├── docs
├── _config.yml
└── README.md
├── project
├── README.md
├── cuda.py
├── optim.py
├── CoordinateWiseLSTM.py
├── learning_to_learn.py
├── main.py
└── learner.py
├── simple_learning_to_learn.py
├── README.md
├── Simple_LSTM.py
├── LICENSE
└── learning_to_learn.py
/docs/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-slate
--------------------------------------------------------------------------------
/project/README.md:
--------------------------------------------------------------------------------
1 | # The Whole Project
2 |
--------------------------------------------------------------------------------
/project/cuda.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | USE_CUDA = torch.cuda.is_available()
4 |
--------------------------------------------------------------------------------
/simple_learning_to_learn.py:
--------------------------------------------------------------------------------
1 | def learning_to_learn(f, x, LSTM_Optimizer, Adam_Optimizer ,T ,TT, unrolled_step):
2 |
3 | for tt in range(TT):
4 |
5 | L = 0
6 |
7 | for t in range(T):
8 |
9 | loss = f(x)
10 |
11 | x_grad = loss.backward(retain_graph=True)
12 |
13 | x += LSTM_Optimizer(x_grad)
14 |
15 | L += loss
16 |
17 | if (t+1)% unrolled_step ==0:
18 |
19 | LSTM_grad = L.backward()
20 |
21 | LSTM_Optimizer.parameters += Adam_Optimizer( LSTM_grad)
22 |
23 | L = 0
24 |
25 | return LSTM_Optimizer
26 |
--------------------------------------------------------------------------------
/project/optim.py:
--------------------------------------------------------------------------------
1 | import torch
2 | USE_CUDA = torch.cuda.is_available()
3 |
4 |
5 | ###############################################################
6 |
7 | ###################### 手工的优化器 ###################
8 |
9 | def SGD(gradients, state, learning_rate=0.001):
10 |
11 | return -gradients*learning_rate, state
12 |
13 | def RMS(gradients, state, learning_rate=0.01, decay_rate=0.9):
14 | if state is None:
15 | state = torch.zeros(gradients.size()[-1])
16 | if USE_CUDA == True:
17 | state = state.cuda()
18 |
19 | state = decay_rate*state + (1-decay_rate)*torch.pow(gradients, 2)
20 | update = -learning_rate*gradients / (torch.sqrt(state+1e-5))
21 | return update, state
22 |
23 | def adam():
24 | return torch.optim.Adam()
25 |
26 | ##########################################################
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # learning to_learn by gradient descent by gradient descent
2 |
3 | Learning to learn by gradient descent by gradient descent
4 |
5 | A simple re-implementation by `PyTorch-1.0`
6 |
7 | - [x] For Quadratic experiments
8 | - [ ] For Mnist
9 | - [ ] For CIFAR10
10 | - [ ] For Neural Art
11 |
12 | Add:
13 |
14 | - [x] Viusalize the learning process of LSTM optimizer.
15 |
16 | The project can be run by this [python file](learning_to_learn.py).
17 |
18 | ```
19 | python learning_to_learn.py
20 | ```
21 |
22 | This code is designed for a better understanding and easy implementation of paper `Learning to learn by gradient descent by gradient descent`.
23 |
24 | # Reference
25 |
26 | [1. Learning to learn by gradient descent by gradient descent - 2016 - NIPS](https://arxiv.org/abs/1606.04474)
27 |
28 | [2. Learning to learn in Tensorflow by DeepMind](https://github.com/deepmind/learning-to-learn)
29 |
30 |
31 |
32 |
33 |
34 |
--------------------------------------------------------------------------------
/Simple_LSTM.py:
--------------------------------------------------------------------------------
1 | class Simple_LSTM_Optimizer(torch.nn.Module):
2 |
3 | def __init__(self, args):
4 | super(LSTM_Optimizer,self).__init__()
5 | input_dim, hidden_dim, num_stacks, output_dim = args()
6 |
7 | # LSTM 模块
8 | self.lstm = torch.nn.LSTM(input_dim, hidden_dim, num_stacks)
9 | self.Linear = torch.nn.Linear(hidden_dim, output_dim)
10 |
11 | def Output_And_Update(self, input_gradients, prev_state):
12 |
13 | if prev_state is None: #init_state
14 | (cell , hidden) = prev_state.init()
15 |
16 | # LSTM 更新cell和hidden,并输出hidden
17 | update , (cell,hidden) = self.lstm(input_gradients, (cell, hidden))
18 | update = self.Linear(update)
19 |
20 | return update, (cell, hidden)
21 |
22 | def forward(self,input_gradients, prev_state):
23 |
24 | # 输入梯度,输出预测梯度 并更新隐状态
25 | update , next_state = self.Output_And_Update (input_gradients , prev_state)
26 |
27 | return update , next_state
28 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2018 senius
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/project/CoordinateWiseLSTM.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from cuda import USE_CUDA
4 |
5 | ##################### LSTM 优化器的模型 ##########################
6 | class LSTM_optimizer_Model(torch.nn.Module):
7 | """LSTM优化器"""
8 |
9 | def __init__(self,input_size,output_size, hidden_size, num_stacks, batchsize, preprocess = True ,p = 10 ,output_scale = 1):
10 | super(LSTM_optimizer_Model,self).__init__()
11 | self.preprocess_flag = preprocess
12 | self.p = p
13 | self.input_flag = 2
14 | if preprocess != True:
15 | self.input_flag = 1
16 | self.output_scale = output_scale #论文
17 | self.lstm = torch.nn.LSTM(input_size*self.input_flag, hidden_size, num_stacks)
18 | self.Linear = torch.nn.Linear(hidden_size,output_size) #1-> output_size
19 | self.Layers = num_stacks
20 | self.batchsize = batchsize
21 | self.Hidden_nums = hidden_size
22 |
23 | def LogAndSign_Preprocess_Gradient(self,gradients):
24 | """
25 | Args:
26 | gradients: `Tensor` of gradients with shape `[d_1, ..., d_n]`.
27 | p : `p` > 0 is a parameter controlling how small gradients are disregarded
28 | Returns:
29 | `Tensor` with shape `[d_1, ..., d_n-1, 2 * d_n]`. The first `d_n` elements
30 | along the nth dimension correspond to the `log output` \in [-1,1] and the remaining
31 | `d_n` elements to the `sign output`.
32 | """
33 | p = self.p
34 | log = torch.log(torch.abs(gradients))
35 | clamp_log = torch.clamp(log/p , min = -1.0,max = 1.0)
36 | clamp_sign = torch.clamp(torch.exp(torch.Tensor(p))*gradients, min = -1.0, max =1.0)
37 | return torch.cat((clamp_log,clamp_sign),dim = -1) #在gradients的最后一维input_dims拼接
38 |
39 | def Output_Gradient_Increment_And_Update_LSTM_Hidden_State(self, input_gradients, prev_state):
40 | """LSTM的核心操作 coordinate-wise LSTM """
41 |
42 | Layers,batchsize,Hidden_nums = self.Layers, self.batchsize, self.Hidden_nums
43 |
44 | if prev_state is None: #init_state
45 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums),
46 | torch.zeros(Layers,batchsize,Hidden_nums))
47 | if USE_CUDA :
48 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums).cuda(),
49 | torch.zeros(Layers,batchsize,Hidden_nums).cuda())
50 |
51 | update , next_state = self.lstm(input_gradients, prev_state)
52 | update = self.Linear(update) * self.output_scale #因为LSTM的输出是当前步的Hidden,需要变换到output的相同形状上
53 | return update, next_state
54 |
55 | def forward(self,input_gradients, prev_state):
56 | if USE_CUDA:
57 | input_gradients = input_gradients.cuda()
58 | #LSTM的输入为梯度,pytorch要求torch.nn.lstm的输入为(1,batchsize,input_dim)
59 | #原gradient.size()=torch.size[5] ->[1,1,5]
60 | gradients = input_gradients.unsqueeze(0)
61 |
62 | if self.preprocess_flag == True:
63 | gradients = self.LogAndSign_Preprocess_Gradient(gradients)
64 |
65 | update , next_state = self.Output_Gradient_Increment_And_Update_LSTM_Hidden_State(gradients , prev_state)
66 | # Squeeze to make it a single batch again.[1,1,5]->[5]
67 | update = update.squeeze().squeeze()
68 |
69 | return update , next_state
70 |
--------------------------------------------------------------------------------
/project/learning_to_learn.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from cuda import USE_CUDA
3 | import torch.nn as nn
4 | from timeit import default_timer as timer
5 | from learner import Learner
6 |
7 | ####### LSTM 优化器的训练过程 Learning to learn ###############
8 |
9 | def Learning_to_learn_global_training(f,optimizer, global_taining_steps, optimizer_Train_Steps, UnRoll_STEPS, Evaluate_period ,optimizer_lr):
10 | """ Training the LSTM optimizer . Learning to learn
11 |
12 | Args:
13 | `optimizer` : DeepLSTMCoordinateWise optimizer model
14 | `global_taining_steps` : how many steps for optimizer training optimizer
15 | `optimizer_Train_Steps` : how many step for optimizer opimitzing each function sampled from IID.
16 | `UnRoll_STEPS` :: how many steps for LSTM optimizer being unrolled to construct a computing graph to BPTT.
17 | """
18 | global_loss_list = []
19 | Total_Num_Unroll = optimizer_Train_Steps // UnRoll_STEPS
20 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = optimizer_lr)
21 |
22 | LSTM_Learner = Learner(f, optimizer, UnRoll_STEPS, retain_graph_flag=True, reset_theta=True,reset_function_from_IID_distirbution = False)
23 | #这里考虑Batchsize代表IID的化,那么就可以不需要每次都重新IID采样
24 |
25 | best_sum_loss = 999999
26 | best_final_loss = 999999
27 | best_flag = False
28 | for i in range(global_taining_steps):
29 |
30 | print('\n=============> global training steps: {}'.format(i))
31 |
32 | for num in range(Total_Num_Unroll):
33 |
34 | start = timer()
35 | _,global_loss = LSTM_Learner(num)
36 |
37 | adam_global_optimizer.zero_grad()
38 |
39 | global_loss.backward()
40 |
41 | adam_global_optimizer.step()
42 |
43 | global_loss_list.append(global_loss.detach_())
44 | time = timer() - start
45 | print('--> time consuming [{:.4f}s] optimizer train steps : [{}] | Global_Loss = [{:.1f}]'.format(time,(num +1)* UnRoll_STEPS,global_loss))
46 |
47 | if (i + 1) % Evaluate_period == 0:
48 |
49 | best_sum_loss, best_final_loss, best_flag = evaluate(f, optimizer,best_sum_loss,best_final_loss,best_flag,optimizer_lr)
50 |
51 |
52 | return global_loss_list,best_flag
53 |
54 |
55 | def evaluate(f, optimizer, best_sum_loss,best_final_loss, best_flag,lr):
56 | print('\n --> evalute the model')
57 | STEPS = 100
58 | LSTM_learner = Learner(f , optimizer, STEPS, eval_flag=True,reset_theta=True, retain_graph_flag=True)
59 | lstm_losses, sum_loss = LSTM_learner()
60 | try:
61 | best = torch.load('best_loss.txt')
62 | except IOError:
63 | print ('can not find best_loss.txt')
64 | pass
65 | else:
66 | best_sum_loss = best[0]
67 | best_final_loss = best[1]
68 | print("load_best_final_loss and sum_loss")
69 | if lstm_losses[-1] < best_final_loss and sum_loss < best_sum_loss:
70 | best_final_loss = lstm_losses[-1]
71 | best_sum_loss = sum_loss
72 |
73 | print('\n\n===> best of final LOSS[{}]: = {}, best_sum_loss ={}'.format(STEPS, best_final_loss,best_sum_loss))
74 | torch.save(optimizer.state_dict(),'best_LSTM_optimizer.pth')
75 | torch.save([best_sum_loss ,best_final_loss,lr ],'best_loss.txt')
76 | best_flag = True
77 |
78 | return best_sum_loss, best_final_loss, best_flag
79 |
--------------------------------------------------------------------------------
/project/main.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from timeit import default_timer as timer
4 | from optim import SGD, RMS, adam
5 | from learner import Learner
6 | from CoordinateWiseLSTM import LSTM_optimizer_Model
7 | from learning_to_learn import Learning_to_learn_global_training
8 | from cuda import USE_CUDA
9 |
10 | ##################### 优化问题 ##########################
11 | def f(W,Y,x):
12 | """quadratic function : f(\theta) = \|W\theta - y\|_2^2"""
13 | if USE_CUDA:
14 | W = W.cuda()
15 | Y = Y.cuda()
16 | x = x.cuda()
17 |
18 | return ((torch.matmul(W,x.unsqueeze(-1)).squeeze()-Y)**2).sum(dim=1).mean(dim=0)
19 |
20 | USE_CUDA = USE_CUDA
21 | DIM = 10
22 | batchsize = 128
23 |
24 | print('\n\nUSE_CUDA = {}\n\n'.format(USE_CUDA))
25 |
26 | ################# 优化器模型参数 ##############################
27 | Layers = 2
28 | Hidden_nums = 20
29 | Input_DIM = DIM
30 | Output_DIM = DIM
31 | output_scale_value=1
32 |
33 | ####### 构造一个优化器 #######
34 | LSTM_optimizer = LSTM_optimizer_Model(Input_DIM, Output_DIM, Hidden_nums ,Layers , batchsize=batchsize,\
35 | preprocess=False,output_scale=output_scale_value)
36 | print(LSTM_optimizer)
37 |
38 | if USE_CUDA:
39 | LSTM_optimizer = LSTM_optimizer.cuda()
40 |
41 |
42 |
43 | #################### Learning to learn (优化optimizer) ######################
44 | Global_Train_Steps = 2000
45 | optimizer_Train_Steps = 100
46 | UnRoll_STEPS = 20
47 | Evaluate_period = 1
48 | optimizer_lr = 0.1
49 |
50 | global_loss_list ,flag = Learning_to_learn_global_training( f, LSTM_optimizer,
51 | Global_Train_Steps,
52 | optimizer_Train_Steps,
53 | UnRoll_STEPS,
54 | Evaluate_period,
55 | optimizer_lr)
56 |
57 | if flag ==True :
58 | print('\n=== > load best LSTM model')
59 | torch.save(LSTM_optimizer.state_dict(),'final_LSTM_optimizer.pth')
60 | LSTM_optimizer.load_state_dict( torch.load('best_LSTM_optimizer.pth'))
61 |
62 |
63 |
64 | ######################################################################3#
65 | ########################## show results ###############################
66 |
67 | import numpy as np
68 | import matplotlib
69 | import matplotlib.pyplot as plt
70 | #import seaborn as sns; #sns.set(color_codes=True)
71 | #sns.set_style("white")
72 | #Global_T = np.arange(len(global_loss_list))
73 | #p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
74 | #plt.legend(handles=[p1])
75 | #plt.title('Training LSTM optimizer by gradient descent ')
76 | #plt.show()
77 |
78 |
79 | STEPS = 100
80 | x = np.arange(STEPS)
81 |
82 | Adam = 'Adam' #因为这里Adam使用Pytorch
83 |
84 | for _ in range(3):
85 |
86 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
87 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
88 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
89 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
90 |
91 | sgd_losses, sgd_sum_loss = SGD_Learner()
92 | rms_losses, rms_sum_loss = RMS_Learner()
93 | adam_losses, adam_sum_loss = Adam_Learner()
94 | lstm_losses, lstm_sum_loss = LSTM_learner()
95 |
96 | p1, = plt.plot(x, sgd_losses, label='SGD')
97 | p2, = plt.plot(x, rms_losses, label='RMS')
98 | p3, = plt.plot(x, adam_losses, label='Adam')
99 | p4, = plt.plot(x, lstm_losses, label='LSTM')
100 | #plt.yscale('log')
101 | #plt.legend(handles=[p1, p2, p3, p4])
102 | #plt.title('Losses')
103 | #plt.show()
104 | #print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
105 |
--------------------------------------------------------------------------------
/project/learner.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from cuda import USE_CUDA
3 |
4 | class Learner( object ):
5 | """
6 | Args :
7 | `f` : 要学习的问题
8 | `optimizer` : 使用的优化器
9 | `train_steps` : 对于其他SGD,Adam等是训练周期,对于LSTM训练时的展开周期
10 | `retain_graph_flag=False` : 默认每次loss_backward后 释放动态图
11 | `reset_theta = False ` : 默认每次学习前 不随机初始化参数
12 | `reset_function_from_IID_distirbution = True` : 默认从分布中随机采样函数
13 |
14 | Return :
15 | `losses` : reserves each loss value in each iteration
16 | `global_loss_graph` : constructs the graph of all Unroll steps for LSTM's BPTT
17 | """
18 | def __init__(self, f , optimizer, train_steps ,
19 | eval_flag = False,
20 | retain_graph_flag=False,
21 | reset_theta = False ,
22 | reset_function_from_IID_distirbution = True):
23 | self.f = f
24 | self.optimizer = optimizer
25 | self.train_steps = train_steps
26 |
27 | self.eval_flag = eval_flag
28 | self.retain_graph_flag = retain_graph_flag
29 | self.reset_theta = reset_theta
30 | self.reset_function_from_IID_distirbution = reset_function_from_IID_distirbution
31 | self.init_theta_of_f()
32 | self.state = None
33 |
34 | self.global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
35 | self.losses = [] # 保存每个训练周期的loss值
36 |
37 | def init_theta_of_f(self,):
38 | ''' 初始化 优化问题 f 的参数 '''
39 | self.DIM = 10
40 | self.batchsize = 128
41 | self.W = torch.randn(self.batchsize,self.DIM,self.DIM) #代表 已知的数据 # 独立同分布的标准正太分布
42 | self.Y = torch.randn(self.batchsize,self.DIM)
43 | self.x = torch.zeros(self.batchsize,self.DIM)
44 | self.x.requires_grad = True
45 | if USE_CUDA:
46 | self.W = self.W.cuda()
47 | self.Y = self.Y.cuda()
48 | self.x = self.x.cuda()
49 |
50 |
51 | def Reset_Or_Reuse(self , x , W , Y , state, num_roll):
52 | ''' re-initialize the `W, Y, x , state` at the begining of each global training
53 | IF `num_roll` == 0 '''
54 |
55 | reset_theta =self.reset_theta
56 | reset_function_from_IID_distirbution = self.reset_function_from_IID_distirbution
57 |
58 |
59 | if num_roll == 0 and reset_theta == True:
60 | theta = torch.zeros(self.batchsize,self.DIM)
61 | ##独立同分布的 标准正太分布
62 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
63 | x = theta_init_new
64 |
65 | print('Reset x to zero')
66 | ################ 每次全局训练迭代,从独立同分布的Normal Gaussian采样函数 ##################
67 | if num_roll == 0 and reset_function_from_IID_distirbution == True :
68 | W = torch.randn(self.batchsize,self.DIM,self.DIM) #代表 已知的数据 # 独立同分布的标准正太分布
69 | Y = torch.randn(self.batchsize,self.DIM) #代表 数据的标签 # 独立同分布的标准正太分布
70 |
71 | print('reset W and Y ')
72 | if num_roll == 0:
73 | state = None
74 | print('reset state to None')
75 |
76 | if USE_CUDA:
77 | W = W.cuda()
78 | Y = Y.cuda()
79 | x = x.cuda()
80 | x.retain_grad()
81 |
82 |
83 | return x , W , Y , state
84 |
85 |
86 | def __call__(self, num_roll=0) :
87 | '''
88 | Total Training steps = Unroll_Train_Steps * the times of `Learner` been called
89 |
90 | SGD,RMS,LSTM 用上述定义的
91 | Adam优化器直接使用pytorch里的,所以代码上有区分 后面可以完善!'''
92 | f = self.f
93 | x , W , Y , state = self.Reset_Or_Reuse(self.x , self.W , self.Y , self.state , num_roll )
94 | self.global_loss_graph = 0 #每个unroll的开始需要 重新置零
95 | optimizer = self.optimizer
96 |
97 | if optimizer!='Adam':
98 |
99 | for i in range(self.train_steps):
100 | loss = f(W,Y,x)
101 | #global_loss_graph += torch.exp(torch.Tensor([-i/20]))*loss
102 | self.global_loss_graph += (i/20+1)*loss
103 |
104 | loss.backward(retain_graph=self.retain_graph_flag) # 默认为False,当优化LSTM设置为True
105 |
106 | update, state = optimizer(x.grad, state)
107 |
108 | self.losses.append(loss)
109 |
110 | x = x + update
111 | x.retain_grad()
112 | update.retain_grad()
113 | if state is not None:
114 | self.state = (state[0].detach(),state[1].detach())
115 | return self.losses ,self.global_loss_graph
116 |
117 | else: #Pytorch Adam
118 |
119 | x.detach_()
120 | x.requires_grad = True
121 | optimizer= torch.optim.Adam( [x],lr=0.1 )
122 |
123 | for i in range(self.train_steps):
124 |
125 | optimizer.zero_grad()
126 | loss = f(W,Y,x)
127 |
128 | self.global_loss_graph += loss
129 |
130 | loss.backward(retain_graph=self.retain_graph_flag)
131 | optimizer.step()
132 | self.losses.append(loss.detach_())
133 |
134 | return self.losses, self.global_loss_graph
135 |
--------------------------------------------------------------------------------
/learning_to_learn.py:
--------------------------------------------------------------------------------
1 | # coding: utf-8
2 |
3 | # Learning to learn by gradient descent by gradient descent
4 | # =========================#
5 |
6 | # https://arxiv.org/abs/1611.03824
7 | # https://yangsenius.github.io/blog/LSTM_Meta/
8 | # author:yangsen
9 | # #### “通过梯度下降来学习如何通过梯度下降学习”
10 | # #### "learning to learn by gradient descent by gradient descent"
11 | # #### 要让优化器学会这样 "为了更好地得到,要先去舍弃" 这样类似的知识!
12 | # #### make the optimizer to learn the knowledge of "sometimes, in order to get it better, you have to give up first. "
13 |
14 | import torch
15 | import torch.nn as nn
16 | from timeit import default_timer as timer
17 | ##################### 优化问题 ##########################
18 | ##################### optimization ##########################
19 | USE_CUDA = False
20 | DIM = 10
21 | batchsize = 128
22 |
23 | if torch.cuda.is_available():
24 | USE_CUDA = True
25 |
26 | print('\n\nUSE_CUDA = {}\n\n'.format(USE_CUDA))
27 |
28 |
29 | def f(W,Y,x):
30 | """quadratic function : f(\theta) = \|W\theta - y\|_2^2"""
31 | if USE_CUDA:
32 | W = W.cuda()
33 | Y = Y.cuda()
34 | x = x.cuda()
35 |
36 | return ((torch.matmul(W,x.unsqueeze(-1)).squeeze()-Y)**2).sum(dim=1).mean(dim=0)
37 |
38 | ###############################################################
39 |
40 | ###################### 手工的优化器 ###################
41 | ###################### hand-craft optimizer ###################
42 |
43 | def SGD(gradients, state, learning_rate=0.001):
44 |
45 | return -gradients*learning_rate, state
46 |
47 | def RMS(gradients, state, learning_rate=0.01, decay_rate=0.9):
48 | if state is None:
49 | state = torch.zeros(DIM)
50 | if USE_CUDA == True:
51 | state = state.cuda()
52 |
53 | state = decay_rate*state + (1-decay_rate)*torch.pow(gradients, 2)
54 | update = -learning_rate*gradients / (torch.sqrt(state+1e-5))
55 | return update, state
56 |
57 | def adam():
58 | return torch.optim.Adam()
59 |
60 | ##########################################################
61 |
62 |
63 | ##################### 自动 LSTM 优化器模型 ##########################
64 | ##################### auto LSTM optimizer model ##########################
65 | class LSTM_optimizer_Model(torch.nn.Module):
66 | """LSTM优化器
67 | LSTM optimizer"""
68 |
69 | def __init__(self,input_size,output_size, hidden_size, num_stacks, batchsize, preprocess = True ,p = 10 ,output_scale = 1):
70 | super(LSTM_optimizer_Model,self).__init__()
71 | self.preprocess_flag = preprocess
72 | self.p = p
73 | self.input_flag = 2
74 | if preprocess != True:
75 | self.input_flag = 1
76 | self.output_scale = output_scale
77 | self.lstm = torch.nn.LSTM(input_size*self.input_flag, hidden_size, num_stacks)
78 | self.Linear = torch.nn.Linear(hidden_size,output_size) #1-> output_size
79 |
80 | def LogAndSign_Preprocess_Gradient(self,gradients):
81 | """
82 | Args:
83 | gradients: `Tensor` of gradients with shape `[d_1, ..., d_n]`.
