38 |
40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/低代码平台/00~低代码设计理念/99~参考资料/2023~Low-Code Programming Models.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext)
2 |
3 | # Low-Code Programming Models
4 |
5 | Low-code is the subject of much current enthusiasm stirred by market research companies and confirmed by vendors rushing to embrace the label.7,31 But what low-code programming means is somewhat cryptic, let alone how it works. Moreover, scientific literature rarely uses the term. We can decode the term by breaking it into its components. Programming means developing computer programs, which comprise instructions for a computer to execute. Traditionally, programming means writing code in a textual programming language, such as C, Java, or Python. In contrast, low-code programming minimizes the use of a textual programming language. Instead, it aims to use alternative techniques closer to how users naturally think about their task.
6 |
7 | Users of low-code range from professional developers to so-called citizen developers. A citizen developer is an amateur programmer with little professional programming education. Citizen developers, having chosen a career different from programming, tend to have more domain expertise. Low-code enables domain experts to become citizen developers. At the same time, low-code platforms should also strive to make pro-developers (professionals with an education or career in software development) more productive.
8 |
9 | Whether used by a citizen developer or a pro-developer, low-code programming aims to save the time and tedium of performing a task by hand.35 Further motivation for individuals comes from the joy of creating something useful, thinking about tasks in a computational way, and acquiring programming skills that can advance their career. Businesses may have their own motivation for adopting low-code platforms, which can alleviate the shortage of pro-developers, reduce mistakes of tedious manual tasks, and multiply the time savings from one individual's low-code program to their colleagues.31 Another factor driving low-code is the rise of cloud-based software as a service, providing both more interfaces to automate and a platform on which to deploy automations.
10 |
11 | A few concepts are closely related to low-code programming. No-code programming is more purist, with zero handwritten code in a textual programming language. End-user programming (EUP) puts the emphasis on who is doing the programming (the end-user as citizen developer) rather than on how they are not doing their programming (not with textual code).6 This term is common in the academic literature and overlaps with low-code, but does not preclude the use of a textual programming language. Another gap between EUP and low-code is the latter aims to serve not just end users but also pro-developers.7,31
12 |
13 | Bock and Frank7 and Sahay et al.31 recently compared commercial low-code platforms, and Barricelli et al. recently mapped the EUP literature.6 In contrast, this article bridges the gap between low-code and the academic literature and adds missing details and perspective. Low-code encompasses more specialized techniques, such as visual programming languages (VPLs), programming by demonstration (PBD), programming by example (PBE), robotic process automation (RPA), programming by natural language (PBNL), and others. Surveys on these techniques are more specific and often dated.4,8,20,35 In contrast, this article reviews recent literature across all these techniques.
14 |
15 | Given that low-code offers citizen developers a model to create computer programs, this article explores low-code from the perspective of programming models. A programming model is a set of abstractions that supports developing computer programs. Programming models can be low-code or not, and they can be domain-specific or general-purpose. Some programming models are languages; for example, Java is a general-purpose language and SQL is domain-specific, and neither is low-code. Scratch is a low-code programming model for kids that is media-centric,29 making it domain-specific. The programming-model perspective helps highlight common techniques for writing, reading, and executing programs, and it helps relate low-code to research into program synthesis and domain-specific languages.
16 |
17 | This article includes a deep-dive into three prominent low-code techniques: visual programming, programming by demonstration, and programming by natural language. The deep-dive focuses on fundamental building blocks and a unifying framework common to all three. The citations in this article cover both seminal work and recent advances in low-code programming models, for instance, based on artificial intelligence. Moreover, this article aims to cut through the buzz surrounding low-code so as to expose the technical foundations underneath. Hopefully, doing so will foster better development of the field through awareness of existing (albeit scattered) research, and will ultimately lead to even more empowered citizen developers.
18 |
19 | ### Problem Statement
20 |
21 | If low-code is the solution, then what is the problem? Given the term low-code, it might seem the answer is obviously code. Unfortunately, that answer is superficial and nonconstructive. Defining a thing solely by what it is not, as the term low-code appears to do, causes confusion. Consider two other recent similarly named trends: NoSQL and serverless. At the surface, one might think NoSQL was mostly about rejecting SQL, but in fact, it was more about flexible data and consistency models than about the query language. Similarly, serverless computing was not about eliminating compute servers, but about hiding them behind better abstractions. Defining a new trend by rejecting an old one grabs attention at the expense of being misleading. Just like serverless still needs servers, low-code (and even no-code!) still needs code.
22 |
23 | The three terms—low-code, NoSQL, and serverless—have one thing in common: a desire to avoid specific baggage while preserving core value. In NoSQL, the core value is durable and consistent storage. In serverless, it is portable and elastic compute. What then is the core value that low-code aims to preserve? This article argues it is computer programming. Programming is to low-code what computing is to serverless. Low-code is about creating instructions for a computer to execute or interpret. These instructions form a computer program, typically in a domain-specific language (DSL). For instance, low-code is often based on search-based program synthesis, and synthesis usually targets a DSL carefully crafted for the purpose.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) The program may not be exposed to the user, but it is there.
24 |
25 | One way to better understand the problem statement behind low-code is to look at who it is for. The top portion of [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) shows the spectrum of low-code users. They range from citizen developers at one end to pro-developers at the other, with intermediate stages here dubbed semi developers. In this simplified view, users at the citizen developer end of the spectrum tend to have the most domain knowledge and users at the pro-developer end have the most programming expertise. Low-code can enable citizen developers to self-serve their programming needs instead of depending on pro-developers. At the same time, low-code can make pro-developers more productive, for example, in a new domain. Finally, low-code can break barriers between developers across the spectrum and help them collaborate on common ground.
26 |
27 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg)
28 | **Figure 1. Low-code users and techniques.**
29 |
30 | The middle portion of [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) shows three representative low-code techniques. Programming expertise induces a Venn diagram over the users, with the smallest subset being able to use the largest range of programming techniques. An edge between a set of users and a low-code technique indicates the users write or read a program with that technique. Specifically, all users can use programming by demonstration and programming by natural language (edges to the outermost set of users encompassing citizen-, semi-, and pro-developers). Only semi-developers and pro-developers can readily use visual programming, though citizen developers may be easily trained to do so, as evidenced by Scratch.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) And only pro-developers are likely to directly use a DSL. Therefore, while low-code typically targets a DSL, that DSL may not be exposed, or if it is, may only be exposed to pro-developers. That is especially true in the common case of a DSL that is embedded[17](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R17) in a general-purpose textual programming language such as Python.
31 |
32 | ---
33 |
34 | > _Just like serverless still needs servers, low-code (and even no-code!) still needs code._
35 |
36 | ---
37 |
38 | If the core value of low-code is to create computer programs, what exactly is it about created programs that is deemed valuable? One way to shed more light on this question is to look at a seemingly opposing trend, namely the as-code movement. The as-code movement started with infrastructure as code, which automates standing up compute resources and the services running on them from a source code repository and a backup.[18](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R18) Treating this process as code can speed it up, reduce mistakes, and facilitate testing. Another instance of as-code is security as code, where security policies, templates, and configuration files all live in a source code repository.[25](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R25) Treating them as code lets them be versioned, inspected by humans, and checked by machines. To summarize, the as-code movement sees value in programs that are repeatable, tested, versioned, human-readable, and machine-checkable. These are also desirable properties for low-code programs.
39 |
40 | When citizen developers use low-code, it is typically to create a program for a task they would otherwise do by hand. So what tasks is low-code good for? Generally speaking, low-code helps if it shaves off more time from a task than the time spent doing the low-code programming. This is true for tasks that are repetitive or time-consuming. Of course, the equation shifts when the program can be used not just by the developer who created it, but also by others, shaving time off their tasks as well. In the extreme, pro-developers create programs used by millions. Low-code is most appropriate when it saves time, but not enough time to make professional coding economically feasible. Low-code is suitable for tasks that are rule-based and low on exceptions. And besides the time savings, it can be even more beneficial when the tedium of doing the task by hand causes errors.
41 |
42 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
43 |
44 | ### Techniques
45 |
46 | Here, we take a deep-dive into three representative techniques for low-code programming: VPLs, PBD, and PBNL. These three are a good set for the following reasons. Sahay et al.'s paper declares low-code as synonymous with just one technique, VPLs,[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31) but that perspective seems too narrow. Barricelli et al. list 14 different techniques for EUP,[6](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R6) but they are not clearly separated, and reviewing them all in detail would get too long-winded. In the past, the dominant low-code technique has been spreadsheets.[9](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R9) The three chosen techniques instead align with present and future trends: VPLs are central to current commercial low-code platforms;[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31) PBD is the backbone of RPA, which often uses record-and-replay;[35](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R35) and PBNL is poised to grow thanks to advances in deep learning-based large language models.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11),[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33),[39](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R39)
47 |
48 | Furthermore, the three techniques are well-suited for citizen developers by drawing upon universal skills: VPLs draw upon seeing, PBD draws upon the ability to use a computer application, and PBNL draws upon speaking. In fact, low-code can offer an alternative modality when some other approach is impeded, such as using speech interfaces when a user's hands or eyes are unavailable. Finally, VPLs, PBD, and PBNL are sufficient to span a set of building blocks that can also be arranged differently for use with other low-code techniques, such as spreadsheets, rules, wizards, or templates. Not all building blocks appear in all techniques, but the following blocks recur enough to warrant brief up-front definitions:
49 |
50 | - code canvas: renders code, for example, visually as a flow graph;
51 | - palette: offers components for drag-and-drop selection;
52 | - text box: holds natural-language text used for code search, description, or generation;
53 | - player: has buttons for capture, replay, pause, or step;
54 | - stage: shows the effect of code execution; and,
55 | - configuration pane: lets the user customize components, for example, via graphical controls such as checkboxes or sliders, or textually by typing small formulas.
56 |
57 | Low-code techniques support not just writing programs, but also reading and executing them. A low-code system can execute the program immediately after it is written or save it for later, and the user may choose to execute the program multiple times, for example, after input data changes. Low-code techniques differ in which of the listed building blocks are engaged to read, write, or execute programs. Whereas [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) blurred the read/write/execute distinction by using undirected edges, the rest of this section explicates the distinction by using directed edges and colors (orange for read, dark blue for write, and purple for execute).
58 |
59 | **Visual programming languages.** _The user drags visual components from a palette to a canvas, connects them, and configures them._
60 |
61 | _Description._ Visual programming languages let users write programs by directly manipulating their visual representation. There is a plethora of possible visual representations,[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) often inspired by domain notation, such as electrical circuit diagrams. Two prominent domain-independent visual representations are boxes-and-arrows (for example, BPMN[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27)) or interlocking puzzle pieces (for example, Scratch[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29)). Here, boxes or puzzle pieces represent instructions in the program, and arrows between boxes or the interlock of pieces represent how data and control flows between instructions.
62 |
63 | Despite the diversity in visual languages, their programming environments tend to comprise similar building blocks, as depicted in [Figure 2](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f2.jpg). The central building block is the code canvas, where the user can both read (orange arrow from canvas to eye) and write (dark blue arrow from hand to canvas) the program. Writing the program also involves dragging components from the palette to the canvas and possibly configuring them in a separate configuration pane. The programming environment also often includes a stage, which visually shows a program execution, ideally live.[34](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R34) For example, in Scratch, the stage shows sprites in a virtual world. Besides making the environment more engaging, the stage is also crucial for program understanding and debugging. To facilitate this, the stage is usually tightly connected to the canvas, helping the user navigate back and forth.
64 |
65 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f2.jpg)
66 | **Figure 2. Visual programming languages.**
67 |
68 | _Strengths, weaknesses, and mitigations._ One strength of VPLs is they tend to be easy to read, especially when reusing notation already familiar to the domain expert,[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) or in visual builders for graphical user interfaces.[24](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R24) Another strength is that, in contrast to PBD or PBNL, VPLs are usually unambiguous, thus increasing programmer control and reducing mistakes. Finally, compared to textual programming languages, visual languages can rule out syntax errors[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) and even simple type errors[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) by construction.
69 |
70 | In the context of low-code programming, the main weakness of visual programming languages is they are not always self-explanatory; that is why [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) connects them to semi-developers. The mitigation for this need-to-learn is user education, and for some VPLs, education is a primary purpose.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) The visual notation can take up a lot of screen real estate; the mitigation is to elide detail, for example, by requiring a configuration pane or via modular language constructs.[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3),[26](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R26) Even the palette can get too full, hindering discoverability, which can be mitigated by search facilities. A drawback of visual languages compared to textual languages is they tend to be co-dependent on their visual programming environment, hindering the use of basic tools such as diffing or search, or of third-party tools such as linters or code generators. This can be mitigated by backing the visual language with a textual domain-specific language.[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37)
71 |
72 | _Literature._ Some seminal VPLs include BPMN-on-BPEL for modeling and executing business processes[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27) and the Scratch language for teaching kids programming.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) Boshernitsan and Downes chronicle early VPLs and categorize them into purely visual vs. hybrid (mixed with text), and complete (sufficient procedural abstraction and data abstraction to be self-hosting) or not.[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) Today, VPLs are central to commercial low-code platforms such as Appian, Mendix, and OutSystems.[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31)
73 |
74 | Other papers address VPL implementation approaches, such as meta-tools (tool used to implement other tools) and the model-view-controller (MVC) pattern, which lets users manipulate the same model through multiple synchronized views. VisPro is a meta-tool for creating visual programming environments.[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) VisPro advocates for a coordinated set of visual and textual languages, using MVC to expose the same program (model) via multiple languages (views). More recently, Blockly is a meta-tool for creating VPLs with interlocking puzzle pieces[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28) such as those in Scratch. Some VPLs target pro-developers and are embedded in professional programming environments or languages. Projectional editing, such as in MPS,[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) doubles down on the MVC paradigm, where even the textual language is projected into a view precluding syntax errors. More recent work has demonstrated VPLs as libraries extending textual languages. A livelit is a user-defined VPL widget that can be used in place of a textual literal,[26](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R26) and Andersen et al. let users implement VPL widgets for literals, patterns, and templates.[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3)
75 |
76 | **Programming by demonstration.** _The user demonstrates the behavior on a canvas, with some configuration during or after recording._
77 |
78 | _Description._ In PBD, the user demonstrates how to perform a task by hand via the mouse and keyboard, and the PBD system records a program that can perform the same task automatically. As shown in [Figure 3](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f3.jpg), the demonstration happens on a stage, which may be a specific application like a spreadsheet, or a Web browser visiting a variety of sites and apps, or even a general computer desktop or smart-phone screen. Ideally, the recorded program abstracts from perceptions to a symbolic representation, for instance, by mapping pixel coordinates to a user-interface widget, or several keystrokes to a text string. Besides the stage, most PBD systems have a player with buttons to record and replay, plus often additional buttons such as pause or step (reminiscent of interactive debuggers).
79 |
80 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f3.jpg)
81 | **Figure 3. Programming by demonstration.**
82 |
83 | The program is most useful if executing it does not yield the same behavior as the initial demonstration, but rather, generalizes to different data. For example, a program for ordering a taxi to any new location is more general and more useful than a program for ordering a taxi to only a single hard-coded location. Generalizing typically requires identifying variables or parameters, and may even entail adding conditionals, loops, or function calls. Unfortunately, a single demonstration is an inherently ambiguous specification for such a more general program. Therefore, PBD systems often provide a configuration pane that allows users to disambiguate the generalization either during or after demonstration. Some PBD systems also have a code canvas that renders the recorded program for the user to read, for example, visually or in natural language.
84 |
85 | _Strengths, weaknesses, and mitigations._ The main strength of programming by demonstration is that the user can work directly with the software applications they are already familiar with from their day-to-day work.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) This makes PBD well suited for citizen developers, as there is no indirection between programming and execution. Furthermore, a demonstration is more concrete than a program in a different paradigm, since it works on specific values and has a straight-line flow of control and data.
86 |
87 | ---
88 |
89 | > _To turn a demonstration into a program, it must be generalized, and automatic generalization may not capture user's intent._
90 |
91 | ---
92 |
93 | Unfortunately, being so concrete is also PBD's main weakness: to turn a demonstration into a program, it must be generalized, and automatic generalization may not capture the user's intent.[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14) Mitigations include hand-configuration[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) or multishot demonstration.[15](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R15) PBD can be brittle with respect to the graphical user interface of the application on stage, especially when that changes; mitigations include heuristics and specialized recorders that can map perception to application-level concepts.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32) Generalization can also overshoot, allowing a program to plow ahead even in unforeseen circumstances.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) This can be mitigated by providing guardrails, such as an attended execution mode that asks the user to confirm before certain actions. Finally, PBD can result in programs that are difficult to understand because they include spurious steps or are too fine-grained, which is of course a problem in low-code programming.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) This can be mitigated by pruning and by discovering macro-steps.
94 |
95 | _Literature._ A good example of a PBD system is CoScripter, where the stage is a Web browser and the code canvas displays the program in natural language.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) The CoScripter paper describes interviews that informed its design, as well as experiences from real-world usage in a business setting. In Rousillon, the stage is also a Web browser and the canvas displays the program in a VPL, fusing sequences of several low-level steps into a single puzzle piece.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) In VASTA, the stage is the display of a mobile phone, and the system uses machine learning to reverse-engineer screenshots into user interface elements.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32) In DIYA, the stage is a Web browser and users customize the program during recording via voice input.[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14) PBD is used in commercial robotic process automation products (such as UIPath, Automation Anywhere, and BluePrism) that let a human demonstrate a process on the existing software and then refer to the automatic replay engine as a robot.[35](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R35)
96 |
97 | PBD is closely related to PBE, since a demonstration is an elaborate example. FlashFill is a seminal PBE system that uses example input and output columns in a spreadsheet to synthesize a program for transforming inputs to outputs.[15](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R15) Both PBD and PBE are based on program synthesis.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) Recent work has harnessed novel machine-learning techniques for program synthesis, such as learned search strategies in DeepCoder[5](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R5) and learned libraries in DreamCoder.[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13)
98 |
99 | PBD can be profitably combined with other low-code techniques. The play-in/play-out approach is a PBD system codesigned with its own VPL based on sequence diagrams.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) And SwaggerBot is a PBD system embedded in a natural-language conversational agent, enabling a form of PBNL.[36](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R36)
100 |
101 | **Programming by natural language.** _The user enters natural language text via keyboard or voice, and the system synthesizes a program._
102 |
103 | _Description._ In this low-code technique, the user enters text in natural language, either by typing on the keyboard or via speech-to-text. [Figure 4](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg) indicates these two possibilities via blue arrows from the user's hand or mouth to the text canvas. The PBNL system translates the user's text, or utterance, to a program. The system can optionally render the program on a code canvas for the user to read. This rendering might use a VPL, or it might use a controlled natural language[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) for a disambiguated version of the user's utterance. The system can also optionally show the effect of the program's execution on a stage. For example, if the program is a query in a spreadsheet, the spreadsheet is the stage, and the result can be shown as a new table.
104 |
105 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg)
106 | **Figure 4. Programming by natural language.**
107 |
108 | _Strengths, weaknesses, and mitigations._ The main strength of PBNL is that it is not just low-code, but more generally, low on demands during programming. As shown in [Figure 4](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg), its programming environment has only three building blocks (text canvas, code canvas, and stage), all optional. That means PBNL in principle even works in circumstances where the user's hands and eyes are otherwise occupied.
109 |
110 | PBNL makes it particularly easy for citizen developers to create programs, but unfortunately, those programs are often wrong.[4](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R4) Natural language is ambiguous, since humans are often vague and tend to assume common ground and omit context. On top of that, natural language processing (NLP) technologies are imperfect. The optional code canvas and stage can mitigate this weakness, by showing the user the synthesized program or its effect, thus giving them a chance to correct it. Another mitigation is to encourage users to keep their utterances short and not take advantage of the full expressiveness of natural language, since simpler programs are easier to get right.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) Furthermore, some PBNL systems support hand-editing the program.
111 |
112 | ---
113 |
114 | > _A strength of programming by natural language is its expressiveness: natural language can express virtually anything humans want to communicate._
115 |
116 | ---
117 |
118 | Another strength of PBNL is its expressiveness: natural language can express virtually anything humans want to communicate. In theory, PBNL restricts neither the sophistication nor the domains of programs. On the flip-side, PBNL systems often require an aligned corpus of utterances and programs to train NLP models, and obtaining such a corpus is expensive. Mitigating this is an active research topic in the machine-learning research community.[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33),[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38)
119 |
120 | _Literature._ As an interdisciplinary field of research, PBNL is best illuminated through multiple surveys. Androutsopoulos et al. surveyed natural-language interfaces to databases, a prominent form of PBNL going back to the 1960s.[4](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R4) A common approach is to parse a natural-language utterance into a tree and then map that tree to a database query. Kuhn surveyed controlled natural languages (CNLs), which restrict inputs to be unambiguous while preserving some natural properties.[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) Compared to unrestricted natural language, CNLs may make it harder for citizen developers to write programs but may make it easier to write correct programs. Allamanis et al. surveyed machine learning for code, arguing that code has a "naturalness" that makes it possible to adapt various NLP technologies to work on code.[1](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R1) The survey covers some code-generating models relevant to PBNL.
121 |
122 | The most successful NLP technology applied to PBNL is semantic parsers, which are machine-learning models that translate from natural language to an abstract syntax tree (AST) of a program. For instance, SILT learns rule-based semantic parsers that have been demonstrated for programs that coach robotic soccer teams or for programs that query geographic databases.[19](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R19) The Overnight paper addresses the problem of obtaining an aligned corpus for training a semantic parser via synthetic data generation and crowdsourced paraphrasing.[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38) Pumice tackles the ambiguity of natural language by a dialogue, where the system prompts for clarification which the user can provide via natural language or demonstration.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) And Shin et al. show how to coax a pretrained large language model into doing semantic parsing without requiring fine-tuning.[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33)
123 |
124 | Another approach to PBNL is program synthesis, which typically searches a space of possible programs.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) Desai et al. describe a meta-synthesizer that, given a DSL grammar and an aligned corpus, creates a synthesizer from natural language to programs in the DSL.[12](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R12) PBNL is not limited to domain-specific languages for citizen developers. Yin and Neubig describe a semantic parser that uses deep learning to encode a sequence of natural-language tokens, then decodes that into a Python AST.[39](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R39) Codex is a pre-trained large language model for natural language first fine-tuned on unlabeled code, then fine-tuned again on an aligned corpus of utterances and programs.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11)
125 |
126 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
127 |
128 | ### Perspectives
129 |
130 | While the previous discussion covered three low-code techniques in depth, here we cover cross-cutting topics beyond any single technique. The accompanying [table](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/ut1.jpg) compares the techniques discussed earlier. The Activity columns indicate how each technique supports the user in writing, reading, and executing programs. The main difference is in the Write column: users write programs mainly on the code canvas for VPLs, the stage for PBD, and a text canvas in PBNL. On the other hand, there is little difference in the Read and Execute columns: users read programs on a code canvas (if provided), and watch them executing on the stage (if visible). That hints at an opportunity for reuse across tools for different techniques.
