publishTopic = client.getTopic("baeldung");
63 | long clientsReceivedMessage
64 | = publishTopic.publish(new CustomMessage("This is a message"));
65 | ```
66 |
67 | 这可以从另一个应用程序或服务器发布。CustomMessage 对象将由侦听器接收,并按 onMessage 方法中的定义进行处理。
68 |
--------------------------------------------------------------------------------
/03~Spring Security/权限验证/表单登录.md:
--------------------------------------------------------------------------------
1 | # Spring Security 表单登录
2 |
3 | # Form Login | 用户名密码表单登录
4 |
5 | 本部分完整代码参考 [spring-security-form-login](https://github.com/wx-chevalier/Backend-Boilerplate/tree/master/java/spring/spring-security-login), 首先在 WebSecurityConfig 的 configure 方法中,注册路由表:
6 |
7 | ```java
8 | @Override
9 | protected void configure(HttpSecurity http) throws Exception {
10 | http
11 | .authorizeRequests()
12 | .antMatchers("/", "/home").permitAll()
13 | .anyRequest().authenticated()
14 | .and()
15 | .formLogin()
16 | .loginPage("/login")
17 | .permitAll()
18 | .and()
19 | .logout()
20 | .permitAll();
21 | }
22 | ```
23 |
24 | 然后需要声明 UserDetailsService,以供 Spring Context 来自动获取用户实例,该方法会在 `authenticationManager.authenticate()` 调用时被调用:
25 |
26 | ```java
27 | @Bean
28 | @Override
29 | public UserDetailsService userDetailsService() {
30 | UserDetails user =
31 | User.withDefaultPasswordEncoder()
32 | .username("user")
33 | .password("password")
34 | .roles("USER")
35 | .build();
36 |
37 | return new InMemoryUserDetailsManager(user);
38 | }
39 | ```
40 |
41 | 此时 Spring Security 为我们自动生成了 `/login` 与 `/logout` 两个 POST 接口,分别用来处理用户登录与登出,其对应的前台 Form 表单如下所示:
42 |
43 | ```html
44 |
53 | ```
54 |
55 | 在很多情况下,我们位于第三方存储中的密码是经过 Hash 混淆处理的,而不是直接读取的明文信息;此时我们可以为 Spring Security 提供自定义的密码编码器,来方便其执行比较操作:
56 |
57 | ```java
58 | @Override
59 | public void configure(AuthenticationManagerBuilder auth) throws Exception {
60 | auth.userDetailsService(userDetailsService).passwordEncoder(bCryptPasswordEncoder);
61 | }
62 | ```
63 |
64 | # Links
65 |
66 | - https://www.baeldung.com/spring-security-login
67 |
--------------------------------------------------------------------------------
/01~基础使用/03~依赖注入/应用上下文/自动配置.md:
--------------------------------------------------------------------------------
1 | # Spring 自动配置
2 |
3 | Spring 为我们提供了 @EnableAutoConfiguration 注解,当使用了该注解,Spring 会自动地扫描本地以及依赖中的 @Configuration 等注解的类来生成 Bean。
4 |
5 | # @Configuration
6 |
7 | 在早期的 Spring Boot 项目中,我们需要手动地指定 @Configuration:
8 |
9 | ```java
10 | @Configuration
11 | @ConfigurationProperties(prefix = "mail")
12 | public class ConfigProperties {
13 | private String hostName;
14 | private int port;
15 | private String from;
16 | // standard getters and setters
17 | }
18 | ```
19 |
20 | 如果我们不使用 @Configuration,则需要 `@EnableConfigurationProperties(ConfigProperties.class)` 在 Spring 应用类中进行绑定:
21 |
22 | ```java
23 | @SpringBootApplication
24 | @EnableConfigurationProperties(ConfigProperties.class)
25 | public class DemoApplication {
26 |
27 | public static void main(String[] args) {
28 | SpringApplication.run(DemoApplication.class, args);
29 | }
30 | }
31 | ```
32 |
33 | Spring 将自动绑定属性文件中定义的任何属性,该属性文件中带有前缀 mail 且名称与 ConfigProperties 类中的字段之一相同。或者使用 AutoConfiguration,这里配置的 EnableAutoConfiguration 会自动搜索使用 `@Configuration` 进行注解的类,同时 @ImportResource 是自动导入关联的 XML 文件。
34 |
35 | ```java
36 | @EnableAutoConfiguration
37 | @ImportResource("classpath:spring/applicationContext.xml")
38 | public class Application {
39 |
40 | public static void main(String[] args) throws Exception {
41 | SpringApplication.run(Application.class, args);
42 | }
43 | }
44 | ```
45 |
46 | 而在 Spring Boot 2.2 版本之后,Spring 通过类路径扫描查找并注册@ConfigurationProperties 类。因此,无需使用 @Component(和其他元注释,如@Configuration)注释此类,甚至无需使用 @EnableConfigurationProperties:
47 |
48 | ```java
49 | @ConfigurationProperties(prefix = "mail")
50 | public class ConfigProperties {
51 | private String hostName;
52 | private int port;
53 | private String from;
54 | // standard getters and setters
55 | }
56 | ```
57 |
58 | 当然,我们还可以使用 @ConfigurationPropertiesScan 来指定自定义地扫描路径:
59 |
60 | ```java
61 | @SpringBootApplication
62 | @ConfigurationPropertiesScan("wx")
63 | public class DemoApplication {
64 |
65 | public static void main(String[] args) {
66 | SpringApplication.run(DemoApplication.class, args);
67 | }
68 | }
69 | ```
70 |
--------------------------------------------------------------------------------
/02~数据库/02~MyBatis/Mybatis Plus/2023~Mybatis Plus 官方案例/06~多租户与优化.md:
--------------------------------------------------------------------------------
1 | # 多租户
2 |
3 | ```java
4 | public interface TenantLineHandler {
5 |
6 | /**
7 | * 获取租户 ID 值表达式,只支持单个 ID 值
8 | *
9 | *
10 | * @return 租户 ID 值表达式
11 | */
12 | Expression getTenantId();
13 |
14 | /**
15 | * 获取租户字段名
16 | *
17 | * 默认字段名叫: tenant_id
18 | *
19 | * @return 租户字段名
20 | */
21 | default String getTenantIdColumn() {
22 | return "tenant_id";
23 | }
24 |
25 | /**
26 | * 根据表名判断是否忽略拼接多租户条件
27 | *
28 | * 默认都要进行解析并拼接多租户条件
29 | *
30 | * @param tableName 表名
31 | * @return 是否忽略, true:表示忽略,false:需要解析并拼接多租户条件
32 | */
33 | default boolean ignoreTable(String tableName) {
34 | return false;
35 | }
36 | }
37 | ```
38 |
39 | - Mybatis Plus 配置
40 |
41 | ```java
42 | @Configuration
43 | @MapperScan("com.baomidou.mybatisplus.samples.tenant.mapper")
44 | public class MybatisPlusConfig {
45 |
46 | /**
47 | * 新多租户插件配置,一缓和二缓遵循mybatis的规则,需要设置 MybatisConfiguration#useDeprecatedExecutor = false 避免缓存万一出现问题
48 | */
49 | @Bean
50 | public MybatisPlusInterceptor mybatisPlusInterceptor() {
51 | MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
52 | interceptor.addInnerInterceptor(new TenantLineInnerInterceptor(new TenantLineHandler() {
53 | @Override
54 | public Expression getTenantId() {
55 | return new LongValue(1);
56 | }
57 |
58 | // 这是 default 方法,默认返回 false 表示所有表都需要拼多租户条件
59 | @Override
60 | public boolean ignoreTable(String tableName) {
61 | return !"user".equalsIgnoreCase(tableName);
62 | }
63 | }));
64 | // 如果用了分页插件注意先 add TenantLineInnerInterceptor 再 add PaginationInnerInterceptor
65 | // 用了分页插件必须设置 MybatisConfiguration#useDeprecatedExecutor = false
66 | // interceptor.addInnerInterceptor(new PaginationInnerInterceptor());
67 | return interceptor;
68 | }
69 |
70 | @Bean
71 | public ConfigurationCustomizer configurationCustomizer() {
72 | return configuration -> configuration.setUseDeprecatedExecutor(false);
73 | }
74 | }
75 | ```
76 |
--------------------------------------------------------------------------------
/04~工程实践/测试/JUnit 4/测试用例.md:
--------------------------------------------------------------------------------
1 | # JUnit 4
2 |
3 | - @Test(expected = Exception.class) 表示预期会抛出 Exception.class 的异常
4 | - @Ignore 含义是“某些方法尚未完成,暂不参与此次测试”。这样的话测试结果就会提示你有几个测试被忽略,而不是失败。一旦你完成了相应函数,只需要把@Ignore 注解删去,就可以进行正常的测试。
5 | - @Test(timeout=100) 表示预期方法执行不会超过 100 毫秒,控制死循环
6 | - @Before 表示该方法在每一个测试方法之前运行,可以使用该方法进行初始化之类的操作
7 | - @After 表示该方法在每一个测试方法之后运行,可以使用该方法进行释放资源,回收内存之类的操
8 | - @BeforeClass 表示该方法只执行一次,并且在所有方法之前执行。一般可以使用该方法进行数据库连接操作,注意该注解运用在静态方法。
9 | - @AfterClass 表示该方法只执行一次,并且在所有方法之后执行。一般可以使用该方法进行数据库连接关闭操作,注意该注解运用在静态方法。
10 |
11 | # TestSuite
12 |
13 | 如果你须有多个测试单元,可以合并成一个测试套件进行测试,况且在一个项目中,只写一个测试类是不可能的,我们会写出很多很多个测试类。可是这些测试类必须一个一个的执行,也是比较麻烦的事情。鉴于此,JUnit 为我们提供了打包测试的功能,将所有需要运行的测试类集中起来,一次性的运行完毕,大大的方便了我们的测试工作。并且可以按照指定的顺序执行所有的测试类。下面的代码示例创建了一个测试套件来执行两个测试单元。如果你要添加其他的测试单元可以使用语句 @Suite.SuiteClasses 进行注解。
14 |
15 | ```java
16 | @RunWith(Suite.class)
17 | @SuiteClasses({ JUnit1Test.class, StringUtilTest.class })
18 | public class JSuit {}
19 | ```
20 |
21 | TestSuite 测试包类——多个测试的组合 TestSuite 类负责组装多个 Test Cases。待测得类中可能包括了对被测类的多个测试,而 TestSuit 负责收集这些测试,使我们可以在一个测试中,完成全部的对被测类的多个测试。TestSuite 类实现了 Test 接口,且可以包含其它的 TestSuites。它可以处理加入 Test 时的所有抛出的异常。
22 |
23 | TestResult 结果类集合了任意测试累加结果,通过 TestResult 实例传递个每个测试的 Run() 方法。TestResult 在执行 TestCase 是如果失败会异常抛出 TestListener 接口是个事件监听规约,可供 TestRunner 类使用。它通知 listener 的对象相关事件,方法包括测试开始 startTest(Test test),测试结束 endTest(Test test),错误,增加异常 addError(Test test, Throwable t) 和增加失败 addFailure(Test test, AssertionFailedError t)。TestFailure 失败类是个“失败”状况的收集类,解释每次测试执行过程中出现的异常情况,其 toString() 方法返回“失败”状况的简要描述。
24 |
25 | # Assert
26 |
27 | JUnit 中的 assert 方法全部放在 Assert 类中,总结一下 JUnit 类中 assert 方法的分类:
28 |
29 | - `assertTrue/False([String message,]boolean condition)`: 判断一个条件是 true 还是 false。感觉这个最好用了,不用记下来那么多的方法名。
30 |
31 | - `fail([String message,])`: 失败,可以有消息,也可以没有消息。
32 |
33 | - `assertEquals([String message,]Object expected,Object actual)`: 判断是否相等,可以指定输出错误信息。第一个参数是期望值,第二个参数是实际的值。这个方法对各个变量有多种实现。在 JDK1.5 中基本一样。但是需要主意的是 float 和 double 最后面多一个 delta 的值。
34 |
35 | - `assertNotNull/Null([String message,]Object obj)`: 判读一个对象是否非空(非空)。
36 |
37 | - `assertSame/NotSame([String message,]Object expected,Object actual)`: 通过内存地址,判断两个对象是否指向同一个对象。
38 |
39 | - `failNotSame/failNotEquals(String message, Object expected, Object actual)`: 当不指向同一个内存地址或者不相等的时候,输出错误信息。注意信息是必须的,而且这个输出是格式化过的。
40 |
--------------------------------------------------------------------------------
/03~Spring Security/OAuth/Keycloak/README.md:
--------------------------------------------------------------------------------
1 | # 集成 Spring Security
2 |
3 | 之前,Spring Security OAuth 协议栈提供了将授权服务器设置为 Spring 应用的可能性。然后,我们必须将其配置为使用 JwtTokenStore,这样我们就可以使用 JWT 令牌。然而,OAuth 协议栈已经被 Spring 废弃,现在我们将使用 Keycloak 作为我们的授权服务器。所以这次,我们将把我们的授权服务器设置为 Spring Boot 应用中的嵌入式 Keycloak 服务器。它默认会发出 JWT 令牌,所以在这方面不需要任何其他配置。
4 |
5 | # Resource Server
6 |
7 | 首先在 application.yml 中进行如下定义:
8 |
9 | ```yaml
10 | server:
11 | port: 8081
12 | servlet:
13 | context-path: /resource-server
14 |
15 | spring:
16 | security:
17 | oauth2:
18 | resourceserver:
19 | jwt:
20 | issuer-uri: http://localhost:8083/auth/realms/baeldung
21 | jwk-set-uri: http://localhost:8083/auth/realms/baeldung/protocol/openid-connect/certs
22 | ```
23 |
24 | JWTs 包括 Token 内的所有信息。因此,资源服务器需要验证 Token 的签名,以确保数据没有被修改。jwk-set-uri 属性包含了服务器可用于此目的的公钥。issuer-uri 属性指向基础授权服务器的 URI,它也可以用来验证 iss 声明,作为一种额外的安全措施。
25 |
26 | 此外,如果没有设置 jwk-set-uri 属性,资源服务器将尝试使用 issuer-ui 从授权服务器元数据端点确定该密钥的位置。重要的是,添加 issuer-uri 属性强制要求我们在启动 Resource Server 应用程序之前,应该先让 Authorization Server 运行。现在让我们看看如何使用 Java 配置来配置 JWT 支持。
27 |
28 | ```java
29 | @Configuration
30 | public class SecurityConfig extends WebSecurityConfigurerAdapter {
31 |
32 | @Override
33 | protected void configure(HttpSecurity http) throws Exception {
34 | http.cors()
35 | .and()
36 | .authorizeRequests()
37 | .antMatchers(HttpMethod.GET, "/user/info", "/api/foos/**")
38 | .hasAuthority("SCOPE_read")
39 | .antMatchers(HttpMethod.POST, "/api/foos")
40 | .hasAuthority("SCOPE_write")
41 | .anyRequest()
42 | .authenticated()
43 | .and()
44 | .oauth2ResourceServer()
45 | .jwt();
46 | }
47 | }
48 | ```
49 |
50 | 在这里,我们覆盖了默认的 Http 安全配置。因此,我们需要明确地指定,我们希望这是个资源服务器,并且我们将分别使用 oauth2ResourceServer()和 jwt()方法来使用 JWT 格式的访问令牌。上面的 JWT 配置是默认的 Spring Boot 实例为我们提供的。这也可以被定制,我们很快就会看到。
51 |
52 | # Custom Claims in the Token
53 |
54 | 现在让我们设置一些基础设施,以便能够在授权服务器返回的访问令牌中添加一些自定义声明。框架提供的标准声明都是很好的,但大多数时候我们需要在令牌中添加一些额外的信息,以便在客户端使用。
55 |
56 | 让我们举一个自定义声明的例子,组织,它将包含一个给定用户的组织名称。
57 |
58 | ## Authorization Server Configuration
59 |
60 | 为此,我们需要在域定义文件 baeldung-realm.json 中添加一些配置:
61 |
62 | # Links
63 |
64 | - https://www.baeldung.com/spring-security-oauth-jwt
65 |
--------------------------------------------------------------------------------
/01~基础使用/03~依赖注入/Bean/Bean 注入.md:
--------------------------------------------------------------------------------
1 | # Bean 注入
2 |
3 | # Autowired
4 |
5 | ## 多线程注入
6 |
7 | 在多线程下如果使用 Autowired 来进行依赖注入,可能会出现 Null 异常,譬如如下代码:
8 |
9 | ```java
10 | public class UserThreadTask implements Runnable {
11 | @Autowired
12 | private UserThreadService userThreadService;
13 |
14 | @Override
15 | public void run() {
16 | AdeUser user = userThreadService.get("0");
17 | System.out.println(user);
18 | }
19 | }
20 | ```
21 |
22 | 造成这种注入失败的原因就是 spring 和多线程的安全问题,不支持这样的注入方式。我们可以通过构造函数传入到多线程环境中:
23 |
24 | ```java
25 | public class UserThreadTask implements Runnable {
26 | private UserThreadService userThreadService;
27 |
28 | public UserThreadTask(UserThreadService userThreadService) {
29 | this.userThreadService = userThreadService;
30 | }
31 |
32 | @Override
33 | public void run() {
34 | AdeUser user = userThreadService.get("0");
35 | System.out.println(user);
36 | }
37 | }
38 | ```
39 |
40 | 调用方式如下:
41 |
42 | ```java
43 | Thread t = new Thread(new UserThreadTask(userThreadService));
44 | t.start();
45 | ```
46 |
47 | 我们也可以通过 ApplicaContext 获取所需的 Service:
48 |
49 | ```java
50 | import org.springframework.beans.BeansException;
51 | import org.springframework.context.ApplicationContext;
52 | import org.springframework.context.ApplicationContextAware;
53 |
54 | public class ApplicationContextHolder implements ApplicationContextAware {
55 | private static ApplicationContext context;
56 |
57 | @Override
58 | public void setApplicationContext(ApplicationContext context)
59 | throws BeansException {
60 | ApplicationContextHolder.context = context;
61 | }
62 |
63 | // 根据 Bean name 获取实例
64 | public static Object getBeanByName(String beanName) {
65 | if (beanName == null || context == null) {
66 | return null;
67 | }
68 | return context.getBean(beanName);
69 | }
70 |
71 | // 只适合一个 class 只被定义一次的 bean(也就是说,根据 class 不能匹配出多个该 class 的实例)
72 | public static Object getBeanByType(Class clazz) {
73 | if (clazz == null || context == null) {
74 | return null;
75 | }
76 | return context.getBean(clazz);
77 | }
78 |
79 | public static String[] getBeanDefinitionNames() {
80 | return context.getBeanDefinitionNames();
81 | }
82 | }
83 | ```
84 |
85 | 调用方式如下:
86 |
87 | ```java
88 | UserService user = (UserService) ApplicationContextHolder.getBeanByName("userService");
89 | ```
90 |
91 | 这种方式不管是否为多线程,还是不接收 Spring 管理的类,都可以用这种方式获得 spring 管理的类。
92 |
--------------------------------------------------------------------------------
/03~Spring Security/策略配置/CSRF.md:
--------------------------------------------------------------------------------
1 | # CSRF
2 |
3 | 基于 Token 做 CSRF 防范的话,最基础的需要解决 Token 的生成、存储、查询等问题。针对这些问题,Spring Security 定义了 CSRF Token 仓库接口 org.springframework.security.web.csrf.CsrfTokenRepository.java。目前该接口有 3 个实现类:CookieCsrfTokenRepository、HttpSessionCsrfTokenRepository 以及 LazyCsrfTokenRepository。
4 |
5 | CookieCsrfTokenRepository 将 Token 信息存放于客户端的 Cookie 中;每次生成 Token 后将其保存到 Cookie 中,该 Token 随 Cookie 一起返回给客户端。客户端请求被 CSRF 保护的 URL 时,需要携带 Cookie,便于服务端 loadToken 使用。使用该类型 Token 仓库时,通常需要允许 Javascript 脚本从 Cookied 中获取 Token,因此需要将 Cookie 的 httpOnly 属性值设置为 false。如果 Javascript 不需要从 Cookie 中获取 Token(例如将 Token 存放于 Session 中),建议将 httponly 设置为 true,以提高安全性。默认存放在 Cookie 中的 Token 名为 XSRF-TOKEN。
6 |
7 | 服务端在收到请求以后,会从请求中提取 Token,并与仓库中的 Token 校验,以判断该请求是否合法。具体看,Spring Security 通过 Filter 的方式提供了 CSRF 校验逻辑 org.springframework.security.web.csrf.CsrfFilter。
8 |
9 | ```java
10 | @Override
11 | protected void doFilterInternal(HttpServletRequest request,
12 | HttpServletResponse response, FilterChain filterChain)
13 | throws ServletException, IOException {
14 | request.setAttribute(HttpServletResponse.class.getName(), response);
15 |
16 | // 从Token仓库中加载token。如果不存在则生成并保存之
17 | CsrfToken csrfToken = this.tokenRepository.loadToken(request);
18 | final boolean missingToken = csrfToken == null;
19 | if (missingToken) {
20 | csrfToken = this.tokenRepository.generateToken(request);
21 | this.tokenRepository.saveToken(csrfToken, request, response);
22 | }
23 | request.setAttribute(CsrfToken.class.getName(), csrfToken);
24 | request.setAttribute(csrfToken.getParameterName(), csrfToken);
25 |
26 | // 判断是否为需要保护的路径
27 | if (!this.requireCsrfProtectionMatcher.matches(request)) {
28 | filterChain.doFilter(request, response);
29 | return;
30 | }
31 |
32 | // 从请求头或参数中获取携带的token
33 | String actualToken = request.getHeader(csrfToken.getHeaderName());
34 | if (actualToken == null) {
35 | actualToken = request.getParameter(csrfToken.getParameterName());
36 | }
37 |
38 | // 比较请求中携带的token和仓库中的token是否一致,若不一致则请求非法
39 | if (!csrfToken.getToken().equals(actualToken)) {
40 | ...
41 | }
42 |
43 | filterChain.doFilter(request, response);
44 | }
45 | ```
46 |
47 | # Links
48 |
49 | - https://www.baeldung.com/spring-security-csrf
50 | - https://www.codesandnotes.be/2015/02/05/spring-securitys-csrf-protection-for-rest-services-the-client-side-and-the-server-side/
51 |
--------------------------------------------------------------------------------
/03~Spring Security/权限验证/基于 JWT 的验证/99~参考资料/2023~实现基于 JWT 的登录认证/02~注册与登录.md:
--------------------------------------------------------------------------------
1 | # 注册与登录
2 |
3 | 这里我们开始讨论 UserDetailsService 的具体实现,首先我们定义用到的用户模型:
4 |
5 | ```java
6 | @Entity
7 | @Data
8 | public class User {
9 |
10 | @Id
11 | @GeneratedValue(strategy= GenerationType.AUTO)
12 | private long id;
13 | @Column
14 | private String username;
15 | @Column
16 | @JsonIgnore
17 | private String password;
18 | @Column
19 | private long salary;
20 | @Column
21 | private int age;
22 |
23 | @ManyToMany(fetch = FetchType.EAGER, cascade = CascadeType.ALL)
24 | @JoinTable(name = "USER_ROLES", joinColumns = {
25 | @JoinColumn(name = "USER_ID") }, inverseJoinColumns = {
26 | @JoinColumn(name = "ROLE_ID") })
27 | private Set roles;
28 | }
29 |
30 | @Data
31 | @Entity
32 | public class Role {
33 |
34 | @Id
35 | @GeneratedValue(strategy = GenerationType.AUTO)
36 | private long id;
37 |
38 | @Column private String name;
39 |
40 | @Column private String description;
41 | }
42 | ```
43 |
44 | 然后我们定义 UserServiceImpl,其继承了 UserDetailsService,提供了 loadUserByUsername 方法:
45 |
46 | ```java
47 |
48 | @Service(value = "userService")
49 | public class UserServiceImpl implements UserDetailsService, UserService {
50 |
51 | @Autowired private UserDAO userDao;
52 |
53 | @Autowired private BCryptPasswordEncoder bcryptEncoder;
54 |
55 | @Override
56 | public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
57 | User user = userDao.findByUsername(username);
58 | if (user == null) {
59 | throw new UsernameNotFoundException("Invalid username or password.");
60 | }
61 | return new org.springframework.security.core.userdetails.User(
62 | user.getUsername(), user.getPassword(), getAuthority(user));
63 | }
64 |
65 | private Set getAuthority(User user) {
66 | Set authorities = new HashSet<>();
67 | user.getRoles()
68 | .forEach(
69 | role -> {
70 | // authorities.add(new SimpleGrantedAuthority(role.getName()));
71 | authorities.add(new SimpleGrantedAuthority("ROLE_" + role.getName()));
72 | });
73 | return authorities;
74 | // return Arrays.asList(new SimpleGrantedAuthority("ROLE_ADMIN"));
75 | }
76 |
77 | // ...