84 | p : `p` > 0 is a parameter controlling how small gradients are disregarded
85 | Returns:
86 | `Tensor` with shape `[d_1, ..., d_n-1, 2 * d_n]`. The first `d_n` elements
87 | along the nth dimension correspond to the `log output` \in [-1,1] and the remaining
88 | `d_n` elements to the `sign output`.
89 | """
90 | p = self.p
91 | log = torch.log(torch.abs(gradients))
92 | clamp_log = torch.clamp(log/p , min = -1.0,max = 1.0)
93 | clamp_sign = torch.clamp(torch.exp(torch.Tensor(p))*gradients, min = -1.0, max =1.0)
94 | return torch.cat((clamp_log,clamp_sign),dim = -1) #在gradients的最后一维input_dims拼接 # concatenate in final dim
95 |
96 | def Output_Gradient_Increment_And_Update_LSTM_Hidden_State(self, input_gradients, prev_state):
97 | """LSTM的核心操作 core operation
98 | coordinate-wise LSTM """
99 | if prev_state is None: #init_state
100 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums),
101 | torch.zeros(Layers,batchsize,Hidden_nums))
102 | if USE_CUDA :
103 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums).cuda(),
104 | torch.zeros(Layers,batchsize,Hidden_nums).cuda())
105 |
106 | update , next_state = self.lstm(input_gradients, prev_state)
107 | update = self.Linear(update) * self.output_scale # transform the LSTM output to the target output dim
108 | return update, next_state
109 |
110 | def forward(self,input_gradients, prev_state):
111 | if USE_CUDA:
112 | input_gradients = input_gradients.cuda()
113 | #pytorch requires the `torch.nn.lstm`'s input as(1,batchsize,input_dim)
114 | # original gradient.size()=torch.size[5] ->[1,1,5]
115 | gradients = input_gradients.unsqueeze(0)
116 | if self.preprocess_flag == True:
117 | gradients = self.LogAndSign_Preprocess_Gradient(gradients)
118 | update , next_state = self.Output_Gradient_Increment_And_Update_LSTM_Hidden_State(gradients , prev_state)
119 | # Squeeze to make it a single batch again.[1,1,5]->[5]
120 | update = update.squeeze().squeeze()
121 |
122 | return update , next_state
123 |
124 | ################# 优化器模型参数 ##############################
125 | ################# Parameters of optimizer ##############################
126 | Layers = 2
127 | Hidden_nums = 20
128 | Input_DIM = DIM
129 | Output_DIM = DIM
130 | output_scale_value=1
131 |
132 | ####### 构造一个优化器 #######
133 | ####### construct a optimizer #######
134 | LSTM_optimizer = LSTM_optimizer_Model(Input_DIM, Output_DIM, Hidden_nums ,Layers , batchsize=batchsize,\
135 | preprocess=False,output_scale=output_scale_value)
136 | print(LSTM_optimizer)
137 |
138 | if USE_CUDA:
139 | LSTM_optimizer = LSTM_optimizer.cuda()
140 |
141 |
142 | ###################### 优化问题目标函数的学习过程 ###############
143 | ###################### the learning process of optimizing the target function ###############
144 |
145 | class Learner( object ):
146 | """
147 | Args :
148 | `f` : 要学习的问题 the learning problem, also called `optimizee` in the paper
149 | `optimizer` : 使用的优化器 the used optimizer
150 | `train_steps` : 对于其他SGD,Adam等是训练周期,对于LSTM训练时的展开周期 training steps for SGD and ADAM, unfolded step for LSTM train
151 | `retain_graph_flag=False` : 默认每次loss_backward后 释放动态图 default: free the dynamic graph after the loss backward
152 | `reset_theta = False ` : 默认每次学习前 不随机初始化参数 default: do not initialize the theta
153 | `reset_function_from_IID_distirbution = True` : 默认从分布中随机采样函数 default: random sample from distribution
154 |
155 | Return :
156 | `losses` : reserves each loss value in each iteration
157 | `global_loss_graph` : constructs the graph of all Unroll steps for LSTM's BPTT
158 | """
159 | def __init__(self, f , optimizer, train_steps ,
160 | eval_flag = False,
161 | retain_graph_flag=False,
162 | reset_theta = False ,
163 | reset_function_from_IID_distirbution = True):
164 | self.f = f
165 | self.optimizer = optimizer
166 | self.train_steps = train_steps
167 | #self.num_roll=num_roll
168 | self.eval_flag = eval_flag
169 | self.retain_graph_flag = retain_graph_flag
170 | self.reset_theta = reset_theta
171 | self.reset_function_from_IID_distirbution = reset_function_from_IID_distirbution
172 | self.init_theta_of_f()
173 | self.state = None
174 |
175 | self.global_loss_graph = 0 # global loss for optimizing LSTM
176 | self.losses = [] # KEEP each loss of all epoches
177 |
178 | def init_theta_of_f(self,):
179 | ''' 初始化 优化问题 f 的参数
180 | initialize the theta of optimization f '''
181 | self.DIM = 10
182 | self.batchsize = 128
183 | self.W = torch.randn(batchsize,DIM,DIM) # represents IID
184 | self.Y = torch.randn(batchsize,DIM)
185 | self.x = torch.zeros(self.batchsize,self.DIM)
186 | self.x.requires_grad = True
187 | if USE_CUDA:
188 | self.W = self.W.cuda()
189 | self.Y = self.Y.cuda()
190 | self.x = self.x.cuda()
191 |
192 |
193 | def Reset_Or_Reuse(self , x , W , Y , state, num_roll):
194 | ''' re-initialize the `W, Y, x , state` at the begining of each global training
195 | IF `num_roll` == 0 '''
196 |
197 | reset_theta =self.reset_theta
198 | reset_function_from_IID_distirbution = self.reset_function_from_IID_distirbution
199 |
200 |
201 | if num_roll == 0 and reset_theta == True:
202 | theta = torch.zeros(batchsize,DIM)
203 | theta_init_new = theta.clone().detach().requires_grad_(True)
204 | x = theta_init_new
205 |
206 |
207 | ################ 每次全局训练迭代,从独立同分布的Normal Gaussian采样函数 ##################
208 | ################ at the first iteration , sample from IID Normal Gaussian ##################
209 | if num_roll == 0 and reset_function_from_IID_distirbution == True :
210 | W = torch.randn(batchsize,DIM,DIM) # represents IID
211 | Y = torch.randn(batchsize,DIM) # represents IID
212 |
213 |
214 | if num_roll == 0:
215 | state = None
216 | print('reset the values of `W`, `x`, `Y` and `state` for this optimizer')
217 |
218 | if USE_CUDA:
219 | W = W.cuda()
220 | Y = Y.cuda()
221 | x = x.cuda()
222 | x.retain_grad()
223 |
224 |
225 | return x , W , Y , state
226 |
227 | def __call__(self, num_roll=0) :
228 | '''
229 | Total Training steps = Unroll_Train_Steps * the times of `Learner` been called
230 |
231 | SGD,RMS,LSTM FROM defination above
232 | but Adam is adopted by pytorch~ This can be improved later'''
233 | f = self.f
234 | x , W , Y , state = self.Reset_Or_Reuse(self.x , self.W , self.Y , self.state , num_roll )
235 | self.global_loss_graph = 0 #at the beginning of unroll, reset to 0
236 | optimizer = self.optimizer
237 |
238 | if optimizer!='Adam':
239 |
240 | for i in range(self.train_steps):
241 | loss = f(W,Y,x)
242 | #self.global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
243 | self.global_loss_graph += loss
244 |
245 | loss.backward(retain_graph=self.retain_graph_flag) # default as False,set to True for LSTMS
246 | update, state = optimizer(x.grad.clone().detach(), state)
247 | self.losses.append(loss)
248 |
249 | x = x + update
250 | x.retain_grad()
251 | update.retain_grad()
252 |
253 | if state is not None:
254 | self.state = (state[0].detach(),state[1].detach())
255 |
256 | return self.losses ,self.global_loss_graph
257 |
258 | else: #Pytorch Adam
259 |
260 | x.detach_()
261 | x.requires_grad = True
262 | optimizer= torch.optim.Adam( [x],lr=0.1 )
263 |
264 | for i in range(self.train_steps):
265 |
266 | optimizer.zero_grad()
267 | loss = f(W,Y,x)
268 |
269 | self.global_loss_graph += loss
270 |
271 | loss.backward(retain_graph=self.retain_graph_flag)
272 | optimizer.step()
273 | self.losses.append(loss.detach_())
274 |
275 | return self.losses, self.global_loss_graph
276 |
277 |
278 | ####### LSTM 优化器的训练过程 Learning to learn ###############
279 | ####### LSTM training Learning to learn ###############
280 |
281 | def Learning_to_learn_global_training(optimizer, global_taining_steps, optimizer_Train_Steps, UnRoll_STEPS, Evaluate_period ,optimizer_lr=0.1):
282 | """ Training the LSTM optimizer . Learning to learn
283 |
284 | Args:
285 | `optimizer` : DeepLSTMCoordinateWise optimizer model
286 | `global_taining_steps` : how many steps for optimizer training o可以ptimizee
287 | `optimizer_Train_Steps` : how many step for optimizer opimitzing each function sampled from IID.
288 | `UnRoll_STEPS` :: how many steps for LSTM optimizer being unrolled to construct a computing graph to BPTT.
289 | """
290 | global_loss_list = []
291 | Total_Num_Unroll = optimizer_Train_Steps // UnRoll_STEPS
292 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = optimizer_lr)
293 |
294 | LSTM_Learner = Learner(f, optimizer, UnRoll_STEPS, retain_graph_flag=True, reset_theta=True,)
295 | #这里考虑Batchsize代表IID的话,那么就可以不需要每次都重新IID采样
296 | # If regarding `Batchsize` as `IID` ,there is no need for reset the theta
297 | #That is ,reset_function_from_IID_distirbution = False else it is True
298 |
299 | best_sum_loss = 999999
300 | best_final_loss = 999999
301 | best_flag = False
302 | for i in range(Global_Train_Steps):
303 |
304 | print('\n========================================> global training steps: {}'.format(i))
305 |
306 | for num in range(Total_Num_Unroll):
307 |
308 | start = timer()
309 | _,global_loss = LSTM_Learner(num)
310 |
311 | adam_global_optimizer.zero_grad()
312 | global_loss.backward()
313 |
314 | adam_global_optimizer.step()
315 | # print('xxx',[(z.grad,z.requires_grad) for z in optimizer.lstm.parameters() ])
316 | global_loss_list.append(global_loss.detach_())
317 | time = timer() - start
318 | #if i % 10 == 0:
319 | print('-> time consuming [{:.1f}s] optimizer train steps : [{}] | Global_Loss = [{:.1f}] '\
320 | .format(time,(num +1)* UnRoll_STEPS,global_loss,))
321 |
322 | if (i + 1) % Evaluate_period == 0:
323 |
324 | best_sum_loss, best_final_loss, best_flag = evaluate(best_sum_loss,best_final_loss,best_flag , optimizer_lr)
325 | return global_loss_list,best_flag
326 |
327 |
328 | def evaluate(best_sum_loss,best_final_loss, best_flag,lr):
329 | print('\n --------> evalute the model')
330 |
331 | STEPS = 100
332 | x = np.arange(STEPS)
333 | Adam = 'Adam'
334 |
335 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True, retain_graph_flag=True)
336 |
337 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
338 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
339 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
340 |
341 |
342 | sgd_losses, sgd_sum_loss = SGD_Learner()
343 | rms_losses, rms_sum_loss = RMS_Learner()
344 | adam_losses, adam_sum_loss = Adam_Learner()
345 | lstm_losses, lstm_sum_loss = LSTM_learner()
346 |
347 | p1, = plt.plot(x, sgd_losses, label='SGD')
348 | p2, = plt.plot(x, rms_losses, label='RMS')
349 | p3, = plt.plot(x, adam_losses, label='Adam')
350 | p4, = plt.plot(x, lstm_losses, label='LSTM')
351 | plt.yscale('log')
352 | plt.legend(handles=[p1, p2, p3, p4])
353 | plt.title('Losses')
354 | plt.pause(1.5)
355 | #plt.show()
356 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
357 | plt.close()
358 | torch.save(LSTM_optimizer.state_dict(),'current_LSTM_optimizer_ckpt.pth')
359 |
360 | try:
361 | best = torch.load('best_loss.txt')
362 | except IOError:
363 | print ('can not find best_loss.txt')
364 | now_sum_loss = lstm_sum_loss.cpu()
365 | now_final_loss = lstm_losses[-1].cpu()
366 | pass
367 | else:
368 | best_sum_loss = best[0].cpu()
369 | best_final_loss = best[1].cpu()
370 | now_sum_loss = lstm_sum_loss.cpu()
371 | now_final_loss = lstm_losses[-1].cpu()
372 |
373 | print(" ==> History: sum loss = [{:.1f}] \t| final loss = [{:.2f}]".format(best_sum_loss,best_final_loss))
374 | print(" ==> Current: sum loss = [{:.1f}] \t| final loss = [{:.2f}]".format(now_sum_loss,now_final_loss))
375 |
376 | # save the best model according to the conditions below
377 | # there may be several choices to make a trade-off
378 | if now_final_loss < best_final_loss: # and now_sum_loss < best_sum_loss:
379 |
380 | best_final_loss = now_final_loss
381 | best_sum_loss = now_sum_loss
382 |
383 | print('\n\n===> update new best of final LOSS[{}]: = {}, best_sum_loss ={}'.format(STEPS, best_final_loss,best_sum_loss))
384 | torch.save(LSTM_optimizer.state_dict(),'best_LSTM_optimizer.pth')
385 | torch.save([best_sum_loss ,best_final_loss,lr ],'best_loss.txt')
386 | best_flag = True
387 |
388 | return best_sum_loss, best_final_loss, best_flag
389 |
390 |
391 | ########################## before learning LSTM optimizer ###############################
392 | import numpy as np
393 | import matplotlib
394 | import matplotlib.pyplot as plt
395 |
396 | STEPS = 100
397 | x = np.arange(STEPS)
398 |
399 | Adam = 'Adam' # Adam in Pytorch
400 |
401 | for _ in range(1):
402 |
403 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
404 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
405 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
406 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
407 |
408 | sgd_losses, sgd_sum_loss = SGD_Learner()
409 | rms_losses, rms_sum_loss = RMS_Learner()
410 | adam_losses, adam_sum_loss = Adam_Learner()
411 | lstm_losses, lstm_sum_loss = LSTM_learner()
412 |
413 | p1, = plt.plot(x, sgd_losses, label='SGD')
414 | p2, = plt.plot(x, rms_losses, label='RMS')
415 | p3, = plt.plot(x, adam_losses, label='Adam')
416 | p4, = plt.plot(x, lstm_losses, label='LSTM')
417 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
418 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
419 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
420 | plt.yscale('log')
421 | plt.legend(handles=[p1, p2, p3, p4])
422 | plt.title('Losses')
423 | plt.pause(2.5)
424 | print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
425 |
426 |
427 |
428 | #################### Learning to learn (optimizing optimizer) ######################
429 | Global_Train_Steps = 1000 #可修改 changeable
430 | optimizer_Train_Steps = 100
431 | UnRoll_STEPS = 20
432 | Evaluate_period = 1 #可修改 changeable
433 | optimizer_lr = 0.1 #可修改 changeable
434 | global_loss_list ,flag = Learning_to_learn_global_training( LSTM_optimizer,
435 | Global_Train_Steps,
436 | optimizer_Train_Steps,
437 | UnRoll_STEPS,
438 | Evaluate_period,
439 | optimizer_lr)
440 |
441 |
442 | ######################################################################3#
443 | ########################## show learning process results
444 | #torch.load('best_LSTM_optimizer.pth'))
445 | #import numpy as np
446 | #import matplotlib
447 | #import matplotlib.pyplot as plt
448 |
449 | #Global_T = np.arange(len(global_loss_list))
450 | #p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
451 | #plt.legend(handles=[p1])
452 | #plt.title('Training LSTM optimizer by gradient descent ')
453 | #plt.show()
454 |
455 |
456 | ######################################################################3#
457 | ########################## show contrast results SGD,ADAM, RMS ,LSTM ###############################
458 | import copy
459 | import numpy as np
460 | import matplotlib
461 | import matplotlib.pyplot as plt
462 |
463 | if flag ==True :
464 | print('\n==== > load best LSTM model')
465 | last_state_dict = copy.deepcopy(LSTM_optimizer.state_dict())
466 | torch.save(LSTM_optimizer.state_dict(),'final_LSTM_optimizer.pth')
467 | LSTM_optimizer.load_state_dict( torch.load('best_LSTM_optimizer.pth'))
468 |
469 | LSTM_optimizer.load_state_dict(torch.load('best_LSTM_optimizer.pth'))
470 | #LSTM_optimizer.load_state_dict(torch.load('final_LSTM_optimizer.pth'))
471 | STEPS = 100
472 | x = np.arange(STEPS)
473 |
474 | Adam = 'Adam'
475 |
476 | for _ in range(3): #可以多试几次测试实验,LSTM不稳定 for several test, the trained LSTM is not stable?
477 |
478 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
479 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
480 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
481 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
482 |
483 |
484 | sgd_losses, sgd_sum_loss = SGD_Learner()
485 | rms_losses, rms_sum_loss = RMS_Learner()
486 | adam_losses, adam_sum_loss = Adam_Learner()
487 | lstm_losses, lstm_sum_loss = LSTM_learner()
488 |
489 | p1, = plt.plot(x, sgd_losses, label='SGD')
490 | p2, = plt.plot(x, rms_losses, label='RMS')
491 | p3, = plt.plot(x, adam_losses, label='Adam')
492 | p4, = plt.plot(x, lstm_losses, label='LSTM')
493 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
494 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
495 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
496 | #p4.set_dashes([2, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
497 | plt.yscale('log')
498 | plt.legend(handles=[p1, p2, p3, p4])
499 | plt.title('Losses')
500 | plt.show()
501 | print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
502 |
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | # learning to_learn by gradient descent by gradient descent
2 |
3 | Learning to learn by gradient descent by gradient descent
4 |
5 | A simple re-implementation by PyTorch
6 |
7 | - For Quadratic experiments
8 |
9 |
10 | > 原创博文,转载请注明来源
11 |
12 |
13 |
14 | ## 引言
15 |
16 | “浪费75金币买控制守卫有什么用,还不是让人给拆了?我要攒钱!早晚憋出来我的灭世者的死亡之帽!”
17 |
18 | Learning to learn,即学会学习,是每个人都具备的能力,具体指的是一种在学习的过程中去反思自己的学习行为来进一步提升学习能力的能力。这在日常生活中其实很常见,比如在通过一本书来学习某个陌生专业的领域知识时(如《机器学习》),面对大量的专业术语与陌生的公式符号,初学者很容易看不下去,而比较好的方法就是先浏览目录,掌握一些简单的概念(回归与分类啊,监督与无监督啊),并在按顺序的阅读过程学会“前瞻”与“回顾”,进行快速学习。又比如在早期接受教育的学习阶段,盲目的“题海战术”或死记硬背的“知识灌输”如果不加上恰当的反思和总结,往往会耗时耗力,最后达到的效果却一般,这是因为在接触新东西,掌握新技能时,是需要“技巧性”的。
19 |
20 |
21 | 从学习知识到学习策略的层面上,总会有“最强王者”在告诉我们,“钻石的操作、黄铜的意识”也许并不能取胜,要“战略上最佳,战术上谨慎”才能更快更好地进步。
22 |
23 | 这跟本文要讲的内容有什么关系呢?进入正题。
24 | >
25 | > 其实读者可以先回顾自己从初高中到大学甚至研究生的整个历程,是不是发现自己已经具备了“learning to learn”的能力?
26 |
27 |
28 |
29 | 
30 | ## Learning to learn by gradient descent by gradient descent
31 |
32 |
33 | **通过梯度下降来学习如何通过梯度下降学习**
34 |
35 |
36 |
37 | > 是否可以让优化器学会 "为了更好地得到,要先去舍弃" 这样的“策略”?
38 |
39 |
40 |
41 | 本博客结合具体实践来解读《Learning to learn by gradient descent by gradient descent》,这是一篇Meta-learning(元学习)领域的[论文](https://arxiv.org/abs/1606.04474),发表在2016年的NIPS。类似“回文”结构的起名,让这篇论文变得有趣,是不是可以再套一层,"Learning to learn to learn by gradient descent by gradient descent by gradient descent"?再套一层?
42 |
43 | 首先别被论文题目给误导,==它不是求梯度的梯度,这里不涉及到二阶导的任何操作,而是跟如何学会更好的优化有关==,正确的断句方法为learning to (learn by gradient descent ) by gradient descent 。
44 |
45 | 第一次读完后,不禁惊叹作者巧妙的构思--使用LSTM(long short-term memory)优化器来替代传统优化器如(SGD,RMSProp,Adam等),然后使用梯度下降来优化优化器本身。
46 |
47 | 虽然明白了作者的出发点,但总感觉一些细节自己没有真正理解。然后就去看原作的代码实现,读起来也是很费劲。查阅了一些博客,但网上对这篇论文解读很少,停留于论文翻译理解上。再次揣摩论文后,打算做一些实验来理解。 在用PyTorch写代码的过程,才恍然大悟,作者的思路是如此简单巧妙,论文名字起的也很恰当,没在故弄玄虚,但是在实现的过程却费劲了周折!
48 |
49 | ## 文章目录
50 | [TOC]
51 |
52 | **如果想看最终版代码和结果,可以直接跳到文档的最后!!**
53 |
54 | 下面写的一些文字与代码主要站在我自身的角度,记录自己在学习研究这篇论文和代码过程中的所有历程,如何想的,遇到了什么错误,问题在哪里,我把自己理解领悟“learning to learn”这篇论文的过程剖析了一下,也意味着我自己也在“learning to learn”!为了展现自己的心路历程,我基本保留了所有的痕迹,这意味着有些代码不够整洁,不过文档的最后是最终简洁完整版。
55 | ==提醒:看完整个文档需要大量的耐心 : )==
56 |
57 | 我默认读者已经掌握了一些必要知识,也希望通过回顾这些经典研究给自己和一些读者带来切实的帮助和启发。
58 |
59 | 用Pytorch实现这篇论文想法其实很方便,但是论文作者来自DeepMind,他们用[Tensorflow写的项目](https://github.com/deepmind/learning-to-learn),读他们的代码你就会领教到最前沿的一线AI工程师们是如何进行工程实践的。
60 |
61 | 下面进入正题,我会按照最简单的思路,循序渐进地展开, <0..0>。
62 |
63 | ## 优化问题
64 | 经典的机器学习问题,包括当下的深度学习相关问题,大多可以被表达成一个目标函数的优化问题:
65 |
66 | $$\theta ^{*}= \arg\min_{\theta\in \Theta }f\left ( \theta \right )$$
67 |
68 | 一些优化方法可以求解上述问题,最常见的即梯度更新策略:
69 | $$\theta_{t+1}=\theta_{t}-\alpha_{t}*\nabla f\left ( \theta_{t}\right )$$
70 |
71 | 早期的梯度下降会忽略梯度的二阶信息,而经典的优化技术通过加入**曲率信息**改变步长来纠正,比如Hessian矩阵的二阶偏导数。
72 | **Deep learning**社区的壮大,演生出很多求解高维非凸的优化求解器,如
73 | **momentum**[Nesterov, 1983, Tseng, 1998], **Rprop** [Riedmiller and Braun, 1993], **Adagrad** [Duchi et al., 2011], **RMSprop** [Tieleman and Hinton, 2012], and **ADAM** [Kingma and Ba, 2015].
