├── _ext
├── __init__.py
└── cunnex
│ └── __init__.py
├── .gitignore
├── floyd_requirements.txt
├── AdaConv.pptx
├── .floydexpt
├── images
├── first.png
├── second.png
└── README.md
├── .idea
├── markdown-navigator
│ └── profiles_settings.xml
├── misc.xml
├── modules.xml
├── pytorch-sepconv-master.iml
├── markdown-navigator.xml
└── workspace.xml
├── src
├── SeparableConvolution_cuda.h
├── SeparableConvolution_kernel.h
├── SeparableConvolution_cuda.c
└── SeparableConvolution_kernel.cu
├── .floydignore
├── install.bash
├── floyd.yml
├── install.py
├── SeparableConvolution.py
├── README.md
└── run.py
/_ext/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | /.project
2 |
3 | .pytorch
4 | .o
--------------------------------------------------------------------------------
/floyd_requirements.txt:
--------------------------------------------------------------------------------
1 | moviepy
2 | pillow
3 | cffi
--------------------------------------------------------------------------------
/AdaConv.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/youyuge34/sepconv_video/HEAD/AdaConv.pptx
--------------------------------------------------------------------------------
/.floydexpt:
--------------------------------------------------------------------------------
1 | {"name": "adaconv", "family_id": "prj_cdHJokKGnyjctrfr", "namespace": "youyuge34"}
--------------------------------------------------------------------------------
/images/first.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/youyuge34/sepconv_video/HEAD/images/first.png
--------------------------------------------------------------------------------
/images/second.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/youyuge34/sepconv_video/HEAD/images/second.png
--------------------------------------------------------------------------------
/images/README.md:
--------------------------------------------------------------------------------
1 | The used example originates from the Middlebury benchmark for Optical Flow: http://vision.middlebury.edu/flow
--------------------------------------------------------------------------------
/.idea/markdown-navigator/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
--------------------------------------------------------------------------------
/src/SeparableConvolution_cuda.h:
--------------------------------------------------------------------------------
1 | int SeparableConvolution_cuda_forward(
2 | THCudaTensor* input,
3 | THCudaTensor* vertical,
4 | THCudaTensor* horizontal,
5 | THCudaTensor* output
6 | );
--------------------------------------------------------------------------------
/.floydignore:
--------------------------------------------------------------------------------
1 |
2 | # Directories and files to ignore when uploading code to floyd
3 |
4 | .git
5 | .eggs
6 | eggs
7 | lib
8 | lib64
9 | parts
10 | sdist
11 | var
12 | *.pyc
13 | *.swp
14 | .DS_Store
15 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/src/SeparableConvolution_kernel.h:
--------------------------------------------------------------------------------
1 | #ifdef __cplusplus
2 | extern "C" {
3 | #endif
4 |
5 | void SeparableConvolution_kernel_forward(
6 | THCState* state,
7 | THCudaTensor* input,
8 | THCudaTensor* vertical,
9 | THCudaTensor* horizontal,
10 | THCudaTensor* output
11 | );
12 |
13 | #ifdef __cplusplus
14 | }
15 | #endif
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/pytorch-sepconv-master.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/_ext/cunnex/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from torch.utils.ffi import _wrap_function
3 | from ._cunnex import lib as _lib, ffi as _ffi
4 |
5 | __all__ = []
6 | def _import_symbols(locals):
