├── .gitattributes
├── .gitignore
├── .nojekyll
├── HomePage.md
├── README.md
├── _coverpage.md
├── code
└── java
│ └── ThreadPoolExecutorDemo
│ ├── .idea
│ ├── .gitignore
│ ├── checkstyle-idea.xml
│ ├── inspectionProfiles
│ │ └── Project_Default.xml
│ ├── misc.xml
│ ├── modules.xml
│ ├── uiDesigner.xml
│ └── vcs.xml
│ ├── ThreadPoolExecutorDemo.iml
│ ├── out
│ └── production
│ │ └── ThreadPoolExecutorDemo
│ │ ├── META-INF
│ │ └── ThreadPoolExecutorDemo.kotlin_module
│ │ ├── callable
│ │ ├── CallableDemo.class
│ │ └── MyCallable.class
│ │ ├── common
│ │ └── ThreadPoolConstants.class
│ │ ├── scheduledThreadPoolExecutor
│ │ ├── ScheduledThreadPoolExecutorDemo.class
│ │ └── Task.class
│ │ └── threadPoolExecutor
│ │ ├── MyRunnable.class
│ │ └── ThreadPoolExecutorDemo.class
│ └── src
│ ├── callable
│ ├── CallableDemo.java
│ └── MyCallable.java
│ ├── common
│ └── ThreadPoolConstants.java
│ └── threadPoolExecutor
│ ├── MyRunnable.java
│ └── ThreadPoolExecutorDemo.java
├── docs
├── data
│ ├── java-recommended-books.md
│ └── spring-boot-practical-projects.md
├── dataStructures-algorithms
│ ├── Backtracking-NQueens.md
│ ├── data-structure
│ │ └── bloom-filter.md
│ ├── 公司真题.md
│ ├── 几道常见的子符串算法题.md
│ ├── 几道常见的链表算法题.md
│ ├── 剑指offer部分编程题.md
│ ├── 数据结构.md
│ └── 算法学习资源推荐.md
├── database
│ ├── MySQL Index.md
│ ├── MySQL.md
│ ├── MySQL高性能优化规范建议.md
│ ├── Redis
│ │ ├── Redis.md
│ │ ├── Redis持久化.md
│ │ ├── Redlock分布式锁.md
│ │ ├── redis集群以及应用场景.md
│ │ └── 如何做可靠的分布式锁,Redlock真的可行么.md
│ ├── 一千行MySQL命令.md
│ ├── 一条sql语句在mysql中如何执行的.md
│ ├── 事务隔离级别(图文详解).md
│ ├── 数据库连接池.md
│ └── 阿里巴巴开发手册数据库部分的一些最佳实践.md
├── essential-content-for-interview
│ ├── BATJrealInterviewExperience
│ │ ├── 2019alipay-pinduoduo-toutiao.md
│ │ ├── 5面阿里,终获offer.md
│ │ └── 蚂蚁金服实习生面经总结(已拿口头offer).md
│ ├── PreparingForInterview
│ │ ├── JavaInterviewLibrary.md
│ │ ├── JavaProgrammerNeedKnow.md
│ │ ├── interviewPrepare.md
│ │ ├── 应届生面试最爱问的几道Java基础问题.md
│ │ ├── 程序员的简历之道.md
│ │ ├── 美团面试常见问题总结.md
│ │ └── 面试官-你有什么问题要问我.md
│ ├── real-interview-experience-analysis
│ │ └── alibaba-1.md
│ ├── 手把手教你用Markdown写一份高质量的简历.md
│ ├── 简历模板.md
│ └── 面试必备之乐观锁与悲观锁.md
├── github-trending
│ ├── 2018-12.md
│ ├── 2019-1.md
│ ├── 2019-2.md
│ ├── 2019-3.md
│ ├── 2019-4.md
│ ├── 2019-5.md
│ ├── 2019-6.md
│ └── JavaGithubTrending.md
├── java
│ ├── BIO-NIO-AIO.md
│ ├── Basis
│ │ ├── Arrays,CollectionsCommonMethods.md
│ │ └── final、static、this、super.md
│ ├── J2EE基础知识.md
│ ├── Java IO与NIO.md
│ ├── Java基础知识.md
│ ├── Java疑难点.md
│ ├── Java程序设计题.md
│ ├── Java编程规范.md
│ ├── Multithread
│ │ ├── AQS.md
│ │ ├── Atomic.md
│ │ ├── JavaConcurrencyAdvancedCommonInterviewQuestions.md
│ │ ├── JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
│ │ ├── ThredLocal.md
│ │ ├── java线程池学习总结.md
│ │ ├── synchronized.md
│ │ ├── 并发容器总结.md
│ │ └── 并发编程基础知识.md
│ ├── What's New in JDK8
│ │ ├── Java8Tutorial.md
│ │ ├── Java8foreach指南.md
│ │ └── Java8教程推荐.md
│ ├── collection
│ │ ├── ArrayList-Grow.md
│ │ ├── ArrayList.md
│ │ ├── HashMap.md
│ │ ├── Java集合框架常见面试题.md
│ │ └── LinkedList.md
│ ├── jvm
│ │ ├── GC调优参数.md
│ │ ├── JDK监控和故障处理工具总结.md
│ │ ├── JVM垃圾回收.md
│ │ ├── Java内存区域.md
│ │ ├── jvm 知识点汇总.md
│ │ ├── 最重要的JVM参数指南.md
│ │ ├── 类加载器.md
│ │ ├── 类加载过程.md
│ │ └── 类文件结构.md
│ └── 多线程系列.md
├── network
│ ├── HTTPS中的TLS.md
│ ├── 干货:计算机网络知识总结.md
│ └── 计算机网络.md
├── operating-system
│ ├── Shell.md
│ └── 后端程序员必备的Linux基础知识.md
├── questions
│ ├── java-learning-path-and-methods.md
│ ├── java-learning-website-blog.md
│ └── java-training-4-month.md
├── system-design
│ ├── authority-certification
│ │ ├── JWT-advantages-and-disadvantages.md
│ │ └── basis-of-authority-certification.md
│ ├── data-communication
│ │ ├── Kafka入门看这一篇就够了.md
│ │ ├── Kafka系统设计开篇-面试看这篇就够了.md
│ │ ├── RocketMQ-Questions.md
│ │ ├── dubbo.md
│ │ ├── message-queue.md
│ │ ├── rabbitmq.md
│ │ ├── summary.md
│ │ └── why-use-rpc.md
│ ├── framework
│ │ ├── ZooKeeper.md
│ │ ├── ZooKeeper数据模型和常见命令.md
│ │ └── spring
│ │ │ ├── Spring-Design-Patterns.md
│ │ │ ├── Spring.md
│ │ │ ├── SpringBean.md
│ │ │ ├── SpringInterviewQuestions.md
│ │ │ └── SpringMVC-Principle.md
│ ├── micro-service
│ │ ├── API网关.md
│ │ └── 分布式id生成方案总结.md
│ ├── website-architecture
│ │ ├── 8 张图读懂大型网站技术架构.md
│ │ ├── 关于大型网站系统架构你不得不懂的10个问题.md
│ │ └── 分布式.md
│ └── 设计模式.md
├── tools
│ ├── Docker-Image.md
│ ├── Docker.md
│ ├── Git.md
│ ├── github
│ │ └── github-star-ranking.md
│ └── 阿里云服务器使用经验.md
└── 公众号历史文章汇总.md
├── index.html
├── media
├── pictures
│ ├── kafka
│ │ ├── Broker和集群.png
│ │ ├── Partition与消费模型.png
│ │ ├── kafka存在文件系统上.png
│ │ ├── segment是kafka文件存储的最小单位.png
│ │ ├── 主题与分区.png
│ │ ├── 前言.md
│ │ ├── 发送消息.png
│ │ ├── 启动服务.png
│ │ ├── 消费者设计概要1.png
│ │ ├── 消费者设计概要2.png
│ │ ├── 消费者设计概要3.png
│ │ ├── 消费者设计概要4.png
│ │ ├── 消费者设计概要5.png
│ │ ├── 生产者和消费者.png
│ │ └── 生产者设计概要.png
│ └── rostyslav-savchyn-5joK905gcGc-unsplash.jpg
└── sponsor
│ └── WechatIMG143.jpeg
└── submission.html
/.gitattributes:
--------------------------------------------------------------------------------
1 | * text=auto
2 | *.js linguist-language=java
3 | *.css linguist-language=java
4 | *.html linguist-language=java
5 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .gradle
2 | /build/
3 | /**/build/
4 |
5 | ### STS ###
6 | .apt_generated
7 | .classpath
8 | .factorypath
9 | .project
10 | .settings
11 | .springBeans
12 | .sts4-cache
13 |
14 | ### IntelliJ IDEA ###
15 | .idea
16 | *.iws
17 | *.iml
18 | *.ipr
19 | /out/
20 | /**/out/
21 | .shelf/
22 | .ideaDataSources/
23 | dataSources/
24 |
25 | ### NetBeans ###
26 | /nbproject/private/
27 | /nbbuild/
28 | /dist/
29 | /nbdist/
30 | /.nb-gradle/
31 | /node_modules/
32 |
33 | ### OS ###
34 | .DS_Store
35 |
--------------------------------------------------------------------------------
/.nojekyll:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/.nojekyll
--------------------------------------------------------------------------------
/_coverpage.md:
--------------------------------------------------------------------------------
1 |
2 |  3 |
3 |
4 |
5 | Java 学习/面试指南
6 |
7 | [常用资源](https://shimo.im/docs/MuiACIg1HlYfVxrj/)
8 | [GitHub]()
9 | [开始阅读](#java)
10 |
11 | 
12 |
13 |
14 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /workspace.xml
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/.idea/checkstyle-idea.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
15 |
16 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/.idea/inspectionProfiles/Project_Default.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
11 |
17 |
23 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/ThreadPoolExecutorDemo.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/META-INF/ThreadPoolExecutorDemo.kotlin_module:
--------------------------------------------------------------------------------
1 | ����������������
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/callable/CallableDemo.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/callable/CallableDemo.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/callable/MyCallable.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/callable/MyCallable.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/common/ThreadPoolConstants.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/common/ThreadPoolConstants.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/scheduledThreadPoolExecutor/ScheduledThreadPoolExecutorDemo.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/scheduledThreadPoolExecutor/ScheduledThreadPoolExecutorDemo.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/scheduledThreadPoolExecutor/Task.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/scheduledThreadPoolExecutor/Task.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/threadPoolExecutor/MyRunnable.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/threadPoolExecutor/MyRunnable.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/threadPoolExecutor/ThreadPoolExecutorDemo.class:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/code/java/ThreadPoolExecutorDemo/out/production/ThreadPoolExecutorDemo/threadPoolExecutor/ThreadPoolExecutorDemo.class
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/src/callable/CallableDemo.java:
--------------------------------------------------------------------------------
1 | package callable;
2 |
3 | import java.util.ArrayList;
4 | import java.util.Date;
5 | import java.util.List;
6 | import java.util.concurrent.ArrayBlockingQueue;
7 | import java.util.concurrent.Callable;
8 | import java.util.concurrent.ExecutionException;
9 | import java.util.concurrent.Future;
10 | import java.util.concurrent.ThreadPoolExecutor;
11 | import java.util.concurrent.TimeUnit;
12 |
13 | import static common.ThreadPoolConstants.CORE_POOL_SIZE;
14 | import static common.ThreadPoolConstants.KEEP_ALIVE_TIME;
15 | import static common.ThreadPoolConstants.MAX_POOL_SIZE;
16 | import static common.ThreadPoolConstants.QUEUE_CAPACITY;
17 |
18 | public class CallableDemo {
19 | public static void main(String[] args) {
20 | //使用阿里巴巴推荐的创建线程池的方式
21 | //通过ThreadPoolExecutor构造函数自定义参数创建
22 | ThreadPoolExecutor executor = new ThreadPoolExecutor(
23 | CORE_POOL_SIZE,
24 | MAX_POOL_SIZE,
25 | KEEP_ALIVE_TIME,
26 | TimeUnit.SECONDS,
27 | new ArrayBlockingQueue<>(QUEUE_CAPACITY),
28 | new ThreadPoolExecutor.CallerRunsPolicy());
29 |
30 | List> futureList = new ArrayList<>();
31 | Callable callable = new MyCallable();
32 | for (int i = 0; i < 10; i++) {
33 | //提交任务到线程池
34 | Future future = executor.submit(callable);
35 | //将返回值 future 添加到 list,我们可以通过 future 获得 执行 Callable 得到的返回值
36 | futureList.add(future);
37 | }
38 | for (Future fut : futureList) {
39 | try {
40 | System.out.println(new Date() + "::" + fut.get());
41 | } catch (InterruptedException | ExecutionException e) {
42 | e.printStackTrace();
43 | }
44 | }
45 | //关闭线程池
46 | executor.shutdown();
47 | }
48 | }
49 |
50 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/src/callable/MyCallable.java:
--------------------------------------------------------------------------------
1 | package callable;
2 |
3 | import java.util.concurrent.Callable;
4 |
5 | public class MyCallable implements Callable {
6 |
7 | @Override
8 | public String call() throws Exception {
9 | Thread.sleep(1000);
10 | //返回执行当前 Callable 的线程名字
11 | return Thread.currentThread().getName();
12 | }
13 | }
14 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/src/common/ThreadPoolConstants.java:
--------------------------------------------------------------------------------
1 | package common;
2 |
3 | public class ThreadPoolConstants {
4 | public static final int CORE_POOL_SIZE = 5;
5 | public static final int MAX_POOL_SIZE = 10;
6 | public static final int QUEUE_CAPACITY = 100;
7 | public static final Long KEEP_ALIVE_TIME = 1L;
8 | private ThreadPoolConstants(){
9 |
10 | }
11 | }
12 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/src/threadPoolExecutor/MyRunnable.java:
--------------------------------------------------------------------------------
1 | package threadPoolExecutor;
2 |
3 | import java.util.Date;
4 |
5 | /**
6 | * 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
7 | * @author shuang.kou
8 | */
9 | public class MyRunnable implements Runnable {
10 |
11 | private String command;
12 |
13 | public MyRunnable(String s) {
14 | this.command = s;
15 | }
16 |
17 | @Override
18 | public void run() {
19 | System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
20 | processCommand();
21 | System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
22 | }
23 |
24 | private void processCommand() {
25 | try {
26 | Thread.sleep(5000);
27 | } catch (InterruptedException e) {
28 | e.printStackTrace();
29 | }
30 | }
31 |
32 | @Override
33 | public String toString() {
34 | return this.command;
35 | }
36 | }
37 |
--------------------------------------------------------------------------------
/code/java/ThreadPoolExecutorDemo/src/threadPoolExecutor/ThreadPoolExecutorDemo.java:
--------------------------------------------------------------------------------
1 | package threadPoolExecutor;
2 |
3 | import java.util.concurrent.ArrayBlockingQueue;
4 | import java.util.concurrent.ThreadPoolExecutor;
5 | import java.util.concurrent.TimeUnit;
6 |
7 | import static common.ThreadPoolConstants.CORE_POOL_SIZE;
8 | import static common.ThreadPoolConstants.KEEP_ALIVE_TIME;
9 | import static common.ThreadPoolConstants.MAX_POOL_SIZE;
10 | import static common.ThreadPoolConstants.QUEUE_CAPACITY;
11 |
12 |
13 | public class ThreadPoolExecutorDemo {
14 |
15 | public static void main(String[] args) {
16 |
17 | //使用阿里巴巴推荐的创建线程池的方式
18 | //通过ThreadPoolExecutor构造函数自定义参数创建
19 | ThreadPoolExecutor executor = new ThreadPoolExecutor(
20 | CORE_POOL_SIZE,
21 | MAX_POOL_SIZE,
22 | KEEP_ALIVE_TIME,
23 | TimeUnit.SECONDS,
24 | new ArrayBlockingQueue<>(QUEUE_CAPACITY),
25 | new ThreadPoolExecutor.CallerRunsPolicy());
26 |
27 | for (int i = 0; i < 10; i++) {
28 | //创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
29 | Runnable worker = new MyRunnable("" + i);
30 | //执行Runnable
31 | executor.execute(worker);
32 | }
33 | //终止线程池
34 | executor.shutdown();
35 | while (!executor.isTerminated()) {
36 | }
37 | System.out.println("Finished all threads");
38 | }
39 | }
40 |
--------------------------------------------------------------------------------
/docs/data/spring-boot-practical-projects.md:
--------------------------------------------------------------------------------
1 | 最近经常被读者问到有没有 Spring Boot 实战项目可以学习,于是,我就去 Github 上找了 10 个我觉得还不错的实战项目。对于这些实战项目,有部分是比较适合 Spring Boot 刚入门的朋友学习的,还有一部分可能要求你对 Spring Boot 相关技术比较熟悉。需要的朋友可以根据个人实际情况进行选择。如果你对 Spring Boot 不太熟悉的话,可以看我最近开源的 springboot-guide:https://github.com/Snailclimb/springboot-guide 入门(还在持续更新中)。
2 |
3 | ### mall
4 |
5 | - **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
6 | - **star**: 22.9k
7 | - **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
8 |
9 | ### jeecg-boot
10 |
11 | - **Github地址**:[https://github.com/zhangdaiscott/jeecg-boot](https://github.com/zhangdaiscott/jeecg-boot)
12 | - **star**: 6.4k
13 | - **介绍**: 一款基于代码生成器的JAVA快速开发平台!采用最新技术,前后端分离架构:SpringBoot 2.x,Ant Design&Vue,Mybatis,Shiro,JWT。强大的代码生成器让前后端代码一键生成,无需写任何代码,绝对是全栈开发福音!! JeecgBoot的宗旨是提高UI能力的同时,降低前后分离的开发成本,JeecgBoot还独创在线开发模式,No代码概念,一系列在线智能开发:在线配置表单、在线配置报表、在线设计流程等等。
14 |
15 | ### eladmin
16 |
17 | - **Github地址**:[https://github.com/elunez/eladmin](https://github.com/elunez/eladmin)
18 | - **star**: 3.9k
19 | - **介绍**: 项目基于 Spring Boot 2.1.0 、 Jpa、 Spring Security、redis、Vue的前后端分离的后台管理系统,项目采用分模块开发方式, 权限控制采用 RBAC,支持数据字典与数据权限管理,支持一键生成前后端代码,支持动态路由。
20 |
21 | ### paascloud-master
22 |
23 | - **Github地址**:[https://github.com/paascloud/paascloud-master](https://github.com/paascloud/paascloud-master)
24 | - **star**: 5.9k
25 | - **介绍**: spring cloud + vue + oAuth2.0全家桶实战,前后端分离模拟商城,完整的购物流程、后端运营平台,可以实现快速搭建企业级微服务项目。支持微信登录等三方登录。
26 |
27 | ### vhr
28 |
29 | - **Github地址**:[https://github.com/lenve/vhr](https://github.com/lenve/vhr)
30 | - **star**: 10.6k
31 | - **介绍**: 微人事是一个前后端分离的人力资源管理系统,项目采用SpringBoot+Vue开发。
32 |
33 | ### One mall
34 |
35 | - **Github地址**:[https://github.com/YunaiV/onemall](https://github.com/YunaiV/onemall)
36 | - **star**: 1.2k
37 | - **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
38 |
39 | ### Guns
40 |
41 | - **Github地址**:[https://github.com/stylefeng/Guns](https://github.com/stylefeng/Guns)
42 | - **star**: 2.3k
43 | - **介绍**: Guns基于SpringBoot 2,致力于做更简洁的后台管理系统,完美整合springmvc + shiro + mybatis-plus + beetl!Guns项目代码简洁,注释丰富,上手容易,同时Guns包含许多基础模块(用户管理,角色管理,部门管理,字典管理等10个模块),可以直接作为一个后台管理系统的脚手架!