74 |
75 | 目前用于大规模图像识别的模型往往使用卷积网络CNN通过定义一个代价函数来拟合数据与标签,其本质还是一个优化问题。
76 |
77 | 这里我们考虑一个简单的优化问题,比如求一个四次非凸函数的最小值点。对于更复杂的模型,下面的方法同样适用。
78 | ### 定义要优化的目标函数
79 |
80 | ```python
81 | import torch
82 | import torch.nn as nn
83 | DIM = 10
84 | w = torch.empty(DIM)
85 | torch.nn.init.uniform_(w,a=0.5,b=1.5)
86 |
87 | def f(x): #定义要优化的函数,求x的最优解
88 | x= w*(x-1)
89 | return ((x+1)*(x+0.5)*x*(x-1)).sum()
90 |
91 | ```
92 |
93 | ### 定义常用的优化器如SGD, RMSProp, Adam。
94 |
95 |
96 | SGD仅仅只是给梯度乘以一个学习率。
97 |
98 | RMSProp的方法是:
99 |
100 | $$E[g^2]_t = 0.9 E[g^2]_{t-1} + 0.1 g^2_t$$
101 |
102 |
103 | $$\theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{E[g^2]_t + \epsilon}} g_{t}$$
104 |
105 | 当前时刻下,用当前梯度和历史梯度的平方加权和(越老的历史梯度,其权重越低)来重新调节学习率(如果历史梯度越低,“曲面更平坦”,那么学习率越大,梯度下降更“激进”一些,如果历史梯度越高,“曲面更陡峭”那么学习率越小,梯度下降更“谨慎”一些),来更快更好地朝着全局最优解收敛。
106 |
107 | Adam是RMSProp的变体:
108 | $$m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t \\
109 | v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2$$
110 |
111 | $$\hat{m}_t = \dfrac{m_t}{1 - \beta^t_1} \\
112 | \hat{v}_t = \dfrac{v_t}{1 - \beta^t_2}$$
113 |
114 | $$\theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t$$
115 | 即通过估计当前梯度的一阶矩估计和二阶矩估计来代替,梯度和梯度的平方,然后更新策略和RMSProp一样。
116 |
117 |
118 | ```python
119 | def SGD(gradients, state, learning_rate=0.001):
120 |
121 | return -gradients*learning_rate, state
122 |
123 | def RMS(gradients, state, learning_rate=0.1, decay_rate=0.9):
124 | if state is None:
125 | state = torch.zeros(DIM)
126 |
127 | state = decay_rate*state + (1-decay_rate)*torch.pow(gradients, 2)
128 | update = -learning_rate*gradients / (torch.sqrt(state+1e-5))
129 | return update, state
130 |
131 | def Adam():
132 | return torch.optim.Adam()
133 | ```
134 |
135 | 这里的Adam优化器直接用了Pytorch里定义的。然后我们通过优化器来求解极小值x,通过梯度下降的过程,我们期望的函数值是逐步下降的。
136 | 这是我们一般人为设计的学习策略,即==逐步梯度下降法,以“每次都比上一次进步一些” 为原则进行学习!==
137 |
138 | ### 接下来 构造优化算法
139 |
140 |
141 | ```python
142 | TRAINING_STEPS = 15
143 | theta = torch.empty(DIM)
144 | torch.nn.init.uniform_(theta,a=-1,b=1.0)
145 | theta_init = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
146 |
147 | def learn(optimizer,unroll_train_steps,retain_graph_flag=False,reset_theta = False):
148 | """retain_graph_flag=False PyTorch 默认每次loss_backward后 释放动态图
149 | # reset_theta = False 默认每次学习前 不随机初始化参数"""
150 |
151 | if reset_theta == True:
152 | theta_new = torch.empty(DIM)
153 | torch.nn.init.uniform_(theta_new,a=-1,b=1.0)
154 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
155 | x = theta_init_new
156 | else:
157 | x = theta_init
158 |
159 | global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
160 | state = None
161 | x.requires_grad = True
162 | if optimizer.__name__ !='Adam':
163 | losses = []
164 | for i in range(unroll_train_steps):
165 | x.requires_grad = True
166 |
167 | loss = f(x)
168 |
169 | #global_loss_graph += (0.8*torch.log10(torch.Tensor([i]))+1)*loss
170 |
171 | global_loss_graph += loss
172 |
173 | #print(loss)
174 | loss.backward(retain_graph=retain_graph_flag) # 默认为False,当优化LSTM设置为True
175 | update, state = optimizer(x.grad, state)
176 | losses.append(loss)
177 |
178 | #这个操作 直接把x中包含的图给释放了,
179 |
180 | x = x + update
181 |
182 | x = x.detach_()
183 | #这个操作 直接把x中包含的图给释放了,
184 | #那传递给下次训练的x从子节点变成了叶节点,那么梯度就不能沿着这个路回传了,
185 | #之前写这一步是因为这个子节点在下一次迭代不可以求导,那么应该用x.retain_grad()这个操作,
186 | #然后不需要每次新的的开始给x.requires_grad = True
187 |
188 | #x.retain_grad()
189 | #print(x.retain_grad())
190 |
191 |
192 | #print(x)
193 | return losses ,global_loss_graph
194 |
195 | else:
196 | losses = []
197 | x.requires_grad = True
198 | optimizer= torch.optim.Adam( [x],lr=0.1 )
199 |
200 | for i in range(unroll_train_steps):
201 |
202 | optimizer.zero_grad()
203 | loss = f(x)
204 | global_loss_graph += loss
205 |
206 | loss.backward(retain_graph=retain_graph_flag)
207 | optimizer.step()
208 | losses.append(loss.detach_())
209 | #print(x)
210 | return losses,global_loss_graph
211 |
212 | ```
213 |
214 | ### 对比不同优化器的优化效果
215 |
216 |
217 | ```python
218 | import matplotlib
219 | import matplotlib.pyplot as plt
220 | %matplotlib inline
221 | import numpy as np
222 |
223 | T = np.arange(TRAINING_STEPS)
224 | for _ in range(1):
225 |
226 | sgd_losses, sgd_sum_loss = learn(SGD,TRAINING_STEPS,reset_theta=True)
227 | rms_losses, rms_sum_loss = learn(RMS,TRAINING_STEPS,reset_theta=True)
228 | adam_losses, adam_sum_loss = learn(Adam,TRAINING_STEPS,reset_theta=True)
229 | p1, = plt.plot(T, sgd_losses, label='SGD')
230 | p2, = plt.plot(T, rms_losses, label='RMS')
231 | p3, = plt.plot(T, adam_losses, label='Adam')
232 | plt.legend(handles=[p1, p2, p3])
233 | plt.title('Losses')
234 | plt.show()
235 | print("sum_loss:sgd={},rms={},adam={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss ))
236 | ```
237 |
238 |
239 |
240 | 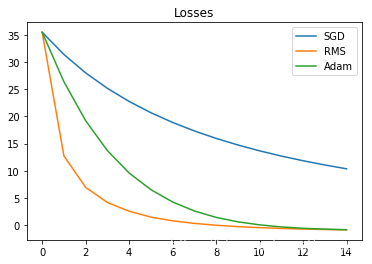
241 |
242 | sum_loss:sgd=289.9213562011719,rms=60.56287384033203,adam=117.2123031616211
243 |
244 |
245 | 通过上述实验可以发现,这些优化器都可以发挥作用,似乎RMS表现更加优越一些,不过这并不代表RMS就比其他的好,可能这个优化问题还是较为简单,调整要优化的函数,可能就会看到不同的结果。
246 |
247 | ## Meta-optimizer :从手工设计优化器迈步到自动设计优化器
248 |
249 | 上述这些优化器的更新策略是根据人的经验主观设计,要来解决一般的优化问题的。
250 |
251 | **No Free Lunch Theorems for Optimization** [Wolpert and Macready, 1997] 表明组合优化设置下,==没有一个算法可以绝对好过一个随机策略==。这暗示,一般来讲,对于一个子问题,特殊化其优化方法是提升性能的唯一方法。
252 |
253 | 而针对一个特定的优化问题,也许一个特定的优化器能够更好的优化它,我们是否可以不根据人工设计,而是让优化器本身根据模型与数据,自适应地调节,这就涉及到了meta-learning
254 | ### 用一个可学习的梯度更新规则,替代手工设计的梯度更新规则
255 |
256 | $$\theta_{t+1}=\theta_{t}+g\textit{}_{t}\left (f\left ( \theta_{t}\right ),\phi \right)$$
257 |
258 | 这里的$g(\cdot)$代表其梯度更新规则函数,通过参数$\phi$来确定,其输出为目标函数f当前迭代的更新梯度值,$g$函数通过RNN模型来表示,保持状态并动态迭代
259 |
260 |
261 | 假如一个优化器可以根据历史优化的经验来自身调解自己的优化策略,那么就一定程度上做到了自适应,这个不是说像Adam,momentum,RMSprop那样自适应地根据梯度调节学习率,(其梯度更新规则还是不变的),而是说自适应地改变其梯度更新规则,而Learning to learn 这篇论文就使用LSTM(RNN)优化器做到了这一点,毕竟RNN存在一个可以保存历史信息的隐状态,LSTM可以从一个历史的全局去适应这个特定的优化过程,做到论文提到的所谓的“CoordinateWise”,我的理解是:LSTM的参数对每个时刻节点都保持“聪明”,是一种“全局性的聪明”,适应每分每秒。
262 |
263 | #### 构建LSTM优化器
264 |
265 |
266 | ```python
267 | Layers = 2
268 | Hidden_nums = 20
269 | Input_DIM = DIM
270 | Output_DIM = DIM
271 | # "coordinate-wise" RNN
272 | lstm=torch.nn.LSTM(Input_DIM,Hidden_nums ,Layers)
273 | Linear = torch.nn.Linear(Hidden_nums,Output_DIM)
274 | batchsize = 1
275 |
276 | print(lstm)
277 |
278 | def LSTM_optimizer(gradients, state):
279 | #LSTM的输入为梯度,pytorch要求torch.nn.lstm的输入为(1,batchsize,input_dim)
280 | #原gradient.size()=torch.size[5] ->[1,1,5]
281 | gradients = gradients.unsqueeze(0).unsqueeze(0)
282 | if state is None:
283 | state = (torch.zeros(Layers,batchsize,Hidden_nums),
284 | torch.zeros(Layers,batchsize,Hidden_nums))
285 |
286 | update, state = lstm(gradients, state) # 用optimizer_lstm代替 lstm
287 | update = Linear(update)
288 | # Squeeze to make it a single batch again.[1,1,5]->[5]
289 | return update.squeeze().squeeze(), state
290 | ```
291 |
292 | LSTM(10, 20, num_layers=2)
293 |
294 |
295 | 从上面LSTM优化器的设计来看,我们几乎没有加入任何先验的人为经验在里面,只是用了长短期记忆神经网络的架构
296 |
297 | #### 优化器本身的参数即LSTM的参数,代表了我们的更新策略
298 |
299 | **这个优化器的参数代表了我们的更新策略,后面我们会学习这个参数,即学习用什么样的更新策略**
300 |
301 | 对了如果你不太了解LSTM的话,我就放这个网站 http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 博客的几个图,它很好解释了什么是RNN和LSTM:
302 |
303 |
304 |  305 |
305 |  306 |
306 |  307 |
307 |  308 |
308 |  309 |
309 |  310 |
311 | ##### 好了,看一下我们使用刚刚初始化的LSTM优化器后的优化结果
312 |
313 |
314 | ```python
315 | import matplotlib
316 | import matplotlib.pyplot as plt
317 | %matplotlib inline
318 | import numpy as np
319 |
320 | x = np.arange(TRAINING_STEPS)
321 |
322 |
323 | for _ in range(1):
324 |
325 | sgd_losses, sgd_sum_loss = learn(SGD,TRAINING_STEPS,reset_theta=True)
326 | rms_losses, rms_sum_loss = learn(RMS,TRAINING_STEPS,reset_theta=True)
327 | adam_losses, adam_sum_loss = learn(Adam,TRAINING_STEPS,reset_theta=True)
328 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,TRAINING_STEPS,reset_theta=True,retain_graph_flag = True)
329 | p1, = plt.plot(T, sgd_losses, label='SGD')
330 | p2, = plt.plot(T, rms_losses, label='RMS')
331 | p3, = plt.plot(T, adam_losses, label='Adam')
332 | p4, = plt.plot(x, lstm_losses, label='LSTM')
333 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
334 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
335 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
336 | #plt.yscale('log')
337 | plt.legend(handles=[p1, p2, p3, p4])
338 | plt.title('Losses')
339 | plt.show()
340 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
341 | ```
342 |
343 |
344 |
345 | 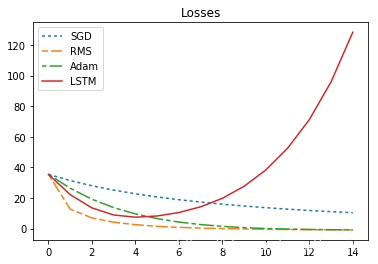
346 |
347 | sum_loss:sgd=289.9213562011719,rms=60.56287384033203,adam=117.2123031616211,lstm=554.2158203125
348 |
349 |
350 | ##### 咦,为什么LSTM优化器那么差,根本没有优化效果?
351 |
352 | **先别着急质疑!因为我们还没有学习LSTM优化器!**
353 |
354 | 用到的LSTM模型完全是随机初始化的!并且LSTM的参数在TRAIN_STEPS=[0,T]中的每个节点都是保持不变的!
355 |
356 | #### 下面我们就来优化LSTM优化器的参数!
357 |
358 | 不论是原始优化问题,还是隶属元学习的LSTM优化目标,我们都一个共同的学习目标:
359 |
360 | $$\theta ^{*}= \arg\min_{\theta\in \Theta }f\left ( \theta \right )$$
361 |
362 | 或者说我们希望迭代后的loss值变得很小,传统方法,是基于每个迭代周期,一步一步,让loss值变小,可以说,传统优化器进行梯度下降时所站的视角是在某个周期下的,那么,我们其实可以换一个视角,更全局的视角,即,我们希望所有周期迭代的loss值都很小,这和传统优化是不违背的,并且是全局的,这里做个比喻,优化就像是下棋,优化器就是
363 |
364 | ##### “下棋手 ”
365 |
366 | 如果一个棋手,在每走一步之前,都能看未来很多步被这一步的影响,那么它就能在当前步做出最佳策略,而LSTM的优化过程,就是把一个历史全局的“步”放在一起进行优化,所以LSTM的优化就具备了“瞻前顾后”的能力!
367 |
368 | 关于这一点,论文给出了一个期望loss的定义:
369 | $$ L\left(\phi \right) =E_f \left[ f \left ( \theta ^{*}\left ( f,\phi \right )\right ) \right]$$
370 |
371 | 但这个实现起来并不现实,我们只需要将其思想具体化。
372 |
373 | - Meta-optimizer优化:目标函数“所有周期的loss都要很小!”,而且这个目标函数是独立同分布采样的(比如,这里意味着任意初始化一个优化问题模型的参数,我们都希望这个优化器能够找到一个优化问题的稳定的解)
374 |
375 | - 传统优化器:"对于当前的目标函数,只要这一步的loss比上一步的loss值要小就行”
376 |
377 | ##### 特点 : 2.考虑优化器优化过程的历史全局性信息 3.独立同分布地采样优化问题目标函数的参数
378 |
379 | 接下来我们就站在更全局的角度,来优化LSTM优化器的参数
380 |
381 | LSTM是循环神经网络,它可以连续记录并传递所有周期时刻的信息,其每个周期循环里的子图共同构建一个巨大的图,然后使用Back-Propagation Through Time (BPTT)来求导更新
382 |
383 |
384 | ```python
385 | lstm_losses,global_graph_loss= learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True) # [loss1,loss2,...lossT] 所有周期的loss
386 | # 因为这里要保留所有周期的计算图所以retain_graph_flag =True
387 | all_computing_graph_loss = torch.tensor(lstm_losses).sum()
388 | #构建一个所有周期子图构成的总计算图,使用BPTT来梯度更新LSTM参数
389 |
390 | print(all_computing_graph_loss,global_graph_loss )
391 | print(global_graph_loss)
392 | ```
393 |
394 | tensor(554.2158) tensor(554.2158, grad_fn=)
395 | tensor(554.2158, grad_fn=)
396 |
397 |
398 | 可以看到,变量**global_graph_loss**保留了所有周期产生的计算图grad_fn=
399 |
400 | 下面针对LSTM的参数进行全局优化,优化目标:“所有周期之和的loss都很小”。
401 | 值得说明一下:在LSTM优化时的参数,是在所有Unroll_TRAIN_STEPS=[0,T]中保持不变的,在进行完所有Unroll_TRAIN_STEPS以后,再整体优化LSTM的参数。
402 |
403 | 这也就是论文里面提到的coordinate-wise,即“对每个时刻点都保持‘全局聪明’”,即学习到LSTM的参数是全局最优的了。因为我们是站在所有TRAIN_STEPS=[0,T]的视角下进行的优化!
404 |
405 | 优化LSTM优化器选择的是Adam优化器进行梯度下降
406 |
407 | #### 通过梯度下降法来优化 优化器
408 |
409 |
410 | ```python
411 | Global_Train_Steps = 2
412 |
413 | def global_training(optimizer):
414 | global_loss_list = []
415 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = 0.0001)
416 | _,global_loss_1 = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = True)
417 |
418 | #print(global_loss_1)
419 |
420 | for i in range(Global_Train_Steps):
421 | _,global_loss = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = False)
422 | #adam_global_optimizer.zero_grad()
423 | print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
424 | #print(i,global_loss)
425 | global_loss.backward() #每次都是优化这个固定的图,不可以释放动态图的缓存
426 | #print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
427 | adam_global_optimizer.step()
428 | print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
429 | global_loss_list.append(global_loss.detach_())
430 |
431 | #print(global_loss)
432 | return global_loss_list
433 |
434 | # 要把图放进函数体内,直接赋值的话图会丢失
435 | # 优化optimizer
436 | global_loss_list = global_training(lstm)
437 |
438 | ```
439 |
440 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
441 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
442 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
443 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
444 |
445 |
446 | ##### 为什么loss值没有改变?为什么LSTM参数的梯度不存在的?
447 |
448 | 通过分析推理,我发现了LSTM参数的梯度为None,那么反向传播就完全没有更新LSTM的参数!
449 |
450 | 为什么参数的梯度为None呢,优化器并没有更新指定的LSTM的模型参数,一定是什么地方出了问题,我想了好久,还是做一些简单的实验来找一找问题吧。
451 |
452 | > ps: 其实写代码做实验的过程,也体现了人类本身学会学习的高级能力,那就是:通过实验来实现想法时,实验结果往往和预期差别很大,那一定有什么地方出了问题,盲目地大量试错法可能找不到真正问题所在,如何找到问题所在并解决,就是一种学会如何学习的能力,也是一种强化学习的能力。这里我采用的人类智能是:以小见大法。
453 | In a word , if we want the machine achieving to AGI, it must imiate human's ability of reasoning and finding where the problem is and figuring out how to solve the problem. Meta Learning contains this idea.
454 |
455 |
456 | ```python
457 | import torch
458 | z= torch.empty(2)
459 | torch.nn.init.uniform_(z , -2, 2)
460 | z.requires_grad = True
461 | z.retain_grad()
462 | def f(z):
463 | return (z*z).sum()
464 |
465 | optimizer = torch.optim.Adam([z],lr=0.01)
466 | grad =[]
467 | losses= []
468 | zgrad =[]
469 |
470 | for i in range(2):
471 | optimizer.zero_grad()
472 | q = f(z)
473 | loss = q**2
474 | #z.retain_grad()
475 | loss.backward(retain_graph = True)
476 | optimizer.step()
477 | #print(x,x.grad,loss,)
478 |
479 | loss.retain_grad()
480 | print(q.grad,q.requires_grad)
481 | grad.append((z.grad))
482 | losses.append(loss)
483 | zgrad.append(q.grad)
484 |
485 | print(grad)
486 | print(losses)
487 | print(zgrad)
488 | ```
489 |
490 | None True
491 | None True
492 | [tensor([-44.4396, -36.7740]), tensor([-44.4396, -36.7740])]
493 | [tensor(35.9191, grad_fn=), tensor(35.0999, grad_fn=)]
494 | [None, None]
495 |
496 |
497 | ##### 问题出在哪里?
498 |
499 | 经过多方面的实验修改,我发现LSTM的参数在每个周期内BPTT的周期内,并没有产生梯度!!怎么回事呢?我做了上面的小实验。
500 |
501 | 可以看到z.grad = None,但是z.requres_grad = True,z变量作为x变量的子节点,其在计算图中的梯度没有被保留或者没办法获取,那么我就应该通过修改一些PyTorch的代码,使得计算图中的叶子节点的梯度得以存在。然后我找到了retain_grad()这个函数,实验证明,它必须在backward()之前使用才能保存中间叶子节点的梯度!这样的方法也就适合于LSTM优化器模型参数的更新了吧?
502 |
503 |
504 | 那么如何保留LSTM的参数在每个周期中产生的梯度是接下来要修改的!
505 |
506 |
507 | 这是因为我计算loss = f(x),然后loss.backward() 这里的loss计算并没有和LSTM产生关系,我先来想一想loss和LSTM的关系在哪里?
508 |
509 | 论文里有一张图,可以作为参考:
510 |
511 | 图2
310 |
311 | ##### 好了,看一下我们使用刚刚初始化的LSTM优化器后的优化结果
312 |
313 |
314 | ```python
315 | import matplotlib
316 | import matplotlib.pyplot as plt
317 | %matplotlib inline
318 | import numpy as np
319 |
320 | x = np.arange(TRAINING_STEPS)
321 |
322 |
323 | for _ in range(1):
324 |
325 | sgd_losses, sgd_sum_loss = learn(SGD,TRAINING_STEPS,reset_theta=True)
326 | rms_losses, rms_sum_loss = learn(RMS,TRAINING_STEPS,reset_theta=True)
327 | adam_losses, adam_sum_loss = learn(Adam,TRAINING_STEPS,reset_theta=True)
328 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,TRAINING_STEPS,reset_theta=True,retain_graph_flag = True)
329 | p1, = plt.plot(T, sgd_losses, label='SGD')
330 | p2, = plt.plot(T, rms_losses, label='RMS')
331 | p3, = plt.plot(T, adam_losses, label='Adam')
332 | p4, = plt.plot(x, lstm_losses, label='LSTM')
333 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
334 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
335 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
336 | #plt.yscale('log')
337 | plt.legend(handles=[p1, p2, p3, p4])
338 | plt.title('Losses')
339 | plt.show()
340 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
341 | ```
342 |
343 |
344 |
345 | 
346 |
347 | sum_loss:sgd=289.9213562011719,rms=60.56287384033203,adam=117.2123031616211,lstm=554.2158203125
348 |
349 |
350 | ##### 咦,为什么LSTM优化器那么差,根本没有优化效果?
