23 | Would be helpful to also include the context where the problem arised. For example the steps you did to arrive to the error, the kind of data you are using, etc.
24 |
25 |
26 |
27 |
28 |
29 | {{ details }}
30 |
31 |
32 |
33 | {% endblock %}
--------------------------------------------------------------------------------
/sovabids/bids.py:
--------------------------------------------------------------------------------
1 | """Module with bids utilities."""
2 | import os
3 | import json
4 |
5 | from mne_bids.utils import _write_json
6 |
7 | def update_dataset_description(dataset_description,bids_path,do_not_create=False):
8 | """Update the dataset_description.json located at bids_path given a dictionary.
9 |
10 | If it exist, updates with the new given values. If it doesn't exist, then creates it.
11 |
12 | Parameters
13 | ----------
14 |
15 | dataset_description : dict
16 | The dataset_description dictionary to update with, following the schema of the dataset_description.json file of bids.
17 | bids_path : str
18 | The bids_path of the dataset description file, basically the folder where the file is.
19 | do_not_create : bool
20 | If true, does not create the file if it does not exist.
21 | """
22 | jsonfile = os.path.join(bids_path,'dataset_description.json')
23 | os.makedirs(bids_path,exist_ok=True)
24 | if os.path.isfile(jsonfile):
25 | with open(jsonfile) as f:
26 | info = json.load(f)
27 | else:
28 | info = {}
29 | if dataset_description != {}:
30 | info.update(dataset_description)
31 | if not do_not_create and os.path.isfile(jsonfile):
32 | _write_json(jsonfile,info,overwrite=True)
33 | # Problem: Authors with strange characters are written incorrectly.
--------------------------------------------------------------------------------
/.github/workflows/joss-draft.yml:
--------------------------------------------------------------------------------
1 | name: Generate Paper PDFs
2 | on: [push]
3 |
4 | jobs:
5 | paper:
6 | runs-on: ubuntu-latest
7 | name: Paper Draft and Preprint
8 | steps:
9 | - name: Checkout Repository
10 | uses: actions/checkout@v4
11 |
12 | # ✅ Generate Draft PDF using inara
13 | - name: Build Draft PDF
14 | uses: ./.github/actions/openjournals-pdf
15 | with:
16 | journal: joss
17 | paper-path: paper/paper.md
18 | output-type: pdf
19 |
20 | # ✅ Upload the Draft PDF
21 | - name: Upload Draft PDF
22 | uses: actions/upload-artifact@v4
23 | with:
24 | name: draft-paper
25 | path: paper/paper.pdf
26 |
27 | # ✅ Generate Preprint LaTeX File (`paper.preprint.tex`)
28 | - name: Build Preprint LaTeX File
29 | uses: ./.github/actions/openjournals-pdf
30 | with:
31 | journal: joss
32 | paper-path: paper/paper.md
33 | output-type: preprint
34 |
35 | # ✅ Print files to verify `paper.preprint.tex` exists
36 | - name: List contents of paper/
37 | run: ls -lah paper/
38 |
39 | # ✅ Upload the Preprint LaTeX file (`paper.preprint.tex`)
40 | - name: Upload Preprint LaTeX File
41 | uses: actions/upload-artifact@v4
42 | with:
43 | name: preprint-tex
44 | path: paper/paper.preprint.tex
45 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | name = sovabids
3 | url = https://github.com/yjmantilla/sovabids/
4 | author = sovabids developers
5 | maintainer = Yorguin Mantilla
6 | maintainer_email = yjmantilla@gmail.com
7 | description = Automated eeg2bids conversion
8 | long-description = file: README.rst
9 | long-description-content-type = text/x-rst; charset=UTF-8
10 | keywords = EEG eeg bids mne mne-bids conversion
11 | platforms = any
12 | classifiers =
13 | Topic :: Scientific/Engineering
14 | Programming Language :: Python :: 3
15 | Intended Audience :: Science/Research
16 | Development Status :: 3 - Alpha
17 | Operating System :: POSIX :: Linux
18 | Operating System :: Unix
19 | Operating System :: MacOS
20 | Operating System :: Microsoft :: Windows
21 | project_urls =
22 | Documentation = https://sovabids.readthedocs.io/en/latest/
23 | Bug Reports = https://github.com/yjmantilla/sovabids/issues
24 | Source = https://github.com/yjmantilla/sovabids
25 |
26 | [options]
27 | python_requires = >= 3.8
28 | packages = find:
29 | include_package_data = True
30 |
31 | [options.packages.find]
32 | exclude =
33 | tests
34 | front
35 |
36 | [coverage:run]
37 | omit =
38 | # Do not include test script in coverage report
39 | *tests*
40 | setup.py
41 | sovabids/_version.py
42 |
43 | [versioneer]
44 | VCS = git
45 | style = pep440
46 | versionfile_source = sovabids/_version.py
47 | versionfile_build = sovabids/_version.py
48 | tag_prefix =
49 | parentdir_prefix =
50 |
--------------------------------------------------------------------------------
/sovabids/misc.py:
--------------------------------------------------------------------------------
1 | "Module with misc utilities for sovabids."
2 |
3 | import numpy as np
4 |
5 | def flat_paren_counter(string):
6 | """Count the number of non-nested balanced parentheses in the string. If parenthesis is not balanced then return -1.
7 |
8 | Parameters
9 | ----------
10 |
11 | string : str
12 | The string we will inspect for balanced parentheses.
13 |
14 | Returns
15 | -------
16 |
17 | int :
18 | The number of non-nested balanced parentheses or -1 if the string has unbalanced parentheses.
19 | """
20 | #Modified from
21 | #jeremy radcliff
22 | #https://codereview.stackexchange.com/questions/153078/balanced-parentheses-checker-in-python
23 | counter = 0
24 | times = 0
25 | inside = False
26 | for c in string:
27 | if not inside and c == '(':
28 | counter += 1
29 | inside = True
30 | elif inside and c == ')':
31 | counter -= 1
32 | times +=1
33 | inside = False
34 | if counter < 0:
35 | return -1
36 |
37 | if counter == 0:
38 | return times
39 | return -1
40 |
41 |
42 |
43 | def get_num_digits(N):
44 | """Return the number of digits of the given number N.
45 |
46 | Parameters
47 | ----------
48 | N : int
49 | The number we want to apply the function to.
50 |
51 | Returns
52 | -------
53 | int :
54 | The numbers of digits needed to represent the number N.
55 | """
56 | return int(np.log10(N))+1
57 |
58 |
59 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | BSD 3-Clause License
2 |
3 | Copyright (c) 2023, sovabids developers
4 |
5 | Redistribution and use in source and binary forms, with or without
6 | modification, are permitted provided that the following conditions are met:
7 |
8 | 1. Redistributions of source code must retain the above copyright notice, this
9 | list of conditions and the following disclaimer.
10 |
11 | 2. Redistributions in binary form must reproduce the above copyright notice,
12 | this list of conditions and the following disclaimer in the documentation
13 | and/or other materials provided with the distribution.
14 |
15 | 3. Neither the name of the copyright holder nor the names of its
16 | contributors may be used to endorse or promote products derived from
17 | this software without specific prior written permission.
18 |
19 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
20 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
21 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
22 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
23 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
24 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
25 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
26 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
27 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
28 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
29 |
--------------------------------------------------------------------------------
/front/app/templates/index.html:
--------------------------------------------------------------------------------
1 | {% extends "base.html" %}
2 | {% set active_page = "index" %}
3 |
4 | {% block content %}
5 |
59 | {% endblock %}
--------------------------------------------------------------------------------
/sovabids/heuristics.py:
--------------------------------------------------------------------------------
1 | """Heuristics Module
2 |
3 | Functions should return a dictionary.
4 | """
5 | from sovabids.parsers import parse_path_pattern_from_entities
6 | from sovabids.parsers import parse_entities_from_bidspath
7 | from sovabids.parsers import find_bidsroot
8 | from bids_validator import BIDSValidator
9 |
10 | def from_io_example(sourcepath,targetpath):
11 | """Get the path pattern from a source-target mapping example.
12 |
13 | The name of the function means "from input-output example", as one provides an input and output pair of (source,target) paths.
14 |
15 | Parameters
16 | ----------
17 | sourcepath : str
18 | The sourcepath that will be modified to get the path pattern
19 | targetpath : str
20 | The bidspath we are going to derive the information on.
21 |
22 | Returns
23 | -------
24 | dict :
25 | {
26 | 'pattern': The path pattern in placeholder format.
27 | }
28 | """
29 | # TODO: Should we also allow the user to just populate the bids stuff by himself
30 | # That is, instead of providing the target , directly provide the values
31 | # of the entities he expects on a dictionary
32 | # In example: source = 'data/lemon/V001/resting/010002.vhdr'
33 | # target = {'subject':'010002','task':'resting','session':'001'}
34 | # With the currently implemented functions this is rather trivial. Is just a matter of exposing it.
35 | validator = BIDSValidator()
36 | # Find the root since we need it relative to the bidspath for the validator to work
37 | try:
38 | bidsroot = find_bidsroot(targetpath)
39 | except:
40 | raise IOError(f'targetpath :{targetpath} is not a valid bidspath.')
41 | targetpath2 = targetpath.replace(bidsroot,'') # avoid side-effects explicitly, although this shouldnt affect the str as it is immutable
42 | targetpath2 = targetpath2.replace('\\','/')
43 | # add / prefix
44 | if targetpath2[0] != '/':
45 | targetpath2 = '/' + targetpath2
46 | assert validator.is_bids(targetpath2),'ERROR: The provided target-path is not a valid bids-path'
47 | bids_entities=parse_entities_from_bidspath(targetpath)
48 | pattern = parse_path_pattern_from_entities(sourcepath,bids_entities)
49 | return {'pattern':pattern}
50 |
--------------------------------------------------------------------------------
/front/app/templates/base.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | {% block head %}
5 |
6 |
7 |
8 | Document
9 |
10 |
11 |
12 |
13 |
14 | {% endblock %}
15 |
16 |
17 |
30 | {% block content %}
31 | {% endblock %}
32 |
38 |
39 |
--------------------------------------------------------------------------------
/sovabids/files.py:
--------------------------------------------------------------------------------
1 | """Module with file utilities."""
2 | import os
3 | import requests
4 | import yaml
5 | def _get_files(root_path):
6 | """Recursively scan the directory for files, returning a list with the full-paths to each.
7 |
8 | Parameters
9 | ----------
10 |
11 | root_path : str
12 | The path we want to obtain the files from.
13 |
14 | Returns
15 | -------
16 |
17 | filepaths : list of str
18 | A list containing the path to each file in root_path.
19 | """
20 | filepaths = []
21 | for root, dirs, files in os.walk(root_path, topdown=False):
22 | for name in files:
23 | filepaths.append(os.path.join(root, name).replace('\\','/'))
24 | return filepaths
25 |
26 | def _write_yaml(dictionary,path=None):
27 | """Write a yaml file based on the dictionary to the specified path.
28 |
29 | Parameters
30 | ----------
31 | dictionary : dict
32 | The dictionary to be written.
33 | path : str | None
34 | Full path to the yaml file to be written. If None, no file will be written.
35 |
36 | Returns
37 | -------
38 |
39 | str :
40 | The dump version of the generated yaml document.
41 | """
42 | if path is not None:
43 | outputfolder,outputname = os.path.split(path)
44 | os.makedirs(outputfolder,exist_ok=True)
45 | full_path = os.path.join(outputfolder,outputname)
46 | with open(full_path, 'w') as outfile:
47 | yaml.dump(dictionary, outfile, default_flow_style=False)
48 | return yaml.dump(dictionary, default_flow_style=False)
49 |
50 |
51 |
52 | def download(url,path):
53 | """Download in the path the file from the given url.
54 |
55 | From H S Umer farooq answer at https://stackoverflow.com/questions/22676/how-to-download-a-file-over-http
56 |
57 | Parameters
58 | ----------
59 |
60 | url : str
61 | The url of the file to download.
62 | path : str
63 | The path where to download the file.
64 | """
65 | get_response = requests.get(url,stream=True)
66 | file_name = url.split("/")[-1]
67 | p = os.path.abspath(os.path.join(path))
68 | os.makedirs(p,exist_ok=True)
69 | print('Downloading',file_name,'at',p)
70 | if not os.path.isfile(os.path.join(p,file_name)):
71 | with open(os.path.join(p,file_name), 'wb') as f:
72 | for chunk in get_response.iter_content(chunk_size=1024):
73 | if chunk: # filter out keep-alive new chunks
74 | f.write(chunk)
75 | print('100')
76 | else:
77 | print("WARNING: File already existed. Skipping...")
--------------------------------------------------------------------------------
/.github/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing to sovabids
2 |
3 | Thank you for your interest in contributing to sovabids! This document provides guidelines for contributing to the project.
4 |
5 | ## Prerequisites
6 |
7 | - Python 3.8+
8 | - Git
9 | - Basic knowledge of EEG data processing and BIDS specification
10 | - Understanding of MNE-Python and MNE-BIDS
11 |
12 | ## Quick Start
13 |
14 | 1. **Fork the repository** on GitHub
15 | 2. **Clone your fork** locally:
16 | ```bash
17 | git clone https://github.com/your-username/sovabids.git
18 | cd sovabids
19 | ```
20 | 3. **Create a development environment**:
21 | ```bash
22 | pip install -r requirements-dev.txt
23 | ```
24 | 4. **Run tests** to ensure everything works:
25 | ```bash
26 | python -m pytest tests/ -v
27 | ```
28 |
29 | ## Making Changes
30 |
31 | ### Branch Naming
32 |
33 | Use descriptive branch names:
34 |
35 | - `test/improve-coverage`
36 |
37 | ### Commit Messages
38 |
39 | Follow conventional commit format:
40 |
41 | ```
42 | type(scope): brief description
43 |
44 | Longer description if needed
45 |
46 | - Bullet points for details
47 | - Reference issues: fixes #123
48 | ```
49 |
50 | ## Testing
51 |
52 | ### Running Tests
53 |
54 | ```bash
55 | # Run all tests
56 | python -m pytest tests/ -v
57 |
58 | # Run specific test files
59 | python -m pytest tests/test_bids.py -v
60 |
61 | # Run with coverage
62 | python -m pytest tests/ --cov=sovabids --cov-report=html
63 | ```
64 |
65 | ## Documentation
66 |
67 |
68 | ### Building Documentation
69 |
70 | ```bash
71 | cd docs
72 | make html
73 | ```
74 |
75 | ## Pull Request Process
76 |
77 | ### Before Submitting
78 |
79 | 1. **Run tests**: Ensure all tests pass
80 | 2. **Update documentation**: Update relevant docs
81 | 3. **Add tests**: Include tests for new functionality
82 |
83 | ### PR Checklist
84 |
85 | - [ ] Tests pass locally
86 | - [ ] Documentation updated
87 | - [ ] Tests added for new functionality
88 | - [ ] Commit messages follow conventional format
89 | - [ ] Branch name is descriptive
90 |
91 | ### PR Description Template
92 |
93 | ```markdown
94 | ## Summary
95 | Brief description of changes
96 |
97 | ## Type of Change
98 | - [ ] Bug fix
99 | - [ ] New feature
100 | - [ ] Documentation update
101 | - [ ] Test improvement
102 |
103 | ## Testing
104 | - [ ] Existing tests pass
105 | - [ ] New tests added
106 |
107 | ## Documentation
108 | - [ ] Docstrings updated
109 | - [ ] User documentation updated
110 | - [ ] Examples provided
111 |
112 | ## Related Issues
113 | Fixes #issue_number
114 | ```
115 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # test files
2 |
3 | front/app/media/
4 | front/app/_uploads/
5 | front/app/_convert/
6 | front/app/uploads/
7 |
8 |
9 | src/
10 | _data/
11 | _temp/
12 | _ideas/
13 |
14 | .vscode/
15 |
16 | # Byte-compiled / optimized / DLL files
17 | __pycache__/
18 | *.py[cod]
19 | *$py.class
20 |
21 | # C extensions
22 | *.so
23 |
24 | # Distribution / packaging
25 | .Python
26 | build/
27 | develop-eggs/
28 | dist/
29 | downloads/
30 | eggs/
31 | .eggs/
32 | lib/
33 | lib64/
34 | parts/
35 | sdist/
36 | var/
37 | wheels/
38 | pip-wheel-metadata/
39 | share/python-wheels/
40 | *.egg-info/
41 | .installed.cfg
42 | *.egg
43 | MANIFEST
44 |
45 | # PyInstaller
46 | # Usually these files are written by a python script from a template
47 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
48 | *.manifest
49 | *.spec
50 |
51 | # Installer logs
52 | pip-log.txt
53 | pip-delete-this-directory.txt
54 |
55 | # Unit test / coverage reports
56 | htmlcov/
57 | .tox/
58 | .nox/
59 | .coverage
60 | .coverage.*
61 | .cache
62 | nosetests.xml
63 | coverage.xml
64 | *.cover
65 | *.py,cover
66 | .hypothesis/
67 | .pytest_cache/
68 |
69 | # Translations
70 | *.mo
71 | *.pot
72 |
73 | # Django stuff:
74 | *.log
75 | local_settings.py
76 | db.sqlite3
77 | db.sqlite3-journal
78 |
79 | # Flask stuff:
80 | instance/
81 | .webassets-cache
82 |
83 | # Scrapy stuff:
84 | .scrapy
85 |
86 | # Sphinx documentation
87 | docs/_build/
88 | make.bat
89 | docs/source/generated
90 | docs/source/auto_examples
91 | # PyBuilder
92 | target/
93 |
94 | # Jupyter Notebook
95 | .ipynb_checkpoints
96 |
97 | # IPython
98 | profile_default/
99 | ipython_config.py
100 |
101 | # pyenv
102 | .python-version
103 |
104 | # pipenv
105 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
106 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
107 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
108 | # install all needed dependencies.
109 | #Pipfile.lock
110 |
111 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
112 | __pypackages__/
113 |
114 | # Celery stuff
115 | celerybeat-schedule
116 | celerybeat.pid
117 |
118 | # SageMath parsed files
119 | *.sage.py
120 |
121 | # Environments
122 | .env
123 | .venv
124 | env/
125 | venv/
126 | ENV/
127 | env.bak/
128 | venv.bak/
129 |
130 | # Spyder project settings
131 | .spyderproject
132 | .spyproject
133 |
134 | # Rope project settings
135 | .ropeproject
136 |
137 | # mkdocs documentation
138 | /site
139 |
140 | # mypy
141 | .mypy_cache/
142 | .dmypy.json
143 | dmypy.json
144 |
145 | # Pyre type checker
146 | .pyre/
147 |
--------------------------------------------------------------------------------
/sovabids/loggers.py:
--------------------------------------------------------------------------------
1 | """Module dealing with logging related functionality and settings"""
2 |
3 | import os
4 | import logging
5 | import sys
6 | from datetime import datetime
7 |
8 | def _excepthook(*args):
9 | """Catch Exceptions to logger.
10 |
11 | Notes
12 | -----
13 | See https://code.activestate.com/recipes/577074-logging-asserts/
14 | """
15 | logging.getLogger().error('Uncaught exception:', exc_info=args)
16 |
17 | sys.excepthook = _excepthook # See _excepthook documentation
18 |
19 |
20 | def setup_logging(log_file=None, debug=False):
21 | """Setup the logging
22 |
23 | Parameters
24 | ----------
25 | log_file: str
26 | Name of the logfile
27 | debug: bool
28 | Set log level to DEBUG if debug==True
29 |
30 | Returns
31 | -------
32 | logging.logger:
33 | The logger.
34 |
35 |
36 | Notes
37 | -----
38 | This function is a copy of the one found in bidscoin.
39 | https://github.com/Donders-Institute/bidscoin/blob/748ea2ba537b06d8eee54ac7217b909bdf91a812/bidscoin/bidscoin.py#L41-L83
40 | """
41 | currentDT = datetime.now()
42 | currentDT.strftime("%Y-%m-%d %H:%M:%S")
43 |
44 | noDate = True
45 | # Get the root logger
46 | logger = logging.getLogger()
47 |
48 | # Set the format and logging level
49 | if debug:
50 | fmt = '%(asctime)s - %(name)s - %(levelname)s | %(message)s'
51 | logger.setLevel(logging.DEBUG)
52 | else:
53 | fmt = '%(asctime)s - %(levelname)s | %(message)s'
54 | logger.setLevel(logging.INFO)
55 | datefmt = '%Y-%m-%d %H:%M:%S'
56 | formatter = logging.Formatter(fmt=fmt, datefmt=datefmt)
57 |
58 | # Set & add the streamhandler and add some color to those boring terminal logs! :-)
59 | #coloredlogs.install(level=logger.level, fmt=fmt, datefmt=datefmt)
60 |
61 | if not log_file:
62 | return logger
63 |
64 | # Set & add the log filehandler
65 | logdir,log_name = os.path.split(log_file)
66 | os.makedirs(logdir,exist_ok=True) # Create the log dir if it does not exist
67 | log_name = os.path.join(logdir,currentDT.strftime("%Y-%m-%d__%H_%M_%S") + '__' + log_name)
68 | if noDate:
69 | log_name=log_file
70 | loghandler = logging.FileHandler(log_name)
71 | loghandler.setLevel(logging.DEBUG)
72 | loghandler.setFormatter(formatter)
73 | loghandler.set_name('loghandler')
74 | logger.addHandler(loghandler)
75 |
76 | # Set & add the error / warnings handler
77 | error_file = log_name +'.errors' # Derive the name of the error logfile from the normal log_file
78 | errorhandler = logging.FileHandler(error_file, mode='w')
79 | errorhandler.setLevel(logging.WARNING)
80 | errorhandler.setFormatter(formatter)
81 | errorhandler.set_name('errorhandler')
82 | logger.addHandler(errorhandler)
83 | return logger
84 |
--------------------------------------------------------------------------------
/tests/test_heuristics.py:
--------------------------------------------------------------------------------
1 | from sovabids.heuristics import from_io_example
2 | from sovabids.rules import apply_rules_to_single_file
3 | from sovabids.dicts import deep_merge_N
4 | from sovabids.rules import load_rules
5 | import os
6 | import pytest
7 | try:
8 | from test_bids import dummy_dataset
9 | except ImportError:
10 | from .test_bids import dummy_dataset
11 |
12 |
13 | def test_from_io_example():
14 |
15 | # check if there is already an example dataset to save time
16 |
17 | pattern_type='placeholder'#defaults of dummy_dataset function
18 | mode='python'#defaults of dummy_dataset function
19 | # Getting current file path and then going to _data directory
20 | this_dir = os.path.dirname(__file__)
21 | data_dir = os.path.join(this_dir,'..','_data')
22 | data_dir = os.path.abspath(data_dir)
23 |
24 | # Defining relevant conversion paths
25 | test_root = os.path.join(data_dir,'DUMMY')
26 | input_root = os.path.join(test_root,'DUMMY_SOURCE')
27 | mode_str = '_' + mode
28 | bids_path = os.path.join(test_root,'DUMMY_BIDS'+'_'+pattern_type+mode_str)
29 | mapping_file = os.path.join(bids_path,'code','sovabids','mappings.yml')
30 | if not os.path.isfile(mapping_file):
31 | mappings = dummy_dataset()
32 | else:
33 | mappings = load_rules(mapping_file)
34 | sourcepath=mappings['Individual'][0]['IO']['source']
35 | targetpath=mappings['Individual'][0]['IO']['target']
36 | answer=mappings['Individual'][0]['non-bids']['path_analysis']['pattern']
37 | pattern = from_io_example(sourcepath,targetpath)['pattern']
38 | assert pattern == answer
39 | rules = mappings['General']
40 | example_rule = {'non-bids':{'path_analysis':{'pattern':'None','source':sourcepath,'target':targetpath}}}
41 | rules = deep_merge_N([rules,example_rule])
42 | ind_mapping = apply_rules_to_single_file(sourcepath,rules,rules['IO']['target'])
43 | assert ind_mapping[0]['IO']['target'] == targetpath
44 |
45 | source = 'data/lemon/V001/resting/010002.vhdr'
46 | target = 'data_bids/sub-010002/ses-001/eeg/sub-010002_ses-001_task-resting_eeg.vhdr'
47 | pattern = from_io_example(source,target)['pattern']
48 | assert pattern == 'V%entities.session%/%entities.task%/%entities.subject%.vhdr'
49 |
50 |
51 | source = 'data/lemon/V001/resting/010002.vhdr'
52 | target = 'data_bids/sub-010002/ses-001/eeg/010002.vhdr'
53 | with pytest.raises(IOError):
54 | from_io_example(source,target)
55 |
56 | target = 'data_bids/sub-010002/ses-001/eeg/sub-010002_.vhdr'
57 | with pytest.raises(AssertionError):
58 | from_io_example(source,target)
59 |
60 | source='data/lemon/session001/taskT001/010002.vhdr'
61 | target='data_bids/sub-010002/ses-001/eeg/sub-010002_ses-001_task-T001_eeg.vhdr'
62 |
63 |
64 | with pytest.raises(ValueError):
65 | from_io_example(source,target)
66 |
67 | source='data/lemon/session009/taskT001/010002.vhdr'
68 | target='data_bids/sub-010002/ses-009/eeg/sub-010002_ses-009_task-T001_eeg.vhdr'
69 |
70 | pattern = from_io_example(source,target)
71 | assert pattern['pattern'] == 'session%entities.session%/task%entities.task%/%entities.subject%.vhdr'
72 | print('hallelujah')
73 |
74 | if __name__ == '__main__':
75 | test_from_io_example()
76 | print('ok')
--------------------------------------------------------------------------------
/sovabids/convert.py:
--------------------------------------------------------------------------------
1 | """Module to perform the conversions.
