├── notes
├── adversarial_examples.md
├── ambient_sound.md
├── PPGN.md
├── gn_physics_engine.md
├── black_box_attack.md
├── info_GAN.md
├── perceptual_similarity.md
├── adversarial_intro.md
├── MAML.md
├── world_models.md
├── synthesizing_inputs_for_GAN.md
├── soundnet.md
└── outsider_tour_of_RL_1.md
└── README.md
/notes/adversarial_examples.md:
--------------------------------------------------------------------------------
1 |
2 | [Breaking Linear Classifiers on ImageNet](http://karpathy.github.io/2015/03/30/breaking-convnets/) by Karpathy is a really good start point for this topic.
3 |
--------------------------------------------------------------------------------
/notes/ambient_sound.md:
--------------------------------------------------------------------------------
1 | ## [Ambient Sound Provides Supervision for Visual Learning]()
2 |
3 |
4 | ### Key Points
5 | - Ambient sounds can serve as a supervisory signal for learning visual models.
6 | - By predicting sound associated with a video frame, network learns a representation that conveys information about objects and scenes.
7 | - The correspondence between video and sound is free, we don't have to collect data.
8 |
9 | ### Method
10 | - Clustering
11 | - Binary
12 |
13 | ### Exp
14 |
15 | Image features learnt through this paper's sound-prediction task can be used for object and scene recognition.
16 |
17 |
18 | ### Thought
19 |
20 |
21 | ### Questions
22 |
--------------------------------------------------------------------------------
/notes/PPGN.md:
--------------------------------------------------------------------------------
1 | ## [Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space](https://arxiv.org/abs/1612.00005)
2 |
3 | This paper introduced a framework bases on activation maximization and composed of
4 |
5 | 1. A generator network G that is capable of drawing a wide range of image types
6 | 2. A **replacable** condition network C that tells the gnerator what to draw
7 |
8 | The proposed model is able to generate images for all 1000 ImageNet classes or become a text-to-image model conditioning on caption **without** retraining G.
9 |
10 | ### Key Points
11 | -
12 |
13 | ### Model
14 |
15 |
16 | ### Exp
17 |
18 |
19 | ### Thought
20 |
21 | ### Questions
22 |
23 |
--------------------------------------------------------------------------------
/notes/gn_physics_engine.md:
--------------------------------------------------------------------------------
1 | ## [Graph Networks as Learnable Physics Engines for Inference and Control](https://arxiv.org/abs/1806.01242)
2 |
3 | This paper introduced GN-based forward and inference models, and demonstrate their usage with MPC to solve control tasks.
4 |
5 | ### Key Points
6 | - GN is an object-based representation of the physics system and hence leads to combinatorial generalization.
7 | - Inference model can be used to perform "implicit" system identification, which in turn improves forward model's accuracy.
8 |
9 | ### Exp
10 | - They demonstrate results on DeepMind control suite.
11 |
12 | ### Thought
13 | - Object-based model-based RL looks promising.
14 |
15 | ### Questions
16 |
17 | - How to solve forward model's compound error? (maybe a simple bi-directional solution may help)
18 |
--------------------------------------------------------------------------------
/notes/black_box_attack.md:
--------------------------------------------------------------------------------
1 | ## [Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples](https://arxiv.org/abs/1602.02697)
2 |
3 |
4 | ### Key Points
5 | - This paper attacks against black-box DNN classifiers without knowledge of the classifier training data or model.
6 | - The black-box attack evades defenses proposed in the literature because the substitute trained by the adversary is unaffected by defenses deployed on
7 | the targeted oracle model to reduce its vulnerability
8 |
9 | ### Method
10 | Since adversarial examples transfer between architectures, we can
11 |
12 | 1. Substitute Model Training: learn a substitute DNN approximating the target using a dataset constructed with synthetic inputs and labels observed from the oracle
13 | 2. Adversarial Sample Crafting: craft adversarial example using the substitute trained by first step
14 |
15 | Generally, the goal of the adversary is to produce a **minimally** altered, i.e., imperceptible, version of input which will be misclassifyed by target model.
16 |
17 | ### Exp
18 |
19 |
20 | ### Thought
21 |
22 |
23 | ### Questions
24 |
--------------------------------------------------------------------------------
/notes/info_GAN.md:
--------------------------------------------------------------------------------
1 | ## [InforGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets]()
2 |
3 | ### Preliminaries
4 | Mutual information `I(X;Y)`, measures the **amount of information** learned from knowledge of random variable Y about the other random variable X.
5 |
6 | It can be expressed as the difference of two entropies terms:
7 | ```
8 | I(X;Y) = H(X) - H(X|Y) = H(Y) - H(Y|X)
9 | ```
10 |
11 | ### Problem
12 |
13 | Normal GANs use a simple factored continuous input noise vector z, while imposing no restrictions on the manner in which the generator may use this noise. As a result, it is possible that the noise will be used by the generator in a highly entangled way, causing the individual dimensions of z to not correspond to semantic features of the data.
14 |
15 | ### Key Points
16 |
17 |
18 |
19 | ### Model
20 |
21 |
22 | ### Exp
23 |
24 |
25 | ### Thought
26 |
27 | ### Questions
28 | - What does it mean by "even though it is easy to construct perfect generative models with arbitrarily bad representations"?
