├── README.md
├── config.py
├── download_paper_by_URLfile.py
├── download_paper_by_pageURL.py
├── img
├── exit.ico
├── ieee.png
└── root.ico
├── main.py
├── main_ui.py
├── url.txt
└── utils.py
/README.md:
--------------------------------------------------------------------------------
1 | # 写综述必备!自动批量下载IEEE的论文
2 |
3 |
4 |
5 |  6 |
7 |
8 |
6 |
7 |
8 |  9 |
10 |
11 |
9 |
10 |
11 |  12 |
13 |
14 |
12 |
13 |
14 |  15 |
16 |
17 |
18 |
19 |
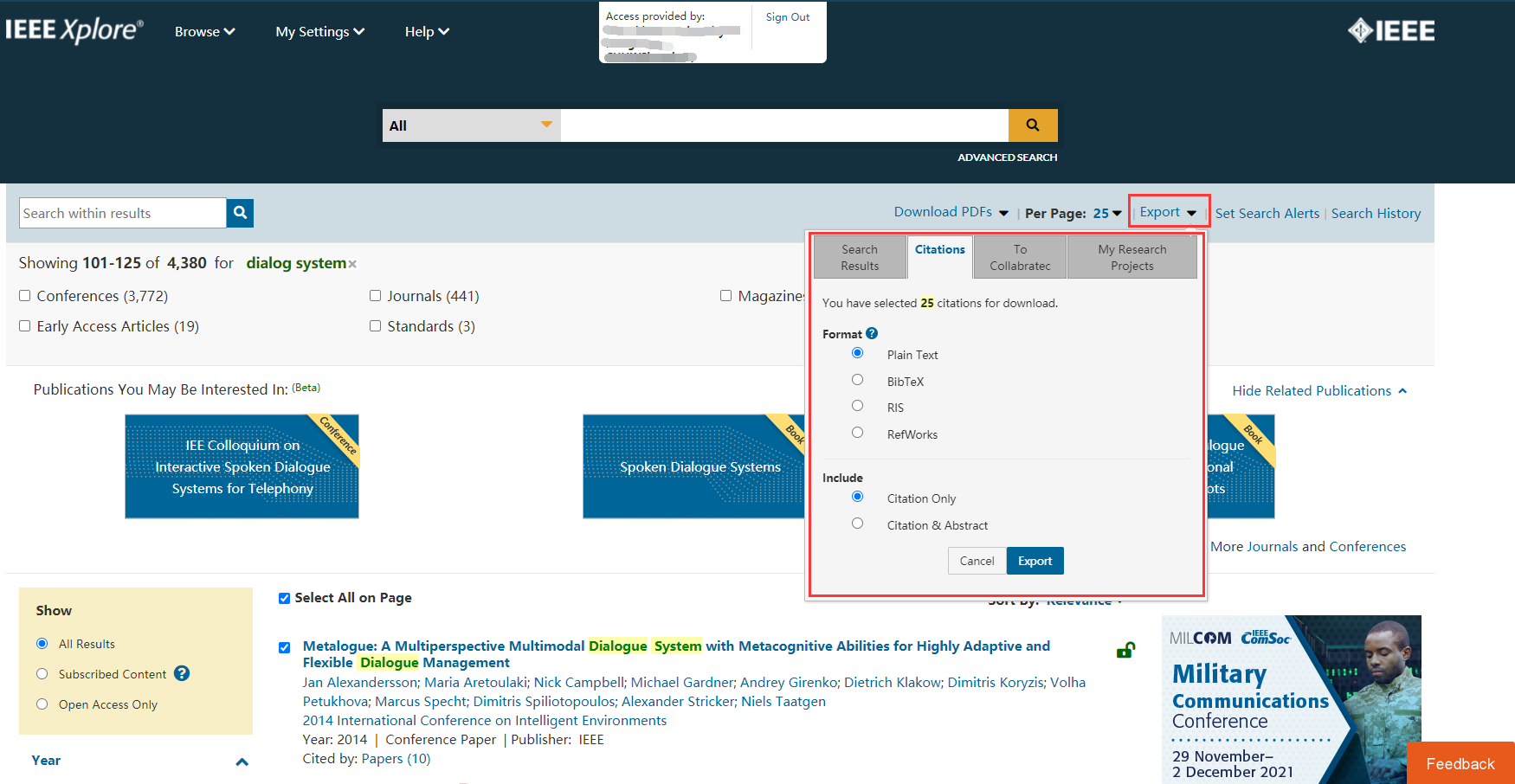
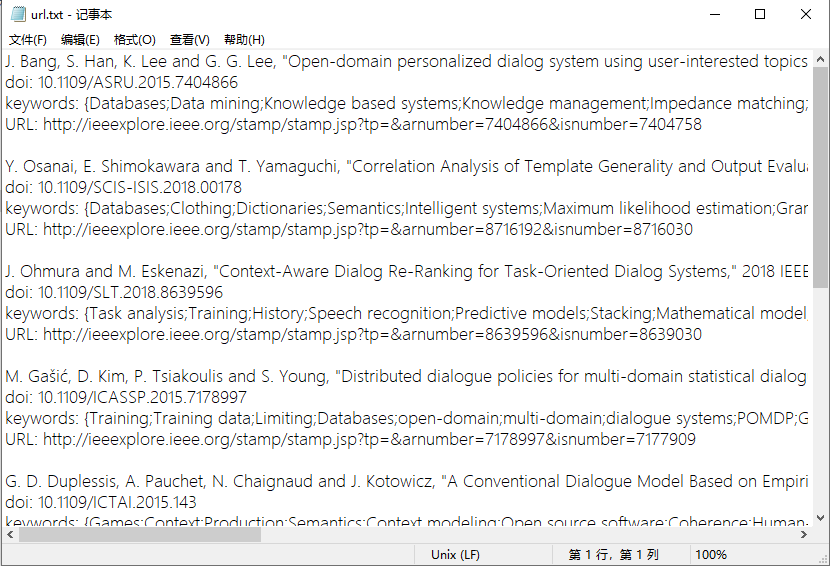
