├── .gitignore
├── LICENSE
├── README.md
├── base
├── __init__.py
├── base_dataloader.py
├── base_dataset.py
├── base_model.py
└── base_trainer.py
├── configs
└── config.json
├── dataloaders
├── __init__.py
├── voc.py
└── voc_splits
│ ├── 1000_train_supervised.txt
│ ├── 1000_train_unsupervised.txt
│ ├── 100_train_supervised.txt
│ ├── 100_train_unsupervised.txt
│ ├── 1464_train_supervised.txt
│ ├── 1464_train_unsupervised.txt
│ ├── 200_train_supervised.txt
│ ├── 200_train_unsupervised.txt
│ ├── 300_train_supervised.txt
│ ├── 300_train_unsupervised.txt
│ ├── 500_train_supervised.txt
│ ├── 500_train_unsupervised.txt
│ ├── 60_train_supervised.txt
│ ├── 60_train_unsupervised.txt
│ ├── 800_train_supervised.txt
│ ├── 800_train_unsupervised.txt
│ ├── boxes.json
│ ├── classes.json
│ └── val.txt
├── inference.py
├── models
├── __init__.py
├── backbones
│ ├── __init__.py
│ ├── get_pretrained_model.sh
│ ├── module_helper.py
│ ├── resnet_backbone.py
│ └── resnet_models.py
├── decoders.py
├── encoder.py
└── model.py
├── pseudo_labels
├── README.md
├── cam_to_pseudo_labels.py
├── make_cam.py
├── misc
│ ├── imutils.py
│ ├── pyutils.py
│ └── torchutils.py
├── net
│ ├── resnet50.py
│ └── resnet50_cam.py
├── run.py
├── train_cam.py
└── voc12
│ ├── cls_labels.npy
│ ├── dataloader.py
│ ├── make_cls_labels.py
│ ├── test.txt
│ ├── train.txt
│ ├── train_aug.txt
│ └── val.txt
├── requirements.txt
├── train.py
├── trainer.py
└── utils
├── __init__.py
├── helpers.py
├── htmlwriter.py
├── logger.py
├── losses.py
├── lr_scheduler.py
├── metrics.py
├── pallete.py
└── ramps.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 | pretrained/
9 | tb_history/
10 | logs/
11 | cls_runs/
12 | slurm_logs/
13 |
14 | #experiments/
15 | experiments/
16 | experiments_da/
17 | config[0-9]*
18 | *.png
19 | *.pth
20 |
21 | # Distribution / packaging
22 | .Python
23 | env/
24 | build/
25 | develop-eggs/
26 | dist/
27 | downloads/
28 | eggs/
29 | .eggs/
30 | lib/
31 | lib64/
32 | parts/
33 | sdist/
34 | var/
35 | wheels/
36 | *.egg-info/
37 | .installed.cfg
38 | *.egg
39 |
40 | # PyInstaller
41 | # Usually these files are written by a python script from a template
42 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
43 | *.manifest
44 | *.spec
45 |
46 | # Installer logs
47 | pip-log.txt
48 | pip-delete-this-directory.txt
49 |
50 | # Unit test / coverage reports
51 | htmlcov/
52 | .tox/
53 | .coverage
54 | .coverage.*
55 | .cache
56 | nosetests.xml
57 | coverage.xml
58 | *.cover
59 | .hypothesis/
60 |
61 | # Translations
62 | *.mo
63 | *.pot
64 |
65 | # Django stuff:
66 | *.log
67 | local_settings.py
68 |
69 | # Flask stuff:
70 | instance/
71 | .webassets-cache
72 |
73 | # Scrapy stuff:
74 | .scrapy
75 |
76 | # Sphinx documentation
77 | docs/_build/
78 |
79 | # PyBuilder
80 | target/
81 |
82 | # Jupyter Notebook
83 | .ipynb_checkpoints
84 |
85 | # pyenv
86 | .python-version
87 |
88 | # celery beat schedule file
89 | celerybeat-schedule
90 |
91 | # SageMath parsed files
92 | *.sage.py
93 |
94 | # dotenv
95 | .env
96 |
97 | # virtualenv
98 | .venv
99 | venv/
100 | ENV/
101 |
102 | # Spyder project settings
103 | .spyderproject
104 | .spyproject
105 |
106 | # Rope project settings
107 | .ropeproject
108 |
109 | # mkdocs documentation
110 | /site
111 |
112 | # mypy
113 | .mypy_cache/
114 |
115 | # input data, saved log, checkpoints
116 | data/
117 | input/
118 | saved/
119 | outputs/
120 | datasets/
121 |
122 | # editor, os cache directory
123 | .vscode/
124 | .idea/
125 | __MACOSX/
126 |
127 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Yassine Ouali
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Semi-Supervised Semantic Segmentation with Cross-Consistency Training (CCT)
4 |
5 | #### [Paper](https://arxiv.org/abs/2003.09005), [Project Page](https://yassouali.github.io/cct_page/)
6 |
7 | This repo contains the official implementation of CVPR 2020 paper: Semi-Supervised Semantic Segmentation with Cross-Consistency Training, which
8 | adapts the traditional consistency training framework of semi-supervised learning for semantic segmentation, with an extension to weak-supervised
9 | learning and learning on multiple domains.
10 |
11 | 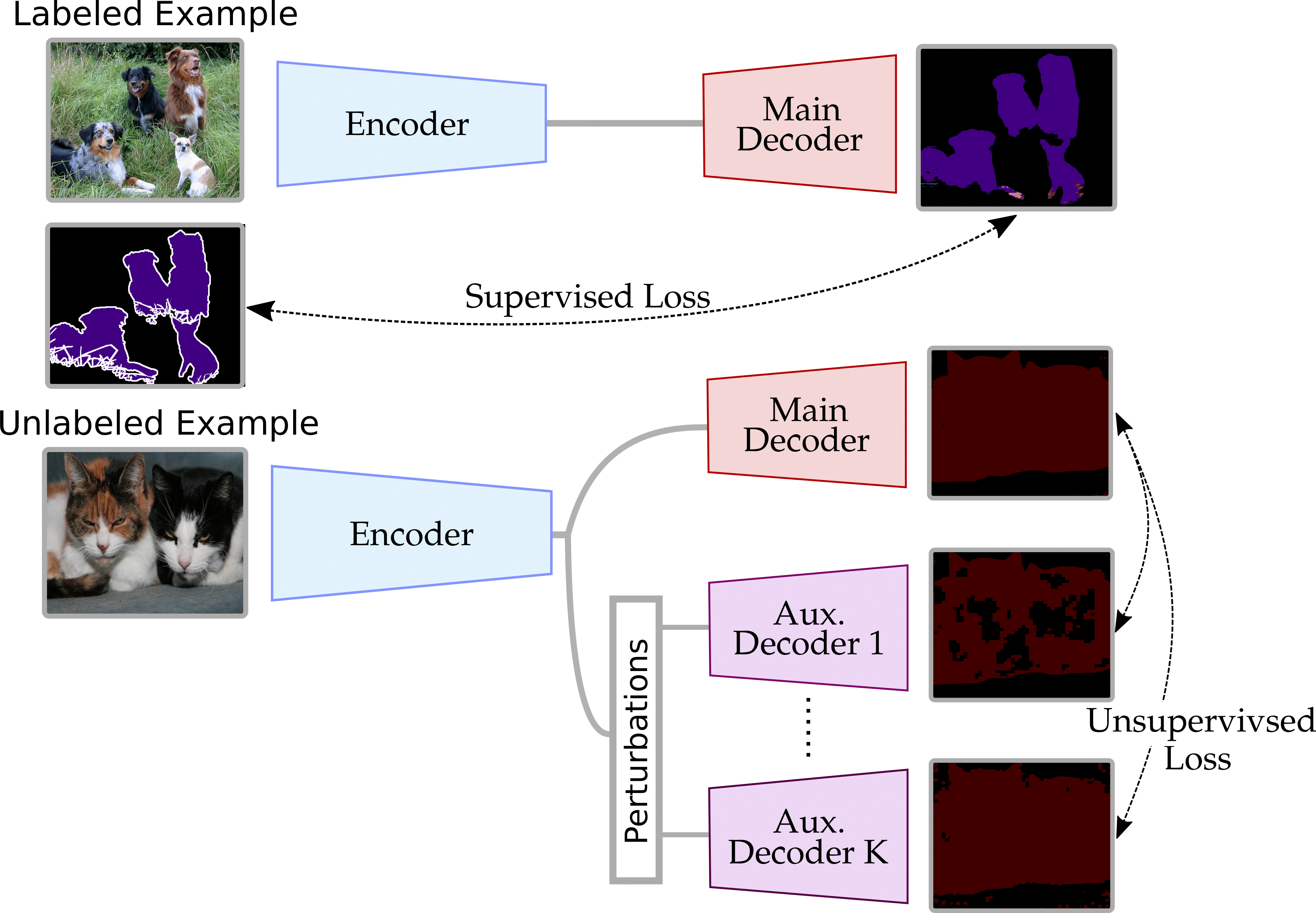
12 |
13 | ### Highlights
14 |
15 | **(1) Consistency Training for semantic segmentation.** \
16 | We observe that for semantic segmentation, due to the dense nature of the task,
17 | the cluster assumption is more easily enforced over the hidden representations rather than the inputs.
18 |
19 | **(2) Cross-Consistency Training.** \
20 | We propose CCT (Cross-Consistency Training) for semi-supervised semantic segmentation, where we define
21 | a number of novel perturbations, and show the effectiveness of enforcing consistency over the encoder's outputs
22 | rather than the inputs.
23 |
24 | **(3) Using weak-labels and pixel-level labels from multiple domains.** \
25 | The proposed method is quite simple and flexible, and can easily be extended to use image-level labels and
26 | pixel-level labels from multiple-domains.
27 |
28 |
29 |
30 | ### Requirements
31 |
32 | This repo was tested with Ubuntu 18.04.3 LTS, Python 3.7, PyTorch 1.1.0, and CUDA 10.0. But it should be runnable with recent PyTorch versions >=1.1.0.
33 |
34 | The required packages are `pytorch` and `torchvision`, together with `PIL` and `opencv` for data-preprocessing and `tqdm` for showing the training progress.
35 | With some additional modules like `dominate` to save the results in the form of HTML files. To setup the necessary modules, simply run:
36 |
37 | ```bash
38 | pip install -r requirements.txt
39 | ```
40 |
41 | ### Dataset
42 |
43 | In this repo, we use **Pascal VOC**, to obtain it, first download the [original dataset](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar), after extracting the files we'll end up with `VOCtrainval_11-May-2012/VOCdevkit/VOC2012` containing the image sets, the XML annotation for both object detection and segmentation, and JPEG images.\
44 | The second step is to augment the dataset using the additionnal annotations provided by [Semantic Contours from Inverse Detectors](http://home.bharathh.info/pubs/pdfs/BharathICCV2011.pdf). Download the rest of the annotations [SegmentationClassAug](https://www.dropbox.com/s/oeu149j8qtbs1x0/SegmentationClassAug.zip?dl=0) and add them to the path `VOCtrainval_11-May-2012/VOCdevkit/VOC2012`, now we're set, for training use the path to `VOCtrainval_11-May-2012`.
45 |
46 |
47 | ### Training
48 |
49 | To train a model, first download PASCAL VOC as detailed above, then set `data_dir` to the dataset path in the config file in `configs/config.json` and set the rest of the parameters, like the number of GPUs, cope size, data augmentation ... etc ,you can also change CCT hyperparameters if you wish, more details below. Then simply run:
50 |
51 | ```bash
52 | python train.py --config configs/config.json
53 | ```
54 |
55 | The log files and the `.pth` checkpoints will be saved in `saved\EXP_NAME`, to monitor the training using tensorboard, please run:
56 |
57 | ```bash
58 | tensorboard --logdir saved
59 | ```
60 |
61 | To resume training using a saved `.pth` model:
62 |
63 | ```bash
64 | python train.py --config configs/config.json --resume saved/CCT/checkpoint.pth
65 | ```
66 |
67 | **Results**: The results will be saved in `saved` as an html file, containing the validation results,
68 | and the name it will take is `experim_name` specified in `configs/config.json`.
69 |
70 | ### Pseudo-labels
71 |
72 | If you want to use image level labels to train the auxiliary labels as explained in section 3.3 of the paper. First generate the pseudo-labels
73 | using the code in `pseudo_labels`:
74 |
75 |
76 | ```bash
77 | cd pseudo_labels
78 | python run.py --voc12_root DATA_PATH
79 | ```
80 |
81 | `DATA_PATH` must point to the folder containing `JPEGImages` in Pascal Voc dataset. The results will be
82 | saved in `pseudo_labels/result/pseudo_labels` as PNG files, the flag `use_weak_labels` needs to be set to True in the config file, and
83 | then we can train the model as detailed above.
84 |
85 |
86 | ### Inference
87 |
88 | For inference, we need a pretrained model, the jpg images we'd like to segment and the config used in training (to load the correct model and other parameters),
89 |
90 | ```bash
91 | python inference.py --config config.json --model best_model.pth --images images_folder
92 | ```
93 |
94 | The predictions will be saved as `.png` images in `outputs\` is used, for Pacal VOC the default palette is:
95 |
96 | 
97 |
98 | Here are the flags available for inference:
99 |
100 | ```
101 | --images Folder containing the jpg images to segment.
102 | --model Path to the trained pth model.
103 | --config The config file used for training the model.
104 | ```
105 |
106 | ### Pre-trained models
107 |
108 | Pre-trained models can be downloaded [here](https://github.com/yassouali/CCT/releases).
109 |
110 | ### Citation ✏️ 📄
111 |
112 | If you find this repo useful for your research, please consider citing the paper as follows:
113 |
114 | ```
115 | @InProceedings{Ouali_2020_CVPR,
116 | author = {Ouali, Yassine and Hudelot, Celine and Tami, Myriam},
117 | title = {Semi-Supervised Semantic Segmentation With Cross-Consistency Training},
118 | booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
119 | month = {June},
120 | year = {2020}
121 | }
122 | ```
123 |
124 | For any questions, please contact Yassine Ouali.
125 |
126 | #### Config file details ⚙️
127 |
128 | Bellow we detail the CCT parameters that can be controlled in the config file `configs/config.json`, the rest of the parameters
129 | are self-explanatory.
130 |
131 | ```javascript
132 | {
133 | "name": "CCT",
134 | "experim_name": "CCT", // The name the results will take (html and the folder in /saved)
135 | "n_gpu": 1, // Number of GPUs
136 | "n_labeled_examples": 1000, // Number of labeled examples (choices are 60, 100, 200,
137 | // 300, 500, 800, 1000, 1464, and the splits are in dataloaders/voc_splits)
138 | "diff_lrs": true,
139 | "ramp_up": 0.1, // The unsupervised loss will be slowly scaled up in the first 10% of Training time
140 | "unsupervised_w": 30, // Weighting of the unsupervised loss
141 | "ignore_index": 255,
142 | "lr_scheduler": "Poly",
143 | "use_weak_labels": false, // If the pseudo-labels were generated, we can use them to train the aux. decoders
144 | "weakly_loss_w": 0.4, // Weighting of the weakly-supervised loss
145 | "pretrained": true,
146 |
147 | "model":{
148 | "supervised": true, // Supervised setting (training only on the labeled examples)
149 | "semi": false, // Semi-supervised setting
150 | "supervised_w": 1, // Weighting of the supervised loss
151 |
152 | "sup_loss": "CE", // supervised loss, choices are CE and ab-CE = ["CE", "ABCE"]
153 | "un_loss": "MSE", // unsupervised loss, choices are CE and KL-divergence = ["MSE", "KL"]
154 |
155 | "softmax_temp": 1,
156 | "aux_constraint": false, // Pair-wise loss (sup. mat.)
157 | "aux_constraint_w": 1,
158 | "confidence_masking": false, // Confidence masking (sup. mat.)
159 | "confidence_th": 0.5,
160 |
161 | "drop": 6, // Number of DropOut decoders
162 | "drop_rate": 0.5, // Dropout probability
163 | "spatial": true,
164 |
165 | "cutout": 6, // Number of G-Cutout decoders
166 | "erase": 0.4, // We drop 40% of the area
167 |
168 | "vat": 2, // Number of I-VAT decoders
169 | "xi": 1e-6, // VAT parameters
170 | "eps": 2.0,
171 |
172 | "context_masking": 2, // Number of Con-Msk decoders
173 | "object_masking": 2, // Number of Obj-Msk decoders
174 | "feature_drop": 6, // Number of F-Drop decoders
175 |
176 | "feature_noise": 6, // Number of F-Noise decoders
177 | "uniform_range": 0.3 // The range of the noise
178 | },
179 | ```
180 |
181 | #### Acknowledgements
182 |
183 | - Pseudo-labels generation is based on Jiwoon Ahn's implementation [irn](https://github.com/jiwoon-ahn/irn).
184 | - Code structure was based on [Pytorch-Template](https://github.com/victoresque/pytorch-template/blob/master/README.m)
185 | - ResNet backbone was downloaded from [torchcv](https://github.com/donnyyou/torchcv)
186 |
--------------------------------------------------------------------------------
/base/__init__.py:
--------------------------------------------------------------------------------
1 | from .base_dataloader import *
2 | from .base_dataset import *
3 | from .base_model import *
4 | from .base_trainer import *
5 |
6 |
7 |
--------------------------------------------------------------------------------
/base/base_dataloader.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from copy import deepcopy
3 | import torch
4 | from torch.utils.data import DataLoader
5 | from torch.utils.data.sampler import SubsetRandomSampler
6 |
7 | class BaseDataLoader(DataLoader):
8 | def __init__(self, dataset, batch_size, shuffle, num_workers, val_split = 0.0):
9 | self.shuffle = shuffle
10 | self.dataset = dataset
11 | self.nbr_examples = len(dataset)
12 | if val_split:
13 | self.train_sampler, self.val_sampler = self._split_sampler(val_split)
14 | else:
15 | self.train_sampler, self.val_sampler = None, None
16 |
17 | self.init_kwargs = {
18 | 'dataset': self.dataset,
19 | 'batch_size': batch_size,
20 | 'shuffle': self.shuffle,
21 | 'num_workers': num_workers,
22 | 'pin_memory': True
23 | }
24 | super(BaseDataLoader, self).__init__(sampler=self.train_sampler, **self.init_kwargs)
25 |
26 | def _split_sampler(self, split):
27 | if split == 0.0:
28 | return None, None
29 |
30 | self.shuffle = False
31 |
32 | split_indx = int(self.nbr_examples * split)
33 | np.random.seed(0)
34 |
35 | indxs = np.arange(self.nbr_examples)
36 | np.random.shuffle(indxs)
37 | train_indxs = indxs[split_indx:]
38 | val_indxs = indxs[:split_indx]
39 | self.nbr_examples = len(train_indxs)
40 |
41 | train_sampler = SubsetRandomSampler(train_indxs)
42 | val_sampler = SubsetRandomSampler(val_indxs)
43 | return train_sampler, val_sampler
44 |
45 | def get_val_loader(self):
46 | if self.val_sampler is None:
47 | return None
48 | return DataLoader(sampler=self.val_sampler, **self.init_kwargs)
49 |
--------------------------------------------------------------------------------
/base/base_dataset.py:
--------------------------------------------------------------------------------
1 | import random, math
2 | import numpy as np
3 | import cv2
4 | import torch
5 | import torch.nn.functional as F
6 | from torch.utils.data import Dataset
7 | from PIL import Image
8 | from torchvision import transforms
9 | from scipy import ndimage
10 | from math import ceil
11 |
12 | class BaseDataSet(Dataset):
13 | def __init__(self, data_dir, split, mean, std, ignore_index, base_size=None, augment=True, val=False,
14 | jitter=False, use_weak_lables=False, weak_labels_output=None, crop_size=None, scale=False, flip=False, rotate=False,
15 | blur=False, return_id=False, n_labeled_examples=None):
16 |
17 | self.root = data_dir
18 | self.split = split
19 | self.mean = mean
20 | self.std = std
21 | self.augment = augment
22 | self.crop_size = crop_size
23 | self.jitter = jitter
24 | self.image_padding = (np.array(mean)*255.).tolist()
25 | self.ignore_index = ignore_index
26 | self.return_id = return_id
27 | self.n_labeled_examples = n_labeled_examples
28 | self.val = val
29 |
30 | self.use_weak_lables = use_weak_lables
31 | self.weak_labels_output = weak_labels_output
32 |
33 | if self.augment:
34 | self.base_size = base_size
35 | self.scale = scale
36 | self.flip = flip
37 | self.rotate = rotate
38 | self.blur = blur
39 |
40 | self.jitter_tf = transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1)
41 | self.to_tensor = transforms.ToTensor()
42 | self.normalize = transforms.Normalize(mean, std)
43 |
44 | self.files = []
45 | self._set_files()
46 |
47 | cv2.setNumThreads(0)
48 |
49 | def _set_files(self):
50 | raise NotImplementedError
51 |
52 | def _load_data(self, index):
53 | raise NotImplementedError
54 |
55 | def _rotate(self, image, label):
56 | # Rotate the image with an angle between -10 and 10
57 | h, w, _ = image.shape
58 | angle = random.randint(-10, 10)
59 | center = (w / 2, h / 2)
60 | rot_matrix = cv2.getRotationMatrix2D(center, angle, 1.0)
61 | image = cv2.warpAffine(image, rot_matrix, (w, h), flags=cv2.INTER_CUBIC)#, borderMode=cv2.BORDER_REFLECT)
62 | label = cv2.warpAffine(label, rot_matrix, (w, h), flags=cv2.INTER_NEAREST)#, borderMode=cv2.BORDER_REFLECT)
63 | return image, label
64 |
65 | def _crop(self, image, label):
66 | # Padding to return the correct crop size
67 | if (isinstance(self.crop_size, list) or isinstance(self.crop_size, tuple)) and len(self.crop_size) == 2:
68 | crop_h, crop_w = self.crop_size
69 | elif isinstance(self.crop_size, int):
70 | crop_h, crop_w = self.crop_size, self.crop_size
71 | else:
72 | raise ValueError
73 |
74 | h, w, _ = image.shape
75 | pad_h = max(crop_h - h, 0)
76 | pad_w = max(crop_w - w, 0)
77 | pad_kwargs = {
78 | "top": 0,
79 | "bottom": pad_h,
80 | "left": 0,
81 | "right": pad_w,
82 | "borderType": cv2.BORDER_CONSTANT,}
83 | if pad_h > 0 or pad_w > 0:
84 | image = cv2.copyMakeBorder(image, value=self.image_padding, **pad_kwargs)
85 | label = cv2.copyMakeBorder(label, value=self.ignore_index, **pad_kwargs)
86 |
87 | # Cropping
88 | h, w, _ = image.shape
89 | start_h = random.randint(0, h - crop_h)
90 | start_w = random.randint(0, w - crop_w)
91 | end_h = start_h + crop_h
92 | end_w = start_w + crop_w
93 | image = image[start_h:end_h, start_w:end_w]
94 | label = label[start_h:end_h, start_w:end_w]
95 | return image, label
96 |
97 | def _blur(self, image, label):
98 | # Gaussian Blud (sigma between 0 and 1.5)
99 | sigma = random.random() * 1.5
100 | ksize = int(3.3 * sigma)
101 | ksize = ksize + 1 if ksize % 2 == 0 else ksize
102 | image = cv2.GaussianBlur(image, (ksize, ksize), sigmaX=sigma, sigmaY=sigma, borderType=cv2.BORDER_REFLECT_101)
103 | return image, label
104 |
105 | def _flip(self, image, label):
106 | # Random H flip
107 | if random.random() > 0.5:
108 | image = np.fliplr(image).copy()
109 | label = np.fliplr(label).copy()
110 | return image, label
111 |
112 | def _resize(self, image, label, bigger_side_to_base_size=True):
113 | if isinstance(self.base_size, int):
114 | h, w, _ = image.shape
115 | if self.scale:
116 | longside = random.randint(int(self.base_size*0.5), int(self.base_size*2.0))
117 | #longside = random.randint(int(self.base_size*0.5), int(self.base_size*1))
118 | else:
119 | longside = self.base_size
120 |
121 | if bigger_side_to_base_size:
122 | h, w = (longside, int(1.0 * longside * w / h + 0.5)) if h > w else (int(1.0 * longside * h / w + 0.5), longside)
123 | else:
124 | h, w = (longside, int(1.0 * longside * w / h + 0.5)) if h < w else (int(1.0 * longside * h / w + 0.5), longside)
125 | image = np.asarray(Image.fromarray(np.uint8(image)).resize((w, h), Image.BICUBIC))
126 | label = cv2.resize(label, (w, h), interpolation=cv2.INTER_NEAREST)
127 | return image, label
128 |
129 | elif (isinstance(self.base_size, list) or isinstance(self.base_size, tuple)) and len(self.base_size) == 2:
130 | h, w, _ = image.shape
131 | if self.scale:
132 | scale = random.random() * 1.5 + 0.5 # Scaling between [0.5, 2]
133 | h, w = int(self.base_size[0] * scale), int(self.base_size[1] * scale)
134 | else:
135 | h, w = self.base_size
136 | image = np.asarray(Image.fromarray(np.uint8(image)).resize((w, h), Image.BICUBIC))
137 | label = cv2.resize(label, (w, h), interpolation=cv2.INTER_NEAREST)
138 | return image, label
139 |
140 | else:
141 | raise ValueError
142 |
143 | def _val_augmentation(self, image, label):
144 | if self.base_size is not None:
145 | image, label = self._resize(image, label)
146 | image = self.normalize(self.to_tensor(Image.fromarray(np.uint8(image))))
147 | return image, label
148 |
149 | image = self.normalize(self.to_tensor(Image.fromarray(np.uint8(image))))
150 | return image, label
151 |
152 | def _augmentation(self, image, label):
153 | h, w, _ = image.shape
154 |
155 | if self.base_size is not None:
156 | image, label = self._resize(image, label)
157 |
158 | if self.crop_size is not None:
159 | image, label = self._crop(image, label)
160 |
161 | if self.flip:
162 | image, label = self._flip(image, label)
163 |
164 | image = Image.fromarray(np.uint8(image))
165 | image = self.jitter_tf(image) if self.jitter else image
166 |
167 | return self.normalize(self.to_tensor(image)), label
168 |
169 | def __len__(self):
170 | return len(self.files)
171 |
172 | def __getitem__(self, index):
173 | image, label, image_id = self._load_data(index)
174 | if self.val:
175 | image, label = self._val_augmentation(image, label)
176 | elif self.augment:
177 | image, label = self._augmentation(image, label)
178 |
179 | label = torch.from_numpy(np.array(label, dtype=np.int32)).long()
180 | return image, label
181 |
182 | def __repr__(self):
183 | fmt_str = "Dataset: " + self.__class__.__name__ + "\n"
184 | fmt_str += " # data: {}\n".format(self.__len__())
185 | fmt_str += " Split: {}\n".format(self.split)
186 | fmt_str += " Root: {}".format(self.root)
187 | return fmt_str
188 |
189 |
--------------------------------------------------------------------------------
/base/base_model.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import torch.nn as nn
3 | import numpy as np
4 |
5 | class BaseModel(nn.Module):
6 | def __init__(self):
7 | super(BaseModel, self).__init__()
8 | self.logger = logging.getLogger(self.__class__.__name__)
9 |
10 | def forward(self):
11 | raise NotImplementedError
12 |
13 | def summary(self):
14 | model_parameters = filter(lambda p: p.requires_grad, self.parameters())
15 | nbr_params = sum([np.prod(p.size()) for p in model_parameters])
16 | self.logger.info(f'Nbr of trainable parameters: {nbr_params}')
17 |
18 | def __str__(self):
19 | model_parameters = filter(lambda p: p.requires_grad, self.parameters())
20 | nbr_params = int(sum([np.prod(p.size()) for p in model_parameters]))
21 | return f'\nNbr of trainable parameters: {nbr_params}'
22 | #return super(BaseModel, self).__str__() + f'\nNbr of trainable parameters: {nbr_params}'
23 |
--------------------------------------------------------------------------------
/base/base_trainer.py:
--------------------------------------------------------------------------------
1 | import os, json, math, logging, sys, datetime
2 | import torch
3 | from torch.utils import tensorboard
4 | from utils import helpers
5 | from utils import logger
6 | import utils.lr_scheduler
7 | from utils.htmlwriter import HTML
8 |
9 | def get_instance(module, name, config, *args):
10 | return getattr(module, config[name]['type'])(*args, **config[name]['args'])
11 |
12 | class BaseTrainer:
13 | def __init__(self, model, resume, config, iters_per_epoch, train_logger=None):
14 | self.model = model
15 | self.config = config
16 |
17 | self.train_logger = train_logger
18 | self.logger = logging.getLogger(self.__class__.__name__)
19 | self.do_validation = self.config['trainer']['val']
20 | self.start_epoch = 1
21 | self.improved = False
22 |
23 | # SETTING THE DEVICE
24 | self.device, availble_gpus = self._get_available_devices(self.config['n_gpu'])
25 | self.model = torch.nn.DataParallel(self.model, device_ids=availble_gpus)
26 | self.model.to(self.device)
27 |
28 | # CONFIGS
29 | cfg_trainer = self.config['trainer']
30 | self.epochs = cfg_trainer['epochs']
31 | self.save_period = cfg_trainer['save_period']
32 |
33 | # OPTIMIZER
34 | trainable_params = [{'params': filter(lambda p:p.requires_grad, self.model.module.get_other_params())},
35 | {'params': filter(lambda p:p.requires_grad, self.model.module.get_backbone_params()),
36 | 'lr': config['optimizer']['args']['lr'] / 10}]
37 |
38 | self.optimizer = get_instance(torch.optim, 'optimizer', config, trainable_params)
39 | model_params = sum([i.shape.numel() for i in list(model.parameters())])
40 | opt_params = sum([i.shape.numel() for j in self.optimizer.param_groups for i in j['params']])
41 | assert opt_params == model_params, 'some params are missing in the opt'
42 |
43 | self.lr_scheduler = getattr(utils.lr_scheduler, config['lr_scheduler'])(optimizer=self.optimizer, num_epochs=self.epochs,
44 | iters_per_epoch=iters_per_epoch)
45 |
46 | # MONITORING
47 | self.monitor = cfg_trainer.get('monitor', 'off')
48 | if self.monitor == 'off':
49 | self.mnt_mode = 'off'
50 | self.mnt_best = 0
51 | else:
52 | self.mnt_mode, self.mnt_metric = self.monitor.split()
53 | assert self.mnt_mode in ['min', 'max']
54 | self.mnt_best = -math.inf if self.mnt_mode == 'max' else math.inf
55 | self.early_stoping = cfg_trainer.get('early_stop', math.inf)
56 |
57 | # CHECKPOINTS & TENSOBOARD
58 | date_time = datetime.datetime.now().strftime('%m-%d_%H-%M')
59 | run_name = config['experim_name']
60 | self.checkpoint_dir = os.path.join(cfg_trainer['save_dir'], run_name)
61 | helpers.dir_exists(self.checkpoint_dir)
62 | config_save_path = os.path.join(self.checkpoint_dir, 'config.json')
63 | with open(config_save_path, 'w') as handle:
64 | json.dump(self.config, handle, indent=4, sort_keys=True)
65 |
66 | writer_dir = os.path.join(cfg_trainer['log_dir'], run_name)
67 | self.writer = tensorboard.SummaryWriter(writer_dir)
68 | self.html_results = HTML(web_dir=config['trainer']['save_dir'], exp_name=config['experim_name'],
69 | save_name=config['experim_name'], config=config, resume=resume)
70 |
71 | if resume: self._resume_checkpoint(resume)
72 |
73 | def _get_available_devices(self, n_gpu):
74 | sys_gpu = torch.cuda.device_count()
75 | if sys_gpu == 0:
76 | self.logger.warning('No GPUs detected, using the CPU')
77 | n_gpu = 0
78 | elif n_gpu > sys_gpu:
79 | self.logger.warning(f'Nbr of GPU requested is {n_gpu} but only {sys_gpu} are available')
80 | n_gpu = sys_gpu
81 |
82 | device = torch.device('cuda:0' if n_gpu > 0 else 'cpu')
83 | self.logger.info(f'Detected GPUs: {sys_gpu} Requested: {n_gpu}')
84 | available_gpus = list(range(n_gpu))
85 | return device, available_gpus
86 |
87 |
88 |
89 | def train(self):
90 | for epoch in range(self.start_epoch, self.epochs+1):
91 | results = self._train_epoch(epoch)
92 | if self.do_validation and epoch % self.config['trainer']['val_per_epochs'] == 0:
93 | results = self._valid_epoch(epoch)
94 | self.logger.info('\n\n')
95 | for k, v in results.items():
96 | self.logger.info(f' {str(k):15s}: {v}')
97 |
98 | if self.train_logger is not None:
99 | log = {'epoch' : epoch, **results}
100 | self.train_logger.add_entry(log)
101 |
102 | # CHECKING IF THIS IS THE BEST MODEL (ONLY FOR VAL)
103 | if self.mnt_mode != 'off' and epoch % self.config['trainer']['val_per_epochs'] == 0:
104 | try:
105 | if self.mnt_mode == 'min': self.improved = (log[self.mnt_metric] < self.mnt_best)
106 | else: self.improved = (log[self.mnt_metric] > self.mnt_best)
107 | except KeyError:
108 | self.logger.warning(f'The metrics being tracked ({self.mnt_metric}) has not been calculated. Training stops.')
