├── LICENSE
├── README.md
├── data
└── README.md
├── dataset
└── referit_loader.py
├── ln_data
├── README.md
└── download_data.sh
├── model
├── darknet.py
├── grounding_model.py
└── yolov3.cfg
├── saved_models
├── README.md
└── yolov3_weights.sh
├── train_yolo.py
└── utils
├── __init__.py
├── losses.py
├── misc_utils.py
├── parsing_metrics.py
├── transforms.py
├── utils.py
└── word_utils.py
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Zhengyuan Yang
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # One-Stage Visual Grounding
2 | **\*\*\*\*\* New: Our recent work on One-stage VG is available at [ReSC](https://github.com/zyang-ur/ReSC).\*\*\*\*\***
3 |
4 |
5 | [A Fast and Accurate One-Stage Approach to Visual Grounding](https://arxiv.org/pdf/1908.06354.pdf)
6 |
7 | by [Zhengyuan Yang](http://cs.rochester.edu/u/zyang39/), [Boqing Gong](http://boqinggong.info/), [Liwei Wang](http://www.deepcv.net/), Wenbing Huang, Dong Yu, and [Jiebo Luo](http://cs.rochester.edu/u/jluo)
8 |
9 | IEEE International Conference on Computer Vision (ICCV), 2019, Oral
10 |
11 |
12 | ### Introduction
13 | We propose a simple, fast, and accurate one-stage approach
14 | to visual grounding. For more details, please refer to our
15 | [paper](https://arxiv.org/pdf/1908.06354.pdf).
16 |
17 |
19 |
20 | 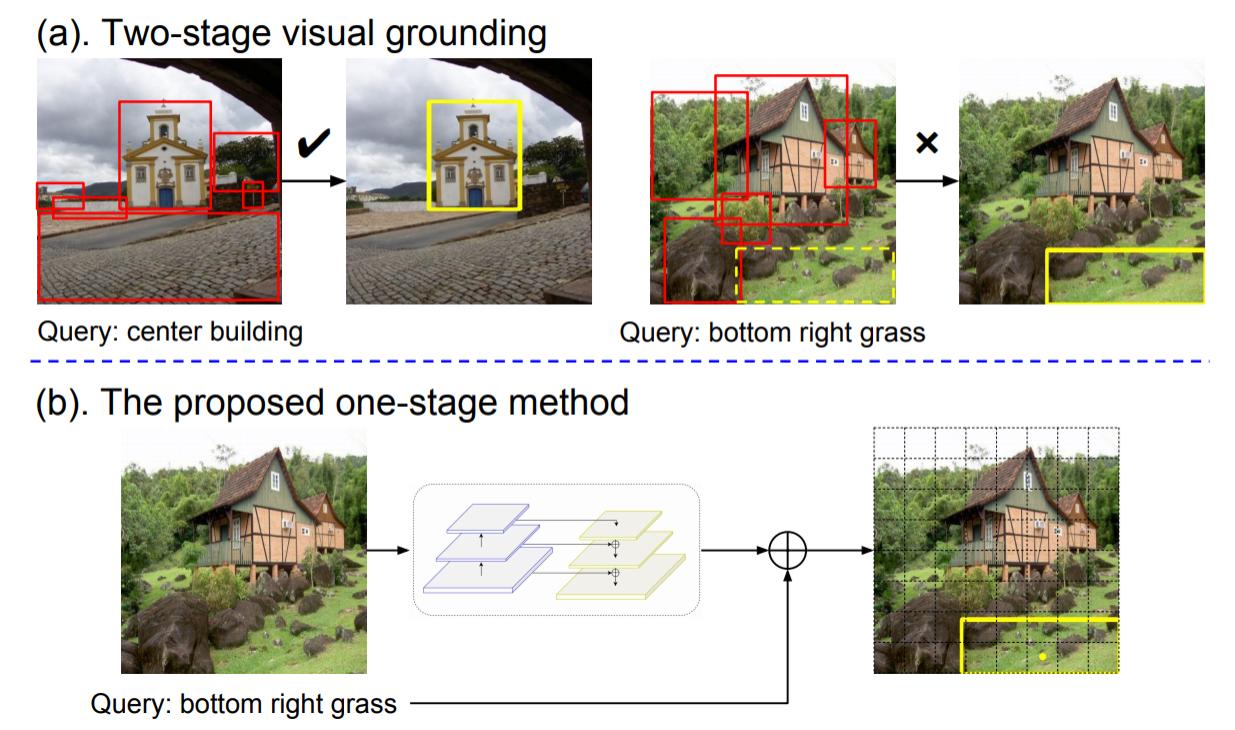 21 |
21 |
22 |
23 | ### Citation
24 |
25 | @inproceedings{yang2019fast,
26 | title={A Fast and Accurate One-Stage Approach to Visual Grounding},
27 | author={Yang, Zhengyuan and Gong, Boqing and Wang, Liwei and Huang
28 | , Wenbing and Yu, Dong and Luo, Jiebo},
29 | booktitle={ICCV},
30 | year={2019}
31 | }
32 |
33 | ### Prerequisites
34 |
35 | * Python 3.5 (3.6 tested)
36 | * Pytorch 0.4.1
37 | * Others ([Pytorch-Bert](https://pypi.org/project/pytorch-pretrained-bert/), OpenCV, Matplotlib, scipy, etc.)
38 |
39 | ## Installation
40 |
41 | 1. Clone the repository
42 |
43 | ```
44 | git clone https://github.com/zyang-ur/onestage_grounding.git
45 | ```
46 |
47 | 2. Prepare the submodules and associated data
48 |
49 | * RefCOCO & ReferItGame Dataset: place the data or the soft link of dataset folder under ``./ln_data/``. We follow dataset structure [DMS](https://github.com/BCV-Uniandes/DMS). To accomplish this, the ``download_dataset.sh`` [bash script](https://github.com/BCV-Uniandes/DMS/blob/master/download_data.sh) from DMS can be used.
50 | ```bash
51 | bash ln_data/download_data.sh --path ./ln_data
52 | ```
53 |
54 |
60 | * Flickr30K Entities Dataset: please download the images for the dataset on the website for the [Flickr30K Entities Dataset](http://bryanplummer.com/Flickr30kEntities/) and the original [Flickr30k Dataset](http://shannon.cs.illinois.edu/DenotationGraph/). Images should be placed under ``./ln_data/Flickr30k/flickr30k_images``.
61 |
62 |
63 | * Data index: download the generated index files and place them as the ``./data`` folder. Availble at [[Gdrive]](https://drive.google.com/open?id=1cZI562MABLtAzM6YU4WmKPFFguuVr0lZ), [[One Drive]](https://uofr-my.sharepoint.com/:f:/g/personal/zyang39_ur_rochester_edu/Epw5WQ_mJ-tOlAbK5LxsnrsBElWwvNdU7aus0UIzWtwgKQ?e=XHQm7F).
64 | ```
65 | rm -r data
66 | tar xf data.tar
67 | ```
68 |
69 | * Model weights: download the pretrained model of [Yolov3](https://pjreddie.com/media/files/yolov3.weights) and place the file in ``./saved_models``.
70 | ```
71 | sh saved_models/yolov3_weights.sh
72 | ```
73 | More pretrained models are availble in the performance table [[Gdrive]](https://drive.google.com/open?id=1-DXvhEbWQtVWAUT_-G19zlz-0Ekcj5d7), [[One Drive]](https://uofr-my.sharepoint.com/:f:/g/personal/zyang39_ur_rochester_edu/ErrXDnw1igFGghwbH5daoKwBX4vtE_erXbOo1JGnraCE4Q?e=tQUCk7) and should also be placed in ``./saved_models``.
74 |
75 |
76 | ### Training
77 | 3. Train the model, run the code under main folder.
78 | Using flag ``--lstm`` to access lstm encoder, Bert is used as the default.
79 | Using flag ``--light`` to access the light model.
80 |
81 | ```
82 | python train_yolo.py --data_root ./ln_data/ --dataset referit \
83 | --gpu gpu_id --batch_size 32 --resume saved_models/lstm_referit_model.pth.tar \
84 | --lr 1e-4 --nb_epoch 100 --lstm
85 | ```
86 |
87 | 4. Evaluate the model, run the code under main folder.
88 | Using flag ``--test`` to access test mode.
89 |
90 | ```
91 | python train_yolo.py --data_root ./ln_data/ --dataset referit \
92 | --gpu gpu_id --resume saved_models/lstm_referit_model.pth.tar \
93 | --lstm --test
94 | ```
95 |
96 | 5. Visulizations. Flag ``--save_plot`` will save visulizations.
97 |
98 |
99 | ## Performance and Pre-trained Models
100 | Please check the detailed experiment settings in our [paper](https://arxiv.org/pdf/1908.06354.pdf).
101 |
102 |
103 |
104 | | Dataset |
105 | Ours-LSTM |
106 | Performance (Accu@0.5) |
107 | Ours-Bert |
108 | Performance (Accu@0.5) |
109 |
110 |
111 |
112 |
113 | | ReferItGame |
114 | Gdrive |
115 | 58.76 |
116 | Gdrive |
117 | 59.30 |
118 |
119 |
120 | | Flickr30K Entities |
121 | One Drive |
122 | 67.62 |
123 | One Drive |
124 | 68.69 |
125 |
126 |
127 | | RefCOCO |
128 |
129 | | val: 73.66 |
130 |
131 | | val: 72.05 |
132 |
133 |
134 | | testA: 75.78 |
135 | testA: 74.81 |
136 |
137 |
138 | | testB: 71.32 |
139 | testB: 67.59 |
140 |
141 |
142 |
143 |
144 |
145 | ### Credits
146 | Part of the code or models are from
147 | [DMS](https://github.com/BCV-Uniandes/DMS),
148 | [MAttNet](https://github.com/lichengunc/MAttNet),
149 | [Yolov3](https://pjreddie.com/darknet/yolo/) and
150 | [Pytorch-yolov3](https://github.com/eriklindernoren/PyTorch-YOLOv3).
151 |
--------------------------------------------------------------------------------
/data/README.md:
--------------------------------------------------------------------------------
1 | Please download cache from [Gdrive](https://drive.google.com/open?id=1i9fjhZ3cmn5YOxlacGMpcxWmrNnRNU4B), or [OneDrive]
--------------------------------------------------------------------------------
/dataset/referit_loader.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | ReferIt, UNC, UNC+ and GRef referring image segmentation PyTorch dataset.
5 |
6 | Define and group batches of images, segmentations and queries.
7 | Based on:
8 | https://github.com/chenxi116/TF-phrasecut-public/blob/master/build_batches.py
9 | """
10 |
11 | import os
12 | import sys
13 | import cv2
14 | import json
15 | import uuid
16 | import tqdm
17 | import math
18 | import torch
19 | import random
20 | # import h5py
21 | import numpy as np
22 | import os.path as osp
23 | import scipy.io as sio
24 | import torch.utils.data as data
25 | from collections import OrderedDict
26 | sys.path.append('.')
27 | import utils
28 | from utils import Corpus
29 |
30 | import argparse
31 | import collections
32 | import logging
33 | import json
34 | import re
35 |
36 | from pytorch_pretrained_bert.tokenization import BertTokenizer
37 | from pytorch_pretrained_bert.modeling import BertModel
38 | from utils.transforms import letterbox, random_affine
39 |
40 | sys.modules['utils'] = utils
41 |
42 | cv2.setNumThreads(0)
43 |
44 | def read_examples(input_line, unique_id):
45 | """Read a list of `InputExample`s from an input file."""
46 | examples = []
47 | # unique_id = 0
48 | line = input_line #reader.readline()
49 | # if not line:
50 | # break
51 | line = line.strip()
52 | text_a = None
53 | text_b = None
54 | m = re.match(r"^(.*) \|\|\| (.*)$", line)
55 | if m is None:
56 | text_a = line
57 | else:
58 | text_a = m.group(1)
59 | text_b = m.group(2)
60 | examples.append(
61 | InputExample(unique_id=unique_id, text_a=text_a, text_b=text_b))
62 | # unique_id += 1
63 | return examples
64 |
65 | def bbox_randscale(bbox, miniou=0.75):
66 | w,h = bbox[2]-bbox[0], bbox[3]-bbox[1]
67 | scale_shrink = (1-math.sqrt(miniou))/2.
68 | scale_expand = (math.sqrt(1./miniou)-1)/2.
69 | w1,h1 = random.uniform(-scale_expand, scale_shrink)*w, random.uniform(-scale_expand, scale_shrink)*h
70 | w2,h2 = random.uniform(-scale_shrink, scale_expand)*w, random.uniform(-scale_shrink, scale_expand)*h
71 | bbox[0],bbox[2] = bbox[0]+w1,bbox[2]+w2
72 | bbox[1],bbox[3] = bbox[1]+h1,bbox[3]+h2
73 | return bbox
74 |
75 | ## Bert text encoding
76 | class InputExample(object):
77 | def __init__(self, unique_id, text_a, text_b):
78 | self.unique_id = unique_id
79 | self.text_a = text_a
80 | self.text_b = text_b
81 |
82 | class InputFeatures(object):
83 | """A single set of features of data."""
84 | def __init__(self, unique_id, tokens, input_ids, input_mask, input_type_ids):
85 | self.unique_id = unique_id
86 | self.tokens = tokens
87 | self.input_ids = input_ids
88 | self.input_mask = input_mask
89 | self.input_type_ids = input_type_ids
90 |
91 | def convert_examples_to_features(examples, seq_length, tokenizer):
92 | """Loads a data file into a list of `InputBatch`s."""
93 | features = []
94 | for (ex_index, example) in enumerate(examples):
95 | tokens_a = tokenizer.tokenize(example.text_a)
96 |
97 | tokens_b = None
98 | if example.text_b:
99 | tokens_b = tokenizer.tokenize(example.text_b)
100 |
101 | if tokens_b:
102 | # Modifies `tokens_a` and `tokens_b` in place so that the total
103 | # length is less than the specified length.
104 | # Account for [CLS], [SEP], [SEP] with "- 3"
105 | _truncate_seq_pair(tokens_a, tokens_b, seq_length - 3)
106 | else:
107 | # Account for [CLS] and [SEP] with "- 2"
108 | if len(tokens_a) > seq_length - 2:
109 | tokens_a = tokens_a[0:(seq_length - 2)]
110 | tokens = []
111 | input_type_ids = []
112 | tokens.append("[CLS]")
113 | input_type_ids.append(0)
114 | for token in tokens_a:
115 | tokens.append(token)
116 | input_type_ids.append(0)
117 | tokens.append("[SEP]")
118 | input_type_ids.append(0)
119 |
120 | if tokens_b:
121 | for token in tokens_b:
122 | tokens.append(token)
123 | input_type_ids.append(1)
124 | tokens.append("[SEP]")
125 | input_type_ids.append(1)
126 |
127 | input_ids = tokenizer.convert_tokens_to_ids(tokens)
128 |
129 | # The mask has 1 for real tokens and 0 for padding tokens. Only real
130 | # tokens are attended to.
131 | input_mask = [1] * len(input_ids)
132 |
133 | # Zero-pad up to the sequence length.
134 | while len(input_ids) < seq_length:
135 | input_ids.append(0)
136 | input_mask.append(0)
137 | input_type_ids.append(0)
138 |
139 | assert len(input_ids) == seq_length
140 | assert len(input_mask) == seq_length
141 | assert len(input_type_ids) == seq_length
142 | features.append(
143 | InputFeatures(
144 | unique_id=example.unique_id,
145 | tokens=tokens,
146 | input_ids=input_ids,
147 | input_mask=input_mask,
148 | input_type_ids=input_type_ids))
149 | return features
150 |
151 | class DatasetNotFoundError(Exception):
152 | pass
153 |
154 | class ReferDataset(data.Dataset):
155 | SUPPORTED_DATASETS = {
156 | 'referit': {'splits': ('train', 'val', 'trainval', 'test')},
157 | 'unc': {
158 | 'splits': ('train', 'val', 'trainval', 'testA', 'testB'),
159 | 'params': {'dataset': 'refcoco', 'split_by': 'unc'}
160 | },
161 | 'unc+': {
162 | 'splits': ('train', 'val', 'trainval', 'testA', 'testB'),
163 | 'params': {'dataset': 'refcoco+', 'split_by': 'unc'}
164 | },
165 | 'gref': {
166 | 'splits': ('train', 'val'),
167 | 'params': {'dataset': 'refcocog', 'split_by': 'google'}
168 | },
169 | 'flickr': {
170 | 'splits': ('train', 'val', 'test')}
171 | }
172 |
173 | def __init__(self, data_root, split_root='data', dataset='referit', imsize=256,
174 | transform=None, augment=False, return_idx=False, testmode=False,
175 | split='train', max_query_len=128, lstm=False, bert_model='bert-base-uncased'):
176 | self.images = []
177 | self.data_root = data_root
178 | self.split_root = split_root
179 | self.dataset = dataset
180 | self.imsize = imsize
181 | self.query_len = max_query_len
182 | self.lstm = lstm
183 | self.corpus = Corpus()
184 | self.transform = transform
185 | self.testmode = testmode
186 | self.split = split
187 | self.tokenizer = BertTokenizer.from_pretrained(bert_model, do_lower_case=True)
188 | self.augment=augment
189 | self.return_idx=return_idx
190 |
191 | if self.dataset == 'referit':
192 | self.dataset_root = osp.join(self.data_root, 'referit')
193 | self.im_dir = osp.join(self.dataset_root, 'images')
194 | self.split_dir = osp.join(self.dataset_root, 'splits')
195 | elif self.dataset == 'flickr':
196 | self.dataset_root = osp.join(self.data_root, 'Flickr30k')
197 | self.im_dir = osp.join(self.dataset_root, 'flickr30k_images')
198 | else: ## refcoco, etc.