44 |
45 | ### SpringCloud
46 |
47 | - **Github地址**:[https://github.com/YunaiV/onemall](https://github.com/YunaiV/onemall)
48 | - **star**: 1.2k
49 | - **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
50 |
51 | ### SpringBoot-Shiro-Vue
52 |
53 | - **Github地址**:[https://github.com/Heeexy/SpringBoot-Shiro-Vue](https://github.com/Heeexy/SpringBoot-Shiro-Vue)
54 | - **star**: 1.8k
55 | - **介绍**: 提供一套基于Spring Boot-Shiro-Vue的权限管理思路.前后端都加以控制,做到按钮/接口级别的权限。
56 |
57 | ### newbee-mall
58 |
59 | 最近开源的一个商城项目。
60 |
61 | - **Github地址**:[https://github.com/newbee-ltd/newbee-mall](https://github.com/newbee-ltd/newbee-mall)
62 | - **star**: 50
63 | - **介绍**: newbee-mall 项目是一套电商系统,包括 newbee-mall 商城系统及 newbee-mall-admin 商城后台管理系统,基于 Spring Boot 2.X 及相关技术栈开发。 前台商城系统包含首页门户、商品分类、新品上线、首页轮播、商品推荐、商品搜索、商品展示、购物车、订单结算、订单流程、个人订单管理、会员中心、帮助中心等模块。 后台管理系统包含数据面板、轮播图管理、商品管理、订单管理、会员管理、分类管理、设置等模块。
64 |
65 |
66 |
67 |
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/Backtracking-NQueens.md:
--------------------------------------------------------------------------------
1 | # N皇后
2 | [51. N皇后](https://leetcode-cn.com/problems/n-queens/)
3 | ### 题目描述
4 | > n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
5 | >
6 | 
7 | >
8 | 上图为 8 皇后问题的一种解法。
9 | >
10 | 给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
11 | >
12 | 每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
13 |
14 | 示例:
15 |
16 | ```
17 | 输入: 4
18 | 输出: [
19 | [".Q..", // 解法 1
20 | "...Q",
21 | "Q...",
22 | "..Q."],
23 |
24 | ["..Q.", // 解法 2
25 | "Q...",
26 | "...Q",
27 | ".Q.."]
28 | ]
29 | 解释: 4 皇后问题存在两个不同的解法。
30 | ```
31 |
32 | ### 问题分析
33 | 约束条件为每个棋子所在的行、列、对角线都不能有另一个棋子。
34 |
35 | 使用一维数组表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
36 | 每行只存储一个元素,然后递归到下一行,这样就不用判断行了,只需要判断列和对角线。
37 | ### Solution1
38 | 当result[row] = column时,即row行的棋子在column列。
39 |
40 | 对于[0, row-1]的任意一行(i 行),若 row 行的棋子和 i 行的棋子在同一列,则有result[i] == column;
41 | 若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
42 |
43 | 布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
44 | ```
45 | public List> solveNQueens(int n) {
46 | // 下标代表行,值代表列。如result[0] = 3 表示第1行的Q在第3列
47 | int[] result = new int[n];
48 | List> resultList = new LinkedList<>();
49 | dfs(resultList, result, 0, n);
50 | return resultList;
51 | }
52 |
53 | void dfs(List> resultList, int[] result, int row, int n) {
54 | // 递归终止条件
55 | if (row == n) {
56 | List list = new LinkedList<>();
57 | for (int x = 0; x < n; ++x) {
58 | StringBuilder sb = new StringBuilder();
59 | for (int y = 0; y < n; ++y)
60 | sb.append(result[x] == y ? "Q" : ".");
61 | list.add(sb.toString());
62 | }
63 | resultList.add(list);
64 | return;
65 | }
66 | for (int column = 0; column < n; ++column) {
67 | boolean isValid = true;
68 | result[row] = column;
69 | /*
70 | * 逐行往下考察每一行。同列,result[i] == column
71 | * 同对角线,row - i == Math.abs(result[i] - column)
72 | */
73 | for (int i = row - 1; i >= 0; --i) {
74 | if (result[i] == column || row - i == Math.abs(result[i] - column)) {
75 | isValid = false;
76 | break;
77 | }
78 | }
79 | if (isValid) dfs(resultList, result, row + 1, n);
80 | }
81 | }
82 | ```
83 | ### Solution2
84 | 使用LinkedList表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
85 |
86 | 解法二和解法一的不同在于,相同列以及相同对角线的校验。
87 | 将对角线抽象成【一次函数】这个简单的数学模型,根据一次函数的截距是常量这一特性进行校验。
88 |
89 | 这里,我将右上-左下对角线,简称为“\”对角线;左上-右下对角线简称为“/”对角线。
90 |
91 | “/”对角线斜率为1,对应方程为y = x + b,其中b为截距。
92 | 对于线上任意一点,均有y - x = b,即row - i = b;
93 | 定义一个布尔类型数组anti_diag,将b作为下标,当anti_diag[b] = true时,表示相应对角线上已经放置棋子。
94 | 但row - i有可能为负数,负数不能作为数组下标,row - i 的最小值为-n(当row = 0,i = n时),可以加上n作为数组下标,即将row -i + n 作为数组下标。
95 | row - i + n 的最大值为 2n(当row = n,i = 0时),故anti_diag的容量设置为 2n 即可。
96 |
97 | 
98 |
99 | “\”对角线斜率为-1,对应方程为y = -x + b,其中b为截距。
100 | 对于线上任意一点,均有y + x = b,即row + i = b;
101 | 同理,定义数组main_diag,将b作为下标,当main_diag[row + i] = true时,表示相应对角线上已经放置棋子。
102 |
103 | 有了两个校验对角线的数组,再来定义一个用于校验列的数组cols,这个太简单啦,不解释。
104 |
105 | **解法二时间复杂度为O(n!),在校验相同列和相同对角线时,引入三个布尔类型数组进行判断。相比解法一,少了一层循环,用空间换时间。**
106 |
107 | ```
108 | List> resultList = new LinkedList<>();
109 |
110 | public List> solveNQueens(int n) {
111 | boolean[] cols = new boolean[n];
112 | boolean[] main_diag = new boolean[2 * n];
113 | boolean[] anti_diag = new boolean[2 * n];
114 | LinkedList result = new LinkedList<>();
115 | dfs(result, 0, cols, main_diag, anti_diag, n);
116 | return resultList;
117 | }
118 |
119 | void dfs(LinkedList result, int row, boolean[] cols, boolean[] main_diag, boolean[] anti_diag, int n) {
120 | if (row == n) {
121 | List list = new LinkedList<>();
122 | for (int x = 0; x < n; ++x) {
123 | StringBuilder sb = new StringBuilder();
124 | for (int y = 0; y < n; ++y)
125 | sb.append(result.get(x) == y ? "Q" : ".");
126 | list.add(sb.toString());
127 | }
128 | resultList.add(list);
129 | return;
130 | }
131 | for (int i = 0; i < n; ++i) {
132 | if (cols[i] || main_diag[row + i] || anti_diag[row - i + n])
133 | continue;
134 | result.add(i);
135 | cols[i] = true;
136 | main_diag[row + i] = true;
137 | anti_diag[row - i + n] = true;
138 | dfs(result, row + 1, cols, main_diag, anti_diag, n);
139 | result.removeLast();
140 | cols[i] = false;
141 | main_diag[row + i] = false;
142 | anti_diag[row - i + n] = false;
143 | }
144 | }
145 | ```
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/公司真题.md:
--------------------------------------------------------------------------------
1 | # 网易 2018
2 |
3 | 下面三道编程题来自网易2018校招编程题,这三道应该来说是非常简单的编程题了,这些题目大家稍微有点编程和数学基础的话应该没什么问题。看答案之前一定要自己先想一下如果是自己做的话会怎么去做,然后再对照这我的答案看看,和你自己想的有什么区别?那一种方法更好?
4 |
5 | ## 问题
6 |
7 | ### 一 获得特定数量硬币问题
8 |
9 | 小易准备去魔法王国采购魔法神器,购买魔法神器需要使用魔法币,但是小易现在一枚魔法币都没有,但是小易有两台魔法机器可以通过投入x(x可以为0)个魔法币产生更多的魔法币。
10 |
11 | 魔法机器1:如果投入x个魔法币,魔法机器会将其变为2x+1个魔法币
12 |
13 | 魔法机器2:如果投入x个魔法币,魔法机器会将其变为2x+2个魔法币
14 |
15 | 小易采购魔法神器总共需要n个魔法币,所以小易只能通过两台魔法机器产生恰好n个魔法币,小易需要你帮他设计一个投入方案使他最后恰好拥有n个魔法币。
16 |
17 | **输入描述:** 输入包括一行,包括一个正整数n(1 ≤ n ≤ 10^9),表示小易需要的魔法币数量。
18 |
19 | **输出描述:** 输出一个字符串,每个字符表示该次小易选取投入的魔法机器。其中只包含字符'1'和'2'。
20 |
21 | **输入例子1:** 10
22 |
23 | **输出例子1:** 122
24 |
25 | ### 二 求“相反数”问题
26 |
27 | 为了得到一个数的"相反数",我们将这个数的数字顺序颠倒,然后再加上原先的数得到"相反数"。例如,为了得到1325的"相反数",首先我们将该数的数字顺序颠倒,我们得到5231,之后再加上原先的数,我们得到5231+1325=6556.如果颠倒之后的数字有前缀零,前缀零将会被忽略。例如n = 100, 颠倒之后是1.
28 |
29 | **输入描述:** 输入包括一个整数n,(1 ≤ n ≤ 10^5)
30 |
31 | **输出描述:** 输出一个整数,表示n的相反数
32 |
33 | **输入例子1:** 1325
34 |
35 | **输出例子1:** 6556
36 |
37 | ### 三 字符串碎片的平均长度
38 |
39 | 一个由小写字母组成的字符串可以看成一些同一字母的最大碎片组成的。例如,"aaabbaaac"是由下面碎片组成的:'aaa','bb','c'。牛牛现在给定一个字符串,请你帮助计算这个字符串的所有碎片的平均长度是多少。
40 |
41 | **输入描述:** 输入包括一个字符串s,字符串s的长度length(1 ≤ length ≤ 50),s只含小写字母('a'-'z')
42 |
43 | **输出描述:** 输出一个整数,表示所有碎片的平均长度,四舍五入保留两位小数。
44 |
45 | **如样例所示:** s = "aaabbaaac"
46 | 所有碎片的平均长度 = (3 + 2 + 3 + 1) / 4 = 2.25
47 |
48 | **输入例子1:** aaabbaaac
49 |
50 | **输出例子1:** 2.25
51 |
52 | ## 答案
53 |
54 | ### 一 获得特定数量硬币问题
55 |
56 | #### 分析:
57 |
58 | 作为该试卷的第一题,这道题应该只要思路正确就很简单了。
59 |
60 | 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
61 |
62 | #### 示例代码
63 |
64 | 注意:由于用户的输入不确定性,一般是为了程序高可用性使需要将捕获用户输入异常然后友好提示用户输入类型错误并重新输入的。所以下面我给了两个版本,这两个版本都是正确的。这里只是给大家演示如何捕获输入类型异常,后面的题目中我给的代码没有异常处理的部分,参照下面两个示例代码,应该很容易添加。(PS:企业面试中没有明确就不用添加异常处理,当然你有的话也更好)
65 |
66 | **不带输入异常处理判断的版本:**
67 |
68 | ```java
69 | import java.util.Scanner;
70 |
71 | public class Main2 {
72 | // 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
73 |
74 | public static void main(String[] args) {
75 | System.out.println("请输入要获得的硬币数量:");
76 | Scanner scanner = new Scanner(System.in);
77 | int coincount = scanner.nextInt();
78 | StringBuilder sb = new StringBuilder();
79 | while (coincount >= 1) {
80 | // 偶数的情况
81 | if (coincount % 2 == 0) {
82 | coincount = (coincount - 2) / 2;
83 | sb.append("2");
84 | // 奇数的情况
85 | } else {
86 | coincount = (coincount - 1) / 2;
87 | sb.append("1");
88 | }
89 | }
90 | // 输出反转后的字符串
91 | System.out.println(sb.reverse());
92 |
93 | }
94 | }
95 | ```
96 |
97 | **带输入异常处理判断的版本(当输入的不是整数的时候会提示重新输入):**
98 |
99 | ```java
100 | import java.util.InputMismatchException;
101 | import java.util.Scanner;
102 |
103 |
104 | public class Main {
105 | // 解题关键:明确魔法机器1只能产生奇数,魔法机器2只能产生偶数即可。我们从后往前一步一步推回去即可。
106 |
107 | public static void main(String[] args) {
108 | System.out.println("请输入要获得的硬币数量:");
109 | Scanner scanner = new Scanner(System.in);
110 | boolean flag = true;
111 | while (flag) {
112 | try {
113 | int coincount = scanner.nextInt();
114 | StringBuilder sb = new StringBuilder();
115 | while (coincount >= 1) {
116 | // 偶数的情况
117 | if (coincount % 2 == 0) {
118 | coincount = (coincount - 2) / 2;
119 | sb.append("2");
120 | // 奇数的情况
121 | } else {
122 | coincount = (coincount - 1) / 2;
123 | sb.append("1");
124 | }
125 | }
126 | // 输出反转后的字符串
127 | System.out.println(sb.reverse());
128 | flag=false;//程序结束
129 | } catch (InputMismatchException e) {
130 | System.out.println("输入数据类型不匹配,请您重新输入:");
131 | scanner.nextLine();
132 | continue;
133 | }
134 | }
135 |
136 | }
137 | }
138 |
139 | ```
140 |
141 | ### 二 求“相反数”问题
142 |
143 | #### 分析:
144 |
145 | 解决本道题有几种不同的方法,但是最快速的方法就是利用reverse()方法反转字符串然后再将字符串转换成int类型的整数,这个方法是快速解决本题关键。我们先来回顾一下下面两个知识点:
146 |
147 | **1)String转int;**
148 |
149 | 在 Java 中要将 String 类型转化为 int 类型时,需要使用 Integer 类中的 parseInt() 方法或者 valueOf() 方法进行转换.
