├── .gitignore
├── .ipynb_checkpoints
├── Tutorial_10 - [transfer learning] Add new variables to graph and save the new model-checkpoint.ipynb
├── Tutorial_8 - A very simple example for tensorboard-checkpoint.ipynb
└── Tutorial_9 - How to save the model-checkpoint.ipynb
├── README.md
├── ckpt
├── bi-lstm.ckpt-12.data-00000-of-00001
├── bi-lstm.ckpt-12.index
├── bi-lstm.ckpt-12.meta
└── checkpoint
├── data
└── msr_train.txt
├── doc
└── problem-solution.md
├── example-notebook
├── .ipynb_checkpoints
│ ├── Tutorial_01 Basic Usage-checkpoint.ipynb
│ ├── Tutorial_02 A simple feedforward network for MNIST-checkpoint.ipynb
│ ├── Tutorial_03_1 The usage of name_scope and variable_scope-checkpoint.ipynb
│ ├── Tutorial_03_2 The usage of Collection-checkpoint.ipynb
│ ├── Tutorial_04_1 Convolutional network for MNIST(1)-checkpoint.ipynb
│ ├── Tutorial_04_2 Convolutional network for MNIST(2)-checkpoint.ipynb
│ ├── Tutorial_04_3 Convolutional network for MNIST(3)-checkpoint.ipynb
│ ├── Tutorial_04_3 Convolutional network for MNIST(4)-BN-checkpoint.ipynb
│ ├── Tutorial_05_1 An understandable example to implement Multi-LSTM for MNIST(1)-Copy1-checkpoint.ipynb
│ ├── Tutorial_05_1 An understandable example to implement Multi-LSTM for MNIST-checkpoint.ipynb
│ ├── Tutorial_05_2 An understandable example to implement Multi-GRU for MNIST-checkpoint.ipynb
│ ├── Tutorial_05_3 Bi-GRU for MNIST-checkpoint.ipynb
│ ├── Tutorial_06 A very simple example for tensorboard-checkpoint.ipynb
│ ├── Tutorial_07 How to save the model-checkpoint.ipynb
│ ├── Tutorial_08 [transfer learning] Add new variables to graph and save the new model-checkpoint.ipynb
│ ├── Tutorial_09 [tfrecord] use tfrecord to store sequences of different length-checkpoint.ipynb
│ ├── Tutorial_10 [Dataset] numpy data-checkpoint.ipynb
│ ├── Tutorial_10_3 [Dataset] sequence data-checkpoint.ipynb
│ ├── Tutorial_11 [Dataset] image data-checkpoint.ipynb
│ ├── Tutorial_12 [tf.layer]high layer API-checkpoint.ipynb
│ └── Untitled-checkpoint.ipynb
├── MNIST_data
│ ├── t10k-images-idx3-ubyte.gz
│ ├── t10k-labels-idx1-ubyte.gz
│ ├── train-images-idx3-ubyte.gz
│ └── train-labels-idx1-ubyte.gz
├── Tutorial_01 Basic Usage.ipynb
├── Tutorial_02 A simple feedforward network for MNIST.ipynb
├── Tutorial_03_1 The usage of name_scope and variable_scope.ipynb
├── Tutorial_03_2 The usage of Collection.ipynb
├── Tutorial_04_1 Convolutional network for MNIST(1).ipynb
├── Tutorial_04_2 Convolutional network for MNIST(2).ipynb
├── Tutorial_04_3 Convolutional network for MNIST(3).ipynb
├── Tutorial_05_1 An understandable example to implement Multi-LSTM for MNIST.ipynb
├── Tutorial_05_2 An understandable example to implement Multi-GRU for MNIST.ipynb
├── Tutorial_05_3 Bi-GRU for MNIST.ipynb
├── Tutorial_06 A very simple example for tensorboard.ipynb
├── Tutorial_07 How to save the model.ipynb
├── Tutorial_08 [transfer learning] Add new variables to graph and save the new model.ipynb
├── Tutorial_09 [tfrecord] use tfrecord to store sequences of different length.ipynb
├── Tutorial_10 [Dataset] numpy data.ipynb
├── Tutorial_11 [Dataset] image data.ipynb
└── Tutorial_12 [tf.layer]high layer API.ipynb
├── example-python
├── .ipynb_checkpoints
│ └── tfrecord_sequence_example-checkpoint.ipynb
├── Tutorial-graph.py
├── Tutorial_10_1_numpy_data_1.py
├── Tutorial_10_1_numpy_data_2.py
├── Tutorial_10_2_image_data_1.py
└── Tutorial_10_2_image_data_2.py
├── figs
├── conv_mnist.png
├── graph2.png
├── lstm_8.png
└── lstm_mnist.png
├── models
├── README.md
├── Tutorial_13 - Basic Seq2seq example.ipynb
├── Tutorial_6 - Bi-directional LSTM for sequence labeling (Chinese segmentation).ipynb
├── m01_batch_normalization
│ ├── README.md
│ ├── __init__.py
│ ├── mnist_cnn.py
│ ├── predict.py
│ └── train.py
├── m02_dcgan
│ ├── README.md
│ ├── __init__.py
│ ├── dcgan 生成二次元头像.ipynb
│ └── dcgan.py
├── m03_wgan
│ ├── README.md
│ ├── wgan.py
│ └── wgan_gp.py
└── m04_pix2pix
│ ├── README.md
│ ├── __init__.py
│ ├── model.py
│ ├── pix2pix.py
│ ├── test.py
│ ├── test.sh
│ ├── train.py
│ ├── train.sh
│ └── utils.py
└── utils
├── u01_logging
├── logging1.py
└── training.log
├── u02_tfrecord
├── README.md
├── __init__.py
├── reader_without_shuffle.ipynb
├── sequence_example_lib.py
├── tfrecord_1_numpy_reader.py
├── tfrecord_1_numpy_reader_without_shuffle.py
├── tfrecord_1_numpy_writer.py
├── tfrecord_2_seqence_reader.py
├── tfrecord_2_seqence_writer.py
├── tfrecord_3_image_reader.py
└── tfrecord_3_image_writer.py
└── u03_flags.py
/.gitignore:
--------------------------------------------------------------------------------
1 | ckpt/*
2 | summary/*
3 | data/*
4 | *.pyc
5 | **/.ipynb_checkpoints/
6 | mnist_png/*
7 | *.tfrecord
8 | **/generated_img/
9 | **/generated_img2/
10 | **/generated_img_gp/
11 | **/MNIST_data/
12 | **/ckpt/
13 | **/ckpt*/
14 | **/summary/
15 | **/data/
16 | events*
17 | **/facades_train/
18 | **/facades_test/
19 |
20 |
21 |
--------------------------------------------------------------------------------
/.ipynb_checkpoints/Tutorial_10 - [transfer learning] Add new variables to graph and save the new model-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 【迁移学习】往一个已经保存好的 模型添加新的变量\n",
8 | "在迁移学习中,通常我们已经训练好一个模型,现在需要修改模型的部分结构,用于我们的新任务。\n",
9 | "\n",
10 | "比如:\n",
11 | "\n",
12 | "在一个图片分类任务中,我们使用别人训练好的网络来提取特征,但是我们的分类数目和原模型不同,这样我们只能取到 fc 层,后面的分类层需要重新写。这样我们就需要添加新的变量。那么这些新加入的变量必须得初始化才能使用。可是我们又不能使用 'tf.global_variables_initializer()' 来初始化,否则原本训练好的模型就没用了。\n",
13 | "\n",
14 | "关于怎么样单独初始化新增的变量,可以参考下面两个链接:\n",
15 | "- [1]https://stackoverflow.com/questions/35164529/in-tensorflow-is-there-any-way-to-just-initialize-uninitialised-variables\n",
16 | "- [2]https://stackoverflow.com/questions/35013080/tensorflow-how-to-get-all-variables-from-rnn-cell-basiclstm-rnn-cell-multirnn\n",
17 | "\n",
18 | "简单的例子可以直接看下面我的实现方式。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### 初始模型定义与保存\n",
26 | "首先定义一个模型,里边有 v1, v2 两个变量,我们把这个模型保存起来。"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {
33 | "collapsed": false
34 | },
35 | "outputs": [
36 | {
37 | "name": "stdout",
38 | "output_type": "stream",
39 | "text": [
40 | "Model saved in file: ./ckpt/test-model.ckpt-1\n"
41 | ]
42 | }
43 | ],
44 | "source": [
45 | "import tensorflow as tf\n",
46 | "config = tf.ConfigProto()\n",
47 | "config.gpu_options.allow_growth = True\n",
48 | "sess = tf.Session(config=config)\n",
49 | "\n",
50 | "# Create some variables.\n",
51 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
52 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
53 | "\n",
54 | "\n",
55 | "init_op = tf.global_variables_initializer()\n",
56 | "saver = tf.train.Saver()\n",
57 | "ckpt_path = './ckpt/test-model.ckpt'\n",
58 | "sess.run(init_op)\n",
59 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
60 | "print(\"Model saved in file: %s\" % save_path)"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "**restart(重启kernel然后执行下面cell的代码)**\n",
68 | "### 导入已经保存好的模型,并添加新的变量\n",
69 | "现在把之前保存好的模型,我只需要其中的 v1 变量。同时我还要添加新的变量 v3。"
70 | ]
71 | },
72 | {
73 | "cell_type": "code",
74 | "execution_count": 1,
75 | "metadata": {
76 | "collapsed": false,
77 | "scrolled": false
78 | },
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "INFO:tensorflow:Restoring parameters from ./ckpt/test-model.ckpt-1\n",
85 | "[ 1. 2.29999995]\n",
86 | "[ 1. 2.29999995]\n",
87 | "666\n"
88 | ]
89 | },
90 | {
91 | "data": {
92 | "text/plain": [
93 | "'./ckpt/test-model.ckpt-2'"
94 | ]
95 | },
96 | "execution_count": 1,
97 | "metadata": {},
98 | "output_type": "execute_result"
99 | }
100 | ],
101 | "source": [
102 | "import tensorflow as tf\n",
103 | "config = tf.ConfigProto()\n",
104 | "config.gpu_options.allow_growth = True\n",
105 | "sess = tf.Session(config=config)\n",
106 | "\n",
107 | "# Create some variables.\n",
108 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
109 | "\n",
110 | "# ** 导入训练好的模型\n",
111 | "saver = tf.train.Saver()\n",
112 | "ckpt_path = './ckpt/test-model.ckpt'\n",
113 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
114 | "print(sess.run(v1))\n",
115 | "\n",
116 | "# ** 定义新的变量并单独初始化新定义的变量\n",
117 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
118 | "init_new = tf.variables_initializer([v3])\n",
119 | "sess.run(init_new)\n",
120 | "# 。。。这里就可以进行 fine-tune 了\n",
121 | "print(sess.run(v1))\n",
122 | "print(sess.run(v3))\n",
123 | "\n",
124 | "# ** 保存新的模型。 \n",
125 | "# 注意!注意!注意! 一定一定一定要重新定义 saver, 这样才能把 v3 添加到 checkpoint 中\n",
126 | "saver = tf.train.Saver()\n",
127 | "saver.save(sess, ckpt_path, global_step=2)"
128 | ]
129 | },
130 | {
131 | "cell_type": "markdown",
132 | "metadata": {},
133 | "source": [
134 | "**restart(重启kernel然后执行下面cell的代码)**\n",
135 | "### 这样就完成了 fine-tune, 得到了新的模型"
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 1,
141 | "metadata": {
142 | "collapsed": false
143 | },
144 | "outputs": [
145 | {
146 | "name": "stdout",
147 | "output_type": "stream",
148 | "text": [
149 | "INFO:tensorflow:Restoring parameters from ./ckpt/test-model.ckpt-2\n",
150 | "Model restored.\n",
151 | "[ 1. 2.29999995]\n",
152 | "666\n"
153 | ]
154 | }
155 | ],
156 | "source": [
157 | "import tensorflow as tf\n",
158 | "config = tf.ConfigProto()\n",
159 | "config.gpu_options.allow_growth = True\n",
160 | "sess = tf.Session(config=config)\n",
161 | "\n",
162 | "# Create some variables.\n",
163 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
164 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
165 | "# Add ops to save and restore all the variables.\n",
166 | "saver = tf.train.Saver()\n",
167 | "\n",
168 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
169 | "# do some work with the model.\n",
170 | "# Restore variables from disk.\n",
171 | "ckpt_path = './ckpt/test-model.ckpt'\n",
172 | "saver.restore(sess, ckpt_path + '-'+ str(2))\n",
173 | "print(\"Model restored.\")\n",
174 | "\n",
175 | "print(sess.run(v1))\n",
176 | "print(sess.run(v3))"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": null,
182 | "metadata": {
183 | "collapsed": true
184 | },
185 | "outputs": [],
186 | "source": []
187 | }
188 | ],
189 | "metadata": {
190 | "anaconda-cloud": {},
191 | "kernelspec": {
192 | "display_name": "Python [conda root]",
193 | "language": "python",
194 | "name": "conda-root-py"
195 | },
196 | "language_info": {
197 | "codemirror_mode": {
198 | "name": "ipython",
199 | "version": 2
200 | },
201 | "file_extension": ".py",
202 | "mimetype": "text/x-python",
203 | "name": "python",
204 | "nbconvert_exporter": "python",
205 | "pygments_lexer": "ipython2",
206 | "version": "2.7.12"
207 | }
208 | },
209 | "nbformat": 4,
210 | "nbformat_minor": 1
211 | }
212 |
--------------------------------------------------------------------------------
/.ipynb_checkpoints/Tutorial_9 - How to save the model-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 如何使用 tf.train.Saver() 来保存模型\n",
8 | "之前一直出错,主要是因为坑爹的编码问题。所以要注意文件的路径绝对不不要出现什么中文呀。"
9 | ]
10 | },
11 | {
12 | "cell_type": "code",
13 | "execution_count": 1,
14 | "metadata": {
15 | "collapsed": false
16 | },
17 | "outputs": [
18 | {
19 | "name": "stdout",
20 | "output_type": "stream",
21 | "text": [
22 | "Model saved in file: ./ckpt/test-model.ckpt-1\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import tensorflow as tf\n",
28 | "config = tf.ConfigProto()\n",
29 | "config.gpu_options.allow_growth = True\n",
30 | "sess = tf.Session(config=config)\n",
31 | "\n",
32 | "# Create some variables.\n",
33 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
34 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
35 | "\n",
36 | "# Add an op to initialize the variables.\n",
37 | "init_op = tf.global_variables_initializer()\n",
38 | "\n",
39 | "# Add ops to save and restore all the variables.\n",
40 | "saver = tf.train.Saver()\n",
41 | "\n",
42 | "ckpt_path = './ckpt/test-model.ckpt'\n",
43 | "# Later, launch the model, initialize the variables, do some work, save the\n",
44 | "# variables to disk.\n",
45 | "sess.run(init_op)\n",
46 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
47 | "print(\"Model saved in file: %s\" % save_path)"
48 | ]
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "metadata": {},
53 | "source": [
54 | "注意,在上面保存完了模型之后。**Restart kernel** 之后才能使用下面的模型导入。否则会因为两次命名 \"v1\" 而导致名字错误。"
55 | ]
56 | },
57 | {
58 | "cell_type": "code",
59 | "execution_count": 1,
60 | "metadata": {
61 | "collapsed": false
62 | },
63 | "outputs": [
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "INFO:tensorflow:Restoring parameters from ./ckpt/test-model.ckpt-1\n",
69 | "Model restored.\n",
70 | "[ 1. 2.29999995]\n",
71 | "55.5\n"
72 | ]
73 | }
74 | ],
75 | "source": [
76 | "import tensorflow as tf\n",
77 | "config = tf.ConfigProto()\n",
78 | "config.gpu_options.allow_growth = True\n",
79 | "sess = tf.Session(config=config)\n",
80 | "\n",
81 | "# Create some variables.\n",
82 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
83 | "v2 = tf.Variable(33.5, name=\"v2\")\n",
84 | "\n",
85 | "# Add ops to save and restore all the variables.\n",
86 | "saver = tf.train.Saver()\n",
87 | "\n",
88 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
89 | "# do some work with the model.\n",
90 | "# Restore variables from disk.\n",
91 | "ckpt_path = './ckpt/test-model.ckpt'\n",
92 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
93 | "print(\"Model restored.\")\n",
94 | "\n",
95 | "print sess.run(v1)\n",
96 | "print sess.run(v2)"
97 | ]
98 | },
99 | {
100 | "cell_type": "markdown",
101 | "metadata": {},
102 | "source": [
103 | "导入模型之前,必须重新再定义一遍变量。\n",
104 | "\n",
105 | "但是并不需要全部变量都重新进行定义,只定义我们需要的变量就行了。\n",
106 | "\n",
107 | "也就是说,**你所定义的变量一定要在 checkpoint 中存在;但不是所有在checkpoint中的变量,你都要重新定义。**"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 1,
113 | "metadata": {
114 | "collapsed": false
115 | },
116 | "outputs": [
117 | {
118 | "name": "stdout",
119 | "output_type": "stream",
120 | "text": [
121 | "INFO:tensorflow:Restoring parameters from ./ckpt/test-model.ckpt-1\n",
122 | "Model restored.\n",
123 | "[ 1. 2.29999995]\n"
124 | ]
125 | }
126 | ],
127 | "source": [
128 | "import tensorflow as tf\n",
129 | "config = tf.ConfigProto()\n",
130 | "config.gpu_options.allow_growth = True\n",
131 | "sess = tf.Session(config=config)\n",
132 | "\n",
133 | "# Create some variables.\n",
134 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
135 | "\n",
136 | "# Add ops to save and restore all the variables.\n",
137 | "saver = tf.train.Saver()\n",
138 | "\n",
139 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
140 | "# do some work with the model.\n",
141 | "# Restore variables from disk.\n",
142 | "ckpt_path = './ckpt/test-model.ckpt'\n",
143 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
144 | "print(\"Model restored.\")\n",
145 | "\n",
146 | "print sess.run(v1)"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "## 关于模型保存的一点心得\n",
154 | "\n",
155 | "```\n",
156 | "saver = tf.train.Saver(max_to_keep=3)\n",
157 | "```\n",
158 | "在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,我都不会保存太多模型,模型多了浪费空间,很多时候其实保存最好的模型就够了。方法就是每次迭代到一定步数就在验证集上计算一次 accuracy 或者 f1 值,如果本次结果比上次好才保存新的模型,否则没必要保存。\n",
159 | "\n",
160 | "如果你想用不同 epoch 保存下来的模型进行融合的话,3到5 个模型已经足够了,假设这各融合的模型成为 M,而最好的一个单模型称为 m_best, 这样融合的话对于M 确实可以比 m_best 更好。但是如果拿这个模型和其他结构的模型再做融合的话,M 的效果并没有 m_best 好,因为M 相当于做了平均操作,减少了该模型的“特性”。"
161 | ]
162 | }
163 | ],
164 | "metadata": {
165 | "anaconda-cloud": {},
166 | "kernelspec": {
167 | "display_name": "Python [conda root]",
168 | "language": "python",
169 | "name": "conda-root-py"
170 | },
171 | "language_info": {
172 | "codemirror_mode": {
173 | "name": "ipython",
174 | "version": 2
175 | },
176 | "file_extension": ".py",
177 | "mimetype": "text/x-python",
178 | "name": "python",
179 | "nbconvert_exporter": "python",
180 | "pygments_lexer": "ipython2",
181 | "version": "2.7.12"
182 | }
183 | },
184 | "nbformat": 4,
185 | "nbformat_minor": 1
186 | }
187 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Tensorflow-Tutorial
2 |
3 | 2018-04 更新说明
4 |
5 | 时间过去一年,TensorFlow 已经从 1.0 版本更新到了 1.8 版本,而且最近更新的非常频繁。最烦的就是每次更新很多 API 都改了,一些老版本的代码就跑不通了。因为本项目关注的人越来越多了,所以自己也感觉到非常有必要更新并更正一些之前的错误,否则误人子弟就不好了。这里不少内容可以直接在官方的教程中找到,官方文档也在不断完善中,我也是把里边的例子跑一下,加深理解而已,更多的还是要自己在具体任务中去搭模型,训模型才能很好地掌握。
6 |
7 | 这一次更新主要内容如下:
8 |
9 | - 使用较新版本的 tfmaster
10 | - 所有的代码改成 python3.5
11 | - 重新整理了基础用例
12 | - 添加实战例子
13 |
14 | 因为工作和学习比较忙,所以这些内容也没办法一下子完成。和之前的版本不同,之前我是作为一个入门菜鸟一遍学一边做笔记。虽然现在依然还是理解得不够,但是比之前掌握的知识应该多了不少,希望能够整理成一个更好的教程。
15 |
16 | 之前的代码我放在了另外一个分支上: https://github.com/yongyehuang/Tensorflow-Tutorial/tree/1.2.1
17 |
18 | 如果有什么问题或者建议,欢迎开issue或者邮件与我联系:yongye@bupt.edu.cn
19 |
20 |
21 | ## 运行环境
22 | - python 3.5
23 | - tensorflow master (gpu version)
24 |
25 |
26 | ## 文件结构
27 | ```
28 | |- Tensorflow-Tutorial
29 | | |- example-notebook # 入门教程 notebook 版
30 | | |- example-python # 入门教程 .py 版
31 | | |- utils # 一些工具函数(logging, tf.flags)
32 | | |- models # 一些实战的例子(BN, GAN, 序列标注,seq2seq 等,持续更新)
33 | | |- data # 数据
34 | | |- doc # 相关文档
35 | ```
36 |
37 | ## 1.入门例子
38 | #### T_01.TensorFlow 的基本用法
39 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_01%20Basic%20Usage.ipynb)
40 |
41 | 介绍 TensorFlow 的变量、常量和基本操作,最后介绍了一个非常简单的回归拟合例子。
42 |
43 |
44 |
45 | #### T_02.实现一个两层的全连接网络对 MNIST 进行分类
46 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_02%20A%20simple%20feedforward%20network%20for%20MNIST.ipynb)
47 |
48 |
49 |
50 | #### T_03.TensorFlow 变量命名管理机制
51 | - [notebook1](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_03_1%20The%20usage%20of%20%20name_scope%20and%20variable_scope.ipynb)
52 | 介绍 tf.Variable() 和 tf.get_variable() 创建变量的区别;介绍如何使用 tf.name_scope() 和 tf.variable_scope() 管理命名空间。
53 |
54 | - [notebook2](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_03_2%20The%20usage%20of%20%20Collection.ipynb)
55 | 除了使用变量命名来管理变量之外,还经常用到 collection 的方式来聚合一些变量或者操作。
56 |
57 |
58 |
59 | #### T_04.实现一个两层的卷积神经网络(CNN)对 MNIST 进行分类
60 | - [notebook1-使用原生API构建CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_04_1%20Convolutional%20network%20for%20MNIST(1).ipynb)
61 |
62 | 构建一个非常简单的 CNN 网络,同时输出中间各个核的可视化来理解 CNN 的原理。
63 |  64 | 第一层卷积核可视化
65 |
66 | - [notebook2-自定义函数构建CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_04_2%20Convolutional%20network%20for%20MNIST(2).ipynb)
67 |
68 | - [notebook3-使用tf.layers高级API构建CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_04_3%20Convolutional%20network%20for%20MNIST(3).ipynb)
69 |
70 | - [code-加入 BN 层的 CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/utils_and_models/m01_batch_normalization)
71 |
72 | 在上一个例子的基础上,加入 BN 层。在 CNN 中,使用 BN 层可以加速收敛速度,同时也能够减小初始化方式的影响。在使用 BN 层的时候要注意训练时用的是 mini-batch 的均值方差,测试时用的是指数平均的均值方差。所以在训练的过程中,一定要记得更新并保存均值方差。
73 |
74 | 在这个小网络中:迭代 10000 步,batch_size=100,大概耗时 45s;添加了 BN 层之后,迭代同样的次数,大概耗时 90s.
75 |
76 |
77 | #### T_05.实现多层的 LSTM 和 GRU 网络对 MNIST 进行分类
78 | - [LSTM-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_05_1%20An%20understandable%20example%20to%20implement%20Multi-LSTM%20for%20MNIST.ipynb)
79 | - [GRU-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_05_2%20An%20understandable%20example%20to%20implement%20Multi-GRU%20for%20MNIST.ipynb)
80 | - [Bi-GRU-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_05_3%20Bi-GRU%20for%20MNIST.ipynb)
81 |
82 |
64 | 第一层卷积核可视化
65 |
66 | - [notebook2-自定义函数构建CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_04_2%20Convolutional%20network%20for%20MNIST(2).ipynb)
67 |
68 | - [notebook3-使用tf.layers高级API构建CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_04_3%20Convolutional%20network%20for%20MNIST(3).ipynb)
69 |
70 | - [code-加入 BN 层的 CNN](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/utils_and_models/m01_batch_normalization)
71 |
72 | 在上一个例子的基础上,加入 BN 层。在 CNN 中,使用 BN 层可以加速收敛速度,同时也能够减小初始化方式的影响。在使用 BN 层的时候要注意训练时用的是 mini-batch 的均值方差,测试时用的是指数平均的均值方差。所以在训练的过程中,一定要记得更新并保存均值方差。
73 |
74 | 在这个小网络中:迭代 10000 步,batch_size=100,大概耗时 45s;添加了 BN 层之后,迭代同样的次数,大概耗时 90s.
75 |
76 |
77 | #### T_05.实现多层的 LSTM 和 GRU 网络对 MNIST 进行分类
78 | - [LSTM-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_05_1%20An%20understandable%20example%20to%20implement%20Multi-LSTM%20for%20MNIST.ipynb)
79 | - [GRU-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_05_2%20An%20understandable%20example%20to%20implement%20Multi-GRU%20for%20MNIST.ipynb)
80 | - [Bi-GRU-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_05_3%20Bi-GRU%20for%20MNIST.ipynb)
81 |
82 |  83 | 字符 8
84 |
85 |
83 | 字符 8
84 |
85 | 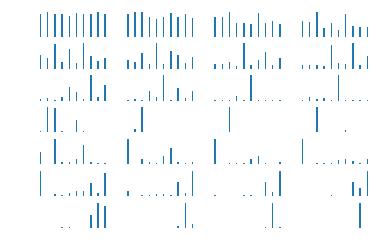 86 | lstm 对字符 8 的识别过程
87 |
88 |
89 |
90 | #### T_06.tensorboard 的简单用法
91 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_06%20A%20very%20simple%20example%20for%20tensorboard.ipynb)
92 |
93 |
86 | lstm 对字符 8 的识别过程
87 |
88 |
89 |
90 | #### T_06.tensorboard 的简单用法
91 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_06%20A%20very%20simple%20example%20for%20tensorboard.ipynb)
92 |
93 | 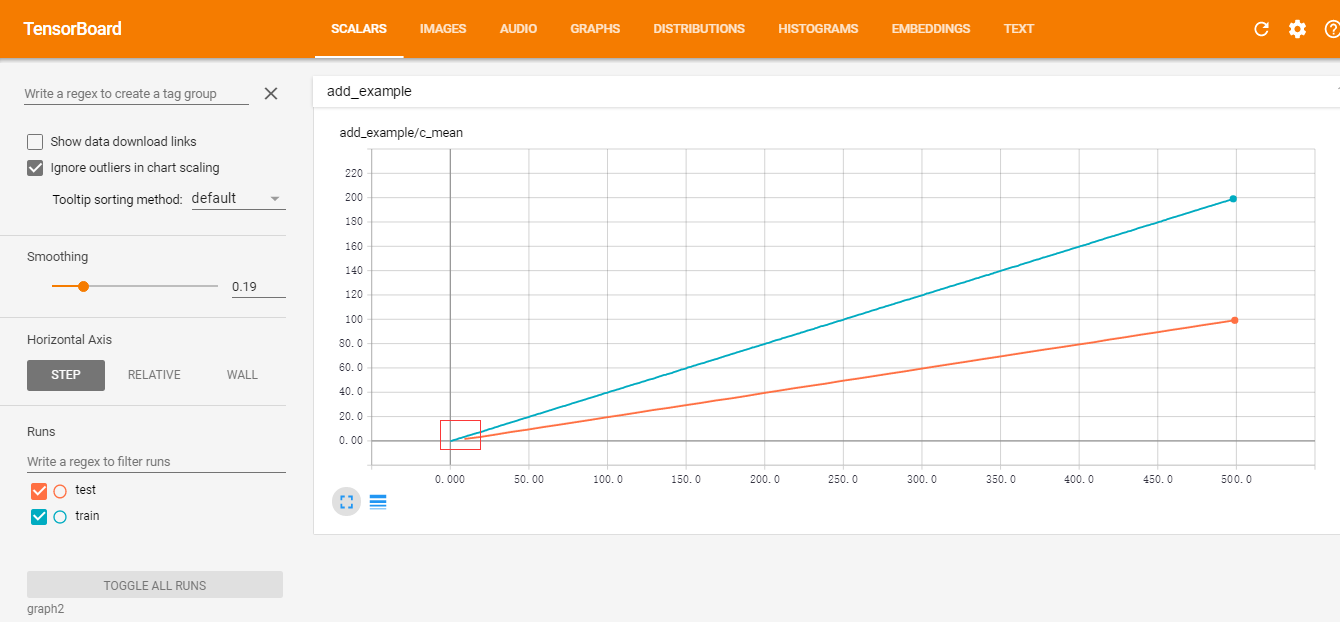 94 | 简单的 tensorboard 可视化
95 |
96 |
97 |
98 | #### T_07.使用 tf.train.Saver() 来保存模型
99 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_07%20How%20to%20save%20the%20model.ipynb)
100 |
101 |
102 |
103 | #### T_08.【迁移学习】往一个已经保存好的 模型添加新的变量
104 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_08%20%20%5Btransfer%20learning%5D%20Add%20new%20variables%20to%20graph%20and%20save%20the%20new%20model.ipynb)
105 |
106 |
107 |
108 | #### T_09.使用 tfrecord 打包不定长的序列数据
109 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_09%20%5Btfrecord%5D%20use%20tfrecord%20to%20store%20sequences%20of%20different%20length.ipynb)
110 | - [reader-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_2_seqence_reader.py)
111 | - [writer-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_2_seqence_writer.py)
112 |
113 |
114 |
115 | #### T_10.使用 tf.data.Dataset 和 tfrecord 给 numpy 数据构建数据集
116 | - [dataset-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_10%20%5BDataset%5D%20numpy%20data.ipynb)
117 | - [tfrecord-reader-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_1_numpy_reader.py)
118 | - [tfrecord-writer-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_1_numpy_writer.py)
119 |
120 |
121 | 下面是对 MNIST 数据训练集 55000 个样本 读取的一个速度比较,统一 `batch_size=128`,主要比较 `one-shot` 和 `initializable` 两种迭代方式:
122 |
123 | |iter_mode|buffer_size|100 batch(s)|
124 | |:----:|:---:|:---:|
125 | |one-shot|2000|125|
126 | |one-shot|5000|149|
127 | |initializable|2000|0.7|
128 | |initializable|5000|0.7|
129 |
130 | 可以看到,使用 `initializable` 方式的速度明显要快很多。因为使用 `one-shot` 方式会把整个矩阵放在图中,计算非常非常慢。
131 |
132 |
133 |
134 | #### T_11.使用 tf.data.Dataset 和 tfrecord 给 图片数据 构建数据集
135 | - [dataset-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_11%20%5BDataset%5D%20image%20data.ipynb)
136 | - [tfrecord-writer-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_3_image_writer.py)
137 | - [tfrecord-reader-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_3_image_reader.py)
138 |
139 | 对于 png 数据的读取,我尝试了 3 组不同的方式: one-shot 方式, tf 的队列方式(queue), tfrecord 方式. 同样是在机械硬盘上操作, 结果是 tfrecord 方式明显要快一些。(batch_size=128,图片大小为256*256,机械硬盘)
140 |
141 | |iter_mode|buffer_size|100 batch(s)|
142 | |:----:|:---:|:---:|
143 | |one-shot|2000|75|
144 | |one-shot|5000|86|
145 | |tf.queue|2000|11|
146 | |tf.queue|5000|11|
147 | |tfrecord|2000|5.3|
148 | |tfrecord|5000|5.3|
149 |
150 | 如果是在 SSD 上面的话,tf 的队列方式应该也是比较快的.打包成 tfrecord 格式只是减少了小文件的读取,其实现也是使用队列的。
151 |
152 |
153 | #### T_12.TensorFlow 高级API tf.layers 的使用
154 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_12%20%5Btf.layer%5Dhigh%20layer%20API.ipynb)
155 |
156 | 使用 TensorFlow 原生的 API 能够帮助自己很好的理解网络的细节,但是往往比较低效。 tf.layers 和 tf.keras 一样,是一个封装得比较好的一个高级库,接口用着挺方便的。所以在开发的时候,可以使用高级的接口能够有效的提高工作效率。
157 |
158 |
159 | # 2.TensorFlow 实战(持续更新)
160 | 下面的每个例子都是相互独立的,每个文件夹下面的代码都是可以单独运行的,不依赖于其他文件夹。
161 |
162 | ## [m01_batch_normalization: Batch Normalization 的使用](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m01_batch_normalization)
163 | 参考:[tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
164 |
165 | ## [m02_dcgan: 使用 DCGAN 生成二次元头像](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m02_dcgan)
166 | 参考:
167 | - [原论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1511.06434)
168 | - [GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059)
169 | - [代码:carpedm20/DCGAN-tensorflow](https://github.com/carpedm20/DCGAN-tensorflow)
170 | - [代码:aymericdamien/TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/dcgan.py)
171 |
172 | 这里的 notebook 和 .py 文件的内容是一样的。本例子和下面的 GAN 模型用的数据集也是用了[GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059) 的二次元头像,感觉这里例子比较有意思。如果想使用其他数据集的话,只需要把数据集换一下就行了。
173 |
174 | 下载链接: https://pan.baidu.com/s/1HBJpfkIFaGh0s2nfNXJsrA 密码: x39r
175 |
176 | 下载后把所有的图片解压到一个文件夹中,比如本例中是: `data_path = '../../data/anime/'`
177 |
178 | 运行: `python dcgan.py `
179 |
180 | ## [m03_wgan: 使用 WGAN 生成二次元头像](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m03_wgan)
181 | 这里的生成器和判别器我只实现了 DCGAN,没有实现 MLP. 如果想实现的话可以参考下面的两个例子。
182 | 参考:
183 | - [原论文:Wasserstein GAN](https://arxiv.org/pdf/1701.07875.pdf)
184 | - [代码:jiamings/wgan](https://github.com/jiamings/wgan)
185 | - [代码:Zardinality/WGAN-tensorflow](https://github.com/Zardinality/WGAN-tensorflow)
186 |
187 | 原版的 wgan: `python wgan.py `
188 |
189 | 改进的 wgan-gp: `python wgan_gp.py`
190 |
191 |
192 | ## [m04_pix2pix: image-to-image](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m04_pix2pix)
193 | 代码来自:[affinelayer/pix2pix-tensorflow](https://github.com/affinelayer/pix2pix-tensorflow)
194 |
195 |
--------------------------------------------------------------------------------
/ckpt/bi-lstm.ckpt-12.data-00000-of-00001:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/ckpt/bi-lstm.ckpt-12.data-00000-of-00001
--------------------------------------------------------------------------------
/ckpt/bi-lstm.ckpt-12.index:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/ckpt/bi-lstm.ckpt-12.index
--------------------------------------------------------------------------------
/ckpt/bi-lstm.ckpt-12.meta:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/ckpt/bi-lstm.ckpt-12.meta
--------------------------------------------------------------------------------
/ckpt/checkpoint:
--------------------------------------------------------------------------------
1 | model_checkpoint_path: "test-model.ckpt-2"
2 | all_model_checkpoint_paths: "test-model.ckpt-2"
3 |
--------------------------------------------------------------------------------
/data/msr_train.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/data/msr_train.txt
--------------------------------------------------------------------------------
/doc/problem-solution.md:
--------------------------------------------------------------------------------
1 | ## 1.为什么 relu 激活函数会有失活现象?
2 | > [一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。](http://blog.csdn.net/cyh_24/article/details/50593400)
3 | > [Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei)](http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html)
4 | > [深度学习系列(8):激活函数](https://plushunter.github.io/2017/05/12/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%B3%BB%E5%88%97%EF%BC%888%EF%BC%89%EF%BC%9A%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0/)
5 |
6 | A: 在某次反向传播中神经元 C 传过一个很大的梯度,和 C 相连的所有权重系数 w 都变成了很大的负数。假设前一层输出也是 relu 激活函数,那么前一层的输出(C 的输入)一定是非负数。那么神经元 C 一定会处于0梯度状态,没有任何数据(输入)能够拯救他。也就是失活了。
7 |
8 | 那么,**我觉得,在初始化的时候,如果本层(L)使用 relu 激活函数,那么 biases 最好使用较小的正数初始化,如0.01,0.005等。这样可以在一定程度上使得输出偏向于正数,从而避免梯度消失。** 但是也有一点好处,由于部分神经元失活了,这和做了 dropout 一样,能够有助于防止过拟合。
9 |
10 | **除了上面的失活现象以外,relu 激活函数还有偏移现象:输出均值恒大于零。** 失活现象和偏移现象会共同影响网络的收敛性。#8.数据偏移怎么影响网络的收敛?#
11 |
12 |
13 |
14 | ## 2.[code]AlexNet(等 CNN model) 调参过程中要注意什么?
15 | > 在 github 上面有很多不同版本的 AlexNet,网络结构基本都是一样的,在官方的 tensorflow slim 框架中也提供了 alexnet-v2 版本。在我的任务中,发现 slim 版本的 alexnet 效果要比其他版本的好很多(2~4个百分点)。明明结构一样,为什么差别这么大。
16 |
17 | A:虽然我觉得 slim 框架很不友好,但是里边的参数应该都是经过测试得到的较好的结果。很多小的细节都会影响最后的结果,具体要注意的有下面这些点:
18 | - 初始化方式。在我的任务中,初始化方式影响很大。slim 中的每一层的初始化方式和 caffe 的版本中基本一致。包括 conv 层, fc 层的 weights, biases。我就是最后一个 fc 层改了一下初始化,loss 嗖嗖地就降了。
19 | - 优化器。在原版中用的是 RMSProp 优化器,但坑的是用的不是默认参数,最好设置成跟 slim 一致。
20 | - 数据预处理。我用 caffe 算出了整个数据集的均值,然后把原始图片[0.~255.]减去均值,效果还不错。
21 | - lrn。在 slim 的 alexnet-v2 版本中去掉了局部响应层。结果没有变差,速度快了大概一倍吧。
22 |
23 |
24 |
25 | ## 3.[code]tensorflow 训练模型,报无法分配 memory,但是程序继续运行,这时运行的结果有问题吗?
26 | >**ran out of memory trying to allocate 3.27GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory is available.** 这时候,使用 watch nvidia-smi 看显卡使用情况,就会发现使用率非常低。
27 |
28 | A:这种情况下就应该把batch_size减小了!!!虽然程序还在运行,但是你会发现,结果根本不对,loss 根本就没降。这不是因为你的模型不好,学习率不对。把 batch_size 调小看看结果再下定论。
29 |
30 |
31 |
32 | ## 4.什么情况下用 sigmoid 会比 relu 好呢?
33 | > sigmoid 函数有陷入饱和区(造成梯度消失),非零中心和计算效率低的缺点。那么有什么情况下用 sigmoid 会好呢?
34 |
35 | A: 如果只是作为一个普通隐含层的激活函数的话,还是用 relu 就好了。但是如果你后继需要对某层特征进行量化处理的话,sigmoid 就起作用了。relu 层的输出范围太大,不适合做量化。这时候就体现出 0 和 1 的优越性了。同样,使用 tanh 层也是可以的。
36 |
37 |
38 |
39 | ## 5.sigmoid 非 zero-center 会有什么影响,relu 有这样的影响吗?怎么理解因此导致梯度下降权重更新时出现 z 字型的下降?
40 | > [Sigmoid函数的输出不是零中心的。这个性质并不是我们想要的,因为在神经网络后面层中神经元得到的数据不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数(比如在 f=wx+b 中每个元素都是 x>0),那么关于 w 的梯度在反向传播中,将会要么全部是正数,或者全部是负数(比如f=-wx+b).这将会导致梯度下降权重更新时出现z字型的下降(如下图所示)。](https://plushunter.github.io/2017/05/12/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%B3%BB%E5%88%97%EF%BC%888%EF%BC%89%EF%BC%9A%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0/)
41 |
42 |
43 |
44 |
45 | ## 6.在 relu 层前面的 BN 层中,为什么不用对 scale 做处理
46 | > [mnist_4.1_batchnorm_five_layers_relu.py](https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_4.1_batchnorm_five_layers_relu.py)
47 |
48 | A:没想明白.
49 |
50 |
51 |
52 | ## 7.在问题 1 中,relu 激活函数的偏移现象就是数据的输入分布(zero-center)和输出分布变了(no-zero-center).在 BN 中也提到过,这种数据分布的变化为什么会影响网络的收敛性?
53 | > [对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。](https://www.zhihu.com/question/38102762) 这样源空间 -> 目标空间 的变化怎么影响网络的收敛?
54 |
55 |
56 |
57 | ## 8.在BN中,为什么通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大,防止梯度消失?
58 | [在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。](https://www.zhihu.com/question/38102762) 在 BN 中,通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差。对于 mini-batch,首先减去均值,方差归一;接着进行 scale and shift 操作,也就是用学习到的全局均值和方差替换掉了 mini-batch 的均值和方差。 然后送入激活函数如(sigmoid)中,**这时候并没有把sigmoid的输入约束到 0 附近呀,为什么就能够避免梯度消失?**
59 |
60 | A:首先,对于 sigmoid 和 tanh 来说,当输入的绝对值很大时就会陷入饱和区。这个激活函数的输入一般指的是 z(=wx)。
61 | z 很大 -> 陷入饱和区
62 | z 很大 -> wx 这两个向量的点积很大 -> 如果 w 或者 x 的元素值很大,较容易使得 wx 很大? -> w,x 的值很大
63 | BN 避免了梯度消失 -> BN 处理使得 x 向 0 靠近了。但是没有呀??
64 |
65 | [BN使得输入分布大致稳定,从而缩短了参数适应分布的过程,进而缩短训练时间](https://zhuanlan.zhihu.com/p/26532249)
66 |
67 |
68 |
69 | ## 9.center loss 训练有什么需要注意的?center loss 会使类间的相对距离增大吗?
70 | > center loss 最小化类内距离,但是并没有显式地去最大化类间距离。在我的实验中,对加了center loss 的高层特征进行统计分析,发现类内特征的方差明显要比原来更小了,但是特征均值也比原来更小了。这样类间的绝对距离也会比原来小,假设类间中心距离为 L-inter,类内的距离为 L-intra, 类间的相对距离为 L-relative = (L-inter / L-intra)。那么,加上 center loss 后, L-relative 怎么变化?
71 |
72 | A:1.在模型训练的时候记得把每个类的中心特征向量留出接口,以便后继分析。
73 |
74 |
75 |
76 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_02 A simple feedforward network for MNIST-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 两层FC层做分类:MNIST\n",
8 | "\n",
9 | "在本教程中,我们来实现一个非常简单的两层全连接层来完成MNIST数据的分类问题。\n",
10 | "\n",
11 | "输入[-1,28*28], FC1 有 1024 个neurons, FC2 有 10 个neurons。这么简单的一个全连接网络,结果测试准确率达到了 0.98。还是非常棒的!!!"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 1,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "from __future__ import print_function\n",
21 | "from __future__ import division\n",
22 | "from __future__ import absolute_import\n",
23 | "\n",
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.Session(config=config)"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "### 1.导入数据\n",
41 | "下面导入数据这部分的警告可以不用管先,TensorFlow 非常恶心的地方就是不停地改 API,改到发麻。"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 2,
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
54 | "Instructions for updating:\n",
55 | "Use the retry module or similar alternatives.\n",
56 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
57 | "Instructions for updating:\n",
58 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
59 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
60 | "Instructions for updating:\n",
61 | "Please write your own downloading logic.\n",
62 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
63 | "Instructions for updating:\n",
64 | "Please use tf.data to implement this functionality.\n",
65 | "Extracting ../data/MNIST_data/train-images-idx3-ubyte.gz\n",
66 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
67 | "Instructions for updating:\n",
68 | "Please use tf.data to implement this functionality.\n",
69 | "Extracting ../data/MNIST_data/train-labels-idx1-ubyte.gz\n",
70 | "Extracting ../data/MNIST_data/t10k-images-idx3-ubyte.gz\n",
71 | "Extracting ../data/MNIST_data/t10k-labels-idx1-ubyte.gz\n",
72 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
73 | "Instructions for updating:\n",
74 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n"
75 | ]
76 | }
77 | ],
78 | "source": [
79 | "# 用tensorflow 导入数据\n",
80 | "from tensorflow.examples.tutorials.mnist import input_data\n",
81 | "mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=False, source_url='http://yann.lecun.com/exdb/mnist/')"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "name": "stdout",
91 | "output_type": "stream",
92 | "text": [
93 | "training data shape (55000, 784)\n",
94 | "training label shape (55000,)\n"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "print('training data shape ', mnist.train.images.shape)\n",
100 | "print('training label shape ', mnist.train.labels.shape)"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "metadata": {},
106 | "source": [
107 | "### 2. 构建网络"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 4,
113 | "metadata": {},
114 | "outputs": [
115 | {
116 | "name": "stdout",
117 | "output_type": "stream",
118 | "text": [
119 | "Tensor(\"add_1:0\", shape=(?, 10), dtype=float32)\n"
120 | ]
121 | }
122 | ],
123 | "source": [
124 | "# 权值初始化\n",
125 | "def weight_variable(shape):\n",
126 | " # 用正态分布来初始化权值\n",
127 | " initial = tf.truncated_normal(shape, stddev=0.1)\n",
128 | " return tf.Variable(initial)\n",
129 | "\n",
130 | "def bias_variable(shape):\n",
131 | " # 本例中用relu激活函数,所以用一个很小的正偏置较好\n",
132 | " initial = tf.constant(0.1, shape=shape)\n",
133 | " return tf.Variable(initial)\n",
134 | "\n",
135 | "\n",
136 | "# input_layer\n",
137 | "X_input = tf.placeholder(tf.float32, [None, 784])\n",
138 | "y_input = tf.placeholder(tf.int64, [None]) # 不使用 one-hot \n",
139 | "\n",
140 | "# FC1\n",
141 | "W_fc1 = weight_variable([784, 1024])\n",
142 | "b_fc1 = bias_variable([1024])\n",
143 | "h_fc1 = tf.nn.relu(tf.matmul(X_input, W_fc1) + b_fc1)\n",
144 | "\n",
145 | "# FC2\n",
146 | "W_fc2 = weight_variable([1024, 10])\n",
147 | "b_fc2 = bias_variable([10])\n",
148 | "# y_pre = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)\n",
149 | "logits = tf.matmul(h_fc1, W_fc2) + b_fc2\n",
150 | "\n",
151 | "print(logits)"
152 | ]
153 | },
154 | {
155 | "cell_type": "markdown",
156 | "metadata": {},
157 | "source": [
158 | "### 3.训练和评估\n",
159 | "下面我们将输入 mnist 的数据来进行训练。在下面有个 mnist.train.next_batch(batch_size=100) 的操作,每次从数据集中取出100个样本。如果想了解怎么实现的话建议看一下源码,其实挺简单的,很多时候需要我们自己去实现读取数据的这个函数。"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 5,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "step 500, train cost=0.153510, acc=0.950000; test cost=0.123346, acc=0.962500\n",
172 | "step 1000, train cost=0.087353, acc=0.960000; test cost=0.104876, acc=0.967400\n",
173 | "step 1500, train cost=0.033138, acc=0.990000; test cost=0.080937, acc=0.975200\n",
174 | "step 2000, train cost=0.028831, acc=0.990000; test cost=0.077214, acc=0.977800\n",
175 | "step 2500, train cost=0.004817, acc=1.000000; test cost=0.066441, acc=0.980000\n",
176 | "step 3000, train cost=0.015692, acc=1.000000; test cost=0.067741, acc=0.979400\n",
177 | "step 3500, train cost=0.011569, acc=1.000000; test cost=0.075138, acc=0.979400\n",
178 | "step 4000, train cost=0.006310, acc=1.000000; test cost=0.074501, acc=0.978300\n",
179 | "step 4500, train cost=0.008795, acc=1.000000; test cost=0.076483, acc=0.979100\n",
180 | "step 5000, train cost=0.027700, acc=0.980000; test cost=0.073973, acc=0.980000\n"
181 | ]
182 | }
183 | ],
184 | "source": [
185 | "# 1.损失函数:cross_entropy\n",
186 | "# 如果label是 one-hot 的话要换一下损失函数,参考:https://blog.csdn.net/tz_zs/article/details/76086457\n",
187 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_input, logits=logits)) \n",
188 | "# 2.优化函数:AdamOptimizer, 优化速度要比 GradientOptimizer 快很多\n",
189 | "train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)\n",
190 | "\n",
191 | "# 3.预测结果评估\n",
192 | "# 预测值中最大值(1)即分类结果,是否等于原始标签中的(1)的位置。argmax()取最大值所在的下标\n",
193 | "correct_prediction = tf.equal(tf.argmax(logits, 1), y_input) \n",
194 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n",
195 | "\n",
196 | "# 开始运行\n",
197 | "sess.run(tf.global_variables_initializer())\n",
198 | "# 这大概迭代了不到 10 个 epoch, 训练准确率已经达到了0.98\n",
199 | "for i in range(5000):\n",
200 | " X_batch, y_batch = mnist.train.next_batch(batch_size=100)\n",
201 | " cost, acc, _ = sess.run([cross_entropy, accuracy, train_step], feed_dict={X_input: X_batch, y_input: y_batch})\n",
202 | " if (i+1) % 500 == 0:\n",
203 | " test_cost, test_acc = sess.run([cross_entropy, accuracy], feed_dict={X_input: mnist.test.images, y_input: mnist.test.labels})\n",
204 | " print(\"step {}, train cost={:.6f}, acc={:.6f}; test cost={:.6f}, acc={:.6f}\".format(i+1, cost, acc, test_cost, test_acc))\n",
205 | " "
206 | ]
207 | }
208 | ],
209 | "metadata": {
210 | "anaconda-cloud": {},
211 | "kernelspec": {
212 | "display_name": "Python 3",
213 | "language": "python",
214 | "name": "python3"
215 | },
216 | "language_info": {
217 | "codemirror_mode": {
218 | "name": "ipython",
219 | "version": 3
220 | },
221 | "file_extension": ".py",
222 | "mimetype": "text/x-python",
223 | "name": "python",
224 | "nbconvert_exporter": "python",
225 | "pygments_lexer": "ipython3",
226 | "version": "3.5.2"
227 | }
228 | },
229 | "nbformat": 4,
230 | "nbformat_minor": 1
231 | }
232 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_03_2 The usage of Collection-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# TensorFlow 变量命名管理机制(二)\n",
8 | "\n",
9 | "\n",
10 | "### 1. 用 collection 来聚合变量\n",
11 | "前面介绍了 tensorflow 的变量命名机制,这里要补充一下 `tf.add_to_collection` 和 `tf.get_collection`的用法。\n",
12 | "\n",
13 | "因为神经网络中的参数非常多,有时候我们 只想对某些参数进行操作。除了前面通过变量名称的方法来获取参数之外, TensorFlow 中还有 collection 这么一种操作。\n",
14 | "\n",
15 | "collection 可以聚合多个**变量**或者**操作**。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import tensorflow as tf\n",
28 | "\n",
29 | "# 设置GPU按需增长\n",
30 | "config = tf.ConfigProto()\n",
31 | "config.gpu_options.allow_growth = True\n",
32 | "sess = tf.Session(config=config)"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "参考:[如何利用tf.add_to_collection、tf.get_collection以及tf.add_n来简化正则项的计算](https://blog.csdn.net/weixin_39980291/article/details/78352125)"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 2,
45 | "metadata": {},
46 | "outputs": [
47 | {
48 | "name": "stdout",
49 | "output_type": "stream",
50 | "text": [
51 | "vars in col1: [, ]\n"
52 | ]
53 | }
54 | ],
55 | "source": [
56 | "# 把变量添加到一个 collection 中\n",
57 | "v1 = tf.Variable([1,2,3], name='v1')\n",
58 | "v2 = tf.Variable([2], name='v2')\n",
59 | "v3 = tf.get_variable(name='v3', shape=(2,3))\n",
60 | "\n",
61 | "tf.add_to_collection('col1', v1) # 把 v1 添加到 col1 中\n",
62 | "tf.add_to_collection('col1', v3)\n",
63 | "\n",
64 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
65 | "print('vars in col1:', col1s)"
66 | ]
67 | },
68 | {
69 | "cell_type": "markdown",
70 | "metadata": {},
71 | "source": [
72 | "除了把变量添加到集合中,还可以把操作添加到集合中。"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 3,
78 | "metadata": {},
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "vars in col1: [, , ]\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "op1 = tf.add(v1, 2, name='add_op')\n",
90 | "tf.add_to_collection('col1', op1)\n",
91 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
92 | "print('vars in col1:', col1s)"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "此外,还可以加上 scope 的约束。"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 3,
105 | "metadata": {},
106 | "outputs": [
107 | {
108 | "name": "stdout",
109 | "output_type": "stream",
110 | "text": [
111 | "vars in col1 with scope=model: []\n"
112 | ]
113 | }
114 | ],
115 | "source": [
116 | "with tf.variable_scope('model'):\n",
117 | " v4 = tf.get_variable('v4', shape=[3,4])\n",
118 | " v5 = tf.Variable([1,2,3], name='v5')\n",
119 | "\n",
120 | "tf.add_to_collection('col1', v5)\n",
121 | "col1_vars = tf.get_collection(key='col1', scope='model') # 获取 col1 的变量\n",
122 | "print('vars in col1 with scope=model: ', col1_vars)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "### 2. tf.GraphKeys \n",
130 | "\n",
131 | "参考:[tf.GraphKeys 函数](https://www.w3cschool.cn/tensorflow_python/tensorflow_python-ne7t2ezd.html)\n",
132 | "\n",
133 | "用于图形集合的标准名称。\n",
134 | "\n",
135 | "\n",
136 | "标准库使用各种已知的名称来收集和检索与图形相关联的值。例如,如果没有指定,则 tf.Optimizer 子类默认优化收集的变量tf.GraphKeys.TRAINABLE_VARIABLES,但也可以传递显式的变量列表。\n",
137 | "\n",
138 | "定义了以下标准键:\n",
139 | "\n",
140 | "- GLOBAL_VARIABLES:默认的 Variable 对象集合,在分布式环境共享(模型变量是其中的子集)。参考:tf.global_variables。通常,所有TRAINABLE_VARIABLES 变量都将在 MODEL_VARIABLES,所有 MODEL_VARIABLES 变量都将在 GLOBAL_VARIABLES。\n",
141 | "- LOCAL_VARIABLES:每台计算机的局部变量对象的子集。通常用于临时变量,如计数器。注意:使用 tf.contrib.framework.local_variable 添加到此集合。\n",
142 | "- MODEL_VARIABLES:在模型中用于推理(前馈)的变量对象的子集。注意:使用 tf.contrib.framework.model_variable 添加到此集合。\n",
143 | "- TRAINABLE_VARIABLES:将由优化器训练的变量对象的子集。\n",
144 | "- SUMMARIES:在关系图中创建的汇总张量对象。\n",
145 | "- QUEUE_RUNNERS:用于为计算生成输入的 QueueRunner 对象。\n",
146 | "- MOVING_AVERAGE_VARIABLES:变量对象的子集,它也将保持移动平均值。\n",
147 | "- REGULARIZATION_LOSSES:在图形构造期间收集的正规化损失。\n",
148 | "\n",
149 | "这个知道就好了,要用的时候知道是怎么回事就行了。比如在 BN 层中就有这东西。"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": []
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": null,
162 | "metadata": {},
163 | "outputs": [],
164 | "source": []
165 | }
166 | ],
167 | "metadata": {
168 | "anaconda-cloud": {},
169 | "kernelspec": {
170 | "display_name": "Python 3",
171 | "language": "python",
172 | "name": "python3"
173 | },
174 | "language_info": {
175 | "codemirror_mode": {
176 | "name": "ipython",
177 | "version": 3
178 | },
179 | "file_extension": ".py",
180 | "mimetype": "text/x-python",
181 | "name": "python",
182 | "nbconvert_exporter": "python",
183 | "pygments_lexer": "ipython3",
184 | "version": "3.5.2"
185 | }
186 | },
187 | "nbformat": 4,
188 | "nbformat_minor": 1
189 | }
190 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_04_3 Convolutional network for MNIST(3)-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CNN做MNIST分类\n",
8 | "\n",
9 | "使用 tf.layers 高级 API 构建 CNN "
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
22 | " from ._conv import register_converters as _register_converters\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.InteractiveSession(config=config)\n",
34 | "\n",
35 | "import time"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "## 1.导入数据,用 tensorflow 导入"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 2,
48 | "metadata": {},
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
55 | "Instructions for updating:\n",
56 | "Use the retry module or similar alternatives.\n",
57 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
58 | "Instructions for updating:\n",
59 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
60 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
61 | "Instructions for updating:\n",
62 | "Please write your own downloading logic.\n",
63 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
64 | "Instructions for updating:\n",
65 | "Please use tf.data to implement this functionality.\n",
66 | "Extracting MNIST_data/train-images-idx3-ubyte.gz\n",
67 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
68 | "Instructions for updating:\n",
69 | "Please use tf.data to implement this functionality.\n",
70 | "Extracting MNIST_data/train-labels-idx1-ubyte.gz\n",
71 | "Extracting MNIST_data/t10k-images-idx3-ubyte.gz\n",
72 | "Extracting MNIST_data/t10k-labels-idx1-ubyte.gz\n",
73 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
74 | "Instructions for updating:\n",
75 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
76 | "(10000,)\n",
77 | "(55000,)\n"
78 | ]
79 | }
80 | ],
81 | "source": [
82 | "# 用tensorflow 导入数据\n",
83 | "from tensorflow.examples.tutorials.mnist import input_data\n",
84 | "mnist = input_data.read_data_sets('MNIST_data', one_hot=False)\n",
85 | "# 看看咱们样本的数量\n",
86 | "print(mnist.test.labels.shape)\n",
87 | "print(mnist.train.labels.shape)"
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {},
93 | "source": [
94 | "## 2. 构建网络"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 3,
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "Finished building network.\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "with tf.name_scope('inputs'):\n",
112 | " X_ = tf.placeholder(tf.float32, [None, 784])\n",
113 | " y_ = tf.placeholder(tf.int64, [None])\n",
114 | "\n",
115 | "# 把X转为卷积所需要的形式\n",
116 | "X = tf.reshape(X_, [-1, 28, 28, 1])\n",
117 | "h_conv1 = tf.layers.conv2d(X, filters=32, kernel_size=5, strides=1, padding='same', activation=tf.nn.relu, name='conv1')\n",
118 | "h_pool1 = tf.layers.max_pooling2d(h_conv1, pool_size=2, strides=2, padding='same', name='pool1')\n",
119 | "\n",
120 | "h_conv2 = tf.layers.conv2d(h_pool1, filters=64, kernel_size=5, strides=1, padding='same',activation=tf.nn.relu, name='conv2')\n",
121 | "h_pool2 = tf.layers.max_pooling2d(h_conv2, pool_size=2, strides=2, padding='same', name='pool2')\n",
122 | "\n",
123 | "# flatten\n",
124 | "h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\n",
125 | "h_fc1 = tf.layers.dense(h_pool2_flat, 1024, name='fc1', activation=tf.nn.relu)\n",
126 | "\n",
127 | "# dropout: 输出的维度和h_fc1一样,只是随机部分值被值为零\n",
128 | "keep_prob = tf.placeholder(tf.float32)\n",
129 | "h_fc1_drop = tf.nn.dropout(h_fc1, 0.5) # 实际测试的时候这里不应该使用 0.5,这里为了方便演示都这样写而已\n",
130 | "h_fc2 = tf.layers.dense(h_fc1_drop, units=10, name='fc2')\n",
131 | "# y_conv = tf.nn.softmax(h_fc2)\n",
132 | "y_conv = h_fc2\n",
133 | "print('Finished building network.')"