131 |
132 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/ut1.jpg)
133 | **Table. Comparing low-code techniques.**
134 |
135 | A core problem with low-code programming is ambiguity. While visual programming languages can be rigorous and unambiguous, there is ambiguity in how to generalize from a demonstration to a program that works in different situations, and natural languages are inherently ambiguous as well. More ambiguous techniques may only work reliably on small and simple problems. Systems for PBD and PBNL must guess at the user's intent and are likely to guess wrong when programs get complicated. This motivates offering users an option to read or even correct programs or their executions.
136 |
137 | A core goal of low-code programming is to reduce the need to learn a programming language. Citizen developers can demonstrate a program or describe it in natural language without having been taught how to do so. Visual programming is often less self-explanatory, which is why [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) associates it more with semi-developers. On the other hand, depending on the user's attitude, the need-to-learn can also be good, since it grows computational thinking skills.
138 |
139 | _Artificial intelligence for low-code._ Does the ongoing rapid progress in AI fuel progress in low-code? This article argues that yes, it does, in proportion to the ambiguity of the low-code technique. Out of the three techniques in the table, AI is most prominent for PBNL, which is also the most ambiguous. PBNL can hardly avoid AI except by using a controlled natural language,[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) but that would make it feel more like code. Currently a rising AI approach for PBNL is to use large language models with code generation.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11),[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33) PBNL will likely grow along with relevant advances in AI. AI is also prominent in PBD, characterized in the table as medium ambiguity. For example, DeepCoder shows the interplay between program synthesis for defining a space of possible programs and checking whether a given program is correct, and AI for guiding the search through that space.[5](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R5) As another example, VASTA uses speech recognition, object recognition, and optical character recognition to better understand a user's demonstration of a task.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32)
140 |
141 | _Communicating with humans and machines._ Pro-developers use code in textual programming languages to communicate with a computer, telling it what to do. In addition, developers can also use programming languages to communicate with each other or with their own future self. A low-level programming language such as C gives developers more control of the computer, whereas a high-level language such as Python arguably makes communication among humans more effective. Similarly, low-code programs can serve both to communicate instructions to a computer and to communicate among low-code users. Being even more high-level than, say, Python, low-code can serve as a lingua franca to help citizen developers and pro-developers communicate more effectively with each other. For instance, a citizen developer might use PBD to communicate a desired behavior to a pro-developer to flesh out.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) Conversely, a pro-developer might use PBNL or a VPL to communicate a proposed behavior to a domain expert for explanation or approval.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21),[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27)
142 |
143 | _Domain-specific languages for low-code._ All three low-code techniques noted earlier are intrinsically related to DSLs: most VPLs are DSLs (for example, Scratch[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29)), and both programming by demonstration and programming by natural language usually target DSLs (DIYA targets its co-designed Thing-Talk 2.0 DSL[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14)). Mernik et al. list further benefits of DSLs: they facilitate program analysis, verification, optimization, parallelization, and transformation (AVOPT).[23](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R23)
144 |
145 | While reviewing the low-code literature reveals a close tie to DSLs, those DSLs are not always exposed to the user. For instance, the DSL may manifest as a proprietary file format or as an undocumented internal representation. If the DSL is exposed, users can more easily read, test, and audit programs, version them and store them in a shared repository, and manipulate them with tools for program transformation or generation. Also, an exposed DSL is less locked into a specific programming environment or its vendor. When exposed, the DSL should be designed for humans, possibly based on interviews and user studies as role-modeled by Leshed et al.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) On the other hand, a DSL that is not exposed will be shaped by different factors, such as the ease of enumerating valid programs, which can be improved by breaking symmetries in the search space.[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13)
146 |
147 | DSLs (including DSLs for low-code) may be embedded in a general-purpose language. Compared to a stand-alone DSL, an embedded DSL is often easier to implement (for example, due to not requiring a custom parser) and easier to use (due to syntax highlighting and auto-completion tools of the host language). The approach to implementing an embedded DSL depends on the facilities of the host language. One approach is Pure Embedding, which uses higher-order functions and lazy evaluation, such as in Haskell.[17](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R17) Another example is Lightweight Modular Staging, which uses operator overloading and dynamic compilation, such as in Scala.[30](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R30)
148 |
149 | _Model view controller._ The current state-of-the-art VPLs and associated meta-tools are based on the MVC pattern.[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28),[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) And in PBD or PBNL, even though the user does not use a code canvas to write a program, the system may optionally provide one for reading it, again using MVC. [Figure 5](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f5.jpg) illustrates MVC with a superset of the components from each low-code technique. Low-code programming tools provide one or more views of the program. Some of these views are read-only, while others are read-write views. When multiple views are present, the system keeps them in sync with a single joint model, and through that, with each other. Edits in one view are projected live to all other views. The model is a program in a DSL. Optionally, the system may even expose the textual DSL as another view, for instance, in a structure editor.[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) Besides the model and the view, the third part of the MVC pattern is the controller, which, for low-code, can contain a player and/or a configuration pane.
150 |
151 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f5.jpg)
152 | **Figure 5. Model-view-controller for low-code.**
153 |
154 | _Combining multiple low-code techniques._ When users write a program by demonstration or by natural language, the system may let them read it on a code canvas. And once a system lets users read programs on a code canvas, a logical next step is to also let them write programs there, such as, to correct mistakes from generalization or from natural language processing. This yields a combination of low-code techniques, where users can write programs in multiple ways. Such combinations can compensate for weaknesses of techniques. For example, in Rousillon, the user first writes a program by demonstrating how to scrape data from web pages;[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) since one weakness of PBD is ambiguity, Rousillon lets the user read the resulting program in a scratch-like VPL.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) Pumice combines PBD with PBNL: the user first writes a program via natural language; since one weakness of PBNL is ambiguity, Pumice next lets the user clarify with PBD.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22)
155 |
156 | _Meta-tools and meta-circularity._ A meta-tool for low-code is a tool used to implement low-code tools. In traditional programming languages, meta-tools (such as parser generators) have long been an essential part of the tool-writer's repertoire. Similarly, meta-tools for low-code can speed up the development of low-code tools by automating well-known but tedious pieces. Thus, meta-tools make it easier to build several tools or variants, for instance, to experiment with the user experience. There are examples of meta-tools for all three low-code techniques discussed previously. Blockly[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28) is a tool for creating VPLs that look similar to Scratch; DreamCoder[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13) is a tool for learning a library of reusable components along with a neural search policy for PBE; and Overnight[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38) is a tool for building semantic parsers for PBNL with synthetic training data.
157 |
158 | A meta-circular tool for low-code is a meta-tool for low-code that is itself a low-code tool. Not all meta-tools are metacircular tools, as that requires them to be powerful enough for serious software development. Supporting all that power can compromise the tool's low-code nature: complex features can get in the way of learning easy ones. On the positive side, meta-circular tools can democratize the creation of low-code tools themselves. Furthermore, tool developers who use their own tools may empathize more with their users' needs. Examples for meta-circular low-code tools include VisPRO[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) and Racket[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3) (both for VPLs).
159 |
160 | _Low-code foundation._ In addition to meta-tools, are there other reusable modules that make it easier to build new low-code tools? The beginning of the Techniques section listed several reusable building blocks for low-code programming interfaces: code canvas, palette, text box, player, stage, and configuration pane. Besides making it easier to create low-code tools, such reuse can also give different tools a more uniform look-and-feel, thus reducing the need-to-learn. In the case of multiple low-code tools for the same domain, reusing the same domain-specific language makes them more interoperable. Of course, low-code tools in different domains will require different DSLs, but they may still be able to reuse some sublanguage, such as expressions or formulas with basic arithmetic and logical operators and a function library. There are also AI components that can be reused across low-code tools, such as speech recognition modules, a search-based program synthesis engine, semantic parsers, or language models.
161 |
162 | _End-user software engineering._ Most of the discussion on low-code programming focuses on writing a program: low-code enables citizen developers to rapidly create a prototype. But what happens over time when these programs stick around, get used in new circumstances that the developer did not foresee, get modified or generalized, and proliferate? At that point, users need end-user software engineering (EUSE) for quality control, for instance, by showing test coverage, letting users add assertions, and helping them localize faults directly in their low-code programming environment.[9](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R9) Citizen developers often struggle with anticipating exceptional contexts for their programs; Pumice is a low-code tool that lets users extend programs with new branches when the unforeseen happens.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) Another way to support EUSE is to expose the DSL, which makes it easier to adopt established software development workflows and the associated tools (such as version-controlled source code repositories, regression tests, or issue trackers) for low-code. Those tools also facilitate collaboration between citizen developers and professional software engineers.
163 |
164 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
165 |
166 | ### Conclusion
167 |
168 | This article reviews research relevant to low-code programming models with a focus on visual programming, programming by demonstration, and programming by natural language. It maps low-code techniques to target users and discusses common building blocks, strengths, and weaknesses. This article argues that domain-specific languages and the model-view-controller pattern constitute a common backbone and unifying principle across low-code techniques.
169 |
170 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
171 |
172 | ### References
173 |
174 | \1. Allamanis, M. et al. A survey of machine learning for big code and naturalness. _ACM Computing Surveys 51_, 4 (July 2018), 81:1–81:37; https://doi.org/10.1145/3212695
175 |
176 | \2. Alur, R. et al. Search-based program synthesis. _Commun. ACM 61_, 11 (Nov. 2018), 84–93; https://doi.org/10.1145/3208071.
177 |
178 | \3. Andersen, L. et al. Adding interactive visual syntax to textual code. In _Proceedings of 2020 Conf. Object-Oriented Programming, Systems, Languages, and Applications_; https://doi.org/10.1145/3428290.
179 |
180 | \4. Androutsopoulos, I. et al. Natural language interfaces to databases—An introduction. _Natural Language Engineering 1_, 1 (1995), 29–81; https://doi.org/10.1017/S135132490000005X.
181 |
182 | \5. Balog, M. et al. DeepCoder: Learning to write programs. In _Proceedings of 2017 Intern. Conf. Learning Representations_; https://openreview.net/forum?id=ByldLrqlx.
183 |
184 | \6. Barricelli, B.R. et al. End-user development, end-user programming and end-user software engineering: A systematic mapping study. _J. Systems and Software 149_, (2019), 101–137; https://doi.org/10.1016/j.jss.2018.11.041.
185 |
186 | \7. Bock, A.C., and Frank, U. Low-code platform. _Business & Information Systems Engineering 63_, (2021), 733–740; https://doi.org/10.1007/s12599-021-00726-8.
187 |
188 | \8. Boshernitsan, M., and Downes, M. Visual Programming Languages: A Survey. _Technical Report UCB/CSD-04-1368, 2004, UC Berkeley_; https://bit.ly/3P0SaX5
189 |
190 | \9. Burnett, M. et al. End-user software engineering. _Commun. ACM 47_, 9 (Sept. 2004), 53–58; https://doi.org/10.1145/1015864.1015889.
191 |
192 | \10. Chasins, S. et al. Rousillon: Scraping distributed hierarchical Web data. In _Proceedings of 2018 Symp. User Interface Software and Technology_, 963–975; https://doi.org/10.1145/3242587.3242661
193 |
194 | \11. Chen, M. Evaluating large language models trained on code, (2021); https://arxiv.org/abs/2107.03374
195 |
196 | \12. Desai, A. Program synthesis using natural language. In _Proceedings of 2016 Intern. Conf. Softw. Eng._, 345–356; https://doi.org/10.1145/2884781.2884786
197 |
198 | \13. Ellis, K. DreamCoder: Bootstrapping inductive program synthesis with wake-sleep library learning. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 835–850; https://doi.org/10.1145/3453483.3454080
199 |
200 | \14. Fischer, M.H. et al. DIY assistant: A multi-modal end-user programmable virtual assistant. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 312–327; https://doi.org/10.1145/3453483.3454046
201 |
202 | \15. Gulwani, S. Automating string processing in spreadsheets using input-output examples. In _Proceedings of 2011 Symp. Principles of Programming Languages._ 317–330; https://doi.org/10.1145/1926385.1926423
203 |
204 | \16. Harel, D., and Marelly, R. Specifying and executing behavioral requirements: The play-in/play-out approach. _Software and Systems Modeling 2_, (2003), 82–107; https://doi.org/10.1007/s10270-002-0015-5.
205 |
206 | \17. Hudak, P. Modular domain specific languages and tools. In _Proceedings of 1998 Intern. Conf. Software Reuse._ 134–142; https://doi.org/10.1109/ICSR.1998.685738
207 |
208 | \18. Jacob, A. Infrastructure as code. _Web Operations: Keeping the Data on Time._ J. Allspaw, and J. Robbins, (eds). O'Reilly, Chapter 5, (2010), 65–80.
209 |
210 | \19. Kate, R.J. et al. Learning to transform natural to formal languages. In _Proceedings of 2005 Conf. Artificial Intelligence._ 1062–106; http://www.aaai.org/Library/AAAI/2005/aaai05-168.php
211 |
212 | \20. Kuhn, T. A survey and classification of controlled natural languages. _Computational Linguistics 40_, 1 (2014), 121–170; https://bit.ly/42t3JsY.
213 |
214 | \21. Leshed, G. et al. CoScripter: Automating and sharing kow-to knowledge in the enterprise. In _Proceedings of 2008 Conf. Human Factors in Computing Systems_, 1719–1728; https://doi.org/10.1145/1357054.1357323
215 |
216 | \22. Li, T.J. et al. PUMICE: A multi-modal agent that learns concepts and conditionals from natural language and demonstrations. In _Proceedings of 2019 Symp. User Interface Software and Technology._ 577–589; https://doi.org/10.1145/3332165.3347899
217 |
218 | \23. Mernik, M. et al. When and how to develop domain-specific languages. _ACM Computing Surveys 37_, 4 (2005), 316–344; https://doi.org/10.1145/1118890.1118892.
219 |
220 | \24. Myers, B. et al. Past, present, and future of user interface software tools. _Trans. Computer-Human Interaction_ (Mar. 2000), 3–28; https://doi.org/10.1145/344949.34495
221 |
222 | \25. Myrbakken, H., and Colomo-Palacios, R. DevSecOps: A multivocal literature review. _Software Process Improvement and Capability Determination_ (2017), 17–29. https://doi.org/10.1007/978-3-319-67383-7_2.
223 |
224 | \26. Omar, C. et al. Filling Typed Holes with Live GUIs. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 511–525; https://doi.org/10.1145/3453483.3454059
225 |
226 | \27. Ouyang, C. From BPMN process models to BPEL Web services. In _Proceedings of Intern. Conf. Web Services._ (2006); https://doi.org/10.1109/ICWS.2006.67
227 |
228 | \28. Pasternak, E. et al. Tips for creating a block language with Blockly. In _Proceedings of Blocks and Beyond Workshop_ (2017); https://doi.org/10.1109/BLOCKS.2017.8120404.
229 |
230 | \29. Resnick, M. et al. Scratch: Programming for all. _Commun. ACM 52_, 11 (Nov.2009), 60–67; https://doi.org/10.1145/1592761.1592779.
231 |
232 | \30. Rompf, T., and Odersky, M. Lightweight modular staging: A pragmatic approach to runtime code generation and compiled DSLs. _Commun. ACM 55_, 6 (June 2012), 121–130; https://doi.org/10.1145/2184319.2184345.
233 |
234 | \31. Sahay, A. et al. Supporting the understanding and comparison of low-code development platforms. In _Proceedings of Euromicro 2020 Conf. Software Engineering and Advanced Applications._ 71–178; https://doi.org/10.1109/SEAA51224.2020.00036
235 |
236 | \32. Sereshkeh, A.R. et al. VASTA: A vision and language-assisted smartphone task automation system. In _Proceedings of 2021 Conf. Intelligent User Interfaces._ 22–32; https://doi.org/10.1145/3377325.3377515
237 |
238 | \33. Shin, R. Constrained language models yield few-shot semantic parsers. In _Proceedings of 2021 Conf. Empirical Methods in Natural Language Processing, 7_, 699–7715; https://doi.org/10.18653/v1/2021.emnlp-main.608
239 |
240 | \34. Tanimoto, S.L. A perspective on the evolution of live programming. In _Proceedings of Intern. Workshop on Live Programming._ (2013), 31–34; https://doi.org/10.1109/LIVE.2013.6617346
241 |
242 | \35. van der Aalst, W.M. et al. Robotic process automation. _Business Spsampsps Information Systems Eng. 60_, (2018), 269–272. https://doi.org/10.1007/s12599018-0542-4.
243 |
244 | \36. Vaziri, M. et al. Generating Chat Bots from Web API Specifications. In _Proceedings of Symp. New Ideas, New Paradigms, and Reflections on Programming and Software._ (2017), 44–57; [http://doi.acm.org/10.1145/3133850.3133864](https://dx.doi.org/10.1145/3133850.3133864)
245 |
246 | \37. Voelter, M., and Lisson, S. Supporting diverse notations in MPS' projectional editor. In _Proceedings of Workshop on the Globalization of Modeling Languages._ (2014), 7–16; https://hal.inria.fr/hal-01074602/file/GEMOC2014-complete.pdf#page=13
247 |
248 | \38. Wang, Y. et al. Building a semantic parser overnight. In _Proceedings of the Annual Meeting of the Assoc. for Computational Linguistics._ (2015), 1332–1342; https://www.aclweb.org/anthology/P15-1129.pdf
249 |
250 | \39. Yin, P., and Neubig, G. A syntactic neural model for general-purpose code generation. In _Proceedings of the Annual Meeting of the Assoc. for Computational Linguistics._ (2017), 440–450; [http://dx.doi.org/10.18653/v1/P17-1041](https://dx.doi.org/10.18653/v1/P17-1041)
251 |
252 | \40. Zhang, K. et al. Design, construction, and application of a generic visual language generation environment. _IEEE Trans Softw Eng. 27_, 4 (2001), 289–307; https://doi.org/10.1109/32.917521.