150 |
151 | ```java
152 | String str = "123";
153 | int a = Integer.parseInt(str);
154 | ```
155 |
156 | 或
157 |
158 | ```java
159 | String str = "123";
160 | int a = Integer.valueOf(str).intValue();
161 | ```
162 |
163 | **2)next()和nextLine()的区别**
164 |
165 | 在Java中输入字符串有两种方法,就是next()和nextLine().两者的区别就是:nextLine()的输入是碰到回车就终止输入,而next()方法是碰到空格,回车,Tab键都会被视为终止符。所以next()不会得到带空格的字符串,而nextLine()可以得到带空格的字符串。
166 |
167 | #### 示例代码:
168 |
169 | ```java
170 | import java.util.Scanner;
171 |
172 | /**
173 | * 本题关键:①String转int;②next()和nextLine()的区别
174 | */
175 | public class Main {
176 |
177 | public static void main(String[] args) {
178 |
179 | System.out.println("请输入一个整数:");
180 | Scanner scanner = new Scanner(System.in);
181 | String s=scanner.next();
182 | //将字符串转换成数字
183 | int number1=Integer.parseInt(s);
184 | //将字符串倒序后转换成数字
185 | //因为Integer.parseInt()的参数类型必须是字符串所以必须加上toString()
186 | int number2=Integer.parseInt(new StringBuilder(s).reverse().toString());
187 | System.out.println(number1+number2);
188 |
189 | }
190 | }
191 | ```
192 |
193 | ### 三 字符串碎片的平均长度
194 |
195 | #### 分析:
196 |
197 | 这道题的意思也就是要求:(字符串的总长度)/(相同字母团构成的字符串的个数)。
198 |
199 | 这样就很简单了,就变成了字符串的字符之间的比较。如果需要比较字符串的字符的话,我们可以利用charAt(i)方法:取出特定位置的字符与后一个字符比较,或者利用toCharArray()方法将字符串转换成字符数组采用同样的方法做比较。
200 |
201 | #### 示例代码
202 |
203 | **利用charAt(i)方法:**
204 |
205 | ```java
206 | import java.util.Scanner;
207 |
208 | public class Main {
209 |
210 | public static void main(String[] args) {
211 |
212 | Scanner sc = new Scanner(System.in);
213 | while (sc.hasNext()) {
214 | String s = sc.next();
215 | //个数至少为一个
216 | float count = 1;
217 | for (int i = 0; i < s.length() - 1; i++) {
218 | if (s.charAt(i) != s.charAt(i + 1)) {
219 | count++;
220 | }
221 | }
222 | System.out.println(s.length() / count);
223 | }
224 | }
225 |
226 | }
227 | ```
228 |
229 | **利用toCharArray()方法:**
230 |
231 | ```java
232 | import java.util.Scanner;
233 |
234 | public class Main2 {
235 |
236 | public static void main(String[] args) {
237 |
238 | Scanner sc = new Scanner(System.in);
239 | while (sc.hasNext()) {
240 | String s = sc.next();
241 | //个数至少为一个
242 | float count = 1;
243 | char [] stringArr = s.toCharArray();
244 | for (int i = 0; i < stringArr.length - 1; i++) {
245 | if (stringArr[i] != stringArr[i + 1]) {
246 | count++;
247 | }
248 | }
249 | System.out.println(s.length() / count);
250 | }
251 | }
252 |
253 | }
254 | ```
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/数据结构.md:
--------------------------------------------------------------------------------
1 | 下面只是简单地总结,给了一些参考文章,后面会对这部分内容进行重构。
2 |
3 |
4 | - [Queue](#queue)
5 | - [什么是队列](#什么是队列)
6 | - [队列的种类](#队列的种类)
7 | - [Java 集合框架中的队列 Queue](#java-集合框架中的队列-queue)
8 | - [推荐文章](#推荐文章)
9 | - [Set](#set)
10 | - [什么是 Set](#什么是-set)
11 | - [补充:有序集合与无序集合说明](#补充:有序集合与无序集合说明)
12 | - [HashSet 和 TreeSet 底层数据结构](#hashset-和-treeset-底层数据结构)
13 | - [推荐文章](#推荐文章-1)
14 | - [List](#list)
15 | - [什么是List](#什么是list)
16 | - [List的常见实现类](#list的常见实现类)
17 | - [ArrayList 和 LinkedList 源码学习](#arraylist-和-linkedlist-源码学习)
18 | - [推荐阅读](#推荐阅读)
19 | - [Map](#map)
20 | - [树](#树)
21 |
22 |
23 |
24 |
25 | ## Queue
26 |
27 | ### 什么是队列
28 | 队列是数据结构中比较重要的一种类型,它支持 FIFO,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。
29 |
30 | ### 队列的种类
31 |
32 | - **单队列**(单队列就是常见的队列, 每次添加元素时,都是添加到队尾,存在“假溢出”的问题也就是明明有位置却不能添加的情况)
33 | - **循环队列**(避免了“假溢出”的问题)
34 |
35 | ### Java 集合框架中的队列 Queue
36 |
37 | Java 集合中的 Queue 继承自 Collection 接口 ,Deque, LinkedList, PriorityQueue, BlockingQueue 等类都实现了它。
38 | Queue 用来存放 等待处理元素 的集合,这种场景一般用于缓冲、并发访问。
39 | 除了继承 Collection 接口的一些方法,Queue 还添加了额外的 添加、删除、查询操作。
40 |
41 | ### 推荐文章
42 |
43 | - [Java 集合深入理解(9):Queue 队列](https://blog.csdn.net/u011240877/article/details/52860924)
44 |
45 | ## Set
46 |
47 | ### 什么是 Set
48 | Set 继承于 Collection 接口,是一个不允许出现重复元素,并且无序的集合,主要 HashSet 和 TreeSet 两大实现类。
49 |
50 | 在判断重复元素的时候,HashSet 集合会调用 hashCode()和 equal()方法来实现;TreeSet 集合会调用compareTo方法来实现。
51 |
52 | ### 补充:有序集合与无序集合说明
53 | - 有序集合:集合里的元素可以根据 key 或 index 访问 (List、Map)
54 | - 无序集合:集合里的元素只能遍历。(Set)
55 |
56 |
57 | ### HashSet 和 TreeSet 底层数据结构
58 |
59 | **HashSet** 是哈希表结构,主要利用 HashMap 的 key 来存储元素,计算插入元素的 hashCode 来获取元素在集合中的位置;
60 |
61 | **TreeSet** 是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序;
62 |
63 |
64 | ### 推荐文章
65 |
66 | - [Java集合--Set(基础)](https://www.jianshu.com/p/b48c47a42916)
67 |
68 | ## List
69 |
70 | ### 什么是List
71 |
72 | 在 List 中,用户可以精确控制列表中每个元素的插入位置,另外用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。 与 Set 不同,List 通常允许重复的元素。 另外 List 是有序集合而 Set 是无序集合。
73 |
74 | ### List的常见实现类
75 |
76 | **ArrayList** 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。
77 |
78 | **LinkedList** 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
79 |
80 | **Vector** 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
81 |
82 | **Stack** 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。相关阅读:[java数据结构与算法之栈(Stack)设计与实现](https://blog.csdn.net/javazejian/article/details/53362993)
83 |
84 | ### ArrayList 和 LinkedList 源码学习
85 |
86 | - [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList.md)
87 | - [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/LinkedList.md)
88 |
89 | ### 推荐阅读
90 |
91 | - [java 数据结构与算法之顺序表与链表深入分析](https://blog.csdn.net/javazejian/article/details/52953190)
92 |
93 |
94 | ## Map
95 |
96 |
97 | - [集合框架源码学习之 HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
98 | - [ConcurrentHashMap 实现原理及源码分析](https://link.juejin.im/?target=http%3A%2F%2Fwww.cnblogs.com%2Fchengxiao%2Fp%2F6842045.html)
99 |
100 | ## 树
101 | * ### 1 二叉树
102 |
103 | [二叉树](https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
104 |
105 | (1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
106 |
107 | (2)[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
108 |
109 | (3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
110 |
111 | * ### 2 完全二叉树
112 |
113 | [完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
114 |
115 | 完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
116 | * ### 3 满二叉树
117 |
118 | [满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,国内外的定义不同)
119 |
120 | 国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
121 | * ### 堆
122 |
123 | [数据结构之堆的定义](https://blog.csdn.net/qq_33186366/article/details/51876191)
124 |
125 | 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
126 | * ### 4 二叉查找树(BST)
127 |
128 | [浅谈算法和数据结构: 七 二叉查找树](http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html)
129 |
130 | 二叉查找树的特点:
131 |
132 | 1. 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
133 | 2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
134 | 3. 任意节点的左、右子树也分别为二叉查找树;
135 | 4. 没有键值相等的节点(no duplicate nodes)。
136 |
137 | * ### 5 平衡二叉树(Self-balancing binary search tree)
138 |
139 | [ 平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等)
140 | * ### 6 红黑树
141 |
142 | - 红黑树特点:
143 | 1. 每个节点非红即黑;
144 | 2. 根节点总是黑色的;
145 | 3. 每个叶子节点都是黑色的空节点(NIL节点);
146 | 4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
147 | 5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
148 |
149 | - 红黑树的应用:
150 |
151 | TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
152 |
153 | - 为什么要用红黑树
154 |
155 | 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
156 |
157 | - 推荐文章:
158 | - [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
159 | - [寻找红黑树的操作手册](http://dandanlove.com/2018/03/18/red-black-tree/)(文章排版以及思路真的不错)
160 | - [红黑树深入剖析及Java实现](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
161 | * ### 7 B-,B+,B*树
162 |
163 | [二叉树学习笔记之B树、B+树、B*树 ](https://yq.aliyun.com/articles/38345)
164 |
165 | [《B-树,B+树,B*树详解》](https://blog.csdn.net/aqzwss/article/details/53074186)
166 |
167 | [《B-树,B+树与B*树的优缺点比较》](https://blog.csdn.net/bigtree_3721/article/details/73632405)
168 |
169 | B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
170 | 1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
171 | 2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
172 | 3. B\*树 是B+树的变体,B\*树分配新结点的概率比B+树要低,空间使用率更高;
173 | * ### 8 LSM 树
174 |
175 | [[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
176 |
177 | B+树最大的性能问题是会产生大量的随机IO
178 |
179 | 为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
180 |
181 | [LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
182 |
183 |
184 | ## 图
185 |
186 |
187 |
188 |
189 | ## BFS及DFS
190 |
191 | - [《使用BFS及DFS遍历树和图的思路及实现》](https://blog.csdn.net/Gene1994/article/details/85097507)
192 |
193 |
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/算法学习资源推荐.md:
--------------------------------------------------------------------------------
1 | 我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
2 |
3 | ## LeetCode
4 |
5 | - [LeetCode(中国)官网](https://leetcode-cn.com/)
6 |
7 | - [如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
8 |
9 |
10 | ## 牛客网
11 |
12 | - [牛客网官网](https://www.nowcoder.com)
13 | - [剑指offer编程题](https://www.nowcoder.com/ta/coding-interviews)
14 |
15 | - [2017校招真题](https://www.nowcoder.com/ta/2017test)
16 | - [华为机试题](https://www.nowcoder.com/ta/huawei)
17 |
18 |
19 | ## 公司真题
20 |
21 | - [ 网易2018校园招聘编程题真题集合](https://www.nowcoder.com/test/6910869/summary)
22 | - [ 网易2018校招内推编程题集合](https://www.nowcoder.com/test/6291726/summary)
23 | - [2017年校招全国统一模拟笔试(第五场)编程题集合](https://www.nowcoder.com/test/5986669/summary)
24 | - [2017年校招全国统一模拟笔试(第四场)编程题集合](https://www.nowcoder.com/test/5507925/summary)
25 | - [2017年校招全国统一模拟笔试(第三场)编程题集合](https://www.nowcoder.com/test/5217106/summary)
26 | - [2017年校招全国统一模拟笔试(第二场)编程题集合](https://www.nowcoder.com/test/4546329/summary)
27 | - [ 2017年校招全国统一模拟笔试(第一场)编程题集合](https://www.nowcoder.com/test/4236887/summary)
28 | - [百度2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4998655/summary)
29 | - [网易2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4575457/summary)
30 | - [网易2017秋招编程题集合](https://www.nowcoder.com/test/2811407/summary)
31 | - [网易有道2017内推编程题](https://www.nowcoder.com/test/2385858/summary)