2 | """
3 | import argparse
4 | import os
5 |
6 | import logging
7 | from sovabids.dicts import deep_get
8 | from sovabids.rules import load_rules,apply_rules_to_single_file
9 | from sovabids.bids import update_dataset_description
10 | from sovabids.loggers import setup_logging
11 | from sovabids.settings import SECTION_STRING
12 |
13 | LOGGER = logging.getLogger(__name__)
14 |
15 | def convert_them(mappings_input):
16 | """Convert eeg files to bids according to the mappings given.
17 |
18 | Parameters
19 | ----------
20 | mappings_input : str|dict
21 | The path to the mapping file or the mapping dictionary:
22 | {
23 | 'General': dict with the general rules,
24 | 'Individual': list of dicts with the individual mappings of each file.
25 | }
26 |
27 | Returns
28 | -------
29 | None
30 | """
31 |
32 | # Loading Mappings
33 | mappings = load_rules(mappings_input)
34 | mapping_file = mappings_input if isinstance(mappings_input,str) else None
35 |
36 | # Verifying Mappings
37 | assert 'Individual' in mappings,f'`Individual` does not exist in the mapping dictionary'
38 | assert 'General' in mappings,f'`General` does not exist in the mapping dictionary'
39 |
40 | # Getting input,output and log path
41 | bids_path = mappings['General']['IO']['target']
42 | source_path = mappings['General']['IO']['source']
43 | log_file = os.path.join(bids_path,'code','sovabids','sovabids.log')
44 |
45 | # Setup the logging
46 | setup_logging(log_file)
47 | LOGGER.info('')
48 | LOGGER.info(SECTION_STRING + ' START CONVERT_THEM ' + SECTION_STRING)
49 | LOGGER.info(f"source_path={source_path} bids_path={bids_path} mapping_file={str(mapping_file)} ")
50 |
51 | LOGGER.info(f"Converting Individual Mappings")
52 | num_files = len(mappings['Individual'])
53 | for i,mapping in enumerate(mappings['Individual']):
54 | input_file=deep_get(mapping,'IO.source',None)
55 | output_file=deep_get(mapping,'IO.target',None)
56 | try:
57 |
58 | LOGGER.info(f"File {i+1} of {num_files} ({(i+1)*100/num_files}%) : {input_file}")
59 | if not os.path.isfile(output_file):
60 | apply_rules_to_single_file(input_file,mapping,bids_path,write=True)
61 | else:
62 | LOGGER.info(f'{output_file} already existed. Skipping...')
63 | except :
64 | LOGGER.exception(f'Error for {input_file}')
65 |
66 | LOGGER.info(f"Conversion Done!")
67 |
68 | LOGGER.info(f"Updating Dataset Description")
69 |
70 | # Grab the info from the last file to make the dataset description
71 | if 'dataset_description' in mappings['General']:
72 | dataset_description = mappings['General']['dataset_description']
73 | update_dataset_description(dataset_description,bids_path)
74 |
75 | LOGGER.info(f"Dataset Description Updated!")
76 |
77 | LOGGER.info(SECTION_STRING + ' END CONVERT_THEM ' + SECTION_STRING)
78 |
79 |
80 | def sovaconvert():
81 | """Console script usage for conversion."""
82 | # see https://github.com/Donders-Institute/bidscoin/blob/master/bidscoin/bidsmapper.py for example of how to make this
83 | parser = argparse.ArgumentParser()
84 | subparsers = parser.add_subparsers()
85 |
86 | parser = subparsers.add_parser('convert_them')
87 | parser.add_argument('mappings',help='The mapping file of the conversion.')
88 | args = parser.parse_args()
89 | convert_them(args.mappings)
90 |
91 | if __name__ == "__main__":
92 | sovaconvert()
93 |
--------------------------------------------------------------------------------
/tests/test_sova2coin.py:
--------------------------------------------------------------------------------
1 | from bidscoin.plugins.sova2coin import is_sourcefile
2 | from pathlib import Path
3 | from bidscoin.bidscoiner import bidscoiner
4 | from bidscoin.bidsmapper import bidsmapper
5 | import os
6 | import shutil
7 | from sovabids.schemas import get_sova2coin_bidsmap
8 | from sovabids.files import _get_files
9 | from sovabids.settings import REPO_PATH
10 | from sovabids.parsers import _modify_entities_of_placeholder_pattern
11 | from sovabids.datasets import lemon_bidscoin_prepare,make_dummy_dataset,save_dummy_vhdr
12 | import yaml
13 |
14 | def test_sova2coin(dataset='dummy_bidscoin',noedit=True):
15 | data_dir = os.path.join(REPO_PATH,'_data')
16 | data_dir = os.path.abspath(data_dir)
17 |
18 | source_path = os.path.abspath(os.path.join(data_dir,dataset+'_input'))
19 | bids_path= os.path.abspath(os.path.join(data_dir,dataset+'_output'))
20 | rules_path = os.path.join(data_dir,'bidscoin_'+dataset+'_rules.yml')
21 | template_path = os.path.join(data_dir,'bidscoin_template.yml')
22 |
23 | if dataset == 'dummy_bidscoin':
24 | pat = 'sub-%entities.subject%/ses-%entities.session%/eeg-%entities.task%-%entities.run%.vhdr'
25 | rules = {
26 | 'entities': None,
27 | 'dataset_description':{'Name':dataset},
28 | 'non-bids':{
29 | 'path_analysis':
30 | {'pattern':pat}
31 | }
32 | }
33 | elif dataset=='lemon_bidscoin':
34 | rules ={
35 | 'entities':{'task':'resting'},
36 | 'dataset_description':{'Name':dataset},
37 | 'sidecar':{'PowerLineFrequency':50,'EEGReference':'FCz'},
38 | 'channels':{'type':{'VEOG':'VEOG'}},
39 | 'non-bids':{'path_analysis':{'pattern':'sub-%entities.subject%/ses-%entities.session%/%ignore%/%ignore%.vhdr'}}
40 | }
41 |
42 | with open(rules_path, 'w') as outfile:
43 | yaml.dump(rules, outfile, default_flow_style=False)
44 |
45 |
46 | #CLEAN BIDS PATH
47 | for dir in [bids_path,source_path]:
48 | try:
49 | shutil.rmtree(dir)
50 | except:
51 | pass
52 |
53 | if dataset=='lemon_bidscoin':
54 | lemon_bidscoin_prepare(source_path)
55 | else:
56 | pat = _modify_entities_of_placeholder_pattern(rules['non-bids']['path_analysis']['pattern'],'cut')
57 | pat = pat.replace('.vhdr','')
58 | try:
59 | shutil.rmtree(source_path)
60 | except:
61 | pass
62 |
63 | # Make example VHDR File
64 | example_fpath = save_dummy_vhdr(os.path.join(data_dir,'dummy.vhdr'))
65 |
66 | make_dummy_dataset(EXAMPLE=example_fpath,DATASET=dataset+'_input',NSUBS=3,NTASKS=2,NSESSIONS=2,NACQS=1,NRUNS=2,PATTERN=pat,ROOT=source_path)
67 |
68 |
69 | files = _get_files(source_path)
70 | any_vhdr = Path([x for x in files if '.vhdr' in x][0])
71 | any_not_vhdr = Path([x for x in files if '.vhdr' not in x][0])
72 |
73 | assert is_sourcefile(any_vhdr)=='EEG'
74 | assert is_sourcefile(any_not_vhdr)==''
75 | # if dataset=='lemon_bidscoin':
76 | # assert get_attribute('EEG',any_vhdr,'sidecar.SamplingFrequency') == 2500.0
77 | # else:
78 | # assert get_attribute('EEG',any_vhdr,'sidecar.SamplingFrequency') == 200.0
79 |
80 | bidsmap = get_sova2coin_bidsmap().format(rules_path)
81 |
82 | with open(template_path,mode='w') as f:
83 | f.write(bidsmap)
84 |
85 | bidsmapper(rawfolder=source_path,bidsfolder=bids_path,subprefix='sub-',sesprefix='ses-',bidsmapfile='bidsmap.yaml',templatefile= template_path,noedit=noedit)
86 |
87 | bidscoiner(rawfolder = source_path,
88 | bidsfolder = bids_path)
89 |
90 | if __name__ == '__main__':
91 | noedit=False
92 | test_sova2coin(noedit=noedit)
93 | #test_sova2coin('lemon_bidscoin',noedit=noedit)
--------------------------------------------------------------------------------
/examples/lemon_example_rules.yml:
--------------------------------------------------------------------------------
1 | entities: # Configuring the file name structure of bids
2 | task : resting # Setting the task of all files to a fixed string
3 |
4 | dataset_description: # Configuring the dataset_description.json file
5 | Name : Lemon # Name of the dataset, set up as a fixed string
6 | Authors: # Here I put the personnel involved in the acquisition of the dataset
7 | - Anahit Babayan # See http://fcon_1000.projects.nitrc.org/indi/retro/MPI_LEMON.html
8 | - Miray Erbey
9 | - Deniz Kumral
10 | - Janis D. Reinelt
11 | - Andrea M. F. Reiter
12 | - Josefin Röbbig
13 | - H. Lina Schaare
14 | - Marie Uhlig
15 | - Alfred Anwander
16 | - Pierre-Louis Bazin
17 | - Annette Horstmann
18 | - Leonie Lampe
19 | - Vadim V. Nikulin
20 | - Hadas Okon-Singer
21 | - Sven Preusser
22 | - André Pampel
23 | - Christiane S. Rohr
24 | - Julia Sacher1
25 | - Angelika Thöne-Otto
26 | - Sabrina Trapp
27 | - Till Nierhaus
28 | - Denise Altmann
29 | - Katrin Arelin
30 | - Maria Blöchl
31 | - Edith Bongartz
32 | - Patric Breig
33 | - Elena Cesnaite
34 | - Sufang Chen
35 | - Roberto Cozatl
36 | - Saskia Czerwonatis
37 | - Gabriele Dambrauskaite
38 | - Maria Dreyer
39 | - Jessica Enders
40 | - Melina Engelhardt
41 | - Marie Michele Fischer
42 | - Norman Forschack
43 | - Johannes Golchert
44 | - Laura Golz
45 | - C. Alexandrina Guran
46 | - Susanna Hedrich
47 | - Nicole Hentschel
48 | - Daria I. Hoffmann
49 | - Julia M. Huntenburg
50 | - Rebecca Jost
51 | - Anna Kosatschek
52 | - Stella Kunzendorf
53 | - Hannah Lammers
54 | - Mark E. Lauckner
55 | - Keyvan Mahjoory
56 | - Natacha Mendes
57 | - Ramona Menger
58 | - Enzo Morino
59 | - Karina Näthe
60 | - Jennifer Neubauer
61 | - Handan Noyan
62 | - Sabine Oligschläger
63 | - Patricia Panczyszyn-Trzewik
64 | - Dorothee Poehlchen
65 | - Nadine Putzke
66 | - Sabrina Roski
67 | - Marie-Catherine Schaller
68 | - Anja Schieferbein
69 | - Benito Schlaak
70 | - Hanna Maria Schmidt
71 | - Robert Schmidt
72 | - Anne Schrimpf
73 | - Sylvia Stasch
74 | - Maria Voss
75 | - Anett Wiedemann
76 | - Daniel S. Margulies
77 | - Michael Gaebler
78 | - Arno Villringer
79 |
80 | sidecar: # Configuring the sidecar eeg file
81 | PowerLineFrequency : 50 # Noted from the visual inspection of the eeg spectrum
82 | EEGReference : FCz # As mentioned in https://www.nature.com/articles/sdata2018308
83 |
84 | channels: # Configuring the channels tsv
85 | type : # This property allow us to overwrite channel types inferred by MNE
86 | VEOG : VEOG # Here the syntax is :
87 | F3 : EEG # Here we set the type of F3, it was already correctly inferred by mne but it is included to illustrate retyping of various channels.
88 | non-bids: # Additional configuration not belonging specifically to any of the previous objects
89 | eeg_extension : .vhdr # Sets which extension to read as an eeg file
90 | path_analysis: # Some bids properties can be inferred from the path of the source files
91 | pattern : RSEEG/sub-%entities.subject%.vhdr # For example here we extract from the path the "subject" child of the "entities" object
92 |
--------------------------------------------------------------------------------
/examples/example_heuristic_source_target_pair.py:
--------------------------------------------------------------------------------
1 | """
2 | ===================================
3 | Usage example of source,target pair
4 | ===================================
5 |
6 | This example illustrates how does the inference of the path_pattern from a (source,target) pair example works.
7 |
8 | The main elements of this example are:
9 | * A source example path of one of your files
10 | * A target path that will be the expected mapping of your file.
11 | * The from_io_example heuristic that internally does the inference work.
12 | * A path pattern inferred from the above.
13 |
14 |
15 | Be sure to read `the Rules File Schema documentation section relating to the Paired Example `_ before doing this example for more context.
16 |
17 |
18 | .. mermaid::
19 |
20 | graph LR
21 | S>"source path example"]
22 | B>"target path example"]
23 | AR(("from_io_example"))
24 | M>"path pattern"]
25 | S --> AR
26 | B --> AR
27 | AR --> M
28 |
29 | The Rules File
30 | --------------
31 | The Rules File we are dealing here has the following path_analysis rule
32 |
33 | """
34 |
35 | import json # utility
36 | from sovabids.files import _write_yaml # To print the yaml file
37 |
38 | # The rule we are dealing with
39 | rule = {
40 | 'non-bids':{
41 | 'path_analysis':
42 | {
43 | 'source' : 'data/lemon/V001/resting/010002.vhdr',
44 | 'target' : 'data_bids/sub-010002/ses-001/eeg/sub-010002_ses-001_task-resting_eeg.vhdr'
45 | }
46 | }
47 | }
48 |
49 | yaml_file = _write_yaml(rule)
50 |
51 | print('Rules File:\n\n',yaml_file)
52 |
53 | #%%
54 | # The from_io_example function
55 | # -----------------------------
56 | #
57 | # Although this is hidden from the user, internally sovabids uses this function to infer the pattern.
58 | #
59 | # The name of the function means "from input-output example", as one provides an input and output pair of (source,target) paths.
60 | #
61 | # Here we will illustrate how this function behaves. Lets see the documentation of the function:
62 | #
63 |
64 | from sovabids.heuristics import from_io_example # The function itself
65 |
66 | print('from_io_example:\n\n',from_io_example.__doc__)
67 |
68 | #%%
69 | # The result of the function
70 | # -----------------------------
71 | #
72 | # The function will return the placeholder pattern as explained in `the Rules File Schema documentation section relating to the Placeholder Pattern `_ .
73 | #
74 | #
75 | sourcepath = rule['non-bids']['path_analysis']['source']
76 | targetpath = rule['non-bids']['path_analysis']['target']
77 | result = from_io_example(sourcepath,targetpath)
78 |
79 | print('Result:\n\n',result)
80 |
81 |
82 | #%%
83 | # Ambiguity
84 | # ----------
85 | #
86 | # This is explained in more detail in `the warning section of the the Paired Example documentation `_ .
87 | # Be sure to read it before for fully understading what ambiguity means here.
88 | #
89 | # An ambiguous rule would be:
90 | #
91 |
92 | rule = {
93 | 'non-bids':{
94 | 'path_analysis':
95 | {
96 | 'source':'data/lemon/session001/taskT001/010002.vhdr',
97 | 'target':'data_bids/sub-010002/ses-001/eeg/sub-010002_ses-001_task-T001_eeg.vhdr'
98 | }
99 | }
100 | }
101 |
102 | yaml_file = _write_yaml(rule)
103 |
104 | print('Ambiguous Example:\n\n',yaml_file)
105 |
106 | #%%
107 | # If your example is ambiguous, the function will raise an error.
108 | #
109 | # Notice the last bit of the message, it will hint you about what part of the example is suspected to have ambiguity.
110 | #
111 | from traceback import format_exc
112 |
113 | try:
114 | sourcepath = rule['non-bids']['path_analysis']['source']
115 | targetpath = rule['non-bids']['path_analysis']['target']
116 | result = from_io_example(sourcepath,targetpath)
117 | except:
118 | print('Error:\n\n',format_exc())
119 |
--------------------------------------------------------------------------------
/sovabids/schemas/bidsmap_sova2coin.yml:
--------------------------------------------------------------------------------
1 | # --------------------------------------------------------------------------------
2 | # This is a bidsmap YAML file with the key-value mappings for the different BIDS
3 | # datatypes (anat, func, dwi, etc). The datatype attributes are the keys that map
4 | # onto the BIDS labels. The bidsmap data-structure should be 5 levels deep:
5 | #
6 | # dict : dict : list : dict : dict
7 | # dataformat : datatype : run-item : bidsmapping : mapping-data
8 | #
9 | # NB:
10 | # 1) Edit the bidsmap file to your needs before feeding it to bidscoiner.py
11 | # 2) (Institute) users may create their own bidsmap_[template].yaml or
12 | # bidsmap_[sample].yaml file
13 | #
14 | # For more information, see: https://bidscoin.readthedocs.io
15 | # --------------------------------------------------------------------------------
16 |
17 |
18 | Options:
19 | # --------------------------------------------------------------------------------
20 | # General options and plugins
21 | # --------------------------------------------------------------------------------
22 | bidscoin:
23 | version: 3.7.0-dev # BIDScoin version (should correspond with the version in ../bidscoin/version.txt)
24 | bidsignore: extra_data/ # Semicolon-separated list of entries that are added to the .bidsignore file (for more info, see BIDS specifications), e.g. extra_data/;pet/;myfile.txt;yourfile.csv
25 | subprefix: sub- # The default subject prefix of the source data
26 | sesprefix: ses- # The default session prefix of the source data
27 | plugins: # List of plugins with plugin-specific key-value pairs (that can be used by the plugin)
28 | README: # The plugin basename that is installed in the default bidscoin/plugins folder
29 | dcm2bidsmap: # The default plugin that is used by the bidsmapper to map DICOM and PAR/REC source data
30 | dcm2niix2bids: # See dcm2niix -h and https://www.nitrc.org/plugins/mwiki/index.php/dcm2nii:MainPage#General_Usage for more info
31 | path: module add dcm2niix; # Command to set the path to dcm2niix (note the semi-colon), e.g. module add dcm2niix/1.0.20180622; or PATH=/opt/dcm2niix/bin:$PATH; or /opt/dcm2niix/bin/ or '"C:\Program Files\dcm2niix\"' (note the quotes to deal with the whitespace)
32 | args: -b y -z y -i n # Argument string that is passed to dcm2niix. Tip: SPM users may want to use '-z n' (which produces unzipped nifti's, see dcm2niix -h for more information)
33 | sova2coin: # sovabids module
34 | rules : {} #
35 |
36 |
37 | EEG:
38 | # --------------------------------------------------------------------------------
39 | # EEG key-value heuristics (sovabids fields that are mapped to the BIDS labels)
40 | # --------------------------------------------------------------------------------
41 | subject: <>
42 | session: <>
43 |
44 | eeg: # ----------------------- All eeg runs --------------------
45 | - provenance: # The fullpath name of the EEG file from which the attributes are read. Serves also as a look-up key to find a run in the bidsmap
46 | properties: &fileprop # This is an optional (stub) entry of filesystem matching (could be added to any run-item)
47 | filepath: # File folder, e.g. ".*Parkinson.*" or ".*(phantom|bottle).*"
48 | filename: .* # File name, e.g. ".*fmap.*" or ".*(fmap|field.?map|B0.?map).*"
49 | filesize: # File size, e.g. "2[4-6]\d MB" for matching files between 240-269 MB
50 | nrfiles: # Number of files in the folder that match the above criteria, e.g. "5/d/d" for matching a number between 500-599
51 | attributes: &eeg_attr # An empty / non-matching reference dictionary that can be derefenced in other run-items of this data type
52 | sidecar:
53 | channels.name:
54 | channels.type:
55 | channels.units:
56 | entities.subject:
57 | entities.task:
58 | entities.session:
59 | entities.run:
60 | dataset_description:
61 | bids: &eeg_bids # See: schema/datatypes/eeg.yaml
62 | task: <> # Note Dynamic values are not previewed in the bids editor but they do work, this should be fixed anyway
63 | acq:
64 | run: <>
65 | suffix: eeg
66 | meta: # This is an optional entry for meta-data that will be appended to the json sidecar files. Currently not supported in sova2coin.