199 | self.dataset_root = osp.join(self.data_root, 'other')
200 | self.im_dir = osp.join(
201 | self.dataset_root, 'images', 'mscoco', 'images', 'train2014')
202 | self.split_dir = osp.join(self.dataset_root, 'splits')
203 |
204 | if not self.exists_dataset():
205 | # self.process_dataset()
206 | print('Please download index cache to data folder: \n \
207 | https://drive.google.com/open?id=1cZI562MABLtAzM6YU4WmKPFFguuVr0lZ')
208 | exit(0)
209 |
210 | dataset_path = osp.join(self.split_root, self.dataset)
211 | corpus_path = osp.join(dataset_path, 'corpus.pth')
212 | valid_splits = self.SUPPORTED_DATASETS[self.dataset]['splits']
213 |
214 | if split not in valid_splits:
215 | raise ValueError(
216 | 'Dataset {0} does not have split {1}'.format(
217 | self.dataset, split))
218 | self.corpus = torch.load(corpus_path)
219 |
220 | splits = [split]
221 | if self.dataset != 'referit':
222 | splits = ['train', 'val'] if split == 'trainval' else [split]
223 | for split in splits:
224 | imgset_file = '{0}_{1}.pth'.format(self.dataset, split)
225 | imgset_path = osp.join(dataset_path, imgset_file)
226 | self.images += torch.load(imgset_path)
227 |
228 | def exists_dataset(self):
229 | return osp.exists(osp.join(self.split_root, self.dataset))
230 |
231 | def pull_item(self, idx):
232 | if self.dataset == 'flickr':
233 | img_file, bbox, phrase = self.images[idx]
234 | else:
235 | img_file, _, bbox, phrase, attri = self.images[idx]
236 | ## box format: to x1y1x2y2
237 | if not (self.dataset == 'referit' or self.dataset == 'flickr'):
238 | bbox = np.array(bbox, dtype=int)
239 | bbox[2], bbox[3] = bbox[0]+bbox[2], bbox[1]+bbox[3]
240 | else:
241 | bbox = np.array(bbox, dtype=int)
242 |
243 | img_path = osp.join(self.im_dir, img_file)
244 | img = cv2.imread(img_path)
245 | ## duplicate channel if gray image
246 | if img.shape[-1] > 1:
247 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
248 | else:
249 | img = np.stack([img] * 3)
250 | return img, phrase, bbox
251 |
252 | def tokenize_phrase(self, phrase):
253 | return self.corpus.tokenize(phrase, self.query_len)
254 |
255 | def untokenize_word_vector(self, words):
256 | return self.corpus.dictionary[words]
257 |
258 | def __len__(self):
259 | return len(self.images)
260 |
261 | def __getitem__(self, idx):
262 | img, phrase, bbox = self.pull_item(idx)
263 | # phrase = phrase.decode("utf-8").encode().lower()
264 | phrase = phrase.lower()
265 | if self.augment:
266 | augment_flip, augment_hsv, augment_affine = True,True,True
267 |
268 | ## seems a bug in torch transformation resize, so separate in advance
269 | h,w = img.shape[0], img.shape[1]
270 | if self.augment:
271 | ## random horizontal flip
272 | if augment_flip and random.random() > 0.5:
273 | img = cv2.flip(img, 1)
274 | bbox[0], bbox[2] = w-bbox[2]-1, w-bbox[0]-1
275 | phrase = phrase.replace('right','*&^special^&*').replace('left','right').replace('*&^special^&*','left')
276 | ## random intensity, saturation change
277 | if augment_hsv:
278 | fraction = 0.50
279 | img_hsv = cv2.cvtColor(cv2.cvtColor(img, cv2.COLOR_RGB2BGR), cv2.COLOR_BGR2HSV)
280 | S = img_hsv[:, :, 1].astype(np.float32)
281 | V = img_hsv[:, :, 2].astype(np.float32)
282 | a = (random.random() * 2 - 1) * fraction + 1
283 | if a > 1:
284 | np.clip(S, a_min=0, a_max=255, out=S)
285 | a = (random.random() * 2 - 1) * fraction + 1
286 | V *= a
287 | if a > 1:
288 | np.clip(V, a_min=0, a_max=255, out=V)
289 |
290 | img_hsv[:, :, 1] = S.astype(np.uint8)
291 | img_hsv[:, :, 2] = V.astype(np.uint8)
292 | img = cv2.cvtColor(cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR), cv2.COLOR_BGR2RGB)
293 | img, _, ratio, dw, dh = letterbox(img, None, self.imsize)
294 | bbox[0], bbox[2] = bbox[0]*ratio+dw, bbox[2]*ratio+dw
295 | bbox[1], bbox[3] = bbox[1]*ratio+dh, bbox[3]*ratio+dh
296 | ## random affine transformation
297 | if augment_affine:
298 | img, _, bbox, M = random_affine(img, None, bbox, \
299 | degrees=(-5, 5), translate=(0.10, 0.10), scale=(0.90, 1.10))
300 | else: ## should be inference, or specified training
301 | img, _, ratio, dw, dh = letterbox(img, None, self.imsize)
302 | bbox[0], bbox[2] = bbox[0]*ratio+dw, bbox[2]*ratio+dw
303 | bbox[1], bbox[3] = bbox[1]*ratio+dh, bbox[3]*ratio+dh
304 |
305 | ## Norm, to tensor
306 | if self.transform is not None:
307 | img = self.transform(img)
308 | if self.lstm:
309 | phrase = self.tokenize_phrase(phrase)
310 | word_id = phrase
311 | word_mask = np.zeros(word_id.shape)
312 | else:
313 | ## encode phrase to bert input
314 | examples = read_examples(phrase, idx)
315 | features = convert_examples_to_features(
316 | examples=examples, seq_length=self.query_len, tokenizer=self.tokenizer)
317 | word_id = features[0].input_ids
318 | word_mask = features[0].input_mask
319 | if self.testmode:
320 | return img, np.array(word_id, dtype=int), np.array(word_mask, dtype=int), \
321 | np.array(bbox, dtype=np.float32), np.array(ratio, dtype=np.float32), \
322 | np.array(dw, dtype=np.float32), np.array(dh, dtype=np.float32), self.images[idx][0]
323 | else:
324 | return img, np.array(word_id, dtype=int), np.array(word_mask, dtype=int), \
325 | np.array(bbox, dtype=np.float32)
326 |
327 | if __name__ == '__main__':
328 | import nltk
329 | import argparse
330 | from torch.utils.data import DataLoader
331 | from torchvision.transforms import Compose, ToTensor, Normalize
332 | # from utils.transforms import ResizeImage, ResizeAnnotation
333 | parser = argparse.ArgumentParser(
334 | description='Dataloader test')
335 | parser.add_argument('--size', default=416, type=int,
336 | help='image size')
337 | parser.add_argument('--data', type=str, default='./ln_data/',
338 | help='path to ReferIt splits data folder')
339 | parser.add_argument('--dataset', default='referit', type=str,
340 | help='referit/flickr/unc/unc+/gref')
341 | parser.add_argument('--split', default='train', type=str,
342 | help='name of the dataset split used to train')
343 | parser.add_argument('--time', default=20, type=int,
344 | help='maximum time steps (lang length) per batch')
345 | args = parser.parse_args()
346 |
347 | torch.manual_seed(13)
348 | np.random.seed(13)
349 | torch.backends.cudnn.deterministic = True
350 | torch.backends.cudnn.benchmark = False
351 |
352 | input_transform = Compose([
353 | ToTensor(),
354 | Normalize(
355 | mean=[0.485, 0.456, 0.406],
356 | std=[0.229, 0.224, 0.225])
357 | ])
358 |
359 | refer_val = ReferDataset(data_root=args.data,
360 | dataset=args.dataset,
361 | split='val',
362 | imsize = args.size,
363 | transform=input_transform,
364 | max_query_len=args.time,
365 | testmode=True)
366 | val_loader = DataLoader(refer_val, batch_size=8, shuffle=False,
367 | pin_memory=False, num_workers=0)
368 |
369 |
370 | bbox_list=[]
371 | for batch_idx, (imgs, masks, word_id, word_mask, bbox) in enumerate(val_loader):
372 | bboxes = (bbox[:,2:]-bbox[:,:2]).numpy().tolist()
373 | for bbox in bboxes:
374 | bbox_list.append(bbox)
375 | if batch_idx%10000==0 and batch_idx!=0:
376 | print(batch_idx)
--------------------------------------------------------------------------------
/ln_data/README.md:
--------------------------------------------------------------------------------
1 | # Data Folder
2 | * RefCOCO & ReferItGame Dataset: place the soft link of dataset folder under the current folder. We follow dataset structure [DMS](https://github.com/BCV-Uniandes/DMS). To accomplish this, the ``download_dataset.sh`` [bash script](https://github.com/BCV-Uniandes/DMS/blob/master/download_data.sh) from DMS can be used.
3 | ```bash
4 | bash download_data --path .
5 | ```
6 |
7 |
11 | * Flickr30K Entities Dataset: please download the images for the dataset on the website for the [Flickr30K Entities Dataset](http://bryanplummer.com/Flickr30kEntities/) and the original [Flickr30k Dataset](http://shannon.cs.illinois.edu/DenotationGraph/). Images should be placed under ``./Flickr30k/flickr30k_images``.
12 |
13 | * Data index: download the generated index files and place them in the ``../data`` folder. Availble at [[Gdrive]](https://drive.google.com/open?id=1cZI562MABLtAzM6YU4WmKPFFguuVr0lZ), [[One Drive]](https://uofr-my.sharepoint.com/:f:/g/personal/zyang39_ur_rochester_edu/Epw5WQ_mJ-tOlAbK5LxsnrsBElWwvNdU7aus0UIzWtwgKQ?e=XHQm7F).
14 | ```
15 | cd ..
16 | rm -r data
17 | tar xf data.tar
18 | ```
--------------------------------------------------------------------------------
/ln_data/download_data.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | version="0.1"
4 |
5 | # This is an optional arguments-only example of Argbash potential
6 | #
7 | # ARG_OPTIONAL_SINGLE([path],[p],[path onto which files are to be downloaded],[data])
8 | # ARG_VERSION([echo test v$version])
9 | # ARG_HELP([The general script's help msg])
10 | # ARGBASH_GO()
11 | # needed because of Argbash --> m4_ignore([
12 | ### START OF CODE GENERATED BY Argbash v2.5.0 one line above ###
13 | # Argbash is a bash code generator used to get arguments parsing right.
14 | # Argbash is FREE SOFTWARE, see https://argbash.io for more info
15 | # Generated online by https://argbash.io/generate
16 |
17 | die()
18 | {
19 | local _ret=$2
20 | test -n "$_ret" || _ret=1
21 | test "$_PRINT_HELP" = yes && print_help >&2
22 | echo "$1" >&2
23 | exit ${_ret}
24 | }
25 |
26 | begins_with_short_option()
27 | {
28 | local first_option all_short_options
29 | all_short_options='pvh'
30 | first_option="${1:0:1}"
31 | test "$all_short_options" = "${all_short_options/$first_option/}" && return 1 || return 0
32 | }
33 |
34 |
35 |
36 | # THE DEFAULTS INITIALIZATION - OPTIONALS
37 | _arg_path="referit_data"
38 |
39 | print_help ()
40 | {
41 | printf "%s\n" "download ReferIt data script"
42 | printf 'Usage: %s [-p|--path ] [-v|--version] [-h|--help]\n' "$0"
43 | printf "\t%s\n" "-p,--path: path onto which files are to be downloaded (default: '"referit_data"')"
44 | printf "\t%s\n" "-v,--version: Prints version"
45 | printf "\t%s\n" "-h,--help: Prints help"
46 | }
47 |
48 | parse_commandline ()
49 | {
50 | while test $# -gt 0
51 | do
52 | _key="$1"
53 | case "$_key" in
54 | -p|--path)
55 | test $# -lt 2 && die "Missing value for the optional argument '$_key'." 1
56 | _arg_path="$2"
57 | shift
58 | ;;
59 | --path=*)
60 | _arg_path="${_key##--path=}"
61 | ;;
62 | -p*)
63 | _arg_path="${_key##-p}"
64 | ;;
65 | -v|--version)
66 | echo test v$version
67 | exit 0
68 | ;;
69 | -v*)
70 | echo test v$version
71 | exit 0
72 | ;;
73 | -h|--help)
74 | print_help
75 | exit 0
76 | ;;
77 | -h*)
78 | print_help
79 | exit 0
80 | ;;
81 | *)
82 | _PRINT_HELP=yes die "FATAL ERROR: Got an unexpected argument '$1'" 1
83 | ;;
84 | esac
85 | shift
86 | done
87 | }
88 |
89 | parse_commandline "$@"
90 |
91 | # OTHER STUFF GENERATED BY Argbash
92 |
93 | ### END OF CODE GENERATED BY Argbash (sortof) ### ])
94 | # [ <-- needed because of Argbash
95 |
96 |
97 | echo "Save data to: $_arg_path"
98 |
99 |
100 | REFERIT_SPLITS_URL="https://s3-sa-east-1.amazonaws.com/query-objseg/referit_splits.tar.bz2"
101 | REFERIT_DATA_URL="http://www.eecs.berkeley.edu/~ronghang/projects/cvpr16_text_obj_retrieval/referitdata.tar.gz"
102 | COCO_DATA_URL="http://images.cocodataset.org/zips/train2014.zip"
103 |
104 | REFCOCO_URL="http://bvisionweb1.cs.unc.edu/licheng/referit/data/refcoco.zip"
105 | REFCOCO_PLUS_URL="http://bvisionweb1.cs.unc.edu/licheng/referit/data/refcoco+.zip"
106 | REFCOCOG_URL="http://bvisionweb1.cs.unc.edu/licheng/referit/data/refcocog.zip"
107 |
108 | REFERIT_FILE=${REFERIT_DATA_URL#*cvpr16_text_obj_retrieval/}
109 | SPLIT_FILE=${REFERIT_SPLITS_URL#*query-objseg/}
110 | COCO_FILE=${COCO_DATA_URL#*zips/}
111 |
112 |
113 | if [ ! -d $_arg_path ]; then
114 | mkdir $_arg_path
115 | fi
116 | cd $_arg_path
117 |
118 | mkdir referit
119 | cd referit
120 |
121 | printf "Downloading ReferIt dataset (This may take a while...)"
122 | aria2c -x 8 $REFERIT_DATA_URL
123 |
124 |
125 | printf "Uncompressing data..."
126 | tar -xzvf $REFERIT_FILE
127 | rm $REFERIT_FILE
128 |
129 | mkdir splits
130 | cd splits
131 |
132 | printf "Downloading ReferIt Splits..."
133 | aria2c -x 8 $REFERIT_SPLITS_URL
134 |
135 | tar -xjvf $SPLIT_FILE
136 | rm $SPLIT_FILE
137 |
138 | cd ../..
139 |
140 | mkdir -p other/images/mscoco/images
141 | cd other/images/mscoco/images
142 |
143 | printf "Downloading MS COCO 2014 train images (This may take a while...)"
144 | aria2c -x 8 $COCO_DATA_URL
145 |
146 | unzip $COCO_FILE
147 | rm $COCO_FILE
148 |
149 | cd ../../..
150 | printf "Downloading refcoco, refcocog and refcoco+ splits..."
151 | aria2c -x 8 $REFCOCO_URL
152 | aria2c -x 8 $REFCOCO_PLUS_URL
153 | aria2c -x 8 $REFCOCOG_URL
154 |
155 | unzip "*.zip"
156 | rm *.zip
--------------------------------------------------------------------------------
/model/darknet.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 |
3 | import math
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from torch.autograd import Variable
8 | import numpy as np
9 | from collections import defaultdict, OrderedDict
10 |
11 | from PIL import Image
12 |
13 | # from utils.parse_config import *
14 | from utils.utils import *
15 | # import matplotlib.pyplot as plt
16 | # import matplotlib.patches as patches
17 |
18 | exist_id = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, \
19 | 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, \
20 | 23, 24, 25, 27, 28, 31, 32, 33, 34, 35, 36, \
21 | 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, \
22 | 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, \
23 | 60, 61, 62, 63, 64, 65, 67, 70, 72, 73, 74, \
24 | 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, \
25 | 87, 88, 89, 90]
26 | catmap_dict = OrderedDict()
27 | for ii in range(len(exist_id)):
28 | catmap_dict[exist_id[ii]] = ii
29 |
30 | def build_object_targets(
31 | pred_boxes, pred_conf, pred_cls, target, anchors, num_anchors, num_classes, grid_size, ignore_thres, img_dim
32 | ):
33 | nB = target.size(0)
34 | nA = num_anchors
35 | nC = num_classes
36 | nG = grid_size
37 | mask = torch.zeros(nB, nA, nG, nG)
38 | conf_mask = torch.ones(nB, nA, nG, nG)
39 | tx = torch.zeros(nB, nA, nG, nG)
40 | ty = torch.zeros(nB, nA, nG, nG)
41 | tw = torch.zeros(nB, nA, nG, nG)
42 | th = torch.zeros(nB, nA, nG, nG)
43 | tconf = torch.ByteTensor(nB, nA, nG, nG).fill_(0)
44 | tcls = torch.ByteTensor(nB, nA, nG, nG, nC).fill_(0)
45 |
46 | nGT = 0
47 | nCorrect = 0
48 | for b in range(nB):
49 | for t in range(target.shape[1]):
50 | if target[b, t].sum() == 0:
51 | continue
52 | nGT += 1
53 | # Convert to position relative to box
54 | gx = target[b, t, 1] * nG
55 | gy = target[b, t, 2] * nG
56 | gw = target[b, t, 3] * nG
57 | gh = target[b, t, 4] * nG
58 | # Get grid box indices
59 | gi = int(gx)
60 | gj = int(gy)
61 | # Get shape of gt box
62 | gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0)
63 | # Get shape of anchor box
64 | anchor_shapes = torch.FloatTensor(np.concatenate((np.zeros((len(anchors), 2)), np.array(anchors)), 1))
65 | # Calculate iou between gt and anchor shapes
66 | anch_ious = bbox_iou(gt_box, anchor_shapes)
67 | # Where the overlap is larger than threshold set mask to zero (ignore)
68 | conf_mask[b, anch_ious > ignore_thres, gj, gi] = 0
69 | # Find the best matching anchor box
70 | best_n = np.argmax(anch_ious)
71 | # Get ground truth box
72 | gt_box = torch.FloatTensor(np.array([gx, gy, gw, gh])).unsqueeze(0)
73 | # Get the best prediction
74 | pred_box = pred_boxes[b, best_n, gj, gi].unsqueeze(0)
75 | # Masks
76 | mask[b, best_n, gj, gi] = 1
77 | conf_mask[b, best_n, gj, gi] = 1
78 | # Coordinates
79 | tx[b, best_n, gj, gi] = gx - gi
80 | ty[b, best_n, gj, gi] = gy - gj
81 | # Width and height
82 | tw[b, best_n, gj, gi] = math.log(gw / anchors[best_n][0] + 1e-16)
83 | th[b, best_n, gj, gi] = math.log(gh / anchors[best_n][1] + 1e-16)
84 | # One-hot encoding of label
85 | target_label = int(target[b, t, 0])
86 | target_label = catmap_dict[target_label]
87 | tcls[b, best_n, gj, gi, target_label] = 1
88 | tconf[b, best_n, gj, gi] = 1
89 |
90 | # Calculate iou between ground truth and best matching prediction
91 | iou = bbox_iou(gt_box, pred_box, x1y1x2y2=False)
92 | pred_label = torch.argmax(pred_cls[b, best_n, gj, gi])
93 | score = pred_conf[b, best_n, gj, gi]
94 | if iou > 0.5 and pred_label == target_label and score > 0.5:
95 | nCorrect += 1
96 |
97 | return nGT, nCorrect, mask, conf_mask, tx, ty, tw, th, tconf, tcls
98 |
99 | def parse_model_config(path):
100 | """Parses the yolo-v3 layer configuration file and returns module definitions"""
101 | file = open(path, 'r')
102 | lines = file.read().split('\n')
103 | lines = [x for x in lines if x and not x.startswith('#')]
104 | lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespaces
105 | module_defs = []
