├── .idea
├── .gitignore
├── checkstyle-idea.xml
├── misc.xml
├── modules.xml
├── vcs.xml
└── workspace.xml
├── LICENSE
├── README.md
├── dockerNotes
└── docker必知必会.md
├── java virtual machine
└── JVM虚拟机.md
├── leetcode
└── Leetcode 题解刷题顺序.md
├── network of computer
└── 计算机网络.md
├── open source project learning method
└── 开源项目学习.md
├── operation system
└── 操作系统.md
├── 刷题册.md
├── 小曾Linux私房菜.pdf
├── 常用命令合集.pdf
├── 操作系统查漏补缺.md
├── 数据库查漏补缺.md
├── 注解开发笔记.pdf
└── 计算机网络查漏补缺.md
/.idea/.gitignore:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/zzzzzzzzyt/JavaLearningNotes/d53263b10ab6655900423e19437efb3936f4a223/.idea/.gitignore
--------------------------------------------------------------------------------
/.idea/checkstyle-idea.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
14 |
15 |
16 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
5 |
7 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
6 |
--------------------------------------------------------------------------------
/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
7 |
12 |
13 |
15 |
16 |
17 |
18 |
21 |
22 |
23 |
24 |
26 |
27 |
29 |
30 |
31 |
36 |
37 |
38 |
40 |
41 |
42 |
43 |
47 |
48 |
49 |
52 |
54 |
55 |
68 |
69 |
70 |
76 |
77 |
80 |
81 |
83 | C:\Users\asus\AppData\Roaming\Subversion
84 |
87 |
88 |
89 | 1642382313276
91 | 1642382313276
94 |
544 |
545 | 1668405408708
546 | 1668405408708
550 |
551 |
552 | 1668472640752
553 | 1668472640753
557 |
558 |
559 | 1668560541012
560 | 1668560541013
564 |
565 |
566 | 1668653228753
567 | 1668653228753
571 |
572 |
573 | 1668735985091
574 | 1668735985092
578 |
579 |
580 | 1668918493258
581 | 1668918493258
585 |
586 |
587 | 1668993452929
588 | 1668993452930
592 |
593 |
594 | 1669087012668
595 | 1669087012668
599 |
600 |
601 | 1669168070438
602 | 1669168070439
606 |
607 |
608 | 1669269017327
609 | 1669269017328
613 |
614 |
615 | 1669340552796
616 | 1669340552796
620 |
621 |
622 | 1669341673717
623 | 1669341673717
627 |
628 |
629 | 1669428064513
630 | 1669428064513
634 |
635 |
636 | 1669514755862
637 | 1669514755863
641 |
642 |
643 | 1669601573333
644 | 1669601573334
648 |
649 |
650 | 1669681733682
651 | 1669681733684
655 |
656 |
657 | 1669769503178
658 | 1669769503178
662 |
663 |
664 | 1669948380979
665 | 1669948380979
669 |
670 |