29 |
30 | ### References
31 | http://www.inference.vc/infogan-variational-bound-on-mutual-information-twice
32 |
--------------------------------------------------------------------------------
/notes/perceptual_similarity.md:
--------------------------------------------------------------------------------
1 | ## [Generating Images with Perceptual Similarity based on Deep Networks]()
2 |
3 | This paper proposed a class of loss functions applicable to image generation that are based on distance in feature spaces:
4 |
5 | 
6 |
7 | ### Key Points
8 | - Using only l2 loss in image space yields over-smoothed results since it leads to averaging all likely locations of details.
9 | - L_feat measures the distance in suitable feature space and therefore preserves distribution of fine details instead of exact locations.
10 | - Using only L_feat yields bad results since feature representations are contractive. Many non-natural images also mapped to the same feature vector.
11 | - By introducing a natural image prior - GAN, we can make sure that samples lie on the natural image manifold.
12 |
13 | ### Model
14 |
15 | 
16 |
17 | ### Exp
18 | - Training Autoencoder
19 | - Generate images using VAE
20 | - Invert feature
21 |
22 | ### Thought
23 | I think the experiment section is a little complicated to comprehend. However, the proposed loss seems really promising and can be applied to many tasks related to image generation.
24 |
25 | ### Questions
26 | - Section 4.2 & 4.3 are hard to follow for me, need to pay more attention in the future
27 |
--------------------------------------------------------------------------------
/notes/adversarial_intro.md:
--------------------------------------------------------------------------------
1 | ## [A Brief Introduction to Adversarial Examples](http://people.csail.mit.edu/madry/lab/blog/adversarial/2018/07/06/adversarial_intro/)
2 |
3 | The authors briefly introduce the definitoin of adversarial examples and **why it's really a thing**.
4 |
5 | ### Key Points
6 |
7 | - Beyond security, studying adversarial examples can provide us insight on
8 | - Robustness of ML-based system
9 | - Difference between ML-based system and human. (e.g., many models have achieved human-surpassing performance but not robust to small perturbation, which means that ML-based system works very differently compared to human.)
10 | - Adversarial examples are beyond image classification. They also appear in other important applications such as speech recognition, question answering system.
11 |
12 | ### My two cents
13 | I really like how this post motivates why studying adversarial examples is important beyond security concerns. In addition, the authors enumerate lots of interesting examples with references (e.g., [Do neural nets dream of electric sheep?](http://aiweirdness.com/post/171451900302/do-neural-nets-dream-of-electric-sheep), [The Shallowness of Google Translate](https://www.theatlantic.com/technology/archive/2018/01/the-shallowness-of-google-translate/551570/), and [Adversarial examples in the context of GMail spam filtering](https://elie.net/blog/ai/attacks-against-machine-learning-an-overview)) to illustrate their argument, which makes their points really convincing.
14 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # paper-notes
2 |
3 | ### 2018 / 12
4 | - [Combining Physical Simulators and Object-Based Networks for Control](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/sain.md)
5 | - [Graph Networks as Learnable Physics Engines for Inference and Control](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/gn_physics_engine.md)
6 |
7 |
8 | ### 2018 / 08
9 | - [World Models](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/world_models.md)
10 |
11 | ### 2018 / 07
12 | - [Part 1 of An Outsider’s Tour of Reinforcement Learning - Make It Happen](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/outsider_tour_of_RL_1.md)
13 | - [A Brief Introduction to Adversarial Examples](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/adversarial_intro.md)
14 |
15 | ### 2018 / 06
16 | - Investigating Human Priors For Playing Video Games
17 |
18 | ### Before 2018
19 |
20 | - [Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/MAML.md)
21 | - [SoundNet: Learning Sound Representations from Unlabeled Video](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/soundnet.md)
22 | - [Synthesizing the preferred inputs for neurons in neural networks via deep generator networks](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/synthesizing_inputs_for_GAN.md)
23 | - [Generating Images with Perceptual Similarity based on Deep Networks](https://github.com/yenchenlin/deep-learning-paper-notes/blob/master/notes/perceptual_similarity.md)
24 |
25 |
--------------------------------------------------------------------------------
/notes/MAML.md:
--------------------------------------------------------------------------------
1 | ## [Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks](https://arxiv.org/abs/1703.03400)
2 |
3 | The authors propose an algorithm for meta-learning that is compatible with any model trained with gradient descent, and show that it works on various domain including supervised learning and reinforcement learning. This is done by explicitly train the network such that a small number of gradient steps with a small amount of training data from a new task will produce good generalization performance on that task.
4 |
5 | ### Key Points
6 |
7 | - MAML is actually finding a good **initialization** of model parameters for several tasks.
8 | - Good initialization of parameters means that it can achieve good performance on several tasks with small number of gradient steps.
9 |
10 | ### Method
11 | - Simultaneously optimize the **initialization** of model parameters of different meta-training tasks, hoping that it can quickly adapt to new meta-testing tasks.