134 | ]
135 | },
136 | {
137 | "cell_type": "code",
138 | "execution_count": 4,
139 | "metadata": {},
140 | "outputs": [
141 | {
142 | "name": "stdout",
143 | "output_type": "stream",
144 | "text": [
145 | "Tensor(\"conv1/Relu:0\", shape=(?, 28, 28, 32), dtype=float32)\n",
146 | "Tensor(\"pool1/MaxPool:0\", shape=(?, 14, 14, 32), dtype=float32)\n",
147 | "Tensor(\"conv2/Relu:0\", shape=(?, 14, 14, 64), dtype=float32)\n",
148 | "Tensor(\"pool2/MaxPool:0\", shape=(?, 7, 7, 64), dtype=float32)\n",
149 | "Tensor(\"Reshape_1:0\", shape=(?, 3136), dtype=float32)\n",
150 | "Tensor(\"fc1/Relu:0\", shape=(?, 1024), dtype=float32)\n",
151 | "Tensor(\"fc2/BiasAdd:0\", shape=(?, 10), dtype=float32)\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "print(h_conv1)\n",
157 | "print(h_pool1)\n",
158 | "print(h_conv2)\n",
159 | "print(h_pool2)\n",
160 | "\n",
161 | "print(h_pool2_flat)\n",
162 | "print(h_fc1)\n",
163 | "print(h_fc2)"
164 | ]
165 | },
166 | {
167 | "cell_type": "markdown",
168 | "metadata": {},
169 | "source": [
170 | "## 3.训练和评估"
171 | ]
172 | },
173 | {
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | " 在测试的时候不使用 mini_batch, 那么测试的时候会占用较多的GPU(4497M),这在 notebook 交互式编程中是不推荐的。"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": null,
183 | "metadata": {
184 | "scrolled": false
185 | },
186 | "outputs": [
187 | {
188 | "name": "stdout",
189 | "output_type": "stream",
190 | "text": [
191 | "step 0, training accuracy = 0.1100, pass 1.18s \n",
192 | "step 1000, training accuracy = 0.9800, pass 6.01s \n",
193 | "step 2000, training accuracy = 0.9800, pass 10.82s \n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "# cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\n",
199 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
200 | " labels=tf.cast(y_, dtype=tf.int32), logits=y_conv))\n",
201 | "\n",
202 | "train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
203 | "\n",
204 | "correct_prediction = tf.equal(tf.argmax(y_conv,1), y_)\n",
205 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n",
206 | "sess.run(tf.global_variables_initializer())\n",
207 | "\n",
208 | "tic = time.time()\n",
209 | "for i in range(10000):\n",
210 | " batch = mnist.train.next_batch(100)\n",
211 | " if i%1000 == 0:\n",
212 | " train_accuracy = accuracy.eval(feed_dict={\n",
213 | " X_:batch[0], y_: batch[1], keep_prob: 1.0})\n",
214 | " print(\"step {}, training accuracy = {:.4f}, pass {:.2f}s \".format(i, train_accuracy, time.time() - tic))\n",
215 | " train_step.run(feed_dict={X_: batch[0], y_: batch[1]})\n",
216 | "\n",
217 | "print(\"test accuracy %g\"%accuracy.eval(feed_dict={\n",
218 | " X_: mnist.test.images, y_: mnist.test.labels}))"
219 | ]
220 | }
221 | ],
222 | "metadata": {
223 | "anaconda-cloud": {},
224 | "kernelspec": {
225 | "display_name": "Python 3",
226 | "language": "python",
227 | "name": "python3"
228 | },
229 | "language_info": {
230 | "codemirror_mode": {
231 | "name": "ipython",
232 | "version": 3
233 | },
234 | "file_extension": ".py",
235 | "mimetype": "text/x-python",
236 | "name": "python",
237 | "nbconvert_exporter": "python",
238 | "pygments_lexer": "ipython3",
239 | "version": "3.5.2"
240 | }
241 | },
242 | "nbformat": 4,
243 | "nbformat_minor": 1
244 | }
245 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_04_3 Convolutional network for MNIST(4)-BN-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CNN做MNIST分类(四)\n",
8 | "\n",
9 | "使用 tf.layers 高级 API 构建 CNN,添加 BN 层。"
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
22 | " from ._conv import register_converters as _register_converters\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.InteractiveSession(config=config)\n",
34 | "\n",
35 | "import time"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "## 1.导入数据,用 tensorflow 导入"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 2,
48 | "metadata": {},
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
55 | "Instructions for updating:\n",
56 | "Use the retry module or similar alternatives.\n",
57 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
58 | "Instructions for updating:\n",
59 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
60 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
61 | "Instructions for updating:\n",
62 | "Please write your own downloading logic.\n",
63 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:219: retry..wrap..wrapped_fn (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
64 | "Instructions for updating:\n",
65 | "Please use urllib or similar directly.\n",
66 | "Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.\n",
67 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
68 | "Instructions for updating:\n",
69 | "Please use tf.data to implement this functionality.\n",
70 | "Extracting MNIST_data/train-images-idx3-ubyte.gz\n",
71 | "Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.\n",
72 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
73 | "Instructions for updating:\n",
74 | "Please use tf.data to implement this functionality.\n",
75 | "Extracting MNIST_data/train-labels-idx1-ubyte.gz\n",
76 | "Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.\n",
77 | "Extracting MNIST_data/t10k-images-idx3-ubyte.gz\n",
78 | "Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.\n",
79 | "Extracting MNIST_data/t10k-labels-idx1-ubyte.gz\n",
80 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
81 | "Instructions for updating:\n",
82 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
83 | "(10000,)\n",
84 | "(55000,)\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "# 用tensorflow 导入数据\n",
90 | "from tensorflow.examples.tutorials.mnist import input_data\n",
91 | "mnist = input_data.read_data_sets('MNIST_data', one_hot=False)\n",
92 | "# 看看咱们样本的数量\n",
93 | "print(mnist.test.labels.shape)\n",
94 | "print(mnist.train.labels.shape)"
95 | ]
96 | },
97 | {
98 | "cell_type": "markdown",
99 | "metadata": {},
100 | "source": [
101 | "## 2. 构建网络"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 3,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "name": "stdout",
111 | "output_type": "stream",
112 | "text": [
113 | "Finished building network.\n"
114 | ]
115 | }
116 | ],
117 | "source": [
118 | "with tf.name_scope('inputs'):\n",
119 | " X_ = tf.placeholder(tf.float32, [None, 784])\n",
120 | " y_ = tf.placeholder(tf.int64, [None])\n",
121 | "\n",
122 | "# 把X转为卷积所需要的形式\n",
123 | "X = tf.reshape(X_, [-1, 28, 28, 1])\n",
124 | "h_conv1 = tf.layers.conv2d(X, filters=32, kernel_size=5, strides=1, padding='same', name='conv1')\n",
125 | "h_bn1 = tf.layers.batch_normalization(h_conv1, )\n",
126 | "h_pool1 = tf.layers.max_pooling2d(h_conv1, pool_size=2, strides=2, padding='same', name='pool1')\n",
127 | "\n",
128 | "h_conv2 = tf.layers.conv2d(h_pool1, filters=64, kernel_size=5, strides=1, padding='same',activation=tf.nn.relu, name='conv2')\n",
129 | "h_pool2 = tf.layers.max_pooling2d(h_conv2, pool_size=2, strides=2, padding='same', name='pool2')\n",
130 | "\n",
131 | "# flatten\n",
132 | "h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\n",
133 | "h_fc1 = tf.layers.dense(h_pool2_flat, 1024, name='fc1', activation=tf.nn.relu)\n",
134 | "\n",
135 | "# dropout: 输出的维度和h_fc1一样,只是随机部分值被值为零\n",
136 | "keep_prob = tf.placeholder(tf.float32)\n",
137 | "h_fc1_drop = tf.nn.dropout(h_fc1, 0.5) # 实际测试的时候这里不应该使用 0.5,这里为了方便演示都这样写而已\n",
138 | "h_fc2 = tf.layers.dense(h_fc1_drop, units=10, name='fc2')\n",
139 | "# y_conv = tf.nn.softmax(h_fc2)\n",
140 | "y_conv = h_fc2\n",
141 | "print('Finished building network.')"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 4,
147 | "metadata": {},
148 | "outputs": [
149 | {
150 | "name": "stdout",
151 | "output_type": "stream",
152 | "text": [
153 | "Tensor(\"conv1/Relu:0\", shape=(?, 28, 28, 32), dtype=float32)\n",
154 | "Tensor(\"pool1/MaxPool:0\", shape=(?, 14, 14, 32), dtype=float32)\n",
155 | "Tensor(\"conv2/Relu:0\", shape=(?, 14, 14, 64), dtype=float32)\n",
156 | "Tensor(\"pool2/MaxPool:0\", shape=(?, 7, 7, 64), dtype=float32)\n",
157 | "Tensor(\"Reshape_1:0\", shape=(?, 3136), dtype=float32)\n",
158 | "Tensor(\"fc1/Relu:0\", shape=(?, 1024), dtype=float32)\n",
159 | "Tensor(\"fc2/BiasAdd:0\", shape=(?, 10), dtype=float32)\n"
160 | ]
161 | }
162 | ],
163 | "source": [
164 | "print(h_conv1)\n",
165 | "print(h_pool1)\n",
166 | "print(h_conv2)\n",
167 | "print(h_pool2)\n",
168 | "\n",
169 | "print(h_pool2_flat)\n",
170 | "print(h_fc1)\n",
171 | "print(h_fc2)"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "## 3.训练和评估"
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | " 在测试的时候不使用 mini_batch, 那么测试的时候会占用较多的GPU(4497M),这在 notebook 交互式编程中是不推荐的。"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 5,
191 | "metadata": {
192 | "scrolled": false
193 | },
194 | "outputs": [
195 | {
196 | "name": "stdout",
197 | "output_type": "stream",
198 | "text": [
199 | "step 0, training accuracy = 0.1100, pass 1.18s \n",
200 | "step 1000, training accuracy = 0.9800, pass 6.01s \n",
201 | "step 2000, training accuracy = 0.9800, pass 10.82s \n",
202 | "step 3000, training accuracy = 0.9700, pass 15.65s \n",
203 | "step 4000, training accuracy = 1.0000, pass 20.40s \n",
204 | "step 5000, training accuracy = 0.9800, pass 25.26s \n",
205 | "step 6000, training accuracy = 1.0000, pass 30.00s \n",
206 | "step 7000, training accuracy = 0.9900, pass 34.84s \n",
207 | "step 8000, training accuracy = 1.0000, pass 39.66s \n",
208 | "step 9000, training accuracy = 1.0000, pass 44.55s \n",
209 | "test accuracy 0.9924\n"
210 | ]
211 | }
212 | ],
213 | "source": [
214 | "# cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\n",
215 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
216 | " labels=tf.cast(y_, dtype=tf.int32), logits=y_conv))\n",
217 | "\n",
218 | "train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
219 | "\n",
220 | "correct_prediction = tf.equal(tf.argmax(y_conv,1), y_)\n",
221 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n",
222 | "sess.run(tf.global_variables_initializer())\n",
223 | "\n",
224 | "tic = time.time()\n",
225 | "for i in range(10000):\n",
226 | " batch = mnist.train.next_batch(100)\n",
227 | " if i%1000 == 0:\n",
228 | " train_accuracy = accuracy.eval(feed_dict={\n",
229 | " X_:batch[0], y_: batch[1], keep_prob: 1.0})\n",
230 | " print(\"step {}, training accuracy = {:.4f}, pass {:.2f}s \".format(i, train_accuracy, time.time() - tic))\n",
231 | " train_step.run(feed_dict={X_: batch[0], y_: batch[1]})\n",
232 | "\n",
233 | "print(\"test accuracy %g\"%accuracy.eval(feed_dict={\n",
234 | " X_: mnist.test.images, y_: mnist.test.labels}))"
235 | ]
236 | }
237 | ],
238 | "metadata": {
239 | "anaconda-cloud": {},
240 | "kernelspec": {
241 | "display_name": "Python 3",
242 | "language": "python",
243 | "name": "python3"
244 | },
245 | "language_info": {
246 | "codemirror_mode": {
247 | "name": "ipython",
248 | "version": 3
249 | },
250 | "file_extension": ".py",
251 | "mimetype": "text/x-python",
252 | "name": "python",
253 | "nbconvert_exporter": "python",
254 | "pygments_lexer": "ipython3",
255 | "version": "3.5.2"
256 | }
257 | },
258 | "nbformat": 4,
259 | "nbformat_minor": 1
260 | }
261 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_07 How to save the model-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 如何使用 tf.train.Saver() 来保存模型\n",
8 | "之前一直出错,主要是因为坑爹的编码问题。所以要注意文件的路径绝对不不要出现什么中文呀。"
9 | ]
10 | },
11 | {
12 | "cell_type": "code",
13 | "execution_count": 1,
14 | "metadata": {},
15 | "outputs": [
16 | {
17 | "name": "stderr",
18 | "output_type": "stream",
19 | "text": [
20 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
21 | " from ._conv import register_converters as _register_converters\n"
22 | ]
23 | },
24 | {
25 | "name": "stdout",
26 | "output_type": "stream",
27 | "text": [
28 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
29 | ]
30 | }
31 | ],
32 | "source": [
33 | "import tensorflow as tf\n",
34 | "config = tf.ConfigProto()\n",
35 | "config.gpu_options.allow_growth = True\n",
36 | "sess = tf.Session(config=config)\n",
37 | "\n",
38 | "# Create some variables.\n",
39 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
40 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
41 | "\n",
42 | "# Add an op to initialize the variables.\n",
43 | "init_op = tf.global_variables_initializer()\n",
44 | "\n",
45 | "# Add ops to save and restore all the variables.\n",
46 | "saver = tf.train.Saver()\n",
47 | "\n",
48 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
49 | "# Later, launch the model, initialize the variables, do some work, save the\n",
50 | "# variables to disk.\n",
51 | "sess.run(init_op)\n",
52 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
53 | "print(\"Model saved in file: %s\" % save_path)"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "注意,在上面保存完了模型之后。**Restart kernel** 之后才能使用下面的模型导入。否则会因为两次命名 \"v1\" 而导致名字错误。"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 1,
66 | "metadata": {},
67 | "outputs": [
68 | {
69 | "name": "stderr",
70 | "output_type": "stream",
71 | "text": [
72 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
73 | " from ._conv import register_converters as _register_converters\n"
74 | ]
75 | },
76 | {
77 | "name": "stdout",
78 | "output_type": "stream",
79 | "text": [
80 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
81 | "Model restored.\n",
82 | "[1. 2.3]\n",
83 | "55.5\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "import tensorflow as tf\n",
89 | "config = tf.ConfigProto()\n",
90 | "config.gpu_options.allow_growth = True\n",
91 | "sess = tf.Session(config=config)\n",
92 | "\n",
93 | "# Create some variables.\n",
94 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
95 | "v2 = tf.Variable(33.5, name=\"v2\")\n",
96 | "\n",
97 | "# Add ops to save and restore all the variables.\n",
98 | "saver = tf.train.Saver()\n",
99 | "\n",
100 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
101 | "# do some work with the model.\n",
102 | "# Restore variables from disk.\n",
103 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
104 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
105 | "print(\"Model restored.\")\n",
106 | "\n",
107 | "print(sess.run(v1))\n",
108 | "print(sess.run(v2))"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "导入模型之前,必须重新再定义一遍变量。\n",
116 | "\n",
117 | "但是并不需要全部变量都重新进行定义,只定义我们需要的变量就行了。\n",
118 | "\n",
119 | "也就是说,**你所定义的变量一定要在 checkpoint 中存在;但不是所有在checkpoint中的变量,你都要重新定义。**"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 1,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "name": "stderr",
129 | "output_type": "stream",
130 | "text": [
131 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
132 | " from ._conv import register_converters as _register_converters\n"
133 | ]
134 | },
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
140 | "Model restored.\n",
141 | "[1. 2.3]\n"
142 | ]
143 | }
144 | ],
145 | "source": [
146 | "import tensorflow as tf\n",
147 | "config = tf.ConfigProto()\n",
148 | "config.gpu_options.allow_growth = True\n",
149 | "sess = tf.Session(config=config)\n",
150 | "\n",
151 | "# Create some variables.\n",
152 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
153 | "\n",
154 | "# Add ops to save and restore all the variables.\n",
155 | "saver = tf.train.Saver()\n",
156 | "\n",
157 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
158 | "# do some work with the model.\n",
159 | "# Restore variables from disk.\n",
160 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
161 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
162 | "print(\"Model restored.\")\n",
163 | "\n",
164 | "print(sess.run(v1))"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "## 关于模型保存的一点心得\n",
172 | "\n",
173 | "```\n",
174 | "saver = tf.train.Saver(max_to_keep=3)\n",
175 | "```\n",
176 | "在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,我都不会保存太多模型,模型多了浪费空间,很多时候其实保存最好的模型就够了。方法就是每次迭代到一定步数就在验证集上计算一次 accuracy 或者 f1 值,如果本次结果比上次好才保存新的模型,否则没必要保存。\n",
177 | "\n",
178 | "如果你想用不同 epoch 保存下来的模型进行融合的话,3到5 个模型已经足够了,假设这各融合的模型成为 M,而最好的一个单模型称为 m_best, 这样融合的话对于M 确实可以比 m_best 更好。但是如果拿这个模型和其他结构的模型再做融合的话,M 的效果并没有 m_best 好,因为M 相当于做了平均操作,减少了该模型的“特性”。"
179 | ]
180 | }
181 | ],
182 | "metadata": {
183 | "anaconda-cloud": {},
184 | "kernelspec": {
185 | "display_name": "Python 3",
186 | "language": "python",
187 | "name": "python3"
188 | },
189 | "language_info": {
190 | "codemirror_mode": {
191 | "name": "ipython",
192 | "version": 3
193 | },
194 | "file_extension": ".py",
195 | "mimetype": "text/x-python",
196 | "name": "python",
197 | "nbconvert_exporter": "python",
198 | "pygments_lexer": "ipython3",
199 | "version": "3.5.2"
200 | }
201 | },
202 | "nbformat": 4,
203 | "nbformat_minor": 1
204 | }
205 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_08 [transfer learning] Add new variables to graph and save the new model-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 【迁移学习】往一个已经保存好的 模型添加新的变量\n",
8 | "在迁移学习中,通常我们已经训练好一个模型,现在需要修改模型的部分结构,用于我们的新任务。\n",
9 | "\n",
10 | "比如:\n",
11 | "\n",
12 | "在一个图片分类任务中,我们使用别人训练好的网络来提取特征,但是我们的分类数目和原模型不同,这样我们只能取到 fc 层,后面的分类层需要重新写。这样我们就需要添加新的变量。那么这些新加入的变量必须得初始化才能使用。可是我们又不能使用 'tf.global_variables_initializer()' 来初始化,否则原本训练好的模型就没用了。\n",
13 | "\n",
14 | "关于怎么样单独初始化新增的变量,可以参考下面两个链接:\n",
15 | "- [1]https://stackoverflow.com/questions/35164529/in-tensorflow-is-there-any-way-to-just-initialize-uninitialised-variables\n",
16 | "- [2]https://stackoverflow.com/questions/35013080/tensorflow-how-to-get-all-variables-from-rnn-cell-basiclstm-rnn-cell-multirnn\n",
17 | "\n",
18 | "简单的例子可以直接看下面我的实现方式。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### 初始模型定义与保存\n",
26 | "首先定义一个模型,里边有 v1, v2 两个变量,我们把这个模型保存起来。"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {},
33 | "outputs": [
34 | {
35 | "name": "stderr",
36 | "output_type": "stream",
37 | "text": [
38 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
39 | " from ._conv import register_converters as _register_converters\n"
40 | ]
41 | },
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "import tensorflow as tf\n",
52 | "config = tf.ConfigProto()\n",
53 | "config.gpu_options.allow_growth = True\n",
54 | "sess = tf.Session(config=config)\n",
55 | "\n",
56 | "# Create some variables.\n",
57 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
58 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
59 | "\n",
60 | "\n",
61 | "init_op = tf.global_variables_initializer()\n",
62 | "saver = tf.train.Saver()\n",
63 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
64 | "sess.run(init_op)\n",
65 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
66 | "print(\"Model saved in file: %s\" % save_path)"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**restart(重启kernel然后执行下面cell的代码)**\n",
74 | "### 导入已经保存好的模型,并添加新的变量\n",
75 | "现在把之前保存好的模型,我只需要其中的 v1 变量。同时我还要添加新的变量 v3。"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 1,
81 | "metadata": {
82 | "scrolled": false
83 | },
84 | "outputs": [
85 | {
86 | "name": "stderr",
87 | "output_type": "stream",
88 | "text": [
89 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
90 | " from ._conv import register_converters as _register_converters\n"
91 | ]
92 | },
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
98 | "[1. 2.3]\n",
99 | "[1. 2.3]\n",
100 | "666\n"
101 | ]
102 | },
103 | {
104 | "data": {
105 | "text/plain": [
106 | "'../ckpt/test-model.ckpt-2'"
107 | ]
108 | },
109 | "execution_count": 1,
110 | "metadata": {},
111 | "output_type": "execute_result"
112 | }
113 | ],
114 | "source": [
115 | "import tensorflow as tf\n",
116 | "config = tf.ConfigProto()\n",
117 | "config.gpu_options.allow_growth = True\n",
118 | "sess = tf.Session(config=config)\n",
119 | "\n",
120 | "# Create some variables.\n",
121 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
122 | "\n",
123 | "# ** 导入训练好的模型\n",
124 | "saver = tf.train.Saver()\n",
125 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
126 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
127 | "print(sess.run(v1))\n",
128 | "\n",
129 | "# ** 定义新的变量并单独初始化新定义的变量\n",
130 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
131 | "init_new = tf.variables_initializer([v3])\n",
132 | "sess.run(init_new)\n",
133 | "# 。。。这里就可以进行 fine-tune 了\n",
134 | "print(sess.run(v1))\n",
135 | "print(sess.run(v3))\n",
136 | "\n",
137 | "# ** 保存新的模型。 \n",
138 | "# 注意!注意!注意! 一定一定一定要重新定义 saver, 这样才能把 v3 添加到 checkpoint 中\n",
139 | "saver = tf.train.Saver()\n",
140 | "saver.save(sess, ckpt_path, global_step=2)"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "**restart(重启kernel然后执行下面cell的代码)**\n",
148 | "### 这样就完成了 fine-tune, 得到了新的模型"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 1,
154 | "metadata": {
155 | "scrolled": false
156 | },
157 | "outputs": [
158 | {
159 | "name": "stderr",
160 | "output_type": "stream",
161 | "text": [
162 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
163 | " from ._conv import register_converters as _register_converters\n"
164 | ]
165 | },
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-2\n",
171 | "Model restored.\n",
172 | "[1. 2.3]\n",
173 | "666\n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "import tensorflow as tf\n",
179 | "config = tf.ConfigProto()\n",
180 | "config.gpu_options.allow_growth = True\n",
181 | "sess = tf.Session(config=config)\n",
182 | "\n",
183 | "# Create some variables.\n",
184 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
185 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
186 | "# Add ops to save and restore all the variables.\n",
187 | "saver = tf.train.Saver()\n",
188 | "\n",
189 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
190 | "# do some work with the model.\n",
191 | "# Restore variables from disk.\n",
192 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
193 | "saver.restore(sess, ckpt_path + '-'+ str(2))\n",
194 | "print(\"Model restored.\")\n",
195 | "\n",
196 | "print(sess.run(v1))\n",
197 | "print(sess.run(v3))"
198 | ]
199 | },
200 | {
201 | "cell_type": "code",
202 | "execution_count": null,
203 | "metadata": {
204 | "collapsed": true
205 | },
206 | "outputs": [],
207 | "source": []
208 | }
209 | ],
210 | "metadata": {
211 | "anaconda-cloud": {},
212 | "kernelspec": {
213 | "display_name": "Python 3",
214 | "language": "python",
215 | "name": "python3"
216 | },
217 | "language_info": {
218 | "codemirror_mode": {
219 | "name": "ipython",
220 | "version": 3
221 | },
222 | "file_extension": ".py",
223 | "mimetype": "text/x-python",
224 | "name": "python",
225 | "nbconvert_exporter": "python",
226 | "pygments_lexer": "ipython3",
227 | "version": "3.5.2"
228 | }
229 | },
230 | "nbformat": 4,
231 | "nbformat_minor": 1
232 | }
233 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Untitled-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import warnings\n",
10 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
11 | "\n",
12 | "import tensorflow as tf\n",
13 | "\n",
14 | "# 设置GPU按需增长\n",
15 | "config = tf.ConfigProto()\n",
16 | "config.gpu_options.allow_growth = True\n",
17 | "sess = tf.Session(config=config)\n",
18 | "\n",
19 | "import numpy as np"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 4,
25 | "metadata": {},
26 | "outputs": [
27 | {
28 | "name": "stdout",
29 | "output_type": "stream",
30 | "text": [
31 | "Tensor(\"inputs_2:0\", shape=(?, 256, 256, 3), dtype=float32)\n",
32 | "conv1 Tensor(\"conv1/Relu:0\", shape=(?, 62, 62, 96), dtype=float32)\n",
33 | "pool1 Tensor(\"pool1/MaxPool:0\", shape=(?, 30, 30, 96), dtype=float32)\n",
34 | "conv2 \n",
35 | "pool2 Tensor(\"pool2/MaxPool:0\", shape=(?, 14, 14, 256), dtype=float32)\n",
36 | "conv3 Tensor(\"conv3/Relu:0\", shape=(?, 14, 14, 384), dtype=float32)\n",
37 | "conv4 Tensor(\"conv4/Relu:0\", shape=(?, 14, 14, 384), dtype=float32)\n",
38 | "conv5 Tensor(\"conv5/Relu:0\", shape=(?, 14, 14, 256), dtype=float32)\n",
39 | "pool5 Tensor(\"pool5/MaxPool:0\", shape=(?, 6, 6, 256), dtype=float32)\n"
40 | ]
41 | }
42 | ],
43 | "source": [
44 | "def conv2d(scope, x, filter_shape, strides_x, strides_y, padding, std=0.01, biases=0.1):\n",
45 | " \"\"\" 高斯初始化: std=0.01, biases=0.1\n",
46 | " Args:\n",
47 | " scope: scope name of this layer.\n",
48 | " x: 4-D inputs. [batch_size, in_height, in_width, in_channels]\n",
49 | " filter_shape: A list of ints.[filter_height, filter_width, in_channels, out_channels]\n",
50 | " strides: A list of ints. 1-D tensor of length 4. The stride of the sliding window for each dimension of input.\n",
51 | " padding: A string from: \"SAME\", \"VALID\". The type of padding algorithm to use.\n",
52 | " Returns:\n",
53 | " h_conv: A 4-D tensor. [batch_size, out_height, out_width, out_channels].\n",
54 | " if padding is 'SAME', then out_height==in_height.\n",
55 | " else, out_height = in_height - filter_height + 1.\n",
56 | " the same for out_width.\n",
57 | " \"\"\"\n",
58 | " assert padding in ['SAME', 'VALID']\n",
59 | " strides = [1, strides_x, strides_y, 1]\n",
60 | " with tf.variable_scope(scope):\n",
61 | " W_conv = tf.Variable(tf.truncated_normal(filter_shape, dtype=tf.float32, stddev=std), name='weights')\n",
62 | " b_conv = tf.Variable(tf.constant(biases, shape=[filter_shape[-1]], dtype=tf.float32), name='biases')\n",
63 | " h_conv = tf.nn.conv2d(x, W_conv, strides=strides, padding=padding)\n",
64 | " h_conv_relu = tf.nn.relu(h_conv + b_conv)\n",
65 | " return h_conv_relu\n",
66 | "\n",
67 | "def max_pooling(scope, x, k_height, k_width, strides_x, strides_y, padding='SAME'):\n",
68 | " \"\"\"max pooling layer.\"\"\"\n",
69 | " with tf.variable_scope(scope):\n",
70 | " ksize = [1, k_height, k_width, 1]\n",
71 | " strides = [1, strides_x, strides_y, 1]\n",
72 | " h_pool = tf.nn.max_pool(x, ksize, strides, padding)\n",
73 | " return h_pool\n",
74 | "\n",
75 | "\n",
76 | "\n",
77 | "inputs = tf.placeholder(dtype=tf.float32, shape=[None, 256, 256, 3], name='inputs')\n",
78 | "print(inputs)\n",
79 | "\n",
80 | "# 1st Layer: Conv (w ReLu) -> Lrn -> Pool\n",
81 | "conv1 = conv2d('conv1', inputs, [11, 11, 3, 96], 4, 4, 'VALID', biases=0.0)\n",
82 | "pool1 = max_pooling('pool1', conv1, 3, 3, 2, 2, 'VALID')\n",
83 | "print('conv1', conv1)\n",
84 | "print('pool1', pool1)\n",
85 | "\n",
86 | "# 2nd Layer: Conv (w ReLu) -> Lrn -> Pool with 2 groups\n",
87 | "conv2 = conv2d('conv2', pool1, [5, 5, 96, 256], 1, 1, 'SAME')\n",
88 | "pool2 = max_pooling('pool2', conv2, 3, 3, 2, 2, 'VALID')\n",
89 | "print('conv2', conv2d)\n",
90 | "print('pool2', pool2)\n",
91 | "\n",
92 | "# 3rd Layer: Conv (w ReLu)\n",
93 | "conv3 = conv2d('conv3', pool2, [3, 3, 256, 384], 1, 1, 'SAME')\n",
94 | "print('conv3', conv3)\n",
95 | "\n",
96 | "# 4th Layer: Conv (w ReLu)\n",
97 | "conv4 = conv2d('conv4', conv3, [3, 3, 384, 384], 1, 1, 'SAME')\n",
98 | "print('conv4', conv4)\n",
99 | "\n",
100 | "# 5th Layer: Conv (w ReLu) -> Pool splitted into two groups\n",
101 | "conv5 = conv2d('conv5', conv4, [3, 3, 384, 256], 1, 1, 'SAME')\n",
102 | "pool5 = max_pooling('pool5', conv5, 3, 3, 2, 2, 'VALID')\n",
103 | "print('conv5', conv5)\n",
104 | "print('pool5', pool5)\n",
105 | "\n",
106 | "\n",
107 | "# # 6th Layer: Flatten -> FC (w ReLu) -> Dropout\n",
108 | "# flattened = tf.reshape(pool5, [-1, 6 * 6 * 256])\n",
109 | "# fc6 = fc('fc6', flattened, 6 * 6 * 256, 4096, std=0.005, biases=0.1, use_relu=True)\n",
110 | "# dropout6 = dropout(fc6, keep_prob)\n",
111 | "\n",
112 | "# # 7th Layer: FC (w ReLu) -> Dropout\n",
113 | "# fc7 = fc('fc7', dropout6, 4096, 4096, std=0.005, biases=0.1, use_relu=True)\n",
114 | "# dropout7 = dropout(fc7, keep_prob)\n",
115 | "\n",
116 | "# # 8th Layer: FC and return unscaled activations\n",
117 | "# fc8 = fc('fc8', dropout7, 4096, n_class, std=0.01, biases=0.0, use_relu=False)"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": []
126 | }
127 | ],
128 | "metadata": {
129 | "kernelspec": {
130 | "display_name": "Python 3",
131 | "language": "python",
132 | "name": "python3"
133 | },
134 | "language_info": {
135 | "codemirror_mode": {
136 | "name": "ipython",
137 | "version": 3
138 | },
139 | "file_extension": ".py",
140 | "mimetype": "text/x-python",
141 | "name": "python",
142 | "nbconvert_exporter": "python",
143 | "pygments_lexer": "ipython3",
144 | "version": "3.5.2"
145 | }
146 | },
147 | "nbformat": 4,
148 | "nbformat_minor": 2
149 | }
150 |
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/t10k-images-idx3-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/t10k-images-idx3-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/t10k-labels-idx1-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/t10k-labels-idx1-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/train-images-idx3-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/train-images-idx3-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/train-labels-idx1-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/train-labels-idx1-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/Tutorial_02 A simple feedforward network for MNIST.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 两层FC层做分类:MNIST\n",
8 | "\n",
9 | "在本教程中,我们来实现一个非常简单的两层全连接层来完成MNIST数据的分类问题。\n",
10 | "\n",
11 | "输入[-1,28*28], FC1 有 1024 个neurons, FC2 有 10 个neurons。这么简单的一个全连接网络,结果测试准确率达到了 0.98。还是非常棒的!!!"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 1,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "from __future__ import print_function\n",
21 | "from __future__ import division\n",
22 | "from __future__ import absolute_import\n",
23 | "\n",
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.Session(config=config)"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "### 1.导入数据\n",
41 | "下面导入数据这部分的警告可以不用管先,TensorFlow 非常恶心的地方就是不停地改 API,改到发麻。"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 2,
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
54 | "Instructions for updating:\n",
55 | "Use the retry module or similar alternatives.\n",
56 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
57 | "Instructions for updating:\n",
58 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
59 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
60 | "Instructions for updating:\n",
61 | "Please write your own downloading logic.\n",
62 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
63 | "Instructions for updating:\n",
64 | "Please use tf.data to implement this functionality.\n",
65 | "Extracting ../data/MNIST_data/train-images-idx3-ubyte.gz\n",
66 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
67 | "Instructions for updating:\n",
68 | "Please use tf.data to implement this functionality.\n",
69 | "Extracting ../data/MNIST_data/train-labels-idx1-ubyte.gz\n",
70 | "Extracting ../data/MNIST_data/t10k-images-idx3-ubyte.gz\n",
71 | "Extracting ../data/MNIST_data/t10k-labels-idx1-ubyte.gz\n",
72 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
73 | "Instructions for updating:\n",
74 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n"
75 | ]
76 | }
77 | ],
78 | "source": [
79 | "# 用tensorflow 导入数据\n",
80 | "from tensorflow.examples.tutorials.mnist import input_data\n",
81 | "mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=False, source_url='http://yann.lecun.com/exdb/mnist/')"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "name": "stdout",
91 | "output_type": "stream",
92 | "text": [
93 | "training data shape (55000, 784)\n",
94 | "training label shape (55000,)\n"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "print('training data shape ', mnist.train.images.shape)\n",
100 | "print('training label shape ', mnist.train.labels.shape)"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "metadata": {},
106 | "source": [
107 | "### 2. 构建网络"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 4,
113 | "metadata": {},
114 | "outputs": [
115 | {
116 | "name": "stdout",
117 | "output_type": "stream",
118 | "text": [
119 | "Tensor(\"add_1:0\", shape=(?, 10), dtype=float32)\n"
120 | ]
121 | }
122 | ],
123 | "source": [
124 | "# 权值初始化\n",
125 | "def weight_variable(shape):\n",
126 | " # 用正态分布来初始化权值\n",
127 | " initial = tf.truncated_normal(shape, stddev=0.1)\n",
128 | " return tf.Variable(initial)\n",
129 | "\n",
130 | "def bias_variable(shape):\n",
131 | " # 本例中用relu激活函数,所以用一个很小的正偏置较好\n",
132 | " initial = tf.constant(0.1, shape=shape)\n",
133 | " return tf.Variable(initial)\n",
134 | "\n",
135 | "\n",
136 | "# input_layer\n",
137 | "X_input = tf.placeholder(tf.float32, [None, 784])\n",
138 | "y_input = tf.placeholder(tf.int64, [None]) # 不使用 one-hot \n",
139 | "\n",
140 | "# FC1\n",
141 | "W_fc1 = weight_variable([784, 1024])\n",
142 | "b_fc1 = bias_variable([1024])\n",
143 | "h_fc1 = tf.nn.relu(tf.matmul(X_input, W_fc1) + b_fc1)\n",
144 | "\n",
145 | "# FC2\n",
146 | "W_fc2 = weight_variable([1024, 10])\n",
147 | "b_fc2 = bias_variable([10])\n",
148 | "# y_pre = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)\n",
149 | "logits = tf.matmul(h_fc1, W_fc2) + b_fc2\n",
150 | "\n",
151 | "print(logits)"
152 | ]
153 | },
154 | {
155 | "cell_type": "markdown",
156 | "metadata": {},
157 | "source": [
158 | "### 3.训练和评估\n",
159 | "下面我们将输入 mnist 的数据来进行训练。在下面有个 mnist.train.next_batch(batch_size=100) 的操作,每次从数据集中取出100个样本。如果想了解怎么实现的话建议看一下源码,其实挺简单的,很多时候需要我们自己去实现读取数据的这个函数。"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 5,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "step 500, train cost=0.153510, acc=0.950000; test cost=0.123346, acc=0.962500\n",
172 | "step 1000, train cost=0.087353, acc=0.960000; test cost=0.104876, acc=0.967400\n",
173 | "step 1500, train cost=0.033138, acc=0.990000; test cost=0.080937, acc=0.975200\n",
174 | "step 2000, train cost=0.028831, acc=0.990000; test cost=0.077214, acc=0.977800\n",
175 | "step 2500, train cost=0.004817, acc=1.000000; test cost=0.066441, acc=0.980000\n",
176 | "step 3000, train cost=0.015692, acc=1.000000; test cost=0.067741, acc=0.979400\n",
177 | "step 3500, train cost=0.011569, acc=1.000000; test cost=0.075138, acc=0.979400\n",
178 | "step 4000, train cost=0.006310, acc=1.000000; test cost=0.074501, acc=0.978300\n",
179 | "step 4500, train cost=0.008795, acc=1.000000; test cost=0.076483, acc=0.979100\n",
180 | "step 5000, train cost=0.027700, acc=0.980000; test cost=0.073973, acc=0.980000\n"
181 | ]
182 | }
183 | ],
184 | "source": [
185 | "# 1.损失函数:cross_entropy\n",
186 | "# 如果label是 one-hot 的话要换一下损失函数,参考:https://blog.csdn.net/tz_zs/article/details/76086457\n",
187 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_input, logits=logits)) \n",
188 | "# 2.优化函数:AdamOptimizer, 优化速度要比 GradientOptimizer 快很多\n",
189 | "train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)\n",
190 | "\n",
191 | "# 3.预测结果评估\n",
192 | "# 预测值中最大值(1)即分类结果,是否等于原始标签中的(1)的位置。argmax()取最大值所在的下标\n",
193 | "correct_prediction = tf.equal(tf.argmax(logits, 1), y_input) \n",
194 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n",
195 | "\n",
196 | "# 开始运行\n",
197 | "sess.run(tf.global_variables_initializer())\n",
198 | "# 这大概迭代了不到 10 个 epoch, 训练准确率已经达到了0.98\n",
199 | "for i in range(5000):\n",
200 | " X_batch, y_batch = mnist.train.next_batch(batch_size=100)\n",
201 | " cost, acc, _ = sess.run([cross_entropy, accuracy, train_step], feed_dict={X_input: X_batch, y_input: y_batch})\n",
202 | " if (i+1) % 500 == 0:\n",
203 | " test_cost, test_acc = sess.run([cross_entropy, accuracy], feed_dict={X_input: mnist.test.images, y_input: mnist.test.labels})\n",
204 | " print(\"step {}, train cost={:.6f}, acc={:.6f}; test cost={:.6f}, acc={:.6f}\".format(i+1, cost, acc, test_cost, test_acc))\n",
205 | " "
206 | ]
207 | }
208 | ],
209 | "metadata": {
210 | "anaconda-cloud": {},
211 | "kernelspec": {
212 | "display_name": "Python 3",
213 | "language": "python",
214 | "name": "python3"
215 | },
216 | "language_info": {
217 | "codemirror_mode": {
218 | "name": "ipython",
219 | "version": 3
220 | },
221 | "file_extension": ".py",
222 | "mimetype": "text/x-python",
223 | "name": "python",
224 | "nbconvert_exporter": "python",
225 | "pygments_lexer": "ipython3",
226 | "version": "3.5.2"
227 | }
228 | },
229 | "nbformat": 4,
230 | "nbformat_minor": 1
231 | }
232 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_03_2 The usage of Collection.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# TensorFlow 变量命名管理机制(二)\n",
8 | "\n",
9 | "\n",
10 | "### 1. 用 collection 来聚合变量\n",
11 | "前面介绍了 tensorflow 的变量命名机制,这里要补充一下 `tf.add_to_collection` 和 `tf.get_collection`的用法。\n",
12 | "\n",
13 | "因为神经网络中的参数非常多,有时候我们 只想对某些参数进行操作。除了前面通过变量名称的方法来获取参数之外, TensorFlow 中还有 collection 这么一种操作。\n",
14 | "\n",
15 | "collection 可以聚合多个**变量**或者**操作**。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import tensorflow as tf\n",
28 | "\n",
29 | "# 设置GPU按需增长\n",
30 | "config = tf.ConfigProto()\n",
31 | "config.gpu_options.allow_growth = True\n",
32 | "sess = tf.Session(config=config)"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "参考:[如何利用tf.add_to_collection、tf.get_collection以及tf.add_n来简化正则项的计算](https://blog.csdn.net/weixin_39980291/article/details/78352125)"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 2,
45 | "metadata": {},
46 | "outputs": [
47 | {
48 | "name": "stdout",
49 | "output_type": "stream",
50 | "text": [
51 | "vars in col1: [, ]\n"
52 | ]
53 | }
54 | ],
55 | "source": [
56 | "# 把变量添加到一个 collection 中\n",
57 | "v1 = tf.Variable([1,2,3], name='v1')\n",
58 | "v2 = tf.Variable([2], name='v2')\n",
59 | "v3 = tf.get_variable(name='v3', shape=(2,3))\n",
60 | "\n",
61 | "tf.add_to_collection('col1', v1) # 把 v1 添加到 col1 中\n",
62 | "tf.add_to_collection('col1', v3)\n",
63 | "\n",
64 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
65 | "print('vars in col1:', col1s)"
66 | ]
67 | },
68 | {
69 | "cell_type": "markdown",
70 | "metadata": {},
71 | "source": [
72 | "除了把变量添加到集合中,还可以把操作添加到集合中。"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 3,
78 | "metadata": {},
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "vars in col1: [, , ]\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "op1 = tf.add(v1, 2, name='add_op')\n",
90 | "tf.add_to_collection('col1', op1)\n",
91 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
92 | "print('vars in col1:', col1s)"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "此外,还可以加上 scope 的约束。"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 3,
105 | "metadata": {},
106 | "outputs": [
107 | {
108 | "name": "stdout",
109 | "output_type": "stream",
110 | "text": [
111 | "vars in col1 with scope=model: []\n"
112 | ]
113 | }
114 | ],
115 | "source": [
116 | "with tf.variable_scope('model'):\n",
117 | " v4 = tf.get_variable('v4', shape=[3,4])\n",
118 | " v5 = tf.Variable([1,2,3], name='v5')\n",
119 | "\n",
120 | "tf.add_to_collection('col1', v5)\n",
121 | "col1_vars = tf.get_collection(key='col1', scope='model') # 获取 col1 的变量\n",
122 | "print('vars in col1 with scope=model: ', col1_vars)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "### 2. tf.GraphKeys \n",
130 | "\n",
131 | "参考:[tf.GraphKeys 函数](https://www.w3cschool.cn/tensorflow_python/tensorflow_python-ne7t2ezd.html)\n",
132 | "\n",
133 | "用于图形集合的标准名称。\n",
134 | "\n",
135 | "\n",
136 | "标准库使用各种已知的名称来收集和检索与图形相关联的值。例如,如果没有指定,则 tf.Optimizer 子类默认优化收集的变量tf.GraphKeys.TRAINABLE_VARIABLES,但也可以传递显式的变量列表。\n",
137 | "\n",
138 | "定义了以下标准键:\n",
139 | "\n",
140 | "- GLOBAL_VARIABLES:默认的 Variable 对象集合,在分布式环境共享(模型变量是其中的子集)。参考:tf.global_variables。通常,所有TRAINABLE_VARIABLES 变量都将在 MODEL_VARIABLES,所有 MODEL_VARIABLES 变量都将在 GLOBAL_VARIABLES。\n",
141 | "- LOCAL_VARIABLES:每台计算机的局部变量对象的子集。通常用于临时变量,如计数器。注意:使用 tf.contrib.framework.local_variable 添加到此集合。\n",
142 | "- MODEL_VARIABLES:在模型中用于推理(前馈)的变量对象的子集。注意:使用 tf.contrib.framework.model_variable 添加到此集合。\n",
143 | "- TRAINABLE_VARIABLES:将由优化器训练的变量对象的子集。\n",
144 | "- SUMMARIES:在关系图中创建的汇总张量对象。\n",
145 | "- QUEUE_RUNNERS:用于为计算生成输入的 QueueRunner 对象。\n",
146 | "- MOVING_AVERAGE_VARIABLES:变量对象的子集,它也将保持移动平均值。\n",
147 | "- REGULARIZATION_LOSSES:在图形构造期间收集的正规化损失。\n",
148 | "\n",
149 | "这个知道就好了,要用的时候知道是怎么回事就行了。比如在 BN 层中就有这东西。"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": []
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": null,
162 | "metadata": {},
163 | "outputs": [],
164 | "source": []
165 | }
166 | ],
167 | "metadata": {
168 | "anaconda-cloud": {},
169 | "kernelspec": {
170 | "display_name": "Python 3",
171 | "language": "python",
172 | "name": "python3"
173 | },
174 | "language_info": {
175 | "codemirror_mode": {
176 | "name": "ipython",
177 | "version": 3
178 | },
179 | "file_extension": ".py",
180 | "mimetype": "text/x-python",
181 | "name": "python",
182 | "nbconvert_exporter": "python",
183 | "pygments_lexer": "ipython3",
184 | "version": "3.5.2"
185 | }
186 | },
187 | "nbformat": 4,
188 | "nbformat_minor": 1
189 | }
190 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_04_3 Convolutional network for MNIST(3).ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CNN做MNIST分类\n",
8 | "\n",
9 | "使用 tf.layers 高级 API 构建 CNN "
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
22 | " from ._conv import register_converters as _register_converters\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.InteractiveSession(config=config)\n",
34 | "\n",
35 | "import time"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "## 1.导入数据,用 tensorflow 导入"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 2,
48 | "metadata": {},
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
55 | "Instructions for updating:\n",
56 | "Use the retry module or similar alternatives.\n",
57 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
58 | "Instructions for updating:\n",
59 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
60 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
61 | "Instructions for updating:\n",
62 | "Please write your own downloading logic.\n",
63 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
64 | "Instructions for updating:\n",
65 | "Please use tf.data to implement this functionality.\n",
66 | "Extracting MNIST_data/train-images-idx3-ubyte.gz\n",
67 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
68 | "Instructions for updating:\n",
69 | "Please use tf.data to implement this functionality.\n",
70 | "Extracting MNIST_data/train-labels-idx1-ubyte.gz\n",
71 | "Extracting MNIST_data/t10k-images-idx3-ubyte.gz\n",
72 | "Extracting MNIST_data/t10k-labels-idx1-ubyte.gz\n",
73 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
74 | "Instructions for updating:\n",
75 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
76 | "(10000,)\n",
77 | "(55000,)\n"
78 | ]
79 | }
80 | ],
81 | "source": [
82 | "# 用tensorflow 导入数据\n",
83 | "from tensorflow.examples.tutorials.mnist import input_data\n",
84 | "mnist = input_data.read_data_sets('MNIST_data', one_hot=False)\n",
85 | "# 看看咱们样本的数量\n",
86 | "print(mnist.test.labels.shape)\n",
87 | "print(mnist.train.labels.shape)"
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {},
93 | "source": [
94 | "## 2. 构建网络"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 3,
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "Finished building network.\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "with tf.name_scope('inputs'):\n",
112 | " X_ = tf.placeholder(tf.float32, [None, 784])\n",
113 | " y_ = tf.placeholder(tf.int64, [None])\n",
114 | "\n",
115 | "# 把X转为卷积所需要的形式\n",
116 | "X = tf.reshape(X_, [-1, 28, 28, 1])\n",
117 | "h_conv1 = tf.layers.conv2d(X, filters=32, kernel_size=5, strides=1, padding='same', activation=tf.nn.relu, name='conv1')\n",
118 | "h_pool1 = tf.layers.max_pooling2d(h_conv1, pool_size=2, strides=2, padding='same', name='pool1')\n",
119 | "\n",
120 | "h_conv2 = tf.layers.conv2d(h_pool1, filters=64, kernel_size=5, strides=1, padding='same',activation=tf.nn.relu, name='conv2')\n",
121 | "h_pool2 = tf.layers.max_pooling2d(h_conv2, pool_size=2, strides=2, padding='same', name='pool2')\n",
122 | "\n",
123 | "# flatten\n",
124 | "h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\n",
125 | "h_fc1 = tf.layers.dense(h_pool2_flat, 1024, name='fc1', activation=tf.nn.relu)\n",
126 | "\n",
127 | "# dropout: 输出的维度和h_fc1一样,只是随机部分值被值为零\n",
128 | "keep_prob = tf.placeholder(tf.float32)\n",
129 | "h_fc1_drop = tf.nn.dropout(h_fc1, 0.5) # 实际测试的时候这里不应该使用 0.5,这里为了方便演示都这样写而已\n",
130 | "h_fc2 = tf.layers.dense(h_fc1_drop, units=10, name='fc2')\n",
131 | "# y_conv = tf.nn.softmax(h_fc2)\n",
132 | "y_conv = h_fc2\n",
133 | "print('Finished building network.')"
