├── .gitignore
├── LICENSE
├── README.md
├── SUMMARY.md
├── book.json
├── chapter2.md
├── chapter2
├── 0c23bb5c3335df21eafb04c3ec3feeb9.png
├── 0d9efd7d6113fc8ae6ead068d65f69a3.png
├── 56760245043951a56bc5f202ccbc74f4.png
└── 5af6d65cbb1e756e48484e4dd2af99f8.png
├── chapter3.md
├── chapter3
├── Marathon填写信息.png
├── Marathon搭建.png
├── Marathon运行信息.png
├── README.md
├── bamboo_1.png
├── bamboo_v2.png
├── bamboo_v3.png
├── bamboo_v4.png
├── bamboo_v5.png
├── bamboo_v6.png
├── bamboo_v7.png
├── bamboo_v8.png
├── docker.md
├── marathon.md
├── marathon_salve-02.png
├── marathon_salve_01.png
├── marathon_slave-03.png
├── mesos_bamboo_1.png
├── mesos_cluster_master.png
├── mesos_floow节点.png
├── mesos_master节点.png
├── mesos搭建.png
├── mesos正在运行信息.png
├── set_up.md
├── summary.md
├── think_about.md
└── zatan.md
├── chapter4
├── 12DF1664-8DE5-4AEE-B420-94D14F6E6543.png
├── Cluster-mesos.png
├── README.md
├── chapter4.md
├── mesos-cluster.png
├── singa on mesos.png
├── singa运行结果1.png
└── singa运行结果2.png
├── chapter5.md
├── chapter6.md
├── chapter7.md
├── chapter7
├── ContinuousDeliveryMatrix.png
├── Jenkins - scm-sync-config - Display Status.png
├── Jenkins - scm-sync-configuration - Comment prompt2.png
├── building-jobs.png
├── challenges.md
├── ci.md
├── ebay-mesos-jenkins.png
├── how-jenkins-master-run-on-mesos.png
├── how-marathon-run-jenkins-on-mesos.png
├── jenkins-config-slave.png
├── jenkins-configure.png
├── jenkins-framework-on-mesos.png
├── jenkins-master-on-marathon.png
├── jenkins-master-on-mesos-slave-2.png
├── jenkins-master-on-mesos-slave.png
├── jenkins-mesos-configure.png
├── jenkins-on-mesos.md
├── jenkins-slave-detail.png
├── jenkins-slave.png
├── jenkins-utilization.png
├── jenkins.md
├── refers.md
├── summary.md
└── test-job-config.png
├── concepts
├── concepts.md
├── index.md
└── objects.md
├── mesos-frameworks
├── README.md
├── assets
│ └── mesos-frameworks-periodic-table.png
├── chronos
│ ├── README.md
│ ├── assets
│ │ ├── chronos-architecture.png
│ │ ├── chronos-create-hello.png
│ │ ├── chronos-download.png
│ │ ├── chronos-ha.graphml
│ │ ├── chronos-ha.png
│ │ ├── chronos-hello-chronos-finished.png
│ │ ├── chronos-hello-chronos-output.png
│ │ ├── chronos-hello-finished-1.png
│ │ ├── chronos-homepage.png
│ │ ├── chronos-internal.png
│ │ ├── chronos-on-marathon-staged.png
│ │ ├── chronos-registered.png
│ │ ├── create-chronos-on-marathon.png
│ │ └── hello-chronos-script.png
│ ├── basics.md
│ ├── job.md
│ ├── setup.md
│ └── summary.md
├── marathon
│ ├── README.md
│ ├── app.md
│ ├── assets
│ │ ├── docker-2048-v2.json
│ │ ├── docker-2048-v3.json
│ │ ├── docker-2048.json
│ │ ├── marathon-api-create-app.png
│ │ ├── marathon-constraints.png
│ │ ├── marathon-docker-2048-created-by-api.png
│ │ ├── marathon-docker-2048-health-check.png
│ │ ├── marathon-docker-2048-running.png
│ │ ├── marathon-docker-2048-task.png
│ │ ├── marathon-docker-2048.png
│ │ ├── marathon-hello-marathon-1.png
│ │ ├── marathon-hello-marathon-detail.png
│ │ ├── marathon-hello-marathon-stdout.png
│ │ ├── marathon-new-app-1.png
│ │ ├── marathon-new-docker-2048.png
│ │ ├── marathon-registered.png
│ │ ├── marathon-scale-application.png
│ │ ├── marathon-web-ui-home.png
│ │ └── mesos-slave-active-tasks.png
│ ├── basics.md
│ ├── setup.md
│ └── summary.md
├── overview.md
├── spark
│ ├── README.md
│ ├── assets
│ │ ├── download-spark-hadoop.png
│ │ ├── download-spark.png
│ │ ├── spark-components.png
│ │ ├── spark-driver-mesos.png
│ │ ├── spark-framework-registered.png
│ │ ├── spark-homepage.png
│ │ ├── spark-worker-homepage.png
│ │ └── spark-worker-registered.png
│ ├── basics.md
│ ├── job.md
│ ├── setup.md
│ └── summary.md
└── summary.md
├── mesos
├── assets
│ ├── mesos-3-slaves.png
│ ├── mesos-arch.png
│ ├── mesos-frameworks-list.png
│ ├── mesos-frameworks.png
│ ├── mesos-goto-leader.png
│ ├── mesos-master-web.png
│ ├── mesos-offer.png
│ ├── mesos-offers.png
│ ├── mesos-slave-detail.png
│ ├── mesos-slaves-list.png
│ ├── mesosphere-download.png
│ ├── mesosphere-homepage.png
│ ├── zookeeper-download.png
│ └── zookeeper-project.png
├── build-a-mesos-cluster.md
├── how-mesos-works.md
└── summary.md
├── mesosben_shen_shi_yi_ge_fen_bu_shi_zi_yuan_diao_du.png
├── mesosshi-zhan-pian.md
├── rong_qi_bian_pai_ff1a.png
└── wercker.yml
/.gitignore:
--------------------------------------------------------------------------------
1 | # Node rules:
2 | ## Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
3 | .grunt
4 |
5 | ## Dependency directory
6 | ## Commenting this out is preferred by some people, see
7 | ## https://docs.npmjs.com/misc/faq#should-i-check-my-node_modules-folder-into-git
8 | node_modules
9 |
10 | # Book build output
11 | _book
12 |
13 | # eBook build output
14 | *.epub
15 | *.mobi
16 | *.pdf
17 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | Copyright 2017 Xiao Deshi
179 |
180 | Licensed under the Apache License, Version 2.0 (the "License");
181 | you may not use this file except in compliance with the License.
182 | You may obtain a copy of the License at
183 |
184 | http://www.apache.org/licenses/LICENSE-2.0
185 |
186 | Unless required by applicable law or agreed to in writing, software
187 | distributed under the License is distributed on an "AS IS" BASIS,
188 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
189 | See the License for the specific language governing permissions and
190 | limitations under the License.
191 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Mesos最佳实践指南(Mesos Handbook)
2 |
3 | ## 前言
4 |
5 | 肖德时篇
6 |
7 | Apache Mesos是Apache软件基金会下属的顶级开源项目,它是目前开源分布式集群领域少数应用在生产环境的基础设施软件,通常被用户类比于Linux操作系统的中心系统-Kernel,在全球知名的互联网公司Twitter、AirBnb、Apple、Netflix等公司内部支撑着众多核心的业务系统。随着近几年云计算技术的发展,大量的创业公司也把Mesos系统选择为下一代云平台的核心组件,为搭建分布式系平台系统构建强有力的底座支撑。
8 |
9 | 笔者是在加入创业公司之后才开始接触Apache Mesos系统的。初次使用的过程中映像深刻的地方就是搭建一套分布式容器平台很容易上手,使用规则也非常符合新用户的习惯。但是在深度使用Mesos系统之后发现,对于初学者本地环境的多样性问题,Mesos系统并不能快速的解决问题。所以,Apache Mesos的使用体验并没有Docker Swarm那样轻量级别,让开发者快速部署一套Mesos环境还是很困难的事情。这个问题一直到Cisco开源了一套MiniMesos之后才得到一定的缓解。MiniMesos项目是通过Docker Compose编排系统来在本地开发环境自动构建一套Apache Zookeeper + Apache Mesos + Marathon + Consul + Mesos DNS + Registrator全家桶。可以方便开发者快速通过这套Mesos环境一键部署全家桶完成Mesos环境的部署,方便调度框架的二次开发工作。Cisco就是利用这套miniMesos工具快速做出了一个Elasticsearch on mesos应用调度框架。
10 |
11 | Mesos社区拥有很多中国开发者,大家也非常热情和耐心帮助Mesos社区的成长,大家通过大量的Mesos使用经实践已经积累了很多案例,所以我期望通过本书的汇总学习,给读者提供一份完整学习体系的Mesos使用手册。在此感谢这些作者的贡献。
12 |
13 | * 陈显鹭 - 灵雀云开发工程师\(xianlubird@gmail.com\)
14 | * 徐磊 - 去哪儿系统开发工程师\(49068995@qq.com\)
15 | * 赵英俊 - 城云科技(杭州)有限公司\(zyj@citycloud.com.cn\)
16 | * 周伟涛 - 阿里云\(zhouwtlord@gmail.com)
17 | * 杨成伟 - 爱奇艺\(me@chengweiyang.cn\)
18 |
19 | 还有最后,作为本书的作者,一直忙于创业、朋友、家庭的事务权衡之中。期间经历了二孩的出生。所以我将把这本书作为礼物献给我的妻子和二个宝宝。谢谢他们对我事业默默的支持。
20 |
21 | 在写作本书时,安装的所有组件、所用示例和操作等皆基于 **Mesos 1.3.1** 版本。
22 |
23 | [文章目录](SUMMARY.md)
24 |
25 | GitHub 地址: https://github.com/xiaods/mesos-handbook
26 |
27 | Gitbook 在线浏览:https://xiaods.gitbooks.io/mesos-handbook/
28 |
29 | ## 如何使用本书
30 |
31 | **在线浏览**
32 |
33 | 访问 [gitbook](https://xiaods.gitbooks.io/mesos-handbook/)
34 |
35 | **注意**:文中涉及的配置文件和代码链接在 gitbook 中会无法打开,请下载 github
36 | 源码后,在 MarkDown
37 | 编辑器中打开,点击链接将跳转到你的本地目录,推荐使用[typora](https://www.typora.io)。
38 |
39 | **本地查看**
40 |
41 | 1. 将代码克隆到本地
42 | 2. 安装 gitbook:[Setup and Installation of GitBook](https://github.com/GitbookIO/gitbook/blob/master/docs/setup.md)
43 | 3. 执行 gitbook serve
44 | 4. 在浏览器中访问http://localhost:4000
45 | 5. 生成的文档在 `_book` 目录下
46 |
47 | ## 贡献文档
48 |
49 | ### 文档的组织规则
50 |
51 | - 如果要创建一个大的主题就在最顶层创建一个目录;
52 | - 如果要创建一个大的主题就在最顶层创建一个目录;
53 | - 全书五大主题,每个主题一个目录,其下不再设二级目录;
54 | - 所有的图片都放在最顶层的 `images` 目录下,原则上文章中用到的图片都保存在本地;
55 | - 所有的文档的文件名使用英文命名,可以包含数字和中划线;
56 | - `etc`、`manifests`目录专门用来保存配置文件和文档中用到的其他相关文件;
57 |
58 | ### 添加文档
59 |
60 | 1. 在该文章相关主题的目录下创建文档;
61 | 2. 在 `SUMMARY.md` 中在相应的章节下添加文章链接;
62 | 3. 执行 `gitbook serve` 测试是否报错,访问 http://localhost:4000 查看该文档是否出现在相应主题的目录下;
63 | 4. 提交PR
64 |
65 |
66 |
67 | ## 关于
68 |
69 | [贡献者列表](https://github.com/xiaods/mesos-handbook/graphs/contributors)
70 |
71 |
72 |
73 |
--------------------------------------------------------------------------------
/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Summary
2 |
3 | - [1. 前言](README.md)
4 | - [2. Mesos理论篇](concepts/index.md)
5 | - [2.1 设计理念](concepts/concepts.md)
6 | - [2.2 主要概念](concepts/objects.md)
7 | - [3.Mesos实战篇](mesosshi-zhan-pian.md)
8 | - [Mesos搭建日志处理系统实战](chapter2.md)
9 | - [Mesos搭建企业级容器云实战](chapter3.md)
10 | - [Mesos搭建企业级容器云项目概述](chapter3/README.md)
11 | - [docker基础知识介绍](chapter3/docker.md)
12 | - [Marathon Framework 介绍](chapter3/marathon.md)
13 | - [容器云平台基础概述](chapter3/think_about.md)
14 | - [容器云搭建](chapter3/set_up.md)
15 | - [关于容器云平台的其他一些杂谈](chapter3/zatan.md)
16 | - [Mesos搭建大数据平台Hadoop和深度机器学习平台Singa实战](chapter4/README.md)
17 | - [Mesos搭建分布式生物信息算法计算系统实战](chapter5.md)
18 | - [Mesos搭建视频压缩批处理系统实战](chapter6.md)
19 | - [7 Mesos搭建持续集成系统实战](chapter7.md)
20 | - [7.1 Mesos 搭建持续集成系统概述](chapter7/summary.md)
21 | - [7.2 持续集成概念介绍](chapter7/ci.md)
22 | - [7.3 Jenkins 开源软件介绍](chapter7/jenkins.md)
23 | - [7.4 持续集成系统搭建](chapter7/jenkins-on-mesos.md)
24 | - [7.5 持续集成系统的维护心得](chapter7/challenges.md)
25 | - [7.6 参考](chapter7/refers.md)
26 |
--------------------------------------------------------------------------------
/book.json:
--------------------------------------------------------------------------------
1 | {
2 | "title": "Mesos Handbook",
3 | "description": "Let's play fun with Mesos!",
4 | "language": "zh-cn",
5 | "author": "Xiao Deshi",
6 | "plugins": [
7 | "github",
8 | "codesnippet",
9 | "splitter",
10 | "page-toc-button",
11 | "image-captions",
12 | "page-footer-ex",
13 | "editlink",
14 | "-lunr", "-search", "search-plus"
15 | ],
16 | "pluginsConfig": {
17 | "github": {
18 | "url": "https://github.com/xiaods/mesos-handbook"
19 | },
20 | "editlink": {
21 | "base": "https://github.com/xiaods/mesos-handbook/blob/master/",
22 | "label": "编辑本页"
23 | }
24 | },
25 | "page-footer-ex": {
26 | "copyright": "Xiao Deshi",
27 | "update_label": "最后更新:",
28 | "update_format": "YYYY-MM-DD HH:mm:ss"
29 | },
30 | "image-captions": {
31 | "caption": "图片 - _CAPTION_"
32 | }
33 | }
--------------------------------------------------------------------------------
/chapter2.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建日志处理系统实战
2 |
3 | ## 平台介绍
4 | 我们是在今年的5月份开始调研并尝试使用Mesos,第一个试点就是我们的日志平台,我们将日志分析全部托管在Mesos平台上。日志平台面向业务线开发、测试、运营人员,方便定位、追溯线上问题和运营报表。
5 |
6 | 
7 |
8 | 这个是我们平台的结构概览。
9 |
10 | 日志分析我们使用ELK(Elasticsearch、Logstash、Kibana),这三个应该说是目前非常常见的工具了。而且方案成熟,文档丰富,社区活跃(以上几点可以作为开源选型的重要参考点)。稍微定制了下Kibana和Logstash,主要是为了接入公司的监控和认证体系。
11 |
12 | 日志的入口有很多,如kernel、mail、cron、dmesg等日志通过rsyslog收集。业务日志通过flume收集,容器日志则使用mozilla的heka和fluentd收集。
13 |
14 | 这里稍稍给heka和fluentd打个广告,两者配合收集Mesos平台内的容器日志非常方便,可以直接利用MESOS_TASK_ID区分容器(此环境变量由Mesos启动容器时注入)。而且我们也有打算用heka替换logstash。
15 |
16 | ## Mesos技术栈
17 |
18 | 下面主要分享一下Mesos这块,我们使用了两个框架:Marathon和Chronos,另外自己开发了一个监控框架Universe。
19 |
20 | 先说Marathon,eventSubscriptions是个好功能,通过它的httpcallback可以有很多玩法,群里经常提到的bamboo就是利用这个功能做的。利用好这个功能,做容器监控就非常简单了。
21 |
22 | 接着是Marathon的重启(更新),推荐设置一下minimumHealthCapacity,这样可以减少重启(更新)时的资源占用,防止同时启动多个运行实例时消耗过多集群资源。
23 |
24 | 服务发现,Marathon提供了servicerouter.py导出haproxy配置,或者是bamboo,但是我们现在没有使用这两个。而是按协议分成了两部分,HTTP协议的服务是使用OpenResty开发了一个插件,动态加载Marathon(Mesos)内的应用信息,外部访问的时候proxy_pass到Mesos集群内的一个应用,支持upstream的配置。
25 |
26 | 非HTTP的应用,比如集群内部的statsd的UDP消息,我们就直接用Mesos DNS + 固定端口来做了。随即端口的应用依赖entrypoint拉取域名+端口动态替换。
27 |
28 | 带有UNIQUE attribute的应用,官方目前还无法做到自动扩容,从我们的使用情况来看,基于UNIQUE方式发布的应用全部是基础服务,比如statsd、heka(收集本机的Docker日志)、cAdvisor(监控容器)等,集群新加机器的时候Marathon不会自动scale UNIQUE实例的数量,这块功能社区正在考虑加进去。我们自己写了一个daemon,专门用来监控UNIQUE的服务,发现有新机器就自动scale,省的自己上去点了。
29 |
30 |
31 | 
32 |
33 | 另外一个问题,资源碎片化,Marathon只是个框架,关注点也不在这里。Mesos的UI里虽然有统计,但是很难反应真实的情况,于是我们就自己写了一个Mesos的框架,专门来计算资源碎片和真实的余量,模拟发布情况,这样我们发布新应用或者扩容的时候,就知道集群内真实的资源余量能否支持本次发布,这些数据会抄送一份给我们的监控/报警系统。Chronos我们主要是跑一些定时清理和监控的脚本。
34 |
35 | Docker这块,我们没有做什么改动,网络都使用host模式。Docker的监控和日志上面也提到了,我们用的是cAdvisor和heka,很好很强大,美中不足的是cAdvisor接入我们自己的监控系统要做定制。
36 |
37 | 我们也捣鼓了一个Docker SSH Proxy,可能是我们更习惯用虚拟机的缘故吧,有时候还是喜欢进入到容器里去干点啥的(其实业务线对这个需求更强烈),就是第一张图里的octopus,模拟docker exec -it的工作原理,对接Mesos和Marathon抓取容器信息。这样开发人员在自己机器上就能SSH到容器内部debug了,也省去了申请机器账号的时间了。
38 |
39 | ## 应用方案
40 |
41 | 接着说说我们的日志平台。这个平台的日志解析部分全部跑在Mesos上,平台自身与业务线整合度比较深,对接了一些内部系统,主要是为了考虑兼容性和业务线资源复用的问题,我尽量省略与内部系统关联的部分,毕竟这块不是通用性的。
42 |
43 | 平台目前跑了有600+的容器,网络是Docker自带的host模式,每天给业务线处理51亿+日志,延时控制在60~100ms以内。
44 |
45 | 最先遇到的问题是镜像,是把镜像做成代码库,还是一个运行环境?或者更极端点,做一个通用的base image?结合Logstash、heka、statsd等应用特点后,我们发现运行环境更适合,这些应用变化最大的经常是配置文件。所以我们先剥离配置文件到GitLab,版本控制交给GitLab,镜像启动后再根据tag拉取。
46 |
47 | 另外,Logstash的监控比较少,能用的也就一个metrics filter,写Ruby代码调试不太方便。索性就直接改了Logstash源码,加了一些监控项进去,主要是监控两个Queue的状态,顺便也监控了下EPS和解析延时。
48 |
49 | Kafka的partition lag统计跑在了Chronos上,配合我们每个机房专门用来引流的Logstash,监控业务线日志的流量变得轻松多了。
50 |
51 | 
52 |
53 | 容器监控最开始是自己开发的,从Mesos的接口里获取的数据,后来发现hostname:UNIQUE的应用Mesos经常取不到数据,就转而使用cAdvisor了,对于Mesos/Marathon发布的应用,cAdvisor需要通过libcontainer读取容器的config.json文件,获取ENV列表,拿到MESOS_TASK_ID和MARATHON_APP_ID,根据这两个值做聚合后再发到statsd里(上面提到的定制思路)。
54 |
55 | 发布这块我们围绕这Jenkins做了一个串接。业务线的开发同学写filter并提交到GitLab,打tag就发布了。发布的时候会根据集群规划替换input和output,并验证配置,发布到线上。本地也提供了一个sandbox,模拟线上的环境给开发人员debug自己的filter用。
56 |
57 | 
58 |
59 | 同时发布过程中我们还会做一些小动作,比如Kibana索引的自动创建,Dashboard的导入导出,尽最大可能减少业务线配置Kibana的时间。每个应用都会启动独立的Kibana实例,这样不同业务线间的ACL也省略了,简单粗暴,方便管理。没人使用的时候自动回收Kibana容器,有访问了再重新发一个。
60 |
61 | 除了ELK,我们也在尝试Storm on Mesos,感觉这个坑还挺多的,正在努力的趟坑中。扫清后再与大家一起交流。
--------------------------------------------------------------------------------
/chapter2/0c23bb5c3335df21eafb04c3ec3feeb9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter2/0c23bb5c3335df21eafb04c3ec3feeb9.png
--------------------------------------------------------------------------------
/chapter2/0d9efd7d6113fc8ae6ead068d65f69a3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter2/0d9efd7d6113fc8ae6ead068d65f69a3.png
--------------------------------------------------------------------------------
/chapter2/56760245043951a56bc5f202ccbc74f4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter2/56760245043951a56bc5f202ccbc74f4.png
--------------------------------------------------------------------------------
/chapter2/5af6d65cbb1e756e48484e4dd2af99f8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter2/5af6d65cbb1e756e48484e4dd2af99f8.png
--------------------------------------------------------------------------------
/chapter3.md:
--------------------------------------------------------------------------------
1 |
2 | * [Mesos 搭建企业级容器云项目概述](chapter3/summary.md)
3 |
4 | * [Docker 基础知识介绍](chapter3/docker.md)
5 |
6 | * [Marathon Framework 介绍](chapter3/marathon.md)
7 |
8 | * [容器云平台基础概述](chapter3/think_about.md)
9 |
10 | * 容器云平台搭建
11 |
12 | * 企业级容器云的一些坑
13 |
--------------------------------------------------------------------------------
/chapter3/Marathon填写信息.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/Marathon填写信息.png
--------------------------------------------------------------------------------
/chapter3/Marathon搭建.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/Marathon搭建.png
--------------------------------------------------------------------------------
/chapter3/Marathon运行信息.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/Marathon运行信息.png
--------------------------------------------------------------------------------
/chapter3/README.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建企业级容器云项目概述
2 |
3 | 随着docker的兴起,容器一词变得十分的火热,到处都可以看到容器的身影。身在云计算时代,不讨论一下容器,都不好意思说自己是做云计算的。
4 |
5 | 引领这一浪潮的,莫过于docker这一项技术。docker使用Linux的namespace和cgroups实现了容器级别的隔离,然后又加入了image这一概念,使得部署变得十分简单。现在只需要开发代码,build一个镜像,然后就可以借助docker的东风将它无障碍的部署到各种linux发行版中,甚至是 Windows。很好的解决了线上环境和开发环境不同带来的问题,让程序的部署变得更加简单。
6 |
7 | 更加让人激动的是,项目被docker容器化后,就具有了可以扩容的能力。你可以简单的将项目由一个实例变成两个或者更多个而无需复杂的线上配置。而且容器化后的项目可以很好的在分布式环境中运行,自由在多个主机之间迁移。这是传统项目所不具备的。
8 |
9 | 分布式应用在传统项目里门槛很高,会有各种各样的问题。但是现在借助mesos,我们可以非常容易的管理众多主机组成的集群,就像操作一台大型机器一样。
10 |
11 | 对于长时间运行的任务,marathon framewor很好的帮助我们解决了调度和监控的问题。使用它可以很方便的在mesos集群中启动容器,然后对他进行健康监控。
12 |
13 | 在集群中运行的容器随时都会被扩容或者迁移到其他机器,那么对于他们的访问,也就是服务发现,一般使用反向代理技术来解决,我们使用开源项目bamboo来实现这样的功能。
14 |
15 | 高可用也是企业级云平台一个非常重要的问题。mesos默认使用zookeeper来完成主从节点的选择和高可用,后面我们也会详细介绍。
16 |
17 | 综上是搭建一个企业级容器云平台需要的基础构建,可以看到,几乎清一色的开源项目。后面我们会以此为例子,一步步搭建一个分布式容器云平台。
18 |
19 | FIXME: private docker-registry。
20 |
--------------------------------------------------------------------------------
/chapter3/bamboo_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_1.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v2.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v3.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v4.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v5.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v6.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v7.png
--------------------------------------------------------------------------------
/chapter3/bamboo_v8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/bamboo_v8.png
--------------------------------------------------------------------------------
/chapter3/docker.md:
--------------------------------------------------------------------------------
1 | # docker基础知识介绍
2 |
3 | 什么是docker,引用官方的一句话
4 |
5 | > Build, Ship and Run Any Application, Anywhere
6 |
7 | docker就是一个这样的工具。它可以帮助开发者很方便的去构建,部署,运行自己的程序。它可以让你非常迅速的测试和部署你的项目到生产环境中。
8 |
9 | 对于docker的具体实现和原理我们不多讲,让我们直接来做一个简单的例子来体验一下docker的魅力。
10 |
11 | 首先你需要在你自己的机器上安装docker,详细的安装文档请参考 [Docker 官方文档](https://docs.docker.com/installation)(FIXME: hard copy book isn't a browser, URL is meanningless)。
12 |
13 | 这里以在 Ubuntu 14.04 系统上安装 Docker 为例。
14 |
15 | curl -sSL https://get.docker.com | sh
16 |
17 | 一段美妙的小脚本就被安装到了你的机器上,他完成了你安装docker需要的所有内容。下面我们就开始使用它吧。
18 |
19 | 如果我们以一个简单的小应用来演示肯定激发不了你的兴趣,那么我们以安装一个wordpress为例,看看docker是如何快速安装一个wordpress 的。
20 |
21 | 以前安装wordpress,你可能需要去了解PHP,mysql,然后还有你的服务器的系统,最后才是去安装wordpress。非常的麻烦,但是如果我们换一种方式,使用docker来安装呢。
22 |
23 | docker run -d -p 80:80 --name wordpress index.alauda.cn/alauda/wordpress
24 |
25 | 运行以上命令,docker就会自动从灵雀云平台拉取wordpress镜像,这个镜像是已经被build好的,包含了PHP,mysql和wordpress,你所做的工作就是等待docker帮你启动起来以后,在浏览器上访问你服务器的IP就可以看到wordpress的安装页面,然后一步步的点击页面安装即可。对于你的mysql密码
26 |
27 | echo $(docker logs wordpress | grep password)
28 | 这个命令就可以获得mysql密码,填写到网页中,这样你就得到了一个可以运行的wordpress,然后开始愉快的使用他吧。
29 |
30 | 是不是感受到了docker的威力。其实这只是docker强大功能的冰山一角。快速部署是docker其中一个特性。你不需要去登录到服务器,将运行环境一个一个的安装好,最后再部署你自己的代码。docker像集装箱一样,帮助你打包好了一切,你只需要开箱使用即可。就像我们刚才的例子,我们还可以非常简单的再次运行刚才的命令,只需要换一下映射的端口,就可以再启动一个wordpress,这是安装原生应用所不敢想象的。
31 |
32 | docker由client,daemon,registry组成。下面图就列出了docker的基本结构。
33 | (FIXME:local image)
34 |
35 | 更加细节的docker介绍和讲解请参考docker文档。
36 |
37 |
38 |
39 |
--------------------------------------------------------------------------------
/chapter3/marathon.md:
--------------------------------------------------------------------------------
1 | # Marathon Framework 介绍
2 |
3 | 前面章节已经介绍了Mesos,我们就不再冗余。对于在Mesos上面长时间运行的服务,Mesos提供了Framework来帮助解决调度,健康监控的功能。
4 |
5 | 每一个运行在Mesos上的容器,都会运行一段时间,对外或者对其他应用提供服务。当启动一个容器的时候,到底这个容器该被分配到Mesos集群上的哪台机器上,运行过程中如果容器异常退出了,能否报告健康状态或者重启这个容器,有些容器在运行中需要公开端口,但是用户没有显示指定,需要系统来动态的决定分配给一个什么端口。上面的这些功能,marathon framework都帮我们做了,下面我们来介绍一下这个framework。
6 |
7 | 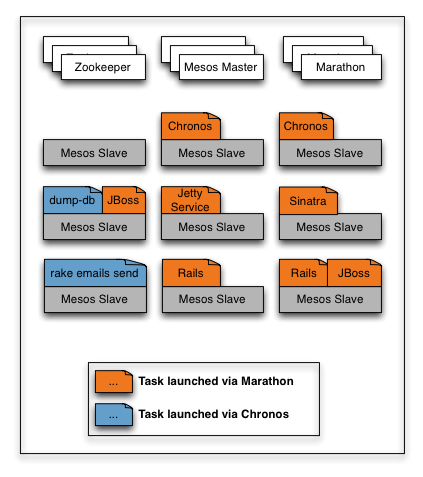
8 |
9 | 这张图是Marathon官方用来描述Marathon工作状态的一个例子。由于加入了chronos可能显的有些复杂,我们只关心Marathon的部分。(FIXME: re-draw a graph)
10 |
11 | 首先看到,由于Marathon是Mesos的一个framework,因此他需要运行在Mesos上。当然,运行Mesos需要依赖zookeeper去做选举和一些数据一致性的问题。可以看到,橘黄色部分的任务都是被Marathon启动的,他们被分配到了一个个Mesos slave上面,然后在运行过程中,如果服务宕掉了,Marathon会去重新启动它,保证你服务在一直运行的过程。用户所需要操作的就是向Marathon rest API 发送创建服务请求,剩下的事情Marathon就会帮你做好。
12 |
13 | 更加具体的信息请参考[Marathon文档](https://mesosphere.github.io/marathon/docs/).下面我们就动手搭建一个简单的Marathon例子来体验一下。
14 |
15 | 官方文档里面介绍了安装方式是原生安装,我们将会使用docker安装方式,更加快捷方便。
16 |
17 | # Mesos容器化安装
18 |
19 | 在运行Marathon之前,我们需要有一个Mesos环境,作为例子,我们先搭建一个简单的单节点master。Mesos在运行的时候需要master来分配资源和管理salve,而真正干活的则是slave节点。
20 |
21 | 首先是运行zookeeper,因为Mesos需要使用zookeeper来管理集群。
22 |
23 | docker run -d -e MYID=1 -e SERVERS=172.31.35.175 --name=zookeeper --net=host --restart=always mesoscloud/zookeeper:3.4.6-ubuntu-14.04
24 |
25 | 我们使用zookeeper 3.4.6版本。`MYID`为当前zookeeper的ID用来在zookeeper集群中标示,`SERVERS`为机器IP,`--net`为网络方式,我们使用host共享宿主机网络方式。 `--restart`是指定当容器异常退出的时候由docker daemon帮助你重启,最后是镜像的名称。
26 |
27 | 下面来部署Mesos master。
28 |
29 | docker run -d -e MESOS_HOSTNAME=172.31.35.175 -e MESOS_IP=172.31.35.175 -e MESOS_QUORUM=1 -e MESOS_ZK=zk://172.31.35.175:2181/mesos --name mesos-master --net host --restart always mesoscloud/mesos-master:0.23.0-ubuntu-14.04
30 |
31 | 这个参数比较多,我们来一一解释一下。
32 |
33 | - `MESOS_HOSTNAME`是用来指定当前Mesos master的主机名
34 | - `MESOS_IP`是当前机器的IP
35 | - `MESOS_QUORUM`为mesos master的数量,当前为单节点,后面我们会使用高可用模式。
36 | - `MESOS_ZK`是zookeeper的地址,mesos用来向其中写入数据来保证一致性。
37 |
38 | 后面的参数前面已经说过了,都是类似的。
39 |
40 | Mesos的master有了,那么下面就是干活的slave了。你可以将slave部署到一台新的机器上,也可以部署在和master的同一台机器上,由于我们只是使用一下Marathon的例子,不需要特别的复杂,因此可以将slave部署在一台机器上。
41 |
42 | docker run -d -e MESOS_HOSTNAME=172.31.35.175 -e MESOS_IP=172.31.35.175 -e MESOS_MASTER=zk://172.31.35.175:2181/mesos -v /sys/fs/cgroup:/sys/fs/cgroup -v /var/run/docker.sock:/var/run/docker.sock --name mesos-slave --net host --privileged --restart always mesoscloud/mesos-slave:0.23.0-ubuntu-14.04
43 |
44 | slave的参数也不少,前面两个MESOS_HOSTNAME和 MESOS_IP是指你部署这个salve所在机器的IP,MESOS_MASTER是指zookeeper所在服务器的地址,mesos通过这个节点去寻找master通信,zookeeper可以保证master的可用性。(FIXME:这里就一个 master,zookeeper 无能为力,实战最好还是介绍下 multiple node 的情况)
45 |
46 | 后面的参数就有些复杂。`-v`是docker挂载vloumn的命令,可以将宿主机的磁盘内容挂载到容器内部的指定位置。这里挂载了`cgroup`和`docker.sock`。原因是docker需要使用cgroup来实现容器隔离,而docker.sock是docker daemon通信的通道。将这两个目录挂载到容器里面,这样运行在容器里面的mesos slave就可以通过他们来管理宿主机的docker daemon从而实现在宿主机上启动和管理容器。
47 |
48 | 这里面有一个新的参数,`privileged`。 默认情况下,docker的privileged是关闭的。目的是为了限制容器内部去访问宿主机的设备。比如你想在容器内部运行一个docker daemon默认情况下就是不支持的。如果你设置了`privileged`,那么容器就能去接触到宿主机的所有设备,这里设置 `privileged` 选项是因为 mesos-slave 需要执行一些特权操作,例如:控制 cgroups。
49 |
50 | 这样一个mesos环境就搭建好了,可以访问一下IP:5050看一下效果。mesos默认开启5050端口提供浏览器访问。
51 | 你的页面应该和这个类似,左侧是mesos集群的一些信息,右侧为目前正在运行的任务和已经运行完毕的任务,如果你没有运行过,那么就不会有记录。
52 |
53 |
54 | # Marathon环境搭建
55 |
56 | 通过前面的步骤,我们已经有了一个可用的Mesos集群环境,那么下面我们就可以在这个环境下运行Marathon framework了。
57 |
58 | docker run -d -e MARATHON_HOSTNAME=172.31.35.175 -e MARATHON_HTTPS_ADDRESS=172.31.35.175 -e MARATHON_HTTP_ADDRESS=172.31.35.175 -e MARATHON_MASTER=zk://172.31.35.175:2181/mesos -e MARATHON_ZK=zk://172.31.35.175:2181/marathon --name marathonv0.11.1 --net host --restart always mesosphere/marathon:v0.11.1
59 |
60 | Marathon的参数也是比较多的。`MARATHON_HOSTNAME`是部署Marathon本机的IP。`MARATHON_HTTPS_ADDRESS`是部署Marathon的机器IP。`MARATHON_MASTER`为mesos所在zookeeper的节点,因为Marathon作为一个framework需要注册到mesos上。`MARATHON_ZK`为Marathon所在zookeeper的节点。
61 |
62 | 这样我们就安装好了Marathon环境,使用浏览器请求一下Marathon所在IP:8080看一下效果。
63 |
64 | 这样Marathon的环境就搭建好了。我们可以使用右上角的New App来创建一个简单的应用。
65 |
66 | {
67 | "id": "basic-0",
68 | "cmd": "while [ true ] ; do echo 'Hello Marathon' ; sleep 5 ; done",
69 | "cpus": 0.1,
70 | "mem": 10.0,
71 | "instances": 1
72 | }
73 |
74 | 只需要在弹出框里面填写上对应的信息即可。
75 | 
76 |
77 | 
78 | 在这里你就可以看到运行的效果,这样就代表运行成功,Marathon给这个实例分配了机器资源,他就成功的运行在了mesos集群中。
79 |
80 | 我们也可以访问5050端口,在mesos控制台信息里面,也可以看到正在运行的任务。
81 | 
82 |
--------------------------------------------------------------------------------
/chapter3/marathon_salve-02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/marathon_salve-02.png
--------------------------------------------------------------------------------
/chapter3/marathon_salve_01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/marathon_salve_01.png
--------------------------------------------------------------------------------
/chapter3/marathon_slave-03.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/marathon_slave-03.png
--------------------------------------------------------------------------------
/chapter3/mesos_bamboo_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/mesos_bamboo_1.png
--------------------------------------------------------------------------------
/chapter3/mesos_cluster_master.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/mesos_cluster_master.png
--------------------------------------------------------------------------------
/chapter3/mesos_floow节点.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/mesos_floow节点.png
--------------------------------------------------------------------------------
/chapter3/mesos_master节点.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/mesos_master节点.png
--------------------------------------------------------------------------------
/chapter3/mesos搭建.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/mesos搭建.png
--------------------------------------------------------------------------------
/chapter3/mesos正在运行信息.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter3/mesos正在运行信息.png
--------------------------------------------------------------------------------
/chapter3/set_up.md:
--------------------------------------------------------------------------------
1 | # 容器云搭建
2 |
3 | 本章我们将开始真正的环境搭建。
4 |
5 | 提前声明,在整个项目中,我们使用四台服务器。
6 |
7 | Node1 : 172.31.35.175
8 | Node2 : 172.31.23.17
9 | Node3 : 172.31.40.200
10 | Node4 : 172.31.37.173
11 |
12 | #zookeeper 集群
13 | 前面章节我们搭建的zookeeper是单点的,这里我们需要搭建一个zookeeper集群,这里我们先搭建一个拥有三个节点的zookeeper集群。
14 |
15 | 首先在Node1上:
16 |
17 | docker run -d -e MYID=1 -e SERVERS=172.31.35.175,172.31.23.17,172.31.40.200 --name=zookeeper --net=host --restart=always mesoscloud/zookeeper:3.4.6-ubuntu-14.04
18 |
19 | 其中的参数,`MYID`为zookeeper集群中的唯一值,用来确定当前节点在集群中的ID。`SERVERS`为指定当前集群每个zookeeper节点所在服务器的IP。
20 |
21 | 然后在Node2上:
22 |
23 | docker run -d -e MYID=2 -e SERVERS=172.31.35.175,172.31.23.17,172.31.40.200 --name=zookeeper --net=host --restart=always mesoscloud/zookeeper:3.4.6-ubuntu-14.04
24 |
25 | Node3:
26 |
27 | docker run -d -e MYID=3 -e SERVERS=172.31.35.175,172.31.23.17,172.31.40.200 --name=zookeeper --net=host --restart=always mesoscloud/zookeeper:3.4.6-ubuntu-14.04
28 |
29 | 启动完毕后,我们进入各个机器的容器查看zookeeper启动情况。
30 |
31 | root@ip-172-31-23-17:/opt/zookeeper/bin# ./zkServer.sh status
32 | JMX enabled by default
33 | Using config: /opt/zookeeper/bin/../conf/zoo.cfg
34 | Mode: leader
35 |
36 | root@ip-172-31-35-175:/opt/zookeeper/bin# ./zkServer.sh status
37 | JMX enabled by default
38 | Using config: /opt/zookeeper/bin/../conf/zoo.cfg
39 | Mode: follower
40 |
41 | root@ip-172-31-40-200:/opt/zookeeper/bin# ./zkServer.sh status
42 | JMX enabled by default
43 | Using config: /opt/zookeeper/bin/../conf/zoo.cfg
44 | Mode: follower
45 |
46 | 可以看到,`172.31.23.17`为leader,其他的为follower,这样zookeeper集群就搭建完毕了。
47 |
48 | #Mesos 集群搭建
49 | 前面章节我们搭建的mesos集群都是单master节点,生产环境下一定是需要HA的。因此我们这里搭建一个三个master节点的mesos集群。
50 |
51 | docker run -d -e MESOS_HOSTNAME=172.31.35.175 -e MESOS_IP=172.31.35.175 -e MESOS_QUORUM=2 -e MESOS_ZK=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos --name mesos-master --net host --restart always mesoscloud/mesos-master:0.23.0-ubuntu-14.04
52 |
53 | 这是在机器Node1上执行的命令。其中的参数没什么变化,只是zk那里加了三个zookeeper节点。同样的在Node2,和Node3上执行类似的命令。
54 |
55 | docker run -d -e MESOS_HOSTNAME=172.31.23.17 -e MESOS_IP=172.31.23.17 -e MESOS_QUORUM=2 -e MESOS_ZK=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos --name mesos-master --net host --restart always mesoscloud/mesos-master:0.23.0-ubuntu-14.04
56 |
57 | docker run -d -e MESOS_HOSTNAME=172.31.40.200 -e MESOS_IP=172.31.40.200 -e MESOS_QUORUM=2 -e MESOS_ZK=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos --name mesos-master --net host --restart always mesoscloud/mesos-master:0.23.0-ubuntu-14.04
58 |
59 | 这样我们尝试访问其中一个Node的页面。
60 | 
61 |
62 | 可以看到当前访问的节点并不是master节点,说明在这三个节点的选举中,他没有被选举上。mesos会自动帮你跳转到当前master节点所在的服务器。
63 | 
64 |
65 | 这样一个具有三个master节点的mesos集群就配置好了,如果其中一个master宕机,另外两个master就会选举出来一个新的master,保证当前集群不会因为没有master而宕掉。
66 |
67 | 我们在zookeeper的mesos znode上也可以看到选举的结果信息。
68 |
69 | [zk: 127.0.0.1:2181(CONNECTED) 5] get /mesos/info_0000000003
70 | !20151103-021835-3358072748-5050-1????