12 |
13 | 
14 |
15 | - Training procedure:
16 |
17 | 
18 |
19 |
20 |
21 | ### Exp
22 |
23 | - It acheived performance that is comparable to the state-of-the-art on classification/regression/reinforcement learning tasks.
24 |
25 | ### Thought
26 | I think the experiments are thorough since they proved that this technique can be applied to both supervised and reinforcement learning. However, the method is not novel provided that [Optimization a A Midel For Few-shot Learning](https://openreview.net/pdf?id=rJY0-Kcll) already proposed to learn initialization of parameters.
27 |
--------------------------------------------------------------------------------
/notes/world_models.md:
--------------------------------------------------------------------------------
1 | ## [World Models](https://arxiv.org/abs/1803.10122)
2 |
3 | The author proposed a model-based method to learn policy. Specifically, the system consists of three components:
4 |
5 | 1. Encoder (V)
6 | 2. Future predictor (M)
7 | 3. Controller (C)
8 |
9 | 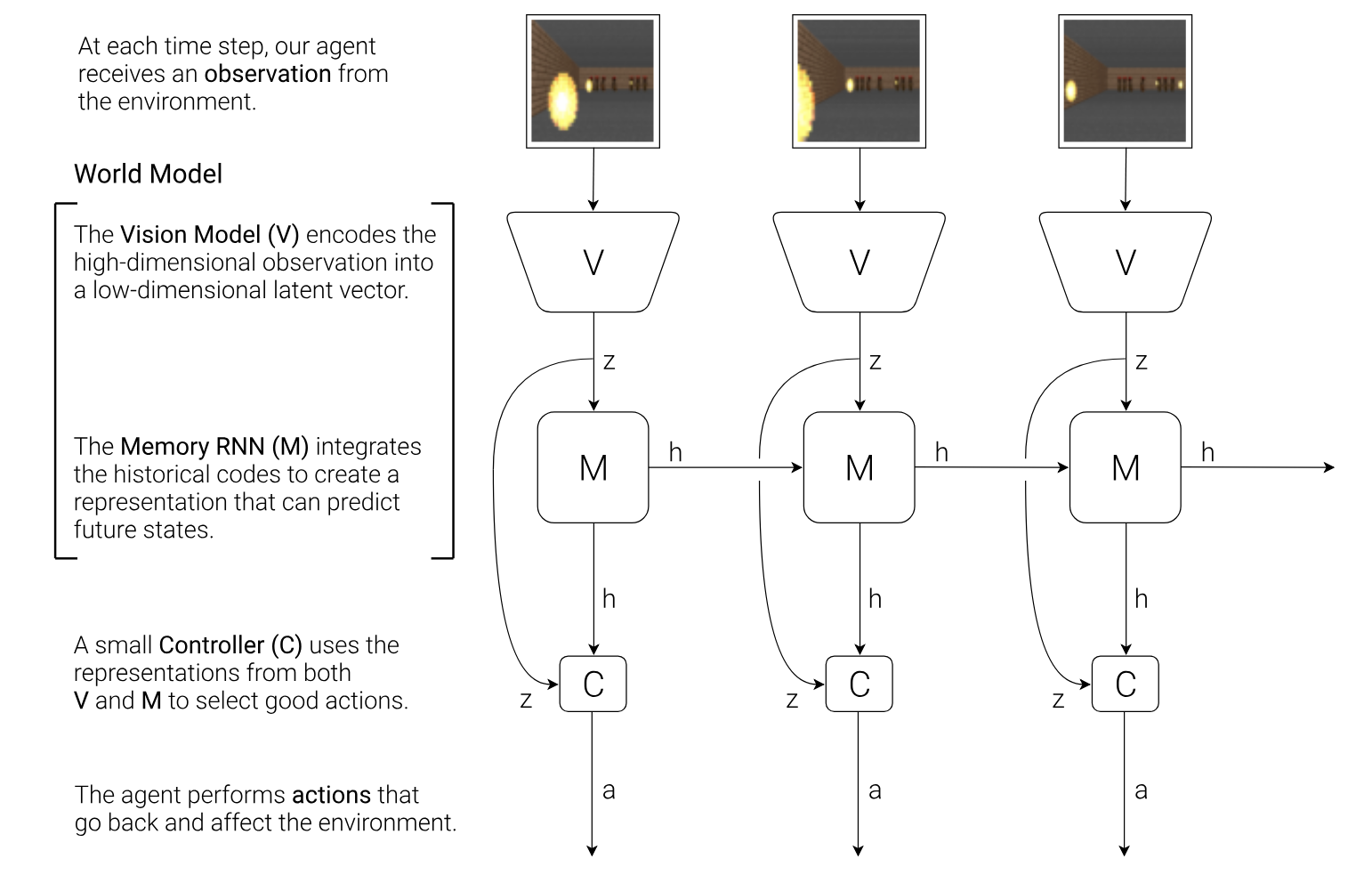 10 |
11 | The author shows that it's possible to train a controller in a simulated environment.
12 |
13 | ### Key Points
14 |
15 | - By keeping model capacity of V and M large, we can learn a compact feature space (i.e., dimension 32) for C and thus being able to apply ES to get good policy.
16 |
17 |
18 |
19 | ### Method
20 |
21 | 1. Randomly collect trajectories in the environment.