671 | 1670076987893
672 | 1670076987893
676 |
677 |
678 | 1670117117126
679 | 1670117117127
683 |
684 |
685 | 1670287340673
686 | 1670287340675
690 |
691 |
692 | 1670633641402
693 | 1670633641403
697 |
698 |
699 | 1670722122339
700 | 1670722122340
704 |
705 |
706 | 1671155863190
707 | 1671155863190
711 |
712 |
713 | 1671349567703
714 | 1671349567704
718 |
719 |
720 | 1671413622692
721 | 1671413622692
725 |
726 |
727 | 1671547969409
728 | 1671547969409
732 |
733 |
734 | 1671615662728
735 | 1671615662728
739 |
740 |
741 | 1672203887647
742 | 1672203887647
746 |
747 |
748 | 1672368964498
749 | 1672368964499
753 |
754 |
755 | 1672470924811
756 | 1672470924811
760 |
761 |
762 | 1672716550275
763 | 1672716550275
767 |
768 |
769 | 1672897530883
770 | 1672897530883
774 |
775 |
776 | 1673077350073
777 | 1673077350074
781 |
782 |
783 | 1673330303247
784 | 1673330303248
788 |
789 |
790 | 1673837916705
791 | 1673837916705
795 |
796 |
797 | 1674299823816
798 | 1674299823817
802 |
803 |
804 | 1674715418003
805 | 1674715418004
809 |
810 |
811 | 1675330785386
812 | 1675330785386
816 |
817 |
818 | 1675601263285
819 | 1675601263285
823 |
824 |
825 | 1676167997229
826 | 1676167997229
830 |
831 |
832 | 1676510698634
833 | 1676510698634
837 |
838 |
839 | 1676814189849
840 | 1676814189849
844 |
845 |
846 | 1677314363719
847 | 1677314363719
851 |
852 |
853 | 1678070715645
854 | 1678070715645
858 |
859 |
860 | 1678754203187
861 | 1678754203188
865 |
866 |
867 | 1680398612559
868 | 1680398612560
872 |
873 |
874 | 1681383258462
875 | 1681383258463
879 |
880 |
881 | 1683082659050
882 | 1683082659051
886 |
887 |
890 |
891 |
893 |
894 |
895 |
896 |
901 |
902 |
903 |
904 |
905 |
906 |
907 |
908 |
909 |
910 |
911 |
912 |
913 |
914 |
916 |
917 |
918 |
919 |
920 |
921 |
922 |
923 |
924 |
925 |
926 |
927 |
954 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # java学习笔记
2 |
3 | ✨ *special to meet you* ✨
4 |
5 |
6 |
7 | k -1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
275 |
276 | d 为偏差的加权平均值。
697 |
698 | ## TCP 滑动窗口
699 |
700 | 窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
701 |
702 | 发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
703 |
704 | 接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
705 |
706 | 1 和 M2 ,此时收到 M4 ,应当发送对 M2 的确认。
742 |