106 | for line in lines:
107 | if line.startswith('['): # This marks the start of a new block
108 | module_defs.append({})
109 | module_defs[-1]['type'] = line[1:-1].rstrip()
110 | if module_defs[-1]['type'] == 'convolutional' or module_defs[-1]['type'] == 'yoloconvolutional':
111 | module_defs[-1]['batch_normalize'] = 0
112 | else:
113 | key, value = line.split("=")
114 | value = value.strip()
115 | module_defs[-1][key.rstrip()] = value.strip()
116 | return module_defs
117 |
118 | class ConvBatchNormReLU(nn.Sequential):
119 | def __init__(
120 | self,
121 | in_channels,
122 | out_channels,
123 | kernel_size,
124 | stride,
125 | padding,
126 | dilation,
127 | leaky=False,
128 | relu=True,
129 | ):
130 | super(ConvBatchNormReLU, self).__init__()
131 | self.add_module(
132 | "conv",
133 | nn.Conv2d(
134 | in_channels=in_channels,
135 | out_channels=out_channels,
136 | kernel_size=kernel_size,
137 | stride=stride,
138 | padding=padding,
139 | dilation=dilation,
140 | bias=False,
141 | ),
142 | )
143 | self.add_module(
144 | "bn",
145 | nn.BatchNorm2d(
146 | num_features=out_channels, eps=1e-5, momentum=0.999, affine=True
147 | ),
148 | )
149 |
150 | if leaky:
151 | self.add_module("relu", nn.LeakyReLU(0.1))
152 | elif relu:
153 | self.add_module("relu", nn.ReLU())
154 |
155 | def forward(self, x):
156 | return super(ConvBatchNormReLU, self).forward(x)
157 |
158 | class MyUpsample2(nn.Module):
159 | def forward(self, x):
160 | return x[:, :, :, None, :, None].expand(-1, -1, -1, 2, -1, 2).reshape(x.size(0), x.size(1), x.size(2)*2, x.size(3)*2)
161 |
162 | def create_modules(module_defs):
163 | """
164 | Constructs module list of layer blocks from module configuration in module_defs
165 | """
166 | hyperparams = module_defs.pop(0)
167 | output_filters = [int(hyperparams["channels"])]
168 | module_list = nn.ModuleList()
169 | for i, module_def in enumerate(module_defs):
170 | modules = nn.Sequential()
171 |
172 | if module_def["type"] == "convolutional" or module_def["type"] == "yoloconvolutional":
173 | bn = int(module_def["batch_normalize"])
174 | filters = int(module_def["filters"])
175 | kernel_size = int(module_def["size"])
176 | pad = (kernel_size - 1) // 2 if int(module_def["pad"]) else 0
177 | modules.add_module(
178 | "conv_%d" % i,
179 | nn.Conv2d(
180 | in_channels=output_filters[-1],
181 | out_channels=filters,
182 | kernel_size=kernel_size,
183 | stride=int(module_def["stride"]),
184 | padding=pad,
185 | bias=not bn,
186 | ),
187 | )
188 | if bn:
189 | modules.add_module("batch_norm_%d" % i, nn.BatchNorm2d(filters))
190 | if module_def["activation"] == "leaky":
191 | modules.add_module("leaky_%d" % i, nn.LeakyReLU(0.1))
192 |
193 | elif module_def["type"] == "maxpool":
194 | kernel_size = int(module_def["size"])
195 | stride = int(module_def["stride"])
196 | if kernel_size == 2 and stride == 1:
197 | padding = nn.ZeroPad2d((0, 1, 0, 1))
198 | modules.add_module("_debug_padding_%d" % i, padding)
199 | maxpool = nn.MaxPool2d(
200 | kernel_size=int(module_def["size"]),
201 | stride=int(module_def["stride"]),
202 | padding=int((kernel_size - 1) // 2),
203 | )
204 | modules.add_module("maxpool_%d" % i, maxpool)
205 |
206 | elif module_def["type"] == "upsample":
207 | # upsample = nn.Upsample(scale_factor=int(module_def["stride"]), mode="nearest")
208 | assert(int(module_def["stride"])==2)
209 | upsample = MyUpsample2()
210 | modules.add_module("upsample_%d" % i, upsample)
211 |
212 | elif module_def["type"] == "route":
213 | layers = [int(x) for x in module_def["layers"].split(",")]
214 | filters = sum([output_filters[layer_i] for layer_i in layers])
215 | modules.add_module("route_%d" % i, EmptyLayer())
216 |
217 | elif module_def["type"] == "shortcut":
218 | filters = output_filters[int(module_def["from"])]
219 | modules.add_module("shortcut_%d" % i, EmptyLayer())
220 |
221 | elif module_def["type"] == "yolo":
222 | anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
223 | # Extract anchors
224 | anchors = [int(x) for x in module_def["anchors"].split(",")]
225 | anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
226 | anchors = [anchors[i] for i in anchor_idxs]
227 | num_classes = int(module_def["classes"])
228 | img_height = int(hyperparams["height"])
229 | # Define detection layer
230 | # yolo_layer = YOLOLayer(anchors, num_classes, img_height)
231 | yolo_layer = YOLOLayer(anchors, num_classes, 256)
232 | modules.add_module("yolo_%d" % i, yolo_layer)
233 | # Register module list and number of output filters
234 | module_list.append(modules)
235 | output_filters.append(filters)
236 |
237 | return hyperparams, module_list
238 |
239 | class EmptyLayer(nn.Module):
240 | """Placeholder for 'route' and 'shortcut' layers"""
241 |
242 | def __init__(self):
243 | super(EmptyLayer, self).__init__()
244 |
245 | class YOLOLayer(nn.Module):
246 | """Detection layer"""
247 |
248 | def __init__(self, anchors, num_classes, img_dim):
249 | super(YOLOLayer, self).__init__()
250 | self.anchors = anchors
251 | self.num_anchors = len(anchors)
252 | self.num_classes = num_classes
253 | self.bbox_attrs = 5 + num_classes
254 | self.image_dim = img_dim
255 | self.ignore_thres = 0.5
256 | self.lambda_coord = 1
257 |
258 | self.mse_loss = nn.MSELoss(size_average=True) # Coordinate loss
259 | self.bce_loss = nn.BCELoss(size_average=True) # Confidence loss
260 | self.ce_loss = nn.CrossEntropyLoss() # Class loss
261 |
262 | def forward(self, x, targets=None):
263 | nA = self.num_anchors
264 | nB = x.size(0)
265 | nG = x.size(2)
266 | stride = self.image_dim / nG
267 |
268 | # Tensors for cuda support
269 | FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
270 | LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
271 | ByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensor
272 |
273 | prediction = x.view(nB, nA, self.bbox_attrs, nG, nG).permute(0, 1, 3, 4, 2).contiguous()
274 |
275 | # Get outputs
276 | x = torch.sigmoid(prediction[..., 0]) # Center x
277 | y = torch.sigmoid(prediction[..., 1]) # Center y
278 | w = prediction[..., 2] # Width
279 | h = prediction[..., 3] # Height
280 | pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
281 | pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
282 |
283 | # Calculate offsets for each grid
284 | grid_x = torch.arange(nG).repeat(nG, 1).view([1, 1, nG, nG]).type(FloatTensor)
285 | grid_y = torch.arange(nG).repeat(nG, 1).t().view([1, 1, nG, nG]).type(FloatTensor)
286 | # scaled_anchors = FloatTensor([(a_w / stride, a_h / stride) for a_w, a_h in self.anchors])
287 | scaled_anchors = FloatTensor([(a_w / (416 / nG), a_h / (416 / nG)) for a_w, a_h in self.anchors])
288 | anchor_w = scaled_anchors[:, 0:1].view((1, nA, 1, 1))
289 | anchor_h = scaled_anchors[:, 1:2].view((1, nA, 1, 1))
290 |
291 | # Add offset and scale with anchors
292 | pred_boxes = FloatTensor(prediction[..., :4].shape)
293 | pred_boxes[..., 0] = x.data + grid_x
294 | pred_boxes[..., 1] = y.data + grid_y
295 | pred_boxes[..., 2] = torch.exp(w.data) * anchor_w
296 | pred_boxes[..., 3] = torch.exp(h.data) * anchor_h
297 |
298 | # Training
299 | if targets is not None:
300 | targets = targets.clone()
301 | targets[:,:,1:] = targets[:,:,1:]/self.image_dim
302 | for b_i in range(targets.shape[0]):
303 | targets[b_i,:,1:] = xyxy2xywh(targets[b_i,:,1:])
304 |
305 | if x.is_cuda:
306 | self.mse_loss = self.mse_loss.cuda()
307 | self.bce_loss = self.bce_loss.cuda()
308 | self.ce_loss = self.ce_loss.cuda()
309 |
310 | nGT, nCorrect, mask, conf_mask, tx, ty, tw, th, tconf, tcls = build_object_targets(
311 | pred_boxes=pred_boxes.cpu().data,
312 | pred_conf=pred_conf.cpu().data,
313 | pred_cls=pred_cls.cpu().data,
314 | target=targets.cpu().data,
315 | anchors=scaled_anchors.cpu().data,
316 | num_anchors=nA,
317 | num_classes=self.num_classes,
318 | grid_size=nG,
319 | ignore_thres=self.ignore_thres,
320 | img_dim=self.image_dim,
321 | )
322 |
323 | nProposals = int((pred_conf > 0.5).sum().item())
324 | recall = float(nCorrect / nGT) if nGT else 1
325 | precision = float(nCorrect / nProposals) if nProposals else 0
326 |
327 | # Handle masks
328 | mask = Variable(mask.type(ByteTensor))
329 | conf_mask = Variable(conf_mask.type(ByteTensor))
330 |
331 | # Handle target variables
332 | tx = Variable(tx.type(FloatTensor), requires_grad=False)
333 | ty = Variable(ty.type(FloatTensor), requires_grad=False)
334 | tw = Variable(tw.type(FloatTensor), requires_grad=False)
335 | th = Variable(th.type(FloatTensor), requires_grad=False)
336 | tconf = Variable(tconf.type(FloatTensor), requires_grad=False)
337 | tcls = Variable(tcls.type(LongTensor), requires_grad=False)
338 |
339 | # Get conf mask where gt and where there is no gt
340 | conf_mask_true = mask
341 | conf_mask_false = conf_mask - mask
342 |
343 | # Mask outputs to ignore non-existing objects
344 | loss_x = self.mse_loss(x[mask], tx[mask])
345 | loss_y = self.mse_loss(y[mask], ty[mask])
346 | loss_w = self.mse_loss(w[mask], tw[mask])
347 | loss_h = self.mse_loss(h[mask], th[mask])
348 | loss_conf = self.bce_loss(pred_conf[conf_mask_false], tconf[conf_mask_false]) + self.bce_loss(
349 | pred_conf[conf_mask_true], tconf[conf_mask_true]
350 | )
351 | loss_cls = (1 / nB) * self.ce_loss(pred_cls[mask], torch.argmax(tcls[mask], 1))
352 | loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
353 | return (
354 | loss,
355 | loss_x.item(),
356 | loss_y.item(),
357 | loss_w.item(),
358 | loss_h.item(),
359 | loss_conf.item(),
360 | loss_cls.item(),
361 | recall,
362 | precision,
363 | )
364 |
365 | else:
366 | # If not in training phase return predictions
367 | output = torch.cat(
368 | (
369 | pred_boxes.view(nB, -1, 4) * stride,
370 | pred_conf.view(nB, -1, 1),
371 | pred_cls.view(nB, -1, self.num_classes),
372 | ),
373 | -1,
374 | )
375 | return output
376 |
377 | class Darknet(nn.Module):
378 | """YOLOv3 object detection model"""
379 |
380 | def __init__(self, config_path='./model/yolov3.cfg', img_size=416, obj_out=False):
381 | super(Darknet, self).__init__()
382 | self.config_path = config_path
383 | self.obj_out = obj_out
384 | self.module_defs = parse_model_config(config_path)
385 | self.hyperparams, self.module_list = create_modules(self.module_defs)
386 | self.img_size = img_size
387 | self.seen = 0
388 | self.header_info = np.array([0, 0, 0, self.seen, 0])
389 | self.loss_names = ["x", "y", "w", "h", "conf", "cls", "recall", "precision"]
390 |
391 | def forward(self, x, targets=None):
392 | batch = x.shape[0]
393 | is_training = targets is not None
394 | output, output_obj = [], []
395 | self.losses = defaultdict(float)
396 | layer_outputs = []
397 | for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
398 | if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
399 | x = module(x)
400 | elif module_def["type"] == "route":
401 | layer_i = [int(x) for x in module_def["layers"].split(",")]
402 | x = torch.cat([layer_outputs[i] for i in layer_i], 1)
403 | elif module_def["type"] == "shortcut":
404 | layer_i = int(module_def["from"])
405 | x = layer_outputs[-1] + layer_outputs[layer_i]
406 | elif module_def["type"] == "yoloconvolutional":
407 | output.append(x) ## save final feature block
408 | x = module(x)
409 | elif module_def["type"] == "yolo":
410 | # Train phase: get loss
411 | if is_training:
412 | x, *losses = module[0](x, targets)
413 | for name, loss in zip(self.loss_names, losses):
414 | self.losses[name] += loss
415 | # Test phase: Get detections
416 | else:
417 | x = module(x)
418 | output_obj.append(x)
419 | # x = module(x)
420 | # output.append(x)
421 | layer_outputs.append(x)
422 |
423 | self.losses["recall"] /= 3
424 | self.losses["precision"] /= 3
425 | # return sum(output) if is_training else torch.cat(output, 1)
426 | # return torch.cat(output, 1)
427 | if self.obj_out:
428 | return output, sum(output_obj) if is_training else torch.cat(output_obj, 1), self.losses["precision"], self.losses["recall"]
429 | # return output, sum(output_obj)/(len(output_obj)*batch) if is_training else torch.cat(output_obj, 1)
430 | else:
431 | return output
432 |
433 | def load_weights(self, weights_path):
434 | """Parses and loads the weights stored in 'weights_path'"""
435 |
436 | # Open the weights file
437 | fp = open(weights_path, "rb")
438 | if self.config_path=='./model/yolo9000.cfg':
439 | header = np.fromfile(fp, dtype=np.int32, count=4) # First five are header values
440 | else:
441 | header = np.fromfile(fp, dtype=np.int32, count=5) # First five are header values
442 | # Needed to write header when saving weights
443 | self.header_info = header
444 |
445 | self.seen = header[3]
446 | weights = np.fromfile(fp, dtype=np.float32) # The rest are weights
447 | fp.close()
448 |
449 | ptr = 0
450 | for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
451 | if module_def["type"] == "convolutional" or module_def["type"] == "yoloconvolutional":
452 | conv_layer = module[0]
453 | if module_def["batch_normalize"]:
454 | # Load BN bias, weights, running mean and running variance
455 | bn_layer = module[1]
456 | num_b = bn_layer.bias.numel() # Number of biases
457 | # Bias
458 | bn_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.bias)
459 | bn_layer.bias.data.copy_(bn_b)
460 | ptr += num_b
461 | # Weight
462 | bn_w = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.weight)
463 | bn_layer.weight.data.copy_(bn_w)
464 | ptr += num_b
465 | # Running Mean
466 | bn_rm = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_mean)
467 | bn_layer.running_mean.data.copy_(bn_rm)
468 | ptr += num_b
469 | # Running Var
470 | bn_rv = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_var)
471 | bn_layer.running_var.data.copy_(bn_rv)
472 | ptr += num_b
473 | else:
474 | # Load conv. bias
475 | num_b = conv_layer.bias.numel()
476 | conv_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(conv_layer.bias)
477 | conv_layer.bias.data.copy_(conv_b)
478 | ptr += num_b
479 | # Load conv. weights
480 | num_w = conv_layer.weight.numel()
481 | conv_w = torch.from_numpy(weights[ptr : ptr + num_w]).view_as(conv_layer.weight)
482 | conv_layer.weight.data.copy_(conv_w)
483 | ptr += num_w
484 |
485 | """
486 | @:param path - path of the new weights file
487 | @:param cutoff - save layers between 0 and cutoff (cutoff = -1 -> all are saved)
488 | """
489 |
490 | def save_weights(self, path, cutoff=-1):
491 |
492 | fp = open(path, "wb")
493 | self.header_info[3] = self.seen
494 | self.header_info.tofile(fp)
495 |
496 | # Iterate through layers
497 | for i, (module_def, module) in enumerate(zip(self.module_defs[:cutoff], self.module_list[:cutoff])):
498 | if module_def["type"] == "convolutional":
499 | conv_layer = module[0]
500 | # If batch norm, load bn first
501 | if module_def["batch_normalize"]:
502 | bn_layer = module[1]
503 | bn_layer.bias.data.cpu().numpy().tofile(fp)
504 | bn_layer.weight.data.cpu().numpy().tofile(fp)
505 | bn_layer.running_mean.data.cpu().numpy().tofile(fp)
506 | bn_layer.running_var.data.cpu().numpy().tofile(fp)
507 | # Load conv bias
508 | else:
509 | conv_layer.bias.data.cpu().numpy().tofile(fp)
510 | # Load conv weights
511 | conv_layer.weight.data.cpu().numpy().tofile(fp)
512 |
513 | fp.close
514 |
515 |
516 | if __name__ == "__main__":
517 | import torch
518 | import numpy as np
519 | torch.manual_seed(13)
520 | np.random.seed(13)
521 | torch.backends.cudnn.deterministic = True
522 | torch.backends.cudnn.benchmark = False
523 |
524 | model = Darknet()
525 | model.load_weights('./saved_models/yolov3.weights')
526 | # model.eval()
527 |
528 | image = torch.autograd.Variable(torch.randn(1, 3, 416, 416))
529 | output1, output2, output3 = model(image)
530 | print(output1)
531 | # print(output1.size(), output2.size(), output3.size())
532 | # print(model(image))
533 | # print(len(output), output[0].size(), output[1].size(), output[2].size())
534 |
--------------------------------------------------------------------------------
/model/grounding_model.py:
--------------------------------------------------------------------------------
1 | from collections import OrderedDict
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | import torch.utils.model_zoo as model_zoo
7 | from torch.utils.data import TensorDataset, DataLoader, SequentialSampler
8 | from torch.utils.data.distributed import DistributedSampler
9 |
10 | from .darknet import *
11 |
12 | import argparse
13 | import collections
14 | import logging
15 | import json
16 | import re
17 | import time
18 | ## can be commented if only use LSTM encoder
19 | from pytorch_pretrained_bert.tokenization import BertTokenizer
20 | from pytorch_pretrained_bert.modeling import BertModel
21 |
22 | def generate_coord(batch, height, width):
23 | # coord = Variable(torch.zeros(batch,8,height,width).cuda())