134 | ]
135 | },
136 | {
137 | "cell_type": "code",
138 | "execution_count": 4,
139 | "metadata": {},
140 | "outputs": [
141 | {
142 | "name": "stdout",
143 | "output_type": "stream",
144 | "text": [
145 | "Tensor(\"conv1/Relu:0\", shape=(?, 28, 28, 32), dtype=float32)\n",
146 | "Tensor(\"pool1/MaxPool:0\", shape=(?, 14, 14, 32), dtype=float32)\n",
147 | "Tensor(\"conv2/Relu:0\", shape=(?, 14, 14, 64), dtype=float32)\n",
148 | "Tensor(\"pool2/MaxPool:0\", shape=(?, 7, 7, 64), dtype=float32)\n",
149 | "Tensor(\"Reshape_1:0\", shape=(?, 3136), dtype=float32)\n",
150 | "Tensor(\"fc1/Relu:0\", shape=(?, 1024), dtype=float32)\n",
151 | "Tensor(\"fc2/BiasAdd:0\", shape=(?, 10), dtype=float32)\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "print(h_conv1)\n",
157 | "print(h_pool1)\n",
158 | "print(h_conv2)\n",
159 | "print(h_pool2)\n",
160 | "\n",
161 | "print(h_pool2_flat)\n",
162 | "print(h_fc1)\n",
163 | "print(h_fc2)"
164 | ]
165 | },
166 | {
167 | "cell_type": "markdown",
168 | "metadata": {},
169 | "source": [
170 | "## 3.训练和评估"
171 | ]
172 | },
173 | {
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | " 在测试的时候不使用 mini_batch, 那么测试的时候会占用较多的GPU(4497M),这在 notebook 交互式编程中是不推荐的。"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": 5,
183 | "metadata": {
184 | "scrolled": false
185 | },
186 | "outputs": [
187 | {
188 | "name": "stdout",
189 | "output_type": "stream",
190 | "text": [
191 | "step 0, training accuracy = 0.1100, pass 1.18s \n",
192 | "step 1000, training accuracy = 0.9800, pass 6.01s \n",
193 | "step 2000, training accuracy = 0.9800, pass 10.82s \n",
194 | "step 3000, training accuracy = 0.9700, pass 15.65s \n",
195 | "step 4000, training accuracy = 1.0000, pass 20.40s \n",
196 | "step 5000, training accuracy = 0.9800, pass 25.26s \n",
197 | "step 6000, training accuracy = 1.0000, pass 30.00s \n",
198 | "step 7000, training accuracy = 0.9900, pass 34.84s \n",
199 | "step 8000, training accuracy = 1.0000, pass 39.66s \n",
200 | "step 9000, training accuracy = 1.0000, pass 44.55s \n",
201 | "test accuracy 0.9924\n"
202 | ]
203 | }
204 | ],
205 | "source": [
206 | "# cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\n",
207 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
208 | " labels=tf.cast(y_, dtype=tf.int32), logits=y_conv))\n",
209 | "\n",
210 | "train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
211 | "\n",
212 | "correct_prediction = tf.equal(tf.argmax(y_conv,1), y_)\n",
213 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n",
214 | "sess.run(tf.global_variables_initializer())\n",
215 | "\n",
216 | "tic = time.time()\n",
217 | "for i in range(10000):\n",
218 | " batch = mnist.train.next_batch(100)\n",
219 | " if i%1000 == 0:\n",
220 | " train_accuracy = accuracy.eval(feed_dict={\n",
221 | " X_:batch[0], y_: batch[1], keep_prob: 1.0})\n",
222 | " print(\"step {}, training accuracy = {:.4f}, pass {:.2f}s \".format(i, train_accuracy, time.time() - tic))\n",
223 | " train_step.run(feed_dict={X_: batch[0], y_: batch[1]})\n",
224 | "\n",
225 | "print(\"test accuracy %g\"%accuracy.eval(feed_dict={\n",
226 | " X_: mnist.test.images, y_: mnist.test.labels}))"
227 | ]
228 | }
229 | ],
230 | "metadata": {
231 | "anaconda-cloud": {},
232 | "kernelspec": {
233 | "display_name": "Python 3",
234 | "language": "python",
235 | "name": "python3"
236 | },
237 | "language_info": {
238 | "codemirror_mode": {
239 | "name": "ipython",
240 | "version": 3
241 | },
242 | "file_extension": ".py",
243 | "mimetype": "text/x-python",
244 | "name": "python",
245 | "nbconvert_exporter": "python",
246 | "pygments_lexer": "ipython3",
247 | "version": "3.5.2"
248 | }
249 | },
250 | "nbformat": 4,
251 | "nbformat_minor": 1
252 | }
253 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_07 How to save the model.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 如何使用 tf.train.Saver() 来保存模型\n",
8 | "之前一直出错,主要是因为坑爹的编码问题。所以要注意文件的路径绝对不不要出现什么中文呀。"
9 | ]
10 | },
11 | {
12 | "cell_type": "code",
13 | "execution_count": 1,
14 | "metadata": {},
15 | "outputs": [
16 | {
17 | "name": "stderr",
18 | "output_type": "stream",
19 | "text": [
20 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
21 | " from ._conv import register_converters as _register_converters\n"
22 | ]
23 | },
24 | {
25 | "name": "stdout",
26 | "output_type": "stream",
27 | "text": [
28 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
29 | ]
30 | }
31 | ],
32 | "source": [
33 | "import tensorflow as tf\n",
34 | "config = tf.ConfigProto()\n",
35 | "config.gpu_options.allow_growth = True\n",
36 | "sess = tf.Session(config=config)\n",
37 | "\n",
38 | "# Create some variables.\n",
39 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
40 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
41 | "\n",
42 | "# Add an op to initialize the variables.\n",
43 | "init_op = tf.global_variables_initializer()\n",
44 | "\n",
45 | "# Add ops to save and restore all the variables.\n",
46 | "saver = tf.train.Saver()\n",
47 | "\n",
48 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
49 | "# Later, launch the model, initialize the variables, do some work, save the\n",
50 | "# variables to disk.\n",
51 | "sess.run(init_op)\n",
52 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
53 | "print(\"Model saved in file: %s\" % save_path)"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "注意,在上面保存完了模型之后。**Restart kernel** 之后才能使用下面的模型导入。否则会因为两次命名 \"v1\" 而导致名字错误。"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 1,
66 | "metadata": {},
67 | "outputs": [
68 | {
69 | "name": "stderr",
70 | "output_type": "stream",
71 | "text": [
72 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
73 | " from ._conv import register_converters as _register_converters\n"
74 | ]
75 | },
76 | {
77 | "name": "stdout",
78 | "output_type": "stream",
79 | "text": [
80 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
81 | "Model restored.\n",
82 | "[1. 2.3]\n",
83 | "55.5\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "import tensorflow as tf\n",
89 | "config = tf.ConfigProto()\n",
90 | "config.gpu_options.allow_growth = True\n",
91 | "sess = tf.Session(config=config)\n",
92 | "\n",
93 | "# Create some variables.\n",
94 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
95 | "v2 = tf.Variable(33.5, name=\"v2\")\n",
96 | "\n",
97 | "# Add ops to save and restore all the variables.\n",
98 | "saver = tf.train.Saver()\n",
99 | "\n",
100 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
101 | "# do some work with the model.\n",
102 | "# Restore variables from disk.\n",
103 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
104 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
105 | "print(\"Model restored.\")\n",
106 | "\n",
107 | "print(sess.run(v1))\n",
108 | "print(sess.run(v2))"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "导入模型之前,必须重新再定义一遍变量。\n",
116 | "\n",
117 | "但是并不需要全部变量都重新进行定义,只定义我们需要的变量就行了。\n",
118 | "\n",
119 | "也就是说,**你所定义的变量一定要在 checkpoint 中存在;但不是所有在checkpoint中的变量,你都要重新定义。**"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 1,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "name": "stderr",
129 | "output_type": "stream",
130 | "text": [
131 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
132 | " from ._conv import register_converters as _register_converters\n"
133 | ]
134 | },
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
140 | "Model restored.\n",
141 | "[1. 2.3]\n"
142 | ]
143 | }
144 | ],
145 | "source": [
146 | "import tensorflow as tf\n",
147 | "config = tf.ConfigProto()\n",
148 | "config.gpu_options.allow_growth = True\n",
149 | "sess = tf.Session(config=config)\n",
150 | "\n",
151 | "# Create some variables.\n",
152 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
153 | "\n",
154 | "# Add ops to save and restore all the variables.\n",
155 | "saver = tf.train.Saver()\n",
156 | "\n",
157 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
158 | "# do some work with the model.\n",
159 | "# Restore variables from disk.\n",
160 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
161 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
162 | "print(\"Model restored.\")\n",
163 | "\n",
164 | "print(sess.run(v1))"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "## 关于模型保存的一点心得\n",
172 | "\n",
173 | "```\n",
174 | "saver = tf.train.Saver(max_to_keep=3)\n",
175 | "```\n",
176 | "在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,我都不会保存太多模型,模型多了浪费空间,很多时候其实保存最好的模型就够了。方法就是每次迭代到一定步数就在验证集上计算一次 accuracy 或者 f1 值,如果本次结果比上次好才保存新的模型,否则没必要保存。\n",
177 | "\n",
178 | "如果你想用不同 epoch 保存下来的模型进行融合的话,3到5 个模型已经足够了,假设这各融合的模型成为 M,而最好的一个单模型称为 m_best, 这样融合的话对于M 确实可以比 m_best 更好。但是如果拿这个模型和其他结构的模型再做融合的话,M 的效果并没有 m_best 好,因为M 相当于做了平均操作,减少了该模型的“特性”。"
179 | ]
180 | }
181 | ],
182 | "metadata": {
183 | "anaconda-cloud": {},
184 | "kernelspec": {
185 | "display_name": "Python 3",
186 | "language": "python",
187 | "name": "python3"
188 | },
189 | "language_info": {
190 | "codemirror_mode": {
191 | "name": "ipython",
192 | "version": 3
193 | },
194 | "file_extension": ".py",
195 | "mimetype": "text/x-python",
196 | "name": "python",
197 | "nbconvert_exporter": "python",
198 | "pygments_lexer": "ipython3",
199 | "version": "3.5.2"
200 | }
201 | },
202 | "nbformat": 4,
203 | "nbformat_minor": 1
204 | }
205 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_08 [transfer learning] Add new variables to graph and save the new model.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 【迁移学习】往一个已经保存好的 模型添加新的变量\n",
8 | "在迁移学习中,通常我们已经训练好一个模型,现在需要修改模型的部分结构,用于我们的新任务。\n",
9 | "\n",
10 | "比如:\n",
11 | "\n",
12 | "在一个图片分类任务中,我们使用别人训练好的网络来提取特征,但是我们的分类数目和原模型不同,这样我们只能取到 fc 层,后面的分类层需要重新写。这样我们就需要添加新的变量。那么这些新加入的变量必须得初始化才能使用。可是我们又不能使用 'tf.global_variables_initializer()' 来初始化,否则原本训练好的模型就没用了。\n",
13 | "\n",
14 | "关于怎么样单独初始化新增的变量,可以参考下面两个链接:\n",
15 | "- [1]https://stackoverflow.com/questions/35164529/in-tensorflow-is-there-any-way-to-just-initialize-uninitialised-variables\n",
16 | "- [2]https://stackoverflow.com/questions/35013080/tensorflow-how-to-get-all-variables-from-rnn-cell-basiclstm-rnn-cell-multirnn\n",
17 | "\n",
18 | "简单的例子可以直接看下面我的实现方式。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### 初始模型定义与保存\n",
26 | "首先定义一个模型,里边有 v1, v2 两个变量,我们把这个模型保存起来。"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {},
33 | "outputs": [
34 | {
35 | "name": "stderr",
36 | "output_type": "stream",
37 | "text": [
38 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
39 | " from ._conv import register_converters as _register_converters\n"
40 | ]
41 | },
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "import tensorflow as tf\n",
52 | "config = tf.ConfigProto()\n",
53 | "config.gpu_options.allow_growth = True\n",
54 | "sess = tf.Session(config=config)\n",
55 | "\n",
56 | "# Create some variables.\n",
57 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
58 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
59 | "\n",
60 | "\n",
61 | "init_op = tf.global_variables_initializer()\n",
62 | "saver = tf.train.Saver()\n",
63 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
64 | "sess.run(init_op)\n",
65 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
66 | "print(\"Model saved in file: %s\" % save_path)"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**restart(重启kernel然后执行下面cell的代码)**\n",
74 | "### 导入已经保存好的模型,并添加新的变量\n",
75 | "现在把之前保存好的模型,我只需要其中的 v1 变量。同时我还要添加新的变量 v3。"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 1,
81 | "metadata": {
82 | "scrolled": false
83 | },
84 | "outputs": [
85 | {
86 | "name": "stderr",
87 | "output_type": "stream",
88 | "text": [
89 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
90 | " from ._conv import register_converters as _register_converters\n"
91 | ]
92 | },
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
98 | "[1. 2.3]\n",
99 | "[1. 2.3]\n",
100 | "666\n"
101 | ]
102 | },
103 | {
104 | "data": {
105 | "text/plain": [
106 | "'../ckpt/test-model.ckpt-2'"
107 | ]
108 | },
109 | "execution_count": 1,
110 | "metadata": {},
111 | "output_type": "execute_result"
112 | }
113 | ],
114 | "source": [
115 | "import tensorflow as tf\n",
116 | "config = tf.ConfigProto()\n",
117 | "config.gpu_options.allow_growth = True\n",
118 | "sess = tf.Session(config=config)\n",
119 | "\n",
120 | "# Create some variables.\n",
121 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
122 | "\n",
123 | "# ** 导入训练好的模型\n",
124 | "saver = tf.train.Saver()\n",
125 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
126 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
127 | "print(sess.run(v1))\n",
128 | "\n",
129 | "# ** 定义新的变量并单独初始化新定义的变量\n",
130 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
131 | "init_new = tf.variables_initializer([v3])\n",
132 | "sess.run(init_new)\n",
133 | "# 。。。这里就可以进行 fine-tune 了\n",
134 | "print(sess.run(v1))\n",
135 | "print(sess.run(v3))\n",
136 | "\n",
137 | "# ** 保存新的模型。 \n",
138 | "# 注意!注意!注意! 一定一定一定要重新定义 saver, 这样才能把 v3 添加到 checkpoint 中\n",
139 | "saver = tf.train.Saver()\n",
140 | "saver.save(sess, ckpt_path, global_step=2)"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "**restart(重启kernel然后执行下面cell的代码)**\n",
148 | "### 这样就完成了 fine-tune, 得到了新的模型"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 1,
154 | "metadata": {
155 | "scrolled": false
156 | },
157 | "outputs": [
158 | {
159 | "name": "stderr",
160 | "output_type": "stream",
161 | "text": [
162 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
163 | " from ._conv import register_converters as _register_converters\n"
164 | ]
165 | },
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-2\n",
171 | "Model restored.\n",
172 | "[1. 2.3]\n",
173 | "666\n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "import tensorflow as tf\n",
179 | "config = tf.ConfigProto()\n",
180 | "config.gpu_options.allow_growth = True\n",
181 | "sess = tf.Session(config=config)\n",
182 | "\n",
183 | "# Create some variables.\n",
184 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
185 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
186 | "# Add ops to save and restore all the variables.\n",
187 | "saver = tf.train.Saver()\n",
188 | "\n",
189 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
190 | "# do some work with the model.\n",
191 | "# Restore variables from disk.\n",
192 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
193 | "saver.restore(sess, ckpt_path + '-'+ str(2))\n",
194 | "print(\"Model restored.\")\n",
195 | "\n",
196 | "print(sess.run(v1))\n",
197 | "print(sess.run(v3))"
198 | ]
199 | },
200 | {
201 | "cell_type": "code",
202 | "execution_count": null,
203 | "metadata": {
204 | "collapsed": true
205 | },
206 | "outputs": [],
207 | "source": []
208 | }
209 | ],
210 | "metadata": {
211 | "anaconda-cloud": {},
212 | "kernelspec": {
213 | "display_name": "Python 3",
214 | "language": "python",
215 | "name": "python3"
216 | },
217 | "language_info": {
218 | "codemirror_mode": {
219 | "name": "ipython",
220 | "version": 3
221 | },
222 | "file_extension": ".py",
223 | "mimetype": "text/x-python",
224 | "name": "python",
225 | "nbconvert_exporter": "python",
226 | "pygments_lexer": "ipython3",
227 | "version": "3.5.2"
228 | }
229 | },
230 | "nbformat": 4,
231 | "nbformat_minor": 1
232 | }
233 |
--------------------------------------------------------------------------------
/example-python/Tutorial-graph.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import os
5 |
6 | config = tf.ConfigProto()
7 | config.gpu_options.allow_growth = True
8 | sess = tf.Session(config=config)
9 |
10 | """TensorBoard 简单例子。
11 | tf.summary.scalar('var_name', var) # 记录标量的变化
12 | tf.summary.histogram('vec_name', vec) # 记录向量或者矩阵,tensor的数值分布变化。
13 |
14 | merged = tf.summary.merge_all() # 把所有的记录并把他们写到 log_dir 中
15 | train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph) # 保存位置
16 |
17 | 运行完后,在命令行中输入 tensorboard --logdir=log_dir_path
18 | """
19 |
20 | tf.app.flags.DEFINE_string('log_dir', 'summary/graph/', 'log saving path')
21 | FLAGS = tf.app.flags.FLAGS
22 | if os.path.exists(FLAGS.log_dir):
23 | os.rmdir(FLAGS.log_dir)
24 | os.makedirs(FLAGS.log_dir)
25 | print 'created log_dir path'
26 |
27 | with tf.name_scope('add_example'):
28 | a = tf.Variable(tf.truncated_normal([100, 1], mean=0.5, stddev=0.5), name='var_a')
29 | tf.summary.histogram('a_hist', a)
30 | b = tf.Variable(tf.truncated_normal([100, 1], mean=-0.5, stddev=1.0), name='var_b')
31 | tf.summary.histogram('b_hist', b)
32 | increase_b = tf.assign(b, b + 0.05)
33 | c = tf.add(a, b)
34 | tf.summary.histogram('c_hist', c)
35 | c_mean = tf.reduce_mean(c)
36 | tf.summary.scalar('c_mean', c_mean)
37 | merged = tf.summary.merge_all()
38 | writer = tf.summary.FileWriter(FLAGS.log_dir + 'add_example', sess.graph)
39 |
40 |
41 | def main(_):
42 | sess.run(tf.global_variables_initializer())
43 | for step in xrange(500):
44 | sess.run([merged, increase_b]) # 每步改变一次 b 的值
45 | summary = sess.run(merged)
46 | writer.add_summary(summary, step)
47 | writer.close()
48 |
49 |
50 | if __name__ == '__main__':
51 | tf.app.run()
52 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_1_numpy_data_1.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for numpy data.
2 | With dataset.make_one_shot_iterator(), it is easy but very slow.
3 | """
4 |
5 | from __future__ import print_function
6 | from __future__ import division
7 | from __future__ import absolute_import
8 |
9 | import warnings
10 |
11 | warnings.filterwarnings('ignore') # 不打印 warning
12 | import tensorflow as tf
13 |
14 | # 设置GPU按需增长
15 | config = tf.ConfigProto()
16 | config.gpu_options.allow_growth = True
17 | sess = tf.Session(config=config)
18 |
19 | import numpy as np
20 | import time
21 | import sys
22 |
23 | from tensorflow.examples.tutorials.mnist import input_data
24 |
25 | mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=True)
26 |
27 | X = mnist.train.images
28 | y = mnist.train.labels
29 |
30 | batch_size = 128
31 | # 创建 dataset
32 | dataset = tf.data.Dataset.from_tensor_slices((X, y))
33 | print('dataset is', dataset)
34 |
35 | # 对数据进行操作
36 | # def pre_func(X, y):
37 | # X = tf.multiply(X, 2)
38 | # return X, y
39 | # dataset = dataset.map(pre_func)
40 |
41 | dataset = dataset.shuffle(buffer_size=5000) # 设置 buffle_size 越大,shuffle 越均匀
42 | dataset = dataset.repeat().batch(batch_size)
43 | print('after get batch', dataset)
44 |
45 | # 生成迭代器
46 | iterator = dataset.make_one_shot_iterator()
47 | print(iterator)
48 |
49 | # 迭代取值
50 | time0 = time.time()
51 | for count in range(100): # 100batch 125 seconds
52 | X_batch, y_batch = sess.run(iterator.get_next())
53 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
54 | sys.stdout.flush()
55 | # print('count = {} : y = {}'.format(count, y_batch.reshape([-1])))
56 |
57 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_1_numpy_data_2.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for numpy data.
2 | With dataset.make_initializable_iterator(), it is more faster then dataset.make_one_shot_iterator().
3 | """
4 |
5 | from __future__ import print_function
6 | from __future__ import division
7 | from __future__ import absolute_import
8 |
9 | import warnings
10 |
11 | warnings.filterwarnings('ignore') # 不打印 warning
12 | import tensorflow as tf
13 |
14 | # 设置GPU按需增长
15 | config = tf.ConfigProto()
16 | config.gpu_options.allow_growth = True
17 | sess = tf.Session(config=config)
18 |
19 | import numpy as np
20 | import time
21 | import sys
22 |
23 | from tensorflow.examples.tutorials.mnist import input_data
24 |
25 | mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=True)
26 |
27 | X = mnist.train.images
28 | y = mnist.train.labels
29 |
30 | # 使用 placeholder 来取代 array,并使用 initiable iterator, 在需要的时候再将 array 传进去
31 | # 这样能够避免把大数组保存在图中
32 | X_placeholder = tf.placeholder(dtype=X.dtype, shape=X.shape)
33 | y_placeholder = tf.placeholder(dtype=y.dtype, shape=y.shape)
34 |
35 | batch_size = 128
36 | # 创建 dataset
37 | dataset = tf.data.Dataset.from_tensor_slices((X_placeholder, y_placeholder))
38 | print('dataset is', dataset)
39 |
40 | # 对数据进行操作
41 | # def pre_func(X, y):
42 | # X = tf.multiply(X, 2)
43 | # return X, y
44 | # dataset = dataset.map(pre_func)
45 |
46 | dataset = dataset.shuffle(buffer_size=5000) # 设置 buffle_size 越大,shuffle 越均匀
47 | dataset = dataset.repeat().batch(batch_size)
48 | print('after get batch', dataset)
49 |
50 | # 生成迭代器
51 | iterator = dataset.make_initializable_iterator()
52 | print(iterator)
53 | sess.run(iterator.initializer, feed_dict={X_placeholder: X, y_placeholder: y})
54 |
55 | # 迭代取值
56 | time0 = time.time()
57 | for count in range(100): # 100batch 1.95 seconds
58 | X_batch, y_batch = sess.run(iterator.get_next())
59 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
60 | sys.stdout.flush()
61 | # print('count = {} : y = {}'.format(count, y_batch.reshape([-1])))
62 |
63 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_2_image_data_1.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for image(png) data.
2 | With one-shot
3 | """
4 |
5 | from __future__ import print_function
6 | from __future__ import division
7 | from __future__ import absolute_import
8 |
9 | import warnings
10 |
11 | warnings.filterwarnings('ignore') # 不打印 warning
12 | import tensorflow as tf
13 |
14 |
15 | # 设置GPU按需增长
16 | config = tf.ConfigProto()
17 | config.gpu_options.allow_growth = True
18 | sess = tf.Session(config=config)
19 |
20 | import numpy as np
21 | import sys
22 | import os
23 | import time
24 |
25 |
26 | def get_file_path(data_path='../data/sketchy_000000000000/'):
27 | """解析文件夹,获取每个文件的路径和标签。"""
28 | img_paths = list()
29 | labels = list()
30 | class_dirs = sorted(os.listdir(data_path))
31 | dict_class2id = dict()
32 | for i in range(len(class_dirs)):
33 | label = i
34 | class_dir = class_dirs[i]
35 | dict_class2id[class_dir] = label
36 | class_path = os.path.join(data_path, class_dir) # 每类的路径
37 | file_names = sorted(os.listdir(class_path))
38 | for file_name in file_names:
39 | file_path = os.path.join(class_path, file_name)
40 | img_paths.append(file_path)
41 | labels.append(label)
42 | return img_paths, labels
43 |
44 |
45 | def parse_png(img_path, label, height=256, width=256, channel=3):
46 | """根据 img_path 读入图片并做相应处理"""
47 | # 从硬盘上读取图片
48 | img = tf.read_file(img_path)
49 | img_decoded = tf.image.decode_png(img, channels=channel)
50 | # resize
51 | img_resized = tf.image.resize_images(img_decoded, [height, width])
52 | # normalize
53 | img_norm = img_resized * 1.0 / 127.5 - 1.0
54 | return img_norm, label
55 |
56 |
57 | img_paths, labels = get_file_path()
58 | batch_size = 128
59 | dataset = tf.data.Dataset.from_tensor_slices((img_paths, labels))
60 | dataset = dataset.map(parse_png)
61 | print('parsing image', dataset)
62 | dataset = dataset.shuffle(buffer_size=5000).repeat().batch(batch_size)
63 | print('batch', dataset)
64 |
65 | # 生成迭代器
66 | iterator = dataset.make_one_shot_iterator()
67 | print(iterator)
68 |
69 | time0 = time.time()
70 | for count in range(100):
71 | X_batch, y_batch = sess.run(iterator.get_next())
72 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
73 | sys.stdout.flush()
74 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_2_image_data_2.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for image(png) data.
2 | With TF Queue, shuffle data
3 |
4 | refer: https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/5_DataManagement/build_an_image_dataset.py
5 | """
6 |
7 | from __future__ import print_function
8 | from __future__ import division
9 | from __future__ import absolute_import
10 |
11 | import warnings
12 |
13 | warnings.filterwarnings('ignore') # 不打印 warning
14 | import tensorflow as tf
15 |
16 | # 设置GPU按需增长
17 | config = tf.ConfigProto()
18 | config.gpu_options.allow_growth = True
19 | sess = tf.Session(config=config)
20 |
21 | import numpy as np
22 | import sys
23 | import os
24 | import time
25 |
26 |
27 | def get_file_path(data_path='../data/sketchy_000000000000/'):
28 | """解析文件夹,获取每个文件的路径和标签。"""
29 | img_paths = list()
30 | labels = list()
31 | class_dirs = sorted(os.listdir(data_path))
32 | dict_class2id = dict()
33 | for i in range(len(class_dirs)):
34 | label = i
35 | class_dir = class_dirs[i]
36 | dict_class2id[class_dir] = label
37 | class_path = os.path.join(data_path, class_dir) # 每类的路径
38 | file_names = sorted(os.listdir(class_path))
39 | for file_name in file_names:
40 | file_path = os.path.join(class_path, file_name)
41 | img_paths.append(file_path)
42 | labels.append(label)
43 | return img_paths, labels
44 |
45 |
46 | def get_batch(img_paths, labels, batch_size=128, height=256, width=256, channel=3):
47 | """根据 img_path 读入图片并做相应处理"""
48 | # 从硬盘上读取图片
49 | img_paths = np.asarray(img_paths)
50 | labels = np.asarray(labels)
51 |
52 | img_paths = tf.convert_to_tensor(img_paths, dtype=tf.string)
53 | labels = tf.convert_to_tensor(labels, dtype=tf.int32)
54 | # Build a TF Queue, shuffle data
55 | image, label = tf.train.slice_input_producer([img_paths, labels], shuffle=True)
56 | # Read images from disk
57 | image = tf.read_file(image)
58 | image = tf.image.decode_jpeg(image, channels=channel)
59 | # Resize images to a common size
60 | image = tf.image.resize_images(image, [height, width])
61 | # Normalize
62 | image = image * 1.0 / 127.5 - 1.0
63 | # Create batches
64 | X_batch, y_batch = tf.train.batch([image, label], batch_size=batch_size,
65 | capacity=batch_size * 8,
66 | num_threads=4)
67 | return X_batch, y_batch
68 |
69 |
70 | img_paths, labels = get_file_path()
71 | X_batch, y_batch = get_batch(img_paths, labels)
72 |
73 | sess.run(tf.global_variables_initializer())
74 | tf.train.start_queue_runners(sess=sess)
75 |
76 | time0 = time.time()
77 | for count in range(100): # 11s for 100batch
78 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
79 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
80 | sys.stdout.flush()
81 |
--------------------------------------------------------------------------------
/figs/conv_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/conv_mnist.png
--------------------------------------------------------------------------------
/figs/graph2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/graph2.png
--------------------------------------------------------------------------------
/figs/lstm_8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/lstm_8.png
--------------------------------------------------------------------------------
/figs/lstm_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/lstm_mnist.png
--------------------------------------------------------------------------------
/models/README.md:
--------------------------------------------------------------------------------
1 | # TensorFlow 实战
2 | 下面的每个例子都是相互独立的,每个文件夹下面的代码都是可以单独运行的,不依赖于其他文件夹。
3 |
4 | ## m01_batch_normalization: Batch Normalization 的使用。
5 | 参考:[tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
6 |
7 | ## m02_dcgan: 使用 DCGAN 生成二次元头像
8 | 参考:
9 | - [原论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1511.06434)
10 | - [GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059)
11 | - [代码:carpedm20/DCGAN-tensorflow](https://github.com/carpedm20/DCGAN-tensorflow)
12 | - [代码:aymericdamien/TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/dcgan.py)
13 |
14 | 这里的 notebook 和 .py 文件的内容是一样的。本例子和下面的 GAN 模型用的数据集也是用了[GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059) 的二次元头像,感觉这里例子比较有意思。如果想使用其他数据集的话,只需要把数据集换一下就行了。
15 |
16 | 下载链接: https://pan.baidu.com/s/1HBJpfkIFaGh0s2nfNXJsrA 密码: x39r
17 |
18 | 下载后把所有的图片解压到一个文件夹中,比如本例中是: `data_path = '../../data/anime/'`
19 |
20 | 运行: `python dcgan.py `
21 |
22 | ## m03_wgan: 使用 WGAN 生成二次元头像
23 | 这里的生成器和判别器我只实现了 DCGAN,没有实现 MLP. 如果想实现的话可以参考下面的两个例子。
24 | 参考:
25 | - [原论文:Wasserstein GAN](https://arxiv.org/pdf/1701.07875.pdf)
26 | - [代码:jiamings/wgan](https://github.com/jiamings/wgan)
27 | - [代码:Zardinality/WGAN-tensorflow](https://github.com/Zardinality/WGAN-tensorflow)
28 |
29 | 原版的 wgan: `python wgan.py `
30 |
31 | 改进的 wgan-gp: `python wgan_gp.py`
32 |
33 |
34 | ## m04_pix2pix: image-to-image GAN
35 |
36 |
37 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/README.md:
--------------------------------------------------------------------------------
1 | Batch Normalization 的使用。
2 |
3 | 参考:[tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
4 |
5 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/mnist_cnn.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | """网络结构定义。
4 | 关于 tf.layers.batch_normalization() 的理解参考: [tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
5 | """
6 |
7 | from __future__ import print_function, division, absolute_import
8 |
9 | import tensorflow as tf
10 |
11 |
12 | class Model(object):
13 | def __init__(self, settings):
14 | self.model_name = settings.model_name
15 | self.img_size = settings.img_size
16 | self.n_channel = settings.n_channel
17 | self.n_class = settings.n_class
18 | self.drop_rate = settings.drop_rate
19 | self.global_step = tf.Variable(0, trainable=False, name='Global_Step')
20 | self.learning_rate = tf.train.exponential_decay(settings.learning_rate,
21 | self.global_step, settings.decay_step,
22 | settings.decay_rate, staircase=True)
23 |
24 | self.conv_weight_initializer = tf.contrib.layers.xavier_initializer(uniform=True)
25 | self.conv_biases_initializer = tf.zeros_initializer()
26 | # 最后一个全连接层的初始化
27 | self.fc_weight_initializer = tf.truncated_normal_initializer(0.0, 0.005)
28 | self.fc_biases_initializer = tf.constant_initializer(0.1)
29 |
30 | # placeholders
31 | with tf.name_scope('Inputs'):
32 | self.X_inputs = tf.placeholder(tf.float32, [None, self.img_size, self.img_size, self.n_channel],
33 | name='X_inputs')
34 | self.y_inputs = tf.placeholder(tf.int64, [None], name='y_input')
35 |
36 | self.logits_train = self.inference(is_training=True, reuse=False)
37 | self.logits_test = self.inference(is_training=False, reuse=True)
38 |
39 | # 预测结果
40 | self.pred_lables = tf.argmax(self.logits_test, axis=1)
41 | self.pred_probas = tf.nn.softmax(self.logits_test)
42 | self.test_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
43 | labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_test))
44 | self.test_acc = tf.reduce_mean(tf.cast(tf.equal(self.pred_lables, self.y_inputs), tf.float32))
45 |
46 | # 训练结果
47 | self.train_lables = tf.argmax(self.logits_train, axis=1)
48 | self.train_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
49 | labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_train))
50 | self.train_acc = tf.reduce_mean(tf.cast(tf.equal(self.train_lables, self.y_inputs), tf.float32))
51 |
52 | self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
53 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
54 | """
55 | **注意:** 下面一定要使用这样的方式来写。
56 | with tf.control_dependencies(update_ops) 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作。
57 | 这里的 update_ops 在这里主要是更新 BN 层的滑动平均值和滑动方差。
58 |
59 | 除了 BN 层外,还有 center loss 中也采用这样的方式,在 center loss 中,update_ops 操作主要更新类中心向量。
60 | 因为之前在 center loss 犯过没更新 center 的错误,所以印象非常深刻。
61 | """
62 | with tf.control_dependencies(update_ops): # 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作
63 | self.train_op = self.optimizer.minimize(self.train_loss, global_step=self.global_step)
64 |
65 | def inference(self, is_training, reuse=False):
66 | """带 BN 层的CNN """
67 | with tf.variable_scope('cnn', reuse=reuse):
68 | # 第一个卷积层 + BN + max_pooling
69 | conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding='same',
70 | kernel_initializer=self.conv_weight_initializer, name='conv1')
71 | bn1 = tf.layers.batch_normalization(conv1, training=is_training, name='bn1')
72 | bn1 = tf.nn.relu(bn1) # 一般都是先经过 BN 层再加激活函数的
73 | pool1 = tf.layers.max_pooling2d(bn1, pool_size=2, strides=2, padding='same', name='pool1')
74 |
75 | # 第二个卷积层 + BN + max_pooling
76 | conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding='same',
77 | kernel_initializer=self.conv_weight_initializer, name='conv2')
78 | bn2 = tf.layers.batch_normalization(conv2, training=is_training, name='bn2')
79 | bn2 = tf.nn.relu(bn2) # 一般都是先经过 BN 层再加激活函数的
80 | pool2 = tf.layers.max_pooling2d(bn2, pool_size=2, strides=2, padding='same', name='pool2')
81 |
82 | # 全连接,使用卷积来实现
83 | _, k_height, k_width, k_depth = pool2.get_shape().as_list()
84 | fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, name='fc1')
85 | bn3 = tf.layers.batch_normalization(fc1, training=is_training, name='bn3')
86 | bn3 = tf.nn.relu(bn3)
87 |
88 | # dropout, 如果 is_training = False 就不会执行 dropout
89 | fc1_drop = tf.layers.dropout(bn3, rate=self.drop_rate, training=is_training)
90 |
91 | # 最后的输出层
92 | flatten_layer = tf.layers.flatten(fc1_drop)
93 | out = tf.layers.dense(flatten_layer, units=self.n_class)
94 | return out
95 |
96 | def inference2(self, is_training, reuse=False):
97 | """不带 BN 层的 CNN。"""
98 | with tf.variable_scope('cnn', reuse=reuse):
99 | # 第一个卷积层 + BN + max_pooling
100 | conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding='same',
101 | activation=tf.nn.relu,
102 | kernel_initializer=self.conv_weight_initializer, name='conv1')
103 | pool1 = tf.layers.max_pooling2d(conv1, pool_size=2, strides=2, padding='same', name='pool1')
104 |
105 | # 第二个卷积层 + BN + max_pooling
106 | conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding='same',
107 | activation=tf.nn.relu,
108 | kernel_initializer=self.conv_weight_initializer, name='conv2')
109 | pool2 = tf.layers.max_pooling2d(conv2, pool_size=2, strides=2, padding='same', name='pool2')
110 |
111 | # 全连接,使用卷积来实现
112 | _, k_height, k_width, k_depth = pool2.get_shape().as_list()
113 | fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, activation=tf.nn.relu, name='fc1')
114 |
115 | # dropout, 如果 is_training = False 就不会执行 dropout
116 | fc1_drop = tf.layers.dropout(fc1, rate=self.drop_rate, training=is_training)
117 |
118 | # 最后的输出层
119 | flatten_layer = tf.layers.flatten(fc1_drop)
120 | out = tf.layers.dense(flatten_layer, units=self.n_class)
121 | return out
122 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/predict.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | from __future__ import print_function, division, absolute_import
4 |
5 | import tensorflow as tf
6 | import numpy as np
7 | import os
8 | import time
9 |
10 | from mnist_cnn import Model
11 |
12 |
13 | class Settings(object):
14 | def __init__(self):
15 | self.model_name = 'mnist_cnn'
16 | self.img_size = 28
17 | self.n_channel = 1
18 | self.n_class = 10
19 | self.drop_rate = 0.5
20 | self.learning_rate = 0.001
21 | self.decay_step = 2000
22 | self.decay_rate = 0.5
23 | self.training_steps = 10000
24 | self.batch_size = 100
25 |
26 | self.summary_path = 'summary/' + self.model_name + '/'
27 | self.ckpt_path = 'ckpt/' + self.model_name + '/'
28 |
29 | if not os.path.exists(self.summary_path):
30 | os.makedirs(self.summary_path)
31 | if not os.path.exists(self.ckpt_path):
32 | os.makedirs(self.ckpt_path)
33 |
34 |
35 | def main():
36 | """模型训练。"""
37 | from tensorflow.examples.tutorials.mnist import input_data
38 |
39 | mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False)
40 | print(mnist.test.labels.shape)
41 | print(mnist.train.labels.shape)
42 |
43 | my_setting = Settings()
44 | with tf.variable_scope(my_setting.model_name):
45 | model = Model(my_setting)
46 |
47 | # 模型要保存的变量
48 | var_list = tf.trainable_variables()
49 | if model.global_step not in var_list:
50 | var_list.append(model.global_step)
51 | # 添加 BN 层的均值和方差
52 | global_vars = tf.global_variables()
53 | bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
54 | bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
55 | var_list += bn_moving_vars
56 | # 创建Saver
57 | saver = tf.train.Saver(var_list=var_list)
58 |
59 | config = tf.ConfigProto()
60 | config.gpu_options.allow_growth = True
61 | with tf.Session(config=config) as sess:
62 | if not os.path.exists(my_setting.ckpt_path + 'checkpoint'):
63 | print("There is no checkpoit, please check out.")
64 | exit()
65 | saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path))
66 | tic = time.time()
67 | n_batch = len(mnist.test.labels) // my_setting.batch_size
68 | predict_labels = list()
69 | true_labels = list()
70 | for step in range(n_batch):
71 | X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=False)
72 | X_batch = X_batch.reshape([-1, 28, 28, 1])
73 | pred_label, test_loss, test_acc = sess.run([model.pred_lables, model.test_loss, model.test_acc],
74 | feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
75 | predict_labels.append(pred_label)
76 | true_labels.append(y_batch)
77 | predict_labels = np.hstack(predict_labels)
78 | true_labels = np.hstack(true_labels)
79 | acc = np.sum(predict_labels == true_labels) / len(true_labels)
80 | print("Test sample number = {}, acc = {:.4f}, pass {:.2f}s".format(len(true_labels), acc, time.time() - tic))
81 |
82 |
83 | if __name__ == '__main__':
84 | main()
85 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/train.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | from __future__ import print_function, division, absolute_import
4 |
5 | import tensorflow as tf
6 | import os
7 | import time
8 |
9 | from mnist_cnn import Model
10 |
11 |
12 | class Settings(object):
13 | def __init__(self):
14 | self.model_name = 'mnist_cnn'
15 | self.img_size = 28
16 | self.n_channel = 1
17 | self.n_class = 10
18 | self.drop_rate = 0.5
19 | self.learning_rate = 0.001
20 | self.decay_step = 2000
21 | self.decay_rate = 0.5
22 | self.training_steps = 10000 # 耗时 90s
23 | self.batch_size = 100
24 |
25 | self.summary_path = 'summary/' + self.model_name + '/'
26 | self.ckpt_path = 'ckpt/' + self.model_name + '/'
27 |
28 | if not os.path.exists(self.summary_path):
29 | os.makedirs(self.summary_path)
30 | if not os.path.exists(self.ckpt_path):
31 | os.makedirs(self.ckpt_path)
32 |
33 |
34 | def main():
35 | """模型训练。"""
36 | from tensorflow.examples.tutorials.mnist import input_data
37 |
38 | mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False)
39 | print(mnist.test.labels.shape)
40 | print(mnist.train.labels.shape)
41 |
42 | my_setting = Settings()
43 | with tf.variable_scope(my_setting.model_name):
44 | model = Model(my_setting)
45 |
46 | # 模型要保存的变量
47 | var_list = tf.trainable_variables()
48 | if model.global_step not in var_list:
49 | var_list.append(model.global_step)
50 | # 添加 BN 层的均值和方差
51 | global_vars = tf.global_variables()
52 | bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
53 | bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
54 | var_list += bn_moving_vars
55 | # 创建Saver
56 | saver = tf.train.Saver(var_list=var_list)
57 |
58 | config = tf.ConfigProto()
59 | config.gpu_options.allow_growth = True
60 | with tf.Session(config=config) as sess:
61 | print("initializing variables.")
62 | sess.run(tf.global_variables_initializer())
63 | sess.run(tf.local_variables_initializer())
64 | if os.path.exists(my_setting.ckpt_path + 'checkpoint'):
65 | print("restore checkpoint.")
66 | saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path))
67 | tic = time.time()
68 | for step in range(my_setting.training_steps):
69 | if 0 == step % 100:
70 | X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True)
71 | X_batch = X_batch.reshape([-1, 28, 28, 1])
72 | _, g_step, train_loss, train_acc = sess.run(
73 | [model.train_op, model.global_step, model.train_loss, model.train_acc],
74 | feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
75 | X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=True)
76 | X_batch = X_batch.reshape([-1, 28, 28, 1])
77 | test_loss, test_acc = sess.run([model.test_loss, model.test_acc],
78 | feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
79 | print(
80 | "Global_step={:.2f}, train_loss={:.2f}, train_acc={:.2f}; test_loss={:.2f}, test_acc={:.2f}; pass {:.2f}s".format(
81 | g_step, train_loss, train_acc, test_loss, test_acc, time.time() - tic
82 | ))
83 | else:
84 | X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True)
85 | X_batch = X_batch.reshape([-1, 28, 28, 1])
86 | sess.run([model.train_op], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
87 | if 0 == (step + 1) % 1000:
88 | path = saver.save(sess, os.path.join(my_setting.ckpt_path, 'model.ckpt'),
89 | global_step=sess.run(model.global_step))
90 | print("Save model to {} ".format(path))
91 |
92 |
93 | if __name__ == '__main__':
94 | main()
95 |
--------------------------------------------------------------------------------
/models/m02_dcgan/README.md:
--------------------------------------------------------------------------------
1 | ## 使用 DCGAN 生成二次元头像
2 | 参考:
3 | - [原论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1511.06434)
4 | - [GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059)
5 | - [代码:carpedm20/DCGAN-tensorflow](https://github.com/carpedm20/DCGAN-tensorflow)
6 | - [代码:aymericdamien/TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/dcgan.py)
7 |
8 |
9 | 这里的 notebook 和 .py 文件的内容是一样的。
10 |
11 | 运行: `python dcgan.py ` 即可
--------------------------------------------------------------------------------
/models/m02_dcgan/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/models/m03_wgan/README.md:
--------------------------------------------------------------------------------
1 | ## 使用 WGAN 生成二次元头像
2 | 参考:
3 | - [原论文:Wasserstein GAN](https://arxiv.org/pdf/1701.07875.pdf)
4 | - [代码:jiamings/wgan](https://github.com/jiamings/wgan)
5 | - [代码:Zardinality/WGAN-tensorflow](https://github.com/Zardinality/WGAN-tensorflow)
6 |
7 |
8 | 运行: `python wgan.py ` 即可
9 |
10 | (wgan-gp.py 仍有bug...)
11 |
--------------------------------------------------------------------------------
/models/m03_wgan/wgan.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | from __future__ import print_function, division, absolute_import
4 |
5 | import warnings
6 |
7 | warnings.filterwarnings('ignore') # 不打印 warning
8 |
9 | import matplotlib
10 |
11 | matplotlib.use('Agg')
12 |
13 | import numpy as np
14 | import tensorflow as tf
15 | import matplotlib.pyplot as plt
16 |
17 | import time
18 | import os
19 | import sys
20 |
21 |
22 | # Generator Network
23 | # Input: Noise, Output: Image
24 | def generator(z, reuse=False):
25 | """输入噪声,输出图片。
26 | G网络中使用ReLU作为激活函数,最后一层使用tanh.
27 | 每一层都加 BN
28 | """
29 | with tf.variable_scope('Generator', reuse=reuse) as scope:
30 | # 按照论文的网络结构,第一层用一个全连接层
31 | x = tf.layers.dense(z, units=4 * 4 * 1024)
32 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn1'))
33 | # Reshape to a 4-D array of images: (batch, height, width, channels)
34 | # 然后把全链接层的输出 reshape 成 4D 的 tensor
35 | x = tf.reshape(x, shape=[-1, 4, 4, 1024])
36 | print('tr_conv4:', x)
37 | # Deconvolution, image shape: (batch, 8, 8, 512)
38 | x = tf.layers.conv2d_transpose(x, 512, 5, strides=2, padding='same')
39 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn2'))
40 | print('tr_conv3:', x)
41 | # Deconvolution, image shape: (batch, 16, 16, 256)
42 | x = tf.layers.conv2d_transpose(x, 256, 5, strides=2, padding='same')
43 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn3'))
44 | print('tr_conv2:', x)
45 | # Deconvolution, image shape: (batch, 32, 32, 128)
46 | x = tf.layers.conv2d_transpose(x, 128, 5, strides=2, padding='same')
47 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn4'))
48 | print('tr_conv1:', x)
49 | # Deconvolution, image shape: (batch, 64, 64, 3)
50 | x = tf.layers.conv2d_transpose(x, 3, 5, strides=2, padding='same')
51 | x = tf.nn.tanh(tf.layers.batch_normalization(x, training=True, name='bn5'))
52 | print('output_image:', x)
53 | return x
54 |
55 |
56 | def discriminator(x, reuse=False):
57 | """判别器。
58 | D网络中使用LeakyReLU作为激活函数。
59 | """
60 | with tf.variable_scope('Discriminator', reuse=reuse):
61 | # Typical convolutional neural network to classify images.
62 | print('input_image:', x)
63 | x = tf.layers.conv2d(x, 128, 5, strides=2, padding='same')
64 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn1'))
65 | print('conv1:', x)
66 | x = tf.layers.conv2d(x, 256, 5, strides=2, padding='same')
67 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn2'))
68 | print('conv2:', x)
69 | x = tf.layers.conv2d(x, 512, 5, strides=2, padding='same')
70 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn3'))
71 | print('conv3:', x)
72 | x = tf.layers.conv2d(x, 1024, 5, strides=2, padding='same')
73 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn4'))
74 | print('conv4:', x)
75 | x = tf.layers.flatten(x)
76 | x = tf.layers.dense(x, 1)
77 | print('output:', x)
78 | return x
79 |
80 |
81 | def get_file_path(data_path='../../data/anime/'):
82 | """解析文件夹,获取每个文件的路径和标签(在这个例子中所有的真实图片的标签都是1)。"""
83 | files = os.listdir(data_path)
84 | img_paths = [file for file in files if file.endswith('.jpg')]
85 | img_paths = list(map(lambda s: os.path.join(data_path, s), img_paths))
86 | labels = [1] * len(img_paths)
87 | return img_paths, labels
88 |
89 |
90 | def get_batch(img_paths, labels, batch_size=50, height=64, width=64, channel=3):
91 | """根据 img_path 读入图片并做相应处理"""
92 | # 从硬盘上读取图片
93 | img_paths = np.asarray(img_paths)
94 | labels = np.asarray(labels)
95 |
96 | img_paths = tf.convert_to_tensor(img_paths, dtype=tf.string)
97 | labels = tf.convert_to_tensor(labels, dtype=tf.int32)
98 | # Build a TF Queue, shuffle data
99 | image, label = tf.train.slice_input_producer([img_paths, labels], shuffle=True)
100 | # Read images from disk
101 | image = tf.read_file(image)
102 | image = tf.image.decode_jpeg(image, channels=channel)
103 | # Resize images to a common size
104 | image = tf.image.resize_images(image, [height, width])
105 | # Normalize
106 | image = image * 1.0 / 127.5 - 1.0
107 | # Create batches
108 | X_batch, y_batch = tf.train.batch([image, label], batch_size=batch_size,
109 | capacity=batch_size * 8,
110 | num_threads=4)
111 | return X_batch, y_batch
112 |
113 |
114 | def generate_img(sess, seed=3, show=False, save_path='generated_img'):
115 | """利用随机噪声生成图片, 并保存图片。"""
116 | if not os.path.exists(save_path):
117 | os.makedirs(save_path)
118 | step = sess.run(global_step)
119 | n_row, n_col = 5, 10
120 | f, a = plt.subplots(n_row, n_col, figsize=(n_col, n_row))
121 | np.random.seed(seed) # 每次都用相同的随机数便于对比结果
122 | z_batch = np.random.uniform(-1., 1., size=[n_row * n_col, noise_dim])
123 | fake_imgs = sess.run(gen_image, feed_dict={noise_input: z_batch})
124 | for i in range(n_row):
125 | # Noise input.
126 | for j in range(n_col):
127 | # Generate image from noise. Extend to 3 channels for matplot figure.