109 | break
110 |
111 | if self.improved:
112 | self.mnt_best = log[self.mnt_metric]
113 | self.not_improved_count = 0
114 | else:
115 | self.not_improved_count += 1
116 |
117 | if self.not_improved_count > self.early_stoping:
118 | self.logger.info(f'\nPerformance didn\'t improve for {self.early_stoping} epochs')
119 | self.logger.warning('Training Stoped')
120 | break
121 |
122 | # SAVE CHECKPOINT
123 | if epoch % self.save_period == 0:
124 | self._save_checkpoint(epoch, save_best=self.improved)
125 | self.html_results.save()
126 |
127 |
128 | def _save_checkpoint(self, epoch, save_best=False):
129 | state = {
130 | 'arch': type(self.model).__name__,
131 | 'epoch': epoch,
132 | 'state_dict': self.model.state_dict(),
133 | 'monitor_best': self.mnt_best,
134 | 'config': self.config
135 | }
136 |
137 | filename = os.path.join(self.checkpoint_dir, f'checkpoint.pth')
138 | self.logger.info(f'\nSaving a checkpoint: {filename} ...')
139 | torch.save(state, filename)
140 |
141 | if save_best:
142 | filename = os.path.join(self.checkpoint_dir, f'best_model.pth')
143 | torch.save(state, filename)
144 | self.logger.info("Saving current best: best_model.pth")
145 |
146 | def _resume_checkpoint(self, resume_path):
147 | self.logger.info(f'Loading checkpoint : {resume_path}')
148 | checkpoint = torch.load(resume_path)
149 | self.start_epoch = checkpoint['epoch'] + 1
150 | self.mnt_best = checkpoint['monitor_best']
151 | self.not_improved_count = 0
152 |
153 | try:
154 | self.model.load_state_dict(checkpoint['state_dict'])
155 | except Exception as e:
156 | print(f'Error when loading: {e}')
157 | self.model.load_state_dict(checkpoint['state_dict'], strict=False)
158 |
159 | if "logger" in checkpoint.keys():
160 | self.train_logger = checkpoint['logger']
161 | self.logger.info(f'Checkpoint <{resume_path}> (epoch {self.start_epoch}) was loaded')
162 |
163 | def _train_epoch(self, epoch):
164 | raise NotImplementedError
165 |
166 | def _valid_epoch(self, epoch):
167 | raise NotImplementedError
168 |
169 | def _eval_metrics(self, output, target):
170 | raise NotImplementedError
171 |
--------------------------------------------------------------------------------
/configs/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "CCT",
3 | "experim_name": "CCT",
4 | "n_gpu": 1,
5 | "n_labeled_examples": 1464,
6 | "diff_lrs": true,
7 | "ramp_up": 0.1,
8 | "unsupervised_w": 30,
9 | "ignore_index": 255,
10 | "lr_scheduler": "Poly",
11 | "use_weak_lables":false,
12 | "weakly_loss_w": 0.4,
13 | "pretrained": true,
14 |
15 | "model":{
16 | "supervised": false,
17 | "semi": true,
18 | "supervised_w": 1,
19 |
20 | "sup_loss": "CE",
21 | "un_loss": "MSE",
22 |
23 | "softmax_temp": 1,
24 | "aux_constraint": false,
25 | "aux_constraint_w": 1,
26 | "confidence_masking": false,
27 | "confidence_th": 0.5,
28 |
29 | "drop": 6,
30 | "drop_rate": 0.5,
31 | "spatial": true,
32 |
33 | "cutout": 6,
34 | "erase": 0.4,
35 |
36 | "vat": 2,
37 | "xi": 1e-6,
38 | "eps": 2.0,
39 |
40 | "context_masking": 2,
41 | "object_masking": 2,
42 | "feature_drop": 6,
43 |
44 | "feature_noise": 6,
45 | "uniform_range": 0.3
46 | },
47 |
48 |
49 | "optimizer": {
50 | "type": "SGD",
51 | "args":{
52 | "lr": 1e-2,
53 | "weight_decay": 1e-4,
54 | "momentum": 0.9
55 | }
56 | },
57 |
58 |
59 | "train_supervised": {
60 | "data_dir": "VOCtrainval_11-May-2012",
61 | "batch_size": 10,
62 | "crop_size": 320,
63 | "shuffle": true,
64 | "base_size": 400,
65 | "scale": true,
66 | "augment": true,
67 | "flip": true,
68 | "rotate": false,
69 | "blur": false,
70 | "split": "train_supervised",
71 | "num_workers": 8
72 | },
73 |
74 | "train_unsupervised": {
75 | "data_dir": "VOCtrainval_11-May-2012",
76 | "weak_labels_output": "pseudo_labels/result/pseudo_labels",
77 | "batch_size": 10,
78 | "crop_size": 320,
79 | "shuffle": true,
80 | "base_size": 400,
81 | "scale": true,
82 | "augment": true,
83 | "flip": true,
84 | "rotate": false,
85 | "blur": false,
86 | "split": "train_unsupervised",
87 | "num_workers": 8
88 | },
89 |
90 | "val_loader": {
91 | "data_dir": "VOCtrainval_11-May-2012",
92 | "batch_size": 1,
93 | "val": true,
94 | "split": "val",
95 | "shuffle": false,
96 | "num_workers": 4
97 | },
98 |
99 | "trainer": {
100 | "epochs": 80,
101 | "save_dir": "saved/",
102 | "save_period": 5,
103 |
104 | "monitor": "max Mean_IoU",
105 | "early_stop": 10,
106 |
107 | "tensorboardX": true,
108 | "log_dir": "saved/",
109 | "log_per_iter": 20,
110 |
111 | "val": true,
112 | "val_per_epochs": 5
113 | }
114 | }
115 |
--------------------------------------------------------------------------------
/dataloaders/__init__.py:
--------------------------------------------------------------------------------
1 | from .voc import VOC
--------------------------------------------------------------------------------
/dataloaders/voc.py:
--------------------------------------------------------------------------------
1 | from base import BaseDataSet, BaseDataLoader
2 | from utils import pallete
3 | import numpy as np
4 | import os
5 | import scipy
6 | import torch
7 | from PIL import Image
8 | import cv2
9 | from torch.utils.data import Dataset
10 | from torchvision import transforms
11 | import json
12 |
13 | class VOCDataset(BaseDataSet):
14 | def __init__(self, **kwargs):
15 | self.num_classes = 21
16 |
17 | self.palette = pallete.get_voc_pallete(self.num_classes)
18 | super(VOCDataset, self).__init__(**kwargs)
19 |
20 | def _set_files(self):
21 | self.root = os.path.join(self.root, 'VOCdevkit/VOC2012')
22 | if self.split == "val":
23 | file_list = os.path.join("dataloaders/voc_splits", f"{self.split}" + ".txt")
24 | elif self.split in ["train_supervised", "train_unsupervised"]:
25 | file_list = os.path.join("dataloaders/voc_splits", f"{self.n_labeled_examples}_{self.split}" + ".txt")
26 | else:
27 | raise ValueError(f"Invalid split name {self.split}")
28 |
29 | file_list = [line.rstrip().split(' ') for line in tuple(open(file_list, "r"))]
30 | self.files, self.labels = list(zip(*file_list))
31 |
32 | def _load_data(self, index):
33 | image_path = os.path.join(self.root, self.files[index][1:])
34 | image = np.asarray(Image.open(image_path), dtype=np.float32)
35 | image_id = self.files[index].split("/")[-1].split(".")[0]
36 | if self.use_weak_lables:
37 | label_path = os.path.join(self.weak_labels_output, image_id+".png")
38 | else:
39 | label_path = os.path.join(self.root, self.labels[index][1:])
40 | label = np.asarray(Image.open(label_path), dtype=np.int32)
41 | return image, label, image_id
42 |
43 | class VOC(BaseDataLoader):
44 | def __init__(self, kwargs):
45 |
46 | self.MEAN = [0.485, 0.456, 0.406]
47 | self.STD = [0.229, 0.224, 0.225]
48 | self.batch_size = kwargs.pop('batch_size')
49 | kwargs['mean'] = self.MEAN
50 | kwargs['std'] = self.STD
51 | kwargs['ignore_index'] = 255
52 | try:
53 | shuffle = kwargs.pop('shuffle')
54 | except:
55 | shuffle = False
56 | num_workers = kwargs.pop('num_workers')
57 |
58 | self.dataset = VOCDataset(**kwargs)
59 |
60 | super(VOC, self).__init__(self.dataset, self.batch_size, shuffle, num_workers, val_split=None)
61 |
--------------------------------------------------------------------------------
/dataloaders/voc_splits/100_train_supervised.txt:
--------------------------------------------------------------------------------
1 | /JPEGImages/2007_000032.jpg /SegmentationClassAug/2007_000032.png
2 | /JPEGImages/2007_000039.jpg /SegmentationClassAug/2007_000039.png
3 | /JPEGImages/2007_000063.jpg /SegmentationClassAug/2007_000063.png
4 | /JPEGImages/2007_000068.jpg /SegmentationClassAug/2007_000068.png
5 | /JPEGImages/2007_000121.jpg /SegmentationClassAug/2007_000121.png
6 | /JPEGImages/2007_000170.jpg /SegmentationClassAug/2007_000170.png
7 | /JPEGImages/2007_000241.jpg /SegmentationClassAug/2007_000241.png
8 | /JPEGImages/2007_000243.jpg /SegmentationClassAug/2007_000243.png
9 | /JPEGImages/2007_000250.jpg /SegmentationClassAug/2007_000250.png
10 | /JPEGImages/2007_000256.jpg /SegmentationClassAug/2007_000256.png
11 | /JPEGImages/2007_000333.jpg /SegmentationClassAug/2007_000333.png
12 | /JPEGImages/2007_000363.jpg /SegmentationClassAug/2007_000363.png
13 | /JPEGImages/2007_000364.jpg /SegmentationClassAug/2007_000364.png
14 | /JPEGImages/2007_000392.jpg /SegmentationClassAug/2007_000392.png
15 | /JPEGImages/2007_000480.jpg /SegmentationClassAug/2007_000480.png
16 | /JPEGImages/2007_000504.jpg /SegmentationClassAug/2007_000504.png
17 | /JPEGImages/2007_000515.jpg /SegmentationClassAug/2007_000515.png
18 | /JPEGImages/2007_000528.jpg /SegmentationClassAug/2007_000528.png
19 | /JPEGImages/2007_000549.jpg /SegmentationClassAug/2007_000549.png
20 | /JPEGImages/2007_000584.jpg /SegmentationClassAug/2007_000584.png
21 | /JPEGImages/2007_000645.jpg /SegmentationClassAug/2007_000645.png
22 | /JPEGImages/2007_000648.jpg /SegmentationClassAug/2007_000648.png
23 | /JPEGImages/2007_000713.jpg /SegmentationClassAug/2007_000713.png
24 | /JPEGImages/2007_000720.jpg /SegmentationClassAug/2007_000720.png
25 | /JPEGImages/2007_000733.jpg /SegmentationClassAug/2007_000733.png
26 | /JPEGImages/2007_000738.jpg /SegmentationClassAug/2007_000738.png
27 | /JPEGImages/2007_000768.jpg /SegmentationClassAug/2007_000768.png
28 | /JPEGImages/2007_000793.jpg /SegmentationClassAug/2007_000793.png
29 | /JPEGImages/2007_000822.jpg /SegmentationClassAug/2007_000822.png
30 | /JPEGImages/2007_000836.jpg /SegmentationClassAug/2007_000836.png
31 | /JPEGImages/2007_000876.jpg /SegmentationClassAug/2007_000876.png
32 | /JPEGImages/2007_000904.jpg /SegmentationClassAug/2007_000904.png
33 | /JPEGImages/2007_001027.jpg /SegmentationClassAug/2007_001027.png
34 | /JPEGImages/2007_001073.jpg /SegmentationClassAug/2007_001073.png
35 | /JPEGImages/2007_001149.jpg /SegmentationClassAug/2007_001149.png
36 | /JPEGImages/2007_001185.jpg /SegmentationClassAug/2007_001185.png
37 | /JPEGImages/2007_001225.jpg /SegmentationClassAug/2007_001225.png
38 | /JPEGImages/2007_001397.jpg /SegmentationClassAug/2007_001397.png
39 | /JPEGImages/2007_001416.jpg /SegmentationClassAug/2007_001416.png
40 | /JPEGImages/2007_001420.jpg /SegmentationClassAug/2007_001420.png
41 | /JPEGImages/2007_001439.jpg /SegmentationClassAug/2007_001439.png
42 | /JPEGImages/2007_001487.jpg /SegmentationClassAug/2007_001487.png
43 | /JPEGImages/2007_001595.jpg /SegmentationClassAug/2007_001595.png
44 | /JPEGImages/2007_001602.jpg /SegmentationClassAug/2007_001602.png
45 | /JPEGImages/2007_001609.jpg /SegmentationClassAug/2007_001609.png
46 | /JPEGImages/2007_001698.jpg /SegmentationClassAug/2007_001698.png
47 | /JPEGImages/2007_001704.jpg /SegmentationClassAug/2007_001704.png
48 | /JPEGImages/2007_001709.jpg /SegmentationClassAug/2007_001709.png
49 | /JPEGImages/2007_001724.jpg /SegmentationClassAug/2007_001724.png
50 | /JPEGImages/2007_001764.jpg /SegmentationClassAug/2007_001764.png
51 | /JPEGImages/2007_001825.jpg /SegmentationClassAug/2007_001825.png
52 | /JPEGImages/2007_001834.jpg /SegmentationClassAug/2007_001834.png
53 | /JPEGImages/2007_001857.jpg /SegmentationClassAug/2007_001857.png
54 | /JPEGImages/2007_001872.jpg /SegmentationClassAug/2007_001872.png
55 | /JPEGImages/2007_001901.jpg /SegmentationClassAug/2007_001901.png
56 | /JPEGImages/2007_001917.jpg /SegmentationClassAug/2007_001917.png
57 | /JPEGImages/2007_001960.jpg /SegmentationClassAug/2007_001960.png
58 | /JPEGImages/2007_002024.jpg /SegmentationClassAug/2007_002024.png
59 | /JPEGImages/2007_002055.jpg /SegmentationClassAug/2007_002055.png
60 | /JPEGImages/2007_002088.jpg /SegmentationClassAug/2007_002088.png
61 | /JPEGImages/2007_002099.jpg /SegmentationClassAug/2007_002099.png
62 | /JPEGImages/2007_002105.jpg /SegmentationClassAug/2007_002105.png
63 | /JPEGImages/2007_002212.jpg /SegmentationClassAug/2007_002212.png
64 | /JPEGImages/2007_002216.jpg /SegmentationClassAug/2007_002216.png
65 | /JPEGImages/2007_002227.jpg /SegmentationClassAug/2007_002227.png
66 | /JPEGImages/2007_002234.jpg /SegmentationClassAug/2007_002234.png
67 | /JPEGImages/2007_002281.jpg /SegmentationClassAug/2007_002281.png
68 | /JPEGImages/2007_002361.jpg /SegmentationClassAug/2007_002361.png
69 | /JPEGImages/2007_002368.jpg /SegmentationClassAug/2007_002368.png
70 | /JPEGImages/2007_002370.jpg /SegmentationClassAug/2007_002370.png
71 | /JPEGImages/2007_002462.jpg /SegmentationClassAug/2007_002462.png
72 | /JPEGImages/2007_002760.jpg /SegmentationClassAug/2007_002760.png
73 | /JPEGImages/2007_002845.jpg /SegmentationClassAug/2007_002845.png
74 | /JPEGImages/2007_002896.jpg /SegmentationClassAug/2007_002896.png
75 | /JPEGImages/2007_002953.jpg /SegmentationClassAug/2007_002953.png
76 | /JPEGImages/2007_002967.jpg /SegmentationClassAug/2007_002967.png
77 | /JPEGImages/2007_003178.jpg /SegmentationClassAug/2007_003178.png
78 | /JPEGImages/2007_003189.jpg /SegmentationClassAug/2007_003189.png
79 | /JPEGImages/2007_003190.jpg /SegmentationClassAug/2007_003190.png
80 | /JPEGImages/2007_003207.jpg /SegmentationClassAug/2007_003207.png
81 | /JPEGImages/2007_003251.jpg /SegmentationClassAug/2007_003251.png
82 | /JPEGImages/2007_003286.jpg /SegmentationClassAug/2007_003286.png
83 | /JPEGImages/2007_003525.jpg /SegmentationClassAug/2007_003525.png
84 | /JPEGImages/2007_003593.jpg /SegmentationClassAug/2007_003593.png
85 | /JPEGImages/2007_003604.jpg /SegmentationClassAug/2007_003604.png
86 | /JPEGImages/2007_003788.jpg /SegmentationClassAug/2007_003788.png
87 | /JPEGImages/2007_003815.jpg /SegmentationClassAug/2007_003815.png
88 | /JPEGImages/2007_004081.jpg /SegmentationClassAug/2007_004081.png
89 | /JPEGImages/2007_004627.jpg /SegmentationClassAug/2007_004627.png
90 | /JPEGImages/2007_004707.jpg /SegmentationClassAug/2007_004707.png
91 | /JPEGImages/2007_005210.jpg /SegmentationClassAug/2007_005210.png
92 | /JPEGImages/2007_005273.jpg /SegmentationClassAug/2007_005273.png
93 | /JPEGImages/2007_005902.jpg /SegmentationClassAug/2007_005902.png
94 | /JPEGImages/2007_006530.jpg /SegmentationClassAug/2007_006530.png
95 | /JPEGImages/2007_006581.jpg /SegmentationClassAug/2007_006581.png
96 | /JPEGImages/2007_006605.jpg /SegmentationClassAug/2007_006605.png
97 | /JPEGImages/2007_007432.jpg /SegmentationClassAug/2007_007432.png
98 | /JPEGImages/2007_009709.jpg /SegmentationClassAug/2007_009709.png
99 | /JPEGImages/2007_009788.jpg /SegmentationClassAug/2007_009788.png
100 | /JPEGImages/2008_000015.jpg /SegmentationClassAug/2008_000015.png
101 |
--------------------------------------------------------------------------------
/dataloaders/voc_splits/200_train_supervised.txt:
--------------------------------------------------------------------------------
1 | /JPEGImages/2007_000032.jpg /SegmentationClassAug/2007_000032.png
2 | /JPEGImages/2007_000039.jpg /SegmentationClassAug/2007_000039.png
3 | /JPEGImages/2007_000063.jpg /SegmentationClassAug/2007_000063.png
4 | /JPEGImages/2007_000068.jpg /SegmentationClassAug/2007_000068.png
5 | /JPEGImages/2007_000121.jpg /SegmentationClassAug/2007_000121.png
6 | /JPEGImages/2007_000170.jpg /SegmentationClassAug/2007_000170.png
7 | /JPEGImages/2007_000241.jpg /SegmentationClassAug/2007_000241.png
8 | /JPEGImages/2007_000243.jpg /SegmentationClassAug/2007_000243.png
9 | /JPEGImages/2007_000250.jpg /SegmentationClassAug/2007_000250.png
10 | /JPEGImages/2007_000256.jpg /SegmentationClassAug/2007_000256.png
11 | /JPEGImages/2007_000333.jpg /SegmentationClassAug/2007_000333.png
12 | /JPEGImages/2007_000363.jpg /SegmentationClassAug/2007_000363.png
13 | /JPEGImages/2007_000364.jpg /SegmentationClassAug/2007_000364.png
14 | /JPEGImages/2007_000392.jpg /SegmentationClassAug/2007_000392.png
15 | /JPEGImages/2007_000480.jpg /SegmentationClassAug/2007_000480.png
16 | /JPEGImages/2007_000504.jpg /SegmentationClassAug/2007_000504.png
17 | /JPEGImages/2007_000515.jpg /SegmentationClassAug/2007_000515.png
18 | /JPEGImages/2007_000528.jpg /SegmentationClassAug/2007_000528.png
19 | /JPEGImages/2007_000549.jpg /SegmentationClassAug/2007_000549.png
20 | /JPEGImages/2007_000584.jpg /SegmentationClassAug/2007_000584.png
21 | /JPEGImages/2007_000645.jpg /SegmentationClassAug/2007_000645.png
22 | /JPEGImages/2007_000648.jpg /SegmentationClassAug/2007_000648.png
23 | /JPEGImages/2007_000713.jpg /SegmentationClassAug/2007_000713.png
24 | /JPEGImages/2007_000720.jpg /SegmentationClassAug/2007_000720.png
25 | /JPEGImages/2007_000733.jpg /SegmentationClassAug/2007_000733.png
26 | /JPEGImages/2007_000738.jpg /SegmentationClassAug/2007_000738.png
27 | /JPEGImages/2007_000768.jpg /SegmentationClassAug/2007_000768.png
28 | /JPEGImages/2007_000793.jpg /SegmentationClassAug/2007_000793.png
29 | /JPEGImages/2007_000822.jpg /SegmentationClassAug/2007_000822.png
30 | /JPEGImages/2007_000836.jpg /SegmentationClassAug/2007_000836.png
31 | /JPEGImages/2007_000876.jpg /SegmentationClassAug/2007_000876.png
32 | /JPEGImages/2007_000904.jpg /SegmentationClassAug/2007_000904.png
33 | /JPEGImages/2007_001027.jpg /SegmentationClassAug/2007_001027.png
34 | /JPEGImages/2007_001073.jpg /SegmentationClassAug/2007_001073.png
35 | /JPEGImages/2007_001149.jpg /SegmentationClassAug/2007_001149.png
36 | /JPEGImages/2007_001185.jpg /SegmentationClassAug/2007_001185.png
37 | /JPEGImages/2007_001225.jpg /SegmentationClassAug/2007_001225.png
38 | /JPEGImages/2007_001340.jpg /SegmentationClassAug/2007_001340.png
39 | /JPEGImages/2007_001397.jpg /SegmentationClassAug/2007_001397.png
40 | /JPEGImages/2007_001416.jpg /SegmentationClassAug/2007_001416.png
41 | /JPEGImages/2007_001420.jpg /SegmentationClassAug/2007_001420.png
42 | /JPEGImages/2007_001439.jpg /SegmentationClassAug/2007_001439.png
43 | /JPEGImages/2007_001487.jpg /SegmentationClassAug/2007_001487.png
44 | /JPEGImages/2007_001595.jpg /SegmentationClassAug/2007_001595.png
45 | /JPEGImages/2007_001602.jpg /SegmentationClassAug/2007_001602.png
46 | /JPEGImages/2007_001609.jpg /SegmentationClassAug/2007_001609.png
47 | /JPEGImages/2007_001698.jpg /SegmentationClassAug/2007_001698.png
48 | /JPEGImages/2007_001704.jpg /SegmentationClassAug/2007_001704.png
49 | /JPEGImages/2007_001709.jpg /SegmentationClassAug/2007_001709.png
50 | /JPEGImages/2007_001724.jpg /SegmentationClassAug/2007_001724.png
51 | /JPEGImages/2007_001764.jpg /SegmentationClassAug/2007_001764.png
52 | /JPEGImages/2007_001825.jpg /SegmentationClassAug/2007_001825.png
53 | /JPEGImages/2007_001834.jpg /SegmentationClassAug/2007_001834.png
54 | /JPEGImages/2007_001857.jpg /SegmentationClassAug/2007_001857.png
55 | /JPEGImages/2007_001872.jpg /SegmentationClassAug/2007_001872.png
56 | /JPEGImages/2007_001901.jpg /SegmentationClassAug/2007_001901.png
57 | /JPEGImages/2007_001917.jpg /SegmentationClassAug/2007_001917.png
58 | /JPEGImages/2007_001960.jpg /SegmentationClassAug/2007_001960.png
59 | /JPEGImages/2007_002024.jpg /SegmentationClassAug/2007_002024.png
60 | /JPEGImages/2007_002055.jpg /SegmentationClassAug/2007_002055.png
61 | /JPEGImages/2007_002088.jpg /SegmentationClassAug/2007_002088.png
62 | /JPEGImages/2007_002099.jpg /SegmentationClassAug/2007_002099.png
63 | /JPEGImages/2007_002105.jpg /SegmentationClassAug/2007_002105.png
64 | /JPEGImages/2007_002107.jpg /SegmentationClassAug/2007_002107.png
65 | /JPEGImages/2007_002120.jpg /SegmentationClassAug/2007_002120.png
66 | /JPEGImages/2007_002142.jpg /SegmentationClassAug/2007_002142.png
67 | /JPEGImages/2007_002198.jpg /SegmentationClassAug/2007_002198.png
68 | /JPEGImages/2007_002212.jpg /SegmentationClassAug/2007_002212.png
69 | /JPEGImages/2007_002216.jpg /SegmentationClassAug/2007_002216.png
70 | /JPEGImages/2007_002227.jpg /SegmentationClassAug/2007_002227.png
71 | /JPEGImages/2007_002234.jpg /SegmentationClassAug/2007_002234.png
72 | /JPEGImages/2007_002273.jpg /SegmentationClassAug/2007_002273.png
73 | /JPEGImages/2007_002281.jpg /SegmentationClassAug/2007_002281.png
74 | /JPEGImages/2007_002293.jpg /SegmentationClassAug/2007_002293.png
75 | /JPEGImages/2007_002361.jpg /SegmentationClassAug/2007_002361.png
76 | /JPEGImages/2007_002368.jpg /SegmentationClassAug/2007_002368.png
77 | /JPEGImages/2007_002370.jpg /SegmentationClassAug/2007_002370.png
78 | /JPEGImages/2007_002403.jpg /SegmentationClassAug/2007_002403.png
79 | /JPEGImages/2007_002462.jpg /SegmentationClassAug/2007_002462.png
80 | /JPEGImages/2007_002488.jpg /SegmentationClassAug/2007_002488.png
81 | /JPEGImages/2007_002545.jpg /SegmentationClassAug/2007_002545.png
82 | /JPEGImages/2007_002611.jpg /SegmentationClassAug/2007_002611.png
83 | /JPEGImages/2007_002669.jpg /SegmentationClassAug/2007_002669.png
84 | /JPEGImages/2007_002760.jpg /SegmentationClassAug/2007_002760.png
85 | /JPEGImages/2007_002789.jpg /SegmentationClassAug/2007_002789.png
86 | /JPEGImages/2007_002845.jpg /SegmentationClassAug/2007_002845.png
87 | /JPEGImages/2007_002896.jpg /SegmentationClassAug/2007_002896.png
88 | /JPEGImages/2007_002953.jpg /SegmentationClassAug/2007_002953.png
89 | /JPEGImages/2007_002967.jpg /SegmentationClassAug/2007_002967.png
90 | /JPEGImages/2007_003000.jpg /SegmentationClassAug/2007_003000.png
91 | /JPEGImages/2007_003178.jpg /SegmentationClassAug/2007_003178.png
92 | /JPEGImages/2007_003189.jpg /SegmentationClassAug/2007_003189.png
93 | /JPEGImages/2007_003190.jpg /SegmentationClassAug/2007_003190.png
94 | /JPEGImages/2007_003207.jpg /SegmentationClassAug/2007_003207.png
95 | /JPEGImages/2007_003251.jpg /SegmentationClassAug/2007_003251.png
96 | /JPEGImages/2007_003267.jpg /SegmentationClassAug/2007_003267.png
97 | /JPEGImages/2007_003286.jpg /SegmentationClassAug/2007_003286.png
98 | /JPEGImages/2007_003330.jpg /SegmentationClassAug/2007_003330.png
99 | /JPEGImages/2007_003451.jpg /SegmentationClassAug/2007_003451.png
100 | /JPEGImages/2007_003525.jpg /SegmentationClassAug/2007_003525.png
101 | /JPEGImages/2007_003565.jpg /SegmentationClassAug/2007_003565.png
102 | /JPEGImages/2007_003593.jpg /SegmentationClassAug/2007_003593.png
103 | /JPEGImages/2007_003604.jpg /SegmentationClassAug/2007_003604.png
104 | /JPEGImages/2007_003668.jpg /SegmentationClassAug/2007_003668.png
105 | /JPEGImages/2007_003715.jpg /SegmentationClassAug/2007_003715.png
106 | /JPEGImages/2007_003778.jpg /SegmentationClassAug/2007_003778.png
107 | /JPEGImages/2007_003788.jpg /SegmentationClassAug/2007_003788.png
108 | /JPEGImages/2007_003815.jpg /SegmentationClassAug/2007_003815.png
109 | /JPEGImages/2007_003876.jpg /SegmentationClassAug/2007_003876.png
110 | /JPEGImages/2007_003889.jpg /SegmentationClassAug/2007_003889.png
111 | /JPEGImages/2007_003910.jpg /SegmentationClassAug/2007_003910.png
112 | /JPEGImages/2007_004003.jpg /SegmentationClassAug/2007_004003.png
113 | /JPEGImages/2007_004009.jpg /SegmentationClassAug/2007_004009.png
114 | /JPEGImages/2007_004065.jpg /SegmentationClassAug/2007_004065.png
115 | /JPEGImages/2007_004081.jpg /SegmentationClassAug/2007_004081.png
116 | /JPEGImages/2007_004166.jpg /SegmentationClassAug/2007_004166.png
117 | /JPEGImages/2007_004423.jpg /SegmentationClassAug/2007_004423.png
118 | /JPEGImages/2007_004481.jpg /SegmentationClassAug/2007_004481.png
119 | /JPEGImages/2007_004500.jpg /SegmentationClassAug/2007_004500.png
120 | /JPEGImages/2007_004537.jpg /SegmentationClassAug/2007_004537.png
121 | /JPEGImages/2007_004627.jpg /SegmentationClassAug/2007_004627.png
122 | /JPEGImages/2007_004663.jpg /SegmentationClassAug/2007_004663.png
123 | /JPEGImages/2007_004705.jpg /SegmentationClassAug/2007_004705.png
124 | /JPEGImages/2007_004707.jpg /SegmentationClassAug/2007_004707.png
125 | /JPEGImages/2007_004768.jpg /SegmentationClassAug/2007_004768.png
126 | /JPEGImages/2007_004810.jpg /SegmentationClassAug/2007_004810.png
127 | /JPEGImages/2007_004830.jpg /SegmentationClassAug/2007_004830.png
128 | /JPEGImages/2007_004948.jpg /SegmentationClassAug/2007_004948.png
129 | /JPEGImages/2007_004951.jpg /SegmentationClassAug/2007_004951.png
130 | /JPEGImages/2007_004998.jpg /SegmentationClassAug/2007_004998.png
131 | /JPEGImages/2007_005124.jpg /SegmentationClassAug/2007_005124.png
132 | /JPEGImages/2007_005130.jpg /SegmentationClassAug/2007_005130.png
133 | /JPEGImages/2007_005210.jpg /SegmentationClassAug/2007_005210.png
134 | /JPEGImages/2007_005212.jpg /SegmentationClassAug/2007_005212.png
135 | /JPEGImages/2007_005248.jpg /SegmentationClassAug/2007_005248.png
136 | /JPEGImages/2007_005262.jpg /SegmentationClassAug/2007_005262.png
137 | /JPEGImages/2007_005264.jpg /SegmentationClassAug/2007_005264.png
138 | /JPEGImages/2007_005266.jpg /SegmentationClassAug/2007_005266.png
139 | /JPEGImages/2007_005273.jpg /SegmentationClassAug/2007_005273.png
140 | /JPEGImages/2007_005314.jpg /SegmentationClassAug/2007_005314.png
141 | /JPEGImages/2007_005360.jpg /SegmentationClassAug/2007_005360.png
142 | /JPEGImages/2007_005647.jpg /SegmentationClassAug/2007_005647.png
143 | /JPEGImages/2007_005688.jpg /SegmentationClassAug/2007_005688.png
144 | /JPEGImages/2007_005878.jpg /SegmentationClassAug/2007_005878.png
145 | /JPEGImages/2007_005902.jpg /SegmentationClassAug/2007_005902.png
146 | /JPEGImages/2007_005951.jpg /SegmentationClassAug/2007_005951.png
147 | /JPEGImages/2007_006066.jpg /SegmentationClassAug/2007_006066.png
148 | /JPEGImages/2007_006134.jpg /SegmentationClassAug/2007_006134.png
149 | /JPEGImages/2007_006136.jpg /SegmentationClassAug/2007_006136.png
150 | /JPEGImages/2007_006151.jpg /SegmentationClassAug/2007_006151.png
151 | /JPEGImages/2007_006254.jpg /SegmentationClassAug/2007_006254.png
152 | /JPEGImages/2007_006281.jpg /SegmentationClassAug/2007_006281.png
153 | /JPEGImages/2007_006303.jpg /SegmentationClassAug/2007_006303.png
154 | /JPEGImages/2007_006317.jpg /SegmentationClassAug/2007_006317.png