24 | xv, yv = torch.meshgrid([torch.arange(0,height), torch.arange(0,width)])
25 | xv_min = (xv.float()*2 - width)/width
26 | yv_min = (yv.float()*2 - height)/height
27 | xv_max = ((xv+1).float()*2 - width)/width
28 | yv_max = ((yv+1).float()*2 - height)/height
29 | xv_ctr = (xv_min+xv_max)/2
30 | yv_ctr = (yv_min+yv_max)/2
31 | hmap = torch.ones(height,width)*(1./height)
32 | wmap = torch.ones(height,width)*(1./width)
33 | coord = torch.autograd.Variable(torch.cat([xv_min.unsqueeze(0), yv_min.unsqueeze(0),\
34 | xv_max.unsqueeze(0), yv_max.unsqueeze(0),\
35 | xv_ctr.unsqueeze(0), yv_ctr.unsqueeze(0),\
36 | hmap.unsqueeze(0), wmap.unsqueeze(0)], dim=0).cuda())
37 | coord = coord.unsqueeze(0).repeat(batch,1,1,1)
38 | return coord
39 |
40 | class RNNEncoder(nn.Module):
41 | def __init__(self, vocab_size, word_embedding_size, word_vec_size, hidden_size, bidirectional=False,
42 | input_dropout_p=0, dropout_p=0, n_layers=1, rnn_type='lstm', variable_lengths=True):
43 | super(RNNEncoder, self).__init__()
44 | self.variable_lengths = variable_lengths
45 | self.embedding = nn.Embedding(vocab_size, word_embedding_size)
46 | self.input_dropout = nn.Dropout(input_dropout_p)
47 | self.mlp = nn.Sequential(nn.Linear(word_embedding_size, word_vec_size),
48 | nn.ReLU())
49 | self.rnn_type = rnn_type
50 | self.rnn = getattr(nn, rnn_type.upper())(word_vec_size, hidden_size, n_layers,
51 | batch_first=True,
52 | bidirectional=bidirectional,
53 | dropout=dropout_p)
54 | self.num_dirs = 2 if bidirectional else 1
55 |
56 | def forward(self, input_labels):
57 | """
58 | Inputs:
59 | - input_labels: Variable long (batch, seq_len)
60 | Outputs:
61 | - output : Variable float (batch, max_len, hidden_size * num_dirs)
62 | - hidden : Variable float (batch, num_layers * num_dirs * hidden_size)
63 | - embedded: Variable float (batch, max_len, word_vec_size)
64 | """
65 | if self.variable_lengths:
66 | input_lengths = (input_labels!=0).sum(1) # Variable (batch, )
67 |
68 | # make ixs
69 | input_lengths_list = input_lengths.data.cpu().numpy().tolist()
70 | sorted_input_lengths_list = np.sort(input_lengths_list)[::-1].tolist() # list of sorted input_lengths
71 | sort_ixs = np.argsort(input_lengths_list)[::-1].tolist() # list of int sort_ixs, descending
72 | s2r = {s: r for r, s in enumerate(sort_ixs)} # O(n)
73 | recover_ixs = [s2r[s] for s in range(len(input_lengths_list))] # list of int recover ixs
74 | assert max(input_lengths_list) == input_labels.size(1)
75 |
76 | # move to long tensor
77 | sort_ixs = input_labels.data.new(sort_ixs).long() # Variable long
78 | recover_ixs = input_labels.data.new(recover_ixs).long() # Variable long
79 |
80 | # sort input_labels by descending order
81 | input_labels = input_labels[sort_ixs]
82 |
83 | # embed
84 | embedded = self.embedding(input_labels) # (n, seq_len, word_embedding_size)
85 | embedded = self.input_dropout(embedded) # (n, seq_len, word_embedding_size)
86 | embedded = self.mlp(embedded) # (n, seq_len, word_vec_size)
87 | if self.variable_lengths:
88 | embedded = nn.utils.rnn.pack_padded_sequence(embedded, sorted_input_lengths_list, batch_first=True)
89 | # forward rnn
90 | output, hidden = self.rnn(embedded)
91 | # recover
92 | if self.variable_lengths:
93 | # recover rnn
94 | output, _ = nn.utils.rnn.pad_packed_sequence(output, batch_first=True) # (batch, max_len, hidden)
95 | output = output[recover_ixs]
96 | sent_output = []
97 | for ii in range(output.shape[0]):
98 | sent_output.append(output[ii,int(input_lengths_list[ii]-1),:])
99 | return torch.stack(sent_output, dim=0)
100 |
101 | class grounding_model(nn.Module):
102 | def __init__(self, corpus=None, emb_size=256, jemb_drop_out=0.1, bert_model='bert-base-uncased', \
103 | coordmap=True, leaky=False, dataset=None, light=False):
104 | super(grounding_model, self).__init__()
105 | self.coordmap = coordmap
106 | self.light = light
107 | self.lstm = (corpus is not None)
108 | self.emb_size = emb_size
109 | if bert_model=='bert-base-uncased':
110 | self.textdim=768
111 | else:
112 | self.textdim=1024
113 | ## Visual model
114 | self.visumodel = Darknet(config_path='./model/yolov3.cfg')
115 | self.visumodel.load_weights('./saved_models/yolov3.weights')
116 | ## Text model
117 | if self.lstm:
118 | self.textdim, self.embdim=1024, 512
119 | self.textmodel = RNNEncoder(vocab_size=len(corpus),
120 | word_embedding_size=self.embdim,
121 | word_vec_size=self.textdim//2,
122 | hidden_size=self.textdim//2,
123 | bidirectional=True,
124 | input_dropout_p=0.2,
125 | variable_lengths=True)
126 | else:
127 | self.textmodel = BertModel.from_pretrained(bert_model)
128 |
129 | ## Mapping module
130 | self.mapping_visu = nn.Sequential(OrderedDict([
131 | ('0', ConvBatchNormReLU(1024, emb_size, 1, 1, 0, 1, leaky=leaky)),
132 | ('1', ConvBatchNormReLU(512, emb_size, 1, 1, 0, 1, leaky=leaky)),
133 | ('2', ConvBatchNormReLU(256, emb_size, 1, 1, 0, 1, leaky=leaky))
134 | ]))
135 | self.mapping_lang = torch.nn.Sequential(
136 | nn.Linear(self.textdim, emb_size),
137 | nn.BatchNorm1d(emb_size),
138 | nn.ReLU(),
139 | nn.Dropout(jemb_drop_out),
140 | nn.Linear(emb_size, emb_size),
141 | nn.BatchNorm1d(emb_size),
142 | nn.ReLU(),
143 | )
144 | embin_size = emb_size*2
145 | if self.coordmap:
146 | embin_size+=8
147 | if self.light:
148 | self.fcn_emb = nn.Sequential(OrderedDict([
149 | ('0', torch.nn.Sequential(
150 | ConvBatchNormReLU(embin_size, emb_size, 1, 1, 0, 1, leaky=leaky),)),
151 | ('1', torch.nn.Sequential(
152 | ConvBatchNormReLU(embin_size, emb_size, 1, 1, 0, 1, leaky=leaky),)),
153 | ('2', torch.nn.Sequential(
154 | ConvBatchNormReLU(embin_size, emb_size, 1, 1, 0, 1, leaky=leaky),)),
155 | ]))
156 | self.fcn_out = nn.Sequential(OrderedDict([
157 | ('0', torch.nn.Sequential(
158 | nn.Conv2d(emb_size, 3*5, kernel_size=1),)),
159 | ('1', torch.nn.Sequential(
160 | nn.Conv2d(emb_size, 3*5, kernel_size=1),)),
161 | ('2', torch.nn.Sequential(
162 | nn.Conv2d(emb_size, 3*5, kernel_size=1),)),
163 | ]))
164 | else:
165 | self.fcn_emb = nn.Sequential(OrderedDict([
166 | ('0', torch.nn.Sequential(
167 | ConvBatchNormReLU(embin_size, emb_size, 1, 1, 0, 1, leaky=leaky),
168 | ConvBatchNormReLU(emb_size, emb_size, 3, 1, 1, 1, leaky=leaky),
169 | ConvBatchNormReLU(emb_size, emb_size, 1, 1, 0, 1, leaky=leaky),)),
170 | ('1', torch.nn.Sequential(
171 | ConvBatchNormReLU(embin_size, emb_size, 1, 1, 0, 1, leaky=leaky),
172 | ConvBatchNormReLU(emb_size, emb_size, 3, 1, 1, 1, leaky=leaky),
173 | ConvBatchNormReLU(emb_size, emb_size, 1, 1, 0, 1, leaky=leaky),)),
174 | ('2', torch.nn.Sequential(
175 | ConvBatchNormReLU(embin_size, emb_size, 1, 1, 0, 1, leaky=leaky),
176 | ConvBatchNormReLU(emb_size, emb_size, 3, 1, 1, 1, leaky=leaky),
177 | ConvBatchNormReLU(emb_size, emb_size, 1, 1, 0, 1, leaky=leaky),)),
178 | ]))
179 | self.fcn_out = nn.Sequential(OrderedDict([
180 | ('0', torch.nn.Sequential(
181 | ConvBatchNormReLU(emb_size, emb_size//2, 1, 1, 0, 1, leaky=leaky),
182 | nn.Conv2d(emb_size//2, 3*5, kernel_size=1),)),
183 | ('1', torch.nn.Sequential(
184 | ConvBatchNormReLU(emb_size, emb_size//2, 1, 1, 0, 1, leaky=leaky),
185 | nn.Conv2d(emb_size//2, 3*5, kernel_size=1),)),
186 | ('2', torch.nn.Sequential(
187 | ConvBatchNormReLU(emb_size, emb_size//2, 1, 1, 0, 1, leaky=leaky),
188 | nn.Conv2d(emb_size//2, 3*5, kernel_size=1),)),
189 | ]))
190 |
191 | def forward(self, image, word_id, word_mask):
192 | ## Visual Module
193 | ## [1024, 13, 13], [512, 26, 26], [256, 52, 52]
194 | batch_size = image.size(0)
195 | raw_fvisu = self.visumodel(image)
196 | fvisu = []
197 | for ii in range(len(raw_fvisu)):
198 | fvisu.append(self.mapping_visu._modules[str(ii)](raw_fvisu[ii]))
199 | fvisu[ii] = F.normalize(fvisu[ii], p=2, dim=1)
200 |
201 | ## Language Module
202 | if self.lstm:
203 | # max_len = (word_id != 0).sum(1).max().data[0]
204 | max_len = (word_id != 0).sum(1).max().item()
205 | word_id = word_id[:, :max_len]
206 | raw_flang = self.textmodel(word_id)
207 | else:
208 | all_encoder_layers, _ = self.textmodel(word_id, \
209 | token_type_ids=None, attention_mask=word_mask)
210 | ## Sentence feature at the first position [cls]
211 | raw_flang = (all_encoder_layers[-1][:,0,:] + all_encoder_layers[-2][:,0,:]\
212 | + all_encoder_layers[-3][:,0,:] + all_encoder_layers[-4][:,0,:])/4
213 | ## fix bert during training
214 | raw_flang = raw_flang.detach()
215 | flang = self.mapping_lang(raw_flang)
216 | flang = F.normalize(flang, p=2, dim=1)
217 |
218 | flangvisu = []
219 | for ii in range(len(fvisu)):
220 | flang_tile = flang.view(flang.size(0), flang.size(1), 1, 1).\
221 | repeat(1, 1, fvisu[ii].size(2), fvisu[ii].size(3))
222 | if self.coordmap:
223 | coord = generate_coord(batch_size, fvisu[ii].size(2), fvisu[ii].size(3))
224 | flangvisu.append(torch.cat([fvisu[ii], flang_tile, coord], dim=1))
225 | else:
226 | flangvisu.append(torch.cat([fvisu[ii], flang_tile], dim=1))
227 | ## fcn
228 | intmd_fea, outbox = [], []
229 | for ii in range(len(fvisu)):
230 | intmd_fea.append(self.fcn_emb._modules[str(ii)](flangvisu[ii]))
231 | outbox.append(self.fcn_out._modules[str(ii)](intmd_fea[ii]))
232 | return outbox
233 |
234 | if __name__ == "__main__":
235 | import sys
236 | import argparse
237 | sys.path.append('.')
238 | from dataset.referit_loader import *
239 | from torch.autograd import Variable
240 | from torch.utils.data import DataLoader
241 | from torchvision.transforms import Compose, ToTensor, Normalize
242 | from utils.transforms import ResizeImage, ResizeAnnotation
243 | parser = argparse.ArgumentParser(
244 | description='Dataloader test')
245 | parser.add_argument('--size', default=416, type=int,
246 | help='image size')
247 | parser.add_argument('--data', type=str, default='./ln_data/',
248 | help='path to ReferIt splits data folder')
249 | parser.add_argument('--dataset', default='referit', type=str,
250 | help='referit/flickr/unc/unc+/gref')
251 | parser.add_argument('--split', default='train', type=str,
252 | help='name of the dataset split used to train')
253 | parser.add_argument('--time', default=20, type=int,
254 | help='maximum time steps (lang length) per batch')
255 | parser.add_argument('--emb_size', default=256, type=int,
256 | help='word embedding dimensions')
257 | # parser.add_argument('--lang_layers', default=3, type=int,
258 | # help='number of SRU/LSTM stacked layers')
259 |
260 | args = parser.parse_args()
261 |
262 | torch.manual_seed(13)
263 | np.random.seed(13)
264 | torch.backends.cudnn.deterministic = True
265 | torch.backends.cudnn.benchmark = False
266 | input_transform = Compose([
267 | ToTensor(),
268 | # ResizeImage(args.size),
269 | Normalize(
270 | mean=[0.485, 0.456, 0.406],
271 | std=[0.229, 0.224, 0.225])
272 | ])
273 |
274 | refer = ReferDataset(data_root=args.data,
275 | dataset=args.dataset,
276 | split=args.split,
277 | imsize = args.size,
278 | transform=input_transform,
279 | max_query_len=args.time)
280 |
281 | train_loader = DataLoader(refer, batch_size=2, shuffle=True,
282 | pin_memory=True, num_workers=1)
283 |
284 | model = textcam_yolo_light(emb_size=args.emb_size)
285 |
286 | for batch_idx, (imgs, word_id, word_mask, bbox) in enumerate(train_loader):
287 | image = Variable(imgs)
288 | word_id = Variable(word_id)
289 | word_mask = Variable(word_mask)
290 | bbox = Variable(bbox)
291 | bbox = torch.clamp(bbox,min=0,max=args.size-1)
292 |
293 | pred_anchor_list = model(image, word_id, word_mask)
294 | for pred_anchor in pred_anchor_list:
295 | print(pred_anchor)
296 | print(pred_anchor.shape)
297 |
--------------------------------------------------------------------------------
/model/yolov3.cfg:
--------------------------------------------------------------------------------
1 | [net]
2 | # Testing
3 | #batch=1
4 | #subdivisions=1
5 | # Training
6 | batch=16
7 | subdivisions=1
8 | width=416
9 | height=416
10 | channels=3
11 | momentum=0.9
12 | decay=0.0005
13 | angle=0
14 | saturation = 1.5
15 | exposure = 1.5
16 | hue=.1
17 |
18 | learning_rate=0.001
19 | burn_in=1000
20 | max_batches = 500200
21 | policy=steps
22 | steps=400000,450000
23 | scales=.1,.1
24 |
25 | [convolutional]
26 | batch_normalize=1
27 | filters=32
28 | size=3
29 | stride=1
30 | pad=1
31 | activation=leaky
32 |
33 | # Downsample
34 |
35 | [convolutional]
36 | batch_normalize=1
37 | filters=64
38 | size=3
39 | stride=2
40 | pad=1
41 | activation=leaky
42 |
43 | [convolutional]
44 | batch_normalize=1
45 | filters=32
46 | size=1
47 | stride=1
48 | pad=1
49 | activation=leaky
50 |
51 | [convolutional]
52 | batch_normalize=1
53 | filters=64
54 | size=3
55 | stride=1
56 | pad=1
57 | activation=leaky
58 |
59 | [shortcut]
60 | from=-3
61 | activation=linear
62 |
63 | # Downsample
64 |
65 | [convolutional]
66 | batch_normalize=1
67 | filters=128
68 | size=3
69 | stride=2
70 | pad=1
71 | activation=leaky
72 |
73 | [convolutional]
74 | batch_normalize=1
75 | filters=64
76 | size=1
77 | stride=1
78 | pad=1
79 | activation=leaky
80 |
81 | [convolutional]
82 | batch_normalize=1
83 | filters=128
84 | size=3
85 | stride=1
86 | pad=1
87 | activation=leaky
88 |
89 | [shortcut]
90 | from=-3
91 | activation=linear
92 |
93 | [convolutional]
94 | batch_normalize=1
95 | filters=64
96 | size=1
97 | stride=1
98 | pad=1
99 | activation=leaky
100 |
101 | [convolutional]
102 | batch_normalize=1
103 | filters=128
104 | size=3
105 | stride=1
106 | pad=1
107 | activation=leaky
108 |
109 | [shortcut]
110 | from=-3
111 | activation=linear
112 |
113 | # Downsample
114 |
115 | [convolutional]
116 | batch_normalize=1
117 | filters=256
118 | size=3
119 | stride=2
120 | pad=1
121 | activation=leaky
122 |
123 | [convolutional]
124 | batch_normalize=1
125 | filters=128
126 | size=1
127 | stride=1
128 | pad=1
129 | activation=leaky
130 |
131 | [convolutional]
132 | batch_normalize=1
133 | filters=256
134 | size=3
135 | stride=1
136 | pad=1
137 | activation=leaky
138 |
139 | [shortcut]
140 | from=-3
141 | activation=linear
142 |
143 | [convolutional]
144 | batch_normalize=1
145 | filters=128
146 | size=1
147 | stride=1
148 | pad=1
149 | activation=leaky
150 |
151 | [convolutional]
152 | batch_normalize=1
153 | filters=256
154 | size=3
155 | stride=1
156 | pad=1
157 | activation=leaky
158 |
159 | [shortcut]
160 | from=-3
161 | activation=linear
162 |
163 | [convolutional]
164 | batch_normalize=1
165 | filters=128
166 | size=1
167 | stride=1
168 | pad=1
169 | activation=leaky
170 |
171 | [convolutional]
172 | batch_normalize=1
173 | filters=256
174 | size=3
175 | stride=1
176 | pad=1
177 | activation=leaky
178 |
179 | [shortcut]
180 | from=-3
181 | activation=linear
182 |
183 | [convolutional]
184 | batch_normalize=1
185 | filters=128
186 | size=1
187 | stride=1
188 | pad=1
189 | activation=leaky
190 |
191 | [convolutional]
192 | batch_normalize=1
193 | filters=256
194 | size=3
195 | stride=1
196 | pad=1
197 | activation=leaky
198 |
199 | [shortcut]
200 | from=-3
201 | activation=linear
202 |
203 |
204 | [convolutional]
205 | batch_normalize=1
206 | filters=128
207 | size=1
208 | stride=1
209 | pad=1
210 | activation=leaky
211 |
212 | [convolutional]
213 | batch_normalize=1
214 | filters=256
215 | size=3
216 | stride=1
217 | pad=1
218 | activation=leaky
219 |
220 | [shortcut]
221 | from=-3
222 | activation=linear
223 |
224 | [convolutional]
225 | batch_normalize=1
226 | filters=128
227 | size=1
228 | stride=1
229 | pad=1
230 | activation=leaky
231 |
232 | [convolutional]
233 | batch_normalize=1
234 | filters=256
235 | size=3
236 | stride=1
237 | pad=1
238 | activation=leaky
239 |
240 | [shortcut]
241 | from=-3
242 | activation=linear
243 |
244 | [convolutional]
245 | batch_normalize=1
246 | filters=128
247 | size=1
248 | stride=1
249 | pad=1
250 | activation=leaky
251 |
252 | [convolutional]
253 | batch_normalize=1
254 | filters=256
255 | size=3
256 | stride=1
257 | pad=1
258 | activation=leaky
259 |
260 | [shortcut]
261 | from=-3
262 | activation=linear
263 |
264 | [convolutional]
265 | batch_normalize=1
266 | filters=128
267 | size=1
268 | stride=1
269 | pad=1
270 | activation=leaky
271 |
272 | [convolutional]
273 | batch_normalize=1
274 | filters=256
275 | size=3
276 | stride=1
277 | pad=1
278 | activation=leaky
279 |
280 | [shortcut]
281 | from=-3
282 | activation=linear
283 |
284 | # Downsample
285 |
286 | [convolutional]
287 | batch_normalize=1
288 | filters=512
289 | size=3
290 | stride=2
291 | pad=1
292 | activation=leaky
293 |
294 | [convolutional]
295 | batch_normalize=1
296 | filters=256
297 | size=1
298 | stride=1
299 | pad=1
300 | activation=leaky
301 |
302 | [convolutional]
303 | batch_normalize=1
304 | filters=512
305 | size=3
306 | stride=1
307 | pad=1
308 | activation=leaky
309 |
310 | [shortcut]
311 | from=-3
312 | activation=linear
313 |
314 |
315 | [convolutional]