71 | '"master@172.31.40.200:5050*
72 | cZxid = 0x100000016
73 | ctime = Tue Nov 03 02:18:22 UTC 2015
74 | mZxid = 0x100000016
75 | mtime = Tue Nov 03 02:18:22 UTC 2015
76 | pZxid = 0x100000016
77 | cversion = 0
78 | dataVersion = 0
79 | aclVersion = 0
80 | ephemeralOwner = 0x350cb21c20f0004
81 | dataLength = 94
82 | numChildren = 0
83 |
84 | 我们向其中加入一个slave实验一下。
85 |
86 | docker run -d -e MESOS_HOSTNAME=172.31.35.175 -e MESOS_IP=172.31.35.175 -e MESOS_MASTER=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos -v /sys/fs/cgroup:/sys/fs/cgroup -v /var/run/docker.sock:/var/run/docker.sock --name mesos-slave --net host --privileged --restart always mesoscloud/mesos-slave:0.23.0-ubuntu-14.04
87 |
88 | 
89 |
90 | 可以看到,salve已经注册成功,这样我们就搭建了一个具有三个master节点的mesos集群。
91 |
92 | #Marathon 搭建
93 | 有了Mesos集群,搭建Marathon 就变得非常的简单。Marathon默认支持高可用模式。只要多个运行的Marathon 实例使用同一个zookeeper集群即可,zookeeper来保证Marathon的leader失效时的选举等问题。
94 |
95 | docker run -d -e MARATHON_HOSTNAME=172.31.35.175 -e MARATHON_HTTPS_ADDRESS=172.31.35.175 -e MARATHON_HTTP_ADDRESS=172.31.35.175 -e MARATHON_MASTER=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos -e MARATHON_ZK=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/marathon -e MARATHON_EVENT_SUBSCRIBER=http_callback --name marathonv0.11.1 --net host --restart always mesosphere/marathon:v0.11.1
96 |
97 | 首先我们在Node1上起了一个Marathon实例。这里面的参数前面都讲过,主要的改变就是由原来的一个zookeeper节点变成了一个zookeeper集群。`MARATHON_EVENT_SUBSCRIBER=http_callback`这里多了一个参数。这个参数是开启Marathon的事件订阅模式,我们使用了`http_callback`,这样我们可以通过注册一个http回调事件,当Marathon启动,关闭,或者扩容某个实例的时候,我们都可以接收到通知,这为我们下一步做服务发现提供了数据源。
98 |
99 | 为了防止单点问题,我们启动三个Marathon实例,下面我们分别在Node2和Node3上面再启动两个Marathon实例。
100 |
101 | docker run -d -e MARATHON_HOSTNAME=172.31.23.17 -e MARATHON_HTTPS_ADDRESS=172.31.23.17 -e MARATHON_HTTP_ADDRESS=172.31.23.17 -e MARATHON_MASTER=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos -e MARATHON_ZK=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/marathon -e MARATHON_EVENT_SUBSCRIBER=http_callback --name marathonv0.11.1 --net host --restart always mesosphere/marathon:v0.11.1
102 |
103 | docker run -d -e MARATHON_HOSTNAME=172.31.40.200 -e MARATHON_HTTPS_ADDRESS=172.31.40.200 -e MARATHON_HTTP_ADDRESS=172.31.40.200 -e MARATHON_MASTER=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos -e MARATHON_ZK=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/marathon -e MARATHON_EVENT_SUBSCRIBER=http_callback --name marathonv0.11.1 --net host --restart always mesosphere/marathon:v0.11.1
104 |
105 | 这样我们就启动了含有三个实例的Marathon集群。由于这三个Marathon实例都是共享一个zookeeper集群,因此他们的数据也是同步的。你在其中任何一个节点创建的应用在其他两个Marathon实例上也可以看到。
106 |
107 | 
108 | 可以看到,三个tab页面分别打开的的三个服务器上的Marathon页面。我们在请求第一台机器的Marathon创建一个简单的服务。
109 | 
110 | 在第一个tab上我们已经可以看到了这个被创建的服务,现在我们切换到第三个tab看一下。
111 | 
112 | 可以看到,在第三个tab页面上,看到了和第一个tab一样的效果。这就说明了,目前的Marathon集群,他们之间的数据是共享的,在其中任何一个实例上创建服务,其他的实例都可以看到。我们进入zookeeper里面看一下Marathon集群的状态信息。
113 |
114 | [zk: 127.0.0.1:2181(CONNECTED) 3] ls /marathon/leader
115 | [member_0000000001, member_0000000002, member_0000000000]
116 | 可以看到leader节点下有三个member,对应着我们启动的三个实例。每个member节点里面记录的信息就是当前这个实例额一些具体的状态。
117 |
118 | [zk: 127.0.0.1:2181(CONNECTED) 6] get /marathon/leader/member_0000000000
119 | 172.31.35.175:8080
120 | cZxid = 0x100000020
121 | ctime = Wed Nov 04 07:11:13 UTC 2015
122 | mZxid = 0x100000020
123 | mtime = Wed Nov 04 07:11:13 UTC 2015
124 | pZxid = 0x100000020
125 | cversion = 0
126 | dataVersion = 0
127 | aclVersion = 0
128 | ephemeralOwner = 0x350cb21c20f0006
129 | dataLength = 18
130 | numChildren = 0
131 | 这样我们就搭建起来了一个高可用模式的Marathon集群。
132 |
133 | #Bamboo 搭建
134 | 经过前面的步骤,我们已经有了一个可以运行和管理docker容器的集群环境。我们现在可以通过Marathon启动一个或多个容器,他会被分配到我们集群salve上运行。在运行过程中,Marathon可以保证我们容器运行状态的监控,宕掉重启等活动。但是一般来说,mesos和marathon集群都是搭建在内网或者一个不可以被外部直接访问的网络环境里面,我们需要一个出口,通过这个出口外部可以访问我们容器内提供的服务。而且一般来说,Marathon管理的容器,被分配的salve机器不一定是同一台,在scale和update的时候,会出现IP的变换,这就需要我们有一套服务发现的机制。
135 |
136 | Marathon其实提供了服务发现的功能。通过在运行Marathon的机器上跑一个haproxy,Marathon在服务有变动的时候,自动生成haproxy配置文件,然后重启。这种方式对于简单的应用来说应该足够,但是对于需要多租户,自定义ACL规则等功能,这个就显得不太足够。还好Marathon提供了Event_Callback功能,我们可以通过注册事件回调,获取Marathon上运行容器的信息,然后根据某些haproxy模板来自动生成haproxy配置文件,reload后就可以访问。
137 |
138 | 上面说的这些功能已经被一个名为bamboo的开源项目实现。[地址](https://github.com/QubitProducts/bamboo)。他不仅提供了上面提到的服务发现等功能,还可以自定义ACL规则,这样就给我们做服务发现提供了很大的空间。bamboo提供了rest api,我们可以很方便的把它集成到我们自己的项目中。
139 |
140 | 
141 |
142 | 这是bamboo的部署图。在每个slave上部署一个haproxy加bamboo,然后他们之间可以负载均衡,通过zookeeper同步数据。当Marathon运行的容器有变化的时候,会通过http_call_back通知bamboo,然后bamboo就可以感知变化,我们就可以通过api或者bamboo的页面设置这个容器的acl访问规则,这样就完成了外部访问容器提供的服务的功能。下面我们来搭建Haproxy和bamboo。
143 |
144 | 首先我们在Node3,Node4上分别启动一个mesos_slave。
145 |
146 | docker run -d -e MESOS_HOSTNAME=172.31.40.200 -e MESOS_IP=172.31.40.200 -e MESOS_MASTER=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos -v /sys/fs/cgroup:/sys/fs/cgroup -v /var/run/docker.sock:/var/run/docker.sock --name mesos-slave --net host --privileged --restart always mesoscloud/mesos-slave:0.23.0-ubuntu-14.04
147 |
148 | docker run -d -e MESOS_HOSTNAME=172.31.37.173 -e MESOS_IP=172.31.37.173 -e MESOS_MASTER=zk://172.31.35.175:2181,172.31.23.17:2181,172.31.40.200:2181/mesos -v /sys/fs/cgroup:/sys/fs/cgroup -v /var/run/docker.sock:/var/run/docker.sock --name mesos-slave --net host --privileged --restart always mesoscloud/mesos-slave:0.23.0-ubuntu-14.04
149 |
150 | 如果你有更多机器,可以按照上面的命令,更改一下MESOS_HOSTNAME和 MESOS_IP就可以非常简单的继续向我们现在的集群增加节点。
151 |
152 | 
153 |
154 | 通过查看mesos页面,我们可以看到目前我们有两个slave提供服务。现在我们向这两个slave部署bamboo。
155 |
156 | 首先向Node4部署一个bamboo。
157 |
158 | docker run -d -p 8000:8000 -p 80:80 -e MARATHON_ENDPOINT=http://172.31.35.175:8080,http://172.31.23.17:8080,http://172.31.40.200:8080 -e BAMBOO_ENDPOINT=http://公网IP:8000 -e BAMBOO_ZK_HOST=172.31.23.17:2181,172.31.40.200:2181,172.31.35.175:2181 -e BAMBOO_ZK_PATH=/bamboo -e BIND=":8000" -e CONFIG_PATH="config/production.example.json" -e BAMBOO_DOCKER_AUTO_HOST=true xianlubird/bamboo
159 |
160 | 这里面的参数,其中8000是bamboo公开的端口,我们可以通过这个端口访问他的控制页面,或者通过这个端口请求他的rest api。80端口是公开给haproxy使用,这个镜像里面内置了haproxy,你不需要自己再安装haproxy。`MARATHON_ENDPOINT`是Marathon集群的地址,bamboo通过这个地址向Marathon注册回调事件通知函数。`BAMBOO_ENDPOINT`为bamboo的公开访问的地址,你应该填充你自己的可以被外访问的公网IP地址。`BAMBOO_ZK_HOST`为zookeeper集群的地址,bamboo通过这个同步各个节点的数据。`BAMBOO_ZK_PATH`为bamboo使用的znode名称.`CONFIG_PATH`为bamboo使用的配置文件,虽然已经有一些配置通过环境变量的方式传进去了,但是像haproxy的模板格式,重启haproxy的命令等还是需要配置文件导入的。这里直接使用的官方默认的部署配置文件,你也可以针对这个配置文件按做自己的定制。
161 |
162 | {
163 | "Marathon": {
164 | "Endpoint": "http://marathon1:8080,http://marathon2:8080,http://marathon3:8080"
165 | },
166 |
167 | "Bamboo": {
168 | "Endpoint": "http://haproxy-ip-address:8000",
169 | "Zookeeper": {
170 | "Host": "zk01.example.com:2181,zk02.example.com:2181",
171 | "Path": "/marathon-haproxy/state",
172 | "ReportingDelay": 5
173 | }
174 | },
175 |
176 | "HAProxy": {
177 | "TemplatePath": "config/haproxy_template.cfg",
178 | "OutputPath": "/etc/haproxy/haproxy.cfg",
179 | "ReloadCommand": "haproxy -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid -D -sf $(cat /var/run/haproxy.pid)",
180 | "ReloadValidationCommand": "haproxy -c -f "
181 | },
182 |
183 | "StatsD": {
184 | "Enabled": false,
185 | "Host": "localhost:8125",
186 | "Prefix": "bamboo-server.development."
187 | }
188 | }
189 |
190 | 部署完毕后,我们可以访问bamboo所在的机器的8000端口。
191 | 
192 | 这里就可以看到bamboo的界面,说明我们部署成功。下面我们向Maraton提交一个容器,我们使用`tutum/hello-world`这个image,来测试一下bamboo的效果。
193 |
194 | 向Marathon提交运行容器,你可以使用Marathon的网页,但是更通用的方式是通过Marathon的restapi来提交,这样更加容易的集成到开发环境中,我们使用Marathon的python 库来提交请求。
195 |
196 | def create_docker_app():
197 | url = 'http://172.31.23.17:8080'
198 | c = MarathonClient(url)
199 | app = MarathonApp(
200 | id='docker-01',
201 | cmd='',
202 | cpus=0.3,
203 | mem=30,
204 | container={
205 | 'type': 'DOCKER',
206 | 'docker': {
207 | 'image': 'tutum/hello-world',
208 | 'network': 'BRIDGE',
209 | 'portMappings': [{
210 | 'containerPort': 80,
211 | 'hostPort': 0,
212 | }]
213 | }
214 | }
215 | )
216 | c.create_app('hello-001', app)
217 |
218 | 你可以向你Marathon集群的任何一个节点发起部署请求。
219 | 
220 | 可以看到Marathon已经运行起来了这个容器,他被部署到Node4机器上,被分配了一个31162端口。由于这些都是内网IP,我们无法通过外网访问,现在我们再来看一下bamboo的页面.
221 | 
222 | 可以看到bamboo已经检测到了新启动的容器,现在我们通过bamboo给他设置ACL规则。
223 | 
224 | 现在我们访问一下bamboo所在机器的http://IP/hello
225 | 
226 | 可以看到,我们部署的容器已经可通过haproxy解析访问到了。
227 |
228 | #Bamboo Ha Mode
229 | 下面我们在Node3上面再部署一个Bamboo实例。
230 |
231 | docker run -d -p 8000:8000 -p 80:80 -e MARATHON_ENDPOINT=http://172.31.35.175:8080,http://172.31.23.17:8080,http://172.31.40.200:8080 -e BAMBOO_ENDPOINT=http://52.32.37.21:8000 -e BAMBOO_ZK_HOST=172.31.23.17:2181,172.31.40.200:2181,172.31.35.175:2181 -e BAMBOO_ZK_PATH=/bamboo -e BIND=":8000" -e CONFIG_PATH="config/production.example.json" -e BAMBOO_DOCKER_AUTO_HOST=true xianlubird/bamboo
232 |
233 | 下面我们分别访问Node3的bamboo和Node4的bamboo,并且同时访问Node3/hello和Node4/hello,看一下效果。
234 | 
235 | 可以看到,无论通过哪一个bamboo实例,我们都可以访问到刚才创建的容器。我们进入bamboo容器内部可以看到他生成的haproxy.cfg
236 |
237 | # Template Customization
238 | frontend http-in
239 | bind *:80
240 |
241 |
242 | acl ::hello-001-aclrule path_beg -i /hello
243 | use_backend ::hello-001-cluster if ::hello-001-aclrule
244 |
245 |
246 | stats enable
247 | # CHANGE: Your stats credentials
248 | stats auth admin:admin
249 | stats uri /haproxy_stats
250 |
251 |
252 | backend ::hello-001-cluster
253 | balance leastconn
254 | option httpclose
255 | option forwardfor
256 |
257 | server ::hello-001-172.31.37.173-31162 172.31.37.173:31162
258 |
259 | 下面我们将当前的一个实例scale到三个。
260 | 
261 | 可以看到,他们中,有一个实例被分配到了Node3,另外两个实例在Node4。我们现在什么都不需要操作,继续访问我们刚才访问容器的路径,Node4 IP/hello。可以发现容器是可以正常访问的,而且打开bamboo的控制页面可以看到。
262 | 
263 |
264 | bamboo自动检测到了目前实例已经变成了3个,而且帮助我们使用haproxy做了负载均衡。当我们的容器扩容缩容,或者迁移的时候,IP地址发生了变化,我们不需要去关心,我们只需要继续访问我们刚才 设置好的路径,bamboo会帮我们做好这些。我们再来看一下现在haproxy的配置文件。
265 |
266 | #Template Customization
267 | frontend http-in
268 | bind *:80
269 |
270 | acl ::hello-001-aclrule path_beg -i /hello
271 | use_backend ::hello-001-cluster if ::hello-001-aclrule
272 |
273 |
274 | stats enable
275 | # CHANGE: Your stats credentials
276 | stats auth admin:admin
277 | stats uri /haproxy_stats
278 |
279 |
280 | backend ::hello-001-cluster
281 | balance leastconn
282 | option httpclose
283 | option forwardfor
284 |
285 | server ::hello-001-172.31.37.173-31162 172.31.37.173:31162
286 | server ::hello-001-172.31.40.200-31770 172.31.40.200:31770
287 | server ::hello-001-172.31.37.173-31195 172.31.37.173:31195
288 |
289 | 可以看到,bamboo已经帮我们发现了新创建的服务的Ip和端口,并且生成了haproxy的配置文件,并在这三台服务器中做了负载,以后我们不管是scale到0还是scale到10个,bamboo都可以帮助我们自动生成haproxy的配置文件并生效,我们需要做的就是继续访问以前的域名就可以继续使用我们的服务。这样就做到了服务发现和自动的负载均衡。
290 |
291 | 这样我们就完成了一个基本的高可用的容器云平台的搭建。当然,如果要想把这个流程自动化起来,可能还需要再这个基础上增加一些功能,必须使用他们的restapi 提交请求,而不是使用网页等等。对于数据的持久化,volumn的挂载,我们没有做过多的讨论。后面我们会提及一下实现的思路。
292 |
293 |
--------------------------------------------------------------------------------
/chapter3/summary.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建企业级容器云项目概述
2 |
3 | 随着docker的兴起,容器一词变得十分的火热,到处都可以看到容器的身影。身在云计算时代,不讨论一下容器,都不好意思说自己是做云计算的。
4 |
5 | 引领这一浪潮的,莫过于docker这一项技术。docker使用Linux的namespace和cgroups实现了容器级别的隔离,然后又加入了image这一概念,使得部署变得十分简单。现在只需要开发代码,build一个镜像,然后就可以借助docker的东风将它无障碍的部署到各种linux发行版中。很好的解决了线上环境和开发环境不同带来的问题,让程序的部署变得更加简单。
6 |
7 | 更加让人激动的是,项目被docker容器化后,就具有了可以扩容的能力。你可以简单的将项目由一个实例变成两个或者更多个而无需复杂的线上配置。而且容器化后的项目可以很好的在分布式环境中运行,自由在多个主机之间迁移。这是传统项目所不具备的。
8 |
9 | 分布式应用在传统项目里门槛很高,会有各种各样的问题。但是现在借助mesos,我们可以非常容易的管理众多主机组成的集群,就像操作一台大型机器一样。
10 |
11 | 对于docker容器这种长时间运行的任务,marathon framewor很好的帮助我们解决了调度和监控的问题。使用它可以很方便的在mesos集群启动容器,然后对他进行健康监控。
12 |
13 | 在集群中运行的容器随时都会被扩容或者迁移到其他机器,那么对于他们的访问,也就是服务发现,一般会使用一些负载均衡器来解决,我们使用开源项目bamboo来实现这样的功能。
14 |
15 | 高可用也是企业级云平台一个非常重要的问题。mesos默认使用zookeeper来完成主从节点的选择和高可用,后面我们也会详细介绍。
16 |
17 | 综上是搭建一个企业级容器云平台需要的基础构建,可以看到,几乎清一色的开源项目。后面我们会以此为例子,一步步搭建一个分布式容器云平台。
--------------------------------------------------------------------------------
/chapter3/think_about.md:
--------------------------------------------------------------------------------
1 | # 容器云平台基础概述
2 |
3 | 经过前面的搭建,我们已经拥有了一个mesos集群和一个Marathon framework。而对于企业级容器云平台来说,拥有这些还是不足的。
4 |
5 | 设想一下企业级容器云实际使用情况。我们需要一个高可用的环境。因此需要zookeeper多节点,mesos master 多节点以做备份。然后Marathon 也有ha模式,可以有效的防止master失效导致环境不可用。
6 |
7 | 实际使用中,我们应该会使用Marathon的rest api来发起部署请求,将我们需要部署的镜像和相关的环境变量交给Marathon,这样的功能一定是集成到我们自己的一个平台里面的。在Marathon部署的时候,我们的容器可能会被分配到一个随机的节点,因此我们需要一种服务发现机制。一般来说,mesos 和Marathon都是部署在内网环境中,一般不允许外部直接访问。我们应该有一个节点专门负责对外访问的负载均衡的功能。Marathon本身内置了服务发现的功能。我们可以通过开启他来让Marathon帮助你自动生成haproxy的配置文件,然后reload来实现服务发现。但是这样可定制性不是很强,而且因为和Marathon绑定,我们不太容易迁移和扩展。因此我们这里使用bamboo这个开源项目来做服务发现。bamboo是一个使go开发的能够自动生成haproxy的配置文件然后reload的项目。他的信息来源是通过注册了Marathon的事件订阅机制,Marathon再有变化的时候会自动通知它,然后bamboo就会完成一系列的生成配置文件然后reload haproxy的功能。关于bamboo的详细介绍可以看[这里](https://github.com/QubitProducts/bamboo)。
8 |
9 | 由于bamboo也提供了rest api,因此我们可以很方便的使用代码去完成服务发现,到最终部署的服务可以被外网访问到这一个完整的流程,下面我们就开始搭建。
--------------------------------------------------------------------------------
/chapter3/zatan.md:
--------------------------------------------------------------------------------
1 | # 关于容器云平台的其他一些杂谈
2 |
3 | 前面我们搭建的这个平台,大部分操作都是通过使用框架提供的网页来操作,实际生产环境中,肯定需要我们自己来实现一套自动化的系统来帮助我们完成这些事情。我们可以根据前面章节提供的这些开源组件以及他们的功能来开发自己的容器云平台。
4 |
5 |
6 | #对于数据持久化
7 | 前面章节我们搭建的mesos集群和Marathon集群都没提及数据持久化问题。其实docker对于数据持久化做的很方便,只需要使用volume将需要存储的路径挂载到宿主机的磁盘上即可。我们可以根据需要,将mesos的日志文件或者zookeeper的存储文件挂载到自己指定的地方即可。其实我们在运行的时候,这些container在dockerfile中声明了vloume,docker会在自己的/var/lib/docker/volume文件夹中存储容器中挂载出来的目录。
8 |
9 | 这是对于基础平台的数据持久化。但是如果是运行在我们平台上的容器,如果他被scale到别的机器或者被重启后迁移,他挂载在宿主机的磁盘数据如何跟随他自己迁移呢。这里推荐使用flocker。flocker可以将docker的volume在不同主机之间迁移,保证用户的数据不被丢失。这里有一个官方demo的架构图。
10 |
11 | 
12 |
13 | 当左侧的node1失效的时候,salve宕机,flocker可以自动将存储在EBS volume上的数据同步到node2上,这样就可以实现docker volume的迁移,对于数据库等应用非常的适合。具体的搭建步骤参考[flocker-marathon](https://clusterhq.com/2015/10/06/marathon-ha-demo/)。
14 |
15 | #流程的优化
16 | 如何将我们前面搭建的架构使用代码串联起来,也是实际搭建容器云平台的一个问题。首先对于这些image的获取,docker pull 官方的image会比较慢,可以通过加速器来加快流程。可以使用[灵雀云](http://www.alauda.cn/)提供的镜像加速服务来快速pull镜像,如果有能力也可以自己搭建一个registry,自己管理images。
17 |
18 | Marathon的client可以根据自己的语言喜好,有各种版本的client。整个平台创建一个容器的流程大概如下。根据用户选择的image和填写的参数以及环境变量等,使用client向Marathon发送请求,然后Marathon接受请求后开始部署。部署完毕后,bamboo就发现了这个服务的IP和port等信息,然后调用bamboo的rest api,给这个服务添加acl规则,这个时候bamboo就会根据你的规则生成对应的haproxy配置文件,然后haproxy会进行reload来使新的服务生效,这个时候就可以根据IP或者域名访问到部署上去的服务。
19 |
20 | 如果用户需要扩容,client可以直接向Marathon发送扩容的请求,Marathon就会完成扩容的动作,并且bamboo会自动发现实例数量的变化,reload haproxy,用户这边没有任何感知就可以继续使用原来的域名访问他们的服务,但是这时候后台已经有多个服务在通过haproxy的负载均衡策略提供服务。这样一个基本的容器云服务平台就搭建完成,也可以基本的使用,我们可以很方便的通过增加mesos slave来向集群添加机器,mesos和Marathon会帮我们做好机器之间的选择与部署。
21 |
--------------------------------------------------------------------------------
/chapter4/12DF1664-8DE5-4AEE-B420-94D14F6E6543.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter4/12DF1664-8DE5-4AEE-B420-94D14F6E6543.png
--------------------------------------------------------------------------------
/chapter4/Cluster-mesos.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter4/Cluster-mesos.png
--------------------------------------------------------------------------------
/chapter4/README.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建大数据平台Hadoop和深度机器学习平台Singa实战
2 |
3 | # Mesos系统简介
4 |
5 | Mesos是一个跨应用集群的共享资源调度和隔离的分布式集群管理系统,它可以在集群应用如:Hadoop MapReduce、Hbase、MPI等之间共享资源并保证各个应用之间的隔离。Mesos是Apache基金会的顶级项目,一经推出就饱受推崇和关注,Twitter是最早的将其应用在自己生态系统架构中的公司。在Twitter内部,Mesos被当作成了DCOS系统,几乎所有的应用服务都使用Mesos进行分布式资源调度。随后像APPLE这样的大型科技公司也将Mesos引入到自己的数据中心,随着越来越多的大型公司将Mesos作为自己数据中心的操作系统,Mesos作为DCOS的应用被广泛的讨论和应用实践。在国内也有Mesos作为DCOS的用案例,如数人云等。
6 |
7 | ## 1.1、Mesos与其他分布式调度系统的对比
8 |
9 | ### 1.1.1 Mesos VS Kubernetes
10 |
11 | 关于Mesos在前面一小节已经根据官方的定义进行了说明,那么关于Kubernetes官方的定义是这样的:Kubernetes is an open source orchestration system for Docker containers.\(Kubernetes是一个开源的Docker容器调度编排系统。)
12 | 换句话说,Kubernetes是一个Docker容器的高级管理系统,可以从集群应用层面出发满足对应用进行集群化部署、管理的需求。下图可以很形象的说明这种特性:
13 |
14 | 
15 | (图片来自Kuberbetes官网)
16 |
17 | 关于Mesos和Kubernetes的区别,我准备这样表述:Mesos更偏重于对应用资源的分布式调度和管理,它只负责资源的均衡分布式调度,至于资源的使用是由各种框架来实现的。而Kubernetes更偏重于提供一个基于Docker容器的轻量级应用集群部署平台,它着重于如何更有效的帮助开发运维人员实现一个应用的分布式集群部署。
18 |
19 | 对于到底是Mesos更有前景还是Kubernetes能够取代Mesos这里不做争论,我认为这两个项目都是非常优秀的开源项目,在不同的应用场景下具备各自不同的优势,如对于一些非分布式任务型的应用(如一些移动APP),这些应用更多的通过分布式集群部署实现服务的负载均衡和弹性伸缩以及快速迭代部署,那么这种情况下我认为面向应用且被各大软将厂商支持的Kubernetes更有优势;而对于一些分布式任务型的应用(如Hadoop、spark等),这些应用是通过分布式集群资源调度系统实现计算资源的逻辑上一致性,进而实现任务的并行计算等功能,那么这种情况下我认为面向底层资源并采用双层调度机制的Mesos更具优势。
20 |
21 | ### 1.1.2 Mesos VS Yarn
22 |
23 | 对于YARN的介绍在百度百科是这样描述的:YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
24 |
25 | Mesos和Yarn都采用了双层调度机制,这种机制很好的解决了集中式资源调度机制在资源集群调度过程中扩展性差、兼容性不好的问题。Mesos和Yarn都是面向底层资源调度的分布式集群系统,其应用场景基本是类似的(Hadoop、spark等),但是由于Yarn是从Hadoop1.0发展出来的,所以在Hadoop体系的项目以及基于这些项目的应用对Yarn都有比较好的兼容性和丰富的应用实践。
26 | 关于Mesos与Yarn的对比,每个我只从一个优势方面阐述一下。Mesos相对与Yarn的优势之一是它的二层调度机制更开放,在第一层对资源的调度颗粒度更大,这样的好处是给予第二层调度机制的资源管理权限更大,对计算框架的限制更少,这是因为Mesos的二层调度机制是基于Resoure Officer的,而Yarn是基于solt的。Yarn相对对于Mesos的优势之一是其具备成熟的生态圈,特别是在Hadoop系统中,各个子项目都有基于Yarn的成熟应用实践和丰富的生态群应用。
27 |
28 | ## 1.3 搭建环境简介
29 |
30 | 本次搭建的环境以及下一节的Mesos集群的部署都是参考我之前在Dockerone上写的一篇文章,因为这个环境是现成的且结构比较全(3个maste节点和3个slave节点\),而且那篇部署教程在写完之后我自己还进行过重新部署,是写的比较全面且坑比较少的部署教程。以下是部署环境的简介:
31 | 
32 |
33 | 如图所示其中master节点都需要运行ZooKeeper、Mesos-master、Marathon,在slave节点上只需要运行master-slave就可以了,但是需要修改ZooKeeper的内容来保证slave能够被master发现和管理。为了节约时间和搞错掉,我在公司内部云平台上开一个虚拟机把所有的软件都安装上去,做成快照进行批量的创建,这样只需要在slave节点上关闭ZooKeeper、Mesos-master服务器就可以了,在文中我是通过制定系统启动规则来实现的。希望我交代清楚了,现在开始部署。
34 |
35 | ## 1.4 Mesos集群部署
36 |
37 | ### 1.4.1准备部署环境
38 |
39 | * 在Ubuntu 14.04的虚拟机上安装所有用到软件,并保证虚拟机可以上互联网。
40 |
41 | * 安装Python依赖
42 | * `apt-get install curl python-setuptools python-pip python-dev python-protobuf`
43 | * 安装配置zookeeper
44 | * \`\`\`apt-get install ZooKeeperd &
45 | echo 1 \| sudo dd of=/var/lib/ZooKeeper/myid\`\`\`
46 | * 安装配置Mesos-master和Mesos-slave
47 | * `curl-fL http://downloads.Mesosphere.io/master/ubuntu/14.04/Mesos_0.19.0~ubuntu14.04%2B1_amd64.deb -o /tmp/Mesos.deb`
48 | * `dpkg -i /tmp/Mesos.deb`
49 | * `mkdir -p /etc/Mesos-master`
50 | * `echo in_memory | sudo dd of=/etc/Mesos-master/registry`
51 | * 安装配置Mesos的Python框架
52 | * `curl -fL http://downloads.Mesosphere.io/master/ubuntu/14.04/Mesos-0.19.0_rc2-py2.7-linux-x86_64.egg -o /tmp/Mesos.egg`
53 | * `easy_install /tmp/Mesos.egg`
54 | * 下载安装Mesos管理Docker的代理组件Deimos
55 | * `pip install deimos`
56 | * 配置Mesos使用Deimos
57 | * `mkdir -p /etc/mesos-slave`
58 | * `echo /usr/local/bin/deimos | sudo dd of=/etc/Mesos-slave/containerizer_path`
59 | * `echo external | sudo dd of=/etc/Mesos-slave/isolation`
60 | * 安装Docker
61 | * `echo deb http://get.Docker.io/ubuntu Docker main | sudo tee /etc/apt/sources.list.d/Docker.list`
62 | * `sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9`
63 | * `apt-get update && apt-get install lxc-Docker`
64 | 至此在一个虚拟机上就完成了所有组件的安装部署,下面就是对虚拟机打快照,然后快速的复制出6个一样的虚拟机,按照上图的ip配置进行配置之后就可以进入下个阶段,当然为了保险你可以测试一下上处组件是否安装成功和配置正确。如果你没有使用云平台,或者不具备快照功能,那就只能在6个虚拟机上重复6遍上处过程了。
65 |
66 | ### 1.4.2、在所有的节点上配置ZooKeeper
67 |
68 | 在配置maser节点和slave节点之前,需要先在所有的6个节点上配置一下ZooKeeper,配置步骤如下:
69 |
70 | * 修改zk的内容
71 | * `sudo vi /etc/Mesos/zk`
72 | * 将zk的内容修改为如下:
73 | * `zk://10.162.2.91:2181,10.162.2.92:2181,10.162.2.93:2181/Mesos`
74 |
75 | ### 1.4.3配置集群中的三个master节点
76 |
77 | 在所有的master节点上都要进行如下操作:
78 |
79 | * 修改ZooKeeper的myid的内容
80 | * `sudo vi /etc/zooKeeper/conf/myid`
81 | * 将三个master节点的myid按照顺序修改为1,2,3。
82 | * 修改ZooKeeper的zoo.cfg
83 | * `sudo vi/etc/zooKeeper/conf/zoo.cfg`
84 | * 配置内容如下:
85 | * `server.1=10.162.2.91:2888:3888`
86 | * `server.2=10.162.2.92:2888:3888`
87 | * `server.3=10.162.2.93:2888:3888`
88 | * 修改Mesos的quorum
89 | * `sudo vi /etc/mesos-master/quorum`
90 | * 将值修改为2。
91 | * 配置master节点的Mesos 识别ip和和hostname\(以在master1上的配置为例)
92 | * `echo 10.162.2.91 | sudo tee /etc/mesos-master/ip`
93 | * `sudo cp /etc/mesos-master/ip /etc/mesos-master/hostname`
94 | * 配置master节点服务启动规则(重启不启动slave服务)
95 | * \`\`\`sudo stop Mesos-slave
96 | echo manual \| sudo tee /etc/init/Mesos-slave.override\`\`\`
97 |
98 | ### 1.4.4、配置集群中的的slave节点
99 |
100 | * 配置slave节点的服务启动规则(重启不启动zookeeper和slave服务)
101 | * `sudo stop zooKeeper`
102 | * `echo manual | sudo tee /etc/init/zooKeeper.override`
103 | * `echo manual | sudo tee /etc/init/mesos-master.override`
104 | * `sudo stop mesos-master`
105 | * 配置slave节点的识别ip和hostname(以slave1节点为例)
106 | * `echo 192.168.2.94 | sudo tee /etc/mesos-slave/ip`
107 | * `sudo cp /etc/Mesos-slave/ip /etc/mesos-slave/hostname`
108 |
109 | ### 1.4.5、在集群的所有节点上启动相应的服务
110 |
111 | * 启动master节点的服务(zookeeper和mesos-master服务)
112 | * `initctl reload-configuration`
113 | * `service zookeeper start`
114 | * `service mesos-master start`
115 | * 启动slave节点上的相应服务(mesos-slave服务)
116 | * `sudo start mesos-slave`
117 |
118 | ### 1.4.5、Troubleshooting
119 |
120 | 由于有的网络情况和设备情况不一样,所以选举的过程有的快有的慢,但刷新几次就可以完成选举。当发现slave节点有些正常有些不正常时,可以通过reboot来促使自己被master发现。
121 |
122 | ## 1.5、Hadoop在Mesos集群上部署
123 |
124 | ### 1.5.1、部署前准备
125 |
126 | * 在部署和HDFS初始化过程中都需要跨节点的操作和SSH,因此首先在Mesos集群的所有节点上关闭防火墙。如下:
127 | * `chkconfig iptables off`(在root用户下操作)
128 | * 关闭selinux
129 | * `setenforce 0`\(在root用户下操作)
130 | * 在HDFS部署中,或者说在分布式架构的部署过程中节点之间的通信都是以主机名为地址标识,因此要保证每个节点主机名的唯一。
131 | * 在Master1节点上配置hostname:
132 | * `vi /etc/hostname`
133 | * `master1`
134 | * 在Masrer1节点上配置hosts
135 | * `vi /etc/hosts`
136 | * `127.0.0.1 localhost`
137 | * `10.162.2.91 master1`
138 | * `10.162.2.92 master2`
139 | * `10.162.2.93 master3`
140 | * `10.162.2.94 slave1`
141 | * `10.162.2.95 slave2`
142 | * `10.162.2.96 slave3`
143 | * 在其他节点上都参照上述配置进行修改hostname和hosts.