155 | /JPEGImages/2007_006400.jpg /SegmentationClassAug/2007_006400.png
156 | /JPEGImages/2007_006409.jpg /SegmentationClassAug/2007_006409.png
157 | /JPEGImages/2007_006490.jpg /SegmentationClassAug/2007_006490.png
158 | /JPEGImages/2007_006530.jpg /SegmentationClassAug/2007_006530.png
159 | /JPEGImages/2007_006581.jpg /SegmentationClassAug/2007_006581.png
160 | /JPEGImages/2007_006605.jpg /SegmentationClassAug/2007_006605.png
161 | /JPEGImages/2007_006641.jpg /SegmentationClassAug/2007_006641.png
162 | /JPEGImages/2007_006660.jpg /SegmentationClassAug/2007_006660.png
163 | /JPEGImages/2007_006699.jpg /SegmentationClassAug/2007_006699.png
164 | /JPEGImages/2007_006704.jpg /SegmentationClassAug/2007_006704.png
165 | /JPEGImages/2007_006832.jpg /SegmentationClassAug/2007_006832.png
166 | /JPEGImages/2007_006899.jpg /SegmentationClassAug/2007_006899.png
167 | /JPEGImages/2007_006900.jpg /SegmentationClassAug/2007_006900.png
168 | /JPEGImages/2007_007098.jpg /SegmentationClassAug/2007_007098.png
169 | /JPEGImages/2007_007250.jpg /SegmentationClassAug/2007_007250.png
170 | /JPEGImages/2007_007398.jpg /SegmentationClassAug/2007_007398.png
171 | /JPEGImages/2007_007432.jpg /SegmentationClassAug/2007_007432.png
172 | /JPEGImages/2007_007530.jpg /SegmentationClassAug/2007_007530.png
173 | /JPEGImages/2007_007585.jpg /SegmentationClassAug/2007_007585.png
174 | /JPEGImages/2007_007890.jpg /SegmentationClassAug/2007_007890.png
175 | /JPEGImages/2007_007930.jpg /SegmentationClassAug/2007_007930.png
176 | /JPEGImages/2007_008140.jpg /SegmentationClassAug/2007_008140.png
177 | /JPEGImages/2007_008203.jpg /SegmentationClassAug/2007_008203.png
178 | /JPEGImages/2007_008468.jpg /SegmentationClassAug/2007_008468.png
179 | /JPEGImages/2007_008948.jpg /SegmentationClassAug/2007_008948.png
180 | /JPEGImages/2007_009216.jpg /SegmentationClassAug/2007_009216.png
181 | /JPEGImages/2007_009550.jpg /SegmentationClassAug/2007_009550.png
182 | /JPEGImages/2007_009605.jpg /SegmentationClassAug/2007_009605.png
183 | /JPEGImages/2007_009709.jpg /SegmentationClassAug/2007_009709.png
184 | /JPEGImages/2007_009788.jpg /SegmentationClassAug/2007_009788.png
185 | /JPEGImages/2007_009889.jpg /SegmentationClassAug/2007_009889.png
186 | /JPEGImages/2007_009899.jpg /SegmentationClassAug/2007_009899.png
187 | /JPEGImages/2008_000015.jpg /SegmentationClassAug/2008_000015.png
188 | /JPEGImages/2008_000043.jpg /SegmentationClassAug/2008_000043.png
189 | /JPEGImages/2008_000067.jpg /SegmentationClassAug/2008_000067.png
190 | /JPEGImages/2008_000133.jpg /SegmentationClassAug/2008_000133.png
191 | /JPEGImages/2008_000154.jpg /SegmentationClassAug/2008_000154.png
192 | /JPEGImages/2008_000188.jpg /SegmentationClassAug/2008_000188.png
193 | /JPEGImages/2008_000191.jpg /SegmentationClassAug/2008_000191.png
194 | /JPEGImages/2008_000194.jpg /SegmentationClassAug/2008_000194.png
195 | /JPEGImages/2008_000196.jpg /SegmentationClassAug/2008_000196.png
196 | /JPEGImages/2008_000272.jpg /SegmentationClassAug/2008_000272.png
197 | /JPEGImages/2008_000703.jpg /SegmentationClassAug/2008_000703.png
198 | /JPEGImages/2008_001225.jpg /SegmentationClassAug/2008_001225.png
199 | /JPEGImages/2008_001405.jpg /SegmentationClassAug/2008_001405.png
200 | /JPEGImages/2008_001744.jpg /SegmentationClassAug/2008_001744.png
201 |
--------------------------------------------------------------------------------
/dataloaders/voc_splits/300_train_supervised.txt:
--------------------------------------------------------------------------------
1 | /JPEGImages/2007_000032.jpg /SegmentationClassAug/2007_000032.png
2 | /JPEGImages/2007_000039.jpg /SegmentationClassAug/2007_000039.png
3 | /JPEGImages/2007_000063.jpg /SegmentationClassAug/2007_000063.png
4 | /JPEGImages/2007_000068.jpg /SegmentationClassAug/2007_000068.png
5 | /JPEGImages/2007_000121.jpg /SegmentationClassAug/2007_000121.png
6 | /JPEGImages/2007_000170.jpg /SegmentationClassAug/2007_000170.png
7 | /JPEGImages/2007_000241.jpg /SegmentationClassAug/2007_000241.png
8 | /JPEGImages/2007_000243.jpg /SegmentationClassAug/2007_000243.png
9 | /JPEGImages/2007_000250.jpg /SegmentationClassAug/2007_000250.png
10 | /JPEGImages/2007_000256.jpg /SegmentationClassAug/2007_000256.png
11 | /JPEGImages/2007_000333.jpg /SegmentationClassAug/2007_000333.png
12 | /JPEGImages/2007_000363.jpg /SegmentationClassAug/2007_000363.png
13 | /JPEGImages/2007_000364.jpg /SegmentationClassAug/2007_000364.png
14 | /JPEGImages/2007_000392.jpg /SegmentationClassAug/2007_000392.png
15 | /JPEGImages/2007_000480.jpg /SegmentationClassAug/2007_000480.png
16 | /JPEGImages/2007_000504.jpg /SegmentationClassAug/2007_000504.png
17 | /JPEGImages/2007_000515.jpg /SegmentationClassAug/2007_000515.png
18 | /JPEGImages/2007_000528.jpg /SegmentationClassAug/2007_000528.png
19 | /JPEGImages/2007_000549.jpg /SegmentationClassAug/2007_000549.png
20 | /JPEGImages/2007_000584.jpg /SegmentationClassAug/2007_000584.png
21 | /JPEGImages/2007_000645.jpg /SegmentationClassAug/2007_000645.png
22 | /JPEGImages/2007_000648.jpg /SegmentationClassAug/2007_000648.png
23 | /JPEGImages/2007_000713.jpg /SegmentationClassAug/2007_000713.png
24 | /JPEGImages/2007_000720.jpg /SegmentationClassAug/2007_000720.png
25 | /JPEGImages/2007_000733.jpg /SegmentationClassAug/2007_000733.png
26 | /JPEGImages/2007_000738.jpg /SegmentationClassAug/2007_000738.png
27 | /JPEGImages/2007_000768.jpg /SegmentationClassAug/2007_000768.png
28 | /JPEGImages/2007_000793.jpg /SegmentationClassAug/2007_000793.png
29 | /JPEGImages/2007_000822.jpg /SegmentationClassAug/2007_000822.png
30 | /JPEGImages/2007_000836.jpg /SegmentationClassAug/2007_000836.png
31 | /JPEGImages/2007_000876.jpg /SegmentationClassAug/2007_000876.png
32 | /JPEGImages/2007_000904.jpg /SegmentationClassAug/2007_000904.png
33 | /JPEGImages/2007_001027.jpg /SegmentationClassAug/2007_001027.png
34 | /JPEGImages/2007_001073.jpg /SegmentationClassAug/2007_001073.png
35 | /JPEGImages/2007_001149.jpg /SegmentationClassAug/2007_001149.png
36 | /JPEGImages/2007_001185.jpg /SegmentationClassAug/2007_001185.png
37 | /JPEGImages/2007_001225.jpg /SegmentationClassAug/2007_001225.png
38 | /JPEGImages/2007_001340.jpg /SegmentationClassAug/2007_001340.png
39 | /JPEGImages/2007_001397.jpg /SegmentationClassAug/2007_001397.png
40 | /JPEGImages/2007_001416.jpg /SegmentationClassAug/2007_001416.png
41 | /JPEGImages/2007_001420.jpg /SegmentationClassAug/2007_001420.png
42 | /JPEGImages/2007_001439.jpg /SegmentationClassAug/2007_001439.png
43 | /JPEGImages/2007_001487.jpg /SegmentationClassAug/2007_001487.png
44 | /JPEGImages/2007_001595.jpg /SegmentationClassAug/2007_001595.png
45 | /JPEGImages/2007_001602.jpg /SegmentationClassAug/2007_001602.png
46 | /JPEGImages/2007_001609.jpg /SegmentationClassAug/2007_001609.png
47 | /JPEGImages/2007_001698.jpg /SegmentationClassAug/2007_001698.png
48 | /JPEGImages/2007_001704.jpg /SegmentationClassAug/2007_001704.png
49 | /JPEGImages/2007_001709.jpg /SegmentationClassAug/2007_001709.png
50 | /JPEGImages/2007_001724.jpg /SegmentationClassAug/2007_001724.png
51 | /JPEGImages/2007_001764.jpg /SegmentationClassAug/2007_001764.png
52 | /JPEGImages/2007_001825.jpg /SegmentationClassAug/2007_001825.png
53 | /JPEGImages/2007_001834.jpg /SegmentationClassAug/2007_001834.png
54 | /JPEGImages/2007_001857.jpg /SegmentationClassAug/2007_001857.png
55 | /JPEGImages/2007_001872.jpg /SegmentationClassAug/2007_001872.png
56 | /JPEGImages/2007_001901.jpg /SegmentationClassAug/2007_001901.png
57 | /JPEGImages/2007_001917.jpg /SegmentationClassAug/2007_001917.png
58 | /JPEGImages/2007_001960.jpg /SegmentationClassAug/2007_001960.png
59 | /JPEGImages/2007_002024.jpg /SegmentationClassAug/2007_002024.png
60 | /JPEGImages/2007_002055.jpg /SegmentationClassAug/2007_002055.png
61 | /JPEGImages/2007_002088.jpg /SegmentationClassAug/2007_002088.png
62 | /JPEGImages/2007_002099.jpg /SegmentationClassAug/2007_002099.png
63 | /JPEGImages/2007_002105.jpg /SegmentationClassAug/2007_002105.png
64 | /JPEGImages/2007_002107.jpg /SegmentationClassAug/2007_002107.png
65 | /JPEGImages/2007_002120.jpg /SegmentationClassAug/2007_002120.png
66 | /JPEGImages/2007_002142.jpg /SegmentationClassAug/2007_002142.png
67 | /JPEGImages/2007_002198.jpg /SegmentationClassAug/2007_002198.png
68 | /JPEGImages/2007_002212.jpg /SegmentationClassAug/2007_002212.png
69 | /JPEGImages/2007_002216.jpg /SegmentationClassAug/2007_002216.png
70 | /JPEGImages/2007_002227.jpg /SegmentationClassAug/2007_002227.png
71 | /JPEGImages/2007_002234.jpg /SegmentationClassAug/2007_002234.png
72 | /JPEGImages/2007_002273.jpg /SegmentationClassAug/2007_002273.png
73 | /JPEGImages/2007_002281.jpg /SegmentationClassAug/2007_002281.png
74 | /JPEGImages/2007_002293.jpg /SegmentationClassAug/2007_002293.png
75 | /JPEGImages/2007_002361.jpg /SegmentationClassAug/2007_002361.png
76 | /JPEGImages/2007_002368.jpg /SegmentationClassAug/2007_002368.png
77 | /JPEGImages/2007_002370.jpg /SegmentationClassAug/2007_002370.png
78 | /JPEGImages/2007_002403.jpg /SegmentationClassAug/2007_002403.png
79 | /JPEGImages/2007_002462.jpg /SegmentationClassAug/2007_002462.png
80 | /JPEGImages/2007_002488.jpg /SegmentationClassAug/2007_002488.png
81 | /JPEGImages/2007_002545.jpg /SegmentationClassAug/2007_002545.png
82 | /JPEGImages/2007_002611.jpg /SegmentationClassAug/2007_002611.png
83 | /JPEGImages/2007_002639.jpg /SegmentationClassAug/2007_002639.png
84 | /JPEGImages/2007_002668.jpg /SegmentationClassAug/2007_002668.png
85 | /JPEGImages/2007_002669.jpg /SegmentationClassAug/2007_002669.png
86 | /JPEGImages/2007_002760.jpg /SegmentationClassAug/2007_002760.png
87 | /JPEGImages/2007_002789.jpg /SegmentationClassAug/2007_002789.png
88 | /JPEGImages/2007_002845.jpg /SegmentationClassAug/2007_002845.png
89 | /JPEGImages/2007_002895.jpg /SegmentationClassAug/2007_002895.png
90 | /JPEGImages/2007_002896.jpg /SegmentationClassAug/2007_002896.png
91 | /JPEGImages/2007_002914.jpg /SegmentationClassAug/2007_002914.png
92 | /JPEGImages/2007_002953.jpg /SegmentationClassAug/2007_002953.png
93 | /JPEGImages/2007_002954.jpg /SegmentationClassAug/2007_002954.png
94 | /JPEGImages/2007_002967.jpg /SegmentationClassAug/2007_002967.png
95 | /JPEGImages/2007_003000.jpg /SegmentationClassAug/2007_003000.png
96 | /JPEGImages/2007_003178.jpg /SegmentationClassAug/2007_003178.png
97 | /JPEGImages/2007_003189.jpg /SegmentationClassAug/2007_003189.png
98 | /JPEGImages/2007_003190.jpg /SegmentationClassAug/2007_003190.png
99 | /JPEGImages/2007_003207.jpg /SegmentationClassAug/2007_003207.png
100 | /JPEGImages/2007_003251.jpg /SegmentationClassAug/2007_003251.png
101 | /JPEGImages/2007_003267.jpg /SegmentationClassAug/2007_003267.png
102 | /JPEGImages/2007_003286.jpg /SegmentationClassAug/2007_003286.png
103 | /JPEGImages/2007_003330.jpg /SegmentationClassAug/2007_003330.png
104 | /JPEGImages/2007_003451.jpg /SegmentationClassAug/2007_003451.png
105 | /JPEGImages/2007_003525.jpg /SegmentationClassAug/2007_003525.png
106 | /JPEGImages/2007_003565.jpg /SegmentationClassAug/2007_003565.png
107 | /JPEGImages/2007_003593.jpg /SegmentationClassAug/2007_003593.png
108 | /JPEGImages/2007_003604.jpg /SegmentationClassAug/2007_003604.png
109 | /JPEGImages/2007_003668.jpg /SegmentationClassAug/2007_003668.png
110 | /JPEGImages/2007_003715.jpg /SegmentationClassAug/2007_003715.png
111 | /JPEGImages/2007_003778.jpg /SegmentationClassAug/2007_003778.png
112 | /JPEGImages/2007_003788.jpg /SegmentationClassAug/2007_003788.png
113 | /JPEGImages/2007_003815.jpg /SegmentationClassAug/2007_003815.png
114 | /JPEGImages/2007_003876.jpg /SegmentationClassAug/2007_003876.png
115 | /JPEGImages/2007_003889.jpg /SegmentationClassAug/2007_003889.png
116 | /JPEGImages/2007_003910.jpg /SegmentationClassAug/2007_003910.png
117 | /JPEGImages/2007_004003.jpg /SegmentationClassAug/2007_004003.png
118 | /JPEGImages/2007_004009.jpg /SegmentationClassAug/2007_004009.png
119 | /JPEGImages/2007_004065.jpg /SegmentationClassAug/2007_004065.png
120 | /JPEGImages/2007_004081.jpg /SegmentationClassAug/2007_004081.png
121 | /JPEGImages/2007_004166.jpg /SegmentationClassAug/2007_004166.png
122 | /JPEGImages/2007_004423.jpg /SegmentationClassAug/2007_004423.png
123 | /JPEGImages/2007_004459.jpg /SegmentationClassAug/2007_004459.png
124 | /JPEGImages/2007_004481.jpg /SegmentationClassAug/2007_004481.png
125 | /JPEGImages/2007_004500.jpg /SegmentationClassAug/2007_004500.png
126 | /JPEGImages/2007_004537.jpg /SegmentationClassAug/2007_004537.png
127 | /JPEGImages/2007_004627.jpg /SegmentationClassAug/2007_004627.png
128 | /JPEGImages/2007_004663.jpg /SegmentationClassAug/2007_004663.png
129 | /JPEGImages/2007_004705.jpg /SegmentationClassAug/2007_004705.png
130 | /JPEGImages/2007_004707.jpg /SegmentationClassAug/2007_004707.png
131 | /JPEGImages/2007_004768.jpg /SegmentationClassAug/2007_004768.png
132 | /JPEGImages/2007_004810.jpg /SegmentationClassAug/2007_004810.png
133 | /JPEGImages/2007_004830.jpg /SegmentationClassAug/2007_004830.png
134 | /JPEGImages/2007_004841.jpg /SegmentationClassAug/2007_004841.png
135 | /JPEGImages/2007_004948.jpg /SegmentationClassAug/2007_004948.png
136 | /JPEGImages/2007_004951.jpg /SegmentationClassAug/2007_004951.png
137 | /JPEGImages/2007_004988.jpg /SegmentationClassAug/2007_004988.png
138 | /JPEGImages/2007_004998.jpg /SegmentationClassAug/2007_004998.png
139 | /JPEGImages/2007_005043.jpg /SegmentationClassAug/2007_005043.png
140 | /JPEGImages/2007_005124.jpg /SegmentationClassAug/2007_005124.png
141 | /JPEGImages/2007_005130.jpg /SegmentationClassAug/2007_005130.png
142 | /JPEGImages/2007_005210.jpg /SegmentationClassAug/2007_005210.png
143 | /JPEGImages/2007_005212.jpg /SegmentationClassAug/2007_005212.png
144 | /JPEGImages/2007_005248.jpg /SegmentationClassAug/2007_005248.png
145 | /JPEGImages/2007_005262.jpg /SegmentationClassAug/2007_005262.png
146 | /JPEGImages/2007_005264.jpg /SegmentationClassAug/2007_005264.png
147 | /JPEGImages/2007_005266.jpg /SegmentationClassAug/2007_005266.png
148 | /JPEGImages/2007_005273.jpg /SegmentationClassAug/2007_005273.png
149 | /JPEGImages/2007_005314.jpg /SegmentationClassAug/2007_005314.png
150 | /JPEGImages/2007_005360.jpg /SegmentationClassAug/2007_005360.png
151 | /JPEGImages/2007_005647.jpg /SegmentationClassAug/2007_005647.png
152 | /JPEGImages/2007_005688.jpg /SegmentationClassAug/2007_005688.png
153 | /JPEGImages/2007_005797.jpg /SegmentationClassAug/2007_005797.png
154 | /JPEGImages/2007_005878.jpg /SegmentationClassAug/2007_005878.png
155 | /JPEGImages/2007_005902.jpg /SegmentationClassAug/2007_005902.png
156 | /JPEGImages/2007_005951.jpg /SegmentationClassAug/2007_005951.png
157 | /JPEGImages/2007_005989.jpg /SegmentationClassAug/2007_005989.png
158 | /JPEGImages/2007_006066.jpg /SegmentationClassAug/2007_006066.png
159 | /JPEGImages/2007_006134.jpg /SegmentationClassAug/2007_006134.png
160 | /JPEGImages/2007_006136.jpg /SegmentationClassAug/2007_006136.png
161 | /JPEGImages/2007_006151.jpg /SegmentationClassAug/2007_006151.png
162 | /JPEGImages/2007_006212.jpg /SegmentationClassAug/2007_006212.png
163 | /JPEGImages/2007_006254.jpg /SegmentationClassAug/2007_006254.png
164 | /JPEGImages/2007_006281.jpg /SegmentationClassAug/2007_006281.png
165 | /JPEGImages/2007_006303.jpg /SegmentationClassAug/2007_006303.png
166 | /JPEGImages/2007_006317.jpg /SegmentationClassAug/2007_006317.png
167 | /JPEGImages/2007_006400.jpg /SegmentationClassAug/2007_006400.png
168 | /JPEGImages/2007_006409.jpg /SegmentationClassAug/2007_006409.png
169 | /JPEGImages/2007_006445.jpg /SegmentationClassAug/2007_006445.png
170 | /JPEGImages/2007_006490.jpg /SegmentationClassAug/2007_006490.png
171 | /JPEGImages/2007_006530.jpg /SegmentationClassAug/2007_006530.png
172 | /JPEGImages/2007_006581.jpg /SegmentationClassAug/2007_006581.png
173 | /JPEGImages/2007_006585.jpg /SegmentationClassAug/2007_006585.png
174 | /JPEGImages/2007_006605.jpg /SegmentationClassAug/2007_006605.png
175 | /JPEGImages/2007_006641.jpg /SegmentationClassAug/2007_006641.png
176 | /JPEGImages/2007_006660.jpg /SegmentationClassAug/2007_006660.png
177 | /JPEGImages/2007_006673.jpg /SegmentationClassAug/2007_006673.png
178 | /JPEGImages/2007_006699.jpg /SegmentationClassAug/2007_006699.png
179 | /JPEGImages/2007_006704.jpg /SegmentationClassAug/2007_006704.png
180 | /JPEGImages/2007_006803.jpg /SegmentationClassAug/2007_006803.png
181 | /JPEGImages/2007_006832.jpg /SegmentationClassAug/2007_006832.png
182 | /JPEGImages/2007_006865.jpg /SegmentationClassAug/2007_006865.png
183 | /JPEGImages/2007_006899.jpg /SegmentationClassAug/2007_006899.png
184 | /JPEGImages/2007_006900.jpg /SegmentationClassAug/2007_006900.png
185 | /JPEGImages/2007_006944.jpg /SegmentationClassAug/2007_006944.png
186 | /JPEGImages/2007_007003.jpg /SegmentationClassAug/2007_007003.png
187 | /JPEGImages/2007_007021.jpg /SegmentationClassAug/2007_007021.png
188 | /JPEGImages/2007_007048.jpg /SegmentationClassAug/2007_007048.png
189 | /JPEGImages/2007_007098.jpg /SegmentationClassAug/2007_007098.png
190 | /JPEGImages/2007_007230.jpg /SegmentationClassAug/2007_007230.png
191 | /JPEGImages/2007_007250.jpg /SegmentationClassAug/2007_007250.png
192 | /JPEGImages/2007_007355.jpg /SegmentationClassAug/2007_007355.png
193 | /JPEGImages/2007_007387.jpg /SegmentationClassAug/2007_007387.png
194 | /JPEGImages/2007_007398.jpg /SegmentationClassAug/2007_007398.png
195 | /JPEGImages/2007_007415.jpg /SegmentationClassAug/2007_007415.png
196 | /JPEGImages/2007_007432.jpg /SegmentationClassAug/2007_007432.png
197 | /JPEGImages/2007_007480.jpg /SegmentationClassAug/2007_007480.png
198 | /JPEGImages/2007_007481.jpg /SegmentationClassAug/2007_007481.png
199 | /JPEGImages/2007_007523.jpg /SegmentationClassAug/2007_007523.png
200 | /JPEGImages/2007_007530.jpg /SegmentationClassAug/2007_007530.png
201 | /JPEGImages/2007_007585.jpg /SegmentationClassAug/2007_007585.png
202 | /JPEGImages/2007_007591.jpg /SegmentationClassAug/2007_007591.png
203 | /JPEGImages/2007_007621.jpg /SegmentationClassAug/2007_007621.png
204 | /JPEGImages/2007_007726.jpg /SegmentationClassAug/2007_007726.png
205 | /JPEGImages/2007_007772.jpg /SegmentationClassAug/2007_007772.png
206 | /JPEGImages/2007_007773.jpg /SegmentationClassAug/2007_007773.png
207 | /JPEGImages/2007_007783.jpg /SegmentationClassAug/2007_007783.png
208 | /JPEGImages/2007_007878.jpg /SegmentationClassAug/2007_007878.png
209 | /JPEGImages/2007_007890.jpg /SegmentationClassAug/2007_007890.png
210 | /JPEGImages/2007_007902.jpg /SegmentationClassAug/2007_007902.png
211 | /JPEGImages/2007_007908.jpg /SegmentationClassAug/2007_007908.png
212 | /JPEGImages/2007_007930.jpg /SegmentationClassAug/2007_007930.png
213 | /JPEGImages/2007_007947.jpg /SegmentationClassAug/2007_007947.png
214 | /JPEGImages/2007_007948.jpg /SegmentationClassAug/2007_007948.png
215 | /JPEGImages/2007_008085.jpg /SegmentationClassAug/2007_008085.png
216 | /JPEGImages/2007_008140.jpg /SegmentationClassAug/2007_008140.png
217 | /JPEGImages/2007_008142.jpg /SegmentationClassAug/2007_008142.png
218 | /JPEGImages/2007_008203.jpg /SegmentationClassAug/2007_008203.png
219 | /JPEGImages/2007_008219.jpg /SegmentationClassAug/2007_008219.png
220 | /JPEGImages/2007_008307.jpg /SegmentationClassAug/2007_008307.png
221 | /JPEGImages/2007_008403.jpg /SegmentationClassAug/2007_008403.png
222 | /JPEGImages/2007_008468.jpg /SegmentationClassAug/2007_008468.png
223 | /JPEGImages/2007_008526.jpg /SegmentationClassAug/2007_008526.png
224 | /JPEGImages/2007_008571.jpg /SegmentationClassAug/2007_008571.png
225 | /JPEGImages/2007_008575.jpg /SegmentationClassAug/2007_008575.png
226 | /JPEGImages/2007_008764.jpg /SegmentationClassAug/2007_008764.png
227 | /JPEGImages/2007_008821.jpg /SegmentationClassAug/2007_008821.png
228 | /JPEGImages/2007_008927.jpg /SegmentationClassAug/2007_008927.png
229 | /JPEGImages/2007_008945.jpg /SegmentationClassAug/2007_008945.png
230 | /JPEGImages/2007_008948.jpg /SegmentationClassAug/2007_008948.png
231 | /JPEGImages/2007_009052.jpg /SegmentationClassAug/2007_009052.png
232 | /JPEGImages/2007_009082.jpg /SegmentationClassAug/2007_009082.png
233 | /JPEGImages/2007_009216.jpg /SegmentationClassAug/2007_009216.png
234 | /JPEGImages/2007_009295.jpg /SegmentationClassAug/2007_009295.png
235 | /JPEGImages/2007_009322.jpg /SegmentationClassAug/2007_009322.png
236 | /JPEGImages/2007_009435.jpg /SegmentationClassAug/2007_009435.png
237 | /JPEGImages/2007_009436.jpg /SegmentationClassAug/2007_009436.png
238 | /JPEGImages/2007_009464.jpg /SegmentationClassAug/2007_009464.png
239 | /JPEGImages/2007_009527.jpg /SegmentationClassAug/2007_009527.png
240 | /JPEGImages/2007_009550.jpg /SegmentationClassAug/2007_009550.png
241 | /JPEGImages/2007_009594.jpg /SegmentationClassAug/2007_009594.png
242 | /JPEGImages/2007_009605.jpg /SegmentationClassAug/2007_009605.png
243 | /JPEGImages/2007_009630.jpg /SegmentationClassAug/2007_009630.png
244 | /JPEGImages/2007_009665.jpg /SegmentationClassAug/2007_009665.png
245 | /JPEGImages/2007_009709.jpg /SegmentationClassAug/2007_009709.png
246 | /JPEGImages/2007_009779.jpg /SegmentationClassAug/2007_009779.png
247 | /JPEGImages/2007_009788.jpg /SegmentationClassAug/2007_009788.png
248 | /JPEGImages/2007_009832.jpg /SegmentationClassAug/2007_009832.png
249 | /JPEGImages/2007_009889.jpg /SegmentationClassAug/2007_009889.png
250 | /JPEGImages/2007_009899.jpg /SegmentationClassAug/2007_009899.png
251 | /JPEGImages/2008_000002.jpg /SegmentationClassAug/2008_000002.png
252 | /JPEGImages/2008_000015.jpg /SegmentationClassAug/2008_000015.png
253 | /JPEGImages/2008_000019.jpg /SegmentationClassAug/2008_000019.png
254 | /JPEGImages/2008_000023.jpg /SegmentationClassAug/2008_000023.png
255 | /JPEGImages/2008_000043.jpg /SegmentationClassAug/2008_000043.png
256 | /JPEGImages/2008_000053.jpg /SegmentationClassAug/2008_000053.png
257 | /JPEGImages/2008_000059.jpg /SegmentationClassAug/2008_000059.png
258 | /JPEGImages/2008_000066.jpg /SegmentationClassAug/2008_000066.png
259 | /JPEGImages/2008_000067.jpg /SegmentationClassAug/2008_000067.png
260 | /JPEGImages/2008_000070.jpg /SegmentationClassAug/2008_000070.png
261 | /JPEGImages/2008_000078.jpg /SegmentationClassAug/2008_000078.png
262 | /JPEGImages/2008_000084.jpg /SegmentationClassAug/2008_000084.png
263 | /JPEGImages/2008_000089.jpg /SegmentationClassAug/2008_000089.png
264 | /JPEGImages/2008_000093.jpg /SegmentationClassAug/2008_000093.png
265 | /JPEGImages/2008_000115.jpg /SegmentationClassAug/2008_000115.png
266 | /JPEGImages/2008_000128.jpg /SegmentationClassAug/2008_000128.png
267 | /JPEGImages/2008_000133.jpg /SegmentationClassAug/2008_000133.png
268 | /JPEGImages/2008_000145.jpg /SegmentationClassAug/2008_000145.png
269 | /JPEGImages/2008_000154.jpg /SegmentationClassAug/2008_000154.png
270 | /JPEGImages/2008_000188.jpg /SegmentationClassAug/2008_000188.png
271 | /JPEGImages/2008_000191.jpg /SegmentationClassAug/2008_000191.png
272 | /JPEGImages/2008_000194.jpg /SegmentationClassAug/2008_000194.png
273 | /JPEGImages/2008_000196.jpg /SegmentationClassAug/2008_000196.png
274 | /JPEGImages/2008_000227.jpg /SegmentationClassAug/2008_000227.png
275 | /JPEGImages/2008_000272.jpg /SegmentationClassAug/2008_000272.png
276 | /JPEGImages/2008_000273.jpg /SegmentationClassAug/2008_000273.png
277 | /JPEGImages/2008_000274.jpg /SegmentationClassAug/2008_000274.png
278 | /JPEGImages/2008_000287.jpg /SegmentationClassAug/2008_000287.png
279 | /JPEGImages/2008_000305.jpg /SegmentationClassAug/2008_000305.png
280 | /JPEGImages/2008_000321.jpg /SegmentationClassAug/2008_000321.png
281 | /JPEGImages/2008_000335.jpg /SegmentationClassAug/2008_000335.png
282 | /JPEGImages/2008_000397.jpg /SegmentationClassAug/2008_000397.png
283 | /JPEGImages/2008_000491.jpg /SegmentationClassAug/2008_000491.png
284 | /JPEGImages/2008_000564.jpg /SegmentationClassAug/2008_000564.png
285 | /JPEGImages/2008_000703.jpg /SegmentationClassAug/2008_000703.png
286 | /JPEGImages/2008_000790.jpg /SegmentationClassAug/2008_000790.png
287 | /JPEGImages/2008_001077.jpg /SegmentationClassAug/2008_001077.png
288 | /JPEGImages/2008_001225.jpg /SegmentationClassAug/2008_001225.png
289 | /JPEGImages/2008_001336.jpg /SegmentationClassAug/2008_001336.png
290 | /JPEGImages/2008_001405.jpg /SegmentationClassAug/2008_001405.png
291 | /JPEGImages/2008_001626.jpg /SegmentationClassAug/2008_001626.png
292 | /JPEGImages/2008_001744.jpg /SegmentationClassAug/2008_001744.png
293 | /JPEGImages/2008_001813.jpg /SegmentationClassAug/2008_001813.png
294 | /JPEGImages/2008_002005.jpg /SegmentationClassAug/2008_002005.png
295 | /JPEGImages/2008_002153.jpg /SegmentationClassAug/2008_002153.png
296 | /JPEGImages/2008_002204.jpg /SegmentationClassAug/2008_002204.png
297 | /JPEGImages/2008_002292.jpg /SegmentationClassAug/2008_002292.png
298 | /JPEGImages/2008_002372.jpg /SegmentationClassAug/2008_002372.png
299 | /JPEGImages/2008_002418.jpg /SegmentationClassAug/2008_002418.png
300 | /JPEGImages/2008_003579.jpg /SegmentationClassAug/2008_003579.png
301 |
--------------------------------------------------------------------------------
/dataloaders/voc_splits/60_train_supervised.txt:
--------------------------------------------------------------------------------
1 | /JPEGImages/2007_000032.jpg /SegmentationClassAug/2007_000032.png
2 | /JPEGImages/2007_000039.jpg /SegmentationClassAug/2007_000039.png
3 | /JPEGImages/2007_000063.jpg /SegmentationClassAug/2007_000063.png
4 | /JPEGImages/2007_000068.jpg /SegmentationClassAug/2007_000068.png
5 | /JPEGImages/2007_000121.jpg /SegmentationClassAug/2007_000121.png
6 | /JPEGImages/2007_000170.jpg /SegmentationClassAug/2007_000170.png