253 |
--------------------------------------------------------------------------------
/低代码平台/00~低代码设计理念/低代码的不足.md:
--------------------------------------------------------------------------------
1 | # 低代码的不足
2 |
3 | 个人认为低代码就是个噱头,远远没有概念所说的具备那么广的适用性,只能是针对某个垂直领域业务的问题解决方案:软件设计 CAP 原则:性能、可用性,可延展性,三取二,低代码为了通用性,必然要舍弃性能跟可用性之一,而商业产品必须保证可用性,所以性能必然不够优先(三点都要也不是做不到,成本将大副增加),这就导致只能应用到对性能不敏感的 toB,toG,二这个领域又是各种 SAAS 服务商,系统集成商,云服务商的竞争之地,只靠低代码这个点无法获得足够的优势,最终只能靠与某服务商进行捆绑,否则一定会被淘汰。
4 |
--------------------------------------------------------------------------------
/低代码平台/README.md:
--------------------------------------------------------------------------------
1 | # 低代码搭建
2 |
3 | 低代码开发就是开发人员可以通过编写少量代码就可以快速生成应用程序的一种方法。所谓的低代码(low code),即可以看作一个像 Python 语言和 C# 语言一样的一种“东西”;也可以代表一种应用程序开发方式。因为用这种方式开发应用程序时,你需要手写的代码比通常的开发方式要少。简单来说,低代码开发就是将已有代码的可视化模块拖放到工作流中以创建应用程序的过程。由于它可以完全取代传统的手工编码应用程序的开发方法,技术娴熟的开发人员可以更智能、更高效地工作,而不会被重复的编码束缚住。相反,他们可以将精力集中于创建应用程序的 10% 部分,并使其具有与众不同的功能。
4 |
5 | 这个领域是创新最活跃的地方,从过去的发展历程中能看到一些演进脉络,从 Engine 的角度看,演进的背后有两种理念:
6 |
7 | 1、Coding Less:通过强大的 SDK、框架和工具让工程师更好地 Coding,专注在实现业务上
8 | 2、No Coding:通过可视化 IDE 达成不写代码,通过拖拽、编写配置文件就能完成应用开发
9 |
10 | 从开发者角度看,对 Engine 有三个期待:
11 |
12 | 1、Productivity:必须能提升生产力,让工程师可以高效地写出健壮、易维护的代码
13 | 2、Simple & Stupid:KISS 原则 的核心,让开发变简单不仅能提升效率,还能让更多人成为前端工程师
14 | 3、Business More:研发资源非常宝贵,让工程师专注在业务上是提升效能的关键
15 |
16 | 未来的演化也会遵循这些脉络,Coding Less、No Coding 各有其应用场景,需要结合业务特点选择侧重点进行投入。但有一点我觉得是必然的:要开发优质应用,还得靠 Coding,不过写的代码会越来越少。No Coding 过于完美,应用场景有限,再加上有成品 SaaS 作为更好的替代品,我更倾向于用 Coding Less 模式去实现业务主线,把一些机械性、重复性、一次性的开发工作通过 No Coding 模式搞定。不过 No Coding 的一个分支 Visual Programming 非常值得关注,它在编程教育领域应用前景非常好,Scratch、Blockly 是典型代表,而编程教育不仅蕴藏着巨大的商机,而且还会给我们带来源源不断的生力军。
17 |
18 | ## 低代码平台分类
19 |
20 | # 优劣分析
21 |
22 | ## 优势
23 |
24 | 低代码开发的好处主要有以下四点:
25 |
26 | - 速度:使用低代码开发,你可以同时为多个平台构建应用程序,并且在几天甚至在几小时以内就可以向项目相关人员提交工作示例。
27 |
28 | - 更多的资源:如果你在一个大型项目上工作,使用低代码开发,你就不必再等待具有专业技能的开发人员完成另一个冗长的项目,这意味着项目可以更高效、以更低廉的成本完成。
29 |
30 | - 低风险/高投资回报率:使用低代码开发,意味着强大的安全流程,数据集成和跨平台支持已经内置,并且可以轻松定制,这通常意味着更低的风险,并且可以将更多的时间集中在业务逻辑的实现上。
31 |
32 | - 快速部署:项目上线总是会让人神经紧张。而使用低代码开发,部署前的影响评估可以确保你的应用程序按预期工作。如果有任何异常发生,只需要一次单击,你就可以回滚你所做的所有改变。
33 |
34 | ## 缺陷
35 |
36 |
--------------------------------------------------------------------------------
/低代码平台/开源低代码平台/Supabase/README.md:
--------------------------------------------------------------------------------
1 | # Supabase
2 |
3 | # Links
4 |
5 | - https://supabase.com/blog/type-constraints-in-65-lines-of-sql
6 |
--------------------------------------------------------------------------------
/低代码平台/流程系统/README.md:
--------------------------------------------------------------------------------
1 | # 流程系统
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/README.md:
--------------------------------------------------------------------------------
1 | # Dynamic Form | 动态表单
2 |
3 | 所谓的动态表单,即前后端约定一套表单定义规范;根据此规范,后端提供表单描述配置 JSON Schema;前端将此配置传入到动态表单框架后即可动态渲染出整个表单。只需要通过一份配置,就能生产一个表单应用,它能够极大地提升我们的效率,组件的复用率等等。动态表单会提供一个基本的组件库,供业务或者开发同学通过可视化的一种方式来配置所要的表单。同时为了满足业务对表单校验逻辑、数据初始化、级联、业务属性等要求而抽象的一套功能模型。此外,为了使各种系统能够快速接入动态表单,采用插件的方式嵌入业务系统中,从而保证业务系统的操作连贯性。对于表单的 JSON Schema 描述,互联网工程组(IETF)组织曾经制定过相关草案。这份草案约定通过 jsonSchema、uiSchema、formData 三个 JSON Object 来完整的描述一个静态表单。
4 |
5 | - 组件库:丰富的自定义组件、沉淀业务组件
6 | - 可视化:提供可视化配置功能,实现所见即所得
7 | - 功能模型:校验器、数据源、业务属性等等
8 | - 业务隔离:平台工具,不提供具体业务,提供标准接口业务实现
9 | - 插件化:可嵌入业务系统中,保持业务系统配置的连续性
10 |
11 | 表单模型共有 6 个模块构成: 属性、数据源、校验器、字段、表单/模板、数据。对于表单的 JSON Schema 描述,互联网工程组(IETF)组织曾经制定过相关草案。这份草案约定通过 jsonSchema、uiSchema、formData 三个 JSON Object 来完整的描述一个静态表单。
12 |
13 | 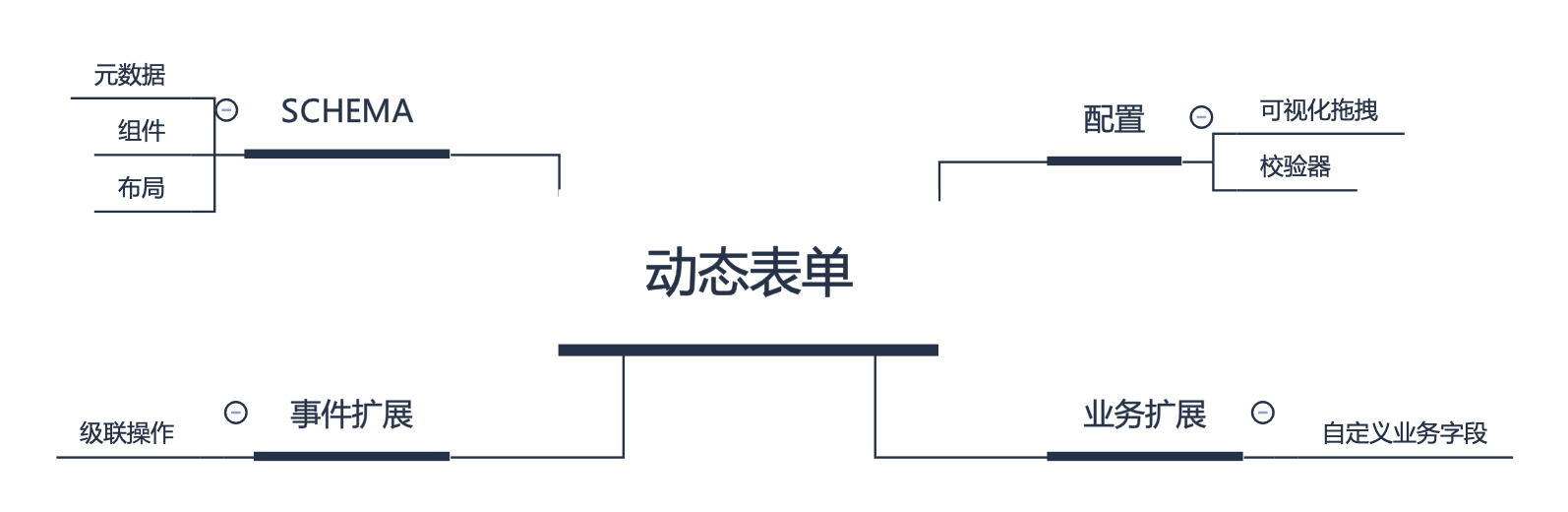
14 |
15 | 其实当你的业务量达到一定的量级,做很多流程审批任务协同之类的中后台产品的时候就会发现表单的需求真的是源源不断,大同小异,既浪费时间也浪费精力。我们通过 json schema 规范每个 UI 组件。这个规范其实包括了中后台系统的 UI 规范,约束设计师的随意发挥,从而降低开发维护成本。
16 |
17 | 
18 |
19 | # 表单配置可视化
20 |
21 | 表单的配置化其实就是将表单开发的逻辑,转化成为了一种结构,在前端看来,它是个 JSON 或者是个对象。手动编写表单配置是可以被可视化的工具所替代的,这样,表单的开发和维护就变得更加清晰、简便了,效率也会得到提升。一份配置对应着一个表单的时候,但我们在一个网站应用(业务)上有多种场景需要多个表单,这时候就会有多份配置,多份配置会就需要对齐进行管理,甚至需要动态化异步加载配置。我把配置相关的事情,也一并列入表单中台的设计之中,让链路更加地完整。
22 |
23 | 实现可视化的手段,就是通过表单来生产配置,然后渲染表单。
24 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/表单 Schema.md:
--------------------------------------------------------------------------------
1 | # Schema
2 |
3 | 在项目开发初期我们需要定义一个合适的 JSON Schema,所谓合适的 JSON Schema,就是指能满足现有的业务模型,尽量减少冗余的字段,又能支持一定的扩展。方便后续的维护更新扩展。一个 form 表单由 jsonSchema、uiSchema、formData、bizData 四个 json 来描述:
4 |
5 | - jsonSchema 中描述了表单的数据类型、数据源、数据项等配置;
6 |
7 | - uiSchema 描述了表单字段的渲染方法、渲染参数等;
8 |
9 | - formData 描述了表单初始填充的各个字段的初始值;
10 |
11 | - bizData 中是对表单字段的业务属性,注意的是,bizData 不会影响 Form 的渲染
12 |
13 | # react-json-schema
14 |
15 | react-jsonschema-form 是最初由 Firefox 开源的能够从 JSON Schema 中渲染出实际表单的 React 组件。
16 |
17 | ## JSONSchema
18 |
19 | ```json
20 | {
21 | "title": "A registration form",
22 | "description": "A simple form example.",
23 | "type": "object",
24 | "required": ["firstName", "lastName"],
25 | "properties": {
26 | "firstName": {
27 | "type": "string",
28 | "title": "First name"
29 | },
30 | "lastName": {
31 | "type": "string",
32 | "title": "Last name"
33 | },
34 | "age": {
35 | "type": "integer",
36 | "title": "Age"
37 | },
38 | "bio": {
39 | "type": "string",
40 | "title": "Bio"
41 | },
42 | "password": {
43 | "type": "string",
44 | "title": "Password",
45 | "minLength": 3
46 | },
47 | "telephone": {
48 | "type": "string",
49 | "title": "Telephone",
50 | "minLength": 10
51 | }
52 | }
53 | }
54 | ```
55 |
56 | ## UISchema
57 |
58 | ```json
59 | {
60 | "firstName": {
61 | "ui:autofocus": true,
62 | "ui:emptyValue": ""
63 | },
64 | "age": {
65 | "ui:widget": "updown",
66 | "ui:title": "Age of person",
67 | "ui:description": "(earthian year)"
68 | },
69 | "bio": {
70 | "ui:widget": "textarea"
71 | },
72 | "password": {
73 | "ui:widget": "password",
74 | "ui:help": "Hint: Make it strong!"
75 | },
76 | "date": {
77 | "ui:widget": "alt-datetime"
78 | },
79 | "telephone": {
80 | "ui:options": {
81 | "inputType": "tel"
82 | }
83 | }
84 | }
85 | ```
86 |
87 | ## 合并的 Schema
88 |
89 | ```json
90 | {
91 | "title": "A registration form",
92 | "description": "A simple form example.",
93 | "type": "object",
94 | "required": ["firstName", "lastName"],
95 | "properties": {
96 | "firstName": {
97 | "type": "string",
98 | "title": "First name",
99 | "ui:autofocus": true,
100 | "ui:emptyValue": ""
101 | },
102 | "lastName": {
103 | "type": "string",
104 | "title": "Last name"
105 | },
106 | "age": {
107 | "type": "integer",
108 | "title": "Age",
109 | "ui:widget": "updown",
110 | "ui:title": "Age of person",
111 | "ui:description": "(earthian year)"
112 | },
113 | "bio": {
114 | "type": "string",
115 | "title": "Bio",
116 | "ui:widget": "textarea"
117 | },
118 | "password": {
119 | "type": "string",
120 | "title": "Password",
121 | "minLength": 3,
122 | "ui:widget": "password",
123 | "ui:help": "Hint: Make it strong!"
124 | },
125 | "telephone": {
126 | "type": "string",
127 | "title": "Telephone",
128 | "minLength": 10,
129 | "ui:options": {
130 | "inputType": "tel"
131 | }
132 | }
133 | }
134 | }
135 | ```
136 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/表单中台.md:
--------------------------------------------------------------------------------
1 | # 表单中台
2 |
3 | 表单中台是通过对表单进行了抽象,然后单独针对网站应用上的所有表单而设计的。它是对一个网站应用上面的所有表单,从前端开发者对表单相关的开发维护到用户提交数据到服务端,这样一个完整链路的抽象封装。表单中台是一个可以完全由前端驱动的产品,因为表单里面跟数据存储查询是可以相对对立的部分,不管数据跟哪个服务器进行通信,都是不需要关心的,标准应该有前端进行制定。这样,它就是一个去中心化的产品,同时也具备成为一个中台的可能。因为它是一个中台,所以它也是能够支撑和驱动各种 N 个中后台和业务发展的。
4 |
5 | 
6 |
7 | # 通信层与服务器
8 |
9 | 通信层磨平了与服务器进行通信的过程,这其中包括了配置的增删改查,表单数据的读写。接口标准由前端进行了定义。例如配置查询的接口:
10 |
11 | | 参数 | 类型 | 是否必须 | 说明 |
12 | | ------ | ---- | -------- | ------------------------------------------------------------------------ |
13 | | formId | Long | 否 | 表单 ID |
14 | | type | Long | 是 | 0 表示根据 userId 获取用户的配置列表,1 表示根据 formId 获取某个具体配置 |
15 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/展示型页面/H5 宣传页.md:
--------------------------------------------------------------------------------
1 | # H5 宣传页
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/展示型页面/展示型主页.md:
--------------------------------------------------------------------------------
1 | # 展示型主页
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/搭建协议/README.md:
--------------------------------------------------------------------------------
1 | # 搭建协议
2 |
3 | 所谓的搭建协议,即是一套面向开发者的 Schema 规范,用于规范化约束可视化编辑器的输出和渲染引擎(或者 Schema2Code)的输入,将编辑器和渲染引擎(或者 Schema2Code)解耦,保障编辑器和渲染引擎(或者 Schema2Code)的独立升级。
4 |
5 | 搭建协议的要求如下:
6 |
7 | - **语义化**:语义清晰,简明易懂,可读性强。
8 |
9 | - **渐进性描述**:搭建的本质是通过 源码组件 进行嵌套组合,从小往大、依次组合生成 组件、区块、页面,最终通过云端构建生成 应用 的过程。因此在搭建基础协议中,我们需要知道如何去渐进性的描述组件、区块、页面、应用这 4 个实体概念。
10 |
11 | - **生成标准源码**:明确每一个属性与源码对应的转换关系,可生成跟手写无差异的高质量标准源代码。
12 |
13 | - **可流通性**:产物能在不同搭建产品中流通,不涉及任何私域数据存储。
14 |
15 | - **面向多端**:不能仅面向 React,还有小程序等多端。
16 |
17 | - **支持国际化&无障碍访问标准的实现**
18 |
19 | # LegoSchema
20 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/搭建协议/组件系统.md:
--------------------------------------------------------------------------------
1 | # 低代码搭建系统
2 |
3 | 
4 |
5 | # 物料系统与组件分类
6 |
7 | - 业务场景搭建能力:可视化搭建、配置辅助编辑(JSON)、配置定向输出
8 |
9 | - 业务场景配置能力:商业规则(Biz Rules),场景化切割
10 |
11 | - 业务组件容器沉淀:端约束(Terminal Constraints),应用加载、数据采集、布局编排、组件通信
12 |
13 | - 业务组件物料沉淀:商业能力模型(Biz Model),电商域(会员,订单,物流,退款),CRM 域
14 |
15 | - 领域界面渲染引擎:表单域(Form),卡片域(Card),表格域(Table)
16 |
17 | - 通用组件物料沉淀:设计语言(Design Language),Ant Design,基础业务组件(Biz Components)
18 |
19 | - 通用视图底层框架:React,View,Angular
20 |
21 | 基于上面的业务视角的分类,我们可以在技术视角对组件层次再进行梳理:
22 |
23 | - 基础组件:
24 |
25 | - 基础组件定义了其 HTML 布局方式,与数据绑定规范,典型的譬如不包含指令/自定义元素的 Vue.js 模板。
26 | - 基础组件会提供渲染函数,执行数据到界面绑定的真实渲染操作。
27 | - 基础组件是系统的原子单元,由系统预置,不可再进行切分,也不可进行嵌套。
28 |
29 | - 组件样式:
30 |
31 | - 组件样式定义了组件统一的样式规范。
32 | - 仅有基础组件可以接收样式对象,根据统一的渲染规则渲染为样式组件。
33 |
34 | - 布局组件:
35 |
36 | - 组件布局会包含多个特殊的布局组件,允许某个业务组件为自身及其子组件进行布局。
37 |
38 | - 业务组件
39 |
40 | - 业务组件即可以有部分预置,也允许用户界面化自定义(Widget)。
41 | - 业务组件是对于样式组件、布局组件与数据的集合,最简单的业务组件譬如 Text 基础组件加上文本内容数据。
42 | - 业务组件会关心数据的获取方式,并且负责为自身的子基础组件渲染数据;业务组件会根据指定的子基础组件的 Key 值,将自身所具有的数据根据 Key 值提取,传递给子基础组件的渲染函数。
43 | - 业务组件仅提供*无参渲染函数*,换言之,某个业务组件的数据,应该由服务端直接指定,或者指定其获取方式。
44 |
45 | - 嵌套结构:描述了业务组件的嵌套层次。
46 | - 业务组件可以包含多个基础组件或者业务组件作为其子组件,使用布局组件描述组件间布局方式。
47 | - 业务组件具有唯一 ID,_扁平化存放_,允许根据 ID 进行动态索引,允许进行自身局部刷新;react-jsonschema-form 就是典型的业务组件。
48 | - 业务组件会将数据按照子基础组件 Key 值切分传递给自身的子基础组件,并且调用子基础组件的渲染函数,得到渲染后的界面。
49 | - 业务组件会将自身的子业务组件当做黑盒看待,业务组件仅会存放子业务组件的 ID,并且直接调用子业务组件的*无参渲染函数*,得到渲染后的界面。
50 | - 以 BList 业务组件为例,如果业务场景是每行结构皆相同的列表,那么 BList 会包含某个 List 基础组件,调用其渲染函数获得界面;如果业务场景是复杂的,每行不一致的业务组件,那么 BList 会包含多个子业务组件,并且调用每个业务组件的无参渲染函数,得到渲染后的界面。
51 | - 以 BDataGrid 业务组件为例,如果业务场景是每列皆为基础组件,那么直接由 BDataGrid 获取数据,并且根据每列的 Key 值,调用对应基础组件的渲染函数;如果业务场景是某些列为业务组件,那么会根据根据指定的业务组件 ID 调用对应业务组件的无参渲染函数,该业务组件的数据规则由服务端指定。
52 | - 该嵌套方式可能产生 N+1 Query 问题,由 API 模块或者服务端缓存解决。
53 |
--------------------------------------------------------------------------------
/电商系统/README.link:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/Solutions-Notes/45e603418fb3ca5ea111d70dd049dc00fea2d5d8/电商系统/README.link
--------------------------------------------------------------------------------
 40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/低代码平台/00~低代码设计理念/99~参考资料/2023~Low-Code Programming Models.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext)
2 |
3 | # Low-Code Programming Models
4 |
5 | Low-code is the subject of much current enthusiasm stirred by market research companies and confirmed by vendors rushing to embrace the label.7,31 But what low-code programming means is somewhat cryptic, let alone how it works. Moreover, scientific literature rarely uses the term. We can decode the term by breaking it into its components. Programming means developing computer programs, which comprise instructions for a computer to execute. Traditionally, programming means writing code in a textual programming language, such as C, Java, or Python. In contrast, low-code programming minimizes the use of a textual programming language. Instead, it aims to use alternative techniques closer to how users naturally think about their task.
6 |
7 | Users of low-code range from professional developers to so-called citizen developers. A citizen developer is an amateur programmer with little professional programming education. Citizen developers, having chosen a career different from programming, tend to have more domain expertise. Low-code enables domain experts to become citizen developers. At the same time, low-code platforms should also strive to make pro-developers (professionals with an education or career in software development) more productive.
8 |
9 | Whether used by a citizen developer or a pro-developer, low-code programming aims to save the time and tedium of performing a task by hand.35 Further motivation for individuals comes from the joy of creating something useful, thinking about tasks in a computational way, and acquiring programming skills that can advance their career. Businesses may have their own motivation for adopting low-code platforms, which can alleviate the shortage of pro-developers, reduce mistakes of tedious manual tasks, and multiply the time savings from one individual's low-code program to their colleagues.31 Another factor driving low-code is the rise of cloud-based software as a service, providing both more interfaces to automate and a platform on which to deploy automations.
10 |
11 | A few concepts are closely related to low-code programming. No-code programming is more purist, with zero handwritten code in a textual programming language. End-user programming (EUP) puts the emphasis on who is doing the programming (the end-user as citizen developer) rather than on how they are not doing their programming (not with textual code).6 This term is common in the academic literature and overlaps with low-code, but does not preclude the use of a textual programming language. Another gap between EUP and low-code is the latter aims to serve not just end users but also pro-developers.7,31
12 |
13 | Bock and Frank7 and Sahay et al.31 recently compared commercial low-code platforms, and Barricelli et al. recently mapped the EUP literature.6 In contrast, this article bridges the gap between low-code and the academic literature and adds missing details and perspective. Low-code encompasses more specialized techniques, such as visual programming languages (VPLs), programming by demonstration (PBD), programming by example (PBE), robotic process automation (RPA), programming by natural language (PBNL), and others. Surveys on these techniques are more specific and often dated.4,8,20,35 In contrast, this article reviews recent literature across all these techniques.
14 |
15 | Given that low-code offers citizen developers a model to create computer programs, this article explores low-code from the perspective of programming models. A programming model is a set of abstractions that supports developing computer programs. Programming models can be low-code or not, and they can be domain-specific or general-purpose. Some programming models are languages; for example, Java is a general-purpose language and SQL is domain-specific, and neither is low-code. Scratch is a low-code programming model for kids that is media-centric,29 making it domain-specific. The programming-model perspective helps highlight common techniques for writing, reading, and executing programs, and it helps relate low-code to research into program synthesis and domain-specific languages.
16 |
17 | This article includes a deep-dive into three prominent low-code techniques: visual programming, programming by demonstration, and programming by natural language. The deep-dive focuses on fundamental building blocks and a unifying framework common to all three. The citations in this article cover both seminal work and recent advances in low-code programming models, for instance, based on artificial intelligence. Moreover, this article aims to cut through the buzz surrounding low-code so as to expose the technical foundations underneath. Hopefully, doing so will foster better development of the field through awareness of existing (albeit scattered) research, and will ultimately lead to even more empowered citizen developers.
18 |
19 | ### Problem Statement
20 |
21 | If low-code is the solution, then what is the problem? Given the term low-code, it might seem the answer is obviously code. Unfortunately, that answer is superficial and nonconstructive. Defining a thing solely by what it is not, as the term low-code appears to do, causes confusion. Consider two other recent similarly named trends: NoSQL and serverless. At the surface, one might think NoSQL was mostly about rejecting SQL, but in fact, it was more about flexible data and consistency models than about the query language. Similarly, serverless computing was not about eliminating compute servers, but about hiding them behind better abstractions. Defining a new trend by rejecting an old one grabs attention at the expense of being misleading. Just like serverless still needs servers, low-code (and even no-code!) still needs code.
22 |
23 | The three terms—low-code, NoSQL, and serverless—have one thing in common: a desire to avoid specific baggage while preserving core value. In NoSQL, the core value is durable and consistent storage. In serverless, it is portable and elastic compute. What then is the core value that low-code aims to preserve? This article argues it is computer programming. Programming is to low-code what computing is to serverless. Low-code is about creating instructions for a computer to execute or interpret. These instructions form a computer program, typically in a domain-specific language (DSL). For instance, low-code is often based on search-based program synthesis, and synthesis usually targets a DSL carefully crafted for the purpose.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) The program may not be exposed to the user, but it is there.
24 |
25 | One way to better understand the problem statement behind low-code is to look at who it is for. The top portion of [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) shows the spectrum of low-code users. They range from citizen developers at one end to pro-developers at the other, with intermediate stages here dubbed semi developers. In this simplified view, users at the citizen developer end of the spectrum tend to have the most domain knowledge and users at the pro-developer end have the most programming expertise. Low-code can enable citizen developers to self-serve their programming needs instead of depending on pro-developers. At the same time, low-code can make pro-developers more productive, for example, in a new domain. Finally, low-code can break barriers between developers across the spectrum and help them collaborate on common ground.
26 |
27 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg)
28 | **Figure 1. Low-code users and techniques.**
29 |
30 | The middle portion of [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) shows three representative low-code techniques. Programming expertise induces a Venn diagram over the users, with the smallest subset being able to use the largest range of programming techniques. An edge between a set of users and a low-code technique indicates the users write or read a program with that technique. Specifically, all users can use programming by demonstration and programming by natural language (edges to the outermost set of users encompassing citizen-, semi-, and pro-developers). Only semi-developers and pro-developers can readily use visual programming, though citizen developers may be easily trained to do so, as evidenced by Scratch.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) And only pro-developers are likely to directly use a DSL. Therefore, while low-code typically targets a DSL, that DSL may not be exposed, or if it is, may only be exposed to pro-developers. That is especially true in the common case of a DSL that is embedded[17](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R17) in a general-purpose textual programming language such as Python.