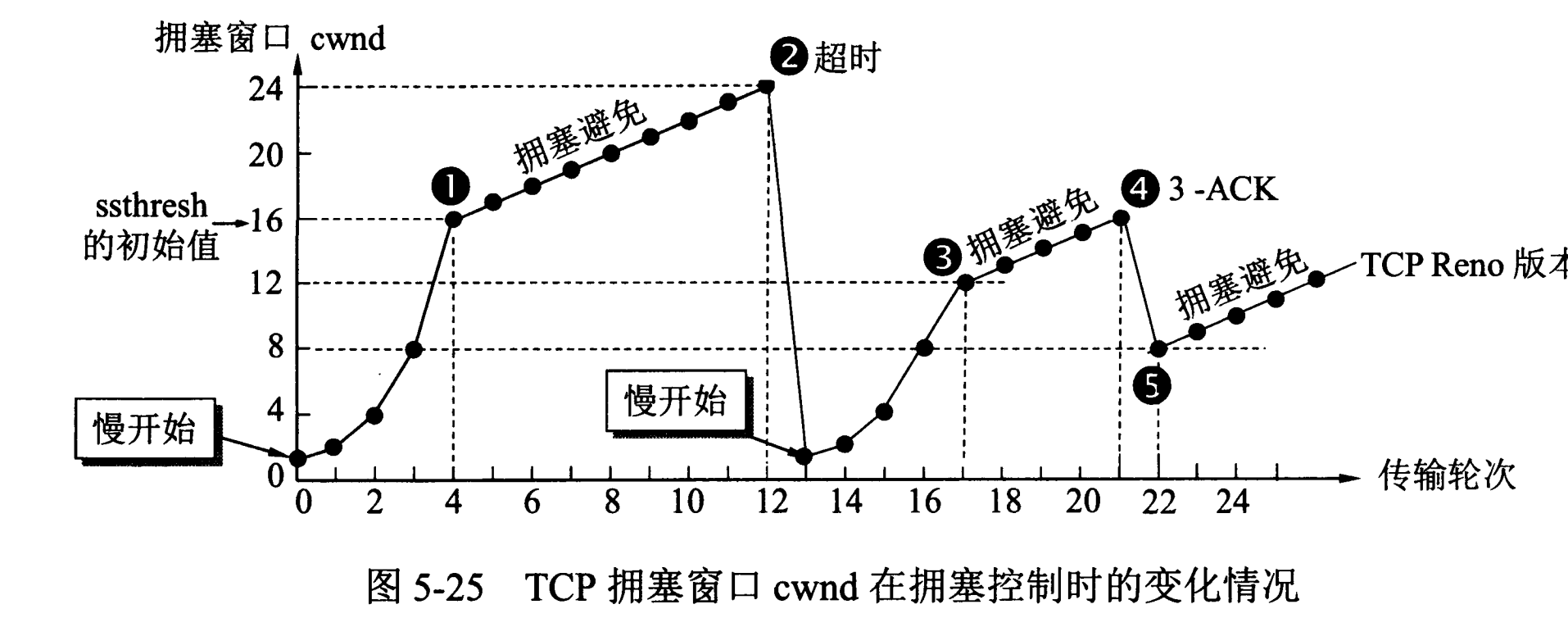
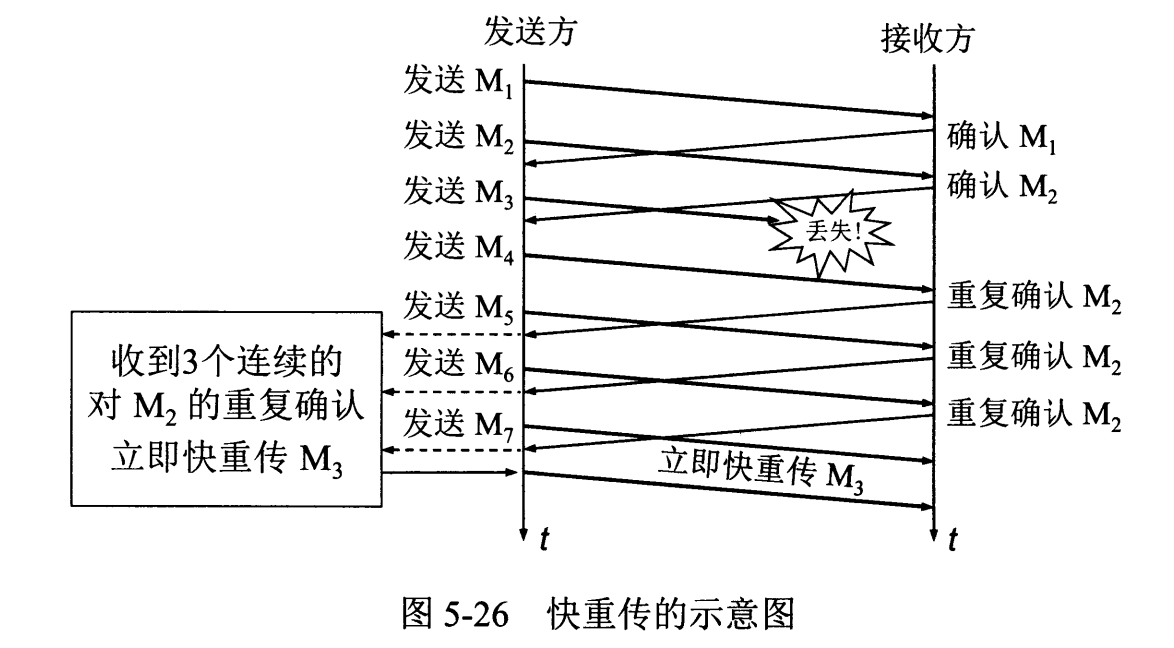
743 | 在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2 ,则 M3 丢失,立即重传 M3 。
744 |
745 | 在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
746 |
747 | 慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
748 |
749 | FF:\FF:\FF:\FF:FF,将广播到与交换机连接的所有设备。
871 |
872 | - 连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
873 |
874 | - 该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
875 |
876 | - 主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
877 |
878 | ### 2. ARP 解析 MAC 地址
879 |
880 | - 主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
881 |
882 | - 主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
883 |
884 | - 该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
885 |
886 | - 该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
887 |
888 | - DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
889 |
890 | - 主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:\FF:\FF:\FF:\FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。
891 |
892 | - 网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
893 |
894 | ### 3. DNS 解析域名
895 |
896 | - 知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
897 |
898 | - 网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
899 |
900 | - 因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
901 |
902 | - 到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
903 |
904 | - 找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
905 |
906 | ### 4. HTTP 请求页面
907 |
908 | - 有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
909 |
910 | - 在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
911 |
912 | - HTTP 服务器收到该报文段之后,生成 TCP SYN ACK 报文段,发回给主机。
913 |
914 | - 连接建立之后,浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
915 |
916 | - HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个 HTTP 响应报文,将 Web 页面内容放入报文主体中,发回给主机。
917 |
918 | - 浏览器收到 HTTP 响应报文后,抽取出 Web 页面内容,之后进行渲染,显示 Web 页面。
--------------------------------------------------------------------------------
/open source project learning method/开源项目学习.md:
--------------------------------------------------------------------------------
1 | # 开源项目学习
2 |
3 |
4 |
5 |
6 |
7 | ## 学习步骤(对所有开源项目来说)
8 |
9 |
10 |
11 | ### 开源项目下载
12 |
13 | 下载完毕,然后解压,优先使用码云下载!