128 | img = (fake_imgs[n_col * i + j] + 1) / 2
129 | a[i][j].imshow(img)
130 | a[i][j].axis('off')
131 | f.savefig(os.path.join(save_path, '{}.png'.format(step)), dpi=100)
132 | if show:
133 | f.show()
134 |
135 |
136 | # 构建网络
137 | # Network Params
138 | image_dim = 64 # 头像的尺度
139 | n_channel = 3
140 | noise_dim = 100 # 输入噪声 z 的维度
141 |
142 | noise_input = tf.placeholder(tf.float32, shape=[None, noise_dim])
143 | real_img_input = tf.placeholder(tf.float32, shape=[None, image_dim, image_dim, n_channel])
144 |
145 | # 构造网络:生成器
146 | gen_image = generator(noise_input)
147 |
148 | # 判别器有两种输入,一种真实图像,一种生成器生成的假图像
149 | disc_real = discriminator(real_img_input) # 真图像输出的结果
150 | disc_fake = discriminator(gen_image, reuse=True)
151 |
152 | # 损失函数 (与DCGAN第1个改变)
153 | disc_loss = tf.reduce_mean(disc_fake - disc_real)
154 | gen_loss = tf.reduce_mean(-disc_fake)
155 |
156 | # 两个优化器
157 | # Build Optimizers (第2个改变)
158 | global_step = tf.Variable(0, trainable=False, name='Global_Step')
159 | optimizer_gen = tf.train.RMSPropOptimizer(learning_rate=5e-5)
160 | optimizer_disc = tf.train.RMSPropOptimizer(learning_rate=5e-5)
161 |
162 | # G 和 D 的参数
163 | gen_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Generator')
164 | # Discriminator Network Variables
165 | disc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Discriminator')
166 |
167 | # 对于 D 的参数进行裁剪 (第3个改变,注意每次更新完 D 后都要执行裁剪)
168 | clipped_disc = [tf.assign(v, tf.clip_by_value(v, -0.01, 0.01)) for v in disc_vars]
169 |
170 | # Create training operations
171 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
172 | with tf.control_dependencies(update_ops): # 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作
173 | train_gen = optimizer_gen.minimize(gen_loss, var_list=gen_vars, global_step=global_step)
174 | train_disc = optimizer_disc.minimize(disc_loss, var_list=disc_vars)
175 |
176 | # 模型要保存的变量
177 | # var_list = tf.global_variables() + tf.local_variables() # 这样保存所有变量不会出错,但是很多没必要的变量也保存了。414M 每个 ckpt
178 | var_list = tf.trainable_variables()
179 | if global_step not in var_list:
180 | var_list.append(global_step)
181 | # 添加 BN 层的均值和方差
182 | global_vars = tf.global_variables()
183 | bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
184 | bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
185 | var_list += bn_moving_vars
186 | # 创建Saver
187 |
188 | saver = tf.train.Saver(var_list=var_list)
189 |
190 | # 模型保存路径
191 | ckpt_path = 'ckpt/'
192 | if not os.path.exists(ckpt_path):
193 | os.makedirs(ckpt_path)
194 |
195 | # Training Params
196 | num_steps = 500000
197 | batch_size = 64
198 | d_iters = 5 # 更新 d_iters 次 D, 更新 1 次 G
199 |
200 | # 构建数据读取函数
201 | img_paths, labels = get_file_path()
202 | print("n_sample={}".format(len(img_paths)))
203 | get_X_batch, get_y_batch = get_batch(img_paths, labels, batch_size=batch_size)
204 |
205 | # Start training
206 | config = tf.ConfigProto()
207 | config.gpu_options.allow_growth = True
208 | with tf.Session(config=config) as sess:
209 | print("initializing variables.")
210 | sess.run(tf.global_variables_initializer())
211 | sess.run(tf.local_variables_initializer())
212 |
213 | if os.path.exists(ckpt_path + 'checkpoint'):
214 | print("restore checkpoint.")
215 | saver.restore(sess, tf.train.latest_checkpoint(ckpt_path))
216 |
217 | # 启动数据读取队列
218 | coord = tf.train.Coordinator()
219 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
220 |
221 |
222 | def get_batch():
223 | # 准备输入数据:真实图片
224 | X_batch, _ = sess.run([get_X_batch, get_y_batch]) # 本例中不管 _y_batch 的label
225 | # 准备噪声输入
226 | z_batch = np.random.uniform(-1., 1., size=[batch_size, noise_dim])
227 | # Training 这里的输入不需要 target
228 | feed_dict = {real_img_input: X_batch, noise_input: z_batch}
229 | return feed_dict
230 |
231 |
232 | try:
233 | tic = time.time()
234 | for i in range(1, num_steps + 1):
235 | # update 5 次 D,update 1 次 G
236 | dl = 0.0
237 | for _ in range(d_iters):
238 | _, _, dl = sess.run([train_disc, clipped_disc, disc_loss], feed_dict=get_batch())
239 | _, gl = sess.run([train_gen, gen_loss], feed_dict=get_batch())
240 |
241 | if i % 5 == 0:
242 | print(
243 | 'Step {}: Generator Loss: {:.2f}, Discriminator Loss: {:.2f}. Time passed {:.2f}s'.format(i, gl, dl,
244 | time.time() - tic))
245 | if i % 200 == 0: # 每训练 1000 step,生成一次图片
246 | generate_img(sess)
247 | path = saver.save(sess, os.path.join(ckpt_path, 'model.ckpt'), global_step=sess.run(global_step))
248 | print("Save model to {} ".format(path))
249 |
250 | generate_img(sess) # 最后一次生成图像
251 | except Exception as e:
252 | print(e)
253 | finally:
254 | coord.request_stop()
255 | coord.join(threads)
256 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/README.md:
--------------------------------------------------------------------------------
1 | # pix2pix
2 |
3 | 代码来自:[affinelayer/pix2pix-tensorflow](https://github.com/affinelayer/pix2pix-tensorflow)
4 |
5 | pix2pix.py 是原代码。
6 |
7 | 原始的代码比较长,包括数据读取,模型结构,模型训练和测试都是放在一个文件中。
8 |
9 | 根据原始代码,整理成了四个文件:
10 | - utils.py: 数据读取和数据处理函数。
11 | - model.py: pix2pix GAN 模型代码。
12 | - train.py: 模型训练的代码。
13 | - test.py: 模型测试的代码。
14 |
15 | 运行:
16 | - 训练: `sh train.sh`
17 | - 测试:`sh test.sh`
18 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/test.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | """模型训练代码"""
4 | from __future__ import print_function, division, absolute_import
5 |
6 | import tensorflow as tf
7 | import numpy as np
8 | import argparse
9 | import os
10 | import json
11 | import glob
12 | import random
13 | import collections
14 | import math
15 | import time
16 | import sys
17 |
18 | sys.path.append('.')
19 | from utils import *
20 | from model import *
21 |
22 | parser = argparse.ArgumentParser()
23 | parser.add_argument("--input_dir", help="path to folder containing images")
24 | parser.add_argument("--mode", type=str, default="test", choices=["train", "test", "export"])
25 | parser.add_argument("--output_dir", required=True, help="where to put output files")
26 | parser.add_argument("--seed", type=int)
27 | parser.add_argument("--checkpoint", default=None,
28 | help="directory with checkpoint to resume training from or use for testing")
29 |
30 | parser.add_argument("--max_steps", type=int, help="number of training steps (0 to disable)")
31 | parser.add_argument("--max_epochs", type=int, help="number of training epochs")
32 | parser.add_argument("--summary_freq", type=int, default=100, help="update summaries every summary_freq steps")
33 | parser.add_argument("--progress_freq", type=int, default=50, help="display progress every progress_freq steps")
34 | parser.add_argument("--trace_freq", type=int, default=0, help="trace execution every trace_freq steps")
35 | parser.add_argument("--display_freq", type=int, default=0,
36 | help="write current training images every display_freq steps")
37 | parser.add_argument("--save_freq", type=int, default=5000, help="save model every save_freq steps, 0 to disable")
38 |
39 | parser.add_argument("--separable_conv", action="store_true", help="use separable convolutions in the generator")
40 | parser.add_argument("--aspect_ratio", type=float, default=1.0, help="aspect ratio of output images (width/height)")
41 | parser.add_argument("--lab_colorization", action="store_true",
42 | help="split input image into brightness (A) and color (B)")
43 | parser.add_argument("--batch_size", type=int, default=1, help="number of images in batch")
44 | parser.add_argument("--which_direction", type=str, default="AtoB", choices=["AtoB", "BtoA"])
45 | parser.add_argument("--ngf", type=int, default=64, help="number of generator filters in first conv layer")
46 | parser.add_argument("--ndf", type=int, default=64, help="number of discriminator filters in first conv layer")
47 | parser.add_argument("--scale_size", type=int, default=286, help="scale images to this size before cropping to 256x256")
48 | parser.add_argument("--flip", dest="flip", action="store_true", help="flip images horizontally")
49 | parser.add_argument("--no_flip", dest="flip", action="store_false", help="don't flip images horizontally")
50 | parser.set_defaults(flip=True)
51 | parser.add_argument("--lr", type=float, default=0.0002, help="initial learning rate for adam")
52 | parser.add_argument("--beta1", type=float, default=0.5, help="momentum term of adam")
53 | parser.add_argument("--l1_weight", type=float, default=100.0, help="weight on L1 term for generator gradient")
54 | parser.add_argument("--gan_weight", type=float, default=1.0, help="weight on GAN term for generator gradient")
55 |
56 | # export options
57 | parser.add_argument("--output_filetype", default="png", choices=["png", "jpeg"])
58 | a = parser.parse_args()
59 |
60 |
61 | def main():
62 | if a.seed is None:
63 | a.seed = random.randint(0, 2 ** 31 - 1)
64 |
65 | tf.set_random_seed(a.seed)
66 | np.random.seed(a.seed)
67 | random.seed(a.seed)
68 |
69 | if not os.path.exists(a.output_dir):
70 | os.makedirs(a.output_dir)
71 |
72 | if a.checkpoint is None:
73 | raise Exception("checkpoint required for test mode")
74 |
75 | # load some options from the checkpoint
76 | options = {"which_direction", "ngf", "ndf", "lab_colorization"}
77 | with open(os.path.join(a.checkpoint, "options.json")) as f:
78 | for key, val in json.loads(f.read()).items():
79 | if key in options:
80 | print("loaded", key, "=", val)
81 | setattr(a, key, val)
82 | # disable these features in test mode
83 | a.scale_size = CROP_SIZE
84 | a.flip = False
85 |
86 | # 打印参数
87 | for k, v in a._get_kwargs():
88 | print(k, "=", v)
89 |
90 | # 写入参数
91 | with open(os.path.join(a.output_dir, "options.json"), "w") as f:
92 | f.write(json.dumps(vars(a), sort_keys=True, indent=4))
93 |
94 | # 准备数据读入
95 | examples = load_examples(input_dir=a.input_dir, batch_size=a.batch_size, mode=a.mode,
96 | which_direction=a.which_direction)
97 | print("examples count = %d" % examples.count)
98 |
99 | # 创建模型
100 | # inputs and targets are [batch_size, height, width, channels]
101 | model = create_model(examples.inputs, examples.targets)
102 |
103 | # undo colorization splitting on images that we use for display/output
104 | if a.lab_colorization:
105 | if a.which_direction == "AtoB":
106 | # inputs is brightness, this will be handled fine as a grayscale image
107 | # need to augment targets and outputs with brightness
108 | targets = augment(examples.targets, examples.inputs)
109 | outputs = augment(model.outputs, examples.inputs)
110 | # inputs can be deprocessed normally and handled as if they are single channel
111 | # grayscale images
112 | inputs = deprocess(examples.inputs)
113 | elif a.which_direction == "BtoA":
114 | # inputs will be color channels only, get brightness from targets
115 | inputs = augment(examples.inputs, examples.targets)
116 | targets = deprocess(examples.targets)
117 | outputs = deprocess(model.outputs)
118 | else:
119 | raise Exception("invalid direction")
120 | else: # 把数据映射回到 (0, 1) 之间便于最后保存图片
121 | inputs = deprocess(examples.inputs)
122 | targets = deprocess(examples.targets)
123 | outputs = deprocess(model.outputs)
124 |
125 | def convert(image):
126 | """把原始的img改成整形的类型,自动的映射到 [0,255]间"""
127 | if a.aspect_ratio != 1.0: # 如果 aspect_ratio 不是 1 (不是方形)的话需要resize恢复大小
128 | # upscale to correct aspect ratio
129 | size = [CROP_SIZE, int(round(CROP_SIZE * a.aspect_ratio))]
130 | image = tf.image.resize_images(image, size=size, method=tf.image.ResizeMethod.BICUBIC)
131 |
132 | return tf.image.convert_image_dtype(image, dtype=tf.uint8, saturate=True)
133 |
134 | # reverse any processing on images so they can be written to disk or displayed to user
135 | with tf.name_scope("convert_inputs"):
136 | converted_inputs = convert(inputs)
137 |
138 | with tf.name_scope("convert_targets"):
139 | converted_targets = convert(targets)
140 |
141 | with tf.name_scope("convert_outputs"):
142 | converted_outputs = convert(outputs)
143 |
144 | with tf.name_scope("encode_images"):
145 | display_fetches = {
146 | "paths": examples.paths,
147 | "inputs": tf.map_fn(tf.image.encode_png, converted_inputs, dtype=tf.string, name="input_pngs"),
148 | "targets": tf.map_fn(tf.image.encode_png, converted_targets, dtype=tf.string, name="target_pngs"),
149 | "outputs": tf.map_fn(tf.image.encode_png, converted_outputs, dtype=tf.string, name="output_pngs"),
150 | }
151 |
152 | # summaries
153 | with tf.name_scope("inputs_summary"):
154 | tf.summary.image("inputs", converted_inputs)
155 |
156 | with tf.name_scope("targets_summary"):
157 | tf.summary.image("targets", converted_targets)
158 |
159 | with tf.name_scope("outputs_summary"):
160 | tf.summary.image("outputs", converted_outputs)
161 |
162 | with tf.name_scope("predict_real_summary"):
163 | tf.summary.image("predict_real", tf.image.convert_image_dtype(model.predict_real, dtype=tf.uint8))
164 |
165 | with tf.name_scope("predict_fake_summary"):
166 | tf.summary.image("predict_fake", tf.image.convert_image_dtype(model.predict_fake, dtype=tf.uint8))
167 |
168 | tf.summary.scalar("discriminator_loss", model.discrim_loss)
169 | tf.summary.scalar("generator_loss_GAN", model.gen_loss_GAN)
170 | tf.summary.scalar("generator_loss_L1", model.gen_loss_L1)
171 |
172 | for var in tf.trainable_variables():
173 | tf.summary.histogram(var.op.name + "/values", var)
174 |
175 | for grad, var in model.discrim_grads_and_vars + model.gen_grads_and_vars:
176 | tf.summary.histogram(var.op.name + "/gradients", grad)
177 |
178 | with tf.name_scope("parameter_count"):
179 | parameter_count = tf.reduce_sum([tf.reduce_prod(tf.shape(v)) for v in tf.trainable_variables()])
180 |
181 | saver = tf.train.Saver(max_to_keep=1)
182 |
183 | logdir = a.output_dir if (a.trace_freq > 0 or a.summary_freq > 0) else None
184 | sv = tf.train.Supervisor(logdir=logdir, save_summaries_secs=0, saver=None)
185 | with sv.managed_session() as sess:
186 | print("parameter_count =", sess.run(parameter_count))
187 |
188 | if a.checkpoint is not None:
189 | print("loading model from checkpoint")
190 | checkpoint = tf.train.latest_checkpoint(a.checkpoint)
191 | saver.restore(sess, checkpoint)
192 |
193 | max_steps = 2 ** 32
194 | if a.max_epochs is not None:
195 | max_steps = examples.steps_per_epoch * a.max_epochs
196 | if a.max_steps is not None:
197 | max_steps = a.max_steps
198 |
199 | # testing
200 | # at most, process the test data once
201 | start = time.time()
202 | max_steps = min(examples.steps_per_epoch, max_steps)
203 | for step in range(max_steps):
204 | results = sess.run(display_fetches)
205 | filesets = save_images(results, output_dir=a.output_dir)
206 | for i, f in enumerate(filesets):
207 | print("evaluated image", f["name"])
208 | index_path = append_index(filesets, output_dir=a.output_dir)
209 | print("wrote index at", index_path)
210 | print("rate", (time.time() - start) / max_steps)
211 |
212 |
213 |
214 | if __name__ == '__main__':
215 | main()
--------------------------------------------------------------------------------
/models/m04_pix2pix/test.sh:
--------------------------------------------------------------------------------
1 | python3 test.py \
2 | --mode test \
3 | --output_dir "facades_test" \
4 | --input_dir "../../data/facades/test" \
5 | --checkpoint "facades_train" \
6 | --which_direction BtoA
7 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/train.sh:
--------------------------------------------------------------------------------
1 | python3 train.py \
2 | --mode train \
3 | --output_dir "facades_train" \
4 | --max_epochs 200 \
5 | --input_dir "../../data/facades/train" \
6 | --which_direction BtoA
7 |
--------------------------------------------------------------------------------
/utils/u01_logging/logging1.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import logging
4 | import logging.handlers
5 |
6 | """the use of logging.
7 | refer: http://blog.csdn.net/chosen0ne/article/details/7319306
8 |
9 | - handler:将日志记录(log record)发送到合适的目的地(destination),比如文件,socket等。
10 | 一个logger对象可以通过addHandler方法添加0到多个handler,每个handler又可以定义不同日志级别,以实现日志分级过滤显示。
11 | - formatter:指定日志记录输出的具体格式。formatter的构造方法需要两个参数:消息的格式字符串和日期字符串,这两个参数都是可选的。
12 | """
13 |
14 | # 1.保存至日志文件
15 | LOG_FILE = 'training.log'
16 | # 2.设置日志,maxBytes设置文件大小,backpuCount设置文件数量
17 | handler = logging.handlers.RotatingFileHandler(LOG_FILE, maxBytes=1024 * 1024, backupCount=5) # 实例化handler
18 | # 3.设置消息输出格式
19 | fmt = '%(asctime)s - %(filename)s:%(lineno)s - %(name)s - %(message)s'
20 |
21 | formatter = logging.Formatter(fmt) # 实例化formatter
22 | handler.setFormatter(formatter) # 为handler添加formatter
23 |
24 | logger = logging.getLogger('train') # 获取名为tst的logger
25 | logger.addHandler(handler) # 为logger添加handler
26 | logger.setLevel(logging.DEBUG)
27 |
28 | for i in range(10):
29 | logger.info('first info message %d' % i)
30 | logger.debug('first debug message %d' % i)
31 |
--------------------------------------------------------------------------------
/utils/u01_logging/training.log:
--------------------------------------------------------------------------------
1 | 2017-09-10 22:21:16,411 - logging1.py:28 - train - first info message 0
2 | 2017-09-10 22:21:16,411 - logging1.py:29 - train - first debug message 0
3 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 1
4 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 1
5 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 2
6 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 2
7 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 3
8 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 3
9 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 4
10 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 4
11 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 5
12 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 5
13 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 6
14 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 6
15 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 7
16 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 7
17 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 8
18 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 8
19 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 9
20 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 9
21 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/README.md:
--------------------------------------------------------------------------------
1 | ### 使用 tfrecord 打包数据
2 | 这里主要针对的是 tf1.2 及以前的版本,tf1.3和tf1.4 提供了新的 data API。等这个月把手头的实验做完更新后再尝试新的接口。
3 |
4 | #### 数据维度相同
5 | 比如固定大小的矩阵,数组,图片等,比较简单,可以使用 tf.train.Example() 进行打包。参考:
6 | - tfrecord-1-numpy-writer.py
7 | - tfrecord-1-numpy-reader.py
8 | - tfrecord-1-numpy-reader_without_shuffle.py
9 |
10 | #### 数据维度不同(变长序列)
11 | 比如文本数据,每个序列的长度都是不固定的。可以使用 tf.train.SequenceExample() 进行打包。参考:
12 | - tfrecord-2-seqence-writer.py
13 | - tfrecord-2-seqence-reader.py
14 |
15 | [sequence_example_lib.py](https://github.com/tensorflow/magenta/blob/master/magenta/common/sequence_example_lib.py)是官方提供一个例子,但是在官方文档中并没有提到这个例子,我也是费了好大力气才找到这个例子。tf1.3增加了 Dataset API,但是在 tf1.2 中的文档中,却没有一点说明,巨坑。
16 |
17 | 在 tf.train.Example() 中,通过 tf.train.Features() 把数据写入 tfrecord 文件。这些数据必须是具有相同的长度的**数组**,如果我们需要写入的是矩阵的话,我一般都是先reshape成 1D 的数组再进行写入。在读取数据的时候可以使用 tf.train.shuffle_batch() 直接读取数据。在读取数据的时候一定要明确指定数组的维度。
18 |
19 | 在 tf.train.SequenceExample(),包括 context 和 feature_lists 两部分。context 和 tf.train.Example() 作用类似,用于保存维度固定的数据。feature_lists 用于保存任意长度的序列数据。具体的写法参照 Tutorial-tfrecord-seqence-writer.py
20 |
21 | 在数据读取的时候,不能简单的通过 tf.train.shuffle_batch() 进行 batch 读取,因为我们没法给定数据的维度。解决方法是使用 tf.train.batch() 来进行读取,而且 **dynamic_pad 参数必须为 True,自动把batch中的数据填充0至一样的长度。** (所以在定义词典的时候,一定要把 '' 的 id 对应为 0.)由于 batch() 函数不能进行 shuffle,所以我们只能借助 tf.RandomShuffleQueue() 函数维护一个队列来实现 shuffle。
22 |
23 |
24 | #### 图片数据
25 | - tfrecord-3-image-writer.py
26 | - tfrecord-3-image-reader.py
27 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/reader_without_shuffle.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {
7 | "collapsed": false,
8 | "scrolled": false
9 | },
10 | "outputs": [
11 | {
12 | "name": "stdout",
13 | "output_type": "stream",
14 | "text": [
15 | "Tensor(\"tfrecord_data/ParseSingleExample/Squeeze_X:0\", shape=(2,), dtype=float32)\n",
16 | "Tensor(\"tfrecord_data/ParseSingleExample/Squeeze_y:0\", shape=(), dtype=int64)\n",
17 | "** batch 0\n",
18 | "('_y_batch:', array([0, 1, 2, 3]))\n",
19 | "** batch 1\n",
20 | "('_y_batch:', array([4, 5, 6, 7]))\n",
21 | "** batch 2\n",
22 | "('_y_batch:', array([ 8, 9, 10, 11]))\n",
23 | "** batch 3\n",
24 | "('_y_batch:', array([12, 13, 15, 14]))\n",
25 | "** batch 4\n",
26 | "('_y_batch:', array([17, 16, 19, 18]))\n",
27 | "** batch 5\n",
28 | "('_y_batch:', array([20, 21, 22, 23]))\n",
29 | "** batch 6\n",
30 | "('_y_batch:', array([24, 25, 26, 27]))\n",
31 | "** batch 7\n",
32 | "('_y_batch:', array([29, 28, 30, 31]))\n",
33 | "** batch 8\n",
34 | "('_y_batch:', array([33, 32, 34, 35]))\n",
35 | "** batch 9\n",
36 | "('_y_batch:', array([36, 37, 38, 39]))\n",
37 | "** batch 10\n",
38 | "('_y_batch:', array([40, 42, 41, 44]))\n",
39 | "** batch 11\n",
40 | "('_y_batch:', array([43, 46, 45, 47]))\n",
41 | "** batch 12\n",
42 | "('_y_batch:', array([48, 0, 49, 2]))\n",
43 | "** batch 13\n",
44 | "('_y_batch:', array([1, 3, 4, 6]))\n",
45 | "** batch 14\n",
46 | "('_y_batch:', array([5, 8, 7, 9]))\n",
47 | "** batch 15\n",
48 | "('_y_batch:', array([10, 12, 11, 13]))\n",
49 | "** batch 16\n",
50 | "('_y_batch:', array([14, 16, 15, 17]))\n",
51 | "** batch 17\n",
52 | "('_y_batch:', array([18, 20, 19, 21]))\n",
53 | "** batch 18\n",
54 | "('_y_batch:', array([22, 23, 24, 26]))\n",
55 | "** batch 19\n",
56 | "('_y_batch:', array([25, 27, 28, 29]))\n",
57 | "** batch 20\n",
58 | "('_y_batch:', array([30, 31, 32, 33]))\n",
59 | "** batch 21\n",
60 | "('_y_batch:', array([35, 34, 37, 36]))\n",
61 | "** batch 22\n",
62 | "('_y_batch:', array([39, 38, 41, 40]))\n",
63 | "** batch 23\n",
64 | "('_y_batch:', array([43, 42, 44, 45]))\n",
65 | "** batch 24\n",
66 | "('_y_batch:', array([46, 47, 49, 48]))\n",
67 | "** batch 25\n",
68 | "('_y_batch:', array([1, 0, 2, 3]))\n",
69 | "** batch 26\n",
70 | "('_y_batch:', array([4, 5, 6, 7]))\n",
71 | "** batch 27\n",
72 | "('_y_batch:', array([ 8, 9, 10, 11]))\n",
73 | "** batch 28\n",
74 | "('_y_batch:', array([12, 13, 15, 14]))\n",
75 | "** batch 29\n",
76 | "('_y_batch:', array([17, 16, 19, 18]))\n",
77 | "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 14, 17, 16, 19, 18, 20, 21, 22, 23, 24, 25, 26, 27, 29, 28, 30, 31, 33, 32, 34, 35, 36, 37, 38, 39, 40, 42, 41, 44, 43, 46, 45, 47, 48, 0, 49, 2, 1, 3, 4, 6, 5, 8, 7, 9, 10, 12, 11, 13, 14, 16, 15, 17, 18, 20, 19, 21, 22, 23, 24, 26, 25, 27, 28, 29, 30, 31, 32, 33, 35, 34, 37, 36, 39, 38, 41, 40, 43, 42, 44, 45, 46, 47, 49, 48, 1, 0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 14, 17, 16, 19, 18]\n"
78 | ]
79 | }
80 | ],
81 | "source": [
82 | "# -*- coding:utf-8 -*- \n",
83 | "\n",
84 | "import tensorflow as tf\n",
85 | "\n",
86 | "'''read data.\n",
87 | "without shuffle, for validation or test data.\n",
88 | "'''\n",
89 | "\n",
90 | "# output file name string to a queue\n",
91 | "with tf.variable_scope('tfrecord_data'):\n",
92 | " filename_queue = tf.train.string_input_producer(['../data/test1.tfrecord', '../data/test2.tfrecord'], num_epochs=None,\n",
93 | " shuffle=False)\n",
94 | " # create a reader from file queue\n",
95 | " reader = tf.TFRecordReader()\n",
96 | " _, serialized_example = reader.read(filename_queue)\n",
97 | " # get feature from serialized example\n",
98 | " features = tf.parse_single_example(serialized_example,\n",
99 | " features={\n",
100 | " 'X': tf.FixedLenFeature([2], tf.float32),\n",
101 | " 'y': tf.FixedLenFeature([], tf.int64)}\n",
102 | " )\n",
103 | " X_out = features['X']\n",
104 | " y_out = features['y']\n",
105 | "\n",
106 | " print(X_out)\n",
107 | " print(y_out)\n",
108 | " X_batch, y_batch = tf.train.batch([X_out, y_out],\n",
109 | " batch_size=4,\n",
110 | " capacity=10,\n",
111 | " num_threads=2,\n",
112 | " allow_smaller_final_batch=True)\n",
113 | " new_ops = [v for v in tf.global_variables() if v.name.startswith(vs.name + '/')]\n",
114 | " \n",
115 | "sess = tf.Session()\n",
116 | "# init = tf.global_variables_initializer()\n",
117 | "init = tf.group(tf.global_variables_initializer(),\n",
118 | " tf.local_variables_initializer())\n",
119 | "sess.run(init)\n",
120 | "\n",
121 | "coord = tf.train.Coordinator()\n",
122 | "threads = tf.train.start_queue_runners(sess=sess, coord=coord)\n",
123 | "y_outputs = list()\n",
124 | "for i in xrange(30):\n",
125 | " try:\n",
126 | " _X_batch, _y_batch = sess.run([X_batch, y_batch])\n",
127 | " print('** batch %d' % i)\n",
128 | " print('_y_batch:', _y_batch)\n",
129 | " y_outputs.extend(_y_batch.tolist())\n",
130 | " except tf.errors.OutOfRangeError, e:\n",
131 | " print(e.message)\n",
132 | " break\n",
133 | "print(y_outputs)\n",
134 | "\n",
135 | "coord.request_stop()\n",
136 | "coord.join(threads)"
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 7,
142 | "metadata": {
143 | "collapsed": true
144 | },
145 | "outputs": [],
146 | "source": [
147 | "tf.train.Coordinator?"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": 6,
153 | "metadata": {
154 | "collapsed": false
155 | },
156 | "outputs": [
157 | {
158 | "name": "stdout",
159 | "output_type": "stream",
160 | "text": [
161 | "FIFOQueue '_2_tfrecord_data/batch/fifo_queue' is closed and has insufficient elements (requested 4, current size 0)\n",
162 | "\t [[Node: tfrecord_data/batch = QueueDequeueUpToV2[component_types=[DT_FLOAT, DT_INT64], timeout_ms=-1, _device=\"/job:localhost/replica:0/task:0/cpu:0\"](tfrecord_data/batch/fifo_queue, tfrecord_data/batch/n)]]\n",
163 | "[]\n",
164 | "[]\n"
165 | ]
166 | }
167 | ],
168 | "source": [
169 | "y_outputs = list()\n",
170 | "sess.run(tf.variables_initializer(new_ops))\n",
171 | "coord1 = tf.train.Coordinator()\n",
172 | "threads = tf.train.start_queue_runners(sess=sess, coord=coord1)\n",
173 | "for i in xrange(30):\n",
174 | " try:\n",
175 | " _X_batch, _y_batch = sess.run([X_batch, y_batch])\n",
176 | " print('** batch %d' % i)\n",
177 | " print('_y_batch:', _y_batch)\n",
178 | " y_outputs.extend(_y_batch.tolist())\n",
179 | " except tf.errors.OutOfRangeError, e:\n",
180 | " print(e.message)\n",
181 | " break\n",
182 | "print(y_outputs)\n",
183 | "print(sorted(y_outputs))"
184 | ]
185 | },
186 | {
187 | "cell_type": "code",
188 | "execution_count": null,
189 | "metadata": {
190 | "collapsed": true
191 | },
192 | "outputs": [],
193 | "source": []
194 | }
195 | ],
196 | "metadata": {
197 | "anaconda-cloud": {},
198 | "kernelspec": {
199 | "display_name": "Python [conda root]",
200 | "language": "python",
201 | "name": "conda-root-py"
202 | },
203 | "language_info": {
204 | "codemirror_mode": {
205 | "name": "ipython",
206 | "version": 2
207 | },
208 | "file_extension": ".py",
209 | "mimetype": "text/x-python",
210 | "name": "python",
211 | "nbconvert_exporter": "python",
212 | "pygments_lexer": "ipython2",
213 | "version": "2.7.12"
214 | }
215 | },
216 | "nbformat": 4,
217 | "nbformat_minor": 1
218 | }
219 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/sequence_example_lib.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | # Copyright 2016 Google Inc. All Rights Reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | """Utility functions for working with tf.train.SequenceExamples.
17 | https://github.com/tensorflow/magenta/blob/master/magenta/common/sequence_example_lib.py
18 | """
19 |
20 | import math
21 | import tensorflow as tf
22 |
23 | QUEUE_CAPACITY = 500
24 | SHUFFLE_MIN_AFTER_DEQUEUE = QUEUE_CAPACITY // 5
25 |
26 |
27 | def make_sequence_example(inputs, labels):
28 | """Returns a SequenceExample for the given inputs and labels.
29 |
30 | Args:
31 | inputs: A list of input vectors. Each input vector is a list of floats.
32 | labels: A list of ints.
33 |
34 | Returns:
35 | A tf.train.SequenceExample containing inputs and labels.
36 | """
37 | input_features = [
38 | tf.train.Feature(float_list=tf.train.FloatList(value=input_))
39 | for input_ in inputs]
40 | label_features = [
41 | tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
42 | for label in labels]
43 | feature_list = {
44 | 'inputs': tf.train.FeatureList(feature=input_features),
45 | 'labels': tf.train.FeatureList(feature=label_features)
46 | }
47 | feature_lists = tf.train.FeatureLists(feature_list=feature_list)
48 | return tf.train.SequenceExample(feature_lists=feature_lists)
49 |
50 |
51 | def _shuffle_inputs(input_tensors, capacity, min_after_dequeue, num_threads):
52 | """Shuffles tensors in `input_tensors`, maintaining grouping."""
53 | shuffle_queue = tf.RandomShuffleQueue(
54 | capacity, min_after_dequeue, dtypes=[t.dtype for t in input_tensors])
55 | enqueue_op = shuffle_queue.enqueue(input_tensors)
56 | runner = tf.train.QueueRunner(shuffle_queue, [enqueue_op] * num_threads)
57 | tf.train.add_queue_runner(runner)
58 |
59 | output_tensors = shuffle_queue.dequeue()
60 |
61 | for i in range(len(input_tensors)):
62 | output_tensors[i].set_shape(input_tensors[i].shape)
63 |
64 | return output_tensors
65 |
66 |
67 | def get_padded_batch(file_list, batch_size, input_size,
68 | num_enqueuing_threads=4, shuffle=False):
69 | """Reads batches of SequenceExamples from TFRecords and pads them.
70 |
71 | Can deal with variable length SequenceExamples by padding each batch to the
72 | length of the longest sequence with zeros.
73 |
74 | Args:
75 | file_list: A list of paths to TFRecord files containing SequenceExamples.
76 | batch_size: The number of SequenceExamples to include in each batch.
77 | input_size: The size of each input vector. The returned batch of inputs
78 | will have a shape [batch_size, num_steps, input_size].
79 | num_enqueuing_threads: The number of threads to use for enqueuing
80 | SequenceExamples.
81 | shuffle: Whether to shuffle the batches.
82 |
83 | Returns:
84 | inputs: A tensor of shape [batch_size, num_steps, input_size] of floats32s.
85 | labels: A tensor of shape [batch_size, num_steps] of int64s.
86 | lengths: A tensor of shape [batch_size] of int32s. The lengths of each
87 | SequenceExample before padding.
88 | Raises:
89 | ValueError: If `shuffle` is True and `num_enqueuing_threads` is less than 2.
90 | """
91 | file_queue = tf.train.string_input_producer(file_list)
92 | reader = tf.TFRecordReader()
93 | _, serialized_example = reader.read(file_queue)
94 |
95 | sequence_features = {
96 | 'inputs': tf.FixedLenSequenceFeature(shape=[input_size],
97 | dtype=tf.float32),
98 | 'labels': tf.FixedLenSequenceFeature(shape=[],
99 | dtype=tf.int64)}
100 |
101 | _, sequence = tf.parse_single_sequence_example(
102 | serialized_example, sequence_features=sequence_features)
103 |
104 | length = tf.shape(sequence['inputs'])[0] # 序列长度
105 | input_tensors = [sequence['inputs'], sequence['labels'], length]
106 |
107 | if shuffle:
108 | if num_enqueuing_threads < 2:
109 | raise ValueError(
110 | '`num_enqueuing_threads` must be at least 2 when shuffling.')
111 | shuffle_threads = int(math.ceil(num_enqueuing_threads) / 2.)
112 |
113 | # Since there may be fewer records than SHUFFLE_MIN_AFTER_DEQUEUE, take the
114 | # minimum of that number and the number of records.
115 | min_after_dequeue = count_records(
116 | file_list, stop_at=SHUFFLE_MIN_AFTER_DEQUEUE)
117 | input_tensors = _shuffle_inputs(
118 | input_tensors, capacity=QUEUE_CAPACITY,
119 | min_after_dequeue=min_after_dequeue,
120 | num_threads=shuffle_threads)
121 |
122 | num_enqueuing_threads -= shuffle_threads
123 |
124 | tf.logging.info(input_tensors)
125 | return tf.train.batch(
126 | input_tensors,
127 | batch_size=batch_size,
128 | capacity=QUEUE_CAPACITY,
129 | num_threads=num_enqueuing_threads,
130 | dynamic_pad=True,
131 | allow_smaller_final_batch=False)
132 |
133 |
134 | def count_records(file_list, stop_at=None):
135 | """Counts number of records in files from `file_list` up to `stop_at`.
136 |
137 | Args:
138 | file_list: List of TFRecord files to count records in.
139 | stop_at: Optional number of records to stop counting at.
140 |
141 | Returns:
142 | Integer number of records in files from `file_list` up to `stop_at`.
143 | """
144 | num_records = 0
145 | for tfrecord_file in file_list:
146 | tf.logging.info('Counting records in %s.', tfrecord_file)
147 | for _ in tf.python_io.tf_record_iterator(tfrecord_file):
148 | num_records += 1
149 | if stop_at and num_records >= stop_at:
150 | tf.logging.info('Number of records is at least %d.', num_records)
151 | return num_records
152 | tf.logging.info('Total records: %d', num_records)
153 | return num_records
154 |
155 |
156 | def flatten_maybe_padded_sequences(maybe_padded_sequences, lengths=None):
157 | """Flattens the batch of sequences, removing padding (if applicable).
158 |
159 | Args:
160 | maybe_padded_sequences: A tensor of possibly padded sequences to flatten,
161 | sized `[N, M, ...]` where M = max(lengths).
162 | lengths: Optional length of each sequence, sized `[N]`. If None, assumes no
163 | padding.
164 |
165 | Returns:
166 | flatten_maybe_padded_sequences: The flattened sequence tensor, sized
167 | `[sum(lengths), ...]`.
168 | """
169 |
170 | def flatten_unpadded_sequences():
171 | # The sequences are equal length, so we should just flatten over the first
172 | # two dimensions.
173 | return tf.reshape(maybe_padded_sequences,
174 | [-1] + maybe_padded_sequences.shape.as_list()[2:])
175 |
176 | if lengths is None:
177 | return flatten_unpadded_sequences()
178 |
179 | def flatten_padded_sequences():
180 | indices = tf.where(tf.sequence_mask(lengths))
181 | return tf.gather_nd(maybe_padded_sequences, indices)
182 |
183 | return tf.cond(
184 | tf.equal(tf.reduce_min(lengths), tf.shape(maybe_padded_sequences)[1]),
185 | flatten_unpadded_sequences,
186 | flatten_padded_sequences)
187 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_1_numpy_reader.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import os
5 | import sys
6 | import time
7 |
8 | '''read data
9 | 从 tfrecord 文件中读取数据,对应数据的格式为固定shape的数据。
10 | '''
11 |
12 | # **1.把所有的 tfrecord 文件名列表写入队列中
13 | tfrecord_dir = 'tfrecord/numpy/'
14 | tfrecord_files = os.listdir(tfrecord_dir)
15 | tfrecord_files = list(map(lambda s: os.path.join(tfrecord_dir, s), tfrecord_files))
16 |
17 | filename_queue = tf.train.string_input_producer(tfrecord_files, num_epochs=None, shuffle=True)
18 |
19 | # **2.创建一个读取器
20 | reader = tf.TFRecordReader()
21 | _, serialized_example = reader.read(filename_queue)
22 | # **3.根据你写入的格式对应说明读取的格式
23 | features = tf.parse_single_example(serialized_example,
24 | features={
25 | 'X': tf.FixedLenFeature([784], tf.float32), # 注意如果不是标量,需要说明数组长度
26 | 'y': tf.FixedLenFeature([], tf.int64)} # 而标量就不用说明
27 | )
28 | X_out = features['X']
29 | y_out = features['y']
30 |
31 | print(X_out)
32 | print(y_out)
33 | # **4.通过 tf.train.shuffle_batch 或者 tf.train.batch 函数读取数据
34 | """
35 | 在shuffle_batch 函数中,有几个参数的作用如下:
36 | capacity: 队列的容量,容量越大的话,shuffle 得就更加均匀,但是占用内存也会更多
37 | num_threads: 读取进程数,进程越多,读取速度相对会快些,根据个人配置决定
38 | min_after_dequeue: 保证队列中最少的数据量。
39 | 假设我们设定了队列的容量C,在我们取走部分数据m以后,队列中只剩下了 (C-m) 个数据。然后队列会不断补充数据进来,
40 | 如果后勤供应(CPU性能,线程数量)补充速度慢的话,那么下一次取数据的时候,可能才补充了一点点,如果补充完后的数据个数少于
41 | min_after_dequeue 的话,不能取走数据,得继续等它补充超过 min_after_dequeue 个样本以后才让取走数据。
42 | 这样做保证了队列中混着足够多的数据,从而才能保证 shuffle 取值更加随机。
43 | 但是,min_after_dequeue 不能设置太大,否则补充时间很长,读取速度会很慢。
44 | """
45 | X_batch, y_batch = tf.train.shuffle_batch([X_out, y_out], batch_size=128,
46 | capacity=2000, min_after_dequeue=100, num_threads=4)
47 | sess = tf.Session()
48 | init = tf.global_variables_initializer()
49 | sess.run(init)
50 |
51 | # **5.启动队列进行数据读取
52 | # 下面的 coord 是个线程协调器,把启动队列的时候加上线程协调器。
53 | # 这样,在数据读取完毕以后,调用协调器把线程全部都关了。
54 | coord = tf.train.Coordinator()
55 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
56 | # y_outputs = list()
57 | # for i in range(5):
58 | # _X_batch, _y_batch = sess.run([X_batch, y_batch])
59 | # print('** batch %d' % i)
60 | # print('_X_batch:\n', _X_batch)
61 | # print('_y_batch:\n', _y_batch)
62 | # y_outputs.extend(_y_batch.tolist())
63 | # print('All y_outputs: \n', y_outputs)
64 |
65 | # 迭代取值
66 | time0 = time.time()
67 | for count in range(100): # 100batch 125 seconds
68 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
69 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
70 | sys.stdout.flush()
71 |
72 | # **6.最后记得把队列关掉
73 | coord.request_stop()
74 | coord.join(threads)
75 |
76 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_1_numpy_reader_without_shuffle.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import os
5 | import time
6 |
7 | '''read data.
8 | without shuffle, for validation or test data.
9 | 遍历一次数据集,针对验证集或者训练集,我们不需要使用 shuffle 的方式读取 batch,而是需要保证完整的遍历一次数据集。
10 | 和 tf.train.shuffle_batch 的读取方式类似,只是有几个地方需要注意:
11 | 1.把文件名字写入队列的时候,记得设 shuffle=False
12 | 2.同时设置 num_epochs 参数为 1. 这样当读取完一个epoch以后就会抛出 OutOfRangeError.
13 | 3.tf.train.batch() 函数的 allow_smaller_final_batch 参数一定要设置 True, 才不会漏掉最后不满 batch_size 的一小部分数据
14 | 4.在初始化的时候加上 tf.initialize_local_variables(), 否则会报错。
15 | 5.记得加上 try...except... 来捕获 OutOfRangeError
16 | '''
17 |
18 | # **1.把所有的 tfrecord 文件名列表写入队列中
19 | tfrecord_dir = 'tfrecord/numpy/'
20 | tfrecord_files = os.listdir(tfrecord_dir)
21 | tfrecord_files = list(map(lambda s: os.path.join(tfrecord_dir, s), tfrecord_files))
22 |
23 | filename_queue = tf.train.string_input_producer(tfrecord_files, num_epochs=None, shuffle=True)
24 |
25 | # create a reader from file queue
26 | reader = tf.TFRecordReader()
27 | _, serialized_example = reader.read(filename_queue)
28 | # get feature from serialized example
29 | features = tf.parse_single_example(serialized_example,
30 | features={
31 | 'X': tf.FixedLenFeature([784], tf.float32),
32 | 'y': tf.FixedLenFeature([], tf.int64)}
33 | )
34 | X_out = features['X']
35 | y_out = features['y']
36 |
37 | batch_size = 128
38 | X_batch, y_batch = tf.train.batch([X_out, y_out],
39 | batch_size=2,
40 | capacity=2000,
41 | num_threads=4,
42 | allow_smaller_final_batch=True) # 保证遍历完整个数据集
43 |
44 | # 如果设定了读取轮数(num_epochs)为1,所以就算使用 shuffle_batch, 也会保证只取一个epoch,不重复,也不会漏失
45 | # X_batch, y_batch = tf.train.shuffle_batch([X_out, y_out],
46 | # batch_size=6,
47 | # capacity=20,
48 | # min_after_dequeue=10,
49 | # num_threads=2,
50 | # allow_smaller_final_batch=True)
51 |
52 | sess = tf.Session()
53 | # 注意下面这个,如果设了 num_epoch,需要初始化 local_variables
54 | init = tf.group(tf.global_variables_initializer(),
55 | tf.initialize_local_variables())
56 | sess.run(init)
57 |
58 | coord = tf.train.Coordinator()
59 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
60 | y_outputs = list()
61 | for i in range(25):
62 | try:
63 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
64 | print('** batch %d' % i)
65 | print('_y_batch:\n', _y_batch)
66 | y_outputs.extend(_y_batch.tolist())
67 | except tf.errors.OutOfRangeError as e:
68 | print(e.message)
69 | break
70 | print('all y_outputs:', y_outputs)
71 | print('sorted y_outputs:', sorted(y_outputs))
72 |
73 | coord.request_stop()
74 | coord.join(threads)
75 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_1_numpy_writer.py:
--------------------------------------------------------------------------------
1 | """tfrecord 写入数据.
2 | 将固定shape的矩阵写入 tfrecord 文件。这种形式的数据写入 tfrecord 是最简单的。
3 | refer: http://blog.csdn.net/qq_16949707/article/details/53483493
4 | """
5 |
6 | from __future__ import print_function
7 | from __future__ import division
8 | from __future__ import absolute_import
9 |
10 | import tensorflow as tf
11 | import numpy as np
12 | from tqdm import tqdm
13 | import os
14 | import sys
15 | import time
16 |
17 | from tensorflow.examples.tutorials.mnist import input_data
18 |
19 | mnist = input_data.read_data_sets('../../data/MNIST_data', one_hot=False)
20 | X = mnist.train.images
21 | y = mnist.train.labels
22 |
23 | NUM_SHARDS = 64 # tfrecord 文件的数量,稍微大些对 shuffle 会好些
24 | n_sample = len(X)
25 | num_per_shard = n_sample // NUM_SHARDS # 每个 tfrecord 的样本数量
26 | # 在打包之前先手动打乱一次
27 | new_idxs = np.random.permutation(n_sample)
28 | X = X[new_idxs]
29 | y = y[new_idxs]
30 |
31 | tfrecord_dir = 'tfrecord/numpy/'
32 | if not os.path.exists(tfrecord_dir):
33 | os.makedirs(tfrecord_dir)
34 |
35 | time0 = time.time()
36 | for shard_id in range(NUM_SHARDS):
37 | output_filename = '%d-of-%d.tfrecord' % (shard_id, NUM_SHARDS)
38 | output_path = os.path.join(tfrecord_dir, output_filename)
39 | with tf.python_io.TFRecordWriter(output_path) as writer:
40 | start_ndx = shard_id * num_per_shard
41 | end_ndx = min((shard_id + 1) * num_per_shard, n_sample)
42 | for i in range(start_ndx, end_ndx):
43 | sys.stdout.write('\r>> Converting image %d/%d shard %d, %g s' % (
44 | i + 1, n_sample, shard_id, time.time() - time0))
45 | sys.stdout.flush()
46 |
47 | X_sample = X[i].tolist()
48 | y_sample = y[i]
49 | # **3.定义数据类型,按照这里固定的形式写,有float_list(好像只有32位), int64_list, bytes_list.
50 | example = tf.train.Example(
51 | features=tf.train.Features(
52 | feature={'X': tf.train.Feature(float_list=tf.train.FloatList(value=X_sample)),
53 | 'y': tf.train.Feature(int64_list=tf.train.Int64List(value=[y_sample]))}))
54 | # **4.序列化数据并写入文件中
55 | serialized = example.SerializeToString()
56 | writer.write(serialized)
57 |
58 | print('Finished writing training data to tfrecord files.')
59 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_2_seqence_reader.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import math
5 |
6 | QUEUE_CAPACITY = 100
7 | SHUFFLE_MIN_AFTER_DEQUEUE = QUEUE_CAPACITY // 5
8 |
9 | """
10 | 读取变长序列数据。
11 | 和固定shape的数据读取方式不一样,在读取变长序列中,我们无法使用 tf.train.shuffle_batch() 函数,只能使用
12 | tf.train.batch() 函数进行读取,而且,在读取的时候,必须设置 dynamic_pad 参数为 True, 把所有的序列 padding
13 | 到固定长度(该batch中最长的序列长度),padding部分为 0。
14 |
15 | 此外,在训练的时候为了实现 shuffle 功能,我们可以使用 RandomShuffleQueue 队列来完成。详见下面的 _shuffle_inputs 函数。
16 | """
17 |
18 |
19 | def _shuffle_inputs(input_tensors, capacity, min_after_dequeue, num_threads):
20 | """Shuffles tensors in `input_tensors`, maintaining grouping."""
21 | shuffle_queue = tf.RandomShuffleQueue(
22 | capacity, min_after_dequeue, dtypes=[t.dtype for t in input_tensors])
23 | enqueue_op = shuffle_queue.enqueue(input_tensors)
24 | runner = tf.train.QueueRunner(shuffle_queue, [enqueue_op] * num_threads)
25 | tf.train.add_queue_runner(runner)
26 |
27 | output_tensors = shuffle_queue.dequeue()
28 |
29 | for i in range(len(input_tensors)):
30 | output_tensors[i].set_shape(input_tensors[i].shape)
31 |
32 | return output_tensors
33 |
34 |
35 | def get_padded_batch(file_list, batch_size, num_enqueuing_threads=4, shuffle=False):
36 | """Reads batches of SequenceExamples from TFRecords and pads them.
37 |
38 | Can deal with variable length SequenceExamples by padding each batch to the
39 | length of the longest sequence with zeros.
40 |
41 | Args:
42 | file_list: A list of paths to TFRecord files containing SequenceExamples.
43 | batch_size: The number of SequenceExamples to include in each batch.
44 | num_enqueuing_threads: The number of threads to use for enqueuing
45 | SequenceExamples.
46 | shuffle: Whether to shuffle the batches.
47 |
48 | Returns:
49 | labels: A tensor of shape [batch_size] of int64s.
50 | frames: A tensor of shape [batch_size, num_steps] of floats32s. note that
51 | num_steps is the max time_step of all the tensors.
52 | Raises:
53 | ValueError: If `shuffle` is True and `num_enqueuing_threads` is less than 2.
54 | """
55 | file_queue = tf.train.string_input_producer(file_list)
56 | reader = tf.TFRecordReader()
57 | _, serialized_example = reader.read(file_queue)
58 |
59 | context_features = {
60 | "label": tf.FixedLenFeature([], dtype=tf.int64)
61 | }
62 | sequence_features = {
63 | "frame": tf.FixedLenSequenceFeature([], dtype=tf.int64)
64 | }
65 |
66 | context_parsed, sequence_parsed = tf.parse_single_sequence_example(
67 | serialized=serialized_example,
68 | context_features=context_features,
69 | sequence_features=sequence_features
70 | )
71 |
72 | labels = context_parsed['label']
73 | frames = sequence_parsed['frame']
74 | input_tensors = [labels, frames]
75 |
76 | if shuffle:
77 | if num_enqueuing_threads < 2:
78 | raise ValueError(
79 | '`num_enqueuing_threads` must be at least 2 when shuffling.')
80 | shuffle_threads = int(math.ceil(num_enqueuing_threads) / 2.)
81 |
82 | # Since there may be fewer records than SHUFFLE_MIN_AFTER_DEQUEUE, take the
83 | # minimum of that number and the number of records.
84 | min_after_dequeue = count_records(
85 | file_list, stop_at=SHUFFLE_MIN_AFTER_DEQUEUE)
86 | input_tensors = _shuffle_inputs(
87 | input_tensors, capacity=QUEUE_CAPACITY,
88 | min_after_dequeue=min_after_dequeue,
89 | num_threads=shuffle_threads)
90 |
91 | num_enqueuing_threads -= shuffle_threads
92 |
93 | tf.logging.info(input_tensors)
94 | return tf.train.batch(
95 | input_tensors,
96 | batch_size=batch_size,
97 | capacity=QUEUE_CAPACITY,
98 | num_threads=num_enqueuing_threads,
99 | dynamic_pad=True,
100 | allow_smaller_final_batch=False)
101 |
102 |
103 | def count_records(file_list, stop_at=None):
104 | """Counts number of records in files from `file_list` up to `stop_at`.
105 |
106 | Args:
107 | file_list: List of TFRecord files to count records in.
108 | stop_at: Optional number of records to stop counting at.
109 |
110 | Returns:
111 | Integer number of records in files from `file_list` up to `stop_at`.
112 | """
113 | num_records = 0
114 | for tfrecord_file in file_list:
115 | tf.logging.info('Counting records in %s.', tfrecord_file)
116 | for _ in tf.python_io.tf_record_iterator(tfrecord_file):
117 | num_records += 1
118 | if stop_at and num_records >= stop_at:
119 | tf.logging.info('Number of records is at least %d.', num_records)
120 | return num_records
121 | tf.logging.info('Total records: %d', num_records)
122 | return num_records
123 |
124 |
125 | if __name__ == '__main__':
126 | tfrecord_file_names = ['../../data/seq_test1.tfrecord', '../../data/seq_test2.tfrecord']
127 | label_batch, frame_batch = get_padded_batch(tfrecord_file_names, 10, shuffle=True)
128 | config = tf.ConfigProto()
129 | config.gpu_options.allow_growth = True
130 | sess = tf.Session(config=config)
131 | tf.train.start_queue_runners(sess=sess)
132 | for i in xrange(3):
133 | _frames_batch, _label_batch = sess.run([frame_batch, label_batch])
134 | print('** batch %d' % i)
135 | print(_label_batch)
136 | print(_frames_batch)
137 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_2_seqence_writer.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 | from tqdm import tqdm
6 |
7 | '''tfrecord 写入序列数据,每个样本的长度不固定。
8 | 和固定 shape 的数据处理方式类似,前者使用 tf.train.Example() 方式,而对于变长序列数据,需要使用
9 | tf.train.SequenceExample()。 在 tf.train.SequenceExample() 中,又包括了两部分:
10 | context 来放置非序列化部分;
11 | feature_lists 放置变长序列。
12 |
13 | refer:
14 | https://github.com/tensorflow/magenta/blob/master/magenta/common/sequence_example_lib.py
15 | https://github.com/dennybritz/tf-rnn
16 | http://leix.me/2017/01/09/tensorflow-practical-guides/
17 | https://github.com/siavash9000/im2txt_demo/blob/master/im2txt/im2txt/ops/inputs.py
18 | '''
19 |
20 | # **1.创建文件
21 | writer1 = tf.python_io.TFRecordWriter('../../data/seq_test1.tfrecord')
22 | writer2 = tf.python_io.TFRecordWriter('../../data/seq_test2.tfrecord')
23 |
24 | # 非序列数据
25 | labels = [1, 2, 3, 4, 5, 1, 2, 3, 4]
26 | # 长度不固定的序列
27 | frames = [[1], [2, 2], [3, 3, 3], [4, 4, 4, 4], [5, 5, 5, 5, 5],
28 | [1], [2, 2], [3, 3, 3], [4, 4, 4, 4]]
29 |
30 |
31 | writer = writer1
32 | for i in tqdm(xrange(len(labels))): # **2.对于每个样本
33 | if i == len(labels) / 2:
34 | writer = writer2
35 | print('\nThere are %d sample writen into writer1' % i)
36 | label = labels[i]
37 | frame = frames[i]
38 | # 非序列化
39 | label_feature = tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
40 | # 序列化
41 | frame_feature = [
42 | tf.train.Feature(int64_list=tf.train.Int64List(value=[frame_])) for frame_ in frame
43 | ]
44 |
45 | seq_example = tf.train.SequenceExample(
46 | # context 来放置非序列化部分
47 | context=tf.train.Features(feature={
48 | "label": label_feature
49 | }),
50 | # feature_lists 放置变长序列
51 | feature_lists=tf.train.FeatureLists(feature_list={
52 | "frame": tf.train.FeatureList(feature=frame_feature),
53 | })
54 | )
55 |
56 | serialized = seq_example.SerializeToString()
57 | writer.write(serialized) # **4.写入文件中
58 |
59 | print('Finished.')
60 | writer1.close()
61 | writer2.close()
62 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_3_image_reader.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 |
5 | import os
6 | import time
7 | import sys
8 |
9 | '''read data
10 | 从 tfrecord 文件中读取数据,对应数据的格式为 png 格式。
11 | '''
12 |
13 | # **1.把所有的 tfrecord 文件名列表写入队列中
14 | TFRECORD_DIR = 'tfrecord/sketchy_image/'
15 | tfrecord_files = os.listdir(TFRECORD_DIR)
16 | tfrecord_files = list(map(lambda s: os.path.join(TFRECORD_DIR, s), tfrecord_files))
17 |
18 | filename_queue = tf.train.string_input_producer(tfrecord_files, num_epochs=None, shuffle=True)
19 | # **2.创建一个读取器
20 | reader = tf.TFRecordReader()
21 | _, serialized_example = reader.read(filename_queue)
22 | # **3.根据你写入的格式对应说明读取的格式
23 | features = tf.parse_single_example(serialized_example,
24 | features={
25 | 'image': tf.FixedLenFeature([], tf.string),
26 | 'label': tf.FixedLenFeature([], tf.int64)
27 | }
28 | )
29 | img = features['image']
30 | # 这里需要对图片进行解码
31 | img = tf.image.decode_png(img, channels=3) # 这里,也可以解码为 1 通道
32 | img = tf.image.resize_images(images=img, size=(224, 224))
33 | # img = tf.image.resize_image_with_crop_or_pad(img, 224, 224)
34 | # img = tf.reshape(img, [256, 256, 3]) # 256*256*3
35 |
36 | label = features['label']
37 |
38 | print('img is', img)
39 | print('label is', label)
40 | # **4.通过 tf.train.shuffle_batch 或者 tf.train.batch 函数读取数据
41 | """
42 | 这里,你会发现每次取出来的数据都是一个类别的,除非你把 capacity 和 min_after_dequeue 设得很大,如
43 | X_batch, y_batch = tf.train.shuffle_batch([img, label], batch_size=100,
44 | capacity=20000, min_after_dequeue=10000, num_threads=3)
45 | 这是因为在打包的时候都是一个类别一个类别的顺序打包的,所以每次填数据都是按照那个顺序填充进来。
46 | 只有当我们把队列容量舍得非常大,这样在队列中才会混杂各个类别的数据。但是这样非常不好,因为这样的话,
47 | 读取速度就会非常慢。所以解决方法是:
48 | 1.在写入数据的时候先进行数据 shuffle。
49 | 2.多存几个 tfrecord 文件,比如 64 个。
50 | """
51 |
52 | X_batch, y_batch = tf.train.shuffle_batch([img, label], batch_size=128,
53 | capacity=5000, min_after_dequeue=100, num_threads=2)
54 |
55 | config = tf.ConfigProto()
56 | config.gpu_options.allow_growth = True
57 | sess = tf.Session(config=config)
58 | init = tf.global_variables_initializer()
59 | sess.run(init)
60 |
61 | # **5.启动队列进行数据读取
62 | # 下面的 coord 是个线程协调器,把启动队列的时候加上线程协调器。
63 | # 这样,在数据读取完毕以后,调用协调器把线程全部都关了。
64 | coord = tf.train.Coordinator()
65 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
66 | # y_outputs = list()
67 | # for i in range(5):
68 | # _X_batch, _y_batch = sess.run([X_batch, y_batch])
69 | # print('** batch %d' % i)
70 | # print('_X_batch.shape:', _X_batch.shape)
71 | # print('_y_batch:', _y_batch)
72 | # y_outputs.extend(_y_batch.tolist())
73 | # print(y_outputs)
74 |
75 | time0 = time.time()
76 | # 只解析图片 200batch 9.6 seconds
77 | # resize_images 200batch 22.8 seconds
78 | # resize_image_with_crop_or_pad 200batch 22.4 seconds
79 | for count in range(500):
80 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
81 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
82 | sys.stdout.flush()
83 |
84 | # **6.最后记得把队列关掉
85 | coord.request_stop()
86 | coord.join(threads)
87 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_3_image_writer.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 | from tqdm import tqdm
6 | import sys
7 | import os
8 | import time
9 |
10 | '''tfrecord 写入数据.
11 | 将图片数据写入 tfrecord 文件。以 png格式数据集为例。
12 |
13 | 现在网上关于打包图片的例子非常多,实现方式各式各样,效率也相差非常多。
14 | 选择合适的方式能够有效地节省时间和硬盘空间。
15 | 有几点需要注意:
16 | 1.打包 tfrecord 的时候,千万不要使用 Image.open() 或者 matplotlib.image.imread() 等方式读取。
17 | 1张小于10kb的png图片,前者(Image.open) 打开后,生成的对象100+kb, 后者直接生成 numpy 数组,大概是原图片的几百倍大小。
18 | 所以应该直接使用 tf.gfile.FastGFile() 方式读入图片。
19 | 2.从 tfrecord 中取数据的时候,再用 tf.image.decode_png() 对图片进行解码。
20 | 3.不要随便使用 tf.image.resize_image_with_crop_or_pad 等函数,可以直接使用 tf.reshape()。前者速度极慢。
21 | '''
22 |
23 | # png 文件路径
24 | IMG_DIR = '../../data/sketchy_000000000000/'
25 | TFRECORD_DIR = 'tfrecord/sketchy_image/'
26 | NUM_SHARDS = 64 # tfrecord 文件的数量,稍微大些对 shuffle 会好些
27 |
28 |
29 | def get_file_path(data_path='../../data/sketchy_000000000000/'):
30 | """解析文件夹,获取每个文件的路径和标签。"""
31 | img_paths = list()
32 | labels = list()
33 | # 必须保证测试集 和 训练集中类别数相同,如果不同的话应该使用 dict_class2id 来保证类别对应正确。
34 | class_dirs = sorted(os.listdir(data_path))
35 | dict_class2id = dict()
36 | for i in range(len(class_dirs)):
37 | label = i
38 | class_dir = class_dirs[i]
39 | dict_class2id[class_dir] = label
40 | class_path = os.path.join(data_path, class_dir) # 每类的路径
41 | file_names = sorted(os.listdir(class_path))
42 | for file_name in file_names:
43 | file_path = os.path.join(class_path, file_name)
44 | img_paths.append(file_path)
45 | labels.append(label)
46 | img_paths = np.asarray(img_paths)
47 | labels = np.asarray(labels)
48 | return img_paths, labels
49 |
50 |
51 | def bytes_feature(values):
52 | return tf.train.Feature(bytes_list=tf.train.BytesList(value=[values]))
53 |
54 |
55 | def int64_feature(values):
56 | return tf.train.Feature(int64_list=tf.train.Int64List(value=[values]))
57 |
58 |
59 | def convert_tfrecord_dataset(tfrecord_dir, n_shards, img_paths, labels, shuffle=True):
60 | """ convert samples to tfrecord dataset.
61 | Args:
62 | dataset_dir: 数据集的路径。
63 | tfrecord_dir: 保存 tfrecord 文件的路径。
64 | n_shards: tfrecord 文件个数
65 | img_paths: 图片的名字。
66 | labels:图片的标签。
67 | """
68 | if not os.path.exists(tfrecord_dir):
69 | os.makedirs(tfrecord_dir)
70 | n_sample = len(img_paths)
71 | num_per_shard = n_sample // n_shards # 每个 tfrecord 的样本数量
72 |
73 | # 在打包之前先手动打乱一次
74 | if shuffle:
75 | new_idxs = np.random.permutation(n_sample)
76 | img_paths = img_paths[new_idxs]
77 | labels = labels[new_idxs]
78 |
79 | time0 = time.time()
80 | for shard_id in range(n_shards):
81 | output_filename = '%d-of-%d.tfrecord' % (shard_id, n_shards)
82 | output_path = os.path.join(tfrecord_dir, output_filename)
83 | with tf.python_io.TFRecordWriter(output_path) as writer:
84 | start_ndx = shard_id * num_per_shard
85 | end_ndx = min((shard_id + 1) * num_per_shard, n_sample)
86 | for i in range(start_ndx, end_ndx):
87 | sys.stdout.write('\r>> Converting image %d/%d shard %d, %g s' % (
88 | i + 1, n_sample, shard_id, time.time() - time0))
89 | sys.stdout.flush()
90 | png_path = img_paths[i]
91 | label = labels[i]
92 | img = tf.gfile.FastGFile(png_path, 'rb').read() # 读入图片
93 | example = tf.train.Example(
94 | features=tf.train.Features(
95 | feature={
96 | 'image': bytes_feature(img),
97 | 'label': int64_feature(label)
98 | }))
99 | serialized = example.SerializeToString()
100 | writer.write(serialized)
101 | print('\nFinished writing data to tfrecord files.')
102 |
103 |
104 | if __name__ == '__main__':
105 | img_paths, labels = get_file_path()
106 | convert_tfrecord_dataset(TFRECORD_DIR, NUM_SHARDS, img_paths, labels, shuffle=True)
107 |
--------------------------------------------------------------------------------
/utils/u03_flags.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 |
5 | """tf.app.flags 用来实现对命令行参数进行解析。
6 | 一般先使用 tf.app.flags.DEFINE_ ... 来定义参数;
7 | 然后通过 tf.app.flags.FLAGS 对象取各个参数。
8 | """
9 |
10 | flags = tf.flags
11 | logging = tf.logging
12 |
13 | FLAGS = flags.FLAGS
14 | flags.DEFINE_string('name', 'huang', 'str_name')
15 | flags.DEFINE_integer('age', 99, 'people age')
16 | flags.DEFINE_float('weight', 51.1, 'people weight')
17 |
18 | def main(_):
19 | print 'FLAGS.name=', FLAGS.name
20 | print 'FLAGS.age=', FLAGS.age
21 | print 'FLAGS.weight=', FLAGS.weight
22 |
23 | if __name__ == '__main__':
24 | tf.app.run() # 会自动运行 main() 函数
25 |
--------------------------------------------------------------------------------
94 | 简单的 tensorboard 可视化
95 |
96 |
97 |
98 | #### T_07.使用 tf.train.Saver() 来保存模型
99 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_07%20How%20to%20save%20the%20model.ipynb)
100 |
101 |
102 |
103 | #### T_08.【迁移学习】往一个已经保存好的 模型添加新的变量
104 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_08%20%20%5Btransfer%20learning%5D%20Add%20new%20variables%20to%20graph%20and%20save%20the%20new%20model.ipynb)
105 |
106 |
107 |
108 | #### T_09.使用 tfrecord 打包不定长的序列数据
109 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_09%20%5Btfrecord%5D%20use%20tfrecord%20to%20store%20sequences%20of%20different%20length.ipynb)
110 | - [reader-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_2_seqence_reader.py)
111 | - [writer-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_2_seqence_writer.py)
112 |
113 |
114 |
115 | #### T_10.使用 tf.data.Dataset 和 tfrecord 给 numpy 数据构建数据集
116 | - [dataset-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_10%20%5BDataset%5D%20numpy%20data.ipynb)
117 | - [tfrecord-reader-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_1_numpy_reader.py)
118 | - [tfrecord-writer-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_1_numpy_writer.py)
119 |
120 |
121 | 下面是对 MNIST 数据训练集 55000 个样本 读取的一个速度比较,统一 `batch_size=128`,主要比较 `one-shot` 和 `initializable` 两种迭代方式:
122 |
123 | |iter_mode|buffer_size|100 batch(s)|
124 | |:----:|:---:|:---:|
125 | |one-shot|2000|125|
126 | |one-shot|5000|149|
127 | |initializable|2000|0.7|
128 | |initializable|5000|0.7|
129 |
130 | 可以看到,使用 `initializable` 方式的速度明显要快很多。因为使用 `one-shot` 方式会把整个矩阵放在图中,计算非常非常慢。
131 |
132 |
133 |
134 | #### T_11.使用 tf.data.Dataset 和 tfrecord 给 图片数据 构建数据集
135 | - [dataset-notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_11%20%5BDataset%5D%20image%20data.ipynb)
136 | - [tfrecord-writer-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_3_image_writer.py)
137 | - [tfrecord-reader-code](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/utils_and_models/u02_tfrecord/tfrecord_3_image_reader.py)
138 |
139 | 对于 png 数据的读取,我尝试了 3 组不同的方式: one-shot 方式, tf 的队列方式(queue), tfrecord 方式. 同样是在机械硬盘上操作, 结果是 tfrecord 方式明显要快一些。(batch_size=128,图片大小为256*256,机械硬盘)
140 |
141 | |iter_mode|buffer_size|100 batch(s)|
142 | |:----:|:---:|:---:|
143 | |one-shot|2000|75|
144 | |one-shot|5000|86|
145 | |tf.queue|2000|11|
146 | |tf.queue|5000|11|
147 | |tfrecord|2000|5.3|
148 | |tfrecord|5000|5.3|
149 |
150 | 如果是在 SSD 上面的话,tf 的队列方式应该也是比较快的.打包成 tfrecord 格式只是减少了小文件的读取,其实现也是使用队列的。
151 |
152 |
153 | #### T_12.TensorFlow 高级API tf.layers 的使用
154 | - [notebook](https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/example-notebook/Tutorial_12%20%5Btf.layer%5Dhigh%20layer%20API.ipynb)
155 |
156 | 使用 TensorFlow 原生的 API 能够帮助自己很好的理解网络的细节,但是往往比较低效。 tf.layers 和 tf.keras 一样,是一个封装得比较好的一个高级库,接口用着挺方便的。所以在开发的时候,可以使用高级的接口能够有效的提高工作效率。
157 |
158 |
159 | # 2.TensorFlow 实战(持续更新)
160 | 下面的每个例子都是相互独立的,每个文件夹下面的代码都是可以单独运行的,不依赖于其他文件夹。
161 |
162 | ## [m01_batch_normalization: Batch Normalization 的使用](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m01_batch_normalization)
163 | 参考:[tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
164 |
165 | ## [m02_dcgan: 使用 DCGAN 生成二次元头像](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m02_dcgan)
166 | 参考:
167 | - [原论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1511.06434)
168 | - [GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059)
169 | - [代码:carpedm20/DCGAN-tensorflow](https://github.com/carpedm20/DCGAN-tensorflow)
170 | - [代码:aymericdamien/TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/dcgan.py)
171 |
172 | 这里的 notebook 和 .py 文件的内容是一样的。本例子和下面的 GAN 模型用的数据集也是用了[GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059) 的二次元头像,感觉这里例子比较有意思。如果想使用其他数据集的话,只需要把数据集换一下就行了。
173 |
174 | 下载链接: https://pan.baidu.com/s/1HBJpfkIFaGh0s2nfNXJsrA 密码: x39r
175 |
176 | 下载后把所有的图片解压到一个文件夹中,比如本例中是: `data_path = '../../data/anime/'`
177 |
178 | 运行: `python dcgan.py `
179 |
180 | ## [m03_wgan: 使用 WGAN 生成二次元头像](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m03_wgan)
181 | 这里的生成器和判别器我只实现了 DCGAN,没有实现 MLP. 如果想实现的话可以参考下面的两个例子。
182 | 参考:
183 | - [原论文:Wasserstein GAN](https://arxiv.org/pdf/1701.07875.pdf)
184 | - [代码:jiamings/wgan](https://github.com/jiamings/wgan)
185 | - [代码:Zardinality/WGAN-tensorflow](https://github.com/Zardinality/WGAN-tensorflow)
186 |
187 | 原版的 wgan: `python wgan.py `
188 |
189 | 改进的 wgan-gp: `python wgan_gp.py`
190 |
191 |
192 | ## [m04_pix2pix: image-to-image](https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m04_pix2pix)
193 | 代码来自:[affinelayer/pix2pix-tensorflow](https://github.com/affinelayer/pix2pix-tensorflow)
194 |
195 |
--------------------------------------------------------------------------------
/ckpt/bi-lstm.ckpt-12.data-00000-of-00001:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/ckpt/bi-lstm.ckpt-12.data-00000-of-00001
--------------------------------------------------------------------------------
/ckpt/bi-lstm.ckpt-12.index:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/ckpt/bi-lstm.ckpt-12.index
--------------------------------------------------------------------------------
/ckpt/bi-lstm.ckpt-12.meta:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/ckpt/bi-lstm.ckpt-12.meta
--------------------------------------------------------------------------------
/ckpt/checkpoint:
--------------------------------------------------------------------------------
1 | model_checkpoint_path: "test-model.ckpt-2"
2 | all_model_checkpoint_paths: "test-model.ckpt-2"
3 |
--------------------------------------------------------------------------------
/data/msr_train.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/data/msr_train.txt
--------------------------------------------------------------------------------
/doc/problem-solution.md:
--------------------------------------------------------------------------------
1 | ## 1.为什么 relu 激活函数会有失活现象?
2 | > [一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。](http://blog.csdn.net/cyh_24/article/details/50593400)
3 | > [Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei)](http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html)
4 | > [深度学习系列(8):激活函数](https://plushunter.github.io/2017/05/12/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%B3%BB%E5%88%97%EF%BC%888%EF%BC%89%EF%BC%9A%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0/)
5 |
6 | A: 在某次反向传播中神经元 C 传过一个很大的梯度,和 C 相连的所有权重系数 w 都变成了很大的负数。假设前一层输出也是 relu 激活函数,那么前一层的输出(C 的输入)一定是非负数。那么神经元 C 一定会处于0梯度状态,没有任何数据(输入)能够拯救他。也就是失活了。
7 |
8 | 那么,**我觉得,在初始化的时候,如果本层(L)使用 relu 激活函数,那么 biases 最好使用较小的正数初始化,如0.01,0.005等。这样可以在一定程度上使得输出偏向于正数,从而避免梯度消失。** 但是也有一点好处,由于部分神经元失活了,这和做了 dropout 一样,能够有助于防止过拟合。
9 |
10 | **除了上面的失活现象以外,relu 激活函数还有偏移现象:输出均值恒大于零。** 失活现象和偏移现象会共同影响网络的收敛性。#8.数据偏移怎么影响网络的收敛?#
11 |
12 |
13 |
14 | ## 2.[code]AlexNet(等 CNN model) 调参过程中要注意什么?
15 | > 在 github 上面有很多不同版本的 AlexNet,网络结构基本都是一样的,在官方的 tensorflow slim 框架中也提供了 alexnet-v2 版本。在我的任务中,发现 slim 版本的 alexnet 效果要比其他版本的好很多(2~4个百分点)。明明结构一样,为什么差别这么大。
16 |
17 | A:虽然我觉得 slim 框架很不友好,但是里边的参数应该都是经过测试得到的较好的结果。很多小的细节都会影响最后的结果,具体要注意的有下面这些点:
18 | - 初始化方式。在我的任务中,初始化方式影响很大。slim 中的每一层的初始化方式和 caffe 的版本中基本一致。包括 conv 层, fc 层的 weights, biases。我就是最后一个 fc 层改了一下初始化,loss 嗖嗖地就降了。
19 | - 优化器。在原版中用的是 RMSProp 优化器,但坑的是用的不是默认参数,最好设置成跟 slim 一致。
20 | - 数据预处理。我用 caffe 算出了整个数据集的均值,然后把原始图片[0.~255.]减去均值,效果还不错。
21 | - lrn。在 slim 的 alexnet-v2 版本中去掉了局部响应层。结果没有变差,速度快了大概一倍吧。
22 |
23 |
24 |
25 | ## 3.[code]tensorflow 训练模型,报无法分配 memory,但是程序继续运行,这时运行的结果有问题吗?
26 | >**ran out of memory trying to allocate 3.27GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory is available.** 这时候,使用 watch nvidia-smi 看显卡使用情况,就会发现使用率非常低。
27 |
28 | A:这种情况下就应该把batch_size减小了!!!虽然程序还在运行,但是你会发现,结果根本不对,loss 根本就没降。这不是因为你的模型不好,学习率不对。把 batch_size 调小看看结果再下定论。
29 |
30 |
31 |
32 | ## 4.什么情况下用 sigmoid 会比 relu 好呢?
33 | > sigmoid 函数有陷入饱和区(造成梯度消失),非零中心和计算效率低的缺点。那么有什么情况下用 sigmoid 会好呢?
34 |
35 | A: 如果只是作为一个普通隐含层的激活函数的话,还是用 relu 就好了。但是如果你后继需要对某层特征进行量化处理的话,sigmoid 就起作用了。relu 层的输出范围太大,不适合做量化。这时候就体现出 0 和 1 的优越性了。同样,使用 tanh 层也是可以的。
36 |
37 |
38 |
39 | ## 5.sigmoid 非 zero-center 会有什么影响,relu 有这样的影响吗?怎么理解因此导致梯度下降权重更新时出现 z 字型的下降?
40 | > [Sigmoid函数的输出不是零中心的。这个性质并不是我们想要的,因为在神经网络后面层中神经元得到的数据不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数(比如在 f=wx+b 中每个元素都是 x>0),那么关于 w 的梯度在反向传播中,将会要么全部是正数,或者全部是负数(比如f=-wx+b).这将会导致梯度下降权重更新时出现z字型的下降(如下图所示)。](https://plushunter.github.io/2017/05/12/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%B3%BB%E5%88%97%EF%BC%888%EF%BC%89%EF%BC%9A%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0/)
41 |
42 |
43 |
44 |
45 | ## 6.在 relu 层前面的 BN 层中,为什么不用对 scale 做处理
46 | > [mnist_4.1_batchnorm_five_layers_relu.py](https://github.com/martin-gorner/tensorflow-mnist-tutorial/blob/master/mnist_4.1_batchnorm_five_layers_relu.py)
47 |
48 | A:没想明白.
49 |
50 |
51 |
52 | ## 7.在问题 1 中,relu 激活函数的偏移现象就是数据的输入分布(zero-center)和输出分布变了(no-zero-center).在 BN 中也提到过,这种数据分布的变化为什么会影响网络的收敛性?
53 | > [对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。](https://www.zhihu.com/question/38102762) 这样源空间 -> 目标空间 的变化怎么影响网络的收敛?
54 |
55 |
56 |
57 | ## 8.在BN中,为什么通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大,防止梯度消失?
58 | [在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。可以说是一种更有效的local response normalization方法(见4.2.1节)。](https://www.zhihu.com/question/38102762) 在 BN 中,通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差。对于 mini-batch,首先减去均值,方差归一;接着进行 scale and shift 操作,也就是用学习到的全局均值和方差替换掉了 mini-batch 的均值和方差。 然后送入激活函数如(sigmoid)中,**这时候并没有把sigmoid的输入约束到 0 附近呀,为什么就能够避免梯度消失?**
59 |
60 | A:首先,对于 sigmoid 和 tanh 来说,当输入的绝对值很大时就会陷入饱和区。这个激活函数的输入一般指的是 z(=wx)。
61 | z 很大 -> 陷入饱和区
62 | z 很大 -> wx 这两个向量的点积很大 -> 如果 w 或者 x 的元素值很大,较容易使得 wx 很大? -> w,x 的值很大
63 | BN 避免了梯度消失 -> BN 处理使得 x 向 0 靠近了。但是没有呀??
64 |
65 | [BN使得输入分布大致稳定,从而缩短了参数适应分布的过程,进而缩短训练时间](https://zhuanlan.zhihu.com/p/26532249)
66 |
67 |
68 |
69 | ## 9.center loss 训练有什么需要注意的?center loss 会使类间的相对距离增大吗?
70 | > center loss 最小化类内距离,但是并没有显式地去最大化类间距离。在我的实验中,对加了center loss 的高层特征进行统计分析,发现类内特征的方差明显要比原来更小了,但是特征均值也比原来更小了。这样类间的绝对距离也会比原来小,假设类间中心距离为 L-inter,类内的距离为 L-intra, 类间的相对距离为 L-relative = (L-inter / L-intra)。那么,加上 center loss 后, L-relative 怎么变化?
71 |
72 | A:1.在模型训练的时候记得把每个类的中心特征向量留出接口,以便后继分析。
73 |
74 |
75 |
76 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_02 A simple feedforward network for MNIST-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 两层FC层做分类:MNIST\n",
8 | "\n",
9 | "在本教程中,我们来实现一个非常简单的两层全连接层来完成MNIST数据的分类问题。\n",
10 | "\n",
11 | "输入[-1,28*28], FC1 有 1024 个neurons, FC2 有 10 个neurons。这么简单的一个全连接网络,结果测试准确率达到了 0.98。还是非常棒的!!!"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 1,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "from __future__ import print_function\n",
21 | "from __future__ import division\n",
22 | "from __future__ import absolute_import\n",
23 | "\n",
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.Session(config=config)"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "### 1.导入数据\n",
41 | "下面导入数据这部分的警告可以不用管先,TensorFlow 非常恶心的地方就是不停地改 API,改到发麻。"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 2,
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
54 | "Instructions for updating:\n",
55 | "Use the retry module or similar alternatives.\n",
56 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
57 | "Instructions for updating:\n",
58 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
59 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
60 | "Instructions for updating:\n",
61 | "Please write your own downloading logic.\n",
62 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
63 | "Instructions for updating:\n",
64 | "Please use tf.data to implement this functionality.\n",
65 | "Extracting ../data/MNIST_data/train-images-idx3-ubyte.gz\n",
66 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
67 | "Instructions for updating:\n",
68 | "Please use tf.data to implement this functionality.\n",
69 | "Extracting ../data/MNIST_data/train-labels-idx1-ubyte.gz\n",
70 | "Extracting ../data/MNIST_data/t10k-images-idx3-ubyte.gz\n",
71 | "Extracting ../data/MNIST_data/t10k-labels-idx1-ubyte.gz\n",
72 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
73 | "Instructions for updating:\n",
74 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n"
75 | ]
76 | }
77 | ],
78 | "source": [
79 | "# 用tensorflow 导入数据\n",
80 | "from tensorflow.examples.tutorials.mnist import input_data\n",
81 | "mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=False, source_url='http://yann.lecun.com/exdb/mnist/')"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "name": "stdout",
91 | "output_type": "stream",
92 | "text": [
93 | "training data shape (55000, 784)\n",
94 | "training label shape (55000,)\n"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "print('training data shape ', mnist.train.images.shape)\n",
100 | "print('training label shape ', mnist.train.labels.shape)"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "metadata": {},
106 | "source": [
107 | "### 2. 构建网络"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 4,
113 | "metadata": {},
114 | "outputs": [
115 | {
116 | "name": "stdout",
117 | "output_type": "stream",
118 | "text": [
119 | "Tensor(\"add_1:0\", shape=(?, 10), dtype=float32)\n"
120 | ]
121 | }
122 | ],
123 | "source": [
124 | "# 权值初始化\n",
125 | "def weight_variable(shape):\n",
126 | " # 用正态分布来初始化权值\n",
127 | " initial = tf.truncated_normal(shape, stddev=0.1)\n",
128 | " return tf.Variable(initial)\n",
129 | "\n",
130 | "def bias_variable(shape):\n",
131 | " # 本例中用relu激活函数,所以用一个很小的正偏置较好\n",
132 | " initial = tf.constant(0.1, shape=shape)\n",
133 | " return tf.Variable(initial)\n",
134 | "\n",
135 | "\n",
136 | "# input_layer\n",
137 | "X_input = tf.placeholder(tf.float32, [None, 784])\n",
138 | "y_input = tf.placeholder(tf.int64, [None]) # 不使用 one-hot \n",
139 | "\n",
140 | "# FC1\n",
141 | "W_fc1 = weight_variable([784, 1024])\n",
142 | "b_fc1 = bias_variable([1024])\n",
143 | "h_fc1 = tf.nn.relu(tf.matmul(X_input, W_fc1) + b_fc1)\n",
144 | "\n",
145 | "# FC2\n",
146 | "W_fc2 = weight_variable([1024, 10])\n",
147 | "b_fc2 = bias_variable([10])\n",
148 | "# y_pre = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)\n",
149 | "logits = tf.matmul(h_fc1, W_fc2) + b_fc2\n",
150 | "\n",
151 | "print(logits)"
152 | ]
153 | },
154 | {
155 | "cell_type": "markdown",
156 | "metadata": {},
157 | "source": [
158 | "### 3.训练和评估\n",
159 | "下面我们将输入 mnist 的数据来进行训练。在下面有个 mnist.train.next_batch(batch_size=100) 的操作,每次从数据集中取出100个样本。如果想了解怎么实现的话建议看一下源码,其实挺简单的,很多时候需要我们自己去实现读取数据的这个函数。"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 5,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "step 500, train cost=0.153510, acc=0.950000; test cost=0.123346, acc=0.962500\n",
172 | "step 1000, train cost=0.087353, acc=0.960000; test cost=0.104876, acc=0.967400\n",
173 | "step 1500, train cost=0.033138, acc=0.990000; test cost=0.080937, acc=0.975200\n",
174 | "step 2000, train cost=0.028831, acc=0.990000; test cost=0.077214, acc=0.977800\n",
175 | "step 2500, train cost=0.004817, acc=1.000000; test cost=0.066441, acc=0.980000\n",
176 | "step 3000, train cost=0.015692, acc=1.000000; test cost=0.067741, acc=0.979400\n",
177 | "step 3500, train cost=0.011569, acc=1.000000; test cost=0.075138, acc=0.979400\n",
178 | "step 4000, train cost=0.006310, acc=1.000000; test cost=0.074501, acc=0.978300\n",
179 | "step 4500, train cost=0.008795, acc=1.000000; test cost=0.076483, acc=0.979100\n",
180 | "step 5000, train cost=0.027700, acc=0.980000; test cost=0.073973, acc=0.980000\n"
181 | ]
182 | }
183 | ],
184 | "source": [
185 | "# 1.损失函数:cross_entropy\n",
186 | "# 如果label是 one-hot 的话要换一下损失函数,参考:https://blog.csdn.net/tz_zs/article/details/76086457\n",
187 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_input, logits=logits)) \n",
188 | "# 2.优化函数:AdamOptimizer, 优化速度要比 GradientOptimizer 快很多\n",
189 | "train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)\n",
190 | "\n",
191 | "# 3.预测结果评估\n",
192 | "# 预测值中最大值(1)即分类结果,是否等于原始标签中的(1)的位置。argmax()取最大值所在的下标\n",
193 | "correct_prediction = tf.equal(tf.argmax(logits, 1), y_input) \n",
194 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n",
195 | "\n",
196 | "# 开始运行\n",
197 | "sess.run(tf.global_variables_initializer())\n",
198 | "# 这大概迭代了不到 10 个 epoch, 训练准确率已经达到了0.98\n",
199 | "for i in range(5000):\n",
200 | " X_batch, y_batch = mnist.train.next_batch(batch_size=100)\n",
201 | " cost, acc, _ = sess.run([cross_entropy, accuracy, train_step], feed_dict={X_input: X_batch, y_input: y_batch})\n",
202 | " if (i+1) % 500 == 0:\n",
203 | " test_cost, test_acc = sess.run([cross_entropy, accuracy], feed_dict={X_input: mnist.test.images, y_input: mnist.test.labels})\n",
204 | " print(\"step {}, train cost={:.6f}, acc={:.6f}; test cost={:.6f}, acc={:.6f}\".format(i+1, cost, acc, test_cost, test_acc))\n",
205 | " "
206 | ]
207 | }
208 | ],
209 | "metadata": {
210 | "anaconda-cloud": {},
211 | "kernelspec": {
212 | "display_name": "Python 3",
213 | "language": "python",
214 | "name": "python3"
215 | },
216 | "language_info": {
217 | "codemirror_mode": {
218 | "name": "ipython",
219 | "version": 3
220 | },
221 | "file_extension": ".py",
222 | "mimetype": "text/x-python",
223 | "name": "python",
224 | "nbconvert_exporter": "python",
225 | "pygments_lexer": "ipython3",
226 | "version": "3.5.2"
227 | }
228 | },
229 | "nbformat": 4,
230 | "nbformat_minor": 1
231 | }
232 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_03_2 The usage of Collection-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# TensorFlow 变量命名管理机制(二)\n",
8 | "\n",
9 | "\n",
10 | "### 1. 用 collection 来聚合变量\n",
11 | "前面介绍了 tensorflow 的变量命名机制,这里要补充一下 `tf.add_to_collection` 和 `tf.get_collection`的用法。\n",
12 | "\n",
13 | "因为神经网络中的参数非常多,有时候我们 只想对某些参数进行操作。除了前面通过变量名称的方法来获取参数之外, TensorFlow 中还有 collection 这么一种操作。\n",
14 | "\n",
15 | "collection 可以聚合多个**变量**或者**操作**。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import tensorflow as tf\n",
28 | "\n",
29 | "# 设置GPU按需增长\n",
30 | "config = tf.ConfigProto()\n",
31 | "config.gpu_options.allow_growth = True\n",
32 | "sess = tf.Session(config=config)"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "参考:[如何利用tf.add_to_collection、tf.get_collection以及tf.add_n来简化正则项的计算](https://blog.csdn.net/weixin_39980291/article/details/78352125)"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 2,
45 | "metadata": {},
46 | "outputs": [
47 | {
48 | "name": "stdout",
49 | "output_type": "stream",
50 | "text": [
51 | "vars in col1: [, ]\n"
52 | ]
53 | }
54 | ],
55 | "source": [
56 | "# 把变量添加到一个 collection 中\n",
57 | "v1 = tf.Variable([1,2,3], name='v1')\n",
58 | "v2 = tf.Variable([2], name='v2')\n",
59 | "v3 = tf.get_variable(name='v3', shape=(2,3))\n",
60 | "\n",
61 | "tf.add_to_collection('col1', v1) # 把 v1 添加到 col1 中\n",
62 | "tf.add_to_collection('col1', v3)\n",
63 | "\n",
64 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
65 | "print('vars in col1:', col1s)"
66 | ]
67 | },
68 | {
69 | "cell_type": "markdown",
70 | "metadata": {},
71 | "source": [
72 | "除了把变量添加到集合中,还可以把操作添加到集合中。"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 3,
78 | "metadata": {},
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "vars in col1: [, , ]\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "op1 = tf.add(v1, 2, name='add_op')\n",
90 | "tf.add_to_collection('col1', op1)\n",
91 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
92 | "print('vars in col1:', col1s)"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "此外,还可以加上 scope 的约束。"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 3,
105 | "metadata": {},
106 | "outputs": [
107 | {
108 | "name": "stdout",
109 | "output_type": "stream",
110 | "text": [
111 | "vars in col1 with scope=model: []\n"
112 | ]
113 | }
114 | ],
115 | "source": [
116 | "with tf.variable_scope('model'):\n",
117 | " v4 = tf.get_variable('v4', shape=[3,4])\n",
118 | " v5 = tf.Variable([1,2,3], name='v5')\n",
119 | "\n",
120 | "tf.add_to_collection('col1', v5)\n",
121 | "col1_vars = tf.get_collection(key='col1', scope='model') # 获取 col1 的变量\n",
122 | "print('vars in col1 with scope=model: ', col1_vars)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "### 2. tf.GraphKeys \n",
130 | "\n",
131 | "参考:[tf.GraphKeys 函数](https://www.w3cschool.cn/tensorflow_python/tensorflow_python-ne7t2ezd.html)\n",
132 | "\n",
133 | "用于图形集合的标准名称。\n",
134 | "\n",
135 | "\n",
136 | "标准库使用各种已知的名称来收集和检索与图形相关联的值。例如,如果没有指定,则 tf.Optimizer 子类默认优化收集的变量tf.GraphKeys.TRAINABLE_VARIABLES,但也可以传递显式的变量列表。\n",
137 | "\n",
138 | "定义了以下标准键:\n",
139 | "\n",
140 | "- GLOBAL_VARIABLES:默认的 Variable 对象集合,在分布式环境共享(模型变量是其中的子集)。参考:tf.global_variables。通常,所有TRAINABLE_VARIABLES 变量都将在 MODEL_VARIABLES,所有 MODEL_VARIABLES 变量都将在 GLOBAL_VARIABLES。\n",
141 | "- LOCAL_VARIABLES:每台计算机的局部变量对象的子集。通常用于临时变量,如计数器。注意:使用 tf.contrib.framework.local_variable 添加到此集合。\n",
142 | "- MODEL_VARIABLES:在模型中用于推理(前馈)的变量对象的子集。注意:使用 tf.contrib.framework.model_variable 添加到此集合。\n",
143 | "- TRAINABLE_VARIABLES:将由优化器训练的变量对象的子集。\n",
144 | "- SUMMARIES:在关系图中创建的汇总张量对象。\n",
145 | "- QUEUE_RUNNERS:用于为计算生成输入的 QueueRunner 对象。\n",
146 | "- MOVING_AVERAGE_VARIABLES:变量对象的子集,它也将保持移动平均值。\n",
147 | "- REGULARIZATION_LOSSES:在图形构造期间收集的正规化损失。\n",
148 | "\n",
149 | "这个知道就好了,要用的时候知道是怎么回事就行了。比如在 BN 层中就有这东西。"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": []
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": null,
162 | "metadata": {},
163 | "outputs": [],
164 | "source": []
165 | }
166 | ],
167 | "metadata": {
168 | "anaconda-cloud": {},
169 | "kernelspec": {
170 | "display_name": "Python 3",
171 | "language": "python",
172 | "name": "python3"
173 | },
174 | "language_info": {
175 | "codemirror_mode": {
176 | "name": "ipython",
177 | "version": 3
178 | },
179 | "file_extension": ".py",
180 | "mimetype": "text/x-python",
181 | "name": "python",
182 | "nbconvert_exporter": "python",
183 | "pygments_lexer": "ipython3",
184 | "version": "3.5.2"
185 | }
186 | },
187 | "nbformat": 4,
188 | "nbformat_minor": 1
189 | }
190 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_04_3 Convolutional network for MNIST(3)-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CNN做MNIST分类\n",
8 | "\n",
9 | "使用 tf.layers 高级 API 构建 CNN "
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
22 | " from ._conv import register_converters as _register_converters\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.InteractiveSession(config=config)\n",
34 | "\n",
35 | "import time"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "## 1.导入数据,用 tensorflow 导入"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 2,
48 | "metadata": {},
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
55 | "Instructions for updating:\n",
56 | "Use the retry module or similar alternatives.\n",
57 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
58 | "Instructions for updating:\n",
59 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
60 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
61 | "Instructions for updating:\n",
62 | "Please write your own downloading logic.\n",
63 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
64 | "Instructions for updating:\n",
65 | "Please use tf.data to implement this functionality.\n",
66 | "Extracting MNIST_data/train-images-idx3-ubyte.gz\n",
67 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
68 | "Instructions for updating:\n",
69 | "Please use tf.data to implement this functionality.\n",
70 | "Extracting MNIST_data/train-labels-idx1-ubyte.gz\n",
71 | "Extracting MNIST_data/t10k-images-idx3-ubyte.gz\n",
72 | "Extracting MNIST_data/t10k-labels-idx1-ubyte.gz\n",
73 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
74 | "Instructions for updating:\n",
75 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
76 | "(10000,)\n",
77 | "(55000,)\n"
78 | ]
79 | }
80 | ],
81 | "source": [
82 | "# 用tensorflow 导入数据\n",
83 | "from tensorflow.examples.tutorials.mnist import input_data\n",
84 | "mnist = input_data.read_data_sets('MNIST_data', one_hot=False)\n",
85 | "# 看看咱们样本的数量\n",
86 | "print(mnist.test.labels.shape)\n",
87 | "print(mnist.train.labels.shape)"
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {},
93 | "source": [
94 | "## 2. 构建网络"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 3,
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "Finished building network.\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "with tf.name_scope('inputs'):\n",
112 | " X_ = tf.placeholder(tf.float32, [None, 784])\n",
113 | " y_ = tf.placeholder(tf.int64, [None])\n",
114 | "\n",
115 | "# 把X转为卷积所需要的形式\n",
116 | "X = tf.reshape(X_, [-1, 28, 28, 1])\n",
117 | "h_conv1 = tf.layers.conv2d(X, filters=32, kernel_size=5, strides=1, padding='same', activation=tf.nn.relu, name='conv1')\n",
118 | "h_pool1 = tf.layers.max_pooling2d(h_conv1, pool_size=2, strides=2, padding='same', name='pool1')\n",
119 | "\n",
120 | "h_conv2 = tf.layers.conv2d(h_pool1, filters=64, kernel_size=5, strides=1, padding='same',activation=tf.nn.relu, name='conv2')\n",
121 | "h_pool2 = tf.layers.max_pooling2d(h_conv2, pool_size=2, strides=2, padding='same', name='pool2')\n",
122 | "\n",
123 | "# flatten\n",
124 | "h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\n",
125 | "h_fc1 = tf.layers.dense(h_pool2_flat, 1024, name='fc1', activation=tf.nn.relu)\n",
126 | "\n",
127 | "# dropout: 输出的维度和h_fc1一样,只是随机部分值被值为零\n",
128 | "keep_prob = tf.placeholder(tf.float32)\n",
129 | "h_fc1_drop = tf.nn.dropout(h_fc1, 0.5) # 实际测试的时候这里不应该使用 0.5,这里为了方便演示都这样写而已\n",
130 | "h_fc2 = tf.layers.dense(h_fc1_drop, units=10, name='fc2')\n",
131 | "# y_conv = tf.nn.softmax(h_fc2)\n",
132 | "y_conv = h_fc2\n",
133 | "print('Finished building network.')"
134 | ]
135 | },
136 | {
137 | "cell_type": "code",
138 | "execution_count": 4,
139 | "metadata": {},
140 | "outputs": [
141 | {
142 | "name": "stdout",
143 | "output_type": "stream",
144 | "text": [
145 | "Tensor(\"conv1/Relu:0\", shape=(?, 28, 28, 32), dtype=float32)\n",
146 | "Tensor(\"pool1/MaxPool:0\", shape=(?, 14, 14, 32), dtype=float32)\n",
147 | "Tensor(\"conv2/Relu:0\", shape=(?, 14, 14, 64), dtype=float32)\n",
148 | "Tensor(\"pool2/MaxPool:0\", shape=(?, 7, 7, 64), dtype=float32)\n",
149 | "Tensor(\"Reshape_1:0\", shape=(?, 3136), dtype=float32)\n",
150 | "Tensor(\"fc1/Relu:0\", shape=(?, 1024), dtype=float32)\n",
151 | "Tensor(\"fc2/BiasAdd:0\", shape=(?, 10), dtype=float32)\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "print(h_conv1)\n",
157 | "print(h_pool1)\n",
158 | "print(h_conv2)\n",
159 | "print(h_pool2)\n",
160 | "\n",
161 | "print(h_pool2_flat)\n",
162 | "print(h_fc1)\n",
163 | "print(h_fc2)"
164 | ]
165 | },
166 | {
167 | "cell_type": "markdown",
168 | "metadata": {},
169 | "source": [
170 | "## 3.训练和评估"
171 | ]
172 | },
173 | {
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | " 在测试的时候不使用 mini_batch, 那么测试的时候会占用较多的GPU(4497M),这在 notebook 交互式编程中是不推荐的。"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": null,
183 | "metadata": {
184 | "scrolled": false
185 | },
186 | "outputs": [
187 | {
188 | "name": "stdout",
189 | "output_type": "stream",
190 | "text": [
191 | "step 0, training accuracy = 0.1100, pass 1.18s \n",
192 | "step 1000, training accuracy = 0.9800, pass 6.01s \n",
193 | "step 2000, training accuracy = 0.9800, pass 10.82s \n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "# cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\n",
199 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
200 | " labels=tf.cast(y_, dtype=tf.int32), logits=y_conv))\n",
201 | "\n",
202 | "train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
203 | "\n",
204 | "correct_prediction = tf.equal(tf.argmax(y_conv,1), y_)\n",
205 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n",
206 | "sess.run(tf.global_variables_initializer())\n",
207 | "\n",
208 | "tic = time.time()\n",
209 | "for i in range(10000):\n",
210 | " batch = mnist.train.next_batch(100)\n",
211 | " if i%1000 == 0:\n",
212 | " train_accuracy = accuracy.eval(feed_dict={\n",
213 | " X_:batch[0], y_: batch[1], keep_prob: 1.0})\n",
214 | " print(\"step {}, training accuracy = {:.4f}, pass {:.2f}s \".format(i, train_accuracy, time.time() - tic))\n",
215 | " train_step.run(feed_dict={X_: batch[0], y_: batch[1]})\n",
216 | "\n",
217 | "print(\"test accuracy %g\"%accuracy.eval(feed_dict={\n",
218 | " X_: mnist.test.images, y_: mnist.test.labels}))"
219 | ]
220 | }
221 | ],
222 | "metadata": {
223 | "anaconda-cloud": {},
224 | "kernelspec": {
225 | "display_name": "Python 3",
226 | "language": "python",
227 | "name": "python3"
228 | },
229 | "language_info": {
230 | "codemirror_mode": {
231 | "name": "ipython",
232 | "version": 3
233 | },
234 | "file_extension": ".py",
235 | "mimetype": "text/x-python",
236 | "name": "python",
237 | "nbconvert_exporter": "python",
238 | "pygments_lexer": "ipython3",
239 | "version": "3.5.2"
240 | }
241 | },
242 | "nbformat": 4,
243 | "nbformat_minor": 1
244 | }
245 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_04_3 Convolutional network for MNIST(4)-BN-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CNN做MNIST分类(四)\n",
8 | "\n",
9 | "使用 tf.layers 高级 API 构建 CNN,添加 BN 层。"
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
22 | " from ._conv import register_converters as _register_converters\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.InteractiveSession(config=config)\n",
34 | "\n",
35 | "import time"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "## 1.导入数据,用 tensorflow 导入"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 2,
48 | "metadata": {},
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
55 | "Instructions for updating:\n",
56 | "Use the retry module or similar alternatives.\n",
57 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
58 | "Instructions for updating:\n",
59 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
60 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
61 | "Instructions for updating:\n",
62 | "Please write your own downloading logic.\n",
63 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:219: retry..wrap..wrapped_fn (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
64 | "Instructions for updating:\n",
65 | "Please use urllib or similar directly.\n",
66 | "Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.\n",
67 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
68 | "Instructions for updating:\n",
69 | "Please use tf.data to implement this functionality.\n",
70 | "Extracting MNIST_data/train-images-idx3-ubyte.gz\n",
71 | "Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.\n",
72 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
73 | "Instructions for updating:\n",
74 | "Please use tf.data to implement this functionality.\n",
75 | "Extracting MNIST_data/train-labels-idx1-ubyte.gz\n",
76 | "Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.\n",
77 | "Extracting MNIST_data/t10k-images-idx3-ubyte.gz\n",
78 | "Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.\n",
79 | "Extracting MNIST_data/t10k-labels-idx1-ubyte.gz\n",
80 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
81 | "Instructions for updating:\n",
82 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
83 | "(10000,)\n",
84 | "(55000,)\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "# 用tensorflow 导入数据\n",
90 | "from tensorflow.examples.tutorials.mnist import input_data\n",
91 | "mnist = input_data.read_data_sets('MNIST_data', one_hot=False)\n",
92 | "# 看看咱们样本的数量\n",
93 | "print(mnist.test.labels.shape)\n",
94 | "print(mnist.train.labels.shape)"
95 | ]
96 | },
97 | {
98 | "cell_type": "markdown",
99 | "metadata": {},
100 | "source": [
101 | "## 2. 构建网络"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 3,
107 | "metadata": {},
108 | "outputs": [
109 | {
110 | "name": "stdout",
111 | "output_type": "stream",
112 | "text": [
113 | "Finished building network.\n"
114 | ]
115 | }
116 | ],
117 | "source": [
118 | "with tf.name_scope('inputs'):\n",
119 | " X_ = tf.placeholder(tf.float32, [None, 784])\n",
120 | " y_ = tf.placeholder(tf.int64, [None])\n",
121 | "\n",
122 | "# 把X转为卷积所需要的形式\n",
123 | "X = tf.reshape(X_, [-1, 28, 28, 1])\n",
124 | "h_conv1 = tf.layers.conv2d(X, filters=32, kernel_size=5, strides=1, padding='same', name='conv1')\n",
125 | "h_bn1 = tf.layers.batch_normalization(h_conv1, )\n",
126 | "h_pool1 = tf.layers.max_pooling2d(h_conv1, pool_size=2, strides=2, padding='same', name='pool1')\n",
127 | "\n",
128 | "h_conv2 = tf.layers.conv2d(h_pool1, filters=64, kernel_size=5, strides=1, padding='same',activation=tf.nn.relu, name='conv2')\n",
129 | "h_pool2 = tf.layers.max_pooling2d(h_conv2, pool_size=2, strides=2, padding='same', name='pool2')\n",
130 | "\n",
131 | "# flatten\n",
132 | "h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\n",
133 | "h_fc1 = tf.layers.dense(h_pool2_flat, 1024, name='fc1', activation=tf.nn.relu)\n",
134 | "\n",
135 | "# dropout: 输出的维度和h_fc1一样,只是随机部分值被值为零\n",
136 | "keep_prob = tf.placeholder(tf.float32)\n",
137 | "h_fc1_drop = tf.nn.dropout(h_fc1, 0.5) # 实际测试的时候这里不应该使用 0.5,这里为了方便演示都这样写而已\n",
138 | "h_fc2 = tf.layers.dense(h_fc1_drop, units=10, name='fc2')\n",
139 | "# y_conv = tf.nn.softmax(h_fc2)\n",
140 | "y_conv = h_fc2\n",
141 | "print('Finished building network.')"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 4,
147 | "metadata": {},
148 | "outputs": [
149 | {
150 | "name": "stdout",
151 | "output_type": "stream",
152 | "text": [
153 | "Tensor(\"conv1/Relu:0\", shape=(?, 28, 28, 32), dtype=float32)\n",
154 | "Tensor(\"pool1/MaxPool:0\", shape=(?, 14, 14, 32), dtype=float32)\n",
155 | "Tensor(\"conv2/Relu:0\", shape=(?, 14, 14, 64), dtype=float32)\n",
156 | "Tensor(\"pool2/MaxPool:0\", shape=(?, 7, 7, 64), dtype=float32)\n",
157 | "Tensor(\"Reshape_1:0\", shape=(?, 3136), dtype=float32)\n",
158 | "Tensor(\"fc1/Relu:0\", shape=(?, 1024), dtype=float32)\n",
159 | "Tensor(\"fc2/BiasAdd:0\", shape=(?, 10), dtype=float32)\n"
160 | ]
161 | }
162 | ],
163 | "source": [
164 | "print(h_conv1)\n",
165 | "print(h_pool1)\n",
166 | "print(h_conv2)\n",
167 | "print(h_pool2)\n",
168 | "\n",
169 | "print(h_pool2_flat)\n",
170 | "print(h_fc1)\n",
171 | "print(h_fc2)"
172 | ]
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "metadata": {},
177 | "source": [
178 | "## 3.训练和评估"
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | " 在测试的时候不使用 mini_batch, 那么测试的时候会占用较多的GPU(4497M),这在 notebook 交互式编程中是不推荐的。"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 5,
191 | "metadata": {
192 | "scrolled": false
193 | },
194 | "outputs": [
195 | {
196 | "name": "stdout",
197 | "output_type": "stream",
198 | "text": [
199 | "step 0, training accuracy = 0.1100, pass 1.18s \n",
200 | "step 1000, training accuracy = 0.9800, pass 6.01s \n",
201 | "step 2000, training accuracy = 0.9800, pass 10.82s \n",
202 | "step 3000, training accuracy = 0.9700, pass 15.65s \n",
203 | "step 4000, training accuracy = 1.0000, pass 20.40s \n",
204 | "step 5000, training accuracy = 0.9800, pass 25.26s \n",
205 | "step 6000, training accuracy = 1.0000, pass 30.00s \n",
206 | "step 7000, training accuracy = 0.9900, pass 34.84s \n",
207 | "step 8000, training accuracy = 1.0000, pass 39.66s \n",
208 | "step 9000, training accuracy = 1.0000, pass 44.55s \n",
209 | "test accuracy 0.9924\n"
210 | ]
211 | }
212 | ],
213 | "source": [
214 | "# cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\n",
215 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
216 | " labels=tf.cast(y_, dtype=tf.int32), logits=y_conv))\n",
217 | "\n",
218 | "train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
219 | "\n",
220 | "correct_prediction = tf.equal(tf.argmax(y_conv,1), y_)\n",
221 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n",
222 | "sess.run(tf.global_variables_initializer())\n",
223 | "\n",
224 | "tic = time.time()\n",
225 | "for i in range(10000):\n",
226 | " batch = mnist.train.next_batch(100)\n",
227 | " if i%1000 == 0:\n",
228 | " train_accuracy = accuracy.eval(feed_dict={\n",
229 | " X_:batch[0], y_: batch[1], keep_prob: 1.0})\n",
230 | " print(\"step {}, training accuracy = {:.4f}, pass {:.2f}s \".format(i, train_accuracy, time.time() - tic))\n",
231 | " train_step.run(feed_dict={X_: batch[0], y_: batch[1]})\n",
232 | "\n",
233 | "print(\"test accuracy %g\"%accuracy.eval(feed_dict={\n",
234 | " X_: mnist.test.images, y_: mnist.test.labels}))"
235 | ]
236 | }
237 | ],
238 | "metadata": {
239 | "anaconda-cloud": {},
240 | "kernelspec": {
241 | "display_name": "Python 3",
242 | "language": "python",
243 | "name": "python3"
244 | },
245 | "language_info": {
246 | "codemirror_mode": {
247 | "name": "ipython",
248 | "version": 3
249 | },
250 | "file_extension": ".py",
251 | "mimetype": "text/x-python",
252 | "name": "python",
253 | "nbconvert_exporter": "python",
254 | "pygments_lexer": "ipython3",
255 | "version": "3.5.2"
256 | }
257 | },
258 | "nbformat": 4,
259 | "nbformat_minor": 1
260 | }
261 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_07 How to save the model-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 如何使用 tf.train.Saver() 来保存模型\n",
8 | "之前一直出错,主要是因为坑爹的编码问题。所以要注意文件的路径绝对不不要出现什么中文呀。"
9 | ]
10 | },
11 | {
12 | "cell_type": "code",
13 | "execution_count": 1,
14 | "metadata": {},
15 | "outputs": [
16 | {
17 | "name": "stderr",
18 | "output_type": "stream",
19 | "text": [
20 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
21 | " from ._conv import register_converters as _register_converters\n"
22 | ]
23 | },
24 | {
25 | "name": "stdout",
26 | "output_type": "stream",
27 | "text": [
28 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
29 | ]
30 | }
31 | ],
32 | "source": [
33 | "import tensorflow as tf\n",
34 | "config = tf.ConfigProto()\n",
35 | "config.gpu_options.allow_growth = True\n",
36 | "sess = tf.Session(config=config)\n",
37 | "\n",
38 | "# Create some variables.\n",
39 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
40 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
41 | "\n",
42 | "# Add an op to initialize the variables.\n",
43 | "init_op = tf.global_variables_initializer()\n",
44 | "\n",
45 | "# Add ops to save and restore all the variables.\n",
46 | "saver = tf.train.Saver()\n",
47 | "\n",
48 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
49 | "# Later, launch the model, initialize the variables, do some work, save the\n",
50 | "# variables to disk.\n",
51 | "sess.run(init_op)\n",
52 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
53 | "print(\"Model saved in file: %s\" % save_path)"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "注意,在上面保存完了模型之后。**Restart kernel** 之后才能使用下面的模型导入。否则会因为两次命名 \"v1\" 而导致名字错误。"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 1,
66 | "metadata": {},
67 | "outputs": [
68 | {
69 | "name": "stderr",
70 | "output_type": "stream",
71 | "text": [
72 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
73 | " from ._conv import register_converters as _register_converters\n"
74 | ]
75 | },
76 | {
77 | "name": "stdout",
78 | "output_type": "stream",
79 | "text": [
80 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
81 | "Model restored.\n",
82 | "[1. 2.3]\n",
83 | "55.5\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "import tensorflow as tf\n",
89 | "config = tf.ConfigProto()\n",
90 | "config.gpu_options.allow_growth = True\n",
91 | "sess = tf.Session(config=config)\n",
92 | "\n",
93 | "# Create some variables.\n",
94 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
95 | "v2 = tf.Variable(33.5, name=\"v2\")\n",
96 | "\n",
97 | "# Add ops to save and restore all the variables.\n",
98 | "saver = tf.train.Saver()\n",
99 | "\n",
100 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
101 | "# do some work with the model.\n",
102 | "# Restore variables from disk.\n",
103 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
104 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
105 | "print(\"Model restored.\")\n",
106 | "\n",
107 | "print(sess.run(v1))\n",
108 | "print(sess.run(v2))"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "导入模型之前,必须重新再定义一遍变量。\n",
116 | "\n",
117 | "但是并不需要全部变量都重新进行定义,只定义我们需要的变量就行了。\n",
118 | "\n",
119 | "也就是说,**你所定义的变量一定要在 checkpoint 中存在;但不是所有在checkpoint中的变量,你都要重新定义。**"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 1,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "name": "stderr",
129 | "output_type": "stream",
130 | "text": [
131 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
132 | " from ._conv import register_converters as _register_converters\n"
133 | ]
134 | },
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
140 | "Model restored.\n",
141 | "[1. 2.3]\n"
142 | ]
143 | }
144 | ],
145 | "source": [
146 | "import tensorflow as tf\n",
147 | "config = tf.ConfigProto()\n",
148 | "config.gpu_options.allow_growth = True\n",
149 | "sess = tf.Session(config=config)\n",
150 | "\n",
151 | "# Create some variables.\n",
152 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
153 | "\n",
154 | "# Add ops to save and restore all the variables.\n",
155 | "saver = tf.train.Saver()\n",
156 | "\n",
157 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
158 | "# do some work with the model.\n",
159 | "# Restore variables from disk.\n",
160 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
161 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
162 | "print(\"Model restored.\")\n",
163 | "\n",
164 | "print(sess.run(v1))"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "## 关于模型保存的一点心得\n",
172 | "\n",
173 | "```\n",
174 | "saver = tf.train.Saver(max_to_keep=3)\n",
175 | "```\n",
176 | "在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,我都不会保存太多模型,模型多了浪费空间,很多时候其实保存最好的模型就够了。方法就是每次迭代到一定步数就在验证集上计算一次 accuracy 或者 f1 值,如果本次结果比上次好才保存新的模型,否则没必要保存。\n",
177 | "\n",
178 | "如果你想用不同 epoch 保存下来的模型进行融合的话,3到5 个模型已经足够了,假设这各融合的模型成为 M,而最好的一个单模型称为 m_best, 这样融合的话对于M 确实可以比 m_best 更好。但是如果拿这个模型和其他结构的模型再做融合的话,M 的效果并没有 m_best 好,因为M 相当于做了平均操作,减少了该模型的“特性”。"
179 | ]
180 | }
181 | ],
182 | "metadata": {
183 | "anaconda-cloud": {},
184 | "kernelspec": {
185 | "display_name": "Python 3",
186 | "language": "python",
187 | "name": "python3"
188 | },
189 | "language_info": {
190 | "codemirror_mode": {
191 | "name": "ipython",
192 | "version": 3
193 | },
194 | "file_extension": ".py",
195 | "mimetype": "text/x-python",
196 | "name": "python",
197 | "nbconvert_exporter": "python",
198 | "pygments_lexer": "ipython3",
199 | "version": "3.5.2"
200 | }
201 | },
202 | "nbformat": 4,
203 | "nbformat_minor": 1
204 | }
205 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Tutorial_08 [transfer learning] Add new variables to graph and save the new model-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 【迁移学习】往一个已经保存好的 模型添加新的变量\n",
8 | "在迁移学习中,通常我们已经训练好一个模型,现在需要修改模型的部分结构,用于我们的新任务。\n",
9 | "\n",
10 | "比如:\n",
11 | "\n",
12 | "在一个图片分类任务中,我们使用别人训练好的网络来提取特征,但是我们的分类数目和原模型不同,这样我们只能取到 fc 层,后面的分类层需要重新写。这样我们就需要添加新的变量。那么这些新加入的变量必须得初始化才能使用。可是我们又不能使用 'tf.global_variables_initializer()' 来初始化,否则原本训练好的模型就没用了。\n",
13 | "\n",
14 | "关于怎么样单独初始化新增的变量,可以参考下面两个链接:\n",
15 | "- [1]https://stackoverflow.com/questions/35164529/in-tensorflow-is-there-any-way-to-just-initialize-uninitialised-variables\n",
16 | "- [2]https://stackoverflow.com/questions/35013080/tensorflow-how-to-get-all-variables-from-rnn-cell-basiclstm-rnn-cell-multirnn\n",
17 | "\n",
18 | "简单的例子可以直接看下面我的实现方式。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### 初始模型定义与保存\n",
26 | "首先定义一个模型,里边有 v1, v2 两个变量,我们把这个模型保存起来。"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {},
33 | "outputs": [
34 | {
35 | "name": "stderr",
36 | "output_type": "stream",
37 | "text": [
38 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
39 | " from ._conv import register_converters as _register_converters\n"
40 | ]
41 | },
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "import tensorflow as tf\n",
52 | "config = tf.ConfigProto()\n",
53 | "config.gpu_options.allow_growth = True\n",
54 | "sess = tf.Session(config=config)\n",
55 | "\n",
56 | "# Create some variables.\n",
57 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
58 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
59 | "\n",
60 | "\n",
61 | "init_op = tf.global_variables_initializer()\n",
62 | "saver = tf.train.Saver()\n",
63 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
64 | "sess.run(init_op)\n",
65 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
66 | "print(\"Model saved in file: %s\" % save_path)"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**restart(重启kernel然后执行下面cell的代码)**\n",
74 | "### 导入已经保存好的模型,并添加新的变量\n",
75 | "现在把之前保存好的模型,我只需要其中的 v1 变量。同时我还要添加新的变量 v3。"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 1,
81 | "metadata": {
82 | "scrolled": false
83 | },
84 | "outputs": [
85 | {
86 | "name": "stderr",
87 | "output_type": "stream",
88 | "text": [
89 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
90 | " from ._conv import register_converters as _register_converters\n"
91 | ]
92 | },
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
98 | "[1. 2.3]\n",
99 | "[1. 2.3]\n",
100 | "666\n"
101 | ]
102 | },
103 | {
104 | "data": {
105 | "text/plain": [
106 | "'../ckpt/test-model.ckpt-2'"
107 | ]
108 | },
109 | "execution_count": 1,
110 | "metadata": {},
111 | "output_type": "execute_result"
112 | }
113 | ],
114 | "source": [
115 | "import tensorflow as tf\n",
116 | "config = tf.ConfigProto()\n",
117 | "config.gpu_options.allow_growth = True\n",
118 | "sess = tf.Session(config=config)\n",
119 | "\n",
120 | "# Create some variables.\n",
121 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
122 | "\n",
123 | "# ** 导入训练好的模型\n",
124 | "saver = tf.train.Saver()\n",
125 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
126 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
127 | "print(sess.run(v1))\n",
128 | "\n",
129 | "# ** 定义新的变量并单独初始化新定义的变量\n",
130 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
131 | "init_new = tf.variables_initializer([v3])\n",
132 | "sess.run(init_new)\n",
133 | "# 。。。这里就可以进行 fine-tune 了\n",
134 | "print(sess.run(v1))\n",
135 | "print(sess.run(v3))\n",
136 | "\n",
137 | "# ** 保存新的模型。 \n",
138 | "# 注意!注意!注意! 一定一定一定要重新定义 saver, 这样才能把 v3 添加到 checkpoint 中\n",
139 | "saver = tf.train.Saver()\n",
140 | "saver.save(sess, ckpt_path, global_step=2)"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "**restart(重启kernel然后执行下面cell的代码)**\n",
148 | "### 这样就完成了 fine-tune, 得到了新的模型"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 1,
154 | "metadata": {
155 | "scrolled": false
156 | },
157 | "outputs": [
158 | {
159 | "name": "stderr",
160 | "output_type": "stream",
161 | "text": [
162 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
163 | " from ._conv import register_converters as _register_converters\n"
164 | ]
165 | },
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-2\n",
171 | "Model restored.\n",
172 | "[1. 2.3]\n",
173 | "666\n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "import tensorflow as tf\n",
179 | "config = tf.ConfigProto()\n",
180 | "config.gpu_options.allow_growth = True\n",
181 | "sess = tf.Session(config=config)\n",
182 | "\n",
183 | "# Create some variables.\n",
184 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
185 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
186 | "# Add ops to save and restore all the variables.\n",
187 | "saver = tf.train.Saver()\n",
188 | "\n",
189 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
190 | "# do some work with the model.\n",
191 | "# Restore variables from disk.\n",
192 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
193 | "saver.restore(sess, ckpt_path + '-'+ str(2))\n",
194 | "print(\"Model restored.\")\n",
195 | "\n",
196 | "print(sess.run(v1))\n",
197 | "print(sess.run(v3))"
198 | ]
199 | },
200 | {
201 | "cell_type": "code",
202 | "execution_count": null,
203 | "metadata": {
204 | "collapsed": true
205 | },
206 | "outputs": [],
207 | "source": []
208 | }
209 | ],
210 | "metadata": {
211 | "anaconda-cloud": {},
212 | "kernelspec": {
213 | "display_name": "Python 3",
214 | "language": "python",
215 | "name": "python3"
216 | },
217 | "language_info": {
218 | "codemirror_mode": {
219 | "name": "ipython",
220 | "version": 3
221 | },
222 | "file_extension": ".py",
223 | "mimetype": "text/x-python",
224 | "name": "python",
225 | "nbconvert_exporter": "python",
226 | "pygments_lexer": "ipython3",
227 | "version": "3.5.2"
228 | }
229 | },
230 | "nbformat": 4,
231 | "nbformat_minor": 1
232 | }
233 |
--------------------------------------------------------------------------------
/example-notebook/.ipynb_checkpoints/Untitled-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import warnings\n",
10 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
11 | "\n",
12 | "import tensorflow as tf\n",
13 | "\n",
14 | "# 设置GPU按需增长\n",
15 | "config = tf.ConfigProto()\n",
16 | "config.gpu_options.allow_growth = True\n",
17 | "sess = tf.Session(config=config)\n",
18 | "\n",
19 | "import numpy as np"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 4,
25 | "metadata": {},
26 | "outputs": [
27 | {
28 | "name": "stdout",
29 | "output_type": "stream",
30 | "text": [
31 | "Tensor(\"inputs_2:0\", shape=(?, 256, 256, 3), dtype=float32)\n",
32 | "conv1 Tensor(\"conv1/Relu:0\", shape=(?, 62, 62, 96), dtype=float32)\n",
33 | "pool1 Tensor(\"pool1/MaxPool:0\", shape=(?, 30, 30, 96), dtype=float32)\n",
34 | "conv2 \n",
35 | "pool2 Tensor(\"pool2/MaxPool:0\", shape=(?, 14, 14, 256), dtype=float32)\n",
36 | "conv3 Tensor(\"conv3/Relu:0\", shape=(?, 14, 14, 384), dtype=float32)\n",
37 | "conv4 Tensor(\"conv4/Relu:0\", shape=(?, 14, 14, 384), dtype=float32)\n",
38 | "conv5 Tensor(\"conv5/Relu:0\", shape=(?, 14, 14, 256), dtype=float32)\n",
39 | "pool5 Tensor(\"pool5/MaxPool:0\", shape=(?, 6, 6, 256), dtype=float32)\n"
40 | ]
41 | }
42 | ],
43 | "source": [
44 | "def conv2d(scope, x, filter_shape, strides_x, strides_y, padding, std=0.01, biases=0.1):\n",
45 | " \"\"\" 高斯初始化: std=0.01, biases=0.1\n",
46 | " Args:\n",
47 | " scope: scope name of this layer.\n",
48 | " x: 4-D inputs. [batch_size, in_height, in_width, in_channels]\n",
49 | " filter_shape: A list of ints.[filter_height, filter_width, in_channels, out_channels]\n",
50 | " strides: A list of ints. 1-D tensor of length 4. The stride of the sliding window for each dimension of input.\n",
51 | " padding: A string from: \"SAME\", \"VALID\". The type of padding algorithm to use.\n",
52 | " Returns:\n",
53 | " h_conv: A 4-D tensor. [batch_size, out_height, out_width, out_channels].\n",
54 | " if padding is 'SAME', then out_height==in_height.\n",
55 | " else, out_height = in_height - filter_height + 1.\n",
56 | " the same for out_width.\n",
57 | " \"\"\"\n",
58 | " assert padding in ['SAME', 'VALID']\n",
59 | " strides = [1, strides_x, strides_y, 1]\n",
60 | " with tf.variable_scope(scope):\n",
61 | " W_conv = tf.Variable(tf.truncated_normal(filter_shape, dtype=tf.float32, stddev=std), name='weights')\n",
62 | " b_conv = tf.Variable(tf.constant(biases, shape=[filter_shape[-1]], dtype=tf.float32), name='biases')\n",
63 | " h_conv = tf.nn.conv2d(x, W_conv, strides=strides, padding=padding)\n",
64 | " h_conv_relu = tf.nn.relu(h_conv + b_conv)\n",
65 | " return h_conv_relu\n",
66 | "\n",
67 | "def max_pooling(scope, x, k_height, k_width, strides_x, strides_y, padding='SAME'):\n",
68 | " \"\"\"max pooling layer.\"\"\"\n",
69 | " with tf.variable_scope(scope):\n",
70 | " ksize = [1, k_height, k_width, 1]\n",
71 | " strides = [1, strides_x, strides_y, 1]\n",
72 | " h_pool = tf.nn.max_pool(x, ksize, strides, padding)\n",
73 | " return h_pool\n",
74 | "\n",
75 | "\n",
76 | "\n",
77 | "inputs = tf.placeholder(dtype=tf.float32, shape=[None, 256, 256, 3], name='inputs')\n",
78 | "print(inputs)\n",
79 | "\n",
80 | "# 1st Layer: Conv (w ReLu) -> Lrn -> Pool\n",
81 | "conv1 = conv2d('conv1', inputs, [11, 11, 3, 96], 4, 4, 'VALID', biases=0.0)\n",
82 | "pool1 = max_pooling('pool1', conv1, 3, 3, 2, 2, 'VALID')\n",
83 | "print('conv1', conv1)\n",
84 | "print('pool1', pool1)\n",
85 | "\n",
86 | "# 2nd Layer: Conv (w ReLu) -> Lrn -> Pool with 2 groups\n",
87 | "conv2 = conv2d('conv2', pool1, [5, 5, 96, 256], 1, 1, 'SAME')\n",
88 | "pool2 = max_pooling('pool2', conv2, 3, 3, 2, 2, 'VALID')\n",
89 | "print('conv2', conv2d)\n",
90 | "print('pool2', pool2)\n",
91 | "\n",
92 | "# 3rd Layer: Conv (w ReLu)\n",
93 | "conv3 = conv2d('conv3', pool2, [3, 3, 256, 384], 1, 1, 'SAME')\n",
94 | "print('conv3', conv3)\n",
95 | "\n",
96 | "# 4th Layer: Conv (w ReLu)\n",
97 | "conv4 = conv2d('conv4', conv3, [3, 3, 384, 384], 1, 1, 'SAME')\n",
98 | "print('conv4', conv4)\n",
99 | "\n",
100 | "# 5th Layer: Conv (w ReLu) -> Pool splitted into two groups\n",
101 | "conv5 = conv2d('conv5', conv4, [3, 3, 384, 256], 1, 1, 'SAME')\n",
102 | "pool5 = max_pooling('pool5', conv5, 3, 3, 2, 2, 'VALID')\n",
103 | "print('conv5', conv5)\n",
104 | "print('pool5', pool5)\n",
105 | "\n",
106 | "\n",
107 | "# # 6th Layer: Flatten -> FC (w ReLu) -> Dropout\n",
108 | "# flattened = tf.reshape(pool5, [-1, 6 * 6 * 256])\n",
109 | "# fc6 = fc('fc6', flattened, 6 * 6 * 256, 4096, std=0.005, biases=0.1, use_relu=True)\n",
110 | "# dropout6 = dropout(fc6, keep_prob)\n",
111 | "\n",
112 | "# # 7th Layer: FC (w ReLu) -> Dropout\n",
113 | "# fc7 = fc('fc7', dropout6, 4096, 4096, std=0.005, biases=0.1, use_relu=True)\n",
114 | "# dropout7 = dropout(fc7, keep_prob)\n",
115 | "\n",
116 | "# # 8th Layer: FC and return unscaled activations\n",
117 | "# fc8 = fc('fc8', dropout7, 4096, n_class, std=0.01, biases=0.0, use_relu=False)"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": []
126 | }
127 | ],
128 | "metadata": {
129 | "kernelspec": {
130 | "display_name": "Python 3",
131 | "language": "python",
132 | "name": "python3"
133 | },
134 | "language_info": {
135 | "codemirror_mode": {
136 | "name": "ipython",
137 | "version": 3
138 | },
139 | "file_extension": ".py",
140 | "mimetype": "text/x-python",
141 | "name": "python",
142 | "nbconvert_exporter": "python",
143 | "pygments_lexer": "ipython3",
144 | "version": "3.5.2"
145 | }
146 | },
147 | "nbformat": 4,
148 | "nbformat_minor": 2
149 | }
150 |
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/t10k-images-idx3-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/t10k-images-idx3-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/t10k-labels-idx1-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/t10k-labels-idx1-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/train-images-idx3-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/train-images-idx3-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/MNIST_data/train-labels-idx1-ubyte.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/example-notebook/MNIST_data/train-labels-idx1-ubyte.gz
--------------------------------------------------------------------------------
/example-notebook/Tutorial_02 A simple feedforward network for MNIST.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 两层FC层做分类:MNIST\n",
8 | "\n",
9 | "在本教程中,我们来实现一个非常简单的两层全连接层来完成MNIST数据的分类问题。\n",
10 | "\n",
11 | "输入[-1,28*28], FC1 有 1024 个neurons, FC2 有 10 个neurons。这么简单的一个全连接网络,结果测试准确率达到了 0.98。还是非常棒的!!!"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 1,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "from __future__ import print_function\n",
21 | "from __future__ import division\n",
22 | "from __future__ import absolute_import\n",
23 | "\n",
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.Session(config=config)"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "### 1.导入数据\n",
41 | "下面导入数据这部分的警告可以不用管先,TensorFlow 非常恶心的地方就是不停地改 API,改到发麻。"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 2,
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
54 | "Instructions for updating:\n",
55 | "Use the retry module or similar alternatives.\n",
56 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
57 | "Instructions for updating:\n",
58 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
59 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
60 | "Instructions for updating:\n",
61 | "Please write your own downloading logic.\n",
62 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
63 | "Instructions for updating:\n",
64 | "Please use tf.data to implement this functionality.\n",
65 | "Extracting ../data/MNIST_data/train-images-idx3-ubyte.gz\n",
66 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
67 | "Instructions for updating:\n",
68 | "Please use tf.data to implement this functionality.\n",
69 | "Extracting ../data/MNIST_data/train-labels-idx1-ubyte.gz\n",
70 | "Extracting ../data/MNIST_data/t10k-images-idx3-ubyte.gz\n",
71 | "Extracting ../data/MNIST_data/t10k-labels-idx1-ubyte.gz\n",
72 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
73 | "Instructions for updating:\n",
74 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n"
75 | ]
76 | }
77 | ],
78 | "source": [
79 | "# 用tensorflow 导入数据\n",
80 | "from tensorflow.examples.tutorials.mnist import input_data\n",
81 | "mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=False, source_url='http://yann.lecun.com/exdb/mnist/')"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "name": "stdout",
91 | "output_type": "stream",
92 | "text": [
93 | "training data shape (55000, 784)\n",
94 | "training label shape (55000,)\n"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "print('training data shape ', mnist.train.images.shape)\n",
100 | "print('training label shape ', mnist.train.labels.shape)"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "metadata": {},
106 | "source": [
107 | "### 2. 构建网络"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": 4,
113 | "metadata": {},
114 | "outputs": [
115 | {
116 | "name": "stdout",
117 | "output_type": "stream",
118 | "text": [
119 | "Tensor(\"add_1:0\", shape=(?, 10), dtype=float32)\n"
120 | ]
121 | }
122 | ],
123 | "source": [
124 | "# 权值初始化\n",
125 | "def weight_variable(shape):\n",
126 | " # 用正态分布来初始化权值\n",
127 | " initial = tf.truncated_normal(shape, stddev=0.1)\n",
128 | " return tf.Variable(initial)\n",
129 | "\n",
130 | "def bias_variable(shape):\n",
131 | " # 本例中用relu激活函数,所以用一个很小的正偏置较好\n",
132 | " initial = tf.constant(0.1, shape=shape)\n",
133 | " return tf.Variable(initial)\n",
134 | "\n",
135 | "\n",
136 | "# input_layer\n",
137 | "X_input = tf.placeholder(tf.float32, [None, 784])\n",
138 | "y_input = tf.placeholder(tf.int64, [None]) # 不使用 one-hot \n",
139 | "\n",
140 | "# FC1\n",
141 | "W_fc1 = weight_variable([784, 1024])\n",
142 | "b_fc1 = bias_variable([1024])\n",
143 | "h_fc1 = tf.nn.relu(tf.matmul(X_input, W_fc1) + b_fc1)\n",
144 | "\n",
145 | "# FC2\n",
146 | "W_fc2 = weight_variable([1024, 10])\n",
147 | "b_fc2 = bias_variable([10])\n",
148 | "# y_pre = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)\n",
149 | "logits = tf.matmul(h_fc1, W_fc2) + b_fc2\n",
150 | "\n",
151 | "print(logits)"
152 | ]
153 | },
154 | {
155 | "cell_type": "markdown",
156 | "metadata": {},
157 | "source": [
158 | "### 3.训练和评估\n",
159 | "下面我们将输入 mnist 的数据来进行训练。在下面有个 mnist.train.next_batch(batch_size=100) 的操作,每次从数据集中取出100个样本。如果想了解怎么实现的话建议看一下源码,其实挺简单的,很多时候需要我们自己去实现读取数据的这个函数。"
160 | ]
161 | },
162 | {
163 | "cell_type": "code",
164 | "execution_count": 5,
165 | "metadata": {},
166 | "outputs": [
167 | {
168 | "name": "stdout",
169 | "output_type": "stream",
170 | "text": [
171 | "step 500, train cost=0.153510, acc=0.950000; test cost=0.123346, acc=0.962500\n",
172 | "step 1000, train cost=0.087353, acc=0.960000; test cost=0.104876, acc=0.967400\n",
173 | "step 1500, train cost=0.033138, acc=0.990000; test cost=0.080937, acc=0.975200\n",
174 | "step 2000, train cost=0.028831, acc=0.990000; test cost=0.077214, acc=0.977800\n",
175 | "step 2500, train cost=0.004817, acc=1.000000; test cost=0.066441, acc=0.980000\n",
176 | "step 3000, train cost=0.015692, acc=1.000000; test cost=0.067741, acc=0.979400\n",
177 | "step 3500, train cost=0.011569, acc=1.000000; test cost=0.075138, acc=0.979400\n",
178 | "step 4000, train cost=0.006310, acc=1.000000; test cost=0.074501, acc=0.978300\n",
179 | "step 4500, train cost=0.008795, acc=1.000000; test cost=0.076483, acc=0.979100\n",
180 | "step 5000, train cost=0.027700, acc=0.980000; test cost=0.073973, acc=0.980000\n"
181 | ]
182 | }
183 | ],
184 | "source": [
185 | "# 1.损失函数:cross_entropy\n",
186 | "# 如果label是 one-hot 的话要换一下损失函数,参考:https://blog.csdn.net/tz_zs/article/details/76086457\n",
187 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_input, logits=logits)) \n",
188 | "# 2.优化函数:AdamOptimizer, 优化速度要比 GradientOptimizer 快很多\n",
189 | "train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)\n",
190 | "\n",
191 | "# 3.预测结果评估\n",
192 | "# 预测值中最大值(1)即分类结果,是否等于原始标签中的(1)的位置。argmax()取最大值所在的下标\n",
193 | "correct_prediction = tf.equal(tf.argmax(logits, 1), y_input) \n",
194 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n",
195 | "\n",
196 | "# 开始运行\n",
197 | "sess.run(tf.global_variables_initializer())\n",
198 | "# 这大概迭代了不到 10 个 epoch, 训练准确率已经达到了0.98\n",
199 | "for i in range(5000):\n",
200 | " X_batch, y_batch = mnist.train.next_batch(batch_size=100)\n",
201 | " cost, acc, _ = sess.run([cross_entropy, accuracy, train_step], feed_dict={X_input: X_batch, y_input: y_batch})\n",
202 | " if (i+1) % 500 == 0:\n",
203 | " test_cost, test_acc = sess.run([cross_entropy, accuracy], feed_dict={X_input: mnist.test.images, y_input: mnist.test.labels})\n",
204 | " print(\"step {}, train cost={:.6f}, acc={:.6f}; test cost={:.6f}, acc={:.6f}\".format(i+1, cost, acc, test_cost, test_acc))\n",
205 | " "
206 | ]
207 | }
208 | ],
209 | "metadata": {
210 | "anaconda-cloud": {},
211 | "kernelspec": {
212 | "display_name": "Python 3",
213 | "language": "python",
214 | "name": "python3"
215 | },
216 | "language_info": {
217 | "codemirror_mode": {
218 | "name": "ipython",
219 | "version": 3
220 | },
221 | "file_extension": ".py",
222 | "mimetype": "text/x-python",
223 | "name": "python",
224 | "nbconvert_exporter": "python",
225 | "pygments_lexer": "ipython3",
226 | "version": "3.5.2"
227 | }
228 | },
229 | "nbformat": 4,
230 | "nbformat_minor": 1
231 | }
232 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_03_2 The usage of Collection.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# TensorFlow 变量命名管理机制(二)\n",
8 | "\n",
9 | "\n",
10 | "### 1. 用 collection 来聚合变量\n",
11 | "前面介绍了 tensorflow 的变量命名机制,这里要补充一下 `tf.add_to_collection` 和 `tf.get_collection`的用法。\n",
12 | "\n",
13 | "因为神经网络中的参数非常多,有时候我们 只想对某些参数进行操作。除了前面通过变量名称的方法来获取参数之外, TensorFlow 中还有 collection 这么一种操作。\n",
14 | "\n",
15 | "collection 可以聚合多个**变量**或者**操作**。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [],
23 | "source": [
24 | "import warnings\n",
25 | "warnings.filterwarnings('ignore') # 不打印 warning \n",
26 | "\n",
27 | "import tensorflow as tf\n",
28 | "\n",
29 | "# 设置GPU按需增长\n",
30 | "config = tf.ConfigProto()\n",
31 | "config.gpu_options.allow_growth = True\n",
32 | "sess = tf.Session(config=config)"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "参考:[如何利用tf.add_to_collection、tf.get_collection以及tf.add_n来简化正则项的计算](https://blog.csdn.net/weixin_39980291/article/details/78352125)"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 2,
45 | "metadata": {},
46 | "outputs": [
47 | {
48 | "name": "stdout",
49 | "output_type": "stream",
50 | "text": [
51 | "vars in col1: [, ]\n"
52 | ]
53 | }
54 | ],
55 | "source": [
56 | "# 把变量添加到一个 collection 中\n",
57 | "v1 = tf.Variable([1,2,3], name='v1')\n",
58 | "v2 = tf.Variable([2], name='v2')\n",
59 | "v3 = tf.get_variable(name='v3', shape=(2,3))\n",
60 | "\n",
61 | "tf.add_to_collection('col1', v1) # 把 v1 添加到 col1 中\n",
62 | "tf.add_to_collection('col1', v3)\n",
63 | "\n",
64 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
65 | "print('vars in col1:', col1s)"
66 | ]
67 | },
68 | {
69 | "cell_type": "markdown",
70 | "metadata": {},
71 | "source": [
72 | "除了把变量添加到集合中,还可以把操作添加到集合中。"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 3,
78 | "metadata": {},
79 | "outputs": [
80 | {
81 | "name": "stdout",
82 | "output_type": "stream",
83 | "text": [
84 | "vars in col1: [, , ]\n"
85 | ]
86 | }
87 | ],
88 | "source": [
89 | "op1 = tf.add(v1, 2, name='add_op')\n",
90 | "tf.add_to_collection('col1', op1)\n",
91 | "col1s = tf.get_collection(key='col1') # 获取 col1 的变量\n",
92 | "print('vars in col1:', col1s)"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "此外,还可以加上 scope 的约束。"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 3,
105 | "metadata": {},
106 | "outputs": [
107 | {
108 | "name": "stdout",
109 | "output_type": "stream",
110 | "text": [
111 | "vars in col1 with scope=model: []\n"
112 | ]
113 | }
114 | ],
115 | "source": [
116 | "with tf.variable_scope('model'):\n",
117 | " v4 = tf.get_variable('v4', shape=[3,4])\n",
118 | " v5 = tf.Variable([1,2,3], name='v5')\n",
119 | "\n",
120 | "tf.add_to_collection('col1', v5)\n",
121 | "col1_vars = tf.get_collection(key='col1', scope='model') # 获取 col1 的变量\n",
122 | "print('vars in col1 with scope=model: ', col1_vars)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "### 2. tf.GraphKeys \n",
130 | "\n",
131 | "参考:[tf.GraphKeys 函数](https://www.w3cschool.cn/tensorflow_python/tensorflow_python-ne7t2ezd.html)\n",
132 | "\n",
133 | "用于图形集合的标准名称。\n",
134 | "\n",
135 | "\n",
136 | "标准库使用各种已知的名称来收集和检索与图形相关联的值。例如,如果没有指定,则 tf.Optimizer 子类默认优化收集的变量tf.GraphKeys.TRAINABLE_VARIABLES,但也可以传递显式的变量列表。\n",
137 | "\n",
138 | "定义了以下标准键:\n",
139 | "\n",
140 | "- GLOBAL_VARIABLES:默认的 Variable 对象集合,在分布式环境共享(模型变量是其中的子集)。参考:tf.global_variables。通常,所有TRAINABLE_VARIABLES 变量都将在 MODEL_VARIABLES,所有 MODEL_VARIABLES 变量都将在 GLOBAL_VARIABLES。\n",
141 | "- LOCAL_VARIABLES:每台计算机的局部变量对象的子集。通常用于临时变量,如计数器。注意:使用 tf.contrib.framework.local_variable 添加到此集合。\n",
142 | "- MODEL_VARIABLES:在模型中用于推理(前馈)的变量对象的子集。注意:使用 tf.contrib.framework.model_variable 添加到此集合。\n",
143 | "- TRAINABLE_VARIABLES:将由优化器训练的变量对象的子集。\n",
144 | "- SUMMARIES:在关系图中创建的汇总张量对象。\n",
145 | "- QUEUE_RUNNERS:用于为计算生成输入的 QueueRunner 对象。\n",
146 | "- MOVING_AVERAGE_VARIABLES:变量对象的子集,它也将保持移动平均值。\n",
147 | "- REGULARIZATION_LOSSES:在图形构造期间收集的正规化损失。\n",
148 | "\n",
149 | "这个知道就好了,要用的时候知道是怎么回事就行了。比如在 BN 层中就有这东西。"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {},
156 | "outputs": [],
157 | "source": []
158 | },
159 | {
160 | "cell_type": "code",
161 | "execution_count": null,
162 | "metadata": {},
163 | "outputs": [],
164 | "source": []
165 | }
166 | ],
167 | "metadata": {
168 | "anaconda-cloud": {},
169 | "kernelspec": {
170 | "display_name": "Python 3",
171 | "language": "python",
172 | "name": "python3"
173 | },
174 | "language_info": {
175 | "codemirror_mode": {
176 | "name": "ipython",
177 | "version": 3
178 | },
179 | "file_extension": ".py",
180 | "mimetype": "text/x-python",
181 | "name": "python",
182 | "nbconvert_exporter": "python",
183 | "pygments_lexer": "ipython3",
184 | "version": "3.5.2"
185 | }
186 | },
187 | "nbformat": 4,
188 | "nbformat_minor": 1
189 | }
190 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_04_3 Convolutional network for MNIST(3).ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CNN做MNIST分类\n",
8 | "\n",
9 | "使用 tf.layers 高级 API 构建 CNN "
10 | ]
11 | },
12 | {
13 | "cell_type": "code",
14 | "execution_count": 1,
15 | "metadata": {},
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
22 | " from ._conv import register_converters as _register_converters\n"
23 | ]
24 | }
25 | ],
26 | "source": [
27 | "import numpy as np\n",
28 | "import tensorflow as tf\n",
29 | "\n",
30 | "# 设置按需使用GPU\n",
31 | "config = tf.ConfigProto()\n",
32 | "config.gpu_options.allow_growth = True\n",
33 | "sess = tf.InteractiveSession(config=config)\n",
34 | "\n",
35 | "import time"
36 | ]
37 | },
38 | {
39 | "cell_type": "markdown",
40 | "metadata": {},
41 | "source": [
42 | "## 1.导入数据,用 tensorflow 导入"
43 | ]
44 | },
45 | {
46 | "cell_type": "code",
47 | "execution_count": 2,
48 | "metadata": {},
49 | "outputs": [
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
55 | "Instructions for updating:\n",
56 | "Use the retry module or similar alternatives.\n",
57 | "WARNING:tensorflow:From :3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
58 | "Instructions for updating:\n",
59 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
60 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\n",
61 | "Instructions for updating:\n",
62 | "Please write your own downloading logic.\n",
63 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
64 | "Instructions for updating:\n",
65 | "Please use tf.data to implement this functionality.\n",
66 | "Extracting MNIST_data/train-images-idx3-ubyte.gz\n",
67 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
68 | "Instructions for updating:\n",
69 | "Please use tf.data to implement this functionality.\n",
70 | "Extracting MNIST_data/train-labels-idx1-ubyte.gz\n",
71 | "Extracting MNIST_data/t10k-images-idx3-ubyte.gz\n",
72 | "Extracting MNIST_data/t10k-labels-idx1-ubyte.gz\n",
73 | "WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\n",
74 | "Instructions for updating:\n",
75 | "Please use alternatives such as official/mnist/dataset.py from tensorflow/models.\n",
76 | "(10000,)\n",
77 | "(55000,)\n"
78 | ]
79 | }
80 | ],
81 | "source": [
82 | "# 用tensorflow 导入数据\n",
83 | "from tensorflow.examples.tutorials.mnist import input_data\n",
84 | "mnist = input_data.read_data_sets('MNIST_data', one_hot=False)\n",
85 | "# 看看咱们样本的数量\n",
86 | "print(mnist.test.labels.shape)\n",
87 | "print(mnist.train.labels.shape)"
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {},
93 | "source": [
94 | "## 2. 构建网络"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 3,
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "Finished building network.\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "with tf.name_scope('inputs'):\n",
112 | " X_ = tf.placeholder(tf.float32, [None, 784])\n",
113 | " y_ = tf.placeholder(tf.int64, [None])\n",
114 | "\n",
115 | "# 把X转为卷积所需要的形式\n",
116 | "X = tf.reshape(X_, [-1, 28, 28, 1])\n",
117 | "h_conv1 = tf.layers.conv2d(X, filters=32, kernel_size=5, strides=1, padding='same', activation=tf.nn.relu, name='conv1')\n",
118 | "h_pool1 = tf.layers.max_pooling2d(h_conv1, pool_size=2, strides=2, padding='same', name='pool1')\n",
119 | "\n",
120 | "h_conv2 = tf.layers.conv2d(h_pool1, filters=64, kernel_size=5, strides=1, padding='same',activation=tf.nn.relu, name='conv2')\n",
121 | "h_pool2 = tf.layers.max_pooling2d(h_conv2, pool_size=2, strides=2, padding='same', name='pool2')\n",
122 | "\n",
123 | "# flatten\n",
124 | "h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\n",
125 | "h_fc1 = tf.layers.dense(h_pool2_flat, 1024, name='fc1', activation=tf.nn.relu)\n",
126 | "\n",
127 | "# dropout: 输出的维度和h_fc1一样,只是随机部分值被值为零\n",
128 | "keep_prob = tf.placeholder(tf.float32)\n",
129 | "h_fc1_drop = tf.nn.dropout(h_fc1, 0.5) # 实际测试的时候这里不应该使用 0.5,这里为了方便演示都这样写而已\n",
130 | "h_fc2 = tf.layers.dense(h_fc1_drop, units=10, name='fc2')\n",
131 | "# y_conv = tf.nn.softmax(h_fc2)\n",
132 | "y_conv = h_fc2\n",
133 | "print('Finished building network.')"
134 | ]
135 | },
136 | {
137 | "cell_type": "code",
138 | "execution_count": 4,
139 | "metadata": {},
140 | "outputs": [
141 | {
142 | "name": "stdout",
143 | "output_type": "stream",
144 | "text": [
145 | "Tensor(\"conv1/Relu:0\", shape=(?, 28, 28, 32), dtype=float32)\n",
146 | "Tensor(\"pool1/MaxPool:0\", shape=(?, 14, 14, 32), dtype=float32)\n",
147 | "Tensor(\"conv2/Relu:0\", shape=(?, 14, 14, 64), dtype=float32)\n",
148 | "Tensor(\"pool2/MaxPool:0\", shape=(?, 7, 7, 64), dtype=float32)\n",
149 | "Tensor(\"Reshape_1:0\", shape=(?, 3136), dtype=float32)\n",
150 | "Tensor(\"fc1/Relu:0\", shape=(?, 1024), dtype=float32)\n",
151 | "Tensor(\"fc2/BiasAdd:0\", shape=(?, 10), dtype=float32)\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "print(h_conv1)\n",
157 | "print(h_pool1)\n",
158 | "print(h_conv2)\n",
159 | "print(h_pool2)\n",
160 | "\n",
161 | "print(h_pool2_flat)\n",
162 | "print(h_fc1)\n",
163 | "print(h_fc2)"
164 | ]
165 | },
166 | {
167 | "cell_type": "markdown",
168 | "metadata": {},
169 | "source": [
170 | "## 3.训练和评估"
171 | ]
172 | },
173 | {
174 | "cell_type": "markdown",
175 | "metadata": {},
176 | "source": [
177 | " 在测试的时候不使用 mini_batch, 那么测试的时候会占用较多的GPU(4497M),这在 notebook 交互式编程中是不推荐的。"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": 5,
183 | "metadata": {
184 | "scrolled": false
185 | },
186 | "outputs": [
187 | {
188 | "name": "stdout",
189 | "output_type": "stream",
190 | "text": [
191 | "step 0, training accuracy = 0.1100, pass 1.18s \n",
192 | "step 1000, training accuracy = 0.9800, pass 6.01s \n",
193 | "step 2000, training accuracy = 0.9800, pass 10.82s \n",
194 | "step 3000, training accuracy = 0.9700, pass 15.65s \n",
195 | "step 4000, training accuracy = 1.0000, pass 20.40s \n",
196 | "step 5000, training accuracy = 0.9800, pass 25.26s \n",
197 | "step 6000, training accuracy = 1.0000, pass 30.00s \n",
198 | "step 7000, training accuracy = 0.9900, pass 34.84s \n",
199 | "step 8000, training accuracy = 1.0000, pass 39.66s \n",
200 | "step 9000, training accuracy = 1.0000, pass 44.55s \n",
201 | "test accuracy 0.9924\n"
202 | ]
203 | }
204 | ],
205 | "source": [
206 | "# cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\n",
207 | "cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(\n",
208 | " labels=tf.cast(y_, dtype=tf.int32), logits=y_conv))\n",
209 | "\n",
210 | "train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n",
211 | "\n",
212 | "correct_prediction = tf.equal(tf.argmax(y_conv,1), y_)\n",
213 | "accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n",
214 | "sess.run(tf.global_variables_initializer())\n",
215 | "\n",
216 | "tic = time.time()\n",
217 | "for i in range(10000):\n",
218 | " batch = mnist.train.next_batch(100)\n",
219 | " if i%1000 == 0:\n",
220 | " train_accuracy = accuracy.eval(feed_dict={\n",
221 | " X_:batch[0], y_: batch[1], keep_prob: 1.0})\n",
222 | " print(\"step {}, training accuracy = {:.4f}, pass {:.2f}s \".format(i, train_accuracy, time.time() - tic))\n",
223 | " train_step.run(feed_dict={X_: batch[0], y_: batch[1]})\n",
224 | "\n",
225 | "print(\"test accuracy %g\"%accuracy.eval(feed_dict={\n",
226 | " X_: mnist.test.images, y_: mnist.test.labels}))"
227 | ]
228 | }
229 | ],
230 | "metadata": {
231 | "anaconda-cloud": {},
232 | "kernelspec": {
233 | "display_name": "Python 3",
234 | "language": "python",
235 | "name": "python3"
236 | },
237 | "language_info": {
238 | "codemirror_mode": {
239 | "name": "ipython",
240 | "version": 3
241 | },
242 | "file_extension": ".py",
243 | "mimetype": "text/x-python",
244 | "name": "python",
245 | "nbconvert_exporter": "python",
246 | "pygments_lexer": "ipython3",
247 | "version": "3.5.2"
248 | }
249 | },
250 | "nbformat": 4,
251 | "nbformat_minor": 1
252 | }
253 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_07 How to save the model.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 如何使用 tf.train.Saver() 来保存模型\n",
8 | "之前一直出错,主要是因为坑爹的编码问题。所以要注意文件的路径绝对不不要出现什么中文呀。"
9 | ]
10 | },
11 | {
12 | "cell_type": "code",
13 | "execution_count": 1,
14 | "metadata": {},
15 | "outputs": [
16 | {
17 | "name": "stderr",
18 | "output_type": "stream",
19 | "text": [
20 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
21 | " from ._conv import register_converters as _register_converters\n"
22 | ]
23 | },
24 | {
25 | "name": "stdout",
26 | "output_type": "stream",
27 | "text": [
28 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
29 | ]
30 | }
31 | ],
32 | "source": [
33 | "import tensorflow as tf\n",
34 | "config = tf.ConfigProto()\n",
35 | "config.gpu_options.allow_growth = True\n",
36 | "sess = tf.Session(config=config)\n",
37 | "\n",
38 | "# Create some variables.\n",
39 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
40 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
41 | "\n",
42 | "# Add an op to initialize the variables.\n",
43 | "init_op = tf.global_variables_initializer()\n",
44 | "\n",
45 | "# Add ops to save and restore all the variables.\n",
46 | "saver = tf.train.Saver()\n",
47 | "\n",
48 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
49 | "# Later, launch the model, initialize the variables, do some work, save the\n",
50 | "# variables to disk.\n",
51 | "sess.run(init_op)\n",
52 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
53 | "print(\"Model saved in file: %s\" % save_path)"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "注意,在上面保存完了模型之后。**Restart kernel** 之后才能使用下面的模型导入。否则会因为两次命名 \"v1\" 而导致名字错误。"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 1,
66 | "metadata": {},
67 | "outputs": [
68 | {
69 | "name": "stderr",
70 | "output_type": "stream",
71 | "text": [
72 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
73 | " from ._conv import register_converters as _register_converters\n"
74 | ]
75 | },
76 | {
77 | "name": "stdout",
78 | "output_type": "stream",
79 | "text": [
80 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
81 | "Model restored.\n",
82 | "[1. 2.3]\n",
83 | "55.5\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "import tensorflow as tf\n",
89 | "config = tf.ConfigProto()\n",
90 | "config.gpu_options.allow_growth = True\n",
91 | "sess = tf.Session(config=config)\n",
92 | "\n",
93 | "# Create some variables.\n",
94 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
95 | "v2 = tf.Variable(33.5, name=\"v2\")\n",
96 | "\n",
97 | "# Add ops to save and restore all the variables.\n",
98 | "saver = tf.train.Saver()\n",
99 | "\n",
100 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
101 | "# do some work with the model.\n",
102 | "# Restore variables from disk.\n",
103 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
104 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
105 | "print(\"Model restored.\")\n",
106 | "\n",
107 | "print(sess.run(v1))\n",
108 | "print(sess.run(v2))"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "导入模型之前,必须重新再定义一遍变量。\n",
116 | "\n",
117 | "但是并不需要全部变量都重新进行定义,只定义我们需要的变量就行了。\n",
118 | "\n",
119 | "也就是说,**你所定义的变量一定要在 checkpoint 中存在;但不是所有在checkpoint中的变量,你都要重新定义。**"
120 | ]
121 | },
122 | {
123 | "cell_type": "code",
124 | "execution_count": 1,
125 | "metadata": {},
126 | "outputs": [
127 | {
128 | "name": "stderr",
129 | "output_type": "stream",
130 | "text": [
131 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
132 | " from ._conv import register_converters as _register_converters\n"
133 | ]
134 | },
135 | {
136 | "name": "stdout",
137 | "output_type": "stream",
138 | "text": [
139 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
140 | "Model restored.\n",
141 | "[1. 2.3]\n"
142 | ]
143 | }
144 | ],
145 | "source": [
146 | "import tensorflow as tf\n",
147 | "config = tf.ConfigProto()\n",
148 | "config.gpu_options.allow_growth = True\n",
149 | "sess = tf.Session(config=config)\n",
150 | "\n",
151 | "# Create some variables.\n",
152 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
153 | "\n",
154 | "# Add ops to save and restore all the variables.\n",
155 | "saver = tf.train.Saver()\n",
156 | "\n",
157 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
158 | "# do some work with the model.\n",
159 | "# Restore variables from disk.\n",
160 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
161 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
162 | "print(\"Model restored.\")\n",
163 | "\n",
164 | "print(sess.run(v1))"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "## 关于模型保存的一点心得\n",
172 | "\n",
173 | "```\n",
174 | "saver = tf.train.Saver(max_to_keep=3)\n",
175 | "```\n",
176 | "在定义 saver 的时候一般会定义最多保存模型的数量,一般来说,我都不会保存太多模型,模型多了浪费空间,很多时候其实保存最好的模型就够了。方法就是每次迭代到一定步数就在验证集上计算一次 accuracy 或者 f1 值,如果本次结果比上次好才保存新的模型,否则没必要保存。\n",
177 | "\n",
178 | "如果你想用不同 epoch 保存下来的模型进行融合的话,3到5 个模型已经足够了,假设这各融合的模型成为 M,而最好的一个单模型称为 m_best, 这样融合的话对于M 确实可以比 m_best 更好。但是如果拿这个模型和其他结构的模型再做融合的话,M 的效果并没有 m_best 好,因为M 相当于做了平均操作,减少了该模型的“特性”。"
179 | ]
180 | }
181 | ],
182 | "metadata": {
183 | "anaconda-cloud": {},
184 | "kernelspec": {
185 | "display_name": "Python 3",
186 | "language": "python",
187 | "name": "python3"
188 | },
189 | "language_info": {
190 | "codemirror_mode": {
191 | "name": "ipython",
192 | "version": 3
193 | },
194 | "file_extension": ".py",
195 | "mimetype": "text/x-python",
196 | "name": "python",
197 | "nbconvert_exporter": "python",
198 | "pygments_lexer": "ipython3",
199 | "version": "3.5.2"
200 | }
201 | },
202 | "nbformat": 4,
203 | "nbformat_minor": 1
204 | }
205 |
--------------------------------------------------------------------------------
/example-notebook/Tutorial_08 [transfer learning] Add new variables to graph and save the new model.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 【迁移学习】往一个已经保存好的 模型添加新的变量\n",
8 | "在迁移学习中,通常我们已经训练好一个模型,现在需要修改模型的部分结构,用于我们的新任务。\n",
9 | "\n",
10 | "比如:\n",
11 | "\n",
12 | "在一个图片分类任务中,我们使用别人训练好的网络来提取特征,但是我们的分类数目和原模型不同,这样我们只能取到 fc 层,后面的分类层需要重新写。这样我们就需要添加新的变量。那么这些新加入的变量必须得初始化才能使用。可是我们又不能使用 'tf.global_variables_initializer()' 来初始化,否则原本训练好的模型就没用了。\n",
13 | "\n",
14 | "关于怎么样单独初始化新增的变量,可以参考下面两个链接:\n",
15 | "- [1]https://stackoverflow.com/questions/35164529/in-tensorflow-is-there-any-way-to-just-initialize-uninitialised-variables\n",
16 | "- [2]https://stackoverflow.com/questions/35013080/tensorflow-how-to-get-all-variables-from-rnn-cell-basiclstm-rnn-cell-multirnn\n",
17 | "\n",
18 | "简单的例子可以直接看下面我的实现方式。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### 初始模型定义与保存\n",
26 | "首先定义一个模型,里边有 v1, v2 两个变量,我们把这个模型保存起来。"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 1,
32 | "metadata": {},
33 | "outputs": [
34 | {
35 | "name": "stderr",
36 | "output_type": "stream",
37 | "text": [
38 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
39 | " from ._conv import register_converters as _register_converters\n"
40 | ]
41 | },
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | "Model saved in file: ../ckpt/test-model.ckpt-1\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "import tensorflow as tf\n",
52 | "config = tf.ConfigProto()\n",
53 | "config.gpu_options.allow_growth = True\n",
54 | "sess = tf.Session(config=config)\n",
55 | "\n",
56 | "# Create some variables.\n",
57 | "v1 = tf.Variable([1.0, 2.3], name=\"v1\")\n",
58 | "v2 = tf.Variable(55.5, name=\"v2\")\n",
59 | "\n",
60 | "\n",
61 | "init_op = tf.global_variables_initializer()\n",
62 | "saver = tf.train.Saver()\n",
63 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
64 | "sess.run(init_op)\n",
65 | "save_path = saver.save(sess, ckpt_path, global_step=1)\n",
66 | "print(\"Model saved in file: %s\" % save_path)"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**restart(重启kernel然后执行下面cell的代码)**\n",
74 | "### 导入已经保存好的模型,并添加新的变量\n",
75 | "现在把之前保存好的模型,我只需要其中的 v1 变量。同时我还要添加新的变量 v3。"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 1,
81 | "metadata": {
82 | "scrolled": false
83 | },
84 | "outputs": [
85 | {
86 | "name": "stderr",
87 | "output_type": "stream",
88 | "text": [
89 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
90 | " from ._conv import register_converters as _register_converters\n"
91 | ]
92 | },
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-1\n",
98 | "[1. 2.3]\n",
99 | "[1. 2.3]\n",
100 | "666\n"
101 | ]
102 | },
103 | {
104 | "data": {
105 | "text/plain": [
106 | "'../ckpt/test-model.ckpt-2'"
107 | ]
108 | },
109 | "execution_count": 1,
110 | "metadata": {},
111 | "output_type": "execute_result"
112 | }
113 | ],
114 | "source": [
115 | "import tensorflow as tf\n",
116 | "config = tf.ConfigProto()\n",
117 | "config.gpu_options.allow_growth = True\n",
118 | "sess = tf.Session(config=config)\n",
119 | "\n",
120 | "# Create some variables.\n",
121 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
122 | "\n",
123 | "# ** 导入训练好的模型\n",
124 | "saver = tf.train.Saver()\n",
125 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
126 | "saver.restore(sess, ckpt_path + '-'+ str(1))\n",
127 | "print(sess.run(v1))\n",
128 | "\n",
129 | "# ** 定义新的变量并单独初始化新定义的变量\n",
130 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
131 | "init_new = tf.variables_initializer([v3])\n",
132 | "sess.run(init_new)\n",
133 | "# 。。。这里就可以进行 fine-tune 了\n",
134 | "print(sess.run(v1))\n",
135 | "print(sess.run(v3))\n",
136 | "\n",
137 | "# ** 保存新的模型。 \n",
138 | "# 注意!注意!注意! 一定一定一定要重新定义 saver, 这样才能把 v3 添加到 checkpoint 中\n",
139 | "saver = tf.train.Saver()\n",
140 | "saver.save(sess, ckpt_path, global_step=2)"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "**restart(重启kernel然后执行下面cell的代码)**\n",
148 | "### 这样就完成了 fine-tune, 得到了新的模型"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 1,
154 | "metadata": {
155 | "scrolled": false
156 | },
157 | "outputs": [
158 | {
159 | "name": "stderr",
160 | "output_type": "stream",
161 | "text": [
162 | "/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n",
163 | " from ._conv import register_converters as _register_converters\n"
164 | ]
165 | },
166 | {
167 | "name": "stdout",
168 | "output_type": "stream",
169 | "text": [
170 | "INFO:tensorflow:Restoring parameters from ../ckpt/test-model.ckpt-2\n",
171 | "Model restored.\n",
172 | "[1. 2.3]\n",
173 | "666\n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "import tensorflow as tf\n",
179 | "config = tf.ConfigProto()\n",
180 | "config.gpu_options.allow_growth = True\n",
181 | "sess = tf.Session(config=config)\n",
182 | "\n",
183 | "# Create some variables.\n",
184 | "v1 = tf.Variable([11.0, 16.3], name=\"v1\")\n",
185 | "v3 = tf.Variable(666, name='v3', dtype=tf.int32)\n",
186 | "# Add ops to save and restore all the variables.\n",
187 | "saver = tf.train.Saver()\n",
188 | "\n",
189 | "# Later, launch the model, use the saver to restore variables from disk, and\n",
190 | "# do some work with the model.\n",
191 | "# Restore variables from disk.\n",
192 | "ckpt_path = '../ckpt/test-model.ckpt'\n",
193 | "saver.restore(sess, ckpt_path + '-'+ str(2))\n",
194 | "print(\"Model restored.\")\n",
195 | "\n",
196 | "print(sess.run(v1))\n",
197 | "print(sess.run(v3))"
198 | ]
199 | },
200 | {
201 | "cell_type": "code",
202 | "execution_count": null,
203 | "metadata": {
204 | "collapsed": true
205 | },
206 | "outputs": [],
207 | "source": []
208 | }
209 | ],
210 | "metadata": {
211 | "anaconda-cloud": {},
212 | "kernelspec": {
213 | "display_name": "Python 3",
214 | "language": "python",
215 | "name": "python3"
216 | },
217 | "language_info": {
218 | "codemirror_mode": {
219 | "name": "ipython",
220 | "version": 3
221 | },
222 | "file_extension": ".py",
223 | "mimetype": "text/x-python",
224 | "name": "python",
225 | "nbconvert_exporter": "python",
226 | "pygments_lexer": "ipython3",
227 | "version": "3.5.2"
228 | }
229 | },
230 | "nbformat": 4,
231 | "nbformat_minor": 1
232 | }
233 |
--------------------------------------------------------------------------------
/example-python/Tutorial-graph.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import os
5 |
6 | config = tf.ConfigProto()
7 | config.gpu_options.allow_growth = True
8 | sess = tf.Session(config=config)
9 |
10 | """TensorBoard 简单例子。
11 | tf.summary.scalar('var_name', var) # 记录标量的变化
12 | tf.summary.histogram('vec_name', vec) # 记录向量或者矩阵,tensor的数值分布变化。
13 |
14 | merged = tf.summary.merge_all() # 把所有的记录并把他们写到 log_dir 中
15 | train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph) # 保存位置
16 |
17 | 运行完后,在命令行中输入 tensorboard --logdir=log_dir_path
18 | """
19 |
20 | tf.app.flags.DEFINE_string('log_dir', 'summary/graph/', 'log saving path')
21 | FLAGS = tf.app.flags.FLAGS
22 | if os.path.exists(FLAGS.log_dir):
23 | os.rmdir(FLAGS.log_dir)
24 | os.makedirs(FLAGS.log_dir)
25 | print 'created log_dir path'
26 |
27 | with tf.name_scope('add_example'):
28 | a = tf.Variable(tf.truncated_normal([100, 1], mean=0.5, stddev=0.5), name='var_a')
29 | tf.summary.histogram('a_hist', a)
30 | b = tf.Variable(tf.truncated_normal([100, 1], mean=-0.5, stddev=1.0), name='var_b')
31 | tf.summary.histogram('b_hist', b)
32 | increase_b = tf.assign(b, b + 0.05)
33 | c = tf.add(a, b)
34 | tf.summary.histogram('c_hist', c)
35 | c_mean = tf.reduce_mean(c)
36 | tf.summary.scalar('c_mean', c_mean)
37 | merged = tf.summary.merge_all()
38 | writer = tf.summary.FileWriter(FLAGS.log_dir + 'add_example', sess.graph)
39 |
40 |
41 | def main(_):
42 | sess.run(tf.global_variables_initializer())
43 | for step in xrange(500):
44 | sess.run([merged, increase_b]) # 每步改变一次 b 的值
45 | summary = sess.run(merged)
46 | writer.add_summary(summary, step)
47 | writer.close()
48 |
49 |
50 | if __name__ == '__main__':
51 | tf.app.run()
52 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_1_numpy_data_1.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for numpy data.