144 | * 在部署HDFS和Hadoop时,需要使用非root用户来进行操作,虽然大部分情况下也可以在root用户下操作,但以往的经验是非root用户下操作部署更顺畅。
145 | * 添加新的用户
146 | * `addusr hadoop`
147 | * 重置hadoop用户的密码
148 | \*`passwd hadoop`
149 |
150 | ### 1.5.2、在Mesos集群中部署HDFS
151 |
152 | * 本次案例的集群中master有三个节点,slave有三个节点,在master节点中使用zookeeper进行服务选举,在部署HDFS时也会用到zookeeper进行namenode节点的选举。
153 |
154 | ### 在master节点上部署namenode
155 |
156 | * 创建一个文件目录用于
157 | * `mkdir -p /mnt/cloudera-hdfs/1/dfs/nn /nfsmount/dfs/nn`
158 | * 修改文件目录的用户权限,给上一步创建的文件目录添加用户hadoop操作权限
159 | * `chown -R hadoop:hadoop /mnt/cloudera-hdfs/1/dfs/nn /nfsmount/dfs/nn`
160 | * 修改文件目录的操作权限
161 | * `chmod 700 /mnt/cloudera-hdfs/1/dfs/nn /nfsmount/dfs/nn`
162 | * 使用apt-get 安装hadoop-hdfs-namenode,这样可以避免使用二进制文件在编译过程中遇到的坑。
163 | * `wget http://archive.cloudera.com/cdh5/one-click-install/precise/amd64/cdh5-repository_1.0_all.deb`
164 | * `sudo dpkg -i cdh5-repository_1.0_all.deb`
165 | * `sudo apt-get update; sudo apt-get install hadoop-hdfs-namenode`
166 | \*`cp /etc/hadoop/conf.empty/log4j.properties/etc/hadoop/conf.name/log4j.properties`
167 |
168 | ### 1.5.3、在slave节点上部署datanode
169 |
170 | * 创建挂载目录
171 | * `mkdir -p /mnt/cloudera-hdfs/1/dfs/dn /mnt/cloudera-hdfs/2/dfs/dn /mnt/cloudera-hdfs/3/dfs/dn /mnt/cloudera-hdfs/4/dfs/dn`
172 | * 修改挂在目录所属的用户组
173 | * `chown -R hadoop:hadoop /mnt/cloudera-hdfs/1/dfs/dn/mnt/cloudera-hdfs/2/dfs/dn /mnt/cloudera-hdfs/3/dfs/dn /mnt/cloudera-hdfs/4/dfs/dn`
174 | * 使用apt-get 安装hadoop-hdfs-datanode
175 | * `wget http://archive.cloudera.com/cdh5/one-click-install/precise/amd64/cdh5-repository_1.0_all.deb`
176 | * `dpkg -i cdh5-repository_1.0_all.deb`
177 | * `sudo apt-get update; sudo apt-get install hadoop-hdfs-datanode`
178 | * `sudo apt-get install hadoop-client`
179 |
180 | ### 1.5.4、 格式化并启动namenode节点
181 |
182 | * `sudo -u hadoop hadoop namenode -format`
183 | * `service hadoop-hdfs-namenode start`
184 |
185 | ### 1.5.5、启动slave节点
186 |
187 | * `service hadoop-hdfs-datanode start`
188 |
189 | ### 1.5.6 配置服务自启动
190 |
191 | * 在namenode节点上
192 | * `update-rc.d hadoop-hdfs-namenode defaults`
193 | * `update-rc.d zookeeper-server defaults`
194 | \*在slave节点上
195 | * `update-rc.d hadoop-hdfs-datanode defaults`
196 |
197 | ## 1.6、在Mesos集群中部署Hadoop
198 |
199 | ### 1.6.1、Hadoop的基本安装
200 |
201 | * 下载Hadoop安装文件包
202 | * `wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.3.0-cdh5.1.2.tar.gz`
203 | * 将安装文件包解压缩
204 | * `tar zxf hadoop-2.3.0-cdh5.1.2.tar.gz`
205 | * 下载hadooponmesos二进制文件
206 | * `git clone https://github.com/mesos/hadoop.git hadoopOnMesos`
207 | * 使用mvn编译hadooponmesos文件
208 | * `mvn package`
209 | * 注意:mvn package要在下载的hadoopOnMesos文件夹中执行,编译好后可以在target文件夹中找到一个编译好的jar文件。
210 |
211 | * 将编译好的jar文件拷贝到hadoo-hdfs安装文件夹和下载的hadoop安装文件夹中
212 |
213 | * `cp hadoopOnMesos/target/hadoop-mesos-0.1.0.jar /usr/lib/hadoop-0.20-mapreduce/lib/`
214 | * `cp hadoopOnMesos/target/hadoop-mesos-0.1.0.jar hadoop-2.3.0-cdh5.1.2/share/hadoop/common/lib/`
215 | * 配置CDH5使用MRv1,因为在MRv2中hadoop的任务调度是使用yarn的
216 | * `cd hadoop-2.3.0-cdh5.1.2`
217 | * `mv bin bin-mapreduce2`
218 | * `mv examples examples-mapreduce2`
219 | * `ln -s bin-mapreduce1 bin`
220 | * `ln -s examples-mapreduce1 examples`
221 | * `pushd etc`
222 | * `mv hadoop hadoop-mapreduce2`
223 | * `ln -s hadoop-mapreduce1 hadoop`
224 | * `popd`
225 | * `pushd share/hadoop`
226 | * `rm mapreduce`
227 | * `ln -s mapreduce1 mapreduce`
228 | * `popd`
229 | * 配置Hadoop运行所需的环境和配置文件:
230 | * `cp target/hadoop-mesos-0.1.0.jar /usr/lib/hadoop-0.20-mapreduce/lib`
231 | * \*/上一步是将hadoopOnmesos编译好的jar包放到hadoop调用库文件夹中,以便hadoop可以使用mesos调度资源运行job任务。
232 | * `vim /etc/profile.d/hadoop.sh`
233 | * `export HADOOP_MAPRED_HOME=/usr/lib/hadoop-0.20-mapreduce`
234 | * `export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/libmesos.so`
235 | * \*/上一步是在hadoop的运行脚本中配置HOME路径和Mesos的原生库。
236 | * `chmod +x /etc/profile.d/hadoop.sh`
237 | * `/etc/profile.d/hadoop.sh`
238 | * `cd ..`
239 | * `rm hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz`
240 | * \*/删除下载的cdh5原始文件
241 | * `tar czf hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop-2.3.0-cdh5.1.2/`
242 | * \*/上一步是将配置好的hadoop安装文件重新打包
243 | * `hadoop dfs -put hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz /`
244 | * \*/上一步是将打包好的hadoop安装包上传到hdfs上
245 |
246 | ### 1.6.2、 Hadoop配置文件配置
247 |
248 | * 配置mapred-site.xml
249 | * `vi /etc/hadoop/conf.cluster-name/mapred-site.xml`
250 | * mapred-site.xml需要配置文件内容
251 | * `mapred.jobtracker.taskScheduler`
252 | * `org.apache.hadoop.mapred.MesosScheduler`
253 | * \*/上一步是通过配置mapred的jobtrackerd.taskSchedule来告诉Hadoop使用Mesos来调度管理任务。
254 | * `mapred.mesos.taskScheduler`
255 | * `org.apache.hadoop.mapred.JobQueueTaskScheduler`
256 | * `mapred.mesos.master`
257 | * `zk:10.162.2.91:2181,10.162.2.92:2181,10.162.2.93:2181/mesos`
258 | * \*/上一步配置是保证mapred能够准确的找到mesos master节点通过zookeeper选举出来的的主节点。
259 | * `mapred.mesos.executor.uri`
260 | * `hdfs:/10.162.2.92:9000/hadoop-2.3.0-cdh5.1.2-mesos.0.20.tar.gz`
261 | * \*/上一步是配置hadoop的路径,这样mapred可以知道到那里调用hadoop代码执行task,这里10.162.2.92是本地主机的IP地址,在10.162.2.91主机上时就改成10.162.2.91.
262 | * `mapred.job.tracker`
263 | * `10.162.2.92:9001`
264 | * \*/上一步是配置jobtracker的主机IP地址,和上一步一样这要配置本机的IP地址
265 | * 配置本地的Mesos原生库
266 | * `vim /usr/lib/hadoop-0.20-mapreduce/bin/hadoop-daemon.sh`
267 | * `export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/libmesos.so`
268 | \*完成上述配置后尝试启动jobtracker,验证是否安装部署成功。
269 | * `service hadoop-0.20-mapreduce-jobtracker start`
270 | * 可以通过jps查看jobtracker进程是否在运行
271 | * `jps`
272 |
273 | ### 1.6.3、 在其他namenode和datanode上完成部署
274 |
275 | * 在其他两个Master节点上完成相应的配置
276 | * 将之前重新打包好的hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz发送到三个datanode节点上
277 | * `scp -r hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop@10.162.2.94:/hadoop`
278 | * `scp -r hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop@10.162.2.95:/hadoop`
279 | * `scp -r hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop@10.162.2.96:/hadoop`
280 | \*重启HDFS的nomenode和datanode
281 |
282 | ## 1.7 Troubleshoting
283 |
284 | 注意:在每次重启HDFS服务的时候,需要先确保Mesos集群是正常运行的。namenode重启的时候可以先重新format一下。
285 |
286 | ## 1.8、基于Mesos搭建深度机器学习平台Singa
287 |
288 | ### 1.8.1、 Singa项目简介
289 |
290 | Singa是由NUS、浙江大学、网易联合进行开发并开源的一个深度机器学习平台,其设计目的是为多种深度学习模型(如CNN、DBN\)提供一个有效的、易用的、高扩展的分布式实现平台。在Singa平台上,用户可以像在Hadoop上实现Map/Reducer一样轻易的训练他们所需要的抽象的深度学习模型。Singa的详细信息可以访问[https://wiki.apache.org/incubator/SingaProposal。](https://wiki.apache.org/incubator/SingaProposal。)
291 |
292 | ### 1.8.2、 Singa on mesos部署架构
293 |
294 | Singa在设计其底层的资源调度系统时选择了Mesos这一优秀的分布式集群资源调度系统,如下图所示:
295 |
296 | 
297 | (图片来自[https://github.com/apache/incubator-singa/tree/master/tool/mesos)](https://github.com/apache/incubator-singa/tree/master/tool/mesos))
298 |
299 | 如上图所示,在统一分布式存储层面使用了HDFS,这样有利于整个singa在运行过程中提高文件的读写效率,在分布式资源调度层面使用mesos进行统一的资源调度。
300 |
301 | ### 1.8.3、 Singa on mesos部署过程
302 |
303 | 本次部署的过程是在ubuntu14.04上ubuntu用户下完成部署的。
304 |
305 | * 更换/bin/sh为/bin/bash
306 | * `rm /bin/sh && ln -s /bin/bash /bin/sh`
307 | * 更新源,这里使用的是网易的源
308 | * `vi /etc/apt/sources.list`
309 | * `deb http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
310 | deb http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
311 | deb http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
312 | deb http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
313 | deb http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
314 | deb-src http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
315 | deb-src http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
316 | deb-src http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
317 | deb-src http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
318 | deb-src http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse`
319 |
320 | * 安装各种依赖,这些依赖有的已经系统自带了,但为了保证没有遗漏可以都执行一遍
321 |
322 | * `apt-get update && apt-get -y install g++-4.8 build-essential git vim wget zip`
323 | * `apt-get install automake libtool man python-dev python-boto libcurl4-nss-dev`
324 | * `apt-get install libsasl2-dev maven libapr1-dev libsvn-dev openssh-server supervisor`
325 | * 下载安装jdk
326 | * `cd /opt && wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u60-b27/jdk-8u60-linux-x64.tar.gz && cd /opt && tar -zxvf jdk-8u60-linux-x64.tar.gz && rm -rf jdk-8u60-linux-x64.tar.gz`
327 | * 下载singa安装文件
328 | * `git clone https://github.com/apache/incubator-singa.git`
329 | * 更新ssh.conf .bashrc .vimr
330 | * `cd incubator-singa/tool/docker/singa/`
331 | * `cp ssh.conf /etc/supervisor/conf.d/`
332 | * `cp .bashrc /root/.bashrc`
333 | * `cp .vimrc /root/.vimrc`
334 | * 使刚才更新的源生效
335 | * `source /root/.bashrc`
336 | * 下载和安装第三方应用
337 | * `cd incubator-singa && ./thirdparty/install.sh all`
338 | * 下载并解压protobuf
339 | * `cd thirdparty/ && wget https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz && tar -zxvf protobuf-2.5.0.tar.gz`
340 | * 编译并安装protobuf
341 | * `cd protobuf-2.5.0 && ./configure && make && make install`
342 | * 安装zookeeper
343 | * `cd ../../ && cp thirdparty/install.sh . && rm -rf thirdparty/* && mv install.sh thirdparty/ && ./thirdparty/install.sh zookeeper && ./autogen.sh && ./configure && make && make install`
344 | * 下载一个机器学习CNN的运行实例
345 | * `cd examples/cifar10 && mv Makefile.example Makefile && make download && make create`
346 | * 启动ssh服务
347 | * `service ssh start`
348 | * 更新.bashrc
349 | * `cd incubator-singa/tool/docker/mesos/`
350 | * `cp .bashrc /root/.bashrc`
351 | * 使用自动安装脚本进行安装
352 | * `install.sh /opt/install.sh`
353 | * `cd /opt && source ./install.sh`
354 | * 安装各种依赖软件
355 | * `apt-get -y install curl cmake libxml2 libxml2-dev uuid-dev protobuf-compiler libprotobuf-dev libgsasl7-dev libkrb5-dev libboost1.54-all-dev`
356 | * 下载安装hadoop-2.6
357 | * `cd /opt && source /root/.bashrc && wget -c http://www.eu.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz && tar -zxvf hadoop-2.6.0.tar.gz && git clone https://github.com/PivotalRD/libhdfs3.git && cd libhdfs3 && mkdir build && cd build && cmake ../ && make && make instal`
358 | * 编译安装mesos
359 | * `source ~/.bashrc && cd /root/incubator-singa/tool/mesos && make`
360 | * 将hadoop的配置文件放到hadoop的安装目录下
361 | * `cd/incubator-singa/tool/docker/mesos`
362 | * `cp *.xml /opt/hadoop-2.6.0/etc/hadoop/`
363 | * 和hadoop的部署一样需要配置免认证登录
364 | * `ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa && cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys && echo 'StrictHostKeyChecking no' >> ~/.ssh/config`
365 | * 至此在单一节点的安装部署已经完成,在安装过程中使用了大量的自动化脚本和依赖软件集体安装,所以这一过程要确保网络环境良好,如果发现报错或者下载不了则需要重新的下载和安装。
366 | * 通过虚拟化快照的方式迅速扩展到多个节点,并依次启动各节点的服务,本次以两个节点为例,包含了master\(namenode\)和slave\(datanode\)
367 | * 修改Hadoop的节点配置,增加datanode节点
368 | * `cd/opt/hadoop-2.6.0/etc/hadoop`
369 | * `vi slaves`
370 | * 修改各个节点的hosts,增加namenode和datanode
371 | `vi /etc/hosts`
372 | * 在master节点上启动master
373 | `mesos-master`
374 | * 在slave节点启动slave
375 | * `mesos-slave --master=10.10.245.23`
376 | * 在master节点上启动hdfs
377 | * `hadoop namonode`
378 | * 启动一个训练示例,开始使用signa进行训练
379 | * \`\`\`$ cd ../../
380 | $ ./bin/zk-service.sh start
381 | $ ./bin/singa-run.sh -conf examples/cifar10/job.conf\`\`\`
382 |
383 | 运行结果如下:
384 | 
385 |
386 | 
387 |
388 | 以上就是简单的部署过程,如果要深入的研究singa的使用可以关注NUS的signa开源项目。
389 |
390 |
--------------------------------------------------------------------------------
/chapter4/chapter4.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建大数据平台Hadoop和深度机器学习平台Singa实战
2 |
3 |
4 |
5 | #Mesos系统简介
6 |
7 | Mesos是一个跨应用集群的共享资源调度和隔离的分布式集群管理系统,它可以在集群应用如:Hadoop MapReduce、Hbase、MPI等之间共享资源并保证各个应用之间的隔离。Mesos是Apache基金会的顶级项目,一经推出就饱受推崇和关注,Twitter是最早的将其应用在自己生态系统架构中的公司。在Twitter内部,Mesos被当作成了DCOS系统,几乎所有的应用服务都使用Mesos进行分布式资源调度。随后像APPLE这样的大型科技公司也将Mesos引入到自己的数据中心,随着越来越多的大型公司将Mesos作为自己数据中心的操作系统,Mesos作为DCOS的应用被广泛的讨论和应用实践。在国内也有Mesos作为DCOS的用案例,如数人云等。
8 |
9 | ## 1.1、Mesos与其他分布式调度系统的对比
10 |
11 | ### 1.1.1 Mesos VS Kubernetes
12 | 关于Mesos在前面一小节已经根据官方的定义进行了说明,那么关于Kubernetes官方的定义是这样的:Kubernetes is an open source orchestration system for Docker containers.(Kubernetes是一个开源的Docker容器调度编排系统。)
13 | 换句话说,Kubernetes是一个Docker容器的高级管理系统,可以从集群应用层面出发满足对应用进行集群化部署、管理的需求。下图可以很形象的说明这种特性:
14 |
15 | 
16 | (图片来自Kuberbetes官网)
17 |
18 | 关于Mesos和Kubernetes的区别,我准备这样表述:Mesos更偏重于对应用资源的分布式调度和管理,它只负责资源的均衡分布式调度,至于资源的使用是由各种框架来实现的。而Kubernetes更偏重于提供一个基于Docker容器的轻量级应用集群部署平台,它着重于如何更有效的帮助开发运维人员实现一个应用的分布式集群部署。
19 |
20 | 对于到底是Mesos更有前景还是Kubernetes能够取代Mesos这里不做争论,我认为这两个项目都是非常优秀的开源项目,在不同的应用场景下具备各自不同的优势,如对于一些非分布式任务型的应用(如一些移动APP),这些应用更多的通过分布式集群部署实现服务的负载均衡和弹性伸缩以及快速迭代部署,那么这种情况下我认为面向应用且被各大软将厂商支持的Kubernetes更有优势;而对于一些分布式任务型的应用(如Hadoop、spark等),这些应用是通过分布式集群资源调度系统实现计算资源的逻辑上一致性,进而实现任务的并行计算等功能,那么这种情况下我认为面向底层资源并采用双层调度机制的Mesos更具优势。
21 | ### 1.1.2 Mesos VS Yarn
22 | 对于YARN的介绍在百度百科是这样描述的:YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
23 |
24 | Mesos和Yarn都采用了双层调度机制,这种机制很好的解决了集中式资源调度机制在资源集群调度过程中扩展性差、兼容性不好的问题。Mesos和Yarn都是面向底层资源调度的分布式集群系统,其应用场景基本是类似的(Hadoop、spark等),但是由于Yarn是从Hadoop1.0发展出来的,所以在Hadoop体系的项目以及基于这些项目的应用对Yarn都有比较好的兼容性和丰富的应用实践。
25 | 关于Mesos与Yarn的对比,每个我只从一个优势方面阐述一下。Mesos相对与Yarn的优势之一是它的二层调度机制更开放,在第一层对资源的调度颗粒度更大,这样的好处是给予第二层调度机制的资源管理权限更大,对计算框架的限制更少,这是因为Mesos的二层调度机制是基于Resoure Officer的,而Yarn是基于solt的。Yarn相对对于Mesos的优势之一是其具备成熟的生态圈,特别是在Hadoop系统中,各个子项目都有基于Yarn的成熟应用实践和丰富的生态群应用。
26 |
27 |
28 | ## 1.3 搭建环境简介
29 | 本次搭建的环境以及下一节的Mesos集群的部署都是参考我之前在Dockerone上写的一篇文章,因为这个环境是现成的且结构比较全(3个maste节点和3个slave节点),而且那篇部署教程在写完之后我自己还进行过重新部署,是写的比较全面且坑比较少的部署教程。以下是部署环境的简介:
30 | 
31 |
32 | 如图所示其中master节点都需要运行ZooKeeper、Mesos-master、Marathon,在slave节点上只需要运行master-slave就可以了,但是需要修改ZooKeeper的内容来保证slave能够被master发现和管理。为了节约时间和搞错掉,我在公司内部云平台上开一个虚拟机把所有的软件都安装上去,做成快照进行批量的创建,这样只需要在slave节点上关闭ZooKeeper、Mesos-master服务器就可以了,在文中我是通过制定系统启动规则来实现的。希望我交代清楚了,现在开始部署。
33 |
34 |
35 | ## 1.4 Mesos集群部署
36 |
37 |
38 | ### 1.4.1准备部署环境
39 | * 在Ubuntu 14.04的虚拟机上安装所有用到软件,并保证虚拟机可以上互联网。
40 |
41 | * 安装Python依赖
42 | * ```apt-get install curl python-setuptools python-pip python-dev python-protobuf```
43 | * 安装配置zookeeper
44 | * ```apt-get install ZooKeeperd &
45 | echo 1 | sudo dd of=/var/lib/ZooKeeper/myid```
46 | * 安装配置Mesos-master和Mesos-slave
47 | * ```curl-fL http://downloads.Mesosphere.io/master/ubuntu/14.04/Mesos_0.19.0~ubuntu14.04%2B1_amd64.deb -o /tmp/Mesos.deb ```
48 | * ```dpkg -i /tmp/Mesos.deb```
49 | * ```mkdir -p /etc/Mesos-master```
50 | * ```echo in_memory | sudo dd of=/etc/Mesos-master/registry```
51 | * 安装配置Mesos的Python框架
52 | * ```curl -fL http://downloads.Mesosphere.io/master/ubuntu/14.04/Mesos-0.19.0_rc2-py2.7-linux-x86_64.egg -o /tmp/Mesos.egg```
53 | * ```easy_install /tmp/Mesos.egg```
54 | * 下载安装Mesos管理Docker的代理组件Deimos
55 | * ```pip install deimos```
56 | * 配置Mesos使用Deimos
57 | * ```mkdir -p /etc/mesos-slave```
58 | * ```echo /usr/local/bin/deimos | sudo dd of=/etc/Mesos-slave/containerizer_path```
59 | * ```echo external | sudo dd of=/etc/Mesos-slave/isolation```
60 | * 安装Docker
61 | * ```echo deb http://get.Docker.io/ubuntu Docker main | sudo tee /etc/apt/sources.list.d/Docker.list```
62 | * ```sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9```
63 | * ```apt-get update && apt-get install lxc-Docker```
64 | 至此在一个虚拟机上就完成了所有组件的安装部署,下面就是对虚拟机打快照,然后快速的复制出6个一样的虚拟机,按照上图的ip配置进行配置之后就可以进入下个阶段,当然为了保险你可以测试一下上处组件是否安装成功和配置正确。如果你没有使用云平台,或者不具备快照功能,那就只能在6个虚拟机上重复6遍上处过程了。
65 |
66 |
67 | ### 1.4.2、在所有的节点上配置ZooKeeper
68 |
69 | 在配置maser节点和slave节点之前,需要先在所有的6个节点上配置一下ZooKeeper,配置步骤如下:
70 | * 修改zk的内容
71 | * ```sudo vi /etc/Mesos/zk```
72 | * 将zk的内容修改为如下:
73 | * ```zk://10.162.2.91:2181,10.162.2.92:2181,10.162.2.93:2181/Mesos```
74 |
75 |
76 | ### 1.4.3配置集群中的三个master节点
77 |
78 | 在所有的master节点上都要进行如下操作:
79 | * 修改ZooKeeper的myid的内容
80 | * ```sudo vi /etc/zooKeeper/conf/myid```
81 | * 将三个master节点的myid按照顺序修改为1,2,3。
82 | * 修改ZooKeeper的zoo.cfg
83 | * ```sudo vi/etc/zooKeeper/conf/zoo.cfg```
84 | * 配置内容如下:
85 | * ```server.1=10.162.2.91:2888:3888```
86 | * ```server.2=10.162.2.92:2888:3888```
87 | * ```server.3=10.162.2.93:2888:3888```
88 | * 修改Mesos的quorum
89 | * ```sudo vi /etc/mesos-master/quorum```
90 | * 将值修改为2。
91 | * 配置master节点的Mesos 识别ip和和hostname(以在master1上的配置为例)
92 | * ```echo 10.162.2.91 | sudo tee /etc/mesos-master/ip ```
93 | * ```sudo cp /etc/mesos-master/ip /etc/mesos-master/hostname```
94 | * 配置master节点服务启动规则(重启不启动slave服务)
95 | * ```sudo stop Mesos-slave
96 | echo manual | sudo tee /etc/init/Mesos-slave.override```
97 |
98 |
99 |
100 | ### 1.4.4、配置集群中的的slave节点
101 | * 配置slave节点的服务启动规则(重启不启动zookeeper和slave服务)
102 | * ```sudo stop zooKeeper```
103 | * ```echo manual | sudo tee /etc/init/zooKeeper.override```
104 | * ```echo manual | sudo tee /etc/init/mesos-master.override```
105 | * ```sudo stop mesos-master```
106 | * 配置slave节点的识别ip和hostname(以slave1节点为例)
107 | * ```echo 192.168.2.94 | sudo tee /etc/mesos-slave/ip```
108 | * ```sudo cp /etc/Mesos-slave/ip /etc/mesos-slave/hostname```
109 |
110 | ### 1.4.5、在集群的所有节点上启动相应的服务
111 | * 启动master节点的服务(zookeeper和mesos-master服务)
112 | * ```initctl reload-configuration```
113 | * ```service zookeeper start```
114 | * ```service mesos-master start```
115 | * 启动slave节点上的相应服务(mesos-slave服务)
116 | * ```sudo start mesos-slave```
117 |
118 |
119 | ### 1.4.5、Troubleshooting
120 | 由于有的网络情况和设备情况不一样,所以选举的过程有的快有的慢,但刷新几次就可以完成选举。当发现slave节点有些正常有些不正常时,可以通过reboot来促使自己被master发现。
121 |
122 |
123 |
124 | ## 1.5、Hadoop在Mesos集群上部署
125 |
126 |
127 | ### 1.5.1、部署前准备
128 | * 在部署和HDFS初始化过程中都需要跨节点的操作和SSH,因此首先在Mesos集群的所有节点上关闭防火墙。如下:
129 | * ```chkconfig iptables off ```(在root用户下操作)
130 | * 关闭selinux
131 | * ```setenforce 0```(在root用户下操作)
132 | * 在HDFS部署中,或者说在分布式架构的部署过程中节点之间的通信都是以主机名为地址标识,因此要保证每个节点主机名的唯一。
133 | * 在Master1节点上配置hostname:
134 | * ```vi /etc/hostname```
135 | * ```master1```
136 | * 在Masrer1节点上配置hosts
137 | * ```vi /etc/hosts```
138 | * ```127.0.0.1 localhost```
139 | * ```10.162.2.91 master1```
140 | * ```10.162.2.92 master2```
141 | * ```10.162.2.93 master3```
142 | * ```10.162.2.94 slave1```
143 | * ```10.162.2.95 slave2```
144 | * ```10.162.2.96 slave3```
145 | * 在其他节点上都参照上述配置进行修改hostname和hosts.
146 | * 在部署HDFS和Hadoop时,需要使用非root用户来进行操作,虽然大部分情况下也可以在root用户下操作,但以往的经验是非root用户下操作部署更顺畅。
147 | * 添加新的用户
148 | * ```addusr hadoop```
149 | * 重置hadoop用户的密码
150 | *```passwd hadoop```
151 |
152 |
153 | ### 1.5.2、在Mesos集群中部署HDFS
154 | * 本次案例的集群中master有三个节点,slave有三个节点,在master节点中使用zookeeper进行服务选举,在部署HDFS时也会用到zookeeper进行namenode节点的选举。
155 |
156 | ### 在master节点上部署namenode
157 | * 创建一个文件目录用于
158 | * ```mkdir -p /mnt/cloudera-hdfs/1/dfs/nn /nfsmount/dfs/nn```
159 | * 修改文件目录的用户权限,给上一步创建的文件目录添加用户hadoop操作权限
160 | * ```chown -R hadoop:hadoop /mnt/cloudera-hdfs/1/dfs/nn /nfsmount/dfs/nn```
161 | * 修改文件目录的操作权限
162 | * ```chmod 700 /mnt/cloudera-hdfs/1/dfs/nn /nfsmount/dfs/nn```
163 | * 使用apt-get 安装hadoop-hdfs-namenode,这样可以避免使用二进制文件在编译过程中遇到的坑。
164 | * ```wget http://archive.cloudera.com/cdh5/one-click-install/precise/amd64/cdh5-repository_1.0_all.deb```
165 | * ```sudo dpkg -i cdh5-repository_1.0_all.deb```
166 | * ```sudo apt-get update; sudo apt-get install hadoop-hdfs-namenode```
167 | *```cp /etc/hadoop/conf.empty/log4j.properties/etc/hadoop/conf.name/log4j.properties```
168 |
169 | ### 1.5.3、在slave节点上部署datanode
170 | * 创建挂载目录
171 | * ```mkdir -p /mnt/cloudera-hdfs/1/dfs/dn /mnt/cloudera-hdfs/2/dfs/dn /mnt/cloudera-hdfs/3/dfs/dn /mnt/cloudera-hdfs/4/dfs/dn```
172 | * 修改挂在目录所属的用户组
173 | * ```chown -R hadoop:hadoop /mnt/cloudera-hdfs/1/dfs/dn/mnt/cloudera-hdfs/2/dfs/dn /mnt/cloudera-hdfs/3/dfs/dn /mnt/cloudera-hdfs/4/dfs/dn```
174 | * 使用apt-get 安装hadoop-hdfs-datanode
175 | * ```wget http://archive.cloudera.com/cdh5/one-click-install/precise/amd64/cdh5-repository_1.0_all.deb```
176 | * ```dpkg -i cdh5-repository_1.0_all.deb```
177 | * ```sudo apt-get update; sudo apt-get install hadoop-hdfs-datanode```
178 | * ```sudo apt-get install hadoop-client```
179 |
180 |
181 | ### 1.5.4、 格式化并启动namenode节点
182 | * ```sudo -u hadoop hadoop namenode -format```
183 | * ```service hadoop-hdfs-namenode start```
184 |
185 | ### 1.5.5、启动slave节点
186 | * ```service hadoop-hdfs-datanode start```
187 |
188 | ### 1.5.6 配置服务自启动
189 | * 在namenode节点上
190 | * ```update-rc.d hadoop-hdfs-namenode defaults```
191 | * ```update-rc.d zookeeper-server defaults```
192 | *在slave节点上
193 | * ```update-rc.d hadoop-hdfs-datanode defaults```
194 |
195 | ## 1.6、在Mesos集群中部署Hadoop
196 |
197 | ### 1.6.1、Hadoop的基本安装
198 | * 下载Hadoop安装文件包
199 | * ```wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.3.0-cdh5.1.2.tar.gz```
200 | * 将安装文件包解压缩
201 | * ```tar zxf hadoop-2.3.0-cdh5.1.2.tar.gz```
202 | * 下载hadooponmesos二进制文件
203 | * ```git clone https://github.com/mesos/hadoop.git hadoopOnMesos```
204 | * 使用mvn编译hadooponmesos文件
205 | * ```mvn package```
206 | * 注意:mvn package要在下载的hadoopOnMesos文件夹中执行,编译好后可以在target文件夹中找到一个编译好的jar文件。
207 |
208 | * 将编译好的jar文件拷贝到hadoo-hdfs安装文件夹和下载的hadoop安装文件夹中
209 | * ```cp hadoopOnMesos/target/hadoop-mesos-0.1.0.jar /usr/lib/hadoop-0.20-mapreduce/lib/```
210 | * ```cp hadoopOnMesos/target/hadoop-mesos-0.1.0.jar hadoop-2.3.0-cdh5.1.2/share/hadoop/common/lib/```
211 | * 配置CDH5使用MRv1,因为在MRv2中hadoop的任务调度是使用yarn的
212 | * ```cd hadoop-2.3.0-cdh5.1.2```
213 | * ```mv bin bin-mapreduce2```
214 | * ```mv examples examples-mapreduce2```
215 | * ```ln -s bin-mapreduce1 bin```
216 | * ```ln -s examples-mapreduce1 examples```
217 | * ```pushd etc```
218 | * ```mv hadoop hadoop-mapreduce2```
219 | * ```ln -s hadoop-mapreduce1 hadoop```
220 | * ```popd```
221 | * ```pushd share/hadoop```
222 | * ```rm mapreduce```
223 | * ```ln -s mapreduce1 mapreduce```
224 | * ```popd```
225 | * 配置Hadoop运行所需的环境和配置文件:
226 | * ```cp target/hadoop-mesos-0.1.0.jar /usr/lib/hadoop-0.20-mapreduce/lib```
227 | * */上一步是将hadoopOnmesos编译好的jar包放到hadoop调用库文件夹中,以便hadoop可以使用mesos调度资源运行job任务。
228 | * ```vim /etc/profile.d/hadoop.sh```
229 | * ```export HADOOP_MAPRED_HOME=/usr/lib/hadoop-0.20-mapreduce```
230 | * ```export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/libmesos.so```
231 | * */上一步是在hadoop的运行脚本中配置HOME路径和Mesos的原生库。
232 | * ```chmod +x /etc/profile.d/hadoop.sh```
233 | * ```/etc/profile.d/hadoop.sh```
234 | * ```cd ..```
235 | * ```rm hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz```
236 | * */删除下载的cdh5原始文件
237 | * ```tar czf hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop-2.3.0-cdh5.1.2/```
238 | * */上一步是将配置好的hadoop安装文件重新打包
239 | * ```hadoop dfs -put hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz /```
240 | * */上一步是将打包好的hadoop安装包上传到hdfs上
241 |
242 | ### 1.6.2、 Hadoop配置文件配置
243 |
244 | * 配置mapred-site.xml
245 | * ```vi /etc/hadoop/conf.cluster-name/mapred-site.xml ```
246 | * mapred-site.xml需要配置文件内容
247 | * ```mapred.jobtracker.taskScheduler```
248 | * ```org.apache.hadoop.mapred.MesosScheduler```
249 | * */上一步是通过配置mapred的jobtrackerd.taskSchedule来告诉Hadoop使用Mesos来调度管理任务。
250 | * ```mapred.mesos.taskScheduler```
251 | * ```org.apache.hadoop.mapred.JobQueueTaskScheduler```
252 | * ```mapred.mesos.master```
253 | * ```zk:10.162.2.91:2181,10.162.2.92:2181,10.162.2.93:2181/mesos```
254 | * */上一步配置是保证mapred能够准确的找到mesos master节点通过zookeeper选举出来的的主节点。
255 | * ```mapred.mesos.executor.uri```
256 | * ```hdfs:/10.162.2.92:9000/hadoop-2.3.0-cdh5.1.2-mesos.0.20.tar.gz```
257 | * */上一步是配置hadoop的路径,这样mapred可以知道到那里调用hadoop代码执行task,这里10.162.2.92是本地主机的IP地址,在10.162.2.91主机上时就改成10.162.2.91.