14 |
15 | 解压,先不要着急运行!
16 |
17 | **观察:**
18 |
19 | 1、用了那些技术
20 |
21 | 2、是否有数据库
22 |
23 | 3、你的环境是否匹配
24 |
25 | 通过了,然后再想办法运行!
26 |
27 |
28 |
29 | ### 跑起来是第一步
30 |
31 | 1、安装数据库,执行SQL(如果它没有建库语句 则自己进行建库)
32 |
33 | 2、前端需要跑起来 前端依赖下载等...
34 |
35 | 3、后端项目==导入==跑起来 (idea直接import Project open的话会很麻烦的)
36 |
37 | 4、**启动后端项目(一般前后端项目 前端是依赖后端的)** 启动的先后顺序 先分析模块 主要分析common、system等模块 如果发现有redis等 需要先启动redis, 进而还要看看它的配置文件,看看端口号是否和自己是一致,再看看有那些配置需要改成自己的配置,比如数据库账号密码等
38 |
39 | tip:只要发现了Swagger,那么跑起来的第一步就是先进入Swagger-ui页面!因为这里面都是接口!
40 |
41 |
42 |
43 | ### 前后端分离项目固定套路
44 |
45 | 1、从前端开始分析。打开控制台,点一个接口,分析一波调用关系!
46 |
47 | 2、前后端端口调用不一致~8013 -- 8000
48 |
49 | - 封装了接口请求 ajax axios request
50 |
51 | - 找到配置
52 |
53 | 
54 |
55 | - 前后端分离项目的重点:找到接口的调用关系
56 | - Springboot提供服务!前端调用接口数据!Vue负责渲染页面!
57 |
58 | 
59 |
60 | - 前端项目固定套路
61 |
62 | 
63 |
64 | - 在api中每个方法 后端都一定有接口 复制一下路径到idea中用CTRL+SHIFT+F 来看
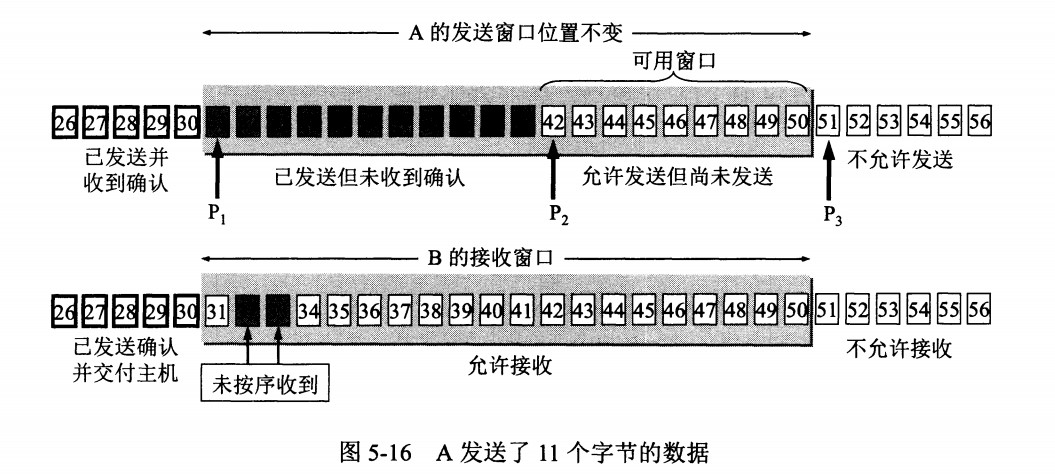
65 | - 通过抓取前端的请求,找到后端对应接口
66 |
67 | 
68 |
69 | - 去后端进行全局搜索 找到后端对应的地址 接下来就可以进行深挖了
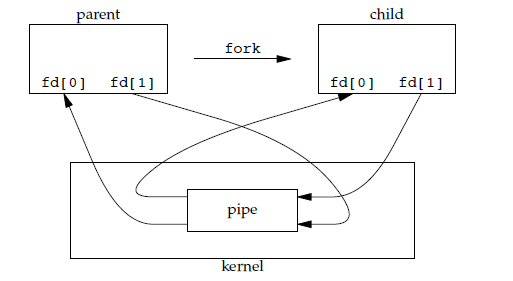
70 |
71 | 
72 |
73 | - Controller--Service--Dao:接下来就能看懂了
74 | - 现在从前到后可以分析了!但是如何渲染到视图上呢?看前端
75 |
76 | 
77 |
78 | - vue标准套路
79 |
80 | ```vue
81 |
82 | 视图层
83 |
84 |
85 |
92 |
93 |
96 | ```
97 |
98 |
99 |
100 | - 如果你现在自己的项目或者你要学习一个模块,将这个模块独立抽取出来即可!删除法
101 |
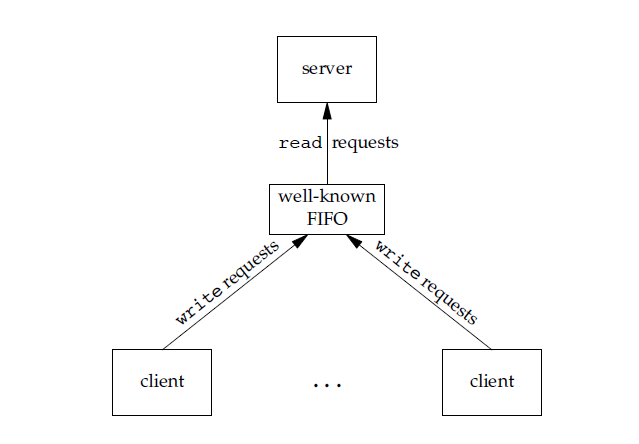
102 |
103 |
104 | ### 如何找到一个好的开源项目
105 |
106 |
107 |
108 | 1、找分类 JAVA
109 |
110 | 2、看收藏,开源项目,所有人觉得不错,那就是好的!
111 |
112 | 3、看具有价值
113 |
114 | 4、根据自身的理解情况去看
115 |
116 |
117 |
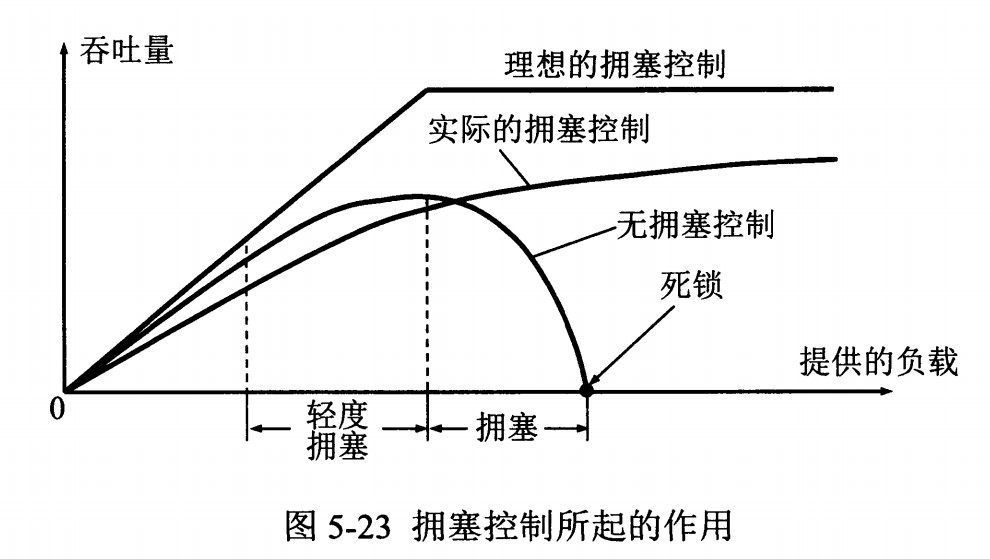
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
--------------------------------------------------------------------------------
/operation system/操作系统.md:
--------------------------------------------------------------------------------
1 | # 操作系统
2 |
3 | # 计算机操作系统 - 概述
4 |
5 | * [计算机操作系统 - 概述](#计算机操作系统---概述)
6 | * [基本特征](#基本特征)
7 | * [1. 并发](#1-并发)
8 | * [2. 共享](#2-共享)
9 | * [3. 虚拟](#3-虚拟)
10 | * [4. 异步](#4-异步)
11 | * [基本功能](#基本功能)
12 | * [1. 进程管理](#1-进程管理)