316 | batch_normalize=1
317 | filters=256
318 | size=1
319 | stride=1
320 | pad=1
321 | activation=leaky
322 |
323 | [convolutional]
324 | batch_normalize=1
325 | filters=512
326 | size=3
327 | stride=1
328 | pad=1
329 | activation=leaky
330 |
331 | [shortcut]
332 | from=-3
333 | activation=linear
334 |
335 |
336 | [convolutional]
337 | batch_normalize=1
338 | filters=256
339 | size=1
340 | stride=1
341 | pad=1
342 | activation=leaky
343 |
344 | [convolutional]
345 | batch_normalize=1
346 | filters=512
347 | size=3
348 | stride=1
349 | pad=1
350 | activation=leaky
351 |
352 | [shortcut]
353 | from=-3
354 | activation=linear
355 |
356 |
357 | [convolutional]
358 | batch_normalize=1
359 | filters=256
360 | size=1
361 | stride=1
362 | pad=1
363 | activation=leaky
364 |
365 | [convolutional]
366 | batch_normalize=1
367 | filters=512
368 | size=3
369 | stride=1
370 | pad=1
371 | activation=leaky
372 |
373 | [shortcut]
374 | from=-3
375 | activation=linear
376 |
377 | [convolutional]
378 | batch_normalize=1
379 | filters=256
380 | size=1
381 | stride=1
382 | pad=1
383 | activation=leaky
384 |
385 | [convolutional]
386 | batch_normalize=1
387 | filters=512
388 | size=3
389 | stride=1
390 | pad=1
391 | activation=leaky
392 |
393 | [shortcut]
394 | from=-3
395 | activation=linear
396 |
397 |
398 | [convolutional]
399 | batch_normalize=1
400 | filters=256
401 | size=1
402 | stride=1
403 | pad=1
404 | activation=leaky
405 |
406 | [convolutional]
407 | batch_normalize=1
408 | filters=512
409 | size=3
410 | stride=1
411 | pad=1
412 | activation=leaky
413 |
414 | [shortcut]
415 | from=-3
416 | activation=linear
417 |
418 |
419 | [convolutional]
420 | batch_normalize=1
421 | filters=256
422 | size=1
423 | stride=1
424 | pad=1
425 | activation=leaky
426 |
427 | [convolutional]
428 | batch_normalize=1
429 | filters=512
430 | size=3
431 | stride=1
432 | pad=1
433 | activation=leaky
434 |
435 | [shortcut]
436 | from=-3
437 | activation=linear
438 |
439 | [convolutional]
440 | batch_normalize=1
441 | filters=256
442 | size=1
443 | stride=1
444 | pad=1
445 | activation=leaky
446 |
447 | [convolutional]
448 | batch_normalize=1
449 | filters=512
450 | size=3
451 | stride=1
452 | pad=1
453 | activation=leaky
454 |
455 | [shortcut]
456 | from=-3
457 | activation=linear
458 |
459 | # Downsample
460 |
461 | [convolutional]
462 | batch_normalize=1
463 | filters=1024
464 | size=3
465 | stride=2
466 | pad=1
467 | activation=leaky
468 |
469 | [convolutional]
470 | batch_normalize=1
471 | filters=512
472 | size=1
473 | stride=1
474 | pad=1
475 | activation=leaky
476 |
477 | [convolutional]
478 | batch_normalize=1
479 | filters=1024
480 | size=3
481 | stride=1
482 | pad=1
483 | activation=leaky
484 |
485 | [shortcut]
486 | from=-3
487 | activation=linear
488 |
489 | [convolutional]
490 | batch_normalize=1
491 | filters=512
492 | size=1
493 | stride=1
494 | pad=1
495 | activation=leaky
496 |
497 | [convolutional]
498 | batch_normalize=1
499 | filters=1024
500 | size=3
501 | stride=1
502 | pad=1
503 | activation=leaky
504 |
505 | [shortcut]
506 | from=-3
507 | activation=linear
508 |
509 | [convolutional]
510 | batch_normalize=1
511 | filters=512
512 | size=1
513 | stride=1
514 | pad=1
515 | activation=leaky
516 |
517 | [convolutional]
518 | batch_normalize=1
519 | filters=1024
520 | size=3
521 | stride=1
522 | pad=1
523 | activation=leaky
524 |
525 | [shortcut]
526 | from=-3
527 | activation=linear
528 |
529 | [convolutional]
530 | batch_normalize=1
531 | filters=512
532 | size=1
533 | stride=1
534 | pad=1
535 | activation=leaky
536 |
537 | [convolutional]
538 | batch_normalize=1
539 | filters=1024
540 | size=3
541 | stride=1
542 | pad=1
543 | activation=leaky
544 |
545 | [shortcut]
546 | from=-3
547 | activation=linear
548 |
549 | ######################
550 |
551 | [convolutional]
552 | batch_normalize=1
553 | filters=512
554 | size=1
555 | stride=1
556 | pad=1
557 | activation=leaky
558 |
559 | [convolutional]
560 | batch_normalize=1
561 | size=3
562 | stride=1
563 | pad=1
564 | filters=1024
565 | activation=leaky
566 |
567 | [convolutional]
568 | batch_normalize=1
569 | filters=512
570 | size=1
571 | stride=1
572 | pad=1
573 | activation=leaky
574 |
575 | [convolutional]
576 | batch_normalize=1
577 | size=3
578 | stride=1
579 | pad=1
580 | filters=1024
581 | activation=leaky
582 |
583 | [yoloconvolutional]
584 | batch_normalize=1
585 | filters=512
586 | size=1
587 | stride=1
588 | pad=1
589 | activation=leaky
590 |
591 | [convolutional]
592 | batch_normalize=1
593 | size=3
594 | stride=1
595 | pad=1
596 | filters=1024
597 | activation=leaky
598 |
599 | [convolutional]
600 | size=1
601 | stride=1
602 | pad=1
603 | filters=255
604 | activation=linear
605 |
606 |
607 | [yolo]
608 | mask = 6,7,8
609 | anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
610 | classes=80
611 | num=9
612 | jitter=.3
613 | ignore_thresh = .7
614 | truth_thresh = 1
615 | random=1
616 |
617 |
618 | [route]
619 | layers = -4
620 |
621 | [convolutional]
622 | batch_normalize=1
623 | filters=256
624 | size=1
625 | stride=1
626 | pad=1
627 | activation=leaky
628 |
629 | [upsample]
630 | stride=2
631 |
632 | [route]
633 | layers = -1, 61
634 |
635 |
636 |
637 | [convolutional]
638 | batch_normalize=1
639 | filters=256
640 | size=1
641 | stride=1
642 | pad=1
643 | activation=leaky
644 |
645 | [convolutional]
646 | batch_normalize=1
647 | size=3
648 | stride=1
649 | pad=1
650 | filters=512
651 | activation=leaky
652 |
653 | [convolutional]
654 | batch_normalize=1
655 | filters=256
656 | size=1
657 | stride=1
658 | pad=1
659 | activation=leaky
660 |
661 | [convolutional]
662 | batch_normalize=1
663 | size=3
664 | stride=1
665 | pad=1
666 | filters=512
667 | activation=leaky
668 |
669 | [yoloconvolutional]
670 | batch_normalize=1
671 | filters=256
672 | size=1
673 | stride=1
674 | pad=1
675 | activation=leaky
676 |
677 | [convolutional]
678 | batch_normalize=1
679 | size=3
680 | stride=1
681 | pad=1
682 | filters=512
683 | activation=leaky
684 |
685 | [convolutional]
686 | size=1
687 | stride=1
688 | pad=1
689 | filters=255
690 | activation=linear
691 |
692 |
693 | [yolo]
694 | mask = 3,4,5
695 | anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
696 | classes=80
697 | num=9
698 | jitter=.3
699 | ignore_thresh = .7
700 | truth_thresh = 1
701 | random=1
702 |
703 |
704 |
705 | [route]
706 | layers = -4
707 |
708 | [convolutional]
709 | batch_normalize=1
710 | filters=128
711 | size=1
712 | stride=1
713 | pad=1
714 | activation=leaky
715 |
716 | [upsample]
717 | stride=2
718 |
719 | [route]
720 | layers = -1, 36
721 |
722 |
723 |
724 | [convolutional]
725 | batch_normalize=1
726 | filters=128
727 | size=1
728 | stride=1
729 | pad=1
730 | activation=leaky
731 |
732 | [convolutional]
733 | batch_normalize=1
734 | size=3
735 | stride=1
736 | pad=1
737 | filters=256
738 | activation=leaky
739 |
740 | [convolutional]
741 | batch_normalize=1
742 | filters=128
743 | size=1
744 | stride=1
745 | pad=1
746 | activation=leaky
747 |
748 | [convolutional]
749 | batch_normalize=1
750 | size=3
751 | stride=1
752 | pad=1
753 | filters=256
754 | activation=leaky
755 |
756 | [yoloconvolutional]
757 | batch_normalize=1
758 | filters=128
759 | size=1
760 | stride=1
761 | pad=1
762 | activation=leaky
763 |
764 | [convolutional]
765 | batch_normalize=1
766 | size=3
767 | stride=1
768 | pad=1
769 | filters=256
770 | activation=leaky
771 |
772 | [convolutional]
773 | size=1
774 | stride=1
775 | pad=1
776 | filters=255
777 | activation=linear
778 |
779 |
780 | [yolo]
781 | mask = 0,1,2
782 | anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
783 | classes=80
784 | num=9
785 | jitter=.3
786 | ignore_thresh = .7
787 | truth_thresh = 1
788 | random=1
789 |
--------------------------------------------------------------------------------
/saved_models/README.md:
--------------------------------------------------------------------------------
1 | ## Performance and Pre-trained Models
2 | Please check the detailed experiment settings in our [paper](https://arxiv.org/).
3 |
4 |
5 |
6 | | Dataset |
7 | Ours-LSTM |
8 | Performance (Accu@0.5) |
9 | Ours-Bert |
10 | Performance (Accu@0.5) |
11 |
12 |
13 |
14 |
15 | | ReferItGame |
16 | Gdrive |
17 | 58.76 |
18 | Gdrive |
19 | 59.58 |
20 |
21 |
22 | | Flickr30K Entities |
23 | One Drive |
24 | 67.62 |
25 | One Drive |
26 | 68.69 |
27 |
28 |
29 | | RefCOCO |
30 |
31 | | val: 73.66 |
32 |
33 | | val: 72.05 |
34 |
35 |
36 | | testA: 75.78 |
37 | testA: 74.81 |
38 |
39 |
40 | | testB: 71.32 |
41 | testB: 67.59 |
42 |
43 |
44 |
--------------------------------------------------------------------------------
/saved_models/yolov3_weights.sh:
--------------------------------------------------------------------------------
1 | wget -P saved_models https://pjreddie.com/media/files/yolov3.weights
2 |
--------------------------------------------------------------------------------
/train_yolo.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import argparse
4 | import shutil
5 | import time
6 | import random
7 | import gc
8 | import json
9 | from distutils.version import LooseVersion
10 | import scipy.misc
11 | import logging
12 |
13 | import matplotlib as mpl
14 | mpl.use('Agg')
15 | from matplotlib import pyplot as plt
16 |
17 | from PIL import Image
18 | import numpy as np
19 | import torch
20 | import torch.nn as nn
21 | import torch.nn.parallel
22 | import torch.backends.cudnn as cudnn
23 | import torch.distributed as dist
24 | import torch.optim
25 | import torch.utils.data as data
26 | import torch.utils.data.distributed
27 | import torchvision
28 | import torchvision.transforms as transforms
29 | import torchvision.datasets as datasets
30 | import torchvision.models as models
31 | import torch.nn.functional as F
32 |
33 | from torch.autograd import Variable
34 | from torch.utils.data import DataLoader
35 | from torchvision.transforms import Compose, ToTensor, Normalize
36 | from utils.transforms import ResizeImage, ResizeAnnotation
37 |
38 | from dataset.referit_loader import *
39 | from model.grounding_model import *
40 | from utils.parsing_metrics import *
41 | from utils.utils import *
42 |
43 | def yolo_loss(input, target, gi, gj, best_n_list, w_coord=5., w_neg=1./5, size_average=True):
44 | mseloss = torch.nn.MSELoss(size_average=True)
45 | celoss = torch.nn.CrossEntropyLoss(size_average=True)
46 | batch = input[0].size(0)
47 |
48 | pred_bbox = Variable(torch.zeros(batch,4).cuda())
49 | gt_bbox = Variable(torch.zeros(batch,4).cuda())
50 | for ii in range(batch):
51 | pred_bbox[ii, 0:2] = F.sigmoid(input[best_n_list[ii]//3][ii,best_n_list[ii]%3,0:2,gj[ii],gi[ii]])
52 | pred_bbox[ii, 2:4] = input[best_n_list[ii]//3][ii,best_n_list[ii]%3,2:4,gj[ii],gi[ii]]
53 | gt_bbox[ii, :] = target[best_n_list[ii]//3][ii,best_n_list[ii]%3,:4,gj[ii],gi[ii]]
54 | loss_x = mseloss(pred_bbox[:,0], gt_bbox[:,0])
55 | loss_y = mseloss(pred_bbox[:,1], gt_bbox[:,1])
56 | loss_w = mseloss(pred_bbox[:,2], gt_bbox[:,2])
57 | loss_h = mseloss(pred_bbox[:,3], gt_bbox[:,3])
58 |
59 | pred_conf_list, gt_conf_list = [], []
60 | for scale_ii in range(len(input)):
61 | pred_conf_list.append(input[scale_ii][:,:,4,:,:].contiguous().view(batch,-1))
62 | gt_conf_list.append(target[scale_ii][:,:,4,:,:].contiguous().view(batch,-1))
63 | pred_conf = torch.cat(pred_conf_list, dim=1)
64 | gt_conf = torch.cat(gt_conf_list, dim=1)
65 | loss_conf = celoss(pred_conf, gt_conf.max(1)[1])
66 | return (loss_x+loss_y+loss_w+loss_h)*w_coord + loss_conf
67 |
68 | def save_segmentation_map(bbox, target_bbox, input, mode, batch_start_index, \
69 | merge_pred=None, pred_conf_visu=None, save_path='./visulizations/'):
70 | n = input.shape[0]
71 | save_path=save_path+mode
72 |
73 | input=input.data.cpu().numpy()
74 | input=input.transpose(0,2,3,1)
75 | for ii in range(n):
76 | os.system('mkdir -p %s/sample_%d'%(save_path,batch_start_index+ii))
77 | imgs = input[ii,:,:,:].copy()
78 | imgs = (imgs*np.array([0.299, 0.224, 0.225])+np.array([0.485, 0.456, 0.406]))*255.
79 | # imgs = imgs.transpose(2,0,1)
80 | imgs = np.array(imgs, dtype=np.float32)
81 | imgs = cv2.cvtColor(imgs, cv2.COLOR_RGB2BGR)
82 | cv2.rectangle(imgs, (bbox[ii,0], bbox[ii,1]), (bbox[ii,2], bbox[ii,3]), (255,0,0), 2)
83 | cv2.rectangle(imgs, (target_bbox[ii,0], target_bbox[ii,1]), (target_bbox[ii,2], target_bbox[ii,3]), (0,255,0), 2)
84 | cv2.imwrite('%s/sample_%d/pred_yolo.png'%(save_path,batch_start_index+ii),imgs)
85 |
86 | def lr_poly(base_lr, iter, max_iter, power):
87 | return base_lr * ((1 - float(iter) / max_iter) ** (power))
88 |
89 | def adjust_learning_rate(optimizer, i_iter):
90 | # print(optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr'])
91 | if args.power!=0.:
92 | lr = lr_poly(args.lr, i_iter, args.nb_epoch, args.power)
93 | optimizer.param_groups[0]['lr'] = lr
94 | if len(optimizer.param_groups) > 1:
95 | optimizer.param_groups[1]['lr'] = lr / 10
96 |
97 | def save_checkpoint(state, is_best, filename='default'):
98 | if filename=='default':
99 | filename = 'model_%s_batch%d'%(args.dataset,args.batch_size)
100 |
101 | checkpoint_name = './saved_models/%s_checkpoint.pth.tar'%(filename)
102 | best_name = './saved_models/%s_model_best.pth.tar'%(filename)
103 | torch.save(state, checkpoint_name)
104 | if is_best:
105 | shutil.copyfile(checkpoint_name, best_name)
106 |
107 | def build_target(raw_coord, pred):
108 | coord_list, bbox_list = [],[]
109 | for scale_ii in range(len(pred)):
110 | coord = Variable(torch.zeros(raw_coord.size(0), raw_coord.size(1)).cuda())
111 | batch, grid = raw_coord.size(0), args.size//(32//(2**scale_ii))
112 | coord[:,0] = (raw_coord[:,0] + raw_coord[:,2])/(2*args.size)
113 | coord[:,1] = (raw_coord[:,1] + raw_coord[:,3])/(2*args.size)
114 | coord[:,2] = (raw_coord[:,2] - raw_coord[:,0])/(args.size)
115 | coord[:,3] = (raw_coord[:,3] - raw_coord[:,1])/(args.size)
116 | coord = coord * grid
117 | coord_list.append(coord)
118 | bbox_list.append(torch.zeros(coord.size(0),3,5,grid, grid))
119 |
120 | best_n_list, best_gi, best_gj = [],[],[]
121 |
122 | for ii in range(batch):
123 | anch_ious = []
124 | for scale_ii in range(len(pred)):
125 | batch, grid = raw_coord.size(0), args.size//(32//(2**scale_ii))
126 | gi = coord_list[scale_ii][ii,0].long()
127 | gj = coord_list[scale_ii][ii,1].long()
128 | tx = coord_list[scale_ii][ii,0] - gi.float()
129 | ty = coord_list[scale_ii][ii,1] - gj.float()
130 |
131 | gw = coord_list[scale_ii][ii,2]
132 | gh = coord_list[scale_ii][ii,3]
133 |
134 | anchor_idxs = [x + 3*scale_ii for x in [0,1,2]]
135 | anchors = [anchors_full[i] for i in anchor_idxs]
136 | scaled_anchors = [ (x[0] / (args.anchor_imsize/grid), \
137 | x[1] / (args.anchor_imsize/grid)) for x in anchors]
138 |
139 | ## Get shape of gt box
140 | gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0)
141 | ## Get shape of anchor box
142 | anchor_shapes = torch.FloatTensor(np.concatenate((np.zeros((len(scaled_anchors), 2)), np.array(scaled_anchors)), 1))
143 | ## Calculate iou between gt and anchor shapes
144 | anch_ious += list(bbox_iou(gt_box, anchor_shapes))
145 | ## Find the best matching anchor box
146 | best_n = np.argmax(np.array(anch_ious))
147 | best_scale = best_n//3
148 |
149 | batch, grid = raw_coord.size(0), args.size//(32/(2**best_scale))
150 | anchor_idxs = [x + 3*best_scale for x in [0,1,2]]
151 | anchors = [anchors_full[i] for i in anchor_idxs]
152 | scaled_anchors = [ (x[0] / (args.anchor_imsize/grid), \
153 | x[1] / (args.anchor_imsize/grid)) for x in anchors]
154 |
155 | gi = coord_list[best_scale][ii,0].long()
156 | gj = coord_list[best_scale][ii,1].long()
157 | tx = coord_list[best_scale][ii,0] - gi.float()
158 | ty = coord_list[best_scale][ii,1] - gj.float()
159 | gw = coord_list[best_scale][ii,2]
160 | gh = coord_list[best_scale][ii,3]
161 | tw = torch.log(gw / scaled_anchors[best_n%3][0] + 1e-16)
162 | th = torch.log(gh / scaled_anchors[best_n%3][1] + 1e-16)
163 |
164 | bbox_list[best_scale][ii, best_n%3, :, gj, gi] = torch.stack([tx, ty, tw, th, torch.ones(1).cuda().squeeze()])
165 | best_n_list.append(int(best_n))
166 | best_gi.append(gi)
167 | best_gj.append(gj)
168 |
169 | for ii in range(len(bbox_list)):
170 | bbox_list[ii] = Variable(bbox_list[ii].cuda())
171 | return bbox_list, best_gi, best_gj, best_n_list
172 |
173 | def main():
174 | parser = argparse.ArgumentParser(
175 | description='Dataloader test')
176 | parser.add_argument('--gpu', default='0', help='gpu id')
177 | parser.add_argument('--workers', default=16, type=int, help='num workers for data loading')
178 | parser.add_argument('--nb_epoch', default=100, type=int, help='training epoch')
179 | parser.add_argument('--lr', default=1e-4, type=float, help='learning rate')