32 | - [ 滴滴出行2017秋招笔试真题-编程题汇总](https://www.nowcoder.com/test/3701760/summary)
33 | - [腾讯2017暑期实习生编程题](https://www.nowcoder.com/test/1725829/summary)
34 | - [今日头条2017客户端工程师实习生笔试题](https://www.nowcoder.com/test/1649301/summary)
35 | - [今日头条2017后端工程师实习生笔试题](https://www.nowcoder.com/test/1649268/summary)
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
--------------------------------------------------------------------------------
/docs/database/MySQL Index.md:
--------------------------------------------------------------------------------
1 |
2 | # 思维导图-索引篇
3 |
4 | > 系列思维导图源文件(数据库+架构)以及思维导图制作软件—XMind8 破解安装,公众号后台回复:**“思维导图”** 免费领取!(下面的图片不是很清楚,原图非常清晰,另外提供给大家源文件也是为了大家根据自己需要进行修改)
5 |
6 | 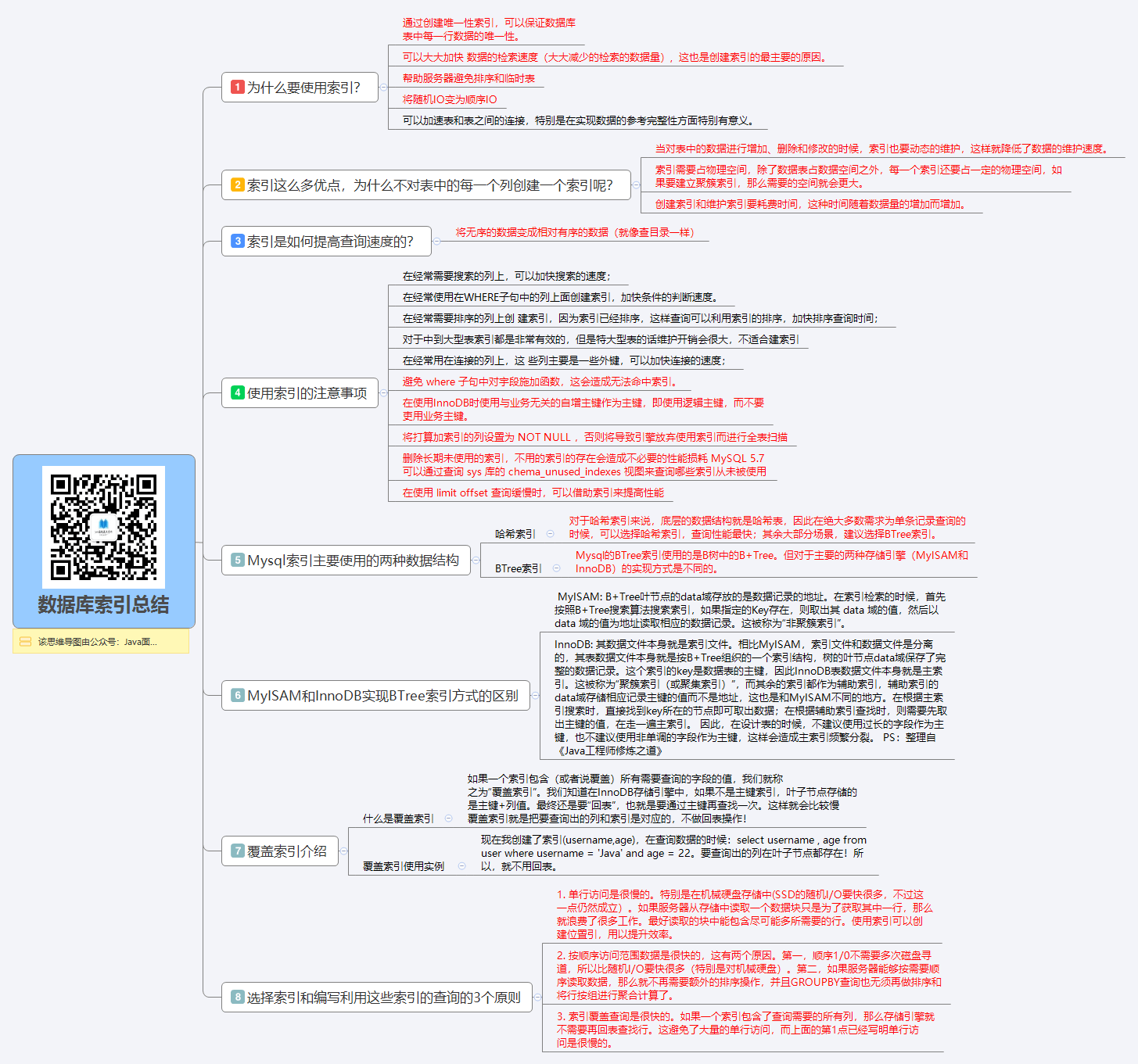
7 |
8 | > **下面是我补充的一些内容**
9 |
10 | # 为什么索引能提高查询速度
11 |
12 | > 以下内容整理自:
13 | > 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
14 | > 作者 :Java3y
15 |
16 | ### 先从 MySQL 的基本存储结构说起
17 |
18 | MySQL的基本存储结构是页(记录都存在页里边):
19 |
20 | 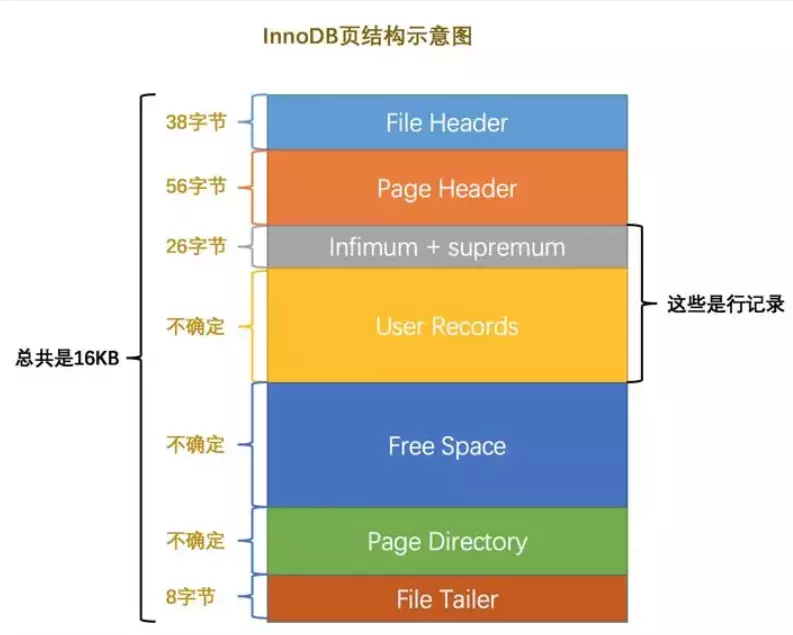
21 |
22 | 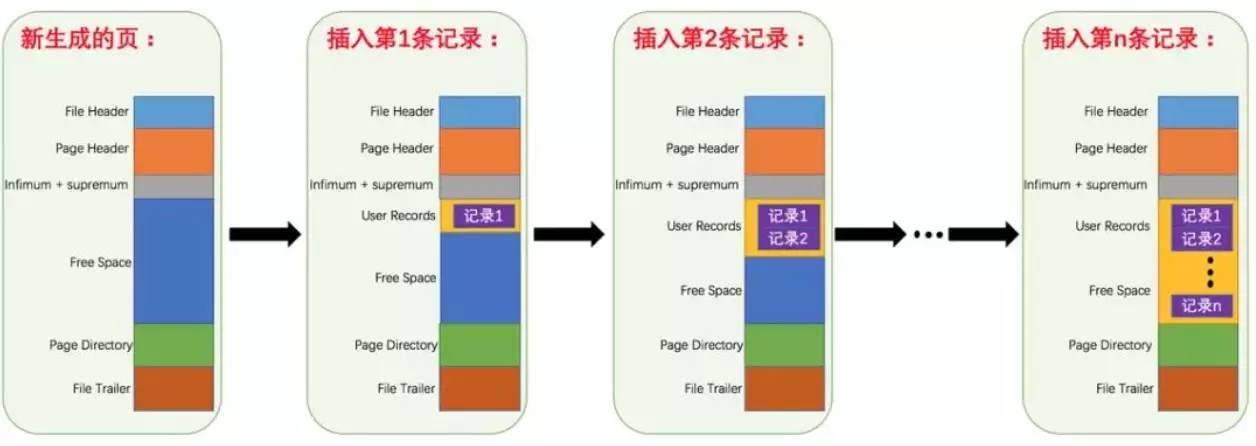
23 |
24 | - **各个数据页可以组成一个双向链表**
25 | - **每个数据页中的记录又可以组成一个单向链表**
26 | - 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
27 | - 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
28 |
29 | 所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
30 |
31 | 1. **定位到记录所在的页:需要遍历双向链表,找到所在的页**
32 | 2. **从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了**
33 |
34 | 很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为O(n)。
35 |
36 |
37 | ### 使用索引之后
38 |
39 | 索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):
40 |
41 | 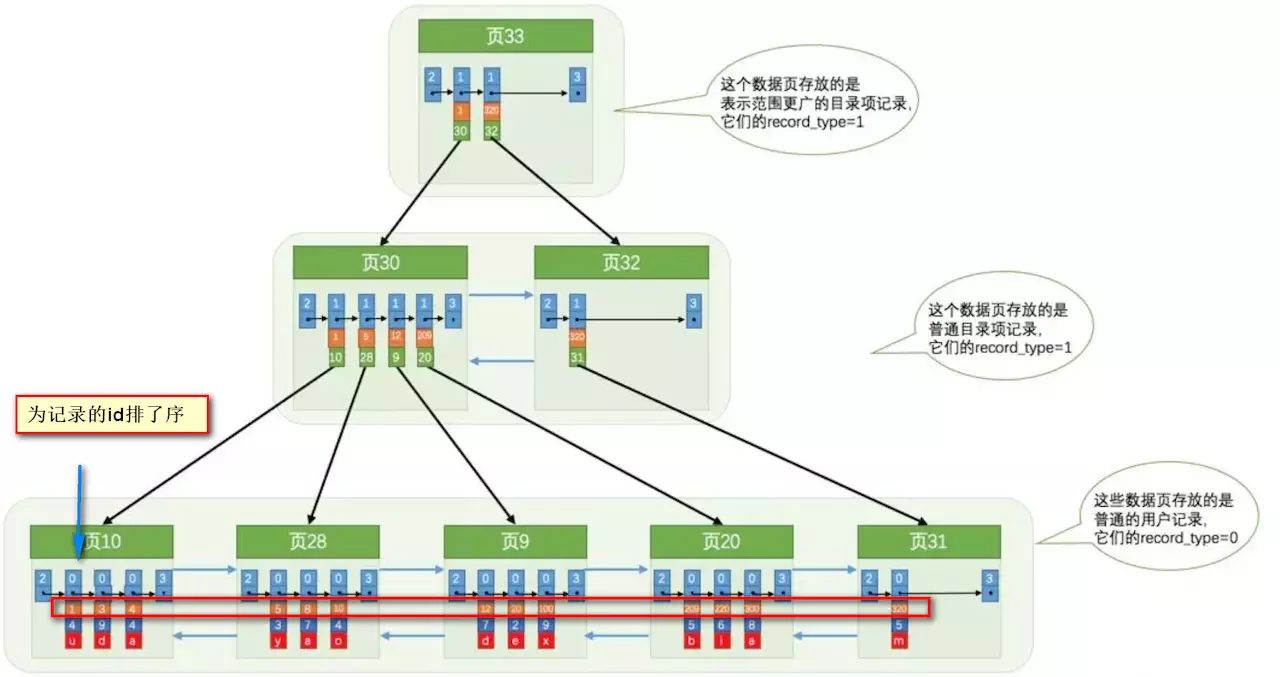
42 |
43 | 要找到id为8的记录简要步骤:
44 |
45 | 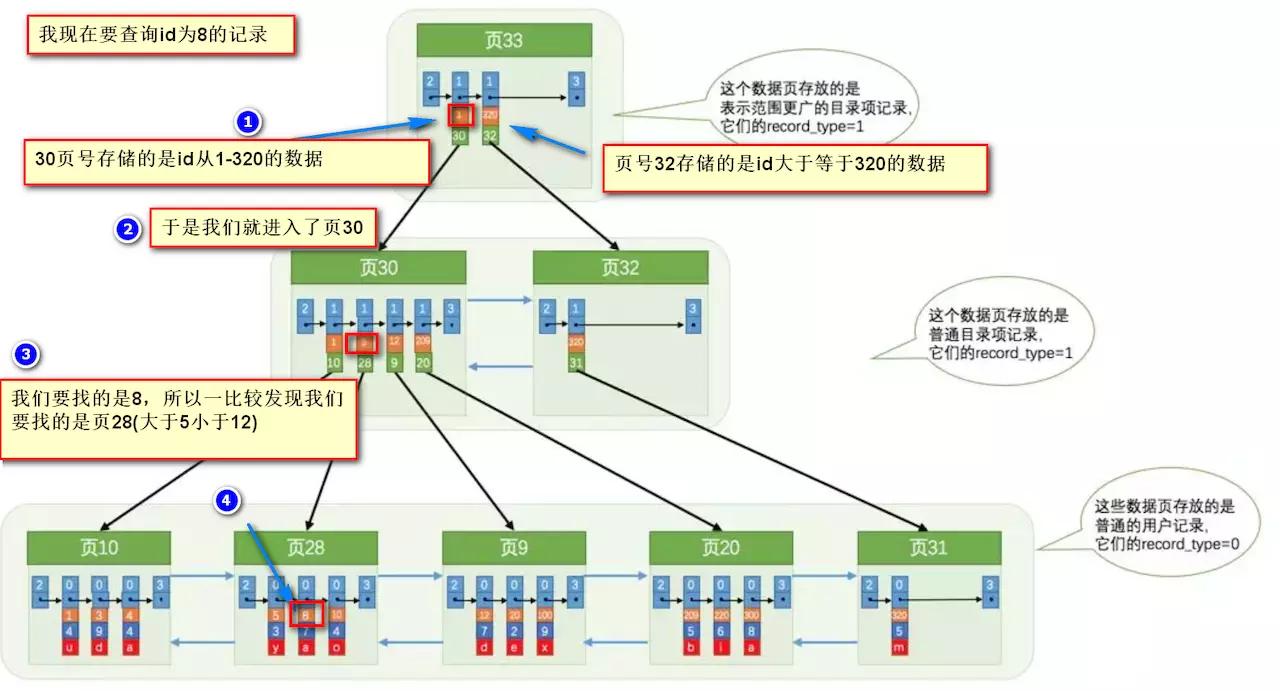
46 |
47 | 很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 **“目录”** 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为O(logn))
48 |
49 | 其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
50 |
51 | # 关于索引其他重要的内容补充
52 |
53 | > 以下内容整理自:《Java工程师修炼之道》
54 |
55 |
56 | ### 最左前缀原则
57 |
58 | MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
59 |
60 | ```
61 | select * from user where name=xx and city=xx ; //可以命中索引
62 | select * from user where name=xx ; // 可以命中索引
63 | select * from user where city=xx ; // 无法命中索引
64 | ```
65 | 这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 `city= xx and name =xx`,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
66 |
67 | 由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
68 |
69 | ### 注意避免冗余索引
70 |
71 | 冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
72 |
73 | MySQL 5.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
74 |
75 | ### Mysql如何为表字段添加索引???
76 |
77 | 1.添加PRIMARY KEY(主键索引)
78 |
79 | ```
80 | ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
81 | ```
82 | 2.添加UNIQUE(唯一索引)
83 |
84 | ```
85 | ALTER TABLE `table_name` ADD UNIQUE ( `column` )
86 | ```
87 |
88 | 3.添加INDEX(普通索引)
89 |
90 | ```
91 | ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
92 | ```
93 |
94 | 4.添加FULLTEXT(全文索引)
95 |
96 | ```
97 | ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
98 | ```
99 |
100 | 5.添加多列索引
101 |
102 | ```
103 | ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
104 | ```
105 |
106 |
107 | # 参考
108 |
109 | - 《Java工程师修炼之道》
110 | - 《MySQL高性能书籍_第3版》
111 | - https://juejin.im/post/5b55b842f265da0f9e589e79
112 |
113 |
--------------------------------------------------------------------------------
/docs/database/Redis/Redis持久化.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | 非常感谢《redis实战》真本书,本文大多内容也参考了书中的内容。非常推荐大家看一下《redis实战》这本书,感觉书中的很多理论性东西还是很不错的。
4 |
5 | 为什么本文的名字要加上春夏秋冬又一春,哈哈 ,这是一部韩国的电影,我感觉电影不错,所以就用在文章名字上了,没有什么特别的含义,然后下面的有些配图也是电影相关镜头。
6 |
7 | 
8 |
9 | **很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后回复数据),或者是为了防止系统故障而将数据备份到一个远程位置。**
10 |
11 | Redis不同于Memcached的很重一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
12 |
13 |
14 | ## 快照(snapshotting)持久化
15 |
16 | Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
17 |
18 |
19 | 
20 |
21 | **快照持久化是Redis默认采用的持久化方式**,在redis.conf配置文件中默认有此下配置:
22 | ```
23 |
24 | save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
25 |
26 | save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
27 |
28 | save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
29 | ```
30 |
31 | 根据配置,快照将被写入dbfilename选项指定的文件里面,并存储在dir选项指定的路径上面。如果在新的快照文件创建完毕之前,Redis、系统或者硬件这三者中的任意一个崩溃了,那么Redis将丢失最近一次创建快照写入的所有数据。
32 |
33 | 举个例子:假设Redis的上一个快照是2:35开始创建的,并且已经创建成功。下午3:06时,Redis又开始创建新的快照,并且在下午3:08快照创建完毕之前,有35个键进行了更新。如果在下午3:06到3:08期间,系统发生了崩溃,导致Redis无法完成新快照的创建工作,那么Redis将丢失下午2:35之后写入的所有数据。另一方面,如果系统恰好在新的快照文件创建完毕之后崩溃,那么Redis将丢失35个键的更新数据。
34 |
35 | **创建快照的办法有如下几种:**
36 |
37 | - **BGSAVE命令:** 客户端向Redis发送 **BGSAVE命令** 来创建一个快照。对于支持BGSAVE命令的平台来说(基本上所有平台支持,除了Windows平台),Redis会调用fork来创建一个子进程,然后子进程负责将快照写入硬盘,而父进程则继续处理命令请求。
38 | - **SAVE命令:** 客户端还可以向Redis发送 **SAVE命令** 来创建一个快照,接到SAVE命令的Redis服务器在快照创建完毕之前不会再响应任何其他命令。SAVE命令不常用,我们通常只会在没有足够内存去执行BGSAVE命令的情况下,又或者即使等待持久化操作执行完毕也无所谓的情况下,才会使用这个命令。
39 | - **save选项:** 如果用户设置了save选项(一般会默认设置),比如 **save 60 10000**,那么从Redis最近一次创建快照之后开始算起,当“60秒之内有10000次写入”这个条件被满足时,Redis就会自动触发BGSAVE命令。
40 | - **SHUTDOWN命令:** 当Redis通过SHUTDOWN命令接收到关闭服务器的请求时,或者接收到标准TERM信号时,会执行一个SAVE命令,阻塞所有客户端,不再执行客户端发送的任何命令,并在SAVE命令执行完毕之后关闭服务器。
41 | - **一个Redis服务器连接到另一个Redis服务器:** 当一个Redis服务器连接到另一个Redis服务器,并向对方发送SYNC命令来开始一次复制操作的时候,如果主服务器目前没有执行BGSAVE操作,或者主服务器并非刚刚执行完BGSAVE操作,那么主服务器就会执行BGSAVE命令
42 |
43 | 如果系统真的发生崩溃,用户将丢失最近一次生成快照之后更改的所有数据。因此,快照持久化只适用于即使丢失一部分数据也不会造成一些大问题的应用程序。不能接受这个缺点的话,可以考虑AOF持久化。
44 |
45 |
46 |
47 | ## **AOF(append-only file)持久化**
48 | 与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
49 | ```
50 | appendonly yes
51 | ```
52 |
53 | 开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
54 |
55 | 
56 |
57 | **在Redis的配置文件中存在三种同步方式,它们分别是:**
58 |
59 | ```
60 |
61 | appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
62 | appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
63 | appendfsync no #让操作系统决定何时进行同步
64 | ```
65 |
66 | **appendfsync always** 可以实现将数据丢失减到最少,不过这种方式需要对硬盘进行大量的写入而且每次只写入一个命令,十分影响Redis的速度。另外使用固态硬盘的用户谨慎使用appendfsync always选项,因为这会明显降低固态硬盘的使用寿命。
67 |
68 | 为了兼顾数据和写入性能,用户可以考虑 **appendfsync everysec选项** ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
69 |
70 |
71 | **appendfsync no** 选项一般不推荐,这种方案会使Redis丢失不定量的数据而且如果用户的硬盘处理写入操作的速度不够的话,那么当缓冲区被等待写入的数据填满时,Redis的写入操作将被阻塞,这会导致Redis的请求速度变慢。
72 |
73 | **虽然AOF持久化非常灵活地提供了多种不同的选项来满足不同应用程序对数据安全的不同要求,但AOF持久化也有缺陷——AOF文件的体积太大。**
74 |
75 | ## 重写/压缩AOF
76 |
77 | AOF虽然在某个角度可以将数据丢失降低到最小而且对性能影响也很小,但是极端的情况下,体积不断增大的AOF文件很可能会用完硬盘空间。另外,如果AOF体积过大,那么还原操作执行时间就可能会非常长。
78 |
79 | 为了解决AOF体积过大的问题,用户可以向Redis发送 **BGREWRITEAOF命令** ,这个命令会通过移除AOF文件中的冗余命令来重写(rewrite)AOF文件来减小AOF文件的体积。BGREWRITEAOF命令和BGSAVE创建快照原理十分相似,所以AOF文件重写也需要用到子进程,这样会导致性能问题和内存占用问题,和快照持久化一样。更糟糕的是,如果不加以控制的话,AOF文件的体积可能会比快照文件大好几倍。
80 |
81 | **文件重写流程:**
82 |
83 | 
84 | 和快照持久化可以通过设置save选项来自动执行BGSAVE一样,AOF持久化也可以通过设置
85 |
86 | ```
87 | auto-aof-rewrite-percentage
88 | ```
89 |
90 | 选项和
91 |
92 | ```
93 | auto-aof-rewrite-min-size
94 | ```
95 |
96 | 选项自动执行BGREWRITEAOF命令。举例:假设用户对Redis设置了如下配置选项并且启用了AOF持久化。那么当AOF文件体积大于64mb,并且AOF的体积比上一次重写之后的体积大了至少一倍(100%)的时候,Redis将执行BGREWRITEAOF命令。
97 |
98 | ```
99 | auto-aof-rewrite-percentage 100
100 | auto-aof-rewrite-min-size 64mb
101 | ```
102 |
103 | 无论是AOF持久化还是快照持久化,将数据持久化到硬盘上都是非常有必要的,但除了进行持久化外,用户还必须对持久化得到的文件进行备份(最好是备份到不同的地方),这样才能尽量避免数据丢失事故发生。如果条件允许的话,最好能将快照文件和重新重写的AOF文件备份到不同的服务器上面。
104 |
105 | 随着负载量的上升,或者数据的完整性变得 越来越重要时,用户可能需要使用到复制特性。
106 |
107 | ## Redis 4.0 对于持久化机制的优化
108 | Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
109 |
110 | 如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分就是压缩格式不再是 AOF 格式,可读性较差。
111 |
112 | 参考:
113 |
114 | 《Redis实战》
115 |
116 | [深入学习Redis(2):持久化](https://www.cnblogs.com/kismetv/p/9137897.html)
117 |
118 |
119 |
--------------------------------------------------------------------------------
/docs/database/Redis/Redlock分布式锁.md:
--------------------------------------------------------------------------------
1 | 这篇文章主要是对 Redis 官方网站刊登的 [Distributed locks with Redis](https://redis.io/topics/distlock) 部分内容的总结和翻译。
2 |
3 | ## 什么是 RedLock
4 |
5 | Redis 官方站这篇文章提出了一种权威的基于 Redis 实现分布式锁的方式名叫 *Redlock*,此种方式比原先的单节点的方法更安全。它可以保证以下特性:
6 |
7 | 1. 安全特性:互斥访问,即永远只有一个 client 能拿到锁
8 | 2. 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash 了或者出现了网络分区
9 | 3. 容错性:只要大部分 Redis 节点存活就可以正常提供服务
10 |
11 | ## 怎么在单节点上实现分布式锁
12 |
13 | > SET resource_name my_random_value NX PX 30000
14 |
15 | 主要依靠上述命令,该命令仅当 Key 不存在时(NX保证)set 值,并且设置过期时间 3000ms (PX保证),值 my_random_value 必须是所有 client 和所有锁请求发生期间唯一的,释放锁的逻辑是:
16 |
17 | ```lua
18 | if redis.call("get",KEYS[1]) == ARGV[1] then
19 | return redis.call("del",KEYS[1])
20 | else
21 | return 0
22 | end
23 | ```
24 |
25 | 上述实现可以避免释放另一个client创建的锁,如果只有 del 命令的话,那么如果 client1 拿到 lock1 之后因为某些操作阻塞了很长时间,此时 Redis 端 lock1 已经过期了并且已经被重新分配给了 client2,那么 client1 此时再去释放这把锁就会造成 client2 原本获取到的锁被 client1 无故释放了,但现在为每个 client 分配一个 unique 的 string 值可以避免这个问题。至于如何去生成这个 unique string,方法很多随意选择一种就行了。
26 |
27 | ## Redlock 算法
28 |
29 | 算法很易懂,起 5 个 master 节点,分布在不同的机房尽量保证可用性。为了获得锁,client 会进行如下操作:
30 |
31 | 1. 得到当前的时间,微秒单位
32 | 2. 尝试顺序地在 5 个实例上申请锁,当然需要使用相同的 key 和 random value,这里一个 client 需要合理设置与 master 节点沟通的 timeout 大小,避免长时间和一个 fail 了的节点浪费时间
33 | 3. 当 client 在大于等于 3 个 master 上成功申请到锁的时候,且它会计算申请锁消耗了多少时间,这部分消耗的时间采用获得锁的当下时间减去第一步获得的时间戳得到,如果锁的持续时长(lock validity time)比流逝的时间多的话,那么锁就真正获取到了。
34 | 4. 如果锁申请到了,那么锁真正的 lock validity time 应该是 origin(lock validity time) - 申请锁期间流逝的时间
35 | 5. 如果 client 申请锁失败了,那么它就会在少部分申请成功锁的 master 节点上执行释放锁的操作,重置状态
36 |
37 | ## 失败重试
38 |
39 | 如果一个 client 申请锁失败了,那么它需要稍等一会在重试避免多个 client 同时申请锁的情况,最好的情况是一个 client 需要几乎同时向 5 个 master 发起锁申请。另外就是如果 client 申请锁失败了它需要尽快在它曾经申请到锁的 master 上执行 unlock 操作,便于其他 client 获得这把锁,避免这些锁过期造成的时间浪费,当然如果这时候网络分区使得 client 无法联系上这些 master,那么这种浪费就是不得不付出的代价了。
40 |
41 | ## 放锁
42 |
43 | 放锁操作很简单,就是依次释放所有节点上的锁就行了
44 |
45 | ## 性能、崩溃恢复和 fsync
46 |