13 | * [2. 内存管理](#2-内存管理)
14 | * [3. 文件管理](#3-文件管理)
15 | * [4. 设备管理](#4-设备管理)
16 | * [系统调用](#系统调用)
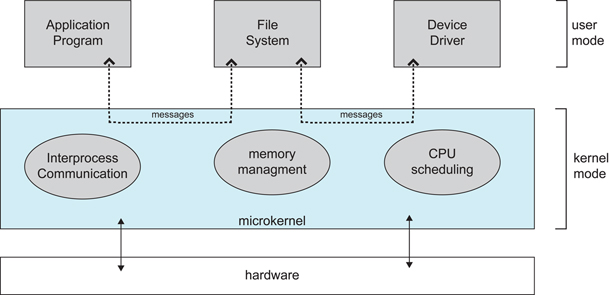
17 | * [宏内核和微内核](#宏内核和微内核)
18 | * [1. 宏内核](#1-宏内核)
19 | * [2. 微内核](#2-微内核)
20 | * [中断分类](#中断分类)
21 | * [1. 外中断](#1-外中断)
22 | * [2. 异常](#2-异常)
23 | * [3. 陷入](#3-陷入)
24 |
25 |
26 |
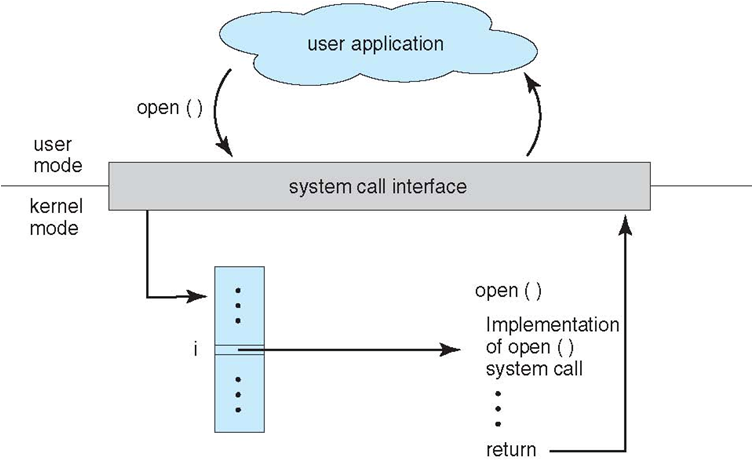
27 | ## 基本特征
28 |
29 | ### 1. 并发
30 |
31 | 并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
32 |
33 | 并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
34 |
35 | 操作系统通过引入进程和线程,使得程序能够并发运行。
36 |
37 | ### 2. 共享
38 |
39 | 共享是指系统中的资源可以被多个并发进程共同使用。
40 |
41 | 有两种共享方式:互斥共享和同时共享。
42 |
43 | 互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
44 |
45 | ### 3. 虚拟
46 |
47 | 虚拟技术把一个物理实体转换为多个逻辑实体。
48 |
49 | 主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
50 |
51 | 多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
52 |
53 | 虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
54 |
55 | ### 4. 异步
56 |
57 | 异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
58 |
59 | ## 基本功能
60 |
61 | ### 1. 进程管理
62 |
63 | 进程控制、进程同步、进程通信、死锁处理、处理机调度等。
64 |
65 | ### 2. 内存管理
66 |
67 | 内存分配、地址映射、内存保护与共享、虚拟内存等。
68 |
69 | ### 3. 文件管理
70 |
71 | 文件存储空间的管理、目录管理、文件读写管理和保护等。
72 |
73 | ### 4. 设备管理
74 |
75 | 完成用户的 I/O 请求,方便用户使用各种设备,并提高设备的利用率。
76 |
77 | 主要包括缓冲管理、设备分配、设备处理、虛拟设备等。
78 |
79 | ## 系统调用
80 |
81 | 如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。
82 |
83 | **使用信号量实现生产者-消费者问题** \ \
349 |
350 | 问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
351 |
352 | 因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
353 |
354 | 为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
355 |
356 | 注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。(导致死锁 ) (P应该将导致互斥的信号量放到同步的信号量之后)
357 |
358 | ```c
359 | #define N 100
360 | typedef int semaphore;
361 | semaphore mutex = 1;
362 | semaphore empty = N;
363 | semaphore full = 0;
364 |
365 | void producer() {
366 | while(TRUE) {
367 | int item = produce_item();
368 | down(&empty);
