOUxBXII7jOE4hXIG0lyXtFqBBXP724vK3l76X330gjuM4TiF8BuI4juMUwhWI4ziOUwhXIC1E0vsk3SmpEua8xI17q6S7w3L1Z7ZSxiQaLcPfLtK+T0kTwrYA94ZtAma1Xsp4Msh/gqS1Nd/5Se2QMwpJSyWtkfTbmPWSdH54brdLOrDVMiaRQf5DJT1d893/n1bLmISkfSVdL+mu8N7zsYgxxf8HZuavFr2AlwMvBW4AZseMGQTuA14IjAd+A+zfbtlD2b4CnBm+PxP4csy4Te2WNc/3CZwKXBS+Pw74frvlzin/CcAF7ZY1Rv43AwcCv41Z/3bgZ4CA1wE3t1vmnPIfCvyk3XImyL83cGD4fjLwh4jrp/D/wGcgLcTMfmdmd6cMmwPca2b3m9k2goz7o5svXSYKl+FvI1m+z9rz+iEwL2wb0Al08vWQipn9F7A+YcjRwL9ZwE0Ede72bo106WSQv6Mxs8fM7Ffh+43A7xhbvbzw/8AVSOfxPOChms+J5epbTCNl+NtFlu9zZIwFBTqfJmgb0AlkvR7eE5offihp39aIVgqdfL1n5fWSfiPpZ5Je0W5h4ghNs68Bbq5bVfh/0LRqvP1KUhl7M+v4oo/NKsNvZveVLaszwpXA98xsq6T/j2A29Vdtlqlf+BXB9b5J0tuB/wu8pM0yjUHSJIJK5h83sw1l7dcVSMlYQhn7jDwC1D5BtrRcfZL8DZbhb5cCyfJ9Vsc8LGkcsCuwrjXipZIqv5nVynoxga+qW2jr9d4otTdjM/uppG9Kmm5mHVNkUdJOBMrjMjP7UcSQwv8DN2F1HrcCL5H0AknjCZy6bY9kCilchr9lEo4ly/dZe17vBa6z0LvYAaTKX2evnk9g5+4WlgMfCiOBXgc8XWMm7Xgk7VX1l0maQ3BP7ZSHj2oL8G8DvzOzr8UMK/4/aHeUQD+9gHcR2Be3An8Grg6X7wP8tGbc2wmiJe4jMH21XfZQrmnACuAe4BfA7uHy2cDF4fs3AHcQRAvdAXy4A+Qe830CXwTmh++HgB8A9wK3AC9st8w55f8ScGf4nV8PvKzdMtfI/j3gMeC58Nr/MHAyQdsGCCJ/LgzP7Q5iohM7WP6P1Hz3NwFvaLfMdfK/CTDgduC28PX2sv4HXsrEcRzHKYSbsBzHcZxCuAJxHMdxCuEKxHEcxymEKxDHcRynEK5AHMdxnEK4AnG6hpoqv7+V9ANJE2PG/U/B/c+WdH4D8m2KWb6XpMsl3SdptaSfSvqLosfpBMIqtG+IWfcySf8raaukT7VaNqd1uAJxuolnzewAM/tLYBtBLPsIYRY5ZhZ5Y0vDzFaZ2emNizlKJgE/Bm4wsxeZ2UHAZ4ivI9YtglIA3wAAA7hJREFUHEqQ8xPFeuB04Kstk8ZpC65AnG5lJfDi8El4pYK+I3fBjplAuO6GsMDg7yVdVpM1/FpJ/xMWwbtF0uRw/E/C9Z+XdGn4JH2PpL8Jl0+StELSryTdISmtMu5hwHNmdlF1gZn9xsxWhpm//xjOqO6QdGyN3DdK+k9J90s6V9LxoZx3SHpROO67ki4KC1f+QdJfh8uHJH0nHPtrSYeFy0+Q9CNJPw/PaaTkiaQjwnP9VTi7mxQuf0DSF2rO92UKivKdDHwinBHOrT1hM1tjZrcSJN85PYzXwnK6jnCm8Tbg5+GiA4G/NLM/Rgx/DfAK4FHgl8AbJd0CfB841sxulTQFeDZi21cR9EfYBfi1pKsI6n+9y8w2hKVabpK03OIzcv8SWB2z7t3AAcCrgenArZL+K1z3aoL+MeuB+wky/ecoaAj0UeDj4bhZBCXfXwRcL+nFwGkE9S5fKellwDU1JrMDwu9kK3C3pG+E534W8BYze0bSGcAnCbLdAZ4wswMlnQp8ysxOknQRQd8Xn2X0Ma5AnG5iZ0m3he9XEtT4eQNwS4zyIFz3MEC47SyCcu2PhU/JWFgQT2NbgPynmT0LPCvpeoIb9VXAOZLeDFQIyl7vSVDePi9vIqiiOwz8WdKNwGuBDcCtFtYjknQfcE24zR0Es5oqV5hZBbhH0v3Ay8L9fiM8t99L+hNQVSArzOzpcL93AfsBU4H9gV+G38F44H9rjlEtwLeaQOk5DuAKxOkunjWzA2oXhDe8ZxK22Vrzfph813z9rMKA44EZwEFm9pykBwhqacVxJ0GBxrzUyl2p+Vxh9DlEyZh1v9XvQ8C1Zvb+lG3yfn9Oj+M+EKcfuRvYW9JrAUL/R9SN8ejQnzCNwGl8K0Gp9zWh8jiM4Ak+ieuACZIWVxdIelXoN1gJHCtpUNIMgvapt+Q8l/dJGgj9Ii8Mz20lgaIjNF3NDJfHcROBae/F4Ta7KD1KbCNBi1Snj3EF4vQdFrSGPRb4hqTfANcSPYu4naC67U3A35vZo8BlwGxJdwAfAn6fciwjqML8FgVhvHcSVM99nCA663aCSq7XAX9rZnlNYQ8SKJ2fEVRX3QJ8ExgIZfw+cIKZbY3bgZmtJeir/j1JtxOYr16WctwrgXdFOdEVhC0/TOBHOUvSw6GfyekxvBqv40Qg6fN0uJNY0neBn5jZD9sti9Of+AzEcRzHKYTPQBzHcZxC+AzEcRzHKYQrEMdxHKcQrkAcx3GcQrgCcRzHcQrhCsRxHMcpxP8DJ2FC1F/7Kr0AAAAASUVORK5CYII=\n",
181 | "text/plain": [
182 | ""
183 | ]
184 | },
185 | "metadata": {
186 | "tags": [],
187 | "needs_background": "light"
188 | }
189 | }
190 | ]
191 | }
192 | ]
193 | }
--------------------------------------------------------------------------------
 12 |
13 |
14 |
12 |
13 |
14 |  40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
142 |
143 |
144 |
145 |
154 |
155 |
156 |
--------------------------------------------------------------------------------