22 | 2. Train a VAE for every states.
23 | 3. Use the encoder of VAE, V, to encode the states z = V(s). Then, train a predictive model, P(z_t+1 | z_t, h_t, a_t).
24 | 4. Use ES to evolve a controller which takes [z_t h_t] as input and outputs an action a_t.
25 |
26 | If we want to train the agent to entirely in **dream**, we can use the predictive model as a simulator and
27 |
28 |
29 | ### Exp
30 |
31 | The author performs the experiments in two domains:
32 |
33 | - Racing Car
34 | - Vizdoom
35 |
36 | In Racing Car, the author shows that World Models achieve state of the art performance against RL methods such as PPO.
37 |
38 | In Vizdoom, the authore went one step further to train an agent entirely in its **dream** and then apply the controller back to real world environment. It turns out it can score even higher score in real environments compared to imperfect simulated environment by M.
39 |
40 | ### Thought
41 |
42 | I think the paper is well-presented and shows lots of cool findings. However, it's obvious that unsupervised learning of V and M cannot learn really compact features for the downstream specific task that C is addressing since there is no reward. If we can backprop the reward signal back to both V and M then this issue is solved but then the problem is not simplified compared to deep learning anyway.
43 |
44 | ### Questions
45 |
46 | - Why we can't use RL for C?
47 |
--------------------------------------------------------------------------------
/notes/synthesizing_inputs_for_GAN.md:
--------------------------------------------------------------------------------
1 | ## [Synthesizing the preferred inputs for neurons in neural networks via deep generator networks](https://www.google.com.tw/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0ahUKEwj_jOqc6dvQAhWKfbwKHaG3B8YQFggaMAA&url=https%3A%2F%2Farxiv.org%2Fabs%2F1605.09304&usg=AFQjCNFSkaNfiK04_LFwaUwo5l4yD4sfcw&sig2=52CYBnpnwFlgjs5s3ov-bw)
2 |
3 | This paper performs activation maximization (AM) using Deep Generator Network (DGN), which served as a learned natural iamge prior, to synthesize realistic images as inputs and feed it into the DNN we want to understand.
4 | By visualizing synthesized images that highly activate particular neurons in the DNN, we can interpret what each of neurons in the DNN learned to detect.
5 |
6 | ### Key Points
7 |
8 | - DGN (natural image prior) generates more coherent images when optimizing fully-connected layer codes instead of low-level codes. However, previous studies showed that low-level features results in better reconstructions beacuse it contains more image details. The difference is that here DGN-AM is trying to synthesize an entire layer code from scratch. Features in low-level only has a small, local receptive field so that the optimization process has to independently tune image without knowing the global structure. Also, the code space at a convolutional layer is much more high-dimensional, making it harder to optimize.
9 |
10 | - The learned prior trained on ImageNet can also generalize to Places.
11 | - It doesn't generalize well if architecture of the encoder trained with DGN is different with the DNN we wish to inspect.
12 | - The learned prior also generalizes to visualize hidden neurons, producing more realistic textures/colors.
13 | - When visualizing hidden neurons, DGN-AM trained on ImageNet also generalize to Places and produce similar results as [1].
14 | - The synthesized images are showed to teach us what neurons in DNN we wish to inspect prefer instead of what prior prefer.
15 |
16 | ### Model
17 |
18 | 
19 |
20 | ### Thought
21 | Solid paper with diverse visualizations and thorough analysis.
22 |
23 | ### Reference
24 | [1] Object Detectors Emerge In Deep Scene CNNs, B.Zhou et. al.
25 |
--------------------------------------------------------------------------------
/notes/soundnet.md:
--------------------------------------------------------------------------------
1 | ## [SoundNet: Learning Sound Representations from Unlabeled Video](http://web.mit.edu/vondrick/soundnet.pdf)
2 |
3 | This paper developed a semantically rich representation for natural sound using unlabeled videos as a bridge to
4 | transfer discriminative visual knowledge from well-established visual recognition models into the sound modality.
5 | The learned sound representation yields significant performance improvements on standard benchmarks for acoustic
6 | scene classification task.
7 |
8 | ### Key Points
9 |
10 | - The natural synchronization between vision and sound can be leveraged as a supervision signal for each other.
11 | - Cross-modal learning can overcome overfitting if the target modal have much fewer data than other modals, which is essential for deep networks to work well.
12 | - In the sound classification task, **pool5** and **conv6** extracted from SoundNet achieve best performance.
13 |
14 | ### Model
15 | - The authors proposed a student-teacher training procedure to transfer discriminative visual knowledge from visual recognition models
16 | trained on ImageNet and Places into the SoundNet by minimizing KL divergence between their predictions.
17 | 
18 | - Two reasons to use CNN for sound: 1. invariant to translations; 2. stacking layers to detect higher-level concepts.
19 |
20 |
21 | ### Exp
22 |
23 | - Adding a linear SVM upon representation learned from SoundNet outperforms other existing methods 10%.
24 | - Using lots of unlabeled videos as supervision signals enable the deeper SoundNet to work, or otherwise the 8-layer networks
25 | performs poorly due to overfitting.
26 | - Simultaneous Using Places and ImageNet as supervision beats using only one of them 3%.
27 | - Multi-modal recognition models use visual and sound data together yields 2% gain in classification accuracy.
28 |
29 | ### Thought
30 | I think this paper is really complete since it contains good intuition, ablation analysis, representation visualization, hidden unit visualization, and significent performance imporvements.
31 |
32 | ### Questions
33 | - Although paper said that "To handle variable-temporal-length of input sound, this model uses a fully convolutional network and produces an output over multiple timesteps in video.", but the code seems to set the length of each excerpts fixed to 5 seconds.
34 | - It looks not clear for me about the data augmentation technique used in training.
35 |
--------------------------------------------------------------------------------
/notes/outsider_tour_of_RL_1.md:
--------------------------------------------------------------------------------
1 | ## [Make It Happen](http://www.argmin.net/2018/01/29/taxonomy/)
2 |
3 | The author motivates why RL is harder and more important than supervised and unsupervised learning. However, I don't fully agree with these arguments, see **My Two Cents** section at the bottom for my justification.
4 |
5 | ### Key Points
6 |
7 | - Here is an approximated taxonomy of ML:
8 |
9 |
10 |
11 | The author shows that it's possible to train a controller in a simulated environment.
12 |
13 | ### Key Points
14 |
15 | - By keeping model capacity of V and M large, we can learn a compact feature space (i.e., dimension 32) for C and thus being able to apply ES to get good policy.
16 |
17 |
18 |
19 | ### Method
20 |
21 | 1. Randomly collect trajectories in the environment.
22 | 2. Train a VAE for every states.
23 | 3. Use the encoder of VAE, V, to encode the states z = V(s). Then, train a predictive model, P(z_t+1 | z_t, h_t, a_t).
24 | 4. Use ES to evolve a controller which takes [z_t h_t] as input and outputs an action a_t.
25 |
26 | If we want to train the agent to entirely in **dream**, we can use the predictive model as a simulator and
27 |
28 |
29 | ### Exp
30 |
31 | The author performs the experiments in two domains:
32 |
33 | - Racing Car
34 | - Vizdoom
35 |
36 | In Racing Car, the author shows that World Models achieve state of the art performance against RL methods such as PPO.
37 |
38 | In Vizdoom, the authore went one step further to train an agent entirely in its **dream** and then apply the controller back to real world environment. It turns out it can score even higher score in real environments compared to imperfect simulated environment by M.
39 |
40 | ### Thought
41 |
42 | I think the paper is well-presented and shows lots of cool findings. However, it's obvious that unsupervised learning of V and M cannot learn really compact features for the downstream specific task that C is addressing since there is no reward. If we can backprop the reward signal back to both V and M then this issue is solved but then the problem is not simplified compared to deep learning anyway.
43 |
44 | ### Questions
45 |
46 | - Why we can't use RL for C?
47 |
--------------------------------------------------------------------------------
/notes/synthesizing_inputs_for_GAN.md:
--------------------------------------------------------------------------------
1 | ## [Synthesizing the preferred inputs for neurons in neural networks via deep generator networks](https://www.google.com.tw/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0ahUKEwj_jOqc6dvQAhWKfbwKHaG3B8YQFggaMAA&url=https%3A%2F%2Farxiv.org%2Fabs%2F1605.09304&usg=AFQjCNFSkaNfiK04_LFwaUwo5l4yD4sfcw&sig2=52CYBnpnwFlgjs5s3ov-bw)
2 |
3 | This paper performs activation maximization (AM) using Deep Generator Network (DGN), which served as a learned natural iamge prior, to synthesize realistic images as inputs and feed it into the DNN we want to understand.
4 | By visualizing synthesized images that highly activate particular neurons in the DNN, we can interpret what each of neurons in the DNN learned to detect.
5 |
6 | ### Key Points
7 |
8 | - DGN (natural image prior) generates more coherent images when optimizing fully-connected layer codes instead of low-level codes. However, previous studies showed that low-level features results in better reconstructions beacuse it contains more image details. The difference is that here DGN-AM is trying to synthesize an entire layer code from scratch. Features in low-level only has a small, local receptive field so that the optimization process has to independently tune image without knowing the global structure. Also, the code space at a convolutional layer is much more high-dimensional, making it harder to optimize.
9 |
10 | - The learned prior trained on ImageNet can also generalize to Places.
11 | - It doesn't generalize well if architecture of the encoder trained with DGN is different with the DNN we wish to inspect.
12 | - The learned prior also generalizes to visualize hidden neurons, producing more realistic textures/colors.
13 | - When visualizing hidden neurons, DGN-AM trained on ImageNet also generalize to Places and produce similar results as [1].
14 | - The synthesized images are showed to teach us what neurons in DNN we wish to inspect prefer instead of what prior prefer.
15 |
16 | ### Model
17 |
18 | 
19 |
20 | ### Thought
21 | Solid paper with diverse visualizations and thorough analysis.
22 |
23 | ### Reference
24 | [1] Object Detectors Emerge In Deep Scene CNNs, B.Zhou et. al.
25 |
--------------------------------------------------------------------------------
/notes/soundnet.md:
--------------------------------------------------------------------------------
1 | ## [SoundNet: Learning Sound Representations from Unlabeled Video](http://web.mit.edu/vondrick/soundnet.pdf)
2 |
3 | This paper developed a semantically rich representation for natural sound using unlabeled videos as a bridge to
4 | transfer discriminative visual knowledge from well-established visual recognition models into the sound modality.
5 | The learned sound representation yields significant performance improvements on standard benchmarks for acoustic
6 | scene classification task.
7 |
8 | ### Key Points
9 |
10 | - The natural synchronization between vision and sound can be leveraged as a supervision signal for each other.
11 | - Cross-modal learning can overcome overfitting if the target modal have much fewer data than other modals, which is essential for deep networks to work well.
12 | - In the sound classification task, **pool5** and **conv6** extracted from SoundNet achieve best performance.
13 |
14 | ### Model
15 | - The authors proposed a student-teacher training procedure to transfer discriminative visual knowledge from visual recognition models
16 | trained on ImageNet and Places into the SoundNet by minimizing KL divergence between their predictions.
17 | 
18 | - Two reasons to use CNN for sound: 1. invariant to translations; 2. stacking layers to detect higher-level concepts.
19 |
20 |
21 | ### Exp
22 |
23 | - Adding a linear SVM upon representation learned from SoundNet outperforms other existing methods 10%.
24 | - Using lots of unlabeled videos as supervision signals enable the deeper SoundNet to work, or otherwise the 8-layer networks
25 | performs poorly due to overfitting.
26 | - Simultaneous Using Places and ImageNet as supervision beats using only one of them 3%.
27 | - Multi-modal recognition models use visual and sound data together yields 2% gain in classification accuracy.
28 |
29 | ### Thought
30 | I think this paper is really complete since it contains good intuition, ablation analysis, representation visualization, hidden unit visualization, and significent performance imporvements.
31 |
32 | ### Questions
33 | - Although paper said that "To handle variable-temporal-length of input sound, this model uses a fully convolutional network and produces an output over multiple timesteps in video.", but the code seems to set the length of each excerpts fixed to 5 seconds.
34 | - It looks not clear for me about the data augmentation technique used in training.
35 |
--------------------------------------------------------------------------------
/notes/outsider_tour_of_RL_1.md:
--------------------------------------------------------------------------------
1 | ## [Make It Happen](http://www.argmin.net/2018/01/29/taxonomy/)
2 |
3 | The author motivates why RL is harder and more important than supervised and unsupervised learning. However, I don't fully agree with these arguments, see **My Two Cents** section at the bottom for my justification.
4 |
5 | ### Key Points
6 |
7 | - Here is an approximated taxonomy of ML:
8 |
9 | 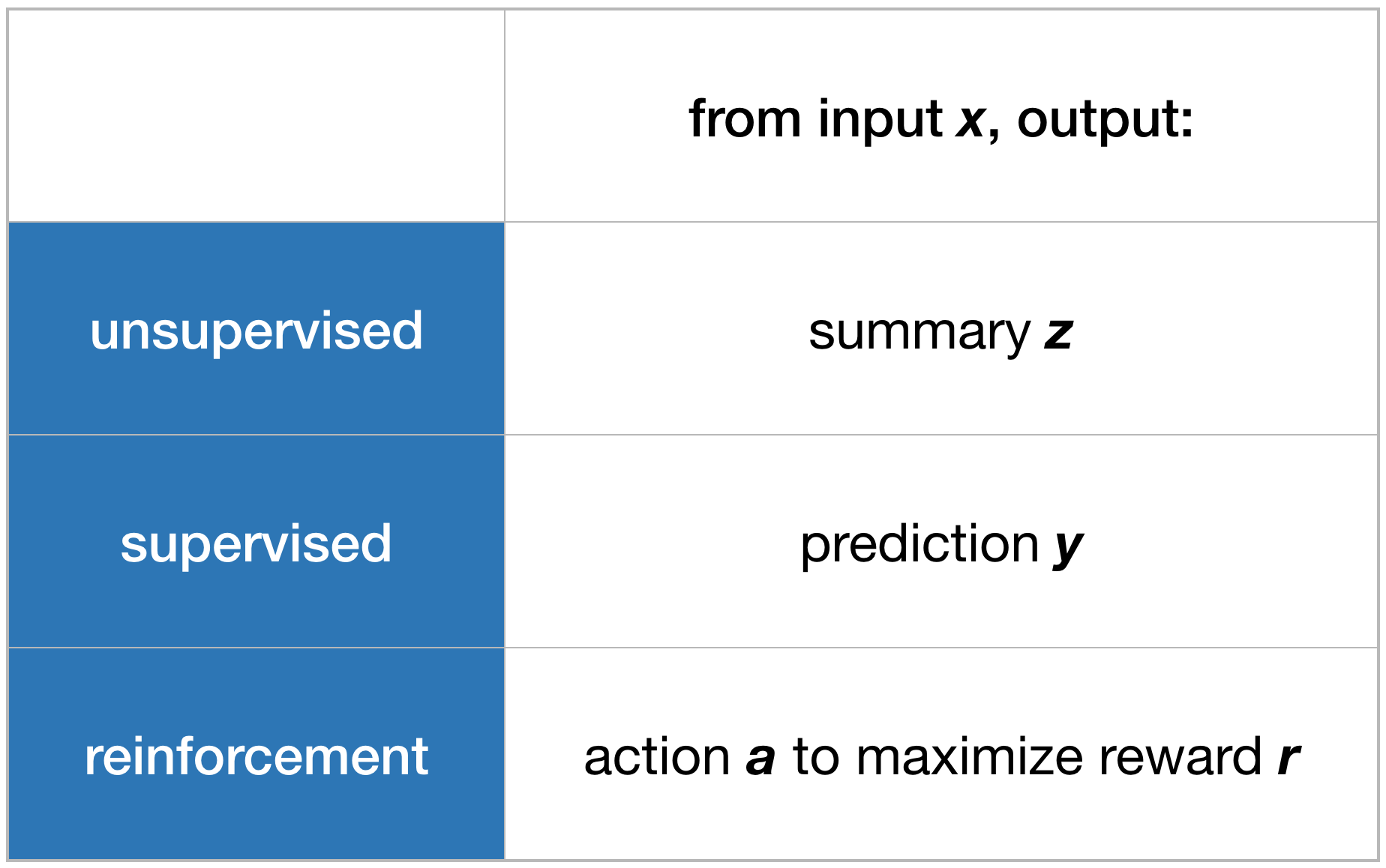 10 |
11 | - Coincidentally, it turns out the field of Data Science also has terminology for this trichotomy:
12 | - **Descriptive Analytics**: summarizing data to make it more interpretable, similar to **Unsupervised Learning**.
13 | - **Predictive Analytics**: estimating outcomes from current data, similar to **Supervised Learning**.
14 | - **Prescriptive Analytics**: guiding actions to achieve the goal, similar to **Reinforcement Learning**.
15 |
16 |
10 |
11 | - Coincidentally, it turns out the field of Data Science also has terminology for this trichotomy:
12 | - **Descriptive Analytics**: summarizing data to make it more interpretable, similar to **Unsupervised Learning**.
13 | - **Predictive Analytics**: estimating outcomes from current data, similar to **Supervised Learning**.
14 | - **Prescriptive Analytics**: guiding actions to achieve the goal, similar to **Reinforcement Learning**.
15 |
16 |  17 |
18 | - According to the figurer above, the author claims that:
19 |
20 | 1. Unsupervised Searning is by far the easiest of the three types of ML problems because the stakes are low. There is no wrong answer for summarization.
21 | 2. Supervised Learning is more challenging as we can evaluate accuracy in a principled manner on new data.
22 | 3. RL is the hardest as it needs to deal with evolving environment and complicated feedback resulting from interaction.
23 |
24 | - RL (prescriptive analytics) has the highest value among ML's trichotomy since it directly outputs actions with the promist that these actions will lead to valuable returns.
25 | - RL is a great tool to conceptualize interaction in machine learning.
26 |
27 | ### My two cents
28 |
29 | I think the author goes too far to motivate the value of RL by disdaining other ML regimes.
30 |
31 | Let's summon Yann Lecun's cake again:
32 |
33 |
17 |
18 | - According to the figurer above, the author claims that:
19 |
20 | 1. Unsupervised Searning is by far the easiest of the three types of ML problems because the stakes are low. There is no wrong answer for summarization.
21 | 2. Supervised Learning is more challenging as we can evaluate accuracy in a principled manner on new data.
22 | 3. RL is the hardest as it needs to deal with evolving environment and complicated feedback resulting from interaction.
23 |
24 | - RL (prescriptive analytics) has the highest value among ML's trichotomy since it directly outputs actions with the promist that these actions will lead to valuable returns.
25 | - RL is a great tool to conceptualize interaction in machine learning.
26 |
27 | ### My two cents
28 |
29 | I think the author goes too far to motivate the value of RL by disdaining other ML regimes.
30 |
31 | Let's summon Yann Lecun's cake again:
32 |
33 |  34 |
35 | The rich information available to unsupervised learning has been proven to be very helpful for RL agent as auxialiary tasks [1]. In several Lecun's talks, he also emphasizes that:
36 |
37 | > Good representation learnt by unsupervised learning is the key to solve RL's biggest deficiency: sample efficiency.
38 |
39 | Besides learning good representation, unsupervised learning also enables generative modeling of the world, an essential component for agents that are not just reactive but able to perform planning in long horizon. The god father of Reinforcement Learning, Rich Sutton, once proposed an architecture called Dyna in which the main idea is to **try things in your head before acting**. He claimed that:
40 |
41 | > The main idea of Dyna is the old, commonsense idea that planning is *trying things in your head* using an internal
42 | model of the world. This suggests the existence of a more primitive process for trying things not in your head, but through direct
43 | interaction with the world. Reinforcement learning is the name we use for this more primitive, direct kind of trying,
44 | and Dyna is the extension of reinforcement learning to include a learned world model.
45 |
46 | This is very intuitive, see this [funny birds video](https://www.youtube.com/watch?v=LI92DLRdKYE) for how important to think before you act :)
47 |
48 | Moreover, generative model is useful for exploration in RL [2] and provides a different paradigm to implement cognitive science-motivated behavior learning [3].