369 | down(&mutex);
370 | insert_item(item);
371 | up(&mutex);
372 | up(&full);
373 | }
374 | }
375 |
376 | void consumer() {
377 | while(TRUE) {
378 | down(&full);
379 | down(&mutex);
380 | int item = remove_item();
381 | consume_item(item);
382 | up(&mutex);
383 | up(&empty);
384 | }
385 | }
386 | ```
387 |
388 | ### 4. 管程
389 |
390 | 使用信号量机制实现的生产 者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。 (目的无非就是要更方便地实现进程互斥和同步)
391 |
392 | c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
393 |
394 | ```pascal
395 | monitor ProducerConsumer
396 | integer i;
397 | condition c;
398 |
399 | procedure insert();
400 | begin
401 | // ...
402 | end;
403 |
404 | procedure remove();
405 | begin
406 | // ...
407 | end;
408 | end monitor;
409 | ```
410 |
411 | 管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
412 |
413 | 管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
414 |
415 | **使用管程实现生产者-消费者问题**
592 | down(&readLock); // reader is trying to enter
593 | down(&rmutex); // lock to increase readcount
594 | readcount++;
595 | if (readcount == 1)
596 | down(&resource); //if you are the first reader then lock the resource
597 | up(&rmutex); //release for other readers
598 | up(&readLock); //Done with trying to access the resource
599 |
600 |
601 | //reading is performed
602 |
603 |
604 | down(&rmutex); //reserve exit section - avoids race condition with readers
605 | readcount--; //indicate you're leaving
606 | if (readcount == 0) //checks if you are last reader leaving
607 | up(&resource); //if last, you must release the locked resource
608 | up(&rmutex); //release exit section for other readers
609 | }
610 |
611 | //WRITER
612 | void writer() {
613 |
614 | down(&wmutex); //reserve entry section for writers - avoids race conditions
615 | writecount++; //report yourself as a writer entering
616 | if (writecount == 1) //checks if you're first writer
617 | down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
618 | up(&wmutex); //release entry section
619 |
620 |