7 | /JPEGImages/2007_000241.jpg /SegmentationClassAug/2007_000241.png
8 | /JPEGImages/2007_000243.jpg /SegmentationClassAug/2007_000243.png
9 | /JPEGImages/2007_000250.jpg /SegmentationClassAug/2007_000250.png
10 | /JPEGImages/2007_000256.jpg /SegmentationClassAug/2007_000256.png
11 | /JPEGImages/2007_000333.jpg /SegmentationClassAug/2007_000333.png
12 | /JPEGImages/2007_000363.jpg /SegmentationClassAug/2007_000363.png
13 | /JPEGImages/2007_000364.jpg /SegmentationClassAug/2007_000364.png
14 | /JPEGImages/2007_000392.jpg /SegmentationClassAug/2007_000392.png
15 | /JPEGImages/2007_000480.jpg /SegmentationClassAug/2007_000480.png
16 | /JPEGImages/2007_000504.jpg /SegmentationClassAug/2007_000504.png
17 | /JPEGImages/2007_000515.jpg /SegmentationClassAug/2007_000515.png
18 | /JPEGImages/2007_000528.jpg /SegmentationClassAug/2007_000528.png
19 | /JPEGImages/2007_000549.jpg /SegmentationClassAug/2007_000549.png
20 | /JPEGImages/2007_000584.jpg /SegmentationClassAug/2007_000584.png
21 | /JPEGImages/2007_000645.jpg /SegmentationClassAug/2007_000645.png
22 | /JPEGImages/2007_000648.jpg /SegmentationClassAug/2007_000648.png
23 | /JPEGImages/2007_000713.jpg /SegmentationClassAug/2007_000713.png
24 | /JPEGImages/2007_000720.jpg /SegmentationClassAug/2007_000720.png
25 | /JPEGImages/2007_000733.jpg /SegmentationClassAug/2007_000733.png
26 | /JPEGImages/2007_000768.jpg /SegmentationClassAug/2007_000768.png
27 | /JPEGImages/2007_000793.jpg /SegmentationClassAug/2007_000793.png
28 | /JPEGImages/2007_000822.jpg /SegmentationClassAug/2007_000822.png
29 | /JPEGImages/2007_000836.jpg /SegmentationClassAug/2007_000836.png
30 | /JPEGImages/2007_000876.jpg /SegmentationClassAug/2007_000876.png
31 | /JPEGImages/2007_001027.jpg /SegmentationClassAug/2007_001027.png
32 | /JPEGImages/2007_001073.jpg /SegmentationClassAug/2007_001073.png
33 | /JPEGImages/2007_001149.jpg /SegmentationClassAug/2007_001149.png
34 | /JPEGImages/2007_001225.jpg /SegmentationClassAug/2007_001225.png
35 | /JPEGImages/2007_001397.jpg /SegmentationClassAug/2007_001397.png
36 | /JPEGImages/2007_001416.jpg /SegmentationClassAug/2007_001416.png
37 | /JPEGImages/2007_001420.jpg /SegmentationClassAug/2007_001420.png
38 | /JPEGImages/2007_001439.jpg /SegmentationClassAug/2007_001439.png
39 | /JPEGImages/2007_001487.jpg /SegmentationClassAug/2007_001487.png
40 | /JPEGImages/2007_001595.jpg /SegmentationClassAug/2007_001595.png
41 | /JPEGImages/2007_001602.jpg /SegmentationClassAug/2007_001602.png
42 | /JPEGImages/2007_001609.jpg /SegmentationClassAug/2007_001609.png
43 | /JPEGImages/2007_001704.jpg /SegmentationClassAug/2007_001704.png
44 | /JPEGImages/2007_001764.jpg /SegmentationClassAug/2007_001764.png
45 | /JPEGImages/2007_001857.jpg /SegmentationClassAug/2007_001857.png
46 | /JPEGImages/2007_001872.jpg /SegmentationClassAug/2007_001872.png
47 | /JPEGImages/2007_001901.jpg /SegmentationClassAug/2007_001901.png
48 | /JPEGImages/2007_002227.jpg /SegmentationClassAug/2007_002227.png
49 | /JPEGImages/2007_002281.jpg /SegmentationClassAug/2007_002281.png
50 | /JPEGImages/2007_002361.jpg /SegmentationClassAug/2007_002361.png
51 | /JPEGImages/2007_002462.jpg /SegmentationClassAug/2007_002462.png
52 | /JPEGImages/2007_002845.jpg /SegmentationClassAug/2007_002845.png
53 | /JPEGImages/2007_002953.jpg /SegmentationClassAug/2007_002953.png
54 | /JPEGImages/2007_002967.jpg /SegmentationClassAug/2007_002967.png
55 | /JPEGImages/2007_003178.jpg /SegmentationClassAug/2007_003178.png
56 | /JPEGImages/2007_003189.jpg /SegmentationClassAug/2007_003189.png
57 | /JPEGImages/2007_003207.jpg /SegmentationClassAug/2007_003207.png
58 | /JPEGImages/2007_003788.jpg /SegmentationClassAug/2007_003788.png
59 | /JPEGImages/2007_005273.jpg /SegmentationClassAug/2007_005273.png
60 | /JPEGImages/2007_006530.jpg /SegmentationClassAug/2007_006530.png
61 |
--------------------------------------------------------------------------------
/inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import scipy, math
3 | from scipy import ndimage
4 | import cv2
5 | import numpy as np
6 | import sys
7 | import json
8 | import models
9 | import dataloaders
10 | from utils.helpers import colorize_mask
11 | from utils.pallete import get_voc_pallete
12 | from utils import metrics
13 | import torch
14 | import torch.nn as nn
15 | from torchvision import transforms
16 | import torch.nn.functional as F
17 | from torch.utils.data import DataLoader, Dataset
18 | import os
19 | from tqdm import tqdm
20 | from math import ceil
21 | from PIL import Image
22 | from pathlib import Path
23 |
24 |
25 | class testDataset(Dataset):
26 | def __init__(self, images):
27 | mean = [0.485, 0.456, 0.406]
28 | std = [0.229, 0.224, 0.225]
29 | images_path = Path(images)
30 | self.filelist = list(images_path.glob("*.jpg"))
31 | self.to_tensor = transforms.ToTensor()
32 | self.normalize = transforms.Normalize(mean, std)
33 |
34 | def __len__(self):
35 | return len(self.filelist)
36 |
37 | def __getitem__(self, index):
38 | image_path = self.filelist[index]
39 | image_id = str(image_path).split("/")[-1].split(".")[0]
40 | image = Image.open(image_path)
41 | image = self.normalize(self.to_tensor(image))
42 | return image, image_id
43 |
44 | def multi_scale_predict(model, image, scales, num_classes, flip=True):
45 | H, W = (image.size(2), image.size(3))
46 | upsize = (ceil(H / 8) * 8, ceil(W / 8) * 8)
47 | upsample = nn.Upsample(size=upsize, mode='bilinear', align_corners=True)
48 | pad_h, pad_w = upsize[0] - H, upsize[1] - W
49 | image = F.pad(image, pad=(0, pad_w, 0, pad_h), mode='reflect')
50 |
51 | total_predictions = np.zeros((num_classes, image.shape[2], image.shape[3]))
52 |
53 | for scale in scales:
54 | scaled_img = F.interpolate(image, scale_factor=scale, mode='bilinear', align_corners=False)
55 | scaled_prediction = upsample(model(scaled_img))
56 |
57 | if flip:
58 | fliped_img = scaled_img.flip(-1)
59 | fliped_predictions = upsample(model(fliped_img))
60 | scaled_prediction = 0.5 * (fliped_predictions.flip(-1) + scaled_prediction)
61 | total_predictions += scaled_prediction.data.cpu().numpy().squeeze(0)
62 |
63 | total_predictions /= len(scales)
64 | return total_predictions[:, :H, :W]
65 |
66 | def main():
67 | args = parse_arguments()
68 |
69 | # CONFIG
70 | assert args.config
71 | config = json.load(open(args.config))
72 | scales = [0.5, 0.75, 1.0, 1.25, 1.5]
73 |
74 | # DATA
75 | testdataset = testDataset(args.images)
76 | loader = DataLoader(testdataset, batch_size=1, shuffle=False, num_workers=1)
77 | num_classes = 21
78 | palette = get_voc_pallete(num_classes)
79 |
80 | # MODEL
81 | config['model']['supervised'] = True; config['model']['semi'] = False
82 | model = models.CCT(num_classes=num_classes,
83 | conf=config['model'], testing=True)
84 | checkpoint = torch.load(args.model)
85 | model = torch.nn.DataParallel(model)
86 | try:
87 | model.load_state_dict(checkpoint['state_dict'], strict=True)
88 | except Exception as e:
89 | print(f'Some modules are missing: {e}')
90 | model.load_state_dict(checkpoint['state_dict'], strict=False)
91 | model.eval()
92 | model.cuda()
93 |
94 | if args.save and not os.path.exists('outputs'):
95 | os.makedirs('outputs')
96 |
97 | # LOOP OVER THE DATA
98 | tbar = tqdm(loader, ncols=100)
99 | total_inter, total_union, total_correct, total_label = 0, 0, 0, 0
100 | labels, predictions = [], []
101 |
102 | for index, data in enumerate(tbar):
103 | image, image_id = data
104 | image = image.cuda()
105 |
106 | # PREDICT
107 | with torch.no_grad():
108 | output = multi_scale_predict(model, image, scales, num_classes)
109 | prediction = np.asarray(np.argmax(output, axis=0), dtype=np.uint8)
110 |
111 | # SAVE RESULTS
112 | prediction_im = colorize_mask(prediction, palette)
113 | prediction_im.save('outputs/'+image_id[0]+'.png')
114 |
115 | def parse_arguments():
116 | parser = argparse.ArgumentParser(description='PyTorch Training')
117 | parser.add_argument('--config', default='configs/config.json',type=str,
118 | help='Path to the config file')
119 | parser.add_argument( '--model', default=None, type=str,
120 | help='Path to the trained .pth model')
121 | parser.add_argument( '--save', action='store_true', help='Save images')
122 | parser.add_argument('--images', default="/home/yassine/Datasets/vision/PascalVoc/VOC/VOCdevkit/VOC2012/test_images", type=str,
123 | help='Test images for Pascal VOC')
124 | args = parser.parse_args()
125 | return args
126 |
127 | if __name__ == '__main__':
128 | main()
129 |
130 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | from .model import CCT
--------------------------------------------------------------------------------
/models/backbones/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yassouali/CCT/65d4e5bd4501ae3c564493d0ce18924a908639f5/models/backbones/__init__.py
--------------------------------------------------------------------------------
/models/backbones/get_pretrained_model.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | FILENAME="models/backbones/pretrained/3x3resnet50-imagenet.pth"
4 |
5 | mkdir -p models/backbones/pretrained
6 | wget https://github.com/yassouali/CCT/releases/download/v0.1/3x3resnet50-imagenet.pth -O $FILENAME
7 |
--------------------------------------------------------------------------------
/models/backbones/module_helper.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 | # Author: Donny You (youansheng@gmail.com)
4 |
5 |
6 | import os
7 | import torch
8 | import torch.nn as nn
9 | import torch.nn.functional as F
10 |
11 | try:
12 | from urllib import urlretrieve
13 | except ImportError:
14 | from urllib.request import urlretrieve
15 |
16 | class FixedBatchNorm(nn.BatchNorm2d):
17 | def forward(self, input):
18 | return F.batch_norm(input, self.running_mean, self.running_var, self.weight, self.bias, training=False, eps=self.eps)
19 |
20 | class ModuleHelper(object):
21 |
22 | @staticmethod
23 | def BNReLU(num_features, norm_type=None, **kwargs):
24 | if norm_type == 'batchnorm':
25 | return nn.Sequential(
26 | nn.BatchNorm2d(num_features, **kwargs),
27 | nn.ReLU()
28 | )
29 | elif norm_type == 'encsync_batchnorm':
30 | from encoding.nn import BatchNorm2d
31 | return nn.Sequential(
32 | BatchNorm2d(num_features, **kwargs),
33 | nn.ReLU()
34 | )
35 | elif norm_type == 'instancenorm':
36 | return nn.Sequential(
37 | nn.InstanceNorm2d(num_features, **kwargs),
38 | nn.ReLU()
39 | )
40 | elif norm_type == 'fixed_batchnorm':
41 | return nn.Sequential(
42 | FixedBatchNorm(num_features, **kwargs),
43 | nn.ReLU()
44 | )
45 | else:
46 | raise ValueError('Not support BN type: {}.'.format(norm_type))
47 |
48 | @staticmethod
49 | def BatchNorm3d(norm_type=None, ret_cls=False):
50 | if norm_type == 'batchnorm':
51 | return nn.BatchNorm3d
52 | elif norm_type == 'encsync_batchnorm':
53 | from encoding.nn import BatchNorm3d
54 | return BatchNorm3d
55 | elif norm_type == 'instancenorm':
56 | return nn.InstanceNorm3d
57 | else:
58 | raise ValueError('Not support BN type: {}.'.format(norm_type))
59 |
60 | @staticmethod
61 | def BatchNorm2d(norm_type=None, ret_cls=False):
62 | if norm_type == 'batchnorm':
63 | return nn.BatchNorm2d
64 | elif norm_type == 'encsync_batchnorm':
65 | from encoding.nn import BatchNorm2d
66 | return BatchNorm2d
67 |
68 | elif norm_type == 'instancenorm':
69 | return nn.InstanceNorm2d
70 | else:
71 | raise ValueError('Not support BN type: {}.'.format(norm_type))
72 |
73 | @staticmethod
74 | def BatchNorm1d(norm_type=None, ret_cls=False):
75 | if norm_type == 'batchnorm':
76 | return nn.BatchNorm1d
77 | elif norm_type == 'encsync_batchnorm':
78 | from encoding.nn import BatchNorm1d
79 | return BatchNorm1d
80 | elif norm_type == 'instancenorm':
81 | return nn.InstanceNorm1d
82 | else:
83 | raise ValueError('Not support BN type: {}.'.format(norm_type))
84 |
85 | @staticmethod
86 | def load_model(model, pretrained=None, all_match=True, map_location='cpu'):
87 | if pretrained is None:
88 | return model
89 |
90 | if not os.path.exists(pretrained):
91 | print('{} not exists.'.format(pretrained))
92 | return model
93 |
94 | print('Loading pretrained model:{}'.format(pretrained))
95 | if all_match:
96 | pretrained_dict = torch.load(pretrained, map_location=map_location)
97 | model_dict = model.state_dict()
98 | load_dict = dict()
99 | for k, v in pretrained_dict.items():
100 | if 'prefix.{}'.format(k) in model_dict:
101 | load_dict['prefix.{}'.format(k)] = v
102 | else:
103 | load_dict[k] = v
104 | model.load_state_dict(load_dict)
105 |
106 | else:
107 | pretrained_dict = torch.load(pretrained)
108 | model_dict = model.state_dict()
109 | load_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
110 | print('Matched Keys: {}'.format(load_dict.keys()))
111 | model_dict.update(load_dict)
112 | model.load_state_dict(model_dict)
113 |
114 | return model
115 |
116 | @staticmethod
117 | def load_url(url, map_location=None):
118 | model_dir = os.path.join('~', '.TorchCV', 'model')
119 | if not os.path.exists(model_dir):
120 | os.makedirs(model_dir)
121 |
122 | filename = url.split('/')[-1]
123 | cached_file = os.path.join(model_dir, filename)
124 | if not os.path.exists(cached_file):
125 | print('Downloading: "{}" to {}\n'.format(url, cached_file))
126 | urlretrieve(url, cached_file)
127 |
128 | print('Loading pretrained model:{}'.format(cached_file))
129 | return torch.load(cached_file, map_location=map_location)
130 |
131 | @staticmethod
132 | def constant_init(module, val, bias=0):
133 | nn.init.constant_(module.weight, val)
134 | if hasattr(module, 'bias') and module.bias is not None:
135 | nn.init.constant_(module.bias, bias)
136 |
137 | @staticmethod
138 | def xavier_init(module, gain=1, bias=0, distribution='normal'):
139 | assert distribution in ['uniform', 'normal']
140 | if distribution == 'uniform':
141 | nn.init.xavier_uniform_(module.weight, gain=gain)
142 | else:
143 | nn.init.xavier_normal_(module.weight, gain=gain)
144 | if hasattr(module, 'bias') and module.bias is not None:
145 | nn.init.constant_(module.bias, bias)
146 |
147 | @staticmethod
148 | def normal_init(module, mean=0, std=1, bias=0):
149 | nn.init.normal_(module.weight, mean, std)
150 | if hasattr(module, 'bias') and module.bias is not None:
151 | nn.init.constant_(module.bias, bias)
152 |
153 | @staticmethod
154 | def uniform_init(module, a=0, b=1, bias=0):
155 | nn.init.uniform_(module.weight, a, b)
156 | if hasattr(module, 'bias') and module.bias is not None:
157 | nn.init.constant_(module.bias, bias)
158 |
159 | @staticmethod
160 | def kaiming_init(module,
161 | mode='fan_in',
162 | nonlinearity='leaky_relu',
163 | bias=0,
164 | distribution='normal'):
165 | assert distribution in ['uniform', 'normal']
166 | if distribution == 'uniform':
167 | nn.init.kaiming_uniform_(
168 | module.weight, mode=mode, nonlinearity=nonlinearity)
169 | else:
170 | nn.init.kaiming_normal_(
171 | module.weight, mode=mode, nonlinearity=nonlinearity)
172 | if hasattr(module, 'bias') and module.bias is not None:
173 | nn.init.constant_(module.bias, bias)
174 |
175 |
--------------------------------------------------------------------------------
/models/backbones/resnet_backbone.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 | # Author: Donny You(youansheng@gmail.com)
4 |
5 |
6 | import torch.nn as nn
7 | from models.backbones.resnet_models import *
8 |
9 |
10 | class NormalResnetBackbone(nn.Module):
11 | def __init__(self, orig_resnet):
12 | super(NormalResnetBackbone, self).__init__()
13 |
14 | self.num_features = 2048
15 | # take pretrained resnet, except AvgPool and FC
16 | self.prefix = orig_resnet.prefix
17 | self.maxpool = orig_resnet.maxpool
18 | self.layer1 = orig_resnet.layer1
19 | self.layer2 = orig_resnet.layer2
20 | self.layer3 = orig_resnet.layer3
21 | self.layer4 = orig_resnet.layer4
22 |
23 | def get_num_features(self):
24 | return self.num_features
25 |
26 | def forward(self, x):
27 | tuple_features = list()
28 | x = self.prefix(x)
29 | x = self.maxpool(x)
30 | x = self.layer1(x)
31 | tuple_features.append(x)
32 | x = self.layer2(x)
33 | tuple_features.append(x)
34 | x = self.layer3(x)
35 | tuple_features.append(x)
36 | x = self.layer4(x)
37 | tuple_features.append(x)
38 |
39 | return tuple_features
40 |
41 |
42 | class DilatedResnetBackbone(nn.Module):
43 | def __init__(self, orig_resnet, dilate_scale=8, multi_grid=(1, 2, 4)):
44 | super(DilatedResnetBackbone, self).__init__()
45 |
46 | self.num_features = 2048
47 | from functools import partial
48 |
49 | if dilate_scale == 8:
50 | orig_resnet.layer3.apply(partial(self._nostride_dilate, dilate=2))
51 | if multi_grid is None:
52 | orig_resnet.layer4.apply(partial(self._nostride_dilate, dilate=4))
53 | else:
54 | for i, r in enumerate(multi_grid):
55 | orig_resnet.layer4[i].apply(partial(self._nostride_dilate, dilate=int(4 * r)))
56 |
57 | elif dilate_scale == 16:
58 | if multi_grid is None:
59 | orig_resnet.layer4.apply(partial(self._nostride_dilate, dilate=2))
60 | else:
61 | for i, r in enumerate(multi_grid):
62 | orig_resnet.layer4[i].apply(partial(self._nostride_dilate, dilate=int(2 * r)))
63 |
64 | # Take pretrained resnet, except AvgPool and FC
65 | self.prefix = orig_resnet.prefix
66 | self.maxpool = orig_resnet.maxpool
67 | self.layer1 = orig_resnet.layer1
68 | self.layer2 = orig_resnet.layer2
69 | self.layer3 = orig_resnet.layer3
70 | self.layer4 = orig_resnet.layer4
71 |
72 | def _nostride_dilate(self, m, dilate):
73 | classname = m.__class__.__name__
74 | if classname.find('Conv') != -1:
75 | # the convolution with stride
76 | if m.stride == (2, 2):
77 | m.stride = (1, 1)
78 | if m.kernel_size == (3, 3):
79 | m.dilation = (dilate // 2, dilate // 2)
80 | m.padding = (dilate // 2, dilate // 2)
81 | # other convoluions
82 | else:
83 | if m.kernel_size == (3, 3):
84 | m.dilation = (dilate, dilate)
85 | m.padding = (dilate, dilate)
86 |
87 | def get_num_features(self):
88 | return self.num_features
89 |
90 | def forward(self, x):
91 | tuple_features = list()
92 | x = self.prefix(x)
93 | x = self.maxpool(x)
94 |
95 | x = self.layer1(x)
96 | tuple_features.append(x)
97 | x = self.layer2(x)
98 | tuple_features.append(x)
99 | x = self.layer3(x)
100 | tuple_features.append(x)
101 | x = self.layer4(x)
102 | tuple_features.append(x)
103 |
104 | return tuple_features
105 |
106 |
107 | def ResNetBackbone(backbone=None, pretrained=None, multi_grid=None, norm_type='batchnorm'):
108 | arch = backbone
109 | if arch == 'resnet34':
110 | orig_resnet = resnet34(pretrained=pretrained)
111 | arch_net = NormalResnetBackbone(orig_resnet)
112 | arch_net.num_features = 512
113 |
114 | elif arch == 'resnet34_dilated8':
115 | orig_resnet = resnet34(pretrained=pretrained)
116 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=8, multi_grid=multi_grid)
117 | arch_net.num_features = 512
118 |
119 | elif arch == 'resnet34_dilated16':
120 | orig_resnet = resnet34(pretrained=pretrained)
121 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=16, multi_grid=multi_grid)
122 | arch_net.num_features = 512
123 |
124 | elif arch == 'resnet50':
125 | orig_resnet = resnet50(pretrained=pretrained)
126 | arch_net = NormalResnetBackbone(orig_resnet)
127 |
128 | elif arch == 'resnet50_dilated8':
129 | orig_resnet = resnet50(pretrained=pretrained)
130 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=8, multi_grid=multi_grid)
131 |
132 | elif arch == 'resnet50_dilated16':
133 | orig_resnet = resnet50(pretrained=pretrained)
134 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=16, multi_grid=multi_grid)
135 |
136 | elif arch == 'deepbase_resnet50':
137 | if pretrained:
138 | pretrained = 'models/backbones/pretrained/3x3resnet50-imagenet.pth'
139 | orig_resnet = deepbase_resnet50(pretrained=pretrained)
140 | arch_net = NormalResnetBackbone(orig_resnet)
141 |
142 | elif arch == 'deepbase_resnet50_dilated8':
143 | if pretrained:
144 | pretrained = 'models/backbones/pretrained/3x3resnet50-imagenet.pth'
145 | orig_resnet = deepbase_resnet50(pretrained=pretrained)
146 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=8, multi_grid=multi_grid)
147 |
148 | elif arch == 'deepbase_resnet50_dilated16':
149 | orig_resnet = deepbase_resnet50(pretrained=pretrained)
150 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=16, multi_grid=multi_grid)
151 |
152 | elif arch == 'resnet101':
153 | orig_resnet = resnet101(pretrained=pretrained)
154 | arch_net = NormalResnetBackbone(orig_resnet)
155 |
156 | elif arch == 'resnet101_dilated8':
157 | orig_resnet = resnet101(pretrained=pretrained)
158 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=8, multi_grid=multi_grid)
159 |
160 | elif arch == 'resnet101_dilated16':
161 | orig_resnet = resnet101(pretrained=pretrained)
162 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=16, multi_grid=multi_grid)
163 |
164 | elif arch == 'deepbase_resnet101':
165 | orig_resnet = deepbase_resnet101(pretrained=pretrained)
166 | arch_net = NormalResnetBackbone(orig_resnet)
167 |
168 | elif arch == 'deepbase_resnet101_dilated8':
169 | if pretrained:
170 | pretrained = 'models/backbones/pretrained/3x3resnet101-imagenet.pth'
171 | orig_resnet = deepbase_resnet101(pretrained=pretrained)
172 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=8, multi_grid=multi_grid)
173 |
174 | elif arch == 'deepbase_resnet101_dilated16':
175 | orig_resnet = deepbase_resnet101(pretrained=pretrained)
176 | arch_net = DilatedResnetBackbone(orig_resnet, dilate_scale=16, multi_grid=multi_grid)
177 |
178 | else:
179 | raise Exception('Architecture undefined!')
180 |
181 | return arch_net
182 |
--------------------------------------------------------------------------------
/models/backbones/resnet_models.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding:utf-8 -*-
3 | # Author: Donny You(youansheng@gmail.com)
4 |
5 |
6 | import math
7 | import torch.nn as nn
8 | from collections import OrderedDict
9 |
10 | from models.backbones.module_helper import ModuleHelper
11 |
12 |
13 | model_urls = {
14 | 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
15 | 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
16 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
17 | 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
18 | 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
19 | }
20 |
21 |
22 | def conv3x3(in_planes, out_planes, stride=1):
23 | "3x3 convolution with padding"
24 | return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
25 | padding=1, bias=False)
26 |
27 |
28 | class BasicBlock(nn.Module):
29 | expansion = 1
30 |
31 | def __init__(self, inplanes, planes, stride=1, downsample=None, norm_type=None):
32 | super(BasicBlock, self).__init__()
33 | self.conv1 = conv3x3(inplanes, planes, stride)
34 | self.bn1 = ModuleHelper.BatchNorm2d(norm_type=norm_type)(planes)
35 | self.relu = nn.ReLU(inplace=True)
36 | self.conv2 = conv3x3(planes, planes)
37 | self.bn2 = ModuleHelper.BatchNorm2d(norm_type=norm_type)(planes)
38 | self.downsample = downsample
39 | self.stride = stride
40 |
41 | def forward(self, x):
42 | residual = x
43 |
44 | out = self.conv1(x)
45 | out = self.bn1(out)
46 | out = self.relu(out)
47 |
48 | out = self.conv2(out)
49 | out = self.bn2(out)
50 |
51 | if self.downsample is not None:
52 | residual = self.downsample(x)
53 |
54 | out += residual
55 | out = self.relu(out)
56 |
57 | return out
58 |
59 |
60 | class Bottleneck(nn.Module):
61 | expansion = 4
62 |
63 | def __init__(self, inplanes, planes, stride=1, downsample=None, norm_type=None):
64 | super(Bottleneck, self).__init__()
65 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
66 | self.bn1 = ModuleHelper.BatchNorm2d(norm_type=norm_type)(planes)
67 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
68 | padding=1, bias=False)
69 | self.bn2 = ModuleHelper.BatchNorm2d(norm_type=norm_type)(planes)
70 | self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
71 | self.bn3 = ModuleHelper.BatchNorm2d(norm_type=norm_type)(planes * 4)
72 | self.relu = nn.ReLU(inplace=True)
73 | self.downsample = downsample
74 | self.stride = stride
75 |
76 | def forward(self, x):
77 | residual = x
78 |
79 | out = self.conv1(x)
80 | out = self.bn1(out)
81 | out = self.relu(out)
82 |
83 | out = self.conv2(out)
84 | out = self.bn2(out)
85 | out = self.relu(out)
86 |
87 | out = self.conv3(out)
88 | out = self.bn3(out)
89 |
90 | if self.downsample is not None:
91 | residual = self.downsample(x)
92 |
93 | out += residual
94 | out = self.relu(out)
95 |
96 | return out
97 |
98 |
99 | class ResNet(nn.Module):
100 |
101 | def __init__(self, block, layers, num_classes=1000, deep_base=False, norm_type=None):
102 | super(ResNet, self).__init__()
103 | self.inplanes = 128 if deep_base else 64
104 | if deep_base:
105 | self.prefix = nn.Sequential(OrderedDict([
106 | ('conv1', nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)),
107 | ('bn1', ModuleHelper.BatchNorm2d(norm_type=norm_type)(64)),
108 | ('relu1', nn.ReLU(inplace=False)),
109 | ('conv2', nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False)),
110 | ('bn2', ModuleHelper.BatchNorm2d(norm_type=norm_type)(64)),
111 | ('relu2', nn.ReLU(inplace=False)),
112 | ('conv3', nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=False)),
113 | ('bn3', ModuleHelper.BatchNorm2d(norm_type=norm_type)(self.inplanes)),
114 | ('relu3', nn.ReLU(inplace=False))]
115 | ))
116 | else:
117 | self.prefix = nn.Sequential(OrderedDict([
118 | ('conv1', nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)),
119 | ('bn1', ModuleHelper.BatchNorm2d(norm_type=norm_type)(self.inplanes)),
120 | ('relu', nn.ReLU(inplace=False))]
121 | ))
122 |
123 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False) # change.