351 |
352 | **先别着急质疑!因为我们还没有学习LSTM优化器!**
353 |
354 | 用到的LSTM模型完全是随机初始化的!并且LSTM的参数在TRAIN_STEPS=[0,T]中的每个节点都是保持不变的!
355 |
356 | #### 下面我们就来优化LSTM优化器的参数!
357 |
358 | 不论是原始优化问题,还是隶属元学习的LSTM优化目标,我们都一个共同的学习目标:
359 |
360 | $$\theta ^{*}= \arg\min_{\theta\in \Theta }f\left ( \theta \right )$$
361 |
362 | 或者说我们希望迭代后的loss值变得很小,传统方法,是基于每个迭代周期,一步一步,让loss值变小,可以说,传统优化器进行梯度下降时所站的视角是在某个周期下的,那么,我们其实可以换一个视角,更全局的视角,即,我们希望所有周期迭代的loss值都很小,这和传统优化是不违背的,并且是全局的,这里做个比喻,优化就像是下棋,优化器就是
363 |
364 | ##### “下棋手 ”
365 |
366 | 如果一个棋手,在每走一步之前,都能看未来很多步被这一步的影响,那么它就能在当前步做出最佳策略,而LSTM的优化过程,就是把一个历史全局的“步”放在一起进行优化,所以LSTM的优化就具备了“瞻前顾后”的能力!
367 |
368 | 关于这一点,论文给出了一个期望loss的定义:
369 | $$ L\left(\phi \right) =E_f \left[ f \left ( \theta ^{*}\left ( f,\phi \right )\right ) \right]$$
370 |
371 | 但这个实现起来并不现实,我们只需要将其思想具体化。
372 |
373 | - Meta-optimizer优化:目标函数“所有周期的loss都要很小!”,而且这个目标函数是独立同分布采样的(比如,这里意味着任意初始化一个优化问题模型的参数,我们都希望这个优化器能够找到一个优化问题的稳定的解)
374 |
375 | - 传统优化器:"对于当前的目标函数,只要这一步的loss比上一步的loss值要小就行”
376 |
377 | ##### 特点 : 2.考虑优化器优化过程的历史全局性信息 3.独立同分布地采样优化问题目标函数的参数
378 |
379 | 接下来我们就站在更全局的角度,来优化LSTM优化器的参数
380 |
381 | LSTM是循环神经网络,它可以连续记录并传递所有周期时刻的信息,其每个周期循环里的子图共同构建一个巨大的图,然后使用Back-Propagation Through Time (BPTT)来求导更新
382 |
383 |
384 | ```python
385 | lstm_losses,global_graph_loss= learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True) # [loss1,loss2,...lossT] 所有周期的loss
386 | # 因为这里要保留所有周期的计算图所以retain_graph_flag =True
387 | all_computing_graph_loss = torch.tensor(lstm_losses).sum()
388 | #构建一个所有周期子图构成的总计算图,使用BPTT来梯度更新LSTM参数
389 |
390 | print(all_computing_graph_loss,global_graph_loss )
391 | print(global_graph_loss)
392 | ```
393 |
394 | tensor(554.2158) tensor(554.2158, grad_fn=)
395 | tensor(554.2158, grad_fn=)
396 |
397 |
398 | 可以看到,变量**global_graph_loss**保留了所有周期产生的计算图grad_fn=
399 |
400 | 下面针对LSTM的参数进行全局优化,优化目标:“所有周期之和的loss都很小”。
401 | 值得说明一下:在LSTM优化时的参数,是在所有Unroll_TRAIN_STEPS=[0,T]中保持不变的,在进行完所有Unroll_TRAIN_STEPS以后,再整体优化LSTM的参数。
402 |
403 | 这也就是论文里面提到的coordinate-wise,即“对每个时刻点都保持‘全局聪明’”,即学习到LSTM的参数是全局最优的了。因为我们是站在所有TRAIN_STEPS=[0,T]的视角下进行的优化!
404 |
405 | 优化LSTM优化器选择的是Adam优化器进行梯度下降
406 |
407 | #### 通过梯度下降法来优化 优化器
408 |
409 |
410 | ```python
411 | Global_Train_Steps = 2
412 |
413 | def global_training(optimizer):
414 | global_loss_list = []
415 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = 0.0001)
416 | _,global_loss_1 = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = True)
417 |
418 | #print(global_loss_1)
419 |
420 | for i in range(Global_Train_Steps):
421 | _,global_loss = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = False)
422 | #adam_global_optimizer.zero_grad()
423 | print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
424 | #print(i,global_loss)
425 | global_loss.backward() #每次都是优化这个固定的图,不可以释放动态图的缓存
426 | #print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
427 | adam_global_optimizer.step()
428 | print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
429 | global_loss_list.append(global_loss.detach_())
430 |
431 | #print(global_loss)
432 | return global_loss_list
433 |
434 | # 要把图放进函数体内,直接赋值的话图会丢失
435 | # 优化optimizer
436 | global_loss_list = global_training(lstm)
437 |
438 | ```
439 |
440 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
441 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
442 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
443 | xxx [(None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True), (None, True)]
444 |
445 |
446 | ##### 为什么loss值没有改变?为什么LSTM参数的梯度不存在的?
447 |
448 | 通过分析推理,我发现了LSTM参数的梯度为None,那么反向传播就完全没有更新LSTM的参数!
449 |
450 | 为什么参数的梯度为None呢,优化器并没有更新指定的LSTM的模型参数,一定是什么地方出了问题,我想了好久,还是做一些简单的实验来找一找问题吧。
451 |
452 | > ps: 其实写代码做实验的过程,也体现了人类本身学会学习的高级能力,那就是:通过实验来实现想法时,实验结果往往和预期差别很大,那一定有什么地方出了问题,盲目地大量试错法可能找不到真正问题所在,如何找到问题所在并解决,就是一种学会如何学习的能力,也是一种强化学习的能力。这里我采用的人类智能是:以小见大法。
453 | In a word , if we want the machine achieving to AGI, it must imiate human's ability of reasoning and finding where the problem is and figuring out how to solve the problem. Meta Learning contains this idea.
454 |
455 |
456 | ```python
457 | import torch
458 | z= torch.empty(2)
459 | torch.nn.init.uniform_(z , -2, 2)
460 | z.requires_grad = True
461 | z.retain_grad()
462 | def f(z):
463 | return (z*z).sum()
464 |
465 | optimizer = torch.optim.Adam([z],lr=0.01)
466 | grad =[]
467 | losses= []
468 | zgrad =[]
469 |
470 | for i in range(2):
471 | optimizer.zero_grad()
472 | q = f(z)
473 | loss = q**2
474 | #z.retain_grad()
475 | loss.backward(retain_graph = True)
476 | optimizer.step()
477 | #print(x,x.grad,loss,)
478 |
479 | loss.retain_grad()
480 | print(q.grad,q.requires_grad)
481 | grad.append((z.grad))
482 | losses.append(loss)
483 | zgrad.append(q.grad)
484 |
485 | print(grad)
486 | print(losses)
487 | print(zgrad)
488 | ```
489 |
490 | None True
491 | None True
492 | [tensor([-44.4396, -36.7740]), tensor([-44.4396, -36.7740])]
493 | [tensor(35.9191, grad_fn=), tensor(35.0999, grad_fn=)]
494 | [None, None]
495 |
496 |
497 | ##### 问题出在哪里?
498 |
499 | 经过多方面的实验修改,我发现LSTM的参数在每个周期内BPTT的周期内,并没有产生梯度!!怎么回事呢?我做了上面的小实验。
500 |
501 | 可以看到z.grad = None,但是z.requres_grad = True,z变量作为x变量的子节点,其在计算图中的梯度没有被保留或者没办法获取,那么我就应该通过修改一些PyTorch的代码,使得计算图中的叶子节点的梯度得以存在。然后我找到了retain_grad()这个函数,实验证明,它必须在backward()之前使用才能保存中间叶子节点的梯度!这样的方法也就适合于LSTM优化器模型参数的更新了吧?
502 |
503 |
504 | 那么如何保留LSTM的参数在每个周期中产生的梯度是接下来要修改的!
505 |
506 |
507 | 这是因为我计算loss = f(x),然后loss.backward() 这里的loss计算并没有和LSTM产生关系,我先来想一想loss和LSTM的关系在哪里?
508 |
509 | 论文里有一张图,可以作为参考:
510 |
511 | 图2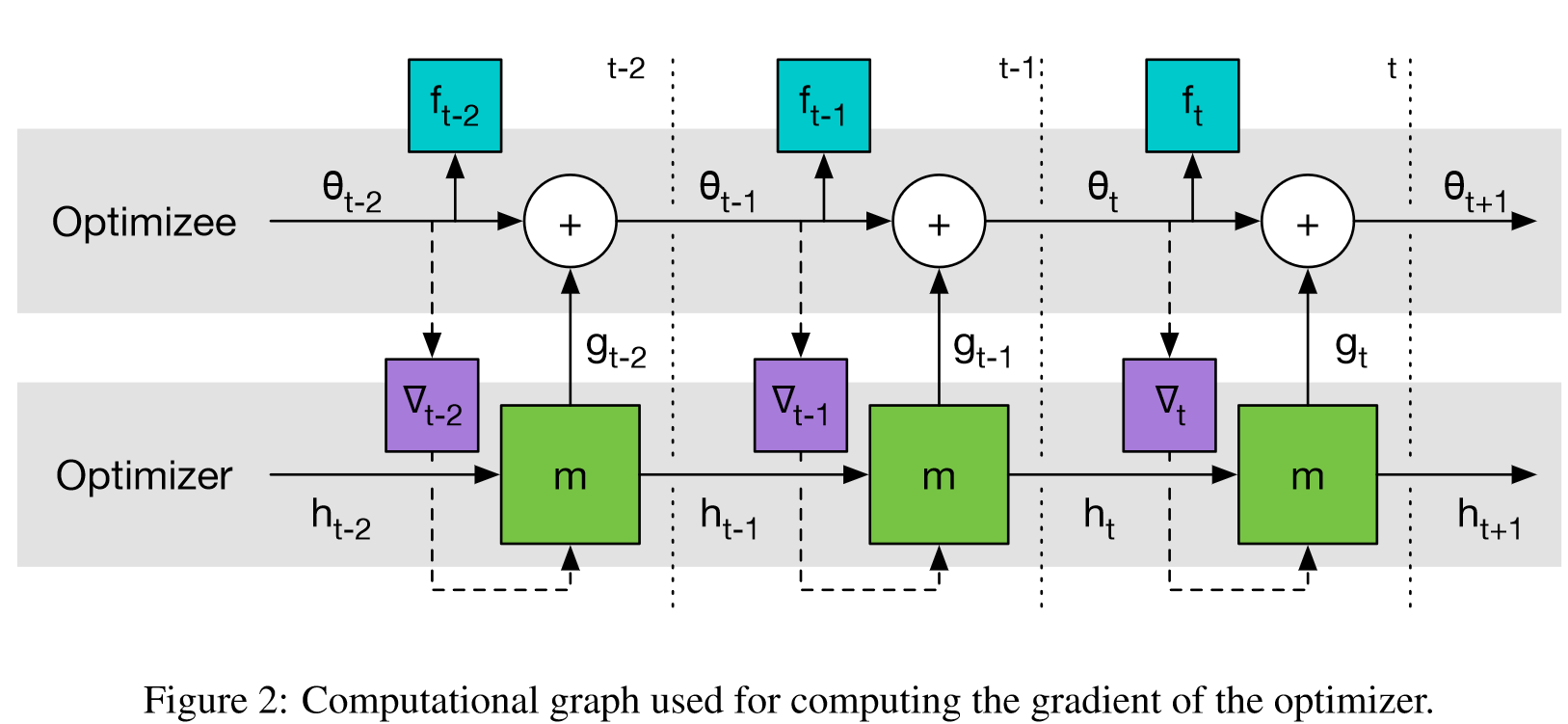 512 |
513 |
514 | **LSTM参数的梯度来自于每次输出的“update”的梯度 update的梯度包含在生成的下一次迭代的参数x的梯度中**
515 |
516 |
517 | 哦!因为参数$x_t = x_{t-1}+update_{t-1}$ 在BPTT的每个周期里$\frac{\partial loss_t}{\partial \theta_{LSTM}}=\frac{\partial loss_t}{\partial update_{t-1}}*\frac{\partial update_{t-1}}{\partial \theta_{LSTM}}$,那么我们想通过$loss_0,loss_1,..,loss_t$之和来更新$\theta_{LSTM}$的话,就必须让梯度经过$x_t$ 中 的$update_{t-1}$流回去,那么每次得到的$x_t$就必须包含了上一次更新产生的图(可以想像,这个计算图是越来越大的),想一想我写的代码,似乎没有保留上一次的计算图在$x_t$节点中,因为我用了x = x.detach_() 把x从图中拿了下来!这似乎是问题最关键所在!!!(而tensorflow静态图的构建,直接建立了一个完整所有周期的图,似乎Pytorch的动态图不合适?no,no)
518 |
519 | (注:以上来自代码中的$x_t$对应上图的$\theta_t$,$update_{t}$对应上图的$g_t$)
520 |
521 | 我为什么会加入x = x.detach_() 是因为不加的话,x变成了子节点,下一次求导pytorch不允许,其实只需要加一行x.retain_grad()代码就行了,并且总的计算图的globa_graph_loss在逐步降低!问题解决!
522 |
523 | 目前在运行global_training(lstm)函数的话,就会发现LSTM的参数已经根据计算图中的梯度回流产生了梯度,每一步可以更新参数了,
524 | 但是这个BPTT算法用cpu算起来,有点慢了~
525 |
526 |
527 |
528 | ```python
529 | def learn(optimizer,unroll_train_steps,retain_graph_flag=False,reset_theta = False):
530 | """retain_graph_flag=False 默认每次loss_backward后 释放动态图
531 | # reset_theta = False 默认每次学习前 不随机初始化参数"""
532 |
533 | if reset_theta == True:
534 | theta_new = torch.empty(DIM)
535 | torch.nn.init.uniform_(theta_new,a=-1,b=1.0)
536 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
537 | x = theta_init_new
538 | else:
539 | x = theta_init
540 |
541 | global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
542 | state = None
543 | x.requires_grad = True
544 | if optimizer.__name__ !='Adam':
545 | losses = []
546 | for i in range(unroll_train_steps):
547 |
548 | loss = f(x)
549 |
550 | #global_loss_graph += torch.exp(torch.Tensor([-i/20]))*loss
551 | #global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
552 | global_loss_graph += loss
553 |
554 |
555 | loss.backward(retain_graph=retain_graph_flag) # 默认为False,当优化LSTM设置为True
556 | update, state = optimizer(x.grad, state)
557 | losses.append(loss)
558 |
559 | x = x + update
560 |
561 | # x = x.detach_()
562 | #这个操作 直接把x中包含的图给释放了,
563 | #那传递给下次训练的x从子节点变成了叶节点,那么梯度就不能沿着这个路回传了,
564 | #之前写这一步是因为这个子节点在下一次迭代不可以求导,那么应该用x.retain_grad()这个操作,
565 | #然后不需要每次新的的开始给x.requires_grad = True
566 |
567 | x.retain_grad()
568 | #print(x.retain_grad())
569 |
570 |
571 | #print(x)
572 | return losses ,global_loss_graph
573 |
574 | else:
575 | losses = []
576 | x.requires_grad = True
577 | optimizer= torch.optim.Adam( [x],lr=0.1 )
578 |
579 | for i in range(unroll_train_steps):
580 |
581 | optimizer.zero_grad()
582 | loss = f(x)
583 | global_loss_graph += loss
584 |
585 | loss.backward(retain_graph=retain_graph_flag)
586 | optimizer.step()
587 | losses.append(loss.detach_())
588 | #print(x)
589 | return losses,global_loss_graph
590 |
591 | Global_Train_Steps = 1000
592 |
593 | def global_training(optimizer):
594 | global_loss_list = []
595 | adam_global_optimizer = torch.optim.Adam([{'params':optimizer.parameters()},{'params':Linear.parameters()}],lr = 0.0001)
596 | _,global_loss_1 = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = True)
597 | print(global_loss_1)
598 | for i in range(Global_Train_Steps):
599 | _,global_loss = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = False)
600 | adam_global_optimizer.zero_grad()
601 |
602 | #print(i,global_loss)
603 | global_loss.backward() #每次都是优化这个固定的图,不可以释放动态图的缓存
604 | #print('xxx',[(z,z.requires_grad) for z in optimizer.parameters() ])
605 | adam_global_optimizer.step()
606 | #print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
607 | global_loss_list.append(global_loss.detach_())
608 |
609 | print(global_loss)
610 | return global_loss_list
611 |
612 | # 要把图放进函数体内,直接赋值的话图会丢失
613 | # 优化optimizer
614 | global_loss_list = global_training(lstm)
615 | ```
616 |
617 | tensor(193.6147, grad_fn=)
618 | tensor(7.6411)
619 |
620 |
621 | ##### 计算图不再丢失了,LSTM的参数的梯度经过计算图的流动已经产生了!
622 |
623 |
624 | ```python
625 | Global_T = np.arange(Global_Train_Steps)
626 |
627 | p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
628 | plt.legend(handles=[p1])
629 | plt.title('Training LSTM optimizer by gradient descent ')
630 | plt.show()
631 | ```
632 |
633 | 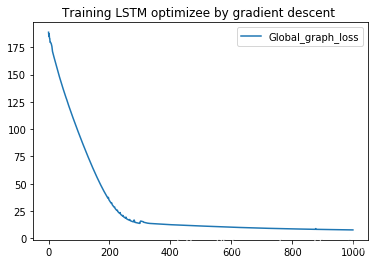
634 |
635 |
636 |
637 | ```python
638 | import matplotlib
639 | import matplotlib.pyplot as plt
640 | %matplotlib inline
641 | import numpy as np
642 | STEPS = 15
643 | x = np.arange(STEPS)
644 |
645 |
646 | for _ in range(2):
647 |
648 | sgd_losses, sgd_sum_loss = learn(SGD,STEPS,reset_theta=True)
649 | rms_losses, rms_sum_loss = learn(RMS,STEPS,reset_theta=True)
650 | adam_losses, adam_sum_loss = learn(Adam,STEPS,reset_theta=True)
651 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,STEPS,reset_theta=True,retain_graph_flag = True)
652 | p1, = plt.plot(x, sgd_losses, label='SGD')
653 | p2, = plt.plot(x, rms_losses, label='RMS')
654 | p3, = plt.plot(x, adam_losses, label='Adam')
655 | p4, = plt.plot(x, lstm_losses, label='LSTM')
656 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
657 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
658 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
659 | plt.legend(handles=[p1, p2, p3, p4])
660 | #plt.yscale('log')
661 | plt.title('Losses')
662 | plt.show()
663 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
664 | ```
665 |
666 | 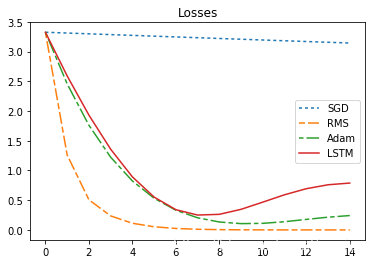
667 |
668 |
669 |
670 | sum_loss:sgd=48.513607025146484,rms=5.537945747375488,adam=11.781242370605469,lstm=15.151629447937012
671 |
672 |
673 | 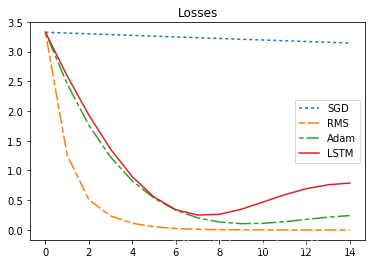
674 |
675 |
676 |
677 | sum_loss:sgd=48.513607025146484,rms=5.537945747375488,adam=11.781242370605469,lstm=15.151629447937012
678 |
679 |
680 | 可以看出来,经过优化后的LSTM优化器,似乎已经开始掌握如何优化的方法,即我们基本训练出了一个可以训练模型的优化器!
681 |
682 | **但是效果并不是很明显!**
683 |
684 | 不过代码编写取得一定进展\ (0 ..0) /,接下就是让效果更明显,性能更稳定了吧?
685 |
686 | **不过我先再多测试一些周期看看LSTM的优化效果!先别高兴太早!**
687 |
688 |
689 | ```python
690 | import matplotlib
691 | import matplotlib.pyplot as plt
692 | %matplotlib inline
693 | import numpy as np
694 | STEPS = 50
695 | x = np.arange(STEPS)
696 |
697 |
698 | for _ in range(1):
699 |
700 | sgd_losses, sgd_sum_loss = learn(SGD,STEPS,reset_theta=True)
701 | rms_losses, rms_sum_loss = learn(RMS,STEPS,reset_theta=True)
702 | adam_losses, adam_sum_loss = learn(Adam,STEPS,reset_theta=True)
703 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,STEPS,reset_theta=True,retain_graph_flag = True)
704 | p1, = plt.plot(x, sgd_losses, label='SGD')
705 | p2, = plt.plot(x, rms_losses, label='RMS')
706 | p3, = plt.plot(x, adam_losses, label='Adam')
707 | p4, = plt.plot(x, lstm_losses, label='LSTM')
708 | plt.legend(handles=[p1, p2, p3, p4])
709 | #plt.yscale('log')
710 | plt.title('Losses')
711 | plt.show()
712 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
713 | ```
714 |
715 | 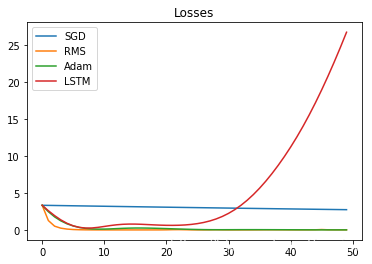
716 |
717 |
718 |
719 | sum_loss:sgd=150.99790954589844,rms=5.940474033355713,adam=14.17563247680664,lstm=268.0199279785156
720 |
721 |
722 |
723 | #### 又出了什么幺蛾子?
724 |
725 | 即我们基本训练出了一个可以训练模型的优化器!但是 经过更长周期的测试,发现训练好的优化器只是优化了指定的周期的loss,而并没有学会“全局优化”的本领,这个似乎是个大问题!
726 |
727 | ##### 不同周期下输入LSTM的梯度幅值数量级不在一个等级上面
728 |
729 | 要处理一下!
730 |
731 | 论文里面提到了对梯度的预处理,即处理不同数量级别的梯度,来进行BPTT,因为每个周期的产生的梯度幅度是完全不在一个数量级,前期梯度下降很快,中后期梯度下降平缓,这个对于LSTM的输入,变化裕度太大,应该归一化,但这个我并没有考虑,接下似乎该写这个部分的代码了
732 |
733 | 论文里提到了:
734 | One potential challenge in training optimizers is that different input coordinates (i.e. the gradients w.r.t. different
735 | optimizer parameters) can have very different magnitudes.
736 | This is indeed the case e.g. when the optimizer is a neural network and different parameters
737 | correspond to weights in different layers.
738 | This can make training an optimizer difficult, because neural networks
739 | naturally disregard small variations in input signals and concentrate on bigger input values.
740 |
741 | ##### 用梯度的(归一化幅值,方向)二元组替代原梯度作为LSTM的输入
742 | To this aim we propose to preprocess the optimizer's inputs.