621 | down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
622 | //writing is performed
623 | up(&resource); //release file
624 |
625 |
626 | down(&wmutex); //reserve exit section
627 | writecount--; //indicate you're leaving
628 | if (writecount == 0) //checks if you're the last writer
629 | up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
630 | up(&wmutex); //release exit section
631 | }
632 | ```
633 |
634 | We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
635 |
636 | From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
637 |
638 | ```source-c
639 | int readCount; // init to 0; number of readers currently accessing resource
640 |
641 | // all semaphores initialised to 1
642 | Semaphore resourceAccess; // controls access (read/write) to the resource
643 | Semaphore readCountAccess; // for syncing changes to shared variable readCount
644 | Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
645 |
646 | void writer()
647 | {
648 | down(&serviceQueue); // wait in line to be servicexs
649 | //
650 | down(&resourceAccess); // request exclusive access to resource
651 | //
652 | up(&serviceQueue); // let next in line be serviced
653 |
654 | //
655 | writeResource(); // writing is performed
656 | //
657 |
658 | //
659 | up(&resourceAccess); // release resource access for next reader/writer
660 | //
661 | }
662 |
663 | void reader()
664 | {
665 | down(&serviceQueue); // wait in line to be serviced
666 | down(&readCountAccess); // request exclusive access to readCount
667 | //
668 | if (readCount == 0) // if there are no readers already reading:
669 | down(&resourceAccess); // request resource access for readers (writers blocked)
670 | readCount++; // update count of active readers
671 | //
672 | up(&serviceQueue); // let next in line be serviced
673 | up(&readCountAccess); // release access to readCount
674 |
675 | //
676 | readResource(); // reading is performed
677 | //
678 |
679 | down(&readCountAccess); // request exclusive access to readCount
680 | //