47 | 如果我们的节点没有持久化机制,client 从 5 个 master 中的 3 个处获得了锁,然后其中一个重启了,这是注意 **整个环境中又出现了 3 个 master 可供另一个 client 申请同一把锁!** 违反了互斥性。如果我们开启了 AOF 持久化那么情况会稍微好转一些,因为 Redis 的过期机制是语义层面实现的,所以在 server 挂了的时候时间依旧在流逝,重启之后锁状态不会受到污染。但是考虑断电之后呢,AOF部分命令没来得及刷回磁盘直接丢失了,除非我们配置刷回策略为 fsnyc = always,但这会损伤性能。解决这个问题的方法是,当一个节点重启之后,我们规定在 max TTL 期间它是不可用的,这样它就不会干扰原本已经申请到的锁,等到它 crash 前的那部分锁都过期了,环境不存在历史锁了,那么再把这个节点加进来正常工作。
48 |
--------------------------------------------------------------------------------
/docs/database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md:
--------------------------------------------------------------------------------
1 | 本文是对 [Martin Kleppmann](https://martin.kleppmann.com/) 的文章 [How to do distributed locking](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html) 部分内容的翻译和总结,上次写 Redlock 的原因就是看到了 Martin 的这篇文章,写得很好,特此翻译和总结。感兴趣的同学可以翻看原文,相信会收获良多。
2 |
3 | 开篇作者认为现在 Redis 逐渐被使用到数据管理领域,这个领域需要更强的数据一致性和耐久性,这使得他感到担心,因为这不是 Redis 最初设计的初衷(事实上这也是很多业界程序员的误区,越来越把 Redis 当成数据库在使用),其中基于 Redis 的分布式锁就是令人担心的其一。
4 |
5 | Martin 指出首先你要明确你为什么使用分布式锁,为了性能还是正确性?为了帮你区分这二者,在这把锁 fail 了的时候你可以询问自己以下问题:
6 | 1. **要性能的:** 拥有这把锁使得你不会重复劳动(例如一个 job 做了两次),如果这把锁 fail 了,两个节点同时做了这个 Job,那么这个 Job 增加了你的成本。
7 | 2. **要正确性的:** 拥有锁可以防止并发操作污染你的系统或者数据,如果这把锁 fail 了两个节点同时操作了一份数据,结果可能是数据不一致、数据丢失、file 冲突等,会导致严重的后果。
8 |
9 | 上述二者都是需求锁的正确场景,但是你必须清楚自己是因为什么原因需要分布式锁。
10 |
11 | 如果你只是为了性能,那没必要用 Redlock,它成本高且复杂,你只用一个 Redis 实例也够了,最多加个从防止主挂了。当然,你使用单节点的 Redis 那么断电或者一些情况下,你会丢失锁,但是你的目的只是加速性能且断电这种事情不会经常发生,这并不是什么大问题。并且如果你使用了单节点 Redis,那么很显然你这个应用需要的锁粒度是很模糊粗糙的,也不会是什么重要的服务。
12 |
13 | 那么是否 Redlock 对于要求正确性的场景就合适呢?Martin 列举了若干场景证明 Redlock 这种算法是不可靠的。
14 |
15 | ## 用锁保护资源
16 | 这节里 Martin 先将 Redlock 放在了一边而是仅讨论总体上一个分布式锁是怎么工作的。在分布式环境下,锁比 mutex 这类复杂,因为涉及到不同节点、网络通信并且他们随时可能无征兆的 fail 。
17 | Martin 假设了一个场景,一个 client 要修改一个文件,它先申请得到锁,然后修改文件写回,放锁。另一个 client 再申请锁 ... 代码流程如下:
18 |
19 | ```java
20 | // THIS CODE IS BROKEN
21 | function writeData(filename, data) {
22 | var lock = lockService.acquireLock(filename);
23 | if (!lock) {
24 | throw 'Failed to acquire lock';
25 | }
26 |
27 | try {
28 | var file = storage.readFile(filename);
29 | var updated = updateContents(file, data);
30 | storage.writeFile(filename, updated);
31 | } finally {
32 | lock.release();
33 | }
34 | }
35 | ```
36 |
37 | 可惜即使你的锁服务非常完美,上述代码还是可能跪,下面的流程图会告诉你为什么:
38 |
39 | 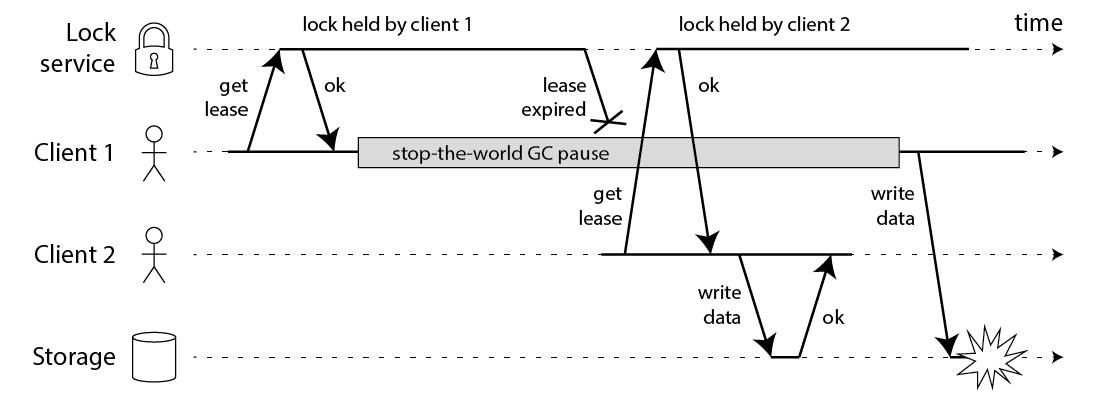
40 |
41 | 上述图中,得到锁的 client1 在持有锁的期间 pause 了一段时间,例如 GC 停顿。锁有过期时间(一般叫租约,为了防止某个 client 崩溃之后一直占有锁),但是如果 GC 停顿太长超过了锁租约时间,此时锁已经被另一个 client2 所得到,原先的 client1 还没有感知到锁过期,那么奇怪的结果就会发生,曾经 HBase 就发生过这种 Bug。即使你在 client1 写回之前检查一下锁是否过期也无助于解决这个问题,因为 GC 可能在任何时候发生,即使是你非常不便的时候(在最后的检查与写操作期间)。
42 | 如果你认为自己的程序不会有长时间的 GC 停顿,还有其他原因会导致你的进程 pause。例如进程可能读取尚未进入内存的数据,所以它得到一个 page fault 并且等待 page 被加载进缓存;还有可能你依赖于网络服务;或者其他进程占用 CPU;或者其他人意外发生 SIGSTOP 等。
43 |
44 | ... .... 这里 Martin 又增加了一节列举各种进程 pause 的例子,为了证明上面的代码是不安全的,无论你的锁服务多完美。
45 |
46 | ## 使用 Fencing (栅栏)使得锁变安全
47 | 修复问题的方法也很简单:你需要在每次写操作时加入一个 fencing token。这个场景下,fencing token 可以是一个递增的数字(lock service 可以做到),每次有 client 申请锁就递增一次:
48 |
49 | 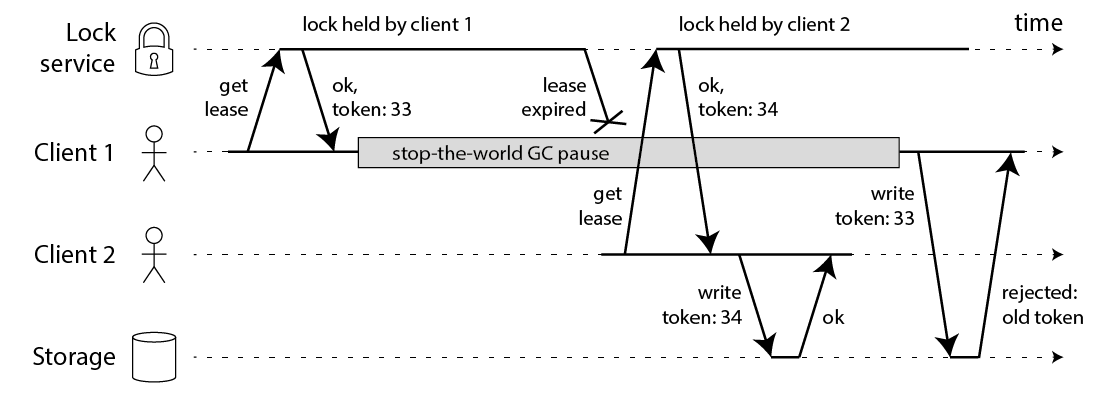
50 |
51 | client1 申请锁同时拿到 token33,然后它进入长时间的停顿锁也过期了。client2 得到锁和 token34 写入数据,紧接着 client1 活过来之后尝试写入数据,自身 token33 比 34 小因此写入操作被拒绝。注意这需要存储层来检查 token,但这并不难实现。如果你使用 Zookeeper 作为 lock service 的话那么你可以使用 zxid 作为递增数字。
52 | 但是对于 Redlock 你要知道,没什么生成 fencing token 的方式,并且怎么修改 Redlock 算法使其能产生 fencing token 呢?好像并不那么显而易见。因为产生 token 需要单调递增,除非在单节点 Redis 上完成但是这又没有高可靠性,你好像需要引进一致性协议来让 Redlock 产生可靠的 fencing token。
53 |
54 | ## 使用时间来解决一致性
55 | Redlock 无法产生 fencing token 早该成为在需求正确性的场景下弃用它的理由,但还有一些值得讨论的地方。
56 |
57 | 学术界有个说法,算法对时间不做假设:因为进程可能pause一段时间、数据包可能因为网络延迟延后到达、时钟可能根本就是错的。而可靠的算法依旧要在上述假设下做正确的事情。
58 |
59 | 对于 failure detector 来说,timeout 只能作为猜测某个节点 fail 的依据,因为网络延迟、本地时钟不正确等其他原因的限制。考虑到 Redis 使用 gettimeofday,而不是单调的时钟,会受到系统时间的影响,可能会突然前进或者后退一段时间,这会导致一个 key 更快或更慢地过期。
60 |
61 | 可见,Redlock 依赖于许多时间假设,它假设所有 Redis 节点都能对同一个 Key 在其过期前持有差不多的时间、跟过期时间相比网络延迟很小、跟过期时间相比进程 pause 很短。
62 |
63 | ## 用不可靠的时间打破 Redlock
64 | 这节 Martin 举了个因为时间问题,Redlock 不可靠的例子。
65 |
66 | 1. client1 从 ABC 三个节点处申请到锁,DE由于网络原因请求没有到达
67 | 2. C节点的时钟往前推了,导致 lock 过期
68 | 3. client2 在CDE处获得了锁,AB由于网络原因请求未到达
69 | 4. 此时 client1 和 client2 都获得了锁
70 |
71 | **在 Redlock 官方文档中也提到了这个情况,不过是C崩溃的时候,Redlock 官方本身也是知道 Redlock 算法不是完全可靠的,官方为了解决这种问题建议使用延时启动,相关内容可以看之前的[这篇文章](https://zhuanlan.zhihu.com/p/40915772)。但是 Martin 这里分析得更加全面,指出延时启动不也是依赖于时钟的正确性的么?**
72 |
73 | 接下来 Martin 又列举了进程 Pause 时而不是时钟不可靠时会发生的问题:
74 |
75 | 1. client1 从 ABCDE 处获得了锁
76 | 2. 当获得锁的 response 还没到达 client1 时 client1 进入 GC 停顿
77 | 3. 停顿期间锁已经过期了
78 | 4. client2 在 ABCDE 处获得了锁
79 | 5. client1 GC 完成收到了获得锁的 response,此时两个 client 又拿到了同一把锁
80 |
81 | **同时长时间的网络延迟也有可能导致同样的问题。**
82 |
83 | ## Redlock 的同步性假设
84 | 这些例子说明了,仅有在你假设了一个同步性系统模型的基础上,Redlock 才能正常工作,也就是系统能满足以下属性:
85 |
86 | 1. 网络延时边界,即假设数据包一定能在某个最大延时之内到达
87 | 2. 进程停顿边界,即进程停顿一定在某个最大时间之内
88 | 3. 时钟错误边界,即不会从一个坏的 NTP 服务器处取得时间
89 |
90 | ## 结论
91 | Martin 认为 Redlock 实在不是一个好的选择,对于需求性能的分布式锁应用它太重了且成本高;对于需求正确性的应用来说它不够安全。因为它对高危的时钟或者说其他上述列举的情况进行了不可靠的假设,如果你的应用只需要高性能的分布式锁不要求多高的正确性,那么单节点 Redis 够了;如果你的应用想要保住正确性,那么不建议 Redlock,建议使用一个合适的一致性协调系统,例如 Zookeeper,且保证存在 fencing token。
92 |
--------------------------------------------------------------------------------
/docs/database/一条sql语句在mysql中如何执行的.md:
--------------------------------------------------------------------------------
1 | 本文来自[木木匠](https://github.com/kinglaw1204)投稿。
2 |
3 |
4 |
5 | - [一 MySQL 基础架构分析](#一-mysql-基础架构分析)
6 | - [1.1 MySQL 基本架构概览](#11-mysql-基本架构概览)
7 | - [1.2 Server 层基本组件介绍](#12-server-层基本组件介绍)
8 | - [1) 连接器](#1-连接器)
9 | - [2) 查询缓存(MySQL 8.0 版本后移除)](#2-查询缓存mysql-80-版本后移除)
10 | - [3) 分析器](#3-分析器)
11 | - [4) 优化器](#4-优化器)
12 | - [5) 执行器](#5-执行器)
13 | - [二 语句分析](#二-语句分析)
14 | - [2.1 查询语句](#21-查询语句)
15 | - [2.2 更新语句](#22-更新语句)
16 | - [三 总结](#三-总结)
17 | - [四 参考](#四-参考)
18 |
19 |
20 |
21 | 本篇文章会分析下一个 sql 语句在 MySQL 中的执行流程,包括 sql 的查询在 MySQL 内部会怎么流转,sql 语句的更新是怎么完成的。
22 |
23 | 在分析之前我会先带着你看看 MySQL 的基础架构,知道了 MySQL 由那些组件组成已经这些组件的作用是什么,可以帮助我们理解和解决这些问题。
24 |
25 | ## 一 MySQL 基础架构分析
26 |
27 | ### 1.1 MySQL 基本架构概览
28 |
29 | 下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到用户的 SQL 语句在 MySQL 内部是如何执行的。
30 |
31 | 先简单介绍一下下图涉及的一些组件的基本作用帮助大家理解这幅图,在 1.2 节中会详细介绍到这些组件的作用。
32 |
33 | - **连接器:** 身份认证和权限相关(登录 MySQL 的时候)。
34 | - **查询缓存:** 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
35 | - **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
36 | - **优化器:** 按照 MySQL 认为最优的方案去执行。
37 | - **执行器:** 执行语句,然后从存储引擎返回数据。
38 |
39 | 
40 |
41 | 简单来说 MySQL 主要分为 Server 层和存储引擎层:
42 |
43 | - **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
44 | - **存储引擎**: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了。**
45 |
46 | ### 1.2 Server 层基本组件介绍
47 |
48 | #### 1) 连接器
49 |
50 | 连接器主要和身份认证和权限相关的功能相关,就好比一个级别很高的门卫一样。
51 |
52 | 主要负责用户登录数据库,进行用户的身份认证,包括校验账户密码,权限等操作,如果用户账户密码已通过,连接器会到权限表中查询该用户的所有权限,之后在这个连接里的权限逻辑判断都是会依赖此时读取到的权限数据,也就是说,后续只要这个连接不断开,即时管理员修改了该用户的权限,该用户也是不受影响的。
53 |
54 | #### 2) 查询缓存(MySQL 8.0 版本后移除)
55 |
56 | 查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
57 |
58 | 连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 sql 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询预计,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
59 |
60 | MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
61 |
62 | 所以,一般在大多数情况下我们都是不推荐去使用查询缓存的。
63 |
64 | MySQL 8.0 版本后删除了缓存的功能,官方也是认为该功能在实际的应用场景比较少,所以干脆直接删掉了。
65 |
66 | #### 3) 分析器
67 |
68 | MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用来分析 SQL 语句是来干嘛的,分析器也会分为几步:
69 |
70 | **第一步,词法分析**,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
71 |
72 | **第二步,语法分析**,主要就是判断你输入的 sql 是否正确,是否符合 MySQL 的语法。
73 |
74 | 完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
75 |
76 | #### 4) 优化器
77 |
78 | 优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优,这篇文章涉及对这部分知识的深入讲解),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
79 |
80 | 可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
81 |
82 | #### 5) 执行器
83 |
84 | 当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
85 |
86 | ## 二 语句分析
87 |
88 | ### 2.1 查询语句
89 |
90 | 说了以上这么多,那么究竟一条 sql 语句是如何执行的呢?其实我们的 sql 可以分为两种,一种是查询,一种是更新(增加,更新,删除)。我们先分析下查询语句,语句如下:
91 |
92 | ```sql
93 | select * from tb_student A where A.age='18' and A.name=' 张三 ';
94 | ```
95 |
96 | 结合上面的说明,我们分析下这个语句的执行流程:
97 |
98 | * 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 sql 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
99 | * 通过分析器进行词法分析,提取 sql 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 sql 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
100 | * 接下来就是优化器进行确定执行方案,上面的 sql 语句,可以有两种执行方案:
101 |
102 | a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
103 | b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
104 | 那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
105 |
106 | * 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
107 |
108 | ### 2.2 更新语句
109 |
110 | 以上就是一条查询 sql 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?sql 语句如下:
111 |
112 | ```
113 | update tb_student A set A.age='19' where A.name=' 张三 ';
114 | ```
115 | 我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块式 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
116 |
117 | * 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
118 | * 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
119 | * 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
120 | * 更新完成。
121 |
122 | **这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
123 |
124 | 这是因为最开始 MySQL 并没与 InnoDB 引擎( InnoDB 引擎是其他公司以插件形式插入 MySQL 的) ,MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
125 |
126 | 并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
127 |
128 | * **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 bingog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
129 | * **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
130 |
131 | 如果采用 redo log 两阶段提交的方式就不一样了,写完 binglog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binglog 也已经写完了,这个时候发生了异常重启会怎么样呢?