--------------------------------------------------------------------------------
/docs/source/conf.py:
--------------------------------------------------------------------------------
1 | # Configuration file for the Sphinx documentation builder.
2 | #
3 | # This file only contains a selection of the most common options. For a full
4 | # list see the documentation:
5 | # https://www.sphinx-doc.org/en/master/usage/configuration.html
6 |
7 | # -- Path setup --------------------------------------------------------------
8 |
9 | # If extensions (or modules to document with autodoc) are in another directory,
10 | # add these directories to sys.path here. If the directory is relative to the
11 | # documentation root, use os.path.abspath to make it absolute, like shown here.
12 | #
13 | import os
14 | import sys
15 | from datetime import date
16 | import sovabids
17 | # sys.path.insert(0, os.path.abspath('.'))
18 |
19 | curdir = os.path.dirname(__file__)
20 | sys.path.append(os.path.abspath(os.path.join(curdir, "..", "sovabids")))
21 |
22 | # -- Project information -----------------------------------------------------
23 |
24 | project = 'sovabids'
25 | copyright = '2021, sovabids team'
26 | author = "sovabids developers"
27 | _today = date.today()
28 | copyright = f"2021-{_today.year}, sovabids developers. Last updated {_today.isoformat()}"
29 |
30 | # The short X.Y version
31 | version = sovabids.__version__
32 | release = version
33 |
34 | # -- General configuration ---------------------------------------------------
35 |
36 | # Add any Sphinx extension module names here, as strings. They can be
37 | # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
38 | # ones.
39 | extensions = [
40 | "myst_parser",
41 | "sphinx.ext.autodoc",
42 | "sphinx.ext.autosummary",
43 | # "sphinx.ext.intersphinx",
44 | #"numpydoc",
45 | "sphinx_gallery.gen_gallery",
46 | #"gh_substitutions", # custom extension, see ./sphinxext/gh_substitutions.py
47 | "sphinx_copybutton",
48 | 'sphinxcontrib.mermaid',
49 | 'sphinx.ext.napoleon',
50 | ]
51 |
52 | copybutton_prompt_text = r">>> |\.\.\. "
53 | copybutton_prompt_is_regexp = True
54 |
55 |
56 | master_doc = "index"
57 | autosummary_generate = True
58 |
59 | autodoc_default_options = {
60 | "members": True,
61 | "inherited-members": True,
62 | "show-inheritance": True,
63 | }
64 |
65 | sphinx_gallery_conf = {
66 | "doc_module": "sovabids",
67 | "reference_url": {
68 | "sovabids": None,
69 | },
70 | "examples_dirs": "../../examples",
71 | "gallery_dirs": "auto_examples",
72 | "filename_pattern": "^((?!sgskip).)*$",
73 | "backreferences_dir": "generated",
74 | 'run_stale_examples': False, #Force (or not) re running examples
75 | }
76 |
77 | # List of patterns, relative to source directory, that match files and
78 | # directories to ignore when looking for source files.
79 | # This patterns also effect to html_static_path and html_extra_path
80 | exclude_patterns = ["_build", "Thumbs.db", ".DS_Store",'_ideas']
81 |
82 | # Add any paths that contain templates here, relative to this directory.
83 | templates_path = ['_templates']
84 |
85 | # -- Options for HTML output -------------------------------------------------
86 |
87 | # The theme to use for HTML and HTML Help pages. See the documentation for
88 | # a list of builtin themes.
89 | #
90 | html_theme = 'furo'
91 |
92 | # Add any paths that contain custom static files (such as style sheets) here,
93 | # relative to this directory. They are copied after the builtin static files,
94 | # so a file named "default.css" will overwrite the builtin "default.css".
95 | #html_static_path = ['_static'] #already done in the setup(app) section
96 | html_extra_path = ['_copyover']
97 |
98 | ###################################################################################################
99 | # Seems like this is not needed anymore ###########################################################
100 | # Replace gallery.css for changing the highlight of the output cells in sphinx gallery
101 | # See:
102 | # https://github.com/sphinx-gallery/sphinx-gallery/issues/399
103 | # https://github.com/sphinx-doc/sphinx/issues/2090
104 | # https://github.com/sphinx-doc/sphinx/issues/7747
105 | # def setup(app):
106 | # app.connect('builder-inited', lambda app: app.config.html_static_path.append('_static'))
107 | # app.add_css_file('gallery.css')
108 | ###################################################################################################
109 |
110 | # Auto API
111 | extensions += ['autoapi.extension']
112 |
113 | autoapi_type = 'python'
114 | autoapi_dirs = ["../../sovabids"]
115 |
116 | extensions += ['sphinx.ext.viewcode'] #see https://github.com/readthedocs/sphinx-autoapi/issues/422
--------------------------------------------------------------------------------
/docs/source/_static/gallery.css:
--------------------------------------------------------------------------------
1 | /*
2 | Sphinx-Gallery has compatible CSS to fix default sphinx themes
3 | Tested for Sphinx 1.3.1 for all themes: default, alabaster, sphinxdoc,
4 | scrolls, agogo, traditional, nature, haiku, pyramid
5 | Tested for Read the Docs theme 0.1.7 */
6 | .sphx-glr-thumbcontainer {
7 | background: #fff;
8 | border: solid #fff 1px;
9 | -moz-border-radius: 5px;
10 | -webkit-border-radius: 5px;
11 | border-radius: 5px;
12 | box-shadow: none;
13 | float: left;
14 | margin: 5px;
15 | min-height: 230px;
16 | padding-top: 5px;
17 | position: relative;
18 | }
19 | .sphx-glr-thumbcontainer:hover {
20 | border: solid #b4ddfc 1px;
21 | box-shadow: 0 0 15px rgba(142, 176, 202, 0.5);
22 | }
23 | .sphx-glr-thumbcontainer a.internal {
24 | bottom: 0;
25 | display: block;
26 | left: 0;
27 | padding: 150px 10px 0;
28 | position: absolute;
29 | right: 0;
30 | top: 0;
31 | }
32 | /* Next one is to avoid Sphinx traditional theme to cover all the
33 | thumbnail with its default link Background color */
34 | .sphx-glr-thumbcontainer a.internal:hover {
35 | background-color: transparent;
36 | }
37 |
38 | .sphx-glr-thumbcontainer p {
39 | margin: 0 0 .1em 0;
40 | }
41 | .sphx-glr-thumbcontainer .figure {
42 | margin: 10px;
43 | width: 160px;
44 | }
45 | .sphx-glr-thumbcontainer img {
46 | display: inline;
47 | max-height: 112px;
48 | max-width: 160px;
49 | }
50 | .sphx-glr-thumbcontainer[tooltip]:hover:after {
51 | background: rgba(0, 0, 0, 0.8);
52 | -webkit-border-radius: 5px;
53 | -moz-border-radius: 5px;
54 | border-radius: 5px;
55 | color: #fff;
56 | content: attr(tooltip);
57 | left: 95%;
58 | padding: 5px 15px;
59 | position: absolute;
60 | z-index: 98;
61 | width: 220px;
62 | bottom: 52%;
63 | }
64 | .sphx-glr-thumbcontainer[tooltip]:hover:before {
65 | border: solid;
66 | border-color: #333 transparent;
67 | border-width: 18px 0 0 20px;
68 | bottom: 58%;
69 | content: '';
70 | left: 85%;
71 | position: absolute;
72 | z-index: 99;
73 | }
74 |
75 | .sphx-glr-script-out {
76 | color: #888;
77 | margin: 0;
78 | }
79 | p.sphx-glr-script-out {
80 | padding-top: 0.7em;
81 | }
82 | .sphx-glr-script-out .highlight {
83 | background-color: #1f4d61;
84 | margin-left: 2.5em;
85 | margin-top: -2.1em;
86 | }
87 | .sphx-glr-script-out .highlight pre {
88 | background-color: #1f4d61;
89 | border: 0;
90 | max-height: 30em;
91 | overflow: auto;
92 | padding-left: 1ex;
93 | margin: 0px;
94 | word-break: break-word;
95 | }
96 | .sphx-glr-script-out + p {
97 | margin-top: 1.8em;
98 | }
99 | blockquote.sphx-glr-script-out {
100 | margin-left: 0pt;
101 | }
102 | .sphx-glr-script-out.highlight-pytb .highlight pre {
103 | color: #000;
104 | background-color: #1f4d61;
105 | border: 1px solid #f66;
106 | margin-top: 10px;
107 | padding: 7px;
108 | }
109 |
110 | div.sphx-glr-footer {
111 | text-align: center;
112 | }
113 |
114 | div.sphx-glr-download {
115 | margin: 1em auto;
116 | vertical-align: middle;
117 | }
118 |
119 | div.sphx-glr-download a {
120 | background-color: #ffc;
121 | background-image: linear-gradient(to bottom, #FFC, #d5d57e);
122 | border-radius: 4px;
123 | border: 1px solid #c2c22d;
124 | color: #000;
125 | display: inline-block;
126 | font-weight: bold;
127 | padding: 1ex;
128 | text-align: center;
129 | }
130 |
131 | div.sphx-glr-download code.download {
132 | display: inline-block;
133 | white-space: normal;
134 | word-break: normal;
135 | overflow-wrap: break-word;
136 | /* border and background are given by the enclosing 'a' */
137 | border: none;
138 | background: none;
139 | }
140 |
141 | div.sphx-glr-download a:hover {
142 | box-shadow: inset 0 1px 0 rgba(255,255,255,.1), 0 1px 5px rgba(0,0,0,.25);
143 | text-decoration: none;
144 | background-image: none;
145 | background-color: #d5d57e;
146 | }
147 |
148 | .sphx-glr-example-title:target::before {
149 | display: block;
150 | content: "";
151 | margin-top: -50px;
152 | height: 50px;
153 | visibility: hidden;
154 | }
155 |
156 | ul.sphx-glr-horizontal {
157 | list-style: none;
158 | padding: 0;
159 | }
160 | ul.sphx-glr-horizontal li {
161 | display: inline;
162 | }
163 | ul.sphx-glr-horizontal img {
164 | height: auto !important;
165 | }
166 |
167 | .sphx-glr-single-img {
168 | margin: auto;
169 | display: block;
170 | max-width: 100%;
171 | }
172 |
173 | .sphx-glr-multi-img {
174 | max-width: 42%;
175 | height: auto;
176 | }
177 |
178 | div.sphx-glr-animation {
179 | margin: auto;
180 | display: block;
181 | max-width: 100%;
182 | }
183 | div.sphx-glr-animation .animation{
184 | display: block;
185 | }
186 |
187 | p.sphx-glr-signature a.reference.external {
188 | -moz-border-radius: 5px;
189 | -webkit-border-radius: 5px;
190 | border-radius: 5px;
191 | padding: 3px;
192 | font-size: 75%;
193 | text-align: right;
194 | margin-left: auto;
195 | display: table;
196 | }
197 |
198 | .sphx-glr-clear{
199 | clear: both;
200 | }
201 |
202 | a.sphx-glr-backref-instance {
203 | text-decoration: none;
204 | }
205 |
--------------------------------------------------------------------------------
/sovabids/dicts.py:
--------------------------------------------------------------------------------
1 | """Module with dictionary utilities."""
2 |
3 | import collections
4 | from functools import reduce
5 | def deep_get(dictionary, keys, default=None,sep='.'):
6 | """Safe nested dictionary getter.
7 |
8 | Parameters
9 | ----------
10 | dictionary: dict
11 | The dictionary from which to get the value.
12 | keys: str
13 | The nested keys using sep as separator.
14 | Ie: 'person.name.lastname' if `sep`='.'
15 | default: object
16 | The default value to return if the key is not found
17 | sep : str, optional
18 | The separator to indicate nesting/branching/hierarchy.
19 |
20 | Returns
21 | -------
22 |
23 | object:
24 | The value of the required key. `default` if the key is not found.
25 |
26 | Notes
27 | -----
28 | Taken from https://stackoverflow.com/a/46890853/14068216
29 | """
30 | return reduce(lambda d, key: d.get(key, default) if isinstance(d, dict) else default, keys.split(sep), dictionary)
31 |
32 | def deep_merge_N(l):
33 | """Merge the list of dictionaries, such that the latest one has the greater precedence.
34 |
35 | Parameters
36 | ----------
37 |
38 | l : list of dict
39 | List containing the dictionaries to be merged, having precedence on the last ones.
40 |
41 | Returns
42 | -------
43 |
44 | dict :
45 | The merged dictionary.
46 | """
47 | d = {}
48 | while True:
49 | if len(l) == 0:
50 | return {}
51 | if len(l) == 1:
52 | return l[0]
53 | d1 = l.pop(0)
54 | d2 = l.pop(0)
55 | d = deep_merge(d1,d2)
56 | l.insert(0, d)
57 |
58 | def deep_merge(a, b):
59 | """
60 | Merge two values, with `b` taking precedence over `a`.
61 |
62 | Semantics:
63 | - If either `a` or `b` is not a dictionary, `a` will be returned only if
64 | `b` is `None`. Otherwise `b` will be returned.
65 | - If both values are dictionaries, they are merged as follows:
66 | * Each key that is found only in `a` or only in `b` will be included in
67 | the output collection with its value intact.
68 | * For any key in common between `a` and `b`, the corresponding values
69 | will be merged with the same semantics.
70 |
71 | From David Schneider answer at https://stackoverflow.com/questions/7204805/how-to-merge-dictionaries-of-dictionaries/15836901#15836901
72 |
73 | Parameters
74 | ----------
75 |
76 | a : object
77 | b : object
78 |
79 | Returns
80 | -------
81 |
82 | dict :
83 | Merged dictionary.
84 | """
85 | if not isinstance(a, dict) or not isinstance(b, dict):
86 | return a if b is None else b
87 | else:
88 | # If we're here, both a and b must be dictionaries or subtypes thereof.
89 |
90 | # Compute set of all keys in both dictionaries.
91 | keys = set(a.keys()) | set(b.keys())
92 |
93 | # Build output dictionary, merging recursively values with common keys,
94 | # where `None` is used to mean the absence of a value.
95 | return {
96 | key: deep_merge(a.get(key), b.get(key))
97 | for key in keys
98 | }
99 |
100 |
101 | def flatten(d, parent_key='', sep='.'):
102 | """Flatten the nested dictionary structure using the given separator.
103 |
104 | If parent_key is given, then that level is added at the start of the tree.
105 |
106 | Parameters
107 | ----------
108 |
109 | d : dict
110 | The dictionary to flat.
111 | parent_key : str, optional
112 | The optional top-level field of the dictionary.
113 | sep : str, optional
114 | The separator to indicate nesting/branching/hierarchy.
115 |
116 | Returns
117 | -------
118 | dict :
119 | A dictionary with only one level of fields.
120 | """
121 | items = []
122 | for k, v in d.items():
123 | new_key = parent_key + sep + k if parent_key else k
124 | if isinstance(v, collections.MutableMapping):
125 | items.extend(flatten(v, new_key, sep=sep).items())
126 | else:
127 | items.append((new_key, v))
128 | return dict(items)
129 |
130 |
131 | def nested_notation_to_tree(key,value,leaf='.'):
132 | """Create a nested dictionary from the single (key,value) pair, with the key being branched by the leaf separator.
133 |
134 | Parameters
135 | ----------
136 | key : str
137 | The key/field to be nested, assuming nesting is represented with the "leaf" parameters.
138 | value : object
139 | The value that it will have at the last level of nesting.
140 | leaf : str, optional
141 | The separator used to indicate nesting in "key" parameter.
142 |
143 | Returns
144 | -------
145 |
146 | dict :
147 | Nested dictionary.
148 | """
149 | if leaf in key:
150 | tree_list = key.split(leaf)
151 | tree_dict = value
152 | for key in reversed(tree_list):
153 | tree_dict = {key: tree_dict}
154 | return tree_dict
155 | else:
156 | return {key:value}
157 |
--------------------------------------------------------------------------------
/sovabids/schemas/rules.yml:
--------------------------------------------------------------------------------
1 | #TODO: Do a validator of this file schema
2 | # # eeg bids fields collection
3 | # # Unsupported files are commented
4 | entities : #see https://github.com/bids-standard/bids-specification/blob/66d8532065bdae6a7275efd8bbe05a8e00dc1031/src/schema/datatypes/eeg.yaml#L13-L18
5 | subject : REQUIRED # this is mostly used if you are doing a single user, better to do it from the path
6 | session : OPTIONAL
7 | task : REQUIRED
8 | acquisition : OPTIONAL
9 | run : OPTIONAL
10 |
11 | dataset_description : #https://bids-specification.readthedocs.io/en/latest/03-modality-agnostic-files.html
12 | # we for now will support only what mne_bids.make_dataset_description supports
13 | Name : REQUIRED
14 | # BIDSVersion : REQUIRED
15 | # HEDVersion : RECOMMENDED
16 | # DatasetType : RECOMMENDED
17 | # License : RECOMMENDED
18 | Authors : OPTIONAL
19 | # Acknowledgements : OPTIONAL
20 | # HowToAcknowledge : OPTIONAL
21 | # Funding : OPTIONAL
22 | # EthicsApprovals : OPTIONAL
23 | # ReferencesAndLinks : OPTIONAL
24 | # DatasetDOI : OPTIONAL
25 |
26 | # #https://bids-specification.readthedocs.io/en/latest/04-modality-specific-files/03-electroencephalography.html
27 | sidecar :
28 | # TaskName : REQUIRED
29 | # InstitutionName : RECOMMENDED
30 | # InstitutionAddress : RECOMMENDED
31 | # Manufacturer : RECOMMENDED
32 | # ManufacturersModelName : RECOMMENDED
33 | # SoftwareVersions : RECOMMENDED
34 | # TaskDescription : RECOMMENDED
35 | # Instructions : RECOMMENDED
36 | # CogAtlasID : RECOMMENDED
37 | # CogPOID : RECOMMENDED
38 | # DeviceSerialNumber : RECOMMENDED
39 | EEGReference : REQUIRED
40 | # SamplingFrequency : REQUIRED
41 | PowerLineFrequency : REQUIRED
42 | SoftwareFilters : REQUIRED # do a dictionary tree like {"Anti-aliasing filter": {"half-amplitude cutoff (Hz)": 500, "Roll-off": "6dB/Octave"}}
43 | # CapManufacturer : RECOMMENDED
44 | # CapManufacturersModelName : RECOMMENDED
45 | # EEGChannelCount : RECOMMENDED
46 | # ECGChannelCount : RECOMMENDED
47 | # EMGChannelCount : RECOMMENDED
48 | # EOGChannelCount : RECOMMENDED
49 | # MiscChannelCount : RECOMMENDED
50 | # TriggerChannelCount : RECOMMENDED
51 | # RecordingDuration : RECOMMENDED
52 | # RecordingType : RECOMMENDED
53 | # EpochLength : RECOMMENDED
54 | # EEGGround : RECOMMENDED
55 | # HeadCircumference : RECOMMENDED
56 | # EEGPlacementScheme : RECOMMENDED
57 | # HardwareFilters : RECOMMENDED
58 | # SubjectArtefactDescription : RECOMMENDED
59 |
60 | channels :
61 | name : REQUIRED #notice, this will be applied first so if other fields are changed use the new name as index
62 | type : REQUIRED #dictionary following name : bids-type
63 | # units : REQUIRED
64 | # description : OPTIONAL
65 | # sampling_frequency : OPTIONAL
66 | # reference : OPTIONAL
67 | # low_cutoff : OPTIONAL
68 | # high_cutoff : OPTIONAL
69 | # notch : OPTIONAL
70 | # status : OPTIONAL
71 | # status_description : OPTIONAL
72 |
73 | # electrodes :
74 | # name : REQUIRED
75 | # x : REQUIRED
76 | # y : REQUIRED
77 | # z : REQUIRED
78 | # type : RECOMMENDED
79 | # material : RECOMMENDED
80 | # impedance : RECOMMENDED
81 |
82 | # coordsystem : # this has special logic for the requirements but the default is implemented
83 | # # https://bids-specification.readthedocs.io/en/latest/04-modality-specific-files/03-electroencephalography.html
84 | # IntendedFor : OPTIONAL
85 | # EEGCoordinateSystem : REQUIRED
86 | # EEGCoordinateUnits : REQUIRED
87 | # EEGCoordinateSystemDescription : RECOMMENDED
88 | # FiducialsDescription : OPTIONAL
89 | # FiducialsCoordinates : RECOMMENDED
90 | # FiducialsCoordinateSystem : RECOMMENDED
91 | # FiducialsCoordinateUnits : RECOMMENDED
92 | # FiducialsCoordinateSystemDescription : RECOMMENDED
93 | # AnatomicalLandmarkCoordinates : RECOMMENDED
94 | # AnatomicalLandmarkCoordinateSystem : RECOMMENDED
95 | # AnatomicalLandmarkCoordinateUnits : RECOMMENDED
96 | # AnatomicalLandmarkCoordinateSystemDescription : RECOMMENDED
97 |
98 | # events:
99 | # onset : REQUIRED
100 | # duration : REQUIRED
101 | # sample : OPTIONAL
102 | # trial_type : OPTIONAL
103 | # response_time : OPTIONAL
104 | # value : OPTIONAL
105 | # HED : OPTIONAL
106 | # stim_file : OPTIONAL
107 | # StimulusPresentation : RECOMMENDED
108 | # OperatingSystem : RECOMMENDED
109 | # SoftwareName : RECOMMENDED
110 | # SoftwareRRID : RECOMMENDED
111 | # SoftwareVersion : RECOMMENDED
112 | # Code : RECOMMENDED
113 |
114 | non-bids :
115 | eeg_extension : OPTIONAL # to say which files to take into account when reading a directory, can be a list of extensions or a single one
116 | path_analysis : #OPTIONAL #USE POSIX REQUIRED
117 | pattern: REQUIRED-IF-PATH-ANALYSIS # Either regex or custom notation (which would have the fields already inside)
118 | fields: #REQUIRED if regex # dot notation of the other dicts, same order as they appear in the regex pattern
119 | - field1.something
120 | - field2
121 | encloser : OPTIONAL # the split symbol, only for custom notation of path pattern, defaults to %
122 | matcher : OPTIONAL # the regex matcher that replaces %field% to translate it to regex, only for custom notation.defaults to (.+)
123 | code_execution : OPTIONAL # if the code itself needs ie quotes, escape characters may be nedeed
124 | # example: raw.set_channel_mapping({\"VEOG\":\"eog\"})" # this is an example, this line of code actually doesnt work
125 |
126 | IO: # INPUT-OUTPUT
127 | source : UNUSED for RULES, REQUIRED for MAPPINGS (the source file path for individual mappings,the source data root path for general mapping)
128 | target : UNUSED for RULES, REQUIRED for MAPPINGS (the target file path for individual mappings,the target bids root path for general mapping)
129 |
--------------------------------------------------------------------------------
/tests/test_path_parser.py:
--------------------------------------------------------------------------------
1 | """sovareject tests
2 | Run tests:
3 | >>> pytest
4 |
5 | Run coverage
6 | >>> coverage run -m pytest
7 |
8 | Basic coverage reports
9 | >>> coverage report
10 |
11 | HTML coverage reports
12 | >>> coverage html
13 |
14 | For debugging:
15 | Remove fixtures from functions
16 | (since fixtures cannot be called directly)
17 | and use the functions directly
18 | In example:
19 | >>> test_eegthresh(rej_matrix_tuple())
20 | """
21 | from sovabids.parsers import parse_from_placeholder
22 | from sovabids.parsers import parse_from_regex
23 | from sovabids.parsers import find_bidsroot
24 | from sovabids.parsers import parse_path_pattern_from_entities
25 | import pytest
26 |
27 | def test_parse_from_regex():
