310 |
321 | ```
322 |
323 | react 对于 fiber 结构的创建和更新,都是采用深度优先遍历,从 rootFiber(此处对应 id 为 root 的节点)开始,首先创建 child a1,然后发现 a1 有子节点 b1,继续对 b1 进行遍历,b1 有子节点 c1,再去创建 c1 的子节点 d1、d2、d3,直至发现 d1、d2、d3 都没有子节点来了,再回去创建 c2.
324 |
325 | 上面的过程,每个节点开始创建时,执行 `beginWork` 流程,直至该节点的所有子孙节点都创建(更新)完成后,执行 `completeWork` 流程,过程的图示如下:
326 |
311 |
320 |
312 |
319 |
313 |
314 |
315 |
316 |
317 |
318 |
336 |
348 | ```
349 |
350 | react 会根据新的 jsx 解析后的内容,调用 `createWorkInProgress` 函数创建 workInProgress fiber,对其标记副作用:
351 |
352 | ```js
353 | // packages/react-reconciler/src/ReactFiber.old.js
354 |
355 | export function createWorkInProgress(current: Fiber, pendingProps: any): Fiber {
356 | let workInProgress = current.alternate;
357 | if (workInProgress === null) {
358 | // 区分 mount 还是 update
359 | workInProgress = createFiber(
360 | current.tag,
361 | pendingProps,
362 | current.key,
363 | current.mode
364 | );
365 | workInProgress.elementType = current.elementType;
366 | workInProgress.type = current.type;
367 | workInProgress.stateNode = current.stateNode;
368 |
369 | if (__DEV__) {
370 | workInProgress._debugID = current._debugID;
371 | workInProgress._debugSource = current._debugSource;
372 | workInProgress._debugOwner = current._debugOwner;
373 | workInProgress._debugHookTypes = current._debugHookTypes;
374 | }
375 |
376 | workInProgress.alternate = current;
377 | current.alternate = workInProgress;
378 | } else {
379 | workInProgress.pendingProps = pendingProps;
380 | workInProgress.type = current.type;
381 |
382 | workInProgress.subtreeFlags = NoFlags;
383 | workInProgress.deletions = null;
384 |
385 | if (enableProfilerTimer) {
386 | workInProgress.actualDuration = 0;
387 | workInProgress.actualStartTime = -1;
388 | }
389 | }
390 |
391 | // 重置所有的副作用
392 | workInProgress.flags = current.flags & StaticMask;
393 | workInProgress.childLanes = current.childLanes;
394 | workInProgress.lanes = current.lanes;
395 |
396 | workInProgress.child = current.child;
397 | workInProgress.memoizedProps = current.memoizedProps;
398 | workInProgress.memoizedState = current.memoizedState;
399 | workInProgress.updateQueue = current.updateQueue;
400 |
401 | // 克隆依赖
402 | const currentDependencies = current.dependencies;
403 | workInProgress.dependencies =
404 | currentDependencies === null
405 | ? null
406 | : {
407 | lanes: currentDependencies.lanes,
408 | firstContext: currentDependencies.firstContext,
409 | };
410 |
411 | workInProgress.sibling = current.sibling;
412 | workInProgress.index = current.index;
413 | workInProgress.ref = current.ref;
414 |
415 | if (enableProfilerTimer) {
416 | workInProgress.selfBaseDuration = current.selfBaseDuration;
417 | workInProgress.treeBaseDuration = current.treeBaseDuration;
418 | }
419 |
420 | if (__DEV__) {
421 | workInProgress._debugNeedsRemount = current._debugNeedsRemount;
422 | switch (workInProgress.tag) {
423 | case IndeterminateComponent:
424 | case FunctionComponent:
425 | case SimpleMemoComponent:
426 | workInProgress.type = resolveFunctionForHotReloading(current.type);
427 | break;
428 | case ClassComponent:
429 | workInProgress.type = resolveClassForHotReloading(current.type);
430 | break;
431 | case ForwardRef:
432 | workInProgress.type = resolveForwardRefForHotReloading(current.type);
433 | break;
434 | default:
435 | break;
436 | }
437 | }
438 |
439 | return workInProgress;
440 | }
441 | ```
442 |
443 | 最终生成的 workInProgress fiber 图示如下:
444 |
337 |
347 |
338 |
346 |
339 |
340 | -
341 | -
342 |
343 | -
344 | + new content
345 | 11 | 12 | > react 源码解析(5),本章节将结合源码解析 diff 算法,包括如下内容: 13 | > 14 | > - react diff 算法的介绍 15 | > - diff 策略 16 | > - diff 源码解析 17 | 18 | 上一章中 react 的 render 阶段,其中 `begin` 时会调用 `reconcileChildren` 函数, `reconcileChildren` 中做的事情就是 react 知名的 diff 过程,本章会对 diff 算法进行讲解。 19 | 20 | ## diff 算法介绍 21 | 22 | react 的每次更新,都会将新的 ReactElement 内容与旧的 fiber 树作对比,比较出它们的差异后,构建新的 fiber 树,将差异点放入更新队列之中,从而对真实 dom 进行 render。简单来说就是如何通过最小代价将旧的 fiber 树转换为新的 fiber 树。 23 | 24 | [经典的 diff 算法](https://grfia.dlsi.ua.es/ml/algorithms/references/editsurvey_bille.pdf) 中,将一棵树转为另一棵树的最低时间复杂度为 O(n^3),其中 n 为树种节点的个数。假如采用这种 diff 算法,一个应用有 1000 个节点的情况下,需要比较 十亿 次才能将 dom 树更新完成,显然这个性能是无法让人接受的。 25 | 26 | 因此,想要将 diff 应用于 virtual dom 中,必须实现一种高效的 diff 算法。React 便通过制定了一套大胆的策略,实现了 O(n) 的时间复杂度更新 virtual dom。 27 | 28 | ## diff 策略 29 | 30 | react 将 diff 算法优化到 O(n) 的时间复杂度,基于了以下三个前提策略: 31 | 32 | - 只对同级元素进行比较。Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计,如果出现跨层级的 dom 节点更新,则不进行复用。 33 | - 两个不同类型的组件会产生两棵不同的树形结构。 34 | - 对同一层级的子节点,开发者可以通过 `key` 来确定哪些子元素可以在不同渲染中保持稳定。 35 | 36 | 上面的三种 diff 策略,分别对应着 tree diff、component diff 和 element diff。 37 | 38 | ## tree diff 39 | 40 | 根据策略一,react 会对 fiber 树进行分层比较,只比较同级元素。这里的同级指的是同一个父节点下的子节点(往上的祖先节点也都是同一个),而不是树的深度相同。 41 | 42 |
51 |  52 |
52 |
53 |
54 | ### 引入 react 源码及修改 webpack
55 |
56 | 由于 node_modules 中的 react 包是打包好之后的文件,许多代码掺杂在一个文件中,不便于我们对源码进行调试。因此在 debug-react 的 src 目录下引入 react 的源码:
57 |
58 | ```
59 | git clone https://github.com/facebook/react.git -b 17.0.2
60 | ```
61 |
62 | 并在刚刚引入的 `src/react` 目录下执行一下命令安装依赖:
63 |
64 | ```
65 | yarn install
66 | ```
67 |
68 | 然后我们修改 webpack 的配置,使得在代码中引入的 react 等 npm 包的指向由 node_modules 改为刚刚引入的源码。在 `config/webpack.config.js` 下新增如下几个包的引用:
69 |
70 | ```diff
71 | // ...
72 | module.exports = {
73 | // ...
74 | resolve: {
75 | alias: {
76 | // Support React Native Web
77 | // https://www.smashingmagazine.com/2016/08/a-glimpse-into-the-future-with-react-native-for-web/
78 | 'react-native': 'react-native-web',
79 | // Allows for better profiling with ReactDevTools
80 | ...(isEnvProductionProfile && {
81 | 'react-dom$': 'react-dom/profiling',
82 | 'scheduler/tracing': 'scheduler/tracing-profiling',
83 | }),
84 | ...(modules.webpackAliases || {}),
85 | + 'react': path.resolve(__dirname, '../src/react/packages/react'),
86 | + 'react-dom': path.resolve(__dirname, '../src/react/packages/react-dom'),
87 | + 'shared': path.resolve(__dirname, '../src/react/packages/shared'),
88 | + 'react-reconciler': path.resolve(__dirname, '../src/react/packages/react-reconciler'),
89 | },
90 | }
91 | }
92 | ```
93 |
94 | ### 修改环境变量
95 |
96 | 我们将 `__DEV__` 等环境变量默认启用,便于开发调试,修改 `config/env.js`:
97 |
98 | ```diff
99 | // ...
100 | function getClientEnvironment(publicUrl) {
101 | // ...
102 | const stringified = {
103 | + __DEV__: true,
104 | + __PROFILE__: true,
105 | + __UMD__: true,
106 | + __EXPERIMENTAL__: true,
107 | 'process.env': Object.keys(raw).reduce((env, key) => {
108 | env[key] = JSON.stringify(raw[key]);
109 | return env;
110 | }, {}),
111 | };
112 |
113 | return { raw, stringified };
114 | }
115 | ```
116 |
117 | 在 debug-react 的根目录下创建 `.eslintrc.json` 文件,内容如下:
118 |
119 | ```json
120 | {
121 | "extends": "react-app",
122 | "globals": {
123 | "__DEV__": true,
124 | "__PROFILE__": true,
125 | "__UMD__": true,
126 | "__EXPERIMENTAL__": true
127 | }
128 | }
129 | ```
130 |
131 | ### 解决一系列报错
132 |
133 | 上面的环境配置好之后,通过 `yarn start` 启动会出现一系列的报错问题,因为 react 中某些遍历是在打包时根据环境注入生成的,我们现在要直接调试源码,不进行 react 的打包,所以要解决这些报错。下面直接讲问题解决了。
134 |
135 | #### 添加 ReactFiberHostConfig 引用
136 |
137 | 如下报错
138 |
139 | ```
140 | Attempted import error: 'afterActiveInstanceBlur' is not exported from './ReactFiberHostConfig'.
141 | ```
142 |
143 | 解决方式:
144 |
145 | 直接修改 `src/react/packages/react-reconciler/src/ReactFiberHostConfig.js` 的内容如下:
146 |
147 | ```diff
148 | - import invariant from 'shared/invariant';
149 | - invariant(false, 'This module must be shimmed by a specific renderer.');
150 |
151 | + export * from './forks/ReactFiberHostConfig.dom'
152 | ```
153 |
154 | 另外修改 `src/react/packages/shared/ReactSharedInternals.js`,直接从引入 ReactSharedInternals 并导出:
155 |
156 | ```diff
157 | - import * as React from 'react';
158 | - const ReactSharedInternals = React.__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED;
159 |
160 | + import ReactSharedInternals from '../react/src/ReactSharedInternals';
161 | ```
162 |
163 | #### 修改 react 引用方式
164 |
165 | 如下报错
166 |
167 | ```
168 | Attempted import error: 'react' does not contain a default export (imported actFiberHosts 'React').
169 | ```
170 |
171 | 解决方式:
172 |
173 | 修改 `src/index.js` 中 react 和 react-dom 的引入方式:
174 |
175 | ```diff
176 | - import React from 'react';
177 | - import ReactDOM from 'react-dom';
178 | + import * as React from 'react';
179 | + import * as ReactDOM from 'react-dom';
180 | ```
181 |
182 | #### 修改 inveriant
183 |
184 | 如下报错
185 |
186 | ```
187 | Error: Internal React error: invariant() is meant to be replaced at compile time. There is no runtime version.
188 | ```
189 |
190 | 解决方式:
191 |
192 | 修改 `src/react/packages/shared/invariant.js` 的内容:
193 |
194 | ```diff
195 | export default function invariant(condition, format, a, b, c, d, e, f) {
196 | + if (condition) {
197 | + return;
198 | + }
199 | throw new Error(
200 | 'Internal React error: invariant() is meant to be replaced at compile ' +
201 | 'time. There is no runtime version.',
202 | );
203 | }
204 | ```
205 |
206 | #### 解决 eslint 报错
207 |
208 | 还剩下一堆有关 eslint 的报错,诸如:
209 |
210 | ```
211 | Failed to load config "fbjs" to extend from.
212 | ```
213 |
214 | 解决方式:
215 |
216 | eslint 报错的内容实在太多了,我这里直接简单粗暴的将 webpack 中 eslint 插件给关掉,修改 `src/config/webpack.config.js` 文件:
217 |
218 | ```diff
219 | module.exports = {
220 | // ...
221 | plugins: [
222 | // ...
223 | - !disableESLintPlugin &&
224 | - new ESLintPlugin({
225 | - // Plugin options
226 | - extensions: ['js', 'mjs', 'jsx', 'ts', 'tsx'],
227 | - formatter: require.resolve('react-dev-utils/eslintFormatter'),
228 | - eslintPath: require.resolve('eslint'),
229 | - failOnError: !(isEnvDevelopment && emitErrorsAsWarnings),
230 | - context: paths.appSrc,
231 | - cache: true,
232 | - cacheLocation: path.resolve(
233 | - paths.appNodeModules,
234 | - '.cache/.eslintcache'
235 | - ),
236 | - // ESLint class options
237 | - cwd: paths.appPath,
238 | - resolvePluginsRelativeTo: __dirname,
239 | - baseConfig: {
240 | - extends: [require.resolve('eslint-config-react-app/base')],
241 | - rules: {
242 | - ...(!hasJsxRuntime && {
243 | - 'react/react-in-jsx-scope': 'error',
244 | - }),
245 | - },
246 | - },
247 | - }),
248 | ]
249 | }
250 | ```
251 |
252 | ## 总结
253 |
254 | 至此,我们的调试环境就搭建完成了,可以在 react 源码中通过 `debugger` 打断点或者 `console.log()` 输出日志进行愉快地调试了!