681 | readCount--; // update count of active readers
682 | if (readCount == 0) // if there are no readers left:
683 | up(&resourceAccess); // release resource access for all
684 | //
685 | up(&readCountAccess); // release access to readCount
686 | }
687 |
688 | ```
689 |
690 | ## 进程通信
691 |
692 | 进程同步与进程通信很容易混淆,它们的区别在于:
693 |
694 | - 进程同步:控制多个进程按一定顺序执行;
695 | - 进程通信:进程间传输信息。
696 |
697 | 进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
698 |
699 | ### 1. 管道
700 |
701 | 是指用于连续读写进程的一个共享文件。其实就是再内存中开辟一个大小固定的缓冲区。
702 |
703 | (各进程要互地访问管道)
704 |
705 | 管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
706 |
707 | ```c
708 | #include
709 | int pipe(int fd[2]);
710 | ```
711 |
712 | 它具有以下限制:
713 |
714 | - 只支持半双工通信(单向交替传输);
715 | - 只能在父子进程或者兄弟进程中使用。
716 |
717 |
725 | int mkfifo(const char *path, mode_t mode);
726 | int mkfifoat(int fd, const char *path, mode_t mode);
727 | ```
728 |
729 | FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
730 |
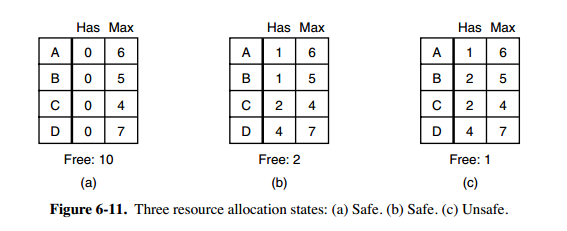
731 | 1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
833 |
834 | 算法总结如下:
835 |
836 | 每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
837 |
838 | 1. 寻找一个没有标记的进程 Pi ,它所请求的资源小于等于 A。
839 | 2. 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
840 | 3. 如果没有这样一个进程,算法终止。
841 |
842 | ### 3. 死锁恢复
843 |
844 | - 利用抢占恢复
845 | - 利用回滚恢复
846 | - 通过杀死进程恢复
847 |
848 | ## 死锁预防
849 |
850 | 在程序运行之前预防发生死锁。
851 |
852 | ### 1. 破坏互斥条件
853 |
854 | 例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
855 |
856 | ### 2. 破坏占有和等待条件
857 |
858 | 一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
859 |
860 | ### 3. 破坏不可抢占条件
861 |
862 | ### 4. 破坏环路等待
863 |
864 | 给资源统一编号,进程只能按编号顺序来请求资源。
865 |
866 | ## 死锁避免
867 |
868 | 在程序运行时避免发生死锁。
869 |
870 | ### 1. 安全状态
871 |
872 |
1138 |
1139 | int main()
1140 | {
1141 | printf("hello, world\n");
1142 | return 0;
1143 | }
1144 | ```
1145 |
1146 | 在 Unix 系统上,由编译器把源文件转换为目标文件。
1147 |
1148 | ```bash
1149 | gcc -o hello hello.c
1150 | ```
1151 |
1152 | 这个过程大致如下:
1153 |
1154 |