258 | * ```mapred.job.tracker```
259 | * ```10.162.2.92:9001```
260 | * */上一步是配置jobtracker的主机IP地址,和上一步一样这要配置本机的IP地址
261 | * 配置本地的Mesos原生库
262 | * ```vim /usr/lib/hadoop-0.20-mapreduce/bin/hadoop-daemon.sh```
263 | * ```export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/libmesos.so```
264 | *完成上述配置后尝试启动jobtracker,验证是否安装部署成功。
265 | * ```service hadoop-0.20-mapreduce-jobtracker start```
266 | * 可以通过jps查看jobtracker进程是否在运行
267 | * ```jps```
268 |
269 | ### 1.6.3、 在其他namenode和datanode上完成部署
270 |
271 | * 在其他两个Master节点上完成相应的配置
272 | * 将之前重新打包好的hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz发送到三个datanode节点上
273 | * ```scp -r hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop@10.162.2.94:/hadoop```
274 | * ```scp -r hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop@10.162.2.95:/hadoop```
275 | * ```scp -r hadoop-2.3.0-cdh5.1.2-mesos-0.20.tar.gz hadoop@10.162.2.96:/hadoop```
276 | *重启HDFS的nomenode和datanode
277 |
278 |
279 | ## 1.7 Troubleshoting
280 |
281 | 注意:在每次重启HDFS服务的时候,需要先确保Mesos集群是正常运行的。namenode重启的时候可以先重新format一下。
282 |
283 |
284 | ## 1.8、基于Mesos搭建深度机器学习平台Singa
285 |
286 |
287 | ### 1.8.1、 Singa项目简介
288 |
289 | Singa是由NUS、浙江大学、网易联合进行开发并开源的一个深度机器学习平台,其设计目的是为多种深度学习模型(如CNN、DBN)提供一个有效的、易用的、高扩展的分布式实现平台。在Singa平台上,用户可以像在Hadoop上实现Map/Reducer一样轻易的训练他们所需要的抽象的深度学习模型。Singa的详细信息可以访问https://wiki.apache.org/incubator/SingaProposal。
290 |
291 |
292 | ### 1.8.2、 Singa on mesos部署架构
293 | Singa在设计其底层的资源调度系统时选择了Mesos这一优秀的分布式集群资源调度系统,如下图所示:
294 |
295 | 
296 | (图片来自https://github.com/apache/incubator-singa/tree/master/tool/mesos)
297 |
298 | 如上图所示,在统一分布式存储层面使用了HDFS,这样有利于整个singa在运行过程中提高文件的读写效率,在分布式资源调度层面使用mesos进行统一的资源调度。
299 |
300 |
301 | ### 1.8.3、 Singa on mesos部署过程
302 |
303 | 本次部署的过程是在ubuntu14.04上ubuntu用户下完成部署的。
304 |
305 | * 更换/bin/sh为/bin/bash
306 | * ```rm /bin/sh && ln -s /bin/bash /bin/sh```
307 | * 更新源,这里使用的是网易的源
308 | * ```vi /etc/apt/sources.list```
309 | * ```deb http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
310 | deb http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
311 | deb http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
312 | deb http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
313 | deb http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
314 | deb-src http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
315 | deb-src http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
316 | deb-src http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
317 | deb-src http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
318 | deb-src http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse ```
319 |
320 | * 安装各种依赖,这些依赖有的已经系统自带了,但为了保证没有遗漏可以都执行一遍
321 | * ```apt-get update && apt-get -y install g++-4.8 build-essential git vim wget zip```
322 | * ```apt-get install automake libtool man python-dev python-boto libcurl4-nss-dev```
323 | * ```apt-get install libsasl2-dev maven libapr1-dev libsvn-dev openssh-server supervisor```
324 | * 下载安装jdk
325 | * ```cd /opt && wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u60-b27/jdk-8u60-linux-x64.tar.gz && cd /opt && tar -zxvf jdk-8u60-linux-x64.tar.gz && rm -rf jdk-8u60-linux-x64.tar.gz```
326 | * 下载singa安装文件
327 | * ``` git clone https://github.com/apache/incubator-singa.git```
328 | * 更新ssh.conf .bashrc .vimr
329 | * ```cd incubator-singa/tool/docker/singa/```
330 | * ```cp ssh.conf /etc/supervisor/conf.d/```
331 | * ```cp .bashrc /root/.bashrc```
332 | * ```cp .vimrc /root/.vimrc```
333 | * 使刚才更新的源生效
334 | * ```source /root/.bashrc```
335 | * 下载和安装第三方应用
336 | * ```cd incubator-singa && ./thirdparty/install.sh all ```
337 | * 下载并解压protobuf
338 | * ``` cd thirdparty/ && wget https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz && tar -zxvf protobuf-2.5.0.tar.gz ```
339 | * 编译并安装protobuf
340 | * ```cd protobuf-2.5.0 && ./configure && make && make install```
341 | * 安装zookeeper
342 | * ```cd ../../ && cp thirdparty/install.sh . && rm -rf thirdparty/* && mv install.sh thirdparty/ && ./thirdparty/install.sh zookeeper && ./autogen.sh && ./configure && make && make install ```
343 | * 下载一个机器学习CNN的运行实例
344 | * ```cd examples/cifar10 && mv Makefile.example Makefile && make download && make create ```
345 | * 启动ssh服务
346 | * ```service ssh start```
347 | * 更新.bashrc
348 | * ```cd incubator-singa/tool/docker/mesos/```
349 | * ```cp .bashrc /root/.bashrc```
350 | * 使用自动安装脚本进行安装
351 | * ```install.sh /opt/install.sh```
352 | * ```cd /opt && source ./install.sh```
353 | * 安装各种依赖软件
354 | * ```apt-get -y install curl cmake libxml2 libxml2-dev uuid-dev protobuf-compiler libprotobuf-dev libgsasl7-dev libkrb5-dev libboost1.54-all-dev```
355 | * 下载安装hadoop-2.6
356 | * ```cd /opt && source /root/.bashrc && wget -c http://www.eu.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz && tar -zxvf hadoop-2.6.0.tar.gz && git clone https://github.com/PivotalRD/libhdfs3.git && cd libhdfs3 && mkdir build && cd build && cmake ../ && make && make instal```
357 | * 编译安装mesos
358 | * ```source ~/.bashrc && cd /root/incubator-singa/tool/mesos && make```
359 | * 将hadoop的配置文件放到hadoop的安装目录下
360 | * ```cd/incubator-singa/tool/docker/mesos```
361 | * ```cp *.xml /opt/hadoop-2.6.0/etc/hadoop/```
362 | * 和hadoop的部署一样需要配置免认证登录
363 | * ```ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa && cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys && echo 'StrictHostKeyChecking no' >> ~/.ssh/config```
364 | * 至此在单一节点的安装部署已经完成,在安装过程中使用了大量的自动化脚本和依赖软件集体安装,所以这一过程要确保网络环境良好,如果发现报错或者下载不了则需要重新的下载和安装。
365 | * 通过虚拟化快照的方式迅速扩展到多个节点,并依次启动各节点的服务,本次以两个节点为例,包含了master(namenode)和slave(datanode)
366 | * 修改Hadoop的节点配置,增加datanode节点
367 | * ```cd/opt/hadoop-2.6.0/etc/hadoop```
368 | * ```vi slaves```
369 | * 修改各个节点的hosts,增加namenode和datanode
370 | ```vi /etc/hosts```
371 | * 在master节点上启动master
372 | ```mesos-master ```
373 | * 在slave节点启动slave
374 | * ```mesos-slave --master=10.10.245.23```
375 | * 在master节点上启动hdfs
376 | * ```hadoop namonode ```
377 | * 启动一个训练示例,开始使用signa进行训练
378 | * ```$ cd ../../
379 | $ ./bin/zk-service.sh start
380 | $ ./bin/singa-run.sh -conf examples/cifar10/job.conf```
381 |
382 | 运行结果如下:
383 | 
384 |
385 | 
386 |
387 | 以上就是简单的部署过程,如果要深入的研究singa的使用可以关注NUS的signa开源项目。
388 |
389 |
390 |
391 |
392 |
393 |
394 |
395 |
396 |
397 |
398 |
399 |
400 |
401 |
402 |
403 |
404 |
405 |
406 |
407 |
408 |
409 |
410 |
411 |
412 |
413 |
414 |
415 |
416 |
--------------------------------------------------------------------------------
/chapter4/mesos-cluster.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter4/mesos-cluster.png
--------------------------------------------------------------------------------
/chapter4/singa on mesos.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter4/singa on mesos.png
--------------------------------------------------------------------------------
/chapter4/singa运行结果1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter4/singa运行结果1.png
--------------------------------------------------------------------------------
/chapter4/singa运行结果2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter4/singa运行结果2.png
--------------------------------------------------------------------------------
/chapter5.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建分布式生物信息算法计算系统实战
2 |
3 |
4 | Refs:
5 | https://github.com/rabix/rabix
--------------------------------------------------------------------------------
/chapter6.md:
--------------------------------------------------------------------------------
1 | # Mesos搭建视频压缩批处理系统实战
2 |
3 | 如何使用Chronos来压缩视频
4 |
--------------------------------------------------------------------------------
/chapter7.md:
--------------------------------------------------------------------------------
1 | * [Mesos 搭建持续集成系统概述](chapter7/summary.md)
2 | * [持续集成简介](chapter7/ci.md)
3 | * [Jenkins 开源软件介绍](chapter7/jenkins.md)
4 | * [持续集成系统搭建](chapter7/jenkins-on-mesos.md)
5 | * [持续集成系统的维护心得](chapter7/challenges.md)
6 | * [参考](chapter7/refers.md)
--------------------------------------------------------------------------------
/chapter7/ContinuousDeliveryMatrix.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/ContinuousDeliveryMatrix.png
--------------------------------------------------------------------------------
/chapter7/Jenkins - scm-sync-config - Display Status.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/Jenkins - scm-sync-config - Display Status.png
--------------------------------------------------------------------------------
/chapter7/Jenkins - scm-sync-configuration - Comment prompt2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/Jenkins - scm-sync-configuration - Comment prompt2.png
--------------------------------------------------------------------------------
/chapter7/building-jobs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/building-jobs.png
--------------------------------------------------------------------------------
/chapter7/challenges.md:
--------------------------------------------------------------------------------
1 | # 7.5 持续集成系统维护心得
2 |
3 | ## 7.5.1 持续集成的交付方式
4 |
5 | 这里的交付方式指的是开发者将项目以何种方式交付给运维人员,或者项目以何种方式部署到服务器。常见的交付方式有
6 |
7 | * 源代码交付
8 | > 源代码交付需要将源代码以 tar 包等方式 download 到服务器,然后在服务器上借助程序的构建脚本去构建可执行程序,显然这种方式会经常因服务器环境差异,构建环境初始化失败等问题导致无法构建可执行程序。严重依赖于构建脚本的完备程度。
9 | * 二进制包交付
10 | > 二进制包交付常见的例子是 Linux 标准包的交付,将项目的依赖通过 Linux deb 或者 rpm 来管理,由于这种方式更符合 Linux 规范,间接的提高了项目在服务器上部署的成功率。
11 | * 虚拟镜像交付
12 | > 虚拟镜像交付指的是我们将项目在虚拟机里测试成功后直接将该虚拟镜像部署到服务器上。显然,这种方式部署成功率接近100%。但是随之而来的问题就是虚拟镜像本身对服务器资源的消耗。
13 | * docker image 交付
14 | > docker image 交付是虚拟镜像交付的进一步演进,在保证系统隔离的同时,docker image 对服务器的资源消耗更低。当然,由于 docker 技术仍在发展之中,docker 本身到稳定性还有待提高。我们团队目前正在使用这种方式进行交付。
15 |
16 | ## 7.5.2 不同环境下的配置管理
17 |
18 | 对于一个常规的项目来说,开发环境,测试环境与生产环境的配置是不一样的,譬如,这三种环境需要使用不同的域名等。在以 docker 镜像交付时,我们可以通过环境变量来保证配置的差异性。
19 |
20 | ## 7.5.3 持续集成可靠性的保证
21 |
22 | 这里我想阐明的是持续集成本身并不能保证项目的可靠性,持续集成是项目可靠性的一个必要非充分条件。只有为你的项目添加单元测试,集成测试等才能达到更可靠的交付。即,可靠交付的更多人力在提高测试覆盖率。
23 |
24 | ## 7.5.4 js 的配置管理问题
25 |
26 | js 代码不同于在服务器端运行的代码,JS 在不同环境下的配置管理需要额外的操作,目前已知有两种:
27 |
28 | * 使用初始化脚本动态的替换 JS 配置文件中的关键词,即初始化脚本获取环境变量后动态替换 配置文件中相应的值。
29 | * 使用 URL 匹配,为不同的环境设置不同的URL,譬如测试环境与开发环境的URL分别为:
30 |
31 | * 测试环境: http://www.mesos-in-action.com?env=test
32 | * 开发环境: http://www.mesos-in-action.com?env=devel
33 |
34 | 从而使用不同的 JS 配置文件。这是 StackOverflow 推荐的一个比较优雅的解决方案。
35 |
36 | ## 7.5.5 自动生成 ReleaseNote
37 |
38 | 在多人协作的项目开发中,由于多人频繁的 merge 代码,ReleaseNote 的管理也会成为团队的负担。我这里推荐的做法是团队达成一个 agreement:
39 | >对重大 feature 或 bug-fix 的提交都需要在目录 `pending-release` 里面创建相应的 markdown 文件,并将改动添加到里面。
40 |
41 | 这样,我们可以控制 CI 服务器在构建代码时扫描 `pending-release` 目录并将其中的文本 merge 到一起生成这次构建的 ReleaseNote。
42 |
43 | 同时,为了避免团队成员忘记这个agreement, 我们还可以在本地的 `git-precommit-hook` 中添加相应的提醒。
44 |
45 | ## 7.5.6 频繁发布的版本确认
46 |
47 | 前期,我们团队在频繁发布项目时遇到的一个尴尬问题是无法确认线上版本是不是最新的版本,或者说无法直观的确认新的change是否部署成功。由于我们的项目是通过html页面与用户交互的,我们通过控制 CI 服务器将每次 release 的 `commit id` 缀到 `html` 页面的右下角解决了这个问题。 对于非 Web 项目来说,建议的做法是控制 CI 服务器将每次 Relase 的 `commit id` 推送到一个内部的 Web 服务器,这样,团队就可以非常直观的确认当前版本了。
48 |
49 | ## 7.5.7 持续集成的消息通知
50 |
51 | 显然,团队希望 CI 服务器在执行了持续集成后能够及时的将集成结果通知团队成员,Jenkins 本身是有 `irc notification` 插件的,但是国内开发者可能使用 IRC 的并不多。微信是小团队使用比较多的沟通工具,但是微信不支持机器人调用,退而求其次,我们可以使用 email 通知的方式。或者使用国内的 `LessChart` 等交流工具,它们本身支持 `webhook` 调用。
--------------------------------------------------------------------------------
/chapter7/ci.md:
--------------------------------------------------------------------------------
1 | # 7.2 持续集成简介
2 |
3 | 大师 Martin Fowler 对持续集成是这样定义的:持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。许多团队发现这个过程可以大大减少集成的问题,让团队能够更快的开发内聚的软件。
4 |
5 | 本章主要结合实践经验介绍持续集成的价值,涉及到的主要工具以及持续集成的大致流程等。
6 |
7 | ## 7.2.1 持续集成能为团队带来什么
8 |
9 | 我们一致认为,持续集成至少可以为团队带来下述几点[价值](http://baike.baidu.com/link?url=YUuGXCCgfPK9Z_Yf728mCkL7ccEAxEBGVOOrQETCTP_w7R-N3qtqS7Hd4ZV6XibkC5YxuFw1HfLW90dL8B0KKa):
10 |
11 | - 有效的控制或降低风险
12 | > 软件一天中进行多次的集成,并触发了相应的测试,这样有利于检查缺陷,了解软件的健康状况,减少假定,从而有效的控制或降低了风险。
13 | - 提高团队效率
14 | > 减少重复的过程可以节省团队的时间、费用和工作量。在软件开发过程中,浪费时间的重复劳动可能在我们的项目活动的任何一个环节发生,包括代码编译、数据库集成、测试、审查、部署及反馈。通过持续集成可以将这些重复的动作都变成自动化的,无需太多人工干预,让团队成员将时间更多的投入到动脑筋的、更高价值的事情上。
15 | - 提高软件交付速度
16 | > 持续集成可以让团队在任何时间发布可以部署的软件。从外界来看,这是持续集成最明显的好处,我们可以对改进软件品质和减少风险说起来滔滔不绝,但对于客户来说,可以部署的软件产品是最实际的资产。利用持续集成,团队任何成员都可以经常对源代码进行一些小改动,并将这些改动和其他的代码进行集成。如果出现问题,项目成员马上就会被通知到,问题会第一时间被修复。不采用持续集成的情况下,这些问题有可能到交付前的集成测试的时候才发现,有可能会导致延迟发布产品,而在急于修复这些缺陷的时候又有可能引入新的缺陷,最终可能导致项目失败。
17 | - 提高客户及团队对项目的把控能力
18 | > 持续集成让客户及团队能够注意到趋势并进行有效的决策。如果没有真实或最新的数据提供支持,项目就会遇到麻烦,每个人都会提出他最好的猜测。通常,项目成员通过手工收集这些信息,增加了负担,也很耗时。持续集成可以带来两点积极效果:
19 | - 有效决策:持续集成系统为项目构建状态和品质指标提供了及时的信息,有些持续集成系统可以报告功能完成度和缺陷率。
20 | - 注意到趋势:由于经常集成,我们可以看到一些趋势,如构建成功或失败、总体品质以及其它的项目信息。
21 | - 建立团队对开发产品的信心
22 | > 持续集成可以建立开发团队对开发产品的信心,因为他们清楚的知道每一次构建的结果,他们知道他们对软件的改动造成了哪些影响,结果怎么样。
23 |
24 | ## 7.2.2 持续集成涉及到的主要工具
25 |
26 | * 版本控制/配置管理工具
27 | > 版本控制与配置管理工具主要负责源代码,配置文件的管理。常见的工具如 git,svn 等, 其中 git 是当下最流行的版本控制工具。
28 |
29 | * 构建工具
30 | > 实现主要负责自动化地编译、测试、部署等,这是持续集成的核心工具;构建工具是编程语言依赖型的,不同编程语言使用不同的构建工具。
31 |
32 | * CI 服务器
33 | > CI 服务器主要负责将版本控制仓库和构建工具有机整合起来,并通过设置一种或多种构建触发条件来触发构建。常见的CI工具有
34 | >> * [jenkins](http://jenkins-ci.org/)
35 | >> * [travis](https://travis-ci.com/)
36 | >> * [codeship](https://codeship.com/)
37 | >> * [stridercd]( http://stridercd.com)
38 |
39 | ## 7.2.3 持续集成的流程
40 |
41 | 关于CI的流程,首先我们需要明确的是,基于不同的项目规模,不同的项目阶段,不同的团队大小以及不同的团队经验,CI 的流程是相应调整的。CI 流程本身也是一个逐步迭代,逐步完善的过程。
42 |
43 | 下面列出的是一个基本的,泛化的持续集成过程:
44 |
45 | * 团队开发人员频繁的从源代码仓库下载同步代码
46 | * 团队开发编写代码、测试用例,并提交更新结果给版本控制仓库
47 | * CI服务器根据触发条件,从版本控制仓库提取最新代码,交给构建工具的工作空间
48 | * 构建工具对代码进行编译、测试,并进行打包。
49 | * 通过构建工具与版本控制工具的配合,实现产品版本控制与管理
50 | * 建立、管理项目开发的工作网站
51 |
52 | 另外下面的图片(图7-2-1)是我在[atlassian wiki](https://chrisshayan.atlassian.net/wiki/display/my/2013/07/23/Continuous+Delivery+Matrix)下载的持续交付成熟度矩阵。这里我们不需要要考虑持续集成与持续交付的差别,或者说,在本文中,持续集成与持续交付是一样的。
53 |
54 | 
55 | 图7-2-1 持续交付成熟度矩阵
56 |
57 | 通过这张图片我们可以看出,CI流程的演进过程,从初期的 nightly build 到最终的 镜像交付; 从 merges are rare 到自动生成 ReleaseNote;从简单的将构建结果通知 committer 到向客户分享构建报告与统计结果,等等。我们可以发现,一个成熟的继续交付系统可以极大的提高生产率。
--------------------------------------------------------------------------------
/chapter7/ebay-mesos-jenkins.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/ebay-mesos-jenkins.png
--------------------------------------------------------------------------------
/chapter7/how-jenkins-master-run-on-mesos.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/how-jenkins-master-run-on-mesos.png
--------------------------------------------------------------------------------
/chapter7/how-marathon-run-jenkins-on-mesos.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/how-marathon-run-jenkins-on-mesos.png
--------------------------------------------------------------------------------
/chapter7/jenkins-config-slave.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-config-slave.png
--------------------------------------------------------------------------------
/chapter7/jenkins-configure.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-configure.png
--------------------------------------------------------------------------------
/chapter7/jenkins-framework-on-mesos.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-framework-on-mesos.png
--------------------------------------------------------------------------------
/chapter7/jenkins-master-on-marathon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-master-on-marathon.png
--------------------------------------------------------------------------------
/chapter7/jenkins-master-on-mesos-slave-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-master-on-mesos-slave-2.png
--------------------------------------------------------------------------------
/chapter7/jenkins-master-on-mesos-slave.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-master-on-mesos-slave.png
--------------------------------------------------------------------------------
/chapter7/jenkins-mesos-configure.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-mesos-configure.png
--------------------------------------------------------------------------------
/chapter7/jenkins-on-mesos.md:
--------------------------------------------------------------------------------
1 | # 7.4 持续集成系统搭建
2 |
3 | ## 7.4.1 如何配置保证 Jenkins 的资源弹性,以及 Jenkins Master 的高可用
4 |
5 | ### 环境设置
6 |
7 | 为了便于理解,这里我简化了 Mesos/Marathon 集群的架构,不再考虑集群本身的高可用性。至于如何利用 zookeeper 配置高可用的 mesos/marathon 集群,可以参考[Mesosphere的官方文档](https://mesos.apache.org/documentation/latest/mesos-architecture/),这里不再展开。
8 |
9 | 我搭建了一个包含40个节点 ``192.168.3.4-192.168.3.43`` 的 Mesos 集群,其中一个节点用作运行 Marthon 及 Mesos-master,其它39个节点作为 mesos 的 slave,如下所示。
10 |
11 | 192.168.3.4 marathon/mesos-master
12 | 192.168.3.5 mesos-slave
13 | 192.168.3.6 mesos-slave
14 | ......
15 | 192.168.3.43 mesos-slave
16 |
17 | 参照[http://get.dataman.io](http://get.dataman.io)的文档配置启动 Marathon,Mesos-Master 和 Mesos-Slave,下面的整个操作都将在这个集群上完成。
18 |
19 |
20 | ### 在 Marathon 上部署 Jenkins 的 master 实例
21 |
22 | Marathon 支持 web 页面或者 RESTapi 两种方式发布应用,在``192.168.3.*``内网执行下面的 bash 命令,就会通过 Marathon 的 RESTapi 在 mesos slave 上启动一个 Jenkins master 实例。
23 |
24 | ```bash
25 | git clone git@github.com:Dataman-Cloud/jenkins-on-mesos.git && cd jenkins-on-mesos && curl -v -X POST \
26 | -H 'Accept: application/json' \
27 | -H 'Accept-Encoding: gzip, deflate' \
28 | -H 'Content-Type: application/json; charset=utf-8' \
29 | -H 'User-Agent: HTTPie/0.8.0' \
30 | -d@marathon.json \
31 | http://192.168.3.4:8080/v2/apps
32 | ```
33 |
34 | *这里我在github上fork了[mesosphere的jenkins-on-mesos的repo](https://github.com/mesosphere/jenkins-on-mesos)到[DataMan-Cloud/jenkins-on-mesos](https://github.com/Dataman-Cloud/jenkins-on-mesos),并进行了一些[改进](https://github.com/Dataman-Cloud/jenkins-on-mesos/commits?author=vitan)。*
35 |
36 | 如果Jenkins master实例被成功部署,通过浏览器访问``http://192.168.3.4:8080``(**请确定你的浏览器能够访问内网,譬如可以利用设置浏览器代理等方式来搞定**)可以在running tasks列表中找到jenkins,点击进入详细信息页面,我们会看到下图(图7-4-1):
37 | 
38 | 图7-4-1 Jenkins Master 实例信息
39 |
40 | 访问``http://192.168.3.4:5050/#/frameworks``并在**Active Frameworks**中找到Marathon,点击进入详细信息页面,可以在该页面找到Jenkins Master具体运行到Mesos哪一台Slave上,如下图(图7-4-2)所示:
41 | 
42 | 图7-4-2 Jenkins Master 运行在 Mesos slave 上
43 |
44 | 点击sandbox(图7-4-3)
45 |
46 | 
47 | 图7-4-3 Jenkins Master 运行在 Mesos slave 上
48 |
49 | 至此,我们的 Jenkins Master 已经在 marathon 上被成功启动了。
50 |
51 | ### 配置 Jenkins Master 实现弹性伸缩
52 |
53 | 接下来是配置 Jenkins 注册成为 Mesos 的 Framework,需要通过浏览器访问``http://192.168.3.25:31052/``来到 Jenkins Master 的 UI 页面。下面的截图是我逐步配置的全过程。
54 |
55 | 
56 | 图7-4-4 Jenkins Master 配置页面
57 |
58 | 
59 | 图7-4-5 Jenkins Master 连接 Mesos 集群
60 |
61 | 1. 来到 Jenins
62 | Master 配置页面
63 | 2. 点击系统设置
64 | 3. ``Mesos native library path`` 设置: Mesos lib 库路径,一般在/usr/lib/libmesos.so,拷贝无效,必须安装 Mesos
65 | 4. ``Mesos Master [hostname:port]`` 设置: Mesos-Master 地址加端口,如果单 Mesos-Master 模式,使用 mesos-master-ip:5050格式,如果是多 Mesos-Master 使用 zk://zk1:2181,zk2:2181,zk3:2181/mesos 格式设置 Mesos Master 为 192.168.3.4:5050
66 | 5. ``Framework Name`` 设置: Mesos Master 查看到的应用框架名称
67 | 6. ``Slave username`` 设置: Slave的名字
68 | 7. ``On-demand framework registration`` 设置: 是否在无任务的情况下,从 Mesos-Master 注销应用框架
69 | 8. 点击测试链接, 如果链接成功,页面会弹出连接到 Mesos 成功
70 | 9. 点击应用,将设置保存
71 |
72 | 如果 Jenkins 在 Mesos 上注册成功,访问``http://192.168.3.4:5050/#/frameworks``,我们可以找到jenkins Framework,如下图(图7-4-6)所示:
73 |
74 | 
75 | 图7-4-6 Jenkins framework on mesos
76 |
77 | 现在我们可以同时启动多个构建作业来看一下 Jenkins 在 Mesos 上的弹性伸缩,在 ``http://192.168.3.25:31052/`` 上新建一个名为 ``test`` 的工程,配置其构建过程为运行一个 shell 命令 ``top`` ,如下图(图7-4-7)所示:
78 |
79 | 
80 | 图7-4-7 配置构建作业
81 |
82 | 把该工程复制3份 ``test2``、``test3`` 和 ``test4``,并同时启动这4个工程的构建作业,Jenkins Master 会向 Mesos 申请资源,如果资源分配成功,Jenkins Master 就在获得的 slave 节点上进行作业构建,如下图(图7-4-8)所示:
83 |
84 | 
85 | 图7-4-8 构建作业列表
86 |
87 | 因为在前面的系统配置里我们设置了**执行者数量**为2(即最多有两个作业同时进行构建),所以在上图中我们看到两个正在进行构建的作业,而另外两个作业在排队等待。
88 |
89 | 下图(图7-4-9)展示了当前的Jenkins作业构建共使用了0.6CPU和1.4G内存,
90 |
91 | 
92 | 图7-4-9 Jenkins 资源使用
93 |
94 | 正在使用的slave节点的详细信息
95 |
96 | 
97 | 图7-4-10 slave 节点详细信息
98 |
99 | 
100 | 图7-4-11 slave 节点详细信息
101 |
102 | #### 配置 Jenkins Slave 参数(可选)
103 |
104 | 在使用 Jenkins 进行项目构建时,我们经常会面临这样一种情形,不同的作业会有不同的资源需求,有些作业需要在配置很高的 slave 机器上运行,但是有些则不需要。为了提高资源利用率,显然,我们需要一种手段来向不同的作业分配不同的资源。通过设置 Jenkins Mesos Cloud 插件的 slave info,我们可以很容易的满足上述要求。 具体的配置如下图(图7-4-12)所示:
105 |
106 | 
107 | 图7-4-12 Jenkins 配置 slave
108 |
109 | 1. ``Label String`` 设置: Slave 标签
110 | 2. ``Maximum number of Executors per Slave``: 每个 Slave 可以同时执行几个任务
111 | 3. ``Mesos Offer Selection Attributes``: 选择在哪些 Mesos Slave 标签资源上运行,格式
112 | ```json
113 | {"clusterType":"标签"}
114 | ```
115 |
116 | 利用mesos为jenkins弹性的提供资源,同时配置Jenkins Slave的参数来满足不同作业的资源需求,这些都大大提高了集群的资源利用率。另外,由于 Marathon 会自动检查运行在它之上的app的健康状态, 并重新发布崩溃掉的应用程序。
117 |
118 | ## 7.4.2 如何达到 Jenkins 数据持久化
119 |
120 | 由于我们通过 Marathon 来启动 Jenkins Master , 在 Jenkins Master 异常导致重新部署时,我们需要考虑 Jenkins Master 的数据持久化问题。 一种显而易见的方式是限制 Marathon 将 Jenkins Master 部署到同一个数据节点,但这会导致分布式的单点问题。 这里我们介绍另一种方法,即:使用 jenkins 插件 [SCM Sync configuration plugin](https://wiki.jenkins-ci.org/display/JENKINS/SCM+Sync+configuration+plugin) 来将数据同步到 git repo 上。把锅扔出去,扔到 github 上 :-)。
121 |
122 | ### 在内部的代码库或者 github 上创建一个 git repo
123 |
124 | 我们需要在内部的代码库或者公共代码库创建一个名为 **jenkins-on-mesos** 的 gitrepo , 譬如:**git@gitlab.dataman.io:wtzhou/jenkins-on-mesos.git** 。 这个 repo 是 jenkins 插件 [SCM Sync configuration plugin](https://wiki.jenkins-ci.org/display/JENKINS/SCM+Sync+configuration+plugin) 用来同步jenkins数据的。
125 |
126 | 另外,对于 SCM-Sync-Configuration 来说,非常关键的一步是保证其有权限 pull/push 上面我们所创建的 gitrepo。 以我们公司的内部环境为例, 在 mesos 集群搭建时,我们首先使用 ansible 为所有的 mesos slave 节点添加了用户 **core** 并生成了相同的 **ssh keypair**,同时在内部的gitlab上注册了用户 **core** 并上传其在slave节点上的公钥,然后添加该用户 **core** 为 repo **git@gitlab.dataman.io:wtzhou/jenkins-on-mesos.git** 的 **developer** 或者 **owner**,这样每个 mesos slave 节点都可以以用户 **core** 来 pull/push 这个gitrepo了。
127 |
128 | ### 使用 marathon 部署可持久化的 Jenkins Master
129 |
130 | 我们首先需要 wget 两个文件:
131 |
132 | ```bash
133 | wget -O start-jenkins.app.sh https://raw.githubusercontent.com/Dataman-Cloud/jenkins-on-mesos/master/start-jenkins.app.sh.template
134 | wget https://raw.githubusercontent.com/Dataman-Cloud/jenkins-on-mesos/master/marathon.json
135 | ```
136 |
137 | 其中 ``start-jenkins.app.sh`` 是需要配置的,
138 |
139 | ```bash
140 | #! /bin/bash
141 |
142 | # Sync the config with SCM_SYNC_GIT
143 | # SCM_SYNC_GIT format: git@gitlab.dataman.io:wtzhou/jenkins-on-mesos.git
144 | SCM_SYNC_GIT=
145 |
146 | # deploy jenkins on marathon as user APP_USER, who has been granted to pull/push repo SCM_SYNC_GIT
147 | APP_USER=
148 |
149 | # Marathon PORTAL, for example: http://192.168.3.4:8080/v2/apps
150 | MARATHON_PORTAL=
151 | ......
152 | ......
153 | ......
154 | ```
155 |
156 | 编辑如下3个变量:
157 |
158 | 1. **SCM_SYNC_GIT**: 上面所配置的 gitrepo 地址, 格式例子: git@gitlab.dataman.io:wtzhou/jenkins-on-mesos.git
159 | 2. **APP_USER**: marathon 会以用户 **APP_USER** 来部署 jenkins ,从而插件**SCM-Sync-Configuration**会以用户**APP_USER**来跟gitrepo进行同步。 所以在我们的这个例子里,我们让``APP_USER=core``。
160 | 3. **MARATHON_PORTAL**: marathon 的 RESTapi 入口,例如: http://marathon.dataman.io:8080/v2/apps
161 |
162 | 接下来就可以执行命令:
163 |
164 | ```bash
165 | bash start-jenkins.app.sh
166 | ```
167 |
168 | 来让 marathon 部署我们的 Jenkins Master 了。这样, 我们在 Jenkins Master 上所保存的任何配置,创建的任何job都会被 **SCM-Sync-Configuration** 同步到 repo 里,并在 Jenkins Master 被重新发布后 download 到本地。
169 |
170 | ### 关于SCM-Sync-Configuration的更多信息
171 |
172 | SCM-Sync-Configuration 初始化完成后(在我们环境里初始化过程会被自动触发),每次配置更新或者添加,编辑构建作业时,我们会得到一个提示页面来为新的 commit message 添加 comment,如下图(图7-4-13)所示,
173 |
174 | 
175 | 图7-4-13 commit comment
176 |
177 | 当前,所支持的配置文件如下:
178 |
179 | 1. 构建作业的配置文件 (/jobs/*/config.xml)
180 | 2. 全局的 Jenkins/Hudson 系统配置文件 (/config.xml)
181 | 3. 基本的插件的配置文件 (/hudson*.xml, /scm-sync-configuration.xml)
182 | 4. 用户手动指定的配置文件
183 |
184 | 另外,我们可以在每一页的下面看到 scm sync config 的状态, 下图(图7-4-14)是同步出错时的截图,你可以去**System Log**查看具体的出错信息。
185 |
186 | 
187 | 图7-4-14 scm sysnc status
--------------------------------------------------------------------------------
/chapter7/jenkins-slave-detail.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-slave-detail.png
--------------------------------------------------------------------------------
/chapter7/jenkins-slave.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-slave.png
--------------------------------------------------------------------------------
/chapter7/jenkins-utilization.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/jenkins-utilization.png
--------------------------------------------------------------------------------
/chapter7/jenkins.md:
--------------------------------------------------------------------------------
1 | # 7.3 Jenkins
2 |
3 | 在上一章提到的常用CI工具中,Jenkins 常用的CI开源工具。 其官方网站对 Jenkins 是这样定义的:
4 |
5 | > Jenkins 是一个[获奖无数](https://wiki.jenkins-ci.org/display/JENKINS/Awards)的,能够提高你产出的,跨平台的持续集成与持续交付工具。 通过使用 Jenkins 来不间断的构建,测试你的项目,可以更方便的把开发者的 changes 集成到项目中,更快的向用户交付最新的构建。 同时,通过提供接口来定义构建流程,集成多种测试和部署技巧, Jenkins 也可以帮助你持续的交付软件。
6 |
7 | Jenkins 以其
8 |
9 | * 易于安装:只要把 jenkins.war 部署到 Servlet 容器,不需要数据库支持。
10 | * 易于配置:所有配置都是通过其提供的 Web 界面实现。
11 | * 丰富的插件生态
12 | * 可扩展性:支持扩展插件,你可以开发适合自己团队使用的工具。
13 | * 分布式构建:Jenkins 能够让多台计算机一起构建/测试。
14 | * 集成 RSS/E-mail: 通过 RSS 发布构建结果或当构建完成时通过 E-mail 通知。
15 | * 生成 JUnit/TestNG 测试报告。
16 | * 文件识别: Jenkins 能够跟踪哪次构建生成哪些 jar ,哪次构建使用哪个版本的 jar 等。
17 |
18 | 等特性广受开发者欢迎。 许多的公司,开源项目都在使用 Jenkins ,譬如 github, yahoo!, Dell, LinkedIn, eBay 等, 你在这里可以看到[Who is using Jenkins](https://wiki.jenkins-ci.org/pages/viewpage.action?pageId=58001258)。
19 |
20 | ### 7.3.1 为什么要把 Jenkins 运行到 Apache Mesos 上
21 |
22 | 使用 Jenkins 时,如果遇到构建作业很多,又需要同一时间进行处理,超过单机计算能力的硬件资源时,单机版本 Jenkins 就无法胜任工作了。在这个情况下,Jenkins 提供了添加独立的 Slave 节点的方式给 Jenkins 任务更多的计算资源来解决这个问题(再进一步 Jenkins 还提供 Docker 化的 Slave 节点)。 比如ebay之前的模式是每个开发工程师各有一个虚拟机跑自己的jenkins来解决持续集成问题,最后导致资源利用率极低。
23 |
24 | 在动态资源调度,分布式计算盛行的今天,再使用纯静态资源分配的分布式,未免太过时了。还好 Jenkins 提供了很强大的插件功能,可以为分布式提供动态资源调度。
25 |
26 | 把 Jenkins 运行到 Apache Mesos 上,或者说利用 Apache Mesos 向 Jenkins 提供 slave 资源,最主要的目的是利用 Mesos 的弹性资源分配来提高资源利用率。
27 |
28 |
29 | ### 7.3.2 Marathon 运行 Jenkins Master
30 |
31 | Jenkins Master 负责提供整个 Jenkin 的设置、webui、工作流控制定制等。 另外,Marathon 会对发布到它之上的应用程序进行健康检查,从而在应用程序由于某些原因意外崩溃后自动重启该应用。这样,选择利用 Marathon 管理 Jenkins Master 保证了该构建系统的全局高可用。而且,Jenkins Master本身也通过 Marathon 部署运行在 Mesos 资源池内,进一步实现了资源共享,提高了资源利用率。
32 |
33 | 下面这张图形象的说明了 Marathon 将 Jenkins Master 部署到 Mesos 资源池(图7-3-1) 的过程。
34 |
35 | 
36 | 图7-3-1 Marathon 运行 Jenkins Master
37 |
38 | ### 7.3.3 Jenkins 使用 Mesos 资源池
39 |
40 | 通过配置 Jenkins-mesos-plugin 插件,Jenkins Master 可以在作业构建时根据实际需要动态的向 Mesos 申请 Jenkins-slave 节点,并在构建完成后的一段时间后,将节点归还给 Mesos。下图 Jenkins Master 使用 Mesos 资源池进行作业构建的整个过程(图7-3-2)。
41 |
42 | 
43 | 图7-3-2 Jenkins 使用 Mesos 资源池
44 |
45 | ### 7.3.4 Mesos 整体调度流程
46 |
47 | 图片(图7-3-3)来源ebay
48 |
49 | 
50 | 图7-3-3 Mesos 整体调度流程
--------------------------------------------------------------------------------
/chapter7/refers.md:
--------------------------------------------------------------------------------
1 | # 7.6 参考链接
2 |
3 | * http://www.ebaytechblog.com/2014/04/04/delivering-ebays-ci-solution-with-apache-mesos-part-i/#.U2cRpfldVyw
4 | * http://www.ebaytechblog.com/2014/05/12/delivering-ebays-ci-solution-with-apache-mesos-part-ii/
5 | * https://codeship.com/continuous-integration-essentials
6 | * https://blog.risingstack.com/continuous-deployment-of-node-js-applications/
7 | * http://blog.crisp.se/2013/02/05/yassalsundman/continuous-delivery-vs-continuous-deployment
8 | * http://blog.csdn.net/leijiantian/article/details/7916483
9 | * http://baike.baidu.com/link?url=YUuGXCCgfPK9Z_Yf728mCkL7ccEAxEBGVOOrQETCTP_w7R-N3qtqS7Hd4ZV6XibkC5YxuFw1HfLW90dL8B0KKa
--------------------------------------------------------------------------------
/chapter7/summary.md:
--------------------------------------------------------------------------------
1 | # 7.1 summary
2 |
3 | 软件的开发及部署,早已形成了一套标准流程,其中非常重要的组成部分就是持续集成(Continuous integration,简称CI)。
4 |
5 | **持续集成(CI)** 是一种软件开发实践,其目的是通过频繁的将代码 merge 到主分支来实现产品的快速迭代。在团队合作开发过程中,持续集成不仅可以帮助团队成员及时发现集成错误,而且也避免了个人的分支工作大幅偏离主分支而导致的代码冲突。使用得当,持续集成会极大的提高软件开发效率并保障软件开发质量。
6 |
7 | **Jenkins** 是基于 Java 开发的一种持续集成 (CI) 工具,它提供了一种易于使用的持续集成系统。
8 |
9 | **Mesos** 是 Apache 下的一个开源的统一资源管理与调度平台,它被称为是分布式系统的内核。
10 |
11 | **Marathon** 是注册到 Apache Mesos 上的管理长时应用(long-running applications)的 Framework,如果把 Mesos 比作数据中心 kernel 的话,那么 Marathon 就是 init 或者 upstart 的 daemon。
12 |
13 | 本章节旨在探讨如何利用 Jenkins,Apache Mesos 和 Marathon 搭建一套**弹性**的,**高可用**的持续集成环境。
--------------------------------------------------------------------------------
/chapter7/test-job-config.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/chapter7/test-job-config.png
--------------------------------------------------------------------------------
/concepts/concepts.md:
--------------------------------------------------------------------------------
1 | # 概念原理
2 |
3 | 本章将对 Mesos项目的概念原理进行详细的梳理和解读,方便读者对 Mesos项目能够有比较全面的了解,包括:Mesos 历史、生态、能够做什么、怎样搭建一个 Mesos集群以及 Mesos 工作原理解析。
4 |
5 | Mesos是 Apache顶级的分布式系统开源项目,致力于构建数据中心级别的集群管理系统。它通过虚拟化主机(物理主机或虚拟主机)之上的CPU、内存、磁盘以及其它计算资源,构建高容错的、可弹性伸缩的分布式系统,让运行计算任务快捷有效。
6 |
7 | Mesos可以帮助分布式应用开发者在一个统一的资源池基础之上开发部署应用,简化了运行分布式系统的复杂度。为了应对企业系统的各种复杂需求,开发者可以把业界各种优秀的应用系统部署到Mesos 集群中,并通过统一的API接口来管理调度,从而让弹性扩展的能力在整个数据中心甚至云计算环境中可以被充分的利用起来。Mesos系统类似个人计算机操作系统 Linux 中的 Kernel,已然成为云计算领域中构建分布式系统的必备“Kernel”。
8 |
9 | ## 1.1 Mesos 简介
10 |
11 | Apache Mesos是由美国伯克利大学(UCB)的AMPLab研发并贡献到 Apache 基金会的一款开源群集管理系统,支持 Hadoop、ElasticSearch、Spark、Storm 和 Kafka 等应用架构。Mesos特性如下:
12 |
13 | - 弹性扩展支持10,000个计算节点
14 | - 使用ZooKeeper 实现 Master 和 Slave 的多容错副本技术
15 | - 支持 Docker 容器技术
16 | - 支持原生的 Linux 容器技术隔离任务
17 | - 基于多资源调度,包括内存,CPU、磁盘、端口
18 | - 提供 Java,Python,C++等多种语言 API接口开发新的分布式应用
19 | - 提供 Web UI 界面查看集群状态
20 |
21 | Apache Mesos架构图如下:
22 |
23 | 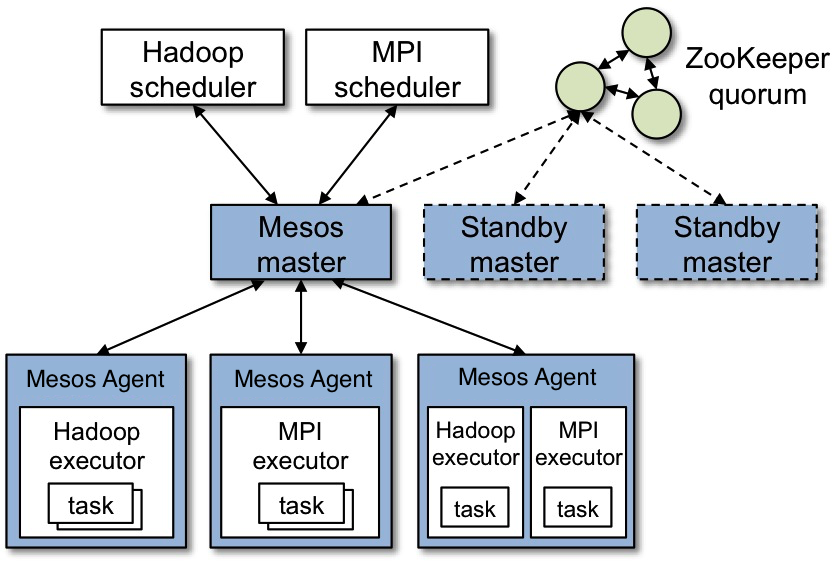
24 |
25 | 通过以上架构图,我们可以了解到:
26 |
27 | - Mesos本身包含两个组件:Master Daemon和Agent Daemon。
28 | - Master Daemon
29 | - 管理所有的 Slave Daemon。
30 | - 用 Resource Offers 实现跨应用细粒度资源共享,如 cpu、内存、磁盘、网络等。
31 | - 限制和提供资源给应用框架使用。
32 | - 使用可拔插的模块化的架构,方便增加新的策略控制机制。
33 | - Agent Daemon
34 | - 负责接收和管理 Master 发来的需求任务(Task)
35 | - 支持使用各种环境运行各种任务(Task),如Docker、VM、进程调度(纯硬件)。
36 | - Mesos上的任务(Task)由2个组件管理:调度器(Scheduler)和执行进程(Executor Process)
37 | - 调度器(Scheduler)
38 | - 调度器通过注册 Mesos Master获得集群资源调度权限
39 | - 调度器( Scheduler)可通过 MesosSchedule Driver 接口和 Mesos Master 交互
40 | - 执行进程(Executor Process)
41 | - 用于启动框架内部的任务(Task)
42 | - 不同的调度器使用不同的执行进程(Executor Process)
43 | - Mesos 集群为了避免单点故障,所以使用 Zookeeper 提供高容错的副本机制。
44 |
45 | ### 1.1.1 Mesos的运行方式
46 |
47 | 下图描述了一个 Framework 如何通过调度来运行一个 Task
48 | 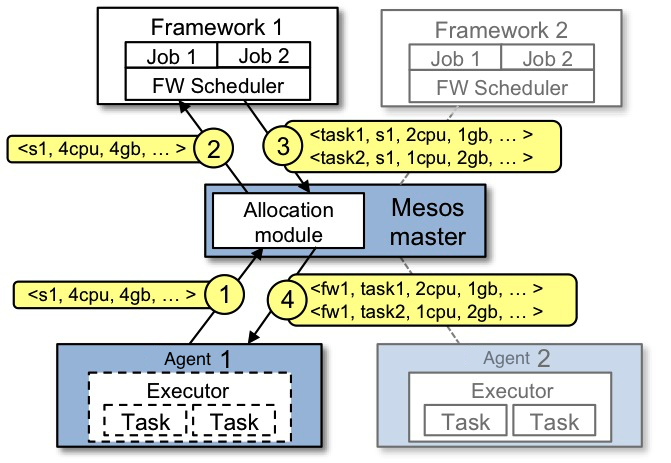
49 |
50 | 事件流程:
51 |
52 | 1. Agent1 向 Master 报告,有4个CPU和4 GB内存可用
53 | 2. Master 发送一个 Resource Offer 给 Framework1 来描述 Agent1 有多少可用资源
54 | 3. FrameWork1 中的 FW Scheduler会答复 Master,我有两个 Task 需要运行在 Agent1,一个 Task 需要<2个CPU,1 GB内存>,另外一个Task需要<1个CPU,2 GB内存>
55 | 4. 最后,Master 发送这些 Tasks 给 Agent1。然后,Agent1还有1个CPU和1 GB内存没有使用,所以分配模块可以把这些资源提供给 Framework2
56 |
57 | > 注意:当 Tasks 完成和有新的空闲资源时,Resource Offer会不断重复这一个过程。
58 |
59 | ### 1.1.2 Meoss的应用场景
60 |
61 | - **容器编排**
62 |
63 | Mesos本身是一个分布式资源调度管理系统,而且是一个比较开放通用的资源调度管理系统。其北向提供了开放性的Framework框架平台,允许其他应用框架的友好接入(如spark、hadoop等),其南向定义了Executor执行器机制,允许容器、虚拟机等作为执行器进行任务的处理等工作。容器技术随着Docker的出现,目前越来越受到热捧,关于如何更好更快的将容器技术应用到生产实践中全世界都在进行广泛的实践和探索。容器技术不可以质疑的是最佳的执行者,但其缺少一个上层的编排调度系统。应用框架+Mesos+容器的架构当前被大量的讨论,也有一些企业在对这一架构进行了实践,总体上来说是一个比较稳定可靠合理的架构。因为这个架构下,不管对于应用框架还是对于执行器来说都是统一通用的,这个样似乎更加符合DCOS的设想。
64 |
65 |
66 | - **提升资源利用率**
67 |
68 | 提升资源利用率这个词语一定会和虚拟化或云计算一起出现,的确目前在各个层面都在追逐提升资源利用率,因为在大规模服务器的数据中心中,资源利用率的提升代表着更少的资源投入。对于使用超过50台服务器的公司而言,一个通常的使用Mesos的动机就是提升资源利用率,并且减少运维成本。目前已经有许多这样的公司,比如各种公有云和私有云服务的提供商。在Ebay的案例中,它们曾经在Mesos上运行Jenkins这样可以减少虚拟机的使用。Mesosphere也发布了相关的文章对于HubSpot(运行在AWS上)的案例研究,文章中介绍了HubSpot是如何使用几十台大型的服务器来替代了几百台小型的服务器,使得硬件的利用率更高。
69 |
70 |
71 | - **批处理应用和长时间运行应用**
72 |
73 | 所谓的批处理应用与长时间运行应用共存,是指可以在一个Mesos集群中混合运行批处理应用以及其他的长时间运行应用,这将对资源利用率的提升起到关键作用,同时这也是mesos一直所追求目标:统一的数据中心操作系统(DCOS)。如在一个Mesos集群中可以运行如MapReduce、Spark等批处理应用,也可以运行如Jenkins等普通应用。这样就不用在一个数据中心划分不同的服务运行区域,进行资源的隔离和精确匹配。
74 |
75 | ## 1.2 总结
76 |
77 | Mesos持有独特地两层资源调度机制和面向二次开发友好的调度框架应用接口,使得Mesos在企业内部自研数据中心操作系统选型中得到广泛的应用。在Mesos社区和企业用户的探索和实践下,Mesos正在向着统一的云数据中心操作系统这一伟大目标前进,我们可以乐观地预见或许不久之后Mesos能够像Openstack技术那样成为企业数据中心环境中必不可少的核心技术组件之一。
78 |
--------------------------------------------------------------------------------
/concepts/index.md:
--------------------------------------------------------------------------------
1 | # 理论篇
2 |
3 | Mesos项目从2011年进入Apache孵化器项目经历过多年的淬炼并最终成为Apache顶级开源项目,已经汇聚了大量优秀分布式开发者的设计经验和理论基础,本篇试图通过系列文章尽最大的能力梳理汇总这些篇章,帮助读者系统的研读Mesos项目的架构设计理念和核心技术。
4 |
--------------------------------------------------------------------------------
/concepts/objects.md:
--------------------------------------------------------------------------------
1 | # 主要概念
2 |
3 |
4 |
5 | - Attributes and Resources
6 | - Fetcher Cache
7 | - Multiple Disks
8 | - Containerizers
9 | - Oversubscription
10 | - Persistent Volume
11 | - Quota
12 | - Replicated Log
13 | - Reservation
14 | - Shared Resources
--------------------------------------------------------------------------------
/mesos-frameworks/README.md:
--------------------------------------------------------------------------------
1 | # Mesos 框架
2 |
3 | 在 Mesos 出现之前,各个分布式计算框架都是以独占的方式使用集群资源,
4 | Mesos 的出现,使计算框架之间共享集群计算资源成为了可能,以便更好的利用集群资源,
5 | 降低部署、运维成本。
6 |
7 | 目前有许多计算框架都能完美的运行在 Mesos 之上,比如:Hadoop, Spark, Storm,
8 | Chronos, Marathon, Cassandra 等等。
9 |
10 | 本章将首先对目前 Mesosphere 官方宣称可以完美运行在 Mesos 之上的所有框架作简要介绍,
11 | 然后重点介绍几个使用比较广泛的计算框架:
12 |
13 | - Marathon, 长时任务处理框架
14 | - Chronos, 批处理任务处理框架
15 | - Spark, 大数据处理框架
16 |
17 | 如果读者需要用到本书中未介绍的框架,可以参考项目文档动手实践,以及和开源社区交流。
18 |
--------------------------------------------------------------------------------
/mesos-frameworks/assets/mesos-frameworks-periodic-table.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/assets/mesos-frameworks-periodic-table.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/README.md:
--------------------------------------------------------------------------------
1 | # Chronos
2 |
3 | Chronos 是一个基于 Mesos 的批处理任务处理框架,最初由 Airbnb 开发,目前由
4 | Mesosphere 维护,属于 Mesos 生态中较为活跃的项目之一。
5 |
6 | 本节将从以下几个方面介绍 Chronos:
7 |
8 | - Chronos 简介
9 | - 怎样搭建 Chronos 服务
10 | - 运行 Chronos 任务
11 |
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-architecture.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-create-hello.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-create-hello.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-download.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-download.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-ha.graphml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 | Chronos
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 | Chronos
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 | Chronos
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 | 负载均衡器
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 | Mesos Cluster
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 | ZooKeeper
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 | 转发请求
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 | 转发请求
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-ha.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-ha.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-hello-chronos-finished.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-hello-chronos-finished.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-hello-chronos-output.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-hello-chronos-output.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-hello-finished-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-hello-finished-1.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-homepage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-homepage.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-internal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-internal.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-on-marathon-staged.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-on-marathon-staged.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/chronos-registered.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/chronos-registered.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/create-chronos-on-marathon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/create-chronos-on-marathon.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/assets/hello-chronos-script.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/chronos/assets/hello-chronos-script.png
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/basics.md:
--------------------------------------------------------------------------------
1 | # Chronos 简介
2 |
3 | Chronos 是一个基于 Mesos 的分布式的 Cron 任务处理框架,最初由 Airbnb 公司开发,
4 | 目前由 Mesosphere 公司负责维护。作为短任务框架,Chronos 几乎可以用于任何地方,
5 | 只要用户有批处理任务需求即可,特别是原生支持 Docker 以后,Chronos
6 | 任务的运行环境将不再受到 Mesos 计算结点的限制。
7 |
8 | ## Chronos 架构
9 |
10 | Chronos 在架构上和 Marathon 非常相似,只是二者面向的业务类型不同,Chronos 主要面向批处理任务,定时重复执行的任务,而 Marathon 面向长时运行任务。
11 |
12 | 下图是 Chronos 官方的一个示例架构图:
13 |
14 | 
15 |
16 | 其中矩形框内是 Chronos 架构,而框外部是其它服务。所以,Chronos 本身是一个运行在 Mesos 之上的框架。
17 |
18 | ## Chronos 工作原理
19 |
20 | 下图展示了 Chronos 内部功能模块:
21 |
22 | 
23 |
24 | 主要包含了以下几个功能模块:
25 |
26 | - Mesos Scheduler API,主要负责实现 Mesos 定义的 Scheduler API 接口,以便和
27 | Mesos 通信,获取资源,提交任务,获得任务状态更新等事件
28 | - Persistent Store,Chronos 使用 ZooKeeper 作为数据持久化存储后端,
29 | 所有需要存储的数据都存储在 ZooKeeper 中;所以,除了依赖于 Mesos 外,Chronos 还依赖于 ZooKeeper。
30 | - ISO8601 模块负责解析 ISO8601 标准定义的重复任务属性
31 | - DAG,有向无环图实现了对任务间依赖关系的支持,任务间依赖也是 Chronos 的一大亮点,当所有前置任务完成后,后置任务会被自动触发
32 | - API Server,一个 Web API Server 负责接收处理收到的 API 请求,Chronos 实现了高可用性,在任意时刻,同一个服务中只有一个 Chronos 实例作为 Leader 负责处理请求,其它 Chronos 实例的 API Server 此时会将请求转发给 Leader
33 | - Queue,任务队列,以便将可运行的任务调度到队列中,在有合适资源时将任务调度到 Mesos 集群中运行
34 | - RESTful API,Chronos 提供了完善的 RESTful API 来使用 Chronos
35 | - WEB UI,Chronos 也提供了 Web 用户界面,能够实现对任务的大部分操作
36 |
37 | 在了解了 Chronos 各个功能模块之后,也就大概了解了 Chronos 工作原理,总的来说:作为一个 Mesos 计算框架,计算资源的获取,计算任务状态更新都需要由 Mesos 来辅助完成,所以 Chronos 主要实现了对任务的存储,调度,搜索等任务逻辑层的功能。
38 |
39 | ## Chronos 特性
40 |
41 | Chronos 作为一个分布式的 Cron 批处理任务计算框架,除了支持定时任务外,还有许多高级特性:
42 |
43 | - Web 用户界面
44 | - RESTful API
45 | - ISO8601 重复任务支持
46 | - 任务依赖关系
47 | - 任务状态查看及任务历史
48 | - 可配置的失败重试次数
49 | - 屏蔽底层结点故障
50 | - 原生 Docker 支持
51 |
52 | 下面对每个特性分别做简要介绍。
53 |
54 | ### Web 用户界面
55 |
56 | Chronos 的 Web 用户界面如下图所示:
57 |
58 | 
59 |
60 | 在这个 Web 用户界面,用户可以完成大部分操作,包括对任务的增删查改,
61 | 搜索,查看状态,运行历史等等。
62 |
63 | 但是,需要注意的是,Chronos Web 用户界面的性能并不高,当 Chronos
64 | 上积累的任务过多时,会导致加载速度变慢。所以,如果对 Chronos 使用量较大,
65 | 推荐使用 API 方式管理任务,更高效。
66 |
67 | ### RESTful API
68 |
69 | Chronos 提供了完善的 RESTful API,完善的 API 对于批处理任务框架来说比 Web
70 | 用户界面更重要,因为批处理任务往往意味着运行时间短,量大,所以通过 Web
71 | 用户界面来控制批处理任务显得非常低效,这时,通过 API 控制任务显然更加高效。
72 |
73 | ### ISO8601 重复任务支持
74 |
75 | 和 Cron 标准类似,ISO8601 定义了一种表示重复任务的标准,包括对:日期,时间,间隔,重复的定义,例如:`R3/2015-12-20T13:44:00Z/P1Y2M10DT2H30M10S` 表示从 UTC 时间 2015 年 12 月 20 日 13 点 44 分 00 秒开始,以间隔 1 年 2 个月 10 天 2 小时 30 分 10 秒发生 3 次;所以,事件的第一次发生会在 2015 年 12 月 20 日 13 点 44 分 00 秒,第二次发生则在 1 年 2 个月 10 天 2 小时 30 分 10 秒之后。
76 |
77 | ### 任务依赖关系
78 |
79 | Chronos 通过 DAG(有向无环图)实现了任务依赖关系的支持,依赖任务只有在其所有被依赖任务成功完成之后才会被触发,所以用户可以定义非常复杂的任务依赖关系;显然,互相依赖或者闭环的依赖是不被允许的。
80 |
81 | ### 任务状态查看及任务历史
82 |
83 | Chronos 会在 Web 用户界面实时显示当前任务的状态,并且用户可以手动激活任务。由于任务可能会被重复执行,Chronos 还支持对任务历史状态的查看。
84 |
85 | ### 可配置的失败重试次数
86 |
87 | 用户可以针对每个任务配置失败重试任务,当任务在失败时自动进行重试,非常方便。
88 |
89 | ### 屏蔽底层结点故障
90 |
91 | 由于 Mesos 能够区分任务的失败是由于任务自身运行的失败还是由于底层计算节点故障导致的任务失败,所以 Chronos 能够自动屏蔽由计算结点导致的任务失败,并对用户屏蔽这种失败,自动发起重试。
92 |
93 | ### 原生 Docker 支持
94 |
95 | 原生 Docker 支持的引入,使 Chronos 任务不再依赖于 Mesos 计算结点的环境,例如:Chronos 的任务可能需要调用某一个外部命令,而这个外部命令如果不存在,显然会导致任务的失败。
96 |
97 | 另外,使用 shell executor 执行 Chronos 任务也非常危险,因为有可能任务中包含了破坏性的命令,一旦以不当的权限运行,那么将会对 Mesos 计算节点造成破坏,例如:以 root 用户权限执行了 `rm -rf /` 显然会破坏整个 Mesos 计算结点。
98 |
99 | 所以,对 Docker 的原生支持极大的提高了 Chronos 的可用性。
100 |
101 |
102 |
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/job.md:
--------------------------------------------------------------------------------
1 | # 运行Chronos任务
2 |
3 | 在搭建了 Chronos 服务后,就可以使用 Chronos 来运行任务了,Chronos
4 | 面向的是基于时间的可重复的短时运行任务。
5 |
6 | - 基于时间:任务在指定的时间点开始执行,也可以是即时任务,提交后立即执行
7 | - 可重复:任务可以配置重复执行的策略
8 | - 短时运行:任务在运行一段时间后会结束
9 | - 任务间依赖:任务间可以有依赖关系
10 | - 同步、异步任务
11 |
12 | Chronos 同时提供了 RESTful API 和 Web 用户界面来管理任务,这里分别对其进行介绍。
13 |
14 | ## Web 用户界面
15 |
16 | Chronos Web 用户界面的主页如下图所示:
17 |
18 | 
19 |
20 | 通过 Web 用户界面可以提交任务,查看任务状态,历史运行情况等,还可以搜索任务。
21 | 下面提交一个任务输出 "Hello Chronos!"。如下图所示:
22 |
23 | 
24 |
25 | 这里我们提交的是一个即时任务,所以任务一旦提交就会被立即调度,如果 Mesos
26 | 集群有资源,那么任务将立即启动,否则将在 Chronos 调度队列中等待。
27 |
28 | 很快,可以发现任务已经完成了,如下图所示:
29 |
30 | 
31 |
32 | 从 Chronos web UI 也可以看到任务的状态,如下图所示:
33 |
34 | 
35 |
36 | 但是,任务的输出从哪里查看呢?可以从 Mesos Web 用户界面找到这个任务,并且进入
37 | `Sandbox` 中,查看 `stdout` 文件,即可找到。如下图所示:
38 |
39 | 
40 |
41 | 可见,Mesos 启动了 shell 执行器来执行 Chronos 任务的命令,由于这里只执行了一条
42 | `echo` 命令,所以可以在 Web 用户界面上输入,但是,如果任务要执行的是一个脚本呢?
43 | 再从 Chronos Web 用户界面输入显然不合适:
44 |
45 | - 每次输入比较麻烦,容易输入错误等
46 | - Web UI 使用起来比较低效
47 |
48 | 下面来看看怎样使用 Chronos API 来管理任务。
49 |
50 | ## RESTful API
51 |
52 | 创建一个叫 `hello-chronos.sh` 的脚本,内容如下:
53 |
54 | ```
55 | #!/bin/sh
56 | set -e
57 | echo "Hello Chronos!"
58 | echo "This is a complicated script"
59 | sleep 10
60 | echo "Mission complete"
61 | ```
62 |
63 | 并且将这个文件放到一个在 Mesos 计算节点上可以访问的地方,
64 | 例如:HDFS, HTTP 服务器,甚至计算结点上。这里将这个脚本部署在了所有计算结点上,
65 | 存放在 `/usr/local/mesos/chronos/hello-chronos.sh`,并且赋予可执行权限:
66 |
67 | ```
68 | # chmod +x /usr/local/mesos/chronos/hello-chronos.sh
69 | ```
70 |
71 | 在这里,读者可能在好奇为什么不把脚本放在例如:HDFS 或者 HTTP 服务器上,
72 | 而是将其部署在 Mesos 计算节点上。在实际生产环境中,为了加快任务启动速度,
73 | 往往会选择将需要下载的文件都部署在本地,这样能够避免网络下载时间,
74 | 避免网络抖动带来的影响等。特别是当需要下载的文件特别大时,部署在本地就更能加快任务启动速度。
75 |
76 | 另外,对于短时任务来说,启动速度更加重要,因为短时任务运行的时间一般不长。
77 |
78 | 对于批处理任务来说,通过 API 提交的方式更加高效实用,Chronos 提供了完善的
79 | RESTful API,这里将介绍怎样实用 API 来提交任务,完整的 API 读者可以参考 Chronos
80 | 官方文档。
81 |
82 | 以提交 `hello-chronos.sh` 为例,创建一个 hello-chronos.json,内容如下:
83 |
84 | ```
85 | {
86 | "name": "hello-chronos-script",
87 | "command": "./hello-chronos.sh",
88 | "uris": [
89 | "/usr/local/mesos/chronos/hello-chronos.sh"
90 | ]
91 | }
92 | ```
93 |
94 | 然后,使用 curl 命令提交这个任务:
95 |
96 | ```
97 | $ curl -H 'Content-Type: application/json' -X POST -d @hello-chronos.json http://10.23.85.233:8080/scheduler/iso8601
98 | ```
99 |
100 | 这里使用了 `curl` 作为 HTTP 客户端提交任务,各个参数的意义如下:
101 |
102 | - `-H`, 指定 HTTP header
103 | - `-X`, 指定方法,HTTP 支持多种方法,常见的有:GET, POST, PUT, DELETE
104 | - `-d`, 设置负载数据,这里的数据是 JSON 内容
105 |
106 | 最后指定的是 Chronos 服务地址及其 API 地址。
107 |
108 | 提交完成后,前往 Chronos Web 用户界面,可以看到刚才提交的任务已经完成了,如下图所示:
109 |
110 | 
111 |
112 | 这是因为上面的命令提交的是一个即时任务。在 Chronos 中,省略 `schedule`
113 | 表示即时任务,即提交后立即执行。
114 |
115 | 现在,对上面的 hello-chronos.json 稍作修改,变成一个重复执行的定时任务。
116 |
117 | ```
118 | {
119 | "schedule": "R3/2016-05-23T09:30:00.000Z/PT5M",
120 | "name": "hello-chronos-script-cron",
121 | "command": "./hello-chronos.sh",
122 | "uris": [
123 | "/usr/local/mesos/chronos/hello-chronos.sh"
124 | ]
125 | }
126 | ```
127 |
128 | 上面的命令,相较于上一次的提交有两个改变:
129 |
130 | 1. `name` 为 `hello-chronos-script-cron`,这是因为 Chronos 任务中的 name 必须唯一
131 | 2. `schedule` 为 `R3/2016-05-23T09:30:00.000Z/PT5M`,R3 表示任务要执行 3
132 | 次,2016-05-23T09:30:00.000Z 表示在 UTC 时间 2016 年 05 月 23 日 09
133 | 点 30 分开始第一次执行,也就是北京时间的 17 点 30 分,PT5M 表示重复执行的间隔为 5
134 | 分钟
135 |
136 | ## 基于 Docker 的任务
137 |
138 | 前面介绍的任务使用的都是 shell 执行器来执行的,所以会直接在 Mesos
139 | 计算节点上以配置的用户执行,如果执行的脚本中有误操作,例如:删除系统上的文件,
140 | 那么将非常危险。用户不恰当的操作可能会破坏平台的计算环境甚至稳定性。
141 |
142 | 而使用 Docker,可以将任务的运行环境更好的隔离,包括文件系统方面的隔离,
143 | 所以更加安全,同时,任务也将不再依赖于 Mesos 计算结点上的环境,例如:任务需要
144 | Python 3 环境但是计算结点只有 python 2.x 环境,用户需要 Go
145 | 运行环境,但是计算结点却没有安装 Go 等。
146 |
147 | Chronos 和 Mesos 都原生支持 Docker 任务,所以这里将提交一个 Docker 任务,
148 | 并且同样的,将执行 `hello-chronos.sh` 脚本。
149 |
150 | 首先,构建一个 Docker 镜像,将 `hello-chronos.sh` 放在 Docker 镜像中,
151 | 并且设置为启动命令,构建镜像的 Dockerfile 如下所示:
152 |
153 | ```
154 | FROM alpine
155 | MAINTAINER Chengwei Yang
156 |
157 | ADD hello-chronos.sh /
158 | RUN chmod +x /hello-chronos.sh
159 |
160 | CMD ["/hello-chronos.sh"]
161 | ```
162 |
163 | 将 `hello-chronos.sh` 和 Dockerfile 都保存在同一个目录中,如下所示:
164 |
165 | ```
166 | $ tree .
167 | .
168 | ├── Dockerfile
169 | └── hello-chronos.sh
170 |
171 | 0 directories, 2 files
172 | ```
173 |
174 | 然后构建 Docker 镜像,如下所示:
175 |
176 | ```
177 | $ docker build -t mesos-in-action/hello-chronos:v1 .
178 | $ docker push mesos-in-action/hello-chronos:v1
179 | ```
180 |
181 | 将 Docker 镜像上传到 Docker Hub 之后,就可以提交任务了。创建一个 hello-chronos-docker.json 文件,内容如下:
182 |
183 | ```
184 | {
185 | "name": "hello-chronos-docker",
186 | "container": {
187 | "type": "DOCKER",
188 | "image": "mesos-in-action/hello-chronos:v1"
189 | },
190 | "cpus": "0.5",
191 | "mem": "512",
192 | "command": ""
193 | }
194 | ```
195 |
196 | 然后,使用 curl 命令提交这个任务,命令行和前面的一样:
197 |
198 | ```
199 | $ curl -H 'Content-Type: application/json' -X POST -d @hello-chronos-docker.json http://10.23.85.233:8080/scheduler/iso8601
200 | ```
201 |
202 | 任务提交后,当任务被初次调度到计算结点时,计算结点需要下载 Docker
203 | 镜像,这需要花一定的时间,视网络情况而定。由于 Docker Hub
204 | 在国内非常慢,甚至有时不可访问,所以读者也可以配置 Mesos 计算节点使用一些国内的
205 | Docker Hub 镜像服务,例如:道客云提供永久免费的 Docker Hub 镜像服务。
206 |
207 | 另外,在实际生产环境中,往往选择搭建私有的 Docker
208 | 镜像服务,这部分内容这里不再介绍。
209 |
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/setup.md:
--------------------------------------------------------------------------------
1 | # 搭建Chronos服务
2 |
3 | 在了解了 Chronos 的工作原理和特性后,这里将介绍怎样搭建一个生产环境可用的 Chronos 服务,生产环境可用意味着要实现服务的高可用性。
4 |
5 | 我们知道 Chronos 将所有需要持久化的数据都存储到了 ZooKeeper 服务中,所以 Chronos 数据的可靠性由 ZooKeeper 服务来保障,由于 Chronos 是单一 Leader 模型,所以本身不存在数据一致性的问题,但是由于 ZooKeeper 服务是分布式的,所以需要保障数据的一致性。
6 |
7 | 本节首先介绍 Chronos 高可用性模型,然后动手搭建一个高可用的 Chronos 服务,更进一步,我们将 Chronos 作为一个 Marathon App 运行在 Marathon 之上,从而进一步减少对 Chronos 的运维。
8 |
9 | ## Chronos 高可用性
10 |
11 | 得益于将所有数据持久化在 ZooKeeper 服务中,Chronos 的高可用性模型非常简单。Chronos 使用 ZooKeeper 来实现服务内部实例之间的 Leader 选举,任意时刻只有一个服务实例作为 Leader 提供服务,其它实例均作为跟随者,虽然可以接受请求,但是并不对请求进行处理,而是简单的转发,Chronos 会监听 Leader 改变事件,实时知道当前的 Leader 实例。
12 |
13 | 下图是一个高可用性的 Chronos 服务在生产环境中运行的示例:
14 |
15 | 
16 |
17 | 首先,上图中部署了 3 个 Chronos 实例,但是在任意时刻,最多只有一个实例作为 leader 来真正的处理请求,其它 Chronos 则会将收到的请求转发到 leader 实例。
18 |
19 | 而为了实现 Chronos 服务故障对用户不可见,在 Chronos 前端搭建了一个负载均衡器,同时也作为一个反向代理,这样,当 Chronos leader 故障,切换 leader 后,用户不需要任何修改。
20 |
21 | Chronos 的高可用性非常简单,在任意时刻只需要有一个 Chronos 实例在运行即可提供服务,所以,由两个实例组成的 Chronos 服务即可提供高可用服务。
22 |
23 | ## 搭建 Chronos 服务
24 |
25 | 在编写本书之时,Chronos 最新发布的稳定版本是 2.4.0,并且支持 Mesos 0.24.0,而当前 Mesos 最新的稳定版本是 0.25.0,所以这里我们将搭建 Chronos-2.4.0_mesos-0.25.0,所以需要重新基于 Mesos 0.25.0 编译 Chronos。
26 |
27 | ### 编译 Chronos
28 |
29 | 首先,从 mesosphere 或者 GitHub 上下载 Chronos-0.24.0_mesos-0.24.0 源码包,这里以从 GitHub 下载为例,如下图所示:
30 |
31 | 
32 |
33 | 这里我们下载 tar.gz 格式的包,假设下载到了本地的 `~/Downloads` 目录下。
34 |
35 | 接下来,执行下面的命令解压下载好的代码包。
36 |
37 | ```
38 | $ tar xzf chronos-2.4.0_mesos-0.24.tar.gz
39 | ```
40 |
41 | 然后,修改目录的名字为 chronos-2.4.0_mesos-0.25
42 |
43 | ```
44 | $ mv chronos-2.4.0_mesos-0.2{4,5}
45 | $ cd chronos-2.4.0_mesos-0.25
46 | ```
47 |
48 | 修改 `pom.xml` 文件中的第 34 行
49 |
50 | ```
51 | 0.24.0
52 |
53 | 修改为
54 |
55 | 0.25.0
56 | ```
57 |
58 | `mesos-utils` 是 Mesosphere 为 Scala 提供的编译包,感兴趣的读者可以前往其项目主页:https://github.com/mesosphere/mesos-utils 了解更多。
59 |
60 | 现在,可以编译 Chronos-0.24.0_mesos-0.25 了,这里我们介绍两种编译 Chronos 的方法,一种是传统的将其编译成 jar 包的方式,一种是直接构建出 Chronos Docker 镜像。
61 |
62 | #### 编译 Chronos Jar
63 |
64 | Chronos 使用 Maven 来编译,所以首先需要安装配置好 Maven 以及 JDK,这里不再赘述,读者可以参考 Maven 及 JDK 官方文档。
65 |
66 | 设置好 Maven 和 JDK 之后,运行 mvn 命令编译项目,如下:
67 |
68 | ```
69 | $ mvn clean package -Dmaven.test.skip=true
70 | ```
71 |
72 | 上面的命令表示执行两个 mvn task:
73 | - clean,清除之前构建的文件
74 | - package,重新执行一次编译并打包
75 |
76 | 命令中的 `-Dmaven.test.skip=true` 表示忽略构建测试用例,这样能够加尽快完成打包;由于我们是在使用 release 版本而非参与开发,所以可以忽略构建测试用例。
77 |
78 | 编译完成后,会在当前目录生成一个 target 目录,并且在这里可以找到构建好的 Chronos jar 包,如下所示:
79 |
80 | ```
81 | $ ls -l target
82 | total 38728
83 | drwxr-xr-x 2 chengwei chengwei 4096 May 19 15:54 antrun
84 | -rw-r--r-- 1 chengwei chengwei 36836527 May 19 15:56 chronos-2.4.0.jar
85 | drwxr-xr-x 4 chengwei chengwei 4096 May 19 15:55 classes
86 | -rw-r--r-- 1 chengwei chengwei 1 May 19 15:55 classes.-837014839.timestamp
87 | drwxr-xr-x 2 chengwei chengwei 4096 May 19 15:56 maven-archiver
88 | -rw-r--r-- 1 chengwei chengwei 2797728 May 19 15:56 original-chronos-2.4.0.jar
89 | ```
90 |
91 | chronos-2.4.0.jar 既是我们需要使用的 chronos jar 文件。
92 |
93 | #### 编译 Chronos Docker 镜像
94 |
95 | 另一种编译 Chronos 的方式,是将 Chronos 直接编译成可启动的 Docker 镜像,在 chronos-0.24.0_mesos-0.25 目录中,可以找到一个 `Dockerfile` 文件,直接在本目录下运行 `docker build` 命令即可直接构建出 Chronos 的镜像,例如:
96 |
97 | ```
98 | $ docker build -t chronos:0.24.0_mesos-0.25 .