31 |
32 | ---
33 |
34 | > _Just like serverless still needs servers, low-code (and even no-code!) still needs code._
35 |
36 | ---
37 |
38 | If the core value of low-code is to create computer programs, what exactly is it about created programs that is deemed valuable? One way to shed more light on this question is to look at a seemingly opposing trend, namely the as-code movement. The as-code movement started with infrastructure as code, which automates standing up compute resources and the services running on them from a source code repository and a backup.[18](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R18) Treating this process as code can speed it up, reduce mistakes, and facilitate testing. Another instance of as-code is security as code, where security policies, templates, and configuration files all live in a source code repository.[25](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R25) Treating them as code lets them be versioned, inspected by humans, and checked by machines. To summarize, the as-code movement sees value in programs that are repeatable, tested, versioned, human-readable, and machine-checkable. These are also desirable properties for low-code programs.
39 |
40 | When citizen developers use low-code, it is typically to create a program for a task they would otherwise do by hand. So what tasks is low-code good for? Generally speaking, low-code helps if it shaves off more time from a task than the time spent doing the low-code programming. This is true for tasks that are repetitive or time-consuming. Of course, the equation shifts when the program can be used not just by the developer who created it, but also by others, shaving time off their tasks as well. In the extreme, pro-developers create programs used by millions. Low-code is most appropriate when it saves time, but not enough time to make professional coding economically feasible. Low-code is suitable for tasks that are rule-based and low on exceptions. And besides the time savings, it can be even more beneficial when the tedium of doing the task by hand causes errors.
41 |
42 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
43 |
44 | ### Techniques
45 |
46 | Here, we take a deep-dive into three representative techniques for low-code programming: VPLs, PBD, and PBNL. These three are a good set for the following reasons. Sahay et al.'s paper declares low-code as synonymous with just one technique, VPLs,[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31) but that perspective seems too narrow. Barricelli et al. list 14 different techniques for EUP,[6](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R6) but they are not clearly separated, and reviewing them all in detail would get too long-winded. In the past, the dominant low-code technique has been spreadsheets.[9](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R9) The three chosen techniques instead align with present and future trends: VPLs are central to current commercial low-code platforms;[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31) PBD is the backbone of RPA, which often uses record-and-replay;[35](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R35) and PBNL is poised to grow thanks to advances in deep learning-based large language models.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11),[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33),[39](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R39)
47 |
48 | Furthermore, the three techniques are well-suited for citizen developers by drawing upon universal skills: VPLs draw upon seeing, PBD draws upon the ability to use a computer application, and PBNL draws upon speaking. In fact, low-code can offer an alternative modality when some other approach is impeded, such as using speech interfaces when a user's hands or eyes are unavailable. Finally, VPLs, PBD, and PBNL are sufficient to span a set of building blocks that can also be arranged differently for use with other low-code techniques, such as spreadsheets, rules, wizards, or templates. Not all building blocks appear in all techniques, but the following blocks recur enough to warrant brief up-front definitions:
49 |
50 | - code canvas: renders code, for example, visually as a flow graph;
51 | - palette: offers components for drag-and-drop selection;
52 | - text box: holds natural-language text used for code search, description, or generation;
53 | - player: has buttons for capture, replay, pause, or step;
54 | - stage: shows the effect of code execution; and,
55 | - configuration pane: lets the user customize components, for example, via graphical controls such as checkboxes or sliders, or textually by typing small formulas.
56 |
57 | Low-code techniques support not just writing programs, but also reading and executing them. A low-code system can execute the program immediately after it is written or save it for later, and the user may choose to execute the program multiple times, for example, after input data changes. Low-code techniques differ in which of the listed building blocks are engaged to read, write, or execute programs. Whereas [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) blurred the read/write/execute distinction by using undirected edges, the rest of this section explicates the distinction by using directed edges and colors (orange for read, dark blue for write, and purple for execute).
58 |
59 | **Visual programming languages.** _The user drags visual components from a palette to a canvas, connects them, and configures them._
60 |
61 | _Description._ Visual programming languages let users write programs by directly manipulating their visual representation. There is a plethora of possible visual representations,[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) often inspired by domain notation, such as electrical circuit diagrams. Two prominent domain-independent visual representations are boxes-and-arrows (for example, BPMN[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27)) or interlocking puzzle pieces (for example, Scratch[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29)). Here, boxes or puzzle pieces represent instructions in the program, and arrows between boxes or the interlock of pieces represent how data and control flows between instructions.
62 |
63 | Despite the diversity in visual languages, their programming environments tend to comprise similar building blocks, as depicted in [Figure 2](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f2.jpg). The central building block is the code canvas, where the user can both read (orange arrow from canvas to eye) and write (dark blue arrow from hand to canvas) the program. Writing the program also involves dragging components from the palette to the canvas and possibly configuring them in a separate configuration pane. The programming environment also often includes a stage, which visually shows a program execution, ideally live.[34](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R34) For example, in Scratch, the stage shows sprites in a virtual world. Besides making the environment more engaging, the stage is also crucial for program understanding and debugging. To facilitate this, the stage is usually tightly connected to the canvas, helping the user navigate back and forth.
64 |
65 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f2.jpg)
66 | **Figure 2. Visual programming languages.**
67 |
68 | _Strengths, weaknesses, and mitigations._ One strength of VPLs is they tend to be easy to read, especially when reusing notation already familiar to the domain expert,[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) or in visual builders for graphical user interfaces.[24](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R24) Another strength is that, in contrast to PBD or PBNL, VPLs are usually unambiguous, thus increasing programmer control and reducing mistakes. Finally, compared to textual programming languages, visual languages can rule out syntax errors[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) and even simple type errors[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) by construction.
69 |
70 | In the context of low-code programming, the main weakness of visual programming languages is they are not always self-explanatory; that is why [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) connects them to semi-developers. The mitigation for this need-to-learn is user education, and for some VPLs, education is a primary purpose.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) The visual notation can take up a lot of screen real estate; the mitigation is to elide detail, for example, by requiring a configuration pane or via modular language constructs.[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3),[26](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R26) Even the palette can get too full, hindering discoverability, which can be mitigated by search facilities. A drawback of visual languages compared to textual languages is they tend to be co-dependent on their visual programming environment, hindering the use of basic tools such as diffing or search, or of third-party tools such as linters or code generators. This can be mitigated by backing the visual language with a textual domain-specific language.[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37)
71 |
72 | _Literature._ Some seminal VPLs include BPMN-on-BPEL for modeling and executing business processes[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27) and the Scratch language for teaching kids programming.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) Boshernitsan and Downes chronicle early VPLs and categorize them into purely visual vs. hybrid (mixed with text), and complete (sufficient procedural abstraction and data abstraction to be self-hosting) or not.[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) Today, VPLs are central to commercial low-code platforms such as Appian, Mendix, and OutSystems.[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31)
73 |
74 | Other papers address VPL implementation approaches, such as meta-tools (tool used to implement other tools) and the model-view-controller (MVC) pattern, which lets users manipulate the same model through multiple synchronized views. VisPro is a meta-tool for creating visual programming environments.[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) VisPro advocates for a coordinated set of visual and textual languages, using MVC to expose the same program (model) via multiple languages (views). More recently, Blockly is a meta-tool for creating VPLs with interlocking puzzle pieces[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28) such as those in Scratch. Some VPLs target pro-developers and are embedded in professional programming environments or languages. Projectional editing, such as in MPS,[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) doubles down on the MVC paradigm, where even the textual language is projected into a view precluding syntax errors. More recent work has demonstrated VPLs as libraries extending textual languages. A livelit is a user-defined VPL widget that can be used in place of a textual literal,[26](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R26) and Andersen et al. let users implement VPL widgets for literals, patterns, and templates.[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3)
75 |
76 | **Programming by demonstration.** _The user demonstrates the behavior on a canvas, with some configuration during or after recording._
77 |
78 | _Description._ In PBD, the user demonstrates how to perform a task by hand via the mouse and keyboard, and the PBD system records a program that can perform the same task automatically. As shown in [Figure 3](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f3.jpg), the demonstration happens on a stage, which may be a specific application like a spreadsheet, or a Web browser visiting a variety of sites and apps, or even a general computer desktop or smart-phone screen. Ideally, the recorded program abstracts from perceptions to a symbolic representation, for instance, by mapping pixel coordinates to a user-interface widget, or several keystrokes to a text string. Besides the stage, most PBD systems have a player with buttons to record and replay, plus often additional buttons such as pause or step (reminiscent of interactive debuggers).
79 |
80 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f3.jpg)
81 | **Figure 3. Programming by demonstration.**
82 |
83 | The program is most useful if executing it does not yield the same behavior as the initial demonstration, but rather, generalizes to different data. For example, a program for ordering a taxi to any new location is more general and more useful than a program for ordering a taxi to only a single hard-coded location. Generalizing typically requires identifying variables or parameters, and may even entail adding conditionals, loops, or function calls. Unfortunately, a single demonstration is an inherently ambiguous specification for such a more general program. Therefore, PBD systems often provide a configuration pane that allows users to disambiguate the generalization either during or after demonstration. Some PBD systems also have a code canvas that renders the recorded program for the user to read, for example, visually or in natural language.
84 |
85 | _Strengths, weaknesses, and mitigations._ The main strength of programming by demonstration is that the user can work directly with the software applications they are already familiar with from their day-to-day work.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) This makes PBD well suited for citizen developers, as there is no indirection between programming and execution. Furthermore, a demonstration is more concrete than a program in a different paradigm, since it works on specific values and has a straight-line flow of control and data.
86 |
87 | ---
88 |
89 | > _To turn a demonstration into a program, it must be generalized, and automatic generalization may not capture user's intent._
90 |
91 | ---
92 |
93 | Unfortunately, being so concrete is also PBD's main weakness: to turn a demonstration into a program, it must be generalized, and automatic generalization may not capture the user's intent.[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14) Mitigations include hand-configuration[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) or multishot demonstration.[15](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R15) PBD can be brittle with respect to the graphical user interface of the application on stage, especially when that changes; mitigations include heuristics and specialized recorders that can map perception to application-level concepts.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32) Generalization can also overshoot, allowing a program to plow ahead even in unforeseen circumstances.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) This can be mitigated by providing guardrails, such as an attended execution mode that asks the user to confirm before certain actions. Finally, PBD can result in programs that are difficult to understand because they include spurious steps or are too fine-grained, which is of course a problem in low-code programming.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) This can be mitigated by pruning and by discovering macro-steps.
94 |
95 | _Literature._ A good example of a PBD system is CoScripter, where the stage is a Web browser and the code canvas displays the program in natural language.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) The CoScripter paper describes interviews that informed its design, as well as experiences from real-world usage in a business setting. In Rousillon, the stage is also a Web browser and the canvas displays the program in a VPL, fusing sequences of several low-level steps into a single puzzle piece.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) In VASTA, the stage is the display of a mobile phone, and the system uses machine learning to reverse-engineer screenshots into user interface elements.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32) In DIYA, the stage is a Web browser and users customize the program during recording via voice input.[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14) PBD is used in commercial robotic process automation products (such as UIPath, Automation Anywhere, and BluePrism) that let a human demonstrate a process on the existing software and then refer to the automatic replay engine as a robot.[35](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R35)
96 |
97 | PBD is closely related to PBE, since a demonstration is an elaborate example. FlashFill is a seminal PBE system that uses example input and output columns in a spreadsheet to synthesize a program for transforming inputs to outputs.[15](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R15) Both PBD and PBE are based on program synthesis.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) Recent work has harnessed novel machine-learning techniques for program synthesis, such as learned search strategies in DeepCoder[5](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R5) and learned libraries in DreamCoder.[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13)
98 |
99 | PBD can be profitably combined with other low-code techniques. The play-in/play-out approach is a PBD system codesigned with its own VPL based on sequence diagrams.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) And SwaggerBot is a PBD system embedded in a natural-language conversational agent, enabling a form of PBNL.[36](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R36)
100 |
101 | **Programming by natural language.** _The user enters natural language text via keyboard or voice, and the system synthesizes a program._
102 |
103 | _Description._ In this low-code technique, the user enters text in natural language, either by typing on the keyboard or via speech-to-text. [Figure 4](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg) indicates these two possibilities via blue arrows from the user's hand or mouth to the text canvas. The PBNL system translates the user's text, or utterance, to a program. The system can optionally render the program on a code canvas for the user to read. This rendering might use a VPL, or it might use a controlled natural language[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) for a disambiguated version of the user's utterance. The system can also optionally show the effect of the program's execution on a stage. For example, if the program is a query in a spreadsheet, the spreadsheet is the stage, and the result can be shown as a new table.
104 |
105 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg)
106 | **Figure 4. Programming by natural language.**
107 |
108 | _Strengths, weaknesses, and mitigations._ The main strength of PBNL is that it is not just low-code, but more generally, low on demands during programming. As shown in [Figure 4](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg), its programming environment has only three building blocks (text canvas, code canvas, and stage), all optional. That means PBNL in principle even works in circumstances where the user's hands and eyes are otherwise occupied.
109 |
110 | PBNL makes it particularly easy for citizen developers to create programs, but unfortunately, those programs are often wrong.[4](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R4) Natural language is ambiguous, since humans are often vague and tend to assume common ground and omit context. On top of that, natural language processing (NLP) technologies are imperfect. The optional code canvas and stage can mitigate this weakness, by showing the user the synthesized program or its effect, thus giving them a chance to correct it. Another mitigation is to encourage users to keep their utterances short and not take advantage of the full expressiveness of natural language, since simpler programs are easier to get right.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) Furthermore, some PBNL systems support hand-editing the program.
111 |
112 | ---
113 |
114 | > _A strength of programming by natural language is its expressiveness: natural language can express virtually anything humans want to communicate._
115 |
116 | ---
117 |
118 | Another strength of PBNL is its expressiveness: natural language can express virtually anything humans want to communicate. In theory, PBNL restricts neither the sophistication nor the domains of programs. On the flip-side, PBNL systems often require an aligned corpus of utterances and programs to train NLP models, and obtaining such a corpus is expensive. Mitigating this is an active research topic in the machine-learning research community.[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33),[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38)
119 |
120 | _Literature._ As an interdisciplinary field of research, PBNL is best illuminated through multiple surveys. Androutsopoulos et al. surveyed natural-language interfaces to databases, a prominent form of PBNL going back to the 1960s.[4](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R4) A common approach is to parse a natural-language utterance into a tree and then map that tree to a database query. Kuhn surveyed controlled natural languages (CNLs), which restrict inputs to be unambiguous while preserving some natural properties.[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) Compared to unrestricted natural language, CNLs may make it harder for citizen developers to write programs but may make it easier to write correct programs. Allamanis et al. surveyed machine learning for code, arguing that code has a "naturalness" that makes it possible to adapt various NLP technologies to work on code.[1](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R1) The survey covers some code-generating models relevant to PBNL.
121 |
122 | The most successful NLP technology applied to PBNL is semantic parsers, which are machine-learning models that translate from natural language to an abstract syntax tree (AST) of a program. For instance, SILT learns rule-based semantic parsers that have been demonstrated for programs that coach robotic soccer teams or for programs that query geographic databases.[19](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R19) The Overnight paper addresses the problem of obtaining an aligned corpus for training a semantic parser via synthetic data generation and crowdsourced paraphrasing.[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38) Pumice tackles the ambiguity of natural language by a dialogue, where the system prompts for clarification which the user can provide via natural language or demonstration.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) And Shin et al. show how to coax a pretrained large language model into doing semantic parsing without requiring fine-tuning.[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33)
123 |
124 | Another approach to PBNL is program synthesis, which typically searches a space of possible programs.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) Desai et al. describe a meta-synthesizer that, given a DSL grammar and an aligned corpus, creates a synthesizer from natural language to programs in the DSL.[12](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R12) PBNL is not limited to domain-specific languages for citizen developers. Yin and Neubig describe a semantic parser that uses deep learning to encode a sequence of natural-language tokens, then decodes that into a Python AST.[39](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R39) Codex is a pre-trained large language model for natural language first fine-tuned on unlabeled code, then fine-tuned again on an aligned corpus of utterances and programs.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11)
125 |
126 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
127 |
128 | ### Perspectives
129 |
130 | While the previous discussion covered three low-code techniques in depth, here we cover cross-cutting topics beyond any single technique. The accompanying [table](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/ut1.jpg) compares the techniques discussed earlier. The Activity columns indicate how each technique supports the user in writing, reading, and executing programs. The main difference is in the Write column: users write programs mainly on the code canvas for VPLs, the stage for PBD, and a text canvas in PBNL. On the other hand, there is little difference in the Read and Execute columns: users read programs on a code canvas (if provided), and watch them executing on the stage (if visible). That hints at an opportunity for reuse across tools for different techniques.
131 |
132 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/ut1.jpg)
133 | **Table. Comparing low-code techniques.**
134 |
135 | A core problem with low-code programming is ambiguity. While visual programming languages can be rigorous and unambiguous, there is ambiguity in how to generalize from a demonstration to a program that works in different situations, and natural languages are inherently ambiguous as well. More ambiguous techniques may only work reliably on small and simple problems. Systems for PBD and PBNL must guess at the user's intent and are likely to guess wrong when programs get complicated. This motivates offering users an option to read or even correct programs or their executions.
136 |
137 | A core goal of low-code programming is to reduce the need to learn a programming language. Citizen developers can demonstrate a program or describe it in natural language without having been taught how to do so. Visual programming is often less self-explanatory, which is why [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) associates it more with semi-developers. On the other hand, depending on the user's attitude, the need-to-learn can also be good, since it grows computational thinking skills.
138 |
139 | _Artificial intelligence for low-code._ Does the ongoing rapid progress in AI fuel progress in low-code? This article argues that yes, it does, in proportion to the ambiguity of the low-code technique. Out of the three techniques in the table, AI is most prominent for PBNL, which is also the most ambiguous. PBNL can hardly avoid AI except by using a controlled natural language,[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) but that would make it feel more like code. Currently a rising AI approach for PBNL is to use large language models with code generation.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11),[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33) PBNL will likely grow along with relevant advances in AI. AI is also prominent in PBD, characterized in the table as medium ambiguity. For example, DeepCoder shows the interplay between program synthesis for defining a space of possible programs and checking whether a given program is correct, and AI for guiding the search through that space.[5](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R5) As another example, VASTA uses speech recognition, object recognition, and optical character recognition to better understand a user's demonstration of a task.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32)
140 |
141 | _Communicating with humans and machines._ Pro-developers use code in textual programming languages to communicate with a computer, telling it what to do. In addition, developers can also use programming languages to communicate with each other or with their own future self. A low-level programming language such as C gives developers more control of the computer, whereas a high-level language such as Python arguably makes communication among humans more effective. Similarly, low-code programs can serve both to communicate instructions to a computer and to communicate among low-code users. Being even more high-level than, say, Python, low-code can serve as a lingua franca to help citizen developers and pro-developers communicate more effectively with each other. For instance, a citizen developer might use PBD to communicate a desired behavior to a pro-developer to flesh out.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) Conversely, a pro-developer might use PBNL or a VPL to communicate a proposed behavior to a domain expert for explanation or approval.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21),[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27)
142 |
143 | _Domain-specific languages for low-code._ All three low-code techniques noted earlier are intrinsically related to DSLs: most VPLs are DSLs (for example, Scratch[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29)), and both programming by demonstration and programming by natural language usually target DSLs (DIYA targets its co-designed Thing-Talk 2.0 DSL[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14)). Mernik et al. list further benefits of DSLs: they facilitate program analysis, verification, optimization, parallelization, and transformation (AVOPT).[23](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R23)
144 |
145 | While reviewing the low-code literature reveals a close tie to DSLs, those DSLs are not always exposed to the user. For instance, the DSL may manifest as a proprietary file format or as an undocumented internal representation. If the DSL is exposed, users can more easily read, test, and audit programs, version them and store them in a shared repository, and manipulate them with tools for program transformation or generation. Also, an exposed DSL is less locked into a specific programming environment or its vendor. When exposed, the DSL should be designed for humans, possibly based on interviews and user studies as role-modeled by Leshed et al.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) On the other hand, a DSL that is not exposed will be shaped by different factors, such as the ease of enumerating valid programs, which can be improved by breaking symmetries in the search space.[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13)
146 |
147 | DSLs (including DSLs for low-code) may be embedded in a general-purpose language. Compared to a stand-alone DSL, an embedded DSL is often easier to implement (for example, due to not requiring a custom parser) and easier to use (due to syntax highlighting and auto-completion tools of the host language). The approach to implementing an embedded DSL depends on the facilities of the host language. One approach is Pure Embedding, which uses higher-order functions and lazy evaluation, such as in Haskell.[17](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R17) Another example is Lightweight Modular Staging, which uses operator overloading and dynamic compilation, such as in Scala.[30](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R30)
148 |
149 | _Model view controller._ The current state-of-the-art VPLs and associated meta-tools are based on the MVC pattern.[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28),[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) And in PBD or PBNL, even though the user does not use a code canvas to write a program, the system may optionally provide one for reading it, again using MVC. [Figure 5](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f5.jpg) illustrates MVC with a superset of the components from each low-code technique. Low-code programming tools provide one or more views of the program. Some of these views are read-only, while others are read-write views. When multiple views are present, the system keeps them in sync with a single joint model, and through that, with each other. Edits in one view are projected live to all other views. The model is a program in a DSL. Optionally, the system may even expose the textual DSL as another view, for instance, in a structure editor.[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) Besides the model and the view, the third part of the MVC pattern is the controller, which, for low-code, can contain a player and/or a configuration pane.
150 |
151 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f5.jpg)
152 | **Figure 5. Model-view-controller for low-code.**
153 |
154 | _Combining multiple low-code techniques._ When users write a program by demonstration or by natural language, the system may let them read it on a code canvas. And once a system lets users read programs on a code canvas, a logical next step is to also let them write programs there, such as, to correct mistakes from generalization or from natural language processing. This yields a combination of low-code techniques, where users can write programs in multiple ways. Such combinations can compensate for weaknesses of techniques. For example, in Rousillon, the user first writes a program by demonstrating how to scrape data from web pages;[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) since one weakness of PBD is ambiguity, Rousillon lets the user read the resulting program in a scratch-like VPL.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) Pumice combines PBD with PBNL: the user first writes a program via natural language; since one weakness of PBNL is ambiguity, Pumice next lets the user clarify with PBD.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22)
155 |
156 | _Meta-tools and meta-circularity._ A meta-tool for low-code is a tool used to implement low-code tools. In traditional programming languages, meta-tools (such as parser generators) have long been an essential part of the tool-writer's repertoire. Similarly, meta-tools for low-code can speed up the development of low-code tools by automating well-known but tedious pieces. Thus, meta-tools make it easier to build several tools or variants, for instance, to experiment with the user experience. There are examples of meta-tools for all three low-code techniques discussed previously. Blockly[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28) is a tool for creating VPLs that look similar to Scratch; DreamCoder[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13) is a tool for learning a library of reusable components along with a neural search policy for PBE; and Overnight[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38) is a tool for building semantic parsers for PBNL with synthetic training data.