49 |
50 | Finally, from the perspective of Data Science [4]:
51 |
52 | > prescriptive analytics is about helping you see what the probable outcome relies on each decision. That helps you to decide what business decision to make.
53 |
54 | According to this definition, it's clear that generative modeling lies at the heart of prescriptive analytics and directly classifying unsupervised learning as a whole into descriptive analytics is unfair.
55 |
56 | In conclusion, I think it's inappropriate to argue that a) Unsupervised Learning has lower values compared to RL and b) there is an one-to-one connection between the three regimes in ML and Data Science. Different regimes in ML are actually complementary to each other in order to build **Prescriptive Analytics**.
57 |
58 | What are some more inspirations we can draw from the field of Data Science? According to [5], expert recently postulated that **Automated Analytics** is a further extension to **Prescriptive Analytics**, eliminating the need for the human to make the final decision according to prescriptive analytics. In my opinion, as functions produced by machine learning algorithms gradually get used in important applications, their security and robustness becomes more crucial than ever before. More advances in ML safety would be essential for **Automated Analytics**.
59 |
60 | ### Reference
61 |
62 | [1] [Reinforcement Learning with Unsupervised Auxiliary Tasks](https://arxiv.org/abs/1611.05397)
63 |
64 | [2] [Curiosity-driven Exploration by Self-supervised Prediction](https://arxiv.org/abs/1705.05363)
65 |
66 | [3] [Zero-Shot Visual Imitation](https://arxiv.org/abs/1804.08606)
67 |
68 | [4] [Why Prescriptive Analytics Is the Future of Big Data](https://www.linkedin.com/pulse/why-prescriptive-analytics-future-big-data-mark-van-rijmenam/)
69 |
70 | [5] [Predictive Analytics - A Case For Private Equity?](https://www.forbes.com/sites/lutzfinger/2015/02/10/predictive-analytics-case-for-private-equity/#234d26097584)
71 |
--------------------------------------------------------------------------------
34 |
35 | The rich information available to unsupervised learning has been proven to be very helpful for RL agent as auxialiary tasks [1]. In several Lecun's talks, he also emphasizes that:
36 |
37 | > Good representation learnt by unsupervised learning is the key to solve RL's biggest deficiency: sample efficiency.
38 |
39 | Besides learning good representation, unsupervised learning also enables generative modeling of the world, an essential component for agents that are not just reactive but able to perform planning in long horizon. The god father of Reinforcement Learning, Rich Sutton, once proposed an architecture called Dyna in which the main idea is to **try things in your head before acting**. He claimed that:
40 |
41 | > The main idea of Dyna is the old, commonsense idea that planning is *trying things in your head* using an internal
42 | model of the world. This suggests the existence of a more primitive process for trying things not in your head, but through direct
43 | interaction with the world. Reinforcement learning is the name we use for this more primitive, direct kind of trying,
44 | and Dyna is the extension of reinforcement learning to include a learned world model.
45 |
46 | This is very intuitive, see this [funny birds video](https://www.youtube.com/watch?v=LI92DLRdKYE) for how important to think before you act :)
47 |
48 | Moreover, generative model is useful for exploration in RL [2] and provides a different paradigm to implement cognitive science-motivated behavior learning [3].
49 |
50 | Finally, from the perspective of Data Science [4]:
51 |
52 | > prescriptive analytics is about helping you see what the probable outcome relies on each decision. That helps you to decide what business decision to make.
53 |
54 | According to this definition, it's clear that generative modeling lies at the heart of prescriptive analytics and directly classifying unsupervised learning as a whole into descriptive analytics is unfair.
55 |
56 | In conclusion, I think it's inappropriate to argue that a) Unsupervised Learning has lower values compared to RL and b) there is an one-to-one connection between the three regimes in ML and Data Science. Different regimes in ML are actually complementary to each other in order to build **Prescriptive Analytics**.
57 |
58 | What are some more inspirations we can draw from the field of Data Science? According to [5], expert recently postulated that **Automated Analytics** is a further extension to **Prescriptive Analytics**, eliminating the need for the human to make the final decision according to prescriptive analytics. In my opinion, as functions produced by machine learning algorithms gradually get used in important applications, their security and robustness becomes more crucial than ever before. More advances in ML safety would be essential for **Automated Analytics**.
59 |
60 | ### Reference
61 |
62 | [1] [Reinforcement Learning with Unsupervised Auxiliary Tasks](https://arxiv.org/abs/1611.05397)
63 |
64 | [2] [Curiosity-driven Exploration by Self-supervised Prediction](https://arxiv.org/abs/1705.05363)
65 |
66 | [3] [Zero-Shot Visual Imitation](https://arxiv.org/abs/1804.08606)
67 |
68 | [4] [Why Prescriptive Analytics Is the Future of Big Data](https://www.linkedin.com/pulse/why-prescriptive-analytics-future-big-data-mark-van-rijmenam/)
69 |
70 | [5] [Predictive Analytics - A Case For Private Equity?](https://www.forbes.com/sites/lutzfinger/2015/02/10/predictive-analytics-case-for-private-equity/#234d26097584)
71 |
--------------------------------------------------------------------------------