99 | ```
100 |
101 | 不过,读者首先需要在次机器上安装 Docker 环境,构建完成后,即生成了一个镜像,可以使用 `docker images` 查看,输入如下:
102 |
103 | ```
104 | $ docker images
105 | REPOSITORY TAG IMAGE ID CREATED SIZ
106 | E
107 | chronos 0.24.0_mesos-0.25 30f102b4345b 17 hours ago 1.2
108 | 03 GB
109 | ```
110 |
111 | 不管以何种方式编译 Chronos,在完成之后,就可以启动 Chronos 了。
112 |
113 | ### 运行单个 Chronos 服务
114 |
115 | #### 本地运行 Chronos
116 |
117 | 在编译好 Chronos 之后,就可以启动 Chronos 服务了,执行 chronos-0.24.0_mesos-0.25 目录下的 `bin/start-chronos.sh` 即可,首先查看帮助文档,如下:
118 |
119 | ```
120 | [root@10 chronos-2.4.0_mesos-0.25]# ./bin/start-chronos.bash --help
121 | Chronos home set to /root/chronos-2.4.0_mesos-0.25
122 | Using jar file: /root/chronos-2.4.0_mesos-0.25/target/chronos-2.4.0.jar[0]
123 | [2016-05-22 14:49:50,468] INFO --------------------- (org.apache.mesos.chronos.scheduler.Main$:26)
124 | [2016-05-22 14:49:50,469] INFO Initializing chronos. (org.apache.mesos.chronos.scheduler.Main$:27)
125 | [2016-05-22 14:49:50,471] INFO --------------------- (org.apache.mesos.chronos.scheduler.Main$:28)
126 | --assets_path Set a local file system path to
127 | load assets from, instead of
128 | loading them from the packaged
129 | jar.
130 | --cassandra_consistency Consistency to use for Cassandra
131 | (default = ANY)
132 | -c, --cassandra_contact_points Comma separated list of contact
133 | points for Cassandra
134 | --cassandra_keyspace Keyspace to use for Cassandra
135 | (default = metrics)
136 | --cassandra_port Port for Cassandra
137 | (default = 9042)
138 | ... 省略若干行 ...
139 | ```
140 |
141 | Chronos 有很多可以配置的选项,但是为了启动一个 Chronos 服务,只需要配置少数几个必须的项即可:
142 |
143 | - `--master`,配置 mesos 集群地址
144 | - `--zk_hosts`,配置 ZooKeeper 服务地址
145 |
146 | 从前面 Chronos 介绍中我们知道,Chronos 依赖于 mesos 集群以及 ZooKeeper 服务,所以这两个参数是必须的。
147 |
148 | 这里以前面搭建的 mesos 集群和 ZooKeeper 服务为例来启动 Chronos 服务,如下:
149 |
150 | ```
151 | # [root@10 chronos-2.4.0_mesos-0.25]# ./bin/start-chronos.bash --master zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos --zk_hosts zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181
152 | ```
153 |
154 | 启动后,Chronos 会默认监听在 8080 端口接收服务请求,使用浏览器打开本地的 8080 端口地址,例如:`http://10.23.85.233:8080`,可以看到 Chronos Web 用户界面,如下图所示:
155 |
156 | 
157 |
158 | 同时,在 Mesos master WEB 界面上也可以看到新注册的 Chronos 框架,如下图所示:
159 |
160 | 
161 |
162 | #### 以 Docker 的方式
163 |
164 | 除了直接在主机上启动 Chronos 外,还可以将 Chronos 运行在 Docker 中,使用 `docker run` 命令来启动在前面构建的 Chronos 镜像,例如:
165 |
166 | ```
167 | $ docker run -p 8080:8080 --name=chronos chronos:0.24.0_mesos-0.25 --master zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos --zk_hosts zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181
168 | ```
169 |
170 | 这里使用了两个 `docker run` 的参数:
171 |
172 | - `-p`, 映射容器内部指定端口到主机指定端口
173 | - `--name`, 制定容器名称,这里为 chronos
174 |
175 | Chronos 默认会监听 8080 端口,这里我们将其映射到主机端口 8080,所以在启动 Chronos 容器之前,首先需要确保主机的 8080 端口没有被占用,否则将失败。
176 |
177 | ### Chronos 配置参数
178 |
179 | Chronos 有许多配置参数可以用来修改其默认行为,这里介绍一些比较常用的参数。
180 |
181 | 参数 | 默认值 | 含义
182 | --- | ------ | ---
183 | `--decline_offer_duration `| 5 秒 | 设置过滤被拒绝的 Mesos Offer 的时间,单位为毫秒,如果不设置,则采用 Mesos 默认的过滤时间 5 秒
184 | `--disable_after_failures ` | 0 | 设置在任务失败多少次之后,禁止任务,默认为不禁止
185 | `--failover_timeout ` | 604800 秒,即一周 | 设置 Chronos 框架 failover 的时间超时;在 Mesos 中,如果框架异常失败,则会设置一个 failover 超时,如果在次时间内恢复,则还可以重新注册并且获取到失败之前的任务状态
186 | `--failure_retry ` | 60000 毫秒 | 设置任务失败重试的时间间隔,默认为 60000 毫秒,即 60 秒
187 | `--graphite_group_prefix ` | 空 | 设置 Chronos metrics 导出到 Graphite 中的路径前缀,Graphite 是一个基于时间的数据存储,非常适合存储运行状态数据,Chronos 也支持将运行数据发送到 Graphite,以便查看历史运行状态
188 | `--graphite_host_port ` | 空 | 设置 Graphite 主机和端口,格式为 `host:port`
189 | `--graphite_reporting_interval ` | 默认值 60 秒 | 设置汇报运行数据的时间间隔,单位为秒
190 | `--hostname ` | 本机 `hostname` | 设置可访问的主机名,一定要能够被其它 Chronos 实例访问,否则当本实例作为 Leader 时,其它实例不能转发请求到本实例
191 | `--http_credentials ` | 空 | 设置 HTTP basic 认证使用的用户名和密码,格式为:`user:password`
192 | `--job_history_limit ` | 5 | 设置显示任务的历史数量
193 | `--master ` | local | Mesos 服务地址
194 | `--mesos_checkpoint` | 否 | 设置是否开启框架的 checkpoint,推荐开启
195 | `--mesos_framework_name ` | 空 | 设置本框架的名称,默认值将有 chronos 加版本号组成,例如:chronos-2.4.0
196 | `--mesos_role ` | * | 设置框架的 role,role 是 Mesos 的属性,用来将框架归类,从而实现资源的隔离,默认的 role 为 `*`,即不使用特殊 role,即共享资源的 role
197 | `--mesos_task_cpu ` | 0.1 | 任务申请的 CPU 量,可以在每个任务中设置
198 | `--mesos_task_disk ` | 256 | 任务申请的磁盘量,可以在每个任务中设置,单位为 MB
199 | `--mesos_task_mem ` | 128 | 任务申请的内存,可以在每个任务中设置,单位为 MB
200 | `--task_epsilon ` | 60 | 设置任务错过时间,单位为秒,在调度时,如果任务应该启动的时间早于当前时间超过这里设置的时间,将忽略任务的本次调度
201 | `--user ` | root | Chronos 运行该任务是的权限,可见,默认的 root 权限非常开放,如果 mesos-slave 以 root 权限运行,那么一不小心可能执行了错误的任务,导致计算结点被破坏,或者如果 mesos-slave 以非 root 权限运行,显然任务启动会失败,所以,推荐使用 Chronos 时,只以 Docker 的方式提交任务
202 | `--zk_hosts ` | localhost:2181 | ZooKeeper 服务的地址,Chronos 使用 ZooKeeper 来存储所有持久化数据
203 | `--zk_path ` | /chronos/state | Chronos 在 ZooKeeper 中使用的存储路径,Chronos 将把所有数据存储在该目录下
204 | `--zk_timeout ` | 10000,即 10 秒 | ZooKeeper 操作的超时时间
205 |
206 | 在了解了上表中常用的 Chronos 参数后,我们知道,上一小节中启动的 Chronos 没有做任何配置,所以它会以本地方式运行,所以实际上没有任何用处,接下来我们将对 Chronos 进行一些配置,并且结合上一章介绍的 Mesos 生产环境和 ZooKeeper 生产环境,搭建高可用,可用于生产环境的 Chronos 服务。
207 |
208 | ### 搭建高可用 Chronos 服务
209 |
210 | 在启动了一个 Chronos 实例后,Chronos 就可以提供服务了,Chronos
211 | 在高可用方面实现原理和 Marathon 类似,都使用了 ZooKeeper
212 | 作为持久化存储服务,只要在任意时刻有一个实例在运行即可提供服务。
213 |
214 | 所以,要搭建高可用的 Chronos 服务,非常简单,在其它机器上以同样的配置,启动多个
215 | Chronos 即可。
216 |
217 | 这里假设在 10.23.85.234 上再启动一个 Chronos,这样就实现了高可用。
218 |
219 | 但是,由于 Chronos 暴露服务的方式是直接通过 IP 和端口暴露,所以,当 Leader
220 | 故障后,虽然存活的 Chronos 能够自动选举为 Leader,继续服务,
221 | 但是服务地址和端口却改变了。这对于使用方来说并不是透明的,
222 | 因为用户需要修改访问地址才能继续访问 Chronos。
223 |
224 | 为了能够对用户透明,需要为 Chronos 服务提供一个统一的服务地址和端口,
225 | 而后端由多个 Chronos 实例来支撑,这样,当后端的 Chronos
226 | 实例故障之后,用户并不需要做任何修改。
227 |
228 | 关于实现透明的高可用服务,在上一节的 Marathon 配置中已经介绍过,这里不再重复。
229 |
230 | ## 将 Chronos 运行在 Marathon 上
231 |
232 | 将 Chronos 运行在 Marathon 上将非常有趣。它们二者都是基于 Mesos
233 | 的计算框架,Marathon 是一个长时任务框架,而 Chronos 是一个短时批处理任务框架。
234 |
235 | 通过将 Chronos 运行在 Marathon 上,能够实现服务实例故障自动转移、恢复,结合
236 | Marathon 提供的健康检查机制以及服务发现机制,能够让我们的 Chronos
237 | 服务做到对用户透明的高可用性服务,并且实现服务实例故障自动转移,恢复,极大降低运维成本。
238 |
239 | 首先,假设我们使用在上一节中搭建的 Marathon 服务,并且使用本节中介绍的以 Docker
240 | 运行 Chronos 的方式将 Chronos 运行在 Marathon 上。
241 |
242 | ### 启动 Chronos
243 |
244 | 在 Marathon 一节中,曾介绍过怎样创建一个基于 Docker 的 2048
245 | 网页版游戏,这里我们使用同样的方式,启动一个 Chronos 应用,由于启动 Chronos 镜像需要传递额外的参数 `--master` 和 `--zk_hosts`,而 Marathon 的 WEB 界面目前还不支持,所以这里介绍怎样用命令行来创建。
246 |
247 | 首先,准备一个 chronos-on-marathon.json 文件,内容如下:
248 |
249 | ```
250 | {
251 | "id": "chronos",
252 | "container": {
253 | "docker": {
254 | "image": "docker-registry.qiyi.virtual/yangchengwei/chronos:0.24.0_mesos-0.25",
255 | "network": "BRIDGE",
256 | "portMappings": [{ "containerPort": 8080, "hostPort": 0, "protocol": "tcp" }]
257 | },
258 | "type": "DOCKER"
259 | },
260 | "args": [
261 | "--master", "zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos",
262 | "--zk_hosts", "zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181"
263 | ],
264 | "cpus": 1.0,
265 | "mem": 1024.0,
266 | "instances": 2
267 | }
268 | ```
269 |
270 | 然后使用 curl 命令来提交,如下:
271 |
272 | ```
273 | $ curl -H "Content-type: application/json" -d @chronos-on-marathon.json -X POST http://10.23.85.233:8080/v2/apps {"id":"/chronos","cmd":null,"args":["--master","zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos","--zk_hosts","zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181"],"user":null,"env":{},"instances":2,"cpus":1,"mem":1024,"disk":0,"executor":"","constraints":[],"uris":[],"storeUrls":[],"ports":[0],"requirePorts":false,"backoffSeconds":1,"backoffFactor":1.15,"maxLaunchDelaySeconds":3600,"container":{"type":"DOCKER","volumes":[],"docker":{"image":"docker-registry.qiyi.virtual/yangchengwei/chronos:0.24.0_mesos-0.25","network":"BRIDGE","privileged":false,"parameters":[],"forcePullImage":false}},"healthChecks":[],"dependencies":[],"upgradeStrategy":{"minimumHealthCapacity":1,"maximumOverCapacity":1},"labels":{},"acceptedResourceRoles":null,"version":"2016-05-22T08:27:11.469Z","tasksStaged":0,"tasksRunning":0,"tasksHealthy":0,"tasksUnhealthy":0,"deployments":[{"id":"26552208-6ab7-4dbe-8c98-758e4adfa8cb"}],"tasks":[]}%
274 | ```
275 |
276 | 提交完成后,可以看到有 2 个任务处于 Staged 状态,如下图所示:
277 |
278 | 
279 |
280 | 这是因为 Mesos 计算节点需要下载 Chronos 镜像到本地,之后才能启动容器,所以根据下载时间的长短,可能需要等几分钟到几十分钟。
281 |
282 | **注意:这里假设使用了共有的 docker hub 服务,所以 mesos 集群的计算节点需要能够从 docker hub 服务上下载镜像,否则将不能启动,另一种较复杂的方式是读者可以搭建私有的 docker-registry 服务来存储镜像**
283 |
284 | 当任务处于运行状态后,使用浏览器打开任意一个 Chronos 实例,可以看到 Chronos 服务已经在正常运行了。
285 |
286 | ### 服务发现和负载均衡
287 |
288 | 我们知道,当运行在 Marathon 上的 Chronos 任务出现故障时,Marathon 会自动启动新的 Chronos
289 | 实例,几乎可以肯定的是,这个新实例运行的地址和端口和原来的不一样。所以,
290 | 在真实的生产环境中,为了对外提供对用户透明的高可用 Chronos 服务,需要在 Chronos 实例前端添加一层负载均衡器,同时也充当反向代理的作用。
291 |
292 | 对于 Marathon 来说,marathon 提供了两种服务发现和负载均衡的方式:
293 |
294 | - mesos-dns
295 | - marathon-lb
296 |
297 | 二者的配置稍显复杂,这里留给感兴趣的读者自行研究。
298 |
299 | ## 小结
300 |
301 | 本节介绍了 Chronos 高可用模型,怎样搭建高可用的 Chronos 服务,以及将 Chronos 运行在 Marathon 之上,进一步提高可用性,降低对 Chronos 的维护成本。
302 |
--------------------------------------------------------------------------------
/mesos-frameworks/chronos/summary.md:
--------------------------------------------------------------------------------
1 | # 小结
2 |
3 | 本节介绍了 Mesos 上的短时任务框架 Chronos,包括 Chronos 特性,怎样搭建 Chronos
4 | 服务,搭建高可用的 Chronos 服务,以及怎样使用 Chronos。
5 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/README.md:
--------------------------------------------------------------------------------
1 | # Marathon
2 |
3 | Marathon 是 Mesosphere 开发的支持长时任务(long running service)的框架,只能运行在 Mesos 上。
4 | Mesosphere 是一家初创公司,由 Mesos 作者等人创办,所以 Marathon 也算是 Mesos
5 | 生态中标准的长时任务处理框架了。
6 |
7 | 首先,我们来了解一下这里的长时任务是什么,
8 | 简单的说:长时任务在这里是指一旦任务运行起来,就不期望其结束。
9 | 如果读者了解 Linux 系统,那么 Linux 系统中的守护进程(daemon)就是一种长时任务,
10 | 总是被期望在系统运行期间都在运行。
11 |
12 | 那么,在实际生产环境中,哪些任务是我们说的长时任务呢?最常见的莫过于 web
13 | 服务了。除了 web 服务外,也可以是一些 RPC 服务;另外,长时任务不仅可以是服务,
14 | 也可以是一些 worker。
15 |
16 | Marathon 为什么适合运行长时任务?因为它为长时任务提供了许多辅助特性,包括但不限于:
17 |
18 | - 失败自动重启
19 | - 健康检查
20 | - 横向扩展
21 | - 服务发现
22 |
23 | 所以,一旦将长时任务运行在 Marathon 上,你总是可以期望你的任务总是在线,
24 | 而不用担心计算结点故障导致任务失败。
25 |
26 | 本节将简单介绍 Marathon 的特性,用法以及运行一个网页版的 2048 游戏,
27 | 更多的高级特性需要读者继续挖掘。
28 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/app.md:
--------------------------------------------------------------------------------
1 | # 运行 Marathon 任务
2 |
3 | 在搭建了 Marathon 框架后,本节将介绍怎样提交一个任务到 Marathon,通常,我们将
4 | Marathon 任务称作为 App,Application 的缩写。
5 |
6 | 本节将首先介绍怎样使用 Marathon 启动一个 `Hello Marathon` 任务,然后介绍怎样运行基于 Docker 的任务:怎样搭建一个 Web 版 2048 游戏。
7 |
8 | ## Hello Marathon
9 |
10 | 这里将创建一个 `hello-marathon` App 来演示怎样通过 Marathon Web 界面创建 App。
11 |
12 | Marathon Web 顾名思义就是 Marathon 的 Web 界面,通过 Marathon Web 界面,可以了解很多有用的信息,例如:有多少 App 正在运行,各个 App 的实例列表,运行状态等等。不仅如此,还可以通过 Web 界面实现一些对 App 的控制,例如:调整实例数,暂停 App,删除 App,创建 App 等。
13 |
14 | 用浏览器打开已经启动的 Marathon 服务(http://10.23.85.233:8080),如下图所示:
15 |
16 | 
17 |
18 | 点击左上角的 **Create** 按钮创建一个新的 App, 如下图所示:
19 |
20 | 
21 |
22 | 在新建页面,可以配置很多应用的选项,主要包括以下几部分:
23 |
24 | - 基本信息,容器资源配置等
25 | - Docker 容器配置,如果使用了 Docker 来封装应用的话
26 | - 环境变量,会被传递给应用
27 | - 标签,方便过滤,归类等
28 | - 健康检查
29 | - 其它可选配置
30 |
31 | 为了创建 `hello-marathon`,我们只需要输入几个必须的配置即可,如下图所示:
32 |
33 | 
34 |
35 | 输入完成后,点击 **+Create** 完成 App 的创建,现在,在 Marathon Web 上,可以看到刚才创建的 `hello-marathon` 已经处于 `Running` 状态了,如果用户操作足够快,应该还能看到在 `Running` 之前,还有一个 `Deploying` 状态;其对应于 Mesos 中的 `Staging` 状态,表示正在启动任务。
36 |
37 | Mesos 的任务具有以下几个状态:
38 |
39 | - Staging,表示任务已经收到,正在准备启动
40 | - Running,任务已经启动
41 | - Failed,任务失败
42 | - Lost,任务丢失
43 | - Killed,被杀死
44 |
45 | 在 Marathon 界面,点击 `hello-marathon` 可以看到这个 App 的详情,在 `Tasks` 卡片页可以看到当前 App 的实例;在 `Configuration` 卡片页可以看到任务配置的详情,历史版本等信息,如下图所示:
46 |
47 | 
48 |
49 | 另外,在上方还有几个控制按钮:
50 |
51 | - Scale Application, 调整 App 运行实例数量
52 | - Restart,重启 App 所有实例
53 | - Suspend, 挂起 App,相当于杀死所有正在运行的实例,但是保留 App 的配置
54 | - Destroy App, 彻底删除 App
55 |
56 | 从 Tasks 中,可以看到,`hello-marathon` 启动了一个任务,运行在 10.23.85.234 上,那么,怎样看到 `hello-marathon` 的输出呢?`hello-marathon` 任务执行了如下任务:
57 |
58 | ```
59 | while true; do echo "$(date): hello marathon"; sleep 1; done
60 | ```
61 |
62 | 任务的效果是每隔 1 秒钟,输出 `hello marathon` 字符串,所以我们应该能够在任务进程的 `stdout` 看到输出。
63 |
64 | 现在我们打开 Mesos 集群页面,在 `Slaves` 页面,找到这个计算节点,然后进入结点页面,找到 `hello-marathon` 这个任务,如下图所示:
65 |
66 | 
67 |
68 | 点击任务后面的 `Sandbox` 链接,可以看到当前任务运行的目录,这里有两个文件:
69 |
70 | - stdout, 任务的 stdout 输出会被重定向到这个文件
71 | - stderr, 任务的 stderr 输出会被重定向到这个文件
72 |
73 | 所以,打开 stdout 文件的内容,就可以看到 `hello-marathon` 输出了,如下图所示:
74 |
75 | 
76 |
77 | 并且,保持这个文件打开,文件内容会自动更新,实时查看到任务的 stdout,非常棒!
78 |
79 | 好了,现在已经通过 Marathon Web 界面创建了一个 App,并且这个 App 只有一个实例在运行,那么,试试运行两个实例呢,只需要点击在 Marathon Web 界面上点击 `Scale Application`,然后输入数字 `2` 即可,可以看到,很快就会有两个 `hello-marathon` 实例在运行了,如下图所示:
80 |
81 | 
82 |
83 | 同样,可以通过 `Suspend` 来暂停 App,这里的暂停不是让已经在运行的两个实例进程暂停,而是整个 App 意义上的暂停,即停止所有正在运行的实例,所以任务会被杀死;但是,可以很方便的恢复运行,`Destroy` 不仅会杀死所有正在运行的实例,还会将 App 配置一起删除。
84 |
85 | ## Hello Docker-2048
86 |
87 | `hello-marathon` 实际上是将任务直接运行在 Mesos 计算结点上的,运行环境需要由计算结点来保证,例如:hello-marathon 运行了 shell 脚本,那么计算结点上必须有 shell 环境;如果 App 要依赖 python 环境,perl 环境,PHP 环境,Go 环境等等,那么可以想见,为了运行任务,计算节点上必须同时支持所有需要的环境;计算结点将非常臃肿,甚至,如果任务使用的环境有冲突,那么这时计算结点就无能为力了。
88 |
89 | Docker 一面世,就掀起了一场云计算革命,Docker 能够将任务运行在隔离的环境中,各自任务都将自己的依赖环境全部打包到 Docker 镜像中,所以不再对底层的计算结点强依赖;相反,只需要底层计算结点支持运行 Docker 即可。
90 |
91 | Mesos 和 Marathon 也原生对 Docker 进行了支持,所以,用户可以很方便的将 Docker 任务通过 Marathon 调度到 Mesos 集群中执行。这里将创建一个 基于 Docker 的 Marathon App:docker-2048。
92 |
93 | 同样,在 Marathon WEB 界面中,点击 **Create** 按钮来创建新的 App,这里输入如下图所示参数:
94 |
95 | 
96 |
97 | 虽然这里还有很多其它配置项,但是只需要输入上图中的几项即可,非常简单,和 `hello-marathon` 相比,这里有以下几点不同:
98 |
99 | - 没有输入 **Command** 参数
100 | - 输入了一个 **Docker Image**,表示将启动这个 Docker 镜像
101 | - 选择了使用 Bridged 模式的网络,默认为无
102 | - 一个容器端口参数 80
103 |
104 | 以上参数表示:在启动这个应用时,从 Docker 镜像启动,并且使用 Bridged 网络模式将容器内部的 80 端口随机映射到主机上。
105 |
106 | 输入完成后,点击 **+Create** 按钮,创建应用,稍等一段时间后,可以看到,任务已经启动了,如下图所示:
107 |
108 | 
109 |
110 | 打开 `docker-2048` 应用详情页面,找到 Task 所在的主机,如下图所示:
111 |
112 | 
113 |
114 | 点击任务下面的主机端口号,将在新的浏览器页面中打开该地址,如下图所示:
115 |
116 | 
117 |
118 | 可以看到,一个基于 Web 的 2048 游戏已经运行起来了,酷!
119 |
120 | **注意:考虑到国内特殊情况,如果不能访问 alexwhen/docker-2048 镜像,那么任务将不能启动**
121 |
122 | ## 使用 API 来创建 App
123 |
124 | Marathon 提供了比 Web 界面功能更强大的 RESTful API,相应地,Marathon Web 界面实际上也通过 Marathon API 来管理 App。
125 |
126 | Marathon API 采用 JSON 格式来封装数据,如下为 `docker-2048` 的 JSON 数据,我们将其保存在一个名为 `docker-2048.json` 的文件中。
127 |
128 | ```
129 | {
130 | "id": "docker-2048-created-by-api",
131 | "container": {
132 | "type": "DOCKER",
133 | "docker": {
134 | "image": "alexwhen/docker-2048",
135 | "network": "BRIDGE",
136 | "portMappings": [
137 | { "containerPort": 80, "hostPort": 0 }
138 | ]
139 | }
140 | },
141 | "cpus": 0.5,
142 | "mem": 512.0,
143 | "instances": 1
144 | }
145 | ```
146 |
147 | 可以看到,`docker-2048.json` 内容非常简单,除了之前已经在 `hello-marathon` 中使用过的几个参数:
148 |
149 | - id, App 唯一标识
150 | - cpus, 申请使用的 CPU
151 | - mem, 申请使用的内存
152 | - instances, 实例数
153 |
154 | 这里多了另一个参数:`container`,它又有几个参数组成:
155 |
156 | - type, 指定 container 的类型,这里是 `DOCKER`
157 | - docker, 指定 docker 的一些参数
158 | - `image`,指明使用的 Docker 镜像
159 | - `portMappings`, 指明端口映射规则,containerPort 表示容器内部端口,hostPort 表示映射到计算结点的端口,0 表示随机分配
160 |
161 | Marathon API 中关于 App 的定义还有许多参数,这里只介绍了最简单的运行 Docker 任务的几个必须参数,其它参数后面将分类做简单介绍。
162 |
163 | 现在,使用任何支持传递 JSON 数据的客户端都可以向 Marathon 提交这个 App 了,只需要遵守 Marathon 定义的 API 格式。
164 |
165 | 下面使用 curl 来提交 `docker-2048.json` 到 Marathon 以便创建 docker-2048 这个 App,创建 App 的 API 格式如下:
166 |
167 | 
168 |
169 | 所以,只需要将 `docker-2048.json` 使用 POST 方法提交到 Marathon 服务的 /v2/apps 即可。这里我们将使用 `curl` 作为客户端来提交 `docker-2048.json`,如下所示:
170 |
171 | ```
172 | $ curl -H "Content-type: application/json" -d @docker-2048.json -X POST http://10.23.85.233:8080/v2/apps
173 | ```
174 |
175 | `curl` 是一个在 Linux 环境下广泛使用的 HTTP 客户端,支持 JSON 格式的数据,上面的命令中,使用了 3 个选项:
176 |
177 | - `-H`, 添加一个 HTTP Header
178 | - `-d`, 数据,`@` 符号表示使用该文件的内容
179 | - `-X`, 指定使用的方法,常用的 HTTP 方法还有 GET,POST,DELETE 等
180 |
181 | 提交完成后,可以看到 Marathon Web 界面上新建了一个叫做 `docker-2048-created-by-api` 的 App,如下图所示:
182 |
183 | 
184 |
185 | ## Marathon 任务配置
186 |
187 | 在前面两个例子中,我们只使用非常少的几个配置参数就创建了 Marathon App,其实,Marathon App 有非常多配置,可以配置 App 的方方面面,下面介绍两类最常用的任务配置:
188 |
189 | - 健康检查
190 | - Constraints
191 |
192 | 健康检查能够根据 App 配置来检查 App 是否健康,并且在不健康的时候采取相应的动作;而 Constraints 则能够控制 App 在制定的结点上运行。
193 |
194 | ### 健康检查
195 |
196 | 作为长时任务,我们总是期望任务在运行的时候都是正常的,而不是表面上在运行,实际上却不正常了。以 Web 服务来说,许多反向代理或者负载均衡器都提供健康检查机制,例如:Nginx, HAProxy 等;类似地,Marathon 对任务也提供了健康检查机制。
197 |
198 | Marathon 健康检查机制分为 3 类:
199 |
200 | - HTTP, 定时访问指定 HTTP 接口,根据返回状态码来判断任务是否健康
201 | - TCP, 定时建立到任务的 TCP 连接,根据是否可连接来判断任务是否健康
202 | - COMMAND, 定时执行一个命令,根据命令的返回值来判断任务是否健康
203 |
204 | Marathon 还提供了可以配置的策略,当检查到任务不健康时,可以采取相应的动作,例如:杀死当前实例并且启动一个新的实例。
205 |
206 | 以 `docker-2048` 为例,我们可以添加一个 HTTP 机制的健康检查,添加后,`docker-2048-v2.json` 将变成下面这个样子:
207 |
208 | ```
209 | {
210 | "id": "docker-2048-created-by-api-v2",
211 | "container": {
212 | "type": "DOCKER",
213 | "docker": {
214 | "image": "alexwhen/docker-2048",
215 | "network": "BRIDGE",
216 | "portMappings": [
217 | { "containerPort": 80, "hostPort": 0 }
218 | ]
219 | }
220 | },
221 | "cpus": 0.5,
222 | "mem": 512.0,
223 | "instances": 1,
224 | "healthChecks": [
225 | {
226 | "protocol": "HTTP",
227 | "path": "/",
228 | "gracePeriodSeconds": 30,
229 | "intervalSeconds": 10,
230 | "portIndex": 0,
231 | "timeoutSeconds": 10,
232 | "maxConsecutiveFailures": 3
233 | }
234 | ]
235 | }
236 | ```
237 |
238 | 我们在 `docker-2048-v2.json` 中添加了一个 `healthChecks` 配置,其中包含一个配置,使用的是 HTTP 方式,各参数的含义如下:
239 |
240 | - protocol, 检查方式,可选的为:HTTP, TCP, COMMAND
241 | - path, uri 路径,可选的,默认为 '/',只对 HTTP 有用
242 | - gracePeriodSeconds, 任务变成 Running 后多长时间内忽略健康检查失败事件,默认为 15 秒,如果任务启动后需要很长一段时间才能提供服务,例如:可能进行内部初始化需要很长事件,那么最好设置一个较大值,或者不要使用该参数,则表示直到第一次任务变成 health 未知
243 | - portIndex, 第几个内部端口,默认值为 0,docker-2048 在 portMappings 中只配置了一个端口,所以也只能指定为 0
244 | - timeoutSeconds, 单次健康检查的超时,默认为 10 秒
245 | - maxConsecutiveFailures, 最大连续失败次数,达到指定次数后,任务将被杀死,默认为 3
246 |
247 | 在更新了 `docker-2048-v2.json` 后,我们可以通过 `curl` 来提交更新后的 App,如下所示:
248 |
249 | ```
250 | $ curl -H "Content-type: application/json" -d @docker-2048-v2.json -X PUT http://10.23.85.233:8080/v2/apps/docker-2048-created-by-api
251 | ```
252 |
253 | 更新已有 App 使用的是 PUT 方法,并且需要在 url 中指定原有 App 的 id,这里为 `docker-2048-created-by-api`。
254 |
255 | 更新完成后,打开 Marathon Web 界面,可以看到 docker-2048-created-by-api 的 **Running Instances** 状态处显示了一条绿色的进度条,如下图所示:
256 |
257 | 
258 |
259 | 绿色表示该 App 所有运行实例都正常。
260 |
261 | ### Constraints
262 |
263 | 在一个实际生产环境中,Mesos 集群的计算结点可能具有差异性,例如:
264 |
265 | - 从机器类型看:结点可能虚机或者是物理机
266 | - 从网络带宽看:结点可能配备了千兆网卡,万兆网卡,40G 网卡等
267 | - 从是否可访问英特网看:结点可能是外网直连,通过代理,NAT,或者不能访问英特网
268 | - 从网络运营商看:结点可能使用电信,联通,移动等网络出口
269 |
270 | 以及还有很多其它方面,所以,如果 App 对结点配置有要求,那么就需要使用 `constraints` 来限制只能在制定的结点上启动 App 运行实例,要使用 `constraints` 来过滤计算结点,需要为结点配置适当的属性(attributes),这些属性可以在启动 mesos-slave 进程的时候配置。
271 |
272 | 除了 mesos-slave 配置的属性外,Marathon 还支持按照计算节点名字过滤。
273 |
274 | 除了用来过滤计算结点外,`constraints` 还可以用来控制 App 运行实例的分布特性,例如:
275 |
276 | - 平均分布:尽量在启动实例的结点上均匀分布实例
277 | - 唯一分布:在一个计算节点上只能启动一个运行实例
278 |
279 | 这里,我们为 `docker-2048` 添加一个基于主机名的限制条件,使其只能运行在 `10.23.85.234` 上,修改后的 `docker-2048-v3.json` 内容如下:
280 |
281 | ```
282 | {
283 | "id": "docker-2048-created-by-api",
284 | "container": {
285 | "type": "DOCKER",
286 | "docker": {
287 | "image": "alexwhen/docker-2048",
288 | "network": "BRIDGE",
289 | "portMappings": [
290 | { "containerPort": 80, "hostPort": 0 }
291 | ]
292 | }
293 | },
294 | "cpus": 0.5,
295 | "mem": 512.0,
296 | "instances": 1,
297 | "healthChecks": [
298 | {
299 | "protocol": "HTTP",
300 | "path": "/",
301 | "gracePeriodSeconds": 30,
302 | "intervalSeconds": 10,
303 | "portIndex": 0,
304 | "timeoutSeconds": 10,
305 | "maxConsecutiveFailures": 3
306 | }
307 | ],
308 | "constraints": [["hostname", "LIKE", "10.23.85.234"]]
309 | }
310 | ```
311 |
312 | 然后,使用 `curl` 命令提交修改后的 `docker-2048-v3.json` 到 Maraton,更新已经存在的 `docker-2048` App。
313 |
314 | ```
315 | $ curl -H "Content-type: application/json" -d @docker-2048-v3.json -X PUT http://10.23.85.233:8080/v2/apps/docker-2048-created-by-api
316 | ```
317 |
318 | App 更新后,可以看到 App 的一个实例在 `10.23.85.234` 上运行了,限制,可以测试将 App 运行实例数设置为 4,可以看到,随后又在 `10.23.85.234` 上启动了 3 个运行实例,却没有在其它结点上启动任何实例。
319 |
320 | 
321 |
322 | 读者甚至可以停止掉 `10.23.85.234` 上的 mesos-slave 进程来验证,看看 marathon 会不会在其它结点上启动 `docker-2048` 的运行实例。
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/docker-2048-v2.json:
--------------------------------------------------------------------------------
1 | {
2 | "id": "docker-2048-created-by-api",
3 | "container": {
4 | "type": "DOCKER",
5 | "docker": {
6 | "image": "alexwhen/docker-2048",
7 | "network": "BRIDGE",
8 | "portMappings": [
9 | { "containerPort": 80, "hostPort": 0 }
10 | ]
11 | }
12 | },
13 | "cpus": 0.5,
14 | "mem": 512.0,
15 | "instances": 1,
16 | "healthChecks": [
17 | {
18 | "protocol": "HTTP",
19 | "path": "/",
20 | "gracePeriodSeconds": 30,
21 | "intervalSeconds": 10,
22 | "portIndex": 0,
23 | "timeoutSeconds": 10,
24 | "maxConsecutiveFailures": 3
25 | }
26 | ]
27 | }
28 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/docker-2048-v3.json:
--------------------------------------------------------------------------------
1 | {
2 | "id": "docker-2048-created-by-api",
3 | "container": {
4 | "type": "DOCKER",
5 | "docker": {
6 | "image": "alexwhen/docker-2048",
7 | "network": "BRIDGE",
8 | "portMappings": [
9 | { "containerPort": 80, "hostPort": 0 }
10 | ]
11 | }
12 | },
13 | "cpus": 0.5,
14 | "mem": 512.0,
15 | "instances": 1,
16 | "healthChecks": [
17 | {
18 | "protocol": "HTTP",
19 | "path": "/",
20 | "gracePeriodSeconds": 30,
21 | "intervalSeconds": 10,
22 | "portIndex": 0,
23 | "timeoutSeconds": 10,
24 | "maxConsecutiveFailures": 3
25 | }
26 | ],
27 | "constraints": [["hostname", "LIKE", "10.23.85.234"]]
28 | }
29 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/docker-2048.json:
--------------------------------------------------------------------------------
1 | {
2 | "id": "docker-2048-created-by-api",
3 | "container": {
4 | "type": "DOCKER",
5 | "docker": {
6 | "image": "alexwhen/docker-2048",
7 | "network": "BRIDGE",
8 | "portMappings": [
9 | { "containerPort": 80, "hostPort": 0 }
10 | ]
11 | }
12 | },
13 | "cpus": 0.5,
14 | "mem": 512.0,
15 | "instances": 1
16 | }
17 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-api-create-app.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-api-create-app.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-constraints.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-constraints.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-docker-2048-created-by-api.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-docker-2048-created-by-api.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-docker-2048-health-check.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-docker-2048-health-check.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-docker-2048-running.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-docker-2048-running.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-docker-2048-task.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-docker-2048-task.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-docker-2048.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-docker-2048.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-hello-marathon-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-hello-marathon-1.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-hello-marathon-detail.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-hello-marathon-detail.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-hello-marathon-stdout.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-hello-marathon-stdout.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-new-app-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-new-app-1.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-new-docker-2048.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-new-docker-2048.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-registered.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-registered.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-scale-application.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-scale-application.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/marathon-web-ui-home.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/marathon-web-ui-home.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/assets/mesos-slave-active-tasks.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/marathon/assets/mesos-slave-active-tasks.png
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/basics.md:
--------------------------------------------------------------------------------
1 | # Marathon 简介
2 |
3 | Marathon 是 Mesosphere 专门为 Mesos 开发的长时任务处理框架,并且在 GitHub
4 | 上开源,利用 Marathon 以及一些其它开源软件,加上一些本地开发,
5 | 结合当前流行的容器解决方案 Docker, 就可以搭建一个基于 Mesos 的
6 | PaaS(Platform as a Service) 平台。
7 |
8 | 当然,Docker 并不是必须的,但是由于 Docker 能够很好的解决构建、打包、
9 | 分发和运行的问题,所以加入 Docker 也就成了不二之选,Mesos, Marathon 都原生支持
10 | Docker,所以使用起来非常方便。
11 |
12 | 截止本书写作之时,Marathon 的最新版本为 0.13.0,支持以下特性:
13 |
14 | - HA(High Availability)
15 | - Constraints
16 | - 服务发现和负载均衡
17 | - 健康检查
18 | - 事件机制
19 | - Web UI
20 | - RESTful API
21 | - Basic Auth 以及支持 SSL
22 | - Metrics
23 |
24 | 下面将对以上特性逐一介绍。
25 |
26 | ## HA(High Availability)
27 |
28 | Marathon 的 HA 实现非常简单,Marathon 将所有数据持久化到 ZooKeeper 服务中,
29 | 自身是一个无状态的服务,而各个服务实例之间通过 ZooKeeper 实现 Leader 选举,
30 | 任意时刻,只有最多一个服务实例作为 Leader,其它实例则作为 Follower,
31 | 任何到达 Follower 的请求都将被转发到 Leader。所以,任意时刻,只要有一个 Marathon
32 | 服务实例存活,整个 Marathon 服务都是可用的。
33 |
34 | 所以,在生产环境中,要实现 Marathon 服务的高可用性,至少需要搭建 2 个 Marathon
35 | 服务实例组成一个服务。
36 |
37 | ## Constraints
38 |
39 | 在生产环境中,保持集群中所有结点的一致性显然是不可能的事,总是有一些特性能够将
40 | Mesos 计算结点区分开来,例如:
41 |
42 | - 结点所在的机架
43 | - 结点的网络带宽
44 | - 结点是否可以访问外网,通过何种方式
45 | - 结点所在机房的运营商
46 | - 结点是物理机还是虚拟机
47 | - 等等
48 |
49 | 所以,Marathon 使用 Constraints 特性来支持将任务运行在具有指定特性的计算结点上。
50 |
51 | ## 服务发现和负载均衡
52 |
53 | 想象一下在传统的 Web 服务部署中,通常是将服务直接部署在固定的一台或多台物理机或者
54 | 虚拟机上,然后,将这些服务器的 IP 地址绑定到负载均衡器中,对外提供服务。但是,
55 | 当服务器故障时怎么办呢?需要故障处理和恢复,如果故障的服务器不能恢复,
56 | 需要部署新的服务器并加入到负载均衡器中,避免影响服务的稳定性。
57 |
58 | 想象一下,将这样的 Web 服务通过 Marathon 运行在 Mesos 集群中会是什么样?Marathon
59 | 会自动将服务的多个实例运行在一些计算结点上,当结点或者实例故障时,会自动重启一个新的实例,
60 | 那么这里存在的问题是在任意时刻怎样知道服务实例运行的地址呢?