28 | string = r'Y:\code\sovabids\_data\lemon2\sub-010002\ses-001\resting\sub-010002.vhdr'
29 | path_pattern = '.*?\\/.*?\\/.*?\\/.*?\\/.*?\\/sub-(.*?)\\/ses-(.*?)\\/(.*?)\\/sub-(.*?).vhdr'
30 | fields = ['ignore','entities.session','entities.task','entities.subject']
31 | result = parse_from_regex(string,path_pattern,fields)
32 | assert result['entities']['subject'] == '010002'
33 | assert result['entities']['session']=='001'
34 | assert result['entities']['task']=='resting'
35 | assert result['ignore']=='010002'
36 |
37 | string = r'Y:\code\sovabids\_data\lemon2\sub-010004\ses-001\sub-010004.vhdr'
38 |
39 | path_pattern = 'ses-(.*?)\\/s(.*?)-(.*?).vhdr'
40 | fields = ['entities.session','ignore','entities.subject']
41 | result = parse_from_regex(string,path_pattern,fields)
42 | assert result['entities']['session']=='001'
43 | assert result['entities']['subject']=='010004'
44 | assert result['ignore']=='ub'
45 |
46 | string = 'y:\\code\\sovabids\\_data\\lemon\\sub-010002.vhdr'
47 | path_pattern = 'sub-(.*?).vhdr'
48 | fields = 'entities.subject'
49 | result = parse_from_regex(string,path_pattern,fields)
50 | assert result['entities']['subject'] == '010002'
51 |
52 | path_pattern = '(.*?)\\/sub-(.*?).vhdr'
53 | fields = ['ignore','entities.subject']
54 | result = parse_from_regex(string,path_pattern,fields)
55 | assert result['entities']['subject'] == '010002'
56 | assert result['ignore'] == 'y:/code/sovabids/_data/lemon' #USE POSIX
57 |
58 | path_pattern = '(.*?).vhdr'
59 | fields = 'entities.subject'
60 | result = parse_from_regex(string,path_pattern,fields)
61 | assert result['entities']['subject'] == 'y:/code/sovabids/data/lemon/sub010002'
62 | # Notice replacement of '_' to '', expected as bids does not accept _,-
63 |
64 | path_pattern = 'sub-(.*)' # notice no "?",or use .+
65 | fields = 'entities.subject'
66 | result = parse_from_regex(string,path_pattern,fields)
67 | assert result['entities']['subject'] == '010002.vhdr'
68 |
69 |
70 | def test_parse_from_placeholder():
71 | matcher = '(.+)'
72 | string = r'Y:\code\sovabids\_data\lemon2\sub-010002\ses-001\resting\sub-010002.vhdr'
73 | path_pattern = 'sub-%ignore%\ses-%entities.session%\%entities.task%\sub-%entities.subject%.vhdr'
74 | result = parse_from_placeholder(string,path_pattern,matcher=matcher)
75 | assert result['entities']['subject'] == '010002'
76 | assert result['entities']['session']=='001'
77 | assert result['entities']['task']=='resting'
78 | assert result['ignore']=='010002'
79 |
80 | string = r'Y:\code\sovabids\_data\lemon2\sub-010004\ses-001\sub-010004.vhdr'
81 | path_pattern = 'ses-%entities.session%/s%ignore%-%entities.subject%.vhdr'
82 | result = parse_from_placeholder(string,path_pattern,matcher=matcher)
83 | assert result['entities']['session']=='001'
84 | assert result['entities']['subject']=='010004'
85 | assert result['ignore']=='ub'
86 |
87 | string = 'y:\\code\\sovabids\\_data\\lemon\\sub-010002.vhdr'
88 | path_pattern = 'sub-%entities.subject%.vhdr'
89 | result = parse_from_placeholder(string,path_pattern,matcher=matcher)
90 | assert result['entities']['subject'] == '010002'
91 |
92 | path_pattern = '%ignore%\sub-%entities.subject%.vhdr'
93 | result = parse_from_placeholder(string,path_pattern,matcher=matcher)
94 | assert result['entities']['subject'] == '010002'
95 | assert result['ignore'] == 'y:/code/sovabids/_data/lemon' #USE POSIX
96 |
97 | path_pattern = '%entities.subject%.vhdr'
98 | result = parse_from_placeholder(string,path_pattern,matcher=matcher)
99 | assert result['entities']['subject'] == 'y:/code/sovabids/data/lemon/sub010002'
100 | # Notice replacement of '_' to '', expected as bids does not accept _,-
101 |
102 | path_pattern = 'sub-%entities.subject%'
103 | result = parse_from_placeholder(string,path_pattern,matcher=matcher)
104 | assert result['entities']['subject'] == '010002.vhdr'
105 |
106 | def test_find_bidsroot():
107 | path = 'y:\code\sovabids\_data\DUMMY\DUMMY_BIDS_placeholder_python\sub-SU0\ses-SE0\eeg\sub-SU0_ses-SE0_task-TA0_acq-AC0_run-0_eeg.vhdr'
108 | bidsroot=find_bidsroot(path)
109 | assert bidsroot=='y:\\code\\sovabids\\_data\\DUMMY\\DUMMY_BIDS_placeholder_python\\'
110 |
111 | def test_parse_path_pattern_from_entities():
112 |
113 | # ambiguous
114 | with pytest.raises(ValueError):
115 | source='data/lemon/sessionV001/task001/010002.vhdr'
116 | entities = {'sub':'010002','task':'001','ses':'V001'}
117 | parse_path_pattern_from_entities(source,entities)
118 |
119 | # non-ambiguous
120 | source='data/lemon/sessionV001/task009/010002.vhdr'
121 | entities = {'sub':'010002','task':'009','ses':'V001'}
122 | pattern =parse_path_pattern_from_entities(source,entities)
123 | assert pattern == 'session%entities.session%/task%entities.task%/%entities.subject%.vhdr'
124 |
125 | if __name__ == '__main__':
126 | test_parse_from_regex()
127 | test_parse_from_placeholder()
128 | test_find_bidsroot()
129 | test_parse_path_pattern_from_entities()
130 | print('ok')
--------------------------------------------------------------------------------
/examples/gui_example.py:
--------------------------------------------------------------------------------
1 |
2 | """
3 | ===============================
4 | GUI example with LEMON dataset
5 | ===============================
6 |
7 | This example illustrates the use of ``sovabids`` on the `LEMON dataset `_
8 | using the preliminary GUI tool.
9 |
10 | Install Sovabids in gui-usage mode
11 | ---------------------------------------
12 | (`see here `_)
13 |
14 | Download the Lemon dataset
15 | -----------------------------
16 | (if you have not already done so)
17 | If you need to download the files, you can use:
18 |
19 | .. code-block:: bash
20 |
21 | python -c 'from sovabids.datasets import lemon_prepare; lemon_prepare()'
22 |
23 | This will download the lemon dataset to a '_data' subfolder that will be created in the installed packages folder.
24 |
25 | Run front/app/app.py in a terminal
26 | ----------------------------------
27 | (the front folder is the one in the root of the cloned sovabids repository.)
28 |
29 | Assuming you are at the root of the sovabids cloned repository, you can use:
30 |
31 | .. code-block:: bash
32 |
33 | python front/app/app.py
34 |
35 |
36 | Go to your browser at http://127.0.0.1:5000/
37 | ---------------------------------------------
38 |
39 | You will see:
40 |
41 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_1_intro.png
42 |
43 | This is an introductory page of the GUI.
44 |
45 | Click Upload Files
46 | -------------------
47 |
48 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_2_click_upload.png
49 |
50 | Choose Files
51 | --------------
52 |
53 | In a terminal, run the following command to find the installed packages folder:
54 |
55 | .. code-block:: bash
56 |
57 | pip show sovabids
58 |
59 | The path to the installed packages folder is given in the 'Location:' field.
60 |
61 |
62 | Click 'Choose Files', go to the installed packages folder, click on the _data subfolder, and then select the lemon subfolder. Click submit.
63 |
64 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_3_upload.png
65 |
66 | You will need to wait while the files are copied to the server. Since these are heavy eegs, it will take a bit.
67 |
68 | Deselect any files you want to skip
69 | ------------------------------------
70 |
71 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_4_deselect.png
72 |
73 | Here we won't skip any files. Notice though that there are non-eeg files (.csv and tar.gz ) mixed in there. Sovabids will skip them automatically.
74 |
75 | Click Send.
76 |
77 | Confirm detected eegs
78 | ------------------------
79 |
80 | Sovabids will show the individual eegs found. Notice that since this is a brainvision dataset, sovabids lists the main files of this format (the .vhdr files) since the other ones (.eeg and .vmrk) are sidecars.
81 |
82 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_5_detected.png
83 |
84 |
85 | The rules files
86 | -----------------
87 |
88 | A suitable rules file is already at examples/lemon_example_rules.yml within the cloned sovabids repositry, you can upload that one.
89 |
90 | Click Choose File, then in the popup window select the rules file, click open and then submit.
91 |
92 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_6_upload_rules.png
93 |
94 | After that you will notice the text pane is updated:
95 |
96 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_7_inspect_rules.png
97 |
98 | You can edit the rules directly, as shown here where we modify the dataset name to "Modified Name'.
99 |
100 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_8_edit_rules.png
101 |
102 | Once ready, scroll down to find another submit and click it to continue.
103 |
104 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_9_submit_rules.png
105 |
106 |
107 | Edit individual mappings
108 | --------------------------
109 |
110 | You will now see a list of the eeg files, for each you can edit its mapping. At first you will see an empty text pane since no eeg file is chosen.
111 |
112 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_10_mappings.png
113 |
114 | Click any of the files for editing it:
115 |
116 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_11_select_mapping.png
117 |
118 | Once clicked, you will see the corresponding mapping:
119 |
120 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_12_the_mapping.png
121 |
122 | You can edit the INDIVIDUAL mapping of this file, in example here we will change the power line frequency of this eeg to 60 Hz.
123 |
124 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_13_edit_mapping.png
125 |
126 | To save the edited individual mapping, press Send at the right:
127 |
128 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_14_save_mapping.png
129 |
130 | You will be redirected to the empty mapping, but if you click the same eeg file again you will notice the changes are saved:
131 |
132 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_15_check_mapping.png
133 |
134 | Once the mappings are ready, click next:
135 |
136 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_16_mappings_ready.png
137 |
138 |
139 | Proceed to the conversion
140 | --------------------------
141 |
142 | Click on the button:
143 |
144 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_17_conversion_click.png
145 |
146 | Once clicked it will take a while before the program finishes (a feedback information of the progress is not yet implemented on this preliminary GUI).
147 |
148 | Save your conversion
149 | ------------------------
150 |
151 | When the files are ready you will see:
152 |
153 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_18_download_click.png
154 |
155 | Once you click there, sovabids will begin compressing your files so it will take a bit until the download windows is shown. Select where you want to download the file and press save.
156 |
157 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_19_download_popup.png
158 |
159 | When the download is ready, navigate to the chosen folder and decompress the files. Go into the correspondent folder to see the converted files:
160 |
161 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_20_converted_files.png
162 |
163 | Inspect the sovabids logs and mappings
164 | ---------------------------------------
165 |
166 | Inside the code/sovabids subdirectory you will see the mappings and log files.
167 |
168 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_21_sovabids_files.png
169 |
170 | The mappings.yml file will hold the mappings:
171 |
172 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_22_mapping_file.png
173 |
174 | The logs will hold run-time information of the procedure:
175 |
176 | .. image:: https://github.com/yjmantilla/sovabids/raw/main/docs/source/_static/front_23_log_files.png
177 |
178 | """
179 |
--------------------------------------------------------------------------------
/README.rst:
--------------------------------------------------------------------------------
1 | .. image:: https://img.shields.io/codecov/c/github/yjmantilla/sovabids
2 | :target: https://app.codecov.io/gh/yjmantilla/sovabids
3 | :alt: codecov
4 |
5 | .. image:: https://img.shields.io/github/actions/workflow/status/yjmantilla/sovabids/python-tests.yml?branch=main&label=tests
6 | :target: https://github.com/yjmantilla/sovabids/actions?query=workflow%3Apython-tests
7 | :alt: Python tests
8 |
9 | .. image:: https://readthedocs.org/projects/sovabids/badge/?version=latest
10 | :target: https://sovabids.readthedocs.io/en/latest/?badge=latest
11 | :alt: Documentation Status
12 |
13 | .. image:: https://img.shields.io/badge/Preprint-Zenodo-orange
14 | :target: https://doi.org/10.5281/zenodo.10292410
15 |
16 | sovabids
17 | ========
18 |
19 | `Visit the documentation `_
20 |
21 | .. after-init-label
22 |
23 | * sovabids is a python package for automating eeg2bids conversion.
24 |
25 | * sovabids can be used through (click to see the examples):
26 | a. `its python API `_
27 | b. `its CLI entry points `_
28 | c. `its JSON-RPC entry points (needs a server running the backend) `_
29 | d. `its minimal web-app GUI `_
30 |
31 | .. note::
32 |
33 | The advantage of the JSON-RPC way is that it can be used from other programming languages.
34 |
35 | Limitation:
36 |
37 | Do notice that at the moment the files have to be on the same computer that runs the server.
38 |
39 | .. warning::
40 |
41 | Currently meg2bids conversion is not supported, but this is a targeted feature.
42 |
43 | .. tip::
44 |
45 | By default sovabids will skip files already converted. If you want to overwrite previous conversions currently you need to delete the output folder (by yourself) and start sovabids over again.
46 |
47 | Architecture
48 | ------------
49 |
50 | The main elements of sovabids are:
51 | * A source path with the original dataset.
52 | * A bids path that will be the output path of the conversion.
53 | * A rules file that configures how the conversion is done from the general perspective.
54 | * A mapping file that encodes how the conversion is performed to each individual file of the dataset.
55 |
56 | .. image:: https://mermaid.ink/svg/eyJjb2RlIjoiZ3JhcGggTFJcbiAgICBTPlwiU291cmNlIHBhdGhcIl1cbiAgICBCPlwiQmlkcyBwYXRoXCJdXG4gICAgUj5cIlJ1bGVzIGZpbGVcIl1cbiAgICBBUigoXCJBcHBseSBSdWxlc1wiKSlcbiAgICBNPlwiTWFwcGluZ3MgZmlsZVwiXVxuICAgIENUKChcIkNvbnZlcnQgVGhlbVwiKSlcbiAgICBPWyhcIkNvbnZlcnRlZCBkYXRhc2V0XCIpXVxuICAgIFMgLS0-IEFSXG4gICAgQiAtLT4gQVJcbiAgICBSIC0tPiBBUlxuICAgIEFSIC0tPiBNXG4gICAgTSAtLT4gQ1RcbiAgICBDVCAtLT4gT1xuICAiLCJtZXJtYWlkIjp7InRoZW1lIjoiZm9yZXN0In0sInVwZGF0ZUVkaXRvciI6ZmFsc2UsImF1dG9TeW5jIjp0cnVlLCJ1cGRhdGVEaWFncmFtIjpmYWxzZX0
57 |
58 | Internally sovabids uses `MNE-Python `_ and `MNE-BIDS `_ to perform the conversion. In a sense is a wrapper that allows to do conversions from the command line.
59 |
60 | Installation
61 | ------------
62 |
63 | .. code-block:: bash
64 |
65 | git clone https://github.com/yjmantilla/sovabids.git
66 | cd sovabids
67 | pip install -r requirements-user.txt
68 |
69 | Installation for GUI usage
70 | -------------------------------
71 |
72 | This will install sovabids for usage with an experimental web gui, and as an experimental plugin for bidscoin.
73 |
74 | .. code-block:: bash
75 |
76 | git clone https://github.com/yjmantilla/sovabids.git
77 | cd sovabids
78 | pip install -r requirements-gui.txt
79 |
80 |
81 | Installation for developers
82 | ---------------------------
83 |
84 | Fork this repo and run:
85 |
86 | .. code-block:: bash
87 |
88 | git clone https://github.com//sovabids.git
89 | cd sovabids
90 | pip install -r requirements-dev.txt
91 |
92 | Notice that the requirements-dev.txt file already has the sovabids installation using editable mode.
93 |
94 |
95 | Basic Usage
96 | -----------
97 |
98 | The easiest way is to use sovabids through its CLI entry-points as follows:
99 |
100 | sovapply
101 | ^^^^^^^^
102 |
103 | Use the sovapply entry-point to produce a mapping file from a source path, an output bids root path and a rules filepath.
104 |
105 |
106 | .. code-block:: bash
107 |
108 | sovapply source_path bids_path rules_path
109 |
110 | By default the mapping file made will have the following filepath:
111 |
112 | .. code-block:: text
113 |
114 | bids_path/code/sovabids/mappings.yml
115 |
116 |
117 | sovaconvert
118 | ^^^^^^^^^^^
119 |
120 | Use the sovaconvert entry-point to convert the dataset given its mapping file.
121 |
122 | .. code-block:: bash
123 |
124 | sovaconvert mapping_file
125 |
126 | Funding
127 | -------
128 |
129 | .. raw:: html
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 | Acknowledgments
139 | ---------------
140 |
141 | sovabids is developed with the help of the following entities:
142 |
143 | .. raw:: html
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 | Academic Works
161 | ---------------
162 |
163 | * `Poster for the Big Data Neuroscience Workshop 2022 (Austin, Texas) `_
164 |
165 | * `Poster for OHBM 2022 Anual Meeting `_
166 |
167 | * `Video for OHBM 2022 Anual Meeting `_
168 |
169 | * `Poster for the eResearch Australasia Conference 2021 `_
170 |
171 |
172 |
173 | What does sova means?
174 | ---------------------
175 |
176 | sova is a contraction of 'eso va' which mean 'that goes' in spanish.
177 |
178 | Nevertheless the real usage by the original developers is just to convey the idea of :
179 |
180 | we will make it happen, we dont know how, but we will
181 |
--------------------------------------------------------------------------------
/docs/source/mappings_schema.rst:
--------------------------------------------------------------------------------
1 | Mappings File Schema
2 | ====================
3 |
4 | The **Mappings File** setups the way the conversion is done from an individual point of view, that is, in a per-file basis. It is intended to be produced by the **apply_rules** (in the cli **sovapply**) module, or by a GUI editor that allows the user to edit the mapping in a per-file basis.
5 |
6 | The **Mappings File** is in yaml format. As of now the purpose of this documentation is not to teach yaml (we may have a dedicated file for that in the future). For now, you can check this `guide `_ though.
7 |
8 | The Typical Mapping File
9 | ------------------------
10 |
11 | A typical mapping file looks like this:
12 |
13 | .. code-block:: yaml
14 |
15 |
16 | General:
17 | IO:
18 | source: Y:\code\sovabids\_data\DUMMY\DUMMY_SOURCE
19 | target: Y:\code\sovabids\_data\DUMMY\DUMMY_BIDS_custom
20 | channels:
21 | name:
22 | '0': ECG_CHAN
23 | '1': EOG_CHAN
24 | type:
25 | ECG_CHAN: ECG
26 | EOG_CHAN: EOG
27 | dataset_description:
28 | Authors:
29 | - A1
30 | - A2
31 | Name: Dummy
32 | non-bids:
33 | code_execution:
34 | - print('some good code')
35 | - print(raw.info)
36 | - print(some bad code)
37 | eeg_extension: .vhdr
38 | path_analysis:
39 | pattern: T%entities.task%/S%entities.session%/sub%entities.subject%_%entities.acquisition%_%entities.run%.vhdr
40 | sidecar:
41 | EEGReference: FCz
42 | PowerLineFrequency: 50
43 | SoftwareFilters:
44 | Anti-aliasing filter:
45 | Roll-off: 6dB/Octave
46 | half-amplitude cutoff (Hz): 500
47 | Individual:
48 | - IO:
49 | source: Y:\code\sovabids\_data\DUMMY\DUMMY_SOURCE\T0\S0\sub0_0_0.vhdr
50 | target: Y:\code\sovabids\_data\DUMMY\DUMMY_BIDS_custom\sub-0\ses-0\eeg\sub-0_ses-0_task-0_acq-0_run-0_eeg.vhdr
51 | channels:
52 | name:
53 | '0': ECG_CHAN
54 | '1': EOG_CHAN
55 | type:
56 | ECG_CHAN: ECG
57 | EOG_CHAN: EOG
58 | dataset_description:
59 | Authors:
60 | - A1
61 | - A2
62 | Name: Dummy
63 | entities:
64 | acquisition: '0'
65 | run: '0'
66 | session: '0'
67 | subject: '0'
68 | task: '0'
69 | non-bids:
70 | code_execution:
71 | - print('some good code')
72 | - print(raw.info)
73 | - print(some bad code)
74 | eeg_extension: .vhdr
75 | path_analysis:
76 | pattern: T%entities.task%/S%entities.session%/sub%entities.subject%_%entities.acquisition%_%entities.run%.vhdr
77 | sidecar:
78 | EEGReference: FCz
79 | PowerLineFrequency: 50
80 | SoftwareFilters:
81 | Anti-aliasing filter:
82 | Roll-off: 6dB/Octave
83 | half-amplitude cutoff (Hz): 500
84 | - IO:
85 | source: Y:\code\sovabids\_data\DUMMY\DUMMY_SOURCE\T0\S0\sub0_0_1.vhdr
86 | target: Y:\code\sovabids\_data\DUMMY\DUMMY_BIDS_custom\sub-0\ses-0\eeg\sub-0_ses-0_task-0_acq-0_run-1_eeg.vhdr
87 | channels:
88 | name:
89 | '0': ECG_CHAN
90 | '1': EOG_CHAN
91 | type:
92 | ECG_CHAN: ECG
93 | EOG_CHAN: EOG
94 | dataset_description:
95 | Authors:
96 | - A1
97 | - A2
98 | Name: Dummy
99 | entities:
100 | acquisition: '0'
101 | run: '1'
102 | session: '0'
103 | subject: '0'
104 | task: '0'
105 | non-bids:
106 | code_execution:
107 | - print('some good code')
108 | - print(raw.info)
109 | - print(some bad code)
110 | eeg_extension: .vhdr
111 | path_analysis:
112 | pattern: T%entities.task%/S%entities.session%/sub%entities.subject%_%entities.acquisition%_%entities.run%.vhdr
113 | sidecar:
114 | EEGReference: FCz
115 | PowerLineFrequency: 50
116 | SoftwareFilters:
117 | Anti-aliasing filter:
118 | Roll-off: 6dB/Octave
119 | half-amplitude cutoff (Hz): 500
120 |
121 |
122 | Relation to the Rules File
123 | --------------------------
124 |
125 | As you may have noticed, the **Mappings File** has a lot of similiraties with the **Rules File**. This is because the **Mappings File** is just the rules after being applied to each file.