180 | parser.add_argument('--power', default=0.9, type=float, help='lr poly power')
181 | parser.add_argument('--batch_size', default=32, type=int, help='batch size')
182 | parser.add_argument('--size_average', dest='size_average',
183 | default=False, action='store_true', help='size_average')
184 | parser.add_argument('--size', default=256, type=int, help='image size')
185 | parser.add_argument('--anchor_imsize', default=416, type=int,
186 | help='scale used to calculate anchors defined in model cfg file')
187 | parser.add_argument('--data_root', type=str, default='./ln_data/',
188 | help='path to ReferIt splits data folder')
189 | parser.add_argument('--split_root', type=str, default='data',
190 | help='location of pre-parsed dataset info')
191 | parser.add_argument('--dataset', default='referit', type=str,
192 | help='referit/flickr/unc/unc+/gref')
193 | parser.add_argument('--time', default=20, type=int,
194 | help='maximum time steps (lang length) per batch')
195 | parser.add_argument('--emb_size', default=512, type=int,
196 | help='fusion module embedding dimensions')
197 | parser.add_argument('--resume', default='', type=str, metavar='PATH',
198 | help='path to latest checkpoint (default: none)')
199 | parser.add_argument('--pretrain', default='', type=str, metavar='PATH',
200 | help='pretrain support load state_dict that are not identical, while have no loss saved as resume')
201 | parser.add_argument('--optimizer', default='RMSprop', help='optimizer: sgd, adam, RMSprop')
202 | parser.add_argument('--print_freq', '-p', default=2000, type=int,
203 | metavar='N', help='print frequency (default: 1e3)')
204 | parser.add_argument('--savename', default='default', type=str, help='Name head for saved model')
205 | parser.add_argument('--save_plot', dest='save_plot', default=False, action='store_true', help='save visulization plots')
206 | parser.add_argument('--seed', default=13, type=int, help='random seed')
207 | parser.add_argument('--bert_model', default='bert-base-uncased', type=str, help='bert model')
208 | parser.add_argument('--test', dest='test', default=False, action='store_true', help='test')
209 | parser.add_argument('--light', dest='light', default=False, action='store_true', help='if use smaller model')
210 | parser.add_argument('--lstm', dest='lstm', default=False, action='store_true', help='if use lstm as language module instead of bert')
211 |
212 | global args, anchors_full
213 | args = parser.parse_args()
214 | print('----------------------------------------------------------------------')
215 | print(sys.argv[0])
216 | print(args)
217 | print('----------------------------------------------------------------------')
218 | os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
219 | os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
220 | ## fix seed
221 | cudnn.benchmark = False
222 | cudnn.deterministic = True
223 | random.seed(args.seed)
224 | np.random.seed(args.seed+1)
225 | torch.manual_seed(args.seed+2)
226 | torch.cuda.manual_seed_all(args.seed+3)
227 |
228 | eps=1e-10
229 | ## following anchor sizes calculated by kmeans under args.anchor_imsize=416
230 | if args.dataset=='refeit':
231 | anchors = '30,36, 78,46, 48,86, 149,79, 82,148, 331,93, 156,207, 381,163, 329,285'
232 | elif args.dataset=='flickr':
233 | anchors = '29,26, 55,58, 137,71, 82,121, 124,205, 204,132, 209,263, 369,169, 352,294'
234 | else:
235 | anchors = '10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326'
236 | anchors = [float(x) for x in anchors.split(',')]
237 | anchors_full = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)][::-1]
238 |
239 | ## save logs
240 | if args.savename=='default':
241 | args.savename = 'model_%s_batch%d'%(args.dataset,args.batch_size)
242 | if not os.path.exists('./logs'):
243 | os.mkdir('logs')
244 | logging.basicConfig(level=logging.DEBUG, filename="./logs/%s"%args.savename, filemode="a+",
245 | format="%(asctime)-15s %(levelname)-8s %(message)s")
246 |
247 | input_transform = Compose([
248 | ToTensor(),
249 | Normalize(
250 | mean=[0.485, 0.456, 0.406],
251 | std=[0.229, 0.224, 0.225])
252 | ])
253 |
254 | train_dataset = ReferDataset(data_root=args.data_root,
255 | split_root=args.split_root,
256 | dataset=args.dataset,
257 | split='train',
258 | imsize = args.size,
259 | transform=input_transform,
260 | max_query_len=args.time,
261 | lstm=args.lstm,
262 | augment=True)
263 | val_dataset = ReferDataset(data_root=args.data_root,
264 | split_root=args.split_root,
265 | dataset=args.dataset,
266 | split='val',
267 | imsize = args.size,
268 | transform=input_transform,
269 | max_query_len=args.time,
270 | lstm=args.lstm)
271 | ## note certain dataset does not have 'test' set:
272 | ## 'unc': {'train', 'val', 'trainval', 'testA', 'testB'}
273 | test_dataset = ReferDataset(data_root=args.data_root,
274 | split_root=args.split_root,
275 | dataset=args.dataset,
276 | testmode=True,
277 | split='test',
278 | imsize = args.size,
279 | transform=input_transform,
280 | max_query_len=args.time,
281 | lstm=args.lstm)
282 | train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True,
283 | pin_memory=True, drop_last=True, num_workers=args.workers)
284 | val_loader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False,
285 | pin_memory=True, drop_last=True, num_workers=args.workers)
286 | test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False,
287 | pin_memory=True, drop_last=True, num_workers=0)
288 |
289 | ## Model
290 | ## input ifcorpus=None to use bert as text encoder
291 | ifcorpus = None
292 | if args.lstm:
293 | ifcorpus = train_dataset.corpus
294 | model = grounding_model(corpus=ifcorpus, light=args.light, emb_size=args.emb_size, coordmap=True,\
295 | bert_model=args.bert_model, dataset=args.dataset)
296 | model = torch.nn.DataParallel(model).cuda()
297 |
298 | if args.pretrain:
299 | if os.path.isfile(args.pretrain):
300 | pretrained_dict = torch.load(args.pretrain)['state_dict']
301 | model_dict = model.state_dict()
302 | pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
303 | assert (len([k for k, v in pretrained_dict.items()])!=0)
304 | model_dict.update(pretrained_dict)
305 | model.load_state_dict(model_dict)
306 | print("=> loaded pretrain model at {}"
307 | .format(args.pretrain))
308 | logging.info("=> loaded pretrain model at {}"
309 | .format(args.pretrain))
310 | else:
311 | print(("=> no pretrained file found at '{}'".format(args.pretrain)))
312 | logging.info("=> no pretrained file found at '{}'".format(args.pretrain))
313 | if args.resume:
314 | if os.path.isfile(args.resume):
315 | print(("=> loading checkpoint '{}'".format(args.resume)))
316 | logging.info("=> loading checkpoint '{}'".format(args.resume))
317 | checkpoint = torch.load(args.resume)
318 | args.start_epoch = checkpoint['epoch']
319 | best_loss = checkpoint['best_loss']
320 | model.load_state_dict(checkpoint['state_dict'])
321 | print(("=> loaded checkpoint (epoch {}) Loss{}"
322 | .format(checkpoint['epoch'], best_loss)))
323 | logging.info("=> loaded checkpoint (epoch {}) Loss{}"
324 | .format(checkpoint['epoch'], best_loss))
325 | else:
326 | print(("=> no checkpoint found at '{}'".format(args.resume)))
327 | logging.info(("=> no checkpoint found at '{}'".format(args.resume)))
328 |
329 | print('Num of parameters:', sum([param.nelement() for param in model.parameters()]))
330 | logging.info('Num of parameters:%d'%int(sum([param.nelement() for param in model.parameters()])))
331 |
332 | visu_param = model.module.visumodel.parameters()
333 | rest_param = [param for param in model.parameters() if param not in visu_param]
334 | visu_param = list(model.module.visumodel.parameters())
335 | sum_visu = sum([param.nelement() for param in visu_param])
336 | sum_text = sum([param.nelement() for param in model.module.textmodel.parameters()])
337 | sum_fusion = sum([param.nelement() for param in rest_param]) - sum_text
338 | print('visu, text, fusion module parameters:', sum_visu, sum_text, sum_fusion)
339 |
340 | ## optimizer; rmsprop default
341 | if args.optimizer=='adam':
342 | optimizer = torch.optim.Adam(model.parameters(), lr=args.lr, weight_decay=0.0005)
343 | elif args.optimizer=='sgd':
344 | optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=0.99)
345 | else:
346 | optimizer = torch.optim.RMSprop([{'params': rest_param},
347 | {'params': visu_param, 'lr': args.lr/10.}], lr=args.lr, weight_decay=0.0005)
348 |
349 | ## training and testing
350 | best_accu = -float('Inf')
351 | if args.test:
352 | _ = test_epoch(test_loader, model, args.size_average)
353 | exit(0)
354 | for epoch in range(args.nb_epoch):
355 | adjust_learning_rate(optimizer, epoch)
356 | train_epoch(train_loader, model, optimizer, epoch, args.size_average)
357 | accu_new = validate_epoch(val_loader, model, args.size_average)
358 | ## remember best accu and save checkpoint
359 | is_best = accu_new > best_accu
360 | best_accu = max(accu_new, best_accu)
361 | save_checkpoint({
362 | 'epoch': epoch + 1,
363 | 'state_dict': model.state_dict(),
364 | 'best_loss': accu_new,
365 | 'optimizer' : optimizer.state_dict(),
366 | }, is_best, filename=args.savename)
367 | print('\nBest Accu: %f\n'%best_accu)
368 | logging.info('\nBest Accu: %f\n'%best_accu)
369 |
370 | def train_epoch(train_loader, model, optimizer, epoch, size_average):
371 | batch_time = AverageMeter()
372 | data_time = AverageMeter()
373 | losses = AverageMeter()
374 | acc = AverageMeter()
375 | acc_center = AverageMeter()
376 | miou = AverageMeter()
377 |
378 | model.train()
379 | end = time.time()
380 |
381 | for batch_idx, (imgs, word_id, word_mask, bbox) in enumerate(train_loader):
382 | imgs = imgs.cuda()
383 | word_id = word_id.cuda()
384 | word_mask = word_mask.cuda()
385 | bbox = bbox.cuda()
386 | image = Variable(imgs)
387 | word_id = Variable(word_id)
388 | word_mask = Variable(word_mask)
389 | bbox = Variable(bbox)
390 | bbox = torch.clamp(bbox,min=0,max=args.size-1)
391 |
392 | ## Note LSTM does not use word_mask
393 | pred_anchor = model(image, word_id, word_mask)
394 | ## convert gt box to center+offset format
395 | gt_param, gi, gj, best_n_list = build_target(bbox, pred_anchor)
396 | ## flatten anchor dim at each scale
397 | for ii in range(len(pred_anchor)):
398 | pred_anchor[ii] = pred_anchor[ii].view( \
399 | pred_anchor[ii].size(0),3,5,pred_anchor[ii].size(2),pred_anchor[ii].size(3))
400 | ## loss
401 | loss = yolo_loss(pred_anchor, gt_param, gi, gj, best_n_list)
402 | optimizer.zero_grad()
403 | loss.backward()
404 | optimizer.step()
405 | losses.update(loss.data[0], imgs.size(0))
406 |
407 | ## training offset eval: if correct with gt center loc
408 | ## convert offset pred to boxes
409 | pred_coord = torch.zeros(args.batch_size,4)
410 | for ii in range(args.batch_size):
411 | best_scale_ii = best_n_list[ii]//3
412 | grid, grid_size = args.size//(32//(2**best_scale_ii)), 32//(2**best_scale_ii)
413 | anchor_idxs = [x + 3*best_scale_ii for x in [0,1,2]]
414 | anchors = [anchors_full[i] for i in anchor_idxs]
415 | scaled_anchors = [ (x[0] / (args.anchor_imsize/grid), \
416 | x[1] / (args.anchor_imsize/grid)) for x in anchors]
417 |
418 | pred_coord[ii,0] = F.sigmoid(pred_anchor[best_scale_ii][ii, best_n_list[ii]%3, 0, gj[ii], gi[ii]]) + gi[ii].float()
419 | pred_coord[ii,1] = F.sigmoid(pred_anchor[best_scale_ii][ii, best_n_list[ii]%3, 1, gj[ii], gi[ii]]) + gj[ii].float()
420 | pred_coord[ii,2] = torch.exp(pred_anchor[best_scale_ii][ii, best_n_list[ii]%3, 2, gj[ii], gi[ii]]) * scaled_anchors[best_n_list[ii]%3][0]
421 | pred_coord[ii,3] = torch.exp(pred_anchor[best_scale_ii][ii, best_n_list[ii]%3, 3, gj[ii], gi[ii]]) * scaled_anchors[best_n_list[ii]%3][1]
422 | pred_coord[ii,:] = pred_coord[ii,:] * grid_size
423 | pred_coord = xywh2xyxy(pred_coord)
424 | ## box iou
425 | target_bbox = bbox
426 | iou = bbox_iou(pred_coord, target_bbox.data.cpu(), x1y1x2y2=True)
427 | accu = np.sum(np.array((iou.data.cpu().numpy()>0.5),dtype=float))/args.batch_size
428 | ## evaluate if center location is correct
429 | pred_conf_list, gt_conf_list = [], []
430 | for ii in range(len(pred_anchor)):
431 | pred_conf_list.append(pred_anchor[ii][:,:,4,:,:].contiguous().view(args.batch_size,-1))
432 | gt_conf_list.append(gt_param[ii][:,:,4,:,:].contiguous().view(args.batch_size,-1))
433 | pred_conf = torch.cat(pred_conf_list, dim=1)
434 | gt_conf = torch.cat(gt_conf_list, dim=1)
435 | accu_center = np.sum(np.array(pred_conf.max(1)[1] == gt_conf.max(1)[1], dtype=float))/args.batch_size
436 | ## metrics
437 | miou.update(iou.data[0], imgs.size(0))
438 | acc.update(accu, imgs.size(0))
439 | acc_center.update(accu_center, imgs.size(0))
440 |
441 | # measure elapsed time
442 | batch_time.update(time.time() - end)
443 | end = time.time()
444 |
445 | if args.save_plot:
446 | # if batch_idx%100==0 and epoch==args.nb_epoch-1:
447 | if True:
448 | save_segmentation_map(pred_coord,target_bbox,imgs,'train',batch_idx*imgs.size(0),\
449 | save_path='./visulizations/%s/'%args.dataset)
450 |
451 | if batch_idx % args.print_freq == 0:
452 | print_str = 'Epoch: [{0}][{1}/{2}]\t' \
453 | 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' \
454 | 'Data Time {data_time.val:.3f} ({data_time.avg:.3f})\t' \
455 | 'Loss {loss.val:.4f} ({loss.avg:.4f})\t' \
456 | 'Accu {acc.val:.4f} ({acc.avg:.4f})\t' \
457 | 'Mean_iu {miou.val:.4f} ({miou.avg:.4f})\t' \
458 | 'Accu_c {acc_c.val:.4f} ({acc_c.avg:.4f})\t' \
459 | .format( \
460 | epoch, batch_idx, len(train_loader), batch_time=batch_time, \
461 | data_time=data_time, loss=losses, miou=miou, acc=acc, acc_c=acc_center)
462 | print(print_str)
463 | logging.info(print_str)
464 |
465 | def validate_epoch(val_loader, model, size_average, mode='val'):
466 | batch_time = AverageMeter()
467 | data_time = AverageMeter()
468 | losses = AverageMeter()
469 | acc = AverageMeter()
470 | acc_center = AverageMeter()
471 | miou = AverageMeter()
472 |
473 | model.eval()
474 | end = time.time()
475 |
476 | for batch_idx, (imgs, word_id, word_mask, bbox) in enumerate(val_loader):
477 | imgs = imgs.cuda()
478 | word_id = word_id.cuda()
479 | word_mask = word_mask.cuda()
480 | bbox = bbox.cuda()
481 | image = Variable(imgs)
482 | word_id = Variable(word_id)
483 | word_mask = Variable(word_mask)
484 | bbox = Variable(bbox)
485 | bbox = torch.clamp(bbox,min=0,max=args.size-1)
486 |
487 | with torch.no_grad():
488 | ## Note LSTM does not use word_mask
489 | pred_anchor = model(image, word_id, word_mask)
490 | for ii in range(len(pred_anchor)):
491 | pred_anchor[ii] = pred_anchor[ii].view( \
492 | pred_anchor[ii].size(0),3,5,pred_anchor[ii].size(2),pred_anchor[ii].size(3))
493 | gt_param, target_gi, target_gj, best_n_list = build_target(bbox, pred_anchor)
494 |
495 | ## eval: convert center+offset to box prediction
496 | ## calculate at rescaled image during validation for speed-up
497 | pred_conf_list, gt_conf_list = [], []
498 | for ii in range(len(pred_anchor)):
499 | pred_conf_list.append(pred_anchor[ii][:,:,4,:,:].contiguous().view(args.batch_size,-1))
500 | gt_conf_list.append(gt_param[ii][:,:,4,:,:].contiguous().view(args.batch_size,-1))
501 |
502 | pred_conf = torch.cat(pred_conf_list, dim=1)
503 | gt_conf = torch.cat(gt_conf_list, dim=1)
504 | max_conf, max_loc = torch.max(pred_conf, dim=1)
505 |
506 | pred_bbox = torch.zeros(args.batch_size,4)
507 | pred_gi, pred_gj, pred_best_n = [],[],[]
508 | for ii in range(args.batch_size):
509 | if max_loc[ii] < 3*(args.size//32)**2:
510 | best_scale = 0
511 | elif max_loc[ii] < 3*(args.size//32)**2 + 3*(args.size//16)**2:
512 | best_scale = 1
513 | else:
514 | best_scale = 2
515 |
516 | grid, grid_size = args.size//(32//(2**best_scale)), 32//(2**best_scale)
517 | anchor_idxs = [x + 3*best_scale for x in [0,1,2]]
518 | anchors = [anchors_full[i] for i in anchor_idxs]
519 | scaled_anchors = [ (x[0] / (args.anchor_imsize/grid), \
520 | x[1] / (args.anchor_imsize/grid)) for x in anchors]
521 |
522 | pred_conf = pred_conf_list[best_scale].view(args.batch_size,3,grid,grid).data.cpu().numpy()
523 | max_conf_ii = max_conf.data.cpu().numpy()
524 |
525 | # print(max_conf[ii],max_loc[ii],pred_conf_list[best_scale][ii,max_loc[ii]-64])
526 | (best_n, gj, gi) = np.where(pred_conf[ii,:,:,:] == max_conf_ii[ii])
527 | best_n, gi, gj = int(best_n[0]), int(gi[0]), int(gj[0])
528 | pred_gi.append(gi)
529 | pred_gj.append(gj)
530 | pred_best_n.append(best_n+best_scale*3)
531 |
532 | pred_bbox[ii,0] = F.sigmoid(pred_anchor[best_scale][ii, best_n, 0, gj, gi]) + gi
533 | pred_bbox[ii,1] = F.sigmoid(pred_anchor[best_scale][ii, best_n, 1, gj, gi]) + gj
534 | pred_bbox[ii,2] = torch.exp(pred_anchor[best_scale][ii, best_n, 2, gj, gi]) * scaled_anchors[best_n][0]
535 | pred_bbox[ii,3] = torch.exp(pred_anchor[best_scale][ii, best_n, 3, gj, gi]) * scaled_anchors[best_n][1]