61 |
62 | 服务发现和负载均衡特性就是为了解决这个问题,Marathon 能够为长时任务生成 HAProxy
63 | 配置文件,如果使用 HAProxy 作为负载均衡器,那么服务实例的故障是完全不用运维的。
64 | 虽然 Marathon 没有提供其它负载均衡器的支持,但是已经不乏这样的开源软件,
65 | 例如:Bamboo, Consule 等。
66 |
67 | ## 健康检查
68 |
69 | 由于 Marathon 专为长时任务设计,并且支持自动重启故障的任务,任务的故障有很多种,
70 | 计算结点导致的故障可以由 Mesos 通知,但是如果是任务内部的异常,Mesos
71 | 则无能为力了,例如:Web 服务正在运行,但是已经不能响应服务请求了,
72 | 那么有什么机制能够发现并处理这种异常吗?
73 |
74 | 熟悉 HAProxy, Nginx 的读者应该知道,它们可以通过检测后端服务器的服务接口来自动屏蔽异常的服务器,
75 | Marathon 也实现了类似的机制,叫做健康检查,能够自动检查服务实例并且在发现异常后做出响应,
76 | 例如:杀掉异常的服务实例并且重新启动一个新的服务实例。
77 |
78 | ## 事件机制
79 |
80 | 事件机制为开发者提供了无限的可能,开发者可以通过注册到 Marathon 的事件总线,
81 | 及时知道自己感兴趣的事件,从而做出相应。
82 |
83 | 例如:通过事件机制,可以监听到服务实例的变化,自动配置负载均衡器。
84 |
85 | ## Web UI
86 |
87 | Marathon 提供了实用的 Web UI,能够方便用户管理长时任务,实现任务的增、删、查、改操作。
88 | 下图是一个 Marathon Web UI 截图。
89 |
90 | 
91 |
92 | ## RESTful API
93 |
94 | Marathon 不仅提供了 Web UI,还提供了 RESTful API,对于开发者来说,良好设计的 API
95 | 更值得拥有,你可以通过 Marathon API 实现通过 Web UI 能够实现的所有功能,甚至一些
96 | Web UI 不支持的功能。例如:强制重新部署。
97 |
98 | ## Basic Auth 以及支持 SSL
99 |
100 | Marathon 实现了 Basic Auth,Basic Auth 是一种简单的用户名密码认证方式,目前
101 | Marathon 只支持单用户,所有任务都只能属于这个用户,所以本质上,
102 | 如果有多个用户在一个 Marathon 服务上创建了任务,那么是有可能误操作的。
103 |
104 | 在通信安全方面,Marathon 支持 SSL 加密。
105 |
106 | ## Metrics
107 |
108 | 通过 Metrics,用户可以很方便的知道 Marathon
109 | 的运行情况,例如:任务数量,使用的资源等等。
110 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/setup.md:
--------------------------------------------------------------------------------
1 | # 搭建Marathon服务
2 |
3 | 在编写本书时,Marathon 最新的稳定版本是 0.13.0,所以这里将以 Marathon 0.13.0
4 | 版本为例来搭建 Marathon 服务。
5 |
6 | ## 准备环境
7 |
8 | Marathon 是运行在 Mesos 之上的长时任务处理框架,并且依赖 ZooKeeper
9 | 服务来持久化数据,所以在开始搭建 Marathon 服务之前,首先需要有可用的 Mesos
10 | 集群以及 ZooKeeper 服务。
11 |
12 | 这里我们将使用在前一章中搭建的 Mesos 集群以及 ZooKeeper 服务,虽然 Mesos
13 | 也是基于此 ZooKeeper 服务,但是这里纯属巧合,Marathon 可以使用任何其它可用的
14 | ZooKeeper 服务。
15 |
16 | 所以,Mesos 集群的地址为:
17 | `zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos`;
18 | ZooKeeper 服务地址为:
19 | `zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181`。
20 |
21 | 这里,我们选择在 10.23.85.233 上搭建 Marathon 服务,也就是 Mesos
22 | 集群中的其中一台,我们在上一章中称为 A 的机器,这里我们继续称之为 A。
23 |
24 | 之所以选择 A,并没有什么特殊的原因,读者也可以选择在 B 或者 C 上安装 Marathon,方法和这里相同,只是需要注意的是:安装 Marathon 首先要安装 Mesos,因为 Marathon 依赖于 Mesos 库,所以不能在一台没有安装 Mesos 的机器上安装 Marathon。
25 |
26 | ## 下载 Marathon
27 |
28 | 首先,到 Github 上下载 Marathon,下载地址为:https://github.com/mesosphere/marathon/releases/tag/v0.13.0。
29 |
30 | 假设将 Marathon 下载到了 ~/Downloads 目录下,或者执行下面的命令进行下载:
31 |
32 | ```
33 | $ cd ~/Downloads
34 | $ curl -O http://downloads.mesosphere.com/marathon/v0.13.0/marathon-0.13.0.tgz
35 | ```
36 |
37 | 使用下面的命令解压下载好的压缩包
38 |
39 | ```
40 | $ tar xzf marathon-0.13.0.tgz
41 | $ cd marathon-0.13.0
42 | $ ls
43 | bin Dockerfile docs examples LICENSE README.md target
44 | ```
45 |
46 | 执行解压后的 `bin/start` 脚本即可启动 marathon,如下所示:
47 |
48 | ```
49 | $ ./bin/start --master zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos \
50 | > --zk zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/marathon
51 | ```
52 |
53 | 上面命令中有两个参数:
54 |
55 | - `--master`, 指定 Mesos 集群控制结点服务地址
56 | - `--zk`, 指定 ZooKeeper 服务地址
57 |
58 | 上面的命令可能会报如下错误:
59 |
60 | ```
61 | MESOS_NATIVE_JAVA_LIBRARY is not set. Searching in /usr/lib /usr/local/lib.
62 | MESOS_NATIVE_LIBRARY, MESOS_NATIVE_JAVA_LIBRARY set to ''
63 | Exception in thread "main" java.lang.UnsupportedClassVersionError: mesosphere/marathon/Main : Unsupported major.minor version 52.0
64 | at java.lang.ClassLoader.defineClass1(Native Method)
65 | at java.lang.ClassLoader.defineClass(ClassLoader.java:803)
66 | at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
67 | at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
68 | at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
69 | at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
70 | at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
71 | at java.security.AccessController.doPrivileged(Native Method)
72 | at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
73 | at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
74 | at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
75 | at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
76 | at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:482)
77 | ```
78 |
79 | `Unsupported major.minor version 52.0` 这个错误表示 Marathon 是使用 Java 1.8 编译的,并且不兼容老版本,而本机上安装的 Java 版本为 1.7.0,所以执行时才会出现错误。
80 |
81 | 解决办法就是升级本机的 Java 版本,或者从源码编译安装 Marathon,升级 Java 版本很简单,直接通过 YUM 从 CentOS 软件源中安装即可。
82 |
83 | ```
84 | # yum install -y java-1.8.0-openjdk
85 | ```
86 |
87 | 安装完成后,再次运行上面的命令,可以看到,已经不再报这个错误了,但是,可能会报下面的错误。
88 |
89 | ```
90 | Failed to load native Mesos library from
91 | Exception in thread "pool-1-thread-2" java.lang.UnsatisfiedLinkError: Expecting an absolute path of the library:
92 | at java.lang.Runtime.load0(Runtime.java:806)
93 | at java.lang.System.load(System.java:1086)
94 | at org.apache.mesos.MesosNativeLibrary.load(MesosNativeLibrary.java:159)
95 | at org.apache.mesos.MesosNativeLibrary.load(MesosNativeLibrary.java:188)
96 | ```
97 |
98 | 这是因为 Marathon 没有找到 Mesos 库导致的,修复这个问题也很简单,设置一个环节变量,再启动 Marathon 即可,如下:
99 |
100 | ```
101 | $ MESOS_NATIVE_JAVA_LIBRARY=/usr/lib64/libmesos.so ./bin/start --master zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos --zk zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/marathon
102 | ```
103 |
104 | 如果用户直接从 Mesosphere 软件源中安装 Mesos 包,则不会发生这个错误,因为 Mesosphere 的安装包将 Mesos 库安装到了 /usr/local/lib 下。
105 |
106 | 启动完成后,打开浏览器访问本机的 `8080` 端口,就可以看到 Marathon UI 了,如下图所示:
107 |
108 | 
109 |
110 | Marathon 启动后,会将自己注册到 Mesos 集群中,并且将数据持久化到 `--zk` 指定的
111 | ZooKeeper 服务中的指定地址。
112 |
113 | 现在,打开 Mesos 服务的 Web UI,就可以看到刚刚注册的 Marathon
114 | 服务了,如下图所示:
115 |
116 | 
117 |
118 | 到现在为止,一个可用的 Marathon 服务就搭建起来了,非常简单,Marathon
119 | 还有一些可配置的参数,这里介绍一些读者可能会用到的参数。
120 |
121 | ## Marathon 参数
122 |
123 | marathon 只有一个必须的参数,即 `--master`,以便知道 Mesos 的服务地址。
124 | 其它一些比较常用的可选参数如下表所示:
125 |
126 | 参数 |默认值 |示例 |含义
127 | ------------------------|-------------------------|-------------------------|-----
128 | `--zk` | 无 | `--zk=zk://host1:port1,host2:port2,host3:port3/path` | 指定 ZooKeeper 服务地址,指定后 marathon 将会使用 ZooKeeper 作为持久化存储后端
129 | `--[disable_]checkpoint`|`--checkpoint` |`--checkpoint ` |是否开启任务 checkpoint, 开启 checkpoint 后,在 mesos-slave 重启或者 marathon failover 期间,任务会继续运行;注意:开启 checkpoint 必须在 mesos-slave 相应地开启 checkpoint,如果关闭,则任务会在 mesos-slave 重启或者 marathon failover 期间失败
130 | `--failover_timeout` | 604800 | `--failover_timeout=86400` | 设置 mesos-master 允许 marathon failover 的时间,如果 marathon 没有在此时间内恢复,mesos 将删除 marathon 的任务
131 | `--hostname` |主机的 hostname | `--hostname=10.23.85.233` | 如果你的机器主机名没有被正确配置,很可能需要手动指定,否则可能导致 marathon 不能和 mesos 通信,或者不能和其它 marathon 服务实例通信
132 | `--mesos_role` | 无 | `--mesos_role=marathon` | 设置其在 mesos 中的 role,mesos 的资源预留和共享机制建立在 role 之上,默认不指定 role 的框架具有的 role 为 `*`,表示使用共享资源,注意:这里指定的 role 必须是在 mesos-master 中指定的 `roles` 中的值
133 | `--default_accepted_resource_roles` | 所有资源 | `--default_accepted_resource_roles=marathon` | 接受具有指定 role 类型的资源,注意,所有资源类型都必须具有指定 role,例如:cpus(marathon):20;mem(*):20480; 将不被接受,因为内存只有 `*` 资源,而没有 `marathon` 资源
134 | `--task_launch_timeout` |300000, 5 分钟| `--task_launch_timeout=1800000` |设置任务启动时间,也就是从提交任务到任务进入 RUNNING 的时间,通常来说,如果需要进行比较长的准备时间,需要将该值增大,例如:从 docker-registry 下载镜像
135 | `--event_subscriber` | 无 | `--event_subscriber=http_callback` | 设置开启的事件订阅模块,目前只支持 `http_callback` 一种类型,开启后,marathon 将接受用户的事件订阅,并且相应地在发生事件时,回调注册的 http_callback,并且将事件内容以 JSON 的方式传递给 http_callbak
136 | `--http_address` | 所有网络地址 | `--http_address=10.23.85.233` | 监听的网络地址,通常来说,Linux 系统中都会有一个本地回环 IP: 127.0.0.1,往往映射到主机名 localhost,只能通过本机访问,另外,还有至少一张配置好的网卡和其它主机通信,例如:10.23.85.233
137 | `--http_credentials` | 无 | `--http_credentials=admin:adminpass` | marathon basic auth 的用户名和密码
138 | `--http_port` | 8080 | `--http_port=80` | marathon 服务监听的端口
139 | `--http_max_concurrent_requests` | 无 | `--http_max_concurrent_requests=100` | 最大并发请求数,当请求队列超过该值时,直接返回 503 错误代码,如果 marathon 服务并发很大,那么为了避免服务不稳定或出现故障,最好设置该值,以便客户端收到失败返回后重试
140 |
141 | Marathon 的参数还可以通过环境变量来配置,这和 Mesos 类似,只需要将参数全部大写,并且加上 MARATHON_ 前缀,例如:
142 |
143 | - `--zk` 参数可以通过环境变量 `MARATHON_ZK` 来指定
144 | - `--mesos_role` 可以通过环境变量 `MARATHON_MESOS_ROLE` 来指定
145 |
146 | 需要注意的是,如果一个参数同时通过环境变量指定,又通过命令行参数指定,那么命令行参数将会覆盖环境变量。
147 |
148 | ## 服务的高可用性
149 |
150 | 在上一节中,我们了解了 Marathon 高可用性实现方案,Marathon
151 | 将所有需要持久化的数据都存储在 ZooKeeper 服务中,并且多个实例之间由 ZooKeeper
152 | 来实现 Leader Election。所以,实现高可用性不需要任何配置即可完成。
153 |
154 | 但是,对于 Marathon 用户来说,Marathon 这种高可用性却不是透明的,因为,当
155 | Marathon Leader 故障时,新的 Leader 提供的服务地址和以前的 Leader
156 | 服务地址不一样,所以用户需要更改访问的地址。
157 |
158 | 所以,对用户透明的高可用性就非常有需要了,特别是对于通过 HTTP
159 | 协议来访问的用户来说。
160 |
161 | 下面将介绍两种实现透明高可用性的方案:
162 |
163 | - 虚拟 IP 方案
164 | - 负载均衡方案
165 |
166 | ### 虚拟 IP 方案
167 |
168 | 虚拟 IP 方案基于 VRRP (Virtual Router Redundancy Protocol) 协议,VRRP 的工作原理如下:
169 |
170 | ![FIXME: how vrrp works]()
171 |
172 | 简单的说,有两个设备同时提供一个虚拟 IP,两个设备采用主备的方式工作,
173 | 任意时间只有一个设备提供虚拟 IP,当主机点故障时,备用结点提供虚拟 IP,
174 | 当主节点恢复时,主节点提供虚拟 IP。所以,主节点总是优先。
175 |
176 | Linux 下常见的实现虚拟 IP HA 的软件有:
177 |
178 | - keepalived
179 | - ucarp
180 | - heartbeat
181 |
182 | 回顾一下 Marathon HA 的工作原理可以知道,这种主备工作方式的 HA 并不适合
183 | Marathon,包括后面将要介绍的 Chronos,它具有和 Marathon 相同的 HA 实现方式。
184 |
185 | 原因是在 Marathon 服务中,所有跟随者实例都需要将请求转发给
186 | Leader,所以,当 Marathon Leader 运行在 keepalived 或者 ucarp 中的备用结点上时,
187 | 所有的请求都需要经过转发才能到达 Marathon Leader,降低了效率。
188 |
189 | 举个例子:假设有 A, B 两台服务器,使用 keepalived 实现了 IP HA,并且配置了 A
190 | 服务器作为主结点,B 作为备结点。同时在 A, B 两天服务器上搭建了 Marathon 服务,
191 | 服务启动时,A 结点上的 Marathon 作为 Leader,所以所有通过虚拟 IP
192 | 到达的请求都直接由 Marathon Leader 处理,但是,假设某一时刻服务器 A 故障宕机,
193 | 显然,服务器 B 上的 Marathon 会作为新的 Marathon Leader 并且所有通过虚拟 IP
194 | 到达的请求都将直接到达 B,此时所有的请求也是直接由 Marathon Leader
195 | 处理的,看起来一切工作的非常好。
196 |
197 | 但是,过了一段时间后,服务器 A 恢复了,重新上线,由于 A 被配置成了虚拟 IP
198 | 的主结点,所以当 A 在线时,所有对虚拟 IP 的访问都将发往 A,但是,此时服务器 A
199 | 上的 Marathon 并非 Leader,所以,Marathon 收到请求后,需要将请求转发给服务器 B
200 | 上的 Marathon Leader,直到下次 B 上的 Marathon 故障,将服务器 A 上的 Marathon
201 | 重新选举为 Leader。
202 |
203 | 简单的说,只有当虚拟 IP 主结点和 Marathon Leader
204 | 是同一个结点时,才能避免服务转发。
205 |
206 | ### 负载均衡方案
207 |
208 | 负载均衡器顾名思义是用来实现各个服务器之间负载均衡的设备,包括软硬件设备,在软件定义以及开源软件大行其道的今天,可选的开源负载均衡软件也不少,最常见的有:
209 |
210 | - LVS(Linux Virtual Server)
211 | - HAProxy
212 | - Nginx
213 |
214 | 负载均衡器器由于可以通过心跳来检查后端服务器的健康状况,所以,也能够在实现负载均衡的同时,
215 | 也实现服务的高可用性,负载均衡器能够根据配置的心跳检测策略检查后端服务器,
216 | 并且避免将流量继续发往故障的后端服务器。
217 |
218 | 使用负载均衡器和使用 IP HA 方式相比,几乎总是有一半的流量会通过 Marathon
219 | 跟随结点转发到 Marathon Leader 结点上,不会太坏,也不会太好。
220 |
221 | 当然,这里介绍的是最简单的配置情况下,读者可以通过一些编程,实现动态配置,从而避免转发,
222 | 这里不再赘述,留给读者自行研究。
223 |
--------------------------------------------------------------------------------
/mesos-frameworks/marathon/summary.md:
--------------------------------------------------------------------------------
1 | # 小结
2 |
3 | 本节介绍了 Marathon 计算框架,包括适用的场景,特性;怎样搭建 Marathon
4 | 生产环境;最后介绍了一个实例。Marathon 作为基础的长时任务计算框架,读者可以基于
5 | Marathon 做出更好更酷的产品,例如:编写一个集成业务逻辑的控制器,
6 | 根据业务情况来自动调节 App 实例数的数量,达到 Auto Scaling
7 | 的目的;业务逻辑可以是 QPS, 活跃连接数等等。
8 |
--------------------------------------------------------------------------------
/mesos-frameworks/overview.md:
--------------------------------------------------------------------------------
1 | # Mesos 框架概览
2 |
3 | 从上一章我们知道,移植一个现有的分布式计算框架到 Mesos 平台难度并不高,所以
4 | Mesos 生态迅速得到了其它已有分布式计算框架的支持,下图是 Mesosphere
5 | 社区文档中发布的一张框架元素周期表,大概概括了目前能够完美运行在 Mesos 之上的计算框架。
6 |
7 | 
8 |
9 | Mesosphere 官方宣称有超过 40 个计算框架支持 Mesos。
10 |
11 | 在上图中,按照颜色将框架分为了 4 类,从左到右:
12 |
13 | - PaaS 或者长时任务框架
14 | - 大数据框架
15 | - 短任务或者批处理框架
16 | - 数据存储框架
17 |
18 | 同时,Apache Mesos 官方文档也有对支持 Mesos 的计算框架的简单介绍。
19 |
20 | ## PaaS 或者长时任务框架
21 |
22 | 上图中的左边第一列既是 PaaS 或者长时任务框架,包括 Aurora, Marathon 和 SSSP。
23 |
24 | ### Aurora
25 |
26 | Aurora 最初由 Twitter 开发,后来贡献给 Apache 软件基金会,目前已经成功 Apache
27 | 顶级项目。
28 |
29 | Aurora 是专门为运行在 Mesos 之上开发的,而非移植到 Mesos 的框架,
30 | 它实际上支持两类任务:长时任务和批处理任务,虽然这里将其归类为 PaaS
31 | 或者长时任务框架。
32 |
33 | Aurora 的核心特性包括:
34 |
35 | - 平滑的升级及回滚
36 | - 资源配额以及多用户支持
37 | - 强大的 DSL 描述语言
38 | - 服务发现
39 |
40 | Aurora 的任务配置非常灵活,强大,但也稍显复杂,所以目前在国内的用户并不多。
41 |
42 | ### Marathon
43 |
44 | Marathon 是 Mesosphere 专门为 Mesos 开发的长时任务框架,根正苗红,目前是 Mesos
45 | 平台上使用最广泛的 PaaS 框架。Marathon 目标是成为 Mesos 集群中的类似 init
46 | 进程之于操作系统的功能,能够启动长时任务,并且保证长时任务总是在线。
47 |
48 | 根据 Marathon 的特点,Mesosphere 也推荐将其它框架使用 Marathon 来运行,
49 | 这样其它框架就能够更简单的实现高可用性,失败转移等特性,降低运维成本。
50 | 本章将会有专门的篇幅来介绍 Marathon,所以这里就此打住。
51 |
52 | ### SSSP
53 |
54 | SSSP 即 S3 Proxy Mesos Framework 是一个 Amazon S3 存储的 Proxy,由 Mesosphere
55 | 开发并开源,由于 S3 在国内并不可用,所以这里不对 SSSP
56 | 做介绍;另外,此项目也已经停止开发近两年,所以没有必要再对其进行介绍。
57 |
58 | ## 大数据框架
59 |
60 | ### Cray Chapel
61 |
62 | Cray Chapel 是一种并行编程语言,最初为高性能并行计算开发,后来逐步改善兼容性,
63 | 现在也能运行在常见的支持类 Linux 系统上。
64 |
65 | Cray Chapel on Mesos 调度框架则实现了将使用 Chapel 编写的应用运行在 Mesos
66 | 集群中。
67 |
68 | ### Exelixi
69 |
70 | Exelixi 是一个将基因算法应用运行在 Mesos 集群中的框架。
71 |
72 | ### MPI
73 |
74 | MPI (Message Passing Interface)
75 | 是一种并行计算消息通信接口,主要面向高性能并行计算,MPI on Mesos
76 | 框架主要是能够让 MPI 运行在 Mesos 集群中。
77 |
78 | ### Dpark
79 |
80 | Dpark 是国内公司豆瓣开发的,使用 Python 语言重新实现了 Spark,支持 Map-Reduce
81 | 任务,并且在 GitHub 上开源。
82 |
83 | ### Hadoop
84 |
85 | Hadoop 应该是当前大数据领域炙手可热的计算框架了,开发灵感来自于 Google 公布的
86 | Map-Reduce 论文,Hadoop 项目包含了许多子项目,是一个完整的大数据解决方案生态,
87 | 最基础的莫过于分布式文件系统 HDFS 和 Map-Reduce 计算框架,Hadoop 也是一个 Apache
88 | 软件基金会的顶级项目,并且其生态圈中,有非常多的子项目同时也是 Apache
89 | 软件基金会顶级项目。
90 |
91 | Hadoop on Mesos 项目能够将 Hadoop 运行在 Mesos 集群中,但是随着 YARN(Map-Reduce
92 | v2) 的发布,Hadoop on Mesos 的进度就转移到了怎样将 YARN 运行在 Mesos 之上,
93 | 并且在 Apache 软件基金会孵化了一个项目: Apache Myriad,目前发布了 0.1 版本。
94 |
95 | ### Spark
96 |
97 | Spark 是一个 Apache 软件基金会顶级项目,是另一个非常活跃的大数据计算框架,
98 | 支持 Map-Reduce 任务,得益于基于内存的计算模型,Spark 宣称运行速度在
99 | Hadoop Map-Reduce 百倍以上;即使基于磁盘计算,速度也在 Hadoop Map-Reduce
100 | 十倍以上。
101 |
102 | 值得一提的是,Spark 可谓是 Mesos 的同门,最初都有伯克利 AMPLab 创建,Spark
103 | 发展到现在,已经不仅仅支持 Map-Reduce 任务了,还支持 Spark SQL, Spark Streaming
104 | 实时流式计算,MLlib 机器学习以及 GraphX 图计算。
105 |
106 | ### Concord
107 |
108 | Concord 是一个基于 Mesos 的实时流计算框架,和 Apache Storm 类似。
109 |
110 | ### Storm
111 |
112 | Storm 是 Apache 软件基金会的顶级项目,面向实时流计算。
113 |
114 | ## 短任务或者批处理框架
115 |
116 | ### Chronos
117 |
118 | Chronos 是一个目前比较活跃的 Mesos 批处理任务框架,最初由 Airbnb 开发,目前由
119 | Mesosphere 维护,Chronos 类似于分布式的 Cron,它支持 ISO8601 标准的定时任务,
120 | 以及支持优先级,同步、异步任务,任务依赖等等。
121 |
122 | ### Jenkins
123 |
124 | Jenkins 是老牌 Continuous Integration(CI) 开源软件,使用非常广泛,
125 | 本书也有专门的实战案例介绍怎样使用 Jenkins + Mesos 搭建可扩展的可持续集成服务。
126 |
127 | ### Torque
128 |
129 | Torque 虽然出现在了元素周期表中,但是由于基本上处于无维护状态,
130 | 所以已经不推荐使用了。
131 |
132 | ## 数据存储框架
133 |
134 | ### ElasticSearch
135 |
136 | ElasticSearch 更为出名的是作为 ELK(ElasticSearch, Logstash, Kibana) 的一员,
137 | ELK 被广泛应用在日志采集、处理、分析、检索、报表领域。
138 |
139 | ### Cassandra
140 |
141 | Cassandra 同样是一个 Apache 软件基金会的顶级项目,提供分布式,
142 | 可先行扩展的数据存储服务,并且支持跨数据中心的冗余。
143 |
144 | ### Hypertable
145 |
146 | Hypertable 是一个开源的分布式数据库软件,设计理念来源于 Google Bigtable,
147 | 着眼于可扩展性,可扩展性也是目前 NoSQL 相对于 SQL 数据库的主要优点之一,
148 | 但随之妥协的往往是稍差的性能和一致性。
149 |
150 | Hypertable 号称在扩展性,性能以及一致性方面都做得非常出色。
151 |
--------------------------------------------------------------------------------
/mesos-frameworks/spark/README.md:
--------------------------------------------------------------------------------
1 | # Spark
2 |
3 | Spark 是一个大数据处理框架,近几年社区发展非常快,从最初的 Map-Reduce
4 | 计算模型扩展到 SQL 结构化数据,机器学习,图计算,流计算等。
5 |
6 | Spark 和 Mesos 都出自加州大学伯克利分校的 AMPLab,Spark 也出现在 Mesos
7 | 原型论文中,和 Mesos 一样,Spark 也贡献给了 Apache
8 | 软件基金会,并且很快成长为顶级项目。
9 |
10 | 本节将介绍 Spark 基础,怎样搭建 Spark 集群,Spark on Mesos 集群以及怎样使用
11 | Spark。
12 |
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/download-spark-hadoop.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/download-spark-hadoop.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/download-spark.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/download-spark.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/spark-components.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/spark-components.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/spark-driver-mesos.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/spark-driver-mesos.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/spark-framework-registered.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/spark-framework-registered.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/spark-homepage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/spark-homepage.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/spark-worker-homepage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/spark-worker-homepage.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/assets/spark-worker-registered.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos-frameworks/spark/assets/spark-worker-registered.png
--------------------------------------------------------------------------------
/mesos-frameworks/spark/basics.md:
--------------------------------------------------------------------------------
1 | # Spark 简介
2 |
3 | Spark 是一个快速、通用的大数据处理引擎。在速度上,Spark 宣称和
4 | Hadoop 相比,有百倍的提升,得益于其基于内存的计算模型;但是,即使使用磁盘,
5 | 也有十倍的速度提升。
6 |
7 | Spark 支持多种高级编程语言,如:Java, Scala, Python, R
8 | 等;并且提供了许多高级操作符,大大降低用户编写 Spark 任务的难度。
9 |
10 | ## Spark 集群模型
11 |
12 | Spark 可以单独以集群的方式运行,也可以运行在 Mesos, YARN 之上。Spark
13 | 包含以下几种组件。
14 |
15 | 
16 |
17 | Cluster Manager 扮演集群资源管理者,例如:Mesos, YARN,或者是 Spark
18 | 本身;Driver Program 负责和 Cluster Manager
19 | 协调,申请资源,并且调度根据资源调度任务到相应的 Worker Node 上。Executor
20 | 负责启动具体的任务进程,并且实现和 Driver Program 之间的协调,完成任务的管理。
21 |
22 | 这一点和前面介绍的 Marathon 和 Chronos 不一样,Marathon 和 Chronos
23 | 对任务都是不可知的,它们实际上只对任务的状态感兴趣,完全不介入任务的逻辑。
24 | 而 Spark 是一个大数据处理框架,它需要切割,组装任务,提供任务间缓存等。
25 |
--------------------------------------------------------------------------------
/mesos-frameworks/spark/job.md:
--------------------------------------------------------------------------------
1 | # 运行 Spark 任务
2 |
3 | 在上一节中我们介绍了怎样搭建一个运行在 Mesos 集群之上的 Spark 服务,并且可以通过 ZooKeeper 实现 Spark 服务的高可用性。
4 |
5 | 本节将介绍怎样提交 Spark 任务,以及怎样将 Spark 任务运行在 Docker 中。
6 |
7 | Spark 提供了多种编程语言绑定,包括:Java, Scala, Python, R 等。介于目前 Java 在大数据领域的绝对优势,这里介绍怎样提交 Java 任务,另外,由于 Scala 也是一种 JVM 语言,提交 Scala 任务和提交 Java 任务的方式类似。
8 |
9 | ## spark-submit
10 |
11 | Spark 提供了一个工具用来提交任务到 Spark 服务中,即:spark-submit,在 `bin` 目录下。spark-submit 支持许多参数来定制提交任务的行为,包括一些必要的参数和可选的参数。
12 |
13 | `spark-submit --help` 能够打印出 spark-submit 的帮助文档,下面介绍一些常用的参数。
14 |
15 | 参数 | 含义
16 | ------ | -----
17 | `--master MASTER_URL` | 指定 spark 服务地址,例如:mesos://10.23.85.234:7077
18 | `--deploy-mode DEPLOY_MODE` | 指定提交任务的方式,合法值为 client 或者 cluster,默认为 client
19 | `--class CLASS_NAME` | 指定将要被运行的 Java/Scala class 名称
20 | `--name NAME` | 任务的名称
21 | `--conf PROP=VALUE` | 设置 Spark 属性
22 | `--properties-file FILE` | 指定 Spark 配置文件,默认为 conf/spark-defaults.conf
23 | `--driver-memory MEM` | 指定 spark driver 使用的内存,默认为 1024M
24 | `--executor-memory MEM` | 指定 spark executor 使用的内存,默认为 1G
25 |
26 | 以下参数在 standalone 和 Mesos 集群方式下有效。
27 |
28 | 参数 | 含义
29 | ------ | -----
30 | `--total-executor-cores NUM` | 所有 executor 占用的 cpu 核数
31 |
32 | 以下参数只有在 standalone 和 Mesos 集群方式,并且在 `--deploy-mode` 为 cluster 时才有效。
33 |
34 | 参数 | 含义
35 | ------ | -----
36 | `--supervise` | 如果指定,当 spark driver 退出时会被自动重启
37 | `--kill SUBMISSION_ID` | 停止任务
38 | `--status SUBMISSION_ID` | 查看任务状态
39 |
40 | ## 提交任务
41 |
42 | 在学习了 spark-submit 常用参数后,下面使用 spark-submit 来提交任务。提交一个 Java/Scala 任务,需要指定以下参数:
43 |
44 | - `--master`
45 | - `--class`
46 |
47 | 以提交 SparkPi 这个示例应用为例,在 10.23.85.235 上 /home/spark/spark-1.5.2-bin-hadoop2.6/bin 目录中,执行下面的命令。
48 |
49 | ```
50 | $ ./spark-submit --master mesos://10.23.85.234:7077 --class org.apache.spark.examples.SparkPi --name "Spark PI example" ../lib/spark-examples-1.5.2-hadoop2.6.0.jar 100
51 | FIXME: output
52 | ```
53 |
54 | 上面的命令首先指定了 spark 服务地址,这里是上节我们搭建的 spark on mesos 服务地址,然后指定了要运行的类名称,然后还指定了本次任务的名称,最后指定了包含任务内容的 jar 文件。
55 |
56 | spark-submit 默认会以 client 的方式提交任务,所以 spark driver 会在本地前台执行,任务的输出会直接通过终端打印出来。
57 |
58 | 如果修改上面的命令,添加 `--deploy-mode cluster` 参数,那么任务将会以 cluster 的方式运行,如下所示:
59 |
60 | ```
61 | $ ./spark-submit --master mesos://10.23.85.234:7077 --class org.apache.spark.examples.SparkPi --name "Spark PI example" --deploy-mode cluster ../lib/spark-examples-1.5.2-hadoop2.6.0.jar 100
62 | FIXME: output
63 | ```
64 |
65 | 通常来说,对于运行在 Mesos 上的 Spark 任务,我们都可以指定 executor 能够使用的资源上限,避免 spark 任务占用过多的资源,例如:
66 |
67 | ```
68 | $ ./spark-submit --master mesos://10.23.85.234:7077 --class org.apache.spark.examples.SparkPi --name "Spark PI example" --deploy-mode cluster --total-executor-cores 10 ../lib/spark-examples-1.5.2-hadoop2.6.0.jar 100
69 | FIXME: output
70 | ```
71 |
72 | 由于 executor 默认会占用 1GB 内存,1 核 CPU,所以本次提交最多占用 10 核 CPU,10GB 内存。
73 |
74 | 对于 Spark 任务来说,通常需要指定较大的 executor 内存,因为 Spark 专门为内存计算设计,在较大内存中更容易获得更快的执行速度,例如:为每个 executor 指定 20GB 内存大小,甚至更大,由于本书的实验环境虚拟机内存大小为 16GB,所以不宜指定太大的 executor 内存。
75 |
76 | 还需要注意的是,spark 任务的 jar 应该要包含除 spark 之外的其它所有依赖,以免集群中的节点并没有配置所有的依赖包。
77 |
78 | ## 集成 Docker
79 |
80 |
--------------------------------------------------------------------------------
/mesos-frameworks/spark/setup.md:
--------------------------------------------------------------------------------
1 | # 搭建Spark服务
2 |
3 | Spark 可以以多种方式运行,最简单的为本地运行方式,适合于开发测试;还可以以 Spark
4 | 集群的方式运行;运行在 Mesos 或者 YARN 上。
5 |
6 | 这里将以两种方式搭建 Spark 服务:集群方式和 Mesos 方式。
7 |
8 | ## Spark 集群
9 |
10 | 在生产环境中搭建 Spark 服务,最简单的应该就是以独立 Spark 集群的方式提供 Spark
11 | 服务,因为这种方式更简单,不用处理与其它框架整合,例如:Mesos 和 YARN,
12 | 然后不可避免的还需要和其它计算框架共享集群。
13 |
14 | 在开始之前,首先下载 Spark,在编写本书之际,Spark 最新的稳定版本是 1.5.2,可以从
15 | Spark 官网上下载,如下图所示:
16 |
17 | 
18 |
19 | 点击页面中的 `Download Spark` 后,跳转到下载页面,如下图所示:
20 |
21 | 
22 |