126 |
127 |
128 | The General and Invididual Objects
129 | ----------------------------------
130 |
131 | Essentially, the mappings file will have a **General** and an **Invididual** object at the top level.
132 |
133 | The **General** object will contain a copy of the "general" rules; the **Individual** object will hold rules for each of the files to be converted. That is, each file holds "a copy" of the rules along with the modifications that apply to that particular file.
134 |
135 | .. code-block:: yaml
136 |
137 | General :
138 | rules
139 | Individual :
140 | list of rules
141 |
142 |
143 | In the example shown above you may notice that the **General** object does not have an **entities** object, thats because the **entities** object was inferred from the **path_analysis** rule.
144 | Nevertheless, the **Individual** object does show the entities object . That is because the **entities** object was filled by applying the **path_analysis** rule.
145 |
146 | .. note::
147 |
148 | As of now, the only object that actually shows the result of applying the rules is the **entities** object. The other ones will just show the rule applied to that particular file.
149 |
150 | The Individual object as a list
151 | -------------------------------
152 |
153 | An important difference between the **General** object and the **Individual** object is that the **General** object holds a single set of rules, whereas the **Individual** object maintains a list of them; in other words, one set of rules for each file. As a result of this, the **Individual** object will be a list; that why it has a (``-``) at the start of every mapping it holds:
154 |
155 | .. code-block:: yaml
156 |
157 | General :
158 | rules
159 | Individual :
160 | - rules for file 1
161 | - rules for file 2
162 | ...
163 | - rules for file N
164 |
165 | THE IO object
166 | -------------
167 |
168 | A difference you will notice between the **Rules File** and the **Mappings File** is the **IO** object.
169 |
170 | This object just holds input/output information, or more specifically, the **source** and **target**.
171 |
172 | IO in the General object
173 | ^^^^^^^^^^^^^^^^^^^^^^^^
174 |
175 | For the **General** object we will have :
176 |
177 | .. code-block:: yaml
178 |
179 | General:
180 | IO:
181 | source: source path - root folder of the data to be converted (input)
182 | target: target path - root folder of the bids directory (output)
183 |
184 |
185 | IO in the Invididual object
186 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^
187 |
188 | For one of the elements of the **Invididual** object we will have :
189 |
190 | .. code-block:: yaml
191 |
192 | Individual:
193 | IO:
194 | source: source filepath - non-bids input data to be converted
195 | target: target filepath - bids output of that file
196 |
197 | Conclusions
198 | -----------
199 |
200 | In essence, the **Mappings File** is just the **Rules File** copied once for each file, plus one more to have the "General" perspective. The copies of the rules made for each file will also hold any modification of the rules that apply for that particular file.
201 |
202 | The **IO** object just holds input/output information from the point-of-view of files.
--------------------------------------------------------------------------------
/sovabids/sovarpc.py:
--------------------------------------------------------------------------------
1 | """
2 | Action Oriented RPC API for Sovabids.
3 | """
4 |
5 | import traceback
6 | import fastapi_jsonrpc as jsonrpc
7 | from typing import List, Optional
8 | import sovabids.rules as ru
9 | import sovabids.convert as co
10 | import sovabids.files as fi
11 | from sovabids.errors import ApplyError,ConvertError,SaveError,RulesError,FileListError
12 | app = jsonrpc.API()
13 |
14 | api = jsonrpc.Entrypoint('/api/sovabids')
15 |
16 |
17 | # Sadly we will need to manage the docstring of these methods by hand since the fastapi documentation
18 | # Does not support sphinx references
19 | @api.method(errors=[ApplyError])
20 | def apply_rules(
21 | file_list: List[str],
22 | bids_path: str,
23 | rules: dict,
24 | mapping_path: str
25 | ) -> dict:
26 | """Apply rules to a set of files.
27 |
28 | Parameters
29 | ----------
30 |
31 | file_list : list of str
32 | List of str with the paths of the files we want to convert (ie the output of get_files).
33 | bids_path : str
34 | The path we want the converted files in.
35 | rules : dict
36 | A dictionary with the rules.
37 | mapping_path : str, optional
38 | The fullpath where we want to write the mappings file.
39 | If '', then bids_path/code/sovabids/mappings.yml will be used.
40 |
41 | Returns
42 | -------
43 |
44 | dict :
45 | A dictionary following: {
46 | 'General': rules given,
47 | 'Individual':list of mapping dictionaries for each file
48 | }
49 |
50 |
51 | Notes
52 | -----
53 | A wrapper of around rules.apply_rules function.
54 | See docstring of :py:func:`apply_rules() ` in :py:mod:`rules`
55 | """
56 | try:
57 | mappings = ru.apply_rules(source_path=file_list,bids_path=bids_path,rules=rules,mapping_path=mapping_path)
58 | except:
59 | raise ApplyError(data={'details': traceback.format_exc()})
60 | return mappings
61 |
62 | @api.method(errors=[ConvertError])
63 | def convert_them(
64 | general : dict,
65 | individual: List[dict]
66 | ) -> None:
67 | """Convert eeg files to bids according to the mappings given.
68 |
69 | Parameters
70 | ----------
71 | general : dict
72 | The general rules
73 | individual: list[dict]
74 | List with the individual mappings of each file.
75 |
76 | Notes
77 | -----
78 | A wrapper of around convert.convert_them function.
79 |
80 | See docstring of :py:func:`convert_them() ` in :py:mod:`convert`
81 |
82 | Returns
83 | -------
84 | None
85 | """
86 | try:
87 | data = {'General':general,'Individual':individual}
88 | co.convert_them(mappings_input=data)
89 | except:
90 | raise ConvertError(data={'details': traceback.format_exc()})
91 |
92 | @api.method(errors=[RulesError])
93 | def load_rules(
94 | rules_path: str,
95 | ) -> dict:
96 | """Load rules from a path.
97 |
98 | Parameters
99 | ----------
100 |
101 | rules_path : str
102 | The path to the rules file.
103 |
104 | Returns
105 | -------
106 |
107 | dict
108 | The rules dictionary.
109 |
110 | Notes
111 | -----
112 | A wrapper of around rules.load_rules function.
113 |
114 | See docstring of :py:func:`load_rules() ` in :py:mod:`rules`
115 | """
116 |
117 | try:
118 | rules = ru.load_rules(rules_path)
119 | except:
120 | raise RulesError(data={'details': traceback.format_exc()})
121 | return rules
122 |
123 | @api.method(errors=[ApplyError])
124 | def apply_rules_to_single_file(
125 | file:str,
126 | rules:dict,
127 | bids_path:str,
128 | write:bool=False,
129 | preview:bool=False
130 | ) -> dict:
131 | """Apply rules to a single file.
132 |
133 | Parameters
134 | ----------
135 |
136 | file : str
137 | Path to the file.
138 | rules : dict
139 | The rules dictionary.
140 | bids_path : str
141 | Path to the bids directory
142 | write : bool, optional
143 | Whether to write the converted files to disk or not.
144 | preview : bool, optional
145 | Whether to return a dictionary with a "preview" of the conversion.
146 | This dict will have the same schema as the "Mapping File Schema" but may have flat versions of its fields.
147 | *UNDER CONSTRUCTION*
148 |
149 | Returns
150 | -------
151 |
152 | dict:
153 | {
154 | mapping : dict
155 | The mapping obtained from applying the rules to the given file
156 | preview : bool|dict
157 | If preview = False, then False. If True, then the preview dictionary.
158 | }
159 |
160 | Notes
161 | -----
162 | A wrapper of around rules.apply_rules_to_single_file function.
163 |
164 | See docstring of :py:func:`apply_rules_to_single_file() ` in :py:mod:`rules`
165 | """
166 |
167 | try:
168 | mapping,preview=ru.apply_rules_to_single_file(file,rules,bids_path,write,preview)
169 | except:
170 | raise ApplyError(data={'details': traceback.format_exc()})
171 | return {'mapping':mapping,'preview':preview}
172 |
173 | @api.method(errors=[SaveError])
174 | def save_rules(
175 | rules:dict,
176 | path:str
177 | ) -> None:
178 | """Save rules as a yaml file to a path.
179 |
180 | Parameters
181 | ----------
182 | rules: dict
183 | The rules dictionary to save
184 | path : str
185 | The full-path (including filename) where to save the rules as yaml.
186 |
187 | Returns
188 | -------
189 |
190 | None
191 |
192 | Notes
193 | -----
194 |
195 | A wrapper of around files._write_yaml function.
196 |
197 | See docstring of :py:func:`_write_yaml() ` in :py:mod:`files`
198 | """
199 |
200 | try:
201 | fi._write_yaml(rules,path)
202 | except:
203 | raise SaveError(data={'details': traceback.format_exc()})
204 | return
205 |
206 | @api.method(errors=[SaveError])
207 | def save_mappings(
208 | path:str,
209 | general:dict,
210 | individual:List[dict]
211 | ) -> None:
212 | """Save mappings as a yaml file to a path.
213 |
214 | Parameters
215 | ----------
216 |
217 | path : str
218 | The full-path (including filename) where to save the mappings as yaml.
219 | general: dict
220 | The general rules dictionary.
221 | individual: list of dict
222 | A list containing the mapping dictionary of each file.
223 |
224 | Returns
225 | -------
226 |
227 | None
228 |
229 | Notes
230 | -----
231 |
232 | A wrapper of around files._write_yaml function.
233 |
234 | See docstring of :py:func:`_write_yaml() ` in :py:mod:`files`
235 | """
236 |
237 | try:
238 | data = {'General':general,'Individual':individual}
239 | fi._write_yaml(data,path)
240 | except:
241 | raise SaveError(data={'details': traceback.format_exc()})
242 | return
243 |
244 | @api.method(errors=[FileListError])
245 | def get_files(
246 | path:str,
247 | rules:dict
248 | ) -> list:
249 | """Recursively scan the directory for valid files, returning a list with the full-paths to each.
250 |
251 | The valid files are given by the 'non-bids.eeg_extension' rule. See the "Rules File Schema".
252 |
253 | Parameters
254 | ----------
255 |
256 | path : str
257 | The path we want to obtain the files from.
258 | rules : dict
259 | The rules dictionary.
260 |
261 | Returns
262 | -------
263 |
264 | list[str]:
265 | A list containing the path to each valid file in the source_path.
266 |
267 |
268 | Notes
269 | -----
270 |
271 | A wrapper of around rules.get_files function.
272 |
273 | See docstring of :py:func:`get_files() ` in :py:mod:`rules`
274 | """
275 |
276 | try:
277 | filelist = ru.get_files(path,rules)
278 | except:
279 | raise FileListError(data={'details': traceback.format_exc()})
280 | return filelist
281 |
282 |
283 | app.bind_entrypoint(api)
284 |
285 | def main(entry='sovarpc:app',port=5000,debug=False):
286 | import uvicorn
287 | uvicorn.run(entry, port=port, access_log=False)
288 |
289 | if __name__ == '__main__':
290 | main(port=5100)
291 |
--------------------------------------------------------------------------------
/examples/lemon_example.py:
--------------------------------------------------------------------------------
1 |
2 | """
3 | ======================
4 | LEMON dataset example
5 | ======================
6 |
7 | This example illustrates the use of ``sovabids`` on the `LEMON dataset `_
8 | using both the python API and the CLI tool.
9 |
10 | The main elements of this example are:
11 | * A source path with the original dataset.
12 | * A bids path that will be the output path of the conversion.
13 | * A rules file that configures how the conversion is done.
14 | * A mapping file that encodes how the conversion is performed to each individual file of the dataset.
15 |
16 | .. mermaid::
17 |
18 | graph LR
19 | S>"Source path"]
20 | B>"Bids path"]
21 | R>"Rules file"]
22 | AR(("Apply Rules"))
23 | M>"Mappings file"]
24 | CT(("Convert Them"))
25 | O[("Converted dataset")]
26 | S --> AR
27 | B --> AR
28 | R --> AR
29 | AR --> M
30 | M --> CT
31 | CT --> O
32 | """
33 |
34 | #%%
35 | # Using the python API
36 | # --------------------
37 | # First we will illustrate how to run the software within python.
38 | #
39 | # Imports
40 | # ^^^^^^^
41 | # First we import some functions we will need:
42 |
43 | import os # For path manipulation
44 | import shutil # File manipulation
45 | from mne_bids import print_dir_tree # To show the input/output directories structures inside this example
46 | from sovabids.rules import apply_rules # Apply rules for conversion
47 | from sovabids.convert import convert_them # Do the conversion
48 | from sovabids.datasets import lemon_prepare # Download the dataset
49 | from sovabids.settings import REPO_PATH
50 | #%%
51 | # Getting and preparing the dataset
52 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
53 | # We have to download and decompress the dataset. We also need to fix a filename inconsistency
54 | # (without this correction the file won't be able to be opened in mne). Luckily all of that is
55 | # encapsulated in the lemon_prepare function since these issues are not properly of sovabids.
56 | #
57 | # By default the files are saved in the '_data' directory of the sovabids project.
58 | lemon_prepare()
59 |
60 | #%%
61 | # Setting up the paths
62 | # ^^^^^^^^^^^^^^^^^^^^
63 | # Now we will set up four paths. Because this example is intended to run relative
64 | # to the repository directory we use relative path but for real use-cases it is
65 | # easier to just input the absolute-path. We will print these paths for more clarity.
66 |
67 | source_path = os.path.abspath(os.path.join(REPO_PATH,'_data','lemon')) # For the input data we will convert
68 | bids_path= os.path.abspath(os.path.join(REPO_PATH,'_data','lemon_bids')) # The output directory that will have the converted data
69 | rules_path = os.path.abspath(os.path.join(REPO_PATH,'examples','lemon_example_rules.yml')) # The rules file that setups the rule for conversion
70 | mapping_path = os.path.abspath(os.path.join(bids_path,'code','sovabids','mappings.yml')) # The mapping file that will hold the results of applying the rules to each file
71 |
72 | print('source_path:',source_path.replace(REPO_PATH,''))
73 | print('bids_path:', bids_path.replace(REPO_PATH,''))
74 | print('rules_path:',rules_path.replace(REPO_PATH,''))
75 | print('mapping_path:',mapping_path.replace(REPO_PATH,''))
76 |
77 | #%%
78 | # Cleaning the output directory
79 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
80 | # We will clean the output path as a safety measure from previous conversions.
81 |
82 | try:
83 | shutil.rmtree(bids_path)
84 | except:
85 | pass
86 |
87 | #%%
88 | # The input directory
89 | # ^^^^^^^^^^^^^^^^^^^
90 | # For clarity purposes we will print here the directory we are trying to convert to BIDS.
91 |
92 | print_dir_tree(source_path)
93 |
94 | #%%
95 | # Making the rules
96 | # ^^^^^^^^^^^^^^^^
97 | # The most important and complicated part of this is making the rules file,
98 | # either by hand or by the "DISCOVER_RULES" module (which is not yet implemented).
99 | #
100 | # This part is already done for you, but for clarification here are the rules
101 | # we are applying. Please read the following output as the yaml has some basic
102 | # documentation comments.
103 | #
104 | # See the Rules File Schema documentation for help regarding making this rules file.
105 | #
106 | with open(rules_path,encoding="utf-8") as f:
107 | rules = f.read()
108 | print(rules)
109 |
110 | #%%
111 | # Applying the rules
112 | # ^^^^^^^^^^^^^^^^^^
113 | # We apply the rules to the input dataset by giving the input,ouput,rules, and mapping paths to the apply_rules function.
114 | #
115 | # This will produce by default a 'mappings.yml' file at the specified directory of 'bids_path/code/sovabids'.
116 | #
117 | # This file holds the result of applying the rules to each of the dataset files.
118 | apply_rules(source_path,bids_path,rules_path,mapping_path)
119 |
120 | #%%
121 | # Doing the conversion
122 | # ^^^^^^^^^^^^^^^^^^^^
123 | # We now do the conversion of the dataset by reading the mapping file ('mappings.yml') with the convert them module.
124 | convert_them(mapping_path)
125 |
126 | #%%
127 | # Checking the conversion
128 | # ^^^^^^^^^^^^^^^^^^^^^^^
129 | # For clarity purposes we will check the output directory we got from sovabids.
130 |
131 | print_dir_tree(bids_path)
132 |
133 | print('LEMON CONVERSION FINISHED!')
134 |
135 | #%%
136 | # Using the CLI tool
137 | # ------------------
138 | #
139 | # sovabids can also be used through the command line. Here we provide an example of how to do so.
140 | #
141 | #
142 | # The overview of what we are doing is now:
143 | #
144 | # .. mermaid::
145 | #
146 | # graph LR
147 | # S>"Source path"]
148 | # B>"Bids path"]
149 | # R>"Rules file"]
150 | # AR(("sovapply"))
151 | # M>"Mappings file"]
152 | # CT(("sovaconvert"))
153 | # O[("Converted dataset")]
154 | # S --> AR
155 | # B --> AR
156 | # R --> AR
157 | # AR --> M
158 | # M --> CT
159 | # CT --> O
160 |
161 | #%%
162 | # Same old blues
163 | # ^^^^^^^^^^^^^^
164 | # Notice that we will run this inside of python so that the example can be run without needing configuration.
165 | #
166 | # To run this locally you will need to run lemon_prepare() function from the command line. You can do so by running:
167 | # .. code-block:: bash
168 | #
169 | # python -c "from sovabids.datasets import lemon_prepare; lemon_prepare()"
170 | #
171 | # Since we already have run lemon_prepare() inside this example, we will start from this step.
172 | #
173 | # We set up the paths again, but now we will change the output to a new path (with "_cli" at the end). We will also clean this path as we did before.
174 | #
175 | source_path = os.path.abspath(os.path.join(REPO_PATH,'_data','lemon')) # For the input data we will convert
176 | bids_path= os.path.abspath(os.path.join(REPO_PATH,'_data','lemon_bids_cli')) # The output directory that will have the converted data
177 | rules_path = os.path.abspath(os.path.join(REPO_PATH,'examples','lemon_example_rules.yml')) # The rules file that setups the rule for conversion
178 | mapping_path = os.path.abspath(os.path.join(bids_path,'code','sovabids','mappings.yml')) # The mapping file that will hold the results of applying the rules to each file
179 |
180 | print('source_path:',source_path.replace(REPO_PATH,''))
181 | print('bids_path:', bids_path.replace(REPO_PATH,''))
182 | print('rules_path:',rules_path.replace(REPO_PATH,''))
183 | print('mapping_path:',mapping_path.replace(REPO_PATH,''))
184 |
185 | try:
186 | shutil.rmtree(bids_path)
187 | except:
188 | pass
189 |
190 | # %%
191 | # Some necessary code
192 | # ^^^^^^^^^^^^^^^^^^^
193 | # To be able to run commands from this notebook and capture their outputs we need to define the following, nevertheless this is not relevant to actually running this from the command line.
194 |
195 | from subprocess import PIPE, run
196 |
197 | def out(command):
198 | result = run(command, stdout=PIPE, stderr=PIPE, universal_newlines=True, shell=True)
199 | return result.stdout
200 |
201 | my_output = out("echo hello world")
202 | print(my_output)
203 |
204 | #%%
205 | # sovapply
206 | # ^^^^^^^^
207 | # In this example we have already made the rules. So we will apply them using the sovapply tool.
208 | #
209 | # Use the following command to print the help of the tool:
210 | #
211 | command = "sovapply --help"
212 | print(command)
213 | #%%
214 | # This will give the following output
215 | #
216 | my_output= out(command)
217 | print(my_output)
218 |
219 | #%%
220 | # Now we will use the following command to get the mappings file.
221 | #
222 | command = 'sovapply '+source_path + ' '+ bids_path + ' ' + rules_path + ' -m ' + mapping_path
223 | print(command)
224 |
225 | #%%
226 | # This will produce the following output:
227 | my_output= out(command)
228 | print(my_output)
229 |
230 | #%%
231 | # sovaconvert
232 | # ^^^^^^^^^^^
233 | # Now we are ready to perform the conversion given the mapping file just made.
234 | #
235 | # Use the following command to print the help of the tool:
236 | #
237 | command = "sovaconvert --help"
238 | print(command)
239 | #%%
240 | # This will give the following output
241 | #
242 | my_output= out(command)
243 | print(my_output)
244 |
245 | #%%
246 | # Now we will use the following command to perform the conversion.
247 | #
248 | command = 'sovaconvert ' + mapping_path
249 | print(command)
250 |
251 | #%%
252 | # This will produce the following output:
253 | my_output= out(command)
254 | print(my_output)
255 |
256 | #%%
257 | # Checking the conversion
258 | # ^^^^^^^^^^^^^^^^^^^^^^^
259 | # For clarity purposes we will check the output directory we got from sovabids.
260 |
261 | print_dir_tree(bids_path)
262 |
263 | print('LEMON CLI CONVERSION FINISHED!')
264 |
265 |
266 |
267 |
--------------------------------------------------------------------------------
/tests/test_bids.py:
--------------------------------------------------------------------------------
1 | import os
2 | import shutil
3 | import yaml
4 | from fastapi.testclient import TestClient
5 | from sovabids.sovarpc import app
6 | import json
7 |
8 | from bids_validator import BIDSValidator
9 |
10 | from sovabids.parsers import placeholder_to_regex,_modify_entities_of_placeholder_pattern
11 | from sovabids.rules import apply_rules,load_rules
12 | from sovabids.dicts import deep_merge_N
13 | from sovabids.datasets import make_dummy_dataset,save_dummy_vhdr,save_dummy_cnt
14 | from sovabids.convert import convert_them
15 |
16 | def dummy_dataset(pattern_type='placeholder',write=True,mode='python',format='.vhdr'):
17 |
18 | # Getting current file path and then going to _data directory
19 | this_dir = os.path.dirname(__file__)
20 | data_dir = os.path.join(this_dir,'..','_data')
21 | data_dir = os.path.abspath(data_dir)
22 |
23 | # Defining relevant conversion paths
24 | test_root = os.path.join(data_dir,'DUMMY')
25 | input_root = os.path.join(test_root,'DUMMY_SOURCE')
26 | mode_str = '_' + mode
27 | bids_path = os.path.join(test_root,'DUMMY_BIDS'+'_'+pattern_type+mode_str+'_'+format.replace('.',''))
28 |
29 | # Make example File
30 | if format == '.vhdr':
31 | example_fpath = save_dummy_vhdr(os.path.join(data_dir,'dummy.vhdr'))
32 | elif format == '.cnt':
33 | example_fpath = save_dummy_cnt(os.path.join(data_dir,'dummy.cnt'))
34 |
35 | # PARAMS for making the dummy dataset
36 | DATA_PARAMS ={ 'EXAMPLE':example_fpath,
37 | 'PATTERN':'T%task%/S%session%/sub%subject%_%acquisition%_%run%',
38 | 'DATASET' : 'DUMMY',
39 | 'NSUBS' : 2,
40 | 'NTASKS' : 2,
41 | 'NRUNS' : 2,
42 | 'NSESSIONS' : 2,
43 | 'ROOT' : input_root
44 | }
45 |
46 | if mode == 'rpc':
47 | client = TestClient(app)
48 | else:
49 | client = None
50 |
51 | # Preparing directories
52 | dirs = [input_root,bids_path] #dont include test_root for saving multiple conversions
53 | for dir in dirs:
54 | try:
55 | shutil.rmtree(dir)
56 | except:
57 | pass
58 |
59 | [os.makedirs(dir,exist_ok=True) for dir in dirs]
60 |
61 | # Generating the dummy dataset
62 | make_dummy_dataset(**DATA_PARAMS)
63 |
64 | # Making rules for the dummy conversion
65 |
66 | # Gotta fix the pattern that wrote the dataset to the notation of the rules file
67 | FIXED_PATTERN =DATA_PARAMS.get('PATTERN',None)
68 |
69 | FIXED_PATTERN = _modify_entities_of_placeholder_pattern(FIXED_PATTERN,'append')
70 | FIXED_PATTERN = FIXED_PATTERN + format
71 |
72 | # Making the rules dictionary
73 | data={
74 | 'dataset_description':
75 | {
76 | 'Name':'Dummy',
77 | 'Authors':['A1','A2'],
78 | },
79 | 'sidecar':
80 | {
81 | 'PowerLineFrequency' : 50,
82 | 'EEGReference':'FCz',
83 | 'SoftwareFilters':{"Anti-aliasing filter": {"half-amplitude cutoff (Hz)": 500, "Roll-off": "6dB/Octave"}}
84 | },
85 | 'non-bids':
86 | {
87 | 'eeg_extension':format,
88 | 'path_analysis':{'pattern':FIXED_PATTERN},
89 | 'code_execution':['print(\'some good code\')','print(raw.info)','print(some bad code)']
90 | },
91 | 'channels':
92 | {'name':{'1':'ECG_CHAN','2':'EOG_CHAN'}, #Note example vhdr and CNT have these channels
93 | 'type':{'ECG_CHAN':'ECG','EOG_CHAN':'EOG'}} # Names (keys) are after the rename of the previous line
94 | }
95 |
96 | if pattern_type == 'regex':
97 | FIXED_PATTERN_RE,fields = placeholder_to_regex(FIXED_PATTERN)
98 | dregex = {'non-bids':{'path_analysis':{'fields':fields,'pattern':FIXED_PATTERN_RE}}}
99 | data = deep_merge_N([data,dregex])
100 | # Writing the rules file
101 | outputname = 'dummy_rules'+'_'+pattern_type+'.yml'
102 |
103 | full_rules_path = os.path.join(test_root,outputname)
104 | with open(full_rules_path, 'w') as outfile:
105 | yaml.dump(data, outfile, default_flow_style=False)
106 |
107 | mappings_path=None
108 |
109 | if mode=='python':
110 | # Loading the rules file (yes... kind of redundant but tests the io of the rules file)
111 | rules = load_rules(full_rules_path)
112 |
113 | file_mappings = apply_rules(source_path=input_root,bids_path=bids_path,rules=rules)
114 | elif mode=='cli':
115 | os.system('sovapply '+input_root + ' '+ bids_path + ' ' + full_rules_path)
116 | mappings_path = os.path.join(bids_path,'code','sovabids','mappings.yml')
117 | file_mappings = load_rules(mappings_path)
118 | elif mode=='rpc':
119 |
120 | # Load Rules
121 | request=json.dumps({ #jsondumps important to avoid parse errors
122 | "jsonrpc": "2.0",
123 | "id": 0,
124 | "method": "load_rules",
125 | "params": {
126 | "rules_path": full_rules_path
127 | }
128 | })
129 |
130 | response = client.post("/api/sovabids/load_rules",data=request )
131 | print(request,'response',response.content.decode())
132 | rules = json.loads(response.content.decode())['result']
133 |
134 | # Save Rules
135 | request = json.dumps({
136 | "jsonrpc": "2.0",
137 | "id": 0,
138 | "method": "save_rules",
139 | "params": {
140 | "rules": rules,
141 | "path": full_rules_path+'.bkp'
142 | }
143 | })
144 | response = client.post("/api/sovabids/save_rules",data=request )
145 | print(request,'response',response.content.decode())
146 |
147 | # Get Files
148 | request = json.dumps({
149 | "jsonrpc": "2.0",
150 | "id": 0,
151 | "method": "get_files",
152 | "params": {
153 | "rules": rules,
154 | "path": input_root
155 | }
156 | })
157 | response = client.post("/api/sovabids/get_files",data=request )
158 | print(request,'response',response.content.decode())
159 | filelist = json.loads(response.content.decode())['result']
160 |
161 | # Preview Single File
162 |
163 | request=json.dumps({ #jsondumps important to avoid parse errors
164 | "jsonrpc": "2.0",
165 | "id": 0,
166 | "method": "apply_rules_to_single_file",
167 | "params": {
168 | "file": filelist[0],
169 | "bids_path": bids_path+'.preview',
170 | "rules": rules,
171 | "write":False,
172 | "preview":True
173 | }
174 | })
175 | response = client.post("/api/sovabids/apply_rules_to_single_file",data=request )
176 | print(request,'response',response.content.decode())
177 | single_file = json.loads(response.content.decode())
178 | print(single_file)
179 |
180 | # Get Mappings
181 | request=json.dumps({ #jsondumps important to avoid parse errors
182 | "jsonrpc": "2.0",
183 | "id": 0,
184 | "method": "apply_rules",
185 | "params": {
186 | "file_list": filelist,
187 | "bids_path": bids_path,
188 | "rules": rules,
189 | "mapping_path":''
190 | }
191 | })
192 | response = client.post("/api/sovabids/apply_rules",data=request )
193 | print(request,'response',response.content.decode())
194 | file_mappings = json.loads(response.content.decode())
195 | file_mappings=file_mappings['result']
196 | mappings_path = os.path.join(bids_path,'code','sovabids','mappings.yml')
197 |
198 | # Save Mappings
199 | request = json.dumps({
200 | "jsonrpc": "2.0",
201 | "id": 0,
202 | "method": "save_mappings",
203 | "params": {
204 | "general": file_mappings['General'],
205 | "individual":file_mappings['Individual'],
206 | "path": mappings_path+'.bkp'
207 | }
208 | })
209 | response = client.post("/api/sovabids/save_mappings",data=request )
210 | print(request,'response',response.content.decode())
211 |
212 | individuals=file_mappings['Individual']
213 |
214 | # Testing the mappings (at the moment it only test the filepaths)
215 | validator = BIDSValidator()
216 | filepaths = [x['IO']['target'].replace(bids_path,'') for x in individuals]
217 | for filepath in filepaths:
218 | assert validator.is_bids(filepath),'{} is not a valid bids path'.format(filepath)
219 | if write:
220 | if mode=='python':
221 | convert_them(file_mappings)
222 | elif mode=='cli':
223 | os.system('sovaconvert '+mappings_path)
224 | elif mode=='rpc':
225 | request=json.dumps({ #jsondumps important to avoid parse errors
226 | "jsonrpc": "2.0",
227 | "id": 0,
228 | "method": "convert_them",
229 | "params": {
230 | "general": file_mappings['General'],
231 | "individual":file_mappings['Individual']
232 | }
233 | })
234 | response = client.post("/api/sovabids/convert_them",data=request)
235 |
236 | print('okrpc')
237 | return file_mappings
238 | def test_dummy_dataset():
239 | # apparently it cannot download the cnt consistenly on the github actions machine
240 | #dummy_dataset('placeholder',write=True,format='.cnt') # Test cnt conversion
241 | dummy_dataset('placeholder',write=True)
242 | dummy_dataset('regex',write=True)
243 | dummy_dataset('placeholder',write=True,mode='cli')
244 | dummy_dataset('regex',write=True,mode='cli')
245 | dummy_dataset('placeholder',write=True,mode='rpc')
246 | dummy_dataset('regex',write=True,mode='rpc')
247 |
248 | #TODO: A test for incremental conversion
249 | if __name__ == '__main__':
250 | test_dummy_dataset()
251 | print('ok')
--------------------------------------------------------------------------------
/examples/rpc_example.py:
--------------------------------------------------------------------------------
1 |
2 | """
3 | ========================================
4 | RPC API example with the LEMON dataset
5 | ========================================
6 |
7 | This example illustrates the use of ``sovabids`` on the `LEMON dataset `_
8 | using the RPC API.
9 |
10 | .. warning::
11 | To run this example, you need to install sovabids in 'advanced-usage' mode ( `see here `_ ).
12 |
13 | """
14 |
15 | #%%
16 | # Sovabids uses an action-oriented API. Here we will illustrate each of the available functionalities.
17 | #
18 | # Imports
19 | # -------
20 | # First we import some functions we will need:
21 |
22 |
23 | import os # For path manipulation
24 | import shutil # File manipulation
25 | from mne_bids import print_dir_tree # To show the input/output directories structures inside this example
26 | from sovabids.datasets import lemon_prepare # Download the dataset
27 | from sovabids.settings import REPO_PATH
28 | from sovabids.sovarpc import app as sovapp # The RPC API application
29 | import sovabids.sovarpc as sovarpc
30 | from fastapi.testclient import TestClient # This will be for simulating ourselves as a client of the RPC API
31 | import json # for making json-based requests
32 | import copy # just to make deep copies of variables
33 |
34 | #%%
35 | # Getting and preparing the dataset
36 | # ---------------------------------
37 | # We have to download and decompress the dataset. We also need to fix a filename inconsistency
38 | # (without this correction the file won't be able to be opened in mne). Luckily all of that is
39 | # encapsulated in the lemon_prepare function since these issues are not properly of sovabids.
40 | #
41 | # By default the files are saved in the '_data' directory of the sovabids project.
42 | lemon_prepare()
43 |
44 | #%%
45 | # Setting up the paths
46 | # --------------------
47 | # Now we will set up four paths. Because this example is intended to run relative
48 | # to the repository directory we use relative path but for real use-cases it is
49 | # easier to just input the absolute-path. We will print these paths for more clarity.
50 |
51 | source_path = os.path.abspath(os.path.join(REPO_PATH,'_data','lemon')) # For the input data we will convert
52 | bids_path= os.path.abspath(os.path.join(REPO_PATH,'_data','lemon_bids_rpc')) # The output directory that will have the converted data
53 | rules_path = os.path.abspath(os.path.join(REPO_PATH,'examples','lemon_example_rules.yml')) # The rules file that setups the rule for conversion
54 | mapping_path = os.path.abspath(os.path.join(bids_path,'code','sovabids','mappings.yml')) # The mapping file that will hold the results of applying the rules to each file
55 |
56 | print('source_path:',source_path.replace(REPO_PATH,''))
57 | print('bids_path:', bids_path.replace(REPO_PATH,''))
58 | print('rules_path:',rules_path.replace(REPO_PATH,''))
59 | print('mapping_path:',mapping_path.replace(REPO_PATH,''))
60 |
61 | #%%
62 | # Cleaning the output directory
63 | # -----------------------------
64 | # We will clean the output path as a safety measure from previous conversions.
65 |
66 | try:
67 | shutil.rmtree(bids_path)
68 | except:
69 | pass
70 |
71 | #%%
72 | # The input directory
73 | # -------------------
74 | # For clarity purposes we will print here the directory we are trying to convert to BIDS.
75 |
76 | print_dir_tree(source_path)
77 |
78 |
79 |
80 | #%%
81 | # RPC API
82 | # -------
83 | # Simulating ourselves as clients
84 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
85 | # We will use the TestClient class to send requests to the API (the sovapp variable)
86 |
87 | client = TestClient(sovapp)
88 |
89 | #%%
90 | # The general request
91 | # ^^^^^^^^^^^^^^^^^^^
92 | # We will define a function to make a request to the API
93 | # given the name of the method and its parameters as a dictionary
94 |
95 | def make_request(method,params):
96 | print('Method:',method)
97 | print('');print('');
98 | print('Parameters:')
99 | print(json.dumps(params, indent=4))
100 | print('');print('');
101 | # We create the complete request
102 | request= {
103 | "jsonrpc": "2.0",
104 | "id": 0,
105 | "method": method,
106 | "params": params}
107 | print('Request:')
108 | print(json.dumps(request, indent=4))
109 | print('');print('');
110 | # json dumps is important to avoid parsing errors in the API request
111 | request = json.dumps(request)
112 |
113 | # Send the request
114 | request_url = "/api/sovabids/" +method
115 | print('Request URL:')
116 | print(request_url)
117 | print('');print('');
118 | response = client.post(request_url,data=request ) # POST request as common in RPC-based APIs
119 |
120 | # Get the answer
121 | result = json.loads(response.content.decode())['result']
122 | print('Answer:')
123 | print(json.dumps(result, indent=4))
124 | print('');print('');
125 | return result
126 |
127 | #%%
128 | # load_rules
129 | # ^^^^^^^^^^
130 | # For loading a yaml rules file.
131 | # Lets see the docstring of this method
132 |
133 | print(sovarpc.load_rules.__doc__)
134 |
135 | #%%
136 | # Lets define the request
137 |
138 | method = 'load_rules' # Just a variable for the method name
139 |
140 | params = { # Parameters of the method
141 | "rules_path": rules_path
142 | }
143 |
144 | #%%
145 | # And proceed with it
146 |
147 | result = make_request(method,params)
148 |
149 | rules = copy.deepcopy(result)
150 |
151 | #%%
152 | # save_rules
153 | # ^^^^^^^^^^
154 | # We can for example use it as a way to save a backup of the already-existing rules file.
155 | # Lets see the docstring of this method
156 | print(sovarpc.save_rules.__doc__)
157 |
158 | #%%
159 | # Lets define the request
160 | method = "save_rules" # Just a variable for the method name
161 |
162 | params = { # Parameters of the method
163 | "rules": rules,
164 | "path": mapping_path.replace('mappings','rules')+'.bkp' # We will do it as if we were saving a backup of the rules
165 | # Since the rules file already exists
166 | }
167 |
168 | #%%
169 | # And proceed with it
170 | result = make_request(method,params)
171 |
172 | #%%
173 | # get_files
174 | # ^^^^^^^^^
175 | # Useful for getting the files on a directory.
176 | # Lets see the docstring of this method
177 | print(sovarpc.get_files.__doc__)
178 |
179 | #%%
180 | # .. note::
181 | #
182 | # get_files uses the rules because of the non-bids.eeg_extension configuration.
183 |
184 |
185 | #%%
186 | # Lets define the request
187 | method = "get_files" # Just a variable for the method name
188 |
189 | params = { # Parameters of the method
190 | "rules": rules,
191 | "path": source_path
192 | }
193 |
194 | #%%
195 | # And proceed with it
196 | result = make_request(method,params)
197 |
198 | filelist = copy.deepcopy(result)
199 |
200 | #%%
201 | # apply_rules_to_single_file
202 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^
203 | # We can use this to get a mapping for a single mapping
204 | # and for previewing the bids files that would be written.
205 | # Lets see the docstring of this method
206 | print(sovarpc.apply_rules_to_single_file.__doc__)
207 |
208 | #%%
209 | # Lets define the request
210 | method = "apply_rules_to_single_file" # Just a variable for the method name
211 |
212 | params = { # Parameters of the method
213 | "file": filelist[0],
214 | "bids_path": bids_path+'.preview',
215 | "rules": rules,
216 | "write":False,
217 | "preview":True
218 | }
219 |
220 | #%%
221 | # And proceed with it
222 | result = make_request(method,params)
223 |
224 |
225 | #%%
226 | # apply_rules
227 | # ^^^^^^^^^^^
228 | # We can use this to get the mappings for all the files in a list of them.
229 | # Lets see the docstring of this method
230 | print(sovarpc.apply_rules.__doc__)
231 |
232 | #%%
233 | # Lets define the request
234 | method = "apply_rules" # Just a variable for the method name
235 |
236 | params = { # Parameters of the method
237 | "file_list": filelist,
238 | "bids_path": bids_path,
239 | "rules": rules,
240 | "mapping_path":mapping_path
241 | }
242 |
243 | #%%
244 | # And proceed with it
245 | result = make_request(method,params)
246 |
247 | file_mappings=copy.deepcopy(result)
248 |
249 | #%%
250 | # save_mappings
251 | # ^^^^^^^^^^^^^
252 | # We can use this to save a backup of the mappings.
253 | # Lets see the docstring of this method
254 | print(sovarpc.save_mappings.__doc__)
255 |
256 | #%%
257 | # Lets define the request
258 | method = "save_mappings" # Just a variable for the method name
259 |
260 | params = { # Parameters of the method
261 | "general": file_mappings['General'],
262 | "individual":file_mappings['Individual'],
263 | "path": mapping_path+'.bkp'
264 | }
265 |
266 | #%%
267 | # And proceed with it
268 | result = make_request(method,params)
269 |
270 | #%%
271 | # convert_them
272 | # ^^^^^^^^^^^^
273 | # We can use this to perform the conversion given the mappings.
274 | # Lets see the docstring of this method
275 | print(sovarpc.convert_them.__doc__)
276 |
277 | #%%
278 | # Lets define the request
279 | method = "convert_them" # Just a variable for the method name
280 |
281 | params = { # Parameters of the method
282 | "general": file_mappings['General'],
283 | "individual":file_mappings['Individual']
284 | }
285 |
286 | #%%
287 | # And proceed with it
288 | result = make_request(method,params)
289 |
290 |
291 | #%%
292 | # Checking the conversion
293 | # -----------------------
294 | # For clarity purposes we will check the output directory we got from sovabids.
295 |
296 | print_dir_tree(bids_path)
297 |
298 | print('LEMON CONVERSION FINISHED!')
299 |
300 | #%%
301 | # The ideal GUI for the designed API
302 | # ----------------------------------
303 | # Here is the GUI schematic we had in mind when we designed the API
304 | #
305 | # .. image:: https://user-images.githubusercontent.com/36543115/125894264-9e1bd421-41e2-444b-adcb-ecf11e81d1a0.png
306 | # :alt: Ideal GUI
307 | #
308 | # .. warning::
309 | #
310 | # The only difference is that apply_rules will receive a list of the paths of the files we want to convert rather than a single input directory path
311 | #
--------------------------------------------------------------------------------
/sovabids/parsers.py:
--------------------------------------------------------------------------------
1 | """Module with parser utilities."""
2 | import re
3 | from copy import deepcopy
4 |
5 | from sovabids.misc import flat_paren_counter
6 | from sovabids.dicts import deep_merge_N,nested_notation_to_tree
7 |
8 | def placeholder_to_regex(placeholder,encloser='%',matcher='(.+)'):
9 | """Translate a placeholder pattern to a regex pattern.
10 |
11 | Parameters
12 | ----------
13 | placeholder : str
14 | The placeholder pattern to translate.
15 | matcher : str, optional
16 | The regex pattern to use for the placeholder, ie : (.*?),(.*),(.+).
17 | encloser : str, optional
18 | The symbol which encloses the fields of the placeholder pattern.
19 |
20 | Returns
21 | -------
22 |
23 | pattern : str
24 | The regex pattern.
25 | fields : list of str
26 | The fields as they appear in the regex pattern.
27 | """
28 | pattern = placeholder
29 | pattern = pattern.replace('\\','/')
30 | if pattern.count('%') == 0 or pattern.count('%') % 2 != 0:
31 | return '',[]
32 | else:
33 | borders = pattern.split(encloser)[::2]
34 | fields = pattern.split(encloser)[1::2]
35 | for field in fields:
36 | pattern = pattern.replace(encloser+field+encloser, matcher, 1)
37 | pattern = pattern.replace('/','\\/')
38 | return pattern,fields
39 |
40 | def parse_from_placeholder(string,pattern,encloser='%',matcher='(.+)'):
41 | """Parse string from a placeholder pattern.
42 |
43 | Danger: It will replace underscores and hyphens with an empty character in all fields
44 | except for the ignore field. This to accomodate to the bids standard restrictions automatically.
45 |
46 | Parameters
47 | ----------
48 |
49 | string : str
50 | The string to parse.
51 | pattern : str
52 | The placeholder pattern to use for parsing.
53 | matcher : str, optional
54 | The regex pattern to use for the placeholder, ie : (.*?),(.*),(.+).
55 | encloser : str, optional
56 | The symbol which encloses the fields of the placeholder pattern.
57 |
58 | Returns
59 | -------
60 |
61 | dict
62 | The dictionary with the fields and values requested.
63 | """
64 | pattern,fields = placeholder_to_regex(pattern,encloser,matcher)
65 | return parse_from_regex(string,pattern,fields)
66 |
67 | def parse_from_regex(string,pattern,fields,invalid_replace=''):
68 | """Parse string from regex pattern.
69 |
70 | Danger: It will replace underscores and hyphens with an empty character in all fields
71 | except for the ignore field. This to accomodate to the bids standard restrictions automatically.
72 |
73 | Parameters
74 | ----------
75 | string : str
76 | The string to parse.
77 | pattern : str
78 | The regex pattern to use for parsing.
79 | fields : list of str
80 | List of fields in the same order as they appear in the regex pattern.
81 | invalid_replace: str
82 | String that will replace '-' and '_' that appear on extracted fields.
83 | Returns
84 | -------
85 |
86 | dict
87 | The dictionary with the fields and values requested.
88 | """
89 |
90 | string = string.replace('\\','/') # USE POSIX PLEASE
91 | num_groups = flat_paren_counter(pattern)
92 | if isinstance(fields,str):
93 | fields = [fields]
94 | num_fields = len(fields)
95 | if not num_fields == num_groups:
96 | return {}
97 | match = re.search(pattern,string)
98 |
99 | if not hasattr(match, 'groups'):
100 | raise AttributeError(f"Couldn't find fields in the string {string} using the pattern {pattern}. Recheck the pattern for errors.")
101 |
102 | if not num_groups == len(match.groups()):
103 | return {}
104 |
105 | l = []
106 |
107 | for field,value in zip(fields,list(match.groups())):
108 | if field != 'ignore' and ('_' in value or '-' in value):
109 | value2 = value.replace('_',invalid_replace)
110 | value2 = value2.replace('-',invalid_replace)
111 | d = nested_notation_to_tree(field,value2)
112 | else:
113 | d = nested_notation_to_tree(field,value)
114 | l.append(d)
115 | return deep_merge_N(l)
116 |
117 | def parse_entity_from_bidspath(path,entity,mode='r2l'):
118 | """Get the value of a bids-entity from a path.
119 |
120 | Parameters
121 | ----------
122 | path : str
123 | The bidspath we are going to derive the information on.
124 | Should be the complete path of file of a modality (ie an _eeg file).
125 | entity : str
126 | The entity we are going to extract.
127 | SHOULD be one of sub|ses|task|acq|run
128 | mode : str
129 | Direction of lookup. One of r2l|l2r .
130 | r2l (right to left)
131 | l2r (left to right)
132 |
133 | Returns
134 | -------
135 | value : str
136 | The extracted value of the entity as a string.
137 | If None, it means the entity was not found on the string.
138 | """
139 | entity = entity if '-' in entity else entity + '-'
140 | # Easier to find it from the tail of the bidspath
141 | if mode == 'r2l':
142 | entity_position = path.rfind(entity)
143 | elif mode == 'l2r':
144 | entity_position = path.find(entity)
145 | else:
146 | raise ValueError('Incorrect usage of the mode argument.')
147 |
148 | if entity_position == -1:
149 | return None
150 |
151 | little_path = path[entity_position:]
152 |
153 | value = re.search('%s(.*?)%s' % ('-', '_'), little_path,).group(1)
154 |
155 | return value
156 |
157 | def _modify_entities_of_placeholder_pattern(pattern,mode='append'):
158 | """Convert between sovabids entities pattern notation and the shorter notation.
159 |
160 | The shorter notation is:
161 | %dataset%, %task%, %session%, %subject%, %run%, %acquisition%
162 |
163 | Parameters
164 | ----------
165 | string : str
166 | The pattern string to convert.
167 | mode : str
168 | Whether to append 'entities' or cut it. One of {'append','cut'}
169 |
170 | Returns
171 | -------
172 | str
173 | The converted pattern string.
174 | """
175 | if mode == 'append':
176 | for keyword in ['%task%','%session%','%subject%','%run%','%acquisition%']:
177 | pattern = pattern.replace(keyword,'%entities.'+keyword[1:])
178 | pattern = pattern.replace('%dataset%','%dataset_description.Name%')
179 | elif mode == 'cut':
180 | for keyword in ['%task%','%session%','%subject%','%run%','%acquisition%']:
181 | pattern = pattern.replace('%entities.'+keyword[1:],keyword)
182 | pattern = pattern.replace('%dataset_description.Name%','%dataset%')
183 | return pattern
184 |
185 | def parse_entities_from_bidspath(targetpath,entities=['sub','ses','task','acq','run'],mode='r2l'):
186 | """Get the bids entities from a bidspath.
187 |
188 | Parameters
189 | ----------
190 | targetpath : str
191 | The bidspath we are going to derive the information on.
192 | entities : list of str
193 | The entities we are going to extract.
194 | Defaults to sub,ses,task,acq,run
195 | mode : str
196 | Direction of lookup. One of r2l|l2r .
197 | r2l (right to left)
198 | l2r (left to right)
199 |
200 | Returns
201 | -------
202 | dict
203 | A dictionary with the extracted entities.
204 | {'sub':'11','task':'resting','ses':'V1','acq':'A','run':1}
205 | """
206 | path = deepcopy(targetpath)
207 | bids_dict = dict()
208 | for entity in entities:
209 | bids_dict[entity] = parse_entity_from_bidspath(path,entity,mode)
210 | # Clean Non Existent key
211 | bids_dict2 = {key:value for key,value in bids_dict.items() if value is not None}
212 | return bids_dict2
213 |
214 | def parse_path_pattern_from_entities(sourcepath,bids_entities):
215 | """Get the path pattern from a path and a dictionary of bids entities and their values.
216 |
217 | Parameters
218 | ----------
219 | sourcepath : str
220 | The sourcepath that will be modified to get the path pattern
221 | bids_entities : dict
222 | Dictionary with the entities and their values on the path.
223 | Ie {'sub':'11','task':'resting','ses':'V1','acq':'A','run':1}
224 | There should be no ambiguity between the sourcepath and each of the values.
225 | Otherwise an error will be raised.
226 |
227 | Returns
228 | -------
229 |
230 | str :
231 | The path pattern in placeholder format
232 | """
233 | path = deepcopy(sourcepath)
234 | values = [val for key,val in bids_entities.items()]
235 | key_map={
236 | 'sub':'%subject%',
237 | 'ses':'%session%',
238 | 'task':'%task%',
239 | 'acq':'%acquisition%',
240 | 'run':'%run%'
241 | }
242 | assert '%' not in path # otherwise it will mess up the logic
243 | for key,val in bids_entities.items():
244 | pathcopy = deepcopy(path)
245 | # Replace all other values which are superstrings of the current one
246 | superstrings = [x for x in values if val in x and val!=x]
247 | for string in superstrings:
248 | pathcopy = pathcopy.replace(string,'*'*len(string))
249 | # handle ambiguity
250 | if pathcopy.count(val) > 1:
251 | raise ValueError('Ambiguity: The path has multiple instances of {}'.format(val))
252 | if pathcopy.count(val) < 1:
253 | superstrings = [x for x in bids_entities.values() if val in x and val!=x]
254 | substrings = [x for x in bids_entities.values() if x in val and val!=x]
255 | possible_ambiguity_with = set(superstrings+substrings)
256 | raise ValueError(f'{val} seems to be ambiguous with any of the following values {possible_ambiguity_with}')
257 | path = path.replace(val,key_map[key])
258 | values[values.index(val)] = key_map[key]
259 | path = _modify_entities_of_placeholder_pattern(path)
260 | path = path.replace('\\','/')
261 | # Find first changing value and put the pattern from there
262 | first_placeholder = path.find('%')
263 | # Identify where should the pattern start
264 | start = path[:first_placeholder].rfind('/') + 1 if '/' in path[:first_placeholder] else 0
265 | path = path[start:]
266 | return path
267 |
268 | def find_bidsroot(path):
269 | """Get the bidsroot from an absolute path describing a bids file inside a subject subfolder.
270 |
271 | Parameters
272 | ----------
273 | path : str
274 | The absolute path to any bids file inside a sub- folder.
275 |
276 | Returns
277 | -------
278 |
279 | str :
280 | The bidsroot absolute path.
281 | """
282 | sub = parse_entities_from_bidspath(path,entities=['sub'],mode='r2l')
283 | index = path.find(sub['sub'])
284 | #We know the bids root is the path up until that index minus some stuff
285 | bidsroot = path[:index-4] #remove sub- prefix
286 | return bidsroot
287 |
--------------------------------------------------------------------------------
/examples/bidscoin_example.py:
--------------------------------------------------------------------------------
1 |
2 | """
3 | ===================================
4 | LEMON dataset example with BIDSCOIN
5 | ===================================
6 |
7 | This example illustrates the use of ``sovabids`` on the `LEMON dataset `_
8 | using bidscoin.
9 |
10 | The main elements of this example are:
11 | * A source path with the original dataset.
12 | * A bids path that will be the output path of the conversion.
13 | * A rules file that configures how the conversion is done.
14 | * A bidsmap template required by bidscoin. (Equivalent to our rules file)
15 | * A study bidsmap. (Equivalent to our mappings file)
16 |
17 | Refer to the `bidscoin documentation `_ to understand the components and workflow of bidscoin.
18 |
19 | In summary, bidscoin uses a bidsmap to encode how a conversion is done.
20 |
21 | Intuitively, the bidsmapper grabs a template to produce a study bidsmap, which may or may not be customized for each file through the bidseditor. Either way the final study bidsmap is passed to bidscoiner to perform the conversion.
22 |
23 | The connection of sovabids and bidscoin is through a plugin called **sova2coin** which helps the bidscoin modules by dealing with the EEG data.
24 |
25 | .. mermaid::
26 |
27 | graph LR
28 | S>"Source path"]
29 | B>"Bids path"]
30 | R>"Rules file"]
31 | O[("Converted dataset")]
32 | BM((bidsmapper))
33 | BC((bidscoiner))
34 | BE((bidseditor))
35 | BF>bidsmap template]
36 | SOVA((sova2coin)) --> BM
37 | B-->BM
38 | BM-->|bidsmap|BE
39 | BE-->|user-edited bidsmap|BC
40 | BC-->O
41 | R --> SOVA
42 | BF -->BM
43 | S --> BM
44 | SOVA-->BC
45 |
46 |
47 | .. warning::
48 | If you didn't install sovabids in 'gui-usage' mode ( `see here `_ ), you will probably need to install bidscoin:
49 |
50 | Install our `bidscoin branch `_
51 |
52 | That is, you need to run:
53 |
54 | .. code-block:: bash
55 |
56 | pip install git+https://github.com/yjmantilla/bidscoin.git@sovabids
57 |
58 | If that doesn't work try:
59 |
60 | .. code-block:: bash
61 |
62 | git clone https://github.com/yjmantilla/bidscoin/tree/sovabids
63 | cd bidscoin
64 | pip install .
65 | """
66 |
67 | #%%
68 | # Imports
69 | # ^^^^^^^
70 | # First we import some functions we will need:
71 |
72 | import os
73 | import shutil # File manipulation
74 | import yaml # To do yaml operations
75 | from mne_bids import print_dir_tree # To show the input/output directories structures inside this example
76 | from sovabids.datasets import lemon_bidscoin_prepare # Dataset
77 | from sovabids.schemas import get_sova2coin_bidsmap # bidsmap template schema
78 | from sovabids.settings import REPO_PATH
79 | #%%
80 | # Setting up the paths
81 | # ^^^^^^^^^^^^^^^^^^^^
82 | # First, we will set up four paths. Because this example is intended to run relative
83 | # to the repository directory we use relative path but for real use-cases it is
84 | # easier to just input the absolute-path. We will print these paths for more clarity.
85 |
86 | dataset = 'lemon_bidscoin' # Just folder name where to save or dataset
87 | data_dir = os.path.join(REPO_PATH,'_data')
88 | data_dir = os.path.abspath(data_dir)
89 |
90 | source_path = os.path.abspath(os.path.join(data_dir,dataset+'_input'))
91 | bids_path= os.path.abspath(os.path.join(data_dir,dataset+'_output'))
92 | code_path = os.path.join(bids_path,'code','bidscoin')
93 | rules_path = os.path.join(code_path,'rules.yml')
94 | template_path = os.path.join(code_path,'template.yml')
95 | bidsmap_path = os.path.join( code_path,'bidsmap.yaml')
96 | print('source_path:',source_path.replace(data_dir,''))
97 | print('bids_path:', bids_path.replace(data_dir,''))
98 | print('rules_path:',rules_path.replace(data_dir,''))
99 | print('template_path:',template_path.replace(data_dir,''))
100 | print('bidsmap_path:',bidsmap_path.replace(data_dir,''))
101 |
102 | #%%
103 | # Cleaning the output directory
104 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
105 | # We will clean the output path as a safety measure from previous conversions.
106 |
107 | try:
108 | shutil.rmtree(bids_path)
109 | except:
110 | pass
111 |
112 | #%%
113 | #
114 | # Make the folders if they don't exist to avoid errors
115 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
116 | for p in [source_path,bids_path,code_path]:
117 | os.makedirs(p,exist_ok=True)
118 |
119 | #%%
120 | # Getting and preparing the dataset
121 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
122 | # We have to download and decompress the dataset. We also need to fix a filename inconsistency
123 | # (without this correction the file won't be able to be opened in mne). Luckily all of that is
124 | # encapsulated in the lemon_prepare function since these issues are not properly of sovabids.
125 | #
126 | # We also need to prepare the data to the `bidscoin required source data structure `_ .
127 | #
128 | # We will save this input data to source_path .
129 | lemon_bidscoin_prepare(source_path)
130 |
131 |
132 | #%%
133 | # The input directory
134 | # ^^^^^^^^^^^^^^^^^^^
135 | # For clarity purposes we will print here the directory we are trying to convert to BIDS.
136 |
137 | print_dir_tree(source_path)
138 |
139 | #%%
140 | # Making the rules
141 | # ^^^^^^^^^^^^^^^^
142 | # See the Rules File Schema documentation for help regarding making this rules file.
143 | #
144 | # Here we will make the rules from a python dictionary.
145 |
146 | rules ={
147 | 'entities':{'task':'resting'},
148 | 'dataset_description':{'Name':dataset},
149 | 'sidecar':{'PowerLineFrequency':50,'EEGReference':'FCz'},
150 | 'channels':{'type':{'VEOG':'VEOG'}},
151 | 'non-bids':{'path_analysis':{'pattern':'sub-%entities.subject%/ses-%entities.session%/%ignore%/%ignore%.vhdr'}}
152 | }
153 | with open(rules_path, 'w') as outfile:
154 | yaml.dump(rules, outfile, default_flow_style=False)
155 |
156 | #%%
157 | # Now print the rules to see how the yaml file we made from the python dictionary looks like
158 | #
159 | with open(rules_path,encoding="utf-8") as f:
160 | rules = f.read()
161 | print(rules)
162 |
163 | #%%
164 | # Making the bidsmap template
165 | # ^^^^^^^^^^^^^^^^^^^^^^^^^^^
166 | # The template is equivalent to the "rules" file of sovabids. It encodes the general way of doing the conversion.
167 | #
168 | # Explaining this file is out of scope of this example (this is bidscoin territory).
169 | #
170 | # We will notice however that:
171 | #
172 | # * We input our rules file as an option to the sova2coin plugin.
173 | # * We are interested in a "EEG" dataformat with an "eeg" datatype.
174 | # * We match every file with a .* in the properties.filename section
175 | # * The attributes are basically the metadata information extracted from the files which may be used to derive bids-related information.
176 | # * In the attributes section we have the objects as they are named in our rules file schema (that is, here we deal with sovabids terminology using a dot notation for nesting)
177 | # * We populate bids-related info with the extracted attributes (see subject, session and bids sections of the file)
178 | # * We set the suffix to eeg.
179 | # * The ``<`` and ``<<`` is best explained `here `_
180 | template = get_sova2coin_bidsmap().format(rules_path)
181 |
182 | print(template)
183 |
184 | with open(template_path,mode='w') as f:
185 | f.write(template)
186 |
187 | #%%
188 | # .. tip::
189 | #
190 | # You can also input the rules directly (ie writing the rules instead of the path to the rules file)
191 | #
192 | # What is important is that inside the "rules" field of the sova2coin "options"
193 | #
194 | # .. note::
195 | # The EEG:eeg hierarchy just says that there is an 'EEG' dataformat which a general 'eeg' datatype.
196 | #
197 | # This is a bit redundant but it happens because bidscoin was originally thought for DICOM (dataformat)
198 | # which holds many datatypes (anat,perf,etc). In eeg this doesnt happens.
199 | #
200 | # Some necessary code
201 | # ^^^^^^^^^^^^^^^^^^^
202 | # To be able to run commands from this notebook and capture their outputs we need to define the following, nevertheless this is not relevant to actually running this from the command line.
203 |
204 | from subprocess import PIPE, run
205 |
206 | def out(command):
207 | result = run(command, stdout=PIPE, stderr=PIPE, universal_newlines=True, shell=True)
208 | return result.stdout
209 |
210 | my_output = out("echo hello world")
211 | print(my_output)
212 |
213 | #%%
214 | # bidsmapper
215 | # ^^^^^^^^^^
216 | # First we execute the bidsmapper to get a study bidsmap from our bidsmap template.
217 | #
218 | # The bidsmap file is equivalent to our "mappings" file; it encodes how the conversion is done on a per-file basis.
219 | #
220 | # Lets see the help:
221 |
222 | command = "bidsmapper --help"
223 | print(command)
224 | #%%
225 | # This will give the following output
226 | #
227 | my_output= out(command)
228 | print(my_output)
229 |
230 | #%%
231 | # Now we will use the following command to get the bidsmap study file.
232 | #
233 | # Note we use -t to set the template and -a to run this without the bidseditor
234 | #
235 | # You can skip the -a option if you are able to open the bidseditor (ie you are able to give user-input in its interface)
236 | #
237 | # Just remember to save the bidsmap yaml at the end.
238 | #
239 | # See the `bidseditor documentation `_ for more info.
240 | command = 'bidsmapper '+source_path + ' '+ bids_path + ' -t ' + template_path + ' -a'
241 | print(command)
242 |
243 | #%%
244 | # This will produce the following study bidsmap:
245 |
246 | my_output= out(command)
247 | print(my_output)
248 |
249 | with open(bidsmap_path,encoding="utf8", errors='ignore') as f:
250 | bidsmap= f.read()
251 | print(bidsmap)
252 |
253 | #%%
254 | # at the following path:
255 |
256 | print(bidsmap_path)
257 |
258 | #%%
259 | # bidscoiner
260 | # ^^^^^^^^^^
261 | # Now we are ready to perform the conversion given the study bidsmap file just made.
262 | #
263 | # Use the following command to print the help of the tool:
264 | #
265 | command = "bidscoiner --help"
266 | print(command)
267 | #%%
268 | # This will give the following output
269 | #
270 | my_output= out(command)
271 | print(my_output)
272 |
273 | #%%
274 | # Now we will use the following command to perform the conversion.
275 | #
276 | command = 'bidscoiner '+source_path + ' '+ bids_path + ' -b '+ bidsmap_path
277 |
278 | print(command)
279 |
280 | #%%
281 | # This will produce the following output:
282 | my_output= out(command)
283 | print(my_output)
284 |
285 | #%%
286 | # Checking the conversion
287 | # ^^^^^^^^^^^^^^^^^^^^^^^
288 | # For clarity purposes we will check the output directory we got from sovabids.
289 |
290 | print_dir_tree(bids_path)
291 |
292 | print('BIDSCOIN CONVERSION FINISHED!')
293 |
294 |
295 |
296 |
--------------------------------------------------------------------------------
/gsoc_proposal.md:
--------------------------------------------------------------------------------
1 | # GSoC Proposal
2 |
3 | SOVABIDS: A python package for the automatic conversion of MEG/EEG datasets to the BIDS standard, with a focus on making the most out of metadata
4 |
5 | ## Abstract
6 |
7 | BIDS is a standard for neuroimaging datasets that helps with data sharing and reusability; as a result it has been widely adopted by the community. Although developed for MRI originally, it has gained popularity within the EEG and MEG realms. Converting raw data to the BIDS standard is not difficult but requires a lot of time if done by hand. Currently software like mne-bids and Biscuit are available to assist and facilitate this conversion but there is still no automated way to produce a valid BIDS dataset for the EEG and MEG use-cases. Mostly what is missing is metadata. Here a python package is proposed to be able to infer the missing information from files accompanying the EEG and MEG files and/or a single bids-conversion example provided by the user. The idea of having simple human-readable configuration files is also explored since this would help the sharing of common conversion parameters within similar communities. If this proposal was successfully implemented then batch conversion of BIDS datasets in the EEG and MEG cases would be realized. Moreover, since the design is constrained to simple configuration files, the software could potentially expand BIDS adoption to people not experienced with scripting. It is hoped that this package becomes the backend of an hypothetical web application that assists the conversion of MEG-EEG datasets to BIDS.
8 |
9 | ## Problem Statement
10 |
11 | Data is a fundamental asset for science, sadly it is usually stored in such a way that only the original researcher knows how to make use of it; the neuroimaging community is no stranger to this phenomenon. As the accumulation and sharing of data becomes more important following the data-intensive needs of neuroimaging, it has become critical the existence of an unified way to store data among researchers. One of the solutions to this is the BIDS standard for neuroimaging data, originally developed for MRI. As the BIDS adoption increases, it expands its range of application; in particular the MEG and EEG extensions are becoming more popular in their respective communities.
12 |
13 | In essence, BIDS is a specification that sets how data is saved on the storage medium: its folder structure, the filenames, the metadata format, etc. The BIDS standard is simple to understand but doing the conversion from a raw source may demand a lot of time. Luckily semi-automatic and automatic converters have been developed to address this, although mainly for MRI. As of now for MEG and EEG conversion some software packages have been developed: MNE-BIDS (working mainly by python scripts), Biscuit (GUI-based converter done in python), some plugins for EEGLAB, FieldTrip and SPM. and some manufacturer specific converters (BrainVision, for example). Most of these softwares will infer the technical characteristics to populate the BIDS dataset but will require the user to input the non-technical metadata (in example subjects ids, demographic characteristics,etc) through either scripting or GUI interfaces. The previous limitation makes the process of the -to BIDS- conversion complex and not completely automatic. In a lot of cases the information missing is available through metadata files, only needing a way for them to be read and incorporated into the already extracted technical information. In general the user ends up inputting a lot of information by hand or he needs to do scripts particular for his use-case. Since a lot of the MEG and EEG researchers don’t have a programming background this task will end up being manual. Moreover, the path containing the files usually encodes study design information, which is not usually used to improve the automation. MNE-BIDS for example will require inputting the subject,session and run through a python script, BISCUITS will require the user to set some of these parameters manually through a GUI and so on.
14 |
15 | Another improvement that could be made for automatic “MEG/EEG datasets to BIDS” conversion is to have a file that encodes the conversion parameters, so that they can be easily shared within a community with the same storage pattern. In addition, some individual MEG/EEG records may have particular characteristics not shared between all the records, thus requiring another file that characterizes the conversion for a particular case. The two files mentioned previously should be simple and intuitive enough so that people not experienced with scripting and programming can make use of the software. Similarly, the learning curve of the software should be low enough for people to adopt it.
16 |
17 | Motivated by the previous discussion, the proposed solution mainly addresses the following questions:
18 |
19 | - How can we infer as much as we can from the metadata files available and from a single bids conversion example provided by the user?.
20 | - How can we encode the information inferred previously in a simple and intuitive human-readable way?
21 | - How can we encode in a file the “to-bids” mapping that setups the conversion of a single record ?