157 |
158 | A meta-circular tool for low-code is a meta-tool for low-code that is itself a low-code tool. Not all meta-tools are metacircular tools, as that requires them to be powerful enough for serious software development. Supporting all that power can compromise the tool's low-code nature: complex features can get in the way of learning easy ones. On the positive side, meta-circular tools can democratize the creation of low-code tools themselves. Furthermore, tool developers who use their own tools may empathize more with their users' needs. Examples for meta-circular low-code tools include VisPRO[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) and Racket[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3) (both for VPLs).
159 |
160 | _Low-code foundation._ In addition to meta-tools, are there other reusable modules that make it easier to build new low-code tools? The beginning of the Techniques section listed several reusable building blocks for low-code programming interfaces: code canvas, palette, text box, player, stage, and configuration pane. Besides making it easier to create low-code tools, such reuse can also give different tools a more uniform look-and-feel, thus reducing the need-to-learn. In the case of multiple low-code tools for the same domain, reusing the same domain-specific language makes them more interoperable. Of course, low-code tools in different domains will require different DSLs, but they may still be able to reuse some sublanguage, such as expressions or formulas with basic arithmetic and logical operators and a function library. There are also AI components that can be reused across low-code tools, such as speech recognition modules, a search-based program synthesis engine, semantic parsers, or language models.
161 |
162 | _End-user software engineering._ Most of the discussion on low-code programming focuses on writing a program: low-code enables citizen developers to rapidly create a prototype. But what happens over time when these programs stick around, get used in new circumstances that the developer did not foresee, get modified or generalized, and proliferate? At that point, users need end-user software engineering (EUSE) for quality control, for instance, by showing test coverage, letting users add assertions, and helping them localize faults directly in their low-code programming environment.[9](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R9) Citizen developers often struggle with anticipating exceptional contexts for their programs; Pumice is a low-code tool that lets users extend programs with new branches when the unforeseen happens.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) Another way to support EUSE is to expose the DSL, which makes it easier to adopt established software development workflows and the associated tools (such as version-controlled source code repositories, regression tests, or issue trackers) for low-code. Those tools also facilitate collaboration between citizen developers and professional software engineers.
163 |
164 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
165 |
166 | ### Conclusion
167 |
168 | This article reviews research relevant to low-code programming models with a focus on visual programming, programming by demonstration, and programming by natural language. It maps low-code techniques to target users and discusses common building blocks, strengths, and weaknesses. This article argues that domain-specific languages and the model-view-controller pattern constitute a common backbone and unifying principle across low-code techniques.
169 |
170 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
171 |
172 | ### References
173 |
174 | \1. Allamanis, M. et al. A survey of machine learning for big code and naturalness. _ACM Computing Surveys 51_, 4 (July 2018), 81:1–81:37; https://doi.org/10.1145/3212695
175 |
176 | \2. Alur, R. et al. Search-based program synthesis. _Commun. ACM 61_, 11 (Nov. 2018), 84–93; https://doi.org/10.1145/3208071.
177 |
178 | \3. Andersen, L. et al. Adding interactive visual syntax to textual code. In _Proceedings of 2020 Conf. Object-Oriented Programming, Systems, Languages, and Applications_; https://doi.org/10.1145/3428290.
179 |
180 | \4. Androutsopoulos, I. et al. Natural language interfaces to databases—An introduction. _Natural Language Engineering 1_, 1 (1995), 29–81; https://doi.org/10.1017/S135132490000005X.
181 |
182 | \5. Balog, M. et al. DeepCoder: Learning to write programs. In _Proceedings of 2017 Intern. Conf. Learning Representations_; https://openreview.net/forum?id=ByldLrqlx.
183 |
184 | \6. Barricelli, B.R. et al. End-user development, end-user programming and end-user software engineering: A systematic mapping study. _J. Systems and Software 149_, (2019), 101–137; https://doi.org/10.1016/j.jss.2018.11.041.
185 |
186 | \7. Bock, A.C., and Frank, U. Low-code platform. _Business & Information Systems Engineering 63_, (2021), 733–740; https://doi.org/10.1007/s12599-021-00726-8.
187 |
188 | \8. Boshernitsan, M., and Downes, M. Visual Programming Languages: A Survey. _Technical Report UCB/CSD-04-1368, 2004, UC Berkeley_; https://bit.ly/3P0SaX5
189 |
190 | \9. Burnett, M. et al. End-user software engineering. _Commun. ACM 47_, 9 (Sept. 2004), 53–58; https://doi.org/10.1145/1015864.1015889.
191 |
192 | \10. Chasins, S. et al. Rousillon: Scraping distributed hierarchical Web data. In _Proceedings of 2018 Symp. User Interface Software and Technology_, 963–975; https://doi.org/10.1145/3242587.3242661
193 |
194 | \11. Chen, M. Evaluating large language models trained on code, (2021); https://arxiv.org/abs/2107.03374
195 |
196 | \12. Desai, A. Program synthesis using natural language. In _Proceedings of 2016 Intern. Conf. Softw. Eng._, 345–356; https://doi.org/10.1145/2884781.2884786
197 |
198 | \13. Ellis, K. DreamCoder: Bootstrapping inductive program synthesis with wake-sleep library learning. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 835–850; https://doi.org/10.1145/3453483.3454080
199 |
200 | \14. Fischer, M.H. et al. DIY assistant: A multi-modal end-user programmable virtual assistant. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 312–327; https://doi.org/10.1145/3453483.3454046
201 |
202 | \15. Gulwani, S. Automating string processing in spreadsheets using input-output examples. In _Proceedings of 2011 Symp. Principles of Programming Languages._ 317–330; https://doi.org/10.1145/1926385.1926423
203 |
204 | \16. Harel, D., and Marelly, R. Specifying and executing behavioral requirements: The play-in/play-out approach. _Software and Systems Modeling 2_, (2003), 82–107; https://doi.org/10.1007/s10270-002-0015-5.
205 |
206 | \17. Hudak, P. Modular domain specific languages and tools. In _Proceedings of 1998 Intern. Conf. Software Reuse._ 134–142; https://doi.org/10.1109/ICSR.1998.685738
207 |
208 | \18. Jacob, A. Infrastructure as code. _Web Operations: Keeping the Data on Time._ J. Allspaw, and J. Robbins, (eds). O'Reilly, Chapter 5, (2010), 65–80.
209 |
210 | \19. Kate, R.J. et al. Learning to transform natural to formal languages. In _Proceedings of 2005 Conf. Artificial Intelligence._ 1062–106; http://www.aaai.org/Library/AAAI/2005/aaai05-168.php
211 |
212 | \20. Kuhn, T. A survey and classification of controlled natural languages. _Computational Linguistics 40_, 1 (2014), 121–170; https://bit.ly/42t3JsY.
213 |
214 | \21. Leshed, G. et al. CoScripter: Automating and sharing kow-to knowledge in the enterprise. In _Proceedings of 2008 Conf. Human Factors in Computing Systems_, 1719–1728; https://doi.org/10.1145/1357054.1357323
215 |
216 | \22. Li, T.J. et al. PUMICE: A multi-modal agent that learns concepts and conditionals from natural language and demonstrations. In _Proceedings of 2019 Symp. User Interface Software and Technology._ 577–589; https://doi.org/10.1145/3332165.3347899
217 |
218 | \23. Mernik, M. et al. When and how to develop domain-specific languages. _ACM Computing Surveys 37_, 4 (2005), 316–344; https://doi.org/10.1145/1118890.1118892.
219 |
220 | \24. Myers, B. et al. Past, present, and future of user interface software tools. _Trans. Computer-Human Interaction_ (Mar. 2000), 3–28; https://doi.org/10.1145/344949.34495
221 |
222 | \25. Myrbakken, H., and Colomo-Palacios, R. DevSecOps: A multivocal literature review. _Software Process Improvement and Capability Determination_ (2017), 17–29. https://doi.org/10.1007/978-3-319-67383-7_2.
223 |
224 | \26. Omar, C. et al. Filling Typed Holes with Live GUIs. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 511–525; https://doi.org/10.1145/3453483.3454059
225 |
226 | \27. Ouyang, C. From BPMN process models to BPEL Web services. In _Proceedings of Intern. Conf. Web Services._ (2006); https://doi.org/10.1109/ICWS.2006.67
227 |
228 | \28. Pasternak, E. et al. Tips for creating a block language with Blockly. In _Proceedings of Blocks and Beyond Workshop_ (2017); https://doi.org/10.1109/BLOCKS.2017.8120404.
229 |
230 | \29. Resnick, M. et al. Scratch: Programming for all. _Commun. ACM 52_, 11 (Nov.2009), 60–67; https://doi.org/10.1145/1592761.1592779.
231 |
232 | \30. Rompf, T., and Odersky, M. Lightweight modular staging: A pragmatic approach to runtime code generation and compiled DSLs. _Commun. ACM 55_, 6 (June 2012), 121–130; https://doi.org/10.1145/2184319.2184345.
233 |
234 | \31. Sahay, A. et al. Supporting the understanding and comparison of low-code development platforms. In _Proceedings of Euromicro 2020 Conf. Software Engineering and Advanced Applications._ 71–178; https://doi.org/10.1109/SEAA51224.2020.00036
235 |
236 | \32. Sereshkeh, A.R. et al. VASTA: A vision and language-assisted smartphone task automation system. In _Proceedings of 2021 Conf. Intelligent User Interfaces._ 22–32; https://doi.org/10.1145/3377325.3377515
237 |
238 | \33. Shin, R. Constrained language models yield few-shot semantic parsers. In _Proceedings of 2021 Conf. Empirical Methods in Natural Language Processing, 7_, 699–7715; https://doi.org/10.18653/v1/2021.emnlp-main.608
239 |
240 | \34. Tanimoto, S.L. A perspective on the evolution of live programming. In _Proceedings of Intern. Workshop on Live Programming._ (2013), 31–34; https://doi.org/10.1109/LIVE.2013.6617346
241 |
242 | \35. van der Aalst, W.M. et al. Robotic process automation. _Business Spsampsps Information Systems Eng. 60_, (2018), 269–272. https://doi.org/10.1007/s12599018-0542-4.
243 |
244 | \36. Vaziri, M. et al. Generating Chat Bots from Web API Specifications. In _Proceedings of Symp. New Ideas, New Paradigms, and Reflections on Programming and Software._ (2017), 44–57; [http://doi.acm.org/10.1145/3133850.3133864](https://dx.doi.org/10.1145/3133850.3133864)
245 |
246 | \37. Voelter, M., and Lisson, S. Supporting diverse notations in MPS' projectional editor. In _Proceedings of Workshop on the Globalization of Modeling Languages._ (2014), 7–16; https://hal.inria.fr/hal-01074602/file/GEMOC2014-complete.pdf#page=13
247 |
248 | \38. Wang, Y. et al. Building a semantic parser overnight. In _Proceedings of the Annual Meeting of the Assoc. for Computational Linguistics._ (2015), 1332–1342; https://www.aclweb.org/anthology/P15-1129.pdf
249 |
250 | \39. Yin, P., and Neubig, G. A syntactic neural model for general-purpose code generation. In _Proceedings of the Annual Meeting of the Assoc. for Computational Linguistics._ (2017), 440–450; [http://dx.doi.org/10.18653/v1/P17-1041](https://dx.doi.org/10.18653/v1/P17-1041)
251 |
252 | \40. Zhang, K. et al. Design, construction, and application of a generic visual language generation environment. _IEEE Trans Softw Eng. 27_, 4 (2001), 289–307; https://doi.org/10.1109/32.917521.
253 |
--------------------------------------------------------------------------------
/低代码平台/00~低代码设计理念/低代码的不足.md:
--------------------------------------------------------------------------------
1 | # 低代码的不足
2 |
3 | 个人认为低代码就是个噱头,远远没有概念所说的具备那么广的适用性,只能是针对某个垂直领域业务的问题解决方案:软件设计 CAP 原则:性能、可用性,可延展性,三取二,低代码为了通用性,必然要舍弃性能跟可用性之一,而商业产品必须保证可用性,所以性能必然不够优先(三点都要也不是做不到,成本将大副增加),这就导致只能应用到对性能不敏感的 toB,toG,二这个领域又是各种 SAAS 服务商,系统集成商,云服务商的竞争之地,只靠低代码这个点无法获得足够的优势,最终只能靠与某服务商进行捆绑,否则一定会被淘汰。
4 |
--------------------------------------------------------------------------------
/低代码平台/README.md:
--------------------------------------------------------------------------------
1 | # 低代码搭建
2 |
3 | 低代码开发就是开发人员可以通过编写少量代码就可以快速生成应用程序的一种方法。所谓的低代码(low code),即可以看作一个像 Python 语言和 C# 语言一样的一种“东西”;也可以代表一种应用程序开发方式。因为用这种方式开发应用程序时,你需要手写的代码比通常的开发方式要少。简单来说,低代码开发就是将已有代码的可视化模块拖放到工作流中以创建应用程序的过程。由于它可以完全取代传统的手工编码应用程序的开发方法,技术娴熟的开发人员可以更智能、更高效地工作,而不会被重复的编码束缚住。相反,他们可以将精力集中于创建应用程序的 10% 部分,并使其具有与众不同的功能。
4 |
5 | 这个领域是创新最活跃的地方,从过去的发展历程中能看到一些演进脉络,从 Engine 的角度看,演进的背后有两种理念:
6 |
7 | 1、Coding Less:通过强大的 SDK、框架和工具让工程师更好地 Coding,专注在实现业务上
8 | 2、No Coding:通过可视化 IDE 达成不写代码,通过拖拽、编写配置文件就能完成应用开发
9 |
10 | 从开发者角度看,对 Engine 有三个期待:
11 |
12 | 1、Productivity:必须能提升生产力,让工程师可以高效地写出健壮、易维护的代码
13 | 2、Simple & Stupid:KISS 原则 的核心,让开发变简单不仅能提升效率,还能让更多人成为前端工程师
14 | 3、Business More:研发资源非常宝贵,让工程师专注在业务上是提升效能的关键
15 |
16 | 未来的演化也会遵循这些脉络,Coding Less、No Coding 各有其应用场景,需要结合业务特点选择侧重点进行投入。但有一点我觉得是必然的:要开发优质应用,还得靠 Coding,不过写的代码会越来越少。No Coding 过于完美,应用场景有限,再加上有成品 SaaS 作为更好的替代品,我更倾向于用 Coding Less 模式去实现业务主线,把一些机械性、重复性、一次性的开发工作通过 No Coding 模式搞定。不过 No Coding 的一个分支 Visual Programming 非常值得关注,它在编程教育领域应用前景非常好,Scratch、Blockly 是典型代表,而编程教育不仅蕴藏着巨大的商机,而且还会给我们带来源源不断的生力军。
17 |
18 | ## 低代码平台分类
19 |
20 | # 优劣分析
21 |
22 | ## 优势
23 |
24 | 低代码开发的好处主要有以下四点:
25 |
26 | - 速度:使用低代码开发,你可以同时为多个平台构建应用程序,并且在几天甚至在几小时以内就可以向项目相关人员提交工作示例。
27 |
28 | - 更多的资源:如果你在一个大型项目上工作,使用低代码开发,你就不必再等待具有专业技能的开发人员完成另一个冗长的项目,这意味着项目可以更高效、以更低廉的成本完成。
29 |
30 | - 低风险/高投资回报率:使用低代码开发,意味着强大的安全流程,数据集成和跨平台支持已经内置,并且可以轻松定制,这通常意味着更低的风险,并且可以将更多的时间集中在业务逻辑的实现上。
31 |
32 | - 快速部署:项目上线总是会让人神经紧张。而使用低代码开发,部署前的影响评估可以确保你的应用程序按预期工作。如果有任何异常发生,只需要一次单击,你就可以回滚你所做的所有改变。
33 |
34 | ## 缺陷
35 |
36 |
--------------------------------------------------------------------------------
/低代码平台/开源低代码平台/Supabase/README.md:
--------------------------------------------------------------------------------
1 | # Supabase
2 |
3 | # Links
4 |
5 | - https://supabase.com/blog/type-constraints-in-65-lines-of-sql
6 |
--------------------------------------------------------------------------------
/低代码平台/流程系统/README.md:
--------------------------------------------------------------------------------
1 | # 流程系统
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/README.md:
--------------------------------------------------------------------------------
1 | # Dynamic Form | 动态表单
2 |
3 | 所谓的动态表单,即前后端约定一套表单定义规范;根据此规范,后端提供表单描述配置 JSON Schema;前端将此配置传入到动态表单框架后即可动态渲染出整个表单。只需要通过一份配置,就能生产一个表单应用,它能够极大地提升我们的效率,组件的复用率等等。动态表单会提供一个基本的组件库,供业务或者开发同学通过可视化的一种方式来配置所要的表单。同时为了满足业务对表单校验逻辑、数据初始化、级联、业务属性等要求而抽象的一套功能模型。此外,为了使各种系统能够快速接入动态表单,采用插件的方式嵌入业务系统中,从而保证业务系统的操作连贯性。对于表单的 JSON Schema 描述,互联网工程组(IETF)组织曾经制定过相关草案。这份草案约定通过 jsonSchema、uiSchema、formData 三个 JSON Object 来完整的描述一个静态表单。
4 |
5 | - 组件库:丰富的自定义组件、沉淀业务组件
6 | - 可视化:提供可视化配置功能,实现所见即所得
7 | - 功能模型:校验器、数据源、业务属性等等
8 | - 业务隔离:平台工具,不提供具体业务,提供标准接口业务实现
9 | - 插件化:可嵌入业务系统中,保持业务系统配置的连续性
10 |
11 | 表单模型共有 6 个模块构成: 属性、数据源、校验器、字段、表单/模板、数据。对于表单的 JSON Schema 描述,互联网工程组(IETF)组织曾经制定过相关草案。这份草案约定通过 jsonSchema、uiSchema、formData 三个 JSON Object 来完整的描述一个静态表单。
12 |
13 | 
14 |
15 | 其实当你的业务量达到一定的量级,做很多流程审批任务协同之类的中后台产品的时候就会发现表单的需求真的是源源不断,大同小异,既浪费时间也浪费精力。我们通过 json schema 规范每个 UI 组件。这个规范其实包括了中后台系统的 UI 规范,约束设计师的随意发挥,从而降低开发维护成本。
16 |
17 | 
18 |
19 | # 表单配置可视化
20 |
21 | 表单的配置化其实就是将表单开发的逻辑,转化成为了一种结构,在前端看来,它是个 JSON 或者是个对象。手动编写表单配置是可以被可视化的工具所替代的,这样,表单的开发和维护就变得更加清晰、简便了,效率也会得到提升。一份配置对应着一个表单的时候,但我们在一个网站应用(业务)上有多种场景需要多个表单,这时候就会有多份配置,多份配置会就需要对齐进行管理,甚至需要动态化异步加载配置。我把配置相关的事情,也一并列入表单中台的设计之中,让链路更加地完整。
22 |
23 | 实现可视化的手段,就是通过表单来生产配置,然后渲染表单。
24 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/表单 Schema.md:
--------------------------------------------------------------------------------
1 | # Schema
2 |
3 | 在项目开发初期我们需要定义一个合适的 JSON Schema,所谓合适的 JSON Schema,就是指能满足现有的业务模型,尽量减少冗余的字段,又能支持一定的扩展。方便后续的维护更新扩展。一个 form 表单由 jsonSchema、uiSchema、formData、bizData 四个 json 来描述:
4 |
5 | - jsonSchema 中描述了表单的数据类型、数据源、数据项等配置;
6 |
7 | - uiSchema 描述了表单字段的渲染方法、渲染参数等;
8 |
9 | - formData 描述了表单初始填充的各个字段的初始值;
10 |
11 | - bizData 中是对表单字段的业务属性,注意的是,bizData 不会影响 Form 的渲染
12 |
13 | # react-json-schema
14 |
15 | react-jsonschema-form 是最初由 Firefox 开源的能够从 JSON Schema 中渲染出实际表单的 React 组件。
16 |
17 | ## JSONSchema
18 |
19 | ```json
20 | {
21 | "title": "A registration form",
22 | "description": "A simple form example.",
23 | "type": "object",
24 | "required": ["firstName", "lastName"],
25 | "properties": {
26 | "firstName": {
27 | "type": "string",
28 | "title": "First name"
29 | },
30 | "lastName": {
31 | "type": "string",
32 | "title": "Last name"
33 | },
34 | "age": {
35 | "type": "integer",
36 | "title": "Age"
37 | },
38 | "bio": {
39 | "type": "string",
40 | "title": "Bio"
41 | },
42 | "password": {
43 | "type": "string",
44 | "title": "Password",
45 | "minLength": 3
46 | },
47 | "telephone": {
48 | "type": "string",
49 | "title": "Telephone",
50 | "minLength": 10
51 | }
52 | }
53 | }
54 | ```
55 |
56 | ## UISchema
57 |
58 | ```json
59 | {
60 | "firstName": {
61 | "ui:autofocus": true,
62 | "ui:emptyValue": ""
63 | },
64 | "age": {
65 | "ui:widget": "updown",
66 | "ui:title": "Age of person",
67 | "ui:description": "(earthian year)"
68 | },
69 | "bio": {
70 | "ui:widget": "textarea"
71 | },
72 | "password": {
73 | "ui:widget": "password",
74 | "ui:help": "Hint: Make it strong!"
75 | },
76 | "date": {
77 | "ui:widget": "alt-datetime"
78 | },
79 | "telephone": {
80 | "ui:options": {
81 | "inputType": "tel"
82 | }
83 | }
84 | }
85 | ```
86 |
87 | ## 合并的 Schema
88 |
89 | ```json
90 | {
91 | "title": "A registration form",
92 | "description": "A simple form example.",
93 | "type": "object",
94 | "required": ["firstName", "lastName"],
95 | "properties": {
96 | "firstName": {
97 | "type": "string",
98 | "title": "First name",
99 | "ui:autofocus": true,
100 | "ui:emptyValue": ""
101 | },
102 | "lastName": {
103 | "type": "string",
104 | "title": "Last name"
105 | },
106 | "age": {
107 | "type": "integer",
108 | "title": "Age",
109 | "ui:widget": "updown",
110 | "ui:title": "Age of person",
111 | "ui:description": "(earthian year)"
112 | },
113 | "bio": {
114 | "type": "string",
115 | "title": "Bio",
116 | "ui:widget": "textarea"
117 | },
118 | "password": {
119 | "type": "string",
120 | "title": "Password",
121 | "minLength": 3,
122 | "ui:widget": "password",
123 | "ui:help": "Hint: Make it strong!"
124 | },
125 | "telephone": {
126 | "type": "string",
127 | "title": "Telephone",
128 | "minLength": 10,
129 | "ui:options": {
130 | "inputType": "tel"
131 | }
132 | }
133 | }
134 | }
135 | ```
136 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/表单中台.md:
--------------------------------------------------------------------------------
1 | # 表单中台
2 |
3 | 表单中台是通过对表单进行了抽象,然后单独针对网站应用上的所有表单而设计的。它是对一个网站应用上面的所有表单,从前端开发者对表单相关的开发维护到用户提交数据到服务端,这样一个完整链路的抽象封装。表单中台是一个可以完全由前端驱动的产品,因为表单里面跟数据存储查询是可以相对对立的部分,不管数据跟哪个服务器进行通信,都是不需要关心的,标准应该有前端进行制定。这样,它就是一个去中心化的产品,同时也具备成为一个中台的可能。因为它是一个中台,所以它也是能够支撑和驱动各种 N 个中后台和业务发展的。
4 |
5 | 
6 |
7 | # 通信层与服务器
8 |
9 | 通信层磨平了与服务器进行通信的过程,这其中包括了配置的增删改查,表单数据的读写。接口标准由前端进行了定义。例如配置查询的接口:
10 |
11 | | 参数 | 类型 | 是否必须 | 说明 |
12 | | ------ | ---- | -------- | ------------------------------------------------------------------------ |
13 | | formId | Long | 否 | 表单 ID |
14 | | type | Long | 是 | 0 表示根据 userId 获取用户的配置列表,1 表示根据 formId 获取某个具体配置 |
15 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/展示型页面/H5 宣传页.md:
--------------------------------------------------------------------------------
1 | # H5 宣传页
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/展示型页面/展示型主页.md:
--------------------------------------------------------------------------------
1 | # 展示型主页
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/搭建协议/README.md:
--------------------------------------------------------------------------------
1 | # 搭建协议
2 |
3 | 所谓的搭建协议,即是一套面向开发者的 Schema 规范,用于规范化约束可视化编辑器的输出和渲染引擎(或者 Schema2Code)的输入,将编辑器和渲染引擎(或者 Schema2Code)解耦,保障编辑器和渲染引擎(或者 Schema2Code)的独立升级。
4 |
5 | 搭建协议的要求如下:
6 |
7 | - **语义化**:语义清晰,简明易懂,可读性强。
8 |
9 | - **渐进性描述**:搭建的本质是通过 源码组件 进行嵌套组合,从小往大、依次组合生成 组件、区块、页面,最终通过云端构建生成 应用 的过程。因此在搭建基础协议中,我们需要知道如何去渐进性的描述组件、区块、页面、应用这 4 个实体概念。
10 |
11 | - **生成标准源码**:明确每一个属性与源码对应的转换关系,可生成跟手写无差异的高质量标准源代码。
12 |
13 | - **可流通性**:产物能在不同搭建产品中流通,不涉及任何私域数据存储。
14 |
15 | - **面向多端**:不能仅面向 React,还有小程序等多端。
16 |
17 | - **支持国际化&无障碍访问标准的实现**
18 |
19 | # LegoSchema
20 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/搭建协议/组件系统.md:
--------------------------------------------------------------------------------
1 | # 低代码搭建系统
2 |
3 | 
4 |
5 | # 物料系统与组件分类
6 |
7 | - 业务场景搭建能力:可视化搭建、配置辅助编辑(JSON)、配置定向输出
8 |
9 | - 业务场景配置能力:商业规则(Biz Rules),场景化切割
10 |
11 | - 业务组件容器沉淀:端约束(Terminal Constraints),应用加载、数据采集、布局编排、组件通信
12 |
13 | - 业务组件物料沉淀:商业能力模型(Biz Model),电商域(会员,订单,物流,退款),CRM 域
14 |
15 | - 领域界面渲染引擎:表单域(Form),卡片域(Card),表格域(Table)
16 |
17 | - 通用组件物料沉淀:设计语言(Design Language),Ant Design,基础业务组件(Biz Components)
18 |
19 | - 通用视图底层框架:React,View,Angular
20 |
21 | 基于上面的业务视角的分类,我们可以在技术视角对组件层次再进行梳理:
22 |
23 | - 基础组件:
24 |
25 | - 基础组件定义了其 HTML 布局方式,与数据绑定规范,典型的譬如不包含指令/自定义元素的 Vue.js 模板。
26 | - 基础组件会提供渲染函数,执行数据到界面绑定的真实渲染操作。
27 | - 基础组件是系统的原子单元,由系统预置,不可再进行切分,也不可进行嵌套。
28 |
29 | - 组件样式:
30 |
31 | - 组件样式定义了组件统一的样式规范。
32 | - 仅有基础组件可以接收样式对象,根据统一的渲染规则渲染为样式组件。
33 |
34 | - 布局组件:
35 |
36 | - 组件布局会包含多个特殊的布局组件,允许某个业务组件为自身及其子组件进行布局。
37 |
38 | - 业务组件
39 |
40 | - 业务组件即可以有部分预置,也允许用户界面化自定义(Widget)。
41 | - 业务组件是对于样式组件、布局组件与数据的集合,最简单的业务组件譬如 Text 基础组件加上文本内容数据。
42 | - 业务组件会关心数据的获取方式,并且负责为自身的子基础组件渲染数据;业务组件会根据指定的子基础组件的 Key 值,将自身所具有的数据根据 Key 值提取,传递给子基础组件的渲染函数。
43 | - 业务组件仅提供*无参渲染函数*,换言之,某个业务组件的数据,应该由服务端直接指定,或者指定其获取方式。
44 |
45 | - 嵌套结构:描述了业务组件的嵌套层次。
46 | - 业务组件可以包含多个基础组件或者业务组件作为其子组件,使用布局组件描述组件间布局方式。
47 | - 业务组件具有唯一 ID,_扁平化存放_,允许根据 ID 进行动态索引,允许进行自身局部刷新;react-jsonschema-form 就是典型的业务组件。
48 | - 业务组件会将数据按照子基础组件 Key 值切分传递给自身的子基础组件,并且调用子基础组件的渲染函数,得到渲染后的界面。
49 | - 业务组件会将自身的子业务组件当做黑盒看待,业务组件仅会存放子业务组件的 ID,并且直接调用子业务组件的*无参渲染函数*,得到渲染后的界面。
50 | - 以 BList 业务组件为例,如果业务场景是每行结构皆相同的列表,那么 BList 会包含某个 List 基础组件,调用其渲染函数获得界面;如果业务场景是复杂的,每行不一致的业务组件,那么 BList 会包含多个子业务组件,并且调用每个业务组件的无参渲染函数,得到渲染后的界面。
51 | - 以 BDataGrid 业务组件为例,如果业务场景是每列皆为基础组件,那么直接由 BDataGrid 获取数据,并且根据每列的 Key 值,调用对应基础组件的渲染函数;如果业务场景是某些列为业务组件,那么会根据根据指定的业务组件 ID 调用对应业务组件的无参渲染函数,该业务组件的数据规则由服务端指定。
52 | - 该嵌套方式可能产生 N+1 Query 问题,由 API 模块或者服务端缓存解决。
53 |
--------------------------------------------------------------------------------
/电商系统/README.link:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/Solutions-Notes/45e603418fb3ca5ea111d70dd049dc00fea2d5d8/电商系统/README.link
--------------------------------------------------------------------------------
40 |
45 |
46 |
47 |
64 |
97 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
143 |
144 |
145 |
146 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/低代码平台/00~低代码设计理念/99~参考资料/2023~Low-Code Programming Models.md:
--------------------------------------------------------------------------------
1 | > [原文地址](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext)
2 |
3 | # Low-Code Programming Models
4 |
5 | Low-code is the subject of much current enthusiasm stirred by market research companies and confirmed by vendors rushing to embrace the label.7,31 But what low-code programming means is somewhat cryptic, let alone how it works. Moreover, scientific literature rarely uses the term. We can decode the term by breaking it into its components. Programming means developing computer programs, which comprise instructions for a computer to execute. Traditionally, programming means writing code in a textual programming language, such as C, Java, or Python. In contrast, low-code programming minimizes the use of a textual programming language. Instead, it aims to use alternative techniques closer to how users naturally think about their task.
6 |
7 | Users of low-code range from professional developers to so-called citizen developers. A citizen developer is an amateur programmer with little professional programming education. Citizen developers, having chosen a career different from programming, tend to have more domain expertise. Low-code enables domain experts to become citizen developers. At the same time, low-code platforms should also strive to make pro-developers (professionals with an education or career in software development) more productive.
8 |
9 | Whether used by a citizen developer or a pro-developer, low-code programming aims to save the time and tedium of performing a task by hand.35 Further motivation for individuals comes from the joy of creating something useful, thinking about tasks in a computational way, and acquiring programming skills that can advance their career. Businesses may have their own motivation for adopting low-code platforms, which can alleviate the shortage of pro-developers, reduce mistakes of tedious manual tasks, and multiply the time savings from one individual's low-code program to their colleagues.31 Another factor driving low-code is the rise of cloud-based software as a service, providing both more interfaces to automate and a platform on which to deploy automations.
10 |
11 | A few concepts are closely related to low-code programming. No-code programming is more purist, with zero handwritten code in a textual programming language. End-user programming (EUP) puts the emphasis on who is doing the programming (the end-user as citizen developer) rather than on how they are not doing their programming (not with textual code).6 This term is common in the academic literature and overlaps with low-code, but does not preclude the use of a textual programming language. Another gap between EUP and low-code is the latter aims to serve not just end users but also pro-developers.7,31
12 |
13 | Bock and Frank7 and Sahay et al.31 recently compared commercial low-code platforms, and Barricelli et al. recently mapped the EUP literature.6 In contrast, this article bridges the gap between low-code and the academic literature and adds missing details and perspective. Low-code encompasses more specialized techniques, such as visual programming languages (VPLs), programming by demonstration (PBD), programming by example (PBE), robotic process automation (RPA), programming by natural language (PBNL), and others. Surveys on these techniques are more specific and often dated.4,8,20,35 In contrast, this article reviews recent literature across all these techniques.
14 |
15 | Given that low-code offers citizen developers a model to create computer programs, this article explores low-code from the perspective of programming models. A programming model is a set of abstractions that supports developing computer programs. Programming models can be low-code or not, and they can be domain-specific or general-purpose. Some programming models are languages; for example, Java is a general-purpose language and SQL is domain-specific, and neither is low-code. Scratch is a low-code programming model for kids that is media-centric,29 making it domain-specific. The programming-model perspective helps highlight common techniques for writing, reading, and executing programs, and it helps relate low-code to research into program synthesis and domain-specific languages.
16 |
17 | This article includes a deep-dive into three prominent low-code techniques: visual programming, programming by demonstration, and programming by natural language. The deep-dive focuses on fundamental building blocks and a unifying framework common to all three. The citations in this article cover both seminal work and recent advances in low-code programming models, for instance, based on artificial intelligence. Moreover, this article aims to cut through the buzz surrounding low-code so as to expose the technical foundations underneath. Hopefully, doing so will foster better development of the field through awareness of existing (albeit scattered) research, and will ultimately lead to even more empowered citizen developers.
18 |
19 | ### Problem Statement
20 |
21 | If low-code is the solution, then what is the problem? Given the term low-code, it might seem the answer is obviously code. Unfortunately, that answer is superficial and nonconstructive. Defining a thing solely by what it is not, as the term low-code appears to do, causes confusion. Consider two other recent similarly named trends: NoSQL and serverless. At the surface, one might think NoSQL was mostly about rejecting SQL, but in fact, it was more about flexible data and consistency models than about the query language. Similarly, serverless computing was not about eliminating compute servers, but about hiding them behind better abstractions. Defining a new trend by rejecting an old one grabs attention at the expense of being misleading. Just like serverless still needs servers, low-code (and even no-code!) still needs code.
22 |
23 | The three terms—low-code, NoSQL, and serverless—have one thing in common: a desire to avoid specific baggage while preserving core value. In NoSQL, the core value is durable and consistent storage. In serverless, it is portable and elastic compute. What then is the core value that low-code aims to preserve? This article argues it is computer programming. Programming is to low-code what computing is to serverless. Low-code is about creating instructions for a computer to execute or interpret. These instructions form a computer program, typically in a domain-specific language (DSL). For instance, low-code is often based on search-based program synthesis, and synthesis usually targets a DSL carefully crafted for the purpose.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) The program may not be exposed to the user, but it is there.
24 |
25 | One way to better understand the problem statement behind low-code is to look at who it is for. The top portion of [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) shows the spectrum of low-code users. They range from citizen developers at one end to pro-developers at the other, with intermediate stages here dubbed semi developers. In this simplified view, users at the citizen developer end of the spectrum tend to have the most domain knowledge and users at the pro-developer end have the most programming expertise. Low-code can enable citizen developers to self-serve their programming needs instead of depending on pro-developers. At the same time, low-code can make pro-developers more productive, for example, in a new domain. Finally, low-code can break barriers between developers across the spectrum and help them collaborate on common ground.
26 |
27 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg)
28 | **Figure 1. Low-code users and techniques.**
29 |
30 | The middle portion of [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) shows three representative low-code techniques. Programming expertise induces a Venn diagram over the users, with the smallest subset being able to use the largest range of programming techniques. An edge between a set of users and a low-code technique indicates the users write or read a program with that technique. Specifically, all users can use programming by demonstration and programming by natural language (edges to the outermost set of users encompassing citizen-, semi-, and pro-developers). Only semi-developers and pro-developers can readily use visual programming, though citizen developers may be easily trained to do so, as evidenced by Scratch.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) And only pro-developers are likely to directly use a DSL. Therefore, while low-code typically targets a DSL, that DSL may not be exposed, or if it is, may only be exposed to pro-developers. That is especially true in the common case of a DSL that is embedded[17](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R17) in a general-purpose textual programming language such as Python.
31 |
32 | ---
33 |
34 | > _Just like serverless still needs servers, low-code (and even no-code!) still needs code._
35 |
36 | ---
37 |
38 | If the core value of low-code is to create computer programs, what exactly is it about created programs that is deemed valuable? One way to shed more light on this question is to look at a seemingly opposing trend, namely the as-code movement. The as-code movement started with infrastructure as code, which automates standing up compute resources and the services running on them from a source code repository and a backup.[18](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R18) Treating this process as code can speed it up, reduce mistakes, and facilitate testing. Another instance of as-code is security as code, where security policies, templates, and configuration files all live in a source code repository.[25](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R25) Treating them as code lets them be versioned, inspected by humans, and checked by machines. To summarize, the as-code movement sees value in programs that are repeatable, tested, versioned, human-readable, and machine-checkable. These are also desirable properties for low-code programs.
39 |
40 | When citizen developers use low-code, it is typically to create a program for a task they would otherwise do by hand. So what tasks is low-code good for? Generally speaking, low-code helps if it shaves off more time from a task than the time spent doing the low-code programming. This is true for tasks that are repetitive or time-consuming. Of course, the equation shifts when the program can be used not just by the developer who created it, but also by others, shaving time off their tasks as well. In the extreme, pro-developers create programs used by millions. Low-code is most appropriate when it saves time, but not enough time to make professional coding economically feasible. Low-code is suitable for tasks that are rule-based and low on exceptions. And besides the time savings, it can be even more beneficial when the tedium of doing the task by hand causes errors.
41 |
42 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
43 |
44 | ### Techniques
45 |
46 | Here, we take a deep-dive into three representative techniques for low-code programming: VPLs, PBD, and PBNL. These three are a good set for the following reasons. Sahay et al.'s paper declares low-code as synonymous with just one technique, VPLs,[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31) but that perspective seems too narrow. Barricelli et al. list 14 different techniques for EUP,[6](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R6) but they are not clearly separated, and reviewing them all in detail would get too long-winded. In the past, the dominant low-code technique has been spreadsheets.[9](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R9) The three chosen techniques instead align with present and future trends: VPLs are central to current commercial low-code platforms;[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31) PBD is the backbone of RPA, which often uses record-and-replay;[35](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R35) and PBNL is poised to grow thanks to advances in deep learning-based large language models.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11),[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33),[39](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R39)
47 |
48 | Furthermore, the three techniques are well-suited for citizen developers by drawing upon universal skills: VPLs draw upon seeing, PBD draws upon the ability to use a computer application, and PBNL draws upon speaking. In fact, low-code can offer an alternative modality when some other approach is impeded, such as using speech interfaces when a user's hands or eyes are unavailable. Finally, VPLs, PBD, and PBNL are sufficient to span a set of building blocks that can also be arranged differently for use with other low-code techniques, such as spreadsheets, rules, wizards, or templates. Not all building blocks appear in all techniques, but the following blocks recur enough to warrant brief up-front definitions:
49 |
50 | - code canvas: renders code, for example, visually as a flow graph;
51 | - palette: offers components for drag-and-drop selection;
52 | - text box: holds natural-language text used for code search, description, or generation;
53 | - player: has buttons for capture, replay, pause, or step;
54 | - stage: shows the effect of code execution; and,
55 | - configuration pane: lets the user customize components, for example, via graphical controls such as checkboxes or sliders, or textually by typing small formulas.
56 |
57 | Low-code techniques support not just writing programs, but also reading and executing them. A low-code system can execute the program immediately after it is written or save it for later, and the user may choose to execute the program multiple times, for example, after input data changes. Low-code techniques differ in which of the listed building blocks are engaged to read, write, or execute programs. Whereas [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) blurred the read/write/execute distinction by using undirected edges, the rest of this section explicates the distinction by using directed edges and colors (orange for read, dark blue for write, and purple for execute).
58 |
59 | **Visual programming languages.** _The user drags visual components from a palette to a canvas, connects them, and configures them._
60 |
61 | _Description._ Visual programming languages let users write programs by directly manipulating their visual representation. There is a plethora of possible visual representations,[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) often inspired by domain notation, such as electrical circuit diagrams. Two prominent domain-independent visual representations are boxes-and-arrows (for example, BPMN[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27)) or interlocking puzzle pieces (for example, Scratch[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29)). Here, boxes or puzzle pieces represent instructions in the program, and arrows between boxes or the interlock of pieces represent how data and control flows between instructions.
62 |
63 | Despite the diversity in visual languages, their programming environments tend to comprise similar building blocks, as depicted in [Figure 2](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f2.jpg). The central building block is the code canvas, where the user can both read (orange arrow from canvas to eye) and write (dark blue arrow from hand to canvas) the program. Writing the program also involves dragging components from the palette to the canvas and possibly configuring them in a separate configuration pane. The programming environment also often includes a stage, which visually shows a program execution, ideally live.[34](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R34) For example, in Scratch, the stage shows sprites in a virtual world. Besides making the environment more engaging, the stage is also crucial for program understanding and debugging. To facilitate this, the stage is usually tightly connected to the canvas, helping the user navigate back and forth.
64 |
65 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f2.jpg)
66 | **Figure 2. Visual programming languages.**
67 |
68 | _Strengths, weaknesses, and mitigations._ One strength of VPLs is they tend to be easy to read, especially when reusing notation already familiar to the domain expert,[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) or in visual builders for graphical user interfaces.[24](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R24) Another strength is that, in contrast to PBD or PBNL, VPLs are usually unambiguous, thus increasing programmer control and reducing mistakes. Finally, compared to textual programming languages, visual languages can rule out syntax errors[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) and even simple type errors[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) by construction.
69 |
70 | In the context of low-code programming, the main weakness of visual programming languages is they are not always self-explanatory; that is why [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) connects them to semi-developers. The mitigation for this need-to-learn is user education, and for some VPLs, education is a primary purpose.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) The visual notation can take up a lot of screen real estate; the mitigation is to elide detail, for example, by requiring a configuration pane or via modular language constructs.[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3),[26](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R26) Even the palette can get too full, hindering discoverability, which can be mitigated by search facilities. A drawback of visual languages compared to textual languages is they tend to be co-dependent on their visual programming environment, hindering the use of basic tools such as diffing or search, or of third-party tools such as linters or code generators. This can be mitigated by backing the visual language with a textual domain-specific language.[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37)
71 |
72 | _Literature._ Some seminal VPLs include BPMN-on-BPEL for modeling and executing business processes[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27) and the Scratch language for teaching kids programming.[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29) Boshernitsan and Downes chronicle early VPLs and categorize them into purely visual vs. hybrid (mixed with text), and complete (sufficient procedural abstraction and data abstraction to be self-hosting) or not.[8](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R8) Today, VPLs are central to commercial low-code platforms such as Appian, Mendix, and OutSystems.[31](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R31)
73 |
74 | Other papers address VPL implementation approaches, such as meta-tools (tool used to implement other tools) and the model-view-controller (MVC) pattern, which lets users manipulate the same model through multiple synchronized views. VisPro is a meta-tool for creating visual programming environments.[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) VisPro advocates for a coordinated set of visual and textual languages, using MVC to expose the same program (model) via multiple languages (views). More recently, Blockly is a meta-tool for creating VPLs with interlocking puzzle pieces[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28) such as those in Scratch. Some VPLs target pro-developers and are embedded in professional programming environments or languages. Projectional editing, such as in MPS,[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) doubles down on the MVC paradigm, where even the textual language is projected into a view precluding syntax errors. More recent work has demonstrated VPLs as libraries extending textual languages. A livelit is a user-defined VPL widget that can be used in place of a textual literal,[26](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R26) and Andersen et al. let users implement VPL widgets for literals, patterns, and templates.[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3)
75 |
76 | **Programming by demonstration.** _The user demonstrates the behavior on a canvas, with some configuration during or after recording._
77 |
78 | _Description._ In PBD, the user demonstrates how to perform a task by hand via the mouse and keyboard, and the PBD system records a program that can perform the same task automatically. As shown in [Figure 3](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f3.jpg), the demonstration happens on a stage, which may be a specific application like a spreadsheet, or a Web browser visiting a variety of sites and apps, or even a general computer desktop or smart-phone screen. Ideally, the recorded program abstracts from perceptions to a symbolic representation, for instance, by mapping pixel coordinates to a user-interface widget, or several keystrokes to a text string. Besides the stage, most PBD systems have a player with buttons to record and replay, plus often additional buttons such as pause or step (reminiscent of interactive debuggers).
79 |
80 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f3.jpg)
81 | **Figure 3. Programming by demonstration.**
82 |
83 | The program is most useful if executing it does not yield the same behavior as the initial demonstration, but rather, generalizes to different data. For example, a program for ordering a taxi to any new location is more general and more useful than a program for ordering a taxi to only a single hard-coded location. Generalizing typically requires identifying variables or parameters, and may even entail adding conditionals, loops, or function calls. Unfortunately, a single demonstration is an inherently ambiguous specification for such a more general program. Therefore, PBD systems often provide a configuration pane that allows users to disambiguate the generalization either during or after demonstration. Some PBD systems also have a code canvas that renders the recorded program for the user to read, for example, visually or in natural language.
84 |
85 | _Strengths, weaknesses, and mitigations._ The main strength of programming by demonstration is that the user can work directly with the software applications they are already familiar with from their day-to-day work.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) This makes PBD well suited for citizen developers, as there is no indirection between programming and execution. Furthermore, a demonstration is more concrete than a program in a different paradigm, since it works on specific values and has a straight-line flow of control and data.
86 |
87 | ---
88 |
89 | > _To turn a demonstration into a program, it must be generalized, and automatic generalization may not capture user's intent._
90 |
91 | ---
92 |
93 | Unfortunately, being so concrete is also PBD's main weakness: to turn a demonstration into a program, it must be generalized, and automatic generalization may not capture the user's intent.[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14) Mitigations include hand-configuration[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) or multishot demonstration.[15](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R15) PBD can be brittle with respect to the graphical user interface of the application on stage, especially when that changes; mitigations include heuristics and specialized recorders that can map perception to application-level concepts.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32) Generalization can also overshoot, allowing a program to plow ahead even in unforeseen circumstances.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) This can be mitigated by providing guardrails, such as an attended execution mode that asks the user to confirm before certain actions. Finally, PBD can result in programs that are difficult to understand because they include spurious steps or are too fine-grained, which is of course a problem in low-code programming.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) This can be mitigated by pruning and by discovering macro-steps.
94 |
95 | _Literature._ A good example of a PBD system is CoScripter, where the stage is a Web browser and the code canvas displays the program in natural language.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) The CoScripter paper describes interviews that informed its design, as well as experiences from real-world usage in a business setting. In Rousillon, the stage is also a Web browser and the canvas displays the program in a VPL, fusing sequences of several low-level steps into a single puzzle piece.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) In VASTA, the stage is the display of a mobile phone, and the system uses machine learning to reverse-engineer screenshots into user interface elements.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32) In DIYA, the stage is a Web browser and users customize the program during recording via voice input.[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14) PBD is used in commercial robotic process automation products (such as UIPath, Automation Anywhere, and BluePrism) that let a human demonstrate a process on the existing software and then refer to the automatic replay engine as a robot.[35](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R35)
96 |
97 | PBD is closely related to PBE, since a demonstration is an elaborate example. FlashFill is a seminal PBE system that uses example input and output columns in a spreadsheet to synthesize a program for transforming inputs to outputs.[15](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R15) Both PBD and PBE are based on program synthesis.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) Recent work has harnessed novel machine-learning techniques for program synthesis, such as learned search strategies in DeepCoder[5](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R5) and learned libraries in DreamCoder.[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13)
98 |
99 | PBD can be profitably combined with other low-code techniques. The play-in/play-out approach is a PBD system codesigned with its own VPL based on sequence diagrams.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) And SwaggerBot is a PBD system embedded in a natural-language conversational agent, enabling a form of PBNL.[36](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R36)
100 |
101 | **Programming by natural language.** _The user enters natural language text via keyboard or voice, and the system synthesizes a program._
102 |
103 | _Description._ In this low-code technique, the user enters text in natural language, either by typing on the keyboard or via speech-to-text. [Figure 4](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg) indicates these two possibilities via blue arrows from the user's hand or mouth to the text canvas. The PBNL system translates the user's text, or utterance, to a program. The system can optionally render the program on a code canvas for the user to read. This rendering might use a VPL, or it might use a controlled natural language[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) for a disambiguated version of the user's utterance. The system can also optionally show the effect of the program's execution on a stage. For example, if the program is a query in a spreadsheet, the spreadsheet is the stage, and the result can be shown as a new table.
104 |
105 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg)
106 | **Figure 4. Programming by natural language.**
107 |
108 | _Strengths, weaknesses, and mitigations._ The main strength of PBNL is that it is not just low-code, but more generally, low on demands during programming. As shown in [Figure 4](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f4.jpg), its programming environment has only three building blocks (text canvas, code canvas, and stage), all optional. That means PBNL in principle even works in circumstances where the user's hands and eyes are otherwise occupied.
109 |
110 | PBNL makes it particularly easy for citizen developers to create programs, but unfortunately, those programs are often wrong.[4](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R4) Natural language is ambiguous, since humans are often vague and tend to assume common ground and omit context. On top of that, natural language processing (NLP) technologies are imperfect. The optional code canvas and stage can mitigate this weakness, by showing the user the synthesized program or its effect, thus giving them a chance to correct it. Another mitigation is to encourage users to keep their utterances short and not take advantage of the full expressiveness of natural language, since simpler programs are easier to get right.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) Furthermore, some PBNL systems support hand-editing the program.
111 |
112 | ---
113 |
114 | > _A strength of programming by natural language is its expressiveness: natural language can express virtually anything humans want to communicate._
115 |
116 | ---
117 |
118 | Another strength of PBNL is its expressiveness: natural language can express virtually anything humans want to communicate. In theory, PBNL restricts neither the sophistication nor the domains of programs. On the flip-side, PBNL systems often require an aligned corpus of utterances and programs to train NLP models, and obtaining such a corpus is expensive. Mitigating this is an active research topic in the machine-learning research community.[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33),[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38)
119 |
120 | _Literature._ As an interdisciplinary field of research, PBNL is best illuminated through multiple surveys. Androutsopoulos et al. surveyed natural-language interfaces to databases, a prominent form of PBNL going back to the 1960s.[4](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R4) A common approach is to parse a natural-language utterance into a tree and then map that tree to a database query. Kuhn surveyed controlled natural languages (CNLs), which restrict inputs to be unambiguous while preserving some natural properties.[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) Compared to unrestricted natural language, CNLs may make it harder for citizen developers to write programs but may make it easier to write correct programs. Allamanis et al. surveyed machine learning for code, arguing that code has a "naturalness" that makes it possible to adapt various NLP technologies to work on code.[1](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R1) The survey covers some code-generating models relevant to PBNL.
121 |
122 | The most successful NLP technology applied to PBNL is semantic parsers, which are machine-learning models that translate from natural language to an abstract syntax tree (AST) of a program. For instance, SILT learns rule-based semantic parsers that have been demonstrated for programs that coach robotic soccer teams or for programs that query geographic databases.[19](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R19) The Overnight paper addresses the problem of obtaining an aligned corpus for training a semantic parser via synthetic data generation and crowdsourced paraphrasing.[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38) Pumice tackles the ambiguity of natural language by a dialogue, where the system prompts for clarification which the user can provide via natural language or demonstration.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) And Shin et al. show how to coax a pretrained large language model into doing semantic parsing without requiring fine-tuning.[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33)
123 |
124 | Another approach to PBNL is program synthesis, which typically searches a space of possible programs.[2](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R2) Desai et al. describe a meta-synthesizer that, given a DSL grammar and an aligned corpus, creates a synthesizer from natural language to programs in the DSL.[12](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R12) PBNL is not limited to domain-specific languages for citizen developers. Yin and Neubig describe a semantic parser that uses deep learning to encode a sequence of natural-language tokens, then decodes that into a Python AST.[39](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R39) Codex is a pre-trained large language model for natural language first fine-tuned on unlabeled code, then fine-tuned again on an aligned corpus of utterances and programs.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11)
125 |
126 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
127 |
128 | ### Perspectives
129 |
130 | While the previous discussion covered three low-code techniques in depth, here we cover cross-cutting topics beyond any single technique. The accompanying [table](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/ut1.jpg) compares the techniques discussed earlier. The Activity columns indicate how each technique supports the user in writing, reading, and executing programs. The main difference is in the Write column: users write programs mainly on the code canvas for VPLs, the stage for PBD, and a text canvas in PBNL. On the other hand, there is little difference in the Read and Execute columns: users read programs on a code canvas (if provided), and watch them executing on the stage (if visible). That hints at an opportunity for reuse across tools for different techniques.
131 |
132 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/ut1.jpg)
133 | **Table. Comparing low-code techniques.**
134 |
135 | A core problem with low-code programming is ambiguity. While visual programming languages can be rigorous and unambiguous, there is ambiguity in how to generalize from a demonstration to a program that works in different situations, and natural languages are inherently ambiguous as well. More ambiguous techniques may only work reliably on small and simple problems. Systems for PBD and PBNL must guess at the user's intent and are likely to guess wrong when programs get complicated. This motivates offering users an option to read or even correct programs or their executions.
136 |
137 | A core goal of low-code programming is to reduce the need to learn a programming language. Citizen developers can demonstrate a program or describe it in natural language without having been taught how to do so. Visual programming is often less self-explanatory, which is why [Figure 1](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f1.jpg) associates it more with semi-developers. On the other hand, depending on the user's attitude, the need-to-learn can also be good, since it grows computational thinking skills.
138 |
139 | _Artificial intelligence for low-code._ Does the ongoing rapid progress in AI fuel progress in low-code? This article argues that yes, it does, in proportion to the ambiguity of the low-code technique. Out of the three techniques in the table, AI is most prominent for PBNL, which is also the most ambiguous. PBNL can hardly avoid AI except by using a controlled natural language,[20](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R20) but that would make it feel more like code. Currently a rising AI approach for PBNL is to use large language models with code generation.[11](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R11),[33](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R33) PBNL will likely grow along with relevant advances in AI. AI is also prominent in PBD, characterized in the table as medium ambiguity. For example, DeepCoder shows the interplay between program synthesis for defining a space of possible programs and checking whether a given program is correct, and AI for guiding the search through that space.[5](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R5) As another example, VASTA uses speech recognition, object recognition, and optical character recognition to better understand a user's demonstration of a task.[32](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R32)
140 |
141 | _Communicating with humans and machines._ Pro-developers use code in textual programming languages to communicate with a computer, telling it what to do. In addition, developers can also use programming languages to communicate with each other or with their own future self. A low-level programming language such as C gives developers more control of the computer, whereas a high-level language such as Python arguably makes communication among humans more effective. Similarly, low-code programs can serve both to communicate instructions to a computer and to communicate among low-code users. Being even more high-level than, say, Python, low-code can serve as a lingua franca to help citizen developers and pro-developers communicate more effectively with each other. For instance, a citizen developer might use PBD to communicate a desired behavior to a pro-developer to flesh out.[16](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R16) Conversely, a pro-developer might use PBNL or a VPL to communicate a proposed behavior to a domain expert for explanation or approval.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21),[27](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R27)
142 |
143 | _Domain-specific languages for low-code._ All three low-code techniques noted earlier are intrinsically related to DSLs: most VPLs are DSLs (for example, Scratch[29](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R29)), and both programming by demonstration and programming by natural language usually target DSLs (DIYA targets its co-designed Thing-Talk 2.0 DSL[14](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R14)). Mernik et al. list further benefits of DSLs: they facilitate program analysis, verification, optimization, parallelization, and transformation (AVOPT).[23](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R23)
144 |
145 | While reviewing the low-code literature reveals a close tie to DSLs, those DSLs are not always exposed to the user. For instance, the DSL may manifest as a proprietary file format or as an undocumented internal representation. If the DSL is exposed, users can more easily read, test, and audit programs, version them and store them in a shared repository, and manipulate them with tools for program transformation or generation. Also, an exposed DSL is less locked into a specific programming environment or its vendor. When exposed, the DSL should be designed for humans, possibly based on interviews and user studies as role-modeled by Leshed et al.[21](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R21) On the other hand, a DSL that is not exposed will be shaped by different factors, such as the ease of enumerating valid programs, which can be improved by breaking symmetries in the search space.[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13)
146 |
147 | DSLs (including DSLs for low-code) may be embedded in a general-purpose language. Compared to a stand-alone DSL, an embedded DSL is often easier to implement (for example, due to not requiring a custom parser) and easier to use (due to syntax highlighting and auto-completion tools of the host language). The approach to implementing an embedded DSL depends on the facilities of the host language. One approach is Pure Embedding, which uses higher-order functions and lazy evaluation, such as in Haskell.[17](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R17) Another example is Lightweight Modular Staging, which uses operator overloading and dynamic compilation, such as in Scala.[30](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R30)
148 |
149 | _Model view controller._ The current state-of-the-art VPLs and associated meta-tools are based on the MVC pattern.[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28),[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) And in PBD or PBNL, even though the user does not use a code canvas to write a program, the system may optionally provide one for reading it, again using MVC. [Figure 5](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f5.jpg) illustrates MVC with a superset of the components from each low-code technique. Low-code programming tools provide one or more views of the program. Some of these views are read-only, while others are read-write views. When multiple views are present, the system keeps them in sync with a single joint model, and through that, with each other. Edits in one view are projected live to all other views. The model is a program in a DSL. Optionally, the system may even expose the textual DSL as another view, for instance, in a structure editor.[37](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R37) Besides the model and the view, the third part of the MVC pattern is the controller, which, for low-code, can contain a player and/or a configuration pane.
150 |
151 | [](https://dl.acm.org/cms/attachment/html/10.1145/3587691/assets/html/f5.jpg)
152 | **Figure 5. Model-view-controller for low-code.**
153 |
154 | _Combining multiple low-code techniques._ When users write a program by demonstration or by natural language, the system may let them read it on a code canvas. And once a system lets users read programs on a code canvas, a logical next step is to also let them write programs there, such as, to correct mistakes from generalization or from natural language processing. This yields a combination of low-code techniques, where users can write programs in multiple ways. Such combinations can compensate for weaknesses of techniques. For example, in Rousillon, the user first writes a program by demonstrating how to scrape data from web pages;[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) since one weakness of PBD is ambiguity, Rousillon lets the user read the resulting program in a scratch-like VPL.[10](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R10) Pumice combines PBD with PBNL: the user first writes a program via natural language; since one weakness of PBNL is ambiguity, Pumice next lets the user clarify with PBD.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22)
155 |
156 | _Meta-tools and meta-circularity._ A meta-tool for low-code is a tool used to implement low-code tools. In traditional programming languages, meta-tools (such as parser generators) have long been an essential part of the tool-writer's repertoire. Similarly, meta-tools for low-code can speed up the development of low-code tools by automating well-known but tedious pieces. Thus, meta-tools make it easier to build several tools or variants, for instance, to experiment with the user experience. There are examples of meta-tools for all three low-code techniques discussed previously. Blockly[28](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R28) is a tool for creating VPLs that look similar to Scratch; DreamCoder[13](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R13) is a tool for learning a library of reusable components along with a neural search policy for PBE; and Overnight[38](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R38) is a tool for building semantic parsers for PBNL with synthetic training data.
157 |
158 | A meta-circular tool for low-code is a meta-tool for low-code that is itself a low-code tool. Not all meta-tools are metacircular tools, as that requires them to be powerful enough for serious software development. Supporting all that power can compromise the tool's low-code nature: complex features can get in the way of learning easy ones. On the positive side, meta-circular tools can democratize the creation of low-code tools themselves. Furthermore, tool developers who use their own tools may empathize more with their users' needs. Examples for meta-circular low-code tools include VisPRO[40](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R40) and Racket[3](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R3) (both for VPLs).
159 |
160 | _Low-code foundation._ In addition to meta-tools, are there other reusable modules that make it easier to build new low-code tools? The beginning of the Techniques section listed several reusable building blocks for low-code programming interfaces: code canvas, palette, text box, player, stage, and configuration pane. Besides making it easier to create low-code tools, such reuse can also give different tools a more uniform look-and-feel, thus reducing the need-to-learn. In the case of multiple low-code tools for the same domain, reusing the same domain-specific language makes them more interoperable. Of course, low-code tools in different domains will require different DSLs, but they may still be able to reuse some sublanguage, such as expressions or formulas with basic arithmetic and logical operators and a function library. There are also AI components that can be reused across low-code tools, such as speech recognition modules, a search-based program synthesis engine, semantic parsers, or language models.
161 |
162 | _End-user software engineering._ Most of the discussion on low-code programming focuses on writing a program: low-code enables citizen developers to rapidly create a prototype. But what happens over time when these programs stick around, get used in new circumstances that the developer did not foresee, get modified or generalized, and proliferate? At that point, users need end-user software engineering (EUSE) for quality control, for instance, by showing test coverage, letting users add assertions, and helping them localize faults directly in their low-code programming environment.[9](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R9) Citizen developers often struggle with anticipating exceptional contexts for their programs; Pumice is a low-code tool that lets users extend programs with new branches when the unforeseen happens.[22](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#R22) Another way to support EUSE is to expose the DSL, which makes it easier to adopt established software development workflows and the associated tools (such as version-controlled source code repositories, regression tests, or issue trackers) for low-code. Those tools also facilitate collaboration between citizen developers and professional software engineers.
163 |
164 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
165 |
166 | ### Conclusion
167 |
168 | This article reviews research relevant to low-code programming models with a focus on visual programming, programming by demonstration, and programming by natural language. It maps low-code techniques to target users and discusses common building blocks, strengths, and weaknesses. This article argues that domain-specific languages and the model-view-controller pattern constitute a common backbone and unifying principle across low-code techniques.
169 |
170 | [Back to Top](https://cacm.acm.org/magazines/2023/10/276633-low-code-programming-models/fulltext#PageTop)
171 |
172 | ### References
173 |
174 | \1. Allamanis, M. et al. A survey of machine learning for big code and naturalness. _ACM Computing Surveys 51_, 4 (July 2018), 81:1–81:37; https://doi.org/10.1145/3212695
175 |
176 | \2. Alur, R. et al. Search-based program synthesis. _Commun. ACM 61_, 11 (Nov. 2018), 84–93; https://doi.org/10.1145/3208071.
177 |
178 | \3. Andersen, L. et al. Adding interactive visual syntax to textual code. In _Proceedings of 2020 Conf. Object-Oriented Programming, Systems, Languages, and Applications_; https://doi.org/10.1145/3428290.
179 |
180 | \4. Androutsopoulos, I. et al. Natural language interfaces to databases—An introduction. _Natural Language Engineering 1_, 1 (1995), 29–81; https://doi.org/10.1017/S135132490000005X.
181 |
182 | \5. Balog, M. et al. DeepCoder: Learning to write programs. In _Proceedings of 2017 Intern. Conf. Learning Representations_; https://openreview.net/forum?id=ByldLrqlx.
183 |
184 | \6. Barricelli, B.R. et al. End-user development, end-user programming and end-user software engineering: A systematic mapping study. _J. Systems and Software 149_, (2019), 101–137; https://doi.org/10.1016/j.jss.2018.11.041.
185 |
186 | \7. Bock, A.C., and Frank, U. Low-code platform. _Business & Information Systems Engineering 63_, (2021), 733–740; https://doi.org/10.1007/s12599-021-00726-8.
187 |
188 | \8. Boshernitsan, M., and Downes, M. Visual Programming Languages: A Survey. _Technical Report UCB/CSD-04-1368, 2004, UC Berkeley_; https://bit.ly/3P0SaX5
189 |
190 | \9. Burnett, M. et al. End-user software engineering. _Commun. ACM 47_, 9 (Sept. 2004), 53–58; https://doi.org/10.1145/1015864.1015889.
191 |
192 | \10. Chasins, S. et al. Rousillon: Scraping distributed hierarchical Web data. In _Proceedings of 2018 Symp. User Interface Software and Technology_, 963–975; https://doi.org/10.1145/3242587.3242661
193 |
194 | \11. Chen, M. Evaluating large language models trained on code, (2021); https://arxiv.org/abs/2107.03374
195 |
196 | \12. Desai, A. Program synthesis using natural language. In _Proceedings of 2016 Intern. Conf. Softw. Eng._, 345–356; https://doi.org/10.1145/2884781.2884786
197 |
198 | \13. Ellis, K. DreamCoder: Bootstrapping inductive program synthesis with wake-sleep library learning. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 835–850; https://doi.org/10.1145/3453483.3454080
199 |
200 | \14. Fischer, M.H. et al. DIY assistant: A multi-modal end-user programmable virtual assistant. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 312–327; https://doi.org/10.1145/3453483.3454046
201 |
202 | \15. Gulwani, S. Automating string processing in spreadsheets using input-output examples. In _Proceedings of 2011 Symp. Principles of Programming Languages._ 317–330; https://doi.org/10.1145/1926385.1926423
203 |
204 | \16. Harel, D., and Marelly, R. Specifying and executing behavioral requirements: The play-in/play-out approach. _Software and Systems Modeling 2_, (2003), 82–107; https://doi.org/10.1007/s10270-002-0015-5.
205 |
206 | \17. Hudak, P. Modular domain specific languages and tools. In _Proceedings of 1998 Intern. Conf. Software Reuse._ 134–142; https://doi.org/10.1109/ICSR.1998.685738
207 |
208 | \18. Jacob, A. Infrastructure as code. _Web Operations: Keeping the Data on Time._ J. Allspaw, and J. Robbins, (eds). O'Reilly, Chapter 5, (2010), 65–80.
209 |
210 | \19. Kate, R.J. et al. Learning to transform natural to formal languages. In _Proceedings of 2005 Conf. Artificial Intelligence._ 1062–106; http://www.aaai.org/Library/AAAI/2005/aaai05-168.php
211 |
212 | \20. Kuhn, T. A survey and classification of controlled natural languages. _Computational Linguistics 40_, 1 (2014), 121–170; https://bit.ly/42t3JsY.
213 |
214 | \21. Leshed, G. et al. CoScripter: Automating and sharing kow-to knowledge in the enterprise. In _Proceedings of 2008 Conf. Human Factors in Computing Systems_, 1719–1728; https://doi.org/10.1145/1357054.1357323
215 |
216 | \22. Li, T.J. et al. PUMICE: A multi-modal agent that learns concepts and conditionals from natural language and demonstrations. In _Proceedings of 2019 Symp. User Interface Software and Technology._ 577–589; https://doi.org/10.1145/3332165.3347899
217 |
218 | \23. Mernik, M. et al. When and how to develop domain-specific languages. _ACM Computing Surveys 37_, 4 (2005), 316–344; https://doi.org/10.1145/1118890.1118892.
219 |
220 | \24. Myers, B. et al. Past, present, and future of user interface software tools. _Trans. Computer-Human Interaction_ (Mar. 2000), 3–28; https://doi.org/10.1145/344949.34495
221 |
222 | \25. Myrbakken, H., and Colomo-Palacios, R. DevSecOps: A multivocal literature review. _Software Process Improvement and Capability Determination_ (2017), 17–29. https://doi.org/10.1007/978-3-319-67383-7_2.
223 |
224 | \26. Omar, C. et al. Filling Typed Holes with Live GUIs. In _Proceedings of 2021 Conf. Programming Language Design and Implementation._ 511–525; https://doi.org/10.1145/3453483.3454059
225 |
226 | \27. Ouyang, C. From BPMN process models to BPEL Web services. In _Proceedings of Intern. Conf. Web Services._ (2006); https://doi.org/10.1109/ICWS.2006.67
227 |
228 | \28. Pasternak, E. et al. Tips for creating a block language with Blockly. In _Proceedings of Blocks and Beyond Workshop_ (2017); https://doi.org/10.1109/BLOCKS.2017.8120404.
229 |
230 | \29. Resnick, M. et al. Scratch: Programming for all. _Commun. ACM 52_, 11 (Nov.2009), 60–67; https://doi.org/10.1145/1592761.1592779.
231 |
232 | \30. Rompf, T., and Odersky, M. Lightweight modular staging: A pragmatic approach to runtime code generation and compiled DSLs. _Commun. ACM 55_, 6 (June 2012), 121–130; https://doi.org/10.1145/2184319.2184345.
233 |
234 | \31. Sahay, A. et al. Supporting the understanding and comparison of low-code development platforms. In _Proceedings of Euromicro 2020 Conf. Software Engineering and Advanced Applications._ 71–178; https://doi.org/10.1109/SEAA51224.2020.00036
235 |
236 | \32. Sereshkeh, A.R. et al. VASTA: A vision and language-assisted smartphone task automation system. In _Proceedings of 2021 Conf. Intelligent User Interfaces._ 22–32; https://doi.org/10.1145/3377325.3377515
237 |
238 | \33. Shin, R. Constrained language models yield few-shot semantic parsers. In _Proceedings of 2021 Conf. Empirical Methods in Natural Language Processing, 7_, 699–7715; https://doi.org/10.18653/v1/2021.emnlp-main.608
239 |
240 | \34. Tanimoto, S.L. A perspective on the evolution of live programming. In _Proceedings of Intern. Workshop on Live Programming._ (2013), 31–34; https://doi.org/10.1109/LIVE.2013.6617346
241 |
242 | \35. van der Aalst, W.M. et al. Robotic process automation. _Business Spsampsps Information Systems Eng. 60_, (2018), 269–272. https://doi.org/10.1007/s12599018-0542-4.
243 |
244 | \36. Vaziri, M. et al. Generating Chat Bots from Web API Specifications. In _Proceedings of Symp. New Ideas, New Paradigms, and Reflections on Programming and Software._ (2017), 44–57; [http://doi.acm.org/10.1145/3133850.3133864](https://dx.doi.org/10.1145/3133850.3133864)
245 |
246 | \37. Voelter, M., and Lisson, S. Supporting diverse notations in MPS' projectional editor. In _Proceedings of Workshop on the Globalization of Modeling Languages._ (2014), 7–16; https://hal.inria.fr/hal-01074602/file/GEMOC2014-complete.pdf#page=13
247 |
248 | \38. Wang, Y. et al. Building a semantic parser overnight. In _Proceedings of the Annual Meeting of the Assoc. for Computational Linguistics._ (2015), 1332–1342; https://www.aclweb.org/anthology/P15-1129.pdf
249 |
250 | \39. Yin, P., and Neubig, G. A syntactic neural model for general-purpose code generation. In _Proceedings of the Annual Meeting of the Assoc. for Computational Linguistics._ (2017), 440–450; [http://dx.doi.org/10.18653/v1/P17-1041](https://dx.doi.org/10.18653/v1/P17-1041)
251 |
252 | \40. Zhang, K. et al. Design, construction, and application of a generic visual language generation environment. _IEEE Trans Softw Eng. 27_, 4 (2001), 289–307; https://doi.org/10.1109/32.917521.
253 |
--------------------------------------------------------------------------------
/低代码平台/00~低代码设计理念/低代码的不足.md:
--------------------------------------------------------------------------------
1 | # 低代码的不足
2 |
3 | 个人认为低代码就是个噱头,远远没有概念所说的具备那么广的适用性,只能是针对某个垂直领域业务的问题解决方案:软件设计 CAP 原则:性能、可用性,可延展性,三取二,低代码为了通用性,必然要舍弃性能跟可用性之一,而商业产品必须保证可用性,所以性能必然不够优先(三点都要也不是做不到,成本将大副增加),这就导致只能应用到对性能不敏感的 toB,toG,二这个领域又是各种 SAAS 服务商,系统集成商,云服务商的竞争之地,只靠低代码这个点无法获得足够的优势,最终只能靠与某服务商进行捆绑,否则一定会被淘汰。
4 |
--------------------------------------------------------------------------------
/低代码平台/README.md:
--------------------------------------------------------------------------------
1 | # 低代码搭建
2 |
3 | 低代码开发就是开发人员可以通过编写少量代码就可以快速生成应用程序的一种方法。所谓的低代码(low code),即可以看作一个像 Python 语言和 C# 语言一样的一种“东西”;也可以代表一种应用程序开发方式。因为用这种方式开发应用程序时,你需要手写的代码比通常的开发方式要少。简单来说,低代码开发就是将已有代码的可视化模块拖放到工作流中以创建应用程序的过程。由于它可以完全取代传统的手工编码应用程序的开发方法,技术娴熟的开发人员可以更智能、更高效地工作,而不会被重复的编码束缚住。相反,他们可以将精力集中于创建应用程序的 10% 部分,并使其具有与众不同的功能。
4 |
5 | 这个领域是创新最活跃的地方,从过去的发展历程中能看到一些演进脉络,从 Engine 的角度看,演进的背后有两种理念:
6 |
7 | 1、Coding Less:通过强大的 SDK、框架和工具让工程师更好地 Coding,专注在实现业务上
8 | 2、No Coding:通过可视化 IDE 达成不写代码,通过拖拽、编写配置文件就能完成应用开发
9 |
10 | 从开发者角度看,对 Engine 有三个期待:
11 |
12 | 1、Productivity:必须能提升生产力,让工程师可以高效地写出健壮、易维护的代码
13 | 2、Simple & Stupid:KISS 原则 的核心,让开发变简单不仅能提升效率,还能让更多人成为前端工程师
14 | 3、Business More:研发资源非常宝贵,让工程师专注在业务上是提升效能的关键
15 |
16 | 未来的演化也会遵循这些脉络,Coding Less、No Coding 各有其应用场景,需要结合业务特点选择侧重点进行投入。但有一点我觉得是必然的:要开发优质应用,还得靠 Coding,不过写的代码会越来越少。No Coding 过于完美,应用场景有限,再加上有成品 SaaS 作为更好的替代品,我更倾向于用 Coding Less 模式去实现业务主线,把一些机械性、重复性、一次性的开发工作通过 No Coding 模式搞定。不过 No Coding 的一个分支 Visual Programming 非常值得关注,它在编程教育领域应用前景非常好,Scratch、Blockly 是典型代表,而编程教育不仅蕴藏着巨大的商机,而且还会给我们带来源源不断的生力军。
17 |
18 | ## 低代码平台分类
19 |
20 | # 优劣分析
21 |
22 | ## 优势
23 |
24 | 低代码开发的好处主要有以下四点:
25 |
26 | - 速度:使用低代码开发,你可以同时为多个平台构建应用程序,并且在几天甚至在几小时以内就可以向项目相关人员提交工作示例。
27 |
28 | - 更多的资源:如果你在一个大型项目上工作,使用低代码开发,你就不必再等待具有专业技能的开发人员完成另一个冗长的项目,这意味着项目可以更高效、以更低廉的成本完成。
29 |
30 | - 低风险/高投资回报率:使用低代码开发,意味着强大的安全流程,数据集成和跨平台支持已经内置,并且可以轻松定制,这通常意味着更低的风险,并且可以将更多的时间集中在业务逻辑的实现上。
31 |
32 | - 快速部署:项目上线总是会让人神经紧张。而使用低代码开发,部署前的影响评估可以确保你的应用程序按预期工作。如果有任何异常发生,只需要一次单击,你就可以回滚你所做的所有改变。
33 |
34 | ## 缺陷
35 |
36 |
--------------------------------------------------------------------------------
/低代码平台/开源低代码平台/Supabase/README.md:
--------------------------------------------------------------------------------
1 | # Supabase
2 |
3 | # Links
4 |
5 | - https://supabase.com/blog/type-constraints-in-65-lines-of-sql
6 |
--------------------------------------------------------------------------------
/低代码平台/流程系统/README.md:
--------------------------------------------------------------------------------
1 | # 流程系统
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/README.md:
--------------------------------------------------------------------------------
1 | # Dynamic Form | 动态表单
2 |
3 | 所谓的动态表单,即前后端约定一套表单定义规范;根据此规范,后端提供表单描述配置 JSON Schema;前端将此配置传入到动态表单框架后即可动态渲染出整个表单。只需要通过一份配置,就能生产一个表单应用,它能够极大地提升我们的效率,组件的复用率等等。动态表单会提供一个基本的组件库,供业务或者开发同学通过可视化的一种方式来配置所要的表单。同时为了满足业务对表单校验逻辑、数据初始化、级联、业务属性等要求而抽象的一套功能模型。此外,为了使各种系统能够快速接入动态表单,采用插件的方式嵌入业务系统中,从而保证业务系统的操作连贯性。对于表单的 JSON Schema 描述,互联网工程组(IETF)组织曾经制定过相关草案。这份草案约定通过 jsonSchema、uiSchema、formData 三个 JSON Object 来完整的描述一个静态表单。
4 |
5 | - 组件库:丰富的自定义组件、沉淀业务组件
6 | - 可视化:提供可视化配置功能,实现所见即所得
7 | - 功能模型:校验器、数据源、业务属性等等
8 | - 业务隔离:平台工具,不提供具体业务,提供标准接口业务实现
9 | - 插件化:可嵌入业务系统中,保持业务系统配置的连续性
10 |
11 | 表单模型共有 6 个模块构成: 属性、数据源、校验器、字段、表单/模板、数据。对于表单的 JSON Schema 描述,互联网工程组(IETF)组织曾经制定过相关草案。这份草案约定通过 jsonSchema、uiSchema、formData 三个 JSON Object 来完整的描述一个静态表单。
12 |
13 | 
14 |
15 | 其实当你的业务量达到一定的量级,做很多流程审批任务协同之类的中后台产品的时候就会发现表单的需求真的是源源不断,大同小异,既浪费时间也浪费精力。我们通过 json schema 规范每个 UI 组件。这个规范其实包括了中后台系统的 UI 规范,约束设计师的随意发挥,从而降低开发维护成本。
16 |
17 | 
18 |
19 | # 表单配置可视化
20 |
21 | 表单的配置化其实就是将表单开发的逻辑,转化成为了一种结构,在前端看来,它是个 JSON 或者是个对象。手动编写表单配置是可以被可视化的工具所替代的,这样,表单的开发和维护就变得更加清晰、简便了,效率也会得到提升。一份配置对应着一个表单的时候,但我们在一个网站应用(业务)上有多种场景需要多个表单,这时候就会有多份配置,多份配置会就需要对齐进行管理,甚至需要动态化异步加载配置。我把配置相关的事情,也一并列入表单中台的设计之中,让链路更加地完整。
22 |
23 | 实现可视化的手段,就是通过表单来生产配置,然后渲染表单。
24 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/表单 Schema.md:
--------------------------------------------------------------------------------
1 | # Schema
2 |
3 | 在项目开发初期我们需要定义一个合适的 JSON Schema,所谓合适的 JSON Schema,就是指能满足现有的业务模型,尽量减少冗余的字段,又能支持一定的扩展。方便后续的维护更新扩展。一个 form 表单由 jsonSchema、uiSchema、formData、bizData 四个 json 来描述:
4 |
5 | - jsonSchema 中描述了表单的数据类型、数据源、数据项等配置;
6 |
7 | - uiSchema 描述了表单字段的渲染方法、渲染参数等;
8 |
9 | - formData 描述了表单初始填充的各个字段的初始值;
10 |
11 | - bizData 中是对表单字段的业务属性,注意的是,bizData 不会影响 Form 的渲染
12 |
13 | # react-json-schema
14 |
15 | react-jsonschema-form 是最初由 Firefox 开源的能够从 JSON Schema 中渲染出实际表单的 React 组件。
16 |
17 | ## JSONSchema
18 |
19 | ```json
20 | {
21 | "title": "A registration form",
22 | "description": "A simple form example.",
23 | "type": "object",
24 | "required": ["firstName", "lastName"],
25 | "properties": {
26 | "firstName": {
27 | "type": "string",
28 | "title": "First name"
29 | },
30 | "lastName": {
31 | "type": "string",
32 | "title": "Last name"
33 | },
34 | "age": {
35 | "type": "integer",
36 | "title": "Age"
37 | },
38 | "bio": {
39 | "type": "string",
40 | "title": "Bio"
41 | },
42 | "password": {
43 | "type": "string",
44 | "title": "Password",
45 | "minLength": 3
46 | },
47 | "telephone": {
48 | "type": "string",
49 | "title": "Telephone",
50 | "minLength": 10
51 | }
52 | }
53 | }
54 | ```
55 |
56 | ## UISchema
57 |
58 | ```json
59 | {
60 | "firstName": {
61 | "ui:autofocus": true,
62 | "ui:emptyValue": ""
63 | },
64 | "age": {
65 | "ui:widget": "updown",
66 | "ui:title": "Age of person",
67 | "ui:description": "(earthian year)"
68 | },
69 | "bio": {
70 | "ui:widget": "textarea"
71 | },
72 | "password": {
73 | "ui:widget": "password",
74 | "ui:help": "Hint: Make it strong!"
75 | },
76 | "date": {
77 | "ui:widget": "alt-datetime"
78 | },
79 | "telephone": {
80 | "ui:options": {
81 | "inputType": "tel"
82 | }
83 | }
84 | }
85 | ```
86 |
87 | ## 合并的 Schema
88 |
89 | ```json
90 | {
91 | "title": "A registration form",
92 | "description": "A simple form example.",
93 | "type": "object",
94 | "required": ["firstName", "lastName"],
95 | "properties": {
96 | "firstName": {
97 | "type": "string",
98 | "title": "First name",
99 | "ui:autofocus": true,
100 | "ui:emptyValue": ""
101 | },
102 | "lastName": {
103 | "type": "string",
104 | "title": "Last name"
105 | },
106 | "age": {
107 | "type": "integer",
108 | "title": "Age",
109 | "ui:widget": "updown",
110 | "ui:title": "Age of person",
111 | "ui:description": "(earthian year)"
112 | },
113 | "bio": {
114 | "type": "string",
115 | "title": "Bio",
116 | "ui:widget": "textarea"
117 | },
118 | "password": {
119 | "type": "string",
120 | "title": "Password",
121 | "minLength": 3,
122 | "ui:widget": "password",
123 | "ui:help": "Hint: Make it strong!"
124 | },
125 | "telephone": {
126 | "type": "string",
127 | "title": "Telephone",
128 | "minLength": 10,
129 | "ui:options": {
130 | "inputType": "tel"
131 | }
132 | }
133 | }
134 | }
135 | ```
136 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/动态表单/表单中台.md:
--------------------------------------------------------------------------------
1 | # 表单中台
2 |
3 | 表单中台是通过对表单进行了抽象,然后单独针对网站应用上的所有表单而设计的。它是对一个网站应用上面的所有表单,从前端开发者对表单相关的开发维护到用户提交数据到服务端,这样一个完整链路的抽象封装。表单中台是一个可以完全由前端驱动的产品,因为表单里面跟数据存储查询是可以相对对立的部分,不管数据跟哪个服务器进行通信,都是不需要关心的,标准应该有前端进行制定。这样,它就是一个去中心化的产品,同时也具备成为一个中台的可能。因为它是一个中台,所以它也是能够支撑和驱动各种 N 个中后台和业务发展的。
4 |
5 | 
6 |
7 | # 通信层与服务器
8 |
9 | 通信层磨平了与服务器进行通信的过程,这其中包括了配置的增删改查,表单数据的读写。接口标准由前端进行了定义。例如配置查询的接口:
10 |
11 | | 参数 | 类型 | 是否必须 | 说明 |
12 | | ------ | ---- | -------- | ------------------------------------------------------------------------ |
13 | | formId | Long | 否 | 表单 ID |
14 | | type | Long | 是 | 0 表示根据 userId 获取用户的配置列表,1 表示根据 formId 获取某个具体配置 |
15 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/展示型页面/H5 宣传页.md:
--------------------------------------------------------------------------------
1 | # H5 宣传页
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/展示型页面/展示型主页.md:
--------------------------------------------------------------------------------
1 | # 展示型主页
2 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/搭建协议/README.md:
--------------------------------------------------------------------------------
1 | # 搭建协议
2 |
3 | 所谓的搭建协议,即是一套面向开发者的 Schema 规范,用于规范化约束可视化编辑器的输出和渲染引擎(或者 Schema2Code)的输入,将编辑器和渲染引擎(或者 Schema2Code)解耦,保障编辑器和渲染引擎(或者 Schema2Code)的独立升级。
4 |
5 | 搭建协议的要求如下:
6 |
7 | - **语义化**:语义清晰,简明易懂,可读性强。
8 |
9 | - **渐进性描述**:搭建的本质是通过 源码组件 进行嵌套组合,从小往大、依次组合生成 组件、区块、页面,最终通过云端构建生成 应用 的过程。因此在搭建基础协议中,我们需要知道如何去渐进性的描述组件、区块、页面、应用这 4 个实体概念。
10 |
11 | - **生成标准源码**:明确每一个属性与源码对应的转换关系,可生成跟手写无差异的高质量标准源代码。
12 |
13 | - **可流通性**:产物能在不同搭建产品中流通,不涉及任何私域数据存储。
14 |
15 | - **面向多端**:不能仅面向 React,还有小程序等多端。
16 |
17 | - **支持国际化&无障碍访问标准的实现**
18 |
19 | # LegoSchema
20 |
--------------------------------------------------------------------------------
/低代码平台/页面搭建/搭建协议/组件系统.md:
--------------------------------------------------------------------------------
1 | # 低代码搭建系统
2 |
3 | 
4 |
5 | # 物料系统与组件分类
6 |
7 | - 业务场景搭建能力:可视化搭建、配置辅助编辑(JSON)、配置定向输出
8 |
9 | - 业务场景配置能力:商业规则(Biz Rules),场景化切割
10 |
11 | - 业务组件容器沉淀:端约束(Terminal Constraints),应用加载、数据采集、布局编排、组件通信
12 |
13 | - 业务组件物料沉淀:商业能力模型(Biz Model),电商域(会员,订单,物流,退款),CRM 域
14 |
15 | - 领域界面渲染引擎:表单域(Form),卡片域(Card),表格域(Table)
16 |
17 | - 通用组件物料沉淀:设计语言(Design Language),Ant Design,基础业务组件(Biz Components)
18 |
19 | - 通用视图底层框架:React,View,Angular
20 |
21 | 基于上面的业务视角的分类,我们可以在技术视角对组件层次再进行梳理:
22 |
23 | - 基础组件:
24 |
25 | - 基础组件定义了其 HTML 布局方式,与数据绑定规范,典型的譬如不包含指令/自定义元素的 Vue.js 模板。
26 | - 基础组件会提供渲染函数,执行数据到界面绑定的真实渲染操作。
27 | - 基础组件是系统的原子单元,由系统预置,不可再进行切分,也不可进行嵌套。
28 |
29 | - 组件样式:
30 |
31 | - 组件样式定义了组件统一的样式规范。
32 | - 仅有基础组件可以接收样式对象,根据统一的渲染规则渲染为样式组件。
33 |
34 | - 布局组件:
35 |
36 | - 组件布局会包含多个特殊的布局组件,允许某个业务组件为自身及其子组件进行布局。
37 |
38 | - 业务组件
39 |
40 | - 业务组件即可以有部分预置,也允许用户界面化自定义(Widget)。
41 | - 业务组件是对于样式组件、布局组件与数据的集合,最简单的业务组件譬如 Text 基础组件加上文本内容数据。
42 | - 业务组件会关心数据的获取方式,并且负责为自身的子基础组件渲染数据;业务组件会根据指定的子基础组件的 Key 值,将自身所具有的数据根据 Key 值提取,传递给子基础组件的渲染函数。
43 | - 业务组件仅提供*无参渲染函数*,换言之,某个业务组件的数据,应该由服务端直接指定,或者指定其获取方式。
44 |
45 | - 嵌套结构:描述了业务组件的嵌套层次。
46 | - 业务组件可以包含多个基础组件或者业务组件作为其子组件,使用布局组件描述组件间布局方式。
47 | - 业务组件具有唯一 ID,_扁平化存放_,允许根据 ID 进行动态索引,允许进行自身局部刷新;react-jsonschema-form 就是典型的业务组件。
48 | - 业务组件会将数据按照子基础组件 Key 值切分传递给自身的子基础组件,并且调用子基础组件的渲染函数,得到渲染后的界面。
49 | - 业务组件会将自身的子业务组件当做黑盒看待,业务组件仅会存放子业务组件的 ID,并且直接调用子业务组件的*无参渲染函数*,得到渲染后的界面。
50 | - 以 BList 业务组件为例,如果业务场景是每行结构皆相同的列表,那么 BList 会包含某个 List 基础组件,调用其渲染函数获得界面;如果业务场景是复杂的,每行不一致的业务组件,那么 BList 会包含多个子业务组件,并且调用每个业务组件的无参渲染函数,得到渲染后的界面。
51 | - 以 BDataGrid 业务组件为例,如果业务场景是每列皆为基础组件,那么直接由 BDataGrid 获取数据,并且根据每列的 Key 值,调用对应基础组件的渲染函数;如果业务场景是某些列为业务组件,那么会根据根据指定的业务组件 ID 调用对应业务组件的无参渲染函数,该业务组件的数据规则由服务端指定。
52 | - 该嵌套方式可能产生 N+1 Query 问题,由 API 模块或者服务端缓存解决。
53 |
--------------------------------------------------------------------------------
/电商系统/README.link:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/wx-chevalier/Solutions-Notes/45e603418fb3ca5ea111d70dd049dc00fea2d5d8/电商系统/README.link
--------------------------------------------------------------------------------