23 | 由于 Spark 使用了 Hadoop client 来访问 HDFS,所以 Spark 需要基于 Hadoop 来构建,
24 | Spark 下载页面提供了多种下载选择:
25 |
26 | - 源代码
27 | - 不包含 Hadoop 的可执行文件
28 | - 针对各个特性 Hadoop 版本的可执行文件,例如:Hadoop 2.6 及更新版本
29 |
30 | 这里下载 `Pre-built for Hadoop 2.6 and later`,下载的文件名为:`spark-1.5.2-bin-hadoop2.6.tgz`,
31 |
32 | 为了启动集群,需要将 Spark 部署到各个结点中,Spark 集群中只有一个控制结点,
33 | 其余均为计算结点。
34 |
35 | 这里依然假设有 3 台服务器 A, B, C 用来搭建 Spark 集群,其中 A 将作为 Spark
36 | 控制结点,运行 Spark master 进程,而 B 和 C 将作为计算节点,运行 Spark worker
37 | 进程。
38 |
39 | 将下载好的 spark-1.5.2-bin-hadoop2.6.tgz 复制到 3 台服务器的 /opt/spark
40 | 目录下,并且解压。
41 |
42 | ```
43 | # mkdir -p /opt/spark
44 | # cd /opt/spark
45 | # tar xzf spark-1.5.2-bin-hadoop2.6.tgz
46 | # cd spark-1.5.2-bin-hadoop2.6
47 | # ls
48 | bin CHANGES.txt conf data ec2 examples lib LICENSE licenses NOTICE python R README.md RELEASE sbin
49 | ```
50 |
51 |
52 | ### Spark master
53 |
54 | 在服务器 A 上启动 Spark master 进程,如下:
55 |
56 | ```
57 | # cd /opt/spark/spark-1.5.2-bin-hadoop2.6
58 | # ./sbin/start-master.sh
59 | starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-10.23.85.233.out
60 | ```
61 |
62 | Spark master 进程默认会监听本地地址的以下端口:
63 |
64 | - `8080`, Spark master web 用户界面,可以用浏览器查看
65 | - `7077`, Spark master 服务端口,worker 进程将和 master
66 | 进程通过此端口建立连接
67 |
68 | 注意:如果读者在这台机器上启动了 Marathon 或者 Chronos 占用了 8080 端口,需要在启动前使用环境变量修改端口号
69 |
70 | ```
71 | # EXPORT SPARK_MASTER_WEBUI_PORT=8081
72 | # ./sbin/start-master.sh
73 | ```
74 |
75 | 同样,也可以使用环境变量 `SPARK_MASTER_PORT` 修改默认的监听端口 7077。
76 |
77 | 现在,打开浏览器,指向本地地址的 8080 端口,将可以看到 Spark
78 | 集群的运行情况,如下图所示:
79 |
80 | 
81 |
82 | 从 Spark master web 用户界面,可以看到以下几方面的信息:
83 |
84 | - 基本信息:URL,REST URL,Alive Workers 等
85 | - Works:当前的 work
86 | - Running Applications:正在运行的应用
87 | - Completed Applications:已经完成的应用
88 |
89 | 可以看到,目前集群中还没有任何可用的计算结点,所以也不能执行任何任务。
90 | 现在,让我们向集群中添加两个计算结点。
91 |
92 | ### Spark worker
93 |
94 | Spark worker 结点充当 Spark 的计算节点,负责和 Spark 控制节点通信并且运行任务。
95 | 在启动了 Spark 控制节点后,现在分别在服务器 B 和 C 上执行下面的操作来启动 Spark worker 进程。
96 |
97 | ```
98 | $ cd /opt/spark/spark-1.5.2-bin-hadoop2.6
99 | $ ./sbin/start-slave.sh spark://10.23.85.233:7077
100 | starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-10.23.85.235.out
101 | ```
102 |
103 | `start-slave.sh` 接收一个必需的参数,指定 Spark master 运行的地址。Spark worker
104 | 在启动之后,会向 Spark master 注册自己,并且汇报可用的计算资源,默认情况下,
105 | 将汇报所有可用的 CPU 资源以及所有内存减去 1GB,例如:如果计算结点配备了 8GB
106 | 的内存,那么 Spark worker 将汇报有 7GB 可用内存,目的是为计算节点自身稳定运行预留
107 | 1GB 内存。
108 |
109 | Spark worker 默认会监听在本地地址的 8081 端口,提供 web 用户界面,所以,
110 | 用浏览器打开 B 结点的 8081 地址,如下图所示:
111 |
112 | 
113 |
114 | 从 Spark worker web 用户界面,可以了解到以下几方面信息:
115 |
116 | - 基本信息:ID,Master URL,核数,内存大小
117 | - Running Executors:正在运行的 Executors
118 |
119 | 由于这里没有运行任何任务,Running Executors 中为空。
120 |
121 | 另外,再次打开 Spark master 页面,可以看到刚才添加的 2 个 Spark worker,如下图所示:
122 |
123 | 
124 |
125 | ### 启动参数配置
126 |
127 | 在上面启动 Spark master 和 worker 进程时,对于可选参数,都使用了默认值,
128 | 在大多数情况下,这都工作得非常好,但是有些时候可能需要调整一些默认参数。
129 | 下面分别是 start-master.sh 和 start-slave.sh 接受的可选参数。
130 |
131 | #### 公共参数
132 |
133 | start-master.sh 和 start-slave.sh 接受以下公共参数。
134 |
135 | 参数 | 默认值 | 含义
136 | -----| ------ | ----
137 | `-h HOST, --host HOST` | 本地所有地址 | 监听的地址,例如:10.23.85.233
138 | `-i HOST, --ip HOST` | 本地所有地址 | 不再建议使用,建议使用 `-h 或者 --host`
139 | `-p PORT, --port PORT` | 对于 master 来说是 7077,slave 为随机端口 | master 或 slave 和对方通信的端口
140 | `--webui-port PORT` | 对于 master 来说是 8080, slave 是 8081 | master 或 slave web 用户界面监听的端口
141 | `--properties-file FILE` | conf/spark-defaults.conf | 属性配置文件
142 |
143 | #### start-master.sh 参数
144 |
145 | 除了公共参数外,start-master.sh 并没有其它特有的参数。
146 |
147 | #### start-slave.sh 参数
148 |
149 | 除了公共参数外,start-slave.sh 还有一些特有的参数:
150 |
151 | 参数 | 默认值 | 含义
152 | -----| ------ | ----
153 | `-c CORES, --cores CORES` | 本机所有的 CPU | 向 master 注册的可用 CPU 核数
154 | `-m MEM, --memory MEM` | 本机所有的内存减去 1GB | 向 master 注册的可用内存
155 | `-d DIR, --work-dir DIR` | SPARK_HOME/work | 本地工作目录
156 |
157 | 例如,我们可以修改 `--cores`, `--memory` 为本机预留更多的资源,以便计算结点自身更加稳定。
158 | 只需要在启动 `start-slave.sh` 时指定即可,例如:
159 |
160 | ```
161 | $ ./sbin/start-slave.sh --cores 7 --memory 14G spark://10.23.85.233:7077
162 | ```
163 |
164 | ### 集群辅助脚本
165 |
166 | 除了以 `start-master.sh`, `start-slave.sh` 分别启动 master 和 slave
167 | 进程外,Spark 还提供了一次性启动或停止集群的方式,包括以下脚本,
168 | 它们都位于 Spark 的 `sbin` 目录下。
169 |
170 | - start-slaves.sh, 在所有 `conf/slaves` 文件中指定的计算节点上启动
171 | slave 进程
172 | - start-all.sh, 启动 master 和所有 slave 进程
173 | - stop-slaves.sh - 在所有 `conf/slaves` 文件中指定的计算节点上停止 slave 进程
174 | - stop-all.sh - 停止整个集群,包括 master 和 slave 进程
175 |
176 | 这些脚本都通过 SSH 的方式来工作,所以需要事先在其它结点上配置好基于公钥认证的 SSH 登陆配置。
177 | 详细配置方法可以参考本章开始。
178 |
179 | ### 高可用性
180 |
181 | Spark 集群的高可用性包含两方面:Spark master 的高可用性和 Spark worker
182 | 的高可用性。
183 |
184 | Spark worker 的高可用性通过将运行在其上的任务转移到其它结点来实现,所以 Spark
185 | 本身即实现了 worker 的高可用性。
186 |
187 | 而 Spark master 在整个集群中只有一个,所以是一个单点故障,
188 | 从而需要借助其它方式来实现 master 的高可用性。Spark 提供了两种方式:
189 |
190 | - 基于 ZooKeeper
191 | - 基于本地文件
192 |
193 | #### 基于 ZooKeeper
194 |
195 | 在前面的章节已经介绍过 ZooKeeper 的基础知识,以及怎样搭建 ZooKeeper 服务。
196 | 而且包括:Mesos, Marathon, Chronos 都无一例外的使用了 ZooKeeper,Spark
197 | 也不例外,使用 ZooKeeper 作为其 master 高可用性方案也是首选。
198 |
199 | 和 Marathon, Chronos 类似,Spark master 也可以将集群元数据存储在 ZooKeeper
200 | 之中,以便在重新启动,或者其它 master 被选举为 Leader 时重新加载数据,
201 | 从而继续提供服务。
202 |
203 | 所以,基于 ZooKeeper 实现 Spark master 的高可用性非常容易理解:
204 | 在不同机器上以相同的配置启动多个 Spark master 进程,都注册到同一个 ZooKeeper
205 | 服务中即可。相关配置如下:
206 |
207 | - spark.deploy.recoveryMode, 设置为 `ZOOKEEPER`
208 | - spark.deploy.zookeeper.url, 设置 ZooKeeper 集群地址
209 | - spark.deploy.zookeeper.dir, ZooKeeper 中用来存储数据的目录,默认为 `/spark`
210 |
211 | 这些参数都通过 SPARK_DAEMON_JAVA_OPTS 来设置,这个变量可以在 conf/spark-env.sh
212 | 中设置。例如:
213 |
214 | ```
215 | $ cd /opt/spark/spark-1.5.2-bin-hadoop2.6
216 | $ cp conf/spark-env.sh.template conf/spark-env.sh
217 | ```
218 |
219 | 默认这个文件中没有开启任何配置,所以在这个文件中添加如下一行来配置上面的参数。
220 |
221 | ```
222 | SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181
223 | ```
224 |
225 | 注意,需要修改所有 Spark 控制结点上的配置。同时,由于现在启动了多个 Spark
226 | master 进程,当当前作为 Leader 的 master 故障时,为了能够让 worker
227 | 能够自动注册到新的 Leader 结点,worker 在启动时需要同时指定所有 Spark
228 | master。如下:
229 |
230 | ```
231 | ./sbin/start-slave.sh spark://host1:port1,host2:port2
232 | ```
233 |
234 | 如果我们在服务器 A 和 B 上启动了 Spark master,那么可以以下面的方式启动 worker
235 |
236 | ```
237 | ./sbin/start-slave.sh spark://10.23.85.233:7077,10.23.85.234:7077
238 | ```
239 |
240 | #### 基于本地文件
241 |
242 | Spark master 除了能够将集群元数据存储在 ZooKeeper
243 | 之外,还可以将数据存储在本地文件,只需要配置以下两个参数:
244 |
245 | - spark.deploy.recoveryMode, 设置为 FILESYSTEM
246 | - spark.deploy.recoveryDirectory, 设置为一个本地目录
247 |
248 | 和基于 ZooKeeper 方式一样,通过设置 conf/spark-env.sh 文件中的
249 | SPARK_DAEMON_JAVA_OPTS 变量即可。
250 |
251 | 基于本地文件方式的高可用性假设本地文件系统足够可靠,并且能够及时重新启动 Spark
252 | master 进程。所以,这种方式本质上不能称作高可用性,也不推荐在生产环境中使用。
253 | 因为首先本地文件并不是可靠的,硬件可能损坏,文件系统可能损坏,操作系统也可能损坏,
254 | 所以很可能需要花很长一段时间来恢复服务。
255 |
256 | 当然,为了避免本地文件系统的不可用性,读者也可以使用网络文件系统,
257 | 但这或许会引入性能问题或者其它复杂度的问题。所以,总是推荐在生产环境中使用基于
258 | ZooKeeper 的高可用性实现方式。
259 |
260 | ## Spark on Mesos
261 |
262 | 上面介绍了 Spark 以独立的方式搭建集群,Spark 还可以和 Mesos 结合,运行在 Mesos 集群之上。
263 |
264 | Spark 最早出现是在 Mesos 的论文里,作为一个运行在 Mesos 之上的框架,
265 | 用来证明 Mesos 是一种可以有效管理集群,且提高集群综合利用率的方案。
266 | 所以,不言而喻,Spark 可以运行在 Mesos 之上。
267 |
268 | Spark 可以以两种方式运行在 Mesos 之上:
269 |
270 | - Client 模式
271 | - Cluster 模式
272 |
273 | 在 Client 模式下,Spark 以 mesos scheduler 的方式直接和任务耦合在一起。直接运行在提交任务的本地节点上。这种方式比较适合提交任务的节点和 Mesos 集群的计算节点相邻,或者位于同一个子网中,以便 spark driver 和 executor 之间能够保证高速通信。
274 |
275 | 而在 Cluster 模式下,Spark scheduler
276 | 不再和任务耦合在一起,任务是从客户端提交的,spark scheduler(driver) 运行在 Mesos 集群中。
277 |
278 | 这里只介绍 Cluster 模式。
279 |
280 | ### 启动 Spark Scheduler
281 |
282 | 假设 Mesos 线上服务为
283 | `zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos`。
284 |
285 | 将 spark-1.5.2-bin-hadoop2.6.tgz 复制到 10.23.85.234 结点上,
286 | 然后启动 Spark Scheduler,命令如下:
287 |
288 | ```
289 | $ tar xzf spark-1.5.2-bin-hadoop2.6.tgz
290 | $ cd spark-1.5.2-bin-hadoop2.6
291 | $ ./sbin/start-mesos-dispatcher.sh --master mesos://zk://10.23.85.233:2181,10.23.85.234:2181,10.23.85.235:2181/mesos
292 | ```
293 |
294 | `start-mesos-dispatcher.sh` 脚本接受一个参数 `--master`,指明 mesos
295 | 集群的地址,这里的格式为 `mesos://`,其中 `mesos://` 为地址前缀,``
296 | 为 mesos 集群地址,这里可以是单个 mesos master 地址也可以是 mesos 集群在
297 | ZooKeeper 中的地址,这里我们使用了在上一章中搭建了 mesos 生产集群。
298 |
299 | 启动了 Spark Scheduler 之后,可以从 Mesos master web 用户页面看到其已经注册了,
300 | 如下图所示:
301 |
302 | 
303 |
304 | 用浏览器打开 `http://10.23.85.234:8081`,可以看到如下 spark 页面:
305 |
306 | 
307 |
308 | 现在,用户可以通过 Spark 客户端向 Spark Scheduler 提交任务了,只需要指明 Spark
309 | Scheduler 的服务地址即可,这里为:`mesos://10.23.85.234:7077`。
310 |
311 | ### 运行模式
312 |
313 | Spark 在 Mesos 上可以有两种运行模式:
314 |
315 | - `fine-grained`
316 | - `coarse-grained`
317 |
318 | fine-grained 为默认模式,在该模式下,每个 Spark 提交在 Mesos
319 | 上都会注册一个框架,而该次提交内部的每个任务则会通过 Mesos 来调度,
320 | 调度每个任务都需要获取资源、调度任务、执行、完成任务释放资源。
321 |
322 | 这种调度方式的优点是 Spark 各个提交中之间动态共享资源,并且和其它 Mesos
323 | 框架也是动态共享资源,缺点是单次任务都需要经过完整的 Mesos 调度周期,调度较慢;
324 | 所以,不太适合用于低延时的任务,例如,交互式查询等。
325 |
326 | coarse-grained 则是另一种粒度更粗的方式,这种方式只会在有资源的 Mesos
327 | 计算结点上启动 Worker,而后续任务的调度则由 Spark Scheduler 直接将任务分发给
328 | Worker,从而避免完整的 Mesos 调度周期。所以,coarse-grained 方式调度更快,
329 | 但是会长期占用资源。
330 |
331 | 运行模式可以通过 SparkConf 的健 `spark.mesos.coarse` 来配置,值为
332 | `true|false`。需要注意的是:`coarse-grained` 模式默认会使用所有 Mesos 分配的
333 | Offer,所以为了避免占用过多的资源,总是应该设置 SparkConf 的 `spark.cores.max`
334 | 为一个合理值。
335 |
336 | ### 使用 Docker
337 |
338 | Spark 支持启动 Docker 容器来运行 Spark 任务,这要求 Mesos 版本等于或高于
339 | 0.21.0,因为 Mesos 在 0.21.0 中引入了对 Docker 的支持。如果要使用 Docker 容器来执行 Spark 任务,需要再 Docker 镜像中配置好
340 | Spark 执行环境。可以通过 SparkConf 的 `spark.mesos.executor.docker.image`
341 | 来配置要使用的镜像。
342 |
343 | ### Spark on Mesos 配置
344 |
345 | Spark 具有非常高的可配置性,所以也有非常多的配置项,这里不再介绍 Spark
346 | 通用的配置项,读者可以参考官方文档或者其它 Spark 书籍。
347 |
348 | 这里将介绍特定于 Spark on Mesos 的配置,如下表所示:
349 |
350 | 配置项 | 默认值 | 含义
351 | ------ | ------ | -----
352 | `spark.mesos.coarse` | false | 是否使用 `coarse-grained` 模式运行
353 | `spark.mesos.extra.cores` | 0 | 只在 `coarse-grained` 模式下使用,表示使用额外的多少核CPU 来启动 worker,但是所有 worker 的 CPU 之和不能超过 `spark.cores.max`
354 | `spark.mesos.mesosExecutor.cores` | 1.0 | 只在 `fine-grained` 模式下使用,表示 Spark Executor 额外使用的 CPU 核
355 | `spark.mesos.executor.docker.image` | 空 | 启动 Spark Executor 使用的 Docker 镜像
356 | `spark.mesos.executor.docker.volumes` | 空 | 启动 Spark Executor 容器时挂载的卷
357 | `spark.mesos.executor.docker.portmaps` | 空 | 启动 Spark Executor 容器时映射的端口
358 | `spark.mesos.executor.home` | Spark Driver 中设置的 SPARK_HOME | 当没有设置 `spark.executor.uri` 时,Spark 需要从该值中找到 Executor 目录并启动 Executor
359 | `spark.mesos.executor.memoryOverhead` | `spark.executor.memory` 的十分之一,最小为 384MB | 每个 Executor 额外的内存,为了保证不占用 task 的内存
360 | `spark.mesos.uris` | 空 | uris 是 Mesos 提供的初始化运行环境的功能,在启动任务之前,会将 uris 指定的资源下载到任务启动目录中
361 | `spark.mesos.principal` | 空 | Mesos 认证需要的 principal
362 | `spark.mesos.secret` | 空 | Mesos 认证需要的 secret
363 | `spark.mesos.role` | * | Spark Scheduler 使用的角色,角色是 Mesos 用来分配计算资源的一种方法
364 | `spark.mesos.constraints` | 空 | 根据 Mesos 计算节点的标签来设置过滤规则,任务将只被调度到符合条件的计算节点上
365 |
--------------------------------------------------------------------------------
/mesos-frameworks/spark/summary.md:
--------------------------------------------------------------------------------
1 | # 小结
2 |
--------------------------------------------------------------------------------
/mesos-frameworks/summary.md:
--------------------------------------------------------------------------------
1 | # 总结
2 |
--------------------------------------------------------------------------------
/mesos/assets/mesos-3-slaves.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-3-slaves.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-arch.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-frameworks-list.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-frameworks-list.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-frameworks.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-frameworks.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-goto-leader.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-goto-leader.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-master-web.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-master-web.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-offer.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-offer.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-offers.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-offers.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-slave-detail.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-slave-detail.png
--------------------------------------------------------------------------------
/mesos/assets/mesos-slaves-list.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesos-slaves-list.png
--------------------------------------------------------------------------------
/mesos/assets/mesosphere-download.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesosphere-download.png
--------------------------------------------------------------------------------
/mesos/assets/mesosphere-homepage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/mesosphere-homepage.png
--------------------------------------------------------------------------------
/mesos/assets/zookeeper-download.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/zookeeper-download.png
--------------------------------------------------------------------------------
/mesos/assets/zookeeper-project.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesos/assets/zookeeper-project.png
--------------------------------------------------------------------------------
/mesos/how-mesos-works.md:
--------------------------------------------------------------------------------
1 | # Mesos 工作原理
2 |
3 | 本节将简单介绍下 Mesos 的工作原理,以及通过简单的实例来展示 Mesos 的魔力。
4 | 更多更具深度,难度的真实案例读者可以参考本书其它章节。
5 |
6 | ## 为什么是 Mesos
7 |
8 | 简单回顾下计算机界的发展历程,可以发现一些规律,例如:CPU 的发展首先是尝试不断提升单核 CPU
9 | 的计算能力,但是当单核计算能力的提升越来越困难时,多核 CPU
10 | 顺势推出,继续提高着单个计算结点的计算能力,但是当单个计算结点计算能力越来越难于提高,
11 | 或者说成本越来越高时,分布式大规模的集群计算迎难而上。
12 |
13 | 而当各种分布式计算框架越来越流行时,问题出现了,各个框架独自占有各自的计算集群,
14 | 即使在任务不多或者没有任务时,资源依然不能被其它框架共享,导致不能充分利用现有的计算资源。究其原因,大概主要有以下几方面。
15 |
16 | ### 集群搭建复杂,配置管理难度大
17 |
18 | 集群搭建复杂,配置难度大,主要在于如果将多个计算框架部署在一个集群上,
19 | 一旦集群结点达到几十甚至上百个,那么配置管理的难度将非常大,并且呈指数上升,因为要维护多个不同的计算框架。
20 |
21 | ### 硬件可能定制化
22 |
23 | 由于各个计算框架都是针对一定使用场景设计的,所以其任务的类型也具有一定特点,例如:
24 | 当前流行的 Hadoop, Spark, Storm 等计算框架,各自都有自己擅长的计算类型;相应地,
25 | 资源需求类型也不同:Hadoop 需要高性能的磁盘 I/O 以便加速 MapReduce 读写的速度,
26 | Spark 需要大容量内存因为其将计算中间结果都存放在内存中。
27 |
28 | 所以,为了更加节省计算资源,充分利用资源,硬件可能定制化,例如:给 Hadoop
29 | 集群配备 SSD,给 Spark 集群配置大容量内存等。
30 |
31 | 所以,定制化的硬件并不能很好的适用于其它计算框架或者说收益成本比不高。
32 |
33 | ### 计算框架间资源抢占,影响稳定性
34 |
35 | 即使将多个框架搭建在同一个集群中,由于各个框架是独立的,互相间并不知道各自的状态,
36 | 那么很可能出现资源抢占,甚至冲突,例如:框架 A 和 B 可能同时提交大量任务,
37 | 导致集群资源不够用,发生 OOM 等严重错误,甚至同时访问相同的资源,例如:
38 | 访问同一个文件,这将导致更严重的数据损坏。
39 |
40 | ### 计算框架间任务隔离性差
41 |
42 | 单个框架独占集群时,由于整个集群的资源都归单个框架调度,所以,
43 | 能够灵活的调度各个任务到各个结点运行,即使任务间采用最简单的进程隔离,问题也不大。
44 |
45 | 但是,如果是多个框架,那么隔离性差,很可能导致框架间的任务互相影响,例如:
46 | 两个框架的两个任务依赖的库文件版本不一样,或者库之间有冲突等等,这时,
47 | 简单的进程隔离完全不能解决问题,需要文件系统的隔离。
48 |
49 | 在细数了为什么不能很好的将多个分布式计算框架运行在同一个集群之上后,我们回到起点:
50 | 为什么要将多个框架运行在一个集群中呢?
51 |
52 | 在提出这个疑问时,我们潜意识里就已经承认了多个分布式计算框架共享集群能够更好的利用资源。
53 | 在著名的 Mesos 论文中,几位作者也通过详尽的建模,编码,测试,分析验证了这个结论。
54 |
55 | 所以这里我们不再论述这个问题,假设读者接受了这个事实:集群共享比独占集群更节省资源。
56 |
57 | ## Mesos 怎样工作
58 |
59 | 首先,引用一下 Mesos 论文中的 Mesos 架构图,FIXME:如果不能直接引用,可以重画。
60 |
61 | 
62 |
63 | 图中显示了 MPI 和 Hadoop 框架同时运行在 Mesos 之上的情景,图中所示 Mesos 集群由
64 | 3 个控制结点和 3 个计算结点组成,并且所依赖的 ZooKeeper 服务也由 3 个实例组成。
65 |
66 | 在某一个时刻,一个计算结点上可能会同时运行着 MPI 和 Hadoop 的任务。而 MPI 和
67 | Hadoop 都通过 Mesos 控制结点来分发任务,而不是直接向计算结点分发任务。
68 |
69 | 在 Mesos 环境中,运行于 Mesos 之上的框架不再直接管理集群中的计算结点,
70 | 以及直接分发任务,而是通过 Mesos
71 | 控制结点来获取当前可用的资源,然后将任务和资源组合发送给 Mesos 控制结点,
72 | 由控制结点代为分发。
73 |
74 | 这样,Mesos 控制结点唯一控制整个集群的所有资源,具有全局资源试图,
75 | 能够协调上层运行的多个计算框架,从而实现集群资源有序共享,而不会导致资源抢占甚至冲突。
76 |
77 | 在任务隔离上,基于 Linux Control Groups, Mesos 可以做到多方面的隔离,
78 | 保证各个任务在一个良好的隔离环境中运行;值得一提的是:Mesos
79 | 支持当前最为流行的容器技术 Docker,Docker CTO 曾公开表示 Mesos 是 Docker
80 | 的黄金搭档。
81 |
82 | 在理解了 Mesos 架构图之后,我们再深入一点,看看 Mesos 是怎样管理资源的。
83 |
84 | 
85 |
86 | 1. 计算节点向控制结点汇报可用资源
87 | 2. 控制结点汇集当前可用的资源,并以 offer 的方式发送给计算框架
88 | 3. 计算框架根据收到的资源,调度自己的任务
89 | 4. 控制结点解析计算框架发送的任务,并调度到计算节点中执行
90 |
91 | 看起来很简单,对吗?我们稍微深入一点实现细节。
92 |
93 | ### 汇报可用资源
94 |
95 | 如果读者观察过 mesos-slave 的日志文件,可以看到 mesos-slave
96 | 在启动时会自动获取当前机器可用的资源,包括:
97 |
98 | - CPU 核数
99 | - 内存大小
100 | - 磁盘大小
101 | - 网络端口
102 |
103 | 如下为 A 机器上 mesos-slave 启动时的相关日志示例。
104 |
105 | ```
106 | ... 省略部分日志 ...
107 | I0403 18:14:33.822067 14747 main.cpp:272] Starting Mesos slave
108 | I0403 18:14:33.822293 14747 slave.cpp:190] Slave started on 1)@10.23.85.234:5051
109 | ... 省略部分日志 ...
110 | I0403 18:14:33.823786 14747 slave.cpp:354] Slave resources: cpus(*):8; mem(*):14862; disk(*):46055; ports(*):[31000-32000]
111 | I0403 18:14:33.824726 14747 slave.cpp:390] Slave hostname: 10.23.85.234
112 | I0403 18:14:33.824758 14747 slave.cpp:395] Slave checkpoint: true
113 | ... 省略部分日志 ...
114 | ```
115 |
116 | 从上面的日志中,我们可以知道,在 A 机器上,mesos-slave 表明自己可用的资源为
117 |
118 | - CPU: 8 核
119 | - 内存:14862 MB
120 | - 磁盘:46055 MB
121 | - 网络端口:[31000-32000]
122 |
123 | 每种资源的括号后都带有一个星号(*),表示这些资源是可共享的资源,在 Mesos 中,默认的资源都是共享的,也可以为计算节点指定为某些 role 预留资源。
124 |
125 | 指定计算资源通过配置 mesos-slave 的 `--resources` 参数实现,格式为:
126 |
127 | ```
128 | name(role):value;name(role):value...
129 | ```
130 |
131 | 其中,`name` 是资源的名称,mesos 内置了以下几种资源:
132 |
133 | - cpus,CPU
134 | - mem,内存
135 | - disk,磁盘
136 | - ports,网络端口
137 |
138 | CPU 和内存是必须资源,缺少其中任何一种都不能运行任务。例如:可以指定 A
139 | 机器的资源为:
140 |
141 | ```
142 | cpus(foo):2;mem(foo):2048;cpus(*):2;mem(*):6144
143 | ```
144 |
145 | 这里我们只指定了两种必须的资源:CPU 和内存,其它资源将以自动检测的为准。
146 | 除了 Mesos 内置的资源外,还可以指定用户自定义的资源,mesos
147 | 同样会将用户定义的资源发送给计算框架,从而调度任务。
148 |
149 | 注意:修改资源配置要在重启 mesos-slave 后才生效,不过,Mesos 在 0.23.0 版本中也引入了动态预留资源,这部分高级特性留给感兴趣的读者自行研究。
150 |
151 | ### 发送 Offer
152 |
153 | 计算节点在启动时,会向控制节点汇报可用资源,而控制节点则会将计算结点加入到注册表中,
154 | 并且将可用资源记录在案,并且在适当的时候根据调度算法将资源以 Offer
155 | 的方式发送给上层运行的计算框架。
156 |
157 | 每个 Offer 代表一个计算节点上的可用资源,所以,为了提高效率,
158 | 控制结点往往会一次性将多个 Offer 发送给一个框架,以便框架能够批量调度任务。
159 |
160 | 查看 mesos-master 的日志,我们可以看到这种事件,例如:
161 |
162 | ```
163 | I0403 20:58:51.936903 1427 master.cpp:4967] Sending 2 offers to framework 20150714-181406-760551178-5050-27792-0000 (marathon) at scheduler-2ccd1a4e-0191-4c1d-be7d-b12e760e98c5@10.23.85.218:26030
164 | ```
165 |
166 | 上面的日志显示 mesos-master 向框架 20150714-181406-760551178-5050-27792-0000 (marathon) 发送了 2 个 Offer。
167 |
168 | 在 Mesos 中,一个 Offer 就是一个计算结点在某一时刻对当前框架的所有可用资源。
169 | 这里,需要注意一些限定:
170 |
171 | - 一个计算结点,也就是说 Offer 和计算结点是一对一的关系
172 | - 当前框架,也就是即使是在同一时刻,各个框架看到的 Offer
173 | 可能是不同的,因为计算结点可能为某些角色预留资源,配置不同的资源等
174 | - 所有可用资源,即总是可以断定,mesos
175 | 不会将一个计算结点对某个框架可用的资源分成不同的 Offer 来发送,
176 | 原因很明显,因为会导致碎片
177 |
178 | ### 调度任务
179 |
180 | 当计算框架收到 Offer 时,便可以根据 Offer
181 | 来调度任务了,例如:有两个任务需要运行,分别为:
182 |
183 | - 任务 A: 2 个 CPU,1GB 内存
184 | - 任务 B: 1 个 CPU, 2GB 内存
185 |
186 | 收到的 2 个 Offer 为:
187 |
188 | - Offer 1: 1.5 个 CPU, 5GB 内存
189 | - Offer 2: 2 个 CPU, 2GB 内存
190 |
191 | 那么,调度框架如果先调度 A(可能 A 的优先级比 B 的高),会发现 Offer 1
192 | 不满足需求,所以可能首先拒绝掉 Offer 1,然后检查 Offer 2,发现可用,
193 | 那么就会组装一个任务,并且声明这个任务使用了 Offer 2 的 2 个 CPU, 1GB 内存;
194 | 然后,继续调度任务 B,发现 Offer 2 已经不够了,而且已经没有更多 Offer 了,
195 | 所以这一轮调度就只能调度一个任务。
196 |
197 | 很显然,这里并没有最优调度,因为任务 B 是可以使用 Offer 1 的,但是 Offer 1
198 | 却被拒绝掉了。
199 |
200 | 这里只是一个简单的任务调度示例,真实的调度算法可以非常复杂,非常高效。
201 |
202 | 当计算框架完成了本轮调度后,就会把组装好的任务发送给控制结点。
203 |
204 | ### 启动任务
205 |
206 | 控制结点在收到任务后,会打开任务,看看这个任务使用的 Offer,并且更新相应的
207 | Offer,减去将要被使用的资源,然后将任务发送到 Offer
208 | 中指定的计算结点,我们知道,Offer 是何计算结点一一对应的。
209 |
210 | 计算结点在收到任务后,就会按照指示,启动任务,并且为任务设置好资源限制,
211 | 以免任务使用超标的资源。
212 |
213 | 接下来,控制节点需要向控制结点汇报任务的状态,如果任务完成,
214 | 那么控制结点就会回收这个任务使用的资源,并且更新相应的 Offer。
215 |
216 | 这样,一个任务的生命周期就完成了,Mesos
217 | 就这样周而复始的动态的管理着整个集群的运转。
218 |
219 | ## 小结
220 |
221 | 本节简单的剖析了 Mesos 的工作原理,希望对读者在阅读后面的实战章节有些帮助,
222 | 本节内容抛砖引玉,只揭开了 Mesos 神秘面纱的一角,更多的秘密需要读者更多实践,
223 | 更多的学习去解开。
224 |
225 | 在下一章,我们将介绍几个 Meoss 生态圈中最常见的计算框架,以及一些基础用例,
226 | 以便读者能更好的理解后续实战章节的内容以及创造自己的实战案例。
227 |
--------------------------------------------------------------------------------
/mesos/summary.md:
--------------------------------------------------------------------------------
1 | # 总结
2 |
3 | 本章简单介绍了 Mesos 的历史,以及怎样搭建一个可用于生产环境的 Mesos 集群,
4 | 还介绍了 Mesos 依赖的 ZooKeeper 服务以及怎样搭建高可用的 ZooKeeper 服务。
5 | 最后,分析了 Mesos 工作原理。
6 |
--------------------------------------------------------------------------------
/mesosben_shen_shi_yi_ge_fen_bu_shi_zi_yuan_diao_du.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesosben_shen_shi_yi_ge_fen_bu_shi_zi_yuan_diao_du.png
--------------------------------------------------------------------------------
/mesosshi-zhan-pian.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/mesosshi-zhan-pian.md
--------------------------------------------------------------------------------
/rong_qi_bian_pai_ff1a.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xiaods/mesos-handbook/16c395ffa746f9b5a26a3f105772c9ec67247a60/rong_qi_bian_pai_ff1a.png
--------------------------------------------------------------------------------
/wercker.yml:
--------------------------------------------------------------------------------
1 | box: billryan/gitbook:base
2 | build:
3 | steps:
4 | - script:
5 | name: build
6 | code: |
7 | gitbook install
8 | gitbook build
9 |
--------------------------------------------------------------------------------