 40 |
41 | ### 对象创建的方式
42 |
43 |
44 |
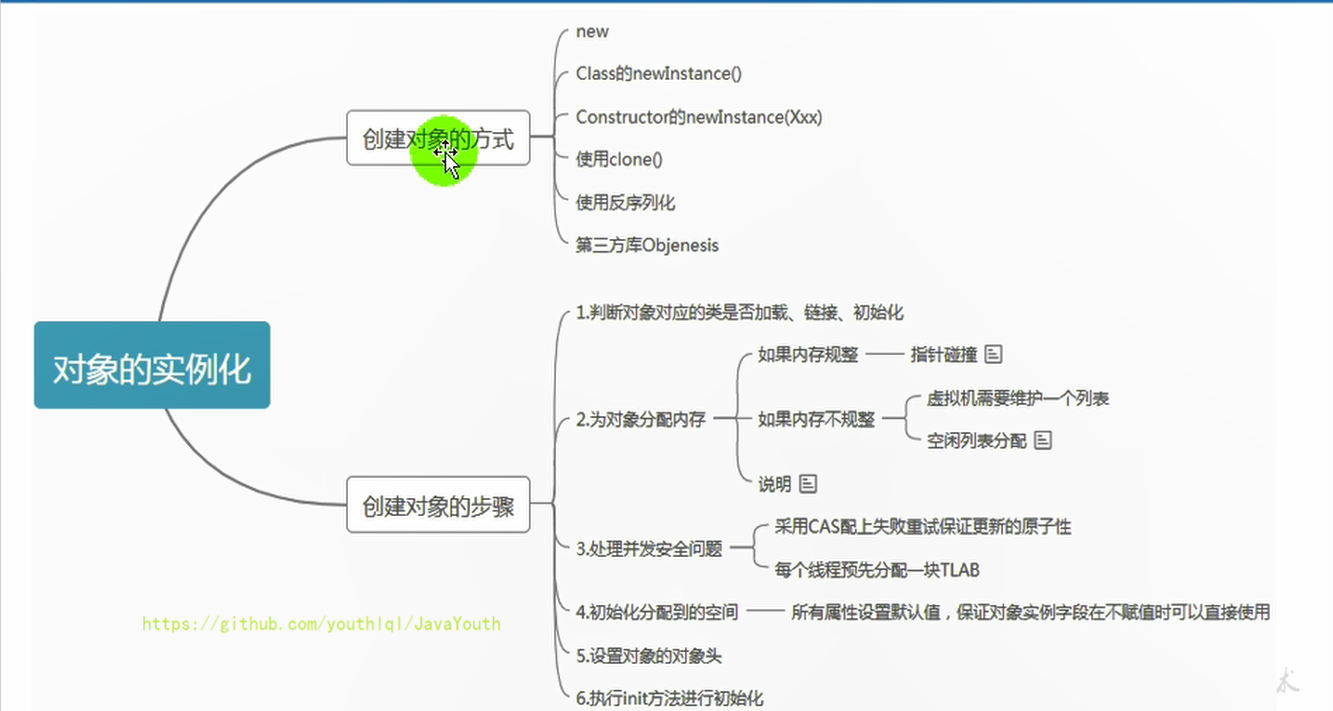
45 | 1. new:最常见的方式、单例类中调用getInstance的静态类方法,XXXFactory的静态方法
46 | 2. Class的newInstance方法:在JDK9里面被标记为过时的方法,因为只能调用空参构造器,并且权限必须为 public
47 | 3. Constructor的newInstance(Xxxx):反射的方式,可以调用空参的,或者带参的构造器
48 | 4. 使用clone():不调用任何的构造器,要求当前的类需要实现Cloneable接口中的clone方法
49 | 5. 使用序列化:从文件中,从网络中获取一个对象的二进制流,序列化一般用于Socket的网络传输
50 | 6. 第三方库 Objenesis
51 |
52 |
53 |
54 | ### 对象创建的步骤
55 |
56 | > **从字节码看待对象的创建过程**
57 |
58 | ```java
59 | public class ObjectTest {
60 | public static void main(String[] args) {
61 | Object obj = new Object();
62 | }
63 | }
64 | ```
65 |
66 |
67 |
68 | ```
69 | public static void main(java.lang.String[]);
70 | descriptor: ([Ljava/lang/String;)V
71 | flags: ACC_PUBLIC, ACC_STATIC
72 | Code:
73 | stack=2, locals=2, args_size=1
74 | 0: new #2 // class java/lang/Object
75 | 3: dup
76 | 4: invokespecial #1 // Method java/lang/Object."
40 |
41 | ### 对象创建的方式
42 |
43 |
44 |
45 | 1. new:最常见的方式、单例类中调用getInstance的静态类方法,XXXFactory的静态方法
46 | 2. Class的newInstance方法:在JDK9里面被标记为过时的方法,因为只能调用空参构造器,并且权限必须为 public
47 | 3. Constructor的newInstance(Xxxx):反射的方式,可以调用空参的,或者带参的构造器
48 | 4. 使用clone():不调用任何的构造器,要求当前的类需要实现Cloneable接口中的clone方法
49 | 5. 使用序列化:从文件中,从网络中获取一个对象的二进制流,序列化一般用于Socket的网络传输
50 | 6. 第三方库 Objenesis
51 |
52 |
53 |
54 | ### 对象创建的步骤
55 |
56 | > **从字节码看待对象的创建过程**
57 |
58 | ```java
59 | public class ObjectTest {
60 | public static void main(String[] args) {
61 | Object obj = new Object();
62 | }
63 | }
64 | ```
65 |
66 |
67 |
68 | ```
69 | public static void main(java.lang.String[]);
70 | descriptor: ([Ljava/lang/String;)V
71 | flags: ACC_PUBLIC, ACC_STATIC
72 | Code:
73 | stack=2, locals=2, args_size=1
74 | 0: new #2 // class java/lang/Object
75 | 3: dup
76 | 4: invokespecial #1 // Method java/lang/Object."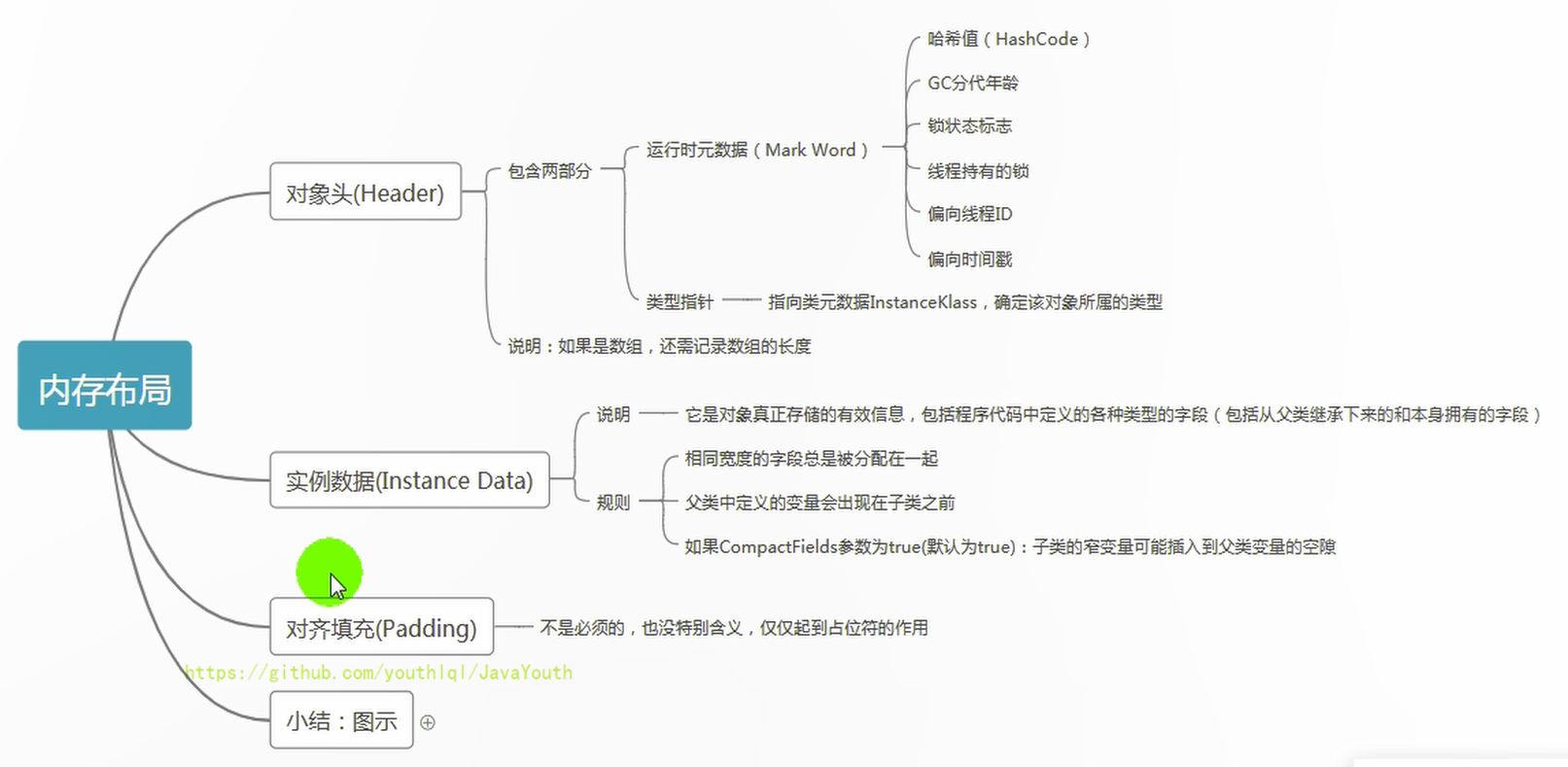 215 |
216 |
217 |
218 | > **内存布局总结**
219 |
220 | ```java
221 | public class Customer{
222 | int id = 1001;
223 | String name;
224 | Account acct;
225 |
226 | {
227 | name = "匿名客户";
228 | }
229 | public Customer(){
230 | acct = new Account();
231 | }
232 | public static void main(String[] args) {
233 | Customer cust = new Customer();
234 | }
235 | }
236 | class Account{
237 |
238 | }
239 | ```
240 |
241 |
242 |
243 | 图解内存布局
244 |
245 |
215 |
216 |
217 |
218 | > **内存布局总结**
219 |
220 | ```java
221 | public class Customer{
222 | int id = 1001;
223 | String name;
224 | Account acct;
225 |
226 | {
227 | name = "匿名客户";
228 | }
229 | public Customer(){
230 | acct = new Account();
231 | }
232 | public static void main(String[] args) {
233 | Customer cust = new Customer();
234 | }
235 | }
236 | class Account{
237 |
238 | }
239 | ```
240 |
241 |
242 |
243 | 图解内存布局
244 |
245 |  246 |
247 |
248 |
249 | 对象的访问定位
250 | ---------
251 |
252 | **JVM是如何通过栈帧中的对象引用访问到其内部的对象实例呢?**
253 |
254 |
246 |
247 |
248 |
249 | 对象的访问定位
250 | ---------
251 |
252 | **JVM是如何通过栈帧中的对象引用访问到其内部的对象实例呢?**
253 |
254 | 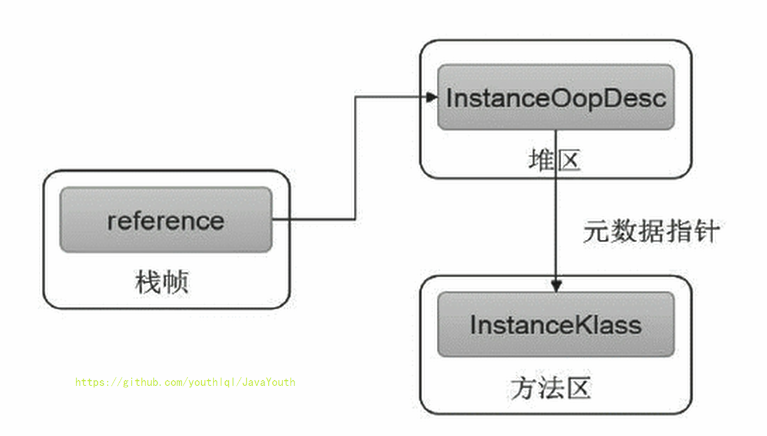 255 |
256 | 定位,通过栈上reference访问
257 |
258 | **对象的两种访问方式:句柄访问和直接指针**
259 |
260 | **1、句柄访问**
261 |
262 | 1. 缺点:在堆空间中开辟了一块空间作为句柄池,句柄池本身也会占用空间;通过两次指针访问才能访问到堆中的对象,效率低
263 | 2. 优点:reference中存储稳定句柄地址,对象被移动(垃圾收集时移动对象很普遍)时只会改变句柄中实例数据指针即可,reference本身不需要被修改
264 |
265 |
255 |
256 | 定位,通过栈上reference访问
257 |
258 | **对象的两种访问方式:句柄访问和直接指针**
259 |
260 | **1、句柄访问**
261 |
262 | 1. 缺点:在堆空间中开辟了一块空间作为句柄池,句柄池本身也会占用空间;通过两次指针访问才能访问到堆中的对象,效率低
263 | 2. 优点:reference中存储稳定句柄地址,对象被移动(垃圾收集时移动对象很普遍)时只会改变句柄中实例数据指针即可,reference本身不需要被修改
264 |
265 |  266 |
267 |
268 |
269 | **2、直接指针(HotSpot采用)**
270 |
271 | 1. 优点:直接指针是局部变量表中的引用,直接指向堆中的实例,在对象实例中有类型指针,指向的是方法区中的对象类型数据
272 | 2. 缺点:对象被移动(垃圾收集时移动对象很普遍)时需要修改 reference 的值
273 |
274 |
266 |
267 |
268 |
269 | **2、直接指针(HotSpot采用)**
270 |
271 | 1. 优点:直接指针是局部变量表中的引用,直接指向堆中的实例,在对象实例中有类型指针,指向的是方法区中的对象类型数据
272 | 2. 缺点:对象被移动(垃圾收集时移动对象很普遍)时需要修改 reference 的值
273 |
274 |  --------------------------------------------------------------------------------
/docs/JVM/JVM系列-第3章-运行时数据区.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: JVM系列-第3章-运行时数据区
3 | tags:
4 | - JVM
5 | - 虚拟机
6 | categories:
7 | - JVM
8 | - 1.内存与垃圾回收篇
9 | keywords: JVM,虚拟机。
10 | description: JVM系列-第3章-运行时数据区。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/jvm.png'
12 | abbrlink: a7ad3cab
13 | date: 2020-11-09 15:38:42
14 | ---
15 |
16 |
17 |
18 |
19 |
20 | > 此章把运行时数据区里比较少的地方讲一下。虚拟机栈,堆,方法区这些地方后续再讲。
21 |
22 | 运行时数据区概述及线程
23 | =================
24 |
25 | 前言
26 | ----
27 |
28 | 本节主要讲的是运行时数据区,也就是下图这部分,它是在类加载完成后的阶段
29 |
30 |
--------------------------------------------------------------------------------
/docs/JVM/JVM系列-第3章-运行时数据区.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: JVM系列-第3章-运行时数据区
3 | tags:
4 | - JVM
5 | - 虚拟机
6 | categories:
7 | - JVM
8 | - 1.内存与垃圾回收篇
9 | keywords: JVM,虚拟机。
10 | description: JVM系列-第3章-运行时数据区。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/jvm.png'
12 | abbrlink: a7ad3cab
13 | date: 2020-11-09 15:38:42
14 | ---
15 |
16 |
17 |
18 |
19 |
20 | > 此章把运行时数据区里比较少的地方讲一下。虚拟机栈,堆,方法区这些地方后续再讲。
21 |
22 | 运行时数据区概述及线程
23 | =================
24 |
25 | 前言
26 | ----
27 |
28 | 本节主要讲的是运行时数据区,也就是下图这部分,它是在类加载完成后的阶段
29 |
30 | 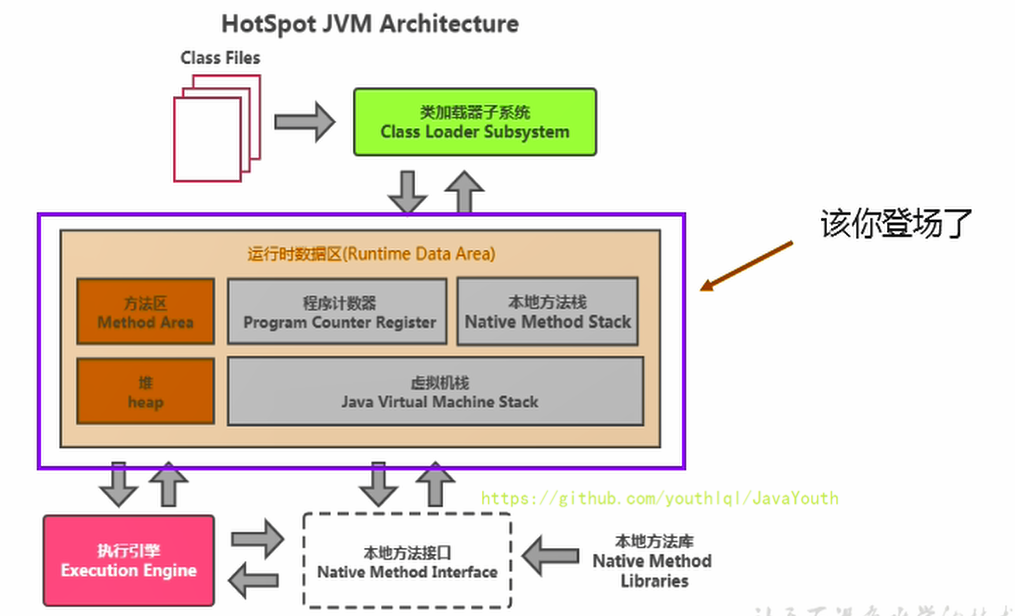 31 |
32 | 当我们通过前面的:类的加载 --> 验证 --> 准备 --> 解析 --\> 初始化,这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时执行引擎将会使用到我们运行时数据区
33 |
34 |
31 |
32 | 当我们通过前面的:类的加载 --> 验证 --> 准备 --> 解析 --\> 初始化,这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时执行引擎将会使用到我们运行时数据区
33 |
34 |  35 |
36 | 类比一下也就是大厨做饭,我们把大厨后面的东西(切好的菜,刀,调料),比作是运行时数据区。而厨师可以类比于执行引擎,将通过准备的东西进行制作成精美的菜品。
37 |
38 |
35 |
36 | 类比一下也就是大厨做饭,我们把大厨后面的东西(切好的菜,刀,调料),比作是运行时数据区。而厨师可以类比于执行引擎,将通过准备的东西进行制作成精美的菜品。
37 |
38 |  39 |
40 |
41 |
42 | 运行时数据区结构
43 | ----------
44 |
45 | ### 运行时数据区与内存
46 |
47 | 1. 内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了Java在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。**不同的JVM对于内存的划分方式和管理机制存在着部分差异**。结合JVM虚拟机规范,来探讨一下经典的JVM内存布局。
48 |
49 | 2. 我们通过磁盘或者网络IO得到的数据,都需要先加载到内存中,然后CPU从内存中获取数据进行读取,也就是说内存充当了CPU和磁盘之间的桥梁
50 |
51 | > 下图来自阿里巴巴手册JDK8
52 |
53 |
39 |
40 |
41 |
42 | 运行时数据区结构
43 | ----------
44 |
45 | ### 运行时数据区与内存
46 |
47 | 1. 内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了Java在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。**不同的JVM对于内存的划分方式和管理机制存在着部分差异**。结合JVM虚拟机规范,来探讨一下经典的JVM内存布局。
48 |
49 | 2. 我们通过磁盘或者网络IO得到的数据,都需要先加载到内存中,然后CPU从内存中获取数据进行读取,也就是说内存充当了CPU和磁盘之间的桥梁
50 |
51 | > 下图来自阿里巴巴手册JDK8
52 |
53 | 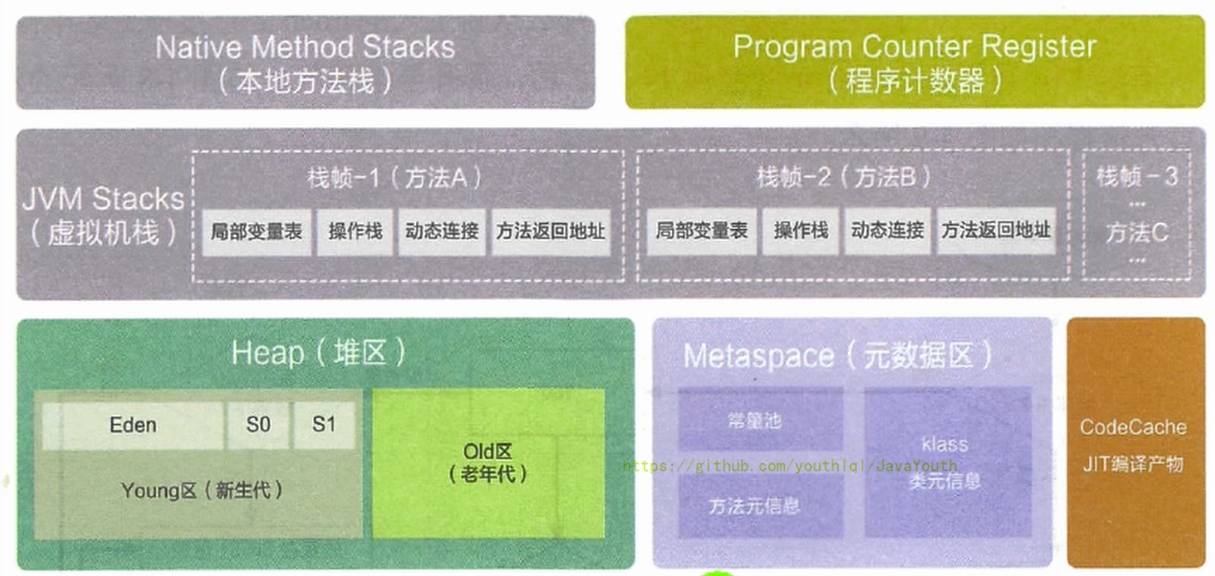 54 |
55 |
56 |
57 | ### 线程的内存空间
58 |
59 | 1. Java虚拟机定义了若干种程序运行期间会使用到的运行时数据区:其中有一些会随着虚拟机启动而创建,随着虚拟机退出而销毁。另外一些则是与线程一一对应的,这些与线程对应的数据区域会随着线程开始和结束而创建和销毁。
60 |
61 | 2. 灰色的为单独线程私有的,红色的为多个线程共享的。即:
62 | - 线程独有:独立包括程序计数器、栈、本地方法栈
63 | - 线程间共享:堆、堆外内存(永久代或元空间、代码缓存)
64 |
65 |
54 |
55 |
56 |
57 | ### 线程的内存空间
58 |
59 | 1. Java虚拟机定义了若干种程序运行期间会使用到的运行时数据区:其中有一些会随着虚拟机启动而创建,随着虚拟机退出而销毁。另外一些则是与线程一一对应的,这些与线程对应的数据区域会随着线程开始和结束而创建和销毁。
60 |
61 | 2. 灰色的为单独线程私有的,红色的为多个线程共享的。即:
62 | - 线程独有:独立包括程序计数器、栈、本地方法栈
63 | - 线程间共享:堆、堆外内存(永久代或元空间、代码缓存)
64 |
65 |  66 |
67 |
68 |
69 | ### Runtime类
70 |
71 | **每个JVM只有一个Runtime实例**。即为运行时环境,相当于内存结构的中间的那个框框:运行时环境。
72 |
73 |
66 |
67 |
68 |
69 | ### Runtime类
70 |
71 | **每个JVM只有一个Runtime实例**。即为运行时环境,相当于内存结构的中间的那个框框:运行时环境。
72 |
73 |  74 |
75 |
76 |
77 | 线程
78 | ----
79 |
80 | ### JVM 线程
81 |
82 |
83 |
84 | 1. 线程是一个程序里的运行单元。JVM允许一个应用有多个线程并行的执行
85 | 2. **在Hotspot JVM里,每个线程都与操作系统的本地线程直接映射**
86 | - 当一个Java线程准备好执行以后,此时一个操作系统的本地线程也同时创建。Java线程执行终止后,本地线程也会回收
87 | 4. 操作系统负责将线程安排调度到任何一个可用的CPU上。一旦本地线程初始化成功,它就会调用Java线程中的run()方法
88 |
89 | > 关于线程,并发可以看笔者的Java并发系列
90 |
91 |
92 |
93 | ### JVM 系统线程
94 |
95 |
96 |
97 | - 如果你使用jconsole或者是任何一个调试工具,都能看到在后台有许多线程在运行。这些后台线程不包括调用`public static void main(String[])`的main线程以及所有这个main线程自己创建的线程。
98 |
99 | - 这些主要的后台系统线程在Hotspot JVM里主要是以下几个:
100 |
101 | 1. **虚拟机线程**:这种线程的操作是需要JVM达到安全点才会出现。这些操作必须在不同的线程中发生的原因是他们都需要JVM达到安全点,这样堆才不会变化。这种线程的执行类型括"stop-the-world"的垃圾收集,线程栈收集,线程挂起以及偏向锁撤销
102 | 2. **周期任务线程**:这种线程是时间周期事件的体现(比如中断),他们一般用于周期性操作的调度执行
103 | 3. **GC线程**:这种线程对在JVM里不同种类的垃圾收集行为提供了支持
104 | 4. **编译线程**:这种线程在运行时会将字节码编译成到本地代码
105 | 5. **信号调度线程**:这种线程接收信号并发送给JVM,在它内部通过调用适当的方法进行处理
106 |
107 |
108 |
109 | 程序计数器(PC寄存器)
110 | ===========
111 |
112 | PC寄存器介绍
113 | ----------
114 |
115 | > 官方文档网址:https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
116 |
117 |
74 |
75 |
76 |
77 | 线程
78 | ----
79 |
80 | ### JVM 线程
81 |
82 |
83 |
84 | 1. 线程是一个程序里的运行单元。JVM允许一个应用有多个线程并行的执行
85 | 2. **在Hotspot JVM里,每个线程都与操作系统的本地线程直接映射**
86 | - 当一个Java线程准备好执行以后,此时一个操作系统的本地线程也同时创建。Java线程执行终止后,本地线程也会回收
87 | 4. 操作系统负责将线程安排调度到任何一个可用的CPU上。一旦本地线程初始化成功,它就会调用Java线程中的run()方法
88 |
89 | > 关于线程,并发可以看笔者的Java并发系列
90 |
91 |
92 |
93 | ### JVM 系统线程
94 |
95 |
96 |
97 | - 如果你使用jconsole或者是任何一个调试工具,都能看到在后台有许多线程在运行。这些后台线程不包括调用`public static void main(String[])`的main线程以及所有这个main线程自己创建的线程。
98 |
99 | - 这些主要的后台系统线程在Hotspot JVM里主要是以下几个:
100 |
101 | 1. **虚拟机线程**:这种线程的操作是需要JVM达到安全点才会出现。这些操作必须在不同的线程中发生的原因是他们都需要JVM达到安全点,这样堆才不会变化。这种线程的执行类型括"stop-the-world"的垃圾收集,线程栈收集,线程挂起以及偏向锁撤销
102 | 2. **周期任务线程**:这种线程是时间周期事件的体现(比如中断),他们一般用于周期性操作的调度执行
103 | 3. **GC线程**:这种线程对在JVM里不同种类的垃圾收集行为提供了支持
104 | 4. **编译线程**:这种线程在运行时会将字节码编译成到本地代码
105 | 5. **信号调度线程**:这种线程接收信号并发送给JVM,在它内部通过调用适当的方法进行处理
106 |
107 |
108 |
109 | 程序计数器(PC寄存器)
110 | ===========
111 |
112 | PC寄存器介绍
113 | ----------
114 |
115 | > 官方文档网址:https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
116 |
117 | 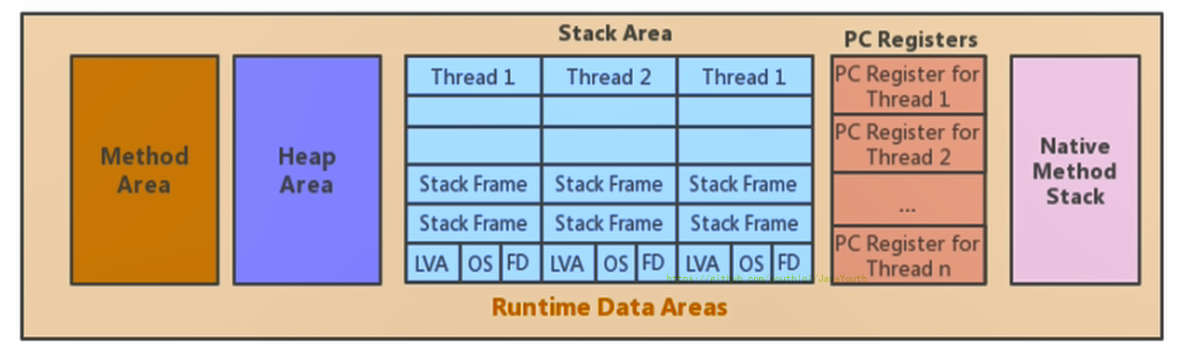 118 |
119 | 1. JVM中的程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,**寄存器存储指令相关的现场信息**。CPU只有把数据装载到寄存器才能够运行。
120 | 2. 这里,并非是广义上所指的物理寄存器,或许将其翻译为PC计数器(或指令计数器)会更加贴切(也称为程序钩子),并且也不容易引起一些不必要的误会。**JVM中的PC寄存器是对物理PC寄存器的一种抽象模拟**。
121 | 3. 它是一块很小的内存空间,几乎可以忽略不记。也是运行速度最快的存储区域。
122 | 4. 在JVM规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程的生命周期保持一致。
123 | 5. 任何时间一个线程都只有一个方法在执行,也就是所谓的**当前方法**。程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;或者,如果是在执行native方法,则是未指定值(undefned)。
124 | 6. 它是**程序控制流**的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
125 | 7. 字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
126 | 8. 它是**唯一一个**在Java虚拟机规范中没有规定任何OutofMemoryError情况的区域。
127 |
128 |
129 |
130 |
131 | ## PC寄存器的作用
132 |
133 | PC寄存器用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令,并执行该指令。
134 |
135 |
118 |
119 | 1. JVM中的程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,**寄存器存储指令相关的现场信息**。CPU只有把数据装载到寄存器才能够运行。
120 | 2. 这里,并非是广义上所指的物理寄存器,或许将其翻译为PC计数器(或指令计数器)会更加贴切(也称为程序钩子),并且也不容易引起一些不必要的误会。**JVM中的PC寄存器是对物理PC寄存器的一种抽象模拟**。
121 | 3. 它是一块很小的内存空间,几乎可以忽略不记。也是运行速度最快的存储区域。
122 | 4. 在JVM规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程的生命周期保持一致。
123 | 5. 任何时间一个线程都只有一个方法在执行,也就是所谓的**当前方法**。程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;或者,如果是在执行native方法,则是未指定值(undefned)。
124 | 6. 它是**程序控制流**的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
125 | 7. 字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
126 | 8. 它是**唯一一个**在Java虚拟机规范中没有规定任何OutofMemoryError情况的区域。
127 |
128 |
129 |
130 |
131 | ## PC寄存器的作用
132 |
133 | PC寄存器用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令,并执行该指令。
134 |
135 | 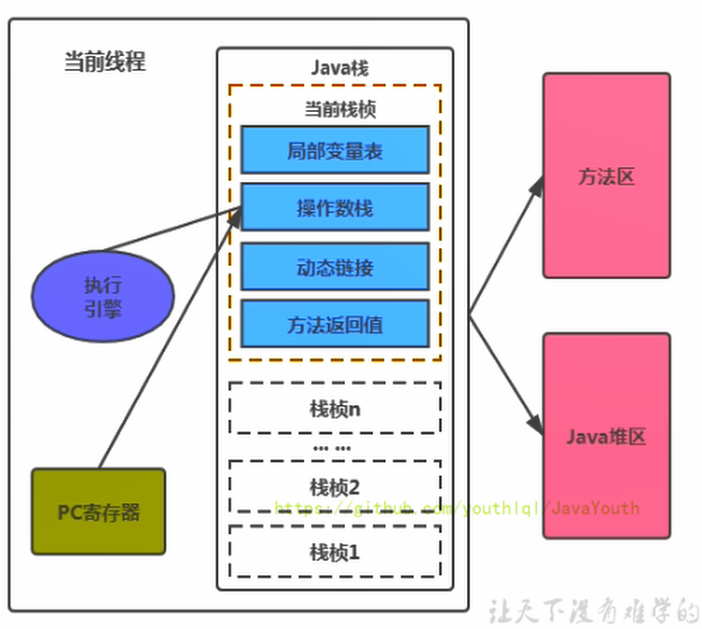 136 |
137 |
138 |
139 | 举例
140 | ------
141 |
142 | ```java
143 | public class PCRegisterTest {
144 |
145 | public static void main(String[] args) {
146 | int i = 10;
147 | int j = 20;
148 | int k = i + j;
149 |
150 | String s = "abc";
151 | System.out.println(i);
152 | System.out.println(k);
153 |
154 | }
155 | }
156 | ```
157 |
158 | 查看字节码
159 |
160 | > 看字节码的方法:https://blog.csdn.net/21aspnet/article/details/88351875
161 |
162 | ```java
163 | Classfile /F:/IDEAWorkSpaceSourceCode/JVMDemo/out/production/chapter04/com/atguigu/java/PCRegisterTest.class
164 | Last modified 2020-11-2; size 675 bytes
165 | MD5 checksum 53b3ef104479ec9e9b7ce5319e5881d3
166 | Compiled from "PCRegisterTest.java"
167 | public class com.atguigu.java.PCRegisterTest
168 | minor version: 0
169 | major version: 52
170 | flags: ACC_PUBLIC, ACC_SUPER
171 | Constant pool:
172 | #1 = Methodref #6.#26 // java/lang/Object."
136 |
137 |
138 |
139 | 举例
140 | ------
141 |
142 | ```java
143 | public class PCRegisterTest {
144 |
145 | public static void main(String[] args) {
146 | int i = 10;
147 | int j = 20;
148 | int k = i + j;
149 |
150 | String s = "abc";
151 | System.out.println(i);
152 | System.out.println(k);
153 |
154 | }
155 | }
156 | ```
157 |
158 | 查看字节码
159 |
160 | > 看字节码的方法:https://blog.csdn.net/21aspnet/article/details/88351875
161 |
162 | ```java
163 | Classfile /F:/IDEAWorkSpaceSourceCode/JVMDemo/out/production/chapter04/com/atguigu/java/PCRegisterTest.class
164 | Last modified 2020-11-2; size 675 bytes
165 | MD5 checksum 53b3ef104479ec9e9b7ce5319e5881d3
166 | Compiled from "PCRegisterTest.java"
167 | public class com.atguigu.java.PCRegisterTest
168 | minor version: 0
169 | major version: 52
170 | flags: ACC_PUBLIC, ACC_SUPER
171 | Constant pool:
172 | #1 = Methodref #6.#26 // java/lang/Object." 272 |
273 |
274 |
275 | 两个面试题
276 | -------
277 |
278 | **使用PC寄存器存储字节码指令地址有什么用呢?**或者问**为什么使用 PC 寄存器来记录当前线程的执行地址呢?**
279 |
280 | 1. 因为CPU需要不停的切换各个线程,这时候切换回来以后,就得知道接着从哪开始继续执行
281 |
282 | 2. JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令
283 |
284 |
285 |
272 |
273 |
274 |
275 | 两个面试题
276 | -------
277 |
278 | **使用PC寄存器存储字节码指令地址有什么用呢?**或者问**为什么使用 PC 寄存器来记录当前线程的执行地址呢?**
279 |
280 | 1. 因为CPU需要不停的切换各个线程,这时候切换回来以后,就得知道接着从哪开始继续执行
281 |
282 | 2. JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令
283 |
284 |
285 | 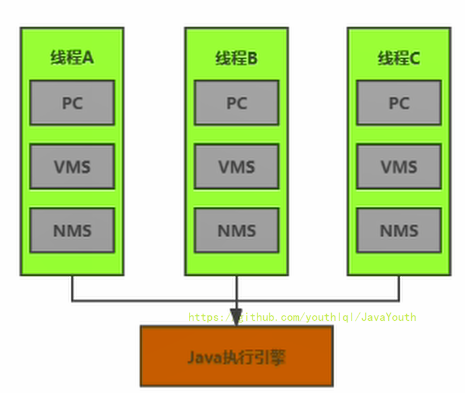 286 |
287 |
288 |
289 | **PC寄存器为什么被设定为私有的?**
290 |
291 | 1. 我们都知道所谓的多线程在一个特定的时间段内只会执行其中某一个线程的方法,CPU会不停地做任务切换,这样必然导致经常中断或恢复,如何保证分毫无差呢?**为了能够准确地记录各个线程正在执行的当前字节码指令地址,最好的办法自然是为每一个线程都分配一个PC寄存器**,这样一来各个线程之间便可以进行独立计算,从而不会出现相互干扰的情况。
292 | 2. 由于CPU时间片轮限制,众多线程在并发执行过程中,任何一个确定的时刻,一个处理器或者多核处理器中的一个内核,只会执行某个线程中的一条指令。
293 | 3. 这样必然导致经常中断或恢复,如何保证分毫无差呢?每个线程在创建后,都会产生自己的程序计数器和栈帧,程序计数器在各个线程之间互不影响。
294 |
295 | > 注意并行和并发的区别,笔者的并发系列有讲
296 |
297 |
298 |
299 | CPU 时间片
300 | ---------
301 |
302 | 1. CPU时间片即CPU分配给各个程序的时间,每个线程被分配一个时间段,称作它的时间片。
303 |
304 | 2. 在宏观上:我们可以同时打开多个应用程序,每个程序并行不悖,同时运行。
305 |
306 | 3. 但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,**每个程序轮流执行**。
307 |
308 |
309 |
286 |
287 |
288 |
289 | **PC寄存器为什么被设定为私有的?**
290 |
291 | 1. 我们都知道所谓的多线程在一个特定的时间段内只会执行其中某一个线程的方法,CPU会不停地做任务切换,这样必然导致经常中断或恢复,如何保证分毫无差呢?**为了能够准确地记录各个线程正在执行的当前字节码指令地址,最好的办法自然是为每一个线程都分配一个PC寄存器**,这样一来各个线程之间便可以进行独立计算,从而不会出现相互干扰的情况。
292 | 2. 由于CPU时间片轮限制,众多线程在并发执行过程中,任何一个确定的时刻,一个处理器或者多核处理器中的一个内核,只会执行某个线程中的一条指令。
293 | 3. 这样必然导致经常中断或恢复,如何保证分毫无差呢?每个线程在创建后,都会产生自己的程序计数器和栈帧,程序计数器在各个线程之间互不影响。
294 |
295 | > 注意并行和并发的区别,笔者的并发系列有讲
296 |
297 |
298 |
299 | CPU 时间片
300 | ---------
301 |
302 | 1. CPU时间片即CPU分配给各个程序的时间,每个线程被分配一个时间段,称作它的时间片。
303 |
304 | 2. 在宏观上:我们可以同时打开多个应用程序,每个程序并行不悖,同时运行。
305 |
306 | 3. 但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,**每个程序轮流执行**。
307 |
308 |
309 |  310 |
311 |
312 |
313 | # 本地方法接口
314 |
315 | ## 本地方法
316 |
317 |
310 |
311 |
312 |
313 | # 本地方法接口
314 |
315 | ## 本地方法
316 |
317 | 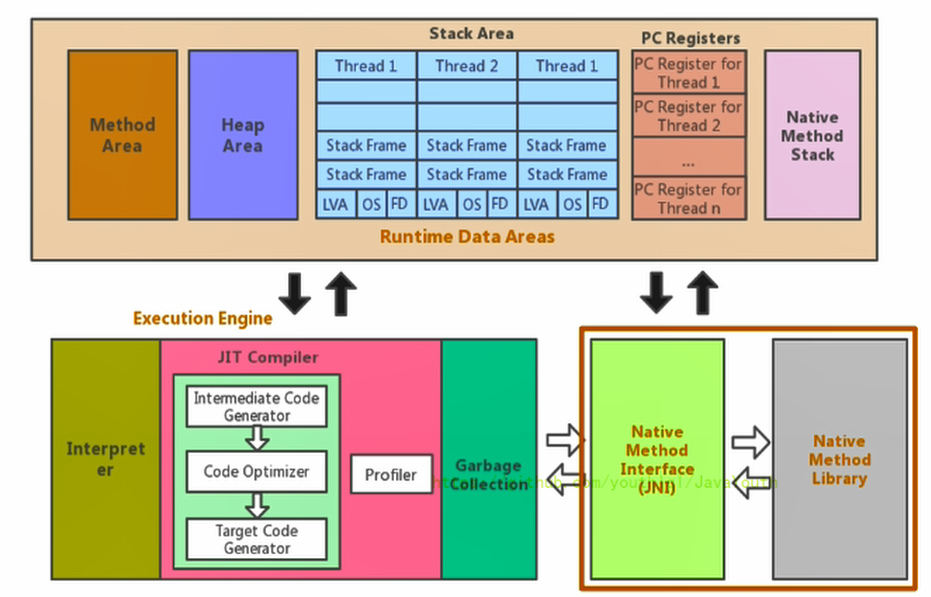 318 |
319 |
320 |
321 | 1. 简单地讲,**一个Native Method是一个Java调用非Java代码的接囗**一个Native Method是这样一个Java方法:该方法的实现由非Java语言实现,比如C。这个特征并非Java所特有,很多其它的编程语言都有这一机制,比如在C++中,你可以用extern 告知C++编译器去调用一个C的函数。
322 | 4. “A native method is a Java method whose implementation is provided by non-java code.”(本地方法是一个非Java的方法,它的具体实现是非Java代码的实现)
323 | 5. 在定义一个native method时,并不提供实现体(有些像定义一个Java interface),因为其实现体是由非java语言在外面实现的。
324 | 6. 本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序。
325 |
326 |
327 |
328 |
329 |
330 | ## 举例
331 |
332 |
333 |
334 | 需要注意的是:标识符native可以与其它java标识符连用,但是abstract除外
335 |
336 | ```java
337 | public class IHaveNatives {
338 | public native void Native1(int x);
339 |
340 | public native static long Native2();
341 |
342 | private native synchronized float Native3(Object o);
343 |
344 | native void Native4(int[] ary) throws Exception;
345 |
346 | }
347 |
348 | ```
349 |
350 |
351 |
352 | ## 为什么要使用 Native Method?
353 |
354 | Java使用起来非常方便,然而有些层次的任务用Java实现起来不容易,或者我们对程序的效率很在意时,问题就来了。
355 |
356 |
357 |
358 | ### 与Java环境外交互
359 |
360 | **有时Java应用需要与Java外面的硬件环境交互,这是本地方法存在的主要原因**。你可以想想Java需要与一些**底层系统**,如操作系统或某些硬件交换信息时的情况。本地方法正是这样一种交流机制:它为我们提供了一个非常简洁的接口,而且我们无需去了解Java应用之外的繁琐的细节。
361 |
362 |
363 |
364 | ### 与操作系统的交互
365 |
366 | 1. JVM支持着Java语言本身和运行时库,它是Java程序赖以生存的平台,它由一个解释器(解释字节码)和一些连接到本地代码的库组成。
367 | 2. 然而不管怎样,它毕竟不是一个完整的系统,它经常依赖于一底层系统的支持。这些底层系统常常是强大的操作系统。
368 | 3. **通过使用本地方法,我们得以用Java实现了jre的与底层系统的交互,甚至JVM的一些部分就是用C写的**。
369 | 4. 还有,如果我们要使用一些Java语言本身没有提供封装的操作系统的特性时,我们也需要使用本地方法。
370 |
371 |
372 |
373 | ### Sun’s Java
374 |
375 | 1. Sun的解释器是用C实现的,这使得它能像一些普通的C一样与外部交互。jre大部分是用Java实现的,它也通过一些本地方法与外界交互。
376 | 2. 例如:类java.lang.Thread的setPriority()方法是用Java实现的,但是它实现调用的是该类里的本地方法setPriority0()。这个本地方法是用C实现的,并被植入JVM内部在Windows 95的平台上,这个本地方法最终将调用Win32 setpriority() API。这是一个本地方法的具体实现由JVM直接提供,更多的情况是本地方法由外部的动态链接库(external dynamic link library)提供,然后被JVM调用。
377 |
378 |
379 |
380 | ### 本地方法的现状
381 |
382 | 目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间的通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍。
383 |
384 |
385 |
386 | # 本地方法栈
387 |
388 | 1. **Java虚拟机栈于管理Java方法的调用,而本地方法栈用于管理本地方法的调用**。
389 | 2. 本地方法栈,也是线程私有的。
390 | 3. 允许被实现成固定或者是可动态扩展的内存大小(在内存溢出方面和虚拟机栈相同)
391 | * 如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java虚拟机将会抛出一个stackoverflowError 异常。
392 | * 如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么Java虚拟机将会抛出一个outofMemoryError异常。
393 | 4. 本地方法一般是使用C语言或C++语言实现的。
394 | 5. 它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。
395 |
396 |
318 |
319 |
320 |
321 | 1. 简单地讲,**一个Native Method是一个Java调用非Java代码的接囗**一个Native Method是这样一个Java方法:该方法的实现由非Java语言实现,比如C。这个特征并非Java所特有,很多其它的编程语言都有这一机制,比如在C++中,你可以用extern 告知C++编译器去调用一个C的函数。
322 | 4. “A native method is a Java method whose implementation is provided by non-java code.”(本地方法是一个非Java的方法,它的具体实现是非Java代码的实现)
323 | 5. 在定义一个native method时,并不提供实现体(有些像定义一个Java interface),因为其实现体是由非java语言在外面实现的。
324 | 6. 本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序。
325 |
326 |
327 |
328 |
329 |
330 | ## 举例
331 |
332 |
333 |
334 | 需要注意的是:标识符native可以与其它java标识符连用,但是abstract除外
335 |
336 | ```java
337 | public class IHaveNatives {
338 | public native void Native1(int x);
339 |
340 | public native static long Native2();
341 |
342 | private native synchronized float Native3(Object o);
343 |
344 | native void Native4(int[] ary) throws Exception;
345 |
346 | }
347 |
348 | ```
349 |
350 |
351 |
352 | ## 为什么要使用 Native Method?
353 |
354 | Java使用起来非常方便,然而有些层次的任务用Java实现起来不容易,或者我们对程序的效率很在意时,问题就来了。
355 |
356 |
357 |
358 | ### 与Java环境外交互
359 |
360 | **有时Java应用需要与Java外面的硬件环境交互,这是本地方法存在的主要原因**。你可以想想Java需要与一些**底层系统**,如操作系统或某些硬件交换信息时的情况。本地方法正是这样一种交流机制:它为我们提供了一个非常简洁的接口,而且我们无需去了解Java应用之外的繁琐的细节。
361 |
362 |
363 |
364 | ### 与操作系统的交互
365 |
366 | 1. JVM支持着Java语言本身和运行时库,它是Java程序赖以生存的平台,它由一个解释器(解释字节码)和一些连接到本地代码的库组成。
367 | 2. 然而不管怎样,它毕竟不是一个完整的系统,它经常依赖于一底层系统的支持。这些底层系统常常是强大的操作系统。
368 | 3. **通过使用本地方法,我们得以用Java实现了jre的与底层系统的交互,甚至JVM的一些部分就是用C写的**。
369 | 4. 还有,如果我们要使用一些Java语言本身没有提供封装的操作系统的特性时,我们也需要使用本地方法。
370 |
371 |
372 |
373 | ### Sun’s Java
374 |
375 | 1. Sun的解释器是用C实现的,这使得它能像一些普通的C一样与外部交互。jre大部分是用Java实现的,它也通过一些本地方法与外界交互。
376 | 2. 例如:类java.lang.Thread的setPriority()方法是用Java实现的,但是它实现调用的是该类里的本地方法setPriority0()。这个本地方法是用C实现的,并被植入JVM内部在Windows 95的平台上,这个本地方法最终将调用Win32 setpriority() API。这是一个本地方法的具体实现由JVM直接提供,更多的情况是本地方法由外部的动态链接库(external dynamic link library)提供,然后被JVM调用。
377 |
378 |
379 |
380 | ### 本地方法的现状
381 |
382 | 目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间的通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍。
383 |
384 |
385 |
386 | # 本地方法栈
387 |
388 | 1. **Java虚拟机栈于管理Java方法的调用,而本地方法栈用于管理本地方法的调用**。
389 | 2. 本地方法栈,也是线程私有的。
390 | 3. 允许被实现成固定或者是可动态扩展的内存大小(在内存溢出方面和虚拟机栈相同)
391 | * 如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java虚拟机将会抛出一个stackoverflowError 异常。
392 | * 如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么Java虚拟机将会抛出一个outofMemoryError异常。
393 | 4. 本地方法一般是使用C语言或C++语言实现的。
394 | 5. 它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。
395 |
396 |  397 |
398 |
399 |
400 | **注意事项**
401 |
402 | 1. 当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。
403 | * 本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区
404 | * 它甚至可以直接使用本地处理器中的寄存器
405 | * 直接从本地内存的堆中分配任意数量的内存
406 | 2. 并不是所有的JVM都支持本地方法。因为Java虚拟机规范并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等。如果JVM产品不打算支持native方法,也可以无需实现本地方法栈。
407 | 3. 在Hotspot JVM中,直接将本地方法栈和虚拟机栈合二为一。
408 |
409 |
--------------------------------------------------------------------------------
/docs/JVM/JVM系列-第8章-执行引擎.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: JVM系列-第8章-执行引擎
3 | tags:
4 | - JVM
5 | - 虚拟机
6 | categories:
7 | - JVM
8 | - 1.内存与垃圾回收篇
9 | keywords: JVM,虚拟机。
10 | description: JVM系列-第8章-执行引擎。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/jvm.png'
12 | abbrlink: 408712f4
13 | date: 2020-11-15 19:48:42
14 | ---
15 |
16 |
17 |
18 | 执行引擎
19 | ===========
20 |
21 | 执行引擎概述
22 | --------
23 |
24 |
25 |
26 |
397 |
398 |
399 |
400 | **注意事项**
401 |
402 | 1. 当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。
403 | * 本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区
404 | * 它甚至可以直接使用本地处理器中的寄存器
405 | * 直接从本地内存的堆中分配任意数量的内存
406 | 2. 并不是所有的JVM都支持本地方法。因为Java虚拟机规范并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等。如果JVM产品不打算支持native方法,也可以无需实现本地方法栈。
407 | 3. 在Hotspot JVM中,直接将本地方法栈和虚拟机栈合二为一。
408 |
409 |
--------------------------------------------------------------------------------
/docs/JVM/JVM系列-第8章-执行引擎.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: JVM系列-第8章-执行引擎
3 | tags:
4 | - JVM
5 | - 虚拟机
6 | categories:
7 | - JVM
8 | - 1.内存与垃圾回收篇
9 | keywords: JVM,虚拟机。
10 | description: JVM系列-第8章-执行引擎。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/jvm.png'
12 | abbrlink: 408712f4
13 | date: 2020-11-15 19:48:42
14 | ---
15 |
16 |
17 |
18 | 执行引擎
19 | ===========
20 |
21 | 执行引擎概述
22 | --------
23 |
24 |
25 |
26 | 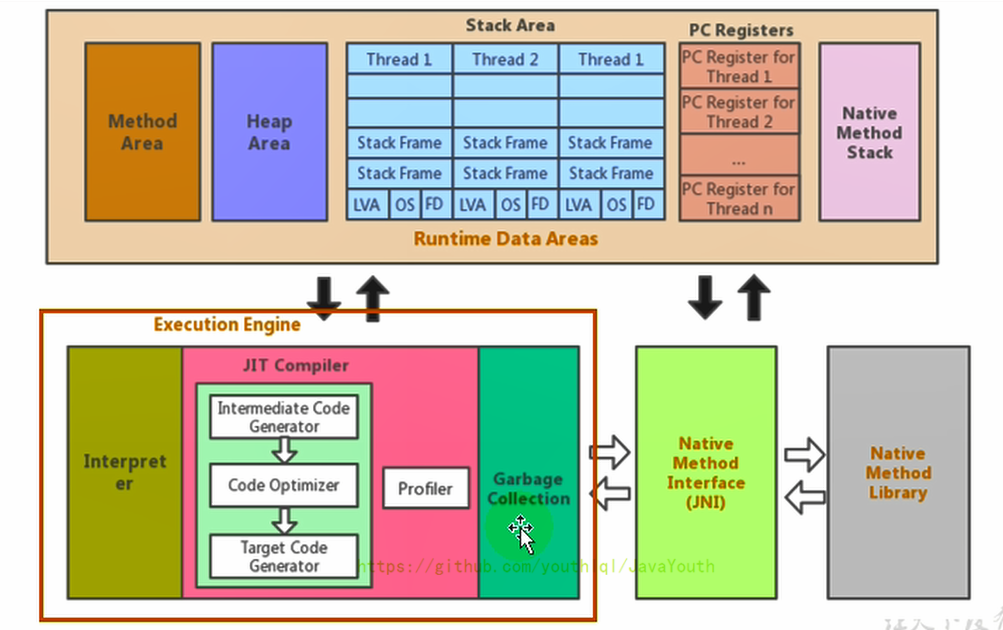 27 |
28 | ### 执行引擎概述
29 |
30 |
31 |
32 | 1. 执行引擎是Java虚拟机核心的组成部分之一。
33 | 2. “虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器、缓存、指令集和操作系统层面上的,而**虚拟机的执行引擎则是由软件自行实现的**,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,**能够执行那些不被硬件直接支持的指令集格式**。
34 | 3. JVM的主要任务是负责**装载字节码到其内部**,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表,以及其他辅助信息。
35 | 4. 那么,如果想要让一个Java程序运行起来,执行引擎(Execution Engine)的任务就是**将字节码指令解释/编译为对应平台上的本地机器指令才可以**。简单来说,JVM中的执行引擎充当了将高级语言翻译为机器语言的译者。
36 |
37 |
27 |
28 | ### 执行引擎概述
29 |
30 |
31 |
32 | 1. 执行引擎是Java虚拟机核心的组成部分之一。
33 | 2. “虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器、缓存、指令集和操作系统层面上的,而**虚拟机的执行引擎则是由软件自行实现的**,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,**能够执行那些不被硬件直接支持的指令集格式**。
34 | 3. JVM的主要任务是负责**装载字节码到其内部**,但字节码并不能够直接运行在操作系统之上,因为字节码指令并非等价于本地机器指令,它内部包含的仅仅只是一些能够被JVM所识别的字节码指令、符号表,以及其他辅助信息。
35 | 4. 那么,如果想要让一个Java程序运行起来,执行引擎(Execution Engine)的任务就是**将字节码指令解释/编译为对应平台上的本地机器指令才可以**。简单来说,JVM中的执行引擎充当了将高级语言翻译为机器语言的译者。
36 |
37 | 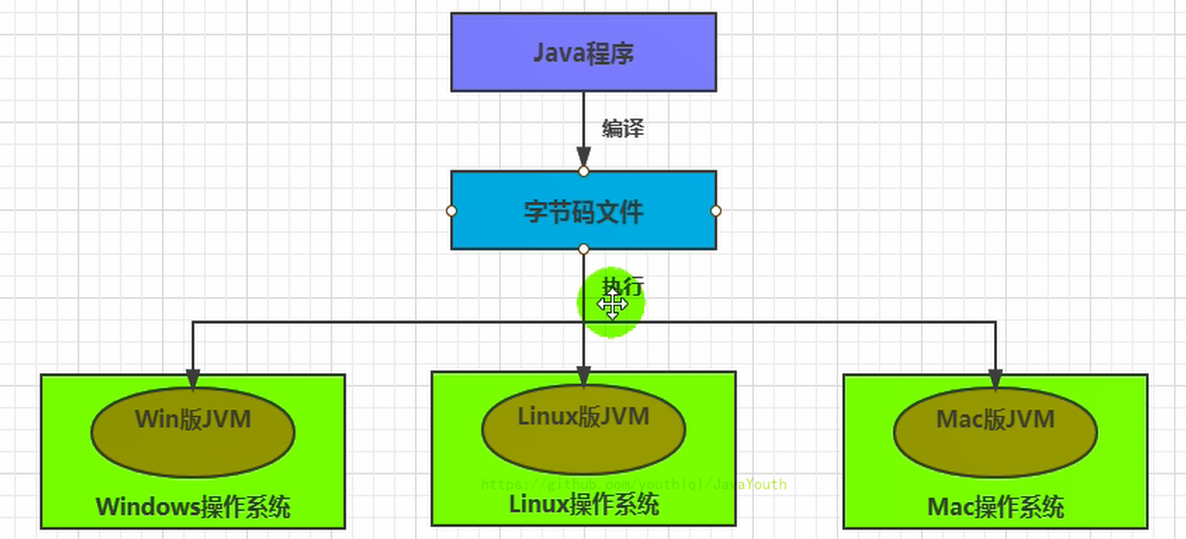 38 |
39 | 1、前端编译:从Java程序员-字节码文件的这个过程叫前端编译
40 |
41 | 2、执行引擎这里有两种行为:一种是解释执行,一种是编译执行(这里的是后端编译)。
42 |
43 |
44 |
45 | ### 执行引擎工作过程
46 |
47 | > **执行引擎工作过程**
48 |
49 | 1. 执行引擎在执行的过程中究竟需要执行什么样的字节码指令完全依赖于PC寄存器。
50 | 2. 每当执行完一项指令操作后,PC寄存器就会更新下一条需要被执行的指令地址。
51 | 3. 当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
52 | 4. 从外观上来看,所有的Java虚拟机的执行引擎输入、处理、输出都是一致的:输入的是字节码二进制流,处理过程是字节码解析执行、即时编译的等效过程,输出的是执行过程。
53 |
54 |
38 |
39 | 1、前端编译:从Java程序员-字节码文件的这个过程叫前端编译
40 |
41 | 2、执行引擎这里有两种行为:一种是解释执行,一种是编译执行(这里的是后端编译)。
42 |
43 |
44 |
45 | ### 执行引擎工作过程
46 |
47 | > **执行引擎工作过程**
48 |
49 | 1. 执行引擎在执行的过程中究竟需要执行什么样的字节码指令完全依赖于PC寄存器。
50 | 2. 每当执行完一项指令操作后,PC寄存器就会更新下一条需要被执行的指令地址。
51 | 3. 当然方法在执行的过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据指针定位到目标对象的类型信息。
52 | 4. 从外观上来看,所有的Java虚拟机的执行引擎输入、处理、输出都是一致的:输入的是字节码二进制流,处理过程是字节码解析执行、即时编译的等效过程,输出的是执行过程。
53 |
54 |  55 |
56 |
57 |
58 | Java代码编译和执行过程
59 | ----------------
60 |
61 | ### 解释执行和即时编译
62 |
63 |
64 |
65 | 大部分的程序代码转换成物理机的目标代码或虚拟机能执行的指令集之前,都需要经过下图中的各个步骤:
66 |
67 | 1. 前面橙色部分是编译生成生成字节码文件的过程(javac编译器来完成,也就是前端编译器),和JVM没有关系。
68 |
69 | 2. 后面绿色(解释执行)和蓝色(即时编译)才是JVM需要考虑的过程
70 |
71 |
72 |
73 |
74 |
55 |
56 |
57 |
58 | Java代码编译和执行过程
59 | ----------------
60 |
61 | ### 解释执行和即时编译
62 |
63 |
64 |
65 | 大部分的程序代码转换成物理机的目标代码或虚拟机能执行的指令集之前,都需要经过下图中的各个步骤:
66 |
67 | 1. 前面橙色部分是编译生成生成字节码文件的过程(javac编译器来完成,也就是前端编译器),和JVM没有关系。
68 |
69 | 2. 后面绿色(解释执行)和蓝色(即时编译)才是JVM需要考虑的过程
70 |
71 |
72 |
73 |
74 | 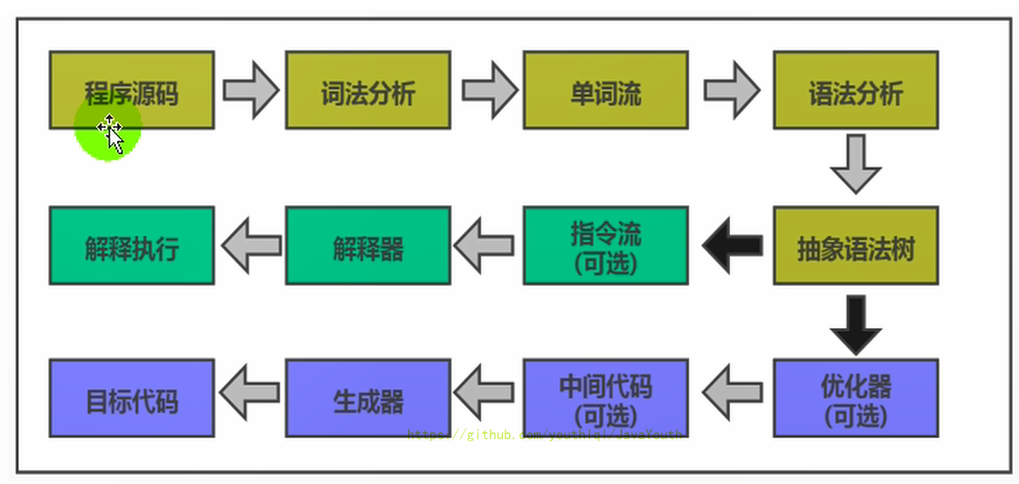 75 |
76 |
77 | 3. javac编译器(前端编译器)流程图如下所示:
78 |
79 |
75 |
76 |
77 | 3. javac编译器(前端编译器)流程图如下所示:
78 |
79 | 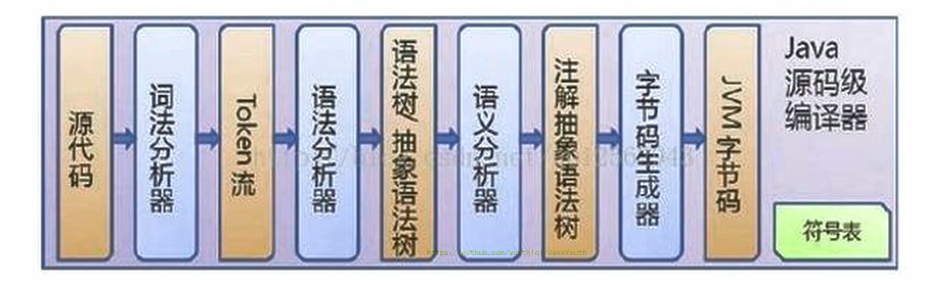 80 |
81 |
82 |
83 | 4. Java字节码的执行是由JVM执行引擎来完成,流程图如下所示
84 |
85 |
80 |
81 |
82 |
83 | 4. Java字节码的执行是由JVM执行引擎来完成,流程图如下所示
84 |
85 |  86 |
87 |
88 |
89 |
90 |
91 | ### 什么是解释器?什么是JIT编译器?
92 |
93 | 1. 解释器:当Java虚拟机启动时会根据预定义的规范对字节码采用**逐行**解释的方式**执行**,将每条字节码文件中的内容“翻译”为对应平台的本地机器指令执行。
94 | 2. JIT(Just In Time Compiler)编译器:就是虚拟机将源代码**一次性直接**编译成和本地机器平台相关的机器语言,**但并不是马上执行**。
95 |
96 |
97 |
98 | **为什么Java是半编译半解释型语言?**
99 |
100 | 1. JDK1.0时代,将Java语言定位为“解释执行”还是比较准确的。再后来,Java也发展出可以直接生成本地代码的编译器。
101 | 2. 现在JVM在执行Java代码的时候,通常都会将解释执行与编译执行二者结合起来进行。
102 | 3. JIT编译器将字节码翻译成本地代码后,就可以做一个缓存操作,存储在方法区的JIT 代码缓存中(执行效率更高了),并且在翻译成本地代码的过程中可以做优化。
103 |
104 |
105 |
106 | **用图总结一下**
107 |
108 |
86 |
87 |
88 |
89 |
90 |
91 | ### 什么是解释器?什么是JIT编译器?
92 |
93 | 1. 解释器:当Java虚拟机启动时会根据预定义的规范对字节码采用**逐行**解释的方式**执行**,将每条字节码文件中的内容“翻译”为对应平台的本地机器指令执行。
94 | 2. JIT(Just In Time Compiler)编译器:就是虚拟机将源代码**一次性直接**编译成和本地机器平台相关的机器语言,**但并不是马上执行**。
95 |
96 |
97 |
98 | **为什么Java是半编译半解释型语言?**
99 |
100 | 1. JDK1.0时代,将Java语言定位为“解释执行”还是比较准确的。再后来,Java也发展出可以直接生成本地代码的编译器。
101 | 2. 现在JVM在执行Java代码的时候,通常都会将解释执行与编译执行二者结合起来进行。
102 | 3. JIT编译器将字节码翻译成本地代码后,就可以做一个缓存操作,存储在方法区的JIT 代码缓存中(执行效率更高了),并且在翻译成本地代码的过程中可以做优化。
103 |
104 |
105 |
106 | **用图总结一下**
107 |
108 | 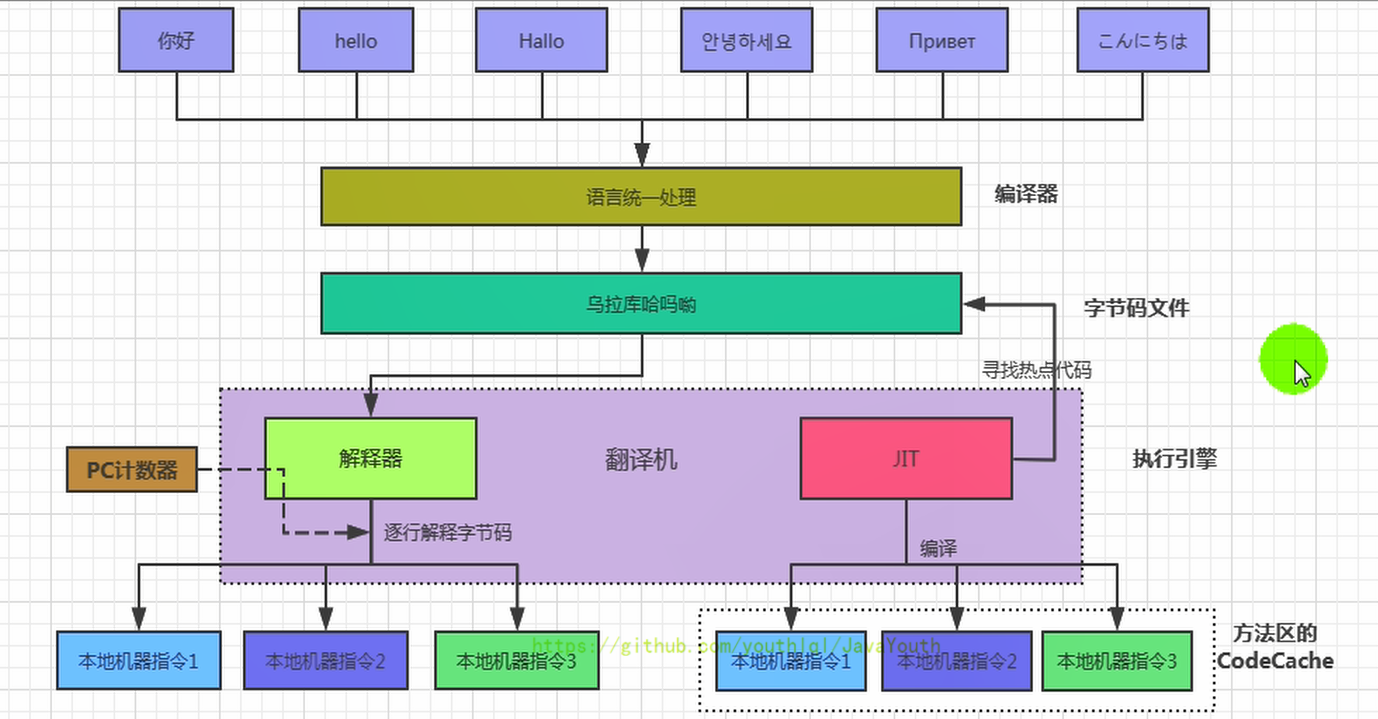 109 |
110 | 机器码 指令 汇编语言
111 | -------------
112 |
113 | ### 机器码
114 |
115 |
116 |
117 | 1. 各种用二进制编码方式表示的指令,叫做机器指令码。开始,人们就用它采编写程序,这就是机器语言。
118 | 2. 机器语言虽然能够被计算机理解和接受,但和人们的语言差别太大,不易被人们理解和记忆,并且用它编程容易出差错。
119 | 3. 用它编写的程序一经输入计算机,CPU直接读取运行,因此和其他语言编的程序相比,执行速度最快。
120 | 4. 机器指令与CPU紧密相关,所以不同种类的CPU所对应的机器指令也就不同。
121 |
122 |
123 |
124 | ### 指令和指令集
125 |
126 | **指令**
127 |
128 | 1. 由于机器码是由0和1组成的二进制序列,可读性实在太差,于是人们发明了指令。
129 |
130 | 2. 指令就是把机器码中特定的0和1序列,简化成对应的指令(一般为英文简写,如mov,inc等),可读性稍好
131 |
132 | 3. 由于不同的硬件平台,执行同一个操作,对应的机器码可能不同,所以不同的硬件平台的同一种指令(比如mov),对应的机器码也可能不同。
133 |
134 |
135 |
136 |
137 | **指令集**
138 |
139 | 不同的硬件平台,各自支持的指令,是有差别的。因此每个平台所支持的指令,称之为对应平台的指令集。如常见的
140 |
141 | 1. x86指令集,对应的是x86架构的平台
142 | 2. ARM指令集,对应的是ARM架构的平台
143 |
144 |
145 |
146 | ### 汇编语言
147 |
148 |
149 |
150 | 1. 由于指令的可读性还是太差,于是人们又发明了汇编语言。
151 | 2. 在汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址。
152 | 3. 在不同的硬件平台,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令。
153 | 4. 由于计算机只认识指令码,所以用汇编语言编写的程序还必须翻译(汇编)成机器指令码,计算机才能识别和执行。
154 |
155 |
156 |
157 | ### 高级语言
158 |
159 |
160 |
161 | 1. 为了使计算机用户编程序更容易些,后来就出现了各种高级计算机语言。高级语言比机器语言、汇编语言更接近人的语言
162 |
163 | 2. 当计算机执行高级语言编写的程序时,仍然需要把程序解释和编译成机器的指令码。完成这个过程的程序就叫做解释程序或编译程序。
164 |
165 |
166 |
167 |
109 |
110 | 机器码 指令 汇编语言
111 | -------------
112 |
113 | ### 机器码
114 |
115 |
116 |
117 | 1. 各种用二进制编码方式表示的指令,叫做机器指令码。开始,人们就用它采编写程序,这就是机器语言。
118 | 2. 机器语言虽然能够被计算机理解和接受,但和人们的语言差别太大,不易被人们理解和记忆,并且用它编程容易出差错。
119 | 3. 用它编写的程序一经输入计算机,CPU直接读取运行,因此和其他语言编的程序相比,执行速度最快。
120 | 4. 机器指令与CPU紧密相关,所以不同种类的CPU所对应的机器指令也就不同。
121 |
122 |
123 |
124 | ### 指令和指令集
125 |
126 | **指令**
127 |
128 | 1. 由于机器码是由0和1组成的二进制序列,可读性实在太差,于是人们发明了指令。
129 |
130 | 2. 指令就是把机器码中特定的0和1序列,简化成对应的指令(一般为英文简写,如mov,inc等),可读性稍好
131 |
132 | 3. 由于不同的硬件平台,执行同一个操作,对应的机器码可能不同,所以不同的硬件平台的同一种指令(比如mov),对应的机器码也可能不同。
133 |
134 |
135 |
136 |
137 | **指令集**
138 |
139 | 不同的硬件平台,各自支持的指令,是有差别的。因此每个平台所支持的指令,称之为对应平台的指令集。如常见的
140 |
141 | 1. x86指令集,对应的是x86架构的平台
142 | 2. ARM指令集,对应的是ARM架构的平台
143 |
144 |
145 |
146 | ### 汇编语言
147 |
148 |
149 |
150 | 1. 由于指令的可读性还是太差,于是人们又发明了汇编语言。
151 | 2. 在汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址。
152 | 3. 在不同的硬件平台,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令。
153 | 4. 由于计算机只认识指令码,所以用汇编语言编写的程序还必须翻译(汇编)成机器指令码,计算机才能识别和执行。
154 |
155 |
156 |
157 | ### 高级语言
158 |
159 |
160 |
161 | 1. 为了使计算机用户编程序更容易些,后来就出现了各种高级计算机语言。高级语言比机器语言、汇编语言更接近人的语言
162 |
163 | 2. 当计算机执行高级语言编写的程序时,仍然需要把程序解释和编译成机器的指令码。完成这个过程的程序就叫做解释程序或编译程序。
164 |
165 |
166 |
167 |  168 |
169 |
170 |
171 | ### 字节码
172 |
173 |
174 |
175 | 1. 字节码是一种中间状态(中间码)的二进制代码(文件),它比机器码更抽象,需要直译器转译后才能成为机器码
176 |
177 | 2. 字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。
178 |
179 | 3. 字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。
180 |
181 | 4. 字节码典型的应用为:Java bytecode
182 |
183 |
184 |
185 |
186 |
187 | ### C、C++源程序执行过程
188 |
189 | **编译过程又可以分成两个阶段:编译和汇编。**
190 |
191 | 1. 编译过程:是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码
192 |
193 | 2. 汇编过程:实际上指把汇编语言代码翻译成目标机器指令的过程。
194 |
195 |
196 |
168 |
169 |
170 |
171 | ### 字节码
172 |
173 |
174 |
175 | 1. 字节码是一种中间状态(中间码)的二进制代码(文件),它比机器码更抽象,需要直译器转译后才能成为机器码
176 |
177 | 2. 字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。
178 |
179 | 3. 字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。
180 |
181 | 4. 字节码典型的应用为:Java bytecode
182 |
183 |
184 |
185 |
186 |
187 | ### C、C++源程序执行过程
188 |
189 | **编译过程又可以分成两个阶段:编译和汇编。**
190 |
191 | 1. 编译过程:是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码
192 |
193 | 2. 汇编过程:实际上指把汇编语言代码翻译成目标机器指令的过程。
194 |
195 |
196 | 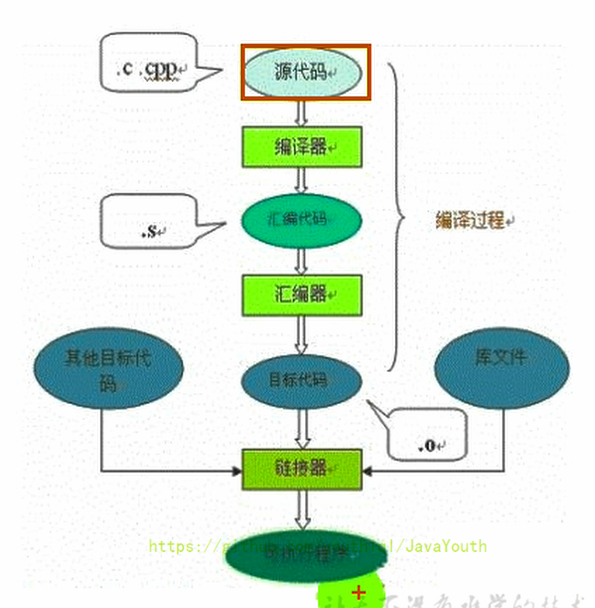 197 |
198 |
199 |
200 | 解释器
201 | -----
202 |
203 | ### 为什么要有解释器
204 |
205 |
206 |
207 | 1. JVM设计者们的初衷仅仅只是单纯地为了满足Java程序实现跨平台特性,因此避免采用静态编译的方式由高级语言直接生成本地机器指令,从而诞生了实现解释器在运行时采用逐行解释字节码执行程序的想法(也就是产生了一个中间产品**字节码**)。
208 |
209 | 2. 解释器真正意义上所承担的角色就是一个运行时“翻译者”,将字节码文件中的内容“翻译”为对应平台的本地机器指令执行。
210 |
211 | 3. 当一条字节码指令被解释执行完成后,接着再根据PC寄存器中记录的下一条需要被执行的字节码指令执行解释操作。
212 |
213 |
214 |
197 |
198 |
199 |
200 | 解释器
201 | -----
202 |
203 | ### 为什么要有解释器
204 |
205 |
206 |
207 | 1. JVM设计者们的初衷仅仅只是单纯地为了满足Java程序实现跨平台特性,因此避免采用静态编译的方式由高级语言直接生成本地机器指令,从而诞生了实现解释器在运行时采用逐行解释字节码执行程序的想法(也就是产生了一个中间产品**字节码**)。
208 |
209 | 2. 解释器真正意义上所承担的角色就是一个运行时“翻译者”,将字节码文件中的内容“翻译”为对应平台的本地机器指令执行。
210 |
211 | 3. 当一条字节码指令被解释执行完成后,接着再根据PC寄存器中记录的下一条需要被执行的字节码指令执行解释操作。
212 |
213 |
214 |  215 |
216 |
217 |
218 | ### 解释器的分类
219 |
220 |
221 |
222 | 1. 在Java的发展历史里,一共有两套解释执行器,即古老的**字节码解释器**、现在普遍使用的**模板解释器**。
223 | * 字节码解释器在执行时通过纯软件代码模拟字节码的执行,效率非常低下。
224 | * 而模板解释器将每一条字节码和一个模板函数相关联,模板函数中直接产生这条字节码执行时的机器码,从而很大程度上提高了解释器的性能。
225 | 2. 在HotSpot VM中,解释器主要由Interpreter模块和Code模块构成。
226 | * Interpreter模块:实现了解释器的核心功能
227 | * Code模块:用于管理HotSpot VM在运行时生成的本地机器指令
228 |
229 | ### 解释器的现状
230 |
231 |
232 |
233 | 1. 由于解释器在设计和实现上非常简单,因此除了Java语言之外,还有许多高级语言同样也是基于解释器执行的,比如Python、Perl、Ruby等。但是在今天,基于解释器执行已经沦落为低效的代名词,并且时常被一些C/C++程序员所调侃。
234 |
235 | 2. 为了解决这个问题,JVM平台支持一种叫作即时编译的技术。即时编译的目的是避免函数被解释执行,而是将整个函数体编译成为机器码,每次函数执行时,只执行编译后的机器码即可,这种方式可以使执行效率大幅度提升。
236 |
237 | 3. 不过无论如何,基于解释器的执行模式仍然为中间语言的发展做出了不可磨灭的贡献。
238 |
239 |
240 |
241 |
242 | ## JIT编译器
243 |
244 |
245 |
246 | ### Java 代码执行的分类
247 |
248 | 1. 第一种是将源代码编译成字节码文件,然后在运行时通过解释器将字节码文件转为机器码执行
249 |
250 | 2. 第二种是编译执行(直接编译成机器码)。现代虚拟机为了提高执行效率,会使用即时编译技术(JIT,Just In Time)将方法编译成机器码后再执行
251 |
252 |
253 |
254 |
255 | 1. HotSpot VM是目前市面上高性能虚拟机的代表作之一。**它采用解释器与即时编译器并存的架构**。在Java虚拟机运行时,解释器和即时编译器能够相互协作,各自取长补短,尽力去选择最合适的方式来权衡编译本地代码的时间和直接解释执行代码的时间。
256 | 3. 在今天,Java程序的运行性能早已脱胎换骨,已经达到了可以和C/C++ 程序一较高下的地步。
257 |
258 |
259 |
260 | ### 为啥我们还需要解释器呢?
261 |
262 | 1. 有些开发人员会感觉到诧异,既然HotSpot VM中已经内置JIT编译器了,那么为什么还需要再使用解释器来“拖累”程序的执行性能呢?比如JRockit VM内部就不包含解释器,字节码全部都依靠即时编译器编译后执行。
263 |
264 | 2. JRockit虚拟机是砍掉了解释器,也就是只采及时编译器。那是因为呢JRockit只部署在服务器上,一般已经有时间让他进行指令编译的过程了,对于响应来说要求不高,等及时编译器的编译完成后,就会提供更好的性能
265 |
266 |
267 | **首先明确两点:**
268 |
269 | 1. 当程序启动后,解释器可以马上发挥作用,**响应速度快**,省去编译的时间,立即执行。
270 | 2. 编译器要想发挥作用,把代码编译成本地代码,**需要一定的执行时间**,但编译为本地代码后,执行效率高。
271 |
272 | **所以:**
273 |
274 | 1. 尽管JRockit VM中程序的执行性能会非常高效,但程序在启动时必然需要花费更长的时间来进行编译。对于服务端应用来说,启动时间并非是关注重点,但对于那些看中启动时间的应用场景而言,或许就需要采用解释器与即时编译器并存的架构来换取一个平衡点。
275 | 2. 在此模式下,在Java虚拟器启动时,解释器可以首先发挥作用,而不必等待即时编译器全部编译完成后再执行,这样可以省去许多不必要的编译时间。随着时间的推移,编译器发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。
276 | 3. 同时,解释执行在编译器进行激进优化不成立的时候,作为编译器的“逃生门”(后备方案)。
277 |
278 | ### 案例
279 |
280 |
281 |
282 | - 当虚拟机启动的时候,解释器可以首先发挥作用,而不必等待即时编译器全部编译完成再执行,这样可以省去许多不必要的编译时间。随着程序运行时间的推移,即时编译器逐渐发挥作用,根据热点探测功能,将有价值的字节码编译为本地机器指令,以换取更高的程序执行效率。
283 |
284 |
285 |
286 | 1. 注意解释执行与编译执行在线上环境微妙的辩证关系。**机器在热机状态(已经运行了一段时间叫热机状态)可以承受的负载要大于冷机状态(刚启动的时候叫冷机状态)**。如果以热机状态时的流量进行切流,可能使处于冷机状态的服务器因无法承载流量而假死。
287 |
288 | 2. 在生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8。曾经有这样的故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT的存在。—**阿里团队**
289 |
290 |
291 |
215 |
216 |
217 |
218 | ### 解释器的分类
219 |
220 |
221 |
222 | 1. 在Java的发展历史里,一共有两套解释执行器,即古老的**字节码解释器**、现在普遍使用的**模板解释器**。
223 | * 字节码解释器在执行时通过纯软件代码模拟字节码的执行,效率非常低下。
224 | * 而模板解释器将每一条字节码和一个模板函数相关联,模板函数中直接产生这条字节码执行时的机器码,从而很大程度上提高了解释器的性能。
225 | 2. 在HotSpot VM中,解释器主要由Interpreter模块和Code模块构成。
226 | * Interpreter模块:实现了解释器的核心功能
227 | * Code模块:用于管理HotSpot VM在运行时生成的本地机器指令
228 |
229 | ### 解释器的现状
230 |
231 |
232 |
233 | 1. 由于解释器在设计和实现上非常简单,因此除了Java语言之外,还有许多高级语言同样也是基于解释器执行的,比如Python、Perl、Ruby等。但是在今天,基于解释器执行已经沦落为低效的代名词,并且时常被一些C/C++程序员所调侃。
234 |
235 | 2. 为了解决这个问题,JVM平台支持一种叫作即时编译的技术。即时编译的目的是避免函数被解释执行,而是将整个函数体编译成为机器码,每次函数执行时,只执行编译后的机器码即可,这种方式可以使执行效率大幅度提升。
236 |
237 | 3. 不过无论如何,基于解释器的执行模式仍然为中间语言的发展做出了不可磨灭的贡献。
238 |
239 |
240 |
241 |
242 | ## JIT编译器
243 |
244 |
245 |
246 | ### Java 代码执行的分类
247 |
248 | 1. 第一种是将源代码编译成字节码文件,然后在运行时通过解释器将字节码文件转为机器码执行
249 |
250 | 2. 第二种是编译执行(直接编译成机器码)。现代虚拟机为了提高执行效率,会使用即时编译技术(JIT,Just In Time)将方法编译成机器码后再执行
251 |
252 |
253 |
254 |
255 | 1. HotSpot VM是目前市面上高性能虚拟机的代表作之一。**它采用解释器与即时编译器并存的架构**。在Java虚拟机运行时,解释器和即时编译器能够相互协作,各自取长补短,尽力去选择最合适的方式来权衡编译本地代码的时间和直接解释执行代码的时间。
256 | 3. 在今天,Java程序的运行性能早已脱胎换骨,已经达到了可以和C/C++ 程序一较高下的地步。
257 |
258 |
259 |
260 | ### 为啥我们还需要解释器呢?
261 |
262 | 1. 有些开发人员会感觉到诧异,既然HotSpot VM中已经内置JIT编译器了,那么为什么还需要再使用解释器来“拖累”程序的执行性能呢?比如JRockit VM内部就不包含解释器,字节码全部都依靠即时编译器编译后执行。
263 |
264 | 2. JRockit虚拟机是砍掉了解释器,也就是只采及时编译器。那是因为呢JRockit只部署在服务器上,一般已经有时间让他进行指令编译的过程了,对于响应来说要求不高,等及时编译器的编译完成后,就会提供更好的性能
265 |
266 |
267 | **首先明确两点:**
268 |
269 | 1. 当程序启动后,解释器可以马上发挥作用,**响应速度快**,省去编译的时间,立即执行。
270 | 2. 编译器要想发挥作用,把代码编译成本地代码,**需要一定的执行时间**,但编译为本地代码后,执行效率高。
271 |
272 | **所以:**
273 |
274 | 1. 尽管JRockit VM中程序的执行性能会非常高效,但程序在启动时必然需要花费更长的时间来进行编译。对于服务端应用来说,启动时间并非是关注重点,但对于那些看中启动时间的应用场景而言,或许就需要采用解释器与即时编译器并存的架构来换取一个平衡点。
275 | 2. 在此模式下,在Java虚拟器启动时,解释器可以首先发挥作用,而不必等待即时编译器全部编译完成后再执行,这样可以省去许多不必要的编译时间。随着时间的推移,编译器发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。
276 | 3. 同时,解释执行在编译器进行激进优化不成立的时候,作为编译器的“逃生门”(后备方案)。
277 |
278 | ### 案例
279 |
280 |
281 |
282 | - 当虚拟机启动的时候,解释器可以首先发挥作用,而不必等待即时编译器全部编译完成再执行,这样可以省去许多不必要的编译时间。随着程序运行时间的推移,即时编译器逐渐发挥作用,根据热点探测功能,将有价值的字节码编译为本地机器指令,以换取更高的程序执行效率。
283 |
284 |
285 |
286 | 1. 注意解释执行与编译执行在线上环境微妙的辩证关系。**机器在热机状态(已经运行了一段时间叫热机状态)可以承受的负载要大于冷机状态(刚启动的时候叫冷机状态)**。如果以热机状态时的流量进行切流,可能使处于冷机状态的服务器因无法承载流量而假死。
287 |
288 | 2. 在生产环境发布过程中,以分批的方式进行发布,根据机器数量划分成多个批次,每个批次的机器数至多占到整个集群的1/8。曾经有这样的故障案例:某程序员在发布平台进行分批发布,在输入发布总批数时,误填写成分为两批发布。如果是热机状态,在正常情况下一半的机器可以勉强承载流量,但由于刚启动的JVM均是解释执行,还没有进行热点代码统计和JIT动态编译,导致机器启动之后,当前1/2发布成功的服务器马上全部宕机,此故障说明了JIT的存在。—**阿里团队**
289 |
290 |
291 |  292 |
293 |
294 |
295 |
296 |
297 | ```java
298 | public class JITTest {
299 | public static void main(String[] args) {
300 | ArrayList
292 |
293 |
294 |
295 |
296 |
297 | ```java
298 | public class JITTest {
299 | public static void main(String[] args) {
300 | ArrayList 321 |
322 |
323 |
324 | ### JIT编译器相关概念
325 |
326 |
327 |
328 | 1. Java 语言的“编译期”其实是一段“不确定”的操作过程,因为它可能是指一个前端编译器(其实叫“编译器的前端”更准确一些)把.java文件转变成.class文件的过程。
329 | 2. 也可能是指虚拟机的后端运行期编译器(JIT编译器,Just In Time Compiler)把字节码转变成机器码的过程。
330 | 3. 还可能是指使用静态提前编译器(AOT编译器,Ahead of Time Compiler)直接把.java文件编译成本地机器代码的过程。(可能是后续发展的趋势)
331 |
332 |
333 |
334 | **典型的编译器:**
335 |
336 | 1. 前端编译器:Sun的javac、Eclipse JDT中的增量式编译器(ECJ)。
337 | 2. JIT编译器:HotSpot VM的C1、C2编译器。
338 | 3. AOT 编译器:GNU Compiler for the Java(GCJ)、Excelsior JET。
339 |
340 |
341 |
342 | ### 热点代码及探测方式
343 |
344 |
345 |
346 | 1. 当然是否需要启动JIT编译器将字节码直接编译为对应平台的本地机器指令,则需要根据代码被调用**执行的频率**而定。
347 | 2. 关于那些需要被编译为本地代码的字节码,也被称之为**“热点代码”**,JIT编译器在运行时会针对那些频繁被调用的“热点代码”做出**深度优化**,将其直接编译为对应平台的本地机器指令,以此提升Java程序的执行性能。
348 | 3. 一个被多次调用的方法,或者是一-个方法体内部循环次数较多的循环体都可以被称之为“热点代码”,因此都可以通过JIT编译器编译为本地机器指令。由于这种编译方式发生在方法的执行过程中,因此也被称之为栈上替换,或简称为OSR (On StackReplacement)编译。
349 | 4. 一个方法究竟要被调用多少次,或者一个循环体究竟需要执行多少次循环才可以达到这个标准?必然需要一个明确的阈值,JIT编译器才会将这些“热点代码”编译为本地机器指令执行。这里主要依靠热点探测功能。
350 | 5. **目前HotSpot VM所采用的热点探测方式是基于计数器的热点探测**。
351 | 6. 采用基于计数器的热点探测,HotSpot VM将会为每一个方法都建立2个不同类型的计数器,分别为方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)。
352 | 1. 方法调用计数器用于统计方法的调用次数
353 | 2. 回边计数器则用于统计循环体执行的循环次数
354 |
355 |
356 |
357 | #### 方法调用计数器
358 |
359 |
360 |
361 | 1. 这个计数器就用于统计方法被调用的次数,它的默认阀值在Client模式下是1500次,在Server模式下是10000次。超过这个阈值,就会触发JIT编译。
362 |
363 | 2. 这个阀值可以通过虚拟机参数 -XX:CompileThreshold 来人为设定。
364 |
365 | 3. 当一个方法被调用时,会先检查该方法是否存在被JIT编译过的版本
366 |
367 | * 如果存在,则优先使用编译后的本地代码来执行
368 | * 如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阀值。
369 | * 如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
370 | * 如果未超过阈值,则使用解释器对字节码文件解释执行
371 |
372 |
321 |
322 |
323 |
324 | ### JIT编译器相关概念
325 |
326 |
327 |
328 | 1. Java 语言的“编译期”其实是一段“不确定”的操作过程,因为它可能是指一个前端编译器(其实叫“编译器的前端”更准确一些)把.java文件转变成.class文件的过程。
329 | 2. 也可能是指虚拟机的后端运行期编译器(JIT编译器,Just In Time Compiler)把字节码转变成机器码的过程。
330 | 3. 还可能是指使用静态提前编译器(AOT编译器,Ahead of Time Compiler)直接把.java文件编译成本地机器代码的过程。(可能是后续发展的趋势)
331 |
332 |
333 |
334 | **典型的编译器:**
335 |
336 | 1. 前端编译器:Sun的javac、Eclipse JDT中的增量式编译器(ECJ)。
337 | 2. JIT编译器:HotSpot VM的C1、C2编译器。
338 | 3. AOT 编译器:GNU Compiler for the Java(GCJ)、Excelsior JET。
339 |
340 |
341 |
342 | ### 热点代码及探测方式
343 |
344 |
345 |
346 | 1. 当然是否需要启动JIT编译器将字节码直接编译为对应平台的本地机器指令,则需要根据代码被调用**执行的频率**而定。
347 | 2. 关于那些需要被编译为本地代码的字节码,也被称之为**“热点代码”**,JIT编译器在运行时会针对那些频繁被调用的“热点代码”做出**深度优化**,将其直接编译为对应平台的本地机器指令,以此提升Java程序的执行性能。
348 | 3. 一个被多次调用的方法,或者是一-个方法体内部循环次数较多的循环体都可以被称之为“热点代码”,因此都可以通过JIT编译器编译为本地机器指令。由于这种编译方式发生在方法的执行过程中,因此也被称之为栈上替换,或简称为OSR (On StackReplacement)编译。
349 | 4. 一个方法究竟要被调用多少次,或者一个循环体究竟需要执行多少次循环才可以达到这个标准?必然需要一个明确的阈值,JIT编译器才会将这些“热点代码”编译为本地机器指令执行。这里主要依靠热点探测功能。
350 | 5. **目前HotSpot VM所采用的热点探测方式是基于计数器的热点探测**。
351 | 6. 采用基于计数器的热点探测,HotSpot VM将会为每一个方法都建立2个不同类型的计数器,分别为方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)。
352 | 1. 方法调用计数器用于统计方法的调用次数
353 | 2. 回边计数器则用于统计循环体执行的循环次数
354 |
355 |
356 |
357 | #### 方法调用计数器
358 |
359 |
360 |
361 | 1. 这个计数器就用于统计方法被调用的次数,它的默认阀值在Client模式下是1500次,在Server模式下是10000次。超过这个阈值,就会触发JIT编译。
362 |
363 | 2. 这个阀值可以通过虚拟机参数 -XX:CompileThreshold 来人为设定。
364 |
365 | 3. 当一个方法被调用时,会先检查该方法是否存在被JIT编译过的版本
366 |
367 | * 如果存在,则优先使用编译后的本地代码来执行
368 | * 如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阀值。
369 | * 如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
370 | * 如果未超过阈值,则使用解释器对字节码文件解释执行
371 |
372 | 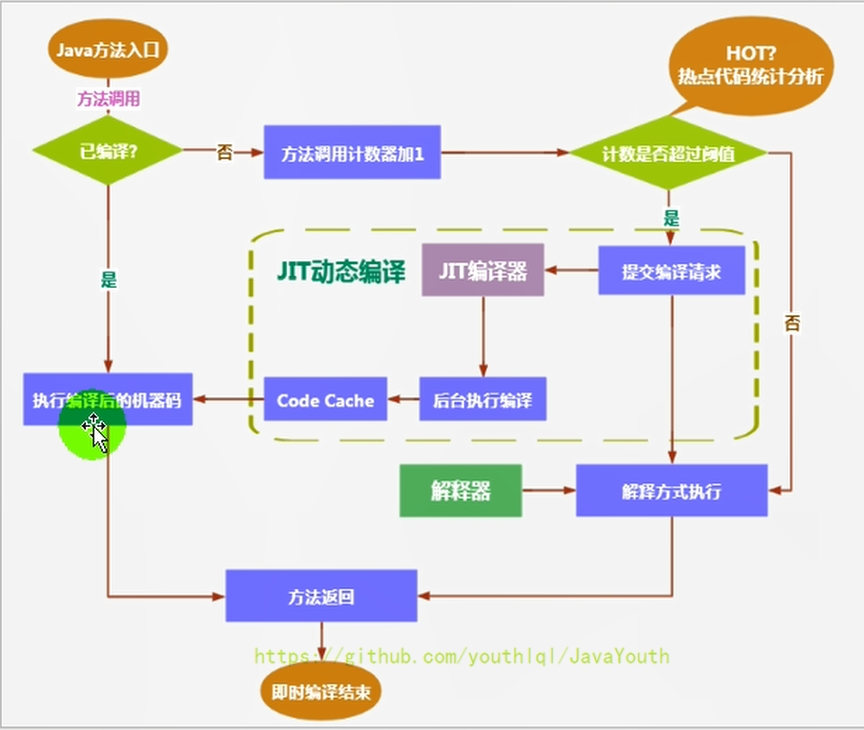 373 |
374 |
375 |
376 | #### 热度衰减
377 |
378 |
379 |
380 | 1. 如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即**一段时间之内方法被调用的次数**。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就称为此方法统计的半衰周期(Counter Half Life Time)(半衰周期是化学中的概念,比如出土的文物通过查看C60来获得文物的年龄)
381 | 2. 进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数 -XX:-UseCounterDecay 来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样的话,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。
382 | 6. 另外,可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位是秒。
383 |
384 |
385 |
386 | #### 回边计数器
387 |
388 | 它的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”(Back Edge)。显然,建立回边计数器统计的目的就是为了触发OSR编译。
389 |
390 |
373 |
374 |
375 |
376 | #### 热度衰减
377 |
378 |
379 |
380 | 1. 如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即**一段时间之内方法被调用的次数**。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就称为此方法统计的半衰周期(Counter Half Life Time)(半衰周期是化学中的概念,比如出土的文物通过查看C60来获得文物的年龄)
381 | 2. 进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数 -XX:-UseCounterDecay 来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样的话,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。
382 | 6. 另外,可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位是秒。
383 |
384 |
385 |
386 | #### 回边计数器
387 |
388 | 它的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”(Back Edge)。显然,建立回边计数器统计的目的就是为了触发OSR编译。
389 |
390 | 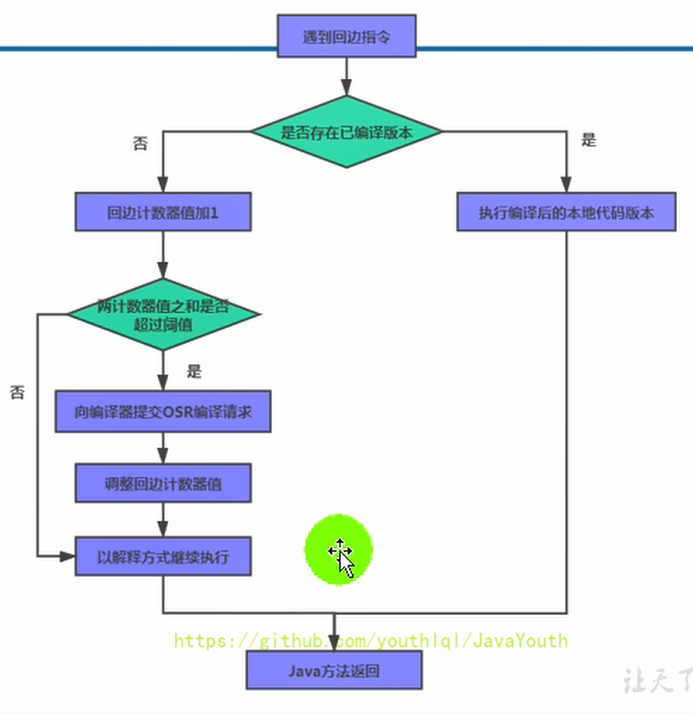 391 |
392 |
393 |
394 | ### HotSpotVM可以设置程序执行方法
395 |
396 | 缺省情况下HotSpot VM是采用解释器与即时编译器并存的架构,当然开发人员可以根据具体的应用场景,通过命令显式地为Java虚拟机指定在运行时到底是完全采用解释器执行,还是完全采用即时编译器执行。如下所示:
397 |
398 | 1. -Xint:完全采用解释器模式执行程序;
399 | 2. -Xcomp:完全采用即时编译器模式执行程序。如果即时编译出现问题,解释器会介入执行
400 | 3. -Xmixed:采用解释器+即时编译器的混合模式共同执行程序。
401 |
402 |
403 |
404 |
391 |
392 |
393 |
394 | ### HotSpotVM可以设置程序执行方法
395 |
396 | 缺省情况下HotSpot VM是采用解释器与即时编译器并存的架构,当然开发人员可以根据具体的应用场景,通过命令显式地为Java虚拟机指定在运行时到底是完全采用解释器执行,还是完全采用即时编译器执行。如下所示:
397 |
398 | 1. -Xint:完全采用解释器模式执行程序;
399 | 2. -Xcomp:完全采用即时编译器模式执行程序。如果即时编译出现问题,解释器会介入执行
400 | 3. -Xmixed:采用解释器+即时编译器的混合模式共同执行程序。
401 |
402 |
403 |
404 |  405 |
406 |
407 |
408 | **代码测试**
409 |
410 | ```java
411 | /**
412 | * 测试解释器模式和JIT编译模式
413 | * -Xint : 6520ms
414 | * -Xcomp : 950ms
415 | * -Xmixed : 936ms
416 | */
417 | public class IntCompTest {
418 | public static void main(String[] args) {
419 |
420 | long start = System.currentTimeMillis();
421 |
422 | testPrimeNumber(1000000);
423 |
424 | long end = System.currentTimeMillis();
425 |
426 | System.out.println("花费的时间为:" + (end - start));
427 |
428 | }
429 |
430 | public static void testPrimeNumber(int count){
431 | for (int i = 0; i < count; i++) {
432 | //计算100以内的质数
433 | label:for(int j = 2;j <= 100;j++){
434 | for(int k = 2;k <= Math.sqrt(j);k++){
435 | if(j % k == 0){
436 | continue label;
437 | }
438 | }
439 | //System.out.println(j);
440 | }
441 |
442 | }
443 | }
444 | }
445 |
446 | ```
447 |
448 | 结论:只用解释器执行是真的慢
449 |
450 | ### HotSpotVM JIT 分类
451 |
452 |
453 |
454 | 在HotSpot VM中内嵌有两个JIT编译器,分别为Client Compiler和Server Compiler,但大多数情况下我们简称为C1编译器 和 C2编译器。开发人员可以通过如下命令显式指定Java虚拟机在运行时到底使用哪一种即时编译器,如下所示:
455 |
456 | 1. -client:指定Java虚拟机运行在Client模式下,并使用C1编译器;
457 | * C1编译器会对字节码进行简单和可靠的优化,耗时短,以达到更快的编译速度。
458 | 2. -server:指定Java虚拟机运行在server模式下,并使用C2编译器。
459 | * C2进行耗时较长的优化,以及激进优化,但优化的代码执行效率更高。(使用C++)
460 |
461 |
462 |
463 |
464 |
465 | ### C1和C2编译器不同的优化策略
466 |
467 | 1. 在不同的编译器上有不同的优化策略,C1编译器上主要有方法内联,去虚拟化、元余消除。
468 | * 方法内联:将引用的函数代码编译到引用点处,这样可以减少栈帧的生成,减少参数传递以及跳转过程
469 | * 去虚拟化:对唯一的实现樊进行内联
470 | * 冗余消除:在运行期间把一些不会执行的代码折叠掉
471 | 2. C2的优化主要是在全局层面,逃逸分析是优化的基础。基于逃逸分析在C2上有如下几种优化:
472 | * 标量替换:用标量值代替聚合对象的属性值
473 | * 栈上分配:对于未逃逸的对象分配对象在栈而不是堆
474 | * 同步消除:清除同步操作,通常指synchronized
475 |
476 | > 也就是说之前的逃逸分析,只有在C2(server模式下)才会触发。那是否说明C1就用不了了?
477 |
478 | ### 分层编译策略
479 |
480 |
481 |
482 | 1. 分层编译(Tiered Compilation)策略:程序解释执行(不开启性能监控)可以触发C1编译,将字节码编译成机器码,可以进行简单优化,也可以加上性能监控,C2编译会根据性能监控信息进行激进优化。
483 |
484 | 2. 不过在Java7版本之后,一旦开发人员在程序中显式指定命令“-server"时,默认将会开启分层编译策略,由C1编译器和C2编译器相互协作共同来执行编译任务。
485 |
486 |
487 |
488 |
489 | 1. 一般来讲,JIT编译出来的机器码性能比解释器解释执行的性能高
490 | 2. C2编译器启动时长比C1慢,系统稳定执行以后,C2编译器执行速度远快于C1编译器
491 |
492 |
493 |
494 | #### Graal 编译器
495 |
496 |
497 |
498 | * 自JDK10起,HotSpot又加入了一个全新的即时编译器:Graal编译器
499 | * 编译效果短短几年时间就追平了G2编译器,未来可期(对应还出现了Graal虚拟机,是有可能替代Hotspot的虚拟机的)
500 | * 目前,带着实验状态标签,需要使用开关参数去激活才能使用
501 |
502 | -XX:+UnlockExperimentalvMOptions -XX:+UseJVMCICompiler
503 |
504 |
505 |
506 |
507 | #### AOT编译器
508 |
509 |
510 |
511 | 1. jdk9引入了AoT编译器(静态提前编译器,Ahead of Time Compiler)
512 |
513 | 2. Java 9引入了实验性AOT编译工具jaotc。它借助了Graal编译器,将所输入的Java类文件转换为机器码,并存放至生成的动态共享库之中。
514 |
515 | 3. 所谓AOT编译,是与即时编译相对立的一个概念。我们知道,即时编译指的是**在程序的运行过程中**,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。而AOT编译指的则是,**在程序运行之前**,便将字节码转换为机器码的过程。
516 |
517 | .java -> .class -> (使用jaotc) -> .so
518 |
519 |
520 |
521 |
522 | **AOT编译器编译器的优缺点**
523 |
524 | **最大的好处:**
525 |
526 | 1. Java虚拟机加载已经预编译成二进制库,可以直接执行。
527 | 2. 不必等待即时编译器的预热,减少Java应用给人带来“第一次运行慢” 的不良体验
528 |
529 |
530 |
531 | **缺点:**
532 |
533 | 1. 破坏了 java “ 一次编译,到处运行”,必须为每个不同的硬件,OS编译对应的发行包
534 | 2. 降低了Java链接过程的动态性,加载的代码在编译器就必须全部已知。
535 | 3. 还需要继续优化中,最初只支持Linux X64 java base
--------------------------------------------------------------------------------
/docs/os/操作系统-IO与零拷贝.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 操作系统-IO与零拷贝
3 | tags:
4 | - 操作系统
5 | - os
6 | - IO
7 | - 零拷贝
8 | categories:
9 | - 操作系统
10 | keywords: 操作系统,IO,零拷贝
11 | description: 基本面试会问到的IO进行了详解,同时本篇文章也对面试以及平时工作中会看到的零拷贝进行了充分的解析。万字长文系列,读到就是赚到。
12 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/os_logo.jpg'
13 | abbrlink: e959db2e
14 | date: 2021-04-08 15:21:58
15 | ---
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 | >
24 | > 1. 本篇文章对于IO相关内容并没有完全讲完,不过也讲的差不多了,基本面试会问到的都讲了,如果想看的更细的,推荐**《操作系统导论》**这本书。
25 | > 2. 同时本篇文章也讲了面试以及平时工作中会看到的零拷贝,因为和IO有比较大的关系,就在这篇文章写一下。
26 | > 3. 零拷贝很多开源项目都用到了,netty,kafka,rocketmq等等。所以还是比较重要的,也是面试常问
27 | > 4. 流程图为processOn手工画的
28 |
29 | # IO
30 |
31 | ## 阻塞与非阻塞 I/O 和 同步与异步 I/O
32 |
33 | > 这应该是大家看到很多文章对IO的一种分类,这只是IO最常见的一种分类。是从是否阻塞,以及是否异步的角度来分类的
34 |
35 | 在这里,我们以一个网络IO来的read来举例,它会涉及到两个东西:一个是产生这个IO的进程,另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
36 |
37 | **阶段1:**等待数据准备
38 |
39 | **阶段2:**数据从内核空间拷贝到用户进程缓冲区的过程
40 |
41 |
42 |
43 | ### 阻塞IO
44 |
45 | 1. 当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。
46 | 2. 于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的TCP包),这个时候**内核**就要等待足够的数据到来。
47 | 3. 而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。
48 | 4. **所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
49 |
50 |
405 |
406 |
407 |
408 | **代码测试**
409 |
410 | ```java
411 | /**
412 | * 测试解释器模式和JIT编译模式
413 | * -Xint : 6520ms
414 | * -Xcomp : 950ms
415 | * -Xmixed : 936ms
416 | */
417 | public class IntCompTest {
418 | public static void main(String[] args) {
419 |
420 | long start = System.currentTimeMillis();
421 |
422 | testPrimeNumber(1000000);
423 |
424 | long end = System.currentTimeMillis();
425 |
426 | System.out.println("花费的时间为:" + (end - start));
427 |
428 | }
429 |
430 | public static void testPrimeNumber(int count){
431 | for (int i = 0; i < count; i++) {
432 | //计算100以内的质数
433 | label:for(int j = 2;j <= 100;j++){
434 | for(int k = 2;k <= Math.sqrt(j);k++){
435 | if(j % k == 0){
436 | continue label;
437 | }
438 | }
439 | //System.out.println(j);
440 | }
441 |
442 | }
443 | }
444 | }
445 |
446 | ```
447 |
448 | 结论:只用解释器执行是真的慢
449 |
450 | ### HotSpotVM JIT 分类
451 |
452 |
453 |
454 | 在HotSpot VM中内嵌有两个JIT编译器,分别为Client Compiler和Server Compiler,但大多数情况下我们简称为C1编译器 和 C2编译器。开发人员可以通过如下命令显式指定Java虚拟机在运行时到底使用哪一种即时编译器,如下所示:
455 |
456 | 1. -client:指定Java虚拟机运行在Client模式下,并使用C1编译器;
457 | * C1编译器会对字节码进行简单和可靠的优化,耗时短,以达到更快的编译速度。
458 | 2. -server:指定Java虚拟机运行在server模式下,并使用C2编译器。
459 | * C2进行耗时较长的优化,以及激进优化,但优化的代码执行效率更高。(使用C++)
460 |
461 |
462 |
463 |
464 |
465 | ### C1和C2编译器不同的优化策略
466 |
467 | 1. 在不同的编译器上有不同的优化策略,C1编译器上主要有方法内联,去虚拟化、元余消除。
468 | * 方法内联:将引用的函数代码编译到引用点处,这样可以减少栈帧的生成,减少参数传递以及跳转过程
469 | * 去虚拟化:对唯一的实现樊进行内联
470 | * 冗余消除:在运行期间把一些不会执行的代码折叠掉
471 | 2. C2的优化主要是在全局层面,逃逸分析是优化的基础。基于逃逸分析在C2上有如下几种优化:
472 | * 标量替换:用标量值代替聚合对象的属性值
473 | * 栈上分配:对于未逃逸的对象分配对象在栈而不是堆
474 | * 同步消除:清除同步操作,通常指synchronized
475 |
476 | > 也就是说之前的逃逸分析,只有在C2(server模式下)才会触发。那是否说明C1就用不了了?
477 |
478 | ### 分层编译策略
479 |
480 |
481 |
482 | 1. 分层编译(Tiered Compilation)策略:程序解释执行(不开启性能监控)可以触发C1编译,将字节码编译成机器码,可以进行简单优化,也可以加上性能监控,C2编译会根据性能监控信息进行激进优化。
483 |
484 | 2. 不过在Java7版本之后,一旦开发人员在程序中显式指定命令“-server"时,默认将会开启分层编译策略,由C1编译器和C2编译器相互协作共同来执行编译任务。
485 |
486 |
487 |
488 |
489 | 1. 一般来讲,JIT编译出来的机器码性能比解释器解释执行的性能高
490 | 2. C2编译器启动时长比C1慢,系统稳定执行以后,C2编译器执行速度远快于C1编译器
491 |
492 |
493 |
494 | #### Graal 编译器
495 |
496 |
497 |
498 | * 自JDK10起,HotSpot又加入了一个全新的即时编译器:Graal编译器
499 | * 编译效果短短几年时间就追平了G2编译器,未来可期(对应还出现了Graal虚拟机,是有可能替代Hotspot的虚拟机的)
500 | * 目前,带着实验状态标签,需要使用开关参数去激活才能使用
501 |
502 | -XX:+UnlockExperimentalvMOptions -XX:+UseJVMCICompiler
503 |
504 |
505 |
506 |
507 | #### AOT编译器
508 |
509 |
510 |
511 | 1. jdk9引入了AoT编译器(静态提前编译器,Ahead of Time Compiler)
512 |
513 | 2. Java 9引入了实验性AOT编译工具jaotc。它借助了Graal编译器,将所输入的Java类文件转换为机器码,并存放至生成的动态共享库之中。
514 |
515 | 3. 所谓AOT编译,是与即时编译相对立的一个概念。我们知道,即时编译指的是**在程序的运行过程中**,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。而AOT编译指的则是,**在程序运行之前**,便将字节码转换为机器码的过程。
516 |
517 | .java -> .class -> (使用jaotc) -> .so
518 |
519 |
520 |
521 |
522 | **AOT编译器编译器的优缺点**
523 |
524 | **最大的好处:**
525 |
526 | 1. Java虚拟机加载已经预编译成二进制库,可以直接执行。
527 | 2. 不必等待即时编译器的预热,减少Java应用给人带来“第一次运行慢” 的不良体验
528 |
529 |
530 |
531 | **缺点:**
532 |
533 | 1. 破坏了 java “ 一次编译,到处运行”,必须为每个不同的硬件,OS编译对应的发行包
534 | 2. 降低了Java链接过程的动态性,加载的代码在编译器就必须全部已知。
535 | 3. 还需要继续优化中,最初只支持Linux X64 java base
--------------------------------------------------------------------------------
/docs/os/操作系统-IO与零拷贝.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 操作系统-IO与零拷贝
3 | tags:
4 | - 操作系统
5 | - os
6 | - IO
7 | - 零拷贝
8 | categories:
9 | - 操作系统
10 | keywords: 操作系统,IO,零拷贝
11 | description: 基本面试会问到的IO进行了详解,同时本篇文章也对面试以及平时工作中会看到的零拷贝进行了充分的解析。万字长文系列,读到就是赚到。
12 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/os_logo.jpg'
13 | abbrlink: e959db2e
14 | date: 2021-04-08 15:21:58
15 | ---
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 | >
24 | > 1. 本篇文章对于IO相关内容并没有完全讲完,不过也讲的差不多了,基本面试会问到的都讲了,如果想看的更细的,推荐**《操作系统导论》**这本书。
25 | > 2. 同时本篇文章也讲了面试以及平时工作中会看到的零拷贝,因为和IO有比较大的关系,就在这篇文章写一下。
26 | > 3. 零拷贝很多开源项目都用到了,netty,kafka,rocketmq等等。所以还是比较重要的,也是面试常问
27 | > 4. 流程图为processOn手工画的
28 |
29 | # IO
30 |
31 | ## 阻塞与非阻塞 I/O 和 同步与异步 I/O
32 |
33 | > 这应该是大家看到很多文章对IO的一种分类,这只是IO最常见的一种分类。是从是否阻塞,以及是否异步的角度来分类的
34 |
35 | 在这里,我们以一个网络IO来的read来举例,它会涉及到两个东西:一个是产生这个IO的进程,另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
36 |
37 | **阶段1:**等待数据准备
38 |
39 | **阶段2:**数据从内核空间拷贝到用户进程缓冲区的过程
40 |
41 |
42 |
43 | ### 阻塞IO
44 |
45 | 1. 当用户进程进行recvfrom这个系统调用,内核就开始了IO的第一个阶段:等待数据准备。
46 | 2. 于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的TCP包),这个时候**内核**就要等待足够的数据到来。
47 | 3. 而在用户进程这边,整 个进程会被阻塞。当**内核**一直等到数据准备好了,它就会将数据从**内核**中拷贝到用户内存,然后**内核**返回果,用户进程才解除 block的状态,重新运行起来。
48 | 4. **所以,blocking IO的特点就是在IO执行的两个阶段都被block了。**
49 |
50 | 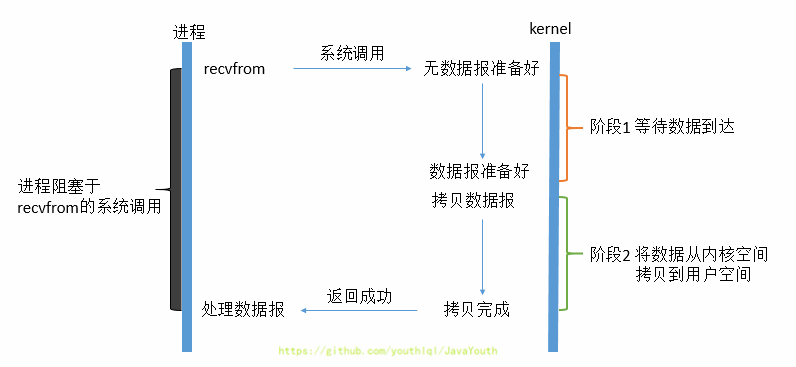 51 |
52 |
53 |
54 | ### 非阻塞IO
55 |
56 | 1. 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
57 | 2. 从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好。用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
58 | 3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
59 | 4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
60 |
61 |
51 |
52 |
53 |
54 | ### 非阻塞IO
55 |
56 | 1. 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
57 | 2. 从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好。用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
58 | 3. 虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
59 | 4. **所以,用户进程第一个阶段不是阻塞的,需要不断的主动询问内核数据好了没有;第二个阶段依然总是阻塞的。**
60 |
61 | 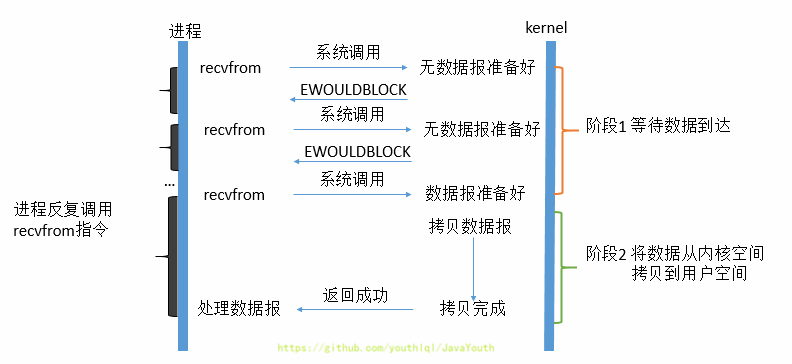 62 |
63 |
64 |
65 | ### IO多路复用
66 |
67 | > 1. 应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
68 | >
69 | > 2. 为了解决这种傻乎乎轮询方式,于是 **I/O 多路复用**技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
70 | >
71 | > 3. 这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
72 | >
73 | > 下面是大概的过程
74 |
75 | 1. IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作
76 | 2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
77 | 3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
78 |
79 |
62 |
63 |
64 |
65 | ### IO多路复用
66 |
67 | > 1. 应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
68 | >
69 | > 2. 为了解决这种傻乎乎轮询方式,于是 **I/O 多路复用**技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
70 | >
71 | > 3. 这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
72 | >
73 | > 下面是大概的过程
74 |
75 | 1. IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作
76 | 2. 它的基本原理就是select /epoll这个函数会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程,正式发起read请求。
77 | 3. 从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket(也就是数据准备好了的socket),即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
78 |
79 | 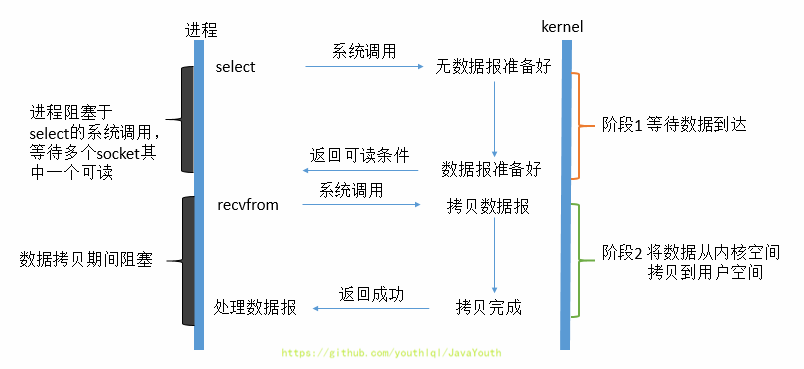 80 |
81 | **select函数**
82 |
83 | > handle_events:实现事件循环
84 | >
85 | > handle_event:进行读/写等操作
86 |
87 | 1. 使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
88 | 2. 如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
89 | 3. IO多路复用模型使用了Reactor设计模式实现了这一机制。
90 | 4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
91 | 5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
92 |
93 |
80 |
81 | **select函数**
82 |
83 | > handle_events:实现事件循环
84 | >
85 | > handle_event:进行读/写等操作
86 |
87 | 1. 使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
88 | 2. 如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
89 | 3. IO多路复用模型使用了Reactor设计模式实现了这一机制。
90 | 4. 通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时(就是数据准备好的时候),则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。
91 | 5. 由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。(一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。)
92 |
93 | 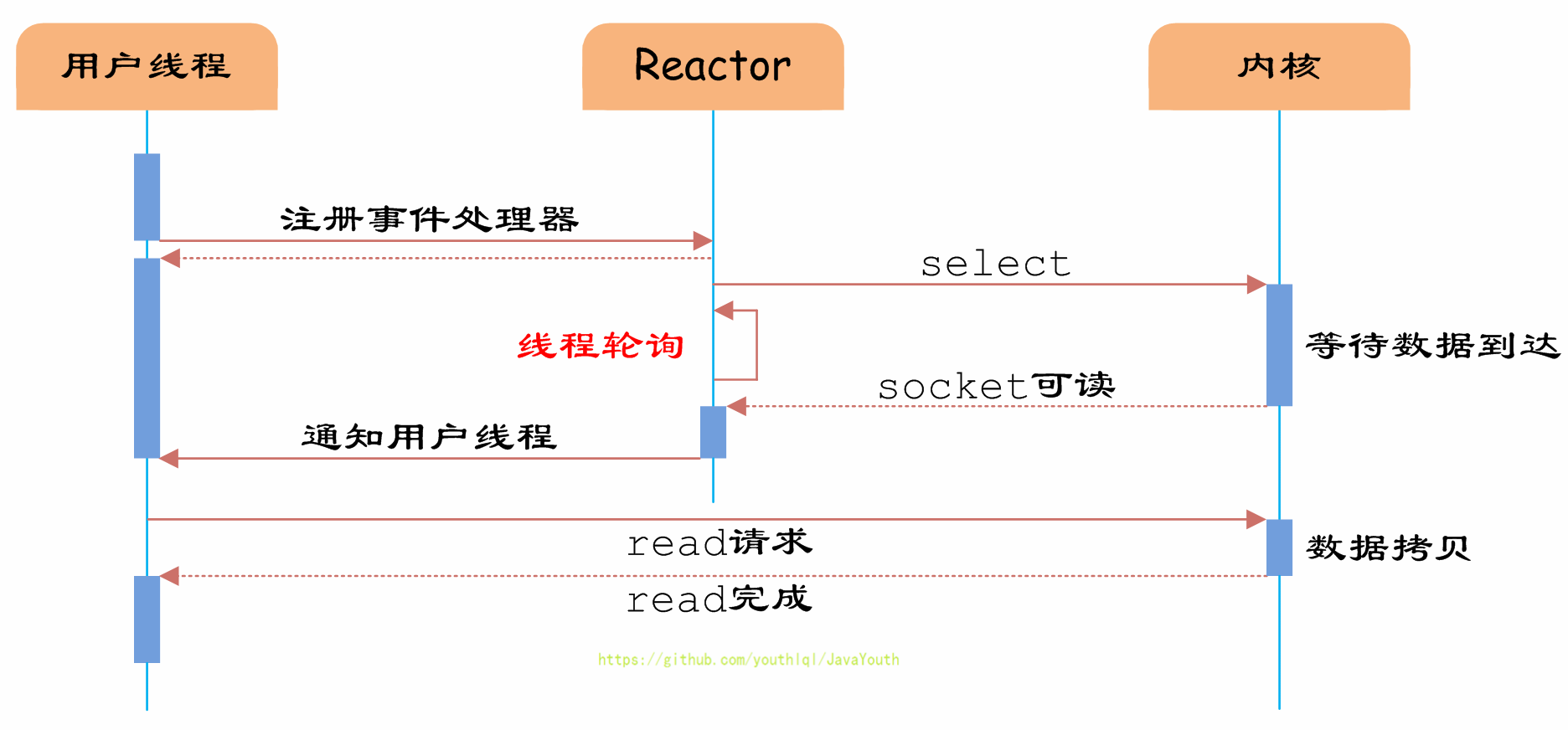 94 |
95 |
96 |
97 | ### 异步IO
98 |
99 | - 实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用**都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用进程空间,这个阶段都是需要等待的。**
100 | - 而真正的**异步 I/O** 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待
101 |
102 |
103 |
104 | 1. 真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,由用户线程自行读取数据、处理数据。
105 | 2. 而在异步IO模型中,用户进程发起read操作之后,立刻就可以开始去做其它的事。
106 | 3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
107 | 4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
108 |
109 |
94 |
95 |
96 |
97 | ### 异步IO
98 |
99 | - 实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用**都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用进程空间,这个阶段都是需要等待的。**
100 | - 而真正的**异步 I/O** 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待
101 |
102 |
103 |
104 | 1. 真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,由用户线程自行读取数据、处理数据。
105 | 2. 而在异步IO模型中,用户进程发起read操作之后,立刻就可以开始去做其它的事。
106 | 3. 而另一方面,从**内核**的角度,当它受到一个异步读之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都 完成之后,**内核**会给用户进程发送一个信号,告诉它read操作完成了,用户线程直接使用即可。 在这整个过程中,进程完全没有被阻塞。
107 | 4. 异步IO模型使用了Proactor设计模式实现了这一机制。**(具体怎么搞得,看上面的文章链接)**
108 |
109 | 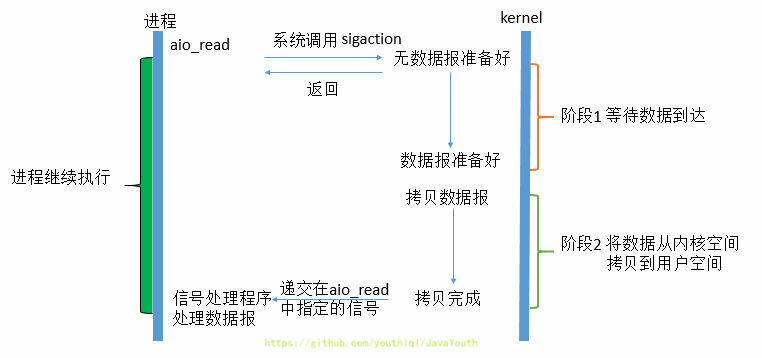 110 |
111 |
112 |
113 | > 有一篇文章以实际例子讲解的比较形象
114 | >
115 | > [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
116 |
117 | ## 直接与非直接I/O
118 |
119 | 1. 磁盘 I/O 是非常慢的,所以 Linux 内核通过减少磁盘 I/O 次数来减少I/O时间,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是【页缓存:PageCache】,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
120 |
121 | 2. **根据是「否利用操作系统的页缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O**:
122 |
123 | * 直接 I/O,不会发生内核缓存和用户程序之间数据复制,跳过操作系统的页缓存,直接经过文件系统访问磁盘。
124 | * 非直接 I/O,正相反,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
125 |
126 | 3. 想要实现直接I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接I/O。
127 |
128 |
129 |
130 | 在进行写操作的时候以下几种场景会触发内核缓存的数据写入磁盘:
131 |
132 | > 以下摘自---**《深入linux内核架构》**
133 | >
134 | > **1、**
135 | >
136 | > 可能因不同原因、在不同的时机触发不同的刷出数据的机制。
137 | >
138 | > - 周期性的内核线程,将扫描脏页的链表,并根据页变脏的时间,来选择一些页写回。如果系统不是太忙于写操作,那么在脏页的数目,以及刷出页所需的硬盘访问操作对系统造成的负荷之间,有一个可接受的比例。
139 | >
140 | > - 如果系统中的脏页过多(例如,一个大型的写操作可能造成这种情况),内核将触发进一步的机制对脏页与后备存储器进行同步,直至脏页的数目降低到一个可接受的程度。而“脏页过多”和“可接受的程度”到底意味着什么,此时尚是一个不确定的问题,将在下文讨论。
141 | >
142 | > - 内核的各个组件可能要求数据必须在特定事件发生时同步,例如在重新装载文件系统时。
143 | >
144 | > 前两种机制由内核线程pdflush实现,该线程执行同步代码,而第三种机制可能由内核中的多处代码触发。
145 | >
146 | >
147 | >
148 | > **2、**
149 | >
150 | > 可以从用户空间通过各种系统调用来启用内核同步机制,以确保内存和块设备之间(完全或部分)的数据完整性。有如下3个基本选项可用。
151 | >
152 | > 1. 使用sync系统调用刷出整个缓存内容。在某些情况下,这可能非常耗时。
153 | >
154 | > 2. 各个文件的内容(以及相关inode的元数据)可以被传输到底层的块设备。内核为此提供了fsync和fdatasync系统调用。尽管sync通常与上文提到的系统工具sync联合使用,但fsync和fdatasync则专用于特定的应用程序,因为刷出的文件是通过特定于进程的文件描述符(在第8章介绍)来选择的。因而,没有一个通用的用户空间工具可以回写特定的文件。
155 | > 3. msync用于同步内存映射
156 |
157 | 1、我们先来说脏页
158 |
159 | 脏页-linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
160 |
161 | 2、通过对上面的解读,我们用通俗的语言翻译以下
162 |
163 | - 周期性的扫描脏页,如果发现脏页存在的时间过了某一时间时,也会把该脏页的数据刷到磁盘上
164 |
165 | * 当发现脏页太多的时候,内核会把一定数量的脏页数据写到磁盘上;
166 | * 用户主动调用 `sync`,`fsync`,`fdatasync`,内核缓存会刷到磁盘上;
167 |
168 | ## 缓冲与非缓冲I/O
169 |
170 | 1. 文件操作的标准库是可以实现数据的缓存,那么**根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O**:
171 |
172 | * 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
173 | * 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
174 |
175 | 2. 这里所说的「缓冲」特指标准库内部实现的缓冲。比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数。
176 | 3. 非缓冲io,因为没有标准库提供的缓冲,只能用操作系统的缓存区,会造成很多次的系统调用,降低效率
177 | 4. 带缓存IO也叫标准IO,符合ANSI C 的标准IO处理,不依赖系统内核,所以移植性强,我们使用标准IO操作很多时候是为了减少对read()和write()的系统调用次数,带缓存IO其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。
178 |
179 |
180 |
181 | > 标准 I/O 库提供缓冲的目的是尽可能减少使用 read 和 write 调用的次数(见图 3-6,其中显示了在不同缓冲区长度情况下,执行 I/O 所需的 CPU 时间量)。它也对每个 I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。遗憾的是,标准 I/O 库最令人迷惑的也是它的缓冲。
182 | >
183 | > 标准 I/O提供了以下3 种类型的缓冲。
184 | >
185 | > 1. 全缓冲。在这种情况下,在填满标准 I/O 缓冲区后才进行实际 I/O 操作。对于驻留在磁盘上的文件通常是由标准 IO库实施全缓冲的。在一个流上执行第一次 I/O 操作时,相关标准 I/O函数通常调用 malloc (见7.8 节)获得需使用的缓冲区。
术语冲洗(fush)说明标准 UO 缓冲区的写操作。缓冲区可由标准 I/O 例程自动地冲洗(例如,当填满一个缓冲区时),或者可以调用函数 fflush 冲洗一个流。值得注意的是,在 UNTX环境中,fush有两种意思。在标准 I/O库方面,flush(冲洗)意味着将缓冲区中的内容写到磁盘上(该缓冲区可能只是部分填满的)。在终端驱动程序方面(例如,在第 18章中所述的tcflush函数),flush(刷清)表示丢弃已存储在缓冲区中的数据。
186 | >2. 行缓冲。在这种情况下,当在输入和输出中遇到换行符时,标准 I/O 库执行 I/O 操作。这允许我们一次输出一个字符(用标准 I/O 函数fputc),但只有在写了一行之后才进行实际 I/O操作。当流涉及一个终端时(如标准输入和标准输出),通常使用行缓冲。
对于行缓冲有两个限制。第一,因为标准 I/O 库用来收集每一行的缓冲区的长度是固定的。所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行 I/O 操作。第二,任何时候只要通过标准 I/O 库要求从(a)一个不带缓冲的流,或者(b)一个行缓冲的流(它从内核请求需要 数据)得到输入数据,那么就会冲洗所有行缓冲输出流。在(b)中带了一个在括号中的说明,其理由是,所需的数据可能已在该缓冲区中,它并不要求一定从内核读数据。很明显,从一个不带缓冲的流中输入(即(a)项)需要从内核获得数据。
187 | > 3. 不带缓冲。标准 I/O 库不对字符进行缓冲存储,例如,若用标准 I/O 函数 fputs 写 15个字符到不带缓冲的流中,我们就期望这 15 个字符能立即输出,很可能使用 3.8 节的write 函数将这些字符写到相关联的打开文件中。
188 |
189 |
190 |
191 | # 零拷贝
192 |
193 | > 讲零拷贝前,讲一下前置知识
194 |
195 | ## 标准设备
196 |
197 | 1. 来看一个标准设备(不是真实存在的,相当于一个逻辑上抽象的东西),通过它来帮助我们更好地理解设备交互的机制。可以看到一个包含两部分重要组件的设备。第一部分是向系统其他部分展现的硬件接口(interface)。同软件一样,硬件也需要一些接口,让系统软件来控制它的操作。因此,所有设备都有自己的特定接口以及典型交互的协议。
198 |
199 |
110 |
111 |
112 |
113 | > 有一篇文章以实际例子讲解的比较形象
114 | >
115 | > [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
116 |
117 | ## 直接与非直接I/O
118 |
119 | 1. 磁盘 I/O 是非常慢的,所以 Linux 内核通过减少磁盘 I/O 次数来减少I/O时间,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是【页缓存:PageCache】,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
120 |
121 | 2. **根据是「否利用操作系统的页缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O**:
122 |
123 | * 直接 I/O,不会发生内核缓存和用户程序之间数据复制,跳过操作系统的页缓存,直接经过文件系统访问磁盘。
124 | * 非直接 I/O,正相反,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
125 |
126 | 3. 想要实现直接I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接I/O。
127 |
128 |
129 |
130 | 在进行写操作的时候以下几种场景会触发内核缓存的数据写入磁盘:
131 |
132 | > 以下摘自---**《深入linux内核架构》**
133 | >
134 | > **1、**
135 | >
136 | > 可能因不同原因、在不同的时机触发不同的刷出数据的机制。
137 | >
138 | > - 周期性的内核线程,将扫描脏页的链表,并根据页变脏的时间,来选择一些页写回。如果系统不是太忙于写操作,那么在脏页的数目,以及刷出页所需的硬盘访问操作对系统造成的负荷之间,有一个可接受的比例。
139 | >
140 | > - 如果系统中的脏页过多(例如,一个大型的写操作可能造成这种情况),内核将触发进一步的机制对脏页与后备存储器进行同步,直至脏页的数目降低到一个可接受的程度。而“脏页过多”和“可接受的程度”到底意味着什么,此时尚是一个不确定的问题,将在下文讨论。
141 | >
142 | > - 内核的各个组件可能要求数据必须在特定事件发生时同步,例如在重新装载文件系统时。
143 | >
144 | > 前两种机制由内核线程pdflush实现,该线程执行同步代码,而第三种机制可能由内核中的多处代码触发。
145 | >
146 | >
147 | >
148 | > **2、**
149 | >
150 | > 可以从用户空间通过各种系统调用来启用内核同步机制,以确保内存和块设备之间(完全或部分)的数据完整性。有如下3个基本选项可用。
151 | >
152 | > 1. 使用sync系统调用刷出整个缓存内容。在某些情况下,这可能非常耗时。
153 | >
154 | > 2. 各个文件的内容(以及相关inode的元数据)可以被传输到底层的块设备。内核为此提供了fsync和fdatasync系统调用。尽管sync通常与上文提到的系统工具sync联合使用,但fsync和fdatasync则专用于特定的应用程序,因为刷出的文件是通过特定于进程的文件描述符(在第8章介绍)来选择的。因而,没有一个通用的用户空间工具可以回写特定的文件。
155 | > 3. msync用于同步内存映射
156 |
157 | 1、我们先来说脏页
158 |
159 | 脏页-linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
160 |
161 | 2、通过对上面的解读,我们用通俗的语言翻译以下
162 |
163 | - 周期性的扫描脏页,如果发现脏页存在的时间过了某一时间时,也会把该脏页的数据刷到磁盘上
164 |
165 | * 当发现脏页太多的时候,内核会把一定数量的脏页数据写到磁盘上;
166 | * 用户主动调用 `sync`,`fsync`,`fdatasync`,内核缓存会刷到磁盘上;
167 |
168 | ## 缓冲与非缓冲I/O
169 |
170 | 1. 文件操作的标准库是可以实现数据的缓存,那么**根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O**:
171 |
172 | * 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
173 | * 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
174 |
175 | 2. 这里所说的「缓冲」特指标准库内部实现的缓冲。比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数。
176 | 3. 非缓冲io,因为没有标准库提供的缓冲,只能用操作系统的缓存区,会造成很多次的系统调用,降低效率
177 | 4. 带缓存IO也叫标准IO,符合ANSI C 的标准IO处理,不依赖系统内核,所以移植性强,我们使用标准IO操作很多时候是为了减少对read()和write()的系统调用次数,带缓存IO其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。
178 |
179 |
180 |
181 | > 标准 I/O 库提供缓冲的目的是尽可能减少使用 read 和 write 调用的次数(见图 3-6,其中显示了在不同缓冲区长度情况下,执行 I/O 所需的 CPU 时间量)。它也对每个 I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。遗憾的是,标准 I/O 库最令人迷惑的也是它的缓冲。
182 | >
183 | > 标准 I/O提供了以下3 种类型的缓冲。
184 | >
185 | > 1. 全缓冲。在这种情况下,在填满标准 I/O 缓冲区后才进行实际 I/O 操作。对于驻留在磁盘上的文件通常是由标准 IO库实施全缓冲的。在一个流上执行第一次 I/O 操作时,相关标准 I/O函数通常调用 malloc (见7.8 节)获得需使用的缓冲区。
术语冲洗(fush)说明标准 UO 缓冲区的写操作。缓冲区可由标准 I/O 例程自动地冲洗(例如,当填满一个缓冲区时),或者可以调用函数 fflush 冲洗一个流。值得注意的是,在 UNTX环境中,fush有两种意思。在标准 I/O库方面,flush(冲洗)意味着将缓冲区中的内容写到磁盘上(该缓冲区可能只是部分填满的)。在终端驱动程序方面(例如,在第 18章中所述的tcflush函数),flush(刷清)表示丢弃已存储在缓冲区中的数据。
186 | >2. 行缓冲。在这种情况下,当在输入和输出中遇到换行符时,标准 I/O 库执行 I/O 操作。这允许我们一次输出一个字符(用标准 I/O 函数fputc),但只有在写了一行之后才进行实际 I/O操作。当流涉及一个终端时(如标准输入和标准输出),通常使用行缓冲。
对于行缓冲有两个限制。第一,因为标准 I/O 库用来收集每一行的缓冲区的长度是固定的。所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行 I/O 操作。第二,任何时候只要通过标准 I/O 库要求从(a)一个不带缓冲的流,或者(b)一个行缓冲的流(它从内核请求需要 数据)得到输入数据,那么就会冲洗所有行缓冲输出流。在(b)中带了一个在括号中的说明,其理由是,所需的数据可能已在该缓冲区中,它并不要求一定从内核读数据。很明显,从一个不带缓冲的流中输入(即(a)项)需要从内核获得数据。
187 | > 3. 不带缓冲。标准 I/O 库不对字符进行缓冲存储,例如,若用标准 I/O 函数 fputs 写 15个字符到不带缓冲的流中,我们就期望这 15 个字符能立即输出,很可能使用 3.8 节的write 函数将这些字符写到相关联的打开文件中。
188 |
189 |
190 |
191 | # 零拷贝
192 |
193 | > 讲零拷贝前,讲一下前置知识
194 |
195 | ## 标准设备
196 |
197 | 1. 来看一个标准设备(不是真实存在的,相当于一个逻辑上抽象的东西),通过它来帮助我们更好地理解设备交互的机制。可以看到一个包含两部分重要组件的设备。第一部分是向系统其他部分展现的硬件接口(interface)。同软件一样,硬件也需要一些接口,让系统软件来控制它的操作。因此,所有设备都有自己的特定接口以及典型交互的协议。
198 |
199 |  200 |
201 | 2. 第2部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。
202 |
203 | ## 标准协议
204 |
205 | 1. 在上图中,一个(简化的)设备接口包含3个寄存器:一个状态(status)寄存器,可以读取并查看设备的当前状态;一个命令(command)寄存器,用于通知设备执行某个具体任务;一个数据(data)寄存器,将数据传给设备或从设备接收数据。通过读写这些寄存器,操作系统可以控制设备的行为
206 | 2. 我们现在来描述操作系统与该设备的典型交互,以便让设备为它做某事。协议如下:
207 |
208 | ```c++
209 | While (STATUS == BUSY);//wait until device is not busy
210 |
211 | Write data to DATA register
212 | Write command to COMMAND register
213 | (Doing so starts the device and executes the command)
214 |
215 | While (STATUS == BUSY);//wait until device is done with your request
216 | ```
217 |
218 | 3. 该协议包含4步。
219 | - 第1步,操作系统通过反复读取状态寄存器,等待设备进入可以接收命令的就绪状态。我们称之为轮询(polling)设备(基本上,就是问它正在做什么)。
220 | - 第2步,操作系统下发数据到数据寄存器。例如,你可以想象如果这是一个磁盘,需要多次写入操作,将一个磁盘块(比如4KB)传递给设备。如果主CPU参与数据移动(就像这个示例协议一样),我们就称之为编程的I/O(programmedI/O,PIO)。
221 | - 第3步,操作系统将命令写入命令寄存器;这样设备就知道数据已经准备好了,它应该开始执行命令。最后一步,操作系统再次通过不断轮询设备,等待并判断设备是否执行完成命令(有可能得到一个指示成功或失败的错误码)。
222 | 4. 这个简单的协议好处是足够简单并且有效。但是难免会有一些低效和不方便。我们注意到这个协议存在的第一个问题就是轮询过程比较低效,在等待设备执行完成命令时浪费大量CPU时间,如果此时操作系统可以切换执行下一个就绪进程,就可以大大提高CPU的利用率。
223 |
224 | > 关键问题:如何减少轮询开销操作系统检查设备状态时如何避免频繁轮询,从而降低管理设备的CPU开销?
225 |
226 | ## 利用中断减少CPU开销
227 |
228 | **概念:**有了中断后,CPU 不再需要不断轮询设备,而是向设备发出一个请求,然后就可以让对应进程睡眠,切换执行其他任务。当设备完成了自身操作,会抛出一个硬件中断,引发CPU跳转执行操作系统预先定义好的中断服务例程(InterruptService Routine,ISR),或更为简单的中断处理程序(interrupt handler)。中断处理程序是一小段操作系统代码,它会结束之前的请求(比如从设备读取到了数据或者错误码)并且唤醒等待I/O的进程继续执行。
229 |
230 | **例子:**
231 |
232 | 1. 没有中断时:进程1在CPU上运行一段时间(对应CPU那一行上重复的1),然后发出一个读取数据的I/O请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成I/O操作(对应其中的p)。当设备完成请求的操作后,进程1又可以继续运行。
233 |
234 |
200 |
201 | 2. 第2部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。
202 |
203 | ## 标准协议
204 |
205 | 1. 在上图中,一个(简化的)设备接口包含3个寄存器:一个状态(status)寄存器,可以读取并查看设备的当前状态;一个命令(command)寄存器,用于通知设备执行某个具体任务;一个数据(data)寄存器,将数据传给设备或从设备接收数据。通过读写这些寄存器,操作系统可以控制设备的行为
206 | 2. 我们现在来描述操作系统与该设备的典型交互,以便让设备为它做某事。协议如下:
207 |
208 | ```c++
209 | While (STATUS == BUSY);//wait until device is not busy
210 |
211 | Write data to DATA register
212 | Write command to COMMAND register
213 | (Doing so starts the device and executes the command)
214 |
215 | While (STATUS == BUSY);//wait until device is done with your request
216 | ```
217 |
218 | 3. 该协议包含4步。
219 | - 第1步,操作系统通过反复读取状态寄存器,等待设备进入可以接收命令的就绪状态。我们称之为轮询(polling)设备(基本上,就是问它正在做什么)。
220 | - 第2步,操作系统下发数据到数据寄存器。例如,你可以想象如果这是一个磁盘,需要多次写入操作,将一个磁盘块(比如4KB)传递给设备。如果主CPU参与数据移动(就像这个示例协议一样),我们就称之为编程的I/O(programmedI/O,PIO)。
221 | - 第3步,操作系统将命令写入命令寄存器;这样设备就知道数据已经准备好了,它应该开始执行命令。最后一步,操作系统再次通过不断轮询设备,等待并判断设备是否执行完成命令(有可能得到一个指示成功或失败的错误码)。
222 | 4. 这个简单的协议好处是足够简单并且有效。但是难免会有一些低效和不方便。我们注意到这个协议存在的第一个问题就是轮询过程比较低效,在等待设备执行完成命令时浪费大量CPU时间,如果此时操作系统可以切换执行下一个就绪进程,就可以大大提高CPU的利用率。
223 |
224 | > 关键问题:如何减少轮询开销操作系统检查设备状态时如何避免频繁轮询,从而降低管理设备的CPU开销?
225 |
226 | ## 利用中断减少CPU开销
227 |
228 | **概念:**有了中断后,CPU 不再需要不断轮询设备,而是向设备发出一个请求,然后就可以让对应进程睡眠,切换执行其他任务。当设备完成了自身操作,会抛出一个硬件中断,引发CPU跳转执行操作系统预先定义好的中断服务例程(InterruptService Routine,ISR),或更为简单的中断处理程序(interrupt handler)。中断处理程序是一小段操作系统代码,它会结束之前的请求(比如从设备读取到了数据或者错误码)并且唤醒等待I/O的进程继续执行。
229 |
230 | **例子:**
231 |
232 | 1. 没有中断时:进程1在CPU上运行一段时间(对应CPU那一行上重复的1),然后发出一个读取数据的I/O请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成I/O操作(对应其中的p)。当设备完成请求的操作后,进程1又可以继续运行。
233 |
234 |  235 |
236 | 2. 有了中断后:中断允许计算与I/O重叠(overlap),这是提高CPU利用率的关键。我们利用中断并允许重叠,操作系统就可以在等待磁盘操作时做其他事情。
237 |
238 |
235 |
236 | 2. 有了中断后:中断允许计算与I/O重叠(overlap),这是提高CPU利用率的关键。我们利用中断并允许重叠,操作系统就可以在等待磁盘操作时做其他事情。
237 |
238 |  239 |
240 | - 在这个例子中,在磁盘处理进程1的请求时,操作系统在CPU上运行进程2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程1继续运行。这样,在这段时间,无论CPU还是磁盘都可以有效地利用。
241 |
242 | > 注意,使用中断并非总是最佳方案。假如有一个非常高性能的设备,它处理请求很快:通常在CPU第一次轮询时就可以返回结果。此时如果使用中断,反而会使系统变慢:切换到其他进程,处理中断,再切换回之前的进程代价不小。因此,如果设备非常快,那么最好的办法反而是轮询。如果设备比较慢,那么采用允许发生重叠的中断更好。如果设备的速度未知,或者时快时慢,可以考虑使用混合(hybrid)策略,先尝试轮询一小段时间,如果设备没有完成操作,此时再使用中断。这种两阶段(two-phased)的办法可以实现两种方法的好处。
243 |
244 | 中断仍旧存在的缺点:
245 |
246 |
239 |
240 | - 在这个例子中,在磁盘处理进程1的请求时,操作系统在CPU上运行进程2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程1继续运行。这样,在这段时间,无论CPU还是磁盘都可以有效地利用。
241 |
242 | > 注意,使用中断并非总是最佳方案。假如有一个非常高性能的设备,它处理请求很快:通常在CPU第一次轮询时就可以返回结果。此时如果使用中断,反而会使系统变慢:切换到其他进程,处理中断,再切换回之前的进程代价不小。因此,如果设备非常快,那么最好的办法反而是轮询。如果设备比较慢,那么采用允许发生重叠的中断更好。如果设备的速度未知,或者时快时慢,可以考虑使用混合(hybrid)策略,先尝试轮询一小段时间,如果设备没有完成操作,此时再使用中断。这种两阶段(two-phased)的办法可以实现两种方法的好处。
243 |
244 | 中断仍旧存在的缺点:
245 |
246 | 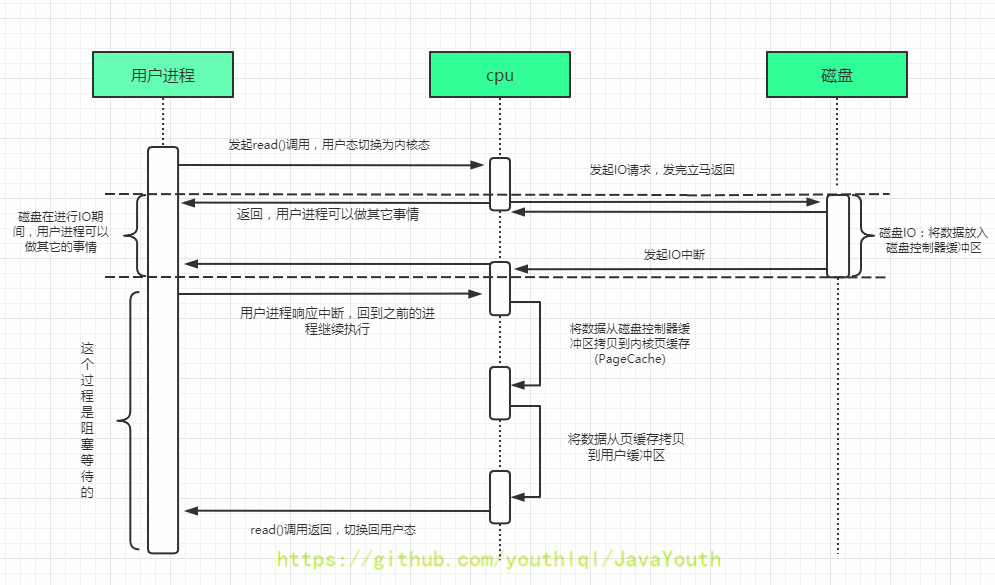 247 |
248 | IO过程简述:
249 |
250 | 1. 用户进程调用 read 方法,向cpu发出 I/O 请求
251 | 2. cpu向磁盘发起IO请求给磁盘控制器,**之后立马返回**。返回之后cpu可以切换到其它进程执行其他任务
252 | 3. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**
253 | 4. CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据读进内核的页缓存【这个过程是可以用DMA进行优化的】。
254 | 5. 接着将数据从内核页缓存拷贝到用户进程空间【这个过程想要优化,只能用到我们上面说的异步IO】
255 | 6. 最后read()调用返回。
256 |
257 | > 注意:
258 | >
259 | > 1. 这里很多博客画的图是错的,讲的也是错的。使用中断减少CPU开销时,在进行磁盘IO期间,CPU可以执行其他的进程不必等待磁盘IO。【因为这是《操作系统导论》里的原话】
260 |
261 |
262 |
263 | ## 利用DMA进行更高效的数据传送
264 |
265 | > 这里为什么要特别强调原文呢?因为可以让读者读的安心,这本经典书籍总不会出错吧
266 |
267 | > 《操作系统导论》原文:
268 | >
269 | > 标准协议还有一点需要我们注意。具体来说,如果使用编程的I/O将一大块数据传给设备,CPU又会因为琐碎的任务而变得负载很重,浪费了时间和算力,本来更好是用于运行其他进程。下面的时间线展示了这个问题:
270 | >
271 | >
247 |
248 | IO过程简述:
249 |
250 | 1. 用户进程调用 read 方法,向cpu发出 I/O 请求
251 | 2. cpu向磁盘发起IO请求给磁盘控制器,**之后立马返回**。返回之后cpu可以切换到其它进程执行其他任务
252 | 3. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**
253 | 4. CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据读进内核的页缓存【这个过程是可以用DMA进行优化的】。
254 | 5. 接着将数据从内核页缓存拷贝到用户进程空间【这个过程想要优化,只能用到我们上面说的异步IO】
255 | 6. 最后read()调用返回。
256 |
257 | > 注意:
258 | >
259 | > 1. 这里很多博客画的图是错的,讲的也是错的。使用中断减少CPU开销时,在进行磁盘IO期间,CPU可以执行其他的进程不必等待磁盘IO。【因为这是《操作系统导论》里的原话】
260 |
261 |
262 |
263 | ## 利用DMA进行更高效的数据传送
264 |
265 | > 这里为什么要特别强调原文呢?因为可以让读者读的安心,这本经典书籍总不会出错吧
266 |
267 | > 《操作系统导论》原文:
268 | >
269 | > 标准协议还有一点需要我们注意。具体来说,如果使用编程的I/O将一大块数据传给设备,CPU又会因为琐碎的任务而变得负载很重,浪费了时间和算力,本来更好是用于运行其他进程。下面的时间线展示了这个问题:
270 | >
271 | >  272 | >
273 | > 进程1在运行过程中需要向磁盘写一些数据,所以它开始进行I/O操作,将数据从内存拷贝到磁盘(其中标示c的过程)。**拷贝结束后,磁盘上的I/O操作开始执行,此时CPU才可以处理其他请求。**
274 |
275 | 也就是说在从**内存拷贝到磁盘或者从磁盘拷贝到内存**这个过程是可以使用DMA(Direct Memory Access)优化的,怎么优化呢?
276 |
277 | > 原文:
278 | >
279 | > DMA工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉DMA引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当DMA的任务完成后,DMA控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
280 | >
281 | >
272 | >
273 | > 进程1在运行过程中需要向磁盘写一些数据,所以它开始进行I/O操作,将数据从内存拷贝到磁盘(其中标示c的过程)。**拷贝结束后,磁盘上的I/O操作开始执行,此时CPU才可以处理其他请求。**
274 |
275 | 也就是说在从**内存拷贝到磁盘或者从磁盘拷贝到内存**这个过程是可以使用DMA(Direct Memory Access)优化的,怎么优化呢?
276 |
277 | > 原文:
278 | >
279 | > DMA工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉DMA引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当DMA的任务完成后,DMA控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
280 | >
281 | > 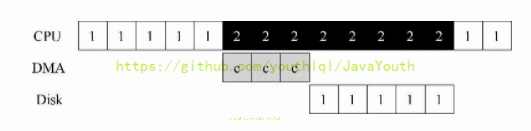 282 | >
283 | > 从时间线中可以看到,数据的拷贝工作都是由DMA控制器来完成的。因为CPU在此时是空闲的,所以操作系统可以让它做一些其他事情,比如此处调度进程2到CPU来运行。因此进程2在进程1再次运行之前可以使用更多的CPU。
284 |
285 | 为了更好理解,看图:
286 |
287 |
282 | >
283 | > 从时间线中可以看到,数据的拷贝工作都是由DMA控制器来完成的。因为CPU在此时是空闲的,所以操作系统可以让它做一些其他事情,比如此处调度进程2到CPU来运行。因此进程2在进程1再次运行之前可以使用更多的CPU。
284 |
285 | 为了更好理解,看图:
286 |
287 | 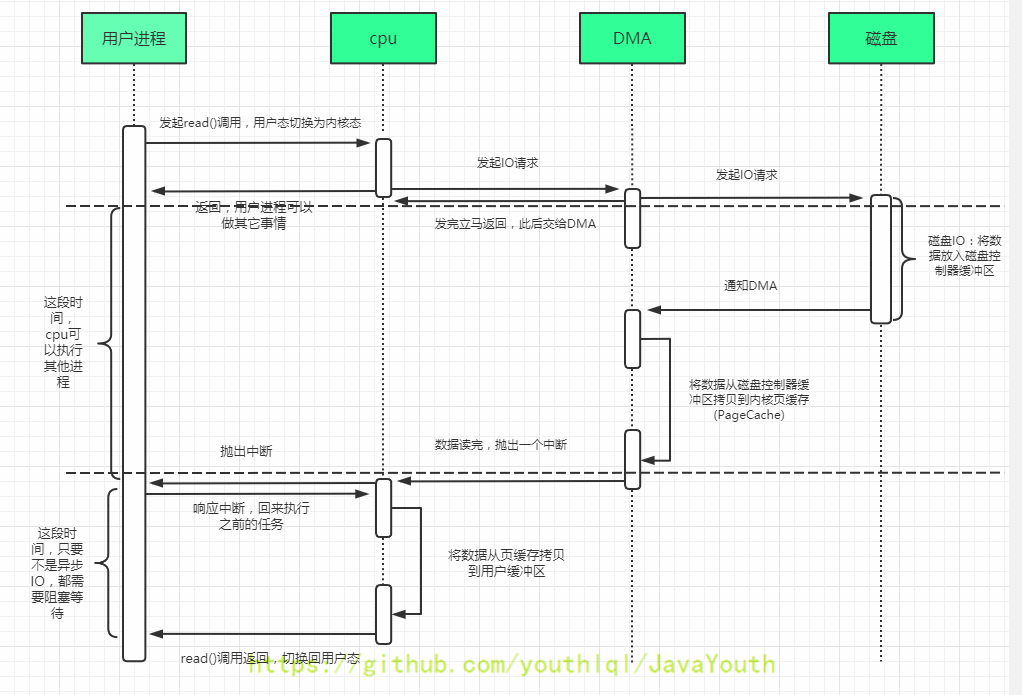 288 |
289 | 过程:
290 |
291 | 1. 用户进程调用 read 方法,向cpu发出 I/O 请求
292 | 2. cpu将IO请求交给DMA控制器,**之后自己立马返回去执行其他进程的任务**
293 | 3. DMA向磁盘发起IO请求
294 | 4. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**。
295 | 5. DMA收到中断后,把磁盘控制器的缓冲区的数据读进内核的页缓存,接着抛出一个中断
296 | 6. 操作系统收到中断后,调度cpu回来执行之前的进程:将数据从内核页缓存拷贝到用户进程空间【这一步还是只能用异步IO来优化】
297 | 7. 最后read()调用返回。
298 |
299 |
300 |
301 | ## 零拷贝 - 传统文件IO
302 |
303 | 场景:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
304 |
305 |
288 |
289 | 过程:
290 |
291 | 1. 用户进程调用 read 方法,向cpu发出 I/O 请求
292 | 2. cpu将IO请求交给DMA控制器,**之后自己立马返回去执行其他进程的任务**
293 | 3. DMA向磁盘发起IO请求
294 | 4. 磁盘控制器收到指令后,于是就开始进行磁盘IO,磁盘IO完成后会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个**中断**。
295 | 5. DMA收到中断后,把磁盘控制器的缓冲区的数据读进内核的页缓存,接着抛出一个中断
296 | 6. 操作系统收到中断后,调度cpu回来执行之前的进程:将数据从内核页缓存拷贝到用户进程空间【这一步还是只能用异步IO来优化】
297 | 7. 最后read()调用返回。
298 |
299 |
300 |
301 | ## 零拷贝 - 传统文件IO
302 |
303 | 场景:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
304 |
305 | 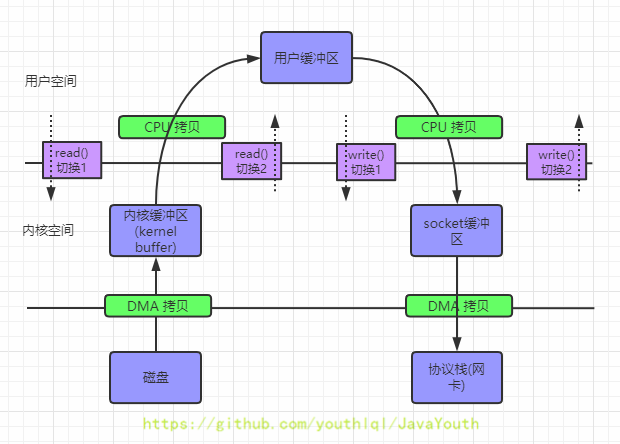 306 |
307 | 1. 很明显发生了4次拷贝
308 |
309 | * 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝是通过 DMA 的。
310 | * 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是应用程序就可以使用这部分数据了,这个拷贝是由 CPU 完成的。
311 | * 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然由 CPU 完成的。
312 | * *第四次拷贝*,把内核的 socket 缓冲区里的数据,拷贝到协议栈里,这个过程又是由 DMA 完成的。
313 |
314 | 2. 发生了4次用户上下文切换,因为发生了两个系统调用read和write。一个系统调用对应两次上下文切换,所以上下文切换次数在一般情况下只可能是偶数。
315 |
316 | > 想要优化文件传输的性能就两个方向
317 | >
318 | > 1. 减少上下文切换次数
319 | > 2. 减少数据拷贝次数
320 | >
321 | > 因为这两个是最耗时的
322 |
323 |
324 |
325 | ## 零拷贝之mmap
326 |
327 | `read()` 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,为了减少这一步开销,我们可以用 `mmap()` 替换 `read()` 系统调用函数。`mmap()` 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间共享缓冲区,就不需要再进行任何的数据拷贝操作。
328 |
329 |
306 |
307 | 1. 很明显发生了4次拷贝
308 |
309 | * 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝是通过 DMA 的。
310 | * 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是应用程序就可以使用这部分数据了,这个拷贝是由 CPU 完成的。
311 | * 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然由 CPU 完成的。
312 | * *第四次拷贝*,把内核的 socket 缓冲区里的数据,拷贝到协议栈里,这个过程又是由 DMA 完成的。
313 |
314 | 2. 发生了4次用户上下文切换,因为发生了两个系统调用read和write。一个系统调用对应两次上下文切换,所以上下文切换次数在一般情况下只可能是偶数。
315 |
316 | > 想要优化文件传输的性能就两个方向
317 | >
318 | > 1. 减少上下文切换次数
319 | > 2. 减少数据拷贝次数
320 | >
321 | > 因为这两个是最耗时的
322 |
323 |
324 |
325 | ## 零拷贝之mmap
326 |
327 | `read()` 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,为了减少这一步开销,我们可以用 `mmap()` 替换 `read()` 系统调用函数。`mmap()` 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间共享缓冲区,就不需要再进行任何的数据拷贝操作。
328 |
329 | 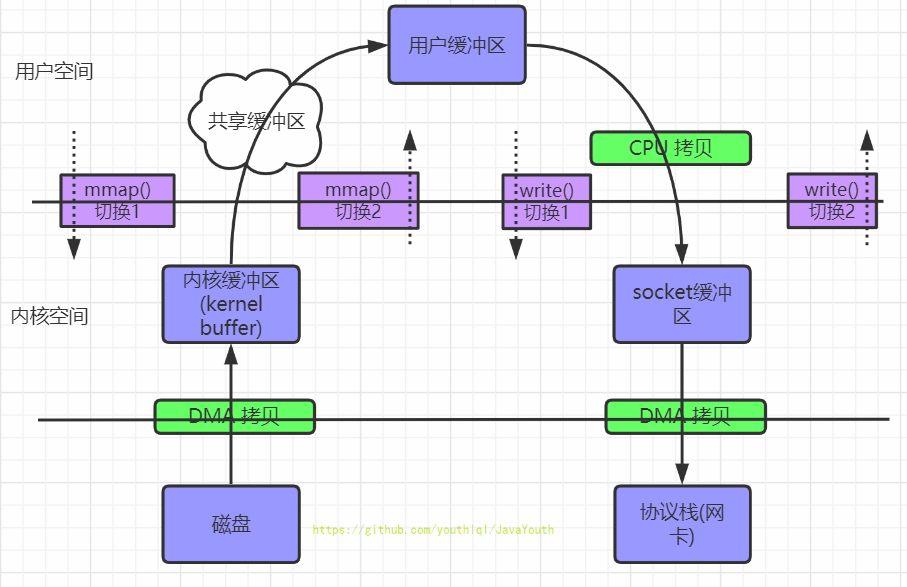 330 |
331 | 总的来说mmap减少了一次数据拷贝,总共4次上下文切换,3次数据拷贝
332 |
333 |
334 |
335 | ## 零拷贝之sendfile
336 |
337 | `Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`
338 |
339 |
330 |
331 | 总的来说mmap减少了一次数据拷贝,总共4次上下文切换,3次数据拷贝
332 |
333 |
334 |
335 | ## 零拷贝之sendfile
336 |
337 | `Linux2.1` 版本提供了 `sendFile` 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 `SocketBuffer`
338 |
339 | 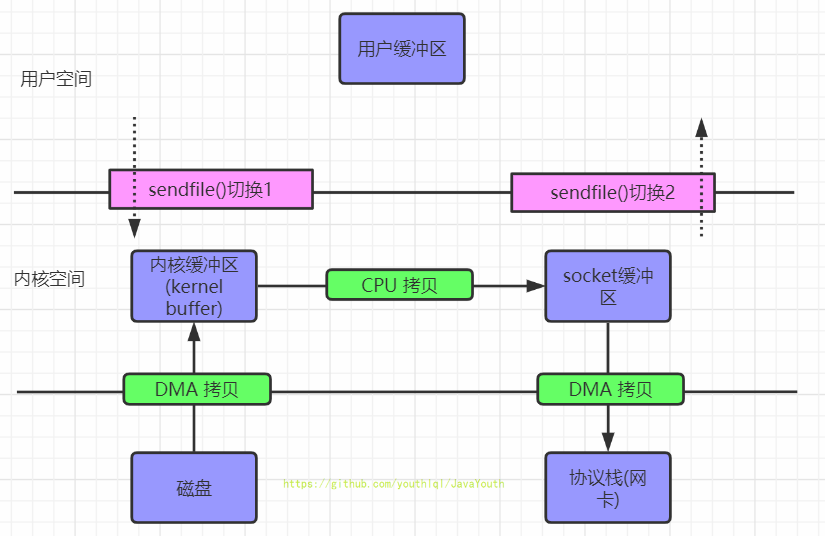 340 |
341 | 总的来说有2次上下文切换,3次数据拷贝。
342 |
343 | ## sendfile再优化
344 |
345 | `Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
346 |
347 |
340 |
341 | 总的来说有2次上下文切换,3次数据拷贝。
342 |
343 | ## sendfile再优化
344 |
345 | `Linux在2.4` 版本中,做了一些修改,避免了从内核缓冲区拷贝到 `Socketbuffer` 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
346 |
347 | 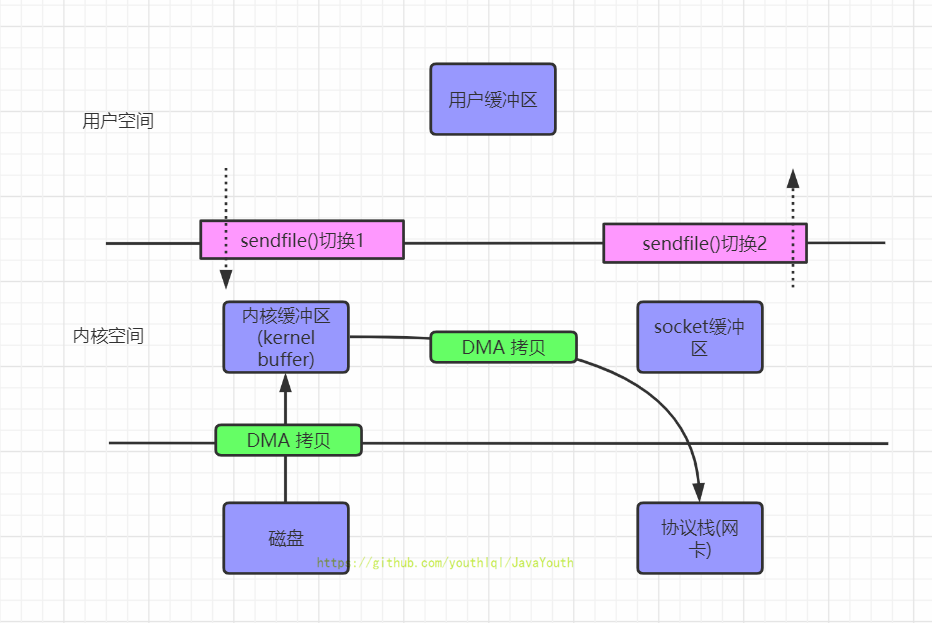 348 |
349 |
350 |
351 | # 文件传输总结
352 |
353 | ## 小文件传输
354 |
355 | 前文一直提到了内核里的页缓存(PageCache),这个页缓存的作用就是用来提升小文件传输的效率
356 |
357 | 原因:
358 |
359 | 1. 读写磁盘相比读写内存的速度慢太多了,这个有点基础的人应该都知道,所以我们应该想办法把读写磁盘换成读写内存。于是,我们通过 DMA 把磁盘里的数据拷贝到内存里,这样就可以用读内存替换读磁盘。读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。这点不是很类似redis和mysql的关系吗,所以说操作系统里的一些设计理念和平时工作应用息息相关,毕竟操作系统可是无数大牛的结晶
360 | 2. 程序运行的时候,具有局部性原理,也就是说刚被访问的数据在短时间内再次被访问的概率很高,通常称为热点数据,于是我们用 PageCache 来缓存这些热点数据,当空间不足时有对应的缓存淘汰策略。
361 |
362 | ## 大文件传输
363 |
364 | Q:PageCache可以用来大文件传输吗?
365 |
366 | A:不能
367 |
368 | Q:为什么呢?
369 |
370 | A:
371 |
372 | 1. 假设你要几G的数据要传输,用户访问这些大文件的时候,内核会把它们载入 PageCache 中, PageCache 空间很快被这些大文件占满。
373 | 2. PageCache 由于长时间被大文件占据,其他热点小文件可能就无法使用到 PageCache,就频繁读写磁盘,效率低下
374 | 3. 而PageCache 中的大文件数据,没有享受到缓存带来的好处,反而却耗费 DMA 多拷贝到 PageCache 一次
375 | 4. 这前前后后加起来,效率低了很多,所以PageCache不适合小文件传输
376 |
377 | 而想不用到内核缓冲区,我们就想到了**直接IO**这个东西,直接IO不经过内核缓存,同时经过上面的讲述,我们也可以知道异步IO效率是最高的。所以大文件传输最好的解决办法应该是:**异步IO+直接IO**
378 |
379 |
380 |
381 | > 读到这里你就会发现,我为何这样安排目录顺序了,前面讲到的,后面都会用到。
382 |
383 |
384 |
385 | # 相关文章
386 |
387 | - 《操作系统导论》 强推
388 |
389 | - [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
390 |
391 | * https://blog.csdn.net/sehanlingfeng/article/details/78920423
392 |
393 | * https://blog.csdn.net/m0_38109046/article/details/89449305
394 |
395 | * https://www.zhihu.com/question/19732473
396 |
397 | * [linux 同步IO: sync、fsync与fdatasync](https://blog.csdn.net/younger_china/article/details/51127127)
398 |
399 |
--------------------------------------------------------------------------------
/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 'Java并发体系-第二阶段-锁与同步-[2]'
3 | tags:
4 | - Java并发
5 | - 原理
6 | - 源码
7 | categories:
8 | - Java并发
9 | - 原理
10 | keywords: Java并发,原理,源码
11 | description: '万字系列长文讲解-Java并发体系-第二阶段,从C++和硬件方面讲解。'
12 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/Java_concurrency.png'
13 | abbrlink: '8210870'
14 | date: 2020-10-07 22:10:58
15 | ---
16 |
17 |
18 |
19 | # 可见性设计的硬件
20 |
21 |
348 |
349 |
350 |
351 | # 文件传输总结
352 |
353 | ## 小文件传输
354 |
355 | 前文一直提到了内核里的页缓存(PageCache),这个页缓存的作用就是用来提升小文件传输的效率
356 |
357 | 原因:
358 |
359 | 1. 读写磁盘相比读写内存的速度慢太多了,这个有点基础的人应该都知道,所以我们应该想办法把读写磁盘换成读写内存。于是,我们通过 DMA 把磁盘里的数据拷贝到内存里,这样就可以用读内存替换读磁盘。读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。这点不是很类似redis和mysql的关系吗,所以说操作系统里的一些设计理念和平时工作应用息息相关,毕竟操作系统可是无数大牛的结晶
360 | 2. 程序运行的时候,具有局部性原理,也就是说刚被访问的数据在短时间内再次被访问的概率很高,通常称为热点数据,于是我们用 PageCache 来缓存这些热点数据,当空间不足时有对应的缓存淘汰策略。
361 |
362 | ## 大文件传输
363 |
364 | Q:PageCache可以用来大文件传输吗?
365 |
366 | A:不能
367 |
368 | Q:为什么呢?
369 |
370 | A:
371 |
372 | 1. 假设你要几G的数据要传输,用户访问这些大文件的时候,内核会把它们载入 PageCache 中, PageCache 空间很快被这些大文件占满。
373 | 2. PageCache 由于长时间被大文件占据,其他热点小文件可能就无法使用到 PageCache,就频繁读写磁盘,效率低下
374 | 3. 而PageCache 中的大文件数据,没有享受到缓存带来的好处,反而却耗费 DMA 多拷贝到 PageCache 一次
375 | 4. 这前前后后加起来,效率低了很多,所以PageCache不适合小文件传输
376 |
377 | 而想不用到内核缓冲区,我们就想到了**直接IO**这个东西,直接IO不经过内核缓存,同时经过上面的讲述,我们也可以知道异步IO效率是最高的。所以大文件传输最好的解决办法应该是:**异步IO+直接IO**
378 |
379 |
380 |
381 | > 读到这里你就会发现,我为何这样安排目录顺序了,前面讲到的,后面都会用到。
382 |
383 |
384 |
385 | # 相关文章
386 |
387 | - 《操作系统导论》 强推
388 |
389 | - [漫画讲IO](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41&scene=21#wechat_redirect)
390 |
391 | * https://blog.csdn.net/sehanlingfeng/article/details/78920423
392 |
393 | * https://blog.csdn.net/m0_38109046/article/details/89449305
394 |
395 | * https://www.zhihu.com/question/19732473
396 |
397 | * [linux 同步IO: sync、fsync与fdatasync](https://blog.csdn.net/younger_china/article/details/51127127)
398 |
399 |
--------------------------------------------------------------------------------
/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[2].md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 'Java并发体系-第二阶段-锁与同步-[2]'
3 | tags:
4 | - Java并发
5 | - 原理
6 | - 源码
7 | categories:
8 | - Java并发
9 | - 原理
10 | keywords: Java并发,原理,源码
11 | description: '万字系列长文讲解-Java并发体系-第二阶段,从C++和硬件方面讲解。'
12 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/Java_concurrency.png'
13 | abbrlink: '8210870'
14 | date: 2020-10-07 22:10:58
15 | ---
16 |
17 |
18 |
19 | # 可见性设计的硬件
20 |
21 | 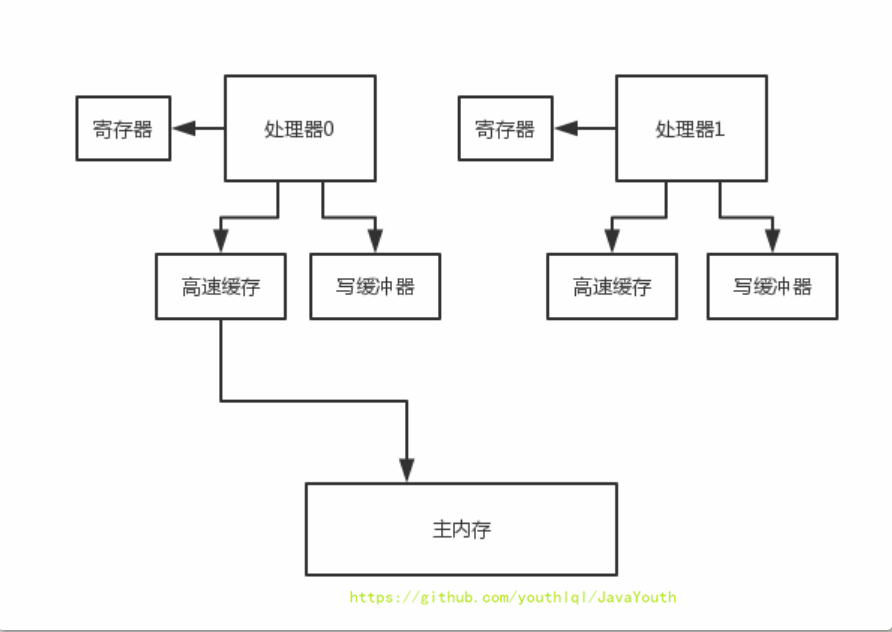 22 |
23 | 从硬件的级别来考虑一下可见性的问题
24 |
25 |
26 |
27 | **1、第一个可见性的场景:**每个处理器都有自己的寄存器(register),所以多个处理器各自运行一个线程的时候,可能导致某个变量给放到寄存器里去,接着就会导致各个线程没法看到其他处理器寄存器里的变量的值修改了,就有可能在寄存器的级别,导致变量副本的更新,无法让其他处理器看到。
28 |
29 | **2、第二个可见性的场景:**然后一个处理器运行的线程对变量的写操作都是针对写缓冲来的(store buffer)并不是直接更新主内存,所以很可能导致一个线程更新了变量,但是仅仅是在写缓冲区里罢了,没有更新到主内存里去。这个时候,其他处理器的线程是没法读到他的写缓冲区的变量值的,所以此时就是会有可见性的问题。
30 |
31 | **3、第三个可见性的场景:**然后即使这个时候一个处理器的线程更新了写缓冲区之后,将更新同步到了自己的高速缓存里(cache,或者是主内存),然后还把这个更新通知给了其他的处理器,但是其他处理器可能就是把这个更新放到无效队列里去,没有更新他的高速缓存。此时其他处理器的线程从高速缓存里读数据的时候,读到的还是过时的旧值。【处理器是优先从自己的高速缓存里取读取变量副本】
32 |
33 |
34 |
35 | 可见性发生的问题
36 |
37 | 如果要实现可见性的话,其中一个方法就是通过MESI协议,这个MESI协议实际上有很多种不同的时间,因为他不过就是一个协议罢了,具体的实现机制要靠具体底层的系统如何实现。
38 |
39 | 根据具体底层硬件的不同,MESI协议的实现是有区别的。比如说MESI协议有一种实现,就是一个处理器将另外一个处理器的高速缓存中的更新后的数据拿到自己的高速缓存中来更新一下,这样大家的缓存不就实现同步了,然后各个处理器的线程看到的数据就一样了。
40 |
41 |
42 |
43 |
44 |
45 | # MESI-缓存一致性协议(简介)
46 |
47 | 1、为了实现MESI协议,有两个配套的专业机制要给大家说一下:flush处理器缓存、refresh处理器缓存。
48 |
49 |
50 |
51 | - flush处理器缓存,他的意思就是把自己更新的值刷新到高速缓存里去(或者是主内存),因为必须要刷到高速缓存(或者是主内存)里,才有可能在后续通过一些特殊的机制让其他的处理器从自己的高速缓存(或者是主内存)里读取到更新的值
52 |
53 | - 除了flush以外,他还会发送一个消息到总线(bus),通知其他处理器,某个变量的值被他给修改了
54 |
55 | - refresh处理器缓存,他的意思就是说,处理器中的线程在读取一个变量的值的时候,如果发现其他处理器的线程更新了变量的值,必须从其他处理器的高速缓存(或者是主内存)里,读取这个最新的值,更新到自己的高速缓存中
56 |
57 |
58 |
59 | 2、所以说,为了保证可见性,在底层是通过MESI协议、flush处理器缓存和refresh处理器缓存,这一整套机制来保障的
60 |
61 | 3、要记住,flush和refresh,这两个操作,flush是强制刷新数据到高速缓存(主内存),不要仅仅停留在写缓冲器里面;refresh,是从总线嗅探发现某个变量被修改,必须强制从其他处理器的高速缓存(或者主内存)加载变量的最新值到自己的高速缓存里去。【不同的硬件,实现可能略有不同】
62 |
63 | 4、内存屏障的使用,在底层硬件级别的原理,其实就是在执行flush和refresh,MESI协议是如何与内存屏障搭配使用的(flush、refresh)
64 |
65 | ```java
66 | volatile boolean isRunning = true;
67 |
68 |
69 | isRunning = false; => 写volatile变量,就会通过执行一个内存屏障,在底层会触发flush处理器缓存的操作;while(isRunning) {},读volatile变量,也会通过执行一个内存屏障,在底层触发refresh操作
70 |
71 | ```
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 | # 内存屏障的相关讲解
80 |
81 | > 上面的文章可能已经把读者搞混了,其实可见性和有序性最主要的就是内存屏障,下面来介绍下内存屏障帮读者梳理一下。
82 |
83 | 内存屏障是被插入两个CPU指令之间的一种指令,用来禁止处理器指令发生重排序(像屏障一样),从而保障有序性的。另外,为了达到屏障的效果,它也会使处理器写入、读取值之前,将写缓冲器的值写入高速缓存,清空无效队列,实现可见性。
84 |
85 | 举例:将写缓冲器数据写入高速缓存,能够避免不同处理器之间不能访问写缓冲器而导致的可见性问题,以及有效地避免了存储转发问题;清空无效队列保证该处理器上高速缓存中不存在旧的副本,进而拿到最新数据
86 |
87 | ## 基本内存屏障
88 |
89 | - LoadLoad屏障: 对于这样的语句 Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
90 |
91 | - StoreStore屏障:对于这样的语句 Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
92 |
93 | - LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被执行前,保证Load1要读取的数据被读取完毕。
94 |
95 | - StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
96 |
97 | 以上的四种屏障主要依据不同处理器支持的重排序(读写,读读,写写,写读)来确定的,比如某些处理器只支持写读重排序,因此只需要StoreLoad屏障
98 |
99 | 下面对上述的基本屏障进行利用,以针对不同的目的用相应的屏障。
100 |
101 | ## 可见性保障
102 |
103 | 主要分为加载屏障(Load Barrier)和存储屏障(Store Barrier)
104 |
105 | - 加载屏障:StoreLoad屏障作为万能屏障,作用是冲刷写缓冲器,清空无效化队列,这样处理器在读取共享变量时,因为本高速缓存中的数据是无效的,因此先从主内存或其他处理器的高速缓存中读取相应变量,更新到自己的缓存中
106 |
107 | - 存储屏障:同样使用StoreLoad屏障,作用是将写缓冲器内容写入高速缓存中,使处理器对共享变量的更新写入高速缓存或者主内存中 ,同时解决存储转发问题,使得写缓冲器中的数据不存在旧值
108 |
109 | 以上两种屏障解决可见性问题。
110 |
111 | ## 有序性保障
112 |
113 | 主要分为获取屏障(Acquire Barrier)和释放屏障(Release Barrier)
114 |
115 | - 获取屏障:相当于LoadLoad屏障和LoadStore屏障的组合,它能禁止该屏障之前的任何读操作与该屏障之后的任何读、写操作之间进行重排序;
116 | - 释放屏障:相当于StoreLoad屏障与StoreStore屏障的组合,它能够禁止该屏障之前的任何读、写操作与该屏障之后的任何写操作之间进行重排序
117 |
118 | 对于其实大家记住volatile修饰的字段和普通修饰的字段同样不可以重排序,因此只要存在读写、写写、写读、读读等操作,包含了volatile关键字,都会在操作指令之间插入屏障的,具体插入什么屏障可以根据对应的操作插入。
119 |
120 |
121 |
122 | ## synchronized
123 |
124 |
125 |
126 | ```
127 | 结论:
128 | (1)原子性:加锁和释放锁,ObjectMonitor
129 |
130 | (2)可见性:加了Load屏障和Store屏障,释放锁flush数据,加锁会refresh数据
131 |
132 | (3)有序性:Acquire屏障和Release屏障,保证同步代码块内部的指令可以重排,但是同步代码块内部的指令和外面的指令是不能重排的
133 | ```
134 |
135 | 举个例子说明加屏障的顺序:
136 |
137 | ```java
138 | int b = 0;
139 |
140 | int c = 0;
141 |
142 | synchronized(this) { -> monitorenter
143 |
144 | //Load内存屏障
145 |
146 | //Acquire内存屏障
147 |
148 | int a = b;
149 |
150 | c = 1; // synchronized代码块里面还是可能会发生指令重排
151 |
152 | //Release内存屏障
153 |
154 | } -> monitorexit
155 |
156 | //Store内存屏障
157 |
158 | ```
159 |
160 | 1、java的并发技术底层很多都对应了内存屏障的使用,包括synchronized,他底层也是依托于各种不同的内存屏障来保证可见性和有序性的
161 |
162 | 2、按照可见性来划分的话,内存屏障可以分为Load屏障和Store屏障。
163 |
164 | - Load屏障的作用是执行refresh处理器缓存的操作,说白了就是对别的处理器更新过的变量,从其他处理器的高速缓存(或者主内存)加载数据到自己的高速缓存来,确保自己看到的是最新的数据。
165 | - Store屏障的作用是执行flush处理器缓存的操作,说白了就是把自己当前处理器更新的变量的值,都刷新到高速缓存(或者主内存)里去
166 |
167 | + 在monitorexit指令之后,会有一个Store屏障,让线程把自己在同步代码块里修改的变量的值都执行flush处理器缓存的操作,刷到高速缓存(或者主内存)里去;然后在monitorenter指令之后会加一个Load屏障,执行refresh处理器缓存的操作,把别的处理器修改过的最新值加载到自己高速缓存里来
168 | + 所以说通过Load屏障和Store屏障,就可以让synchronized保证可见性。
169 |
170 |
171 |
172 | 3、按照有序性保障来划分的话,还可以分为Acquire屏障和Release屏障。
173 |
174 | - 在monitorenter指令之后,Load屏障之后,会加一个Acquire屏障,这个屏障的作用是禁止读操作和读写操作之间发生指令重排序。在monitorexit指令之前,会加一个Release屏障,这个屏障的作用是禁止写操作和读写操作之间发生重排序。
175 | - 所以说,通过 Acquire屏障和Release屏障,就可以让synchronzied保证有序性,只有synchronized内部的指令可以重排序,但是绝对不会跟外部的指令发生重排序。
176 |
177 |
178 |
179 | ## volatile
180 |
181 |
182 |
183 | ```
184 | 前面讲过,lock前缀指令相当于一个内存屏障,lock前缀指令同时保证可见性和有序性
185 |
186 | (1)可见性:加了Load屏障和Store屏障,释放锁flush数据,加锁会refresh数据
187 |
188 | (2)有序性:Acquire屏障和Release屏障,保证同步代码块内部的指令可以重排,但是同步代码块内部的指令和外面的指令是不能重排的
189 |
190 | (3)不保证原子性
191 |
192 | ```
193 |
194 | 1、volatile对原子性的保证真的是非常的有限,其实主要就是32位jvm中的long/double类型变量的赋值操作是不具备原子性的,加上volatile就可以保证原子性了。但是总体上就说不保证原子性。
195 |
196 |
197 |
198 | 2、
199 |
200 | ```java
201 | volatile boolean isRunning = true;
202 |
203 |
204 |
205 | 线程1:
206 |
207 | Release屏障
208 |
209 | isRunning = false;
210 |
211 | Store屏障
212 |
213 |
214 |
215 | 线程2:
216 |
217 | Load屏障
218 |
219 | while(isRunning) {
220 |
221 | Acquire屏障
222 |
223 | // 代码逻辑
224 |
225 | }
226 |
227 | ```
228 |
229 |
230 |
231 | - 在volatile变量写操作的前面会加入一个Release屏障,然后在之后会加入一个Store屏障,这样就可以保证volatile写跟Release屏障之前的任何读写操作都不会指令重排,然后Store屏障保证了,写完数据之后,立马会执行flush处理器缓存的操作
232 | - 在volatile变量读操作的前面会加入一个Load屏障,这样就可以保证对这个变量的读取时,如果被别的处理器修改过了,必须得从其他处理器的高速缓存(或者主内存)中加载到自己本地高速缓存里,保证读到的是最新数据;在之后会加入一个Acquire屏障,禁止volatile读操作之后的任何读写操作会跟volatile读指令重排序
233 |
234 |
235 |
236 | 跟之前讲解的volatie读写内存屏障的知识对比一下,其实你看一下是类似的意思的。
237 |
238 |
239 |
240 | ## 强调
241 |
242 | - 其实不要对内存屏障这个东西太较真,因为说句实话,不同版本的JVM,不同的底层硬件,都可能会导致加的内存屏障有一些区别,所以这个本来就没完全一致的。你只要知道内存屏障是如何保证volatile的可见性和有序性的就可以了
243 | - 看各种并发相关的书和文章,对内存屏障到底是加的什么屏障,莫衷一是,没有任何一个官方权威的说法,因为这个内存屏障太底层了,底层到了涉及到了硬件,硬件不同对内存屏障的实现是不一样的
244 | - 内存屏障这个东西,大概来说,其实就是大概的给你说一下这个意思,尤其是Release屏障,Store屏障和Load屏障还好理解一些,比较简单,Acqurie屏障,莫衷一是,我也没法给你一个官方的定论
245 |
246 | - 如果你一定 要了解清除,到底加的准确的屏障是什么?到底是如何跟上下的指令避免重排的,你自己去研究吧。【我也看过很多的资料,做过很多的研究,硬件对这个东西的实现和承诺,莫衷一是,没有标准和官方定论。-----这句话是某BAT大佬说的】
247 |
248 |
249 |
250 | 内存屏障对应的底层的一些基本的硬件级别的原理,也都讲清楚了
251 |
252 |
253 |
254 |
255 |
256 |
257 |
258 |
259 |
260 | # MESI-缓存一致性协议(进阶)
261 |
262 |
263 |
264 | ## MESI-初步
265 |
266 | 1、处理器高速缓存的底层数据结构实际是一个拉链散列表的结构,就是有很多个bucket,每个bucket挂了很多的cache entry,每个cache entry由三个部分组成:tag、cache line和flag,其中的cache line【缓存行】就是缓存的数据。tag指向了这个缓存数据在主内存中的数据的地址,flag标识了缓存行的状态,另外要注意的一点是,cache line中可以包含多个变量的值
267 |
268 |
269 |
270 | 2、处理器会操作一些变量,怎么在高速缓存里定位到这个变量呢?
271 |
272 | - 那么处理器在读写高速缓存的时候,实际上会根据变量名执行一个内存地址解码的操作,解析出来3个东西,index、tag和offset。index用于定位到拉链散列表中的某个bucket,tag是用于定位cache entry,offset是用于定位一个变量在cache line中的位置
273 | - 如果说可以成功定位到一个高速缓存中的数据,而且flag还标志着有效,则缓存命中;否则不满足上述条件,就是缓存未命中。如果是读数据未命中的话,会从主内存重新加载数据到高速缓存中,现在处理器一般都有三级高速缓存,L1、L2、L3,越靠前面的缓存读写速度越快
274 |
275 | 3、因为有高速缓存的存在,所以就导致各个处理器可能对一个变量会在自己的高速缓存里有自己的副本,这样一个处理器修改了变量值,别的处理器是看不到的,所以就是为了这个问题引入了缓存一致性协议(MESI协议)
276 |
277 | 4、MESI协议规定:对一个共享变量的读操作可以是多个处理器并发执行的,但是如果是对一个共享变量的写操作,只有一个处理器可以执行,其实也会通过排他锁的机制保证就一个处理器能写
278 |
279 | 之前说过那个cache entry的flag代表了缓存数据的状态,MESI协议中划分为:
280 |
281 | - invalid:无效的,标记为I,这个意思就是当前cache entry无效,里面的数据不能使用
282 | - shared:共享的,标记为S,这个意思是当前cache entry有效,而且里面的数据在各个处理器中都有各自的副本,但是这些副本的值跟主内存的值是一样的,各个处理器就是并发的在读而已
283 | - exclusive:独占的,标记为E,这个意思就是当前处理器对这个数据独占了,只有他可以有这个副本,其他的处理器都不能包含这个副本
284 | - modified:修改过的,标记为M,只能有一个处理器对共享数据更新,所以只有更新数据的处理器的cache entry,才是exclusive状态,表明当前线程更新了这个数据,这个副本的数据跟主内存是不一样的
285 |
286 | MESI协议规定了一组消息,就说各个处理器在操作内存数据的时候,都会往总线发送消息,而且各个处理器还会不停的从总线嗅探最新的消息,通过这个总线的消息传递来保证各个处理器的协作
287 |
288 |
289 |
290 | **下面来详细的图解MESI协议的工作原理:**
291 |
292 | 1、处理器0读取某个变量的数据时,首先会根据index、tag和offset从高速缓存的拉链散列表读取数据,如果发现状态为I,也就是无效的,此时就会发送read消息到总线
293 |
294 | 2、接着主内存会返回对应的数据给处理器0,处理器0就会把数据放到高速缓存里,同时cache entry的flag状态是S
295 |
296 | 3、在处理器0对一个数据进行更新的时候,如果数据状态是S,则此时就需要发送一个invalidate消息到总线,尝试让其他的处理器的高速缓存的cache entry全部变为I,以获得数据的独占锁。
297 |
298 | 4、其他的处理器1会从总线嗅探到invalidate消息,此时就会把自己的cache entry设置为I,也就是过期掉自己本地的缓存,然后就是返回invalidate ack消息到总线,传递回处理器0,处理器0必须收到所有处理器返回的ack消息
299 |
300 | 5、接着处理器0就会将cache entry先设置为E,独占这条数据,在独占期间,别的处理器就不能修改数据了,因为别的处理器此时发出invalidate消息,这个处理器0是不会返回invalidate ack消息的,除非他先修改完再说
301 |
302 | 6、接着处理器0就是修改这条数据,接着将数据设置为M,也有可能是把数据此时强制写回到主内存中,具体看底层硬件实现
303 |
304 | 7、然后其他处理器此时这条数据的状态都是I了,那如果要读的话,全部都需要重新发送read消息,从主内存(或者是其他处理器)来加载,这个具体怎么实现要看底层的硬件了,都有可能的
305 |
306 |
307 |
308 |
22 |
23 | 从硬件的级别来考虑一下可见性的问题
24 |
25 |
26 |
27 | **1、第一个可见性的场景:**每个处理器都有自己的寄存器(register),所以多个处理器各自运行一个线程的时候,可能导致某个变量给放到寄存器里去,接着就会导致各个线程没法看到其他处理器寄存器里的变量的值修改了,就有可能在寄存器的级别,导致变量副本的更新,无法让其他处理器看到。
28 |
29 | **2、第二个可见性的场景:**然后一个处理器运行的线程对变量的写操作都是针对写缓冲来的(store buffer)并不是直接更新主内存,所以很可能导致一个线程更新了变量,但是仅仅是在写缓冲区里罢了,没有更新到主内存里去。这个时候,其他处理器的线程是没法读到他的写缓冲区的变量值的,所以此时就是会有可见性的问题。
30 |
31 | **3、第三个可见性的场景:**然后即使这个时候一个处理器的线程更新了写缓冲区之后,将更新同步到了自己的高速缓存里(cache,或者是主内存),然后还把这个更新通知给了其他的处理器,但是其他处理器可能就是把这个更新放到无效队列里去,没有更新他的高速缓存。此时其他处理器的线程从高速缓存里读数据的时候,读到的还是过时的旧值。【处理器是优先从自己的高速缓存里取读取变量副本】
32 |
33 |
34 |
35 | 可见性发生的问题
36 |
37 | 如果要实现可见性的话,其中一个方法就是通过MESI协议,这个MESI协议实际上有很多种不同的时间,因为他不过就是一个协议罢了,具体的实现机制要靠具体底层的系统如何实现。
38 |
39 | 根据具体底层硬件的不同,MESI协议的实现是有区别的。比如说MESI协议有一种实现,就是一个处理器将另外一个处理器的高速缓存中的更新后的数据拿到自己的高速缓存中来更新一下,这样大家的缓存不就实现同步了,然后各个处理器的线程看到的数据就一样了。
40 |
41 |
42 |
43 |
44 |
45 | # MESI-缓存一致性协议(简介)
46 |
47 | 1、为了实现MESI协议,有两个配套的专业机制要给大家说一下:flush处理器缓存、refresh处理器缓存。
48 |
49 |
50 |
51 | - flush处理器缓存,他的意思就是把自己更新的值刷新到高速缓存里去(或者是主内存),因为必须要刷到高速缓存(或者是主内存)里,才有可能在后续通过一些特殊的机制让其他的处理器从自己的高速缓存(或者是主内存)里读取到更新的值
52 |
53 | - 除了flush以外,他还会发送一个消息到总线(bus),通知其他处理器,某个变量的值被他给修改了
54 |
55 | - refresh处理器缓存,他的意思就是说,处理器中的线程在读取一个变量的值的时候,如果发现其他处理器的线程更新了变量的值,必须从其他处理器的高速缓存(或者是主内存)里,读取这个最新的值,更新到自己的高速缓存中
56 |
57 |
58 |
59 | 2、所以说,为了保证可见性,在底层是通过MESI协议、flush处理器缓存和refresh处理器缓存,这一整套机制来保障的
60 |
61 | 3、要记住,flush和refresh,这两个操作,flush是强制刷新数据到高速缓存(主内存),不要仅仅停留在写缓冲器里面;refresh,是从总线嗅探发现某个变量被修改,必须强制从其他处理器的高速缓存(或者主内存)加载变量的最新值到自己的高速缓存里去。【不同的硬件,实现可能略有不同】
62 |
63 | 4、内存屏障的使用,在底层硬件级别的原理,其实就是在执行flush和refresh,MESI协议是如何与内存屏障搭配使用的(flush、refresh)
64 |
65 | ```java
66 | volatile boolean isRunning = true;
67 |
68 |
69 | isRunning = false; => 写volatile变量,就会通过执行一个内存屏障,在底层会触发flush处理器缓存的操作;while(isRunning) {},读volatile变量,也会通过执行一个内存屏障,在底层触发refresh操作
70 |
71 | ```
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 | # 内存屏障的相关讲解
80 |
81 | > 上面的文章可能已经把读者搞混了,其实可见性和有序性最主要的就是内存屏障,下面来介绍下内存屏障帮读者梳理一下。
82 |
83 | 内存屏障是被插入两个CPU指令之间的一种指令,用来禁止处理器指令发生重排序(像屏障一样),从而保障有序性的。另外,为了达到屏障的效果,它也会使处理器写入、读取值之前,将写缓冲器的值写入高速缓存,清空无效队列,实现可见性。
84 |
85 | 举例:将写缓冲器数据写入高速缓存,能够避免不同处理器之间不能访问写缓冲器而导致的可见性问题,以及有效地避免了存储转发问题;清空无效队列保证该处理器上高速缓存中不存在旧的副本,进而拿到最新数据
86 |
87 | ## 基本内存屏障
88 |
89 | - LoadLoad屏障: 对于这样的语句 Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
90 |
91 | - StoreStore屏障:对于这样的语句 Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
92 |
93 | - LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被执行前,保证Load1要读取的数据被读取完毕。
94 |
95 | - StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
96 |
97 | 以上的四种屏障主要依据不同处理器支持的重排序(读写,读读,写写,写读)来确定的,比如某些处理器只支持写读重排序,因此只需要StoreLoad屏障
98 |
99 | 下面对上述的基本屏障进行利用,以针对不同的目的用相应的屏障。
100 |
101 | ## 可见性保障
102 |
103 | 主要分为加载屏障(Load Barrier)和存储屏障(Store Barrier)
104 |
105 | - 加载屏障:StoreLoad屏障作为万能屏障,作用是冲刷写缓冲器,清空无效化队列,这样处理器在读取共享变量时,因为本高速缓存中的数据是无效的,因此先从主内存或其他处理器的高速缓存中读取相应变量,更新到自己的缓存中
106 |
107 | - 存储屏障:同样使用StoreLoad屏障,作用是将写缓冲器内容写入高速缓存中,使处理器对共享变量的更新写入高速缓存或者主内存中 ,同时解决存储转发问题,使得写缓冲器中的数据不存在旧值
108 |
109 | 以上两种屏障解决可见性问题。
110 |
111 | ## 有序性保障
112 |
113 | 主要分为获取屏障(Acquire Barrier)和释放屏障(Release Barrier)
114 |
115 | - 获取屏障:相当于LoadLoad屏障和LoadStore屏障的组合,它能禁止该屏障之前的任何读操作与该屏障之后的任何读、写操作之间进行重排序;
116 | - 释放屏障:相当于StoreLoad屏障与StoreStore屏障的组合,它能够禁止该屏障之前的任何读、写操作与该屏障之后的任何写操作之间进行重排序
117 |
118 | 对于其实大家记住volatile修饰的字段和普通修饰的字段同样不可以重排序,因此只要存在读写、写写、写读、读读等操作,包含了volatile关键字,都会在操作指令之间插入屏障的,具体插入什么屏障可以根据对应的操作插入。
119 |
120 |
121 |
122 | ## synchronized
123 |
124 |
125 |
126 | ```
127 | 结论:
128 | (1)原子性:加锁和释放锁,ObjectMonitor
129 |
130 | (2)可见性:加了Load屏障和Store屏障,释放锁flush数据,加锁会refresh数据
131 |
132 | (3)有序性:Acquire屏障和Release屏障,保证同步代码块内部的指令可以重排,但是同步代码块内部的指令和外面的指令是不能重排的
133 | ```
134 |
135 | 举个例子说明加屏障的顺序:
136 |
137 | ```java
138 | int b = 0;
139 |
140 | int c = 0;
141 |
142 | synchronized(this) { -> monitorenter
143 |
144 | //Load内存屏障
145 |
146 | //Acquire内存屏障
147 |
148 | int a = b;
149 |
150 | c = 1; // synchronized代码块里面还是可能会发生指令重排
151 |
152 | //Release内存屏障
153 |
154 | } -> monitorexit
155 |
156 | //Store内存屏障
157 |
158 | ```
159 |
160 | 1、java的并发技术底层很多都对应了内存屏障的使用,包括synchronized,他底层也是依托于各种不同的内存屏障来保证可见性和有序性的
161 |
162 | 2、按照可见性来划分的话,内存屏障可以分为Load屏障和Store屏障。
163 |
164 | - Load屏障的作用是执行refresh处理器缓存的操作,说白了就是对别的处理器更新过的变量,从其他处理器的高速缓存(或者主内存)加载数据到自己的高速缓存来,确保自己看到的是最新的数据。
165 | - Store屏障的作用是执行flush处理器缓存的操作,说白了就是把自己当前处理器更新的变量的值,都刷新到高速缓存(或者主内存)里去
166 |
167 | + 在monitorexit指令之后,会有一个Store屏障,让线程把自己在同步代码块里修改的变量的值都执行flush处理器缓存的操作,刷到高速缓存(或者主内存)里去;然后在monitorenter指令之后会加一个Load屏障,执行refresh处理器缓存的操作,把别的处理器修改过的最新值加载到自己高速缓存里来
168 | + 所以说通过Load屏障和Store屏障,就可以让synchronized保证可见性。
169 |
170 |
171 |
172 | 3、按照有序性保障来划分的话,还可以分为Acquire屏障和Release屏障。
173 |
174 | - 在monitorenter指令之后,Load屏障之后,会加一个Acquire屏障,这个屏障的作用是禁止读操作和读写操作之间发生指令重排序。在monitorexit指令之前,会加一个Release屏障,这个屏障的作用是禁止写操作和读写操作之间发生重排序。
175 | - 所以说,通过 Acquire屏障和Release屏障,就可以让synchronzied保证有序性,只有synchronized内部的指令可以重排序,但是绝对不会跟外部的指令发生重排序。
176 |
177 |
178 |
179 | ## volatile
180 |
181 |
182 |
183 | ```
184 | 前面讲过,lock前缀指令相当于一个内存屏障,lock前缀指令同时保证可见性和有序性
185 |
186 | (1)可见性:加了Load屏障和Store屏障,释放锁flush数据,加锁会refresh数据
187 |
188 | (2)有序性:Acquire屏障和Release屏障,保证同步代码块内部的指令可以重排,但是同步代码块内部的指令和外面的指令是不能重排的
189 |
190 | (3)不保证原子性
191 |
192 | ```
193 |
194 | 1、volatile对原子性的保证真的是非常的有限,其实主要就是32位jvm中的long/double类型变量的赋值操作是不具备原子性的,加上volatile就可以保证原子性了。但是总体上就说不保证原子性。
195 |
196 |
197 |
198 | 2、
199 |
200 | ```java
201 | volatile boolean isRunning = true;
202 |
203 |
204 |
205 | 线程1:
206 |
207 | Release屏障
208 |
209 | isRunning = false;
210 |
211 | Store屏障
212 |
213 |
214 |
215 | 线程2:
216 |
217 | Load屏障
218 |
219 | while(isRunning) {
220 |
221 | Acquire屏障
222 |
223 | // 代码逻辑
224 |
225 | }
226 |
227 | ```
228 |
229 |
230 |
231 | - 在volatile变量写操作的前面会加入一个Release屏障,然后在之后会加入一个Store屏障,这样就可以保证volatile写跟Release屏障之前的任何读写操作都不会指令重排,然后Store屏障保证了,写完数据之后,立马会执行flush处理器缓存的操作
232 | - 在volatile变量读操作的前面会加入一个Load屏障,这样就可以保证对这个变量的读取时,如果被别的处理器修改过了,必须得从其他处理器的高速缓存(或者主内存)中加载到自己本地高速缓存里,保证读到的是最新数据;在之后会加入一个Acquire屏障,禁止volatile读操作之后的任何读写操作会跟volatile读指令重排序
233 |
234 |
235 |
236 | 跟之前讲解的volatie读写内存屏障的知识对比一下,其实你看一下是类似的意思的。
237 |
238 |
239 |
240 | ## 强调
241 |
242 | - 其实不要对内存屏障这个东西太较真,因为说句实话,不同版本的JVM,不同的底层硬件,都可能会导致加的内存屏障有一些区别,所以这个本来就没完全一致的。你只要知道内存屏障是如何保证volatile的可见性和有序性的就可以了
243 | - 看各种并发相关的书和文章,对内存屏障到底是加的什么屏障,莫衷一是,没有任何一个官方权威的说法,因为这个内存屏障太底层了,底层到了涉及到了硬件,硬件不同对内存屏障的实现是不一样的
244 | - 内存屏障这个东西,大概来说,其实就是大概的给你说一下这个意思,尤其是Release屏障,Store屏障和Load屏障还好理解一些,比较简单,Acqurie屏障,莫衷一是,我也没法给你一个官方的定论
245 |
246 | - 如果你一定 要了解清除,到底加的准确的屏障是什么?到底是如何跟上下的指令避免重排的,你自己去研究吧。【我也看过很多的资料,做过很多的研究,硬件对这个东西的实现和承诺,莫衷一是,没有标准和官方定论。-----这句话是某BAT大佬说的】
247 |
248 |
249 |
250 | 内存屏障对应的底层的一些基本的硬件级别的原理,也都讲清楚了
251 |
252 |
253 |
254 |
255 |
256 |
257 |
258 |
259 |
260 | # MESI-缓存一致性协议(进阶)
261 |
262 |
263 |
264 | ## MESI-初步
265 |
266 | 1、处理器高速缓存的底层数据结构实际是一个拉链散列表的结构,就是有很多个bucket,每个bucket挂了很多的cache entry,每个cache entry由三个部分组成:tag、cache line和flag,其中的cache line【缓存行】就是缓存的数据。tag指向了这个缓存数据在主内存中的数据的地址,flag标识了缓存行的状态,另外要注意的一点是,cache line中可以包含多个变量的值
267 |
268 |
269 |
270 | 2、处理器会操作一些变量,怎么在高速缓存里定位到这个变量呢?
271 |
272 | - 那么处理器在读写高速缓存的时候,实际上会根据变量名执行一个内存地址解码的操作,解析出来3个东西,index、tag和offset。index用于定位到拉链散列表中的某个bucket,tag是用于定位cache entry,offset是用于定位一个变量在cache line中的位置
273 | - 如果说可以成功定位到一个高速缓存中的数据,而且flag还标志着有效,则缓存命中;否则不满足上述条件,就是缓存未命中。如果是读数据未命中的话,会从主内存重新加载数据到高速缓存中,现在处理器一般都有三级高速缓存,L1、L2、L3,越靠前面的缓存读写速度越快
274 |
275 | 3、因为有高速缓存的存在,所以就导致各个处理器可能对一个变量会在自己的高速缓存里有自己的副本,这样一个处理器修改了变量值,别的处理器是看不到的,所以就是为了这个问题引入了缓存一致性协议(MESI协议)
276 |
277 | 4、MESI协议规定:对一个共享变量的读操作可以是多个处理器并发执行的,但是如果是对一个共享变量的写操作,只有一个处理器可以执行,其实也会通过排他锁的机制保证就一个处理器能写
278 |
279 | 之前说过那个cache entry的flag代表了缓存数据的状态,MESI协议中划分为:
280 |
281 | - invalid:无效的,标记为I,这个意思就是当前cache entry无效,里面的数据不能使用
282 | - shared:共享的,标记为S,这个意思是当前cache entry有效,而且里面的数据在各个处理器中都有各自的副本,但是这些副本的值跟主内存的值是一样的,各个处理器就是并发的在读而已
283 | - exclusive:独占的,标记为E,这个意思就是当前处理器对这个数据独占了,只有他可以有这个副本,其他的处理器都不能包含这个副本
284 | - modified:修改过的,标记为M,只能有一个处理器对共享数据更新,所以只有更新数据的处理器的cache entry,才是exclusive状态,表明当前线程更新了这个数据,这个副本的数据跟主内存是不一样的
285 |
286 | MESI协议规定了一组消息,就说各个处理器在操作内存数据的时候,都会往总线发送消息,而且各个处理器还会不停的从总线嗅探最新的消息,通过这个总线的消息传递来保证各个处理器的协作
287 |
288 |
289 |
290 | **下面来详细的图解MESI协议的工作原理:**
291 |
292 | 1、处理器0读取某个变量的数据时,首先会根据index、tag和offset从高速缓存的拉链散列表读取数据,如果发现状态为I,也就是无效的,此时就会发送read消息到总线
293 |
294 | 2、接着主内存会返回对应的数据给处理器0,处理器0就会把数据放到高速缓存里,同时cache entry的flag状态是S
295 |
296 | 3、在处理器0对一个数据进行更新的时候,如果数据状态是S,则此时就需要发送一个invalidate消息到总线,尝试让其他的处理器的高速缓存的cache entry全部变为I,以获得数据的独占锁。
297 |
298 | 4、其他的处理器1会从总线嗅探到invalidate消息,此时就会把自己的cache entry设置为I,也就是过期掉自己本地的缓存,然后就是返回invalidate ack消息到总线,传递回处理器0,处理器0必须收到所有处理器返回的ack消息
299 |
300 | 5、接着处理器0就会将cache entry先设置为E,独占这条数据,在独占期间,别的处理器就不能修改数据了,因为别的处理器此时发出invalidate消息,这个处理器0是不会返回invalidate ack消息的,除非他先修改完再说
301 |
302 | 6、接着处理器0就是修改这条数据,接着将数据设置为M,也有可能是把数据此时强制写回到主内存中,具体看底层硬件实现
303 |
304 | 7、然后其他处理器此时这条数据的状态都是I了,那如果要读的话,全部都需要重新发送read消息,从主内存(或者是其他处理器)来加载,这个具体怎么实现要看底层的硬件了,都有可能的
305 |
306 |
307 |
308 | 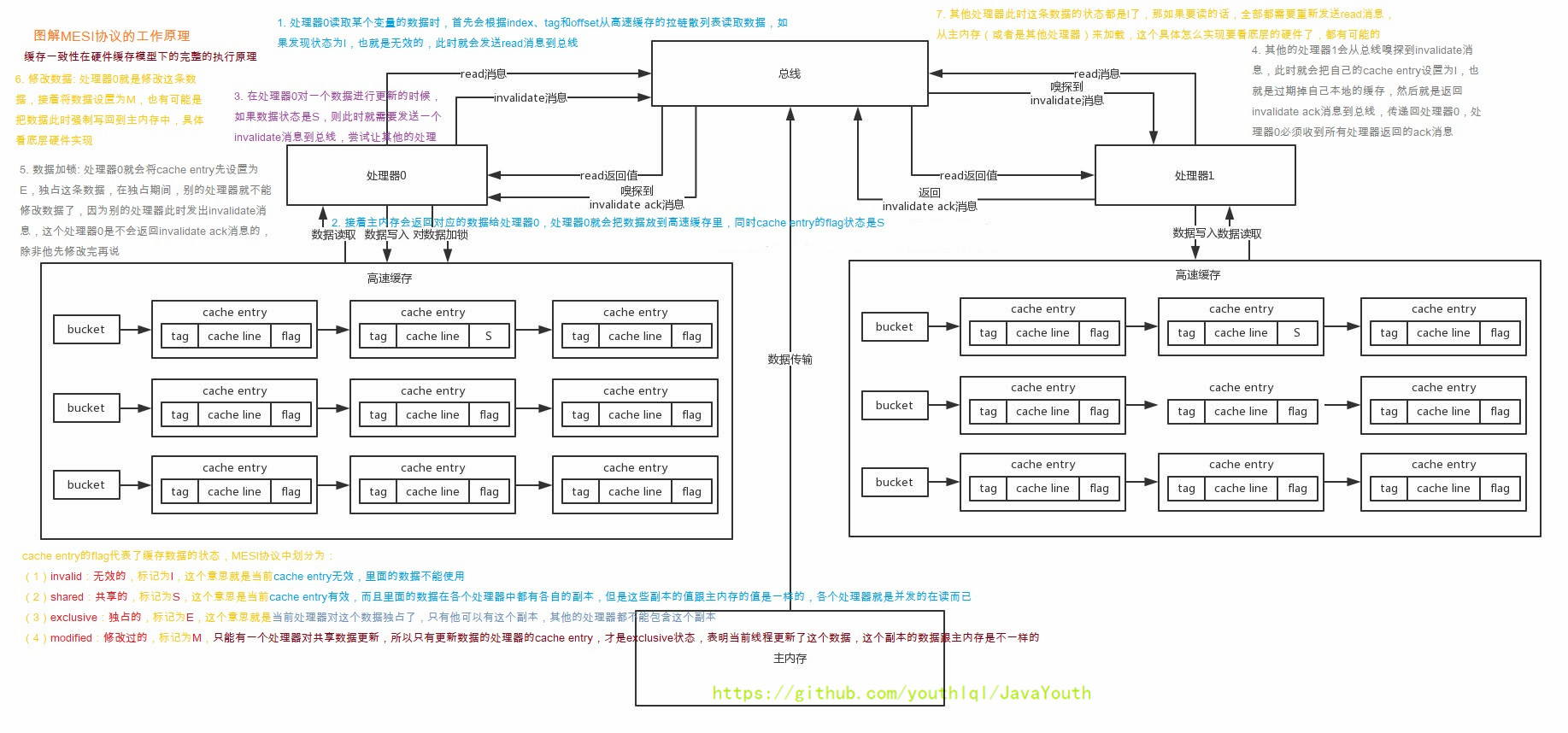 309 |
310 |
311 |
312 | ## MESI-优化
313 |
314 |
309 |
310 |
311 |
312 | ## MESI-优化
313 |
314 | 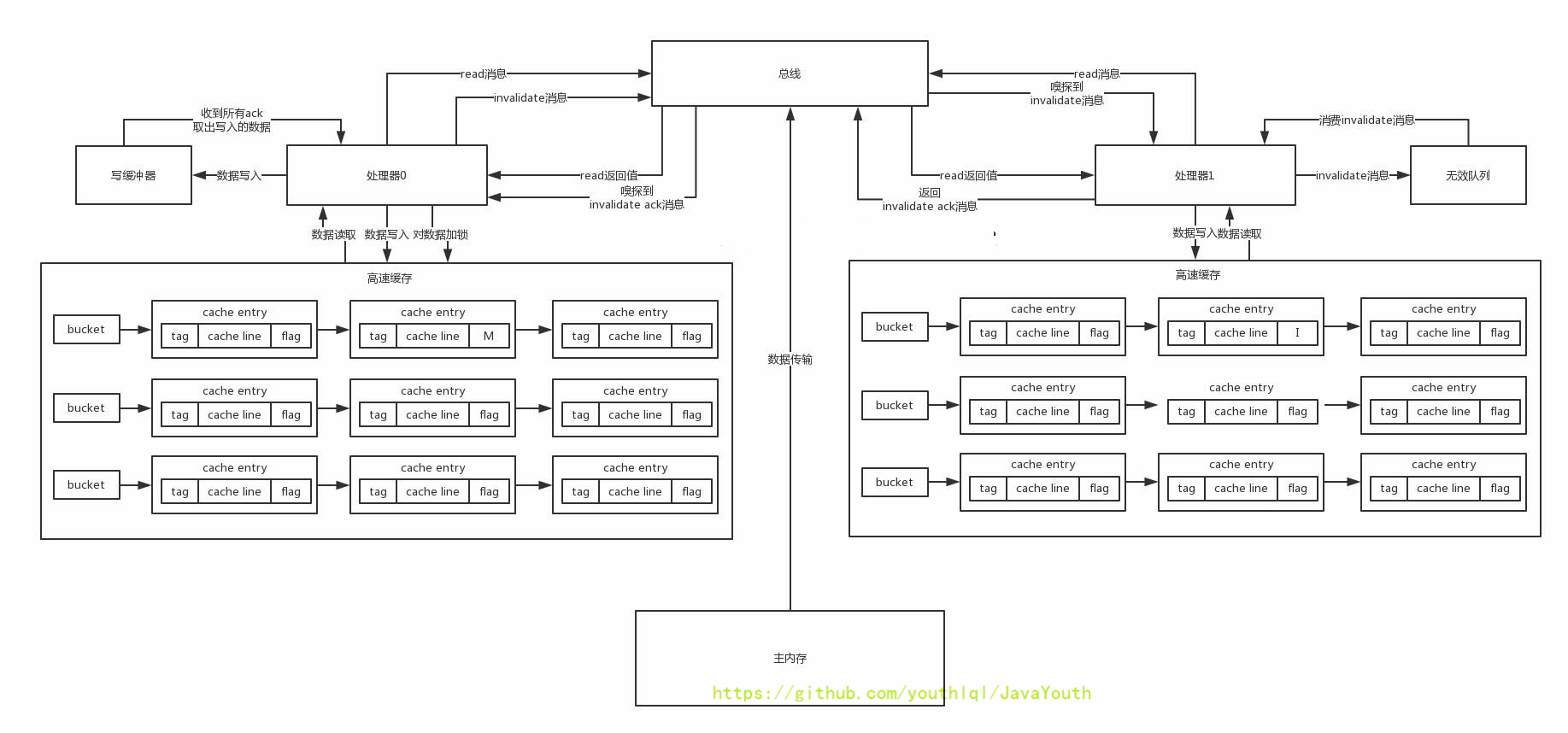 315 |
316 | MESI协议如果每次写数据的时候都要发送invalidate消息等待所有处理器返回ack,然后获取独占锁后才能写数据,那可能就会导致性能很差了,因为这个对共享变量的写操作,实际上在硬件级别变成串行的了。所以为了解决这个问题,硬件层面引入了写缓冲器和无效队列
317 |
318 | 1、
319 |
320 | 写缓冲器的作用是,一个处理器写数据的时候,直接把数据写入缓冲器,同时发送invalidate消息,然后就认为写操作完成了,接着就干别的事儿了,不会阻塞在这里。接着这个处理器如果之后收到其他处理器的ack消息之后才会把写缓冲器中的写结果拿出来,通过对cache entry设置为E加独占锁,同时修改数据,然后设置为M。
321 |
322 | 其实写缓冲器的作用,就是处理器写数据的时候直接写入缓冲器,不需要同步阻塞等待其他处理器的invalidate ack返回,这就大大提升了硬件层面的执行效率了
323 |
324 | 包括查询数据的时候,会先从写缓冲器里查,因为有可能刚修改的值在这里,然后才会从高速缓存里查,这个就是存储转发
325 |
326 | 2、
327 |
328 | 引入无效队列,就是说其他处理器在接收到了invalidate消息之后,不需要立马过期本地缓存,直接把消息放入无效队列,就返回ack给那个写处理器了,这就进一步加速了性能,然后之后从无效队列里取出来消息,过期本地缓存即可
329 |
330 | 通过引入写缓冲器和无效队列,一个处理器要写数据的话,这个性能其实很高的,他直接写数据到写缓冲器,发送一个validate消息出去,就立马返回,执行别的操作了;其他处理器收到invalidate消息之后直接放入无效队列,立马就返回invalidate ack
331 |
332 |
333 |
334 | ## 硬件层面的MESI协议为何会引发有序性和可见性的问题?
335 |
336 | MESI协议在硬件层面的原理其实大家都已经了解的很清晰了。
337 |
338 | 讲了这么多,再来看一下MESI-协议为何会引发可见性和有序性的问题
339 |
340 |
341 |
342 | - 可见性:写缓冲器和无效队列导致的,写数据不一定立马写入自己的高速缓存(或者主内存),是因为可能写入了写缓冲器;读数据不一定立马从别人的高速缓存(或者主内存)刷新最新的值过来,invalidate消息在无效队列里面
343 |
344 |
345 |
346 | - 有序性:
347 |
348 | 简单的举两个例子
349 |
350 | (1)StoreLoad重排序
351 |
352 |
353 |
354 | ```java
355 | int a = 0;
356 |
357 | int c = 1;
358 |
359 | 线程1:
360 |
361 | a = 1; //Store操作
362 |
363 | int b = c; //因为要读C的值,所以这个是load操作
364 |
365 | ```
366 |
367 |
368 |
369 | 这个很简单吧,第一个是Store,第二个是Load。但是可能处理器对store操作先写入了写缓冲器,此时这个写操作相当于没执行。然后就执行了第二行代码,第二行代码的b是局部变量,那这个操作等于是读取c的值,是load操作。
370 |
371 |
372 |
373 | - 第一个store操作写到写缓冲器里去了,导致其他的线程是读不到的,看不到的,好像是第一个写操作没执行一样;第二个load操作成功的执行了
374 |
375 | - 这就导致好像第二行代码的load先执行了,第一行代码的store后执行
376 |
377 | StoreLoad重排,明明Store先执行,Load后执行;看起来好像Load先执行,Store后执行
378 |
379 |
380 |
381 | (2)StoreStore重排序
382 |
383 | ```java
384 | resource = loadResource();
385 |
386 | loaded = true;
387 |
388 | ```
389 |
390 |
391 |
392 | - 两个写操作,但是可能第一个写操作写入了写缓冲器,然后第二个写操作是直接修改的高速缓存【可能此时第二个数据的状态是m】,这个时候不就导致了两个写操作顺序颠倒了?诸如此类的重排序,都可能会因为MESI的机制发生
393 | - 可见性问题也是一样的,写入写缓冲器之后,没刷入高速缓存,导致别人读不到;读数据的时候,可能invalidate消息在无效队列里,导致没法立马感知到过期的缓存,立马加载最新的数据
394 |
395 |
396 |
397 | ## 内存屏障在硬件层面的实现原理
398 |
399 | 1、可见性问题:
400 |
401 | > Store屏障 + Load屏障
402 |
403 | 如果加了Store屏障之后,就会强制性要求你对一个写操作必须阻塞等待到其他的处理器返回invalidate ack之后,对数据加锁,然后修改数据到高速缓存中,必须在写数据之后,强制执行flush操作。
404 |
405 | 他的效果,要求一个写操作必须刷到高速缓存(或者主内存),不能停留在写缓冲里
406 |
407 | 如果加了Load屏障之后,在从高速缓存中读取数据的时候,如果发现无效队列里有一个invalidate消息,此时会立马强制根据那个invalidate消息把自己本地高速缓存的数据,设置为I(过期),然后就可以强制从其他处理器的高速缓存中加载最新的值了。这就是refresh操作
408 |
409 |
410 |
411 | 2、有序性问题
412 |
413 | > 内存屏障,Acquire屏障,Release屏障,但是都是由基础的StoreStore屏障,StoreLoad屏障,可以避免指令重排序的效果
414 |
415 |
416 |
417 | StoreStore屏障,会强制让写数据的操作全部按照顺序写入写缓冲器里,他不会让你第一个写到写缓冲器里去,第二个写直接修改高速缓存了。
418 |
419 | ```java
420 | resource = loadResource();
421 |
422 | StoreStore屏障
423 |
424 | loaded = true;
425 |
426 | ```
427 |
428 |
429 |
430 | StoreLoad屏障,他会强制先将写缓冲器里的数据写入高速缓存中,接着读数据的时候强制清空无效队列,对里面的validate消息全部过期掉高速缓存中的条目,然后强制从主内存里重新加载数据
431 |
432 |
433 |
434 | a = 1; // 强制要求必须直接写入高速缓存,不能停留在写缓冲器里,清空写缓冲器里的这条数据 store
435 |
436 | int b = c; //load
437 |
438 |
439 |
440 |
441 |
442 | > java内存模型是对底层的硬件模型,cpu缓存模型,做了大幅度的简化,提供一个抽象和统一的模型给java程序员易于理解,很多时候如果要理解一些技术的本质,还是要深入到底层去研究的。
443 |
444 |
445 |
446 | # 原子操作的实现原理
447 |
448 | 原子(atomic)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为“不可被中断的一个或一系列操作”。在多处理器上实现原子操作就变得有点复杂。让我们一起来聊一聊在Intel处理器和Java里是如何实现原子操作的。
449 |
450 | ## 相关术语
451 |
452 |
315 |
316 | MESI协议如果每次写数据的时候都要发送invalidate消息等待所有处理器返回ack,然后获取独占锁后才能写数据,那可能就会导致性能很差了,因为这个对共享变量的写操作,实际上在硬件级别变成串行的了。所以为了解决这个问题,硬件层面引入了写缓冲器和无效队列
317 |
318 | 1、
319 |
320 | 写缓冲器的作用是,一个处理器写数据的时候,直接把数据写入缓冲器,同时发送invalidate消息,然后就认为写操作完成了,接着就干别的事儿了,不会阻塞在这里。接着这个处理器如果之后收到其他处理器的ack消息之后才会把写缓冲器中的写结果拿出来,通过对cache entry设置为E加独占锁,同时修改数据,然后设置为M。
321 |
322 | 其实写缓冲器的作用,就是处理器写数据的时候直接写入缓冲器,不需要同步阻塞等待其他处理器的invalidate ack返回,这就大大提升了硬件层面的执行效率了
323 |
324 | 包括查询数据的时候,会先从写缓冲器里查,因为有可能刚修改的值在这里,然后才会从高速缓存里查,这个就是存储转发
325 |
326 | 2、
327 |
328 | 引入无效队列,就是说其他处理器在接收到了invalidate消息之后,不需要立马过期本地缓存,直接把消息放入无效队列,就返回ack给那个写处理器了,这就进一步加速了性能,然后之后从无效队列里取出来消息,过期本地缓存即可
329 |
330 | 通过引入写缓冲器和无效队列,一个处理器要写数据的话,这个性能其实很高的,他直接写数据到写缓冲器,发送一个validate消息出去,就立马返回,执行别的操作了;其他处理器收到invalidate消息之后直接放入无效队列,立马就返回invalidate ack
331 |
332 |
333 |
334 | ## 硬件层面的MESI协议为何会引发有序性和可见性的问题?
335 |
336 | MESI协议在硬件层面的原理其实大家都已经了解的很清晰了。
337 |
338 | 讲了这么多,再来看一下MESI-协议为何会引发可见性和有序性的问题
339 |
340 |
341 |
342 | - 可见性:写缓冲器和无效队列导致的,写数据不一定立马写入自己的高速缓存(或者主内存),是因为可能写入了写缓冲器;读数据不一定立马从别人的高速缓存(或者主内存)刷新最新的值过来,invalidate消息在无效队列里面
343 |
344 |
345 |
346 | - 有序性:
347 |
348 | 简单的举两个例子
349 |
350 | (1)StoreLoad重排序
351 |
352 |
353 |
354 | ```java
355 | int a = 0;
356 |
357 | int c = 1;
358 |
359 | 线程1:
360 |
361 | a = 1; //Store操作
362 |
363 | int b = c; //因为要读C的值,所以这个是load操作
364 |
365 | ```
366 |
367 |
368 |
369 | 这个很简单吧,第一个是Store,第二个是Load。但是可能处理器对store操作先写入了写缓冲器,此时这个写操作相当于没执行。然后就执行了第二行代码,第二行代码的b是局部变量,那这个操作等于是读取c的值,是load操作。
370 |
371 |
372 |
373 | - 第一个store操作写到写缓冲器里去了,导致其他的线程是读不到的,看不到的,好像是第一个写操作没执行一样;第二个load操作成功的执行了
374 |
375 | - 这就导致好像第二行代码的load先执行了,第一行代码的store后执行
376 |
377 | StoreLoad重排,明明Store先执行,Load后执行;看起来好像Load先执行,Store后执行
378 |
379 |
380 |
381 | (2)StoreStore重排序
382 |
383 | ```java
384 | resource = loadResource();
385 |
386 | loaded = true;
387 |
388 | ```
389 |
390 |
391 |
392 | - 两个写操作,但是可能第一个写操作写入了写缓冲器,然后第二个写操作是直接修改的高速缓存【可能此时第二个数据的状态是m】,这个时候不就导致了两个写操作顺序颠倒了?诸如此类的重排序,都可能会因为MESI的机制发生
393 | - 可见性问题也是一样的,写入写缓冲器之后,没刷入高速缓存,导致别人读不到;读数据的时候,可能invalidate消息在无效队列里,导致没法立马感知到过期的缓存,立马加载最新的数据
394 |
395 |
396 |
397 | ## 内存屏障在硬件层面的实现原理
398 |
399 | 1、可见性问题:
400 |
401 | > Store屏障 + Load屏障
402 |
403 | 如果加了Store屏障之后,就会强制性要求你对一个写操作必须阻塞等待到其他的处理器返回invalidate ack之后,对数据加锁,然后修改数据到高速缓存中,必须在写数据之后,强制执行flush操作。
404 |
405 | 他的效果,要求一个写操作必须刷到高速缓存(或者主内存),不能停留在写缓冲里
406 |
407 | 如果加了Load屏障之后,在从高速缓存中读取数据的时候,如果发现无效队列里有一个invalidate消息,此时会立马强制根据那个invalidate消息把自己本地高速缓存的数据,设置为I(过期),然后就可以强制从其他处理器的高速缓存中加载最新的值了。这就是refresh操作
408 |
409 |
410 |
411 | 2、有序性问题
412 |
413 | > 内存屏障,Acquire屏障,Release屏障,但是都是由基础的StoreStore屏障,StoreLoad屏障,可以避免指令重排序的效果
414 |
415 |
416 |
417 | StoreStore屏障,会强制让写数据的操作全部按照顺序写入写缓冲器里,他不会让你第一个写到写缓冲器里去,第二个写直接修改高速缓存了。
418 |
419 | ```java
420 | resource = loadResource();
421 |
422 | StoreStore屏障
423 |
424 | loaded = true;
425 |
426 | ```
427 |
428 |
429 |
430 | StoreLoad屏障,他会强制先将写缓冲器里的数据写入高速缓存中,接着读数据的时候强制清空无效队列,对里面的validate消息全部过期掉高速缓存中的条目,然后强制从主内存里重新加载数据
431 |
432 |
433 |
434 | a = 1; // 强制要求必须直接写入高速缓存,不能停留在写缓冲器里,清空写缓冲器里的这条数据 store
435 |
436 | int b = c; //load
437 |
438 |
439 |
440 |
441 |
442 | > java内存模型是对底层的硬件模型,cpu缓存模型,做了大幅度的简化,提供一个抽象和统一的模型给java程序员易于理解,很多时候如果要理解一些技术的本质,还是要深入到底层去研究的。
443 |
444 |
445 |
446 | # 原子操作的实现原理
447 |
448 | 原子(atomic)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为“不可被中断的一个或一系列操作”。在多处理器上实现原子操作就变得有点复杂。让我们一起来聊一聊在Intel处理器和Java里是如何实现原子操作的。
449 |
450 | ## 相关术语
451 |
452 | 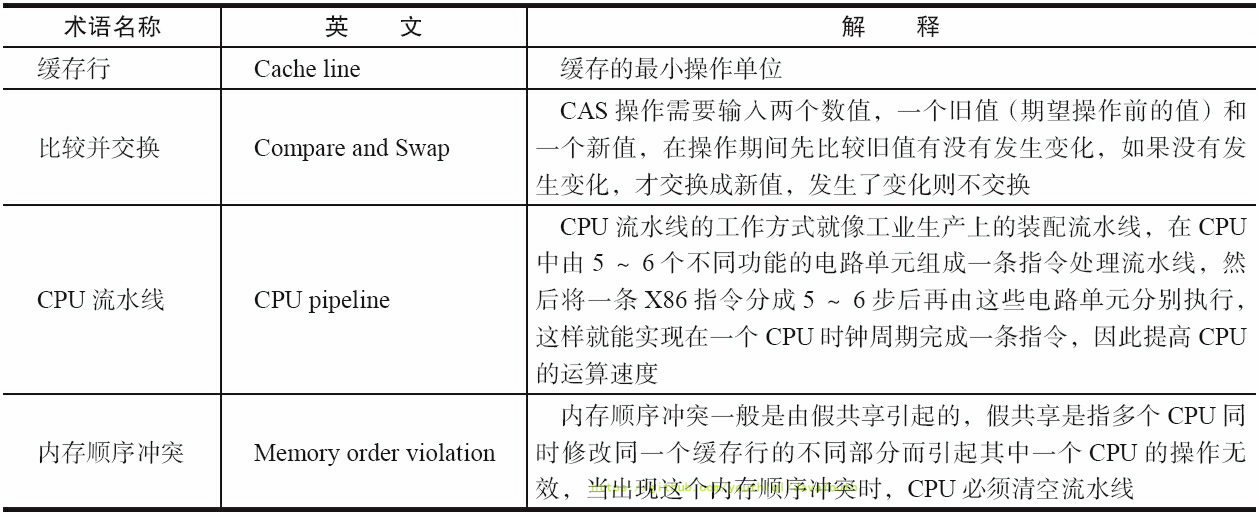 453 |
454 |
455 |
456 | ## 处理器如何实现原子操作
457 |
458 | 32位IA-32处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操 作。首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。Pentium 6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器是不能自动保证其原子性的,比如跨总线宽度、跨多个缓存行和跨页表的访问。但是,处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
459 |
460 | ### 使用总线锁保证原子性
461 |
462 | **第一个机制是通过总线锁保证原子性。**如果多个处理器同时对共享变量进行读改写操作 (i++就是经典的读改写操作),那么共享变量就会被多个处理器同时进行操作,这样读改写操 作就不是原子的,操作完之后共享变量的值会和期望的不一致。举个例子,如果i=1,我们进行 两次i++操作,我们期望的结果是3,但是有可能结果是2,如图所示。
463 |
464 |
453 |
454 |
455 |
456 | ## 处理器如何实现原子操作
457 |
458 | 32位IA-32处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操 作。首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。Pentium 6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器是不能自动保证其原子性的,比如跨总线宽度、跨多个缓存行和跨页表的访问。但是,处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
459 |
460 | ### 使用总线锁保证原子性
461 |
462 | **第一个机制是通过总线锁保证原子性。**如果多个处理器同时对共享变量进行读改写操作 (i++就是经典的读改写操作),那么共享变量就会被多个处理器同时进行操作,这样读改写操 作就不是原子的,操作完之后共享变量的值会和期望的不一致。举个例子,如果i=1,我们进行 两次i++操作,我们期望的结果是3,但是有可能结果是2,如图所示。
463 |
464 |  465 |
466 | 原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入 系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享 变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
467 |
468 | 处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
469 |
470 |
471 |
472 | ### 使用缓存锁保证原子性
473 |
474 | **第二个机制是通过缓存锁定来保证原子性**。在同一时刻,我们只需保证对某个内存地址 的操作是原子性即可,但总线锁定把CPU和内存之间的通信锁住了,这使得锁定期间,其他处 理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,目前处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
475 |
476 | 频繁使用的内存会缓存在处理器的L1、L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行,并不需要声明总线锁,在Pentium 6和目前的处理器中可以使用“缓存锁定”的方式来实现复杂的原子性。所谓“缓存锁定”是指内存区域如果被缓存在处理器的缓存 行中,并且在Lock操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效,在如上图所示的例子中,当CPU1修改缓存行中的i时使用了缓存锁定,那么CPU2就不能同时缓存i的缓存行。
477 |
478 | **但是有两种情况下处理器不会使用缓存锁定。**
479 |
480 | 第一种情况是:当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line)时,则处理器会调用总线锁定。
481 |
482 | 第二种情况是:有些处理器不支持缓存锁定。对于Intel 486和Pentium处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。针对以上两个机制,我们通过Intel处理器提供了很多Lock前缀的指令来实现。例如,位测试和修改指令:BTS、BTR、BTC;交换指令XADD、CMPXCHG,以及其他一些操作数和逻辑指令(如ADD、OR)等,被这些指令操作的内存区域就会加锁,导致其他处理器不能同时访问它。
483 |
484 |
485 |
486 |
487 |
488 | ## Java如何实现原子操作
489 |
490 | (1)使用循环CAS实现原子操作
491 |
492 | (2)使用锁机制实现原子操作
493 |
494 | 锁机制保证了只有获得锁的线程才能够操作锁定的内存区域。JVM内部实现了很多种锁机制,有偏向锁、轻量级锁和互斥锁。有意思的是除了偏向锁,JVM实现锁的方式都用了循环CAS,即当一个线程想进入同步块的时候使用循环CAS的方式来获取锁,当它退出同步块的时候使用循环CAS释放锁。
495 |
496 |
497 |
498 | 传统的锁(也就是下文要说的重量级锁)依赖于系统的同步函数,在linux上使用`mutex`互斥锁,最底层实现依赖于`futex`,这些同步函数都涉及到用户态和内核态的切换、进程的上下文切换,成本较高。对于加了`synchronized`关键字但**运行时并没有多线程竞争,或两个线程接近于交替执行的情况**,使用传统锁机制无疑效率是会比较低的。
499 |
500 | futex由一个内核层的队列和一个用户空间层的atomic integer构成。当获得锁时,尝试cas更改integer,如果integer原始值是0,则修改成功,该线程获得锁,否则就将当期线程放入到 wait queue中(即操作系统的等待队列)。【及其类似于AQS的设计思想,可能AQS就参考了futex的思想】
--------------------------------------------------------------------------------
/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: JVM系列-第1章-JVM与Java体系结构
3 | tags:
4 | - JVM
5 | - 虚拟机
6 | categories:
7 | - JVM
8 | - 1.内存与垃圾回收篇
9 | keywords: JVM,虚拟机。
10 | description: JVM系列-第1章-JVM与Java体系结构。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/jvm.png'
12 | abbrlink: 8c954c6
13 | date: 2020-11-02 11:51:56
14 | ---
15 |
16 |
17 |
18 |
19 |
20 | > 1、本系列博客,主要是面向Java8的虚拟机。如有特殊说明,会进行标注。
21 | >
22 | > 2、本系列博客主要参考**尚硅谷的JVM视频教程**,整理不易,所以图片打上了一些水印,还请读者见谅。后续可能会加上一些补充的东西。
23 | >
24 | > 3、尚硅谷的有些视频还不错(PS:不是广告,毕竟看了人家比较好的教程,得给人家打个call)
25 | >
26 | > 4、转载请注明出处,多谢~,希望大家一起能维护一个良好的开源环境。
27 |
28 | 第1章-JVM和Java体系架构
29 | =====================
30 |
31 | 前言
32 | --------
33 |
34 | 你是否也遇到过这些问题?
35 |
36 | 1. 运行着的线上系统突然卡死,系统无法访问,甚至直接OOM!
37 | 2. 想解决线上JVM GC问题,但却无从下手。
38 | 3. 新项目上线,对各种JVM参数设置一脸茫然,直接默认吧然后就JJ了。
39 | 4. 每次面试之前都要重新背一遍JVM的一些原理概念性的东西,然而面试官却经常问你在实际项目中如何调优VM参数,如何解决GC、OOM等问题,一脸懵逼。
40 |
41 |
465 |
466 | 原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入 系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享 变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
467 |
468 | 处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
469 |
470 |
471 |
472 | ### 使用缓存锁保证原子性
473 |
474 | **第二个机制是通过缓存锁定来保证原子性**。在同一时刻,我们只需保证对某个内存地址 的操作是原子性即可,但总线锁定把CPU和内存之间的通信锁住了,这使得锁定期间,其他处 理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,目前处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
475 |
476 | 频繁使用的内存会缓存在处理器的L1、L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行,并不需要声明总线锁,在Pentium 6和目前的处理器中可以使用“缓存锁定”的方式来实现复杂的原子性。所谓“缓存锁定”是指内存区域如果被缓存在处理器的缓存 行中,并且在Lock操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效,在如上图所示的例子中,当CPU1修改缓存行中的i时使用了缓存锁定,那么CPU2就不能同时缓存i的缓存行。
477 |
478 | **但是有两种情况下处理器不会使用缓存锁定。**
479 |
480 | 第一种情况是:当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line)时,则处理器会调用总线锁定。
481 |
482 | 第二种情况是:有些处理器不支持缓存锁定。对于Intel 486和Pentium处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。针对以上两个机制,我们通过Intel处理器提供了很多Lock前缀的指令来实现。例如,位测试和修改指令:BTS、BTR、BTC;交换指令XADD、CMPXCHG,以及其他一些操作数和逻辑指令(如ADD、OR)等,被这些指令操作的内存区域就会加锁,导致其他处理器不能同时访问它。
483 |
484 |
485 |
486 |
487 |
488 | ## Java如何实现原子操作
489 |
490 | (1)使用循环CAS实现原子操作
491 |
492 | (2)使用锁机制实现原子操作
493 |
494 | 锁机制保证了只有获得锁的线程才能够操作锁定的内存区域。JVM内部实现了很多种锁机制,有偏向锁、轻量级锁和互斥锁。有意思的是除了偏向锁,JVM实现锁的方式都用了循环CAS,即当一个线程想进入同步块的时候使用循环CAS的方式来获取锁,当它退出同步块的时候使用循环CAS释放锁。
495 |
496 |
497 |
498 | 传统的锁(也就是下文要说的重量级锁)依赖于系统的同步函数,在linux上使用`mutex`互斥锁,最底层实现依赖于`futex`,这些同步函数都涉及到用户态和内核态的切换、进程的上下文切换,成本较高。对于加了`synchronized`关键字但**运行时并没有多线程竞争,或两个线程接近于交替执行的情况**,使用传统锁机制无疑效率是会比较低的。
499 |
500 | futex由一个内核层的队列和一个用户空间层的atomic integer构成。当获得锁时,尝试cas更改integer,如果integer原始值是0,则修改成功,该线程获得锁,否则就将当期线程放入到 wait queue中(即操作系统的等待队列)。【及其类似于AQS的设计思想,可能AQS就参考了futex的思想】
--------------------------------------------------------------------------------
/docs/JVM/JVM系列-第1章-JVM与Java体系结构.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: JVM系列-第1章-JVM与Java体系结构
3 | tags:
4 | - JVM
5 | - 虚拟机
6 | categories:
7 | - JVM
8 | - 1.内存与垃圾回收篇
9 | keywords: JVM,虚拟机。
10 | description: JVM系列-第1章-JVM与Java体系结构。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/jvm.png'
12 | abbrlink: 8c954c6
13 | date: 2020-11-02 11:51:56
14 | ---
15 |
16 |
17 |
18 |
19 |
20 | > 1、本系列博客,主要是面向Java8的虚拟机。如有特殊说明,会进行标注。
21 | >
22 | > 2、本系列博客主要参考**尚硅谷的JVM视频教程**,整理不易,所以图片打上了一些水印,还请读者见谅。后续可能会加上一些补充的东西。
23 | >
24 | > 3、尚硅谷的有些视频还不错(PS:不是广告,毕竟看了人家比较好的教程,得给人家打个call)
25 | >
26 | > 4、转载请注明出处,多谢~,希望大家一起能维护一个良好的开源环境。
27 |
28 | 第1章-JVM和Java体系架构
29 | =====================
30 |
31 | 前言
32 | --------
33 |
34 | 你是否也遇到过这些问题?
35 |
36 | 1. 运行着的线上系统突然卡死,系统无法访问,甚至直接OOM!
37 | 2. 想解决线上JVM GC问题,但却无从下手。
38 | 3. 新项目上线,对各种JVM参数设置一脸茫然,直接默认吧然后就JJ了。
39 | 4. 每次面试之前都要重新背一遍JVM的一些原理概念性的东西,然而面试官却经常问你在实际项目中如何调优VM参数,如何解决GC、OOM等问题,一脸懵逼。
40 |
41 |  42 |
43 | 大部分Java开发人员,除了会在项目中使用到与Java平台相关的各种高精尖技术,对于Java技术的核心Java虚拟机了解甚少。
44 |
45 | 开发人员如何看待上层框架
46 | ---------
47 |
48 |
49 |
50 | 1. 一些有一定工作经验的开发人员,打心眼儿里觉得SSM、微服务等上层技术才是重点,基础技术并不重要,这其实是一种本末倒置的“病态”。
51 | 2. 如果我们把核心类库的API比做数学公式的话,那么Java虚拟机的知识就好比公式的推导过程。
52 |
53 |
42 |
43 | 大部分Java开发人员,除了会在项目中使用到与Java平台相关的各种高精尖技术,对于Java技术的核心Java虚拟机了解甚少。
44 |
45 | 开发人员如何看待上层框架
46 | ---------
47 |
48 |
49 |
50 | 1. 一些有一定工作经验的开发人员,打心眼儿里觉得SSM、微服务等上层技术才是重点,基础技术并不重要,这其实是一种本末倒置的“病态”。
51 | 2. 如果我们把核心类库的API比做数学公式的话,那么Java虚拟机的知识就好比公式的推导过程。
52 |
53 |  54 |
55 | - 计算机系统体系对我们来说越来越远,在不了解底层实现方式的前提下,通过高级语言很容易编写程序代码。但事实上计算机并不认识高级语言。
56 |
57 |
58 |
59 | 架构师每天都在思考什么?
60 | ---------
61 |
62 | 1. 应该如何让我的系统更快?
63 | 2. 如何避免系统出现瓶颈?
64 |
65 | **知乎上有条帖子:应该如何看招聘信息,直通年薪50万+?**
66 |
67 | 1. 参与现有系统的性能优化,重构,保证平台性能和稳定性
68 | 2. 根据业务场景和需求,决定技术方向,做技术选型
69 | 3. 能够独立架构和设计海量数据下高并发分布式解决方案,满足功能和非功能需求
70 | 4. 解决各类潜在系统风险,核心功能的架构与代码编写
71 | 5. 分析系统瓶颈,解决各种疑难杂症,性能调优等
72 |
73 | 我们为什么要学习JVM
74 | -----------
75 |
76 | 1. 面试的需要(BATJ、TMD,PKQ等面试都爱问)
77 | 2. 中高级程序员必备技能
78 | - 项目管理、调优的需要
79 | 3. 追求极客的精神,
80 | - 比如:垃圾回收算法、JIT、底层原理
81 |
82 |
83 |
84 | Java VS C++
85 | -------------
86 |
87 | 1. 垃圾收集机制为我们打理了很多繁琐的工作,大大提高了开发的效率,但是,垃圾收集也不是万能的,懂得JVM内部的内存结构、工作机制,是设计高扩展性应用和诊断运行时问题的基础,也是Java工程师进阶的必备能力。
88 | 2. C++语言需要程序员自己来分配内存和回收内存,对于高手来说可能更加舒服,但是对于普通开发者,如果技术实力不够,很容易造成内存泄漏。而Java全部交给JVM进行内存分配和回收,这也是一种趋势,减少程序员的工作量。
89 |
90 |
54 |
55 | - 计算机系统体系对我们来说越来越远,在不了解底层实现方式的前提下,通过高级语言很容易编写程序代码。但事实上计算机并不认识高级语言。
56 |
57 |
58 |
59 | 架构师每天都在思考什么?
60 | ---------
61 |
62 | 1. 应该如何让我的系统更快?
63 | 2. 如何避免系统出现瓶颈?
64 |
65 | **知乎上有条帖子:应该如何看招聘信息,直通年薪50万+?**
66 |
67 | 1. 参与现有系统的性能优化,重构,保证平台性能和稳定性
68 | 2. 根据业务场景和需求,决定技术方向,做技术选型
69 | 3. 能够独立架构和设计海量数据下高并发分布式解决方案,满足功能和非功能需求
70 | 4. 解决各类潜在系统风险,核心功能的架构与代码编写
71 | 5. 分析系统瓶颈,解决各种疑难杂症,性能调优等
72 |
73 | 我们为什么要学习JVM
74 | -----------
75 |
76 | 1. 面试的需要(BATJ、TMD,PKQ等面试都爱问)
77 | 2. 中高级程序员必备技能
78 | - 项目管理、调优的需要
79 | 3. 追求极客的精神,
80 | - 比如:垃圾回收算法、JIT、底层原理
81 |
82 |
83 |
84 | Java VS C++
85 | -------------
86 |
87 | 1. 垃圾收集机制为我们打理了很多繁琐的工作,大大提高了开发的效率,但是,垃圾收集也不是万能的,懂得JVM内部的内存结构、工作机制,是设计高扩展性应用和诊断运行时问题的基础,也是Java工程师进阶的必备能力。
88 | 2. C++语言需要程序员自己来分配内存和回收内存,对于高手来说可能更加舒服,但是对于普通开发者,如果技术实力不够,很容易造成内存泄漏。而Java全部交给JVM进行内存分配和回收,这也是一种趋势,减少程序员的工作量。
89 |
90 |  91 |
92 | ## 什么人需要学JVM?
93 |
94 | 1. 拥有一定开发经验的Java开发人员,希望升职加薪
95 | 2. 软件设计师,架构师
96 | 3. 系统调优人员
97 | 4. 虚拟机爱好者,JVM实践者
98 |
99 | 推荐及参考书籍
100 | ------
101 |
102 | **官方文档**
103 |
104 | **英文文档规范**:https://docs.oracle.com/javase/specs/index.html
105 |
106 |
91 |
92 | ## 什么人需要学JVM?
93 |
94 | 1. 拥有一定开发经验的Java开发人员,希望升职加薪
95 | 2. 软件设计师,架构师
96 | 3. 系统调优人员
97 | 4. 虚拟机爱好者,JVM实践者
98 |
99 | 推荐及参考书籍
100 | ------
101 |
102 | **官方文档**
103 |
104 | **英文文档规范**:https://docs.oracle.com/javase/specs/index.html
105 |
106 |  107 |
108 | **中文书籍:**
109 |
110 |
107 |
108 | **中文书籍:**
109 |
110 |  111 |
112 | > 周志明老师的这本书**非常推荐看**,不过只推荐看第三版,第三版较第二版更新了很多,个人觉得没必要再看第二版。
113 |
114 |
111 |
112 | > 周志明老师的这本书**非常推荐看**,不过只推荐看第三版,第三版较第二版更新了很多,个人觉得没必要再看第二版。
113 |
114 |  115 |
116 |
117 |
118 |
115 |
116 |
117 |
118 |  119 |
120 | TIOBE排行榜
121 | -----------
122 |
123 | **TIOBE 排行榜**:https://www.tiobe.com/tiobe-index/
124 |
125 |
119 |
120 | TIOBE排行榜
121 | -----------
122 |
123 | **TIOBE 排行榜**:https://www.tiobe.com/tiobe-index/
124 |
125 |  126 |
127 | - 世界上没有最好的编程语言,只有最适用于具体应用场景的编程语言。
128 | - 目前网上一直流传Java被python,go撼动Java第一的地位。学习者不需要太担心,Java强大的生态圈,也不是说是朝夕之间可以被撼动的。
129 |
130 |
131 |
132 | Java生态圈
133 | ----------
134 |
135 | Java是目前应用最为广泛的软件开发平台之一。随着Java以及Java社区的不断壮大Java 也早已不再是简简单单的一门计算机语言了,它更是一个平台、一种文化、一个社区。
136 |
137 | 1. 作为一个平台,Java虚拟机扮演着举足轻重的作用
138 | * Groovy、Scala、JRuby、Kotlin等都是Java平台的一部分
139 | 2. 作为一种文化,Java几乎成为了“开源”的代名词。
140 | * 第三方开源软件和框架。如Tomcat、Struts,MyBatis,Spring等。
141 | * 就连JDK和JVM自身也有不少开源的实现,如openJDK、Harmony。
142 | 3. 作为一个社区,Java拥有全世界最多的技术拥护者和开源社区支持,有数不清的论坛和资料。从桌面应用软件、嵌入式开发到企业级应用、后台服务器、中间件,都可以看到Java的身影。其应用形式之复杂、参与人数之众多也令人咋舌。
143 |
144 |
145 |
146 | Java-跨平台的语言
147 | ------------
148 |
149 |
150 |
151 |
126 |
127 | - 世界上没有最好的编程语言,只有最适用于具体应用场景的编程语言。
128 | - 目前网上一直流传Java被python,go撼动Java第一的地位。学习者不需要太担心,Java强大的生态圈,也不是说是朝夕之间可以被撼动的。
129 |
130 |
131 |
132 | Java生态圈
133 | ----------
134 |
135 | Java是目前应用最为广泛的软件开发平台之一。随着Java以及Java社区的不断壮大Java 也早已不再是简简单单的一门计算机语言了,它更是一个平台、一种文化、一个社区。
136 |
137 | 1. 作为一个平台,Java虚拟机扮演着举足轻重的作用
138 | * Groovy、Scala、JRuby、Kotlin等都是Java平台的一部分
139 | 2. 作为一种文化,Java几乎成为了“开源”的代名词。
140 | * 第三方开源软件和框架。如Tomcat、Struts,MyBatis,Spring等。
141 | * 就连JDK和JVM自身也有不少开源的实现,如openJDK、Harmony。
142 | 3. 作为一个社区,Java拥有全世界最多的技术拥护者和开源社区支持,有数不清的论坛和资料。从桌面应用软件、嵌入式开发到企业级应用、后台服务器、中间件,都可以看到Java的身影。其应用形式之复杂、参与人数之众多也令人咋舌。
143 |
144 |
145 |
146 | Java-跨平台的语言
147 | ------------
148 |
149 |
150 |
151 |  152 |
153 | JVM-跨语言的平台
154 | ------
155 |
156 |
157 |
158 |
152 |
153 | JVM-跨语言的平台
154 | ------
155 |
156 |
157 |
158 |  159 |
160 |
161 |
162 | 1. 随着Java7的正式发布,Java虚拟机的设计者们通过JSR-292规范基本实现在Java虚拟机平台上运行非Java语言编写的程序。
163 | 2. Java虚拟机根本不关心运行在其内部的程序到底是使用何种编程语言编写的,它只关心“字节码”文件。也就是说Java虚拟机拥有语言无关性,并不会单纯地与Java语言“终身绑定”,只要其他编程语言的编译结果满足并包含Java虚拟机的内部指令集、符号表以及其他的辅助信息,它就是一个有效的字节码文件,就能够被虚拟机所识别并装载运行。
164 |
165 | - Java不是最强大的语言,但是JVM是最强大的虚拟机
166 |
167 | 1. 我们平时说的java字节码,指的是用java语言编译成的字节码。准确的说任何能在jvm平台上执行的字节码格式都是一样的。所以应该统称为:jvm字节码。
168 |
169 | 2. 不同的编译器,可以编译出相同的字节码文件,字节码文件也可以在不同的JVM上运行。
170 |
171 | 3. Java虚拟机与Java语言并没有必然的联系,它只与特定的二进制文件格式——Class文件格式所关联,Class文件中包含了Java虚拟机指令集(或者称为字节码、Bytecodes)和符号表,还有一些其他辅助信息。
172 |
173 | 多语言混合编程
174 | ----------
175 |
176 | 1. Java平台上的多语言混合编程正成为主流,通过特定领域的语言去解决特定领域的问题是当前软件开发应对日趋复杂的项目需求的一个方向。
177 |
178 | 2. 试想一下,在一个项目之中,并行处理用Clojure语言编写,展示层使用JRuby/Rails,中间层则是Java,每个应用层都将使用不同的编程语言来完成,而且,接口对每一层的开发者都是透明的,各种语言之间的交互不存在任何困难,就像使用自己语言的原生API一样方便,因为它们最终都运行在一个虚拟机之上。
179 |
180 | 3. 对这些运行于Java虚拟机之上、Java之外的语言,来自系统级的、底层的支持正在迅速增强,以JSR-292为核心的一系列项目和功能改进(如DaVinci Machine项目、Nashorn引擎、InvokeDynamic指令、java.lang.invoke包等),推动Java虚拟机从“Java语言的虚拟机”向 “多语言虚拟机”的方向发展。
181 |
182 |
183 | 如何真正搞懂JVM?
184 | -----------
185 |
186 | 1. Java虚拟机非常复杂,要想真正理解它的工作原理,最好的方式就是自己动手编写一个!
187 | 2. 自己动手写一个Java虚拟机,难吗?
188 | 3. 天下事有难易乎?为之,则难者亦易矣;不为,则易者亦难矣
189 |
190 |
159 |
160 |
161 |
162 | 1. 随着Java7的正式发布,Java虚拟机的设计者们通过JSR-292规范基本实现在Java虚拟机平台上运行非Java语言编写的程序。
163 | 2. Java虚拟机根本不关心运行在其内部的程序到底是使用何种编程语言编写的,它只关心“字节码”文件。也就是说Java虚拟机拥有语言无关性,并不会单纯地与Java语言“终身绑定”,只要其他编程语言的编译结果满足并包含Java虚拟机的内部指令集、符号表以及其他的辅助信息,它就是一个有效的字节码文件,就能够被虚拟机所识别并装载运行。
164 |
165 | - Java不是最强大的语言,但是JVM是最强大的虚拟机
166 |
167 | 1. 我们平时说的java字节码,指的是用java语言编译成的字节码。准确的说任何能在jvm平台上执行的字节码格式都是一样的。所以应该统称为:jvm字节码。
168 |
169 | 2. 不同的编译器,可以编译出相同的字节码文件,字节码文件也可以在不同的JVM上运行。
170 |
171 | 3. Java虚拟机与Java语言并没有必然的联系,它只与特定的二进制文件格式——Class文件格式所关联,Class文件中包含了Java虚拟机指令集(或者称为字节码、Bytecodes)和符号表,还有一些其他辅助信息。
172 |
173 | 多语言混合编程
174 | ----------
175 |
176 | 1. Java平台上的多语言混合编程正成为主流,通过特定领域的语言去解决特定领域的问题是当前软件开发应对日趋复杂的项目需求的一个方向。
177 |
178 | 2. 试想一下,在一个项目之中,并行处理用Clojure语言编写,展示层使用JRuby/Rails,中间层则是Java,每个应用层都将使用不同的编程语言来完成,而且,接口对每一层的开发者都是透明的,各种语言之间的交互不存在任何困难,就像使用自己语言的原生API一样方便,因为它们最终都运行在一个虚拟机之上。
179 |
180 | 3. 对这些运行于Java虚拟机之上、Java之外的语言,来自系统级的、底层的支持正在迅速增强,以JSR-292为核心的一系列项目和功能改进(如DaVinci Machine项目、Nashorn引擎、InvokeDynamic指令、java.lang.invoke包等),推动Java虚拟机从“Java语言的虚拟机”向 “多语言虚拟机”的方向发展。
181 |
182 |
183 | 如何真正搞懂JVM?
184 | -----------
185 |
186 | 1. Java虚拟机非常复杂,要想真正理解它的工作原理,最好的方式就是自己动手编写一个!
187 | 2. 自己动手写一个Java虚拟机,难吗?
188 | 3. 天下事有难易乎?为之,则难者亦易矣;不为,则易者亦难矣
189 |
190 |  191 |
192 | Java发展重大事件
193 | ------------
194 |
195 | * 1990年,在Sun计算机公司中,由Patrick Naughton、MikeSheridan及James Gosling领导的小组Green Team,开发出的新的程序语言,命名为Oak,后期命名为Java
196 | * 1995年,Sun正式发布Java和HotJava产品,Java首次公开亮相。
197 | * 1996年1月23日Sun Microsystems发布了JDK 1.0。
198 | * 1998年,JDK1.2版本发布。同时,Sun发布了JSP/Servlet、EJB规范,以及将Java分成了J2EE、J2SE和J2ME。这表明了Java开始向企业、桌面应用和移动设备应用3大领域挺进。
199 | * 2000年,JDK1.3发布,Java HotSpot Virtual Machine正式发布,成为Java的默认虚拟机。
200 | * 2002年,JDK1.4发布,古老的Classic虚拟机退出历史舞台。
201 | * 2003年年底,Java平台的scala正式发布,同年Groovy也加入了Java阵营。
202 | * 2004年,JDK1.5发布。同时JDK1.5改名为JavaSE5.0。
203 | * 2006年,JDK6发布。同年,Java开源并建立了OpenJDK。顺理成章,Hotspot虚拟机也成为了OpenJDK中的默认虚拟机。
204 | * 2007年,Java平台迎来了新伙伴Clojure。
205 | * 2008年,oracle收购了BEA,得到了JRockit虚拟机。
206 | * 2009年,Twitter宣布把后台大部分程序从Ruby迁移到Scala,这是Java平台的又一次大规模应用。
207 | * 2010年,Oracle收购了Sun,获得Java商标和最真价值的HotSpot虚拟机。此时,Oracle拥有市场占用率最高的两款虚拟机HotSpot和JRockit,并计划在未来对它们进行整合:HotRockit。JCP组织管理Java语言
208 | * 2011年,JDK7发布。在JDK1.7u4中,正式启用了新的垃圾回收器G1。
209 | * **2017年,JDK9发布。将G1设置为默认GC,替代CMS**
210 | * 同年,IBM的J9开源,形成了现在的Open J9社区
211 | * 2018年,Android的Java侵权案判决,Google赔偿Oracle计88亿美元
212 | * 同年,Oracle宣告JavagE成为历史名词JDBC、JMS、Servlet赠予Eclipse基金会
213 | * **同年,JDK11发布,LTS版本的JDK,发布革命性的ZGC,调整JDK授权许可**
214 | * 2019年,JDK12发布,加入RedHat领导开发的Shenandoah GC
215 |
216 | ## Open JDK和Oracle JDK
217 |
218 |
191 |
192 | Java发展重大事件
193 | ------------
194 |
195 | * 1990年,在Sun计算机公司中,由Patrick Naughton、MikeSheridan及James Gosling领导的小组Green Team,开发出的新的程序语言,命名为Oak,后期命名为Java
196 | * 1995年,Sun正式发布Java和HotJava产品,Java首次公开亮相。
197 | * 1996年1月23日Sun Microsystems发布了JDK 1.0。
198 | * 1998年,JDK1.2版本发布。同时,Sun发布了JSP/Servlet、EJB规范,以及将Java分成了J2EE、J2SE和J2ME。这表明了Java开始向企业、桌面应用和移动设备应用3大领域挺进。
199 | * 2000年,JDK1.3发布,Java HotSpot Virtual Machine正式发布,成为Java的默认虚拟机。
200 | * 2002年,JDK1.4发布,古老的Classic虚拟机退出历史舞台。
201 | * 2003年年底,Java平台的scala正式发布,同年Groovy也加入了Java阵营。
202 | * 2004年,JDK1.5发布。同时JDK1.5改名为JavaSE5.0。
203 | * 2006年,JDK6发布。同年,Java开源并建立了OpenJDK。顺理成章,Hotspot虚拟机也成为了OpenJDK中的默认虚拟机。
204 | * 2007年,Java平台迎来了新伙伴Clojure。
205 | * 2008年,oracle收购了BEA,得到了JRockit虚拟机。
206 | * 2009年,Twitter宣布把后台大部分程序从Ruby迁移到Scala,这是Java平台的又一次大规模应用。
207 | * 2010年,Oracle收购了Sun,获得Java商标和最真价值的HotSpot虚拟机。此时,Oracle拥有市场占用率最高的两款虚拟机HotSpot和JRockit,并计划在未来对它们进行整合:HotRockit。JCP组织管理Java语言
208 | * 2011年,JDK7发布。在JDK1.7u4中,正式启用了新的垃圾回收器G1。
209 | * **2017年,JDK9发布。将G1设置为默认GC,替代CMS**
210 | * 同年,IBM的J9开源,形成了现在的Open J9社区
211 | * 2018年,Android的Java侵权案判决,Google赔偿Oracle计88亿美元
212 | * 同年,Oracle宣告JavagE成为历史名词JDBC、JMS、Servlet赠予Eclipse基金会
213 | * **同年,JDK11发布,LTS版本的JDK,发布革命性的ZGC,调整JDK授权许可**
214 | * 2019年,JDK12发布,加入RedHat领导开发的Shenandoah GC
215 |
216 | ## Open JDK和Oracle JDK
217 |
218 |  219 |
220 | - 在JDK11之前,Oracle JDK中还会存在一些Open JDK中没有的,闭源的功能。但在JDK11中,我们可以认为Open JDK和Oracle JDK代码实质上已经达到完全一致的程度了。
221 | - 主要的区别就是两者更新周期不一样
222 |
223 | 虚拟机
224 | --------
225 |
226 | ### 虚拟机概念
227 |
228 | - 所谓虚拟机(Virtual Machine),就是一台虚拟的计算机。它是一款软件,用来执行一系列虚拟计算机指令。大体上,虚拟机可以分为系统虚拟机和程序虚拟机。
229 |
230 | - 大名鼎鼎的Virtual Box,VMware就属于系统虚拟机,它们完全是对物理计算机硬件的仿真(模拟),提供了一个可运行完整操作系统的软件平台。
231 |
232 | + 程序虚拟机的典型代表就是Java虚拟机,它专门为执行单个计算机程序而设计,在Java虚拟机中执行的指令我们称为Java字节码指令。
233 |
234 | - 无论是系统虚拟机还是程序虚拟机,在上面运行的软件都被限制于虚拟机提供的资源中。
235 |
236 | ### Java虚拟机
237 |
238 | 1. Java虚拟机是一台执行Java字节码的虚拟计算机,它拥有独立的运行机制,其运行的Java字节码也未必由Java语言编译而成。
239 | 2. JVM平台的各种语言可以共享Java虚拟机带来的跨平台性、优秀的垃圾回器,以及可靠的即时编译器。
240 | 3. **Java技术的核心就是Java虚拟机**(JVM,Java Virtual Machine),因为所有的Java程序都运行在Java虚拟机内部。
241 |
242 |
243 |
244 | **作用:**
245 |
246 | Java虚拟机就是二进制字节码的运行环境,负责装载字节码到其内部,解释/编译为对应平台上的机器指令执行。每一条Java指令,Java虚拟机规范中都有详细定义,如怎么取操作数,怎么处理操作数,处理结果放在哪里。
247 |
248 | **特点:**
249 |
250 | 1. 一次编译,到处运行
251 | 2. 自动内存管理
252 | 3. 自动垃圾回收功能
253 |
254 |
255 |
256 | JVM的位置
257 | ----------
258 |
259 | JVM是运行在操作系统之上的,它与硬件没有直接的交互
260 |
261 |
219 |
220 | - 在JDK11之前,Oracle JDK中还会存在一些Open JDK中没有的,闭源的功能。但在JDK11中,我们可以认为Open JDK和Oracle JDK代码实质上已经达到完全一致的程度了。
221 | - 主要的区别就是两者更新周期不一样
222 |
223 | 虚拟机
224 | --------
225 |
226 | ### 虚拟机概念
227 |
228 | - 所谓虚拟机(Virtual Machine),就是一台虚拟的计算机。它是一款软件,用来执行一系列虚拟计算机指令。大体上,虚拟机可以分为系统虚拟机和程序虚拟机。
229 |
230 | - 大名鼎鼎的Virtual Box,VMware就属于系统虚拟机,它们完全是对物理计算机硬件的仿真(模拟),提供了一个可运行完整操作系统的软件平台。
231 |
232 | + 程序虚拟机的典型代表就是Java虚拟机,它专门为执行单个计算机程序而设计,在Java虚拟机中执行的指令我们称为Java字节码指令。
233 |
234 | - 无论是系统虚拟机还是程序虚拟机,在上面运行的软件都被限制于虚拟机提供的资源中。
235 |
236 | ### Java虚拟机
237 |
238 | 1. Java虚拟机是一台执行Java字节码的虚拟计算机,它拥有独立的运行机制,其运行的Java字节码也未必由Java语言编译而成。
239 | 2. JVM平台的各种语言可以共享Java虚拟机带来的跨平台性、优秀的垃圾回器,以及可靠的即时编译器。
240 | 3. **Java技术的核心就是Java虚拟机**(JVM,Java Virtual Machine),因为所有的Java程序都运行在Java虚拟机内部。
241 |
242 |
243 |
244 | **作用:**
245 |
246 | Java虚拟机就是二进制字节码的运行环境,负责装载字节码到其内部,解释/编译为对应平台上的机器指令执行。每一条Java指令,Java虚拟机规范中都有详细定义,如怎么取操作数,怎么处理操作数,处理结果放在哪里。
247 |
248 | **特点:**
249 |
250 | 1. 一次编译,到处运行
251 | 2. 自动内存管理
252 | 3. 自动垃圾回收功能
253 |
254 |
255 |
256 | JVM的位置
257 | ----------
258 |
259 | JVM是运行在操作系统之上的,它与硬件没有直接的交互
260 |
261 |  262 |
263 |
264 |
265 |
262 |
263 |
264 |
265 |  266 |
267 |
268 |
269 | JVM的整体结构
270 | -------------
271 |
272 | 1. HotSpot VM是目前市面上高性能虚拟机的代表作之一。
273 | 2. 它采用解释器与即时编译器并存的架构。
274 | 3. 在今天,Java程序的运行性能早已脱胎换骨,已经达到了可以和C/C++程序一较高下的地步。
275 |
276 |
277 |
278 |
266 |
267 |
268 |
269 | JVM的整体结构
270 | -------------
271 |
272 | 1. HotSpot VM是目前市面上高性能虚拟机的代表作之一。
273 | 2. 它采用解释器与即时编译器并存的架构。
274 | 3. 在今天,Java程序的运行性能早已脱胎换骨,已经达到了可以和C/C++程序一较高下的地步。
275 |
276 |
277 |
278 |  279 |
280 |
281 |
282 | Java代码执行流程
283 | --------------
284 |
285 | 凡是能生成被Java虚拟机所能解释、运行的字节码文件,那么理论上我们就可以自己设计一套语言了
286 |
287 |
279 |
280 |
281 |
282 | Java代码执行流程
283 | --------------
284 |
285 | 凡是能生成被Java虚拟机所能解释、运行的字节码文件,那么理论上我们就可以自己设计一套语言了
286 |
287 |  288 |
289 |
290 |
291 | JVM的架构模型
292 | -----------
293 |
294 | Java编译器输入的指令流基本上是一种**基于栈的指令集架构**,另外一种指令集架构则是**基于寄存器的指令集架构**。具体来说:这两种架构之间的区别:
295 |
296 | ### 基于栈的指令集架构
297 |
298 | 基于栈式架构的特点:
299 |
300 | 1. 设计和实现更简单,适用于资源受限的系统;
301 | 2. 避开了寄存器的分配难题:使用零地址指令方式分配
302 | 3. 指令流中的指令大部分是零地址指令,其执行过程依赖于操作栈。指令集更小,编译器容易实现
303 | 4. 不需要硬件支持,可移植性更好,更好实现跨平台
304 |
305 | ### 基于寄存器的指令级架构
306 |
307 | 基于寄存器架构的特点:
308 |
309 | 1. 典型的应用是x86的二进制指令集:比如传统的PC以及Android的Davlik虚拟机。
310 | 2. 指令集架构则完全依赖硬件,与硬件的耦合度高,可移植性差
311 | 3. 性能优秀和执行更高效
312 | 4. 花费更少的指令去完成一项操作
313 | 5. 在大部分情况下,基于寄存器架构的指令集往往都以一地址指令、二地址指令和三地址指令为主,而基于栈式架构的指令集却是以零地址指令为主
314 |
315 | ### 两种架构的举例
316 |
317 | 同样执行2+3这种逻辑操作,其指令分别如下:
318 |
319 | * **基于栈的计算流程(以Java虚拟机为例):**
320 |
321 | ```java
322 | iconst_2 //常量2入栈
323 | istore_1
324 | iconst_3 // 常量3入栈
325 | istore_2
326 | iload_1
327 | iload_2
328 | iadd //常量2/3出栈,执行相加
329 | istore_0 // 结果5入栈
330 | ```
331 |
332 | 8个指令
333 |
334 |
335 |
336 | * **而基于寄存器的计算流程**
337 |
338 | ```java
339 | mov eax,2 //将eax寄存器的值设为1
340 | add eax,3 //使eax寄存器的值加3
341 | ```
342 |
343 | 2个指令
344 |
345 | > 具体后面会讲
346 |
347 |
348 |
349 | ### JVM架构总结
350 |
351 | 1. **由于跨平台性的设计,Java的指令都是根据栈来设计的**。不同平台CPU架构不同,所以不能设计为基于寄存器的。栈的优点:跨平台,指令集小,编译器容易实现,缺点是性能比寄存器差一些。
352 |
353 | 2. 时至今日,尽管嵌入式平台已经不是Java程序的主流运行平台了(准确来说应该是HotSpot VM的宿主环境已经不局限于嵌入式平台了),那么为什么不将架构更换为基于寄存器的架构呢?
354 | - 因为基于栈的架构跨平台性好、指令集小,虽然相对于基于寄存器的架构来说,基于栈的架构编译得到的指令更多,执行性能也不如基于寄存器的架构好,但考虑到其跨平台性与移植性,我们还是选用栈的架构
355 |
356 |
357 |
358 |
359 | JVM的生命周期
360 | -----------
361 |
362 | ### 虚拟机的启动
363 |
364 | Java虚拟机的启动是通过引导类加载器(bootstrap class loader)创建一个初始类(initial class)来完成的,这个类是由虚拟机的具体实现指定的。
365 |
366 | ### 虚拟机的执行
367 |
368 | 1. 一个运行中的Java虚拟机有着一个清晰的任务:执行Java程序
369 | 2. 程序开始执行时他才运行,程序结束时他就停止
370 | 3. **执行一个所谓的Java程序的时候,真真正正在执行的是一个叫做Java虚拟机的进程**
371 |
372 | ### 虚拟机的退出
373 |
374 | **有如下的几种情况:**
375 |
376 | 1. 程序正常执行结束
377 |
378 | 2. 程序在执行过程中遇到了异常或错误而异常终止
379 |
380 | 3. 由于操作系统用现错误而导致Java虚拟机进程终止
381 |
382 | 4. 某线程调用Runtime类或System类的exit()方法,或Runtime类的halt()方法,并且Java安全管理器也允许这次exit()或halt()操作。
383 |
384 | 5. 除此之外,JNI(Java Native Interface)规范描述了用JNI Invocation API来加载或卸载 Java虚拟机时,Java虚拟机的退出情况。
385 |
386 |
387 |
388 |
389 | JVM发展历程
390 | -----------
391 |
392 | ### Sun Classic VM
393 |
394 | 1. 早在1996年Java1.0版本的时候,Sun公司发布了一款名为sun classic VM的Java虚拟机,它同时也是**世界上第一款商用Java虚拟机**,JDK1.4时完全被淘汰。
395 | 2. 这款虚拟机内部只提供解释器,没有即时编译器,因此效率比较低。【即时编译器会把热点代码的本地机器指令缓存起来,那么以后使用热点代码的时候,效率就比较高】
396 | 3. 如果使用JIT编译器,就需要进行外挂。但是一旦使用了JIT编译器,JIT就会接管虚拟机的执行系统。解释器就不再工作,解释器和编译器不能配合工作。
397 | - 我们将字节码指令翻译成机器指令也是需要花时间的,如果只使用JIT,就需要把所有字节码指令都翻译成机器指令,就会导致翻译时间过长,也就是说在程序刚启动的时候,等待时间会很长。
398 | - 而解释器就是走到哪,解释到哪。
399 | 4. 现在Hotspot内置了此虚拟机。
400 |
401 | ### Exact VM
402 |
403 | 1. 为了解决上一个虚拟机问题,jdk1.2时,Sun提供了此虚拟机。
404 |
405 | 2. Exact Memory Management:准确式内存管理
406 |
407 | * 也可以叫Non-Conservative/Accurate Memory Management
408 |
409 | * 虚拟机可以知道内存中某个位置的数据具体是什么类型。
410 |
411 | 3. 具备现代高性能虚拟机的维形
412 |
413 | * 热点探测(寻找出热点代码进行缓存)
414 |
415 | * 编译器与解释器混合工作模式
416 |
417 | 4. 只在Solaris平台短暂使用,其他平台上还是classic vm,英雄气短,终被Hotspot虚拟机替换
418 |
419 |
420 | ### HotSpot VM(重点)
421 |
422 | 1. HotSpot历史
423 |
424 | * 最初由一家名为“Longview Technologies”的小公司设计
425 |
426 | * 1997年,此公司被Sun收购;2009年,Sun公司被甲骨文收购。
427 |
428 | * JDK1.3时,HotSpot VM成为默认虚拟机
429 |
430 | 2. 目前**Hotspot占有绝对的市场地位,称霸武林**。
431 |
432 | * 不管是现在仍在广泛使用的JDK6,还是使用比例较多的JDK8中,默认的虚拟机都是HotSpot
433 |
434 | * Sun/oracle JDK和openJDK的默认虚拟机
435 |
436 | * 因此本课程中默认介绍的虚拟机都是HotSpot,相关机制也主要是指HotSpot的GC机制。(比如其他两个商用虚机都没有方法区的概念)
437 |
438 | 3. 从服务器、桌面到移动端、嵌入式都有应用。
439 |
440 | 4. 名称中的HotSpot指的就是它的热点代码探测技术。
441 |
442 | * 通过计数器找到最具编译价值代码,触发即时编译或栈上替换
443 |
444 | * 通过编译器与解释器协同工作,在最优化的程序响应时间与最佳执行性能中取得平衡
445 |
446 | ### JRockit(商用三大虚拟机之一)
447 |
448 | 1. 专注于服务器端应用:它可以不太关注程序启动速度,因此JRockit内部不包含解析器实现,全部代码都靠即时编译器编译后执行。
449 |
450 | 2. 大量的行业基准测试显示,JRockit JVM是世界上最快的JVM:使用JRockit产品,客户已经体验到了显著的性能提高(一些超过了70%)和硬件成本的减少(达50%)。
451 |
452 | 3. 优势:全面的Java运行时解决方案组合
453 |
454 | * JRockit面向延迟敏感型应用的解决方案JRockit Real Time提供以毫秒或微秒级的JVM响应时间,适合财务、军事指挥、电信网络的需要
455 |
456 | * Mission Control服务套件,它是一组以极低的开销来监控、管理和分析生产环境中的应用程序的工具。
457 |
458 | 4. 2008年,JRockit被Oracle收购。
459 |
460 | 5. Oracle表达了整合两大优秀虚拟机的工作,大致在JDK8中完成。整合的方式是在HotSpot的基础上,移植JRockit的优秀特性。
461 |
462 | 6. 高斯林:目前就职于谷歌,研究人工智能和水下机器人
463 |
464 |
465 | ### IBM的J9(商用三大虚拟机之一)
466 |
467 | 1. 全称:IBM Technology for Java Virtual Machine,简称IT4J,内部代号:J9
468 |
469 | 2. 市场定位与HotSpot接近,服务器端、桌面应用、嵌入式等多用途VM广泛用于IBM的各种Java产品。
470 |
471 | 3. 目前,有影响力的三大商用虚拟机之一,也号称是世界上最快的Java虚拟机。
472 |
473 | 4. 2017年左右,IBM发布了开源J9VM,命名为openJ9,交给Eclipse基金会管理,也称为Eclipse OpenJ9
474 |
475 | 5. OpenJDK -> 是JDK开源了,包括了虚拟机
476 |
477 |
478 | ### KVM和CDC/CLDC Hotspot
479 |
480 | 1. Oracle在Java ME产品线上的两款虚拟机为:CDC/CLDC HotSpot Implementation VM
481 | 2. KVM(Kilobyte)是CLDC-HI早期产品
482 | 3. 目前移动领域地位尴尬,智能机被Android和iOS二分天下。
483 | 4. KVM简单、轻量、高度可移植,面向更低端的设备上还维持自己的一片市场
484 |
485 | * 智能控制器、传感器
486 |
487 | * 老人手机、经济欠发达地区的功能手机
488 | 5. 所有的虚拟机的原则:一次编译,到处运行。
489 |
490 |
491 | ### Azul VM
492 |
493 | 1. 前面三大“高性能Java虚拟机”使用在**通用硬件平台上**
494 | 2. 这里Azul VW和BEA Liquid VM是与**特定硬件平台绑定**、软硬件配合的专有虚拟机:高性能Java虚拟机中的战斗机。
495 | 3. Azul VM是Azul Systems公司在HotSpot基础上进行大量改进,运行于Azul Systems公司的专有硬件Vega系统上的Java虚拟机。
496 | 4. 每个Azul VM实例都可以管理至少数十个CPU和数百GB内存的硬件资源,并提供在巨大内存范围内实现可控的GC时间的垃圾收集器、专有硬件优化的线程调度等优秀特性。
497 | 5. 2010年,Azul Systems公司开始从硬件转向软件,发布了自己的Zing JVM,可以在通用x86平台上提供接近于Vega系统的特性。
498 |
499 |
500 | ### Liquid VM
501 |
502 | 1. 高性能Java虚拟机中的战斗机。
503 | 2. BEA公司开发的,直接运行在自家Hypervisor系统上
504 | 3. Liquid VM即是现在的JRockit VE(Virtual Edition)。**Liquid VM不需要操作系统的支持,或者说它自己本身实现了一个专用操作系统的必要功能,如线程调度、文件系统、网络支持等**。
505 | 5. 随着JRockit虚拟机终止开发,Liquid vM项目也停止了。
506 |
507 | ### Apache Marmony
508 |
509 | 1. Apache也曾经推出过与JDK1.5和JDK1.6兼容的Java运行平台Apache Harmony。
510 |
511 | 2. 它是IElf和Intel联合开发的开源JVM,受到同样开源的Open JDK的压制,Sun坚决不让Harmony获得JCP认证,最终于2011年退役,IBM转而参与OpenJDK
512 |
513 | 3. 虽然目前并没有Apache Harmony被大规模商用的案例,但是它的Java类库代码吸纳进了Android SDK。
514 |
515 |
516 | ### Micorsoft JVM
517 |
518 | 1. 微软为了在IE3浏览器中支持Java Applets,开发了Microsoft JVM。
519 |
520 | 2. 只能在window平台下运行。但确是当时Windows下性能最好的Java VM。
521 |
522 | 3. 1997年,Sun以侵犯商标、不正当竞争罪名指控微软成功,赔了Sun很多钱。微软WindowsXP SP3中抹掉了其VM。现在Windows上安装的jdk都是HotSpot。
523 |
524 |
525 | ### Taobao JVM
526 |
527 | 1. 由AliJVM团队发布。阿里,国内使用Java最强大的公司,覆盖云计算、金融、物流、电商等众多领域,需要解决高并发、高可用、分布式的复合问题。有大量的开源产品。
528 |
529 | 2. **基于OpenJDK开发了自己的定制版本AlibabaJDK**,简称AJDK。是整个阿里Java体系的基石。
530 |
531 | 3. 基于OpenJDK Hotspot VM发布的国内第一个优化、深度定制且开源的高性能服务器版Java虚拟机。
532 |
533 | * 创新的GCIH(GCinvisible heap)技术实现了off-heap,**即将生命周期较长的Java对象从heap中移到heap之外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收频率和提升GC的回收效率的目的**。
534 | * GCIH中的**对象还能够在多个Java虚拟机进程中实现共享**
535 | * 使用crc32指令实现JvM intrinsic降低JNI的调用开销
536 | * PMU hardware的Java profiling tool和诊断协助功能
537 | * 针对大数据场景的ZenGC
538 | 4. taobao vm应用在阿里产品上性能高,**硬件严重依赖inte1的cpu,损失了兼容性,但提高了性能**
539 | - 目前已经在淘宝、天猫上线,把Oracle官方JvM版本全部替换了。
540 |
541 |
542 | ### Dalvik VM
543 |
544 | 1. 谷歌开发的,应用于Android系统,并在Android2.2中提供了JIT,发展迅猛。
545 |
546 | 2. **Dalvik VM只能称作虚拟机,而不能称作“Java虚拟机”**,它没有遵循 Java虚拟机规范
547 |
548 | 3. 不能直接执行Java的Class文件
549 |
550 | 4. 基于寄存器架构,不是jvm的栈架构。
551 |
552 | 5. 执行的是编译以后的dex(Dalvik Executable)文件。执行效率比较高。
553 | - 它执行的dex(Dalvik Executable)文件可以通过class文件转化而来,使用Java语法编写应用程序,可以直接使用大部分的Java API等。
554 |
555 | 7. Android 5.0使用支持提前编译(Ahead of Time Compilation,AoT)的ART VM替换Dalvik VM。
556 |
557 |
558 | ### Graal VM(未来虚拟机)
559 |
560 | 1. 2018年4月,Oracle Labs公开了GraalvM,号称 “**Run Programs Faster Anywhere**”,勃勃野心。与1995年java的”write once,run anywhere"遥相呼应。
561 |
562 | 2. GraalVM在HotSpot VM基础上增强而成的**跨语言全栈虚拟机,可以作为“任何语言”**的运行平台使用。语言包括:Java、Scala、Groovy、Kotlin;C、C++、Javascript、Ruby、Python、R等
563 |
564 | 3. 支持不同语言中混用对方的接口和对象,支持这些语言使用已经编写好的本地库文件
565 |
566 | 4. 工作原理是将这些语言的源代码或源代码编译后的中间格式,通过解释器转换为能被Graal VM接受的中间表示。Graal VM提供Truffle工具集快速构建面向一种新语言的解释器。在运行时还能进行即时编译优化,获得比原生编译器更优秀的执行效率。
567 |
568 | 5. **如果说HotSpot有一天真的被取代,Graalvm希望最大**。但是Java的软件生态没有丝毫变化。
569 |
570 |
571 |
572 | ### 总结
573 |
574 | 具体JVM的内存结构,其实取决于其实现,不同厂商的JVM,或者同一厂商发布的不同版本,都有可能存在一定差异。主要以Oracle HotSpot VM为默认虚拟机。
--------------------------------------------------------------------------------
/docs/design_patterns/设计模式-01.设计思想.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 设计模式-01.设计思想
3 | tags:
4 | - 设计模式
5 | - 设计思想
6 | categories:
7 | - 设计模式
8 | - 01.设计思想
9 | keywords: 设计模式,设计思想
10 | description: 设计模式第一部分-常用设计思想。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/design_patterns.jpg'
12 | abbrlink: c3dcce5d
13 | date: 2021-06-07 17:21:58
14 | ---
15 |
16 | # 设计思想
17 |
18 | > 1. 此系列文章非本人原创,是学习笔记。
19 | > 2. 设计模式系列以后会持续更新,包括已经发布的设计模式文章,因为后续还要再多看一下书,教程和开源项目等,继续润色文章。
20 |
21 | 下面讲一些常见的设计思想
22 |
23 | ## 基于接口而非实现编程
24 |
25 | 这个原则非常重要,是一种非常有效的提高代码质量的手段,在平时的开发中特别经常被用到。
26 |
27 | ### 如何解读原则中的“接口”二字?
28 |
29 | 1. “基于接口而非实现编程”这条原则的英文描述是:“Program to an interface, not an implementation”。我们理解这条原则的时候,千万不要一开始就与具体的编程语言挂钩,局限在编程语言的“接口”语法中(比如 Java 中的 interface 接口语法)。这条原则最早出现于 1994 年 GoF 的《设计模式》这本书,它先于很多编程语言而诞生(比如 Java 语言),是一条比较抽象、泛化的设计思想。
30 | 2. 实际上,理解这条原则的关键,就是理解其中的“接口”两个字。还记得我们上一节课讲的“接口”的定义吗?从本质上来看,“接口”就是一组“协议”或者“约定”,是功能提供者提供给使用者的一个“功能列表”。“接口”在不同的应用场景下会有不同的解读,比如服务端与客户端之间的“接口”,类库提供的“接口”,甚至是一组通信的协议都可以叫作“接口”。刚刚对“接口”的理解,都比较偏上层、偏抽象,与实际的写代码离得有点远。如果落实到具体的编码,“基于接口而非实现编程”这条原则中的“接口”,可以理解为编程语言中的接口或者抽象类。
31 | 3. 前面我们提到,这条原则能非常有效地提高代码质量,之所以这么说,那是因为,应用这条原则,可以将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提高扩展性。
32 | 4. 实际上,“基于接口而非实现编程”这条原则的另一个表述方式,是“基于抽象而非实现编程”。后者的表述方式其实更能体现这条原则的设计初衷。在软件开发中,最大的挑战之一就是需求的不断变化,这也是考验代码设计好坏的一个标准。**越抽象、越顶层、越脱离具体某一实现的设计,越能提高代码的灵活性,越能应对未来的需求变化。好的代码设计,不仅能应对当下的需求,而且在将来需求发生变化的时候,仍然能够在不破坏原有代码设计的情况下灵活应对**。而抽象就是提高代码扩展性、灵活性、可维护性最有效的手段之一。
33 |
34 |
35 |
36 | ### 如何将这条原则应用到实战中?
37 |
38 | 假设我们的系统中有很多涉及图片处理和存储的业务逻辑。图片经过处理之后被上传到阿里云上。为了代码复用,我们封装了图片存储相关的代码逻辑,提供了一个统一的 AliyunImageStore 类,供整个系统来使用。具体的代码实现如下所示:
39 |
40 | ```java
41 | public class AliyunImageStore {
42 | //...省略属性、构造函数等...
43 |
44 | public void createBucketIfNotExisting(String bucketName) {
45 | // ...创建bucket代码逻辑...
46 | // ...失败会抛出异常..
47 | }
48 |
49 | public String generateAccessToken() {
50 | // ...根据accesskey/secrectkey等生成access token
51 | }
52 |
53 | public String uploadToAliyun(Image image, String bucketName, String accessToken) {
54 | //...上传图片到阿里云...
55 | //...返回图片存储在阿里云上的地址(url)...
56 | }
57 |
58 | public Image downloadFromAliyun(String url, String accessToken) {
59 | //...从阿里云下载图片...
60 | }
61 | }
62 |
63 | // AliyunImageStore类的使用举例
64 | public class ImageProcessingJob {
65 | private static final String BUCKET_NAME = "ai_images_bucket";
66 | //...省略其他无关代码...
67 |
68 | public void process() {
69 | Image image = ...; //处理图片,并封装为Image对象
70 | AliyunImageStore imageStore = new AliyunImageStore(/*省略参数*/);
71 | imageStore.createBucketIfNotExisting(BUCKET_NAME);
72 | String accessToken = imageStore.generateAccessToken();
73 | imagestore.uploadToAliyun(image, BUCKET_NAME, accessToken);
74 | }
75 |
76 | }
77 | ```
78 |
79 |
80 |
81 | 1. 整个上传流程包含三个步骤:创建 bucket(你可以简单理解为存储目录)、生成 access token 访问凭证、携带 access token 上传图片到指定的 bucket 中。代码实现非常简单,类中的几个方法定义得都很干净,用起来也很清晰,乍看起来没有太大问题,完全能满足我们将图片存储在阿里云的业务需求。
82 | 2. 不过,软件开发中唯一不变的就是变化。过了一段时间后,我们自建了私有云,不再将图片存储到阿里云了,而是将图片存储到自建私有云上。为了满足这样一个需求的变化,我们该如何修改代码呢?
83 | 3. 我们需要重新设计实现一个存储图片到私有云的 PrivateImageStore 类,并用它替换掉项目中所有的 AliyunImageStore 类对象。这样的修改听起来并不复杂,只是简单替换而已,对整个代码的改动并不大。不过,我们经常说,“细节是魔鬼”。这句话在软件开发中特别适用。实际上,刚刚的设计实现方式,就隐藏了很多容易出问题的“魔鬼细节”,我们一块来看看都有哪些。
84 | 4. 新的 PrivateImageStore 类需要设计实现哪些方法,才能在尽量最小化代码修改的情况下,替换掉 AliyunImageStore 类呢?这就要求我们必须将 AliyunImageStore 类中所定义的所有 public 方法,在 PrivateImageStore 类中都逐一定义并重新实现一遍。而这样做就会存在一些问题,我总结了下面两点。
85 | - 首先,AliyunImageStore 类中有些函数命名暴露了实现细节,比如,uploadToAliyun() 和 downloadFromAliyun()。如果开发这个功能的同事没有接口意识、抽象思维,那这种暴露实现细节的命名方式就不足为奇了,毕竟最初我们只考虑将图片存储在阿里云上。而我们把这种包含“aliyun”字眼的方法,照抄到 PrivateImageStore 类中,显然是不合适的。如果我们在新类中重新命名 uploadToAliyun()、downloadFromAliyun() 这些方法,那就意味着,我们要修改项目中所有使用到这两个方法的代码,代码修改量可能就会很大。
86 | - 其次,将图片存储到阿里云的流程,跟存储到私有云的流程,可能并不是完全一致的。比如,阿里云的图片上传和下载的过程中,需要生产 access token,而私有云不需要 access token。一方面,AliyunImageStore 中定义的 generateAccessToken() 方法不能照抄到 PrivateImageStore 中;另一方面,我们在使用 AliyunImageStore 上传、下载图片的时候,代码中用到了 generateAccessToken() 方法,如果要改为私有云的上传下载流程,这些代码都需要做调整。
87 | 5. 那这两个问题该如何解决呢?解决这个问题的根本方法就是,在编写代码的时候,要遵从“基于接口而非实现编程”的原则,具体来讲,我们需要做到下面这 3 点。
88 | 1. 函数的命名不能暴露任何实现细节。比如,前面提到的 uploadToAliyun() 就不符合要求,应该改为去掉 aliyun 这样的字眼,改为更加抽象的命名方式,比如:upload()。
89 | 2. 封装具体的实现细节。比如,跟阿里云相关的特殊上传(或下载)流程不应该暴露给调用者。我们对上传(或下载)流程进行封装,对外提供一个包裹所有上传(或下载)细节的方法,给调用者使用。
90 | 3. 为实现类定义抽象的接口。具体的实现类都依赖统一的接口定义,遵从一致的上传功能协议。使用者依赖接口,而不是具体的实现类来编程。
91 | 6. 我们按照这个思路,把代码重构一下。重构后的代码如下所示:
92 |
93 | ```java
94 | public interface ImageStore {
95 | String upload(Image image, String bucketName);
96 | Image download(String url);
97 | }
98 |
99 | public class AliyunImageStore implements ImageStore {
100 | //...省略属性、构造函数等...
101 |
102 | public String upload(Image image, String bucketName) {
103 | createBucketIfNotExisting(bucketName);
104 | String accessToken = generateAccessToken();
105 | //...上传图片到阿里云...
106 | //...返回图片在阿里云上的地址(url)...
107 | }
108 |
109 | public Image download(String url) {
110 | String accessToken = generateAccessToken();
111 | //...从阿里云下载图片...
112 | }
113 |
114 | private void createBucketIfNotExisting(String bucketName) {
115 | // ...创建bucket...
116 | // ...失败会抛出异常..
117 | }
118 |
119 | private String generateAccessToken() {
120 | // ...根据accesskey/secrectkey等生成access token
121 | }
122 | }
123 |
124 | // 上传下载流程改变:私有云不需要支持access token
125 | public class PrivateImageStore implements ImageStore {
126 | public String upload(Image image, String bucketName) {
127 | createBucketIfNotExisting(bucketName);
128 | //...上传图片到私有云...
129 | //...返回图片的url...
130 | }
131 |
132 | public Image download(String url) {
133 | //...从私有云下载图片...
134 | }
135 |
136 | private void createBucketIfNotExisting(String bucketName) {
137 | // ...创建bucket...
138 | // ...失败会抛出异常..
139 | }
140 | }
141 |
142 | // ImageStore的使用举例
143 | public class ImageProcessingJob {
144 | private static final String BUCKET_NAME = "ai_images_bucket";
145 | //...省略其他无关代码...
146 |
147 | public void process() {
148 | Image image = ...;//处理图片,并封装为Image对象
149 | ImageStore imageStore = new PrivateImageStore(...);
150 | imagestore.upload(image, BUCKET_NAME);
151 | }
152 | }
153 | ```
154 |
155 | 1. 除此之外,很多人在定义接口的时候,希望通过实现类来反推接口的定义。先把实现类写好,然后看实现类中有哪些方法,照抄到接口定义中。如果按照这种思考方式,就有可能导致接口定义不够抽象,依赖具体的实现。这样的接口设计就没有意义了。不过,如果你觉得这种思考方式更加顺畅,那也没问题,只是将实现类的方法搬移到接口定义中的时候,要有选择性的搬移,不要将跟具体实现相关的方法搬移到接口中,比如 AliyunImageStore 中的 generateAccessToken() 方法。
156 | 2. 总结一下,我们在做软件开发的时候,一定要有抽象意识、封装意识、接口意识。在定义接口的时候,不要暴露任何实现细节。接口的定义只表明做什么,而不是怎么做。而且,在设计接口的时候,我们要多思考一下,这样的接口设计是否足够通用,是否能够做到在替换具体的接口实现的时候,不需要任何接口定义的改动。
157 |
158 |
159 |
160 | ### 是否需要为每个类定义接口?
161 |
162 | 1. 看了刚刚的讲解,你可能会有这样的疑问:为了满足这条原则,我是不是需要给每个实现类都定义对应的接口呢?在开发的时候,是不是任何代码都要只依赖接口,完全不依赖实现编程呢?
163 | 2. 做任何事情都要讲求一个“度”,过度使用这条原则,非得给每个类都定义接口,接口满天飞,也会导致不必要的开发负担。至于什么时候,该为某个类定义接口,实现基于接口的编程,什么时候不需要定义接口,直接使用实现类编程,我们做权衡的根本依据,还是要回归到设计原则诞生的初衷上来。只要搞清楚了这条原则是为了解决什么样的问题而产生的,你就会发现,很多之前模棱两可的问题,都会变得豁然开朗。
164 | 3. 前面我们也提到,这条原则的设计初衷是,将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低代码间的耦合性,提高代码的扩展性。
165 | 4. 从这个设计初衷上来看,如果在我们的业务场景中,某个功能只有一种实现方式,未来也不可能被其他实现方式替换,那我们就没有必要为其设计接口,也没有必要基于接口编程,直接使用实现类就可以了。
166 | 5. 除此之外,越是不稳定的系统,我们越是要在代码的扩展性、维护性上下功夫。相反,如果某个系统特别稳定,在开发完之后,基本上不需要做维护,那我们就没有必要为其扩展性,投入不必要的开发时间。
167 |
168 |
169 |
170 | ## 多用组合少用继承
171 |
172 | 在面向对象编程中,有一条非常经典的设计原则,那就是:组合优于继承,多用组合少用继承。为什么不推荐使用继承?组合相比继承有哪些优势?如何判断该用组合还是继承?今天,我们就围绕着这三个问题,来详细讲解一下这条设计原则。
173 |
174 |
175 |
176 |
177 |
178 | ### 为什么不推荐使用继承?
179 |
180 | 1. 继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。所以,对于是否应该在项目中使用继承,网上有很多争议。很多人觉得继承是一种反模式,应该尽量少用,甚至不用。为什么会有这样的争议?我们通过一个例子来解释一下。
181 | 2. 假设我们要设计一个关于鸟的类。我们将“鸟类”这样一个抽象的事物概念,定义为一个抽象类 AbstractBird。所有更细分的鸟,比如麻雀、鸽子、乌鸦等,都继承这个抽象类。
182 | 3. 我们知道,大部分鸟都会飞,那我们可不可以在 AbstractBird 抽象类中,定义一个 fly() 方法呢?答案是否定的。尽管大部分鸟都会飞,但也有特例,比如鸵鸟就不会飞。鸵鸟继承具有 fly() 方法的父类,那鸵鸟就具有“飞”这样的行为,这显然不符合我们对现实世界中事物的认识。当然,你可能会说,我在鸵鸟这个子类中重写(override)fly() 方法,让它抛出 UnSupportedMethodException 异常不就可以了吗?具体的代码实现如下所示:
183 |
184 | ```java
185 | public class AbstractBird {
186 | //...省略其他属性和方法...
187 | public void fly() { //... }
188 | }
189 |
190 | public class Ostrich extends AbstractBird { //鸵鸟
191 | //...省略其他属性和方法...
192 | public void fly() {
193 | throw new UnSupportedMethodException("I can't fly.'");
194 | }
195 | }
196 | ```
197 |
198 | 1. 这种设计思路虽然可以解决问题,但不够优美。因为除了鸵鸟之外,不会飞的鸟还有很多,比如企鹅。对于这些不会飞的鸟来说,我们都需要重写 fly() 方法,抛出异常。这样的设计,一方面,徒增了编码的工作量;另一方面,也违背了我们之后要讲的最小知识原则(Least Knowledge Principle,也叫最少知识原则或者迪米特法则),暴露不该暴露的接口给外部,增加了类使用过程中被误用的概率。
199 | 2. 你可能又会说,那我们再通过 AbstractBird 类派生出两个更加细分的抽象类:会飞的鸟类 AbstractFlyableBird 和不会飞的鸟类 AbstractUnFlyableBird,让麻雀、乌鸦这些会飞的鸟都继承 AbstractFlyableBird,让鸵鸟、企鹅这些不会飞的鸟,都继承 AbstractUnFlyableBird 类,不就可以了吗?具体的继承关系如下图所示:
200 |
201 |
288 |
289 |
290 |
291 | JVM的架构模型
292 | -----------
293 |
294 | Java编译器输入的指令流基本上是一种**基于栈的指令集架构**,另外一种指令集架构则是**基于寄存器的指令集架构**。具体来说:这两种架构之间的区别:
295 |
296 | ### 基于栈的指令集架构
297 |
298 | 基于栈式架构的特点:
299 |
300 | 1. 设计和实现更简单,适用于资源受限的系统;
301 | 2. 避开了寄存器的分配难题:使用零地址指令方式分配
302 | 3. 指令流中的指令大部分是零地址指令,其执行过程依赖于操作栈。指令集更小,编译器容易实现
303 | 4. 不需要硬件支持,可移植性更好,更好实现跨平台
304 |
305 | ### 基于寄存器的指令级架构
306 |
307 | 基于寄存器架构的特点:
308 |
309 | 1. 典型的应用是x86的二进制指令集:比如传统的PC以及Android的Davlik虚拟机。
310 | 2. 指令集架构则完全依赖硬件,与硬件的耦合度高,可移植性差
311 | 3. 性能优秀和执行更高效
312 | 4. 花费更少的指令去完成一项操作
313 | 5. 在大部分情况下,基于寄存器架构的指令集往往都以一地址指令、二地址指令和三地址指令为主,而基于栈式架构的指令集却是以零地址指令为主
314 |
315 | ### 两种架构的举例
316 |
317 | 同样执行2+3这种逻辑操作,其指令分别如下:
318 |
319 | * **基于栈的计算流程(以Java虚拟机为例):**
320 |
321 | ```java
322 | iconst_2 //常量2入栈
323 | istore_1
324 | iconst_3 // 常量3入栈
325 | istore_2
326 | iload_1
327 | iload_2
328 | iadd //常量2/3出栈,执行相加
329 | istore_0 // 结果5入栈
330 | ```
331 |
332 | 8个指令
333 |
334 |
335 |
336 | * **而基于寄存器的计算流程**
337 |
338 | ```java
339 | mov eax,2 //将eax寄存器的值设为1
340 | add eax,3 //使eax寄存器的值加3
341 | ```
342 |
343 | 2个指令
344 |
345 | > 具体后面会讲
346 |
347 |
348 |
349 | ### JVM架构总结
350 |
351 | 1. **由于跨平台性的设计,Java的指令都是根据栈来设计的**。不同平台CPU架构不同,所以不能设计为基于寄存器的。栈的优点:跨平台,指令集小,编译器容易实现,缺点是性能比寄存器差一些。
352 |
353 | 2. 时至今日,尽管嵌入式平台已经不是Java程序的主流运行平台了(准确来说应该是HotSpot VM的宿主环境已经不局限于嵌入式平台了),那么为什么不将架构更换为基于寄存器的架构呢?
354 | - 因为基于栈的架构跨平台性好、指令集小,虽然相对于基于寄存器的架构来说,基于栈的架构编译得到的指令更多,执行性能也不如基于寄存器的架构好,但考虑到其跨平台性与移植性,我们还是选用栈的架构
355 |
356 |
357 |
358 |
359 | JVM的生命周期
360 | -----------
361 |
362 | ### 虚拟机的启动
363 |
364 | Java虚拟机的启动是通过引导类加载器(bootstrap class loader)创建一个初始类(initial class)来完成的,这个类是由虚拟机的具体实现指定的。
365 |
366 | ### 虚拟机的执行
367 |
368 | 1. 一个运行中的Java虚拟机有着一个清晰的任务:执行Java程序
369 | 2. 程序开始执行时他才运行,程序结束时他就停止
370 | 3. **执行一个所谓的Java程序的时候,真真正正在执行的是一个叫做Java虚拟机的进程**
371 |
372 | ### 虚拟机的退出
373 |
374 | **有如下的几种情况:**
375 |
376 | 1. 程序正常执行结束
377 |
378 | 2. 程序在执行过程中遇到了异常或错误而异常终止
379 |
380 | 3. 由于操作系统用现错误而导致Java虚拟机进程终止
381 |
382 | 4. 某线程调用Runtime类或System类的exit()方法,或Runtime类的halt()方法,并且Java安全管理器也允许这次exit()或halt()操作。
383 |
384 | 5. 除此之外,JNI(Java Native Interface)规范描述了用JNI Invocation API来加载或卸载 Java虚拟机时,Java虚拟机的退出情况。
385 |
386 |
387 |
388 |
389 | JVM发展历程
390 | -----------
391 |
392 | ### Sun Classic VM
393 |
394 | 1. 早在1996年Java1.0版本的时候,Sun公司发布了一款名为sun classic VM的Java虚拟机,它同时也是**世界上第一款商用Java虚拟机**,JDK1.4时完全被淘汰。
395 | 2. 这款虚拟机内部只提供解释器,没有即时编译器,因此效率比较低。【即时编译器会把热点代码的本地机器指令缓存起来,那么以后使用热点代码的时候,效率就比较高】
396 | 3. 如果使用JIT编译器,就需要进行外挂。但是一旦使用了JIT编译器,JIT就会接管虚拟机的执行系统。解释器就不再工作,解释器和编译器不能配合工作。
397 | - 我们将字节码指令翻译成机器指令也是需要花时间的,如果只使用JIT,就需要把所有字节码指令都翻译成机器指令,就会导致翻译时间过长,也就是说在程序刚启动的时候,等待时间会很长。
398 | - 而解释器就是走到哪,解释到哪。
399 | 4. 现在Hotspot内置了此虚拟机。
400 |
401 | ### Exact VM
402 |
403 | 1. 为了解决上一个虚拟机问题,jdk1.2时,Sun提供了此虚拟机。
404 |
405 | 2. Exact Memory Management:准确式内存管理
406 |
407 | * 也可以叫Non-Conservative/Accurate Memory Management
408 |
409 | * 虚拟机可以知道内存中某个位置的数据具体是什么类型。
410 |
411 | 3. 具备现代高性能虚拟机的维形
412 |
413 | * 热点探测(寻找出热点代码进行缓存)
414 |
415 | * 编译器与解释器混合工作模式
416 |
417 | 4. 只在Solaris平台短暂使用,其他平台上还是classic vm,英雄气短,终被Hotspot虚拟机替换
418 |
419 |
420 | ### HotSpot VM(重点)
421 |
422 | 1. HotSpot历史
423 |
424 | * 最初由一家名为“Longview Technologies”的小公司设计
425 |
426 | * 1997年,此公司被Sun收购;2009年,Sun公司被甲骨文收购。
427 |
428 | * JDK1.3时,HotSpot VM成为默认虚拟机
429 |
430 | 2. 目前**Hotspot占有绝对的市场地位,称霸武林**。
431 |
432 | * 不管是现在仍在广泛使用的JDK6,还是使用比例较多的JDK8中,默认的虚拟机都是HotSpot
433 |
434 | * Sun/oracle JDK和openJDK的默认虚拟机
435 |
436 | * 因此本课程中默认介绍的虚拟机都是HotSpot,相关机制也主要是指HotSpot的GC机制。(比如其他两个商用虚机都没有方法区的概念)
437 |
438 | 3. 从服务器、桌面到移动端、嵌入式都有应用。
439 |
440 | 4. 名称中的HotSpot指的就是它的热点代码探测技术。
441 |
442 | * 通过计数器找到最具编译价值代码,触发即时编译或栈上替换
443 |
444 | * 通过编译器与解释器协同工作,在最优化的程序响应时间与最佳执行性能中取得平衡
445 |
446 | ### JRockit(商用三大虚拟机之一)
447 |
448 | 1. 专注于服务器端应用:它可以不太关注程序启动速度,因此JRockit内部不包含解析器实现,全部代码都靠即时编译器编译后执行。
449 |
450 | 2. 大量的行业基准测试显示,JRockit JVM是世界上最快的JVM:使用JRockit产品,客户已经体验到了显著的性能提高(一些超过了70%)和硬件成本的减少(达50%)。
451 |
452 | 3. 优势:全面的Java运行时解决方案组合
453 |
454 | * JRockit面向延迟敏感型应用的解决方案JRockit Real Time提供以毫秒或微秒级的JVM响应时间,适合财务、军事指挥、电信网络的需要
455 |
456 | * Mission Control服务套件,它是一组以极低的开销来监控、管理和分析生产环境中的应用程序的工具。
457 |
458 | 4. 2008年,JRockit被Oracle收购。
459 |
460 | 5. Oracle表达了整合两大优秀虚拟机的工作,大致在JDK8中完成。整合的方式是在HotSpot的基础上,移植JRockit的优秀特性。
461 |
462 | 6. 高斯林:目前就职于谷歌,研究人工智能和水下机器人
463 |
464 |
465 | ### IBM的J9(商用三大虚拟机之一)
466 |
467 | 1. 全称:IBM Technology for Java Virtual Machine,简称IT4J,内部代号:J9
468 |
469 | 2. 市场定位与HotSpot接近,服务器端、桌面应用、嵌入式等多用途VM广泛用于IBM的各种Java产品。
470 |
471 | 3. 目前,有影响力的三大商用虚拟机之一,也号称是世界上最快的Java虚拟机。
472 |
473 | 4. 2017年左右,IBM发布了开源J9VM,命名为openJ9,交给Eclipse基金会管理,也称为Eclipse OpenJ9
474 |
475 | 5. OpenJDK -> 是JDK开源了,包括了虚拟机
476 |
477 |
478 | ### KVM和CDC/CLDC Hotspot
479 |
480 | 1. Oracle在Java ME产品线上的两款虚拟机为:CDC/CLDC HotSpot Implementation VM
481 | 2. KVM(Kilobyte)是CLDC-HI早期产品
482 | 3. 目前移动领域地位尴尬,智能机被Android和iOS二分天下。
483 | 4. KVM简单、轻量、高度可移植,面向更低端的设备上还维持自己的一片市场
484 |
485 | * 智能控制器、传感器
486 |
487 | * 老人手机、经济欠发达地区的功能手机
488 | 5. 所有的虚拟机的原则:一次编译,到处运行。
489 |
490 |
491 | ### Azul VM
492 |
493 | 1. 前面三大“高性能Java虚拟机”使用在**通用硬件平台上**
494 | 2. 这里Azul VW和BEA Liquid VM是与**特定硬件平台绑定**、软硬件配合的专有虚拟机:高性能Java虚拟机中的战斗机。
495 | 3. Azul VM是Azul Systems公司在HotSpot基础上进行大量改进,运行于Azul Systems公司的专有硬件Vega系统上的Java虚拟机。
496 | 4. 每个Azul VM实例都可以管理至少数十个CPU和数百GB内存的硬件资源,并提供在巨大内存范围内实现可控的GC时间的垃圾收集器、专有硬件优化的线程调度等优秀特性。
497 | 5. 2010年,Azul Systems公司开始从硬件转向软件,发布了自己的Zing JVM,可以在通用x86平台上提供接近于Vega系统的特性。
498 |
499 |
500 | ### Liquid VM
501 |
502 | 1. 高性能Java虚拟机中的战斗机。
503 | 2. BEA公司开发的,直接运行在自家Hypervisor系统上
504 | 3. Liquid VM即是现在的JRockit VE(Virtual Edition)。**Liquid VM不需要操作系统的支持,或者说它自己本身实现了一个专用操作系统的必要功能,如线程调度、文件系统、网络支持等**。
505 | 5. 随着JRockit虚拟机终止开发,Liquid vM项目也停止了。
506 |
507 | ### Apache Marmony
508 |
509 | 1. Apache也曾经推出过与JDK1.5和JDK1.6兼容的Java运行平台Apache Harmony。
510 |
511 | 2. 它是IElf和Intel联合开发的开源JVM,受到同样开源的Open JDK的压制,Sun坚决不让Harmony获得JCP认证,最终于2011年退役,IBM转而参与OpenJDK
512 |
513 | 3. 虽然目前并没有Apache Harmony被大规模商用的案例,但是它的Java类库代码吸纳进了Android SDK。
514 |
515 |
516 | ### Micorsoft JVM
517 |
518 | 1. 微软为了在IE3浏览器中支持Java Applets,开发了Microsoft JVM。
519 |
520 | 2. 只能在window平台下运行。但确是当时Windows下性能最好的Java VM。
521 |
522 | 3. 1997年,Sun以侵犯商标、不正当竞争罪名指控微软成功,赔了Sun很多钱。微软WindowsXP SP3中抹掉了其VM。现在Windows上安装的jdk都是HotSpot。
523 |
524 |
525 | ### Taobao JVM
526 |
527 | 1. 由AliJVM团队发布。阿里,国内使用Java最强大的公司,覆盖云计算、金融、物流、电商等众多领域,需要解决高并发、高可用、分布式的复合问题。有大量的开源产品。
528 |
529 | 2. **基于OpenJDK开发了自己的定制版本AlibabaJDK**,简称AJDK。是整个阿里Java体系的基石。
530 |
531 | 3. 基于OpenJDK Hotspot VM发布的国内第一个优化、深度定制且开源的高性能服务器版Java虚拟机。
532 |
533 | * 创新的GCIH(GCinvisible heap)技术实现了off-heap,**即将生命周期较长的Java对象从heap中移到heap之外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收频率和提升GC的回收效率的目的**。
534 | * GCIH中的**对象还能够在多个Java虚拟机进程中实现共享**
535 | * 使用crc32指令实现JvM intrinsic降低JNI的调用开销
536 | * PMU hardware的Java profiling tool和诊断协助功能
537 | * 针对大数据场景的ZenGC
538 | 4. taobao vm应用在阿里产品上性能高,**硬件严重依赖inte1的cpu,损失了兼容性,但提高了性能**
539 | - 目前已经在淘宝、天猫上线,把Oracle官方JvM版本全部替换了。
540 |
541 |
542 | ### Dalvik VM
543 |
544 | 1. 谷歌开发的,应用于Android系统,并在Android2.2中提供了JIT,发展迅猛。
545 |
546 | 2. **Dalvik VM只能称作虚拟机,而不能称作“Java虚拟机”**,它没有遵循 Java虚拟机规范
547 |
548 | 3. 不能直接执行Java的Class文件
549 |
550 | 4. 基于寄存器架构,不是jvm的栈架构。
551 |
552 | 5. 执行的是编译以后的dex(Dalvik Executable)文件。执行效率比较高。
553 | - 它执行的dex(Dalvik Executable)文件可以通过class文件转化而来,使用Java语法编写应用程序,可以直接使用大部分的Java API等。
554 |
555 | 7. Android 5.0使用支持提前编译(Ahead of Time Compilation,AoT)的ART VM替换Dalvik VM。
556 |
557 |
558 | ### Graal VM(未来虚拟机)
559 |
560 | 1. 2018年4月,Oracle Labs公开了GraalvM,号称 “**Run Programs Faster Anywhere**”,勃勃野心。与1995年java的”write once,run anywhere"遥相呼应。
561 |
562 | 2. GraalVM在HotSpot VM基础上增强而成的**跨语言全栈虚拟机,可以作为“任何语言”**的运行平台使用。语言包括:Java、Scala、Groovy、Kotlin;C、C++、Javascript、Ruby、Python、R等
563 |
564 | 3. 支持不同语言中混用对方的接口和对象,支持这些语言使用已经编写好的本地库文件
565 |
566 | 4. 工作原理是将这些语言的源代码或源代码编译后的中间格式,通过解释器转换为能被Graal VM接受的中间表示。Graal VM提供Truffle工具集快速构建面向一种新语言的解释器。在运行时还能进行即时编译优化,获得比原生编译器更优秀的执行效率。
567 |
568 | 5. **如果说HotSpot有一天真的被取代,Graalvm希望最大**。但是Java的软件生态没有丝毫变化。
569 |
570 |
571 |
572 | ### 总结
573 |
574 | 具体JVM的内存结构,其实取决于其实现,不同厂商的JVM,或者同一厂商发布的不同版本,都有可能存在一定差异。主要以Oracle HotSpot VM为默认虚拟机。
--------------------------------------------------------------------------------
/docs/design_patterns/设计模式-01.设计思想.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 设计模式-01.设计思想
3 | tags:
4 | - 设计模式
5 | - 设计思想
6 | categories:
7 | - 设计模式
8 | - 01.设计思想
9 | keywords: 设计模式,设计思想
10 | description: 设计模式第一部分-常用设计思想。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/design_patterns.jpg'
12 | abbrlink: c3dcce5d
13 | date: 2021-06-07 17:21:58
14 | ---
15 |
16 | # 设计思想
17 |
18 | > 1. 此系列文章非本人原创,是学习笔记。
19 | > 2. 设计模式系列以后会持续更新,包括已经发布的设计模式文章,因为后续还要再多看一下书,教程和开源项目等,继续润色文章。
20 |
21 | 下面讲一些常见的设计思想
22 |
23 | ## 基于接口而非实现编程
24 |
25 | 这个原则非常重要,是一种非常有效的提高代码质量的手段,在平时的开发中特别经常被用到。
26 |
27 | ### 如何解读原则中的“接口”二字?
28 |
29 | 1. “基于接口而非实现编程”这条原则的英文描述是:“Program to an interface, not an implementation”。我们理解这条原则的时候,千万不要一开始就与具体的编程语言挂钩,局限在编程语言的“接口”语法中(比如 Java 中的 interface 接口语法)。这条原则最早出现于 1994 年 GoF 的《设计模式》这本书,它先于很多编程语言而诞生(比如 Java 语言),是一条比较抽象、泛化的设计思想。
30 | 2. 实际上,理解这条原则的关键,就是理解其中的“接口”两个字。还记得我们上一节课讲的“接口”的定义吗?从本质上来看,“接口”就是一组“协议”或者“约定”,是功能提供者提供给使用者的一个“功能列表”。“接口”在不同的应用场景下会有不同的解读,比如服务端与客户端之间的“接口”,类库提供的“接口”,甚至是一组通信的协议都可以叫作“接口”。刚刚对“接口”的理解,都比较偏上层、偏抽象,与实际的写代码离得有点远。如果落实到具体的编码,“基于接口而非实现编程”这条原则中的“接口”,可以理解为编程语言中的接口或者抽象类。
31 | 3. 前面我们提到,这条原则能非常有效地提高代码质量,之所以这么说,那是因为,应用这条原则,可以将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提高扩展性。
32 | 4. 实际上,“基于接口而非实现编程”这条原则的另一个表述方式,是“基于抽象而非实现编程”。后者的表述方式其实更能体现这条原则的设计初衷。在软件开发中,最大的挑战之一就是需求的不断变化,这也是考验代码设计好坏的一个标准。**越抽象、越顶层、越脱离具体某一实现的设计,越能提高代码的灵活性,越能应对未来的需求变化。好的代码设计,不仅能应对当下的需求,而且在将来需求发生变化的时候,仍然能够在不破坏原有代码设计的情况下灵活应对**。而抽象就是提高代码扩展性、灵活性、可维护性最有效的手段之一。
33 |
34 |
35 |
36 | ### 如何将这条原则应用到实战中?
37 |
38 | 假设我们的系统中有很多涉及图片处理和存储的业务逻辑。图片经过处理之后被上传到阿里云上。为了代码复用,我们封装了图片存储相关的代码逻辑,提供了一个统一的 AliyunImageStore 类,供整个系统来使用。具体的代码实现如下所示:
39 |
40 | ```java
41 | public class AliyunImageStore {
42 | //...省略属性、构造函数等...
43 |
44 | public void createBucketIfNotExisting(String bucketName) {
45 | // ...创建bucket代码逻辑...
46 | // ...失败会抛出异常..
47 | }
48 |
49 | public String generateAccessToken() {
50 | // ...根据accesskey/secrectkey等生成access token
51 | }
52 |
53 | public String uploadToAliyun(Image image, String bucketName, String accessToken) {
54 | //...上传图片到阿里云...
55 | //...返回图片存储在阿里云上的地址(url)...
56 | }
57 |
58 | public Image downloadFromAliyun(String url, String accessToken) {
59 | //...从阿里云下载图片...
60 | }
61 | }
62 |
63 | // AliyunImageStore类的使用举例
64 | public class ImageProcessingJob {
65 | private static final String BUCKET_NAME = "ai_images_bucket";
66 | //...省略其他无关代码...
67 |
68 | public void process() {
69 | Image image = ...; //处理图片,并封装为Image对象
70 | AliyunImageStore imageStore = new AliyunImageStore(/*省略参数*/);
71 | imageStore.createBucketIfNotExisting(BUCKET_NAME);
72 | String accessToken = imageStore.generateAccessToken();
73 | imagestore.uploadToAliyun(image, BUCKET_NAME, accessToken);
74 | }
75 |
76 | }
77 | ```
78 |
79 |
80 |
81 | 1. 整个上传流程包含三个步骤:创建 bucket(你可以简单理解为存储目录)、生成 access token 访问凭证、携带 access token 上传图片到指定的 bucket 中。代码实现非常简单,类中的几个方法定义得都很干净,用起来也很清晰,乍看起来没有太大问题,完全能满足我们将图片存储在阿里云的业务需求。
82 | 2. 不过,软件开发中唯一不变的就是变化。过了一段时间后,我们自建了私有云,不再将图片存储到阿里云了,而是将图片存储到自建私有云上。为了满足这样一个需求的变化,我们该如何修改代码呢?
83 | 3. 我们需要重新设计实现一个存储图片到私有云的 PrivateImageStore 类,并用它替换掉项目中所有的 AliyunImageStore 类对象。这样的修改听起来并不复杂,只是简单替换而已,对整个代码的改动并不大。不过,我们经常说,“细节是魔鬼”。这句话在软件开发中特别适用。实际上,刚刚的设计实现方式,就隐藏了很多容易出问题的“魔鬼细节”,我们一块来看看都有哪些。
84 | 4. 新的 PrivateImageStore 类需要设计实现哪些方法,才能在尽量最小化代码修改的情况下,替换掉 AliyunImageStore 类呢?这就要求我们必须将 AliyunImageStore 类中所定义的所有 public 方法,在 PrivateImageStore 类中都逐一定义并重新实现一遍。而这样做就会存在一些问题,我总结了下面两点。
85 | - 首先,AliyunImageStore 类中有些函数命名暴露了实现细节,比如,uploadToAliyun() 和 downloadFromAliyun()。如果开发这个功能的同事没有接口意识、抽象思维,那这种暴露实现细节的命名方式就不足为奇了,毕竟最初我们只考虑将图片存储在阿里云上。而我们把这种包含“aliyun”字眼的方法,照抄到 PrivateImageStore 类中,显然是不合适的。如果我们在新类中重新命名 uploadToAliyun()、downloadFromAliyun() 这些方法,那就意味着,我们要修改项目中所有使用到这两个方法的代码,代码修改量可能就会很大。
86 | - 其次,将图片存储到阿里云的流程,跟存储到私有云的流程,可能并不是完全一致的。比如,阿里云的图片上传和下载的过程中,需要生产 access token,而私有云不需要 access token。一方面,AliyunImageStore 中定义的 generateAccessToken() 方法不能照抄到 PrivateImageStore 中;另一方面,我们在使用 AliyunImageStore 上传、下载图片的时候,代码中用到了 generateAccessToken() 方法,如果要改为私有云的上传下载流程,这些代码都需要做调整。
87 | 5. 那这两个问题该如何解决呢?解决这个问题的根本方法就是,在编写代码的时候,要遵从“基于接口而非实现编程”的原则,具体来讲,我们需要做到下面这 3 点。
88 | 1. 函数的命名不能暴露任何实现细节。比如,前面提到的 uploadToAliyun() 就不符合要求,应该改为去掉 aliyun 这样的字眼,改为更加抽象的命名方式,比如:upload()。
89 | 2. 封装具体的实现细节。比如,跟阿里云相关的特殊上传(或下载)流程不应该暴露给调用者。我们对上传(或下载)流程进行封装,对外提供一个包裹所有上传(或下载)细节的方法,给调用者使用。
90 | 3. 为实现类定义抽象的接口。具体的实现类都依赖统一的接口定义,遵从一致的上传功能协议。使用者依赖接口,而不是具体的实现类来编程。
91 | 6. 我们按照这个思路,把代码重构一下。重构后的代码如下所示:
92 |
93 | ```java
94 | public interface ImageStore {
95 | String upload(Image image, String bucketName);
96 | Image download(String url);
97 | }
98 |
99 | public class AliyunImageStore implements ImageStore {
100 | //...省略属性、构造函数等...
101 |
102 | public String upload(Image image, String bucketName) {
103 | createBucketIfNotExisting(bucketName);
104 | String accessToken = generateAccessToken();
105 | //...上传图片到阿里云...
106 | //...返回图片在阿里云上的地址(url)...
107 | }
108 |
109 | public Image download(String url) {
110 | String accessToken = generateAccessToken();
111 | //...从阿里云下载图片...
112 | }
113 |
114 | private void createBucketIfNotExisting(String bucketName) {
115 | // ...创建bucket...
116 | // ...失败会抛出异常..
117 | }
118 |
119 | private String generateAccessToken() {
120 | // ...根据accesskey/secrectkey等生成access token
121 | }
122 | }
123 |
124 | // 上传下载流程改变:私有云不需要支持access token
125 | public class PrivateImageStore implements ImageStore {
126 | public String upload(Image image, String bucketName) {
127 | createBucketIfNotExisting(bucketName);
128 | //...上传图片到私有云...
129 | //...返回图片的url...
130 | }
131 |
132 | public Image download(String url) {
133 | //...从私有云下载图片...
134 | }
135 |
136 | private void createBucketIfNotExisting(String bucketName) {
137 | // ...创建bucket...
138 | // ...失败会抛出异常..
139 | }
140 | }
141 |
142 | // ImageStore的使用举例
143 | public class ImageProcessingJob {
144 | private static final String BUCKET_NAME = "ai_images_bucket";
145 | //...省略其他无关代码...
146 |
147 | public void process() {
148 | Image image = ...;//处理图片,并封装为Image对象
149 | ImageStore imageStore = new PrivateImageStore(...);
150 | imagestore.upload(image, BUCKET_NAME);
151 | }
152 | }
153 | ```
154 |
155 | 1. 除此之外,很多人在定义接口的时候,希望通过实现类来反推接口的定义。先把实现类写好,然后看实现类中有哪些方法,照抄到接口定义中。如果按照这种思考方式,就有可能导致接口定义不够抽象,依赖具体的实现。这样的接口设计就没有意义了。不过,如果你觉得这种思考方式更加顺畅,那也没问题,只是将实现类的方法搬移到接口定义中的时候,要有选择性的搬移,不要将跟具体实现相关的方法搬移到接口中,比如 AliyunImageStore 中的 generateAccessToken() 方法。
156 | 2. 总结一下,我们在做软件开发的时候,一定要有抽象意识、封装意识、接口意识。在定义接口的时候,不要暴露任何实现细节。接口的定义只表明做什么,而不是怎么做。而且,在设计接口的时候,我们要多思考一下,这样的接口设计是否足够通用,是否能够做到在替换具体的接口实现的时候,不需要任何接口定义的改动。
157 |
158 |
159 |
160 | ### 是否需要为每个类定义接口?
161 |
162 | 1. 看了刚刚的讲解,你可能会有这样的疑问:为了满足这条原则,我是不是需要给每个实现类都定义对应的接口呢?在开发的时候,是不是任何代码都要只依赖接口,完全不依赖实现编程呢?
163 | 2. 做任何事情都要讲求一个“度”,过度使用这条原则,非得给每个类都定义接口,接口满天飞,也会导致不必要的开发负担。至于什么时候,该为某个类定义接口,实现基于接口的编程,什么时候不需要定义接口,直接使用实现类编程,我们做权衡的根本依据,还是要回归到设计原则诞生的初衷上来。只要搞清楚了这条原则是为了解决什么样的问题而产生的,你就会发现,很多之前模棱两可的问题,都会变得豁然开朗。
164 | 3. 前面我们也提到,这条原则的设计初衷是,将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低代码间的耦合性,提高代码的扩展性。
165 | 4. 从这个设计初衷上来看,如果在我们的业务场景中,某个功能只有一种实现方式,未来也不可能被其他实现方式替换,那我们就没有必要为其设计接口,也没有必要基于接口编程,直接使用实现类就可以了。
166 | 5. 除此之外,越是不稳定的系统,我们越是要在代码的扩展性、维护性上下功夫。相反,如果某个系统特别稳定,在开发完之后,基本上不需要做维护,那我们就没有必要为其扩展性,投入不必要的开发时间。
167 |
168 |
169 |
170 | ## 多用组合少用继承
171 |
172 | 在面向对象编程中,有一条非常经典的设计原则,那就是:组合优于继承,多用组合少用继承。为什么不推荐使用继承?组合相比继承有哪些优势?如何判断该用组合还是继承?今天,我们就围绕着这三个问题,来详细讲解一下这条设计原则。
173 |
174 |
175 |
176 |
177 |
178 | ### 为什么不推荐使用继承?
179 |
180 | 1. 继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。所以,对于是否应该在项目中使用继承,网上有很多争议。很多人觉得继承是一种反模式,应该尽量少用,甚至不用。为什么会有这样的争议?我们通过一个例子来解释一下。
181 | 2. 假设我们要设计一个关于鸟的类。我们将“鸟类”这样一个抽象的事物概念,定义为一个抽象类 AbstractBird。所有更细分的鸟,比如麻雀、鸽子、乌鸦等,都继承这个抽象类。
182 | 3. 我们知道,大部分鸟都会飞,那我们可不可以在 AbstractBird 抽象类中,定义一个 fly() 方法呢?答案是否定的。尽管大部分鸟都会飞,但也有特例,比如鸵鸟就不会飞。鸵鸟继承具有 fly() 方法的父类,那鸵鸟就具有“飞”这样的行为,这显然不符合我们对现实世界中事物的认识。当然,你可能会说,我在鸵鸟这个子类中重写(override)fly() 方法,让它抛出 UnSupportedMethodException 异常不就可以了吗?具体的代码实现如下所示:
183 |
184 | ```java
185 | public class AbstractBird {
186 | //...省略其他属性和方法...
187 | public void fly() { //... }
188 | }
189 |
190 | public class Ostrich extends AbstractBird { //鸵鸟
191 | //...省略其他属性和方法...
192 | public void fly() {
193 | throw new UnSupportedMethodException("I can't fly.'");
194 | }
195 | }
196 | ```
197 |
198 | 1. 这种设计思路虽然可以解决问题,但不够优美。因为除了鸵鸟之外,不会飞的鸟还有很多,比如企鹅。对于这些不会飞的鸟来说,我们都需要重写 fly() 方法,抛出异常。这样的设计,一方面,徒增了编码的工作量;另一方面,也违背了我们之后要讲的最小知识原则(Least Knowledge Principle,也叫最少知识原则或者迪米特法则),暴露不该暴露的接口给外部,增加了类使用过程中被误用的概率。
199 | 2. 你可能又会说,那我们再通过 AbstractBird 类派生出两个更加细分的抽象类:会飞的鸟类 AbstractFlyableBird 和不会飞的鸟类 AbstractUnFlyableBird,让麻雀、乌鸦这些会飞的鸟都继承 AbstractFlyableBird,让鸵鸟、企鹅这些不会飞的鸟,都继承 AbstractUnFlyableBird 类,不就可以了吗?具体的继承关系如下图所示:
200 |
201 |  202 |
203 |
204 |
205 | 1. 从图中我们可以看出,继承关系变成了三层。不过,整体上来讲,目前的继承关系还比较简单,层次比较浅,也算是一种可以接受的设计思路。我们再继续加点难度。在刚刚这个场景中,我们只关注“鸟会不会飞”,但如果我们还关注“鸟会不会叫”,那这个时候,我们又该如何设计类之间的继承关系呢?
206 |
207 | 2. 是否会飞?是否会叫?两个行为搭配起来会产生四种情况:会飞会叫、不会飞会叫、会飞不会叫、不会飞不会叫。如果我们继续沿用刚才的设计思路,那就需要再定义四个抽象类(AbstractFlyableTweetableBird、AbstractFlyableUnTweetableBird、AbstractUnFlyableTweetableBird、AbstractUnFlyableUnTweetableBird)。
208 |
209 |
202 |
203 |
204 |
205 | 1. 从图中我们可以看出,继承关系变成了三层。不过,整体上来讲,目前的继承关系还比较简单,层次比较浅,也算是一种可以接受的设计思路。我们再继续加点难度。在刚刚这个场景中,我们只关注“鸟会不会飞”,但如果我们还关注“鸟会不会叫”,那这个时候,我们又该如何设计类之间的继承关系呢?
206 |
207 | 2. 是否会飞?是否会叫?两个行为搭配起来会产生四种情况:会飞会叫、不会飞会叫、会飞不会叫、不会飞不会叫。如果我们继续沿用刚才的设计思路,那就需要再定义四个抽象类(AbstractFlyableTweetableBird、AbstractFlyableUnTweetableBird、AbstractUnFlyableTweetableBird、AbstractUnFlyableUnTweetableBird)。
208 |
209 | 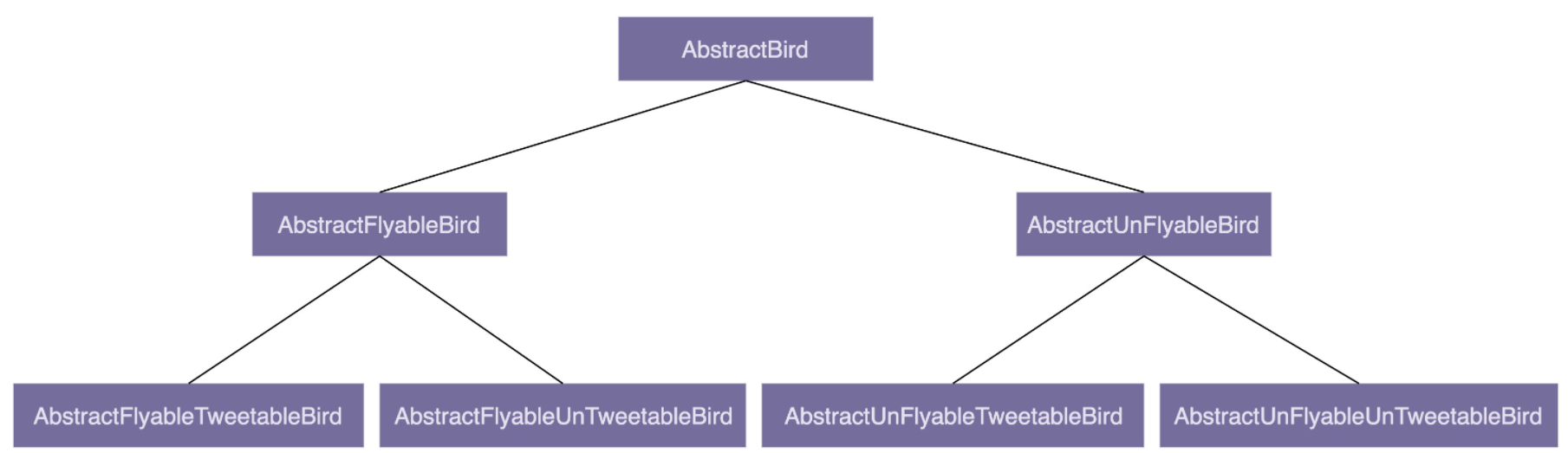 210 |
211 |
212 |
213 | 1. 如果我们还需要考虑“是否会下蛋”这样一个行为,那估计就要组合爆炸了。类的继承层次会越来越深、继承关系会越来越复杂。而这种层次很深、很复杂的继承关系,一方面,会导致代码的可读性变差。因为我们要搞清楚某个类具有哪些方法、属性,必须阅读父类的代码、父类的父类的代码……一直追溯到最顶层父类的代码。另一方面,这也破坏了类的封装特性,将父类的实现细节暴露给了子类。子类的实现依赖父类的实现,两者高度耦合,一旦父类代码修改,就会影响所有子类的逻辑。
214 | 2. 总之,继承最大的问题就在于:继承层次过深、继承关系过于复杂会影响到代码的可读性和可维护性。这也是为什么我们不推荐使用继承。那刚刚例子中继承存在的问题,我们又该如何来解决呢?你可以先自己思考一下,再听我下面的讲解。
215 |
216 |
217 |
218 | ### 组合相比继承有哪些优势?
219 |
220 | 1. 实际上,我们可以利用组合(composition)、接口、委托(delegation)三个技术手段,一块儿来解决刚刚继承存在的问题。
221 | 2. 接口表示具有某种行为特性。针对“会飞”这样一个行为特性,我们可以定义一个 Flyable 接口,只让会飞的鸟去实现这个接口。对于会叫、会下蛋这些行为特性,我们可以类似地定义 Tweetable 接口、EggLayable 接口。我们将这个设计思路翻译成 Java 代码的话,就是下面这个样子:
222 |
223 | ```java
224 | public interface Flyable {
225 | void fly();
226 | }
227 | public interface Tweetable {
228 | void tweet();
229 | }
230 | public interface EggLayable {
231 | void layEgg();
232 | }
233 | public class Ostrich implements Tweetable, EggLayable {//鸵鸟
234 | //... 省略其他属性和方法...
235 | @Override
236 | public void tweet() { //... }
237 | @Override
238 | public void layEgg() { //... }
239 | }
240 | public class Sparrow impelents Flyable, Tweetable, EggLayable {//麻雀
241 | //... 省略其他属性和方法...
242 | @Override
243 | public void fly() { //... }
244 | @Override
245 | public void tweet() { //... }
246 | @Override
247 | public void layEgg() { //... }
248 | }
249 | ```
250 |
251 | 1. 不过,我们知道,接口只声明方法,不定义实现。也就是说,每个会下蛋的鸟都要实现一遍 layEgg() 方法,并且实现逻辑是一样的,这就会导致代码重复的问题。那这个问题又该如何解决呢?
252 | 2. 我们可以针对三个接口再定义三个实现类,它们分别是:实现了 fly() 方法的 FlyAbility 类、实现了 tweet() 方法的 TweetAbility 类、实现了 layEgg() 方法的 EggLayAbility 类。然后,通过组合和委托技术来消除代码重复。具体的代码实现如下所示:
253 |
254 | ```java
255 | public interface Flyable {
256 | void fly();
257 | }
258 | public class FlyAbility implements Flyable {
259 | @Override
260 | public void fly() { //... }
261 | }
262 | //省略Tweetable/TweetAbility/EggLayable/EggLayAbility
263 |
264 | public class Ostrich implements Tweetable, EggLayable {//鸵鸟
265 | private TweetAbility tweetAbility = new TweetAbility(); //组合
266 | private EggLayAbility eggLayAbility = new EggLayAbility(); //组合
267 | //... 省略其他属性和方法...
268 | @Override
269 | public void tweet() {
270 | tweetAbility.tweet(); // 委托
271 | }
272 | @Override
273 | public void layEgg() {
274 | eggLayAbility.layEgg(); // 委托
275 | }
276 | }
277 | ```
278 |
279 |
280 |
281 | 我们知道继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。而这三个作用都可以通过其他技术手段来达成。比如 is-a 关系,我们可以通过组合和接口的 has-a 关系来替代;多态特性我们可以利用接口来实现;代码复用我们可以通过组合和委托来实现。所以,从理论上讲,通过组合、接口、委托三个技术手段,我们完全可以替换掉继承,在项目中不用或者少用继承关系,特别是一些复杂的继承关系。
282 |
283 |
284 |
285 | ### 如何判断该用组合还是继承?
286 |
287 | 1. 尽管我们鼓励多用组合少用继承,但组合也并不是完美的,继承也并非一无是处。从上面的例子来看,继承改写成组合意味着要做更细粒度的类的拆分。这也就意味着,我们要定义更多的类和接口。类和接口的增多也就或多或少地增加代码的复杂程度和维护成本。所以,在实际的项目开发中,我们还是要根据具体的情况,来具体选择该用继承还是组合。
288 | 2. 如果类之间的继承结构稳定(不会轻易改变),继承层次比较浅(比如,最多有两层继承关系),继承关系不复杂,我们就可以大胆地使用继承。反之,系统越不稳定,继承层次很深,继承关系复杂,我们就尽量使用组合来替代继承。
289 | 3. 除此之外,还有一些设计模式会固定使用继承或者组合。比如,装饰者模式(decorator pattern)、策略模式(strategy pattern)、组合模式(composite pattern)等都使用了组合关系,而模板模式(template pattern)使用了继承关系。
290 | 4. 前面我们讲到继承可以实现代码复用。利用继承特性,我们把相同的属性和方法,抽取出来,定义到父类中。子类复用父类中的属性和方法,达到代码复用的目的。但是,有的时候,从业务含义上,A 类和 B 类并不一定具有继承关系。比如,Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。仅仅为了代码复用,生硬地抽象出一个父类出来,会影响到代码的可读性。如果不熟悉背后设计思路的同事,发现 Crawler 类和 PageAnalyzer 类继承同一个父类,而父类中定义的却只是 URL 相关的操作,会觉得这个代码写得莫名其妙,理解不了。这个时候,使用组合就更加合理、更加灵活。具体的代码实现如下所示:
291 |
292 | ```java
293 | public class Url {
294 | //...省略属性和方法
295 | }
296 |
297 | public class Crawler {
298 | private Url url; // 组合
299 | public Crawler() {
300 | this.url = new Url();
301 | }
302 | //...
303 | }
304 |
305 | public class PageAnalyzer {
306 | private Url url; // 组合
307 | public PageAnalyzer() {
308 | this.url = new Url();
309 | }
310 | //..
311 | }
312 | ```
313 |
314 |
315 |
316 | 还有一些特殊的场景要求我们必须使用继承。如果你不能改变一个函数的入参类型,而入参又非接口,为了支持多态,只能采用继承来实现。比如下面这样一段代码,其中 FeignClient 是一个外部类,我们没有权限去修改这部分代码,但是我们希望能重写这个类在运行时执行的 encode() 函数。这个时候,我们只能采用继承来实现了。
317 |
318 |
319 |
320 | ```java
321 | public class FeignClient { // Feign Client框架代码
322 | //...省略其他代码...
323 | public void encode(String url) { //... }
324 | }
325 |
326 | public void demofunction(FeignClient feignClient) {
327 | //...
328 | feignClient.encode(url);
329 | //...
330 | }
331 |
332 | public class CustomizedFeignClient extends FeignClient {
333 | @Override
334 | public void encode(String url) { //...重写encode的实现...}
335 | }
336 |
337 | // 调用
338 | FeignClient client = new CustomizedFeignClient();
339 | demofunction(client);
340 | ```
341 |
342 | 尽管有些人说,要杜绝继承,100% 用组合代替继承,但是我的观点没那么极端!之所以“多用组合少用继承”这个口号喊得这么响,只是因为,长期以来,我们过度使用继承。还是那句话,组合并不完美,继承也不是一无是处。只要我们控制好它们的副作用、发挥它们各自的优势,在不同的场合下,恰当地选择使用继承还是组合,这才是我们所追求的境界。
343 |
344 |
345 |
346 |
347 |
348 | ## 如何通过封装、抽象、模块化、中间层等解耦代码?
349 |
350 | ### “解耦”为何如此重要?
351 |
352 | 1. 软件设计与开发最重要的工作之一就是应对复杂性。人处理复杂性的能力是有限的。过于复杂的代码往往在可读性、可维护性上都不友好。那如何来控制代码的复杂性呢?手段有很多,我个人认为,最关键的就是解耦,保证代码松耦合、高内聚。如果说重构是保证代码质量不至于腐化到无可救药地步的有效手段,那么利用解耦的方法对代码重构,就是保证代码不至于复杂到无法控制的有效手段。
353 | 2. 后文迪米特法则有介绍,什么是“高内聚、松耦合”。。实际上,“高内聚、松耦合”是一个比较通用的设计思想,不仅可以指导细粒度的类和类之间关系的设计,还能指导粗粒度的系统、架构、模块的设计。相对于编码规范,它能够在更高层次上提高代码的可读性和可维护性。
354 | 3. 不管是阅读代码还是修改代码,“高内聚、松耦合”的特性可以让我们聚焦在某一模块或类中,不需要了解太多其他模块或类的代码,让我们的焦点不至于过于发散,降低了阅读和修改代码的难度。而且,因为依赖关系简单,耦合小,修改代码不至于牵一发而动全身,代码改动比较集中,引入 bug 的风险也就减少了很多。同时,“高内聚、松耦合”的代码可测试性也更加好,容易 mock 或者很少需要 mock 外部依赖的模块或者类。
355 | 4. 除此之外,代码“高内聚、松耦合”,也就意味着,代码结构清晰、分层和模块化合理、依赖关系简单、模块或类之间的耦合小,那代码整体的质量就不会差。即便某个具体的类或者模块设计得不怎么合理,代码质量不怎么高,影响的范围是非常有限的。我们可以聚焦于这个模块或者类,做相应的小型重构。而相对于代码结构的调整,这种改动范围比较集中的小型重构的难度就容易多了。
356 |
357 |
358 |
359 | ### 代码是否需要“解耦”?
360 |
361 | 1. 那现在问题来了,我们该怎么判断代码的耦合程度呢?或者说,怎么判断代码是否符合“高内聚、松耦合”呢?再或者说,如何判断系统是否需要解耦重构呢?
362 | 2. 间接的衡量标准有很多,前面我们讲到了一些,比如,看修改代码会不会牵一发而动全身。除此之外,还有一个直接的衡量标准,也是我在阅读源码的时候经常会用到的,那就是把模块与模块之间、类与类之间的依赖关系画出来,根据依赖关系图的复杂性来判断是否需要解耦重构。
363 | 3. 如果依赖关系复杂、混乱,那从代码结构上来讲,可读性和可维护性肯定不是太好,那我们就需要考虑是否可以通过解耦的方法,让依赖关系变得清晰、简单。当然,这种判断还是有比较强的主观色彩,但是可以作为一种参考和梳理依赖的手段,配合间接的衡量标准一块来使用。
364 |
365 | ### 如何给代码“解耦”?
366 |
367 | > 封装与抽象
368 |
369 | 封装和抽象作为两个非常通用的设计思想,可以应用在很多设计场景中,比如系统、模块、lib、组件、接口、类等等的设计。封装和抽象可以有效地隐藏实现的复杂性,隔离实现的易变性,给依赖的模块提供稳定且易用的抽象接口
370 |
371 |
372 |
373 | > 中间层
374 |
375 | 引入中间层能简化模块或类之间的依赖关系。下面这张图是引入中间层前后的依赖关系对比图。在引入数据存储中间层之前,A、B、C 三个模块都要依赖内存一级缓存、Redis 二级缓存、DB 持久化存储三个模块。在引入中间层之后,三个模块只需要依赖数据存储一个模块即可。从图上可以看出,中间层的引入明显地简化了依赖关系,让代码结构更加清晰
376 |
377 |
378 |
379 |
210 |
211 |
212 |
213 | 1. 如果我们还需要考虑“是否会下蛋”这样一个行为,那估计就要组合爆炸了。类的继承层次会越来越深、继承关系会越来越复杂。而这种层次很深、很复杂的继承关系,一方面,会导致代码的可读性变差。因为我们要搞清楚某个类具有哪些方法、属性,必须阅读父类的代码、父类的父类的代码……一直追溯到最顶层父类的代码。另一方面,这也破坏了类的封装特性,将父类的实现细节暴露给了子类。子类的实现依赖父类的实现,两者高度耦合,一旦父类代码修改,就会影响所有子类的逻辑。
214 | 2. 总之,继承最大的问题就在于:继承层次过深、继承关系过于复杂会影响到代码的可读性和可维护性。这也是为什么我们不推荐使用继承。那刚刚例子中继承存在的问题,我们又该如何来解决呢?你可以先自己思考一下,再听我下面的讲解。
215 |
216 |
217 |
218 | ### 组合相比继承有哪些优势?
219 |
220 | 1. 实际上,我们可以利用组合(composition)、接口、委托(delegation)三个技术手段,一块儿来解决刚刚继承存在的问题。
221 | 2. 接口表示具有某种行为特性。针对“会飞”这样一个行为特性,我们可以定义一个 Flyable 接口,只让会飞的鸟去实现这个接口。对于会叫、会下蛋这些行为特性,我们可以类似地定义 Tweetable 接口、EggLayable 接口。我们将这个设计思路翻译成 Java 代码的话,就是下面这个样子:
222 |
223 | ```java
224 | public interface Flyable {
225 | void fly();
226 | }
227 | public interface Tweetable {
228 | void tweet();
229 | }
230 | public interface EggLayable {
231 | void layEgg();
232 | }
233 | public class Ostrich implements Tweetable, EggLayable {//鸵鸟
234 | //... 省略其他属性和方法...
235 | @Override
236 | public void tweet() { //... }
237 | @Override
238 | public void layEgg() { //... }
239 | }
240 | public class Sparrow impelents Flyable, Tweetable, EggLayable {//麻雀
241 | //... 省略其他属性和方法...
242 | @Override
243 | public void fly() { //... }
244 | @Override
245 | public void tweet() { //... }
246 | @Override
247 | public void layEgg() { //... }
248 | }
249 | ```
250 |
251 | 1. 不过,我们知道,接口只声明方法,不定义实现。也就是说,每个会下蛋的鸟都要实现一遍 layEgg() 方法,并且实现逻辑是一样的,这就会导致代码重复的问题。那这个问题又该如何解决呢?
252 | 2. 我们可以针对三个接口再定义三个实现类,它们分别是:实现了 fly() 方法的 FlyAbility 类、实现了 tweet() 方法的 TweetAbility 类、实现了 layEgg() 方法的 EggLayAbility 类。然后,通过组合和委托技术来消除代码重复。具体的代码实现如下所示:
253 |
254 | ```java
255 | public interface Flyable {
256 | void fly();
257 | }
258 | public class FlyAbility implements Flyable {
259 | @Override
260 | public void fly() { //... }
261 | }
262 | //省略Tweetable/TweetAbility/EggLayable/EggLayAbility
263 |
264 | public class Ostrich implements Tweetable, EggLayable {//鸵鸟
265 | private TweetAbility tweetAbility = new TweetAbility(); //组合
266 | private EggLayAbility eggLayAbility = new EggLayAbility(); //组合
267 | //... 省略其他属性和方法...
268 | @Override
269 | public void tweet() {
270 | tweetAbility.tweet(); // 委托
271 | }
272 | @Override
273 | public void layEgg() {
274 | eggLayAbility.layEgg(); // 委托
275 | }
276 | }
277 | ```
278 |
279 |
280 |
281 | 我们知道继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。而这三个作用都可以通过其他技术手段来达成。比如 is-a 关系,我们可以通过组合和接口的 has-a 关系来替代;多态特性我们可以利用接口来实现;代码复用我们可以通过组合和委托来实现。所以,从理论上讲,通过组合、接口、委托三个技术手段,我们完全可以替换掉继承,在项目中不用或者少用继承关系,特别是一些复杂的继承关系。
282 |
283 |
284 |
285 | ### 如何判断该用组合还是继承?
286 |
287 | 1. 尽管我们鼓励多用组合少用继承,但组合也并不是完美的,继承也并非一无是处。从上面的例子来看,继承改写成组合意味着要做更细粒度的类的拆分。这也就意味着,我们要定义更多的类和接口。类和接口的增多也就或多或少地增加代码的复杂程度和维护成本。所以,在实际的项目开发中,我们还是要根据具体的情况,来具体选择该用继承还是组合。
288 | 2. 如果类之间的继承结构稳定(不会轻易改变),继承层次比较浅(比如,最多有两层继承关系),继承关系不复杂,我们就可以大胆地使用继承。反之,系统越不稳定,继承层次很深,继承关系复杂,我们就尽量使用组合来替代继承。
289 | 3. 除此之外,还有一些设计模式会固定使用继承或者组合。比如,装饰者模式(decorator pattern)、策略模式(strategy pattern)、组合模式(composite pattern)等都使用了组合关系,而模板模式(template pattern)使用了继承关系。
290 | 4. 前面我们讲到继承可以实现代码复用。利用继承特性,我们把相同的属性和方法,抽取出来,定义到父类中。子类复用父类中的属性和方法,达到代码复用的目的。但是,有的时候,从业务含义上,A 类和 B 类并不一定具有继承关系。比如,Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。仅仅为了代码复用,生硬地抽象出一个父类出来,会影响到代码的可读性。如果不熟悉背后设计思路的同事,发现 Crawler 类和 PageAnalyzer 类继承同一个父类,而父类中定义的却只是 URL 相关的操作,会觉得这个代码写得莫名其妙,理解不了。这个时候,使用组合就更加合理、更加灵活。具体的代码实现如下所示:
291 |
292 | ```java
293 | public class Url {
294 | //...省略属性和方法
295 | }
296 |
297 | public class Crawler {
298 | private Url url; // 组合
299 | public Crawler() {
300 | this.url = new Url();
301 | }
302 | //...
303 | }
304 |
305 | public class PageAnalyzer {
306 | private Url url; // 组合
307 | public PageAnalyzer() {
308 | this.url = new Url();
309 | }
310 | //..
311 | }
312 | ```
313 |
314 |
315 |
316 | 还有一些特殊的场景要求我们必须使用继承。如果你不能改变一个函数的入参类型,而入参又非接口,为了支持多态,只能采用继承来实现。比如下面这样一段代码,其中 FeignClient 是一个外部类,我们没有权限去修改这部分代码,但是我们希望能重写这个类在运行时执行的 encode() 函数。这个时候,我们只能采用继承来实现了。
317 |
318 |
319 |
320 | ```java
321 | public class FeignClient { // Feign Client框架代码
322 | //...省略其他代码...
323 | public void encode(String url) { //... }
324 | }
325 |
326 | public void demofunction(FeignClient feignClient) {
327 | //...
328 | feignClient.encode(url);
329 | //...
330 | }
331 |
332 | public class CustomizedFeignClient extends FeignClient {
333 | @Override
334 | public void encode(String url) { //...重写encode的实现...}
335 | }
336 |
337 | // 调用
338 | FeignClient client = new CustomizedFeignClient();
339 | demofunction(client);
340 | ```
341 |
342 | 尽管有些人说,要杜绝继承,100% 用组合代替继承,但是我的观点没那么极端!之所以“多用组合少用继承”这个口号喊得这么响,只是因为,长期以来,我们过度使用继承。还是那句话,组合并不完美,继承也不是一无是处。只要我们控制好它们的副作用、发挥它们各自的优势,在不同的场合下,恰当地选择使用继承还是组合,这才是我们所追求的境界。
343 |
344 |
345 |
346 |
347 |
348 | ## 如何通过封装、抽象、模块化、中间层等解耦代码?
349 |
350 | ### “解耦”为何如此重要?
351 |
352 | 1. 软件设计与开发最重要的工作之一就是应对复杂性。人处理复杂性的能力是有限的。过于复杂的代码往往在可读性、可维护性上都不友好。那如何来控制代码的复杂性呢?手段有很多,我个人认为,最关键的就是解耦,保证代码松耦合、高内聚。如果说重构是保证代码质量不至于腐化到无可救药地步的有效手段,那么利用解耦的方法对代码重构,就是保证代码不至于复杂到无法控制的有效手段。
353 | 2. 后文迪米特法则有介绍,什么是“高内聚、松耦合”。。实际上,“高内聚、松耦合”是一个比较通用的设计思想,不仅可以指导细粒度的类和类之间关系的设计,还能指导粗粒度的系统、架构、模块的设计。相对于编码规范,它能够在更高层次上提高代码的可读性和可维护性。
354 | 3. 不管是阅读代码还是修改代码,“高内聚、松耦合”的特性可以让我们聚焦在某一模块或类中,不需要了解太多其他模块或类的代码,让我们的焦点不至于过于发散,降低了阅读和修改代码的难度。而且,因为依赖关系简单,耦合小,修改代码不至于牵一发而动全身,代码改动比较集中,引入 bug 的风险也就减少了很多。同时,“高内聚、松耦合”的代码可测试性也更加好,容易 mock 或者很少需要 mock 外部依赖的模块或者类。
355 | 4. 除此之外,代码“高内聚、松耦合”,也就意味着,代码结构清晰、分层和模块化合理、依赖关系简单、模块或类之间的耦合小,那代码整体的质量就不会差。即便某个具体的类或者模块设计得不怎么合理,代码质量不怎么高,影响的范围是非常有限的。我们可以聚焦于这个模块或者类,做相应的小型重构。而相对于代码结构的调整,这种改动范围比较集中的小型重构的难度就容易多了。
356 |
357 |
358 |
359 | ### 代码是否需要“解耦”?
360 |
361 | 1. 那现在问题来了,我们该怎么判断代码的耦合程度呢?或者说,怎么判断代码是否符合“高内聚、松耦合”呢?再或者说,如何判断系统是否需要解耦重构呢?
362 | 2. 间接的衡量标准有很多,前面我们讲到了一些,比如,看修改代码会不会牵一发而动全身。除此之外,还有一个直接的衡量标准,也是我在阅读源码的时候经常会用到的,那就是把模块与模块之间、类与类之间的依赖关系画出来,根据依赖关系图的复杂性来判断是否需要解耦重构。
363 | 3. 如果依赖关系复杂、混乱,那从代码结构上来讲,可读性和可维护性肯定不是太好,那我们就需要考虑是否可以通过解耦的方法,让依赖关系变得清晰、简单。当然,这种判断还是有比较强的主观色彩,但是可以作为一种参考和梳理依赖的手段,配合间接的衡量标准一块来使用。
364 |
365 | ### 如何给代码“解耦”?
366 |
367 | > 封装与抽象
368 |
369 | 封装和抽象作为两个非常通用的设计思想,可以应用在很多设计场景中,比如系统、模块、lib、组件、接口、类等等的设计。封装和抽象可以有效地隐藏实现的复杂性,隔离实现的易变性,给依赖的模块提供稳定且易用的抽象接口
370 |
371 |
372 |
373 | > 中间层
374 |
375 | 引入中间层能简化模块或类之间的依赖关系。下面这张图是引入中间层前后的依赖关系对比图。在引入数据存储中间层之前,A、B、C 三个模块都要依赖内存一级缓存、Redis 二级缓存、DB 持久化存储三个模块。在引入中间层之后,三个模块只需要依赖数据存储一个模块即可。从图上可以看出,中间层的引入明显地简化了依赖关系,让代码结构更加清晰
376 |
377 |
378 |
379 |  380 |
381 |
382 |
383 | 除此之外,我们在进行重构的时候,引入中间层可以起到过渡的作用,能够让开发和重构同步进行,不互相干扰。比如,某个接口设计得有问题,我们需要修改它的定义,同时,所有调用这个接口的代码都要做相应的改动。如果新开发的代码也用到这个接口,那开发就跟重构冲突了。为了让重构能小步快跑,我们可以分下面四个阶段来完成接口的修改。
384 |
385 |
386 |
387 | - 第一阶段:引入一个中间层,包裹老的接口,提供新的接口定义。
388 | - 第二阶段:新开发的代码依赖中间层提供的新接口。
389 | - 第三阶段:将依赖老接口的代码改为调用新接口。
390 | - 第四阶段:确保所有的代码都调用新接口之后,删除掉老的接口。
391 |
392 | 这样,每个阶段的开发工作量都不会很大,都可以在很短的时间内完成。重构跟开发冲突的概率也变小了。
393 |
394 |
395 |
396 |
397 |
398 | > 模块化
399 |
400 | 模块化是构建复杂系统常用的手段。不仅在软件行业,在建筑、机械制造等行业,这个手段也非常有用。对于一个大型复杂系统来说,没有人能掌控所有的细节。之所以我们能搭建出如此复杂的系统,并且能维护得了,最主要的原因就是将系统划分成各个独立的模块,让不同的人负责不同的模块,这样即便在不了解全部细节的情况下,管理者也能协调各个模块,让整个系统有效运转。
401 |
402 |
403 |
404 |
405 |
406 | > 其他设计思想和原则
407 |
408 | “高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。实际上,在前面的章节中,我们已经多次提到过这个设计思想。很多设计原则都以实现代码的“高内聚、松耦合”为目的。我们来一块总结回顾一下都有哪些原则。
409 |
410 | (这里没有讲的,在后面文章里)
411 |
412 | - 单一职责原则
413 |
414 | 我们前面提到,内聚性和耦合性并非独立的。高内聚会让代码更加松耦合,而实现高内聚的重要指导原则就是单一职责原则。模块或者类的职责设计得单一,而不是大而全,那依赖它的类和它依赖的类就会比较少,代码耦合也就相应的降低了。
415 |
416 |
417 |
418 | - 基于接口而非实现编程
419 |
420 | 基于接口而非实现编程能通过接口这样一个中间层,隔离变化和具体的实现。这样做的好处是,在有依赖关系的两个模块或类之间,一个模块或者类的改动,不会影响到另一个模块或类。实际上,这就相当于将一种强依赖关系(强耦合)解耦为了弱依赖关系(弱耦合)。依赖注入
421 |
422 |
423 |
424 | - 依赖注入
425 |
426 | 跟基于接口而非实现编程思想类似,依赖注入也是将代码之间的强耦合变为弱耦合。尽管依赖注入无法将本应该有依赖关系的两个类,解耦为没有依赖关系,但可以让耦合关系没那么紧密,容易做到插拔替换
427 |
428 |
429 |
430 | - 多用组合少用继承
431 |
432 | 我们知道,继承是一种强依赖关系,父类与子类高度耦合,且这种耦合关系非常脆弱,牵一发而动全身,父类的每一次改动都会影响所有的子类。相反,组合关系是一种弱依赖关系,这种关系更加灵活,所以,对于继承结构比较复杂的代码,利用组合来替换继承,也是一种解耦的有效手段。
433 |
434 |
435 |
436 | - 迪米特法则
437 |
438 | 迪米特法则讲的是,不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。从定义上,我们明显可以看出,这条原则的目的就是为了实现代码的松耦合。至于如何应用这条原则来解耦代码,你可以回过头去阅读一下第 22 讲,这里我就不赘述了。除了上面讲到的这些设计思想和原则之外,还有一些设计模式也是为了解耦依赖,比如观察者模式,有关这一部分的内容,我们留在设计模式模块中慢慢讲解。
439 |
440 |
441 |
442 |
--------------------------------------------------------------------------------
/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HashMap-JDK8源码讲解及常见面试题
3 | tags:
4 | - Java集合
5 | - HashMap
6 | categories:
7 | - Java集合
8 | - HashMap
9 | keywords: Java集合,HashMap。
10 | description: HashMap-JDK8源码讲解及常见面试题。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/java.png'
12 | abbrlink: cbc5672a
13 | date: 2020-11-01 10:22:05
14 | ---
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 | > JDK7说过的东西,本篇文章不再讲解
23 |
24 | # 数据结构
25 |
26 | ## 红黑树
27 |
28 | 在JDK8中,优化了HashMap的数据结构,引入了红黑树。即HashMap的数据结构:数组+链表+红黑树。HashMap变成了这样。
29 |
30 |
380 |
381 |
382 |
383 | 除此之外,我们在进行重构的时候,引入中间层可以起到过渡的作用,能够让开发和重构同步进行,不互相干扰。比如,某个接口设计得有问题,我们需要修改它的定义,同时,所有调用这个接口的代码都要做相应的改动。如果新开发的代码也用到这个接口,那开发就跟重构冲突了。为了让重构能小步快跑,我们可以分下面四个阶段来完成接口的修改。
384 |
385 |
386 |
387 | - 第一阶段:引入一个中间层,包裹老的接口,提供新的接口定义。
388 | - 第二阶段:新开发的代码依赖中间层提供的新接口。
389 | - 第三阶段:将依赖老接口的代码改为调用新接口。
390 | - 第四阶段:确保所有的代码都调用新接口之后,删除掉老的接口。
391 |
392 | 这样,每个阶段的开发工作量都不会很大,都可以在很短的时间内完成。重构跟开发冲突的概率也变小了。
393 |
394 |
395 |
396 |
397 |
398 | > 模块化
399 |
400 | 模块化是构建复杂系统常用的手段。不仅在软件行业,在建筑、机械制造等行业,这个手段也非常有用。对于一个大型复杂系统来说,没有人能掌控所有的细节。之所以我们能搭建出如此复杂的系统,并且能维护得了,最主要的原因就是将系统划分成各个独立的模块,让不同的人负责不同的模块,这样即便在不了解全部细节的情况下,管理者也能协调各个模块,让整个系统有效运转。
401 |
402 |
403 |
404 |
405 |
406 | > 其他设计思想和原则
407 |
408 | “高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。实际上,在前面的章节中,我们已经多次提到过这个设计思想。很多设计原则都以实现代码的“高内聚、松耦合”为目的。我们来一块总结回顾一下都有哪些原则。
409 |
410 | (这里没有讲的,在后面文章里)
411 |
412 | - 单一职责原则
413 |
414 | 我们前面提到,内聚性和耦合性并非独立的。高内聚会让代码更加松耦合,而实现高内聚的重要指导原则就是单一职责原则。模块或者类的职责设计得单一,而不是大而全,那依赖它的类和它依赖的类就会比较少,代码耦合也就相应的降低了。
415 |
416 |
417 |
418 | - 基于接口而非实现编程
419 |
420 | 基于接口而非实现编程能通过接口这样一个中间层,隔离变化和具体的实现。这样做的好处是,在有依赖关系的两个模块或类之间,一个模块或者类的改动,不会影响到另一个模块或类。实际上,这就相当于将一种强依赖关系(强耦合)解耦为了弱依赖关系(弱耦合)。依赖注入
421 |
422 |
423 |
424 | - 依赖注入
425 |
426 | 跟基于接口而非实现编程思想类似,依赖注入也是将代码之间的强耦合变为弱耦合。尽管依赖注入无法将本应该有依赖关系的两个类,解耦为没有依赖关系,但可以让耦合关系没那么紧密,容易做到插拔替换
427 |
428 |
429 |
430 | - 多用组合少用继承
431 |
432 | 我们知道,继承是一种强依赖关系,父类与子类高度耦合,且这种耦合关系非常脆弱,牵一发而动全身,父类的每一次改动都会影响所有的子类。相反,组合关系是一种弱依赖关系,这种关系更加灵活,所以,对于继承结构比较复杂的代码,利用组合来替换继承,也是一种解耦的有效手段。
433 |
434 |
435 |
436 | - 迪米特法则
437 |
438 | 迪米特法则讲的是,不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。从定义上,我们明显可以看出,这条原则的目的就是为了实现代码的松耦合。至于如何应用这条原则来解耦代码,你可以回过头去阅读一下第 22 讲,这里我就不赘述了。除了上面讲到的这些设计思想和原则之外,还有一些设计模式也是为了解耦依赖,比如观察者模式,有关这一部分的内容,我们留在设计模式模块中慢慢讲解。
439 |
440 |
441 |
442 |
--------------------------------------------------------------------------------
/docs/Java/collection/HashMap-JDK8源码讲解及常见面试题.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HashMap-JDK8源码讲解及常见面试题
3 | tags:
4 | - Java集合
5 | - HashMap
6 | categories:
7 | - Java集合
8 | - HashMap
9 | keywords: Java集合,HashMap。
10 | description: HashMap-JDK8源码讲解及常见面试题。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/java.png'
12 | abbrlink: cbc5672a
13 | date: 2020-11-01 10:22:05
14 | ---
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 | > JDK7说过的东西,本篇文章不再讲解
23 |
24 | # 数据结构
25 |
26 | ## 红黑树
27 |
28 | 在JDK8中,优化了HashMap的数据结构,引入了红黑树。即HashMap的数据结构:数组+链表+红黑树。HashMap变成了这样。
29 |
30 | 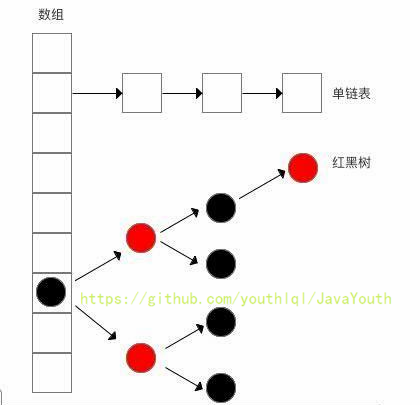 31 |
32 | ### 为什么要引入红黑树
33 |
34 | 1、主要是为了提高HashMap的性能,即解决发生hash冲突后,因为链表过长而导致索引效率慢的问题
35 |
36 | 2、链表的索引速度是O(n),而利用了红黑树快速增删改查的特点,时间复杂度就是O(logn)。
37 |
38 |
39 |
40 | ## Node类
41 |
42 | `HashMap`中的数组元素,链表节点均采用`Node`类 实现,与 `JDK 1.7` 的对比(`Entry`类),仅仅只是换了名字。
43 |
44 | 就是一些常规的方法
45 |
46 | ```java
47 | /**
48 | * Node = HashMap的内部类,实现了Map.Entry接口,本质是 = 一个映射(键值对)
49 | * 实现了getKey()、getValue()、equals(Object o)和hashCode()等方法
50 | **/
51 | static class Node
31 |
32 | ### 为什么要引入红黑树
33 |
34 | 1、主要是为了提高HashMap的性能,即解决发生hash冲突后,因为链表过长而导致索引效率慢的问题
35 |
36 | 2、链表的索引速度是O(n),而利用了红黑树快速增删改查的特点,时间复杂度就是O(logn)。
37 |
38 |
39 |
40 | ## Node类
41 |
42 | `HashMap`中的数组元素,链表节点均采用`Node`类 实现,与 `JDK 1.7` 的对比(`Entry`类),仅仅只是换了名字。
43 |
44 | 就是一些常规的方法
45 |
46 | ```java
47 | /**
48 | * Node = HashMap的内部类,实现了Map.Entry接口,本质是 = 一个映射(键值对)
49 | * 实现了getKey()、getValue()、equals(Object o)和hashCode()等方法
50 | **/
51 | static class Node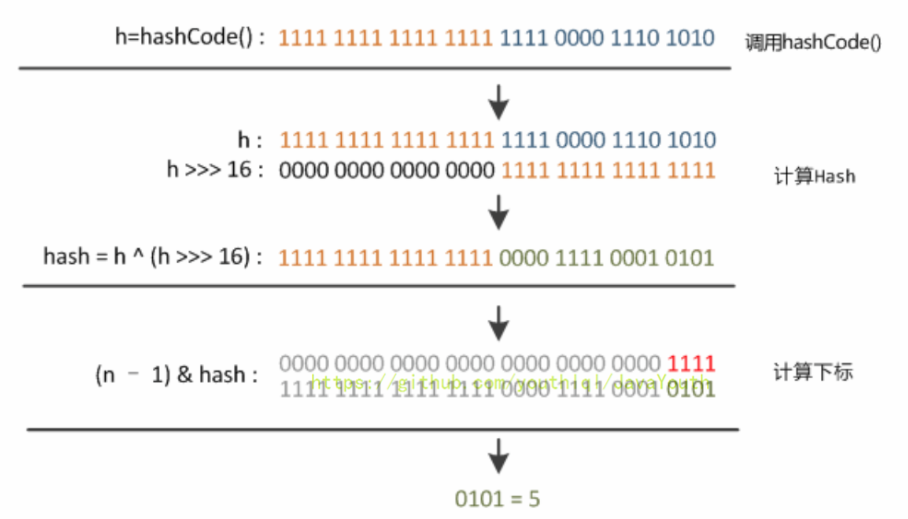 460 |
461 |
462 |
463 |
464 |
465 | ## resize()
466 |
467 | 这个方法改动比较大
468 |
469 | ```java
470 |
471 | //该函数有2种使用情况:1、初始化哈希表 2、当前数组容量过小,需扩容
472 | final Node
460 |
461 |
462 |
463 |
464 |
465 | ## resize()
466 |
467 | 这个方法改动比较大
468 |
469 | ```java
470 |
471 | //该函数有2种使用情况:1、初始化哈希表 2、当前数组容量过小,需扩容
472 | final Node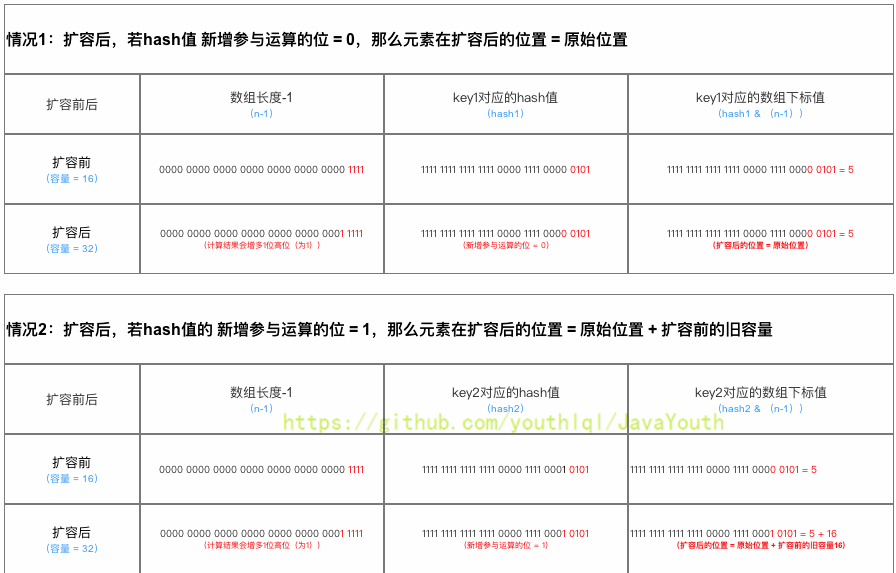 573 |
574 | * `JDK8`根据此结论作出的新元素存储位置计算规则非常简单,提高了扩容效率。
575 |
576 | - 这与 `JDK7`在计算新元素的存储位置有很大区别:`JDK7`在扩容后,都需按照原来方法进行rehash,效率不高。
577 |
578 |
579 |
580 | # get源码
581 |
582 | ```java
583 |
584 | public V get(Object key) {
585 | Node
573 |
574 | * `JDK8`根据此结论作出的新元素存储位置计算规则非常简单,提高了扩容效率。
575 |
576 | - 这与 `JDK7`在计算新元素的存储位置有很大区别:`JDK7`在扩容后,都需按照原来方法进行rehash,效率不高。
577 |
578 |
579 |
580 | # get源码
581 |
582 | ```java
583 |
584 | public V get(Object key) {
585 | Node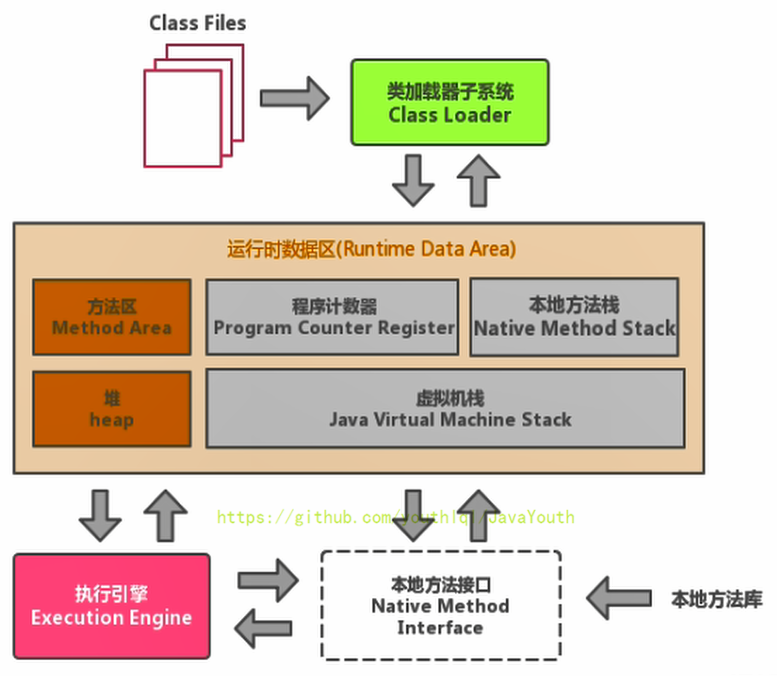 29 |
30 | ### 详细图
31 |
32 | 英文版
33 |
34 |
29 |
30 | ### 详细图
31 |
32 | 英文版
33 |
34 |  35 |
36 |
37 |
38 | 中文版
39 |
40 |
35 |
36 |
37 |
38 | 中文版
39 |
40 | 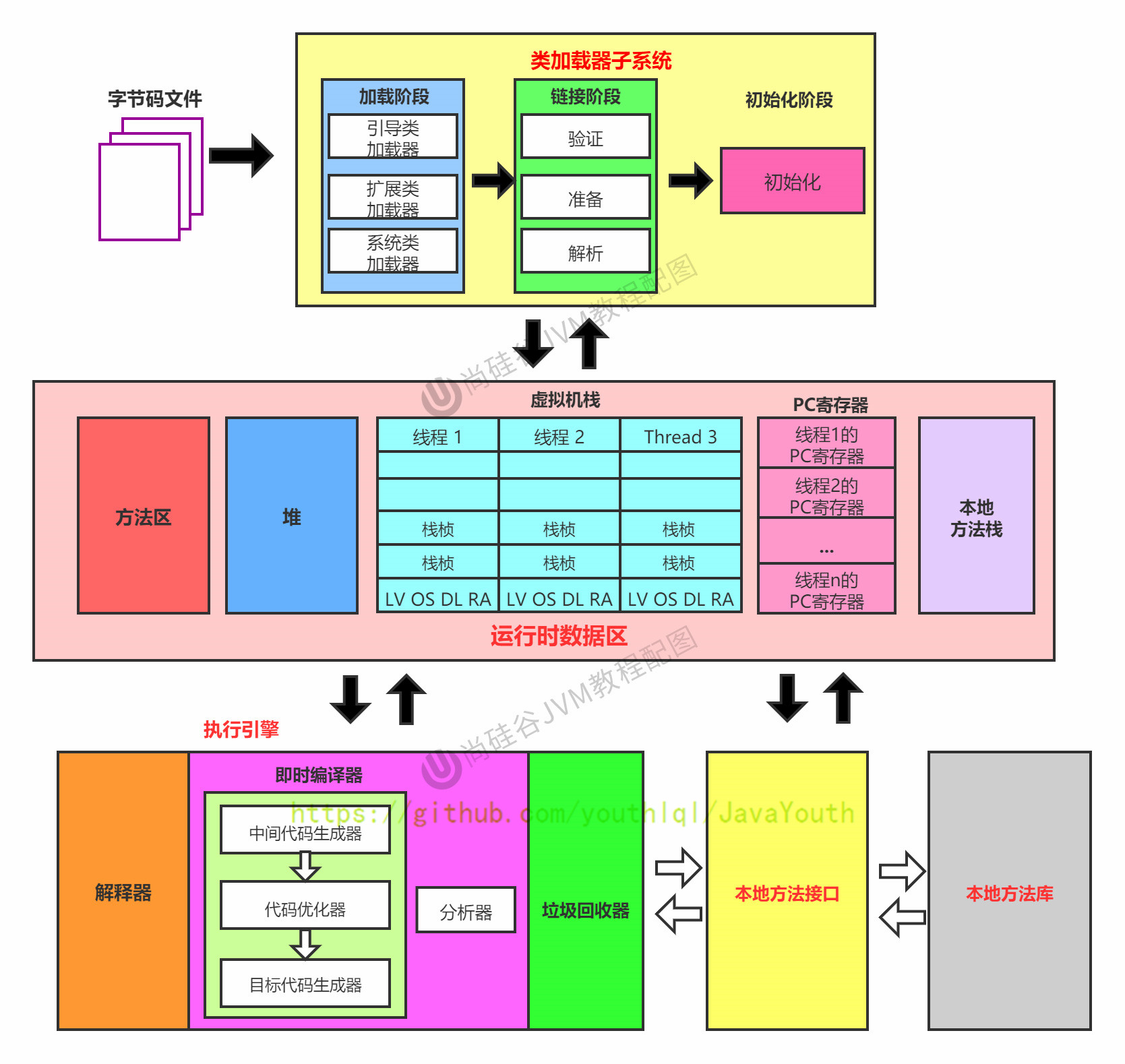 41 |
42 | 注意:方法区只有HotSpot虚拟机有,J9,JRockit都没有
43 |
44 |
45 |
46 | 如果自己想手写一个Java虚拟机的话,主要考虑哪些结构呢?
47 |
48 | 1. 类加载器
49 | 2. 执行引擎
50 |
51 | 类加载器子系统
52 | --------
53 |
54 | **类加载器子系统作用:**
55 |
56 | 1. 类加载器子系统负责从文件系统或者网络中加载Class文件,class文件在文件开头有特定的文件标识。
57 |
58 | 2. ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定。
59 |
60 | 3. **加载的类信息存放于一块称为方法区的内存空间**。除了类的信息外,方法区中还会存放运行时常量池信息,可能还包括字符串字面量和数字常量(这部分常量信息是Class文件中常量池部分的内存映射)
61 |
62 |
41 |
42 | 注意:方法区只有HotSpot虚拟机有,J9,JRockit都没有
43 |
44 |
45 |
46 | 如果自己想手写一个Java虚拟机的话,主要考虑哪些结构呢?
47 |
48 | 1. 类加载器
49 | 2. 执行引擎
50 |
51 | 类加载器子系统
52 | --------
53 |
54 | **类加载器子系统作用:**
55 |
56 | 1. 类加载器子系统负责从文件系统或者网络中加载Class文件,class文件在文件开头有特定的文件标识。
57 |
58 | 2. ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定。
59 |
60 | 3. **加载的类信息存放于一块称为方法区的内存空间**。除了类的信息外,方法区中还会存放运行时常量池信息,可能还包括字符串字面量和数字常量(这部分常量信息是Class文件中常量池部分的内存映射)
61 |
62 |  63 |
64 |
65 |
66 | ## 类加载器ClassLoader角色
67 |
68 | 1. class file(在下图中就是Car.class文件)存在于本地硬盘上,可以理解为设计师画在纸上的模板,而最终这个模板在执行的时候是要加载到JVM当中来根据这个文件实例化出n个一模一样的实例。
69 | 2. class file加载到JVM中,被称为DNA元数据模板(在下图中就是内存中的Car Class),放在方法区。
70 | 3. 在.class文件–>JVM–>最终成为元数据模板,此过程就要一个运输工具(类装载器Class Loader),扮演一个快递员的角色。
71 |
72 |
73 |
74 |
63 |
64 |
65 |
66 | ## 类加载器ClassLoader角色
67 |
68 | 1. class file(在下图中就是Car.class文件)存在于本地硬盘上,可以理解为设计师画在纸上的模板,而最终这个模板在执行的时候是要加载到JVM当中来根据这个文件实例化出n个一模一样的实例。
69 | 2. class file加载到JVM中,被称为DNA元数据模板(在下图中就是内存中的Car Class),放在方法区。
70 | 3. 在.class文件–>JVM–>最终成为元数据模板,此过程就要一个运输工具(类装载器Class Loader),扮演一个快递员的角色。
71 |
72 |
73 |
74 |  75 |
76 | 类加载过程
77 | -------
78 |
79 | ### 概述
80 |
81 | ```java
82 | public class HelloLoader {
83 |
84 | public static void main(String[] args) {
85 | System.out.println("谢谢ClassLoader加载我....");
86 | System.out.println("你的大恩大德,我下辈子再报!");
87 | }
88 | }
89 | ```
90 |
91 |
92 |
93 | 它的加载过程是怎么样的呢?
94 |
95 | * 执行 main() 方法(静态方法)就需要先加载main方法所在类 HelloLoader
96 | * 加载成功,则进行链接、初始化等操作。完成后调用 HelloLoader 类中的静态方法 main
97 | * 加载失败则抛出异常
98 |
99 |
75 |
76 | 类加载过程
77 | -------
78 |
79 | ### 概述
80 |
81 | ```java
82 | public class HelloLoader {
83 |
84 | public static void main(String[] args) {
85 | System.out.println("谢谢ClassLoader加载我....");
86 | System.out.println("你的大恩大德,我下辈子再报!");
87 | }
88 | }
89 | ```
90 |
91 |
92 |
93 | 它的加载过程是怎么样的呢?
94 |
95 | * 执行 main() 方法(静态方法)就需要先加载main方法所在类 HelloLoader
96 | * 加载成功,则进行链接、初始化等操作。完成后调用 HelloLoader 类中的静态方法 main
97 | * 加载失败则抛出异常
98 |
99 |  100 |
101 | 完整的流程图如下所示:
102 |
103 |
100 |
101 | 完整的流程图如下所示:
102 |
103 | 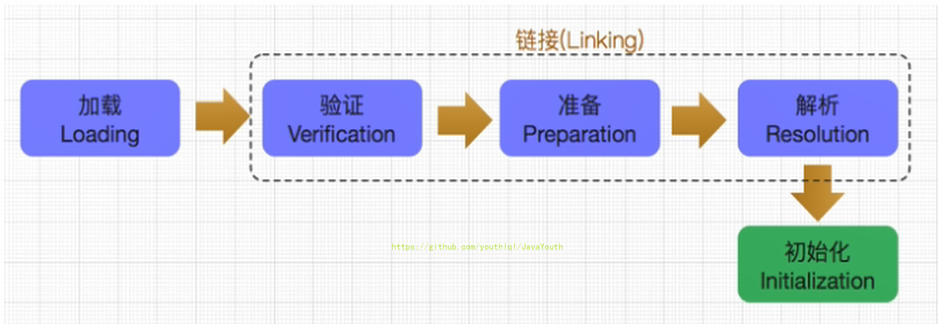 104 |
105 |
106 |
107 | ### 加载阶段
108 |
109 | **加载:**
110 |
111 | 1. 通过一个类的全限定名获取定义此类的二进制字节流
112 |
113 | 2. 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
114 |
115 | 3. **在内存中生成一个代表这个类的java.lang.Class对象**,作为方法区这个类的各种数据的访问入口
116 |
117 | **加载class文件的方式:**
118 |
119 | 1. 从本地系统中直接加载
120 | 2. 通过网络获取,典型场景:Web Applet
121 | 3. 从zip压缩包中读取,成为日后jar、war格式的基础
122 | 4. 运行时计算生成,使用最多的是:动态代理技术
123 | 5. 由其他文件生成,典型场景:JSP应用从专有数据库中提取.class文件,比较少见
124 | 6. 从加密文件中获取,典型的防Class文件被反编译的保护措施
125 |
126 |
127 |
128 | ### 链接阶段
129 |
130 | 链接分为三个子阶段:验证 -> 准备 -> 解析
131 |
132 |
133 |
134 | #### 验证(Verify)
135 |
136 | 1. 目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,保证被加载类的正确性,不会危害虚拟机自身安全
137 | 2. 主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
138 |
139 |
140 |
141 | **举例**
142 |
143 | 使用 BinaryViewer软件查看字节码文件,其开头均为 CAFE BABE ,如果出现不合法的字节码文件,那么将会验证不通过。
144 |
145 |
104 |
105 |
106 |
107 | ### 加载阶段
108 |
109 | **加载:**
110 |
111 | 1. 通过一个类的全限定名获取定义此类的二进制字节流
112 |
113 | 2. 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
114 |
115 | 3. **在内存中生成一个代表这个类的java.lang.Class对象**,作为方法区这个类的各种数据的访问入口
116 |
117 | **加载class文件的方式:**
118 |
119 | 1. 从本地系统中直接加载
120 | 2. 通过网络获取,典型场景:Web Applet
121 | 3. 从zip压缩包中读取,成为日后jar、war格式的基础
122 | 4. 运行时计算生成,使用最多的是:动态代理技术
123 | 5. 由其他文件生成,典型场景:JSP应用从专有数据库中提取.class文件,比较少见
124 | 6. 从加密文件中获取,典型的防Class文件被反编译的保护措施
125 |
126 |
127 |
128 | ### 链接阶段
129 |
130 | 链接分为三个子阶段:验证 -> 准备 -> 解析
131 |
132 |
133 |
134 | #### 验证(Verify)
135 |
136 | 1. 目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,保证被加载类的正确性,不会危害虚拟机自身安全
137 | 2. 主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
138 |
139 |
140 |
141 | **举例**
142 |
143 | 使用 BinaryViewer软件查看字节码文件,其开头均为 CAFE BABE ,如果出现不合法的字节码文件,那么将会验证不通过。
144 |
145 | 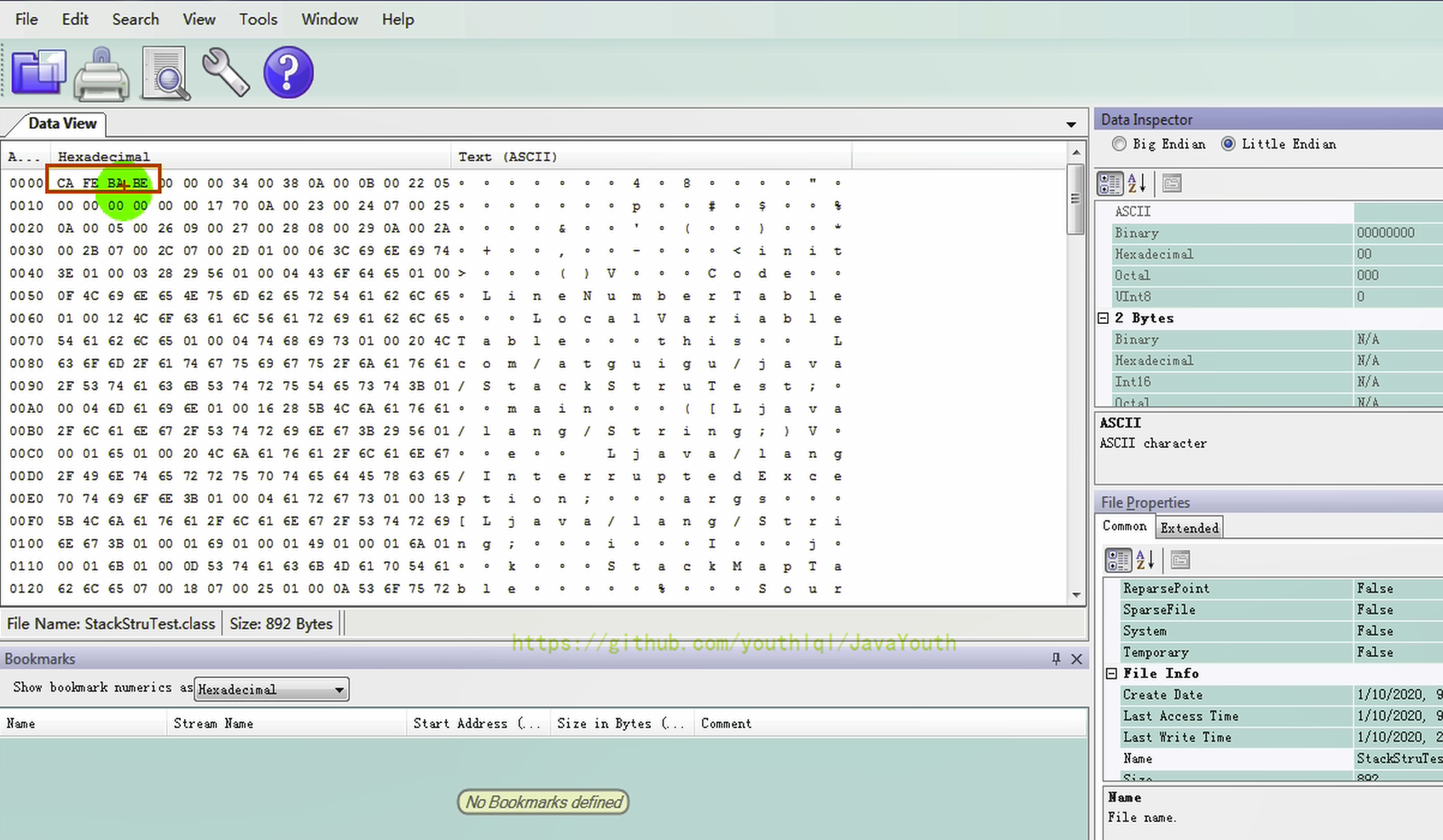 146 |
147 | #### 准备(Prepare)
148 |
149 |
150 |
151 | 1. 为类变量(static变量)分配内存并且设置该类变量的默认初始值,即零值
152 | 2. 这里不包含用final修饰的static,因为final在编译的时候就会分配好了默认值,准备阶段会显式初始化
153 | 3. 注意:这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量是会随着对象一起分配到Java堆中
154 |
155 | **举例**
156 |
157 | 代码:变量a在准备阶段会赋初始值,但不是1,而是0,在初始化阶段会被赋值为 1
158 |
159 | ```java
160 | public class HelloApp {
161 | private static int a = 1;//prepare:a = 0 ---> initial : a = 1
162 |
163 |
164 | public static void main(String[] args) {
165 | System.out.println(a);
166 | }
167 | }
168 | ```
169 |
170 |
171 |
172 | #### 解析(Resolve)
173 |
174 |
175 |
176 | 1. **将常量池内的符号引用转换为直接引用的过程**
177 |
178 | 2. 事实上,解析操作往往会伴随着JVM在执行完初始化之后再执行
179 |
180 | 3. 符号引用就是一组符号来描述所引用的目标。符号引用的字面量形式明确定义在《java虚拟机规范》的class文件格式中。直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄
181 |
182 | 4. 解析动作主要针对类或接口、字段、类方法、接口方法、方法类型等。对应常量池中的CONSTANT Class info、CONSTANT Fieldref info、CONSTANT Methodref info等
183 |
184 | **符号引用**
185 |
186 | * 反编译 class 文件后可以查看符号引用,下面带# 的就是符号引用
187 |
188 |
146 |
147 | #### 准备(Prepare)
148 |
149 |
150 |
151 | 1. 为类变量(static变量)分配内存并且设置该类变量的默认初始值,即零值
152 | 2. 这里不包含用final修饰的static,因为final在编译的时候就会分配好了默认值,准备阶段会显式初始化
153 | 3. 注意:这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量是会随着对象一起分配到Java堆中
154 |
155 | **举例**
156 |
157 | 代码:变量a在准备阶段会赋初始值,但不是1,而是0,在初始化阶段会被赋值为 1
158 |
159 | ```java
160 | public class HelloApp {
161 | private static int a = 1;//prepare:a = 0 ---> initial : a = 1
162 |
163 |
164 | public static void main(String[] args) {
165 | System.out.println(a);
166 | }
167 | }
168 | ```
169 |
170 |
171 |
172 | #### 解析(Resolve)
173 |
174 |
175 |
176 | 1. **将常量池内的符号引用转换为直接引用的过程**
177 |
178 | 2. 事实上,解析操作往往会伴随着JVM在执行完初始化之后再执行
179 |
180 | 3. 符号引用就是一组符号来描述所引用的目标。符号引用的字面量形式明确定义在《java虚拟机规范》的class文件格式中。直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄
181 |
182 | 4. 解析动作主要针对类或接口、字段、类方法、接口方法、方法类型等。对应常量池中的CONSTANT Class info、CONSTANT Fieldref info、CONSTANT Methodref info等
183 |
184 | **符号引用**
185 |
186 | * 反编译 class 文件后可以查看符号引用,下面带# 的就是符号引用
187 |
188 |  189 |
190 | ### 初始化阶段
191 |
192 | #### 类的初始化时机
193 |
194 | 1. 创建类的实例
195 | 2. 访问某个类或接口的静态变量,或者对该静态变量赋值
196 | 3. 调用类的静态方法
197 | 4. 反射(比如:Class.forName(“com.atguigu.Test”))
198 | 5. 初始化一个类的子类
199 | 6. Java虚拟机启动时被标明为启动类的类
200 | 7. JDK7开始提供的动态语言支持:java.lang.invoke.MethodHandle实例的解析结果REF_getStatic、REF putStatic、REF_invokeStatic句柄对应的类没有初始化,则初始化
201 |
202 | 除了以上七种情况,其他使用Java类的方式都被看作是对类的被动使用,都不会导致类的初始化,即不会执行初始化阶段(不会调用 clinit() 方法和 init() 方法)
203 |
204 |
205 |
206 | ### clinit()
207 |
208 | 1. 初始化阶段就是执行类构造器方法`
189 |
190 | ### 初始化阶段
191 |
192 | #### 类的初始化时机
193 |
194 | 1. 创建类的实例
195 | 2. 访问某个类或接口的静态变量,或者对该静态变量赋值
196 | 3. 调用类的静态方法
197 | 4. 反射(比如:Class.forName(“com.atguigu.Test”))
198 | 5. 初始化一个类的子类
199 | 6. Java虚拟机启动时被标明为启动类的类
200 | 7. JDK7开始提供的动态语言支持:java.lang.invoke.MethodHandle实例的解析结果REF_getStatic、REF putStatic、REF_invokeStatic句柄对应的类没有初始化,则初始化
201 |
202 | 除了以上七种情况,其他使用Java类的方式都被看作是对类的被动使用,都不会导致类的初始化,即不会执行初始化阶段(不会调用 clinit() 方法和 init() 方法)
203 |
204 |
205 |
206 | ### clinit()
207 |
208 | 1. 初始化阶段就是执行类构造器方法`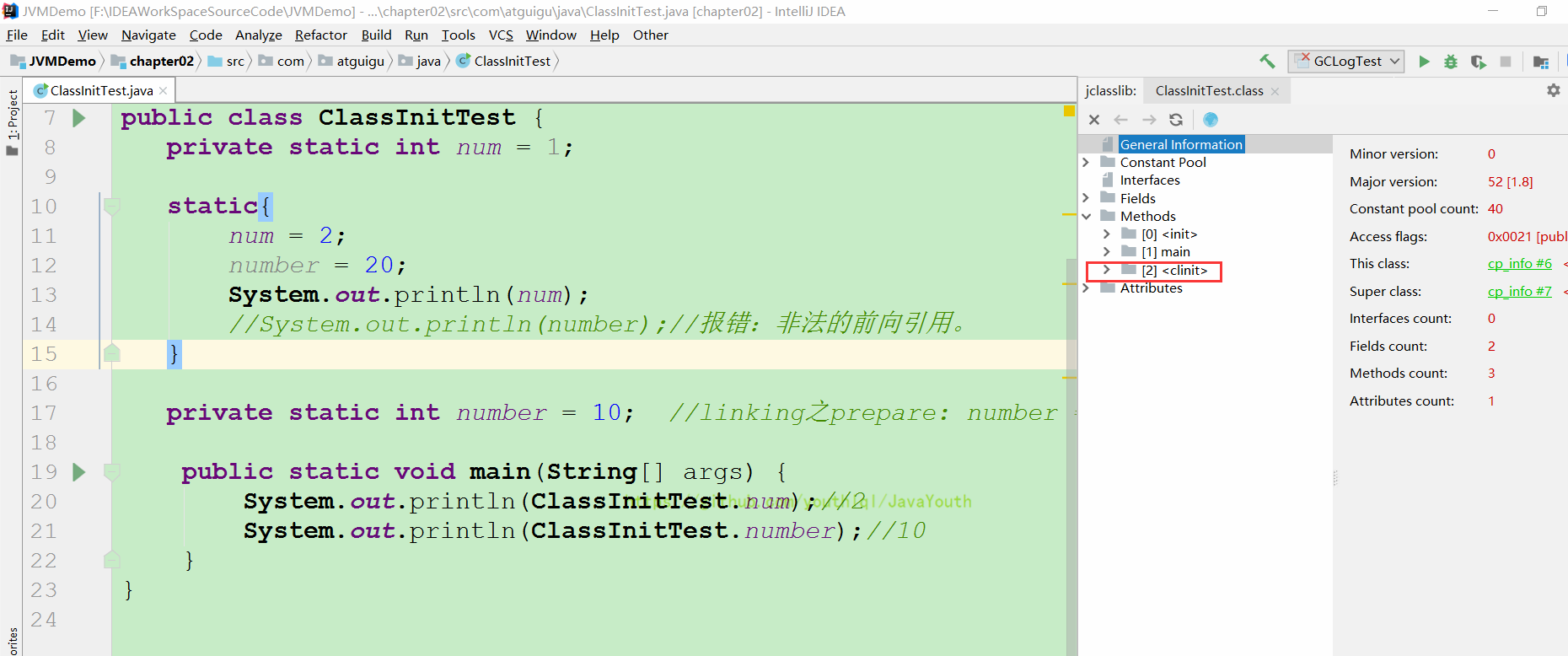 229 |
230 | ```java
231 | public class ClassInitTest {
232 | private static int num = 1;
233 |
234 | static{
235 | num = 2;
236 | number = 20;
237 | System.out.println(num);
238 | //System.out.println(number);//报错:非法的前向引用。
239 | }
240 |
241 | /**
242 | * 1、linking之prepare: number = 0 --> initial: 20 --> 10
243 | * 2、这里因为静态代码块出现在声明变量语句前面,所以之前被准备阶段为0的number变量会
244 | * 首先被初始化为20,再接着被初始化成10(这也是面试时常考的问题哦)
245 | *
246 | */
247 | private static int number = 10;
248 |
249 | public static void main(String[] args) {
250 | System.out.println(ClassInitTest.num);//2
251 | System.out.println(ClassInitTest.number);//10
252 | }
253 | }
254 |
255 | ```
256 |
257 |
229 |
230 | ```java
231 | public class ClassInitTest {
232 | private static int num = 1;
233 |
234 | static{
235 | num = 2;
236 | number = 20;
237 | System.out.println(num);
238 | //System.out.println(number);//报错:非法的前向引用。
239 | }
240 |
241 | /**
242 | * 1、linking之prepare: number = 0 --> initial: 20 --> 10
243 | * 2、这里因为静态代码块出现在声明变量语句前面,所以之前被准备阶段为0的number变量会
244 | * 首先被初始化为20,再接着被初始化成10(这也是面试时常考的问题哦)
245 | *
246 | */
247 | private static int number = 10;
248 |
249 | public static void main(String[] args) {
250 | System.out.println(ClassInitTest.num);//2
251 | System.out.println(ClassInitTest.number);//10
252 | }
253 | }
254 |
255 | ```
256 |
257 |  281 |
282 | 加上之后就有了
283 |
284 |
281 |
282 | 加上之后就有了
283 |
284 | 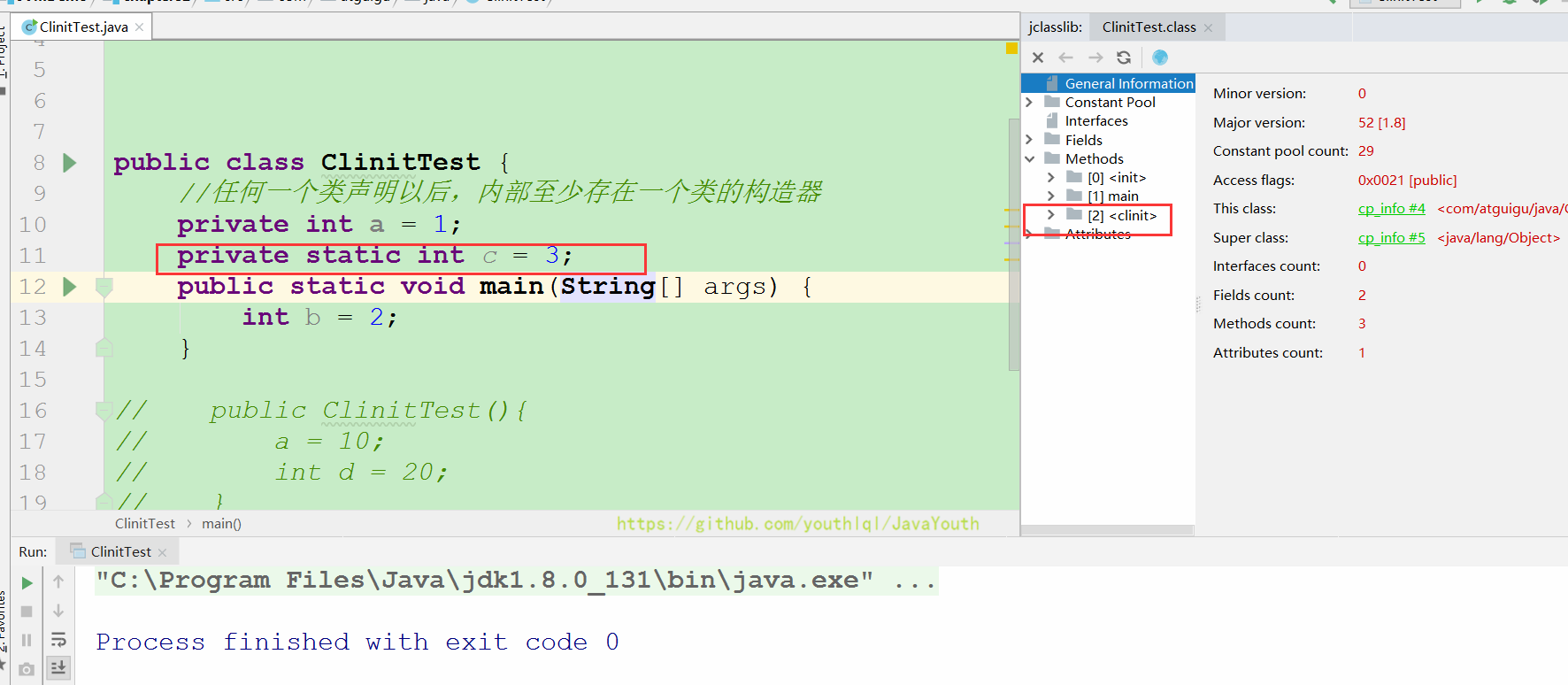 285 |
286 | #### 4说明
287 |
288 |
285 |
286 | #### 4说明
287 |
288 | 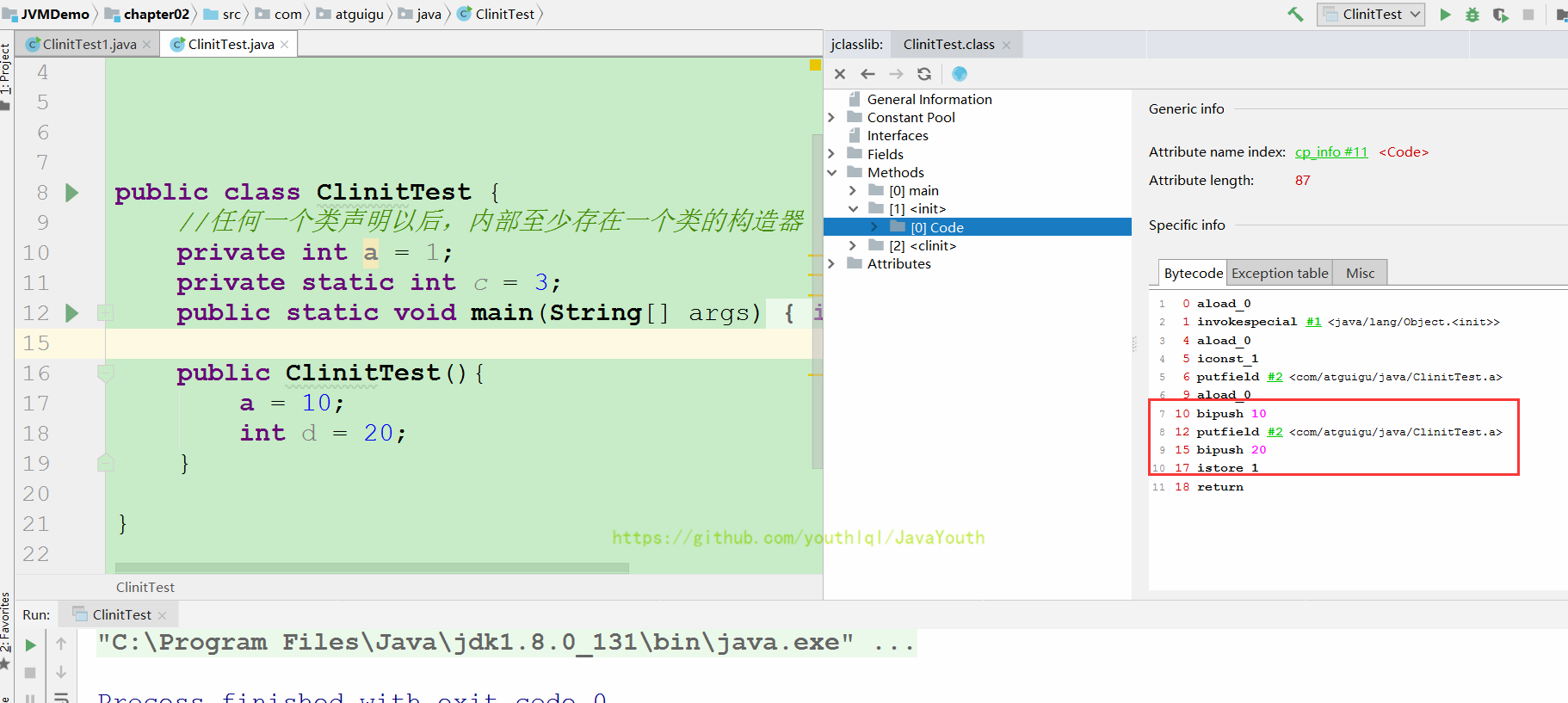 289 |
290 | 在构造器中:
291 |
292 | * 先将类变量 a 赋值为 10
293 | * 再将局部变量赋值为 20
294 |
295 | #### 5说明
296 |
297 | 若该类具有父类,JVM会保证子类的`
289 |
290 | 在构造器中:
291 |
292 | * 先将类变量 a 赋值为 10
293 | * 再将局部变量赋值为 20
294 |
295 | #### 5说明
296 |
297 | 若该类具有父类,JVM会保证子类的` 300 |
301 | 如上代码,加载流程如下:
302 |
303 | * 首先,执行 main() 方法需要加载 ClinitTest1 类
304 | * 获取 Son.B 静态变量,需要加载 Son 类
305 | * Son 类的父类是 Father 类,所以需要先执行 Father 类的加载,再执行 Son 类的加载
306 |
307 |
308 |
309 | #### 6说明
310 |
311 | 虚拟机必须保证一个类的`
300 |
301 | 如上代码,加载流程如下:
302 |
303 | * 首先,执行 main() 方法需要加载 ClinitTest1 类
304 | * 获取 Son.B 静态变量,需要加载 Son 类
305 | * Son 类的父类是 Father 类,所以需要先执行 Father 类的加载,再执行 Son 类的加载
306 |
307 |
308 |
309 | #### 6说明
310 |
311 | 虚拟机必须保证一个类的`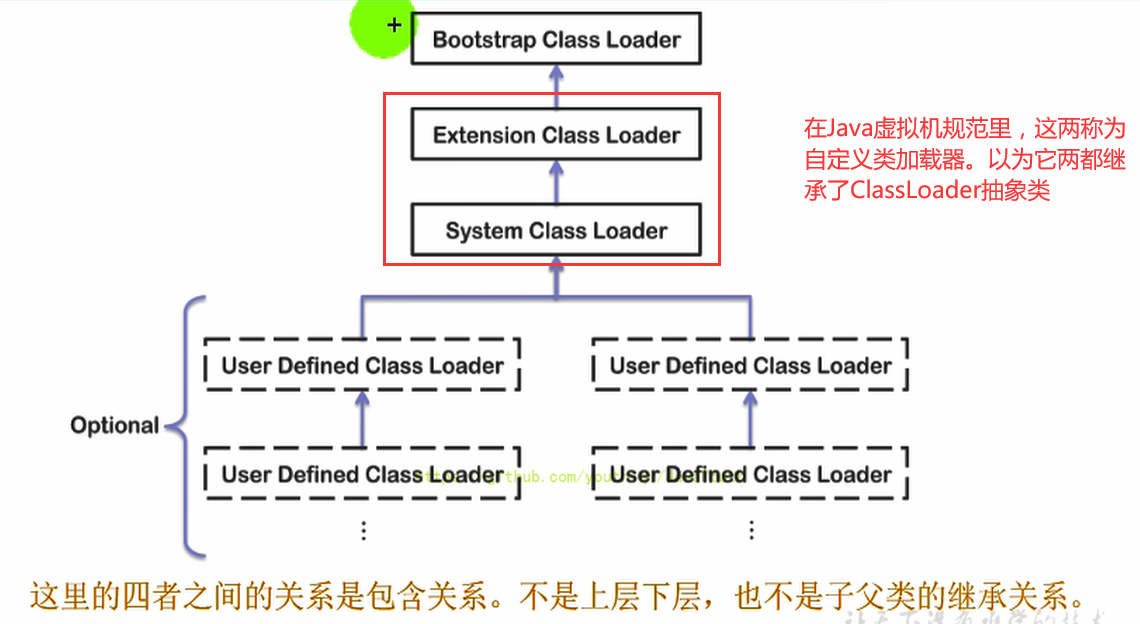 378 |
379 |
380 |
381 | **ExtClassLoader**
382 |
383 |
378 |
379 |
380 |
381 | **ExtClassLoader**
382 |
383 | 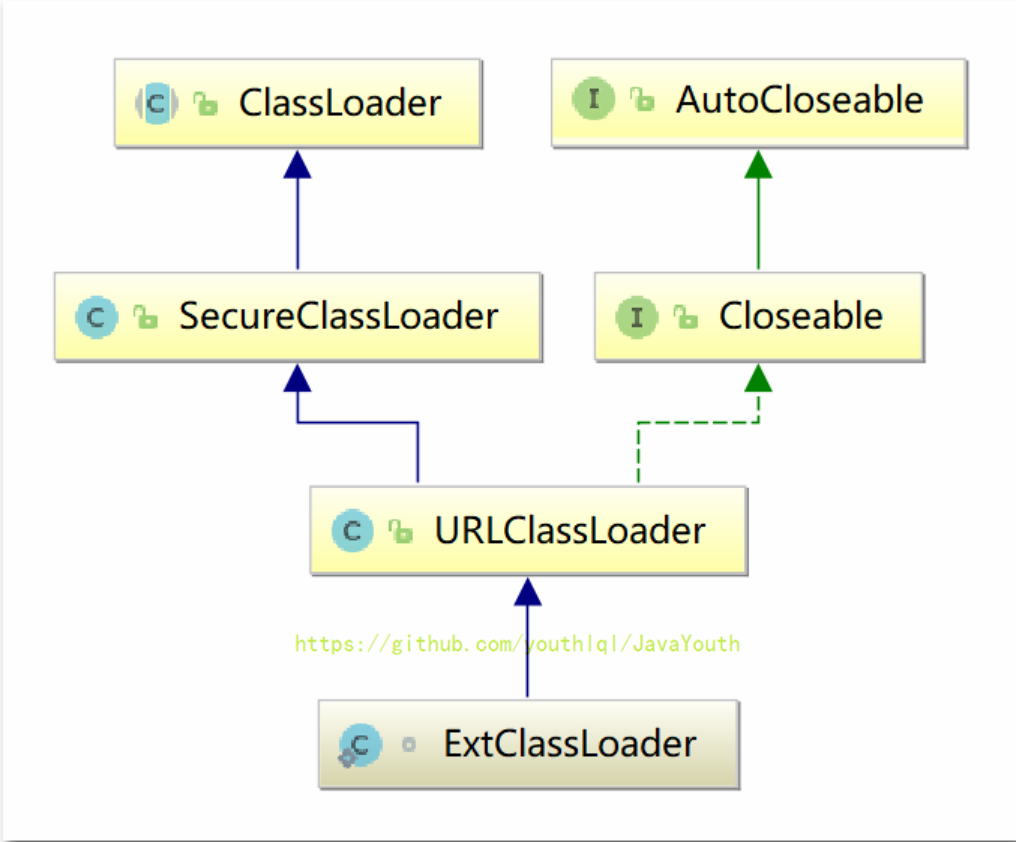 384 |
385 | **AppClassLoader**
386 |
387 |
384 |
385 | **AppClassLoader**
386 |
387 | 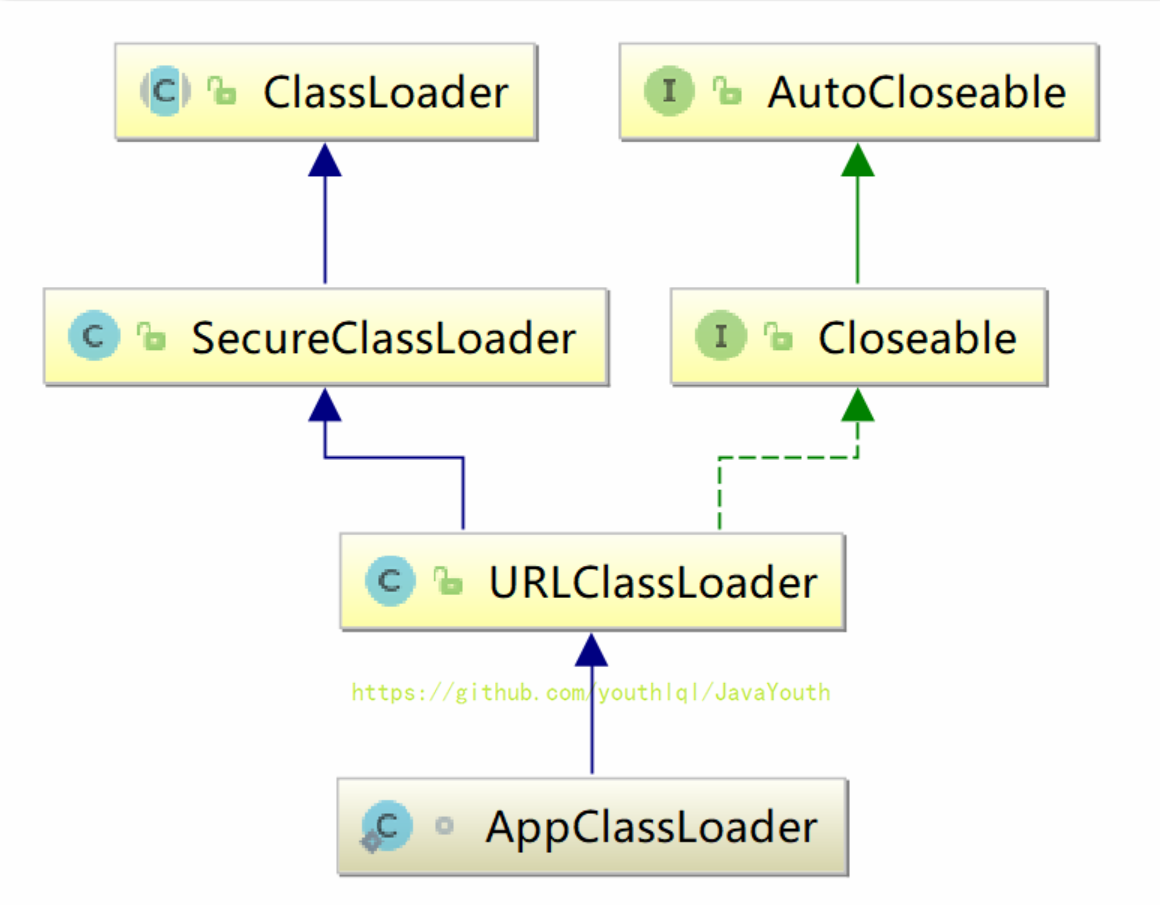 388 |
389 |
390 |
391 | ```java
392 | public class ClassLoaderTest {
393 | public static void main(String[] args) {
394 |
395 | //获取系统类加载器
396 | ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader();
397 | System.out.println(systemClassLoader);//sun.misc.Launcher$AppClassLoader@18b4aac2
398 |
399 | //获取其上层:扩展类加载器
400 | ClassLoader extClassLoader = systemClassLoader.getParent();
401 | System.out.println(extClassLoader);//sun.misc.Launcher$ExtClassLoader@1540e19d
402 |
403 | //获取其上层:获取不到引导类加载器
404 | ClassLoader bootstrapClassLoader = extClassLoader.getParent();
405 | System.out.println(bootstrapClassLoader);//null
406 |
407 | //对于用户自定义类来说:默认使用系统类加载器进行加载
408 | ClassLoader classLoader = ClassLoaderTest.class.getClassLoader();
409 | System.out.println(classLoader);//sun.misc.Launcher$AppClassLoader@18b4aac2
410 |
411 | //String类使用引导类加载器进行加载的。---> Java的核心类库都是使用引导类加载器进行加载的。
412 | ClassLoader classLoader1 = String.class.getClassLoader();
413 | System.out.println(classLoader1);//null
414 |
415 |
416 | }
417 | }
418 | ```
419 |
420 |
421 |
422 | * 我们尝试获取引导类加载器,获取到的值为 null ,这并不代表引导类加载器不存在,**因为引导类加载器右 C/C++ 语言,我们获取不到**
423 | * 两次获取系统类加载器的值都相同:sun.misc.Launcher$AppClassLoader@18b4aac2 ,这说明**系统类加载器是全局唯一的**
424 |
425 |
426 |
427 | ### 虚拟机自带的加载器
428 |
429 | #### 启动类加载器
430 |
431 | > **启动类加载器(引导类加载器,Bootstrap ClassLoader)**
432 |
433 | 1. 这个类加载使用C/C++语言实现的,嵌套在JVM内部
434 | 2. 它用来加载Java的核心库(JAVA_HOME/jre/lib/rt.jar、resources.jar或sun.boot.class.path路径下的内容),用于提供JVM自身需要的类
435 | 3. 并不继承自java.lang.ClassLoader,没有父加载器
436 | 4. 加载扩展类和应用程序类加载器,并作为他们的父类加载器
437 | 5. 出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类
438 |
439 |
440 |
441 | #### 扩展类加载器
442 |
443 | > **扩展类加载器(Extension ClassLoader)**
444 |
445 | 1. Java语言编写,由sun.misc.Launcher$ExtClassLoader实现
446 | 2. 派生于ClassLoader类
447 | 3. 父类加载器为启动类加载器
448 | 4. 从java.ext.dirs系统属性所指定的目录中加载类库,或从JDK的安装目录的jre/lib/ext子目录(扩展目录)下加载类库。如果用户创建的JAR放在此目录下,也会自动由扩展类加载器加载
449 |
450 |
451 |
452 | #### 系统类加载器
453 |
454 | > **应用程序类加载器(也称为系统类加载器,AppClassLoader)**
455 |
456 | 1. Java语言编写,由sun.misc.LaunchersAppClassLoader实现
457 | 2. 派生于ClassLoader类
458 | 3. 父类加载器为扩展类加载器
459 | 4. 它负责加载环境变量classpath或系统属性java.class.path指定路径下的类库
460 | 5. 该类加载是程序中默认的类加载器,一般来说,Java应用的类都是由它来完成加载
461 | 6. 通过classLoader.getSystemclassLoader()方法可以获取到该类加载器
462 |
463 |
464 |
465 | ```java
466 | public class ClassLoaderTest1 {
467 | public static void main(String[] args) {
468 | System.out.println("**********启动类加载器**************");
469 | //获取BootstrapClassLoader能够加载的api的路径
470 | URL[] urLs = sun.misc.Launcher.getBootstrapClassPath().getURLs();
471 | for (URL element : urLs) {
472 | System.out.println(element.toExternalForm());
473 | }
474 | //从上面的路径中随意选择一个类,来看看他的类加载器是什么:引导类加载器
475 | ClassLoader classLoader = Provider.class.getClassLoader();
476 | System.out.println(classLoader);
477 |
478 | System.out.println("***********扩展类加载器*************");
479 | String extDirs = System.getProperty("java.ext.dirs");
480 | for (String path : extDirs.split(";")) {
481 | System.out.println(path);
482 | }
483 |
484 | //从上面的路径中随意选择一个类,来看看他的类加载器是什么:扩展类加载器
485 | ClassLoader classLoader1 = CurveDB.class.getClassLoader();
486 | System.out.println(classLoader1);//sun.misc.Launcher$ExtClassLoader@1540e19d
487 |
488 | }
489 | }
490 |
491 | ```
492 |
493 |
494 |
495 | **输出结果**
496 |
497 | ```java
498 | **********启动类加载器**************
499 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/resources.jar
500 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/rt.jar
501 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/sunrsasign.jar
502 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/jsse.jar
503 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/jce.jar
504 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/charsets.jar
505 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/jfr.jar
506 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/classes
507 | null
508 | ***********扩展类加载器*************
509 | C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext
510 | C:\Windows\Sun\Java\lib\ext
511 | sun.misc.Launcher$ExtClassLoader@29453f44
512 | ```
513 |
514 |
515 |
516 | ### 用户自定义类加载器
517 |
518 | #### 什么时候需要自定义类加载器?
519 |
520 | 在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,来定制类的加载方式。那为什么还需要自定义类加载器?
521 |
522 | 1. 隔离加载类(比如说我假设现在Spring框架,和RocketMQ有包名路径完全一样的类,类名也一样,这个时候类就冲突了。不过一般的主流框架和中间件都会自定义类加载器,实现不同的框架,中间价之间是隔离的)
523 | 2. 修改类加载的方式
524 | 3. 扩展加载源(还可以考虑从数据库中加载类,路由器等等不同的地方)
525 | 4. 防止源码泄漏(对字节码文件进行解密,自己用的时候通过自定义类加载器来对其进行解密)
526 |
527 | #### 如何自定义类加载器?
528 |
529 | 1. 开发人员可以通过继承抽象类java.lang.ClassLoader类的方式,实现自己的类加载器,以满足一些特殊的需求
530 | 2. 在JDK1.2之前,在自定义类加载器时,总会去继承ClassLoader类并重写loadClass()方法,从而实现自定义的类加载类,但是在JDK1.2之后已不再建议用户去覆盖loadClass()方法,而是建议把自定义的类加载逻辑写在findclass()方法中
531 | 3. 在编写自定义类加载器时,如果没有太过于复杂的需求,可以直接继承URIClassLoader类,这样就可以避免自己去编写findclass()方法及其获取字节码流的方式,使自定义类加载器编写更加简洁。
532 |
533 | **代码示例**
534 |
535 | ```java
536 | public class CustomClassLoader extends ClassLoader {
537 | @Override
538 | protected Class findClass(String name) throws ClassNotFoundException {
539 |
540 | try {
541 | byte[] result = getClassFromCustomPath(name);
542 | if (result == null) {
543 | throw new FileNotFoundException();
544 | } else {
545 | //defineClass和findClass搭配使用
546 | return defineClass(name, result, 0, result.length);
547 | }
548 | } catch (FileNotFoundException e) {
549 | e.printStackTrace();
550 | }
551 |
552 | throw new ClassNotFoundException(name);
553 | }
554 | //自定义流的获取方式
555 | private byte[] getClassFromCustomPath(String name) {
556 | //从自定义路径中加载指定类:细节略
557 | //如果指定路径的字节码文件进行了加密,则需要在此方法中进行解密操作。
558 | return null;
559 | }
560 |
561 | public static void main(String[] args) {
562 | CustomClassLoader customClassLoader = new CustomClassLoader();
563 | try {
564 | Class clazz = Class.forName("One", true, customClassLoader);
565 | Object obj = clazz.newInstance();
566 | System.out.println(obj.getClass().getClassLoader());
567 | } catch (Exception e) {
568 | e.printStackTrace();
569 | }
570 | }
571 | }
572 | ```
573 |
574 |
575 |
576 | ### 关于ClassLoader
577 |
578 | > **ClassLoader 类介绍**
579 |
580 | ClassLoader类,它是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器)
581 |
582 |
388 |
389 |
390 |
391 | ```java
392 | public class ClassLoaderTest {
393 | public static void main(String[] args) {
394 |
395 | //获取系统类加载器
396 | ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader();
397 | System.out.println(systemClassLoader);//sun.misc.Launcher$AppClassLoader@18b4aac2
398 |
399 | //获取其上层:扩展类加载器
400 | ClassLoader extClassLoader = systemClassLoader.getParent();
401 | System.out.println(extClassLoader);//sun.misc.Launcher$ExtClassLoader@1540e19d
402 |
403 | //获取其上层:获取不到引导类加载器
404 | ClassLoader bootstrapClassLoader = extClassLoader.getParent();
405 | System.out.println(bootstrapClassLoader);//null
406 |
407 | //对于用户自定义类来说:默认使用系统类加载器进行加载
408 | ClassLoader classLoader = ClassLoaderTest.class.getClassLoader();
409 | System.out.println(classLoader);//sun.misc.Launcher$AppClassLoader@18b4aac2
410 |
411 | //String类使用引导类加载器进行加载的。---> Java的核心类库都是使用引导类加载器进行加载的。
412 | ClassLoader classLoader1 = String.class.getClassLoader();
413 | System.out.println(classLoader1);//null
414 |
415 |
416 | }
417 | }
418 | ```
419 |
420 |
421 |
422 | * 我们尝试获取引导类加载器,获取到的值为 null ,这并不代表引导类加载器不存在,**因为引导类加载器右 C/C++ 语言,我们获取不到**
423 | * 两次获取系统类加载器的值都相同:sun.misc.Launcher$AppClassLoader@18b4aac2 ,这说明**系统类加载器是全局唯一的**
424 |
425 |
426 |
427 | ### 虚拟机自带的加载器
428 |
429 | #### 启动类加载器
430 |
431 | > **启动类加载器(引导类加载器,Bootstrap ClassLoader)**
432 |
433 | 1. 这个类加载使用C/C++语言实现的,嵌套在JVM内部
434 | 2. 它用来加载Java的核心库(JAVA_HOME/jre/lib/rt.jar、resources.jar或sun.boot.class.path路径下的内容),用于提供JVM自身需要的类
435 | 3. 并不继承自java.lang.ClassLoader,没有父加载器
436 | 4. 加载扩展类和应用程序类加载器,并作为他们的父类加载器
437 | 5. 出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类
438 |
439 |
440 |
441 | #### 扩展类加载器
442 |
443 | > **扩展类加载器(Extension ClassLoader)**
444 |
445 | 1. Java语言编写,由sun.misc.Launcher$ExtClassLoader实现
446 | 2. 派生于ClassLoader类
447 | 3. 父类加载器为启动类加载器
448 | 4. 从java.ext.dirs系统属性所指定的目录中加载类库,或从JDK的安装目录的jre/lib/ext子目录(扩展目录)下加载类库。如果用户创建的JAR放在此目录下,也会自动由扩展类加载器加载
449 |
450 |
451 |
452 | #### 系统类加载器
453 |
454 | > **应用程序类加载器(也称为系统类加载器,AppClassLoader)**
455 |
456 | 1. Java语言编写,由sun.misc.LaunchersAppClassLoader实现
457 | 2. 派生于ClassLoader类
458 | 3. 父类加载器为扩展类加载器
459 | 4. 它负责加载环境变量classpath或系统属性java.class.path指定路径下的类库
460 | 5. 该类加载是程序中默认的类加载器,一般来说,Java应用的类都是由它来完成加载
461 | 6. 通过classLoader.getSystemclassLoader()方法可以获取到该类加载器
462 |
463 |
464 |
465 | ```java
466 | public class ClassLoaderTest1 {
467 | public static void main(String[] args) {
468 | System.out.println("**********启动类加载器**************");
469 | //获取BootstrapClassLoader能够加载的api的路径
470 | URL[] urLs = sun.misc.Launcher.getBootstrapClassPath().getURLs();
471 | for (URL element : urLs) {
472 | System.out.println(element.toExternalForm());
473 | }
474 | //从上面的路径中随意选择一个类,来看看他的类加载器是什么:引导类加载器
475 | ClassLoader classLoader = Provider.class.getClassLoader();
476 | System.out.println(classLoader);
477 |
478 | System.out.println("***********扩展类加载器*************");
479 | String extDirs = System.getProperty("java.ext.dirs");
480 | for (String path : extDirs.split(";")) {
481 | System.out.println(path);
482 | }
483 |
484 | //从上面的路径中随意选择一个类,来看看他的类加载器是什么:扩展类加载器
485 | ClassLoader classLoader1 = CurveDB.class.getClassLoader();
486 | System.out.println(classLoader1);//sun.misc.Launcher$ExtClassLoader@1540e19d
487 |
488 | }
489 | }
490 |
491 | ```
492 |
493 |
494 |
495 | **输出结果**
496 |
497 | ```java
498 | **********启动类加载器**************
499 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/resources.jar
500 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/rt.jar
501 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/sunrsasign.jar
502 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/jsse.jar
503 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/jce.jar
504 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/charsets.jar
505 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/lib/jfr.jar
506 | file:/C:/Program%20Files/Java/jdk1.8.0_131/jre/classes
507 | null
508 | ***********扩展类加载器*************
509 | C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext
510 | C:\Windows\Sun\Java\lib\ext
511 | sun.misc.Launcher$ExtClassLoader@29453f44
512 | ```
513 |
514 |
515 |
516 | ### 用户自定义类加载器
517 |
518 | #### 什么时候需要自定义类加载器?
519 |
520 | 在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,来定制类的加载方式。那为什么还需要自定义类加载器?
521 |
522 | 1. 隔离加载类(比如说我假设现在Spring框架,和RocketMQ有包名路径完全一样的类,类名也一样,这个时候类就冲突了。不过一般的主流框架和中间件都会自定义类加载器,实现不同的框架,中间价之间是隔离的)
523 | 2. 修改类加载的方式
524 | 3. 扩展加载源(还可以考虑从数据库中加载类,路由器等等不同的地方)
525 | 4. 防止源码泄漏(对字节码文件进行解密,自己用的时候通过自定义类加载器来对其进行解密)
526 |
527 | #### 如何自定义类加载器?
528 |
529 | 1. 开发人员可以通过继承抽象类java.lang.ClassLoader类的方式,实现自己的类加载器,以满足一些特殊的需求
530 | 2. 在JDK1.2之前,在自定义类加载器时,总会去继承ClassLoader类并重写loadClass()方法,从而实现自定义的类加载类,但是在JDK1.2之后已不再建议用户去覆盖loadClass()方法,而是建议把自定义的类加载逻辑写在findclass()方法中
531 | 3. 在编写自定义类加载器时,如果没有太过于复杂的需求,可以直接继承URIClassLoader类,这样就可以避免自己去编写findclass()方法及其获取字节码流的方式,使自定义类加载器编写更加简洁。
532 |
533 | **代码示例**
534 |
535 | ```java
536 | public class CustomClassLoader extends ClassLoader {
537 | @Override
538 | protected Class findClass(String name) throws ClassNotFoundException {
539 |
540 | try {
541 | byte[] result = getClassFromCustomPath(name);
542 | if (result == null) {
543 | throw new FileNotFoundException();
544 | } else {
545 | //defineClass和findClass搭配使用
546 | return defineClass(name, result, 0, result.length);
547 | }
548 | } catch (FileNotFoundException e) {
549 | e.printStackTrace();
550 | }
551 |
552 | throw new ClassNotFoundException(name);
553 | }
554 | //自定义流的获取方式
555 | private byte[] getClassFromCustomPath(String name) {
556 | //从自定义路径中加载指定类:细节略
557 | //如果指定路径的字节码文件进行了加密,则需要在此方法中进行解密操作。
558 | return null;
559 | }
560 |
561 | public static void main(String[] args) {
562 | CustomClassLoader customClassLoader = new CustomClassLoader();
563 | try {
564 | Class clazz = Class.forName("One", true, customClassLoader);
565 | Object obj = clazz.newInstance();
566 | System.out.println(obj.getClass().getClassLoader());
567 | } catch (Exception e) {
568 | e.printStackTrace();
569 | }
570 | }
571 | }
572 | ```
573 |
574 |
575 |
576 | ### 关于ClassLoader
577 |
578 | > **ClassLoader 类介绍**
579 |
580 | ClassLoader类,它是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器)
581 |
582 | 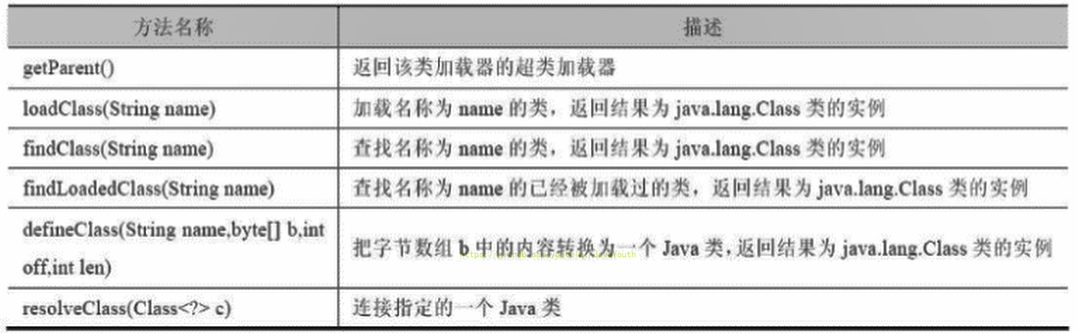 583 |
584 | sun.misc.Launcher 它是一个java虚拟机的入口应用
585 |
586 |
583 |
584 | sun.misc.Launcher 它是一个java虚拟机的入口应用
585 |
586 | 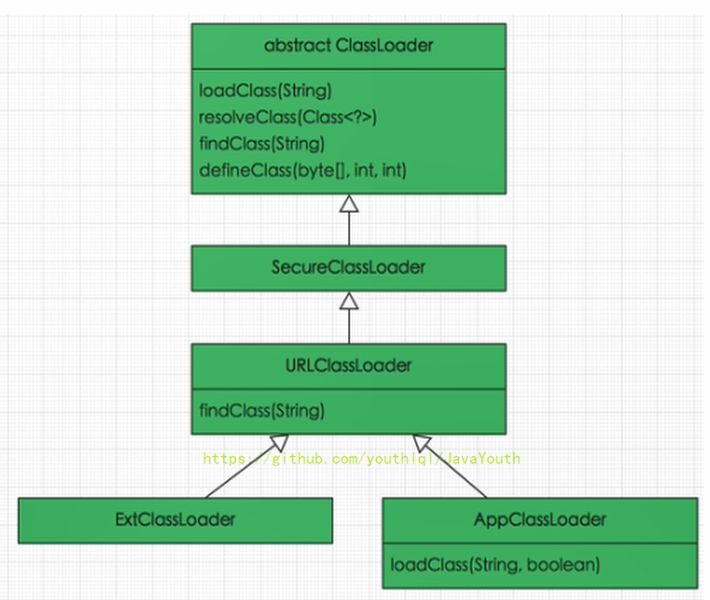 587 |
588 | #### 获取ClassLoader途径
589 |
590 |
587 |
588 | #### 获取ClassLoader途径
589 |
590 |  591 |
592 |
593 |
594 | ```java
595 | public class ClassLoaderTest2 {
596 | public static void main(String[] args) {
597 | try {
598 | //1.
599 | ClassLoader classLoader = Class.forName("java.lang.String").getClassLoader();
600 | System.out.println(classLoader);
601 | //2.
602 | ClassLoader classLoader1 = Thread.currentThread().getContextClassLoader();
603 | System.out.println(classLoader1);
604 |
605 | //3.
606 | ClassLoader classLoader2 = ClassLoader.getSystemClassLoader().getParent();
607 | System.out.println(classLoader2);
608 |
609 | } catch (ClassNotFoundException e) {
610 | e.printStackTrace();
611 | }
612 | }
613 | }
614 |
615 | ```
616 |
617 | 输出结果:
618 |
619 | ```
620 | null
621 | sun.misc.Launcher$AppClassLoader@18b4aac2
622 | sun.misc.Launcher$ExtClassLoader@1540e19d
623 |
624 | Process finished with exit code 0
625 | ```
626 |
627 |
628 |
629 | 双亲委派机制
630 | --------
631 |
632 | ### 双亲委派机制原理
633 |
634 |
635 |
636 | Java虚拟机对class文件采用的是**按需加载**的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成class对象。而且加载某个类的class文件时,Java虚拟机采用的是双亲委派模式,即把请求交由父类处理,它是一种任务委派模式
637 |
638 | 1. 如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行;
639 | 2. 如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器;
640 | 3. 如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
641 | 4. 父类加载器一层一层往下分配任务,如果子类加载器能加载,则加载此类,如果将加载任务分配至系统类加载器也无法加载此类,则抛出异常
642 |
643 |
591 |
592 |
593 |
594 | ```java
595 | public class ClassLoaderTest2 {
596 | public static void main(String[] args) {
597 | try {
598 | //1.
599 | ClassLoader classLoader = Class.forName("java.lang.String").getClassLoader();
600 | System.out.println(classLoader);
601 | //2.
602 | ClassLoader classLoader1 = Thread.currentThread().getContextClassLoader();
603 | System.out.println(classLoader1);
604 |
605 | //3.
606 | ClassLoader classLoader2 = ClassLoader.getSystemClassLoader().getParent();
607 | System.out.println(classLoader2);
608 |
609 | } catch (ClassNotFoundException e) {
610 | e.printStackTrace();
611 | }
612 | }
613 | }
614 |
615 | ```
616 |
617 | 输出结果:
618 |
619 | ```
620 | null
621 | sun.misc.Launcher$AppClassLoader@18b4aac2
622 | sun.misc.Launcher$ExtClassLoader@1540e19d
623 |
624 | Process finished with exit code 0
625 | ```
626 |
627 |
628 |
629 | 双亲委派机制
630 | --------
631 |
632 | ### 双亲委派机制原理
633 |
634 |
635 |
636 | Java虚拟机对class文件采用的是**按需加载**的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成class对象。而且加载某个类的class文件时,Java虚拟机采用的是双亲委派模式,即把请求交由父类处理,它是一种任务委派模式
637 |
638 | 1. 如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行;
639 | 2. 如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器;
640 | 3. 如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
641 | 4. 父类加载器一层一层往下分配任务,如果子类加载器能加载,则加载此类,如果将加载任务分配至系统类加载器也无法加载此类,则抛出异常
642 |
643 |  644 |
645 | ### 双亲委派机制代码演示
646 |
647 |
648 |
649 | #### 举例1
650 |
651 | 1、我们自己建立一个 java.lang.String 类,写上 static 代码块
652 |
653 | ```java
654 | public class String {
655 | //
656 | static{
657 | System.out.println("我是自定义的String类的静态代码块");
658 | }
659 | }
660 | ```
661 |
662 |
663 |
664 | 2、在另外的程序中加载 String 类,看看加载的 String 类是 JDK 自带的 String 类,还是我们自己编写的 String 类
665 |
666 | ```java
667 | public class StringTest {
668 |
669 | public static void main(String[] args) {
670 | java.lang.String str = new java.lang.String();
671 | System.out.println("hello,atguigu.com");
672 |
673 | StringTest test = new StringTest();
674 | System.out.println(test.getClass().getClassLoader());
675 | }
676 | }
677 | ```
678 |
679 | 输出结果:
680 |
681 | ```
682 | hello,atguigu.com
683 | sun.misc.Launcher$AppClassLoader@18b4aac2
684 | ```
685 |
686 |
687 |
688 | 程序并没有输出我们静态代码块中的内容,可见仍然加载的是 JDK 自带的 String 类。
689 |
690 |
691 |
692 |
693 |
694 | 把刚刚的类改一下
695 |
696 | ```java
697 | package java.lang;
698 | public class String {
699 | //
700 | static{
701 | System.out.println("我是自定义的String类的静态代码块");
702 | }
703 | //错误: 在类 java.lang.String 中找不到 main 方法
704 | public static void main(String[] args) {
705 | System.out.println("hello,String");
706 | }
707 | }
708 | ```
709 |
710 |
644 |
645 | ### 双亲委派机制代码演示
646 |
647 |
648 |
649 | #### 举例1
650 |
651 | 1、我们自己建立一个 java.lang.String 类,写上 static 代码块
652 |
653 | ```java
654 | public class String {
655 | //
656 | static{
657 | System.out.println("我是自定义的String类的静态代码块");
658 | }
659 | }
660 | ```
661 |
662 |
663 |
664 | 2、在另外的程序中加载 String 类,看看加载的 String 类是 JDK 自带的 String 类,还是我们自己编写的 String 类
665 |
666 | ```java
667 | public class StringTest {
668 |
669 | public static void main(String[] args) {
670 | java.lang.String str = new java.lang.String();
671 | System.out.println("hello,atguigu.com");
672 |
673 | StringTest test = new StringTest();
674 | System.out.println(test.getClass().getClassLoader());
675 | }
676 | }
677 | ```
678 |
679 | 输出结果:
680 |
681 | ```
682 | hello,atguigu.com
683 | sun.misc.Launcher$AppClassLoader@18b4aac2
684 | ```
685 |
686 |
687 |
688 | 程序并没有输出我们静态代码块中的内容,可见仍然加载的是 JDK 自带的 String 类。
689 |
690 |
691 |
692 |
693 |
694 | 把刚刚的类改一下
695 |
696 | ```java
697 | package java.lang;
698 | public class String {
699 | //
700 | static{
701 | System.out.println("我是自定义的String类的静态代码块");
702 | }
703 | //错误: 在类 java.lang.String 中找不到 main 方法
704 | public static void main(String[] args) {
705 | System.out.println("hello,String");
706 | }
707 | }
708 | ```
709 |
710 |  711 |
712 | 由于双亲委派机制一直找父类,所以最后找到了Bootstrap ClassLoader,Bootstrap ClassLoader找到的是 JDK 自带的 String 类,在那个String类中并没有 main() 方法,所以就报了上面的错误。
713 |
714 |
715 |
716 | #### 举例2
717 |
718 | ```java
719 | package java.lang;
720 |
721 |
722 | public class ShkStart {
723 |
724 | public static void main(String[] args) {
725 | System.out.println("hello!");
726 | }
727 | }
728 | ```
729 |
730 | 输出结果:
731 |
732 | ```java
733 | java.lang.SecurityException: Prohibited package name: java.lang
734 | at java.lang.ClassLoader.preDefineClass(ClassLoader.java:662)
735 | at java.lang.ClassLoader.defineClass(ClassLoader.java:761)
736 | at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
737 | at java.net.URLClassLoader.defineClass(URLClassLoader.java:467)
738 | at java.net.URLClassLoader.access$100(URLClassLoader.java:73)
739 | at java.net.URLClassLoader$1.run(URLClassLoader.java:368)
740 | at java.net.URLClassLoader$1.run(URLClassLoader.java:362)
741 | at java.security.AccessController.doPrivileged(Native Method)
742 | at java.net.URLClassLoader.findClass(URLClassLoader.java:361)
743 | at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
744 | at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
745 | at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
746 | at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:495)
747 | Error: A JNI error has occurred, please check your installation and try again
748 | Exception in thread "main"
749 | Process finished with exit code 1
750 | ```
751 |
752 | 即使类名没有重复,也禁止使用java.lang这种包名。这是一种保护机制
753 |
754 |
755 |
756 | #### 举例3
757 |
758 | 当我们加载jdbc.jar 用于实现数据库连接的时候
759 |
760 | 1. 我们现在程序中需要用到SPI接口,而SPI接口属于rt.jar包中Java核心api
761 | 2. 然后使用双清委派机制,引导类加载器把rt.jar包加载进来,而rt.jar包中的SPI存在一些接口,接口我们就需要具体的实现类了
762 | 3. 具体的实现类就涉及到了某些第三方的jar包了,比如我们加载SPI的实现类jdbc.jar包【首先我们需要知道的是 jdbc.jar是基于SPI接口进行实现的】
763 | 4. 第三方的jar包中的类属于系统类加载器来加载
764 | 5. 从这里面就可以看到SPI核心接口由引导类加载器来加载,SPI具体实现类由系统类加载器来加载
765 |
766 |
767 |
768 |
711 |
712 | 由于双亲委派机制一直找父类,所以最后找到了Bootstrap ClassLoader,Bootstrap ClassLoader找到的是 JDK 自带的 String 类,在那个String类中并没有 main() 方法,所以就报了上面的错误。
713 |
714 |
715 |
716 | #### 举例2
717 |
718 | ```java
719 | package java.lang;
720 |
721 |
722 | public class ShkStart {
723 |
724 | public static void main(String[] args) {
725 | System.out.println("hello!");
726 | }
727 | }
728 | ```
729 |
730 | 输出结果:
731 |
732 | ```java
733 | java.lang.SecurityException: Prohibited package name: java.lang
734 | at java.lang.ClassLoader.preDefineClass(ClassLoader.java:662)
735 | at java.lang.ClassLoader.defineClass(ClassLoader.java:761)
736 | at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
737 | at java.net.URLClassLoader.defineClass(URLClassLoader.java:467)
738 | at java.net.URLClassLoader.access$100(URLClassLoader.java:73)
739 | at java.net.URLClassLoader$1.run(URLClassLoader.java:368)
740 | at java.net.URLClassLoader$1.run(URLClassLoader.java:362)
741 | at java.security.AccessController.doPrivileged(Native Method)
742 | at java.net.URLClassLoader.findClass(URLClassLoader.java:361)
743 | at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
744 | at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
745 | at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
746 | at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:495)
747 | Error: A JNI error has occurred, please check your installation and try again
748 | Exception in thread "main"
749 | Process finished with exit code 1
750 | ```
751 |
752 | 即使类名没有重复,也禁止使用java.lang这种包名。这是一种保护机制
753 |
754 |
755 |
756 | #### 举例3
757 |
758 | 当我们加载jdbc.jar 用于实现数据库连接的时候
759 |
760 | 1. 我们现在程序中需要用到SPI接口,而SPI接口属于rt.jar包中Java核心api
761 | 2. 然后使用双清委派机制,引导类加载器把rt.jar包加载进来,而rt.jar包中的SPI存在一些接口,接口我们就需要具体的实现类了
762 | 3. 具体的实现类就涉及到了某些第三方的jar包了,比如我们加载SPI的实现类jdbc.jar包【首先我们需要知道的是 jdbc.jar是基于SPI接口进行实现的】
763 | 4. 第三方的jar包中的类属于系统类加载器来加载
764 | 5. 从这里面就可以看到SPI核心接口由引导类加载器来加载,SPI具体实现类由系统类加载器来加载
765 |
766 |
767 |
768 | 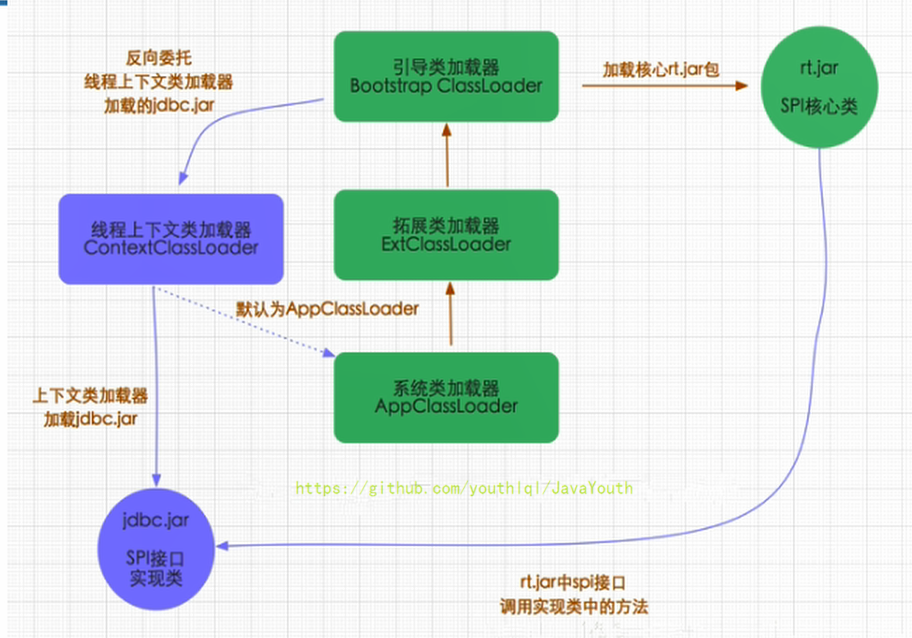 769 |
770 |
771 |
772 | ### 双亲委派机制优势
773 |
774 |
775 |
776 | 通过上面的例子,我们可以知道,双亲机制可以
777 |
778 | 1. 避免类的重复加载
779 |
780 | 2. 保护程序安全,防止核心API被随意篡改
781 |
782 | - 自定义类:自定义java.lang.String 没有被加载。
783 | - 自定义类:java.lang.ShkStart(报错:阻止创建 java.lang开头的类)
784 |
785 |
786 |
787 | 沙箱安全机制
788 | --------
789 |
790 |
791 |
792 | 1. 自定义String类时:在加载自定义String类的时候会率先使用引导类加载器加载,而引导类加载器在加载的过程中会先加载jdk自带的文件(rt.jar包中java.lang.String.class),报错信息说没有main方法,就是因为加载的是rt.jar包中的String类。
793 | 2. 这样可以保证对java核心源代码的保护,这就是沙箱安全机制。
794 |
795 |
796 |
797 | 其他
798 | ----
799 |
800 | ### 如何判断两个class对象是否相同?
801 |
802 | 在JVM中表示两个class对象是否为同一个类存在两个必要条件:
803 |
804 | 1. 类的完整类名必须一致,包括包名
805 | 2. **加载这个类的ClassLoader(指ClassLoader实例对象)必须相同**
806 | 3. 换句话说,在JVM中,即使这两个类对象(class对象)来源同一个Class文件,被同一个虚拟机所加载,但只要加载它们的ClassLoader实例对象不同,那么这两个类对象也是不相等的
807 |
808 |
809 |
810 | ### 对类加载器的引用
811 |
812 | 1. JVM必须知道一个类型是由启动加载器加载的还是由用户类加载器加载的
813 | 2. **如果一个类型是由用户类加载器加载的,那么JVM会将这个类加载器的一个引用作为类型信息的一部分保存在方法区中**
814 | 3. 当解析一个类型到另一个类型的引用的时候,JVM需要保证这两个类型的类加载器是相同的(后面讲)
815 |
816 |
817 |
818 |
--------------------------------------------------------------------------------
/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 'Java并发体系-第二阶段-锁与同步-[1]'
3 | tags:
4 | - Java并发
5 | - 原理
6 | - 源码
7 | categories:
8 | - Java并发
9 | - 原理
10 | keywords: Java并发,原理,源码
11 | description: '万字系列长文讲解-Java并发体系-第二阶段,从C++和硬件方面讲解。'
12 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/Java_concurrency.png'
13 | abbrlink: 230c5bb3
14 | date: 2020-10-06 22:09:58
15 | ---
16 |
17 |
18 |
19 |
20 | > - 本阶段文章讲的略微深入,一些基础性问题不会讲解,如有基础性问题不懂,可自行查看我前面的文章,或者自行学习。
21 | > - 本篇文章比较适合校招和社招的面试,笔者在2020年面试的过程中,也确实被问到了下面的一些问题。
22 |
23 | # 并发编程中的三个问题
24 |
25 | > 由于这个东西,和这篇文章比较配。所以虽然在第一阶段写过了,这里再回顾一遍。
26 |
27 | ## 可见性
28 |
29 |
30 |
31 | ### 可见性概念
32 |
33 | 可见性(Visibility):是指一个线程对共享变量进行修改,另一个线程立即得到修改后的新值。
34 |
35 | ### 可见性演示
36 |
37 | ```java
38 | /* 笔记
39 | * 1.当没有加Volatile的时候,while循环会一直在里面循环转圈
40 | * 2.当加了之后Volatile,由于可见性,一旦num改了之后,就会通知其他线程
41 | * 3.还有注意不能用if,if不会重新拉回来再判断一次。(也叫做虚假唤醒)
42 | * 4.案例演示:一个线程对共享变量的修改,另一个线程不能立即得到新值
43 | * */
44 | public class Video04_01 {
45 |
46 | public static void main(String[] args) {
47 | MyData myData = new MyData();
48 |
49 | new Thread(() ->{
50 | System.out.println(Thread.currentThread().getName() + "\t come in ");
51 | try {
52 | TimeUnit.SECONDS.sleep(3);
53 | } catch (InterruptedException e) {
54 | e.printStackTrace();
55 | }
56 | //睡3秒之后再修改num,防止A线程先修改了num,那么到while循环的时候就会直接跳出去了
57 | myData.addTo60();
58 | System.out.println(Thread.currentThread().getName() + "\t come out");
59 | },"A").start();
60 |
61 |
62 | while(myData.num == 0){
63 | //只有当num不等于0的时候,才会跳出循环
64 | }
65 | }
66 | }
67 |
68 | class MyData{
69 | int num = 0;
70 |
71 | public void addTo60(){
72 | this.num = 60;
73 | }
74 | }
75 | ```
76 |
77 | 由上面代码可以看出,并发编程时,会出现可见性问题,当一个线程对共享变量进行了修改,另外的线程并没有立即看到修改后的最新值。
78 |
79 | ## 原子性
80 |
81 |
82 |
83 | ### 原子性概念
84 |
85 | 原子性(Atomicity):在一次或多次操作中,要么所有的操作都成功执行并且不会受其他因素干扰而中 断,要么所有的操作都不执行或全部执行失败。不会出现中间状态
86 |
87 | ### 原子性演示
88 |
89 | 案例演示:5个线程各执行1000次 i++;
90 |
91 | ```java
92 | /**
93 | * @Author: 吕
94 | * @Date: 2019/9/23 15:50
95 | *
769 |
770 |
771 |
772 | ### 双亲委派机制优势
773 |
774 |
775 |
776 | 通过上面的例子,我们可以知道,双亲机制可以
777 |
778 | 1. 避免类的重复加载
779 |
780 | 2. 保护程序安全,防止核心API被随意篡改
781 |
782 | - 自定义类:自定义java.lang.String 没有被加载。
783 | - 自定义类:java.lang.ShkStart(报错:阻止创建 java.lang开头的类)
784 |
785 |
786 |
787 | 沙箱安全机制
788 | --------
789 |
790 |
791 |
792 | 1. 自定义String类时:在加载自定义String类的时候会率先使用引导类加载器加载,而引导类加载器在加载的过程中会先加载jdk自带的文件(rt.jar包中java.lang.String.class),报错信息说没有main方法,就是因为加载的是rt.jar包中的String类。
793 | 2. 这样可以保证对java核心源代码的保护,这就是沙箱安全机制。
794 |
795 |
796 |
797 | 其他
798 | ----
799 |
800 | ### 如何判断两个class对象是否相同?
801 |
802 | 在JVM中表示两个class对象是否为同一个类存在两个必要条件:
803 |
804 | 1. 类的完整类名必须一致,包括包名
805 | 2. **加载这个类的ClassLoader(指ClassLoader实例对象)必须相同**
806 | 3. 换句话说,在JVM中,即使这两个类对象(class对象)来源同一个Class文件,被同一个虚拟机所加载,但只要加载它们的ClassLoader实例对象不同,那么这两个类对象也是不相等的
807 |
808 |
809 |
810 | ### 对类加载器的引用
811 |
812 | 1. JVM必须知道一个类型是由启动加载器加载的还是由用户类加载器加载的
813 | 2. **如果一个类型是由用户类加载器加载的,那么JVM会将这个类加载器的一个引用作为类型信息的一部分保存在方法区中**
814 | 3. 当解析一个类型到另一个类型的引用的时候,JVM需要保证这两个类型的类加载器是相同的(后面讲)
815 |
816 |
817 |
818 |
--------------------------------------------------------------------------------
/docs/java_concurrency/Java并发体系-第二阶段-锁与同步-[1].md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 'Java并发体系-第二阶段-锁与同步-[1]'
3 | tags:
4 | - Java并发
5 | - 原理
6 | - 源码
7 | categories:
8 | - Java并发
9 | - 原理
10 | keywords: Java并发,原理,源码
11 | description: '万字系列长文讲解-Java并发体系-第二阶段,从C++和硬件方面讲解。'
12 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/Java_concurrency.png'
13 | abbrlink: 230c5bb3
14 | date: 2020-10-06 22:09:58
15 | ---
16 |
17 |
18 |
19 |
20 | > - 本阶段文章讲的略微深入,一些基础性问题不会讲解,如有基础性问题不懂,可自行查看我前面的文章,或者自行学习。
21 | > - 本篇文章比较适合校招和社招的面试,笔者在2020年面试的过程中,也确实被问到了下面的一些问题。
22 |
23 | # 并发编程中的三个问题
24 |
25 | > 由于这个东西,和这篇文章比较配。所以虽然在第一阶段写过了,这里再回顾一遍。
26 |
27 | ## 可见性
28 |
29 |
30 |
31 | ### 可见性概念
32 |
33 | 可见性(Visibility):是指一个线程对共享变量进行修改,另一个线程立即得到修改后的新值。
34 |
35 | ### 可见性演示
36 |
37 | ```java
38 | /* 笔记
39 | * 1.当没有加Volatile的时候,while循环会一直在里面循环转圈
40 | * 2.当加了之后Volatile,由于可见性,一旦num改了之后,就会通知其他线程
41 | * 3.还有注意不能用if,if不会重新拉回来再判断一次。(也叫做虚假唤醒)
42 | * 4.案例演示:一个线程对共享变量的修改,另一个线程不能立即得到新值
43 | * */
44 | public class Video04_01 {
45 |
46 | public static void main(String[] args) {
47 | MyData myData = new MyData();
48 |
49 | new Thread(() ->{
50 | System.out.println(Thread.currentThread().getName() + "\t come in ");
51 | try {
52 | TimeUnit.SECONDS.sleep(3);
53 | } catch (InterruptedException e) {
54 | e.printStackTrace();
55 | }
56 | //睡3秒之后再修改num,防止A线程先修改了num,那么到while循环的时候就会直接跳出去了
57 | myData.addTo60();
58 | System.out.println(Thread.currentThread().getName() + "\t come out");
59 | },"A").start();
60 |
61 |
62 | while(myData.num == 0){
63 | //只有当num不等于0的时候,才会跳出循环
64 | }
65 | }
66 | }
67 |
68 | class MyData{
69 | int num = 0;
70 |
71 | public void addTo60(){
72 | this.num = 60;
73 | }
74 | }
75 | ```
76 |
77 | 由上面代码可以看出,并发编程时,会出现可见性问题,当一个线程对共享变量进行了修改,另外的线程并没有立即看到修改后的最新值。
78 |
79 | ## 原子性
80 |
81 |
82 |
83 | ### 原子性概念
84 |
85 | 原子性(Atomicity):在一次或多次操作中,要么所有的操作都成功执行并且不会受其他因素干扰而中 断,要么所有的操作都不执行或全部执行失败。不会出现中间状态
86 |
87 | ### 原子性演示
88 |
89 | 案例演示:5个线程各执行1000次 i++;
90 |
91 | ```java
92 | /**
93 | * @Author: 吕
94 | * @Date: 2019/9/23 15:50
95 | *
96 | * 功能描述: volatile不保证原子性的代码验证
97 | */
98 | public class Video05_01 {
99 |
100 | public static void main(String[] args) {
101 | MyData03 myData03 = new MyData03();
102 |
103 | for (int i = 0; i < 20; i++) {
104 | new Thread(() ->{
105 | for (int j = 0; j < 1000; j++) {
106 | myData03.increment();
107 | }
108 | },"线程" + String.valueOf(i)).start();
109 | }
110 |
111 | //需要等待上面的20个线程计算完之后再查看计算结果
112 | while(Thread.activeCount() > 2){
113 | Thread.yield();
114 | }
115 |
116 | System.out.println("20个线程执行完之后num:\t" + myData03.num);
117 | }
118 | }
119 |
120 |
121 | class MyData03{
122 | static int num = 0;
123 |
124 | public void increment(){
125 | num++;
126 | }
127 |
128 | }
129 | ```
130 |
131 |
132 |
133 | 1、控制台输出:(由于并发不安全,每次执行的结果都可能不一样)
134 |
135 | > 20个线程执行完之后num: 19706
136 |
137 | 正常来说,如果保证原子性的话,20个线程执行完,结果应该是20000。控制台输出的值却不是这个,说明出现了原子性的问题。
138 |
139 | 2、使用javap反汇编class文件,对于num++可以得到下面的字节码指令:
140 |
141 | ```java
142 | 9: getstatic #12 // Field number:I 取值操作
143 | 12: iconst_1
144 | 13: iadd
145 | 14: putstatic #12 // Field number:I 赋值操作
146 | ```
147 |
148 | 由此可见num++是由多条语句组成,以上多条指令在一个线程的情况下是不会出问题的,但是在多线程情况下就可能会出现问题。
149 |
150 | 比如num刚开始值是7。A线程在执行13: iadd时得到num值是8,B线程又执行9: getstatic得到前一个值是7。马上A线程就把8赋值给了num变量。但是B线程已经拿到了之前的值7,B线程是在A线程真正赋值前拿到的num值。即使A线程最终把值真正的赋给了num变量,但是B线程已经走过了getstaitc取值的这一步,B线程会继续在7的基础上进行++操作,最终的结果依然是8。本来两个线程对7进行分别进行++操作,得到的值应该是9,因为并发问题,导致结果是8。
151 |
152 | 3、并发编程时,会出现原子性问题,当一个线程对共享变量操作到一半时,另外的线程也有可能来操作共 享变量,干扰了前一个线程的操作。
153 |
154 |
155 |
156 | ## 有序性
157 |
158 | ### 有序性概念
159 |
160 | 有序性(Ordering):是指程序中代码的执行顺序,Java在编译时和运行时会对代码进行优化(重排序)来加快速度,会导致程序终的执行顺序不一定就是我们编写代码时的顺序
161 |
162 | ```java
163 | instance = new SingletonDemo() 是被分成以下 3 步完成
164 | memory = allocate(); 分配对象内存空间
165 | instance(memory); 初始化对象
166 | instance = memory; 设置 instance 指向刚分配的内存地址,此时 instance != null
167 | ```
168 |
169 | 步骤2 和 步骤3 不存在数据依赖关系,重排与否的执行结果单线程中是一样的。这种指令重排是被 Java 允许的。当 3 在前时,instance 不为 null,但实际上初始化工作还没完成,会变成一个返回 null 的getInstance。这时候数据就出现了问题。
170 |
171 |
172 |
173 | ### 有序性演示
174 |
175 | jcstress是java并发压测工具。https://wiki.openjdk.java.net/display/CodeTools/jcstress 修改pom文件,添加依赖:
176 |
177 | ```Java
178 |  295 |
296 |
297 |
298 | **指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致**。所以在多线程下,指令重排序可能会导致一些问题。
299 |
300 | ## as-if-serial语义
301 |
302 | as-if-serial语义的意思是:不管编译器和CPU如何重排序,必须保证在单线程情况下程序的结果是正确的。 以下数据有依赖关系,不能重排序。
303 |
304 | 写后读:
305 |
306 | ```
307 | int a = 1;
308 | int b = a;
309 | ```
310 |
311 | 写后写:
312 |
313 | ```
314 | int a = 1;
315 | int a = 2;
316 | ```
317 |
318 | 读后写:
319 |
320 | ```
321 | int a = 1;
322 | int b = a;
323 | int a = 2;
324 | ```
325 |
326 | 编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
327 |
328 | ```
329 | int a = 1;
330 | int b = 2;
331 | int c = a + b;
332 | ```
333 |
334 |
335 |
336 | # Java内存模型(JMM)
337 |
338 | 在介绍Java内存模型之前,先来看一下到底什么是计算机内存模型。
339 |
340 | ## 计算机结构
341 |
342 | ### 计算机结构简介
343 |
344 | 冯诺依曼,提出计算机由五大组成部分,输入设备,输出设备存储器,控制器,运算器。
345 |
346 |
295 |
296 |
297 |
298 | **指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致**。所以在多线程下,指令重排序可能会导致一些问题。
299 |
300 | ## as-if-serial语义
301 |
302 | as-if-serial语义的意思是:不管编译器和CPU如何重排序,必须保证在单线程情况下程序的结果是正确的。 以下数据有依赖关系,不能重排序。
303 |
304 | 写后读:
305 |
306 | ```
307 | int a = 1;
308 | int b = a;
309 | ```
310 |
311 | 写后写:
312 |
313 | ```
314 | int a = 1;
315 | int a = 2;
316 | ```
317 |
318 | 读后写:
319 |
320 | ```
321 | int a = 1;
322 | int b = a;
323 | int a = 2;
324 | ```
325 |
326 | 编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
327 |
328 | ```
329 | int a = 1;
330 | int b = 2;
331 | int c = a + b;
332 | ```
333 |
334 |
335 |
336 | # Java内存模型(JMM)
337 |
338 | 在介绍Java内存模型之前,先来看一下到底什么是计算机内存模型。
339 |
340 | ## 计算机结构
341 |
342 | ### 计算机结构简介
343 |
344 | 冯诺依曼,提出计算机由五大组成部分,输入设备,输出设备存储器,控制器,运算器。
345 |
346 | 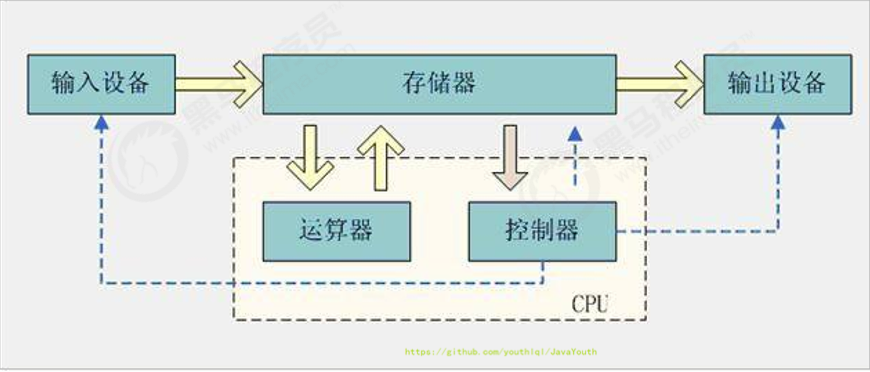 347 |
348 | 输入设备:鼠标,键盘等等
349 |
350 | 输出设备:显示器,打印机等等
351 |
352 | 存储器:内存条
353 |
354 | 运算器和控制器组成CPU
355 |
356 |
357 |
358 | ### CPU
359 |
360 | 中央处理器,是计算机的控制和运算的核心,我们的程序终都会变成指令让CPU去执行,处理程序中 的数据。
361 |
362 | ### 内存
363 |
364 | 我们的程序都是在内存中运行的,内存会保存程序运行时的数据,供CPU处理。
365 |
366 | ### 缓存
367 |
368 | CPU的运算速度和内存的访问速度相差比较大。这就导致CPU每次操作内存都要耗费很多等待时间。内 存的读写速度成为了计算机运行的瓶颈。于是就有了在CPU和主内存之间增加缓存的设计。靠近CPU 的缓存称为L1,然后依次是 L2,L3和主内存,CPU缓存模型如图下图所示。
369 |
370 |
347 |
348 | 输入设备:鼠标,键盘等等
349 |
350 | 输出设备:显示器,打印机等等
351 |
352 | 存储器:内存条
353 |
354 | 运算器和控制器组成CPU
355 |
356 |
357 |
358 | ### CPU
359 |
360 | 中央处理器,是计算机的控制和运算的核心,我们的程序终都会变成指令让CPU去执行,处理程序中 的数据。
361 |
362 | ### 内存
363 |
364 | 我们的程序都是在内存中运行的,内存会保存程序运行时的数据,供CPU处理。
365 |
366 | ### 缓存
367 |
368 | CPU的运算速度和内存的访问速度相差比较大。这就导致CPU每次操作内存都要耗费很多等待时间。内 存的读写速度成为了计算机运行的瓶颈。于是就有了在CPU和主内存之间增加缓存的设计。靠近CPU 的缓存称为L1,然后依次是 L2,L3和主内存,CPU缓存模型如图下图所示。
369 |
370 | 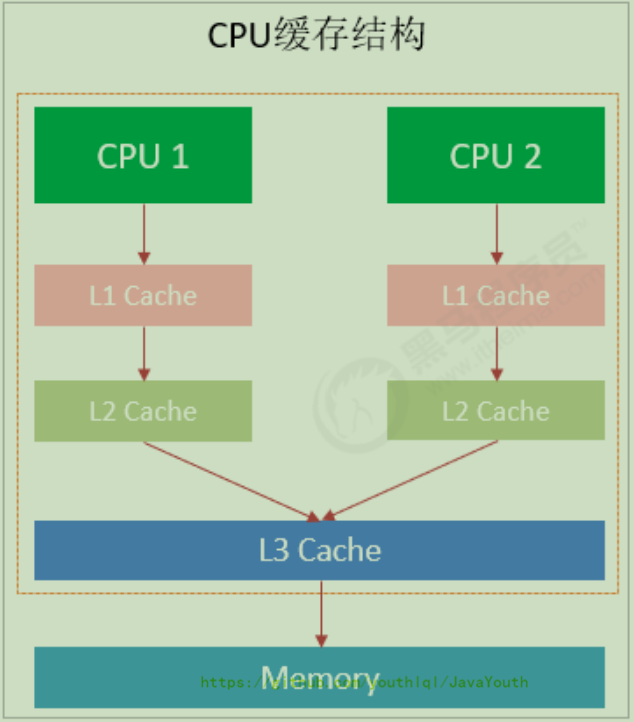 371 |
372 | CPU Cache分成了三个级别: L1, L2, L3。级别越小越接近CPU,速度也更快,同时也代表着容量越小。速度越快的价格越贵。
373 |
374 | 1、L1是接近CPU的,它容量小,例如32K,速度快,每个核上都有一个L1 Cache。
375 |
376 | 2、L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache。
377 |
378 | 3、L3 Cache是三级缓存中大的一级,例如12MB,同时也是缓存中慢的一级,在同一个CPU插槽 之间的核共享一个L3 Cache。
379 |
380 |
371 |
372 | CPU Cache分成了三个级别: L1, L2, L3。级别越小越接近CPU,速度也更快,同时也代表着容量越小。速度越快的价格越贵。
373 |
374 | 1、L1是接近CPU的,它容量小,例如32K,速度快,每个核上都有一个L1 Cache。
375 |
376 | 2、L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache。
377 |
378 | 3、L3 Cache是三级缓存中大的一级,例如12MB,同时也是缓存中慢的一级,在同一个CPU插槽 之间的核共享一个L3 Cache。
379 |
380 |  381 |
382 | 上面的图中有一个Latency指标。比如Memory这个指标为59.4ns,表示CPU在操作内存的时候有59.4ns的延迟,一级缓存最快只有1.2ns。
383 |
384 | **CPU处理数据的流程**
385 |
386 | Cache的出现是为了解决CPU直接访问内存效率低下问题的。
387 |
388 | 1、程序在运行的过程中,CPU接收到指令 后,它会先向CPU中的一级缓存(L1 Cache)去寻找相关的数据,如果命中缓存,CPU进行计算时就可以直接对CPU Cache中的数据进行读取和写人,当运算结束之后,再将CPUCache中的新数据刷新 到主内存当中,CPU通过直接访问Cache的方式替代直接访问主存的方式极大地提高了CPU 的吞吐能 力。
389 |
390 | 2、但是由于一级缓存(L1 Cache)容量较小,所以不可能每次都命中。这时CPU会继续向下一级的二 级缓存(L2 Cache)寻找,同样的道理,当所需要的数据在二级缓存中也没有的话,会继续转向L3 Cache、内存(主存)和硬盘。
391 |
392 |
393 |
394 | ## Java内存模型
395 |
396 | 1、Java Memory Molde (Java内存模型/JMM),千万不要和Java内存结构(JVM划分的那个堆,栈,方法区)混淆。关于“Java内存模型”的权威解释,参考 https://download.oracle.com/otn-pub/jcp/memory_model1.0-pfd-spec-oth-JSpec/memory_model-1_0-pfd-spec.pdf。
397 |
398 | 2、 Java内存模型,是Java虚拟机规范中所定义的一种内存模型,Java内存模型是标准化的,屏蔽掉了底层不同计算机的区别。 Java内存模型是一套规范,描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节,具体如下。
399 |
400 | 3、Java内存模型根据官方的解释,主要是在说两个关键字,一个是`volatile`,一个是`synchronized`。
401 |
402 |
403 |
404 | **主内存**
405 |
406 | 主内存是所有线程都共享的,都能访问的。所有的共享变量都存储于主内存。
407 |
408 | **工作内存**
409 |
410 | 每一个线程有自己的工作内存,工作内存只存储该线程对共享变量的副本。线程对变量的所有的操 作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接 访问对方工作内存中的变量。
411 |
412 |
381 |
382 | 上面的图中有一个Latency指标。比如Memory这个指标为59.4ns,表示CPU在操作内存的时候有59.4ns的延迟,一级缓存最快只有1.2ns。
383 |
384 | **CPU处理数据的流程**
385 |
386 | Cache的出现是为了解决CPU直接访问内存效率低下问题的。
387 |
388 | 1、程序在运行的过程中,CPU接收到指令 后,它会先向CPU中的一级缓存(L1 Cache)去寻找相关的数据,如果命中缓存,CPU进行计算时就可以直接对CPU Cache中的数据进行读取和写人,当运算结束之后,再将CPUCache中的新数据刷新 到主内存当中,CPU通过直接访问Cache的方式替代直接访问主存的方式极大地提高了CPU 的吞吐能 力。
389 |
390 | 2、但是由于一级缓存(L1 Cache)容量较小,所以不可能每次都命中。这时CPU会继续向下一级的二 级缓存(L2 Cache)寻找,同样的道理,当所需要的数据在二级缓存中也没有的话,会继续转向L3 Cache、内存(主存)和硬盘。
391 |
392 |
393 |
394 | ## Java内存模型
395 |
396 | 1、Java Memory Molde (Java内存模型/JMM),千万不要和Java内存结构(JVM划分的那个堆,栈,方法区)混淆。关于“Java内存模型”的权威解释,参考 https://download.oracle.com/otn-pub/jcp/memory_model1.0-pfd-spec-oth-JSpec/memory_model-1_0-pfd-spec.pdf。
397 |
398 | 2、 Java内存模型,是Java虚拟机规范中所定义的一种内存模型,Java内存模型是标准化的,屏蔽掉了底层不同计算机的区别。 Java内存模型是一套规范,描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节,具体如下。
399 |
400 | 3、Java内存模型根据官方的解释,主要是在说两个关键字,一个是`volatile`,一个是`synchronized`。
401 |
402 |
403 |
404 | **主内存**
405 |
406 | 主内存是所有线程都共享的,都能访问的。所有的共享变量都存储于主内存。
407 |
408 | **工作内存**
409 |
410 | 每一个线程有自己的工作内存,工作内存只存储该线程对共享变量的副本。线程对变量的所有的操 作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接 访问对方工作内存中的变量。
411 |
412 |  413 |
414 | Java的线程不能直接在主内存中操作共享变量。而是首先将主内存中的共享变量赋值到自己的工作内存中,再进行操作,操作完成之后,刷回主内存。
415 |
416 | **Java内存模型的作用**
417 |
418 | Java内存模型是一套在多线程读写共享数据时,对共享数据的可见性、有序性、和原子性的规则和保障。 synchronized,volatile
419 |
420 | ## CPU缓存,内存与Java内存模型的关系
421 |
422 | - 通过对前面的CPU硬件内存架构、Java内存模型以及Java多线程的实现原理的了解,我们应该已经意识到,多线程的执行终都会映射到硬件处理器上进行执行。 但Java内存模型和硬件内存架构并不完全一致。
423 | - 对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存和主内存之分,也就是说Java内存模型对内存的划分对硬件内存并没有任何影响, 因为JMM只是一种抽象的概念,是一组规则,不管是工作内存的数据还是主内存的数据,对于计算机硬 件来说都会存储在计算机主内存中,当然也有可能存储到CPU缓存或者寄存器中,因此总体上来说, Java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。
424 |
425 | JMM内存模型与CPU硬件内存架构的关系:
426 |
427 |
413 |
414 | Java的线程不能直接在主内存中操作共享变量。而是首先将主内存中的共享变量赋值到自己的工作内存中,再进行操作,操作完成之后,刷回主内存。
415 |
416 | **Java内存模型的作用**
417 |
418 | Java内存模型是一套在多线程读写共享数据时,对共享数据的可见性、有序性、和原子性的规则和保障。 synchronized,volatile
419 |
420 | ## CPU缓存,内存与Java内存模型的关系
421 |
422 | - 通过对前面的CPU硬件内存架构、Java内存模型以及Java多线程的实现原理的了解,我们应该已经意识到,多线程的执行终都会映射到硬件处理器上进行执行。 但Java内存模型和硬件内存架构并不完全一致。
423 | - 对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存和主内存之分,也就是说Java内存模型对内存的划分对硬件内存并没有任何影响, 因为JMM只是一种抽象的概念,是一组规则,不管是工作内存的数据还是主内存的数据,对于计算机硬 件来说都会存储在计算机主内存中,当然也有可能存储到CPU缓存或者寄存器中,因此总体上来说, Java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。
424 |
425 | JMM内存模型与CPU硬件内存架构的关系:
426 |
427 | 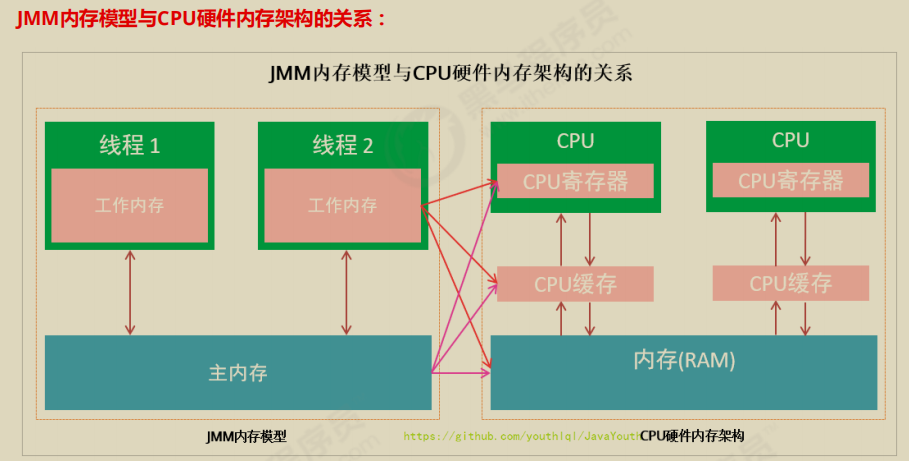 428 |
429 | 工作内存:可能对应CPU寄存器,也可能对应CPU缓存,也可能对应内存。
430 |
431 | - Java内存模型是一套规范,描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量 存储到内存和从内存中读取变量这样的底层细节,Java内存模型是对共享数据的可见性、有序性、和原子性的规则和保障。
432 |
433 |
434 |
435 | ## 再谈可见性
436 |
437 |
428 |
429 | 工作内存:可能对应CPU寄存器,也可能对应CPU缓存,也可能对应内存。
430 |
431 | - Java内存模型是一套规范,描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量 存储到内存和从内存中读取变量这样的底层细节,Java内存模型是对共享数据的可见性、有序性、和原子性的规则和保障。
432 |
433 |
434 |
435 | ## 再谈可见性
436 |
437 | 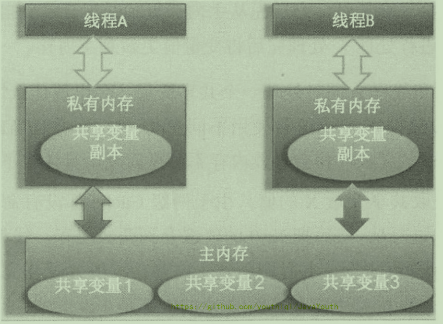 438 |
439 |
438 |
439 |  440 |
441 | 1、图中所示是 个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的1级缓存,在有些架构里面还有1个所有 CPU 共享的2级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 或者 L2 存或者 CPU 寄存器。
442 |
443 | 2、一个线程操作共享变量时,它首先从主内存复制共享变量到自己的工作内存,然后对工作内存里的变量进行处理,处理完后将变量值更新到主内存。
444 |
445 | 3、那么假如线程A和线程B同时处理一个共享变量,会出现什么情况?我们使用图所示CPU架构,假设线程A和线程B使用不同CPU执行,并且当前两级Cache都为空,那么这时候由于Cache的存在,将会导致内存不可见问题,具体看下面的分析。
446 |
447 | - 线程A首先获取共享变量X的值,由于两级Cache都没有命中,所以加载主内存中X的值,假如为0。然后把X=0的值缓存到两级缓存,线程A修改X的值为1,然后将其写入两级Cache,并且刷新到主内存。线程A操作完毕后,线程A所在的CPU的两级Cache 内和主内存里面的X的值都是1。
448 | - 线程B获取X的值,首先一级缓存没有命中,然后看二级缓存,二级缓存命中了,所以返回X=1;到这里一切都是正常的,因为这时候主内存中也是X=1。然后线程B修改X的值为2,并将其存放到线程2所在的一级Cache和共享二级Cache中,最后更新主内存中X 的值为2;到这里一切都是好的。
449 | - 线程A 这次又需要修改X的值,获取时一级缓存命中,并且X=1,到这里问题就出现了,明明线程B已经把X的值修改为了2,为何线程A获取的还是1呢?这就是共享变量的内存不可见问题,也就是线程B写入的值对线程A不可见。那么如何解决共享变量内存不可见问题?使用Java中的volatile和synchronized关键字就可以解决这个问题,下面会有讲解。
450 |
451 | # 主内存与工作内存之间的交互
452 |
453 | 为了保证数据交互时数据的正确性,Java内存模型中定义了8种操作来完成这个交互过程,这8种操作本身都是原子性的。虚拟机实现时必须保证下面 提及的每一种操作都是原子的、不可再分的。
454 |
455 |
440 |
441 | 1、图中所示是 个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的1级缓存,在有些架构里面还有1个所有 CPU 共享的2级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 或者 L2 存或者 CPU 寄存器。
442 |
443 | 2、一个线程操作共享变量时,它首先从主内存复制共享变量到自己的工作内存,然后对工作内存里的变量进行处理,处理完后将变量值更新到主内存。
444 |
445 | 3、那么假如线程A和线程B同时处理一个共享变量,会出现什么情况?我们使用图所示CPU架构,假设线程A和线程B使用不同CPU执行,并且当前两级Cache都为空,那么这时候由于Cache的存在,将会导致内存不可见问题,具体看下面的分析。
446 |
447 | - 线程A首先获取共享变量X的值,由于两级Cache都没有命中,所以加载主内存中X的值,假如为0。然后把X=0的值缓存到两级缓存,线程A修改X的值为1,然后将其写入两级Cache,并且刷新到主内存。线程A操作完毕后,线程A所在的CPU的两级Cache 内和主内存里面的X的值都是1。
448 | - 线程B获取X的值,首先一级缓存没有命中,然后看二级缓存,二级缓存命中了,所以返回X=1;到这里一切都是正常的,因为这时候主内存中也是X=1。然后线程B修改X的值为2,并将其存放到线程2所在的一级Cache和共享二级Cache中,最后更新主内存中X 的值为2;到这里一切都是好的。
449 | - 线程A 这次又需要修改X的值,获取时一级缓存命中,并且X=1,到这里问题就出现了,明明线程B已经把X的值修改为了2,为何线程A获取的还是1呢?这就是共享变量的内存不可见问题,也就是线程B写入的值对线程A不可见。那么如何解决共享变量内存不可见问题?使用Java中的volatile和synchronized关键字就可以解决这个问题,下面会有讲解。
450 |
451 | # 主内存与工作内存之间的交互
452 |
453 | 为了保证数据交互时数据的正确性,Java内存模型中定义了8种操作来完成这个交互过程,这8种操作本身都是原子性的。虚拟机实现时必须保证下面 提及的每一种操作都是原子的、不可再分的。
454 |
455 | 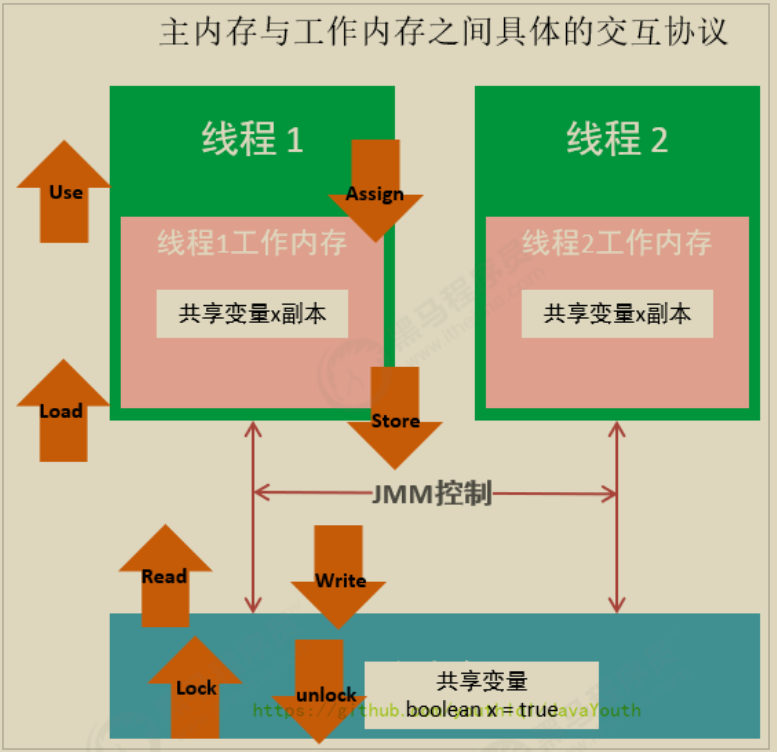 456 |
457 | > (1)lock:作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
458 | >
459 | > (2)unlock:作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其它线程锁定。
460 | >
461 | > (3)read:作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
462 | >
463 | > (4)load:作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
464 | >
465 | > (5)use:作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时都会执行这个操作。
466 | >
467 | > (6)assign:作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
468 | >
469 | > (7)store:作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write使用。
470 | >
471 | > (8)write:作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
472 |
473 | 注意:
474 |
475 | 1. 如果对一个变量执行lock操作,将会清空工作内存中此变量的值
476 | 2. 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中
477 | 3. lock和unlock操作只有加锁才会有。synchronized就是通过这样来保证可见性的。
478 |
479 | 如果没有synchronized,那就是下面这样的
480 |
481 |
456 |
457 | > (1)lock:作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
458 | >
459 | > (2)unlock:作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其它线程锁定。
460 | >
461 | > (3)read:作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
462 | >
463 | > (4)load:作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
464 | >
465 | > (5)use:作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时都会执行这个操作。
466 | >
467 | > (6)assign:作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
468 | >
469 | > (7)store:作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write使用。
470 | >
471 | > (8)write:作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
472 |
473 | 注意:
474 |
475 | 1. 如果对一个变量执行lock操作,将会清空工作内存中此变量的值
476 | 2. 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中
477 | 3. lock和unlock操作只有加锁才会有。synchronized就是通过这样来保证可见性的。
478 |
479 | 如果没有synchronized,那就是下面这样的
480 |
481 | 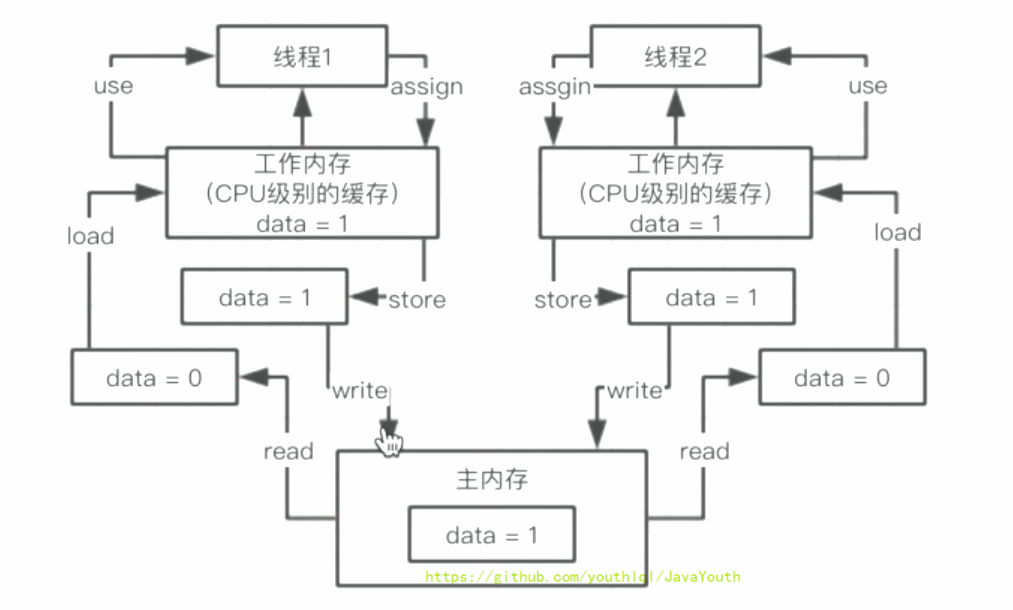 482 |
483 |
484 |
485 | # happens-before
486 |
487 | ## 什么是happens-before?
488 |
489 | 一方面,程序员需要JMM提供一个强的内存模型来编写代码;另一方面,编译器和处理器希望JMM对它们的束缚越少越好,这样它们就可以最可能多的做优化来提高性能,希望的是一个弱的内存模型。
490 |
491 | JMM考虑了这两种需求,并且找到了平衡点,对编译器和处理器来说,**只要不改变程序的执行结果(单线程程序和正确同步了的多线程程序),编译器和处理器怎么优化都行。**
492 |
493 | 而对于程序员,JMM提供了**happens-before规则**(JSR-133规范),满足了程序员的需求——**简单易懂,并且提供了足够强的内存可见性保证。**换言之,程序员只要遵循happens-before规则,那他写的程序就能保证在JMM中具有强的内存可见性。
494 |
495 | JMM使用happens-before的概念来定制两个操作之间的执行顺序。这两个操作可以在一个线程以内,也可以是不同的线程之间。因此,JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证。
496 |
497 | happens-before关系的定义如下:
498 |
499 | 1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
500 | 2. **两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么JMM也允许这样的重排序。**
501 |
502 | happens-before关系本质上和as-if-serial语义是一回事。
503 |
504 | as-if-serial语义保证单线程内重排序后的执行结果和程序代码本身应有的结果是一致的,happens-before关系保证正确同步的多线程程序的执行结果不被重排序改变。
505 |
506 | 总之,**如果操作A happens-before操作B,那么操作A在内存上所做的操作对操作B都是可见的,不管它们在不在一个线程。**
507 |
508 | ## 天然的happens-before关系
509 |
510 | 在Java中,有以下天然的happens-before关系:
511 |
512 | * 1、程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
513 |
514 | * 2、锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作,比如说在代码里有先对一个lock.lock(),lock.unlock(),lock.lock()
515 |
516 | * 3、volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个volatile变量的读操作,volatile变量写,再是读,必须保证是先写,再读
517 |
518 | * 4、传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
519 |
520 | * 5、线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作,thread.start(),thread.interrupt()
521 |
522 | * 6、线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
523 |
524 | * 7、线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
525 |
526 | * 8、对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
527 |
528 |
529 | 上面这8条原则的意思很显而易见,就是程序中的代码如果满足这个条件,就一定会按照这个规则来保证指令的顺序。
530 |
531 | **举例1:**
532 |
533 | ```java
534 | int a = 1; // A操作
535 | int b = 2; // B操作
536 | int sum = a + b;// C 操作
537 | System.out.println(sum);
538 | ```
539 |
540 | 根据以上介绍的happens-before规则,假如只有一个线程,那么不难得出:
541 |
542 | ```
543 | 1> A happens-before B
544 | 2> B happens-before C
545 | 3> A happens-before C
546 | ```
547 |
548 | 注意,真正在执行指令的时候,其实JVM有可能对操作A & B进行重排序,因为无论先执行A还是B,他们都对对方是可见的,并且不影响执行结果。
549 |
550 | 如果这里发生了重排序,这在视觉上违背了happens-before原则,但是JMM是允许这样的重排序的。
551 |
552 | 所以,我们只关心happens-before规则,不用关心JVM到底是怎样执行的。只要确定操作A happens-before操作B就行了。
553 |
554 | 重排序有两类,JMM对这两类重排序有不同的策略:
555 |
556 | * 会改变程序执行结果的重排序,比如 A -> C,JMM要求编译器和处理器都禁止这种重排序。
557 | * 不会改变程序执行结果的重排序,比如 A -> B,JMM对编译器和处理器不做要求,允许这种重排序。
558 |
559 |
560 |
561 | **举例2:**
562 |
563 | ```Java
564 | //伪代码
565 | volatile boolean flag = false;
566 | //线程1
567 | prepare();
568 |
569 | flag = false;
570 |
571 | //线程2
572 | while(!flag){
573 | sleep();
574 | }
575 |
576 | //基于准备好的资源进行操作
577 | execute();
578 | ```
579 |
580 | 这8条原则是避免说出现乱七八糟扰乱秩序的指令重排,要求是这几个重要的场景下,比如是按照顺序来,但是8条规则之外,可以随意重排指令。
581 |
582 | 比如这个例子,如果用volatile来修饰flag变量,一定可以让prepare()指令在flag = true之前先执行,这就禁止了指令重排。
583 |
584 | 因为volatile要求的是,volatile前面的代码一定不能指令重排到volatile变量操作后面,volatile后面的代码也不能指令重排到volatile前面。
585 |
586 | # volatile
587 |
588 | volatile不保证原子性,只保证可见性和禁止指令重排
589 |
590 | ## CPU术语介绍
591 |
592 |
482 |
483 |
484 |
485 | # happens-before
486 |
487 | ## 什么是happens-before?
488 |
489 | 一方面,程序员需要JMM提供一个强的内存模型来编写代码;另一方面,编译器和处理器希望JMM对它们的束缚越少越好,这样它们就可以最可能多的做优化来提高性能,希望的是一个弱的内存模型。
490 |
491 | JMM考虑了这两种需求,并且找到了平衡点,对编译器和处理器来说,**只要不改变程序的执行结果(单线程程序和正确同步了的多线程程序),编译器和处理器怎么优化都行。**
492 |
493 | 而对于程序员,JMM提供了**happens-before规则**(JSR-133规范),满足了程序员的需求——**简单易懂,并且提供了足够强的内存可见性保证。**换言之,程序员只要遵循happens-before规则,那他写的程序就能保证在JMM中具有强的内存可见性。
494 |
495 | JMM使用happens-before的概念来定制两个操作之间的执行顺序。这两个操作可以在一个线程以内,也可以是不同的线程之间。因此,JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证。
496 |
497 | happens-before关系的定义如下:
498 |
499 | 1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
500 | 2. **两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么JMM也允许这样的重排序。**
501 |
502 | happens-before关系本质上和as-if-serial语义是一回事。
503 |
504 | as-if-serial语义保证单线程内重排序后的执行结果和程序代码本身应有的结果是一致的,happens-before关系保证正确同步的多线程程序的执行结果不被重排序改变。
505 |
506 | 总之,**如果操作A happens-before操作B,那么操作A在内存上所做的操作对操作B都是可见的,不管它们在不在一个线程。**
507 |
508 | ## 天然的happens-before关系
509 |
510 | 在Java中,有以下天然的happens-before关系:
511 |
512 | * 1、程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
513 |
514 | * 2、锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作,比如说在代码里有先对一个lock.lock(),lock.unlock(),lock.lock()
515 |
516 | * 3、volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个volatile变量的读操作,volatile变量写,再是读,必须保证是先写,再读
517 |
518 | * 4、传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
519 |
520 | * 5、线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作,thread.start(),thread.interrupt()
521 |
522 | * 6、线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
523 |
524 | * 7、线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
525 |
526 | * 8、对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
527 |
528 |
529 | 上面这8条原则的意思很显而易见,就是程序中的代码如果满足这个条件,就一定会按照这个规则来保证指令的顺序。
530 |
531 | **举例1:**
532 |
533 | ```java
534 | int a = 1; // A操作
535 | int b = 2; // B操作
536 | int sum = a + b;// C 操作
537 | System.out.println(sum);
538 | ```
539 |
540 | 根据以上介绍的happens-before规则,假如只有一个线程,那么不难得出:
541 |
542 | ```
543 | 1> A happens-before B
544 | 2> B happens-before C
545 | 3> A happens-before C
546 | ```
547 |
548 | 注意,真正在执行指令的时候,其实JVM有可能对操作A & B进行重排序,因为无论先执行A还是B,他们都对对方是可见的,并且不影响执行结果。
549 |
550 | 如果这里发生了重排序,这在视觉上违背了happens-before原则,但是JMM是允许这样的重排序的。
551 |
552 | 所以,我们只关心happens-before规则,不用关心JVM到底是怎样执行的。只要确定操作A happens-before操作B就行了。
553 |
554 | 重排序有两类,JMM对这两类重排序有不同的策略:
555 |
556 | * 会改变程序执行结果的重排序,比如 A -> C,JMM要求编译器和处理器都禁止这种重排序。
557 | * 不会改变程序执行结果的重排序,比如 A -> B,JMM对编译器和处理器不做要求,允许这种重排序。
558 |
559 |
560 |
561 | **举例2:**
562 |
563 | ```Java
564 | //伪代码
565 | volatile boolean flag = false;
566 | //线程1
567 | prepare();
568 |
569 | flag = false;
570 |
571 | //线程2
572 | while(!flag){
573 | sleep();
574 | }
575 |
576 | //基于准备好的资源进行操作
577 | execute();
578 | ```
579 |
580 | 这8条原则是避免说出现乱七八糟扰乱秩序的指令重排,要求是这几个重要的场景下,比如是按照顺序来,但是8条规则之外,可以随意重排指令。
581 |
582 | 比如这个例子,如果用volatile来修饰flag变量,一定可以让prepare()指令在flag = true之前先执行,这就禁止了指令重排。
583 |
584 | 因为volatile要求的是,volatile前面的代码一定不能指令重排到volatile变量操作后面,volatile后面的代码也不能指令重排到volatile前面。
585 |
586 | # volatile
587 |
588 | volatile不保证原子性,只保证可见性和禁止指令重排
589 |
590 | ## CPU术语介绍
591 |
592 |  593 |
594 |
595 |
596 |
597 |
598 | ```java
599 | private static volatile SingletonDemo instance = null;
600 |
601 | private SingletonDemo() {
602 | System.out.println(Thread.currentThread().getName() + "\t 执行单例构造函数");
603 | }
604 |
605 | public static SingletonDemo getInstance(){
606 |
607 | if(instance == null){
608 | synchronized (SingletonDemo.class){
609 | if(instance == null){
610 | instance = new SingletonDemo(); //pos_1
611 | }
612 | }
613 | }
614 | return instance;
615 | }
616 | ```
617 |
618 | **pos_1处的代码转换成汇编代码如下**
619 |
620 | ```shell
621 | 0x01a3de1d: movb $0×0,0×1104800(%esi);
622 | 0x01a3de24: lock addl $0×0,(%esp);
623 | ```
624 |
625 | ## volatile保证可见性原理
626 |
627 | 有volatile变量修饰的共享变量进行写操作的时候会多出第二行汇编代码,通过查IA-32架 构软件开发者手册可知,Lock前缀的指令在多核处理器下会引发了两件事情。
628 |
629 | 1)将当前处理器缓存行的数据写回到系统内存。
630 |
631 | 2)这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
632 |
633 | 为了提高处理速度,处理器不直接和主内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。如果对声明了volatile的 变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现MESI缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
634 |
635 | > 注意:lock前缀指令是同时保证可见性和有序性(也就是禁止指令重排)的
636 |
637 | > 注意:lock前缀指令相当于一个内存屏障【后文讲】
638 |
639 |
640 |
641 |
642 |
643 |
644 |
645 |
646 |
647 | ## volatile禁止指令重排的原理
648 |
649 | ```java
650 | public class VolatileExample {
651 | int a = 0;
652 | volatile boolean flag = false;
653 |
654 | public void writer() {
655 | a = 1; // step 1
656 | flag = true; // step 2
657 | }
658 |
659 | public void reader() {
660 | if (flag) { // step 3
661 | System.out.println(a); // step 4
662 | }
663 | }
664 | }
665 | ```
666 |
667 | 在JSR-133之前的旧的Java内存模型中,是允许volatile变量与普通变量重排序的。那上面的案例中,可能就会被重排序成下列时序来执行:
668 |
669 | 1. 线程A写volatile变量,step 2,设置flag为true;
670 | 2. 线程B读同一个volatile,step 3,读取到flag为true;
671 | 3. 线程B读普通变量,step 4,读取到 a = 0;
672 | 4. 线程A修改普通变量,step 1,设置 a = 1;
673 |
674 | 可见,如果volatile变量与普通变量发生了重排序,虽然volatile变量能保证内存可见性,也可能导致普通变量读取错误。
675 |
676 | 所以在旧的内存模型中,volatile的写-读就不能与锁的释放-获取具有相同的内存语义了。为了提供一种比锁更轻量级的**线程间的通信机制**,**JSR-133**专家组决定增强volatile的内存语义:严格限制编译器和处理器对volatile变量与普通变量的重排序。
677 |
678 | 编译器还好说,JVM是怎么还能限制处理器的重排序的呢?它是通过**内存屏障**来实现的。
679 |
680 | 什么是内存屏障?硬件层面,内存屏障分两种:读屏障(Load Barrier)和写屏障(Store Barrier)。内存屏障有两个作用:
681 |
682 | 1. 阻止屏障两侧的指令重排序;
683 | 2. 强制把写缓冲区/高速缓存中的脏数据等写回主内存,或者让缓存中相应的数据失效。
684 |
685 | > 注意这里的缓存主要指的是上文说的CPU缓存,如L1,L2等
686 |
687 | ### 保守策略下
688 |
689 |
690 |
691 | - 在每个volatile写操作的前面插入一个StoreStore屏障。
692 |
693 | - 在每个volatile写操作的后面插入一个StoreLoad屏障。
694 |
695 | - 在每个volatile读操作的前面插入一个LoadLoad屏障。
696 |
697 | - 在每个volatile读操作的后面插入一个LoadStore屏障。
698 |
699 | 编译器在**生成字节码时**,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。编译器选择了一个**比较保守的JMM内存屏障插入策略**,但它可以保证在任意处理器平台,任意的程序中都能 得到正确的volatile内存语义。
700 |
701 | > 再逐个解释一下这几个屏障。注:下述Load代表读操作,Store代表写操作
702 | >
703 | > **LoadLoad屏障**:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
704 | > **StoreStore屏障**:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,这个屏障会吧Store1强制刷新到内存,保证Store1的写入操作对其它处理器可见。
705 | > **LoadStore屏障**:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
706 | > **StoreLoad屏障**:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
707 |
708 | 对于连续多个volatile变量读或者连续多个volatile变量写,编译器做了一定的优化来提高性能,比如:
709 |
710 | > 第一个volatile读;
711 | >
712 | > LoadLoad屏障;
713 | >
714 | > 第二个volatile读;
715 | >
716 | > LoadStore屏障
717 |
718 | **1、下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图**
719 |
720 |
593 |
594 |
595 |
596 |
597 |
598 | ```java
599 | private static volatile SingletonDemo instance = null;
600 |
601 | private SingletonDemo() {
602 | System.out.println(Thread.currentThread().getName() + "\t 执行单例构造函数");
603 | }
604 |
605 | public static SingletonDemo getInstance(){
606 |
607 | if(instance == null){
608 | synchronized (SingletonDemo.class){
609 | if(instance == null){
610 | instance = new SingletonDemo(); //pos_1
611 | }
612 | }
613 | }
614 | return instance;
615 | }
616 | ```
617 |
618 | **pos_1处的代码转换成汇编代码如下**
619 |
620 | ```shell
621 | 0x01a3de1d: movb $0×0,0×1104800(%esi);
622 | 0x01a3de24: lock addl $0×0,(%esp);
623 | ```
624 |
625 | ## volatile保证可见性原理
626 |
627 | 有volatile变量修饰的共享变量进行写操作的时候会多出第二行汇编代码,通过查IA-32架 构软件开发者手册可知,Lock前缀的指令在多核处理器下会引发了两件事情。
628 |
629 | 1)将当前处理器缓存行的数据写回到系统内存。
630 |
631 | 2)这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
632 |
633 | 为了提高处理速度,处理器不直接和主内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。如果对声明了volatile的 变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现MESI缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
634 |
635 | > 注意:lock前缀指令是同时保证可见性和有序性(也就是禁止指令重排)的
636 |
637 | > 注意:lock前缀指令相当于一个内存屏障【后文讲】
638 |
639 |
640 |
641 |
642 |
643 |
644 |
645 |
646 |
647 | ## volatile禁止指令重排的原理
648 |
649 | ```java
650 | public class VolatileExample {
651 | int a = 0;
652 | volatile boolean flag = false;
653 |
654 | public void writer() {
655 | a = 1; // step 1
656 | flag = true; // step 2
657 | }
658 |
659 | public void reader() {
660 | if (flag) { // step 3
661 | System.out.println(a); // step 4
662 | }
663 | }
664 | }
665 | ```
666 |
667 | 在JSR-133之前的旧的Java内存模型中,是允许volatile变量与普通变量重排序的。那上面的案例中,可能就会被重排序成下列时序来执行:
668 |
669 | 1. 线程A写volatile变量,step 2,设置flag为true;
670 | 2. 线程B读同一个volatile,step 3,读取到flag为true;
671 | 3. 线程B读普通变量,step 4,读取到 a = 0;
672 | 4. 线程A修改普通变量,step 1,设置 a = 1;
673 |
674 | 可见,如果volatile变量与普通变量发生了重排序,虽然volatile变量能保证内存可见性,也可能导致普通变量读取错误。
675 |
676 | 所以在旧的内存模型中,volatile的写-读就不能与锁的释放-获取具有相同的内存语义了。为了提供一种比锁更轻量级的**线程间的通信机制**,**JSR-133**专家组决定增强volatile的内存语义:严格限制编译器和处理器对volatile变量与普通变量的重排序。
677 |
678 | 编译器还好说,JVM是怎么还能限制处理器的重排序的呢?它是通过**内存屏障**来实现的。
679 |
680 | 什么是内存屏障?硬件层面,内存屏障分两种:读屏障(Load Barrier)和写屏障(Store Barrier)。内存屏障有两个作用:
681 |
682 | 1. 阻止屏障两侧的指令重排序;
683 | 2. 强制把写缓冲区/高速缓存中的脏数据等写回主内存,或者让缓存中相应的数据失效。
684 |
685 | > 注意这里的缓存主要指的是上文说的CPU缓存,如L1,L2等
686 |
687 | ### 保守策略下
688 |
689 |
690 |
691 | - 在每个volatile写操作的前面插入一个StoreStore屏障。
692 |
693 | - 在每个volatile写操作的后面插入一个StoreLoad屏障。
694 |
695 | - 在每个volatile读操作的前面插入一个LoadLoad屏障。
696 |
697 | - 在每个volatile读操作的后面插入一个LoadStore屏障。
698 |
699 | 编译器在**生成字节码时**,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。编译器选择了一个**比较保守的JMM内存屏障插入策略**,但它可以保证在任意处理器平台,任意的程序中都能 得到正确的volatile内存语义。
700 |
701 | > 再逐个解释一下这几个屏障。注:下述Load代表读操作,Store代表写操作
702 | >
703 | > **LoadLoad屏障**:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
704 | > **StoreStore屏障**:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,这个屏障会吧Store1强制刷新到内存,保证Store1的写入操作对其它处理器可见。
705 | > **LoadStore屏障**:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
706 | > **StoreLoad屏障**:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
707 |
708 | 对于连续多个volatile变量读或者连续多个volatile变量写,编译器做了一定的优化来提高性能,比如:
709 |
710 | > 第一个volatile读;
711 | >
712 | > LoadLoad屏障;
713 | >
714 | > 第二个volatile读;
715 | >
716 | > LoadStore屏障
717 |
718 | **1、下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图**
719 |
720 | 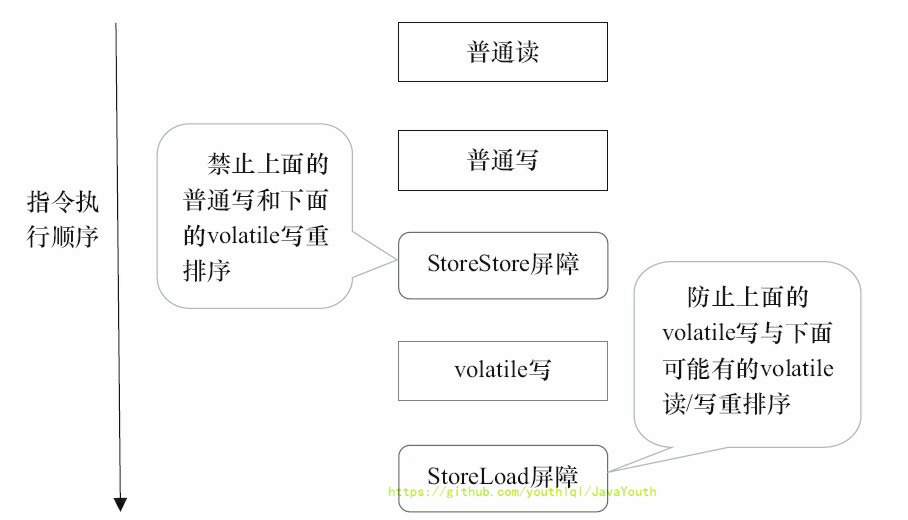 721 |
722 | > 图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任 意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与 后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面 是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确 实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile 读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个 写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时, 选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率
723 |
724 |
725 |
726 | **2、下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图**
727 |
728 |
721 |
722 | > 图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任 意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与 后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面 是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确 实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile 读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个 写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时, 选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率
723 |
724 |
725 |
726 | **2、下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图**
727 |
728 |  729 |
730 | > 图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。 LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。 上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
731 |
732 |
733 |
734 | **优化举例:**
735 |
736 | ```java
737 | class VolatileBarrierExample {
738 | int a;
739 | volatile int v1 = 1;
740 | volatile int v2 = 2;
741 |
742 | void readAndWrite() {
743 | int i = v1; // 第一个volatile读
744 | int j = v2; // 第二个volatile读
745 | a = i + j; // 普通写
746 | v1 = i + 1; // 第一个volatile写
747 | v2 = j * 2; // 第二个 volatile写
748 | }
749 | // 其他方法 }
750 | }
751 | ```
752 |
753 | 针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化
754 |
755 |
729 |
730 | > 图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。 LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。 上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
731 |
732 |
733 |
734 | **优化举例:**
735 |
736 | ```java
737 | class VolatileBarrierExample {
738 | int a;
739 | volatile int v1 = 1;
740 | volatile int v2 = 2;
741 |
742 | void readAndWrite() {
743 | int i = v1; // 第一个volatile读
744 | int j = v2; // 第二个volatile读
745 | a = i + j; // 普通写
746 | v1 = i + 1; // 第一个volatile写
747 | v2 = j * 2; // 第二个 volatile写
748 | }
749 | // 其他方法 }
750 | }
751 | ```
752 |
753 | 针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化
754 |
755 | 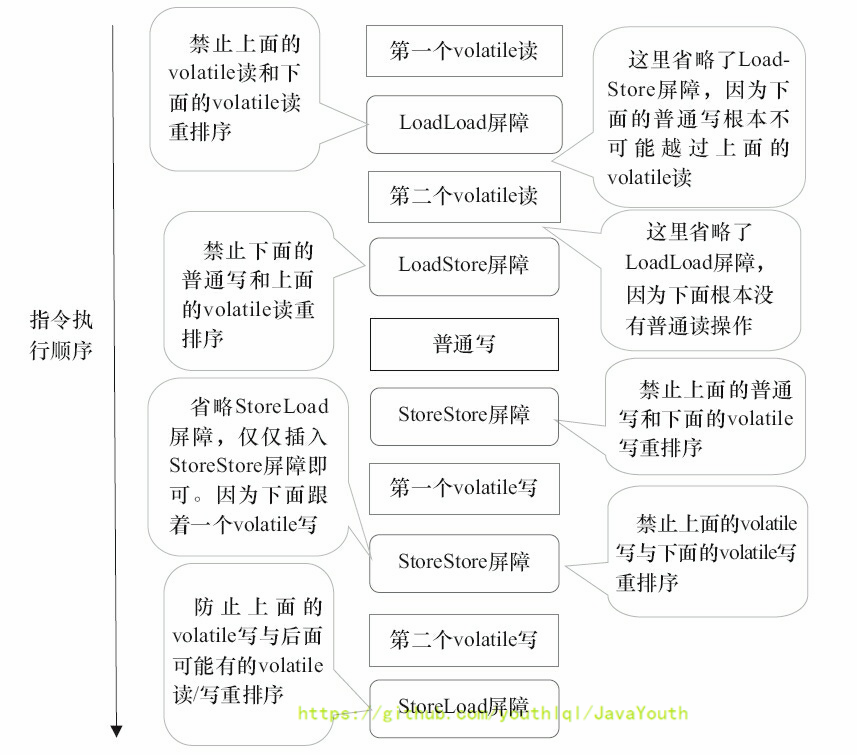 756 |
757 | 注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障。
758 |
759 | 上面的优化针对任意处理器平台,由于不同的处理器有不同“松紧度”的处理器内存模型,内存屏障的插入还可以根据具体的处理器内存模型继续优化。以X86处理器为例,图中除最后的StoreLoad屏障外,其他的屏障都会被省略。
760 |
761 |
762 |
763 | ### X86处理器优化
764 |
765 | 前面保守策略下的volatile读和写,在X86处理器平台可以优化成如下图所示。
766 |
767 | X86处理器仅会对写-读操作做重排序。X86不会对读-读、读-写和写-写操作 做重排序,因此在X86处理器中会省略掉这3种操作类型对应的内存屏障。在X86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在X86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
768 |
769 |
756 |
757 | 注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障。
758 |
759 | 上面的优化针对任意处理器平台,由于不同的处理器有不同“松紧度”的处理器内存模型,内存屏障的插入还可以根据具体的处理器内存模型继续优化。以X86处理器为例,图中除最后的StoreLoad屏障外,其他的屏障都会被省略。
760 |
761 |
762 |
763 | ### X86处理器优化
764 |
765 | 前面保守策略下的volatile读和写,在X86处理器平台可以优化成如下图所示。
766 |
767 | X86处理器仅会对写-读操作做重排序。X86不会对读-读、读-写和写-写操作 做重排序,因此在X86处理器中会省略掉这3种操作类型对应的内存屏障。在X86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在X86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
768 |
769 | 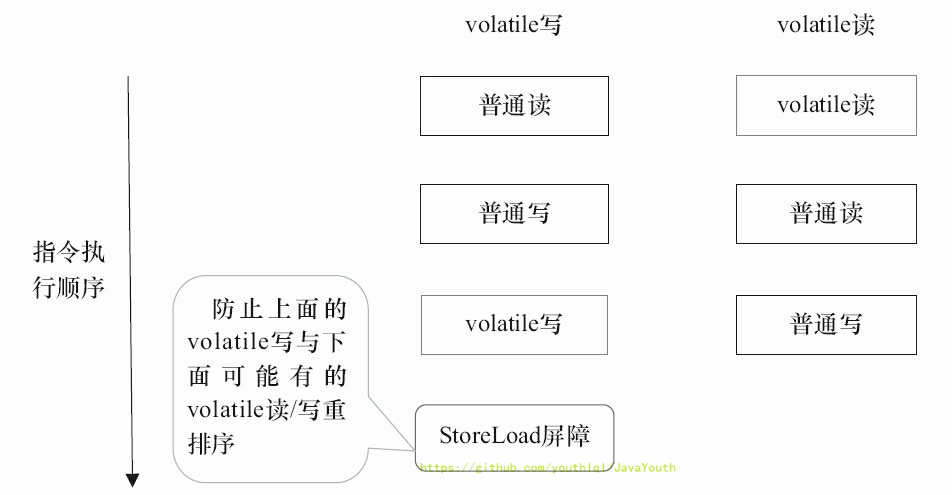 770 |
771 |
772 |
773 | ## volatile的用途
774 |
775 | > 下面的代码在前面可能已经写过了,这里总结一下
776 |
777 | 从volatile的内存语义上来看,volatile可以保证内存可见性且禁止重排序。
778 |
779 | 在保证内存可见性这一点上,volatile有着与锁相同的内存语义,所以可以作为一个“轻量级”的锁来使用。但由于volatile仅仅保证对单个volatile变量的读/写具有原子性,而锁可以保证整个**临界区代码**的执行具有原子性。所以**在功能上,锁比volatile更强大;在性能上,volatile更有优势**。
780 |
781 | 在禁止重排序这一点上,volatile也是非常有用的。比如我们熟悉的单例模式,其中有一种实现方式是“双重锁检查”,比如这样的代码:
782 |
783 | ```java
784 | public class Singleton {
785 |
786 | private static Singleton instance; // 不使用volatile关键字
787 |
788 | // 双重锁检验
789 | public static Singleton getInstance() {
790 | if (instance == null) { // 第7行
791 | synchronized (Singleton.class) {
792 | if (instance == null) {
793 | instance = new Singleton(); // 第10行
794 | }
795 | }
796 | }
797 | return instance;
798 | }
799 | }
800 | ```
801 |
802 | 如果这里的变量声明不使用volatile关键字,是可能会发生错误的。它可能会被重排序:
803 |
804 | ```java
805 | instance = new Singleton(); // 第10行
806 |
807 | // 可以分解为以下三个步骤
808 | 1 memory=allocate();// 分配内存 相当于c的malloc
809 | 2 ctorInstanc(memory) //初始化对象
810 | 3 s=memory //设置s指向刚分配的地址
811 |
812 | // 上述三个步骤可能会被重排序为 1-3-2,也就是:
813 | 1 memory=allocate();// 分配内存 相当于c的malloc
814 | 3 s=memory //设置s指向刚分配的地址
815 | 2 ctorInstanc(memory) //初始化对象
816 | ```
817 |
818 | 而一旦假设发生了这样的重排序,比如线程A在第10行执行了步骤1和步骤3,但是步骤2还没有执行完。这个时候另一个线程B执行到了第7行,它会判定instance不为空,然后直接返回了一个未初始化完成的instance!
819 |
820 | 所以JSR-133对volatile做了增强后,volatile的禁止重排序功能还是非常有用的。
--------------------------------------------------------------------------------
/docs/design_patterns/设计模式-03.01-创建型-单例.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 设计模式-03.01-创建型-单例
3 | tags:
4 | - 设计模式
5 | - 单例
6 | categories:
7 | - 设计模式
8 | - 03.创建型
9 | keywords: 设计模式,单例
10 | description: 详解了单例设计模式。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/design_patterns.jpg'
12 | abbrlink: b5a1ed4a
13 | date: 2021-06-26 21:51:58
14 | ---
15 |
16 |
17 |
18 |
19 |
20 | # 前言
21 |
22 | 23 种经典的设计模式。它们又可以分为三大类:创建型、结构型、行为型。对于这 23 种设计模式的学习,我们要有侧重点,因为有些模式是比较常用的,有些模式是很少被用到的。对于常用的设计模式,我们要花多点时间理解掌握。对于不常用的设计模式,我们只需要稍微了解即可。按照类型和是否常用,对这些设计模式,进行了简单的分类,具体如下所示。
23 |
24 | ### 创建型
25 |
26 | 常用的有:单例模式、工厂模式(工厂方法和抽象工厂)、建造者模式。
27 |
28 | 不常用的有:原型模式。
29 |
30 |
31 |
32 | ### 结构型
33 |
34 | 常用的有:代理模式、桥接模式、装饰者模式、适配器模式。
35 |
36 | 不常用的有:门面模式、组合模式、享元模式。
37 |
38 |
39 |
40 | ### 行为型
41 |
42 | 常用的有:观察者模式、模板模式、策略模式、职责链模式、迭代器模式、状态模式。
43 |
44 | 不常用的有:访问者模式、备忘录模式、命令模式、解释器模式、中介模式。
45 |
46 |
47 |
48 |
49 |
50 | # 单例模式【常用】
51 |
52 | 网上有很多讲解单例模式的文章,但大部分都侧重讲解,如何来实现一个线程安全的单例。今天也会讲到各种单例的实现方法,但是,重点还是希望带你搞清楚下面这样几个问题。
53 |
54 | - 为什么要使用单例?
55 | - 单例存在哪些问题?
56 | - 单例与静态类的区别?
57 | - 有何替代的解决方案?
58 |
59 |
60 |
61 | ## 为什么要使用单例?
62 |
63 | 单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
64 |
65 | 对于单例的概念,我觉得没必要解释太多,你一看就能明白。我们重点看一下,为什么我们需要单例这种设计模式?它能解决哪些问题?接下来我通过两个实战案例来讲解。
66 |
67 |
68 |
69 | ### 实战案例一:处理资源访问冲突
70 |
71 | 我们先来看第一个例子。在这个例子中,我们自定义实现了一个往文件中打印日志的 Logger 类。具体的代码实现如下所示:
72 |
73 | ```java
74 | public class Logger {
75 | private FileWriter writer;
76 |
77 | public Logger() {
78 | File file = new File("/Users/wangzheng/log.txt");
79 | writer = new FileWriter(file, true); //true表示追加写入
80 | }
81 |
82 | public void log(String message) {
83 | writer.write(message);
84 | }
85 | }
86 |
87 | // Logger类的应用示例:
88 | public class UserController {
89 | private Logger logger = new Logger();
90 |
91 | public void login(String username, String password) {
92 | // ...省略业务逻辑代码...
93 | logger.log(username + " logined!");
94 | }
95 | }
96 |
97 | public class OrderController {
98 | private Logger logger = new Logger();
99 |
100 | public void create(OrderVo order) {
101 | // ...省略业务逻辑代码...
102 | logger.log("Created an order: " + order.toString());
103 | }
104 | }
105 | ```
106 |
107 | 在上面的代码中,我们注意到,所有的日志都写入到同一个文件 /Users/wangzheng/log.txt 中。在 UserController 和 OrderController 中,我们分别创建两个 Logger 对象。在 Web 容器的 Servlet 多线程环境下,如果两个 Servlet 线程同时分别执行 login() 和 create() 两个函数,并且同时写日志到 log.txt 文件中,那就有可能存在日志信息互相覆盖的情况。【这属于并发的知识点,看不懂的可以看笔者的并发系列】
108 |
109 |
110 |
111 | 那如何来解决这个问题呢?我们最先想到的就是通过加锁的方式:给 log() 函数加互斥锁,同一时刻只允许一个线程调用执行 log() 函数。
112 |
113 | ```java
114 | public class Logger {
115 | private FileWriter writer;
116 |
117 | public Logger() {
118 | File file = new File("/Users/wangzheng/log.txt");
119 | writer = new FileWriter(file, true); //true表示追加写入
120 | }
121 |
122 | public void log(String message) {
123 | synchronized(this) {
124 | writer.write(mesasge);
125 | }
126 | }
127 | }
128 | ```
129 |
130 | `synchronized(this)`这种对象级别的锁,锁不住,因为不同的对象之间并不共享同一把锁。所以我们换成类级别的锁。
131 |
132 | ```java
133 | public class Logger {
134 | private FileWriter writer;
135 |
136 | public Logger() {
137 | File file = new File("/Users/wangzheng/log.txt");
138 | writer = new FileWriter(file, true); //true表示追加写入
139 | }
140 |
141 | public void log(String message) {
142 | synchronized(Logger.class) { // 类级别的锁
143 | writer.write(mesasge);
144 | }
145 | }
146 | }
147 | ```
148 |
149 | 除了使用类级别锁之外,实际上,解决资源竞争问题的办法还有很多,分布式锁是最常听到的一种解决方案。不过,实现一个安全可靠、无 bug、高性能的分布式锁,并不是件容易的事情。除此之外,并发队列(比如 Java 中的 BlockingQueue)也可以解决这个问题:多个线程同时往并发队列里写日志,一个单独的线程负责将并发队列中的数据,写入到日志文件。这种方式实现起来也稍微有点复杂。
150 |
151 |
152 |
153 | 相对于这两种解决方案,单例模式的解决思路就简单一些了。单例模式相对于之前类级别锁的好处是,不用创建那么多 Logger 对象,一方面节省内存空间,另一方面节省系统文件句柄(对于操作系统来说,文件句柄也是一种资源,不能随便浪费)。
154 |
155 | 我们将 Logger 设计成一个单例类,程序中只允许创建一个 Logger 对象,所有的线程共享使用的这一个 Logger 对象,共享一个 FileWriter 对象,而 FileWriter 本身是对象级别线程安全的,也就避免了多线程情况下写日志会互相覆盖的问题。按照这个设计思路,我们实现了 Logger 单例类。具体代码如下所示:
156 |
157 | ```java
158 | public class Logger {
159 | private FileWriter writer;
160 | private static final Logger instance = new Logger();
161 |
162 | private Logger() {
163 | File file = new File("/Users/wangzheng/log.txt");
164 | writer = new FileWriter(file, true); //true表示追加写入
165 | }
166 |
167 | public static Logger getInstance() {
168 | return instance;
169 | }
170 |
171 | public void log(String message) {
172 | writer.write(mesasge);
173 | }
174 | }
175 |
176 | // Logger类的应用示例:
177 | public class UserController {
178 | public void login(String username, String password) {
179 | // ...省略业务逻辑代码...
180 | Logger.getInstance().log(username + " logined!");
181 | }
182 | }
183 |
184 | public class OrderController {
185 | public void create(OrderVo order) {
186 | // ...省略业务逻辑代码...
187 | Logger.getInstance().log("Created a order: " + order.toString());
188 | }
189 | }
190 | ```
191 |
192 |
193 |
194 | ### 实战案例二:表示全局唯一类
195 |
196 | 从业务概念上,如果有些数据在系统中只应保存一份,那就比较适合设计为单例类。比如,配置信息类。在系统中,我们只有一个配置文件,当配置文件被加载到内存之后,以对象的形式存在,也理所应当只有一份。
197 |
198 | 再比如,唯一递增 ID 号码生成器。如果程序中有两个对象,那就会存在生成重复 ID 的情况,所以,我们应该将 ID 生成器类设计为单例。
199 |
200 | ```java
201 | public class IdGenerator {
202 | // AtomicLong是一个Java并发库中提供的一个原子变量类型,
203 | // 它将一些线程不安全需要加锁的复合操作封装为了线程安全的原子操作,
204 | // 比如下面会用到的incrementAndGet().
205 | private AtomicLong id = new AtomicLong(0);
206 | private static final IdGenerator instance = new IdGenerator();
207 | private IdGenerator() {}
208 | public static IdGenerator getInstance() {
209 | return instance;
210 | }
211 | public long getId() {
212 | return id.incrementAndGet();
213 | }
214 | }
215 |
216 | // IdGenerator使用举例
217 | long id = IdGenerator.getInstance().getId();
218 | ```
219 |
220 |
221 |
222 | ## 如何实现一个单例?
223 |
224 | 尽管介绍如何实现一个单例模式的文章已经有很多了,但为了保证内容的完整性,我这里还是简单介绍一下几种经典实现方式。概括起来,要实现一个单例,我们需要关注的点无外乎下面几个:
225 |
226 | - 构造函数需要是 private 访问权限的,这样才能避免外部通过 new 创建实例;
227 |
228 | - 考虑对象创建时的线程安全问题;
229 |
230 | - 考虑是否支持延迟加载;
231 |
232 | - 考虑 getInstance() 性能是否高(是否加锁)。
233 |
234 |
235 |
236 | ### 饿汉式(静态变量)
237 |
238 | 饿汉式的实现方式比较简单。在类加载的时候,instance 静态实例就已经创建并初始化好了,所以,instance 实例的创建过程是线程安全的。不过,这样的实现方式不支持延迟加载(在真正用到 IdGenerator 的时候,再创建实例),从名字中我们也可以看出这一点。具体的代码实现如下所示:
239 |
240 | ```java
241 | public class IdGenerator {
242 | private AtomicLong id = new AtomicLong(0);
243 | private static final IdGenerator instance = new IdGenerator();
244 | private IdGenerator() {}
245 | public static IdGenerator getInstance() {
246 | return instance;
247 | }
248 | public long getId() {
249 | return id.incrementAndGet();
250 | }
251 | }
252 | ```
253 |
254 |
255 |
256 | 1. 有人觉得这种实现方式不好,因为不支持延迟加载,如果实例占用资源多(比如占用内存多)或初始化耗时长(比如需要加载各种配置文件),提前初始化实例是一种浪费资源的行为。最好的方法应该在用到的时候再去初始化。不过,我个人并不认同这样的观点
257 | 2. 如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)。采用饿汉式实现方式,将耗时的初始化操作,提前到程序启动的时候完成,这样就能避免在程序运行的时候,再去初始化导致的性能问题。
258 | 3. 如果实例占用资源多,按照 fail-fast 的设计原则(有问题及早暴露),那我们也希望在程序启动时就将这个实例初始化好。如果资源不够,就会在程序启动的时候触发报错(比如 Java 中的 PermGen Space OOM),我们可以立即去修复。这样也能避免在程序运行一段时间后,突然因为初始化这个实例占用资源过多,导致系统崩溃,影响系统的可用性。(如果初始化消耗资源过多,反而推荐懒汉式,早日发现问题)
259 |
260 |
261 |
262 | ### 饿汉式(静态代码块)
263 |
264 | ```java
265 |
266 | public class SingletonTest02 {
267 |
268 | public static void main(String[] args) {
269 | // 测试
270 | Singleton instance = Singleton.getInstance();
271 | Singleton instance2 = Singleton.getInstance();
272 | System.out.println(instance == instance2); // true
273 | System.out.println("instance.hashCode=" + instance.hashCode());
274 | System.out.println("instance2.hashCode=" + instance2.hashCode());
275 | }
276 | }
277 |
278 | // 饿汉式(静态变量)
279 |
280 | class Singleton {
281 |
282 | // 1. 构造器私有化
283 | private Singleton() {}
284 |
285 | // 2.本类内部创建对象实例
286 | private static Singleton instance;
287 |
288 | static { // 在静态代码块中,创建单例对象
289 | instance = new Singleton();
290 | }
291 |
292 | // 3. 提供一个公有的静态方法,返回实例对象
293 | public static Singleton getInstance() {
294 | return instance;
295 | }
296 | }
297 |
298 | ```
299 |
300 | 没什么好说的,就是静态变量换成了静态代码块。
301 |
302 |
303 |
304 |
305 |
306 | ### 懒汉式(线程安全,同步方法)
307 |
308 | 懒汉式相对于饿汉式的优势是支持延迟加载。具体的代码实现如下所示:
309 |
310 | ```java
311 | public class IdGenerator {
312 | private AtomicLong id = new AtomicLong(0);
313 | private static IdGenerator instance;
314 | private IdGenerator() {}
315 | public static synchronized IdGenerator getInstance() {
316 | if (instance == null) {
317 | instance = new IdGenerator();
318 | }
319 | return instance;
320 | }
321 | public long getId() {
322 | return id.incrementAndGet();
323 | }
324 | }
325 | ```
326 |
327 | 不过懒汉式的缺点也很明显,我们给 getInstance() 这个方法加了一把大锁(synchronzed),导致这个函数的并发度很低。而这个函数是在单例使用期间,一直会被调用。如果这个单例类偶尔会被用到,那这种实现方式还可以接受。但是,如果频繁地用到,那频繁加锁、释放锁及并发度低等问题,会导致性能瓶颈,这种实现方式就不可取了。
328 |
329 |
330 |
331 | ### 懒汉式(线程安全,同步代码块)
332 |
333 | ```java
334 | // 懒汉式(线程安全,同步代码块)
335 | class Singleton {
336 | private static Singleton instance;
337 |
338 | private Singleton() {}
339 |
340 | public static Singleton getInstance() {
341 | if (instance == null) {
342 | synchronized (Singleton.class) {
343 | instance = new Singleton();
344 | }
345 | }
346 | return instance;
347 | }
348 | }
349 | ```
350 |
351 |
352 |
353 | ### 懒汉式(线程不安全)
354 |
355 |
356 |
357 | ```java
358 | class Singleton {
359 | private static Singleton instance;
360 |
361 | private Singleton() {}
362 |
363 | // 提供一个静态的公有方法,当使用到该方法时,才去创建 instance
364 | // 即懒汉式
365 | public static Singleton getInstance() {
366 | if (instance == null) {
367 | instance = new Singleton();
368 | }
369 | return instance;
370 | }
371 | ```
372 |
373 | 只是为了完整性,写了出来,实际开发不推荐用线程不安全的
374 |
375 | ### 双重检测
376 |
377 | 饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式。在这种实现方式中,只要 instance 被创建之后,即便再调用 getInstance() 函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。具体的代码实现如下所示:
378 |
379 | ```java
380 | public class IdGenerator {
381 | private AtomicLong id = new AtomicLong(0);
382 | private static IdGenerator instance;
383 | private IdGenerator() {}
384 | public static IdGenerator getInstance() {
385 | if (instance == null) {
386 | synchronized(IdGenerator.class) { // 此处为类级别的锁
387 | if (instance == null) {
388 | instance = new IdGenerator();
389 | }
390 | }
391 | }
392 | return instance;
393 | }
394 | public long getId() {
395 | return id.incrementAndGet();
396 | }
397 | }
398 | ```
399 |
400 |
401 |
402 | 这种实现方式有些问题。因为指令重排序,可能会导致 IdGenerator 对象被 new 出来,并且赋值给 instance 之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了。要解决这个问题,我们需要给 instance 成员变量加上 volatile 关键字,禁止指令重排序才行。
403 |
404 | 据说,只有很低版本的 Java 才会有这个问题。我们现在用的高版本的 Java 已经在 JDK 内部实现中解决了这个问题(解决的方法很简单,只要把对象 new 操作和初始化操作设计为原子操作,就自然能禁止重排序)。
405 |
406 |
407 |
408 | ### 静态内部类
409 |
410 | 我们再来看一种比双重检测更加简单的实现方法,那就是利用 Java 的静态内部类。它有点类似饿汉式,但又能做到了延迟加载。具体是怎么做到的呢?我们先来看它的代码实现
411 |
412 | ```java
413 | public class IdGenerator {
414 | private AtomicLong id = new AtomicLong(0);
415 | private IdGenerator() {}
416 |
417 | private static class SingletonHolder{
418 | private static final IdGenerator instance = new IdGenerator();
419 | }
420 |
421 | public static IdGenerator getInstance() {
422 | return SingletonHolder.instance;
423 | }
424 |
425 | public long getId() {
426 | return id.incrementAndGet();
427 | }
428 | }
429 | ```
430 |
431 | SingletonHolder 是一个静态内部类,当外部类 IdGenerator 被加载的时候,并不会创建 SingletonHolder 实例对象。只有当调用 getInstance() 方法时,SingletonHolder 才会被加载,这个时候才会创建 instance。instance 的唯一性、创建过程的线程安全性,都由 JVM 来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
432 |
433 |
434 |
435 | ### 枚举
436 |
437 | 最后,我们介绍一种最简单的实现方式,基于枚举类型的单例实现。这种实现方式通过 Java 枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性。具体的代码如下所示:
438 |
439 | ```java
440 | public enum IdGenerator {
441 | INSTANCE;
442 | private AtomicLong id = new AtomicLong(0);
443 |
444 | public long getId() {
445 | return id.incrementAndGet();
446 | }
447 | }
448 | ```
449 |
450 |
451 |
452 | ## 单例存在哪些问题?
453 |
454 | 尽管单例是一个很常用的设计模式,在实际的开发中,我们也确实经常用到它,但是,有些人认为单例是一种反模式(anti-pattern),并不推荐使用。大部分情况下,我们在项目中使用单例,都是用它来表示一些全局唯一类,比如配置信息类、连接池类、ID 生成器类。单例模式书写简洁、使用方便,在代码中,我们不需要创建对象,直接通过类似 IdGenerator.getInstance().getId() 这样的方法来调用就可以了。但是,这种使用方法有点类似硬编码(hard code),会带来诸多问题。接下来,我们就具体看看到底有哪些问题。
455 |
456 |
457 |
458 | ### 单例对 OOP 特性的支持不友好
459 |
460 | 我们知道,OOP 的四大特性是封装、抽象、继承、多态。单例这种设计模式对于其中的抽象、继承、多态都支持得不好。为什么这么说呢?我们还是通过 IdGenerator 这个例子来讲解。
461 |
462 | ```java
463 | public class Order {
464 | public void create(...) {
465 | //...
466 | long id = IdGenerator.getInstance().getId();
467 | //...
468 | }
469 | }
470 |
471 | public class User {
472 | public void create(...) {
473 | // ...
474 | long id = IdGenerator.getInstance().getId();
475 | //...
476 | }
477 | }
478 | ```
479 |
480 | IdGenerator 的使用方式违背了基于接口而非实现的设计原则,也就违背了广义上理解的 OOP 的抽象特性。如果未来某一天,我们希望针对不同的业务采用不同的 ID 生成算法。比如,订单 ID 和用户 ID 采用不同的 ID 生成器来生成。为了应对这个需求变化,我们需要修改所有用到 IdGenerator 类的地方,这样代码的改动就会比较大。
481 |
482 | ```java
483 | public class Order {
484 | public void create(...) {
485 | //...
486 | long id = IdGenerator.getInstance().getId();
487 | // 需要将上面一行代码,替换为下面一行代码
488 | long id = OrderIdGenerator.getIntance().getId();
489 | //...
490 | }
491 | }
492 |
493 | public class User {
494 | public void create(...) {
495 | // ...
496 | long id = IdGenerator.getInstance().getId();
497 | // 需要将上面一行代码,替换为下面一行代码
498 | long id = UserIdGenerator.getIntance().getId();
499 | }
500 | }
501 | ```
502 |
503 | 除此之外,单例对继承、多态特性的支持也不友好。这里我之所以会用“不友好”这个词,而非“完全不支持”,是因为从理论上来讲,单例类也可以被继承、也可以实现多态,只是实现起来会非常奇怪,会导致代码的可读性变差。不明白设计意图的人,看到这样的设计,会觉得莫名其妙。所以,一旦你选择将某个类设计成到单例类,也就意味着放弃了继承和多态这两个强有力的面向对象特性,也就相当于损失了可以应对未来需求变化的扩展性
504 |
505 |
506 |
507 | ### 单例会隐藏类之间的依赖关系
508 |
509 | 我们知道,代码的可读性非常重要。在阅读代码的时候,我们希望一眼就能看出类与类之间的依赖关系,搞清楚这个类依赖了哪些外部类。通过构造函数、参数传递等方式声明的类之间的依赖关系,我们通过查看函数的定义,就能很容易识别出来。但是,单例类不需要显示创建、不需要依赖参数传递,在函数中直接调用就可以了。如果代码比较复杂,这种调用关系就会非常隐蔽。在阅读代码的时候,我们就需要仔细查看每个函数的代码实现,才能知道这个类到底依赖了哪些单例类。
510 |
511 |
512 |
513 |
514 |
515 | ### 单例对代码的扩展性不友好
516 |
517 | 1. 我们知道,单例类只能有一个对象实例。如果未来某一天,我们需要在代码中创建两个实例或多个实例,那就要对代码有比较大的改动。你可能会说,会有这样的需求吗?既然单例类大部分情况下都用来表示全局类,怎么会需要两个或者多个实例呢?
518 | 2. 实际上,这样的需求并不少见。我们拿数据库连接池来举例解释一下。
519 | 3. 在系统设计初期,我们觉得系统中只应该有一个数据库连接池,这样能方便我们控制对数据库连接资源的消耗。所以,我们把数据库连接池类设计成了单例类。但之后我们发现,系统中有些 SQL 语句运行得非常慢。这些 SQL 语句在执行的时候,长时间占用数据库连接资源,导致其他 SQL 请求无法响应。为了解决这个问题,我们希望将慢 SQL 与其他 SQL 隔离开来执行。为了实现这样的目的,我们可以在系统中创建两个数据库连接池,慢 SQL 独享一个数据库连接池,其他 SQL 独享另外一个数据库连接池,这样就能避免慢 SQL 影响到其他 SQL 的执行。
520 | 4. 如果我们将数据库连接池设计成单例类,显然就无法适应这样的需求变更,也就是说,单例类在某些情况下会影响代码的扩展性、灵活性。所以,数据库连接池、线程池这类的资源池,最好还是不要设计成单例类。实际上,一些开源的数据库连接池、线程池也确实没有设计成单例类。
521 |
522 |
523 |
524 | ### 单例对代码的可测试性不友好
525 |
526 | 1. 单例模式的使用会影响到代码的可测试性。如果单例类依赖比较重的外部资源,比如 DB,我们在写单元测试的时候,希望能通过 mock 的方式将它替换掉。而单例类这种硬编码式的使用方式,导致无法实现 mock 替换。
527 |
528 | 2. 除此之外,如果单例类持有成员变量(比如 IdGenerator 中的 id 成员变量),那它实际上相当于一种全局变量,被所有的代码共享。如果这个全局变量是一个可变全局变量,也就是说,它的成员变量是可以被修改的,那我们在编写单元测试的时候,还需要注意不同测试用例之间,修改了单例类中的同一个成员变量的值,从而导致测试结果互相影响的问题。
529 |
530 |
531 |
532 |
533 |
534 | ### 单例不支持有参数的构造函数
535 |
536 | 单例不支持有参数的构造函数,比如我们创建一个连接池的单例对象,我们没法通过参数来指定连接池的大小。针对这个问题,我们来看下都有哪些解决方案。
537 |
538 |
539 |
540 | **第一种解决思路是**:创建完实例之后,再调用 init() 函数传递参数。需要注意的是,我们在使用这个单例类的时候,要先调用 init() 方法,然后才能调用 getInstance() 方法,否则代码会抛出异常。具体的代码实现如下所示:
541 |
542 | ```java
543 | public class Singleton {
544 | private static Singleton instance = null;
545 | private final int paramA;
546 | private final int paramB;
547 |
548 | private Singleton(int paramA, int paramB) {
549 | this.paramA = paramA;
550 | this.paramB = paramB;
551 | }
552 |
553 | public static Singleton getInstance() {
554 | if (instance == null) {
555 | throw new RuntimeException("Run init() first.");
556 | }
557 | return instance;
558 | }
559 |
560 | public synchronized static Singleton init(int paramA, int paramB) {
561 | if (instance != null){
562 | throw new RuntimeException("Singleton has been created!");
563 | }
564 | instance = new Singleton(paramA, paramB);
565 | return instance;
566 | }
567 | }
568 |
569 | Singleton.init(10, 50); // 先init,再使用
570 | Singleton singleton = Singleton.getInstance();
571 | ```
572 |
573 |
574 |
575 | **第二种解决思路是**:将参数放到 getIntance() 方法中。具体的代码实现如下所示:
576 |
577 | ```java
578 | public class Singleton {
579 | private static Singleton instance = null;
580 | private final int paramA;
581 | private final int paramB;
582 |
583 | private Singleton(int paramA, int paramB) {
584 | this.paramA = paramA;
585 | this.paramB = paramB;
586 | }
587 |
588 | public synchronized static Singleton getInstance(int paramA, int paramB) {
589 | if (instance == null) {
590 | instance = new Singleton(paramA, paramB);
591 | }
592 | return instance;
593 | }
594 | }
595 |
596 | Singleton singleton = Singleton.getInstance(10, 50);
597 | ```
598 |
599 |
600 |
601 | 不知道你有没有发现,上面的代码实现稍微有点问题。如果我们如下两次执行 getInstance() 方法,那获取到的 singleton1 和 signleton2 的 paramA 和 paramB 都是 10 和 50。也就是说,第二次的参数(20,30)没有起作用,而构建的过程也没有给与提示,这样就会误导用户。
602 |
603 | ```java
604 | Singleton singleton1 = Singleton.getInstance(10, 50);
605 | Singleton singleton2 = Singleton.getInstance(20, 30);
606 | ```
607 |
608 |
609 |
610 |
611 |
612 | **第三种解决思路是**:将参数放到另外一个全局变量中。具体的代码实现如下。Config 是一个存储了 paramA 和 paramB 值的全局变量。里面的值既可以像下面的代码那样通过静态常量来定义,也可以从配置文件中加载得到。**实际上,这种方式是最值得推荐的。**
613 |
614 | ```java
615 | public class Config {
616 | public static final int PARAM_A = 123;
617 | public static final int PARAM_B = 245;
618 | }
619 |
620 | public class Singleton {
621 | private static Singleton instance = null;
622 | private final int paramA;
623 | private final int paramB;
624 |
625 | private Singleton() {
626 | this.paramA = Config.PARAM_A;
627 | this.paramB = Config.PARAM_B;
628 | }
629 |
630 | public synchronized static Singleton getInstance() {
631 | if (instance == null) {
632 | instance = new Singleton();
633 | }
634 | return instance;
635 | }
636 | }
637 | ```
638 |
639 |
640 |
641 | ## 有何替代解决方案?
642 |
643 | 刚刚我们提到了单例的很多问题,你可能会说,即便单例有这么多问题,但我不用不行啊。我业务上有表示全局唯一类的需求,如果不用单例,我怎么才能保证这个类的对象全局唯一呢?为了保证全局唯一,除了使用单例,我们还可以用静态方法来实现。这也是项目开发中经常用到的一种实现思路。比如, ID 唯一递增生成器的例子,用静态方法实现一下,就是下面这个样子:
644 |
645 | ```java
646 | // 静态方法实现方式
647 | public class IdGenerator {
648 | private static AtomicLong id = new AtomicLong(0);
649 |
650 | public static long getId() {
651 | return id.incrementAndGet();
652 | }
653 | }
654 | // 使用举例
655 | long id = IdGenerator.getId();
656 | ```
657 |
658 | 不过,静态方法这种实现思路,并不能解决我们之前提到的问题。实际上,它比单例更加不灵活,比如,它无法支持延迟加载。我们再来看看有没有其他办法。实际上,单例除了我们之前讲到的使用方法之外,还有另外一种使用方法。具体的代码如下所示:
659 |
660 | ```java
661 | // 1. 老的使用方式
662 | public demofunction() {
663 | //...
664 | long id = IdGenerator.getInstance().getId();
665 | //...
666 | }
667 |
668 | // 2. 新的使用方式:依赖注入
669 | public demofunction(IdGenerator idGenerator) {
670 | long id = idGenerator.getId();
671 | }
672 | // 外部调用demofunction()的时候,传入idGenerator
673 | IdGenerator idGenerator = IdGenerator.getInsance();
674 | demofunction(idGenerator);
675 | ```
676 |
677 |
678 |
679 | 1. 基于新的使用方式,我们将单例生成的对象,作为参数传递给函数(也可以通过构造函数传递给类的成员变量),可以解决单例隐藏类之间依赖关系的问题。不过,对于单例存在的其他问题,比如对 OOP 特性、扩展性、可测性不友好等问题,还是无法解决。
680 | 2. 所以,如果要完全解决这些问题,我们可能要从根上,寻找其他方式来实现全局唯一类。实际上,类对象的全局唯一性可以通过多种不同的方式来保证。我们既可以通过单例模式来强制保证,也可以通过工厂模式、IOC 容器(比如 Spring IOC 容器)来保证,还可以通过程序员自己来保证(自己在编写代码的时候自己保证不要创建两个类对象)。这就类似 Java 中内存对象的释放由 JVM 来负责,而 C++ 中由程序员自己负责,道理是一样的。
681 | 3. 对于替代方案工厂模式、IOC 容器的详细讲解,我们放到后面讲解。
682 |
683 |
684 |
685 | ## 如何理解单例模式中的唯一性?
686 |
687 | 1. 首先,我们重新看一下单例的定义:“一个类只允许创建唯一一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
688 | 2. ”定义中提到,“一个类只允许创建唯一一个对象”。那对象的唯一性的作用范围是什么呢?是指线程内只允许创建一个对象,还是指进程内只允许创建一个对象?答案是后者,也就是说,单例模式创建的对象是进程唯一的。这里有点不好理解,我来详细地解释一下。
689 | 3. 我们编写的代码,通过编译、链接,组织在一起,就构成了一个操作系统可以执行的文件,也就是我们平时所说的“可执行文件”(比如 Windows 下的 exe 文件)。可执行文件实际上就是代码被翻译成操作系统可理解的一组指令,你完全可以简单地理解为就是代码本身。
690 | 4. 当我们使用命令行或者双击运行这个可执行文件的时候,操作系统会启动一个进程,将这个执行文件从磁盘加载到自己的进程地址空间(可以理解操作系统为进程分配的内存存储区,用来存储代码和数据)。接着,进程就一条一条地执行可执行文件中包含的代码。比如,当进程读到代码中的 User user = new User(); 这条语句的时候,它就在自己的地址空间中创建一个 user 临时变量和一个 User 对象。进程之间是不共享地址空间的,如果我们在一个进程中创建另外一个进程(比如,代码中有一个 fork() 语句,进程执行到这条语句的时候会创建一个新的进程),操作系统会给新进程分配新的地址空间,并且将老进程地址空间的所有内容,重新拷贝一份到新进程的地址空间中,这些内容包括代码、数据(比如 user 临时变量、User 对象)。
691 | 5. 所以,单例类在老进程中存在且只能存在一个对象,在新进程中也会存在且只能存在一个对象。而且,这两个对象并不是同一个对象,这也就说,单例类中对象的唯一性的作用范围是进程内的,在进程间是不唯一的。
692 |
693 |
694 |
695 | ## 如何实现线程唯一的单例?
696 |
697 | 1. 刚刚我们讲了单例类对象是进程唯一的,一个进程只能有一个单例对象。那如何实现一个线程唯一的单例呢?
698 |
699 | 2. 我们先来看一下,什么是线程唯一的单例,以及“线程唯一”和“进程唯一”的区别。
700 |
701 | 3. “进程唯一”指的是进程内唯一,进程间不唯一。类比一下,“线程唯一”指的是线程内唯一,线程间可以不唯一。实际上,“进程唯一”还代表了线程内、线程间都唯一,这也是“进程唯一”和“线程唯一”的区别之处。这段话听起来有点像绕口令,我举个例子来解释一下。
702 |
703 | 4. 假设 IdGenerator 是一个线程唯一的单例类。在线程 A 内,我们可以创建一个单例对象 a。因为线程内唯一,在线程 A 内就不能再创建新的 IdGenerator 对象了,而线程间可以不唯一,所以,在另外一个线程 B 内,我们还可以重新创建一个新的单例对象 b。
704 |
705 | 5. 尽管概念理解起来比较复杂,但线程唯一单例的代码实现很简单,如下所示。在代码中,我们通过一个 HashMap 来存储对象,其中 key 是线程 ID,value 是对象。这样我们就可以做到,不同的线程对应不同的对象,同一个线程只能对应一个对象。实际上,Java 语言本身提供了 ThreadLocal 工具类,可以更加轻松地实现线程唯一单例。不过,ThreadLocal 底层实现原理也是基于下面代码中所示的 HashMap。
706 |
707 |
708 |
709 | ```java
710 | public class IdGenerator {
711 | private AtomicLong id = new AtomicLong(0);
712 |
713 | private static final ConcurrentHashMap
770 |
771 |
772 |
773 | ## volatile的用途
774 |
775 | > 下面的代码在前面可能已经写过了,这里总结一下
776 |
777 | 从volatile的内存语义上来看,volatile可以保证内存可见性且禁止重排序。
778 |
779 | 在保证内存可见性这一点上,volatile有着与锁相同的内存语义,所以可以作为一个“轻量级”的锁来使用。但由于volatile仅仅保证对单个volatile变量的读/写具有原子性,而锁可以保证整个**临界区代码**的执行具有原子性。所以**在功能上,锁比volatile更强大;在性能上,volatile更有优势**。
780 |
781 | 在禁止重排序这一点上,volatile也是非常有用的。比如我们熟悉的单例模式,其中有一种实现方式是“双重锁检查”,比如这样的代码:
782 |
783 | ```java
784 | public class Singleton {
785 |
786 | private static Singleton instance; // 不使用volatile关键字
787 |
788 | // 双重锁检验
789 | public static Singleton getInstance() {
790 | if (instance == null) { // 第7行
791 | synchronized (Singleton.class) {
792 | if (instance == null) {
793 | instance = new Singleton(); // 第10行
794 | }
795 | }
796 | }
797 | return instance;
798 | }
799 | }
800 | ```
801 |
802 | 如果这里的变量声明不使用volatile关键字,是可能会发生错误的。它可能会被重排序:
803 |
804 | ```java
805 | instance = new Singleton(); // 第10行
806 |
807 | // 可以分解为以下三个步骤
808 | 1 memory=allocate();// 分配内存 相当于c的malloc
809 | 2 ctorInstanc(memory) //初始化对象
810 | 3 s=memory //设置s指向刚分配的地址
811 |
812 | // 上述三个步骤可能会被重排序为 1-3-2,也就是:
813 | 1 memory=allocate();// 分配内存 相当于c的malloc
814 | 3 s=memory //设置s指向刚分配的地址
815 | 2 ctorInstanc(memory) //初始化对象
816 | ```
817 |
818 | 而一旦假设发生了这样的重排序,比如线程A在第10行执行了步骤1和步骤3,但是步骤2还没有执行完。这个时候另一个线程B执行到了第7行,它会判定instance不为空,然后直接返回了一个未初始化完成的instance!
819 |
820 | 所以JSR-133对volatile做了增强后,volatile的禁止重排序功能还是非常有用的。
--------------------------------------------------------------------------------
/docs/design_patterns/设计模式-03.01-创建型-单例.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 设计模式-03.01-创建型-单例
3 | tags:
4 | - 设计模式
5 | - 单例
6 | categories:
7 | - 设计模式
8 | - 03.创建型
9 | keywords: 设计模式,单例
10 | description: 详解了单例设计模式。
11 | cover: 'https://npm.elemecdn.com/lql_static@latest/logo/design_patterns.jpg'
12 | abbrlink: b5a1ed4a
13 | date: 2021-06-26 21:51:58
14 | ---
15 |
16 |
17 |
18 |
19 |
20 | # 前言
21 |
22 | 23 种经典的设计模式。它们又可以分为三大类:创建型、结构型、行为型。对于这 23 种设计模式的学习,我们要有侧重点,因为有些模式是比较常用的,有些模式是很少被用到的。对于常用的设计模式,我们要花多点时间理解掌握。对于不常用的设计模式,我们只需要稍微了解即可。按照类型和是否常用,对这些设计模式,进行了简单的分类,具体如下所示。
23 |
24 | ### 创建型
25 |
26 | 常用的有:单例模式、工厂模式(工厂方法和抽象工厂)、建造者模式。
27 |
28 | 不常用的有:原型模式。
29 |
30 |
31 |
32 | ### 结构型
33 |
34 | 常用的有:代理模式、桥接模式、装饰者模式、适配器模式。
35 |
36 | 不常用的有:门面模式、组合模式、享元模式。
37 |
38 |
39 |
40 | ### 行为型
41 |
42 | 常用的有:观察者模式、模板模式、策略模式、职责链模式、迭代器模式、状态模式。
43 |
44 | 不常用的有:访问者模式、备忘录模式、命令模式、解释器模式、中介模式。
45 |
46 |
47 |
48 |
49 |
50 | # 单例模式【常用】
51 |
52 | 网上有很多讲解单例模式的文章,但大部分都侧重讲解,如何来实现一个线程安全的单例。今天也会讲到各种单例的实现方法,但是,重点还是希望带你搞清楚下面这样几个问题。
53 |
54 | - 为什么要使用单例?
55 | - 单例存在哪些问题?
56 | - 单例与静态类的区别?
57 | - 有何替代的解决方案?
58 |
59 |
60 |
61 | ## 为什么要使用单例?
62 |
63 | 单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
64 |
65 | 对于单例的概念,我觉得没必要解释太多,你一看就能明白。我们重点看一下,为什么我们需要单例这种设计模式?它能解决哪些问题?接下来我通过两个实战案例来讲解。
66 |
67 |
68 |
69 | ### 实战案例一:处理资源访问冲突
70 |
71 | 我们先来看第一个例子。在这个例子中,我们自定义实现了一个往文件中打印日志的 Logger 类。具体的代码实现如下所示:
72 |
73 | ```java
74 | public class Logger {
75 | private FileWriter writer;
76 |
77 | public Logger() {
78 | File file = new File("/Users/wangzheng/log.txt");
79 | writer = new FileWriter(file, true); //true表示追加写入
80 | }
81 |
82 | public void log(String message) {
83 | writer.write(message);
84 | }
85 | }
86 |
87 | // Logger类的应用示例:
88 | public class UserController {
89 | private Logger logger = new Logger();
90 |
91 | public void login(String username, String password) {
92 | // ...省略业务逻辑代码...
93 | logger.log(username + " logined!");
94 | }
95 | }
96 |
97 | public class OrderController {
98 | private Logger logger = new Logger();
99 |
100 | public void create(OrderVo order) {
101 | // ...省略业务逻辑代码...
102 | logger.log("Created an order: " + order.toString());
103 | }
104 | }
105 | ```
106 |
107 | 在上面的代码中,我们注意到,所有的日志都写入到同一个文件 /Users/wangzheng/log.txt 中。在 UserController 和 OrderController 中,我们分别创建两个 Logger 对象。在 Web 容器的 Servlet 多线程环境下,如果两个 Servlet 线程同时分别执行 login() 和 create() 两个函数,并且同时写日志到 log.txt 文件中,那就有可能存在日志信息互相覆盖的情况。【这属于并发的知识点,看不懂的可以看笔者的并发系列】
108 |
109 |
110 |
111 | 那如何来解决这个问题呢?我们最先想到的就是通过加锁的方式:给 log() 函数加互斥锁,同一时刻只允许一个线程调用执行 log() 函数。
112 |
113 | ```java
114 | public class Logger {
115 | private FileWriter writer;
116 |
117 | public Logger() {
118 | File file = new File("/Users/wangzheng/log.txt");
119 | writer = new FileWriter(file, true); //true表示追加写入
120 | }
121 |
122 | public void log(String message) {
123 | synchronized(this) {
124 | writer.write(mesasge);
125 | }
126 | }
127 | }
128 | ```
129 |
130 | `synchronized(this)`这种对象级别的锁,锁不住,因为不同的对象之间并不共享同一把锁。所以我们换成类级别的锁。
131 |
132 | ```java
133 | public class Logger {
134 | private FileWriter writer;
135 |
136 | public Logger() {
137 | File file = new File("/Users/wangzheng/log.txt");
138 | writer = new FileWriter(file, true); //true表示追加写入
139 | }
140 |
141 | public void log(String message) {
142 | synchronized(Logger.class) { // 类级别的锁
143 | writer.write(mesasge);
144 | }
145 | }
146 | }
147 | ```
148 |
149 | 除了使用类级别锁之外,实际上,解决资源竞争问题的办法还有很多,分布式锁是最常听到的一种解决方案。不过,实现一个安全可靠、无 bug、高性能的分布式锁,并不是件容易的事情。除此之外,并发队列(比如 Java 中的 BlockingQueue)也可以解决这个问题:多个线程同时往并发队列里写日志,一个单独的线程负责将并发队列中的数据,写入到日志文件。这种方式实现起来也稍微有点复杂。
150 |
151 |
152 |
153 | 相对于这两种解决方案,单例模式的解决思路就简单一些了。单例模式相对于之前类级别锁的好处是,不用创建那么多 Logger 对象,一方面节省内存空间,另一方面节省系统文件句柄(对于操作系统来说,文件句柄也是一种资源,不能随便浪费)。
154 |
155 | 我们将 Logger 设计成一个单例类,程序中只允许创建一个 Logger 对象,所有的线程共享使用的这一个 Logger 对象,共享一个 FileWriter 对象,而 FileWriter 本身是对象级别线程安全的,也就避免了多线程情况下写日志会互相覆盖的问题。按照这个设计思路,我们实现了 Logger 单例类。具体代码如下所示:
156 |
157 | ```java
158 | public class Logger {
159 | private FileWriter writer;
160 | private static final Logger instance = new Logger();
161 |
162 | private Logger() {
163 | File file = new File("/Users/wangzheng/log.txt");
164 | writer = new FileWriter(file, true); //true表示追加写入
165 | }
166 |
167 | public static Logger getInstance() {
168 | return instance;
169 | }
170 |
171 | public void log(String message) {
172 | writer.write(mesasge);
173 | }
174 | }
175 |
176 | // Logger类的应用示例:
177 | public class UserController {
178 | public void login(String username, String password) {
179 | // ...省略业务逻辑代码...
180 | Logger.getInstance().log(username + " logined!");
181 | }
182 | }
183 |
184 | public class OrderController {
185 | public void create(OrderVo order) {
186 | // ...省略业务逻辑代码...
187 | Logger.getInstance().log("Created a order: " + order.toString());
188 | }
189 | }
190 | ```
191 |
192 |
193 |
194 | ### 实战案例二:表示全局唯一类
195 |
196 | 从业务概念上,如果有些数据在系统中只应保存一份,那就比较适合设计为单例类。比如,配置信息类。在系统中,我们只有一个配置文件,当配置文件被加载到内存之后,以对象的形式存在,也理所应当只有一份。
197 |
198 | 再比如,唯一递增 ID 号码生成器。如果程序中有两个对象,那就会存在生成重复 ID 的情况,所以,我们应该将 ID 生成器类设计为单例。
199 |
200 | ```java
201 | public class IdGenerator {
202 | // AtomicLong是一个Java并发库中提供的一个原子变量类型,
203 | // 它将一些线程不安全需要加锁的复合操作封装为了线程安全的原子操作,
204 | // 比如下面会用到的incrementAndGet().
205 | private AtomicLong id = new AtomicLong(0);
206 | private static final IdGenerator instance = new IdGenerator();
207 | private IdGenerator() {}
208 | public static IdGenerator getInstance() {
209 | return instance;
210 | }
211 | public long getId() {
212 | return id.incrementAndGet();
213 | }
214 | }
215 |
216 | // IdGenerator使用举例
217 | long id = IdGenerator.getInstance().getId();
218 | ```
219 |
220 |
221 |
222 | ## 如何实现一个单例?
223 |
224 | 尽管介绍如何实现一个单例模式的文章已经有很多了,但为了保证内容的完整性,我这里还是简单介绍一下几种经典实现方式。概括起来,要实现一个单例,我们需要关注的点无外乎下面几个:
225 |
226 | - 构造函数需要是 private 访问权限的,这样才能避免外部通过 new 创建实例;
227 |
228 | - 考虑对象创建时的线程安全问题;
229 |
230 | - 考虑是否支持延迟加载;
231 |
232 | - 考虑 getInstance() 性能是否高(是否加锁)。
233 |
234 |
235 |
236 | ### 饿汉式(静态变量)
237 |
238 | 饿汉式的实现方式比较简单。在类加载的时候,instance 静态实例就已经创建并初始化好了,所以,instance 实例的创建过程是线程安全的。不过,这样的实现方式不支持延迟加载(在真正用到 IdGenerator 的时候,再创建实例),从名字中我们也可以看出这一点。具体的代码实现如下所示:
239 |
240 | ```java
241 | public class IdGenerator {
242 | private AtomicLong id = new AtomicLong(0);
243 | private static final IdGenerator instance = new IdGenerator();
244 | private IdGenerator() {}
245 | public static IdGenerator getInstance() {
246 | return instance;
247 | }
248 | public long getId() {
249 | return id.incrementAndGet();
250 | }
251 | }
252 | ```
253 |
254 |
255 |
256 | 1. 有人觉得这种实现方式不好,因为不支持延迟加载,如果实例占用资源多(比如占用内存多)或初始化耗时长(比如需要加载各种配置文件),提前初始化实例是一种浪费资源的行为。最好的方法应该在用到的时候再去初始化。不过,我个人并不认同这样的观点
257 | 2. 如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)。采用饿汉式实现方式,将耗时的初始化操作,提前到程序启动的时候完成,这样就能避免在程序运行的时候,再去初始化导致的性能问题。
258 | 3. 如果实例占用资源多,按照 fail-fast 的设计原则(有问题及早暴露),那我们也希望在程序启动时就将这个实例初始化好。如果资源不够,就会在程序启动的时候触发报错(比如 Java 中的 PermGen Space OOM),我们可以立即去修复。这样也能避免在程序运行一段时间后,突然因为初始化这个实例占用资源过多,导致系统崩溃,影响系统的可用性。(如果初始化消耗资源过多,反而推荐懒汉式,早日发现问题)
259 |
260 |
261 |
262 | ### 饿汉式(静态代码块)
263 |
264 | ```java
265 |
266 | public class SingletonTest02 {
267 |
268 | public static void main(String[] args) {
269 | // 测试
270 | Singleton instance = Singleton.getInstance();
271 | Singleton instance2 = Singleton.getInstance();
272 | System.out.println(instance == instance2); // true
273 | System.out.println("instance.hashCode=" + instance.hashCode());
274 | System.out.println("instance2.hashCode=" + instance2.hashCode());
275 | }
276 | }
277 |
278 | // 饿汉式(静态变量)
279 |
280 | class Singleton {
281 |
282 | // 1. 构造器私有化
283 | private Singleton() {}
284 |
285 | // 2.本类内部创建对象实例
286 | private static Singleton instance;
287 |
288 | static { // 在静态代码块中,创建单例对象
289 | instance = new Singleton();
290 | }
291 |
292 | // 3. 提供一个公有的静态方法,返回实例对象
293 | public static Singleton getInstance() {
294 | return instance;
295 | }
296 | }
297 |
298 | ```
299 |
300 | 没什么好说的,就是静态变量换成了静态代码块。
301 |
302 |
303 |
304 |
305 |
306 | ### 懒汉式(线程安全,同步方法)
307 |
308 | 懒汉式相对于饿汉式的优势是支持延迟加载。具体的代码实现如下所示:
309 |
310 | ```java
311 | public class IdGenerator {
312 | private AtomicLong id = new AtomicLong(0);
313 | private static IdGenerator instance;
314 | private IdGenerator() {}
315 | public static synchronized IdGenerator getInstance() {
316 | if (instance == null) {
317 | instance = new IdGenerator();
318 | }
319 | return instance;
320 | }
321 | public long getId() {
322 | return id.incrementAndGet();
323 | }
324 | }
325 | ```
326 |
327 | 不过懒汉式的缺点也很明显,我们给 getInstance() 这个方法加了一把大锁(synchronzed),导致这个函数的并发度很低。而这个函数是在单例使用期间,一直会被调用。如果这个单例类偶尔会被用到,那这种实现方式还可以接受。但是,如果频繁地用到,那频繁加锁、释放锁及并发度低等问题,会导致性能瓶颈,这种实现方式就不可取了。
328 |
329 |
330 |
331 | ### 懒汉式(线程安全,同步代码块)
332 |
333 | ```java
334 | // 懒汉式(线程安全,同步代码块)
335 | class Singleton {
336 | private static Singleton instance;
337 |
338 | private Singleton() {}
339 |
340 | public static Singleton getInstance() {
341 | if (instance == null) {
342 | synchronized (Singleton.class) {
343 | instance = new Singleton();
344 | }
345 | }
346 | return instance;
347 | }
348 | }
349 | ```
350 |
351 |
352 |
353 | ### 懒汉式(线程不安全)
354 |
355 |
356 |
357 | ```java
358 | class Singleton {
359 | private static Singleton instance;
360 |
361 | private Singleton() {}
362 |
363 | // 提供一个静态的公有方法,当使用到该方法时,才去创建 instance
364 | // 即懒汉式
365 | public static Singleton getInstance() {
366 | if (instance == null) {
367 | instance = new Singleton();
368 | }
369 | return instance;
370 | }
371 | ```
372 |
373 | 只是为了完整性,写了出来,实际开发不推荐用线程不安全的
374 |
375 | ### 双重检测
376 |
377 | 饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式。在这种实现方式中,只要 instance 被创建之后,即便再调用 getInstance() 函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。具体的代码实现如下所示:
378 |
379 | ```java
380 | public class IdGenerator {
381 | private AtomicLong id = new AtomicLong(0);
382 | private static IdGenerator instance;
383 | private IdGenerator() {}
384 | public static IdGenerator getInstance() {
385 | if (instance == null) {
386 | synchronized(IdGenerator.class) { // 此处为类级别的锁
387 | if (instance == null) {
388 | instance = new IdGenerator();
389 | }
390 | }
391 | }
392 | return instance;
393 | }
394 | public long getId() {
395 | return id.incrementAndGet();
396 | }
397 | }
398 | ```
399 |
400 |
401 |
402 | 这种实现方式有些问题。因为指令重排序,可能会导致 IdGenerator 对象被 new 出来,并且赋值给 instance 之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了。要解决这个问题,我们需要给 instance 成员变量加上 volatile 关键字,禁止指令重排序才行。
403 |
404 | 据说,只有很低版本的 Java 才会有这个问题。我们现在用的高版本的 Java 已经在 JDK 内部实现中解决了这个问题(解决的方法很简单,只要把对象 new 操作和初始化操作设计为原子操作,就自然能禁止重排序)。
405 |
406 |
407 |
408 | ### 静态内部类
409 |
410 | 我们再来看一种比双重检测更加简单的实现方法,那就是利用 Java 的静态内部类。它有点类似饿汉式,但又能做到了延迟加载。具体是怎么做到的呢?我们先来看它的代码实现
411 |
412 | ```java
413 | public class IdGenerator {
414 | private AtomicLong id = new AtomicLong(0);
415 | private IdGenerator() {}
416 |
417 | private static class SingletonHolder{
418 | private static final IdGenerator instance = new IdGenerator();
419 | }
420 |
421 | public static IdGenerator getInstance() {
422 | return SingletonHolder.instance;
423 | }
424 |
425 | public long getId() {
426 | return id.incrementAndGet();
427 | }
428 | }
429 | ```
430 |
431 | SingletonHolder 是一个静态内部类,当外部类 IdGenerator 被加载的时候,并不会创建 SingletonHolder 实例对象。只有当调用 getInstance() 方法时,SingletonHolder 才会被加载,这个时候才会创建 instance。instance 的唯一性、创建过程的线程安全性,都由 JVM 来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
432 |
433 |
434 |
435 | ### 枚举
436 |
437 | 最后,我们介绍一种最简单的实现方式,基于枚举类型的单例实现。这种实现方式通过 Java 枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性。具体的代码如下所示:
438 |
439 | ```java
440 | public enum IdGenerator {
441 | INSTANCE;
442 | private AtomicLong id = new AtomicLong(0);
443 |
444 | public long getId() {
445 | return id.incrementAndGet();
446 | }
447 | }
448 | ```
449 |
450 |
451 |
452 | ## 单例存在哪些问题?
453 |
454 | 尽管单例是一个很常用的设计模式,在实际的开发中,我们也确实经常用到它,但是,有些人认为单例是一种反模式(anti-pattern),并不推荐使用。大部分情况下,我们在项目中使用单例,都是用它来表示一些全局唯一类,比如配置信息类、连接池类、ID 生成器类。单例模式书写简洁、使用方便,在代码中,我们不需要创建对象,直接通过类似 IdGenerator.getInstance().getId() 这样的方法来调用就可以了。但是,这种使用方法有点类似硬编码(hard code),会带来诸多问题。接下来,我们就具体看看到底有哪些问题。
455 |
456 |
457 |
458 | ### 单例对 OOP 特性的支持不友好
459 |
460 | 我们知道,OOP 的四大特性是封装、抽象、继承、多态。单例这种设计模式对于其中的抽象、继承、多态都支持得不好。为什么这么说呢?我们还是通过 IdGenerator 这个例子来讲解。
461 |
462 | ```java
463 | public class Order {
464 | public void create(...) {
465 | //...
466 | long id = IdGenerator.getInstance().getId();
467 | //...
468 | }
469 | }
470 |
471 | public class User {
472 | public void create(...) {
473 | // ...
474 | long id = IdGenerator.getInstance().getId();
475 | //...
476 | }
477 | }
478 | ```
479 |
480 | IdGenerator 的使用方式违背了基于接口而非实现的设计原则,也就违背了广义上理解的 OOP 的抽象特性。如果未来某一天,我们希望针对不同的业务采用不同的 ID 生成算法。比如,订单 ID 和用户 ID 采用不同的 ID 生成器来生成。为了应对这个需求变化,我们需要修改所有用到 IdGenerator 类的地方,这样代码的改动就会比较大。
481 |
482 | ```java
483 | public class Order {
484 | public void create(...) {
485 | //...
486 | long id = IdGenerator.getInstance().getId();
487 | // 需要将上面一行代码,替换为下面一行代码
488 | long id = OrderIdGenerator.getIntance().getId();
489 | //...
490 | }
491 | }
492 |
493 | public class User {
494 | public void create(...) {
495 | // ...
496 | long id = IdGenerator.getInstance().getId();
497 | // 需要将上面一行代码,替换为下面一行代码
498 | long id = UserIdGenerator.getIntance().getId();
499 | }
500 | }
501 | ```
502 |
503 | 除此之外,单例对继承、多态特性的支持也不友好。这里我之所以会用“不友好”这个词,而非“完全不支持”,是因为从理论上来讲,单例类也可以被继承、也可以实现多态,只是实现起来会非常奇怪,会导致代码的可读性变差。不明白设计意图的人,看到这样的设计,会觉得莫名其妙。所以,一旦你选择将某个类设计成到单例类,也就意味着放弃了继承和多态这两个强有力的面向对象特性,也就相当于损失了可以应对未来需求变化的扩展性
504 |
505 |
506 |
507 | ### 单例会隐藏类之间的依赖关系
508 |
509 | 我们知道,代码的可读性非常重要。在阅读代码的时候,我们希望一眼就能看出类与类之间的依赖关系,搞清楚这个类依赖了哪些外部类。通过构造函数、参数传递等方式声明的类之间的依赖关系,我们通过查看函数的定义,就能很容易识别出来。但是,单例类不需要显示创建、不需要依赖参数传递,在函数中直接调用就可以了。如果代码比较复杂,这种调用关系就会非常隐蔽。在阅读代码的时候,我们就需要仔细查看每个函数的代码实现,才能知道这个类到底依赖了哪些单例类。
510 |
511 |
512 |
513 |
514 |
515 | ### 单例对代码的扩展性不友好
516 |
517 | 1. 我们知道,单例类只能有一个对象实例。如果未来某一天,我们需要在代码中创建两个实例或多个实例,那就要对代码有比较大的改动。你可能会说,会有这样的需求吗?既然单例类大部分情况下都用来表示全局类,怎么会需要两个或者多个实例呢?
518 | 2. 实际上,这样的需求并不少见。我们拿数据库连接池来举例解释一下。
519 | 3. 在系统设计初期,我们觉得系统中只应该有一个数据库连接池,这样能方便我们控制对数据库连接资源的消耗。所以,我们把数据库连接池类设计成了单例类。但之后我们发现,系统中有些 SQL 语句运行得非常慢。这些 SQL 语句在执行的时候,长时间占用数据库连接资源,导致其他 SQL 请求无法响应。为了解决这个问题,我们希望将慢 SQL 与其他 SQL 隔离开来执行。为了实现这样的目的,我们可以在系统中创建两个数据库连接池,慢 SQL 独享一个数据库连接池,其他 SQL 独享另外一个数据库连接池,这样就能避免慢 SQL 影响到其他 SQL 的执行。
520 | 4. 如果我们将数据库连接池设计成单例类,显然就无法适应这样的需求变更,也就是说,单例类在某些情况下会影响代码的扩展性、灵活性。所以,数据库连接池、线程池这类的资源池,最好还是不要设计成单例类。实际上,一些开源的数据库连接池、线程池也确实没有设计成单例类。
521 |
522 |
523 |
524 | ### 单例对代码的可测试性不友好
525 |
526 | 1. 单例模式的使用会影响到代码的可测试性。如果单例类依赖比较重的外部资源,比如 DB,我们在写单元测试的时候,希望能通过 mock 的方式将它替换掉。而单例类这种硬编码式的使用方式,导致无法实现 mock 替换。
527 |
528 | 2. 除此之外,如果单例类持有成员变量(比如 IdGenerator 中的 id 成员变量),那它实际上相当于一种全局变量,被所有的代码共享。如果这个全局变量是一个可变全局变量,也就是说,它的成员变量是可以被修改的,那我们在编写单元测试的时候,还需要注意不同测试用例之间,修改了单例类中的同一个成员变量的值,从而导致测试结果互相影响的问题。
529 |
530 |
531 |
532 |
533 |
534 | ### 单例不支持有参数的构造函数
535 |
536 | 单例不支持有参数的构造函数,比如我们创建一个连接池的单例对象,我们没法通过参数来指定连接池的大小。针对这个问题,我们来看下都有哪些解决方案。
537 |
538 |
539 |
540 | **第一种解决思路是**:创建完实例之后,再调用 init() 函数传递参数。需要注意的是,我们在使用这个单例类的时候,要先调用 init() 方法,然后才能调用 getInstance() 方法,否则代码会抛出异常。具体的代码实现如下所示:
541 |
542 | ```java
543 | public class Singleton {
544 | private static Singleton instance = null;
545 | private final int paramA;
546 | private final int paramB;
547 |
548 | private Singleton(int paramA, int paramB) {
549 | this.paramA = paramA;
550 | this.paramB = paramB;
551 | }
552 |
553 | public static Singleton getInstance() {
554 | if (instance == null) {
555 | throw new RuntimeException("Run init() first.");
556 | }
557 | return instance;
558 | }
559 |
560 | public synchronized static Singleton init(int paramA, int paramB) {
561 | if (instance != null){
562 | throw new RuntimeException("Singleton has been created!");
563 | }
564 | instance = new Singleton(paramA, paramB);
565 | return instance;
566 | }
567 | }
568 |
569 | Singleton.init(10, 50); // 先init,再使用
570 | Singleton singleton = Singleton.getInstance();
571 | ```
572 |
573 |
574 |
575 | **第二种解决思路是**:将参数放到 getIntance() 方法中。具体的代码实现如下所示:
576 |
577 | ```java
578 | public class Singleton {
579 | private static Singleton instance = null;
580 | private final int paramA;
581 | private final int paramB;
582 |
583 | private Singleton(int paramA, int paramB) {
584 | this.paramA = paramA;
585 | this.paramB = paramB;
586 | }
587 |
588 | public synchronized static Singleton getInstance(int paramA, int paramB) {
589 | if (instance == null) {
590 | instance = new Singleton(paramA, paramB);
591 | }
592 | return instance;
593 | }
594 | }
595 |
596 | Singleton singleton = Singleton.getInstance(10, 50);
597 | ```
598 |
599 |
600 |
601 | 不知道你有没有发现,上面的代码实现稍微有点问题。如果我们如下两次执行 getInstance() 方法,那获取到的 singleton1 和 signleton2 的 paramA 和 paramB 都是 10 和 50。也就是说,第二次的参数(20,30)没有起作用,而构建的过程也没有给与提示,这样就会误导用户。
602 |
603 | ```java
604 | Singleton singleton1 = Singleton.getInstance(10, 50);
605 | Singleton singleton2 = Singleton.getInstance(20, 30);
606 | ```
607 |
608 |
609 |
610 |
611 |
612 | **第三种解决思路是**:将参数放到另外一个全局变量中。具体的代码实现如下。Config 是一个存储了 paramA 和 paramB 值的全局变量。里面的值既可以像下面的代码那样通过静态常量来定义,也可以从配置文件中加载得到。**实际上,这种方式是最值得推荐的。**
613 |
614 | ```java
615 | public class Config {
616 | public static final int PARAM_A = 123;
617 | public static final int PARAM_B = 245;
618 | }
619 |
620 | public class Singleton {
621 | private static Singleton instance = null;
622 | private final int paramA;
623 | private final int paramB;
624 |
625 | private Singleton() {
626 | this.paramA = Config.PARAM_A;
627 | this.paramB = Config.PARAM_B;
628 | }
629 |
630 | public synchronized static Singleton getInstance() {
631 | if (instance == null) {
632 | instance = new Singleton();
633 | }
634 | return instance;
635 | }
636 | }
637 | ```
638 |
639 |
640 |
641 | ## 有何替代解决方案?
642 |
643 | 刚刚我们提到了单例的很多问题,你可能会说,即便单例有这么多问题,但我不用不行啊。我业务上有表示全局唯一类的需求,如果不用单例,我怎么才能保证这个类的对象全局唯一呢?为了保证全局唯一,除了使用单例,我们还可以用静态方法来实现。这也是项目开发中经常用到的一种实现思路。比如, ID 唯一递增生成器的例子,用静态方法实现一下,就是下面这个样子:
644 |
645 | ```java
646 | // 静态方法实现方式
647 | public class IdGenerator {
648 | private static AtomicLong id = new AtomicLong(0);
649 |
650 | public static long getId() {
651 | return id.incrementAndGet();
652 | }
653 | }
654 | // 使用举例
655 | long id = IdGenerator.getId();
656 | ```
657 |
658 | 不过,静态方法这种实现思路,并不能解决我们之前提到的问题。实际上,它比单例更加不灵活,比如,它无法支持延迟加载。我们再来看看有没有其他办法。实际上,单例除了我们之前讲到的使用方法之外,还有另外一种使用方法。具体的代码如下所示:
659 |
660 | ```java
661 | // 1. 老的使用方式
662 | public demofunction() {
663 | //...
664 | long id = IdGenerator.getInstance().getId();
665 | //...
666 | }
667 |
668 | // 2. 新的使用方式:依赖注入
669 | public demofunction(IdGenerator idGenerator) {
670 | long id = idGenerator.getId();
671 | }
672 | // 外部调用demofunction()的时候,传入idGenerator
673 | IdGenerator idGenerator = IdGenerator.getInsance();
674 | demofunction(idGenerator);
675 | ```
676 |
677 |
678 |
679 | 1. 基于新的使用方式,我们将单例生成的对象,作为参数传递给函数(也可以通过构造函数传递给类的成员变量),可以解决单例隐藏类之间依赖关系的问题。不过,对于单例存在的其他问题,比如对 OOP 特性、扩展性、可测性不友好等问题,还是无法解决。
680 | 2. 所以,如果要完全解决这些问题,我们可能要从根上,寻找其他方式来实现全局唯一类。实际上,类对象的全局唯一性可以通过多种不同的方式来保证。我们既可以通过单例模式来强制保证,也可以通过工厂模式、IOC 容器(比如 Spring IOC 容器)来保证,还可以通过程序员自己来保证(自己在编写代码的时候自己保证不要创建两个类对象)。这就类似 Java 中内存对象的释放由 JVM 来负责,而 C++ 中由程序员自己负责,道理是一样的。
681 | 3. 对于替代方案工厂模式、IOC 容器的详细讲解,我们放到后面讲解。
682 |
683 |
684 |
685 | ## 如何理解单例模式中的唯一性?
686 |
687 | 1. 首先,我们重新看一下单例的定义:“一个类只允许创建唯一一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
688 | 2. ”定义中提到,“一个类只允许创建唯一一个对象”。那对象的唯一性的作用范围是什么呢?是指线程内只允许创建一个对象,还是指进程内只允许创建一个对象?答案是后者,也就是说,单例模式创建的对象是进程唯一的。这里有点不好理解,我来详细地解释一下。
689 | 3. 我们编写的代码,通过编译、链接,组织在一起,就构成了一个操作系统可以执行的文件,也就是我们平时所说的“可执行文件”(比如 Windows 下的 exe 文件)。可执行文件实际上就是代码被翻译成操作系统可理解的一组指令,你完全可以简单地理解为就是代码本身。
690 | 4. 当我们使用命令行或者双击运行这个可执行文件的时候,操作系统会启动一个进程,将这个执行文件从磁盘加载到自己的进程地址空间(可以理解操作系统为进程分配的内存存储区,用来存储代码和数据)。接着,进程就一条一条地执行可执行文件中包含的代码。比如,当进程读到代码中的 User user = new User(); 这条语句的时候,它就在自己的地址空间中创建一个 user 临时变量和一个 User 对象。进程之间是不共享地址空间的,如果我们在一个进程中创建另外一个进程(比如,代码中有一个 fork() 语句,进程执行到这条语句的时候会创建一个新的进程),操作系统会给新进程分配新的地址空间,并且将老进程地址空间的所有内容,重新拷贝一份到新进程的地址空间中,这些内容包括代码、数据(比如 user 临时变量、User 对象)。
691 | 5. 所以,单例类在老进程中存在且只能存在一个对象,在新进程中也会存在且只能存在一个对象。而且,这两个对象并不是同一个对象,这也就说,单例类中对象的唯一性的作用范围是进程内的,在进程间是不唯一的。
692 |
693 |
694 |
695 | ## 如何实现线程唯一的单例?
696 |
697 | 1. 刚刚我们讲了单例类对象是进程唯一的,一个进程只能有一个单例对象。那如何实现一个线程唯一的单例呢?
698 |
699 | 2. 我们先来看一下,什么是线程唯一的单例,以及“线程唯一”和“进程唯一”的区别。
700 |
701 | 3. “进程唯一”指的是进程内唯一,进程间不唯一。类比一下,“线程唯一”指的是线程内唯一,线程间可以不唯一。实际上,“进程唯一”还代表了线程内、线程间都唯一,这也是“进程唯一”和“线程唯一”的区别之处。这段话听起来有点像绕口令,我举个例子来解释一下。
702 |
703 | 4. 假设 IdGenerator 是一个线程唯一的单例类。在线程 A 内,我们可以创建一个单例对象 a。因为线程内唯一,在线程 A 内就不能再创建新的 IdGenerator 对象了,而线程间可以不唯一,所以,在另外一个线程 B 内,我们还可以重新创建一个新的单例对象 b。
704 |
705 | 5. 尽管概念理解起来比较复杂,但线程唯一单例的代码实现很简单,如下所示。在代码中,我们通过一个 HashMap 来存储对象,其中 key 是线程 ID,value 是对象。这样我们就可以做到,不同的线程对应不同的对象,同一个线程只能对应一个对象。实际上,Java 语言本身提供了 ThreadLocal 工具类,可以更加轻松地实现线程唯一单例。不过,ThreadLocal 底层实现原理也是基于下面代码中所示的 HashMap。
706 |
707 |
708 |
709 | ```java
710 | public class IdGenerator {
711 | private AtomicLong id = new AtomicLong(0);
712 |
713 | private static final ConcurrentHashMap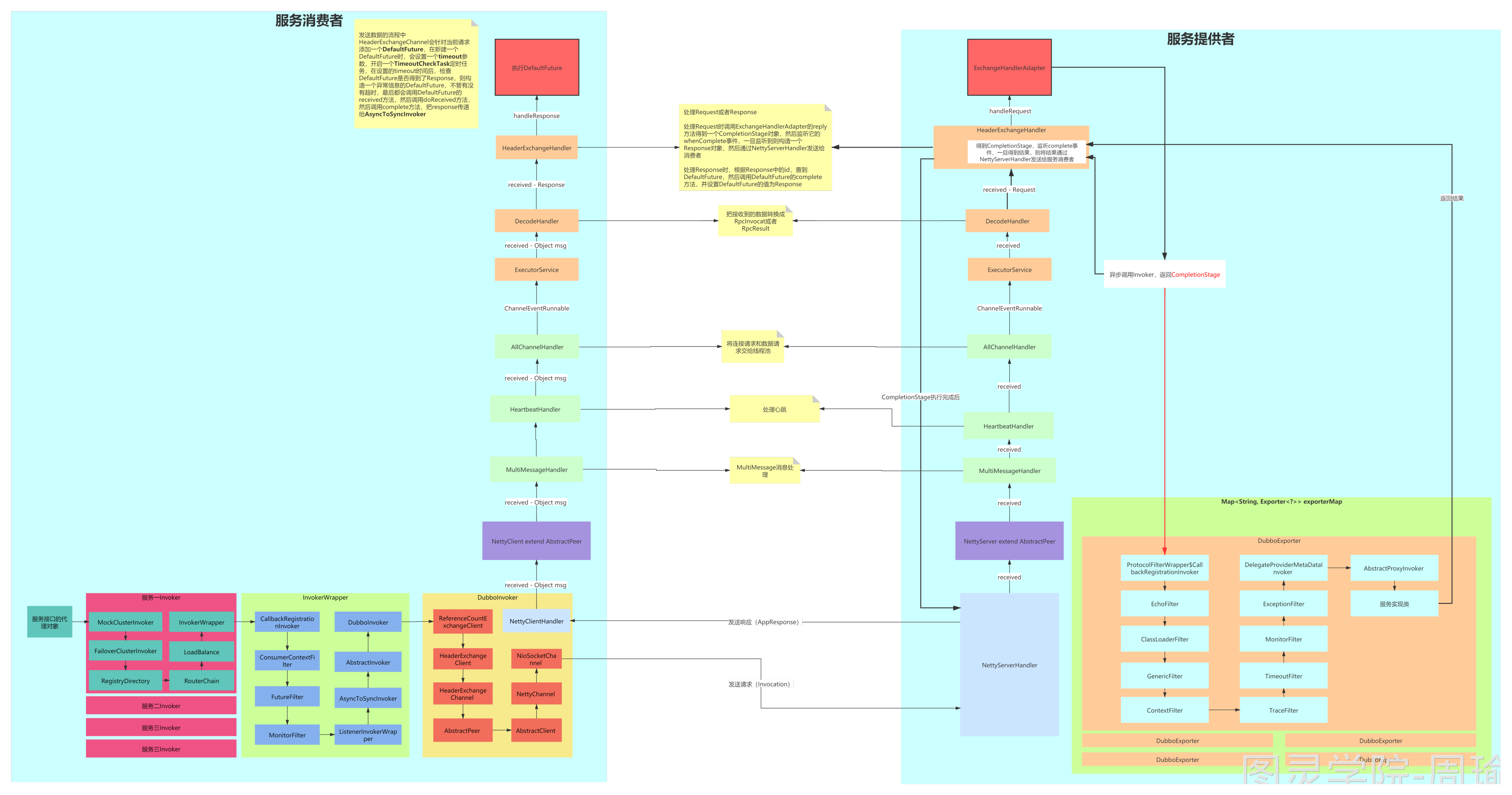 29 |
30 |
31 |
32 |
29 |
30 |
31 |
32 | 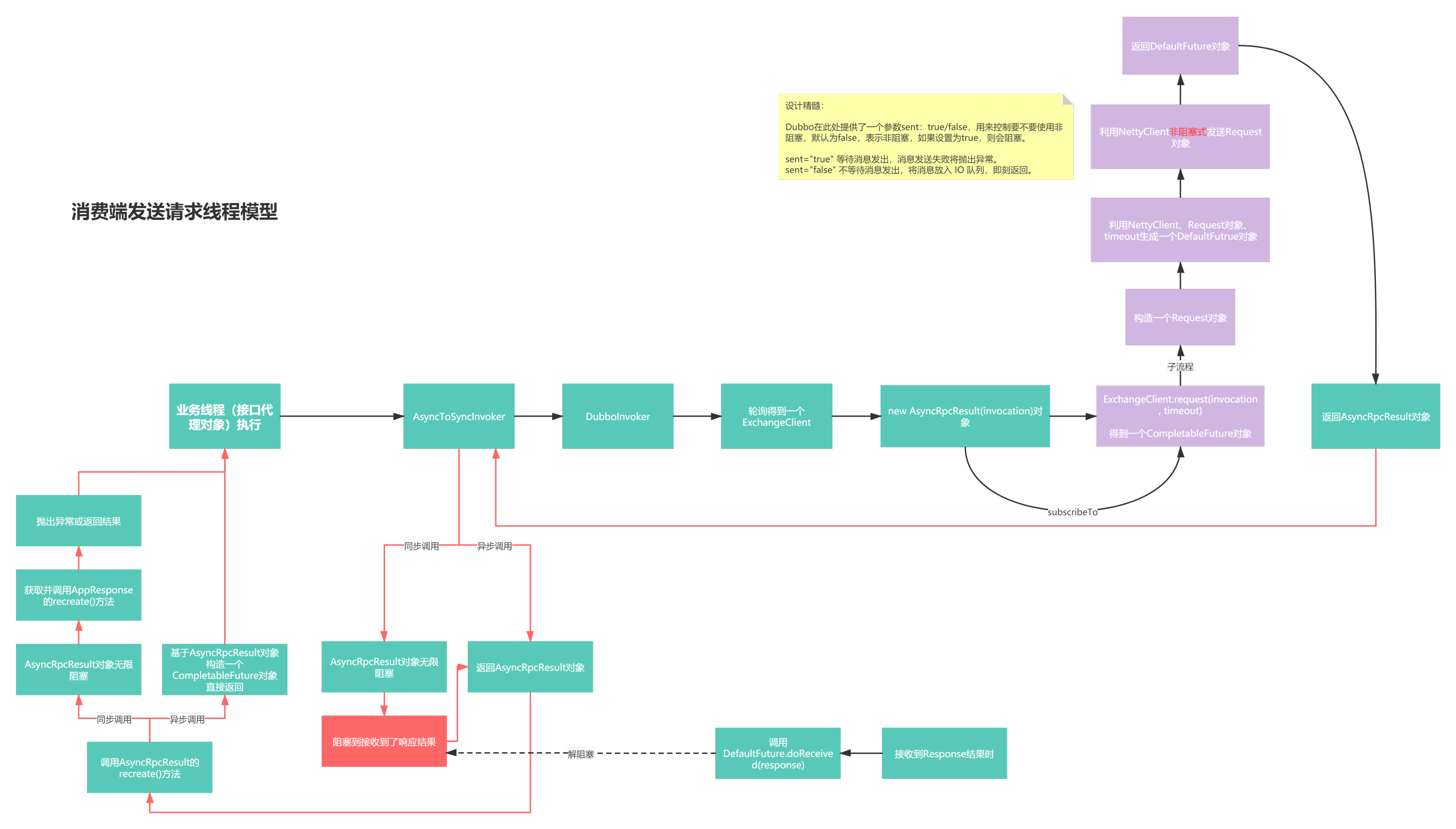 33 |
34 |
35 |
36 |
33 |
34 |
35 |
36 | 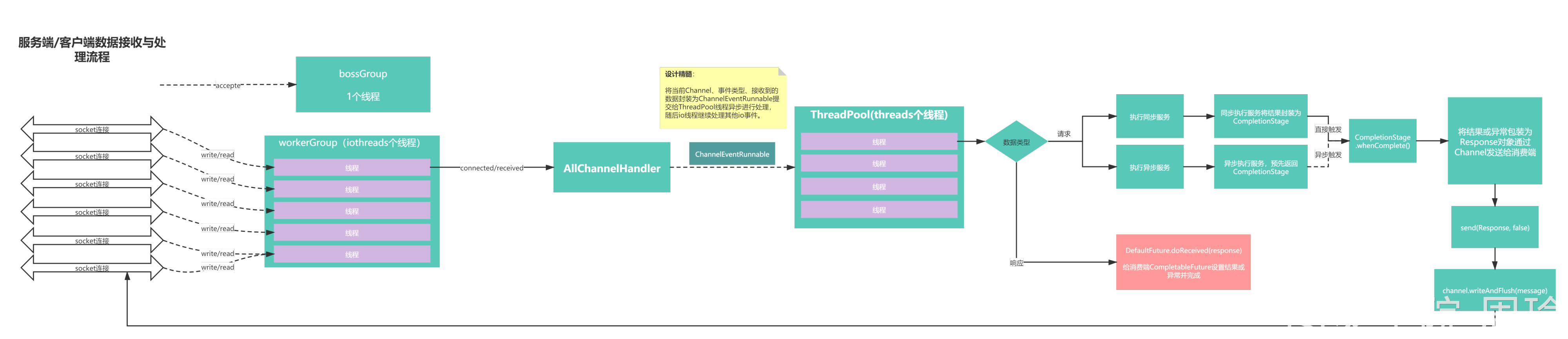 37 |
38 |
37 |
38 |  39 |
40 |
41 |
42 | processon链接:[https://www.processon.com/view/link/60110b847d9c08426cf10e49](https://www.processon.com/view/link/60110b847d9c08426cf10e49)
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 | ### 服务导出的Netty启动源码
51 |
52 | > 最主要的就是构造一个Handler处理链路
53 |
54 | #### DubboProtocol
55 |
56 | ```java
57 | public
39 |
40 |
41 |
42 | processon链接:[https://www.processon.com/view/link/60110b847d9c08426cf10e49](https://www.processon.com/view/link/60110b847d9c08426cf10e49)
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 | ### 服务导出的Netty启动源码
51 |
52 | > 最主要的就是构造一个Handler处理链路
53 |
54 | #### DubboProtocol
55 |
56 | ```java
57 | public