124 |
125 | self.layer1 = self._make_layer(block, 64, layers[0], norm_type=norm_type)
126 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2, norm_type=norm_type)
127 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2, norm_type=norm_type)
128 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2, norm_type=norm_type)
129 | self.avgpool = nn.AvgPool2d(7, stride=1)
130 | self.fc = nn.Linear(512 * block.expansion, num_classes)
131 |
132 | for m in self.modules():
133 | if isinstance(m, nn.Conv2d):
134 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
135 | m.weight.data.normal_(0, math.sqrt(2. / n))
136 | elif isinstance(m, ModuleHelper.BatchNorm2d(norm_type=norm_type, ret_cls=True)):
137 | m.weight.data.fill_(1)
138 | m.bias.data.zero_()
139 |
140 | def _make_layer(self, block, planes, blocks, stride=1, norm_type=None):
141 | downsample = None
142 | if stride != 1 or self.inplanes != planes * block.expansion:
143 | downsample = nn.Sequential(
144 | nn.Conv2d(self.inplanes, planes * block.expansion,
145 | kernel_size=1, stride=stride, bias=False),
146 | ModuleHelper.BatchNorm2d(norm_type=norm_type)(planes * block.expansion),
147 | )
148 |
149 | layers = []
150 | layers.append(block(self.inplanes, planes, stride, downsample, norm_type=norm_type))
151 | self.inplanes = planes * block.expansion
152 | for i in range(1, blocks):
153 | layers.append(block(self.inplanes, planes, norm_type=norm_type))
154 |
155 | return nn.Sequential(*layers)
156 |
157 | def forward(self, x):
158 | x = self.prefix(x)
159 | x = self.maxpool(x)
160 |
161 | x = self.layer1(x)
162 | x = self.layer2(x)
163 | x = self.layer3(x)
164 | x = self.layer4(x)
165 |
166 | x = self.avgpool(x)
167 | x = x.view(x.size(0), -1)
168 | x = self.fc(x)
169 |
170 | return x
171 |
172 |
173 | def resnet18(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
174 | """Constructs a ResNet-18 model.
175 | Args:
176 | pretrained (bool): If True, returns a model pre-trained on Places
177 | norm_type (str): choose norm type
178 | """
179 | model = ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes, deep_base=False, norm_type=norm_type)
180 | model = ModuleHelper.load_model(model, pretrained=pretrained)
181 | return model
182 |
183 | def deepbase_resnet18(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
184 | """Constructs a ResNet-18 model.
185 | Args:
186 | pretrained (bool): If True, returns a model pre-trained on Places
187 | """
188 | model = ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes, deep_base=True, norm_type=norm_type)
189 | model = ModuleHelper.load_model(model, pretrained=pretrained)
190 | return model
191 |
192 | def resnet34(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
193 | """Constructs a ResNet-34 model.
194 | Args:
195 | pretrained (bool): If True, returns a model pre-trained on Places
196 | """
197 | model = ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, deep_base=False, norm_type=norm_type)
198 | model = ModuleHelper.load_model(model, pretrained=pretrained)
199 | return model
200 |
201 | def deepbase_resnet34(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
202 | """Constructs a ResNet-34 model.
203 | Args:
204 | pretrained (bool): If True, returns a model pre-trained on Places
205 | """
206 | model = ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, deep_base=True, norm_type=norm_type)
207 | model = ModuleHelper.load_model(model, pretrained=pretrained)
208 | return model
209 |
210 | def resnet50(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
211 | """Constructs a ResNet-50 model.
212 | Args:
213 | pretrained (bool): If True, returns a model pre-trained on Places
214 | """
215 | model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, deep_base=False, norm_type=norm_type)
216 | model = ModuleHelper.load_model(model, pretrained=pretrained)
217 | return model
218 |
219 | def deepbase_resnet50(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
220 | """Constructs a ResNet-50 model.
221 | Args:
222 | pretrained (bool): If True, returns a model pre-trained on Places
223 | """
224 | model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, deep_base=True, norm_type=norm_type)
225 | model = ModuleHelper.load_model(model, pretrained=pretrained)
226 | return model
227 |
228 | def resnet101(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
229 | """Constructs a ResNet-101 model.
230 | Args:
231 | pretrained (bool): If True, returns a model pre-trained on Places
232 | """
233 | model = ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, deep_base=False, norm_type=norm_type)
234 | model = ModuleHelper.load_model(model, pretrained=pretrained)
235 | return model
236 |
237 | def deepbase_resnet101(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
238 | """Constructs a ResNet-101 model.
239 | Args:
240 | pretrained (bool): If True, returns a model pre-trained on Places
241 | """
242 | model = ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, deep_base=True, norm_type=norm_type)
243 | model = ModuleHelper.load_model(model, pretrained=pretrained)
244 | return model
245 |
246 | def resnet152(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
247 | """Constructs a ResNet-152 model.
248 |
249 | Args:
250 | pretrained (bool): If True, returns a model pre-trained on Places
251 | """
252 | model = ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes, deep_base=False, norm_type=norm_type)
253 | model = ModuleHelper.load_model(model, pretrained=pretrained)
254 | return model
255 |
256 | def deepbase_resnet152(num_classes=1000, pretrained=None, norm_type='batchnorm', **kwargs):
257 | """Constructs a ResNet-152 model.
258 |
259 | Args:
260 | pretrained (bool): If True, returns a model pre-trained on Places
261 | """
262 | model = ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes, deep_base=True, norm_type=norm_type)
263 | model = ModuleHelper.load_model(model, pretrained=pretrained)
264 | return model
265 |
--------------------------------------------------------------------------------
/models/decoders.py:
--------------------------------------------------------------------------------
1 | import math , time
2 | import torch
3 | import torch.nn.functional as F
4 | from torch import nn
5 | from utils.helpers import initialize_weights
6 | from itertools import chain
7 | import contextlib
8 | import random
9 | import numpy as np
10 | import cv2
11 | from torch.distributions.uniform import Uniform
12 |
13 |
14 | def icnr(x, scale=2, init=nn.init.kaiming_normal_):
15 | """
16 | Checkerboard artifact free sub-pixel convolution
17 | https://arxiv.org/abs/1707.02937
18 | """
19 | ni,nf,h,w = x.shape
20 | ni2 = int(ni/(scale**2))
21 | k = init(torch.zeros([ni2,nf,h,w])).transpose(0, 1)
22 | k = k.contiguous().view(ni2, nf, -1)
23 | k = k.repeat(1, 1, scale**2)
24 | k = k.contiguous().view([nf,ni,h,w]).transpose(0, 1)
25 | x.data.copy_(k)
26 |
27 |
28 | class PixelShuffle(nn.Module):
29 | """
30 | Real-Time Single Image and Video Super-Resolution
31 | https://arxiv.org/abs/1609.05158
32 | """
33 | def __init__(self, n_channels, scale):
34 | super(PixelShuffle, self).__init__()
35 | self.conv = nn.Conv2d(n_channels, n_channels*(scale**2), kernel_size=1)
36 | icnr(self.conv.weight)
37 | self.shuf = nn.PixelShuffle(scale)
38 | self.relu = nn.ReLU(inplace=True)
39 |
40 | def forward(self,x):
41 | x = self.shuf(self.relu(self.conv(x)))
42 | return x
43 |
44 |
45 | def upsample(in_channels, out_channels, upscale, kernel_size=3):
46 | # A series of x 2 upsamling until we get to the upscale we want
47 | layers = []
48 | conv1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
49 | nn.init.kaiming_normal_(conv1x1.weight.data, nonlinearity='relu')
50 | layers.append(conv1x1)
51 | for i in range(int(math.log(upscale, 2))):
52 | layers.append(PixelShuffle(out_channels, scale=2))
53 | return nn.Sequential(*layers)
54 |
55 |
56 | class MainDecoder(nn.Module):
57 | def __init__(self, upscale, conv_in_ch, num_classes):
58 | super(MainDecoder, self).__init__()
59 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
60 |
61 | def forward(self, x):
62 | x = self.upsample(x)
63 | return x
64 |
65 |
66 | class DropOutDecoder(nn.Module):
67 | def __init__(self, upscale, conv_in_ch, num_classes, drop_rate=0.3, spatial_dropout=True):
68 | super(DropOutDecoder, self).__init__()
69 | self.dropout = nn.Dropout2d(p=drop_rate) if spatial_dropout else nn.Dropout(drop_rate)
70 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
71 |
72 | def forward(self, x, _):
73 | x = self.upsample(self.dropout(x))
74 | return x
75 |
76 |
77 | class FeatureDropDecoder(nn.Module):
78 | def __init__(self, upscale, conv_in_ch, num_classes):
79 | super(FeatureDropDecoder, self).__init__()
80 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
81 |
82 | def feature_dropout(self, x):
83 | attention = torch.mean(x, dim=1, keepdim=True)
84 | max_val, _ = torch.max(attention.view(x.size(0), -1), dim=1, keepdim=True)
85 | threshold = max_val * np.random.uniform(0.7, 0.9)
86 | threshold = threshold.view(x.size(0), 1, 1, 1).expand_as(attention)
87 | drop_mask = (attention < threshold).float()
88 | return x.mul(drop_mask)
89 |
90 | def forward(self, x, _):
91 | x = self.feature_dropout(x)
92 | x = self.upsample(x)
93 | return x
94 |
95 |
96 | class FeatureNoiseDecoder(nn.Module):
97 | def __init__(self, upscale, conv_in_ch, num_classes, uniform_range=0.3):
98 | super(FeatureNoiseDecoder, self).__init__()
99 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
100 | self.uni_dist = Uniform(-uniform_range, uniform_range)
101 |
102 | def feature_based_noise(self, x):
103 | noise_vector = self.uni_dist.sample(x.shape[1:]).to(x.device).unsqueeze(0)
104 | x_noise = x.mul(noise_vector) + x
105 | return x_noise
106 |
107 | def forward(self, x, _):
108 | x = self.feature_based_noise(x)
109 | x = self.upsample(x)
110 | return x
111 |
112 |
113 |
114 | def _l2_normalize(d):
115 | # Normalizing per batch axis
116 | d_reshaped = d.view(d.shape[0], -1, *(1 for _ in range(d.dim() - 2)))
117 | d /= torch.norm(d_reshaped, dim=1, keepdim=True) + 1e-8
118 | return d
119 |
120 |
121 | def get_r_adv(x, decoder, it=1, xi=1e-1, eps=10.0):
122 | """
123 | Virtual Adversarial Training
124 | https://arxiv.org/abs/1704.03976
125 | """
126 | x_detached = x.detach()
127 | with torch.no_grad():
128 | pred = F.softmax(decoder(x_detached), dim=1)
129 |
130 | d = torch.rand(x.shape).sub(0.5).to(x.device)
131 | d = _l2_normalize(d)
132 |
133 | for _ in range(it):
134 | d.requires_grad_()
135 | pred_hat = decoder(x_detached + xi * d)
136 | logp_hat = F.log_softmax(pred_hat, dim=1)
137 | adv_distance = F.kl_div(logp_hat, pred, reduction='batchmean')
138 | adv_distance.backward()
139 | d = _l2_normalize(d.grad)
140 | decoder.zero_grad()
141 |
142 | r_adv = d * eps
143 | return r_adv
144 |
145 |
146 | class VATDecoder(nn.Module):
147 | def __init__(self, upscale, conv_in_ch, num_classes, xi=1e-1, eps=10.0, iterations=1):
148 | super(VATDecoder, self).__init__()
149 | self.xi = xi
150 | self.eps = eps
151 | self.it = iterations
152 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
153 |
154 | def forward(self, x, _):
155 | r_adv = get_r_adv(x, self.upsample, self.it, self.xi, self.eps)
156 | x = self.upsample(x + r_adv)
157 | return x
158 |
159 |
160 |
161 | def guided_cutout(output, upscale, resize, erase=0.4, use_dropout=False):
162 | if len(output.shape) == 3:
163 | masks = (output > 0).float()
164 | else:
165 | masks = (output.argmax(1) > 0).float()
166 |
167 | if use_dropout:
168 | p_drop = random.randint(3, 6)/10
169 | maskdroped = (F.dropout(masks, p_drop) > 0).float()
170 | maskdroped = maskdroped + (1 - masks)
171 | maskdroped.unsqueeze_(0)
172 | maskdroped = F.interpolate(maskdroped, size=resize, mode='nearest')
173 |
174 | masks_np = []
175 | for mask in masks:
176 | mask_np = np.uint8(mask.cpu().numpy())
177 | mask_ones = np.ones_like(mask_np)
178 | try: # Version 3.x
179 | _, contours, _ = cv2.findContours(mask_np, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
180 | except: # Version 4.x
181 | contours, _ = cv2.findContours(mask_np, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
182 |
183 | polys = [c.reshape(c.shape[0], c.shape[-1]) for c in contours if c.shape[0] > 50]
184 | for poly in polys:
185 | min_w, max_w = poly[:, 0].min(), poly[:, 0].max()
186 | min_h, max_h = poly[:, 1].min(), poly[:, 1].max()
187 | bb_w, bb_h = max_w-min_w, max_h-min_h
188 | rnd_start_w = random.randint(0, int(bb_w*(1-erase)))
189 | rnd_start_h = random.randint(0, int(bb_h*(1-erase)))
190 | h_start, h_end = min_h+rnd_start_h, min_h+rnd_start_h+int(bb_h*erase)
191 | w_start, w_end = min_w+rnd_start_w, min_w+rnd_start_w+int(bb_w*erase)
192 | mask_ones[h_start:h_end, w_start:w_end] = 0
193 | masks_np.append(mask_ones)
194 | masks_np = np.stack(masks_np)
195 |
196 | maskcut = torch.from_numpy(masks_np).float().unsqueeze_(1)
197 | maskcut = F.interpolate(maskcut, size=resize, mode='nearest')
198 |
199 | if use_dropout:
200 | return maskcut.to(output.device), maskdroped.to(output.device)
201 | return maskcut.to(output.device)
202 |
203 |
204 | class CutOutDecoder(nn.Module):
205 | def __init__(self, upscale, conv_in_ch, num_classes, drop_rate=0.3, spatial_dropout=True, erase=0.4):
206 | super(CutOutDecoder, self).__init__()
207 | self.erase = erase
208 | self.upscale = upscale
209 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
210 |
211 | def forward(self, x, pred=None):
212 | maskcut = guided_cutout(pred, upscale=self.upscale, erase=self.erase, resize=(x.size(2), x.size(3)))
213 | x = x * maskcut
214 | x = self.upsample(x)
215 | return x
216 |
217 |
218 | def guided_masking(x, output, upscale, resize, return_msk_context=True):
219 | if len(output.shape) == 3:
220 | masks_context = (output > 0).float().unsqueeze(1)
221 | else:
222 | masks_context = (output.argmax(1) > 0).float().unsqueeze(1)
223 |
224 | masks_context = F.interpolate(masks_context, size=resize, mode='nearest')
225 |
226 | x_masked_context = masks_context * x
227 | if return_msk_context:
228 | return x_masked_context
229 |
230 | masks_objects = (1 - masks_context)
231 | x_masked_objects = masks_objects * x
232 | return x_masked_objects
233 |
234 |
235 | class ContextMaskingDecoder(nn.Module):
236 | def __init__(self, upscale, conv_in_ch, num_classes):
237 | super(ContextMaskingDecoder, self).__init__()
238 | self.upscale = upscale
239 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
240 |
241 | def forward(self, x, pred=None):
242 | x_masked_context = guided_masking(x, pred, resize=(x.size(2), x.size(3)),
243 | upscale=self.upscale, return_msk_context=True)
244 | x_masked_context = self.upsample(x_masked_context)
245 | return x_masked_context
246 |
247 |
248 | class ObjectMaskingDecoder(nn.Module):
249 | def __init__(self, upscale, conv_in_ch, num_classes):
250 | super(ObjectMaskingDecoder, self).__init__()
251 | self.upscale = upscale
252 | self.upsample = upsample(conv_in_ch, num_classes, upscale=upscale)
253 |
254 | def forward(self, x, pred=None):
255 | x_masked_obj = guided_masking(x, pred, resize=(x.size(2), x.size(3)),
256 | upscale=self.upscale, return_msk_context=False)
257 | x_masked_obj = self.upsample(x_masked_obj)
258 |
259 | return x_masked_obj
260 |
261 |
--------------------------------------------------------------------------------
/models/encoder.py:
--------------------------------------------------------------------------------
1 | from models.backbones.resnet_backbone import ResNetBackbone
2 | from utils.helpers import initialize_weights
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | import os
7 |
8 | resnet50 = {
9 | "path": "models/backbones/pretrained/3x3resnet50-imagenet.pth",
10 | }
11 |
12 | class _PSPModule(nn.Module):
13 | def __init__(self, in_channels, bin_sizes):
14 | super(_PSPModule, self).__init__()
15 |
16 | out_channels = in_channels // len(bin_sizes)
17 | self.stages = nn.ModuleList([self._make_stages(in_channels, out_channels, b_s) for b_s in bin_sizes])
18 | self.bottleneck = nn.Sequential(
19 | nn.Conv2d(in_channels+(out_channels * len(bin_sizes)), out_channels,
20 | kernel_size=3, padding=1, bias=False),
21 | nn.BatchNorm2d(out_channels),
22 | nn.ReLU(inplace=True)
23 | )
24 |
25 | def _make_stages(self, in_channels, out_channels, bin_sz):
26 | prior = nn.AdaptiveAvgPool2d(output_size=bin_sz)
27 | conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
28 | bn = nn.BatchNorm2d(out_channels)
29 | relu = nn.ReLU(inplace=True)
30 | return nn.Sequential(prior, conv, bn, relu)
31 |
32 | def forward(self, features):
33 | h, w = features.size()[2], features.size()[3]
34 | pyramids = [features]
35 | pyramids.extend([F.interpolate(stage(features), size=(h, w), mode='bilinear',
36 | align_corners=False) for stage in self.stages])
37 | output = self.bottleneck(torch.cat(pyramids, dim=1))
38 | return output
39 |
40 |
41 | class Encoder(nn.Module):
42 | def __init__(self, pretrained):
43 | super(Encoder, self).__init__()
44 |
45 | if pretrained and not os.path.isfile(resnet50["path"]):
46 | print("Downloading pretrained resnet (source : https://github.com/donnyyou/torchcv)")
47 | os.system('sh models/backbones/get_pretrained_model.sh')
48 |
49 | model = ResNetBackbone(backbone='deepbase_resnet50_dilated8', pretrained=pretrained)
50 | self.base = nn.Sequential(
51 | nn.Sequential(model.prefix, model.maxpool),
52 | model.layer1,
53 | model.layer2,
54 | model.layer3,
55 | model.layer4
56 | )
57 | self.psp = _PSPModule(2048, bin_sizes=[1, 2, 3, 6])
58 |
59 | def forward(self, x):
60 | x = self.base(x)
61 | x = self.psp(x)
62 | return x
63 |
64 | def get_backbone_params(self):
65 | return self.base.parameters()
66 |
67 | def get_module_params(self):
68 | return self.psp.parameters()
69 |
--------------------------------------------------------------------------------
/models/model.py:
--------------------------------------------------------------------------------
1 | import math, time
2 | from itertools import chain
3 | import torch
4 | import torch.nn.functional as F
5 | from torch import nn
6 | from base import BaseModel
7 | from utils.helpers import set_trainable
8 | from utils.losses import *
9 | from models.decoders import *
10 | from models.encoder import Encoder
11 | from utils.losses import CE_loss
12 |
13 | class CCT(BaseModel):
14 | def __init__(self, num_classes, conf, sup_loss=None, cons_w_unsup=None, ignore_index=None, testing=False,
15 | pretrained=True, use_weak_lables=False, weakly_loss_w=0.4):
16 |
17 | if not testing:
18 | assert (ignore_index is not None) and (sup_loss is not None) and (cons_w_unsup is not None)
19 |
20 | super(CCT, self).__init__()
21 | assert int(conf['supervised']) + int(conf['semi']) == 1, 'one mode only'
22 | if conf['supervised']:
23 | self.mode = 'supervised'
24 | else:
25 | self.mode = 'semi'
26 |
27 | # Supervised and unsupervised losses
28 | self.ignore_index = ignore_index
29 | if conf['un_loss'] == "KL":
30 | self.unsuper_loss = softmax_kl_loss
31 | elif conf['un_loss'] == "MSE":
32 | self.unsuper_loss = softmax_mse_loss
33 | elif conf['un_loss'] == "JS":
34 | self.unsuper_loss = softmax_js_loss
35 | else:
36 | raise ValueError(f"Invalid supervised loss {conf['un_loss']}")
37 |
38 | self.unsup_loss_w = cons_w_unsup
39 | self.sup_loss_w = conf['supervised_w']
40 | self.softmax_temp = conf['softmax_temp']
41 | self.sup_loss = sup_loss
42 | self.sup_type = conf['sup_loss']
43 |
44 | # Use weak labels
45 | self.use_weak_lables = use_weak_lables
46 | self.weakly_loss_w = weakly_loss_w
47 | # pair wise loss (sup mat)
48 | self.aux_constraint = conf['aux_constraint']
49 | self.aux_constraint_w = conf['aux_constraint_w']
50 | # confidence masking (sup mat)
51 | self.confidence_th = conf['confidence_th']
52 | self.confidence_masking = conf['confidence_masking']
53 |
54 | # Create the model
55 | self.encoder = Encoder(pretrained=pretrained)
56 |
57 | # The main encoder
58 | upscale = 8
59 | num_out_ch = 2048
60 | decoder_in_ch = num_out_ch // 4
61 | self.main_decoder = MainDecoder(upscale, decoder_in_ch, num_classes=num_classes)
62 |
63 | # The auxilary decoders
64 | if self.mode == 'semi' or self.mode == 'weakly_semi':
65 | vat_decoder = [VATDecoder(upscale, decoder_in_ch, num_classes, xi=conf['xi'],
66 | eps=conf['eps']) for _ in range(conf['vat'])]
67 | drop_decoder = [DropOutDecoder(upscale, decoder_in_ch, num_classes,
68 | drop_rate=conf['drop_rate'], spatial_dropout=conf['spatial'])
69 | for _ in range(conf['drop'])]
70 | cut_decoder = [CutOutDecoder(upscale, decoder_in_ch, num_classes, erase=conf['erase'])
71 | for _ in range(conf['cutout'])]
72 | context_m_decoder = [ContextMaskingDecoder(upscale, decoder_in_ch, num_classes)
73 | for _ in range(conf['context_masking'])]
74 | object_masking = [ObjectMaskingDecoder(upscale, decoder_in_ch, num_classes)
75 | for _ in range(conf['object_masking'])]
76 | feature_drop = [FeatureDropDecoder(upscale, decoder_in_ch, num_classes)
77 | for _ in range(conf['feature_drop'])]
78 | feature_noise = [FeatureNoiseDecoder(upscale, decoder_in_ch, num_classes,
79 | uniform_range=conf['uniform_range'])
80 | for _ in range(conf['feature_noise'])]
81 |
82 | self.aux_decoders = nn.ModuleList([*vat_decoder, *drop_decoder, *cut_decoder,
83 | *context_m_decoder, *object_masking, *feature_drop, *feature_noise])
84 |
85 | def forward(self, x_l=None, target_l=None, x_ul=None, target_ul=None, curr_iter=None, epoch=None):
86 | if not self.training:
87 | return self.main_decoder(self.encoder(x_l))
88 |
89 | # We compute the losses in the forward pass to avoid problems encountered in muti-gpu
90 |
91 | # Forward pass the labels example
92 | input_size = (x_l.size(2), x_l.size(3))
93 | output_l = self.main_decoder(self.encoder(x_l))
94 | if output_l.shape != x_l.shape:
95 | output_l = F.interpolate(output_l, size=input_size, mode='bilinear', align_corners=True)
96 |
97 | # Supervised loss
98 | if self.sup_type == 'CE':
99 | loss_sup = self.sup_loss(output_l, target_l, ignore_index=self.ignore_index, temperature=self.softmax_temp) * self.sup_loss_w
100 | elif self.sup_type == 'FL':
101 | loss_sup = self.sup_loss(output_l,target_l) * self.sup_loss_w
102 | else:
103 | loss_sup = self.sup_loss(output_l, target_l, curr_iter=curr_iter, epoch=epoch, ignore_index=self.ignore_index) * self.sup_loss_w
104 |
105 | # If supervised mode only, return
106 | if self.mode == 'supervised':
107 | curr_losses = {'loss_sup': loss_sup}
108 | outputs = {'sup_pred': output_l}
109 | total_loss = loss_sup
110 | return total_loss, curr_losses, outputs
111 |
112 | # If semi supervised mode
113 | elif self.mode == 'semi':
114 | # Get main prediction
115 | x_ul = self.encoder(x_ul)
116 | output_ul = self.main_decoder(x_ul)
117 |
118 | # Get auxiliary predictions
119 | outputs_ul = [aux_decoder(x_ul, output_ul.detach()) for aux_decoder in self.aux_decoders]
120 | targets = F.softmax(output_ul.detach(), dim=1)
121 |
122 | # Compute unsupervised loss
123 | loss_unsup = sum([self.unsuper_loss(inputs=u, targets=targets, \
124 | conf_mask=self.confidence_masking, threshold=self.confidence_th, use_softmax=False)
125 | for u in outputs_ul])
126 | loss_unsup = (loss_unsup / len(outputs_ul))
127 | curr_losses = {'loss_sup': loss_sup}
128 |
129 | if output_ul.shape != x_l.shape:
130 | output_ul = F.interpolate(output_ul, size=input_size, mode='bilinear', align_corners=True)
131 | outputs = {'sup_pred': output_l, 'unsup_pred': output_ul}
132 |
133 | # Compute the unsupervised loss
134 | weight_u = self.unsup_loss_w(epoch=epoch, curr_iter=curr_iter)
135 | loss_unsup = loss_unsup * weight_u
136 | curr_losses['loss_unsup'] = loss_unsup
137 | total_loss = loss_unsup + loss_sup
138 |
139 | # If case we're using weak lables, add the weak loss term with a weight (self.weakly_loss_w)
140 | if self.use_weak_lables:
141 | weight_w = (weight_u / self.unsup_loss_w.final_w) * self.weakly_loss_w
142 | loss_weakly = sum([CE_loss(outp, target_ul, ignore_index=self.ignore_index) for outp in outputs_ul]) / len(outputs_ul)
143 | loss_weakly = loss_weakly * weight_w
144 | curr_losses['loss_weakly'] = loss_weakly
145 | total_loss += loss_weakly
146 |
147 | # Pair-wise loss
148 | if self.aux_constraint:
149 | pair_wise = pair_wise_loss(outputs_ul) * self.aux_constraint_w
150 | curr_losses['pair_wise'] = pair_wise
151 | loss_unsup += pair_wise
152 |
153 | return total_loss, curr_losses, outputs
154 |
155 | def get_backbone_params(self):
156 | return self.encoder.get_backbone_params()
157 |
158 | def get_other_params(self):
159 | if self.mode == 'semi':
160 | return chain(self.encoder.get_module_params(), self.main_decoder.parameters(),
161 | self.aux_decoders.parameters())
162 |
163 | return chain(self.encoder.get_module_params(), self.main_decoder.parameters())
164 |
165 |
--------------------------------------------------------------------------------
/pseudo_labels/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Generating Pseudo-Labels
4 |
5 | This is a 3rd party code, which was adapted for our case, we thank the original authors for
6 | providing the implementation for their work, please check it out if you are interested:
7 | * Paper: [Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations](https://arxiv.org/abs/1904.05044)
8 | * Code: [Jiwoon Ahn's irn](https://github.com/jiwoon-ahn/irn)
9 |
10 | This code is used for generating pseudo pixel-level from class labels. This is done in three steps:
11 |
12 | * `train_cam.py`: first we fine-tune a pretrained resnet50 (on imagenet from torchvision) on Pascal Voc for image classification
13 | with 21 classes. In this case, for fast training, the batch norm layers are frozen, and we only use high learning rate for the last classification
14 | layer after an average pool.
15 | * `make_cam.py`: Using the pretrained resnet on Pascal Voc, we follows the traditional
16 | ([paper](https://arxiv.org/pdf/1512.04150.pdf)) approach to generate localization maps, this is done
17 | by simply weighting the activations of the last block of resnet by the learned weight of the classification weight.
18 | We then only consider the maps of the ground-truth classes.
19 | * `cam_to_pseudo_labels.py`: The last step is a refinement step to only consider the highly confident regions, and the non-confident regions
20 | are ignored. A CRF refinement step is also applied before saving the pseudo-labels.
21 |
22 |
23 |
24 | To generate the pseudo-labels, simply run:
25 |
26 | ```bash
27 | python run.py --voc12_root DATA_PATH
28 | ```
29 |
30 | `DATA_PATH` must point to the folder containing `JPEGImages` in Pascal Voc dataset.
31 |
32 | The results will be saved in `result/pseudo_labels` as PNG files, which will be used to train the auxiliary decoders of CCT
33 | in weakly semi-supervised setting.
34 |
35 | If you find this code useful, please consider citing the original [paper]((https://arxiv.org/abs/1904.05044)).