132 | 这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
133 |
134 | * 判断 redo log 是否完整,如果判断是完整的,就立即提交。
135 | * 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
136 |
137 | 这样就解决了数据一致性的问题。
138 |
139 | ## 三 总结
140 |
141 | * MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
142 | * 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
143 | * 查询语句的执行流程如下:权限校验(如果命中缓存)---》查询缓存---》分析器---》优化器---》权限校验---》执行器---》引擎
144 | * 更新语句执行流程如下:分析器----》权限校验----》执行器---》引擎---redo log(prepare 状态---》binlog---》redo log(commit状态)
145 |
146 | ## 四 参考
147 |
148 | * 《MySQL 实战45讲》
149 | * MySQL 5.6参考手册:
150 |
--------------------------------------------------------------------------------
/docs/database/事务隔离级别(图文详解).md:
--------------------------------------------------------------------------------
1 | > 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [BugSpeak](https://github.com/BugSpeak) 共同完成。
2 |
3 |
4 | - [事务隔离级别(图文详解)](#事务隔离级别图文详解)
5 | - [什么是事务?](#什么是事务)
6 | - [事务的特性(ACID)](#事务的特性acid)
7 | - [并发事务带来的问题](#并发事务带来的问题)
8 | - [事务隔离级别](#事务隔离级别)
9 | - [实际情况演示](#实际情况演示)
10 | - [脏读(读未提交)](#脏读读未提交)
11 | - [避免脏读(读已提交)](#避免脏读读已提交)
12 | - [不可重复读](#不可重复读)
13 | - [可重复读](#可重复读)
14 | - [防止幻读(可重复读)](#防止幻读可重复读)
15 | - [参考](#参考)
16 |
17 |
18 |
19 | ## 事务隔离级别(图文详解)
20 |
21 | ### 什么是事务?
22 |
23 | 事务是逻辑上的一组操作,要么都执行,要么都不执行。
24 |
25 | 事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
26 |
27 | ### 事务的特性(ACID)
28 |
29 | 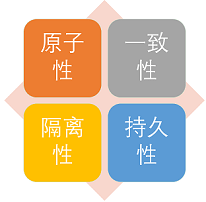
30 |
31 |
32 | 1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
33 | 2. **一致性:** 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
34 | 3. **隔离性:** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
35 | 4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
36 |
37 | ### 并发事务带来的问题
38 |
39 | 在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
40 |
41 | - **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
42 | - **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
43 | - **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
44 | - **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
45 |
46 | **不可重复度和幻读区别:**
47 |
48 | 不可重复读的重点是修改,幻读的重点在于新增或者删除。
49 |
50 | 例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
51 |
52 | 例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
53 |
54 | ### 事务隔离级别
55 |
56 | **SQL 标准定义了四个隔离级别:**
57 |
58 | - **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
59 | - **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
60 | - **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
61 | - **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
62 |
63 | ----
64 |
65 | | 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
66 | | :---: | :---: | :---:| :---: |
67 | | READ-UNCOMMITTED | √ | √ | √ |
68 | | READ-COMMITTED | × | √ | √ |
69 | | REPEATABLE-READ | × | × | √ |
70 | | SERIALIZABLE | × | × | × |
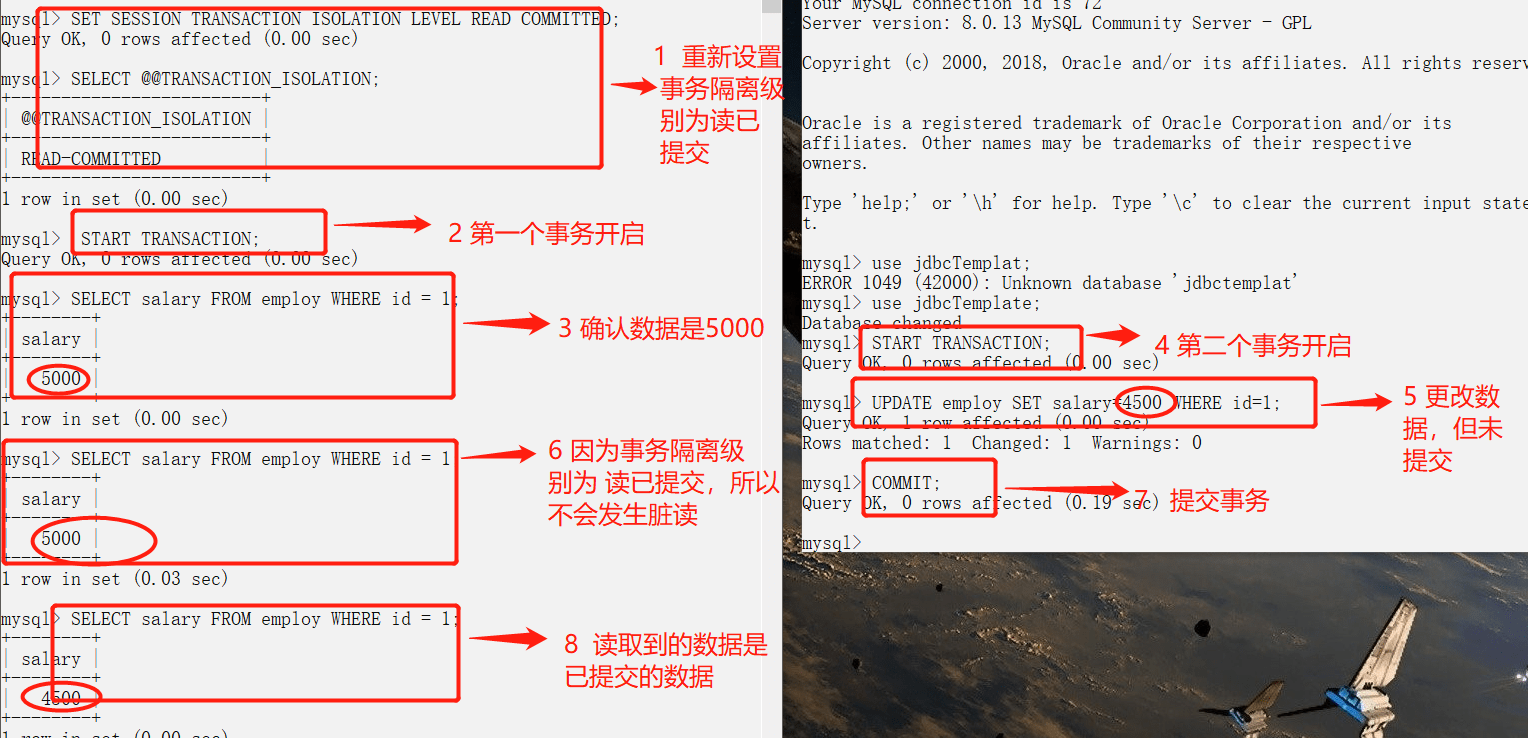
71 |
72 | MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
73 |
74 | ```sql
75 | mysql> SELECT @@tx_isolation;
76 | +-----------------+
77 | | @@tx_isolation |
78 | +-----------------+
79 | | REPEATABLE-READ |
80 | +-----------------+
81 | ```
82 |
83 | 这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 **REPEATABLE-READ(可重读)**事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的**SERIALIZABLE(可串行化)**隔离级别。
84 |
85 | 因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是**READ-COMMITTED(读取提交内容):**,但是你要知道的是InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)**并不会有任何性能损失。
86 |
87 | InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到**SERIALIZABLE(可串行化)**隔离级别。
88 |
89 | ### 实际情况演示
90 |
91 | 在下面我会使用 2 个命令行mysql ,模拟多线程(多事务)对同一份数据的脏读问题。
92 |
93 | MySQL 命令行的默认配置中事务都是自动提交的,即执行SQL语句后就会马上执行 COMMIT 操作。如果要显式地开启一个事务需要使用命令:`START TARNSACTION`。
94 |
95 | 我们可以通过下面的命令来设置隔离级别。
96 |
97 | ```sql
98 | SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
99 | ```
100 |
101 | 我们再来看一下我们在下面实际操作中使用到的一些并发控制语句:
102 |
103 | - `START TARNSACTION` |`BEGIN`:显式地开启一个事务。
104 | - `COMMIT`:提交事务,使得对数据库做的所有修改成为永久性。
105 | - `ROLLBACK`:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
106 |
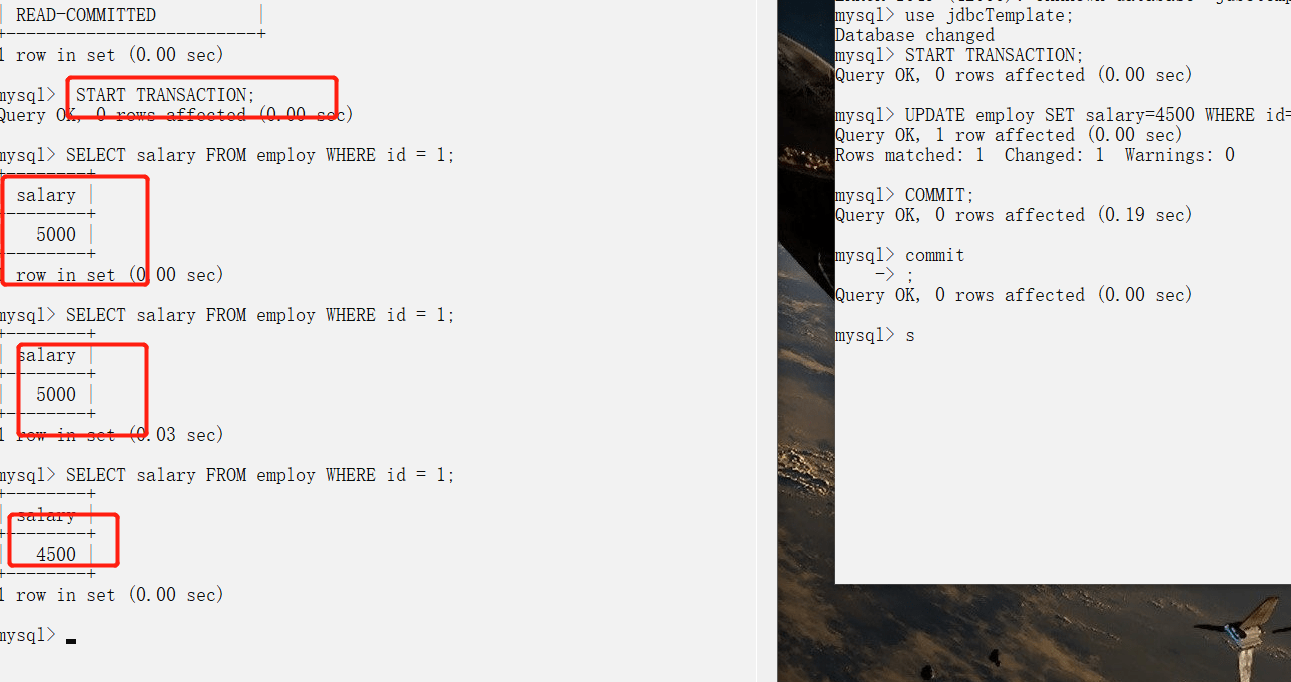
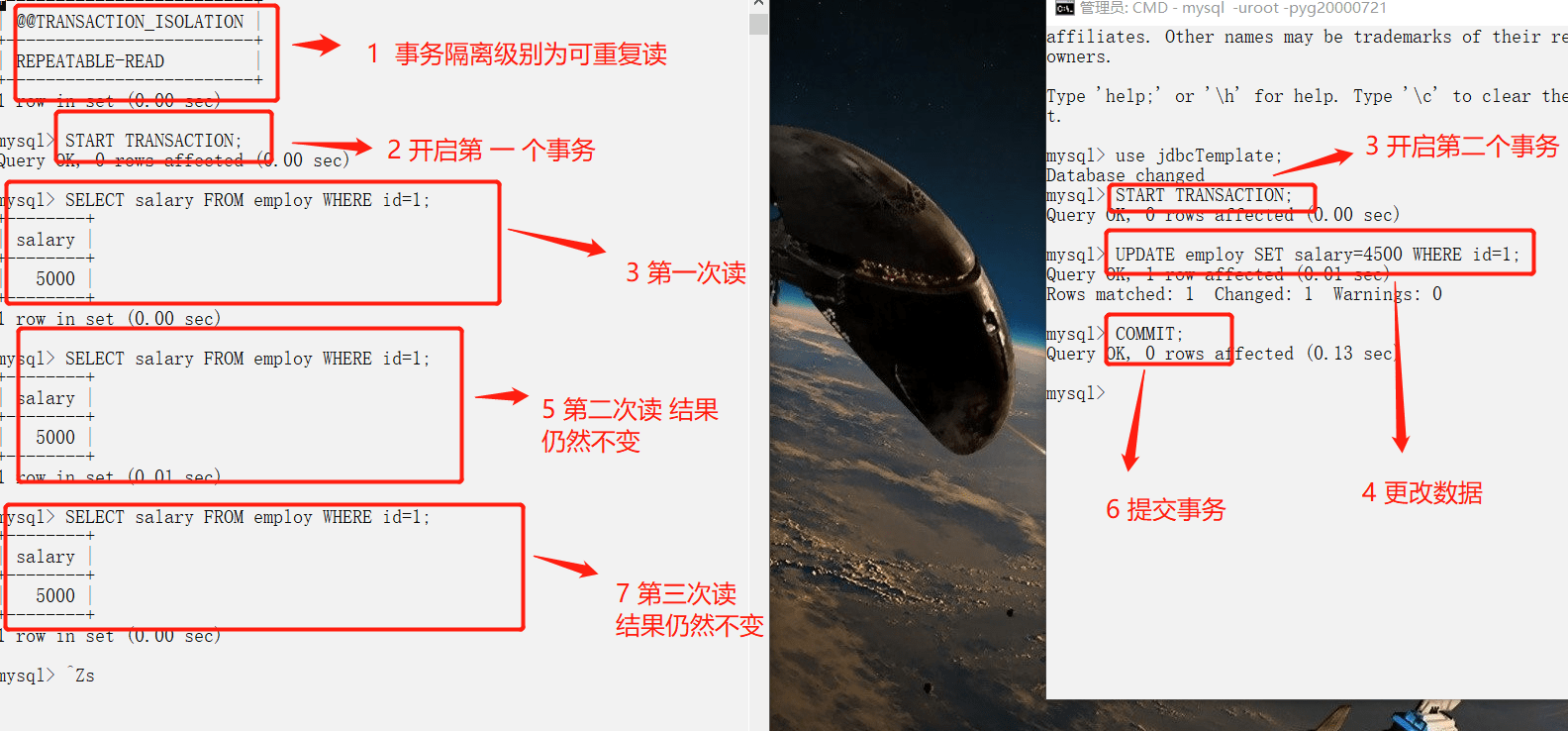
107 | #### 脏读(读未提交)
108 |
109 |
110 |
实例.jpg)
111 |
116 |
117 |
124 |
125 |
130 |
131 |
136 |
.jpg)
137 |
 74 |
75 | 举个例子,这个仓库里面就有两个让你的电脑更好用的开源仓库,Mac 和 Windows都有:
76 |
77 | - Awesome Mac:https://github.com/jaywcjlove/awesome-mac/blob/master/README-zh.m
78 | - Awsome Windows: https://github.com/Awesome-Windows/Awesome/blob/master/README-cn.md
79 |
80 | ### 9. You-Dont-Know-JS
81 |
82 | - **Github地址**:[https://github.com/getify/You-Dont-Know-JS](https://github.com/getify/You-Dont-Know-JS)
83 | - **star**: 112 k
84 | - **介绍**: 您还不认识JS(书籍系列)-第二版
85 |
86 | ### 10. oh-my-zsh
87 |
88 | - **Github地址**:[https://github.com/ohmyzsh/ohmyzsh](https://github.com/ohmyzsh/ohmyzsh)
89 | - **star**: 99.4 k
90 | - **介绍**: 一个令人愉快的社区驱动的框架(拥有近1500个贡献者),用于管理zsh配置。包括200多个可选插件(rails, git, OSX, hub, capistrano, brew, ant, php, python等),140多个主题,可为您的早晨增光添彩,以及一个自动更新工具,可让您轻松保持与来自社区的最新更新……
91 |
92 | 下面就是 oh-my-zsh 提供的一个花里胡哨的主题:
93 |
94 | 
95 |
--------------------------------------------------------------------------------
/docs/tools/阿里云服务器使用经验.md:
--------------------------------------------------------------------------------
1 | 最近很多阿里云双 11 做活动,优惠力度还挺大的,很多朋友都买以最低的价格买到了自己的云服务器。不论是作为学习机还是部署自己的小型网站或者服务来说都是很不错的!