78 | }
79 | ```
80 |
81 | 这里 loadUserByUsername 检索到的用户会被填充到 User 对象中,并被添加到 SecurityContext 上下文中。
82 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/01~Spring 基础/第 2 章 开发 Web 应用程序/2.4 使用视图控制器.md:
--------------------------------------------------------------------------------
1 | ## 2.4 使用视图控制器
2 |
3 | 到目前为止,已经为 Taco Cloud 应用程序编写了三个控制器。尽管每个控制器在应用程序的功能上都有不同的用途,但它们几乎都遵循相同的编程模型:
4 |
5 | - 它们都用 @Controller 进行了注释,以表明它们是控制器类,应该由 Spring 组件扫描自动发现,并在 Spring 应用程序上下文中作为 bean 进行实例化。
6 | - 除了 HomeController 之外,所有的控制器都在类级别上使用 @RequestMapping 进行注释,以定义控制器将处理的基本请求模式。
7 | - 它们都有一个或多个方法,这些方法都用 @GetMapping 或 @PostMapping 进行了注释,以提供关于哪些方法应该处理哪些请求的细节。
8 |
9 | 即将编写的大多数控制器都将遵循这种模式。但是,如果一个控制器足够简单,不填充模型或流程输入(就像 HomeController 一样),那么还有另一种定义控制器的方法。请查看下一个程序清单,了解如何声明视图控制器 —— 一个只将请求转发给视图的控制器。程序清单 2.15 声明视图控制器。
10 |
11 | ```java
12 | package tacos.web;
13 |
14 | import org.springframework.context.annotation.Configuration;
15 | import org.springframework.web.servlet.config.annotation.ViewControllerRegistry;
16 | import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
17 |
18 | @Configuration
19 | public class WebConfig implements WebMvcConfigurer {
20 |
21 | @Override
22 | public void addViewControllers(ViewControllerRegistry registry) {
23 | registry.addViewController("/").setViewName("home");
24 | }
25 | }
26 | ```
27 |
28 | 关于 @WebConfig 最值得注意的是它实现了 WebMvcConfigurer 接口。WebMvcConfigurer 定义了几个配置 Spring MVC 的方法。尽管它是一个接口,但它提供了所有方法的默认实现,因此只需覆盖所需的方法。在本例中,覆盖了 addViewControllers() 方法。
29 |
30 | addViewControllers() 方法提供了一个 ViewControllerRegistry,可以使用它来注册一个或多个视图控制器。在这里,在注册表上调用 addViewController(),传入 “/”,这是视图控制器处理 GET 请求的路径。该方法返回一个 ViewControllerRegistration 对象,在该对象上立即调用 setViewName() 来指定 home 作为应该转发 “/” 请求的视图。
31 |
32 | 就像这样,已经能够用配置类中的几行代码替换 HomeController。现在可以删除 HomeController,应用程序的行为应该与以前一样。惟一需要做的其他更改是重新访问第 1 章中的 HomeControllerTest,从 @WebMvcTest 注释中删除对 HomeController 的引用,这样测试类就可以无错误地编译了。
33 |
34 | 这里,已经创建了一个新的 WebConfig 配置类来存放视图控制器声明。但是任何配置类都可以实现 WebMvcConfigurer 并覆盖 addViewController() 方法。例如,可以将相同的视图控制器声明添加到引导 TacoCloudApplication 类中,如下所示:
35 |
36 | ```java
37 | @SpringBootApplication
38 | public class TacoCloudApplication implements WebMvcConfigurer {
39 |
40 | public static void main(String[] args) {
41 | SpringApplication.run(TacoCloudApplication.class, args);
42 | }
43 |
44 | @Override
45 | public void addViewControllers(ViewControllerRegistry registry) {
46 | registry.addViewController("/").setViewName("home");
47 | }
48 | }
49 | ```
50 |
51 | 通过扩展现有的配置类,可以避免创建新的配置类,从而降低项目工件数量。但是我倾向于为每种配置(web、数据、安全性等等)创建一个新的配置类,保持应用程序引导配置的简洁。
52 |
53 | 说到视图控制器,更一般地说,是控制器将请求转发给的视图,到目前为止,已经为所有视图使用了 Thymeleaf。我非常喜欢 Thymeleaf,但也许你更喜欢应用程序视图的不同模板模型。让我们看看 Spring 支持的许多视图选项。
54 |
--------------------------------------------------------------------------------
/04~工程实践/测试/JUnit 4/单元测试.md:
--------------------------------------------------------------------------------
1 | # Unit Test
2 |
3 | ```java
4 | @RunWith(SpringJUnit4ClassRunner.class)
5 | @WebAppConfiguration
6 | @ActiveProfiles("dev")
7 | @SpringApplicationConfiguration(
8 | classes = { Application.class, MockServletContext.class }
9 | )
10 | @ImportResource("classpath:spring/applicationContext.xml")
11 | public class AbstractTest {}
12 | ```
13 |
14 | You will want to add a test for the endpoint you added, and Spring Test already provides some machinery for that, and it’s easy to include in your project. Add this to your build file’s list of dependencies:
15 |
16 | ```groovy
17 | testCompile("org.springframework.boot:spring-boot-starter-test")
18 | ```
19 |
20 | If you are using Maven, add this to your list of dependencies:
21 |
22 | ```xml
23 |
24 | org.springframework.boot
25 | spring-boot-starter-test
26 | test
27 |
28 | ```
29 |
30 | Now write a simple unit test that mocks the servlet request and response through your endpoint:
31 |
32 | ```java
33 | @RunWith(SpringJUnit4ClassRunner.class)
34 | @SpringApplicationConfiguration(classes = MockServletContext.class)
35 | @WebAppConfiguration
36 | public class HelloControllerTest {
37 | private MockMvc mvc;
38 |
39 | @Autowired
40 | private WebApplicationContext wac;
41 |
42 | /**如果是配置启用整个Web环境
43 | @Before
44 | public void setUp() throws Exception {
45 | this.mvc = MockMvcBuilders.webAppContextSetup(this.wac).build();
46 | }
47 | **/
48 | @Before
49 | public void setUp() throws Exception {
50 | mvc = MockMvcBuilders.standaloneSetup(new HelloController()).build();
51 | }
52 |
53 | @Test
54 | public void getHello() throws Exception {
55 | mvc
56 | .perform(
57 | MockMvcRequestBuilders.get("/").accept(MediaType.APPLICATION_JSON)
58 | )
59 | .andExpect(status().isOk())
60 | .andExpect(content().string(equalTo("Greetings from Spring Boot!")));
61 | }
62 | }
63 | ```
64 |
65 | Note the use of the `MockServletContext` to set up an empty `WebApplicationContext` so the `HelloController` can be created in the `@Before` and passed to`MockMvcBuilders.standaloneSetup()`. An alternative would be to create the full application context using the `Application` class and `@Autowired` the `HelloController` into the test. The `MockMvc` comes from Spring Test and allows you, via a set of convenient builder classes, to send HTTP requests into the `DispatcherServlet` and make assertions about the result.
66 |
--------------------------------------------------------------------------------
/02~数据库/02~MyBatis/MyBatis 基础使用/01~配置使用/2023~MyBatis 基础使用/04~注解映射.md:
--------------------------------------------------------------------------------
1 | # MyBatis 注解方式
2 |
3 | 在 MyBatis 3.0 之后,即可以直接以 Annotation 方式将 SQL 与配置写在 Java 文件中,也可以直接写在 XML 文件中。笔者建议的简单的 SQL 语句可以直接以 Annotation 方式编写,复杂的 SQL 语句可以写在 XML 文件中。
4 |
5 | ```java
6 | public interface BlogMapper
7 | {
8 | @Insert('INSERT INTO BLOG(BLOG_NAME, CREATED_ON) VALUES(#{blogName}, #{createdOn})')
9 | @Options(useGeneratedKeys=true, keyProperty='blogId')
10 | public void insertBlog(Blog blog);
11 |
12 | @Select('SELECT BLOG_ID AS blogId, BLOG_NAME as blogName, CREATED_ON as createdOn FROM BLOG WHERE BLOG_ID=#{blogId}')
13 | public Blog getBlogById(Integer blogId);
14 |
15 | @Select('SELECT * FROM BLOG ')
16 | @Results({
17 | @Result(id=true, property='blogId', column='BLOG_ID'),
18 | @Result(property='blogName', column='BLOG_NAME'),
19 | @Result(property='createdOn', column='CREATED_ON')
20 | })
21 | public List getAllBlogs();
22 |
23 | @Update('UPDATE BLOG SET BLOG_NAME=#{blogName}, CREATED_ON=#{createdOn} WHERE BLOG_ID=#{blogId}')
24 | public void updateBlog(Blog blog);
25 |
26 | @Delete('DELETE FROM BLOG WHERE BLOG_ID=#{blogId}')
27 | public void deleteBlog(Integer blogId);
28 |
29 | }
30 | ```
31 |
32 | # 查询
33 |
34 | # 结果集
35 |
36 | # 插入
37 |
38 | ```java
39 | @Options(useGeneratedKeys = true, keyProperty = "challenge_id")
40 | @Insert("insert into t_challenge(" +
41 | "challenge_user_id_creator," +
42 | "challenge_city_id)" +
43 | "values(" +
44 | "#{challenge_user_id_creator}," +
45 | "#{challenge_city_id}" +
46 | ");")
47 | public boolean insertChallenge(ChallengeResource.Entity challenge);
48 | ```
49 |
50 | ## 多行插入
51 |
52 | ```java
53 | @Options(useGeneratedKeys = false, keyProperty = "challengeAttendResourceList[].challenge_attend_id", keyColumn = "challenge_attend_id")
54 | @Insert("")
66 | public boolean insertChallengeAttendSingleOrMultiple(@Param("challengeAttendResourceList") List challengeAttendResourceList);
67 | ```
68 |
--------------------------------------------------------------------------------
/01~基础使用/05~拦截与切面/异步拦截器.md:
--------------------------------------------------------------------------------
1 | # 异步拦截器
2 |
3 | Spring MVC 给提供了异步拦截器,能让我们更深入的参与进去异步 request 的生命周期里面去。其中最为常用的为:AsyncHandlerInterceptor:
4 |
5 | ```java
6 | public class AsyncHelloInterceptor implements AsyncHandlerInterceptor {
7 |
8 | // 这是Spring3.2提供的方法,专门拦截异步请求的方式
9 | @Override
10 | public void afterConcurrentHandlingStarted(
11 | HttpServletRequest request,
12 | HttpServletResponse response,
13 | Object handler
14 | )
15 | throws Exception {
16 | System.out.println(
17 | Thread.currentThread().getName() +
18 | "---afterConcurrentHandlingStarted-->" +
19 | request.getRequestURI()
20 | );
21 | }
22 |
23 | @Override
24 | public boolean preHandle(
25 | HttpServletRequest request,
26 | HttpServletResponse response,
27 | Object handler
28 | )
29 | throws Exception {
30 | System.out.println(
31 | Thread.currentThread().getName() +
32 | "---preHandle-->" +
33 | request.getRequestURI()
34 | );
35 | return true;
36 | }
37 |
38 | @Override
39 | public void postHandle(
40 | HttpServletRequest request,
41 | HttpServletResponse response,
42 | Object handler,
43 | ModelAndView modelAndView
44 | )
45 | throws Exception {
46 | System.out.println(
47 | Thread.currentThread().getName() +
48 | "---postHandle-->" +
49 | request.getRequestURI()
50 | );
51 | }
52 |
53 | @Override
54 | public void afterCompletion(
55 | HttpServletRequest request,
56 | HttpServletResponse response,
57 | Object handler,
58 | Exception ex
59 | )
60 | throws Exception {
61 | System.out.println(
62 | Thread.currentThread().getName() +
63 | "---afterCompletion-->" +
64 | request.getRequestURI()
65 | );
66 | }
67 | }
68 | ```
69 |
70 | AsyncHandlerInterceptor 提供了一个 afterConcurrentHandlingStarted()方法, 这个方法会在 Controller 方法异步执行时开始执行, 而 Interceptor 的 postHandle 方法则是需要等到 Controller 的异步执行完才能执行。比如我们用 DeferredResult 的话,afterConcurrentHandlingStarted 是在 return 的之后执行,而 postHandle()是执行.setResult()之后执行。
71 |
72 | 需要说明的是:如果我们不是异步请求,afterConcurrentHandlingStarted 是不会执行的。所以我们可以把它当做加强版的 HandlerInterceptor 来用。平时我们若要使用拦截器,建议使用它。同样可以注册 CallableProcessingInterceptor 或者一个 DeferredResultProcessingInterceptor 用于更深度的集成异步 request 的生命周期:
73 |
74 | ```java
75 | @Override
76 | public void configureAsyncSupport(AsyncSupportConfigurer configurer) {
77 | // 注册异步的拦截器、默认的超时时间、任务处理器TaskExecutor等等
78 | //configurer.registerCallableInterceptors();
79 | //configurer.registerDeferredResultInterceptors();
80 | //configurer.setDefaultTimeout();
81 | //configurer.setTaskExecutor();
82 | }
83 | ```
84 |
--------------------------------------------------------------------------------
/01~基础使用/03~依赖注入/参数配置/README.md:
--------------------------------------------------------------------------------
1 | # Spring Boot 参数配置
2 |
3 | Spring Boot 针对我们常用的开发场景提供了一系列自动化配置来减少原本复杂而又几乎很少改动的模板化配置内容。但是,我们还是需要去了解如何在 Spring Boot 中修改这些自动化的配置内容,以应对一些特殊的场景需求,比如:我们在同一台主机上需要启动多个基于 Spring Boot 的 web 应用,若我们不为每个应用指定特别的端口号,那么默认的 8080 端口必将导致冲突。
4 |
5 | # 程序中设置参数
6 |
7 | 在 `database.xml` 中可以这么写:
8 |
9 | ```xml
10 | ...
11 |
16 |
17 |
18 | ...
19 | ```
20 |
21 | 我们可以通过在启动应用程序时设置特定属性或通过自定义嵌入式服务器配置来以编程方式配置端口。
22 |
23 | ```java
24 | @SpringBootApplication
25 | public class CustomApplication {
26 |
27 | public static void main(String[] args) {
28 | SpringApplication app = new SpringApplication(CustomApplication.class);
29 | app.setDefaultProperties(Collections.singletonMap("server.port", "8083"));
30 | app.run(args);
31 | }
32 | }
33 | ```
34 |
35 | 我们也可以直接设置实体类的属性,来修改端口号:
36 |
37 | ```java
38 | @Component
39 | public class ServerPortCustomizer
40 | implements WebServerFactoryCustomizer {
41 |
42 | @Override
43 | public void customize(ConfigurableWebServerFactory factory) {
44 | factory.setPort(8086);
45 | }
46 | }
47 | ```
48 |
49 | 也可以使用 properties 属性:
50 |
51 | ```java
52 | public static void main(String[] args) {
53 | new SpringApplicationBuilder(Application.class).properties(properties()).run(args);
54 | }
55 |
56 | // 手动注入写死的配置信息
57 | private static Properties properties() {
58 | Properties properties = new Properties();
59 |
60 | Locale locale = Locale.getDefault();
61 | properties.setProperty("locale.language", locale.getLanguage());
62 | properties.setProperty("locale.country", locale.getCountry());
63 |
64 | properties.setProperty("management.endpoints.web.exposure.include", "*");
65 | properties.setProperty("management.endpoints.web.exposure.include", "*");
66 |
67 | String druidPrefix = "spring.datasource";
68 |
69 | properties.setProperty(druidPrefix + ".type", "com.alibaba.druid.pool.DruidDataSource");
70 | properties.setProperty(druidPrefix + ".druid.max-active", "50");
71 | properties.setProperty(druidPrefix + ".druid.min-idle", "5");
72 | // properties.setProperty(druidPrefix + ".druid.remove-abandoned", "true");
73 | // properties.setProperty(druidPrefix + ".druid.remove-abandoned-timeout-millis", "120000");
74 |
75 | return properties;
76 | }
77 | ```
78 |
79 | # Links
80 |
81 | - https://mp.weixin.qq.com/s/e0tO2zogV-L6mXLfaiFCfw?from=groupmessage&isappinstalled=0 这样讲 SpringBoot 自动配置原理,你应该能明白了吧
82 |
--------------------------------------------------------------------------------
/02~数据库/05~数据库工具/数据库迁移/Flyway/README.md:
--------------------------------------------------------------------------------
1 | # Flyway
2 |
3 | Flyway 是一个简单开源数据库版本控制器(约定大于配置),主要提供 migrate、clean、info、validate、baseline、repair 等命令。它支持 SQL(PL/SQL、T-SQL)方式和 Java 方式,支持命令行客户端等,还提供一系列的插件支持(Maven、Gradle、SBT、ANT 等)。
4 |
5 | # 快速开始
6 |
7 | 在 start.spring.io 上新建一个 SpringBoot 工程,要求能连上自己本地新建的 mysql 数据库 flyway;但要注意的是,application.properties 中数据库的配置务必配置正确,下述步骤中系统启动时,flyway 需要凭借这些配置连接到数据库:
8 |
9 | ```conf
10 | # db config
11 | spring.datasource.url=jdbc:mysql://localhost:3306/flyway?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT
12 | spring.datasource.username=root
13 | spring.datasource.password=root
14 | spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
15 | ```
16 |
17 | 首先,在 pom 文件中引入 flyway 的核心依赖包:
18 |
19 | ```xml
20 |
21 | org.flywaydb
22 | flyway-core
23 | 5.2.4
24 |
25 | ```
26 |
27 | 其次,在 src/main/resources 目录下面新建 db.migration 文件夹,默认情况下,该目录下的.sql 文件就算是需要被 flyway 做版本控制的数据库 SQL 语句。但是此处的 SQL 语句命名需要遵从一定的规范,否则运行的时候 flyway 会报错。命名规则主要有两种:
28 |
29 | - 仅需要被执行一次的 SQL 命名以大写的"V"开头,后面跟上"0~9"数字的组合,数字之间可以用“.”或者下划线"\_"分割开,然后再以两个下划线分割,其后跟文件名称,最后以.sql 结尾。比如,`V2.1.5__create_user_ddl.sql、V4.1_2__add_user_dml.sql`。
30 | - 可重复运行的 SQL,则以大写的“R”开头,后面再以两个下划线分割,其后跟文件名称,最后以.sql 结尾。比如,`R__truncate_user_dml.sql`。
31 |
32 | 其中,V 开头的 SQL 执行优先级要比 R 开头的 SQL 优先级高。如下,我们准备了三个脚本,分别为:
33 |
34 | - `V1__create_user.sql`,其中代码如下,目的是建立一张 user 表,且只执行一次。
35 |
36 | ```sql
37 | CREATE TABLE IF NOT EXISTS `USER`(
38 | `USER_ID` INT(11) NOT NULL AUTO_INCREMENT,
39 | `USER_NAME` VARCHAR(100) NOT NULL COMMENT '用户姓名',
40 | `AGE` INT(3) NOT NULL COMMENT '年龄',
41 | `CREATED_TIME` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
42 | `CREATED_BY` varchar(100) NOT NULL DEFAULT 'UNKNOWN',
43 | `UPDATED_TIME` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
44 | `UPDATED_BY` varchar(100) NOT NULL DEFAULT 'UNKNOWN',
45 | PRIMARY KEY (`USER_ID`)
46 | )ENGINE=InnoDB DEFAULT CHARSET=utf8;
47 | ```
48 |
49 | - `V2__add_user.sql`,其中代码如下,目的是往 user 表中插入一条数据,且只执行一次。
50 |
51 | ```sql
52 | insert into `user`(user_name,age) values('lisi',33);
53 | ```
54 |
55 | - `R__add_unknown_user.sql`,其中代码如下,目的是每次启动倘若有变化,则往 user 表中插入一条数据。
56 |
57 | ```sql
58 | insert into `user`(user_name,age) values('unknown',33);
59 | ```
60 |
61 | 
62 |
63 | 其中 2.1.6、2.1.7 和 every 的文件夹不会影响 flyway 对 SQL 的识别和运行,可以自行取名和分类。执行 Flyway Migrate 指令,可以看到会生成如下的表:
64 |
65 | 
66 |
67 | 而且,user 表也已经创建好了并插入了两条数据:
68 |
69 | 
70 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/01~Spring 基础/第 1 章 Spring 入门/1.4 俯瞰 Spring 风景线.md:
--------------------------------------------------------------------------------
1 | ## 1.4 俯瞰 Spring 风景线
2 |
3 | 要了解 Spring 的风景线,只需查看完整版 Spring Initializr web 表单上的大量复选框列表即可。它列出了 100 多个依赖项选择,所以我不会在这里全部列出或者提供一个屏幕截图。但我鼓励你们去看看。与此同时,我将提到一些亮点。
4 |
5 | ### 1.4.1 Spring 核心框架
6 |
7 | 正如你所期望的,Spring 核心框架是 Spring 领域中其他一切的基础。它提供了核心容器和依赖注入框架。但它也提供了一些其他的基本特性。
8 |
9 | 其中包括 Spring MVC 和 Spring web 框架。已经了解了如何使用 Spring MVC 编写控制器类来处理 web 请求。但是,您还没有看到的是,Spring MVC 也可以用于创建产生非 HTML 输出的 REST API。我们将在第 2 章深入研究 Spring MVC,然后在第 6 章中讨论如何使用它来创建 REST API。
10 |
11 | Spring 核心框架还提供了一些基本数据持久性支持,特别是基于模板的 JDBC 支持。将在第 3 章中看到如何使用 JdbcTemplate。
12 |
13 | 在 Spring 的最新版本(5.0.8)中,添加了对响应式编程的支持,包括一个新的响应式 web 框架 —— Spring WebFlux,它大量借鉴了 Spring MVC。将在第 3 部分中看到 Spring 的响应式编程模型,并在第 10 章中看到 Spring WebFlux。
14 |
15 | ### 1.4.2 Spring Boot
16 |
17 | 我们已经看到了 Spring Boot 的许多好处,包括启动依赖项和自动配置。在本书中我们确实会尽可能多地使用 Spring Boot,并避免任何形式的显式配置,除非绝对必要。但除了启动依赖和自动配置,Spring Boot 还提供了一些其他有用的特性:
18 |
19 | - Actuator 提供了对应用程序内部工作方式的运行时监控,包括端点、线程 dump 信息、应用程序健康状况和应用程序可用的环境属性。
20 | - 灵活的环境属性规范。
21 | - 在核心框架的测试辅助之外,还有额外的测试支持。
22 |
23 | 此外,Spring Boot 提供了一种基于 Groovy 脚本的替代编程模型,称为 Spring Boot CLI(命令行界面)。使用 Spring Boot CLI,可以将整个应用程序编写为 Groovy 脚本的集合,并从命令行运行它们。我们不会在 Spring Boot CLI 上花太多时间,但是当它适合我们的需要时,我们会接触它。
24 |
25 | Spring Boot 已经成为 Spring 开发中不可或缺的一部分;我无法想象开发一个没有它的 Spring 应用程序。因此,本书采用了以 Spring Boot 为中心的观点,当我提到 Spring Boot 正在做的事情时,你可能会发现我在使用 Spring 这个词。
26 |
27 | ### 1.4.3 Spring Data
28 |
29 | 尽管 Spring 核心框架提供了基本的数据持久性支持,但 Spring Data 提供了一些非常惊人的功能:将应用程序的数据存储库抽象为简单的 Java 接口,同时当定义方法用于如何驱动数据进行存储和检索的问题时,对方法使用了命名约定。
30 |
31 | 更重要的是,Spring Data 能够处理几种不同类型的数据库,包括关系型(JPA)、文档型(Mongo)、图型(Neo4j)等。在第 3 章中,将使用 Spring Data 来帮助创建 Taco Cloud 应用程序的存储库。
32 |
33 | ### 1.4.4 Spring Security
34 |
35 | 应用程序安全性一直是一个重要的主题,而且似乎一天比一天重要。幸运的是,Spring 在 Spring security 中有一个健壮的安全框架。
36 |
37 | Spring Security 解决了广泛的应用程序安全性需求,包括身份验证、授权和 API 安全性。尽管 Spring Security 的范围太大,本书无法恰当地涵盖,但我们将在第 4 章和第 12 章中讨论一些最常见的用例。
38 |
39 | ### 1.4.5 Spring Integration 和 Spring Batch
40 |
41 | 在某种程度上,大多数应用程序将需要与其他应用程序集成,甚至需要与同一应用程序的其他组件集成。为了满足这些需求,出现了几种应用程序集成模式。Spring Integration 和 Spring Batch 为基于 Spring 的应用程序提供了这些模式的实现。
42 |
43 | Spring Integration 解决了实时集成,即数据在可用时进行处理。相反,Spring Batch 解决了批量集成的问题,允许在一段时间内收集数据,直到某个触发器(可能是一个时间触发器)发出信号,表示该处理一批数据了。将在第 9 章中研究 Spring Batch 和 Spring Integration。
44 |
45 | ### 1.4.6 Spring Cloud
46 |
47 | 在我写这篇文章的时候,应用程序开发领域正在进入一个新时代,在这个时代中,我们不再将应用程序作为单个部署单元来开发,而是将由几个称为 _微服务_ 的单个部署单元组成应用程序。
48 |
49 | 微服务是一个热门话题,解决了几个实际的开发和运行时问题。然而,在这样做的同时,他们也带来了自己的挑战。这些挑战都将由 Spring Cloud 直接面对,Spring Cloud 是一组用 Spring 开发云本地应用程序的项目。
50 |