--------------------------------------------------------------------------------
/pseudo_labels/cam_to_pseudo_labels.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import imageio
4 | from torch import multiprocessing
5 | from torch.utils.data import DataLoader
6 | import voc12.dataloader
7 | from misc import torchutils, imutils
8 |
9 |
10 | def _work(process_id, infer_dataset, args):
11 |
12 | databin = infer_dataset[process_id]
13 | infer_data_loader = DataLoader(databin, shuffle=False, num_workers=0, pin_memory=False)
14 |
15 | for iter, pack in enumerate(infer_data_loader):
16 | img_name = voc12.dataloader.decode_int_filename(pack['name'][0])
17 | img = pack['img'][0].numpy()
18 | cam_dict = np.load(os.path.join(args.cam_out_dir, img_name + '.npy'), allow_pickle=True).item()
19 |
20 | cams = cam_dict['high_res']
21 | keys = np.pad(cam_dict['keys'] + 1, (1, 0), mode='constant')
22 |
23 | # 1. find confident fg & bg
24 | fg_conf_cam = np.pad(cams, ((1, 0), (0, 0), (0, 0)), mode='constant', constant_values=args.conf_fg_thres)
25 | fg_conf_cam = np.argmax(fg_conf_cam, axis=0)
26 | pred = imutils.crf_inference_label(img, fg_conf_cam, n_labels=keys.shape[0])
27 | fg_conf = keys[pred]
28 |
29 | bg_conf_cam = np.pad(cams, ((1, 0), (0, 0), (0, 0)), mode='constant', constant_values=args.conf_bg_thres)
30 | bg_conf_cam = np.argmax(bg_conf_cam, axis=0)
31 | pred = imutils.crf_inference_label(img, bg_conf_cam, n_labels=keys.shape[0])
32 | bg_conf = keys[pred]
33 |
34 | # 2. combine confident fg & bg
35 | conf = fg_conf.copy()
36 | conf[fg_conf == 0] = 255
37 | conf[bg_conf + fg_conf == 0] = 0
38 |
39 | imageio.imwrite(os.path.join(args.pseudo_labels_out_dir, img_name + '.png'), conf.astype(np.uint8))
40 |
41 | if process_id == args.num_workers - 1 and iter % (len(databin) // 20) == 0:
42 | print("%d " % ((5 * iter + 1) // (len(databin) // 20)), end='')
43 |
44 | def run(args):
45 | dataset = voc12.dataloader.VOC12ImageDataset(args.train_list, voc12_root=args.voc12_root, img_normal=None, to_torch=False)
46 | dataset = torchutils.split_dataset(dataset, args.num_workers)
47 |
48 | print('[ ', end='')
49 | multiprocessing.spawn(_work, nprocs=args.num_workers, args=(dataset, args), join=True)
50 | print(']')
51 |
--------------------------------------------------------------------------------
/pseudo_labels/make_cam.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import multiprocessing, cuda
3 | from torch.utils.data import DataLoader
4 | import torch.nn.functional as F
5 | from torch.backends import cudnn
6 |
7 | import numpy as np
8 | import importlib
9 | import os
10 |
11 | import voc12.dataloader
12 | from misc import torchutils, imutils
13 |
14 | cudnn.enabled = True
15 |
16 | def _work(process_id, model, dataset, args):
17 |
18 | databin = dataset[process_id]
19 | n_gpus = torch.cuda.device_count()
20 | data_loader = DataLoader(databin, shuffle=False, num_workers=args.num_workers // n_gpus, pin_memory=False)
21 |
22 | with torch.no_grad(), cuda.device(process_id):
23 |
24 | model.cuda()
25 |
26 | for iter, pack in enumerate(data_loader):
27 |
28 | img_name = pack['name'][0]
29 | label = pack['label'][0]
30 | size = pack['size']
31 |
32 | strided_size = imutils.get_strided_size(size, 4)
33 | strided_up_size = imutils.get_strided_up_size(size, 16)
34 |
35 | outputs = [model(img[0].cuda(non_blocking=True))
36 | for img in pack['img']]
37 |
38 | strided_cam = torch.sum(torch.stack(
39 | [F.interpolate(torch.unsqueeze(o, 0), strided_size, mode='bilinear', align_corners=False)[0] for o
40 | in outputs]), 0)
41 |
42 | highres_cam = [F.interpolate(torch.unsqueeze(o, 1), strided_up_size,
43 | mode='bilinear', align_corners=False) for o in outputs]
44 | highres_cam = torch.sum(torch.stack(highres_cam, 0), 0)[:, 0, :size[0], :size[1]]
45 |
46 | valid_cat = torch.nonzero(label)[:, 0]
47 |
48 | strided_cam = strided_cam[valid_cat]
49 | strided_cam /= F.adaptive_max_pool2d(strided_cam, (1, 1)) + 1e-5
50 |
51 | highres_cam = highres_cam[valid_cat]
52 | highres_cam /= F.adaptive_max_pool2d(highres_cam, (1, 1)) + 1e-5
53 |
54 | # save cams
55 | np.save(os.path.join(args.cam_out_dir, img_name + '.npy'),
56 | {"keys": valid_cat, "cam": strided_cam.cpu(), "high_res": highres_cam.cpu().numpy()})
57 |
58 | if process_id == n_gpus - 1 and iter % (len(databin) // 20) == 0:
59 | print("%d " % ((5*iter+1)//(len(databin) // 20)), end='')
60 |
61 |
62 | def run(args):
63 | model = getattr(importlib.import_module(args.cam_network), 'CAM')()
64 | model.load_state_dict(torch.load(args.cam_weights_name + '.pth'), strict=True)
65 | model.eval()
66 |
67 | n_gpus = torch.cuda.device_count()
68 |
69 | dataset = voc12.dataloader.VOC12ClassificationDatasetMSF(args.train_list,
70 | voc12_root=args.voc12_root, scales=args.cam_scales)
71 | dataset = torchutils.split_dataset(dataset, n_gpus)
72 |
73 | print('[ ', end='')
74 | multiprocessing.spawn(_work, nprocs=n_gpus, args=(model, dataset, args), join=True)
75 | print(']')
76 |
77 | torch.cuda.empty_cache()
--------------------------------------------------------------------------------
/pseudo_labels/misc/imutils.py:
--------------------------------------------------------------------------------
1 | import random
2 | import numpy as np
3 |
4 | import pydensecrf.densecrf as dcrf
5 | from pydensecrf.utils import unary_from_labels
6 | from PIL import Image
7 |
8 | def pil_resize(img, size, order):
9 | if size[0] == img.shape[0] and size[1] == img.shape[1]:
10 | return img
11 |
12 | if order == 3:
13 | resample = Image.BICUBIC
14 | elif order == 0:
15 | resample = Image.NEAREST
16 |
17 | return np.asarray(Image.fromarray(img).resize(size[::-1], resample))
18 |
19 | def pil_rescale(img, scale, order):
20 | height, width = img.shape[:2]
21 | target_size = (int(np.round(height*scale)), int(np.round(width*scale)))
22 | return pil_resize(img, target_size, order)
23 |
24 |
25 | def random_resize_long(img, min_long, max_long):
26 | target_long = random.randint(min_long, max_long)
27 | h, w = img.shape[:2]
28 |
29 | if w < h:
30 | scale = target_long / h
31 | else:
32 | scale = target_long / w
33 |
34 | return pil_rescale(img, scale, 3)
35 |
36 | def random_scale(img, scale_range, order):
37 | target_scale = scale_range[0] + random.random() * (scale_range[1] - scale_range[0])
38 | if isinstance(img, tuple):
39 | return (pil_rescale(img[0], target_scale, order[0]), pil_rescale(img[1], target_scale, order[1]))
40 | else:
41 | return pil_rescale(img[0], target_scale, order)
42 |
43 | def random_lr_flip(img):
44 |
45 | if bool(random.getrandbits(1)):
46 | if isinstance(img, tuple):
47 | return [np.fliplr(m) for m in img]
48 | else:
49 | return np.fliplr(img)
50 | else:
51 | return img
52 |
53 | def get_random_crop_box(imgsize, cropsize):
54 | h, w = imgsize
55 |
56 | ch = min(cropsize, h)
57 | cw = min(cropsize, w)
58 |
59 | w_space = w - cropsize
60 | h_space = h - cropsize
61 |
62 | if w_space > 0:
63 | cont_left = 0
64 | img_left = random.randrange(w_space + 1)
65 | else:
66 | cont_left = random.randrange(-w_space + 1)
67 | img_left = 0
68 |
69 | if h_space > 0:
70 | cont_top = 0
71 | img_top = random.randrange(h_space + 1)
72 | else:
73 | cont_top = random.randrange(-h_space + 1)
74 | img_top = 0
75 |
76 | return cont_top, cont_top+ch, cont_left, cont_left+cw, img_top, img_top+ch, img_left, img_left+cw
77 |
78 | def random_crop(images, cropsize, default_values):
79 |
80 | if isinstance(images, np.ndarray): images = (images,)
81 | if isinstance(default_values, int): default_values = (default_values,)
82 |
83 | imgsize = images[0].shape[:2]
84 | box = get_random_crop_box(imgsize, cropsize)
85 |
86 | new_images = []
87 | for img, f in zip(images, default_values):
88 |
89 | if len(img.shape) == 3:
90 | cont = np.ones((cropsize, cropsize, img.shape[2]), img.dtype)*f
91 | else:
92 | cont = np.ones((cropsize, cropsize), img.dtype)*f
93 | cont[box[0]:box[1], box[2]:box[3]] = img[box[4]:box[5], box[6]:box[7]]
94 | new_images.append(cont)
95 |
96 | if len(new_images) == 1:
97 | new_images = new_images[0]
98 |
99 | return new_images
100 |
101 | def top_left_crop(img, cropsize, default_value):
102 |
103 | h, w = img.shape[:2]
104 |
105 | ch = min(cropsize, h)
106 | cw = min(cropsize, w)
107 |
108 | if len(img.shape) == 2:
109 | container = np.ones((cropsize, cropsize), img.dtype)*default_value
110 | else:
111 | container = np.ones((cropsize, cropsize, img.shape[2]), img.dtype)*default_value
112 |
113 | container[:ch, :cw] = img[:ch, :cw]
114 |
115 | return container
116 |
117 | def center_crop(img, cropsize, default_value=0):
118 |
119 | h, w = img.shape[:2]
120 |
121 | ch = min(cropsize, h)
122 | cw = min(cropsize, w)
123 |
124 | sh = h - cropsize
125 | sw = w - cropsize
126 |
127 | if sw > 0:
128 | cont_left = 0
129 | img_left = int(round(sw / 2))
130 | else:
131 | cont_left = int(round(-sw / 2))
132 | img_left = 0
133 |
134 | if sh > 0:
135 | cont_top = 0
136 | img_top = int(round(sh / 2))
137 | else:
138 | cont_top = int(round(-sh / 2))
139 | img_top = 0
140 |
141 | if len(img.shape) == 2:
142 | container = np.ones((cropsize, cropsize), img.dtype)*default_value
143 | else:
144 | container = np.ones((cropsize, cropsize, img.shape[2]), img.dtype)*default_value
145 |
146 | container[cont_top:cont_top+ch, cont_left:cont_left+cw] = \
147 | img[img_top:img_top+ch, img_left:img_left+cw]
148 |
149 | return container
150 |
151 | def HWC_to_CHW(img):
152 | return np.transpose(img, (2, 0, 1))
153 |
154 | def crf_inference_label(img, labels, t=10, n_labels=21, gt_prob=0.7):
155 |
156 | h, w = img.shape[:2]
157 |
158 | d = dcrf.DenseCRF2D(w, h, n_labels)
159 |
160 | unary = unary_from_labels(labels, n_labels, gt_prob=gt_prob, zero_unsure=False)
161 |
162 | d.setUnaryEnergy(unary)
163 | d.addPairwiseGaussian(sxy=3, compat=3)
164 | d.addPairwiseBilateral(sxy=50, srgb=5, rgbim=np.ascontiguousarray(np.copy(img)), compat=10)
165 |
166 | q = d.inference(t)
167 |
168 | return np.argmax(np.array(q).reshape((n_labels, h, w)), axis=0)
169 |
170 |
171 | def get_strided_size(orig_size, stride):
172 | return ((orig_size[0]-1)//stride+1, (orig_size[1]-1)//stride+1)
173 |
174 |
175 | def get_strided_up_size(orig_size, stride):
176 | strided_size = get_strided_size(orig_size, stride)
177 | return strided_size[0]*stride, strided_size[1]*stride
178 |
179 |
180 | def compress_range(arr):
181 | uniques = np.unique(arr)
182 | maximum = np.max(uniques)
183 |
184 | d = np.zeros(maximum+1, np.int32)
185 | d[uniques] = np.arange(uniques.shape[0])
186 |
187 | out = d[arr]
188 | return out - np.min(out)
189 |
190 |
191 | def colorize_score(score_map, exclude_zero=False, normalize=True, by_hue=False):
192 | import matplotlib.colors
193 | if by_hue:
194 | aranged = np.arange(score_map.shape[0]) / (score_map.shape[0])
195 | hsv_color = np.stack((aranged, np.ones_like(aranged), np.ones_like(aranged)), axis=-1)
196 | rgb_color = matplotlib.colors.hsv_to_rgb(hsv_color)
197 |
198 | test = rgb_color[np.argmax(score_map, axis=0)]
199 | test = np.expand_dims(np.max(score_map, axis=0), axis=-1) * test
200 |
201 | if normalize:
202 | return test / (np.max(test) + 1e-5)
203 | else:
204 | return test
205 |
206 | else:
207 | VOC_color = np.array([(0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128),
208 | (0, 128, 128), (128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0),
209 | (64, 0, 128), (192, 0, 128), (64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0),
210 | (0, 192, 0), (128, 192, 0), (0, 64, 128), (255, 255, 255)], np.float32)
211 |
212 | if exclude_zero:
213 | VOC_color = VOC_color[1:]
214 |
215 | test = VOC_color[np.argmax(score_map, axis=0)%22]
216 | test = np.expand_dims(np.max(score_map, axis=0), axis=-1) * test
217 | if normalize:
218 | test /= np.max(test) + 1e-5
219 |
220 | return test
221 |
222 |
223 | def colorize_displacement(disp):
224 |
225 | import matplotlib.colors
226 | import math
227 |
228 | a = (np.arctan2(-disp[0], -disp[1]) / math.pi + 1) / 2
229 |
230 | r = np.sqrt(disp[0] ** 2 + disp[1] ** 2)
231 | s = r / np.max(r)
232 | hsv_color = np.stack((a, s, np.ones_like(a)), axis=-1)
233 | rgb_color = matplotlib.colors.hsv_to_rgb(hsv_color)
234 |
235 | return rgb_color
236 |
237 |
238 | def colorize_label(label_map, normalize=True, by_hue=True, exclude_zero=False, outline=False):
239 |
240 | label_map = label_map.astype(np.uint8)
241 |
242 | if by_hue:
243 | import matplotlib.colors
244 | sz = np.max(label_map)
245 | aranged = np.arange(sz) / sz
246 | hsv_color = np.stack((aranged, np.ones_like(aranged), np.ones_like(aranged)), axis=-1)
247 | rgb_color = matplotlib.colors.hsv_to_rgb(hsv_color)
248 | rgb_color = np.concatenate([np.zeros((1, 3)), rgb_color], axis=0)
249 |
250 | test = rgb_color[label_map]
251 | else:
252 | VOC_color = np.array([(0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128),
253 | (0, 128, 128), (128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0),
254 | (64, 0, 128), (192, 0, 128), (64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0),
255 | (0, 192, 0), (128, 192, 0), (0, 64, 128), (255, 255, 255)], np.float32)
256 |
257 | if exclude_zero:
258 | VOC_color = VOC_color[1:]
259 | test = VOC_color[label_map]
260 | if normalize:
261 | test /= np.max(test)
262 |
263 | if outline:
264 | edge = np.greater(np.sum(np.abs(test[:-1, :-1] - test[1:, :-1]), axis=-1) + np.sum(np.abs(test[:-1, :-1] - test[:-1, 1:]), axis=-1), 0)
265 | edge1 = np.pad(edge, ((0, 1), (0, 1)), mode='constant', constant_values=0)
266 | edge2 = np.pad(edge, ((1, 0), (1, 0)), mode='constant', constant_values=0)
267 | edge = np.repeat(np.expand_dims(np.maximum(edge1, edge2), -1), 3, axis=-1)
268 |
269 | test = np.maximum(test, edge)
270 | return test
271 |
--------------------------------------------------------------------------------
/pseudo_labels/misc/pyutils.py:
--------------------------------------------------------------------------------
1 |
2 | import numpy as np
3 | import time
4 | import sys
5 |
6 | class Logger(object):
7 | def __init__(self, outfile):
8 | self.terminal = sys.stdout
9 | self.log = open(outfile, "w")
10 | sys.stdout = self
11 |
12 | def write(self, message):
13 | self.terminal.write(message)
14 | self.log.write(message)
15 |
16 | def flush(self):
17 | self.terminal.flush()
18 |
19 |
20 | class AverageMeter:
21 | def __init__(self, *keys):
22 | self.__data = dict()
23 | for k in keys:
24 | self.__data[k] = [0.0, 0]
25 |
26 | def add(self, dict):
27 | for k, v in dict.items():
28 | if k not in self.__data:
29 | self.__data[k] = [0.0, 0]
30 | self.__data[k][0] += v
31 | self.__data[k][1] += 1
32 |
33 | def get(self, *keys):
34 | if len(keys) == 1:
35 | return self.__data[keys[0]][0] / self.__data[keys[0]][1]
36 | else:
37 | v_list = [self.__data[k][0] / self.__data[k][1] for k in keys]
38 | return tuple(v_list)
39 |
40 | def pop(self, key=None):
41 | if key is None:
42 | for k in self.__data.keys():
43 | self.__data[k] = [0.0, 0]
44 | else:
45 | v = self.get(key)
46 | self.__data[key] = [0.0, 0]
47 | return v
48 |
49 |
50 | class Timer:
51 | def __init__(self, starting_msg = None):
52 | self.start = time.time()
53 | self.stage_start = self.start
54 |
55 | if starting_msg is not None:
56 | print(starting_msg, time.ctime(time.time()))
57 |
58 | def __enter__(self):
59 | return self
60 |
61 | def __exit__(self, exc_type, exc_val, exc_tb):
62 | return
63 |
64 | def update_progress(self, progress):
65 | self.elapsed = time.time() - self.start
66 | self.est_total = self.elapsed / progress
67 | self.est_remaining = self.est_total - self.elapsed
68 | self.est_finish = int(self.start + self.est_total)
69 |
70 |
71 | def str_estimated_complete(self):
72 | return str(time.ctime(self.est_finish))
73 |
74 | def get_stage_elapsed(self):
75 | return time.time() - self.stage_start
76 |
77 | def reset_stage(self):
78 | self.stage_start = time.time()
79 |
80 | def lapse(self):
81 | out = time.time() - self.stage_start
82 | self.stage_start = time.time()
83 | return out
84 |
85 |
86 | def to_one_hot(sparse_integers, maximum_val=None, dtype=np.bool):
87 |
88 | if maximum_val is None:
89 | maximum_val = np.max(sparse_integers) + 1
90 |
91 | src_shape = sparse_integers.shape
92 |
93 | flat_src = np.reshape(sparse_integers, [-1])
94 | src_size = flat_src.shape[0]
95 |
96 | one_hot = np.zeros((maximum_val, src_size), dtype)
97 | one_hot[flat_src, np.arange(src_size)] = 1
98 |
99 | one_hot = np.reshape(one_hot, [maximum_val] + list(src_shape))
100 |
101 | return one_hot
102 |
--------------------------------------------------------------------------------
/pseudo_labels/misc/torchutils.py:
--------------------------------------------------------------------------------
1 |
2 | import torch
3 |
4 | from torch.utils.data import Subset
5 | import numpy as np
6 | import math
7 |
8 |
9 | class PolyOptimizer(torch.optim.SGD):
10 |
11 | def __init__(self, params, lr, weight_decay, max_step, momentum=0.9):
12 | super().__init__(params, lr, weight_decay)
13 |
14 | self.global_step = 0
15 | self.max_step = max_step
16 | self.momentum = momentum
17 |
18 | self.__initial_lr = [group['lr'] for group in self.param_groups]
19 |
20 |
21 | def step(self, closure=None):
22 |
23 | if self.global_step < self.max_step:
24 | lr_mult = (1 - self.global_step / self.max_step) ** self.momentum
25 |
26 | for i in range(len(self.param_groups)):
27 | self.param_groups[i]['lr'] = self.__initial_lr[i] * lr_mult
28 |
29 | super().step(closure)
30 |
31 | self.global_step += 1
32 |
33 | class SGDROptimizer(torch.optim.SGD):
34 |
35 | def __init__(self, params, steps_per_epoch, lr=0, weight_decay=0, epoch_start=1, restart_mult=2):
36 | super().__init__(params, lr, weight_decay)
37 |
38 | self.global_step = 0
39 | self.local_step = 0
40 | self.total_restart = 0
41 |
42 | self.max_step = steps_per_epoch * epoch_start
43 | self.restart_mult = restart_mult
44 |
45 | self.__initial_lr = [group['lr'] for group in self.param_groups]
46 |
47 |
48 | def step(self, closure=None):
49 |
50 | if self.local_step >= self.max_step:
51 | self.local_step = 0
52 | self.max_step *= self.restart_mult
53 | self.total_restart += 1
54 |
55 | lr_mult = (1 + math.cos(math.pi * self.local_step / self.max_step))/2 / (self.total_restart + 1)
56 |
57 | for i in range(len(self.param_groups)):
58 | self.param_groups[i]['lr'] = self.__initial_lr[i] * lr_mult
59 |
60 | super().step(closure)
61 |
62 | self.local_step += 1
63 | self.global_step += 1
64 |
65 |
66 | def split_dataset(dataset, n_splits):
67 |
68 | return [Subset(dataset, np.arange(i, len(dataset), n_splits)) for i in range(n_splits)]
69 |
70 |
71 | def gap2d(x, keepdims=False):
72 | out = torch.mean(x.view(x.size(0), x.size(1), -1), -1)
73 | if keepdims:
74 | out = out.view(out.size(0), out.size(1), 1, 1)
75 |
76 | return out
77 |
--------------------------------------------------------------------------------
/pseudo_labels/net/resnet50.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | import torch.utils.model_zoo as model_zoo
4 |
5 |
6 | model_urls = {
7 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth'
8 | }
9 |
10 |
11 | class FixedBatchNorm(nn.BatchNorm2d):
12 | def forward(self, input):
13 | return F.batch_norm(input, self.running_mean, self.running_var, self.weight, self.bias,
14 | training=False, eps=self.eps)
15 |
16 |
17 | class Bottleneck(nn.Module):
18 | expansion = 4
19 |
20 | def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
21 | super(Bottleneck, self).__init__()
22 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
23 | self.bn1 = FixedBatchNorm(planes)
24 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
25 | padding=dilation, bias=False, dilation=dilation)
26 | self.bn2 = FixedBatchNorm(planes)
27 | self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
28 | self.bn3 = FixedBatchNorm(planes * 4)
29 | self.relu = nn.ReLU(inplace=True)
30 | self.downsample = downsample
31 | self.stride = stride
32 | self.dilation = dilation
33 |
34 | def forward(self, x):
35 | residual = x
36 |
37 | out = self.conv1(x)
38 | out = self.bn1(out)
39 | out = self.relu(out)
40 |
41 | out = self.conv2(out)
42 | out = self.bn2(out)
43 | out = self.relu(out)
44 |
45 | out = self.conv3(out)
46 | out = self.bn3(out)
47 |
48 | if self.downsample is not None:
49 | residual = self.downsample(x)
50 |
51 | out += residual
52 | out = self.relu(out)
53 |
54 | return out
55 |
56 |
57 | class ResNet(nn.Module):
58 |
59 | def __init__(self, block, layers, strides=(2, 2, 2, 2), dilations=(1, 1, 1, 1)):
60 | self.inplanes = 64
61 | super(ResNet, self).__init__()
62 | self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=strides[0], padding=3,
63 | bias=False)
64 | self.bn1 = FixedBatchNorm(64)
65 | self.relu = nn.ReLU(inplace=True)
66 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
67 | self.layer1 = self._make_layer(block, 64, layers[0], stride=1, dilation=dilations[0])
68 | self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], dilation=dilations[1])
69 | self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], dilation=dilations[2])
70 | self.layer4 = self._make_layer(block, 512, layers[3], stride=strides[3], dilation=dilations[3])
71 | self.inplanes = 1024
72 |
73 | #self.avgpool = nn.AvgPool2d(7, stride=1)
74 | #self.fc = nn.Linear(512 * block.expansion, 1000)
75 |
76 |
77 | def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
78 | downsample = None
79 | if stride != 1 or self.inplanes != planes * block.expansion:
80 | downsample = nn.Sequential(
81 | nn.Conv2d(self.inplanes, planes * block.expansion,
82 | kernel_size=1, stride=stride, bias=False),
83 | FixedBatchNorm(planes * block.expansion),
84 | )
85 |
86 | layers = [block(self.inplanes, planes, stride, downsample, dilation=1)]
87 | self.inplanes = planes * block.expansion
88 | for i in range(1, blocks):
89 | layers.append(block(self.inplanes, planes, dilation=dilation))
90 |
91 | return nn.Sequential(*layers)
92 |
93 | def forward(self, x):
94 | x = self.conv1(x)
95 | x = self.bn1(x)
96 | x = self.relu(x)
97 | x = self.maxpool(x)
98 |
99 | x = self.layer1(x)
100 | x = self.layer2(x)
101 | x = self.layer3(x)
102 | x = self.layer4(x)
103 |
104 | x = self.avgpool(x)
105 | x = x.view(x.size(0), -1)
106 | x = self.fc(x)
107 |
108 | return x
109 |
110 |
111 | def resnet50(pretrained=True, **kwargs):
112 |
113 | model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
114 | if pretrained:
115 | state_dict = model_zoo.load_url(model_urls['resnet50'])
116 | state_dict.pop('fc.weight')
117 | state_dict.pop('fc.bias')
118 | model.load_state_dict(state_dict)
119 | return model
--------------------------------------------------------------------------------
/pseudo_labels/net/resnet50_cam.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | from misc import torchutils
4 | from net import resnet50
5 |
6 |
7 | class Net(nn.Module):
8 |
9 | def __init__(self):
10 | super(Net, self).__init__()
11 |
12 | self.resnet50 = resnet50.resnet50(pretrained=True, strides=(2, 2, 2, 1))
13 |
14 | self.stage1 = nn.Sequential(self.resnet50.conv1, self.resnet50.bn1, self.resnet50.relu, self.resnet50.maxpool,
15 | self.resnet50.layer1)
16 | self.stage2 = nn.Sequential(self.resnet50.layer2)
17 | self.stage3 = nn.Sequential(self.resnet50.layer3)
18 | self.stage4 = nn.Sequential(self.resnet50.layer4)
19 |
20 | self.classifier = nn.Conv2d(2048, 20, 1, bias=False)
21 |
22 | self.backbone = nn.ModuleList([self.stage1, self.stage2, self.stage3, self.stage4])
23 | self.newly_added = nn.ModuleList([self.classifier])
24 |
25 | def forward(self, x):
26 | x = self.stage1(x)
27 | x = self.stage2(x).detach()
28 | x = self.stage3(x)
29 | x = self.stage4(x)
30 | x = torchutils.gap2d(x, keepdims=True)
31 | x = self.classifier(x)
32 | x = x.view(-1, 20)
33 | return x
34 |
35 | def train(self, mode=True):
36 | for p in self.resnet50.conv1.parameters():
37 | p.requires_grad = False
38 | for p in self.resnet50.bn1.parameters():
39 | p.requires_grad = False
40 |
41 | def trainable_parameters(self):
42 | return (list(self.backbone.parameters()), list(self.newly_added.parameters()))
43 |
44 |
45 | class CAM(Net):
46 | def __init__(self):
47 | super(CAM, self).__init__()
48 |
49 | def forward(self, x):
50 | x = self.stage1(x)
51 | x = self.stage2(x)
52 | x = self.stage3(x)
53 | x = self.stage4(x)
54 | x = F.conv2d(x, self.classifier.weight)
55 | x = F.relu(x)
56 | x = x[0] + x[1].flip(-1)
57 | return x
58 |
--------------------------------------------------------------------------------
/pseudo_labels/run.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | from misc import pyutils
4 | import train_cam, make_cam, cam_to_pseudo_labels
5 |
6 | if __name__ == '__main__':
7 |
8 | parser = argparse.ArgumentParser()
9 |
10 | # Environment
11 | parser.add_argument("--num_workers", default=os.cpu_count()//2, type=int)
12 | parser.add_argument("--voc12_root", required=True, type=str,
13 | help="Path to VOC 2012 Devkit, must contain ./JPEGImages as subdirectory.")
14 |
15 | # Dataset
16 | parser.add_argument("--train_list", default="voc12/train_aug.txt", type=str)
17 | parser.add_argument("--val_list", default="voc12/val.txt", type=str)
18 | parser.add_argument("--infer_list", default="voc12/train.txt", type=str,
19 | help="voc12/train_aug.txt to train a fully supervised model, "
20 | "voc12/train.txt or voc12/val.txt to quickly check the quality of the labels.")
