 11 |
12 | ## Golang 📝
13 | ### 面试题
14 |
15 | 1. [Go 面试题: new 和 make 是什么,差异在哪?](https://mp.weixin.qq.com/s/tZg3zmESlLmefAWdTR96Tg)
16 | 2. [Go 群友提问:Goroutine 数量控制在多少合适,会影响 GC 和调度?](https://mp.weixin.qq.com/s/uWP2X6iFu7BtwjIv5H55vw)
17 | 3. [Go 群友提问:学习 defer 时很懵逼,这道不会做!](https://mp.weixin.qq.com/s/lELMqKho003h0gfKkZxhHQ)
18 | 4. [Go 面试题:Go interface 的一个 “坑” 及原理分析](https://mp.weixin.qq.com/s/vNACbdSDxC9S0LOAr7ngLQ)
19 | 5. [Go 群友提问:进程、线程都有 ID,为什么 Goroutine 没有 ID?](https://mp.weixin.qq.com/s/qFAtgpbAsHSPVLuo3PYIhg)
20 | 6. [ Go 面试题:GMP 模型,为什么要有 P?](https://mp.weixin.qq.com/s/an7dml9NLOhqOZjEGLdEEw)
21 | 7. [Go 面试题:Go 结构体是否可以比较,为什么?](https://mp.weixin.qq.com/s/HScH6nm3xf4POXVk774jUA)
22 | 8. [Go 面试题:单核 CPU,开两个 Goroutine,其中一个死循环,会怎么样?](https://mp.weixin.qq.com/s/h27GXmfGYVLHRG3Mu_8axw)
23 | 9. [Go 群友提问:你知道 Go 结构体和结构体指针调用有什么区别吗?](https://mp.weixin.qq.com/s/g-D_eVh-8JaIoRne09bJ3Q)
24 | 10. [跟读者聊 Goroutine 泄露的 N 种方法](https://mp.weixin.qq.com/s/ql01K1nOnEZpdbp--6EDYw)
25 | 11. [详解 Go 程序的启动流程,你知道 g0,m0 是什么吗?](https://mp.weixin.qq.com/s/YK-TD3bZGEgqC0j-8U6VkQ)
26 | 12. [用 Go struct 不能犯的一个低级错误!](https://mp.weixin.qq.com/s/K5B2ItkzOb4eCFLxZI5Wvw)
27 | 13. [嗯,你觉得 Go 在什么时候会抢占 P?](https://mp.weixin.qq.com/s/WAPogwLJ2BZvrquoKTQXzg)
28 | 14. [Go 面试官:什么是协程,协程和线程的区别和联系?](https://mp.weixin.qq.com/s/vW5n_JWa3I-Qopbx4TmIgQ)
29 | 15. [用 Go map 要注意这 1 个细节,避免依赖他!](https://mp.weixin.qq.com/s/MzAktbjNyZD0xRVTPRKHpw)
30 | 16. [为什么 Go map 和 slice 是非线性安全的?](https://mp.weixin.qq.com/s/TzHvDdtfp0FZ9y1ndqeCRw)
31 | 17. [一口气搞懂 Go sync.map 所有知识点](https://mp.weixin.qq.com/s/8aufz1IzElaYR43ccuwMyA)
32 | 18. [Go 面试官问我如何实现面向对象?](https://mp.weixin.qq.com/s/2x4Sajv7HkAjWFPe4oD96g)
33 | 19. [Go 是传值还是传引用?](https://mp.weixin.qq.com/s/qsxvfiyZfRCtgTymO9LBZQ)
34 | 20. [回答我,停止 Goroutine 有几种方法?](https://mp.weixin.qq.com/s/tN8Q1GRmphZyAuaHrkYFEg)
35 |
36 | ### 深度解析
37 |
38 | 1. [Go语言深度解析之slice](golang/deep/slice.md)
39 | 2. [Go语言深度解析之map](golang/deep/map.md)
40 | 3. [Go语言深度解析之channel](golang/deep/channel.md)
41 | 4. [Go语言深度解析之context](golang/deep/context.md)
42 | 5. [Go语言深度解析之unsafe](golang/deep/unsafe.md)
43 | 6. [Go语言深度解析之interface](golang/deep/interface.md)
44 | 7. [Go语言深度解析之reflect](golang/deep/reflect.md)
45 | 8. [Go语言深度解析之内存分配](golang/deep/memory_distribution.md)
46 | 9. [Go语言深度解析之垃圾回收机制](golang/deep/gc.md)
47 | 10. [Go语言深度解析之GPM调度器](golang/deep/gmp.md)
48 |
49 |
50 | ## 计算机基础 💻
51 | ### 操作系统
52 |
53 | - [图解操作系统](cs-basics/operating-system/os.pdf)
54 |
55 | ### 网络
56 |
57 | - [图解计算机网络](cs-basics/network/network.pdf)
58 |
59 | ### 算法 ⌛️
60 |
61 | - [《剑指offer》](https://leetcode-cn.com/study-plan/lcof/)
62 | - 常见共识算法
63 | - [Raft协议](cs-basics/consensus/raft.md)
64 | - [PBFT协议](cs-basics/consensus/pbft.md)
65 | - [Gossip协议](cs-basics/consensus/gossip.md)
66 |
67 | ## 数据库 💾
68 | ### MySQL
69 |
70 | - [MySQL基础](database/mysql/base.md)
71 | - [图解MySQL](https://www.xiaolincoding.com/mysql/)
72 |
73 | ### Redis
74 |
75 | - [Redis基础](middleware/redis/base.md)
76 | - [图解Redis](https://www.xiaolincoding.com/redis/)
77 |
78 | ## 开发框架 🔲
79 | ### Gin
80 |
81 | - [Go Gin 系列一:Go 介绍与环境安装](https://mp.weixin.qq.coam/s?__biz=MzUxMDI4MDc1NA==&mid=2247483714&idx=1&sn=0b536199884cb45a1316c77998895baf&chksm=f904141fce739d0978e02147507dc29fadee2e19ac312d34a3190062ae40e62a490fc58df6ae&scene=178&cur_album_id=1383459655464337409#rd)
82 | - [Go Gin 系列二:初始化项目及公共库](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=1&sn=9c7aede4f675f2de49ddc08ab1a95a71&chksm=f90414c2ce739dd4b8711c0043286fba9744b8d9c86c75c7ac7750d28cd2fed43f749eb5de99&scene=178&cur_album_id=1383459655464337409#rd)
83 | - [Go Gin 系列三:开发标签模块](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=2&sn=513f8e5620db9cc37fea62fe6ff69796&chksm=f90414c2ce739dd4ccc217360b50618c085ec2327e4149dfbc1d136566ef6543dadd80b1e20e&scene=178&cur_album_id=1383459655464337409#rd)
84 | - [Go Gin 系列四:开发文章模块](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=3&sn=d24c23a03579f9ab662826c15174e3f4&chksm=f90414c2ce739dd42a4829099cc1229b51f4770d887f55a5995c584d0015d32fc8b9fe16d751&scene=178&cur_album_id=1383459655464337409#rd)
85 | - [Go Gin 系列五:使用 JWT 进行身份校验](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=4&sn=fae0d5ec098860038bb4de5c45d5d624&chksm=f90414c2ce739dd4b6fb2356afef5304057a49cbf527951000da107456ad07e87d1e69b32370&scene=178&cur_album_id=1383459655464337409#rd)
86 | - [Go Gin 系列六:编写一个简单的文件日志](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=5&sn=dbfc85b5a612a364f323de4703ae98ec&chksm=f90414c2ce739dd484a2c0583c424e59104809da9304ad8d23a85d9b4ff42f3e7d7f146d3930&scene=178&cur_album_id=1383459655464337409#rd)
87 | - [Go Gin 系列七:优雅的重启服务](https://github.com/gravityblast/fresh)
88 | - [Go Gin 系列八:为它加上Swagger](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=7&sn=b73f0fd0ee14cdb43bc28ab6cb7c5644&chksm=f90414c2ce739dd43173eaec770dba45e04417a0849b676a0fa12af8e45a3db69e19eab3ab04&scene=178&cur_album_id=1383459655464337409#rd)
89 | - [Go Gin 系列九:将Golang应用部署到Docker](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=8&sn=b2827c18847397e6d1d37bfe49b2065f&chksm=f90414c2ce739dd4061203ea791b35846a3ecb0aa40680783676fb3e4a39115bda9abe14fbf0&scene=178&cur_album_id=1383459655464337409#rd)
90 | - [Go Gin 系列十:定制 GORM Callbacks](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=1&sn=90a68030b7d3f40b5ccfb9f91ce571d7&chksm=f90414f6ce739de092938728fe189e8d7b490aecaa19dddaa2c1c43eab971df29df0c37aa04a&scene=178&cur_album_id=1383459655464337409#rd)
91 | - [Go Gin 系列十一:Cron定时任务](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=2&sn=a85e39912a709d22dc3529ea9bdc3322&chksm=f90414f6ce739de02d20484b3368476a4ecf19c0b1e38f8e263703432af3c1776365d096c12e&scene=178&cur_album_id=1383459655464337409#rd)
92 | - [Go Gin 系列十二:优化配置结构及实现图片上传](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=3&sn=e76373b6bd530a552f08472d4987854e&chksm=f90414f6ce739de07dc82412e9c7e684a5058921253d1541b58e6ae205301be2fe782df9d6d6&scene=178&cur_album_id=1383459655464337409#rd)
93 | - [Go Gin 系列十三:优化应用结构和实现Redis缓存](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=4&sn=e6f85aa6196688198f3514e1efbbbeca&chksm=f90414f6ce739de0570a358c84023373a4021ed9e74bbaf7eec7c931e61a2c6c292bacae399d&scene=178&cur_album_id=1383459655464337409#rd)
94 | - [Go Gin 系列十四:实现导出、导入 Excel](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=5&sn=780affae40072df28ae6f6e4e226fdd8&chksm=f90414f6ce739de08b373523ea53b11575c64fd2db8ee04ee9237b9d24c93c8f6a0153918afd&scene=178&cur_album_id=1383459655464337409#rd)
95 | - [Go Gin 系列十五:生成二维码、合并海报](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=6&sn=57f8d9031249f61d039477b11d62612f&chksm=f90414f6ce739de0e0c36a5ad3784e2ebd82e7a8941805d162dbd660e54fe169cd87573b7f34&scene=178&cur_album_id=1383459655464337409#rd)
96 | - [Go Gin 系列十六:在图片上绘制文字](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=7&sn=1929b2cf09de3ec6222281def551a901&chksm=f90414f6ce739de04400958b1f4aebbd331715914b03efad26204ac8ba284d59d89f3af86099&scene=178&cur_album_id=1383459655464337409#rd)
97 | - [Go Gin 系列十七:用Nginx部署Go应用](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=8&sn=c64f86744121ba7f4c2f7b8539de8b7d&chksm=f90414f6ce739de012bbdef88a31e18332a21ea24ba773ef676d5d1ba7e3ab7ebed941aca5c1&scene=178&cur_album_id=1383459655464337409#rd)
98 |
99 | ## 中间件 ✉️
100 | ### Kafka
101 | - ...
102 |
103 | ### ElasticSearch
104 | - ...
105 |
106 | ## 微服务 🎰
107 | ### gRPC
108 |
109 | - [gRPC及相关介绍](https://mp.weixin.qq.com/s/bbHqWqtmk_k3-X_1XEDEJw)
110 | - [gRPC Client and Server](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483721&idx=2&sn=5fab143b3cd50209fafc658aaba7c0e9&chksm=f9041414ce739d023611ac6ff38dbfe81d48591ab24ba37eefb3fe6cb121e89dd46fa2fbb1a9&cur_album_id=1383472721040064512&scene=189#rd)
111 | - [gRPC Streaming, Client and Server](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483721&idx=3&sn=b61db0379afd96e0149c279564d8efea&chksm=f9041414ce739d02c1554318a6e86942a0450266f27360913882860f24bc59268d315142f79b&cur_album_id=1383472721040064512&scene=189#rd)
112 | - [gRPC TLS 证书认证](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483719&idx=1&sn=34b3a6a6fd63106a4c369b3a0eaef330&chksm=f904141ace739d0cc5ecd1f40ed03688934a380fd5006ffd10947e45638277b0fcd197ab7ff8&scene=178&cur_album_id=1383472721040064512#rd)
113 | - [gRPC 基于 CA 的 TLS 证书认证](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483719&idx=2&sn=e8208b347f8a38c98fd4f5986bd0df4a&chksm=f904141ace739d0c7106280b5332832353cd1022204089ab46bab6c5b95c8687f34c13a755b3&scene=178&cur_album_id=1383472721040064512#rd)
114 | - [gRPC Unary and Stream interceptor](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483718&idx=1&sn=ae0f6ea8111e7e9aeb152a247a333e68&chksm=f904141bce739d0dac96d1e3276fa141069681740a95c390b7c965f4381a14934075aa01d1c3&cur_album_id=1383472721040064512&scene=189#rd)
115 | - [让你的服务同时提供 HTTP 接口](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483718&idx=2&sn=0e592098eb5c1a837db12387fafe5f9c&chksm=f904141bce739d0d98ec188879258dd81c750a0404ba1a38b0c08610e3318b71fe65025e573c&cur_album_id=1383472721040064512&scene=189#rd)
116 | - [gRPC 对 RPC 方法做自定义认证](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483716&idx=1&sn=2b173c55cbe242cafda64a042b30669e&chksm=f9041419ce739d0fb6d4b210dd70962d96a72b1290d5138246c4b236b14ff1a57798f01969ae&cur_album_id=1383472721040064512&scene=189#rd)
117 | - [gRPC 超时控制](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483716&idx=2&sn=60a9d2e9c6a91c369aba0293e8bdb95b&chksm=f9041419ce739d0f0070b5e7bebeb112cd48ea86dbf9e36ad91ffe7943a944d85cf487ef0fb2&cur_album_id=1383472721040064512&scene=189#rd)
118 | - [gRPC + Zipkin 分布式链路追踪](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483716&idx=3&sn=71c2f616b4bed0af7a6a914e1ee2c1df&chksm=f9041419ce739d0fc3839eaffa7d7075f3be8cda92df241bd3e0e961d7a93b9eafdbf33d2335&cur_album_id=1383472721040064512&scene=189#rd)
119 | - [总结:万字长文 | 从实践到原理,带你参透 gRPC](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247484984&idx=1&sn=392e258f24aec08f58c84ccaba96b2ae&chksm=f9041365ce739a73054b01edcf31fdf3590fb403b1b48aa7dbeccc74c568e5b0e8a4e838c65e&scene=178&cur_album_id=1383472721040064512#rd)
120 |
121 | ### ...
122 |
123 | ## 系统设计 🔬
124 | ### 安全
125 | #### 认证授权
126 |
127 | - [认证授权基础概念详解](system-design/security/basis-of-authority-certification.md)
128 | - [JWT基础概念详解及使用](system-design/security/jwt-intro.md)
129 | - [JWT优缺点分析以及常见问题解决方案](system-design/security/advantages%26disadvantages-of-jwt.md)
130 | - [SSO单点登录详解](system-design/security/sso-intro.md)
131 | - [Casbin访问控制详解及使用](system-design/security/casbin-intro.md)
132 |
133 | ## 开发工具 🔧
134 | ### git
135 |
136 | - [git入门](tools/git-intro.md)
137 | ### Docker
138 |
139 | - [docker介绍](tools/docker/docker.md)
140 | - [docker-compose介绍](tools/docker/docker-compose.md)
141 |
142 | ### Kubernetes
143 | - ...
144 |
145 | ### Golang常用第三方库
146 |
147 | - [常用第三方库](golang/useful_package.md)
148 |
149 |
150 |
151 |
--------------------------------------------------------------------------------
/cs-basics/consensus/gossip.md:
--------------------------------------------------------------------------------
1 | # Gossip协议详解
2 |
3 | ## 一.概述
4 |
5 | Gossip 协议适用于去中心化、容忍时延、读多写少的分布式集群场景。Gossip 过程由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
6 |
7 | Gossip 协议是为了解决分布式环境下监控和事件通知的瓶颈。Gossip 协议中的每个 Agent 会利用 Gossip 协议互相检查在线状态,分担了服务器节点的心跳压力,通过 Gossip 广播的方式发送消息。
8 |
9 | Gossip 协议的最大的好处在于即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许 Consul 管理的集群规模能横向扩展到数千个节点
10 |
11 | ## 二.Gossip 的特点
12 |
13 | 1. **扩展性**:网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
14 | 2. **容错**:网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。
15 | 3. **去中心化**:Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
16 | 4. **一致性收敛**:Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。
17 | 5. **简单**:Gossip 协议的过程极其简单,实现起来几乎没有太多复杂性。
18 |
19 |
20 |
21 | ## 三.Gossip 中的通信模式
22 |
23 | Gossip 协议中的两个节点(A、B)之间存在三种通信方式:
24 |
25 | - Push(A 最新): A 将数据 (key,value,version) 及对应的版本号 Push 给 B,B 更新本地数据。
26 | - Pull(B 最新):A 仅将数据 key, version 推送给 B,B 将本地比 A 新的数据(key, value, version)Push back 给 A,A 更新本地。
27 | - Push/Pull(A/B 一样新):比 Pull 多一步,A 更新本地后,再将数据 Push back B,B更新本地。
28 |
29 | 如果把两个节点数据同步一次定义为一个周期,则在一个周期内,Push 需通信 1 次,Pull 需 2 次,Push/Pull 则需 3 次。虽然消息数增加了,但从效果上来讲,Push/Pull 最好,理论上一个周期内可以使两个节点完全一致。
30 |
31 |
32 |
33 | ## 四.Gossip 的缺点
34 |
35 | - 消息延迟:由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下。
36 | - 消息冗余:Gossip 协议规定,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力。而且,由于是定期发送,因此,即使收到了消息的节点还会反复收到重复消息,加重了消息的冗余。
--------------------------------------------------------------------------------
/cs-basics/consensus/pbft.md:
--------------------------------------------------------------------------------
1 | # PBFT实用拜占庭容错
2 |
3 | ## 一.概述
4 |
5 | 拜占庭将军问题最早是由 Leslie Lamport 在 1982 年发表的论文**《The Byzantine Generals Problem 》**提出的, 他证明了在将军总数大于 3f ,背叛者为f 或者更少时,忠诚的将军可以达成命令上的一致,即 3f+1<=n 。算法复杂度为 O(nf+1) 。而 Miguel Castro 和 Barbara Liskov 在1999年发表的论文**《 Practical Byzantine Fault Tolerance 》**中首次提出 PBFT算法,该算法容错数量也满足 `3f+1<=n`,也即最大的容错作恶节点数`f=(n-1)/3`。算法复杂度为 O(n2),将系统的复杂度由指数级别降低为多项式级别,使得拜占庭容错算法在实际系统应用中变得可行。
6 |
7 | **那么为什么PBFT算法的容错数量满足3f+1<=n呢?**
8 |
9 | 因为 PBFT 算法的除了需要支持容错故障节点之外,还需要支持**容错作恶节点**。假设集群节点数为 N,有问题的节点为 f。有问题的节点中,可以既是故障节点,也可以是作恶节点,或者只是故障节点或者只是作恶节点。那么会产生以下两种极端情况:
10 |
11 | 1. 这f 个有问题节点既是故障节点,又是作恶节点,那么根据少数服从多数的原则,集群里正常节点只需要比f个节点再多一个节点,即 f+1 个节点,确节点的数量就会比故障节点数量多,那么集群就能达成共识,即总节点数为f+(f+1)=n,也就是说这种情况支持的最大容错节点数量是 (n-1)/2。
12 | 2. 故障节点和作恶节点都是不同的节点。那么就会有 f 个作恶节点和 f 个故障节点,当发现节点是作恶节点后,会被集群排除在外,剩下 f 个故障节点,那么根据少数服从多数的原则,集群里正常节点只需要比f个节点再多一个节点,即 f+1 个节点,确节点的数量就会比故障节点数量多,那么集群就能达成共识。所以,所有类型的节点数量加起来就是 f+1 个正常节点,f个故障节点和f个作恶节点,即 3f+1=n。
13 |
14 | 结合上述两种情况,因此PBFT算法支持的最大容错节点数量是(n-1)/3。
15 |
16 | ## 二.PBFT共识算法流程
17 |
18 | **角色划分**
19 |
20 | - **Client:**客户端节点,负责发送交易请求。
21 |
22 | - **Primary**: 主节点,负责将交易打包成区块和区块共识,每轮共识过程中有且仅有一个Primary节点。
23 |
24 | - **Replica**: 副本节点,负责区块共识,每轮共识过程中有多个Replica节点,每个Replica节点的处理过程类似。
25 |
26 | 其中,Primary和Replica节点都属于共识节点。
27 |
28 | **算法流程**
29 |
30 | PBFT 算法的基本流程主要有以下四步:
31 |
32 | 1. 客户端发送请求给主节点
33 | 2. 主节点广播请求给其它节点,节点执行PBFT算法的**三阶段共识流程**。
34 | 3. 节点处理完三阶段流程后,返回消息给客户端。
35 | 4. 客户端收到来自 f+1 个节点的相同消息后,代表共识已经正确完成。
36 |
37 | 
38 |
39 | 算法的核心三个阶段分别是 `pre-prepare` 阶段(预准备阶段),`prepare` 阶段(准备阶段), `commit` 阶段(提交阶段)。图中的C代表客户端,0,1,2,3 代表节点的编号,其中0 是主节点primary,打×的3代表可能是故障节点或者是作恶节点,这里表现的行为就是对其它节点的请求无响应。整个过程大致是如下:
40 |
41 | 首先,客户端向主节点0发起请求`<
11 |
12 | ## Golang 📝
13 | ### 面试题
14 |
15 | 1. [Go 面试题: new 和 make 是什么,差异在哪?](https://mp.weixin.qq.com/s/tZg3zmESlLmefAWdTR96Tg)
16 | 2. [Go 群友提问:Goroutine 数量控制在多少合适,会影响 GC 和调度?](https://mp.weixin.qq.com/s/uWP2X6iFu7BtwjIv5H55vw)
17 | 3. [Go 群友提问:学习 defer 时很懵逼,这道不会做!](https://mp.weixin.qq.com/s/lELMqKho003h0gfKkZxhHQ)
18 | 4. [Go 面试题:Go interface 的一个 “坑” 及原理分析](https://mp.weixin.qq.com/s/vNACbdSDxC9S0LOAr7ngLQ)
19 | 5. [Go 群友提问:进程、线程都有 ID,为什么 Goroutine 没有 ID?](https://mp.weixin.qq.com/s/qFAtgpbAsHSPVLuo3PYIhg)
20 | 6. [ Go 面试题:GMP 模型,为什么要有 P?](https://mp.weixin.qq.com/s/an7dml9NLOhqOZjEGLdEEw)
21 | 7. [Go 面试题:Go 结构体是否可以比较,为什么?](https://mp.weixin.qq.com/s/HScH6nm3xf4POXVk774jUA)
22 | 8. [Go 面试题:单核 CPU,开两个 Goroutine,其中一个死循环,会怎么样?](https://mp.weixin.qq.com/s/h27GXmfGYVLHRG3Mu_8axw)
23 | 9. [Go 群友提问:你知道 Go 结构体和结构体指针调用有什么区别吗?](https://mp.weixin.qq.com/s/g-D_eVh-8JaIoRne09bJ3Q)
24 | 10. [跟读者聊 Goroutine 泄露的 N 种方法](https://mp.weixin.qq.com/s/ql01K1nOnEZpdbp--6EDYw)
25 | 11. [详解 Go 程序的启动流程,你知道 g0,m0 是什么吗?](https://mp.weixin.qq.com/s/YK-TD3bZGEgqC0j-8U6VkQ)
26 | 12. [用 Go struct 不能犯的一个低级错误!](https://mp.weixin.qq.com/s/K5B2ItkzOb4eCFLxZI5Wvw)
27 | 13. [嗯,你觉得 Go 在什么时候会抢占 P?](https://mp.weixin.qq.com/s/WAPogwLJ2BZvrquoKTQXzg)
28 | 14. [Go 面试官:什么是协程,协程和线程的区别和联系?](https://mp.weixin.qq.com/s/vW5n_JWa3I-Qopbx4TmIgQ)
29 | 15. [用 Go map 要注意这 1 个细节,避免依赖他!](https://mp.weixin.qq.com/s/MzAktbjNyZD0xRVTPRKHpw)
30 | 16. [为什么 Go map 和 slice 是非线性安全的?](https://mp.weixin.qq.com/s/TzHvDdtfp0FZ9y1ndqeCRw)
31 | 17. [一口气搞懂 Go sync.map 所有知识点](https://mp.weixin.qq.com/s/8aufz1IzElaYR43ccuwMyA)
32 | 18. [Go 面试官问我如何实现面向对象?](https://mp.weixin.qq.com/s/2x4Sajv7HkAjWFPe4oD96g)
33 | 19. [Go 是传值还是传引用?](https://mp.weixin.qq.com/s/qsxvfiyZfRCtgTymO9LBZQ)
34 | 20. [回答我,停止 Goroutine 有几种方法?](https://mp.weixin.qq.com/s/tN8Q1GRmphZyAuaHrkYFEg)
35 |
36 | ### 深度解析
37 |
38 | 1. [Go语言深度解析之slice](golang/deep/slice.md)
39 | 2. [Go语言深度解析之map](golang/deep/map.md)
40 | 3. [Go语言深度解析之channel](golang/deep/channel.md)
41 | 4. [Go语言深度解析之context](golang/deep/context.md)
42 | 5. [Go语言深度解析之unsafe](golang/deep/unsafe.md)
43 | 6. [Go语言深度解析之interface](golang/deep/interface.md)
44 | 7. [Go语言深度解析之reflect](golang/deep/reflect.md)
45 | 8. [Go语言深度解析之内存分配](golang/deep/memory_distribution.md)
46 | 9. [Go语言深度解析之垃圾回收机制](golang/deep/gc.md)
47 | 10. [Go语言深度解析之GPM调度器](golang/deep/gmp.md)
48 |
49 |
50 | ## 计算机基础 💻
51 | ### 操作系统
52 |
53 | - [图解操作系统](cs-basics/operating-system/os.pdf)
54 |
55 | ### 网络
56 |
57 | - [图解计算机网络](cs-basics/network/network.pdf)
58 |
59 | ### 算法 ⌛️
60 |
61 | - [《剑指offer》](https://leetcode-cn.com/study-plan/lcof/)
62 | - 常见共识算法
63 | - [Raft协议](cs-basics/consensus/raft.md)
64 | - [PBFT协议](cs-basics/consensus/pbft.md)
65 | - [Gossip协议](cs-basics/consensus/gossip.md)
66 |
67 | ## 数据库 💾
68 | ### MySQL
69 |
70 | - [MySQL基础](database/mysql/base.md)
71 | - [图解MySQL](https://www.xiaolincoding.com/mysql/)
72 |
73 | ### Redis
74 |
75 | - [Redis基础](middleware/redis/base.md)
76 | - [图解Redis](https://www.xiaolincoding.com/redis/)
77 |
78 | ## 开发框架 🔲
79 | ### Gin
80 |
81 | - [Go Gin 系列一:Go 介绍与环境安装](https://mp.weixin.qq.coam/s?__biz=MzUxMDI4MDc1NA==&mid=2247483714&idx=1&sn=0b536199884cb45a1316c77998895baf&chksm=f904141fce739d0978e02147507dc29fadee2e19ac312d34a3190062ae40e62a490fc58df6ae&scene=178&cur_album_id=1383459655464337409#rd)
82 | - [Go Gin 系列二:初始化项目及公共库](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=1&sn=9c7aede4f675f2de49ddc08ab1a95a71&chksm=f90414c2ce739dd4b8711c0043286fba9744b8d9c86c75c7ac7750d28cd2fed43f749eb5de99&scene=178&cur_album_id=1383459655464337409#rd)
83 | - [Go Gin 系列三:开发标签模块](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=2&sn=513f8e5620db9cc37fea62fe6ff69796&chksm=f90414c2ce739dd4ccc217360b50618c085ec2327e4149dfbc1d136566ef6543dadd80b1e20e&scene=178&cur_album_id=1383459655464337409#rd)
84 | - [Go Gin 系列四:开发文章模块](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=3&sn=d24c23a03579f9ab662826c15174e3f4&chksm=f90414c2ce739dd42a4829099cc1229b51f4770d887f55a5995c584d0015d32fc8b9fe16d751&scene=178&cur_album_id=1383459655464337409#rd)
85 | - [Go Gin 系列五:使用 JWT 进行身份校验](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=4&sn=fae0d5ec098860038bb4de5c45d5d624&chksm=f90414c2ce739dd4b6fb2356afef5304057a49cbf527951000da107456ad07e87d1e69b32370&scene=178&cur_album_id=1383459655464337409#rd)
86 | - [Go Gin 系列六:编写一个简单的文件日志](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=5&sn=dbfc85b5a612a364f323de4703ae98ec&chksm=f90414c2ce739dd484a2c0583c424e59104809da9304ad8d23a85d9b4ff42f3e7d7f146d3930&scene=178&cur_album_id=1383459655464337409#rd)
87 | - [Go Gin 系列七:优雅的重启服务](https://github.com/gravityblast/fresh)
88 | - [Go Gin 系列八:为它加上Swagger](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=7&sn=b73f0fd0ee14cdb43bc28ab6cb7c5644&chksm=f90414c2ce739dd43173eaec770dba45e04417a0849b676a0fa12af8e45a3db69e19eab3ab04&scene=178&cur_album_id=1383459655464337409#rd)
89 | - [Go Gin 系列九:将Golang应用部署到Docker](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483807&idx=8&sn=b2827c18847397e6d1d37bfe49b2065f&chksm=f90414c2ce739dd4061203ea791b35846a3ecb0aa40680783676fb3e4a39115bda9abe14fbf0&scene=178&cur_album_id=1383459655464337409#rd)
90 | - [Go Gin 系列十:定制 GORM Callbacks](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=1&sn=90a68030b7d3f40b5ccfb9f91ce571d7&chksm=f90414f6ce739de092938728fe189e8d7b490aecaa19dddaa2c1c43eab971df29df0c37aa04a&scene=178&cur_album_id=1383459655464337409#rd)
91 | - [Go Gin 系列十一:Cron定时任务](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=2&sn=a85e39912a709d22dc3529ea9bdc3322&chksm=f90414f6ce739de02d20484b3368476a4ecf19c0b1e38f8e263703432af3c1776365d096c12e&scene=178&cur_album_id=1383459655464337409#rd)
92 | - [Go Gin 系列十二:优化配置结构及实现图片上传](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=3&sn=e76373b6bd530a552f08472d4987854e&chksm=f90414f6ce739de07dc82412e9c7e684a5058921253d1541b58e6ae205301be2fe782df9d6d6&scene=178&cur_album_id=1383459655464337409#rd)
93 | - [Go Gin 系列十三:优化应用结构和实现Redis缓存](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=4&sn=e6f85aa6196688198f3514e1efbbbeca&chksm=f90414f6ce739de0570a358c84023373a4021ed9e74bbaf7eec7c931e61a2c6c292bacae399d&scene=178&cur_album_id=1383459655464337409#rd)
94 | - [Go Gin 系列十四:实现导出、导入 Excel](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=5&sn=780affae40072df28ae6f6e4e226fdd8&chksm=f90414f6ce739de08b373523ea53b11575c64fd2db8ee04ee9237b9d24c93c8f6a0153918afd&scene=178&cur_album_id=1383459655464337409#rd)
95 | - [Go Gin 系列十五:生成二维码、合并海报](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=6&sn=57f8d9031249f61d039477b11d62612f&chksm=f90414f6ce739de0e0c36a5ad3784e2ebd82e7a8941805d162dbd660e54fe169cd87573b7f34&scene=178&cur_album_id=1383459655464337409#rd)
96 | - [Go Gin 系列十六:在图片上绘制文字](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=7&sn=1929b2cf09de3ec6222281def551a901&chksm=f90414f6ce739de04400958b1f4aebbd331715914b03efad26204ac8ba284d59d89f3af86099&scene=178&cur_album_id=1383459655464337409#rd)
97 | - [Go Gin 系列十七:用Nginx部署Go应用](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483819&idx=8&sn=c64f86744121ba7f4c2f7b8539de8b7d&chksm=f90414f6ce739de012bbdef88a31e18332a21ea24ba773ef676d5d1ba7e3ab7ebed941aca5c1&scene=178&cur_album_id=1383459655464337409#rd)
98 |
99 | ## 中间件 ✉️
100 | ### Kafka
101 | - ...
102 |
103 | ### ElasticSearch
104 | - ...
105 |
106 | ## 微服务 🎰
107 | ### gRPC
108 |
109 | - [gRPC及相关介绍](https://mp.weixin.qq.com/s/bbHqWqtmk_k3-X_1XEDEJw)
110 | - [gRPC Client and Server](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483721&idx=2&sn=5fab143b3cd50209fafc658aaba7c0e9&chksm=f9041414ce739d023611ac6ff38dbfe81d48591ab24ba37eefb3fe6cb121e89dd46fa2fbb1a9&cur_album_id=1383472721040064512&scene=189#rd)
111 | - [gRPC Streaming, Client and Server](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483721&idx=3&sn=b61db0379afd96e0149c279564d8efea&chksm=f9041414ce739d02c1554318a6e86942a0450266f27360913882860f24bc59268d315142f79b&cur_album_id=1383472721040064512&scene=189#rd)
112 | - [gRPC TLS 证书认证](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483719&idx=1&sn=34b3a6a6fd63106a4c369b3a0eaef330&chksm=f904141ace739d0cc5ecd1f40ed03688934a380fd5006ffd10947e45638277b0fcd197ab7ff8&scene=178&cur_album_id=1383472721040064512#rd)
113 | - [gRPC 基于 CA 的 TLS 证书认证](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483719&idx=2&sn=e8208b347f8a38c98fd4f5986bd0df4a&chksm=f904141ace739d0c7106280b5332832353cd1022204089ab46bab6c5b95c8687f34c13a755b3&scene=178&cur_album_id=1383472721040064512#rd)
114 | - [gRPC Unary and Stream interceptor](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483718&idx=1&sn=ae0f6ea8111e7e9aeb152a247a333e68&chksm=f904141bce739d0dac96d1e3276fa141069681740a95c390b7c965f4381a14934075aa01d1c3&cur_album_id=1383472721040064512&scene=189#rd)
115 | - [让你的服务同时提供 HTTP 接口](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483718&idx=2&sn=0e592098eb5c1a837db12387fafe5f9c&chksm=f904141bce739d0d98ec188879258dd81c750a0404ba1a38b0c08610e3318b71fe65025e573c&cur_album_id=1383472721040064512&scene=189#rd)
116 | - [gRPC 对 RPC 方法做自定义认证](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483716&idx=1&sn=2b173c55cbe242cafda64a042b30669e&chksm=f9041419ce739d0fb6d4b210dd70962d96a72b1290d5138246c4b236b14ff1a57798f01969ae&cur_album_id=1383472721040064512&scene=189#rd)
117 | - [gRPC 超时控制](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483716&idx=2&sn=60a9d2e9c6a91c369aba0293e8bdb95b&chksm=f9041419ce739d0f0070b5e7bebeb112cd48ea86dbf9e36ad91ffe7943a944d85cf487ef0fb2&cur_album_id=1383472721040064512&scene=189#rd)
118 | - [gRPC + Zipkin 分布式链路追踪](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247483716&idx=3&sn=71c2f616b4bed0af7a6a914e1ee2c1df&chksm=f9041419ce739d0fc3839eaffa7d7075f3be8cda92df241bd3e0e961d7a93b9eafdbf33d2335&cur_album_id=1383472721040064512&scene=189#rd)
119 | - [总结:万字长文 | 从实践到原理,带你参透 gRPC](https://mp.weixin.qq.com/s?__biz=MzUxMDI4MDc1NA==&mid=2247484984&idx=1&sn=392e258f24aec08f58c84ccaba96b2ae&chksm=f9041365ce739a73054b01edcf31fdf3590fb403b1b48aa7dbeccc74c568e5b0e8a4e838c65e&scene=178&cur_album_id=1383472721040064512#rd)
120 |
121 | ### ...
122 |
123 | ## 系统设计 🔬
124 | ### 安全
125 | #### 认证授权
126 |
127 | - [认证授权基础概念详解](system-design/security/basis-of-authority-certification.md)
128 | - [JWT基础概念详解及使用](system-design/security/jwt-intro.md)
129 | - [JWT优缺点分析以及常见问题解决方案](system-design/security/advantages%26disadvantages-of-jwt.md)
130 | - [SSO单点登录详解](system-design/security/sso-intro.md)
131 | - [Casbin访问控制详解及使用](system-design/security/casbin-intro.md)
132 |
133 | ## 开发工具 🔧
134 | ### git
135 |
136 | - [git入门](tools/git-intro.md)
137 | ### Docker
138 |
139 | - [docker介绍](tools/docker/docker.md)
140 | - [docker-compose介绍](tools/docker/docker-compose.md)
141 |
142 | ### Kubernetes
143 | - ...
144 |
145 | ### Golang常用第三方库
146 |
147 | - [常用第三方库](golang/useful_package.md)
148 |
149 |
150 |
151 |
--------------------------------------------------------------------------------
/cs-basics/consensus/gossip.md:
--------------------------------------------------------------------------------
1 | # Gossip协议详解
2 |
3 | ## 一.概述
4 |
5 | Gossip 协议适用于去中心化、容忍时延、读多写少的分布式集群场景。Gossip 过程由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
6 |
7 | Gossip 协议是为了解决分布式环境下监控和事件通知的瓶颈。Gossip 协议中的每个 Agent 会利用 Gossip 协议互相检查在线状态,分担了服务器节点的心跳压力,通过 Gossip 广播的方式发送消息。
8 |
9 | Gossip 协议的最大的好处在于即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许 Consul 管理的集群规模能横向扩展到数千个节点
10 |
11 | ## 二.Gossip 的特点
12 |
13 | 1. **扩展性**:网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
14 | 2. **容错**:网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。
15 | 3. **去中心化**:Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
16 | 4. **一致性收敛**:Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。
17 | 5. **简单**:Gossip 协议的过程极其简单,实现起来几乎没有太多复杂性。
18 |
19 |
20 |
21 | ## 三.Gossip 中的通信模式
22 |
23 | Gossip 协议中的两个节点(A、B)之间存在三种通信方式:
24 |
25 | - Push(A 最新): A 将数据 (key,value,version) 及对应的版本号 Push 给 B,B 更新本地数据。
26 | - Pull(B 最新):A 仅将数据 key, version 推送给 B,B 将本地比 A 新的数据(key, value, version)Push back 给 A,A 更新本地。
27 | - Push/Pull(A/B 一样新):比 Pull 多一步,A 更新本地后,再将数据 Push back B,B更新本地。
28 |
29 | 如果把两个节点数据同步一次定义为一个周期,则在一个周期内,Push 需通信 1 次,Pull 需 2 次,Push/Pull 则需 3 次。虽然消息数增加了,但从效果上来讲,Push/Pull 最好,理论上一个周期内可以使两个节点完全一致。
30 |
31 |
32 |
33 | ## 四.Gossip 的缺点
34 |
35 | - 消息延迟:由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下。
36 | - 消息冗余:Gossip 协议规定,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力。而且,由于是定期发送,因此,即使收到了消息的节点还会反复收到重复消息,加重了消息的冗余。
--------------------------------------------------------------------------------
/cs-basics/consensus/pbft.md:
--------------------------------------------------------------------------------
1 | # PBFT实用拜占庭容错
2 |
3 | ## 一.概述
4 |
5 | 拜占庭将军问题最早是由 Leslie Lamport 在 1982 年发表的论文**《The Byzantine Generals Problem 》**提出的, 他证明了在将军总数大于 3f ,背叛者为f 或者更少时,忠诚的将军可以达成命令上的一致,即 3f+1<=n 。算法复杂度为 O(nf+1) 。而 Miguel Castro 和 Barbara Liskov 在1999年发表的论文**《 Practical Byzantine Fault Tolerance 》**中首次提出 PBFT算法,该算法容错数量也满足 `3f+1<=n`,也即最大的容错作恶节点数`f=(n-1)/3`。算法复杂度为 O(n2),将系统的复杂度由指数级别降低为多项式级别,使得拜占庭容错算法在实际系统应用中变得可行。
6 |
7 | **那么为什么PBFT算法的容错数量满足3f+1<=n呢?**
8 |
9 | 因为 PBFT 算法的除了需要支持容错故障节点之外,还需要支持**容错作恶节点**。假设集群节点数为 N,有问题的节点为 f。有问题的节点中,可以既是故障节点,也可以是作恶节点,或者只是故障节点或者只是作恶节点。那么会产生以下两种极端情况:
10 |
11 | 1. 这f 个有问题节点既是故障节点,又是作恶节点,那么根据少数服从多数的原则,集群里正常节点只需要比f个节点再多一个节点,即 f+1 个节点,确节点的数量就会比故障节点数量多,那么集群就能达成共识,即总节点数为f+(f+1)=n,也就是说这种情况支持的最大容错节点数量是 (n-1)/2。
12 | 2. 故障节点和作恶节点都是不同的节点。那么就会有 f 个作恶节点和 f 个故障节点,当发现节点是作恶节点后,会被集群排除在外,剩下 f 个故障节点,那么根据少数服从多数的原则,集群里正常节点只需要比f个节点再多一个节点,即 f+1 个节点,确节点的数量就会比故障节点数量多,那么集群就能达成共识。所以,所有类型的节点数量加起来就是 f+1 个正常节点,f个故障节点和f个作恶节点,即 3f+1=n。
13 |
14 | 结合上述两种情况,因此PBFT算法支持的最大容错节点数量是(n-1)/3。
15 |
16 | ## 二.PBFT共识算法流程
17 |
18 | **角色划分**
19 |
20 | - **Client:**客户端节点,负责发送交易请求。
21 |
22 | - **Primary**: 主节点,负责将交易打包成区块和区块共识,每轮共识过程中有且仅有一个Primary节点。
23 |
24 | - **Replica**: 副本节点,负责区块共识,每轮共识过程中有多个Replica节点,每个Replica节点的处理过程类似。
25 |
26 | 其中,Primary和Replica节点都属于共识节点。
27 |
28 | **算法流程**
29 |
30 | PBFT 算法的基本流程主要有以下四步:
31 |
32 | 1. 客户端发送请求给主节点
33 | 2. 主节点广播请求给其它节点,节点执行PBFT算法的**三阶段共识流程**。
34 | 3. 节点处理完三阶段流程后,返回消息给客户端。
35 | 4. 客户端收到来自 f+1 个节点的相同消息后,代表共识已经正确完成。
36 |
37 | 
38 |
39 | 算法的核心三个阶段分别是 `pre-prepare` 阶段(预准备阶段),`prepare` 阶段(准备阶段), `commit` 阶段(提交阶段)。图中的C代表客户端,0,1,2,3 代表节点的编号,其中0 是主节点primary,打×的3代表可能是故障节点或者是作恶节点,这里表现的行为就是对其它节点的请求无响应。整个过程大致是如下:
40 |
41 | 首先,客户端向主节点0发起请求`< 70 |
71 | GMP图
72 |
73 | 基于**没有什么是加一个中间层不能解决的**思路,golang在原有的`GM`模型的基础上加入了一个调度器`P`,于是就有了现在的`GMP`模型。
74 |
75 |
70 |
71 | GMP图
72 |
73 | 基于**没有什么是加一个中间层不能解决的**思路,golang在原有的`GM`模型的基础上加入了一个调度器`P`,于是就有了现在的`GMP`模型。
74 |
75 | 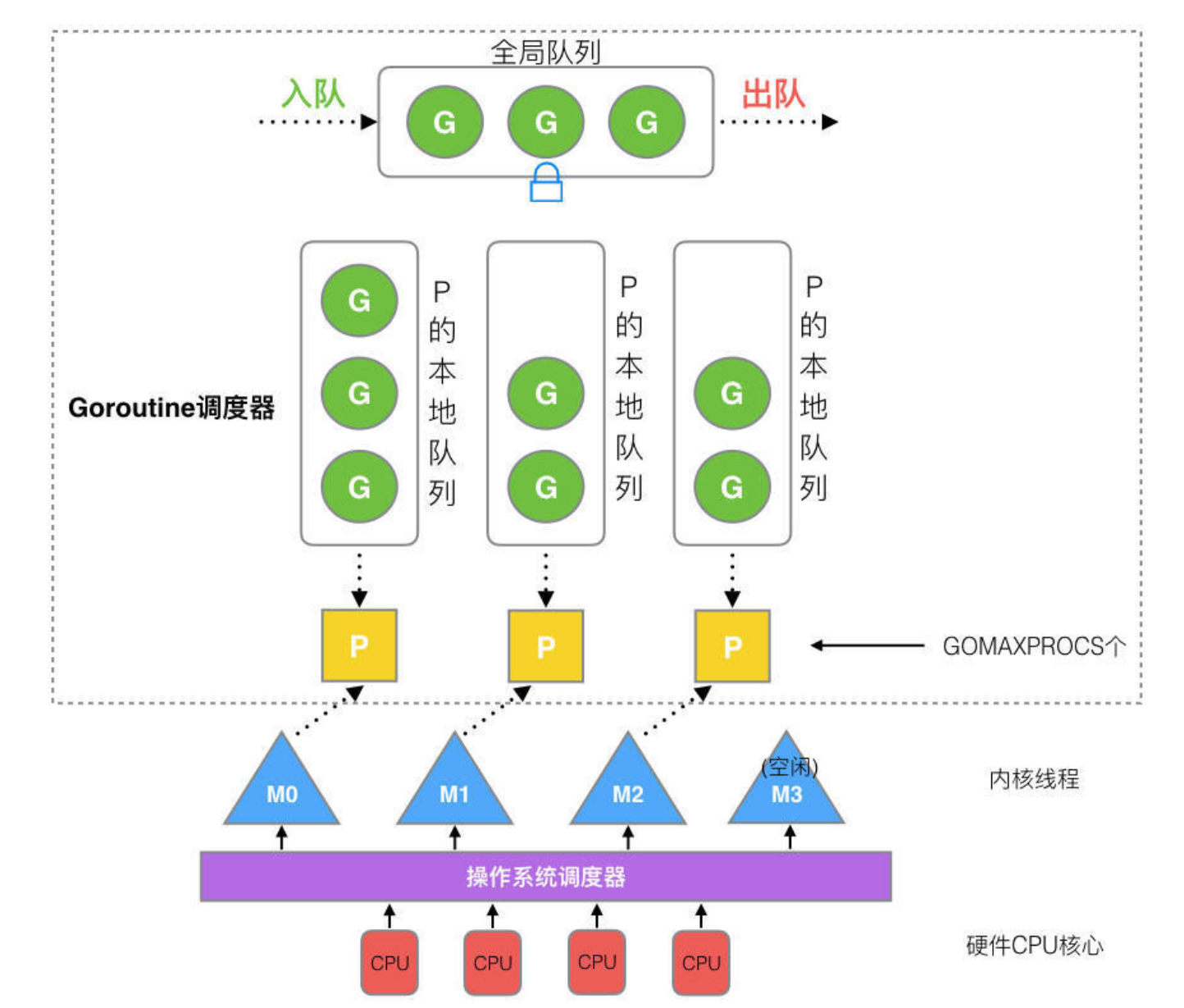 76 |
77 | GMP模型
78 |
79 | 1. **全局队列**:存放等待运行的 `G`。
80 |
81 | 2. **P 的本地队列**:同全局队列类似,存放的也是等待运行的 `G`,存的数量有限,**不超过 256 个**。新建 `G`时,`G`优先加入到 P 的本地队列,如果本地队列满了,则会把**本地队列中一半的 G 移动到全局队列**。
82 |
83 | 3. **P 列表**:所有的` P` 都在程序启动时创建,并保存在数组中,最多有 **GOMAXPROCS(默认是CPU的核数)** 个。
84 |
85 | 4. **M**:`M`想运行任务就得获取 `P`,从 P 的本地队列获取 `G`,**访问本地队列不用加锁**。
86 |
87 | 如果P 的本地队列为空,`M` 会尝试从全局队列拿一批`G` 放到 P 的本地队列。
88 |
89 | 如果全局协程队列为空,`M`会从 其他`P` 的本地队列**偷一半,采用Work Stealing算法**放到自己 P 的本地队列。
90 |
91 | `M` 运行 `G`,`G` 执行之后,`M` 会从 `P `获取下一个 `G`,不断重复下去。
92 |
93 | ### 调度的生命周期
94 |
95 | 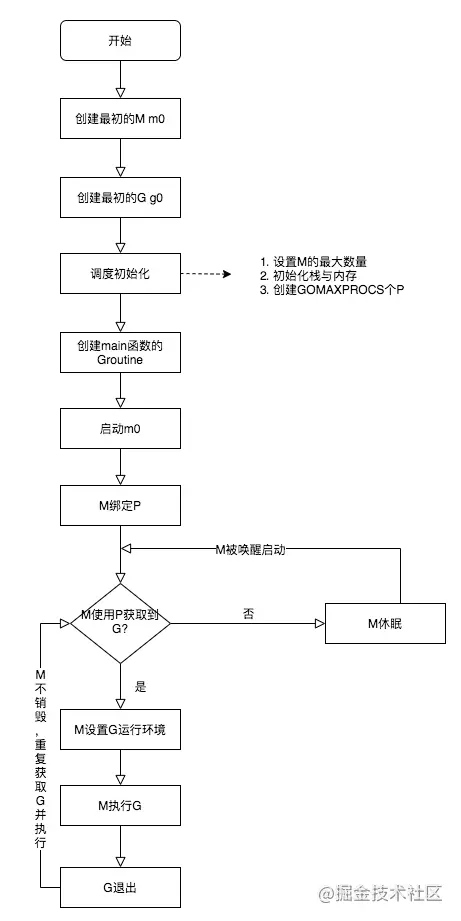
96 |
97 | - `M0` 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了
98 | - `G0` 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0
99 |
100 | 上面生命周期流程说明:
101 |
102 | - runtime 创建最初的线程 m0 和 goroutine g0,并把两者进行关联(g0.m = m0)
103 | - 调度器初始化:设置M最大数量,P个数,栈和内存出事,以及创建 GOMAXPROCS个P
104 | - 示例代码中的 main 函数是 main.main,runtime 中也有 1 个 main 函数 ——runtime.main,代码经过编译后,runtime.main 会调用 main.main,程序启动时会为 runtime.main 创建 goroutine,称它为 main goroutine 吧,然后把 main goroutine 加入到 P 的本地队列。
105 | - 启动 m0,m0 已经绑定了 P,会从 P 的本地队列获取 G,获取到 main goroutine。
106 | - G 拥有栈,M 根据 G 中的栈信息和调度信息设置运行环境
107 | - M 运行 G
108 | - G 退出,再次回到 M 获取可运行的 G,这样重复下去,直到 main.main 退出,runtime.main 执行 Defer 和 Panic 处理,或调用 runtime.exit 退出程序。
109 |
110 | ### 调度的流程状态
111 |
112 | 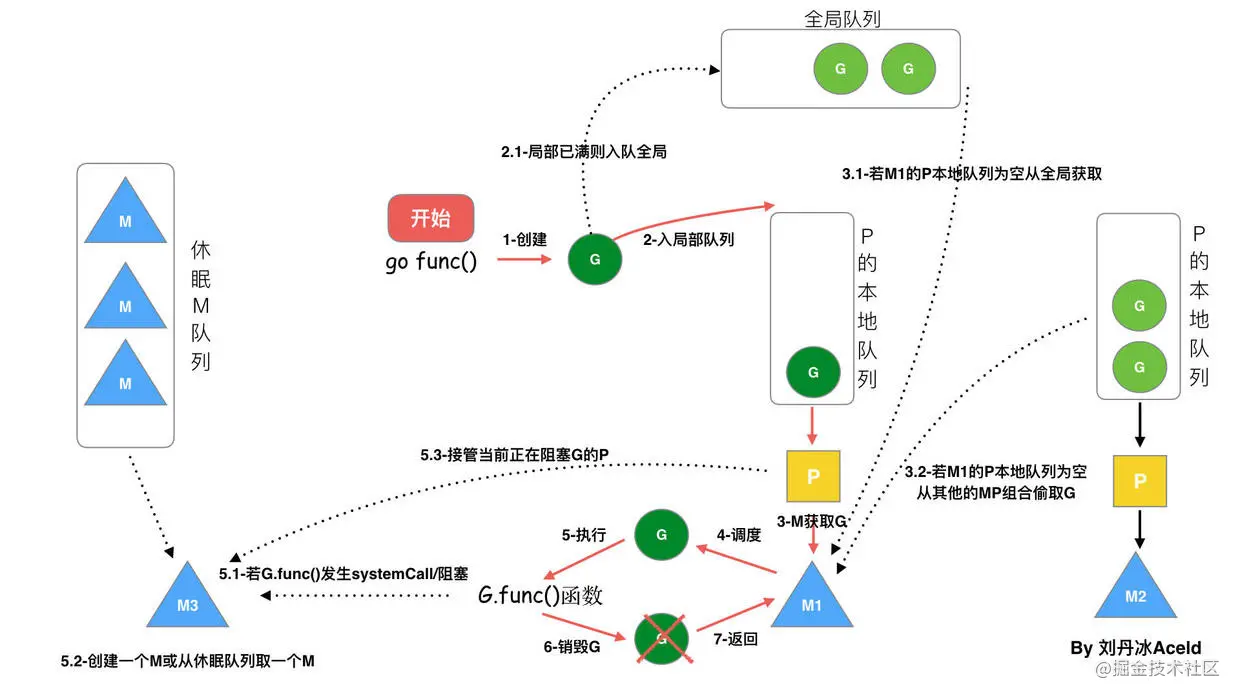
113 |
114 | 从上图我们可以看出来:
115 |
116 | - 每个P有个局部队列,局部队列保存待执行的goroutine(流程2),当M绑定的P的的局部队列已经满了之后就会把goroutine放到全局队列(流程2-1)
117 | - 每个P和一个M绑定,M是真正的执行P中goroutine的实体(流程3),M从绑定的P中的局部队列获取G来执行
118 | - 当M绑定的P的局部队列为空时,M会从全局队列获取到本地队列来执行G(流程3.1),当从全局队列中没有获取到可执行的G时候,M会从其他P的局部队列中偷取G来执行(流程3.2),这种从其他P偷的方式称为**work stealing**
119 | - 当G因系统调用(syscall)阻塞时会阻塞M,此时P会和M解绑即**hand off**,并寻找新的idle的M,若没有idle的M就会新建一个M(流程5.1)。
120 | - 当G因channel或者network I/O阻塞时,不会阻塞M,M会寻找其他runnable的G;当阻塞的G恢复后会重新进入runnable进入P队列等待执行(流程5.3)
121 |
122 | ### 调度过程中阻塞
123 |
124 | GMP模型的阻塞可能发生在下面几种情况:
125 |
126 | - I/O,select
127 | - block on syscall
128 | - channel
129 | - 等待锁
130 | - runtime.Gosched()
131 |
132 | #### 用户态阻塞
133 |
134 | 当goroutine因为channel操作或者network I/O而阻塞时(实际上golang已经用netpoller实现了goroutine网络I/O阻塞不会导致M被阻塞,仅阻塞G),对应的G会被放置到某个wait队列(如channel的waitq),该G的状态由_Gruning变为_Gwaitting,而M会跳过该G尝试获取并执行下一个G,如果此时没有runnable的G供M运行,那么M将解绑P,并进入sleep状态;当阻塞的G被另一端的G2唤醒时(比如channel的可读/写通知),G被标记为runnable,尝试加入G2所在P的runnext,然后再是P的Local队列和Global队列。
135 |
136 | #### 系统调用阻塞
137 |
138 | 当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于 block on syscall 状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。
139 |
140 | ### GMP内部结构
141 |
142 | #### G的结构
143 |
144 | ```go
145 | type g struct {
146 | stack stack // g自己的栈
147 | m *m // 隶属于哪个M
148 | sched gobuf // 保存了g的现场,goroutine切换时通过它来恢复
149 | atomicstatus uint32 // G的运行状态
150 | goid int64
151 | schedlink guintptr // 下一个g, g链表
152 | preempt bool //抢占标记
153 | lockedm muintptr // 锁定的M,g中断恢复指定M执行
154 | gopc uintptr // 创建该goroutine的指令地址
155 | startpc uintptr // goroutine 函数的指令地址
156 | }
157 | ```
158 |
159 | G的状态有以下9种:
160 |
161 | | 状态 | 值 | 含义 |
162 | | ----------------- | ---- | ------------------------------------------------------------ |
163 | | _Gidle | 0 | 刚刚被分配,还没有进行初始化。 |
164 | | _Grunnable | 1 | 已经在运行队列中,还没有执行用户代码。 |
165 | | _Grunning | 2 | 不在运行队列里中,已经可以执行用户代码,此时已经分配了 M 和 P。 |
166 | | _Gsyscall | 3 | 正在执行系统调用,此时分配了 M。 |
167 | | _Gwaiting | 4 | 在运行时被阻止,没有执行用户代码,也不在运行队列中,此时它正在某处阻塞等待中。 |
168 | | _Gmoribund_unused | 5 | 尚未使用,但是在 gdb 中进行了硬编码。 |
169 | | _Gdead | 6 | 尚未使用,这个状态可能是刚退出或是刚被初始化,此时它并没有执行用户代码,有可能有也有可能没有分配堆栈。 |
170 | | _Genqueue_unused | 7 | 尚未使用。 |
171 | | _Gcopystack | 8 | 正在复制堆栈,并没有执行用户代码,也不在运行队列中。 |
172 |
173 | #### M的结构
174 |
175 | ```go
176 | type m struct {
177 | g0 *g // g0, 每个M都有自己独有的g0
178 |
179 | curg *g // 当前正在运行的g
180 | p puintptr // 隶属于哪个P
181 | nextp puintptr // 当m被唤醒时,首先拥有这个p
182 | id int64
183 | spinning bool // 是否处于自旋
184 |
185 | park note
186 | alllink *m // on allm
187 | schedlink muintptr // 下一个m, m链表
188 | mcache *mcache // 内存分配
189 | lockedg guintptr // 和 G 的lockedm对应
190 | freelink *m // on sched.freem
191 | }
192 | 复制代码
193 | ```
194 |
195 | #### P的内部结构
196 |
197 | ```go
198 | type p struct {
199 | id int32
200 | status uint32 // P的状态
201 | link puintptr // 下一个P, P链表
202 | m muintptr // 拥有这个P的M
203 | mcache *mcache
204 |
205 | // P本地runnable状态的G队列,无锁访问
206 | runqhead uint32
207 | runqtail uint32
208 | runq [256]guintptr
209 |
210 | runnext guintptr // 一个比runq优先级更高的runnable G
211 |
212 | // 状态为dead的G链表,在获取G时会从这里面获取
213 | gFree struct {
214 | gList
215 | n int32
216 | }
217 |
218 | gcBgMarkWorker guintptr // (atomic)
219 | gcw gcWork
220 |
221 | }
222 | 复制代码
223 | ```
224 |
225 | P有以下5种状态:
226 |
227 | | 状态 | 值 | 含义 |
228 | | --------- | ---- | ------------------------------------------------------------ |
229 | | _Pidle | 0 | 刚刚被分配,还没有进行进行初始化。 |
230 | | _Prunning | 1 | 当 M 与 P 绑定调用 acquirep 时,P 的状态会改变为 _Prunning。 |
231 | | _Psyscall | 2 | 正在执行系统调用。 |
232 | | _Pgcstop | 3 | 暂停运行,此时系统正在进行 GC,直至 GC 结束后才会转变到下一个状态阶段。 |
233 | | _Pdead | 4 | 废弃,不再使用。 |
234 |
235 | #### 调度器的内部结构
236 |
237 | ```go
238 | type schedt struct {
239 |
240 | lock mutex
241 |
242 | midle muintptr // 空闲M链表
243 | nmidle int32 // 空闲M数量
244 | nmidlelocked int32 // 被锁住的M的数量
245 | mnext int64 // 已创建M的数量,以及下一个M ID
246 | maxmcount int32 // 允许创建最大的M数量
247 | nmsys int32 // 不计入死锁的M数量
248 | nmfreed int64 // 累计释放M的数量
249 |
250 | pidle puintptr // 空闲的P链表
251 | npidle uint32 // 空闲的P数量
252 |
253 | runq gQueue // 全局runnable的G队列
254 | runqsize int32 // 全局runnable的G数量
255 |
256 | // Global cache of dead G's.
257 | gFree struct {
258 | lock mutex
259 | stack gList // Gs with stacks
260 | noStack gList // Gs without stacks
261 | n int32
262 | }
263 |
264 | // freem is the list of m's waiting to be freed when their
265 | // m.exited is set. Linked through m.freelink.
266 | freem *m
267 | }
268 | ```
269 |
270 | ## 为什么要有P
271 |
272 | 如果是想实现本地队列、Work Stealing 算法,那为什么不直接在 M 上加呢,M 也照样可以实现类似的功能。为什么又要再多加一个组件P?
273 |
274 | 结合 `M`的定位来看,若这么做,有以下问题。
275 |
276 | - 一般来讲,`M` 的数量都会多于 `P`。像在 golang 中,**M 的数量最大限制是 10000**,**P 的默认数量的 CPU 核数**。另外由于` M` 的属性,也就是如果存在系统阻塞调用,阻塞了`M`,又不够用的情况下,`M` 会不断增加。
277 | - `M `不断增加的话,如果本地队列挂载在 `M` 上,那就意味着本地队列也会随之增加。这显然是不合理的,因为本地队列的管理会变得复杂,且 `Work Stealing` 性能会大幅度下降。
278 | - `M` 被系统调用阻塞后,我们是期望把他既有未执行的任务分配给其他继续运行的,而不是一阻塞就导致全部停止。
279 |
280 | 因此使用 M 是不合理的,那么引入新的组件 `P`,把本地队列关联到 `P` 上,就能很好的解决这个问题:
281 |
282 | - 每个 `P` 有自己的本地队列,大幅度的减轻了对全局队列的直接依赖,所带来的效果就是锁竞争的减少。而 GM 模型的性能开销大头就是锁竞争。
283 | - 每个 `P` 相对的平衡上,在 GMP 模型中也实现了 `Work Stealing `算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 `G` 来运行,减少空转,提高了资源利用率。
284 |
285 | > 参考:
286 | >
287 | > - [动图图解!GMP模型里为什么要有P?背后的原因让人暖心](https://mp.weixin.qq.com/s/O_GPwa71zqcpIkNdlkWYnQ)
288 | > - [Golang并发调度的GMP模型](https://juejin.cn/post/6886321367604527112)
289 | > - [再见 Go 面试官:GMP 模型,为什么要有 P?](https://mp.weixin.qq.com/s/an7dml9NLOhqOZjEGLdEEw)
--------------------------------------------------------------------------------
/golang/deep/map.md:
--------------------------------------------------------------------------------
1 | # Go语言深度解析之map
2 |
3 | ## map是什么
4 |
5 | `map`在计算机科学里,被称为相关数组、map、符号表或者字典,是由一组 `
76 |
77 | GMP模型
78 |
79 | 1. **全局队列**:存放等待运行的 `G`。
80 |
81 | 2. **P 的本地队列**:同全局队列类似,存放的也是等待运行的 `G`,存的数量有限,**不超过 256 个**。新建 `G`时,`G`优先加入到 P 的本地队列,如果本地队列满了,则会把**本地队列中一半的 G 移动到全局队列**。
82 |
83 | 3. **P 列表**:所有的` P` 都在程序启动时创建,并保存在数组中,最多有 **GOMAXPROCS(默认是CPU的核数)** 个。
84 |
85 | 4. **M**:`M`想运行任务就得获取 `P`,从 P 的本地队列获取 `G`,**访问本地队列不用加锁**。
86 |
87 | 如果P 的本地队列为空,`M` 会尝试从全局队列拿一批`G` 放到 P 的本地队列。
88 |
89 | 如果全局协程队列为空,`M`会从 其他`P` 的本地队列**偷一半,采用Work Stealing算法**放到自己 P 的本地队列。
90 |
91 | `M` 运行 `G`,`G` 执行之后,`M` 会从 `P `获取下一个 `G`,不断重复下去。
92 |
93 | ### 调度的生命周期
94 |
95 | 
96 |
97 | - `M0` 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了
98 | - `G0` 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0
99 |
100 | 上面生命周期流程说明:
101 |
102 | - runtime 创建最初的线程 m0 和 goroutine g0,并把两者进行关联(g0.m = m0)
103 | - 调度器初始化:设置M最大数量,P个数,栈和内存出事,以及创建 GOMAXPROCS个P
104 | - 示例代码中的 main 函数是 main.main,runtime 中也有 1 个 main 函数 ——runtime.main,代码经过编译后,runtime.main 会调用 main.main,程序启动时会为 runtime.main 创建 goroutine,称它为 main goroutine 吧,然后把 main goroutine 加入到 P 的本地队列。
105 | - 启动 m0,m0 已经绑定了 P,会从 P 的本地队列获取 G,获取到 main goroutine。
106 | - G 拥有栈,M 根据 G 中的栈信息和调度信息设置运行环境
107 | - M 运行 G
108 | - G 退出,再次回到 M 获取可运行的 G,这样重复下去,直到 main.main 退出,runtime.main 执行 Defer 和 Panic 处理,或调用 runtime.exit 退出程序。
109 |
110 | ### 调度的流程状态
111 |
112 | 
113 |
114 | 从上图我们可以看出来:
115 |
116 | - 每个P有个局部队列,局部队列保存待执行的goroutine(流程2),当M绑定的P的的局部队列已经满了之后就会把goroutine放到全局队列(流程2-1)
117 | - 每个P和一个M绑定,M是真正的执行P中goroutine的实体(流程3),M从绑定的P中的局部队列获取G来执行
118 | - 当M绑定的P的局部队列为空时,M会从全局队列获取到本地队列来执行G(流程3.1),当从全局队列中没有获取到可执行的G时候,M会从其他P的局部队列中偷取G来执行(流程3.2),这种从其他P偷的方式称为**work stealing**
119 | - 当G因系统调用(syscall)阻塞时会阻塞M,此时P会和M解绑即**hand off**,并寻找新的idle的M,若没有idle的M就会新建一个M(流程5.1)。
120 | - 当G因channel或者network I/O阻塞时,不会阻塞M,M会寻找其他runnable的G;当阻塞的G恢复后会重新进入runnable进入P队列等待执行(流程5.3)
121 |
122 | ### 调度过程中阻塞
123 |
124 | GMP模型的阻塞可能发生在下面几种情况:
125 |
126 | - I/O,select
127 | - block on syscall
128 | - channel
129 | - 等待锁
130 | - runtime.Gosched()
131 |
132 | #### 用户态阻塞
133 |
134 | 当goroutine因为channel操作或者network I/O而阻塞时(实际上golang已经用netpoller实现了goroutine网络I/O阻塞不会导致M被阻塞,仅阻塞G),对应的G会被放置到某个wait队列(如channel的waitq),该G的状态由_Gruning变为_Gwaitting,而M会跳过该G尝试获取并执行下一个G,如果此时没有runnable的G供M运行,那么M将解绑P,并进入sleep状态;当阻塞的G被另一端的G2唤醒时(比如channel的可读/写通知),G被标记为runnable,尝试加入G2所在P的runnext,然后再是P的Local队列和Global队列。
135 |
136 | #### 系统调用阻塞
137 |
138 | 当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于 block on syscall 状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。
139 |
140 | ### GMP内部结构
141 |
142 | #### G的结构
143 |
144 | ```go
145 | type g struct {
146 | stack stack // g自己的栈
147 | m *m // 隶属于哪个M
148 | sched gobuf // 保存了g的现场,goroutine切换时通过它来恢复
149 | atomicstatus uint32 // G的运行状态
150 | goid int64
151 | schedlink guintptr // 下一个g, g链表
152 | preempt bool //抢占标记
153 | lockedm muintptr // 锁定的M,g中断恢复指定M执行
154 | gopc uintptr // 创建该goroutine的指令地址
155 | startpc uintptr // goroutine 函数的指令地址
156 | }
157 | ```
158 |
159 | G的状态有以下9种:
160 |
161 | | 状态 | 值 | 含义 |
162 | | ----------------- | ---- | ------------------------------------------------------------ |
163 | | _Gidle | 0 | 刚刚被分配,还没有进行初始化。 |
164 | | _Grunnable | 1 | 已经在运行队列中,还没有执行用户代码。 |
165 | | _Grunning | 2 | 不在运行队列里中,已经可以执行用户代码,此时已经分配了 M 和 P。 |
166 | | _Gsyscall | 3 | 正在执行系统调用,此时分配了 M。 |
167 | | _Gwaiting | 4 | 在运行时被阻止,没有执行用户代码,也不在运行队列中,此时它正在某处阻塞等待中。 |
168 | | _Gmoribund_unused | 5 | 尚未使用,但是在 gdb 中进行了硬编码。 |
169 | | _Gdead | 6 | 尚未使用,这个状态可能是刚退出或是刚被初始化,此时它并没有执行用户代码,有可能有也有可能没有分配堆栈。 |
170 | | _Genqueue_unused | 7 | 尚未使用。 |
171 | | _Gcopystack | 8 | 正在复制堆栈,并没有执行用户代码,也不在运行队列中。 |
172 |
173 | #### M的结构
174 |
175 | ```go
176 | type m struct {
177 | g0 *g // g0, 每个M都有自己独有的g0
178 |
179 | curg *g // 当前正在运行的g
180 | p puintptr // 隶属于哪个P
181 | nextp puintptr // 当m被唤醒时,首先拥有这个p
182 | id int64
183 | spinning bool // 是否处于自旋
184 |
185 | park note
186 | alllink *m // on allm
187 | schedlink muintptr // 下一个m, m链表
188 | mcache *mcache // 内存分配
189 | lockedg guintptr // 和 G 的lockedm对应
190 | freelink *m // on sched.freem
191 | }
192 | 复制代码
193 | ```
194 |
195 | #### P的内部结构
196 |
197 | ```go
198 | type p struct {
199 | id int32
200 | status uint32 // P的状态
201 | link puintptr // 下一个P, P链表
202 | m muintptr // 拥有这个P的M
203 | mcache *mcache
204 |
205 | // P本地runnable状态的G队列,无锁访问
206 | runqhead uint32
207 | runqtail uint32
208 | runq [256]guintptr
209 |
210 | runnext guintptr // 一个比runq优先级更高的runnable G
211 |
212 | // 状态为dead的G链表,在获取G时会从这里面获取
213 | gFree struct {
214 | gList
215 | n int32
216 | }
217 |
218 | gcBgMarkWorker guintptr // (atomic)
219 | gcw gcWork
220 |
221 | }
222 | 复制代码
223 | ```
224 |
225 | P有以下5种状态:
226 |
227 | | 状态 | 值 | 含义 |
228 | | --------- | ---- | ------------------------------------------------------------ |
229 | | _Pidle | 0 | 刚刚被分配,还没有进行进行初始化。 |
230 | | _Prunning | 1 | 当 M 与 P 绑定调用 acquirep 时,P 的状态会改变为 _Prunning。 |
231 | | _Psyscall | 2 | 正在执行系统调用。 |
232 | | _Pgcstop | 3 | 暂停运行,此时系统正在进行 GC,直至 GC 结束后才会转变到下一个状态阶段。 |
233 | | _Pdead | 4 | 废弃,不再使用。 |
234 |
235 | #### 调度器的内部结构
236 |
237 | ```go
238 | type schedt struct {
239 |
240 | lock mutex
241 |
242 | midle muintptr // 空闲M链表
243 | nmidle int32 // 空闲M数量
244 | nmidlelocked int32 // 被锁住的M的数量
245 | mnext int64 // 已创建M的数量,以及下一个M ID
246 | maxmcount int32 // 允许创建最大的M数量
247 | nmsys int32 // 不计入死锁的M数量
248 | nmfreed int64 // 累计释放M的数量
249 |
250 | pidle puintptr // 空闲的P链表
251 | npidle uint32 // 空闲的P数量
252 |
253 | runq gQueue // 全局runnable的G队列
254 | runqsize int32 // 全局runnable的G数量
255 |
256 | // Global cache of dead G's.
257 | gFree struct {
258 | lock mutex
259 | stack gList // Gs with stacks
260 | noStack gList // Gs without stacks
261 | n int32
262 | }
263 |
264 | // freem is the list of m's waiting to be freed when their
265 | // m.exited is set. Linked through m.freelink.
266 | freem *m
267 | }
268 | ```
269 |
270 | ## 为什么要有P
271 |
272 | 如果是想实现本地队列、Work Stealing 算法,那为什么不直接在 M 上加呢,M 也照样可以实现类似的功能。为什么又要再多加一个组件P?
273 |
274 | 结合 `M`的定位来看,若这么做,有以下问题。
275 |
276 | - 一般来讲,`M` 的数量都会多于 `P`。像在 golang 中,**M 的数量最大限制是 10000**,**P 的默认数量的 CPU 核数**。另外由于` M` 的属性,也就是如果存在系统阻塞调用,阻塞了`M`,又不够用的情况下,`M` 会不断增加。
277 | - `M `不断增加的话,如果本地队列挂载在 `M` 上,那就意味着本地队列也会随之增加。这显然是不合理的,因为本地队列的管理会变得复杂,且 `Work Stealing` 性能会大幅度下降。
278 | - `M` 被系统调用阻塞后,我们是期望把他既有未执行的任务分配给其他继续运行的,而不是一阻塞就导致全部停止。
279 |
280 | 因此使用 M 是不合理的,那么引入新的组件 `P`,把本地队列关联到 `P` 上,就能很好的解决这个问题:
281 |
282 | - 每个 `P` 有自己的本地队列,大幅度的减轻了对全局队列的直接依赖,所带来的效果就是锁竞争的减少。而 GM 模型的性能开销大头就是锁竞争。
283 | - 每个 `P` 相对的平衡上,在 GMP 模型中也实现了 `Work Stealing `算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 `G` 来运行,减少空转,提高了资源利用率。
284 |
285 | > 参考:
286 | >
287 | > - [动图图解!GMP模型里为什么要有P?背后的原因让人暖心](https://mp.weixin.qq.com/s/O_GPwa71zqcpIkNdlkWYnQ)
288 | > - [Golang并发调度的GMP模型](https://juejin.cn/post/6886321367604527112)
289 | > - [再见 Go 面试官:GMP 模型,为什么要有 P?](https://mp.weixin.qq.com/s/an7dml9NLOhqOZjEGLdEEw)
--------------------------------------------------------------------------------
/golang/deep/map.md:
--------------------------------------------------------------------------------
1 | # Go语言深度解析之map
2 |
3 | ## map是什么
4 |
5 | `map`在计算机科学里,被称为相关数组、map、符号表或者字典,是由一组 `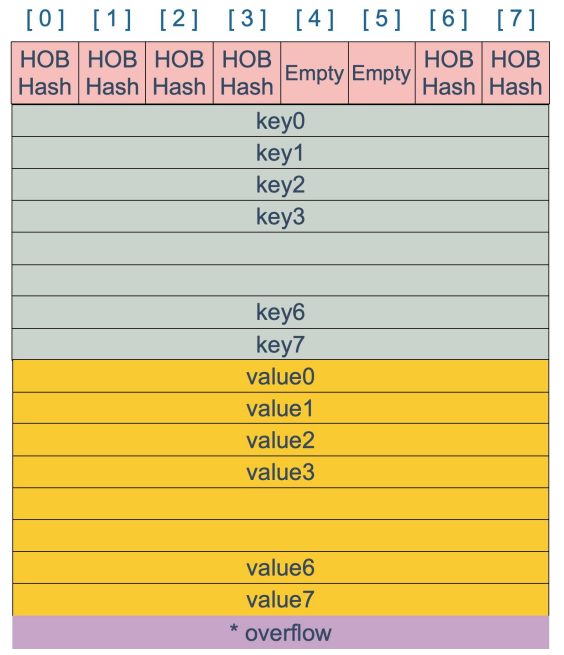 59 |
60 | 注意到 key 和 value 是各自放在一起的,并不是 `key/value/key/value/...` 这样的形式。源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间。
61 |
62 | **举个例子**,有这样一个类型的 map:
63 |
64 | ```
65 | map[int64]int8
66 | ```
67 |
68 | 如果按照 `key/value/key/value/...` 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 `key/key/.../value/value/...`,则只需要在最后添加 padding。
69 |
70 | 每个 bucket 设计成最多只能放 `8个key-value对`,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 `overflow` 指针连接起来。
71 |
72 | **下面来用一个整体的图表示map的结构:**
73 |
74 |
59 |
60 | 注意到 key 和 value 是各自放在一起的,并不是 `key/value/key/value/...` 这样的形式。源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间。
61 |
62 | **举个例子**,有这样一个类型的 map:
63 |
64 | ```
65 | map[int64]int8
66 | ```
67 |
68 | 如果按照 `key/value/key/value/...` 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 `key/key/.../value/value/...`,则只需要在最后添加 padding。
69 |
70 | 每个 bucket 设计成最多只能放 `8个key-value对`,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 `overflow` 指针连接起来。
71 |
72 | **下面来用一个整体的图表示map的结构:**
73 |
74 | 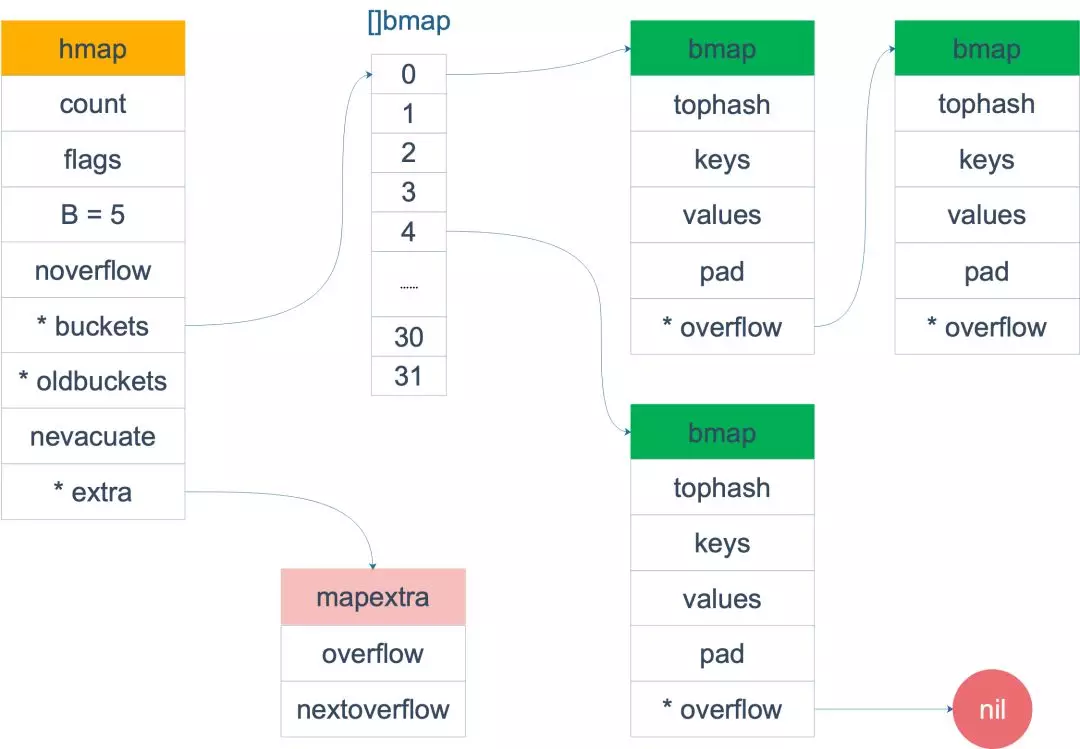 75 |
76 | 当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,**会把 bmap 标记为不含指针**,这样可以避免 gc 时扫描整个 hmap。但是,我们看 bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
77 |
78 | ```go
79 | // go 1.14 src/runtime/map.go
80 | type mapextra struct {
81 | // overflow contains overflow buckets for hmap.buckets.
82 | // oldoverflow contains overflow buckets for hmap.oldbuckets.
83 | overflow *[]*bmap
84 | oldoverflow *[]*bmap
85 |
86 | // nextOverflow holds a pointer to a free overflow bucket.
87 | nextOverflow *bmap
88 | }
89 | ```
90 |
91 | ## map的操作
92 |
93 | ### 创建
94 |
95 | ```go
96 | ageMp := make(map[string]int)
97 | // 指定 map 长度
98 | ageMp := make(map[string]int, 8)
99 | // 创建并初始化内容
100 | ageMp := map[string]int{“id”:1,"age":22}
101 | // ageMp 为 nil,不能向其添加元素,会直接panic: assign to entry in nil map. 因此需要初始化
102 | var ageMp map[string]int
103 | ```
104 |
105 | **注意:**map的声明的时候默认值是**nil** ,此时进行取值,返回的是**对应类型的零值**(不存在也是返回零值)。
106 |
107 | ```go
108 | var m map[int]bool
109 | v, ok := m[1]
110 | fmt.Println(v, ok) // false false
111 | ```
112 |
113 | ### 插入&删除&更新&查询
114 |
115 | ```go
116 | // 插入
117 | m[1] = "hello world"
118 |
119 | // 删除,key不存在则啥也不干
120 | delete(m, 1)
121 |
122 | // 更新
123 | m[1] = "Hello World"
124 |
125 | // 查询,key不存在返回value类型的零值 有三种查询方式
126 | i := m[1]
127 | i, ok := m[1]
128 | _, ok := m[1]
129 | ```
130 |
131 | ### 遍历
132 |
133 | map本身是**无序的**,在遍历的时候并不会按照你传入的顺序,进行传出。
134 |
135 | ```go
136 | package main
137 |
138 | import (
139 | "fmt"
140 | "sort"
141 | )
142 |
143 | func main() {
144 | m := make(map[int]string)
145 | //插入数据
146 | for i := 0; i < 50; i++ {
147 | m[i] = fmt.Sprintf("用户%v", i)
148 | }
149 |
150 | //正常遍历 map中的内容是无序的
151 | for k, v := range m {
152 | fmt.Println(k, v)
153 | }
154 |
155 | fmt.Println("============== 分割线 ================")
156 |
157 | //若想要获得map中的有序值
158 | //可以先用一个slice保存key值
159 | var key []int
160 | for k := range m {
161 | key = append(key, k)
162 | }
163 |
164 | //再用sort包进行排序
165 | sort.Ints(key)
166 |
167 | //最后再遍历,此时就是有序的了
168 | for k := range key {
169 | fmt.Println(k, m[k])
170 | }
171 | }
172 | ```
173 |
174 | ### 函数传参
175 |
176 | Golang中是没有引用传递的,均为值传递。这意味着传递的是数据的拷贝。那么map本身是**引用类型**,作为形参或返回参数的时候,传递的是**值的拷贝,而值是地址**,**扩容**时也**不会改变**这个地址。
177 |
178 | ```go
179 | package main
180 |
181 | import "fmt"
182 |
183 | func main() {
184 | var m map[int]int
185 | m = make(map[int]int, 1)
186 | fmt.Printf("m 原始的地址是:%p\n", m)
187 | changeM(m)
188 | fmt.Printf("m 改变后地址是:%p\n", m)
189 | fmt.Println("m 长度是", len(m))
190 | fmt.Println("m 参数是", m)
191 | }
192 |
193 | // 改变map的函数
194 | func changeM(m map[int]int) {
195 | fmt.Printf("m 函数开始时地址是:%p\n", m)
196 | var max = 5
197 | for i := 0; i < max; i++ {
198 | m[i] = 2
199 | }
200 | fmt.Printf("m 在函数返回前地址是:%p\n", m)
201 | }
202 | ```
203 |
204 | 结果:
205 |
206 | ```
207 | m 原始地址是:0xc42007a180
208 | m 函数开始时地址是:0xc42007a180
209 | m 在函数返回前地址是:0xc42007a180
210 | m 改变后地址是:0xc42007a180
211 | m 长度是 5
212 | m 参数是 map[3:2 4:2 0:2 1:2 2:2]
213 | ```
214 |
215 | ## map的hash计算
216 |
217 | 在第一小节中我们知道bmap中存储的是key-value值,那么具体key是分配到哪个bucket呢?也就是bmap中的tophash是如何计算?
218 |
219 | 具体实现:
220 |
221 | ```go
222 | // go 1.14 src/runtime/map.go
223 | func tophash(hash uintptr) uint8 {
224 | top := uint8(hash >> (sys.PtrSize*8 - 8))
225 | if top < minTopHash {
226 | top += minTopHash
227 | }
228 | return top
229 | }
230 | ```
231 |
232 | key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机)计算它到底要落在哪个桶时,**只会用到最后 B 个 bit 位**。如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 25 = 32。
233 |
234 | **例如**,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
235 |
236 | ```
237 | 10010111 | 000011110110110010001111001010100010010110010101010 │ 00110
238 | ```
239 |
240 | 用最后的 5 个 bit 位,也就是 `00110`,值为 6,也就是 **6 号桶**。这个操作实际上就是取余操作,但是取余开销太大,所以代码实现上用的**位操作**代替。
241 |
242 | 再**用哈希值的高 8 位,找到此 key 在 bucket 中的位置**,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位放入。
243 |
244 | buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
245 |
246 |
75 |
76 | 当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,**会把 bmap 标记为不含指针**,这样可以避免 gc 时扫描整个 hmap。但是,我们看 bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
77 |
78 | ```go
79 | // go 1.14 src/runtime/map.go
80 | type mapextra struct {
81 | // overflow contains overflow buckets for hmap.buckets.
82 | // oldoverflow contains overflow buckets for hmap.oldbuckets.
83 | overflow *[]*bmap
84 | oldoverflow *[]*bmap
85 |
86 | // nextOverflow holds a pointer to a free overflow bucket.
87 | nextOverflow *bmap
88 | }
89 | ```
90 |
91 | ## map的操作
92 |
93 | ### 创建
94 |
95 | ```go
96 | ageMp := make(map[string]int)
97 | // 指定 map 长度
98 | ageMp := make(map[string]int, 8)
99 | // 创建并初始化内容
100 | ageMp := map[string]int{“id”:1,"age":22}
101 | // ageMp 为 nil,不能向其添加元素,会直接panic: assign to entry in nil map. 因此需要初始化
102 | var ageMp map[string]int
103 | ```
104 |
105 | **注意:**map的声明的时候默认值是**nil** ,此时进行取值,返回的是**对应类型的零值**(不存在也是返回零值)。
106 |
107 | ```go
108 | var m map[int]bool
109 | v, ok := m[1]
110 | fmt.Println(v, ok) // false false
111 | ```
112 |
113 | ### 插入&删除&更新&查询
114 |
115 | ```go
116 | // 插入
117 | m[1] = "hello world"
118 |
119 | // 删除,key不存在则啥也不干
120 | delete(m, 1)
121 |
122 | // 更新
123 | m[1] = "Hello World"
124 |
125 | // 查询,key不存在返回value类型的零值 有三种查询方式
126 | i := m[1]
127 | i, ok := m[1]
128 | _, ok := m[1]
129 | ```
130 |
131 | ### 遍历
132 |
133 | map本身是**无序的**,在遍历的时候并不会按照你传入的顺序,进行传出。
134 |
135 | ```go
136 | package main
137 |
138 | import (
139 | "fmt"
140 | "sort"
141 | )
142 |
143 | func main() {
144 | m := make(map[int]string)
145 | //插入数据
146 | for i := 0; i < 50; i++ {
147 | m[i] = fmt.Sprintf("用户%v", i)
148 | }
149 |
150 | //正常遍历 map中的内容是无序的
151 | for k, v := range m {
152 | fmt.Println(k, v)
153 | }
154 |
155 | fmt.Println("============== 分割线 ================")
156 |
157 | //若想要获得map中的有序值
158 | //可以先用一个slice保存key值
159 | var key []int
160 | for k := range m {
161 | key = append(key, k)
162 | }
163 |
164 | //再用sort包进行排序
165 | sort.Ints(key)
166 |
167 | //最后再遍历,此时就是有序的了
168 | for k := range key {
169 | fmt.Println(k, m[k])
170 | }
171 | }
172 | ```
173 |
174 | ### 函数传参
175 |
176 | Golang中是没有引用传递的,均为值传递。这意味着传递的是数据的拷贝。那么map本身是**引用类型**,作为形参或返回参数的时候,传递的是**值的拷贝,而值是地址**,**扩容**时也**不会改变**这个地址。
177 |
178 | ```go
179 | package main
180 |
181 | import "fmt"
182 |
183 | func main() {
184 | var m map[int]int
185 | m = make(map[int]int, 1)
186 | fmt.Printf("m 原始的地址是:%p\n", m)
187 | changeM(m)
188 | fmt.Printf("m 改变后地址是:%p\n", m)
189 | fmt.Println("m 长度是", len(m))
190 | fmt.Println("m 参数是", m)
191 | }
192 |
193 | // 改变map的函数
194 | func changeM(m map[int]int) {
195 | fmt.Printf("m 函数开始时地址是:%p\n", m)
196 | var max = 5
197 | for i := 0; i < max; i++ {
198 | m[i] = 2
199 | }
200 | fmt.Printf("m 在函数返回前地址是:%p\n", m)
201 | }
202 | ```
203 |
204 | 结果:
205 |
206 | ```
207 | m 原始地址是:0xc42007a180
208 | m 函数开始时地址是:0xc42007a180
209 | m 在函数返回前地址是:0xc42007a180
210 | m 改变后地址是:0xc42007a180
211 | m 长度是 5
212 | m 参数是 map[3:2 4:2 0:2 1:2 2:2]
213 | ```
214 |
215 | ## map的hash计算
216 |
217 | 在第一小节中我们知道bmap中存储的是key-value值,那么具体key是分配到哪个bucket呢?也就是bmap中的tophash是如何计算?
218 |
219 | 具体实现:
220 |
221 | ```go
222 | // go 1.14 src/runtime/map.go
223 | func tophash(hash uintptr) uint8 {
224 | top := uint8(hash >> (sys.PtrSize*8 - 8))
225 | if top < minTopHash {
226 | top += minTopHash
227 | }
228 | return top
229 | }
230 | ```
231 |
232 | key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机)计算它到底要落在哪个桶时,**只会用到最后 B 个 bit 位**。如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 25 = 32。
233 |
234 | **例如**,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
235 |
236 | ```
237 | 10010111 | 000011110110110010001111001010100010010110010101010 │ 00110
238 | ```
239 |
240 | 用最后的 5 个 bit 位,也就是 `00110`,值为 6,也就是 **6 号桶**。这个操作实际上就是取余操作,但是取余开销太大,所以代码实现上用的**位操作**代替。
241 |
242 | 再**用哈希值的高 8 位,找到此 key 在 bucket 中的位置**,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位放入。
243 |
244 | buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
245 |
246 | 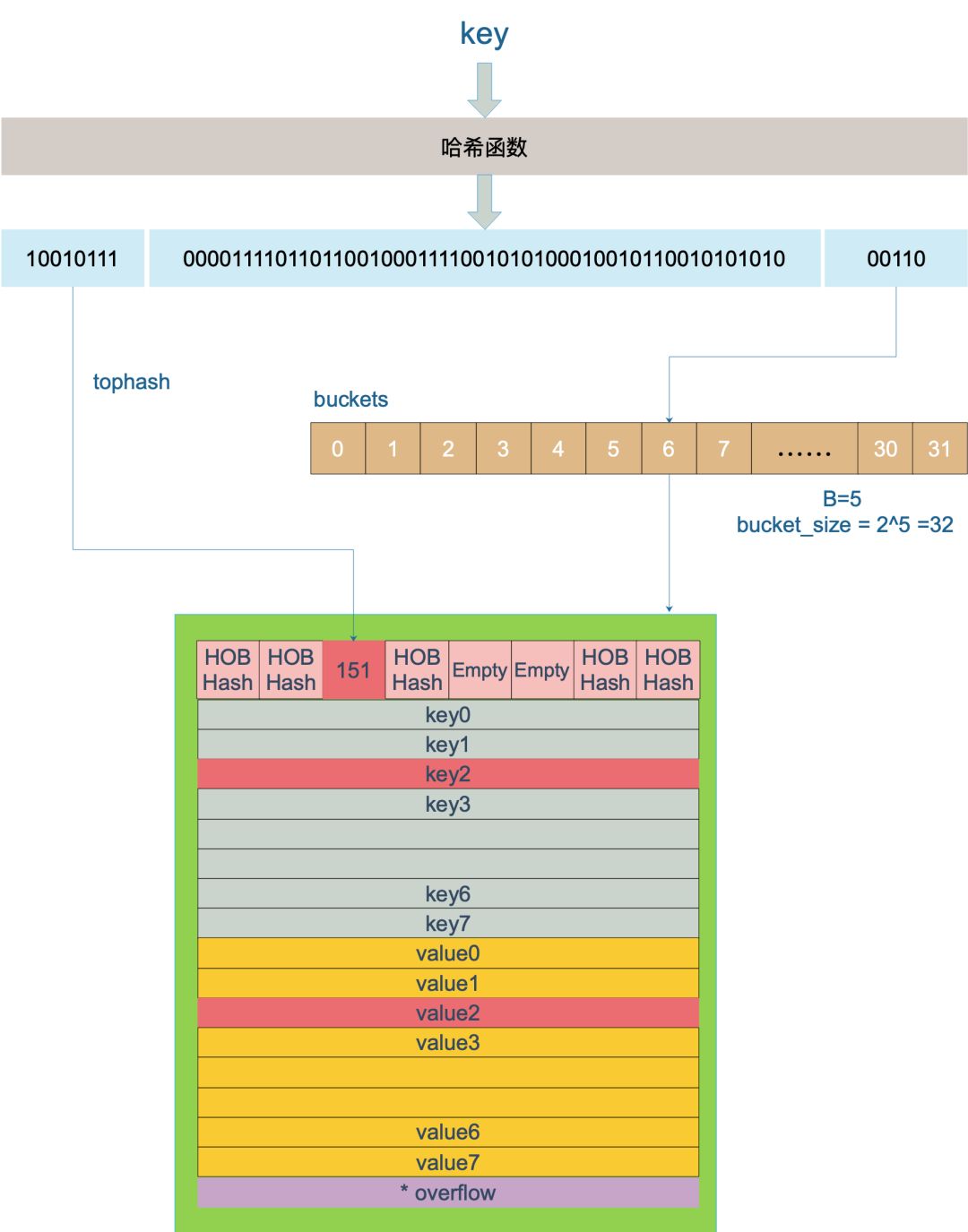 247 |
248 | 上图中,假定 B = 5,所以 bucket 总数就是 25 = 32。首先计算出待查找 key 的哈希,使用低 5 位 `00110`,找到对应的 6 号 bucket,使用高 8 位 `10010111`,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
249 |
250 | **如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket**。
251 |
252 | 具体来看源码:
253 |
254 | ```go
255 | // go 1.14 src/runtime.go
256 | func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
257 | // ……
258 | // 如果 h 什么都没有,返回零值
259 | if h == nil || h.count == 0 {
260 | return unsafe.Pointer(&zeroVal[0])
261 | }
262 | // 写和读冲突
263 | if h.flags&hashWriting != 0 {
264 | throw("concurrent map read and map write")
265 | }
266 | // 不同类型 key 使用的 hash 算法在编译期确定
267 | alg := t.key.alg
268 | // 计算哈希值,并且加入 hash0 引入随机性
269 | hash := alg.hash(key, uintptr(h.hash0))
270 | // 比如 B=5,那 m 就是31,二进制是全 1
271 | // 求 bucket num 时,将 hash 与 m 相与,
272 | // 达到 bucket num 由 hash 的低 8 位决定的效果
273 | m := uintptr(1)<
247 |
248 | 上图中,假定 B = 5,所以 bucket 总数就是 25 = 32。首先计算出待查找 key 的哈希,使用低 5 位 `00110`,找到对应的 6 号 bucket,使用高 8 位 `10010111`,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
249 |
250 | **如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket**。
251 |
252 | 具体来看源码:
253 |
254 | ```go
255 | // go 1.14 src/runtime.go
256 | func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
257 | // ……
258 | // 如果 h 什么都没有,返回零值
259 | if h == nil || h.count == 0 {
260 | return unsafe.Pointer(&zeroVal[0])
261 | }
262 | // 写和读冲突
263 | if h.flags&hashWriting != 0 {
264 | throw("concurrent map read and map write")
265 | }
266 | // 不同类型 key 使用的 hash 算法在编译期确定
267 | alg := t.key.alg
268 | // 计算哈希值,并且加入 hash0 引入随机性
269 | hash := alg.hash(key, uintptr(h.hash0))
270 | // 比如 B=5,那 m 就是31,二进制是全 1
271 | // 求 bucket num 时,将 hash 与 m 相与,
272 | // 达到 bucket num 由 hash 的低 8 位决定的效果
273 | m := uintptr(1)<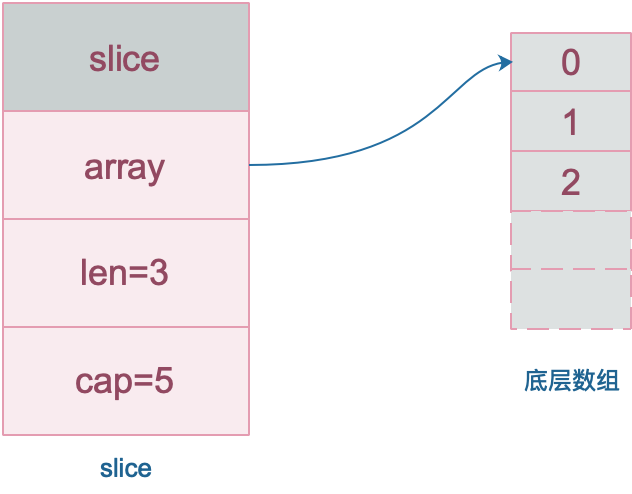 19 |
20 | 可以看到slice共有三个属性,每个属性的解释如上所示,其中在底层数组不进行扩容的情况下,容量也是 slice 可以扩张的最大限度。需要注意的是,**底层数组是可以被多个 slice 同时指向的**,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
21 |
22 | ## slice的创建
23 |
24 | 创建 slice 的方式有以下几种:
25 |
26 | | 序号 | 方式 | 代码示例 |
27 | | ---- | ------------------ | ---------------------------------------------------- |
28 | | 1 | 直接声明 | `var slice []int` |
29 | | 2 | new | `slice := *new([]int)` |
30 | | 3 | 字面量 | `slice := []int{1,2,3,4,5}` |
31 | | 4 | make | `slice := make([]int, 5, 10)` |
32 | | 5 | 从切片或数组“截取” | `slice := array[1:5]` 或 `slice := sourceSlice[1:5]` |
33 |
34 | 其中第一种方式和第二种方式创建出来的切片其实是一种`nil slice`,与之对应的还有一种`empty slice`。
35 |
36 | 区别如下(官方建议使用`nil slice`):
37 |
38 | | 创建方式 | nil切片 | 空切片 |
39 | | ------------- | -------------------- | ----------------------- |
40 | | 方式一 | var s1 []int | var s2 = []int{} |
41 | | 方式二 | var s3 = *new([]int) | var s4 = make([]int, 0) |
42 | | 长度 | 0 | 0 |
43 | | 容量 | 0 | 0 |
44 | | 和 `nil` 比较 | `true` | `false` |
45 |
46 | ```go
47 | package main
48 |
49 | import "fmt"
50 |
51 | func main() {
52 | var s1 []int
53 | var s2 = *new([]int)
54 | var s3 = make([]int, 0)
55 | var s4 = []int{}
56 | fmt.Printf("s1's address is %p\n", s1)
57 | fmt.Printf("s2's address is %p\n", s2)
58 | fmt.Printf("s3's address is %p\n", s3)
59 | fmt.Printf("s4's address is %p\n", s4)
60 | fmt.Printf("s1 equal nil? %v\n", s1 == nil)
61 | fmt.Printf("s2 equal nil? %v\n", s2 == nil)
62 | fmt.Printf("s3 equal nil? %v\n", s3 == nil)
63 | fmt.Printf("s4 equal nil? %v\n", s4 == nil)
64 | }
65 | ```
66 |
67 | ```
68 | 结果如下:
69 | s1's address is 0x0
70 | s2's address is 0x0
71 | s3's address is 0x5a6d48
72 | s4's address is 0x5a6d48
73 | s1 equal nil? true
74 | s2 equal nil? true
75 | s3 equal nil? false
76 | s4 equal nil? false
77 | ```
78 |
79 | 所有的空切片`empty slice`的数据指针都指向**同一个地址`0x5a6d48`**。
80 |
81 | 下面来看看“截取”方式:
82 |
83 | 第一种:
84 |
85 | ```go
86 | data := [...]int{0,1,2,3,4,5,6,7,8,9}
87 | slice := data[2:4] //data[low,high]
88 | ```
89 |
90 | 对 `data` 使用2个索引值,截取出新的`slice`。这里 `data` 可以是数组或者 slice。`low` 是最低索引值,为闭区间,也就是说第一个元素是 data 位于 `low` 索引处的元素(这里为元素`2`);而 `high` 则是开区间,表示最后一个元素只能是索引 `high-1` 处的元素(这里为元素`3`),新的slice的长度计算方式为`high-low`(这里长度为4-2=2),而容量则是从当前low索引往后的元素个数(这里容量为8)。
91 |
92 | ```go
93 | package main
94 |
95 | import "fmt"
96 |
97 | func main() {
98 | data1 := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
99 | slice := data1[2:4]
100 | fmt.Printf("slice is %v\n", slice)
101 | fmt.Printf("slice' length = %v\n", len(slice))
102 | fmt.Printf("slice' cap = %v\n", cap(slice))
103 | }
104 | ```
105 |
106 | ```
107 | 结果:
108 | slice is [2 3]
109 | slice' length = 2
110 | slice' cap = 8
111 | ```
112 |
113 | 第二种:
114 |
115 | ```go
116 | data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
117 | slice := data[2:4:6] // data[low, high, max] 其中max >= high >= low
118 | ```
119 |
120 | 对 `data` 使用3个索引值,多出了一个`max`索引,其中`low`和`high`的作用相同,可以计算出slice的长度为`high-low`(这里长度同样为4-2=2),而`max`也是开区间,而最大容量则只能是索引 `max-1` 处的元素(这里为`5`),slice容量的计算方式为`max-low`(这里容量为6-2=4)。
121 |
122 | ```go
123 | package main
124 |
125 | import "fmt"
126 |
127 | func main() {
128 | data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
129 | slice := data[2:4:6]
130 | fmt.Printf("slice is %v\n", slice)
131 | fmt.Printf("slice' length = %v\n", len(slice))
132 | fmt.Printf("slice' cap = %v\n", cap(slice))
133 | }
134 | ```
135 |
136 | ```
137 | 结果:
138 | slice is [2 3]
139 | slice' length = 2
140 | slice' cap = 4
141 | ```
142 |
143 | 注意:
144 |
145 | - 当 `high == low` 时,新 `slice` 为空。
146 |
147 | - 还有一点,`high` 和 `max` 必须在旧数组或者旧切片的容量范围内。
148 |
149 | **这里引入一道题,对“截取”做一个好好的回顾:**
150 |
151 | ```go
152 | package main
153 | import "fmt"
154 | func main() {
155 | slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
156 |
157 | s1 := slice[2:5]
158 | s2 := s1[2:6:7]
159 |
160 | s2 = append(s2, 100)
161 | s2 = append(s2, 200)
162 |
163 | s1[2] = 20
164 |
165 | fmt.Println(s1)
166 | fmt.Println(s2)
167 | fmt.Println(slice)
168 | }
169 | ```
170 |
171 | ```
172 | 结果:
173 | [2 3 20]
174 | [4 5 6 7 100 200]
175 | [0 1 2 3 20 5 6 7 100 9]
176 | ```
177 |
178 | 来分析一遍代码,初始状态如下:
179 |
180 | ```go
181 | slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
182 | s1 := slice[2:5]
183 | s2 := s1[2:6:7]
184 | ```
185 |
186 | `s1` 从 `slice`的索引 [2,5),长度为3,容量默认到数组结尾,为8。 `s2` 从 `s1`的索引 [2,6),容量大小从[2,7),为5。
187 |
188 |
19 |
20 | 可以看到slice共有三个属性,每个属性的解释如上所示,其中在底层数组不进行扩容的情况下,容量也是 slice 可以扩张的最大限度。需要注意的是,**底层数组是可以被多个 slice 同时指向的**,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
21 |
22 | ## slice的创建
23 |
24 | 创建 slice 的方式有以下几种:
25 |
26 | | 序号 | 方式 | 代码示例 |
27 | | ---- | ------------------ | ---------------------------------------------------- |
28 | | 1 | 直接声明 | `var slice []int` |
29 | | 2 | new | `slice := *new([]int)` |
30 | | 3 | 字面量 | `slice := []int{1,2,3,4,5}` |
31 | | 4 | make | `slice := make([]int, 5, 10)` |
32 | | 5 | 从切片或数组“截取” | `slice := array[1:5]` 或 `slice := sourceSlice[1:5]` |
33 |
34 | 其中第一种方式和第二种方式创建出来的切片其实是一种`nil slice`,与之对应的还有一种`empty slice`。
35 |
36 | 区别如下(官方建议使用`nil slice`):
37 |
38 | | 创建方式 | nil切片 | 空切片 |
39 | | ------------- | -------------------- | ----------------------- |
40 | | 方式一 | var s1 []int | var s2 = []int{} |
41 | | 方式二 | var s3 = *new([]int) | var s4 = make([]int, 0) |
42 | | 长度 | 0 | 0 |
43 | | 容量 | 0 | 0 |
44 | | 和 `nil` 比较 | `true` | `false` |
45 |
46 | ```go
47 | package main
48 |
49 | import "fmt"
50 |
51 | func main() {
52 | var s1 []int
53 | var s2 = *new([]int)
54 | var s3 = make([]int, 0)
55 | var s4 = []int{}
56 | fmt.Printf("s1's address is %p\n", s1)
57 | fmt.Printf("s2's address is %p\n", s2)
58 | fmt.Printf("s3's address is %p\n", s3)
59 | fmt.Printf("s4's address is %p\n", s4)
60 | fmt.Printf("s1 equal nil? %v\n", s1 == nil)
61 | fmt.Printf("s2 equal nil? %v\n", s2 == nil)
62 | fmt.Printf("s3 equal nil? %v\n", s3 == nil)
63 | fmt.Printf("s4 equal nil? %v\n", s4 == nil)
64 | }
65 | ```
66 |
67 | ```
68 | 结果如下:
69 | s1's address is 0x0
70 | s2's address is 0x0
71 | s3's address is 0x5a6d48
72 | s4's address is 0x5a6d48
73 | s1 equal nil? true
74 | s2 equal nil? true
75 | s3 equal nil? false
76 | s4 equal nil? false
77 | ```
78 |
79 | 所有的空切片`empty slice`的数据指针都指向**同一个地址`0x5a6d48`**。
80 |
81 | 下面来看看“截取”方式:
82 |
83 | 第一种:
84 |
85 | ```go
86 | data := [...]int{0,1,2,3,4,5,6,7,8,9}
87 | slice := data[2:4] //data[low,high]
88 | ```
89 |
90 | 对 `data` 使用2个索引值,截取出新的`slice`。这里 `data` 可以是数组或者 slice。`low` 是最低索引值,为闭区间,也就是说第一个元素是 data 位于 `low` 索引处的元素(这里为元素`2`);而 `high` 则是开区间,表示最后一个元素只能是索引 `high-1` 处的元素(这里为元素`3`),新的slice的长度计算方式为`high-low`(这里长度为4-2=2),而容量则是从当前low索引往后的元素个数(这里容量为8)。
91 |
92 | ```go
93 | package main
94 |
95 | import "fmt"
96 |
97 | func main() {
98 | data1 := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
99 | slice := data1[2:4]
100 | fmt.Printf("slice is %v\n", slice)
101 | fmt.Printf("slice' length = %v\n", len(slice))
102 | fmt.Printf("slice' cap = %v\n", cap(slice))
103 | }
104 | ```
105 |
106 | ```
107 | 结果:
108 | slice is [2 3]
109 | slice' length = 2
110 | slice' cap = 8
111 | ```
112 |
113 | 第二种:
114 |
115 | ```go
116 | data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
117 | slice := data[2:4:6] // data[low, high, max] 其中max >= high >= low
118 | ```
119 |
120 | 对 `data` 使用3个索引值,多出了一个`max`索引,其中`low`和`high`的作用相同,可以计算出slice的长度为`high-low`(这里长度同样为4-2=2),而`max`也是开区间,而最大容量则只能是索引 `max-1` 处的元素(这里为`5`),slice容量的计算方式为`max-low`(这里容量为6-2=4)。
121 |
122 | ```go
123 | package main
124 |
125 | import "fmt"
126 |
127 | func main() {
128 | data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
129 | slice := data[2:4:6]
130 | fmt.Printf("slice is %v\n", slice)
131 | fmt.Printf("slice' length = %v\n", len(slice))
132 | fmt.Printf("slice' cap = %v\n", cap(slice))
133 | }
134 | ```
135 |
136 | ```
137 | 结果:
138 | slice is [2 3]
139 | slice' length = 2
140 | slice' cap = 4
141 | ```
142 |
143 | 注意:
144 |
145 | - 当 `high == low` 时,新 `slice` 为空。
146 |
147 | - 还有一点,`high` 和 `max` 必须在旧数组或者旧切片的容量范围内。
148 |
149 | **这里引入一道题,对“截取”做一个好好的回顾:**
150 |
151 | ```go
152 | package main
153 | import "fmt"
154 | func main() {
155 | slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
156 |
157 | s1 := slice[2:5]
158 | s2 := s1[2:6:7]
159 |
160 | s2 = append(s2, 100)
161 | s2 = append(s2, 200)
162 |
163 | s1[2] = 20
164 |
165 | fmt.Println(s1)
166 | fmt.Println(s2)
167 | fmt.Println(slice)
168 | }
169 | ```
170 |
171 | ```
172 | 结果:
173 | [2 3 20]
174 | [4 5 6 7 100 200]
175 | [0 1 2 3 20 5 6 7 100 9]
176 | ```
177 |
178 | 来分析一遍代码,初始状态如下:
179 |
180 | ```go
181 | slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
182 | s1 := slice[2:5]
183 | s2 := s1[2:6:7]
184 | ```
185 |
186 | `s1` 从 `slice`的索引 [2,5),长度为3,容量默认到数组结尾,为8。 `s2` 从 `s1`的索引 [2,6),容量大小从[2,7),为5。
187 |
188 | 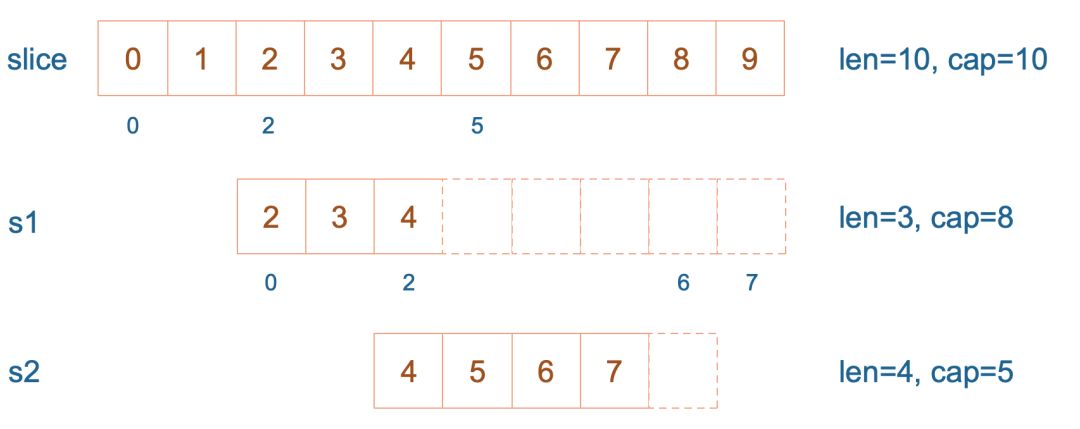 189 |
190 |
191 |
192 | 接着,向 `s2` 尾部追加一个元素 100:
193 |
194 | ```go
195 | s2 = append(s2, 100)
196 | ```
197 |
198 | `s2` 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 `s1` 都可以看得到。
199 |
200 |
189 |
190 |
191 |
192 | 接着,向 `s2` 尾部追加一个元素 100:
193 |
194 | ```go
195 | s2 = append(s2, 100)
196 | ```
197 |
198 | `s2` 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 `s1` 都可以看得到。
199 |
200 | 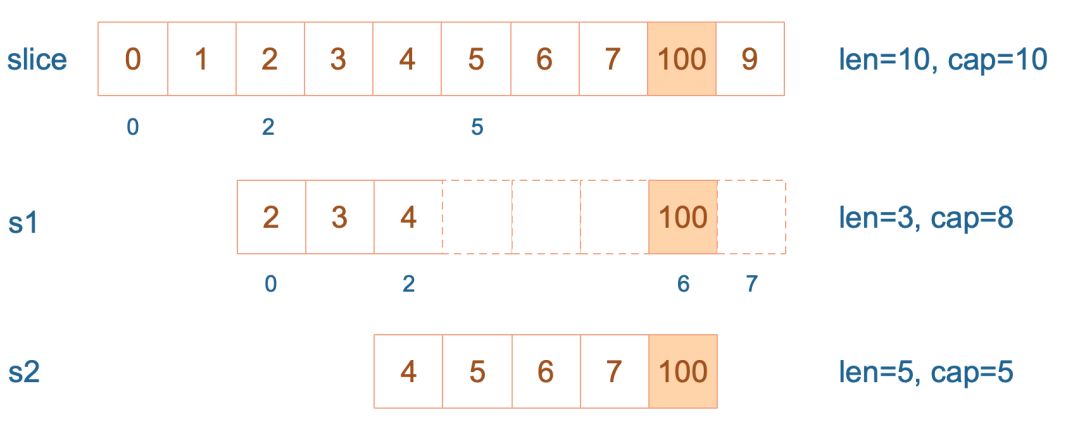 201 |
202 |
203 |
204 | 再次向 `s2` 追加元素200:
205 |
206 | ```go
207 | s2 = append(s2, 100)
208 | ```
209 |
210 | 这时,`s2` 的容量不够用,该扩容了。于是,`s2` 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 `append` 带来的再一次扩容,`s2` 会在此次扩容的时候多留一些 `buffer`,将新的容量将扩大为原始容量的`2倍`(具体见下小节分析),也就是10了。
211 |
212 |
201 |
202 |
203 |
204 | 再次向 `s2` 追加元素200:
205 |
206 | ```go
207 | s2 = append(s2, 100)
208 | ```
209 |
210 | 这时,`s2` 的容量不够用,该扩容了。于是,`s2` 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 `append` 带来的再一次扩容,`s2` 会在此次扩容的时候多留一些 `buffer`,将新的容量将扩大为原始容量的`2倍`(具体见下小节分析),也就是10了。
211 |
212 | 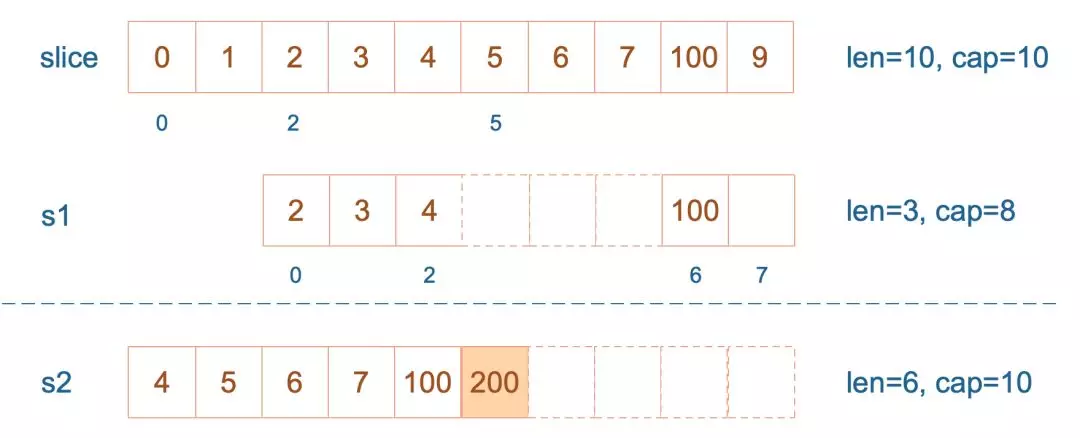 213 |
214 |
215 |
216 | 最后,修改 `s1` 索引为2位置的元素:
217 |
218 | ```go
219 | s1[2] = 20
220 | ```
221 |
222 | 这次只会影响原始数组相应位置的元素。它影响不到 `s2` ,因为不属于同一个底层数组了。
223 |
224 |
213 |
214 |
215 |
216 | 最后,修改 `s1` 索引为2位置的元素:
217 |
218 | ```go
219 | s1[2] = 20
220 | ```
221 |
222 | 这次只会影响原始数组相应位置的元素。它影响不到 `s2` ,因为不属于同一个底层数组了。
223 |
224 | 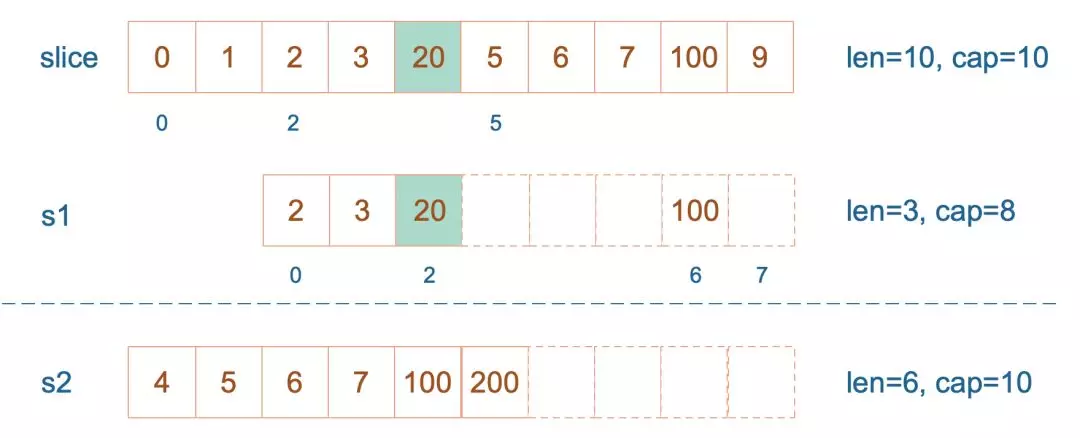 225 |
226 |
227 |
228 | 最后打印 `s1` 的时候,只会打印出 `s1` 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
229 |
230 | ## slice的append操作
231 |
232 | 在2节最后一段提到了append操作,**下面让我们来看看slice的append操作到底做了什么**:
233 |
234 | 先来看看 `append` 函数的原型:
235 |
236 | ```go
237 | func append(slice []Type, elems ...Type) []Type
238 | ```
239 |
240 | append 函数的参数长度可变,因此可以追加多个值到 slice 中,还可以用 `...` 传入 slice,直接追加一个切片。
241 |
242 | ```go
243 | slice = append(slice, elem1, elem2)
244 | slice = append(slice, anotherSlice...)
245 | ```
246 |
247 | 使用 append 可以向 slice 追加元素,实际上是往底层数组添加元素。但是底层数组的长度是固定的,如果索引 `len-1` 所指向的元素已经是底层数组的最后一个元素,就没法再添加了。
248 |
249 | 这时,slice 会迁移到新的内存位置,新底层数组的长度也会增加,这样就可以放置新增的元素。同时,为了应对未来可能再次发生的 append 操作,新的底层数组的长度,也就是新 `slice` 的容量是留了一定的 `buffer` 的。否则,每次添加元素的时候,都会发生迁移,成本太高。
250 |
251 | 新 slice 预留的 `buffer` 大小是有一定规律的。网上大多数的文章都是这样描述的:
252 |
253 | > 当原 slice 容量小于 `1024` 的时候,新 slice 容量变成原来的 `2` 倍;原 slice 容量超过 `1024`,新 slice 容量变成原来的`1.25`倍。
254 |
255 | **这句话是错误的!**
256 |
257 | **举个例子:**
258 |
259 | ```go
260 | package main
261 |
262 | import "fmt"
263 |
264 | func main() {
265 | s := []int{1,2}
266 | s = append(s,4,5,6)
267 | fmt.Printf("len=%d, cap=%d",len(s),cap(s))
268 | }
269 | ```
270 |
271 | ```
272 | 结果:
273 | len=5,cap=6
274 | ```
275 |
276 | 如果按网上各种文章中总结的那样:**原 slice 长度小于 1024 的时候,容量每次增加 1 倍。添加元素 4 的时候,容量变为4;添加元素 5 的时候不变;添加元素 6 的时候容量增加 1 倍,变成 8。**
277 |
278 | 那上面代码的运行结果就是:
279 |
280 | ```
281 | len=5, cap=8
282 | ```
283 |
284 | 这是错误的,下面来看看源码:
285 |
286 | ```go
287 | // go 1.14 src/runtime/slice.go:76
288 | //growslice():它被传递给slice元素类型,旧的slice和所需的新的最小容量,并返回一个至少具有该容量的新slice,并将旧数据复制到其中。
289 | func growslice(et *_type, old slice, cap int) slice {
290 | //...
291 | newcap := old.cap
292 | doublecap := newcap + newcap
293 | //如果新的容量大于旧的两倍,则直接扩容到新的容量
294 | if cap > doublecap {
295 | newcap = cap
296 | } else {
297 | // 当新的容量不大于旧的两倍
298 | // 如果旧长度小于1024,那扩容到旧的两倍
299 | if old.len < 1024 {
300 | newcap = doublecap
301 | } else {
302 | //否则扩容到旧的1.25倍
303 | for 0 < newcap && newcap < cap {
304 | newcap += newcap / 4
305 | }
306 | //...
307 | }
308 |
309 | //...
310 | //内存对齐
311 | capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
312 | newcap = int(capmem / sys.PtrSize)
313 | }
314 | ```
315 |
316 | 如果只看前半部分,现在网上各种文章里说的 `newcap` 的规律是对的。现实是,后半部分还对 `newcap` 作了一个`内存对齐roundupsize`,这个**和内存分配策略相关**。
317 |
318 | > 进行内存对齐之后,新 slice 的容量是要 `大于等于` 旧slice 容量的 `2倍`或者`1.25倍`。
319 |
320 | **例子分析:**
321 |
322 | `growslice`函数的参数依次是 `元素的类型`,`旧slice`,`新slice最小求的容量`。
323 |
324 | 例子中 `s` 原来只有 2 个元素,`len` 和 `cap` 都为 2,append了三个元素后,长度变为 3,容量最小要变成 5,即调用 `growslice` 函数时,传入的第三个参数应该为 5。即 cap=5。而一方面,`doublecap` 是原 slice容量的 2 倍,等于 4。满足第一个 if 条件,所以 `newcap` 变成了 5。
325 |
326 | 接着调用了 `roundupsize` 函数,传入` size=40`。(代码中`sys.PtrSize`是指一个指针的大小,在64位机上是8,即传入5*8)
327 |
328 | ```go
329 | // go 1.14 src/runtime/internal/sys/stubs.go: 8
330 | //拿 64 系统来说,0 取反之后右移 63 位的结果是 1,然后 4 的二进制表示是 0100,左移 1 位的结果是 1000,结果为 8。
331 | const PtrSize = 4 << (^uintptr(0) >> 63)
332 | ```
333 |
334 | 下面来看看roundupsize源码:
335 |
336 | ```go
337 | // go 1.14 src/runtime/msize.go:13
338 | func roundupsize(size uintptr) uintptr {
339 | if size < _MaxSmallSize {
340 | if size <= smallSizeMax-8 {
341 | return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
342 | } else {
343 | return uintptr(class_to_size[size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]])
344 | }
345 | }
346 | //...
347 | }
348 |
349 | 其中:
350 | const _MaxSmallSize = 32768
351 | const smallSizeMax = 1024
352 | const smallSizeDiv = 8
353 | ```
354 |
355 | 传入size=40后,很明显,最后返回
356 |
357 | ```go
358 | class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]]
359 | ```
360 |
361 | 这是 `Go` 源码中有关内存分配的两个 `slice`。`class_to_size`通过 `spanClass`获取 `span`划分的 `object`大小。而 `size_to_class8` 表示通过 `size` 获取它的 `spanClass`。
362 |
363 | ```go
364 | // go 1.14 src/runtime/sizeclasses.go
365 | var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
366 |
367 | var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31}
368 | ```
369 |
370 | 我们传进去的 `size` 等于 40。所以 `(size+smallSizeDiv-1)/smallSizeDiv = 5`;获取 `size_to_class8` 数组中索引为 `5` 的元素为 `4`;获取 `class_to_size` 中索引为 `4` 的元素为 `48`。
371 |
372 | 最终,新的 slice 的容量为 `6`:
373 |
374 | ```
375 | newcap = int(capmem / sys.PtrSize) // 48 / 8 = 6
376 | ```
377 |
378 | ## 为什么 nil slice 可以直接 append
379 |
380 | 其实 `nil slice` 或者 `empty slice` 都是可以通过调用 append 函数来获得底层数组的扩容。最终都是调用 `mallocgc` 来向 Go 的内存管理器申请到一块内存,然后再赋给原来的`nil slice` 或 `empty slice`,然后摇身一变,成为“真正”的 `slice` 了。
381 |
382 | ## 传 slice 和 slice 指针有什么区别
383 |
384 | 当 slice 作为函数参数时,就是一个普通的结构体。其实很好理解:若直接传 slice,在调用者看来,实参 slice 并不会被函数中的操作改变;若传的是 slice 的指针,在调用者看来,是会被改变原 slice 的。
385 |
386 | 值的注意的是,不管传的是 slice 还是 slice 指针,如果改变了 slice 底层数组的数据,会反应到实参 slice 的底层数据。为什么能改变底层数组的数据?很好理解:**底层数据在 slice 结构体里是一个指针,仅管 slice 结构体自身不会被改变,也就是说底层数据地址不会被改变。 但是通过指向底层数据的指针,可以改变切片的底层数据**。
387 |
388 | 通过 slice 的 array 字段就可以拿到数组的地址。在代码里,是直接通过类似 `s[i]=10` 这种操作改变 slice 底层数组元素值。
389 |
390 | 将切片通过参数传递给函数,其实质是复制了slice结构体对象,两个slice结构体的字段值均相等。正常情况下,由于函数内slice结构体的array和函数外slice结构体的array指向的是同一底层数组,所以当对底层数组中的数据做修改时,两者均会受到影响。
391 |
392 | 但是存在这样的问题:如果指向底层数组的指针被覆盖或者修改(copy、重分配、append触发扩容),此时函数内部对数据的修改将不再影响到外部的切片,代表长度的len和容量cap也均不会被修改。
393 |
394 | ## 总结
395 |
396 | - 切片是对底层数组的一个抽象,描述了它的一个片段。
397 | - 切片实际上是一个结构体,它有三个字段:长度,容量,底层数据的地址。
398 | - 多个切片可能共享同一个底层数组,这种情况下,对其中一个切片或者底层数组的更改,会影响到其他切片。
399 | - `append` 函数会在切片容量不够的情况下,调用 `growslice` 函数获取所需要的内存,这称为扩容,扩容会改变元素原来的位置。
400 | - 扩容策略并不是简单的扩为原切片容量的 `2` 倍或 `1.25` 倍,还有**内存对齐的操作**。扩容后的容量 >= 原容量的 `2` 倍或 `1.25` 倍。
401 | - 当直接用切片作为函数参数时,可以改变切片的元素,不能改变切片本身;想要改变切片本身,可以将改变后的切片返回,函数调用者接收改变后的切片或者将切片指针作为函数参数。
402 |
403 |
404 |
405 | > 参考:
406 | >
407 | > [深度解密Go语言之Slice](https://mp.weixin.qq.com/s/MTZ0C9zYsNrb8wyIm2D8BA)
408 | >
409 | > [切片传递与指针传递的区别_zuiyijiangnan的博客-CSDN博客_切片传递](https://blog.csdn.net/zuiyijiangnan/article/details/112673446)
--------------------------------------------------------------------------------
/golang/deep/unsafe.md:
--------------------------------------------------------------------------------
1 | # Go语言深度解析之unsafe
2 |
3 | ## 什么是unsafe
4 |
5 | unsafe 库让 golang 可以像C语言一样操作计算机内存,但这并不是golang推荐使用的,能不用尽量不用,就像它的名字所表达的一样,它绕过了golang的内存安全原则,是不安全的,容易使你的程序出现莫名其妙的问题,不利于程序的扩展与维护。
6 |
7 | 先简单介绍下Golang指针类型:
8 |
9 | 1. `*类型`:普通指针,用于传递对象地址,不能进行指针运算。
10 | 2. `unsafe.Pointer`:通用指针类型,用于转换不同类型的指针,不能进行指针运算。
11 | 3. `uintptr`:用于指针运算,GC 不把 uintptr 当指针,uintptr 无法持有对象,**uintptr 类型的目标会被回收**。
12 |
13 | unsafe.Pointer 可以和 普通指针 进行相互转换。
14 |
15 | unsafe.Pointer 可以和 uintptr 进行相互转换。
16 |
17 | 也就是说 **unsafe.Pointer 是桥梁,可以让任意类型的指针实现相互转换,也可以将任意类型的指针转换为 uintptr 进行指针运算**。
18 |
19 | 
20 |
21 | unsafe底层源码如下:
22 |
23 | 两个类型:
24 |
25 | ```go
26 | // go 1.14 src/unsafe/unsafe.go
27 | type ArbitraryType int
28 | type Pointer *ArbitraryType
29 | ```
30 |
31 | 三个函数:
32 |
33 | ```go
34 | func Sizeof(x ArbitraryType) uintptr
35 | func Offsetof(x ArbitraryType) uintptr
36 | func Alignof(x ArbitraryType) uintptr
37 | ```
38 |
39 | 通过分析发现,这三个函数的参数均是ArbitraryType类型,就是接受任何类型的变量。
40 |
41 | 1. `Sizeof` **返回类型 x 所占据的字节数,但不包含 x 所指向的内容的大小**。例如,对于一个指针,函数返回的大小为 8 字节(64位机上),一个 slice 的大小则为 slice header 的大小。
42 | 2. `Offsetof`返回变量指定属性的偏移量,这个函数虽然接收的是任何类型的变量,但是有一个前提,就是变量要是一个struct类型,且还不能直接将这个struct类型的变量当作参数,只能将这个struct类型变量的属性当作参数。
43 | 3. `Alignof`返回变量对齐字节数量
44 |
45 | ## unsafe包的操作
46 |
47 | ### 大小Sizeof
48 |
49 | unsafe.Sizeof函数返回的就是uintptr类型的值,表示所占据的字节数(表达式,即值的大小):
50 |
51 | ```go
52 | package main
53 |
54 | import (
55 | "fmt"
56 | "reflect"
57 | "unsafe"
58 | )
59 |
60 | func main() {
61 | var a int32
62 | var b = &a
63 | fmt.Println(reflect.TypeOf(unsafe.Sizeof(a))) // uintptr
64 | fmt.Println(unsafe.Sizeof(a)) // 4
65 | fmt.Println(reflect.TypeOf(b).Kind()) // ptr
66 | fmt.Println(unsafe.Sizeof(b)) // 8
67 | }
68 | ```
69 |
70 | 对于 `a`来说,它是`int32`类型,在内存中占4个字节,而对于`b`来说,是`*int32`类型,即底层为`ptr`指针类型,在64位机下占8字节。
71 |
72 | ### 偏移Offsetof
73 |
74 | 对于一个结构体,通过 Offset 函数可以获取结构体成员的偏移量,进而获取成员的地址,读写该地址的内存,就可以达到改变成员值的目的。
75 |
76 | 这里有一个内存分配相关的事实:**结构体会被分配一块连续的内存,结构体的地址也代表了第一个字段的地址。**
77 |
78 | 举个例子:
79 |
80 | ```go
81 | package main
82 |
83 | import (
84 | "fmt"
85 | "unsafe"
86 | )
87 |
88 | type user struct {
89 | id int32
90 | name string
91 | age byte
92 | }
93 |
94 | func main() {
95 | var u = user{
96 | id: 1,
97 | name: "xiaobai",
98 | age: 22,
99 | }
100 | fmt.Println(u)
101 | fmt.Println(unsafe.Offsetof(u.id)) // 0 id在结构体user中的偏移量,也是结构体的地址
102 | fmt.Println(unsafe.Offsetof(u.name)) // 8
103 | fmt.Println(unsafe.Offsetof(u.age)) // 24
104 |
105 | // 根据偏移量修改字段的值 比如将id字段改为1001
106 | // 因为结构体的地址相当于第一个字段id的地址
107 | // 直接用unsafe包自带的Pointer获取id指针
108 | id := (*int)(unsafe.Pointer(&u))
109 | *id = 1001
110 |
111 | // 更加相对于id字段的偏移量获取name字段的地址并修改其内容
112 | // 需要用到uintptr进行指针运算 然后再利用unsafe.Pointer这个媒介将uintptr类型转换成一般的指针类型*string
113 | name := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&u)) + unsafe.Offsetof(u.name)))
114 | *name = "花花"
115 |
116 | // 同理更改age字段
117 | age := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&u)) + unsafe.Offsetof(u.age)))
118 | *age = 33
119 |
120 | fmt.Println(u)
121 | }
122 | ```
123 |
124 | ### 对齐Alignof
125 |
126 | 要了解这个函数,你需要了解`数据对齐`。简单的说,它让数据结构在内存中以某种的布局存放,使该数据的读取性能能够更加的快速。
127 |
128 | CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度。
129 |
130 | #### 普通字段的对齐值
131 |
132 | ```go
133 | fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
134 | fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
135 | fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
136 | fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
137 | fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
138 | fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
139 | fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
140 | ```
141 |
142 | 输出结果:
143 |
144 | ```text
145 | bool align: 1
146 | int32 align: 4
147 | int8 align: 1
148 | int64 align: 8
149 | byte align: 1
150 | string align: 8
151 | map align: 8
152 | ```
153 |
154 | 在 Go 中可以调用 `unsafe.Alignof` 来返回相应类型的对齐系数。通过观察输出结果,可得知基本都是 2n,最大也`不会超过 8`。这是因为我们的**64位编译器默认对齐系数是 8**,因此最大值不会超过这个数。
155 |
156 | #### 对齐规则
157 |
158 | 1. **结构体的成员变量**,第一个成员变量的偏移量为 0。往后的每个成员变量的`对齐值=min(编译器默认对齐长度,当前成员变量类型的长度)`。其`偏移量=对齐值xN`
159 | 2. **结构体本身**,`对齐值=最小整数倍{max(编译器默认对齐长度,结构体的所有成员变量类型中的最大长度)}`,
160 |
161 | 结合以上两点,可得知若编译器默认对齐长度超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
162 |
163 | #### 结构体的对齐值
164 |
165 | 下面来看一下结构体的对齐:
166 |
167 | ```go
168 | type part struct {
169 | a bool // 1
170 | b int32 // 4
171 | c int8 // 1
172 | d int64 // 8
173 | e byte // 1
174 | }
175 |
176 | func main() {
177 | var p part
178 | fmt.Println(unsafe.Sizeof(p)) // 32
179 | }
180 | ```
181 |
182 | 按照普通字段(结构体内成员变量)的对齐方式,我们可以计算得出,这个结构体的大小占`1+4+1+8+1=15`个字节,但是用`unsafe.Sizeof`计算发现`part结构体`占`32`字节,是不是有点惊讶😮
183 |
184 | 这里面就涉及到了内存对齐,下面我们来分析一下:
185 |
186 | | 成员变量 | 类型 | 偏移量 | 自身占用 |
187 | | ---------- | ----- | ------ | -------- |
188 | | a | bool | 0 | 1 |
189 | | 数据对齐 | - | 1 | 3 |
190 | | b | int32 | 4 | 4 |
191 | | c | int8 | 8 | 1 |
192 | | 数据对齐 | - | 9 | 7 |
193 | | d | in64 | 16 | 8 |
194 | | e | byte | 24 | 1 |
195 | | 数据对齐 | - | 25 | 7 |
196 | | 总占用大小 | - | - | 32 |
197 |
198 | - 对于变量a而言
199 |
200 | 类型是bool;大小/对齐值本身为1字节;偏移量为0,**占用了第0位**;此时内存中表示为`a`
201 |
202 | - 对于变量b而言
203 |
204 | 类型是int32;大小/对齐值本身为4字节;根据对齐规则一,偏移量必须为对齐值4的整数倍,故这里的偏移量为4,**占用了第4 ~ 7位**,则**第1 ~ 3位用padding字节填充**;此时内存中表示为`a---|bbbb`,(`|`只起到分隔作用,表示方便一些)
205 |
206 | - 对于变量c而言
207 |
208 | 类型是int8;大小/对齐值本身为1字节;当前偏移量为8,无需扩充,**占用了第8位**;此时内存中表示为`a---|bbbb|c`
209 |
210 | - 对于变量d而言
211 |
212 | 类型是int64;大小/对齐值本身为8字节;根据对齐规则一,偏移量必须为对齐值8的整数倍,故当前偏移量为16,**占用了第16 ~ 23位**,则**第9 ~ 15为用padding字节填充**;此时内存中表示为`a---|bbbb|c---|----|dddd|dddd`
213 |
214 | - 对于变量e而言
215 |
216 | 类型是byte;大小/对齐值本身为1字节;当前偏移量为24,无需扩充,**占用了第24位**;此时内存中表示为`a---|bbbb|c---|----|dddd|dddd|e`
217 |
218 | 这里计算后,发现总共占用25字节,哪里又来的32字节呢?😳
219 |
220 | 再让我们回顾一下对齐原则的第二点,**结构体本身**,`对齐值=最小整数倍{max(编译器默认对齐长度,结构体的所有成员变量类型中的最大长度)}`
221 |
222 | 1. 这里编译器默认对齐长度为8字节(64位机)
223 |
224 | 2. 结构体中所有成员变量类型的最大长度为int64,8字节
225 | 3. 取二者最大数的最小整数倍作为对齐值,我们算的part结构体大小为25字节,不是8字节的整数倍,故还需要填充到32字节。
226 |
227 | 综上,part结构体在内存中表示为`a---|bbbb|c---|----|dddd|dddd|e----|----`
228 |
229 | #### 扩展
230 |
231 | 让我们改变一下part结构体中字段的顺序看看(part结构体完全相同)
232 |
233 | ```go
234 | type part struct {
235 | a bool // 1
236 | c int8 // 1
237 | e byte // 1
238 | b int32 //4
239 | d int64 // 8
240 | }
241 |
242 | func main() {
243 | var p part
244 | fmt.Println(unsafe.Sizeof(p)) // 16
245 | }
246 | ```
247 |
248 | 这时候再用`unsafe.Sizeof`查看会发现,part结构体的内存占用只有`16`字节,瞬间减少了一半的内存空间,大家可以按照前面的步骤分析一下~
249 |
250 | 这里建议在构建结构体时,**按照字段大小的升序进行排序,会减少一点的内存空间**。
251 |
252 | #### 反射包的对齐方法
253 |
254 | 反射包也有某些方法可用于计算对齐值:
255 |
256 | ```go
257 | unsafe.Alignof(w)等价于reflect.TypeOf(w).Align
258 | unsafe.Alignof(w.i)等价于reflect.Typeof(w.i).FieldAlign()
259 | ```
260 |
261 | ## 总结
262 |
263 | - unsafe 包绕过了 Go 的类型系统,达到直接操作内存的目的,使用它有一定的风险性。但是在某些场景下,使用 unsafe 包提供的函数会提升代码的效率,Go 源码中也是大量使用 unsafe 包。
264 |
265 | - unsafe 包定义了 Pointer 和三个函数:
266 |
267 | ```go
268 | type ArbitraryType int
269 | type Pointer *ArbitraryType
270 |
271 | func Sizeof(x ArbitraryType) uintptr
272 | func Offsetof(x ArbitraryType) uintptr
273 | func Alignof(x ArbitraryType) uintptr
274 | ```
275 |
276 | 通过三个函数可以获取变量的大小、偏移、对齐等信息。
277 |
278 | - uintptr 可以和 unsafe.Pointer 进行相互转换,uintptr 可以进行数学运算。这样,通过 uintptr 和 unsafe.Pointer 的结合就解决了 Go 指针不能进行数学运算的限制。
279 |
280 | - 通过 unsafe 相关函数,可以获取结构体私有成员的地址,进而对其做进一步的读写操作,突破 Go 的类型安全限制。
281 |
282 |
283 |
284 | > 参考:
285 | >
286 | > - [深度解密Go语言之unsafe](https://mp.weixin.qq.com/s/OO-kwB4Fp_FnCaNXwGJoEw)
287 | > - [unsafe包的学习和使用 - 离地最远的星 - 博客园 (cnblogs.com)](https://www.cnblogs.com/hualou/p/12070155.html)
288 | > - [在 Go 中恰到好处的内存对齐 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/53413177)
--------------------------------------------------------------------------------
/golang/useful_package.md:
--------------------------------------------------------------------------------
1 | # Golang常用到的库
2 |
3 | | 库 | 地址 |
4 | | ------------------------------------------------------ | ------------------------------------------------------------ |
5 | | 数据库操作,需要装驱动 | https://github.com/go-sql-driver/mysql https://github.com/jinzhu/gorm |
6 | | 搜索es | https://github.com/olivere/elastic |
7 | | rocketmq操作 | https://github.com/apache/rocketmq-client-go/v2 |
8 | | rabbitmq 操作 | https://github.com/streadway/amqp |
9 | | redis 操作 | https://github.com/go-redis/redis https://github.com/gomodule/redigo |
10 | | etcd 操作 | [github.com/coreos/etcd/clientv3](https://pkg.go.dev/go.etcd.io/etcd/clientv3) |
11 | | kafka | https://github.com/Shopify/sarama https://github.com/bsm/sarama-cluste |
12 | | pprof | https://github.com/gin-contrib/pprof |
13 | | testfiy测试库 | https://github.com/stretchr/testify |
14 | | excel 操作 | https://github.com/360EntSecGroup-Skylar/excelize |
15 | | 可以操作任何数据的包 比方sting 转换类型啊 方便编写代码 | https://github.com/Unknwon/com |
16 | | 表单验证器 | https://github.com/go-playground/validator |
17 | | goroutine池 | https://github.com/panjf2000/ants |
18 | | golang的爬虫框架colly | https://github.com/gocolly/colly |
19 | | 命令行程序框架 cobra | https://github.com/spf13/cobra |
20 | | 配置读取viper | https://github.com/spf13/viper |
21 | | go key/value存储 | https://github.com/etcd-io/bbolt |
22 | | golang的绘图库go-echart | https://github.com/go-echarts/go-echarts/v2 |
23 | | golangweb项目热更新 进入项目目录下:fresh启动 | https://github.com/pilu/fresh |
24 | | 轻量级的协程池 | https://github.com/ivpusic/grpool |
25 | | 打印go的详细数据结构 | https://github.com/davecgh/go-spew |
26 | | jwt鉴权 | https://github.com/dgrijalva/jwt-go |
27 | | 拼音 | https://github.com/go-ego/gpy |
28 | | 分词 | https://github.com/go-ego/gse |
29 | | 搜索 | https://github.com/go-ego/riot |
30 | | session | https://github.com/gorilla/sessions |
31 | | 路由 | https://github.com/gorilla/mux |
32 | | websocket | https://github.com/gorilla/websocket |
33 | | Action handler | https://github.com/gorilla/handlers |
34 | | csrf | https://github.com/gorilla/csrf |
35 | | context | https://github.com/gorilla/context |
36 | | 过滤html标签 | https://github.com/grokify/html-strip-tags-go |
37 | | 可配置的HTML标签过滤 | https://github.com/microcosm-cc/bluemonday |
38 | | 根据IP获取地理位置信息 | https://github.com/ipipdotnet/ipdb-go |
39 | | html转markdown | https://github.com/jaytaylor/html2text |
40 | | goroutine 本地存储 | https://github.com/jtolds/gls |
41 | | 彩色输出 | https://github.com/mgutz/ansi |
42 | | 表格打印 | https://github.com/olekukonko/tablewriter |
43 | | reflect 更高效的反射API | https://github.com/modern-go/reflect2 |
44 | | 可取消的goroutine | https://github.com/modern-go/concurrent |
45 | | 深度拷贝 | https://github.com/mohae/deepcopy |
46 | | 安全的类型转换包 | https://github.com/spf13/cast |
47 | | 从文本中提取链接 | https://github.com/mvdan/xurls |
48 | | 字符串格式处理(驼峰转换) | https://godoc.org/github.com/naoina/go-stringutil |
49 | | 文本diff实现 | https://github.com/pmezard/go-difflib |
50 | | uuid相关 | https://github.com/satori/go.uuid https://github.com/snluu/uuid |
51 | | 去除UTF编码中的BOM | https://github.com/ssor/bom |
52 | | 图片缩放 | https://github.com/nfnt/resize |
53 | | 生成 mock server | https://github.com/otokaze/mock |
54 | | go 性能上报到influxdb | https://github.com/rcrowley/go-metrics |
55 | | go zookeeper客户端 | https://github.com/samuel/go-zookeeper |
56 | | go thrift | https://github.com/samuel/go-thrift |
57 | | go 性能上报到influxdb | https://github.com/rcrowley/go-metrics |
58 | | go 性能上报到prometheus | https://github.com/deathowl/go-metrics-prometheus |
59 | | ps utils | https://github.com/shirou/gopsutil |
60 | | 小数处理 | https://github.com/shopspring/decimal |
61 | | 结构化日志处理(json) | https://github.com/sirupsen/logrus |
62 | | grpc操作 | https://google.golang.org/grpc https://github.com/golang/protobuf/protoc-gen-go |
63 | | ceph私有云库 | https://gopkg.in/amz.v1/aws https://gopkg.in/amz.v1/s3 |
64 | | 阿里云oss库 | https://github.com/aliyun/aliyun-oss-go-sdk/oss |
65 |
66 |
67 |
68 |
--------------------------------------------------------------------------------
/system-design/security/advantages&disadvantages-of-jwt.md:
--------------------------------------------------------------------------------
1 | 在 [JWT基础概念详解及使用](./jwt-intro.md)这篇文章中,我介绍了:
2 |
3 | - 什么是 JWT?
4 | - JWT 由哪些部分组成?
5 | - 如何基于 JWT 进行身份验证?
6 | - JWT 如何防止 Token 被篡改?
7 | - 如何加强 JWT 的安全性?
8 |
9 | 这篇文章,我们一起探讨一下 JWT 身份认证的优缺点以及常见问题的解决办法。
10 |
11 | ## JWT 的优势
12 |
13 | 相比于 Session 认证的方式来说,使用 JWT 进行身份认证主要有下面 4 个优势。
14 |
15 | ### 无状态
16 |
17 | JWT 自身包含了身份验证所需要的所有信息,因此,我们的服务器不需要存储 Session 信息。这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。
18 |
19 | 不过,也正是由于 JWT 的无状态,也导致了它最大的缺点:**不可控!**
20 |
21 | 就比如说,我们想要在 JWT 有效期内废弃一个 JWT 或者更改它的权限的话,并不会立即生效,通常需要等到有效期过后才可以。再比如说,当用户 Logout 的话,JWT 也还有效。除非,我们在后端增加额外的处理逻辑比如将失效的 JWT 存储起来,后端先验证 JWT 是否有效再进行处理。具体的解决办法,我们会在后面的内容中详细介绍到,这里只是简单提一下。
22 |
23 | ### 有效避免了 CSRF 攻击
24 |
25 | **CSRF(Cross Site Request Forgery)** 一般被翻译为 **跨站请求伪造**,属于网络攻击领域范围。相比于 SQL 脚本注入、XSS 等安全攻击方式,CSRF 的知名度并没有它们高。但是,它的确是我们开发系统时必须要考虑的安全隐患。就连业内技术标杆 Google 的产品 Gmail 也曾在 2007 年的时候爆出过 CSRF 漏洞,这给 Gmail 的用户造成了很大的损失。
26 |
27 | **那么究竟什么是跨站请求伪造呢?** 简单来说就是用你的身份去做一些不好的事情(发送一些对你不友好的请求比如恶意转账)。
28 |
29 | 举个简单的例子:小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
30 |
31 | ```html
32 | 科学理财,年盈利率过万
33 | ```
34 |
35 | CSRF 攻击需要依赖 Cookie ,Session 认证中 Cookie 中的 `SessionID` 是由浏览器发送到服务端的,只要发出请求,Cookie 就会被携带。借助这个特性,即使黑客无法获取你的 `SessionID`,只要让你误点攻击链接,就可以达到攻击效果。
36 |
37 | 另外,并不是必须点击链接才可以达到攻击效果,很多时候,只要你打开了某个页面,CSRF 攻击就会发生。
38 |
39 | ```html
40 |
225 |
226 |
227 |
228 | 最后打印 `s1` 的时候,只会打印出 `s1` 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
229 |
230 | ## slice的append操作
231 |
232 | 在2节最后一段提到了append操作,**下面让我们来看看slice的append操作到底做了什么**:
233 |
234 | 先来看看 `append` 函数的原型:
235 |
236 | ```go
237 | func append(slice []Type, elems ...Type) []Type
238 | ```
239 |
240 | append 函数的参数长度可变,因此可以追加多个值到 slice 中,还可以用 `...` 传入 slice,直接追加一个切片。
241 |
242 | ```go
243 | slice = append(slice, elem1, elem2)
244 | slice = append(slice, anotherSlice...)
245 | ```
246 |
247 | 使用 append 可以向 slice 追加元素,实际上是往底层数组添加元素。但是底层数组的长度是固定的,如果索引 `len-1` 所指向的元素已经是底层数组的最后一个元素,就没法再添加了。
248 |
249 | 这时,slice 会迁移到新的内存位置,新底层数组的长度也会增加,这样就可以放置新增的元素。同时,为了应对未来可能再次发生的 append 操作,新的底层数组的长度,也就是新 `slice` 的容量是留了一定的 `buffer` 的。否则,每次添加元素的时候,都会发生迁移,成本太高。
250 |
251 | 新 slice 预留的 `buffer` 大小是有一定规律的。网上大多数的文章都是这样描述的:
252 |
253 | > 当原 slice 容量小于 `1024` 的时候,新 slice 容量变成原来的 `2` 倍;原 slice 容量超过 `1024`,新 slice 容量变成原来的`1.25`倍。
254 |
255 | **这句话是错误的!**
256 |
257 | **举个例子:**
258 |
259 | ```go
260 | package main
261 |
262 | import "fmt"
263 |
264 | func main() {
265 | s := []int{1,2}
266 | s = append(s,4,5,6)
267 | fmt.Printf("len=%d, cap=%d",len(s),cap(s))
268 | }
269 | ```
270 |
271 | ```
272 | 结果:
273 | len=5,cap=6
274 | ```
275 |
276 | 如果按网上各种文章中总结的那样:**原 slice 长度小于 1024 的时候,容量每次增加 1 倍。添加元素 4 的时候,容量变为4;添加元素 5 的时候不变;添加元素 6 的时候容量增加 1 倍,变成 8。**
277 |
278 | 那上面代码的运行结果就是:
279 |
280 | ```
281 | len=5, cap=8
282 | ```
283 |
284 | 这是错误的,下面来看看源码:
285 |
286 | ```go
287 | // go 1.14 src/runtime/slice.go:76
288 | //growslice():它被传递给slice元素类型,旧的slice和所需的新的最小容量,并返回一个至少具有该容量的新slice,并将旧数据复制到其中。
289 | func growslice(et *_type, old slice, cap int) slice {
290 | //...
291 | newcap := old.cap
292 | doublecap := newcap + newcap
293 | //如果新的容量大于旧的两倍,则直接扩容到新的容量
294 | if cap > doublecap {
295 | newcap = cap
296 | } else {
297 | // 当新的容量不大于旧的两倍
298 | // 如果旧长度小于1024,那扩容到旧的两倍
299 | if old.len < 1024 {
300 | newcap = doublecap
301 | } else {
302 | //否则扩容到旧的1.25倍
303 | for 0 < newcap && newcap < cap {
304 | newcap += newcap / 4
305 | }
306 | //...
307 | }
308 |
309 | //...
310 | //内存对齐
311 | capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
312 | newcap = int(capmem / sys.PtrSize)
313 | }
314 | ```
315 |
316 | 如果只看前半部分,现在网上各种文章里说的 `newcap` 的规律是对的。现实是,后半部分还对 `newcap` 作了一个`内存对齐roundupsize`,这个**和内存分配策略相关**。
317 |
318 | > 进行内存对齐之后,新 slice 的容量是要 `大于等于` 旧slice 容量的 `2倍`或者`1.25倍`。
319 |
320 | **例子分析:**
321 |
322 | `growslice`函数的参数依次是 `元素的类型`,`旧slice`,`新slice最小求的容量`。
323 |
324 | 例子中 `s` 原来只有 2 个元素,`len` 和 `cap` 都为 2,append了三个元素后,长度变为 3,容量最小要变成 5,即调用 `growslice` 函数时,传入的第三个参数应该为 5。即 cap=5。而一方面,`doublecap` 是原 slice容量的 2 倍,等于 4。满足第一个 if 条件,所以 `newcap` 变成了 5。
325 |
326 | 接着调用了 `roundupsize` 函数,传入` size=40`。(代码中`sys.PtrSize`是指一个指针的大小,在64位机上是8,即传入5*8)
327 |
328 | ```go
329 | // go 1.14 src/runtime/internal/sys/stubs.go: 8
330 | //拿 64 系统来说,0 取反之后右移 63 位的结果是 1,然后 4 的二进制表示是 0100,左移 1 位的结果是 1000,结果为 8。
331 | const PtrSize = 4 << (^uintptr(0) >> 63)
332 | ```
333 |
334 | 下面来看看roundupsize源码:
335 |
336 | ```go
337 | // go 1.14 src/runtime/msize.go:13
338 | func roundupsize(size uintptr) uintptr {
339 | if size < _MaxSmallSize {
340 | if size <= smallSizeMax-8 {
341 | return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
342 | } else {
343 | return uintptr(class_to_size[size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]])
344 | }
345 | }
346 | //...
347 | }
348 |
349 | 其中:
350 | const _MaxSmallSize = 32768
351 | const smallSizeMax = 1024
352 | const smallSizeDiv = 8
353 | ```
354 |
355 | 传入size=40后,很明显,最后返回
356 |
357 | ```go
358 | class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]]
359 | ```
360 |
361 | 这是 `Go` 源码中有关内存分配的两个 `slice`。`class_to_size`通过 `spanClass`获取 `span`划分的 `object`大小。而 `size_to_class8` 表示通过 `size` 获取它的 `spanClass`。
362 |
363 | ```go
364 | // go 1.14 src/runtime/sizeclasses.go
365 | var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
366 |
367 | var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31}
368 | ```
369 |
370 | 我们传进去的 `size` 等于 40。所以 `(size+smallSizeDiv-1)/smallSizeDiv = 5`;获取 `size_to_class8` 数组中索引为 `5` 的元素为 `4`;获取 `class_to_size` 中索引为 `4` 的元素为 `48`。
371 |
372 | 最终,新的 slice 的容量为 `6`:
373 |
374 | ```
375 | newcap = int(capmem / sys.PtrSize) // 48 / 8 = 6
376 | ```
377 |
378 | ## 为什么 nil slice 可以直接 append
379 |
380 | 其实 `nil slice` 或者 `empty slice` 都是可以通过调用 append 函数来获得底层数组的扩容。最终都是调用 `mallocgc` 来向 Go 的内存管理器申请到一块内存,然后再赋给原来的`nil slice` 或 `empty slice`,然后摇身一变,成为“真正”的 `slice` 了。
381 |
382 | ## 传 slice 和 slice 指针有什么区别
383 |
384 | 当 slice 作为函数参数时,就是一个普通的结构体。其实很好理解:若直接传 slice,在调用者看来,实参 slice 并不会被函数中的操作改变;若传的是 slice 的指针,在调用者看来,是会被改变原 slice 的。
385 |
386 | 值的注意的是,不管传的是 slice 还是 slice 指针,如果改变了 slice 底层数组的数据,会反应到实参 slice 的底层数据。为什么能改变底层数组的数据?很好理解:**底层数据在 slice 结构体里是一个指针,仅管 slice 结构体自身不会被改变,也就是说底层数据地址不会被改变。 但是通过指向底层数据的指针,可以改变切片的底层数据**。
387 |
388 | 通过 slice 的 array 字段就可以拿到数组的地址。在代码里,是直接通过类似 `s[i]=10` 这种操作改变 slice 底层数组元素值。
389 |
390 | 将切片通过参数传递给函数,其实质是复制了slice结构体对象,两个slice结构体的字段值均相等。正常情况下,由于函数内slice结构体的array和函数外slice结构体的array指向的是同一底层数组,所以当对底层数组中的数据做修改时,两者均会受到影响。
391 |
392 | 但是存在这样的问题:如果指向底层数组的指针被覆盖或者修改(copy、重分配、append触发扩容),此时函数内部对数据的修改将不再影响到外部的切片,代表长度的len和容量cap也均不会被修改。
393 |
394 | ## 总结
395 |
396 | - 切片是对底层数组的一个抽象,描述了它的一个片段。
397 | - 切片实际上是一个结构体,它有三个字段:长度,容量,底层数据的地址。
398 | - 多个切片可能共享同一个底层数组,这种情况下,对其中一个切片或者底层数组的更改,会影响到其他切片。
399 | - `append` 函数会在切片容量不够的情况下,调用 `growslice` 函数获取所需要的内存,这称为扩容,扩容会改变元素原来的位置。
400 | - 扩容策略并不是简单的扩为原切片容量的 `2` 倍或 `1.25` 倍,还有**内存对齐的操作**。扩容后的容量 >= 原容量的 `2` 倍或 `1.25` 倍。
401 | - 当直接用切片作为函数参数时,可以改变切片的元素,不能改变切片本身;想要改变切片本身,可以将改变后的切片返回,函数调用者接收改变后的切片或者将切片指针作为函数参数。
402 |
403 |
404 |
405 | > 参考:
406 | >
407 | > [深度解密Go语言之Slice](https://mp.weixin.qq.com/s/MTZ0C9zYsNrb8wyIm2D8BA)
408 | >
409 | > [切片传递与指针传递的区别_zuiyijiangnan的博客-CSDN博客_切片传递](https://blog.csdn.net/zuiyijiangnan/article/details/112673446)
--------------------------------------------------------------------------------
/golang/deep/unsafe.md:
--------------------------------------------------------------------------------
1 | # Go语言深度解析之unsafe
2 |
3 | ## 什么是unsafe
4 |
5 | unsafe 库让 golang 可以像C语言一样操作计算机内存,但这并不是golang推荐使用的,能不用尽量不用,就像它的名字所表达的一样,它绕过了golang的内存安全原则,是不安全的,容易使你的程序出现莫名其妙的问题,不利于程序的扩展与维护。
6 |
7 | 先简单介绍下Golang指针类型:
8 |
9 | 1. `*类型`:普通指针,用于传递对象地址,不能进行指针运算。
10 | 2. `unsafe.Pointer`:通用指针类型,用于转换不同类型的指针,不能进行指针运算。
11 | 3. `uintptr`:用于指针运算,GC 不把 uintptr 当指针,uintptr 无法持有对象,**uintptr 类型的目标会被回收**。
12 |
13 | unsafe.Pointer 可以和 普通指针 进行相互转换。
14 |
15 | unsafe.Pointer 可以和 uintptr 进行相互转换。
16 |
17 | 也就是说 **unsafe.Pointer 是桥梁,可以让任意类型的指针实现相互转换,也可以将任意类型的指针转换为 uintptr 进行指针运算**。
18 |
19 | 
20 |
21 | unsafe底层源码如下:
22 |
23 | 两个类型:
24 |
25 | ```go
26 | // go 1.14 src/unsafe/unsafe.go
27 | type ArbitraryType int
28 | type Pointer *ArbitraryType
29 | ```
30 |
31 | 三个函数:
32 |
33 | ```go
34 | func Sizeof(x ArbitraryType) uintptr
35 | func Offsetof(x ArbitraryType) uintptr
36 | func Alignof(x ArbitraryType) uintptr
37 | ```
38 |
39 | 通过分析发现,这三个函数的参数均是ArbitraryType类型,就是接受任何类型的变量。
40 |
41 | 1. `Sizeof` **返回类型 x 所占据的字节数,但不包含 x 所指向的内容的大小**。例如,对于一个指针,函数返回的大小为 8 字节(64位机上),一个 slice 的大小则为 slice header 的大小。
42 | 2. `Offsetof`返回变量指定属性的偏移量,这个函数虽然接收的是任何类型的变量,但是有一个前提,就是变量要是一个struct类型,且还不能直接将这个struct类型的变量当作参数,只能将这个struct类型变量的属性当作参数。
43 | 3. `Alignof`返回变量对齐字节数量
44 |
45 | ## unsafe包的操作
46 |
47 | ### 大小Sizeof
48 |
49 | unsafe.Sizeof函数返回的就是uintptr类型的值,表示所占据的字节数(表达式,即值的大小):
50 |
51 | ```go
52 | package main
53 |
54 | import (
55 | "fmt"
56 | "reflect"
57 | "unsafe"
58 | )
59 |
60 | func main() {
61 | var a int32
62 | var b = &a
63 | fmt.Println(reflect.TypeOf(unsafe.Sizeof(a))) // uintptr
64 | fmt.Println(unsafe.Sizeof(a)) // 4
65 | fmt.Println(reflect.TypeOf(b).Kind()) // ptr
66 | fmt.Println(unsafe.Sizeof(b)) // 8
67 | }
68 | ```
69 |
70 | 对于 `a`来说,它是`int32`类型,在内存中占4个字节,而对于`b`来说,是`*int32`类型,即底层为`ptr`指针类型,在64位机下占8字节。
71 |
72 | ### 偏移Offsetof
73 |
74 | 对于一个结构体,通过 Offset 函数可以获取结构体成员的偏移量,进而获取成员的地址,读写该地址的内存,就可以达到改变成员值的目的。
75 |
76 | 这里有一个内存分配相关的事实:**结构体会被分配一块连续的内存,结构体的地址也代表了第一个字段的地址。**
77 |
78 | 举个例子:
79 |
80 | ```go
81 | package main
82 |
83 | import (
84 | "fmt"
85 | "unsafe"
86 | )
87 |
88 | type user struct {
89 | id int32
90 | name string
91 | age byte
92 | }
93 |
94 | func main() {
95 | var u = user{
96 | id: 1,
97 | name: "xiaobai",
98 | age: 22,
99 | }
100 | fmt.Println(u)
101 | fmt.Println(unsafe.Offsetof(u.id)) // 0 id在结构体user中的偏移量,也是结构体的地址
102 | fmt.Println(unsafe.Offsetof(u.name)) // 8
103 | fmt.Println(unsafe.Offsetof(u.age)) // 24
104 |
105 | // 根据偏移量修改字段的值 比如将id字段改为1001
106 | // 因为结构体的地址相当于第一个字段id的地址
107 | // 直接用unsafe包自带的Pointer获取id指针
108 | id := (*int)(unsafe.Pointer(&u))
109 | *id = 1001
110 |
111 | // 更加相对于id字段的偏移量获取name字段的地址并修改其内容
112 | // 需要用到uintptr进行指针运算 然后再利用unsafe.Pointer这个媒介将uintptr类型转换成一般的指针类型*string
113 | name := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&u)) + unsafe.Offsetof(u.name)))
114 | *name = "花花"
115 |
116 | // 同理更改age字段
117 | age := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&u)) + unsafe.Offsetof(u.age)))
118 | *age = 33
119 |
120 | fmt.Println(u)
121 | }
122 | ```
123 |
124 | ### 对齐Alignof
125 |
126 | 要了解这个函数,你需要了解`数据对齐`。简单的说,它让数据结构在内存中以某种的布局存放,使该数据的读取性能能够更加的快速。
127 |
128 | CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度。
129 |
130 | #### 普通字段的对齐值
131 |
132 | ```go
133 | fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
134 | fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
135 | fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
136 | fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
137 | fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
138 | fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
139 | fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
140 | ```
141 |
142 | 输出结果:
143 |
144 | ```text
145 | bool align: 1
146 | int32 align: 4
147 | int8 align: 1
148 | int64 align: 8
149 | byte align: 1
150 | string align: 8
151 | map align: 8
152 | ```
153 |
154 | 在 Go 中可以调用 `unsafe.Alignof` 来返回相应类型的对齐系数。通过观察输出结果,可得知基本都是 2n,最大也`不会超过 8`。这是因为我们的**64位编译器默认对齐系数是 8**,因此最大值不会超过这个数。
155 |
156 | #### 对齐规则
157 |
158 | 1. **结构体的成员变量**,第一个成员变量的偏移量为 0。往后的每个成员变量的`对齐值=min(编译器默认对齐长度,当前成员变量类型的长度)`。其`偏移量=对齐值xN`
159 | 2. **结构体本身**,`对齐值=最小整数倍{max(编译器默认对齐长度,结构体的所有成员变量类型中的最大长度)}`,
160 |
161 | 结合以上两点,可得知若编译器默认对齐长度超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
162 |
163 | #### 结构体的对齐值
164 |
165 | 下面来看一下结构体的对齐:
166 |
167 | ```go
168 | type part struct {
169 | a bool // 1
170 | b int32 // 4
171 | c int8 // 1
172 | d int64 // 8
173 | e byte // 1
174 | }
175 |
176 | func main() {
177 | var p part
178 | fmt.Println(unsafe.Sizeof(p)) // 32
179 | }
180 | ```
181 |
182 | 按照普通字段(结构体内成员变量)的对齐方式,我们可以计算得出,这个结构体的大小占`1+4+1+8+1=15`个字节,但是用`unsafe.Sizeof`计算发现`part结构体`占`32`字节,是不是有点惊讶😮
183 |
184 | 这里面就涉及到了内存对齐,下面我们来分析一下:
185 |
186 | | 成员变量 | 类型 | 偏移量 | 自身占用 |
187 | | ---------- | ----- | ------ | -------- |
188 | | a | bool | 0 | 1 |
189 | | 数据对齐 | - | 1 | 3 |
190 | | b | int32 | 4 | 4 |
191 | | c | int8 | 8 | 1 |
192 | | 数据对齐 | - | 9 | 7 |
193 | | d | in64 | 16 | 8 |
194 | | e | byte | 24 | 1 |
195 | | 数据对齐 | - | 25 | 7 |
196 | | 总占用大小 | - | - | 32 |
197 |
198 | - 对于变量a而言
199 |
200 | 类型是bool;大小/对齐值本身为1字节;偏移量为0,**占用了第0位**;此时内存中表示为`a`
201 |
202 | - 对于变量b而言
203 |
204 | 类型是int32;大小/对齐值本身为4字节;根据对齐规则一,偏移量必须为对齐值4的整数倍,故这里的偏移量为4,**占用了第4 ~ 7位**,则**第1 ~ 3位用padding字节填充**;此时内存中表示为`a---|bbbb`,(`|`只起到分隔作用,表示方便一些)
205 |
206 | - 对于变量c而言
207 |
208 | 类型是int8;大小/对齐值本身为1字节;当前偏移量为8,无需扩充,**占用了第8位**;此时内存中表示为`a---|bbbb|c`
209 |
210 | - 对于变量d而言
211 |
212 | 类型是int64;大小/对齐值本身为8字节;根据对齐规则一,偏移量必须为对齐值8的整数倍,故当前偏移量为16,**占用了第16 ~ 23位**,则**第9 ~ 15为用padding字节填充**;此时内存中表示为`a---|bbbb|c---|----|dddd|dddd`
213 |
214 | - 对于变量e而言
215 |
216 | 类型是byte;大小/对齐值本身为1字节;当前偏移量为24,无需扩充,**占用了第24位**;此时内存中表示为`a---|bbbb|c---|----|dddd|dddd|e`
217 |
218 | 这里计算后,发现总共占用25字节,哪里又来的32字节呢?😳
219 |
220 | 再让我们回顾一下对齐原则的第二点,**结构体本身**,`对齐值=最小整数倍{max(编译器默认对齐长度,结构体的所有成员变量类型中的最大长度)}`
221 |
222 | 1. 这里编译器默认对齐长度为8字节(64位机)
223 |
224 | 2. 结构体中所有成员变量类型的最大长度为int64,8字节
225 | 3. 取二者最大数的最小整数倍作为对齐值,我们算的part结构体大小为25字节,不是8字节的整数倍,故还需要填充到32字节。
226 |
227 | 综上,part结构体在内存中表示为`a---|bbbb|c---|----|dddd|dddd|e----|----`
228 |
229 | #### 扩展
230 |
231 | 让我们改变一下part结构体中字段的顺序看看(part结构体完全相同)
232 |
233 | ```go
234 | type part struct {
235 | a bool // 1
236 | c int8 // 1
237 | e byte // 1
238 | b int32 //4
239 | d int64 // 8
240 | }
241 |
242 | func main() {
243 | var p part
244 | fmt.Println(unsafe.Sizeof(p)) // 16
245 | }
246 | ```
247 |
248 | 这时候再用`unsafe.Sizeof`查看会发现,part结构体的内存占用只有`16`字节,瞬间减少了一半的内存空间,大家可以按照前面的步骤分析一下~
249 |
250 | 这里建议在构建结构体时,**按照字段大小的升序进行排序,会减少一点的内存空间**。
251 |
252 | #### 反射包的对齐方法
253 |
254 | 反射包也有某些方法可用于计算对齐值:
255 |
256 | ```go
257 | unsafe.Alignof(w)等价于reflect.TypeOf(w).Align
258 | unsafe.Alignof(w.i)等价于reflect.Typeof(w.i).FieldAlign()
259 | ```
260 |
261 | ## 总结
262 |
263 | - unsafe 包绕过了 Go 的类型系统,达到直接操作内存的目的,使用它有一定的风险性。但是在某些场景下,使用 unsafe 包提供的函数会提升代码的效率,Go 源码中也是大量使用 unsafe 包。
264 |
265 | - unsafe 包定义了 Pointer 和三个函数:
266 |
267 | ```go
268 | type ArbitraryType int
269 | type Pointer *ArbitraryType
270 |
271 | func Sizeof(x ArbitraryType) uintptr
272 | func Offsetof(x ArbitraryType) uintptr
273 | func Alignof(x ArbitraryType) uintptr
274 | ```
275 |
276 | 通过三个函数可以获取变量的大小、偏移、对齐等信息。
277 |
278 | - uintptr 可以和 unsafe.Pointer 进行相互转换,uintptr 可以进行数学运算。这样,通过 uintptr 和 unsafe.Pointer 的结合就解决了 Go 指针不能进行数学运算的限制。
279 |
280 | - 通过 unsafe 相关函数,可以获取结构体私有成员的地址,进而对其做进一步的读写操作,突破 Go 的类型安全限制。
281 |
282 |
283 |
284 | > 参考:
285 | >
286 | > - [深度解密Go语言之unsafe](https://mp.weixin.qq.com/s/OO-kwB4Fp_FnCaNXwGJoEw)
287 | > - [unsafe包的学习和使用 - 离地最远的星 - 博客园 (cnblogs.com)](https://www.cnblogs.com/hualou/p/12070155.html)
288 | > - [在 Go 中恰到好处的内存对齐 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/53413177)
--------------------------------------------------------------------------------
/golang/useful_package.md:
--------------------------------------------------------------------------------
1 | # Golang常用到的库
2 |
3 | | 库 | 地址 |
4 | | ------------------------------------------------------ | ------------------------------------------------------------ |
5 | | 数据库操作,需要装驱动 | https://github.com/go-sql-driver/mysql https://github.com/jinzhu/gorm |
6 | | 搜索es | https://github.com/olivere/elastic |
7 | | rocketmq操作 | https://github.com/apache/rocketmq-client-go/v2 |
8 | | rabbitmq 操作 | https://github.com/streadway/amqp |
9 | | redis 操作 | https://github.com/go-redis/redis https://github.com/gomodule/redigo |
10 | | etcd 操作 | [github.com/coreos/etcd/clientv3](https://pkg.go.dev/go.etcd.io/etcd/clientv3) |
11 | | kafka | https://github.com/Shopify/sarama https://github.com/bsm/sarama-cluste |
12 | | pprof | https://github.com/gin-contrib/pprof |
13 | | testfiy测试库 | https://github.com/stretchr/testify |
14 | | excel 操作 | https://github.com/360EntSecGroup-Skylar/excelize |
15 | | 可以操作任何数据的包 比方sting 转换类型啊 方便编写代码 | https://github.com/Unknwon/com |
16 | | 表单验证器 | https://github.com/go-playground/validator |
17 | | goroutine池 | https://github.com/panjf2000/ants |
18 | | golang的爬虫框架colly | https://github.com/gocolly/colly |
19 | | 命令行程序框架 cobra | https://github.com/spf13/cobra |
20 | | 配置读取viper | https://github.com/spf13/viper |
21 | | go key/value存储 | https://github.com/etcd-io/bbolt |
22 | | golang的绘图库go-echart | https://github.com/go-echarts/go-echarts/v2 |
23 | | golangweb项目热更新 进入项目目录下:fresh启动 | https://github.com/pilu/fresh |
24 | | 轻量级的协程池 | https://github.com/ivpusic/grpool |
25 | | 打印go的详细数据结构 | https://github.com/davecgh/go-spew |
26 | | jwt鉴权 | https://github.com/dgrijalva/jwt-go |
27 | | 拼音 | https://github.com/go-ego/gpy |
28 | | 分词 | https://github.com/go-ego/gse |
29 | | 搜索 | https://github.com/go-ego/riot |
30 | | session | https://github.com/gorilla/sessions |
31 | | 路由 | https://github.com/gorilla/mux |
32 | | websocket | https://github.com/gorilla/websocket |
33 | | Action handler | https://github.com/gorilla/handlers |
34 | | csrf | https://github.com/gorilla/csrf |
35 | | context | https://github.com/gorilla/context |
36 | | 过滤html标签 | https://github.com/grokify/html-strip-tags-go |
37 | | 可配置的HTML标签过滤 | https://github.com/microcosm-cc/bluemonday |
38 | | 根据IP获取地理位置信息 | https://github.com/ipipdotnet/ipdb-go |
39 | | html转markdown | https://github.com/jaytaylor/html2text |
40 | | goroutine 本地存储 | https://github.com/jtolds/gls |
41 | | 彩色输出 | https://github.com/mgutz/ansi |
42 | | 表格打印 | https://github.com/olekukonko/tablewriter |
43 | | reflect 更高效的反射API | https://github.com/modern-go/reflect2 |
44 | | 可取消的goroutine | https://github.com/modern-go/concurrent |
45 | | 深度拷贝 | https://github.com/mohae/deepcopy |
46 | | 安全的类型转换包 | https://github.com/spf13/cast |
47 | | 从文本中提取链接 | https://github.com/mvdan/xurls |
48 | | 字符串格式处理(驼峰转换) | https://godoc.org/github.com/naoina/go-stringutil |
49 | | 文本diff实现 | https://github.com/pmezard/go-difflib |
50 | | uuid相关 | https://github.com/satori/go.uuid https://github.com/snluu/uuid |
51 | | 去除UTF编码中的BOM | https://github.com/ssor/bom |
52 | | 图片缩放 | https://github.com/nfnt/resize |
53 | | 生成 mock server | https://github.com/otokaze/mock |
54 | | go 性能上报到influxdb | https://github.com/rcrowley/go-metrics |
55 | | go zookeeper客户端 | https://github.com/samuel/go-zookeeper |
56 | | go thrift | https://github.com/samuel/go-thrift |
57 | | go 性能上报到influxdb | https://github.com/rcrowley/go-metrics |
58 | | go 性能上报到prometheus | https://github.com/deathowl/go-metrics-prometheus |
59 | | ps utils | https://github.com/shirou/gopsutil |
60 | | 小数处理 | https://github.com/shopspring/decimal |
61 | | 结构化日志处理(json) | https://github.com/sirupsen/logrus |
62 | | grpc操作 | https://google.golang.org/grpc https://github.com/golang/protobuf/protoc-gen-go |
63 | | ceph私有云库 | https://gopkg.in/amz.v1/aws https://gopkg.in/amz.v1/s3 |
64 | | 阿里云oss库 | https://github.com/aliyun/aliyun-oss-go-sdk/oss |
65 |
66 |
67 |
68 |
--------------------------------------------------------------------------------
/system-design/security/advantages&disadvantages-of-jwt.md:
--------------------------------------------------------------------------------
1 | 在 [JWT基础概念详解及使用](./jwt-intro.md)这篇文章中,我介绍了:
2 |
3 | - 什么是 JWT?
4 | - JWT 由哪些部分组成?
5 | - 如何基于 JWT 进行身份验证?
6 | - JWT 如何防止 Token 被篡改?
7 | - 如何加强 JWT 的安全性?
8 |
9 | 这篇文章,我们一起探讨一下 JWT 身份认证的优缺点以及常见问题的解决办法。
10 |
11 | ## JWT 的优势
12 |
13 | 相比于 Session 认证的方式来说,使用 JWT 进行身份认证主要有下面 4 个优势。
14 |
15 | ### 无状态
16 |
17 | JWT 自身包含了身份验证所需要的所有信息,因此,我们的服务器不需要存储 Session 信息。这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。
18 |
19 | 不过,也正是由于 JWT 的无状态,也导致了它最大的缺点:**不可控!**
20 |
21 | 就比如说,我们想要在 JWT 有效期内废弃一个 JWT 或者更改它的权限的话,并不会立即生效,通常需要等到有效期过后才可以。再比如说,当用户 Logout 的话,JWT 也还有效。除非,我们在后端增加额外的处理逻辑比如将失效的 JWT 存储起来,后端先验证 JWT 是否有效再进行处理。具体的解决办法,我们会在后面的内容中详细介绍到,这里只是简单提一下。
22 |
23 | ### 有效避免了 CSRF 攻击
24 |
25 | **CSRF(Cross Site Request Forgery)** 一般被翻译为 **跨站请求伪造**,属于网络攻击领域范围。相比于 SQL 脚本注入、XSS 等安全攻击方式,CSRF 的知名度并没有它们高。但是,它的确是我们开发系统时必须要考虑的安全隐患。就连业内技术标杆 Google 的产品 Gmail 也曾在 2007 年的时候爆出过 CSRF 漏洞,这给 Gmail 的用户造成了很大的损失。
26 |
27 | **那么究竟什么是跨站请求伪造呢?** 简单来说就是用你的身份去做一些不好的事情(发送一些对你不友好的请求比如恶意转账)。
28 |
29 | 举个简单的例子:小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
30 |
31 | ```html
32 | 科学理财,年盈利率过万
33 | ```
34 |
35 | CSRF 攻击需要依赖 Cookie ,Session 认证中 Cookie 中的 `SessionID` 是由浏览器发送到服务端的,只要发出请求,Cookie 就会被携带。借助这个特性,即使黑客无法获取你的 `SessionID`,只要让你误点攻击链接,就可以达到攻击效果。
36 |
37 | 另外,并不是必须点击链接才可以达到攻击效果,很多时候,只要你打开了某个页面,CSRF 攻击就会发生。
38 |
39 | ```html
40 |