7 | for symbol in dir(_lib):
8 | fn = getattr(_lib, symbol)
9 | if callable(fn):
10 | locals[symbol] = _wrap_function(fn, _ffi)
11 | else:
12 | locals[symbol] = fn
13 | __all__.append(symbol)
14 |
15 | _import_symbols(locals())
16 |
--------------------------------------------------------------------------------
/src/SeparableConvolution_cuda.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 |
4 | #include "SeparableConvolution_kernel.h"
5 |
6 | extern THCState* state;
7 |
8 | int SeparableConvolution_cuda_forward(
9 | THCudaTensor* input,
10 | THCudaTensor* vertical,
11 | THCudaTensor* horizontal,
12 | THCudaTensor* output
13 | ) {
14 | SeparableConvolution_kernel_forward(
15 | state,
16 | input,
17 | vertical,
18 | horizontal,
19 | output
20 | );
21 |
22 | return 1;
23 | }
--------------------------------------------------------------------------------
/install.bash:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | TORCH=$(python -c "import os; import torch; print(os.path.dirname(torch.__file__))")
4 |
5 | nvcc -c -o src/SeparableConvolution_kernel.o src/SeparableConvolution_kernel.cu --gpu-architecture=compute_52 --gpu-code=compute_52 --compiler-options -fPIC -I ${TORCH}/lib/include/TH -I ${TORCH}/lib/include/THC
6 |
7 | python install.py
8 |
9 | wget --timestamping http://content.sniklaus.com/sepconv/network-l1.pytorch
10 | wget --timestamping http://content.sniklaus.com/sepconv/network-lf.pytorch
--------------------------------------------------------------------------------
/floyd.yml:
--------------------------------------------------------------------------------
1 | # see: https://docs.floydhub.com/floyd_config
2 | # All supported configs:
3 | #
4 | #machine: cpu
5 | #env: tensorflow-1.8
6 | #input:
7 | # - destination: input
8 | # source: foo/datasets/yelp-food/1
9 | # - foo/datasets/yelp-food-test/1:test
10 | #description: this is a test
11 | #max_runtime: 3600
12 | #command: python train.py
13 |
14 | # You can also define multiple tasks to use with --task argument:
15 | #
16 | #task:
17 | # evaluate:
18 | # machine: gpu
19 | # command: python evaluate.py
20 | #
21 | # serve:
22 | # machine: cpu
23 | # mode: serve
24 |
--------------------------------------------------------------------------------
/install.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import torch.utils.ffi
4 |
5 | strBasepath = os.path.split(os.path.abspath(__file__))[0] + '/'
6 | strHeaders = []
7 | strSources = []
8 | strDefines = []
9 | strObjects = []
10 |
11 | if torch.cuda.is_available() == True:
12 | strHeaders += ['src/SeparableConvolution_cuda.h']
13 | strSources += ['src/SeparableConvolution_cuda.c']
14 | strDefines += [('WITH_CUDA', None)]
15 | strObjects += ['src/SeparableConvolution_kernel.o']
16 | # end
17 |
18 | objectExtension = torch.utils.ffi.create_extension(
19 | name='_ext.cunnex',
20 | headers=strHeaders,
21 | sources=strSources,
22 | verbose=False,
23 | with_cuda=any(strDefine[0] == 'WITH_CUDA' for strDefine in strDefines),
24 | package=False,
25 | relative_to=strBasepath,
26 | include_dirs=[os.path.expandvars('$CUDA_HOME') + '/include'],
27 | define_macros=strDefines,
28 | extra_objects=[os.path.join(strBasepath, strObject) for strObject in strObjects]
29 | )
30 |
31 | if __name__ == '__main__':
32 | objectExtension.build()
33 | # end
--------------------------------------------------------------------------------
/SeparableConvolution.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | import _ext.cunnex
4 |
5 | class SeparableConvolution(torch.autograd.Function):
6 | def __init__(self):
7 | super(SeparableConvolution, self).__init__()
8 | # end
9 |
10 | def forward(self, input, vertical, horizontal):
11 | intBatches = input.size(0)