2 |
3 | 但是,很多朋友都不知道如何正确去使用。下面我简单分享一下自己的使用经验。
4 |
5 | 总结一下,主要涉及下面几个部分,对于新手以及没有这么使用过云服务的朋友还是比较友好的:
6 |
7 | 1. 善用阿里云镜像市场节省安装 Java 环境的时间,相关说明都在根目录下的 readme.txt. 文件里面;
8 | 2. 本地通过 SSH 连接阿里云服务器很容易,配置好 Host地址,通过 root 用户加上实例密码直接连接即可。
9 | 3. 本地连接 MySQL 数据库需要简单配置一下安全组和并且允许 root 用户在任何地方进行远程登录。
10 | 4. 通过 Alibaba Cloud Toolkit 部署 Spring Boot 项目到阿里云服务器真的很方便。
11 |
12 | **[活动地址](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
13 |
14 | ### 善用阿里云镜像市场节省安装环境的时间
15 |
16 | 基本的购买流程这里就不多说了,另外这里需要注意的是:其实 Java 环境是不需要我们手动安装配置的,阿里云提供的镜像市场有一些常用的环境。
17 |
18 | > 阿里云镜像市场是指阿里云建立的、由镜像服务商向用户提供其镜像及相关服务的网络平台。这些镜像在操作系统上整合了具体的软件环境和功能,比如Java、PHP运行环境、控制面板等,供有相关需求的用户开通实例时选用。
19 |
20 | 具体如何在购买云服务器的时候通过镜像创建实例或者已有ECS用户如何使用镜像可以查看官方详细的介绍,地址:
21 |
22 | https://help.aliyun.com/knowledge_detail/41987.html?spm=a2c4g.11186631.2.1.561e2098dIdCGZ
23 |
24 | ### 当我们成功购买服务器之后如何通过 SSH 连接呢?
25 |
26 | 创建好 ECS 后,你绑定的手机会收到短信,会告知你初始密码的。你可以登录管理控制台对密码进行修改,修改密码需要在管理控制台重启服务器才能生效。
27 |
28 | 你也可以在阿里云 ECS 控制台重置实例密码,如下图所示。
29 |
30 | 
31 |
32 | **第一种连接方式是直接在阿里云服务器管理的网页上连接**。如上图所示, 点击远程连接,然后输入远程连接密码,这个并不是你重置实例密码得到的密码,如果忘记了直接修改远程连接密码即可。
33 |
34 | **第二种方式是在本地通过命令或者软件连接。** 推荐使用这种方式,更加方便。
35 |
36 | **Windows 推荐使用 Xshell 连接,具体方式如下:**
37 |
38 | > Window电脑在家,这里直接用找到的一些图片给大家展示一个。
39 |
40 | 
41 |
42 | 
43 |
44 | 接着点开,输入账号:root,命名输入刚才设置的密码,点ok就可以了
45 |
46 | 
47 |
48 | **Mac 或者 Linux 系统都可以直接使用 ssh 命令进行连接,非常方便。**
49 |
50 | 成功连接之后,控制台会打印出如下消息。
51 |
52 | ```shell
53 | ➜ ~ ssh root@47.107.159.12 -p 22
54 | root@47.107.159.12's password:
55 | Last login: Wed Oct 30 09:31:31 2019 from 220.249.123.170
56 |
57 | Welcome to Alibaba Cloud Elastic Compute Service !
58 |
59 | 欢迎使用 Tomcat8 JDK8 Mysql5.7 环境
60 |
61 | 使用说明请参考 /root/readme.txt 文件
62 | ```
63 |
64 | 我当时选择是阿里云提供好的 Java 环境,自动就提供了 Tomcat、 JDK8 、Mysql5.7,所以不需要我们再进行安装配置了,节省了很多时间。另外,需要注意的是:**一定要看 /readme.txt ,Tomcat、 JDK8 、Mysql5.7相关配置以及安装路径等说明都在里面。**
65 |
66 | ### 如何连接数据库?
67 |
68 | **如需外网远程访问mysql 请参考以上网址 设置mysql及阿里云安全组**。
69 |
70 | 
71 |
72 | Mysql为了安全性,在默认情况下用户只允许在本地登录,但是可以使用 SSH 方式连接。如果我们不想通过 SSH 方式连接的话就需要对 MySQL 进行简单的配置。
73 |
74 | ```shell
75 | #允许root用户在任何地方进行远程登录,并具有所有库任何操作权限:
76 | # *.*代表所有库表 “%”代表所有IP地址
77 | mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY "自定义密码" WITH GRANT OPTION;
78 | Query OK, 0 rows affected, 1 warning (0.00 sec)
79 | #刷新权限。
80 | mysql>flush privileges;
81 | #退出mysql
82 | mysql>exit
83 | #重启MySQL生效
84 | [root@snailclimb]# systemctl restart mysql
85 | ```
86 |
87 | 这样的话,我们就能在本地进行连接了。Windows 推荐使用Navicat或者SQLyog。
88 |
89 | > Window电脑在家,这里用 Mac 上的MySQL可视化工具Sequel Pro给大家演示一下。
90 |
91 |
74 |
75 | 举个例子,这个仓库里面就有两个让你的电脑更好用的开源仓库,Mac 和 Windows都有:
76 |
77 | - Awesome Mac:https://github.com/jaywcjlove/awesome-mac/blob/master/README-zh.m
78 | - Awsome Windows: https://github.com/Awesome-Windows/Awesome/blob/master/README-cn.md
79 |
80 | ### 9. You-Dont-Know-JS
81 |
82 | - **Github地址**:[https://github.com/getify/You-Dont-Know-JS](https://github.com/getify/You-Dont-Know-JS)
83 | - **star**: 112 k
84 | - **介绍**: 您还不认识JS(书籍系列)-第二版
85 |
86 | ### 10. oh-my-zsh
87 |
88 | - **Github地址**:[https://github.com/ohmyzsh/ohmyzsh](https://github.com/ohmyzsh/ohmyzsh)
89 | - **star**: 99.4 k
90 | - **介绍**: 一个令人愉快的社区驱动的框架(拥有近1500个贡献者),用于管理zsh配置。包括200多个可选插件(rails, git, OSX, hub, capistrano, brew, ant, php, python等),140多个主题,可为您的早晨增光添彩,以及一个自动更新工具,可让您轻松保持与来自社区的最新更新……
91 |
92 | 下面就是 oh-my-zsh 提供的一个花里胡哨的主题:
93 |
94 | 
95 |
--------------------------------------------------------------------------------
/docs/tools/阿里云服务器使用经验.md:
--------------------------------------------------------------------------------
1 | 最近很多阿里云双 11 做活动,优惠力度还挺大的,很多朋友都买以最低的价格买到了自己的云服务器。不论是作为学习机还是部署自己的小型网站或者服务来说都是很不错的!
2 |
3 | 但是,很多朋友都不知道如何正确去使用。下面我简单分享一下自己的使用经验。
4 |
5 | 总结一下,主要涉及下面几个部分,对于新手以及没有这么使用过云服务的朋友还是比较友好的:
6 |
7 | 1. 善用阿里云镜像市场节省安装 Java 环境的时间,相关说明都在根目录下的 readme.txt. 文件里面;
8 | 2. 本地通过 SSH 连接阿里云服务器很容易,配置好 Host地址,通过 root 用户加上实例密码直接连接即可。
9 | 3. 本地连接 MySQL 数据库需要简单配置一下安全组和并且允许 root 用户在任何地方进行远程登录。
10 | 4. 通过 Alibaba Cloud Toolkit 部署 Spring Boot 项目到阿里云服务器真的很方便。
11 |
12 | **[活动地址](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
13 |
14 | ### 善用阿里云镜像市场节省安装环境的时间
15 |
16 | 基本的购买流程这里就不多说了,另外这里需要注意的是:其实 Java 环境是不需要我们手动安装配置的,阿里云提供的镜像市场有一些常用的环境。
17 |
18 | > 阿里云镜像市场是指阿里云建立的、由镜像服务商向用户提供其镜像及相关服务的网络平台。这些镜像在操作系统上整合了具体的软件环境和功能,比如Java、PHP运行环境、控制面板等,供有相关需求的用户开通实例时选用。
19 |
20 | 具体如何在购买云服务器的时候通过镜像创建实例或者已有ECS用户如何使用镜像可以查看官方详细的介绍,地址:
21 |
22 | https://help.aliyun.com/knowledge_detail/41987.html?spm=a2c4g.11186631.2.1.561e2098dIdCGZ
23 |
24 | ### 当我们成功购买服务器之后如何通过 SSH 连接呢?
25 |
26 | 创建好 ECS 后,你绑定的手机会收到短信,会告知你初始密码的。你可以登录管理控制台对密码进行修改,修改密码需要在管理控制台重启服务器才能生效。
27 |
28 | 你也可以在阿里云 ECS 控制台重置实例密码,如下图所示。
29 |
30 | 
31 |
32 | **第一种连接方式是直接在阿里云服务器管理的网页上连接**。如上图所示, 点击远程连接,然后输入远程连接密码,这个并不是你重置实例密码得到的密码,如果忘记了直接修改远程连接密码即可。
33 |
34 | **第二种方式是在本地通过命令或者软件连接。** 推荐使用这种方式,更加方便。
35 |
36 | **Windows 推荐使用 Xshell 连接,具体方式如下:**
37 |
38 | > Window电脑在家,这里直接用找到的一些图片给大家展示一个。
39 |
40 | 
41 |
42 | 
43 |
44 | 接着点开,输入账号:root,命名输入刚才设置的密码,点ok就可以了
45 |
46 | 
47 |
48 | **Mac 或者 Linux 系统都可以直接使用 ssh 命令进行连接,非常方便。**
49 |
50 | 成功连接之后,控制台会打印出如下消息。
51 |
52 | ```shell
53 | ➜ ~ ssh root@47.107.159.12 -p 22
54 | root@47.107.159.12's password:
55 | Last login: Wed Oct 30 09:31:31 2019 from 220.249.123.170
56 |
57 | Welcome to Alibaba Cloud Elastic Compute Service !
58 |
59 | 欢迎使用 Tomcat8 JDK8 Mysql5.7 环境
60 |
61 | 使用说明请参考 /root/readme.txt 文件
62 | ```
63 |
64 | 我当时选择是阿里云提供好的 Java 环境,自动就提供了 Tomcat、 JDK8 、Mysql5.7,所以不需要我们再进行安装配置了,节省了很多时间。另外,需要注意的是:**一定要看 /readme.txt ,Tomcat、 JDK8 、Mysql5.7相关配置以及安装路径等说明都在里面。**
65 |
66 | ### 如何连接数据库?
67 |
68 | **如需外网远程访问mysql 请参考以上网址 设置mysql及阿里云安全组**。
69 |
70 | 
71 |
72 | Mysql为了安全性,在默认情况下用户只允许在本地登录,但是可以使用 SSH 方式连接。如果我们不想通过 SSH 方式连接的话就需要对 MySQL 进行简单的配置。
73 |
74 | ```shell
75 | #允许root用户在任何地方进行远程登录,并具有所有库任何操作权限:
76 | # *.*代表所有库表 “%”代表所有IP地址
77 | mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY "自定义密码" WITH GRANT OPTION;
78 | Query OK, 0 rows affected, 1 warning (0.00 sec)
79 | #刷新权限。
80 | mysql>flush privileges;
81 | #退出mysql
82 | mysql>exit
83 | #重启MySQL生效
84 | [root@snailclimb]# systemctl restart mysql
85 | ```
86 |
87 | 这样的话,我们就能在本地进行连接了。Windows 推荐使用Navicat或者SQLyog。
88 |
89 | > Window电脑在家,这里用 Mac 上的MySQL可视化工具Sequel Pro给大家演示一下。
90 |
91 |  92 |
93 | ### 如何把一个Spring Boot 项目部署到服务器上呢?
94 |
95 | 默认大家都是用 IDEA 进行开发。另外,你要有一个简单的 Spring Boot Web 项目。如果还不了解 Spring Boot 的话,一个简单的 Spring Boot 版 "Hello World "项目,地址如下:
96 |
97 | https://github.com/Snailclimb/springboot-guide/blob/master/docs/start/springboot-hello-world.md 。
98 |
99 | **1.下载一个叫做 Alibaba Cloud Toolkit 的插件。**
100 |
101 |
92 |
93 | ### 如何把一个Spring Boot 项目部署到服务器上呢?