2 | With dataset.make_one_shot_iterator(), it is easy but very slow.
3 | """
4 |
5 | from __future__ import print_function
6 | from __future__ import division
7 | from __future__ import absolute_import
8 |
9 | import warnings
10 |
11 | warnings.filterwarnings('ignore') # 不打印 warning
12 | import tensorflow as tf
13 |
14 | # 设置GPU按需增长
15 | config = tf.ConfigProto()
16 | config.gpu_options.allow_growth = True
17 | sess = tf.Session(config=config)
18 |
19 | import numpy as np
20 | import time
21 | import sys
22 |
23 | from tensorflow.examples.tutorials.mnist import input_data
24 |
25 | mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=True)
26 |
27 | X = mnist.train.images
28 | y = mnist.train.labels
29 |
30 | batch_size = 128
31 | # 创建 dataset
32 | dataset = tf.data.Dataset.from_tensor_slices((X, y))
33 | print('dataset is', dataset)
34 |
35 | # 对数据进行操作
36 | # def pre_func(X, y):
37 | # X = tf.multiply(X, 2)
38 | # return X, y
39 | # dataset = dataset.map(pre_func)
40 |
41 | dataset = dataset.shuffle(buffer_size=5000) # 设置 buffle_size 越大,shuffle 越均匀
42 | dataset = dataset.repeat().batch(batch_size)
43 | print('after get batch', dataset)
44 |
45 | # 生成迭代器
46 | iterator = dataset.make_one_shot_iterator()
47 | print(iterator)
48 |
49 | # 迭代取值
50 | time0 = time.time()
51 | for count in range(100): # 100batch 125 seconds
52 | X_batch, y_batch = sess.run(iterator.get_next())
53 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
54 | sys.stdout.flush()
55 | # print('count = {} : y = {}'.format(count, y_batch.reshape([-1])))
56 |
57 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_1_numpy_data_2.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for numpy data.
2 | With dataset.make_initializable_iterator(), it is more faster then dataset.make_one_shot_iterator().
3 | """
4 |
5 | from __future__ import print_function
6 | from __future__ import division
7 | from __future__ import absolute_import
8 |
9 | import warnings
10 |
11 | warnings.filterwarnings('ignore') # 不打印 warning
12 | import tensorflow as tf
13 |
14 | # 设置GPU按需增长
15 | config = tf.ConfigProto()
16 | config.gpu_options.allow_growth = True
17 | sess = tf.Session(config=config)
18 |
19 | import numpy as np
20 | import time
21 | import sys
22 |
23 | from tensorflow.examples.tutorials.mnist import input_data
24 |
25 | mnist = input_data.read_data_sets('../data/MNIST_data', one_hot=True)
26 |
27 | X = mnist.train.images
28 | y = mnist.train.labels
29 |
30 | # 使用 placeholder 来取代 array,并使用 initiable iterator, 在需要的时候再将 array 传进去
31 | # 这样能够避免把大数组保存在图中
32 | X_placeholder = tf.placeholder(dtype=X.dtype, shape=X.shape)
33 | y_placeholder = tf.placeholder(dtype=y.dtype, shape=y.shape)
34 |
35 | batch_size = 128
36 | # 创建 dataset
37 | dataset = tf.data.Dataset.from_tensor_slices((X_placeholder, y_placeholder))
38 | print('dataset is', dataset)
39 |
40 | # 对数据进行操作
41 | # def pre_func(X, y):
42 | # X = tf.multiply(X, 2)
43 | # return X, y
44 | # dataset = dataset.map(pre_func)
45 |
46 | dataset = dataset.shuffle(buffer_size=5000) # 设置 buffle_size 越大,shuffle 越均匀
47 | dataset = dataset.repeat().batch(batch_size)
48 | print('after get batch', dataset)
49 |
50 | # 生成迭代器
51 | iterator = dataset.make_initializable_iterator()
52 | print(iterator)
53 | sess.run(iterator.initializer, feed_dict={X_placeholder: X, y_placeholder: y})
54 |
55 | # 迭代取值
56 | time0 = time.time()
57 | for count in range(100): # 100batch 1.95 seconds
58 | X_batch, y_batch = sess.run(iterator.get_next())
59 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
60 | sys.stdout.flush()
61 | # print('count = {} : y = {}'.format(count, y_batch.reshape([-1])))
62 |
63 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_2_image_data_1.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for image(png) data.
2 | With one-shot
3 | """
4 |
5 | from __future__ import print_function
6 | from __future__ import division
7 | from __future__ import absolute_import
8 |
9 | import warnings
10 |
11 | warnings.filterwarnings('ignore') # 不打印 warning
12 | import tensorflow as tf
13 |
14 |
15 | # 设置GPU按需增长
16 | config = tf.ConfigProto()
17 | config.gpu_options.allow_growth = True
18 | sess = tf.Session(config=config)
19 |
20 | import numpy as np
21 | import sys
22 | import os
23 | import time
24 |
25 |
26 | def get_file_path(data_path='../data/sketchy_000000000000/'):
27 | """解析文件夹,获取每个文件的路径和标签。"""
28 | img_paths = list()
29 | labels = list()
30 | class_dirs = sorted(os.listdir(data_path))
31 | dict_class2id = dict()
32 | for i in range(len(class_dirs)):
33 | label = i
34 | class_dir = class_dirs[i]
35 | dict_class2id[class_dir] = label
36 | class_path = os.path.join(data_path, class_dir) # 每类的路径
37 | file_names = sorted(os.listdir(class_path))
38 | for file_name in file_names:
39 | file_path = os.path.join(class_path, file_name)
40 | img_paths.append(file_path)
41 | labels.append(label)
42 | return img_paths, labels
43 |
44 |
45 | def parse_png(img_path, label, height=256, width=256, channel=3):
46 | """根据 img_path 读入图片并做相应处理"""
47 | # 从硬盘上读取图片
48 | img = tf.read_file(img_path)
49 | img_decoded = tf.image.decode_png(img, channels=channel)
50 | # resize
51 | img_resized = tf.image.resize_images(img_decoded, [height, width])
52 | # normalize
53 | img_norm = img_resized * 1.0 / 127.5 - 1.0
54 | return img_norm, label
55 |
56 |
57 | img_paths, labels = get_file_path()
58 | batch_size = 128
59 | dataset = tf.data.Dataset.from_tensor_slices((img_paths, labels))
60 | dataset = dataset.map(parse_png)
61 | print('parsing image', dataset)
62 | dataset = dataset.shuffle(buffer_size=5000).repeat().batch(batch_size)
63 | print('batch', dataset)
64 |
65 | # 生成迭代器
66 | iterator = dataset.make_one_shot_iterator()
67 | print(iterator)
68 |
69 | time0 = time.time()
70 | for count in range(100):
71 | X_batch, y_batch = sess.run(iterator.get_next())
72 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
73 | sys.stdout.flush()
74 |
--------------------------------------------------------------------------------
/example-python/Tutorial_10_2_image_data_2.py:
--------------------------------------------------------------------------------
1 | """Use tf.data.Dataset to create dataset for image(png) data.
2 | With TF Queue, shuffle data
3 |
4 | refer: https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/5_DataManagement/build_an_image_dataset.py
5 | """
6 |
7 | from __future__ import print_function
8 | from __future__ import division
9 | from __future__ import absolute_import
10 |
11 | import warnings
12 |
13 | warnings.filterwarnings('ignore') # 不打印 warning
14 | import tensorflow as tf
15 |
16 | # 设置GPU按需增长
17 | config = tf.ConfigProto()
18 | config.gpu_options.allow_growth = True
19 | sess = tf.Session(config=config)
20 |
21 | import numpy as np
22 | import sys
23 | import os
24 | import time
25 |
26 |
27 | def get_file_path(data_path='../data/sketchy_000000000000/'):
28 | """解析文件夹,获取每个文件的路径和标签。"""
29 | img_paths = list()
30 | labels = list()
31 | class_dirs = sorted(os.listdir(data_path))
32 | dict_class2id = dict()
33 | for i in range(len(class_dirs)):
34 | label = i
35 | class_dir = class_dirs[i]
36 | dict_class2id[class_dir] = label
37 | class_path = os.path.join(data_path, class_dir) # 每类的路径
38 | file_names = sorted(os.listdir(class_path))
39 | for file_name in file_names:
40 | file_path = os.path.join(class_path, file_name)
41 | img_paths.append(file_path)
42 | labels.append(label)
43 | return img_paths, labels
44 |
45 |
46 | def get_batch(img_paths, labels, batch_size=128, height=256, width=256, channel=3):
47 | """根据 img_path 读入图片并做相应处理"""
48 | # 从硬盘上读取图片
49 | img_paths = np.asarray(img_paths)
50 | labels = np.asarray(labels)
51 |
52 | img_paths = tf.convert_to_tensor(img_paths, dtype=tf.string)
53 | labels = tf.convert_to_tensor(labels, dtype=tf.int32)
54 | # Build a TF Queue, shuffle data
55 | image, label = tf.train.slice_input_producer([img_paths, labels], shuffle=True)
56 | # Read images from disk
57 | image = tf.read_file(image)
58 | image = tf.image.decode_jpeg(image, channels=channel)
59 | # Resize images to a common size
60 | image = tf.image.resize_images(image, [height, width])
61 | # Normalize
62 | image = image * 1.0 / 127.5 - 1.0
63 | # Create batches
64 | X_batch, y_batch = tf.train.batch([image, label], batch_size=batch_size,
65 | capacity=batch_size * 8,
66 | num_threads=4)
67 | return X_batch, y_batch
68 |
69 |
70 | img_paths, labels = get_file_path()
71 | X_batch, y_batch = get_batch(img_paths, labels)
72 |
73 | sess.run(tf.global_variables_initializer())
74 | tf.train.start_queue_runners(sess=sess)
75 |
76 | time0 = time.time()
77 | for count in range(100): # 11s for 100batch
78 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
79 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
80 | sys.stdout.flush()
81 |
--------------------------------------------------------------------------------
/figs/conv_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/conv_mnist.png
--------------------------------------------------------------------------------
/figs/graph2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/graph2.png
--------------------------------------------------------------------------------
/figs/lstm_8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/lstm_8.png
--------------------------------------------------------------------------------
/figs/lstm_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yongyehuang/Tensorflow-Tutorial/88b5cdbdf402a8ae7f65a540e5f81f3da8f45e7d/figs/lstm_mnist.png
--------------------------------------------------------------------------------
/models/README.md:
--------------------------------------------------------------------------------
1 | # TensorFlow 实战
2 | 下面的每个例子都是相互独立的,每个文件夹下面的代码都是可以单独运行的,不依赖于其他文件夹。
3 |
4 | ## m01_batch_normalization: Batch Normalization 的使用。
5 | 参考:[tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
6 |
7 | ## m02_dcgan: 使用 DCGAN 生成二次元头像
8 | 参考:
9 | - [原论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1511.06434)
10 | - [GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059)
11 | - [代码:carpedm20/DCGAN-tensorflow](https://github.com/carpedm20/DCGAN-tensorflow)
12 | - [代码:aymericdamien/TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/dcgan.py)
13 |
14 | 这里的 notebook 和 .py 文件的内容是一样的。本例子和下面的 GAN 模型用的数据集也是用了[GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059) 的二次元头像,感觉这里例子比较有意思。如果想使用其他数据集的话,只需要把数据集换一下就行了。
15 |
16 | 下载链接: https://pan.baidu.com/s/1HBJpfkIFaGh0s2nfNXJsrA 密码: x39r
17 |
18 | 下载后把所有的图片解压到一个文件夹中,比如本例中是: `data_path = '../../data/anime/'`
19 |
20 | 运行: `python dcgan.py `
21 |
22 | ## m03_wgan: 使用 WGAN 生成二次元头像
23 | 这里的生成器和判别器我只实现了 DCGAN,没有实现 MLP. 如果想实现的话可以参考下面的两个例子。
24 | 参考:
25 | - [原论文:Wasserstein GAN](https://arxiv.org/pdf/1701.07875.pdf)
26 | - [代码:jiamings/wgan](https://github.com/jiamings/wgan)
27 | - [代码:Zardinality/WGAN-tensorflow](https://github.com/Zardinality/WGAN-tensorflow)
28 |
29 | 原版的 wgan: `python wgan.py `
30 |
31 | 改进的 wgan-gp: `python wgan_gp.py`
32 |
33 |
34 | ## m04_pix2pix: image-to-image GAN
35 |
36 |
37 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/README.md:
--------------------------------------------------------------------------------
1 | Batch Normalization 的使用。
2 |
3 | 参考:[tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
4 |
5 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/mnist_cnn.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | """网络结构定义。
4 | 关于 tf.layers.batch_normalization() 的理解参考: [tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html)
5 | """
6 |
7 | from __future__ import print_function, division, absolute_import
8 |
9 | import tensorflow as tf
10 |
11 |
12 | class Model(object):
13 | def __init__(self, settings):
14 | self.model_name = settings.model_name
15 | self.img_size = settings.img_size
16 | self.n_channel = settings.n_channel
17 | self.n_class = settings.n_class
18 | self.drop_rate = settings.drop_rate
19 | self.global_step = tf.Variable(0, trainable=False, name='Global_Step')
20 | self.learning_rate = tf.train.exponential_decay(settings.learning_rate,
21 | self.global_step, settings.decay_step,
22 | settings.decay_rate, staircase=True)
23 |
24 | self.conv_weight_initializer = tf.contrib.layers.xavier_initializer(uniform=True)
25 | self.conv_biases_initializer = tf.zeros_initializer()
26 | # 最后一个全连接层的初始化
27 | self.fc_weight_initializer = tf.truncated_normal_initializer(0.0, 0.005)
28 | self.fc_biases_initializer = tf.constant_initializer(0.1)
29 |
30 | # placeholders
31 | with tf.name_scope('Inputs'):
32 | self.X_inputs = tf.placeholder(tf.float32, [None, self.img_size, self.img_size, self.n_channel],
33 | name='X_inputs')
34 | self.y_inputs = tf.placeholder(tf.int64, [None], name='y_input')
35 |
36 | self.logits_train = self.inference(is_training=True, reuse=False)
37 | self.logits_test = self.inference(is_training=False, reuse=True)
38 |
39 | # 预测结果
40 | self.pred_lables = tf.argmax(self.logits_test, axis=1)
41 | self.pred_probas = tf.nn.softmax(self.logits_test)
42 | self.test_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
43 | labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_test))
44 | self.test_acc = tf.reduce_mean(tf.cast(tf.equal(self.pred_lables, self.y_inputs), tf.float32))
45 |
46 | # 训练结果
47 | self.train_lables = tf.argmax(self.logits_train, axis=1)
48 | self.train_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
49 | labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_train))
50 | self.train_acc = tf.reduce_mean(tf.cast(tf.equal(self.train_lables, self.y_inputs), tf.float32))
51 |
52 | self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
53 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
54 | """
55 | **注意:** 下面一定要使用这样的方式来写。
56 | with tf.control_dependencies(update_ops) 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作。
57 | 这里的 update_ops 在这里主要是更新 BN 层的滑动平均值和滑动方差。
58 |
59 | 除了 BN 层外,还有 center loss 中也采用这样的方式,在 center loss 中,update_ops 操作主要更新类中心向量。
60 | 因为之前在 center loss 犯过没更新 center 的错误,所以印象非常深刻。
61 | """
62 | with tf.control_dependencies(update_ops): # 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作
63 | self.train_op = self.optimizer.minimize(self.train_loss, global_step=self.global_step)
64 |
65 | def inference(self, is_training, reuse=False):
66 | """带 BN 层的CNN """
67 | with tf.variable_scope('cnn', reuse=reuse):
68 | # 第一个卷积层 + BN + max_pooling
69 | conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding='same',
70 | kernel_initializer=self.conv_weight_initializer, name='conv1')
71 | bn1 = tf.layers.batch_normalization(conv1, training=is_training, name='bn1')
72 | bn1 = tf.nn.relu(bn1) # 一般都是先经过 BN 层再加激活函数的
73 | pool1 = tf.layers.max_pooling2d(bn1, pool_size=2, strides=2, padding='same', name='pool1')
74 |
75 | # 第二个卷积层 + BN + max_pooling
76 | conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding='same',
77 | kernel_initializer=self.conv_weight_initializer, name='conv2')
78 | bn2 = tf.layers.batch_normalization(conv2, training=is_training, name='bn2')
79 | bn2 = tf.nn.relu(bn2) # 一般都是先经过 BN 层再加激活函数的
80 | pool2 = tf.layers.max_pooling2d(bn2, pool_size=2, strides=2, padding='same', name='pool2')
81 |
82 | # 全连接,使用卷积来实现
83 | _, k_height, k_width, k_depth = pool2.get_shape().as_list()
84 | fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, name='fc1')
85 | bn3 = tf.layers.batch_normalization(fc1, training=is_training, name='bn3')
86 | bn3 = tf.nn.relu(bn3)
87 |
88 | # dropout, 如果 is_training = False 就不会执行 dropout
89 | fc1_drop = tf.layers.dropout(bn3, rate=self.drop_rate, training=is_training)
90 |
91 | # 最后的输出层
92 | flatten_layer = tf.layers.flatten(fc1_drop)
93 | out = tf.layers.dense(flatten_layer, units=self.n_class)
94 | return out
95 |
96 | def inference2(self, is_training, reuse=False):
97 | """不带 BN 层的 CNN。"""
98 | with tf.variable_scope('cnn', reuse=reuse):
99 | # 第一个卷积层 + BN + max_pooling
100 | conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding='same',
101 | activation=tf.nn.relu,
102 | kernel_initializer=self.conv_weight_initializer, name='conv1')
103 | pool1 = tf.layers.max_pooling2d(conv1, pool_size=2, strides=2, padding='same', name='pool1')
104 |
105 | # 第二个卷积层 + BN + max_pooling
106 | conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding='same',
107 | activation=tf.nn.relu,
108 | kernel_initializer=self.conv_weight_initializer, name='conv2')
109 | pool2 = tf.layers.max_pooling2d(conv2, pool_size=2, strides=2, padding='same', name='pool2')
110 |
111 | # 全连接,使用卷积来实现
112 | _, k_height, k_width, k_depth = pool2.get_shape().as_list()
113 | fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, activation=tf.nn.relu, name='fc1')
114 |
115 | # dropout, 如果 is_training = False 就不会执行 dropout
116 | fc1_drop = tf.layers.dropout(fc1, rate=self.drop_rate, training=is_training)
117 |
118 | # 最后的输出层
119 | flatten_layer = tf.layers.flatten(fc1_drop)
120 | out = tf.layers.dense(flatten_layer, units=self.n_class)
121 | return out
122 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/predict.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | from __future__ import print_function, division, absolute_import
4 |
5 | import tensorflow as tf
6 | import numpy as np
7 | import os
8 | import time
9 |
10 | from mnist_cnn import Model
11 |
12 |
13 | class Settings(object):
14 | def __init__(self):
15 | self.model_name = 'mnist_cnn'
16 | self.img_size = 28
17 | self.n_channel = 1
18 | self.n_class = 10
19 | self.drop_rate = 0.5
20 | self.learning_rate = 0.001
21 | self.decay_step = 2000
22 | self.decay_rate = 0.5
23 | self.training_steps = 10000
24 | self.batch_size = 100
25 |
26 | self.summary_path = 'summary/' + self.model_name + '/'
27 | self.ckpt_path = 'ckpt/' + self.model_name + '/'
28 |
29 | if not os.path.exists(self.summary_path):
30 | os.makedirs(self.summary_path)
31 | if not os.path.exists(self.ckpt_path):
32 | os.makedirs(self.ckpt_path)
33 |
34 |
35 | def main():
36 | """模型训练。"""
37 | from tensorflow.examples.tutorials.mnist import input_data
38 |
39 | mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False)
40 | print(mnist.test.labels.shape)
41 | print(mnist.train.labels.shape)
42 |
43 | my_setting = Settings()
44 | with tf.variable_scope(my_setting.model_name):
45 | model = Model(my_setting)
46 |
47 | # 模型要保存的变量
48 | var_list = tf.trainable_variables()
49 | if model.global_step not in var_list:
50 | var_list.append(model.global_step)
51 | # 添加 BN 层的均值和方差
52 | global_vars = tf.global_variables()
53 | bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
54 | bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
55 | var_list += bn_moving_vars
56 | # 创建Saver
57 | saver = tf.train.Saver(var_list=var_list)
58 |
59 | config = tf.ConfigProto()
60 | config.gpu_options.allow_growth = True
61 | with tf.Session(config=config) as sess:
62 | if not os.path.exists(my_setting.ckpt_path + 'checkpoint'):
63 | print("There is no checkpoit, please check out.")
64 | exit()
65 | saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path))
66 | tic = time.time()
67 | n_batch = len(mnist.test.labels) // my_setting.batch_size
68 | predict_labels = list()
69 | true_labels = list()
70 | for step in range(n_batch):
71 | X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=False)
72 | X_batch = X_batch.reshape([-1, 28, 28, 1])
73 | pred_label, test_loss, test_acc = sess.run([model.pred_lables, model.test_loss, model.test_acc],
74 | feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
75 | predict_labels.append(pred_label)
76 | true_labels.append(y_batch)
77 | predict_labels = np.hstack(predict_labels)
78 | true_labels = np.hstack(true_labels)
79 | acc = np.sum(predict_labels == true_labels) / len(true_labels)
80 | print("Test sample number = {}, acc = {:.4f}, pass {:.2f}s".format(len(true_labels), acc, time.time() - tic))
81 |
82 |
83 | if __name__ == '__main__':
84 | main()
85 |
--------------------------------------------------------------------------------
/models/m01_batch_normalization/train.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | from __future__ import print_function, division, absolute_import
4 |
5 | import tensorflow as tf
6 | import os
7 | import time
8 |
9 | from mnist_cnn import Model
10 |
11 |
12 | class Settings(object):
13 | def __init__(self):
14 | self.model_name = 'mnist_cnn'
15 | self.img_size = 28
16 | self.n_channel = 1
17 | self.n_class = 10
18 | self.drop_rate = 0.5
19 | self.learning_rate = 0.001
20 | self.decay_step = 2000
21 | self.decay_rate = 0.5
22 | self.training_steps = 10000 # 耗时 90s
23 | self.batch_size = 100
24 |
25 | self.summary_path = 'summary/' + self.model_name + '/'
26 | self.ckpt_path = 'ckpt/' + self.model_name + '/'
27 |
28 | if not os.path.exists(self.summary_path):
29 | os.makedirs(self.summary_path)
30 | if not os.path.exists(self.ckpt_path):
31 | os.makedirs(self.ckpt_path)
32 |
33 |
34 | def main():
35 | """模型训练。"""
36 | from tensorflow.examples.tutorials.mnist import input_data
37 |
38 | mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False)
39 | print(mnist.test.labels.shape)
40 | print(mnist.train.labels.shape)
41 |
42 | my_setting = Settings()
43 | with tf.variable_scope(my_setting.model_name):
44 | model = Model(my_setting)
45 |
46 | # 模型要保存的变量
47 | var_list = tf.trainable_variables()
48 | if model.global_step not in var_list:
49 | var_list.append(model.global_step)
50 | # 添加 BN 层的均值和方差
51 | global_vars = tf.global_variables()
52 | bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
53 | bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
54 | var_list += bn_moving_vars
55 | # 创建Saver
56 | saver = tf.train.Saver(var_list=var_list)
57 |
58 | config = tf.ConfigProto()
59 | config.gpu_options.allow_growth = True
60 | with tf.Session(config=config) as sess:
61 | print("initializing variables.")
62 | sess.run(tf.global_variables_initializer())
63 | sess.run(tf.local_variables_initializer())
64 | if os.path.exists(my_setting.ckpt_path + 'checkpoint'):
65 | print("restore checkpoint.")
66 | saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path))
67 | tic = time.time()
68 | for step in range(my_setting.training_steps):
69 | if 0 == step % 100:
70 | X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True)
71 | X_batch = X_batch.reshape([-1, 28, 28, 1])
72 | _, g_step, train_loss, train_acc = sess.run(
73 | [model.train_op, model.global_step, model.train_loss, model.train_acc],
74 | feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
75 | X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=True)
76 | X_batch = X_batch.reshape([-1, 28, 28, 1])
77 | test_loss, test_acc = sess.run([model.test_loss, model.test_acc],
78 | feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
79 | print(
80 | "Global_step={:.2f}, train_loss={:.2f}, train_acc={:.2f}; test_loss={:.2f}, test_acc={:.2f}; pass {:.2f}s".format(
81 | g_step, train_loss, train_acc, test_loss, test_acc, time.time() - tic
82 | ))
83 | else:
84 | X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True)
85 | X_batch = X_batch.reshape([-1, 28, 28, 1])
86 | sess.run([model.train_op], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch})
87 | if 0 == (step + 1) % 1000:
88 | path = saver.save(sess, os.path.join(my_setting.ckpt_path, 'model.ckpt'),
89 | global_step=sess.run(model.global_step))
90 | print("Save model to {} ".format(path))
91 |
92 |
93 | if __name__ == '__main__':
94 | main()
95 |
--------------------------------------------------------------------------------
/models/m02_dcgan/README.md:
--------------------------------------------------------------------------------
1 | ## 使用 DCGAN 生成二次元头像
2 | 参考:
3 | - [原论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1511.06434)
4 | - [GAN学习指南:从原理入门到制作生成Demo](https://zhuanlan.zhihu.com/p/24767059)
5 | - [代码:carpedm20/DCGAN-tensorflow](https://github.com/carpedm20/DCGAN-tensorflow)
6 | - [代码:aymericdamien/TensorFlow-Examples](https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/dcgan.py)
7 |
8 |
9 | 这里的 notebook 和 .py 文件的内容是一样的。
10 |
11 | 运行: `python dcgan.py ` 即可
--------------------------------------------------------------------------------
/models/m02_dcgan/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/models/m03_wgan/README.md:
--------------------------------------------------------------------------------
1 | ## 使用 WGAN 生成二次元头像
2 | 参考:
3 | - [原论文:Wasserstein GAN](https://arxiv.org/pdf/1701.07875.pdf)
4 | - [代码:jiamings/wgan](https://github.com/jiamings/wgan)
5 | - [代码:Zardinality/WGAN-tensorflow](https://github.com/Zardinality/WGAN-tensorflow)
6 |
7 |
8 | 运行: `python wgan.py ` 即可
9 |
10 | (wgan-gp.py 仍有bug...)
11 |
--------------------------------------------------------------------------------
/models/m03_wgan/wgan.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | from __future__ import print_function, division, absolute_import
4 |
5 | import warnings
6 |
7 | warnings.filterwarnings('ignore') # 不打印 warning
8 |
9 | import matplotlib
10 |
11 | matplotlib.use('Agg')
12 |
13 | import numpy as np
14 | import tensorflow as tf
15 | import matplotlib.pyplot as plt
16 |
17 | import time
18 | import os
19 | import sys
20 |
21 |
22 | # Generator Network
23 | # Input: Noise, Output: Image
24 | def generator(z, reuse=False):
25 | """输入噪声,输出图片。
26 | G网络中使用ReLU作为激活函数,最后一层使用tanh.
27 | 每一层都加 BN
28 | """
29 | with tf.variable_scope('Generator', reuse=reuse) as scope:
30 | # 按照论文的网络结构,第一层用一个全连接层
31 | x = tf.layers.dense(z, units=4 * 4 * 1024)
32 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn1'))
33 | # Reshape to a 4-D array of images: (batch, height, width, channels)
34 | # 然后把全链接层的输出 reshape 成 4D 的 tensor
35 | x = tf.reshape(x, shape=[-1, 4, 4, 1024])
36 | print('tr_conv4:', x)
37 | # Deconvolution, image shape: (batch, 8, 8, 512)
38 | x = tf.layers.conv2d_transpose(x, 512, 5, strides=2, padding='same')
39 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn2'))
40 | print('tr_conv3:', x)
41 | # Deconvolution, image shape: (batch, 16, 16, 256)
42 | x = tf.layers.conv2d_transpose(x, 256, 5, strides=2, padding='same')
43 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn3'))
44 | print('tr_conv2:', x)
45 | # Deconvolution, image shape: (batch, 32, 32, 128)
46 | x = tf.layers.conv2d_transpose(x, 128, 5, strides=2, padding='same')
47 | x = tf.nn.relu(tf.layers.batch_normalization(x, training=True, name='bn4'))
48 | print('tr_conv1:', x)
49 | # Deconvolution, image shape: (batch, 64, 64, 3)
50 | x = tf.layers.conv2d_transpose(x, 3, 5, strides=2, padding='same')
51 | x = tf.nn.tanh(tf.layers.batch_normalization(x, training=True, name='bn5'))
52 | print('output_image:', x)
53 | return x
54 |
55 |
56 | def discriminator(x, reuse=False):
57 | """判别器。
58 | D网络中使用LeakyReLU作为激活函数。
59 | """
60 | with tf.variable_scope('Discriminator', reuse=reuse):
61 | # Typical convolutional neural network to classify images.
62 | print('input_image:', x)
63 | x = tf.layers.conv2d(x, 128, 5, strides=2, padding='same')
64 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn1'))
65 | print('conv1:', x)
66 | x = tf.layers.conv2d(x, 256, 5, strides=2, padding='same')
67 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn2'))
68 | print('conv2:', x)
69 | x = tf.layers.conv2d(x, 512, 5, strides=2, padding='same')
70 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn3'))
71 | print('conv3:', x)
72 | x = tf.layers.conv2d(x, 1024, 5, strides=2, padding='same')
73 | x = tf.nn.leaky_relu(tf.layers.batch_normalization(x, training=True, name='bn4'))
74 | print('conv4:', x)
75 | x = tf.layers.flatten(x)
76 | x = tf.layers.dense(x, 1)
77 | print('output:', x)
78 | return x
79 |
80 |
81 | def get_file_path(data_path='../../data/anime/'):
82 | """解析文件夹,获取每个文件的路径和标签(在这个例子中所有的真实图片的标签都是1)。"""
83 | files = os.listdir(data_path)
84 | img_paths = [file for file in files if file.endswith('.jpg')]
85 | img_paths = list(map(lambda s: os.path.join(data_path, s), img_paths))
86 | labels = [1] * len(img_paths)
87 | return img_paths, labels
88 |
89 |
90 | def get_batch(img_paths, labels, batch_size=50, height=64, width=64, channel=3):
91 | """根据 img_path 读入图片并做相应处理"""
92 | # 从硬盘上读取图片
93 | img_paths = np.asarray(img_paths)
94 | labels = np.asarray(labels)
95 |
96 | img_paths = tf.convert_to_tensor(img_paths, dtype=tf.string)
97 | labels = tf.convert_to_tensor(labels, dtype=tf.int32)
98 | # Build a TF Queue, shuffle data
99 | image, label = tf.train.slice_input_producer([img_paths, labels], shuffle=True)
100 | # Read images from disk
101 | image = tf.read_file(image)
102 | image = tf.image.decode_jpeg(image, channels=channel)
103 | # Resize images to a common size
104 | image = tf.image.resize_images(image, [height, width])
105 | # Normalize
106 | image = image * 1.0 / 127.5 - 1.0
107 | # Create batches
108 | X_batch, y_batch = tf.train.batch([image, label], batch_size=batch_size,
109 | capacity=batch_size * 8,
110 | num_threads=4)
111 | return X_batch, y_batch
112 |
113 |
114 | def generate_img(sess, seed=3, show=False, save_path='generated_img'):
115 | """利用随机噪声生成图片, 并保存图片。"""
116 | if not os.path.exists(save_path):
117 | os.makedirs(save_path)
118 | step = sess.run(global_step)
119 | n_row, n_col = 5, 10
120 | f, a = plt.subplots(n_row, n_col, figsize=(n_col, n_row))
121 | np.random.seed(seed) # 每次都用相同的随机数便于对比结果
122 | z_batch = np.random.uniform(-1., 1., size=[n_row * n_col, noise_dim])
123 | fake_imgs = sess.run(gen_image, feed_dict={noise_input: z_batch})
124 | for i in range(n_row):
125 | # Noise input.
126 | for j in range(n_col):
127 | # Generate image from noise. Extend to 3 channels for matplot figure.
128 | img = (fake_imgs[n_col * i + j] + 1) / 2
129 | a[i][j].imshow(img)
130 | a[i][j].axis('off')
131 | f.savefig(os.path.join(save_path, '{}.png'.format(step)), dpi=100)
132 | if show:
133 | f.show()
134 |
135 |
136 | # 构建网络
137 | # Network Params
138 | image_dim = 64 # 头像的尺度
139 | n_channel = 3
140 | noise_dim = 100 # 输入噪声 z 的维度
141 |
142 | noise_input = tf.placeholder(tf.float32, shape=[None, noise_dim])
143 | real_img_input = tf.placeholder(tf.float32, shape=[None, image_dim, image_dim, n_channel])
144 |
145 | # 构造网络:生成器
146 | gen_image = generator(noise_input)
147 |
148 | # 判别器有两种输入,一种真实图像,一种生成器生成的假图像
149 | disc_real = discriminator(real_img_input) # 真图像输出的结果
150 | disc_fake = discriminator(gen_image, reuse=True)
151 |
152 | # 损失函数 (与DCGAN第1个改变)
153 | disc_loss = tf.reduce_mean(disc_fake - disc_real)
154 | gen_loss = tf.reduce_mean(-disc_fake)
155 |
156 | # 两个优化器
157 | # Build Optimizers (第2个改变)
158 | global_step = tf.Variable(0, trainable=False, name='Global_Step')
159 | optimizer_gen = tf.train.RMSPropOptimizer(learning_rate=5e-5)
160 | optimizer_disc = tf.train.RMSPropOptimizer(learning_rate=5e-5)
161 |
162 | # G 和 D 的参数
163 | gen_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Generator')
164 | # Discriminator Network Variables
165 | disc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Discriminator')
166 |
167 | # 对于 D 的参数进行裁剪 (第3个改变,注意每次更新完 D 后都要执行裁剪)
168 | clipped_disc = [tf.assign(v, tf.clip_by_value(v, -0.01, 0.01)) for v in disc_vars]
169 |
170 | # Create training operations
171 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
172 | with tf.control_dependencies(update_ops): # 这句话的意思是当运行下面的内容(train_op) 时,一定先执行 update_ops 的所有操作
173 | train_gen = optimizer_gen.minimize(gen_loss, var_list=gen_vars, global_step=global_step)
174 | train_disc = optimizer_disc.minimize(disc_loss, var_list=disc_vars)
175 |
176 | # 模型要保存的变量
177 | # var_list = tf.global_variables() + tf.local_variables() # 这样保存所有变量不会出错,但是很多没必要的变量也保存了。414M 每个 ckpt
178 | var_list = tf.trainable_variables()
179 | if global_step not in var_list:
180 | var_list.append(global_step)
181 | # 添加 BN 层的均值和方差
182 | global_vars = tf.global_variables()
183 | bn_moving_vars = [v for v in global_vars if 'moving_mean' in v.name]
184 | bn_moving_vars += [v for v in global_vars if 'moving_variance' in v.name]
185 | var_list += bn_moving_vars
186 | # 创建Saver
187 |
188 | saver = tf.train.Saver(var_list=var_list)
189 |
190 | # 模型保存路径
191 | ckpt_path = 'ckpt/'
192 | if not os.path.exists(ckpt_path):
193 | os.makedirs(ckpt_path)
194 |
195 | # Training Params
196 | num_steps = 500000
197 | batch_size = 64
198 | d_iters = 5 # 更新 d_iters 次 D, 更新 1 次 G
199 |
200 | # 构建数据读取函数
201 | img_paths, labels = get_file_path()
202 | print("n_sample={}".format(len(img_paths)))
203 | get_X_batch, get_y_batch = get_batch(img_paths, labels, batch_size=batch_size)
204 |
205 | # Start training
206 | config = tf.ConfigProto()
207 | config.gpu_options.allow_growth = True
208 | with tf.Session(config=config) as sess:
209 | print("initializing variables.")
210 | sess.run(tf.global_variables_initializer())
211 | sess.run(tf.local_variables_initializer())
212 |
213 | if os.path.exists(ckpt_path + 'checkpoint'):
214 | print("restore checkpoint.")
215 | saver.restore(sess, tf.train.latest_checkpoint(ckpt_path))
216 |
217 | # 启动数据读取队列
218 | coord = tf.train.Coordinator()
219 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
220 |
221 |
222 | def get_batch():
223 | # 准备输入数据:真实图片
224 | X_batch, _ = sess.run([get_X_batch, get_y_batch]) # 本例中不管 _y_batch 的label
225 | # 准备噪声输入
226 | z_batch = np.random.uniform(-1., 1., size=[batch_size, noise_dim])
227 | # Training 这里的输入不需要 target
228 | feed_dict = {real_img_input: X_batch, noise_input: z_batch}
229 | return feed_dict
230 |
231 |
232 | try:
233 | tic = time.time()
234 | for i in range(1, num_steps + 1):
235 | # update 5 次 D,update 1 次 G
236 | dl = 0.0
237 | for _ in range(d_iters):
238 | _, _, dl = sess.run([train_disc, clipped_disc, disc_loss], feed_dict=get_batch())
239 | _, gl = sess.run([train_gen, gen_loss], feed_dict=get_batch())
240 |
241 | if i % 5 == 0:
242 | print(
243 | 'Step {}: Generator Loss: {:.2f}, Discriminator Loss: {:.2f}. Time passed {:.2f}s'.format(i, gl, dl,
244 | time.time() - tic))
245 | if i % 200 == 0: # 每训练 1000 step,生成一次图片
246 | generate_img(sess)
247 | path = saver.save(sess, os.path.join(ckpt_path, 'model.ckpt'), global_step=sess.run(global_step))
248 | print("Save model to {} ".format(path))
249 |
250 | generate_img(sess) # 最后一次生成图像
251 | except Exception as e:
252 | print(e)
253 | finally:
254 | coord.request_stop()
255 | coord.join(threads)
256 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/README.md:
--------------------------------------------------------------------------------
1 | # pix2pix
2 |
3 | 代码来自:[affinelayer/pix2pix-tensorflow](https://github.com/affinelayer/pix2pix-tensorflow)
4 |
5 | pix2pix.py 是原代码。
6 |
7 | 原始的代码比较长,包括数据读取,模型结构,模型训练和测试都是放在一个文件中。
8 |
9 | 根据原始代码,整理成了四个文件:
10 | - utils.py: 数据读取和数据处理函数。
11 | - model.py: pix2pix GAN 模型代码。
12 | - train.py: 模型训练的代码。
13 | - test.py: 模型测试的代码。
14 |
15 | 运行:
16 | - 训练: `sh train.sh`
17 | - 测试:`sh test.sh`
18 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/test.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | """模型训练代码"""
4 | from __future__ import print_function, division, absolute_import
5 |
6 | import tensorflow as tf
7 | import numpy as np
8 | import argparse
9 | import os
10 | import json
11 | import glob
12 | import random
13 | import collections
14 | import math
15 | import time
16 | import sys
17 |
18 | sys.path.append('.')
19 | from utils import *
20 | from model import *
21 |
22 | parser = argparse.ArgumentParser()
23 | parser.add_argument("--input_dir", help="path to folder containing images")
24 | parser.add_argument("--mode", type=str, default="test", choices=["train", "test", "export"])
25 | parser.add_argument("--output_dir", required=True, help="where to put output files")
26 | parser.add_argument("--seed", type=int)
27 | parser.add_argument("--checkpoint", default=None,
28 | help="directory with checkpoint to resume training from or use for testing")
29 |
30 | parser.add_argument("--max_steps", type=int, help="number of training steps (0 to disable)")
31 | parser.add_argument("--max_epochs", type=int, help="number of training epochs")
32 | parser.add_argument("--summary_freq", type=int, default=100, help="update summaries every summary_freq steps")
33 | parser.add_argument("--progress_freq", type=int, default=50, help="display progress every progress_freq steps")
34 | parser.add_argument("--trace_freq", type=int, default=0, help="trace execution every trace_freq steps")
35 | parser.add_argument("--display_freq", type=int, default=0,
36 | help="write current training images every display_freq steps")
37 | parser.add_argument("--save_freq", type=int, default=5000, help="save model every save_freq steps, 0 to disable")
38 |
39 | parser.add_argument("--separable_conv", action="store_true", help="use separable convolutions in the generator")
40 | parser.add_argument("--aspect_ratio", type=float, default=1.0, help="aspect ratio of output images (width/height)")
41 | parser.add_argument("--lab_colorization", action="store_true",
42 | help="split input image into brightness (A) and color (B)")
43 | parser.add_argument("--batch_size", type=int, default=1, help="number of images in batch")
44 | parser.add_argument("--which_direction", type=str, default="AtoB", choices=["AtoB", "BtoA"])
45 | parser.add_argument("--ngf", type=int, default=64, help="number of generator filters in first conv layer")
46 | parser.add_argument("--ndf", type=int, default=64, help="number of discriminator filters in first conv layer")
47 | parser.add_argument("--scale_size", type=int, default=286, help="scale images to this size before cropping to 256x256")
48 | parser.add_argument("--flip", dest="flip", action="store_true", help="flip images horizontally")
49 | parser.add_argument("--no_flip", dest="flip", action="store_false", help="don't flip images horizontally")
50 | parser.set_defaults(flip=True)
51 | parser.add_argument("--lr", type=float, default=0.0002, help="initial learning rate for adam")
52 | parser.add_argument("--beta1", type=float, default=0.5, help="momentum term of adam")
53 | parser.add_argument("--l1_weight", type=float, default=100.0, help="weight on L1 term for generator gradient")
54 | parser.add_argument("--gan_weight", type=float, default=1.0, help="weight on GAN term for generator gradient")
55 |
56 | # export options
57 | parser.add_argument("--output_filetype", default="png", choices=["png", "jpeg"])
58 | a = parser.parse_args()
59 |
60 |
61 | def main():
62 | if a.seed is None:
63 | a.seed = random.randint(0, 2 ** 31 - 1)
64 |
65 | tf.set_random_seed(a.seed)
66 | np.random.seed(a.seed)
67 | random.seed(a.seed)
68 |
69 | if not os.path.exists(a.output_dir):
70 | os.makedirs(a.output_dir)
71 |
72 | if a.checkpoint is None:
73 | raise Exception("checkpoint required for test mode")
74 |
75 | # load some options from the checkpoint
76 | options = {"which_direction", "ngf", "ndf", "lab_colorization"}
77 | with open(os.path.join(a.checkpoint, "options.json")) as f:
78 | for key, val in json.loads(f.read()).items():
79 | if key in options:
80 | print("loaded", key, "=", val)
81 | setattr(a, key, val)
82 | # disable these features in test mode
83 | a.scale_size = CROP_SIZE
84 | a.flip = False
85 |
86 | # 打印参数
87 | for k, v in a._get_kwargs():
88 | print(k, "=", v)
89 |
90 | # 写入参数
91 | with open(os.path.join(a.output_dir, "options.json"), "w") as f:
92 | f.write(json.dumps(vars(a), sort_keys=True, indent=4))
93 |
94 | # 准备数据读入
95 | examples = load_examples(input_dir=a.input_dir, batch_size=a.batch_size, mode=a.mode,
96 | which_direction=a.which_direction)
97 | print("examples count = %d" % examples.count)
98 |
99 | # 创建模型
100 | # inputs and targets are [batch_size, height, width, channels]
101 | model = create_model(examples.inputs, examples.targets)
102 |
103 | # undo colorization splitting on images that we use for display/output
104 | if a.lab_colorization:
105 | if a.which_direction == "AtoB":
106 | # inputs is brightness, this will be handled fine as a grayscale image
107 | # need to augment targets and outputs with brightness
108 | targets = augment(examples.targets, examples.inputs)
109 | outputs = augment(model.outputs, examples.inputs)
110 | # inputs can be deprocessed normally and handled as if they are single channel
111 | # grayscale images
112 | inputs = deprocess(examples.inputs)
113 | elif a.which_direction == "BtoA":
114 | # inputs will be color channels only, get brightness from targets
115 | inputs = augment(examples.inputs, examples.targets)
116 | targets = deprocess(examples.targets)
117 | outputs = deprocess(model.outputs)
118 | else:
119 | raise Exception("invalid direction")
120 | else: # 把数据映射回到 (0, 1) 之间便于最后保存图片
121 | inputs = deprocess(examples.inputs)
122 | targets = deprocess(examples.targets)
123 | outputs = deprocess(model.outputs)
124 |
125 | def convert(image):
126 | """把原始的img改成整形的类型,自动的映射到 [0,255]间"""
127 | if a.aspect_ratio != 1.0: # 如果 aspect_ratio 不是 1 (不是方形)的话需要resize恢复大小
128 | # upscale to correct aspect ratio
129 | size = [CROP_SIZE, int(round(CROP_SIZE * a.aspect_ratio))]
130 | image = tf.image.resize_images(image, size=size, method=tf.image.ResizeMethod.BICUBIC)
131 |
132 | return tf.image.convert_image_dtype(image, dtype=tf.uint8, saturate=True)
133 |
134 | # reverse any processing on images so they can be written to disk or displayed to user
135 | with tf.name_scope("convert_inputs"):
136 | converted_inputs = convert(inputs)
137 |
138 | with tf.name_scope("convert_targets"):
139 | converted_targets = convert(targets)
140 |
141 | with tf.name_scope("convert_outputs"):
142 | converted_outputs = convert(outputs)
143 |
144 | with tf.name_scope("encode_images"):
145 | display_fetches = {
146 | "paths": examples.paths,
147 | "inputs": tf.map_fn(tf.image.encode_png, converted_inputs, dtype=tf.string, name="input_pngs"),
148 | "targets": tf.map_fn(tf.image.encode_png, converted_targets, dtype=tf.string, name="target_pngs"),
149 | "outputs": tf.map_fn(tf.image.encode_png, converted_outputs, dtype=tf.string, name="output_pngs"),
150 | }
151 |
152 | # summaries
153 | with tf.name_scope("inputs_summary"):
154 | tf.summary.image("inputs", converted_inputs)
155 |
156 | with tf.name_scope("targets_summary"):
157 | tf.summary.image("targets", converted_targets)
158 |
159 | with tf.name_scope("outputs_summary"):
160 | tf.summary.image("outputs", converted_outputs)
161 |
162 | with tf.name_scope("predict_real_summary"):
163 | tf.summary.image("predict_real", tf.image.convert_image_dtype(model.predict_real, dtype=tf.uint8))
164 |
165 | with tf.name_scope("predict_fake_summary"):
166 | tf.summary.image("predict_fake", tf.image.convert_image_dtype(model.predict_fake, dtype=tf.uint8))
167 |
168 | tf.summary.scalar("discriminator_loss", model.discrim_loss)
169 | tf.summary.scalar("generator_loss_GAN", model.gen_loss_GAN)
170 | tf.summary.scalar("generator_loss_L1", model.gen_loss_L1)
171 |
172 | for var in tf.trainable_variables():
173 | tf.summary.histogram(var.op.name + "/values", var)
174 |
175 | for grad, var in model.discrim_grads_and_vars + model.gen_grads_and_vars:
176 | tf.summary.histogram(var.op.name + "/gradients", grad)
177 |
178 | with tf.name_scope("parameter_count"):
179 | parameter_count = tf.reduce_sum([tf.reduce_prod(tf.shape(v)) for v in tf.trainable_variables()])
180 |
181 | saver = tf.train.Saver(max_to_keep=1)
182 |
183 | logdir = a.output_dir if (a.trace_freq > 0 or a.summary_freq > 0) else None
184 | sv = tf.train.Supervisor(logdir=logdir, save_summaries_secs=0, saver=None)
185 | with sv.managed_session() as sess:
186 | print("parameter_count =", sess.run(parameter_count))
187 |
188 | if a.checkpoint is not None:
189 | print("loading model from checkpoint")
190 | checkpoint = tf.train.latest_checkpoint(a.checkpoint)
191 | saver.restore(sess, checkpoint)
192 |
193 | max_steps = 2 ** 32
194 | if a.max_epochs is not None:
195 | max_steps = examples.steps_per_epoch * a.max_epochs
196 | if a.max_steps is not None:
197 | max_steps = a.max_steps
198 |
199 | # testing
200 | # at most, process the test data once
201 | start = time.time()
202 | max_steps = min(examples.steps_per_epoch, max_steps)
203 | for step in range(max_steps):
204 | results = sess.run(display_fetches)
205 | filesets = save_images(results, output_dir=a.output_dir)
206 | for i, f in enumerate(filesets):
207 | print("evaluated image", f["name"])
208 | index_path = append_index(filesets, output_dir=a.output_dir)
209 | print("wrote index at", index_path)
210 | print("rate", (time.time() - start) / max_steps)
211 |
212 |
213 |
214 | if __name__ == '__main__':
215 | main()
--------------------------------------------------------------------------------
/models/m04_pix2pix/test.sh:
--------------------------------------------------------------------------------
1 | python3 test.py \
2 | --mode test \
3 | --output_dir "facades_test" \
4 | --input_dir "../../data/facades/test" \
5 | --checkpoint "facades_train" \
6 | --which_direction BtoA
7 |
--------------------------------------------------------------------------------
/models/m04_pix2pix/train.sh:
--------------------------------------------------------------------------------
1 | python3 train.py \
2 | --mode train \
3 | --output_dir "facades_train" \
4 | --max_epochs 200 \
5 | --input_dir "../../data/facades/train" \
6 | --which_direction BtoA
7 |
--------------------------------------------------------------------------------
/utils/u01_logging/logging1.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import logging
4 | import logging.handlers
5 |
6 | """the use of logging.