12 | intInputDepth = input.size(1)
13 | intInputHeight = input.size(2)
14 | intInputWidth = input.size(3)
15 | intFilterSize = min(vertical.size(1), horizontal.size(1))
16 | intOutputHeight = min(vertical.size(2), horizontal.size(2))
17 | intOutputWidth = min(vertical.size(3), horizontal.size(3))
18 |
19 | assert(intInputHeight - 51 == intOutputHeight - 1)
20 | assert(intInputWidth - 51 == intOutputWidth - 1)
21 | assert(intFilterSize == 51)
22 |
23 | assert(input.is_contiguous() == True)
24 | assert(vertical.is_contiguous() == True)
25 | assert(horizontal.is_contiguous() == True)
26 |
27 | output = input.new().resize_(intBatches, intInputDepth, intOutputHeight, intOutputWidth).zero_()
28 |
29 | if input.is_cuda == True:
30 | _ext.cunnex.SeparableConvolution_cuda_forward(
31 | input,
32 | vertical,
33 | horizontal,
34 | output
35 | )
36 |
37 | elif input.is_cuda == False:
38 | raise NotImplementedError() # CPU VERSION NOT IMPLEMENTED
39 |
40 | # end
41 |
42 | return output
43 | # end
44 |
45 | def backward(self, gradOutput):
46 | raise NotImplementedError() # BACKPROPAGATION NOT IMPLEMENTED
47 | # end
48 | # end
49 |
--------------------------------------------------------------------------------
/src/SeparableConvolution_kernel.cu:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 |
4 | #define VEC_0(ARRAY) ((ARRAY).x)
5 | #define VEC_1(ARRAY) ((ARRAY).y)
6 | #define VEC_2(ARRAY) ((ARRAY).z)
7 | #define VEC_3(ARRAY) ((ARRAY).w)
8 |
9 | #define IDX_1(ARRAY, X) ((ARRAY)[((X) * (ARRAY##_stride.x))])
10 | #define IDX_2(ARRAY, X, Y) ((ARRAY)[((X) * (ARRAY##_stride.x)) + ((Y) * (ARRAY##_stride.y))])
11 | #define IDX_3(ARRAY, X, Y, Z) ((ARRAY)[((X) * (ARRAY##_stride.x)) + ((Y) * (ARRAY##_stride.y)) + ((Z) * (ARRAY##_stride.z))])
12 | #define IDX_4(ARRAY, X, Y, Z, W) ((ARRAY)[((X) * (ARRAY##_stride.x)) + ((Y) * (ARRAY##_stride.y)) + ((Z) * (ARRAY##_stride.z)) + ((W) * (ARRAY##_stride.w))])
13 |
14 | #ifdef __cplusplus
15 | extern "C" {
16 | #endif
17 |
18 | __global__ void kernel_SeparableConvolution_updateOutput(
19 | const int n,
20 | const float* input, const long4 input_size, const long4 input_stride,
21 | const float* vertical, const long4 vertical_size, const long4 vertical_stride,
22 | const float* horizontal, const long4 horizontal_size, const long4 horizontal_stride,
23 | float* output, const long4 output_size, const long4 output_stride
24 | ) {
25 | int intIndex = blockIdx.x * blockDim.x + threadIdx.x;
26 |
27 | if (intIndex >= n) {
28 | return;
29 | }
30 |
31 | float dblOutput = 0.0;
32 |
33 | int intBatch = ( intIndex / VEC_3(output_size) / VEC_2(output_size) / VEC_1(output_size) ) % VEC_0(output_size);
34 | int intDepth = ( intIndex / VEC_3(output_size) / VEC_2(output_size) ) % VEC_1(output_size);
35 | int intY = ( intIndex / VEC_3(output_size) ) % VEC_2(output_size);
36 | int intX = ( intIndex ) % VEC_3(output_size);
37 |
38 | for (int intFilterY = 0; intFilterY < 51; intFilterY += 1) {
39 | for (int intFilterX = 0; intFilterX < 51; intFilterX += 1) {
40 | dblOutput += IDX_4(input, intBatch, intDepth, intY + intFilterY, intX + intFilterX) * IDX_4(vertical, intBatch, intFilterY, intY, intX) * IDX_4(horizontal, intBatch, intFilterX, intY, intX);
41 | }
42 | }
43 |
44 | output[intIndex] = dblOutput;
45 | }
46 |
47 | void SeparableConvolution_kernel_forward(
48 | THCState* state,
49 | THCudaTensor* input,
50 | THCudaTensor* vertical,
51 | THCudaTensor* horizontal,
52 | THCudaTensor* output
53 | ) {
54 | int n = 0;
55 |
56 | n = THCudaTensor_nElement(state, output);
57 | kernel_SeparableConvolution_updateOutput<<< (n + 512 - 1) / 512, 512, 0, THCState_getCurrentStream(state) >>>(
58 | n,