255 |
256 | 最后贴一下搭建的调试环境的 github 地址:[debug-react](https://github.com/zh-lx/debug-react),不想自己搭建调试环境的话可以直接 clone 我搭好的环境使用。
257 |
--------------------------------------------------------------------------------
/docs/team/代码质量/CodeReview.md:
--------------------------------------------------------------------------------
1 | ---
2 | desc: '众所周知,Code Review 是开发过程中一个非常重要的环节,但是很多公司或者团队是没有这一环节的,今天笔者结合自己所在团队,浅谈 Code Review 的价值及如何实施。'
3 | tag: ['代码规范', 'team']
4 | time: '2021-05-08'
5 | ---
6 |
7 | # 团队如何实施 Code Review
8 |
9 | 众所周知,Code Review 是开发过程中一个非常重要的环节,但是很多公司或者团队是没有这一环节的,今天笔者结合自己所在团队,浅谈 Code Review 的价值及如何实施。
10 |
11 | ## 1. Code Review 的价值
12 |
13 | 许多团队没有 Code Review 环节,或者因为追求项目快速上线,认为 CR 浪费时间;或者团队成员缺少 CR 观念,认为 CR 的价值并不大。所以想要推动 CR 在团队中的实施,最最重要的一点便是增强团队成员对 CR 环节的认同感。
14 | 15 | 16 | Code Review 环节,它更加依赖于团队成员的主观能动性,只有团队成员对其认可,他们才会积极地参入这一环节,CR 的价值才能最大化的体现。如果团队成员不认可 CR,即使强制设置了 CR 流程,也是形同虚设,反而可能阻碍正常开发流程的效率。那么如何让团队成员认可 CR 环节呢,自然是让他们意识到 CR 的价值,然后就会……真香! 17 |
18 | 
19 | 20 | ### 1.1 提升团队代码质量 21 | 22 | 随着团队规模的扩大和项目的迭代升级,团队之间的信息透明度会越来越低,项目的可维护性也会越来越差,可能引发如下一系列问题: 23 | 24 | 1. 已有的 utils 方法,重复造轮子 25 | 2. 代码过于复杂,缺少必要注释,后人难以维护 26 | 3. 目录结构五花八门,杂乱不堪 27 |
28 | …… 29 |
30 | 合理的 CR 环节,可以有效地把控每次提交的代码质量,不至于让项目的可维护性随着版本迭代和时间推移变得太差,这也是 CR 的首要目的。 31 | CR 环节并不会降低开发效率,就一次代码提交来说,也许部分人认为 CR 可能花费了时间,但是有效的 CR 给后人扩展和维护时所节省的时间是远超于此的。 32 | 33 | ### 1.2 团队技术交流 34 | 35 | Reviewer 和 Reviewee,在参与 CR 的过程中,都是可以收获到许多知识,进行技术交流的。 36 | 37 | 1. 有利于帮助新人快速成长,团队有新人加入时(如实习生和校招生),往往需要以为导师带领一段时间,通过 CR 环节,可以使导师最直接的了解到新人开发过程中所遇到的问题,作出相应的指导。 38 | 2. 通过 CR 环节,团队成员可以了解他人的业务,而不局限于自己的所负责的业务范围。项目发现问题时,可以迅速定位到相关业务的负责人进行修改。同时若有的团队成员离职后,也可以减少业务一人负责所带来的后期维护困难。 39 | 3. 学习他人的优秀代码。通过 CR 环节,可以迅速接触到团队成员在项目中解决某些问题的优秀代码,或者使用的一些你所未接触过的一些 api 等。 40 | 41 | ### 1.3 保证项目的统一规范 42 | 43 | 既然要进行 CR,首先要对项目的规范制定要求,包括编码风格规范、目录结构规范、业务规范等等。一方面,统一的项目规范才能保证项目的代码质量,提高项目的质量和可维护性;另一方面,在大家熟悉了统一的规范后,能够提升 CR 的效率,节省时间。 44 | 45 | ## 2. Code Review 的实践 46 | 47 | 关于 Code Review 的实践,要考虑的包括 CR 所花费的时间、CR 的形式、何时进行 CR 等等。 48 | 49 | ### 2.1 预留 CR 的时间 50 | 51 | 首先不得不承认,CR 环节是要耗费一定时间的,所以在项目排期中,不仅要考虑开发、联调、提测、改 bug 等时间,还要预留出 CR 的时间。包括担任 Reviewer 和 Reviewee 角色的时间都要考虑。 52 |
53 | 另外如果遇到的需求比较复杂,为了避免因为 CR 过程导致代码需要大量修改,最好提前和团队成员沟通好需求的设计和结果思路。 54 | 55 | ### 2.2 CR 的形式 56 | 57 | 我所见过的 CR 大多有两种形式。一种是设立一个特定时间,例如每周或者每半月等等,团队成员一起对之前的 Merge Request 进行 CR;另一种是对每次的 Merge Request 都进行 CR。 58 |
59 | 60 | 我个人更偏向于后者。第一种定期 CR,Merge Request 的数量太多,不太可能对所有的 MR 进行 CR,如果 CR 之后再对之前的诸多 MR 进行修改成本太大;而且一次性太多的 CR 会打击团队成员的积极性。第二种 MR 相对就轻松的多,可以考虑轮班每天设置 2-3 人对当天的 MR 进行 CR 即可。 61 | 62 | ### 2.3 CR 的时机 63 | 64 | CR 的环节应该设立在提测环节之前。因为 CR 后如果优化代码虽然理论上只是代码优化,但很可能会对业务逻辑产生影响,如果在提测时候,那么可能会影响到已经测试过的功能点。 65 |
66 | 当然也要分情况,如果遇到比较紧急的需求或者 bug 修复,那么也可以先提测,后续再做相应的 CR。 67 | 68 | ## 3. 对团队成员要求 69 | 70 | 前面已经提到,要增强团队成员对 CR 环节的认同感。作为 CR 环节的参与者,还应该根据自己的团队特点,对团队成员做出相应要求,可以参考我们团队。 71 | 72 | ### 3.1 Reviewer 73 | 74 | 1. 指明 review 的级别。reviewer 再给相应的代码添加评论时,建议指明评论的级别,可以在评论前用[]作出标识,例如:
75 | - [request]xxxxxxx 此条评论的代码必须修改才能予以通过 76 | - [advise]xxxxxxxx 此条评论的代码建议修改,但不修改也可以通过 77 | - [question]xxxxxx 此条评论的代码有疑问,需 reviewee 进一步解释 78 | 2. 讲明该评论的原因。在对代码做出评论时,应当解释清楚原因,如果自己有现成的更好地解决思路,应该把相应的解决思路也评论上,节省 reviewee 的修改时间。 79 | 3. 平等友善的评论。评论者在 review 的过程中,目的是提升项目代码质量,而不是抨击别人,质疑别人的能力,应该保持平等友善的语气。 80 | 4. 享受 Code Review。只有积极的参与 CR,把 CR 作为一种享受,才能将 CR 的价值最大化的体现。 81 | 82 | ### 3.2 Reviewee 83 | 84 | 1. 注重注释。对于复杂代码写明相应注释,在进行 commit 时也应简明的写清楚背景,帮助 reviewer 理解,提高 review 的效率。 85 | 2. 保持乐观的心态接受别人的 review。团队成员的 review 不是对你的批判,而是帮助你的提升,所以要尊重别人的 review,如果 review 你感觉不正确,可以在下面提出疑问,进一步解释。 86 | 3. 完成相应 review 的修改应当在下面及时进行回复,保持信息同步。 87 | -------------------------------------------------------------------------------- /docs/team/代码质量/Js代码可读性.md: -------------------------------------------------------------------------------- 1 | --- 2 | desc: '代码可读性的魅力也是这样,高可读性的代码,让别人抑郁理解,能够大量减少后期的维护时间。今天总结了 10 条常用的提高代码可读性的小方法,望大家不吝赐教。' 3 | tag: ['代码规范', 'js'] 4 | time: '2021-05-18' 5 | --- 6 | 7 | # 10 种方法提高 js 代码可读性! 8 | 9 | 每个人都喜欢可读性高的代码,因为高可读性的代码总是能让人眼前一亮!
10 | 就好比你向周围的人说:快看,老师!周围的人可能不屑一顾:老师有什么好看的?但如果你说:快看,苍老师!那可能很多人会被你这句话所吸引。一字之差,结果截然不同。
11 | 代码可读性的魅力也是这样,高可读性的代码,让别人抑郁理解,能够大量减少后期的维护时间。今天总结了 10 条常用的提高代码可读性的小方法,望大家不吝赐教。 12 | 13 | ### 1.语义化命名 14 | 15 | 在声明变量时,尽量让自己的变量名称具有清晰的语义化,使他人一眼便能够看出这个变量的含义,在这种情况下,可以减少注释的使用。
16 | 17 | 示例: 18 | 19 | ```javascript 20 | // bad 别人看到会疑惑:这个list是什么的集合? 21 | const list = ['Teacher.Cang', 'Teacher.Bo', 'Teacher.XiaoZe']; 22 | 23 | // good 别人看到秒懂:原来是老师们的集合! 24 | const teacherList = ['Teacher.Cang', 'Teacher.Bo', 'Teacher.XiaoZe']; 25 | ``` 26 | 27 | ### 2.各种类型命名 28 | 29 | 对于不同类型的变量值,我们可以通过一定的方式,让别人一看看上去就知道他的值类型。
30 | 一般来说,对于 boolean 类型或者 Array 类型的值,是最好区分的。例如:boolean 类型的值可以用 isXXX、hasXXX、canXXX 等命名;Array 类型的值可以用 xxxList、xxxArray 等方式命名。 31 | 32 | ```javascript 33 | // bad 34 | let belongToTeacher = true; 35 | let teachers = ['Teacher.Cang', 'Teacher.Bo', 'Teacher.XiaoZe']; 36 | 37 | // good 38 | let isTeacher = true; 39 | let teacherList = ['Teacher.Cang', 'Teacher.Bo', 'Teacher.XiaoZe']; 40 | ``` 41 | 42 | ### 3.为常量声明 43 | 44 | 我们在阅读代码时,如果你突然在代码中看到一个字符串常量或者数字常量,你可能要花一定的时间去理解它的含义。如果使用`const`或者`enum`等声明一下这些常量,可读性将会有效得到提升。 45 | 46 | 示例: 47 | 48 | ```javascript 49 | // bad 别人看到会很疑惑:这个36D的含义是什么 50 | if (size === '36D') { 51 | console.log('It is my favorite'); 52 | } 53 | 54 | // good 别人看到秒懂:36D是最喜欢的大小 55 | const FAVORITE_SIZE = '36D'; 56 | if (size === FAVORITE_SIZE) { 57 | console.log('It is my favorite'); 58 | } 59 | ``` 60 | 61 | ### 4.避免上下文依赖 62 | 63 | 在遍历时,很多人会通过 value、item 甚至 v 等命名代表遍历的变量,但是当上下文过长时,这样的命名可读性就会变得很差。我们要尽量做到使读者即使不了解事情的来龙去脉的情况下,也能迅速理解这个变量代表的含义,而不是迫使读者去记住逻辑的上下文。 64 | 65 | ```javascript 66 | const teacherList = ['Teacher.Cang', 'Teacher.Bo', 'Teacher.XiaoZe']; 67 | 68 | // bad 别人看到循环的末尾处的item时需要在去上面看上下文理解item的含义 69 | teacherList.forEach((item) => { 70 | // do something 71 | // do something 72 | // do ………… 73 | doSomethingWith(item); 74 | }); 75 | 76 | // good 别人看到最后一眼就能明白变量的意思是老师 77 | teacherList.forEach((teacher) => { 78 | // do something 79 | // do something 80 | // do ………… 81 | doSomethingWith(teacher); 82 | }); 83 | ``` 84 | 85 | ### 5.避免冗余命名 86 | 87 | 某些情况的变量命名,例如给对象的属性命名,直接命名该属性的含义即可,因为本身这个属性在对象中,无需再添加多余的前缀。 88 | 89 | ```javascript 90 | // bad 91 | const teacher = { 92 | teacherName: 'Teacher.Cang', 93 | teacherAge: 37, 94 | teacherSex: 'female', 95 | }; 96 | console.log(person.personName); 97 | 98 | // good 99 | const teacher = { 100 | name: 'Teacher.Cang', 101 | age: 37, 102 | sex: 'female', 103 | }; 104 | console.log(teacher.name); 105 | ``` 106 | 107 | ### 6.使用参数默认值 108 | 109 | 相比短路,使用 ES6 的参数默认值能让人更轻易地理解未传参数时参数的赋默认值。 110 | 111 | ```javascript 112 | // bad 需要多看一步才能理解是赋默认值 113 | function getTeacherInfo(teacherName) { 114 | teacherName = teacherName || 'Teacher.Cang'; 115 | // do... 116 | } 117 | 118 | // good 一看就能看出是赋默认值 119 | function getTeacherInfo(teacherName = 'Teacher.Cang') { 120 | // do... 121 | } 122 | ``` 123 | 124 | ### 7.回调函数命名 125 | 126 | 很多人命名回调函数,尤其是为页面或者 DOM 元素等设置事件监听的回调函数时,习惯用事件的触发条件进行命名,这样做其实可读性是比较差的,别人看到只知道你出发了这个函数,但却需要花时间去理解这个函数做了什么。
我们在命名回调函数式,应当以函数所要执行的逻辑命名,让别人清晰地理解这个回调函数所要执行的逻辑。 127 | 128 | ```javascript 129 | // bad 需要花时间去看代码理解这个回调函数是做什么的 130 | ; 131 | function handleClick() { 132 | // do... 133 | } 134 | 135 | // good 一眼就能理解这个回调函数是提交表单 136 | ; 137 | function handleSubmitForm() { 138 | // do... 139 | } 140 | ``` 141 | 142 | ### 8.减少函数的参数个数 143 | 144 | 一个函数如果参数的数量太多,使用的时候就难以记住每个参数的含义了,并且函数多个参数有顺序限制,我们在调用时需要去记住每个次序的参数的含义。通常情况下我们一个函数的参数个数在 1-2 个为佳,尽量不要超过三个。
145 | 当函数的参数比较多时,我们可以将同一类的参数使用对象进行合并,然后将合并后的对象作为参数传入,这样在调用该函数时能够很清楚地理解每个参数的含义。 146 | 147 | ```javascript 148 | // bad 调用时传的参数难以理解含义,需要记住顺序 149 | function createTeacher(name, sex, age, height, weight) { 150 | // do... 151 | } 152 | createTeacher('Teacher.Cang', 'female', 37, 155, 45); 153 | 154 | // good 调用时虽然写法略复杂了点,但各个参数含义一目了然,无需刻意记住顺序 155 | function createTeacher({ name, sex, age, height, weight }) { 156 | // do... 157 | } 158 | createTeacher({ 159 | name: 'Teacher.Cang', 160 | sex: 'female', 161 | age: 37, 162 | height: 155, 163 | weight: 45, 164 | }); 165 | ``` 166 | 167 | ### 9.函数拆分 168 | 169 | 一个函数如果代码太长,那么可读性也是比较差的,我们应该尽量保持一个函数只处理一个功能,当逻辑复杂时将函数适当拆分。 170 | 171 | ```javascript 172 | // bad 173 | function initData() { 174 | let resTeacherList = axios.get('/teacher/list'); 175 | teacherList = resTeacherList.data; 176 | const params = { 177 | pageSize: 20, 178 | pageNum: 1, 179 | }; 180 | let resMovieList = axios.get('/movie/list', params); 181 | movieList = resMovieList.data; 182 | } 183 | 184 | // good 185 | function getTeacherList() { 186 | let resTeacherList = axios.get('/teacher/list'); 187 | teacherList = resTeacherList.data; 188 | } 189 | function getMovieList() { 190 | const params = { 191 | pageSize: 20, 192 | pageNum: 1, 193 | }; 194 | let resMovieList = axios.get('/movie/list', params); 195 | movieList = resMovieList.data; 196 | } 197 | function initData() { 198 | getTeacherList(); 199 | getMovieList(); 200 | } 201 | ``` 202 | 203 | ### 10.注重写注释 204 | 205 | 不写注释应该是很多开发者的一个恶习,看别人不写注释的代码也是很多开发者最讨厌的事情。
206 | 所以,无论是为了自己还是别人,都请注重编写注释。 207 | 208 | ```javascript 209 | // bad 不写注释要花大量时间理解这个函数的作用 210 | function formatNumber(num) { 211 | if (num < 1000) { 212 | return num; 213 | } else { 214 | return `${(num / 1000).toFixed(1)}k`; 215 | } 216 | } 217 | 218 | // good 有了注释函数的作用和用法一目了然 219 | /** 220 | * @param num 221 | * @return num | x.xk 222 | * @example formatNumber(1000); 223 | * @description 224 | * 小于1k不转换 225 | * 大于1k转换为x.xk 226 | */ 227 | function formatNumber(num) { 228 | if (num < 1000) { 229 | return num; 230 | } else { 231 | return `${(num / 1000).toFixed(1)}k`; 232 | } 233 | } 234 | ``` 235 | 236 | 提高代码可读性的代码风格其实还有很多,以上笔者主要从变量命名、函数和注释三个方面,总结了 10 条比较常用的提高代码可读性的方法,希望对大家有所帮助。如有补充,欢迎评论。
237 | -------------------------------------------------------------------------------- /docs/team/代码质量/前端规范化实践.md: -------------------------------------------------------------------------------- 1 | --- 2 | desc: '多人协作项目及开源项目,制定团队协作规范十分重要,本篇将从项目 eslint 代码规范、单元测试、持续集成、commit 规范等方面的实践做一些总结。' 3 | tag: ['team'] 4 | time: '2022-03-08' 5 | --- 6 | 7 | 多人协作项目及开源项目,制定团队协作规范十分重要,本篇将从项目 eslint 代码规范、单元测试、持续集成、commit 规范等方面的实践做一些总结。 8 | 9 | ## eslint 篇 10 | 11 | eslint 对多人协作项目配置规范化特别重要。 12 | 13 | ### 安装 eslint 14 | 15 | 执行如下指令,安装 eslint 并初始化: 16 | 17 | ```perl 18 | # 安装 eslint 19 | npm install eslint -D 20 | 21 | # 初始化 22 | npx eslint --init 23 | ``` 24 | 25 | 如果要配合 typescript 使用,提前安装 typescript(如不使用 typescript 可忽略此步): 26 | 27 | ```js 28 | npm install typescript -D 29 | ``` 30 | 31 |  32 | 33 | ### 忽略部分文件的 eslint 检测 34 | 35 | 创建 `.eslintignore` 文件,可配置某些文件忽略 eslint 的检测,例如: 36 | 37 | ``` 38 | src/test.js 39 | ``` 40 | 41 | ### 集成 prettier 42 | 43 | 安装如下几个包: 44 | 45 | ``` 46 | npm install prettier eslint-plugin-prettier eslint-config-prettier -D 47 | ``` 48 | 49 | 在 `.eslintrc.js` 中添加 `plugin:prettier/recommended` 并且添加 prettier 的 rules: 50 | 51 | ```js 52 | module.exports = { 53 | // ... 54 | extends: ['plugin:prettier/recommended'], // 要放在 estends 数组的最后一项 55 | rules: { 56 | 'prettier/prettier': 'error', 57 | // ... 58 | }, 59 | // ... 60 | }; 61 | ``` 62 | 63 | 然后在根目录新建 `.prettierrc` 里面配置自己的 prettier 规则,例如: 64 | 65 | ```json 66 | { 67 | "singleQuote": true, 68 | "semi": true, 69 | "endOfLine": "auto", 70 | "tabWidth": 2, 71 | "printWidth": 80 72 | } 73 | ``` 74 | 75 | ### 集成 husky 和 githook 76 | 77 | 安装 lint-staged 78 | 79 | ``` 80 | npm install lint-staged -D 81 | ``` 82 | 83 | 指定 lint-staged 只对暂存区的文件进行检查,在 `package.json` 中新增如下内容: 84 | 85 | ```json 86 | { 87 | // ... 88 | "lint-staged": { 89 | "**/*.{jsx,txs,ts,js,vue}": ["eslint --fix", "git add"] 90 | } 91 | } 92 | ``` 93 | 94 | 集成 husky,新版本(v7) 的 husky 通过如下方式集成: 95 | 96 | ```perl 97 | # 安装 husky 98 | npm install husky -D 99 | 100 | # husky 初始化,创建 .husky 目录并指定该目录为 git hooks 所在的目录 101 | npx husky install 102 | 103 | # 指定 husky 在 commit 之前运行 lint-staged 来检查代码 104 | npx husky add .husky/pre-commit "npx lint-staged" 105 | ``` 106 | 107 | 由于 husky 是装在本地的,在 `package.json` 中新增如下指令,项目安装依赖时同时预装 husky: 108 | 109 | ```json 110 | { 111 | // ... 112 | "scripts": { 113 | // ... 114 | "prepare": "npx husky install" 115 | } 116 | // ... 117 | } 118 | ``` 119 | 120 | ### 配合 vscode 121 | 122 | vscode 安装 eslint 插件,让我们在编写代码时就能够进行错误提示: 123 | 124 |  125 | 126 | ## 测试篇 127 | 128 | ### 单元测试 129 | 130 | #### 安装测试库 131 | 132 | 执行如下命令,安装测试库 `mocha` + 断言库 `chai`: 133 | 134 | ```perl 135 | npm install mocha chai -D 136 | ``` 137 | 138 | #### 编写测试用例 139 | 140 | 要测试如下 `src/index.js` 中的内容: 141 | 142 | ```js 143 | function add(a, b) { 144 | return a + b; 145 | } 146 | 147 | function sub(a, b) { 148 | return a - b; 149 | } 150 | 151 | module.exports.add = add; 152 | module.exports.sub = sub; 153 | ``` 154 | 155 | 新建 `test/index.test.js` 测试文件,编写如下测试用例: 156 | 157 | ```js 158 | const { add, sub } = require('../src/index'); 159 | const expect = require('chai').expect; 160 | 161 | describe('测试', function () { 162 | it('加法', function () { 163 | const result = add(2, 3); 164 | expect(result).to.be.equal(5); 165 | }); 166 | 167 | it('减法', function () { 168 | const result = sub(2, 3); 169 | expect(result).to.be.equal(-1); 170 | }); 171 | }); 172 | ``` 173 | 174 | #### 执行测试命令 175 | 176 | 在 `package.json` 文件中新增如下 `test` 命令: 177 | 178 | ```json 179 | { 180 | // ... 181 | "scripts": { 182 | // ... 183 | "test": "node_modules/mocha/bin/_mocha" 184 | } 185 | // ... 186 | } 187 | ``` 188 | 189 | 执行 `npm run test`,即可看到测试执行结果: 190 | 191 | 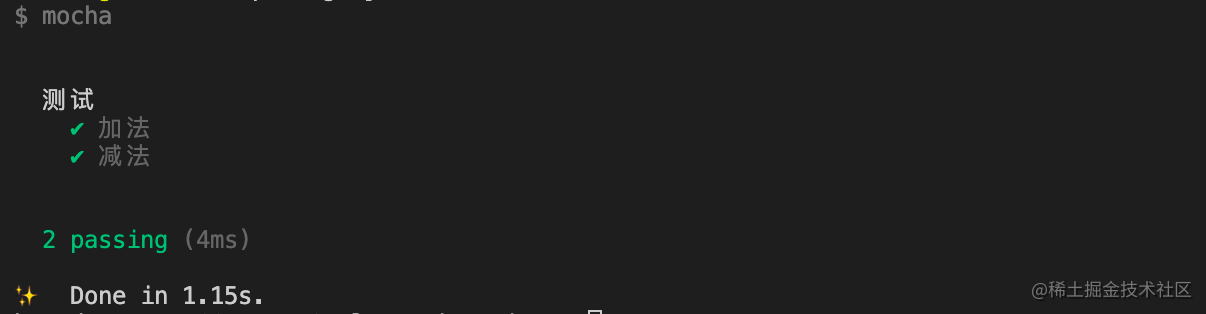 192 | 193 | #### 增加测试覆盖率 194 | 195 | 执行如下命令,安装 [istanbul](https://github.com/gotwarlost/istanbul): 196 | 197 | ``` 198 | npm install istanbul -D 199 | ``` 200 | 201 | 在 `package.json` 中增加如下指令: 202 | 203 | ```json 204 | { 205 | // ... 206 | "scripts": { 207 | // ... 208 | "test": "node_modules/mocha/bin/_mocha", 209 | "test:cover": "istanbul cover node_modules/mocha/bin/_mocha" 210 | } 211 | // ... 212 | } 213 | ``` 214 | 215 | 执行 `npm run test:cover`,即可看到测试覆盖率: 216 | 217 | 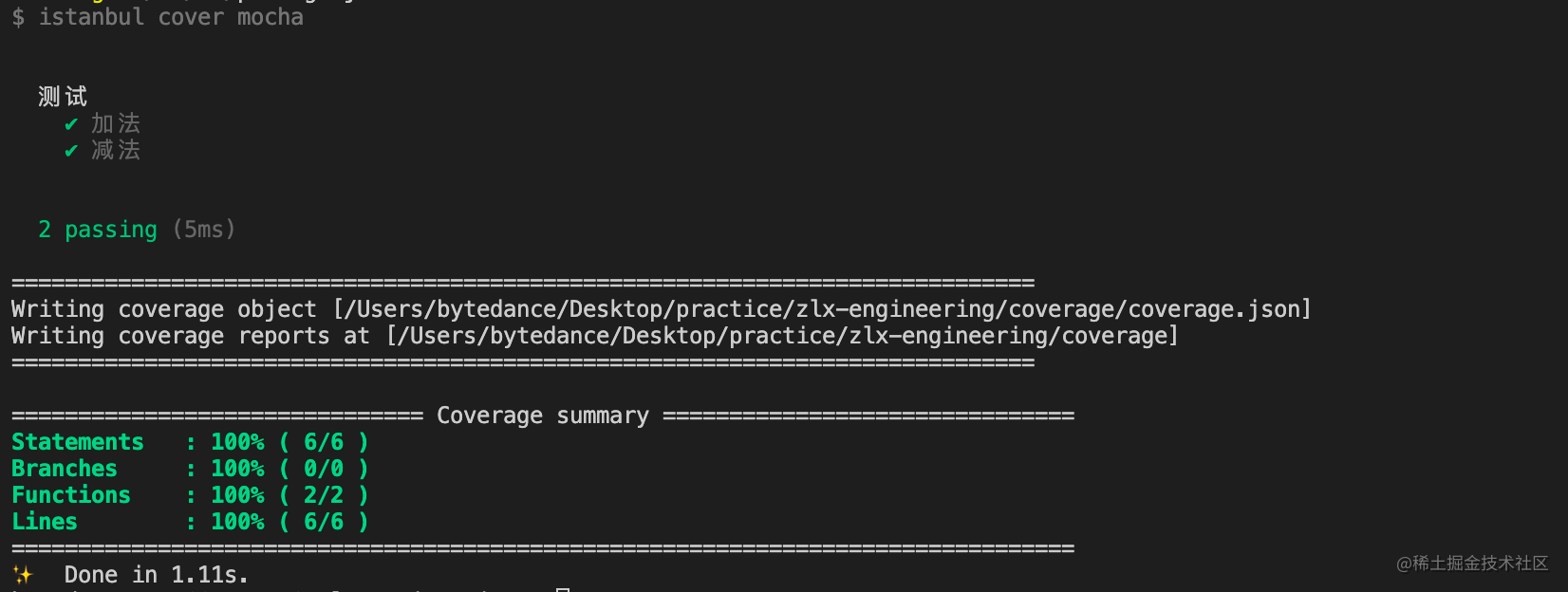 218 | 覆盖率说明: 219 | 220 | - 语句覆盖率(Statements):是否每个语句都执行了 221 | - 分支覆盖率(Branchs):是否每个 if 代码块都执行了 222 | - 函数覆盖率(Functions):是否每个函数都调用了 223 | - 行覆盖率(Lines):是否每一行都执行了 224 | 225 | ## 持续集成(CI) 226 | 227 | 通过持续集成,我们可以进行一些自动化构建的任务以及快速发现错误。 228 | 229 | 常见的 github CI 有 [Travis CI](https://app.travis-ci.com/)、[Circle CI](https://circleci.com/)、[Jenkins](https://www.jenkins.io/) 等,这里我们以 Travis CI 为例。 230 | 231 | ### 登录 Travis 账号 232 | 233 | github 登录 [Travis CI](https://app.travis-ci.com/),选择下图选项,确保对应 git 项目开启了 Travis CI: 234 | 235 |  236 | 237 | ### 创建 .travis.yml 238 | 239 | 在项目根目录添加 `.travis.yml` 文件,添加对应的构建内容,例如: 240 | 241 | ```yml 242 | language: node_js 243 | sudo: false 244 | 245 | cache: 246 | apt: true 247 | directories: 248 | - node_modules # 对 node_modules 文件夹开启缓存以便更快安装依赖 249 | 250 | node_js: stable # 设置相应版本 251 | 252 | install: 253 | - npm install -D # 安装依赖 254 | 255 | script: 256 | - npm run test:cover 257 | ``` 258 | 259 | 项目提交代码后,可以在 [Travis CI](https://app.travis-ci.com/) 看到项目 CI 的情况: 260 | 261 |  262 | 263 | ## 规范 commit & 自动生成 changelog 264 | 265 | 良好的 commit 能够帮助我们更好维护代码以及提高 code review 的效率。 266 | 267 | ### commit 准则 268 | 269 | 大多数团队都会通过在 commit 最前面加上一个 tag 的方式来快速区分 commit 类型: 270 | 271 | - feat: 新功能特性 272 | - fix: 修复问题 273 | - refactor: 代码重构,没有新增功能或者修复问题 274 | - docs: 仅修改了文档 275 | - style: 代码格式修改,如增加空格,修改单双引号等 276 | - test: 测试用例修改 277 | - chore: 改变构建流程、增加依赖库或者工具等 278 | - revert: 回滚上一个版本 279 | - ci:ci 流程修改 280 | - perf: 体验、性能优化 281 | 282 | ### 使用 git-cz 规范 commit 283 | 284 | 执行以下命令,安装 `commitizen` 和 `cz-conventional-changelog`: 285 | 286 | ```perl 287 | npm install commitizen cz-conventional-changelog -D 288 | ``` 289 | 290 | 修改 `package.json` 文件,新增以下内容: 291 | 292 | ```json 293 | { 294 | // ... 295 | "scripts": { 296 | // ... 297 | "commit": "git-cz" 298 | }, 299 | "config": { 300 | "commitizen": { 301 | "path": "./node_modules/cz-conventional-changelog" 302 | } 303 | } 304 | // ... 305 | } 306 | ``` 307 | 308 | 执行 `npm run commit` 命令,即可自动进行规范化提交: 309 | 310 |  311 | 312 | ### 自动生成 changelog 313 | 314 | 执行如下命令安装 `conventional-changelog-cli`: 315 | 316 | ``` 317 | npm install conventional-changelog-cli -D 318 | ``` 319 | 320 | 在 `package.json` 中新增如下内容: 321 | 322 | ```json 323 | { 324 | // ... 325 | "scripts": { 326 | // ... 327 | "genlog": "conventional-changelog -p angular -i CHANGELOG.md -s" 328 | } 329 | // ... 330 | } 331 | ``` 332 | 333 | 执行 `npm run genlog` 命令,会自动在 `CHANGELOG.md` 文件中增加 commit 的信息: 334 | 335 |  336 | -------------------------------------------------------------------------------- /docs/vue2/通信方式.md: -------------------------------------------------------------------------------- 1 | --- 2 | desc: 'vue 组件通信的方式,这是在面试中一个非常高频的问题,今天对 vue 组件通信方式进行一下总结。' 3 | cover: 'https://github.com/zh-lx/blog/assets/73059627/4be45e22-e429-4b6f-9881-3ab517f01fd5' 4 | tag: ['vue', 'vue2'] 5 | time: '2021-04-24' 6 | --- 7 | 8 | # Vue 组件通信方式汇总 9 | 10 | vue 组件通信的方式,这是在面试中一个非常高频的问题,我刚开始找实习便经常遇到这个问题,当时只知道回到 props 和$emit,后来随着学习的深入,才发现 vue 组件的通信方式竟然有这么多!
11 | 今天对 vue 组件通信方式进行一下总结,如写的有疏漏之处还请大家不吝赐教。 12 | 13 | ## 1. props/\$emit 14 | 15 | ### 简介 16 | 17 | props 和\$emit 相信大家十分的熟悉了,这是我们最常用的 vue 通信方式。
18 | props:props 可以是数组或对象,用于接收来自父组件通过 v-bind 传递的数据。当 props 为数组时,直接接收父组件传递的属性;当 props 为对象时,可以通过 type、default、required、validator 等配置来设置属性的类型、默认值、是否必传和校验规则。
19 | \$emit:在父子组件通信时,我们通常会使用\$emit 来触发父组件 v-on 在子组件上绑定相应事件的监听。 20 | 21 | ### 代码实例 22 | 23 | 下面通过代码来实现一下 props 和\$emit 的父子组件通信,在这个实例中,我们都实现了以下的通信:
24 | 25 | - 父向子传值:父组件通过`:messageFromParent="message"`将父组件 message 值传递给子组件,当父组件的 input 标签输入时,子组件 p 标签中的内容就会相应改变。
26 | - 子向父传值:父组件通过`@on-receive="receive"`在子组件上绑定了 receive 事件的监听,子组件 input 标签输入时,会触发 receive 回调函数, 通过`this.$emit('on-receive', this.message)`将子组件 message 的值赋值给父组件 messageFromChild ,改变父组件 p 标签的内容。 27 | 请看代码: 28 | 29 | ```html 30 | // 子组件代码 31 | 32 |
33 |
37 |
38 |
54 | ```
55 |
56 | ```html
57 | // 父组件代码
58 |
59 | this is child component
34 | 35 |收到来自父组件的消息:{{ messageFromParent }}
36 |
60 |
65 |
66 |
87 | ```
88 |
89 | ### 效果预览
90 |
91 | 
92 |
93 | ## 2. v-slot
94 |
95 | ### 简介
96 |
97 | v-slot 是 Vue2.6 版本中新增的用于统一实现插槽和具名插槽的 api,用于替代`slot(2.6.0废弃)`、`slot-scope(2.6.0废弃)`、`scope(2.5.0废弃)`等 api。this is parent component
61 | 62 |收到来自子组件的消息:{{ messageFromChild }}
63 |98 | v-slot 在 template 标签中用于提供具名插槽或需要接收 prop 的插槽,如果不指定 v-slot ,则取默认值 default 。 99 | 100 | ### 代码实例 101 | 102 | 下面请看 v-slot 的代码实例,在这个实例中我们实现了:
103 | 104 | - 父向子传值:父组件通过`{{ message }}`将父组件的 message 值传递给子组件,子组件通过`
110 |
116 |
117 | ```
118 |
119 | ```html
120 |
121 | this is child component
111 |
112 | 收到来自父组件的消息:
122 |
125 |
126 | {{ message }}
127 |
128 |
129 |
130 |
131 |
132 |
146 | ```
147 |
148 | ### 效果预览
149 |
150 | 
151 |
152 | ## 3. \$refs/\$parent/\$children/\$root
153 |
154 | ### 简介
155 |
156 | 我们也同样可以通过 `$refs/$parent/$children/$root` 等方式获取 Vue 组件实例,得到实例上绑定的属性及方法等,来实现组件之间的通信。this is parent component
123 | 124 |157 | \$refs:我们通常会将 \$refs 绑定在 DOM 元素上,来获取 DOM 元素的 attributes。在实现组件通信上,我们也可以将 \$refs 绑定在子组件上,从而获取子组件实例。
158 | \$parent:我们可以在 Vue 中直接通过`this.$parent`来获取当前组件的父组件实例(如果有的话)。
159 | \$children:同理,我们也可以在 Vue 中直接通过`this.$children`来获取当前组件的子组件实例的数组。但是需要注意的是,`this.$children`数组中的元素下标并不一定对用父组件引用的子组件的顺序,例如有异步加载的子组件,可能影响其在 children 数组中的顺序。所以使用时需要根据一定的条件例如子组件的 name 去找到相应的子组件。
160 | \$root:获取当前组件树的根 Vue 实例。如果当前实例没有父实例,此实例将会是其自己。通过 $root ,我们可以实现组件之间的跨级通信。 161 | 162 | ### 代码实例 163 | 164 | 下面来看一个 \$parent 和 \$children 使用的实例(由于这几个 api 的使用方式大同小异,所以关于 \$refs 和 \$root 的使用就不在这里展开了,在这个实例中实现了:
165 | 166 | - 父向子传值:子组件通过`$parent.message`获取到父组件中 message 的值。 167 | - 子向父传值:父组件通过`$children`获取子组件实例的数组,在通过对数组进行遍历,通过实例的 name 获取到对应 Child1 子组件实例将其赋值给 child1,然后通过`child1.message`获取到 Child1 子组件的 message。 168 | 代码如下: 169 | 170 | ```html 171 | // 子组件 172 | 173 |
174 |
179 |
180 |
190 | ```
191 |
192 | ```html
193 | // 父组件
194 |
195 | this is child component
175 | 176 |收到来自父组件的消息:{{ $parent.message }}
177 | 178 |
196 |
202 |
203 |
223 | ```
224 |
225 | ### 效果预览
226 |
227 | 
228 |
229 | ## 4. \$attrs/\$listener
230 |
231 | ### 简介
232 |
233 | \$attrs 和 \$listeners 都是 Vue2.4 中新增加的属性,主要是用来供使用者用来开发高级组件的。this is parent component
197 | 198 |收到来自子组件的消息:{{ child1.message }}
199 | 200 |234 | \$attrs:用来接收父作用域中不作为 prop 被识别的 attribute 属性,并且可以通过`v-bind="$attrs"`传入内部组件——在创建高级别的组件时非常有用。
235 | 试想一下,当你创建了一个组件,你要接收 param1 、param2、param3 …… 等数十个参数,如果通过 props,那你需要通过`props: ['param1', 'param2', 'param3', ……]`等声明一大堆。如果这些 props 还有一些需要往更深层次的子组件传递,那将会更加麻烦。
236 | 而使用 \$attrs ,你不需要任何声明,直接通过`$attrs.param1`、`$attrs.param2`……就可以使用,而且向深层子组件传递上面也给了示例,十分方便。
237 | \$listeners:包含了父作用域中的 v-on 事件监听器。它可以通过 `v-on="$listeners"` 传入内部组件——在创建更高层次的组件时非常有用,这里在传递时的使用方法和 \$attrs 十分类似。 238 | 239 | ### 代码实例 240 | 241 | 在这个实例中,共有三个组件:A、B、C,其关系为:[ A [ B [C] ] ],A 为 B 的父组件,B 为 C 的父组件。即:1 级组件 A,2 级组件 B,3 级组件 C。我们实现了:
242 | 243 | - 父向子传值:1 级组件 A 通过`:messageFromA="message"`将 message 属性传递给 2 级组件 B,2 级组件 B 通过`$attrs.messageFromA`获取到 1 级组件 A 的 message 。 244 | - 跨级向下传值:1 级组件 A 通过`:messageFromA="message"`将 message 属性传递给 2 级组件 B,2 级组件 B 再通过` v-bind="$attrs"`将其传递给 3 级组件 C,3 级组件 C 通过`$attrs.messageFromA`获取到 1 级组件 A 的 message 。 245 | - 子向父传值:1 级组件 A 通过`@keyup="receive"`在子孙组件上绑定 keyup 事件的监听,2 级组件 B 在通过`v-on="$listeners"`来将 keyup 事件绑定在其 input 标签上。当 2 级组件 B input 输入框输入时,便会触发 1 级组件 A 的 receive 回调,将 2 级组件 B 的 input 输入框中的值赋值给 1 级组件 A 的 messageFromComp ,从而实现子向父传值。 246 | - 跨级向上传值:1 级组件 A 通过`@keyup="receive"`在子孙组件上绑定 keyup 事件的监听,2 级组件 B 在通过`
253 |
258 |
259 |
269 | ```
270 |
271 | ```html
272 | // 2级组件B
273 |
274 | this is C component
254 | 255 | 256 |收到来自A组件的消息:{{ $attrs.messageFromA }}
257 |
275 |
282 |
283 |
297 | ```
298 |
299 | ```html
300 | // A组件
301 |
302 | this is B component
276 | 277 | 278 |收到来自A组件的消息:{{ $attrs.messageFromA }}
279 |
303 |
309 |
310 |
333 | ```
334 |
335 | ### 效果预览
336 |
337 | 
338 |
339 | ## 5. provide/inject
340 |
341 | ### 简介
342 |
343 | provide/inject 这对选项需要一起使用,以允许一个祖先组件向其所有子孙后代注入一个依赖,不论组件层次有多深,并在其上下游关系成立的时间里始终生效。如果你是熟悉 React 的同学,你一定会立刻想到 Context 这个 api,二者是十分相似的。this is A component
304 | 305 |收到来自{{ comp }}的消息:{{ messageFromComp }}
306 |344 | provide:是一个对象,或者是一个返回对象的函数。该对象包含可注入其子孙的 property ,即要传递给子孙的属性和属性值。
345 | injcet:一个字符串数组,或者是一个对象。当其为字符串数组时,使用方式和 props 十分相似,只不过接收的属性由 data 变成了 provide 中的属性。当其为对象时,也和 props 类似,可以通过配置 default 和 from 等属性来设置默认值,在子组件中使用新的命名属性等。 346 | 347 | ### 代码实例 348 | 349 | 这个实例中有三个组件,1 级组件 A,2 级组件 B,3 级组件 C:[ A [ B [C] ] ],A 是 B 的父组件,B 是 C 的父组件。实例中实现了:
350 | 351 | - 父向子传值:1 级组件 A 通过 provide 将 message 注入给子孙组件,2 级组件 B 通过`inject: ['messageFromA']`来接收 1 级组件 A 中的 message,并通过`messageFromA.content`获取 1 级组件 A 中 message 的 content 属性值。 352 | - 跨级向下传值:1 级组件 A 通过 provide 将 message 注入给子孙组件,3 级组件 C 通过`inject: ['messageFromA']`来接收 1 级组件 A 中的 message,并通过`messageFromA.content`获取 1 级组件 A 中 message 的 content 属性值,实现跨级向下传值。 353 | 代码如下: 354 | 355 | ```html 356 | // 1级组件A 357 | 358 |
359 |
363 |
364 |
385 | ```
386 |
387 | ```html
388 | // 2级组件B
389 |
390 | this is A component
360 | 361 |
391 |
395 |
396 |
406 | ```
407 |
408 | ```html
409 | // 3级组件C
410 |
411 | this is B component
392 |收到来自A组件的消息:{{ messageFromA && messageFromA.content }}
393 |
412 |
415 |
416 |
422 | ```
423 |
424 | 注意点:this is C component
413 |收到来自A组件的消息:{{ messageFromA && messageFromA.content }}
414 |425 | 426 | 1. 可能有同学想问我上面 1 级组件 A 中的 message 为什么要用 object 类型而不是 string 类型,因为在 vue provide 和 inject 绑定并不是可响应的。如果 message 是 string 类型,在 1 级组件 A 中通过 input 输入框改变 message 值后无法再赋值给 messageFromA,如果是 object 类型,当对象属性值改变后,messageFromA 里面的属性值还是可以随之改变的,子孙组件 inject 接收到的对象属性值也可以相应变化。 427 | 2. 子孙 provide 和祖先同样的属性,会在后代中覆盖祖先的 provide 值。例如 2 级组件 B 中也通过 provide 向 3 级组件 C 中注入一个 messageFromA 的值,则 3 级组件 C 中的 messageFromA 会优先接收 2 级组件 B 注入的值而不是 1 级组件 A。 428 | 429 | ### 效果预览 430 | 431 |  432 | 433 | ## 6. eventBus 434 | 435 | ### 简介 436 | 437 | eventBus 又称事件总线,通过注册一个新的 Vue 实例,通过调用这个实例的\$emit 和\$on 等来监听和触发这个实例的事件,通过传入参数从而实现组件的全局通信。它是一个不具备 DOM 的组件,有的仅仅只是它实例方法而已,因此非常的轻便。
438 | 我们可以通过在全局 Vue 实例上注册: 439 | 440 | ```javascript 441 | // main.js 442 | Vue.prototype.$Bus = new Vue(); 443 | ``` 444 | 445 | 但是当项目过大时,我们最好将事件总线抽象为单个文件,将其导入到需要使用的每个组件文件中。这样,它不会污染全局命名空间: 446 | 447 | ```javascript 448 | // bus.js,使用时通过import引入 449 | import Vue from 'vue'; 450 | export const Bus = new Vue(); 451 | ``` 452 | 453 | ### 原理分析 454 | 455 | eventBus 的原理其实比较简单,就是使用订阅-发布模式,实现\$emit 和\$on 两个方法即可: 456 | 457 | ```javascript 458 | // eventBus原理 459 | export default class Bus { 460 | constructor() { 461 | this.callbacks = {}; 462 | } 463 | $on(event, fn) { 464 | this.callbacks[event] = this.callbacks[event] || []; 465 | this.callbacks[event].push(fn); 466 | } 467 | $emit(event, args) { 468 | this.callbacks[event].forEach((fn) => { 469 | fn(args); 470 | }); 471 | } 472 | } 473 | 474 | // 在main.js中引入以下 475 | // Vue.prototype.$bus = new Bus() 476 | ``` 477 | 478 | ### 代码实例 479 | 480 | 在这个实例中,共包含了 4 个组件:[ A [ B [ C、D ] ] ],1 级组件 A,2 级组件 B,3 级组件 C 和 3 级组件 D。我们通过使用 eventBus 实现了: 481 | 482 | - 全局通信:即包括了父子组件相互通信、兄弟组件相互通信、跨级组件相互通信。4 个组件的操作逻辑相同,都是在 input 输入框时,通过`this.$bus.$emit('sendMessage', obj)`触发 sendMessage 事件回调,将 sender 和 message 封装成对象作为参数传入;同时通过`this.$bus.$on('sendMessage', obj)`监听其他组件的 sendMessage 事件,实例当前组件示例 sender 和 message 的值。这样任一组件 input 输入框值改变时,其他组件都能接收到相应的信息,实现全局通信。
483 | 代码如下: 484 | 485 | ```main.js 486 | // main.js 487 | Vue.prototype.$bus = new Vue() 488 | ``` 489 | 490 | ```html 491 | // 1级组件A 492 | 493 |
494 |
501 |
502 |
535 | ```
536 |
537 | ```html
538 | // 2级组件B
539 |
540 | this is CompA
495 | 496 |497 | 收到{{ sender }}的消息:{{ messageFromBus }} 498 |
499 |
541 |
549 |
550 |
585 | ```
586 |
587 | ```html
588 | // 3级组件C
589 |
590 | this is CompB
542 | 543 |544 | 收到{{ sender }}的消息:{{ messageFromBus }} 545 |
546 |
591 |
597 |
598 |
627 | ```
628 |
629 | ```html
630 | // 3级组件D
631 |
632 | this is CompC
592 | 593 |594 | 收到{{ sender }}的消息:{{ messageFromBus }} 595 |
596 |
633 |
639 |
640 |
669 | ```
670 |
671 | ### 效果预览
672 |
673 | 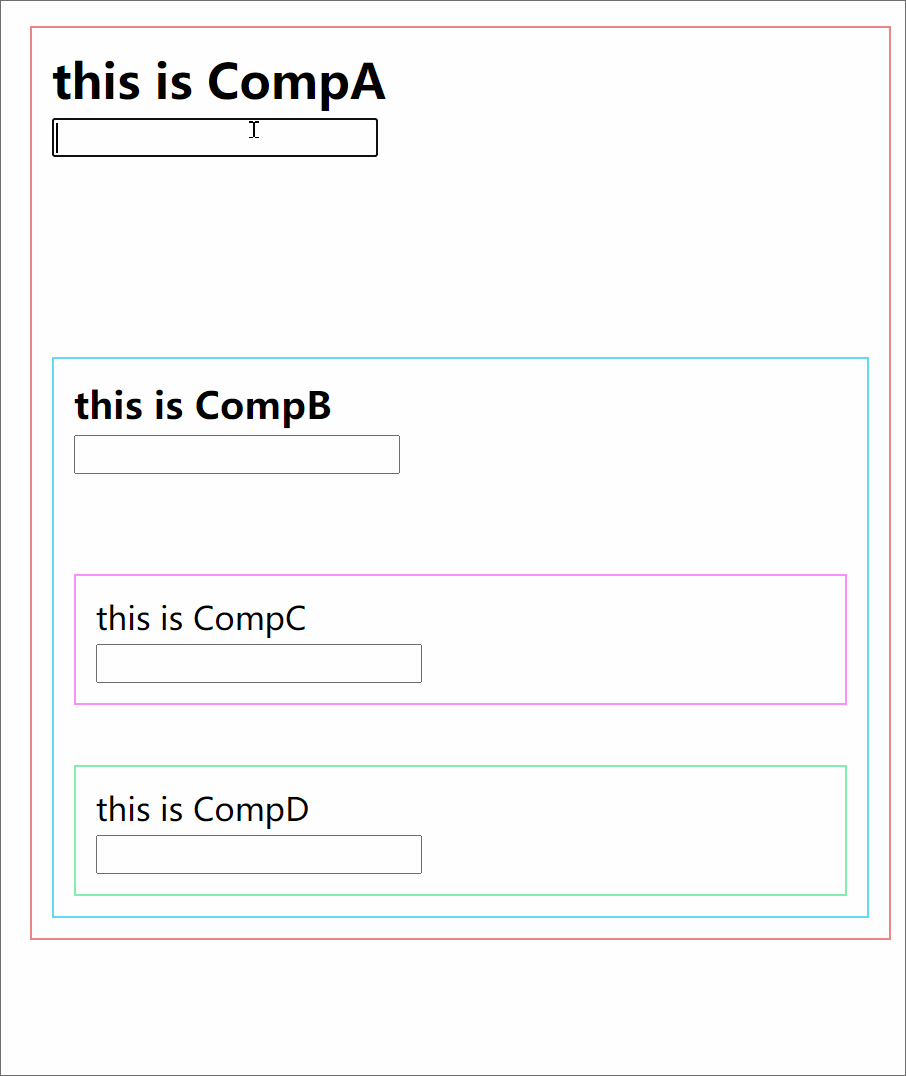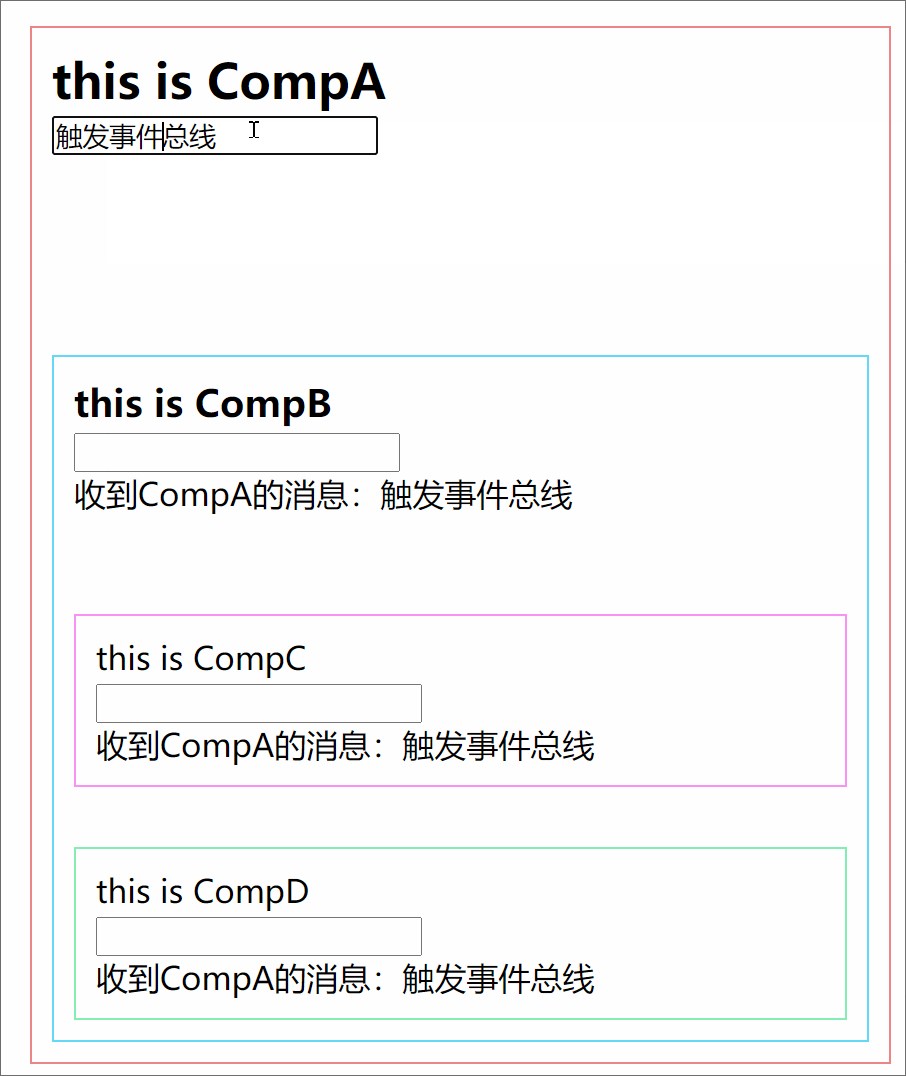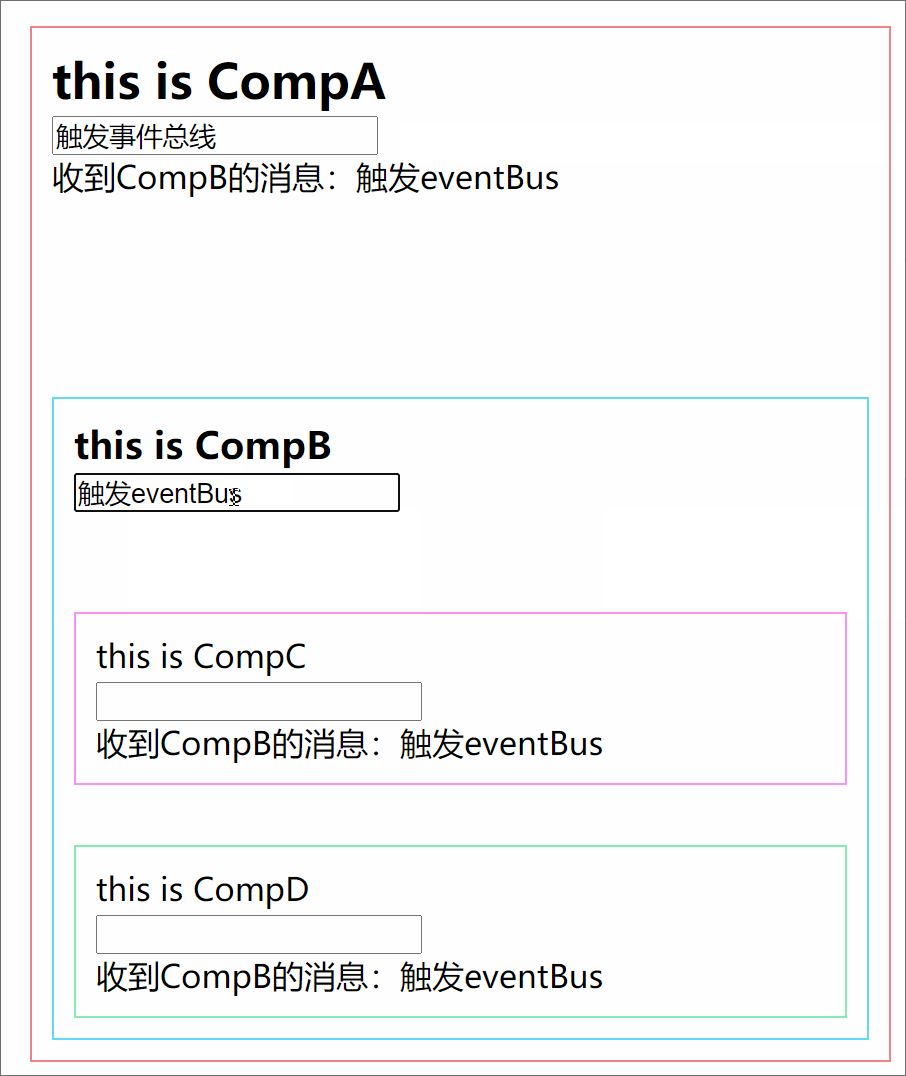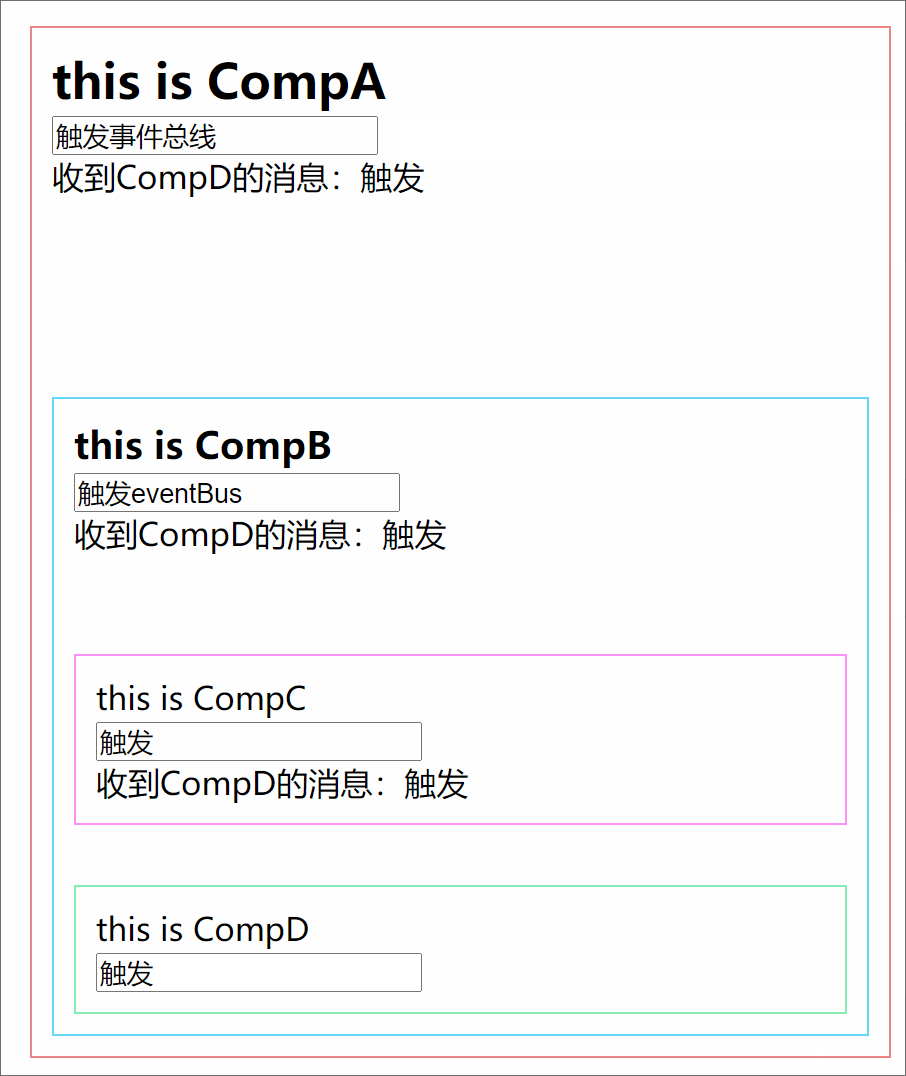
674 |
675 | ## 7. Vuex
676 |
677 | 当项目庞大以后,在多人维护同一个项目时,如果使用事件总线进行全局通信,容易让全局的变量的变化难以预测。于是有了 Vuex 的诞生。this is CompD
634 | 635 |636 | 收到{{ sender }}的消息:{{ messageFromBus }} 637 |
638 |678 | Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。
679 | 有关 Vuex 的内容,可以参考[Vuex 官方文档](https://vuex.vuejs.org/zh/),我就不在这里班门弄斧了,直接看代码。 680 | 681 | ### 代码实例 682 | 683 | Vuex 的实例和事件总线 leisi,同样是包含了 4 个组件:[ A [ B [ C、D ] ] ],1 级组件 A,2 级组件 B,3 级组件 C 和 3 级组件 D。我们在这个实例中实现了:
684 | 685 | - 全局通信:代码的内容和 eventBus 也类似,不过要比 eventBus 使用方便很多。每个组件通过 watch 监听 input 输入框的变化,把 input 的值通过 vuex 的 commit 触发 mutations,从而改变 stroe 的值。然后每个组件都通过 computed 动态获取 store 中的数据,从而实现全局通信。 686 | 687 | ```javascript 688 | // store.js 689 | import Vue from 'vue'; 690 | import Vuex from 'vuex'; 691 | Vue.use(Vuex); 692 | export default new Vuex.Store({ 693 | state: { 694 | message: { 695 | sender: '', 696 | content: '', 697 | }, 698 | }, 699 | mutations: { 700 | sendMessage(state, obj) { 701 | state.message = { 702 | sender: obj.sender, 703 | content: obj.content, 704 | }; 705 | }, 706 | }, 707 | }); 708 | ``` 709 | 710 | ```html 711 | // 组件A 712 | 713 |
714 |
721 |
722 |
752 | ```
753 |
754 | 同样和 eventBus 中一样,B,C,D 组件中的代码除了引入子组件的不同,script 部分都是一样的,就不再往上写了。
755 |
756 | ### 效果预览
757 |
758 | 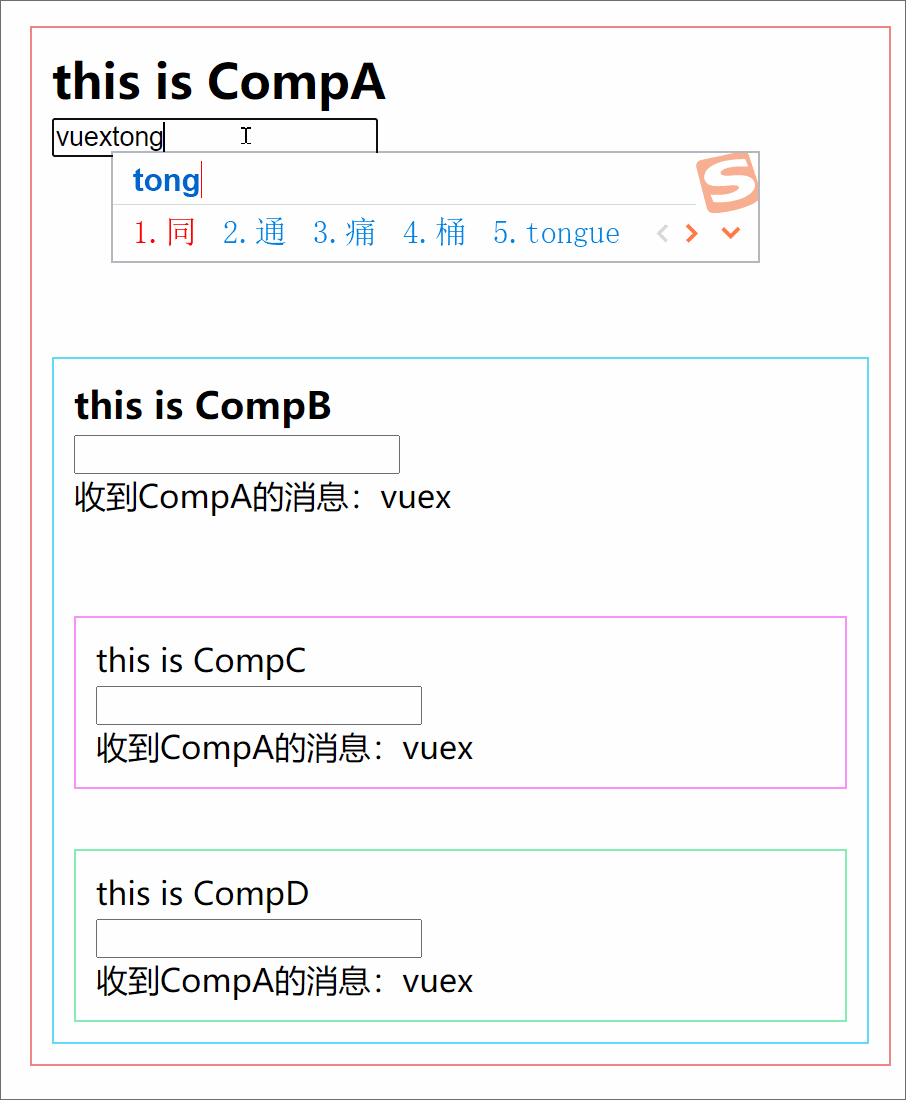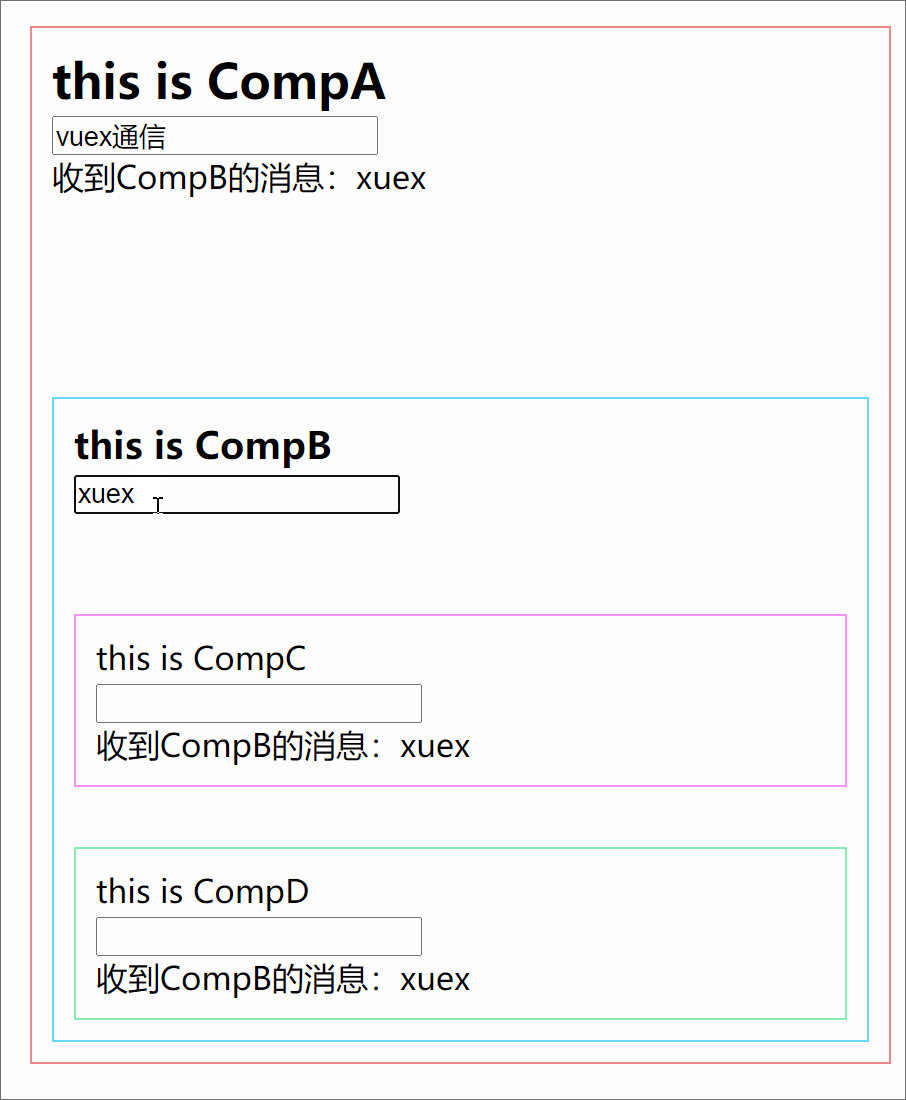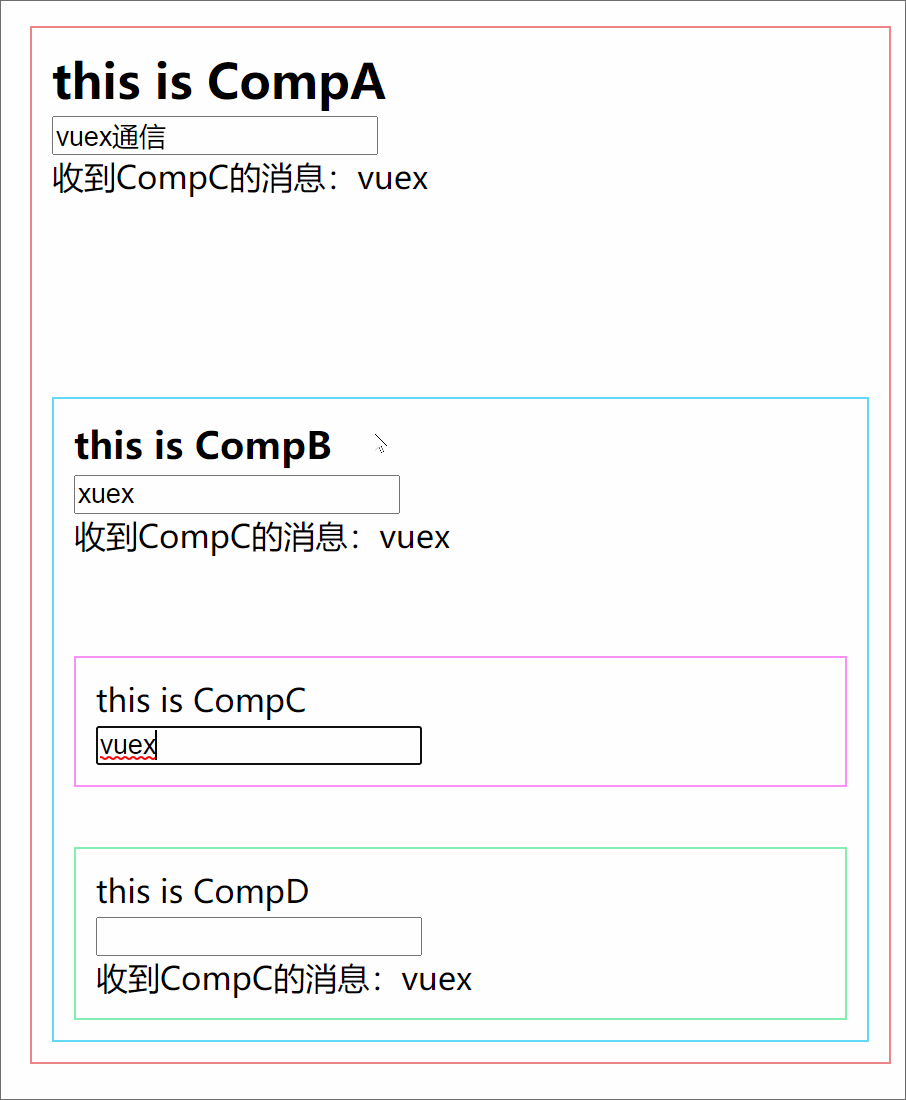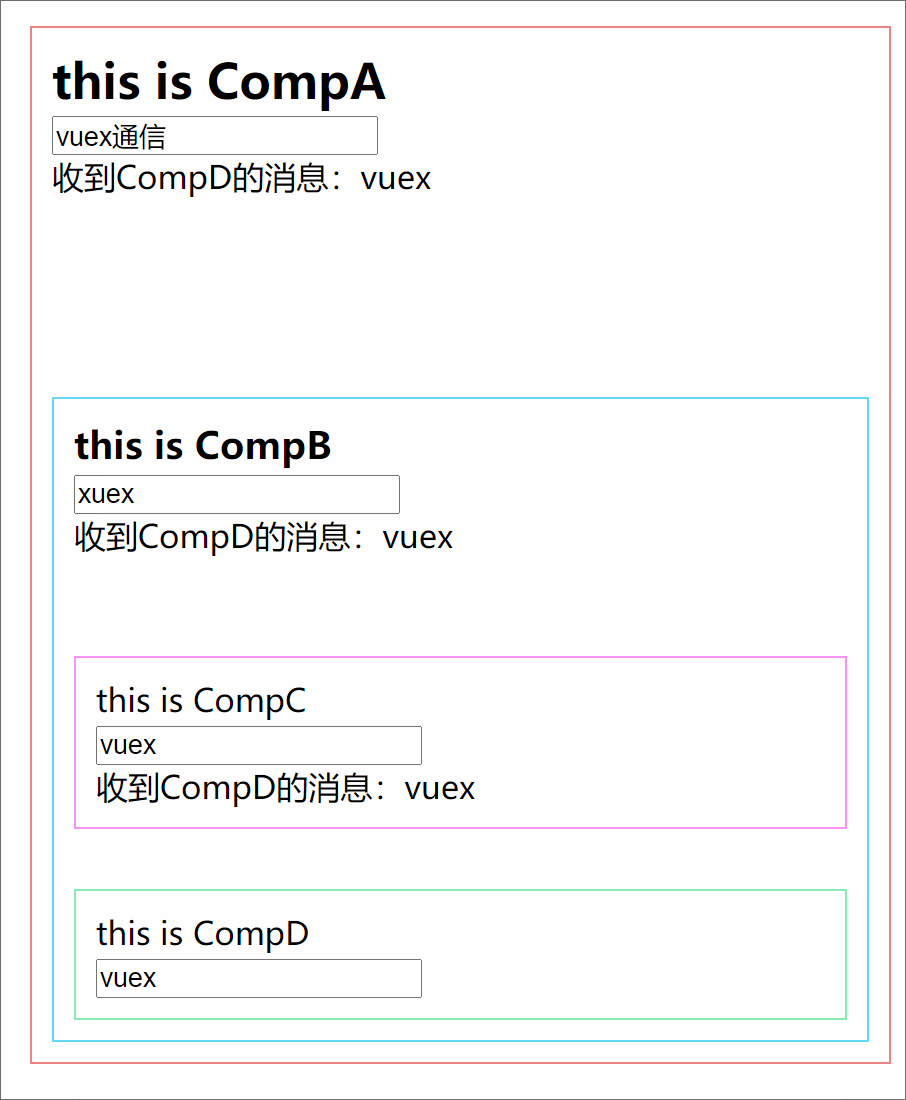
759 |
760 | ## 总结
761 |
762 | 上面总共提到了 7 中 Vue 的组件通信方式,他们能够进行的通信种类如下图所示:
763 | this is CompA
715 | 716 |717 | 收到{{ sender }}的消息:{{ messageFromStore }} 718 |
719 |764 | 765 | - props/\$emit:可以实现父子组件的双向通信,在日常的父子组件通信中一般会作为我们的最常用选择。 766 | - v-slot:可以实现父子组件单向通信(父向子传值),在实现可复用组件,向组件中传入 DOM 节点、html 等内容以及某些组件库的表格值二次处理等情况时,可以优先考虑 v-slot。 767 | - \$refs/\$parent/\$children/\$root:可以实现父子组件双向通信,其中\$root 可以实现根组件实例向子孙组件跨级单向传值。在父组件没有传递值或通过 v-on 绑定监听时,父子间想要获取彼此的属性或方法可以考虑使用这些 api。 768 | - \$attrs/\$listeners:能够实现跨级双向通信,能够让你简单的获取传入的属性和绑定的监听,并且方便地向下级子组件传递,在构建高级组件时十分好用。 769 | - provide/inject:可以实现跨级单向通信,轻量地向子孙组件注入依赖,这是你在实现高级组件、创建组件库时的不二之选。 770 | - eventBus:可以实现全局通信,在项目规模不大的情况下,可以利用 eventBus 实现全局的事件监听。但是 eventBus 要慎用,避免全局污染和内存泄漏等情况。 771 | - Vuex:可以实现全局通信,是 vue 项目全局状态管理的最佳实践。在项目比较庞大,想要集中式管理全局组件状态时,那么安装 Vuex 准没错! 772 | 773 | > 最后,鲁迅说过:“一碗酸辣汤,耳闻口讲的,总不如亲自呷一口的明白。”
(鲁迅:这句话我真说过!)
看了这么多,不如自己亲手去敲一敲更能理解,看完可以去手动敲一敲加深理解。 774 | -------------------------------------------------------------------------------- /docs/代码仓库/git/Git操作指令大全.md: -------------------------------------------------------------------------------- 1 | --- 2 | desc: '本文总结了日常工作中常用的 git 指令,涵盖了绝大部分的使用场景,让你能够轻松应对各种 git 协作流程。' 3 | cover: 'https://github.com/zh-lx/blog/assets/73059627/789ee5e2-6e23-4ab5-9e1c-37b2ebaef68d' 4 | tag: ['git'] 5 | time: '2021-12-31' 6 | --- 7 | 8 | # Git 操作指令大全 9 | 10 | 本文总结了日常工作中常用的 git 指令,涵盖了绝大部分的使用场景,让你能够轻松应对各种 git 协作流程。 11 | 12 | ## 理解 git 工作区域 13 | 14 | 根据 git 的几个文件存储区域,git 的工作区域可以划分为 4 个: 15 | 16 | - 工作区:你在本地编辑器里改动的代码,所见即所得,里面的内容都是最新的 17 | - 暂存区:通过 `git add` 指令,会将你工作区改动的代码提交到暂存区里 18 | - 本地仓库:通过 `git commit` 指令,会将暂存区变动的代码提交到本地仓库中,本地仓库位于你的电脑上 19 | - 远程仓库:远端用来托管代码的仓库,通过 `git push` 指令,会将本地仓库的代码推送到远程仓库中 20 | 21 |  22 | 23 | ## 初始配置 24 | 25 | ### 配置用户信息 26 | 27 | 首次使用 git 时,设置提交代码时的信息: 28 | 29 | ```perl 30 | # 配置用户名 31 | git config --global user.name "yourname" 32 | 33 | # 配置用户邮箱 34 | git config --global user.email "youremail@xxx.com" 35 | 36 | # 查看当前的配置信息 37 | git config --global --list 38 | 39 | # 通过 alias 配置简写 40 | ## 例如使用 git co 代替 git checkout 41 | git config --global alias.co checkout 42 | ``` 43 | 44 | ### ssh key 45 | 46 | 向远端仓库提交代码时,需要在远端仓库添加本地生成的 ssh key。 47 | 48 | 1. 生成本地 ssh key,若已有直接到第 2 步: 49 | 50 | ``` 51 | ssh-keygen -t rsa -C "youremail@xxx.com" 52 | ``` 53 | 54 | 2. 查看本地 ssh key: 55 | 56 | ``` 57 | cat ~/.ssh/id_rsa.pub 58 | ``` 59 | 60 | 3. 将 ssh key 粘贴到远端仓库: 61 | 62 | 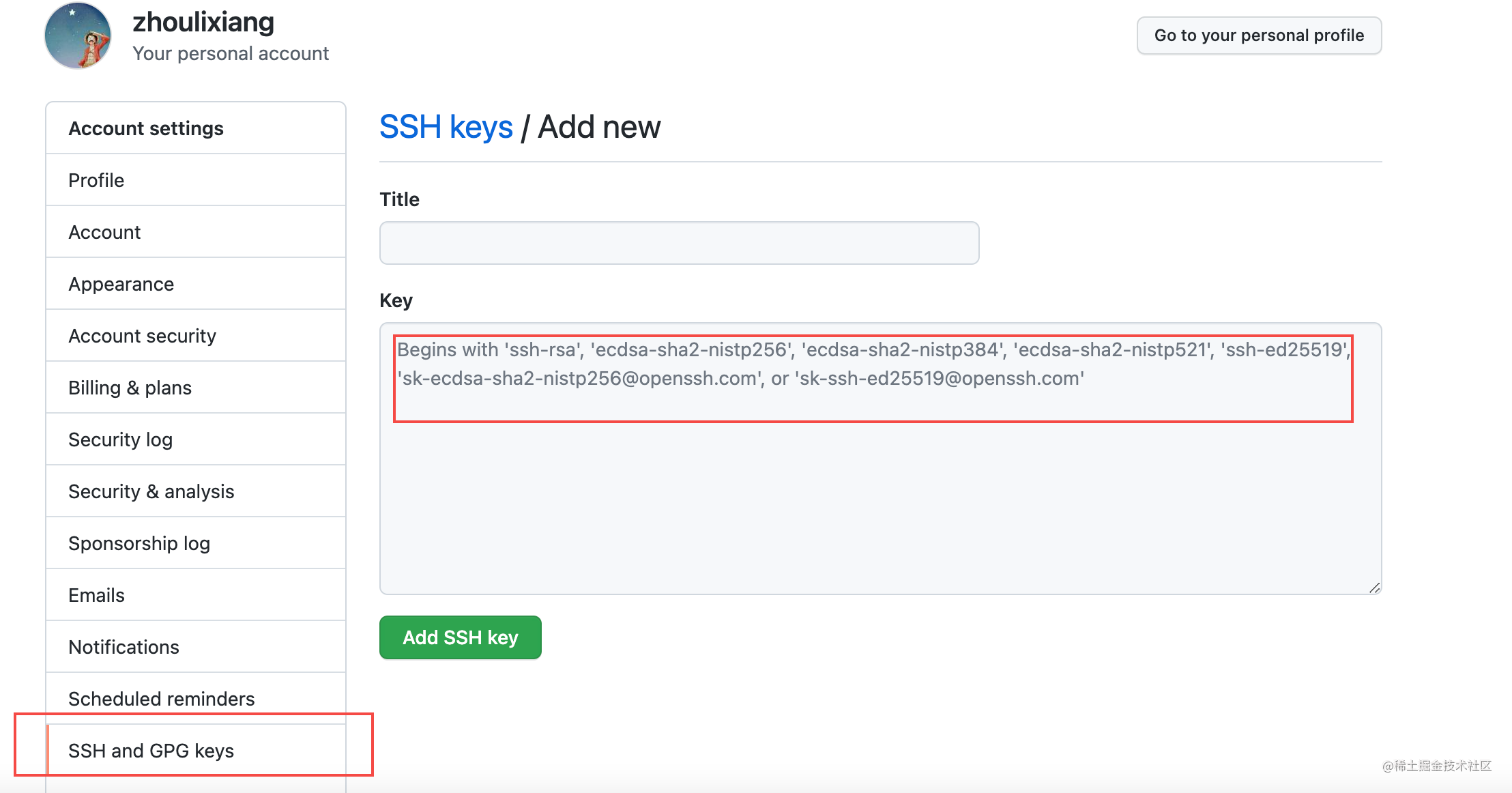 63 | 64 | ## 高频命令 65 | 66 | 以下是最常用的操作,需要任何一个开发者学会的 git 命令: 67 | 68 | ### git clone: 克隆仓库 69 | 70 | ```perl 71 | # 克隆远端仓库到本地 72 | git clone
230 | 研发老哥的 commit 记录如下: 231 | 232 | 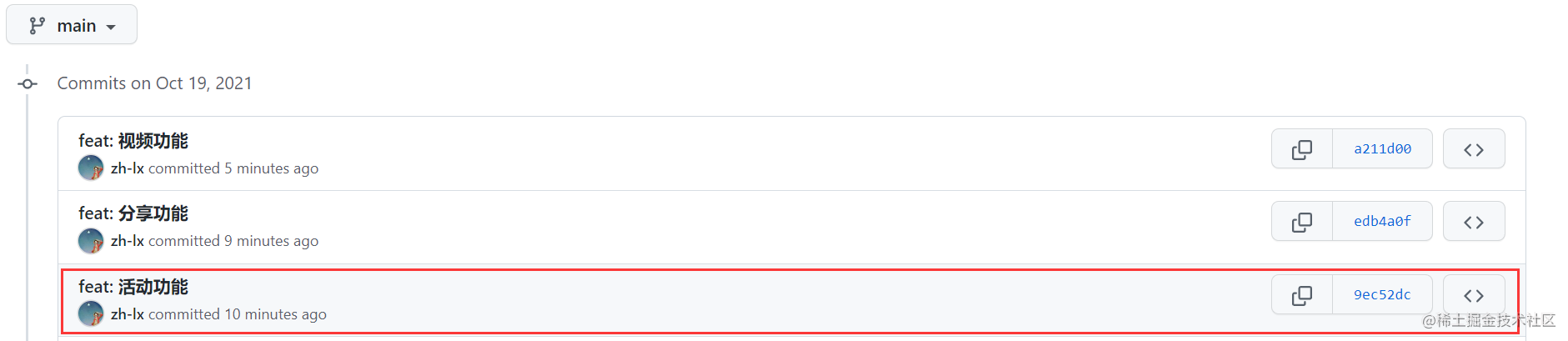 233 | 234 | 现在想要做的就是取消掉第一次活动功能的 commit,但是视频功能和分享功能的 commit 还需要保留,所以肯定不能使用 `git reset` 了, 这时候 `git revert` 就派上用场了。 235 | 236 | 执行 `git revert 9ec52dc`,再重新 `git push`,活动功能的 commit 内容就会被覆盖掉了: 237 | 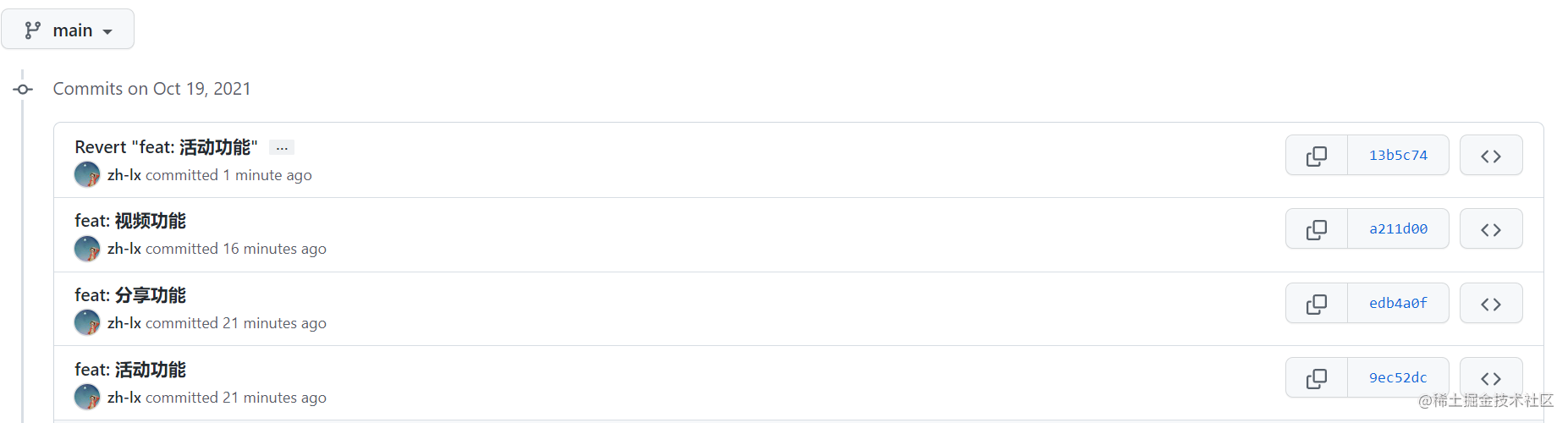 238 | 239 | ### git rebase: 简洁 commit 记录 240 | 241 | `git rebase` 命令主要是针对 commit 的,目的是令 commit 记录变得更加简洁清晰。 242 | 243 | #### 多次 commit 合并为一次 244 | 245 | 可以通过 `git rebase -i` 合并多次 commit 为一次。注意:此操作会修改 commit-sha,因此只能在自己的分支上操作,不能在公共分支操作,不然会引起他人的合并冲突 246 | 247 | ##### 说明 248 | 249 | ```perl 250 | # 进行 git rebase 可交互命令变基,end-commit-sha 可选,不填则默认为 HEAD 251 | ## start 和 end commit-sha 左开右闭原则 252 | git rebase -i
297 | 在线体验地址:https://video.etherpad.com/ 298 | - [ot.js](https://github.com/Operational-Transformation/ot.js):字符串格式的 ot 实现,上述的 OT 用例中就是以该库的 operation 进行讲解。封装了根据字符串的变更创建对应的 operation 以及 operation 的 transform 操作,缺点是需要自己手动实现 WebSocket 及相关的前后端通信逻辑,且只支持字符串格式。
299 | 教学 demo:https://github.com/Operational-Transformation/ot-demo 300 | - [shareDB](https://github.com/share/sharedb):支持多种字符串、富文本、json 等多种 operation 及其 transform,由于支持的转换格式丰富,所以如果是想要针对自己的产品实现 OT 协同,应用比较广泛。 301 |
教学 demo:https://github.com/share/sharedb/tree/master/examples 302 | 303 | #### CRDT 304 | 305 | CRDT (Conflict-free Replicated Data Type)即“无冲突复制数据类型”,它主要被应用在分布式系统中,保证分布式应用的数据一致性。文档协同编辑可以理解为分布式应用的一种,它的本质是数据结构,通过数据结构的设计保证并发操作数据的最终一致性。 306 | 307 | CRDT 的提出时间比 OT 要晚很多,所以在多人协作编辑场景下的成熟产品相对较少,但是也有了一些应用,例如:atom 编辑器的 teletype、PingCode Wiki、以及 figma 的协作编辑也是借鉴了 CRDT 的思想。 308 | 309 | ##### CRDT 核心思想 310 | 311 | 前面提到 CRDT 主要应用于分布式系统,那么它的数据操作,都需要符合可交换性和幂等性,已解决以下可能遇到的问题: 312 | 313 | - 网络问题导致发送接收顺序不一致(可交换性) 314 | - 以及多次发送(幂等性) 315 | 那么放到我们的编辑场景中,首先要保证操作的可交换性,那么我们只需要知道所有操作的顺序,最后对操作进行排序就可以了。我们可以依据每个操作的 timeStamp,对操作进行排序。每个用户都有一个 UID,多个不同用户如果出现 timeStamp 相同的情况下,我们可以按照 UID 进行升序,保证并发操作的顺序。 316 | 317 | 同时,UID 和 timeStamp 组合在一起,就保证了每一个操作都具备唯一的 ID,可以实现幂等性,解决统一操作多次发送的问题。 318 | 319 | ##### CRDT 树状结构 320 | 321 | 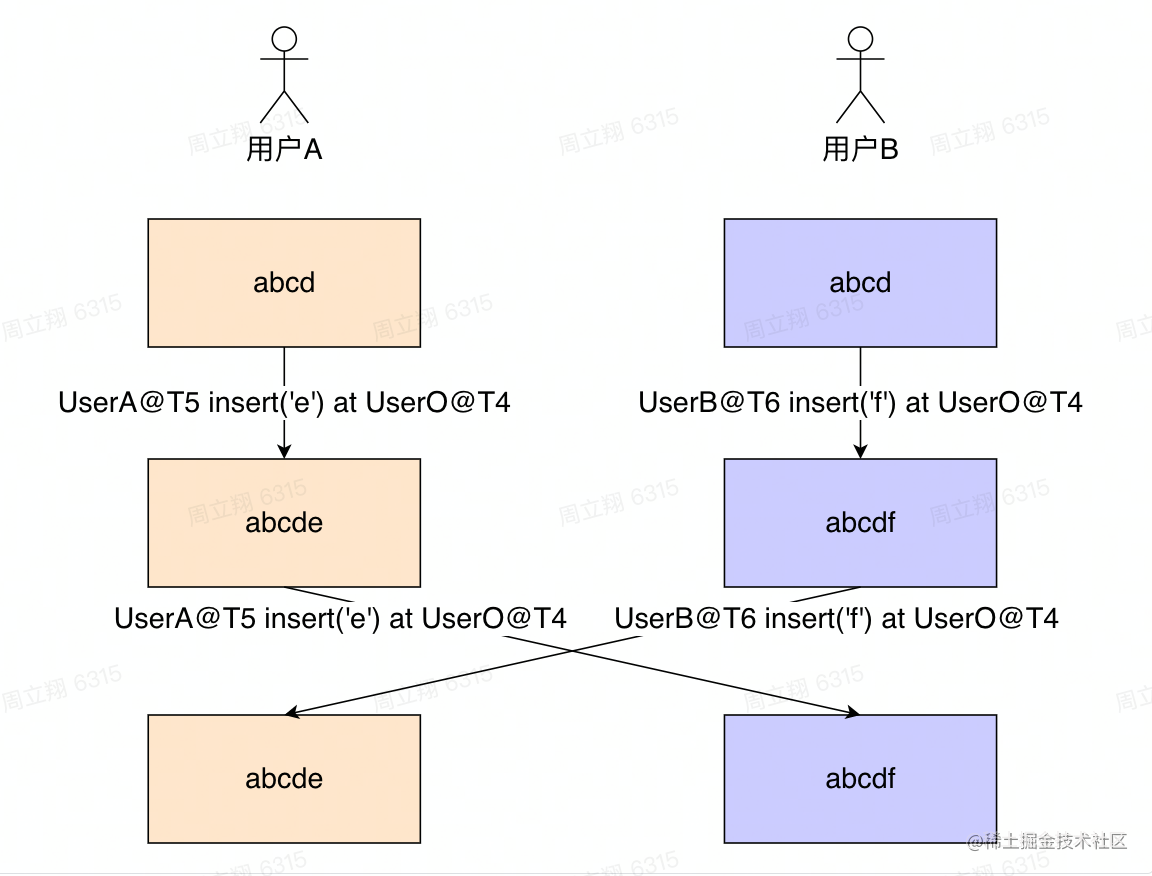 322 | 323 | 还是以上面的这个场景为例,在 CRDT 中,会为每一个字符都创建一个操作标识,假如初始状态 `abcd` 中的 `d` 的标识为 `UserO@T4`,那么用户 A 和用户 B 的操作都是基于操作标识的: 324 | 325 | ``` 326 | UserA@T5: insert('e') at UserO@T4 327 | UserB@T6: insert('f') at UserO@T4 328 | ``` 329 | 330 | 那么这两个操作只需要保证好他们的顺序,不需要转换就能够保证最终修改结果的一致,实际的操作数据结构如下: 331 | 332 | 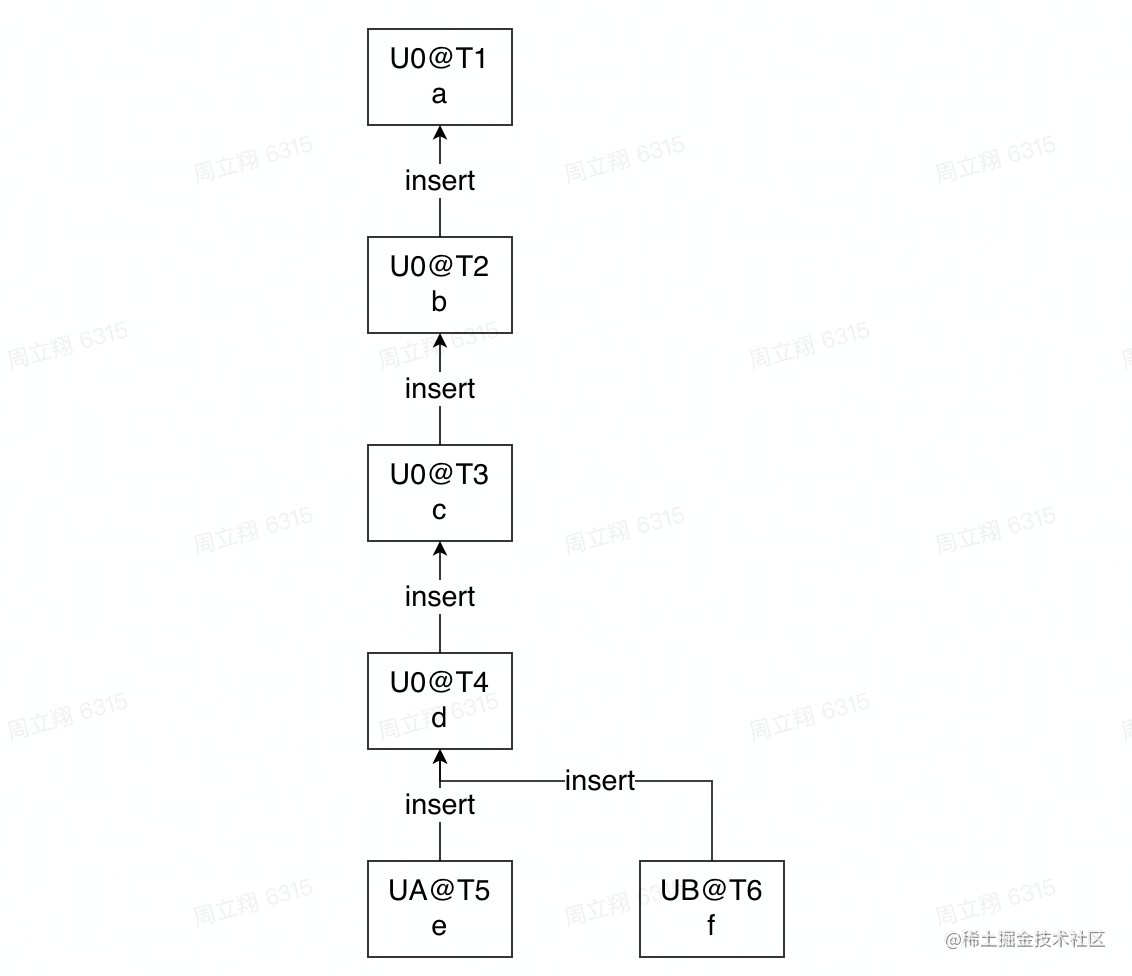 333 | 334 | 从这个操作结构我们可以看得出,为了保证 CRDT 的实现,数据库中需要存储每一个字符的标志符,同时当有新的操作产生时,需要遍历操作的树状结构,找到与当前操作所关联的那个节点。 335 | 336 | ##### 基于 CRDT 的开源库 337 | 338 | - [Yjs](https://github.com/yjs/yjs):社区最知名的 CRDT 框架,从 V8 的角度去优化 Yjs 结构对象的创建,整体思路就是让 Yjs 创建对象的过程能够被浏览器优化,无论是内存占用还是对象创建速度。 339 | 其他的基于 Yjs 的框架还有 [SyncedStore](https://github.com/yousefed/SyncedStore) 等。 340 | 341 | #### OT 与 CRDT 对比 342 | 343 | OT 算法由于发展时间长,已经相对成熟,但是社区很多人对 CRDT 在多人协作场景的应用表示看好,并且认为未来 CRDT 会比 OT 更加有前景。就目前来说,二者对比如下: 344 | 345 | | 框架 | 优势 | 劣势 | 346 | | ---- | ----------------------------------------------------------------- | ------------------------------------------------- | 347 | | OT | 1. 高性能