51 | Spring Cloud 覆盖了很多地方,这本书不可能涵盖所有的地方。我们将在第 13、14 和 15 章中查看 Spring Cloud 的一些最常见的组件。关于 Spring Cloud 的更完整的讨论,我建议看看 John Carnell 的 Spring Microservices in Action(Manning, 2017, www.manning.com/books/spring-microservices-in-action)。
52 |
--------------------------------------------------------------------------------
/02~数据库/05~数据库工具/嵌入式数据库/HSQLDB/集成到 Spring Boot.md:
--------------------------------------------------------------------------------
1 | # Spring Boot 中集成使用 HSQLDB
2 |
3 | 首先我们添加最新的依赖:
4 |
5 | ```xml
6 |
7 | org.springframework.boot
8 | spring-boot-starter-data-jpa
9 | 2.1.1.RELEASE
10 |
11 |
12 | org.hsqldb
13 | hsqldb
14 | 2.4.0
15 | runtime
16 |
17 | ```
18 |
19 | 然后可以以服务器模式运行 HSQLDB:
20 |
21 | ```sh
22 | java -cp ../lib/hsqldb.jar org.hsqldb.server.Server --database.0 file.testdb --dbname0.testdb
23 | ```
24 |
25 | 或者以内存模式运行,其配置方式分别如下:
26 |
27 | ```s
28 | spring.datasource.driver-class-name=org.hsqldb.jdbc.JDBCDriver
29 | spring.datasource.url=jdbc:hsqldb:hsql://localhost/testdb
30 | spring.datasource.username=sa
31 | spring.datasource.password=
32 | spring.jpa.hibernate.ddl-auto=update
33 |
34 | spring.datasource.driver-class-name=org.hsqldb.jdbc.JDBCDriver
35 | spring.datasource.url=jdbc:hsqldb:mem:testdb;DB_CLOSE_DELAY=-1
36 | spring.datasource.username=sa
37 | spring.datasource.password=
38 | spring.jpa.hibernate.ddl-auto=create
39 | ```
40 |
41 | 然后我们创建实体类以及 CrudRepository:
42 |
43 | ```java
44 | @Entity
45 | @Table(name = "customers")
46 | public class Customer {
47 | @Id
48 | @GeneratedValue(strategy = GenerationType.AUTO)
49 | private long id;
50 |
51 | private String name;
52 |
53 | private String email;
54 | // standard constructors / setters / getters / toString
55 | }
56 |
57 | @Repository
58 | public interface CustomerRepository extends CrudRepository {}
59 | ```
60 |
61 | 最后的测试代码如下所示:
62 |
63 | ```java
64 | @RunWith(SpringRunner.class)
65 | @SpringBootTest
66 | public class CustomerRepositoryTest {
67 | @Autowired
68 | private CustomerRepository customerRepository;
69 |
70 | @Test
71 | public void whenFindingCustomerById_thenCorrect() {
72 | customerRepository.save(new Customer("John", "john@domain.com"));
73 | assertThat(customerRepository.findById(1L)).isInstanceOf(Optional.class);
74 | }
75 |
76 | @Test
77 | public void whenFindingAllCustomers_thenCorrect() {
78 | customerRepository.save(new Customer("John", "john@domain.com"));
79 | customerRepository.save(new Customer("Julie", "julie@domain.com"));
80 | assertThat(customerRepository.findAll()).isInstanceOf(List.class);
81 | }
82 |
83 | @Test
84 | public void whenSavingCustomer_thenCorrect() {
85 | customerRepository.save(new Customer("Bob", "bob@domain.com"));
86 | Customer customer = customerRepository
87 | .findById(1L)
88 | .orElseGet(() -> new Customer("john", "john@domain.com"));
89 | assertThat(customer.getName()).isEqualTo("Bob");
90 | }
91 | }
92 | ```
93 |
--------------------------------------------------------------------------------
/01~基础使用/05~拦截与切面/过滤器.md:
--------------------------------------------------------------------------------
1 | # Filter | 过滤器
2 |
3 | # 过滤器配置
4 |
5 | 现在我们通过过滤器来实现记录请求执行时间的功能,其实现如下:
6 |
7 | ```java
8 | public class LogCostFilter implements Filter {
9 | @Override
10 | public void init(FilterConfig filterConfig) throws ServletException {
11 |
12 | }
13 |
14 | @Override
15 | public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
16 | long start = System.currentTimeMillis();
17 | filterChain.doFilter(servletRequest,servletResponse);
18 | System.out.println("Execute cost="+(System.currentTimeMillis()-start));
19 | }
20 |
21 | @Override
22 | public void destroy() {
23 |
24 | }
25 | }
26 | ```
27 |
28 | 这段代码的逻辑比较简单,就是在方法执行前先记录时间戳,然后通过过滤器链完成请求的执行,在返回结果之间计算执行的时间。这里需要主要,这个类必须继承 Filter 类,这个是 Servlet 的规范,这个跟以前的 Web 项目没区别。但是,有了过滤器类以后,以前的 web 项目可以在 web.xml 中进行配置,但是 spring boot 项目并没有 web.xml 这个文件,那怎么配置?在 Spring boot 中,我们需要 FilterRegistrationBean 来完成配置。其实现过程如下:
29 |
30 | ```java
31 | @Configuration
32 | public class FilterConfig {
33 |
34 | @Bean
35 | public FilterRegistrationBean registFilter() {
36 | FilterRegistrationBean registration = new FilterRegistrationBean();
37 | registration.setFilter(new LogCostFilter());
38 | registration.addUrlPatterns("/*");
39 | registration.setName("LogCostFilter");
40 | registration.setOrder(1);
41 | return registration;
42 | }
43 |
44 | }
45 | ```
46 |
47 | 除了通过 FilterRegistrationBean 来配置以外,还有一种更直接的办法,直接通过注解就可以完成了:
48 |
49 | ```java
50 | @WebFilter(urlPatterns = "/*", filterName = "logFilter2")
51 | public class LogCostFilter2 implements Filter {
52 | @Override
53 | public void init(FilterConfig filterConfig) throws ServletException {
54 |
55 | }
56 |
57 | @Override
58 | public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
59 | long start = System.currentTimeMillis();
60 | filterChain.doFilter(servletRequest, servletResponse);
61 | System.out.println("LogFilter2 Execute cost=" + (System.currentTimeMillis() - start));
62 | }
63 |
64 | @Override
65 | public void destroy() {
66 |
67 | }
68 | }
69 | ```
70 |
71 | 这里直接用@WebFilter 就可以进行配置,同样,可以设置 url 匹配模式,过滤器名称等。这里需要注意一点的是@WebFilter 这个注解是 Servlet3.0 的规范,并不是 Spring boot 提供的。除了这个注解以外,我们还需在配置类中加另外一个注解:@ServletComponetScan,指定扫描的包。
72 |
73 | ```java
74 | @SpringBootApplication
75 | @MapperScan("com.pandy.blog.dao")
76 | @ServletComponentScan("com.pandy.blog.filters")
77 | public class Application {
78 | public static void main(String[] args) throws Exception {
79 | SpringApplication.run(Application.class, args);
80 | }
81 | }
82 | ```
83 |
--------------------------------------------------------------------------------
/03~Spring Security/权限验证/基于 JWT 的验证/99~参考资料/2023~实现基于 JWT 的登录认证/03~访问与鉴权.md:
--------------------------------------------------------------------------------
1 | # 访问与鉴权
2 |
3 | 首先是用户的注册与登录:
4 |
5 | ```java
6 |
7 | @CrossOrigin(origins = "*", maxAge = 3600)
8 | @RestController
9 | @RequestMapping("/auth")
10 | public class AuthController {
11 |
12 | @Autowired private AuthenticationManager authenticationManager;
13 |
14 | @Autowired private TokenProvider jwtTokenUtil;
15 |
16 | @Autowired private UserService userService;
17 |
18 | @RequestMapping(value = "/sign_in", method = RequestMethod.POST)
19 | public ResponseEntity sign_in(@RequestBody LoginUser loginUser)
20 | throws AuthenticationException {
21 |
22 | final Authentication authentication =
23 | authenticationManager.authenticate(
24 | new UsernamePasswordAuthenticationToken(
25 | loginUser.getUsername(), loginUser.getPassword()));
26 |
27 | SecurityContextHolder.getContext().setAuthentication(authentication);
28 | final String token = jwtTokenUtil.generateToken(authentication);
29 | return ResponseEntity.ok(new AuthToken(token));
30 | }
31 |
32 | @RequestMapping(value = "/sign_up", method = RequestMethod.POST)
33 | public User saveUser(@RequestBody UserDTO user) {
34 | return userService.save(user);
35 | }
36 | }
37 |
38 | ```
39 |
40 | 我们需要使用声明的编码器加密密码后放入数据库:
41 |
42 | ```java
43 | @Override
44 | public User save(UserDTO user) {
45 | User newUser = new User();
46 | newUser.setUsername(user.getUsername());
47 | newUser.setPassword(bcryptEncoder.encode(user.getPassword()));
48 | newUser.setAge(user.getAge());
49 | newUser.setSalary(user.getSalary());
50 | return userDao.save(newUser);
51 | }
52 | ```
53 |
54 | 而在登录的时候:
55 |
56 | ```java
57 | authenticationManager.authenticate(
58 | new UsernamePasswordAuthenticationToken(
59 | loginUser.getUsername(), loginUser.getPassword()));
60 | ```
61 |
62 | authenticationManager 会根据传入的用户信息,调用 UserDetailsService 判断用户是否真实,然后创建 JWT 的 Token 并返回。注意,这里是把密码从数据库中读取出来,然后再次进行核对。最后在具体的接口访问,譬如在访问用户信息时,我们可以通过注解来指定某个接口的权限控制:
63 |
64 | ```java
65 | @CrossOrigin(origins = "*", maxAge = 3600)
66 | @RestController
67 | public class UserController {
68 |
69 | @Autowired private UserService userService;
70 |
71 | // @Secured({"ROLE_ADMIN", "ROLE_USER"})
72 | @PreAuthorize("hasRole('ADMIN')")
73 | @RequestMapping(value = "/users", method = RequestMethod.GET)
74 | public List listUser() {
75 | return userService.findAll();
76 | }
77 |
78 | // @Secured("ROLE_USER")
79 | @PreAuthorize("hasRole('USER')")
80 | //// @PreAuthorize("hasAnyRole('USER', 'ADMIN')")
81 | @RequestMapping(value = "/users/{id}", method = RequestMethod.GET)
82 | public User getOne(@PathVariable(value = "id") Long id) {
83 | return userService.findById(id);
84 | }
85 | }
86 | ```
87 |
--------------------------------------------------------------------------------
/01~基础使用/04~请求与响应/路由与参数/README.md:
--------------------------------------------------------------------------------
1 | # 路由与参数
2 |
3 | # 路由
4 |
5 | ## 路径匹配
6 |
7 | @RequestMapping 是 Spring MVC 中最常用的注解之一,`org.springframework.web.bind.annotation.RequestMapping` 被用于将某个请求映射到具体的处理类或者方法中:
8 |
9 | ```java
10 | // @RequestMapping with Class
11 | @Controller
12 | @RequestMapping("/home")
13 | public class HomeController {}
14 |
15 | // @RequestMapping with Method
16 | @RequestMapping(value="/method0")
17 | @ResponseBody
18 | public String method0(){
19 | return "method0";
20 | }
21 |
22 | // @RequestMapping with Multiple URI
23 | @RequestMapping(value={"/method1","/method1/second"})
24 | @ResponseBody
25 | public String method1(){
26 | return "method1";
27 | }
28 |
29 | // @RequestMapping with HTTP Method
30 | @RequestMapping(value="/method3", method={RequestMethod.POST,RequestMethod.GET})
31 | @ResponseBody
32 | public String method3(){
33 | return "method3";
34 | }
35 |
36 | // @RequestMapping default method
37 | @RequestMapping()
38 | @ResponseBody
39 | public String defaultMethod(){
40 | return "default method";
41 | }
42 |
43 | // @RequestMapping fallback method
44 | @RequestMapping("*")
45 | @ResponseBody
46 | public String fallbackMethod(){
47 | return "fallback method";
48 | }
49 |
50 | // @RequestMapping headers
51 | @RequestMapping(value="/method5", headers={"name=pankaj", "id=1"})
52 | @ResponseBody
53 | public String method5(){
54 | return "method5";
55 | }
56 |
57 | // 表示将功能处理方法将生产 json 格式的数据,此时根据请求头中的 Accept 进行匹配,如请求头 Accept:application/json 时即可匹配;
58 | @RequestMapping(value = "/produces", produces = "application/json")
59 | @RequestMapping(produces={"text/html", "application/json"})
60 | ```
61 |
62 | ## 路由日志
63 |
64 | 该 Spring Boot 2.1.x 版本开始,将这些日志的打印级别做了调整:从原来的 INFO 调整为 TRACE。所以,当我们希望在应用启动的时候打印这些信息的话,只需要在配置文件增增加对 RequestMappingHandlerMapping 类的打印级别设置即可,比如在 application.properties 中增加下面这行配置:
65 |
66 | ```sh
67 | logging.level.org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping=trace
68 | ```
69 |
70 | 在增加了上面的配置之后重启应用,便可以看到如下的日志打印:
71 |
72 | ```sh
73 | 2020-02-11 15:36:09.787 TRACE 49215 --- [main] s.w.s.m.m.a.RequestMappingHandlerMapping :
74 | c.d.c.UserController:
75 | {PUT /users/{id}}: putUser(Long,User)
76 | {GET /users/{id}}: getUser(Long)
77 | {POST /users/}: postUser(User)
78 | {GET /users/}: getUserList()
79 | {DELETE /users/{id}}: deleteUser(Long)
80 | 2020-02-11 15:36:09.791 TRACE 49215 --- [main] s.w.s.m.m.a.RequestMappingHandlerMapping :
81 | o.s.b.a.w.s.e.BasicErrorController:
82 | { /error}: error(HttpServletRequest)
83 | { /error, produces [text/html]}: errorHtml(HttpServletRequest,HttpServletResponse)
84 | 2020-02-11 15:36:09.793 DEBUG 49215 --- [main] s.w.s.m.m.a.RequestMappingHandlerMapping : 7 mappings in 'requestMappingHandlerMapping'
85 |
86 | ```
87 |
88 | 可以看到在 2.1.x 版本之后,除了调整了日志级别之外,对于打印内容也做了调整。现在的打印内容根据接口创建的 Controller 类做了分类打印,这样更有助于开发者根据自己编写的 Controller 来查找初始化了那些 HTTP 接口。
89 |
--------------------------------------------------------------------------------
/02~数据库/04~缓存与 KV 存储/进程内缓存/Cache 注解.md:
--------------------------------------------------------------------------------
1 | # Cache 注解
2 |
3 | User 实体的数据访问实现:
4 |
5 | ```java
6 | public interface UserRepository extends JpaRepository {
7 |
8 | User findByName(String name);
9 |
10 | User findByNameAndAge(String name, Integer age);
11 |
12 | @Query("from User u where u.name=:name")
13 | User findUser(@Param("name") String name);
14 |
15 | }
16 | ```
17 |
18 | 在 pom.xml 中引入 cache 依赖,添加如下内容:
19 |
20 | ```xml
21 |
22 | org.springframework.boot
23 | spring-boot-starter-cache
24 |
25 | ```
26 |
27 | 在 Spring Boot 主类中增加@EnableCaching 注解开启缓存功能,如下:
28 |
29 | ```java
30 | @EnableCaching
31 | @SpringBootApplication
32 | public class Chapter51Application {
33 |
34 | public static void main(String[] args) {
35 | SpringApplication.run(Chapter51Application.class, args);
36 | }
37 |
38 | }
39 | ```
40 |
41 | 在数据访问接口中,增加缓存配置注解,如:
42 |
43 | ```java
44 | @CacheConfig(cacheNames = "users")
45 | public interface UserRepository extends JpaRepository {
46 |
47 | @Cacheable
48 | User findByName(String name);
49 |
50 | }
51 | ```
52 |
53 | 到这里,我们可以看到,在调用第二次 findByName 函数时,没有再执行 select 语句,也就直接减少了一次数据库的读取操作。
54 |
55 | 回过头来我们再来看这里使用到的两个注解分别作了什么事情:
56 |
57 | - `@CacheConfig`:主要用于配置该类中会用到的一些共用的缓存配置。在这里`@CacheConfig(cacheNames = "users")`:配置了该数据访问对象中返回的内容将存储于名为 users 的缓存对象中,我们也可以不使用该注解,直接通过`@Cacheable`自己配置缓存集的名字来定义。
58 |
59 | - @Cacheable:配置了 findByName 函数的返回值将被加入缓存。同时在查询时,会先从缓存中获取,若不存在才再发起对数据库的访问。该注解主要有下面几个参数:
60 |
61 | - `value`、`cacheNames`:两个等同的参数(`cacheNames`为 Spring 4 新增,作为`value`的别名),用于指定缓存存储的集合名。由于 Spring 4 中新增了`@CacheConfig`,因此在 Spring 3 中原本必须有的`value`属性,也成为非必需项了
62 | - `key`:缓存对象存储在 Map 集合中的 key 值,非必需,缺省按照函数的所有参数组合作为 key 值,若自己配置需使用 SpEL 表达式,比如:`@Cacheable(key = "#p0")`:使用函数第一个参数作为缓存的 key 值,更多关于 SpEL 表达式的详细内容可参考[官方文档](http://docs.spring.io/spring/docs/current/spring-framework-reference/html/cache.html#cache-spel-context)
63 | - `condition`:缓存对象的条件,非必需,也需使用 SpEL 表达式,只有满足表达式条件的内容才会被缓存,比如:`@Cacheable(key = "#p0", condition = "#p0.length() < 3")`,表示只有当第一个参数的长度小于 3 的时候才会被缓存,若做此配置上面的 AAA 用户就不会被缓存,读者可自行实验尝试。
64 | - `unless`:另外一个缓存条件参数,非必需,需使用 SpEL 表达式。它不同于`condition`参数的地方在于它的判断时机,该条件是在函数被调用之后才做判断的,所以它可以通过对 result 进行判断。
65 | - `keyGenerator`:用于指定 key 生成器,非必需。若需要指定一个自定义的 key 生成器,我们需要去实现`org.springframework.cache.interceptor.KeyGenerator`接口,并使用该参数来指定。需要注意的是:**该参数与`key`是互斥的**
66 | - `cacheManager`:用于指定使用哪个缓存管理器,非必需。只有当有多个时才需要使用
67 | - `cacheResolver`:用于指定使用那个缓存解析器,非必需。需通过`org.springframework.cache.interceptor.CacheResolver`接口来实现自己的缓存解析器,并用该参数指定。
68 |
69 | 除了这里用到的两个注解之外,还有下面几个核心注解:
70 |
71 | - `@CachePut`:配置于函数上,能够根据参数定义条件来进行缓存,它与`@Cacheable`不同的是,它每次都会真是调用函数,所以主要用于数据新增和修改操作上。它的参数与`@Cacheable`类似,具体功能可参考上面对`@Cacheable`参数的解析
72 | - @CacheEvict:配置于函数上,通常用在删除方法上,用来从缓存中移除相应数据。除了同@Cacheable 一样的参数之外,它还有下面两个参数:
73 | - `allEntries`:非必需,默认为 false。当为 true 时,会移除所有数据
74 | - `beforeInvocation`:非必需,默认为 false,会在调用方法之后移除数据。当为 true 时,会在调用方法之前移除数据。
75 |
--------------------------------------------------------------------------------
/02~数据库/05~数据库工具/嵌入式数据库/H2/README.md:
--------------------------------------------------------------------------------
1 | # H2
2 |
3 | H2 是一个用 Java 开发的嵌入式数据库,它本身只是一个类库,即只有一个 jar 文件,可以直接嵌入到应用项目中。H2 主要有如下三个用途:
4 |
5 | - 第一个用途,也是最常使用的用途就在于可以同应用程序打包在一起发布,这样可以非常方便地存储少量结构化数据。
6 |
7 | - 第二个用途是用于单元测试。启动速度快,而且可以关闭持久化功能,每一个用例执行完随即还原到初始状态。
8 |
9 | - 第三个用途是作为缓存,即当做内存数据库,作为 NoSQL 的一个补充。当某些场景下数据模型必须为关系型,可以拿它当 Memcached 使,作为后端 MySQL/Oracle 的一个缓冲层,缓存一些不经常变化但需要频繁访问的数据,比如字典表、权限表。
10 |
11 | # 连接方式
12 |
13 | H2 支持以下三种连接模式:
14 |
15 | - 嵌入式模式(使用 JDBC 的本地连接)
16 |
17 | - 服务器模式(使用 JDBC 或 ODBC 在 TCP/IP 上的远程连接)
18 |
19 | - 混合模式(本地和远程连接同时进行)
20 |
21 | ## 嵌入式模式
22 |
23 | 在嵌入式模式下,应用程序使用 JDBC 从同一 JVM 中打开数据库。这是最快也是最容易的连接方式。缺点是数据库可能只在任何时候在一个虚拟机(和类加载器)中打开。与所有模式一样,支持持久性和内存数据库。对并发打开数据库的数量或打开连接的数量没有限制。
24 |
25 | 
26 |
27 | ## 服务器模式
28 |
29 | 当使用服务器模式(有时称为远程模式或客户机/服务器模式)时,应用程序使用 JDBC 或 ODBC API 远程打开数据库。服务器需要在同一台或另一台虚拟机上启动,或者在另一台计算机上启动。许多应用程序可以通过连接到这个服务器同时连接到同一个数据库。在内部,服务器进程在嵌入式模式下打开数据库。
30 |
31 | 服务器模式比嵌入式模式慢,因为所有数据都通过 TCP/IP 传输。与所有模式一样,支持持久性和内存数据库。对每个服务器并发打开的数据库数量或打开连接的数量没有限制。
32 |
33 | 
34 |
35 | ## 混合模式
36 |
37 | 混合模式是嵌入式和服务器模式的结合。连接到数据库的第一个应用程序在嵌入式模式下运行,但也启动服务器,以便其他应用程序(在不同进程或虚拟机中运行)可以同时访问相同的数据。本地连接的速度与数据库在嵌入式模式中的使用速度一样快,而远程连接速度稍慢。
38 |
39 | 服务器可以从应用程序内(使用服务器 API)启动或停止,或自动(自动混合模式)。当使用自动混合模式时,所有想要连接到数据库的客户端(无论是本地连接还是远程连接)都可以使用完全相同的数据库 URL 来实现。
40 |
41 | 
42 |
43 | # Spring Boot 中使用
44 |
45 | ## 数据准备
46 |
47 | 我们要创建两个 Sql 文件,以便项目启动的时候,将表结构和数据初始化到数据库。表结构文件(schema-h2.sql)内容:
48 |
49 | ```sql
50 | DROP TABLE IF EXISTS user;
51 |
52 | CREATE TABLE user
53 | (
54 | id BIGINT(20) NOT NULL COMMENT '主键ID',
55 | name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
56 | age INT(11) NULL DEFAULT NULL COMMENT '年龄',
57 | email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
58 | PRIMARY KEY (id)
59 | );
60 | ```
61 |
62 | 表数据文件(data-h2.sql)内容:
63 |
64 | ```sql
65 | INSERT INTO user (id, name, age, email) VALUES
66 | (1, 'neo', 18, 'smile1@ityouknow.com'),
67 | (2, 'keep', 36, 'smile2@ityouknow.com'),
68 | (3, 'pure', 28, 'smile3@ityouknow.com'),
69 | (4, 'smile', 21, 'smile4@ityouknow.com'),
70 | (5, 'it', 24, 'smile5@ityouknow.com');
71 | ```
72 |
73 | 在示例项目的 resources 目录下创建 db 文件夹,将两个文件放入其中。
74 |
75 | ## 添加依赖
76 |
77 | 添加相关依赖包,pom.xml 中的相关依赖内容如下:
78 |
79 | ```xml
80 |
81 |
82 | com.h2database
83 | h2
84 | runtime
85 |
86 |
87 | ```
88 |
89 | 然后配置文件如下:
90 |
91 | ```yml
92 | # DataSource Config
93 | spring:
94 | datasource:
95 | driver-class-name: org.h2.Driver
96 | schema: classpath:db/schema-h2.sql
97 | data: classpath:db/data-h2.sql
98 | url: jdbc:h2:mem:test
99 | username: root
100 | password: test
101 |
102 | # Logger Config
103 | logging:
104 | level:
105 | wx: debug
106 | ```
107 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/01~Spring 基础/第 4 章 Spring 安全/4.4 了解你的用户.md:
--------------------------------------------------------------------------------
1 | ## 4.4 了解你的用户
2 |
3 | 通常,仅仅知道用户已经登录是不够的。通常重要的是要知道他们是谁,这样才能调整他们的体验。
4 |
5 | 例如,在 OrderController 中,当最初创建绑定到订单表单的订单对象时,如果能够用用户名和地址预先填充订单就更好了,这样他们就不必为每个订单重新输入它。也许更重要的是,在保存订单时,应该将订单实体与创建订单的用户关联起来。
6 |
7 | 为了在 Order 实体和 User 实体之间实现所需的连接,需要向 Order 类添加一个新属性:
8 |
9 | ```java
10 | @Data
11 | @Entity
12 | @Table(name="Taco_Order")
13 | public class Order implements Serializable {
14 | ...