7 | refer: http://blog.csdn.net/chosen0ne/article/details/7319306
8 |
9 | - handler:将日志记录(log record)发送到合适的目的地(destination),比如文件,socket等。
10 | 一个logger对象可以通过addHandler方法添加0到多个handler,每个handler又可以定义不同日志级别,以实现日志分级过滤显示。
11 | - formatter:指定日志记录输出的具体格式。formatter的构造方法需要两个参数:消息的格式字符串和日期字符串,这两个参数都是可选的。
12 | """
13 |
14 | # 1.保存至日志文件
15 | LOG_FILE = 'training.log'
16 | # 2.设置日志,maxBytes设置文件大小,backpuCount设置文件数量
17 | handler = logging.handlers.RotatingFileHandler(LOG_FILE, maxBytes=1024 * 1024, backupCount=5) # 实例化handler
18 | # 3.设置消息输出格式
19 | fmt = '%(asctime)s - %(filename)s:%(lineno)s - %(name)s - %(message)s'
20 |
21 | formatter = logging.Formatter(fmt) # 实例化formatter
22 | handler.setFormatter(formatter) # 为handler添加formatter
23 |
24 | logger = logging.getLogger('train') # 获取名为tst的logger
25 | logger.addHandler(handler) # 为logger添加handler
26 | logger.setLevel(logging.DEBUG)
27 |
28 | for i in range(10):
29 | logger.info('first info message %d' % i)
30 | logger.debug('first debug message %d' % i)
31 |
--------------------------------------------------------------------------------
/utils/u01_logging/training.log:
--------------------------------------------------------------------------------
1 | 2017-09-10 22:21:16,411 - logging1.py:28 - train - first info message 0
2 | 2017-09-10 22:21:16,411 - logging1.py:29 - train - first debug message 0
3 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 1
4 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 1
5 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 2
6 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 2
7 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 3
8 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 3
9 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 4
10 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 4
11 | 2017-09-10 22:21:16,412 - logging1.py:28 - train - first info message 5
12 | 2017-09-10 22:21:16,412 - logging1.py:29 - train - first debug message 5
13 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 6
14 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 6
15 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 7
16 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 7
17 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 8
18 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 8
19 | 2017-09-10 22:21:16,413 - logging1.py:28 - train - first info message 9
20 | 2017-09-10 22:21:16,413 - logging1.py:29 - train - first debug message 9
21 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/README.md:
--------------------------------------------------------------------------------
1 | ### 使用 tfrecord 打包数据
2 | 这里主要针对的是 tf1.2 及以前的版本,tf1.3和tf1.4 提供了新的 data API。等这个月把手头的实验做完更新后再尝试新的接口。
3 |
4 | #### 数据维度相同
5 | 比如固定大小的矩阵,数组,图片等,比较简单,可以使用 tf.train.Example() 进行打包。参考:
6 | - tfrecord-1-numpy-writer.py
7 | - tfrecord-1-numpy-reader.py
8 | - tfrecord-1-numpy-reader_without_shuffle.py
9 |
10 | #### 数据维度不同(变长序列)
11 | 比如文本数据,每个序列的长度都是不固定的。可以使用 tf.train.SequenceExample() 进行打包。参考:
12 | - tfrecord-2-seqence-writer.py
13 | - tfrecord-2-seqence-reader.py
14 |
15 | [sequence_example_lib.py](https://github.com/tensorflow/magenta/blob/master/magenta/common/sequence_example_lib.py)是官方提供一个例子,但是在官方文档中并没有提到这个例子,我也是费了好大力气才找到这个例子。tf1.3增加了 Dataset API,但是在 tf1.2 中的文档中,却没有一点说明,巨坑。
16 |
17 | 在 tf.train.Example() 中,通过 tf.train.Features() 把数据写入 tfrecord 文件。这些数据必须是具有相同的长度的**数组**,如果我们需要写入的是矩阵的话,我一般都是先reshape成 1D 的数组再进行写入。在读取数据的时候可以使用 tf.train.shuffle_batch() 直接读取数据。在读取数据的时候一定要明确指定数组的维度。
18 |
19 | 在 tf.train.SequenceExample(),包括 context 和 feature_lists 两部分。context 和 tf.train.Example() 作用类似,用于保存维度固定的数据。feature_lists 用于保存任意长度的序列数据。具体的写法参照 Tutorial-tfrecord-seqence-writer.py
20 |
21 | 在数据读取的时候,不能简单的通过 tf.train.shuffle_batch() 进行 batch 读取,因为我们没法给定数据的维度。解决方法是使用 tf.train.batch() 来进行读取,而且 **dynamic_pad 参数必须为 True,自动把batch中的数据填充0至一样的长度。** (所以在定义词典的时候,一定要把 '' 的 id 对应为 0.)由于 batch() 函数不能进行 shuffle,所以我们只能借助 tf.RandomShuffleQueue() 函数维护一个队列来实现 shuffle。
22 |
23 |
24 | #### 图片数据
25 | - tfrecord-3-image-writer.py
26 | - tfrecord-3-image-reader.py
27 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/reader_without_shuffle.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {
7 | "collapsed": false,
8 | "scrolled": false
9 | },
10 | "outputs": [
11 | {
12 | "name": "stdout",
13 | "output_type": "stream",
14 | "text": [
15 | "Tensor(\"tfrecord_data/ParseSingleExample/Squeeze_X:0\", shape=(2,), dtype=float32)\n",
16 | "Tensor(\"tfrecord_data/ParseSingleExample/Squeeze_y:0\", shape=(), dtype=int64)\n",
17 | "** batch 0\n",
18 | "('_y_batch:', array([0, 1, 2, 3]))\n",
19 | "** batch 1\n",
20 | "('_y_batch:', array([4, 5, 6, 7]))\n",
21 | "** batch 2\n",
22 | "('_y_batch:', array([ 8, 9, 10, 11]))\n",
23 | "** batch 3\n",
24 | "('_y_batch:', array([12, 13, 15, 14]))\n",
25 | "** batch 4\n",
26 | "('_y_batch:', array([17, 16, 19, 18]))\n",
27 | "** batch 5\n",
28 | "('_y_batch:', array([20, 21, 22, 23]))\n",
29 | "** batch 6\n",
30 | "('_y_batch:', array([24, 25, 26, 27]))\n",
31 | "** batch 7\n",
32 | "('_y_batch:', array([29, 28, 30, 31]))\n",
33 | "** batch 8\n",
34 | "('_y_batch:', array([33, 32, 34, 35]))\n",
35 | "** batch 9\n",
36 | "('_y_batch:', array([36, 37, 38, 39]))\n",
37 | "** batch 10\n",
38 | "('_y_batch:', array([40, 42, 41, 44]))\n",
39 | "** batch 11\n",
40 | "('_y_batch:', array([43, 46, 45, 47]))\n",
41 | "** batch 12\n",
42 | "('_y_batch:', array([48, 0, 49, 2]))\n",
43 | "** batch 13\n",
44 | "('_y_batch:', array([1, 3, 4, 6]))\n",
45 | "** batch 14\n",
46 | "('_y_batch:', array([5, 8, 7, 9]))\n",
47 | "** batch 15\n",
48 | "('_y_batch:', array([10, 12, 11, 13]))\n",
49 | "** batch 16\n",
50 | "('_y_batch:', array([14, 16, 15, 17]))\n",
51 | "** batch 17\n",
52 | "('_y_batch:', array([18, 20, 19, 21]))\n",
53 | "** batch 18\n",
54 | "('_y_batch:', array([22, 23, 24, 26]))\n",
55 | "** batch 19\n",
56 | "('_y_batch:', array([25, 27, 28, 29]))\n",
57 | "** batch 20\n",
58 | "('_y_batch:', array([30, 31, 32, 33]))\n",
59 | "** batch 21\n",
60 | "('_y_batch:', array([35, 34, 37, 36]))\n",
61 | "** batch 22\n",
62 | "('_y_batch:', array([39, 38, 41, 40]))\n",
63 | "** batch 23\n",
64 | "('_y_batch:', array([43, 42, 44, 45]))\n",
65 | "** batch 24\n",
66 | "('_y_batch:', array([46, 47, 49, 48]))\n",
67 | "** batch 25\n",
68 | "('_y_batch:', array([1, 0, 2, 3]))\n",
69 | "** batch 26\n",
70 | "('_y_batch:', array([4, 5, 6, 7]))\n",
71 | "** batch 27\n",
72 | "('_y_batch:', array([ 8, 9, 10, 11]))\n",
73 | "** batch 28\n",
74 | "('_y_batch:', array([12, 13, 15, 14]))\n",
75 | "** batch 29\n",
76 | "('_y_batch:', array([17, 16, 19, 18]))\n",
77 | "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 14, 17, 16, 19, 18, 20, 21, 22, 23, 24, 25, 26, 27, 29, 28, 30, 31, 33, 32, 34, 35, 36, 37, 38, 39, 40, 42, 41, 44, 43, 46, 45, 47, 48, 0, 49, 2, 1, 3, 4, 6, 5, 8, 7, 9, 10, 12, 11, 13, 14, 16, 15, 17, 18, 20, 19, 21, 22, 23, 24, 26, 25, 27, 28, 29, 30, 31, 32, 33, 35, 34, 37, 36, 39, 38, 41, 40, 43, 42, 44, 45, 46, 47, 49, 48, 1, 0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 14, 17, 16, 19, 18]\n"
78 | ]
79 | }
80 | ],
81 | "source": [
82 | "# -*- coding:utf-8 -*- \n",
83 | "\n",
84 | "import tensorflow as tf\n",
85 | "\n",
86 | "'''read data.\n",
87 | "without shuffle, for validation or test data.\n",
88 | "'''\n",
89 | "\n",
90 | "# output file name string to a queue\n",
91 | "with tf.variable_scope('tfrecord_data'):\n",
92 | " filename_queue = tf.train.string_input_producer(['../data/test1.tfrecord', '../data/test2.tfrecord'], num_epochs=None,\n",
93 | " shuffle=False)\n",
94 | " # create a reader from file queue\n",
95 | " reader = tf.TFRecordReader()\n",
96 | " _, serialized_example = reader.read(filename_queue)\n",
97 | " # get feature from serialized example\n",
98 | " features = tf.parse_single_example(serialized_example,\n",
99 | " features={\n",
100 | " 'X': tf.FixedLenFeature([2], tf.float32),\n",
101 | " 'y': tf.FixedLenFeature([], tf.int64)}\n",
102 | " )\n",
103 | " X_out = features['X']\n",
104 | " y_out = features['y']\n",
105 | "\n",
106 | " print(X_out)\n",
107 | " print(y_out)\n",
108 | " X_batch, y_batch = tf.train.batch([X_out, y_out],\n",
109 | " batch_size=4,\n",
110 | " capacity=10,\n",
111 | " num_threads=2,\n",
112 | " allow_smaller_final_batch=True)\n",
113 | " new_ops = [v for v in tf.global_variables() if v.name.startswith(vs.name + '/')]\n",
114 | " \n",
115 | "sess = tf.Session()\n",
116 | "# init = tf.global_variables_initializer()\n",
117 | "init = tf.group(tf.global_variables_initializer(),\n",
118 | " tf.local_variables_initializer())\n",
119 | "sess.run(init)\n",
120 | "\n",
121 | "coord = tf.train.Coordinator()\n",
122 | "threads = tf.train.start_queue_runners(sess=sess, coord=coord)\n",
123 | "y_outputs = list()\n",
124 | "for i in xrange(30):\n",
125 | " try:\n",
126 | " _X_batch, _y_batch = sess.run([X_batch, y_batch])\n",
127 | " print('** batch %d' % i)\n",
128 | " print('_y_batch:', _y_batch)\n",
129 | " y_outputs.extend(_y_batch.tolist())\n",
130 | " except tf.errors.OutOfRangeError, e:\n",
131 | " print(e.message)\n",
132 | " break\n",
133 | "print(y_outputs)\n",
134 | "\n",
135 | "coord.request_stop()\n",
136 | "coord.join(threads)"
137 | ]
138 | },
139 | {
140 | "cell_type": "code",
141 | "execution_count": 7,
142 | "metadata": {
143 | "collapsed": true
144 | },
145 | "outputs": [],
146 | "source": [
147 | "tf.train.Coordinator?"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": 6,
153 | "metadata": {
154 | "collapsed": false
155 | },
156 | "outputs": [
157 | {
158 | "name": "stdout",
159 | "output_type": "stream",
160 | "text": [
161 | "FIFOQueue '_2_tfrecord_data/batch/fifo_queue' is closed and has insufficient elements (requested 4, current size 0)\n",
162 | "\t [[Node: tfrecord_data/batch = QueueDequeueUpToV2[component_types=[DT_FLOAT, DT_INT64], timeout_ms=-1, _device=\"/job:localhost/replica:0/task:0/cpu:0\"](tfrecord_data/batch/fifo_queue, tfrecord_data/batch/n)]]\n",
163 | "[]\n",
164 | "[]\n"
165 | ]
166 | }
167 | ],
168 | "source": [
169 | "y_outputs = list()\n",
170 | "sess.run(tf.variables_initializer(new_ops))\n",
171 | "coord1 = tf.train.Coordinator()\n",
172 | "threads = tf.train.start_queue_runners(sess=sess, coord=coord1)\n",
173 | "for i in xrange(30):\n",
174 | " try:\n",
175 | " _X_batch, _y_batch = sess.run([X_batch, y_batch])\n",
176 | " print('** batch %d' % i)\n",
177 | " print('_y_batch:', _y_batch)\n",
178 | " y_outputs.extend(_y_batch.tolist())\n",
179 | " except tf.errors.OutOfRangeError, e:\n",
180 | " print(e.message)\n",
181 | " break\n",
182 | "print(y_outputs)\n",
183 | "print(sorted(y_outputs))"
184 | ]
185 | },
186 | {
187 | "cell_type": "code",
188 | "execution_count": null,
189 | "metadata": {
190 | "collapsed": true
191 | },
192 | "outputs": [],
193 | "source": []
194 | }
195 | ],
196 | "metadata": {
197 | "anaconda-cloud": {},
198 | "kernelspec": {
199 | "display_name": "Python [conda root]",
200 | "language": "python",
201 | "name": "conda-root-py"
202 | },
203 | "language_info": {
204 | "codemirror_mode": {
205 | "name": "ipython",
206 | "version": 2
207 | },
208 | "file_extension": ".py",
209 | "mimetype": "text/x-python",
210 | "name": "python",
211 | "nbconvert_exporter": "python",
212 | "pygments_lexer": "ipython2",
213 | "version": "2.7.12"
214 | }
215 | },
216 | "nbformat": 4,
217 | "nbformat_minor": 1
218 | }
219 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/sequence_example_lib.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | # Copyright 2016 Google Inc. All Rights Reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | """Utility functions for working with tf.train.SequenceExamples.
17 | https://github.com/tensorflow/magenta/blob/master/magenta/common/sequence_example_lib.py
18 | """
19 |
20 | import math
21 | import tensorflow as tf
22 |
23 | QUEUE_CAPACITY = 500
24 | SHUFFLE_MIN_AFTER_DEQUEUE = QUEUE_CAPACITY // 5
25 |
26 |
27 | def make_sequence_example(inputs, labels):
28 | """Returns a SequenceExample for the given inputs and labels.
29 |
30 | Args:
31 | inputs: A list of input vectors. Each input vector is a list of floats.
32 | labels: A list of ints.
33 |
34 | Returns:
35 | A tf.train.SequenceExample containing inputs and labels.
36 | """
37 | input_features = [
38 | tf.train.Feature(float_list=tf.train.FloatList(value=input_))
39 | for input_ in inputs]
40 | label_features = [
41 | tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
42 | for label in labels]
43 | feature_list = {
44 | 'inputs': tf.train.FeatureList(feature=input_features),
45 | 'labels': tf.train.FeatureList(feature=label_features)
46 | }
47 | feature_lists = tf.train.FeatureLists(feature_list=feature_list)
48 | return tf.train.SequenceExample(feature_lists=feature_lists)
49 |
50 |
51 | def _shuffle_inputs(input_tensors, capacity, min_after_dequeue, num_threads):
52 | """Shuffles tensors in `input_tensors`, maintaining grouping."""
53 | shuffle_queue = tf.RandomShuffleQueue(
54 | capacity, min_after_dequeue, dtypes=[t.dtype for t in input_tensors])
55 | enqueue_op = shuffle_queue.enqueue(input_tensors)
56 | runner = tf.train.QueueRunner(shuffle_queue, [enqueue_op] * num_threads)
57 | tf.train.add_queue_runner(runner)
58 |
59 | output_tensors = shuffle_queue.dequeue()
60 |
61 | for i in range(len(input_tensors)):
62 | output_tensors[i].set_shape(input_tensors[i].shape)
63 |
64 | return output_tensors
65 |
66 |
67 | def get_padded_batch(file_list, batch_size, input_size,
68 | num_enqueuing_threads=4, shuffle=False):
69 | """Reads batches of SequenceExamples from TFRecords and pads them.
70 |
71 | Can deal with variable length SequenceExamples by padding each batch to the
72 | length of the longest sequence with zeros.
73 |
74 | Args:
75 | file_list: A list of paths to TFRecord files containing SequenceExamples.
76 | batch_size: The number of SequenceExamples to include in each batch.
77 | input_size: The size of each input vector. The returned batch of inputs
78 | will have a shape [batch_size, num_steps, input_size].
79 | num_enqueuing_threads: The number of threads to use for enqueuing
80 | SequenceExamples.
81 | shuffle: Whether to shuffle the batches.
82 |
83 | Returns:
84 | inputs: A tensor of shape [batch_size, num_steps, input_size] of floats32s.
85 | labels: A tensor of shape [batch_size, num_steps] of int64s.
86 | lengths: A tensor of shape [batch_size] of int32s. The lengths of each
87 | SequenceExample before padding.
88 | Raises:
89 | ValueError: If `shuffle` is True and `num_enqueuing_threads` is less than 2.
90 | """
91 | file_queue = tf.train.string_input_producer(file_list)
92 | reader = tf.TFRecordReader()
93 | _, serialized_example = reader.read(file_queue)
94 |
95 | sequence_features = {
96 | 'inputs': tf.FixedLenSequenceFeature(shape=[input_size],
97 | dtype=tf.float32),
98 | 'labels': tf.FixedLenSequenceFeature(shape=[],
99 | dtype=tf.int64)}
100 |
101 | _, sequence = tf.parse_single_sequence_example(
102 | serialized_example, sequence_features=sequence_features)
103 |
104 | length = tf.shape(sequence['inputs'])[0] # 序列长度
105 | input_tensors = [sequence['inputs'], sequence['labels'], length]
106 |
107 | if shuffle:
108 | if num_enqueuing_threads < 2:
109 | raise ValueError(
110 | '`num_enqueuing_threads` must be at least 2 when shuffling.')
111 | shuffle_threads = int(math.ceil(num_enqueuing_threads) / 2.)
112 |
113 | # Since there may be fewer records than SHUFFLE_MIN_AFTER_DEQUEUE, take the
114 | # minimum of that number and the number of records.
115 | min_after_dequeue = count_records(
116 | file_list, stop_at=SHUFFLE_MIN_AFTER_DEQUEUE)
117 | input_tensors = _shuffle_inputs(
118 | input_tensors, capacity=QUEUE_CAPACITY,
119 | min_after_dequeue=min_after_dequeue,
120 | num_threads=shuffle_threads)
121 |
122 | num_enqueuing_threads -= shuffle_threads
123 |
124 | tf.logging.info(input_tensors)
125 | return tf.train.batch(
126 | input_tensors,
127 | batch_size=batch_size,
128 | capacity=QUEUE_CAPACITY,
129 | num_threads=num_enqueuing_threads,
130 | dynamic_pad=True,
131 | allow_smaller_final_batch=False)
132 |
133 |
134 | def count_records(file_list, stop_at=None):
135 | """Counts number of records in files from `file_list` up to `stop_at`.
136 |
137 | Args:
138 | file_list: List of TFRecord files to count records in.
139 | stop_at: Optional number of records to stop counting at.
140 |
141 | Returns:
142 | Integer number of records in files from `file_list` up to `stop_at`.
143 | """
144 | num_records = 0
145 | for tfrecord_file in file_list:
146 | tf.logging.info('Counting records in %s.', tfrecord_file)
147 | for _ in tf.python_io.tf_record_iterator(tfrecord_file):
148 | num_records += 1
149 | if stop_at and num_records >= stop_at:
150 | tf.logging.info('Number of records is at least %d.', num_records)
151 | return num_records
152 | tf.logging.info('Total records: %d', num_records)
153 | return num_records
154 |
155 |
156 | def flatten_maybe_padded_sequences(maybe_padded_sequences, lengths=None):
157 | """Flattens the batch of sequences, removing padding (if applicable).
158 |
159 | Args:
160 | maybe_padded_sequences: A tensor of possibly padded sequences to flatten,
161 | sized `[N, M, ...]` where M = max(lengths).
162 | lengths: Optional length of each sequence, sized `[N]`. If None, assumes no
163 | padding.
164 |
165 | Returns:
166 | flatten_maybe_padded_sequences: The flattened sequence tensor, sized
167 | `[sum(lengths), ...]`.
168 | """
169 |
170 | def flatten_unpadded_sequences():
171 | # The sequences are equal length, so we should just flatten over the first
172 | # two dimensions.
173 | return tf.reshape(maybe_padded_sequences,
174 | [-1] + maybe_padded_sequences.shape.as_list()[2:])
175 |
176 | if lengths is None:
177 | return flatten_unpadded_sequences()
178 |
179 | def flatten_padded_sequences():
180 | indices = tf.where(tf.sequence_mask(lengths))
181 | return tf.gather_nd(maybe_padded_sequences, indices)
182 |
183 | return tf.cond(
184 | tf.equal(tf.reduce_min(lengths), tf.shape(maybe_padded_sequences)[1]),
185 | flatten_unpadded_sequences,
186 | flatten_padded_sequences)
187 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_1_numpy_reader.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import os
5 | import sys
6 | import time
7 |
8 | '''read data
9 | 从 tfrecord 文件中读取数据,对应数据的格式为固定shape的数据。
10 | '''
11 |
12 | # **1.把所有的 tfrecord 文件名列表写入队列中
13 | tfrecord_dir = 'tfrecord/numpy/'
14 | tfrecord_files = os.listdir(tfrecord_dir)
15 | tfrecord_files = list(map(lambda s: os.path.join(tfrecord_dir, s), tfrecord_files))
16 |
17 | filename_queue = tf.train.string_input_producer(tfrecord_files, num_epochs=None, shuffle=True)
18 |
19 | # **2.创建一个读取器
20 | reader = tf.TFRecordReader()
21 | _, serialized_example = reader.read(filename_queue)
22 | # **3.根据你写入的格式对应说明读取的格式
23 | features = tf.parse_single_example(serialized_example,
24 | features={
25 | 'X': tf.FixedLenFeature([784], tf.float32), # 注意如果不是标量,需要说明数组长度
26 | 'y': tf.FixedLenFeature([], tf.int64)} # 而标量就不用说明
27 | )
28 | X_out = features['X']
29 | y_out = features['y']
30 |
31 | print(X_out)
32 | print(y_out)
33 | # **4.通过 tf.train.shuffle_batch 或者 tf.train.batch 函数读取数据
34 | """
35 | 在shuffle_batch 函数中,有几个参数的作用如下:
36 | capacity: 队列的容量,容量越大的话,shuffle 得就更加均匀,但是占用内存也会更多
37 | num_threads: 读取进程数,进程越多,读取速度相对会快些,根据个人配置决定
38 | min_after_dequeue: 保证队列中最少的数据量。
39 | 假设我们设定了队列的容量C,在我们取走部分数据m以后,队列中只剩下了 (C-m) 个数据。然后队列会不断补充数据进来,
40 | 如果后勤供应(CPU性能,线程数量)补充速度慢的话,那么下一次取数据的时候,可能才补充了一点点,如果补充完后的数据个数少于
41 | min_after_dequeue 的话,不能取走数据,得继续等它补充超过 min_after_dequeue 个样本以后才让取走数据。
42 | 这样做保证了队列中混着足够多的数据,从而才能保证 shuffle 取值更加随机。
43 | 但是,min_after_dequeue 不能设置太大,否则补充时间很长,读取速度会很慢。
44 | """
45 | X_batch, y_batch = tf.train.shuffle_batch([X_out, y_out], batch_size=128,
46 | capacity=2000, min_after_dequeue=100, num_threads=4)
47 | sess = tf.Session()
48 | init = tf.global_variables_initializer()
49 | sess.run(init)
50 |
51 | # **5.启动队列进行数据读取
52 | # 下面的 coord 是个线程协调器,把启动队列的时候加上线程协调器。
53 | # 这样,在数据读取完毕以后,调用协调器把线程全部都关了。
54 | coord = tf.train.Coordinator()
55 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
56 | # y_outputs = list()
57 | # for i in range(5):
58 | # _X_batch, _y_batch = sess.run([X_batch, y_batch])
59 | # print('** batch %d' % i)
60 | # print('_X_batch:\n', _X_batch)
61 | # print('_y_batch:\n', _y_batch)
62 | # y_outputs.extend(_y_batch.tolist())
63 | # print('All y_outputs: \n', y_outputs)
64 |
65 | # 迭代取值
66 | time0 = time.time()
67 | for count in range(100): # 100batch 125 seconds
68 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
69 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
70 | sys.stdout.flush()
71 |
72 | # **6.最后记得把队列关掉
73 | coord.request_stop()
74 | coord.join(threads)
75 |
76 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_1_numpy_reader_without_shuffle.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import os
5 | import time
6 |
7 | '''read data.
8 | without shuffle, for validation or test data.
9 | 遍历一次数据集,针对验证集或者训练集,我们不需要使用 shuffle 的方式读取 batch,而是需要保证完整的遍历一次数据集。
10 | 和 tf.train.shuffle_batch 的读取方式类似,只是有几个地方需要注意:
11 | 1.把文件名字写入队列的时候,记得设 shuffle=False
12 | 2.同时设置 num_epochs 参数为 1. 这样当读取完一个epoch以后就会抛出 OutOfRangeError.
13 | 3.tf.train.batch() 函数的 allow_smaller_final_batch 参数一定要设置 True, 才不会漏掉最后不满 batch_size 的一小部分数据
14 | 4.在初始化的时候加上 tf.initialize_local_variables(), 否则会报错。
15 | 5.记得加上 try...except... 来捕获 OutOfRangeError
16 | '''
17 |
18 | # **1.把所有的 tfrecord 文件名列表写入队列中
19 | tfrecord_dir = 'tfrecord/numpy/'
20 | tfrecord_files = os.listdir(tfrecord_dir)
21 | tfrecord_files = list(map(lambda s: os.path.join(tfrecord_dir, s), tfrecord_files))
22 |
23 | filename_queue = tf.train.string_input_producer(tfrecord_files, num_epochs=None, shuffle=True)
24 |
25 | # create a reader from file queue
26 | reader = tf.TFRecordReader()
27 | _, serialized_example = reader.read(filename_queue)
28 | # get feature from serialized example
29 | features = tf.parse_single_example(serialized_example,
30 | features={
31 | 'X': tf.FixedLenFeature([784], tf.float32),
32 | 'y': tf.FixedLenFeature([], tf.int64)}
33 | )
34 | X_out = features['X']
35 | y_out = features['y']
36 |
37 | batch_size = 128
38 | X_batch, y_batch = tf.train.batch([X_out, y_out],
39 | batch_size=2,
40 | capacity=2000,
41 | num_threads=4,
42 | allow_smaller_final_batch=True) # 保证遍历完整个数据集
43 |
44 | # 如果设定了读取轮数(num_epochs)为1,所以就算使用 shuffle_batch, 也会保证只取一个epoch,不重复,也不会漏失
45 | # X_batch, y_batch = tf.train.shuffle_batch([X_out, y_out],
46 | # batch_size=6,
47 | # capacity=20,
48 | # min_after_dequeue=10,
49 | # num_threads=2,
50 | # allow_smaller_final_batch=True)
51 |
52 | sess = tf.Session()
53 | # 注意下面这个,如果设了 num_epoch,需要初始化 local_variables
54 | init = tf.group(tf.global_variables_initializer(),
55 | tf.initialize_local_variables())
56 | sess.run(init)
57 |
58 | coord = tf.train.Coordinator()
59 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
60 | y_outputs = list()
61 | for i in range(25):
62 | try:
63 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
64 | print('** batch %d' % i)
65 | print('_y_batch:\n', _y_batch)
66 | y_outputs.extend(_y_batch.tolist())
67 | except tf.errors.OutOfRangeError as e:
68 | print(e.message)
69 | break
70 | print('all y_outputs:', y_outputs)
71 | print('sorted y_outputs:', sorted(y_outputs))
72 |
73 | coord.request_stop()
74 | coord.join(threads)
75 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_1_numpy_writer.py:
--------------------------------------------------------------------------------
1 | """tfrecord 写入数据.
2 | 将固定shape的矩阵写入 tfrecord 文件。这种形式的数据写入 tfrecord 是最简单的。
3 | refer: http://blog.csdn.net/qq_16949707/article/details/53483493
4 | """
5 |
6 | from __future__ import print_function
7 | from __future__ import division
8 | from __future__ import absolute_import
9 |
10 | import tensorflow as tf
11 | import numpy as np
12 | from tqdm import tqdm
13 | import os
14 | import sys
15 | import time
16 |
17 | from tensorflow.examples.tutorials.mnist import input_data
18 |
19 | mnist = input_data.read_data_sets('../../data/MNIST_data', one_hot=False)
20 | X = mnist.train.images
21 | y = mnist.train.labels
22 |
23 | NUM_SHARDS = 64 # tfrecord 文件的数量,稍微大些对 shuffle 会好些
24 | n_sample = len(X)
25 | num_per_shard = n_sample // NUM_SHARDS # 每个 tfrecord 的样本数量
26 | # 在打包之前先手动打乱一次
27 | new_idxs = np.random.permutation(n_sample)
28 | X = X[new_idxs]
29 | y = y[new_idxs]
30 |
31 | tfrecord_dir = 'tfrecord/numpy/'
32 | if not os.path.exists(tfrecord_dir):
33 | os.makedirs(tfrecord_dir)
34 |
35 | time0 = time.time()
36 | for shard_id in range(NUM_SHARDS):
37 | output_filename = '%d-of-%d.tfrecord' % (shard_id, NUM_SHARDS)
38 | output_path = os.path.join(tfrecord_dir, output_filename)
39 | with tf.python_io.TFRecordWriter(output_path) as writer:
40 | start_ndx = shard_id * num_per_shard
41 | end_ndx = min((shard_id + 1) * num_per_shard, n_sample)
42 | for i in range(start_ndx, end_ndx):
43 | sys.stdout.write('\r>> Converting image %d/%d shard %d, %g s' % (
44 | i + 1, n_sample, shard_id, time.time() - time0))
45 | sys.stdout.flush()
46 |
47 | X_sample = X[i].tolist()
48 | y_sample = y[i]
49 | # **3.定义数据类型,按照这里固定的形式写,有float_list(好像只有32位), int64_list, bytes_list.
50 | example = tf.train.Example(
51 | features=tf.train.Features(
52 | feature={'X': tf.train.Feature(float_list=tf.train.FloatList(value=X_sample)),
53 | 'y': tf.train.Feature(int64_list=tf.train.Int64List(value=[y_sample]))}))
54 | # **4.序列化数据并写入文件中
55 | serialized = example.SerializeToString()
56 | writer.write(serialized)
57 |
58 | print('Finished writing training data to tfrecord files.')
59 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_2_seqence_reader.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import math
5 |
6 | QUEUE_CAPACITY = 100
7 | SHUFFLE_MIN_AFTER_DEQUEUE = QUEUE_CAPACITY // 5
8 |
9 | """
10 | 读取变长序列数据。
11 | 和固定shape的数据读取方式不一样,在读取变长序列中,我们无法使用 tf.train.shuffle_batch() 函数,只能使用
12 | tf.train.batch() 函数进行读取,而且,在读取的时候,必须设置 dynamic_pad 参数为 True, 把所有的序列 padding
13 | 到固定长度(该batch中最长的序列长度),padding部分为 0。
14 |
15 | 此外,在训练的时候为了实现 shuffle 功能,我们可以使用 RandomShuffleQueue 队列来完成。详见下面的 _shuffle_inputs 函数。
16 | """
17 |
18 |
19 | def _shuffle_inputs(input_tensors, capacity, min_after_dequeue, num_threads):
20 | """Shuffles tensors in `input_tensors`, maintaining grouping."""
21 | shuffle_queue = tf.RandomShuffleQueue(
22 | capacity, min_after_dequeue, dtypes=[t.dtype for t in input_tensors])
23 | enqueue_op = shuffle_queue.enqueue(input_tensors)
24 | runner = tf.train.QueueRunner(shuffle_queue, [enqueue_op] * num_threads)
25 | tf.train.add_queue_runner(runner)
26 |
27 | output_tensors = shuffle_queue.dequeue()
28 |
29 | for i in range(len(input_tensors)):
30 | output_tensors[i].set_shape(input_tensors[i].shape)
31 |
32 | return output_tensors
33 |
34 |
35 | def get_padded_batch(file_list, batch_size, num_enqueuing_threads=4, shuffle=False):
36 | """Reads batches of SequenceExamples from TFRecords and pads them.
37 |
38 | Can deal with variable length SequenceExamples by padding each batch to the
39 | length of the longest sequence with zeros.
40 |
41 | Args:
42 | file_list: A list of paths to TFRecord files containing SequenceExamples.
43 | batch_size: The number of SequenceExamples to include in each batch.
44 | num_enqueuing_threads: The number of threads to use for enqueuing
45 | SequenceExamples.
46 | shuffle: Whether to shuffle the batches.
47 |
48 | Returns:
49 | labels: A tensor of shape [batch_size] of int64s.
50 | frames: A tensor of shape [batch_size, num_steps] of floats32s. note that
51 | num_steps is the max time_step of all the tensors.
52 | Raises:
53 | ValueError: If `shuffle` is True and `num_enqueuing_threads` is less than 2.
54 | """
55 | file_queue = tf.train.string_input_producer(file_list)
56 | reader = tf.TFRecordReader()
57 | _, serialized_example = reader.read(file_queue)
58 |
59 | context_features = {
60 | "label": tf.FixedLenFeature([], dtype=tf.int64)
61 | }
62 | sequence_features = {
63 | "frame": tf.FixedLenSequenceFeature([], dtype=tf.int64)
64 | }
65 |
66 | context_parsed, sequence_parsed = tf.parse_single_sequence_example(
67 | serialized=serialized_example,
68 | context_features=context_features,
69 | sequence_features=sequence_features
70 | )
71 |
72 | labels = context_parsed['label']
73 | frames = sequence_parsed['frame']
74 | input_tensors = [labels, frames]
75 |
76 | if shuffle:
77 | if num_enqueuing_threads < 2:
78 | raise ValueError(
79 | '`num_enqueuing_threads` must be at least 2 when shuffling.')
80 | shuffle_threads = int(math.ceil(num_enqueuing_threads) / 2.)
81 |
82 | # Since there may be fewer records than SHUFFLE_MIN_AFTER_DEQUEUE, take the
83 | # minimum of that number and the number of records.
84 | min_after_dequeue = count_records(
85 | file_list, stop_at=SHUFFLE_MIN_AFTER_DEQUEUE)
86 | input_tensors = _shuffle_inputs(
87 | input_tensors, capacity=QUEUE_CAPACITY,
88 | min_after_dequeue=min_after_dequeue,
89 | num_threads=shuffle_threads)
90 |
91 | num_enqueuing_threads -= shuffle_threads
92 |
93 | tf.logging.info(input_tensors)
94 | return tf.train.batch(
95 | input_tensors,
96 | batch_size=batch_size,
97 | capacity=QUEUE_CAPACITY,
98 | num_threads=num_enqueuing_threads,
99 | dynamic_pad=True,
100 | allow_smaller_final_batch=False)
101 |
102 |
103 | def count_records(file_list, stop_at=None):
104 | """Counts number of records in files from `file_list` up to `stop_at`.
105 |
106 | Args:
107 | file_list: List of TFRecord files to count records in.
108 | stop_at: Optional number of records to stop counting at.
109 |
110 | Returns:
111 | Integer number of records in files from `file_list` up to `stop_at`.
112 | """
113 | num_records = 0
114 | for tfrecord_file in file_list:
115 | tf.logging.info('Counting records in %s.', tfrecord_file)
116 | for _ in tf.python_io.tf_record_iterator(tfrecord_file):
117 | num_records += 1
118 | if stop_at and num_records >= stop_at:
119 | tf.logging.info('Number of records is at least %d.', num_records)
120 | return num_records
121 | tf.logging.info('Total records: %d', num_records)
122 | return num_records
123 |
124 |
125 | if __name__ == '__main__':
126 | tfrecord_file_names = ['../../data/seq_test1.tfrecord', '../../data/seq_test2.tfrecord']
127 | label_batch, frame_batch = get_padded_batch(tfrecord_file_names, 10, shuffle=True)
128 | config = tf.ConfigProto()
129 | config.gpu_options.allow_growth = True
130 | sess = tf.Session(config=config)
131 | tf.train.start_queue_runners(sess=sess)
132 | for i in xrange(3):
133 | _frames_batch, _label_batch = sess.run([frame_batch, label_batch])
134 | print('** batch %d' % i)
135 | print(_label_batch)
136 | print(_frames_batch)
137 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_2_seqence_writer.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 | from tqdm import tqdm
6 |
7 | '''tfrecord 写入序列数据,每个样本的长度不固定。
8 | 和固定 shape 的数据处理方式类似,前者使用 tf.train.Example() 方式,而对于变长序列数据,需要使用
9 | tf.train.SequenceExample()。 在 tf.train.SequenceExample() 中,又包括了两部分:
10 | context 来放置非序列化部分;
11 | feature_lists 放置变长序列。
12 |
13 | refer:
14 | https://github.com/tensorflow/magenta/blob/master/magenta/common/sequence_example_lib.py
15 | https://github.com/dennybritz/tf-rnn
16 | http://leix.me/2017/01/09/tensorflow-practical-guides/
17 | https://github.com/siavash9000/im2txt_demo/blob/master/im2txt/im2txt/ops/inputs.py
18 | '''
19 |
20 | # **1.创建文件
21 | writer1 = tf.python_io.TFRecordWriter('../../data/seq_test1.tfrecord')
22 | writer2 = tf.python_io.TFRecordWriter('../../data/seq_test2.tfrecord')
23 |
24 | # 非序列数据
25 | labels = [1, 2, 3, 4, 5, 1, 2, 3, 4]
26 | # 长度不固定的序列
27 | frames = [[1], [2, 2], [3, 3, 3], [4, 4, 4, 4], [5, 5, 5, 5, 5],
28 | [1], [2, 2], [3, 3, 3], [4, 4, 4, 4]]
29 |
30 |
31 | writer = writer1
32 | for i in tqdm(xrange(len(labels))): # **2.对于每个样本
33 | if i == len(labels) / 2:
34 | writer = writer2
35 | print('\nThere are %d sample writen into writer1' % i)
36 | label = labels[i]
37 | frame = frames[i]
38 | # 非序列化
39 | label_feature = tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
40 | # 序列化
41 | frame_feature = [
42 | tf.train.Feature(int64_list=tf.train.Int64List(value=[frame_])) for frame_ in frame
43 | ]
44 |
45 | seq_example = tf.train.SequenceExample(
46 | # context 来放置非序列化部分
47 | context=tf.train.Features(feature={
48 | "label": label_feature
49 | }),
50 | # feature_lists 放置变长序列
51 | feature_lists=tf.train.FeatureLists(feature_list={
52 | "frame": tf.train.FeatureList(feature=frame_feature),
53 | })
54 | )
55 |
56 | serialized = seq_example.SerializeToString()
57 | writer.write(serialized) # **4.写入文件中
58 |
59 | print('Finished.')
60 | writer1.close()
61 | writer2.close()
62 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_3_image_reader.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 |
5 | import os
6 | import time
7 | import sys
8 |
9 | '''read data
10 | 从 tfrecord 文件中读取数据,对应数据的格式为 png 格式。
11 | '''
12 |
13 | # **1.把所有的 tfrecord 文件名列表写入队列中
14 | TFRECORD_DIR = 'tfrecord/sketchy_image/'
15 | tfrecord_files = os.listdir(TFRECORD_DIR)
16 | tfrecord_files = list(map(lambda s: os.path.join(TFRECORD_DIR, s), tfrecord_files))
17 |
18 | filename_queue = tf.train.string_input_producer(tfrecord_files, num_epochs=None, shuffle=True)
19 | # **2.创建一个读取器
20 | reader = tf.TFRecordReader()
21 | _, serialized_example = reader.read(filename_queue)
22 | # **3.根据你写入的格式对应说明读取的格式
23 | features = tf.parse_single_example(serialized_example,
24 | features={
25 | 'image': tf.FixedLenFeature([], tf.string),
26 | 'label': tf.FixedLenFeature([], tf.int64)
27 | }
28 | )
29 | img = features['image']
30 | # 这里需要对图片进行解码
31 | img = tf.image.decode_png(img, channels=3) # 这里,也可以解码为 1 通道
32 | img = tf.image.resize_images(images=img, size=(224, 224))
33 | # img = tf.image.resize_image_with_crop_or_pad(img, 224, 224)
34 | # img = tf.reshape(img, [256, 256, 3]) # 256*256*3
35 |
36 | label = features['label']
37 |
38 | print('img is', img)
39 | print('label is', label)
40 | # **4.通过 tf.train.shuffle_batch 或者 tf.train.batch 函数读取数据
41 | """
42 | 这里,你会发现每次取出来的数据都是一个类别的,除非你把 capacity 和 min_after_dequeue 设得很大,如
43 | X_batch, y_batch = tf.train.shuffle_batch([img, label], batch_size=100,
44 | capacity=20000, min_after_dequeue=10000, num_threads=3)
45 | 这是因为在打包的时候都是一个类别一个类别的顺序打包的,所以每次填数据都是按照那个顺序填充进来。
46 | 只有当我们把队列容量舍得非常大,这样在队列中才会混杂各个类别的数据。但是这样非常不好,因为这样的话,
47 | 读取速度就会非常慢。所以解决方法是:
48 | 1.在写入数据的时候先进行数据 shuffle。
49 | 2.多存几个 tfrecord 文件,比如 64 个。
50 | """
51 |
52 | X_batch, y_batch = tf.train.shuffle_batch([img, label], batch_size=128,
53 | capacity=5000, min_after_dequeue=100, num_threads=2)
54 |
55 | config = tf.ConfigProto()
56 | config.gpu_options.allow_growth = True
57 | sess = tf.Session(config=config)
58 | init = tf.global_variables_initializer()
59 | sess.run(init)
60 |
61 | # **5.启动队列进行数据读取
62 | # 下面的 coord 是个线程协调器,把启动队列的时候加上线程协调器。
63 | # 这样,在数据读取完毕以后,调用协调器把线程全部都关了。
64 | coord = tf.train.Coordinator()
65 | threads = tf.train.start_queue_runners(sess=sess, coord=coord)
66 | # y_outputs = list()
67 | # for i in range(5):
68 | # _X_batch, _y_batch = sess.run([X_batch, y_batch])
69 | # print('** batch %d' % i)
70 | # print('_X_batch.shape:', _X_batch.shape)
71 | # print('_y_batch:', _y_batch)
72 | # y_outputs.extend(_y_batch.tolist())
73 | # print(y_outputs)
74 |
75 | time0 = time.time()
76 | # 只解析图片 200batch 9.6 seconds
77 | # resize_images 200batch 22.8 seconds
78 | # resize_image_with_crop_or_pad 200batch 22.4 seconds
79 | for count in range(500):
80 | _X_batch, _y_batch = sess.run([X_batch, y_batch])
81 | sys.stdout.write("\rloop {}, pass {:.2f}s".format(count, time.time() - time0))
82 | sys.stdout.flush()
83 |
84 | # **6.最后记得把队列关掉
85 | coord.request_stop()
86 | coord.join(threads)
87 |
--------------------------------------------------------------------------------
/utils/u02_tfrecord/tfrecord_3_image_writer.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 | from tqdm import tqdm
6 | import sys
7 | import os
8 | import time
9 |
10 | '''tfrecord 写入数据.
11 | 将图片数据写入 tfrecord 文件。以 png格式数据集为例。
12 |
13 | 现在网上关于打包图片的例子非常多,实现方式各式各样,效率也相差非常多。
14 | 选择合适的方式能够有效地节省时间和硬盘空间。
15 | 有几点需要注意:
16 | 1.打包 tfrecord 的时候,千万不要使用 Image.open() 或者 matplotlib.image.imread() 等方式读取。
17 | 1张小于10kb的png图片,前者(Image.open) 打开后,生成的对象100+kb, 后者直接生成 numpy 数组,大概是原图片的几百倍大小。
18 | 所以应该直接使用 tf.gfile.FastGFile() 方式读入图片。
19 | 2.从 tfrecord 中取数据的时候,再用 tf.image.decode_png() 对图片进行解码。
20 | 3.不要随便使用 tf.image.resize_image_with_crop_or_pad 等函数,可以直接使用 tf.reshape()。前者速度极慢。
21 | '''
22 |
23 | # png 文件路径
24 | IMG_DIR = '../../data/sketchy_000000000000/'
25 | TFRECORD_DIR = 'tfrecord/sketchy_image/'
26 | NUM_SHARDS = 64 # tfrecord 文件的数量,稍微大些对 shuffle 会好些
27 |
28 |
29 | def get_file_path(data_path='../../data/sketchy_000000000000/'):
30 | """解析文件夹,获取每个文件的路径和标签。"""
31 | img_paths = list()
32 | labels = list()
33 | # 必须保证测试集 和 训练集中类别数相同,如果不同的话应该使用 dict_class2id 来保证类别对应正确。
34 | class_dirs = sorted(os.listdir(data_path))
35 | dict_class2id = dict()
36 | for i in range(len(class_dirs)):
37 | label = i
38 | class_dir = class_dirs[i]
39 | dict_class2id[class_dir] = label
40 | class_path = os.path.join(data_path, class_dir) # 每类的路径
41 | file_names = sorted(os.listdir(class_path))
42 | for file_name in file_names:
43 | file_path = os.path.join(class_path, file_name)
44 | img_paths.append(file_path)
45 | labels.append(label)
46 | img_paths = np.asarray(img_paths)
47 | labels = np.asarray(labels)
48 | return img_paths, labels
49 |
50 |
51 | def bytes_feature(values):
52 | return tf.train.Feature(bytes_list=tf.train.BytesList(value=[values]))
53 |
54 |
55 | def int64_feature(values):
56 | return tf.train.Feature(int64_list=tf.train.Int64List(value=[values]))
57 |
58 |
59 | def convert_tfrecord_dataset(tfrecord_dir, n_shards, img_paths, labels, shuffle=True):
60 | """ convert samples to tfrecord dataset.
61 | Args:
62 | dataset_dir: 数据集的路径。
63 | tfrecord_dir: 保存 tfrecord 文件的路径。
64 | n_shards: tfrecord 文件个数
65 | img_paths: 图片的名字。
66 | labels:图片的标签。
67 | """
68 | if not os.path.exists(tfrecord_dir):
69 | os.makedirs(tfrecord_dir)
70 | n_sample = len(img_paths)
71 | num_per_shard = n_sample // n_shards # 每个 tfrecord 的样本数量
72 |
73 | # 在打包之前先手动打乱一次
74 | if shuffle:
75 | new_idxs = np.random.permutation(n_sample)
76 | img_paths = img_paths[new_idxs]
77 | labels = labels[new_idxs]
78 |
79 | time0 = time.time()
80 | for shard_id in range(n_shards):
81 | output_filename = '%d-of-%d.tfrecord' % (shard_id, n_shards)
82 | output_path = os.path.join(tfrecord_dir, output_filename)
83 | with tf.python_io.TFRecordWriter(output_path) as writer:
84 | start_ndx = shard_id * num_per_shard
85 | end_ndx = min((shard_id + 1) * num_per_shard, n_sample)
86 | for i in range(start_ndx, end_ndx):
87 | sys.stdout.write('\r>> Converting image %d/%d shard %d, %g s' % (
88 | i + 1, n_sample, shard_id, time.time() - time0))
89 | sys.stdout.flush()
90 | png_path = img_paths[i]
91 | label = labels[i]
92 | img = tf.gfile.FastGFile(png_path, 'rb').read() # 读入图片
93 | example = tf.train.Example(
94 | features=tf.train.Features(
95 | feature={
96 | 'image': bytes_feature(img),
97 | 'label': int64_feature(label)
98 | }))
99 | serialized = example.SerializeToString()
100 | writer.write(serialized)
101 | print('\nFinished writing data to tfrecord files.')
102 |
103 |
104 | if __name__ == '__main__':
105 | img_paths, labels = get_file_path()
106 | convert_tfrecord_dataset(TFRECORD_DIR, NUM_SHARDS, img_paths, labels, shuffle=True)
107 |
--------------------------------------------------------------------------------
/utils/u03_flags.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 |
3 | import tensorflow as tf
4 |
5 | """tf.app.flags 用来实现对命令行参数进行解析。
6 | 一般先使用 tf.app.flags.DEFINE_ ... 来定义参数;
7 | 然后通过 tf.app.flags.FLAGS 对象取各个参数。
8 | """
9 |
10 | flags = tf.flags
11 | logging = tf.logging
12 |
13 | FLAGS = flags.FLAGS
14 | flags.DEFINE_string('name', 'huang', 'str_name')
15 | flags.DEFINE_integer('age', 99, 'people age')
16 | flags.DEFINE_float('weight', 51.1, 'people weight')
17 |
18 | def main(_):
19 | print 'FLAGS.name=', FLAGS.name
20 | print 'FLAGS.age=', FLAGS.age
21 | print 'FLAGS.weight=', FLAGS.weight
22 |
23 | if __name__ == '__main__':
24 | tf.app.run() # 会自动运行 main() 函数
25 |
--------------------------------------------------------------------------------