21 |
22 | # Class Activation Map
23 | parser.add_argument("--cam_network", default="net.resnet50_cam", type=str)
24 | parser.add_argument("--cam_crop_size", default=512, type=int)
25 | parser.add_argument("--cam_batch_size", default=16, type=int)
26 | parser.add_argument("--cam_num_epoches", default=5, type=int)
27 | parser.add_argument("--cam_learning_rate", default=0.1, type=float)
28 | parser.add_argument("--cam_weight_decay", default=1e-4, type=float)
29 | parser.add_argument("--cam_eval_thres", default=0.15, type=float)
30 | parser.add_argument("--cam_scales", default=(1.0, 0.5, 1.5, 2.0), help="Multi-scale inferences")
31 | parser.add_argument("--conf_fg_thres", default=0.30, type=float)
32 | parser.add_argument("--conf_bg_thres", default=0.05, type=float)
33 |
34 | # Output Path
35 | parser.add_argument("--cam_weights_name", default="saved/res50_cam.pth", type=str)
36 | parser.add_argument("--cam_out_dir", default="result/cam", type=str)
37 | parser.add_argument("--pseudo_labels_out_dir", default="result/pseudo_labels", type=str)
38 |
39 | args = parser.parse_args()
40 | os.makedirs("saved", exist_ok=True)
41 | os.makedirs(args.cam_out_dir, exist_ok=True)
42 | os.makedirs(args.pseudo_labels_out_dir, exist_ok=True)
43 |
44 | print(vars(args))
45 |
46 | # Train resnet on pascal voc for classification
47 | timer = pyutils.Timer('step.train_cam:')
48 | train_cam.run(args)
49 | # Generate class activation maps from pretrained resnet
50 | timer = pyutils.Timer('step.make_cam:')
51 | make_cam.run(args)
52 | # Generate pseudo labels from CAMs
53 | timer = pyutils.Timer('step.cam_to_ir_label:')
54 | cam_to_pseudo_labels.run(args)
55 |
--------------------------------------------------------------------------------
/pseudo_labels/train_cam.py:
--------------------------------------------------------------------------------
1 |
2 | import torch
3 | from torch.backends import cudnn
4 | cudnn.enabled = True
5 | from torch.utils.data import DataLoader
6 | import torch.nn.functional as F
7 |
8 | import importlib
9 |
10 | import voc12.dataloader
11 | from misc import pyutils, torchutils
12 |
13 |
14 | def validate(model, data_loader):
15 | print('validating ... ', flush=True, end='')
16 | val_loss_meter = pyutils.AverageMeter('loss1', 'loss2')
17 | model.eval()
18 |
19 | with torch.no_grad():
20 | for pack in data_loader:
21 | img = pack['img']
22 | label = pack['label'].cuda(non_blocking=True)
23 | x = model(img)
24 | loss1 = F.multilabel_soft_margin_loss(x, label)
25 | val_loss_meter.add({'loss1': loss1.item()})
26 |
27 | model.train()
28 | print('loss: %.4f' % (val_loss_meter.pop('loss1')))
29 | return
30 |
31 |
32 | def run(args):
33 | model = getattr(importlib.import_module(args.cam_network), 'Net')()
34 | train_dataset = voc12.dataloader.VOC12ClassificationDataset(args.train_list, voc12_root=args.voc12_root,
35 | resize_long=(320, 640), hor_flip=True,
36 | crop_size=512, crop_method="random")
37 | train_data_loader = DataLoader(train_dataset, batch_size=args.cam_batch_size,
38 | shuffle=True, num_workers=args.num_workers, pin_memory=True, drop_last=True)
39 | max_step = (len(train_dataset) // args.cam_batch_size) * args.cam_num_epoches
40 | val_dataset = voc12.dataloader.VOC12ClassificationDataset(args.val_list, voc12_root=args.voc12_root,
41 | crop_size=512)
42 | val_data_loader = DataLoader(val_dataset, batch_size=args.cam_batch_size,
43 | shuffle=False, num_workers=args.num_workers, pin_memory=True, drop_last=True)
44 |
45 | param_groups = model.trainable_parameters()
46 | optimizer = torchutils.PolyOptimizer([
47 | {'params': param_groups[0], 'lr': args.cam_learning_rate, 'weight_decay': args.cam_weight_decay},
48 | {'params': param_groups[1], 'lr': 10*args.cam_learning_rate, 'weight_decay': args.cam_weight_decay},
49 | ], lr=args.cam_learning_rate, weight_decay=args.cam_weight_decay, max_step=max_step)
50 |
51 | model = torch.nn.DataParallel(model).cuda()
52 | model.train()
53 | avg_meter = pyutils.AverageMeter()
54 | timer = pyutils.Timer()
55 | for ep in range(args.cam_num_epoches):
56 | print('Epoch %d/%d' % (ep+1, args.cam_num_epoches))
57 | for step, pack in enumerate(train_data_loader):
58 | img = pack['img']
59 | label = pack['label'].cuda(non_blocking=True)
60 | x = model(img)
61 | loss = F.multilabel_soft_margin_loss(x, label)
62 | avg_meter.add({'loss1': loss.item()})
63 | optimizer.zero_grad()
64 | loss.backward()
65 | optimizer.step()
66 |
67 | if (optimizer.global_step-1)%100 == 0:
68 | timer.update_progress(optimizer.global_step / max_step)
69 | print('step:%5d/%5d' % (optimizer.global_step - 1, max_step),
70 | 'loss:%.4f' % (avg_meter.pop('loss1')),
71 | 'imps:%.1f' % ((step + 1) * args.cam_batch_size / timer.get_stage_elapsed()),
72 | 'lr: %.4f' % (optimizer.param_groups[0]['lr']),
73 | 'etc:%s' % (timer.str_estimated_complete()), flush=True)
74 |
75 | else:
76 | validate(model, val_data_loader)
77 | timer.reset_stage()
78 |
79 | torch.save(model.module.state_dict(), args.cam_weights_name + '.pth')
80 | torch.cuda.empty_cache()
--------------------------------------------------------------------------------
/pseudo_labels/voc12/cls_labels.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yassouali/CCT/65d4e5bd4501ae3c564493d0ce18924a908639f5/pseudo_labels/voc12/cls_labels.npy
--------------------------------------------------------------------------------
/pseudo_labels/voc12/dataloader.py:
--------------------------------------------------------------------------------
1 |
2 | import numpy as np
3 | import torch
4 | from torch.utils.data import Dataset
5 | import os.path
6 | import imageio
7 | from misc import imutils
8 |
9 | IMG_FOLDER_NAME = "JPEGImages"
10 | ANNOT_FOLDER_NAME = "Annotations"
11 | IGNORE = 255
12 |
13 | CAT_LIST = ['aeroplane', 'bicycle', 'bird', 'boat',
14 | 'bottle', 'bus', 'car', 'cat', 'chair',
15 | 'cow', 'diningtable', 'dog', 'horse',
16 | 'motorbike', 'person', 'pottedplant',
17 | 'sheep', 'sofa', 'train',
18 | 'tvmonitor']
19 |
20 | N_CAT = len(CAT_LIST)
21 |
22 | CAT_NAME_TO_NUM = dict(zip(CAT_LIST,range(len(CAT_LIST))))
23 |
24 | cls_labels_dict = np.load('voc12/cls_labels.npy', allow_pickle=True).item()
25 |
26 | def decode_int_filename(int_filename):
27 | s = str(int(int_filename))
28 | return s[:4] + '_' + s[4:]
29 |
30 | def load_image_label_from_xml(img_name, voc12_root):
31 | from xml.dom import minidom
32 |
33 | elem_list = minidom.parse(os.path.join(voc12_root, ANNOT_FOLDER_NAME, decode_int_filename(img_name) + '.xml')).getElementsByTagName('name')
34 |
35 | multi_cls_lab = np.zeros((N_CAT), np.float32)
36 |
37 | for elem in elem_list:
38 | cat_name = elem.firstChild.data
39 | if cat_name in CAT_LIST:
40 | cat_num = CAT_NAME_TO_NUM[cat_name]
41 | multi_cls_lab[cat_num] = 1.0
42 |
43 | return multi_cls_lab
44 |
45 | def load_image_label_list_from_xml(img_name_list, voc12_root):
46 |
47 | return [load_image_label_from_xml(img_name, voc12_root) for img_name in img_name_list]
48 |
49 | def load_image_label_list_from_npy(img_name_list):
50 |
51 | return np.array([cls_labels_dict[img_name] for img_name in img_name_list])
52 |
53 | def get_img_path(img_name, voc12_root):
54 | if not isinstance(img_name, str):
55 | img_name = decode_int_filename(img_name)
56 | return os.path.join(voc12_root, IMG_FOLDER_NAME, img_name + '.jpg')
57 |
58 | def load_img_name_list(dataset_path):
59 |
60 | img_name_list = np.loadtxt(dataset_path, dtype=np.int32)
61 |
62 | return img_name_list
63 |
64 |
65 | class TorchvisionNormalize():
66 | def __init__(self, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
67 | self.mean = mean
68 | self.std = std
69 |
70 | def __call__(self, img):
71 | imgarr = np.asarray(img)
72 | proc_img = np.empty_like(imgarr, np.float32)
73 |
74 | proc_img[..., 0] = (imgarr[..., 0] / 255. - self.mean[0]) / self.std[0]
75 | proc_img[..., 1] = (imgarr[..., 1] / 255. - self.mean[1]) / self.std[1]
76 | proc_img[..., 2] = (imgarr[..., 2] / 255. - self.mean[2]) / self.std[2]
77 |
78 | return proc_img
79 |
80 | class GetAffinityLabelFromIndices():
81 |
82 | def __init__(self, indices_from, indices_to):
83 |
84 | self.indices_from = indices_from
85 | self.indices_to = indices_to
86 |
87 | def __call__(self, segm_map):
88 |
89 | segm_map_flat = np.reshape(segm_map, -1)
90 |
91 | segm_label_from = np.expand_dims(segm_map_flat[self.indices_from], axis=0)
92 | segm_label_to = segm_map_flat[self.indices_to]
93 |
94 | valid_label = np.logical_and(np.less(segm_label_from, 21), np.less(segm_label_to, 21))
95 |
96 | equal_label = np.equal(segm_label_from, segm_label_to)
97 |
98 | pos_affinity_label = np.logical_and(equal_label, valid_label)
99 |
100 | bg_pos_affinity_label = np.logical_and(pos_affinity_label, np.equal(segm_label_from, 0)).astype(np.float32)
101 | fg_pos_affinity_label = np.logical_and(pos_affinity_label, np.greater(segm_label_from, 0)).astype(np.float32)
102 |
103 | neg_affinity_label = np.logical_and(np.logical_not(equal_label), valid_label).astype(np.float32)
104 |
105 | return torch.from_numpy(bg_pos_affinity_label), torch.from_numpy(fg_pos_affinity_label), \
106 | torch.from_numpy(neg_affinity_label)
107 |
108 |
109 | class VOC12ImageDataset(Dataset):
110 | def __init__(self, img_name_list_path, voc12_root,
111 | resize_long=None, rescale=None, img_normal=TorchvisionNormalize(), hor_flip=False,
112 | crop_size=None, crop_method=None, to_torch=True):
113 |
114 | self.img_name_list = load_img_name_list(img_name_list_path)
115 | self.voc12_root = voc12_root
116 |
117 | self.resize_long = resize_long
118 | self.rescale = rescale
119 | self.crop_size = crop_size
120 | self.img_normal = img_normal
121 | self.hor_flip = hor_flip
122 | self.crop_method = crop_method
123 | self.to_torch = to_torch
124 |
125 | def __len__(self):
126 | return len(self.img_name_list)
127 |
128 | def __getitem__(self, idx):
129 | name = self.img_name_list[idx]
130 | name_str = decode_int_filename(name)
131 |
132 | img = np.asarray(imageio.imread(get_img_path(name_str, self.voc12_root)))
133 |
134 | if self.resize_long:
135 | img = imutils.random_resize_long(img, self.resize_long[0], self.resize_long[1])
136 |
137 | if self.rescale:
138 | img = imutils.random_scale(img, scale_range=self.rescale, order=3)
139 |
140 | if self.img_normal:
141 | img = self.img_normal(img)
142 |
143 | if self.hor_flip:
144 | img = imutils.random_lr_flip(img)
145 |
146 | if self.crop_size:
147 | if self.crop_method == "random":
148 | img = imutils.random_crop(img, self.crop_size, 0)
149 | else:
150 | img = imutils.top_left_crop(img, self.crop_size, 0)
151 |
152 | if self.to_torch:
153 | img = imutils.HWC_to_CHW(img)
154 |
155 | return {'name': name_str, 'img': img}
156 |
157 | class VOC12ClassificationDataset(VOC12ImageDataset):
158 |
159 | def __init__(self, img_name_list_path, voc12_root,
160 | resize_long=None, rescale=None, img_normal=TorchvisionNormalize(), hor_flip=False,
161 | crop_size=None, crop_method=None):
162 | super().__init__(img_name_list_path, voc12_root,
163 | resize_long, rescale, img_normal, hor_flip,
164 | crop_size, crop_method)
165 | self.label_list = load_image_label_list_from_npy(self.img_name_list)
166 |
167 | def __getitem__(self, idx):
168 | out = super().__getitem__(idx)
169 |
170 | out['label'] = torch.from_numpy(self.label_list[idx])
171 |
172 | return out
173 |
174 | class VOC12ClassificationDatasetMSF(VOC12ClassificationDataset):
175 |
176 | def __init__(self, img_name_list_path, voc12_root,
177 | img_normal=TorchvisionNormalize(),
178 | scales=(1.0,)):
179 | self.scales = scales
180 |
181 | super().__init__(img_name_list_path, voc12_root, img_normal=img_normal)
182 | self.scales = scales
183 |
184 | def __getitem__(self, idx):
185 | name = self.img_name_list[idx]
186 | name_str = decode_int_filename(name)
187 |
188 | img = imageio.imread(get_img_path(name_str, self.voc12_root))
189 |
190 | ms_img_list = []
191 | for s in self.scales:
192 | if s == 1:
193 | s_img = img
194 | else:
195 | s_img = imutils.pil_rescale(img, s, order=3)
196 | s_img = self.img_normal(s_img)
197 | s_img = imutils.HWC_to_CHW(s_img)
198 | ms_img_list.append(np.stack([s_img, np.flip(s_img, -1)], axis=0))
199 | if len(self.scales) == 1:
200 | ms_img_list = ms_img_list[0]
201 |
202 | out = {"name": name_str, "img": ms_img_list, "size": (img.shape[0], img.shape[1]),
203 | "label": torch.from_numpy(self.label_list[idx])}
204 | return out
205 |
206 | class VOC12SegmentationDataset(Dataset):
207 |
208 | def __init__(self, img_name_list_path, label_dir, crop_size, voc12_root,
209 | rescale=None, img_normal=TorchvisionNormalize(), hor_flip=False,
210 | crop_method = 'random'):
211 |
212 | self.img_name_list = load_img_name_list(img_name_list_path)
213 | self.voc12_root = voc12_root
214 |
215 | self.label_dir = label_dir
216 |
217 | self.rescale = rescale
218 | self.crop_size = crop_size
219 | self.img_normal = img_normal
220 | self.hor_flip = hor_flip
221 | self.crop_method = crop_method
222 |
223 | def __len__(self):
224 | return len(self.img_name_list)
225 |
226 | def __getitem__(self, idx):
227 | name = self.img_name_list[idx]
228 | name_str = decode_int_filename(name)
229 |
230 | img = imageio.imread(get_img_path(name_str, self.voc12_root))
231 | label = imageio.imread(os.path.join(self.label_dir, name_str + '.png'))
232 |
233 | img = np.asarray(img)
234 |
235 | if self.rescale:
236 | img, label = imutils.random_scale((img, label), scale_range=self.rescale, order=(3, 0))
237 |
238 | if self.img_normal:
239 | img = self.img_normal(img)
240 |
241 | if self.hor_flip:
242 | img, label = imutils.random_lr_flip((img, label))
243 |
244 | if self.crop_method == "random":
245 | img, label = imutils.random_crop((img, label), self.crop_size, (0, 255))
246 | else:
247 | img = imutils.top_left_crop(img, self.crop_size, 0)
248 | label = imutils.top_left_crop(label, self.crop_size, 255)
249 |
250 | img = imutils.HWC_to_CHW(img)
251 |
252 | return {'name': name, 'img': img, 'label': label}
253 |
254 | class VOC12AffinityDataset(VOC12SegmentationDataset):
255 | def __init__(self, img_name_list_path, label_dir, crop_size, voc12_root,
256 | indices_from, indices_to,
257 | rescale=None, img_normal=TorchvisionNormalize(), hor_flip=False, crop_method=None):
258 | super().__init__(img_name_list_path, label_dir, crop_size, voc12_root, rescale, img_normal, hor_flip, crop_method=crop_method)
259 |
260 | self.extract_aff_lab_func = GetAffinityLabelFromIndices(indices_from, indices_to)
261 |
262 | def __len__(self):
263 | return len(self.img_name_list)
264 |
265 | def __getitem__(self, idx):
266 | out = super().__getitem__(idx)
267 |
268 | reduced_label = imutils.pil_rescale(out['label'], 0.25, 0)
269 |
270 | out['aff_bg_pos_label'], out['aff_fg_pos_label'], out['aff_neg_label'] = self.extract_aff_lab_func(reduced_label)
271 |
272 | return out
273 |
274 |
--------------------------------------------------------------------------------
/pseudo_labels/voc12/make_cls_labels.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import voc12.dataloader
3 | import numpy as np
4 |
5 | if __name__ == '__main__':
6 |
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument("--train_list", default='train_aug.txt', type=str)
9 | parser.add_argument("--val_list", default='val.txt', type=str)
10 | parser.add_argument("--out", default="cls_labels.npy", type=str)
11 | parser.add_argument("--voc12_root", default="../../../Dataset/VOC2012", type=str)
12 | args = parser.parse_args()
13 |
14 | train_name_list = voc12.dataloader.load_img_name_list(args.train_list)
15 | val_name_list = voc12.dataloader.load_img_name_list(args.val_list)
16 |
17 | train_val_name_list = np.concatenate([train_name_list, val_name_list], axis=0)
18 | label_list = voc12.dataloader.load_image_label_list_from_xml(train_val_name_list, args.voc12_root)
19 |
20 | total_label = np.zeros(20)
21 |
22 | d = dict()
23 | for img_name, label in zip(train_val_name_list, label_list):
24 | d[img_name] = label
25 | total_label += label
26 |
27 | print(total_label)
28 | np.save(args.out, d)
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.1.0
2 | torchvision
3 | dominate
4 | matplotlib>=3.1.1
5 | opencv-python>=4.1.1.26
6 | tensorboard
7 | tqdm>=4.38.0
8 | numpy>=1.16.3
9 | cython
10 | imageio>=2.5.0
11 | scikit-image>=0.15.0
12 | git+https://github.com/lucasb-eyer/pydensecrf.git
13 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import argparse
4 | import torch
5 | import dataloaders
6 | import models
7 | import math
8 | from utils import Logger
9 | from trainer import Trainer
10 | import torch.nn.functional as F
11 | from utils.losses import abCE_loss, CE_loss, consistency_weight, FocalLoss, softmax_helper, get_alpha
12 |
13 |
14 | def get_instance(module, name, config, *args):
15 | # GET THE CORRESPONDING CLASS / FCT
16 | return getattr(module, config[name]['type'])(*args, **config[name]['args'])
17 |
18 | def main(config, resume):
19 | torch.manual_seed(42)
20 | train_logger = Logger()
21 |
22 | # DATA LOADERS
23 | config['train_supervised']['n_labeled_examples'] = config['n_labeled_examples']
24 | config['train_unsupervised']['n_labeled_examples'] = config['n_labeled_examples']
25 | config['train_unsupervised']['use_weak_lables'] = config['use_weak_lables']
26 | supervised_loader = dataloaders.VOC(config['train_supervised'])
27 | unsupervised_loader = dataloaders.VOC(config['train_unsupervised'])
28 | val_loader = dataloaders.VOC(config['val_loader'])
29 | iter_per_epoch = len(unsupervised_loader)
30 |
31 | # SUPERVISED LOSS
32 | if config['model']['sup_loss'] == 'CE':
33 | sup_loss = CE_loss
34 | elif config['model']['sup_loss'] == 'FL':
35 | alpha = get_alpha(supervised_loader) # calculare class occurences
36 | sup_loss = FocalLoss(apply_nonlin = softmax_helper, ignore_index = config['ignore_index'], alpha = alpha, gamma = 2, smooth = 1e-5)
37 | else:
38 | sup_loss = abCE_loss(iters_per_epoch=iter_per_epoch, epochs=config['trainer']['epochs'],
39 | num_classes=val_loader.dataset.num_classes)
40 |
41 | # MODEL
42 | rampup_ends = int(config['ramp_up'] * config['trainer']['epochs'])
43 | cons_w_unsup = consistency_weight(final_w=config['unsupervised_w'], iters_per_epoch=len(unsupervised_loader),
44 | rampup_ends=rampup_ends)
45 |
46 | model = models.CCT(num_classes=val_loader.dataset.num_classes, conf=config['model'],
47 | sup_loss=sup_loss, cons_w_unsup=cons_w_unsup,
48 | weakly_loss_w=config['weakly_loss_w'], use_weak_lables=config['use_weak_lables'],
49 | ignore_index=val_loader.dataset.ignore_index)
50 | print(f'\n{model}\n')
51 |
52 | # TRAINING
53 | trainer = Trainer(
54 | model=model,
55 | resume=resume,
56 | config=config,
57 | supervised_loader=supervised_loader,
58 | unsupervised_loader=unsupervised_loader,
59 | val_loader=val_loader,
60 | iter_per_epoch=iter_per_epoch,
61 | train_logger=train_logger)
62 |
63 | trainer.train()
64 |
65 | if __name__=='__main__':
66 | # PARSE THE ARGS
67 | parser = argparse.ArgumentParser(description='PyTorch Training')
68 | parser.add_argument('-c', '--config', default='configs/config.json',type=str,
69 | help='Path to the config file')
70 | parser.add_argument('-r', '--resume', default=None, type=str,
71 | help='Path to the .pth model checkpoint to resume training')
72 | parser.add_argument('-d', '--device', default=None, type=str,
73 | help='indices of GPUs to enable (default: all)')
74 | parser.add_argument('--local', action='store_true', default=False)
75 | args = parser.parse_args()
76 |
77 | config = json.load(open(args.config))
78 | torch.backends.cudnn.benchmark = True
79 | main(config, args.resume)
80 |
--------------------------------------------------------------------------------
/trainer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import time, random, cv2, sys
3 | from math import ceil
4 | import numpy as np
5 | from itertools import cycle
6 | import torch.nn.functional as F
7 | from torchvision.utils import make_grid
8 | from torchvision import transforms
9 | from base import BaseTrainer
10 | from utils.helpers import colorize_mask
11 | from utils.metrics import eval_metrics, AverageMeter
12 | from tqdm import tqdm
13 | from PIL import Image
14 | from utils.helpers import DeNormalize
15 |
16 |
17 |
18 | class Trainer(BaseTrainer):
19 | def __init__(self, model, resume, config, supervised_loader, unsupervised_loader, iter_per_epoch,
20 | val_loader=None, train_logger=None):
21 | super(Trainer, self).__init__(model, resume, config, iter_per_epoch, train_logger)
22 |
23 | self.supervised_loader = supervised_loader
24 | self.unsupervised_loader = unsupervised_loader
25 | self.val_loader = val_loader
26 |
27 | self.ignore_index = self.val_loader.dataset.ignore_index
28 | self.wrt_mode, self.wrt_step = 'train_', 0
29 | self.log_step = config['trainer'].get('log_per_iter', int(np.sqrt(self.val_loader.batch_size)))
30 | if config['trainer']['log_per_iter']:
31 | self.log_step = int(self.log_step / self.val_loader.batch_size) + 1
32 |
33 | self.num_classes = self.val_loader.dataset.num_classes
34 | self.mode = self.model.module.mode
35 |
36 | # TRANSORMS FOR VISUALIZATION
37 | self.restore_transform = transforms.Compose([
38 | DeNormalize(self.val_loader.MEAN, self.val_loader.STD),
39 | transforms.ToPILImage()])
40 | self.viz_transform = transforms.Compose([
41 | transforms.Resize((400, 400)),
42 | transforms.ToTensor()])
43 |
44 | self.start_time = time.time()
45 |
46 |
47 |
48 | def _train_epoch(self, epoch):
49 | self.html_results.save()
50 |
51 | self.logger.info('\n')
52 | self.model.train()
53 |
54 | if self.mode == 'supervised':
55 | dataloader = iter(self.supervised_loader)
56 | tbar = tqdm(range(len(self.supervised_loader)), ncols=135)
57 | else:
58 | dataloader = iter(zip(cycle(self.supervised_loader), self.unsupervised_loader))
59 | tbar = tqdm(range(len(self.unsupervised_loader)), ncols=135)
60 |
61 | self._reset_metrics()
62 | for batch_idx in tbar:
63 | if self.mode == 'supervised':
64 | (input_l, target_l), (input_ul, target_ul) = next(dataloader), (None, None)
65 | else:
66 | (input_l, target_l), (input_ul, target_ul) = next(dataloader)
67 | input_ul, target_ul = input_ul.cuda(non_blocking=True), target_ul.cuda(non_blocking=True)
68 |
69 | input_l, target_l = input_l.cuda(non_blocking=True), target_l.cuda(non_blocking=True)
70 | self.optimizer.zero_grad()
71 |
72 | total_loss, cur_losses, outputs = self.model(x_l=input_l, target_l=target_l, x_ul=input_ul,
73 | curr_iter=batch_idx, target_ul=target_ul, epoch=epoch-1)
74 | total_loss = total_loss.mean()
75 | total_loss.backward()
76 | self.optimizer.step()
77 |
78 | self._update_losses(cur_losses)
79 | self._compute_metrics(outputs, target_l, target_ul, epoch-1)
80 | logs = self._log_values(cur_losses)
81 |
82 | if batch_idx % self.log_step == 0:
83 | self.wrt_step = (epoch - 1) * len(self.unsupervised_loader) + batch_idx
84 | self._write_scalars_tb(logs)
85 |
86 | if batch_idx % int(len(self.unsupervised_loader)*0.9) == 0:
87 | self._write_img_tb(input_l, target_l, input_ul, target_ul, outputs, epoch)
88 |
89 | del input_l, target_l, input_ul, target_ul
90 | del total_loss, cur_losses, outputs
91 |
92 | tbar.set_description('T ({}) | Ls {:.2f} Lu {:.2f} Lw {:.2f} PW {:.2f} m1 {:.2f} m2 {:.2f}|'.format(
93 | epoch, self.loss_sup.average, self.loss_unsup.average, self.loss_weakly.average,
94 | self.pair_wise.average, self.mIoU_l, self.mIoU_ul))
95 |
96 | self.lr_scheduler.step(epoch=epoch-1)
97 |
98 | return logs
99 |
100 |
101 |
102 | def _valid_epoch(self, epoch):
103 | if self.val_loader is None:
104 | self.logger.warning('Not data loader was passed for the validation step, No validation is performed !')
105 | return {}
106 | self.logger.info('\n###### EVALUATION ######')
107 |
108 | self.model.eval()
109 | self.wrt_mode = 'val'
110 | total_loss_val = AverageMeter()
111 | total_inter, total_union = 0, 0
112 | total_correct, total_label = 0, 0
113 |
114 | tbar = tqdm(self.val_loader, ncols=130)
115 | with torch.no_grad():
116 | val_visual = []
117 | for batch_idx, (data, target) in enumerate(tbar):
118 | target, data = target.cuda(non_blocking=True), data.cuda(non_blocking=True)
119 |
120 | H, W = target.size(1), target.size(2)
121 | up_sizes = (ceil(H / 8) * 8, ceil(W / 8) * 8)
122 | pad_h, pad_w = up_sizes[0] - data.size(2), up_sizes[1] - data.size(3)
123 | data = F.pad(data, pad=(0, pad_w, 0, pad_h), mode='reflect')
124 | output = self.model(data)
125 | output = output[:, :, :H, :W]
126 |
127 | # LOSS
128 | loss = F.cross_entropy(output, target, ignore_index=self.ignore_index)
129 | total_loss_val.update(loss.item())
130 |
131 | correct, labeled, inter, union = eval_metrics(output, target, self.num_classes, self.ignore_index)
132 | total_inter, total_union = total_inter+inter, total_union+union
133 | total_correct, total_label = total_correct+correct, total_label+labeled
134 |
135 | # LIST OF IMAGE TO VIZ (15 images)
136 | if len(val_visual) < 15:
137 | if isinstance(data, list): data = data[0]
138 | target_np = target.data.cpu().numpy()
139 | output_np = output.data.max(1)[1].cpu().numpy()
140 | val_visual.append([data[0].data.cpu(), target_np[0], output_np[0]])
141 |
142 | # PRINT INFO
143 | pixAcc = 1.0 * total_correct / (np.spacing(1) + total_label)
144 | IoU = 1.0 * total_inter / (np.spacing(1) + total_union)
145 | mIoU = IoU.mean()
146 | seg_metrics = {"Pixel_Accuracy": np.round(pixAcc, 3), "Mean_IoU": np.round(mIoU, 3),
147 | "Class_IoU": dict(zip(range(self.num_classes), np.round(IoU, 3)))}
148 |
149 | tbar.set_description('EVAL ({}) | Loss: {:.3f}, PixelAcc: {:.2f}, Mean IoU: {:.2f} |'.format( epoch,
150 | total_loss_val.average, pixAcc, mIoU))
151 |
152 | self._add_img_tb(val_visual, 'val')
153 |
154 | # METRICS TO TENSORBOARD
155 | self.wrt_step = (epoch) * len(self.val_loader)
156 | self.writer.add_scalar(f'{self.wrt_mode}/loss', total_loss_val.average, self.wrt_step)
157 | for k, v in list(seg_metrics.items())[:-1]:
158 | self.writer.add_scalar(f'{self.wrt_mode}/{k}', v, self.wrt_step)
159 |
160 | log = {
161 | 'val_loss': total_loss_val.average,
162 | **seg_metrics
163 | }
164 | self.html_results.add_results(epoch=epoch, seg_resuts=log)
165 | self.html_results.save()
166 |
167 | if (time.time() - self.start_time) / 3600 > 22:
168 | self._save_checkpoint(epoch, save_best=self.improved)
169 | return log
170 |
171 |
172 |
173 | def _reset_metrics(self):
174 | self.loss_sup = AverageMeter()
175 | self.loss_unsup = AverageMeter()
176 | self.loss_weakly = AverageMeter()
177 | self.pair_wise = AverageMeter()
178 | self.total_inter_l, self.total_union_l = 0, 0
179 | self.total_correct_l, self.total_label_l = 0, 0
180 | self.total_inter_ul, self.total_union_ul = 0, 0
181 | self.total_correct_ul, self.total_label_ul = 0, 0
182 | self.mIoU_l, self.mIoU_ul = 0, 0
183 | self.pixel_acc_l, self.pixel_acc_ul = 0, 0
184 | self.class_iou_l, self.class_iou_ul = {}, {}
185 |
186 |
187 |
188 | def _update_losses(self, cur_losses):
189 | if "loss_sup" in cur_losses.keys():
190 | self.loss_sup.update(cur_losses['loss_sup'].mean().item())
191 | if "loss_unsup" in cur_losses.keys():
192 | self.loss_unsup.update(cur_losses['loss_unsup'].mean().item())
193 | if "loss_weakly" in cur_losses.keys():
194 | self.loss_weakly.update(cur_losses['loss_weakly'].mean().item())
195 | if "pair_wise" in cur_losses.keys():
196 | self.pair_wise.update(cur_losses['pair_wise'].mean().item())
197 |
198 |
199 |
200 | def _compute_metrics(self, outputs, target_l, target_ul, epoch):
201 | seg_metrics_l = eval_metrics(outputs['sup_pred'], target_l, self.num_classes, self.ignore_index)
202 | self._update_seg_metrics(*seg_metrics_l, True)
203 | seg_metrics_l = self._get_seg_metrics(True)
204 | self.pixel_acc_l, self.mIoU_l, self.class_iou_l = seg_metrics_l.values()
205 |
206 | if self.mode == 'semi':
207 | seg_metrics_ul = eval_metrics(outputs['unsup_pred'], target_ul, self.num_classes, self.ignore_index)
208 | self._update_seg_metrics(*seg_metrics_ul, False)
209 | seg_metrics_ul = self._get_seg_metrics(False)
210 | self.pixel_acc_ul, self.mIoU_ul, self.class_iou_ul = seg_metrics_ul.values()
211 |
212 |
213 |
214 | def _update_seg_metrics(self, correct, labeled, inter, union, supervised=True):
215 | if supervised:
216 | self.total_correct_l += correct
217 | self.total_label_l += labeled
218 | self.total_inter_l += inter
219 | self.total_union_l += union
220 | else:
221 | self.total_correct_ul += correct
222 | self.total_label_ul += labeled
223 | self.total_inter_ul += inter
224 | self.total_union_ul += union
225 |
226 |
227 |
228 | def _get_seg_metrics(self, supervised=True):
229 | if supervised:
230 | pixAcc = 1.0 * self.total_correct_l / (np.spacing(1) + self.total_label_l)
231 | IoU = 1.0 * self.total_inter_l / (np.spacing(1) + self.total_union_l)
232 | else:
233 | pixAcc = 1.0 * self.total_correct_ul / (np.spacing(1) + self.total_label_ul)
234 | IoU = 1.0 * self.total_inter_ul / (np.spacing(1) + self.total_union_ul)
235 | mIoU = IoU.mean()
236 | return {
237 | "Pixel_Accuracy": np.round(pixAcc, 3),
238 | "Mean_IoU": np.round(mIoU, 3),
239 | "Class_IoU": dict(zip(range(self.num_classes), np.round(IoU, 3)))
240 | }
241 |
242 |
243 |
244 | def _log_values(self, cur_losses):
245 | logs = {}
246 | if "loss_sup" in cur_losses.keys():
247 | logs['loss_sup'] = self.loss_sup.average
248 | if "loss_unsup" in cur_losses.keys():
249 | logs['loss_unsup'] = self.loss_unsup.average
250 | if "loss_weakly" in cur_losses.keys():
251 | logs['loss_weakly'] = self.loss_weakly.average
252 | if "pair_wise" in cur_losses.keys():
253 | logs['pair_wise'] = self.pair_wise.average
254 |
255 | logs['mIoU_labeled'] = self.mIoU_l
256 | logs['pixel_acc_labeled'] = self.pixel_acc_l
257 | if self.mode == 'semi':
258 | logs['mIoU_unlabeled'] = self.mIoU_ul
259 | logs['pixel_acc_unlabeled'] = self.pixel_acc_ul
260 | return logs
261 |
262 |
263 | def _write_scalars_tb(self, logs):
264 | for k, v in logs.items():
265 | if 'class_iou' not in k: self.writer.add_scalar(f'train/{k}', v, self.wrt_step)
266 | for i, opt_group in enumerate(self.optimizer.param_groups):
267 | self.writer.add_scalar(f'train/Learning_rate_{i}', opt_group['lr'], self.wrt_step)
268 | current_rampup = self.model.module.unsup_loss_w.current_rampup
269 | self.writer.add_scalar('train/Unsupervised_rampup', current_rampup, self.wrt_step)
270 |
271 |
272 |
273 | def _add_img_tb(self, val_visual, wrt_mode):
274 | val_img = []
275 | palette = self.val_loader.dataset.palette
276 | for imgs in val_visual:
277 | imgs = [self.restore_transform(i) if (isinstance(i, torch.Tensor) and len(i.shape) == 3)
278 | else colorize_mask(i, palette) for i in imgs]
279 | imgs = [i.convert('RGB') for i in imgs]
280 | imgs = [self.viz_transform(i) for i in imgs]
281 | val_img.extend(imgs)
282 | val_img = torch.stack(val_img, 0)
283 | val_img = make_grid(val_img.cpu(), nrow=val_img.size(0)//len(val_visual), padding=5)
284 | self.writer.add_image(f'{wrt_mode}/inputs_targets_predictions', val_img, self.wrt_step)
285 |
286 |
287 |
288 | def _write_img_tb(self, input_l, target_l, input_ul, target_ul, outputs, epoch):
289 | outputs_l_np = outputs['sup_pred'].data.max(1)[1].cpu().numpy()
290 | targets_l_np = target_l.data.cpu().numpy()
291 | imgs = [[i.data.cpu(), j, k] for i, j, k in zip(input_l, outputs_l_np, targets_l_np)]
292 | self._add_img_tb(imgs, 'supervised')
293 |
294 | if self.mode == 'semi':
295 | outputs_ul_np = outputs['unsup_pred'].data.max(1)[1].cpu().numpy()
296 | targets_ul_np = target_ul.data.cpu().numpy()
297 | imgs = [[i.data.cpu(), j, k] for i, j, k in zip(input_ul, outputs_ul_np, targets_ul_np)]
298 | self._add_img_tb(imgs, 'unsupervised')
299 |
300 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .logger import Logger
--------------------------------------------------------------------------------
/utils/helpers.py:
--------------------------------------------------------------------------------
1 | import os
2 | import requests
3 | import datetime
4 | from torchvision.utils import make_grid
5 | from torchvision import transforms
6 | from torch.utils.tensorboard import SummaryWriter
7 | import torch
8 | import torch.nn as nn
9 | import numpy as np
10 | import math
11 | import PIL
12 | import cv2
13 | from matplotlib import colors
14 | from matplotlib import pyplot as plt
15 | import matplotlib.cm as cmx
16 | from utils import pallete
17 |
18 |
19 | class DeNormalize(object):
20 | def __init__(self, mean, std):
21 | self.mean = mean
22 | self.std = std
23 |
24 | def __call__(self, tensor):
25 | for t, m, s in zip(tensor, self.mean, self.std):
26 | t.mul_(s).add_(m)
27 | return tensor
28 |
29 |
30 | def dir_exists(path):
31 | if not os.path.exists(path):
32 | os.makedirs(path)
33 |
34 |
35 | def initialize_weights(*models):
36 | for model in models:
37 | for m in model.modules():
38 | if isinstance(m, nn.Conv2d):
39 | nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
40 | if m.bias is not None:
41 | nn.init.constant_(m.bias, 0)
42 | elif isinstance(m, nn.BatchNorm2d):
43 | nn.init.constant_(m.weight, 1)
44 | nn.init.constant_(m.bias, 0)
45 | elif isinstance(m, nn.Linear):
46 | nn.init.normal_(m.weight, 0, 0.01)
47 | nn.init.constant_(m.bias, 0)
48 |
49 |
50 | def colorize_mask(mask, palette):
51 | zero_pad = 256 * 3 - len(palette)
52 | for i in range(zero_pad):
53 | palette.append(0)
54 | palette[-3:] = [255, 255, 255]
55 | new_mask = PIL.Image.fromarray(mask.astype(np.uint8)).convert('P')
56 | new_mask.putpalette(palette)
57 | return new_mask
58 |
59 |
60 | def set_trainable_attr(m,b):
61 | m.trainable = b
62 | for p in m.parameters(): p.requires_grad = b
63 |
64 | def apply_leaf(m, f):
65 | c = m if isinstance(m, (list, tuple)) else list(m.children())
66 | if isinstance(m, nn.Module):
67 | f(m)
68 | if len(c)>0:
69 | for l in c:
70 | apply_leaf(l,f)
71 |
72 | def set_trainable(l, b):
73 | apply_leaf(l, lambda m: set_trainable_attr(m,b))
74 |
75 |
--------------------------------------------------------------------------------
/utils/htmlwriter.py:
--------------------------------------------------------------------------------
1 | import dominate
2 | from dominate.tags import *
3 | import os, json, datetime
4 |
5 | class HTML:
6 | def __init__(self, web_dir, exp_name, config, title='seg results', save_name='index', reflesh=0, resume=None):
7 | self.title = title
8 | self.web_dir = web_dir
9 | self.save_name = save_name+'.html'
10 |
11 | if not os.path.exists(self.web_dir):
12 | os.makedirs(self.web_dir)
13 |
14 | html_file = os.path.join(self.web_dir, self.save_name)
15 |
16 | if resume is not None and os.path.isfile(html_file):
17 | self.old_content = open(html_file).read()
18 | else :
19 | self.old_content = None
20 |
21 | self.doc = dominate.document(title=title)
22 | if reflesh > 0:
23 | with self.doc.head:
24 | meta(http_equiv="reflesh", content=str(reflesh))
25 |
26 | date_time = datetime.datetime.now().strftime('%m-%d_%H-%M')
27 | header = f'Experiment name: {exp_name}, Date: {date_time}'
28 | self.add_header(header)
29 | self.add_header('Configs')
30 | self.add_config(config)
31 | with self.doc:
32 | hr()
33 | hr()
34 | self.add_table()
35 |
36 | def add_header(self, str):
37 | with self.doc:
38 | h3(str)
39 |
40 | def add_table(self, border=1):
41 | self.t = table(border=border, style="table-layout: fixed;")
42 | self.doc.add(self.t)
43 |
44 | def add_config(self, config):
45 | t = table(border=1, style="table-layout: fixed;")
46 | self.doc.add(t)
47 | conf_model = config['model']
48 | with t:
49 | with tr():
50 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
51 | td(f'Epochs : {config["trainer"]["epochs"]}')
52 | td(f'Lr scheduler : {config["lr_scheduler"]}')
53 | td(f'Lr : {config["optimizer"]["args"]["lr"]}')
54 | if "datasets" in list(config.keys()): td(f'Datasets : {config["datasets"]}')
55 | td(f"""Decoders : Vat {conf_model["vat"]} Dropout {conf_model["drop"]} Cutout {conf_model["cutout"]}
56 | FeatureNoise {conf_model["feature_noise"]} FeatureDrop {conf_model["feature_drop"]}
57 | ContextMsk {conf_model["context_masking"]} ObjMsk {conf_model["object_masking"]}""")
58 | if "datasets" in list(config.keys()):
59 | self.doc.add(p(json.dumps(config[config["datasets"]], indent=4, sort_keys=True)))
60 | else:
61 | self.doc.add(p(json.dumps(config["train_supervised"], indent=4, sort_keys=True)))
62 |
63 | def add_results(self, epoch, seg_resuts, width=400, domain=None):
64 | para = p(__pretty=False)
65 | with self.t:
66 | with tr():
67 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
68 | td(f'Epoch : {epoch}')
69 | if domain is not None:
70 | td(f'Mean_IoU_{domain} : {seg_resuts[f"Mean_IoU_{domain}"]}')
71 | td(f'PixelAcc_{domain} : {seg_resuts[f"Pixel_Accuracy_{domain}"]}')
72 | td(f'Val Loss_{domain} : {seg_resuts[f"val_loss_{domain}"]}')
73 | else:
74 | td(f'Mean_IoU : {seg_resuts["Mean_IoU"]}')
75 | td(f'PixelAcc : {seg_resuts["Pixel_Accuracy"]}')
76 | td(f'Val Loss : {seg_resuts["val_loss"]}')
77 |
78 |
79 | def save(self):
80 | html_file = os.path.join(self.web_dir, self.save_name)
81 | f = open(html_file, 'w')
82 | if self.old_content is not None:
83 | f.write(self.old_content + self.doc.render())
84 | else:
85 | f.write(self.doc.render())
86 | f.close()
--------------------------------------------------------------------------------
/utils/logger.py:
--------------------------------------------------------------------------------
1 | import json
2 | import logging
3 |
4 | logging.basicConfig(level=logging.INFO, format='')
5 |
6 | class Logger:
7 | """
8 | Training process logger
9 |
10 | Note:
11 | Used by BaseTrainer to save training history.