2. 能够保存用户操作意图
3. 不影响文档体积 | 1. 需要中心化服务器
2. 算法设计复杂
| 348 | | CRDT | 1. 去中心化
2. 算法设计相对简单
3. 稳定性高 | 1. 比较消耗内存和性能
2. 损失用户操作意图 | 349 | 350 | ## 总结 351 | 352 | 本文总结了多种解决多人编辑场景下的内容覆盖的方案,针对不同场景,我们可以选择不同的方案。 353 | 354 | - 如果只是想解决内容覆盖问题,没有多人协作的要求,那么推荐使用编辑锁 355 | - 如果有多人协作需求,但对内容的实时性要求低,那么可以考虑采用版本合并的方案 356 | - 如果想要实现多人实时协作,那么只能考虑采用 OT 或者 CRDT 实现协同编辑。 357 | 358 | ## 参考 359 | 360 | - [多人协同编辑技术的演进](https://zhuanlan.zhihu.com/p/425265438?utm_medium=social&utm_oi=685143097629872128) 361 | - [实时协同编辑的实现](https://fex.baidu.com/blog/2014/04/realtime-collaboration/) 362 | - [什么是 CRDT](https://www.zhihu.com/question/507425610/answer/2299709925) 363 | - [OT 算法在协同编辑中的应用](https://segmentfault.com/a/1190000040203619?utm_source=sf-hot-article) 364 | -------------------------------------------------------------------------------- /home-footer/index.vue: -------------------------------------------------------------------------------- 1 | 2 |
3 | 鲁ICP备20023182号-1
6 | CopyRight@2022
7 |
8 |
9 |
10 |
11 |
12 |
35 |
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "docs",
3 | "version": "1.0.0",
4 | "description": "zh-lx学习记录",
5 | "main": "index.js",
6 | "repository": "git@github.com:zh-lx/docs.git",
7 | "author": "zh-lx <18366276315@163.com>",
8 | "license": "MIT",
9 | "devDependencies": {
10 | "@types/node": "^15.0.2",
11 | "@vuepress/bundler-webpack": "2.0.0-beta.59",
12 | "@vuepress/plugin-register-components": "^1.9.7",
13 | "postcss-loader": "^5.2.0",
14 | "sass-loader": "^13.2.0",
15 | "vuepress": "2.0.0-beta.59"
16 | },
17 | "scripts": {
18 | "dev": "vuepress dev docs",
19 | "build:local": "vuepress build docs",
20 | "build": "git pull && git submodule update --init --recursive && yarn install && vuepress build docs",
21 | "eject": "./node_modules/@vuepress/cli/bin/vuepress.js eject",
22 | "pull": "git pull && git submodule update --init --recursive"
23 | },
24 | "dependencies": {
25 | "@vuepress/plugin-search": "2.0.0-beta.59",
26 | "@vuepress/plugin-theme-data": "2.0.0-beta.59"
27 | }
28 | }
29 |
--------------------------------------------------------------------------------
/tsconfig.json:
--------------------------------------------------------------------------------
1 | {
2 | "compilerOptions": {
3 | "lib": ["dom", "esnext", "ES2015"],
4 | "module": "es2015",
5 | "types": ["node"],
6 | "moduleResolution": "node",
7 | "preserveConstEnums": true,
8 | "removeComments": true,
9 | "sourceMap": true,
10 | "target": "es5",
11 | "strict": false,
12 | "allowSyntheticDefaultImports": true,
13 | "baseUrl": ".",
14 | "paths": {
15 | "@/*": ["vuepress-theme-writing/src/client/*"]
16 | }
17 | }
18 | }
19 |
--------------------------------------------------------------------------------
/vuepress.config.ts:
--------------------------------------------------------------------------------
1 | import * as path from 'path';
2 | import { webpackBundler } from '@vuepress/bundler-webpack';
3 | import { defineUserConfig } from '@vuepress/cli';
4 | import WriteTheme from './vuepress-theme-writing/src/node/index';
5 |
6 | export default defineUserConfig({
7 | title: '前端技术分享',
8 | description:
9 | '欢迎来到周立翔的小窝,这里记录我个人学习过程中的感悟和小结,与诸君共勉',
10 | theme: WriteTheme({
11 | logo: '/images/logo.png',
12 | repo: 'zh-lx/blog',
13 | sidebarDepth: 6,
14 | }),
15 | alias: {
16 | HomeFooter: path.resolve(__dirname, './home-footer/index.vue'),
17 | },
18 | bundler: webpackBundler({}),
19 | define: {
20 | $Site: {
21 | title: '周立翔的小窝',
22 | description:
23 | '欢迎来到周立翔的小窝,这里记录我个人学习过程中的感悟和小结,与诸君共勉',
24 | // type: 'docs',
25 | },
26 | $Author: {
27 | name: '周立翔',
28 | avatar: '/images/avatar.jpg',
29 | introduction: 'a geek developer',
30 | },
31 | $Contact: {
32 | juejin: 'https://juejin.cn/user/650530414137534',
33 | github: 'https://github.com/zh-lx',
34 | qq: '1134558955',
35 | wechat: 'zhoulx1688888',
36 | // email: '1134558955@qq.com',
37 | // csdn: '',
38 | // zhihu: 'https://www.zhihu.com/people/zhou-li-xiang-66-91',
39 | },
40 | },
41 | });
42 |
--------------------------------------------------------------------------------