94 |
95 | 默认大家都是用 IDEA 进行开发。另外,你要有一个简单的 Spring Boot Web 项目。如果还不了解 Spring Boot 的话,一个简单的 Spring Boot 版 "Hello World "项目,地址如下:
96 |
97 | https://github.com/Snailclimb/springboot-guide/blob/master/docs/start/springboot-hello-world.md 。
98 |
99 | **1.下载一个叫做 Alibaba Cloud Toolkit 的插件。**
100 |
101 | 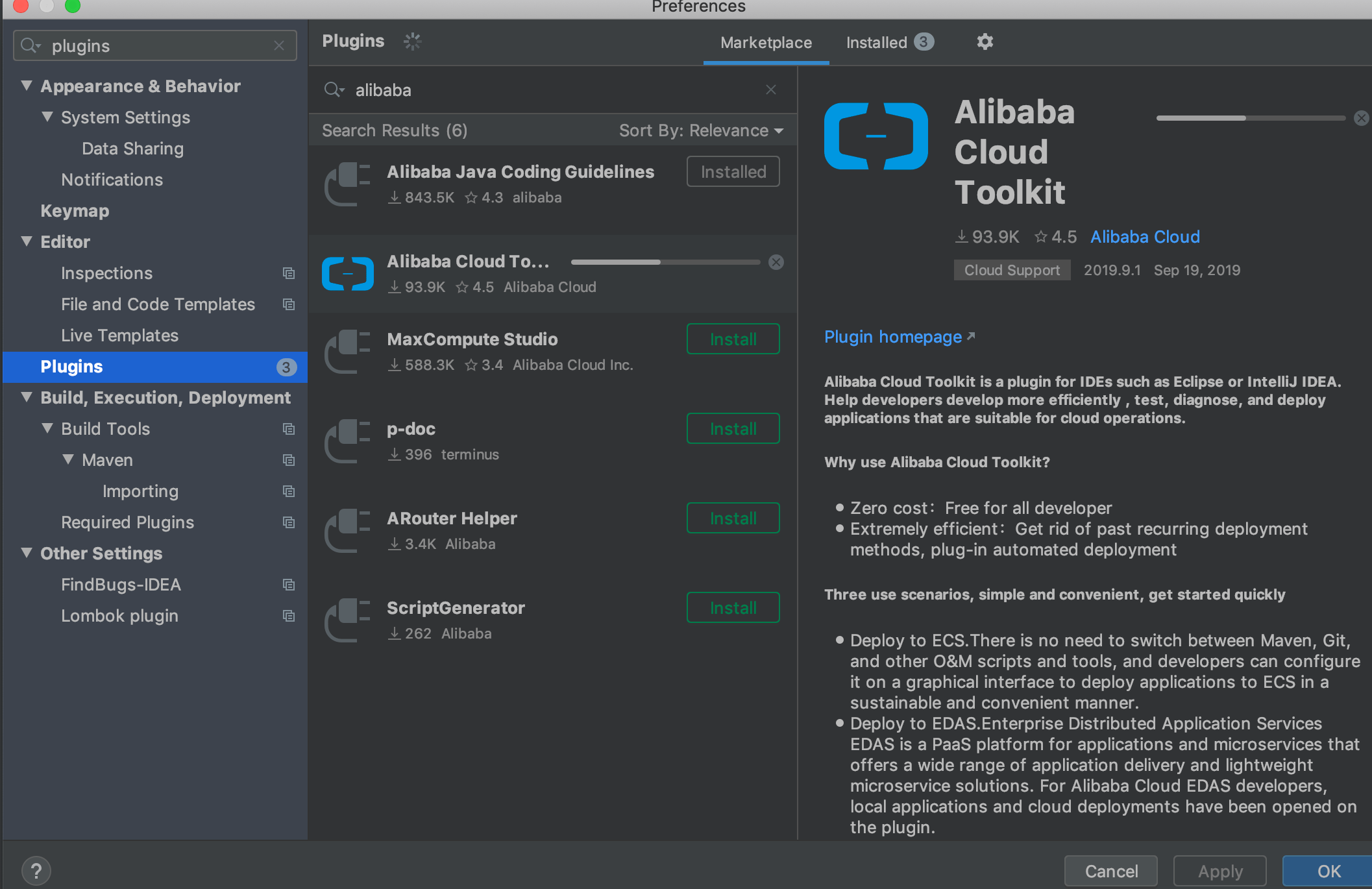 102 |
103 | **2.进入 Preference 配置一个 Access Key ID 和 Access Key Secret。**
104 |
105 |
102 |
103 | **2.进入 Preference 配置一个 Access Key ID 和 Access Key Secret。**
104 |
105 | 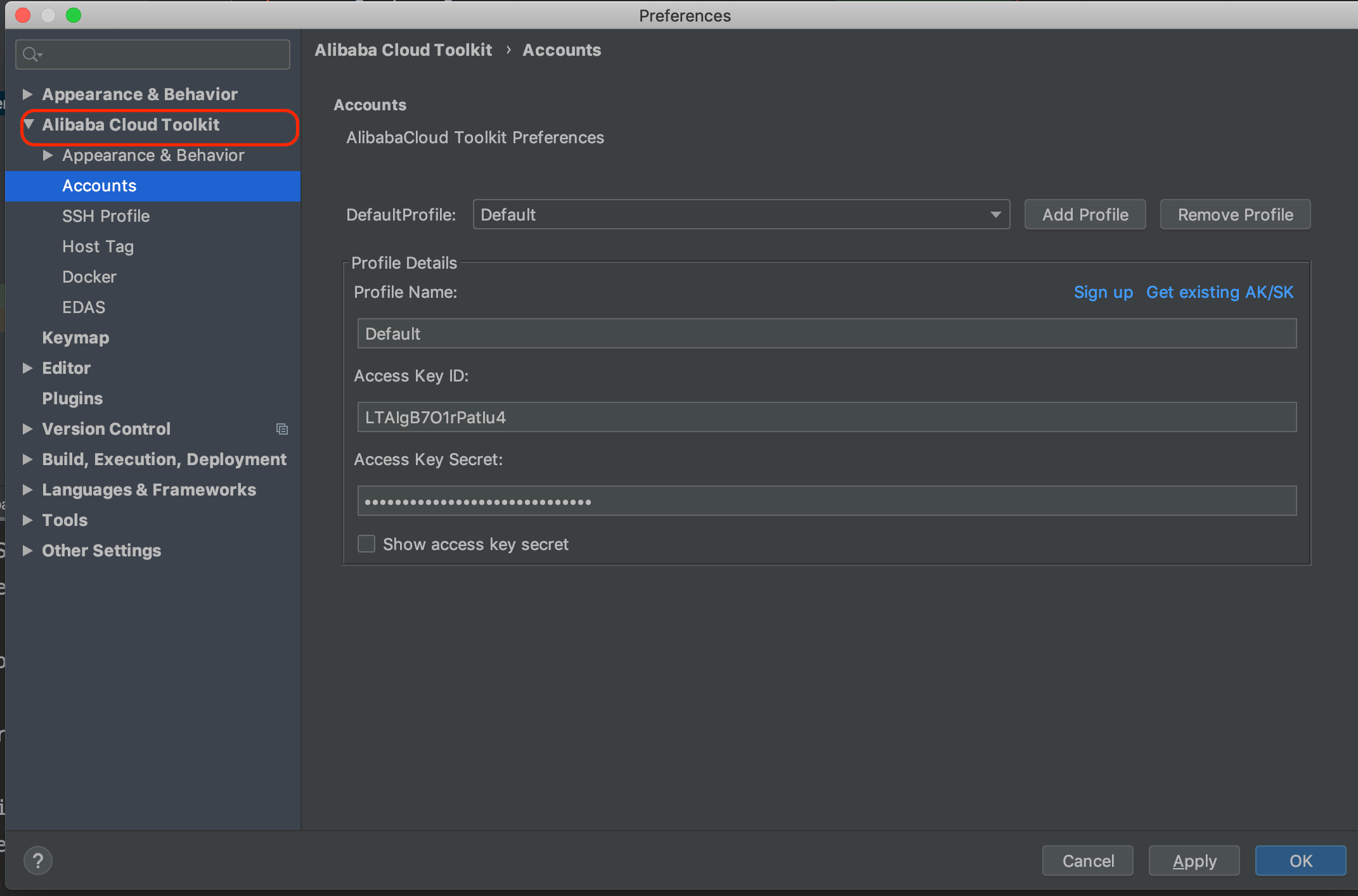 106 |
107 | **3.部署项目到 ECS 上。**
108 |
109 | 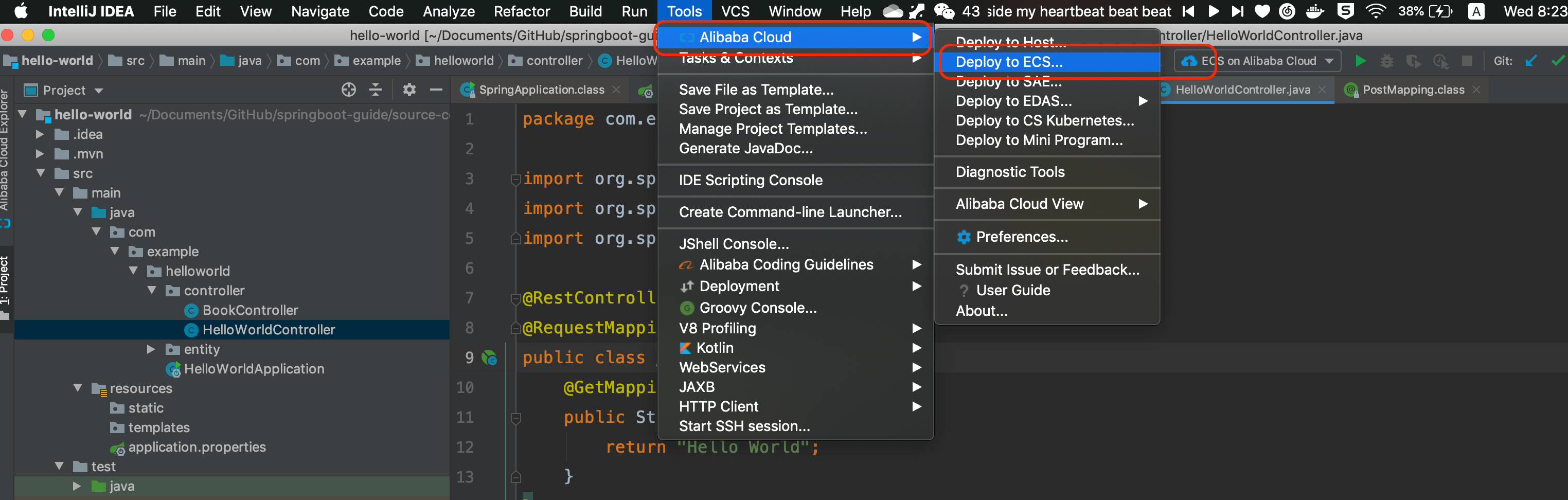
110 |
111 |
106 |
107 | **3.部署项目到 ECS 上。**
108 |
109 | 
110 |
111 | 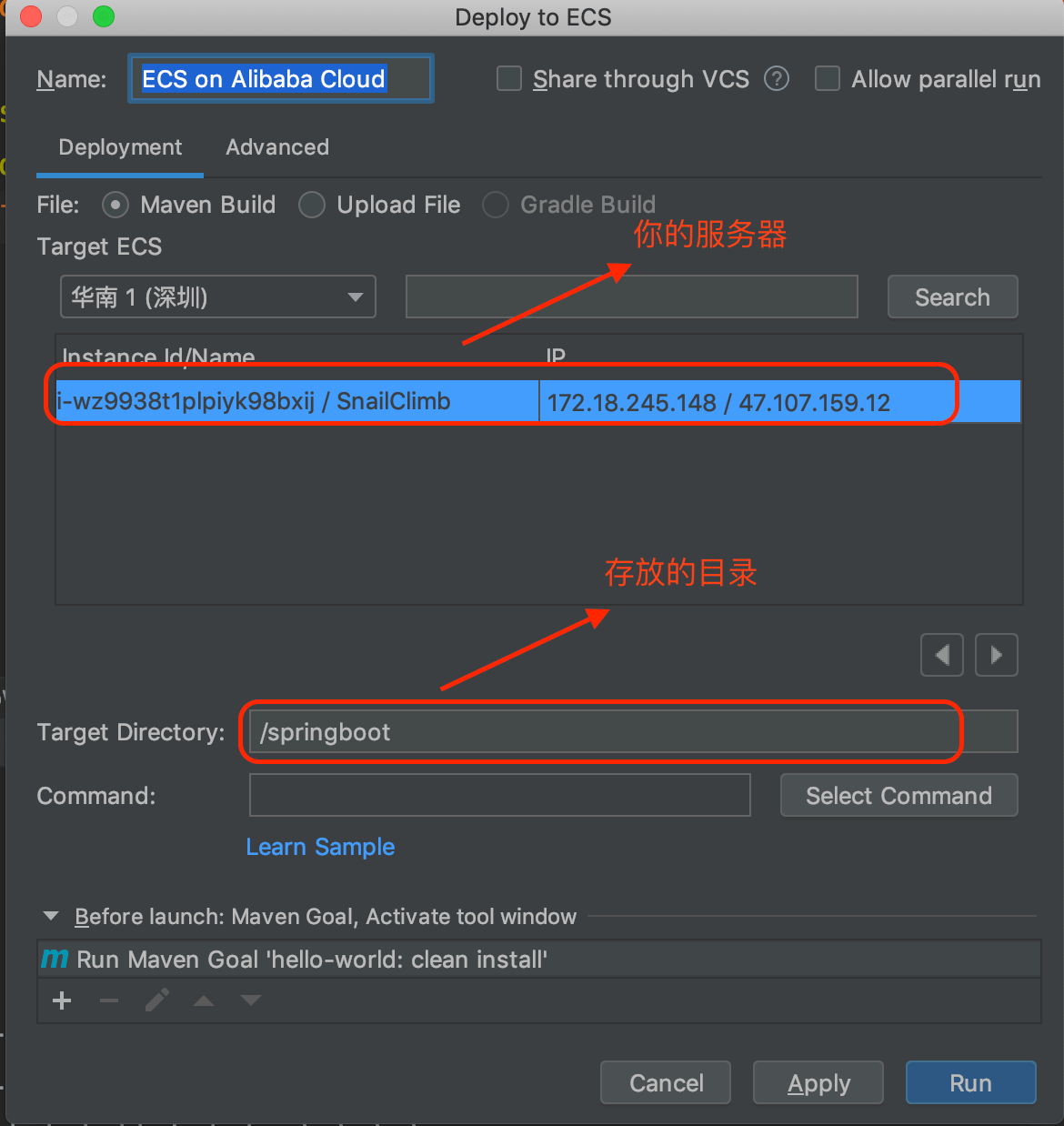 112 |
113 | 按照上面这样填写完基本配置之后,然后点击 run 运行即可。运行成功,控制台会打印出如下信息:
114 |
115 | ```shell
116 | [INFO] Deployment File is Uploading...
117 | [INFO] IDE Version:IntelliJ IDEA 2019.2
118 | [INFO] Alibaba Cloud Toolkit Version:2019.9.1
119 | [INFO] Start upload hello-world-0.0.1-SNAPSHOT.jar
120 | [INFO][##################################################] 100% (18609645/18609645)
121 | [INFO] Succeed to upload, 18609645 bytes have been uploaded.
122 | [INFO] Upload Deployment File to OSS Success
123 | [INFO] Target Deploy ECS: { 172.18.245.148 / 47.107.159.12 }
124 | [INFO] Command: { source /etc/profile; cd /springboot; }
125 | Tip: The deployment package will be temporarily stored in Alibaba Cloud Security OSS and will be
126 | deleted after the deployment is complete. Please be assured that no one can access it except you.
127 |
128 | [INFO] Create Deploy Directory Success.
129 |
130 | [INFO] Deployment File is Downloading...
131 | [INFO] Download Deployment File from OSS Success
132 |
133 | [INFO] File Upload Total time: 16.676 s
134 | ```
135 |
136 | 通过控制台答应出的信息可以看出:通过这个插件会自动把这个 Spring Boot 项目打包成一个 jar 包,然后上传到你的阿里云服务器中指定的文件夹中,你只需要登录你的阿里云服务器,然后通过 `java -jar hello-world-0.0.1-SNAPSHOT.jar`命令运行即可。
137 |
138 | ```shell
139 | [root@snailclimb springboot]# ll
140 | total 18176
141 | -rw-r--r-- 1 root root 18609645 Oct 30 08:25 hello-world-0.0.1-SNAPSHOT.jar
142 | [root@snailclimb springboot]# java -jar hello-world-0.0.1-SNAPSHOT.jar
143 | ```
144 |
145 | 然后你就可以在本地访问访问部署在你的阿里云 ECS 上的服务了。
146 |
147 |
112 |
113 | 按照上面这样填写完基本配置之后,然后点击 run 运行即可。运行成功,控制台会打印出如下信息:
114 |
115 | ```shell
116 | [INFO] Deployment File is Uploading...
117 | [INFO] IDE Version:IntelliJ IDEA 2019.2
118 | [INFO] Alibaba Cloud Toolkit Version:2019.9.1
119 | [INFO] Start upload hello-world-0.0.1-SNAPSHOT.jar
120 | [INFO][##################################################] 100% (18609645/18609645)
121 | [INFO] Succeed to upload, 18609645 bytes have been uploaded.
122 | [INFO] Upload Deployment File to OSS Success
123 | [INFO] Target Deploy ECS: { 172.18.245.148 / 47.107.159.12 }
124 | [INFO] Command: { source /etc/profile; cd /springboot; }
125 | Tip: The deployment package will be temporarily stored in Alibaba Cloud Security OSS and will be
126 | deleted after the deployment is complete. Please be assured that no one can access it except you.
127 |
128 | [INFO] Create Deploy Directory Success.
129 |
130 | [INFO] Deployment File is Downloading...
131 | [INFO] Download Deployment File from OSS Success
132 |
133 | [INFO] File Upload Total time: 16.676 s
134 | ```
135 |
136 | 通过控制台答应出的信息可以看出:通过这个插件会自动把这个 Spring Boot 项目打包成一个 jar 包,然后上传到你的阿里云服务器中指定的文件夹中,你只需要登录你的阿里云服务器,然后通过 `java -jar hello-world-0.0.1-SNAPSHOT.jar`命令运行即可。
137 |
138 | ```shell
139 | [root@snailclimb springboot]# ll
140 | total 18176
141 | -rw-r--r-- 1 root root 18609645 Oct 30 08:25 hello-world-0.0.1-SNAPSHOT.jar
142 | [root@snailclimb springboot]# java -jar hello-world-0.0.1-SNAPSHOT.jar
143 | ```
144 |
145 | 然后你就可以在本地访问访问部署在你的阿里云 ECS 上的服务了。
146 |
147 |  148 |
149 | **[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | JavaGuide
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
34 |
35 |
36 |
37 |
38 |
39 |
43 |
44 |
45 |
--------------------------------------------------------------------------------
/media/pictures/kafka/Broker和集群.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/Broker和集群.png
--------------------------------------------------------------------------------
/media/pictures/kafka/Partition与消费模型.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/Partition与消费模型.png
--------------------------------------------------------------------------------
/media/pictures/kafka/kafka存在文件系统上.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/kafka存在文件系统上.png
--------------------------------------------------------------------------------
/media/pictures/kafka/segment是kafka文件存储的最小单位.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/segment是kafka文件存储的最小单位.png
--------------------------------------------------------------------------------
/media/pictures/kafka/主题与分区.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/主题与分区.png
--------------------------------------------------------------------------------
/media/pictures/kafka/发送消息.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/发送消息.png
--------------------------------------------------------------------------------
/media/pictures/kafka/启动服务.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/启动服务.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要1.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要2.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要3.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要4.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要5.png
--------------------------------------------------------------------------------
/media/pictures/kafka/生产者和消费者.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/生产者和消费者.png
--------------------------------------------------------------------------------
/media/pictures/kafka/生产者设计概要.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/生产者设计概要.png
--------------------------------------------------------------------------------
/media/pictures/rostyslav-savchyn-5joK905gcGc-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/rostyslav-savchyn-5joK905gcGc-unsplash.jpg
--------------------------------------------------------------------------------
/media/sponsor/WechatIMG143.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/sponsor/WechatIMG143.jpeg
--------------------------------------------------------------------------------
148 |
149 | **[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | JavaGuide
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
34 |
35 |
36 |
37 |
38 |
39 |
43 |
44 |
45 |
--------------------------------------------------------------------------------
/media/pictures/kafka/Broker和集群.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/Broker和集群.png
--------------------------------------------------------------------------------
/media/pictures/kafka/Partition与消费模型.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/Partition与消费模型.png
--------------------------------------------------------------------------------
/media/pictures/kafka/kafka存在文件系统上.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/kafka存在文件系统上.png
--------------------------------------------------------------------------------
/media/pictures/kafka/segment是kafka文件存储的最小单位.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/segment是kafka文件存储的最小单位.png
--------------------------------------------------------------------------------
/media/pictures/kafka/主题与分区.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/主题与分区.png
--------------------------------------------------------------------------------
/media/pictures/kafka/发送消息.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/发送消息.png
--------------------------------------------------------------------------------
/media/pictures/kafka/启动服务.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/启动服务.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要1.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要2.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要3.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要4.png
--------------------------------------------------------------------------------
/media/pictures/kafka/消费者设计概要5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/消费者设计概要5.png
--------------------------------------------------------------------------------
/media/pictures/kafka/生产者和消费者.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/生产者和消费者.png
--------------------------------------------------------------------------------
/media/pictures/kafka/生产者设计概要.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/kafka/生产者设计概要.png
--------------------------------------------------------------------------------
/media/pictures/rostyslav-savchyn-5joK905gcGc-unsplash.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/pictures/rostyslav-savchyn-5joK905gcGc-unsplash.jpg
--------------------------------------------------------------------------------
/media/sponsor/WechatIMG143.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/yueyi2019/JavaGuide/675fe2c9079582f8f2689684b848dddbf87b50aa/media/sponsor/WechatIMG143.jpeg
--------------------------------------------------------------------------------