15 |
16 | @ManyToOne
17 | private User user;
18 |
19 | ...
20 | }
21 | ```
22 |
23 | 此属性上的 @ManyToOne 注解表明一个订单属于单个用户,相反,一个用户可能有多个订单。(因为使用的是 Lombok,所以不需要显式地定义属性的访问方法。)
24 |
25 | 在 OrderController 中,processOrder() 方法负责保存订单。需要对其进行修改,以确定经过身份验证的用户是谁,并调用 Order 对象上的 setUser() 以将 Order 与该用户连接起来。
26 |
27 | 有几种方法可以确定用户是谁。以下是一些最常见的方法:
28 |
29 | - 将主体对象注入控制器方法
30 | - 将身份验证对象注入控制器方法
31 | - 使用 SecurityContext 获取安全上下文
32 | - 使用 @AuthenticationPrincipal 注解的方法
33 |
34 | 例如,可以修改 processOrder() 来接受 java.security.Principal 作为参数。然后可以使用主体名从 UserRepository 查找用户:
35 |
36 | ```java
37 | @PostMapping
38 | public String processOrder(@Valid Order order, Errors errors,
39 | SessionStatus sessionStatus,
40 | Principal principal) {
41 | ...
42 |
43 | User user = userRepository.findByUsername(principal.getName());
44 | order.setUser(user);
45 |
46 | ...
47 | }
48 | ```
49 |
50 | 这可以很好地工作,但是它会将与安全性无关的代码与安全代码一起丢弃。可以通过修改 processOrder() 来减少一些特定于安全的代码,以接受 Authentication 对象作为参数而不是 Principal:
51 |
52 | ```java
53 | @PostMapping
54 | public String processOrder(@Valid Order order, Errors errors,
55 | SessionStatus sessionStatus,
56 | Authentication authentication) {
57 | ...
58 |
59 | User user = (User) authentication.getPrincipal();
60 | order.setUser(user);
61 |
62 | ...
63 | }
64 | ```
65 |
66 | 有了身份验证,可以调用 getPrincipal() 来获取主体对象,在本例中,该对象是一个用户。注意,getPrincipal() 返回一个 java.util.Object,因此需要将其转换为 User。
67 |
68 | 然而,也许最干净的解决方案是简单地接受 processOrder() 中的用户对象,但是使用 @AuthenticationPrincipal 对其进行注解,以便它成为身份验证的主体:
69 |
70 | ```java
71 | @PostMapping
72 | public String processOrder(@Valid Order order, Errors errors,
73 | SessionStatus sessionStatus,
74 | @AuthenticationPrincipal User user) {
75 | if (errors.hasErrors()) {
76 | return "orderForm";
77 | }
78 |
79 | order.setUser(user);
80 |
81 | orderRepo.save(order);
82 | sessionStatus.setComplete();
83 |
84 | return "redirect:/";
85 | }
86 | ```
87 |
88 | @AuthenticationPrincipal 的优点在于它不需要强制转换(与身份验证一样),并且将特定于安全性的代码限制为注释本身。当在 processOrder() 中获得 User 对象时,它已经准备好被使用并分配给订单了。
89 |
90 | 还有一种方法可以识别通过身份验证的用户是谁,尽管这种方法有点麻烦,因为它包含了大量与安全相关的代码。你可以从安全上下文获取一个认证对象,然后像这样请求它的主体:
91 |
92 | ```java
93 | Authentication authentication =
94 | SecurityContextHolder.getContext().getAuthentication();
95 | User user = (User) authentication.getPrincipal();
96 | ```
97 |
98 | 尽管这个代码段充满了与安全相关的代码,但是它与所描述的其他方法相比有一个优点:它可以在应用程序的任何地方使用,而不仅仅是在控制器的处理程序方法中,这使得它适合在较低级别的代码中使用。
99 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/01~Spring 基础/第 1 章 Spring 入门/1.1 什么是 Spring.md:
--------------------------------------------------------------------------------
1 | ## 1.1 什么是 Spring?
2 |
3 | 我知道你可能很想开始编写 Spring 应用程序,我向你保证,在本章结束之前,你将开发一个简单的应用程序。但是首先,我得介绍一些 Spring 的基本概念,以帮助你了解 Spring 的变化。
4 |
5 | 任何不平凡的应用程序都由许多组件组成,每个组件负责自己的在整体应用程序中的那部分功能,并与其他应用程序元素协调以完成工作。在运行应用程序时,需要以某种方式创建这些组件并相互引用。
6 |
7 | Spring 的核心是一个 _容器_,通常称为 _Spring 应用程序上下文_,用于创建和管理应用程序组件。这些组件(或 bean)在 Spring 应用程序上下文中连接在一起以构成一个完整的应用程序,就像将砖、灰浆、木材、钉子、管道和电线绑在一起以组成房屋。
8 |
9 | 将 bean 连接在一起的行为是基于一种称为 _依赖注入_(DI)的模式。依赖项注入的应用程序不是由组件自身创建和维护它们依赖的其他 bean 的生命周期,而是依赖于单独的实体(容器)来创建和维护所有组件,并将这些组件注入需要它们的 bean。通常通过构造函数参数或属性访问器方法完成此操作。
10 |
11 | 例如,假设在应用程序的许多组件中,要处理两个组件:inventory service(用于获取库存级别)和 product service(用于提供基本产品信息)。product service 取决于 inventory service,以便能够提供有关产品的完整信息。图 1.1 说明了这些 bean 与 Spring 应用程序上下文之间的关系。
12 |
13 | 除了其核心容器之外,Spring 和完整的相关库产品组合还提供 Web 框架、各种数据持久性选项、安全框架与其他系统的集成、运行时监视、微服务支持、响应式编程模型以及许多其他功能,应用于现代应用程序开发。
14 |
15 | 从历史上看,引导 Spring 应用程序上下文将 bean 连接在一起的方式是使用一个或多个 XML 文件,这些文件描述了组件及其与其他组件的关系。例如,以下 XML 声明两个 bean,一个 `InventoryService` bean 和一个 `ProductService` bean,然后通过构造函数参数将 `InventoryService` bean 注入到 `ProductService` 中:
16 |
17 | 
18 |
19 | **图 1-1 通过 Spring 应用程序上下文管理应用程序组件并将它们相互注入**
20 |
21 | ```xml
22 |
23 |
24 |
25 |
26 | ```
27 |
28 | 但是,在最新版本的 Spring 中,基于 Java 的配置更为常见。以下基于 Java 的配置类等效于 XML 配置:
29 |
30 | ```java
31 | @Configuration
32 | public class ServiceConfiguration {
33 | @Bean
34 | public InventoryService inventoryService() {
35 | return new InventoryService();
36 | }
37 |
38 | @Bean
39 | public ProductService productService() {
40 | return new ProductService(inventoryService());
41 | }
42 | }
43 | ```
44 |
45 | `@Configuration` 注释向 Spring 表明这是一个配置类,它将为 Spring 应用程序上下文提供 beans。配置的类方法带有 `@Bean` 注释,指示它们返回的对象应作为 beans 添加到应用程序上下文中(默认情况下,它们各自的 bean IDs 将与定义它们的方法的名称相同)。
46 |
47 | 与基于 XML 的配置相比,基于 Java 的配置具有多个优点,包括更高的类型安全性和改进的可重构性。即使这样,仅当 Spring 无法自动配置组件时,才需要使用 Java 或 XML 进行显式配置。
48 |
49 | 自动配置起源于 Spring 技术,即 _自动装配_ 和 _组件扫描_。借助组件扫描,Spring 可以自动从应用程序的类路径中发现组件,并将其创建为 Spring 应用程序上下文中的 bean。通过自动装配,Spring 会自动将组件与它们依赖的其他 bean 一起注入。
50 |
51 | 最近,随着 Spring Boot 的推出,自动配置的优势已经远远超出了组件扫描和自动装配。Spring Boot 是 Spring 框架的扩展,它提供了多项生产力增强功能。这些增强功能中最著名的就是 _自动配置_,在这种配置中,Spring Boot 可以根据类路径中的条目、环境变量和其他因素,合理地猜测需要配置哪些组件,并将它们连接在一起。
52 |
53 | 这里想要展示一些演示自动配置的示例代码,但是并没有这样的代码,自动配置就如同风一样,可以看到它的效果,但是没有代码可以展示。我可以说 “看!这是自动配置的示例!” 事情发生、组件启用并且提供了功能,而无需编写代码。缺少代码是自动配置必不可少的要素,这使它如此出色。
54 |
55 | Spring Boot 自动配置大大减少了构建应用程序所需的显式配置(无论是 XML 还是 Java)的数量。实际上,当完成本章中的示例时,将拥有一个正在运行的 Spring 应用程序,该应用程序仅包含一行 Spring 配置代码!
56 |
57 | Spring Boot 极大地增强了 Spring 开发的能力,很难想象没有它如何开发 Spring 应用程序。因此,本书将 Spring 和 Spring Boot 视为一模一样。我们将尽可能使用 Spring Boot,并仅在必要时使用显式配置。而且,由于 Spring XML 配置是使用 Spring 的老派方式,因此我们将主要关注基于 Java 的 Spring 配置。
58 |
59 | 但是有这些功能就足够了,本书的标题包括 _实战_ 这个词语,因此让我们动起来,立马开始使用 Spring 编写第一个应用程序。
60 |
--------------------------------------------------------------------------------
/00~特性与生态/生态圈/Spring Integration.md:
--------------------------------------------------------------------------------
1 | # Spring Integration
2 |
3 | Spring Integration 提供了 Spring 编程模型的扩展用来支持企业集成模式(Enterprise Integration Patterns),是对 Spring Messaging 的扩展。它提出了不少新的概念,包括消息路由 MessageRoute、消息分发 MessageDispatcher、消息过滤 Filter、消息转换 Transformer、消息聚合 Aggregator、消息分割 Splitter 等等。同时还提供了 MessageChannel 和 MessageHandler 的实现,分别包括 DirectChannel、ExecutorChannel、PublishSubscribeChannel 和 MessageFilter、ServiceActivatingHandler、MethodInvokingSplitter 等内容。
4 |
5 | # 消息处理
6 |
7 | 消息的分割:
8 |
9 | 
10 |
11 | 消息的聚合:
12 |
13 | 
14 |
15 | 消息的过滤:
16 |
17 | 
18 |
19 | 消息的分发:
20 |
21 | 
22 |
23 | # 简单实例
24 |
25 | ```java
26 | SubscribableChannel messageChannel =new DirectChannel(); // 1
27 |
28 | messageChannel.subscribe(msg-> { // 2
29 | System.out.println("receive: " +msg.getPayload());
30 | });
31 |
32 | messageChannel.send(MessageBuilder.withPayload("msgfrom alibaba").build()); // 3
33 | ```
34 |
35 | 1. 构造一个可订阅的消息通道 `messageChannel`;
36 |
37 | 2. 使用 `MessageHandler` 去消费这个消息通道里的消息;
38 |
39 | 3. 发送一条消息到这个消息通道,消息最终被消息通道里的 `MessageHandler` 所消费。
40 |
41 | 最后控制台打印出: `receive: msg from alibaba`;
42 |
43 | `DirectChannel` 内部有个 `UnicastingDispatcher` 类型的消息分发器,会分发到对应的消息通道 `MessageChannel` 中,从名字也可以看出来,`UnicastingDispatcher` 是个单播的分发器,只能选择一个消息通道。那么如何选择呢? 内部提供了 `LoadBalancingStrategy` 负载均衡策略,默认只有轮询的实现,可以进行扩展。
44 |
45 | 我们对上段代码做一点修改,使用多个 `MessageHandler` 去处理消息:
46 |
47 | ```java
48 | SubscribableChannel messageChannel = new DirectChannel();
49 |
50 | messageChannel.subscribe(msg -> {
51 | System.out.println("receive1: " + msg.getPayload());
52 | });
53 |
54 | messageChannel.subscribe(msg -> {
55 | System.out.println("receive2: " + msg.getPayload());
56 | });
57 |
58 | messageChannel.send(MessageBuilder.withPayload("msg from alibaba").build());
59 | messageChannel.send(MessageBuilder.withPayload("msg from alibaba").build());
60 | ```
61 |
62 | 由于 `DirectChannel` 内部的消息分发器是 `UnicastingDispatcher` 单播的方式,并且采用轮询的负载均衡策略,所以这里两次的消费分别对应这两个 `MessageHandler`。控制台打印出:
63 |
64 | ```java
65 | receive1: msg from alibaba
66 | receive2: msg from alibaba
67 | ```
68 |
69 | 既然存在单播的消息分发器 `UnicastingDispatcher`,必然也会存在广播的消息分发器,那就是 `BroadcastingDispatcher`,它被 `PublishSubscribeChannel` 这个消息通道所使用。广播消息分发器会把消息分发给所有的 `MessageHandler`:
70 |
71 | ```java
72 | SubscribableChannel messageChannel = new PublishSubscribeChannel();
73 |
74 | messageChannel.subscribe(msg -> {
75 | System.out.println("receive1: " + msg.getPayload());
76 | });
77 |
78 | messageChannel.subscribe(msg -> {
79 | System.out.println("receive2: " + msg.getPayload());
80 | });
81 |
82 | messageChannel.send(MessageBuilder.withPayload("msg from alibaba").build());
83 | messageChannel.send(MessageBuilder.withPayload("msg from alibaba").build());
84 | ```
85 |
86 | 发送两个消息,都被所有的 `MessageHandler` 所消费。控制台打印:
87 |
88 | ```java
89 | receive1: msg from alibaba
90 | receive2: msg from alibaba
91 | receive1: msg from alibaba
92 | receive2: msg from alibaba
93 | ```
94 |
--------------------------------------------------------------------------------
/02~数据库/01~Spring JDBC/Spring 数据库连接池.md:
--------------------------------------------------------------------------------
1 | # Spring 数据库连接池
2 |
3 | 由于 Spring Boot 的自动化配置机制,大部分对于数据源的配置都可以通过配置参数的方式去改变。只有一些特殊情况,比如:更换默认数据源,多数据源共存等情况才需要去修改覆盖初始化的 Bean 内容。在 Spring Boot 自动化配置中,对于数据源的配置可以分为两类:
4 |
5 | - 通用配置:以`spring.datasource.*`的形式存在,主要是对一些即使使用不同数据源也都需要配置的一些常规内容。比如:数据库链接地址、用户名、密码等。这里就不做过多说明了,通常就这些配置:
6 |
7 | ```java
8 | spring.datasource.url=jdbc:mysql://localhost:3306/test
9 | spring.datasource.username=root
10 | spring.datasource.password=123456
11 | spring.datasource.driver-class-name=com.mysql.jdbc.Driver
12 | ```
13 |
14 | - 数据源连接池配置:以`spring.datasource.<数据源名称>.*`的形式存在,比如:Hikari 的配置参数就是`spring.datasource.hikari.*`形式。下面这个是我们最常用的几个配置项及对应说明:
15 |
16 | ```java
17 | spring.datasource.hikari.minimum-idle=10
18 | spring.datasource.hikari.maximum-pool-size=20
19 | spring.datasource.hikari.idle-timeout=500000
20 | spring.datasource.hikari.max-lifetime=540000
21 | spring.datasource.hikari.connection-timeout=60000
22 | spring.datasource.hikari.connection-test-query=SELECT 1
23 | ```
24 |
25 | 这些配置的含义:
26 |
27 | - `spring.datasource.hikari.minimum-idle`: 最小空闲连接,默认值 10,小于 0 或大于 maximum-pool-size,都会重置为 maximum-pool-size
28 | - `spring.datasource.hikari.maximum-pool-size`: 最大连接数,小于等于 0 会被重置为默认值 10;大于零小于 1 会被重置为 minimum-idle 的值
29 | - `spring.datasource.hikari.idle-timeout`: 空闲连接超时时间,默认值 600000(10 分钟),大于等于 max-lifetime 且 max-lifetime>0,会被重置为 0;不等于 0 且小于 10 秒,会被重置为 10 秒。
30 | - `spring.datasource.hikari.max-lifetime`: 连接最大存活时间,不等于 0 且小于 30 秒,会被重置为默认值 30 分钟.设置应该比 mysql 设置的超时时间短
31 | - `spring.datasource.hikari.connection-timeout`: 连接超时时间:毫秒,小于 250 毫秒,否则被重置为默认值 30 秒
32 | - `spring.datasource.hikari.connection-test-query`: 用于测试连接是否可用的查询语句
33 |
34 | ## 手动创建连接池
35 |
36 | 现在,如果我们坚持使用 Spring Boot 的自动 DataSource 配置,并在当前状态下运行我们的项目,它就会像预期的那样工作。Spring Boot 将为我们完成所有繁重的基础架构工作。这包括创建一个 H2 DataSource 实现,它将由 HikariCP、Apache Tomcat 或 Commons DBCP 自动处理,并设置一个内存数据库实例。
37 |
38 | 此外,我们甚至不需要创建一个 application.properties 文件,因为 Spring Boot 也会提供一些默认的数据库设置。正如我们之前提到的,有时我们需要更高层次的定制,因此我们必须以编程的方式配置自己的 DataSource 实现。最简单的方法是定义一个 DataSource 工厂方法,并将其放置在用 @Configuration 注解的类中。
39 |
40 | ```java
41 | @Configuration
42 | public class DataSourceConfig {
43 |
44 | @Bean
45 | public DataSource getDataSource() {
46 | DataSourceBuilder dataSourceBuilder = DataSourceBuilder.create();
47 | dataSourceBuilder.driverClassName("org.h2.Driver");
48 | dataSourceBuilder.url("jdbc:h2:mem:test");
49 | dataSourceBuilder.username("SA");
50 | dataSourceBuilder.password("");
51 | return dataSourceBuilder.build();
52 | }
53 | }
54 | ```
55 |
56 | 当然,我们也可以局部地应用 application.properties 中定义的属性:
57 |
58 | ```java
59 | @Bean
60 | public DataSource getDataSource() {
61 | DataSourceBuilder dataSourceBuilder = DataSourceBuilder.create();
62 | dataSourceBuilder.username("SA");
63 | dataSourceBuilder.password("");
64 | return dataSourceBuilder.build();
65 | }
66 |
67 | ```
68 |
69 | 并在 application.properties 文件中额外指定一些:
70 |
71 | ```xml
72 | spring.datasource.url=jdbc:h2:mem:test
73 | spring.datasource.driver-class-name=org.h2.Driver
74 | ```
75 |
76 | # Links
77 |
78 | - https://mp.weixin.qq.com/s/cgR-KVs1UKEM-xTEjIWKQg
79 |
--------------------------------------------------------------------------------
/04~工程实践/测试/JUnit 5/测试用例.md:
--------------------------------------------------------------------------------
1 | # 测试用例
2 |
3 | JUnit4 和 JUnit5 在测试编码风格上没有太大变化,这是其生命周期方法的样本测试。
4 |
5 | ```java
6 | public class AppTest {
7 |
8 | @BeforeAll
9 | static void setup() {
10 | System.out.println("@BeforeAll executed");
11 | }
12 |
13 | @BeforeEach
14 | void setupThis() {
15 | System.out.println("@BeforeEach executed");
16 | }
17 |
18 | @Tag("DEV")
19 | @Test
20 | void testCalcOne() {
21 | System.out.println("======TEST ONE EXECUTED=======");
22 | Assertions.assertEquals(4, Calculator.add(2, 2));
23 | }
24 |
25 | @Tag("PROD")
26 | @Disabled
27 | @Test
28 | void testCalcTwo() {
29 | System.out.println("======TEST TWO EXECUTED=======");
30 | Assertions.assertEquals(6, Calculator.add(2, 4));
31 | }
32 |
33 | @AfterEach
34 | void tearThis() {
35 | System.out.println("@AfterEach executed");
36 | }
37 |
38 | @AfterAll
39 | static void tear() {
40 | System.out.println("@AfterAll executed");
41 | }
42 | }
43 | ```
44 |
45 | ## 测试套件
46 |
47 | 使用 JUnit5 的测试套件,可以将测试扩展到多个测试类和不同的软件包。JUnit5 提供了两个注解:@SelectPackages 和 @SelectClasses 来创建测试套件。要执行测试套件,可以是使用 `@RunWith(JUnitPlatform.class)`
48 |
49 | ```java
50 | @RunWith(JUnitPlatform.class)
51 | @SelectPackages("test.junit5.examples")
52 | public class JUnit5TestSuiteExample {}
53 | ```
54 |
55 | 另外,你也可以使用以下注解来过滤测试包、类甚至测试方法。
56 |
57 | - @IncludePackages 和 `@ExcludePackages` 来过滤包
58 | - @IncludeClassNamePatterns 和 `@ExcludeClassNamePatterns` 过滤测试类
59 | - @IncludeTags 和 `@ExcludeTags` 过滤测试方法
60 |
61 | ```java
62 | @RunWith(JUnitPlatform.class)
63 | @SelectPackages("test.junit5.examples")
64 | @IncludePackages("test.junit5.examples.packageC")
65 | @ExcludeTags("PROD")
66 | public class JUnit5TestSuiteExample {
67 | // ...
68 | }
69 | ```
70 |
71 | ## 断言
72 |
73 | 断言有助于使用测试用例的实际输出验证预期输出。为了保持简单,所有 JUnit Jupiter 断言是 org.junit.jupiter.Assertions 类中的静态方法,例如 assertEquals(),assertNotEquals()。
74 |
75 | ```java
76 | void testCase()
77 | {
78 | //Test will pass
79 | Assertions.assertNotEquals(3, Calculator.add(2, 2));
80 | //Test will fail
81 | Assertions.assertNotEquals(4, Calculator.add(2, 2), "Calculator.add(2, 2) test failed");
82 | //Test will fail
83 | Supplier messageSupplier = ()-> "Calculator.add(2, 2) test failed";
84 | Assertions.assertNotEquals(4, Calculator.add(2, 2), messageSupplier);
85 | }
86 | ```
87 |
88 | ## 假设
89 |
90 | Assumptions 类提供了静态方法来支持基于假设的条件测试执行。失败的假设导致测试被中止。无论何时继续执行给定的测试方法没有意义,通常使用假设。在测试报告中,这些测试将被标记为已通过。JUnit 的 Jupiter 假设类有两个这样的方法:assumeFalse(),assumeTrue()。
91 |
92 | ```java
93 | public class AppTest {
94 |
95 | @Test
96 | void testOnDev() {
97 | System.setProperty("ENV", "DEV");
98 | Assumptions.assumeTrue(
99 | "DEV".equals(System.getProperty("ENV")),
100 | AppTest::message
101 | );
102 | }
103 |
104 | @Test
105 | void testOnProd() {
106 | System.setProperty("ENV", "PROD");
107 | Assumptions.assumeFalse("DEV".equals(System.getProperty("ENV")));
108 | }
109 |
110 | private static String message() {
111 | return "TEST Execution Failed::";
112 | }
113 | }
114 | ```
115 |
--------------------------------------------------------------------------------
/02~数据库/03~ORM/99~参考资料/2021-Java ORM 概念总结.md:
--------------------------------------------------------------------------------
1 | ## 什么是 ORM?
2 |
3 | ORM,即对象关系映射(**O**bject **R**elational **M**apping)模式
4 |
5 | 在初学 Java 的时候,都是使用 JDBC 方式连接数据库。之后逐步使用 EclipseLink、iBATIS(半自动) 和 Hibernate(全自动)等开源 ORM 框架。
6 |
7 | JDBC 的使用流程为:
8 |
9 | 1. 加载数据库驱动 (JDBC Driver)
10 | 2. 创建数据库链接
11 | 3. 创建编译对象(预编译对象 PrepareStatement)
12 | 4. 设置入参执行 SQL
13 | 5. 返回结果集 (resultSet)
14 |
15 | 
16 |
17 | JDBC 使用流程
18 |
19 | 
20 |
21 | 使用 JDBC 连接数据库
22 |
23 | **ORM 框架主要可以解决面向对象与关系数据库之间互不匹配的问题,即用于处理面向对象编程语言中不同类型系统间的数据转换**
24 |
25 | ### [#](https://www.bantanger.fun/pages/5f5e77/#jdbc-的缺点)JDBC 的缺点
26 |
27 | - 硬编码 --> 反射,封装,代理
28 | - 频繁释放数据库连接资源 --> 连接池
29 |
30 | 
31 |
32 | ### [#](https://www.bantanger.fun/pages/5f5e77/#为什么会出现-orm-思想)为什么会出现 ORM 思想
33 |
34 | 先从项目中数据流存储形式这个角度说起.简单拿 MVC 这种分层模式来说,Model 作为数据承载实体. 在用户界面层和业务逻辑层之间数据实现面向对象 OO 形式传递. 当我们需要通过 Control 层分发请求把数据持久化时我们会发现. 内存中的面向对象的 **OO** 如何**持久化成**关系型数据中存储**一条实际数据记录**呢?
35 |
36 | 面向对象是从软件工程基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从数学理论发展而来的。两者之间是不匹配的。而 ORM 作为项目中间件形式实现数据在不同场景下数据关系映射。**对象关系映射(Object Relational Mapping,简称 ORM)是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术**,ORM 就是这样而来的.
37 |
38 | ORM 是连接数据库的桥梁,只要提供了持久化类与表的映射关系,ORM 框架在运行是就能**参照映射文件的信息将对象持久化到数据库中**
39 |
40 | 它的作用就是在关系型数据库和业务实体对象之间做**一层映射**,这样在具体操作业务对象时,就不需要和复杂的 SQL 语句打交道,而只需简单操作对象的属性和方法
41 |
42 | 
43 |
44 | ### [#](https://www.bantanger.fun/pages/5f5e77/#优缺点)优缺点
45 |
46 | 优点:
47 |
48 | 1. 隐藏数据访问细节,封闭的进行交互。
49 | 2. 构造固化数据结构简单。
50 |
51 | 缺点:
52 |
53 | 1. 自动化意味着映射和关联管理,代价是牺牲性能(现在 ORM 采用各种方法减轻这块,LazyLoad Cache)
54 | 2. 面对复杂查询,ORM 力不从心
55 |
56 | ### [#](https://www.bantanger.fun/pages/5f5e77/#orm-框架和-mybatis-的区别)ORM 框架和 MyBatis 的区别
57 |
58 | ORM 框架:将数据库表一行对应一个类实例。对类的操作会影响到数据库
59 |
60 | MyBatis:将查询语句所得到的 ResultSet 映射成类,在使用数据库时需要写 SQL 语句,对类的修改不会影响到数据库
61 |
62 | 参考:
63 |
64 | [什么是 ORM,设计架构(opens new window)](https://zhuanlan.zhihu.com/p/486987053)
65 |
66 | ## [#](https://www.bantanger.fun/pages/5f5e77/#orm-框架设计)ORM 框架设计
67 |
68 | ORM 框架主要通过**参数映射、SQL 解析和执行,以及结果映射**的方式对数据库进行操作
69 |
70 | 
71 |
72 | ORM 框架实现的核心类包括加载配置文件、解析 XML 文件、获取数据库 Session、操作数据库以及返回结果
73 |
74 | 
75 |
76 | - SqlSession 时对数据库进行定义和处理的类,包括常用的方法,如 selectOne、selectList 等
77 | - DefaultSqlSessionFactory 对数据库配置的开启绘画的工厂处理类,这里的工厂会操作 DefaultSqlSession
78 | - SqlSessionFactoryBuilder 是对数据库进行操作的核心类,包括处理工厂、解析解析 和获取会话
79 |
80 | ## [#](https://www.bantanger.fun/pages/5f5e77/#如果让你实现一个-mybatis-应该怎么设计)如果让你实现一个 MyBatis ,应该怎么设计?
81 |
82 | 
83 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/02~集成 Spring/第 7 章 调用 REST 服务/7.2 使用 Traverson 引导 REST API.md:
--------------------------------------------------------------------------------
1 | ## 7.2 使用 Traverson 引导 REST API
2 |
3 | Traverson 附带了 Spring Data HATEOAS,作为在 Spring 应用程序中使用超媒体 API 的开箱即用解决方案。这个基于 Java 的库的灵感来自于同名的类似的 JavaScript 库(https://github.com/traverson)。
4 |
5 | 你可能已经注意到 Traverson 的名字听起来有点像 “traverse on”,这是描述它用法的好方式。在本节中,将通过遍历关系名称上的 API 来调用 API。
6 |
7 | 要使用 Traverson,首先需要实例化一个 Traverson 对象和一个 API 的基础 URI:
8 |
9 | ```java
10 | Traverson traverson = new Traverson(
11 | URI.create("http://localhost:8080/api"), MediaType.HAL_JSON);
12 | ```
13 |
14 | 这里将 Traverson 指向 Taco Cloud 的基本 URL(在本地运行),这是需要给 Traverson 的唯一 URL。从这里开始,将通过链接关系名称来引导 API。还将指定 API 将生成带有 HAL 风格的超链接的 JSON 响应,以便 Traverson 知道如何解析传入的资源数据。与 RestTemplate 一样,可以选择在使用 Traverson 对象之前实例化它,或者将它声明为一个 bean,以便在需要的地方注入它。
15 |
16 | 有了 Traverson 对象,可以通过以下链接开始使用 API。例如,假设想检索所有 Ingredient 的列表。从第 6.3.1 节了解到,Ingredient 链接有一个链接到配料资源的 href 属性,需要点击这个链接:
17 |
18 | ```java
19 | ParameterizedTypeReference> ingredientType =
20 | new ParameterizedTypeReference>() {};
21 |
22 | Resources ingredientRes =
23 | traverson.follow("ingredients").toObject(ingredientType);
24 |
25 | Collection ingredients = ingredientRes.getContent();
26 | ```
27 |
28 | 通过调用 Traverson 对象上的 follow() 方法,可以引导到链接关系名称为 ingredients 的资源。现在客户端已经引导到 ingredients,需要通过调用 toObject() 来提取该资源的内容。
29 |
30 | toObject() 方法要求你告诉它要将数据读入哪种对象。考虑到需要将其作为 Resources 对象读入,而 Java 类型擦除机制使让其为泛型提供类型信息变得困难,因此这可能有点棘手。但是创建一个 ParameterizedTypeReference 有助于实现这一点。
31 |
32 | 打个比方,假设这不是一个 REST API,而是一个网站的主页。设想这是在浏览器中查看的主页,而不是 REST 客户端代码。在页面上看到一个链接,上面写着 Ingredient,然后点击这个链接。当到达下一页时,将读取该页,这类似于 Traverson 以 Resources 对象的形式提取内容。
33 |
34 | 现在让我们考虑一个更有趣的用例,假设想获取最近创建的 tacos,从 home 资源开始,可以引导到最近的 tacos 资源,像这样:
35 |
36 | ```java
37 | ParameterizeTypeReference> tacoType =
38 | new ParameterizedTypeReference>() {};
39 |
40 | Resources tacoRes =
41 | traverson.follow("tacos").follow("recents").toObject(tacoType);
42 |
43 | Collection tacos = tacoRes.getContent();
44 | ```
45 |
46 | 在这里可以点击 Tacos 链接,然后点击 Recents 链接。这会将你带到你所感兴趣的资源,因此使用适当的 ParameterizedTypeReference 调用 toObject() 可以得到想要的结果。调用 follow() 方法可以通过列出跟随的关系名称来简化:
47 |
48 | ```java
49 | Resources tacoRes =
50 | traverson.follow("tacos", "recents").toObject(tacoType);
51 | ```
52 |
53 | Traverson 可以轻松地引导启用了 HATEOAS 的 API 并调用其资源。但有一件事它没有提供任何方法来编写或删除这些 API。相比之下,RestTemplate 可以编写和删除资源,但不便于引导 API。
54 |
55 | 当需要同时引导 API 和更新或删除资源时,需要同时使用 RestTemplate 和 Traverson。Traverson 仍然可以用于引导到将创建新资源的链接。然后可以给 RestTemplate 一个链接来执行 POST、PUT、DELETE 或任何其他 HTTP 请求。
56 |
57 | 例如,假设想要向 Taco Cloud 菜单添加新的 Ingredient。下面的 addIngredient() 方法将 Traverson 和 RestTemplate 组合起来,向 API POST 一个新 Ingredient:
58 |
59 | ```java
60 | private Ingredient addIngredient(Ingredient ingredient) {
61 | String ingredientsUrl = traverson.follow("ingredients")
62 | .asLink().getHref();
63 |
64 | return rest.postForObject(ingredientsUrl,
65 | ingredient,
66 | Ingredient.class);
67 | }
68 | ```
69 |
70 | 在 follow Ingredient 链接之后,通过调用 asLink() 请求链接本身。在该链接中,通过调用 getHref() 请求链接的 URL。有了 URL,就有了在 RestTemplate 实例上调用 postForObject() 并保存新 Ingredient 所需的一切。
71 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/03~响应式 Spring/第 10 章 Reactor 介绍/10.2 Reactor.md:
--------------------------------------------------------------------------------
1 | ## 10.2 Reactor
2 |
3 | 响应式编程需要我们从与命令式编程完全不同的角度去思考。响应式编程是通过直接建立一个用于数据流通的管道,而不是描述一系列需要进行的步骤。作为数据流通的管道,它可以被改变或以某种方式被使用。
4 |
5 | 例如,假设你想到利用一个人的名字,把它的所有字母变为大写,然后用它来创建一个问候语,最后将它打印出来。在命令式编程模型中,代码会是这个样子:
6 |
7 | ```java
8 | String name = "Craig";
9 | String capitalName = name.toUpperCase();
10 | String greeting = "Hello, " + capitalName + "!";
11 | System.out.println(greeting);
12 | ```
13 |
14 | 在命令式编程中,每一行为一步,一步接着一步,同时绝对是在同一个线程中。每一步都会阻塞直到完成才能进行下一步动作。
15 |
16 | 相反,函数式的响应式代码可以以下面这种方式达到目的:
17 |
18 | ```java
19 | Mono.just("Craig")
20 | .map(n -> n.toUpperCase())
21 | .map(cn -> "Hello, " + cn + "!")
22 | .subscribe(System.out::println);
23 | ```
24 |
25 | 不要太担心这个例子中的细节;我们很快将讨论所有关于 just()、map() 和 subscribe() 的操作。就目前而言,要了解的是,虽然响应式的例子似乎仍然遵循一步一步的模式,但是这确实是一个用于数据流的管道。在管道的每个阶段,数据被以某种方式修改了,但是不能知道哪一步操作被哪一个线程执行了的。它们可能在同一个线程也可能不是。
26 |
27 | 例子中的 Mono 是 Reactor 的两个核心类型之一,另一个是 Flux。两者都是响应式流的 Publisher 的实现。Flux 表示零个、一个或多个(可能是无限个)数据项的管道。Mono 特定用于已知的数据返回项不多于一个的响应式类型。
28 |
29 | > Reactor 与 RxJava
30 | >
31 | > 如果你已经熟悉 RxJava 或 ReactiveX,你可能会认为 Mono 和 Flux 听起来很像 Observable 和 Single。事实上,它们在语义上近似相等,甚至提供许多相同的操作。
32 | >
33 | > 尽管我们在本书中重点讨论 Reactor,但可以在 Reactor 和 RxJava 类型之间进行转换。此外,你将在下面的章节中看到 Spring 还可以使用 RxJava 的类型。
34 |
35 | 在前面的例子中实际上有三个 Mono。just() 操作创建了第一个。当 Mono 发出一个值时,该值将被赋予大写操作的 map() 并用于创建另一个 Mono。当第二个 Mono 发布其数据时,被赋予第二个 map() 操作来执行一些字符串连接,其结果用于创建第三个 Mono。最后,对 Mono 的 subscribe() 进行调用,接收数据并打印它。
36 |
37 | ### 10.2.1 图解响应式流
38 |
39 | 响应式流通常使用弹珠图(Marble Diagram)进行绘制。弹珠图最简单的形式就是,在最上面画出数据流经 Flux 或是 Mono 的时间线,在中间画出操作,在最下面画出 Flux 或是 Mono 结果的时间线。图 10.1 展示了 Flux 的弹珠图模板。正如你所看到的,当数据流通过原始的 Flux 后,它通过一些操作进行处理,通过数据流处理后产生一个新的 Flux。
40 |
41 | 图 10.2 展示了一个类似的弹珠图,但是是对于 Mono 而言的。正如你所看到的,关键的区别在于 Mono 会有零个或一个数据项,或一个错误。
42 |
43 | 在 10.3 节中,我们将探讨 Flux 和 Mono 支持的许多操作,将使用弹珠图来想象它们是如何工作的。
44 |
45 | 
46 |
47 | **图 10.1 Flux 基本流的可视化弹珠图**
48 |
49 | 
50 |
51 | **图 10.2 Flux 基本流的可视化弹珠图**
52 |
53 | ### 10.2.2 添加 Reactor 依赖
54 |
55 | 让我们开始使用 Reactor 吧,把一下依赖添加到项目构建中:
56 |
57 | ```xml
58 |
59 | io.projectreactor
60 | reactor-core
61 |
62 | ```
63 |
64 | Reactor 还提供了测试支持。你会写在你的 Reactor 代码周围写很多的测试,所以你肯定会想把这个依赖添加到项目构建中:
65 |
66 | ```xml
67 |
68 | io.projectreactor
69 | reactor-test
70 | test
71 |
72 | ```
73 |
74 | 我假定你要向 Spring Boot 项目中添加这些依赖,它可以为你处理的依赖管理,所以没有必要指定依赖的 元素。但是如果你想在非 Spring Boot 项目中使用 Reactor,那么你需要在构建中设置 Reactor 的 BOM(物料清单)。下面的依赖管理条目增加了 Reactor 的 Bismuth-RELEASE 到构建中:
75 |
76 | ```xml
77 |
78 |
79 |
80 | io.projectreactor
81 | reactor-bom
82 | Bismuth-RELEASE
83 | pom
84 | import
85 |
86 |
87 |
88 | ```
89 |
90 | 现在,Reactor 在你的项目构建中了,可以使用 Mono 和 Flux 开始创建响应式管道了。对于本章的其余部分,我们将使用 Mono 和 Flux 提供的一些操作。
91 |
--------------------------------------------------------------------------------
/10~Spring Cloud/Spring Cloud Alibaba/Sofa/SOFABoot/快速开始.md:
--------------------------------------------------------------------------------
1 | # 快速开始
2 |
3 | 在 Springboot init 脚手架生成的项目中,首先修改 maven 项目的配置文件 pom.xml,将
4 |
5 | ```xml
6 |
7 | org.springframework.boot
8 | spring-boot-starter-parent
9 | ${spring.boot.version}
10 |
11 |
12 | ```
13 |
14 | 修改为:
15 |
16 | ```xml
17 |
18 | com.alipay.sofa
19 | sofaboot-dependencies
20 | ${sofa.boot.version}
21 |
22 | ```
23 |
24 | 然后,添加 SOFABoot 健康检查扩展能力的依赖及 Web 依赖(方便查看健康检查结果):
25 |
26 | ```xml
27 |
28 | com.alipay.sofa
29 | healthcheck-sofa-boot-starter
30 |
31 |
32 |
33 | org.springframework.boot
34 | spring-boot-starter-web
35 |
36 | ```
37 |
38 | 最后,在工程的 application.properties 文件下添加 SOFABoot 工程常用的参数配置,其中 spring.application.name 是必需的参数,用于标示当前应用的名称;logging path 用于指定日志的输出目录。
39 |
40 | ```properties
41 | # Application Name
42 | spring.application.name=SOFABoot Demo
43 | # logging path
44 | logging.path=./logs
45 | ```
46 |
47 | 直接运行我们的启动类 main 方法,日志如下:
48 |
49 | ```java
50 | ,---. ,-----. ,------. ,---. ,-----. ,--.
51 | ' .-' ' .-. ' | .---' / O \ | |) /_ ,---. ,---. ,-' '-.
52 | `. `-. | | | | | `--, | .-. | | .-. \ | .-. | | .-. | '-. .-'
53 | .-' | ' '-' ' | |` | | | | | '--' / ' '-' ' ' '-' ' | |
54 | `-----' `-----' `--' `--' `--' `------' `---' `---' `--'
55 |
56 |
57 | Spring Boot Version: 2.1.13.RELEASE (v2.1.13.RELEASE)
58 | SOFABoot Version: 3.4.6 (v3.4.6)
59 | Powered By Ant Group
60 | ...
61 | 2021-01-05 09:57:50.623 INFO 12720 --- [2)-172.17.160.1] o.s.web.servlet.DispatcherServlet : Completed initialization in 7 ms
62 | ```
63 |
64 | ## 检查
65 |
66 | 直接浏览器访问 http://localhost:8080/actuator/versions 来查看当前 SOFABoot 中使用 Maven 插件生成的版本信息汇总。我们选取一个,如下:
67 |
68 | ```json
69 | {
70 | "GroupId": "com.alipay.sofa",
71 | "Doc-Url": "http://www.sofastack.tech/sofa-boot/docs/Home",
72 | "ArtifactId": "healthcheck-sofa-boot-starter",
73 | "Commit-Time": "2020-11-18T13:07:33+0800",
74 | "Commit-Id": "0e6f10b9f5f1c4c8070814691b8ef9cbff8a550d",
75 | "Version": "3.4.6",
76 | "Build-Time": "2020-11-23T13:49:02+0800"
77 | }
78 | ```
79 |
80 | 可以通过在浏览器中输入 http://localhost:8080/actuator/readiness 查看应用 Readiness Check 的状况
81 |
82 | ```json
83 | {
84 | "status": "UP",
85 | "details": {
86 | "SOFABootReadinessHealthCheckInfo": {
87 | "status": "UP",
88 | "details": {
89 | "HealthChecker": { "sofaComponentHealthChecker": { "status": "UP" } }
90 | }
91 | },
92 | "diskSpace": {
93 | "status": "UP",
94 | "details": {
95 | "total": 127083565056,
96 | "free": 69193203712,
97 | "threshold": 10485760
98 | }
99 | }
100 | }
101 | }
102 | ```
103 |
104 | SOFABoot 也提供了日志的物理隔离:
105 |
106 | ```log
107 | ./logs
108 | ├── health-check
109 | │ ├── sofaboot-common-default.log
110 | │ └── sofaboot-common-error.log
111 | ├── infra
112 | │ ├── common-default.log
113 | │ └── common-error.log
114 | └── spring.log
115 | ```
116 |
--------------------------------------------------------------------------------
/03~Spring Security/README.md:
--------------------------------------------------------------------------------
1 | # Spring Security CheatSheet
2 |
3 | Spring Security 是一个能够为基于 Spring 的企业应用系统提供声明式的安全访问控制解决方案的安全框架。它提供了一组可以在 Spring 应用上下文中配置的 Bean,充分利用了 Spring IoC(Inversion of Control 控制反转),DI(Dependency Injection 依赖注入)和 AOP(面向切面编程)功能,为应用系统提供声明式的安全访问控制功能,减少了为企业系统安全控制编写大量重复代码的工作。Spring Security 拥有以下特性:
4 |
5 | - 对身份验证和授权的全面且可扩展的支持
6 | - 防御会话固定、点击劫持,跨站请求伪造等攻击
7 | - 支持 Servlet API 集成
8 | - 支持与 Spring Web MVC 集成
9 |
10 | 目前 Spring Security 5 支持与以下技术进行集成:
11 |
12 | - HTTP basic access authentication
13 | - LDAP system
14 | - OpenID identity providers
15 | - JAAS API
16 | - CAS Server
17 | - ESB Platform
18 | - ……
19 | - Your own authentication system
20 |
21 | 在进入 Spring Security 正题之前,我们先来了解一下它的整体架构:
22 |
23 | 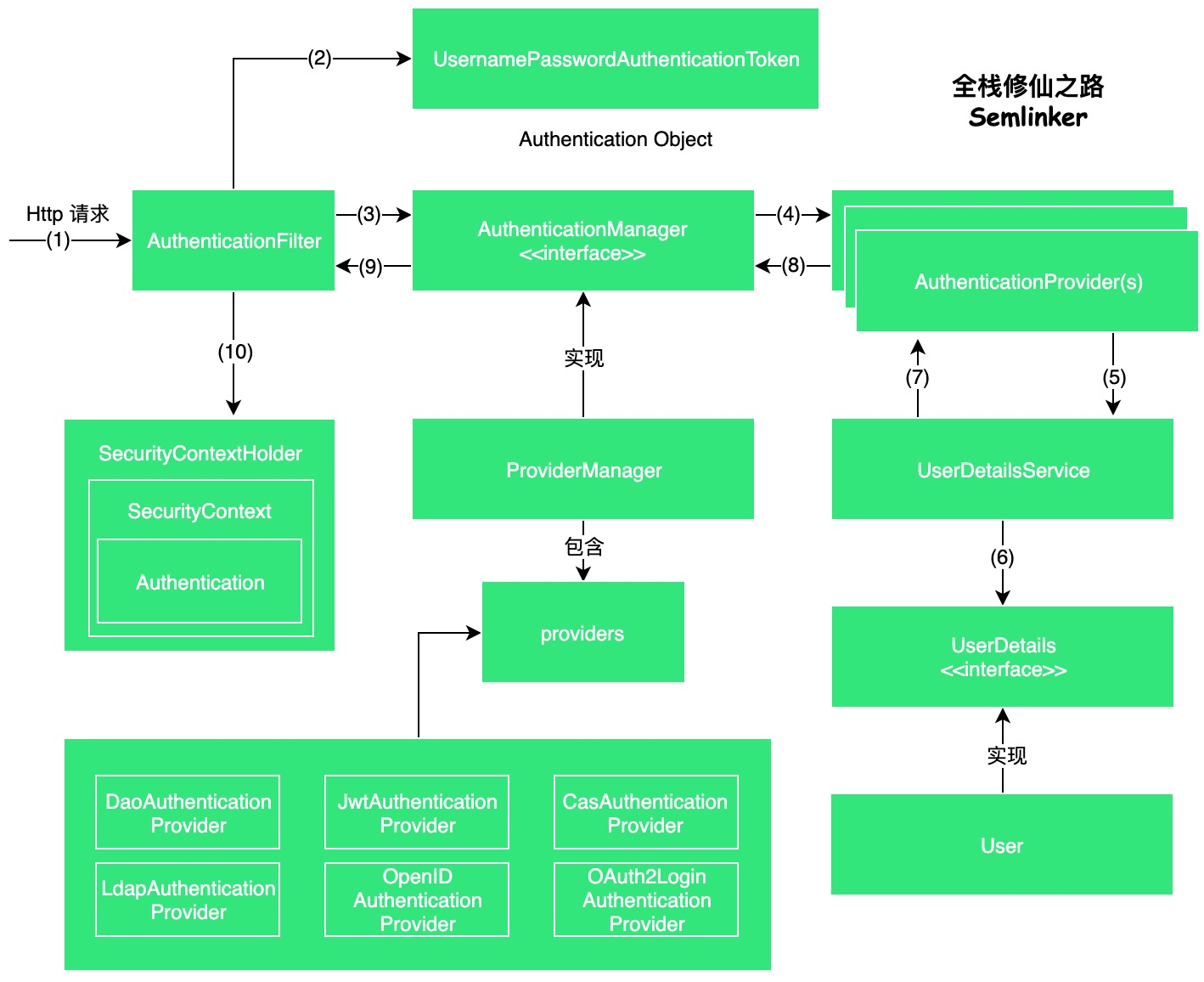
24 |
25 | # 核心组件
26 |
27 | Spring Security 的核心处理过程如下:
28 |
29 | - 用户登陆,会被 AuthenticationProcessingFilter 拦截,调用 AuthenticationManager 的实现,而且 AuthenticationManager 会调用 ProviderManager 来获取用户验证信息(不同的 Provider 调用的服务不同,因为这些信息可以是在数据库上,可以是在 LDAP 服务器上,可以是 xml 配置文件上等),如果验证通过后会将用户的权限信息封装一个 User 放到 Spring 的全局缓存 SecurityContextHolder 中,以备后面访问资源时使用。
30 |
31 | - 访问资源(即授权管理),访问 url 时,会通过 AbstractSecurityInterceptor 拦截器拦截,其中会调用 FilterInvocationSecurityMetadataSource 的方法来获取被拦截 url 所需的全部权限,在调用授权管理器 AccessDecisionManager,这个授权管理器会通过 spring 的全局缓存 SecurityContextHolder 获取用户的权限信息,还会获取被拦截的 url 和被拦截 url 所需的全部权限,然后根据所配的策略(有:一票决定,一票否定,少数服从多数等),如果权限足够,则返回,权限不够则报错并调用权限不足页面。
32 |
33 | ## SecurityContextHolder,SecurityContext 和 Authentication
34 |
35 | 最基本的对象是 SecurityContextHolder,它是我们存储当前应用程序安全上下文的详细信息,其中包括当前使用应用程序的主体的详细信息。如当前操作的用户是谁,该用户是否已经被认证,他拥有哪些角色权限等。默认情况下,SecurityContextHolder 使用 ThreadLocal 来存储这些详细信息,这意味着 Security Context 始终可用于同一执行线程中的方法,即使 Security Context 未作为这些方法的参数显式传递。
36 |
37 | ## 获取当前用户的信息
38 |
39 | 因为身份信息与当前执行线程已绑定,所以可以使用以下代码块在应用程序中获取当前已验证用户的用户名:
40 |
41 | ```java
42 | Object principal = SecurityContextHolder.getContext()
43 | .getAuthentication().getPrincipal();
44 |
45 | if (principal instanceof UserDetails) {
46 | String username = ((UserDetails)principal).getUsername();
47 | } else {
48 | String username = principal.toString();
49 | }
50 | ```
51 |
52 | 调用 getContext() 返回的对象是 SecurityContext 接口的一个实例,对应 SecurityContext 接口定义如下:
53 |
54 | ```java
55 | // org/springframework/security/core/context/SecurityContext.java
56 | public interface SecurityContext extends Serializable {
57 | Authentication getAuthentication();
58 | void setAuthentication(Authentication authentication);
59 | }
60 | ```
61 |
62 | ## Authentication
63 |
64 | 在 SecurityContext 接口中定义了 getAuthentication 和 setAuthentication 两个抽象方法,当调用 getAuthentication 方法后会返回一个 Authentication 类型的对象,这里的 Authentication 也是一个接口,它的定义如下:
65 |
66 | ```java
67 | // org/springframework/security/core/Authentication.java
68 | public interface Authentication extends Principal, Serializable {
69 | // 权限信息列表,默认是GrantedAuthority接口的一些实现类,通常是代表权限信息的一系列字符串。
70 | Collection getAuthorities();
71 | // 密码信息,用户输入的密码字符串,在认证过后通常会被移除,用于保障安全。
72 | Object getCredentials();
73 | Object getDetails();
74 | // 最重要的身份信息,大部分情况下返回的是UserDetails接口的实现类,也是框架中的常用接口之一。
75 | Object getPrincipal();
76 | boolean isAuthenticated();
77 | void setAuthenticated(boolean isAuthenticated) throws IllegalArgumentException;
78 | }
79 | ```
80 |
81 | 以上的 Authentication 接口是 spring-security-core jar 包中的接口,直接继承自 Principal 类,而 Principal 是位于 java.security 包中,由此可知 Authentication 是 spring security 中核心的接口。通过这个 Authentication 接口的实现类,我们可以得到用户拥有的权限信息列表,密码,用户细节信息,用户身份信息,认证信息等。
82 |
--------------------------------------------------------------------------------
/02~数据库/01~连接池/HikariCP/README.md:
--------------------------------------------------------------------------------
1 | # HikariCP
2 |
3 | HikariCP 是一个高性能的 JDBC 连接池,基于 BoneCP 做了不少的改进和优化。它提供了很多特性,使得它成为 Java 应用程序中常用的连接池之一。以下是 HikariCP 的一些主要特性和优点:
4 |
5 | - 快速启动时间:HikariCP 具有非常快速的启动时间,这意味着当应用程序启动时,它可以迅速准备好数据库连接池,而不会造成长时间的延迟。
6 | - 高性能:HikariCP 以高效的方式管理连接池,减少了与数据库交互时的延迟。它的设计目标是最小化对数据库的负载,同时最大化性能。
7 | - 轻量级:HikariCP 是一个轻量级的连接池,jar 文件大小很小,且没有依赖其他库,这使得它在应用程序中的集成变得非常简单。
8 | - 自动化管理:HikariCP 可以自动地管理连接的生命周期,包括创建、释放、回收等操作,开发者无需手动干预连接的管理。
9 | - 高度可配置:HikariCP 提供了丰富的配置选项,允许开发者根据应用程序的需求进行调整和优化。这些配置选项包括连接池大小、最大连接数、最小空闲连接数、连接超时等。
10 | - 监控和诊断:HikariCP 内置了监控和诊断功能,可以实时地监视连接池的状态,包括活动连接数、空闲连接数、连接等待时间等指标。
11 | - 兼容性:HikariCP 与各种数据库和 JDBC 驱动程序兼容性良好,可以与 MySQL、PostgreSQL、Oracle 等主流数据库无缝集成。
12 | - 开源:HikariCP 是一个开源项目,代码托管在 GitHub 上,可以自由获取、使用和修改。
13 |
14 | # 快速开始
15 |
16 | 以下是一个简单的 Java 应用程序示例,演示如何在 Java 项目中使用 HikariCP 连接到数据库:首先,确保将 HikariCP 的 jar 文件(例如 hikaricp-xxx.jar)添加到你的项目中的 classpath 中。接下来,创建一个 HikariCP 连接池并使用它来获取数据库连接。
17 |
18 | ```java
19 | import com.zaxxer.hikari.HikariConfig;
20 | import com.zaxxer.hikari.HikariDataSource;
21 | import java.sql.Connection;
22 | import java.sql.PreparedStatement;
23 | import java.sql.ResultSet;
24 | import java.sql.SQLException;
25 |
26 | public class HikariCPExample {
27 |
28 | public static void main(String[] args) {
29 | // 创建Hikari配置对象
30 | HikariConfig config = new HikariConfig();
31 | config.setJdbcUrl("jdbc:mysql://localhost:3306/mydatabase");
32 | config.setUsername("username");
33 | config.setPassword("password");
34 |
35 | // 设置连接池属性
36 | config.setMaximumPoolSize(10);
37 | config.setMinimumIdle(5);
38 | config.setConnectionTimeout(30000); // 30秒超时
39 |
40 | // 创建Hikari数据源
41 | HikariDataSource dataSource = new HikariDataSource(config);
42 |
43 | Connection connection = null;
44 | PreparedStatement preparedStatement = null;
45 | ResultSet resultSet = null;
46 |
47 | try {
48 | // 从连接池获取连接
49 | connection = dataSource.getConnection();
50 |
51 | // 执行SQL查询
52 | String sql = "SELECT * FROM my_table";
53 | preparedStatement = connection.prepareStatement(sql);
54 | resultSet = preparedStatement.executeQuery();
55 |
56 | // 处理查询结果
57 | while (resultSet.next()) {
58 | // 处理结果集
59 | String column1 = resultSet.getString("column1");
60 | int column2 = resultSet.getInt("column2");
61 | // 输出结果
62 | System.out.println("Column1: " + column1 + ", Column2: " + column2);
63 | }
64 | } catch (SQLException e) {
65 | e.printStackTrace();
66 | } finally {
67 | // 关闭资源
68 | try {
69 | if (resultSet != null) resultSet.close();
70 | if (preparedStatement != null) preparedStatement.close();
71 | if (connection != null) connection.close();
72 | } catch (SQLException e) {
73 | e.printStackTrace();
74 | }
75 | }
76 |
77 | // 关闭数据源
78 | dataSource.close();
79 | }
80 | }
81 | ```
82 |
83 | 在这个示例中,我们首先创建了一个 HikariConfig 对象,设置了数据库的连接 URL、用户名和密码等信息,然后配置了连接池的一些属性,比如最大连接数、最小空闲连接数、连接超时等。
84 |
85 | 然后,我们通过创建 HikariDataSource 来实例化数据源,该数据源可以用于从连接池中获取数据库连接。接着,我们通过调用 getConnection()方法从连接池中获取一个连接,然后执行 SQL 查询,并处理查询结果。最后,我们在 finally 块中关闭了所有资源,包括连接、预处理语句和结果集,并调用数据源的 close() 方法关闭数据源。
86 |
87 | 这是一个简单的 HikariCP 入门示例,演示了如何在 Java 应用程序中使用 HikariCP 连接到数据库并执行 SQL 查询。
88 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/01~Spring 基础/第 2 章 开发 Web 应用程序/2.5 选择视图模板库.md:
--------------------------------------------------------------------------------
1 | ## 2.5 选择视图模板库
2 |
3 | 在大多数情况下,对视图模板库的选择取决于个人喜好。Spring 非常灵活,支持许多常见的模板选项。除了一些小的例外,所选择的模板库本身甚至不知道它是在 Spring 中工作的。
4 |
5 | 表 2.2 列出了 Spring Boot 自动配置支持的模板选项。表 2.2 支持的模板选项。
6 |
7 | | 模板 | Spring Boot starter 依赖 |
8 | | -------------------- | ------------------------------------ |
9 | | FreeMarker | spring-boot-starter-freemarker |
10 | | Groovy Templates | spring-boot-starter-groovy-templates |
11 | | JavaServer Page(JSP) | None (provided by Tomcat or Jetty) |
12 | | Mustache | spring-boot-starter-mustache |
13 | | Thymeleaf | spring-boot-starter-thymeleaf |
14 |
15 | 一般来说,可以选择想要的视图模板库,将其作为依赖项添加到构建中,然后开始在 /templates 目录中(在 Maven 或 Gradl 构建项目的 src/main/resources 目录下)编写模板。Spring Boot 将检测选择的模板库,并自动配置所需的组件来为 Spring MVC 控制器提供视图。
16 |
17 | 已经在 Taco Cloud 应用程序中用 Thymeleaf 实现了这一点。在第 1 章中,在初始化项目时选择了 Thymeleaf 复选框。这导致 Spring Boot 的 Thymeleaf starter 被包含在 pom.xml 文件中。当应用程序启动时,Spring Boot 自动配置会检测到 Thymeleaf 的存在,并自动配置 Thymeleaf bean。现在要做的就是开始在 /templates 中编写模板。
18 |
19 | 如果希望使用不同的模板库,只需在项目初始化时选择它,或者编辑现有的项目构建以包含新选择的模板库。
20 |
21 | 例如,假设想使用 Mustache 而不是 Thymeleaf。没有问题。只需访问项目 pom.xml 文件,将:
22 |
23 | ```xml
24 |
25 | org.springframework.boot
26 | spring-boot-starter-thymeleaf
27 |
28 | ```
29 |
30 | 替换为:
31 |
32 | ```xml
33 |
34 | org.springframework.boot
35 | spring-boot-starter-mustache
36 |
37 | ```
38 |
39 | 当然,需要确保使用 Mustache 语法而不是 Thymeleaf 标签来编写所有模板。Mustache 的使用细节(或选择的任何模板语言)不在这本书的范围之内,但为了让你知道会发生什么,这里有一个从 Mustache 模板摘录过来的片段,这个片段渲染了玉米饼设计表单的成分列表中的一个:
40 |
41 | ```html
42 | Designate your wrap:
43 | {{#wrap}}
44 |
45 |
46 | {{name}}
47 |
48 | {{/wrap}}
49 | ```
50 |
51 | 这是 Mustache 与第 2.1.3 节中的 Thymeleaf 片段的等价替换。`{{#wrap}}` 块(以 `{{/wrap}}` 结尾)迭代 request 属性中的一个集合,该集合的键为 wrap,并为每个项目呈现嵌入的 HTML。`{{id}}` 和 `{{name}}` 标记引用项目的 id 和 name 属性(应该是一个 Ingredient)。
52 |
53 | 在表 2.2 中请注意,JSP 在构建中不需要任何特殊的依赖关系。这是因为 servlet 容器本身(默认情况下是 Tomcat)实现了 JSP 规范,因此不需要进一步的依赖关系。
54 |
55 | 但是如果选择使用 JSP,就会遇到一个问题。事实证明,Java servlet 容器 —— 包括嵌入式 Tomcat 和 Jetty 容器 —— 通常在 /WEB-INF 下寻找 jsp。但是如果将应用程序构建为一个可执行的 JAR 文件,就没有办法满足这个需求。因此,如果将应用程序构建为 WAR 文件并将其部署在传统的 servlet 容器中,那么 JSP 只是一个选项。如果正在构建一个可执行的 JAR 文件,必须选择 Thymeleaf、FreeMarker 或表 2.2 中的其他选项之一。
56 |
57 | ### 2.5.1 缓存模板
58 |
59 | 默认情况下,模板在第一次使用时只解析一次,解析的结果被缓存以供后续使用。对于生产环境来说,这是一个很好的特性,因为它可以防止对每个请求进行冗余的模板解析,从而提高性能。
60 |
61 | 但是,在开发时,这个特性并不那么好。假设启动了应用程序并点击了玉米饼设计页面,并决定对其进行一些更改。当刷新 web 浏览器时,仍然会显示原始版本。查看更改的惟一方法是重新启动应用程序,这非常不方便。
62 |
63 | 幸运的是,有一种方法可以禁用缓存。只需将 templateappropriate 高速缓存属性设置为 false。表 2.3 列出了每个支持的模板库的缓存属性。
64 |
65 | **表 2.3 启用/禁用模板缓存的属性**
66 |
67 | | 模板 | 缓存使能属性 |
68 | | ---------------- | ---------------------------- |
69 | | Freemarker | spring.freemarker.cache |
70 | | Groovy Templates | spring.groovy.template.cache |
71 | | Mustache | spring.mustache.cache |
72 | | Thymeleaf | spring.thymeleaf.cache |
73 |
74 | 默认情况下,所有这些属性都设置为 true 以启用缓存。可以通过将其缓存属性设置为 false 来禁用所选模板引擎的缓存。例如,要禁用 Thymeleaf 缓存,请在 application.properties 中添加以下行:
75 |
76 | ```properties
77 | spring.thymeleaf.cache = false
78 | ```
79 |
80 | 惟一的问题是,在将应用程序部署到生产环境之前,一定要删除这一行(或将其设置为 true)。一种选择是在 profile 文件中设置属性。(我们将在第 5 章讨论 profiles 文件。)
81 |
82 | 一个更简单的选择是使用 Spring Boot 的 DevTools,就像我们在第 1 章中选择的那样。在 DevTools 提供的许多有用的开发时帮助中,它将禁用所有模板库的缓存,但在部署应用程序时将禁用自身(从而重新启用模板缓存)。
83 |
--------------------------------------------------------------------------------
/02~数据库/01~Spring JDBC/事务/编程式事务.md:
--------------------------------------------------------------------------------
1 | # 编程式事务
2 |
3 | ## PlatformTransactionManager
4 |
5 | ```java
6 | DefaultTransactionDefinition def = new DefaultTransactionDefinition();
7 | // explicitly setting the transaction name is something that can only be done programmatically
8 |
9 | def.setName("SomeTxName");
10 | def.setPropagationBehavior(PROPAGATION_REQUIRED);
11 |
12 | TransactionStatus status = txManager.getTransaction(def);
13 | try {
14 | // execute your business logic here
15 | }
16 | catch (MyException ex) {
17 | txManager.rollback(status);
18 | throw ex;
19 | }
20 | txManager.commit(status);
21 | ```
22 |
23 | ## TransactionTemplate
24 |
25 | 如果使用 TransactionTemplate 的话,那么整个应用的代码必须包裹在一个事务的上下文中,如下所示。一般来说用匿名内部类来实现一个`TransactionCallback`中的`execute(..)`方法。
26 |
27 | ```java
28 | public class SimpleService implements Service {
29 | // single TransactionTemplate shared amongst all methods in this instance
30 | private final TransactionTemplate transactionTemplate;
31 |
32 | // use constructor-injection to supply the PlatformTransactionManager
33 | public SimpleService(PlatformTransactionManager transactionManager) {
34 | Assert.notNull(
35 | transactionManager,
36 | "The 'transactionManager' argument must not be null."
37 | );
38 | this.transactionTemplate = new TransactionTemplate(transactionManager);
39 | }
40 |
41 | public Object someServiceMethod() {
42 | return transactionTemplate.execute(
43 | new TransactionCallback() {
44 |
45 | // the code in this method executes in a transactional context
46 | public Object doInTransaction(TransactionStatus status) {
47 | updateOperation1();
48 | return resultOfUpdateOperation2();
49 | }
50 | }
51 | );
52 | }
53 | }
54 | ```
55 |
56 | 如果你不希望有返回值,可以用如下:
57 |
58 | ```java
59 | transactionTemplate.execute(new TransactionCallbackWithoutResult() {
60 | protected void doInTransactionWithoutResult(TransactionStatus status) {
61 | updateOperation1();
62 | updateOperation2();
63 | }
64 | });
65 | ```
66 |
67 | 也可以手动地控制回滚:
68 |
69 | ```java
70 | transactionTemplate.execute(new TransactionCallbackWithoutResult() {
71 | protected void doInTransactionWithoutResult(TransactionStatus status) {
72 | try {
73 | updateOperation1();
74 | updateOperation2();
75 | } catch (SomeBusinessExeption ex) {
76 | status.setRollbackOnly();
77 | }
78 | }
79 | });
80 | ```
81 |
82 | ### Settings
83 |
84 | ```java
85 | public class SimpleService implements Service {
86 | private final TransactionTemplate transactionTemplate;
87 |
88 | public SimpleService(PlatformTransactionManager transactionManager) {
89 | Assert.notNull(
90 | transactionManager,
91 | "The 'transactionManager' argument must not be null."
92 | );
93 | this.transactionTemplate = new TransactionTemplate(transactionManager);
94 |
95 | // the transaction settings can be set here explicitly if so desired
96 | this.transactionTemplate.setIsolationLevel(
97 | ISOLATION_READ_UNCOMMITTED
98 | );
99 | this.transactionTemplate.setTimeout(30); // 30 seconds
100 | // and so forth...
101 | }
102 | }
103 | ```
104 |
105 | 或者直接配置在 XML 中:
106 |
107 | ```xml
108 |
110 |
111 |
112 | "
113 | ```
114 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [![Contributors][contributors-shield]][contributors-url]
2 | [![Forks][forks-shield]][forks-url]
3 | [![Stargazers][stars-shield]][stars-url]
4 | [![Issues][issues-shield]][issues-url]
5 | [][license-url]
6 |
7 |
8 |
9 |
10 |
11 |  12 |
13 |
14 |
12 |
13 |
14 |
15 | 在线阅读 >>
16 |
17 |
18 | 代码案例
19 | ·
20 | 参考资料
21 |
22 |
23 |
24 |
25 | # Spring Series | Spring 微服务与云原生实战
26 |
27 | 
28 |
29 | Spring 的设计目标是为我们提供一个一站式的轻量级应用开发平台,抽象了应用开发中遇到的共性问题。作为平台,它考虑到了企业应用资源的使用,比如数据的持久化、数据集成、事务处理、消息中间件、分布式式计算等高效可靠处理企业数据方法的技术抽象。开发过程中的共性问题,Spring 封装成了各种组件,而且 Spring 通过社区,形成了一个开放的生态系统,比如 Spring Security 就是来源于一个社区贡献。
30 |
31 | 使用 Spring 进行开发,对开发人员比较轻量,可以使用 POJO 和 Java Bean 的开发方式,使应用面向接口开发,充分支持了面向对象的设计方法。通过 IOC 容器减少了直接耦合,通过 AOP 以动态和非侵入的方式增加了服务的功能,为灵活选取不同的服务实现提供了基础,这也是 Spring 的核心。轻量级是相对于传统 J2EE 而言的,传统的 J2EE 开发,需要依赖按照 J2EE 规范实现的 J2EE 应用服务器,设计和实现时,需要遵循一系列的接口标准,这种开发方式耦合性高,使应用在可测试性和部署上都有影响,对技术的理解和要求相对较高。
32 |
33 | 
34 |
35 | 本篇是[《服务端开发实践与工程架构](https://ng-tech.icu/books/Backend-Notes/#/)》系列文章的一部分,关联的示例代码请参考 [java-snippets](https://github.com/Dev-Snippets/java-snippets),[spring-examples](https://github.com/BE-Kits/spring-snippets)。
36 |
37 | > 如果你是才入门的新手,那么建议首先阅读 [《Java Series]()》、[《数据结构与算法]()》。如果你已经有了一定的经验,想了解更多工程架构方面的知识,那么建议阅读 []()。如果你想寻求分布式系统的解决方案,那么建议阅读 []()。
38 |
39 | # About
40 |
41 | ## Copyright
42 |
43 | 
 44 |
45 | 笔者所有文章遵循 [知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.zh),欢迎转载,尊重版权。如果觉得本系列对你有所帮助,欢迎给我家布丁买点狗粮(支付宝扫码)~
46 |
47 | ## Copyright & More | 延伸阅读
48 |
49 | 您还可以前往 [NGTE Books](https://ng-tech.icu/books-gallery/) 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
50 |
51 | [](https://ng-tech.icu/books-gallery/)
52 |
53 | ## Links
54 |
55 | - https://zhuanlan.zhihu.com/p/78104880
56 | - https://netfilx.github.io/spring-boot/
57 |
58 |
59 |
60 |
61 | [contributors-shield]: https://img.shields.io/github/contributors/wx-chevalier/Spring-Notes.svg?style=flat-square
62 | [contributors-url]: https://github.com/wx-chevalier/Spring-Notes/graphs/contributors
63 | [forks-shield]: https://img.shields.io/github/forks/wx-chevalier/Spring-Notes.svg?style=flat-square
64 | [forks-url]: https://github.com/wx-chevalier/Spring-Notes/network/members
65 | [stars-shield]: https://img.shields.io/github/stars/wx-chevalier/Spring-Notes.svg?style=flat-square
66 | [stars-url]: https://github.com/wx-chevalier/Spring-Notes/stargazers
67 | [issues-shield]: https://img.shields.io/github/issues/wx-chevalier/Spring-Notes.svg?style=flat-square
68 | [issues-url]: https://github.com/wx-chevalier/Spring-Notes/issues
69 | [license-shield]: https://img.shields.io/github/license/wx-chevalier/Spring-Notes.svg?style=flat-square
70 | [license-url]: https://github.com/wx-chevalier/Spring-Notes/blob/master/LICENSE.txt
71 |
--------------------------------------------------------------------------------
/02~数据库/02~MyBatis/MyBatis 基础使用/01~配置使用/2023~MyBatis 基础使用/06~流式查询.md:
--------------------------------------------------------------------------------
1 | # 流式查询
2 |
3 | 流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 1000 万条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。
4 | 流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。
5 |
6 | # MyBatis 流式查询接口
7 |
8 | MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:
9 |
10 | - Cursor 是可关闭的;
11 | - Cursor 是可遍历的。
12 |
13 | 除此之外,Cursor 还提供了三个方法:
14 |
15 | - isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;
16 | - isConsumed():用于判断查询结果是否全部取完。
17 | - getCurrentIndex():返回已经获取了多少条数据
18 |
19 | 因为 Cursor 实现了迭代器接口,因此在实际使用当中,从 Cursor 取数据非常简单:
20 |
21 | ```java
22 | cursor.forEach(rowObject -> {...});
23 | ```
24 |
25 | 但构建 Cursor 的过程不简单,下面是一个 Mapper 类:
26 |
27 | ```java
28 | @Mapper
29 | public interface FooMapper {
30 | @Select("select * from foo limit #{limit}")
31 | Cursor scan(@Param("limit") int limit);
32 | }
33 | ```
34 |
35 | 方法 scan() 是一个非常简单的查询。通过指定 Mapper 方法的返回值为 Cursor 类型,MyBatis 就知道这个查询方法一个流式查询。然后我们再写一个 SpringMVC Controller 方法来调用 Mapper(无关的代码已经省略):
36 |
37 | ```java
38 | @GetMapping("foo/scan/0/{limit}")
39 | public void scanFoo0(@PathVariable("limit") int limit) throws Exception {
40 | try (Cursor cursor = fooMapper.scan(limit)) { // 1
41 | cursor.forEach(foo -> {}); // 2
42 | }
43 | }
44 | ```
45 |
46 | 上面的代码中,fooMapper 是 @Autowired 进来的。注释 1 处调用 scan 方法,得到 Cursor 对象并保证它能最后关闭;2 处则是从 cursor 中取数据。上面的代码看上去没什么问题,但是执行 scanFoo0() 时会报错:
47 |
48 | ```
49 | java.lang.IllegalStateException: A Cursor is already closed.
50 | ```
51 |
52 | 这是因为我们前面说了在取数据的过程中需要保持数据库连接,而 Mapper 方法通常在执行完后连接就关闭了,因此 Cusor 也一并关闭了。
53 |
54 | # SqlSessionFactory
55 |
56 | 我们可以用 SqlSessionFactory 来手工打开数据库连接,将 Controller 方法修改如下:
57 |
58 | ```java
59 | @GetMapping("foo/scan/1/{limit}")
60 | public void scanFoo1(@PathVariable("limit") int limit) throws Exception {
61 | try (
62 | SqlSession sqlSession = sqlSessionFactory.openSession(); // 1
63 | Cursor cursor =
64 | sqlSession.getMapper(FooMapper.class).scan(limit) // 2
65 | ) {
66 | cursor.forEach(foo -> { });
67 | }
68 | }
69 | ```
70 |
71 | 上面的代码中,1 处我们开启了一个 SqlSession (实际上也代表了一个数据库连接),并保证它最后能关闭;2 处我们使用 SqlSession 来获得 Mapper 对象。这样才能保证得到的 Cursor 对象是打开状态的。
72 |
73 | # TransactionTemplate
74 |
75 | 在 Spring 中,我们可以用 TransactionTemplate 来执行一个数据库事务,这个过程中数据库连接同样是打开的。代码如下:
76 |
77 | ```java
78 | @GetMapping("foo/scan/2/{limit}")
79 | public void scanFoo2(@PathVariable("limit") int limit) throws Exception {
80 | TransactionTemplate transactionTemplate =
81 | new TransactionTemplate(transactionManager); // 1
82 |
83 | transactionTemplate.execute(status -> { // 2
84 | try (Cursor cursor = fooMapper.scan(limit)) {
85 | cursor.forEach(foo -> { });
86 | } catch (IOException e) {
87 | e.printStackTrace();
88 | }
89 | return null;
90 | });
91 | }
92 | ```
93 |
94 | 上面的代码中,1 处我们创建了一个 TransactionTemplate 对象(此处 transactionManager 是怎么来的不用多解释,本文假设读者对 Spring 数据库事务的使用比较熟悉了),2 处执行数据库事务,而数据库事务的内容则是调用 Mapper 对象的流式查询。注意这里的 Mapper 对象无需通过 SqlSession 创建。
95 |
96 | # @Transactional 注解
97 |
98 | 这个本质上和方案二一样,代码如下:
99 |
100 | ```java
101 | @GetMapping("foo/scan/3/{limit}")
102 | @Transactional
103 | public void scanFoo3(@PathVariable("limit") int limit) throws Exception {
104 | try (Cursor cursor = fooMapper.scan(limit)) {
105 | cursor.forEach(foo -> { });
106 | }
107 | }
108 | ```
109 |
110 | 它仅仅是在原来方法上面加了个 @Transactional 注解。这个方案看上去最简洁,但请注意 Spring 框架当中注解使用的坑:只在外部调用时生效。在当前类中调用这个方法,依旧会报错。
111 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/03~响应式 Spring/第 10 章 Reactor 介绍/10.1 理解响应式编程.md:
--------------------------------------------------------------------------------
1 | ## 10.1 理解响应式编程
2 |
3 | 响应式编程是对命令式编程进行替代的一个范例。这种替代的存在是因为响应式编程解决了命令式编程的限制。通过了解这些限制,可以更好地把握响应式模式的好处。
4 |
5 | > 注意:响应式编程不是银弹。不应该从这章或是其他任何对于响应式编程的讨论中推断出命令式编程是魔鬼而响应式编程是天使。与作为一个开发人员学习的任何东西一样,响应式编程在某些地方很合适,在某些地方完全没有,应该对症下药。
6 |
7 | 如果和许多开发者一样,都是从命令式编程起步的。很自然地,现在你所写的大多数代码都是命令式的。命令式编程是非常直观的,现在的学生在他们学校的 STEM 课程中很轻松地学习它,它很强大,以至于它构成了大部分的代码,驱动着最大的企业。
8 |
9 | 这个想法很简单:你写的代码就是一行接一行的指令,按照它们的顺序一次一条地出现。一个任务被执行,程序就需要等到它执行完了,才能执行下一个任务。每一步,数据都需要完全获取到了才能被处理,因此它需要作为一个整体来处理。
10 |
11 | 这样做还行吧...直到它不得行了。当正在执行的任务被阻塞了,特别是它是一个 IO 任务,例如将数据写入到数据库或从远程服务器获取数据,那么调用该任务的线程将无法做任何事情,直到任务完成。说穿了,阻塞的线程就是一种浪费。
12 |
13 | 大多数编程语言,包括 Java,支持并发编程。在 Java 中启动另一个线程并将其发送到执行某项工作的分支上是相当容易的,而调用线程则继续执行其他工作。尽管很容易创建线程,但这些线程可能最终会阻塞自己。在管理在多线程里面的并发是很具有挑战性的。更多的线程意味着更高的复杂度。
14 |
15 | 相反,响应式编程是函数式和声明式的。响应式编程涉及描述通过该数据流的 pipeline 或 stream,而不是描述的一组按顺序执行的步骤。响应式流处理数据时只要数据是可用的就进行处理,而不是需要将数据作为一个整体进行提供。事实上,输入数据可以是无穷的(例如,一个地点的实时温度数据的恒定流)。
16 |
17 | 应用于一个真实世界的类比就是,将命令式编程看做一个装水的气球,响应式编程看做花园里面的水管。两者都是在炎热的夏天让你的朋友惊喜并沉浸其中的方式。但是它们的执行风格是不同的:
18 |
19 | - 一个水气球一次能携带的它的有效载荷,在撞击的那一刻浸湿了它预定的目标。然而,水球的容量是有限的,如果你想用水泡更多的人(或把同一个人淋得更湿),你唯一的选择就是增加水球的数量。
20 | - 一根花园水龙带将其有效载荷作为一股水流从水龙头流向喷嘴。花园水龙头接的水带的容量可能是有限的,但在打水仗的过程中水是源源不断的。只要水从水龙头进入软管,就会一直通过软管然后从喷嘴喷出。同一个花园软管是很容易扩展的,你和朋友们可以玩得更尽兴。
21 |
22 | 命令式编程就类似打水仗中的水球,本质上没有什么问题,但是拿着类似响应式编程的水管的人在可扩展性和性能方面是有优势的。
23 |
24 | ### 10.1.1 定义响应式流
25 |
26 | Reactive Streams 是 2013 年底由 Netflix、Lightbend 和 Pivotal(Spring 背后的公司)的工程师发起的一项计划。响应式流旨在为无阻塞异步流处理提供一个标准。
27 |
28 | 我们已经谈到了响应式编程的异步特性;它使我们能够并行执行任务以获得更大的可伸缩性。Backpressure(译者注:[如何形象的描述反应式编程中的背压(Backpressure)机制?](https://www.zhihu.com/question/49618581/answer/237078934) )是一种手段,通过对用户愿意处理的数据量设定限制,数据消费者可以避免被生产速度过快的数据淹没。
29 |
30 | > **Java Streams** 与 **Reactive Streams** 对比
31 | >
32 | > 在 Java 流和响应式流之间有很大的相似性。首先,它们的名字中都含有 Streams。它们也都为处理数据提供函数式接口。事实上,稍后当学到容器的时候,你会看到,其实它们有很多共同操作。
33 | >
34 | > 然而,Java 流通常是同步的,同时只能处理有限数据集。它们本质上是使用函数式进行集合迭代的一种手段。
35 | >
36 | > 响应式流支持任何大小的数据集,包括无限数据集的异步处理。它们使实时处理数据成为了可能。
37 |
38 | 响应式流的规范可以通过四个接口定义来概括:Publisher,Subscriber,Subscription 和 Processor。Publisher 为每一个 Subscription 的 Subscriber 生产数据。Publisher 接口声明了一个 subscribe() 方法,通过这个方法 Subscriber 可以订阅 Publisher:
39 |
40 | ```java
41 | public interface Publisher {
42 | void subscribe(Subscriber subscriber);
43 | }
44 | ```
45 |
46 | Subscriber 一旦进行了订阅,就可以从 Publisher 中接收消息,这些消息都是通过 Subscriber 接口中的方法进行发送:
47 |
48 | ```java
49 | public interface Subscriber {
50 | void onSubscribe(Subscription sub);
51 | void onNext(T item);
52 | void onError(Throwable ex);
53 | void onComplete();
54 | }
55 | ```
56 |
57 | Subscriber 通过调用 onSubscribe() 函数将会收到第一个消息。当 Publisher 调用 onSubscribe(),它通过一个 Subscription 对象将消息传输给 Subscriber。消息是通过 Subscription 进行传递的,Subscriber 可以管理他自己的订阅内容:
58 |
59 | ```java
60 | public interface Subscription {
61 | void request(long n);
62 | void cancel();
63 | }
64 | ```
65 |
66 | Subscriber 可以调用 request() 去请求被被发送了的数据,或者调用 cancel() 来表明他对接收的数据不感兴趣,并取消订阅。当调用 request() 时,Subscriber 通过传递一个 long 值的参数来表示它将会接收多少数据。这时就会引进 backpressure,用以阻止 Publisher 发送的数据超过 Subscriber 能够处理的数据。在 Publisher 发送了足够的被请求的数据后,Subscriber 可以再次调用 request() 来请求更多的数据。
67 |
68 | 一旦 Subcriber 已经接收到数据,数据就通过流开始流动了。每一个 Publisher 发布的项目都会通过调用 onNext() 方法将数据传输到 Subscriber。如果出现错误,onError() 方法将被调用。如果 Publisher 没有更多的数据需要发送了,同时也不会再生产任何数据了,将会调用 onComplete() 方法来告诉 Subscriber,它已经结束了。
69 |
70 | 对于 Processor 接口而言,它连接了 Subscriber 和 Publisher:
71 |
72 | ```java
73 | public interface Processor extends Subscriber, Publisher {}
74 | ```
75 |
76 | 作为 Subscriber,Processor 将会接收数据然后以一定的方式处理这些数据。然后它会像变戏法一样地变为一个 Publisher 将处理的结果发布给 Subscriber。
77 |
78 | 正如你所看到的,响应式流规范相当地简单。关于如何从 Publisher 开始建立起一个数据处理的通道,这也是一件很容易的事情了,通过将数据不输入或是输入到多个 Processor 中,然后将最终结果传递到 Subscriber 中就行了。
79 |
80 | Reactor 工程实现了响应式流的规范,它提供由响应式流组成的函数式 API。正如你将在后面的章节中看到的,Reactor 是 Spring 5 响应式编程模型的基础。在本章的剩余部分,我们将探索 Reactor 工程。
81 |
--------------------------------------------------------------------------------
/02~数据库/02~MyBatis/Mybatis Plus/2024.11~MyBatis Plus BaseMapper 与 IService 差异.md:
--------------------------------------------------------------------------------
1 | # BaseMapper 与 IService 对比
2 |
3 | ## 1. 基本概念
4 |
5 | ### BaseMapper
6 |
7 | - 最基础的 Mapper 接口,提供基本的 CRUD 操作
8 | - 直接与数据库交互的 DAO 层接口
9 | - 操作粒度较细,方法都是原子性的
10 |
11 | ### IService
12 |
13 | - 在 BaseMapper 的基础上进行了封装,提供了更多的批量操作和链式调用方法
14 | - 业务服务层接口,通常用在 Service 层
15 | - 提供了更高层次的封装,包含了事务等特性
16 |
17 | ## 2. 主要区别
18 |
19 | ### 2.1 功能范围
20 |
21 | ```java
22 | // BaseMapper - 基础功能
23 | public interface BaseMapper {
24 | int insert(T entity);
25 | int deleteById(Serializable id);
26 | int updateById(@Param("et") T entity);
27 | T selectById(Serializable id);
28 | // ...基础方法
29 | }
30 |
31 | // IService - 扩展功能
32 | public interface IService {
33 | // 包含 BaseMapper 的所有功能,并且扩展了:
34 | boolean saveBatch(Collection entityList);
35 | boolean saveOrUpdateBatch(Collection entityList);
36 | boolean updateBatchById(Collection entityList);
37 | // ...更多批量操作和链式调用方法
38 | }
39 | ```
40 |
41 | ### 2.2 使用场景对比
42 |
43 | #### BaseMapper 适用场景:
44 |
45 | ```java
46 | @Mapper
47 | public interface UserMapper extends BaseMapper {
48 | // 1. 单表的基础 CRUD 操作
49 | // 2. 需要自定义 SQL 的场景
50 | // 3. 需要直接操作数据库的原子操作
51 | // 4. 与其他 ORM 框架配合使用
52 |
53 | // 自定义 SQL 示例
54 | @Select("SELECT * FROM user WHERE age > #{age}")
55 | List selectOlderThan(@Param("age") Integer age);
56 | }
57 | ```
58 |
59 | #### IService 适用场景:
60 |
61 | ```java
62 | @Service
63 | public class UserServiceImpl extends ServiceImpl implements IService {
64 | // 1. 批量操作场景
65 | public void batchOperationDemo() {
66 | List users = new ArrayList<>();
67 | // ... 添加用户
68 | // 批量保存,自动分批处理
69 | this.saveBatch(users, 1000);
70 | }
71 |
72 | // 2. 链式调用场景
73 | public void chainOperationDemo() {
74 | // 链式查询
75 | this.lambdaQuery()
76 | .like(User::getName, "张")
77 | .ge(User::getAge, 18)
78 | .list();
79 |
80 | // 链式更新
81 | this.lambdaUpdate()
82 | .set(User::getAge, 20)
83 | .eq(User::getName, "张三")
84 | .update();
85 | }
86 |
87 | // 3. 事务场景
88 | @Transactional(rollbackFor = Exception.class)
89 | public void transactionDemo() {
90 | // 批量操作自动开启事务
91 | this.saveOrUpdateBatch(userList);
92 | }
93 | }
94 | ```
95 |
96 | ## 3. 使用建议
97 |
98 | ### 3.1 使用 BaseMapper 的情况
99 |
100 | 1. 需要进行简单的 CRUD 操作
101 | 2. 需要自定义 SQL 语句
102 | 3. 对性能要求较高的场景
103 | 4. 需要精确控制 SQL 执行的场景
104 |
105 | ### 3.2 使用 IService 的情况
106 |
107 | 1. 需要进行批量操作
108 | 2. 需要使用链式调用提高代码可读性
109 | 3. 需要事务管理
110 | 4. 需要更复杂的业务逻辑封装
111 |
112 | ## 4. 最佳实践
113 |
114 | ### 4.1 分层使用
115 |
116 | ```java
117 | // Mapper 层:使用 BaseMapper
118 | @Mapper
119 | public interface UserMapper extends BaseMapper {
120 | // 自定义方法
121 | }
122 |
123 | // Service 层:使用 IService
124 | @Service
125 | public class UserServiceImpl extends ServiceImpl implements UserService {
126 | // 业务方法
127 | }
128 | ```
129 |
130 | ### 4.2 混合使用
131 |
132 | ```java
133 | @Service
134 | public class UserServiceImpl extends ServiceImpl implements UserService {
135 | @Autowired
136 | private UserMapper userMapper; // 注入 BaseMapper
137 |
138 | public void complexOperation() {
139 | // 使用 IService 的批量方法
140 | this.saveBatch(userList);
141 |
142 | // 使用 BaseMapper 的自定义方法
143 | userMapper.selectOlderThan(18);
144 | }
145 | }
146 | ```
147 |
148 | ## 5. 总结
149 |
150 | 1. **BaseMapper**
151 |
152 | - 偏向底层的数据库操作
153 | - 适合单一的、原子性的数据库操作
154 | - 可以自定义 SQL
155 | - 性能较好
156 |
157 | 2. **IService**
158 | - 偏向业务层的封装
159 | - 提供了更多的批量操作和便利方法
160 | - 支持链式调用
161 | - 自动管理事务
162 |
--------------------------------------------------------------------------------
/01~基础使用/04~请求与响应/异步处理/Async/Async.md:
--------------------------------------------------------------------------------
1 | # Async Support
2 |
3 | 在 Spring Boot 中,我们可以通过 Java 注解的方式来启用异步处理:
4 |
5 | ```java
6 | @Configuration
7 | @EnableAsync
8 | public class SpringAsyncConfig { ... }
9 | ```
10 |
11 | 或者以 XML 的方式启用:
12 |
13 | ```xml
14 |
15 |
16 | ```
17 |
18 | # @Async
19 |
20 | @Async 注解只能作用于 public 方法,并且不能够自调用。
21 |
22 | ```java
23 | @Async
24 | public void asyncMethodWithVoidReturnType() {
25 | System.out.println("Execute method asynchronously. "
26 | + Thread.currentThread().getName());
27 | }
28 |
29 | @Async
30 | public Future asyncMethodWithReturnType() {
31 | System.out.println("Execute method asynchronously - "
32 | + Thread.currentThread().getName());
33 | try {
34 | Thread.sleep(5000);
35 | return new AsyncResult("hello world !!!!");
36 | } catch (InterruptedException e) {
37 | //
38 | }
39 |
40 | return null;
41 | }
42 | ```
43 |
44 | Spring 还提供了一个实现 Future 的 AsyncResult 类。这可以用来跟踪异步方法执行的结果。现在,让我们调用上述方法,并使用 Future 对象检索异步过程的结果。
45 |
46 | ```java
47 | public void testAsyncAnnotationForMethodsWithReturnType()
48 | throws InterruptedException, ExecutionException {
49 | System.out.println("Invoking an asynchronous method. "
50 | + Thread.currentThread().getName());
51 | Future future = asyncAnnotationExample.asyncMethodWithReturnType();
52 |
53 | while (true) {
54 | if (future.isDone()) {
55 | System.out.println("Result from asynchronous process - " + future.get());
56 | break;
57 | }
58 | System.out.println("Continue doing something else. ");
59 | Thread.sleep(1000);
60 | }
61 | }
62 | ```
63 |
64 | # Executor
65 |
66 | 默认情况下,Spring 使用 SimpleAsyncTaskExecutor 实际异步运行这些方法。可以在两个级别上覆盖默认值:在应用程序级别或单个方法级别。
67 |
68 | ## 方法级别复写
69 |
70 | 所需的执行程序需要在配置类中声明:
71 |
72 | ```java
73 | @Configuration
74 | @EnableAsync
75 | public class SpringAsyncConfig {
76 |
77 | @Bean(name = "threadPoolTaskExecutor")
78 | public Executor threadPoolTaskExecutor() {
79 | return new ThreadPoolTaskExecutor();
80 | }
81 | }
82 |
83 | @Async("threadPoolTaskExecutor")
84 | public void asyncMethodWithConfiguredExecutor() {
85 | System.out.println("Execute method with configured executor - "
86 | + Thread.currentThread().getName());
87 | }
88 | ```
89 |
90 | ## 应用级别复写
91 |
92 | 配置类应实现 AsyncConfigurer 接口,这意味着它具有实现 getAsyncExecutor() 方法。在这里,我们将返回整个应用程序的执行程序–现在,它成为运行以 @Async 注释的方法的默认执行程序:
93 |
94 | ```java
95 | @Configuration
96 | @EnableAsync
97 | public class SpringAsyncConfig implements AsyncConfigurer {
98 |
99 | @Override
100 | public Executor getAsyncExecutor() {
101 | return new ThreadPoolTaskExecutor();
102 | }
103 | }
104 | ```
105 |
106 | # 异常处理
107 |
108 | 当方法返回类型为 Future 时,异常处理很容易:Future.get() 方法将引发异常。但是,如果返回类型为 void,则异常不会传播到调用线程;因此,我们需要添加额外的配置来处理异常。我们将通过实现 AsyncUncaughtExceptionHandler 接口来创建自定义异步异常处理程序。当存在任何未捕获的异步异常时,将调用 handleUncaughtException() 方法:
109 |
110 | ```java
111 | public class CustomAsyncExceptionHandler
112 | implements AsyncUncaughtExceptionHandler {
113 |
114 | @Override
115 | public void handleUncaughtException(
116 | Throwable throwable,
117 | Method method,
118 | Object... obj
119 | ) {
120 | System.out.println("Exception message - " + throwable.getMessage());
121 | System.out.println("Method name - " + method.getName());
122 | for (Object param : obj) {
123 | System.out.println("Parameter value - " + param);
124 | }
125 | }
126 | }
127 | ```
128 |
129 | 在上一节中,我们介绍了由配置类实现的 AsyncConfigurer 接口。作为其中的一部分,我们还需要重写 getAsyncUncaughtExceptionHandler() 方法以返回我们的自定义异步异常处理程序:
130 |
131 | ```java
132 | @Override
133 | public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
134 | return new CustomAsyncExceptionHandler();
135 | }
136 | ```
137 |
138 | # Links
139 |
140 |
141 |
--------------------------------------------------------------------------------
44 |
45 | 笔者所有文章遵循 [知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.zh),欢迎转载,尊重版权。如果觉得本系列对你有所帮助,欢迎给我家布丁买点狗粮(支付宝扫码)~
46 |
47 | ## Copyright & More | 延伸阅读
48 |
49 | 您还可以前往 [NGTE Books](https://ng-tech.icu/books-gallery/) 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
50 |
51 | [](https://ng-tech.icu/books-gallery/)
52 |
53 | ## Links
54 |
55 | - https://zhuanlan.zhihu.com/p/78104880
56 | - https://netfilx.github.io/spring-boot/
57 |
58 |
59 |
60 |
61 | [contributors-shield]: https://img.shields.io/github/contributors/wx-chevalier/Spring-Notes.svg?style=flat-square
62 | [contributors-url]: https://github.com/wx-chevalier/Spring-Notes/graphs/contributors
63 | [forks-shield]: https://img.shields.io/github/forks/wx-chevalier/Spring-Notes.svg?style=flat-square
64 | [forks-url]: https://github.com/wx-chevalier/Spring-Notes/network/members
65 | [stars-shield]: https://img.shields.io/github/stars/wx-chevalier/Spring-Notes.svg?style=flat-square
66 | [stars-url]: https://github.com/wx-chevalier/Spring-Notes/stargazers
67 | [issues-shield]: https://img.shields.io/github/issues/wx-chevalier/Spring-Notes.svg?style=flat-square
68 | [issues-url]: https://github.com/wx-chevalier/Spring-Notes/issues
69 | [license-shield]: https://img.shields.io/github/license/wx-chevalier/Spring-Notes.svg?style=flat-square
70 | [license-url]: https://github.com/wx-chevalier/Spring-Notes/blob/master/LICENSE.txt
71 |
--------------------------------------------------------------------------------
/02~数据库/02~MyBatis/MyBatis 基础使用/01~配置使用/2023~MyBatis 基础使用/06~流式查询.md:
--------------------------------------------------------------------------------
1 | # 流式查询
2 |
3 | 流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 1000 万条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。
4 | 流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。
5 |
6 | # MyBatis 流式查询接口
7 |
8 | MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:
9 |
10 | - Cursor 是可关闭的;
11 | - Cursor 是可遍历的。
12 |
13 | 除此之外,Cursor 还提供了三个方法:
14 |
15 | - isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;
16 | - isConsumed():用于判断查询结果是否全部取完。
17 | - getCurrentIndex():返回已经获取了多少条数据
18 |
19 | 因为 Cursor 实现了迭代器接口,因此在实际使用当中,从 Cursor 取数据非常简单:
20 |
21 | ```java
22 | cursor.forEach(rowObject -> {...});
23 | ```
24 |
25 | 但构建 Cursor 的过程不简单,下面是一个 Mapper 类:
26 |
27 | ```java
28 | @Mapper
29 | public interface FooMapper {
30 | @Select("select * from foo limit #{limit}")
31 | Cursor scan(@Param("limit") int limit);
32 | }
33 | ```
34 |
35 | 方法 scan() 是一个非常简单的查询。通过指定 Mapper 方法的返回值为 Cursor 类型,MyBatis 就知道这个查询方法一个流式查询。然后我们再写一个 SpringMVC Controller 方法来调用 Mapper(无关的代码已经省略):
36 |
37 | ```java
38 | @GetMapping("foo/scan/0/{limit}")
39 | public void scanFoo0(@PathVariable("limit") int limit) throws Exception {
40 | try (Cursor cursor = fooMapper.scan(limit)) { // 1
41 | cursor.forEach(foo -> {}); // 2
42 | }
43 | }
44 | ```
45 |
46 | 上面的代码中,fooMapper 是 @Autowired 进来的。注释 1 处调用 scan 方法,得到 Cursor 对象并保证它能最后关闭;2 处则是从 cursor 中取数据。上面的代码看上去没什么问题,但是执行 scanFoo0() 时会报错:
47 |
48 | ```
49 | java.lang.IllegalStateException: A Cursor is already closed.
50 | ```
51 |
52 | 这是因为我们前面说了在取数据的过程中需要保持数据库连接,而 Mapper 方法通常在执行完后连接就关闭了,因此 Cusor 也一并关闭了。
53 |
54 | # SqlSessionFactory
55 |
56 | 我们可以用 SqlSessionFactory 来手工打开数据库连接,将 Controller 方法修改如下:
57 |
58 | ```java
59 | @GetMapping("foo/scan/1/{limit}")
60 | public void scanFoo1(@PathVariable("limit") int limit) throws Exception {
61 | try (
62 | SqlSession sqlSession = sqlSessionFactory.openSession(); // 1
63 | Cursor cursor =
64 | sqlSession.getMapper(FooMapper.class).scan(limit) // 2
65 | ) {
66 | cursor.forEach(foo -> { });
67 | }
68 | }
69 | ```
70 |
71 | 上面的代码中,1 处我们开启了一个 SqlSession (实际上也代表了一个数据库连接),并保证它最后能关闭;2 处我们使用 SqlSession 来获得 Mapper 对象。这样才能保证得到的 Cursor 对象是打开状态的。
72 |
73 | # TransactionTemplate
74 |
75 | 在 Spring 中,我们可以用 TransactionTemplate 来执行一个数据库事务,这个过程中数据库连接同样是打开的。代码如下:
76 |
77 | ```java
78 | @GetMapping("foo/scan/2/{limit}")
79 | public void scanFoo2(@PathVariable("limit") int limit) throws Exception {
80 | TransactionTemplate transactionTemplate =
81 | new TransactionTemplate(transactionManager); // 1
82 |
83 | transactionTemplate.execute(status -> { // 2
84 | try (Cursor cursor = fooMapper.scan(limit)) {
85 | cursor.forEach(foo -> { });
86 | } catch (IOException e) {
87 | e.printStackTrace();
88 | }
89 | return null;
90 | });
91 | }
92 | ```
93 |
94 | 上面的代码中,1 处我们创建了一个 TransactionTemplate 对象(此处 transactionManager 是怎么来的不用多解释,本文假设读者对 Spring 数据库事务的使用比较熟悉了),2 处执行数据库事务,而数据库事务的内容则是调用 Mapper 对象的流式查询。注意这里的 Mapper 对象无需通过 SqlSession 创建。
95 |
96 | # @Transactional 注解
97 |
98 | 这个本质上和方案二一样,代码如下:
99 |
100 | ```java
101 | @GetMapping("foo/scan/3/{limit}")
102 | @Transactional
103 | public void scanFoo3(@PathVariable("limit") int limit) throws Exception {
104 | try (Cursor cursor = fooMapper.scan(limit)) {
105 | cursor.forEach(foo -> { });
106 | }
107 | }
108 | ```
109 |
110 | 它仅仅是在原来方法上面加了个 @Transactional 注解。这个方案看上去最简洁,但请注意 Spring 框架当中注解使用的坑:只在外部调用时生效。在当前类中调用这个方法,依旧会报错。
111 |
--------------------------------------------------------------------------------
/99~参考资料/2015~《Spring in Action》~V5/03~响应式 Spring/第 10 章 Reactor 介绍/10.1 理解响应式编程.md:
--------------------------------------------------------------------------------
1 | ## 10.1 理解响应式编程
2 |
3 | 响应式编程是对命令式编程进行替代的一个范例。这种替代的存在是因为响应式编程解决了命令式编程的限制。通过了解这些限制,可以更好地把握响应式模式的好处。
4 |
5 | > 注意:响应式编程不是银弹。不应该从这章或是其他任何对于响应式编程的讨论中推断出命令式编程是魔鬼而响应式编程是天使。与作为一个开发人员学习的任何东西一样,响应式编程在某些地方很合适,在某些地方完全没有,应该对症下药。
6 |
7 | 如果和许多开发者一样,都是从命令式编程起步的。很自然地,现在你所写的大多数代码都是命令式的。命令式编程是非常直观的,现在的学生在他们学校的 STEM 课程中很轻松地学习它,它很强大,以至于它构成了大部分的代码,驱动着最大的企业。
8 |
9 | 这个想法很简单:你写的代码就是一行接一行的指令,按照它们的顺序一次一条地出现。一个任务被执行,程序就需要等到它执行完了,才能执行下一个任务。每一步,数据都需要完全获取到了才能被处理,因此它需要作为一个整体来处理。
10 |
11 | 这样做还行吧...直到它不得行了。当正在执行的任务被阻塞了,特别是它是一个 IO 任务,例如将数据写入到数据库或从远程服务器获取数据,那么调用该任务的线程将无法做任何事情,直到任务完成。说穿了,阻塞的线程就是一种浪费。
12 |
13 | 大多数编程语言,包括 Java,支持并发编程。在 Java 中启动另一个线程并将其发送到执行某项工作的分支上是相当容易的,而调用线程则继续执行其他工作。尽管很容易创建线程,但这些线程可能最终会阻塞自己。在管理在多线程里面的并发是很具有挑战性的。更多的线程意味着更高的复杂度。
14 |
15 | 相反,响应式编程是函数式和声明式的。响应式编程涉及描述通过该数据流的 pipeline 或 stream,而不是描述的一组按顺序执行的步骤。响应式流处理数据时只要数据是可用的就进行处理,而不是需要将数据作为一个整体进行提供。事实上,输入数据可以是无穷的(例如,一个地点的实时温度数据的恒定流)。
16 |
17 | 应用于一个真实世界的类比就是,将命令式编程看做一个装水的气球,响应式编程看做花园里面的水管。两者都是在炎热的夏天让你的朋友惊喜并沉浸其中的方式。但是它们的执行风格是不同的:
18 |
19 | - 一个水气球一次能携带的它的有效载荷,在撞击的那一刻浸湿了它预定的目标。然而,水球的容量是有限的,如果你想用水泡更多的人(或把同一个人淋得更湿),你唯一的选择就是增加水球的数量。
20 | - 一根花园水龙带将其有效载荷作为一股水流从水龙头流向喷嘴。花园水龙头接的水带的容量可能是有限的,但在打水仗的过程中水是源源不断的。只要水从水龙头进入软管,就会一直通过软管然后从喷嘴喷出。同一个花园软管是很容易扩展的,你和朋友们可以玩得更尽兴。
21 |
22 | 命令式编程就类似打水仗中的水球,本质上没有什么问题,但是拿着类似响应式编程的水管的人在可扩展性和性能方面是有优势的。
23 |
24 | ### 10.1.1 定义响应式流
25 |
26 | Reactive Streams 是 2013 年底由 Netflix、Lightbend 和 Pivotal(Spring 背后的公司)的工程师发起的一项计划。响应式流旨在为无阻塞异步流处理提供一个标准。
27 |
28 | 我们已经谈到了响应式编程的异步特性;它使我们能够并行执行任务以获得更大的可伸缩性。Backpressure(译者注:[如何形象的描述反应式编程中的背压(Backpressure)机制?](https://www.zhihu.com/question/49618581/answer/237078934) )是一种手段,通过对用户愿意处理的数据量设定限制,数据消费者可以避免被生产速度过快的数据淹没。
29 |
30 | > **Java Streams** 与 **Reactive Streams** 对比
31 | >
32 | > 在 Java 流和响应式流之间有很大的相似性。首先,它们的名字中都含有 Streams。它们也都为处理数据提供函数式接口。事实上,稍后当学到容器的时候,你会看到,其实它们有很多共同操作。
33 | >
34 | > 然而,Java 流通常是同步的,同时只能处理有限数据集。它们本质上是使用函数式进行集合迭代的一种手段。
35 | >
36 | > 响应式流支持任何大小的数据集,包括无限数据集的异步处理。它们使实时处理数据成为了可能。
37 |
38 | 响应式流的规范可以通过四个接口定义来概括:Publisher,Subscriber,Subscription 和 Processor。Publisher 为每一个 Subscription 的 Subscriber 生产数据。Publisher 接口声明了一个 subscribe() 方法,通过这个方法 Subscriber 可以订阅 Publisher:
39 |
40 | ```java
41 | public interface Publisher {
42 | void subscribe(Subscriber subscriber);
43 | }
44 | ```
45 |
46 | Subscriber 一旦进行了订阅,就可以从 Publisher 中接收消息,这些消息都是通过 Subscriber 接口中的方法进行发送:
47 |
48 | ```java
49 | public interface Subscriber {
50 | void onSubscribe(Subscription sub);
51 | void onNext(T item);
52 | void onError(Throwable ex);
53 | void onComplete();
54 | }
55 | ```
56 |
57 | Subscriber 通过调用 onSubscribe() 函数将会收到第一个消息。当 Publisher 调用 onSubscribe(),它通过一个 Subscription 对象将消息传输给 Subscriber。消息是通过 Subscription 进行传递的,Subscriber 可以管理他自己的订阅内容:
58 |
59 | ```java
60 | public interface Subscription {
61 | void request(long n);
62 | void cancel();
63 | }
64 | ```
65 |
66 | Subscriber 可以调用 request() 去请求被被发送了的数据,或者调用 cancel() 来表明他对接收的数据不感兴趣,并取消订阅。当调用 request() 时,Subscriber 通过传递一个 long 值的参数来表示它将会接收多少数据。这时就会引进 backpressure,用以阻止 Publisher 发送的数据超过 Subscriber 能够处理的数据。在 Publisher 发送了足够的被请求的数据后,Subscriber 可以再次调用 request() 来请求更多的数据。
67 |
68 | 一旦 Subcriber 已经接收到数据,数据就通过流开始流动了。每一个 Publisher 发布的项目都会通过调用 onNext() 方法将数据传输到 Subscriber。如果出现错误,onError() 方法将被调用。如果 Publisher 没有更多的数据需要发送了,同时也不会再生产任何数据了,将会调用 onComplete() 方法来告诉 Subscriber,它已经结束了。
69 |
70 | 对于 Processor 接口而言,它连接了 Subscriber 和 Publisher:
71 |
72 | ```java
73 | public interface Processor extends Subscriber, Publisher {}
74 | ```
75 |
76 | 作为 Subscriber,Processor 将会接收数据然后以一定的方式处理这些数据。然后它会像变戏法一样地变为一个 Publisher 将处理的结果发布给 Subscriber。
77 |
78 | 正如你所看到的,响应式流规范相当地简单。关于如何从 Publisher 开始建立起一个数据处理的通道,这也是一件很容易的事情了,通过将数据不输入或是输入到多个 Processor 中,然后将最终结果传递到 Subscriber 中就行了。
79 |
80 | Reactor 工程实现了响应式流的规范,它提供由响应式流组成的函数式 API。正如你将在后面的章节中看到的,Reactor 是 Spring 5 响应式编程模型的基础。在本章的剩余部分,我们将探索 Reactor 工程。
81 |
--------------------------------------------------------------------------------
/02~数据库/02~MyBatis/Mybatis Plus/2024.11~MyBatis Plus BaseMapper 与 IService 差异.md:
--------------------------------------------------------------------------------
1 | # BaseMapper 与 IService 对比
2 |
3 | ## 1. 基本概念
4 |
5 | ### BaseMapper
6 |
7 | - 最基础的 Mapper 接口,提供基本的 CRUD 操作
8 | - 直接与数据库交互的 DAO 层接口
9 | - 操作粒度较细,方法都是原子性的
10 |
11 | ### IService
12 |
13 | - 在 BaseMapper 的基础上进行了封装,提供了更多的批量操作和链式调用方法
14 | - 业务服务层接口,通常用在 Service 层
15 | - 提供了更高层次的封装,包含了事务等特性
16 |
17 | ## 2. 主要区别
18 |
19 | ### 2.1 功能范围
20 |
21 | ```java
22 | // BaseMapper - 基础功能
23 | public interface BaseMapper {
24 | int insert(T entity);
25 | int deleteById(Serializable id);
26 | int updateById(@Param("et") T entity);
27 | T selectById(Serializable id);
28 | // ...基础方法
29 | }
30 |
31 | // IService - 扩展功能
32 | public interface IService {
33 | // 包含 BaseMapper 的所有功能,并且扩展了:
34 | boolean saveBatch(Collection entityList);
35 | boolean saveOrUpdateBatch(Collection entityList);
36 | boolean updateBatchById(Collection entityList);
37 | // ...更多批量操作和链式调用方法
38 | }
39 | ```
40 |
41 | ### 2.2 使用场景对比
42 |
43 | #### BaseMapper 适用场景:
44 |
45 | ```java
46 | @Mapper
47 | public interface UserMapper extends BaseMapper {
48 | // 1. 单表的基础 CRUD 操作
49 | // 2. 需要自定义 SQL 的场景
50 | // 3. 需要直接操作数据库的原子操作
51 | // 4. 与其他 ORM 框架配合使用
52 |
53 | // 自定义 SQL 示例
54 | @Select("SELECT * FROM user WHERE age > #{age}")
55 | List selectOlderThan(@Param("age") Integer age);
56 | }
57 | ```
58 |
59 | #### IService 适用场景:
60 |
61 | ```java
62 | @Service
63 | public class UserServiceImpl extends ServiceImpl implements IService {
64 | // 1. 批量操作场景
65 | public void batchOperationDemo() {
66 | List users = new ArrayList<>();
67 | // ... 添加用户
68 | // 批量保存,自动分批处理
69 | this.saveBatch(users, 1000);
70 | }
71 |
72 | // 2. 链式调用场景
73 | public void chainOperationDemo() {
74 | // 链式查询
75 | this.lambdaQuery()
76 | .like(User::getName, "张")
77 | .ge(User::getAge, 18)
78 | .list();
79 |
80 | // 链式更新
81 | this.lambdaUpdate()
82 | .set(User::getAge, 20)
83 | .eq(User::getName, "张三")
84 | .update();
85 | }
86 |
87 | // 3. 事务场景
88 | @Transactional(rollbackFor = Exception.class)
89 | public void transactionDemo() {
90 | // 批量操作自动开启事务
91 | this.saveOrUpdateBatch(userList);
92 | }
93 | }
94 | ```
95 |
96 | ## 3. 使用建议
97 |
98 | ### 3.1 使用 BaseMapper 的情况
99 |
100 | 1. 需要进行简单的 CRUD 操作
101 | 2. 需要自定义 SQL 语句
102 | 3. 对性能要求较高的场景
103 | 4. 需要精确控制 SQL 执行的场景
104 |
105 | ### 3.2 使用 IService 的情况
106 |
107 | 1. 需要进行批量操作
108 | 2. 需要使用链式调用提高代码可读性
109 | 3. 需要事务管理
110 | 4. 需要更复杂的业务逻辑封装
111 |
112 | ## 4. 最佳实践
113 |
114 | ### 4.1 分层使用
115 |
116 | ```java
117 | // Mapper 层:使用 BaseMapper
118 | @Mapper
119 | public interface UserMapper extends BaseMapper {
120 | // 自定义方法
121 | }
122 |
123 | // Service 层:使用 IService
124 | @Service
125 | public class UserServiceImpl extends ServiceImpl implements UserService {
126 | // 业务方法
127 | }
128 | ```
129 |
130 | ### 4.2 混合使用
131 |
132 | ```java
133 | @Service
134 | public class UserServiceImpl extends ServiceImpl implements UserService {
135 | @Autowired
136 | private UserMapper userMapper; // 注入 BaseMapper
137 |
138 | public void complexOperation() {
139 | // 使用 IService 的批量方法
140 | this.saveBatch(userList);
141 |
142 | // 使用 BaseMapper 的自定义方法
143 | userMapper.selectOlderThan(18);
144 | }
145 | }
146 | ```
147 |
148 | ## 5. 总结
149 |
150 | 1. **BaseMapper**
151 |
152 | - 偏向底层的数据库操作
153 | - 适合单一的、原子性的数据库操作
154 | - 可以自定义 SQL
155 | - 性能较好
156 |
157 | 2. **IService**
158 | - 偏向业务层的封装
159 | - 提供了更多的批量操作和便利方法
160 | - 支持链式调用
161 | - 自动管理事务
162 |
--------------------------------------------------------------------------------
/01~基础使用/04~请求与响应/异步处理/Async/Async.md:
--------------------------------------------------------------------------------
1 | # Async Support
2 |
3 | 在 Spring Boot 中,我们可以通过 Java 注解的方式来启用异步处理:
4 |
5 | ```java
6 | @Configuration
7 | @EnableAsync
8 | public class SpringAsyncConfig { ... }
9 | ```
10 |
11 | 或者以 XML 的方式启用:
12 |
13 | ```xml
14 |
15 |
16 | ```
17 |
18 | # @Async
19 |
20 | @Async 注解只能作用于 public 方法,并且不能够自调用。
21 |
22 | ```java
23 | @Async
24 | public void asyncMethodWithVoidReturnType() {
25 | System.out.println("Execute method asynchronously. "
26 | + Thread.currentThread().getName());
27 | }
28 |
29 | @Async
30 | public Future asyncMethodWithReturnType() {
31 | System.out.println("Execute method asynchronously - "
32 | + Thread.currentThread().getName());
33 | try {
34 | Thread.sleep(5000);
35 | return new AsyncResult("hello world !!!!");
36 | } catch (InterruptedException e) {
37 | //
38 | }
39 |
40 | return null;
41 | }
42 | ```
43 |
44 | Spring 还提供了一个实现 Future 的 AsyncResult 类。这可以用来跟踪异步方法执行的结果。现在,让我们调用上述方法,并使用 Future 对象检索异步过程的结果。
45 |
46 | ```java
47 | public void testAsyncAnnotationForMethodsWithReturnType()
48 | throws InterruptedException, ExecutionException {
49 | System.out.println("Invoking an asynchronous method. "
50 | + Thread.currentThread().getName());
51 | Future future = asyncAnnotationExample.asyncMethodWithReturnType();
52 |
53 | while (true) {
54 | if (future.isDone()) {
55 | System.out.println("Result from asynchronous process - " + future.get());
56 | break;
57 | }
58 | System.out.println("Continue doing something else. ");
59 | Thread.sleep(1000);
60 | }
61 | }
62 | ```
63 |
64 | # Executor
65 |
66 | 默认情况下,Spring 使用 SimpleAsyncTaskExecutor 实际异步运行这些方法。可以在两个级别上覆盖默认值:在应用程序级别或单个方法级别。
67 |
68 | ## 方法级别复写
69 |
70 | 所需的执行程序需要在配置类中声明:
71 |
72 | ```java
73 | @Configuration
74 | @EnableAsync
75 | public class SpringAsyncConfig {
76 |
77 | @Bean(name = "threadPoolTaskExecutor")
78 | public Executor threadPoolTaskExecutor() {
79 | return new ThreadPoolTaskExecutor();
80 | }
81 | }
82 |
83 | @Async("threadPoolTaskExecutor")
84 | public void asyncMethodWithConfiguredExecutor() {
85 | System.out.println("Execute method with configured executor - "
86 | + Thread.currentThread().getName());
87 | }
88 | ```
89 |
90 | ## 应用级别复写
91 |
92 | 配置类应实现 AsyncConfigurer 接口,这意味着它具有实现 getAsyncExecutor() 方法。在这里,我们将返回整个应用程序的执行程序–现在,它成为运行以 @Async 注释的方法的默认执行程序:
93 |
94 | ```java
95 | @Configuration
96 | @EnableAsync
97 | public class SpringAsyncConfig implements AsyncConfigurer {
98 |
99 | @Override
100 | public Executor getAsyncExecutor() {
101 | return new ThreadPoolTaskExecutor();
102 | }
103 | }
104 | ```
105 |
106 | # 异常处理
107 |
108 | 当方法返回类型为 Future 时,异常处理很容易:Future.get() 方法将引发异常。但是,如果返回类型为 void,则异常不会传播到调用线程;因此,我们需要添加额外的配置来处理异常。我们将通过实现 AsyncUncaughtExceptionHandler 接口来创建自定义异步异常处理程序。当存在任何未捕获的异步异常时,将调用 handleUncaughtException() 方法:
109 |
110 | ```java
111 | public class CustomAsyncExceptionHandler
112 | implements AsyncUncaughtExceptionHandler {
113 |
114 | @Override
115 | public void handleUncaughtException(
116 | Throwable throwable,
117 | Method method,
118 | Object... obj
119 | ) {
120 | System.out.println("Exception message - " + throwable.getMessage());
121 | System.out.println("Method name - " + method.getName());
122 | for (Object param : obj) {
123 | System.out.println("Parameter value - " + param);
124 | }
125 | }
126 | }
127 | ```
128 |
129 | 在上一节中,我们介绍了由配置类实现的 AsyncConfigurer 接口。作为其中的一部分,我们还需要重写 getAsyncUncaughtExceptionHandler() 方法以返回我们的自定义异步异常处理程序:
130 |
131 | ```java
132 | @Override
133 | public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
134 | return new CustomAsyncExceptionHandler();
135 | }
136 | ```
137 |
138 | # Links
139 |
140 |
141 |
--------------------------------------------------------------------------------