12 | """
13 | def __init__(self):
14 | self.entries = {}
15 |
16 | def add_entry(self, entry):
17 | self.entries[len(self.entries) + 1] = entry
18 |
19 | def __str__(self):
20 | return json.dumps(self.entries, sort_keys=True, indent=4)
21 |
--------------------------------------------------------------------------------
/utils/losses.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn.functional as F
4 | import torch.nn as nn
5 | from utils import ramps
6 |
7 |
8 |
9 | class consistency_weight(object):
10 | """
11 | ramp_types = ['sigmoid_rampup', 'linear_rampup', 'cosine_rampup', 'log_rampup', 'exp_rampup']
12 | """
13 | def __init__(self, final_w, iters_per_epoch, rampup_starts=0, rampup_ends=7, ramp_type='sigmoid_rampup'):
14 | self.final_w = final_w
15 | self.iters_per_epoch = iters_per_epoch
16 | self.rampup_starts = rampup_starts * iters_per_epoch
17 | self.rampup_ends = rampup_ends * iters_per_epoch
18 | self.rampup_length = (self.rampup_ends - self.rampup_starts)
19 | self.rampup_func = getattr(ramps, ramp_type)
20 | self.current_rampup = 0
21 |
22 | def __call__(self, epoch, curr_iter):
23 | cur_total_iter = self.iters_per_epoch * epoch + curr_iter
24 | if cur_total_iter < self.rampup_starts:
25 | return 0
26 | self.current_rampup = self.rampup_func(cur_total_iter - self.rampup_starts, self.rampup_length)
27 | return self.final_w * self.current_rampup
28 |
29 |
30 | def CE_loss(input_logits, target_targets, ignore_index, temperature=1):
31 | return F.cross_entropy(input_logits/temperature, target_targets, ignore_index=ignore_index)
32 |
33 | # for FocalLoss
34 | def softmax_helper(x):
35 | # copy from: https://github.com/MIC-DKFZ/nnUNet/blob/master/nnunet/utilities/nd_softmax.py
36 | rpt = [1 for _ in range(len(x.size()))]
37 | rpt[1] = x.size(1)
38 | x_max = x.max(1, keepdim=True)[0].repeat(*rpt)
39 | e_x = torch.exp(x - x_max)
40 | return e_x / e_x.sum(1, keepdim=True).repeat(*rpt)
41 |
42 | def get_alpha(supervised_loader):
43 | # get number of classes
44 | num_labels = 0
45 | for image_batch, label_batch in supervised_loader:
46 | label_batch.data[label_batch.data==255] = 0 # pixels of ignore class added to background
47 | l_unique = torch.unique(label_batch.data)
48 | list_unique = [element.item() for element in l_unique.flatten()]
49 | num_labels = max(max(list_unique),num_labels)
50 | num_classes = num_labels + 1
51 | # count class occurrences
52 | alpha = [0 for i in range(num_classes)]
53 | for image_batch, label_batch in supervised_loader:
54 | label_batch.data[label_batch.data==255] = 0 # pixels of ignore class added to background
55 | l_unique = torch.unique(label_batch.data)
56 | list_unique = [element.item() for element in l_unique.flatten()]
57 | l_unique_count = torch.stack([(label_batch.data==x_u).sum() for x_u in l_unique]) # tensor([65920, 36480])
58 | list_count = [count.item() for count in l_unique_count.flatten()]
59 | for index in list_unique:
60 | alpha[index] += list_count[list_unique.index(index)]
61 | return alpha
62 |
63 | # for FocalLoss
64 | def softmax_helper(x):
65 | # copy from: https://github.com/MIC-DKFZ/nnUNet/blob/master/nnunet/utilities/nd_softmax.py
66 | rpt = [1 for _ in range(len(x.size()))]
67 | rpt[1] = x.size(1)
68 | x_max = x.max(1, keepdim=True)[0].repeat(*rpt)
69 | e_x = torch.exp(x - x_max)
70 | return e_x / e_x.sum(1, keepdim=True).repeat(*rpt)
71 |
72 |
73 | class FocalLoss(nn.Module):
74 | """
75 | copy from: https://github.com/Hsuxu/Loss_ToolBox-PyTorch/blob/master/FocalLoss/FocalLoss.py
76 | This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
77 | 'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
78 | Focal_Loss= -1*alpha*(1-pt)*log(pt)
79 | :param num_class:
80 | :param alpha: (tensor) 3D or 4D the scalar factor for this criterion
81 | :param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
82 | focus on hard misclassified example
83 | :param smooth: (float,double) smooth value when cross entropy
84 | :param balance_index: (int) balance class index, should be specific when alpha is float
85 | :param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
86 | """
87 |
88 | def __init__(self, apply_nonlin=None, ignore_index = None, alpha=None, gamma=2, balance_index=0, smooth=1e-5, size_average=True):
89 | super(FocalLoss, self).__init__()
90 | self.apply_nonlin = apply_nonlin
91 | self.alpha = alpha
92 | self.gamma = gamma
93 | self.balance_index = balance_index
94 | self.smooth = smooth
95 | self.size_average = size_average
96 |
97 | if self.smooth is not None:
98 | if self.smooth < 0 or self.smooth > 1.0:
99 | raise ValueError('smooth value should be in [0,1]')
100 |
101 | def forward(self, logit, target):
102 | if self.apply_nonlin is not None:
103 | logit = self.apply_nonlin(logit)
104 | num_class = logit.shape[1]
105 |
106 | if logit.dim() > 2:
107 | # N,C,d1,d2 -> N,C,m (m=d1*d2*...)
108 | logit = logit.view(logit.size(0), logit.size(1), -1)
109 | logit = logit.permute(0, 2, 1).contiguous()
110 | logit = logit.view(-1, logit.size(-1))
111 | target = torch.squeeze(target, 1)
112 | target = target.view(-1, 1)
113 |
114 | valid_mask = None
115 | if self.ignore_index is not None:
116 | valid_mask = target != self.ignore_index
117 | target = target * valid_mask
118 |
119 | alpha = self.alpha
120 |
121 | if alpha is None:
122 | alpha = torch.ones(num_class, 1)
123 | elif isinstance(alpha, (list, np.ndarray)):
124 | assert len(alpha) == num_class
125 | alpha = torch.FloatTensor(alpha).view(num_class, 1)
126 | alpha = alpha / alpha.sum()
127 | alpha = 1/alpha # inverse of class frequency
128 | elif isinstance(alpha, float):
129 | alpha = torch.ones(num_class, 1)
130 | alpha = alpha * (1 - self.alpha)
131 | alpha[self.balance_index] = self.alpha
132 |
133 | else:
134 | raise TypeError('Not support alpha type')
135 |
136 | if alpha.device != logit.device:
137 | alpha = alpha.to(logit.device)
138 |
139 | idx = target.cpu().long()
140 |
141 | one_hot_key = torch.FloatTensor(target.size(0), num_class).zero_()
142 |
143 | # to resolve error in idx in scatter_
144 | idx[idx==225]=0
145 |
146 | one_hot_key = one_hot_key.scatter_(1, idx, 1)
147 | if one_hot_key.device != logit.device:
148 | one_hot_key = one_hot_key.to(logit.device)
149 |
150 | if self.smooth:
151 | one_hot_key = torch.clamp(
152 | one_hot_key, self.smooth/(num_class-1), 1.0 - self.smooth)
153 | pt = (one_hot_key * logit).sum(1) + self.smooth
154 | logpt = pt.log()
155 |
156 | gamma = self.gamma
157 |
158 | alpha = alpha[idx]
159 | alpha = torch.squeeze(alpha)
160 | loss = -1 * alpha * torch.pow((1 - pt), gamma) * logpt
161 |
162 | if valid_mask is not None:
163 | loss = loss * valid_mask.squeeze()
164 |
165 | if self.size_average:
166 | loss = loss.mean()
167 | else:
168 | loss = loss.sum()
169 | return loss
170 |
171 |
172 | class abCE_loss(nn.Module):
173 | """
174 | Annealed-Bootstrapped cross-entropy loss
175 | """
176 | def __init__(self, iters_per_epoch, epochs, num_classes, weight=None,
177 | reduction='mean', thresh=0.7, min_kept=1, ramp_type='log_rampup'):
178 | super(abCE_loss, self).__init__()
179 | self.weight = torch.FloatTensor(weight) if weight is not None else weight
180 | self.reduction = reduction
181 | self.thresh = thresh
182 | self.min_kept = min_kept
183 | self.ramp_type = ramp_type
184 |
185 | if ramp_type is not None:
186 | self.rampup_func = getattr(ramps, ramp_type)
187 | self.iters_per_epoch = iters_per_epoch
188 | self.num_classes = num_classes
189 | self.start = 1/num_classes
190 | self.end = 0.9
191 | self.total_num_iters = (epochs - (0.6 * epochs)) * iters_per_epoch
192 |
193 | def threshold(self, curr_iter, epoch):
194 | cur_total_iter = self.iters_per_epoch * epoch + curr_iter
195 | current_rampup = self.rampup_func(cur_total_iter, self.total_num_iters)
196 | return current_rampup * (self.end - self.start) + self.start
197 |
198 | def forward(self, predict, target, ignore_index, curr_iter, epoch):
199 | batch_kept = self.min_kept * target.size(0)
200 | prob_out = F.softmax(predict, dim=1)
201 | tmp_target = target.clone()
202 | tmp_target[tmp_target == ignore_index] = 0
203 | prob = prob_out.gather(1, tmp_target.unsqueeze(1))
204 | mask = target.contiguous().view(-1, ) != ignore_index
205 | sort_prob, sort_indices = prob.contiguous().view(-1, )[mask].contiguous().sort()
206 |
207 | if self.ramp_type is not None:
208 | thresh = self.threshold(curr_iter=curr_iter, epoch=epoch)
209 | else:
210 | thresh = self.thresh
211 |
212 | min_threshold = sort_prob[min(batch_kept, sort_prob.numel() - 1)] if sort_prob.numel() > 0 else 0.0
213 | threshold = max(min_threshold, thresh)
214 | loss_matrix = F.cross_entropy(predict, target,
215 | weight=self.weight.to(predict.device) if self.weight is not None else None,
216 | ignore_index=ignore_index, reduction='none')
217 | loss_matirx = loss_matrix.contiguous().view(-1, )
218 | sort_loss_matirx = loss_matirx[mask][sort_indices]
219 | select_loss_matrix = sort_loss_matirx[sort_prob < threshold]
220 | if self.reduction == 'sum' or select_loss_matrix.numel() == 0:
221 | return select_loss_matrix.sum()
222 | elif self.reduction == 'mean':
223 | return select_loss_matrix.mean()
224 | else:
225 | raise NotImplementedError('Reduction Error!')
226 |
227 |
228 |
229 | def softmax_mse_loss(inputs, targets, conf_mask=False, threshold=None, use_softmax=False):
230 | assert inputs.requires_grad == True and targets.requires_grad == False
231 | assert inputs.size() == targets.size() # (batch_size * num_classes * H * W)
232 | inputs = F.softmax(inputs, dim=1)
233 | if use_softmax:
234 | targets = F.softmax(targets, dim=1)
235 |
236 | if conf_mask:
237 | loss_mat = F.mse_loss(inputs, targets, reduction='none')
238 | mask = (targets.max(1)[0] > threshold)
239 | loss_mat = loss_mat[mask.unsqueeze(1).expand_as(loss_mat)]
240 | if loss_mat.shape.numel() == 0: loss_mat = torch.tensor([0.]).to(inputs.device)
241 | return loss_mat.mean()
242 | else:
243 | return F.mse_loss(inputs, targets, reduction='mean') # take the mean over the batch_size
244 |
245 |
246 | def softmax_kl_loss(inputs, targets, conf_mask=False, threshold=None, use_softmax=False):
247 | assert inputs.requires_grad == True and targets.requires_grad == False
248 | assert inputs.size() == targets.size()
249 | input_log_softmax = F.log_softmax(inputs, dim=1)
250 | if use_softmax:
251 | targets = F.softmax(targets, dim=1)
252 |
253 | if conf_mask:
254 | loss_mat = F.kl_div(input_log_softmax, targets, reduction='none')
255 | mask = (targets.max(1)[0] > threshold)
256 | loss_mat = loss_mat[mask.unsqueeze(1).expand_as(loss_mat)]
257 | if loss_mat.shape.numel() == 0: loss_mat = torch.tensor([0.]).to(inputs.device)
258 | return loss_mat.sum() / mask.shape.numel()
259 | else:
260 | return F.kl_div(input_log_softmax, targets, reduction='mean')
261 |
262 |
263 | def softmax_js_loss(inputs, targets, **_):
264 | assert inputs.requires_grad == True and targets.requires_grad == False
265 | assert inputs.size() == targets.size()
266 | epsilon = 1e-5
267 |
268 | M = (F.softmax(inputs, dim=1) + targets) * 0.5
269 | kl1 = F.kl_div(F.log_softmax(inputs, dim=1), M, reduction='mean')
270 | kl2 = F.kl_div(torch.log(targets+epsilon), M, reduction='mean')
271 | return (kl1 + kl2) * 0.5
272 |
273 |
274 |
275 | def pair_wise_loss(unsup_outputs, size_average=True, nbr_of_pairs=8):
276 | """
277 | Pair-wise loss in the sup. mat.
278 | """
279 | if isinstance(unsup_outputs, list):
280 | unsup_outputs = torch.stack(unsup_outputs)
281 |
282 | # Only for a subset of the aux outputs to reduce computation and memory
283 | unsup_outputs = unsup_outputs[torch.randperm(unsup_outputs.size(0))]
284 | unsup_outputs = unsup_outputs[:nbr_of_pairs]
285 |
286 | temp = torch.zeros_like(unsup_outputs) # For grad purposes
287 | for i, u in enumerate(unsup_outputs):
288 | temp[i] = F.softmax(u, dim=1)
289 | mean_prediction = temp.mean(0).unsqueeze(0) # Mean over the auxiliary outputs
290 | pw_loss = ((temp - mean_prediction)**2).mean(0) # Variance
291 | pw_loss = pw_loss.sum(1) # Sum over classes
292 | if size_average:
293 | return pw_loss.mean()
294 | return pw_loss.sum()
295 |
296 |
--------------------------------------------------------------------------------
/utils/lr_scheduler.py:
--------------------------------------------------------------------------------
1 | import math
2 | from torch.optim.lr_scheduler import _LRScheduler
3 |
4 |
5 | class Step(_LRScheduler):
6 | def __init__(self, optimizer, num_epochs, steps=2, gamma=0.1, last_epoch=-1, **_):
7 | self.step_size = num_epochs // steps
8 | self.num_epochs = num_epochs
9 | self.gamma = gamma
10 | super(Step, self).__init__(optimizer, last_epoch)
11 |
12 | def get_lr(self):
13 | if self.step_size != 0:
14 | return [base_lr * self.gamma ** (self.last_epoch // self.step_size)
15 | for base_lr in self.base_lrs]
16 | return self.base_lrs
17 |
18 | class Poly(_LRScheduler):
19 | def __init__(self, optimizer, num_epochs, iters_per_epoch, warmup_epochs=0, last_epoch=-1):
20 | self.iters_per_epoch = iters_per_epoch
21 | self.cur_iter = 0
22 | self.N = num_epochs * iters_per_epoch
23 | self.warmup_iters = warmup_epochs * iters_per_epoch
24 | super(Poly, self).__init__(optimizer, last_epoch)
25 |
26 | def get_lr(self):
27 | T = self.last_epoch * self.iters_per_epoch + self.cur_iter
28 | factor = pow((1 - 1.0 * T / self.N), 0.9)
29 | if self.warmup_iters > 0 and T < self.warmup_iters:
30 | factor = 1.0 * T / self.warmup_iters
31 |
32 | self.cur_iter %= self.iters_per_epoch
33 | self.cur_iter += 1
34 | assert factor >= 0, 'error in lr_scheduler'
35 | return [base_lr * factor for base_lr in self.base_lrs]
36 |
37 | class OneCycle(_LRScheduler):
38 | def __init__(self, optimizer, num_epochs, iters_per_epoch=0, last_epoch=-1,
39 | momentums = (0.85, 0.95), div_factor = 25, phase1=0.3):
40 | self.iters_per_epoch = iters_per_epoch
41 | self.cur_iter = 0
42 | self.N = num_epochs * iters_per_epoch
43 | self.phase1_iters = int(self.N * phase1)
44 | self.phase2_iters = (self.N - self.phase1_iters)
45 | self.momentums = momentums
46 | self.mom_diff = momentums[1] - momentums[0]
47 |
48 | self.low_lrs = [opt_grp['lr']/div_factor for opt_grp in optimizer.param_groups]
49 | self.final_lrs = [opt_grp['lr']/(div_factor * 1e4) for opt_grp in optimizer.param_groups]
50 | super(OneCycle, self).__init__(optimizer, last_epoch)
51 |
52 | def get_lr(self):
53 | T = self.last_epoch * self.iters_per_epoch + self.cur_iter
54 | self.cur_iter %= self.iters_per_epoch
55 | self.cur_iter += 1
56 |
57 | # Going from base_lr / 25 -> base_lr
58 | if T <= self.phase1_iters:
59 | cos_anneling = (1 + math.cos(math.pi * T / self.phase1_iters)) / 2
60 | for i in range(len(self.optimizer.param_groups)):
61 | self.optimizer.param_groups[i]['momentum'] = self.momentums[0] + self.mom_diff * cos_anneling
62 |
63 | return [base_lr - (base_lr - low_lr) * cos_anneling
64 | for base_lr, low_lr in zip(self.base_lrs, self.low_lrs)]
65 |
66 | # Going from base_lr -> base_lr / (25e4)
67 | T -= self.phase1_iters
68 | cos_anneling = (1 + math.cos(math.pi * T / self.phase2_iters)) / 2
69 | for i in range(len(self.optimizer.param_groups)):
70 | self.optimizer.param_groups[i]['momentum'] = self.momentums[1] - self.mom_diff * cos_anneling
71 | return [final_lr + (base_lr - final_lr) * cos_anneling
72 | for base_lr, final_lr in zip(self.base_lrs, self.final_lrs)]
73 |
--------------------------------------------------------------------------------
/utils/metrics.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn.functional as F
4 | import torch.nn as nn
5 |
6 | class AverageMeter(object):
7 | """Computes and stores the average and current value"""
8 | def __init__(self):
9 | self.initialized = False
10 | self.val = 0
11 | self.avg = 0
12 | self.sum = 0
13 | self.count = 0
14 |
15 | def initialize(self, val, weight):
16 | self.val = val
17 | self.avg = val
18 | self.sum = np.multiply(val, weight)
19 | self.count = weight
20 | self.initialized = True
21 |
22 | def update(self, val, weight=1):
23 | if not self.initialized:
24 | self.initialize(val, weight)
25 | else:
26 | self.add(val, weight)
27 |
28 | def add(self, val, weight):
29 | self.val = val
30 | self.sum = np.add(self.sum, np.multiply(val, weight))
31 | self.count = self.count + weight
32 | self.avg = self.sum / self.count
33 |
34 | @property
35 | def value(self):
36 | return self.val
37 |
38 | @property
39 | def average(self):
40 | return np.round(self.avg, 5)
41 |
42 |
43 | def batch_pix_accuracy(output, target):
44 | _, predict = torch.max(output, 1)
45 |
46 | predict = predict.int() + 1
47 | target = target.int() + 1
48 |
49 | pixel_labeled = (target > 0).sum()
50 | pixel_correct = ((predict == target)*(target > 0)).sum()
51 | assert pixel_correct <= pixel_labeled, "Correct area should be smaller than Labeled"
52 | return pixel_correct.cpu().numpy(), pixel_labeled.cpu().numpy()
53 |
54 |
55 | def batch_intersection_union(output, target, num_class):
56 | _, predict = torch.max(output, 1)
57 | predict = predict + 1
58 | target = target + 1
59 |
60 | predict = predict * (target > 0).long()
61 | intersection = predict * (predict == target).long()
62 |
63 | area_inter = torch.histc(intersection.float(), bins=num_class, max=num_class, min=1)
64 | area_pred = torch.histc(predict.float(), bins=num_class, max=num_class, min=1)
65 | area_lab = torch.histc(target.float(), bins=num_class, max=num_class, min=1)
66 | area_union = area_pred + area_lab - area_inter
67 | assert (area_inter <= area_union).all(), "Intersection area should be smaller than Union area"
68 | return area_inter.cpu().numpy(), area_union.cpu().numpy()
69 |
70 |
71 | def eval_metrics(output, target, num_classes, ignore_index):
72 | target = target.clone()
73 | target[target == ignore_index] = -1
74 | correct, labeled = batch_pix_accuracy(output.data, target)
75 | inter, union = batch_intersection_union(output.data, target, num_classes)
76 | return [np.round(correct, 5), np.round(labeled, 5), np.round(inter, 5), np.round(union, 5)]
77 |
78 |
79 | # ref https://github.com/CSAILVision/sceneparsing/blob/master/evaluationCode/utils_eval.py
80 | def pixel_accuracy(output, target):
81 | output = np.asarray(output)
82 | target = np.asarray(target)
83 | pixel_labeled = np.sum(target > 0)
84 | pixel_correct = np.sum((output == target) * (target > 0))
85 | return pixel_correct, pixel_labeled
86 |
87 |
88 | def inter_over_union(output, target, num_class):
89 | output = np.asarray(output) + 1
90 | target = np.asarray(target) + 1
91 | output = output * (target > 0)
92 |
93 | intersection = output * (output == target)
94 | area_inter, _ = np.histogram(intersection, bins=num_class, range=(1, num_class))
95 | area_pred, _ = np.histogram(output, bins=num_class, range=(1, num_class))
96 | area_lab, _ = np.histogram(target, bins=num_class, range=(1, num_class))
97 | area_union = area_pred + area_lab - area_inter
98 | return area_inter, area_union
--------------------------------------------------------------------------------
/utils/pallete.py:
--------------------------------------------------------------------------------
1 |
2 | def get_voc_pallete(num_classes):
3 | n = num_classes
4 | pallete = [0]*(n*3)
5 | for j in range(0,n):
6 | lab = j
7 | pallete[j*3+0] = 0
8 | pallete[j*3+1] = 0
9 | pallete[j*3+2] = 0
10 | i = 0
11 | while (lab > 0):
12 | pallete[j*3+0] |= (((lab >> 0) & 1) << (7-i))
13 | pallete[j*3+1] |= (((lab >> 1) & 1) << (7-i))
14 | pallete[j*3+2] |= (((lab >> 2) & 1) << (7-i))
15 | i = i + 1
16 | lab >>= 3
17 | return pallete
18 |
--------------------------------------------------------------------------------
/utils/ramps.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def sigmoid_rampup(current, rampup_length):
4 | if rampup_length == 0:
5 | return 1.0
6 | current = np.clip(current, 0.0, rampup_length)
7 | phase = 1.0 - current / rampup_length
8 | return float(np.exp(-5.0 * phase * phase))
9 |
10 | def linear_rampup(current, rampup_length):
11 | assert current >= 0 and rampup_length >= 0
12 | if current >= rampup_length:
13 | return 1.0
14 | return current / rampup_length
15 |
16 | def cosine_rampup(current, rampup_length):
17 | if rampup_length == 0:
18 | return 1.0
19 | current = np.clip(current, 0.0, rampup_length)
20 | return 1 - float(.5 * (np.cos(np.pi * current / rampup_length) + 1))
21 |
22 | def log_rampup(current, rampup_length):
23 | if rampup_length == 0:
24 | return 1.0
25 | current = np.clip(current, 0.0, rampup_length)
26 | return float(1- np.exp(-5.0 * current / rampup_length))
27 |
28 | def exp_rampup(current, rampup_length):
29 | if rampup_length == 0:
30 | return 1.0
31 | current = np.clip(current, 0.0, rampup_length)
32 | return float(np.exp(5.0 * (current / rampup_length - 1)))
33 |
--------------------------------------------------------------------------------