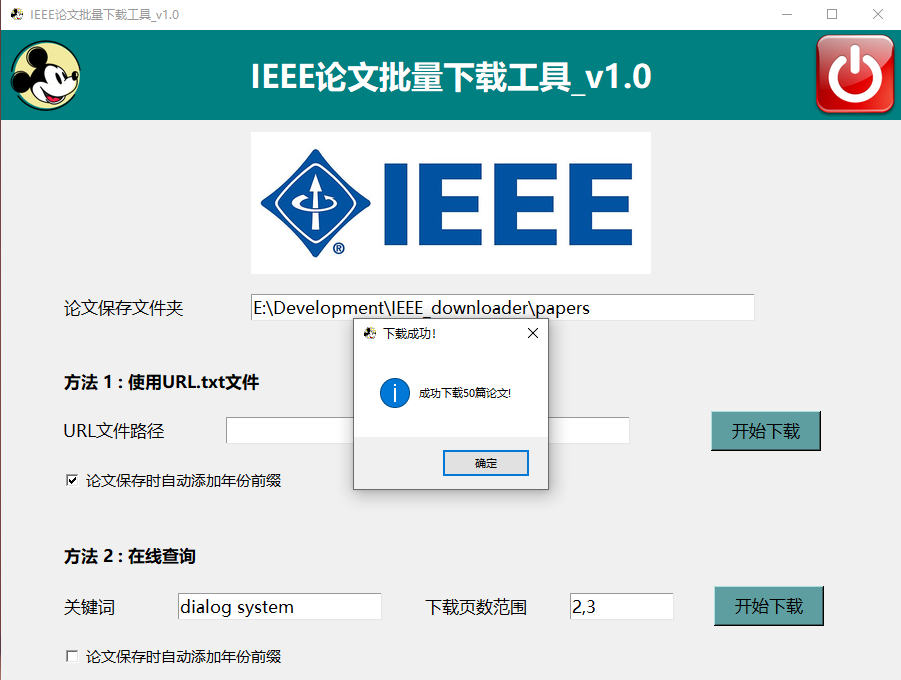
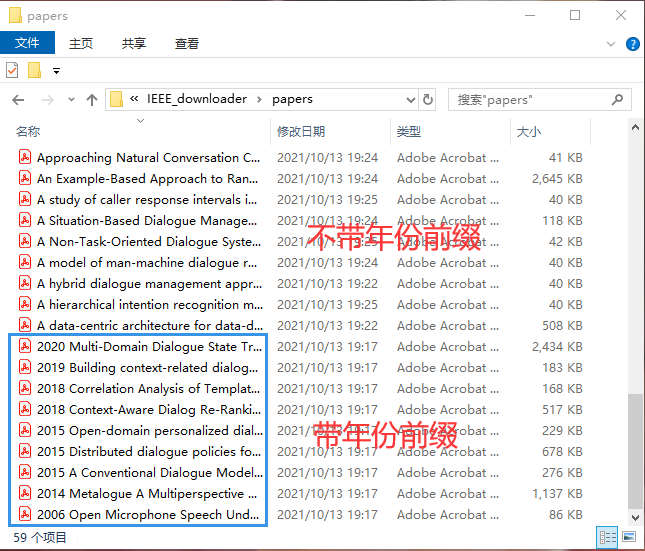
20 | > 如果领域内的大量论文需要下载,基于本工具实现半自动化,无需到IEEE网站手动一篇一篇下载论文啦,科研效率翻倍!
21 | > 工具使用前提: 一定要在能够有权限下载IEEE论文的网络下才能正常使用。
22 |
23 | 如下,介绍两种方法实现批量下载,代码流程和详细介绍请参考博客。
24 |
25 | ## 软件界面
26 |
27 |
15 |
16 |
17 |
18 |
19 |
20 | > 如果领域内的大量论文需要下载,基于本工具实现半自动化,无需到IEEE网站手动一篇一篇下载论文啦,科研效率翻倍!
21 | > 工具使用前提: 一定要在能够有权限下载IEEE论文的网络下才能正常使用。
22 |
23 | 如下,介绍两种方法实现批量下载,代码流程和详细介绍请参考博客。
24 |
25 | ## 软件界面
26 |
27 |
28 |

29 |
40 |
41 |
47 |
48 |
62 |

63 |
68 |
69 |
74 |
75 |
80 |

81 |