59 | THCudaTensor_data(state, input), make_long4(input->size[0], input->size[1], input->size[2], input->size[3]), make_long4(input->stride[0], input->stride[1], input->stride[2], input->stride[3]),
60 | THCudaTensor_data(state, vertical), make_long4(vertical->size[0], vertical->size[1], vertical->size[2], vertical->size[3]), make_long4(vertical->stride[0], vertical->stride[1], vertical->stride[2], vertical->stride[3]),
61 | THCudaTensor_data(state, horizontal), make_long4(horizontal->size[0], horizontal->size[1], horizontal->size[2], horizontal->size[3]), make_long4(horizontal->stride[0], horizontal->stride[1], horizontal->stride[2], horizontal->stride[3]),
62 | THCudaTensor_data(state, output), make_long4(output->size[0], output->size[1], output->size[2], output->size[3]), make_long4(output->stride[0], output->stride[1], output->stride[2], output->stride[3])
63 | );
64 |
65 | THCudaCheck(cudaGetLastError());
66 | }
67 |
68 | #ifdef __cplusplus
69 | }
70 | #endif
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Introduction
2 | This project is updated from [dagf2101/pytorch-sepconv](https://github.com/dagf2101/pytorch-sepconv)
3 |
4 | updates:
5 |
6 | 1. some code robustness
7 | 2. now the output video has audio
8 | 3. increase a progress bar when processing
9 |
10 | **Chinese introduction and practice lesson video:** [【中文】 基于SepConv深度学习的视频补帧 插帧 论文+代码+实战教程](https://www.bilibili.com/video/av29090385/)
11 |
12 |
13 | ## Warning!!!
14 | The code is old and has bugs,that it needs a high calculation capability GPU(`K80` is not enough)to run successfully. Also it is not friendly to Windows users.
15 |
16 |
17 | So u should refer to the origin author [sniklaus/pytorch-sepconv](https://github.com/sniklaus/pytorch-sepconv) to get newest code which used cupy to compile automatically. But it can only handle photos.
18 |
19 | > Below is the origin 'readme'
20 |
21 | ------------------------------
22 |
23 | # pytorch-sepconv
24 | This is a reference implementation of Video Frame Interpolation via Adaptive Separable Convolution [1] using PyTorch. Given two frames, it will make use of adaptive convolution [2] in a separable manner to interpolate the intermediate frame. Should you be making use of our work, please cite our paper [1].
25 |
26 |  27 |
28 | For the Torch version of this work, please see: https://github.com/sniklaus/torch-sepconv
29 |
30 | ## setup
31 | To build the implementation and download the pre-trained networks, run `bash install.bash` and make sure that you configured the `CUDA_HOME` environment variable. After successfully completing this step, run `python run.py` to test it. Should you receive an error message regarding an invalid device function during execution, configure the utilized CUDA architecture within `install.bash` to something your graphics card supports.
32 |
33 | ## usage
34 | To run it on your own pair of frames, use the following command. You can either select the `l1` or the `lf` model, please see our paper for more details.
35 |
36 | Image:
37 | ```
38 | python run.py --model lf --first ./images/first.png --second ./images/second.png --out ./result.png
39 | ```
40 | Video:
41 | ```
42 | python run.py --model lf --video ./video.mp4 --video-out ./result.mp4
43 | ```
44 |
45 | ## video
46 |
27 |
28 | For the Torch version of this work, please see: https://github.com/sniklaus/torch-sepconv
29 |
30 | ## setup
31 | To build the implementation and download the pre-trained networks, run `bash install.bash` and make sure that you configured the `CUDA_HOME` environment variable. After successfully completing this step, run `python run.py` to test it. Should you receive an error message regarding an invalid device function during execution, configure the utilized CUDA architecture within `install.bash` to something your graphics card supports.