/header.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/特征工程/特征降维/README.md:
--------------------------------------------------------------------------------
1 | # 特征降纬
2 |
3 | 维度变换是将现有数据降低到更小的维度,尽量保证数据信息的完整性。楼主将介绍常用的几种有损失的维度变换方法,将大大地提高实践中建模的效率:
4 |
5 | - 主成分分析(PCA)和因子分析(FA):PCA 通过空间映射的方式,将当前维度映射到更低的维度,使得每个变量在新空间的方差最大。FA 则是找到当前特征向量的公因子(维度更小),用公因子的线性组合来描述当前的特征向量。
6 |
7 | - 奇异值分解(SVD):SVD 的降维可解释性较低,且计算量比 PCA 大,一般用在稀疏矩阵上降维,例如图片压缩,推荐系统。
8 |
9 | - 聚类:将某一类具有相似性的特征聚到单个变量,从而大大降低维度。
10 |
11 | - 线性组合:将多个变量做线性回归,根据每个变量的表决系数,赋予变量权重,可将该类变量根据权重组合成一个变量。
12 |
13 | - 流行学习:流行学习中一些复杂的非线性方法,可参考 skearn:LLE Example
14 |
15 | - [维度打击,机器学习中的降维算法:ISOMAP & MDS ](http://blog.csdn.net/dark_scope/article/details/53229427)
16 |
17 | # Dimensionality Reduction(降维)
18 |
19 | 
20 |
21 | Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarise or describe data using less information.
22 |
23 | This can be useful to visualize dimensional data or to simplify data which can then be used in a supervized learning method. Many of these methods can be adapted for use in classification and regression.
24 |
25 | - Principal Component Analysis (PCA)
26 | - Principal Component Regression (PCR)
27 | - Partial Least Squares Regression (PLSR)
28 | - Sammon Mapping
29 | - Multidimensional Scaling (MDS)
30 | - Projection Pursuit
31 | - Linear Discriminant Analysis (LDA)
32 | - Mixture Discriminant Analysis (MDA)
33 | - Quadratic Discriminant Analysis (QDA)
34 | - Flexible Discriminant Analysis (FDA)
35 |
36 | 降维的必要性:
37 |
38 | 1.多重共线性--预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。2.高维空间本身具有稀疏性。一维正态分布有 68%的值落于正负标准差之间,而在十维空间上只有 0.02%。3.过多的变量会妨碍查找规律的建立。4.仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
39 | 降维的目的:1.减少预测变量的个数 2.确保这些变量是相互独立的 3.提供一个框架来解释结果
40 | 降维的方法有:主成分分析、因子分析、用户自定义复合等。
41 |
42 | # 数据的向量表示
43 |
44 | 一般情况下,在数据挖掘和机器学习中,数据被表示为向量。例如某个淘宝店 2012 年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
45 | (日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)
46 | 其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条看起来大约是这个样子:
47 | $
48 | (500,240,25,13,2312.15)^T
49 | $
50 | 注意这里我用了转置,因为习惯上使用列向量表示一条记录(后面会看到原因),本文后面也会遵循这个准则。不过为了方便有时我会省略转置符号,但我们说到向量默认都是指列向量。
51 | 我们当然可以对这一组五维向量进行分析和挖掘,不过我们知道,很多机器学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈 指数级关联。当然,这里区区五维的数据,也许还无所谓,但是实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗 是不可接受的,因此我们必须对数据进行降维。
52 | 降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低。
53 | 举个例子,假如某学籍数据有两列 M 和 F,其中 M 列的取值是如何此学生为男性取值 1,为女性取值 0;而 F 列是学生为女性取值 1,男 性取值 0。此时如果我们统计全部学籍数据,会发现对于任何一条记录来说,当 M 为 1 时 F 必定为 0,反之当 M 为 0 时 F 必定为 1。在这种情况下,我们将 M 或 F 去 掉实际上没有任何信息的损失,因为只要保留一列就可以完全还原另一列。
54 | 当然上面是一个极端的情况,在现实中也许不会出现,不过类似的情况还是很常见的。例如上面淘宝店铺的数据,从经验我们可以知道,“浏览量”和“访客数”往往具有较强的相关关系,而“下单数”和“成交数”也具有较强的相关关系。这里我们非正式的使用“相关关系”这个词,可以直观理解 为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。后面的章节中我们会给出相关性的严格数学定义。
55 | 这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。
56 | 上面给出的是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。例如,我们到底删除哪一列损 失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始 数据决定具体的降维操作步骤?