536 | pred_bbox[ii,:] = pred_bbox[ii,:] * grid_size
537 | pred_bbox = xywh2xyxy(pred_bbox)
538 | target_bbox = bbox
539 |
540 | ## metrics
541 | iou = bbox_iou(pred_bbox, target_bbox.data.cpu(), x1y1x2y2=True)
542 | accu_center = np.sum(np.array((target_gi == np.array(pred_gi)) * (target_gj == np.array(pred_gj)), dtype=float))/args.batch_size
543 | accu = np.sum(np.array((iou.data.cpu().numpy()>0.5),dtype=float))/args.batch_size
544 |
545 | acc.update(accu, imgs.size(0))
546 | acc_center.update(accu_center, imgs.size(0))
547 | miou.update(iou.data[0], imgs.size(0))
548 |
549 | # measure elapsed time
550 | batch_time.update(time.time() - end)
551 | end = time.time()
552 |
553 | if args.save_plot:
554 | if batch_idx%1==0:
555 | save_segmentation_map(pred_bbox,target_bbox,imgs,'val',batch_idx*imgs.size(0),\
556 | save_path='./visulizations/%s/'%args.dataset)
557 |
558 | if batch_idx % args.print_freq == 0:
559 | print_str = '[{0}/{1}]\t' \
560 | 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' \
561 | 'Data Time {data_time.val:.3f} ({data_time.avg:.3f})\t' \
562 | 'Accu {acc.val:.4f} ({acc.avg:.4f})\t' \
563 | 'Mean_iu {miou.val:.4f} ({miou.avg:.4f})\t' \
564 | 'Accu_c {acc_c.val:.4f} ({acc_c.avg:.4f})\t' \
565 | .format( \
566 | batch_idx, len(val_loader), batch_time=batch_time, \
567 | data_time=data_time, \
568 | acc=acc, acc_c=acc_center, miou=miou)
569 | print(print_str)
570 | logging.info(print_str)
571 | print(best_n_list, pred_best_n)
572 | print(np.array(target_gi), np.array(pred_gi))
573 | print(np.array(target_gj), np.array(pred_gj),'-')
574 | print(acc.avg, miou.avg,acc_center.avg)
575 | logging.info("%f,%f,%f"%(acc.avg, float(miou.avg),acc_center.avg))
576 | return acc.avg
577 |
578 | def test_epoch(val_loader, model, size_average, mode='test'):
579 | batch_time = AverageMeter()
580 | data_time = AverageMeter()
581 | losses = AverageMeter()
582 | acc = AverageMeter()
583 | acc_center = AverageMeter()
584 | miou = AverageMeter()
585 |
586 | model.eval()
587 | end = time.time()
588 |
589 | for batch_idx, (imgs, word_id, word_mask, bbox, ratio, dw, dh, im_id) in enumerate(val_loader):
590 | imgs = imgs.cuda()
591 | word_id = word_id.cuda()
592 | word_mask = word_mask.cuda()
593 | bbox = bbox.cuda()
594 | image = Variable(imgs)
595 | word_id = Variable(word_id)
596 | word_mask = Variable(word_mask)
597 | bbox = Variable(bbox)
598 | bbox = torch.clamp(bbox,min=0,max=args.size-1)
599 |
600 | with torch.no_grad():
601 | ## Note LSTM does not use word_mask
602 | pred_anchor = model(image, word_id, word_mask)
603 | for ii in range(len(pred_anchor)):
604 | pred_anchor[ii] = pred_anchor[ii].view( \
605 | pred_anchor[ii].size(0),3,5,pred_anchor[ii].size(2),pred_anchor[ii].size(3))
606 | gt_param, target_gi, target_gj, best_n_list = build_target(bbox, pred_anchor)
607 |
608 | ## test: convert center+offset to box prediction
609 | pred_conf_list, gt_conf_list = [], []
610 | for ii in range(len(pred_anchor)):
611 | pred_conf_list.append(pred_anchor[ii][:,:,4,:,:].contiguous().view(1,-1))
612 | gt_conf_list.append(gt_param[ii][:,:,4,:,:].contiguous().view(1,-1))
613 |
614 | pred_conf = torch.cat(pred_conf_list, dim=1)
615 | gt_conf = torch.cat(gt_conf_list, dim=1)
616 | max_conf, max_loc = torch.max(pred_conf, dim=1)
617 |
618 | pred_bbox = torch.zeros(1,4)
619 |
620 | pred_gi, pred_gj, pred_best_n = [],[],[]
621 | for ii in range(1):
622 | if max_loc[ii] < 3*(args.size//32)**2:
623 | best_scale = 0
624 | elif max_loc[ii] < 3*(args.size//32)**2 + 3*(args.size//16)**2:
625 | best_scale = 1
626 | else:
627 | best_scale = 2
628 |
629 | grid, grid_size = args.size//(32//(2**best_scale)), 32//(2**best_scale)
630 | anchor_idxs = [x + 3*best_scale for x in [0,1,2]]
631 | anchors = [anchors_full[i] for i in anchor_idxs]
632 | scaled_anchors = [ (x[0] / (args.anchor_imsize/grid), \
633 | x[1] / (args.anchor_imsize/grid)) for x in anchors]
634 |
635 | pred_conf = pred_conf_list[best_scale].view(1,3,grid,grid).data.cpu().numpy()
636 | max_conf_ii = max_conf.data.cpu().numpy()
637 |
638 | # print(max_conf[ii],max_loc[ii],pred_conf_list[best_scale][ii,max_loc[ii]-64])
639 | (best_n, gj, gi) = np.where(pred_conf[ii,:,:,:] == max_conf_ii[ii])
640 | best_n, gi, gj = int(best_n[0]), int(gi[0]), int(gj[0])
641 | pred_gi.append(gi)
642 | pred_gj.append(gj)
643 | pred_best_n.append(best_n+best_scale*3)
644 |
645 | pred_bbox[ii,0] = F.sigmoid(pred_anchor[best_scale][ii, best_n, 0, gj, gi]) + gi
646 | pred_bbox[ii,1] = F.sigmoid(pred_anchor[best_scale][ii, best_n, 1, gj, gi]) + gj
647 | pred_bbox[ii,2] = torch.exp(pred_anchor[best_scale][ii, best_n, 2, gj, gi]) * scaled_anchors[best_n][0]
648 | pred_bbox[ii,3] = torch.exp(pred_anchor[best_scale][ii, best_n, 3, gj, gi]) * scaled_anchors[best_n][1]
649 | pred_bbox[ii,:] = pred_bbox[ii,:] * grid_size
650 | pred_bbox = xywh2xyxy(pred_bbox)
651 | target_bbox = bbox.data.cpu()
652 | pred_bbox[:,0], pred_bbox[:,2] = (pred_bbox[:,0]-dw)/ratio, (pred_bbox[:,2]-dw)/ratio
653 | pred_bbox[:,1], pred_bbox[:,3] = (pred_bbox[:,1]-dh)/ratio, (pred_bbox[:,3]-dh)/ratio
654 | target_bbox[:,0], target_bbox[:,2] = (target_bbox[:,0]-dw)/ratio, (target_bbox[:,2]-dw)/ratio
655 | target_bbox[:,1], target_bbox[:,3] = (target_bbox[:,1]-dh)/ratio, (target_bbox[:,3]-dh)/ratio
656 |
657 | ## convert pred, gt box to original scale with meta-info
658 | top, bottom = round(float(dh[0]) - 0.1), args.size - round(float(dh[0]) + 0.1)
659 | left, right = round(float(dw[0]) - 0.1), args.size - round(float(dw[0]) + 0.1)
660 | img_np = imgs[0,:,top:bottom,left:right].data.cpu().numpy().transpose(1,2,0)
661 |
662 | ratio = float(ratio)
663 | new_shape = (round(img_np.shape[1] / ratio), round(img_np.shape[0] / ratio))
664 | ## also revert image for visualization
665 | img_np = cv2.resize(img_np, new_shape, interpolation=cv2.INTER_CUBIC)
666 | img_np = Variable(torch.from_numpy(img_np.transpose(2,0,1)).cuda().unsqueeze(0))
667 |
668 | pred_bbox[:,:2], pred_bbox[:,2], pred_bbox[:,3] = \
669 | torch.clamp(pred_bbox[:,:2], min=0), torch.clamp(pred_bbox[:,2], max=img_np.shape[3]), torch.clamp(pred_bbox[:,3], max=img_np.shape[2])
670 | target_bbox[:,:2], target_bbox[:,2], target_bbox[:,3] = \
671 | torch.clamp(target_bbox[:,:2], min=0), torch.clamp(target_bbox[:,2], max=img_np.shape[3]), torch.clamp(target_bbox[:,3], max=img_np.shape[2])
672 |
673 | iou = bbox_iou(pred_bbox, target_bbox, x1y1x2y2=True)
674 | accu_center = np.sum(np.array((target_gi == np.array(pred_gi)) * (target_gj == np.array(pred_gj)), dtype=float))/1
675 | accu = np.sum(np.array((iou.data.cpu().numpy()>0.5),dtype=float))/1
676 |
677 | acc.update(accu, imgs.size(0))
678 | acc_center.update(accu_center, imgs.size(0))
679 | miou.update(iou.data[0], imgs.size(0))
680 |
681 | # measure elapsed time
682 | batch_time.update(time.time() - end)
683 | end = time.time()
684 |
685 | if args.save_plot:
686 | if batch_idx%1==0:
687 | save_segmentation_map(pred_bbox,target_bbox,img_np,'test',batch_idx*imgs.size(0),\
688 | save_path='./visulizations/%s/'%args.dataset)
689 |
690 | if batch_idx % args.print_freq == 0:
691 | print_str = '[{0}/{1}]\t' \
692 | 'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t' \
693 | 'Data Time {data_time.val:.3f} ({data_time.avg:.3f})\t' \
694 | 'Accu {acc.val:.4f} ({acc.avg:.4f})\t' \
695 | 'Mean_iu {miou.val:.4f} ({miou.avg:.4f})\t' \
696 | 'Accu_c {acc_c.val:.4f} ({acc_c.avg:.4f})\t' \
697 | .format( \
698 | batch_idx, len(val_loader), batch_time=batch_time, \
699 | data_time=data_time, \
700 | acc=acc, acc_c=acc_center, miou=miou)
701 | print(print_str)
702 | logging.info(print_str)
703 | print(best_n_list, pred_best_n)
704 | print(np.array(target_gi), np.array(pred_gi))
705 | print(np.array(target_gj), np.array(pred_gj),'-')
706 | print(acc.avg, miou.avg,acc_center.avg)
707 | logging.info("%f,%f,%f"%(acc.avg, float(miou.avg),acc_center.avg))
708 | return acc.avg
709 |
710 |
711 | if __name__ == "__main__":
712 | main()
713 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # -----------------------------------------------------------------------------
3 | # Copyright (c) Edgar Andrés Margffoy-Tuay, Emilio Botero and Juan Camilo Pérez
4 | #
5 | # Licensed under the terms of the MIT License
6 | # (see LICENSE for details)
7 | # -----------------------------------------------------------------------------
8 |
9 | """Misc data and other helping utillites."""
10 |
11 | from .word_utils import Corpus
12 | from .transforms import ResizeImage, ResizeAnnotation
13 |
14 | Corpus
15 | ResizeImage
16 | ResizeAnnotation
17 |
18 |
19 | class AverageMeter(object):
20 | """Computes and stores the average and current value"""
21 |
22 | def __init__(self):
23 | self.reset()
24 |
25 | def reset(self):
26 | self.val = 0
27 | self.avg = 0
28 | self.sum = 0
29 | self.count = 0
30 |
31 | def update(self, val, n=1):
32 | self.val = val
33 | self.sum += val * n
34 | self.count += n
35 | self.avg = self.sum / self.count
36 |
--------------------------------------------------------------------------------
/utils/losses.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | Custom loss function definitions.
5 | """
6 |
7 | import torch.nn as nn
8 | import torch.nn.functional as F
9 |
10 |
11 | class IoULoss(nn.Module):
12 | """
13 | Creates a criterion that computes the Intersection over Union (IoU)
14 | between a segmentation mask and its ground truth.
15 |
16 | Rahman, M.A. and Wang, Y:
17 | Optimizing Intersection-Over-Union in Deep Neural Networks for
18 | Image Segmentation. International Symposium on Visual Computing (2016)
19 | http://www.cs.umanitoba.ca/~ywang/papers/isvc16.pdf
20 | """
21 |
22 | def __init__(self, size_average=True):
23 | super().__init__()
24 | self.size_average = size_average
25 |
26 | def forward(self, input, target):
27 | input = F.sigmoid(input)
28 | intersection = (input * target).sum()
29 | union = ((input + target) - (input * target)).sum()
30 | iou = intersection / union
31 | iou_dual = input.size(0) - iou
32 | if self.size_average:
33 | iou_dual = iou_dual / input.size(0)
34 | return iou_dual
35 |
--------------------------------------------------------------------------------
/utils/misc_utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | Misc download and visualization helper functions and class wrappers.
5 | """
6 |
7 | import sys
8 | import time
9 | import torch
10 | from visdom import Visdom
11 |
12 |
13 | def reporthook(count, block_size, total_size):
14 | global start_time
15 | if count == 0:
16 | start_time = time.time()
17 | return
18 | duration = time.time() - start_time
19 | progress_size = int(count * block_size)
20 | speed = int(progress_size / (1024 * duration))
21 | percent = min(int(count * block_size * 100 / total_size), 100)
22 | sys.stdout.write("\r...%d%%, %d MB, %d KB/s, %d seconds passed" %
23 | (percent, progress_size / (1024 * 1024), speed, duration))
24 | sys.stdout.flush()
25 |
26 |
27 | class VisdomWrapper(Visdom):
28 | def __init__(self, *args, env=None, **kwargs):
29 | Visdom.__init__(self, *args, **kwargs)
30 | self.env = env
31 | self.plots = {}
32 |
33 | def init_line_plot(self, name,
34 | X=torch.zeros((1,)).cpu(),
35 | Y=torch.zeros((1,)).cpu(), **opts):
36 | self.plots[name] = self.line(X=X, Y=Y, env=self.env, opts=opts)
37 |
38 | def plot_line(self, name, **kwargs):
39 | self.line(win=self.plots[name], env=self.env, **kwargs)
40 |
--------------------------------------------------------------------------------
/utils/parsing_metrics.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import os
4 |
5 | # from plot_util import plot_confusion_matrix
6 | # from makemask import *
7 |
8 | def _fast_hist(label_true, label_pred, n_class):
9 | mask = (label_true >= 0) & (label_true < n_class)
10 | hist = np.bincount(
11 | n_class * label_true[mask].astype(int) +
12 | label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
13 | return hist
14 |
15 | def label_accuracy_score(label_trues, label_preds, n_class, bg_thre=200):
16 | """Returns accuracy score evaluation result.
17 | - overall accuracy
18 | - mean accuracy
19 | - mean IU
20 | - fwavacc
21 | """
22 | hist = np.zeros((n_class, n_class))
23 | for lt, lp in zip(label_trues, label_preds):
24 | # hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
25 | hist += _fast_hist(lt[lt 0] * iu[freq > 0]).sum()
33 | return acc, acc_cls, mean_iu, fwavacc
34 |
35 | def label_confusion_matrix(label_trues, label_preds, n_class, bg_thre=200):
36 | # eps=1e-20
37 | hist=np.zeros((n_class,n_class),dtype=float)
38 | """ (8,256,256), (256,256) """
39 | for lt,lp in zip(label_trues, label_preds):
40 | # hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
41 | hist += _fast_hist(lt[lt 0] * iu[freq > 0]).sum()
72 | return acc, acc_cls, mean_iu, fwavacc, iu
73 |
74 | # if __name__ == '__main__':
75 | # """ Evaluating from saved png segmentation maps
76 | # 0.862723060822 0.608076070823 0.503493670787 0.76556929118
77 | # """
78 | # import csv
79 | # from PIL import Image
80 | # import matplotlib as mpl
81 | # mpl.use('Agg')
82 | # from matplotlib import pyplot as plt
83 | # eps=1e-20
84 |
85 | # class AverageMeter(object):
86 | # """Computes and stores the average and current value"""
87 | # def __init__(self):
88 | # self.reset()
89 |
90 | # def reset(self):
91 | # self.val = 0
92 | # self.avg = 0
93 | # self.sum = 0
94 | # self.count = 0
95 |
96 | # def update(self, val, n=1):
97 | # self.val = val
98 | # self.sum += val * n
99 | # self.count += n
100 | # self.avg = self.sum / self.count
101 | # def load_csv(csv_file):
102 | # img_list, kpt_list, conf_list=[],[],[]
103 | # with open(csv_file, 'rb') as f:
104 | # reader = csv.reader(f)
105 | # for row in reader:
106 | # img_list.append(row[0])
107 | # kpt_list.append([row[i] for i in range(1,len(row)) if i%3!=0])
108 | # conf_list.append([row[i] for i in range(1,len(row)) if i%3==0])
109 | # # print len(img_list),len(kpt_list[0]),len(conf_list[0])
110 | # return img_list,kpt_list,conf_list
111 |
112 | # n_class = 7
113 | # superpixel_smooth = False
114 | # # valfile = '../../ln_data/LIP/TrainVal_pose_annotations/lip_val_set.csv'
115 | # # pred_folder = '../../../git_code/LIP_JPPNet/output/parsing/val/'
116 | # # pred_folder = '../visulizations/refinenet_baseline/test_out/'
117 | # pred_folder = '../visulizations/refinenet_splittask/test_out/'
118 | # gt_folder = '../../ln_data/pascal_data/SegmentationPart/'
119 | # img_path = '../../ln_data/pascal_data/JPEGImages/'
120 |
121 | # file = '../../ln_data/pascal_data/val_id.txt'
122 | # missjoints = '../../ln_data/pascal_data/no_joint_list.txt'
123 | # img_list = [x.strip().split(' ')[0] for x in open(file)]
124 | # miss_list = [x.strip().split(' ')[0] for x in open(missjoints)]
125 |
126 | # conf_matrices = AverageMeter()
127 | # for index in range(len(img_list)):
128 | # img_name = img_list[index]
129 | # if img_name in miss_list:
130 | # continue
131 | # if not os.path.isfile(pred_folder + img_name + '.png'):
132 | # continue
133 | # pred_file = pred_folder + img_name + '.png'
134 | # pred = Image.open(pred_file)
135 | # gt_file = gt_folder + img_name + '.png'
136 | # gt = Image.open(gt_file)
137 | # pred, gt = np.array(pred, dtype=np.int32), np.array(gt, dtype=np.int32)
138 | # if superpixel_smooth:
139 | # img_file = img_path+img_name+'.jpg'
140 | # img = Image.open(img_file)
141 | # pred = superpixel_expand(np.array(img),pred)
142 | # confusion, _ = label_confusion_matrix(gt, pred, n_class)
143 | # conf_matrices.update(confusion,1)
144 | # acc, acc_cls, mean_iu, fwavacc, iu = hist_based_accu_cal(conf_matrices.avg)
145 | # print(acc, acc_cls, mean_iu, fwavacc)
146 | # print(iu)
147 |
148 | # ## SAVE CONFUSION MATRIX
149 | # figure=plt.figure()
150 | # class_name=['bg', 'head', 'torso', 'upper arm', 'lower arm', 'upper leg', 'lower leg']
151 | # conf_matrices = conf_matrices.avg
152 | # for i in range(n_class):
153 | # conf_matrices[i,:]=(conf_matrices[i,:]+eps)/sum(conf_matrices[i,:]+eps)
154 | # plot_confusion_matrix(conf_matrices, classes=class_name,
155 | # rotation=0, include_text=True,
156 | # title='Confusion matrix, without normalization')
157 | # plt.show()
158 | # plt.savefig('../saved_models/Baseline_refinenet_test.jpg')
159 | # plt.close('all')
160 |
--------------------------------------------------------------------------------
/utils/transforms.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | Generic Image Transform utillities.
5 | """
6 |
7 | import cv2
8 | import random, math
9 | import numpy as np
10 | from collections import Iterable
11 |
12 | import torch.nn.functional as F
13 | from torch.autograd import Variable
14 |
15 |
16 | class ResizePad:
17 | """
18 | Resize and pad an image to given size.