22 |
23 | ## Proposed Solution
24 |
25 | The following schematic illustrates the overall design of the proposed software:
26 |
27 | 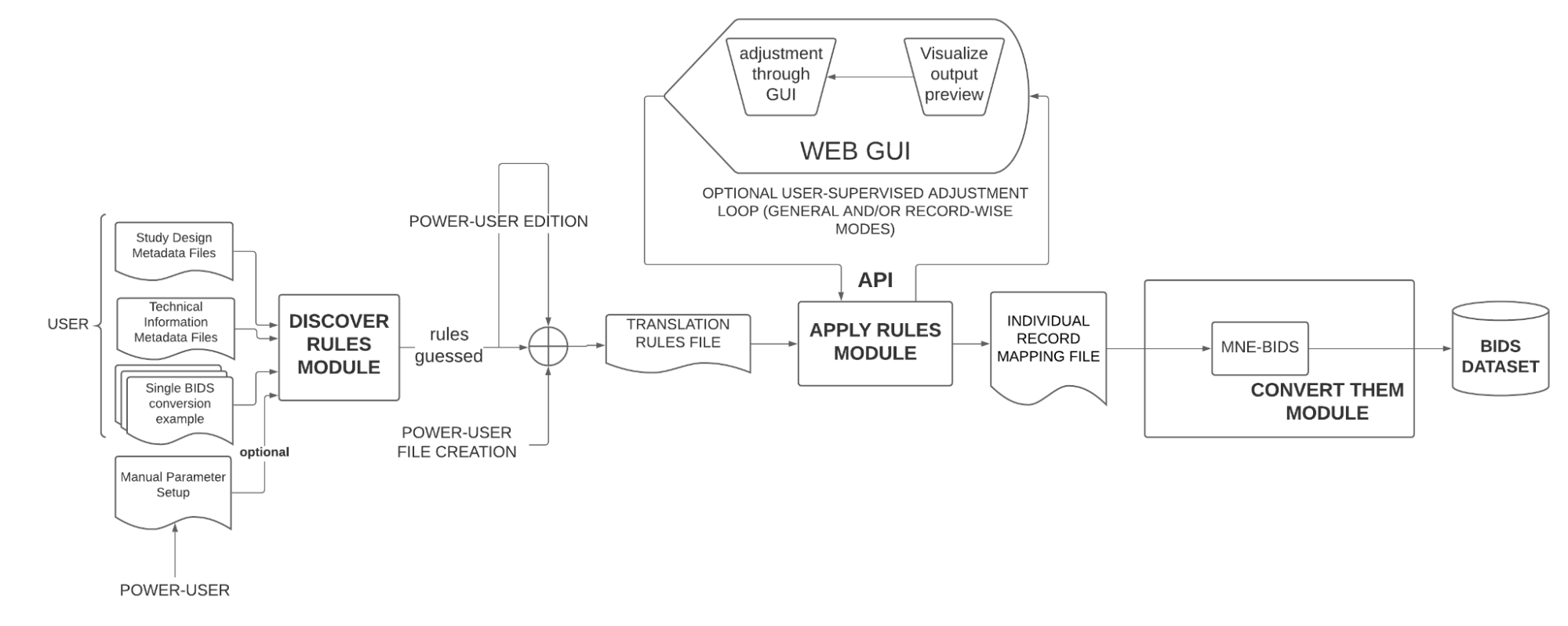
28 |
29 | The software is designed to work with EEG and MEG files, but because of the time constraints of the program, the GSoC project will focus on the conversion of EEG files from (at least) two different EEG system vendors. Moreover, the GUI of the “user-supervised adjustment loop”, although designed to be in the final version, won’t be developed during GSoC because of the same reason.
30 |
31 | The three main modules illustrated previously are expanded accordingly:
32 |
33 | ### “Discover Rules” Module
34 |
35 | This module is in charge of obtaining a “Translation Rules File” that describes the general rules for the conversion of the MEG/EEG dataset. For that it will infer characteristics from two sources:
36 |
37 | - A single example of a successful bids conversion provided by the user.
38 | - Metadata files available.
39 |
40 | From the structural point of view, the metadata files contemplated here are:
41 |
42 | - Manufacturer-Specific
43 | - Tabular Files
44 | - Dictionary Files
45 |
46 | Internally, this module is made out of functions that will apply different heuristics to get the information of interest.
47 |
48 | From the functional point of view two types of metadata arise:
49 |
50 | - Study Design Metadata
51 | - Technical Metadata of the Acquisition
52 |
53 | Researchers are usually accustomed to the study design details, whereas the technical metadata may be known by a technical user. It is possible that either of these two users would want to set directly some parameters rather than them to be guessed. Because of this, the module should have a way to set directly some details rather than guess them.
54 |
55 | ### “Apply Rules” Module
56 |
57 | This module interprets the “Translation Rules” file and outputs a “Individual Record Mapping” file. This is mainly applying the rules of the “Translation Rules File” to a single record.
58 |
59 | Power-users may produce the “Translation Rules” file on their own if they wish to do so; thus skipping the “Discover Rules” module. This would be possible since the file is designed to be simple and intuitive syntax.
60 |
61 | Since the “guessed” rules from the previous module are not necessarily correct in all cases, an user-supervised adjustment loop powered by a GUI is included in the design of the software. This GUI should show the user the hypothetical results of the conversion and offer a way to change the parameters so that the user gets the expected results. The changes should be applied on the “Translation Rule” if the change is a general one or on the “Individual Record Mapping” for record-wise changes.
62 |
63 | The “Apply Rules” Module should plug into the mentioned GUI through an API so as to not limit the visualization possibilities of the package. That is, during this GSoC, an effort will be made to implement the necessary API to achieve this rather than on a GUI.
64 |
65 | ### “Convert Them” Module
66 |
67 | This module grabs the “Individual Record Mapping” file (or a collection of them) and performs the conversion using the mne-bids package. A way to override the inferences done by the mne-bids package module should be applied if the user specifies to do so.
68 |
69 | ## Deliverables
70 |
71 | Python package that contains the following modules:
72 |
73 | - “Discover Rules” Module.
74 | - “Apply Rules” Module.
75 | - “Convert Them” Module.
76 | - “Translation Rules” File Schema
77 | - “Individual Record Mapping” File Schema
78 | - Use-case examples illustrating the conversion process of files from 2 different EEG System Vendors
79 | - Documentation.
80 |
81 | ## Community Impact
82 |
83 | If this software was successfully developed it would contribute to the adoption of the BIDS standard in EEG and MEG communities that don’t have a scripting/programming background. It would allow the automatic conversion of EEG/MEG datasets on servers since the conversion is controlled by configuration files. These same configurations files open the possibility for exchange of conversion mappings between communities that have a similar storage strategy.
84 |
85 | ## Suitability for the project
86 |
87 | I have some experience working with EEG data and how it is handled by BIDS. This experience was mostly acquired through an internship in a research group of the University Of Antioquia called “Neuropsychology and Behaviour Group” (GRUNECO). There I learned mostly resting EEG processing. Since the research group was (and is) trying to standardize their datasets I learned about the BIDS standard for EEG; coincidentally, I worked with a partner in this group to make a proof-of-concept software that does the conversion of a raw dataset to the BIDS standard. Although this software was a rudimentary initial design, it tackled problems similar to those explored in this proposal. I also have experience with python and in particular I contributed to some bug fixing and refactoring in the open source package [“pyprep”](https://github.com/sappelhoff/pyprep). Through these last efforts I acquired some knowledge about the mne package workings. As a result of these experiences I have knowledge of the python language, the EEG files, the BIDS ecosystem and the mne package library; all of these are essential for the execution of this project.
88 |
89 | Apart from the previous, I also collaborated with my mentor Oren Civier to build this proposal: starting from the initial conversations through the NeuroStars forum up to using google docs to collaborate.
90 |
91 | ## Timeline
92 |
93 | Note: During the course of GSoC I will be attending my university classes.
94 |
95 | This timeline provides a rough guideline of how the project will be done.
96 |
97 | ### 17 - 23 May
98 |
99 | Exploration of common EEG metadata formats.
100 |
101 | ### 24 - 30 May
102 |
103 | Learning of the BIDS specification for EEG.
104 |
105 | ### 31 May - 6 June
106 |
107 | Familiarisation with the mne-bids package to produce BIDS datasets.
108 |
109 | ### 7 - 27 June
110 |
111 | Design of the “Translation Rules” file schema that defines the conversion process of the dataset from a general point of view.
112 |
113 | Deliverables:
114 |
115 | - “Translation Rules” File Schema
116 |
117 | ### 21 June - 4 July
118 |
119 | Design of the “Individual Record Mapping” file schema and development of the “Apply Rules” module that outputs mapping files for each record.
120 |
121 | Deliverables:
122 |
123 | - “Individual Record Mapping” File Schema
124 | - “Apply Rules” Module
125 |
126 | ### 28 June - 25 July
127 |
128 | Development of the “Discover Rules” module with functions for each metadata file format explored and for the analysis of a single bids-conversion example provided by the user.
129 |
130 | Deliverables:
131 |
132 | - “Discover Rules” Module
133 |
134 | ### 19 July - 1 August
135 |
136 | Development of a module in charge of obtaining, through the mapping file, the specific parameters to be passed to the mne-bids package. This will store the data in the structure specified by the BIDS standard.
137 |
138 | Deliverables:
139 |
140 | - “Convert Records” Module
141 |
142 | ### 2 - 8 August
143 |
144 | Testing and correction of possible errors found and development conversion examples.
145 |
146 | Deliverables:
147 |
148 | - Examples illustrating the conversion process of files from 2 different EEG System Vendors
149 |
150 | ### 9 - 15 August
151 |
152 | Documentation of the software.
153 |
154 | Deliverables:
155 |
156 | - Documentation
157 |
--------------------------------------------------------------------------------
/sovabids/datasets.py:
--------------------------------------------------------------------------------
1 | """Module with dataset utilities.
2 | """
3 | import os
4 | from pandas import read_csv
5 | import shutil
6 | from sovabids.files import download,_get_files
7 | from sovabids.misc import get_num_digits
8 | from sovabids.parsers import parse_from_regex
9 | import mne
10 | import numpy as np
11 | from mne_bids.write import _write_raw_brainvision
12 | import fileinput
13 |
14 |
15 | def lemon_prepare():
16 | """Download and prepare a few files of the LEMON dataset.
17 |
18 | Notes
19 | -----
20 |
21 | See the `LEMON dataset `_ .
22 | """
23 |
24 | # Path Configuration
25 |
26 | this_dir = os.path.dirname(__file__)
27 | data_dir = os.path.join(this_dir,'..','_data')
28 | root_path = os.path.abspath(os.path.join(data_dir,'lemon'))
29 | os.makedirs(data_dir,exist_ok=True)
30 |
31 | # Download lemon Database
32 |
33 | urls = ['https://fcp-indi.s3.amazonaws.com/data/Projects/INDI/MPI-LEMON/Compressed_tar/EEG_MPILMBB_LEMON/EEG_Raw_BIDS_ID/sub-032301.tar.gz',
34 | 'https://fcp-indi.s3.amazonaws.com/data/Projects/INDI/MPI-LEMON/Compressed_tar/EEG_MPILMBB_LEMON/EEG_Raw_BIDS_ID/sub-032302.tar.gz',
35 | 'https://fcp-indi.s3.amazonaws.com/data/Projects/INDI/MPI-LEMON/Compressed_tar/EEG_MPILMBB_LEMON/EEG_Raw_BIDS_ID/sub-032303.tar.gz',
36 | 'https://fcp-indi.s3.amazonaws.com/data/Projects/INDI/MPI-LEMON/name_match.csv']
37 |
38 | for url in urls:
39 | download(url,os.path.join(data_dir,'lemon'))
40 |
41 | # Generate all filepaths
42 |
43 | filepaths = _get_files(root_path)
44 |
45 |
46 | # Label Correction
47 | name_match = read_csv(os.path.join(root_path,'name_match.csv'))
48 |
49 | # Unpack files
50 |
51 | # TAR FILES
52 | tars = [x for x in filepaths if 'tar.gz' in x ]
53 |
54 | # SUBJECTS
55 | # ignore field so that it doesnt get rid of - or _
56 | old_ids = [parse_from_regex(x,'(sub-.*?).tar.gz',['ignore']) for x in tars]
57 | old_ids = [x['ignore'] for x in old_ids]
58 | new_ids = [name_match.loc[(name_match.INDI_ID==x),'Initial_ID']._values[0] for x in old_ids]
59 |
60 | # EEG FILES
61 | not_tars = [x for x in filepaths if '.vhdr' in x ]
62 | not_tars_ids = [parse_from_regex(x,'RSEEG\\/(sub-.*?).vhdr',['id']) for x in not_tars]
63 | not_tars_ids = [x['id'] for x in not_tars_ids]
64 |
65 |
66 | assert len(tars) == len(old_ids) == len(new_ids)
67 |
68 | if set(new_ids) == set(not_tars_ids): # all done
69 | return
70 | else:
71 | for file,old,new in zip(tars,old_ids,new_ids):
72 | if not new in not_tars_ids: # skip already prepared files
73 | shutil.unpack_archive(file,root_path)
74 | olddir = os.path.join(root_path,old)
75 | subject_files = _get_files(olddir)
76 | for subfile in subject_files: # fix sub-id
77 | new_path = subfile.replace(old,new)
78 | dir,_ = os.path.split(new_path)
79 | os.makedirs(dir,exist_ok=True)
80 | shutil.move(subfile,new_path)
81 | shutil.rmtree(olddir)
82 | print('LEMON PREPARE DONE!')
83 |
84 | def lemon_bidscoin_prepare(src_path):
85 | """Download and prepare a few files of the LEMON dataset to be used with BIDSCOIN.
86 |
87 | Parameters
88 | ----------
89 | src_path : str
90 | The path where the BIDSCOIN-ready LEMON files will be
91 |
92 | See Also
93 | --------
94 |
95 | datasets.lemon_prepare
96 | """
97 | lemon_prepare()
98 | this_dir = os.path.dirname(__file__)
99 | data_dir = os.path.join(this_dir,'..','_data')
100 | root_path = os.path.abspath(os.path.join(data_dir,'lemon'))
101 | bidscoin_input_path = src_path
102 |
103 | os.makedirs(bidscoin_input_path,exist_ok=True)
104 |
105 | files = _get_files(root_path)
106 | files = [x for x in files if x.split('.')[-1] in ['eeg','vmrk','vhdr'] ]
107 |
108 | files_out = []
109 | for f in files:
110 | session = 'ses-001'
111 | task = 'resting'
112 | head,tail=os.path.split(f)
113 | sub = tail.split('.')[0]
114 | new_path = os.path.join(bidscoin_input_path,sub,session,task,tail)
115 | files_out.append(new_path)
116 |
117 | for old,new in zip(files,files_out):
118 | print(old,' to ',new)
119 | os.makedirs(os.path.split(new)[0], exist_ok=True)
120 | if not os.path.isfile(new):
121 | shutil.copy2(old,new)
122 | else:
123 | print('already done, skipping...')
124 | print('finish')
125 |
126 | def make_dummy_dataset(EXAMPLE,
127 | PATTERN='T%task%/S%session%/sub%subject%_%acquisition%_%run%',
128 | DATASET = 'DUMMY',
129 | NSUBS = 2,
130 | NSESSIONS = 2,
131 | NTASKS = 2,
132 | NACQS = 2,
133 | NRUNS = 2,
134 | PREFIXES = {'subject':'SU','session':'SE','task':'TA','acquisition':'AC','run':'RU'},
135 | ROOT=None,
136 | ):
137 | """Create a dummy dataset given some parameters.
138 |
139 | Parameters
140 | ----------
141 | EXAMPLE : str,PathLike|list , required
142 | Path of the file to replicate as each file in the dummy dataset.
143 | If a list, it is assumed each item is a file. All of these items are replicated.
144 | PATTERN : str, optional
145 | The pattern in placeholder notation using the following fields:
146 | %dataset%, %task%, %session%, %subject%, %run%, %acquisition%
147 | DATASET : str, optional
148 | Name of the dataset.
149 | NSUBS : int, optional
150 | Number of subjects.
151 | NSESSIONS : int, optional
152 | Number of sessions.
153 | NTASKS : int, optional
154 | Number of tasks.
155 | NACQS : int, optional
156 | Number of acquisitions.
157 | NRUNS : int, optional
158 | Number of runs.
159 | PREFIXES : dict, optional
160 | Dictionary with the following keys:'subject', 'session', 'task' and 'acquisition'.
161 | The values are the corresponding prefix. RUN is not present because it has to be a number.
162 | ROOT : str, optional
163 | Path where the files will be generated.
164 | If None, the _data subdir will be used.
165 |
166 | """
167 |
168 | if ROOT is None:
169 | this_dir = os.path.dirname(__file__)
170 | data_dir = os.path.abspath(os.path.join(this_dir,'..','_data'))
171 | else:
172 | data_dir = ROOT
173 | os.makedirs(data_dir,exist_ok=True)
174 |
175 | sub_zeros = get_num_digits(NSUBS)
176 | subs = [ PREFIXES['subject']+ str(x).zfill(sub_zeros) for x in range(NSUBS)]
177 |
178 | task_zeros = get_num_digits(NTASKS)
179 | tasks = [ PREFIXES['task']+str(x).zfill(task_zeros) for x in range(NTASKS)]
180 |
181 | run_zeros = get_num_digits(NRUNS)
182 | runs = [str(x).zfill(run_zeros) for x in range(NRUNS)]
183 |
184 | ses_zeros = get_num_digits(NSESSIONS)
185 | sessions = [ PREFIXES['session']+str(x).zfill(ses_zeros) for x in range(NSESSIONS)]
186 |
187 | acq_zeros = get_num_digits(NACQS)
188 | acquisitions = [ PREFIXES['acquisition']+str(x).zfill(acq_zeros) for x in range(NACQS)]
189 |
190 |
191 | for task in tasks:
192 | for session in sessions:
193 | for run in runs:
194 | for sub in subs:
195 | for acq in acquisitions:
196 | dummy = PATTERN.replace('%dataset%',DATASET)
197 | dummy = dummy.replace('%task%',task)
198 | dummy = dummy.replace('%session%',session)
199 | dummy = dummy.replace('%subject%',sub)
200 | dummy = dummy.replace('%run%',run)
201 | dummy = dummy.replace('%acquisition%',acq)
202 | path = [data_dir] +dummy.split('/')
203 | fpath = os.path.join(*path)
204 | dirpath = os.path.join(*path[:-1])
205 | os.makedirs(dirpath,exist_ok=True)
206 | if isinstance(EXAMPLE,list):
207 | for ff in EXAMPLE:
208 | fname, ext = os.path.splitext(ff)
209 | shutil.copyfile(ff, fpath+ext)
210 | if 'vmrk' in ext or 'vhdr' in ext:
211 | replace_brainvision_filename(fpath+ext,path[-1])
212 | else:
213 | fname, ext = os.path.splitext(EXAMPLE)
214 | shutil.copyfile(EXAMPLE, fpath+ext)
215 |
216 |
217 | def generate_1_over_f_noise(n_channels, n_times, exponent=1.0, random_state=None):
218 | rng = np.random.default_rng(random_state)
219 | noise = np.zeros((n_channels, n_times))
220 |
221 | freqs = np.fft.rfftfreq(n_times, d=1.0) # d=1.0 assumes unit sampling rate
222 | freqs[0] = freqs[1] # avoid division by zero at DC
223 |
224 | scale = 1.0 / np.power(freqs, exponent)
225 |
226 | for ch in range(n_channels):
227 | # Generate white noise in time domain
228 | white = rng.standard_normal(n_times)
229 | # Transform to frequency domain
230 | white_fft = np.fft.rfft(white)
231 | # Apply 1/f scaling
232 | pink_fft = white_fft * scale
233 | # Transform back to time domain
234 | pink = np.fft.irfft(pink_fft, n=n_times)
235 | # Normalize to zero mean, unit variance
236 | pink = (pink - pink.mean()) / pink.std()
237 | noise[ch, :] = pink
238 |
239 | return noise
240 |
241 | def get_dummy_raw(NCHANNELS = 5,
242 | SFREQ = 200,
243 | STOP = 10,
244 | NUMEVENTS = 10,
245 | ):
246 | """
247 | Create a dummy MNE Raw file given some parameters.
248 |
249 | Parameters
250 | ----------
251 | NCHANNELS : int, optional
252 | Number of channels.
253 | SFREQ : float, optional
254 | Sampling frequency of the data.
255 | STOP : float, optional
256 | Time duration of the data in seconds.
257 | NUMEVENTS : int, optional
258 | Number of events along the duration.
259 | """
260 | # Create some dummy metadata
261 | n_channels = NCHANNELS
262 | sampling_freq = SFREQ # in Hertz
263 | info = mne.create_info(n_channels, sfreq=sampling_freq)
264 |
265 | times = np.linspace(0, STOP, STOP*sampling_freq, endpoint=False)
266 | data = generate_1_over_f_noise(NCHANNELS, times.shape[0], exponent=1.0)
267 | #np.zeros((NCHANNELS,times.shape[0]))
268 |
269 | raw = mne.io.RawArray(data, info)
270 | raw.set_channel_types({x:'eeg' for x in raw.ch_names})
271 | new_events = mne.make_fixed_length_events(raw, duration=STOP//NUMEVENTS)
272 |
273 | return raw,new_events
274 |
275 | def save_dummy_vhdr(fpath,dummy_args={}
276 | ):
277 | """
278 | Save a dummy vhdr file.
279 |
280 | Parameters
281 | ----------
282 | fpath : str, required
283 | Path where to save the file.
284 | kwargs : dict, optional
285 | Dictionary with the arguments of the get_dummy_raw function.
286 |
287 | Returns
288 | -------
289 | List with the Paths of the desired vhdr file, if those were succesfully created,
290 | None otherwise.
291 | """
292 |
293 | raw,new_events = get_dummy_raw(**dummy_args)
294 | _write_raw_brainvision(raw,fpath,new_events,overwrite=True)
295 | eegpath =fpath.replace('.vhdr','.eeg')
296 | vmrkpath = fpath.replace('.vhdr','.vmrk')
297 | if all(os.path.isfile(x) for x in [fpath,eegpath,vmrkpath]):
298 | return [fpath,eegpath,vmrkpath]
299 | else:
300 | return None
301 |
302 | def save_dummy_cnt(fpath,
303 | ):
304 | """
305 | Save a dummy cnt file.
306 |
307 | Parameters
308 | ----------
309 | fpath : str, required
310 | Path where to save the file.
311 |
312 | Returns
313 | -------
314 | Path of the desired file if the file was succesfully created,
315 | None otherwise.
316 | """
317 | fname = 'scan41_short.cnt'
318 | cnt_dict={'dataset_name': 'cnt_sample',
319 | 'archive_name': 'scan41_short.cnt',
320 | 'hash': 'md5:7ab589254e83e001e52bee31eae859db',
321 | 'url': 'https://github.com/mne-tools/mne-testing-data/blob/master/CNT/scan41_short.cnt?raw=true',
322 | 'folder_name': 'cnt_sample',
323 | }
324 | data_path = mne.datasets.fetch_dataset(cnt_dict)
325 | shutil.copyfile(os.path.join(data_path,'scan41_short.cnt'), fpath) #copyfile overwrites by default
326 | if os.path.isfile(fpath):
327 | return fpath
328 | else:
329 | return None
330 |
331 | def replace_brainvision_filename(fpath,newname):
332 | if '.eeg' in newname:
333 | newname = newname.replace('.eeg','')
334 | if '.vmrk' in newname:
335 | newname = newname.replace('.vmrk','')
336 | for line in fileinput.input(fpath, inplace=True):
337 | if 'DataFile' in line:
338 | print(f'DataFile={newname}.eeg'.format(fileinput.filelineno(), line))
339 | elif 'MarkerFile' in line:
340 | print(f'MarkerFile={newname}.vmrk'.format(fileinput.filelineno(), line))
341 | else:
342 | print('{}'.format(line), end='')
343 |
--------------------------------------------------------------------------------
 135 |
136 |
137 |
138 | Acknowledgments
139 | ---------------
140 |
141 | sovabids is developed with the help of the following entities:
142 |
143 | .. raw:: html
144 |
145 |
135 |
136 |
137 |
138 | Acknowledgments
139 | ---------------
140 |
141 | sovabids is developed with the help of the following entities:
142 |
143 | .. raw:: html
144 |
145 |  151 |
151 |  155 |
155 |