57 | 要回答上面的问题,就要对降维问题进行数学化和形式化的讨论。而 PCA 是一种具有严格数学基础并且已被广泛采用的降维方法。下面我不会直接描述 PCA,而是通过逐步分析问题,让我们一起重新“发明”一遍 PCA。
58 |
59 | ## 向量的表示及基变换
60 |
61 | ## 内积与投影
62 |
63 | 两个维数相同的向量的内积被定义为:
64 |
65 | $$
66 | (a_1,a_2,\cdots,a_n)^{T}\cdot (b_1,b_2,\cdots,b_n)^{T}=a_1b_1+a_2b_2+\cdots+a_nb_n
67 | $$
68 |
69 | 内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。下面我们分析内积的几何意义。假设 A 和 B 是两个 n 维向量,我们知道 n 维向量可以等价表示为 n 维空间中的一条从原点发射的有向线段,为了简单起见我们假设 A 和 B 均为二维向量,则 A=(x_1,y_1),B=(x_2,y_2)。则在二维平面上 A 和 B 可以用两条发自原点的有向线段表示,见下图:
70 | 
71 | 好,现在我们从 A 点向 B 所在直线引一条垂线。我们知道垂线与 B 的交点叫做 A 在 B 上的投影,再设 A 与 B 的夹角是 a,则投影的矢量长度为$|A|cos(a)$,其中$|A|=\sqrt{x_1^2+y_1^2}$是向量 A 的模,也就是 A 线段的标量长度。
72 | 注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于 0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
73 | 到这里还是看不出内积和这东西有什么关系,不过如果我们将内积表示为另一种我们熟悉的形式:
74 | $A\cdot B=|A||B|cos(a)$
75 | x(1,0)T+y(0,1)T
76 |
77 | 现在事情似乎是有点眉目了:A 与 B 的内积等于 A 到 B 的投影长度乘以 B 的模。再进一步,如果我们假设 B 的模为 1,即让|B|=1,那么就变成了:
78 | $A\cdot B=|A|cos(a)$
79 | 也就是说,设向量 B 的模为 1,则 A 与 B 的内积值等于 A 向 B 所在直线投影的矢量长度!这就是内积的一种几何解释,也是我们得到的第一个重要结论。在后面的推导中,将反复使用这个结论。
80 |
81 | ## 基
82 |
83 | 一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。例如下面这个向量:
84 | 
85 | 在代数表示方面,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2),这是我们再熟悉不过的向量表示。
86 | 不过我们常常忽略,只有一个(3,2)本身是不能够精确表示一个向量的。我们仔细看一下,这里的 3 实际表示的是向量在 x 轴上的投影值是 3,在 y 轴上的投影值是 2。也就是说我们其实隐式引入了一个定义:以 x 轴和 y 轴上正方向长度 为 1 的向量为标准。那么一个向量(3,2)实际是说在 x 轴投影为 3 而 y 轴的投影为 2。注意投影是一个矢量,所以可以为负。
87 | 更正式的说,向量(x,y)实际上表示线性组合:
88 | $x(1,0)^{T}+y(0,1)^{T}$
89 | (52,−12)
90 |
91 | 不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
92 | 
93 | 所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。只不过我们经常省略第一步,而默认以(1,0)和(0,1)为基。
94 | 我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为它们分别是 x 和 y 轴正方向上的单位向量,因此就使得二维平 面上点坐标和向量一一对应,非常方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上 的向量。
95 | 例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是 1,因为从内积的意义可以看到,如果基的模是 1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为 1 的向量,只要让两个分量分别除以模 就好了。例如,上面的基可以变为$(\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
96 | $和$(-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
97 | $。
98 | 现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为$(\frac{5}{\sqrt{2}},-\frac{1}{\sqrt{2}})
99 | $。下图给出了新的基以及(3,2)在新基上坐标值的示意图:
100 | 
101 | 另外这里要注意的是,我们列举的例子中基是正交的(即内积为 0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
102 |
103 | ## 基变换的矩阵表示
104 |
105 | 下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个 新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
106 |
107 | $$
108 | \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 3 \\ 2 \end{pmatrix} = \begin{pmatrix} 5/\sqrt{2} \\ -1/\sqrt{2} \end{pmatrix}
109 | $$
110 |
111 | 太漂亮了!其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。可以稍微推广一下,如果我们有 m 个二维向量,只要 将二维向量按列排成一个两行 m 列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变 换到刚才那组基上,则可以这样表示:
112 |
113 | $$
114 | \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3 \end{pmatrix} = \begin{pmatrix} 2/\sqrt{2} & 4/\sqrt{2} & 6/\sqrt{2} \\ 0 & 0 & 0 \end{pmatrix}
115 | $$
116 |
117 | aj
118 | 于是一组向量的基变换被干净的表示为矩阵的相乘。
119 | 一般的,如果我们有 M 个 N 维向量,想将其变换为由 R 个 N 维向量表示的新空间中,那么首先将 R 个基按行组成矩阵 A,然后将向量按列组成矩阵 B,那么两矩阵的乘积 AB 就是变换结果,其中 AB 的第 m 列为 A 中第 m 列变换后的结果。
120 | 数学表示为:
121 |
122 | $$
123 | \begin{pmatrix} p_1 \\ p_2 \\ \vdots \\ p_R \end{pmatrix} \begin{pmatrix} a_1 & a_2 & \cdots & a_M \end{pmatrix} = \begin{pmatrix} p_1a_1 & p_1a_2 & \cdots & p_1a_M \\ p_2a_1 & p_2a_2 & \cdots & p_2a_M \\ \vdots & \vdots & \ddots & \vdots \\ p_Ra_1 & p_Ra_2 & \cdots & p_Ra_M \end{pmatrix}
124 | $$
125 |
126 | (1124213344)
127 | 其中$p_i
128 | $是一个行向量,表示第 i 个基,$a_j$是一个列向量,表示第 j 个原始数据记录。
129 | 特别要注意的是,这里 R 可以小于 N,而 R 决定了变换后数据的维数。也就是说,我们可以将一 N 维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
130 | 最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
131 |
132 | ## 协方差矩阵及优化目标
133 |
134 | 上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但 是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组 N 维向量,现在要将其降到 K 维(K 小于 N),那么我们应该如何选择 K 个基才能最大程度保留原有的信息?
135 | 要完全数学化这个问题非常繁杂,这里我们用一种非形式化的直观方法来看这个问题。
136 | 为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
137 |
138 | $$
139 | \begin{pmatrix} 1 & 1 & 2 & 4 & 2 \\ 1 & 3 & 3 & 4 & 4 \end{pmatrix}
140 | $$
141 |
142 | 其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为 0(这样做的道理和好处后面会看到)。
143 | 我们看上面的数据,第一个字段均值为 2,第二个字段均值为 3,所以变换后:
144 |
145 | $$
146 | \begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}
147 | $$
148 |
149 | 
150 | 现在问题来了:如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
151 | 通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
152 | 那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
153 | 以上图为例,可以看出如果向 x 轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二 维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向 y 轴投影最上面的两个点和分布在 x 轴上的两个点也会重叠。所以看来 x 和 y 轴都不是 最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
154 | 下面,我们用数学方法表述这个问题。
155 |
156 | ### 方差
157 |
158 | 上文说到,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
159 | $Var(a)=\frac{1}{m}\sum_{i=1}^m{(a_i-\mu)^2}$
160 | X=(a1a2⋯amb1b2⋯bm)
161 | 由于上面我们已经将每个字段的均值都化为 0 了,因此方差可以直接用每个元素的平方和除以元素个数表示:
162 | $Var(a)=\frac{1}{m}\sum_{i=1}^m{a_i^2}$
163 | 1mXXT=(1m∑i=1mai21m∑i=1maibi1m∑i=1maibi1m∑i=1mbi2)
164 | 于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
165 |
166 | ### 协方差
167 |
168 | 对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
169 | 如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因 此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完 全独立,必然存在重复表示的信息。
170 | 数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为 0,则:
171 | $Cov(a,b)=\frac{1}{m}\sum_{i=1}^m{a_ib_i}$
172 | D=1mYYT=1m(PX)(PX)T=1mPXXTPT=P(1mXXT)PT=PCPT
173 | 可以看到,在字段均值为 0 的情况下,两个字段的协方差简洁的表示为其内积除以元素数 m。
174 | 当协方差为 0 时,表示两个字段完全独立。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
175 | 至此,我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维(K 大于 0,小于 N),其目标是选择 K 个单位(模为 1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为 0,而字段的方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
176 |
177 | ### 协方差矩阵
178 |
179 | 上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
180 | 我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感:
181 | 假设我们只有 a 和 b 两个字段,那么我们将它们按行组成矩阵 X:
182 | $X=\begin{pmatrix} a_1 & a_2 & \cdots & a_m \\ b_1 & b_2 & \cdots & b_m \end{pmatrix}$
183 | (e1e2⋯en)
184 | 然后我们用 X 乘以 X 的转置,并乘上系数 1/m:
185 | $\frac{1}{m}XX^\mathsf{T}=\begin{pmatrix} \frac{1}{m}\sum_{i=1}^m{a_i^2} & \frac{1}{m}\sum_{i=1}^m{a_ib_i} \\ \frac{1}{m}\sum_{i=1}^m{a_ib_i} & \frac{1}{m}\sum_{i=1}^m{b_i^2} \end{pmatrix}$
186 | (λ1λ2⋱λn)
187 | 奇迹出现了!这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵的。
188 | 根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
189 | 设我们有 m 个 n 维数据记录,将其按列排成 n 乘 m 的矩阵 X,设 C=\frac{1}{m}XX^\mathsf{T},则 C 是一个对称矩阵,其对角线分别个各个字段的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个字段的协方差。
190 |
191 | ## 协方差矩阵对角化
192 |
193 | 根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
194 | 设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:
195 | \begin{array}{l l l} D & = & \frac{1}{m}YY^\mathsf{T} \\ & = & \frac{1}{m}(PX)(PX)^\mathsf{T} \\ & = & \frac{1}{m}PXX^\mathsf{T}P^\mathsf{T} \\ & = & P(\frac{1}{m}XX^\mathsf{T})P^\mathsf{T} \\ & = & PCP^\mathsf{T} \end{array}
196 | 现在事情很明白了!我们要找的 P 不是别的,而是能让原始协方差矩阵对角化的 P。换句话说,优化目标变成了寻找一个矩阵 P,满足 PCP^\mathsf{T}是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
197 | 至此,我们离“发明”PCA 还有仅一步之遥!
198 | 现在所有焦点都聚焦在了协方差矩阵对角化问题上,有时,我们真应该感谢数学家的先行,因为矩阵对角化在线性代数领域已经属于被玩烂了的东西,所以这在数学上根本不是问题。
199 | 由上文知道,协方差矩阵 C 是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:1)实对称矩阵不同特征值对应的特征向量必然正交。2)设特征向量\lambda 重数为 r,则必然存在 r 个线性无关的特征向量对应于\lambda,因此可以将这 r 个特征向量单位正交化。
200 | 由上面两条可知,一个 n 行 n 列的实对称矩阵一定可以找到 n 个单位正交特征向量,设这 n 个特征向量为 e_1,e_2,\cdots,e_n,我们将其按列组成矩阵:
201 | E=\begin{pmatrix} e_1 & e_2 & \cdots & e_n \end{pmatrix}
202 | 则对协方差矩阵 C 有如下结论:
203 | E^\mathsf{T}CE=\Lambda=\begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix}
204 | 其中\Lambda 为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
205 | 以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。
206 | 到这里,我们发现我们已经找到了需要的矩阵 P:
207 | P=E^\mathsf{T}
208 | P 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 C 的一个特征向量。如果设 P 按照\Lambda 中特征值的从大到小,将特征向量从上到下排列,则用 P 的前 K 行组成的矩阵乘以原始数据矩阵 X,就得到了我们需要的降维后的数据矩阵 Y。
209 | 至此我们完成了整个 PCA 的数学原理讨论。在下面的一节,我们将给出 PCA 的一个实例。
210 |
--------------------------------------------------------------------------------
/特征工程/数据集/文本/常用数据集介绍.md:
--------------------------------------------------------------------------------
1 | # 搜狗实验室数据
2 |
3 | 
4 |
5 | 搜狗实验室(Sogo Labs)是搜狗搜索核心研发团队对外交流的窗口,包含数据资源、数据挖掘云、研究合作等几个栏目。数据资源包括评测集合、语料数据、新闻数据、图片数据和自然语言处理相关数据,网址为[这里](http://www.sogou.com/labs/resource/list_pingce.php)
6 |
7 | ## 互联网语料库(SogouT)
8 |
9 | SogouT 来自互联网各种类型的 1.3 亿个原始网页, 压缩前的大小超过了 5TB,格式如下:
10 |
11 | ```xml
12 |
40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
142 |
143 |
144 |
145 |
154 |
155 |
156 |
--------------------------------------------------------------------------------
/header.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/特征工程/特征降维/README.md:
--------------------------------------------------------------------------------
1 | # 特征降纬
2 |
3 | 维度变换是将现有数据降低到更小的维度,尽量保证数据信息的完整性。楼主将介绍常用的几种有损失的维度变换方法,将大大地提高实践中建模的效率:
4 |
5 | - 主成分分析(PCA)和因子分析(FA):PCA 通过空间映射的方式,将当前维度映射到更低的维度,使得每个变量在新空间的方差最大。FA 则是找到当前特征向量的公因子(维度更小),用公因子的线性组合来描述当前的特征向量。
6 |
7 | - 奇异值分解(SVD):SVD 的降维可解释性较低,且计算量比 PCA 大,一般用在稀疏矩阵上降维,例如图片压缩,推荐系统。
8 |
9 | - 聚类:将某一类具有相似性的特征聚到单个变量,从而大大降低维度。
10 |
11 | - 线性组合:将多个变量做线性回归,根据每个变量的表决系数,赋予变量权重,可将该类变量根据权重组合成一个变量。
12 |
13 | - 流行学习:流行学习中一些复杂的非线性方法,可参考 skearn:LLE Example
14 |
15 | - [维度打击,机器学习中的降维算法:ISOMAP & MDS ](http://blog.csdn.net/dark_scope/article/details/53229427)
16 |
17 | # Dimensionality Reduction(降维)
18 |
19 | 
20 |
21 | Like clustering methods, dimensionality reduction seek and exploit the inherent structure in the data, but in this case in an unsupervised manner or order to summarise or describe data using less information.
22 |
23 | This can be useful to visualize dimensional data or to simplify data which can then be used in a supervized learning method. Many of these methods can be adapted for use in classification and regression.
24 |
25 | - Principal Component Analysis (PCA)
26 | - Principal Component Regression (PCR)
27 | - Partial Least Squares Regression (PLSR)
28 | - Sammon Mapping
29 | - Multidimensional Scaling (MDS)
30 | - Projection Pursuit
31 | - Linear Discriminant Analysis (LDA)
32 | - Mixture Discriminant Analysis (MDA)
33 | - Quadratic Discriminant Analysis (QDA)
34 | - Flexible Discriminant Analysis (FDA)
35 |
36 | 降维的必要性:
37 |
38 | 1.多重共线性--预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。2.高维空间本身具有稀疏性。一维正态分布有 68%的值落于正负标准差之间,而在十维空间上只有 0.02%。3.过多的变量会妨碍查找规律的建立。4.仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
39 | 降维的目的:1.减少预测变量的个数 2.确保这些变量是相互独立的 3.提供一个框架来解释结果
40 | 降维的方法有:主成分分析、因子分析、用户自定义复合等。
41 |
42 | # 数据的向量表示
43 |
44 | 一般情况下,在数据挖掘和机器学习中,数据被表示为向量。例如某个淘宝店 2012 年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
45 | (日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)
46 | 其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条看起来大约是这个样子:
47 | $
48 | (500,240,25,13,2312.15)^T
49 | $
50 | 注意这里我用了转置,因为习惯上使用列向量表示一条记录(后面会看到原因),本文后面也会遵循这个准则。不过为了方便有时我会省略转置符号,但我们说到向量默认都是指列向量。
51 | 我们当然可以对这一组五维向量进行分析和挖掘,不过我们知道,很多机器学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈 指数级关联。当然,这里区区五维的数据,也许还无所谓,但是实际机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗 是不可接受的,因此我们必须对数据进行降维。
52 | 降维当然意味着信息的丢失,不过鉴于实际数据本身常常存在的相关性,我们可以想办法在降维的同时将信息的损失尽量降低。
53 | 举个例子,假如某学籍数据有两列 M 和 F,其中 M 列的取值是如何此学生为男性取值 1,为女性取值 0;而 F 列是学生为女性取值 1,男 性取值 0。此时如果我们统计全部学籍数据,会发现对于任何一条记录来说,当 M 为 1 时 F 必定为 0,反之当 M 为 0 时 F 必定为 1。在这种情况下,我们将 M 或 F 去 掉实际上没有任何信息的损失,因为只要保留一列就可以完全还原另一列。
54 | 当然上面是一个极端的情况,在现实中也许不会出现,不过类似的情况还是很常见的。例如上面淘宝店铺的数据,从经验我们可以知道,“浏览量”和“访客数”往往具有较强的相关关系,而“下单数”和“成交数”也具有较强的相关关系。这里我们非正式的使用“相关关系”这个词,可以直观理解 为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。后面的章节中我们会给出相关性的严格数学定义。
55 | 这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。
56 | 上面给出的是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。例如,我们到底删除哪一列损 失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始 数据决定具体的降维操作步骤?
57 | 要回答上面的问题,就要对降维问题进行数学化和形式化的讨论。而 PCA 是一种具有严格数学基础并且已被广泛采用的降维方法。下面我不会直接描述 PCA,而是通过逐步分析问题,让我们一起重新“发明”一遍 PCA。
58 |
59 | ## 向量的表示及基变换
60 |
61 | ## 内积与投影
62 |
63 | 两个维数相同的向量的内积被定义为:
64 |
65 | $$
66 | (a_1,a_2,\cdots,a_n)^{T}\cdot (b_1,b_2,\cdots,b_n)^{T}=a_1b_1+a_2b_2+\cdots+a_nb_n
67 | $$
68 |
69 | 内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。下面我们分析内积的几何意义。假设 A 和 B 是两个 n 维向量,我们知道 n 维向量可以等价表示为 n 维空间中的一条从原点发射的有向线段,为了简单起见我们假设 A 和 B 均为二维向量,则 A=(x_1,y_1),B=(x_2,y_2)。则在二维平面上 A 和 B 可以用两条发自原点的有向线段表示,见下图:
70 | 
71 | 好,现在我们从 A 点向 B 所在直线引一条垂线。我们知道垂线与 B 的交点叫做 A 在 B 上的投影,再设 A 与 B 的夹角是 a,则投影的矢量长度为$|A|cos(a)$,其中$|A|=\sqrt{x_1^2+y_1^2}$是向量 A 的模,也就是 A 线段的标量长度。
72 | 注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于 0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
73 | 到这里还是看不出内积和这东西有什么关系,不过如果我们将内积表示为另一种我们熟悉的形式:
74 | $A\cdot B=|A||B|cos(a)$
75 | x(1,0)T+y(0,1)T
76 |
77 | 现在事情似乎是有点眉目了:A 与 B 的内积等于 A 到 B 的投影长度乘以 B 的模。再进一步,如果我们假设 B 的模为 1,即让|B|=1,那么就变成了:
78 | $A\cdot B=|A|cos(a)$
79 | 也就是说,设向量 B 的模为 1,则 A 与 B 的内积值等于 A 向 B 所在直线投影的矢量长度!这就是内积的一种几何解释,也是我们得到的第一个重要结论。在后面的推导中,将反复使用这个结论。
80 |
81 | ## 基
82 |
83 | 一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。例如下面这个向量:
84 | 
85 | 在代数表示方面,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2),这是我们再熟悉不过的向量表示。
86 | 不过我们常常忽略,只有一个(3,2)本身是不能够精确表示一个向量的。我们仔细看一下,这里的 3 实际表示的是向量在 x 轴上的投影值是 3,在 y 轴上的投影值是 2。也就是说我们其实隐式引入了一个定义:以 x 轴和 y 轴上正方向长度 为 1 的向量为标准。那么一个向量(3,2)实际是说在 x 轴投影为 3 而 y 轴的投影为 2。注意投影是一个矢量,所以可以为负。
87 | 更正式的说,向量(x,y)实际上表示线性组合:
88 | $x(1,0)^{T}+y(0,1)^{T}$
89 | (52,−12)
90 |
91 | 不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
92 | 
93 | 所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。只不过我们经常省略第一步,而默认以(1,0)和(0,1)为基。
94 | 我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为它们分别是 x 和 y 轴正方向上的单位向量,因此就使得二维平 面上点坐标和向量一一对应,非常方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上 的向量。
95 | 例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是 1,因为从内积的意义可以看到,如果基的模是 1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为 1 的向量,只要让两个分量分别除以模 就好了。例如,上面的基可以变为$(\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
96 | $和$(-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})
97 | $。
98 | 现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为$(\frac{5}{\sqrt{2}},-\frac{1}{\sqrt{2}})
99 | $。下图给出了新的基以及(3,2)在新基上坐标值的示意图:
100 | 
101 | 另外这里要注意的是,我们列举的例子中基是正交的(即内积为 0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
102 |
103 | ## 基变换的矩阵表示
104 |
105 | 下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个 新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
106 |
107 | $$
108 | \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 3 \\ 2 \end{pmatrix} = \begin{pmatrix} 5/\sqrt{2} \\ -1/\sqrt{2} \end{pmatrix}
109 | $$
110 |
111 | 太漂亮了!其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。可以稍微推广一下,如果我们有 m 个二维向量,只要 将二维向量按列排成一个两行 m 列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变 换到刚才那组基上,则可以这样表示:
112 |
113 | $$
114 | \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3 \end{pmatrix} = \begin{pmatrix} 2/\sqrt{2} & 4/\sqrt{2} & 6/\sqrt{2} \\ 0 & 0 & 0 \end{pmatrix}
115 | $$
116 |
117 | aj
118 | 于是一组向量的基变换被干净的表示为矩阵的相乘。
119 | 一般的,如果我们有 M 个 N 维向量,想将其变换为由 R 个 N 维向量表示的新空间中,那么首先将 R 个基按行组成矩阵 A,然后将向量按列组成矩阵 B,那么两矩阵的乘积 AB 就是变换结果,其中 AB 的第 m 列为 A 中第 m 列变换后的结果。
120 | 数学表示为:
121 |
122 | $$
123 | \begin{pmatrix} p_1 \\ p_2 \\ \vdots \\ p_R \end{pmatrix} \begin{pmatrix} a_1 & a_2 & \cdots & a_M \end{pmatrix} = \begin{pmatrix} p_1a_1 & p_1a_2 & \cdots & p_1a_M \\ p_2a_1 & p_2a_2 & \cdots & p_2a_M \\ \vdots & \vdots & \ddots & \vdots \\ p_Ra_1 & p_Ra_2 & \cdots & p_Ra_M \end{pmatrix}
124 | $$
125 |
126 | (1124213344)
127 | 其中$p_i
128 | $是一个行向量,表示第 i 个基,$a_j$是一个列向量,表示第 j 个原始数据记录。
129 | 特别要注意的是,这里 R 可以小于 N,而 R 决定了变换后数据的维数。也就是说,我们可以将一 N 维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
130 | 最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
131 |
132 | ## 协方差矩阵及优化目标
133 |
134 | 上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但 是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组 N 维向量,现在要将其降到 K 维(K 小于 N),那么我们应该如何选择 K 个基才能最大程度保留原有的信息?