19 | """
20 |
21 | def __init__(self, size):
22 | if not isinstance(size, (int, Iterable)):
23 | raise TypeError('Got inappropriate size arg: {}'.format(size))
24 |
25 | self.h, self.w = size
26 |
27 | def __call__(self, img):
28 | h, w = img.shape[:2]
29 | scale = min(self.h / h, self.w / w)
30 | resized_h = int(np.round(h * scale))
31 | resized_w = int(np.round(w * scale))
32 | pad_h = int(np.floor(self.h - resized_h) / 2)
33 | pad_w = int(np.floor(self.w - resized_w) / 2)
34 |
35 | resized_img = cv2.resize(img, (resized_w, resized_h))
36 |
37 | # if img.ndim > 2:
38 | if img.ndim > 2:
39 | new_img = np.zeros(
40 | (self.h, self.w, img.shape[-1]), dtype=resized_img.dtype)
41 | else:
42 | resized_img = np.expand_dims(resized_img, -1)
43 | new_img = np.zeros((self.h, self.w, 1), dtype=resized_img.dtype)
44 | new_img[pad_h: pad_h + resized_h,
45 | pad_w: pad_w + resized_w, ...] = resized_img
46 | return new_img
47 |
48 |
49 | class CropResize:
50 | """Remove padding and resize image to its original size."""
51 |
52 | def __call__(self, img, size):
53 | if not isinstance(size, (int, Iterable)):
54 | raise TypeError('Got inappropriate size arg: {}'.format(size))
55 | im_h, im_w = img.data.shape[:2]
56 | input_h, input_w = size
57 | scale = max(input_h / im_h, input_w / im_w)
58 | # scale = torch.Tensor([[input_h / im_h, input_w / im_w]]).max()
59 | resized_h = int(np.round(im_h * scale))
60 | # resized_h = torch.round(im_h * scale)
61 | resized_w = int(np.round(im_w * scale))
62 | # resized_w = torch.round(im_w * scale)
63 | crop_h = int(np.floor(resized_h - input_h) / 2)
64 | # crop_h = torch.floor(resized_h - input_h) // 2
65 | crop_w = int(np.floor(resized_w - input_w) / 2)
66 | # crop_w = torch.floor(resized_w - input_w) // 2
67 | # resized_img = cv2.resize(img, (resized_w, resized_h))
68 | resized_img = F.upsample(
69 | img.unsqueeze(0).unsqueeze(0), size=(resized_h, resized_w),
70 | mode='bilinear')
71 |
72 | resized_img = resized_img.squeeze().unsqueeze(0)
73 |
74 | return resized_img[0, crop_h: crop_h + input_h,
75 | crop_w: crop_w + input_w]
76 |
77 |
78 | class ResizeImage:
79 | """Resize the largest of the sides of the image to a given size"""
80 | def __init__(self, size):
81 | if not isinstance(size, (int, Iterable)):
82 | raise TypeError('Got inappropriate size arg: {}'.format(size))
83 |
84 | self.size = size
85 |
86 | def __call__(self, img):
87 | im_h, im_w = img.shape[-2:]
88 | scale = min(self.size / im_h, self.size / im_w)
89 | resized_h = int(np.round(im_h * scale))
90 | resized_w = int(np.round(im_w * scale))
91 | out = F.upsample(
92 | Variable(img).unsqueeze(0), size=(resized_h, resized_w),
93 | mode='bilinear').squeeze().data
94 | return out
95 |
96 |
97 | class ResizeAnnotation:
98 | """Resize the largest of the sides of the annotation to a given size"""
99 | def __init__(self, size):
100 | if not isinstance(size, (int, Iterable)):
101 | raise TypeError('Got inappropriate size arg: {}'.format(size))
102 |
103 | self.size = size
104 |
105 | def __call__(self, img):
106 | im_h, im_w = img.shape[-2:]
107 | scale = min(self.size / im_h, self.size / im_w)
108 | resized_h = int(np.round(im_h * scale))
109 | resized_w = int(np.round(im_w * scale))
110 | out = F.upsample(
111 | Variable(img).unsqueeze(0).unsqueeze(0),
112 | size=(resized_h, resized_w),
113 | mode='bilinear').squeeze().data
114 | return out
115 |
116 |
117 | class ToNumpy:
118 | """Transform an torch.*Tensor to an numpy ndarray."""
119 |
120 | def __call__(self, x):
121 | return x.numpy()
122 |
123 | def letterbox(img, mask, height, color=(123.7, 116.3, 103.5)): # resize a rectangular image to a padded square
124 | shape = img.shape[:2] # shape = [height, width]
125 | ratio = float(height) / max(shape) # ratio = old / new
126 | new_shape = (round(shape[1] * ratio), round(shape[0] * ratio))
127 | dw = (height - new_shape[0]) / 2 # width padding
128 | dh = (height - new_shape[1]) / 2 # height padding
129 | top, bottom = round(dh - 0.1), round(dh + 0.1)
130 | left, right = round(dw - 0.1), round(dw + 0.1)
131 | img = cv2.resize(img, new_shape, interpolation=cv2.INTER_AREA) # resized, no border
132 | img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # padded square
133 | if mask is not None:
134 | mask = cv2.resize(mask, new_shape, interpolation=cv2.INTER_NEAREST) # resized, no border
135 | mask = cv2.copyMakeBorder(mask, top, bottom, left, right, cv2.BORDER_CONSTANT, value=255) # padded square
136 | return img, mask, ratio, dw, dh
137 |
138 | def random_affine(img, mask, targets, degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-2, 2),
139 | borderValue=(123.7, 116.3, 103.5), all_bbox=None):
140 | border = 0 # width of added border (optional)
141 | height = max(img.shape[0], img.shape[1]) + border * 2
142 |
143 | # Rotation and Scale
144 | R = np.eye(3)
145 | a = random.random() * (degrees[1] - degrees[0]) + degrees[0]
146 | # a += random.choice([-180, -90, 0, 90]) # 90deg rotations added to small rotations
147 | s = random.random() * (scale[1] - scale[0]) + scale[0]
148 | R[:2] = cv2.getRotationMatrix2D(angle=a, center=(img.shape[1] / 2, img.shape[0] / 2), scale=s)
149 |
150 | # Translation
151 | T = np.eye(3)
152 | T[0, 2] = (random.random() * 2 - 1) * translate[0] * img.shape[0] + border # x translation (pixels)
153 | T[1, 2] = (random.random() * 2 - 1) * translate[1] * img.shape[1] + border # y translation (pixels)
154 |
155 | # Shear
156 | S = np.eye(3)
157 | S[0, 1] = math.tan((random.random() * (shear[1] - shear[0]) + shear[0]) * math.pi / 180) # x shear (deg)
158 | S[1, 0] = math.tan((random.random() * (shear[1] - shear[0]) + shear[0]) * math.pi / 180) # y shear (deg)
159 |
160 | M = S @ T @ R # Combined rotation matrix. ORDER IS IMPORTANT HERE!!
161 | imw = cv2.warpPerspective(img, M, dsize=(height, height), flags=cv2.INTER_LINEAR,
162 | borderValue=borderValue) # BGR order borderValue
163 | if mask is not None:
164 | maskw = cv2.warpPerspective(mask, M, dsize=(height, height), flags=cv2.INTER_NEAREST,
165 | borderValue=255) # BGR order borderValue
166 | else:
167 | maskw = None
168 |
169 | # Return warped points also
170 | if type(targets)==type([1]):
171 | targetlist=[]
172 | for bbox in targets:
173 | targetlist.append(wrap_points(bbox, M, height, a))
174 | return imw, maskw, targetlist, M
175 | elif all_bbox is not None:
176 | targets = wrap_points(targets, M, height, a)
177 | for ii in range(all_bbox.shape[0]):
178 | all_bbox[ii,:] = wrap_points(all_bbox[ii,:], M, height, a)
179 | return imw, maskw, targets, all_bbox, M
180 | elif targets is not None: ## previous main
181 | targets = wrap_points(targets, M, height, a)
182 | return imw, maskw, targets, M
183 | else:
184 | return imw
185 |
186 | def wrap_points(targets, M, height, a):
187 | # n = targets.shape[0]
188 | # points = targets[:, 1:5].copy()
189 | points = targets.copy()
190 | # area0 = (points[:, 2] - points[:, 0]) * (points[:, 3] - points[:, 1])
191 | area0 = (points[2] - points[0]) * (points[3] - points[1])
192 |
193 | # warp points
194 | xy = np.ones((4, 3))
195 | xy[:, :2] = points[[0, 1, 2, 3, 0, 3, 2, 1]].reshape(4, 2) # x1y1, x2y2, x1y2, x2y1
196 | xy = (xy @ M.T)[:, :2].reshape(1, 8)
197 |
198 | # create new boxes
199 | x = xy[:, [0, 2, 4, 6]]
200 | y = xy[:, [1, 3, 5, 7]]
201 | xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, 1).T
202 |
203 | # apply angle-based reduction
204 | radians = a * math.pi / 180
205 | reduction = max(abs(math.sin(radians)), abs(math.cos(radians))) ** 0.5
206 | x = (xy[:, 2] + xy[:, 0]) / 2
207 | y = (xy[:, 3] + xy[:, 1]) / 2
208 | w = (xy[:, 2] - xy[:, 0]) * reduction
209 | h = (xy[:, 3] - xy[:, 1]) * reduction
210 | xy = np.concatenate((x - w / 2, y - h / 2, x + w / 2, y + h / 2)).reshape(4, 1).T
211 |
212 | # reject warped points outside of image
213 | np.clip(xy, 0, height, out=xy)
214 | w = xy[:, 2] - xy[:, 0]
215 | h = xy[:, 3] - xy[:, 1]
216 | area = w * h
217 | ar = np.maximum(w / (h + 1e-16), h / (w + 1e-16))
218 | i = (w > 4) & (h > 4) & (area / (area0 + 1e-16) > 0.1) & (ar < 10)
219 |
220 | ## print(targets, xy)
221 | ## [ 56 36 108 210] [[ 47.80464857 15.6096533 106.30993434 196.71267693]]
222 | # targets = targets[i]
223 | # targets[:, 1:5] = xy[i]
224 | targets = xy[0]
225 | return targets
--------------------------------------------------------------------------------
/utils/utils.py:
--------------------------------------------------------------------------------
1 | import random
2 |
3 | import cv2
4 | import numpy as np
5 | import torch
6 | import torch.nn.functional as F
7 |
8 | class AverageMeter(object):
9 | """Computes and stores the average and current value"""
10 | def __init__(self):
11 | self.reset()
12 |
13 | def reset(self):
14 | self.val = 0
15 | self.avg = 0
16 | self.sum = 0
17 | self.count = 0
18 |
19 | def update(self, val, n=1):
20 | self.val = val
21 | self.sum += val * n
22 | self.count += n
23 | self.avg = self.sum / self.count
24 |
25 | def xyxy2xywh(x): # Convert bounding box format from [x1, y1, x2, y2] to [x, y, w, h]
26 | y = torch.zeros(x.shape) if x.dtype is torch.float32 else np.zeros(x.shape)
27 | y[:, 0] = (x[:, 0] + x[:, 2]) / 2
28 | y[:, 1] = (x[:, 1] + x[:, 3]) / 2
29 | y[:, 2] = x[:, 2] - x[:, 0]
30 | y[:, 3] = x[:, 3] - x[:, 1]
31 | return y
32 |
33 |
34 | def xywh2xyxy(x): # Convert bounding box format from [x, y, w, h] to [x1, y1, x2, y2]
35 | y = torch.zeros(x.shape) if x.dtype is torch.float32 else np.zeros(x.shape)
36 | y[:, 0] = (x[:, 0] - x[:, 2] / 2)
37 | y[:, 1] = (x[:, 1] - x[:, 3] / 2)
38 | y[:, 2] = (x[:, 0] + x[:, 2] / 2)
39 | y[:, 3] = (x[:, 1] + x[:, 3] / 2)
40 | return y
41 |
42 | def bbox_iou_numpy(box1, box2):
43 | """Computes IoU between bounding boxes.
44 | Parameters
45 | ----------
46 | box1 : ndarray
47 | (N, 4) shaped array with bboxes
48 | box2 : ndarray
49 | (M, 4) shaped array with bboxes
50 | Returns
51 | -------
52 | : ndarray
53 | (N, M) shaped array with IoUs
54 | """
55 | area = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1])
56 |
57 | iw = np.minimum(np.expand_dims(box1[:, 2], axis=1), box2[:, 2]) - np.maximum(
58 | np.expand_dims(box1[:, 0], 1), box2[:, 0]
59 | )
60 | ih = np.minimum(np.expand_dims(box1[:, 3], axis=1), box2[:, 3]) - np.maximum(
61 | np.expand_dims(box1[:, 1], 1), box2[:, 1]
62 | )
63 |
64 | iw = np.maximum(iw, 0)
65 | ih = np.maximum(ih, 0)
66 |
67 | ua = np.expand_dims((box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1]), axis=1) + area - iw * ih
68 |
69 | ua = np.maximum(ua, np.finfo(float).eps)
70 |
71 | intersection = iw * ih
72 |
73 | return intersection / ua
74 |
75 |
76 | def bbox_iou(box1, box2, x1y1x2y2=True):
77 | """
78 | Returns the IoU of two bounding boxes
79 | """
80 | if x1y1x2y2:
81 | # Get the coordinates of bounding boxes
82 | b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
83 | b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
84 | else:
85 | # Transform from center and width to exact coordinates
86 | b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
87 | b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
88 | b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
89 | b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
90 |
91 | # get the coordinates of the intersection rectangle
92 | inter_rect_x1 = torch.max(b1_x1, b2_x1)
93 | inter_rect_y1 = torch.max(b1_y1, b2_y1)
94 | inter_rect_x2 = torch.min(b1_x2, b2_x2)
95 | inter_rect_y2 = torch.min(b1_y2, b2_y2)
96 | # Intersection area
97 | inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1, 0) * torch.clamp(inter_rect_y2 - inter_rect_y1, 0)
98 | # Union Area
99 | b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
100 | b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
101 |
102 | # print(box1, box1.shape)
103 | # print(box2, box2.shape)
104 | return inter_area / (b1_area + b2_area - inter_area + 1e-16)
105 |
106 | def multiclass_metrics(pred, gt):
107 | """
108 | check precision and recall for predictions.
109 | Output: overall = {precision, recall, f1}
110 | """
111 | eps=1e-6
112 | overall = {'precision': -1, 'recall': -1, 'f1': -1}
113 | NP, NR, NC = 0, 0, 0 # num of pred, num of recall, num of correct
114 | for ii in range(pred.shape[0]):
115 | pred_ind = np.array(pred[ii]>0.5, dtype=int)
116 | gt_ind = np.array(gt[ii]>0.5, dtype=int)
117 | inter = pred_ind * gt_ind
118 | # add to overall
119 | NC += np.sum(inter)
120 | NP += np.sum(pred_ind)
121 | NR += np.sum(gt_ind)
122 | if NP > 0:
123 | overall['precision'] = float(NC)/NP
124 | if NR > 0:
125 | overall['recall'] = float(NC)/NR
126 | if NP > 0 and NR > 0:
127 | overall['f1'] = 2*overall['precision']*overall['recall']/(overall['precision']+overall['recall']+eps)
128 | return overall
129 |
130 | def compute_ap(recall, precision):
131 | """ Compute the average precision, given the recall and precision curves.
132 | Code originally from https://github.com/rbgirshick/py-faster-rcnn.
133 | # Arguments
134 | recall: The recall curve (list).
135 | precision: The precision curve (list).
136 | # Returns
137 | The average precision as computed in py-faster-rcnn.
138 | """
139 | # correct AP calculation
140 | # first append sentinel values at the end
141 | mrec = np.concatenate(([0.0], recall, [1.0]))
142 | mpre = np.concatenate(([0.0], precision, [0.0]))
143 |
144 | # compute the precision envelope
145 | for i in range(mpre.size - 1, 0, -1):
146 | mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
147 |
148 | # to calculate area under PR curve, look for points
149 | # where X axis (recall) changes value
150 | i = np.where(mrec[1:] != mrec[:-1])[0]
151 |
152 | # and sum (\Delta recall) * prec
153 | ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
154 | return ap
155 |
--------------------------------------------------------------------------------
/utils/word_utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | Language-related data loading helper functions and class wrappers.
5 | """
6 |
7 | import re
8 | import torch
9 | import codecs
10 |
11 | UNK_TOKEN = ''
12 | PAD_TOKEN = ''
13 | END_TOKEN = ''
14 | SENTENCE_SPLIT_REGEX = re.compile(r'(\W+)')
15 |
16 |
17 | class Dictionary(object):
18 | def __init__(self):
19 | self.word2idx = {}
20 | self.idx2word = []
21 |
22 | def add_word(self, word):
23 | if word not in self.word2idx:
24 | self.idx2word.append(word)
25 | self.word2idx[word] = len(self.idx2word) - 1
26 | return self.word2idx[word]
27 |
28 | def __len__(self):
29 | return len(self.idx2word)
30 |
31 | def __getitem__(self, a):
32 | if isinstance(a, int):
33 | return self.idx2word[a]
34 | elif isinstance(a, list):
35 | return [self.idx2word[x] for x in a]
36 | elif isinstance(a, str):
37 | return self.word2idx[a]
38 | else:
39 | raise TypeError("Query word/index argument must be int or str")
40 |
41 | def __contains__(self, word):
42 | return word in self.word2idx
43 |
44 |
45 | class Corpus(object):
46 | def __init__(self):
47 | self.dictionary = Dictionary()
48 |
49 | def set_max_len(self, value):
50 | self.max_len = value
51 |
52 | def load_file(self, filename):
53 | with codecs.open(filename, 'r', 'utf-8') as f:
54 | for line in f:
55 | line = line.strip()
56 | self.add_to_corpus(line)
57 | self.dictionary.add_word(UNK_TOKEN)
58 | self.dictionary.add_word(PAD_TOKEN)
59 |
60 | def add_to_corpus(self, line):
61 | """Tokenizes a text line."""
62 | # Add words to the dictionary
63 | words = line.split()
64 | # tokens = len(words)
65 | for word in words:
66 | word = word.lower()
67 | self.dictionary.add_word(word)
68 |
69 | def tokenize(self, line, max_len=20):
70 | # Tokenize line contents
71 | words = SENTENCE_SPLIT_REGEX.split(line.strip())
72 | # words = [w.lower() for w in words if len(w) > 0]
73 | words = [w.lower() for w in words if (len(w) > 0 and w!=' ')] ## do not include space as a token
74 |
75 | if words[-1] == '.':
76 | words = words[:-1]
77 |
78 | if max_len > 0:
79 | if len(words) > max_len:
80 | words = words[:max_len]
81 | elif len(words) < max_len:
82 | # words = [PAD_TOKEN] * (max_len - len(words)) + words
83 | words = words + [END_TOKEN] + [PAD_TOKEN] * (max_len - len(words) - 1)
84 |
85 | tokens = len(words) ## for end token
86 | ids = torch.LongTensor(tokens)
87 | token = 0
88 | for word in words:
89 | if word not in self.dictionary:
90 | word = UNK_TOKEN
91 | # print(word, type(word), word.encode('ascii','ignore').decode('ascii'), type(word.encode('ascii','ignore').decode('ascii')))
92 | if type(word)!=type('a'):
93 | print(word, type(word), word.encode('ascii','ignore').decode('ascii'), type(word.encode('ascii','ignore').decode('ascii')))
94 | word = word.encode('ascii','ignore').decode('ascii')
95 | ids[token] = self.dictionary[word]
96 | token += 1
97 | # ids[token] = self.dictionary[END_TOKEN]
98 | return ids
99 |
100 | def __len__(self):
101 | return len(self.dictionary)
102 |
--------------------------------------------------------------------------------