743 | One solution would be to give the optimizer $\left(\log(|\nabla|),\,\operatorname{sgn}(\nabla)\right)$ as an input, where
744 | $\nabla$ is the gradient in the current timestep.
745 | This has a problem that $\log(|\nabla|)$ diverges for $\nabla \rightarrow 0$.
746 | Therefore, we use the following preprocessing formula
747 |
748 | $\nabla$ is the gradient in the current timestep.
749 | This has a problem that $\log(|\nabla|)$ diverges for $\nabla \rightarrow 0$.
750 | Therefore, we use the following preprocessing formula
751 |
752 | $$\nabla^k\rightarrow \left\{\begin{matrix}
753 | \left(\frac{\log(|\nabla|)}{p}\,, \operatorname{sgn}(\nabla)\right)& \text{if } |\nabla| \geq e^{-p}\\
754 | (-1, e^p \nabla) & \text{otherwise}
755 | \end{matrix}\right.$$
756 |
757 | 作者将不同幅度和方向下的梯度,用一个标准化到$[-1,1]$的幅值和符号方向二元组来表示原来的梯度张量!这样将有助于LSTM的参数学习!
758 | 那我就重新定义LSTM优化器!
759 |
760 |
761 | ```python
762 | Layers = 2
763 | Hidden_nums = 20
764 |
765 | Input_DIM = DIM
766 | Output_DIM = DIM
767 | # "coordinate-wise" RNN
768 | #lstm1=torch.nn.LSTM(Input_DIM*2,Hidden_nums ,Layers)
769 | #Linear = torch.nn.Linear(Hidden_nums,Output_DIM)
770 |
771 |
772 | class LSTM_optimizer_Model(torch.nn.Module):
773 | """LSTM优化器"""
774 |
775 | def __init__(self,input_size,output_size, hidden_size, num_stacks, batchsize, preprocess = True ,p = 10 ,output_scale = 1):
776 | super(LSTM_optimizer_Model,self).__init__()
777 | self.preprocess_flag = preprocess
778 | self.p = p
779 | self.output_scale = output_scale #论文
780 | self.lstm = torch.nn.LSTM(input_size, hidden_size, num_stacks)
781 | self.Linear = torch.nn.Linear(hidden_size,output_size)
782 | #elf.lstm = torch.nn.LSTM(10, 20,2)
783 | #elf.Linear = torch.nn.Linear(20,10)
784 |
785 | def LogAndSign_Preprocess_Gradient(self,gradients):
786 | """
787 | Args:
788 | gradients: `Tensor` of gradients with shape `[d_1, ..., d_n]`.
789 | p : `p` > 0 is a parameter controlling how small gradients are disregarded
790 | Returns:
791 | `Tensor` with shape `[d_1, ..., d_n-1, 2 * d_n]`. The first `d_n` elements
792 | along the nth dimension correspond to the `log output` \in [-1,1] and the remaining
793 | `d_n` elements to the `sign output`.
794 | """
795 | p = self.p
796 | log = torch.log(torch.abs(gradients))
797 | clamp_log = torch.clamp(log/p , min = -1.0,max = 1.0)
798 | clamp_sign = torch.clamp(torch.exp(torch.Tensor(p))*gradients, min = -1.0, max =1.0)
799 | return torch.cat((clamp_log,clamp_sign),dim = -1) #在gradients的最后一维input_dims拼接
800 |
801 | def Output_Gradient_Increment_And_Update_LSTM_Hidden_State(self, input_gradients, prev_state):
802 | """LSTM的核心操作"""
803 | if prev_state is None: #init_state
804 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums),
805 | torch.zeros(Layers,batchsize,Hidden_nums))
806 |
807 | update , next_state = self.lstm(input_gradients, prev_state)
808 |
809 | update = Linear(update) * self.output_scale #因为LSTM的输出是当前步的Hidden,需要变换到output的相同形状上
810 | return update, next_state
811 |
812 | def forward(self,gradients, prev_state):
813 |
814 | #LSTM的输入为梯度,pytorch要求torch.nn.lstm的输入为(1,batchsize,input_dim)
815 | #原gradient.size()=torch.size[5] ->[1,1,5]
816 | gradients = gradients.unsqueeze(0).unsqueeze(0)
817 | if self.preprocess_flag == True:
818 | gradients = self.LogAndSign_Preprocess_Gradient(gradients)
819 |
820 | update , next_state = self.Output_Gradient_Increment_And_Update_LSTM_Hidden_State(gradients , prev_state)
821 |
822 | # Squeeze to make it a single batch again.[1,1,5]->[5]
823 | update = update.squeeze().squeeze()
824 | return update , next_state
825 |
826 | LSTM_optimizer = LSTM_optimizer_Model(Input_DIM*2, Output_DIM, Hidden_nums ,Layers , batchsize=1,)
827 |
828 |
829 | grads = torch.randn(10)*10
830 | print(grads.size())
831 |
832 | update,state = LSTM_optimizer(grads,None)
833 | print(update.size(),)
834 | ```
835 |
836 | torch.Size([10])
837 | torch.Size([10])
838 |
839 |
840 | 编写成功!
841 | 执行!
842 |
843 |
844 | ```python
845 | def learn(optimizer,unroll_train_steps,retain_graph_flag=False,reset_theta = False):
846 | """retain_graph_flag=False 默认每次loss_backward后 释放动态图
847 | # reset_theta = False 默认每次学习前 不随机初始化参数"""
848 |
849 | if reset_theta == True:
850 | theta_new = torch.empty(DIM)
851 | torch.nn.init.uniform_(theta_new,a=-1,b=1.0)
852 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
853 | x = theta_init_new
854 | else:
855 | x = theta_init
856 |
857 | global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
858 | state = None
859 | x.requires_grad = True
860 | if optimizer!='Adam':
861 | losses = []
862 | for i in range(unroll_train_steps):
863 | loss = f(x)
864 | #global_loss_graph += torch.exp(torch.Tensor([-i/20]))*loss
865 | #global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
866 | global_loss_graph += loss
867 | # print('loss{}:'.format(i),loss)
868 | loss.backward(retain_graph=retain_graph_flag) # 默认为False,当优化LSTM设置为True
869 |
870 | update, state = optimizer(x.grad, state)
871 | #print(update)
872 | losses.append(loss)
873 | x = x + update
874 | x.retain_grad()
875 | return losses ,global_loss_graph
876 |
877 | else:
878 | losses = []
879 | x.requires_grad = True
880 | optimizer= torch.optim.Adam( [x],lr=0.1 )
881 |
882 | for i in range(unroll_train_steps):
883 |
884 | optimizer.zero_grad()
885 | loss = f(x)
886 |
887 | global_loss_graph += loss
888 |
889 | loss.backward(retain_graph=retain_graph_flag)
890 | optimizer.step()
891 | losses.append(loss.detach_())
892 | #print(x)
893 | return losses,global_loss_graph
894 |
895 | Global_Train_Steps = 100
896 |
897 | def global_training(optimizer):
898 | global_loss_list = []
899 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = 0.0001)
900 | _,global_loss_1 = learn(optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = True)
901 | print(global_loss_1)
902 | for i in range(Global_Train_Steps):
903 | _,global_loss = learn(optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = False)
904 | adam_global_optimizer.zero_grad()
905 |
906 | #print(i,global_loss)
907 | global_loss.backward() #每次都是优化这个固定的图,不可以释放动态图的缓存
908 | #print('xxx',[(z,z.requires_grad) for z in optimizer.parameters() ])
909 | adam_global_optimizer.step()
910 | #print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
911 | global_loss_list.append(global_loss.detach_())
912 |
913 | print(global_loss)
914 | return global_loss_list
915 |
916 | # 要把图放进函数体内,直接赋值的话图会丢失
917 | # 优化optimizer
918 | global_loss_list = global_training(LSTM_optimizer)
919 | ```
920 |
921 | tensor(239.6029, grad_fn=)
922 | tensor(158.0625)
923 |
924 |
925 |
926 | ```python
927 | Global_T = np.arange(Global_Train_Steps)
928 |
929 | p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
930 | plt.legend(handles=[p1])
931 | plt.title('Training LSTM optimizer by gradient descent ')
932 | plt.show()
933 | ```
934 |
935 | 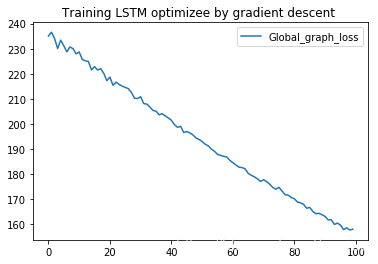
936 |
937 |
938 |
939 |
940 | ```python
941 | import matplotlib
942 | import matplotlib.pyplot as plt
943 | %matplotlib inline
944 | import numpy as np
945 | STEPS = 30
946 | x = np.arange(STEPS)
947 |
948 | Adam = 'Adam'
949 | for _ in range(1):
950 |
951 | sgd_losses, sgd_sum_loss = learn(SGD,STEPS,reset_theta=True)
952 | rms_losses, rms_sum_loss = learn(RMS,STEPS,reset_theta=True)
953 | adam_losses, adam_sum_loss = learn(Adam,STEPS,reset_theta=True)
954 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,STEPS,reset_theta=True,retain_graph_flag = True)
955 | p1, = plt.plot(x, sgd_losses, label='SGD')
956 | p2, = plt.plot(x, rms_losses, label='RMS')
957 | p3, = plt.plot(x, adam_losses, label='Adam')
958 | p4, = plt.plot(x, lstm_losses, label='LSTM')
959 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
960 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
961 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
962 | plt.legend(handles=[p1, p2, p3, p4])
963 | plt.title('Losses')
964 | plt.show()
965 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
966 | ```
967 |
968 | 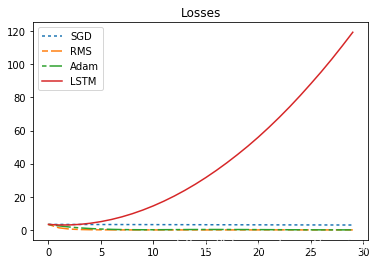
969 |
970 |
971 | sum_loss:sgd=94.19924926757812,rms=5.705832481384277,adam=13.772469520568848,lstm=1224.2393798828125
972 |
973 |
974 | **为什么loss出现了NaN???为什么优化器的泛化性能很差??很烦**
975 |
976 | 即超过Unroll周期以后,LSTM优化器不再具备优化性能???
977 |
978 | 然后我又回顾论文,发现,对优化器进行优化的每个周期开始,要重新随机化,优化问题的参数,即确保我们的LSTM不针对一个特定优化问题过拟合,什么?优化器也会过拟合!是的!l
979 |
980 | 论文里面其实也有提到:
981 |
982 | Given a distribution of functions $f$ we will write
983 | the expected loss as:
984 | $$ L\left(\phi \right) =E_f \left[ f \left ( \theta ^{*}\left ( f,\phi \right )\right ) \right](1)$$
985 |
986 | 其中f是随机分布的,那么就需要在Unroll的初始进行从IID 标准Gaussian分布随机采样函数的参数
987 |
988 | 另外我完善了代码,根据原作代码实现,把LSTM的输出乘以一个系数0.01,那么LSTM的学习变得更加快速了。
989 |
990 | 还有一个地方,就是作者优化optimiee用了100个周期,即5个连续的Unroll周期,这一点似乎我之前也没有考虑到!
991 |
992 | --------------------------------------------------------------------------------------------------
993 |
994 | --------------------------------------------------------------------------------------------------
995 |
996 |
997 | ## 以上是代码编写遇到的种种问题,下面就是最完整的有效代码了!!!
998 |
999 |
1000 |
1001 | **我们考虑优化论文中提到的Quadratic函数,并且用论文中完全一样的实验条件!**
1002 |
1003 | $$f(\theta) = \|W\theta - y\|_2^2$$
1004 | for different 10x10 matrices $W$ and 10-dimensional vectors $y$ whose elements are drawn
1005 | from an IID Gaussian distribution.
1006 | Optimizers were trained by optimizing random functions from this family and
1007 | tested on newly sampled functions from the same distribution. Each function was
1008 | optimized for 100 steps and the trained optimizers were unrolled for 20 steps.
1009 | We have not used any preprocessing, nor postprocessing.
1010 |
1011 |
1012 | ```python
1013 | # coding: utf-8
1014 |
1015 | # Learning to learn by gradient descent by gradient descent
1016 | # =========================#
1017 |
1018 | # https://arxiv.org/abs/1611.03824
1019 | # https://yangsenius.github.io/blog/LSTM_Meta/
1020 | # https://github.com/yangsenius/learning-to-learn-by-pytorch
1021 | # author:yangsen
1022 | # #### “通过梯度下降来学习如何通过梯度下降学习”
1023 | # #### 要让优化器学会这样 "为了更好地得到,要先去舍弃" 这样类似的知识!
1024 |
1025 | import torch
1026 | import torch.nn as nn
1027 | from timeit import default_timer as timer
1028 | ##################### 优化问题 ##########################
1029 | USE_CUDA = False
1030 | DIM = 10
1031 | batchsize = 128
1032 |
1033 | if torch.cuda.is_available():
1034 | USE_CUDA = True
1035 | USE_CUDA = False
1036 |
1037 |
1038 | print('\n\nUSE_CUDA = {}\n\n'.format(USE_CUDA))
1039 |
1040 |
1041 | def f(W,Y,x):
1042 | """quadratic function : f(\theta) = \|W\theta - y\|_2^2"""
1043 | if USE_CUDA:
1044 | W = W.cuda()
1045 | Y = Y.cuda()
1046 | x = x.cuda()
1047 |
1048 | return ((torch.matmul(W,x.unsqueeze(-1)).squeeze()-Y)**2).sum(dim=1).mean(dim=0)
1049 |
1050 | ###############################################################
1051 |
1052 | ###################### 手工的优化器 ###################
1053 |
1054 | def SGD(gradients, state, learning_rate=0.001):
1055 |
1056 | return -gradients*learning_rate, state
1057 |
1058 | def RMS(gradients, state, learning_rate=0.01, decay_rate=0.9):
1059 | if state is None:
1060 | state = torch.zeros(DIM)
1061 | if USE_CUDA == True:
1062 | state = state.cuda()
1063 |
1064 | state = decay_rate*state + (1-decay_rate)*torch.pow(gradients, 2)
1065 | update = -learning_rate*gradients / (torch.sqrt(state+1e-5))
1066 | return update, state
1067 |
1068 | def adam():
1069 | return torch.optim.Adam()
1070 |
1071 | ##########################################################
1072 |
1073 |
1074 | ##################### 自动 LSTM 优化器模型 ##########################
1075 | class LSTM_optimizer_Model(torch.nn.Module):
1076 | """LSTM优化器"""
1077 |
1078 | def __init__(self,input_size,output_size, hidden_size, num_stacks, batchsize, preprocess = True ,p = 10 ,output_scale = 1):
1079 | super(LSTM_optimizer_Model,self).__init__()
1080 | self.preprocess_flag = preprocess
1081 | self.p = p
1082 | self.input_flag = 2
1083 | if preprocess != True:
1084 | self.input_flag = 1
1085 | self.output_scale = output_scale #论文
1086 | self.lstm = torch.nn.LSTM(input_size*self.input_flag, hidden_size, num_stacks)
1087 | self.Linear = torch.nn.Linear(hidden_size,output_size) #1-> output_size
1088 |
1089 | def LogAndSign_Preprocess_Gradient(self,gradients):
1090 | """
1091 | Args:
1092 | gradients: `Tensor` of gradients with shape `[d_1, ..., d_n]`.
1093 | p : `p` > 0 is a parameter controlling how small gradients are disregarded
1094 | Returns:
1095 | `Tensor` with shape `[d_1, ..., d_n-1, 2 * d_n]`. The first `d_n` elements
1096 | along the nth dimension correspond to the `log output` \in [-1,1] and the remaining
1097 | `d_n` elements to the `sign output`.
1098 | """
1099 | p = self.p
1100 | log = torch.log(torch.abs(gradients))
1101 | clamp_log = torch.clamp(log/p , min = -1.0,max = 1.0)
1102 | clamp_sign = torch.clamp(torch.exp(torch.Tensor(p))*gradients, min = -1.0, max =1.0)
1103 | return torch.cat((clamp_log,clamp_sign),dim = -1) #在gradients的最后一维input_dims拼接
1104 |
1105 | def Output_Gradient_Increment_And_Update_LSTM_Hidden_State(self, input_gradients, prev_state):
1106 | """LSTM的核心操作
1107 | coordinate-wise LSTM """
1108 | if prev_state is None: #init_state
1109 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums),
1110 | torch.zeros(Layers,batchsize,Hidden_nums))
1111 | if USE_CUDA :
1112 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums).cuda(),
1113 | torch.zeros(Layers,batchsize,Hidden_nums).cuda())
1114 |
1115 | update , next_state = self.lstm(input_gradients, prev_state)
1116 | update = self.Linear(update) * self.output_scale #因为LSTM的输出是当前步的Hidden,需要变换到output的相同形状上
1117 | return update, next_state
1118 |
1119 | def forward(self,input_gradients, prev_state):
1120 | if USE_CUDA:
1121 | input_gradients = input_gradients.cuda()
1122 | #LSTM的输入为梯度,pytorch要求torch.nn.lstm的输入为(1,batchsize,input_dim)
1123 | #原gradient.size()=torch.size[5] ->[1,1,5]
1124 | gradients = input_gradients.unsqueeze(0)
1125 |
1126 | if self.preprocess_flag == True:
1127 | gradients = self.LogAndSign_Preprocess_Gradient(gradients)
1128 |
1129 | update , next_state = self.Output_Gradient_Increment_And_Update_LSTM_Hidden_State(gradients , prev_state)
1130 | # Squeeze to make it a single batch again.[1,1,5]->[5]
1131 | update = update.squeeze().squeeze()
1132 |
1133 | return update , next_state
1134 |
1135 | ################# 优化器模型参数 ##############################
1136 | Layers = 2
1137 | Hidden_nums = 20
1138 | Input_DIM = DIM
1139 | Output_DIM = DIM
1140 | output_scale_value=1
1141 |
1142 | ####### 构造一个优化器 #######
1143 | LSTM_optimizer = LSTM_optimizer_Model(Input_DIM, Output_DIM, Hidden_nums ,Layers , batchsize=batchsize,\
1144 | preprocess=False,output_scale=output_scale_value)
1145 | print(LSTM_optimizer)
1146 |
1147 | if USE_CUDA:
1148 | LSTM_optimizer = LSTM_optimizer.cuda()
1149 |
1150 |
1151 | ###################### 优化问题目标函数的学习过程 ###############
1152 |
1153 |
1154 | class Learner( object ):
1155 | """
1156 | Args :
1157 | `f` : 要学习的问题
1158 | `optimizer` : 使用的优化器
1159 | `train_steps` : 对于其他SGD,Adam等是训练周期,对于LSTM训练时的展开周期
1160 | `retain_graph_flag=False` : 默认每次loss_backward后 释放动态图
1161 | `reset_theta = False ` : 默认每次学习前 不随机初始化参数
1162 | `reset_function_from_IID_distirbution = True` : 默认从分布中随机采样函数
1163 |
1164 | Return :
1165 | `losses` : reserves each loss value in each iteration
1166 | `global_loss_graph` : constructs the graph of all Unroll steps for LSTM's BPTT
1167 | """
1168 | def __init__(self, f , optimizer, train_steps ,
1169 | eval_flag = False,
1170 | retain_graph_flag=False,
1171 | reset_theta = False ,
1172 | reset_function_from_IID_distirbution = True):
1173 | self.f = f
1174 | self.optimizer = optimizer
1175 | self.train_steps = train_steps
1176 | #self.num_roll=num_roll
1177 | self.eval_flag = eval_flag
1178 | self.retain_graph_flag = retain_graph_flag
1179 | self.reset_theta = reset_theta
1180 | self.reset_function_from_IID_distirbution = reset_function_from_IID_distirbution
1181 | self.init_theta_of_f()
1182 | self.state = None
1183 |
1184 | self.global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
1185 | self.losses = [] # 保存每个训练周期的loss值
1186 |
1187 | def init_theta_of_f(self,):
1188 | ''' 初始化 优化问题 f 的参数 '''
1189 | self.DIM = 10
1190 | self.batchsize = 128
1191 | self.W = torch.randn(batchsize,DIM,DIM) #代表 已知的数据 # 独立同分布的标准正太分布
1192 | self.Y = torch.randn(batchsize,DIM)
1193 | self.x = torch.zeros(self.batchsize,self.DIM)
1194 | self.x.requires_grad = True
1195 | if USE_CUDA:
1196 | self.W = self.W.cuda()
1197 | self.Y = self.Y.cuda()
1198 | self.x = self.x.cuda()
1199 |
1200 |
1201 | def Reset_Or_Reuse(self , x , W , Y , state, num_roll):
1202 | ''' re-initialize the `W, Y, x , state` at the begining of each global training
1203 | IF `num_roll` == 0 '''
1204 |
1205 | reset_theta =self.reset_theta
1206 | reset_function_from_IID_distirbution = self.reset_function_from_IID_distirbution
1207 |
1208 |
1209 | if num_roll == 0 and reset_theta == True:
1210 | theta = torch.zeros(batchsize,DIM)
1211 |
1212 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
1213 | x = theta_init_new
1214 |
1215 |
1216 | ################ 每次全局训练迭代,从独立同分布的Normal Gaussian采样函数 ##################
1217 | if num_roll == 0 and reset_function_from_IID_distirbution == True :
1218 | W = torch.randn(batchsize,DIM,DIM) #代表 已知的数据 # 独立同分布的标准正太分布
1219 | Y = torch.randn(batchsize,DIM) #代表 数据的标签 # 独立同分布的标准正太分布
1220 |
1221 |
1222 | if num_roll == 0:
1223 | state = None
1224 | print('reset W, x , Y, state ')
1225 |
1226 | if USE_CUDA:
1227 | W = W.cuda()
1228 | Y = Y.cuda()
1229 | x = x.cuda()
1230 | x.retain_grad()
1231 |
1232 |
1233 | return x , W , Y , state
1234 |
1235 | def __call__(self, num_roll=0) :
1236 | '''
1237 | Total Training steps = Unroll_Train_Steps * the times of `Learner` been called
1238 |
1239 | SGD,RMS,LSTM 用上述定义的
1240 | Adam优化器直接使用pytorch里的,所以代码上有区分 后面可以完善!'''
1241 | f = self.f
1242 | x , W , Y , state = self.Reset_Or_Reuse(self.x , self.W , self.Y , self.state , num_roll )
1243 | self.global_loss_graph = 0 #每个unroll的开始需要 重新置零
1244 | optimizer = self.optimizer
1245 | print('state is None = {}'.format(state == None))
1246 |
1247 | if optimizer!='Adam':
1248 |
1249 | for i in range(self.train_steps):
1250 | loss = f(W,Y,x)
1251 | #self.global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
1252 | self.global_loss_graph += loss
1253 |
1254 | loss.backward(retain_graph=self.retain_graph_flag) # 默认为False,当优化LSTM设置为True
1255 |
1256 | update, state = optimizer(x.grad, state)
1257 |
1258 | self.losses.append(loss)
1259 |
1260 | x = x + update
1261 | x.retain_grad()
1262 | update.retain_grad()
1263 |
1264 | if state is not None:
1265 | self.state = (state[0].detach(),state[1].detach())
1266 |
1267 | return self.losses ,self.global_loss_graph
1268 |
1269 | else: #Pytorch Adam
1270 |
1271 | x.detach_()
1272 | x.requires_grad = True
1273 | optimizer= torch.optim.Adam( [x],lr=0.1 )
1274 |
1275 | for i in range(self.train_steps):
1276 |
1277 | optimizer.zero_grad()
1278 | loss = f(W,Y,x)
1279 |
1280 | self.global_loss_graph += loss
1281 |
1282 | loss.backward(retain_graph=self.retain_graph_flag)
1283 | optimizer.step()
1284 | self.losses.append(loss.detach_())
1285 |
1286 | return self.losses, self.global_loss_graph
1287 |
1288 |
1289 | ####### LSTM 优化器的训练过程 Learning to learn ###############
1290 |
1291 | def Learning_to_learn_global_training(optimizer, global_taining_steps, optimizer_Train_Steps, UnRoll_STEPS, Evaluate_period ,optimizer_lr=0.1):
1292 | """ Training the LSTM optimizer . Learning to learn
1293 |
1294 | Args:
1295 | `optimizer` : DeepLSTMCoordinateWise optimizer model
1296 | `global_taining_steps` : how many steps for optimizer training o可以ptimizee
1297 | `optimizer_Train_Steps` : how many step for optimizer opimitzing each function sampled from IID.