135 | 要完全数学化这个问题非常繁杂,这里我们用一种非形式化的直观方法来看这个问题。
136 | 为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
137 |
138 | $$
139 | \begin{pmatrix} 1 & 1 & 2 & 4 & 2 \\ 1 & 3 & 3 & 4 & 4 \end{pmatrix}
140 | $$
141 |
142 | 其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为 0(这样做的道理和好处后面会看到)。
143 | 我们看上面的数据,第一个字段均值为 2,第二个字段均值为 3,所以变换后:
144 |
145 | $$
146 | \begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}
147 | $$
148 |
149 | 
150 | 现在问题来了:如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
151 | 通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
152 | 那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
153 | 以上图为例,可以看出如果向 x 轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二 维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向 y 轴投影最上面的两个点和分布在 x 轴上的两个点也会重叠。所以看来 x 和 y 轴都不是 最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
154 | 下面,我们用数学方法表述这个问题。
155 |
156 | ### 方差
157 |
158 | 上文说到,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
159 | $Var(a)=\frac{1}{m}\sum_{i=1}^m{(a_i-\mu)^2}$
160 | X=(a1a2⋯amb1b2⋯bm)
161 | 由于上面我们已经将每个字段的均值都化为 0 了,因此方差可以直接用每个元素的平方和除以元素个数表示:
162 | $Var(a)=\frac{1}{m}\sum_{i=1}^m{a_i^2}$
163 | 1mXXT=(1m∑i=1mai21m∑i=1maibi1m∑i=1maibi1m∑i=1mbi2)
164 | 于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
165 |
166 | ### 协方差
167 |
168 | 对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
169 | 如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因 此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完 全独立,必然存在重复表示的信息。
170 | 数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为 0,则:
171 | $Cov(a,b)=\frac{1}{m}\sum_{i=1}^m{a_ib_i}$
172 | D=1mYYT=1m(PX)(PX)T=1mPXXTPT=P(1mXXT)PT=PCPT
173 | 可以看到,在字段均值为 0 的情况下,两个字段的协方差简洁的表示为其内积除以元素数 m。
174 | 当协方差为 0 时,表示两个字段完全独立。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
175 | 至此,我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维(K 大于 0,小于 N),其目标是选择 K 个单位(模为 1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为 0,而字段的方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
176 |
177 | ### 协方差矩阵
178 |
179 | 上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
180 | 我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感:
181 | 假设我们只有 a 和 b 两个字段,那么我们将它们按行组成矩阵 X:
182 | $X=\begin{pmatrix} a_1 & a_2 & \cdots & a_m \\ b_1 & b_2 & \cdots & b_m \end{pmatrix}$
183 | (e1e2⋯en)
184 | 然后我们用 X 乘以 X 的转置,并乘上系数 1/m:
185 | $\frac{1}{m}XX^\mathsf{T}=\begin{pmatrix} \frac{1}{m}\sum_{i=1}^m{a_i^2} & \frac{1}{m}\sum_{i=1}^m{a_ib_i} \\ \frac{1}{m}\sum_{i=1}^m{a_ib_i} & \frac{1}{m}\sum_{i=1}^m{b_i^2} \end{pmatrix}$
186 | (λ1λ2⋱λn)
187 | 奇迹出现了!这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵的。
188 | 根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
189 | 设我们有 m 个 n 维数据记录,将其按列排成 n 乘 m 的矩阵 X,设 C=\frac{1}{m}XX^\mathsf{T},则 C 是一个对称矩阵,其对角线分别个各个字段的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个字段的协方差。
190 |
191 | ## 协方差矩阵对角化
192 |
193 | 根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
194 | 设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:
195 | \begin{array}{l l l} D & = & \frac{1}{m}YY^\mathsf{T} \\ & = & \frac{1}{m}(PX)(PX)^\mathsf{T} \\ & = & \frac{1}{m}PXX^\mathsf{T}P^\mathsf{T} \\ & = & P(\frac{1}{m}XX^\mathsf{T})P^\mathsf{T} \\ & = & PCP^\mathsf{T} \end{array}
196 | 现在事情很明白了!我们要找的 P 不是别的,而是能让原始协方差矩阵对角化的 P。换句话说,优化目标变成了寻找一个矩阵 P,满足 PCP^\mathsf{T}是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
197 | 至此,我们离“发明”PCA 还有仅一步之遥!
198 | 现在所有焦点都聚焦在了协方差矩阵对角化问题上,有时,我们真应该感谢数学家的先行,因为矩阵对角化在线性代数领域已经属于被玩烂了的东西,所以这在数学上根本不是问题。
199 | 由上文知道,协方差矩阵 C 是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:1)实对称矩阵不同特征值对应的特征向量必然正交。2)设特征向量\lambda 重数为 r,则必然存在 r 个线性无关的特征向量对应于\lambda,因此可以将这 r 个特征向量单位正交化。
200 | 由上面两条可知,一个 n 行 n 列的实对称矩阵一定可以找到 n 个单位正交特征向量,设这 n 个特征向量为 e_1,e_2,\cdots,e_n,我们将其按列组成矩阵:
201 | E=\begin{pmatrix} e_1 & e_2 & \cdots & e_n \end{pmatrix}
202 | 则对协方差矩阵 C 有如下结论:
203 | E^\mathsf{T}CE=\Lambda=\begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix}
204 | 其中\Lambda 为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
205 | 以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。
206 | 到这里,我们发现我们已经找到了需要的矩阵 P:
207 | P=E^\mathsf{T}
208 | P 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 C 的一个特征向量。如果设 P 按照\Lambda 中特征值的从大到小,将特征向量从上到下排列,则用 P 的前 K 行组成的矩阵乘以原始数据矩阵 X,就得到了我们需要的降维后的数据矩阵 Y。
209 | 至此我们完成了整个 PCA 的数学原理讨论。在下面的一节,我们将给出 PCA 的一个实例。
210 |
--------------------------------------------------------------------------------
/特征工程/数据集/文本/常用数据集介绍.md:
--------------------------------------------------------------------------------
1 | # 搜狗实验室数据
2 |
3 | 
4 |
5 | 搜狗实验室(Sogo Labs)是搜狗搜索核心研发团队对外交流的窗口,包含数据资源、数据挖掘云、研究合作等几个栏目。数据资源包括评测集合、语料数据、新闻数据、图片数据和自然语言处理相关数据,网址为[这里](http://www.sogou.com/labs/resource/list_pingce.php)
6 |
7 | ## 互联网语料库(SogouT)
8 |
9 | SogouT 来自互联网各种类型的 1.3 亿个原始网页, 压缩前的大小超过了 5TB,格式如下:
10 |
11 | ```xml
12 |