32 |
33 | ## usage
34 | To run it on your own pair of frames, use the following command. You can either select the `l1` or the `lf` model, please see our paper for more details.
35 |
36 | Image:
37 | ```
38 | python run.py --model lf --first ./images/first.png --second ./images/second.png --out ./result.png
39 | ```
40 | Video:
41 | ```
42 | python run.py --model lf --video ./video.mp4 --video-out ./result.mp4
43 | ```
44 |
45 | ## video
46 | 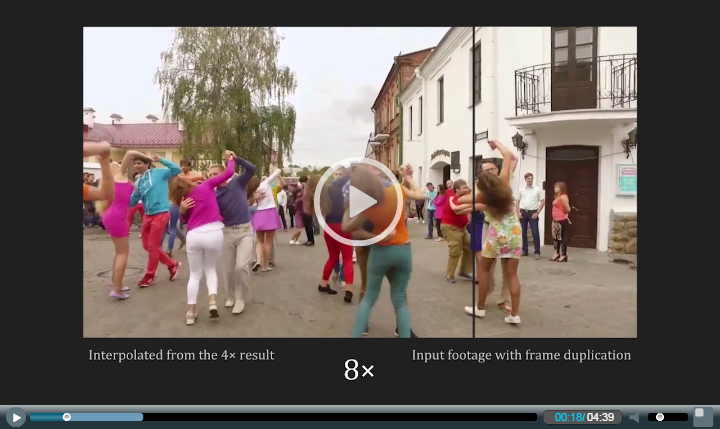 47 |
48 | ## license
49 | The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
50 |
51 | ## references
52 | ```
53 | [1] @inproceedings{Niklaus_ICCV_2017,
54 | author = {Simon Niklaus and Long Mai and Feng Liu},
55 | title = {Video Frame Interpolation via Adaptive Separable Convolution},
56 | booktitle = {IEEE International Conference on Computer Vision},
57 | year = {2017}
58 | }
59 | ```
60 |
61 | ```
62 | [2] @inproceedings{Niklaus_CVPR_2017,
63 | author = {Simon Niklaus and Long Mai and Feng Liu},
64 | title = {Video Frame Interpolation via Adaptive Convolution},
65 | booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
66 | year = {2017}
67 | }
68 | ```
69 |
70 | ## acknowledgment
71 | This work was supported by NSF IIS-1321119. The video above uses materials under a Creative Common license or with the owner's permission, as detailed at the end.
72 |
--------------------------------------------------------------------------------
/.idea/markdown-navigator.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
47 |
48 | ## license
49 | The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
50 |
51 | ## references
52 | ```
53 | [1] @inproceedings{Niklaus_ICCV_2017,
54 | author = {Simon Niklaus and Long Mai and Feng Liu},
55 | title = {Video Frame Interpolation via Adaptive Separable Convolution},
56 | booktitle = {IEEE International Conference on Computer Vision},
57 | year = {2017}
58 | }
59 | ```
60 |
61 | ```
62 | [2] @inproceedings{Niklaus_CVPR_2017,
63 | author = {Simon Niklaus and Long Mai and Feng Liu},
64 | title = {Video Frame Interpolation via Adaptive Convolution},
65 | booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
66 | year = {2017}
67 | }
68 | ```
69 |
70 | ## acknowledgment
71 | This work was supported by NSF IIS-1321119. The video above uses materials under a Creative Common license or with the owner's permission, as detailed at the end.
72 |
--------------------------------------------------------------------------------
/.idea/markdown-navigator.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
34 |
35 |
36 |
37 |
38 | true
39 | DEFINITION_ORDER
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |