├── examples
├── chainlit.md
├── public
│ ├── favicon.png
│ ├── logo_light.png
│ ├── hide-watermark.js
│ ├── theme.json
│ ├── elements
│ │ └── DataDisplay.jsx
│ └── logo_light.svg
├── particle_trajectory_analysis.png
├── README.md
├── particle_trajectory_analysis.yaml
├── .chainlit
│ └── config.toml
├── writing_improvement.py
└── trajectory_analysis.py
├── assets
└── logo.jpg
├── pyproject.toml
├── requirements.txt
├── MANIFEST.in
├── CITATION.cff
├── setup.py
├── LICENSE
├── nodeology
├── __init__.py
├── log.py
├── client.py
├── state.py
├── interface.py
└── node.py
├── CONTRIBUTING.md
├── .gitignore
├── README.md
└── tests
├── test_state.py
└── test_node.py
/examples/chainlit.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/assets/logo.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xyin-anl/Nodeology/HEAD/assets/logo.jpg
--------------------------------------------------------------------------------
/examples/public/favicon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xyin-anl/Nodeology/HEAD/examples/public/favicon.png
--------------------------------------------------------------------------------
/examples/public/logo_light.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xyin-anl/Nodeology/HEAD/examples/public/logo_light.png
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = ["setuptools>=45", "wheel"]
3 | build-backend = "setuptools.build_meta"
--------------------------------------------------------------------------------
/examples/particle_trajectory_analysis.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/xyin-anl/Nodeology/HEAD/examples/particle_trajectory_analysis.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | requests
2 | pyyaml
3 | typing-extensions
4 | numpy
5 | plotly
6 | kaleido
7 | langgraph<=0.2.45
8 | litellm>=1.0.0
9 | langfuse>=2.0.0
10 | chainlit>=2.0.0
11 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include LICENSE
2 | include README.md
3 | include requirements.txt
4 | include CITATION.cff
5 | include CONTRIBUTING.md
6 | recursive-include examples *
7 | recursive-include tests *
8 | recursive-include nodeology *
--------------------------------------------------------------------------------
/CITATION.cff:
--------------------------------------------------------------------------------
1 | cff-version: 1.2.0
2 | message: "If you use this software, please cite it as below."
3 | authors:
4 | - family-names: "Xiangyu"
5 | given-names: "Yin"
6 | orcid: "https://orcid.org/0000-0003-2868-1728"
7 | title: "Nodeology"
8 | version: 0.0.1
9 | date-released: 2024-11-20
10 | url: "https://github.com/xyin-anl/Nodeology"
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | with open("README.md", "r", encoding="utf-8") as fh:
4 | long_description = fh.read()
5 |
6 | with open("requirements.txt", "r", encoding="utf-8") as fh:
7 | requirements = [
8 | line.strip() for line in fh if line.strip() and not line.startswith("#")
9 | ]
10 |
11 | setup(
12 | name="nodeology",
13 | version="0.0.2",
14 | author="Xiangyu Yin",
15 | author_email="xyin@anl.gov",
16 | description="Foundation AI-Enhanced Scientific Workflow",
17 | long_description=long_description,
18 | long_description_content_type="text/markdown",
19 | url="https://github.com/xyin-anl/nodeology",
20 | packages=find_packages(),
21 | include_package_data=True,
22 | package_data={
23 | "": ["*.md", "*.cff", "LICENSE"],
24 | "nodeology": ["examples/*", "tests/*"],
25 | },
26 | classifiers=[
27 | "Intended Audience :: Science/Research",
28 | "Programming Language :: Python :: 3",
29 | ],
30 | python_requires=">=3.10",
31 | install_requires=requirements,
32 | )
33 |
--------------------------------------------------------------------------------
/examples/README.md:
--------------------------------------------------------------------------------
1 | # Nodeology Examples
2 |
3 | This directory contains example applications built with Nodeology, demonstrating features of the framework.
4 |
5 | ## Prerequisites
6 |
7 | Before running the examples, ensure you have `nodeology` installed
8 |
9 | ```bash
10 | pip install nodeology
11 | ```
12 |
13 | ## Directory Structure
14 |
15 | - `writing_improvement.py` - Text analysis and improvement workflow
16 | - `trajectory_analysis.py` - Particle trajectory simulation and visualization
17 | - `public/` - Static assets for the examples (needed for `nodeology` UI elements)
18 | - `.chainlit/` - Chainlit configuration files (needed for `nodeology` UI settings)
19 |
20 | ## Available Examples
21 |
22 | ### 1. Writing Improvement (`writing_improvement.py`)
23 |
24 | An interactive application that helps users improve their writing through analysis and suggestions. This example demonstrates:
25 |
26 | - State management with Nodeology
27 | - Interactive user input handling
28 | - Text analysis workflow
29 | - Chainlit UI integration
30 |
31 | To run this example:
32 |
33 | ```bash
34 | cd examples
35 | python writing_improvement.py
36 | ```
37 |
38 | ### 2. Particle Trajectory Analysis (`trajectory_analysis.py`)
39 |
40 | A scientific application that simulates and visualizes particle trajectories under electromagnetic fields. This example showcases:
41 |
42 | - Complex scientific calculations
43 | - Interactive parameter input
44 | - Data visualization
45 | - State management for scientific workflows
46 | - Advanced Chainlit UI features
47 |
48 | To run this example:
49 |
50 | ```bash
51 | cd examples
52 | python trajectory_analysis.py
53 | ```
54 |
55 | ## Usage Tips
56 |
57 | 1. Each example will open in your default web browser when launched
58 | 2. Follow the interactive prompts in the Chainlit UI
59 | 3. You can modify parameters and experiment with different inputs
60 | 4. Use the chat interface to interact with the applications
61 |
62 | ## License
63 |
64 | These examples are provided under the same license as the main Nodeology project. See the license headers in individual files for details.
65 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (c) 2024, UChicago Argonne, LLC. All rights reserved.
2 |
3 | Copyright 2024. UChicago Argonne, LLC. This software was produced
4 | under U.S. Government contract DE-AC02-06CH11357 for Argonne National
5 | Laboratory (ANL), which is operated by UChicago Argonne, LLC for the
6 | U.S. Department of Energy. The U.S. Government has rights to use,
7 | reproduce, and distribute this software. NEITHER THE GOVERNMENT NOR
8 | UChicago Argonne, LLC MAKES ANY WARRANTY, EXPRESS OR IMPLIED, OR
9 | ASSUMES ANY LIABILITY FOR THE USE OF THIS SOFTWARE. If software is
10 | modified to produce derivative works, such modified software should
11 | be clearly marked, so as not to confuse it with the version available
12 | from ANL.
13 |
14 | Additionally, redistribution and use in source and binary forms, with
15 | or without modification, are permitted provided that the following
16 | conditions are met:
17 |
18 | * Redistributions of source code must retain the above copyright
19 | notice, this list of conditions and the following disclaimer.
20 |
21 | * Redistributions in binary form must reproduce the above copyright
22 | notice, this list of conditions and the following disclaimer in
23 | the documentation and/or other materials provided with the
24 | distribution.
25 |
26 | * Neither the name of UChicago Argonne, LLC, Argonne National
27 | Laboratory, ANL, the U.S. Government, nor the names of its
28 | contributors may be used to endorse or promote products derived
29 | from this software without specific prior written permission.
30 |
31 | THIS SOFTWARE IS PROVIDED BY UChicago Argonne, LLC AND CONTRIBUTORS
32 | "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
33 | LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
34 | FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL UChicago
35 | Argonne, LLC OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
36 | INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
37 | BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
38 | LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
39 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
40 | LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
41 | ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
42 | POSSIBILITY OF SUCH DAMAGE.
--------------------------------------------------------------------------------
/nodeology/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Copyright (c) 2024, UChicago Argonne, LLC. All rights reserved.
3 |
4 | Copyright 2024. UChicago Argonne, LLC. This software was produced
5 | under U.S. Government contract DE-AC02-06CH11357 for Argonne National
6 | Laboratory (ANL), which is operated by UChicago Argonne, LLC for the
7 | U.S. Department of Energy. The U.S. Government has rights to use,
8 | reproduce, and distribute this software. NEITHER THE GOVERNMENT NOR
9 | UChicago Argonne, LLC MAKES ANY WARRANTY, EXPRESS OR IMPLIED, OR
10 | ASSUMES ANY LIABILITY FOR THE USE OF THIS SOFTWARE. If software is
11 | modified to produce derivative works, such modified software should
12 | be clearly marked, so as not to confuse it with the version available
13 | from ANL.
14 |
15 | Additionally, redistribution and use in source and binary forms, with
16 | or without modification, are permitted provided that the following
17 | conditions are met:
18 |
19 | * Redistributions of source code must retain the above copyright
20 | notice, this list of conditions and the following disclaimer.
21 |
22 | * Redistributions in binary form must reproduce the above copyright
23 | notice, this list of conditions and the following disclaimer in
24 | the documentation and/or other materials provided with the
25 | distribution.
26 |
27 | * Neither the name of UChicago Argonne, LLC, Argonne National
28 | Laboratory, ANL, the U.S. Government, nor the names of its
29 | contributors may be used to endorse or promote products derived
30 | from this software without specific prior written permission.
31 |
32 | THIS SOFTWARE IS PROVIDED BY UChicago Argonne, LLC AND CONTRIBUTORS
33 | "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
34 | LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
35 | FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL UChicago
36 | Argonne, LLC OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
37 | INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
38 | BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
39 | LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
40 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
41 | LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
42 | ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
43 | POSSIBILITY OF SUCH DAMAGE.
44 | """
45 |
46 | ### Initial Author <2024>: Xiangyu Yin
47 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing to Nodeology
2 |
3 | Thank you for your interest in contributing to Nodeology! This document provides guidelines and information about contributing to the project.
4 |
5 | ## Ways to Contribute
6 |
7 | ### Code Contributions
8 |
9 | 1. **Core Framework**
10 |
11 | - Bug fixes and improvements
12 | - Performance optimizations
13 | - New features
14 | - Test coverage
15 |
16 | 2. **Pre-built Components**
17 | - New node types
18 | - State definitions
19 | - Workflow templates
20 | - Domain-specific tools
21 |
22 | ### Documentation
23 |
24 | - API documentation
25 | - Usage examples
26 | - Tutorials
27 | - Best practices
28 |
29 | ### Research Collaborations
30 |
31 | 1. **Workflow Patterns**
32 |
33 | - Novel automation patterns
34 | - Optimization strategies
35 | - Human-AI interaction interfaces
36 | - Error handling approaches
37 |
38 | 2. **Scientific Integration**
39 |
40 | - Domain-specific applications
41 | - Instrument interfaces
42 | - Data processing pipelines
43 | - Analysis tools
44 |
45 | 3. **Evaluation Methods**
46 |
47 | - Benchmark development
48 | - Performance metrics
49 | - Reliability assessment
50 | - Comparison frameworks
51 |
52 | 4. **AI Integration**
53 | - Prompt optimization
54 | - Model evaluation
55 | - Hybrid processing
56 | - Knowledge integration
57 |
58 | ## Getting Started
59 |
60 | 1. **Development Setup**
61 |
62 | ```bash
63 | # Clone repository
64 | git clone https://github.com/xyin-anl/nodeology.git
65 | cd nodeology
66 |
67 | # Create virtual environment using venv or conda
68 | python -m venv venv
69 | source venv/bin/activate
70 |
71 | # Install dependencies
72 | pip install -r requirements.txt
73 |
74 | # Install pytest
75 | pip install pytest
76 |
77 | # Run tests
78 | pytest tests/
79 | ```
80 |
81 | ## Guidelines
82 |
83 | 1. **Code Contributions**
84 |
85 | - Fork repository
86 | - Create feature branch
87 | - Submit pull request
88 | - Use `black` formatter
89 | - Write clear commit messages
90 | - Add unit tests
91 | - Update/create documentation if possible
92 | - Include example usage if possible
93 |
94 | 2. **Documentation**
95 |
96 | - Clear, concise writing
97 | - Practical examples
98 | - Proper formatting
99 | - Complete coverage
100 |
101 | 3. **Community**
102 | - Be respectful
103 | - Provide constructive feedback
104 | - Help new users
105 | - Share knowledge
106 |
--------------------------------------------------------------------------------
/examples/particle_trajectory_analysis.yaml:
--------------------------------------------------------------------------------
1 | name: TrajectoryWorkflow_03_13_2025_20_06_45
2 | state_defs:
3 | - current_node_type: str
4 | - previous_node_type: str
5 | - human_input: str
6 | - input: str
7 | - output: str
8 | - messages: List[dict]
9 | - mass: float
10 | - charge: float
11 | - initial_velocity: ndarray
12 | - E_field: ndarray
13 | - B_field: ndarray
14 | - confirm_parameters: bool
15 | - parameters_updater_output: str
16 | - positions: List[ndarray]
17 | - trajectory_plot: str
18 | - trajectory_plot_path: str
19 | - analysis_result: dict
20 | - continue_simulation: bool
21 | nodes:
22 | display_parameters:
23 | type: display_parameters
24 | next: ask_confirm_parameters
25 | ask_confirm_parameters:
26 | type: ask_confirm_parameters
27 | sink: confirm_parameters
28 | next:
29 | condition: confirm_parameters
30 | then: calculate_trajectory
31 | otherwise: ask_parameters_input
32 | ask_parameters_input:
33 | type: ask_parameters_input
34 | sink: human_input
35 | next: update_parameters
36 | update_parameters:
37 | type: prompt
38 | template: 'Update the parameters based on the user''s input. Current parameters:
39 | mass: {mass} charge: {charge} initial_velocity: {initial_velocity} E_field:
40 | {E_field} B_field: {B_field} User input: {human_input} Please return the updated
41 | parameters in JSON format. {{ "mass": float, "charge": float, "initial_velocity":
42 | list[float], "E_field": list[float], "B_field": list[float] }}'
43 | sink: parameters_updater_output
44 | next: display_parameters
45 | calculate_trajectory:
46 | type: calculate_trajectory
47 | sink: positions
48 | next: plot_trajectory
49 | plot_trajectory:
50 | type: plot_trajectory
51 | sink: [trajectory_plot, trajectory_plot_path]
52 | next: analyze_trajectory
53 | analyze_trajectory:
54 | type: prompt
55 | template: 'Analyze this particle trajectory plot. Please determine: 1. The type
56 | of motion (linear, circular, helical, or chaotic) 2. Key physical features (radius,
57 | period, pitch angle if applicable) 3. Explanation of the motion 4. Anomalies
58 | in the motion Output in JSON format: {{ "trajectory_type": "type_name", "key_features":
59 | { "feature1": value, "feature2": value }, "explanation": "detailed explanation",
60 | "anomalies": "anomaly description" }}'
61 | sink: analysis_result
62 | image_keys: trajectory_plot_path
63 | next: ask_continue_simulation
64 | ask_continue_simulation:
65 | type: ask_continue_simulation
66 | sink: continue_simulation
67 | next:
68 | condition: continue_simulation
69 | then: display_parameters
70 | otherwise: END
71 | entry_point: display_parameters
72 | llm: gemini/gemini-2.0-flash
73 | vlm: gemini/gemini-2.0-flash
74 | exit_commands: [stop workflow, quit workflow, terminate workflow]
75 |
--------------------------------------------------------------------------------
/examples/public/hide-watermark.js:
--------------------------------------------------------------------------------
1 | function hideWatermark() {
2 | // Try multiple selector approaches
3 | const selectors = [
4 | "#chainlit-copilot",
5 | ".cl-copilot-container",
6 | "[data-testid='copilot-container']",
7 | // Add any other potential selectors
8 | ];
9 |
10 | for (const selector of selectors) {
11 | const elements = document.querySelectorAll(selector);
12 |
13 | elements.forEach(element => {
14 | // Try to access shadow DOM if it exists
15 | if (element.shadowRoot) {
16 | const watermarks = element.shadowRoot.querySelectorAll("a.watermark, .watermark, [class*='watermark']");
17 | watermarks.forEach(watermark => {
18 | watermark.style.display = "none";
19 | watermark.style.visibility = "hidden";
20 | watermark.remove(); // Try to remove it completely
21 | });
22 | }
23 |
24 | // Also check for watermarks in the regular DOM
25 | const directWatermarks = element.querySelectorAll("a.watermark, .watermark, [class*='watermark']");
26 | directWatermarks.forEach(watermark => {
27 | watermark.style.display = "none";
28 | watermark.style.visibility = "hidden";
29 | watermark.remove(); // Try to remove it completely
30 | });
31 | });
32 | }
33 |
34 | // Add CSS to hide watermarks globally
35 | const style = document.createElement('style');
36 | style.textContent = `
37 | a.watermark, .watermark, [class*='watermark'] {
38 | display: none !important;
39 | visibility: hidden !important;
40 | opacity: 0 !important;
41 | pointer-events: none !important;
42 | }
43 | `;
44 | document.head.appendChild(style);
45 | }
46 |
47 | // More aggressive approach with mutation observer for the entire document
48 | function setupGlobalObserver() {
49 | const observer = new MutationObserver((mutations) => {
50 | let shouldCheck = false;
51 |
52 | for (const mutation of mutations) {
53 | if (mutation.addedNodes.length > 0) {
54 | shouldCheck = true;
55 | break;
56 | }
57 | }
58 |
59 | if (shouldCheck) {
60 | hideWatermark();
61 | }
62 | });
63 |
64 | observer.observe(document.body, {
65 | childList: true,
66 | subtree: true
67 | });
68 | }
69 |
70 | // Run on page load
71 | document.addEventListener("DOMContentLoaded", function() {
72 | // Try immediately
73 | hideWatermark();
74 |
75 | // Setup global observer
76 | setupGlobalObserver();
77 |
78 | // Try again after delays to catch late-loading elements
79 | setTimeout(hideWatermark, 1000);
80 | setTimeout(hideWatermark, 3000);
81 |
82 | // Periodically check
83 | setInterval(hideWatermark, 5000);
84 | });
85 |
86 | // Also run the script immediately in case the DOM is already loaded
87 | if (document.readyState === "complete" || document.readyState === "interactive") {
88 | hideWatermark();
89 | setTimeout(setupGlobalObserver, 0);
90 | }
91 |
--------------------------------------------------------------------------------
/examples/public/theme.json:
--------------------------------------------------------------------------------
1 | {
2 | "custom_fonts": [],
3 | "variables": {
4 | "light": {
5 | "--font-sans": "'Inter', sans-serif",
6 | "--font-mono": "source-code-pro, Menlo, Monaco, Consolas, 'Courier New', monospace",
7 | "--background": "0 0% 100%",
8 | "--foreground": "0 0% 5%",
9 | "--card": "0 0% 100%",
10 | "--card-foreground": "0 0% 5%",
11 | "--popover": "0 0% 100%",
12 | "--popover-foreground": "0 0% 5%",
13 | "--primary": "150 40% 60%",
14 | "--primary-foreground": "0 0% 100%",
15 | "--secondary": "150 30% 90%",
16 | "--secondary-foreground": "150 30% 20%",
17 | "--muted": "0 0% 90%",
18 | "--muted-foreground": "150 15% 30%",
19 | "--accent": "0 0% 95%",
20 | "--accent-foreground": "150 30% 20%",
21 | "--destructive": "0 84.2% 60.2%",
22 | "--destructive-foreground": "210 40% 98%",
23 | "--border": "150 30% 75%",
24 | "--input": "150 30% 75%",
25 | "--ring": "150 40% 60%",
26 | "--radius": "0.75rem",
27 | "--sidebar-background": "0 0% 98%",
28 | "--sidebar-foreground": "240 5.3% 26.1%",
29 | "--sidebar-primary": "150 40% 60%",
30 | "--sidebar-primary-foreground": "0 0% 98%",
31 | "--sidebar-accent": "240 4.8% 95.9%",
32 | "--sidebar-accent-foreground": "240 5.9% 10%",
33 | "--sidebar-border": "220 13% 91%",
34 | "--sidebar-ring": "217.2 91.2% 59.8%"
35 | },
36 | "dark": {
37 | "--font-sans": "'Inter', sans-serif",
38 | "--font-mono": "source-code-pro, Menlo, Monaco, Consolas, 'Courier New', monospace",
39 | "--background": "0 0% 13%",
40 | "--foreground": "0 0% 93%",
41 | "--card": "0 0% 18%",
42 | "--card-foreground": "210 40% 98%",
43 | "--popover": "0 0% 18%",
44 | "--popover-foreground": "210 40% 98%",
45 | "--primary": "150 45% 50%",
46 | "--primary-foreground": "0 0% 100%",
47 | "--secondary": "150 35% 25%",
48 | "--secondary-foreground": "0 0% 98%",
49 | "--muted": "150 15% 30%",
50 | "--muted-foreground": "150 10% 80%",
51 | "--accent": "150 40% 40%",
52 | "--accent-foreground": "0 0% 98%",
53 | "--destructive": "0 62.8% 30.6%",
54 | "--destructive-foreground": "210 40% 98%",
55 | "--border": "150 30% 40%",
56 | "--input": "150 30% 40%",
57 | "--ring": "150 45% 50%",
58 | "--sidebar-background": "0 0% 9%",
59 | "--sidebar-foreground": "240 4.8% 95.9%",
60 | "--sidebar-primary": "150 45% 50%",
61 | "--sidebar-primary-foreground": "0 0% 100%",
62 | "--sidebar-accent": "150 25% 20%",
63 | "--sidebar-accent-foreground": "240 4.8% 95.9%",
64 | "--sidebar-border": "240 3.7% 15.9%",
65 | "--sidebar-ring": "217.2 91.2% 59.8%"
66 | }
67 | }
68 | }
--------------------------------------------------------------------------------
/examples/.chainlit/config.toml:
--------------------------------------------------------------------------------
1 | [project]
2 | # Whether to enable telemetry (default: true). No personal data is collected.
3 | enable_telemetry = false
4 |
5 | # List of environment variables to be provided by each user to use the app.
6 | user_env = []
7 |
8 | # Duration (in seconds) during which the session is saved when the connection is lost
9 | session_timeout = 3600
10 |
11 | # Duration (in seconds) of the user session expiry
12 | user_session_timeout = 1296000 # 15 days
13 |
14 | # Enable third parties caching (e.g LangChain cache)
15 | cache = false
16 |
17 | # Authorized origins
18 | allow_origins = ["*"]
19 |
20 | [features]
21 | # Process and display HTML in messages. This can be a security risk (see https://stackoverflow.com/questions/19603097/why-is-it-dangerous-to-render-user-generated-html-or-javascript)
22 | unsafe_allow_html = false
23 |
24 | # Process and display mathematical expressions. This can clash with "$" characters in messages.
25 | latex = false
26 |
27 | # Automatically tag threads with the current chat profile (if a chat profile is used)
28 | auto_tag_thread = true
29 |
30 | # Allow users to edit their own messages
31 | edit_message = true
32 |
33 | # Authorize users to spontaneously upload files with messages
34 | [features.spontaneous_file_upload]
35 | enabled = true
36 | # Define accepted file types using MIME types
37 | # Examples:
38 | # 1. For specific file types:
39 | # accept = ["image/jpeg", "image/png", "application/pdf"]
40 | # 2. For all files of certain type:
41 | # accept = ["image/*", "audio/*", "video/*"]
42 | # 3. For specific file extensions:
43 | # accept = { "application/octet-stream" = [".xyz", ".pdb"] }
44 | # Note: Using "*/*" is not recommended as it may cause browser warnings
45 | accept = ["*/*"]
46 | max_files = 20
47 | max_size_mb = 500
48 |
49 | [features.audio]
50 | # Sample rate of the audio
51 | sample_rate = 24000
52 |
53 | [UI]
54 | # Name of the assistant.
55 | name = "Assistant"
56 |
57 | # default_theme = "light"
58 |
59 | # layout = "wide"
60 |
61 | # Description of the assistant. This is used for HTML tags.
62 | # description = ""
63 |
64 | # Chain of Thought (CoT) display mode. Can be "hidden", "tool_call" or "full".
65 | cot = "full"
66 |
67 | # Specify a CSS file that can be used to customize the user interface.
68 | # The CSS file can be served from the public directory or via an external link.
69 | # custom_css = "/public/test.css"
70 |
71 | # Specify a Javascript file that can be used to customize the user interface.
72 | # The Javascript file can be served from the public directory.
73 | custom_js = "/public/hide-watermark.js"
74 |
75 | # Specify a custom meta image url.
76 | # custom_meta_image_url = "https://chainlit-cloud.s3.eu-west-3.amazonaws.com/logo/chainlit_banner.png"
77 |
78 | # Specify a custom build directory for the frontend.
79 | # This can be used to customize the frontend code.
80 | # Be careful: If this is a relative path, it should not start with a slash.
81 | # custom_build = "./public/build"
82 |
83 | # Specify optional one or more custom links in the header.
84 | # [[UI.header_links]]
85 | # name = "Nodeology"
86 | # icon_url = "https://avatars.githubusercontent.com/u/128686189?s=200&v=4"
87 | # url = "https://github.com/xyin-anl/Nodeology"
88 |
89 | [meta]
90 | generated_by = "2.2.1"
91 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # poetry
98 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
99 | # This is especially recommended for binary packages to ensure reproducibility, and is more
100 | # commonly ignored for libraries.