1298 | `UnRoll_STEPS` :: how many steps for LSTM optimizer being unrolled to construct a computing graph to BPTT.
1299 | """
1300 | global_loss_list = []
1301 | Total_Num_Unroll = optimizer_Train_Steps // UnRoll_STEPS
1302 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = optimizer_lr)
1303 |
1304 | LSTM_Learner = Learner(f, optimizer, UnRoll_STEPS, retain_graph_flag=True, reset_theta=True,)
1305 | #这里考虑Batchsize代表IID的话,那么就可以不需要每次都重新IID采样
1306 | #即reset_function_from_IID_distirbution = False 否则为True
1307 |
1308 | best_sum_loss = 999999
1309 | best_final_loss = 999999
1310 | best_flag = False
1311 | for i in range(Global_Train_Steps):
1312 |
1313 | print('\n=======> global training steps: {}'.format(i))
1314 |
1315 | for num in range(Total_Num_Unroll):
1316 |
1317 | start = timer()
1318 | _,global_loss = LSTM_Learner(num)
1319 |
1320 | adam_global_optimizer.zero_grad()
1321 | global_loss.backward()
1322 |
1323 | adam_global_optimizer.step()
1324 | # print('xxx',[(z.grad,z.requires_grad) for z in optimizer.lstm.parameters() ])
1325 | global_loss_list.append(global_loss.detach_())
1326 | time = timer() - start
1327 | #if i % 10 == 0:
1328 | print('-> time consuming [{:.1f}s] optimizer train steps : [{}] | Global_Loss = [{:.1f}] '\
1329 | .format(time,(num +1)* UnRoll_STEPS,global_loss,))
1330 |
1331 | if (i + 1) % Evaluate_period == 0:
1332 |
1333 | best_sum_loss, best_final_loss, best_flag = evaluate(best_sum_loss,best_final_loss,best_flag , optimizer_lr)
1334 |
1335 | return global_loss_list,best_flag
1336 |
1337 |
1338 | def evaluate(best_sum_loss,best_final_loss, best_flag,lr):
1339 | print('\n --> evalute the model')
1340 | STEPS = 100
1341 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True, retain_graph_flag=True)
1342 | lstm_losses, sum_loss = LSTM_learner()
1343 | try:
1344 | best = torch.load('best_loss.txt')
1345 | except IOError:
1346 | print ('can not find best_loss.txt')
1347 | pass
1348 | else:
1349 | best_sum_loss = best[0]
1350 | best_final_loss = best[1]
1351 | print("load_best_final_loss and sum_loss")
1352 | if lstm_losses[-1] < best_final_loss and sum_loss < best_sum_loss:
1353 | best_final_loss = lstm_losses[-1]
1354 | best_sum_loss = sum_loss
1355 |
1356 | print('\n\n===> update new best of final LOSS[{}]: = {}, best_sum_loss ={}'.format(STEPS, best_final_loss,best_sum_loss))
1357 | torch.save(LSTM_optimizer.state_dict(),'best_LSTM_optimizer.pth')
1358 | torch.save([best_sum_loss ,best_final_loss,lr ],'best_loss.txt')
1359 | best_flag = True
1360 |
1361 | return best_sum_loss, best_final_loss, best_flag
1362 |
1363 |
1364 | ```
1365 |
1366 |
1367 |
1368 | USE_CUDA = False
1369 |
1370 |
1371 | LSTM_optimizer_Model(
1372 | (lstm): LSTM(10, 20, num_layers=2)
1373 | (Linear): Linear(in_features=20, out_features=10, bias=True)
1374 | )
1375 |
1376 |
1377 | ### 我们先来看看随机初始化的LSTM优化器的效果
1378 |
1379 |
1380 | ```python
1381 | ############# 注意:接上一片段的代码!! #######################3#
1382 | ########################## before learning LSTM optimizer ###############################
1383 | import numpy as np
1384 | import matplotlib
1385 | import matplotlib.pyplot as plt
1386 |
1387 | STEPS = 100
1388 | x = np.arange(STEPS)
1389 |
1390 | Adam = 'Adam' #因为这里Adam使用Pytorch
1391 |
1392 | for _ in range(1):
1393 |
1394 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
1395 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
1396 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
1397 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
1398 |
1399 | sgd_losses, sgd_sum_loss = SGD_Learner()
1400 | rms_losses, rms_sum_loss = RMS_Learner()
1401 | adam_losses, adam_sum_loss = Adam_Learner()
1402 | lstm_losses, lstm_sum_loss = LSTM_learner()
1403 |
1404 | p1, = plt.plot(x, sgd_losses, label='SGD')
1405 | p2, = plt.plot(x, rms_losses, label='RMS')
1406 | p3, = plt.plot(x, adam_losses, label='Adam')
1407 | p4, = plt.plot(x, lstm_losses, label='LSTM')
1408 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1409 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1410 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1411 | plt.yscale('log')
1412 | plt.legend(handles=[p1, p2, p3, p4])
1413 | plt.title('Losses')
1414 | plt.show()
1415 | print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
1416 | ```
1417 |
1418 | reset W, x , Y, state
1419 | state is None = True
1420 | reset W, x , Y, state
1421 | state is None = True
1422 | reset W, x , Y, state
1423 | state is None = True
1424 | reset W, x , Y, state
1425 | state is None = True
1426 |
1427 |
1428 | 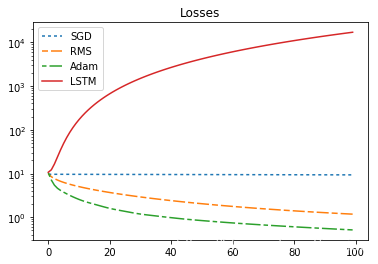
1429 |
1430 |
1431 |
1432 |
1433 |
1434 | sum_loss:sgd=945.0716552734375,rms=269.4500427246094,adam=134.2750244140625,lstm=562912.125
1435 |
1436 | ##### 随机初始化的LSTM优化器没有任何效果,loss发散了,因为还没训练优化器
1437 |
1438 | ```python
1439 | ####### 注意:接上一段的代码!!
1440 | #################### Learning to learn (优化optimizer) ######################
1441 | Global_Train_Steps = 1000 #可修改
1442 | optimizer_Train_Steps = 100
1443 | UnRoll_STEPS = 20
1444 | Evaluate_period = 1 #可修改
1445 | optimizer_lr = 0.1 #可修改
1446 | global_loss_list ,flag = Learning_to_learn_global_training( LSTM_optimizer,
1447 | Global_Train_Steps,
1448 | optimizer_Train_Steps,
1449 | UnRoll_STEPS,
1450 | Evaluate_period,
1451 | optimizer_lr)
1452 |
1453 |
1454 | ######################################################################3#
1455 | ########################## show learning process results
1456 | #torch.load('best_LSTM_optimizer.pth'))
1457 | #import numpy as np
1458 | #import matplotlib
1459 | #import matplotlib.pyplot as plt
1460 |
1461 | #Global_T = np.arange(len(global_loss_list))
1462 | #p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
1463 | #plt.legend(handles=[p1])
1464 | #plt.title('Training LSTM optimizer by gradient descent ')
1465 | #plt.show()
1466 | ```
1467 |
1468 |
1469 | =======> global training steps: 0
1470 | reset W, x , Y, state
1471 | state is None = True
1472 | -> time consuming [0.2s] optimizer train steps : [20] | Global_Loss = [4009.4]
1473 | state is None = False
1474 | -> time consuming [0.3s] optimizer train steps : [40] | Global_Loss = [21136.7]
1475 | state is None = False
1476 | -> time consuming [0.2s] optimizer train steps : [60] | Global_Loss = [136640.5]
1477 | state is None = False
1478 | -> time consuming [0.2s] optimizer train steps : [80] | Global_Loss = [4017.9]
1479 | state is None = False
1480 | -> time consuming [0.2s] optimizer train steps : [100] | Global_Loss = [9107.1]
1481 |
1482 |
1483 | --> evalute the model
1484 | reset W, x , Y, state
1485 | state is None = True
1486 |
1487 | ...........
1488 | ...........
1489 |
1490 | 输出结果已经省略大部分
1491 |
1492 | ##### 接下来看一下优化好的LSTM优化器模型和SGD,RMSProp,Adam的优化性能对比表现吧~
1493 |
1494 | 鸡冻
1495 |
1496 | ```python
1497 | ############### **注意: **接上一片段的代码****
1498 | ######################################################################3#
1499 | ########################## show contrast results SGD,ADAM, RMS ,LSTM ###############################
1500 | import copy
1501 | import numpy as np
1502 | import matplotlib
1503 | import matplotlib.pyplot as plt
1504 |
1505 | if flag ==True :
1506 | print('\n==== > load best LSTM model')
1507 | last_state_dict = copy.deepcopy(LSTM_optimizer.state_dict())
1508 | torch.save(LSTM_optimizer.state_dict(),'final_LSTM_optimizer.pth')
1509 | LSTM_optimizer.load_state_dict( torch.load('best_LSTM_optimizer.pth'))
1510 |
1511 | LSTM_optimizer.load_state_dict(torch.load('best_LSTM_optimizer.pth'))
1512 | #LSTM_optimizer.load_state_dict(torch.load('final_LSTM_optimizer.pth'))
1513 | STEPS = 100
1514 | x = np.arange(STEPS)
1515 |
1516 | Adam = 'Adam' #因为这里Adam使用Pytorch
1517 |
1518 | for _ in range(2): #可以多试几次测试实验,LSTM不稳定
1519 |
1520 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
1521 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
1522 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
1523 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
1524 |
1525 |
1526 | sgd_losses, sgd_sum_loss = SGD_Learner()
1527 | rms_losses, rms_sum_loss = RMS_Learner()
1528 | adam_losses, adam_sum_loss = Adam_Learner()
1529 | lstm_losses, lstm_sum_loss = LSTM_learner()
1530 |
1531 | p1, = plt.plot(x, sgd_losses, label='SGD')
1532 | p2, = plt.plot(x, rms_losses, label='RMS')
1533 | p3, = plt.plot(x, adam_losses, label='Adam')
1534 | p4, = plt.plot(x, lstm_losses, label='LSTM')
1535 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1536 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1537 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1538 | #p4.set_dashes([2, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1539 | plt.yscale('log')
1540 | plt.legend(handles=[p1, p2, p3, p4])
1541 | plt.title('Losses')
1542 | plt.show()
1543 | print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
1544 | ```
1545 |
1546 |
1547 | ==== > load best LSTM model
1548 | reset W, x , Y, state
1549 | state is None = True
1550 | reset W, x , Y, state
1551 | state is None = True
1552 | reset W, x , Y, state
1553 | state is None = True
1554 | reset W, x , Y, state
1555 | state is None = True
1556 |
1557 |
1558 |
1559 | 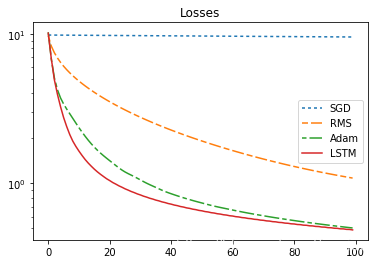
1560 |
1561 |
1562 |
1563 | sum_loss:sgd=967.908935546875,rms=257.03814697265625,adam=122.87742614746094,lstm=105.06891632080078
1564 | reset W, x , Y, state
1565 | state is None = True
1566 | reset W, x , Y, state
1567 | state is None = True
1568 | reset W, x , Y, state
1569 | state is None = True
1570 | reset W, x , Y, state
1571 | state is None = True
1572 |
1573 |
1574 |
1575 | 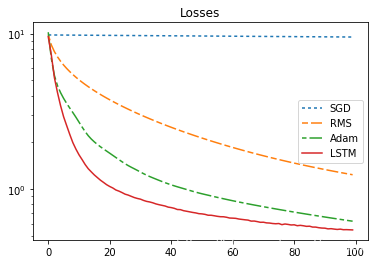
1576 |
1577 |
1578 |
1579 |
1580 | sum_loss:sgd=966.5319213867188,rms=277.1605224609375,adam=143.6751251220703,lstm=109.35062408447266
1581 | (以上代码在一个文件里面执行。复制粘贴格式代码好像需要Chrome或者IE浏览器打开才行???)
1582 |
1583 | ## 实验结果分析与结论
1584 |
1585 | 可以看到:==**SGD 优化器**对于这个问题已经**不具备优化能力**,RMSprop优化器表现良好,**Adam优化器表现依旧突出,LSTM优化器能够媲美甚至超越Adam(Adam已经是业界认可并大规模使用的优化器了)**==
1586 |
1587 | ### 请注意:LSTM优化器最终优化策略是没有任何人工设计的经验
1588 |
1589 | **是自动学习出的一种学习策略!并且这种方法理论上可以应用到任何优化问题**
1590 |
1591 | 换一个角度讲,针对给定的优化问题,LSTM可以逼近或超越现有的任何人工优化器,不过对于大型的网络和复杂的优化问题,这个方法的优化成本太大,优化器性能的稳定性也值得考虑,所以这个工作的创意是独特的,实用性有待考虑~~
1592 |
1593 | 以上代码参考Deepmind的[Tensorflow版本](https://github.com/deepmind/learning-to-learn),遵照论文思路,加上个人理解,力求最简,很多地方写得不够完备,如果有问题,还请多多指出!
1594 |
1595 |
1596 | 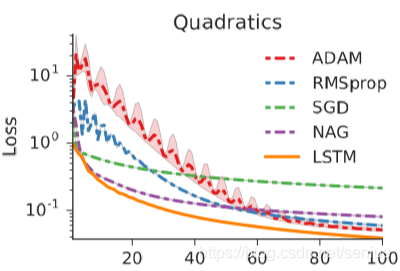
1597 | 上图是论文中给出的结果,作者取最好的实验结果的平均表现(试出了最佳学习率?)展示,我用下面和论文中一样的实验条件(不过没使用NAG优化器),基本达到了论文中所示的同样效果?性能稳定性较差一些
1598 |
1599 | (我怀疑论文的实验Batchsize不是代码中的128?又或者作者把batchsize当作函数的随机采样?我这里把batchsize当作确定的参数,随机采样单独编写)。
1600 |
1601 | ## 实验条件:
1602 |
1603 | - PyTorch-0.4.1 cpu
1604 | - 优化问题为Quadratic函数:
1605 | - W : [128,10,10] Y: [128 , 10] x: [128, 10] 从IID的标准Gaussian分布中采样,初始 x = 0
1606 | - 全局优化器optimizer使用Adam优化器, 学习率为0.1(或许有更好的选择,没有进行对比实验)
1607 |
1608 | - CoordinateWise LSTM 使用LSTM_optimizer_Model:
1609 | - (lstm): LSTM(10, 20, num_layers=2)
1610 | - (Linear): Linear(in_features=20, out_features=10, bias=True)
1611 | - ==未使用任何数据预处理==(LogAndSign)和后处理
1612 | - UnRolled Steps = 20 optimizer_Training_Steps = 100
1613 | - *Global_Traing_steps = 1000 原代码=10000,或许进一步优化LSTM优化器,能够到达更稳定的效果。
1614 | - 另外,原论文进行了mnist和cifar10的实验,本篇博客没有进行实验,代码部分还有待完善,还是希望读者多读原论文和原代码,多动手编程实验!
1615 |
1616 |
1617 | ```python
1618 | def learn():
1619 | return "知识"
1620 |
1621 | def learning_to(learn):
1622 | print(learn())
1623 | return "学习策略"
1624 |
1625 | print(learning_to(learn))
1626 | ```
1627 |
1628 | ## 后叙
1629 |
1630 | > 人可以从自身认识与客观存在的差异中学习,来不断的提升认知能力,这是最基本的学习能力。而另一种潜在不容易发掘,但却是更强大的能力--在学习中不断调整适应自身与外界的学习技巧或者规则--其实构建了我们更高阶的智能。比如,我们在学习知识时,我们总会先接触一些简单容易理解的基本概念,遇到一些理解起来困难或者十分抽象的概念时,我们往往不是采取强行记忆,即我们并不会立刻学习跟我们当前认知的偏差非常大的事物,而是把它先放到一边,继续学习更多简单的概念,直到有所“领悟”发现先前的困难概念变得容易理解
1631 |
1632 |
1633 |
1634 | > 心理学上,元认知被称作反省认知,指人对自我认知的认知。弗拉威尔称,元认知是关于个人自己认知过程的知识和调节这些过程的能力:对思维和学习活动的知识和控制。那么学会适应性地调整学习策略,也成为机器学习的一个研究课题,a most ordinary problem for machine learning is that although we expect to find the invariant pattern in all data, for an individual instance in a specified dataset,it has its own unique attribute, which requires the model taking different policy to understand them seperately .
1635 |
1636 | > 以上均为原创,转载请注明来源
1637 | > https://blog.csdn.net/senius/article/details/84483329
1638 | > or https://yangsenius.github.io/blog/LSTM_Meta/
1639 | > 溜了溜了
1640 |
1641 | ## 下载地址与参考
1642 |
1643 | **[下载代码: learning_to_learn_by_pytorch.py](https://yangsenius.github.io/blog/LSTM_Meta/learning_to_learn_by_pytorch.py)**
1644 |
1645 | [Github地址](https://github.com/yangsenius/learning-to-learn-by-pytorch)
1646 |
1647 | 参考:
1648 | [1.Learning to learn by gradient descent by gradient descent](https://arxiv.org/abs/1606.04474)
1649 | [2. Learning to learn in Tensorflow by DeepMind](https://github.com/deepmind/learning-to-learn)
1650 | [3.learning-to-learn-by-gradient-descent-by-gradient-descent-4da2273d64f2](https://hackernoon.com/learning-to-learn-by-gradient-descent-by-gradient-descent-4da2273d64f2)
1651 |
1652 | *目录*
1653 | [TOC]
1654 |
1655 |
--------------------------------------------------------------------------------
512 |
513 |
514 | **LSTM参数的梯度来自于每次输出的“update”的梯度 update的梯度包含在生成的下一次迭代的参数x的梯度中**
515 |
516 |
517 | 哦!因为参数$x_t = x_{t-1}+update_{t-1}$ 在BPTT的每个周期里$\frac{\partial loss_t}{\partial \theta_{LSTM}}=\frac{\partial loss_t}{\partial update_{t-1}}*\frac{\partial update_{t-1}}{\partial \theta_{LSTM}}$,那么我们想通过$loss_0,loss_1,..,loss_t$之和来更新$\theta_{LSTM}$的话,就必须让梯度经过$x_t$ 中 的$update_{t-1}$流回去,那么每次得到的$x_t$就必须包含了上一次更新产生的图(可以想像,这个计算图是越来越大的),想一想我写的代码,似乎没有保留上一次的计算图在$x_t$节点中,因为我用了x = x.detach_() 把x从图中拿了下来!这似乎是问题最关键所在!!!(而tensorflow静态图的构建,直接建立了一个完整所有周期的图,似乎Pytorch的动态图不合适?no,no)
518 |
519 | (注:以上来自代码中的$x_t$对应上图的$\theta_t$,$update_{t}$对应上图的$g_t$)
520 |
521 | 我为什么会加入x = x.detach_() 是因为不加的话,x变成了子节点,下一次求导pytorch不允许,其实只需要加一行x.retain_grad()代码就行了,并且总的计算图的globa_graph_loss在逐步降低!问题解决!
522 |
523 | 目前在运行global_training(lstm)函数的话,就会发现LSTM的参数已经根据计算图中的梯度回流产生了梯度,每一步可以更新参数了,
524 | 但是这个BPTT算法用cpu算起来,有点慢了~
525 |
526 |
527 |
528 | ```python
529 | def learn(optimizer,unroll_train_steps,retain_graph_flag=False,reset_theta = False):
530 | """retain_graph_flag=False 默认每次loss_backward后 释放动态图
531 | # reset_theta = False 默认每次学习前 不随机初始化参数"""
532 |
533 | if reset_theta == True:
534 | theta_new = torch.empty(DIM)
535 | torch.nn.init.uniform_(theta_new,a=-1,b=1.0)
536 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
537 | x = theta_init_new
538 | else:
539 | x = theta_init
540 |
541 | global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
542 | state = None
543 | x.requires_grad = True
544 | if optimizer.__name__ !='Adam':
545 | losses = []
546 | for i in range(unroll_train_steps):
547 |
548 | loss = f(x)
549 |
550 | #global_loss_graph += torch.exp(torch.Tensor([-i/20]))*loss
551 | #global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
552 | global_loss_graph += loss
553 |
554 |
555 | loss.backward(retain_graph=retain_graph_flag) # 默认为False,当优化LSTM设置为True
556 | update, state = optimizer(x.grad, state)
557 | losses.append(loss)
558 |
559 | x = x + update
560 |
561 | # x = x.detach_()
562 | #这个操作 直接把x中包含的图给释放了,
563 | #那传递给下次训练的x从子节点变成了叶节点,那么梯度就不能沿着这个路回传了,
564 | #之前写这一步是因为这个子节点在下一次迭代不可以求导,那么应该用x.retain_grad()这个操作,
565 | #然后不需要每次新的的开始给x.requires_grad = True
566 |
567 | x.retain_grad()
568 | #print(x.retain_grad())
569 |
570 |
571 | #print(x)
572 | return losses ,global_loss_graph
573 |
574 | else:
575 | losses = []
576 | x.requires_grad = True
577 | optimizer= torch.optim.Adam( [x],lr=0.1 )
578 |
579 | for i in range(unroll_train_steps):
580 |
581 | optimizer.zero_grad()
582 | loss = f(x)
583 | global_loss_graph += loss
584 |
585 | loss.backward(retain_graph=retain_graph_flag)
586 | optimizer.step()
587 | losses.append(loss.detach_())
588 | #print(x)
589 | return losses,global_loss_graph
590 |
591 | Global_Train_Steps = 1000
592 |
593 | def global_training(optimizer):
594 | global_loss_list = []
595 | adam_global_optimizer = torch.optim.Adam([{'params':optimizer.parameters()},{'params':Linear.parameters()}],lr = 0.0001)
596 | _,global_loss_1 = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = True)
597 | print(global_loss_1)
598 | for i in range(Global_Train_Steps):
599 | _,global_loss = learn(LSTM_optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = False)
600 | adam_global_optimizer.zero_grad()
601 |
602 | #print(i,global_loss)
603 | global_loss.backward() #每次都是优化这个固定的图,不可以释放动态图的缓存
604 | #print('xxx',[(z,z.requires_grad) for z in optimizer.parameters() ])
605 | adam_global_optimizer.step()
606 | #print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
607 | global_loss_list.append(global_loss.detach_())
608 |
609 | print(global_loss)
610 | return global_loss_list
611 |
612 | # 要把图放进函数体内,直接赋值的话图会丢失
613 | # 优化optimizer
614 | global_loss_list = global_training(lstm)
615 | ```
616 |
617 | tensor(193.6147, grad_fn=)
618 | tensor(7.6411)
619 |
620 |
621 | ##### 计算图不再丢失了,LSTM的参数的梯度经过计算图的流动已经产生了!
622 |
623 |
624 | ```python
625 | Global_T = np.arange(Global_Train_Steps)
626 |
627 | p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
628 | plt.legend(handles=[p1])
629 | plt.title('Training LSTM optimizer by gradient descent ')
630 | plt.show()
631 | ```
632 |
633 | 
634 |
635 |
636 |
637 | ```python
638 | import matplotlib
639 | import matplotlib.pyplot as plt
640 | %matplotlib inline
641 | import numpy as np
642 | STEPS = 15
643 | x = np.arange(STEPS)
644 |
645 |
646 | for _ in range(2):
647 |
648 | sgd_losses, sgd_sum_loss = learn(SGD,STEPS,reset_theta=True)
649 | rms_losses, rms_sum_loss = learn(RMS,STEPS,reset_theta=True)
650 | adam_losses, adam_sum_loss = learn(Adam,STEPS,reset_theta=True)
651 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,STEPS,reset_theta=True,retain_graph_flag = True)
652 | p1, = plt.plot(x, sgd_losses, label='SGD')
653 | p2, = plt.plot(x, rms_losses, label='RMS')
654 | p3, = plt.plot(x, adam_losses, label='Adam')
655 | p4, = plt.plot(x, lstm_losses, label='LSTM')
656 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
657 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
658 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
659 | plt.legend(handles=[p1, p2, p3, p4])
660 | #plt.yscale('log')
661 | plt.title('Losses')
662 | plt.show()
663 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
664 | ```
665 |
666 | 
667 |
668 |
669 |
670 | sum_loss:sgd=48.513607025146484,rms=5.537945747375488,adam=11.781242370605469,lstm=15.151629447937012
671 |
672 |
673 | 
674 |
675 |
676 |
677 | sum_loss:sgd=48.513607025146484,rms=5.537945747375488,adam=11.781242370605469,lstm=15.151629447937012
678 |
679 |
680 | 可以看出来,经过优化后的LSTM优化器,似乎已经开始掌握如何优化的方法,即我们基本训练出了一个可以训练模型的优化器!
681 |
682 | **但是效果并不是很明显!**
683 |
684 | 不过代码编写取得一定进展\ (0 ..0) /,接下就是让效果更明显,性能更稳定了吧?
685 |
686 | **不过我先再多测试一些周期看看LSTM的优化效果!先别高兴太早!**
687 |
688 |
689 | ```python
690 | import matplotlib
691 | import matplotlib.pyplot as plt
692 | %matplotlib inline
693 | import numpy as np
694 | STEPS = 50
695 | x = np.arange(STEPS)
696 |
697 |
698 | for _ in range(1):
699 |
700 | sgd_losses, sgd_sum_loss = learn(SGD,STEPS,reset_theta=True)
701 | rms_losses, rms_sum_loss = learn(RMS,STEPS,reset_theta=True)
702 | adam_losses, adam_sum_loss = learn(Adam,STEPS,reset_theta=True)
703 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,STEPS,reset_theta=True,retain_graph_flag = True)
704 | p1, = plt.plot(x, sgd_losses, label='SGD')
705 | p2, = plt.plot(x, rms_losses, label='RMS')
706 | p3, = plt.plot(x, adam_losses, label='Adam')
707 | p4, = plt.plot(x, lstm_losses, label='LSTM')
708 | plt.legend(handles=[p1, p2, p3, p4])
709 | #plt.yscale('log')
710 | plt.title('Losses')
711 | plt.show()
712 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
713 | ```
714 |
715 | 
716 |
717 |
718 |
719 | sum_loss:sgd=150.99790954589844,rms=5.940474033355713,adam=14.17563247680664,lstm=268.0199279785156
720 |
721 |
722 |
723 | #### 又出了什么幺蛾子?
724 |
725 | 即我们基本训练出了一个可以训练模型的优化器!但是 经过更长周期的测试,发现训练好的优化器只是优化了指定的周期的loss,而并没有学会“全局优化”的本领,这个似乎是个大问题!
726 |
727 | ##### 不同周期下输入LSTM的梯度幅值数量级不在一个等级上面
728 |
729 | 要处理一下!
730 |
731 | 论文里面提到了对梯度的预处理,即处理不同数量级别的梯度,来进行BPTT,因为每个周期的产生的梯度幅度是完全不在一个数量级,前期梯度下降很快,中后期梯度下降平缓,这个对于LSTM的输入,变化裕度太大,应该归一化,但这个我并没有考虑,接下似乎该写这个部分的代码了
732 |
733 | 论文里提到了:
734 | One potential challenge in training optimizers is that different input coordinates (i.e. the gradients w.r.t. different
735 | optimizer parameters) can have very different magnitudes.
736 | This is indeed the case e.g. when the optimizer is a neural network and different parameters
737 | correspond to weights in different layers.
738 | This can make training an optimizer difficult, because neural networks
739 | naturally disregard small variations in input signals and concentrate on bigger input values.
740 |
741 | ##### 用梯度的(归一化幅值,方向)二元组替代原梯度作为LSTM的输入
742 | To this aim we propose to preprocess the optimizer's inputs.
743 | One solution would be to give the optimizer $\left(\log(|\nabla|),\,\operatorname{sgn}(\nabla)\right)$ as an input, where
744 | $\nabla$ is the gradient in the current timestep.
745 | This has a problem that $\log(|\nabla|)$ diverges for $\nabla \rightarrow 0$.
746 | Therefore, we use the following preprocessing formula
747 |
748 | $\nabla$ is the gradient in the current timestep.
749 | This has a problem that $\log(|\nabla|)$ diverges for $\nabla \rightarrow 0$.
750 | Therefore, we use the following preprocessing formula
751 |
752 | $$\nabla^k\rightarrow \left\{\begin{matrix}
753 | \left(\frac{\log(|\nabla|)}{p}\,, \operatorname{sgn}(\nabla)\right)& \text{if } |\nabla| \geq e^{-p}\\
754 | (-1, e^p \nabla) & \text{otherwise}
755 | \end{matrix}\right.$$
756 |
757 | 作者将不同幅度和方向下的梯度,用一个标准化到$[-1,1]$的幅值和符号方向二元组来表示原来的梯度张量!这样将有助于LSTM的参数学习!
758 | 那我就重新定义LSTM优化器!
759 |
760 |
761 | ```python
762 | Layers = 2
763 | Hidden_nums = 20
764 |
765 | Input_DIM = DIM
766 | Output_DIM = DIM
767 | # "coordinate-wise" RNN
768 | #lstm1=torch.nn.LSTM(Input_DIM*2,Hidden_nums ,Layers)
769 | #Linear = torch.nn.Linear(Hidden_nums,Output_DIM)
770 |
771 |
772 | class LSTM_optimizer_Model(torch.nn.Module):
773 | """LSTM优化器"""
774 |
775 | def __init__(self,input_size,output_size, hidden_size, num_stacks, batchsize, preprocess = True ,p = 10 ,output_scale = 1):
776 | super(LSTM_optimizer_Model,self).__init__()
777 | self.preprocess_flag = preprocess
778 | self.p = p
779 | self.output_scale = output_scale #论文
780 | self.lstm = torch.nn.LSTM(input_size, hidden_size, num_stacks)
781 | self.Linear = torch.nn.Linear(hidden_size,output_size)
782 | #elf.lstm = torch.nn.LSTM(10, 20,2)
783 | #elf.Linear = torch.nn.Linear(20,10)
784 |
785 | def LogAndSign_Preprocess_Gradient(self,gradients):
786 | """
787 | Args:
788 | gradients: `Tensor` of gradients with shape `[d_1, ..., d_n]`.
789 | p : `p` > 0 is a parameter controlling how small gradients are disregarded
790 | Returns:
791 | `Tensor` with shape `[d_1, ..., d_n-1, 2 * d_n]`. The first `d_n` elements
792 | along the nth dimension correspond to the `log output` \in [-1,1] and the remaining
793 | `d_n` elements to the `sign output`.
794 | """
795 | p = self.p
796 | log = torch.log(torch.abs(gradients))
797 | clamp_log = torch.clamp(log/p , min = -1.0,max = 1.0)
798 | clamp_sign = torch.clamp(torch.exp(torch.Tensor(p))*gradients, min = -1.0, max =1.0)
799 | return torch.cat((clamp_log,clamp_sign),dim = -1) #在gradients的最后一维input_dims拼接
800 |
801 | def Output_Gradient_Increment_And_Update_LSTM_Hidden_State(self, input_gradients, prev_state):
802 | """LSTM的核心操作"""
803 | if prev_state is None: #init_state
804 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums),
805 | torch.zeros(Layers,batchsize,Hidden_nums))
806 |
807 | update , next_state = self.lstm(input_gradients, prev_state)
808 |
809 | update = Linear(update) * self.output_scale #因为LSTM的输出是当前步的Hidden,需要变换到output的相同形状上
810 | return update, next_state
811 |
812 | def forward(self,gradients, prev_state):
813 |
814 | #LSTM的输入为梯度,pytorch要求torch.nn.lstm的输入为(1,batchsize,input_dim)
815 | #原gradient.size()=torch.size[5] ->[1,1,5]
816 | gradients = gradients.unsqueeze(0).unsqueeze(0)
817 | if self.preprocess_flag == True:
818 | gradients = self.LogAndSign_Preprocess_Gradient(gradients)
819 |
820 | update , next_state = self.Output_Gradient_Increment_And_Update_LSTM_Hidden_State(gradients , prev_state)
821 |
822 | # Squeeze to make it a single batch again.[1,1,5]->[5]
823 | update = update.squeeze().squeeze()
824 | return update , next_state
825 |
826 | LSTM_optimizer = LSTM_optimizer_Model(Input_DIM*2, Output_DIM, Hidden_nums ,Layers , batchsize=1,)
827 |
828 |
829 | grads = torch.randn(10)*10
830 | print(grads.size())
831 |
832 | update,state = LSTM_optimizer(grads,None)
833 | print(update.size(),)
834 | ```
835 |
836 | torch.Size([10])
837 | torch.Size([10])
838 |
839 |
840 | 编写成功!
841 | 执行!
842 |
843 |
844 | ```python
845 | def learn(optimizer,unroll_train_steps,retain_graph_flag=False,reset_theta = False):
846 | """retain_graph_flag=False 默认每次loss_backward后 释放动态图
847 | # reset_theta = False 默认每次学习前 不随机初始化参数"""
848 |
849 | if reset_theta == True:
850 | theta_new = torch.empty(DIM)
851 | torch.nn.init.uniform_(theta_new,a=-1,b=1.0)
852 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
853 | x = theta_init_new
854 | else:
855 | x = theta_init
856 |
857 | global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
858 | state = None
859 | x.requires_grad = True
860 | if optimizer!='Adam':
861 | losses = []
862 | for i in range(unroll_train_steps):
863 | loss = f(x)
864 | #global_loss_graph += torch.exp(torch.Tensor([-i/20]))*loss
865 | #global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
866 | global_loss_graph += loss
867 | # print('loss{}:'.format(i),loss)
868 | loss.backward(retain_graph=retain_graph_flag) # 默认为False,当优化LSTM设置为True
869 |
870 | update, state = optimizer(x.grad, state)
871 | #print(update)
872 | losses.append(loss)
873 | x = x + update
874 | x.retain_grad()
875 | return losses ,global_loss_graph
876 |
877 | else:
878 | losses = []
879 | x.requires_grad = True
880 | optimizer= torch.optim.Adam( [x],lr=0.1 )
881 |
882 | for i in range(unroll_train_steps):
883 |
884 | optimizer.zero_grad()
885 | loss = f(x)
886 |
887 | global_loss_graph += loss
888 |
889 | loss.backward(retain_graph=retain_graph_flag)
890 | optimizer.step()
891 | losses.append(loss.detach_())
892 | #print(x)
893 | return losses,global_loss_graph
894 |
895 | Global_Train_Steps = 100
896 |
897 | def global_training(optimizer):
898 | global_loss_list = []
899 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = 0.0001)
900 | _,global_loss_1 = learn(optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = True)
901 | print(global_loss_1)
902 | for i in range(Global_Train_Steps):
903 | _,global_loss = learn(optimizer,TRAINING_STEPS,retain_graph_flag =True ,reset_theta = False)
904 | adam_global_optimizer.zero_grad()
905 |
906 | #print(i,global_loss)
907 | global_loss.backward() #每次都是优化这个固定的图,不可以释放动态图的缓存
908 | #print('xxx',[(z,z.requires_grad) for z in optimizer.parameters() ])
909 | adam_global_optimizer.step()
910 | #print('xxx',[(z.grad,z.requires_grad) for z in optimizer.parameters() ])
911 | global_loss_list.append(global_loss.detach_())
912 |
913 | print(global_loss)
914 | return global_loss_list
915 |
916 | # 要把图放进函数体内,直接赋值的话图会丢失
917 | # 优化optimizer
918 | global_loss_list = global_training(LSTM_optimizer)
919 | ```
920 |
921 | tensor(239.6029, grad_fn=)
922 | tensor(158.0625)
923 |
924 |
925 |
926 | ```python
927 | Global_T = np.arange(Global_Train_Steps)
928 |
929 | p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
930 | plt.legend(handles=[p1])
931 | plt.title('Training LSTM optimizer by gradient descent ')
932 | plt.show()
933 | ```
934 |
935 | 
936 |
937 |
938 |
939 |
940 | ```python
941 | import matplotlib
942 | import matplotlib.pyplot as plt
943 | %matplotlib inline
944 | import numpy as np
945 | STEPS = 30
946 | x = np.arange(STEPS)
947 |
948 | Adam = 'Adam'
949 | for _ in range(1):
950 |
951 | sgd_losses, sgd_sum_loss = learn(SGD,STEPS,reset_theta=True)
952 | rms_losses, rms_sum_loss = learn(RMS,STEPS,reset_theta=True)
953 | adam_losses, adam_sum_loss = learn(Adam,STEPS,reset_theta=True)
954 | lstm_losses,lstm_sum_loss = learn(LSTM_optimizer,STEPS,reset_theta=True,retain_graph_flag = True)
955 | p1, = plt.plot(x, sgd_losses, label='SGD')
956 | p2, = plt.plot(x, rms_losses, label='RMS')
957 | p3, = plt.plot(x, adam_losses, label='Adam')
958 | p4, = plt.plot(x, lstm_losses, label='LSTM')
959 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
960 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
961 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
962 | plt.legend(handles=[p1, p2, p3, p4])
963 | plt.title('Losses')
964 | plt.show()
965 | print("sum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
966 | ```
967 |
968 | 
969 |
970 |
971 | sum_loss:sgd=94.19924926757812,rms=5.705832481384277,adam=13.772469520568848,lstm=1224.2393798828125
972 |
973 |
974 | **为什么loss出现了NaN???为什么优化器的泛化性能很差??很烦**
975 |
976 | 即超过Unroll周期以后,LSTM优化器不再具备优化性能???
977 |
978 | 然后我又回顾论文,发现,对优化器进行优化的每个周期开始,要重新随机化,优化问题的参数,即确保我们的LSTM不针对一个特定优化问题过拟合,什么?优化器也会过拟合!是的!l
979 |
980 | 论文里面其实也有提到:
981 |
982 | Given a distribution of functions $f$ we will write
983 | the expected loss as:
984 | $$ L\left(\phi \right) =E_f \left[ f \left ( \theta ^{*}\left ( f,\phi \right )\right ) \right](1)$$
985 |
986 | 其中f是随机分布的,那么就需要在Unroll的初始进行从IID 标准Gaussian分布随机采样函数的参数
987 |
988 | 另外我完善了代码,根据原作代码实现,把LSTM的输出乘以一个系数0.01,那么LSTM的学习变得更加快速了。
989 |
990 | 还有一个地方,就是作者优化optimiee用了100个周期,即5个连续的Unroll周期,这一点似乎我之前也没有考虑到!
991 |
992 | --------------------------------------------------------------------------------------------------
993 |
994 | --------------------------------------------------------------------------------------------------
995 |
996 |
997 | ## 以上是代码编写遇到的种种问题,下面就是最完整的有效代码了!!!
998 |
999 |
1000 |
1001 | **我们考虑优化论文中提到的Quadratic函数,并且用论文中完全一样的实验条件!**
1002 |
1003 | $$f(\theta) = \|W\theta - y\|_2^2$$
1004 | for different 10x10 matrices $W$ and 10-dimensional vectors $y$ whose elements are drawn
1005 | from an IID Gaussian distribution.
1006 | Optimizers were trained by optimizing random functions from this family and
1007 | tested on newly sampled functions from the same distribution. Each function was
1008 | optimized for 100 steps and the trained optimizers were unrolled for 20 steps.
1009 | We have not used any preprocessing, nor postprocessing.
1010 |
1011 |
1012 | ```python
1013 | # coding: utf-8
1014 |
1015 | # Learning to learn by gradient descent by gradient descent
1016 | # =========================#
1017 |
1018 | # https://arxiv.org/abs/1611.03824
1019 | # https://yangsenius.github.io/blog/LSTM_Meta/
1020 | # https://github.com/yangsenius/learning-to-learn-by-pytorch
1021 | # author:yangsen
1022 | # #### “通过梯度下降来学习如何通过梯度下降学习”
1023 | # #### 要让优化器学会这样 "为了更好地得到,要先去舍弃" 这样类似的知识!
1024 |
1025 | import torch
1026 | import torch.nn as nn
1027 | from timeit import default_timer as timer
1028 | ##################### 优化问题 ##########################
1029 | USE_CUDA = False
1030 | DIM = 10
1031 | batchsize = 128
1032 |
1033 | if torch.cuda.is_available():
1034 | USE_CUDA = True
1035 | USE_CUDA = False
1036 |
1037 |
1038 | print('\n\nUSE_CUDA = {}\n\n'.format(USE_CUDA))
1039 |
1040 |
1041 | def f(W,Y,x):
1042 | """quadratic function : f(\theta) = \|W\theta - y\|_2^2"""
1043 | if USE_CUDA:
1044 | W = W.cuda()
1045 | Y = Y.cuda()
1046 | x = x.cuda()
1047 |
1048 | return ((torch.matmul(W,x.unsqueeze(-1)).squeeze()-Y)**2).sum(dim=1).mean(dim=0)
1049 |
1050 | ###############################################################
1051 |
1052 | ###################### 手工的优化器 ###################
1053 |
1054 | def SGD(gradients, state, learning_rate=0.001):
1055 |
1056 | return -gradients*learning_rate, state
1057 |
1058 | def RMS(gradients, state, learning_rate=0.01, decay_rate=0.9):
1059 | if state is None:
1060 | state = torch.zeros(DIM)
1061 | if USE_CUDA == True:
1062 | state = state.cuda()
1063 |
1064 | state = decay_rate*state + (1-decay_rate)*torch.pow(gradients, 2)
1065 | update = -learning_rate*gradients / (torch.sqrt(state+1e-5))
1066 | return update, state
1067 |
1068 | def adam():
1069 | return torch.optim.Adam()
1070 |
1071 | ##########################################################
1072 |
1073 |
1074 | ##################### 自动 LSTM 优化器模型 ##########################
1075 | class LSTM_optimizer_Model(torch.nn.Module):
1076 | """LSTM优化器"""
1077 |
1078 | def __init__(self,input_size,output_size, hidden_size, num_stacks, batchsize, preprocess = True ,p = 10 ,output_scale = 1):
1079 | super(LSTM_optimizer_Model,self).__init__()
1080 | self.preprocess_flag = preprocess
1081 | self.p = p
1082 | self.input_flag = 2
1083 | if preprocess != True:
1084 | self.input_flag = 1
1085 | self.output_scale = output_scale #论文
1086 | self.lstm = torch.nn.LSTM(input_size*self.input_flag, hidden_size, num_stacks)
1087 | self.Linear = torch.nn.Linear(hidden_size,output_size) #1-> output_size
1088 |
1089 | def LogAndSign_Preprocess_Gradient(self,gradients):
1090 | """
1091 | Args:
1092 | gradients: `Tensor` of gradients with shape `[d_1, ..., d_n]`.
1093 | p : `p` > 0 is a parameter controlling how small gradients are disregarded
1094 | Returns:
1095 | `Tensor` with shape `[d_1, ..., d_n-1, 2 * d_n]`. The first `d_n` elements
1096 | along the nth dimension correspond to the `log output` \in [-1,1] and the remaining
1097 | `d_n` elements to the `sign output`.
1098 | """
1099 | p = self.p
1100 | log = torch.log(torch.abs(gradients))
1101 | clamp_log = torch.clamp(log/p , min = -1.0,max = 1.0)
1102 | clamp_sign = torch.clamp(torch.exp(torch.Tensor(p))*gradients, min = -1.0, max =1.0)
1103 | return torch.cat((clamp_log,clamp_sign),dim = -1) #在gradients的最后一维input_dims拼接
1104 |
1105 | def Output_Gradient_Increment_And_Update_LSTM_Hidden_State(self, input_gradients, prev_state):
1106 | """LSTM的核心操作
1107 | coordinate-wise LSTM """
1108 | if prev_state is None: #init_state
1109 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums),
1110 | torch.zeros(Layers,batchsize,Hidden_nums))
1111 | if USE_CUDA :
1112 | prev_state = (torch.zeros(Layers,batchsize,Hidden_nums).cuda(),
1113 | torch.zeros(Layers,batchsize,Hidden_nums).cuda())
1114 |
1115 | update , next_state = self.lstm(input_gradients, prev_state)
1116 | update = self.Linear(update) * self.output_scale #因为LSTM的输出是当前步的Hidden,需要变换到output的相同形状上
1117 | return update, next_state
1118 |
1119 | def forward(self,input_gradients, prev_state):
1120 | if USE_CUDA:
1121 | input_gradients = input_gradients.cuda()
1122 | #LSTM的输入为梯度,pytorch要求torch.nn.lstm的输入为(1,batchsize,input_dim)
1123 | #原gradient.size()=torch.size[5] ->[1,1,5]
1124 | gradients = input_gradients.unsqueeze(0)
1125 |
1126 | if self.preprocess_flag == True:
1127 | gradients = self.LogAndSign_Preprocess_Gradient(gradients)
1128 |
1129 | update , next_state = self.Output_Gradient_Increment_And_Update_LSTM_Hidden_State(gradients , prev_state)
1130 | # Squeeze to make it a single batch again.[1,1,5]->[5]
1131 | update = update.squeeze().squeeze()
1132 |
1133 | return update , next_state
1134 |
1135 | ################# 优化器模型参数 ##############################
1136 | Layers = 2
1137 | Hidden_nums = 20
1138 | Input_DIM = DIM
1139 | Output_DIM = DIM
1140 | output_scale_value=1
1141 |
1142 | ####### 构造一个优化器 #######
1143 | LSTM_optimizer = LSTM_optimizer_Model(Input_DIM, Output_DIM, Hidden_nums ,Layers , batchsize=batchsize,\
1144 | preprocess=False,output_scale=output_scale_value)
1145 | print(LSTM_optimizer)
1146 |
1147 | if USE_CUDA:
1148 | LSTM_optimizer = LSTM_optimizer.cuda()
1149 |
1150 |
1151 | ###################### 优化问题目标函数的学习过程 ###############
1152 |
1153 |
1154 | class Learner( object ):
1155 | """
1156 | Args :
1157 | `f` : 要学习的问题
1158 | `optimizer` : 使用的优化器
1159 | `train_steps` : 对于其他SGD,Adam等是训练周期,对于LSTM训练时的展开周期
1160 | `retain_graph_flag=False` : 默认每次loss_backward后 释放动态图
1161 | `reset_theta = False ` : 默认每次学习前 不随机初始化参数
1162 | `reset_function_from_IID_distirbution = True` : 默认从分布中随机采样函数
1163 |
1164 | Return :
1165 | `losses` : reserves each loss value in each iteration
1166 | `global_loss_graph` : constructs the graph of all Unroll steps for LSTM's BPTT
1167 | """
1168 | def __init__(self, f , optimizer, train_steps ,
1169 | eval_flag = False,
1170 | retain_graph_flag=False,
1171 | reset_theta = False ,
1172 | reset_function_from_IID_distirbution = True):
1173 | self.f = f
1174 | self.optimizer = optimizer
1175 | self.train_steps = train_steps
1176 | #self.num_roll=num_roll
1177 | self.eval_flag = eval_flag
1178 | self.retain_graph_flag = retain_graph_flag
1179 | self.reset_theta = reset_theta
1180 | self.reset_function_from_IID_distirbution = reset_function_from_IID_distirbution
1181 | self.init_theta_of_f()
1182 | self.state = None
1183 |
1184 | self.global_loss_graph = 0 #这个是为LSTM优化器求所有loss相加产生计算图准备的
1185 | self.losses = [] # 保存每个训练周期的loss值
1186 |
1187 | def init_theta_of_f(self,):
1188 | ''' 初始化 优化问题 f 的参数 '''
1189 | self.DIM = 10
1190 | self.batchsize = 128
1191 | self.W = torch.randn(batchsize,DIM,DIM) #代表 已知的数据 # 独立同分布的标准正太分布
1192 | self.Y = torch.randn(batchsize,DIM)
1193 | self.x = torch.zeros(self.batchsize,self.DIM)
1194 | self.x.requires_grad = True
1195 | if USE_CUDA:
1196 | self.W = self.W.cuda()
1197 | self.Y = self.Y.cuda()
1198 | self.x = self.x.cuda()
1199 |
1200 |
1201 | def Reset_Or_Reuse(self , x , W , Y , state, num_roll):
1202 | ''' re-initialize the `W, Y, x , state` at the begining of each global training
1203 | IF `num_roll` == 0 '''
1204 |
1205 | reset_theta =self.reset_theta
1206 | reset_function_from_IID_distirbution = self.reset_function_from_IID_distirbution
1207 |
1208 |
1209 | if num_roll == 0 and reset_theta == True:
1210 | theta = torch.zeros(batchsize,DIM)
1211 |
1212 | theta_init_new = torch.tensor(theta,dtype=torch.float32,requires_grad=True)
1213 | x = theta_init_new
1214 |
1215 |
1216 | ################ 每次全局训练迭代,从独立同分布的Normal Gaussian采样函数 ##################
1217 | if num_roll == 0 and reset_function_from_IID_distirbution == True :
1218 | W = torch.randn(batchsize,DIM,DIM) #代表 已知的数据 # 独立同分布的标准正太分布
1219 | Y = torch.randn(batchsize,DIM) #代表 数据的标签 # 独立同分布的标准正太分布
1220 |
1221 |
1222 | if num_roll == 0:
1223 | state = None
1224 | print('reset W, x , Y, state ')
1225 |
1226 | if USE_CUDA:
1227 | W = W.cuda()
1228 | Y = Y.cuda()
1229 | x = x.cuda()
1230 | x.retain_grad()
1231 |
1232 |
1233 | return x , W , Y , state
1234 |
1235 | def __call__(self, num_roll=0) :
1236 | '''
1237 | Total Training steps = Unroll_Train_Steps * the times of `Learner` been called
1238 |
1239 | SGD,RMS,LSTM 用上述定义的
1240 | Adam优化器直接使用pytorch里的,所以代码上有区分 后面可以完善!'''
1241 | f = self.f
1242 | x , W , Y , state = self.Reset_Or_Reuse(self.x , self.W , self.Y , self.state , num_roll )
1243 | self.global_loss_graph = 0 #每个unroll的开始需要 重新置零
1244 | optimizer = self.optimizer
1245 | print('state is None = {}'.format(state == None))
1246 |
1247 | if optimizer!='Adam':
1248 |
1249 | for i in range(self.train_steps):
1250 | loss = f(W,Y,x)
1251 | #self.global_loss_graph += (0.8*torch.log10(torch.Tensor([i+1]))+1)*loss
1252 | self.global_loss_graph += loss
1253 |
1254 | loss.backward(retain_graph=self.retain_graph_flag) # 默认为False,当优化LSTM设置为True
1255 |
1256 | update, state = optimizer(x.grad, state)
1257 |
1258 | self.losses.append(loss)
1259 |
1260 | x = x + update
1261 | x.retain_grad()
1262 | update.retain_grad()
1263 |
1264 | if state is not None:
1265 | self.state = (state[0].detach(),state[1].detach())
1266 |
1267 | return self.losses ,self.global_loss_graph
1268 |
1269 | else: #Pytorch Adam
1270 |
1271 | x.detach_()
1272 | x.requires_grad = True
1273 | optimizer= torch.optim.Adam( [x],lr=0.1 )
1274 |
1275 | for i in range(self.train_steps):
1276 |
1277 | optimizer.zero_grad()
1278 | loss = f(W,Y,x)
1279 |
1280 | self.global_loss_graph += loss
1281 |
1282 | loss.backward(retain_graph=self.retain_graph_flag)
1283 | optimizer.step()
1284 | self.losses.append(loss.detach_())
1285 |
1286 | return self.losses, self.global_loss_graph
1287 |
1288 |
1289 | ####### LSTM 优化器的训练过程 Learning to learn ###############
1290 |
1291 | def Learning_to_learn_global_training(optimizer, global_taining_steps, optimizer_Train_Steps, UnRoll_STEPS, Evaluate_period ,optimizer_lr=0.1):
1292 | """ Training the LSTM optimizer . Learning to learn
1293 |
1294 | Args:
1295 | `optimizer` : DeepLSTMCoordinateWise optimizer model
1296 | `global_taining_steps` : how many steps for optimizer training o可以ptimizee
1297 | `optimizer_Train_Steps` : how many step for optimizer opimitzing each function sampled from IID.
1298 | `UnRoll_STEPS` :: how many steps for LSTM optimizer being unrolled to construct a computing graph to BPTT.
1299 | """
1300 | global_loss_list = []
1301 | Total_Num_Unroll = optimizer_Train_Steps // UnRoll_STEPS
1302 | adam_global_optimizer = torch.optim.Adam(optimizer.parameters(),lr = optimizer_lr)
1303 |
1304 | LSTM_Learner = Learner(f, optimizer, UnRoll_STEPS, retain_graph_flag=True, reset_theta=True,)
1305 | #这里考虑Batchsize代表IID的话,那么就可以不需要每次都重新IID采样
1306 | #即reset_function_from_IID_distirbution = False 否则为True
1307 |
1308 | best_sum_loss = 999999
1309 | best_final_loss = 999999
1310 | best_flag = False
1311 | for i in range(Global_Train_Steps):
1312 |
1313 | print('\n=======> global training steps: {}'.format(i))
1314 |
1315 | for num in range(Total_Num_Unroll):
1316 |
1317 | start = timer()
1318 | _,global_loss = LSTM_Learner(num)
1319 |
1320 | adam_global_optimizer.zero_grad()
1321 | global_loss.backward()
1322 |
1323 | adam_global_optimizer.step()
1324 | # print('xxx',[(z.grad,z.requires_grad) for z in optimizer.lstm.parameters() ])
1325 | global_loss_list.append(global_loss.detach_())
1326 | time = timer() - start
1327 | #if i % 10 == 0:
1328 | print('-> time consuming [{:.1f}s] optimizer train steps : [{}] | Global_Loss = [{:.1f}] '\
1329 | .format(time,(num +1)* UnRoll_STEPS,global_loss,))
1330 |
1331 | if (i + 1) % Evaluate_period == 0:
1332 |
1333 | best_sum_loss, best_final_loss, best_flag = evaluate(best_sum_loss,best_final_loss,best_flag , optimizer_lr)
1334 |
1335 | return global_loss_list,best_flag
1336 |
1337 |
1338 | def evaluate(best_sum_loss,best_final_loss, best_flag,lr):
1339 | print('\n --> evalute the model')
1340 | STEPS = 100
1341 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True, retain_graph_flag=True)
1342 | lstm_losses, sum_loss = LSTM_learner()
1343 | try:
1344 | best = torch.load('best_loss.txt')
1345 | except IOError:
1346 | print ('can not find best_loss.txt')
1347 | pass
1348 | else:
1349 | best_sum_loss = best[0]
1350 | best_final_loss = best[1]
1351 | print("load_best_final_loss and sum_loss")
1352 | if lstm_losses[-1] < best_final_loss and sum_loss < best_sum_loss:
1353 | best_final_loss = lstm_losses[-1]
1354 | best_sum_loss = sum_loss
1355 |
1356 | print('\n\n===> update new best of final LOSS[{}]: = {}, best_sum_loss ={}'.format(STEPS, best_final_loss,best_sum_loss))
1357 | torch.save(LSTM_optimizer.state_dict(),'best_LSTM_optimizer.pth')
1358 | torch.save([best_sum_loss ,best_final_loss,lr ],'best_loss.txt')
1359 | best_flag = True
1360 |
1361 | return best_sum_loss, best_final_loss, best_flag
1362 |
1363 |
1364 | ```
1365 |
1366 |
1367 |
1368 | USE_CUDA = False
1369 |
1370 |
1371 | LSTM_optimizer_Model(
1372 | (lstm): LSTM(10, 20, num_layers=2)
1373 | (Linear): Linear(in_features=20, out_features=10, bias=True)
1374 | )
1375 |
1376 |
1377 | ### 我们先来看看随机初始化的LSTM优化器的效果
1378 |
1379 |
1380 | ```python
1381 | ############# 注意:接上一片段的代码!! #######################3#
1382 | ########################## before learning LSTM optimizer ###############################
1383 | import numpy as np
1384 | import matplotlib
1385 | import matplotlib.pyplot as plt
1386 |
1387 | STEPS = 100
1388 | x = np.arange(STEPS)
1389 |
1390 | Adam = 'Adam' #因为这里Adam使用Pytorch
1391 |
1392 | for _ in range(1):
1393 |
1394 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
1395 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
1396 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
1397 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
1398 |
1399 | sgd_losses, sgd_sum_loss = SGD_Learner()
1400 | rms_losses, rms_sum_loss = RMS_Learner()
1401 | adam_losses, adam_sum_loss = Adam_Learner()
1402 | lstm_losses, lstm_sum_loss = LSTM_learner()
1403 |
1404 | p1, = plt.plot(x, sgd_losses, label='SGD')
1405 | p2, = plt.plot(x, rms_losses, label='RMS')
1406 | p3, = plt.plot(x, adam_losses, label='Adam')
1407 | p4, = plt.plot(x, lstm_losses, label='LSTM')
1408 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1409 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1410 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1411 | plt.yscale('log')
1412 | plt.legend(handles=[p1, p2, p3, p4])
1413 | plt.title('Losses')
1414 | plt.show()
1415 | print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
1416 | ```
1417 |
1418 | reset W, x , Y, state
1419 | state is None = True
1420 | reset W, x , Y, state
1421 | state is None = True
1422 | reset W, x , Y, state
1423 | state is None = True
1424 | reset W, x , Y, state
1425 | state is None = True
1426 |
1427 |
1428 | 
1429 |
1430 |
1431 |
1432 |
1433 |
1434 | sum_loss:sgd=945.0716552734375,rms=269.4500427246094,adam=134.2750244140625,lstm=562912.125
1435 |
1436 | ##### 随机初始化的LSTM优化器没有任何效果,loss发散了,因为还没训练优化器
1437 |
1438 | ```python
1439 | ####### 注意:接上一段的代码!!
1440 | #################### Learning to learn (优化optimizer) ######################
1441 | Global_Train_Steps = 1000 #可修改
1442 | optimizer_Train_Steps = 100
1443 | UnRoll_STEPS = 20
1444 | Evaluate_period = 1 #可修改
1445 | optimizer_lr = 0.1 #可修改
1446 | global_loss_list ,flag = Learning_to_learn_global_training( LSTM_optimizer,
1447 | Global_Train_Steps,
1448 | optimizer_Train_Steps,
1449 | UnRoll_STEPS,
1450 | Evaluate_period,
1451 | optimizer_lr)
1452 |
1453 |
1454 | ######################################################################3#
1455 | ########################## show learning process results
1456 | #torch.load('best_LSTM_optimizer.pth'))
1457 | #import numpy as np
1458 | #import matplotlib
1459 | #import matplotlib.pyplot as plt
1460 |
1461 | #Global_T = np.arange(len(global_loss_list))
1462 | #p1, = plt.plot(Global_T, global_loss_list, label='Global_graph_loss')
1463 | #plt.legend(handles=[p1])
1464 | #plt.title('Training LSTM optimizer by gradient descent ')
1465 | #plt.show()
1466 | ```
1467 |
1468 |
1469 | =======> global training steps: 0
1470 | reset W, x , Y, state
1471 | state is None = True
1472 | -> time consuming [0.2s] optimizer train steps : [20] | Global_Loss = [4009.4]
1473 | state is None = False
1474 | -> time consuming [0.3s] optimizer train steps : [40] | Global_Loss = [21136.7]
1475 | state is None = False
1476 | -> time consuming [0.2s] optimizer train steps : [60] | Global_Loss = [136640.5]
1477 | state is None = False
1478 | -> time consuming [0.2s] optimizer train steps : [80] | Global_Loss = [4017.9]
1479 | state is None = False
1480 | -> time consuming [0.2s] optimizer train steps : [100] | Global_Loss = [9107.1]
1481 |
1482 |
1483 | --> evalute the model
1484 | reset W, x , Y, state
1485 | state is None = True
1486 |
1487 | ...........
1488 | ...........
1489 |
1490 | 输出结果已经省略大部分
1491 |
1492 | ##### 接下来看一下优化好的LSTM优化器模型和SGD,RMSProp,Adam的优化性能对比表现吧~
1493 |
1494 | 鸡冻
1495 |
1496 | ```python
1497 | ############### **注意: **接上一片段的代码****
1498 | ######################################################################3#
1499 | ########################## show contrast results SGD,ADAM, RMS ,LSTM ###############################
1500 | import copy
1501 | import numpy as np
1502 | import matplotlib
1503 | import matplotlib.pyplot as plt
1504 |
1505 | if flag ==True :
1506 | print('\n==== > load best LSTM model')
1507 | last_state_dict = copy.deepcopy(LSTM_optimizer.state_dict())
1508 | torch.save(LSTM_optimizer.state_dict(),'final_LSTM_optimizer.pth')
1509 | LSTM_optimizer.load_state_dict( torch.load('best_LSTM_optimizer.pth'))
1510 |
1511 | LSTM_optimizer.load_state_dict(torch.load('best_LSTM_optimizer.pth'))
1512 | #LSTM_optimizer.load_state_dict(torch.load('final_LSTM_optimizer.pth'))
1513 | STEPS = 100
1514 | x = np.arange(STEPS)
1515 |
1516 | Adam = 'Adam' #因为这里Adam使用Pytorch
1517 |
1518 | for _ in range(2): #可以多试几次测试实验,LSTM不稳定
1519 |
1520 | SGD_Learner = Learner(f , SGD, STEPS, eval_flag=True,reset_theta=True,)
1521 | RMS_Learner = Learner(f , RMS, STEPS, eval_flag=True,reset_theta=True,)
1522 | Adam_Learner = Learner(f , Adam, STEPS, eval_flag=True,reset_theta=True,)
1523 | LSTM_learner = Learner(f , LSTM_optimizer, STEPS, eval_flag=True,reset_theta=True,retain_graph_flag=True)
1524 |
1525 |
1526 | sgd_losses, sgd_sum_loss = SGD_Learner()
1527 | rms_losses, rms_sum_loss = RMS_Learner()
1528 | adam_losses, adam_sum_loss = Adam_Learner()
1529 | lstm_losses, lstm_sum_loss = LSTM_learner()
1530 |
1531 | p1, = plt.plot(x, sgd_losses, label='SGD')
1532 | p2, = plt.plot(x, rms_losses, label='RMS')
1533 | p3, = plt.plot(x, adam_losses, label='Adam')
1534 | p4, = plt.plot(x, lstm_losses, label='LSTM')
1535 | p1.set_dashes([2, 2, 2, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1536 | p2.set_dashes([4, 2, 8, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1537 | p3.set_dashes([3, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1538 | #p4.set_dashes([2, 2, 10, 2]) # 2pt line, 2pt break, 10pt line, 2pt break
1539 | plt.yscale('log')
1540 | plt.legend(handles=[p1, p2, p3, p4])
1541 | plt.title('Losses')
1542 | plt.show()
1543 | print("\n\nsum_loss:sgd={},rms={},adam={},lstm={}".format(sgd_sum_loss,rms_sum_loss,adam_sum_loss,lstm_sum_loss ))
1544 | ```
1545 |
1546 |
1547 | ==== > load best LSTM model
1548 | reset W, x , Y, state
1549 | state is None = True
1550 | reset W, x , Y, state
1551 | state is None = True
1552 | reset W, x , Y, state
1553 | state is None = True
1554 | reset W, x , Y, state
1555 | state is None = True
1556 |
1557 |
1558 |
1559 | 
1560 |
1561 |
1562 |
1563 | sum_loss:sgd=967.908935546875,rms=257.03814697265625,adam=122.87742614746094,lstm=105.06891632080078
1564 | reset W, x , Y, state
1565 | state is None = True
1566 | reset W, x , Y, state
1567 | state is None = True
1568 | reset W, x , Y, state
1569 | state is None = True
1570 | reset W, x , Y, state
1571 | state is None = True
1572 |
1573 |
1574 |
1575 | 
1576 |
1577 |
1578 |
1579 |
1580 | sum_loss:sgd=966.5319213867188,rms=277.1605224609375,adam=143.6751251220703,lstm=109.35062408447266
1581 | (以上代码在一个文件里面执行。复制粘贴格式代码好像需要Chrome或者IE浏览器打开才行???)
1582 |
1583 | ## 实验结果分析与结论
1584 |
1585 | 可以看到:==**SGD 优化器**对于这个问题已经**不具备优化能力**,RMSprop优化器表现良好,**Adam优化器表现依旧突出,LSTM优化器能够媲美甚至超越Adam(Adam已经是业界认可并大规模使用的优化器了)**==
1586 |
1587 | ### 请注意:LSTM优化器最终优化策略是没有任何人工设计的经验
1588 |
1589 | **是自动学习出的一种学习策略!并且这种方法理论上可以应用到任何优化问题**
1590 |
1591 | 换一个角度讲,针对给定的优化问题,LSTM可以逼近或超越现有的任何人工优化器,不过对于大型的网络和复杂的优化问题,这个方法的优化成本太大,优化器性能的稳定性也值得考虑,所以这个工作的创意是独特的,实用性有待考虑~~
1592 |
1593 | 以上代码参考Deepmind的[Tensorflow版本](https://github.com/deepmind/learning-to-learn),遵照论文思路,加上个人理解,力求最简,很多地方写得不够完备,如果有问题,还请多多指出!
1594 |
1595 |
1596 | 
1597 | 上图是论文中给出的结果,作者取最好的实验结果的平均表现(试出了最佳学习率?)展示,我用下面和论文中一样的实验条件(不过没使用NAG优化器),基本达到了论文中所示的同样效果?性能稳定性较差一些
1598 |
1599 | (我怀疑论文的实验Batchsize不是代码中的128?又或者作者把batchsize当作函数的随机采样?我这里把batchsize当作确定的参数,随机采样单独编写)。
1600 |
1601 | ## 实验条件:
1602 |
1603 | - PyTorch-0.4.1 cpu
1604 | - 优化问题为Quadratic函数:
1605 | - W : [128,10,10] Y: [128 , 10] x: [128, 10] 从IID的标准Gaussian分布中采样,初始 x = 0
1606 | - 全局优化器optimizer使用Adam优化器, 学习率为0.1(或许有更好的选择,没有进行对比实验)
1607 |
1608 | - CoordinateWise LSTM 使用LSTM_optimizer_Model:
1609 | - (lstm): LSTM(10, 20, num_layers=2)
1610 | - (Linear): Linear(in_features=20, out_features=10, bias=True)
1611 | - ==未使用任何数据预处理==(LogAndSign)和后处理
1612 | - UnRolled Steps = 20 optimizer_Training_Steps = 100
1613 | - *Global_Traing_steps = 1000 原代码=10000,或许进一步优化LSTM优化器,能够到达更稳定的效果。
1614 | - 另外,原论文进行了mnist和cifar10的实验,本篇博客没有进行实验,代码部分还有待完善,还是希望读者多读原论文和原代码,多动手编程实验!
1615 |
1616 |
1617 | ```python
1618 | def learn():
1619 | return "知识"
1620 |
1621 | def learning_to(learn):
1622 | print(learn())
1623 | return "学习策略"
1624 |
1625 | print(learning_to(learn))
1626 | ```
1627 |
1628 | ## 后叙
1629 |
1630 | > 人可以从自身认识与客观存在的差异中学习,来不断的提升认知能力,这是最基本的学习能力。而另一种潜在不容易发掘,但却是更强大的能力--在学习中不断调整适应自身与外界的学习技巧或者规则--其实构建了我们更高阶的智能。比如,我们在学习知识时,我们总会先接触一些简单容易理解的基本概念,遇到一些理解起来困难或者十分抽象的概念时,我们往往不是采取强行记忆,即我们并不会立刻学习跟我们当前认知的偏差非常大的事物,而是把它先放到一边,继续学习更多简单的概念,直到有所“领悟”发现先前的困难概念变得容易理解
1631 |
1632 |
1633 |
1634 | > 心理学上,元认知被称作反省认知,指人对自我认知的认知。弗拉威尔称,元认知是关于个人自己认知过程的知识和调节这些过程的能力:对思维和学习活动的知识和控制。那么学会适应性地调整学习策略,也成为机器学习的一个研究课题,a most ordinary problem for machine learning is that although we expect to find the invariant pattern in all data, for an individual instance in a specified dataset,it has its own unique attribute, which requires the model taking different policy to understand them seperately .
1635 |
1636 | > 以上均为原创,转载请注明来源
1637 | > https://blog.csdn.net/senius/article/details/84483329
1638 | > or https://yangsenius.github.io/blog/LSTM_Meta/
1639 | > 溜了溜了
1640 |
1641 | ## 下载地址与参考
1642 |
1643 | **[下载代码: learning_to_learn_by_pytorch.py](https://yangsenius.github.io/blog/LSTM_Meta/learning_to_learn_by_pytorch.py)**
1644 |
1645 | [Github地址](https://github.com/yangsenius/learning-to-learn-by-pytorch)
1646 |
1647 | 参考:
1648 | [1.Learning to learn by gradient descent by gradient descent](https://arxiv.org/abs/1606.04474)
1649 | [2. Learning to learn in Tensorflow by DeepMind](https://github.com/deepmind/learning-to-learn)
1650 | [3.learning-to-learn-by-gradient-descent-by-gradient-descent-4da2273d64f2](https://hackernoon.com/learning-to-learn-by-gradient-descent-by-gradient-descent-4da2273d64f2)
1651 |
1652 | *目录*
1653 | [TOC]
1654 |
1655 |
--------------------------------------------------------------------------------