101 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
102 | #poetry.lock
103 |
104 | # pdm
105 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
106 | #pdm.lock
107 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
108 | # in version control.
109 | # https://pdm.fming.dev/latest/usage/project/#working-with-version-control
110 | .pdm.toml
111 | .pdm-python
112 | .pdm-build/
113 |
114 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
115 | __pypackages__/
116 |
117 | # Celery stuff
118 | celerybeat-schedule
119 | celerybeat.pid
120 |
121 | # SageMath parsed files
122 | *.sage.py
123 |
124 | # Environments
125 | .env
126 | .venv
127 | env/
128 | venv/
129 | ENV/
130 | env.bak/
131 | venv.bak/
132 |
133 | # Spyder project settings
134 | .spyderproject
135 | .spyproject
136 |
137 | # Rope project settings
138 | .ropeproject
139 |
140 | # mkdocs documentation
141 | /site
142 |
143 | # mypy
144 | .mypy_cache/
145 | .dmypy.json
146 | dmypy.json
147 |
148 | # Pyre type checker
149 | .pyre/
150 |
151 | # pytype static type analyzer
152 | .pytype/
153 |
154 | # Cython debug symbols
155 | cython_debug/
156 |
157 | # PyCharm
158 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
159 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
160 | # and can be added to the global gitignore or merged into this file. For a more nuclear
161 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
162 | #.idea/
163 |
164 | # Apple
165 | .DS_Store
166 |
167 | # Nodeology
168 | artifacts/
169 | logs/
170 |
171 | # PyPI
172 | dist/
173 | *.egg-info/
174 | .pypirc
175 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | > [!IMPORTANT]
2 | > This package is actively in development, and breaking changes may occur.
3 |
4 |
5 |
6 |
7 |
8 |
9 | ## 🤖 Foundation AI-Enhanced Scientific Workflow
10 |
11 | Foundation AI holds enormous potential for scientific research, especially in analyzing unstructured data, automating complex reasoning tasks, and simplifying human-computer interactions. However, integrating foundation AI models like LLMs and VLMs into scientific workflows poses challenges: handling diverse data types beyond text and images, managing model inaccuracies (hallucinations), and adapting general-purpose models to highly specialized scientific contexts.
12 |
13 | `nodeology` addresses these challenges by combining the strengths of foundation AI with traditional scientific methods and expert oversight. Built on `langgraph`'s state machine framework, it simplifies creating robust, AI-driven workflows through an intuitive, accessible interface. Originally developed at Argonne National Lab, the framework enables researchers—especially those without extensive programming experience—to quickly design and deploy full-stack AI workflows simply using prompt templates and existing functions as reusable nodes.
14 |
15 | Key features include:
16 |
17 | - Easy creation of AI-integrated workflows without complex syntax
18 | - Flexible and composable node architecture for various tasks
19 | - Seamless human-in-the-loop interactions for expert oversight
20 | - Portable workflow templates for collaboration and reproducibility
21 | - Quickly spin up simple chatbots for immediate AI interaction
22 | - Built-in tracing and telemetry for workflow monitoring and optimization
23 |
24 | ## 🚀 Getting Started
25 |
26 | ### Install the package
27 |
28 | To use the latest development version:
29 |
30 | ```bash
31 | pip install git+https://github.com/xyin-anl/Nodeology.git
32 | ```
33 |
34 | To use the latest release version:
35 |
36 | ```bash
37 | pip install nodeology
38 | ```
39 |
40 | ### Access foundation models
41 |
42 | Nodeology supports various cloud-based/local foundation models via [LiteLLM](https://docs.litellm.ai/docs/), see [provider list](https://docs.litellm.ai/docs/providers). Most of cloud-based models usage requires setting up API key. For example:
43 |
44 | ```bash
45 | # For OpenAI models
46 | export OPENAI_API_KEY='your-api-key'
47 |
48 | # For Anthropic models
49 | export ANTHROPIC_API_KEY='your-api-key'
50 |
51 | # For Gemini models
52 | export GEMINI_API_KEY='your-api-key'
53 |
54 | # For Together AI hosted open weight models
55 | export TOGETHER_API_KEY='your-api-key'
56 | ```
57 |
58 | > **💡 Tip:** The field of foundation models is evolving rapidly with new and improved models emerging frequently. As of **February 2025**, we recommend the following models based on their strengths:
59 | >
60 | > - **gpt-4o**: Excellent for broad general knowledge, writing tasks, and conversational interactions
61 | > - **o3-mini**: Good balance of math, coding, and reasoning capabilities at a lower price point
62 | > - **anthropic/claude-3.7**: Strong performance in general knowledge, math, science, and coding with well-constrained outputs
63 | > - **gemini/gemini-2.0-flash**: Effective for general knowledge tasks with a large context window for processing substantial information
64 | > - **together_ai/deepseek-ai/DeepSeek-R1**: Exceptional reasoning, math, science, and coding capabilities with transparent thinking processes
65 |
66 | **For Argonne Users:** if you are within Argonne network, you will have access to OpenAI's models through Argonne's ARGO inference service and ALCF's open weights model inference service for free. Please check this [link](https://gist.github.com/xyin-anl/0cc744a7862e153414857b15fe31b239) to see how to use them
67 |
68 | ### Langfuse Tracing (Optional)
69 |
70 | Nodeology supports [Langfuse](https://langfuse.com/) for observability and tracing of LLM/VLM calls. To use Langfuse:
71 |
72 | 1. Set up a Langfuse account and get your API keys
73 | 2. Configure Langfuse with your keys:
74 |
75 | ```bash
76 | # Set environment variables
77 | export LANGFUSE_PUBLIC_KEY='your-public-key'
78 | export LANGFUSE_SECRET_KEY='your-secret-key'
79 | export LANGFUSE_HOST='https://cloud.langfuse.com' # Or your self-hosted URL
80 | ```
81 |
82 | Or configure programmatically:
83 |
84 | ```python
85 | from nodeology.client import configure_langfuse
86 |
87 | configure_langfuse(
88 | public_key='your-public-key',
89 | secret_key='your-secret-key',
90 | host='https://cloud.langfuse.com' # Optional
91 | )
92 | ```
93 |
94 | ### Chainlit Interface (Optional)
95 |
96 | Nodeology supports [Chainlit](https://docs.chainlit.io/get-started/overview) for creating chat-based user interfaces. To use this feature, simply set `ui=True` when running your workflow:
97 |
98 | ```python
99 | # Create your workflow
100 | workflow = MyWorkflow()
101 |
102 | # Run with UI enabled
103 | workflow.run(ui=True)
104 | ```
105 |
106 | This will automatically launch a Chainlit server with a chat interface for interacting with your workflow. The interface preserves your workflow's state and configuration, allowing users to interact with it through a user-friendly chat interface.
107 |
108 | When the Chainlit server starts, you can access the interface through your web browser at `http://localhost:8000` by default.
109 |
110 | ## 🧪 Illustrating Examples
111 |
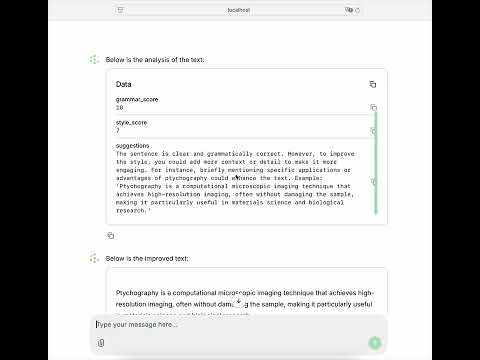
112 | ### [Writing Improvement](https://github.com/xyin-anl/Nodeology/examples/writing_improvement.py)
113 |
114 |
 117 |
118 |
117 |
118 | 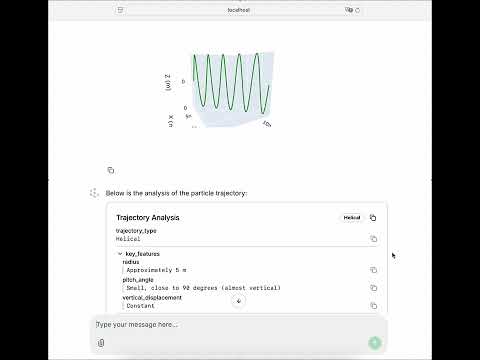 125 |
126 |
125 |
126 |